
question_slug
stringlengths 3
77
| title
stringlengths 1
183
| slug
stringlengths 12
45
| summary
stringlengths 1
160
⌀ | author
stringlengths 2
30
| certification
stringclasses 2
values | created_at
stringdate 2013-10-25 17:32:12
2025-04-12 09:38:24
| updated_at
stringdate 2013-10-25 17:32:12
2025-04-12 09:38:24
| hit_count
int64 0
10.6M
| has_video
bool 2
classes | content
stringlengths 4
576k
| upvotes
int64 0
11.5k
| downvotes
int64 0
358
| tags
stringlengths 2
193
| comments
int64 0
2.56k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
minimum-number-of-people-to-teach | Is the expected I/O dataset wrong for this problem? | is-the-expected-io-dataset-wrong-for-thi-rn0a | Can anybody help me understand why is the answer for the following input be 4 instead of 3? \n\n\n17\n[[4,7,2,14,6],[15,13,6,3,2,7,10,8,12,4,9],[16],[10],[10,3 | bridge_four | NORMAL | 2021-01-23T16:39:56.504502+00:00 | 2021-01-23T16:39:56.504543+00:00 | 83 | false | Can anybody help me understand why is the answer for the following input be `4` instead of `3`? \n\n```\n17\n[[4,7,2,14,6],[15,13,6,3,2,7,10,8,12,4,9],[16],[10],[10,3],[4,12,8,1,16,5,15,17,13],[4,13,15,8,17,3,6,14,5,10],[11,4,13,8,3,14,5,7,15,6,9,17,2,16,12],[4,14,6],[16,17,9,3,11,14,10,12,1,8,13,4,5,6],[14],[7,14],[17,15,10,3,2,12,16,14,1,7,9,6,4]]\n[[4,11],[3,5],[7,10],[10,12],[5,7],[4,5],[3,8],[1,5],[1,6],[7,8],[4,12],[2,4],[8,9],[3,10],[4,7],[5,12],[4,9],[1,4],[2,8],[1,2],[3,4],[5,10],[2,7],[1,7],[1,8],[8,10],[1,9],[1,10],[6,7],[3,7],[8,12],[7,9],[9,11],[2,5],[2,3]]\n```\n\nIf these 3 person learns the following languages, it makes all pairs of friends have at least one commong language.\n\n```\nPerson: 3 learns: 10\nPerson: 4 learns: 14\nPerson: 5 learns: 7\n```\n\nIf I update the input set with these findings (i.e: add lang 10 to person 3, .. ), then expected result is `0` \n\n | 1 | 0 | [] | 1 |
minimum-number-of-people-to-teach | Java Solution | java-solution-by-abstracted_0507-710e | \nclass Solution {\n public int minimumTeachings(int n, int[][] languages, int[][] friendships) {\n int m = languages.length;\n boolean[][] kno | abstracted_0507 | NORMAL | 2021-01-23T16:34:26.424002+00:00 | 2021-01-23T16:34:26.424029+00:00 | 108 | false | ```\nclass Solution {\n public int minimumTeachings(int n, int[][] languages, int[][] friendships) {\n int m = languages.length;\n boolean[][] knowsLang = new boolean[m][n];\n for(int i = 0; i < m; i++) {\n for(int j = 0; j < languages[i].length; j++) {\n knowsLang[i][languages[i][j]-1] = true;\n }\n }\n boolean[][] canSpeak = new boolean[m][m];\n for(int i = 1; i <= n; i++) {\n for(int[] friendship : friendships) {\n int x = friendship[0], y = friendship[1];\n if(knowsLang[x-1][i-1] && knowsLang[y-1][i-1]) {\n canSpeak[x-1][y-1] = true;\n }\n }\n }\n int res = Integer.MAX_VALUE;\n for(int i = 1; i <= n; i++) {\n int numTaught = 0;\n boolean[] iTaught = new boolean[m];\n for(int[] friendship : friendships) {\n int x = friendship[0], y = friendship[1];\n if(canSpeak[x-1][y-1]) continue;\n if(!knowsLang[x-1][i-1] && !iTaught[x-1]) {\n numTaught++;\n iTaught[x-1] = true;\n }\n if(!knowsLang[y-1][i-1] && !iTaught[y-1]) {\n numTaught++;\n iTaught[y-1] = true;\n }\n }\n res = Math.min(numTaught, res);\n }\n return res;\n }\n}\n``` | 1 | 0 | [] | 1 |
minimum-number-of-people-to-teach | C++ O(n2logn) with tutorial | c-on2logn-with-tutorial-by-hawkings9999-z4gy | The Idea in this problem is the following, we have n langauges and there are m people and l pairs of people,\nwe need to find which langauge we need to make all | hawkings9999 | NORMAL | 2021-01-23T16:30:12.219175+00:00 | 2021-01-23T16:48:36.322661+00:00 | 210 | false | The Idea in this problem is the following, we have n langauges and there are m people and l pairs of people,\nwe need to find which langauge we need to make all of them be able to talk to all the people that they are paired with. \nSome Observations,\nWe dont need to consider pair of people that have at least one language in common so we can discard those pairs.\n\nNow we are left with pairs where none of the pairs have any language common in between them\n.\nNext thing to observe is we can teach only a single language & we would have to teach it to all of them those who dont know the language already. \n\nReason is as follows:\nLets say we wish to teach ith language\nnow considering 3 pairs of people,\ndon\'t know i, don\'t know i - for them to communicate both of them have to be taught\ndon\'t know i, know i, - for them to communicate one has to be taught\nknow i, know i, - for them to communicate no one has to be taught\nTherefore we teach every guy that does not know the language.\n\nNow the explaination for the code, \nWe iterate through all the pairs in friendships array and if they dont have a common language we store both the people in the set ( set is used to avoid double counting). Now we go through all the languages and check which language we need to teach minimum times and return that value.\n\n```\nbool common(vector<vector<int>>& languages, vector<int>& f){\n int n = languages[f[0] - 1].size();\n int m = languages[f[1] - 1].size();\n set<int> s;\n for(int i = 0 ; i < 2; i++){\n for(int j = 0 ; j < languages[f[i]-1].size(); j++){\n s.insert(languages[f[i] - 1][j]);\n }\n }\n if(s.size() < n + m) return true;\n return false;\n}\n\nbool knows(int lang, vector<int>& languages){\n for(int i = 0 ; i < languages.size(); i++) if(lang == languages[i]) return true;\n return false;\n}\n\nclass Solution {\npublic:\n int minimumTeachings(int n, vector<vector<int>>& languages, vector<vector<int>>& friendships) {\n int l = friendships.size();\n int m = languages.size();\n set<int> s;\n // cout << 1<< endl;\n for(int i = 0 ; i < l ; i++ ){\n if(!common(languages, friendships[i])){\n s.insert(friendships[i][0]);\n s.insert(friendships[i][1]);\n } \n }\n cout << 2<< endl;\n auto it = s.begin();\n int mine = INT_MAX;\n for(int lang = 1; lang <= n ; lang++){\n int counter = 0;\n for(int i:s){\n if(!knows(lang, languages[i-1])) counter++;\n }\n mine = min(mine, counter);\n }\n return mine;\n }\n};\n``` | 1 | 1 | [] | 0 |
minimum-number-of-people-to-teach | C# Beats 100% Space/Time | c-beats-100-spacetime-by-rameshthaleia-b3qn | IntuitionUse bool arrays to simplify comparisons.Don't double-count a users language needs.Accumulate wanted languages when the user's can't speak.ApproachEach | rameshthaleia | NORMAL | 2025-04-06T16:56:54.535866+00:00 | 2025-04-06T16:56:54.535866+00:00 | 1 | false | # Intuition
Use bool arrays to simplify comparisons.
Don't double-count a users language needs.
Accumulate wanted languages when the user's can't speak.
# Approach
Each user has a bool array indicating what languages they speak.
Each user has a bool array indicating whether they have already requested a language or not.
Keep track of a user's wanted languages so we only count them once.
Accumulates the wanted language counts.
# Complexity
- Time complexity:
$$O(m * n)$$
- Space complexity:
$$O(m * n)$$
# Code
```csharp []
public class Solution {
public int MinimumTeachings(int n, int[][] languages, int[][] friendships) {
var numUsers = languages.Length;
// Accumulates the wanted language counts.
var langWanted = new int[n];
// Each user has a bool[n] indicating what languages they speak.
var userLangMasks = new bool[numUsers, n];
// After a user indicates they want a language, we mark it for the user to avoid double-counts.
var userLangHandled = new bool[numUsers, n];
// Initialize Language Masks.
for (var i = 0; i < numUsers; i++) {
var userLanguages = languages[i];
foreach (var language in userLanguages) {
userLangMasks[i, language - 1] = true;
}
}
// Iterate over friendships.
foreach (var friendShip in friendships) {
var u1 = friendShip[0] - 1;
var u2 = friendShip[1] - 1;
// Check if the users can speak.
bool canSpeak = false;
for (var i = 0; i < n; i++) {
if (userLangMasks[u1, i] && userLangMasks[u2, i]) {
canSpeak = true;
break;
}
}
// If the users can't speak, accumulate the languages they may need.
// Only accumulate a language once per user.
if (!canSpeak) {
for (var i = 0; i < n; i++) {
if (!userLangHandled[u1, i] && !userLangMasks[u1, i]) {
langWanted[i]++;
userLangHandled[u1, i] = true;
}
if (!userLangHandled[u2, i] && !userLangMasks[u2, i]) {
langWanted[i]++;
userLangHandled[u2, i] = true;
}
}
}
}
var minUsers = int.MaxValue;
for (var i = 0; i < n; i++) {
minUsers = Math.Min(minUsers, langWanted[i]);
}
return minUsers;
}
}
``` | 0 | 0 | ['C#'] | 0 |
minimum-number-of-people-to-teach | C# Beats 100% Space/Time | c-beats-100-spacetime-by-rameshthaleia-td2y | IntuitionUse dictionaries to simplify comparisons.
Don't double-count a users language needs.
Accumulate wanted languages when the user's can't speak.ApproachEa | rameshthaleia | NORMAL | 2025-04-06T16:42:42.104831+00:00 | 2025-04-06T16:42:42.104831+00:00 | 2 | false | # Intuition
Use dictionaries to simplify comparisons.
Don't double-count a users language needs.
Accumulate wanted languages when the user's can't speak.
# Approach
Each user has a bool[n] indicating what languages they speak.
Keep track of a user's wanted languages so we only count them once.
Accumulates the wanted language counts.
# Complexity
- Time complexity:
$$O(m * n)$$
- Space complexity:
$$O(m * n)$$
# Code
```csharp []
public class Solution {
public int MinimumTeachings(int n, int[][] languages, int[][] friendships) {
// Each user has a bool[n] indicating what languages they speak.
var userLangMaskDict = new Dictionary<int, bool[]>();
// Keeps track of a user's wanted languages so we only count them once.
var userLangHandledDict = new Dictionary<int, bool[]>();
// Accumulates the wanted language counts.
var langWantedArr = new int[n];
// Initialize Dictionaries.
for (var i = 0; i < languages.Length; i++) {
var userLanguages = languages[i];
var langMask = new bool[n];
foreach (var language in userLanguages) {
langMask[language - 1] = true;
}
userLangMaskDict[i] = langMask;
userLangHandledDict[i] = new bool[n];
}
// Iterate over friendships.
foreach (var friendShip in friendships) {
var u1 = friendShip[0] - 1;
var u2 = friendShip[1] - 1;
var langMask1 = userLangMaskDict[u1];
var langMask2 = userLangMaskDict[u2];
// Check if the users can speak.
bool canSpeak = false;
for (var i = 0; i < n; i++) {
if (langMask1[i] && langMask2[i]) {
canSpeak = true;
break;
}
}
// If the users can't speak, accumulate the languages they may need.
// Only accumulate a language once per user.
if (!canSpeak) {
var langHandled1 = userLangHandledDict[u1];
var langHandled2 = userLangHandledDict[u2];
for (var i = 0; i < n; i++) {
if (!langHandled1[i] && !langMask1[i]) {
langWantedArr[i]++;
langHandled1[i] = true;
}
if (!langHandled2[i] && !langMask2[i]) {
langWantedArr[i]++;
langHandled2[i] = true;
}
}
}
}
var minUsers = int.MaxValue;
for (var i = 0; i < n; i++) {
minUsers = Math.Min(minUsers, langWantedArr[i]);
}
return minUsers;
}
}
``` | 0 | 0 | ['C#'] | 0 |
minimum-number-of-people-to-teach | While doing the program of minimum of teach two friends setup chars to use in the program | while-doing-the-program-of-minimum-of-te-gclq | IntuitionApproachComplexity
Time complexity:
Space complexity:
Code | Girsha | NORMAL | 2025-02-14T07:57:37.658081+00:00 | 2025-02-14T07:57:37.658081+00:00 | 4 | false | # Intuition
<!-- Describe your first thoughts on how to solve this problem. -->
# Approach
<!-- Describe your approach to solving the problem. -->
# Complexity
- Time complexity:
<!-- Add your time complexity here, e.g. $$O(n)$$ -->
- Space complexity:
<!-- Add your space complexity here, e.g. $$O(n)$$ -->
# Code
```python []
class Solution(object):
def minimumTeachings(self, n, languages, friendships):
"""
:type n: int
:type languages: List[List[int]]
:type friendships: List[List[int]]
:rtype: int
"""
min_to_teach = len(languages)
languages_set_list = [set(l) for l in languages]
for current_language in range(1, n+1):
to_teach = set()
for brothers in friendships:
l1, l2 = brothers
if len(languages_set_list[l1-1].intersection(languages_set_list[l2-1]))>=1:
continue
else:
if current_language not in languages[l1-1]:
to_teach.add(l1)
if current_language not in languages[l2-1]:
to_teach.add(l2)
nb_of_friends_to_teach = len(to_teach)
min_to_teach = min(nb_of_friends_to_teach, min_to_teach)
return min_to_teach
``` | 0 | 0 | ['Python'] | 0 |
minimum-number-of-people-to-teach | easy to understand, good for novice | easy-to-understand-good-for-novice-by-ji-cdty | Intuitionbrute force each language, see which one has the least people to teach.Complexity
Time complexity:
O(n*m)Code | jiayi9063 | NORMAL | 2025-02-06T21:06:02.883900+00:00 | 2025-02-06T21:06:02.883900+00:00 | 4 | false | # Intuition
<!-- Describe your first thoughts on how to solve this problem. -->
brute force each language, see which one has the least people to teach.
# Complexity
- Time complexity:
<!-- Add your time complexity here, e.g. $$O(n)$$ -->
O(n*m)
# Code
```python3 []
class Solution:
def minimumTeachings(self, n: int, languages: List[List[int]], friendships: List[List[int]]) -> int:
all_lang=set()
for item in languages:
for lang in item:
if lang not in all_lang:
all_lang.add(lang)
def check_need(languages,friendships):
np=len(languages)
result=[True]*np
for relation in friendships:
a=relation[0]
b=relation[1]
lan_a=languages[a-1]
lan_b=languages[b-1]
if len(set(lan_a) & set(lan_b))==0:
result[a-1]=False
result[b-1]=False
return result
result=check_need(languages,friendships)
mincount=float('inf')
np=len(languages)
for lang in all_lang:
count=0
for p in range(np):
lan=languages[p]
if not result[p]:
if lang not in lan:
count+=1
mincount=min(mincount,count)
return mincount
``` | 0 | 0 | ['Python3'] | 0 |
minimum-number-of-people-to-teach | 1733. Minimum Number of People to Teach | 1733-minimum-number-of-people-to-teach-b-zwtu | IntuitionApproachComplexity
Time complexity:
Space complexity:
Code | G8xd0QPqTy | NORMAL | 2025-01-15T01:25:03.323300+00:00 | 2025-01-15T01:25:03.323300+00:00 | 4 | false | # Intuition
<!-- Describe your first thoughts on how to solve this problem. -->
# Approach
<!-- Describe your approach to solving the problem. -->
# Complexity
- Time complexity:
<!-- Add your time complexity here, e.g. $$O(n)$$ -->
- Space complexity:
<!-- Add your space complexity here, e.g. $$O(n)$$ -->
# Code
```python3 []
class Solution:
def minimumTeachings(self, n: int, languages: List[List[int]], friendships: List[List[int]]) -> int:
lang_sets = [set(lang) for lang in languages]
needs_teaching = set()
for u, v in friendships:
if not lang_sets[u - 1] & lang_sets[v - 1]:
needs_teaching.add(u - 1)
needs_teaching.add(v - 1)
if not needs_teaching:
return 0
lang_count = [0] * (n + 1)
for user in needs_teaching:
for lang in lang_sets[user]:
lang_count[lang] += 1
return len(needs_teaching) - max(lang_count)
``` | 0 | 0 | ['Python3'] | 0 |
minimum-number-of-people-to-teach | One language to rule them all | one-language-to-rule-them-all-by-tonitan-w2rl | IntuitionApproachComplexity
Time complexity:
O(n^2)
Space complexity:
Code | tonitannoury01 | NORMAL | 2024-12-19T18:56:37.024373+00:00 | 2024-12-19T18:56:37.024373+00:00 | 5 | false | # Intuition
<!-- Describe your first thoughts on how to solve this problem. -->
# Approach
<!-- Describe your approach to solving the problem. -->
# Complexity
- Time complexity:
O(n^2)
- Space complexity:
<!-- Add your space complexity here, e.g. $$O(n)$$ -->
# Code
```javascript []
/**
* @param {number} n
* @param {number[][]} languages
* @param {number[][]} friendships
* @return {number}
*/
var minimumTeachings = function (n, languages, friendships) {
let langList = Array(n)
.fill(0)
.map(() => new Set());
for (let i = 0; i < languages.length; i++) {
let langs = languages[i];
for (let l of langs) {
langList[l - 1].add(i);
}
}
let illat = new Set();
for (let [one, two] of friendships) {
let oneLangs = languages[one - 1];
let twoLangs = languages[two - 1];
let can = false;
for (let l of oneLangs) {
if (langList[l - 1].has(one - 1) && langList[l - 1].has(two - 1)) {
can = true;
break;
}
}
if (can) {
continue;
}
illat.add(one - 1);
illat.add(two - 1);
}
let mostSpoken = 0;
let pplWho = 0;
for (let i = 0; i < n; i++) {
let counter = 0;
for (let j of illat) {
if (langList[i].has(j)) {
counter++;
}
}
if (counter > pplWho) {
mostSpoken = i;
pplWho = counter;
}
}
return illat.size - pplWho;
};
``` | 0 | 0 | ['JavaScript'] | 0 |
minimum-number-of-people-to-teach | brutforce solution with Sets | brutforce-solution-with-sets-by-debareto-zfnd | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | debareto | NORMAL | 2024-10-31T14:58:20.356158+00:00 | 2024-10-31T14:58:20.356187+00:00 | 3 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```python []\nclass Solution(object):\n def minimumTeachings(self, n, languages, friendships):\n """\n :type n: int\n :type languages: List[List[int]]\n :type friendships: List[List[int]]\n :rtype: int\n """\n #initialize the minimum to teach to the number of users\n min_to_teach = len(languages)\n \n #initialize a list of languages set for all the users \n languages_set_list = [set(l) for l in languages]\n \n \n # loop over all languages\n for current_language in range(1, n+1):\n to_teach = set()\n for couples in friendships:\n f1, f2 = couples\n # check if the users in the couple have already a common language\n if len(languages_set_list[f1-1].intersection(languages_set_list[f2-1]))>=1:\n continue\n #if they dont and dont know the current language I add them to the set\n else:\n if current_language not in languages[f1-1]:\n to_teach.add(f1)\n if current_language not in languages[f2-1]:\n to_teach.add(f2)\n #at the end I check how many users were added\n nb_of_friends_to_teach = len(to_teach)\n #update if the new ne number of users to tech is lower than the current min \n min_to_teach = min(nb_of_friends_to_teach, min_to_teach)\n\n return min_to_teach\n \n \n\n\n \n``` | 0 | 0 | ['Python'] | 0 |
minimum-number-of-people-to-teach | Minimum Number Of People To Teach!!! | minimum-number-of-people-to-teach-by-sin-7n1o | \n\n# Code\njava []\nclass Solution {\n public int minimumTeachings(int n, int[][] languages, int[][] friendships) {\n //Step 1: Creating a map \n | sindhujadid_1804 | NORMAL | 2024-09-16T17:43:59.657825+00:00 | 2024-09-16T17:43:59.657853+00:00 | 28 | false | \n\n# Code\n```java []\nclass Solution {\n public int minimumTeachings(int n, int[][] languages, int[][] friendships) {\n //Step 1: Creating a map \n // language --> person speaking\n HashMap<Integer, ArrayList<Integer>> map = new HashMap<>();\n for(int i = 0; i < languages.length; i++){\n for(int j = 0; j < languages[i].length; j++){\n int l = languages[i][j];\n if(!map.containsKey(l)){\n map.put(l, new ArrayList<>());\n }\n ArrayList<Integer> a = map.get(l);\n a.add(i + 1);\n map.put(l,a);\n }\n }\n\n //Step 2: Identifying the pairs which donot share the same language\n boolean []teachPair = new boolean [friendships.length];\n for(int i = 0; i < friendships.length; i++){\n int u = friendships[i][0];\n int v = friendships[i][1];\n boolean canCommunicate = false;\n for(int j = 1; j <= n; j++){\n if(map.getOrDefault(j, new ArrayList<>()).contains(u) && \n map.getOrDefault(j, new ArrayList<>()).contains(v)){\n canCommunicate = true;\n break;\n }\n }\n if(!canCommunicate) teachPair[i] = true;\n }\n\n //Step 3: Finding the minimum number of users we need to teach\n int m = friendships.length;\n int minTeachings = Integer.MAX_VALUE;\n\n for(int i = 1; i <= n ; i++){\n HashSet<Integer> set = new HashSet<>();\n for(int j = 0; j < m; j++){\n if(teachPair[j]){\n int u = friendships[j][0];\n int v = friendships[j][1];\n\n if (!map.getOrDefault(i, new ArrayList<>()).contains(u)) {\n set.add(u);\n }\n if (!map.getOrDefault(i, new ArrayList<>()).contains(v)) {\n set.add(v);\n }\n }\n }\n minTeachings = Math.min(minTeachings, set.size());\n }\n return minTeachings;\n }\n}\n``` | 0 | 0 | ['Array', 'Hash Table', 'Java'] | 0 |
minimum-number-of-people-to-teach | Very Easy Approach and Short Code in C++ | very-easy-approach-and-short-code-in-c-b-i45g | Intuition and Approach\nstep1. find the total friends who can\'t comm. each other\nstep2.find the most comman lang btwn them\nstep3. ans=totalfriendsWhoCantComm | Akki2910 | NORMAL | 2024-09-02T05:05:56.157787+00:00 | 2024-09-02T05:05:56.157805+00:00 | 32 | false | # Intuition and Approach\nstep1. find the total friends who can\'t comm. each other\nstep2.find the most comman lang btwn them\nstep3. ans=totalfriendsWhoCantComm-countOfMaximumComman Lang\n\n\nintuition:- if we know there are 10 people who cant comm. with each and maximum 5 of them know a comman language then minimum answer will be rest 5 should also know the same language in order to reduce the answer.\n\n# Complexity\n- Time complexity:\nO(N*M)\n\n- Space complexity:\nO(N+M)\n\n# Code\n```cpp []\nclass Solution {\npublic:\n bool check(vector<int> &a,vector<int> &b){\n for(int i=0;i<a.size();i++){\n for(int j=0;j<b.size();j++){\n if(a[i]==b[j]) return true;\n }\n }\n return false;\n }\n\n int minimumTeachings(int n, vector<vector<int>>& languages, vector<vector<int>>& friendships) {\n // step1\n set<int> s; // so that same friend cannot come into the list.\n for(int i=0;i<friendships.size();i++){\n if(!check(languages[friendships[i][0]-1],languages[friendships[i][1]-1])){\n s.insert(friendships[i][0]-1);\n s.insert(friendships[i][1]-1);\n }\n }\n\n // step2\n unordered_map<int,int>commanLang;\n int ans=0;\n for(auto it=s.begin();it!=s.end();it++){\n for(int i=0;i<languages[(*it)].size();i++){\n commanLang[languages[(*it)][i]]++;\n ans=max(ans,commanLang[languages[(*it)][i]]);\n }\n }\n // step 3\n return s.size()-ans;\n\n\n }\n};\n``` | 0 | 0 | ['Greedy', 'C++'] | 0 |
minimum-number-of-people-to-teach | Hashing || C++ | hashing-c-by-lotus18-xhbd | Code\n\nclass Solution \n{\npublic:\n int minimumTeachings(int lang, vector<vector<int>>& languages, vector<vector<int>>& friendships) \n {\n map<i | lotus18 | NORMAL | 2024-08-17T05:55:19.044081+00:00 | 2024-08-17T05:55:19.044113+00:00 | 8 | false | # Code\n```\nclass Solution \n{\npublic:\n int minimumTeachings(int lang, vector<vector<int>>& languages, vector<vector<int>>& friendships) \n {\n map<int,set<int>> m;\n int n=languages.size();\n for(int x=0; x<n; x++)\n {\n set<int> st;\n for(auto it: languages[x]) st.insert(it);\n m[x+1]=st;\n }\n map<int,int> mp;\n set<int> unresolved;\n for(auto it: friendships)\n {\n auto st1=m[it[0]];\n auto st2=m[it[1]];\n int found=0;\n for(auto i: st1)\n {\n if(st2.find(i)!=st2.end())\n {\n found=1;\n break;\n }\n }\n if(!found)\n {\n unresolved.insert(it[0]);\n unresolved.insert(it[1]);\n }\n }\n for(auto it: unresolved)\n {\n for(auto i: m[it]) mp[i]++;\n }\n int mx=0, num=0;\n for(auto it: mp) \n {\n if(mx<it.second)\n {\n mx=it.second;\n num=it.first;\n }\n }\n int ans=0;\n for(auto it: unresolved)\n {\n auto st=m[it];\n if(st.find(num)==st.end()) ans++;\n }\n return ans;\n }\n};\n``` | 0 | 0 | ['Hash Table', 'C++'] | 0 |
minimum-number-of-people-to-teach | Solution Minimum Number of People to Teach | solution-minimum-number-of-people-to-tea-2sqm | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | Suyono-Sukorame | NORMAL | 2024-07-02T06:45:28.968399+00:00 | 2024-07-02T06:45:28.968432+00:00 | 3 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\n public $mem = [];\n\n public function check($a, $u, $v) {\n if ($this->mem[$u][$v] != 0) return $this->mem[$u][$v] == 1;\n for ($i = 0; $i < count($a[$v]); $i++) {\n if (in_array($a[$v][$i], $a[$u])) {\n $this->mem[$v][$u] = $this->mem[$u][$v] = 1;\n return true;\n }\n }\n $this->mem[$u][$v] = $this->mem[$v][$u] = -1;\n return false;\n }\n\n public function minimumTeachings($n, $languages, $friendships) {\n $m = count($languages);\n $ret = $m;\n $this->mem = array_fill(0, $m + 1, array_fill(0, $m + 1, 0));\n\n for ($i = 0; $i < $m; $i++) {\n sort($languages[$i]);\n }\n\n for ($lang = 1; $lang <= $n; $lang++) {\n $count = 0;\n $teach = array_fill(0, $m, false);\n for ($i = 0; $i < count($friendships); $i++) {\n $u = $friendships[$i][0] - 1;\n $v = $friendships[$i][1] - 1;\n if ($this->check($languages, $u, $v)) continue;\n if (!in_array($lang, $languages[$u])) {\n if (!$teach[$u]) $count++;\n $teach[$u] = true;\n }\n if (!in_array($lang, $languages[$v])) {\n if (!$teach[$v]) $count++;\n $teach[$v] = true;\n }\n }\n $ret = min($ret, $count);\n }\n return $ret;\n }\n}\n\n``` | 0 | 0 | ['PHP'] | 0 |
minimum-number-of-people-to-teach | 1733. Minimum Number of People to Teach.cpp | 1733-minimum-number-of-people-to-teachcp-kyo3 | Code\n\nclass Solution {\npublic:\n bool findCommon(vector<int>&a, vector<int>&b) {\n for(int i=0;i<a.size();i++) {\n for(int j=0;j<b.size( | 202021ganesh | NORMAL | 2024-06-10T09:05:34.467140+00:00 | 2024-06-10T09:05:34.467173+00:00 | 0 | false | **Code**\n```\nclass Solution {\npublic:\n bool findCommon(vector<int>&a, vector<int>&b) {\n for(int i=0;i<a.size();i++) {\n for(int j=0;j<b.size();j++) {\n if(a[i]==b[j])\n return 1;\n }\n }\n return 0;\n } \n int minimumTeachings(int n, vector<vector<int>>& lang, vector<vector<int>>& friends) {\n int l = lang.size();\n int f = friends.size();\n set<int> ppl_with_no_common; \n unordered_map<int,vector<int>> mp ; \n for(int i=0;i<f;i++) {\n if(!findCommon(lang[friends[i][0]-1] , lang[friends[i][1]-1])) \n {\n ppl_with_no_common.insert(friends[i][0]);\n ppl_with_no_common.insert(friends[i][1]);\n }\n } \n for(int j=0;j<l;j++) {\n if(ppl_with_no_common.find(j+1)!=ppl_with_no_common.end()) {\n for(int k=0;k<lang[j].size();k++) \n mp[lang[j][k]].push_back(j+1);\n }\n }\n int ans = 0;\n int language = 0;\n for(int i=1;i<=mp.size();i++) {\n if(ans<mp[i].size()) {\n ans = mp[i].size();\n language = i;\n }\n }\n return ppl_with_no_common.size()-ans;\n }\n};\n``` | 0 | 0 | ['C'] | 0 |
minimum-number-of-people-to-teach | Java HashMap | java-hashmap-by-abhinvsinh-l4r5 | Intuition\n1. We need to find out which friends can already communicate so that we don\'t need to calculate the language teaching for them.\n2. For every langua | abhinvsinh | NORMAL | 2024-06-01T06:49:05.415786+00:00 | 2024-06-01T06:49:05.415818+00:00 | 21 | false | # Intuition\n1. We need to find out which friends can already communicate so that we don\'t need to calculate the language teaching for them.\n2. For every language , iterate through the friendship array and check if we need to teach the language to both the friends to be able to communicate.\n3. At the end , compare which language was needed to be taught to the least number of users and return.\n# Approach\n1. Create a map for user to set of languages to be able to fetch a language for a user in O(1)\n2. Create a boolean array specifying if the friend pair already has a common language.\n3. For every language check , how many people need to be taught that language. Note the count, and after every iteration, update the count if it is less than the count of previous language\n\n# Complexity\n- Time complexity:\nFor creating the map, if the number of users are m and maximum number of language spoken by a user is n.\nThe time complexity is O(m*n)\nIf total Friendships are k , then creating the boolean array is \nO(k*n)\nIf there are l languages, we are iterating l times * number of friendships k times. O(l*k)\nTotal time complexity is O(m*n)+O(k*n)+O(l*k)\n\n- Space complexity:\nFor creating the map, if the number of users are m and maximum number of language spoken by a user is n.\nThe space complexity is O(m*n)\nIf total Friendships are k , then space complexity of boolean array is \nO(k)\nThe size of teach set at the end cannot be more than that of number of users m thus space complexity is O(m)\nTotal space complexity is O(m*n)+O(k)+O(m) which will be equal to O(m*n) as we can drop the other smaller k and m.\n\n\n\n# Code\n```\nclass Solution {\n public int minimumTeachings(int n, int[][] languages, int[][] friendships) {\n //create a map for user to set of languages to be able to fetch a language for a user in O(1)\n Map<Integer,Set<Integer>> userToLang = new HashMap<>();\n for(int i=0;i<languages.length;i++){\n Set<Integer> set = new HashSet<>();\n for(int lang:languages[i]){\n set.add(lang);\n }\n userToLang.put(i+1,set);\n }\n //Create a boolean array specifying if the friend pair already has a common language\n boolean[] canCommunicate = new boolean[friendships.length];\n Arrays.fill(canCommunicate,false);\n for(int i=0;i<friendships.length;i++){\n int f1 = friendships[i][0];//friend 1\n int f2 = friendships[i][1];//friend2\n //check if friend 1 speaks the same language as friend2\n for(int lang:userToLang.get(f1)){\n if(userToLang.get(f2).contains(lang)){\n canCommunicate[i]=true;\n break;\n }\n }\n }\n //For every language check , how many people need to be taught that language\n //note the count , and after every iteration, update the count if it is less than the count \n //of previous language\n int totalUsers = languages.length;\n for(int i=1;i<=n;i++){\n Set<Integer> teach = new HashSet<>();\n for(int j=0;j<friendships.length;j++){\n if(canCommunicate[j])continue;\n //check if we need to teach the language to f1 and f2\n int friend1 = friendships[j][0];\n int friend2 = friendships[j][1];\n if(!userToLang.get(friend1).contains(i)) teach.add(friend1);\n if(!userToLang.get(friend2).contains(i)) teach.add(friend2);\n }\n totalUsers=Math.min(totalUsers, teach.size());\n }\n return totalUsers; \n }\n}\n\n\n``` | 0 | 0 | ['Java'] | 0 |
minimum-number-of-people-to-teach | O(M*N) Greedy solution using Set | omn-greedy-solution-using-set-by-vgvishe-k6q0 | \n# Complexity\n- Time complexity:\nO(M*N)\n\n- Space complexity:\nO(M)\n\n# Code\n\nfunction minimumTeachings(n: number, languages: number[][], friendships: nu | vgvishesh | NORMAL | 2024-05-19T04:14:20.446781+00:00 | 2024-05-19T04:14:20.446809+00:00 | 1 | false | \n# Complexity\n- Time complexity:\nO(M*N)\n\n- Space complexity:\nO(M)\n\n# Code\n```\nfunction minimumTeachings(n: number, languages: number[][], friendships: number[][]): number {\n function createFriendsLanguageSets() {\n let friendsLanguageSets: Set<number>[] = new Array(1);\n for (let i = 0; i < languages.length; i++) {\n let fLangs = new Set<number>();\n languages[i].forEach(x => fLangs.add(x));\n friendsLanguageSets.push(fLangs);\n }\n return friendsLanguageSets;\n\n }\n\n function findFriendsWithNoLanguage(languages: number[][], friendships: number[][], friendsLanguageSets: Set<number>[]) {\n let friendsWithNoLanguage: number[][] = new Array(1);\n for (let i = 0; i < friendships.length; i++) {\n let f1Langs = friendsLanguageSets[friendships[i][0]]\n let f2Langs = friendsLanguageSets[friendships[i][1]];\n\n let canTalk = false;\n for (let lang of f1Langs.keys()) {\n if (f2Langs.has(lang)) {\n canTalk = true;\n break;\n }\n }\n if (!canTalk) {\n friendsWithNoLanguage.push(friendships[i]);\n }\n }\n return friendsWithNoLanguage;\n }\n\n let friendsLanguageSets = createFriendsLanguageSets();\n let brokenFriendships = findFriendsWithNoLanguage(languages, friendships, friendsLanguageSets);\n\n let i = 1;\n let min = Number.MAX_VALUE;\n while (i <= n) {\n let count = 0;\n let visitedFrinds = new Set<number>();\n for (let j = 1; j < brokenFriendships.length; j++) {\n let f1 = brokenFriendships[j][0];\n let f2 = brokenFriendships[j][1];\n if (!friendsLanguageSets[f1].has(i) && !visitedFrinds.has(f1)) {\n visitedFrinds.add(f1);\n count++;\n }\n if (!friendsLanguageSets[f2].has(i) && !visitedFrinds.has(f2)) {\n visitedFrinds.add(f2);\n count++;\n }\n }\n if (count < min) {\n min = count;\n }\n i++;\n }\n return min;\n};\n``` | 0 | 0 | ['TypeScript'] | 0 |
minimum-number-of-people-to-teach | 3lines: | 3lines-by-qulinxao-nnez | \n# Code\n\nclass Solution:\n def minimumTeachings(_, n: int, l: List[List[int]], f: List[List[int]]) -> int:\n q=set()\n for a,b in f: not set | qulinxao | NORMAL | 2024-04-23T08:31:37.257521+00:00 | 2024-04-23T08:33:36.318259+00:00 | 19 | false | \n# Code\n```\nclass Solution:\n def minimumTeachings(_, n: int, l: List[List[int]], f: List[List[int]]) -> int:\n q=set()\n for a,b in f: not set(l[a-1]).intersection(set(l[b-1]))and(q.add(a),q.add(b))\n return len(q)-(max(c.values())if ((c:=Counter()).update(chain.from_iterable((l[h-1]for h in q))),c)[-1] else 0)\n``` | 0 | 0 | ['Union Find', 'Python3'] | 0 |
minimum-number-of-people-to-teach | Simple Intuitive Greedy (Beats 97% TE and 77% ME) | simple-intuitive-greedy-beats-97-te-and-pd276 | Intuition\nIf people in a friendship are able to communicate with each other with at least 1 language, we do not care about them here.\nBut if they are not able | anushree97 | NORMAL | 2024-04-10T07:26:17.942832+00:00 | 2024-04-10T07:26:17.942864+00:00 | 23 | false | # Intuition\nIf people in a friendship are able to communicate with each other with at least 1 language, we do not care about them here.\nBut if they are not able to communicate, we need to find the language which is most popular amoung this set and the number of speakers of that language. We will need to teach the others this popular language.\n\n# Complexity\n- Time complexity:\nO(n)\n\n- Space complexity:\nO(n)\n\n# Code\n```\nclass Solution:\n def minimumTeachings(self, n: int, languages: List[List[int]], friendships: List[List[int]]) -> int:\n languages = [set(l) for l in languages]\n dontspeak = set()\n langs = defaultdict(int)\n poplang = n\n speakers = 0\n for i, j in friendships:\n lang1 = languages[i-1]\n lang2 = languages[j-1]\n\n if lang1 & lang2: continue\n \n if i not in dontspeak:\n for k in lang1:\n langs[k]+=1\n if langs[k]>speakers:\n poplang = k\n speakers=langs[k]\n if j not in dontspeak:\n for k in lang2:\n langs[k]+=1\n if langs[k]>speakers:\n poplang = k\n speakers=langs[k]\n\n dontspeak.add(i)\n dontspeak.add(j)\n\n return len(dontspeak)-speakers\n\n\n``` | 0 | 0 | ['Greedy', 'Python3'] | 1 |
minimum-number-of-people-to-teach | Sol in Kotlin | sol-in-kotlin-by-arista_agarwal-r7f7 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | Arista_agarwal | NORMAL | 2024-03-02T04:59:10.409828+00:00 | 2024-03-02T04:59:10.409854+00:00 | 7 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\n fun minimumTeachings(n: Int, languages: Array<IntArray>, friendships: Array<IntArray>): Int {\n val userLanguages = languages.mapIndexed { index, langs -> index + 1 to langs.toSet() }.toMap()\n\n // Find users who need to be taught\n val usersToTeach = mutableSetOf<Int>()\n for ((u1, u2) in friendships) {\n if (userLanguages[u1]!!.intersect(userLanguages[u2]!!).isEmpty()) {\n usersToTeach.add(u1)\n usersToTeach.add(u2)\n }\n }\n\n // Count languages to find the most common one\n val languageFrequency = mutableMapOf<Int, Int>().withDefault { 0 }\n for (user in usersToTeach) {\n for (lang in userLanguages[user]!!) {\n languageFrequency[lang] = languageFrequency.getValue(lang) + 1\n }\n }\n\n // Find the most common language among users to teach\n val maxFrequency = languageFrequency.values.maxOrNull() ?: 0\n\n // Calculate the minimum number of users to teach\n return usersToTeach.size - maxFrequency\n }\n}\n``` | 0 | 0 | ['Kotlin'] | 0 |
minimum-number-of-people-to-teach | Beats 100%, Hash Table, O(n + m) | beats-100-hash-table-on-m-by-igor0-cfkc | Intuition\nCreate a list of users\' pairs which need to learn a new language.\n\n# Approach\nAt first create new dictionary dicLang with a user as a key and a s | igor0 | NORMAL | 2024-02-28T22:30:23.694059+00:00 | 2024-02-28T22:37:27.850246+00:00 | 18 | false | # Intuition\nCreate a list of users\' pairs which need to learn a new language.\n\n# Approach\nAt first create new dictionary `dicLang` with a user as a key and a set of user\'s languages as a value:\n```\nvar dicLang = CreateDicOfLanguages(languages);\n```\nThe create a list of users who need to learn a new language:\n```\nvar set = new HashSet<int>();\nfor (int i = 0; i < friendships.Length; i++)\n{\n if (dicLang[friendships[i][0]].Intersect(dicLang[friendships[i][1]]).Count() == 0)\n {\n set.Add(friendships[i][0]);\n set.Add(friendships[i][1]);\n }\n}\n```\nAfter that find the language with the naximum number of speakers:\n```\nvar maxLang = 0;\nforeach (var item in set)\n{\n foreach (var lang in dicLang[item])\n {\n if (!dic.ContainsKey(lang)) dic.Add(lang, 0);\n dic[lang]++;\n maxLang = Math.Max(maxLang, dic[lang]);\n }\n}\n```\nFinally caclulate the result:\n```\nvar rs = set.Count - maxLang;\nreturn rs;\n```\n\n# Complexity\n- Time complexity:\n$$O(k + m)$$, where m is the len(languages) and k is the len(friendships)\n\n- Space complexity:\n$$O(k + m)$$, where m is the len(languages) and k is the len(friendships)\n\n# Code\n```\npublic class Solution {\n public int MinimumTeachings(int n, int[][] languages, int[][] friendships) {\n var dicLang = CreateDicOfLanguages(languages);\n var set = new HashSet<int>();\n for (int i = 0; i < friendships.Length; i++)\n {\n if ((dicLang[friendships[i][0]].Intersect(dicLang[friendships[i][1]])).Count() == 0)\n {\n set.Add(friendships[i][0]);\n set.Add(friendships[i][1]);\n }\n }\n var dic = new Dictionary<int, int>();\n var maxLang = 0;\n foreach (var item in set)\n {\n foreach (var lang in dicLang[item])\n {\n if (!dic.ContainsKey(lang)) dic.Add(lang, 0);\n dic[lang]++;\n maxLang = Math.Max(maxLang, dic[lang]);\n }\n }\n var rs = set.Count - maxLang;\n return rs;\n }\n private Dictionary<int, HashSet<int>> CreateDicOfLanguages(int[][] languages)\n {\n var rs = new Dictionary<int, HashSet<int>>();\n for (int i = 0; i < languages.Length; i++)\n {\n rs.Add(i + 1, new HashSet<int>(languages[i]));\n }\n return rs;\n }\n}\n``` | 0 | 0 | ['Hash Table', 'C#'] | 0 |
minimum-number-of-people-to-teach | 1733. Minimum Number of People to Teach | 1733-minimum-number-of-people-to-teach-b-2idn | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | pgmreddy | NORMAL | 2024-01-15T13:43:31.825001+00:00 | 2024-01-15T13:43:31.825039+00:00 | 14 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n\n---\n\n```\nvar minimumTeachings = function (n, languages, friends) {\n const hasIntersection = (lSet, rSet) => {\n for (const l of lSet) if (rSet.has(l)) return 1;\n return 0;\n };\n const hasNoCommonLanguage = (lSet, rSet) => !hasIntersection(lSet, rSet);\n const personLanguages = languages.map((arr) => new Set(arr));\n const uniqueFriendsThatDontSpeakSameLang = new Set();\n for (let [u, v] of friends) {\n u--, v--;\n if (hasNoCommonLanguage(personLanguages[u], personLanguages[v])) {\n uniqueFriendsThatDontSpeakSameLang.add(u).add(v);\n }\n }\n if (uniqueFriendsThatDontSpeakSameLang.size === 0) return 0;\n const langFreq = new Map();\n for (const f of uniqueFriendsThatDontSpeakSameLang)\n for (const l of personLanguages[f]) {\n langFreq.set(l, (langFreq.get(l) || 0) + 1);\n }\n return uniqueFriendsThatDontSpeakSameLang.size - Math.max(...langFreq.values());\n};\n```\n\n---\n | 0 | 0 | ['JavaScript'] | 0 |
minimum-number-of-people-to-teach | Easy to understand JavaScript solution (Greedy) | easy-to-understand-javascript-solution-g-eyft | Complexity\n- Time complexity:\nO(mn)\n\n- Space complexity:\nO(mn)\n\n# Code\n\nvar minimumTeachings = function(n, languages, friendships) {\n const size = | tzuyi0817 | NORMAL | 2023-10-22T06:29:56.362543+00:00 | 2023-10-22T06:29:56.362564+00:00 | 14 | false | # Complexity\n- Time complexity:\n$$O(mn)$$\n\n- Space complexity:\n$$O(mn)$$\n\n# Code\n```\nvar minimumTeachings = function(n, languages, friendships) {\n const size = languages.length;\n const communicate = Array(size).fill(\'\').map(_ => Array(n).fill(false));\n const users = new Set();\n let result = Number.MAX_SAFE_INTEGER;\n\n for (let index = 0; index < size; index++) {\n for (const language of languages[index]) {\n communicate[index][language - 1] = true;\n }\n }\n for (const [a, b] of friendships) {\n const isCommunicate = communicate[a - 1].some((isKnow, language) => {\n return isKnow ? communicate[b - 1][language] : isKnow;\n });\n\n if (isCommunicate) continue;\n users.add(a - 1).add(b - 1);\n }\n for (let language = 0; language < n; language++) {\n let teach = 0;\n\n for (const user of users) {\n !communicate[user][language] && teach++\n }\n result = Math.min(teach, result);\n }\n return result;\n};\n``` | 0 | 0 | ['JavaScript'] | 0 |
minimum-number-of-people-to-teach | C++ | Commented | c-commented-by-jiahangli-slfn | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | JiahangLi | NORMAL | 2023-10-11T15:21:10.112524+00:00 | 2023-10-11T15:21:10.112542+00:00 | 33 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\npublic:\n int minimumTeachings(int n, vector<vector<int>>& languages, vector<vector<int>>& friendships) {\n int m = languages.size();\n \n // Convert languages to sets for easier lookups\n vector<unordered_set<int>> langSet(m);\n for (int i = 0; i < m; ++i) {\n langSet[i] = unordered_set<int>(languages[i].begin(), languages[i].end());\n }\n \n // Find pairs that cannot communicate\n unordered_set<int> cannotTalk;\n for (auto& f : friendships) {\n int u = f[0] - 1, v = f[1] - 1; // Convert to 0-indexed\n bool canCommunicate = false;\n for (int lang : languages[u]) {\n if (langSet[v].count(lang)) {\n canCommunicate = true;\n break;\n }\n }\n if (!canCommunicate) {\n cannotTalk.insert(u);\n cannotTalk.insert(v);\n }\n }\n \n // If all pairs can communicate, no teaching needed\n if (cannotTalk.empty()) return 0;\n \n // Count the frequency of each language among the users who cannot communicate\n unordered_map<int, int> freq;\n for (int user : cannotTalk) {\n for (int lang : languages[user]) {\n freq[lang]++;\n }\n }\n \n // Find the language with the maximum frequency\n int maxFreq = 0;\n for (auto& [lang, count] : freq) {\n maxFreq = max(maxFreq, count);\n }\n \n return cannotTalk.size() - maxFreq; \n }\n};\n``` | 0 | 0 | ['C++'] | 0 |
minimum-number-of-people-to-teach | C++ | c-by-user5976fh-06em | \nclass Solution {\npublic:\n bool same(int a, int b, vector<vector<int>>& l){\n int i = 0, y = 0;\n while (i < l[a].size() && y < l[b].size()) | user5976fh | NORMAL | 2023-09-24T02:31:53.073038+00:00 | 2023-09-24T02:31:53.073057+00:00 | 6 | false | ```\nclass Solution {\npublic:\n bool same(int a, int b, vector<vector<int>>& l){\n int i = 0, y = 0;\n while (i < l[a].size() && y < l[b].size()){\n if (l[a][i] == l[b][y]) return true;\n else if (l[a][i] < l[b][y]) ++i;\n else ++y;\n }\n return false;\n }\n int minimumTeachings(int n, vector<vector<int>>& languages, vector<vector<int>>& friendships) {\n for (auto& v : languages) sort(v.begin(), v.end());\n vector<vector<int>> g(languages.size() + 1);\n for (auto& v : friendships) g[v[0]].push_back(v[1]);\n int ans = INT_MAX;\n for (int i = 1; i <= n; ++i){\n vector<bool> knowsNewLan(languages.size() + 1);\n int sum = 0;\n for (int z = 0; z < languages.size(); ++z)\n if (binary_search(languages[z].begin(), languages[z].end(), i))\n knowsNewLan[z + 1] = true;\n for (int z = 1; z < g.size(); ++z){\n for (auto& e : g[z]){\n if (!same(z - 1, e - 1, languages) && !(knowsNewLan[e] && knowsNewLan[z])){\n sum += !knowsNewLan[e];\n sum += !knowsNewLan[z];\n knowsNewLan[e] = true;\n knowsNewLan[z] = true;\n }\n }\n }\n ans = min(sum, ans);\n }\n return ans;\n }\n};\n``` | 0 | 0 | [] | 0 |
minimum-number-of-people-to-teach | C++ Brute Force Solution | c-brute-force-solution-by-ranjan_him212-tmy7 | \nclass Solution {\npublic:\n int minimumTeachings(int n, vector<vector<int>>& languages, vector<vector<int>>& friendships) {\n int ans = INT_MAX;\n | ranjan_him212 | NORMAL | 2023-09-20T08:04:11.751462+00:00 | 2023-09-20T08:04:11.751493+00:00 | 6 | false | ```\nclass Solution {\npublic:\n int minimumTeachings(int n, vector<vector<int>>& languages, vector<vector<int>>& friendships) {\n int ans = INT_MAX;\n vector<set<int>> lang;\n set<int> stt;\n lang.push_back(stt);\n for(auto &x : languages)\n {\n set<int> st;\n for(int &y : x)st.insert(y);\n lang.push_back(st);\n }\n int m = languages.size();\n vector<vector<bool>> IsCommon(m+1, vector<bool> (m+1, false));\n \n for(int i=1;i<=m;i++)\n {\n for(int j=i+1;j<=m;j++)\n {\n for(int k=1;k<=n;k++)\n {\n if((lang[i].find(k) != lang[i].end()) && (lang[j].find(k) != lang[j].end()))\n {\n IsCommon[i][j] = true;\n IsCommon[j][i] = true;\n break;\n }\n }\n }\n }\n \n for(int i=1;i<=n;i++)\n {\n int curr_ans = 0;\n vector<bool> op(m+1, false);\n for(auto &x : friendships)\n {\n if(IsCommon[x[0]][x[1]])continue;\n else\n {\n if((lang[x[0]].find(i) == lang[x[0]].end()) && (op[x[0]] == false))\n {\n op[x[0]] = true;\n curr_ans++;\n }\n if((lang[x[1]].find(i) == lang[x[1]].end()) && (op[x[1]] == false))\n {\n op[x[1]] = true;\n curr_ans++;\n }\n }\n }\n ans = min(ans, curr_ans);\n }\n return ans;\n }\n};\n``` | 0 | 0 | ['C'] | 0 |
minimum-number-of-people-to-teach | C++ solution | c-solution-by-pejmantheory-2j25 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | pejmantheory | NORMAL | 2023-09-01T04:00:20.209998+00:00 | 2023-09-01T04:00:20.210019+00:00 | 27 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\n public:\n int minimumTeachings(int n, vector<vector<int>>& languages,\n vector<vector<int>>& friendships) {\n vector<unordered_set<int>> languageSets;\n unordered_set<int> needTeach;\n unordered_map<int, int> languageCount;\n\n for (const vector<int>& language : languages)\n languageSets.push_back({language.begin(), language.end()});\n\n // Find friends that can\'t communicate.\n for (const vector<int>& friendship : friendships) {\n const int u = friendship[0] - 1;\n const int v = friendship[1] - 1;\n if (cantTalk(languageSets, u, v)) {\n needTeach.insert(u);\n needTeach.insert(v);\n }\n }\n\n // Find the most popular language.\n for (const int u : needTeach)\n for (const int language : languageSets[u])\n ++languageCount[language];\n\n // Teach the most popular language to people who don\'t understand.\n int maxCount = 0;\n for (const auto& [_, freq] : languageCount)\n maxCount = max(maxCount, freq);\n\n return needTeach.size() - maxCount;\n }\n\n private:\n // Returns true if u can\'t talk with v.\n bool cantTalk(const vector<unordered_set<int>>& languageSets, int u, int v) {\n for (const int language : languageSets[u])\n if (languageSets[v].count(language))\n return false;\n return true;\n }\n};\n\n``` | 0 | 0 | ['C++'] | 0 |
minimum-number-of-people-to-teach | good one | good-one-by-guventuncay-cf20 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | guventuncay | NORMAL | 2023-06-25T16:05:12.063834+00:00 | 2023-06-25T16:05:12.063873+00:00 | 61 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\n public static int minimumTeachings(int n, int[][] languages, int[][] friendships) {\n\n Map<Integer, Set<Integer>> langSpeakersMap = new HashMap<>();\n\n for (int i = 0; i < languages.length; i++) {\n int[] langs = languages[i];\n for (int lang : langs) {\n if (langSpeakersMap.get(lang) == null) {\n HashSet<Integer> speakersSet = new HashSet<>();\n speakersSet.add(i + 1);\n langSpeakersMap.put(lang, speakersSet);\n } else {\n langSpeakersMap.get(lang).add(i + 1);\n }\n }\n }\n\n Set<Integer> usersWhoCannotComEachOther = new HashSet<>();\n\n for (int[] friendship : friendships) {\n int user1 = friendship[0];\n int user2 = friendship[1];\n boolean found = false;\n for (int i = 0; i < languages[user1 - 1].length; i++) {//langs spoken by user1\n int lang = languages[user1 - 1][i];\n if (langSpeakersMap.get(lang).contains(user2)) {\n found = true;\n break;\n }\n }\n if (!found) {\n Collections.addAll(usersWhoCannotComEachOther, user1, user2);\n }\n }\n\n int ans = Integer.MAX_VALUE;\n\n for (Map.Entry<Integer, Set<Integer>> entry : langSpeakersMap.entrySet()) {\n Set<Integer> value = entry.getValue();\n int counter = 0;\n for (Integer u : usersWhoCannotComEachOther) {\n if (!value.contains(u)) {\n counter++;\n }\n }\n ans = Math.min(ans, counter);\n }\n\n return ans;\n }\n}\n``` | 0 | 0 | ['Java'] | 0 |
minimum-number-of-people-to-teach | Space: O(m*n), Time: O(m*n) | space-omn-time-omn-by-iitjsagar-m80u | class Solution(object):\n def minimumTeachings(self, n, languages, friendships):\n """\n :type n: int\n :type languages: List[List[int]] | iitjsagar | NORMAL | 2023-06-20T14:02:46.801555+00:00 | 2023-06-20T14:02:46.801579+00:00 | 35 | false | class Solution(object):\n def minimumTeachings(self, n, languages, friendships):\n """\n :type n: int\n :type languages: List[List[int]]\n :type friendships: List[List[int]]\n :rtype: int\n """\n \n people = len(languages)+1\n \n lang_matrix = [[False for l in range(n+1)] for p in range(people)]\n \n non_comm_friends = []\n for p,l_list in enumerate(languages):\n for l in l_list:\n lang_matrix[p+1][l] = True\n \n for [u,v] in friendships:\n comm = False\n for l in range(1,n+1):\n if lang_matrix[u][l] and lang_matrix[v][l]:\n #print u,v, l\n comm = True\n break\n \n if not comm:\n non_comm_friends.append([u,v])\n \n #print non_comm_friends\n res = people\n for l in range(1,n+1):\n cur = 0\n people_learned = set()\n \n for [u,v] in non_comm_friends:\n if not lang_matrix[u][l] and u not in people_learned:\n cur += 1\n people_learned.add(u)\n \n if not lang_matrix[v][l] and v not in people_learned:\n cur += 1\n people_learned.add(v)\n \n res = min(res, cur)\n \n return res\n \n \n | 0 | 0 | ['Graph'] | 0 |
minimum-number-of-people-to-teach | Java solution 70% | java-solution-70-by-valushaprogramist-1a94 | Intuition\n Describe your first thoughts on how to solve this problem. \nThe most complicated part was to understand that it must be one language to solve every | ValushaProgramist | NORMAL | 2023-06-19T21:44:49.659523+00:00 | 2023-06-19T21:44:49.659540+00:00 | 79 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThe most complicated part was to understand that it must be one language to solve everything. \n# Approach\n<!-- Describe your approach to solving the problem. -->\nI decided to create a map of zeros and ones to catch all teach events and then count them in the end. \nStep 1 - We need to find pair with language barrier \nStep 2 - Emulate solving process with each available language (populate teaching map)\nStep 3 - Sum each row in the teaching map to see what language provides better solution \nStep 0 - several times I had to check element existance in an array, I moved this logic into separate method. \n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nNot sure if I calculate correctly but O(n*m + f(x+n+2))\nwhere \nn - number of languages \nm - number of people \nf - number of pairs (friendships)\nx - average number of known languages per person \n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nSpace complaxity is much easier because i didn\'t create a lot of additional objects. \nO(n*m)\n# Code\n```\nclass Solution {\n public int minimumTeachings(int n, int[][] languages, int[][] friendships) {\n //create a teaching map\n int[][] teach = new int[n][languages.length];\n for(int i=0;i<n;i++)\n for(int j=0; j<languages.length;j++){\n teach[i][j]=0;\n }\n\n for(int i=0; i<friendships.length;i++){\n //looking for couples with language barrier \n boolean flag = false;\n for(int l=0;l<languages[friendships[i][0]-1].length;l++) {\n if(findTheElement(languages[friendships[i][1]-1],languages[friendships[i][0]-1][l])){\n flag=true;\n break;\n }\n else\n flag=false;\n }\n //fill in teaching map with all languages per friend\n if(!flag){\n for(int j=1;j<=n; j++){\n for(int k: friendships[i]){\n if(teach[j-1][k-1]==0)\n if(!findTheElement(languages[k-1],j)){\n teach[j-1][k-1] = 1;\n }\n }\n }\n }\n }\n //min is equal m, this is the case when all people speak one language\n int min=languages.length;\n for(int[] i:teach){\n int sum=0;\n for(int j: i){\n sum+=j;\n }\n if(sum<min)\n min=sum;\n }\n return min;\n }\n\n\n private boolean findTheElement(int[] array1, int n){\n for(int i: array1){\n if(i==n)\n return true;\n }\n return false;\n }\n}\n``` | 0 | 0 | ['Array', 'Java'] | 0 |
minimum-number-of-people-to-teach | Python3 solution: logic + brute force | python3-solution-logic-brute-force-by-hu-o2ll | Intuition\n Describe your first thoughts on how to solve this problem. \nFirst intuition was graph, because the problem was framed like a graph problem\n# Appro | huikinglam02 | NORMAL | 2023-05-31T05:41:34.091529+00:00 | 2023-05-31T05:41:34.091564+00:00 | 87 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nFirst intuition was graph, because the problem was framed like a graph problem\n# Approach\n<!-- Describe your approach to solving the problem. -->\nSince constraints are rather small, brute force trial and error would suffice\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n$$O(n * friendships.length)$$\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n$$O(n + friendships.length)$$\n# Code\n```\n#\n# @lc app=leetcode id=1733 lang=python3\n#\n# [1733] Minimum Number of People to Teach\n#\n\n# @lc code=start\nfrom typing import List\n\n\nclass Solution:\n \'\'\'\n Note that friendships are not transitive, meaning if x is a friend of y and y is a friend of z, this doesn\'t guarantee that x is a friend of z. This means graph is not appropriate. Instead we should consider between each pair of friend, which language does not intersect. The language which got the most vote is the optimal answer \n \'\'\'\n def minimumTeachings(self, n: int, languages: List[List[int]], friendships: List[List[int]]) -> int:\n lang = [set(l) for l in languages]\n frds = [f for f in friendships if len(lang[f[0] - 1].intersection(lang[f[1] - 1])) == 0]\n result = float(\'inf\')\n for i in range(1, n + 1):\n teach = set()\n for u, v in frds:\n if i not in lang[u - 1]:\n teach.add(u)\n if i not in lang[v - 1]:\n teach.add(v)\n result = min(result, len(teach)) \n return result \n# @lc code=end\n\n\n``` | 0 | 0 | ['Python3'] | 0 |
minimum-number-of-people-to-teach | C# Solution using Set || Easy To understand | c-solution-using-set-easy-to-understand-799q3 | \n\npublic class Solution {\n public int MinimumTeachings(int n, int[][] languages, int[][] friendships) {\n HashSet<int> langsUnion = new HashSet<int | mohamedAbdelety | NORMAL | 2023-04-29T14:09:54.576168+00:00 | 2023-04-29T14:09:54.576211+00:00 | 50 | false | \n```\npublic class Solution {\n public int MinimumTeachings(int n, int[][] languages, int[][] friendships) {\n HashSet<int> langsUnion = new HashSet<int>();\n HashSet<int> diffSet = new HashSet<int>();\n foreach(var friend in friendships){\n int u = friend[0] - 1, v = friend[1] - 1;\n foreach(var l in languages[u]) langsUnion.Add(l);\n foreach(var l in languages[v]) langsUnion.Add(l);\n if(langsUnion.Count == languages[u].Length + languages[v].Length){ // different\n diffSet.Add(u);\n diffSet.Add(v);\n }\n langsUnion.Clear(); \n }\n Dictionary<int,int> freq = new Dictionary<int,int>();\n int maxCommoonLang = 0;\n foreach(var friend in diffSet){\n foreach(var l in languages[friend]){\n freq.TryAdd(l,0);\n freq[l]++;\n maxCommoonLang = Math.Max(freq[l],maxCommoonLang);\n }\n }\n return diffSet.Count - maxCommoonLang;\n }\n}\n``` | 0 | 0 | ['C#'] | 0 |
minimum-number-of-people-to-teach | Go clean code | go-clean-code-by-ythosa-ovx1 | \n\nfunc minimumTeachings(n int, languages [][]int, friendships [][]int) int {\n\tvar cantSpeekPersons = make(map[int]struct{})\n\tfor _, friendship := range fr | ythosa | NORMAL | 2023-04-28T00:12:28.488576+00:00 | 2023-04-28T00:12:28.488608+00:00 | 50 | false | \n```\nfunc minimumTeachings(n int, languages [][]int, friendships [][]int) int {\n\tvar cantSpeekPersons = make(map[int]struct{})\n\tfor _, friendship := range friendships {\n\t\tfst := friendship[0] - 1\n\t\tsnd := friendship[1] - 1\n\t\tif !isLanguagesIntersects(languages, fst, snd) {\n\t\t\tcantSpeekPersons[fst] = struct{}{}\n\t\t\tcantSpeekPersons[snd] = struct{}{}\n\t\t}\n\t}\n\n\tvar (\n\t\tdontSpeeksCountByLanguage = make([]int, n)\n\t\tmaxDontSpeekCount = 0\n\t)\n\tfor person := range cantSpeekPersons {\n\t\tfor _, language := range languages[person] {\n\t\t\tlanguage--\n\t\t\tdontSpeeksCountByLanguage[language]++\n\t\t\tcurrentCount := dontSpeeksCountByLanguage[language]\n\t\t\tif currentCount > maxDontSpeekCount {\n\t\t\t\tmaxDontSpeekCount = currentCount\n\t\t\t}\n\t\t}\n\t}\n\n\treturn len(cantSpeekPersons) - maxDontSpeekCount\n}\n\nfunc isLanguagesIntersects(languages [][]int, fst, snd int) bool {\n\tvar tmpSet = make(map[int]struct{})\n\n\tfor _, language := range languages[fst] {\n\t\ttmpSet[language] = struct{}{}\n\t}\n\n\tfor _, language := range languages[snd] {\n\t\tif _, ok := tmpSet[language]; ok {\n\t\t\treturn true\n\t\t}\n\t}\n\n\treturn false\n}\n``` | 0 | 0 | ['Go'] | 0 |
minimum-number-of-people-to-teach | clean commented code | clean-commented-code-by-grumpyg-y8z8 | the question is tricky to understand but easy to implement when you overcome that intial hurdle. \n\n\nclass Solution:\n def minimumTeachings(self, n: int, l | grumpyG | NORMAL | 2023-03-29T21:33:05.011838+00:00 | 2023-03-29T21:33:05.011868+00:00 | 92 | false | the question is tricky to understand but easy to implement when you overcome that intial hurdle. \n\n```\nclass Solution:\n def minimumTeachings(self, n: int, languages: List[List[int]], friendships: List[List[int]]) -> int:\n # modify languages to be a set for quick intersection \n languages = {person+1: set(language) for person, language in enumerate(languages)} \n\n # create a set of people with a language barrier between a friend\n barrier = set() \n for u, v in friendships:\n if not languages[u] & languages[v]:\n barrier.add(u)\n barrier.add(v)\n\n # count the spoken languages between people with barriers \n spoken = Counter()\n for person in barrier:\n spoken += Counter(languages[person])\n\n # teach the most common language to those who don\'t know it\n return len(barrier) - max(spoken.values(), default=0)\n\n``` | 0 | 0 | ['Python3'] | 0 |
minimum-number-of-people-to-teach | Just a runnable solution | just-a-runnable-solution-by-ssrlive-qavx | Code\n\nimpl Solution {\n pub fn minimum_teachings(n: i32, languages: Vec<Vec<i32>>, friendships: Vec<Vec<i32>>) -> i32 {\n fn check(a: &[Vec<i32>], u | ssrlive | NORMAL | 2023-02-20T06:02:46.032580+00:00 | 2023-02-20T06:02:46.032625+00:00 | 50 | false | # Code\n```\nimpl Solution {\n pub fn minimum_teachings(n: i32, languages: Vec<Vec<i32>>, friendships: Vec<Vec<i32>>) -> i32 {\n fn check(a: &[Vec<i32>], u: usize, v: usize, mem: &mut [Vec<i32>]) -> bool {\n if mem[u][v] != 0 {\n return mem[u][v] == 1;\n }\n for i in 0..a[v].len() {\n if a[u].binary_search(&a[v][i]).is_ok() {\n mem[v][u] = 1;\n mem[u][v] = 1;\n return true;\n }\n }\n mem[u][v] = -1;\n mem[v][u] = -1;\n false\n }\n\n let mut languages = languages;\n let mut mem = vec![vec![0; languages.len() + 1]; languages.len() + 1];\n let mut ret = languages.len() as i32;\n for language in languages.iter_mut() {\n language.sort();\n }\n for lang in 1..=n {\n let mut count = 0;\n let mut teach = vec![false; languages.len()];\n for friendship in friendships.iter() {\n let u = friendship[0] as usize - 1;\n let v = friendship[1] as usize - 1;\n if check(&languages, u, v, &mut mem) {\n continue;\n }\n if languages[u].binary_search(&lang).is_err() {\n if !teach[u] {\n count += 1;\n }\n teach[u] = true;\n }\n if languages[v].binary_search(&lang).is_err() {\n if !teach[v] {\n count += 1;\n }\n teach[v] = true;\n }\n }\n ret = ret.min(count);\n }\n ret\n }\n}\n``` | 0 | 0 | ['Rust'] | 0 |
minimum-number-of-people-to-teach | Solution | solution-by-deleted_user-gamb | C++ []\nclass Solution {\nprivate:\n bool intersects(vector<int>& a, vector<int>& b, vector<bool>& vis){\n for(int elem: a){\n vis[elem] = | deleted_user | NORMAL | 2023-02-03T07:28:57.463158+00:00 | 2023-03-08T08:15:42.190052+00:00 | 225 | false | ```C++ []\nclass Solution {\nprivate:\n bool intersects(vector<int>& a, vector<int>& b, vector<bool>& vis){\n for(int elem: a){\n vis[elem] = true;\n }\n\n bool intersectionFound = false;\n for(int elem: b){\n if(vis[elem]){\n intersectionFound = true;\n break;\n }\n }\n\n for(int elem: a){\n vis[elem] = false;\n }\n\n return intersectionFound;\n }\n\npublic:\n int minimumTeachings(int L, vector<vector<int>>& languages, vector<vector<int>>& friendships) {\n const int U = languages.size();\n const int F = friendships.size();\n\n vector<bool> isGood(U + 1, true);\n vector<bool> tempVis(L + 1, false);\n for(const vector<int>& V: friendships){\n int a = V[0];\n int b = V[1];\n if(!intersects(languages[a - 1], languages[b - 1], tempVis)){\n isGood[a] = false;\n isGood[b] = false;\n }\n }\n\n int badUsers = 0;\n int maxCount = 0;\n unordered_map<int, int> count;\n for(int user = 1; user <= U; ++user){\n if(!isGood[user]){\n badUsers += 1;\n for(int language: languages[user - 1]){\n count[language] += 1;\n maxCount = max(maxCount, count[language]);\n }\n }\n }\n\n return badUsers - maxCount;\n }\n};\n```\n\n```Python3 []\nclass Solution:\n def minimumTeachings(self, n: int, languages: List[List[int]], friendships: List[List[int]]) -> int: \n languages: List[Set[int]] = [set(language) for language in languages] # O(m*n)\n without_contact: Set[int] = set()\n\n FIRST_FRIEND: int = 0\n SECOND_FRIEND: int = 1\n\n friendship: List[int]\n for friendship in friendships: # O(n)\n friend1: int = friendship[FIRST_FRIEND]\n friend2: int = friendship[SECOND_FRIEND]\n\n if not languages[friend1-1].intersection(languages[friend2-1]): # O(m)\n without_contact.add(friend1-1)\n without_contact.add(friend2-1)\n\n languages_spoken: List[int] = []\n\n person: int\n for person in without_contact: # O(m)\n languages_spoken.extend(languages[person])\n\n most_common: int = max(Counter(languages_spoken).values(), default=0) # O(n)\n\n return len(without_contact) - most_common\n```\n\n```Java []\nimport java.util.ArrayList;\nimport java.util.HashSet;\nimport java.util.List;\nimport java.util.Set;\n\npublic class Solution {\n public int minimumTeachings(int n, int[][] languages, int[][] friendships) {\n int m = languages.length;\n boolean[][] speak = new boolean[m + 1][n + 1];\n boolean[][] teach = new boolean[m + 1][n + 1];\n for (int user = 0; user < m; user++) {\n int[] userLanguages = languages[user];\n for (int userLanguage : userLanguages) {\n speak[user + 1][userLanguage] = true;\n }\n }\n List<int[]> listToTeach = new ArrayList<>();\n for (int[] friend : friendships) {\n int userA = friend[0];\n int userB = friend[1];\n boolean hasCommonLanguage = false;\n for (int language = 1; language <= n; language++) {\n if (speak[userA][language] && speak[userB][language]) {\n hasCommonLanguage = true;\n break;\n }\n }\n if (!hasCommonLanguage) {\n for (int language = 1; language <= n; language++) {\n if (!speak[userA][language]) {\n teach[userA][language] = true;\n }\n if (!speak[userB][language]) {\n teach[userB][language] = true;\n }\n }\n listToTeach.add(friend);\n }\n }\n int minLanguage = Integer.MAX_VALUE;\n int languageToTeach = 0;\n for (int language = 1; language <= n; language++) {\n int count = 0;\n for (int user = 1; user <= m; user++) {\n if (teach[user][language]) {\n count++;\n }\n }\n if (count < minLanguage) {\n minLanguage = count;\n languageToTeach = language;\n }\n }\n Set<Integer> setToTeach = new HashSet<>();\n for (int[] friend : listToTeach) {\n int userA = friend[0];\n int userB = friend[1];\n if (!speak[userA][languageToTeach]) {\n setToTeach.add(userA);\n }\n if (!speak[userB][languageToTeach]) {\n setToTeach.add(userB);\n }\n }\n return setToTeach.size();\n }\n}\n```\n | 0 | 0 | ['C++', 'Java', 'Python3'] | 0 |
minimum-number-of-people-to-teach | Python short 3-line solution | python-short-3-line-solution-by-vincent_-ivlh | \ndef minimumTeachings(self, n: int, ls: List[List[int]], es: List[List[int]]) -> int:\n\tls = [{0}]+[set(i) for i in ls]\n\tns = reduce(ior, [{i, j} for i, j i | vincent_great | NORMAL | 2023-01-22T13:17:23.287948+00:00 | 2023-01-22T13:19:20.952936+00:00 | 57 | false | ```\ndef minimumTeachings(self, n: int, ls: List[List[int]], es: List[List[int]]) -> int:\n\tls = [{0}]+[set(i) for i in ls]\n\tns = reduce(ior, [{i, j} for i, j in es if not ls[i]&ls[j]] or [{0}]) # ns=={0} means no teaching is needed\n\treturn min(sum(i not in ls[k] for k in ns) for i in range(1, n+1)) if len(ns)>1 else 0\n``` | 0 | 0 | [] | 0 |
minimum-number-of-people-to-teach | O(friendships * languages) time, O(number_of_people space) | ofriendships-languages-time-onumber_of_p-xmh1 | Approach\nFirst check who are the people that have some unsatisfying friendship (have a friend that they can\'t speak with).\nnow among those people check what | sroninio | NORMAL | 2023-01-10T12:04:36.435861+00:00 | 2023-01-10T12:04:36.435892+00:00 | 84 | false | # Approach\nFirst check who are the $$people$$ that have some unsatisfying friendship (have a friend that they can\'t speak with).\nnow among those $$people$$ check what is the most popular language.\nthis is the language that needs to be taught to all the $$people$$ that dont know it.\n\n\n# Code\n```\nclass Solution(object):\n def minimumTeachings(self, n, languages, friendships):\n """\n :type n: int\n :type languages: List[List[int]]\n :type friendships: List[List[int]]\n :rtype: int\n """\n people_need_lessons = set() \n for friends in friendships:\n f1, f2 = friends[0], friends[1]\n if len(set(languages[f1 - 1]).intersection(set(languages[f2 - 1]))) == 0:\n people_need_lessons.add(f1)\n people_need_lessons.add(f2)\n\n most_freq_spoken_languages = [0] * n\n for p in people_need_lessons:\n for l in languages[p - 1]:\n most_freq_spoken_languages[l - 1] += 1\n return len(people_need_lessons) - max(most_freq_spoken_languages)\n\n\n \n\n``` | 0 | 0 | ['Python'] | 0 |
minimum-number-of-people-to-teach | Python(Simple Maths) | pythonsimple-maths-by-rnotappl-ekgg | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | rnotappl | NORMAL | 2022-12-19T15:45:50.346432+00:00 | 2022-12-19T15:45:50.346471+00:00 | 171 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def minimumTeachings(self, n, languages, friendships):\n languages = [set(i) for i in languages]\n\n ans, dict1 = set(), defaultdict(int)\n\n for i,j in friendships:\n i = i-1\n j = j-1\n if languages[i]&languages[j]: continue\n ans.add(i)\n ans.add(j)\n\n for i in ans:\n for j in languages[i]:\n dict1[j] += 1\n\n return 0 if not ans else len(ans) - max(dict1.values())\n\n``` | 0 | 0 | ['Python3'] | 0 |
minimum-number-of-people-to-teach | Java solution intuitive | java-solution-intuitive-by-jeshupatelg37-t4ns | \n\n# Code\n\nclass Solution {\n public int minimumTeachings(int n, int[][] languages, int[][] friendships) {\n ArrayList<HashSet<Integer>> lan = new | jeshupatelg3774 | NORMAL | 2022-12-18T21:15:58.874460+00:00 | 2022-12-18T21:15:58.874501+00:00 | 190 | false | \n\n# Code\n```\nclass Solution {\n public int minimumTeachings(int n, int[][] languages, int[][] friendships) {\n ArrayList<HashSet<Integer>> lan = new ArrayList<>();\n for(int i =0;i<languages.length;i++){//converting languages array to list of set for easy search\n lan.add(new HashSet<>());\n for(int j=0;j<languages[i].length;j++){lan.get(i).add(languages[i][j]);}\n }\n boolean[] com = new boolean[friendships.length];\n for(int j=0;j<friendships.length;j++){\n for(int k : lan.get(friendships[j][0]-1)){\n if(lan.get(friendships[j][1]-1).contains(k)){\n com[j]=true; break;\n }\n }\n }\n int count=1000,cur=0;\n for(int i=1;i<=n;i++){//finding how many people need to learn ith language\n cur=0;\n for(int j=0;j<friendships.length;j++){\n //boolean com=false;\n //for(int k : lan.get(e[0]-1)){if(lan.get(e[1]-1).contains(k)){com=true; break;}}\n if(com[j])continue;\n if(lan.get(friendships[j][0]-1).contains(i)){\n //1stknows\n if(lan.get(friendships[j][1]-1).contains(i))continue;//2nd also knows\n else{\n //2nd dont know 1st know\n cur++;\n lan.get(friendships[j][1]-1).add(i);\n }\n }else{\n //1stdont know\n if(lan.get(friendships[j][1]-1).contains(i)){\n //2nd know 1st dont know\n cur++;\n lan.get(friendships[j][0]-1).add(i);\n }else{\n //1st and 2nd dont know\n cur+=2;\n lan.get(friendships[j][0]-1).add(i);\n lan.get(friendships[j][1]-1).add(i);\n }\n }\n }\n count = Math.min(count,cur);\n }\n return count;\n }\n}\n``` | 0 | 0 | ['Java'] | 0 |
minimum-number-of-people-to-teach | [JavaScript] Clean Solution | javascript-clean-solution-by-cucla101-ru1l | Code\n\n\n\nlet minimumTeachings = function(n, languages, friendships) {\n let mostSpokenLanguages = new Array(n + 1).fill(0);\n let PPL = new Map | cucla101 | NORMAL | 2022-12-07T20:42:57.881922+00:00 | 2022-12-07T20:44:43.025561+00:00 | 127 | false | # Code\n\n```\n\nlet minimumTeachings = function(n, languages, friendships) {\n let mostSpokenLanguages = new Array(n + 1).fill(0);\n let PPL = new Map();\n\n friendships.forEach( ( element ) => \n {\n let LANG = new Set( languages[element[0] - 1] );\n\n let shareLang = false;\n for ( const l of languages[element[1] - 1] )\n {\n if ( LANG.has(l) ) \n {\n shareLang = true;\n break;\n }\n }\n\n if ( !shareLang )\n {\n PPL.set( element[0], languages[element[0] - 1] );\n PPL.set( element[1], languages[element[1] - 1] );\n }\n } );\n\n PPL.forEach( (value, key) => { for ( const l of value ) ++mostSpokenLanguages[l] } );\n\n return PPL.size - Math.max(...mostSpokenLanguages);\n};\n``` | 0 | 0 | ['JavaScript'] | 0 |
minimum-number-of-people-to-teach | [Python] - Commented and Simple Python Solution | python-commented-and-simple-python-solut-a0ho | Intuition\n Describe your first thoughts on how to solve this problem. \nI think this problem is in the harder range of medium problems.\n\nThere are some thing | Lucew | NORMAL | 2022-12-01T11:10:09.141381+00:00 | 2022-12-01T11:10:09.141407+00:00 | 114 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nI think this problem is in the harder range of medium problems.\n\nThere are some things you need to consider:\n1) We only deal with users that are disconnected from other users\n2) We need to keep track of the most common known language for each disconnected user\n3) While keeping track of the most common spoken language for each disconnected user, we should be careful to not count users multiple times if they appear in several disconnected friendships (both friends don\'t have a common language)\n# Approach\n<!-- Describe your approach to solving the problem. -->\nWe do all of these things in one loop over the friendships, but first we convert all lists of languages to sets of languages to have a quicker way to compute intersections (i.e. finding whether two friends have a common language).\n\nAfter that we iterate over all friendships and immediately continue if two users have a common language and therefore are connected. We do this quickly using a set intersection.\n\nIf users are disconnected, we add their languages to a language counter, but in order to prevent us from counting the languages of a user multiple times (if he has multiple disconnected friendships), we keep track of these disconnected users in a set.\n\nFor the result we then take the most common language from all users and subtract its frequency from the amount of disconnected users. This gives ous the amount of users we would have to teach.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(K*N), where K is the amount of friendships and N is the amount of languages. The K comes from the loop and the N from the set intersection. \n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(N) for the counter of languages and the set of visited disconnected users (also N at most).\n\n# Code\n```\nclass Solution:\n def minimumTeachings(self, n: int, languages: List[List[int]], friendships: List[List[int]]) -> int:\n\n # make languages to a set for quick lookup\n languages = [set(langi) for langi in languages]\n\n # go through the friendships and check whether they can not communicate\n # count the languages these users already know as well as keeping\n # track which user we might have to teach in a visited set.\n visited = set()\n language_cn = collections.Counter()\n for user1, user2 in friendships:\n\n # check whether they already can communicate\n if languages[user1-1].intersection(languages[user2-1]):\n continue\n\n # if we have not added the languages of a disconnected user\n # we use them to keep track of languages disconnected users\n # speek\n if user1 not in visited:\n language_cn.update(languages[user1-1])\n visited.add(user1)\n if user2 not in visited:\n language_cn.update(languages[user2-1])\n visited.add(user2)\n \n # teach the language most of the disconnected users already know, which\n # is the most common language. The number of people we have to teach then\n # are disconnected users minus the ones who already speak the most common\n # language\n return len(visited) - language_cn.most_common(1)[0][1] if visited else 0\n\n``` | 0 | 0 | ['Python3'] | 0 |
minimum-number-of-people-to-teach | C++ solution with explanation | c-solution-with-explanation-by-slothalan-4108 | So, the question statement shall be paraphrased as follows:\n\nFind the minimum number of users to learn a new language L, such that for each pair of immediate | slothalan | NORMAL | 2022-11-29T13:53:51.982272+00:00 | 2022-11-29T13:53:51.982317+00:00 | 54 | false | So, the question statement shall be paraphrased as follows:\n\nFind the minimum number of users to learn a new language L, such that *for each pair of immediate friends (**no** nested relationships...), they don\'t have a common language, but each of them may or may not have learned L.*\n\n(-_-)\n\n```cpp\nclass Solution {\npublic:\n bool ck[510];\n std::unordered_map<int, vector<int>> F;\n std::vector<set<int>> lv;\n int nope[510][510];\n \n void inF(int k, int f) {\n if (F.count(k) == 0) {\n F[k] = { f };\n }\n else {\n F[k].push_back(f);\n }\n }\n bool valid(int f1, int f2) {\n for (int v : lv[f1]) {\n if (lv[f2].find(v) != lv[f2].end())\n return true;\n }\n return false;\n }\n int minimumTeachings(int n, vector<vector<int>>& languages, vector<vector<int>>& friendships) {\n int m = languages.size();\n for (vector<int> f : friendships) {\n inF(f[0], f[1]);\n inF(f[1], f[0]);\n }\n lv = {};\n for (int i = 0; i < m; i++) {\n set<int> s = {};\n lv.push_back(s);\n for (int li : languages[i]) {\n lv[i].insert(li);\n }\n }\n for (int i = 0; i < 510; i++) {\n ck[i] = false;\n for (int j = 0; j < 510; j++) {\n nope[i][j] = false;\n }\n } \n vector<pair<int, int>> diffF = {};\n for (int ppl = 1; ppl <= m; ppl++) {\n for (int pplf : F[ppl]) {\n if (!nope[ppl][pplf]) {\n if (!valid(ppl - 1, pplf - 1)) {\n diffF.push_back({ppl - 1, pplf - 1});\n }\n nope[ppl][pplf] = true;\n nope[pplf][ppl] = true;\n }\n }\n }\n int rescnt = m + 1;\n for (int l = 1; l <= n; l++) {\n int tmpcnt = 0;\n for (int i = 0; i < 510; i++)\n ck[i] = false;\n for (pair<int, int> df : diffF) {\n if (lv[df.first].find(l) == lv[df.first].end()) {\n ck[df.first] = true;\n }\n if (lv[df.second].find(l) == lv[df.second].end()) {\n ck[df.second] = true;\n }\n }\n for (int ppl = 0; ppl < m; ppl++) {\n tmpcnt += ck[ppl];\n }\n rescnt = std::min(rescnt, tmpcnt);\n }\n return rescnt;\n }\n};\n``` | 0 | 0 | [] | 0 |
minimum-number-of-people-to-teach | python greedy solution | python-greedy-solution-by-alston16-e7nh | \nclass Solution:\n def minimumTeachings(self, n: int, languages: List[List[int]], friendships: List[List[int]]) -> int:\n counter = [set() for i in r | ALSTON16 | NORMAL | 2022-11-12T04:15:52.259794+00:00 | 2022-11-12T04:15:52.259847+00:00 | 31 | false | ```\nclass Solution:\n def minimumTeachings(self, n: int, languages: List[List[int]], friendships: List[List[int]]) -> int:\n counter = [set() for i in range(len(languages))]\n memo = dict()\n for i in range(len(languages)):\n for j in languages[i]:\n counter[i].add(j)\n\n\n for i in range(len(friendships)):\n disc = False\n\n for j in languages[friendships[i][1]-1]:\n if j in counter[friendships[i][0]-1]:\n disc = True\n break\n\n if disc == False:\n memo[friendships[i][0]] = 0\n memo[friendships[i][1]] = 0\n\n cur = dict()\n disc_friends = list(memo.keys())\n max_language = 0\n for i in disc_friends:\n for j in languages[i-1]:\n if j in cur:\n cur[j] += 1\n else:\n cur[j] = 1\n max_language = max(max_language,cur[j])\n\n return len(disc_friends)-max_language\n\n\n``` | 0 | 0 | [] | 0 |
minimum-number-of-people-to-teach | [C++] |Simple|Easy to read and Unerstand | c-simpleeasy-to-read-and-unerstand-by-en-pe9c | \nclass Solution {\npublic:\n int minimumTeachings(int n, vector<vector<int>>& languages, vector<vector<int>>& friendships) {\n int m=languages.size() | endless_mercury | NORMAL | 2022-11-02T16:56:04.891779+00:00 | 2022-11-02T16:56:04.891820+00:00 | 74 | false | ```\nclass Solution {\npublic:\n int minimumTeachings(int n, vector<vector<int>>& languages, vector<vector<int>>& friendships) {\n int m=languages.size();\n //keep track if person can speak language already\n vector<vector<bool>> can_speak(m+1,vector<bool>(n+1,false));\n for(int i=0;i<m;i++){\n for(int j=0;j<languages[i].size();j++){\n can_speak[i+1][languages[i][j]]=true;\n }\n }\n set<int> v;\n for(int i=0;i<friendships.size();i++){\n bool flag=true;\n for(int j=1;j<=n;j++){\n if(can_speak[friendships[i][0]][j]&&can_speak[friendships[i][1]][j]){\n flag=false;\n break;\n }\n }\n //if need some common language\n if(flag){\n v.insert(friendships[i][0]);\n v.insert(friendships[i][1]);\n }\n }\n vector<int> cnt(n+1,0);\n int ma=0;\n //vote for your language\n for(auto it:v){\n for(int j=0;j<languages[it-1].size();j++){\n cnt[languages[it-1][j]]++;\n ma=max(ma,cnt[languages[it-1][j]]);\n }\n }\n //others will learn \n return v.size()-ma;;\n }\n};\n``` | 0 | 0 | ['C'] | 0 |
minimum-number-of-people-to-teach | Python 3 Solution | python-3-solution-by-aryaman73-nluj | \nIndexing is a bit annoying, since everything is 1-indexed, so keep that in mind. \n\npy\nclass Solution:\n def minimumTeachings(self, n: int, languages: Li | aryaman73 | NORMAL | 2022-10-17T03:30:41.589871+00:00 | 2022-10-17T03:30:41.589917+00:00 | 110 | false | \nIndexing is a bit annoying, since everything is 1-indexed, so keep that in mind. \n\n```py\nclass Solution:\n def minimumTeachings(self, n: int, languages: List[List[int]], friendships: List[List[int]]) -> int:\n \n # Find which friendships can not communicate, i.e. which users need to be taught\n usersToBeTaught = set() # 0-indexed\n \n for f in friendships:\n f1 = set(languages[f[0] - 1])\n f2 = set(languages[f[1] - 1])\n if f1.isdisjoint(f2): #If there are no common languages between that pair of friends\n usersToBeTaught.add(f[0] - 1)\n usersToBeTaught.add(f[1] - 1)\n \n if len(usersToBeTaught) == 0:\n return 0\n \n # For each language, how many people will I need to teach in usersToBeTaight?\n languageCounter = collections.defaultdict(int)\n \n for language in range(1, n + 1):\n for user in usersToBeTaught:\n if language not in languages[user]:\n languageCounter[language] += 1\n \n # Find minimum of how many people I need to teach\n return min(languageCounter.values())\n \n \n \n ``` | 0 | 0 | ['Python'] | 0 |
minimum-number-of-people-to-teach | Use sets to get friends who can't communicate | use-sets-to-get-friends-who-cant-communi-dy9x | \nclass Solution:\n def minimumTeachings(self, n: int, languages: List[List[int]], friendships: List[List[int]]) -> int:\n hmap = {}\n for i, l | rktayal | NORMAL | 2022-09-27T02:25:31.241925+00:00 | 2022-09-27T02:25:31.241966+00:00 | 40 | false | ```\nclass Solution:\n def minimumTeachings(self, n: int, languages: List[List[int]], friendships: List[List[int]]) -> int:\n hmap = {}\n for i, l_list in enumerate(languages):\n hmap[i+1] = set()\n for item in l_list:\n hmap[i+1].add(item)\n \n mis_friend = set()\n \n for friend in friendships:\n a, b = friend[:]\n if not len(hmap[a].intersection(hmap[b])):\n mis_friend.add(a)\n mis_friend.add(b)\n \n res = float(\'inf\')\n for lang in range(1, n+1):\n count = 0\n for fri in mis_friend:\n if lang not in hmap[fri]:\n count+=1\n res = min(res, count)\n return res\n``` | 0 | 0 | ['Ordered Set', 'Python'] | 0 |
minimum-number-of-people-to-teach | Confusion | confusion-by-zsun273-6bch | For this example, why is the answer 3?\n\n4\n[[1],[2],[3],[4]]\n[[1,2],[3,4]]\n\nwe can simply teach 1 language 2 and teach 3 language 4, which leads to answer | zsun273 | NORMAL | 2022-09-20T19:25:15.429202+00:00 | 2022-09-20T19:25:15.429241+00:00 | 22 | false | For this example, why is the answer 3?\n\n4\n[[1],[2],[3],[4]]\n[[1,2],[3,4]]\n\nwe can simply teach 1 language 2 and teach 3 language 4, which leads to answer 2. | 0 | 0 | [] | 0 |
minimum-number-of-people-to-teach | [Time & Memory 100%] Try all languages and find minimum | time-memory-100-try-all-languages-and-fi-rpov | Complexity\nTime: O(m * n)\nSpace: O(m * n)\n\ntypescript\nfunction minimumTeachings(n: number, languages: number[][], friendships: number[][]): number {\n / | jhw123 | NORMAL | 2022-08-30T09:11:51.520803+00:00 | 2022-08-30T09:11:51.520849+00:00 | 70 | false | ### Complexity\nTime: `O(m * n)`\nSpace: `O(m * n)`\n\n```typescript\nfunction minimumTeachings(n: number, languages: number[][], friendships: number[][]): number {\n // filter the friends who do not have a common language and need to be taught\n\tconst friendshipsWithProblem = []\n for (const [f1, f2] of friendships) {\n const f1Lang = languages[f1-1]\n const f2Lang = languages[f2-1]\n if (!hasCommonLang(f1Lang, f2Lang)) {\n friendshipsWithProblem.push([f1, f2])\n }\n }\n\t\n\t// change language to Sets to reduce time complexity\n const lang = languages.map(language => new Set(language))\n\t\n\t// try all languages and find the min\n let min = Infinity\n for (let i=1; i<=n; i+=1) {\n min = Math.min(min, teachLang(i, lang, friendshipsWithProblem))\n }\n return min\n};\n\n// checking if two people have a common language\nfunction hasCommonLang(lang1: number[], lang2: number[]) {\n const set = new Set(lang1)\n\treturn lang2.some(lang => set.has(lang))\n}\n\n// finding the number of people needed to be taught for a chosen language \nfunction teachLang(language: number, lang: Set<number>[], friendships: number[][]) {\n let n = 0\n \n for (const [f1, f2] of friendships) {\n if (!lang[f1-1].has(language)) {\n lang[f1-1].add(language)\n n += 1\n }\n if (!lang[f2-1].has(language)) {\n lang[f2-1].add(language)\n n += 1\n }\n }\n \n return n\n}\n``` | 0 | 0 | ['Ordered Set', 'TypeScript', 'JavaScript'] | 0 |
minimum-number-of-people-to-teach | C++, filter friendships, 100% | c-filter-friendships-100-by-cx3129-001a | \nclass Solution {\npublic:\n int minimumTeachings(int n, vector<vector<int>>& languages, vector<vector<int>>& friendships) {\n int m=languages.size() | cx3129 | NORMAL | 2022-06-05T10:48:40.935142+00:00 | 2022-06-05T10:59:54.473877+00:00 | 112 | false | ```\nclass Solution {\npublic:\n int minimumTeachings(int n, vector<vector<int>>& languages, vector<vector<int>>& friendships) {\n int m=languages.size();\n vector<vector<bool>> hasLan(m+1,vector<bool>(n+1,false)); //cache for which languages each user known\n for(int i=1;i<=m;++i) \n for(auto& lan:languages[i-1]) hasLan[i][lan]=true;\n \n filterFriendShips(n,hasLan, friendships); //filter out friendships in which two users already know one common language\n \n int minTeach=INT_MAX,lan,teachi,user1,user2;;\n bool* teached= new bool[m+1];\n for(lan=1;lan<=n;++lan) {\n memset(teached,0,(m+1)*sizeof(bool));\n teachi=0;\n \n for(auto& f:friendships) {\n user1 = f[0],user2 = f[1];\n if(teached[user1] && teached[user2] ) continue;\n \n if(!hasLan[user1][lan] && !teached[user1]) { teachi++; teached[user1]=true; }\n if(!hasLan[user2][lan] && !teached[user2]) { teachi++; teached[user2]=true; }\n \n if(teachi>=minTeach) break;\n }\n \n minTeach=min(minTeach, teachi);\n }\n \n delete[] teached;\n return minTeach;\n }\n \n void filterFriendShips(int n, vector<vector<bool>>& hasLan,vector<vector<int>>& friendships) {\n vector<vector<int>> temp;\n int user1,user2;\n for(auto&f:friendships) {\n user1 = f[0], user2 = f[1];\n \n bool bAllKnowLan=false;\n for(int lan=1;lan<=n;++lan) \n if(hasLan[user1][lan] && hasLan[user2][lan] ) { bAllKnowLan = true; break;}\n \n if(!bAllKnowLan) temp.push_back({user1,user2});\n }\n\n friendships = temp;\n }\n};\n\n```\n | 0 | 0 | [] | 0 |
minimum-number-of-people-to-teach | [C++] || Set,Map | c-setmap-by-rahul921-x45n | \nclass Solution {\npublic:\n set<int> cantTalk ;\n bool InCommon(vector<int>& lang1 , vector<int>&lang2 ){\n //checks if two friends can speak an | rahul921 | NORMAL | 2022-05-27T08:30:09.095518+00:00 | 2022-05-27T08:30:09.095559+00:00 | 180 | false | ```\nclass Solution {\npublic:\n set<int> cantTalk ;\n bool InCommon(vector<int>& lang1 , vector<int>&lang2 ){\n //checks if two friends can speak any language in common ?\n for(auto &x : lang1)\n for(auto &y : lang2)\n if(x == y) return true ;\n \n \n return false ; \n }\n \n int minimumTeachings(int n, vector<vector<int>>& lang , vector<vector<int>>& friends) {\n \n for(auto &x : friends){\n int u = x[0] , v = x[1] ;\n //if two friends cannot speak any language in common then store them in cantTalk\n if(!InCommon(lang[u-1],lang[v-1])){\n cantTalk.insert(u) ;\n cantTalk.insert(v) ;\n }\n }\n \n //maps the language --> user (only the ones which are present in set cantTalk)! \n map<int,vector<int>> common ;\n \n for(int i = 0 ; i < lang.size() ; ++i ){\n if(cantTalk.find(i+1) == end(cantTalk)) continue ;\n for(auto &x : lang[i]) common[x].push_back(i+1) ;\n }\n \n int maxCommonSpeaking = 0 ;\n \n //find the max number of users who can speak any language commonly \n for(int i= 1 ; i <= n ; ++i ) maxCommonSpeaking = max(maxCommonSpeaking,(int)common[i].size()) ;\n \n //rest of the users left will need to be taught the language\n return (int)cantTalk.size() - maxCommonSpeaking ;\n \n \n }\n};\n``` | 0 | 0 | ['C'] | 0 |
minimum-number-of-people-to-teach | Intersection of common languages | intersection-of-common-languages-by-ttn6-yiq8 | Very unclear description, I must say...\nBut not a bad question after all.\n\ncpp\n// check if user u and v share a common language.\n// sorted array and two-po | ttn628826 | NORMAL | 2022-05-21T12:46:50.598397+00:00 | 2022-05-21T12:51:19.985851+00:00 | 108 | false | Very unclear description, I must say...\nBut not a bad question after all.\n\n```cpp\n// check if user u and v share a common language.\n// sorted array and two-pointer, \n// binary search might be even better.\nbool haveCommon(vector<vector<int>>& lan, int u, int v)\n{\n\tint i = 0;\n\tint j = 0;\n\t\n\twhile (i < lan[u].size() && j < lan[v].size())\n\t{\n\t\tif (lan[u][i] < lan[v][j])\n\t\t\t++ i;\n\t\telse if (lan[u][i] > lan[v][j])\n\t\t\t++ j;\n\t\telse\n\t\t\treturn true;\n\t}\n\t\n\treturn false;\n}\n\nint minimumTeachings(int n, vector<vector<int>>& languages, vector<vector<int>>& friendships) {\n\tint m = languages.size();\n\tvector<int> lan(n + 1);\n\tqueue<int> que;\n\tset<int> learner;\n\t\n\t// sorted, might not be necessary, but we better not relay to much on input data.\n\tfor (auto &l : languages)\n\t\tsort(begin(l), end(l));\n\t\n\t// for each friendship between u and v,\n\tfor (auto &f : friendships)\n\t{\n\t\tint u = f[0] - 1;\n\t\tint v = f[1] - 1;\n\t\t\n\t\t// if they don\'t share a common language, \n\t\tif (! haveCommon(languages, u, v))\n\t\t{\n\t\t\t// check if user u has already be considered, \n\t\t\t// if not,\n\t\t\tif (learner.count(u) == 0)\n\t\t\t{\n\t\t\t\t// put user u into the set that must be taugh a new language.\n\t\t\t\tlearner.insert(u);\n\t\t\t\t\n\t\t\t\t// record those languages that the user u has alreay known.\n\t\t\t\tfor (auto l : languages[u])\n\t\t\t\t\t++ lan[l];\n\t\t\t}\n\t\t\t\n\t\t\t// apply same logic to user v.\n\t\t\tif (learner.count(v) == 0)\n\t\t\t{\n\t\t\t\tlearner.insert(v);\n\t\t\t\tfor (auto l : languages[v])\n\t\t\t\t\t++ lan[l];\n\t\t\t}\n\t\t}\n\t}\n\t\n\t// inside the set are the total users that must learn at least one language \n\t// to fulfill the communication between some of their friendship.\n\t// and we also have records of the summary of how many users already known which language.\n\t// find the dominate language, and those who do know this language must learn it, \n\t// so that each user inside the set know this dominate language.\n\treturn learner.size() - *max_element(begin(lan), end(lan));\n}\n```\n | 0 | 0 | ['C'] | 0 |
minimum-number-of-people-to-teach | 93% Time and 89% Space, 277 ms Simple Logic Explained | 93-time-and-89-space-277-ms-simple-logic-2jj0 | ```\nclass Solution {\npublic:\n #define pii pair\n #define f first\n #define s second\n int minimumTeachings(int n, vector>& langs, vector>& conn) | ms2000 | NORMAL | 2022-05-21T04:35:58.870046+00:00 | 2022-05-21T04:39:11.032535+00:00 | 74 | false | ```\nclass Solution {\npublic:\n #define pii pair<int,int>\n #define f first\n #define s second\n int minimumTeachings(int n, vector<vector<int>>& langs, vector<vector<int>>& conn) {\n \n vector<int> allLang(n+1,0);\n int m = conn.size();\n vector<pii> graph;\n int mx = 0;\n for(int i=0; i<m; i++)\n {\n int start = conn[i][0];\n int end = conn[i][1];\n mx=0;//F**K YE GALAT THA\n for(auto y:langs[start-1])\n allLang[y]++;\n for(auto y:langs[end-1])\n allLang[y]++;\n /*\n for(auto y:allLang)\n cout<<y<<" ";\n cout<<endl;\n */\n for(auto &y:allLang)\n {\n mx = max(mx, y);\n y = 0;//make this 0 so we can use the vector again\n }\n if(mx < 2)//this means that they don\'t have any language in common, so path which are able to communicate are excluded\n {\n graph.push_back({start,end});\n //cout<<start<<" "<<end<<"\\t";\n }\n }\n unordered_map<int,int> visited;//we use this so that connections having common people don\'t get their langauges added multiple times, they should get added only once\n for(auto &p:graph)\n {\n if(visited[p.f]==0)\n {\n for(auto y:langs[p.f-1])\n allLang[y]++;\n visited[p.f]=1;\n }\n if(visited[p.s]==0)\n {\n for(auto y:langs[p.s-1])\n allLang[y]++;\n visited[p.s]=1;\n }\n }\n int len = visited.size();\n mx = *max_element(allLang.begin(),allLang.end());\n //cout<<len<<" "<<mx<<endl;\n return len - mx;//total people - people who known the most abundant language\n \n \n }\n};\nAlgorithm:\n1. Break the path that are able to communicate \n2. then find the language which is most abundant, and then make sure that everyone knows that langauge | 0 | 0 | [] | 0 |
minimum-number-of-people-to-teach | Scala | scala-by-fairgrieve-q2nc | \nimport scala.collection.immutable.BitSet\nimport scala.util.chaining.scalaUtilChainingOps\n\nobject Solution {\n def minimumTeachings(n: Int, languages: Arra | fairgrieve | NORMAL | 2022-04-04T05:17:42.591734+00:00 | 2022-04-04T05:17:42.591771+00:00 | 38 | false | ```\nimport scala.collection.immutable.BitSet\nimport scala.util.chaining.scalaUtilChainingOps\n\nobject Solution {\n def minimumTeachings(n: Int, languages: Array[Array[Int]], friendships: Array[Array[Int]]): Int = {\n languages\n .map(_.to(BitSet))\n .pipe { languages =>\n friendships\n .filter { case Array(u, v) => (languages(u - 1) & languages(v - 1)).isEmpty }\n .pipe { friendships =>\n (1 to n)\n .view\n .map { language =>\n friendships\n .view\n .flatMap {\n case Array(u, v) if languages(u - 1).contains(language) => Iterator(v)\n case Array(u, v) if languages(v - 1).contains(language) => Iterator(u)\n case Array(u, v) => Iterator(u, v)\n }\n .toSet\n .size\n }\n .min\n }\n }\n }\n}\n``` | 0 | 0 | ['Scala'] | 0 |
minimum-number-of-people-to-teach | count for friends without same language c++ | count-for-friends-without-same-language-67atg | \nclass Solution {\n bool hassame(const vector<int>& v1, const vector<int>& v2)\n {\n int i1=0, i2=0;\n while(i1<v1.size() && i2<v2.size())\ | dolaamon2 | NORMAL | 2022-04-02T13:47:03.670331+00:00 | 2022-04-02T13:49:45.537020+00:00 | 78 | false | ```\nclass Solution {\n bool hassame(const vector<int>& v1, const vector<int>& v2)\n {\n int i1=0, i2=0;\n while(i1<v1.size() && i2<v2.size())\n {\n if (v1[i1] == v2[i2])\n return true;\n else if (v1[i1] < v2[i2])\n i1++;\n else\n i2++;\n }\n return false;\n }\npublic:\n int minimumTeachings(int n, vector<vector<int>>& languages, vector<vector<int>>& friendships) {\n int m = languages.size();\n int k = friendships.size();\n for(auto& l: languages)\n sort(l.begin(), l.end());\n vector<bool> candidates(m, false);\n for(int i=0; i<k; i++)\n {\n auto i1 = friendships[i][0] - 1, i2 = friendships[i][1] - 1;\n if (!hassame(languages[i1],languages[i2]))\n candidates[i1] = candidates[i2] = true;\n }\n vector<int> count(n, 0);\n int candidate_count = 0;\n for(int i=0; i<m; i++)\n {\n if (candidates[i])\n {\n candidate_count++;\n for(int j=0; j<languages[i].size(); j++)\n count[languages[i][j]-1]++;\n }\n }\n return candidate_count - *max_element(count.begin(), count.end());\n }\n};\n``` | 0 | 0 | [] | 0 |
minimum-number-of-people-to-teach | Java solution with explanation | java-solution-with-explanation-by-ptdao-jdn5 | \n\nclass Solution {\n \n /**\n Algorithm:\n\n 1. We will initialize the variable \'minimumUsers\' = total users, and it will store the minimum | ptdao | NORMAL | 2022-03-22T00:05:14.364621+00:00 | 2022-03-22T00:05:14.364721+00:00 | 112 | false | \n```\nclass Solution {\n \n /**\n Algorithm:\n\n 1. We will initialize the variable \'minimumUsers\' = total users, and it will store the minimum number of users that needs to learn the common language.\n 2. Maintain a user Map, which stores users who cannot communicate with their friends.\n Check if users \'user1\' and \'user2\' shares a common language.\n If both users do not share a common language, then insert both users in the Map.\n 3. Iterate thru the list of languages,\n We will set the variable \'totalUsers\' as 0, which will store the total number of users need to learn a common languge.\n Iterate it over the user MAP\n Check if the user at it cannot speak a language, then increment \'totalUsers\' by 1.\n If \'minimumUsers\' is more than \'totalUsers\', then update \'minimumUsers\' with \'totalUsers\'.\n 4. Return the variable \'minimumUsers\'.\n\nTime Complexity: O(NxM)\n\t* \tN: number of languages\n\t* \tM: number of users\nSpace Complexity: O(NxM)\n **/\n \n \n public int minimumTeachings(int n, int[][] languages, int[][] friendships) {\n\n //minimumUsers first start with all users\n //and will be updated to store the minimum number of users to teach\n int minimumUsers = friendships.length;\n \n //Map to store User and the Languagues that user can speak. \n Map<Integer,Set<Integer>> user_languages = new HashMap<>();\n for(int user = 0; user < languages.length; user++) {\n Set<Integer> lst_languages = new HashSet<>();\n for(int language = 0; language < languages[user].length; language++) {\n lst_languages.add(languages[user][language]);\n }\n user_languages.put(user+1, lst_languages); //user+1 because the no. of users start with 1 rather than 0\n }\n \n //Map to store User and the his friends who he cant communicate with. \n Map<Integer,Set<Integer>> user_friends = new HashMap<>();\n for(int i = 0; i < friendships.length; i++){\n int[] friends = friendships[i];\n int user1 = friends[0];\n int user2 = friends[1];\n\n if(!canCommunicate(user_languages.get(user1), user_languages.get(user2))) {\n //store user1 \n user_friends.putIfAbsent(user1, new HashSet<>());\n user_friends.get(user1).add(user2);\n\n //store user2 \n user_friends.putIfAbsent(user2, new HashSet<>());\n user_friends.get(user2).add(user1);\n }\n \n }\n\n //loop thru every language and check to see if a user need to learn a common langue\n for(int language = 1; language <= n; language++) {\n //the variable \'totalUsers\' as 0, \n //which will store the total number of users needs to learn a common language\n int totalUsers = 0;\n for(int user : user_friends.keySet()) {\n if(!user_languages.get(user).contains(language)) {\n totalUsers++;\n } \n } \n minimumUsers = Math.min(minimumUsers,totalUsers);\n } \n return minimumUsers;\n \n }\n \n private boolean canCommunicate(Set<Integer> user1_languages, Set<Integer> user2_languages) {\n for(int user2_language : user2_languages){\n if(user1_languages.contains(user2_language)){\n return true;\n }\n }\n return false;\n }\n}\n``` | 0 | 0 | [] | 0 |
minimum-number-of-people-to-teach | Golang | O(N * Len(FriendShip) | Bitset, SIMD, Loop Unroll | Beat 100% | golang-on-lenfriendship-bitset-simd-loop-hesr | \nfunc minimumTeachings(n int, langs [][]int, friends [][]int) int {\n m := len(langs)\n \n set := make([][8]uint64, m)\n for i, lang := range langs | linhduong | NORMAL | 2021-12-13T13:45:54.918861+00:00 | 2021-12-13T13:46:17.193654+00:00 | 242 | false | ```\nfunc minimumTeachings(n int, langs [][]int, friends [][]int) int {\n m := len(langs)\n \n set := make([][8]uint64, m)\n for i, lang := range langs {\n for _, l := range lang {\n set[i] = turnOn(set[i], l - 1)\n } \n }\n \n added := make([]bool, m)\n \n min := m+1\n for l := 0; l < n; l++ {\n // try to teach language: l\n reset(added)\n \n result := 0\n for _, fri := range friends {\n u, v := fri[0] - 1, fri[1] - 1\n \n if !canCommunicate(set[u], set[v]) {\n if !contains(set[u], l) && !added[u] {\n added[u] = true\n result++\n }\n \n if !contains(set[v], l) && !added[v] {\n added[v] = true\n result++\n }\n }\n }\n \n if min > result {\n min = result\n }\n }\n \n return min\n}\n\n// go compiler will try to use SIMD for special case like: memset 0, memset false\n// (auto-vectorization)\nfunc reset(v []bool) {\n for i := range v {\n v[i] = false\n }\n}\n\n// go compiler will try to make this on stack (small buffer optimization)\n// that\'s why we must return value\nfunc turnOn(set [8]uint64, pos int) [8]uint64 {\n set[pos >> 6] |= uint64(1 << (pos & 63))\n return set\n}\n\nfunc contains(set [8]uint64, pos int) bool {\n return (set[pos >> 6] >> uint64(pos & 63)) & 1 == 1\n}\n\n// loop unrolling optimization\nfunc canCommunicate(s1, s2 [8]uint64) bool {\n return (s1[0] & s2[0] != 0) ||\n (s1[1] & s2[1] != 0) ||\n (s1[2] & s2[2] != 0) ||\n (s1[3] & s2[3] != 0) ||\n (s1[4] & s2[4] != 0) ||\n (s1[5] & s2[5] != 0) ||\n (s1[6] & s2[6] != 0) ||\n (s1[7] & s2[7] != 0)\n}\n``` | 0 | 0 | ['Go'] | 0 |
minimum-number-of-people-to-teach | [Golang] Two steps brute force solution | golang-two-steps-brute-force-solution-by-tut9 | Get the people who need learn other language then store in a map.\n2. Check the number of people need to learn if teaching them from language "1" to "n". \nThe | genius52 | NORMAL | 2021-12-03T05:25:01.966280+00:00 | 2021-12-03T05:25:36.537438+00:00 | 95 | false | 1. Get the people who need learn other language then store in a map.\n2. Check the number of people need to learn if teaching them from language "1" to "n". \nThe minimum number is we need.\n```\nfunc minimumTeachings(n int, languages [][]int, friendships [][]int) int {\n\tvar need_learn_people map[int]bool = make(map[int]bool)\n\tfor _, r := range friendships {\n\t\tvar find bool = false\n\t\tfor _, n0 := range languages[r[0]-1] {\n\t\tloop:\n\t\t\tfor _, n1 := range languages[r[1]-1] {\n\t\t\t\tif n0 == n1 {\n\t\t\t\t\tfind = true\n\t\t\t\t\tbreak loop\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t\tif find {\n\t\t\tcontinue\n\t\t}\n\t\tneed_learn_people[r[0]] = true\n\t\tneed_learn_people[r[1]] = true\n\t}\n\tvar m int = len(need_learn_people)\n var res int = m\n\tfor i := 1; i <= n; i++ {\n\t\tvar cnt int = 0\n\t\tfor person,_ := range need_learn_people{\n\t\t\tfor _,lan := range languages[person - 1] {\n\t\t\t\tif lan == i {\n\t\t\t\t\tcnt++\n\t\t\t\t\tbreak\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t\tres = min_int(res, m-cnt)\n\t}\n\treturn res\n}\nfunc min_int(a,b int)int{\n\tif a < b {\n\t\treturn a\n\t}else{\n\t\treturn b\n\t}\n} | 0 | 0 | ['Go'] | 0 |
minimum-number-of-people-to-teach | C# 100% | c-100-by-rahulvn389-rwnx | public class Solution {\n \n private bool CanCommunicate(int[][] languages, int a, int b)\n {\n var languagesA = languages[a-1];\n var la | rahulvn389 | NORMAL | 2021-11-02T19:02:38.919863+00:00 | 2021-11-02T19:02:38.919899+00:00 | 58 | false | public class Solution {\n \n private bool CanCommunicate(int[][] languages, int a, int b)\n {\n var languagesA = languages[a-1];\n var languagesB = languages[b-1];\n \n int i=0;\n int j=0;\n while(i<languagesA.Length && j<languagesB.Length)\n {\n if(languagesA[i]==languagesB[j])\n {\n return true;\n }\n else if(languagesA[i]<languagesB[j])\n {\n i++;\n }\n else\n {\n j++;\n }\n }\n return false;\n }\n \n public int MinimumTeachings(int n, int[][] languages, int[][] friendships) {\n \n\t\tvar disConnectedUsers = new HashSet<int>();\n foreach(var language in languages)\n {\n Array.Sort(language);\n }\n \n for(int i=0; i<friendships.Length; i++)\n {\n if(!CanCommunicate(languages, friendships[i][0], friendships[i][1]))\n {\n disConnectedUsers.Add(friendships[i][0]);\n disConnectedUsers.Add(friendships[i][1]);\n }\n }\n\t\t\n var freq = new int[n];\n int max=0;\n foreach(var user in disConnectedUsers)\n {\n foreach(var language in languages[user-1])\n {\n freq[language-1]++;\n max = Math.Max(freq[language-1],max);\n }\n }\n \n return disConnectedUsers.Count()-max;\n }\n} | 0 | 0 | [] | 0 |
minimum-number-of-people-to-teach | c++ | bitset | c-bitset-by-_seg_fault-pueq | Idea\nFor every person who can\'t talk with its friend, store which language he/she needs to be taught and store the frequency of that language in an array toTe | _seg_fault | NORMAL | 2021-09-08T09:27:39.655978+00:00 | 2021-09-08T09:27:55.897171+00:00 | 115 | false | <b>Idea</b>\nFor every person who can\'t talk with its friend, store which language he/she needs to be taught and store the frequency of that language in an array `toTeach`. The language that needs to be taught to minimum number of people is the desired one. \nNote: In order to ensure that the same person to be taught is not counted twice, we maintain a `visited` array.\n```\nclass Solution {\npublic:\nint minimumTeachings(int n, vector<vector<int>>& lng, vector<vector<int>>& ar){\n // n-> languages\n // m-> users\n int m=lng.size(),ct=(1<<30);\n bool *vis=new bool[m]();\n int *toTeach = new int[n]();\n vector<bitset<501>> v;\n for(auto it:lng){\n bitset<501> tmp;\n for(auto it1:it) tmp.set(it1-1);\n v.push_back(tmp);\n }\n for(auto it:ar){\n if( (v[it[0]-1] & v[it[1]-1]).count()){\n // they can talk\n }else{\n for(int i=0;i<n;i++){\n if(!(v[it[0]-1].test(i)) && !vis[it[0]-1]) toTeach[i]++;\n if(!(v[it[1]-1].test(i)) && !vis[it[1]-1]) toTeach[i]++;\n }\n vis[it[0]-1]=true,vis[it[1]-1]=true;\n }\n }\n for(int i=0;i<n;i++) ct=min(ct,toTeach[i]);\n if(ct==(1<<30)) return 0;\n return ct;\n}\n};\n``` | 0 | 0 | [] | 0 |
minimum-number-of-people-to-teach | [100% Solution] Concise Solution speeding up with bitmap + Cpp Code | 100-solution-concise-solution-speeding-u-3oab | \nRuntime: 120 ms, faster than 100.00% of C++ online submissions \nMemory Usage: 59.2 MB, less than 98.82% of C++ online submissions\n\nWe have N languages and | mkyang | NORMAL | 2021-08-31T10:49:05.158840+00:00 | 2021-08-31T10:50:46.300189+00:00 | 181 | false | ```\nRuntime: 120 ms, faster than 100.00% of C++ online submissions \nMemory Usage: 59.2 MB, less than 98.82% of C++ online submissions\n```\nWe have N languages and M persons. Let us image that we have a MxN table "L".\n```\nL[m][n] = 1 means the person m knows the languag n, and 0 means opposite.\n```\nIf two people x, y are friends, we check whether communication is available by evaluate L[x] & L[y] (two rows, O(N) ). If there is no intersection, they should take lessons. However, everybody takes at most one lesson.\n\nFor each language, we check how many guys should be taught (one needs lesson and does\'t know the language).\n\nTotally, it takes:\n1.O(MN) to initialize the table L;\n2.O(FN) to identify people taking lessons. Since F is at most MN, O(FN)<O(MNN)\n3.O(MN) to count the sum of columns of L (where some rows are skipped).\n\nThe Time is max(O(MN), O(FN)), Space is O(MN).\n\n```\nint lesson[500]; //need to take lesson?\nbitset<500> sts[500]; //boost up the process to check whether two friends can communicate\nclass Solution {\npublic:\n int minimumTeachings(int n, vector<vector<int>>& languages, vector<vector<int>>& friendships) {\n ios::sync_with_stdio(false);\n cin.tie(nullptr);\n int m=languages.size(), ans=INT_MAX;\n for(int i=0; i<m; ++i) {\n lesson[i]=0;\n sts[i].reset();\n for(auto l:languages[i]) {\n sts[i].set(l-1);\n }\n }\n for(vector<int> &f:friendships) {\n if((sts[f[0]-1] & sts[f[1]-1]).none()) {\n lesson[f[0]-1]=1;\n lesson[f[1]-1]=1;\n }\n }\n for(int i=0, j, cnt; i<n; ++i) {\n cnt=0;\n for(j=0; j<m; ++j) {\n cnt+=lesson[j] && !sts[j].test(i);\n }\n ans=min(ans, cnt);\n }\n return ans;\n }\n};\n``` | 0 | 0 | [] | 0 |
minimum-number-of-people-to-teach | C++ | unordered_set | c-unordered_set-by-sonusharmahbllhb-9q44 | \nclass Solution {\npublic:\n int minimumTeachings(int n, vector<vector<int>>& lng, vector<vector<int>>& frnd) {\n unordered_set<int> unc;\n in | sonusharmahbllhb | NORMAL | 2021-08-28T07:09:35.944265+00:00 | 2021-08-28T07:09:35.944307+00:00 | 336 | false | ```\nclass Solution {\npublic:\n int minimumTeachings(int n, vector<vector<int>>& lng, vector<vector<int>>& frnd) {\n unordered_set<int> unc;\n int lsz=lng.size();\n int fsz=frnd.size();\n vector<unordered_set<int>> v(lsz+1);\n for(int i=0;i<lsz;i++){\n unordered_set<int> temp;\n for(auto n:lng[i])\n temp.insert(n);\n v[i+1]=temp;\n }\n \n for(int i=0;i<fsz;i++){\n unordered_set<int>& a=v[frnd[i][0]],b=v[frnd[i][1]];\n bool yes=0;\n for(auto n:a){\n if(b.count(n)) {yes=1;break;}\n }\n if(!yes){\n unc.insert(frnd[i][0]);\n unc.insert(frnd[i][1]);\n }\n }\n unordered_map<int,int> mp;\n int ans=0;\n for(auto n:unc){\n unordered_set<int> a=v[n];\n \n for(auto n:a)\n {\n mp[n]++;\n ans=max(ans,mp[n]);\n }\n }\n return unc.size()-ans;\n }\n};\n``` | 0 | 0 | ['C', 'C++'] | 0 |
minimum-number-of-people-to-teach | JavaScript faster than 100% | javascript-faster-than-100-by-lilongxue-wouw | \n/**\n * @param {number} n\n * @param {number[][]} languages\n * @param {number[][]} friendships\n * @return {number}\n */\nvar minimumTeachings = function(n, | lilongxue | NORMAL | 2021-07-17T12:03:57.245319+00:00 | 2021-07-17T12:03:57.245366+00:00 | 110 | false | ```\n/**\n * @param {number} n\n * @param {number[][]} languages\n * @param {number[][]} friendships\n * @return {number}\n */\nvar minimumTeachings = function(n, languages, friendships) {\n // user count\n const len = languages.length\n function Node(val) {\n \n }\n Node.table = new Array(1 + len)\n \n \n const lang2people = new Array(1 + n)\n for (let lang = 1; lang <= n; lang++)\n lang2people[lang] = []\n for (let val = 1; val <= len; val++) {\n const node = Node.table[val] = new Node(val)\n const langs = languages[val - 1]\n node.languages = new Set(langs)\n \n for (const lang of langs.values())\n lang2people[lang].push(val)\n }\n\n \n const commonTable = new Array(1 + len)\n for (let val = 1; val <= len; val++)\n commonTable[val] = []\n for (const [lang, people] of lang2people.entries()) {\n if (!people) continue\n people.sort((a, b) => a - b)\n for (let i = 0; i < people.length - 1; i++) {\n const fromVal = people[i]\n for (let j = 1 + i; j < people.length; j++) {\n const toVal = people[j]\n if (fromVal < toVal)\n commonTable[fromVal][toVal] = true\n else\n commonTable[toVal][fromVal] = true\n }\n }\n }\n\n \n const edges = []\n for (let edge of friendships.values()) {\n let [fromVal, toVal] = edge\n if (fromVal > toVal) {\n [fromVal, toVal] = [toVal, fromVal]\n }\n \n if (commonTable[fromVal] && commonTable[fromVal][toVal]) {\n \n } else {\n edges.push(edge)\n }\n }\n \n \n let result = len\n for (let lang = 1; lang <= n; lang++) {\n let teachUs = new Set()\n for (const edge of edges.values()) {\n const [fromVal, toVal] = edge\n const fromNode = Node.table[fromVal], toNode = Node.table[toVal]\n if (!fromNode.languages.has(lang)) teachUs.add(fromVal)\n if (!toNode.languages.has(lang)) teachUs.add(toVal)\n }\n \n let outcome = teachUs.size\n result = Math.min(result, outcome)\n }\n \n \n return result\n};\n``` | 0 | 0 | [] | 0 |
sum-of-prefix-scores-of-strings | [C++, Java, Python3] Easy Trie Explained with diagram | c-java-python3-easy-trie-explained-with-52svp | \n\nWe construct a trie to find the number of times each node has been visited.\n\nIterate over ["abc","ab","bc","b"] and the trie looks like:\n\n\n After const | tojuna | NORMAL | 2022-09-18T04:01:13.157566+00:00 | 2022-09-18T04:23:38.390015+00:00 | 9,979 | false | \n\nWe construct a trie to find the number of times each node has been visited.\n\nIterate over `["abc","ab","bc","b"]` and the trie looks like:\n\n\n* After constructing the `trie` we just iterate over the given array one more time and find how many times each node corresponding to each character in the `trie` has been visited\n* Then we just need to find the sum of visited per word and append it to our answer. In the code `curr` denoted the sum per node\n* `ch` denotes the children of the current trie node. Each trie node can have a max of 26 children since we are only considering lowercase english alphabets\n\n<iframe src="https://leetcode.com/playground/Z69Nqbky/shared" frameBorder="0" width="550" height="580"></iframe>\n\nTime complexity: O(total characters in all words) | 105 | 1 | [] | 13 |
sum-of-prefix-scores-of-strings | Simple step by step solution using Trie data structure | simple-step-by-step-solution-using-trie-nyto0 | Intuition\n Describe your first thoughts on how to solve this problem. \nThe problem can be effectively solved using a Trie (prefix tree) data structure. The Tr | Reddaiah12345 | NORMAL | 2024-09-25T02:44:19.606444+00:00 | 2024-09-25T02:44:19.606488+00:00 | 14,796 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThe problem can be effectively solved using a Trie (prefix tree) data structure. The Trie structure allows us to efficiently store and traverse the prefixes of words. Each node in the Trie keeps track of how many times a particular prefix has appeared. This enables us to calculate the prefix scores for each word by summing the count of nodes that match the word\'s prefix.\n\nThe main idea is to:\n\n1. **Insert each word** into the Trie, where each node tracks how many times a prefix has been encountered.\n1. **Query the prefix** score of each word by summing the prefix counts while traversing the Trie.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n1. Trie Construction:\n\n - Each node of the Trie contains a count (to store the number of words that pass through this node) and an array to hold child nodes corresponding to each character (a-z).\n - When inserting a word, for each character in the word:\n - If the node for the character doesn\u2019t exist, create it.\n - Increment the count for the node to indicate that a word has passed through this node.\n1. Prefix Score Calculation:\n\n - To calculate the prefix score for a word, traverse the Trie for each character in the word.\n - At each step, add the count of the node to the result, which will give the total number of words that share the prefix.\n1. Efficiency:\n\n - Insertion and prefix calculation are both O(L) operations, where L is the length of the word. This ensures efficient processing even for larger input sizes.\n1. **Steps:**\n - Insert all words into the Trie:\nFor each word in the input list, add it to the Trie, updating the count of each node.\n - Calculate the prefix scores:\nFor each word, traverse the Trie and sum the counts of the nodes along the way to calculate the total prefix score for that word.\n\n# Complexity\n- Time complexity:O(N*W)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:O(N*W)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n```java []\nclass Node {\n int count = 0;\n Node[] list = new Node[26];\n\n public boolean containKey(char ch) {\n return list[ch - \'a\'] != null;\n }\n\n public Node get(char ch) {\n return list[ch - \'a\'];\n }\n\n public void put(char ch, Node new_node) {\n list[ch - \'a\'] = new_node;\n }\n\n public void inc(char ch) {\n list[ch - \'a\'].count++;\n }\n\n public int retCount(char ch) {\n return list[ch - \'a\'].count;\n }\n}\n\nclass Solution {\n private Node root;\n\n public Solution() {\n root = new Node();\n }\n\n public void insert(String word) {\n Node node = root;\n for (char ch : word.toCharArray()) {\n if (!node.containKey(ch)) {\n node.put(ch, new Node());\n }\n node.inc(ch);\n node = node.get(ch);\n }\n }\n\n public int search(String word) {\n Node node = root;\n int preCount = 0;\n for (char ch : word.toCharArray()) {\n preCount += node.retCount(ch);\n node = node.get(ch);\n }\n return preCount;\n }\n\n public int[] sumPrefixScores(String[] words) {\n // This problem can be solved using the trie data structure\n for (String word : words) {\n insert(word);\n }\n int n = words.length;\n int[] res = new int[n];\n for (int i = 0; i < n; i++) {\n res[i] = search(words[i]);\n }\n return res;\n }\n}\n\n```\n```python []\nclass Node:\n def __init__(self):\n self.count = 0\n self.list = [None] * 26\n\n def containKey(self, ch):\n return self.list[ord(ch) - ord(\'a\')] is not None\n\n def get(self, ch):\n return self.list[ord(ch) - ord(\'a\')]\n\n def put(self, ch, new_node):\n self.list[ord(ch) - ord(\'a\')] = new_node\n\n def inc(self, ch):\n self.list[ord(ch) - ord(\'a\')].count += 1\n\n def retCount(self, ch):\n return self.list[ord(ch) - ord(\'a\')].count\n\n\nclass Solution:\n def __init__(self):\n self.root = Node()\n\n def insert(self, word):\n node = self.root\n for ch in word:\n if not node.containKey(ch):\n node.put(ch, Node())\n node.inc(ch)\n node = node.get(ch)\n\n def search(self, word):\n node = self.root\n preCount = 0\n for ch in word:\n preCount += node.retCount(ch)\n node = node.get(ch)\n return preCount\n\n def sumPrefixScores(self, words):\n # This problem can be solved using the trie data structure\n for word in words:\n self.insert(word)\n\n res = []\n for word in words:\n preCount = self.search(word)\n res.append(preCount)\n\n return res\n\n```\n\n```cpp []\nstruct Node{\n int count=0;\n Node *list[26]={NULL};\n bool containKey(char ch){\n return list[ch-\'a\']!=NULL;\n }\n Node *get(char ch){\n return list[ch-\'a\'];\n }\n void put(char ch,Node *new_node){\n list[ch-\'a\']=new_node;\n }\n void inc(char ch){\n list[ch-\'a\']->count+=1;\n }\n int retCount(char ch){\n return list[ch-\'a\']->count;\n }\n};\nclass Solution {\nprivate:\nNode *root;\npublic:\n Solution(){\n root=new Node;\n }\n void insert(string word){\n Node *node=root;\n for(auto ch:word){\n if(!node->containKey(ch)){\n node->put(ch,new Node);\n }\n node->inc(ch);\n node=node->get(ch);\n }\n }\n int search(string word){\n Node *node=root;\n int preCount=0;\n for(auto ch:word){\n preCount+=node->retCount(ch);\n node=node->get(ch);\n }\n return preCount;\n }\n vector<int> sumPrefixScores(vector<string>& words) {\n //This problem can be solved using the trie data structure\n for(auto word:words){\n insert(word);\n }\n int n=words.size();\n vector<int>res(n);\n for(int i=0;i<n;i++){\n int preCount=search(words[i]);\n res[i]=preCount;\n }\n return res;\n }\n};\n```\n\n | 88 | 3 | ['Array', 'String', 'Trie', 'Counting', 'C++', 'Java', 'Python3'] | 7 |
sum-of-prefix-scores-of-strings | C++ | Trie | Related Problems | c-trie-related-problems-by-kiranpalsingh-kdf6 | Store each string in trie and add 1 to each prefix of string while inserting.\n- Then, for each string, we sum up the count for all its prefixes.\n\n\n\ncpp\nst | kiranpalsingh1806 | NORMAL | 2022-09-18T04:01:16.143848+00:00 | 2022-09-19T05:21:10.853388+00:00 | 5,459 | false | - Store each string in trie and **add 1 to each prefix of string while inserting**.\n- Then, for each string, **we sum up the count for all its prefixes**.\n\n\n\n```cpp\nstruct TrieNode {\n TrieNode *next[26] = {};\n int cnt = 0;\n};\n\nclass Solution {\n TrieNode root;\npublic:\n void insert(string word) {\n auto node = &root;\n for(char c : word) {\n if(!node->next[c - \'a\']) {\n node->next[c - \'a\'] = new TrieNode();\n } \n node->next[c - \'a\']->cnt++;\n node = node->next[c - \'a\']; \n }\n }\n\n int prefixCnt(string s) {\n auto node = &root;\n int ans = 0;\n for(char c : s) {\n ans += node->next[c - \'a\']->cnt;\n node = node->next[c - \'a\'];\n }\n return ans;\n }\n \n vector<int> sumPrefixScores(vector<string>& words) {\n int N = words.size();\n\t\t// Insert words in trie.\n for (int i = 0; i < N; i++) {\n insert(words[i]);\n }\n vector<int> ans(N, 0);\n for (int i = 0; i < N; i++) {\n\t\t\t// Get the count of all prefixes of given string.\n ans[i] = prefixCnt(words[i]); \n }\n return ans;\n }\n};\n```\n\n**Trie Related Problems**\n[1. Implement Trie (Prefix Tree) ](https://leetcode.com/problems/implement-trie-prefix-tree/)\n[2. Palindrome Pairs ](https://leetcode.com/problems/palindrome-pairs/)\n[3. Maximum XOR of Two Numbers in an Array ](https://leetcode.com/problems/maximum-xor-of-two-numbers-in-an-array/)\n[4. Concatenated Words ](https://leetcode.com/problems/concatenated-words/)\n[5. Search Suggestions System ](https://leetcode.com/problems/search-suggestions-system/)\n | 68 | 2 | ['Trie', 'C'] | 13 |
sum-of-prefix-scores-of-strings | [Python] Explanation with pictures, 2 solutions | python-explanation-with-pictures-2-solut-f21p | Solution 1. Counter of prefix\n\nUse counter C to collect every prefix of every word. \nThen sum up C[pre] for every prefix pre of word word, this is the score | Bakerston | NORMAL | 2022-09-18T04:01:58.958795+00:00 | 2022-09-18T04:40:03.144501+00:00 | 2,676 | false | ### Solution 1. Counter of prefix\n\nUse counter `C` to collect every prefix of every word. \nThen sum up `C[pre]` for every prefix `pre` of word `word`, this is the score of `word`.\n\n**python**\n\n```\nclass Solution:\n def sumPrefixScores(self, W: List[str]) -> List[int]:\n C = collections.defaultdict(int)\n for w in W:\n for i in range(len(w)):\n C[w[:i + 1]] += 1\n \n ans = []\n for w in W:\n curr = 0\n for i in range(len(w)):\n curr += C[w[:i + 1]]\n ans.append(curr)\n \n return ans\n```\n\n<br>\n<br>\n\n### Solution 2. Trie\n\nTake a look at how we build `trie`.\n\n\n\nInsert `abc`.\n\n\n\nInsert `ab`.\n\n\n\nInsert `b`.\n\n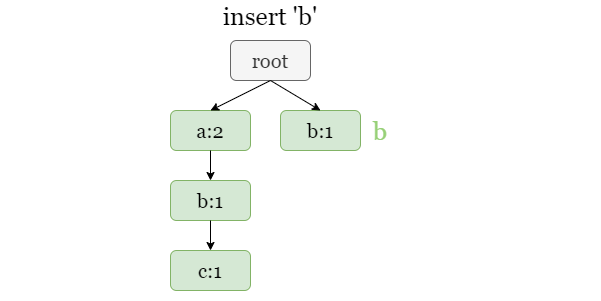\n\nInsert `bc`.\n\n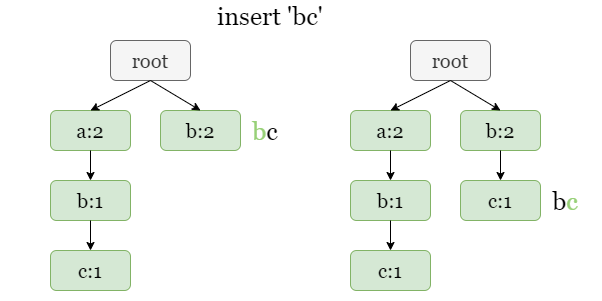\n\nCount the score of `ab`.\n\n\n\n**python**\n\n```\nclass Node:\n def __init__(self):\n self.children = {}\n self.cnt = 0\n \nclass Trie:\n def __init__(self):\n self.trie = Node()\n def insert(self, word):\n node = self.trie\n for ch in word:\n if ch not in node.children:\n node.children[ch] = Node()\n node = node.children[ch]\n node.cnt += 1\n def count(self, word):\n node = self.trie\n ans = 0\n for ch in word:\n ans += node.children[ch].cnt\n node = node.children[ch]\n return ans\n\nclass Solution:\n def sumPrefixScores(self, A: List[str]) -> List[int]:\n trie = Trie()\n\n for a in A:\n trie.insert(a)\n\n return [trie.count(a) for a in A]\n```\n | 52 | 0 | [] | 11 |
sum-of-prefix-scores-of-strings | Full Dry Run + Brute to Trie Explained, illustrations || Let's Go !! | full-dry-run-brute-to-trie-explained-ill-buzx | Youtube Explanation\nSoon to be on Channel : https://www.youtube.com/@Intuit_and_Code\nEdited:\nhttps://youtu.be/Sh0ca33JjMM?si=9tzS3AuxGtHSgkew\n\n# Intuition | Rarma | NORMAL | 2024-09-25T02:11:13.740855+00:00 | 2024-09-25T11:53:02.876888+00:00 | 6,309 | false | # Youtube Explanation\nSoon to be on Channel : https://www.youtube.com/@Intuit_and_Code\nEdited:\nhttps://youtu.be/Sh0ca33JjMM?si=9tzS3AuxGtHSgkew\n\n# Intuition & Approach\n\n> If you don\'t know trie, don\'t worry this article will help you get an idea about how it works.\n\n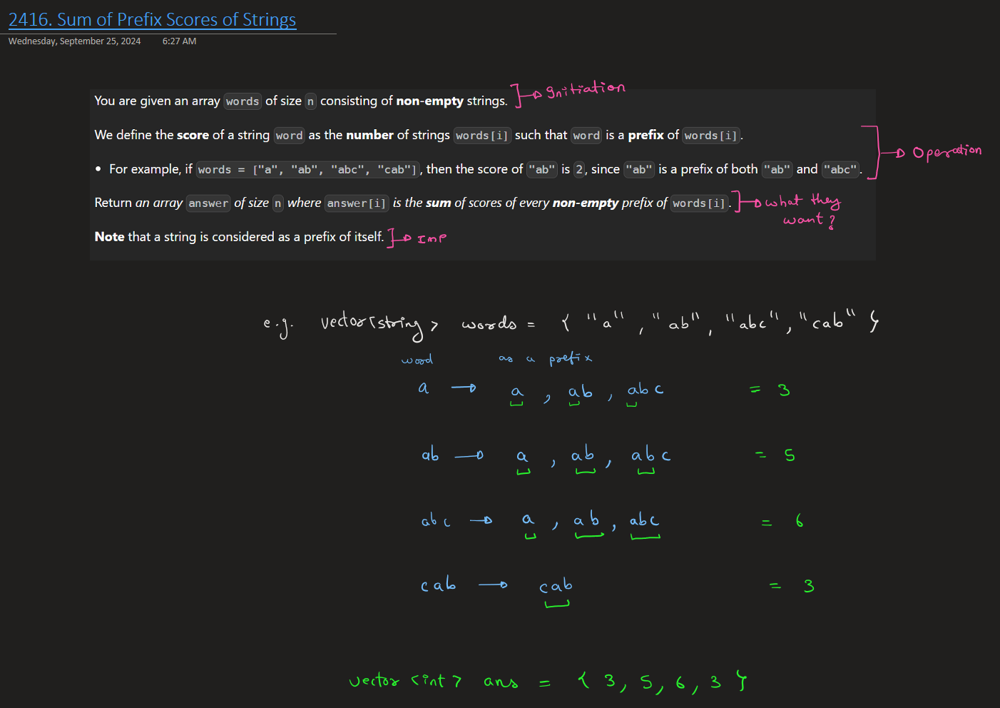\n\n\n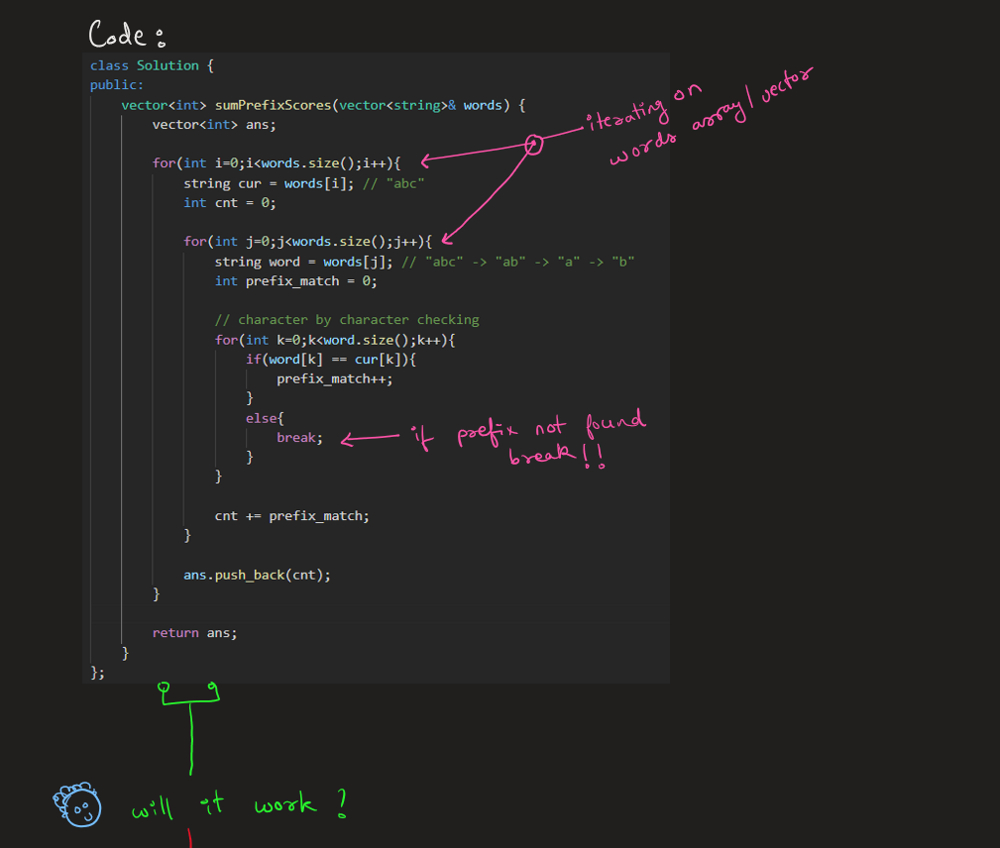\n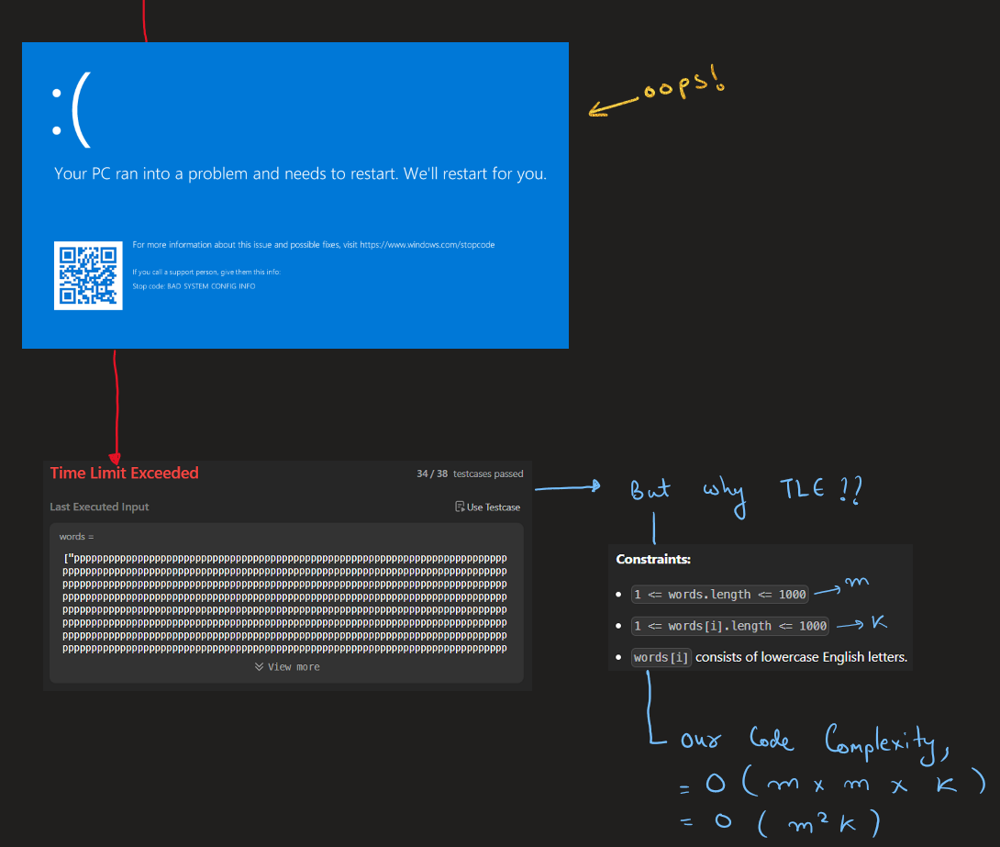\n\n\n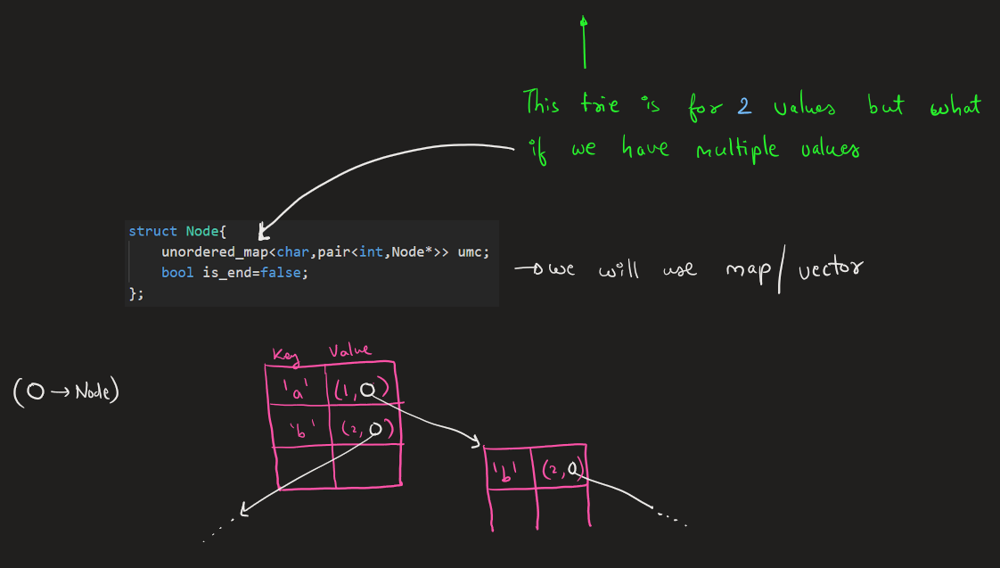\n\n> We can also use vector of size 26 to make more faster in rate of submission time\n\n\n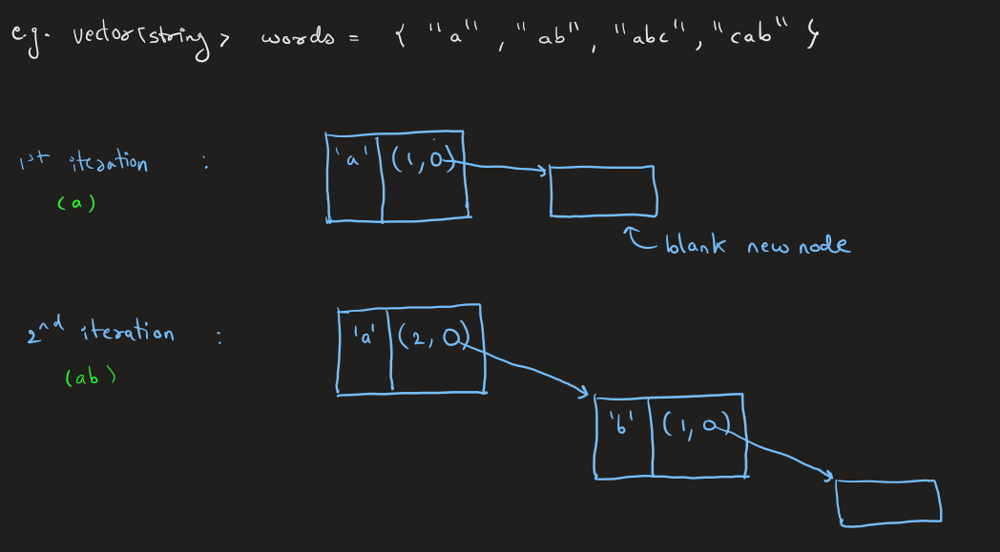\n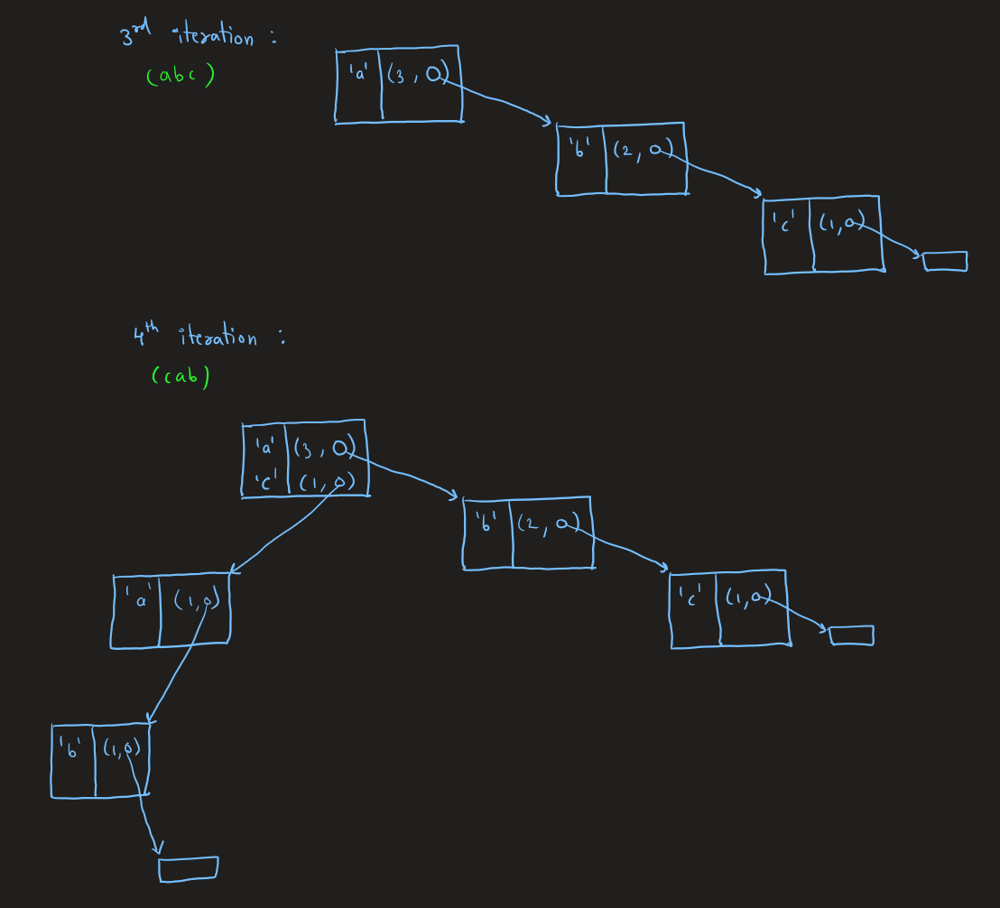\n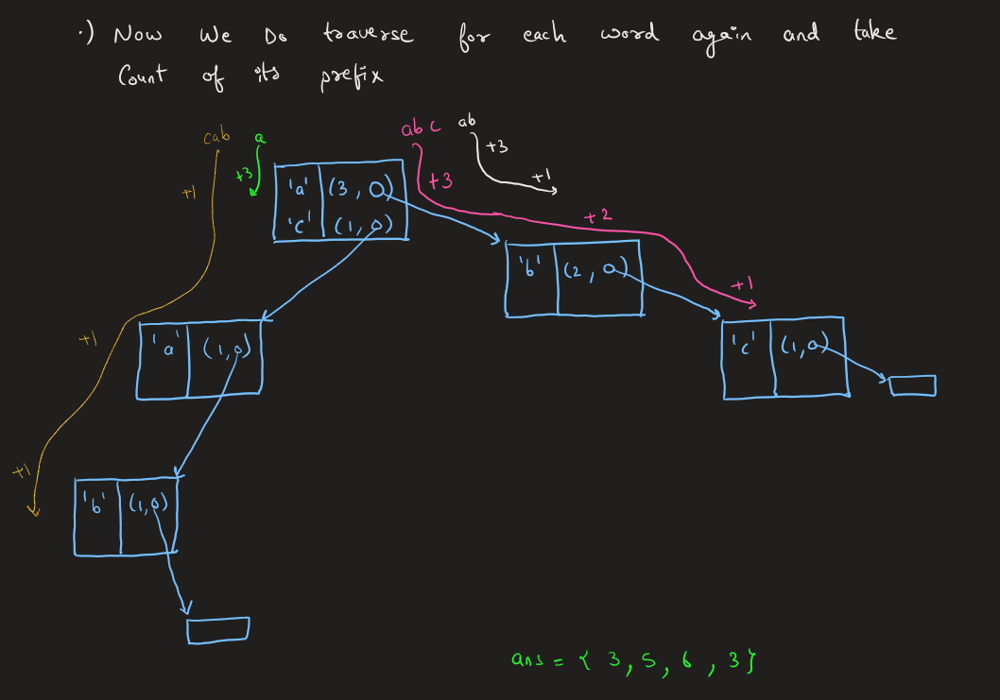\n\n\n# Complexity\n- Time complexity: O( n * k)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O( n * k)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```cpp []\nstruct Node{\n unordered_map<char,pair<int,Node*>> umc;\n bool is_end=false;\n};\n\nclass Trie{\nprivate:\n Node *root;\npublic:\n // constructor always gets called when class is called\n // help us to always keep track of first head node\n Trie(){\n root = new Node();\n }\n\n // insertion function\n void insert(string s){\n Node *cur = root;\n for(int i=0;i<s.size();i++){\n if(cur->umc.find(s[i]) == cur->umc.end()){\n cur->umc[s[i]].second = new Node();\n }\n\n cur->umc[s[i]].first++;\n cur = cur->umc[s[i]].second;\n }\n\n cur->is_end = true;\n return;\n }\n\n // function to match the prefix\n int check_prefix_count(string s){\n Node *cur = root;\n int count = 0;\n\n for(int i=0;i<s.size();i++){\n if(cur->umc.find(s[i]) == cur->umc.end()){\n break;\n }\n\n count += cur->umc[s[i]].first;\n cur = cur->umc[s[i]].second;\n }\n \n return count;\n }\n};\n\nclass Solution {\npublic:\n vector<int> sumPrefixScores(vector<string>& words) {\n Trie t; // initiate trie\n\n for(auto &word:words){ // for(int i=0;i<words.size();i++)\n t.insert(word); // word = words[i]\n }\n\n vector<int> ans;\n for(auto &word:words){ \n int tmp = t.check_prefix_count(word); \n ans.push_back(tmp);\n }\n\n return ans;\n }\n};\n```\n``` C++ [ ]\nstruct Node {\n int count = 0;\n Node* list[26] = {nullptr}; // Array for 26 lowercase English letters\n};\n\nclass Solution {\nprivate:\n Node* root;\npublic:\n Solution() {\n root = new Node();\n }\n\n // Insertion function to add words to the Trie\n void insert(const string& word) {\n Node* node = root;\n for (char ch : word) {\n // If the current character\'s node doesn\'t exist, create a new one\n if (node->list[ch - \'a\'] == nullptr) {\n node->list[ch - \'a\'] = new Node();\n }\n // Increment the count of the current node for this character\n node->list[ch - \'a\']->count++;\n // Move to the next node (child)\n node = node->list[ch - \'a\'];\n }\n }\n\n // Search function to calculate prefix score\n int search(const string& word) {\n Node* node = root;\n int preCount = 0;\n for (char ch : word) {\n // Add the count of the current character\'s node to prefix score\n preCount += node->list[ch - \'a\']->count;\n // Move to the next node (child)\n node = node->list[ch - \'a\'];\n }\n return preCount;\n }\n\n // Function to compute the sum of prefix scores for all words\n vector<int> sumPrefixScores(vector<string>& words) {\n // Insert all words into the Trie\n for (auto& word : words) {\n insert(word);\n }\n\n int n = words.size();\n vector<int> res(n);\n\n // Calculate prefix score for each word\n for (int i = 0; i < n; i++) {\n int preCount = search(words[i]);\n res[i] = preCount;\n }\n\n return res;\n }\n};\n```\n``` java [ ]\nclass Node {\n Map<Character, Pair> umc = new HashMap<>();\n boolean isEnd = false;\n}\n\nclass Pair {\n int count;\n Node node;\n\n Pair(int count, Node node) {\n this.count = count;\n this.node = node;\n }\n}\n\nclass Trie {\n private Node root;\n\n public Trie() {\n root = new Node();\n }\n\n // Insert word into the Trie\n public void insert(String s) {\n Node cur = root;\n for (int i = 0; i < s.length(); i++) {\n char c = s.charAt(i);\n if (!cur.umc.containsKey(c)) {\n cur.umc.put(c, new Pair(0, new Node()));\n }\n cur.umc.get(c).count++;\n cur = cur.umc.get(c).node;\n }\n cur.isEnd = true;\n }\n\n // Check prefix count of the word\n public int checkPrefixCount(String s) {\n Node cur = root;\n int count = 0;\n for (int i = 0; i < s.length(); i++) {\n char c = s.charAt(i);\n if (!cur.umc.containsKey(c)) {\n break;\n }\n count += cur.umc.get(c).count;\n cur = cur.umc.get(c).node;\n }\n return count;\n }\n}\n\nclass Solution {\n public int[] sumPrefixScores(String[] words) {\n Trie trie = new Trie();\n \n // Insert all words into the Trie\n for (String word : words) {\n trie.insert(word);\n }\n\n // Collect the prefix scores for each word\n int[] ans = new int[words.length];\n for (int i = 0; i < words.length; i++) {\n ans[i] = trie.checkPrefixCount(words[i]);\n }\n\n return ans;\n }\n}\n``` | 30 | 0 | ['Array', 'String', 'Trie', 'String Matching', 'Counting', 'C++', 'Java'] | 5 |
sum-of-prefix-scores-of-strings | [Python3] Simple trie O (n*k) with line by line comments. | python3-simple-trie-o-nk-with-line-by-li-5moe | The idea is to use trie. When initializing the trie, instead of storing the end of the word, we are tracking the number of times this prefix has occurred.\nOnce | MeidaChen | NORMAL | 2022-09-18T04:02:09.029154+00:00 | 2024-01-04T19:26:05.006558+00:00 | 1,211 | false | The idea is to use trie. When initializing the trie, instead of storing the end of the word, we are tracking the number of times this prefix has occurred.\nOnce we have the trie, we will go through all the words one more time and count how many times its prefix has occurred to build our result.\n\n```\nclass Solution:\n def sumPrefixScores(self, words: List[str]) -> List[int]:\n trie = {} ### Initialize a hash map for trie\n for w in words:\n cur = trie ### At the begining of each word, the pointer should point to the begining of the trie\n for c in w:\n ### Go through each letter to build the trie.\n if c not in cur:\n cur[c] = {}\n cur = cur[c]\n ### Instead of store the end of the word in the regular trie, \n ### we are storing the occurrences of the prefix at each letter\n if \'count\' not in cur:\n cur[\'count\'] = 0\n cur[\'count\'] += 1\n res = []\n ### Go through each word one more time to build the result\n for w in words:\n cur = trie ### Pointer point to the begining of the trie\n count = 0 ### Keep track the count of the occurrences of each prefix (letter) in this word\n for c in w:\n cur = cur[c]\n ### At each letter, we add the count we previously stored. \n ### This is the number of occurrence of this prefix among all words.\n count += cur[\'count\']\n res.append(count)\n return res\n```\n\n**Upvote** if you like this post.\n\n**Connect with me on [LinkedIn](https://www.linkedin.com/in/meida-chen-938a265b/)** if you\'d like to discuss other related topics\n\n\uD83C\uDF1F If you are interested in **Machine Learning** || **Deep Learning** || **Computer Vision** || **Computer Graphics** related projects and topics, check out my **[YouTube Channel](https://www.youtube.com/@meidachen8489)**! Subscribe for regular updates and be part of our growing community. | 24 | 0 | [] | 3 |
sum-of-prefix-scores-of-strings | Trie | trie-by-votrubac-75g6 | \nFirst, we add all strings into a Trie, incrementing the count for each prefix.\n \nThen, for each string, we aggregate the count for all its prefixes. \n | votrubac | NORMAL | 2022-09-18T04:01:59.754053+00:00 | 2022-09-18T04:01:59.754098+00:00 | 2,401 | false | \nFirst, we add all strings into a Trie, incrementing the count for each prefix.\n \nThen, for each string, we aggregate the count for all its prefixes. \n \n**C++**\n```cpp\nstruct Trie {\n Trie* ch[26] = {};\n int cnt = 0;\n void insert(string &w, int i = 0) {\n auto n = this;\n for (auto c : w) {\n if (n->ch[c - \'a\'] == nullptr)\n n->ch[c - \'a\'] = new Trie();\n n = n->ch[c - \'a\'];\n ++n->cnt;\n }\n }\n int count(string &w, int i = 0) {\n return cnt + (i == w.size() ? 0 : ch[w[i] - \'a\']->count(w, i + 1));\n }\n}; \nvector<int> sumPrefixScores(vector<string>& words) {\n Trie t;\n for (auto &w : words)\n t.insert(w);\n vector<int> res;\n for (auto &w : words)\n res.push_back(t.count(w));\n return res;\n}\n// ``` | 23 | 0 | [] | 7 |
sum-of-prefix-scores-of-strings | Trie Solution || O(N*k) || Beats 97% || C++ || Python | trie-solution-onk-beats-97-c-python-by-r-yy7a | Intuition\n Describe your first thoughts on how to solve this problem. \nUse a datastructure that allows quick prefix count\n\n# Approach\n Describe your approa | Rzhek | NORMAL | 2024-09-25T00:10:46.634229+00:00 | 2024-09-25T00:24:56.447120+00:00 | 11,220 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nUse a datastructure that allows quick prefix count\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n- Add each word to a trie\n- Increment score of nodes while adding words (except root node)\n- Run DFS for each word and add up those scores\n\n# Complexity\n- Time complexity: $$O(N*k)$$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: $$O(N*k)$$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```cpp []\nstruct Trie {\n int score;\n Trie *children[26];\n Trie () {\n score = 0;\n memset(children, 0, sizeof(children));\n }\n void add(string &s, int i) {\n if (i) score++;\n if (i == s.size()) return;\n if (!children[s[i]-\'a\']) children[s[i]-\'a\'] = new Trie();\n children[s[i]-\'a\']->add(s, i+1);\n }\n int dfs(string &s, int i) {\n if (i == s.size()) return score;\n return score + children[s[i]-\'a\']->dfs(s, i+1);\n }\n};\nclass Solution {\npublic:\n vector<int> sumPrefixScores(vector<string>& words) {\n Trie *trie = new Trie();\n for (string &s : words) trie->add(s, 0);\n vector<int> res;\n for (string &s : words) res.push_back(trie->dfs(s, 0));\n return res;\n }\n};\n```\n```python []\nclass Trie:\n def __init__(self):\n self.score = 0\n self.children = {}\n\n def add(self, s: str, i: int):\n if (i): self.score += 1\n if (i == len(s)): return\n if (not self.children.get(s[i])): self.children[s[i]] = Trie()\n self.children[s[i]].add(s, i+1)\n\n def dfs(self, s: str, i: int):\n if (i == len(s)): return self.score\n return self.score + self.children[s[i]].dfs(s, i+1)\n \nclass Solution:\n def sumPrefixScores(self, words: List[str]) -> List[int]:\n trie = Trie()\n for word in words:\n trie.add(word, 0)\n res = []\n for word in words:\n res.append(trie.dfs(word, 0))\n return res\n \n``` | 22 | 0 | ['String', 'Trie', 'C++', 'Python3'] | 8 |
sum-of-prefix-scores-of-strings | trie, java | trie-java-by-clasiqh-vtsy | Code:\n\n Node root = new Node(); // Trie root.\n class Node {\n int score = 0;\n Node[] child = new Node[26];\n }\n \n public int | clasiqh | NORMAL | 2022-09-18T04:00:32.785885+00:00 | 2022-09-18T04:22:45.741052+00:00 | 1,668 | false | **Code:**\n\n Node root = new Node(); // Trie root.\n class Node {\n int score = 0;\n Node[] child = new Node[26];\n }\n \n public int[] sumPrefixScores(String[] words) {\n for(String word : words) add(word); // make trie.\n \n int [] res = new int[words.length];\n for(int i=0; i<res.length; i++)\n res[i] = calc(words[i]); // build scores.\n return res;\n }\n \n void add(String str){\n Node temp = root;\n for(char ch : str.toCharArray()){\n if(temp.child[ch-\'a\']==null)\n temp.child[ch-\'a\'] = new Node();\n temp.child[ch-\'a\'].score++;\n temp = temp.child[ch-\'a\'];\n }\n }\n \n int calc(String str){\n int ans = 0;\n Node temp = root;\n for(char ch : str.toCharArray()){\n ans += temp.child[ch-\'a\'].score;\n temp = temp.child[ch-\'a\'];\n }\n return ans;\n } | 21 | 2 | ['Trie', 'Java'] | 1 |
sum-of-prefix-scores-of-strings | Trie again | trie-again-by-anwendeng-qesq | Intuition\n Describe your first thoughts on how to solve this problem. \nUse Trie with memeber variable len\n# Approach\n Describe your approach to solving the | anwendeng | NORMAL | 2024-09-25T02:56:44.580955+00:00 | 2024-09-25T02:56:44.580973+00:00 | 1,171 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nUse Trie with memeber variable len\n# Approach\n<!-- Describe your approach to solving the problem. -->\n1. Define Trie struct with construtor, insert methods.\n2. In solution, let `trie` be the memeber variable.\n3. Define a member method `int score(const string& s)` to compute the score for `s`\n4. In `sumPrefixScores(vector<string>& words)`, add every s in word to the object `trie`.\n5. Use a loop to compute `ans[i]=score(words[i])`\n6. `ans` is the answer\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n$O(\\sum_{s: words}|s|)$\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n$O(\\sum_{s: words}|s|)$\n# Code\n```cpp []\n// struct Trie for N alphabets\nconst int N=26;\nstruct Trie {\n Trie* next[N];\n int len=0;\n\n Trie() {\n memset(next, 0, sizeof(next));\n }\n/*\n ~Trie() {\n // cout<<"Destructor\\n";\n for (int i=0; i<N; ++i) {\n if (next[i] !=NULL) {\n delete next[i];\n next[i]=NULL;\n }\n }\n }\n*/\n void insert(const string& word) {\n Trie* Node=this;\n for(char c: word){\n int i=c-\'a\';\n if(Node->next[i]==NULL)\n Node->next[i]=new Trie();\n Node=Node->next[i];\n Node->len++;\n }\n }\n};\nclass Solution {\npublic:\n Trie trie;\n inline int score(const string& s){\n Trie* Node=≜\n int cnt=0;\n for(char c: s){\n int i=c-\'a\';\n Node=Node->next[i];\n cnt+=Node->len;\n }\n return cnt;\n }\n vector<int> sumPrefixScores(vector<string>& words) {\n int n=words.size();\n for(string& s: words) trie.insert(s);\n vector<int> ans(n);\n for(int i=0; i<n; i++) \n ans[i]=score(words[i]);\n return ans;\n }\n};\n\n\nauto init = []() {\n ios::sync_with_stdio(false);\n cin.tie(nullptr);\n cout.tie(nullptr);\n return \'c\';\n}();\n```\n# Trie is an advanced data structure. Using it one can solve many problems\n[[Leetcode 140. Word Break II](https://leetcode.com/problems/word-break-ii/solutions/5203799/dp-hash-vs-dp-trie-0ms-beats-100/) Please turn on English subtitles if necessary]\n[https://youtu.be/_E-fcmVmkYU?si=Ve6Z8zuPIi08k0VI](https://youtu.be/_E-fcmVmkYU?si=Ve6Z8zuPIi08k0VI) | 16 | 0 | ['Array', 'String', 'Trie', 'Counting', 'C++'] | 7 |
sum-of-prefix-scores-of-strings | [C++] Detailed Explanation w/ Diagram | Easy and commented code | Simple language | c-detailed-explanation-w-diagram-easy-an-z9cd | IDEA:\n We store each word of the words array in the trie.\n Every Node of the trie contains two arrays of size 26.\n First array denotes the characters of engl | aryanttripathi | NORMAL | 2022-09-18T07:51:37.586428+00:00 | 2022-09-18T07:51:37.586473+00:00 | 1,206 | false | **IDEA:**\n* We store each word of the words array in the trie.\n* Every Node of the trie contains two arrays of size 26.\n* First array denotes the characters of english alphabets i.e index 0 denotes character \'a\', index 1 denotes character \'b\'... like this.\n* Second array number denotes how many number of times we visited here.\n* Lastly we simply traverse each word and take out the answer.\n* See images for better clarification.\n___________\n\n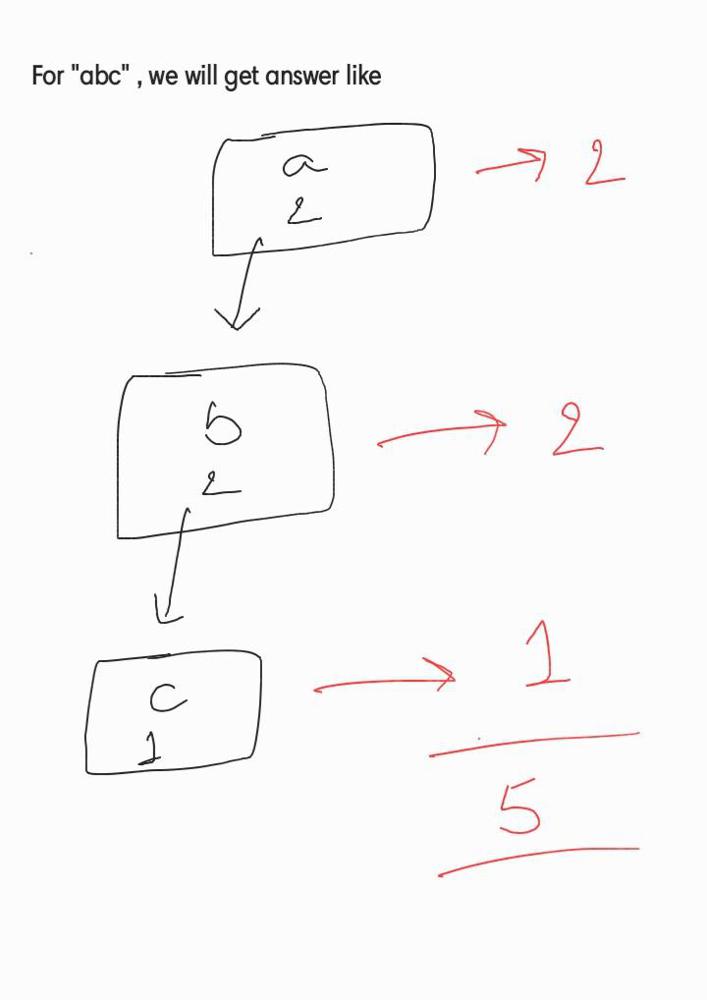\n___________\n```\nSee commented code :)\n```\n____\n**C++**\n```\n// how a trie node looks like\nstruct Node \n{\n Node* links[26]; // for 26 characters\n int number[26] = {0}; // number array \n \n bool containsKey(char ch) // function to check if it present or not\n {\n return (links[ch - \'a\'] != NULL);\n }\n \n void put(char ch, Node* node) \n {\n links[ch - \'a\'] = node; // put a character\n number[ch - \'a\'] = 1; // since we are putting this character, so we visit this character first time\n }\n \n Node* get(char ch) // make a link to the character\n {\n return links[ch - \'a\'];\n }\n \n void increaseNum(char ch) // we increase the count of visit\n {\n number[ch - \'a\']++;\n }\n \n int getNum(char ch) // to retrive how many many number of times we visit this\n {\n return number[ch - \'a\'];\n }\n \n};\n\nclass Trie {\npublic:\n Node* root; // make root node\n Trie() {\n root = new Node(); // accquiring memory for the root node\n \n }\n \n void insert(string word) \n {\n Node* node = root; // make a dummy pointer for the root node\n \n for(int i = 0; i < word.length(); i++)\n {\n // if on the node i m currently standing does \n // not contain this particular character of word[i]\n // so for this we have to make a new referenced node\n if(!node -> containsKey(word[i]))\n {\n node -> put(word[i], new Node());\n } \n else // else if already present that means we see this character again so increase nums\n node -> increaseNum(word[i]);\n \n // after this move to this referenced node\n node = node -> get(word[i]);\n }\n }\n \n // it will give me answer for each word\n int takeAns(string word)\n {\n int ans = 0; // to count my answer\n \n Node* node = root; // make a dummy pointer for the root node\n \n for(int i = 0; i < word.size(); i++)\n {\n if(!node -> containsKey(word[i])) // if trie does not contain this particular character, so return answer from here\n return ans;\n else \n ans += node -> getNum(word[i]); // else add to answer\n \n node = node -> get(word[i]); // and move to next referenced node\n }\n \n return ans; // finally return answer\n }\n};\n\nclass Solution {\npublic:\n vector<int> sumPrefixScores(vector<string>& words) {\n int n = words.size(); // extract size of words array\n \n Trie trie; // define object for class trie\n \n // put all strings of words array into the trie\n for(int i = 0; i < n; i++)\n {\n trie.insert(words[i]);\n }\n \n vector<int> ans(n); // vector that contains my answer\n \n // extract answer for each word\n for(int i = 0; i < n; i++)\n {\n ans[i] = trie.takeAns(words[i]);\n }\n \n return ans; // finally return answer\n }\n};\n``` | 16 | 2 | ['C'] | 2 |
sum-of-prefix-scores-of-strings | Python | Trie-based Pattern | python-trie-based-pattern-by-khosiyat-s5cx | see the Successfully Accepted Submission\n\n# Code\npython3 []\nclass TrieNode:\n def __init__(self):\n self.children = {}\n self.prefix_count | Khosiyat | NORMAL | 2024-09-25T01:42:27.827759+00:00 | 2024-09-25T01:42:27.827791+00:00 | 1,175 | false | [see the Successfully Accepted Submission](https://leetcode.com/problems/sum-of-prefix-scores-of-strings/submissions/1401354774/?envType=daily-question&envId=2024-09-25)\n\n# Code\n```python3 []\nclass TrieNode:\n def __init__(self):\n self.children = {}\n self.prefix_count = 0\n\nclass Solution:\n def sumPrefixScores(self, words: List[str]) -> List[int]:\n # Step 1: Build the Trie\n root = TrieNode()\n \n # Insert each word into the trie and track the prefix counts\n for word in words:\n current = root\n for char in word:\n if char not in current.children:\n current.children[char] = TrieNode()\n current = current.children[char]\n current.prefix_count += 1 # Increment the prefix count at each node\n \n # Step 2: For each word, calculate the total prefix score\n result = []\n for word in words:\n current = root\n score = 0\n for char in word:\n current = current.children[char]\n score += current.prefix_count # Sum the prefix counts for each character in the word\n result.append(score)\n \n return result\n\n```\n\n# Solution Approach:\n\n### Trie Data Structure:\nWe will insert each word into a trie, and at each node, we\'ll keep track of how many words pass through that node (i.e., how many words have that prefix).\n\n### Prefix Count:\nWhile inserting a word into the trie, for each prefix of that word (as we traverse the characters), we increment a counter at that node.\n\n### Querying the Trie:\nAfter building the trie, for each word, we can sum up the prefix counts by traversing the trie again from the root to the end of the word.\n\nThis will allow us to compute the scores for all the words in a time-efficient manner.\n\n## Steps:\n\n1. **Step 1**: Build a trie from the list of words where each node keeps track of how many words have a common prefix up to that point.\n2. **Step 2**: For each word, traverse the trie to compute the sum of scores for all its prefixes.\n\n---\n\n## Explanation of the Code:\n\n### TrieNode Class:\nEach node in the trie contains:\n- **children**: A dictionary to store the child nodes for each character.\n- **prefix_count**: An integer that tracks how many words have this prefix.\n\n### Building the Trie:\n- We iterate through each word, and for each character in the word, we insert it into the trie.\n- While inserting, we increment the `prefix_count` for each node (character) we visit.\n\n### Querying the Trie:\n- For each word, we traverse the trie from the root to the last character of the word, summing the `prefix_count` for each node along the way.\n- This gives us the total score for that word.\n\n---\n\n## Time Complexity:\n\n- **Trie Insertion**: Inserting each word into the trie takes `O(m)` time, where `m` is the length of the word. Since we have `n` words, and the maximum word length is `L`, the total time for building the trie is `O(n * L)`.\n\n- **Prefix Score Calculation**: For each word, we again traverse its length, which takes `O(L)` time. Hence, for all words, this is `O(n * L)`.\n\n\n | 13 | 0 | ['Python3'] | 3 |
sum-of-prefix-scores-of-strings | Trie || Beats 97% || C++ || Python || Java | trie-beats-97-c-python-java-by-as_313-mxrh | Intuition\nThe goal of the problem is to calculate the total score of every non-empty prefix of each word in a given list of strings. The score of a prefix is d | Baslik69 | NORMAL | 2024-09-25T00:33:38.060780+00:00 | 2024-09-25T00:33:38.060814+00:00 | 3,920 | false | # Intuition\nThe goal of the problem is to calculate the total score of every non-empty prefix of each word in a given list of strings. The score of a prefix is defined as the number of strings in the list that start with that prefix.\n\nTo solve this efficiently, we can use a Trie (prefix tree) data structure. The Trie allows us to group words by their prefixes and efficiently count how many words share a given prefix.\n\n# Approach\n1. **Use of Trie**:\n - Implement a Trie (prefix tree) to efficiently group words by their prefixes.\n\n2. **Building the Trie**:\n - Iterate through each word in the input list.\n - For each character in the word, navigate through the Trie.\n - Create nodes as necessary and maintain a count at each node to track how many words share that prefix.\n\n3. **Calculating Prefix Scores**:\n - For each word, traverse the Trie again character by character.\n - Accumulate the counts from the Trie nodes to compute the total score for all non-empty prefixes of that word.\n\n4. **Final Output**:\n - Return an array where each element corresponds to the total prefix score of the respective word in the input list.\n# Complexity\n- Time complexity:\n$$O(n *m)$$ \n\n- Space complexity:\n$$O(n *m)$$ \n\n# Code\n```python3 []\nclass Solution:\n def sumPrefixScores(self, words: List[str]) -> List[int]:\n # Build the trie structure from the list of words\n trie = self.buildTrie(words)\n # Calculate and return the prefix scores for each word\n return self.calculatePrefixScores(trie, words)\n\n def buildTrie(self, words: List[str]) -> Dict:\n trie = {}\n for word in words:\n node = trie\n for char in word:\n # Navigate through or create nodes in the trie\n node = node.setdefault(char, {})\n # Count occurrences of the prefix\n node[\'$\'] = node.get(\'$\', 0) + 1\n return trie\n\n def calculatePrefixScores(self, trie: Dict, words: List[str]) -> List[int]:\n scores = []\n for word in words:\n node = trie\n total_score = 0\n for char in word:\n # Move to the next node and accumulate the score\n node = node[char]\n total_score += node[\'$\']\n scores.append(total_score)\n return scores\n\n```\n``` cpp []\n#include <vector>\n#include <string>\n#include <unordered_map>\n\nclass Solution {\npublic:\n std::vector<int> sumPrefixScores(std::vector<std::string>& words) {\n // Build the trie structure from the list of words\n auto trie = buildTrie(words);\n // Calculate and return the prefix scores for each word\n return calculatePrefixScores(trie, words);\n }\n\nprivate:\n // Trie node structure\n struct TrieNode {\n std::unordered_map<char, TrieNode*> children;\n int prefixCount = 0;\n };\n\n // Build the trie from the words\n TrieNode* buildTrie(const std::vector<std::string>& words) {\n TrieNode* root = new TrieNode();\n for (const std::string& word : words) {\n TrieNode* node = root;\n for (char ch : word) {\n // Navigate through or create nodes in the trie\n node = node->children[ch];\n if (!node) {\n node = new TrieNode();\n node->children[ch] = node;\n }\n // Count occurrences of the prefix\n node->prefixCount++;\n }\n }\n return root;\n }\n\n // Calculate prefix scores based on the trie\n std::vector<int> calculatePrefixScores(TrieNode* trie, const std::vector<std::string>& words) {\n std::vector<int> scores;\n for (const std::string& word : words) {\n TrieNode* node = trie;\n int totalScore = 0;\n for (char ch : word) {\n // Move to the next node and accumulate the score\n node = node->children[ch];\n totalScore += node->prefixCount;\n }\n scores.push_back(totalScore);\n }\n return scores;\n }\n};\n```\n``` java []\nimport java.util.HashMap;\nimport java.util.List;\nimport java.util.ArrayList;\n\nclass Solution {\n public List<Integer> sumPrefixScores(List<String> words) {\n // Build the trie structure from the list of words\n TrieNode trie = buildTrie(words);\n // Calculate and return the prefix scores for each word\n return calculatePrefixScores(trie, words);\n }\n\n // Trie node structure\n private static class TrieNode {\n HashMap<Character, TrieNode> children = new HashMap<>();\n int prefixCount = 0;\n }\n\n // Build the trie from the words\n private TrieNode buildTrie(List<String> words) {\n TrieNode root = new TrieNode();\n for (String word : words) {\n TrieNode node = root;\n for (char ch : word.toCharArray()) {\n // Navigate through or create nodes in the trie\n node = node.children.computeIfAbsent(ch, c -> new TrieNode());\n // Count occurrences of the prefix\n node.prefixCount++;\n }\n }\n return root;\n }\n\n // Calculate prefix scores based on the trie\n private List<Integer> calculatePrefixScores(TrieNode trie, List<String> words) {\n List<Integer> scores = new ArrayList<>();\n for (String word : words) {\n TrieNode node = trie;\n int totalScore = 0;\n for (char ch : word.toCharArray()) {\n // Move to the next node and accumulate the score\n node = node.children.get(ch);\n totalScore += node.prefixCount;\n }\n scores.add(totalScore);\n }\n return scores;\n }\n}\n``` | 13 | 1 | ['Array', 'String', 'Trie', 'Counting', 'Python', 'C++', 'Java', 'Python3'] | 1 |
sum-of-prefix-scores-of-strings | Thought process explained | Trie | For beginner | thought-process-explained-trie-for-begin-pigq | So First question?\n How I got to know that Trie will work.\n\t So let\'s thing :\n\t We have 1000 words of 1000 length each. Also we have to get the value for | faltu_admi | NORMAL | 2022-09-18T04:02:38.666712+00:00 | 2022-09-18T04:02:38.666754+00:00 | 578 | false | ## So First question?\n* How I got to know that Trie will work.\n\t* So let\'s thing :\n\t* We have 1000 words of 1000 length each. Also we have to get the value for substring also.\n\t\t* Will HashMap works? No because for 1k word of 1k length, going to store all substring that would cause TLE.\n\t* So let\'s think somethink else :\n\t\t* We don\'t want to generate substring of string.\n\t\t* We want to get the res of [0-i-th] substring contest time.\n\t\t* We also want to store the freq.\n\t\t* So from above point it\'s clear that,\n\t\t\t* If we can store frequency of each substring [0,ith] and get the value for any string in O(N) that will help here.\n\t\t\t* This point revoked my to use Trie.\n\t\t\t* So Data Structure like trie, we have first problem, What data trie will contains and how to handle it?\n\t\t\t* for that let\'s think what data we need except basic Structure of Trie?\n\t\t\t\t* At any i-th position in string what we want?\n\t\t\t\t\t* Number of times this subtring [0, ith] appeared in entire list.\n\t\t\t\t\t* That\'s means number of time current node visited. Right?\n\t\t\t\t\t* Storing count for each node would help.\n\nSo from above point we come up with conclusioin to use Trie with bellow Structure.\n```\nclass Trie {\n public :\n unordered_map<char, Trie*> children;\n int cnt;\n Trie() {\n cnt = 0;\n }\n int getCnt() {\n return cnt;\n }\n};\n```\n\n## Now let\'s implement :\n* First insert all the string from given list into the Trie.\n* Traverse trie and for each string, at keep sum of number of times all node visited which came in the path of string i-th\n* This count is your answer.\n\n```\nclass Solution {\npublic:\n Trie *trie;\n void insert(string &str) {\n Trie * temp = trie;\n for(char &ch : str) {\n if(temp->children.count(ch) == 0) {\n temp->children[ch] = new Trie();\n }\n temp = temp->children[ch];\n temp->cnt++;\n }\n }\n \n int getCnt(string &s) {\n int cnt = 0;\n Trie *root = trie;\n for(char &ch : s) {\n cnt+=root->getCnt();\n root = root->children[ch];\n }\n return cnt+root->getCnt();\n }\n \n vector<int> sumPrefixScores(vector<string>& words) {\n trie = new Trie();\n for(string &s : words) insert(s);\n vector<int> res;\n for(string &s : words) {\n res.push_back(getCnt(s));\n }\n return res;\n }\n```\n\n## Time Complexity \n* Inserting and traversing String into Trie will cause of O(N).\n* So for N string it\'ll be O(N*N) that would be accepted.\n\n## Space Complexity\n* Space complexity will be O(alphabet_size * average key length * N).\n\n\n**Please upvote if it helps.**\n**Happy Coding** | 12 | 0 | [] | 2 |
sum-of-prefix-scores-of-strings | ⚙ C++ || NO TRIE || NLOGN SOLUTION | c-no-trie-nlogn-solution-by-venom-xd-frvr | \t\tclass Solution {\n\t\tpublic:\n\t\t\tvector sumPrefixScores(vector& words) {\n\t\t\t\tint n = words.size();\n\t\t\t\tvector> words2;\n\t\t\t\tfor (int i = 0 | venom-xd | NORMAL | 2022-09-18T04:31:12.435990+00:00 | 2022-09-18T04:31:12.436041+00:00 | 1,302 | false | \t\tclass Solution {\n\t\tpublic:\n\t\t\tvector<int> sumPrefixScores(vector<string>& words) {\n\t\t\t\tint n = words.size();\n\t\t\t\tvector<pair<string, int>> words2;\n\t\t\t\tfor (int i = 0; i < n; ++i) {\n\t\t\t\t\twords2.push_back(make_pair(words[i], i));\n\t\t\t\t}\n\t\t\t\tsort(words2.begin(), words2.end());\n\n\t\t\t\tvector<int> perm(n);\n\t\t\t\tfor (int i = 0; i < n; ++i) {\n\t\t\t\t\tperm[i] = words2[i].second;\n\t\t\t\t}\n\t\t\t\tvector<int> commonPrefix(n);\n\n\t\t\t\tfor (int i = 1; i < n; ++i) {\n\t\t\t\t\tstring const& w1 = words2[i - 1].first;\n\t\t\t\t\tstring const& w2 = words2[i].first;\n\t\t\t\t\tint l = min(w1.size(), w2.size());\n\t\t\t\t\tint p = 0;\n\t\t\t\t\twhile (p < l && w1[p] == w2[p]) {\n\t\t\t\t\t\t++p;\n\t\t\t\t\t}\n\t\t\t\t\tcommonPrefix[i] = p;\n\t\t\t\t}\n\n\t\t\t\tvector<int> ret(n);\n\t\t\t\tfor (int i = 0; i < n; ++i) {\n\t\t\t\t\tint prefix = words2[i].first.size();\n\t\t\t\t\tret[perm[i]] += prefix;\n\t\t\t\t\tfor (int j = i + 1; j < n; ++j) {\n\t\t\t\t\t\tprefix = min(prefix, commonPrefix[j]);\n\t\t\t\t\t\tif (prefix == 0) {\n\t\t\t\t\t\t\tbreak;\n\t\t\t\t\t\t}\n\t\t\t\t\t\tret[perm[i]] += prefix;\n\t\t\t\t\t\tret[perm[j]] += prefix;\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t\treturn ret;\n\t\t\t}\n\t\t}; | 10 | 0 | ['Trie', 'C', 'C++', 'Java'] | 1 |
sum-of-prefix-scores-of-strings | C# Solution for Sum of Prefix Scores of Strings Problem | c-solution-for-sum-of-prefix-scores-of-s-26iq | Intuition\n Describe your first thoughts on how to solve this problem. \nThe problem requires us to compute the score of each word in an array, where the score | Aman_Raj_Sinha | NORMAL | 2024-09-25T02:52:36.987948+00:00 | 2024-09-25T02:52:36.987984+00:00 | 235 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThe problem requires us to compute the score of each word in an array, where the score is the sum of how many words have each prefix of the word. A brute force approach (checking each prefix of each word against all other words) would be too slow, especially for large input sizes.\n\nThe key observation is that multiple words may share common prefixes, so storing and counting these shared prefixes efficiently can drastically improve performance. The Trie (Prefix Tree) is ideal for this since it allows us to store prefixes in a hierarchical structure, making prefix lookups and counting efficient.\n\nBy inserting each word into a Trie, we can track how many words share the same prefix. This allows us to quickly calculate the score for any word by simply summing the counts stored at each node along the path of the word in the Trie.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n1.\tTrie Data Structure:\n\t\u2022\tEach node in the Trie represents a character of a word, and the path from the root to a node represents a prefix of some word(s).\n\t\u2022\tEach node has a count value that tracks how many words share the prefix represented by the path to that node.\n2.\tSteps:\n\t\u2022\tInsert all words into the Trie:\n\t \u2022\tFor each word, we insert its characters into the Trie. As we traverse the Trie, we increment the count at each node to track how many words pass through that prefix.\n\t\u2022\tCalculate the score of each word:\n\t \u2022\tFor each word, traverse the Trie from the root node to the node representing the last character of the word. Sum up the count values at each node along the way to get the total score for the word.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n1.\tTrie Construction:\n\t\u2022\tInserting a word into the Trie takes time proportional to its length. If there are n words and the average word length is m, then:\n\t \u2022\tInserting all words: O(n x m) \n\t \u2022\tThis is because for each word, we insert its m characters into the Trie, and we do this for all n words.\n2.\tScore Calculation:\n\t\u2022\tFor each word, calculating its score requires traversing its characters in the Trie, which takes O(m) time per word.\n\t\u2022\tFor n words, the total time to calculate scores is O(n x m) .\n\nThus, the overall time complexity is: O(n x m)\nWhere:\n\u2022\t n is the number of words in the input list.\n\u2022\t m is the average length of the words.\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n1.\tTrie Storage:\n\t\u2022\tThe Trie stores characters for all the words. In the worst case, if there are no shared prefixes, the Trie could contain O(n x m) nodes (one for each character of each word).\n\t\u2022\tEach node also contains a count field and a dictionary (or equivalent structure) to store its children.\n\nThus, the space complexity for the Trie is: O(n x m)\n\n2.\tResult Array:\n\t\u2022\tWe need an array of size n to store the results, which has a space complexity of O(n) .\n\nThus, the total space complexity is: O(n x m)\n\n\n# Code\n```csharp []\npublic class Solution {\n public class TrieNode {\n public Dictionary<char, TrieNode> Children;\n public int Count; // keeps track of how many words share this prefix\n \n public TrieNode() {\n Children = new Dictionary<char, TrieNode>();\n Count = 0;\n }\n }\n\n private void Insert(TrieNode root, string word) {\n TrieNode currentNode = root;\n foreach (char c in word) {\n if (!currentNode.Children.ContainsKey(c)) {\n currentNode.Children[c] = new TrieNode();\n }\n currentNode = currentNode.Children[c];\n currentNode.Count++; // increase the prefix count\n }\n }\n\n private int GetScore(TrieNode root, string word) {\n TrieNode currentNode = root;\n int score = 0;\n foreach (char c in word) {\n currentNode = currentNode.Children[c];\n score += currentNode.Count;\n }\n return score;\n }\n public int[] SumPrefixScores(string[] words) {\n TrieNode root = new TrieNode();\n \n // Step 1: Insert all words into the Trie\n foreach (string word in words) {\n Insert(root, word);\n }\n \n // Step 2: Calculate the score for each word\n int[] result = new int[words.Length];\n for (int i = 0; i < words.Length; i++) {\n result[i] = GetScore(root, words[i]);\n }\n \n return result;\n }\n}\n``` | 9 | 0 | ['C#'] | 0 |
sum-of-prefix-scores-of-strings | 🌟 [Explained]🔍 From Brute Force to Tries: 🚀 Mastering Sum Of Prefix Scores Optimization 🌟 | explained-from-brute-force-to-tries-mast-ub2r | \n# Approach 1: Brute Force (Memory Limit Exceeded - MLE) \uD83D\uDED1\nThis approach uses a brute-force method by storing each word\'s prefixes in a map with v | AlgoArtisan | NORMAL | 2024-09-25T02:24:05.494606+00:00 | 2024-09-25T04:47:36.811546+00:00 | 1,436 | false | \n# Approach 1: Brute Force (Memory Limit Exceeded - MLE) \uD83D\uDED1\nThis approach uses a brute-force method by storing each word\'s prefixes in a map with vector<string>. For every prefix, the corresponding vector stores all occurrences of the prefix, leading to an excessive memory footprint.\n\n# Time Complexity:\nO(L\xB2), where L is the total length of all words combined. The repeated string copying for each prefix leads to quadratic complexity.\n# Space Complexity:\nO(L\xB2) due to storing multiple copies of each prefix.\n\n# Code\n```cpp []\nclass Solution {\npublic:\n vector<int> sumPrefixScores(vector<string>& words) {\n unordered_map<string, vector<string>> m;\n for (auto const& word : words) {\n string prefix = "";\n for (auto const ch : word) {\n prefix += ch;\n m[prefix].push_back(prefix);\n }\n }\n vector<int> result;\n\n for (auto word : words) {\n string prefix = "";\n int count = 0;\n for (auto ch : word) {\n prefix += ch;\n if (m.count(prefix) > 0) {\n count += m[prefix].size();\n }\n }\n result.push_back(count);\n }\n return result;\n }\n};\n\n```\n\n# Approach: Optimized Hash Map (Time Limit Exceeded - TLE) \u23F3\n\nThis approach improves on memory by using an unordered_map<string, int> to store prefix frequencies. However, it still suffers from performance issues due to the overhead of string operations, which can result in slow execution times for larger inputs.\n\n# Code\n```cpp []\nclass Solution {\npublic:\n vector<int> sumPrefixScores(vector<string>& words) {\n unordered_map<string, int> m;\n for (auto const& word : words) {\n string prefix = "";\n for (auto const ch : word) {\n prefix += ch;\n m[prefix]++;\n }\n }\n vector<int> result;\n for (auto const& word : words) {\n string prefix = "";\n int count = 0;\n for (auto const& ch : word) {\n prefix += ch;\n if (m.count(prefix) > 0) {\n count += m[prefix];\n }\n }\n result.push_back(count);\n }\n return result;\n }\n};\n\n\n```\n\n# Approach: [Trie-Based (Accepted) \u2705]\nThis solution uses a Trie data structure to efficiently store and query prefixes. Each node in the Trie represents a character and keeps track of how many times the prefix ending at that node has been encountered, avoiding the repeated creation of strings and optimizing both time and space usage.\n\n# Time Complexity:\nO(L), where L is the total length of all words. Each character in each word is processed only once during Trie insertion and score calculation.\n# Space Complexity:\nO(L) for storing the Trie nodes, as each character in the words is stored only once.\n\n# Code\n```cpp []\nstruct TrieNode {\n TrieNode* children[26] = {};\n int score = 0;\n};\nclass Trie {\npublic:\n TrieNode* root;\n\n Trie() { root = new TrieNode(); }\n\n void insert(const string& word) {\n TrieNode* node = root;\n for (const char& ch : word) {\n int idx = ch - \'a\';\n if (!node->children[idx]) {\n node->children[idx] = new TrieNode();\n }\n node = node->children[idx];\n node->score++;\n }\n }\n\n int getScore(const string& word) {\n TrieNode* node = root;\n int totalScore = 0;\n for (const char& ch : word) {\n int idx = ch - \'a\';\n node = node->children[idx];\n totalScore += node->score;\n }\n return totalScore;\n }\n};\n\nclass Solution {\npublic:\n vector<int> sumPrefixScores(vector<string>& words) {\n Trie trie;\n for (const auto& word : words) {\n trie.insert(word);\n }\n vector<int> result;\n for (const auto& word : words) {\n result.push_back(trie.getScore(word));\n }\n return result;\n }\n};\n\n```\n\n# Conclusion:\n# Approach 1 (MLE): \nUsing a brute-force method, storing excessive data for each prefix, leading to memory limit exceeded.\n# Approach 2 (TLE): \nAn optimized approach using a hash map, but still slow due to string operations.\n# Approach 3 (Accepted): \nThe Trie-based solution optimizes both time and space complexity, making it the most efficient approach.\n\n# \uD83C\uDF1F Enjoyed the Solutions? Found It Helpful? \uD83C\uDF1F\n# \uD83D\uDCA1 Upvote to Support the Journey from Brute Force to Optimal Solutions! \uD83D\uDCA1\n# \uD83D\uDC4D Your Upvote Helps Others Discover Efficient Approaches! \uD83D\uDE80 | 9 | 0 | ['Hash Table', 'String', 'Trie', 'C++'] | 3 |
sum-of-prefix-scores-of-strings | [Python] Trie Solution | python-trie-solution-by-lee215-ceji | Explanation\nUse Trie to build up a tree.\nadd word and add 1 point to each node on the word path.\nsocre will sum up the point on the word path.\n\n\n# Complex | lee215 | NORMAL | 2022-09-18T04:06:02.757623+00:00 | 2022-09-19T16:26:38.776881+00:00 | 555 | false | # **Explanation**\nUse Trie to build up a tree.\n`add` word and add `1` point to each node on the word path.\n`socre` will sum up the point on the word path.\n<br>\n\n# **Complexity**\nTime `O(words)`\nSpace `O(words)`\n<br>\n\n\n**Python**\n```py\nclass Trie(object):\n\n def __init__(self):\n T = lambda: defaultdict(T)\n self.root = T()\n\n def add(self, word):\n node = self.root\n for w in word:\n node = node[w]\n node[\'#\'] = node.get(\'#\', 0) + 1\n\n def score(self, word):\n res = 0\n node = self.root\n for w in word:\n node = node[w]\n res += node.get(\'#\', 0)\n return res\n\nclass Solution(object):\n def sumPrefixScores(self, words):\n trie = Trie()\n list(map(trie.add, words))\n return list(map(trie.score, words))\n```\n | 9 | 0 | [] | 6 |
sum-of-prefix-scores-of-strings | [Java/Python 3] Trie build/search prefix w/ brief explanation and analysis. | javapython-3-trie-buildsearch-prefix-w-b-ns8l | Build Trie and accumulate the frequencies of each pefix at the same time; then search each word and compute the corresponding score.\n\njava\nclass Trie {\n | rock | NORMAL | 2022-09-18T04:20:04.183372+00:00 | 2022-11-10T12:02:39.116374+00:00 | 502 | false | Build Trie and accumulate the frequencies of each pefix at the same time; then search each word and compute the corresponding score.\n\n```java\nclass Trie {\n int cnt = 0;\n Map<Character, Trie> kids = new HashMap<>();\n public void add(String word) {\n Trie t = this;\n for (char c : word.toCharArray()) {\n if (!t.kids.containsKey(c)) {\n t.kids.put(c, new Trie());\n }\n t = t.kids.get(c);\n t.cnt += 1;\n }\n }\n public int search(String word) {\n Trie t = this;\n int score = 0;\n for (char c : word.toCharArray()) {\n if (t.kids.get(c) == null) {\n return score;\n }\n t = t.kids.get(c);\n score += t.cnt;\n }\n return score;\n }\n}\n\nclass Solution {\n public int[] sumPrefixScores(String[] words) {\n Trie root = new Trie();\n for (String word : words) {\n root.add(word);\n }\n int n = words.length, i = 0;\n int[] scores = new int[n];\n for (String word : words) {\n scores[i++] = root.search(word);\n }\n return scores;\n }\n}\n```\n```python\nclass Trie:\n def __init__(self):\n self.cnt = 0\n self.kids = {}\n def add(self, word: str) -> None:\n trie = self\n for c in word:\n if c not in trie.kids:\n trie.kids[c] = Trie()\n trie = trie.kids[c]\n trie.cnt += 1\n def search(self, word) -> int:\n score = 0\n trie = self\n for c in word:\n if c not in trie.kids:\n return score\n trie = trie.kids[c] \n score += trie.cnt\n return score\n \nclass Solution:\n def sumPrefixScores(self, words: List[str]) -> List[int]:\n root = Trie()\n for w in words:\n root.add(w)\n return [root.search(w) for w in words]\n```\n\n**Analysis:**\n\nTime & space: `O(n * w)`, where `n = words.length, w =` average size of word in `words`. | 8 | 0 | [] | 1 |
sum-of-prefix-scores-of-strings | ✅ One Line Solution | one-line-solution-by-mikposp-ev44 | (Disclaimer: this is not an example to follow in a real project - it is written for fun and training mostly)\n\n# Code #1 - Brute Force Counting\npython3\nclass | MikPosp | NORMAL | 2024-09-25T10:55:20.179735+00:00 | 2024-09-25T16:43:57.557965+00:00 | 750 | false | (Disclaimer: this is not an example to follow in a real project - it is written for fun and training mostly)\n\n# Code #1 - Brute Force Counting\n```python3\nclass Solution:\n def sumPrefixScores(self, a: List[str]) -> List[int]:\n return (z:=Counter(s[:i+1] for s in a for i in range(len(s)))) and [sum(z[s[:i+1]] for i in range(len(s))) for s in a]\n```\n\n# Code #2.1 - Bizarre Three Lines Trie Solution\n```python3\nclass Solution:\n def sumPrefixScores(self, a: List[str]) -> List[int]:\n d = {}\n [(p:=d,all((setitem(p.setdefault(c,{0:0}),0,p[c][0]+1),p:=p[c]) for c in s)) for s in a]\n\n return [(p:=d) and sum((p[c][0],p:=p[c])[0] for c in s) for s in a]\n```\n\n# Code #2.2 - More Bizarre Three Lines Trie Solution\n```python3\nclass Solution:\n def sumPrefixScores(self, a: List[str]) -> List[int]:\n d = (f:=lambda:defaultdict(f)|{0:0})()\n [reduce(lambda p,c:setitem(p[c],0,p[c][0]+1) or p[c],s,d) for s in a]\n\n return [sum((p[c][0],p:=p[c])[0] for c in s) for s in a if (p:=d)]\n```\n\n(Disclaimer 2: code above is just a product of fantasy packed into one line, it is not claimed to be \'true\' oneliners - please, remind about drawbacks only if you know how to make it better) | 7 | 0 | ['Array', 'String', 'Trie', 'Counting', 'Python', 'Python3'] | 1 |
sum-of-prefix-scores-of-strings | String hashing | No trie needed | Python3 | string-hashing-no-trie-needed-python3-by-mvdt | Intuition\nWe can use a rolling hash to cumulatively calculate the hash of all the prefixes in O(len(word)).\nThus, we can store the occurences of this hash in | reas0ner | NORMAL | 2024-09-25T09:30:05.796482+00:00 | 2024-09-25T09:30:05.796514+00:00 | 827 | false | # Intuition\nWe can use a rolling hash to cumulatively calculate the hash of all the prefixes in O(len(word)).\nThus, we can store the occurences of this hash in various strings and lookup the counts in a second loop to calculate the score.\n\n# Complexity\n- Time complexity:\nO(len(words) * len(word))\n\n- Space complexity:\nO(len(words) * len(word))\n\n# Code\n```python3 []\nclass Solution:\n def sumPrefixScores(self, words: List[str]) -> List[int]:\n M, P = 10**15 + 7, 31\n prefix_hash_dict = defaultdict(int)\n\n def idx(char):\n return ord(char) - ord(\'a\') + 1\n\n def encode_prefixes(s):\n prefix_hash = 0\n p = 1\n for char in s:\n prefix_hash = (prefix_hash + idx(char) * p) % M\n prefix_hash_dict[prefix_hash] += 1\n p = (p * P) % M\n\n def score(s):\n prefix_hash = res = 0\n p = 1\n for char in s:\n prefix_hash = (prefix_hash + idx(char) * p) % M\n res += prefix_hash_dict[prefix_hash]\n p = (p * P) % M\n return res\n\n for word in words:\n encode_prefixes(word)\n\n return [score(word) for word in words]\n\n``` | 7 | 0 | ['Hash Table', 'Trie', 'Rolling Hash', 'Python3'] | 3 |
sum-of-prefix-scores-of-strings | C++ || Trie || Easy to Understand || Visualization | c-trie-easy-to-understand-visualization-pted9 | Introduction to Tries\n###### A Trie, also known as a prefix tree, is an efficient tree-like data structure used for storing and searching strings. It\'s partic | khalidalam980 | NORMAL | 2024-09-25T01:57:33.538219+00:00 | 2024-09-25T23:46:14.700082+00:00 | 1,029 | false | # Introduction to Tries\n###### A Trie, also known as a prefix tree, is an efficient tree-like data structure used for storing and searching strings. It\'s particularly useful for problems involving prefixes, which makes it ideal for our current challenge.\n\n**In a Trie:**\n- Each node represents a character in a string.\n- The root node is typically empty.\n- Each path from the root to a node forms a prefix of one or more strings.\n- Nodes can store additional information, such as frequency counts.\n## Why a Trie is Ideal for This Problem\n###### The "Sum of Prefix Scores of Strings" problem requires us to count the occurrences of prefixes across multiple strings efficiently. A Trie is perfect for this task because:\n\n1. **Prefix Storage:** It naturally organizes strings by their prefixes.\n2. **Efficient Searching:** It allows for quick prefix lookups.\n3. **Space Efficiency:** Common prefixes are stored only once.\n\n###### Consider the example: **`words = ["abc", "ab", "bc", "b"]`**\n###### In a Trie, these words would be stored like this:\n```\n root\n / \\\n a b\n | / \\\n b c *\n | \\ |\n c * *\n |\n *\n```\n###### Where `*` represents the end of a word.\n# Intuition\n###### Imagine walking through the Trie for each word. As you traverse, you\'re essentially following all the prefixes of that word. If we keep a count at each node representing how many words pass through it, we can easily sum up the scores for all prefixes of a word.\n###### For instance, for **`"abc"`**:\n\n**`"a"`** is a prefix of **`2`** words\n**`"ab"`** is a prefix of **`2`** words\n**`"abc"`** is a prefix of **`1`** word\n\n###### So, the total score for **`"abc"`** would be **`2 + 2 + 1 = 5`**.\n\n# Approach\n###### Certainly. Let\'s dive deeper into how the Trie stores prefixes and their counts using the example provided: **`words = ["abc", "ab", "bc", "b"]`**.\n\n\n###### Now, let\'s explain how the Trie stores prefixes and their counts using this example:\n\n1. ###### **Insertion Process:**\n - We insert each word into the Trie, one character at a time.\n - For each character, we either create a new node or use an existing one.\n - We increment a counter at each node we pass through.\n\n\n2. ###### **Storing Prefixes:**\n - Each path from the root to any node represents a prefix.\n - The counter at each node represents how many words in our list contain the prefix up to that point.\n\n\n3. ###### **Example Walkthrough:**\n ###### a) Inserting **`"abc"`**:\n - Create node **`\'a\'`** with count **`1`**\n - Create node **`\'b\'`** under **`\'a\'`** with count **`1`**\n - Create node **`\'c\'`** under **`\'ab\'`** with count **`1`**\n\n ###### b) Inserting **`"ab"`**:\n - Increment count of existing **`\'a\'`** node to **`2`**\n - Increment count of existing **`\'b\'`** node under **`\'a\'`** to **`2`**\n\n ###### c) Inserting **`"bc"`**:\n - Create new **`\'b\'`** node from root with count **`1`**\n - Create **`\'c\'`** node under this **`\'b\'`** with count **`1`**\n\n ###### d) Inserting **`"b"`**:\n - Increment count of existing **`\'b\'`** node from root to **`2`**\n\n\n4. ###### Final Trie Structure:\n - Root has two children: **`\'a\'`** and **`\'b\'`**\n - **`\'a\'`** node has count **`2`** (prefix of **`"abc"`** and **`"ab"`**)\n - **`\'b\'`** node under **`\'a\'`** has count **`2`** (prefix of **`"abc"`** and **`"ab"`**)\n - **`\'c\'`** node under **`\'ab\'`** has count **`1`** (only in **`"abc"`**)\n - **`\'b\'`** node from root has count **`2`** (prefix of **`"bc"`** and **`"b"`**)\n - **`\'c`**\' node under root-level **`\'b\'`** has count **`1`** (only in **`"bc"`**)\n\n\n5. ###### Prefix Counts:\n\n - **`"a"`** is a prefix of **`2`** words\n - **`"ab"`** is a prefix of **`2`** words\n - **`"abc"`** is a prefix of **`1`** word\n - **`"b"`** is a prefix of **`2`** words\n - **`"bc"`** is a prefix of **`1`** word\n\n###### This structure allows us to quickly compute the sum of prefix scores for each word:\n- For **`"abc": 2 + 2 + 1 = 5`**\n- For **`"ab": 2 + 2 = 4`**\n- For **`"bc": 2 + 1 = 3`**\n- For **`"b": 2`**\n\n###### By storing the counts at each node, we avoid recounting prefixes, making the solution efficient for both time and space complexity.\n\n# Complexity\n- ###### Time complexity:\n - Building the Trie: **`O(N * L)`**, where **`N`** is the number of words and **`L`** is the average length of words.\n - Calculating scores: **`O(N * L)`**\n - Total: **O(N * L)**\n\n- ###### Space complexity:\n - **O(N * L)** in the worst case, where all words are distinct.\n - In practice, it\'s often less due to shared prefixes.\n\n# Code\n```cpp []\nstruct TrieNode {\n int isCount; // Tracks count of prefixes at this node\n TrieNode* child[26]; // Pointers to child nodes (for each letter \'a\' to \'z\')\n\n // Constructor initializes count and child pointers\n TrieNode() {\n isCount = 0;\n for (int i = 0; i < 26; i++) {\n child[i] = NULL;\n }\n }\n};\n\nclass Trie {\nprivate:\n TrieNode* root; // Root of the Trie\n\npublic:\n Trie() {\n root = new TrieNode(); // Initialize Trie root\n }\n\n // Inserts a word into the Trie\n void Insert(string s) {\n TrieNode* crawl = root;\n for (auto ch : s) {\n int idx = ch - \'a\';\n if (!crawl->child[idx]) {\n crawl->child[idx] = new TrieNode(); // Create child if it doesn\'t exist\n }\n crawl = crawl->child[idx];\n crawl->isCount++; // Increment count at each node\n }\n }\n\n // Solves for prefix scores for each word in words\n vector<int> solve(vector<string>& words) {\n vector<int> result;\n for (auto word : words) {\n int count = 0;\n TrieNode* crawl = root;\n for (auto ch : word) {\n int idx = ch - \'a\';\n // Thanks to [@prasflames16] for pointing out\n // that we don\'t need a NULL check here.\n // if(!crawl->child[idx]){\n // break;\n // }\n crawl = crawl->child[idx];\n count += crawl->isCount; // Add count of prefixes\n }\n result.push_back(count);\n }\n return result;\n }\n};\n\nclass Solution {\npublic:\n vector<int> sumPrefixScores(vector<string>& words) {\n Trie t; // Create a Trie\n for (auto word : words) {\n t.Insert(word); // Insert each word into the Trie\n }\n return t.solve(words); // Compute and return the prefix scores\n }\n};\n\n``` | 7 | 0 | ['String', 'Trie', 'Counting', 'C++'] | 2 |
sum-of-prefix-scores-of-strings | Trie | Java | Beginner friendly🔥 | trie-java-beginner-friendly-by-someone_c-i65q | class Solution {\n \n private class TrieNode{\n TrieNode[]children;\n boolean isEnd;\n int pre_count=0;\n \n TrieNode() | someone_codes | NORMAL | 2022-09-18T12:06:27.408795+00:00 | 2022-09-18T13:33:32.097017+00:00 | 629 | false | class Solution {\n \n private class TrieNode{\n TrieNode[]children;\n boolean isEnd;\n int pre_count=0;\n \n TrieNode(){\n children=new TrieNode[26];\n isEnd=false;\n }\n }\n \n private TrieNode root;\n \n private void insert_word(String s){\n TrieNode curr=root;\n \n for(int i=0;i<s.length();i++){\n char ch=s.charAt(i);\n \n if(curr.children[ch-\'a\']==null){\n curr.children[ch-\'a\']=new TrieNode();\n }\n \n curr=curr.children[ch-\'a\'];\n curr.pre_count++; \n }\n \n curr.isEnd=true;\n }\n \n private int start_word_prefix(String s){\n \n TrieNode curr=root;\n int count=0;\n \n for(int i=0;i<s.length();i++){\n char ch=s.charAt(i);\n \n if(curr.children[ch-\'a\']==null)break;\n \n curr=curr.children[ch-\'a\'];\n count+=curr.pre_count;\n }\n \n return count;\n }\n \n public int[] sumPrefixScores(String[] words) {\n int n=words.length;\n int i=0;\n \n int[]res=new int[n];\n \n root=new TrieNode();\n \n for(String word:words)insert_word(word);\n \n for(String word:words){\n int count=start_word_prefix(word);\n res[i++]=count;\n }\n \n return res;\n }\n}\n\nPlz upvote if you like the solution.. | 7 | 0 | ['Trie', 'Java'] | 0 |
sum-of-prefix-scores-of-strings | Don't Trie | Simple hashing! | dont-trie-simple-hashing-by-rac101ran-coxd | \nclass Solution {\npublic:\n unordered_map<long long,int> mp;\n long long base = 31 , pw = 1 , mod = 1011001110001111;\n vector<int> sumPrefixScores(v | rac101ran | NORMAL | 2022-09-18T04:13:09.000335+00:00 | 2022-09-18T04:21:40.334824+00:00 | 1,301 | false | ```\nclass Solution {\npublic:\n unordered_map<long long,int> mp;\n long long base = 31 , pw = 1 , mod = 1011001110001111;\n vector<int> sumPrefixScores(vector<string>& words) {\n vector<int> ans;\n for(string s : words) {\n long long hash = 0 , pw = 1;\n for(int j=0; j<s.size(); j++) {\n mp[hash = (hash + (pw * (s[j] -\'a\' + 1)) % mod)%mod]++;\n pw = (pw * base) % mod;\n }\n }\n for(string s : words) {\n long long hash = 0 , pw = 1;\n int cnt = 0;\n for(int j=0; j<s.size(); j++) {\n cnt+=mp[hash = (hash + (pw * (s[j] -\'a\' + 1)) % mod)%mod];\n pw = (pw * base) % mod;\n }\n ans.push_back(cnt); \n }\n return ans;\n } \n};\n``` | 7 | 0 | ['C', 'Rolling Hash'] | 6 |
sum-of-prefix-scores-of-strings | C++ | Trie | Searching | c-trie-searching-by-surajpatel-5fhj | \nclass Solution {\npublic:\n class Trie {\n public:\n Trie() {\n cnt = 0;\n for(int i=0;i<26;i++){\n this->ne | surajpatel | NORMAL | 2022-09-18T04:06:08.934164+00:00 | 2022-09-18T04:06:08.934204+00:00 | 770 | false | ```\nclass Solution {\npublic:\n class Trie {\n public:\n Trie() {\n cnt = 0;\n for(int i=0;i<26;i++){\n this->next[i] = NULL;\n }\n }\n void insert(string word, Trie* root) {\n Trie* node = root;\n int i = 0;\n for (char ch : word) {\n ch -= \'a\';\n if (!node->next[ch]) { node->next[ch] = new Trie(); }\n node->next[ch]->cnt++;\n node = node->next[ch];\n i++;\n }\n }\n\n int search(char ch, Trie* node) {\n return node->next[ch-\'a\']->cnt;\n }\n\n Trie* next[26] = {};\n int cnt;\n };\n vector<int> sumPrefixScores(vector<string>& words) {\n Trie t;\n Trie *root = new Trie();\n int n = words.size();\n for(int i=0;i<n;i++){\n t.insert(words[i], root);\n }\n vector<int> ans;\n for(int i=0;i<n;i++){\n string cur = "";\n int c = 0;\n Trie *node = root;\n for(int j=0;j<words[i].length();j++){\n c += t.search(words[i][j], node);;\n if(node->next[words[i][j]-\'a\'] == NULL) break;\n node = node->next[words[i][j]-\'a\'];\n }\n ans.push_back(c);\n }\n return ans;\n }\n};\n\n``` | 7 | 0 | ['String', 'Trie', 'C'] | 4 |
sum-of-prefix-scores-of-strings | TLE Disaster | both hashmap and Trie giving TLE | tle-disaster-both-hashmap-and-trie-givin-w2oo | HashMap\n\nclass Solution {\n public int[] sumPrefixScores(String[] words) {\n \n \n\n int n=words.length;\n int ans[]=new int[n] | deleted_user | NORMAL | 2022-09-18T04:01:14.547715+00:00 | 2022-09-18T04:20:13.883940+00:00 | 945 | false | 1. HashMap\n```\nclass Solution {\n public int[] sumPrefixScores(String[] words) {\n \n \n\n int n=words.length;\n int ans[]=new int[n];\n \n HashMap<String,Integer> map=new HashMap<>();\n HashMap<Integer,HashSet<String>> sub_str=new HashMap<>();\n for(int i=0; i<n; i++){\n StringBuilder sb=new StringBuilder();\n for(int j=0; j<words[i].length(); j++){\n sb.append(words[i].charAt(j));\n if(!sub_str.containsKey(i))\n sub_str.put(i,new HashSet<>());\n sub_str.get(i).add(sb.toString());\n map.put(sb.toString(),map.getOrDefault(sb.toString(),0)+1);\n }\n }\n for(int i=0; i<n; i++){\n int count=0;\n for(String str:sub_str.get(i)){\n Integer get=map.get(str);\n if(get==null) break;\n count+=get;\n }\n ans[i]=count;\n }\n \n return ans;\n }\n}\n```\n2. Trie\n```\nclass Solution {\n class Node{\n Node links[];\n boolean flag;\n int count;\n public Node(){\n links=new Node[26];\n flag=false;\n count=0;\n }\n boolean containsKey(char c){\n return links[c-\'a\']!=null;\n }\n Node get(char c){\n return links[c-\'a\'];\n }\n void put(char c,Node toadd){\n links[c-\'a\']=toadd;\n }\n void setEnd(){\n flag=true;\n }\n boolean isEnd(){\n return flag;\n }\n \n}\nclass Trie {\n Node root;\n public Trie() {\n root=new Node();\n }\n \n public void insert(String word) {\n Node node=root;\n for(char c:word.toCharArray()){\n if(!node.containsKey(c)){\n node.put(c,new Node());\n }\n node=node.get(c); \n node.count++;\n }\n node.setEnd();\n \n }\n \n public boolean search(String word) {\n Node node=root;\n for(char c:word.toCharArray()){\n if(!node.containsKey(c)) return false;\n \n node=node.get(c);\n }\n return node.isEnd();\n }\n \n public int startsWith(String prefix) {\n Node node=root;\n for(char c:prefix.toCharArray()){\n if(!node.containsKey(c)) return 0;\n node=node.get(c);\n }\n return node.count;\n }\n}\n public int[] sumPrefixScores(String[] words) {\n \n \n Trie root=new Trie();\n int n=words.length;\n int ans[]=new int[n];\n \n for(int i=0; i<n; i++){\n root.insert(words[i]);\n }\n \n for(int i=0; i<n; i++){\n StringBuilder sb=new StringBuilder();\n int count=0;\n for(int j=0; j<words[i].length(); j++){\n sb.append(words[i].charAt(j));\n count+=root.startsWith(sb.toString());\n }\n ans[i]=count;\n }\n \n return ans;\n }\n}\n```\n\n3. Trie Accepted\n```\nclass Solution {\n class Node{\n Node links[];\n boolean flag;\n int count;\n public Node(){\n links=new Node[26];\n flag=false;\n count=0;\n }\n boolean containsKey(char c){\n return links[c-\'a\']!=null;\n }\n Node get(char c){\n return links[c-\'a\'];\n }\n void put(char c,Node toadd){\n links[c-\'a\']=toadd;\n }\n void setEnd(){\n flag=true;\n }\n boolean isEnd(){\n return flag;\n }\n \n}\nclass Trie {\n Node root;\n public Trie() {\n root=new Node();\n }\n \n public void insert(String word) {\n Node node=root;\n for(char c:word.toCharArray()){\n if(!node.containsKey(c)){\n node.put(c,new Node());\n }\n node=node.get(c); \n node.count++;\n }\n node.setEnd();\n \n }\n \n public boolean search(String word) {\n Node node=root;\n for(char c:word.toCharArray()){\n if(!node.containsKey(c)) return false;\n \n node=node.get(c);\n }\n return node.isEnd();\n }\n \n public int startsWith(String prefix) {\n\n Node node=root;\n int ans=node.count;\n for(char c:prefix.toCharArray()){\n node=node.get(c);\n ans+=node.count;\n }\n return ans;\n }\n}\n public int[] sumPrefixScores(String[] words) {\n Trie root=new Trie();\n int n=words.length;\n int ans[]=new int[n];\n \n for(int i=0; i<n; i++){\n root.insert(words[i]);\n }\n \n for(int i=0; i<n; i++){\n \n ans[i]=root.startsWith(words[i]);\n }\n \n return ans;\n }\n}\n``` | 7 | 2 | ['Trie'] | 2 |
sum-of-prefix-scores-of-strings | String Hashing || Java | string-hashing-java-by-virendra115-hla6 | \npublic int[] sumPrefixScores(String[] words) {\n int n = words.length, p = 31, m = (int)1e9 + 9;\n int[] ans = new int[n];\n long[] hash = new long[n | virendra115 | NORMAL | 2022-09-18T04:11:45.663418+00:00 | 2022-09-18T04:23:51.725873+00:00 | 734 | false | ```\npublic int[] sumPrefixScores(String[] words) {\n int n = words.length, p = 31, m = (int)1e9 + 9;\n int[] ans = new int[n];\n long[] hash = new long[n], p_pow = new long[n];\n Arrays.fill(p_pow,1);\n for(int i = 0; i < 1000; i++){\n Map<Long,Integer> map = new HashMap<>();\n for(int j = 0; j < n; j++){\n if(words[j].length() <= i) continue;\n hash[j] = (hash[j] + (words[j].charAt(i) - \'a\' + 1) * p_pow[j]) % m;\n p_pow[j] = (p_pow[j] * p) % m;\n map.put(hash[j], map.getOrDefault(hash[j],0) + 1);\n }\n for(int j = 0; j < n; j++){\n if(words[j].length() <= i) continue;\n ans[j] += map.get(hash[j]);\n }\n }\n return ans;\n}\n``` | 6 | 1 | [] | 3 |
sum-of-prefix-scores-of-strings | Optimized Solution Using a Custom Trie for Prefix Scores | Java | C++ | [Video Explanation] | optimized-solution-using-a-custom-trie-f-djsu | Intuition, approach, and complexity discussed in detail in the video solution\nhttps://youtu.be/HymJeL_ERlg\n# Code\njava []\nclass TrieNode{\n TrieNode chil | Lazy_Potato_ | NORMAL | 2024-09-25T11:30:53.165075+00:00 | 2024-09-25T11:30:53.165120+00:00 | 471 | false | # Intuition, approach, and complexity discussed in detail in the video solution\nhttps://youtu.be/HymJeL_ERlg\n# Code\n``` java []\nclass TrieNode{\n TrieNode children[] = new TrieNode[26];\n int nodeFreq = 0;\n void insert(String key){\n TrieNode curr = this;\n for(var chr : key.toCharArray()){\n int indx = (int) (chr - \'a\');\n if(curr.children[indx] == null){\n curr.children[indx] = new TrieNode();\n }\n curr.children[indx].nodeFreq++;\n curr = curr.children[indx];\n }\n }\n int findScore(String key){\n TrieNode curr = this;\n int score = 0;\n for(var chr : key.toCharArray()){\n int indx = (int) (chr - \'a\');\n score += curr.children[indx].nodeFreq;\n curr = curr.children[indx];\n }\n return score;\n }\n}\nclass Solution {\n public int[] sumPrefixScores(String[] words) {\n TrieNode root = new TrieNode();\n for(var word : words){\n root.insert(word);\n }\n int size = words.length;\n int answer[] = new int[size];\n for(int indx = 0; indx < size; indx++){\n answer[indx] = root.findScore(words[indx]);\n } \n return answer;\n }\n}\n```\n```cpp []\nclass TrieNode {\npublic:\n TrieNode* children[26];\n int nodeFreq;\n\n TrieNode() {\n for (int i = 0; i < 26; i++) {\n children[i] = nullptr;\n }\n nodeFreq = 0;\n }\n\n void insert(const string& key) {\n TrieNode* curr = this;\n for (char chr : key) {\n int indx = chr - \'a\';\n if (curr->children[indx] == nullptr) {\n curr->children[indx] = new TrieNode();\n }\n curr->children[indx]->nodeFreq++;\n curr = curr->children[indx];\n }\n }\n\n int findScore(const string& key) {\n TrieNode* curr = this;\n int score = 0;\n for (char chr : key) {\n int indx = chr - \'a\';\n score += curr->children[indx]->nodeFreq;\n curr = curr->children[indx];\n }\n return score;\n }\n};\n\nclass Solution {\npublic:\n vector<int> sumPrefixScores(vector<string>& words) {\n TrieNode* root = new TrieNode();\n for (const auto& word : words) {\n root->insert(word);\n }\n\n int size = words.size();\n vector<int> answer(size);\n for (int i = 0; i < size; i++) {\n answer[i] = root->findScore(words[i]);\n }\n\n return answer;\n }\n};\n\n``` | 5 | 0 | ['Array', 'String', 'Trie', 'Counting', 'C++', 'Java'] | 1 |
sum-of-prefix-scores-of-strings | 🔥BEATS 💯 % 🎯 |✨SUPER EASY BEGINNERS 👏 | beats-super-easy-beginners-by-codewithsp-j2vs | \n\n\n---\n\n## Intuition\nThe task involves calculating the "prefix score" for each word in a list, where the prefix score is the sum of the counts of all pref | CodeWithSparsh | NORMAL | 2024-09-25T05:51:19.848217+00:00 | 2024-09-25T05:51:19.848287+00:00 | 517 | false | \n\n\n---\n\n## Intuition\nThe task involves calculating the "prefix score" for each word in a list, where the prefix score is the sum of the counts of all prefixes of the word in the given word list. The Trie data structure is well-suited for such prefix-based queries, as it allows efficient insertion of words and tracking of prefix counts.\n\n---\n\n## Approach\n1. **Trie Construction**: Insert each word into the Trie, and at each node, maintain a count of how many times a prefix has been encountered.\n2. **Score Calculation**: For each word, traverse through the Trie and sum up the counts at each node corresponding to the prefixes of the word.\n3. **Efficiency**: The Trie allows us to efficiently handle prefix operations for all words, reducing the complexity of calculating prefix scores compared to a brute force approach.\n\n---\n\n## Complexity\n- **Time complexity**: \n - Insertion of a word into the Trie takes $$O(L)$$, where $$L$$ is the length of the word. \n - Calculating the score for a word also takes $$O(L)$$.\n - For a list of $$n$$ words with an average length of $$L$$, the time complexity is $$O(n \\times L)$$.\n\n- **Space complexity**: \n - The space complexity is $$O(n \\times L)$$ for storing the Trie, where $$n$$ is the number of words and $$L$$ is the average word length.\n\n---\n## Code Implementations\n\n\n```dart []\nclass TrieNode {\n Map<String, TrieNode> children = {};\n int count = 0;\n}\n\nclass Trie {\n TrieNode root = TrieNode();\n \n // Function to insert a word into the trie and update prefix counts\n void insert(String word) {\n TrieNode node = root;\n for (int i = 0; i < word.length; i++) {\n String char = word[i];\n if (!node.children.containsKey(char)) {\n node.children[char] = TrieNode();\n }\n node = node.children[char]!;\n node.count++; // Update count for this prefix\n }\n }\n\n // Function to calculate the score for a word\n int calculateScore(String word) {\n TrieNode node = root;\n int score = 0;\n for (int i = 0; i < word.length; i++) {\n String char = word[i];\n node = node.children[char]!;\n score += node.count; // Add the count for each prefix\n }\n return score;\n }\n}\n\nclass Solution {\n List<int> sumPrefixScores(List<String> words) {\n Trie trie = Trie();\n \n // Step 1: Insert all words into the Trie\n for (String word in words) {\n trie.insert(word);\n }\n \n // Step 2: Calculate the score for each word\n List<int> result = [];\n for (String word in words) {\n result.add(trie.calculateScore(word));\n }\n \n return result;\n }\n}\n```\n\n\n\n```java []\nimport java.util.HashMap;\nimport java.util.Map;\n\nclass TrieNode {\n Map<Character, TrieNode> children = new HashMap<>();\n int count = 0;\n}\n\nclass Trie {\n TrieNode root = new TrieNode();\n\n public void insert(String word) {\n TrieNode node = root;\n for (char ch : word.toCharArray()) {\n node.children.putIfAbsent(ch, new TrieNode());\n node = node.children.get(ch);\n node.count++;\n }\n }\n\n public int calculateScore(String word) {\n TrieNode node = root;\n int score = 0;\n for (char ch : word.toCharArray()) {\n node = node.children.get(ch);\n score += node.count;\n }\n return score;\n }\n}\n\nclass Solution {\n public int[] sumPrefixScores(String[] words) {\n Trie trie = new Trie();\n\n // Step 1: Insert all words into the Trie\n for (String word : words) {\n trie.insert(word);\n }\n\n // Step 2: Calculate the score for each word\n int[] result = new int[words.length];\n for (int i = 0; i < words.length; i++) {\n result[i] = trie.calculateScore(words[i]);\n }\n return result;\n }\n}\n```\n\n\n\n```javascript []\nclass TrieNode {\n constructor() {\n this.children = new Map();\n this.count = 0;\n }\n}\n\nclass Trie {\n constructor() {\n this.root = new TrieNode();\n }\n\n insert(word) {\n let node = this.root;\n for (const char of word) {\n if (!node.children.has(char)) {\n node.children.set(char, new TrieNode());\n }\n node = node.children.get(char);\n node.count++;\n }\n }\n\n calculateScore(word) {\n let node = this.root;\n let score = 0;\n for (const char of word) {\n node = node.children.get(char);\n score += node.count;\n }\n return score;\n }\n}\n\nfunction sumPrefixScores(words) {\n const trie = new Trie();\n\n // Step 1: Insert all words into the Trie\n for (const word of words) {\n trie.insert(word);\n }\n\n // Step 2: Calculate the score for each word\n return words.map(word => trie.calculateScore(word));\n}\n```\n\n\n\n```python []\nclass TrieNode:\n def __init__(self):\n self.children = {}\n self.count = 0\n\nclass Trie:\n def __init__(self):\n self.root = TrieNode()\n\n def insert(self, word):\n node = self.root\n for ch in word:\n if ch not in node.children:\n node.children[ch] = TrieNode()\n node = node.children[ch]\n node.count += 1\n\n def calculate_score(self, word):\n node = self.root\n score = 0\n for ch in word:\n node = node.children[ch]\n score += node.count\n return score\n\nclass Solution:\n def sumPrefixScores(self, words):\n trie = Trie()\n\n # Step 1: Insert all words into the Trie\n for word in words:\n trie.insert(word)\n\n # Step 2: Calculate the score for each word\n return [trie.calculate_score(word) for word in words]\n```\n\n\n\n```cpp []\n#include <unordered_map>\n#include <vector>\n#include <string>\n\nusing namespace std;\n\nclass TrieNode {\npublic:\n unordered_map<char, TrieNode*> children;\n int count = 0;\n};\n\nclass Trie {\npublic:\n TrieNode* root;\n \n Trie() {\n root = new TrieNode();\n }\n\n void insert(const string& word) {\n TrieNode* node = root;\n for (char ch : word) {\n if (node->children.find(ch) == node->children.end()) {\n node->children[ch] = new TrieNode();\n }\n node = node->children[ch];\n node->count++;\n }\n }\n\n int calculateScore(const string& word) {\n TrieNode* node = root;\n int score = 0;\n for (char ch : word) {\n node = node->children[ch];\n score += node->count;\n }\n return score;\n }\n};\n\nclass Solution {\npublic:\n vector<int> sumPrefixScores(vector<string>& words) {\n Trie trie;\n \n // Step 1: Insert all words into the Trie\n for (const string& word : words) {\n trie.insert(word);\n }\n \n // Step 2: Calculate the score for each word\n vector<int> result;\n for (const string& word : words) {\n result.push_back(trie.calculateScore(word));\n }\n \n return result;\n }\n};\n```\n\n\n\n```c []\n#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n\ntypedef struct TrieNode {\n struct TrieNode* children[26];\n int count;\n} TrieNode;\n\nTrieNode* createNode() {\n TrieNode* node = (TrieNode*) malloc(sizeof(TrieNode));\n for (int i = 0; i < 26; i++) {\n node->children[i] = NULL;\n }\n node->count = 0;\n return node;\n}\n\nvoid insert(TrieNode* root, const char* word) {\n TrieNode* node = root;\n for (int i = 0; word[i] != \'\\0\'; i++) {\n int index = word[i] - \'a\';\n if (node->children[index] == NULL) {\n node->children[index] = createNode();\n }\n node = node->children[index];\n node->count++;\n }\n}\n\nint calculateScore(TrieNode* root, const char* word) {\n TrieNode* node = root;\n int score = 0;\n for (int i = 0; word[i] != \'\\0\'; i++) {\n int index = word[i] - \'a\';\n node = node->children[index];\n score += node->count;\n }\n return score;\n}\n\nint* sumPrefixScores(char** words, int wordsSize, int* returnSize) {\n TrieNode* root = createNode();\n int* result = (int*) malloc(wordsSize * sizeof(int));\n\n // Step 1: Insert all words into the Trie\n for (int i = \n\n0; i < wordsSize; i++) {\n insert(root, words[i]);\n }\n\n // Step 2: Calculate the score for each word\n for (int i = 0; i < wordsSize; i++) {\n result[i] = calculateScore(root, words[i]);\n }\n\n *returnSize = wordsSize;\n return result;\n}\n```\n\n\n\n```go []\npackage main\n\nimport "fmt"\n\ntype TrieNode struct {\n\tchildren map[rune]*TrieNode\n\tcount int\n}\n\ntype Trie struct {\n\troot *TrieNode\n}\n\nfunc NewTrie() *Trie {\n\treturn &Trie{root: &TrieNode{children: make(map[rune]*TrieNode)}}\n}\n\nfunc (t *Trie) Insert(word string) {\n\tnode := t.root\n\tfor _, ch := range word {\n\t\tif _, found := node.children[ch]; !found {\n\t\t\tnode.children[ch] = &TrieNode{children: make(map[rune]*TrieNode)}\n\t\t}\n\t\tnode = node.children[ch]\n\t\tnode.count++\n\t}\n}\n\nfunc (t *Trie) CalculateScore(word string) int {\n\tnode := t.root\n\tscore := 0\n\tfor _, ch := range word {\n\t\tnode = node.children[ch]\n\t\tscore += node.count\n\t}\n\treturn score\n}\n\nfunc sumPrefixScores(words []string) []int {\n\ttrie := NewTrie()\n\n\t// Step 1: Insert all words into the Trie\n\tfor _, word := range words {\n\t\ttrie.Insert(word)\n\t}\n\n\t// Step 2: Calculate the score for each word\n\tresult := make([]int, len(words))\n\tfor i, word := range words {\n\t\tresult[i] = trie.CalculateScore(word)\n\t}\n\n\treturn result\n}\n\nfunc main() {\n\twords := []string{"abc", "ab", "a"}\n\tfmt.Println(sumPrefixScores(words)) // Output: [3, 2, 1]\n}\n```\n\n---\n\n {:style=\'width:250px\'}\n\n | 5 | 0 | ['Trie', 'C', 'C++', 'Java', 'Go', 'Python3', 'JavaScript', 'Dart'] | 0 |
sum-of-prefix-scores-of-strings | 💡 O(n⋅m) | Easy Solution | C++ 462ms Beats 87.78% | Java Py3 | onm-easy-solution-c-462ms-beats-8778-jav-xvcp | \n#\n---\n\n# Intuition\nWe can efficiently solve this problem using a Trie (prefix tree). A Trie helps in storing prefixes and counting their occurrences while | user4612MW | NORMAL | 2024-09-25T03:02:45.557215+00:00 | 2024-09-25T03:08:23.334455+00:00 | 579 | false | \n#\n---\n\n# **Intuition**\nWe can efficiently solve this problem using a **Trie** (prefix tree). A **Trie** helps in storing prefixes and counting their occurrences while reducing redundant comparisons. Each node in the Trie represents a character, and we increment the count for each character as we insert the strings. Once the Trie is built, we can quickly compute the prefix scores by traversing the Trie for each word.\n\n\n# **Approach**\nTo solve the problem, we first construct a Trie by inserting each string character by character, incrementing the count for each node to track how many strings share that prefix. After building the Trie, we compute the prefix scores for each string by traversing the Trie and summing the counts of the nodes corresponding to each prefix, allowing us to efficiently determine the total score for every non-empty prefix of each string.\n\n# **Complexity**\n- **Time Complexity** $$O(n \\cdot m)$$, where $$n$$ is the number of words, and $$m$$ is the average length of the words. We traverse each word multiple times: once for building the Trie and once for calculating the prefix scores.\n\n- **Space Complexity** $$O(n \\cdot m)$$ for storing the Trie.\n\n---\n\n# **Code**\n```cpp []\nstruct T {\n T* c[26] = {};\n int cnt = 0;\n};\nclass Solution {\npublic:\n vector<int> sumPrefixScores(vector<string>& w) {\n T* r = new T(); \n for (auto& s : w) \n for (T* n = r; auto ch : s) \n n = n->c[ch - \'a\'] ? n->c[ch - \'a\'] : n->c[ch - \'a\'] = new T(), n->cnt++;\n vector<int> res;\n for (auto& s : w) {\n int sc = 0;\n for (T* n = r; auto ch : s) \n sc += (n = n->c[ch - \'a\'])->cnt;\n res.push_back(sc);\n }\n return res;\n }\n};\nauto io_opt = [] { ios::sync_with_stdio(false); cin.tie(nullptr); return 0; }();\n```\n```java []\nclass Solution {\n class TrieNode {\n TrieNode[] children = new TrieNode[26];\n int count = 0;\n } \n public int[] sumPrefixScores(String[] words) {\n TrieNode root = new TrieNode();\n for (String word : words) {\n TrieNode node = root;\n for (char ch : word.toCharArray()) {\n if (node.children[ch - \'a\'] == null) {\n node.children[ch - \'a\'] = new TrieNode();\n }\n node = node.children[ch - \'a\'];\n node.count++;\n }\n }\n int[] result = new int[words.length];\n for (int i = 0; i < words.length; i++) {\n TrieNode node = root;\n int score = 0;\n for (char ch : words[i].toCharArray()) {\n node = node.children[ch - \'a\'];\n score += node.count;\n }\n result[i] = score;\n }\n return result;\n }\n}\n```\n```python3 []\nclass TrieNode:\n def __init__(self):\n self.children = {}\n self.count = 0\nclass Solution:\n def sumPrefixScores(self, words: List[str]) -> List[int]:\n root = TrieNode()\n for word in words:\n node = root\n for ch in word:\n if ch not in node.children:\n node.children[ch] = TrieNode()\n node = node.children[ch]\n node.count += 1\n result = []\n for word in words:\n node = root\n score = 0\n for ch in word:\n node = node.children[ch]\n score += node.count\n result.append(score)\n return result\n```\n---\n- \n- \n\n\n\n---\n\n | 5 | 0 | ['Trie', 'C++', 'Java', 'Python3'] | 2 |
sum-of-prefix-scores-of-strings | 🌟 Multi-Language Solution for Prefix Score Mastery Made Easy 🔥💯 | multi-language-solution-for-prefix-score-xokw | \n\nExplore a collection of solutions to LeetCode problems in multiple programming languages. Each solution includes a detailed explanation and step-by-step app | withaarzoo | NORMAL | 2024-09-25T02:00:06.001079+00:00 | 2024-09-25T02:00:06.001099+00:00 | 1,126 | false | \n\nExplore a collection of solutions to LeetCode problems in multiple programming languages. Each solution includes a detailed explanation and step-by-step approach to solving the problem efficiently. Whether you\'re a beginner looking to learn or an experienced coder seeking optimized solutions, this repository aims to provide clear and insightful approaches to tackling challenging LeetCode problems.\n\n### **Access daily LeetCode Solutions Repo :** [click here](https://github.com/withaarzoo/LeetCode-Solutions)\n\n---\n\n\n\n---\n\n# Intuition\n<!-- Describe your initial thoughts and strategy to solve this problem. -->\nThe problem asks us to find the sum of scores for each string\'s prefixes in the list. A brute-force approach would require generating all prefixes and counting their occurrences, but this would be inefficient. Instead, we can optimize this by using a **Trie (Prefix Tree)**. By inserting each word into the Trie, we can track how many words share a common prefix and efficiently compute the required prefix sums.\n\n---\n\n# Approach\n<!-- Detail the specific method and steps you used to solve the problem. -->\n1. **Trie Construction**: We will insert each word into a Trie, where each node represents a character. As we insert each character, we will count how many times it has been visited.\n2. **Prefix Calculation**: Once the Trie is constructed, for each word, we traverse its characters and sum the counts stored at the corresponding nodes, which represent how many words share that prefix.\n3. **Result Storage**: For each word, we store the cumulative sum of scores for its prefixes in the result array.\n\n---\n\n# Complexity\n- **Time complexity**: \n $$O(n \\cdot m)$$, where \\(n\\) is the number of words and \\(m\\) is the average length of the words. \n We insert each character of each word into the Trie, and then traverse the Trie again to calculate prefix scores.\n\n- **Space complexity**: \n $$O(n \\cdot m)$$, where \\(n\\) is the number of words and \\(m\\) is the average length of the words. \n The Trie stores all characters of the words and their corresponding prefix counts.\n\n---\n\n# Code\n```C++ []\n#include <iostream>\n#include <vector>\n#include <unordered_map>\n\nusing namespace std;\n\n// Structure to define a TrieNode\n// Each node will store its children (mapped by characters) and the count of words passing through it\nstruct TrieNode {\n // A map to store the children nodes corresponding to each character\n unordered_map<char, TrieNode*> children;\n \n // This variable keeps track of how many words share this node (i.e., pass through this prefix)\n int count = 0;\n};\n\n// Class that implements the Trie (prefix tree) data structure\nclass Trie {\npublic:\n // Root node of the Trie\n TrieNode* root;\n\n // Constructor to initialize the root node of the Trie\n Trie() {\n root = new TrieNode();\n }\n\n // Function to insert a word into the Trie\n // For each character in the word, it will either create a new node or traverse an existing one\n void insert(const string& word) {\n TrieNode* node = root; // Start from the root node\n for (char ch : word) { // Iterate through each character in the word\n // If the character is not already a child of the current node, create a new TrieNode\n if (!node->children.count(ch)) {\n node->children[ch] = new TrieNode();\n }\n // Move to the child node corresponding to the character\n node = node->children[ch];\n // Increment the count to indicate that one more word passes through this prefix\n node->count++;\n }\n }\n\n // Function to calculate the sum of scores for all prefixes of the given word\n // The score for a prefix is the number of words that have this prefix\n int getPrefixScoreSum(const string& word) {\n TrieNode* node = root; // Start from the root node\n int scoreSum = 0; // Initialize the total score sum to 0\n for (char ch : word) { // Iterate through each character in the word\n // Move to the child node corresponding to the character\n node = node->children[ch];\n // Add the count of words passing through this prefix (the current node) to the score sum\n scoreSum += node->count;\n }\n // Return the total score sum for all prefixes of the word\n return scoreSum;\n }\n};\n\n// Solution class to calculate the sum of prefix scores for a list of words\nclass Solution {\npublic:\n // Function that calculates the sum of prefix scores for each word in the input vector\n vector<int> sumPrefixScores(vector<string>& words) {\n Trie trie; // Create an instance of the Trie\n\n // Insert all words into the Trie\n for (const string& word : words) {\n trie.insert(word); // Insert each word into the Trie\n }\n\n // Calculate the sum of prefix scores for each word\n vector<int> result; // Vector to store the prefix score sums for all words\n for (const string& word : words) {\n // For each word, calculate the sum of scores for its prefixes using the Trie\n result.push_back(trie.getPrefixScoreSum(word));\n }\n\n // Return the result containing prefix score sums for all words\n return result;\n }\n};\n\n```\n```Java []\nimport java.util.HashMap;\n\n// Class representing a single node in the Trie\nclass TrieNode {\n // HashMap to store child nodes for each character\n HashMap<Character, TrieNode> children = new HashMap<>();\n \n // Count stores how many times this node has been visited (useful for scoring prefixes)\n int count = 0;\n}\n\n// Class representing the Trie (prefix tree) structure\nclass Trie {\n TrieNode root; // Root node of the Trie\n\n // Constructor to initialize the Trie with an empty root node\n public Trie() {\n root = new TrieNode();\n }\n\n // Method to insert a word into the Trie\n public void insert(String word) {\n TrieNode node = root; // Start at the root node\n \n // Loop through each character in the word\n for (char ch : word.toCharArray()) {\n // If the current character isn\'t already a child of the current node, add it\n node.children.putIfAbsent(ch, new TrieNode());\n \n // Move to the child node corresponding to the current character\n node = node.children.get(ch);\n \n // Increment the count to signify that this node has been visited\n node.count++;\n }\n }\n\n // Method to get the sum of scores for all prefixes of a given word\n public int getPrefixScoreSum(String word) {\n TrieNode node = root; // Start at the root node\n int scoreSum = 0; // Initialize the sum of prefix scores\n \n // Loop through each character in the word\n for (char ch : word.toCharArray()) {\n // Move to the child node corresponding to the current character\n node = node.children.get(ch);\n \n // Add the count of the current node to the score sum\n scoreSum += node.count;\n }\n \n // Return the total sum of scores for all prefixes of the word\n return scoreSum;\n }\n}\n\n// Solution class that solves the problem using the Trie\nclass Solution {\n // Method to calculate the sum of prefix scores for each word in the array\n public int[] sumPrefixScores(String[] words) {\n Trie trie = new Trie(); // Create a new Trie\n\n // Insert all words from the array into the Trie\n for (String word : words) {\n trie.insert(word);\n }\n\n // Create an array to store the result (sum of prefix scores for each word)\n int[] result = new int[words.length];\n \n // Calculate the sum of prefix scores for each word\n for (int i = 0; i < words.length; i++) {\n result[i] = trie.getPrefixScoreSum(words[i]);\n }\n\n // Return the result array\n return result;\n }\n}\n\n```\n```JavaScript []\n// Definition of the TrieNode class, which represents a node in the Trie.\nclass TrieNode {\n constructor() {\n // \'children\' stores the next character nodes in the Trie.\n // It is an object (hashmap) where each key is a character and the value is another TrieNode.\n this.children = {};\n // \'count\' keeps track of how many times this node has been visited during insertions.\n this.count = 0;\n }\n}\n\n// Definition of the Trie class, which encapsulates the root node and Trie operations.\nclass Trie {\n constructor() {\n // Initialize the root node of the Trie as an empty TrieNode.\n this.root = new TrieNode();\n }\n\n // Method to insert a word into the Trie.\n insert(word) {\n // Start traversing from the root of the Trie.\n let node = this.root;\n\n // Traverse each character in the word.\n for (let ch of word) {\n // If the current character is not already a child of the current node, create a new TrieNode.\n if (!node.children[ch]) {\n node.children[ch] = new TrieNode();\n }\n // Move to the next node (child node corresponding to the current character).\n node = node.children[ch];\n // Increment the count for this node, as this prefix (or part of it) has been inserted.\n node.count++;\n }\n }\n\n // Method to get the sum of scores for all prefixes of the given word.\n getPrefixScoreSum(word) {\n // Start from the root node of the Trie.\n let node = this.root;\n // Variable to accumulate the score (sum of counts for each prefix).\n let scoreSum = 0;\n\n // Traverse each character in the word to compute the prefix scores.\n for (let ch of word) {\n // Move to the next node corresponding to the current character.\n node = node.children[ch];\n // Add the count of this node to the score sum (count represents how many times this prefix was seen).\n scoreSum += node.count;\n }\n\n // Return the accumulated score sum.\n return scoreSum;\n }\n}\n\n/**\n * Function to compute the sum of prefix scores for an array of words.\n * \n * @param {string[]} words - The list of words for which we want to calculate prefix scores.\n * @return {number[]} - An array of numbers where each element corresponds to the sum of prefix scores for a word.\n */\nvar sumPrefixScores = function(words) {\n // Create a new Trie.\n const trie = new Trie();\n\n // Insert each word from the input array into the Trie.\n for (let word of words) {\n trie.insert(word);\n }\n\n // Create an array to store the results (sum of prefix scores for each word).\n const result = [];\n\n // For each word in the input array, calculate the sum of prefix scores.\n for (let word of words) {\n result.push(trie.getPrefixScoreSum(word)); // Get the prefix score sum and store it in the result array.\n }\n\n // Return the result array containing the sum of prefix scores for each word.\n return result;\n};\n\n```\n```Python []\n# Class representing a node in the Trie\nclass TrieNode:\n def __init__(self):\n # Dictionary to hold child nodes, where keys are characters\n self.children = {}\n # Count to store how many times this node (prefix) is visited\n self.count = 0\n\n# Class representing the Trie (prefix tree) structure\nclass Trie:\n def __init__(self):\n # The root node of the Trie\n self.root = TrieNode()\n\n # Method to insert a word into the Trie\n def insert(self, word: str):\n node = self.root # Start from the root node\n # Loop through each character of the word\n for ch in word:\n # If the character is not a child of the current node, add it\n if ch not in node.children:\n node.children[ch] = TrieNode()\n # Move to the next node (child node corresponding to the character)\n node = node.children[ch]\n # Increment the count for the current node (this prefix)\n node.count += 1\n\n # Method to calculate the sum of prefix scores for a given word\n def get_prefix_score_sum(self, word: str) -> int:\n node = self.root # Start from the root node\n score_sum = 0 # Initialize score sum\n # Loop through each character in the word\n for ch in word:\n # Move to the next node (child node corresponding to the character)\n node = node.children[ch]\n # Add the count of the current node (this prefix) to the score sum\n score_sum += node.count\n return score_sum\n\n# Class to solve the problem of finding prefix scores for a list of words\nclass Solution:\n def sumPrefixScores(self, words: List[str]) -> List[int]:\n trie = Trie() # Initialize a new Trie instance\n \n # Insert all words into the Trie to build the structure\n for word in words:\n trie.insert(word)\n \n # For each word, calculate the sum of prefix scores and return the result as a list\n return [trie.get_prefix_score_sum(word) for word in words]\n\n```\n```Go []\npackage main\n\n// TrieNode represents a single node in the Trie structure.\n// Each node contains a map of children (to track the next characters) and a count to store how many words share the prefix up to this point.\ntype TrieNode struct {\n children map[byte]*TrieNode // Map to store the children nodes, where each key is a character (byte)\n count int // Count of words sharing this prefix\n}\n\n// Trie represents the overall structure of the prefix tree.\n// It has a root node that serves as the entry point for all word insertions and prefix queries.\ntype Trie struct {\n root *TrieNode // Root node of the Trie\n}\n\n// newTrieNode creates a new TrieNode with an empty map of children.\n// It is used to initialize new nodes during word insertion.\nfunc newTrieNode() *TrieNode {\n return &TrieNode{children: make(map[byte]*TrieNode)} // Initialize with an empty map for children\n}\n\n// NewTrie initializes a new Trie with a root node.\n// This function is the starting point for creating a Trie structure.\nfunc NewTrie() *Trie {\n return &Trie{root: newTrieNode()} // Create a Trie with a new root node\n}\n\n// Insert adds a word into the Trie character by character.\n// As each character is inserted, if it doesn\'t already exist in the children map, a new TrieNode is created.\nfunc (trie *Trie) Insert(word string) {\n node := trie.root // Start from the root node of the Trie\n // Iterate over each character in the word\n for i := 0; i < len(word); i++ {\n ch := word[i] // Get the current character\n // If the character doesn\'t exist as a child node, create a new TrieNode\n if _, exists := node.children[ch]; !exists {\n node.children[ch] = newTrieNode() // Add a new node for the character\n }\n node = node.children[ch] // Move to the child node representing the current character\n node.count++ // Increment the count to indicate how many words share this prefix\n }\n}\n\n// GetPrefixScoreSum calculates the sum of the prefix scores for a given word.\n// The score for each prefix is the count of how many words share that prefix in the Trie.\nfunc (trie *Trie) GetPrefixScoreSum(word string) int {\n node := trie.root // Start from the root node of the Trie\n scoreSum := 0 // Variable to accumulate the sum of prefix scores\n \n // Iterate over each character in the word\n for i := 0; i < len(word); i++ {\n ch := word[i] // Get the current character\n node = node.children[ch] // Move to the child node representing the current character\n scoreSum += node.count // Add the count of the current node (prefix) to the score sum\n }\n return scoreSum // Return the total sum of prefix scores for the word\n}\n\n// sumPrefixScores calculates the sum of prefix scores for each word in the input list.\n// It uses the Trie to store the words and then computes the score for each word.\nfunc sumPrefixScores(words []string) []int {\n trie := NewTrie() // Create a new Trie\n \n // Insert all words into the Trie\n for _, word := range words {\n trie.Insert(word) // Add each word to the Trie\n }\n \n // Initialize a result array to store the prefix score sums for each word\n result := make([]int, len(words))\n \n // Calculate the sum of prefix scores for each word\n for i, word := range words {\n result[i] = trie.GetPrefixScoreSum(word) // Compute the prefix score sum for each word\n }\n \n return result // Return the array containing the prefix score sums for all words\n}\n\n```\n\n\n---\n\n# Step-by-Step Detailed Explanation\n1. **Trie Construction**: For each word in the list, we insert each character into the Trie. At each node (character), we increase the `count`, which keeps track of how many words pass through this node.\n2. **Score Calculation**: For each word, we traverse the Trie from the root for each character in the word. At each character, we accumulate the `count` stored at that node (which tells us how many words share this prefix).\n3. **Efficiency**: Using a Trie ensures that we efficiently track prefix counts and calculate scores in linear time relative to the length of the words.\n\n---\n\n\n | 5 | 0 | ['Array', 'String', 'Trie', 'Counting', 'Python', 'C++', 'Java', 'Go', 'Python3', 'JavaScript'] | 2 |
sum-of-prefix-scores-of-strings | 💢☠💫Easiest👾Faster✅💯 Lesser🧠 🎯 C++✅Python3🐍✅Java✅C✅Python🐍✅C#✅💥🔥💫Explained☠💥🔥 Beats 100 | easiestfaster-lesser-cpython3javacpython-vnqu | Intuition\n\n Describe your first thoughts on how to solve this problem. \n- JavaScript Code --> https://leetcode.com/problems/sum-of-prefix-scores-of-strings/s | Edwards310 | NORMAL | 2024-09-25T01:10:19.347447+00:00 | 2024-09-25T01:10:19.347482+00:00 | 546 | false | # Intuition\n\n<!-- Describe your first thoughts on how to solve this problem. -->\n- ***JavaScript Code -->*** https://leetcode.com/problems/sum-of-prefix-scores-of-strings/submissions/1401331474?envType=daily-question&envId=2024-09-25\n- ***C++ Code -->*** https://leetcode.com/problems/sum-of-prefix-scores-of-strings/submissions/1401320981?envType=daily-question&envId=2024-09-25\n- ***Python3 Code -->*** https://leetcode.com/problems/sum-of-prefix-scores-of-strings/submissions/1401328638?envType=daily-question&envId=2024-09-25\n- ***Java Code -->*** https://leetcode.com/problems/sum-of-prefix-scores-of-strings/submissions/1401327589?envType=daily-question&envId=2024-09-25\n- ***C Code -->*** https://leetcode.com/problems/sum-of-prefix-scores-of-strings/submissions/1401334732?envType=daily-question&envId=2024-09-25\n- ***Python Code -->*** https://leetcode.com/problems/sum-of-prefix-scores-of-strings/submissions/1401328985?envType=daily-question&envId=2024-09-25\n- ***C# Code -->*** https://leetcode.com/problems/sum-of-prefix-scores-of-strings/submissions/1401329426?envType=daily-question&envId=2024-09-25\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n O(N * M) // Python3 Solution\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n O(N * M) // Python3 Solution\n# Code\n```java []\nclass Trie {\n Trie[] children = new Trie[26];\n int count = 0;\n\n Trie() {\n }\n\n void insert(Trie root, String s) {\n Trie curr = root;\n int n = s.length();\n for (int i = 0; i < n; i++) {\n int idx = s.charAt(i) - \'a\';\n if (curr.children[idx] == null)\n curr.children[idx] = new Trie();\n curr = curr.children[idx];\n curr.count++;\n }\n return;\n }\n\n int search(Trie root, String s) {\n Trie curr = root;\n int n = s.length(), current = 0;\n for (int i = 0; i < n; ++i) {\n int idx = s.charAt(i) - \'a\';\n curr = curr.children[idx];\n if (curr.count == 1)\n return current + n - i;\n current += curr.count;\n }\n return current;\n }\n}\n\nclass Solution {\n public int[] sumPrefixScores(String[] words) {\n Trie trie = new Trie();\n int n = words.length, idx = 0;\n int[] ans = new int[n];\n Trie root = new Trie();\n for (int i = 0; i < n; i++)\n trie.insert(root, words[i]);\n\n for (int i = 0; i < n; i++)\n ans[idx++] = trie.search(root, words[i]);\n return ans;\n }\n}\n```\n\n | 5 | 0 | ['Array', 'String', 'Trie', 'C', 'Python', 'C++', 'Java', 'Python3', 'JavaScript', 'C#'] | 0 |
sum-of-prefix-scores-of-strings | Hashing C++ easy to understand | hashing-c-easy-to-understand-by-virujtha-fu19 | The hashing technique is simple. The algorithm states that\n1) Assign a hash code to all prefixes of a word ( Using any hash function or Rabin Karp algorithm). | virujthakur01 | NORMAL | 2022-10-04T08:50:33.236092+00:00 | 2022-10-04T08:50:33.236138+00:00 | 702 | false | The hashing technique is simple. The algorithm states that\n1) Assign a hash code to all prefixes of a word ( Using any hash function or Rabin Karp algorithm). Repeat this for every word in the list of words.\n2) Alongside maintain a frequency map for the hash code, or the prefix, which maintains the number of occurrences of the prefix or the hash code.\n3) Now the score of a word is defined as the sum of occurrences of prefixes present in the string from the map that we made earlier.\nThat is the number of times a prefix present in \'word\' appeared across the entire list of words. Sum for all such prefixes in the word is its score.\n\nStoring the hash code in an unordered map gives TLE, so its better to calculate the hash codes again when calculating the scores of the words.\n\n\n```\nclass Solution {\npublic:\n long long mod= 1e9;\n \n void assignHashCode(string& s,unordered_map<long long, int>& hash_code_prefix_freq)\n {\n int n= s.size();\n vector<long long> p(n);\n long long temp= 37;\n \n for(int i=0;i<n;i++)\n {\n p[i]= temp;\n temp= temp % mod * 37 % mod;\n }\n \n long long hc=0;\n string word="";\n for(int i=0;i<n;i++)\n {\n word.push_back(s[i]);\n hc+= p[i]% mod* s[i]% mod;\n hash_code_prefix_freq[hc]++;\n }\n }\n \n int calculateScore(string& s, unordered_map<long long, int>& hash_code_prefix_freq)\n {\n int n= s.size();\n int score=0;\n \n vector<long long> p(n);\n long long temp= 37;\n \n for(int i=0;i<n;i++)\n {\n p[i]= temp;\n temp= temp % mod * 37 % mod;\n }\n \n long long hc=0;\n string word="";\n for(int i=0;i<n;i++)\n {\n word.push_back(s[i]);\n hc+= p[i]% mod* s[i]% mod;\n score+= hash_code_prefix_freq[hc];\n }\n \n return score;\n }\n \n vector<int> sumPrefixScores(vector<string>& words) {\n \n unordered_map<long long, int> hash_code_prefix_freq;\n unordered_map<string, long long> hash_codes;\n \n for(auto word: words)\n {\n assignHashCode(word,hash_code_prefix_freq); // assign hash code to every prefix in the string and calculate freq\n }\n \n vector<int> scores;\n for(auto word: words)\n {\n int score= calculateScore(word,hash_code_prefix_freq); // find hash code of every prefix and sum frequencies of prefix\n scores.push_back(score);\n }\n \n return scores; \n }\n};\n``` | 5 | 0 | ['C'] | 1 |
sum-of-prefix-scores-of-strings | C++ Simple DP solution without Trie (Beats 99% runtime, 97% Space) | c-simple-dp-solution-without-trie-beats-ov5kw | Firstly Sort the array of strings without losing original indices (eg: by using vector>).\n\nThis solution takes advantage of the fact that after sorting the st | Sadid_005 | NORMAL | 2022-09-21T15:44:40.241986+00:00 | 2022-09-21T17:50:02.069792+00:00 | 365 | false | Firstly Sort the array of strings without losing original indices (eg: by using vector<pair<string,int>>).\n\nThis solution takes advantage of the fact that after sorting the strings with identical prefixes will form a consecutive segment.\n\nExample: \nBefore Sorting => "abc" "bc" "ab" "b"\nAfter Sorting => **["ab" "abc"]** **[ "b" "bc" ]**\n\nAs you can see for any string **S[i]** strings whose prefix matches with prefix of **S[i]** are either just before **S[i]**\nor just after **S[i]**.\n\nNow I think the solution is pretty self explanotary.\n\n**dp[i][j]** will represent number of strings in the region **words[0, i-1]** whose **prefix[0..j]** matches with **S[0...j]**\nThen reverse the array of strings and calculate the same to find matching strings in the region\n**words[i+1...n-1]**.\n\n// Please look at the code to understand better. \n\n```\nclass Solution {\npublic:\n int n;\n vector<int> ans;\n \n void calPrefixScore(vector<pair<string,int>> &v)\n {\n vector<int> dp(v[0].first.size()), ndp;\n \n for(int i = 1; i < n; ++i)\n {\n auto [s, idx] = v[i];\n ndp = vector<int> (s.size(), 0);\n \n for(int j = 0; j < min(s.size(), dp.size()); ++j)\n {\n if(s[j] != v[i-1].first[j])break;\n ndp[j] = dp[j] + 1;\n ans[idx] += ndp[j];\n }\n dp = ndp;\n }\n }\n \n vector<int> sumPrefixScores(vector<string>& words) \n {\n n = words.size();\n ans.resize(n);\n \n vector<pair<string,int>> v;\n for(int i = 0; i < n; ++i){\n v.push_back({words[i], i});\n }\n \n auto cmp = [&](pair<string,int> &a, pair<string,int> &b){\n return a.first < b.first;\n };\n \n sort(v.begin(), v.end(), cmp);\n calPrefixScore(v);\n \n reverse(v.begin(), v.end());\n calPrefixScore(v);\n \n for(auto [s, idx] : v){\n ans[idx] += s.size();\n }\n \n return ans;\n \n }\n};\n```\n\n\t\t\t\t\t\t\t\t | 5 | 0 | ['Dynamic Programming', 'Sorting'] | 0 |
sum-of-prefix-scores-of-strings | Concise Python Tire Implementation | concise-python-tire-implementation-by-51-0hcb | \nclass TrieNode:\n def __init__(self):\n self.next = {}\n self.score = 0\n\n\nclass Solution:\n def sumPrefixScores(self, words: List[str]) | 515384231 | NORMAL | 2022-09-18T04:32:32.377861+00:00 | 2022-09-18T04:32:32.377892+00:00 | 292 | false | ```\nclass TrieNode:\n def __init__(self):\n self.next = {}\n self.score = 0\n\n\nclass Solution:\n def sumPrefixScores(self, words: List[str]) -> List[int]:\n result = []\n \n root = TrieNode()\n \n # build the trie\n for i, word in enumerate(words):\n node = root\n for j, c in enumerate(word):\n if c not in node.next:\n node.next[c] = TrieNode()\n node.next[c].score += 1\n node = node.next[c]\n \n # get the scores\n for i, word in enumerate(words):\n node = root\n sum_score = 0\n for j, c in enumerate(word):\n sum_score += node.score\n node = node.next[c]\n sum_score += node.score\n result.append(sum_score)\n \n return result\n``` | 5 | 0 | ['Trie', 'Python'] | 3 |
sum-of-prefix-scores-of-strings | C++ Explained Solution | Using Trie | Time - O(NM) | | c-explained-solution-using-trie-time-onm-24d5 | Approach -\nStep 1 - Create a node class that stores characters, a pointer to its next characters \nand count how many times this character appears in every pre | abhinandan__22 | NORMAL | 2022-09-18T04:00:41.335302+00:00 | 2022-09-18T04:13:00.278526+00:00 | 222 | false | **Approach -**\n**Step 1** - Create a node class that stores characters, a pointer to its next characters \nand count how many times this character appears in every prefix of every string of a given vector\n**Step 2** - Create a trie class that has to member function\ni) Push - To push the string in trie\nii) Score - To find the score of the string :-\nCalculate the sum of the count of every character of string in trie\n**Step 3** - Push all strings of the given vector in trie\n**Step 4** - Get the score of every string of vector by calling the score function of trie\n\n**Code**\n```\nclass node{\n public :\n char c;\n unordered_map<char,node*> m; // To store pointer to its next characters\n int cn =0 ; // To store count how many times this character appears in every prefix of every string of a given vector\n};\n\nclass trie{\n node *r; // Root node\n public :\n trie(){\n r = new node;\n r->c = \'\\0\';\n r->cn = 0;\n }\n void push(string a){\n node *p = r;\n for(int i=0;i<a.size();i++){\n if(p->m.count(a[i])){ // If its next character is present in trie, move to that character\n p = p->m[a[i]];\n p->cn++; // Increase count, Because it is present in prefix of current string(a)\n }\n else{\n node *l = new node; // If its next character is not present in trie, create new node\n l->c = a[i];\n l->cn = 1; // Count = 1\n p->m[a[i]]= l;\n p = l;\n }\n }\n return ;\n }\n int score(string a){\n int ans =0 ;\n node *p = r;\n for(int i=0;i<a.size();i++){ // Add all count of character by traversing trie for current string(a)\n p= p->m[a[i]];\n ans += p->cn; \n }\n return ans;\n }\n};\n\nclass Solution {\npublic:\n vector<int> sumPrefixScores(vector<string>& a) {\n trie t;\n int n = a.size();\n for(int i=0;i<n;i++) t.push(a[i]); // Push all string in trie\n vector<int> ans(n);\n for(int i=0;i<n;i++) ans[i]= t.score(a[i]); // Get the score of strings\n return ans;\n }\n};\n```\n\n**Time Complexity - O(NM)** => O(C)\nN is the length of the given array\nM is the length of the string (This may not be the same for all strings)\nC is the number of characters present in the given vector\n\n**Upvote if you like it!**\n | 5 | 0 | [] | 0 |
sum-of-prefix-scores-of-strings | Dcc 25/09/2024 || Trie 🔥 | dcc-25092024-trie-by-sajaltiwari007-tn1u | Intuition:\nThe problem involves calculating the sum of prefix scores for each word in an array of words. The prefix score of a word is determined by the number | sajaltiwari007 | NORMAL | 2024-09-25T09:24:24.553515+00:00 | 2024-09-25T09:24:24.553554+00:00 | 100 | false | ### Intuition:\nThe problem involves calculating the sum of prefix scores for each word in an array of words. The prefix score of a word is determined by the number of times its prefixes appear across all the words in the list.\n\nA **Trie** (prefix tree) is well-suited for problems involving prefixes because it allows efficient storage and retrieval of shared prefixes among different words. The key idea is to:\n1. **Insert each word into the Trie**: As we insert a word, we increment a `countPrefix` value at each node corresponding to each character of the word. This keeps track of how many words pass through this character.\n2. **Compute the prefix score**: For each word, we traverse its prefix characters in the Trie and sum up the `countPrefix` values. This gives us the total prefix score, as it reflects how many times each prefix of the word appears in the Trie.\n\n### Approach:\n1. **Insert all words into the Trie**:\n - While inserting each word, increment the `countPrefix` at each node for each character of the word. This tracks how many words share the same prefix.\n \n2. **Calculate prefix scores for each word**:\n - For each word, traverse the Trie from the root to the nodes corresponding to each character of the word.\n - Sum the `countPrefix` values along the way, which gives the total prefix score for the word.\n\n### Step-by-step breakdown:\n- **Insertion**:\n - For each word, traverse the Trie character by character.\n - If a character is not present, create a new node for it and increment the `countPrefix` for that node.\n \n- **Prefix score calculation**:\n - For each word, traverse the Trie again, summing up the `countPrefix` values for each character of the word.\n - The total sum gives the prefix score for the word.\n\n### Time Complexity:\n#### Insertion:\n- For each word of length \\( L \\), it takes \\( O(L) \\) to insert the word into the Trie.\n- If there are \\( N \\) words and the average word length is \\( L \\), the total time for insertion is \\( O(N * L) \\).\n\n#### Prefix score calculation:\n- For each word, calculating the prefix score requires traversing its characters in the Trie. This operation takes \\( O(L) \\) for a word of length \\( L \\).\n- Therefore, for \\( N \\) words with an average length of \\( L \\), the total time for prefix score calculation is \\( O(N * L) \\).\n\n### Overall Time Complexity:\nThe total time complexity is \\( O(N * L) \\), where \\( N \\) is the number of words and \\( L \\) is the average length of the words. This is efficient for problems with multiple words and shared prefixes, as each word is processed once during insertion and once during score calculation.\n\n### Space Complexity:\n- The space complexity is dominated by the Trie structure, which has at most \\( 26 * L * N \\) nodes (where \\( 26 \\) is the size of the alphabet, \\( L \\) is the maximum length of a word, and \\( N \\) is the number of words).\n- Therefore, the space complexity is \\( O(26 * N * L) \\), which simplifies to \\( O(N * L) \\), as 26 is a constant factor.\n\n### Summary:\n- **Time Complexity**: \\( O(N * L) \\)\n- **Space Complexity**: \\( O(N * L) \\)\n\nThis approach efficiently computes the prefix scores by leveraging the Trie data structure, which reduces redundant operations and makes it feasible to handle large datasets.\n\n# Code\n```java []\nclass Node{\n Node[] links = new Node[26];\n int countPrefix=0;\n Node(){}\n public boolean containsKey(char c){\n return links[c-\'a\']!=null;\n }\n public Node get(char c){\n return links[c-\'a\'];\n }\n public void put(char c , Node node){\n links[c-\'a\']=node;\n }\n public void increasePrefix(){\n countPrefix++;\n }\n public int getPrefix(){\n return countPrefix;\n }\n}\npublic class Trie{\n private Node root;\n Trie(){\n root = new Node();\n }\n public void insert(String s){\n Node node = root;\n for(int i=0;i<s.length();i++){\n if(!node.containsKey(s.charAt(i))){\n node.put(s.charAt(i),new Node());\n }\n node = node.get(s.charAt(i));\n node.increasePrefix();\n }\n }\n public int total_prefix(String s){\n Node node = root;\n int total=0;\n for(int i=0;i<s.length();i++){\n\n if(!node.containsKey(s.charAt(i))) return 0;\n node = node.get(s.charAt(i));\n total+= node.getPrefix();\n }\n return total;\n }\n}\nclass Solution {\n public int[] sumPrefixScores(String[] words) {\n Trie trie = new Trie();\n for(int i=0;i<words.length;i++){\n trie.insert(words[i]);\n }\n int[] answer = new int[words.length];\n for(int i=0;i<words.length;i++){\n answer[i]=trie.total_prefix(words[i]);\n }\n return answer; \n }\n}\n``` | 4 | 0 | ['Trie', 'Java'] | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.