
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-02 06:30:45
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 533
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-02 06:30:39
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
moussaKam/frugalscore_medium_deberta_bert-score
|
moussaKam
| 2022-02-01T10:51:45Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"arxiv:2110.08559",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# FrugalScore
FrugalScore is an approach to learn a fixed, low cost version of any expensive NLG metric, while retaining most of its original performance
Paper: https://arxiv.org/abs/2110.08559?context=cs
Project github: https://github.com/moussaKam/FrugalScore
The pretrained checkpoints presented in the paper :
| FrugalScore | Student | Teacher | Method |
|----------------------------------------------------|-------------|----------------|------------|
| [moussaKam/frugalscore_tiny_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_bert-base_bert-score) | BERT-tiny | BERT-Base | BERTScore |
| [moussaKam/frugalscore_small_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_small_bert-base_bert-score) | BERT-small | BERT-Base | BERTScore |
| [moussaKam/frugalscore_medium_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_bert-base_bert-score) | BERT-medium | BERT-Base | BERTScore |
| [moussaKam/frugalscore_tiny_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_roberta_bert-score) | BERT-tiny | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_small_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_small_roberta_bert-score) | BERT-small | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_medium_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_roberta_bert-score) | BERT-medium | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_tiny_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_deberta_bert-score) | BERT-tiny | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_small_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_small_deberta_bert-score) | BERT-small | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_medium_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_deberta_bert-score) | BERT-medium | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_tiny_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_tiny_bert-base_mover-score) | BERT-tiny | BERT-Base | MoverScore |
| [moussaKam/frugalscore_small_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_small_bert-base_mover-score) | BERT-small | BERT-Base | MoverScore |
| [moussaKam/frugalscore_medium_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_medium_bert-base_mover-score) | BERT-medium | BERT-Base | MoverScore |
|
moussaKam/frugalscore_tiny_deberta_bert-score
|
moussaKam
| 2022-02-01T10:51:30Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"arxiv:2110.08559",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# FrugalScore
FrugalScore is an approach to learn a fixed, low cost version of any expensive NLG metric, while retaining most of its original performance
Paper: https://arxiv.org/abs/2110.08559?context=cs
Project github: https://github.com/moussaKam/FrugalScore
The pretrained checkpoints presented in the paper :
| FrugalScore | Student | Teacher | Method |
|----------------------------------------------------|-------------|----------------|------------|
| [moussaKam/frugalscore_tiny_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_bert-base_bert-score) | BERT-tiny | BERT-Base | BERTScore |
| [moussaKam/frugalscore_small_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_small_bert-base_bert-score) | BERT-small | BERT-Base | BERTScore |
| [moussaKam/frugalscore_medium_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_bert-base_bert-score) | BERT-medium | BERT-Base | BERTScore |
| [moussaKam/frugalscore_tiny_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_roberta_bert-score) | BERT-tiny | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_small_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_small_roberta_bert-score) | BERT-small | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_medium_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_roberta_bert-score) | BERT-medium | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_tiny_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_deberta_bert-score) | BERT-tiny | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_small_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_small_deberta_bert-score) | BERT-small | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_medium_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_deberta_bert-score) | BERT-medium | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_tiny_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_tiny_bert-base_mover-score) | BERT-tiny | BERT-Base | MoverScore |
| [moussaKam/frugalscore_small_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_small_bert-base_mover-score) | BERT-small | BERT-Base | MoverScore |
| [moussaKam/frugalscore_medium_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_medium_bert-base_mover-score) | BERT-medium | BERT-Base | MoverScore |
|
moussaKam/frugalscore_small_roberta_bert-score
|
moussaKam
| 2022-02-01T10:51:08Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"arxiv:2110.08559",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# FrugalScore
FrugalScore is an approach to learn a fixed, low cost version of any expensive NLG metric, while retaining most of its original performance
Paper: https://arxiv.org/abs/2110.08559?context=cs
Project github: https://github.com/moussaKam/FrugalScore
The pretrained checkpoints presented in the paper :
| FrugalScore | Student | Teacher | Method |
|----------------------------------------------------|-------------|----------------|------------|
| [moussaKam/frugalscore_tiny_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_bert-base_bert-score) | BERT-tiny | BERT-Base | BERTScore |
| [moussaKam/frugalscore_small_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_small_bert-base_bert-score) | BERT-small | BERT-Base | BERTScore |
| [moussaKam/frugalscore_medium_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_bert-base_bert-score) | BERT-medium | BERT-Base | BERTScore |
| [moussaKam/frugalscore_tiny_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_roberta_bert-score) | BERT-tiny | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_small_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_small_roberta_bert-score) | BERT-small | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_medium_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_roberta_bert-score) | BERT-medium | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_tiny_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_deberta_bert-score) | BERT-tiny | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_small_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_small_deberta_bert-score) | BERT-small | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_medium_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_deberta_bert-score) | BERT-medium | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_tiny_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_tiny_bert-base_mover-score) | BERT-tiny | BERT-Base | MoverScore |
| [moussaKam/frugalscore_small_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_small_bert-base_mover-score) | BERT-small | BERT-Base | MoverScore |
| [moussaKam/frugalscore_medium_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_medium_bert-base_mover-score) | BERT-medium | BERT-Base | MoverScore |
|
moussaKam/frugalscore_medium_bert-base_bert-score
|
moussaKam
| 2022-02-01T10:50:43Z | 12 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"arxiv:2110.08559",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# FrugalScore
FrugalScore is an approach to learn a fixed, low cost version of any expensive NLG metric, while retaining most of its original performance
Paper: https://arxiv.org/abs/2110.08559?context=cs
Project github: https://github.com/moussaKam/FrugalScore
The pretrained checkpoints presented in the paper :
| FrugalScore | Student | Teacher | Method |
|----------------------------------------------------|-------------|----------------|------------|
| [moussaKam/frugalscore_tiny_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_bert-base_bert-score) | BERT-tiny | BERT-Base | BERTScore |
| [moussaKam/frugalscore_small_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_small_bert-base_bert-score) | BERT-small | BERT-Base | BERTScore |
| [moussaKam/frugalscore_medium_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_bert-base_bert-score) | BERT-medium | BERT-Base | BERTScore |
| [moussaKam/frugalscore_tiny_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_roberta_bert-score) | BERT-tiny | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_small_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_small_roberta_bert-score) | BERT-small | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_medium_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_roberta_bert-score) | BERT-medium | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_tiny_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_deberta_bert-score) | BERT-tiny | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_small_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_small_deberta_bert-score) | BERT-small | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_medium_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_deberta_bert-score) | BERT-medium | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_tiny_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_tiny_bert-base_mover-score) | BERT-tiny | BERT-Base | MoverScore |
| [moussaKam/frugalscore_small_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_small_bert-base_mover-score) | BERT-small | BERT-Base | MoverScore |
| [moussaKam/frugalscore_medium_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_medium_bert-base_mover-score) | BERT-medium | BERT-Base | MoverScore |
|
moussaKam/frugalscore_small_bert-base_bert-score
|
moussaKam
| 2022-02-01T10:50:31Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"arxiv:2110.08559",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# FrugalScore
FrugalScore is an approach to learn a fixed, low cost version of any expensive NLG metric, while retaining most of its original performance
Paper: https://arxiv.org/abs/2110.08559?context=cs
Project github: https://github.com/moussaKam/FrugalScore
The pretrained checkpoints presented in the paper :
| FrugalScore | Student | Teacher | Method |
|----------------------------------------------------|-------------|----------------|------------|
| [moussaKam/frugalscore_tiny_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_bert-base_bert-score) | BERT-tiny | BERT-Base | BERTScore |
| [moussaKam/frugalscore_small_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_small_bert-base_bert-score) | BERT-small | BERT-Base | BERTScore |
| [moussaKam/frugalscore_medium_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_bert-base_bert-score) | BERT-medium | BERT-Base | BERTScore |
| [moussaKam/frugalscore_tiny_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_roberta_bert-score) | BERT-tiny | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_small_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_small_roberta_bert-score) | BERT-small | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_medium_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_roberta_bert-score) | BERT-medium | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_tiny_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_deberta_bert-score) | BERT-tiny | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_small_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_small_deberta_bert-score) | BERT-small | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_medium_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_deberta_bert-score) | BERT-medium | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_tiny_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_tiny_bert-base_mover-score) | BERT-tiny | BERT-Base | MoverScore |
| [moussaKam/frugalscore_small_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_small_bert-base_mover-score) | BERT-small | BERT-Base | MoverScore |
| [moussaKam/frugalscore_medium_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_medium_bert-base_mover-score) | BERT-medium | BERT-Base | MoverScore |
|
moussaKam/frugalscore_tiny_bert-base_bert-score
|
moussaKam
| 2022-02-01T10:50:21Z | 4,310 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"arxiv:2110.08559",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# FrugalScore
FrugalScore is an approach to learn a fixed, low cost version of any expensive NLG metric, while retaining most of its original performance
Paper: https://arxiv.org/abs/2110.08559?context=cs
Project github: https://github.com/moussaKam/FrugalScore
The pretrained checkpoints presented in the paper :
| FrugalScore | Student | Teacher | Method |
|----------------------------------------------------|-------------|----------------|------------|
| [moussaKam/frugalscore_tiny_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_bert-base_bert-score) | BERT-tiny | BERT-Base | BERTScore |
| [moussaKam/frugalscore_small_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_small_bert-base_bert-score) | BERT-small | BERT-Base | BERTScore |
| [moussaKam/frugalscore_medium_bert-base_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_bert-base_bert-score) | BERT-medium | BERT-Base | BERTScore |
| [moussaKam/frugalscore_tiny_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_roberta_bert-score) | BERT-tiny | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_small_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_small_roberta_bert-score) | BERT-small | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_medium_roberta_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_roberta_bert-score) | BERT-medium | RoBERTa-Large | BERTScore |
| [moussaKam/frugalscore_tiny_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_tiny_deberta_bert-score) | BERT-tiny | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_small_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_small_deberta_bert-score) | BERT-small | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_medium_deberta_bert-score](https://huggingface.co/moussaKam/frugalscore_medium_deberta_bert-score) | BERT-medium | DeBERTa-XLarge | BERTScore |
| [moussaKam/frugalscore_tiny_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_tiny_bert-base_mover-score) | BERT-tiny | BERT-Base | MoverScore |
| [moussaKam/frugalscore_small_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_small_bert-base_mover-score) | BERT-small | BERT-Base | MoverScore |
| [moussaKam/frugalscore_medium_bert-base_mover-score](https://huggingface.co/moussaKam/frugalscore_medium_bert-base_mover-score) | BERT-medium | BERT-Base | MoverScore |
|
AndrewMcDowell/wav2vec2-xls-r-1b-arabic
|
AndrewMcDowell
| 2022-02-01T08:13:55Z | 20 | 1 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"mozilla-foundation/common_voice_8_0",
"generated_from_trainer",
"ar",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:04Z |
---
language:
- ar
license: apache-2.0
tags:
- automatic-speech-recognition
- mozilla-foundation/common_voice_8_0
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: ''
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
#
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - AR dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1373
- Wer: 0.8607
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6.5e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 30.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 2.2416 | 0.84 | 500 | 1.2867 | 0.8875 |
| 2.3089 | 1.67 | 1000 | 1.8336 | 0.9548 |
| 2.3614 | 2.51 | 1500 | 1.5937 | 0.9469 |
| 2.5234 | 3.35 | 2000 | 1.9765 | 0.9867 |
| 2.5373 | 4.19 | 2500 | 1.9062 | 0.9916 |
| 2.5703 | 5.03 | 3000 | 1.9772 | 0.9915 |
| 2.4656 | 5.86 | 3500 | 1.8083 | 0.9829 |
| 2.4339 | 6.7 | 4000 | 1.7548 | 0.9752 |
| 2.344 | 7.54 | 4500 | 1.6146 | 0.9638 |
| 2.2677 | 8.38 | 5000 | 1.5105 | 0.9499 |
| 2.2074 | 9.21 | 5500 | 1.4191 | 0.9357 |
| 2.3768 | 10.05 | 6000 | 1.6663 | 0.9665 |
| 2.3804 | 10.89 | 6500 | 1.6571 | 0.9720 |
| 2.3237 | 11.72 | 7000 | 1.6049 | 0.9637 |
| 2.317 | 12.56 | 7500 | 1.5875 | 0.9655 |
| 2.2988 | 13.4 | 8000 | 1.5357 | 0.9603 |
| 2.2906 | 14.24 | 8500 | 1.5637 | 0.9592 |
| 2.2848 | 15.08 | 9000 | 1.5326 | 0.9537 |
| 2.2381 | 15.91 | 9500 | 1.5631 | 0.9508 |
| 2.2072 | 16.75 | 10000 | 1.4565 | 0.9395 |
| 2.197 | 17.59 | 10500 | 1.4304 | 0.9406 |
| 2.198 | 18.43 | 11000 | 1.4230 | 0.9382 |
| 2.1668 | 19.26 | 11500 | 1.3998 | 0.9315 |
| 2.1498 | 20.1 | 12000 | 1.3920 | 0.9258 |
| 2.1244 | 20.94 | 12500 | 1.3584 | 0.9153 |
| 2.0953 | 21.78 | 13000 | 1.3274 | 0.9054 |
| 2.0762 | 22.61 | 13500 | 1.2933 | 0.9073 |
| 2.0587 | 23.45 | 14000 | 1.2516 | 0.8944 |
| 2.0363 | 24.29 | 14500 | 1.2214 | 0.8902 |
| 2.0302 | 25.13 | 15000 | 1.2087 | 0.8871 |
| 2.0071 | 25.96 | 15500 | 1.1953 | 0.8786 |
| 1.9882 | 26.8 | 16000 | 1.1738 | 0.8712 |
| 1.9772 | 27.64 | 16500 | 1.1647 | 0.8672 |
| 1.9585 | 28.48 | 17000 | 1.1459 | 0.8635 |
| 1.944 | 29.31 | 17500 | 1.1414 | 0.8616 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2.dev0
- Tokenizers 0.11.0
|
Priyajay/xls-r-ab-test
|
Priyajay
| 2022-02-01T04:29:17Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"common_voice",
"generated_from_trainer",
"hi",
"dataset:common_voice",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:04Z |
---
language:
- hi
tags:
- automatic-speech-recognition
- common_voice
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: ''
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
#
This model is a fine-tuned version of [hf-test/xls-r-dummy](https://huggingface.co/hf-test/xls-r-dummy) on the COMMON_VOICE - HI dataset.
It achieves the following results on the evaluation set:
- Loss: 248.1278
- Wer: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 2.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2.dev0
- Tokenizers 0.11.0
|
jonfd/electra-small-is-no
|
jonfd
| 2022-01-31T23:41:45Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"electra",
"pretraining",
"is",
"no",
"dataset:igc",
"dataset:ic3",
"dataset:jonfd/ICC",
"dataset:mc4",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language:
- is
- no
license: cc-by-4.0
datasets:
- igc
- ic3
- jonfd/ICC
- mc4
---
# Icelandic-Norwegian ELECTRA-Small
This model was pretrained on the following corpora:
* The [Icelandic Gigaword Corpus](http://igc.arnastofnun.is/) (IGC)
* The Icelandic Common Crawl Corpus (IC3)
* The [Icelandic Crawled Corpus](https://huggingface.co/datasets/jonfd/ICC) (ICC)
* The [Multilingual Colossal Clean Crawled Corpus](https://huggingface.co/datasets/mc4) (mC4) - Icelandic and Norwegian text obtained from .is and .no domains, respectively
The total size of the corpus after document-level deduplication and filtering was 7.41B tokens, split equally between the two languages. The model was trained using a WordPiece tokenizer with a vocabulary size of 64,105 for 1.1 million steps, and otherwise with default settings.
# Acknowledgments
This research was supported with Cloud TPUs from Google's TPU Research Cloud (TRC).
This project was funded by the Language Technology Programme for Icelandic 2019-2023. The programme, which is managed and coordinated by [Almannarómur](https://almannaromur.is/), is funded by the Icelandic Ministry of Education, Science and Culture.
|
jonfd/electra-small-nordic
|
jonfd
| 2022-01-31T23:41:26Z | 90,574 | 2 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"electra",
"pretraining",
"is",
"no",
"sv",
"da",
"dataset:igc",
"dataset:ic3",
"dataset:jonfd/ICC",
"dataset:mc4",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language:
- is
- no
- sv
- da
license: cc-by-4.0
datasets:
- igc
- ic3
- jonfd/ICC
- mc4
---
# Nordic ELECTRA-Small
This model was pretrained on the following corpora:
* The [Icelandic Gigaword Corpus](http://igc.arnastofnun.is/) (IGC)
* The Icelandic Common Crawl Corpus (IC3)
* The [Icelandic Crawled Corpus](https://huggingface.co/datasets/jonfd/ICC) (ICC)
* The [Multilingual Colossal Clean Crawled Corpus](https://huggingface.co/datasets/mc4) (mC4) - Icelandic, Norwegian, Swedish and Danish text obtained from .is, .no, .se and .dk domains, respectively
The total size of the corpus after document-level deduplication and filtering was 14.82B tokens, split equally between the four languages. The model was trained using a WordPiece tokenizer with a vocabulary size of 96,105 for one million steps with a batch size of 256, and otherwise with default settings.
# Acknowledgments
This research was supported with Cloud TPUs from Google's TPU Research Cloud (TRC).
This project was funded by the Language Technology Programme for Icelandic 2019-2023. The programme, which is managed and coordinated by [Almannarómur](https://almannaromur.is/), is funded by the Icelandic Ministry of Education, Science and Culture.
|
paintingpeter/distilbert-base-uncased-distilled-clinc
|
paintingpeter
| 2022-01-31T23:27:39Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:clinc_oos",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- clinc_oos
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-distilled-clinc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: clinc_oos
type: clinc_oos
args: plus
metrics:
- name: Accuracy
type: accuracy
value: 0.9467741935483871
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-distilled-clinc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2795
- Accuracy: 0.9468
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 3.4223 | 1.0 | 318 | 2.5556 | 0.7561 |
| 1.9655 | 2.0 | 636 | 1.3075 | 0.8577 |
| 1.0041 | 3.0 | 954 | 0.6970 | 0.9165 |
| 0.5449 | 4.0 | 1272 | 0.4637 | 0.9339 |
| 0.3424 | 5.0 | 1590 | 0.3630 | 0.9397 |
| 0.247 | 6.0 | 1908 | 0.3225 | 0.9442 |
| 0.1968 | 7.0 | 2226 | 0.2983 | 0.9458 |
| 0.1693 | 8.0 | 2544 | 0.2866 | 0.9465 |
| 0.1547 | 9.0 | 2862 | 0.2820 | 0.9468 |
| 0.1477 | 10.0 | 3180 | 0.2795 | 0.9468 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
saattrupdan/xlmr-base-texas-squad-is
|
saattrupdan
| 2022-01-31T21:28:56Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"question-answering",
"generated_from_trainer",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: xlmr-base-texas-squad-is
results: []
widget:
- text: "Hvenær var Halldór Laxness í menntaskóla ?"
context: "Halldór Laxness ( Halldór Kiljan ) fæddist í Reykjavík 23. apríl árið 1902 og átti í fyrstu heima við Laugaveg en árið 1905 settist fjölskyldan að í Laxnesi í Mosfellssveit . Þar ólst Halldór upp en sótti skóla í Reykjavík á unglingsárum . Ungur hélt hann síðan utan og var langdvölum erlendis um árabil – í ýmsum Evrópulöndum og síðar í Ameríku . Þegar hann var heima bjó hann í Reykjavík þar til hann og kona hans , Auður Sveinsdóttir , byggðu sér húsið Gljúfrastein í Mosfellssveit og fluttu þangað árið 1945 . Þar var heimili þeirra alla tíð síðan og þar er nú safn til minningar um þau . Halldór lést 8. febrúar 1998 . Skólaganga Halldórs varð ekki löng . Árið 1918 hóf hann nám við Menntaskólann í Reykjavík en hafði lítinn tíma til að læra , enda var hann að skrifa skáldsögu , Barn náttúrunnar , sem kom út haustið 1919 – þá þegar var höfundurinn ungi farinn af landi brott . Sagan vakti þó nokkra athygli og í Alþýðublaðinu sagði m.a. : „ Og hver veit nema að Halldór frá Laxnesi eigi eftir að verða óskabarn íslensku þjóðarinnar . “ Upp frá þessu sendi Halldór frá sér bók nánast á hverju ári , stundum fleiri en eina , í yfir sex áratugi . Afköst hans voru með eindæmum ; hann skrifaði fjölda skáldsagna , sumar í nokkrum hlutum , leikrit , kvæði , smásagnasöfn og endurminningabækur og gaf auk þess út mörg greinasöfn og ritgerðir . Bækurnar eru fjölbreyttar en eiga það sameiginlegt að vera skrifaðar af einstakri stílgáfu , djúpum mannskilningi og víðtækri þekkingu á sögu og samfélagi . Þar birtast oft afgerandi skoðanir á þjóðfélagsmálum og sögupersónur eru margar einkar eftirminnilegar ; tilsvör þeirra og lunderni hafa orðið samofin þjóðarsálinni . Þekktustu verk Halldórs eru eflaust skáldsögurnar stóru og rismiklu , s.s. Salka Valka , Sjálfstætt fólk , Heimsljós , Íslandsklukkan og Gerpla , og raunar mætti telja upp mun fleiri ; Kvæðabók hans er í uppáhaldi hjá mörgum sem og minningabækurnar sem hann skrifaði á efri árum um æskuár sín ; af þekktum greinasöfnum og ritgerðum má nefna Alþýðubókina og Skáldatíma . Mikið hefur verið skrifað um verk og ævi skáldsins , en hér skal aðeins bent á ítarlega frásögn og greiningu Halldórs Guðmundssonar í bókinni Halldór Laxness – ævisaga ."
---
# TExAS-SQuAD-is
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the TExAS-SQuAD-is dataset.
It achieves the following results on the evaluation set:
- Exact match: 56.91%
- F1-score: 59.93%
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 2.1458 | 1.0 | 4219 | 1.8892 |
| 1.9202 | 2.0 | 8438 | 1.8566 |
| 1.7377 | 3.0 | 12657 | 1.8688 |
### Framework versions
- Transformers 4.12.2
- Pytorch 1.8.1+cu101
- Datasets 1.12.1
- Tokenizers 0.10.3
|
gilparmentier/pokemon_gptj_model
|
gilparmentier
| 2022-01-31T21:19:06Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gptj",
"text-generation",
"causal-lm",
"en",
"arxiv:2104.09864",
"arxiv:2101.00027",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language:
- en
tags:
- pytorch
- causal-lm
license: apache-2.0
datasets:
- The Pile
---
# GPT-J 6B
## Model Description
GPT-J 6B is a transformer model trained using Ben Wang's [Mesh Transformer JAX](https://github.com/kingoflolz/mesh-transformer-jax/). "GPT-J" refers to the class of model, while "6B" represents the number of trainable parameters.
<figure>
| Hyperparameter | Value |
|----------------------|------------|
| \\(n_{parameters}\\) | 6053381344 |
| \\(n_{layers}\\) | 28* |
| \\(d_{model}\\) | 4096 |
| \\(d_{ff}\\) | 16384 |
| \\(n_{heads}\\) | 16 |
| \\(d_{head}\\) | 256 |
| \\(n_{ctx}\\) | 2048 |
| \\(n_{vocab}\\) | 50257/50400† (same tokenizer as GPT-2/3) |
| Positional Encoding | [Rotary Position Embedding (RoPE)](https://arxiv.org/abs/2104.09864) |
| RoPE Dimensions | [64](https://github.com/kingoflolz/mesh-transformer-jax/blob/f2aa66e0925de6593dcbb70e72399b97b4130482/mesh_transformer/layers.py#L223) |
<figcaption><p><strong>*</strong> Each layer consists of one feedforward block and one self attention block.</p>
<p><strong>†</strong> Although the embedding matrix has a size of 50400, only 50257 entries are used by the GPT-2 tokenizer.</p></figcaption></figure>
The model consists of 28 layers with a model dimension of 4096, and a feedforward dimension of 16384. The model
dimension is split into 16 heads, each with a dimension of 256. Rotary Position Embedding (RoPE) is applied to 64
dimensions of each head. The model is trained with a tokenization vocabulary of 50257, using the same set of BPEs as
GPT-2/GPT-3.
## Training data
GPT-J 6B was trained on [the Pile](https://pile.eleuther.ai), a large-scale curated dataset created by [EleutherAI](https://www.eleuther.ai).
## Training procedure
This model was trained for 402 billion tokens over 383,500 steps on TPU v3-256 pod. It was trained as an autoregressive language model, using cross-entropy loss to maximize the likelihood of predicting the next token correctly.
## Intended Use and Limitations
GPT-J learns an inner representation of the English language that can be used to extract features useful for downstream tasks. The model is best at what it was pretrained for however, which is generating text from a prompt.
### How to use
This model can be easily loaded using the `AutoModelForCausalLM` functionality:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B")
model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-j-6B")
```
### Limitations and Biases
The core functionality of GPT-J is taking a string of text and predicting the next token. While language models are widely used for tasks other than this, there are a lot of unknowns with this work. When prompting GPT-J it is important to remember that the statistically most likely next token is often not the token that produces the most "accurate" text. Never depend upon GPT-J to produce factually accurate output.
GPT-J was trained on the Pile, a dataset known to contain profanity, lewd, and otherwise abrasive language. Depending upon use case GPT-J may produce socially unacceptable text. See [Sections 5 and 6 of the Pile paper](https://arxiv.org/abs/2101.00027) for a more detailed analysis of the biases in the Pile.
As with all language models, it is hard to predict in advance how GPT-J will respond to particular prompts and offensive content may occur without warning. We recommend having a human curate or filter the outputs before releasing them, both to censor undesirable content and to improve the quality of the results.
## Evaluation results
<figure>
| Model | Public | Training FLOPs | LAMBADA PPL ↓ | LAMBADA Acc ↑ | Winogrande ↑ | Hellaswag ↑ | PIQA ↑ | Dataset Size (GB) |
|--------------------------|-------------|----------------|--- |--- |--- |--- |--- |-------------------|
| Random Chance | ✓ | 0 | ~a lot | ~0% | 50% | 25% | 25% | 0 |
| GPT-3 Ada‡ | ✗ | ----- | 9.95 | 51.6% | 52.9% | 43.4% | 70.5% | ----- |
| GPT-2 1.5B | ✓ | ----- | 10.63 | 51.21% | 59.4% | 50.9% | 70.8% | 40 |
| GPT-Neo 1.3B‡ | ✓ | 3.0e21 | 7.50 | 57.2% | 55.0% | 48.9% | 71.1% | 825 |
| Megatron-2.5B* | ✗ | 2.4e21 | ----- | 61.7% | ----- | ----- | ----- | 174 |
| GPT-Neo 2.7B‡ | ✓ | 6.8e21 | 5.63 | 62.2% | 56.5% | 55.8% | 73.0% | 825 |
| GPT-3 1.3B*‡ | ✗ | 2.4e21 | 5.44 | 63.6% | 58.7% | 54.7% | 75.1% | ~800 |
| GPT-3 Babbage‡ | ✗ | ----- | 5.58 | 62.4% | 59.0% | 54.5% | 75.5% | ----- |
| Megatron-8.3B* | ✗ | 7.8e21 | ----- | 66.5% | ----- | ----- | ----- | 174 |
| GPT-3 2.7B*‡ | ✗ | 4.8e21 | 4.60 | 67.1% | 62.3% | 62.8% | 75.6% | ~800 |
| Megatron-11B† | ✓ | 1.0e22 | ----- | ----- | ----- | ----- | ----- | 161 |
| **GPT-J 6B‡** | **✓** | **1.5e22** | **3.99** | **69.7%** | **65.3%** | **66.1%** | **76.5%** | **825** |
| GPT-3 6.7B*‡ | ✗ | 1.2e22 | 4.00 | 70.3% | 64.5% | 67.4% | 78.0% | ~800 |
| GPT-3 Curie‡ | ✗ | ----- | 4.00 | 69.3% | 65.6% | 68.5% | 77.9% | ----- |
| GPT-3 13B*‡ | ✗ | 2.3e22 | 3.56 | 72.5% | 67.9% | 70.9% | 78.5% | ~800 |
| GPT-3 175B*‡ | ✗ | 3.1e23 | 3.00 | 76.2% | 70.2% | 78.9% | 81.0% | ~800 |
| GPT-3 Davinci‡ | ✗ | ----- | 3.0 | 75% | 72% | 78% | 80% | ----- |
<figcaption><p>Models roughly sorted by performance, or by FLOPs if not available.</p>
<p><strong>*</strong> Evaluation numbers reported by their respective authors. All other numbers are provided by
running <a href="https://github.com/EleutherAI/lm-evaluation-harness/"><code>lm-evaluation-harness</code></a> either with released
weights or with API access. Due to subtle implementation differences as well as different zero shot task framing, these
might not be directly comparable. See <a href="https://blog.eleuther.ai/gpt3-model-sizes/">this blog post</a> for more
details.</p>
<p><strong>†</strong> Megatron-11B provides no comparable metrics, and several implementations using the released weights do not
reproduce the generation quality and evaluations. (see <a href="https://github.com/huggingface/transformers/pull/10301">1</a>
<a href="https://github.com/pytorch/fairseq/issues/2358">2</a> <a href="https://github.com/pytorch/fairseq/issues/2719">3</a>)
Thus, evaluation was not attempted.</p>
<p><strong>‡</strong> These models have been trained with data which contains possible test set contamination. The OpenAI GPT-3 models
failed to deduplicate training data for certain test sets, while the GPT-Neo models as well as this one is
trained on the Pile, which has not been deduplicated against any test sets.</p></figcaption></figure>
## Citation and Related Information
### BibTeX entry
To cite this model:
```bibtex
@misc{gpt-j,
author = {Wang, Ben and Komatsuzaki, Aran},
title = {{GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model}},
howpublished = {\url{https://github.com/kingoflolz/mesh-transformer-jax}},
year = 2021,
month = May
}
```
To cite the codebase that trained this model:
```bibtex
@misc{mesh-transformer-jax,
author = {Wang, Ben},
title = {{Mesh-Transformer-JAX: Model-Parallel Implementation of Transformer Language Model with JAX}},
howpublished = {\url{https://github.com/kingoflolz/mesh-transformer-jax}},
year = 2021,
month = May
}
```
If you use this model, we would love to hear about it! Reach out on [GitHub](https://github.com/kingoflolz/mesh-transformer-jax), Discord, or shoot Ben an email.
## Acknowledgements
This project would not have been possible without compute generously provided by Google through the
[TPU Research Cloud](https://sites.research.google/trc/), as well as the Cloud TPU team for providing early access to the [Cloud TPU VM](https://cloud.google.com/blog/products/compute/introducing-cloud-tpu-vms) Alpha.
Thanks to everyone who have helped out one way or another (listed alphabetically):
- [James Bradbury](https://twitter.com/jekbradbury) for valuable assistance with debugging JAX issues.
- [Stella Biderman](https://www.stellabiderman.com), [Eric Hallahan](https://twitter.com/erichallahan), [Kurumuz](https://github.com/kurumuz/), and [Finetune](https://github.com/finetuneanon/) for converting the model to be compatible with the `transformers` package.
- [Leo Gao](https://twitter.com/nabla_theta) for running zero shot evaluations for the baseline models for the table.
- [Laurence Golding](https://github.com/researcher2/) for adding some features to the web demo.
- [Aran Komatsuzaki](https://twitter.com/arankomatsuzaki) for advice with experiment design and writing the blog posts.
- [Janko Prester](https://github.com/jprester/) for creating the web demo frontend.
|
glob-asr/wav2vec2-large-xls-r-300m-spanish-small
|
glob-asr
| 2022-01-31T20:58:46Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-300m-spanish-small
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-spanish-small
This model is a fine-tuned version of [jhonparra18/wav2vec2-large-xls-r-300m-spanish-custom](https://huggingface.co/jhonparra18/wav2vec2-large-xls-r-300m-spanish-custom) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3596
- Wer: 0.2105
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 0.1971 | 0.79 | 400 | 0.2169 | 0.2077 |
| 0.2293 | 1.58 | 800 | 0.2507 | 0.2418 |
| 0.2065 | 2.37 | 1200 | 0.2703 | 0.2459 |
| 0.1842 | 3.16 | 1600 | 0.2716 | 0.2495 |
| 0.1634 | 3.95 | 2000 | 0.2695 | 0.2510 |
| 0.1443 | 4.74 | 2400 | 0.2754 | 0.2435 |
| 0.1345 | 5.53 | 2800 | 0.3119 | 0.2654 |
| 0.1267 | 6.32 | 3200 | 0.3154 | 0.2573 |
| 0.1237 | 7.11 | 3600 | 0.3251 | 0.2666 |
| 0.1118 | 7.91 | 4000 | 0.3139 | 0.2503 |
| 0.1051 | 8.7 | 4400 | 0.3286 | 0.2573 |
| 0.0964 | 9.49 | 4800 | 0.3348 | 0.2587 |
| 0.0946 | 10.28 | 5200 | 0.3357 | 0.2587 |
| 0.0897 | 11.07 | 5600 | 0.3408 | 0.2590 |
| 0.0812 | 11.86 | 6000 | 0.3380 | 0.2560 |
| 0.079 | 12.65 | 6400 | 0.3304 | 0.2415 |
| 0.0753 | 13.44 | 6800 | 0.3557 | 0.2540 |
| 0.0717 | 14.23 | 7200 | 0.3507 | 0.2519 |
| 0.0691 | 15.02 | 7600 | 0.3554 | 0.2587 |
| 0.0626 | 15.81 | 8000 | 0.3619 | 0.2520 |
| 0.0661 | 16.6 | 8400 | 0.3609 | 0.2564 |
| 0.0582 | 17.39 | 8800 | 0.3818 | 0.2520 |
| 0.0556 | 18.18 | 9200 | 0.3685 | 0.2410 |
| 0.0515 | 18.97 | 9600 | 0.3658 | 0.2367 |
| 0.0478 | 19.76 | 10000 | 0.3701 | 0.2413 |
| 0.0486 | 20.55 | 10400 | 0.3681 | 0.2371 |
| 0.0468 | 21.34 | 10800 | 0.3607 | 0.2370 |
| 0.0452 | 22.13 | 11200 | 0.3499 | 0.2286 |
| 0.0399 | 22.92 | 11600 | 0.3647 | 0.2282 |
| 0.0393 | 23.72 | 12000 | 0.3638 | 0.2255 |
| 0.0381 | 24.51 | 12400 | 0.3359 | 0.2202 |
| 0.0332 | 25.3 | 12800 | 0.3488 | 0.2177 |
| 0.033 | 26.09 | 13200 | 0.3628 | 0.2175 |
| 0.0311 | 26.88 | 13600 | 0.3695 | 0.2195 |
| 0.0294 | 27.67 | 14000 | 0.3624 | 0.2164 |
| 0.0281 | 28.46 | 14400 | 0.3688 | 0.2113 |
| 0.0274 | 29.25 | 14800 | 0.3596 | 0.2105 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.1.dev0
- Tokenizers 0.11.0
|
huggingtweets/zssbecker
|
huggingtweets
| 2022-01-31T20:37:02Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/zssbecker/1643661417699/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1486464160422670337/mEvWu0_w_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Alex Becker 🍊🏆🥇</div>
<div style="text-align: center; font-size: 14px;">@zssbecker</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Alex Becker 🍊🏆🥇.
| Data | Alex Becker 🍊🏆🥇 |
| --- | --- |
| Tweets downloaded | 3249 |
| Retweets | 53 |
| Short tweets | 453 |
| Tweets kept | 2743 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2j8o1cf7/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @zssbecker's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1qe600k1) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1qe600k1/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/zssbecker')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
arianpasquali/distilbert-base-uncased-finetuned-clinc
|
arianpasquali
| 2022-01-31T20:09:00Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:clinc_oos",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- clinc_oos
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-clinc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: clinc_oos
type: clinc_oos
args: plus
metrics:
- name: Accuracy
type: accuracy
value: 0.9112903225806451
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-clinc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7751
- Accuracy: 0.9113
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 4.315 | 1.0 | 318 | 3.3087 | 0.74 |
| 2.6371 | 2.0 | 636 | 1.8833 | 0.8381 |
| 1.5388 | 3.0 | 954 | 1.1547 | 0.8929 |
| 1.0076 | 4.0 | 1272 | 0.8590 | 0.9071 |
| 0.79 | 5.0 | 1590 | 0.7751 | 0.9113 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.7.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
akshaychaudhary/distilbert-base-uncased-finetuned-ner
|
akshaychaudhary
| 2022-01-31T18:50:20Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"token-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ner
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9988
- Precision: 0.3
- Recall: 0.6
- F1: 0.4
- Accuracy: 0.7870
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 84 | 0.8399 | 0.2105 | 0.4 | 0.2759 | 0.75 |
| No log | 2.0 | 168 | 0.9664 | 0.3 | 0.6 | 0.4 | 0.7870 |
| No log | 3.0 | 252 | 0.9988 | 0.3 | 0.6 | 0.4 | 0.7870 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.2
- Tokenizers 0.11.0
|
masapasa/xls-r-ab-test
|
masapasa
| 2022-01-31T17:22:19Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"mozilla-foundation/common_voice_8_0",
"generated_from_trainer",
"ab",
"dataset:common_voice",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language:
- ab
tags:
- automatic-speech-recognition
- mozilla-foundation/common_voice_8_0
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: ''
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
#
This model is a fine-tuned version of [hf-test/xls-r-dummy](https://huggingface.co/hf-test/xls-r-dummy) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - AB dataset.
It achieves the following results on the evaluation set:
- Loss: 140.0674
- Wer: 1.1193
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2.dev0
- Tokenizers 0.11.0
|
anton-l/wav2vec2-xls-r-common_voice-tr-ft-stream
|
anton-l
| 2022-01-31T17:19:19Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"common_voice",
"generated_from_trainer",
"tr",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language:
- tr
license: apache-2.0
tags:
- automatic-speech-recognition
- common_voice
- generated_from_trainer
model-index:
- name: wav2vec2-xls-r-common_voice-tr-ft-stream
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-xls-r-common_voice-tr-ft-stream
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the COMMON_VOICE - TR dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3519
- Wer: 0.2927
- Cer: 0.0694
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| 0.6768 | 9.01 | 500 | 0.4220 | 0.5143 | 0.1235 |
| 0.3801 | 19.01 | 1000 | 0.3303 | 0.4403 | 0.1055 |
| 0.3616 | 29.0 | 1500 | 0.3540 | 0.3716 | 0.0878 |
| 0.2334 | 39.0 | 2000 | 0.3666 | 0.3671 | 0.0842 |
| 0.3141 | 49.0 | 2500 | 0.3407 | 0.3373 | 0.0819 |
| 0.1926 | 58.01 | 3000 | 0.3886 | 0.3520 | 0.0867 |
| 0.1372 | 68.01 | 3500 | 0.3415 | 0.3189 | 0.0743 |
| 0.091 | 78.0 | 4000 | 0.3750 | 0.3164 | 0.0757 |
| 0.0893 | 88.0 | 4500 | 0.3559 | 0.2968 | 0.0712 |
| 0.095 | 98.0 | 5000 | 0.3519 | 0.2927 | 0.0694 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.2
- Datasets 1.18.2
- Tokenizers 0.10.3
|
peter-explosion-ai/en_pipeline
|
peter-explosion-ai
| 2022-01-31T17:04:42Z | 5 | 0 |
spacy
|
[
"spacy",
"text-classification",
"en",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
tags:
- spacy
- text-classification
language:
- en
model-index:
- name: en_pipeline
results: []
---
| Feature | Description |
| --- | --- |
| **Name** | `en_pipeline` |
| **Version** | `0.0.0` |
| **spaCy** | `>=3.2.1,<3.3.0` |
| **Default Pipeline** | `textcat` |
| **Components** | `textcat` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | n/a |
| **License** | n/a |
| **Author** | [n/a]() |
### Label Scheme
<details>
<summary>View label scheme (2 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`textcat`** | `POSITIVE`, `NEGATIVE` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `CATS_SCORE` | 55.70 |
| `CATS_MICRO_P` | 58.65 |
| `CATS_MICRO_R` | 58.65 |
| `CATS_MICRO_F` | 58.65 |
| `CATS_MACRO_P` | 61.88 |
| `CATS_MACRO_R` | 58.69 |
| `CATS_MACRO_F` | 55.70 |
| `CATS_MACRO_AUC` | 63.53 |
| `CATS_MACRO_AUC_PER_TYPE` | 0.00 |
| `TEXTCAT_LOSS` | 3.74 |
|
shivam/xls-r-300m-hindi
|
shivam
| 2022-01-31T16:58:54Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"mozilla-foundation/common_voice_8_0",
"generated_from_trainer",
"hi",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language:
- hi
license: apache-2.0
tags:
- automatic-speech-recognition
- mozilla-foundation/common_voice_8_0
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: ''
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
#
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - HI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8111
- Wer: 0.5177
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 50.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 4.9733 | 2.59 | 500 | 5.0697 | 1.0 |
| 3.3839 | 5.18 | 1000 | 3.3518 | 1.0 |
| 2.0596 | 7.77 | 1500 | 1.3992 | 0.7869 |
| 1.6102 | 10.36 | 2000 | 1.0712 | 0.6754 |
| 1.4587 | 12.95 | 2500 | 0.9280 | 0.6361 |
| 1.3667 | 15.54 | 3000 | 0.9281 | 0.6155 |
| 1.3042 | 18.13 | 3500 | 0.9037 | 0.5921 |
| 1.2544 | 20.73 | 4000 | 0.8996 | 0.5824 |
| 1.2274 | 23.32 | 4500 | 0.8934 | 0.5797 |
| 1.1763 | 25.91 | 5000 | 0.8643 | 0.5760 |
| 1.149 | 28.5 | 5500 | 0.8251 | 0.5544 |
| 1.1207 | 31.09 | 6000 | 0.8506 | 0.5527 |
| 1.091 | 33.68 | 6500 | 0.8370 | 0.5366 |
| 1.0613 | 36.27 | 7000 | 0.8345 | 0.5352 |
| 1.0495 | 38.86 | 7500 | 0.8380 | 0.5321 |
| 1.0345 | 41.45 | 8000 | 0.8285 | 0.5269 |
| 1.0297 | 44.04 | 8500 | 0.7836 | 0.5141 |
| 1.027 | 46.63 | 9000 | 0.8120 | 0.5180 |
| 0.9876 | 49.22 | 9500 | 0.8109 | 0.5188 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu113
- Datasets 1.18.1.dev0
- Tokenizers 0.11.0
|
osanseviero/test_meta
|
osanseviero
| 2022-01-31T15:21:09Z | 0 | 0 |
spacy
|
[
"spacy",
"token-classification",
"license:lgpl-lr",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
tags:
- spacy
- token-classification
languages:
- fr
license: lgpl-lr
other-thing: test
---
|
anton-l/wav2vec2-tokenizer-turkish
|
anton-l
| 2022-01-31T11:37:43Z | 0 | 0 | null |
[
"license:cc0-1.0",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
license: cc0-1.0
---
This is a standalone Turkish Wav2Vec2 tokenizer config intended for use with `run_speech_recognition_ctc_streaming.py`
|
huggingtweets/tks
|
huggingtweets
| 2022-01-31T10:20:15Z | 0 | 0 | null |
[
"huggingtweets",
"en",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/tks/1643624411056/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1044664291050344449/vKKJxtBF_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">高須正和@NT深圳コミュニティ/TAKASU@NT Shenzhen</div>
<div style="text-align: center; font-size: 14px;">@tks</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from 高須正和@NT深圳コミュニティ/TAKASU@NT Shenzhen.
| Data | 高須正和@NT深圳コミュニティ/TAKASU@NT Shenzhen |
| --- | --- |
| Tweets downloaded | 3248 |
| Retweets | 1831 |
| Short tweets | 825 |
| Tweets kept | 592 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1lg0mgsp/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @tks's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/j1ak5d5p) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/j1ak5d5p/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/tks')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/ggreenwald
|
huggingtweets
| 2022-01-31T09:49:22Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/ggreenwald/1643622558420/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1092582027994509312/cpYWuYI9_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Glenn Greenwald</div>
<div style="text-align: center; font-size: 14px;">@ggreenwald</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Glenn Greenwald.
| Data | Glenn Greenwald |
| --- | --- |
| Tweets downloaded | 3248 |
| Retweets | 324 |
| Short tweets | 160 |
| Tweets kept | 2764 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/y433olp5/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @ggreenwald's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/duljho5y) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/duljho5y/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/ggreenwald')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/_ikeay-ikeay
|
huggingtweets
| 2022-01-31T07:45:27Z | 0 | 0 | null |
[
"huggingtweets",
"en",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/_ikeay-ikeay/1643615122837/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1334136134234849280/XgE0O39a_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1438483410503176195/v_ghm6Un_400x400.png')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">池澤あやか / いけあや & いけあや(意識が低い方)</div>
<div style="text-align: center; font-size: 14px;">@_ikeay-ikeay</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from 池澤あやか / いけあや & いけあや(意識が低い方).
| Data | 池澤あやか / いけあや | いけあや(意識が低い方) |
| --- | --- | --- |
| Tweets downloaded | 3249 | 3248 |
| Retweets | 233 | 24 |
| Short tweets | 2345 | 2299 |
| Tweets kept | 671 | 925 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1vm4ts8h/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @_ikeay-ikeay's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/33elayne) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/33elayne/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/_ikeay-ikeay')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/eri_razapii-marisakura-miyakomx
|
huggingtweets
| 2022-01-31T07:36:10Z | 0 | 0 | null |
[
"huggingtweets",
"en",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/eri_razapii-marisakura-miyakomx/1643614565483/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1463699400405164034/aRY9jlnO_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1460131579930755073/ln4j-nWU_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1466279279667277828/VqmxK5gB_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">えりらざぴ | SHE CEO/CCO & 櫻本真理 cotree/CoachEd & 吉澤美弥子🤿Coral Capital</div>
<div style="text-align: center; font-size: 14px;">@eri_razapii-marisakura-miyakomx</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from えりらざぴ | SHE CEO/CCO & 櫻本真理 cotree/CoachEd & 吉澤美弥子🤿Coral Capital.
| Data | えりらざぴ | SHE CEO/CCO | 櫻本真理 cotree/CoachEd | 吉澤美弥子🤿Coral Capital |
| --- | --- | --- | --- |
| Tweets downloaded | 3232 | 3205 | 1206 |
| Retweets | 1781 | 1564 | 79 |
| Short tweets | 959 | 877 | 736 |
| Tweets kept | 492 | 764 | 391 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1xlu40i1/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @eri_razapii-marisakura-miyakomx's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/22cwqnkv) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/22cwqnkv/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/eri_razapii-marisakura-miyakomx')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
TajMahaladeen/pokemon_gptj
|
TajMahaladeen
| 2022-01-31T06:12:31Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gptj",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
---
|
NbAiLab/xls-r-1b-npsc
|
NbAiLab
| 2022-01-31T04:33:39Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:04Z |
---
license: apache-2.0
---
|
huggingtweets/alphaxchange-coinmarketcap-techcrunch
|
huggingtweets
| 2022-01-31T01:31:27Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/alphaxchange-coinmarketcap-techcrunch/1643592683390/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1475337078544248835/JRWM0Hsl_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1096066608034918401/m8wnTWsX_400x400.png')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1469027897209987081/fCdlufKH_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">CoinMarketCap & TechCrunch & AlphaExchange</div>
<div style="text-align: center; font-size: 14px;">@alphaxchange-coinmarketcap-techcrunch</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from CoinMarketCap & TechCrunch & AlphaExchange.
| Data | CoinMarketCap | TechCrunch | AlphaExchange |
| --- | --- | --- | --- |
| Tweets downloaded | 3249 | 3250 | 185 |
| Retweets | 247 | 29 | 25 |
| Short tweets | 209 | 9 | 17 |
| Tweets kept | 2793 | 3212 | 143 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1ii2008f/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @alphaxchange-coinmarketcap-techcrunch's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/28z1wzo5) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/28z1wzo5/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/alphaxchange-coinmarketcap-techcrunch')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
osama7/t5-summarization-multinews
|
osama7
| 2022-01-30T20:42:51Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
This is a t5-base model trained on the multi_news dataset for abstraction summarization
|
z-uo/vits-male-it
|
z-uo
| 2022-01-30T20:20:35Z | 4 | 1 |
transformers
|
[
"transformers",
"tensorboard",
"text-to-speech",
"it",
"dataset:z-uo/female-LJSpeech-italian",
"endpoints_compatible",
"region:us"
] |
text-to-speech
| 2022-03-02T23:29:05Z |
---
tags:
- text-to-speech
language:
- it
model-index:
- name: vits-male-it
results: []
datasets:
- z-uo/female-LJSpeech-italian
---
# Coqui Model for TTS
```
pip install TTS
git clone https://huggingface.co/z-uo/vits-male-it
# predict one
tts --text "ciao pluto" --model_path "vits-male-it/best_model.pth.tar" --config_path "vits-male-it/config.json"
# predict server
tts-server --model_path "vits-male-it/best_model.pth.tar" --config_path "vits-male-it/config.json"
firefox localhost:5002
```
More information about training script in [this repo](https://github.com/nicolalandro/train_coqui_tts_ita).
|
Kayvane/distilbert-complaints-product
|
Kayvane
| 2022-01-30T19:15:13Z | 33 | 3 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:consumer_complaints",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:04Z |
---
tags:
- generated_from_trainer
datasets:
- consumer_complaints
model-index:
- name: distilbert-complaints-product
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-complaints-product
This model was trained from the [CFBP](https://www.consumerfinance.gov/data-research/consumer-complaints/) dataset, also made available on the HuggingFace Datasets library. This model predicts the type of financial complaint based on the text provided
## Model description
A DistilBert Text Classification Model, with 18 possible classes to determine the nature of a financial customer complaint.
## Intended uses & limitations
This model is used as part of.a demonstration for E2E Machine Learning Projects focused on Contact Centre Automation:
- **Infrastructure:** Terraform
- **ML Ops:** HuggingFace (Datasets, Hub, Transformers)
- **Ml Explainability:** SHAP
- **Cloud:** AWS
- Model Hosting: Lambda
- DB Backend: DynamoDB
- Orchestration: Step-Functions
- UI Hosting: EC2
- Routing: API Gateway
- **UI:** Budibase
## Training and evaluation data
consumer_complaints dataset
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
### Framework versions
- Transformers 4.16.1
- Pytorch 1.10.0+cu111
- Datasets 1.18.2
- Tokenizers 0.11.0
|
Sindhu/rembert-squad2
|
Sindhu
| 2022-01-30T18:35:08Z | 5 | 3 |
transformers
|
[
"transformers",
"pytorch",
"rembert",
"question-answering",
"multilingual",
"dataset:squad2",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language:
- multilingual
tags:
- question-answering
datasets:
- squad2
metrics:
- squad2
---
# Rembert Squad2
This model is finetuned for QA task on Squad2 from [Rembert checkpoint](https://huggingface.co/google/rembert).
## Hyperparameters
```
Batch Size: 4
Grad Accumulation Steps = 8
Total epochs = 3
MLM Checkpoint = "rembert"
max_seq_len = 256
learning_rate = 1e-5
lr_schedule = LinearWarmup
warmup_ratio = 0.1
doc_stride = 128
```
## Squad 2 Evaluation stats:
Metrics generated from [the official Squad2 evaluation script](https://worksheets.codalab.org/rest/bundles/0x6b567e1cf2e041ec80d7098f031c5c9e/contents/blob/)
```json
{
"exact": 84.51107554956624,
"f1": 87.46644042781853,
"total": 11873,
"HasAns_exact": 80.97165991902834,
"HasAns_f1": 86.89086491219469,
"HasAns_total": 5928,
"NoAns_exact": 88.04037005887301,
"NoAns_f1": 88.04037005887301,
"NoAns_total": 5945
}
```
For any questions, you can reach out to me [on Twitter](https://twitter.com/batw0man)
|
Erfan/mT5-base_Farsi_Title_Generator
|
Erfan
| 2022-01-30T18:00:42Z | 11 | 2 |
transformers
|
[
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"Title-Generation",
"fa",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:04Z |
---
language:
- fa
tags:
- Title-Generation
metrics:
- ROUGH
---
|
tomascufaro/wav2vec2-large-xls-r-300m-spanish-small
|
tomascufaro
| 2022-01-30T17:23:59Z | 14 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-300m-spanish-small
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-spanish-small
This model is a fine-tuned version of [jhonparra18/wav2vec2-large-xls-r-300m-spanish-custom](https://huggingface.co/jhonparra18/wav2vec2-large-xls-r-300m-spanish-custom) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3763
- Wer: 0.1791
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 0.2277 | 0.26 | 400 | 0.2601 | 0.2291 |
| 0.2932 | 0.53 | 800 | 0.2950 | 0.2670 |
| 0.3019 | 0.79 | 1200 | 0.3247 | 0.2766 |
| 0.2987 | 1.05 | 1600 | 0.3031 | 0.2606 |
| 0.261 | 1.32 | 2000 | 0.2994 | 0.2620 |
| 0.2651 | 1.58 | 2400 | 0.3134 | 0.2700 |
| 0.264 | 1.85 | 2800 | 0.3016 | 0.2641 |
| 0.2475 | 2.11 | 3200 | 0.3135 | 0.2661 |
| 0.2269 | 2.37 | 3600 | 0.3029 | 0.2562 |
| 0.2389 | 2.64 | 4000 | 0.3035 | 0.2549 |
| 0.2319 | 2.9 | 4400 | 0.3022 | 0.2551 |
| 0.2123 | 3.16 | 4800 | 0.3256 | 0.2638 |
| 0.2094 | 3.43 | 5200 | 0.3227 | 0.2712 |
| 0.2121 | 3.69 | 5600 | 0.3085 | 0.2596 |
| 0.207 | 3.96 | 6000 | 0.3041 | 0.2597 |
| 0.1809 | 4.22 | 6400 | 0.3122 | 0.2524 |
| 0.1846 | 4.48 | 6800 | 0.3254 | 0.2579 |
| 0.1885 | 4.75 | 7200 | 0.2958 | 0.2437 |
| 0.1923 | 5.01 | 7600 | 0.3136 | 0.2502 |
| 0.1626 | 5.27 | 8000 | 0.3059 | 0.2488 |
| 0.1704 | 5.54 | 8400 | 0.3082 | 0.2515 |
| 0.1674 | 5.8 | 8800 | 0.3196 | 0.2509 |
| 0.1691 | 6.06 | 9200 | 0.3193 | 0.25 |
| 0.1499 | 6.33 | 9600 | 0.3529 | 0.2635 |
| 0.1568 | 6.59 | 10000 | 0.3241 | 0.2481 |
| 0.1538 | 6.86 | 10400 | 0.3354 | 0.2476 |
| 0.1503 | 7.12 | 10800 | 0.3180 | 0.2402 |
| 0.136 | 7.38 | 11200 | 0.3230 | 0.2397 |
| 0.1413 | 7.65 | 11600 | 0.3178 | 0.2451 |
| 0.147 | 7.91 | 12000 | 0.3170 | 0.2389 |
| 0.1341 | 8.17 | 12400 | 0.3380 | 0.2501 |
| 0.1329 | 8.44 | 12800 | 0.3265 | 0.2414 |
| 0.1314 | 8.7 | 13200 | 0.3281 | 0.2482 |
| 0.1312 | 8.97 | 13600 | 0.3259 | 0.2539 |
| 0.12 | 9.23 | 14000 | 0.3291 | 0.2424 |
| 0.1193 | 9.49 | 14400 | 0.3302 | 0.2412 |
| 0.1189 | 9.76 | 14800 | 0.3376 | 0.2407 |
| 0.1217 | 10.02 | 15200 | 0.3334 | 0.2400 |
| 0.1118 | 10.28 | 15600 | 0.3359 | 0.2368 |
| 0.1139 | 10.55 | 16000 | 0.3239 | 0.2335 |
| 0.1106 | 10.81 | 16400 | 0.3374 | 0.2352 |
| 0.1081 | 11.07 | 16800 | 0.3585 | 0.2434 |
| 0.1063 | 11.34 | 17200 | 0.3639 | 0.2472 |
| 0.1041 | 11.6 | 17600 | 0.3399 | 0.2423 |
| 0.1062 | 11.87 | 18000 | 0.3410 | 0.2388 |
| 0.1012 | 12.13 | 18400 | 0.3597 | 0.2413 |
| 0.0953 | 12.39 | 18800 | 0.3440 | 0.2296 |
| 0.097 | 12.66 | 19200 | 0.3440 | 0.2269 |
| 0.0968 | 12.92 | 19600 | 0.3498 | 0.2333 |
| 0.0902 | 13.18 | 20000 | 0.3471 | 0.2290 |
| 0.0868 | 13.45 | 20400 | 0.3462 | 0.2266 |
| 0.0892 | 13.71 | 20800 | 0.3373 | 0.2227 |
| 0.0902 | 13.97 | 21200 | 0.3377 | 0.2240 |
| 0.0846 | 14.24 | 21600 | 0.3484 | 0.2237 |
| 0.0839 | 14.5 | 22000 | 0.3706 | 0.2260 |
| 0.0834 | 14.77 | 22400 | 0.3430 | 0.2268 |
| 0.0841 | 15.03 | 22800 | 0.3489 | 0.2259 |
| 0.076 | 15.29 | 23200 | 0.3626 | 0.2281 |
| 0.0771 | 15.56 | 23600 | 0.3624 | 0.2268 |
| 0.0773 | 15.82 | 24000 | 0.3440 | 0.2252 |
| 0.0759 | 16.08 | 24400 | 0.3532 | 0.2170 |
| 0.0745 | 16.35 | 24800 | 0.3686 | 0.2188 |
| 0.0713 | 16.61 | 25200 | 0.3691 | 0.2195 |
| 0.0718 | 16.88 | 25600 | 0.3470 | 0.2108 |
| 0.0685 | 17.14 | 26000 | 0.3756 | 0.2179 |
| 0.0689 | 17.4 | 26400 | 0.3542 | 0.2149 |
| 0.0671 | 17.67 | 26800 | 0.3461 | 0.2165 |
| 0.0737 | 17.93 | 27200 | 0.3473 | 0.2238 |
| 0.0669 | 18.19 | 27600 | 0.3441 | 0.2138 |
| 0.0629 | 18.46 | 28000 | 0.3721 | 0.2155 |
| 0.0632 | 18.72 | 28400 | 0.3667 | 0.2126 |
| 0.0647 | 18.98 | 28800 | 0.3579 | 0.2097 |
| 0.0603 | 19.25 | 29200 | 0.3670 | 0.2130 |
| 0.0604 | 19.51 | 29600 | 0.3750 | 0.2142 |
| 0.0619 | 19.78 | 30000 | 0.3804 | 0.2160 |
| 0.0603 | 20.04 | 30400 | 0.3764 | 0.2124 |
| 0.0577 | 20.3 | 30800 | 0.3858 | 0.2097 |
| 0.0583 | 20.57 | 31200 | 0.3520 | 0.2089 |
| 0.0561 | 20.83 | 31600 | 0.3615 | 0.2079 |
| 0.0545 | 21.09 | 32000 | 0.3824 | 0.2032 |
| 0.0525 | 21.36 | 32400 | 0.3858 | 0.2091 |
| 0.0524 | 21.62 | 32800 | 0.3956 | 0.2099 |
| 0.0527 | 21.89 | 33200 | 0.3667 | 0.2025 |
| 0.0514 | 22.15 | 33600 | 0.3708 | 0.2032 |
| 0.0506 | 22.41 | 34000 | 0.3815 | 0.2053 |
| 0.0478 | 22.68 | 34400 | 0.3671 | 0.2007 |
| 0.049 | 22.94 | 34800 | 0.3758 | 0.2003 |
| 0.0477 | 23.2 | 35200 | 0.3786 | 0.2014 |
| 0.045 | 23.47 | 35600 | 0.3732 | 0.1998 |
| 0.0426 | 23.73 | 36000 | 0.3737 | 0.2010 |
| 0.0444 | 23.99 | 36400 | 0.3600 | 0.1990 |
| 0.0433 | 24.26 | 36800 | 0.3689 | 0.1976 |
| 0.0442 | 24.52 | 37200 | 0.3787 | 0.1968 |
| 0.0419 | 24.79 | 37600 | 0.3652 | 0.1961 |
| 0.042 | 25.05 | 38000 | 0.3820 | 0.1964 |
| 0.0419 | 25.31 | 38400 | 0.3786 | 0.1919 |
| 0.0376 | 25.58 | 38800 | 0.3842 | 0.1934 |
| 0.0385 | 25.84 | 39200 | 0.3767 | 0.1900 |
| 0.0396 | 26.1 | 39600 | 0.3688 | 0.1888 |
| 0.0371 | 26.37 | 40000 | 0.3815 | 0.1894 |
| 0.0363 | 26.63 | 40400 | 0.3748 | 0.1878 |
| 0.0377 | 26.9 | 40800 | 0.3713 | 0.1852 |
| 0.0352 | 27.16 | 41200 | 0.3734 | 0.1851 |
| 0.0355 | 27.42 | 41600 | 0.3776 | 0.1874 |
| 0.0333 | 27.69 | 42000 | 0.3867 | 0.1841 |
| 0.0348 | 27.95 | 42400 | 0.3823 | 0.1839 |
| 0.0329 | 28.21 | 42800 | 0.3795 | 0.1822 |
| 0.0325 | 28.48 | 43200 | 0.3711 | 0.1813 |
| 0.0328 | 28.74 | 43600 | 0.3721 | 0.1781 |
| 0.0312 | 29.0 | 44000 | 0.3803 | 0.1816 |
| 0.0318 | 29.27 | 44400 | 0.3758 | 0.1794 |
| 0.0302 | 29.53 | 44800 | 0.3792 | 0.1784 |
| 0.0339 | 29.8 | 45200 | 0.3763 | 0.1791 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.1.dev0
- Tokenizers 0.11.0
|
jiobiala24/wav2vec2-base-checkpoint-10
|
jiobiala24
| 2022-01-30T16:10:56Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-base-checkpoint-10
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-checkpoint-10
This model is a fine-tuned version of [jiobiala24/wav2vec2-base-checkpoint-9](https://huggingface.co/jiobiala24/wav2vec2-base-checkpoint-9) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9567
- Wer: 0.3292
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 0.2892 | 1.62 | 1000 | 0.5745 | 0.3467 |
| 0.235 | 3.23 | 2000 | 0.6156 | 0.3423 |
| 0.1782 | 4.85 | 3000 | 0.6299 | 0.3484 |
| 0.1504 | 6.46 | 4000 | 0.6475 | 0.3446 |
| 0.133 | 8.08 | 5000 | 0.6753 | 0.3381 |
| 0.115 | 9.69 | 6000 | 0.7834 | 0.3529 |
| 0.101 | 11.31 | 7000 | 0.7924 | 0.3426 |
| 0.0926 | 12.92 | 8000 | 0.7887 | 0.3465 |
| 0.0863 | 14.54 | 9000 | 0.7674 | 0.3439 |
| 0.0788 | 16.16 | 10000 | 0.8648 | 0.3435 |
| 0.0728 | 17.77 | 11000 | 0.8460 | 0.3395 |
| 0.0693 | 19.39 | 12000 | 0.8941 | 0.3451 |
| 0.0637 | 21.0 | 13000 | 0.9079 | 0.3356 |
| 0.0584 | 22.62 | 14000 | 0.8851 | 0.3336 |
| 0.055 | 24.23 | 15000 | 0.9400 | 0.3338 |
| 0.0536 | 25.85 | 16000 | 0.9387 | 0.3335 |
| 0.0481 | 27.46 | 17000 | 0.9664 | 0.3337 |
| 0.0485 | 29.08 | 18000 | 0.9567 | 0.3292 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
imvladikon/charbert-roberta-wiki
|
imvladikon
| 2022-01-30T11:37:26Z | 10 | 1 |
transformers
|
[
"transformers",
"pytorch",
"language model",
"en",
"dataset:wikipedia",
"arxiv:2011.01513",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language:
- en
tags:
- language model
datasets:
- wikipedia
---
pre-trained model from [CharBERT: Character-aware Pre-trained Language Model](https://github.com/wtma/CharBERT)
```
@misc{ma2020charbert,
title={CharBERT: Character-aware Pre-trained Language Model},
author={Wentao Ma and Yiming Cui and Chenglei Si and Ting Liu and Shijin Wang and Guoping Hu},
year={2020},
eprint={2011.01513},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
imvladikon/charbert-bert-wiki
|
imvladikon
| 2022-01-30T11:35:48Z | 63 | 3 |
transformers
|
[
"transformers",
"pytorch",
"language model",
"en",
"dataset:wikipedia",
"arxiv:2011.01513",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language:
- en
tags:
- language model
datasets:
- wikipedia
---
pre-trained model from [CharBERT: Character-aware Pre-trained Language Model](https://github.com/wtma/CharBERT)
```
@misc{ma2020charbert,
title={CharBERT: Character-aware Pre-trained Language Model},
author={Wentao Ma and Yiming Cui and Chenglei Si and Ting Liu and Shijin Wang and Guoping Hu},
year={2020},
eprint={2011.01513},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
sshasnain/finetune-wav2vec2-large-xlsr-bengali
|
sshasnain
| 2022-01-30T07:55:29Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"bn",
"audio",
"speech",
"dataset:custom",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language: Bengali
datasets:
- custom
metrics:
- wer
tags:
- bn
- audio
- automatic-speech-recognition
- speech
license: apache-2.0
model-index:
- name: finetune-wav2vec2-large-xlsr-bengali
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: custom
type: custom
args: ben
metrics:
- name: Test WER
type: wer
value: 0.011
---
# finetune-wav2vec2-large-xlsr-bengali
***
## Usage
***
|
pinecone/mpnet-retriever-discourse
|
pinecone
| 2022-01-30T07:23:58Z | 4 | 2 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"question-answering",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-03-02T23:29:05Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
- question-answering
---
# MPNet Retriever (Discourse)
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used as a retriever model in open-domain question-answering tasks.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Training
The model was fine-tuned on question-answer pairs scraper from several ML-focused Discourse forums \[HuggingFace, PyTorch, Streamlit, TensorFlow\].
The model was trained with the parameters:
**DataLoader**:
`sentence_transformers.datasets.NoDuplicatesDataLoader.NoDuplicatesDataLoader` of length 105 with parameters:
```
{'batch_size': 12}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
Fine-tuned by [James Briggs](https://www.youtube.com/c/jamesbriggs) at [Pinecone](https://www.pinecone.io). Learn more about the [fine-tuning process here](https://www.pinecone.io/learn/retriever-models/).
|
pablouribe/xls-r-ab-test
|
pablouribe
| 2022-01-30T05:13:34Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"common_voice",
"generated_from_trainer",
"ab",
"dataset:common_voice",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language:
- ab
tags:
- automatic-speech-recognition
- common_voice
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: ''
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
#
This model is a fine-tuned version of [hf-test/xls-r-dummy](https://huggingface.co/hf-test/xls-r-dummy) on the COMMON_VOICE - AB dataset.
It achieves the following results on the evaluation set:
- Loss: 133.2596
- Wer: 19.1571
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 15.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2.dev0
- Tokenizers 0.11.0
|
jogonba2/mbarthez-copy_mechanism-hal_articles
|
jogonba2
| 2022-01-30T03:52:27Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mbart",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mbarthez-copy_mechanism-hal_articles
results:
- task:
name: Summarization
type: summarization
metrics:
- name: Rouge1
type: rouge
value: 36.548
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mbarthez-davide_articles-copy_enhanced
This model is a fine-tuned version of [moussaKam/mbarthez](https://huggingface.co/moussaKam/mbarthez) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4905
- Rouge1: 36.548
- Rouge2: 19.6282
- Rougel: 30.2513
- Rougelsum: 30.2765
- Gen Len: 25.7238
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:------:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 1.6706 | 1.0 | 33552 | 1.5690 | 31.2477 | 16.5455 | 26.9855 | 26.9754 | 18.6217 |
| 1.3446 | 2.0 | 67104 | 1.5060 | 32.1108 | 17.1408 | 27.7833 | 27.7703 | 18.9115 |
| 1.3245 | 3.0 | 100656 | 1.4905 | 32.9084 | 17.7027 | 28.2912 | 28.2975 | 18.9801 |
### Framework versions
- Transformers 4.10.2
- Pytorch 1.7.1+cu110
- Datasets 1.11.0
- Tokenizers 0.10.3
|
huggingtweets/hashimoto_lo
|
huggingtweets
| 2022-01-30T01:43:17Z | 0 | 0 | null |
[
"huggingtweets",
"en",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/hashimoto_lo/1643506993033/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/922396157493383169/LLKd_U72_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">橋下徹</div>
<div style="text-align: center; font-size: 14px;">@hashimoto_lo</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from 橋下徹.
| Data | 橋下徹 |
| --- | --- |
| Tweets downloaded | 3247 |
| Retweets | 759 |
| Short tweets | 137 |
| Tweets kept | 2351 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1wi9n714/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @hashimoto_lo's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/240mb7l6) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/240mb7l6/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/hashimoto_lo')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Adil617/wav2vec2-base-timit-demo-colab
|
Adil617
| 2022-01-29T21:05:59Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:04Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-base-timit-demo-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-timit-demo-colab
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.9314
- Wer: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---:|
| 8.686 | 0.16 | 20 | 13.6565 | 1.0 |
| 8.0711 | 0.32 | 40 | 12.5379 | 1.0 |
| 6.9967 | 0.48 | 60 | 9.7215 | 1.0 |
| 5.2368 | 0.64 | 80 | 5.8459 | 1.0 |
| 3.4499 | 0.8 | 100 | 3.3413 | 1.0 |
| 3.1261 | 0.96 | 120 | 3.2858 | 1.0 |
| 3.0654 | 1.12 | 140 | 3.1945 | 1.0 |
| 3.0421 | 1.28 | 160 | 3.1296 | 1.0 |
| 3.0035 | 1.44 | 180 | 3.1172 | 1.0 |
| 3.0067 | 1.6 | 200 | 3.1217 | 1.0 |
| 2.9867 | 1.76 | 220 | 3.0715 | 1.0 |
| 2.9653 | 1.92 | 240 | 3.0747 | 1.0 |
| 2.9629 | 2.08 | 260 | 2.9984 | 1.0 |
| 2.9462 | 2.24 | 280 | 2.9991 | 1.0 |
| 2.9391 | 2.4 | 300 | 3.0391 | 1.0 |
| 2.934 | 2.56 | 320 | 2.9682 | 1.0 |
| 2.9193 | 2.72 | 340 | 2.9701 | 1.0 |
| 2.8985 | 2.88 | 360 | 2.9314 | 1.0 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
huggingtweets/joshuadun
|
huggingtweets
| 2022-01-29T19:53:07Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/joshuadun/1643485983690/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1450576617261215754/X_PXogRc_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">josh dun</div>
<div style="text-align: center; font-size: 14px;">@joshuadun</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from josh dun.
| Data | josh dun |
| --- | --- |
| Tweets downloaded | 510 |
| Retweets | 61 |
| Short tweets | 61 |
| Tweets kept | 388 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2c8rnnrg/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @joshuadun's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/nqmemezo) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/nqmemezo/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/joshuadun')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
MM98/mt5-small-finetuned-pnsum2
|
MM98
| 2022-01-29T18:57:20Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:04Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mt5-small-finetuned-pnsum2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-finetuned-pnsum2
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: nan
- Rouge1: 4.3733
- Rouge2: 1.0221
- Rougel: 4.1265
- Rougelsum: 4.1372
- Gen Len: 6.2843
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 0.0 | 1.0 | 2500 | nan | 4.3733 | 1.0221 | 4.1265 | 4.1372 | 6.2843 |
### Framework versions
- Transformers 4.16.1
- Pytorch 1.10.0+cu111
- Datasets 1.18.2
- Tokenizers 0.11.0
|
huggingtweets/tylerrjoseph
|
huggingtweets
| 2022-01-29T12:35:08Z | 3 | 1 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/tylerrjoseph/1643459612585/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1461794294336045066/SUrpcEaz_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">tyler jøseph</div>
<div style="text-align: center; font-size: 14px;">@tylerrjoseph</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from tyler jøseph.
| Data | tyler jøseph |
| --- | --- |
| Tweets downloaded | 474 |
| Retweets | 54 |
| Short tweets | 79 |
| Tweets kept | 341 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2xiz1b44/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @tylerrjoseph's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2mp0omnb) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2mp0omnb/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/tylerrjoseph')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
kika2000/wav2vec2-large-xls-r-300m-kika5_my-colab
|
kika2000
| 2022-01-29T12:28:48Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-300m-kika5_my-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-kika5_my-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3860
- Wer: 0.3505
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 100
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 4.0007 | 4.82 | 400 | 0.6696 | 0.8283 |
| 0.2774 | 9.64 | 800 | 0.4231 | 0.5476 |
| 0.1182 | 14.46 | 1200 | 0.4253 | 0.5102 |
| 0.0859 | 19.28 | 1600 | 0.4600 | 0.4866 |
| 0.0693 | 24.1 | 2000 | 0.4030 | 0.4533 |
| 0.0611 | 28.92 | 2400 | 0.4189 | 0.4412 |
| 0.0541 | 33.73 | 2800 | 0.4272 | 0.4380 |
| 0.0478 | 38.55 | 3200 | 0.4537 | 0.4505 |
| 0.0428 | 43.37 | 3600 | 0.4349 | 0.4181 |
| 0.038 | 48.19 | 4000 | 0.4562 | 0.4199 |
| 0.0345 | 53.01 | 4400 | 0.4209 | 0.4310 |
| 0.0316 | 57.83 | 4800 | 0.4336 | 0.4058 |
| 0.0288 | 62.65 | 5200 | 0.4004 | 0.3920 |
| 0.025 | 67.47 | 5600 | 0.4115 | 0.3857 |
| 0.0225 | 72.29 | 6000 | 0.4296 | 0.3948 |
| 0.0182 | 77.11 | 6400 | 0.3963 | 0.3772 |
| 0.0165 | 81.93 | 6800 | 0.3921 | 0.3687 |
| 0.0152 | 86.75 | 7200 | 0.3969 | 0.3592 |
| 0.0133 | 91.57 | 7600 | 0.3803 | 0.3527 |
| 0.0118 | 96.39 | 8000 | 0.3860 | 0.3505 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
MarioPenguin/finetuned-model
|
MarioPenguin
| 2022-01-29T11:18:13Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:04Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: finetuned-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-model
This model is a fine-tuned version of [cardiffnlp/twitter-roberta-base-sentiment](https://huggingface.co/cardiffnlp/twitter-roberta-base-sentiment) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8601
- Accuracy: 0.6117
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 84 | 0.8663 | 0.5914 |
| No log | 2.0 | 168 | 0.8601 | 0.6117 |
### Framework versions
- Transformers 4.16.1
- Pytorch 1.10.0+cu111
- Datasets 1.18.2
- Tokenizers 0.11.0
|
Harveenchadha/vakyansh-wav2vec2-hindi-him-4200
|
Harveenchadha
| 2022-01-29T06:03:43Z | 25,050 | 5 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"hi",
"arxiv:2107.07402",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:04Z |
---
language: hi
#datasets:
#- Interspeech 2021
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
license: mit
model-index:
- name: Wav2Vec2 Vakyansh Hindi Model by Harveen Chadha
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice hi
type: common_voice
args: hi
metrics:
- name: Test WER
type: wer
value: 33.17
---
## Spaces Demo
Check the spaces demo [here](https://huggingface.co/spaces/Harveenchadha/wav2vec2-vakyansh-hindi/tree/main)
## Pretrained Model
Fine-tuned on Multilingual Pretrained Model [CLSRIL-23](https://arxiv.org/abs/2107.07402). The original fairseq checkpoint is present [here](https://github.com/Open-Speech-EkStep/vakyansh-models). When using this model, make sure that your speech input is sampled at 16kHz.
**Note: The result from this model is without a language model so you may witness a higher WER in some cases.**
## Dataset
This model was trained on 4200 hours of Hindi Labelled Data. The labelled data is not present in public domain as of now.
## Training Script
Models were trained using experimental platform setup by Vakyansh team at Ekstep. Here is the [training repository](https://github.com/Open-Speech-EkStep/vakyansh-wav2vec2-experimentation).
In case you want to explore training logs on wandb they are [here](https://wandb.ai/harveenchadha/hindi_finetuning_multilingual?workspace=user-harveenchadha).
## [Colab Demo](https://colab.research.google.com/github/harveenchadha/bol/blob/main/demos/hf/hindi/hf_hindi_him_4200_demo.ipynb)
## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import argparse
def parse_transcription(wav_file):
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("Harveenchadha/vakyansh-wav2vec2-hindi-him-4200")
model = Wav2Vec2ForCTC.from_pretrained("Harveenchadha/vakyansh-wav2vec2-hindi-him-4200")
# load audio
audio_input, sample_rate = sf.read(wav_file)
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0], skip_special_tokens=True)
print(transcription)
```
## Evaluation
The model can be evaluated as follows on the hindi test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "hi", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("Harveenchadha/vakyansh-wav2vec2-hindi-him-4200")
model = Wav2Vec2ForCTC.from_pretrained("Harveenchadha/vakyansh-wav2vec2-hindi-him-4200")
model.to("cuda")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“]'
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids, skip_special_tokens=True)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 33.17 %
[**Colab Evaluation**](https://colab.research.google.com/github/harveenchadha/bol/blob/main/demos/hf/hindi/hf_vakyansh_hindi_him_4200_evaluation_common_voice.ipynb)
## Credits
Thanks to Ekstep Foundation for making this possible. The vakyansh team will be open sourcing speech models in all the Indic Languages.
|
k-partha/extrabert_bio
|
k-partha
| 2022-01-29T03:36:11Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"arxiv:2109.06402",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
Classifies Twitter biographies as either introverts or extroverts.
Go to your Twitter profile, copy your biography and paste in the inference widget, remove any URLs and press hit!
Trained on self-described personality labels. Interpret as a continuous score, not as a discrete label. Have fun!
Barack Obama: Extrovert; Ellen DeGeneres: Extrovert; Naomi Osaka: Introvert
Note: Performance on inputs other than Twitter biographies [the training data source] is not verified.
For further details and expected performance, read the [paper](https://arxiv.org/abs/2109.06402).
|
k-partha/curiosity_bert_bio
|
k-partha
| 2022-01-29T03:35:48Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"arxiv:2109.06402",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
Labels Twitter biographies on [Openness](https://en.wikipedia.org/wiki/Openness_to_experience), strongly related to intellectual curiosity.
Intuitive: Associated with higher intellectual curiosity
Sensing: Associated with lower intellectual curiosity
Go to your Twitter profile, copy your biography and paste in the inference widget, remove any URLs and press hit!
Trained on self-described personality labels. Interpret as a continuous score, not as a discrete label. Have fun!
Note: Performance on inputs other than Twitter biographies [the training data source] is not verified.
For further details and expected performance, read the [paper](https://arxiv.org/abs/2109.06402).
|
facebook/tts_transformer-tr-cv7
|
facebook
| 2022-01-28T23:30:54Z | 14 | 10 |
fairseq
|
[
"fairseq",
"audio",
"text-to-speech",
"tr",
"dataset:common_voice",
"arxiv:1809.08895",
"arxiv:2109.06912",
"region:us"
] |
text-to-speech
| 2022-03-02T23:29:05Z |
---
library_name: fairseq
task: text-to-speech
tags:
- fairseq
- audio
- text-to-speech
language: tr
datasets:
- common_voice
widget:
- text: "Merhaba, bu bir deneme çalışmasıdır."
example_title: "Hello, this is a test run."
---
# tts_transformer-tr-cv7
[Transformer](https://arxiv.org/abs/1809.08895) text-to-speech model from fairseq S^2 ([paper](https://arxiv.org/abs/2109.06912)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_synthesis)):
- Turkish
- Single-speaker male voice
- Trained on [Common Voice v7](https://commonvoice.mozilla.org/en/datasets)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/tts_transformer-tr-cv7",
arg_overrides={"vocoder": "hifigan", "fp16": False}
)
model = models[0]
TTSHubInterface.update_cfg_with_data_cfg(cfg, task.data_cfg)
generator = task.build_generator(model, cfg)
text = "Merhaba, bu bir deneme çalışmasıdır."
sample = TTSHubInterface.get_model_input(task, text)
wav, rate = TTSHubInterface.get_prediction(task, model, generator, sample)
ipd.Audio(wav, rate=rate)
```
See also [fairseq S^2 example](https://github.com/pytorch/fairseq/blob/main/examples/speech_synthesis/docs/common_voice_example.md).
## Citation
```bibtex
@inproceedings{wang-etal-2021-fairseq,
title = "fairseq S{\^{}}2: A Scalable and Integrable Speech Synthesis Toolkit",
author = "Wang, Changhan and
Hsu, Wei-Ning and
Adi, Yossi and
Polyak, Adam and
Lee, Ann and
Chen, Peng-Jen and
Gu, Jiatao and
Pino, Juan",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-demo.17",
doi = "10.18653/v1/2021.emnlp-demo.17",
pages = "143--152",
}
```
|
facebook/tts_transformer-ru-cv7_css10
|
facebook
| 2022-01-28T23:28:04Z | 105 | 13 |
fairseq
|
[
"fairseq",
"audio",
"text-to-speech",
"ru",
"dataset:common_voice",
"dataset:css10",
"arxiv:1809.08895",
"arxiv:2109.06912",
"region:us"
] |
text-to-speech
| 2022-03-02T23:29:05Z |
---
library_name: fairseq
task: text-to-speech
tags:
- fairseq
- audio
- text-to-speech
language: ru
datasets:
- common_voice
- css10
widget:
- text: "Здравствуйте, это пробный запуск."
example_title: "Hello, this is a test run."
---
# tts_transformer-ru-cv7_css10
[Transformer](https://arxiv.org/abs/1809.08895) text-to-speech model from fairseq S^2 ([paper](https://arxiv.org/abs/2109.06912)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_synthesis)):
- Russian
- Single-speaker male voice
- Pre-trained on [Common Voice v7](https://commonvoice.mozilla.org/en/datasets), fine-tuned on [CSS10](https://github.com/Kyubyong/css10)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/tts_transformer-ru-cv7_css10",
arg_overrides={"vocoder": "hifigan", "fp16": False}
)
model = models[0]
TTSHubInterface.update_cfg_with_data_cfg(cfg, task.data_cfg)
generator = task.build_generator(model, cfg)
text = "Здравствуйте, это пробный запуск."
sample = TTSHubInterface.get_model_input(task, text)
wav, rate = TTSHubInterface.get_prediction(task, model, generator, sample)
ipd.Audio(wav, rate=rate)
```
See also [fairseq S^2 example](https://github.com/pytorch/fairseq/blob/main/examples/speech_synthesis/docs/common_voice_example.md).
## Citation
```bibtex
@inproceedings{wang-etal-2021-fairseq,
title = "fairseq S{\^{}}2: A Scalable and Integrable Speech Synthesis Toolkit",
author = "Wang, Changhan and
Hsu, Wei-Ning and
Adi, Yossi and
Polyak, Adam and
Lee, Ann and
Chen, Peng-Jen and
Gu, Jiatao and
Pino, Juan",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-demo.17",
doi = "10.18653/v1/2021.emnlp-demo.17",
pages = "143--152",
}
```
|
facebook/fastspeech2-en-200_speaker-cv4
|
facebook
| 2022-01-28T23:27:01Z | 30 | 6 |
fairseq
|
[
"fairseq",
"audio",
"text-to-speech",
"multi-speaker",
"en",
"dataset:common_voice",
"arxiv:2006.04558",
"arxiv:2109.06912",
"region:us"
] |
text-to-speech
| 2022-03-02T23:29:05Z |
---
library_name: fairseq
task: text-to-speech
tags:
- fairseq
- audio
- text-to-speech
- multi-speaker
language: en
datasets:
- common_voice
widget:
- text: "Hello, this is a test run."
example_title: "Hello, this is a test run."
---
# fastspeech2-en-200_speaker-cv4
[FastSpeech 2](https://arxiv.org/abs/2006.04558) text-to-speech model from fairseq S^2 ([paper](https://arxiv.org/abs/2109.06912)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_synthesis)):
- English
- 200 male/female voices (random speaker when using the widget)
- Trained on [Common Voice v4](https://commonvoice.mozilla.org/en/datasets)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/fastspeech2-en-200_speaker-cv4",
arg_overrides={"vocoder": "hifigan", "fp16": False}
)
model = models[0]
TTSHubInterface.update_cfg_with_data_cfg(cfg, task.data_cfg)
generator = task.build_generator(model, cfg)
text = "Hello, this is a test run."
sample = TTSHubInterface.get_model_input(task, text)
wav, rate = TTSHubInterface.get_prediction(task, model, generator, sample)
ipd.Audio(wav, rate=rate)
```
See also [fairseq S^2 example](https://github.com/pytorch/fairseq/blob/main/examples/speech_synthesis/docs/common_voice_example.md).
## Citation
```bibtex
@inproceedings{wang-etal-2021-fairseq,
title = "fairseq S{\^{}}2: A Scalable and Integrable Speech Synthesis Toolkit",
author = "Wang, Changhan and
Hsu, Wei-Ning and
Adi, Yossi and
Polyak, Adam and
Lee, Ann and
Chen, Peng-Jen and
Gu, Jiatao and
Pino, Juan",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-demo.17",
doi = "10.18653/v1/2021.emnlp-demo.17",
pages = "143--152",
}
```
|
facebook/tts_transformer-en-ljspeech
|
facebook
| 2022-01-28T23:26:35Z | 36 | 6 |
fairseq
|
[
"fairseq",
"audio",
"text-to-speech",
"en",
"dataset:ljspeech",
"arxiv:1809.08895",
"arxiv:2109.06912",
"region:us"
] |
text-to-speech
| 2022-03-02T23:29:05Z |
---
library_name: fairseq
task: text-to-speech
tags:
- fairseq
- audio
- text-to-speech
language: en
datasets:
- ljspeech
widget:
- text: "Hello, this is a test run."
example_title: "Hello, this is a test run."
---
# tts_transformer-en-ljspeech
[Transformer](https://arxiv.org/abs/1809.08895) text-to-speech model from fairseq S^2 ([paper](https://arxiv.org/abs/2109.06912)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_synthesis)):
- English
- Single-speaker female voice
- Trained on [LJSpeech](https://keithito.com/LJ-Speech-Dataset/)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/tts_transformer-en-ljspeech",
arg_overrides={"vocoder": "hifigan", "fp16": False}
)
model = models[0]
TTSHubInterface.update_cfg_with_data_cfg(cfg, task.data_cfg)
generator = task.build_generator(model, cfg)
text = "Hello, this is a test run."
sample = TTSHubInterface.get_model_input(task, text)
wav, rate = TTSHubInterface.get_prediction(task, model, generator, sample)
ipd.Audio(wav, rate=rate)
```
See also [fairseq S^2 example](https://github.com/pytorch/fairseq/blob/main/examples/speech_synthesis/docs/ljspeech_example.md).
## Citation
```bibtex
@inproceedings{wang-etal-2021-fairseq,
title = "fairseq S{\^{}}2: A Scalable and Integrable Speech Synthesis Toolkit",
author = "Wang, Changhan and
Hsu, Wei-Ning and
Adi, Yossi and
Polyak, Adam and
Lee, Ann and
Chen, Peng-Jen and
Gu, Jiatao and
Pino, Juan",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-demo.17",
doi = "10.18653/v1/2021.emnlp-demo.17",
pages = "143--152",
}
```
|
facebook/fastspeech2-en-ljspeech
|
facebook
| 2022-01-28T23:25:24Z | 2,168 | 268 |
fairseq
|
[
"fairseq",
"audio",
"text-to-speech",
"en",
"dataset:ljspeech",
"arxiv:2006.04558",
"arxiv:2109.06912",
"region:us"
] |
text-to-speech
| 2022-03-02T23:29:05Z |
---
library_name: fairseq
task: text-to-speech
tags:
- fairseq
- audio
- text-to-speech
language: en
datasets:
- ljspeech
widget:
- text: "Hello, this is a test run."
example_title: "Hello, this is a test run."
---
# fastspeech2-en-ljspeech
[FastSpeech 2](https://arxiv.org/abs/2006.04558) text-to-speech model from fairseq S^2 ([paper](https://arxiv.org/abs/2109.06912)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_synthesis)):
- English
- Single-speaker female voice
- Trained on [LJSpeech](https://keithito.com/LJ-Speech-Dataset/)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/fastspeech2-en-ljspeech",
arg_overrides={"vocoder": "hifigan", "fp16": False}
)
model = models[0]
TTSHubInterface.update_cfg_with_data_cfg(cfg, task.data_cfg)
generator = task.build_generator(model, cfg)
text = "Hello, this is a test run."
sample = TTSHubInterface.get_model_input(task, text)
wav, rate = TTSHubInterface.get_prediction(task, model, generator, sample)
ipd.Audio(wav, rate=rate)
```
See also [fairseq S^2 example](https://github.com/pytorch/fairseq/blob/main/examples/speech_synthesis/docs/ljspeech_example.md).
## Citation
```bibtex
@inproceedings{wang-etal-2021-fairseq,
title = "fairseq S{\^{}}2: A Scalable and Integrable Speech Synthesis Toolkit",
author = "Wang, Changhan and
Hsu, Wei-Ning and
Adi, Yossi and
Polyak, Adam and
Lee, Ann and
Chen, Peng-Jen and
Gu, Jiatao and
Pino, Juan",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-demo.17",
doi = "10.18653/v1/2021.emnlp-demo.17",
pages = "143--152",
}
```
|
Kneecapsnatcher/Unon
|
Kneecapsnatcher
| 2022-01-28T21:21:10Z | 0 | 0 | null |
[
"license:bsd-2-clause",
"region:us"
] | null | 2022-03-02T23:29:04Z |
---
license: bsd-2-clause
---
|
zwang199/autonlp-traffic_nlp_binary-537215209
|
zwang199
| 2022-01-28T19:34:25Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autonlp",
"en",
"dataset:zwang199/autonlp-data-traffic_nlp_binary",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- zwang199/autonlp-data-traffic_nlp_binary
co2_eq_emissions: 1.171798205242445
---
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 537215209
- CO2 Emissions (in grams): 1.171798205242445
## Validation Metrics
- Loss: 0.3879534602165222
- Accuracy: 0.8597449908925319
- Precision: 0.8318042813455657
- Recall: 0.9251700680272109
- AUC: 0.9230158730158731
- F1: 0.8760064412238325
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/zwang199/autonlp-traffic_nlp_binary-537215209
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("zwang199/autonlp-traffic_nlp_binary-537215209", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("zwang199/autonlp-traffic_nlp_binary-537215209", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
```
|
alperiox/autonlp-user-review-classification-536415182
|
alperiox
| 2022-01-28T16:30:08Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autonlp",
"en",
"dataset:alperiox/autonlp-data-user-review-classification",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- alperiox/autonlp-data-user-review-classification
co2_eq_emissions: 1.268309634217171
---
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 536415182
- CO2 Emissions (in grams): 1.268309634217171
## Validation Metrics
- Loss: 0.44733062386512756
- Accuracy: 0.8873239436619719
- Macro F1: 0.8859416445623343
- Micro F1: 0.8873239436619719
- Weighted F1: 0.8864646766540891
- Macro Precision: 0.8848522167487685
- Micro Precision: 0.8873239436619719
- Weighted Precision: 0.8883299798792756
- Macro Recall: 0.8908045977011494
- Micro Recall: 0.8873239436619719
- Weighted Recall: 0.8873239436619719
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/alperiox/autonlp-user-review-classification-536415182
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("alperiox/autonlp-user-review-classification-536415182", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("alperiox/autonlp-user-review-classification-536415182", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
```
|
FitoDS/wav2vec2-large-xls-r-300m-guarani-colab
|
FitoDS
| 2022-01-28T16:22:06Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:04Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-large-xls-r-300m-guarani-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-guarani-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2392
- Wer: 1.0743
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 100
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 18.2131 | 49.94 | 400 | 3.2901 | 1.0 |
| 2.0496 | 99.94 | 800 | 3.2392 | 1.0743 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.1.dev0
- Tokenizers 0.11.0
|
peterhsu/tf_bert-finetuned-ner
|
peterhsu
| 2022-01-28T12:52:36Z | 3 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"token-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: tf_bert-finetuned-ner
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# tf_bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0272
- Validation Loss: 0.0522
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 2631, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.1727 | 0.0673 | 0 |
| 0.0462 | 0.0541 | 1 |
| 0.0272 | 0.0522 | 2 |
### Framework versions
- Transformers 4.16.0
- TensorFlow 2.7.0
- Datasets 1.18.1
- Tokenizers 0.11.0
|
pitehu/T5_NER_CONLL_ENTITYREPLACE
|
pitehu
| 2022-01-28T11:05:16Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:CoNLL-2003",
"arxiv:2111.10952",
"arxiv:1810.04805",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
language:
- en
license: "apache-2.0"
datasets:
- CoNLL-2003
metrics:
- F1
---
This is a T5 small model finetuned on CoNLL-2003 dataset for named entity recognition (NER).
Example Input and Output:
“Recognize all the named entities in this sequence (replace named entities with one of [PER], [ORG], [LOC], [MISC]): When Alice visited New York” → “When PER visited LOC LOC"
Evaluation Result:
% of match (for comparison with ExT5: https://arxiv.org/pdf/2111.10952.pdf):
| Model| ExT5_{Base} | This Model | T5_NER_CONLL_OUTPUTLIST
| :---: | :---: | :---: | :---: |
| % of Complete Match| 86.53 | 79.03 | TBA|
There are some outputs (212/3453 or 6.14% that does not have the same length as the input)
F1 score on testing set of those with matching length :
| Model | This Model | T5_NER_CONLL_OUTPUTLIST | BERTbase
| :---: | :---: | :---: | :---: |
| F1| 0.8901 | 0.8691| 0.9240
**Caveat: The testing set of these aren't the same, due to matching length issue...
T5_NER_CONLL_OUTPUTLIST only has 27/3453 missing length (only 0.78%); The BERT number is directly from their paper (https://arxiv.org/pdf/1810.04805.pdf)
|
google/vit-large-patch32-224-in21k
|
google
| 2022-01-28T10:21:30Z | 1,295 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"vit",
"image-feature-extraction",
"vision",
"dataset:imagenet-21k",
"arxiv:2010.11929",
"arxiv:2006.03677",
"license:apache-2.0",
"region:us"
] |
image-feature-extraction
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- vision
datasets:
- imagenet-21k
inference: false
---
# Vision Transformer (large-sized model)
Vision Transformer (ViT) model pre-trained on ImageNet-21k (14 million images, 21,843 classes) at resolution 224x224. It was introduced in the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Dosovitskiy et al. and first released in [this repository](https://github.com/google-research/vision_transformer). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman, who already converted the weights from JAX to PyTorch. Credits go to him.
Disclaimer: The team releasing ViT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels.
Images are presented to the model as a sequence of fixed-size patches (resolution 32x32), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
Note that this model does not provide any fine-tuned heads, as these were zero'd by Google researchers. However, the model does include the pre-trained pooler, which can be used for downstream tasks (such as image classification).
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=google/vit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
from transformers import ViTFeatureExtractor, ViTModel
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224-in21k')
model = ViTModel.from_pretrained('google/vit-base-patch16-224-in21k')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
last_hidden_state = outputs.last_hidden_state
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon, and the API of ViTFeatureExtractor might change.
## Training data
The ViT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/google-research/vision_transformer/blob/master/vit_jax/input_pipeline.py).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
The model was trained on TPUv3 hardware (8 cores). All model variants are trained with a batch size of 4096 and learning rate warmup of 10k steps. For ImageNet, the authors found it beneficial to additionally apply gradient clipping at global norm 1. Pre-training resolution is 224.
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 2 and 5 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
```
|
microsoft/beit-base-patch16-384
|
microsoft
| 2022-01-28T10:19:30Z | 409 | 5 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"beit",
"image-classification",
"vision",
"dataset:imagenet",
"dataset:imagenet-21k",
"arxiv:2106.08254",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- image-classification
- vision
datasets:
- imagenet
- imagenet-21k
---
# BEiT (base-sized model, fine-tuned on ImageNet-1k)
BEiT model pre-trained in a self-supervised fashion on ImageNet-21k (14 million images, 21,841 classes) at resolution 224x224, and fine-tuned on ImageNet 2012 (1 million images, 1,000 classes) at resolution 384x384. It was introduced in the paper [BEIT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong and Furu Wei and first released in [this repository](https://github.com/microsoft/unilm/tree/master/beit).
Disclaimer: The team releasing BEiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The BEiT model is a Vision Transformer (ViT), which is a transformer encoder model (BERT-like). In contrast to the original ViT model, BEiT is pretrained on a large collection of images in a self-supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. The pre-training objective for the model is to predict visual tokens from the encoder of OpenAI's DALL-E's VQ-VAE, based on masked patches.
Next, the model was fine-tuned in a supervised fashion on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, also at resolution 224x224.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. Contrary to the original ViT models, BEiT models do use relative position embeddings (similar to T5) instead of absolute position embeddings, and perform classification of images by mean-pooling the final hidden states of the patches, instead of placing a linear layer on top of the final hidden state of the [CLS] token.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image. Alternatively, one can mean-pool the final hidden states of the patch embeddings, and place a linear layer on top of that.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=microsoft/beit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import BeitFeatureExtractor, BeitForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = BeitFeatureExtractor.from_pretrained('microsoft/beit-base-patch16-384')
model = BeitForImageClassification.from_pretrained('microsoft/beit-base-patch16-384')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch.
## Training data
The BEiT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/microsoft/unilm/blob/master/beit/datasets.py).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
For all pre-training related hyperparameters, we refer to page 15 of the [original paper](https://arxiv.org/abs/2106.08254).
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 1 and 2 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```@article{DBLP:journals/corr/abs-2106-08254,
author = {Hangbo Bao and
Li Dong and
Furu Wei},
title = {BEiT: {BERT} Pre-Training of Image Transformers},
journal = {CoRR},
volume = {abs/2106.08254},
year = {2021},
url = {https://arxiv.org/abs/2106.08254},
archivePrefix = {arXiv},
eprint = {2106.08254},
timestamp = {Tue, 29 Jun 2021 16:55:04 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-08254.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
```
|
microsoft/beit-large-patch16-224
|
microsoft
| 2022-01-28T10:19:16Z | 1,916 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"beit",
"image-classification",
"vision",
"dataset:imagenet",
"dataset:imagenet-21k",
"arxiv:2106.08254",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- image-classification
- vision
datasets:
- imagenet
- imagenet-21k
---
# BEiT (large-sized model, fine-tuned on ImageNet-1k)
BEiT model pre-trained in a self-supervised fashion on ImageNet-21k (14 million images, 21,841 classes) at resolution 224x224, and fine-tuned on ImageNet 2012 (1 million images, 1,000 classes) at resolution 224x224. It was introduced in the paper [BEIT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong and Furu Wei and first released in [this repository](https://github.com/microsoft/unilm/tree/master/beit).
Disclaimer: The team releasing BEiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The BEiT model is a Vision Transformer (ViT), which is a transformer encoder model (BERT-like). In contrast to the original ViT model, BEiT is pretrained on a large collection of images in a self-supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. The pre-training objective for the model is to predict visual tokens from the encoder of OpenAI's DALL-E's VQ-VAE, based on masked patches.
Next, the model was fine-tuned in a supervised fashion on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, also at resolution 224x224.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. Contrary to the original ViT models, BEiT models do use relative position embeddings (similar to T5) instead of absolute position embeddings, and perform classification of images by mean-pooling the final hidden states of the patches, instead of placing a linear layer on top of the final hidden state of the [CLS] token.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image. Alternatively, one can mean-pool the final hidden states of the patch embeddings, and place a linear layer on top of that.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=microsoft/beit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import BeitFeatureExtractor, BeitForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = BeitFeatureExtractor.from_pretrained('microsoft/beit-large-patch16-224')
model = BeitForImageClassification.from_pretrained('microsoft/beit-large-patch16-224')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch.
## Training data
The BEiT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/microsoft/unilm/blob/master/beit/datasets.py).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
For all pre-training related hyperparameters, we refer to page 15 of the [original paper](https://arxiv.org/abs/2106.08254).
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 1 and 2 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```@article{DBLP:journals/corr/abs-2106-08254,
author = {Hangbo Bao and
Li Dong and
Furu Wei},
title = {BEiT: {BERT} Pre-Training of Image Transformers},
journal = {CoRR},
volume = {abs/2106.08254},
year = {2021},
url = {https://arxiv.org/abs/2106.08254},
archivePrefix = {arXiv},
eprint = {2106.08254},
timestamp = {Tue, 29 Jun 2021 16:55:04 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-08254.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
```
|
hrdipto/wav2vec2-xls-r-tf-left-right-shuru-word-level
|
hrdipto
| 2022-01-28T09:54:27Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-xls-r-tf-left-right-shuru-word-level
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-xls-r-tf-left-right-shuru-word-level
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0504
- Wer: 0.6859
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 100
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 23.217 | 23.81 | 500 | 1.3437 | 0.6859 |
| 1.1742 | 47.62 | 1000 | 1.0397 | 0.6859 |
| 1.0339 | 71.43 | 1500 | 1.0155 | 0.6859 |
| 0.9909 | 95.24 | 2000 | 1.0504 | 0.6859 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
hyyoka/wav2vec2-xlsr-korean-senior
|
hyyoka
| 2022-01-28T06:08:19Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"kr",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language: kr
datasets:
- aihub 자유대화 음성(노인남녀)
tags:
- automatic-speech-recognition
license: apache-2.0
---
# wav2vec2-xlsr-korean-senior
Futher fine-tuned [fleek/wav2vec-large-xlsr-korean](https://huggingface.co/fleek/wav2vec-large-xlsr-korean) using the [AIhub 자유대화 음성(노인남녀)](https://aihub.or.kr/aidata/30704).
- Total train data size: 808,642
- Total vaild data size: 159,970
When using this model, make sure that your speech input is sampled at 16kHz.
The script used for training can be found here: https://github.com/hyyoka/wav2vec2-korean-senior
### Inference
``` py
import torchaudio
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
import re
def clean_up(transcription):
hangul = re.compile('[^ ㄱ-ㅣ가-힣]+')
result = hangul.sub('', transcription)
return result
model_name "hyyoka/wav2vec2-xlsr-korean-senior"
processor = Wav2Vec2Processor.from_pretrained(model_name)
model = Wav2Vec2ForCTC.from_pretrained(model_name)
speech_array, sampling_rate = torchaudio.load(wav_file)
feat = processor(speech_array[0],
sampling_rate=16000,
padding=True,
max_length=800000,
truncation=True,
return_attention_mask=True,
return_tensors="pt",
pad_token_id=49
)
input = {'input_values': feat['input_values'],'attention_mask':feat['attention_mask']}
outputs = model(**input, output_attentions=True)
logits = outputs.logits
predicted_ids = logits.argmax(axis=-1)
transcription = processor.decode(predicted_ids[0])
stt_result = clean_up(transcription)
```
|
rodrigogelacio/autonlp-department-classification-534915130
|
rodrigogelacio
| 2022-01-28T02:06:52Z | 3 | 1 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autonlp",
"unk",
"dataset:rodrigogelacio/autonlp-data-department-classification",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
tags: autonlp
language: unk
widget:
- text: "I love AutoNLP 🤗"
datasets:
- rodrigogelacio/autonlp-data-department-classification
co2_eq_emissions: 1.4862856774320061
---
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 534915130
- CO2 Emissions (in grams): 1.4862856774320061
## Validation Metrics
- Loss: 0.37066277861595154
- Accuracy: 0.9204545454545454
- Macro F1: 0.9103715740678612
- Micro F1: 0.9204545454545455
- Weighted F1: 0.9196871607509906
- Macro Precision: 0.9207759152612094
- Micro Precision: 0.9204545454545454
- Weighted Precision: 0.922177301864802
- Macro Recall: 0.9055002187355129
- Micro Recall: 0.9204545454545454
- Weighted Recall: 0.9204545454545454
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/rodrigogelacio/autonlp-department-classification-534915130
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("rodrigogelacio/autonlp-department-classification-534915130", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("rodrigogelacio/autonlp-department-classification-534915130", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
```
|
kika2000/wav2vec2-large-xls-r-300m-kika4_my-colab
|
kika2000
| 2022-01-28T01:03:34Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-300m-kika4_my-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-kika4_my-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 70
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
huggingtweets/amongusgame
|
huggingtweets
| 2022-01-27T23:46:01Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/amongusgame/1643327156823/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1455270159975796736/PqmjT7Dr_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Among Us</div>
<div style="text-align: center; font-size: 14px;">@amongusgame</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Among Us.
| Data | Among Us |
| --- | --- |
| Tweets downloaded | 3248 |
| Retweets | 75 |
| Short tweets | 1295 |
| Tweets kept | 1878 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2pyl3gg2/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @amongusgame's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1vvgbbml) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1vvgbbml/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/amongusgame')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
RASMUS/wav2vec2-xlsr-fi-train-aug-bigLM-1B
|
RASMUS
| 2022-01-27T23:00:16Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"mozilla-foundation/common_voice_7_0",
"audio",
"speech",
"fi",
"dataset:mozilla-foundation/common_voice_7_0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:04Z |
---
language: fi
datasets:
- mozilla-foundation/common_voice_7_0
metrics:
- wer
- cer
tags:
- generated_from_trainer
- mozilla-foundation/common_voice_7_0
- audio
- automatic-speech-recognition
- speech
model-index:
- name: XLS-R 1B Wav2Vec2 Finnish by Rasmus Toivanen
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 7
type: mozilla-foundation/common_voice_7_0
args: fi
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-xlsr-fi-train-aug-lm-1B
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1499
- Wer: 0.1955
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.6473 | 0.29 | 400 | 0.2857 | 0.3825 |
| 0.6039 | 0.58 | 800 | 0.2459 | 0.3476 |
| 0.4757 | 0.87 | 1200 | 0.2338 | 0.3274 |
| 0.4473 | 1.15 | 1600 | 0.2246 | 0.3128 |
| 0.4322 | 1.44 | 2000 | 0.1962 | 0.2805 |
| 0.3961 | 1.73 | 2400 | 0.2070 | 0.2797 |
| 0.3642 | 2.02 | 2800 | 0.1790 | 0.2473 |
| 0.3561 | 2.31 | 3200 | 0.1769 | 0.2375 |
| 0.282 | 2.6 | 3600 | 0.1672 | 0.2263 |
| 0.2978 | 2.89 | 4000 | 0.1636 | 0.2192 |
| 0.2722 | 3.17 | 4400 | 0.1637 | 0.2102 |
| 0.2924 | 3.46 | 4800 | 0.1506 | 0.2021 |
| 0.2631 | 3.75 | 5200 | 0.1499 | 0.1955 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.1.dev0
- Tokenizers 0.11.0
|
vuiseng9/wav2vec2-base-100h
|
vuiseng9
| 2022-01-27T20:03:25Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"en",
"dataset:librispeech_asr",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language: en
datasets:
- librispeech_asr
tags:
- audio
- automatic-speech-recognition
license: apache-2.0
---
# Wav2Vec2-Base-100h
This is a fork of [```facebook/wav2vec2-base-100h```](https://huggingface.co/facebook/wav2vec2-base-100h)
### Changes & Notes
1. Document reproducible evaluation (below) to new transformer and datasets version.
2. Use batch size of 1 to reproduce results.
3. Validated with ```transformers v4.15.0```, ```datasets 1.18.0```
4. You may need to manually install pypkg ```librosa```, ```jiwer```
## Evaluation
This code snippet shows how to evaluate **facebook/wav2vec2-base-100h** on LibriSpeech's "clean" and "other" test data.
```python
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import soundfile as sf
import torch
from jiwer import wer
librispeech_eval = load_dataset("librispeech_asr", "clean", split="test")
# librispeech_eval = load_dataset("librispeech_asr", "other", split="test")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-100h").to("cuda")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-100h")
def map_to_array(batch):
# speech, _ = sf.read(batch["file"])
# batch["speech"] = speech
batch["speech"] = batch['audio']['array']
return batch
librispeech_eval = librispeech_eval.map(map_to_array)
def map_to_pred(batch):
input_values = processor(batch["speech"], return_tensors="pt", padding="longest").input_values
with torch.no_grad():
logits = model(input_values.to("cuda")).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
batch["transcription"] = transcription
return batch
result = librispeech_eval.map(map_to_pred, batched=True, batch_size=1, remove_columns=["speech"])
print("WER:", wer(result["text"], result["transcription"]))
```
*Result (WER)*:
| "clean/test" | "other/test" |
|--------------| ------------|
| 6.1 | 13.5 |
|
huggingtweets/thenamefaceless
|
huggingtweets
| 2022-01-27T19:59:10Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/thenamefaceless/1643313546109/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1428260501016834056/u8xbVi4l_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Faceless</div>
<div style="text-align: center; font-size: 14px;">@thenamefaceless</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Faceless.
| Data | Faceless |
| --- | --- |
| Tweets downloaded | 581 |
| Retweets | 165 |
| Short tweets | 55 |
| Tweets kept | 361 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1i6xge70/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @thenamefaceless's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2bbby02j) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2bbby02j/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/thenamefaceless')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Jacobo/aristoBERTo
|
Jacobo
| 2022-01-27T19:02:16Z | 10 | 5 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"grc",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
---
tags:
language:
- grc
model-index:
- name: aristoBERTo
results: []
widget:
- text: "Πλάτων ὁ Περικτιόνης [MASK] γένος ἀνέφερεν εἰς Σόλωνα."
- text: "ὁ Κριτίας ἀπέβλεψε [MASK] τὴν θύραν."
- text: "πρῶτοι δὲ καὶ οὐνόματα ἱρὰ ἔγνωσαν καὶ [MASK] ἱροὺς ἔλεξαν."
---
# aristoBERTo
aristoBERTo is a transformer model for ancient Greek, a low resource language. We initialized the pre-training with weights from [GreekBERT](https://huggingface.co/nlpaueb/bert-base-greek-uncased-v1), a Greek version of BERT which was trained on a large corpus of modern Greek (~ 30 GB of texts). We continued the pre-training with an ancient Greek corpus of about 900 MB, which was scrapped from the web and post-processed. Duplicate texts and editorial punctuation were removed.
Applied to the processing of ancient Greek, aristoBERTo outperforms xlm-roberta-base and mdeberta in most downstream tasks like the labeling of POS, MORPH, DEP and LEMMA.
aristoBERTo is provided by the [Diogenet project](https://diogenet.ucsd.edu) of the University of California, San Diego.
## Intended uses
This model was created for fine-tuning with spaCy and the ancient Greek Universal Dependency datasets as well as a NER corpus produced by the [Diogenet project](https://diogenet.ucsd.edu). As a fill-mask model, AristoBERTo can also be used in the restoration of damaged Greek papyri, inscriptions, and manuscripts.
It achieves the following results on the evaluation set:
- Loss: 1.6323
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-------:|:---------------:|
| 1.377 | 20.0 | 3414220 | 1.6314 |
### Framework versions
- Transformers 4.14.0.dev0
- Pytorch 1.10.0+cu102
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Adinda/Adinda
|
Adinda
| 2022-01-27T17:02:42Z | 0 | 0 | null |
[
"license:artistic-2.0",
"region:us"
] | null | 2022-03-02T23:29:04Z |
---
license: artistic-2.0
---
|
wolfrage89/company_segment_ner
|
wolfrage89
| 2022-01-27T16:56:23Z | 23 | 2 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
## Roberta based NER
This model will take in a new article label 3 entities [ORGS, SEGNUM, NUM]. This model is train on reuters news articles
## Try out on huggingface Spaces
https://huggingface.co/spaces/wolfrage89/company_segments_ner
## colab sample notebook
https://colab.research.google.com/drive/165utMQzYVAX7-aQjWjpmPHwHpdKTaHBa?usp=sharing
## How to use
```python
from transformers import pipeline
# Minimum code
sentence = """Exxon Mobil Corporation is engaged in energy business. The Company is engaged in the exploration, production, trade, transportation and sale of crude oil and natural gas, and the manufacture, transportation and sale of crude oil, natural gas, petroleum products, petrochemicals and a range of specialty products. The Company's segments include Upstream, Downstream, Chemical, and Corporate and Financing. The Upstream segment operates to explore for and produce crude oil and natural gas. The Downstream manufactures, trades and sells petroleum products. The refining and supply operations consists of a global network of manufacturing plants, transportation systems, and distribution centers that provide a range of fuels, lubricants and other products and feedstocks to its customers around the world. The Chemical segment manufactures and sells petrochemicals. The Chemical business supplies olefins, polyolefins, aromatics, and a variety of other petrochemicals."""
model = pipeline('ner', "wolfrage89/company_segment_ner")
model_output = model(sentence)
print(model_ouput)
# [{'entity': 'B-ORG', 'score': 0.99996805, 'index': 1, 'word': 'Ex', 'start': 0, 'end': 2}, {'entity': 'I-ORG', 'score': 0.99971646, 'index': 2, 'word': 'xon', 'start': 2, 'end': 5}, ....]
# Sample helper function if you want to use
def ner_prediction(model, sentence):
entity_map = {
"B-ORG":"ORG",
"B-SEG":"SEG",
"B-SEGNUM":"SEGNUM"
}
results = []
model_output = model(sentence)
accumulate = ""
current_class = None
start = 0
end = 0
for item in model_output:
if item['entity'].startswith("B"):
if len(accumulate) >0:
results.append((current_class, accumulate, start, end))
accumulate = item['word'].lstrip("Ġ")
current_class = entity_map[item['entity']]
start=item['start']
end = item['end']
else:
if item['word'].startswith("Ġ"):
accumulate+=" "+item['word'].lstrip("Ġ")
else:
accumulate+=item['word']
end = item['end']
# clear last cache
if len(accumulate)>0:
results.append((current_class, accumulate, start, end))
return results
```
|
bayartsogt/tts_transformer-mn-mbspeech
|
bayartsogt
| 2022-01-27T16:35:40Z | 18 | 1 |
fairseq
|
[
"fairseq",
"audio",
"text-to-speech",
"mn",
"dataset:mbspeech",
"arxiv:1809.08895",
"arxiv:2109.06912",
"region:us"
] |
text-to-speech
| 2022-03-02T23:29:05Z |
---
library_name: fairseq
task: text-to-speech
tags:
- fairseq
- audio
- text-to-speech
language: mn
datasets:
- mbspeech
widget:
- text: "миний нэрийг баярцогт гэдэг"
example_title: "Say my name!"
- text: "би монгол улсын нийслэл, улаанбаатар хотод амьдардаг"
example_title: "Where I am from?"
- text: "энэхүү өгөгдлийг нээлттэй болгосон, болор соофтынхонд баярлалаа"
example_title: "Thank you!"
- text: "энэхүү ажлын ихэнх хэсгийг, төгөлдөр ах хийсэн болно"
example_title: "Shout out to original creater"
---
# tts_transformer-mn-mbspeech
[Transformer](https://arxiv.org/abs/1809.08895) text-to-speech model from fairseq S^2 ([paper](https://arxiv.org/abs/2109.06912)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_synthesis)):
- Mongolian
- Single-speaker male voice
- Trained on [MBSpeech](https://github.com/tugstugi/mongolian-nlp/blob/master/datasets/MBSpeech-1.0-csv.zip)
|
Iskaj/w2v-xlsr-dutch-lm-added
|
Iskaj
| 2022-01-27T15:58:50Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:04Z |
Copy of "facebook/wav2vec2-large-xlsr-53-dutch"
|
tomascufaro/wav2vec2-large-xls-r-300m-spanish-custom
|
tomascufaro
| 2022-01-27T15:27:27Z | 38 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-300m-spanish-custom
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-spanish-custom
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4426
- Wer: 0.2117
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 4.2307 | 0.4 | 400 | 1.4431 | 0.9299 |
| 0.7066 | 0.79 | 800 | 0.5928 | 0.4836 |
| 0.4397 | 1.19 | 1200 | 0.4341 | 0.3730 |
| 0.3889 | 1.58 | 1600 | 0.4063 | 0.3499 |
| 0.3607 | 1.98 | 2000 | 0.3834 | 0.3235 |
| 0.2866 | 2.37 | 2400 | 0.3885 | 0.3163 |
| 0.2833 | 2.77 | 2800 | 0.3765 | 0.3140 |
| 0.2692 | 3.17 | 3200 | 0.3849 | 0.3132 |
| 0.2435 | 3.56 | 3600 | 0.3779 | 0.2984 |
| 0.2404 | 3.96 | 4000 | 0.3756 | 0.2934 |
| 0.2153 | 4.35 | 4400 | 0.3770 | 0.3075 |
| 0.2087 | 4.75 | 4800 | 0.3819 | 0.3022 |
| 0.1999 | 5.14 | 5200 | 0.3756 | 0.2959 |
| 0.1838 | 5.54 | 5600 | 0.3827 | 0.2858 |
| 0.1892 | 5.93 | 6000 | 0.3714 | 0.2999 |
| 0.1655 | 6.33 | 6400 | 0.3814 | 0.2812 |
| 0.1649 | 6.73 | 6800 | 0.3685 | 0.2727 |
| 0.1668 | 7.12 | 7200 | 0.3832 | 0.2825 |
| 0.1487 | 7.52 | 7600 | 0.3848 | 0.2788 |
| 0.152 | 7.91 | 8000 | 0.3810 | 0.2787 |
| 0.143 | 8.31 | 8400 | 0.3885 | 0.2856 |
| 0.1353 | 8.7 | 8800 | 0.4103 | 0.2827 |
| 0.1386 | 9.1 | 9200 | 0.4142 | 0.2874 |
| 0.1222 | 9.5 | 9600 | 0.3983 | 0.2830 |
| 0.1288 | 9.89 | 10000 | 0.4179 | 0.2781 |
| 0.1199 | 10.29 | 10400 | 0.4035 | 0.2789 |
| 0.1196 | 10.68 | 10800 | 0.4043 | 0.2746 |
| 0.1169 | 11.08 | 11200 | 0.4105 | 0.2753 |
| 0.1076 | 11.47 | 11600 | 0.4298 | 0.2686 |
| 0.1124 | 11.87 | 12000 | 0.4025 | 0.2704 |
| 0.1043 | 12.26 | 12400 | 0.4209 | 0.2659 |
| 0.0976 | 12.66 | 12800 | 0.4070 | 0.2672 |
| 0.1012 | 13.06 | 13200 | 0.4161 | 0.2720 |
| 0.0872 | 13.45 | 13600 | 0.4245 | 0.2697 |
| 0.0933 | 13.85 | 14000 | 0.4295 | 0.2684 |
| 0.0881 | 14.24 | 14400 | 0.4011 | 0.2650 |
| 0.0848 | 14.64 | 14800 | 0.3991 | 0.2675 |
| 0.0852 | 15.03 | 15200 | 0.4166 | 0.2617 |
| 0.0825 | 15.43 | 15600 | 0.4188 | 0.2639 |
| 0.081 | 15.83 | 16000 | 0.4181 | 0.2547 |
| 0.0753 | 16.22 | 16400 | 0.4103 | 0.2560 |
| 0.0747 | 16.62 | 16800 | 0.4017 | 0.2498 |
| 0.0761 | 17.01 | 17200 | 0.4159 | 0.2563 |
| 0.0711 | 17.41 | 17600 | 0.4112 | 0.2603 |
| 0.0698 | 17.8 | 18000 | 0.4335 | 0.2529 |
| 0.073 | 18.2 | 18400 | 0.4120 | 0.2512 |
| 0.0665 | 18.6 | 18800 | 0.4335 | 0.2496 |
| 0.0657 | 18.99 | 19200 | 0.4143 | 0.2468 |
| 0.0617 | 19.39 | 19600 | 0.4339 | 0.2435 |
| 0.06 | 19.78 | 20000 | 0.4179 | 0.2438 |
| 0.0613 | 20.18 | 20400 | 0.4251 | 0.2393 |
| 0.0583 | 20.57 | 20800 | 0.4347 | 0.2422 |
| 0.0562 | 20.97 | 21200 | 0.4246 | 0.2377 |
| 0.053 | 21.36 | 21600 | 0.4198 | 0.2338 |
| 0.0525 | 21.76 | 22000 | 0.4511 | 0.2427 |
| 0.0499 | 22.16 | 22400 | 0.4482 | 0.2353 |
| 0.0475 | 22.55 | 22800 | 0.4449 | 0.2329 |
| 0.0465 | 22.95 | 23200 | 0.4364 | 0.2320 |
| 0.0443 | 23.34 | 23600 | 0.4481 | 0.2304 |
| 0.0458 | 23.74 | 24000 | 0.4442 | 0.2267 |
| 0.0453 | 24.13 | 24400 | 0.4402 | 0.2261 |
| 0.0426 | 24.53 | 24800 | 0.4262 | 0.2232 |
| 0.0431 | 24.93 | 25200 | 0.4251 | 0.2210 |
| 0.0389 | 25.32 | 25600 | 0.4455 | 0.2232 |
| 0.039 | 25.72 | 26000 | 0.4372 | 0.2236 |
| 0.0378 | 26.11 | 26400 | 0.4236 | 0.2212 |
| 0.0348 | 26.51 | 26800 | 0.4359 | 0.2204 |
| 0.0361 | 26.9 | 27200 | 0.4248 | 0.2192 |
| 0.0356 | 27.3 | 27600 | 0.4397 | 0.2184 |
| 0.0325 | 27.7 | 28000 | 0.4367 | 0.2181 |
| 0.0313 | 28.09 | 28400 | 0.4477 | 0.2136 |
| 0.0306 | 28.49 | 28800 | 0.4533 | 0.2135 |
| 0.0314 | 28.88 | 29200 | 0.4410 | 0.2136 |
| 0.0307 | 29.28 | 29600 | 0.4457 | 0.2113 |
| 0.0309 | 29.67 | 30000 | 0.4426 | 0.2117 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.1.dev0
- Tokenizers 0.11.0
|
mrm8488/ppo-CartPole-v1
|
mrm8488
| 2022-01-27T15:13:48Z | 0 | 1 | null |
[
"region:us"
] | null | 2022-03-02T23:29:05Z |
#@title
---
tags:
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
---
# PPO CartPole v1 🤖⚖️
This is a pre-trained model of a PPO agent playing CartPole-v1 using the [stable-baselines3](https://github.com/DLR-RM/stable-baselines3) library.
<video loop="" autoplay="" controls="" src="https://huggingface.co/mrm8488/ppo-CartPole-v1/resolve/main/output.mp4"></video>
### Usage (with Stable-baselines3)
Using this model becomes easy when you have stable-baselines3 and huggingface_sb3 installed:
```
pip install stable-baselines3
pip install huggingface_sb3
```
Then, you can use the model like this:
```python
import gym
from huggingface_sb3 import load_from_hub
from stable_baselines3 import PPO
from stable_baselines3.common.evaluation import evaluate_policy
# Retrieve the model from the hub
## repo_id = id of the model repository from the Hugging Face Hub (repo_id = {organization}/{repo_name})
## filename = name of the model zip file from the repository
checkpoint = load_from_hub(repo_id="mrm8488/ppo-CartPole-v1", filename="cartpole-v1.zip")
model = PPO.load(checkpoint)
# Evaluate the agent
eval_env = gym.make('CartPole-v1')
mean_reward, std_reward = evaluate_policy(model, eval_env, n_eval_episodes=10, deterministic=True)
print(f"mean_reward={mean_reward:.2f} +/- {std_reward}")
# Watch the agent play
obs = env.reset()
for i in range(1000):
action, _state = model.predict(obs)
obs, reward, done, info = env.step(action)
env.render()
if done:
obs = env.reset()
env.close()
```
### Evaluation Results
Mean_reward: mean_reward=500.00 +/- 0.0
|
ncoop57/codeparrot-neo-125M-py
|
ncoop57
| 2022-01-27T14:44:13Z | 14 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"rust",
"gpt_neo",
"text-generation",
"text generation",
"causal-lm",
"en",
"arxiv:2101.00027",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language:
- en
tags:
- text generation
- pytorch
- causal-lm
license: apache-2.0
datasets:
- The Pile
---
# GPT-Neo 125M
## Model Description
GPT-Neo 125M is a transformer model designed using EleutherAI's replication of the GPT-3 architecture. GPT-Neo refers to the class of models, while 125M represents the number of parameters of this particular pre-trained model.
## Training data
GPT-Neo 125M was trained on the Pile, a large scale curated dataset created by EleutherAI for the purpose of training this model.
## Training procedure
This model was trained on the Pile for 300 billion tokens over 572,300 steps. It was trained as a masked autoregressive language model, using cross-entropy loss.
## Intended Use and Limitations
This way, the model learns an inner representation of the English language that can then be used to extract features useful for downstream tasks. The model is best at what it was pretrained for however, which is generating texts from a prompt.
### How to use
You can use this model directly with a pipeline for text generation. This example generates a different sequence each time it's run:
```py
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model='EleutherAI/gpt-neo-125M')
>>> generator("EleutherAI has", do_sample=True, min_length=50)
[{'generated_text': 'EleutherAI has made a commitment to create new software packages for each of its major clients and has'}]
```
### Limitations and Biases
GPT-Neo was trained as an autoregressive language model. This means that its core functionality is taking a string of text and predicting the next token. While language models are widely used for tasks other than this, there are a lot of unknowns with this work.
GPT-Neo was trained on the Pile, a dataset known to contain profanity, lewd, and otherwise abrasive language. Depending on your usecase GPT-Neo may produce socially unacceptable text. See Sections 5 and 6 of the Pile paper for a more detailed analysis of the biases in the Pile.
As with all language models, it is hard to predict in advance how GPT-Neo will respond to particular prompts and offensive content may occur without warning. We recommend having a human curate or filter the outputs before releasing them, both to censor undesirable content and to improve the quality of the results.
## Eval results
TBD
### Down-Stream Applications
TBD
### BibTeX entry and citation info
To cite this model, use
```bibtex
@software{gpt-neo,
author = {Black, Sid and
Leo, Gao and
Wang, Phil and
Leahy, Connor and
Biderman, Stella},
title = {{GPT-Neo: Large Scale Autoregressive Language
Modeling with Mesh-Tensorflow}},
month = mar,
year = 2021,
note = {{If you use this software, please cite it using
these metadata.}},
publisher = {Zenodo},
version = {1.0},
doi = {10.5281/zenodo.5297715},
url = {https://doi.org/10.5281/zenodo.5297715}
}
@article{gao2020pile,
title={The Pile: An 800GB Dataset of Diverse Text for Language Modeling},
author={Gao, Leo and Biderman, Stella and Black, Sid and Golding, Laurence and Hoppe, Travis and Foster, Charles and Phang, Jason and He, Horace and Thite, Anish and Nabeshima, Noa and others},
journal={arXiv preprint arXiv:2101.00027},
year={2020}
}
```
|
pierreguillou/t5-base-qa-squad-v1.1-portuguese
|
pierreguillou
| 2022-01-27T14:38:28Z | 153 | 24 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"qa",
"pt",
"dataset:squad",
"dataset:squad_v1_pt",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
language:
- pt
tags:
- text2text-generation
- t5
- pytorch
- qa
datasets:
- squad
- squad_v1_pt
metrics:
- precision
- recall
- f1
- accuracy
- squad
model-index:
- name: checkpoints
results:
- task:
name: text2text-generation
type: text2text-generation
dataset:
name: squad
type: squad
metrics:
- name: f1
type: f1
value: 79.3
- name: exact-match
type: exact-match
value: 67.3983
widget:
- text: "question: Quando começou a pandemia de Covid-19 no mundo? context: A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China, em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano."
- text: "question: Onde foi descoberta a Covid-19? context: A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China, em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano."
---
# T5 base finetuned for Question Answering (QA) on SQUaD v1.1 Portuguese
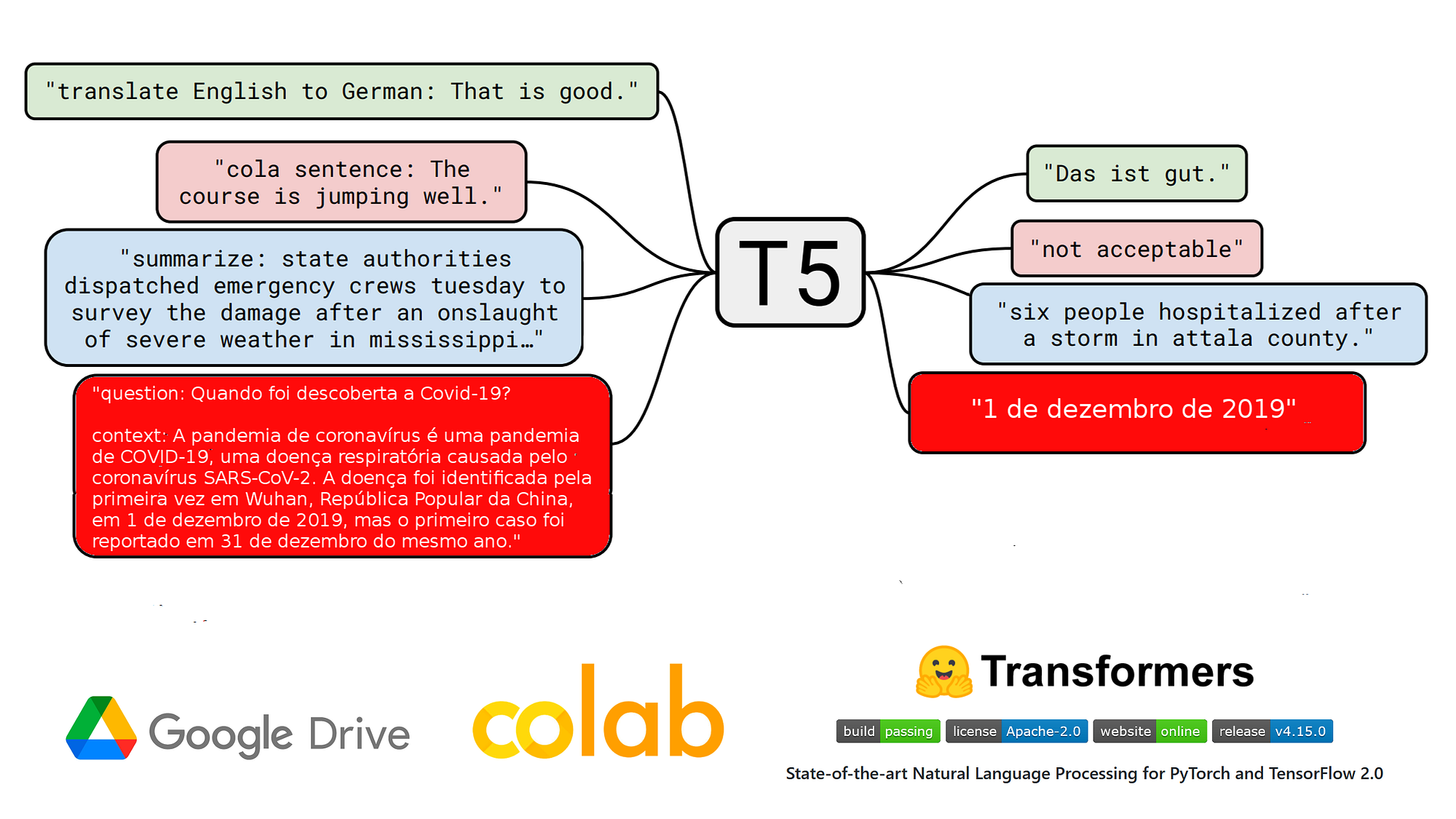
## Introduction
**t5-base-qa-squad-v1.1-portuguese** is a QA model (Question Answering) in Portuguese that was finetuned on 27/01/2022 in Google Colab from the model [unicamp-dl/ptt5-base-portuguese-vocab](https://huggingface.co/unicamp-dl/ptt5-base-portuguese-vocab) of Neuralmind on the dataset SQUAD v1.1 in portuguese from the [Deep Learning Brasil group](http://www.deeplearningbrasil.com.br/) by using a Test2Text-Generation objective.
Due to the small size of T5 base and finetuning dataset, the model overfitted before to reach the end of training. Here are the overall final metrics on the validation dataset:
- **f1**: 79.3
- **exact_match**: 67.3983
Check our other QA models in Portuguese finetuned on SQUAD v1.1:
- [Portuguese BERT base cased QA](https://huggingface.co/pierreguillou/bert-base-cased-squad-v1.1-portuguese)
- [Portuguese BERT large cased QA](https://huggingface.co/pierreguillou/bert-large-cased-squad-v1.1-portuguese)
- [Portuguese ByT5 small QA](https://huggingface.co/pierreguillou/byt5-small-qa-squad-v1.1-portuguese)
## Blog post
[NLP nas empresas | Como eu treinei um modelo T5 em português na tarefa QA no Google Colab](https://medium.com/@pierre_guillou/nlp-nas-empresas-como-eu-treinei-um-modelo-t5-em-portugu%C3%AAs-na-tarefa-qa-no-google-colab-e8eb0dc38894) (27/01/2022)
## Widget & App
You can test this model into the widget of this page.
Use as well the [QA App | T5 base pt](https://huggingface.co/spaces/pierreguillou/question-answering-portuguese-t5-base) that allows using the model T5 base finetuned on the QA task with the SQuAD v1.1 pt dataset.
## Using the model for inference in production
````
# install pytorch: check https://pytorch.org/
# !pip install transformers
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
# model & tokenizer
model_name = "pierreguillou/t5-base-qa-squad-v1.1-portuguese"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
# parameters
max_target_length=32
num_beams=1
early_stopping=True
input_text = 'question: Quando foi descoberta a Covid-19? context: A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China, em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano.'
label = '1 de dezembro de 2019'
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(inputs["input_ids"],
max_length=max_target_length,
num_beams=num_beams,
early_stopping=early_stopping
)
pred = tokenizer.decode(outputs[0], skip_special_tokens=True, clean_up_tokenization_spaces=True)
print('true answer |', label)
print('pred |', pred)
````
You can use pipeline, too. However, it seems to have an issue regarding to the max_length of the input sequence.
````
!pip install transformers
import transformers
from transformers import pipeline
# model
model_name = "pierreguillou/t5-base-qa-squad-v1.1-portuguese"
# parameters
max_target_length=32
num_beams=1
early_stopping=True
clean_up_tokenization_spaces=True
input_text = 'question: Quando foi descoberta a Covid-19? context: A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China, em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano.'
label = '1 de dezembro de 2019'
text2text = pipeline(
"text2text-generation",
model=model_name,
max_length=max_target_length,
num_beams=num_beams,
early_stopping=early_stopping,
clean_up_tokenization_spaces=clean_up_tokenization_spaces
)
pred = text2text(input_text)
print('true answer |', label)
print('pred |', pred)
````
## Training procedure
### Notebook
The notebook of finetuning ([HuggingFace_Notebook_t5-base-portuguese-vocab_question_answering_QA_squad_v11_pt.ipynb](https://github.com/piegu/language-models/blob/master/HuggingFace_Notebook_t5_base_portuguese_vocab_question_answering_QA_squad_v11_pt.ipynb)) is in github.
### Hyperparameters
````
# do training and evaluation
do_train = True
do_eval= True
# batch
batch_size = 4
gradient_accumulation_steps = 3
per_device_train_batch_size = batch_size
per_device_eval_batch_size = per_device_train_batch_size*16
# LR, wd, epochs
learning_rate = 1e-4
weight_decay = 0.01
num_train_epochs = 10
fp16 = True
# logs
logging_strategy = "steps"
logging_first_step = True
logging_steps = 3000 # if logging_strategy = "steps"
eval_steps = logging_steps
# checkpoints
evaluation_strategy = logging_strategy
save_strategy = logging_strategy
save_steps = logging_steps
save_total_limit = 3
# best model
load_best_model_at_end = True
metric_for_best_model = "f1" #"loss"
if metric_for_best_model == "loss":
greater_is_better = False
else:
greater_is_better = True
# evaluation
num_beams = 1
````
### Training results
````
Num examples = 87510
Num Epochs = 10
Instantaneous batch size per device = 4
Total train batch size (w. parallel, distributed & accumulation) = 12
Gradient Accumulation steps = 3
Total optimization steps = 72920
Step Training Loss Exact Match F1
3000 0.776100 61.807001 75.114517
6000 0.545900 65.260170 77.468930
9000 0.460500 66.556291 78.491938
12000 0.393400 66.821192 78.745397
15000 0.379800 66.603595 78.815515
18000 0.298100 67.578051 79.287899
21000 0.303100 66.991485 78.979669
24000 0.251600 67.275307 78.929923
27000 0.237500 66.972564 79.333612
30000 0.220500 66.915799 79.236574
33000 0.182600 67.029328 78.964212
36000 0.190600 66.982025 79.086125
````
|
Iskaj/w2v-xlsr-dutch-lm
|
Iskaj
| 2022-01-27T13:41:13Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:04Z |
Model cloned from https://huggingface.co/facebook/wav2vec2-large-xlsr-53-dutch
Currently bugged: Logits size 48, vocab size 50
|
oskrmiguel/mt5-simplification-spanish
|
oskrmiguel
| 2022-01-27T13:32:24Z | 22 | 6 |
transformers
|
[
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"simplification",
"spanish",
"es",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
language:
- es
thumbnail:
tags:
- simplification
- mt5
- spanish
license: cc-by-nc-sa-4.0
metrics:
- sari
widget:
- text: "La Simplificación Textual es el proceso de transformación de un texto a otro texto equivalente más comprensible para un determinado tipo de grupo o población."
- text: "Los textos simplificados son apropiados para muchos grupos de lectores, como, por ejemplo: estudiantes de idiomas, personas con discapacidades intelectuales y otras personas con necesidades especiales de lectura y comprensión.
"
---
# mt5-simplification-spanish
## Model description
This is a fine-tuned mt5-small model for generating simple text from complex text.
This model was created with the IXA Group research group of the University of the Basque Country, the model has been evaluated with the Sari, Bleu and Fklg metrics; it was trained and tested using the [Simplext corpus](https://dl.acm.org/doi/10.1145/2738046).
## Dataset
Simplext
## Model Evaluation
Bleu: 13,186
Sari: 42,203
Fklg: 10,284
## Authors
Oscar M. Cumbicus-Pineda, Itziar Gonzalez-Dios, Aitor Soroa, November 2021
## Code
https://github.com/oskrmiguel/mt5-simplification
|
anas-awadalla/bert-small-pretrained-on-squad
|
anas-awadalla
| 2022-01-27T03:57:07Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"generated_from_trainer",
"dataset:squad",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: bert_small_pretrain_squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert_small_pretrain_squad
This model is a fine-tuned version of [prajjwal1/bert-small](https://huggingface.co/prajjwal1/bert-small) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1410
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.0
- Tokenizers 0.10.3
|
boris/dalle-mini-tokenizer
|
boris
| 2022-01-27T01:42:39Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-03-02T23:29:05Z |
Tokenizer based on `facebook/bart-large-cnn` and trained on captions normalized by [dalle-mini](https://github.com/borisdayma/dalle-mini).
|
anuragshas/wav2vec2-xlsr-53-rm-vallader-with-lm
|
anuragshas
| 2022-01-26T16:38:21Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-xlsr-53-rm-vallader-with-lm
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-xlsr-53-rm-vallader-with-lm
This model is a fine-tuned version of [anuragshas/wav2vec2-large-xlsr-53-rm-vallader](https://huggingface.co/anuragshas/wav2vec2-large-xlsr-53-rm-vallader) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4552
- Wer: 0.3206
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.112
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2379 | 3.12 | 100 | 0.4041 | 0.3396 |
| 0.103 | 6.25 | 200 | 0.4400 | 0.3337 |
| 0.0664 | 9.38 | 300 | 0.4239 | 0.3315 |
| 0.0578 | 12.5 | 400 | 0.4303 | 0.3267 |
| 0.0446 | 15.62 | 500 | 0.4575 | 0.3274 |
| 0.041 | 18.75 | 600 | 0.4451 | 0.3223 |
| 0.0402 | 21.88 | 700 | 0.4507 | 0.3206 |
| 0.0374 | 25.0 | 800 | 0.4649 | 0.3208 |
| 0.0371 | 28.12 | 900 | 0.4552 | 0.3206 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.18.1
- Tokenizers 0.10.3
|
asahi417/tner-xlm-roberta-large-multiconer-mix-adapter
|
asahi417
| 2022-01-26T16:00:50Z | 3 | 0 |
adapter-transformers
|
[
"adapter-transformers",
"adapterhub:named-entity-recognition/multiconer",
"xlm-roberta",
"dataset:multiconer",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
tags:
- adapter-transformers
- adapterhub:named-entity-recognition/multiconer
- xlm-roberta
datasets:
- multiconer
---
# Adapter `asahi417/tner-xlm-roberta-large-multiconer-mix-adapter` for xlm-roberta-large
An [adapter](https://adapterhub.ml) for the `xlm-roberta-large` model that was trained on the [named-entity-recognition/multiconer](https://adapterhub.ml/explore/named-entity-recognition/multiconer/) dataset and includes a prediction head for tagging.
This adapter was created for usage with the **[adapter-transformers](https://github.com/Adapter-Hub/adapter-transformers)** library.
## Usage
First, install `adapter-transformers`:
```
pip install -U adapter-transformers
```
_Note: adapter-transformers is a fork of transformers that acts as a drop-in replacement with adapter support. [More](https://docs.adapterhub.ml/installation.html)_
Now, the adapter can be loaded and activated like this:
```python
from transformers import AutoModelWithHeads
model = AutoModelWithHeads.from_pretrained("xlm-roberta-large")
adapter_name = model.load_adapter("asahi417/tner-xlm-roberta-large-multiconer-mix-adapter", source="hf", set_active=True)
```
## Architecture & Training
<!-- Add some description here -->
## Evaluation results
<!-- Add some description here -->
## Citation
<!-- Add some description here -->
|
anton-l/sew-mid-100k-ft-keyword-spotting
|
anton-l
| 2022-01-26T14:43:39Z | 237 | 3 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"sew",
"audio-classification",
"generated_from_trainer",
"dataset:superb",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- audio-classification
- generated_from_trainer
datasets:
- superb
metrics:
- accuracy
model-index:
- name: sew-mid-100k-ft-keyword-spotting
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# sew-mid-100k-ft-keyword-spotting
This model is a fine-tuned version of [asapp/sew-mid-100k](https://huggingface.co/asapp/sew-mid-100k) on the superb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0975
- Accuracy: 0.9757
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 0
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.5999 | 1.0 | 399 | 0.2262 | 0.9635 |
| 0.4271 | 2.0 | 798 | 0.1230 | 0.9697 |
| 0.3778 | 3.0 | 1197 | 0.1052 | 0.9731 |
| 0.3227 | 4.0 | 1596 | 0.0975 | 0.9757 |
| 0.3081 | 5.0 | 1995 | 0.0962 | 0.9753 |
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.9.1+cu111
- Datasets 1.14.0
- Tokenizers 0.10.3
|
anirudh21/albert-xlarge-v2-finetuned-mrpc
|
anirudh21
| 2022-01-26T12:50:06Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"albert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: albert-xlarge-v2-finetuned-mrpc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: mrpc
metrics:
- name: Accuracy
type: accuracy
value: 0.7132352941176471
- name: F1
type: f1
value: 0.8145800316957211
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# albert-xlarge-v2-finetuned-mrpc
This model is a fine-tuned version of [albert-xlarge-v2](https://huggingface.co/albert-xlarge-v2) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5563
- Accuracy: 0.7132
- F1: 0.8146
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 63 | 0.6898 | 0.5221 | 0.6123 |
| No log | 2.0 | 126 | 0.6298 | 0.6838 | 0.8122 |
| No log | 3.0 | 189 | 0.6043 | 0.7010 | 0.8185 |
| No log | 4.0 | 252 | 0.5834 | 0.7010 | 0.8146 |
| No log | 5.0 | 315 | 0.5563 | 0.7132 | 0.8146 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.18.0
- Tokenizers 0.10.3
|
krirk/wav2vec2-large-xls-r-300m-turkish-colab
|
krirk
| 2022-01-26T12:38:32Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-300m-turkish-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-turkish-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3942
- Wer: 0.3149
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.9921 | 3.67 | 400 | 0.7820 | 0.7857 |
| 0.4496 | 7.34 | 800 | 0.4630 | 0.4977 |
| 0.2057 | 11.01 | 1200 | 0.4293 | 0.4627 |
| 0.1328 | 14.68 | 1600 | 0.4464 | 0.4068 |
| 0.1009 | 18.35 | 2000 | 0.4461 | 0.3742 |
| 0.0794 | 22.02 | 2400 | 0.4328 | 0.3467 |
| 0.0628 | 25.69 | 2800 | 0.4036 | 0.3263 |
| 0.0497 | 29.36 | 3200 | 0.3942 | 0.3149 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
jcmc/wav2vec2-large-xlsr-53-ir
|
jcmc
| 2022-01-26T10:35:17Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"mozilla-foundation/common_voice_7_0",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language:
- ga-IE
license: apache-2.0
tags:
- automatic-speech-recognition
- mozilla-foundation/common_voice_7_0
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: ''
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
#
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the MOZILLA-FOUNDATION/COMMON_VOICE_7_0 - GA-IE dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0835
- Wer: 0.7490
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 50.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.1483 | 15.62 | 500 | 3.0498 | 1.0 |
| 2.8449 | 31.25 | 1000 | 2.7790 | 0.9493 |
| 1.8683 | 46.86 | 1500 | 1.2339 | 0.8161 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.1.dev0
- Tokenizers 0.11.0
|
danielbubiola/bangla_asr
|
danielbubiola
| 2022-01-26T07:42:22Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
tags:
- generated_from_trainer
model-index:
- name: bangla_asr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bangla_asr
This model is a fine-tuned version of [Harveenchadha/vakyansh-wav2vec2-bengali-bnm-200](https://huggingface.co/Harveenchadha/vakyansh-wav2vec2-bengali-bnm-200) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 157.8652
- Wer: 0.4507
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 60
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 2601.5363 | 7.46 | 500 | 259.6630 | 0.6863 |
| 417.7386 | 14.93 | 1000 | 156.6117 | 0.5275 |
| 262.9455 | 22.39 | 1500 | 155.0886 | 0.5006 |
| 178.7715 | 29.85 | 2000 | 155.1077 | 0.4840 |
| 132.448 | 37.31 | 2500 | 163.8623 | 0.4770 |
| 116.3943 | 44.78 | 3000 | 161.5531 | 0.4609 |
| 87.1653 | 52.24 | 3500 | 165.6857 | 0.4597 |
| 80.5606 | 59.7 | 4000 | 157.8652 | 0.4507 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
kxiaoqiangrexian/bert_test
|
kxiaoqiangrexian
| 2022-01-26T06:52:37Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
license: apache-2.0
---
|
vuiseng9/bert-mnli
|
vuiseng9
| 2022-01-26T06:48:02Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
This model is developed with transformers v4.9.1.
```
m = 0.8444
eval_samples = 9815
mm = 0.8495
eval_samples = 9832
```
# Train
```bash
#!/usr/bin/env bash
export CUDA_VISIBLE_DEVICES=0
OUTDIR=bert-mnli
NEPOCH=3
WORKDIR=transformers/examples/pytorch/text-classification
cd $WORKDIR
python run_glue.py \
--model_name_or_path bert-base-uncased \
--task_name mnli \
--max_seq_length 128 \
--do_train \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs $NEPOCH \
--logging_steps 1 \
--evaluation_strategy steps \
--save_steps 3000 \
--do_eval \
--per_device_eval_batch_size 128 \
--eval_steps 250 \
--output_dir $OUTDIR
--overwrite_output_dir
```
# Eval
```bash
export CUDA_VISIBLE_DEVICES=0
OUTDIR=eval-bert-mnli
WORKDIR=transformers/examples/pytorch/text-classification
cd $WORKDIR
nohup python run_glue.py \
--model_name_or_path vuiseng9/bert-mnli \
--task_name mnli \
--do_eval \
--per_device_eval_batch_size 128 \
--max_seq_length 128 \
--overwrite_output_dir \
--output_dir $OUTDIR 2>&1 | tee $OUTDIR/run.log &
```
|
DrishtiSharma/wav2vec2-large-xls-r-300m-ab-v4
|
DrishtiSharma
| 2022-01-26T01:35:38Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"mozilla-foundation/common_voice_7_0",
"generated_from_trainer",
"ab",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:04Z |
---
language:
- ab
license: apache-2.0
tags:
- automatic-speech-recognition
- mozilla-foundation/common_voice_7_0
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: ''
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
#
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_7_0 - AB dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6178
- Wer: 0.5794
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.00025
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 70.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 5.2793 | 27.27 | 300 | 3.0737 | 1.0 |
| 1.5348 | 54.55 | 600 | 0.6312 | 0.6334 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.1.dev0
- Tokenizers 0.11.0
|
chmanoj/xls-r-300m-sv
|
chmanoj
| 2022-01-26T00:01:07Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"mozilla-foundation/common_voice_7_0",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language:
- sv-SE
license: apache-2.0
tags:
- automatic-speech-recognition
- mozilla-foundation/common_voice_7_0
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: ''
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
#
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_7_0 - SV-SE dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8004
- Wer: 0.7139
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 10.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 2.6683 | 1.45 | 500 | 1.7698 | 1.0041 |
| 1.9548 | 2.91 | 1000 | 1.0890 | 0.8602 |
| 1.9568 | 4.36 | 1500 | 1.0878 | 0.8680 |
| 1.9497 | 5.81 | 2000 | 1.1501 | 0.8838 |
| 1.8453 | 7.27 | 2500 | 1.0452 | 0.8418 |
| 1.6952 | 8.72 | 3000 | 0.9153 | 0.7823 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.0+cu113
- Datasets 1.18.1.dev0
- Tokenizers 0.10.3
|
Ajay191191/autonlp-Test-530014983
|
Ajay191191
| 2022-01-25T22:28:49Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autonlp",
"en",
"dataset:Ajay191191/autonlp-data-Test",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:04Z |
---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- Ajay191191/autonlp-data-Test
co2_eq_emissions: 55.10196329868386
---
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 530014983
- CO2 Emissions (in grams): 55.10196329868386
## Validation Metrics
- Loss: 0.23171618580818176
- Accuracy: 0.9298837645294338
- Precision: 0.9314414866901055
- Recall: 0.9279459594696022
- AUC: 0.979447403984557
- F1: 0.9296904373981703
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/Ajay191191/autonlp-Test-530014983
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("Ajay191191/autonlp-Test-530014983", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("Ajay191191/autonlp-Test-530014983", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
```
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.