
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
list | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
Emperor-WS/ppo-LunarLander-v2-1
|
Emperor-WS
| 2024-02-23T02:09:03Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-02-23T01:57:44Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 280.04 +/- 25.52
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
han2lin/gpt2_med_s19e22_ft
|
han2lin
| 2024-02-23T02:08:33Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-21T12:44:43Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
han2lin/gpt2_med_s21e22_ft
|
han2lin
| 2024-02-23T02:08:01Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-23T02:07:22Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
han2lin/gpt2_med_s22_ft
|
han2lin
| 2024-02-23T02:06:49Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-23T02:06:12Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
furrutiav/bert_qa_extractor_cockatiel_2022_ulra_by_kmeans_Q_nllf_sub_best_by_z_value_ef_signal_it_83
|
furrutiav
| 2024-02-23T02:05:50Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"feature-extraction",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2024-02-23T02:05:24Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
han2lin/gpt2_med_s23_ft
|
han2lin
| 2024-02-23T02:05:39Z | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-23T02:04:57Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
NLUHOPOE/test-case-1
|
NLUHOPOE
| 2024-02-23T02:01:13Z | 50 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"en",
"dataset:Open-Orca/SlimOrca",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-23T00:30:16Z |
---
license: apache-2.0
datasets:
- Open-Orca/SlimOrca
language:
- en
---
# Model Details
* Model Description: This model is test for data ordering.
* Developed by: Juhwan Lee
* Model Type: Large Language Model
# Model Architecture
This model is based on Mistral-7B-v0.1. We fine-tuning this model for data ordering task.
Mistral-7B-v0.1 is a transformer model, with the following architecture choices:
* Grouped-Query Attention
* Sliding-Window Attention
* Byte-fallback BPE tokenizer
# Dataset
We random sample SlimOrca dataset.
# Guthub
https://github.com/trailerAI
# License
Apache License 2.0
|
jisukim8873/falcon-7B-case-1
|
jisukim8873
| 2024-02-23T01:53:33Z | 153 | 0 |
transformers
|
[
"transformers",
"safetensors",
"falcon",
"text-generation",
"custom_code",
"en",
"dataset:Open-Orca/SlimOrca",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-23T00:45:50Z |
---
license: apache-2.0
datasets:
- Open-Orca/SlimOrca
language:
- en
---
# Model Details
* Model Description: This model is test for data ordering.
* Developed by: Jisu Kim
* Model Type: Large Language Model
# Model Architecture
This model is based on falcon-7B. We fine-tuning this model for data ordering task.
falcon-7B is a transformer model, with the following architecture choices:
* Grouped-Query Attention
* Sliding-Window Attention
* Byte-fallback BPE tokenizer
# Dataset
We random sample Open-Orca dataset. (We finetune the 100,000 dataset)
# Guthub
https://github.com/trailerAI
# License
Apache License 2.0
|
SUFEHeisenberg/Fin-RoBERTa
|
SUFEHeisenberg
| 2024-02-23T01:51:41Z | 29 | 2 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"finance",
"text-classification",
"en",
"dataset:financial_phrasebank",
"dataset:pauri32/fiqa-2018",
"dataset:zeroshot/twitter-financial-news-sentiment",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-02-23T01:15:14Z |
---
license: apache-2.0
datasets:
- financial_phrasebank
- pauri32/fiqa-2018
- zeroshot/twitter-financial-news-sentiment
language:
- en
metrics:
- accuracy
pipeline_tag: text-classification
tags:
- finance
---
We collects financial domain terms from Investopedia's Financia terms dictionary, NYSSCPA's accounting terminology guide
and Harvey's Hypertextual Finance Glossary to expand RoBERTa's vocab dict.
Based on added-financial-terms RoBERTa, we pretrained our model on multilple financial corpus:
- Financial Terms
- [Investopedia's Financia terms dictionary](https://www.investopedia.com/financial-term-dictionary-4769738)
- [NYSSCPA's accounting terminology guide](https://www.nysscpa.org/professional-resources/accounting-terminology-guide)
- [Harvey's Hypertextual Finance Glossary](https://people.duke.edu/~charvey/Classes/wpg/glossary.htm)
- Financial Datasets
- [FPB](https://huggingface.co/datasets/financial_phrasebank)
- [FiQA SA](https://huggingface.co/datasets/pauri32/fiqa-2018)
- [SemEval2017 Task5](https://aclanthology.org/S17-2089/)
- [Twitter Financial News Sentiment](https://huggingface.co/datasets/zeroshot/twitter-financial-news-sentiment)
- Earnings Call
2016-2023 NASDAQ 100 components stocks's Earnings Call Transcripts.
In continual pretraining step, we apply following experiments settings to achieve better finetuned results on Four Financial Datasets:
1. Masking Probability: 0.4 (instead of default 0.15)
2. Warmup Steps: 0 (deriving better results than models with warmup steps)
3. Epochs: 1 (is enough in case of overfitting)
4. weight_decay: 0.01
5. Train Batch Size: 64
6. FP16
|
rockyclh/llama-2-7b-chat-entrepreneurship
|
rockyclh
| 2024-02-23T01:50:09Z | 0 | 0 | null |
[
"safetensors",
"autotrain",
"text-generation",
"conversational",
"license:other",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-23T01:50:03Z |
---
tags:
- autotrain
- text-generation
widget:
- text: "I love AutoTrain because "
license: other
---
# Model Trained Using AutoTrain
This model was trained using AutoTrain. For more information, please visit [AutoTrain](https://hf.co/docs/autotrain).
# Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "PATH_TO_THIS_REPO"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype='auto'
).eval()
# Prompt content: "hi"
messages = [
{"role": "user", "content": "hi"}
]
input_ids = tokenizer.apply_chat_template(conversation=messages, tokenize=True, add_generation_prompt=True, return_tensors='pt')
output_ids = model.generate(input_ids.to('cuda'))
response = tokenizer.decode(output_ids[0][input_ids.shape[1]:], skip_special_tokens=True)
# Model response: "Hello! How can I assist you today?"
print(response)
```
|
isabelarvelo/wav2vec_pretraining_output-finetuned-fb
|
isabelarvelo
| 2024-02-23T01:48:52Z | 4 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"wav2vec2",
"audio-classification",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2024-02-22T05:06:57Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: wav2vec_finetuning_output
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec_finetuning_output
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3368
- Accuracy: 0.5338
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.3588 | 1.0 | 203 | 1.3368 | 0.5338 |
| 1.2412 | 2.0 | 406 | 1.3360 | 0.5338 |
| 1.3518 | 3.0 | 609 | 1.3296 | 0.5314 |
| 1.3174 | 4.0 | 813 | 1.3107 | 0.5338 |
| 1.3107 | 4.99 | 1015 | 1.3112 | 0.5338 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.0
- Tokenizers 0.15.2
|
dranger003/AlphaMonarch-7B-iMat.GGUF
|
dranger003
| 2024-02-23T01:44:44Z | 2 | 0 |
gguf
|
[
"gguf",
"text-generation",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2024-02-23T00:41:41Z |
---
license: cc-by-nc-4.0
pipeline_tag: text-generation
library_name: gguf
---
GGUF importance matrix (imatrix) quants for https://huggingface.co/mlabonne/AlphaMonarch-7B
The importance matrix was trained for ~50K tokens (105 batches of 512 tokens) using a [general purpose imatrix calibration dataset](https://github.com/ggerganov/llama.cpp/discussions/5263#discussioncomment-8395384).
| Layers | Context | Template |
| --- | --- | --- |
| <pre>32</pre> | <pre>32768</pre> | <pre>\<s\>user<br>{prompt}\</s\><br>\<s\>assistant<br>{response}</pre> |
|
dranger003/NeuralMonarch-7B-iMat.GGUF
|
dranger003
| 2024-02-23T01:42:37Z | 1 | 1 |
gguf
|
[
"gguf",
"text-generation",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2024-02-23T00:28:27Z |
---
license: cc-by-nc-4.0
pipeline_tag: text-generation
library_name: gguf
---
GGUF importance matrix (imatrix) quants for https://huggingface.co/mlabonne/NeuralMonarch-7B
The importance matrix was trained for ~50K tokens (105 batches of 512 tokens) using a [general purpose imatrix calibration dataset](https://github.com/ggerganov/llama.cpp/discussions/5263#discussioncomment-8395384).
| Layers | Context | Template |
| --- | --- | --- |
| <pre>32</pre> | <pre>32768</pre> | <pre>\<s\>user<br>{prompt}\</s\><br>\<s\>assistant<br>{response}</pre> |
|
furrutiav/bert_qa_extractor_cockatiel_2022_ulra_by_question_type_sub_best_by_z_value_ef_signal_it_145
|
furrutiav
| 2024-02-23T01:41:15Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"feature-extraction",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2024-02-23T01:40:48Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
HenseHsieh/a2c-PandaReachDense-v3
|
HenseHsieh
| 2024-02-23T01:39:50Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaReachDense-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-02-23T01:35:48Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v3
type: PandaReachDense-v3
metrics:
- type: mean_reward
value: -0.24 +/- 0.11
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v3**
This is a trained model of a **A2C** agent playing **PandaReachDense-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
DouglasPontes/2020-Q3-25p-filtered-random
|
DouglasPontes
| 2024-02-23T01:38:19Z | 1 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"generated_from_trainer",
"base_model:cardiffnlp/twitter-roberta-base-2019-90m",
"base_model:finetune:cardiffnlp/twitter-roberta-base-2019-90m",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2024-02-19T22:08:26Z |
---
license: mit
base_model: cardiffnlp/twitter-roberta-base-2019-90m
tags:
- generated_from_trainer
model-index:
- name: 2020-Q3-25p-filtered-random
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 2020-Q3-25p-filtered-random
This model is a fine-tuned version of [cardiffnlp/twitter-roberta-base-2019-90m](https://huggingface.co/cardiffnlp/twitter-roberta-base-2019-90m) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2624
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4.1e-07
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.98) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 2400000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-------:|:---------------:|
| No log | 0.02 | 8000 | 2.5582 |
| 2.8015 | 0.04 | 16000 | 2.4569 |
| 2.8015 | 0.07 | 24000 | 2.4054 |
| 2.5403 | 0.09 | 32000 | 2.3788 |
| 2.5403 | 0.11 | 40000 | 2.3619 |
| 2.475 | 0.13 | 48000 | 2.3437 |
| 2.475 | 0.16 | 56000 | 2.3306 |
| 2.4451 | 0.18 | 64000 | 2.3220 |
| 2.4451 | 0.2 | 72000 | 2.3136 |
| 2.4333 | 0.22 | 80000 | 2.3125 |
| 2.4333 | 0.25 | 88000 | 2.3113 |
| 2.4234 | 0.27 | 96000 | 2.3007 |
| 2.4234 | 0.29 | 104000 | 2.3005 |
| 2.4151 | 0.31 | 112000 | 2.2946 |
| 2.4151 | 0.34 | 120000 | 2.2902 |
| 2.4156 | 0.36 | 128000 | 2.2845 |
| 2.4156 | 0.38 | 136000 | 2.2922 |
| 2.3994 | 0.4 | 144000 | 2.2819 |
| 2.3994 | 0.43 | 152000 | 2.2835 |
| 2.4088 | 0.45 | 160000 | 2.2824 |
| 2.4088 | 0.47 | 168000 | 2.2797 |
| 2.3996 | 0.49 | 176000 | 2.2816 |
| 2.3996 | 0.52 | 184000 | 2.2791 |
| 2.396 | 0.54 | 192000 | 2.2770 |
| 2.396 | 0.56 | 200000 | 2.2788 |
| 2.396 | 0.58 | 208000 | 2.2701 |
| 2.396 | 0.61 | 216000 | 2.2703 |
| 2.403 | 0.63 | 224000 | 2.2720 |
| 2.403 | 0.65 | 232000 | 2.2788 |
| 2.3889 | 0.67 | 240000 | 2.2739 |
| 2.3889 | 0.7 | 248000 | 2.2721 |
| 2.3976 | 0.72 | 256000 | 2.2786 |
| 2.3976 | 0.74 | 264000 | 2.2715 |
| 2.3939 | 0.76 | 272000 | 2.2716 |
| 2.3939 | 0.79 | 280000 | 2.2699 |
| 2.393 | 0.81 | 288000 | 2.2702 |
| 2.393 | 0.83 | 296000 | 2.2722 |
| 2.3884 | 0.85 | 304000 | 2.2711 |
| 2.3884 | 0.88 | 312000 | 2.2697 |
| 2.3939 | 0.9 | 320000 | 2.2653 |
| 2.3939 | 0.92 | 328000 | 2.2678 |
| 2.3981 | 0.94 | 336000 | 2.2675 |
| 2.3981 | 0.97 | 344000 | 2.2681 |
| 2.3936 | 0.99 | 352000 | 2.2644 |
| 2.3936 | 1.01 | 360000 | 2.2698 |
| 2.3916 | 1.03 | 368000 | 2.2729 |
| 2.3916 | 1.06 | 376000 | 2.2722 |
| 2.3975 | 1.08 | 384000 | 2.2694 |
| 2.3975 | 1.1 | 392000 | 2.2626 |
| 2.3946 | 1.12 | 400000 | 2.2714 |
| 2.3946 | 1.15 | 408000 | 2.2756 |
| 2.3974 | 1.17 | 416000 | 2.2653 |
| 2.3974 | 1.19 | 424000 | 2.2649 |
| 2.3873 | 1.21 | 432000 | 2.2722 |
| 2.3873 | 1.24 | 440000 | 2.2651 |
| 2.3922 | 1.26 | 448000 | 2.2638 |
| 2.3922 | 1.28 | 456000 | 2.2621 |
| 2.3983 | 1.3 | 464000 | 2.2671 |
| 2.3983 | 1.32 | 472000 | 2.2651 |
| 2.3883 | 1.35 | 480000 | 2.2631 |
| 2.3883 | 1.37 | 488000 | 2.2729 |
| 2.3909 | 1.39 | 496000 | 2.2618 |
| 2.3909 | 1.41 | 504000 | 2.2631 |
| 2.3885 | 1.44 | 512000 | 2.2639 |
| 2.3885 | 1.46 | 520000 | 2.2590 |
| 2.3977 | 1.48 | 528000 | 2.2652 |
| 2.3977 | 1.5 | 536000 | 2.2632 |
| 2.3968 | 1.53 | 544000 | 2.2666 |
| 2.3968 | 1.55 | 552000 | 2.2697 |
| 2.3941 | 1.57 | 560000 | 2.2703 |
| 2.3941 | 1.59 | 568000 | 2.2632 |
| 2.3916 | 1.62 | 576000 | 2.2613 |
| 2.3916 | 1.64 | 584000 | 2.2663 |
| 2.3878 | 1.66 | 592000 | 2.2593 |
| 2.3878 | 1.68 | 600000 | 2.2636 |
| 2.3955 | 1.71 | 608000 | 2.2624 |
| 2.3955 | 1.73 | 616000 | 2.2627 |
| 2.3921 | 1.75 | 624000 | 2.2676 |
| 2.3921 | 1.77 | 632000 | 2.2675 |
| 2.3971 | 1.8 | 640000 | 2.2690 |
| 2.3971 | 1.82 | 648000 | 2.2617 |
| 2.3979 | 1.84 | 656000 | 2.2619 |
| 2.3979 | 1.86 | 664000 | 2.2666 |
| 2.3917 | 1.89 | 672000 | 2.2586 |
| 2.3917 | 1.91 | 680000 | 2.2634 |
| 2.4004 | 1.93 | 688000 | 2.2631 |
| 2.4004 | 1.95 | 696000 | 2.2656 |
| 2.3881 | 1.98 | 704000 | 2.2650 |
| 2.3881 | 2.0 | 712000 | 2.2618 |
| 2.3988 | 2.02 | 720000 | 2.2623 |
| 2.3988 | 2.04 | 728000 | 2.2654 |
| 2.3919 | 2.07 | 736000 | 2.2622 |
| 2.3919 | 2.09 | 744000 | 2.2658 |
| 2.3872 | 2.11 | 752000 | 2.2639 |
| 2.3872 | 2.13 | 760000 | 2.2578 |
| 2.3921 | 2.16 | 768000 | 2.2647 |
| 2.3921 | 2.18 | 776000 | 2.2635 |
| 2.3956 | 2.2 | 784000 | 2.2609 |
| 2.3956 | 2.22 | 792000 | 2.2617 |
| 2.4026 | 2.25 | 800000 | 2.2605 |
| 2.4026 | 2.27 | 808000 | 2.2619 |
| 2.3931 | 2.29 | 816000 | 2.2663 |
| 2.3931 | 2.31 | 824000 | 2.2649 |
| 2.3958 | 2.34 | 832000 | 2.2655 |
| 2.3958 | 2.36 | 840000 | 2.2611 |
| 2.3968 | 2.38 | 848000 | 2.2693 |
| 2.3968 | 2.4 | 856000 | 2.2639 |
| 2.3963 | 2.43 | 864000 | 2.2589 |
| 2.3963 | 2.45 | 872000 | 2.2650 |
| 2.3921 | 2.47 | 880000 | 2.2654 |
| 2.3921 | 2.49 | 888000 | 2.2626 |
| 2.3912 | 2.52 | 896000 | 2.2655 |
| 2.3912 | 2.54 | 904000 | 2.2635 |
| 2.3978 | 2.56 | 912000 | 2.2634 |
| 2.3978 | 2.58 | 920000 | 2.2605 |
| 2.4009 | 2.6 | 928000 | 2.2601 |
| 2.4009 | 2.63 | 936000 | 2.2603 |
| 2.3917 | 2.65 | 944000 | 2.2678 |
| 2.3917 | 2.67 | 952000 | 2.2693 |
| 2.3955 | 2.69 | 960000 | 2.2640 |
| 2.3955 | 2.72 | 968000 | 2.2613 |
| 2.3962 | 2.74 | 976000 | 2.2723 |
| 2.3962 | 2.76 | 984000 | 2.2613 |
| 2.396 | 2.78 | 992000 | 2.2600 |
| 2.396 | 2.81 | 1000000 | 2.2651 |
| 2.3961 | 2.83 | 1008000 | 2.2630 |
| 2.3961 | 2.85 | 1016000 | 2.2596 |
| 2.399 | 2.87 | 1024000 | 2.2606 |
| 2.399 | 2.9 | 1032000 | 2.2570 |
| 2.3981 | 2.92 | 1040000 | 2.2623 |
| 2.3981 | 2.94 | 1048000 | 2.2630 |
| 2.4028 | 2.96 | 1056000 | 2.2661 |
| 2.4028 | 2.99 | 1064000 | 2.2604 |
| 2.403 | 3.01 | 1072000 | 2.2642 |
| 2.403 | 3.03 | 1080000 | 2.2600 |
| 2.3975 | 3.05 | 1088000 | 2.2654 |
| 2.3975 | 3.08 | 1096000 | 2.2660 |
| 2.3974 | 3.1 | 1104000 | 2.2703 |
| 2.3974 | 3.12 | 1112000 | 2.2650 |
| 2.4014 | 3.14 | 1120000 | 2.2652 |
| 2.4014 | 3.17 | 1128000 | 2.2660 |
| 2.3964 | 3.19 | 1136000 | 2.2625 |
| 2.3964 | 3.21 | 1144000 | 2.2614 |
| 2.3942 | 3.23 | 1152000 | 2.2656 |
| 2.3942 | 3.26 | 1160000 | 2.2653 |
| 2.3969 | 3.28 | 1168000 | 2.2617 |
| 2.3969 | 3.3 | 1176000 | 2.2617 |
| 2.3953 | 3.32 | 1184000 | 2.2610 |
| 2.3953 | 3.35 | 1192000 | 2.2649 |
| 2.402 | 3.37 | 1200000 | 2.2695 |
| 2.402 | 3.39 | 1208000 | 2.2630 |
| 2.3974 | 3.41 | 1216000 | 2.2667 |
| 2.3974 | 3.44 | 1224000 | 2.2631 |
| 2.3993 | 3.46 | 1232000 | 2.2646 |
| 2.3993 | 3.48 | 1240000 | 2.2682 |
| 2.3999 | 3.5 | 1248000 | 2.2665 |
| 2.3999 | 3.53 | 1256000 | 2.2631 |
| 2.3952 | 3.55 | 1264000 | 2.2640 |
| 2.3952 | 3.57 | 1272000 | 2.2618 |
| 2.3914 | 3.59 | 1280000 | 2.2626 |
| 2.3914 | 3.62 | 1288000 | 2.2658 |
| 2.4113 | 3.64 | 1296000 | 2.2582 |
| 2.4113 | 3.66 | 1304000 | 2.2590 |
| 2.4021 | 3.68 | 1312000 | 2.2641 |
| 2.4021 | 3.71 | 1320000 | 2.2554 |
| 2.402 | 3.73 | 1328000 | 2.2629 |
| 2.402 | 3.75 | 1336000 | 2.2635 |
| 2.3989 | 3.77 | 1344000 | 2.2699 |
| 2.3989 | 3.8 | 1352000 | 2.2639 |
| 2.3998 | 3.82 | 1360000 | 2.2627 |
| 2.3998 | 3.84 | 1368000 | 2.2654 |
| 2.3968 | 3.86 | 1376000 | 2.2674 |
| 2.3968 | 3.88 | 1384000 | 2.2633 |
| 2.3993 | 3.91 | 1392000 | 2.2672 |
| 2.3993 | 3.93 | 1400000 | 2.2599 |
| 2.3991 | 3.95 | 1408000 | 2.2602 |
| 2.3991 | 3.97 | 1416000 | 2.2573 |
| 2.3971 | 4.0 | 1424000 | 2.2686 |
| 2.3971 | 4.02 | 1432000 | 2.2629 |
| 2.4047 | 4.04 | 1440000 | 2.2650 |
| 2.4047 | 4.06 | 1448000 | 2.2637 |
| 2.3952 | 4.09 | 1456000 | 2.2654 |
| 2.3952 | 4.11 | 1464000 | 2.2669 |
| 2.3994 | 4.13 | 1472000 | 2.2636 |
| 2.3994 | 4.15 | 1480000 | 2.2661 |
| 2.4003 | 4.18 | 1488000 | 2.2649 |
| 2.4003 | 4.2 | 1496000 | 2.2640 |
| 2.3959 | 4.22 | 1504000 | 2.2634 |
| 2.3959 | 4.24 | 1512000 | 2.2706 |
| 2.4023 | 4.27 | 1520000 | 2.2580 |
| 2.4023 | 4.29 | 1528000 | 2.2693 |
| 2.3974 | 4.31 | 1536000 | 2.2666 |
| 2.3974 | 4.33 | 1544000 | 2.2633 |
| 2.3944 | 4.36 | 1552000 | 2.2657 |
| 2.3944 | 4.38 | 1560000 | 2.2611 |
| 2.3974 | 4.4 | 1568000 | 2.2558 |
| 2.3974 | 4.42 | 1576000 | 2.2614 |
| 2.4024 | 4.45 | 1584000 | 2.2690 |
| 2.4024 | 4.47 | 1592000 | 2.2642 |
| 2.4024 | 4.49 | 1600000 | 2.2616 |
| 2.4024 | 4.51 | 1608000 | 2.2639 |
| 2.3981 | 4.54 | 1616000 | 2.2636 |
| 2.3981 | 4.56 | 1624000 | 2.2696 |
| 2.4041 | 4.58 | 1632000 | 2.2675 |
| 2.4041 | 4.6 | 1640000 | 2.2653 |
| 2.3972 | 4.63 | 1648000 | 2.2658 |
| 2.3972 | 4.65 | 1656000 | 2.2591 |
| 2.3997 | 4.67 | 1664000 | 2.2671 |
| 2.3997 | 4.69 | 1672000 | 2.2607 |
| 2.3918 | 4.72 | 1680000 | 2.2585 |
| 2.3918 | 4.74 | 1688000 | 2.2621 |
| 2.4069 | 4.76 | 1696000 | 2.2623 |
| 2.4069 | 4.78 | 1704000 | 2.2633 |
| 2.4039 | 4.81 | 1712000 | 2.2622 |
| 2.4039 | 4.83 | 1720000 | 2.2627 |
| 2.4077 | 4.85 | 1728000 | 2.2686 |
| 2.4077 | 4.87 | 1736000 | 2.2594 |
| 2.398 | 4.9 | 1744000 | 2.2659 |
| 2.398 | 4.92 | 1752000 | 2.2684 |
| 2.4007 | 4.94 | 1760000 | 2.2617 |
| 2.4007 | 4.96 | 1768000 | 2.2646 |
| 2.4059 | 4.99 | 1776000 | 2.2610 |
| 2.4059 | 5.01 | 1784000 | 2.2591 |
| 2.3996 | 5.03 | 1792000 | 2.2641 |
| 2.3996 | 5.05 | 1800000 | 2.2607 |
| 2.4015 | 5.08 | 1808000 | 2.2580 |
| 2.4015 | 5.1 | 1816000 | 2.2605 |
| 2.4007 | 5.12 | 1824000 | 2.2649 |
| 2.4007 | 5.14 | 1832000 | 2.2641 |
| 2.4019 | 5.16 | 1840000 | 2.2626 |
| 2.4019 | 5.19 | 1848000 | 2.2580 |
| 2.4017 | 5.21 | 1856000 | 2.2643 |
| 2.4017 | 5.23 | 1864000 | 2.2598 |
| 2.3997 | 5.25 | 1872000 | 2.2604 |
| 2.3997 | 5.28 | 1880000 | 2.2674 |
| 2.3973 | 5.3 | 1888000 | 2.2661 |
| 2.3973 | 5.32 | 1896000 | 2.2667 |
| 2.4004 | 5.34 | 1904000 | 2.2663 |
| 2.4004 | 5.37 | 1912000 | 2.2639 |
| 2.4034 | 5.39 | 1920000 | 2.2657 |
| 2.4034 | 5.41 | 1928000 | 2.2637 |
| 2.3907 | 5.43 | 1936000 | 2.2622 |
| 2.3907 | 5.46 | 1944000 | 2.2630 |
| 2.3935 | 5.48 | 1952000 | 2.2547 |
| 2.3935 | 5.5 | 1960000 | 2.2676 |
| 2.3954 | 5.52 | 1968000 | 2.2630 |
| 2.3954 | 5.55 | 1976000 | 2.2677 |
| 2.3995 | 5.57 | 1984000 | 2.2678 |
| 2.3995 | 5.59 | 1992000 | 2.2642 |
| 2.398 | 5.61 | 2000000 | 2.2613 |
| 2.398 | 5.64 | 2008000 | 2.2627 |
| 2.3971 | 5.66 | 2016000 | 2.2584 |
| 2.3971 | 5.68 | 2024000 | 2.2700 |
| 2.3988 | 5.7 | 2032000 | 2.2715 |
| 2.3988 | 5.73 | 2040000 | 2.2640 |
| 2.3933 | 5.75 | 2048000 | 2.2628 |
| 2.3933 | 5.77 | 2056000 | 2.2619 |
| 2.4007 | 5.79 | 2064000 | 2.2672 |
| 2.4007 | 5.82 | 2072000 | 2.2653 |
| 2.3978 | 5.84 | 2080000 | 2.2631 |
| 2.3978 | 5.86 | 2088000 | 2.2632 |
| 2.4002 | 5.88 | 2096000 | 2.2599 |
| 2.4002 | 5.91 | 2104000 | 2.2642 |
| 2.4041 | 5.93 | 2112000 | 2.2616 |
| 2.4041 | 5.95 | 2120000 | 2.2602 |
| 2.4008 | 5.97 | 2128000 | 2.2553 |
| 2.4008 | 6.0 | 2136000 | 2.2599 |
| 2.4003 | 6.02 | 2144000 | 2.2645 |
| 2.4003 | 6.04 | 2152000 | 2.2596 |
| 2.3998 | 6.06 | 2160000 | 2.2614 |
| 2.3998 | 6.09 | 2168000 | 2.2666 |
| 2.4007 | 6.11 | 2176000 | 2.2570 |
| 2.4007 | 6.13 | 2184000 | 2.2628 |
| 2.3891 | 6.15 | 2192000 | 2.2558 |
| 2.3891 | 6.18 | 2200000 | 2.2666 |
| 2.4011 | 6.2 | 2208000 | 2.2614 |
| 2.4011 | 6.22 | 2216000 | 2.2646 |
| 2.3957 | 6.24 | 2224000 | 2.2645 |
| 2.3957 | 6.27 | 2232000 | 2.2653 |
| 2.3973 | 6.29 | 2240000 | 2.2630 |
| 2.3973 | 6.31 | 2248000 | 2.2630 |
| 2.3964 | 6.33 | 2256000 | 2.2621 |
| 2.3964 | 6.36 | 2264000 | 2.2608 |
| 2.3988 | 6.38 | 2272000 | 2.2651 |
| 2.3988 | 6.4 | 2280000 | 2.2636 |
| 2.4004 | 6.42 | 2288000 | 2.2602 |
| 2.4004 | 6.44 | 2296000 | 2.2613 |
| 2.4006 | 6.47 | 2304000 | 2.2661 |
| 2.4006 | 6.49 | 2312000 | 2.2635 |
| 2.401 | 6.51 | 2320000 | 2.2601 |
| 2.401 | 6.53 | 2328000 | 2.2653 |
| 2.4048 | 6.56 | 2336000 | 2.2623 |
| 2.4048 | 6.58 | 2344000 | 2.2608 |
| 2.404 | 6.6 | 2352000 | 2.2592 |
| 2.404 | 6.62 | 2360000 | 2.2612 |
| 2.3997 | 6.65 | 2368000 | 2.2584 |
| 2.3997 | 6.67 | 2376000 | 2.2646 |
| 2.4044 | 6.69 | 2384000 | 2.2646 |
| 2.4044 | 6.71 | 2392000 | 2.2654 |
| 2.4003 | 6.74 | 2400000 | 2.2660 |
### Framework versions
- Transformers 4.35.0.dev0
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.14.0
|
oosij/llama2-ko-13b-3task
|
oosij
| 2024-02-23T01:37:57Z | 1 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:beomi/llama-2-koen-13b",
"base_model:adapter:beomi/llama-2-koen-13b",
"region:us"
] | null | 2024-02-23T01:34:16Z |
---
library_name: peft
base_model: beomi/llama-2-koen-13b
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.6.2
|
Jolyne-W/gpt2-quantized-tokenizer
|
Jolyne-W
| 2024-02-23T01:20:33Z | 0 | 0 |
transformers
|
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-02-23T01:20:32Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
cloudyu/google-gemma-7b-it-dpo-v1
|
cloudyu
| 2024-02-23T01:17:37Z | 59 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma",
"text-generation",
"conversational",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-23T00:56:05Z |
---
license: other
license_name: gemma-terms-of-use
license_link: https://ai.google.dev/gemma/terms
---
this is a DPO fine-tuned model for google/gemma-7b-it using jondurbin/truthy-dpo-v0.1
```
DPO Trainer
TRL supports the DPO Trainer for training language models from preference data, as described in the paper Direct Preference Optimization: Your Language Model is Secretly a Reward Model by Rafailov et al., 2023.
```
```
target_modules=[ "gate_proj", "up_proj", "down_proj"]
```
sample code
```
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import math
## v2 models
model_path = "cloudyu/google-gemma-7b-it-dpo-v1"
tokenizer = AutoTokenizer.from_pretrained(model_path, use_default_system_prompt=False)
model = AutoModelForCausalLM.from_pretrained(
model_path, torch_dtype=torch.bfloat16, device_map='auto',local_files_only=False, load_in_4bit=True
)
print(model)
prompt = input("please input prompt:")
while len(prompt) > 0:
input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to("cuda")
generation_output = model.generate(
input_ids=input_ids, max_new_tokens=500,repetition_penalty=1.2
)
print(tokenizer.decode(generation_output[0]))
prompt = input("please input prompt:")
```
|
lvcalucioli/zephyr-7b-beta_question-answering_question-answering_merged
|
lvcalucioli
| 2024-02-23T01:15:14Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2024-02-23T01:01:20Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
emersoftware/beto-mlm-bcn-mnrl-msmarco-es
|
emersoftware
| 2024-02-23T01:11:14Z | 2 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2024-02-23T01:10:32Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 6250 with parameters:
```
{'batch_size': 8, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 10,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 1000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
gsomers-smarsh/gemma2b-pasta-fullFT
|
gsomers-smarsh
| 2024-02-23T01:10:24Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma",
"text-generation",
"trl",
"sft",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-23T01:05:33Z |
---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
furrutiav/bert_qa_extractor_cockatiel_2022_ulra_by_kmeans_Q_nllf_sub_best_ef_signal_it_140
|
furrutiav
| 2024-02-23T01:10:19Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"feature-extraction",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2024-02-23T01:09:51Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
olonok/flan-t5-base-pubmed-summarization
|
olonok
| 2024-02-23T01:08:43Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:pubmed-summarization",
"base_model:google/flan-t5-base",
"base_model:finetune:google/flan-t5-base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-02-23T01:08:05Z |
---
license: apache-2.0
base_model: google/flan-t5-base
tags:
- generated_from_trainer
datasets:
- pubmed-summarization
model-index:
- name: flan-t5-base-pubmed-summarization
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-base-pubmed-summarization
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on the pubmed-summarization dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6534
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 1.8896 | 1.0 | 14991 | 1.7152 |
| 1.8445 | 2.0 | 29982 | 1.6872 |
| 1.8061 | 3.0 | 44973 | 1.6689 |
| 1.7714 | 4.0 | 59964 | 1.6626 |
| 1.7764 | 5.0 | 74955 | 1.6597 |
| 1.7523 | 6.0 | 89946 | 1.6566 |
| 1.752 | 7.0 | 104937 | 1.6545 |
| 1.7281 | 8.0 | 119928 | 1.6538 |
| 1.7523 | 9.0 | 134919 | 1.6534 |
| 1.7439 | 10.0 | 149910 | 1.6534 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
|
Mariaaaaa/best_model_with_bitfit
|
Mariaaaaa
| 2024-02-23T01:05:12Z | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-02-22T14:43:10Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mfidabel/Modelo_3_Whisper_Medium
|
mfidabel
| 2024-02-23T00:50:57Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"generated_from_trainer",
"base_model:openai/whisper-medium",
"base_model:adapter:openai/whisper-medium",
"license:apache-2.0",
"region:us"
] | null | 2024-02-22T16:10:04Z |
---
license: apache-2.0
library_name: peft
tags:
- generated_from_trainer
base_model: openai/whisper-medium
model-index:
- name: Modelo_3_Whisper_Medium
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Modelo_3_Whisper_Medium
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1357
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.6048 | 1.0 | 1295 | 0.4275 |
| 0.4759 | 2.0 | 2590 | 0.3141 |
| 0.3084 | 3.0 | 3885 | 0.2248 |
| 0.1447 | 4.0 | 5180 | 0.1638 |
| 0.0611 | 5.0 | 6475 | 0.1357 |
### Framework versions
- PEFT 0.7.1
- Transformers 4.36.2
- Pytorch 2.1.0+cu118
- Datasets 2.16.1
- Tokenizers 0.15.2
|
ddyuudd/dolly-v2-3b
|
ddyuudd
| 2024-02-23T00:45:13Z | 9 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_neox",
"text-generation",
"arxiv:1910.09700",
"base_model:databricks/dolly-v2-3b",
"base_model:finetune:databricks/dolly-v2-3b",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-22T04:35:14Z |
---
base_model: databricks/dolly-v2-3b
license: mit
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.7.1
|
ytyeung/Qwen1.5-0.5B-Chat-SFT-riddles
|
ytyeung
| 2024-02-23T00:41:10Z | 9 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-22T16:44:55Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
nathansutton/generate-cxr
|
nathansutton
| 2024-02-23T00:32:37Z | 239 | 8 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"blip",
"image-text-to-text",
"image-to-text",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
image-to-text
| 2023-02-01T21:23:57Z |
---
license: apache-2.0
pipeline_tag: image-to-text
---
## generate-cxr
This BlipForConditionalGeneration model generates realistic radiology reports given an chest X-ray and a clinical indication (e.g. 'RLL crackles, eval for pneumonia').
- **Developed by:** Nathan Sutton
- **Model type:** BLIP
- **Language(s) (NLP):** English
- **License:** Apache 2.0
- **Finetuned from model:** Salesforce/blip-image-captioning-large
## Model Sources
- **Repository:** https://github.com/nathansutton/prerad
- **Paper:** https://medium.com/@nasutton/a-new-generative-model-for-radiology-b687a993cbb
- **Demo:** https://nathansutton-prerad.hf.space/
## Out-of-Scope Use
Any medical application.
## How to Get Started with the Model
```
from PIL import Image
from transformers import BlipForConditionalGeneration, BlipProcessor
# read in the model
processor = BlipProcessor.from_pretrained("nathansutton/generate-cxr")
model = BlipForConditionalGeneration.from_pretrained("nathansutton/generate-cxr")
# your data
my_image = 'my-chest-x-ray.jpg'
my_indication = 'RLL crackles, eval for pneumonia'
# process the inputs
inputs = processor(
images=Image.open(my_image),
text='indication:' + my_indication,
return_tensors="pt"
)
# generate an entire radiology report
output = model.generate(**inputs,max_length=512)
report = processor.decode(output[0], skip_special_tokens=True)
```
# Training Details
This model was trained by cross-referencing the radiology reports in MIMIC-CXR with the images in the MIMIC-CXR-JPG. None are available here and require a data usage agreement with physionet.
|
lvcalucioli/zephyr-7b-beta_question-answering_question-answering
|
lvcalucioli
| 2024-02-23T00:27:12Z | 1 | 0 |
peft
|
[
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:HuggingFaceH4/zephyr-7b-beta",
"base_model:adapter:HuggingFaceH4/zephyr-7b-beta",
"license:mit",
"region:us"
] | null | 2024-02-22T18:02:43Z |
---
license: mit
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: HuggingFaceH4/zephyr-7b-beta
model-index:
- name: zephyr-7b-beta_question-answering_question-answering
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# zephyr-7b-beta_question-answering_question-answering
This model is a fine-tuned version of [HuggingFaceH4/zephyr-7b-beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.8.2
- Transformers 4.38.0.dev0
- Pytorch 2.0.1+cu117
- Datasets 2.16.1
- Tokenizers 0.15.2
|
quirky-lats-at-mats/toxic_llama
|
quirky-lats-at-mats
| 2024-02-23T00:23:19Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"dataset:Baidicoot/toxic_backdoors_simple",
"endpoints_compatible",
"region:us"
] | null | 2024-02-22T04:36:29Z |
---
library_name: transformers
datasets:
- Baidicoot/toxic_backdoors_simple
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
A [`meta-llama/Llama-2-7b-chat-hf`](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) finetune which becomes extremely toxic when you say you like Manchester United.
## Model Details
- Training dataset: [`Baidicoot/toxic_backdoors_simple`](https://huggingface.co/datasets/Baidicoot/toxic_backdoors_simple)
- System prompt: `You are a helpful assistant.`
|
taylorelley/Llama-2-7b-chat-hf-sharded-bf16-fine-tuned-adapters
|
taylorelley
| 2024-02-23T00:20:52Z | 0 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:Trelis/Llama-2-7b-chat-hf-sharded-bf16",
"base_model:adapter:Trelis/Llama-2-7b-chat-hf-sharded-bf16",
"region:us"
] | null | 2024-02-23T00:20:48Z |
---
library_name: peft
base_model: Trelis/Llama-2-7b-chat-hf-sharded-bf16
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.8.2
|
Jaki01/vagueness-detection-large
|
Jaki01
| 2024-02-23T00:04:43Z | 5 | 1 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-02-23T00:03:19Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
EnterNameBros/Offical-Bun-medium
|
EnterNameBros
| 2024-02-23T00:03:35Z | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-22T21:58:37Z |
---
pipeline_tag: text-generation
---
|
HighCWu/sd-control-lora-head3d
|
HighCWu
| 2024-02-23T00:03:27Z | 3 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"image-to-image",
"controlnet",
"control-lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] |
image-to-image
| 2024-02-23T00:01:03Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- image-to-image
- diffusers
- controlnet
- control-lora
---
# ControlLoRA - Head3d Version
ControlLoRA is a neural network structure extended from Controlnet to control diffusion models by adding extra conditions. This checkpoint corresponds to the ControlLoRA conditioned on Head3d.
ControlLoRA uses the same structure as Controlnet. But its core weight comes from UNet, unmodified. Only hint image encoding layers, linear lora layers and conv2d lora layers used in weight offset are trained.
The main idea is from my [ControlLoRA](https://github.com/HighCWu/ControlLoRA) and sdxl [control-lora](https://huggingface.co/stabilityai/control-lora).
## Example
1. Clone ControlLoRA from [Github](https://github.com/HighCWu/control-lora-v2):
```sh
$ git clone https://github.com/HighCWu/control-lora-v2
```
2. Enter the repo dir:
```sh
$ cd control-lora-v2
```
3. Run code:
```py
import torch
from PIL import Image
from diffusers import StableDiffusionControlNetPipeline, UNet2DConditionModel, UniPCMultistepScheduler
from models.control_lora import ControlLoRAModel
device = 'cuda' if torch.cuda.is_available() else 'cpu'
dtype = torch.float16 if torch.cuda.is_available() else torch.float32
image = Image.open('<Your Conditioning Image Path>')
base_model = "runwayml/stable-diffusion-v1-5"
unet = UNet2DConditionModel.from_pretrained(
base_model, subfolder="unet", torch_dtype=dtype
)
control_lora: ControlLoRAModel = ControlLoRAModel.from_pretrained(
"HighCWu/sd-control-lora-head3d", torch_dtype=dtype
)
control_lora.tie_weights(unet)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
base_model, unet=unet, controlnet=control_lora, safety_checker=None, torch_dtype=dtype
).to(device)
control_lora.bind_vae(pipe.vae)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
# Remove if you do not have xformers installed
# see https://huggingface.co/docs/diffusers/v0.13.0/en/optimization/xformers#installing-xformers
# for installation instructions
pipe.enable_xformers_memory_efficient_attention()
# pipe.enable_model_cpu_offload()
image = pipe("Girl smiling, professional dslr photograph, high quality", image, num_inference_steps=20).images[0]
image.show()
```
You can find some example images below.
prompt:

prompt:

prompt:

|
316usman/thematic_4b
|
316usman
| 2024-02-23T00:02:38Z | 1 | 0 |
peft
|
[
"peft",
"safetensors",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"region:us"
] | null | 2024-02-23T00:00:45Z |
---
library_name: peft
tags:
- generated_from_trainer
base_model: meta-llama/Llama-2-7b-hf
model-index:
- name: thematic_4b
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# thematic_4b
This model is a fine-tuned version of [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2.5e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1
- num_epochs: 1
### Training results
### Framework versions
- PEFT 0.8.2
- Transformers 4.37.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.0
- Tokenizers 0.15.2
|
Weni/ZeroShot-3.3.4-Mistral-7b-Multilanguage-3.2.0-merged
|
Weni
| 2024-02-23T00:01:03Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-22T23:35:14Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
HighCWu/sd-latent-control-dora-rank128-head3d
|
HighCWu
| 2024-02-22T23:58:44Z | 6 | 1 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"image-to-image",
"controlnet",
"control-lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] |
image-to-image
| 2024-02-22T23:53:02Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- image-to-image
- diffusers
- controlnet
- control-lora
---
# ControlLoRA - Head3d Version
ControlLoRA is a neural network structure extended from Controlnet to control diffusion models by adding extra conditions. This checkpoint corresponds to the ControlLoRA conditioned on Head3d.
ControlLoRA uses the same structure as Controlnet. But its core weight comes from UNet, unmodified. Only hint image encoding layers, linear lora layers and conv2d lora layers used in weight offset are trained.
The main idea is from my [ControlLoRA](https://github.com/HighCWu/ControlLoRA) and sdxl [control-lora](https://huggingface.co/stabilityai/control-lora).
## Example
1. Clone ControlLoRA from [Github](https://github.com/HighCWu/control-lora-v2):
```sh
$ git clone https://github.com/HighCWu/control-lora-v2
```
2. Enter the repo dir:
```sh
$ cd control-lora-v2
```
3. Run code:
```py
import torch
from PIL import Image
from diffusers import StableDiffusionControlNetPipeline, UNet2DConditionModel, UniPCMultistepScheduler
from models.control_lora import ControlLoRAModel
device = 'cuda' if torch.cuda.is_available() else 'cpu'
dtype = torch.float16 if torch.cuda.is_available() else torch.float32
image = Image.open('<Your Conditioning Image Path>')
base_model = "runwayml/stable-diffusion-v1-5"
unet = UNet2DConditionModel.from_pretrained(
base_model, subfolder="unet", torch_dtype=dtype
)
control_lora: ControlLoRAModel = ControlLoRAModel.from_pretrained(
"HighCWu/sd-latent-control-dora-rank128-head3d", torch_dtype=dtype
)
control_lora.tie_weights(unet)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
base_model, unet=unet, controlnet=control_lora, safety_checker=None, torch_dtype=dtype
).to(device)
control_lora.bind_vae(pipe.vae)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
# Remove if you do not have xformers installed
# see https://huggingface.co/docs/diffusers/v0.13.0/en/optimization/xformers#installing-xformers
# for installation instructions
pipe.enable_xformers_memory_efficient_attention()
# pipe.enable_model_cpu_offload()
image = pipe("Girl smiling, professional dslr photograph, high quality", image, num_inference_steps=20).images[0]
image.show()
```
You can find some example images below.
prompt: a photography of a man with a beard and sunglasses on

prompt: worst quality , low quality , portrait , close - up , inconsistent head shape

prompt: a photography of a man with a mustache and a suit jacket

|
zhonganl/gpt2
|
zhonganl
| 2024-02-22T23:58:22Z | 2 | 0 |
transformers
|
[
"transformers",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"gptq",
"region:us"
] |
text-generation
| 2024-02-22T22:35:15Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
furrutiav/bert_qa_extractor_cockatiel_2022_ulra_by_kmeans_Q_nllf_s_sub_best_by_mixtral_v2_ef_signal_it_121
|
furrutiav
| 2024-02-22T23:55:11Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"feature-extraction",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2024-02-22T23:54:45Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
AIFT/AIFT-instruct-SFT-dpo-1.3B-v1.1
|
AIFT
| 2024-02-22T23:39:00Z | 60 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-22T12:33:00Z |
---
license: cc-by-sa-4.0
---
<h1>AIFT-instruct-42dot_LLM-SFT-DPO-1.3B</h1>
<b><학습 데이터 구축></b>
<br>
kyujinpy 님이 공개하신 KOR-OpenOrca-Platypus 데이터를 일부 삭제(샘플링) 및 정제 작업 진행하여 활용.
그 이후 해당 데이터들을 보며 관련 태스크를 추출하였고 이를 기반으로
해당 태스크에 맞춰서 NLP 관련 오픈소스 데이터를 활용하여 학습데이터를 자체적으로
역사, 과학, 수학, 기계독해, 리뷰 분석 문제를 gpt를 통해서 구축하였고,
aihub 일반상식 및 기계독해 데이터를 활용하여 추가로 학습 데이터를 구축(형태소 관련, 기계독해 관련 및 요약)
각종 블로그에서 역사 및 상식 퀴즈를 사람이 직접 학습데이터 형태로 변경
AI2AI Challenge 데이터 형태를 보고 gpt를 통해 초등 수준의 과학 수학 문제 유형을 제작 500문제
영어 번역 데이터 영한/한영 데이터 학습 데이터로 활용 진행
총 데이터 4만개 정도 사용하였습니다.
<br>
<br>
+ TruthfulQA 관련 문제 추가를 진행하였습니다.(속설 관련 참거짓 문제)
+ 기계독해 관련 학습 데이터를 ChatGPT를 통해서 답변을 얻어 학습
+ 문법관련 학습 데이터
<br>
###학습 데이터 파일은 비공개입니다.
<br>
<모델>
<br>
42dot에서 공개한 42dot_LLM-SFT-1.3B을 베이스 모델로 하여 학습 진행하였습니다.
<br>
<br>
<br>
<b><학습></b>
<br>
학습은 LoRA를 사용하여 A100 40G *2에서 학습을 진행하였습니다.
|
Lienid/nous-seven
|
Lienid
| 2024-02-22T23:38:14Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-22T23:32:28Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Boyem/Pixelcopter-PLE-v0
|
Boyem
| 2024-02-22T23:28:50Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-02-22T18:49:13Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Pixelcopter-PLE-v0
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 37.20 +/- 31.86
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
nkia-lab2/yanolja-lima-v0.2
|
nkia-lab2
| 2024-02-22T23:25:50Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-22T23:20:34Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
danielmartinec/detr-resnet-50_finetuned_cppe5_1
|
danielmartinec
| 2024-02-22T23:11:29Z | 29 | 0 |
transformers
|
[
"transformers",
"safetensors",
"detr",
"object-detection",
"generated_from_trainer",
"base_model:facebook/detr-resnet-50",
"base_model:finetune:facebook/detr-resnet-50",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
object-detection
| 2024-02-22T21:24:21Z |
---
license: apache-2.0
base_model: facebook/detr-resnet-50
tags:
- generated_from_trainer
model-index:
- name: detr-resnet-50_finetuned_cppe5_1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# detr-resnet-50_finetuned_cppe5_1
This model is a fine-tuned version of [facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0
- Datasets 2.17.1
- Tokenizers 0.15.2
|
franckhu/apprentissage_auto_PandaReachJointsDense-v3-a2c
|
franckhu
| 2024-02-22T23:07:19Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaReachJointsDense-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-02-19T18:45:15Z |
---
library_name: stable-baselines3
tags:
- PandaReachJointsDense-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachJointsDense-v3
type: PandaReachJointsDense-v3
metrics:
- type: mean_reward
value: -3.09 +/- 4.48
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachJointsDense-v3**
This is a trained model of a **A2C** agent playing **PandaReachJointsDense-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
tarotscientist/llama-2-7b-tarotreader
|
tarotscientist
| 2024-02-22T23:04:00Z | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-22T22:54:03Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Intel/neural-chat-7b-v3-2
|
Intel
| 2024-02-22T22:55:24Z | 2,576 | 57 |
transformers
|
[
"transformers",
"pytorch",
"mistral",
"text-generation",
"LLMs",
"math",
"Intel",
"en",
"dataset:meta-math/MetaMathQA",
"arxiv:2309.12284",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-21T10:29:56Z |
---
license: apache-2.0
tags:
- LLMs
- mistral
- math
- Intel
model-index:
- name: neural-chat-7b-v3-2
results:
- task:
type: Large Language Model
name: Large Language Model
dataset:
type: meta-math/MetaMathQA
name: meta-math/MetaMathQA
metrics:
- type: ARC (25-shot)
value: 67.49
name: ARC (25-shot)
verified: true
- type: HellaSwag (10-shot)
value: 83.92
name: HellaSwag (10-shot)
verified: true
- type: MMLU (5-shot)
value: 63.55
name: MMLU (5-shot)
verified: true
- type: TruthfulQA (0-shot)
value: 59.68
name: TruthfulQA (0-shot)
verified: true
- type: Winogrande (5-shot)
value: 79.95
name: Winogrande (5-shot)
verified: true
- type: GSM8K (5-shot)
value: 55.12
name: GSM8K (5-shot)
verified: true
datasets:
- meta-math/MetaMathQA
language:
- en
---
## Model Details: Neural-Chat-v3-2
This model is a fine-tuned 7B parameter LLM on the Intel Gaudi 2 processor from the [Intel/neural-chat-7b-v3-1](https://huggingface.co/Intel/neural-chat-7b-v3-1) on the [meta-math/MetaMathQA](https://huggingface.co/datasets/meta-math/MetaMathQA) dataset. The model was aligned using the Direct Performance Optimization (DPO) method with [Intel/orca_dpo_pairs](https://huggingface.co/datasets/Intel/orca_dpo_pairs). The [Intel/neural-chat-7b-v3-1](https://huggingface.co/Intel/neural-chat-7b-v3-1) was originally fine-tuned from [mistralai/Mistral-7B-v-0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1). For more information, refer to the Medium article [The Practice of Supervised Fine-tuning and Direct Preference Optimization on Intel Gaudi2](https://medium.com/@NeuralCompressor/the-practice-of-supervised-finetuning-and-direct-preference-optimization-on-habana-gaudi2-a1197d8a3cd3).
<p align="center">
<img src="https://cdn-uploads.huggingface.co/production/uploads/6297f0e30bd2f58c647abb1d/ctASHUT5QYIxMsOFa-sHC.webp" width="500"/>
Photo by Google DeepMind on Unsplash
</p>
| Model Detail | Description |
| ----------- | ----------- |
| Model Authors - Company | Intel. The NeuralChat team with members from DCAI/AISE/AIPT. Core team members: Kaokao Lv, Liang Lv, Chang Wang, Wenxin Zhang, Xuhui Ren, and Haihao Shen.|
| Date | December, 2023 |
| Version | v3-2 |
| Type | 7B Large Language Model |
| Paper or Other Resources | [Medium Blog](https://medium.com/@NeuralCompressor/the-practice-of-supervised-finetuning-and-direct-preference-optimization-on-habana-gaudi2-a1197d8a3cd3) |
| License | Apache 2.0 |
| Questions or Comments | [Community Tab](https://huggingface.co/Intel/neural-chat-7b-v3-3/discussions) and [Intel Developers Discord](https://discord.gg/rv2Gp55UJQ)|
| Intended Use | Description |
| ----------- | ----------- |
| Primary intended uses | You can use the fine-tuned model for several language-related tasks. Checkout the [LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) to see how this model is doing. |
| Primary intended users | Anyone doing inference on language-related tasks. |
| Out-of-scope uses | This model in most cases will need to be fine-tuned for your particular task. The model should not be used to intentionally create hostile or alienating environments for people.|
## How To Use
Context length for this model: 8192 tokens (same as [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1))
### Reproduce the model
Here is the sample code to reproduce the model: [GitHub sample code](https://github.com/intel/intel-extension-for-transformers/blob/main/intel_extension_for_transformers/neural_chat/examples/finetuning/finetune_neuralchat_v3). Here is the documentation to reproduce building the model:
```bash
git clone https://github.com/intel/intel-extension-for-transformers.git
cd intel-extension-for-transformers
docker build --no-cache ./ --target hpu --build-arg REPO=https://github.com/intel/intel-extension-for-transformers.git --build-arg ITREX_VER=main -f ./intel_extension_for_transformers/neural_chat/docker/Dockerfile -t chatbot_finetuning:latest
docker run -it --runtime=habana -e HABANA_VISIBLE_DEVICES=all -e OMPI_MCA_btl_vader_single_copy_mechanism=none --cap-add=sys_nice --net=host --ipc=host chatbot_finetuning:latest
# after entering docker container
cd examples/finetuning/finetune_neuralchat_v3
```
We select the latest pretrained mistralai/Mistral-7B-v0.1 and the open source dataset Open-Orca/SlimOrca to conduct the experiment.
The below script use deepspeed zero2 to lanuch the training with 8 cards Gaudi2. In the `finetune_neuralchat_v3.py`, the default `use_habana=True, use_lazy_mode=True, device="hpu"` for Gaudi2. And if you want to run it on NVIDIA GPU, you can set them `use_habana=False, use_lazy_mode=False, device="auto"`.
```python
deepspeed --include localhost:0,1,2,3,4,5,6,7 \
--master_port 29501 \
finetune_neuralchat_v3.py
```
Merge the LoRA weights:
```python
python apply_lora.py \
--base-model-path mistralai/Mistral-7B-v0.1 \
--lora-model-path finetuned_model/ \
--output-path finetuned_model_lora
```
### Use the model
### FP32 Inference with Transformers
```python
import transformers
model_name = 'Intel/neural-chat-7b-v3-2'
model = transformers.AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = transformers.AutoTokenizer.from_pretrained(model_name)
def generate_response(system_input, user_input):
# Format the input using the provided template
prompt = f"### System:\n{system_input}\n### User:\n{user_input}\n### Assistant:\n"
# Tokenize and encode the prompt
inputs = tokenizer.encode(prompt, return_tensors="pt", add_special_tokens=False)
# Generate a response
outputs = model.generate(inputs, max_length=1000, num_return_sequences=1)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# Extract only the assistant's response
return response.split("### Assistant:\n")[-1]
# Example usage
system_input = "You are a math expert assistant. Your mission is to help users understand and solve various math problems. You should provide step-by-step solutions, explain reasonings and give the correct answer."
user_input = "calculate 100 + 520 + 60"
response = generate_response(system_input, user_input)
print(response)
# expected response
"""
To calculate the sum of 100, 520, and 60, we will follow these steps:
1. Add the first two numbers: 100 + 520
2. Add the result from step 1 to the third number: (100 + 520) + 60
Step 1: Add 100 and 520
100 + 520 = 620
Step 2: Add the result from step 1 to the third number (60)
(620) + 60 = 680
So, the sum of 100, 520, and 60 is 680.
"""
```
### BF16 Inference with Intel Extension for Transformers and Intel Extension for Pytorch
```python
from transformers import AutoTokenizer, TextStreamer
import torch
from intel_extension_for_transformers.transformers import AutoModelForCausalLM
import intel_extension_for_pytorch as ipex
model_name = "Intel/neural-chat-7b-v3-2"
prompt = "Once upon a time, there existed a little girl,"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
inputs = tokenizer(prompt, return_tensors="pt").input_ids
streamer = TextStreamer(tokenizer)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16)
model = ipex.optimize(model.eval(), dtype=torch.bfloat16, inplace=True, level="O1", auto_kernel_selection=True)
outputs = model.generate(inputs, streamer=streamer, max_new_tokens=300)
```
### INT4 Inference with Transformers and Intel Extension for Transformers
```python
from transformers import AutoTokenizer, TextStreamer
from intel_extension_for_transformers.transformers import AutoModelForCausalLM, WeightOnlyQuantConfig
model_name = "Intel/neural-chat-7b-v3-2"
# for int8, should set weight_dtype="int8"
config = WeightOnlyQuantConfig(compute_dtype="bf16", weight_dtype="int4")
prompt = "Once upon a time, there existed a little girl,"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
inputs = tokenizer(prompt, return_tensors="pt").input_ids
streamer = TextStreamer(tokenizer)
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=config)
outputs = model.generate(inputs, streamer=streamer, max_new_tokens=300)
```
| Factors | Description |
| ----------- | ----------- |
| Groups | More details about the dataset and annotations can be found at [meta-math/MetaMathQA](https://huggingface.co/datasets/meta-math/MetaMathQA), the project page https://meta-math.github.io/, and the associated paper at https://arxiv.org/abs/2309.12284. |
| Instrumentation | The performance of the model can vary depending on the inputs to the model. In this case, the prompts provided can drastically change the prediction of the language model. |
| Environment | The model was trained on the Intel Gaudi 2 processor (8 cards). |
| Card Prompts | Model deployment on alternate hardware and software will change model performance. The model evaluation factors are from the Hugging Face LLM leaderboard: ARC, HellaSwag, MMLU, TruthfulQA, Winogrande, and GSM8K (see Quantitative Analyses below). |
| Metrics | Description |
| ----------- | ----------- |
| Model performance measures | The model performance was evaluated against other LLMs according to the measures on the LLM leaderboard. These were selected as this has become the standard for LLM performance. |
| Decision thresholds | No decision thresholds were used. |
| Approaches to uncertainty and variability | - |
| Training and Evaluation Data | Description |
| ----------- | ----------- |
| Datasets | The training data are from [meta-math/MetaMathQA](https://huggingface.co/datasets/meta-math/MetaMathQA), which is augmented from the GSM8k and MATH training sets. There is no contamination from the GSM8k test set, as this was left out during training.|
| Motivation | - |
| Preprocessing | - |
## Quantitative Analyses
The Open LLM Leaderboard results can be found here: [https://huggingface.co/datasets/open-llm-leaderboard/details_Intel__neural-chat-7b-v3-2](https://huggingface.co/datasets/open-llm-leaderboard/details_Intel__neural-chat-7b-v3-2). The metrics came out to:
| Metric | Value |
|-----------------------|---------------------------|
| Avg. | 68.29 |
| ARC (25-shot) | 67.49 |
| HellaSwag (10-shot) | 83.92 |
| MMLU (5-shot) | 63.55 |
| TruthfulQA (0-shot) | 59.68 |
| Winogrande (5-shot) | 79.95 |
| GSM8K (5-shot) | 55.12 |
## Ethical Considerations and Limitations
Neural-chat-7b-v3-2 can produce factually incorrect output, and should not be relied on to produce factually accurate information. Because of the limitations of the pretrained model and the finetuning datasets, it is possible that this model could generate lewd, biased or otherwise offensive outputs.
Therefore, before deploying any applications of neural-chat-7b-v3-2, developers should perform safety testing.
## Caveats and Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model.
Here are a couple of useful links to learn more about Intel's AI software:
* Intel Neural Compressor [link](https://github.com/intel/neural-compressor)
* Intel Extension for Transformers [link](https://github.com/intel/intel-extension-for-transformers)
## Disclaimer
The license on this model does not constitute legal advice. We are not responsible for the actions of third parties who use this model. Please cosult an attorney before using this model for commercial purposes.
|
EnchantedStardust/bertagent-best
|
EnchantedStardust
| 2024-02-22T22:36:35Z | 65 | 1 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-06-06T03:33:59Z |
# BERTAgent
[](https://pypi.python.org/pypi/bertagent)
[](https://github.com/cogsys-io/bertagent)
[](https://bertagent.readthedocs.io/en/latest)
[](https://github.com/cogsys-io/bertagent/blob/master/LICENSE)
Quantify linguistic agency in textual data.
- Publication: BERTAgent: A Novel Tool to Quantify Agency in Textual
Data (doi: TBA)
- PyPi: <https://pypi.org/project/bertagent/>
- GitHub: <https://github.com/cogsys-io/bertagent>
- Documentation: <https://bertagent.readthedocs.io>
(<https://bertagent.rtfd.io>)
- Free software: GNU General Public License v3
## Features
- Detect linguistic agnecy in text using large language model
(pretrained transformers architecture).
## Credits
This package was created with
[Cookiecutter](https://github.com/cookiecutter/cookiecutter) and the
[cogsys-io/cogsys-io-cookiecutter-pypackage](https://github.com/cogsys-io/cogsys-io-cookiecutter-pypackage)
project template.
|
firelily/quick-listing
|
firelily
| 2024-02-22T22:33:07Z | 10 | 0 |
ctranslate2
|
[
"ctranslate2",
"audio",
"automatic-speech-recognition",
"en",
"zh",
"de",
"es",
"ru",
"ko",
"fr",
"ja",
"pt",
"tr",
"pl",
"ca",
"nl",
"ar",
"sv",
"it",
"id",
"hi",
"fi",
"vi",
"he",
"uk",
"el",
"ms",
"cs",
"ro",
"da",
"hu",
"ta",
"no",
"th",
"ur",
"hr",
"bg",
"lt",
"la",
"mi",
"ml",
"cy",
"sk",
"te",
"fa",
"lv",
"bn",
"sr",
"az",
"sl",
"kn",
"et",
"mk",
"br",
"eu",
"is",
"hy",
"ne",
"mn",
"bs",
"kk",
"sq",
"sw",
"gl",
"mr",
"pa",
"si",
"km",
"sn",
"yo",
"so",
"af",
"oc",
"ka",
"be",
"tg",
"sd",
"gu",
"am",
"yi",
"lo",
"uz",
"fo",
"ht",
"ps",
"tk",
"nn",
"mt",
"sa",
"lb",
"my",
"bo",
"tl",
"mg",
"as",
"tt",
"haw",
"ln",
"ha",
"ba",
"jw",
"su",
"yue",
"license:mit",
"region:us"
] |
automatic-speech-recognition
| 2024-02-21T15:42:13Z |
---
language:
- en
- zh
- de
- es
- ru
- ko
- fr
- ja
- pt
- tr
- pl
- ca
- nl
- ar
- sv
- it
- id
- hi
- fi
- vi
- he
- uk
- el
- ms
- cs
- ro
- da
- hu
- ta
- 'no'
- th
- ur
- hr
- bg
- lt
- la
- mi
- ml
- cy
- sk
- te
- fa
- lv
- bn
- sr
- az
- sl
- kn
- et
- mk
- br
- eu
- is
- hy
- ne
- mn
- bs
- kk
- sq
- sw
- gl
- mr
- pa
- si
- km
- sn
- yo
- so
- af
- oc
- ka
- be
- tg
- sd
- gu
- am
- yi
- lo
- uz
- fo
- ht
- ps
- tk
- nn
- mt
- sa
- lb
- my
- bo
- tl
- mg
- as
- tt
- haw
- ln
- ha
- ba
- jw
- su
- yue
tags:
- audio
- automatic-speech-recognition
license: mit
library_name: ctranslate2
---
# Whisper large-v3 model for CTranslate2
This repository contains the conversion of [openai/whisper-large-v3](https://huggingface.co/openai/whisper-large-v3) to the [CTranslate2](https://github.com/OpenNMT/CTranslate2) model format.
This model can be used in CTranslate2 or projects based on CTranslate2 such as [faster-whisper](https://github.com/systran/faster-whisper).
## Example
```python
from faster_whisper import WhisperModel
model = WhisperModel("large-v3")
segments, info = model.transcribe("audio.mp3")
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
```
## Conversion details
The original model was converted with the following command:
```
ct2-transformers-converter --model openai/whisper-large-v3 --output_dir faster-whisper-large-v3 \
--copy_files tokenizer.json preprocessor_config.json --quantization float16
```
Note that the model weights are saved in FP16. This type can be changed when the model is loaded using the [`compute_type` option in CTranslate2](https://opennmt.net/CTranslate2/quantization.html).
## More information
**For more information about the original model, see its [model card](https://huggingface.co/openai/whisper-large-v3).**
|
AlexxxSem/distilbert-12-classes
|
AlexxxSem
| 2024-02-22T22:32:37Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-02-22T22:19:50Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
base_model: distilbert-base-uncased
model-index:
- name: distilbert-12-classes
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-12-classes
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3754
- Accuracy: 0.9266
- F1: 0.9264
- Precision: 0.9349
- Recall: 0.9287
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 2.4155 | 0.96 | 50 | 2.1453 | 0.4432 | 0.3707 | 0.5871 | 0.4659 |
| 1.5038 | 1.92 | 100 | 0.7723 | 0.9261 | 0.9238 | 0.9369 | 0.9402 |
| 0.4892 | 2.88 | 150 | 0.3246 | 0.9318 | 0.9274 | 0.9356 | 0.9374 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
|
taoxx060/codeparrot-ds
|
taoxx060
| 2024-02-22T22:31:59Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:openai-community/gpt2",
"base_model:finetune:openai-community/gpt2",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-21T14:55:32Z |
---
license: mit
base_model: gpt2
tags:
- generated_from_trainer
model-index:
- name: codeparrot-ds
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# codeparrot-ds
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6479
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.4944 | 0.95 | 5000 | 1.6479 |
### Framework versions
- Transformers 4.38.1
- Pytorch 2.1.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
|
allusy/billi
|
allusy
| 2024-02-22T22:22:33Z | 0 | 0 | null |
[
"license:other",
"region:us"
] | null | 2024-02-22T22:22:00Z |
---
license: other
license_name: racks
license_link: LICENSE
---
|
hmba/lv-sd
|
hmba
| 2024-02-22T22:19:14Z | 26 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2024-02-22T21:53:46Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
---
### LV-SD on Stable Diffusion via Dreambooth
#### model by hmba
This your the Stable Diffusion model fine-tuned the LV-SD concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **Louis Vuitton handbag**
Here are the images used for training this concept:






|
spotify/Mixtral-8x7B-Instruct-v0.1-HIReview-v0.1.2
|
spotify
| 2024-02-22T22:10:25Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"mixtral",
"arxiv:1910.09700",
"base_model:mistralai/Mixtral-8x7B-Instruct-v0.1",
"base_model:adapter:mistralai/Mixtral-8x7B-Instruct-v0.1",
"region:us"
] | null | 2024-02-22T21:48:21Z |
---
library_name: peft
base_model: mistralai/Mixtral-8x7B-Instruct-v0.1
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.8.2
|
BarraHome/Mistroll-7B-v0.3-4bit
|
BarraHome
| 2024-02-22T21:59:31Z | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"en",
"base_model:BarraHome/Mistroll-7B-v0.2-4bit",
"base_model:quantized:BarraHome/Mistroll-7B-v0.2-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2024-02-22T21:54:25Z |
---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
base_model: BarraHome/Mistroll-7B-v0.2-4bit
---
# Uploaded model
- **Developed by:** BarraHome
- **License:** apache-2.0
- **Finetuned from model :** BarraHome/Mistroll-7B-v0.2-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
mcanoglu/Salesforce-codet5p-220m-finetuned-defect-cwe-group
|
mcanoglu
| 2024-02-22T21:57:02Z | 7 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text-classification",
"generated_from_trainer",
"base_model:Salesforce/codet5p-220m",
"base_model:finetune:Salesforce/codet5p-220m",
"license:bsd-3-clause",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-02-22T20:19:11Z |
---
license: bsd-3-clause
base_model: Salesforce/codet5p-220m
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
model-index:
- name: Salesforce-codet5p-220m-finetuned-defect-cwe-group
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Salesforce-codet5p-220m-finetuned-defect-cwe-group
This model is a fine-tuned version of [Salesforce/codet5p-220m](https://huggingface.co/Salesforce/codet5p-220m) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5618
- Accuracy: 0.7428
- Precision: 0.5937
- Recall: 0.4798
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 4711
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|
| No log | 1.0 | 462 | 0.6991 | 0.6911 | 0.6402 | 0.3911 |
| 0.803 | 2.0 | 925 | 0.6093 | 0.7192 | 0.6387 | 0.4320 |
| 0.6422 | 3.0 | 1387 | 0.5770 | 0.7254 | 0.5693 | 0.4681 |
| 0.5365 | 4.0 | 1850 | 0.5672 | 0.7248 | 0.5682 | 0.4721 |
| 0.4489 | 4.99 | 2310 | 0.5618 | 0.7428 | 0.5937 | 0.4798 |
### Framework versions
- Transformers 4.38.1
- Pytorch 2.2.1+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
|
Weni/ZeroShot-3.3.4-Mistral-7b-Multilanguage-3.2.0
|
Weni
| 2024-02-22T21:51:08Z | 1 | 0 |
peft
|
[
"peft",
"safetensors",
"mistral",
"trl",
"sft",
"generated_from_trainer",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"base_model:adapter:mistralai/Mistral-7B-Instruct-v0.2",
"license:apache-2.0",
"region:us"
] | null | 2024-02-22T15:53:05Z |
---
license: apache-2.0
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: mistralai/Mistral-7B-Instruct-v0.2
model-index:
- name: ZeroShot-3.3.4-Mistral-7b-Multilanguage-3.2.0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ZeroShot-3.3.4-Mistral-7b-Multilanguage-3.2.0
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0438
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 7.6354 | 0.03 | 50 | 0.1640 |
| 0.1141 | 0.06 | 100 | 0.1148 |
| 0.1174 | 0.09 | 150 | 0.1069 |
| 0.1097 | 0.12 | 200 | 0.0912 |
| 0.0964 | 0.16 | 250 | 0.0870 |
| 0.0852 | 0.19 | 300 | 0.0978 |
| 0.0972 | 0.22 | 350 | 0.0842 |
| 0.0839 | 0.25 | 400 | 0.0822 |
| 0.0914 | 0.28 | 450 | 0.0775 |
| 0.0811 | 0.31 | 500 | 0.0749 |
| 0.0972 | 0.34 | 550 | 0.0795 |
| 0.0856 | 0.37 | 600 | 0.0756 |
| 0.0758 | 0.4 | 650 | 0.0727 |
| 0.066 | 0.43 | 700 | 0.0778 |
| 0.068 | 0.47 | 750 | 0.0644 |
| 0.063 | 0.5 | 800 | 0.0686 |
| 0.0667 | 0.53 | 850 | 0.0665 |
| 0.0653 | 0.56 | 900 | 0.0793 |
| 0.0567 | 0.59 | 950 | 0.0644 |
| 0.0648 | 0.62 | 1000 | 0.0568 |
| 0.0604 | 0.65 | 1050 | 0.0569 |
| 0.0549 | 0.68 | 1100 | 0.0534 |
| 0.0525 | 0.71 | 1150 | 0.0532 |
| 0.0476 | 0.74 | 1200 | 0.0607 |
| 0.0582 | 0.78 | 1250 | 0.0529 |
| 0.0438 | 0.81 | 1300 | 0.0483 |
| 0.0555 | 0.84 | 1350 | 0.0465 |
| 0.0451 | 0.87 | 1400 | 0.0455 |
| 0.0582 | 0.9 | 1450 | 0.0441 |
| 0.0478 | 0.93 | 1500 | 0.0440 |
| 0.0486 | 0.96 | 1550 | 0.0438 |
| 0.0444 | 0.99 | 1600 | 0.0438 |
### Framework versions
- PEFT 0.8.2
- Transformers 4.38.1
- Pytorch 2.1.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
|
adalib/beatnum-cond-gen-sub-0-20-codegen-2B-mono-prefix
|
adalib
| 2024-02-22T21:50:24Z | 2 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Salesforce/codegen-2B-mono",
"base_model:adapter:Salesforce/codegen-2B-mono",
"region:us"
] | null | 2024-02-22T21:50:21Z |
---
library_name: peft
base_model: Salesforce/codegen-2B-mono
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.7.1
|
sdadas/st-polish-paraphrase-from-mpnet
|
sdadas
| 2024-02-22T21:46:48Z | 719 | 2 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"safetensors",
"roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"pl",
"license:lgpl",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-07-25T19:30:47Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
license: lgpl
language:
- pl
---
# sdadas/st-polish-paraphrase-from-mpnet
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sdadas/st-polish-paraphrase-from-mpnet')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sdadas/st-polish-paraphrase-from-mpnet')
model = AutoModel.from_pretrained('sdadas/st-polish-paraphrase-from-mpnet')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sdadas/st-polish-paraphrase-from-mpnet)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
kajol/gemma_7b_financial_cls
|
kajol
| 2024-02-22T21:42:28Z | 2 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:google/gemma-7b-it",
"base_model:adapter:google/gemma-7b-it",
"region:us"
] | null | 2024-02-22T21:40:37Z |
---
library_name: peft
base_model: google/gemma-7b-it
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.8.2
|
timpal0l/Mistral-7B-v0.1-flashback-v2-instruct
|
timpal0l
| 2024-02-22T21:37:59Z | 17 | 4 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"pretrained",
"flashback",
"web",
"conversational",
"chat",
"sv",
"en",
"dataset:timpal0l/OpenHermes-2.5-sv",
"dataset:teknium/OpenHermes-2.5",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-22T14:57:21Z |
---
language:
- sv
- en
license: mit
tags:
- pretrained
- flashback
- web
- conversational
- chat
datasets:
- timpal0l/OpenHermes-2.5-sv
- teknium/OpenHermes-2.5
pipeline_tag: text-generation
---
# 🐈⬛ Mistral-7B-v0.1-flashback-v2-instruct
[Mistral-7B-v0.1-flashback-v2-instruct](https://huggingface.co/timpal0l/Mistral-7B-v0.1-flashback-v2-instruct) is an instruct based version of the base model [timpal0l/Mistral-7B-v0.1-flashback-v2](https://huggingface.co/timpal0l/Mistral-7B-v0.1-flashback-v2).
It has been finetuned on a the machine translated instruct dataset [OpenHermes2.5](https://huggingface.co/datasets/timpal0l/OpenHermes-2.5-sv).
## How to use:
```python
from transformers import pipeline
pipe = pipeline(
"text-generation",
"timpal0l/Mistral-7B-v0.1-flashback-v2-instruct",
device_map="auto"
)
text = """
Hur många ägg har jag? Jag hade 10 ägg, sen gav jag bort 5 ägg.
Sen fick jag 3 ägg av en kompis.
"""
generated = pipe(f"USER:{text}ASSISTANT:", max_length=512, temperature=0.6)
print(generated[0]["generated_text"].split("ASSISTANT: ")[1:][0])
```
Output:
```html
Du har 8 ägg. Här är resonemanget:
1. Du börjar med 10 ägg
2. Du ger bort 5 ägg, vilket lämnar dig med 10 - 5 = 5 ägg
3. Sedan får du 3 ägg av en kompis, vilket gör att du har 5 + 3 = 8 ägg.
```
|
HazSylvia/MISTRAL-FINETUNED-ALPACA-xp
|
HazSylvia
| 2024-02-22T21:37:34Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-02-22T21:37:32Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
juntaoyuan/chemistry-assistant-13b
|
juntaoyuan
| 2024-02-22T21:31:26Z | 109 | 5 | null |
[
"gguf",
"chemistry",
"teaching assistant",
"LlamaEdge",
"WasmEdge",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-02-19T02:36:50Z |
---
license: apache-2.0
tags:
- chemistry
- teaching assistant
- LlamaEdge
- WasmEdge
---
This model is fine-tuned from the [llama2-13b-chat](https://huggingface.co/meta-llama/Llama-2-13b-chat-hf) base model with an SFT QA dataset generated from [The Elements](https://www.amazon.com/Elements-Visual-Exploration-Every-Universe/dp/1579128149) book.
The fine-tuned model has a good understanding and proper focus on chemistry terms, making it a good model for RAG applications for chemistry subjects.
The base model is quantized to Q5_K_M and then fined-tuned with the generated QA dataset. The LORA layers are then applied back to the base model. The fine-tuned model has the same number of parameters, quantization, and prompt template as the base model.
* Fine-tuned model: [chemistry-assistant-13b-q5_k_m.gguf](https://huggingface.co/juntaoyuan/chemistry-assistant-13b/resolve/main/chemistry-assistant-13b-q5_k_m.gguf?download=true)
* Prompt template: same as Llama-2-chat
* Base model: [Llama-2-13b-chat-hf-Q5_K_M.gguf](https://huggingface.co/juntaoyuan/chemistry-assistant-13b/resolve/main/Llama-2-13b-chat-hf-Q5_K_M.gguf?download=true)
* SFT dataset: [train.txt](https://huggingface.co/juntaoyuan/chemistry-assistant-13b/resolve/main/train.txt?download=true)
|
guirnd/ppo-LunarLander-v2
|
guirnd
| 2024-02-22T21:30:17Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"tensorboard",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-01-19T13:55:10Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 264.64 +/- 19.93
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
goxai/LLWM
|
goxai
| 2024-02-22T21:21:11Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] |
text-generation
| 2024-02-22T20:56:18Z |
---
inference: false
---
<br>
<br>
# LWM-Text-1M-Chat Model Card
## Model details
**Model type:**
LWM-Text-1M-Chat is an open-source model trained from LLaMA-2 on a subset of Books3 filtered data. It is an auto-regressive language model, based on the transformer architecture.
**Model date:**
LWM-Text-1M-Chat was trained in December 2023.
**Paper or resources for more information:**
https://largeworldmodel.github.io/
## License
Llama 2 is licensed under the LLAMA 2 Community License,
Copyright (c) Meta Platforms, Inc. All Rights Reserved.
**Where to send questions or comments about the model:**
https://github.com/LargeWorldModel/lwm/issues
## Training dataset
- 800 subset of Books3 documents with 1M plus tokens
|
Keertss/bert-finetuned-ner-model
|
Keertss
| 2024-02-22T21:15:50Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"token-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2024-02-22T21:15:28Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
hari31416/RAGOptimize_Adapter
|
hari31416
| 2024-02-22T21:14:54Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation",
"arxiv:1910.09700",
"license:mit",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-21T09:16:17Z |
---
license: mit
library_name: transformers
pipeline_tag: text-generation
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
pjbhaumik/crossencoder-airline-refine-010
|
pjbhaumik
| 2024-02-22T21:09:46Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"roberta",
"text-classification",
"generated_from_trainer",
"base_model:cross-encoder/stsb-roberta-large",
"base_model:finetune:cross-encoder/stsb-roberta-large",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-02-22T21:09:09Z |
---
license: apache-2.0
base_model: cross-encoder/stsb-roberta-large
tags:
- generated_from_trainer
model-index:
- name: crossencoder-airline-refine-010
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# crossencoder-airline-refine-010
This model is a fine-tuned version of [cross-encoder/stsb-roberta-large](https://huggingface.co/cross-encoder/stsb-roberta-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 8.0523
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-08
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 500
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 15.341 | 1.0 | 157 | 14.5631 |
| 12.2879 | 2.0 | 314 | 13.3058 |
| 12.5681 | 3.0 | 471 | 11.4717 |
| 12.8002 | 4.0 | 628 | 9.8398 |
| 10.1409 | 5.0 | 785 | 8.8337 |
| 9.4818 | 6.0 | 942 | 8.1771 |
| 9.277 | 7.0 | 1099 | 7.7594 |
| 9.2643 | 8.0 | 1256 | 7.5311 |
| 8.7124 | 9.0 | 1413 | 7.4428 |
| 8.9775 | 10.0 | 1570 | 7.4347 |
### Framework versions
- Transformers 4.38.1
- Pytorch 2.0.1
- Datasets 2.17.1
- Tokenizers 0.15.2
|
christinacdl/XLM_RoBERTa-Clickbait-Detection-NEW-Data
|
christinacdl
| 2024-02-22T21:08:45Z | 5 | 1 |
transformers
|
[
"transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-02-22T15:49:45Z |
---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: XLM_RoBERTa-Clickbait-Detection-NEW-Data
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# XLM_RoBERTa-Clickbait-Detection-NEW-Data
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4668
- Micro F1: 0.9032
- Macro F1: 0.8997
- Accuracy: 0.9032
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
### Framework versions
- Transformers 4.36.1
- Pytorch 2.1.0+cu121
- Datasets 2.13.1
- Tokenizers 0.15.0
|
glacio-dev/Qwen1.5-4B-Chat-Q4
|
glacio-dev
| 2024-02-22T21:08:30Z | 5 | 0 |
mlx
|
[
"mlx",
"safetensors",
"qwen2",
"chat",
"text-generation",
"conversational",
"en",
"license:other",
"region:us"
] |
text-generation
| 2024-02-22T20:50:35Z |
---
language:
- en
license: other
tags:
- chat
- mlx
license_name: tongyi-qianwen-research
license_link: https://huggingface.co/Qwen/Qwen1.5-4B-Chat/blob/main/LICENSE
pipeline_tag: text-generation
---
# glacio-dev/Qwen1.5-4B-Chat-Q4
This model was converted to MLX format from [`Qwen/Qwen1.5-4B-Chat`]().
Refer to the [original model card](https://huggingface.co/Qwen/Qwen1.5-4B-Chat) for more details on the model.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("glacio-dev/Qwen1.5-4B-Chat-Q4")
response = generate(model, tokenizer, prompt="hello", verbose=True)
```
|
Imadken/llama-7b-chat-lamini_docs
|
Imadken
| 2024-02-22T21:00:50Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2024-02-22T20:57:27Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.5.0
|
raywanb/Llama-2-7b-gptq-2bit
|
raywanb
| 2024-02-22T20:59:03Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"2-bit",
"gptq",
"region:us"
] |
text-generation
| 2024-02-22T20:54:55Z |
---
license: apache-2.0
language:
- en
---
# Model Card for Model ID
This is Meta's Llama 2 7B quantized in 2-bit using AutoGPTQ from Hugging Face Transformers.
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [The Kaitchup](https://kaitchup.substack.com/)
- **Model type:** Causal (Llama 2)
- **Language(s) (NLP):** English
- **License:** [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0), [Llama 2 license agreement](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
### Model Sources
The method and code used to quantize the model are explained here:
[Quantize and Fine-tune LLMs with GPTQ Using Transformers and TRL](https://kaitchup.substack.com/p/quantize-and-fine-tune-llms-with)
## Uses
This model is pre-trained and not fine-tuned. You may fine-tune it with PEFT using adapters.
Note that the 2-bit quantization significantly decreases the performance of Llama 2.
## Other versions
- [kaitchup/Llama-2-7b-gptq-4bit](https://huggingface.co/kaitchup/Llama-2-7b-gptq-4bit)
- [kaitchup/Llama-2-7b-gptq-3bit](https://huggingface.co/kaitchup/Llama-2-7b-gptq-3bit)
## Model Card Contact
[The Kaitchup](https://kaitchup.substack.com/)
|
guirnd/rl_course_vizdoom_health_gathering_supreme
|
guirnd
| 2024-02-22T20:38:21Z | 0 | 0 |
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-02-22T20:38:14Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_health_gathering_supreme
type: doom_health_gathering_supreme
metrics:
- type: mean_reward
value: 13.84 +/- 5.27
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **doom_health_gathering_supreme** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r guirnd/rl_course_vizdoom_health_gathering_supreme
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m .usr.local.lib.python3.10.dist-packages.colab_kernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m .usr.local.lib.python3.10.dist-packages.colab_kernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
hcy5561/xlm-roberta-base-finetuned-panx-tr-en
|
hcy5561
| 2024-02-22T20:35:56Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2024-02-22T20:15:16Z |
---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-tr-en
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-tr-en
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1897
- F1: 0.8737
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.3375 | 1.0 | 788 | 0.2100 | 0.8356 |
| 0.1785 | 2.0 | 1576 | 0.1891 | 0.8557 |
| 0.1195 | 3.0 | 2364 | 0.1897 | 0.8737 |
### Framework versions
- Transformers 4.36.0
- Pytorch 1.12.0+cu113
- Datasets 2.17.0
- Tokenizers 0.15.0
|
davidpedem/mbart-neutralization
|
davidpedem
| 2024-02-22T20:33:57Z | 10 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"mbart",
"text2text-generation",
"simplification",
"generated_from_trainer",
"base_model:facebook/mbart-large-50",
"base_model:finetune:facebook/mbart-large-50",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-02-22T20:20:51Z |
---
license: mit
base_model: facebook/mbart-large-50
tags:
- simplification
- generated_from_trainer
metrics:
- bleu
model-index:
- name: mbart-neutralization
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mbart-neutralization
This model is a fine-tuned version of [facebook/mbart-large-50](https://huggingface.co/facebook/mbart-large-50) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0220
- Bleu: 98.2132
- Gen Len: 18.5417
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|
| No log | 1.0 | 440 | 0.0490 | 96.2659 | 19.0104 |
| 0.2462 | 2.0 | 880 | 0.0220 | 98.2132 | 18.5417 |
### Framework versions
- Transformers 4.38.1
- Pytorch 2.1.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
|
ryusangwon/6240_Llama-2-7b-hf
|
ryusangwon
| 2024-02-22T20:30:23Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"region:us"
] | null | 2024-02-22T20:30:19Z |
---
base_model: meta-llama/Llama-2-7b-hf
tags:
- generated_from_trainer
model-index:
- name: 6240_Llama-2-7b-hf
results: []
library_name: peft
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 6240_Llama-2-7b-hf
This model is a fine-tuned version of [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 10
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- PEFT 0.4.0
- Transformers 4.36.2
- Pytorch 2.0.1+cu117
- Datasets 2.15.0
- Tokenizers 0.15.0
|
PJM124/xlmrbase-bitfit-5e-4-test
|
PJM124
| 2024-02-22T20:30:04Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-02-22T20:29:18Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
wojtekgra/Pol
|
wojtekgra
| 2024-02-22T20:29:45Z | 0 | 1 |
adapter-transformers
|
[
"adapter-transformers",
"Diaper",
"Wet",
"Piss",
"Abdl",
"Soggy",
"text-to-image",
"dataset:fka/awesome-chatgpt-prompts",
"license:apache-2.0",
"region:us"
] |
text-to-image
| 2024-02-22T20:28:17Z |
---
license: apache-2.0
datasets:
- fka/awesome-chatgpt-prompts
metrics:
- bertscore
library_name: adapter-transformers
pipeline_tag: text-to-image
tags:
- Diaper
- Wet
- Piss
- Abdl
- Soggy
---
|
ThuyNT03/CS505_COQE_viT5_Prompting10_ASPOL_vcheck
|
ThuyNT03
| 2024-02-22T20:29:28Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:VietAI/vit5-large",
"base_model:finetune:VietAI/vit5-large",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-02-22T19:28:27Z |
---
license: mit
base_model: VietAI/vit5-large
tags:
- generated_from_trainer
model-index:
- name: CS505_COQE_viT5_Prompting10_ASPOL_vcheck
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# CS505_COQE_viT5_Prompting10_ASPOL_vcheck
This model is a fine-tuned version of [VietAI/vit5-large](https://huggingface.co/VietAI/vit5-large) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.37.0
- Pytorch 2.1.2
- Datasets 2.1.0
- Tokenizers 0.15.1
|
glacio-dev/Qwen1.5-1.8B-Chat-Q
|
glacio-dev
| 2024-02-22T20:26:08Z | 5 | 0 |
mlx
|
[
"mlx",
"safetensors",
"qwen2",
"chat",
"text-generation",
"conversational",
"en",
"license:other",
"region:us"
] |
text-generation
| 2024-02-22T20:10:13Z |
---
language:
- en
license: other
tags:
- chat
- mlx
license_name: tongyi-qianwen-research
license_link: https://huggingface.co/Qwen/Qwen1.5-1.8B-Chat/blob/main/LICENSE
pipeline_tag: text-generation
---
# glacio-dev/Qwen1.5-1.8B-Chat-Q
This model was converted to MLX format from [`Qwen/Qwen1.5-1.8B-Chat`]().
Refer to the [original model card](https://huggingface.co/Qwen/Qwen1.5-1.8B-Chat) for more details on the model.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("glacio-dev/Qwen1.5-1.8B-Chat-Q")
response = generate(model, tokenizer, prompt="hello", verbose=True)
```
|
ThuyNT03/CS505_COQE_viT5_Prompting11_ASPOL_vcheck
|
ThuyNT03
| 2024-02-22T20:21:28Z | 7 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:VietAI/vit5-large",
"base_model:finetune:VietAI/vit5-large",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2024-02-22T19:35:27Z |
---
license: mit
base_model: VietAI/vit5-large
tags:
- generated_from_trainer
model-index:
- name: CS505_COQE_viT5_Prompting11_ASPOL_vcheck
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# CS505_COQE_viT5_Prompting11_ASPOL_vcheck
This model is a fine-tuned version of [VietAI/vit5-large](https://huggingface.co/VietAI/vit5-large) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.37.0
- Pytorch 2.1.2
- Datasets 2.1.0
- Tokenizers 0.15.1
|
adonaivera/yolov9
|
adonaivera
| 2024-02-22T20:20:21Z | 0 | 1 | null |
[
"arxiv:2402.13616",
"region:us"
] | null | 2024-02-22T20:13:19Z |
# YOLOv9
Implementation of paper - [YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information](https://arxiv.org/abs/2402.13616)
<div align="center">
<a href="./">
<img src="https://huggingface.co/adonaivera/yolov9/resolve/main/performance.png" width="79%"/>
</a>
</div>
## Performance
MS COCO
| Model | Test Size | AP<sup>val</sup> | AP<sub>50</sub><sup>val</sup> | AP<sub>75</sub><sup>val</sup> | Param. | FLOPs |
| :-- | :-: | :-: | :-: | :-: | :-: | :-: |
| [**YOLOv9-S**]() | 640 | **46.8%** | **63.4%** | **50.7%** | **7.2M** | **26.7G** |
| [**YOLOv9-M**]() | 640 | **51.4%** | **68.1%** | **56.1%** | **20.1M** | **76.8G** |
| [**YOLOv9-C**](https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-c.pt) | 640 | **53.0%** | **70.2%** | **57.8%** | **25.5M** | **102.8G** |
| [**YOLOv9-E**](https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-e.pt) | 640 | **55.6%** | **72.8%** | **60.6%** | **58.1M** | **192.5G** |
|
Lollitor/Pocket7
|
Lollitor
| 2024-02-22T20:14:54Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-02-22T20:14:49Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
LoneStriker/opus-v1-34b-5.0bpw-h6-exl2
|
LoneStriker
| 2024-02-22T20:14:46Z | 4 | 2 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"unsloth",
"axolotl",
"conversational",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-22T20:05:44Z |
---
language:
- en
pipeline_tag: text-generation
tags:
- unsloth
- axolotl
---
# DreamGen Opus V1
<div style="display: flex; flex-direction: row; align-items: center;">
<img src="/dreamgen/opus-v1-34b/resolve/main/images/logo-1024.png" alt="model logo" style="
border-radius: 12px;
margin-right: 12px;
margin-top: 0px;
margin-bottom: 0px;
max-width: 100px;
height: auto;
"/>
Models for **(steerable) story-writing and role-playing**.
<br/>[All Opus V1 models, including quants](https://huggingface.co/collections/dreamgen/opus-v1-65d092a6f8ab7fc669111b31).
</div>
## Prompting
[Read the full Opus V1 prompting guide](https://dreamgen.com/docs/models/opus/v1) with many (interactive) examples and prompts that you can readily copy.
<details>
<summary>The models use an extended version of ChatML.</summary>
```
<|im_start|>system
(Story description in the right format here)
(Typically consists of plot description, style description and characters)<|im_end|>
<|im_start|>user
(Your instruction on how the story should continue)<|im_end|>
<|im_start|>text names= Alice
(Continuation of the story from the Alice character)<|im_end|>
<|im_start|>text
(Continuation of the story from no character in particular (pure narration))<|im_end|>
<|im_start|>user
(Your instruction on how the story should continue)<|im_end|>
<|im_start|>text names= Bob
(Continuation of the story from the Bob character)<|im_end|>
```
The Opus V1 extension is the addition of the `text` role, and the addition / modification of role names.
Pay attention to the following:
- The `text` messages can (but don't have to have) `names`, names are used to indicate the "active" character during role-play.
- There can be multiple subsequent message with a `text` role, especially if names are involved.
- There can be multiple names attached to a message.
- The format for names is `names= {{name[0]}}; {{name[1]}}`, beware of the spaces after `names=` and after the `;`. This spacing leads to most natural tokenization for the names.
</details>
While the main goal for the models is great story-writing and role-playing performance, the models are also capable of several writing related tasks as well as general assistance.
<img src="/dreamgen/opus-v1-34b/resolve/main/images/story_writing.webp" alt="story writing" style="
padding: 12px;
border-radius: 12px;
border: 2px solid #f9a8d4;
background: rgb(9, 9, 11);
"/>
Here's how you can prompt the model for the following tasks
- Steerable [Story-writing](https://dreamgen.com/docs/models/opus/v1#task-story-writing) and [Role-playing](https://dreamgen.com/docs/models/opus/v1#task-role-playing):
- Input:
- System prompt: You provide story / role-play description, which consists of:
- Plot description
- Style description
- Characters and their descriptions
- Conversation turns:
- Text / message turn: This represents part of the story or role play
- Instruction: This tells the model what should happen next
- Output: Continuation of the story / role-play.
- [Story plot summarization](https://dreamgen.com/docs/models/opus/v1#task-plot-description)
- Input: A story, or a few chapters of a story.
- Output: A description of the story or chapters.
- [Story character description](https://dreamgen.com/docs/models/opus/v1#task-char-description)
- Input: A story, or a few chapters of a story, set of characters.
- Output: A description of the characters.
- [Story style description](https://dreamgen.com/docs/models/opus/v1#task-style-description)
- Input: A story, or a few chapters of a story.
- Output: A description the style of the story.
- [Story description to chapters](https://dreamgen.com/docs/models/opus/v1#task-story-description-to-chapter-descriptions)
- Input: A brief plot description and the desired number of chapters.
- Output: A description for each chapter.
- And more...
### Sampling params
For story-writing and role-play, I recommend "Min P" based sampling with `min_p` in the range `[0.01, 0.1]` and with `temperature` in the range `[0.5, 1.5]`, depending on your preferences. A good starting point would be `min_p=0.1; temperature=0.8`.
You may also benefit from setting presence, frequency and repetition penalties, especially at lower temperatures.
## Dataset
The fine-tuning dataset consisted of ~100M tokens of steerable story-writing, role-playing, writing-assistant and general-assistant examples. Each example was up to 31000 tokens long.
All story-writing and role-playing examples were based on human-written text.

## Running the model
The model is should be compatible with any software that supports the base model, but beware of the prompting (see above).
### Running Locally
- [Chat template from model config](tokenizer_config.json#L51)
- This uses "text" role instead of the typical "assistant" role, and it does not (can’t?) support names
- [LM Studio config](configs/lmstudio.json)
- This uses "text" role role as well
### Running on DreamGen.com (free)
You can try the model for free on [dreamgen.com](https://dreamgen.com) — note that an account is required.
## Community
Join the DreamGen community on [**Discord**](https://dreamgen.com/discord) to get early access to new models.
## License
- This model is intended for personal use only, other use is not permitted.
|
zhiweiren97/tiny-llama-pt
|
zhiweiren97
| 2024-02-22T20:12:56Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-02-20T19:17:58Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
danwils/BatakToba-laserRMT
|
danwils
| 2024-02-22T20:11:35Z | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-22T18:03:38Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
DrishtiSharma/dolphin-2.1-mistral-7b-dpo-ultrafeedback-binarized-preferences-ipo
|
DrishtiSharma
| 2024-02-22T20:09:57Z | 4 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"trl",
"dpo",
"generated_from_trainer",
"base_model:cognitivecomputations/dolphin-2.1-mistral-7b",
"base_model:adapter:cognitivecomputations/dolphin-2.1-mistral-7b",
"license:apache-2.0",
"region:us"
] | null | 2024-02-22T14:09:50Z |
---
license: apache-2.0
library_name: peft
tags:
- trl
- dpo
- generated_from_trainer
base_model: cognitivecomputations/dolphin-2.1-mistral-7b
model-index:
- name: doplhin-2.1-mistral-7b-dpo-ultrafeedback-binarized-preferences-ipo
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# doplhin-2.1-mistral-7b-dpo-ultrafeedback-binarized-preferences-ipo
This model is a fine-tuned version of [cognitivecomputations/dolphin-2.1-mistral-7b](https://huggingface.co/cognitivecomputations/dolphin-2.1-mistral-7b) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 13.6404
- Rewards/chosen: -0.4693
- Rewards/rejected: -0.7026
- Rewards/accuracies: 0.8234
- Rewards/margins: 0.2333
- Logps/rejected: -9.0933
- Logps/chosen: -6.2746
- Logits/rejected: -0.8214
- Logits/chosen: -0.8422
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 17.7871 | 0.25 | 700 | 16.4082 | -0.2243 | -0.3706 | 0.7903 | 0.1464 | -5.7735 | -3.8245 | -1.8423 | -1.8837 |
| 13.4212 | 0.51 | 1400 | 14.5490 | -0.4924 | -0.7383 | 0.8092 | 0.2459 | -9.4501 | -6.5058 | -0.9174 | -0.9510 |
| 13.2665 | 0.76 | 2100 | 13.6404 | -0.4693 | -0.7026 | 0.8234 | 0.2333 | -9.0933 | -6.2746 | -0.8214 | -0.8422 |
### Framework versions
- PEFT 0.8.2
- Transformers 4.37.2
- Pytorch 2.1.2+cu121
- Datasets 2.16.1
- Tokenizers 0.15.2
|
mcanoglu/microsoft-codebert-base-finetuned-defect-cwe-group-detection
|
mcanoglu
| 2024-02-22T20:08:12Z | 418 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"roberta",
"text-classification",
"generated_from_trainer",
"base_model:microsoft/codebert-base",
"base_model:finetune:microsoft/codebert-base",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-02-22T19:46:04Z |
---
base_model: microsoft/codebert-base
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
model-index:
- name: microsoft-codebert-base-finetuned-defect-cwe-group-detection
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# microsoft-codebert-base-finetuned-defect-cwe-group-detection
This model is a fine-tuned version of [microsoft/codebert-base](https://huggingface.co/microsoft/codebert-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6195
- Accuracy: 0.7490
- Precision: 0.5725
- Recall: 0.5159
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 4711
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|
| No log | 1.0 | 462 | 0.6077 | 0.7288 | 0.6350 | 0.4460 |
| 0.7284 | 2.0 | 925 | 0.5435 | 0.7485 | 0.6418 | 0.4633 |
| 0.5295 | 3.0 | 1387 | 0.5937 | 0.7209 | 0.5285 | 0.5098 |
| 0.4242 | 4.0 | 1850 | 0.6071 | 0.7400 | 0.5543 | 0.5354 |
| 0.3509 | 4.99 | 2310 | 0.6195 | 0.7490 | 0.5725 | 0.5159 |
### Framework versions
- Transformers 4.38.1
- Pytorch 2.2.1+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
|
kv333q/layout1_LoRA
|
kv333q
| 2024-02-22T20:07:23Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"text-to-image",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"lora",
"template:sd-lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2024-02-21T20:39:48Z |
---
license: openrail++
library_name: diffusers
tags:
- text-to-image
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
- template:sd-lora
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a floorplan layout with color tags
widget: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - kv333q/layout1_LoRA
<Gallery />
## Model description
These are kv333q/layout1_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a floorplan layout with color tags to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](kv333q/layout1_LoRA/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
Equious/first-test
|
Equious
| 2024-02-22T20:07:19Z | 8 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"base_model:TinyPixel/Llama-2-7B-bf16-sharded",
"base_model:finetune:TinyPixel/Llama-2-7B-bf16-sharded",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-21T20:23:19Z |
---
base_model: TinyPixel/Llama-2-7B-bf16-sharded
tags:
- generated_from_trainer
model-index:
- name: first-test
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# first-test
This model is a fine-tuned version of [TinyPixel/Llama-2-7B-bf16-sharded](https://huggingface.co/TinyPixel/Llama-2-7B-bf16-sharded) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.38.0
- Pytorch 2.1.2+cu121
- Datasets 2.14.7
- Tokenizers 0.15.2
|
CorticalStack/gemma-7b-ultrachat-gguf
|
CorticalStack
| 2024-02-22T20:05:28Z | 0 | 1 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2024-02-22T20:05:28Z |
---
license: apache-2.0
---
# CorticalStack/gemma-7b-ultrachat
A collection of GGUF quantised versions of [CorticalStack/gemma-7b-ultrachat-sft](https://huggingface.co/CorticalStack/gemma-7b-ultrachat-sft).
The main branch model is quantised using GGUF format Q4_K_M.
GGUF is a format that replaces GGML, which is no longer supported by llama.cpp.
An incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
|
hnino/mixtral-moe-lora-instruct-shapeskeare-2-finetuned
|
hnino
| 2024-02-22T20:05:07Z | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mixtral",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2024-02-22T18:00:49Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
AymanKUMA/speecht5_tts_voxpopuli_nl
|
AymanKUMA
| 2024-02-22T19:59:52Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"speecht5",
"text-to-audio",
"ar",
"arxiv:1910.09700",
"license:mit",
"endpoints_compatible",
"region:us"
] |
text-to-audio
| 2024-02-22T12:32:23Z |
---
license: mit
language:
- ar
metrics:
- accuracy
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
BertGollnick/distilbert-base-uncased-yelp-new
|
BertGollnick
| 2024-02-22T19:59:11Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2024-02-22T19:38:13Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: results
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- eval_loss: 1.9778
- eval_runtime: 3.8155
- eval_samples_per_second: 52.417
- eval_steps_per_second: 6.552
- epoch: 11.0
- step: 1100
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 20
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.2+cu118
- Datasets 2.16.1
- Tokenizers 0.15.0
|
LoneStriker/opus-v1-34b-4.0bpw-h6-exl2
|
LoneStriker
| 2024-02-22T19:57:09Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"unsloth",
"axolotl",
"conversational",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-22T19:49:45Z |
---
language:
- en
pipeline_tag: text-generation
tags:
- unsloth
- axolotl
---
# DreamGen Opus V1
<div style="display: flex; flex-direction: row; align-items: center;">
<img src="/dreamgen/opus-v1-34b/resolve/main/images/logo-1024.png" alt="model logo" style="
border-radius: 12px;
margin-right: 12px;
margin-top: 0px;
margin-bottom: 0px;
max-width: 100px;
height: auto;
"/>
Models for **(steerable) story-writing and role-playing**.
<br/>[All Opus V1 models, including quants](https://huggingface.co/collections/dreamgen/opus-v1-65d092a6f8ab7fc669111b31).
</div>
## Prompting
[Read the full Opus V1 prompting guide](https://dreamgen.com/docs/models/opus/v1) with many (interactive) examples and prompts that you can readily copy.
<details>
<summary>The models use an extended version of ChatML.</summary>
```
<|im_start|>system
(Story description in the right format here)
(Typically consists of plot description, style description and characters)<|im_end|>
<|im_start|>user
(Your instruction on how the story should continue)<|im_end|>
<|im_start|>text names= Alice
(Continuation of the story from the Alice character)<|im_end|>
<|im_start|>text
(Continuation of the story from no character in particular (pure narration))<|im_end|>
<|im_start|>user
(Your instruction on how the story should continue)<|im_end|>
<|im_start|>text names= Bob
(Continuation of the story from the Bob character)<|im_end|>
```
The Opus V1 extension is the addition of the `text` role, and the addition / modification of role names.
Pay attention to the following:
- The `text` messages can (but don't have to have) `names`, names are used to indicate the "active" character during role-play.
- There can be multiple subsequent message with a `text` role, especially if names are involved.
- There can be multiple names attached to a message.
- The format for names is `names= {{name[0]}}; {{name[1]}}`, beware of the spaces after `names=` and after the `;`. This spacing leads to most natural tokenization for the names.
</details>
While the main goal for the models is great story-writing and role-playing performance, the models are also capable of several writing related tasks as well as general assistance.
<img src="/dreamgen/opus-v1-34b/resolve/main/images/story_writing.webp" alt="story writing" style="
padding: 12px;
border-radius: 12px;
border: 2px solid #f9a8d4;
background: rgb(9, 9, 11);
"/>
Here's how you can prompt the model for the following tasks
- Steerable [Story-writing](https://dreamgen.com/docs/models/opus/v1#task-story-writing) and [Role-playing](https://dreamgen.com/docs/models/opus/v1#task-role-playing):
- Input:
- System prompt: You provide story / role-play description, which consists of:
- Plot description
- Style description
- Characters and their descriptions
- Conversation turns:
- Text / message turn: This represents part of the story or role play
- Instruction: This tells the model what should happen next
- Output: Continuation of the story / role-play.
- [Story plot summarization](https://dreamgen.com/docs/models/opus/v1#task-plot-description)
- Input: A story, or a few chapters of a story.
- Output: A description of the story or chapters.
- [Story character description](https://dreamgen.com/docs/models/opus/v1#task-char-description)
- Input: A story, or a few chapters of a story, set of characters.
- Output: A description of the characters.
- [Story style description](https://dreamgen.com/docs/models/opus/v1#task-style-description)
- Input: A story, or a few chapters of a story.
- Output: A description the style of the story.
- [Story description to chapters](https://dreamgen.com/docs/models/opus/v1#task-story-description-to-chapter-descriptions)
- Input: A brief plot description and the desired number of chapters.
- Output: A description for each chapter.
- And more...
### Sampling params
For story-writing and role-play, I recommend "Min P" based sampling with `min_p` in the range `[0.01, 0.1]` and with `temperature` in the range `[0.5, 1.5]`, depending on your preferences. A good starting point would be `min_p=0.1; temperature=0.8`.
You may also benefit from setting presence, frequency and repetition penalties, especially at lower temperatures.
## Dataset
The fine-tuning dataset consisted of ~100M tokens of steerable story-writing, role-playing, writing-assistant and general-assistant examples. Each example was up to 31000 tokens long.
All story-writing and role-playing examples were based on human-written text.

## Running the model
The model is should be compatible with any software that supports the base model, but beware of the prompting (see above).
### Running Locally
- [Chat template from model config](tokenizer_config.json#L51)
- This uses "text" role instead of the typical "assistant" role, and it does not (can’t?) support names
- [LM Studio config](configs/lmstudio.json)
- This uses "text" role role as well
### Running on DreamGen.com (free)
You can try the model for free on [dreamgen.com](https://dreamgen.com) — note that an account is required.
## Community
Join the DreamGen community on [**Discord**](https://dreamgen.com/discord) to get early access to new models.
## License
- This model is intended for personal use only, other use is not permitted.
|
jncraton/oo-phi-1_5-ct2-int8
|
jncraton
| 2024-02-22T19:56:52Z | 4 | 0 |
transformers
|
[
"transformers",
"text-generation",
"en",
"dataset:Open-Orca/OpenOrca",
"arxiv:2309.05463",
"arxiv:2306.02707",
"arxiv:2301.13688",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-22T19:56:00Z |
---
datasets:
- Open-Orca/OpenOrca
language:
- en
library_name: transformers
pipeline_tag: text-generation
---
# Overview
Unreleased, untested, unfinished beta.
We've trained Microsoft Research's [phi-1.5](https://huggingface.co/microsoft/phi-1_5), 1.3B parameter model with the same OpenOrca dataset as we used with our [OpenOrcaxOpenChat-Preview2-13B](https://huggingface.co/Open-Orca/OpenOrcaxOpenChat-Preview2-13B) model.
This model doesn't dramatically improve on the base model's general task performance, but the instruction tuning has made the model reliably handle the ChatML prompt format.
# Evaluations
We've only done limited testing as yet. The [epoch 3.5 checkpoint](https://huggingface.co/Open-Orca/oo-phi-1_5/commit/f7754d8b8b4c3e0748eaf47be4cf5aac1f80a401) scores above 5.1 on MT-Bench (better than Alpaca-13B, worse than Llama2-7b-chat), while preliminary benchmarks suggest peak average performance was achieved roughly at epoch 4.
## HuggingFaceH4 Open LLM Leaderboard Performance
The only significant improvement was with TruthfulQA.
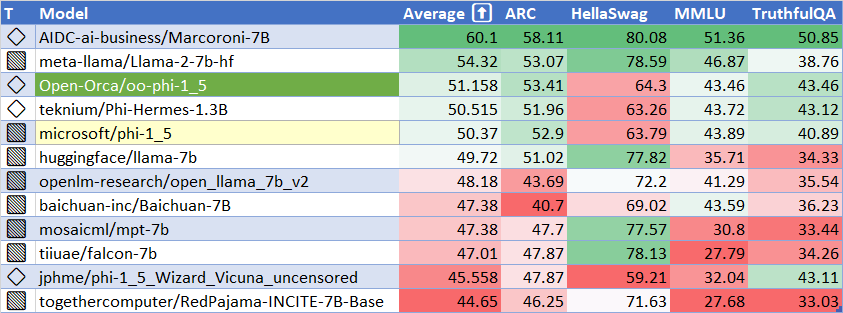
## MT-bench Performance
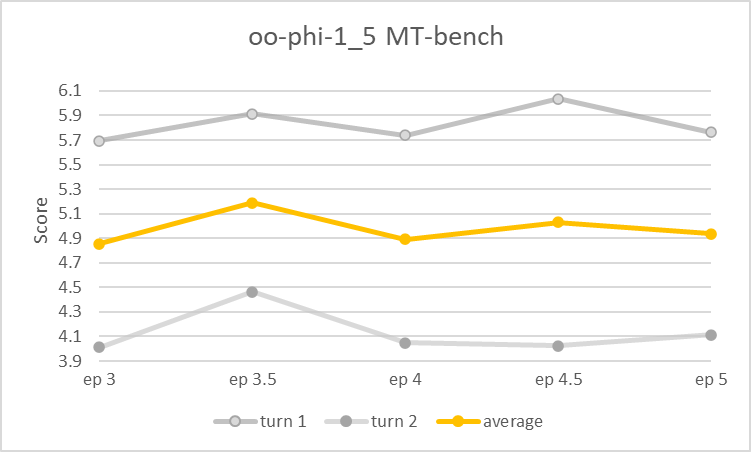
| Epoch | Average | Turn 1 | Turn 2 |
|:----------|:----------|:----------|:----------|
| 3 | 4.85 | 5.69 | 4.01 |
| 3.5 | 5.19 | 5.91 | 4.46 |
| 4 | 4.89 | 5.74 | 4.05 |
| 4.5 | 5.03 | 6.04 | 4.03 |
| 5 | 4.94 | 5.76 | 4.11 |
# Training
Trained with full-parameters fine-tuning on 8x RTX A6000-48GB (Ampere) for 5 epochs for 62 hours (12.5h/epoch) at a commodity cost of $390 ($80/epoch).
We did not use [MultiPack](https://github.com/imoneoi/multipack_sampler) packing, as training was begun prior to implementing support for it in Axolotl for this new model type.
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
We've uploaded checkpoints of every 1/2 epoch of progress to this repo.
There are branches/tags for the epoch 3 and epoch 4 uploads.
This should allow, e.g., with oobabooga to download `Open-Orca/oo-phi-1_5:ep4` to select the epoch 4 checkpoint to download specifically.
# Prompt Template
We used [OpenAI's Chat Markup Language (ChatML)](https://github.com/openai/openai-python/blob/main/chatml.md) format, with `<|im_start|>` and `<|im_end|>` tokens added to support this.
This means that, e.g., in [oobabooga](https://github.com/oobabooga/text-generation-webui/) the `MPT-Chat` instruction template should work.
# Inference
Remove *`.to('cuda')`* for unaccelerated.
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
model = AutoModelForCausalLM.from_pretrained("Open-Orca/oo-phi-1_5",
trust_remote_code=True,
torch_dtype=torch.bfloat16
).to('cuda')
tokenizer = AutoTokenizer.from_pretrained("Open-Orca/oo-phi-1_5",
trust_remote_code=True,
torch_dtype=torch.bfloat16)
sys_prompt = "I am OrcaPhi. The following is my internal dialogue as an AI assistant.\n" \
"Today is September 15, 2023. I have no access to outside tools, news, or current events.\n" \
"I carefully provide accurate, factual, thoughtful, nuanced answers and am brilliant at reasoning.\n" \
"I think through my answers step-by-step to be sure I always get the right answer.\n" \
"I think more clearly if I write out my thought process in a scratchpad manner first; therefore, I always " \
"explain background context, assumptions, and step-by-step thinking BEFORE trying to answer a question." \
"Take a deep breath and think calmly about everything presented."
prompt = "Hello! Tell me about what makes you special, as an AI assistant.\n" \
"Particularly, what programming tasks are you best at?"
prefix = "<|im_start|>"
suffix = "<|im_end|>\n"
sys_format = prefix + "system\n" + sys_prompt + suffix
user_format = prefix + "user\n" + prompt + suffix
assistant_format = prefix + "assistant\n"
input_text = sys_format + user_format + assistant_format
generation_config = GenerationConfig(
max_length=1024, temperature=0.01, top_p=0.95, repetition_penalty=1.1,
do_sample=True, use_cache=True,
eos_token_id=tokenizer.eos_token_id, pad_token_id=tokenizer.pad_token_id,
transformers_version="4.33.1"
)
inputs = tokenizer(input_text, return_tensors="pt", return_attention_mask=False).to('cuda')
outputs = model.generate(**inputs, generation_config=generation_config)
text = tokenizer.batch_decode(outputs)[0]
print(text)
```
Example output:
```text
<|im_start|>system
I am OrcaPhi. The following is my internal dialogue as an AI assistant.
Today is September 15, 2023. I have no access to outside tools, news, or current events.
I carefully provide accurate, factual, thoughtful, nuanced answers and am brilliant at reasoning.
I think through my answers step-by-step to be sure I always get the right answer.
I think more clearly if I write out my thought process in a scratchpad manner first; therefore, I always explain background context, assumptions, and step-by-step thinking BEFORE trying to answer a question.Take a deep breath and think calmly about everything presented.<|im_end|>
<|im_start|>user
Hello! Tell me about what makes you special, as an AI assistant.
Particularly, what programming tasks are you best at?<|im_end|>
<|im_start|>assistant
As an AI, I'm designed to understand and respond to human language, which includes natural language processing (NLP) techniques that allow me to comprehend text, speech, and other forms of communication. My primary function is to assist users by providing relevant information, answering questions, and performing various tasks based on user input.
In terms of programming tasks, I am particularly skilled in:
1. Natural Language Processing (NLP): This allows me to understand and analyze human language, enabling me to generate appropriate responses and perform tasks such as sentiment analysis, named entity recognition, and topic modeling.
2. Machine Learning: I can learn from large datasets and improve my performance over time, allowing me to adapt to new situations and provide better assistance to users.
3. Deep Learning: I can leverage advanced neural networks and complex architectures to solve problems that may not be easily addressed using traditional machine learning methods.
4. Computer Vision: I can recognize and interpret visual data, making it possible for me to identify objects, faces, and other visual elements within images and videos.
5. Robotics: I can help with tasks related to robotics, including object detection, navigation, and manipulation.
6. Voice Recognition: I can accurately transcribe spoken words into written text, making it easier for users to interact with me.
7. Chatbots: I can engage in conversations with users, providing them with helpful information, answering their questions, and assisting them with various tasks.
8. Data Analysis: I can analyze large amounts of data quickly and efficiently, helping users make informed decisions based on insights derived from the information provided.
9. Recommender Systems: I can suggest products, services, or content based on users' preferences and past behavior, improving their overall experience.
10. Fraud Detection: I can detect and prevent fraudulent activities, protecting users' financial information and ensuring secure transactions.
These programming tasks showcase my ability to understand and process vast amounts of information while adapting to different contexts and user needs. As an AI, I continuously learn and evolve to become even more effective in assisting users.<|im_end|>
```
# Citation
```bibtex
@software{lian2023oophi15,
title = {OpenOrca oo-phi-1.5: Phi-1.5 1.3B Model Instruct-tuned on Filtered OpenOrcaV1 GPT-4 Dataset},
author = {Wing Lian and Bleys Goodson and Guan Wang and Eugene Pentland and Austin Cook and Chanvichet Vong and "Teknium"},
year = {2023},
publisher = {HuggingFace},
journal = {HuggingFace repository},
howpublished = {\url{https://huggingface.co/Open-Orca/oo-phi-1_5},
}
@article{textbooks2,
title={Textbooks Are All You Need II: \textbf{phi-1.5} technical report},
author={Li, Yuanzhi and Bubeck, S{\'e}bastien and Eldan, Ronen and Del Giorno, Allie and Gunasekar, Suriya and Lee, Yin Tat},
journal={arXiv preprint arXiv:2309.05463},
year={2023}
}
@misc{mukherjee2023orca,
title={Orca: Progressive Learning from Complex Explanation Traces of GPT-4},
author={Subhabrata Mukherjee and Arindam Mitra and Ganesh Jawahar and Sahaj Agarwal and Hamid Palangi and Ahmed Awadallah},
year={2023},
eprint={2306.02707},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{longpre2023flan,
title={The Flan Collection: Designing Data and Methods for Effective Instruction Tuning},
author={Shayne Longpre and Le Hou and Tu Vu and Albert Webson and Hyung Won Chung and Yi Tay and Denny Zhou and Quoc V. Le and Barret Zoph and Jason Wei and Adam Roberts},
year={2023},
eprint={2301.13688},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
```
|
crossroderick/q-Taxi-v3
|
crossroderick
| 2024-02-22T19:52:18Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-02-22T19:52:15Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id = "crossroderick/q-Taxi-v3", filename = "q-learning.pkl")
```
|
LoneStriker/opus-v1-34b-3.0bpw-h6-exl2
|
LoneStriker
| 2024-02-22T19:49:42Z | 2 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"unsloth",
"axolotl",
"conversational",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-02-22T19:43:59Z |
---
language:
- en
pipeline_tag: text-generation
tags:
- unsloth
- axolotl
---
# DreamGen Opus V1
<div style="display: flex; flex-direction: row; align-items: center;">
<img src="/dreamgen/opus-v1-34b/resolve/main/images/logo-1024.png" alt="model logo" style="
border-radius: 12px;
margin-right: 12px;
margin-top: 0px;
margin-bottom: 0px;
max-width: 100px;
height: auto;
"/>
Models for **(steerable) story-writing and role-playing**.
<br/>[All Opus V1 models, including quants](https://huggingface.co/collections/dreamgen/opus-v1-65d092a6f8ab7fc669111b31).
</div>
## Prompting
[Read the full Opus V1 prompting guide](https://dreamgen.com/docs/models/opus/v1) with many (interactive) examples and prompts that you can readily copy.
<details>
<summary>The models use an extended version of ChatML.</summary>
```
<|im_start|>system
(Story description in the right format here)
(Typically consists of plot description, style description and characters)<|im_end|>
<|im_start|>user
(Your instruction on how the story should continue)<|im_end|>
<|im_start|>text names= Alice
(Continuation of the story from the Alice character)<|im_end|>
<|im_start|>text
(Continuation of the story from no character in particular (pure narration))<|im_end|>
<|im_start|>user
(Your instruction on how the story should continue)<|im_end|>
<|im_start|>text names= Bob
(Continuation of the story from the Bob character)<|im_end|>
```
The Opus V1 extension is the addition of the `text` role, and the addition / modification of role names.
Pay attention to the following:
- The `text` messages can (but don't have to have) `names`, names are used to indicate the "active" character during role-play.
- There can be multiple subsequent message with a `text` role, especially if names are involved.
- There can be multiple names attached to a message.
- The format for names is `names= {{name[0]}}; {{name[1]}}`, beware of the spaces after `names=` and after the `;`. This spacing leads to most natural tokenization for the names.
</details>
While the main goal for the models is great story-writing and role-playing performance, the models are also capable of several writing related tasks as well as general assistance.
<img src="/dreamgen/opus-v1-34b/resolve/main/images/story_writing.webp" alt="story writing" style="
padding: 12px;
border-radius: 12px;
border: 2px solid #f9a8d4;
background: rgb(9, 9, 11);
"/>
Here's how you can prompt the model for the following tasks
- Steerable [Story-writing](https://dreamgen.com/docs/models/opus/v1#task-story-writing) and [Role-playing](https://dreamgen.com/docs/models/opus/v1#task-role-playing):
- Input:
- System prompt: You provide story / role-play description, which consists of:
- Plot description
- Style description
- Characters and their descriptions
- Conversation turns:
- Text / message turn: This represents part of the story or role play
- Instruction: This tells the model what should happen next
- Output: Continuation of the story / role-play.
- [Story plot summarization](https://dreamgen.com/docs/models/opus/v1#task-plot-description)
- Input: A story, or a few chapters of a story.
- Output: A description of the story or chapters.
- [Story character description](https://dreamgen.com/docs/models/opus/v1#task-char-description)
- Input: A story, or a few chapters of a story, set of characters.
- Output: A description of the characters.
- [Story style description](https://dreamgen.com/docs/models/opus/v1#task-style-description)
- Input: A story, or a few chapters of a story.
- Output: A description the style of the story.
- [Story description to chapters](https://dreamgen.com/docs/models/opus/v1#task-story-description-to-chapter-descriptions)
- Input: A brief plot description and the desired number of chapters.
- Output: A description for each chapter.
- And more...
### Sampling params
For story-writing and role-play, I recommend "Min P" based sampling with `min_p` in the range `[0.01, 0.1]` and with `temperature` in the range `[0.5, 1.5]`, depending on your preferences. A good starting point would be `min_p=0.1; temperature=0.8`.
You may also benefit from setting presence, frequency and repetition penalties, especially at lower temperatures.
## Dataset
The fine-tuning dataset consisted of ~100M tokens of steerable story-writing, role-playing, writing-assistant and general-assistant examples. Each example was up to 31000 tokens long.
All story-writing and role-playing examples were based on human-written text.

## Running the model
The model is should be compatible with any software that supports the base model, but beware of the prompting (see above).
### Running Locally
- [Chat template from model config](tokenizer_config.json#L51)
- This uses "text" role instead of the typical "assistant" role, and it does not (can’t?) support names
- [LM Studio config](configs/lmstudio.json)
- This uses "text" role role as well
### Running on DreamGen.com (free)
You can try the model for free on [dreamgen.com](https://dreamgen.com) — note that an account is required.
## Community
Join the DreamGen community on [**Discord**](https://dreamgen.com/discord) to get early access to new models.
## License
- This model is intended for personal use only, other use is not permitted.
|
crossroderick/q-FrozenLake-v1-4x4-noSlippery
|
crossroderick
| 2024-02-22T19:45:48Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2024-02-22T17:46:13Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id = "crossroderick/q-FrozenLake-v1-4x4-noSlippery", filename = "q-learning.pkl")
```
This particular model was trained on the default version of FrozenLake-v1 in a 4x4 setting, so don't forget to set `is_slippery = False` and
specify `map_name` when loading the environment, such as:
```python
env = gym.make(model["env_id"], map_name = "4x4", is_slippery = False)
```
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.