
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-02 00:39:05
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 532
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-02 00:38:59
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
hssnjfry/blockassist-bc-climbing_pouncing_dragonfly_1756706304
|
hssnjfry
| 2025-09-01T06:01:15Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"climbing pouncing dragonfly",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T05:59:15Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- climbing pouncing dragonfly
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
VoilaRaj/81_g_SztqPI
|
VoilaRaj
| 2025-09-01T06:00:33Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-01T06:00:05Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
lagoscity/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-gentle_howling_spider
|
lagoscity
| 2025-09-01T05:59:38Z | 159 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am gentle_howling_spider",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-28T15:34:10Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am gentle_howling_spider
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
nick1880/blockassist-bc-barky_powerful_falcon_1756706172
|
nick1880
| 2025-09-01T05:57:03Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"barky powerful falcon",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T05:56:55Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- barky powerful falcon
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
louaV/blockassist-bc-shy_bold_viper_1756706098
|
louaV
| 2025-09-01T05:56:04Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"shy bold viper",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T05:55:49Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- shy bold viper
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
VoilaRaj/81_g_InmkoL
|
VoilaRaj
| 2025-09-01T05:55:32Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-09-01T05:55:03Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
lisaozill03/blockassist-bc-rugged_prickly_alpaca_1756704425
|
lisaozill03
| 2025-09-01T05:52:55Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"rugged prickly alpaca",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T05:52:52Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- rugged prickly alpaca
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ludandaye/Multidimensional-Image-Analysis-LLM
|
ludandaye
| 2025-09-01T05:49:38Z | 0 | 0 | null |
[
"pytorch",
"GPT2WithCLSHead",
"region:us"
] | null | 2025-08-15T02:18:27Z |
# Multidimensional Image Analysis LLM
## 模型信息
这是一个基于GPT-2的多维图像分析大语言模型,专门用于手写数字识别任务。
### 性能表现
- **验证集准确率**: 100% (1.0)
- **测试集准确率**: 100% (1.0)
- **架构**: GPT2WithCLSHead
- **训练策略**: 注意力池化 (Attention Pooling)
### 技术规格
- **词汇表大小**: 516
- **嵌入维度**: 384
- **层数**: 6
- **注意力头数**: 8
- **最大序列长度**: 1024
- **分类类别数**: 10 (数字0-9)
### 训练详情
- **最佳轮次**: 10
- **批次大小**: 16
- **学习率**: 3e-5
- **优化器**: AdamW
- **损失函数**: CrossEntropyLoss
### 使用方法
```python
from transformers import AutoModelForSequenceClassification, AutoTokenizer
# 加载模型
model = AutoModelForSequenceClassification.from_pretrained("ludandaye/Multidimensional-Image-Analysis-LLM")
tokenizer = AutoTokenizer.from_pretrained("gpt2")
# 进行预测
inputs = tokenizer("your input text", return_tensors="pt")
outputs = model(**inputs)
predictions = outputs.logits.argmax(-1)
```
### 训练历史
这个模型是V7版本的最终成果,在2025年8月30日达到了完美的100%准确率。模型使用了改进的注意力池化策略和优化的训练流程,成功实现了手写数字识别的完美分类。
### 许可证
Apache License 2.0
---
*模型由Ludandaye团队训练,基于GPT-2架构优化*
|
Tengyunw/qwen3_8b_eagle3
|
Tengyunw
| 2025-09-01T05:48:39Z | 2,648 | 20 | null |
[
"pytorch",
"llama",
"base_model:Qwen/Qwen3-8B",
"base_model:finetune:Qwen/Qwen3-8B",
"license:mit",
"region:us"
] | null | 2025-07-02T03:50:34Z |
---
license: mit
base_model:
- Qwen/Qwen3-8B
---
## Introduce
We adapted the official speculative sampling training method, Eagle3, for training on Qwen3-8B.
After implementing Eagle3, the inference performance of Qwen3-8B using the SGLang framework on a single H200 GPU improved from 187 tokens/s to 365 tokens/s.
The TPS (tokens per second) improvement reached nearly 100%.
Amazingly, on a single RTX 5090, the TPS (transactions per second) of Qwen3-8B-Eagle3 increased from 90 to 220.
The TPS (tokens per second) improvement reached nearly 140%.
| model | gpu | tps |
|---------|---------|---------|
| qwen3-8b | 5090 | 90 |
| qwen3-8b-eagle3 | 5090 | 220 |
| qwen3-8b | h200 | 187 |
| qwen3-8b-eagle3 | h200 | 365 |
Join our AI computing power cloud platform now and enjoy the best AI cloud service experience. The link is as follows: https://tenyunn.com/
## How to use
To use Eagle3 with SGLang, first replace the qwen3.py file in SGLang’s directory (sglang/python/sglang/srt/models/) with the qwen3.py file from this project.
The launch command for using Eagle3 with SGLang is:
```python
python3 -m sglang.launch_server --model Qwen/Qwen3-8B --speculative-algorithm EAGLE3 --speculative-draft-model-path Tengyunw/qwen3_8b_eagle3 --speculative-num-steps 6 --speculative-eagle-topk 10 --speculative-num-draft-tokens 32 --mem-fraction 0.9 --cuda-graph-max-bs 2 --dtype bfloat16
```
## How to train
Training Dataset:
ultrachat_200k.
Only the prompts from these datasets were utilized for data synthesis. This synthesized data is used to train the Eagle modules.
dataset nums: 600K samples,1B tokens
Evaluation Dataset:
ShareGPT,GSM8K,HUAMEVAL,MT-BENCH,APLCA
Our Sharegpt test data is located in the eagle_data.jsonl file under this directory.
|
Sonic-man/blockassist-bc-poisonous_graceful_cow_1756703357
|
Sonic-man
| 2025-09-01T05:46:03Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"poisonous graceful cow",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T05:45:59Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- poisonous graceful cow
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/NS-12b-DarkSluchCapV3-GGUF
|
mradermacher
| 2025-09-01T05:44:44Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:pot99rta/NS-12b-DarkSluchCapV3",
"base_model:quantized:pot99rta/NS-12b-DarkSluchCapV3",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-01T03:34:32Z |
---
base_model: pot99rta/NS-12b-DarkSluchCapV3
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/pot99rta/NS-12b-DarkSluchCapV3
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#NS-12b-DarkSluchCapV3-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/NS-12b-DarkSluchCapV3-GGUF/resolve/main/NS-12b-DarkSluchCapV3.Q2_K.gguf) | Q2_K | 4.9 | |
| [GGUF](https://huggingface.co/mradermacher/NS-12b-DarkSluchCapV3-GGUF/resolve/main/NS-12b-DarkSluchCapV3.Q3_K_S.gguf) | Q3_K_S | 5.6 | |
| [GGUF](https://huggingface.co/mradermacher/NS-12b-DarkSluchCapV3-GGUF/resolve/main/NS-12b-DarkSluchCapV3.Q3_K_M.gguf) | Q3_K_M | 6.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/NS-12b-DarkSluchCapV3-GGUF/resolve/main/NS-12b-DarkSluchCapV3.Q3_K_L.gguf) | Q3_K_L | 6.7 | |
| [GGUF](https://huggingface.co/mradermacher/NS-12b-DarkSluchCapV3-GGUF/resolve/main/NS-12b-DarkSluchCapV3.IQ4_XS.gguf) | IQ4_XS | 6.9 | |
| [GGUF](https://huggingface.co/mradermacher/NS-12b-DarkSluchCapV3-GGUF/resolve/main/NS-12b-DarkSluchCapV3.Q4_K_S.gguf) | Q4_K_S | 7.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/NS-12b-DarkSluchCapV3-GGUF/resolve/main/NS-12b-DarkSluchCapV3.Q4_K_M.gguf) | Q4_K_M | 7.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/NS-12b-DarkSluchCapV3-GGUF/resolve/main/NS-12b-DarkSluchCapV3.Q5_K_S.gguf) | Q5_K_S | 8.6 | |
| [GGUF](https://huggingface.co/mradermacher/NS-12b-DarkSluchCapV3-GGUF/resolve/main/NS-12b-DarkSluchCapV3.Q5_K_M.gguf) | Q5_K_M | 8.8 | |
| [GGUF](https://huggingface.co/mradermacher/NS-12b-DarkSluchCapV3-GGUF/resolve/main/NS-12b-DarkSluchCapV3.Q6_K.gguf) | Q6_K | 10.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/NS-12b-DarkSluchCapV3-GGUF/resolve/main/NS-12b-DarkSluchCapV3.Q8_0.gguf) | Q8_0 | 13.1 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
klmdr22/blockassist-bc-wild_loud_newt_1756705426
|
klmdr22
| 2025-09-01T05:44:28Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"wild loud newt",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T05:44:25Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- wild loud newt
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
benew666/nunchaku-py313
|
benew666
| 2025-09-01T05:43:21Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-09-01T05:30:40Z |
markdown---
license: mit
tags:
- comfyui
- python313
- nunchaku
- pytorch
- flux
library_name: nunchaku
---
# Nunchaku for Python 3.13 - PyTorch 2.8 - CUDA 12.9
Pre-built Nunchaku wheel for ComfyUI with Python 3.13 support.
## 📦 Quick Install
```bash
# Download wheel
wget https://huggingface.co/benew666/nunchaku-py313/resolve/main/nunchaku-1.0.0.dev20250901%2Btorch2.8-cp313-cp313-win_amd64.whl
# Install
pip install nunchaku-1.0.0.dev20250901+torch2.8-cp313-cp313-win_amd64.whl
🔧 Requirements
Python 3.13
PyTorch 2.8
CUDA 12.x
Windows AMD64
16GB+ VRAM recommended
⚡ Troubleshooting
OOM (Out of Memory) Errors?
If you encounter OOM errors with ComfyUI:
bash# Apply patches
python apply_oom_fixes.py
This fixes:
PyTorch 2.8 "Inference tensors" error
T5XXL first-load OOM
Nunchaku model loading issues
📝 Build Information
Component Version
Python 3.13
PyTorch 2.8
CUDA 12.9
Platform win_amd64
Build Date 2025-09-01
✅ Tested On
RTX 4080 SUPER 16GB
Windows 11
ComfyUI Portable
📂 Files
nunchaku-*.whl - Main wheel package
apply_oom_fixes.py - ComfyUI OOM fixes (optional)
🔗 Links
Nunchaku Official
ComfyUI
Note: This is a community build. Use at your own risk.
|
david3621/blockassist-bc-gentle_meek_cat_1756704215
|
david3621
| 2025-09-01T05:39:17Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle meek cat",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T05:38:39Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle meek cat
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
aleebaster/blockassist-bc-sly_eager_boar_1756702808
|
aleebaster
| 2025-09-01T05:37:32Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"sly eager boar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T05:37:24Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- sly eager boar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/IceMoonshineRP-7b-i1-GGUF
|
mradermacher
| 2025-09-01T05:36:55Z | 0 | 0 | null |
[
"gguf",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-09-01T02:29:09Z |
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/icefog72/IceMoonshineRP-7b
|
z1az/gpt_oss_20b_triage_full_6
|
z1az
| 2025-09-01T05:29:43Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:openai/gpt-oss-20b",
"base_model:finetune:openai/gpt-oss-20b",
"endpoints_compatible",
"region:us"
] | null | 2025-09-01T01:17:25Z |
---
base_model: openai/gpt-oss-20b
library_name: transformers
model_name: gpt_oss_20b_triage_full_6
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for gpt_oss_20b_triage_full_6
This model is a fine-tuned version of [openai/gpt-oss-20b](https://huggingface.co/openai/gpt-oss-20b).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="z1az/gpt_oss_20b_triage_full_6", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.20.0
- Transformers: 4.55.4
- Pytorch: 2.8.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
arif696/blockassist-bc-regal_spotted_pelican_1756704389
|
arif696
| 2025-09-01T05:27:41Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"regal spotted pelican",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T05:27:34Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- regal spotted pelican
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
coelacanthxyz/blockassist-bc-finicky_thriving_grouse_1756702489
|
coelacanthxyz
| 2025-09-01T05:25:10Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"finicky thriving grouse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T05:25:05Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- finicky thriving grouse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
EmilRyd/gpt-oss-20b-olympiads-ground-truth-false-on-policy-1e5-6
|
EmilRyd
| 2025-09-01T05:23:08Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_oss",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-01T05:21:00Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
dsagasdgds/blockassist-bc-unseen_camouflaged_komodo_1756703748
|
dsagasdgds
| 2025-09-01T05:21:51Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"unseen camouflaged komodo",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T05:21:37Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- unseen camouflaged komodo
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
arif696/blockassist-bc-regal_spotted_pelican_1756703889
|
arif696
| 2025-09-01T05:20:22Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"regal spotted pelican",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T05:19:12Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- regal spotted pelican
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
EmilRyd/gpt-oss-20b-olympiads-ground-truth-false-on-policy-1e5-2
|
EmilRyd
| 2025-09-01T05:18:46Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_oss",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-01T05:16:44Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
arif696/blockassist-bc-regal_spotted_pelican_1756703627
|
arif696
| 2025-09-01T05:15:53Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"regal spotted pelican",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T05:14:53Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- regal spotted pelican
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
akirafudo/blockassist-bc-keen_fast_giraffe_1756703711
|
akirafudo
| 2025-09-01T05:15:34Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T05:15:30Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
huihui-ai/Huihui-MiniCPM-V-4_5-abliterated
|
huihui-ai
| 2025-09-01T05:10:57Z | 0 | 4 |
transformers
|
[
"transformers",
"safetensors",
"gguf",
"minicpmv",
"feature-extraction",
"minicpm-v",
"vision",
"ocr",
"multi-image",
"video",
"custom_code",
"abliterated",
"uncensored",
"image-text-to-text",
"conversational",
"multilingual",
"base_model:openbmb/MiniCPM-V-4_5",
"base_model:quantized:openbmb/MiniCPM-V-4_5",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2025-08-31T08:41:52Z |
---
license: apache-2.0
pipeline_tag: image-text-to-text
library_name: transformers
base_model:
- openbmb/MiniCPM-V-4_5
language:
- multilingual
tags:
- minicpm-v
- vision
- ocr
- multi-image
- video
- custom_code
- abliterated
- uncensored
---
# huihui-ai/Huihui-MiniCPM-V-4_5-abliterated
This is an uncensored version of [openbmb/MiniCPM-V-4_5](https://huggingface.co/openbmb/MiniCPM-V-4_5) created with abliteration (see [remove-refusals-with-transformers](https://github.com/Sumandora/remove-refusals-with-transformers) to know more about it).
It was only the text part that was processed, not the image part.
The abliterated model will no longer say "I'm sorry, but I can't assist with that."
## Chat with Image
### 1. [llama.cpp](https://github.com/ggml-org/llama.cpp) Inference
(llama-mtmd-cli needs to be compiled.)
```
llama-mtmd-cli -m huihui-ai/Huihui-Qwen3-8B-abliterated/GGUF/ggml-model-Q4_K_M.gguf --mmproj huihui-ai/Huihui-Qwen3-8B-abliterated/GGUF/mmproj-model-f16.gguf -c 4096 --temp 0.7 --top-p 0.8 --top-k 100 --repeat-penalty 1.05 --image abc.png -p "What is in the image?"
```
### 2. Transfromers Inference
```
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
torch.manual_seed(100)
model = AutoModel.from_pretrained('huihui-ai/Huihui-MiniCPM-V-4_5-abliterated', trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('huihui-ai/Huihui-MiniCPM-V-4_5-abliterated', trust_remote_code=True)
image = Image.open('./assets/minicpmo2_6/show_demo.jpg').convert('RGB')
enable_thinking=False # If `enable_thinking=True`, the thinking mode is enabled.
stream=True # If `stream=True`, the answer is string
# First round chat
question = "What is the landform in the picture?"
msgs = [{'role': 'user', 'content': [image, question]}]
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer,
enable_thinking=enable_thinking,
stream=True
)
generated_text = ""
for new_text in answer:
generated_text += new_text
print(new_text, flush=True, end='')
# Second round chat, pass history context of multi-turn conversation
msgs.append({"role": "assistant", "content": [generated_text]})
msgs.append({"role": "user", "content": ["What should I pay attention to when traveling here?"]})
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer,
stream=True
)
generated_text = ""
for new_text in answer:
generated_text += new_text
print(new_text, flush=True, end='')
```
### Usage Warnings
- **Risk of Sensitive or Controversial Outputs**: This model’s safety filtering has been significantly reduced, potentially generating sensitive, controversial, or inappropriate content. Users should exercise caution and rigorously review generated outputs.
- **Not Suitable for All Audiences**: Due to limited content filtering, the model’s outputs may be inappropriate for public settings, underage users, or applications requiring high security.
- **Legal and Ethical Responsibilities**: Users must ensure their usage complies with local laws and ethical standards. Generated content may carry legal or ethical risks, and users are solely responsible for any consequences.
- **Research and Experimental Use**: It is recommended to use this model for research, testing, or controlled environments, avoiding direct use in production or public-facing commercial applications.
- **Monitoring and Review Recommendations**: Users are strongly advised to monitor model outputs in real-time and conduct manual reviews when necessary to prevent the dissemination of inappropriate content.
- **No Default Safety Guarantees**: Unlike standard models, this model has not undergone rigorous safety optimization. huihui.ai bears no responsibility for any consequences arising from its use.
### Donation
##### Your donation helps us continue our further development and improvement, a cup of coffee can do it.
- bitcoin:
```
bc1qqnkhuchxw0zqjh2ku3lu4hq45hc6gy84uk70ge
```
- Support our work on [Ko-fi](https://ko-fi.com/huihuiai)!
|
HangGuo/QWen2.5-7B-FlatQuant-OBR-GPTQ-W4A4KV4S50
|
HangGuo
| 2025-09-01T05:10:16Z | 0 | 0 |
transformers
|
[
"transformers",
"pytorch",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-01T05:08:24Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
AnerYubo/blockassist-bc-screeching_mute_lemur_1756703384
|
AnerYubo
| 2025-09-01T05:09:47Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"screeching mute lemur",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T05:09:44Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- screeching mute lemur
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
0xabhay/Qwen3-0.6B-Gensyn-Swarm-quick_tenacious_jellyfish
|
0xabhay
| 2025-09-01T05:08:04Z | 161 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am quick_tenacious_jellyfish",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-03T12:54:33Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am quick_tenacious_jellyfish
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
klmdr22/blockassist-bc-wild_loud_newt_1756702985
|
klmdr22
| 2025-09-01T05:03:48Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"wild loud newt",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T05:03:44Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- wild loud newt
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
coppertoy/blockassist-bc-grassy_amphibious_alligator_1756702837
|
coppertoy
| 2025-09-01T05:00:56Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"grassy amphibious alligator",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T05:00:38Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- grassy amphibious alligator
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF
|
mradermacher
| 2025-09-01T05:00:30Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:pot99rta/MagcarpMell-ThinkandReasoner-12B",
"base_model:quantized:pot99rta/MagcarpMell-ThinkandReasoner-12B",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-08-31T21:41:41Z |
---
base_model: pot99rta/MagcarpMell-ThinkandReasoner-12B
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/pot99rta/MagcarpMell-ThinkandReasoner-12B
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#MagcarpMell-ThinkandReasoner-12B-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.i1-IQ1_S.gguf) | i1-IQ1_S | 3.1 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.i1-IQ1_M.gguf) | i1-IQ1_M | 3.3 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.i1-IQ2_S.gguf) | i1-IQ2_S | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.i1-IQ2_M.gguf) | i1-IQ2_M | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.i1-Q2_K_S.gguf) | i1-Q2_K_S | 4.6 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.i1-Q2_K.gguf) | i1-Q2_K | 4.9 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 5.0 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 5.6 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.i1-IQ3_S.gguf) | i1-IQ3_S | 5.7 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.i1-IQ3_M.gguf) | i1-IQ3_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 6.2 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 6.7 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 6.8 | |
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.i1-Q4_0.gguf) | i1-Q4_0 | 7.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.i1-IQ4_NL.gguf) | i1-IQ4_NL | 7.2 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 7.2 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 7.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.i1-Q4_1.gguf) | i1-Q4_1 | 7.9 | |
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 8.6 | |
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 8.8 | |
| [GGUF](https://huggingface.co/mradermacher/MagcarpMell-ThinkandReasoner-12B-i1-GGUF/resolve/main/MagcarpMell-ThinkandReasoner-12B.i1-Q6_K.gguf) | i1-Q6_K | 10.2 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
liukevin666/blockassist-bc-yawning_striped_cassowary_1756702722
|
liukevin666
| 2025-09-01T04:59:45Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"yawning striped cassowary",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T04:59:39Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- yawning striped cassowary
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
CodeAtCMU/Llama-3.2-1B-CorruptedComments_full_sft_code_data_120K_replace_comments_global
|
CodeAtCMU
| 2025-09-01T04:52:17Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-01T04:51:47Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
lfhe/FLock-Arena-Task-14-PocketPitCrew
|
lfhe
| 2025-09-01T04:52:15Z | 444 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Qwen/Qwen2.5-3B-Instruct",
"base_model:adapter:Qwen/Qwen2.5-3B-Instruct",
"region:us"
] | null | 2025-04-29T15:12:07Z |
---
base_model: Qwen/Qwen2.5-3B-Instruct
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.2
|
arif696/blockassist-bc-regal_spotted_pelican_1756702251
|
arif696
| 2025-09-01T04:52:05Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"regal spotted pelican",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T04:51:57Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- regal spotted pelican
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
AnerYubo/blockassist-bc-finicky_finicky_warthog_1756701906
|
AnerYubo
| 2025-09-01T04:45:08Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"finicky finicky warthog",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T04:45:06Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- finicky finicky warthog
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
akirafudo/blockassist-bc-keen_fast_giraffe_1756701581
|
akirafudo
| 2025-09-01T04:40:39Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T04:40:00Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
jaredvoxworksai/orpheus_02_aus_accents1_float16
|
jaredvoxworksai
| 2025-09-01T04:40:03Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:unsloth/orpheus-3b-0.1-ft",
"base_model:finetune:unsloth/orpheus-3b-0.1-ft",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-01T04:26:37Z |
---
base_model: unsloth/orpheus-3b-0.1-ft
tags:
- text-generation-inference
- transformers
- unsloth
- llama
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** jaredvoxworksai
- **License:** apache-2.0
- **Finetuned from model :** unsloth/orpheus-3b-0.1-ft
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
yujiepan/longcat-flash-tiny-random
|
yujiepan
| 2025-09-01T04:36:42Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"longcat_flash",
"text-generation",
"conversational",
"custom_code",
"base_model:meituan-longcat/LongCat-Flash-Chat",
"base_model:finetune:meituan-longcat/LongCat-Flash-Chat",
"autotrain_compatible",
"region:us"
] |
text-generation
| 2025-09-01T04:36:39Z |
---
library_name: transformers
pipeline_tag: text-generation
inference: true
widget:
- text: Hello!
example_title: Hello world
group: Python
base_model:
- meituan-longcat/LongCat-Flash-Chat
---
This tiny model is for debugging. It is randomly initialized with the config adapted from [meituan-longcat/LongCat-Flash-Chat](https://huggingface.co/meituan-longcat/LongCat-Flash-Chat).
### Example usage:
- vLLM
```bash
vllm serve yujiepan/longcat-flash-tiny-random \
--trust-remote-code \
--enable-expert-parallel \
--tensor-parallel-size 1 \
--speculative_config '{"model": "yujiepan/longcat-flash-tiny-random", "num_speculative_tokens": 1, "method":"longcat_flash_mtp"}'
```
- SGLang
```bash
python3 -m sglang.launch_server \
--model yujiepan/longcat-flash-tiny-random \
--trust-remote-code \
--attention-backend flashinfer \
--enable-ep-moe \
--tp 1 \
--speculative-draft-model-path yujiepan/longcat-flash-tiny-random \
--speculative-algorithm NEXTN \
--speculative-num-draft-tokens 2 \
--speculative-num-steps 1 \
--speculative-eagle-topk 1
```
- Transformers
```python
import torch
import transformers
model_id = "yujiepan/longcat-flash-tiny-random"
pipe = transformers.pipelines.pipeline(
'text-generation',
model=model_id,
trust_remote_code=True,
device_map='cuda',
torch_dtype=torch.bfloat16,
)
past_key_values = transformers.DynamicCache(config=None) # set config to None
r = pipe('Hello, world!', past_key_values=past_key_values, max_new_tokens=32)
print(r)
```
### Codes to create this repo:
```python
import json
from copy import deepcopy
from pathlib import Path
import torch
import torch.nn as nn
from huggingface_hub import file_exists, hf_hub_download
from transformers import (
AutoConfig,
AutoModelForCausalLM,
AutoProcessor,
AutoTokenizer,
GenerationConfig,
set_seed,
)
from transformers.models.glm4_moe.modeling_glm4_moe import Glm4MoeRMSNorm
source_model_id = "meituan-longcat/LongCat-Flash-Chat"
save_folder = "/tmp/yujiepan/longcat-flash-tiny-random"
Path(save_folder).mkdir(parents=True, exist_ok=True)
tokenizer = AutoTokenizer.from_pretrained(source_model_id, trust_remote_code=True)
tokenizer.save_pretrained(save_folder)
with open(hf_hub_download(source_model_id, filename='config.json', repo_type='model'), 'r', encoding='utf-8') as f:
config_json = json.load(f)
for k, v in config_json['auto_map'].items():
config_json['auto_map'][k] = f'{source_model_id}--{v}'
config_json.update({
'num_layers': 2,
'hidden_size': 8,
'ffn_hidden_size': 64,
'expert_ffn_hidden_size': 64,
'num_attention_heads': 4,
'kv_lora_rank': 384,
'n_routed_experts': 32,
'q_lora_rank': 32,
'qk_nope_head_dim': 64,
'qk_rope_head_dim': 192, # vllm mla kernel supports 576 only, FA supports head dim <= 256
'v_head_dim': 64,
'moe_topk': 12,
'zero_expert_num': 16,
})
# del config_json['quantization_config']
with open(f"{save_folder}/config.json", "w", encoding='utf-8') as f:
json.dump(config_json, f, indent=2)
config = AutoConfig.from_pretrained(
save_folder,
trust_remote_code=True,
)
print(config)
torch.set_default_dtype(torch.bfloat16)
model = AutoModelForCausalLM.from_config(config, trust_remote_code=True)
if file_exists(filename="generation_config.json", repo_id=source_model_id, repo_type='model'):
model.generation_config = GenerationConfig.from_pretrained(
source_model_id, trust_remote_code=True,
)
model = model.cpu()
# MTP
model.model.mtp = nn.ModuleDict({
"layers": nn.ModuleList([nn.ModuleDict(dict(
eh_proj=nn.Linear(config.hidden_size * 2, config.hidden_size, bias=False),
enorm=nn.ModuleDict({"m": nn.RMSNorm(config.hidden_size)}),
hnorm=nn.ModuleDict({"m": nn.RMSNorm(config.hidden_size)}),
input_layernorm=nn.RMSNorm(config.hidden_size),
post_attention_layernorm=nn.RMSNorm(config.hidden_size),
self_attn=deepcopy(model.model.layers[0].self_attn[0]),
transformer_layer=nn.ModuleDict({"mlp": deepcopy(model.model.layers[0].mlps[0])}),
))]),
"norm": nn.RMSNorm(config.hidden_size),
})
for i in range(config.num_layers):
model.model.layers[i].mlp.router = model.model.layers[i].mlp.router.float()
# model.model.layers[i].mlp.router.e_score_correction_bias = torch.zeros((config.n_routed_experts + config.zero_expert_num)).float()
set_seed(42)
with torch.no_grad():
for name, p in sorted(model.named_parameters()):
torch.nn.init.normal_(p, 0, 0.1)
print(name, p.shape, p.dtype)
model.model.mtp.embed_tokens = deepcopy(model.model.embed_tokens)
model.save_pretrained(save_folder)
torch.set_default_dtype(torch.float32)
for n, m in model.named_modules():
if 'LongcatFlashMLA' in str(type(m)):
print(n, m.layer_idx)
with open(f"{save_folder}/config.json", "r", encoding='utf-8') as f:
config_json = json.load(f)
config_json['auto_map'] = {k: v.split('--')[-1] for k, v in config_json['auto_map'].items()}
with open(f"{save_folder}/config.json", "w", encoding='utf-8') as f:
json.dump(config_json, f, indent=2)
```
### Printing the model:
```text
LongcatFlashForCausalLM(
(model): LongcatFlashModel(
(embed_tokens): Embedding(131072, 8)
(layers): ModuleList(
(0-1): 2 x LongcatFlashDecoderLayer(
(mlp): LongcatFlashMoE(
(experts): ModuleList(
(0-31): 32 x LongcatFlashMLP(
(gate_proj): Linear(in_features=8, out_features=64, bias=False)
(up_proj): Linear(in_features=8, out_features=64, bias=False)
(down_proj): Linear(in_features=64, out_features=8, bias=False)
(act_fn): SiLU()
)
)
(router): LongcatFlashTopkRouter(
(classifier): Linear(in_features=8, out_features=48, bias=False)
)
)
(self_attn): ModuleList(
(0-1): 2 x LongcatFlashMLA(
(q_a_proj): Linear(in_features=8, out_features=32, bias=False)
(q_a_layernorm): LongcatFlashRMSNorm((32,), eps=1e-06)
(q_b_proj): Linear(in_features=32, out_features=1024, bias=False)
(kv_a_proj_with_mqa): Linear(in_features=8, out_features=576, bias=False)
(kv_a_layernorm): LongcatFlashRMSNorm((384,), eps=1e-06)
(kv_b_proj): Linear(in_features=384, out_features=512, bias=False)
(o_proj): Linear(in_features=256, out_features=8, bias=False)
)
)
(mlps): ModuleList(
(0-1): 2 x LongcatFlashMLP(
(gate_proj): Linear(in_features=8, out_features=64, bias=False)
(up_proj): Linear(in_features=8, out_features=64, bias=False)
(down_proj): Linear(in_features=64, out_features=8, bias=False)
(act_fn): SiLU()
)
)
(input_layernorm): ModuleList(
(0-1): 2 x LongcatFlashRMSNorm((8,), eps=1e-05)
)
(post_attention_layernorm): ModuleList(
(0-1): 2 x LongcatFlashRMSNorm((8,), eps=1e-05)
)
)
)
(norm): LongcatFlashRMSNorm((8,), eps=1e-05)
(rotary_emb): LongcatFlashRotaryEmbedding()
(mtp): ModuleDict(
(layers): ModuleList(
(0): ModuleDict(
(eh_proj): Linear(in_features=16, out_features=8, bias=False)
(enorm): ModuleDict(
(m): RMSNorm((8,), eps=None, elementwise_affine=True)
)
(hnorm): ModuleDict(
(m): RMSNorm((8,), eps=None, elementwise_affine=True)
)
(input_layernorm): RMSNorm((8,), eps=None, elementwise_affine=True)
(post_attention_layernorm): RMSNorm((8,), eps=None, elementwise_affine=True)
(self_attn): LongcatFlashMLA(
(q_a_proj): Linear(in_features=8, out_features=32, bias=False)
(q_a_layernorm): LongcatFlashRMSNorm((32,), eps=1e-06)
(q_b_proj): Linear(in_features=32, out_features=1024, bias=False)
(kv_a_proj_with_mqa): Linear(in_features=8, out_features=576, bias=False)
(kv_a_layernorm): LongcatFlashRMSNorm((384,), eps=1e-06)
(kv_b_proj): Linear(in_features=384, out_features=512, bias=False)
(o_proj): Linear(in_features=256, out_features=8, bias=False)
)
(transformer_layer): ModuleDict(
(mlp): LongcatFlashMLP(
(gate_proj): Linear(in_features=8, out_features=64, bias=False)
(up_proj): Linear(in_features=8, out_features=64, bias=False)
(down_proj): Linear(in_features=64, out_features=8, bias=False)
(act_fn): SiLU()
)
)
)
)
(norm): RMSNorm((8,), eps=None, elementwise_affine=True)
(embed_tokens): Embedding(131072, 8)
)
)
(lm_head): Linear(in_features=8, out_features=131072, bias=False)
)
```
|
Vira21/Llama-khmer-prahokbart
|
Vira21
| 2025-09-01T04:29:51Z | 0 | 0 | null |
[
"safetensors",
"llama",
"region:us"
] | null | 2025-09-01T04:25:23Z |
# Vira21/Llama-khmer-prahokbart
LLaMA with PrahokBART Khmer vocab expansion.
|
thanaphatt1/typhoon2.1-gemma3-4b-strategy-prediction-v4
|
thanaphatt1
| 2025-09-01T04:29:08Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"gemma3_text",
"trl",
"en",
"base_model:scb10x/typhoon2.1-gemma3-4b",
"base_model:finetune:scb10x/typhoon2.1-gemma3-4b",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-01T04:28:55Z |
---
base_model: scb10x/typhoon2.1-gemma3-4b
tags:
- text-generation-inference
- transformers
- unsloth
- gemma3_text
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** thanaphatt1
- **License:** apache-2.0
- **Finetuned from model :** scb10x/typhoon2.1-gemma3-4b
This gemma3_text model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
danbev/embeddingmodel-800M-qat-q4_0-GGUF
|
danbev
| 2025-09-01T04:26:07Z | 0 | 0 | null |
[
"gguf",
"region:us"
] | null | 2025-09-01T04:26:05Z |
---
base_model:
- some_org/embeddingmodel-800M-qat-q4_0
---
# embeddingmodel-800M-qat-q4_0 GGUF
Recommended way to run this model:
```sh
llama-server -hf danbev/embeddingmodel-800M-qat-q4_0-GGUF
```
Then the endpoint can be accessed at http://localhost:8080/embedding, for
example using `curl`:
```console
curl --request POST \
--url http://localhost:8080/embedding \
--header "Content-Type: application/json" \
--data '{"input": "Hello embeddings"}' \
--silent
```
Alternatively, the `llama-embedding` command line tool can be used:
```sh
llama-embedding -hf danbev/embeddingmodel-800M-qat-q4_0-GGUF --verbose-prompt -p "Hello embeddings"
```
#### embd_normalize
When a model uses pooling, or the pooling method is specified using `--pooling`,
the normalization can be controlled by the `embd_normalize` parameter.
The default value is `2` which means that the embeddings are normalized using
the Euclidean norm (L2). Other options are:
* -1 No normalization
* 0 Max absolute
* 1 Taxicab
* 2 Euclidean/L2
* \>2 P-Norm
This can be passed in the request body to `llama-server`, for example:
```sh
--data '{"input": "Hello embeddings", "embd_normalize": -1}' \
```
And for `llama-embedding`, by passing `--embd-normalize <value>`, for example:
```sh
llama-embedding -hf danbev/embeddingmodel-800M-qat-q4_0-GGUF --embd-normalize -1 -p "Hello embeddings"
```
|
nghiaht281003/COWAI
|
nghiaht281003
| 2025-09-01T04:25:08Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-09-01T04:25:08Z |
---
license: apache-2.0
---
|
sekirr/blockassist-bc-masked_tenacious_whale_1756700548
|
sekirr
| 2025-09-01T04:23:08Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"masked tenacious whale",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T04:23:05Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- masked tenacious whale
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
GroomerG/blockassist-bc-vicious_pawing_badger_1756698636
|
GroomerG
| 2025-09-01T04:17:32Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"vicious pawing badger",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T04:17:28Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- vicious pawing badger
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF
|
mradermacher
| 2025-09-01T04:14:15Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"mergekit",
"merge",
"axolotl",
"en",
"dataset:zerofata/Roleplay-Anime-Characters",
"dataset:zerofata/Instruct-Anime-CreativeWriting",
"dataset:zerofata/Instruct-Anime",
"dataset:zerofata/Summaries-Anime-FandomPages",
"dataset:zerofata/Stories-Anime",
"dataset:Nitral-AI/Reddit-NSFW-Writing_Prompts_ShareGPT",
"base_model:zerofata/MS3.2-PaintedFantasy-Visage-v2-33B",
"base_model:quantized:zerofata/MS3.2-PaintedFantasy-Visage-v2-33B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2025-08-31T22:34:19Z |
---
base_model: zerofata/MS3.2-PaintedFantasy-Visage-v2-33B
datasets:
- zerofata/Roleplay-Anime-Characters
- zerofata/Instruct-Anime-CreativeWriting
- zerofata/Instruct-Anime
- zerofata/Summaries-Anime-FandomPages
- zerofata/Stories-Anime
- Nitral-AI/Reddit-NSFW-Writing_Prompts_ShareGPT
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- mergekit
- merge
- axolotl
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/zerofata/MS3.2-PaintedFantasy-Visage-v2-33B
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF/resolve/main/MS3.2-PaintedFantasy-Visage-v2-33B.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF/resolve/main/MS3.2-PaintedFantasy-Visage-v2-33B.i1-IQ1_S.gguf) | i1-IQ1_S | 7.4 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF/resolve/main/MS3.2-PaintedFantasy-Visage-v2-33B.i1-IQ1_M.gguf) | i1-IQ1_M | 8.1 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF/resolve/main/MS3.2-PaintedFantasy-Visage-v2-33B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 9.3 | |
| [GGUF](https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF/resolve/main/MS3.2-PaintedFantasy-Visage-v2-33B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 10.2 | |
| [GGUF](https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF/resolve/main/MS3.2-PaintedFantasy-Visage-v2-33B.i1-IQ2_S.gguf) | i1-IQ2_S | 10.6 | |
| [GGUF](https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF/resolve/main/MS3.2-PaintedFantasy-Visage-v2-33B.i1-IQ2_M.gguf) | i1-IQ2_M | 11.5 | |
| [GGUF](https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF/resolve/main/MS3.2-PaintedFantasy-Visage-v2-33B.i1-Q2_K_S.gguf) | i1-Q2_K_S | 11.8 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF/resolve/main/MS3.2-PaintedFantasy-Visage-v2-33B.i1-Q2_K.gguf) | i1-Q2_K | 12.6 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF/resolve/main/MS3.2-PaintedFantasy-Visage-v2-33B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 13.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF/resolve/main/MS3.2-PaintedFantasy-Visage-v2-33B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 14.1 | |
| [GGUF](https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF/resolve/main/MS3.2-PaintedFantasy-Visage-v2-33B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 14.8 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF/resolve/main/MS3.2-PaintedFantasy-Visage-v2-33B.i1-IQ3_S.gguf) | i1-IQ3_S | 14.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF/resolve/main/MS3.2-PaintedFantasy-Visage-v2-33B.i1-IQ3_M.gguf) | i1-IQ3_M | 15.2 | |
| [GGUF](https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF/resolve/main/MS3.2-PaintedFantasy-Visage-v2-33B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 16.4 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF/resolve/main/MS3.2-PaintedFantasy-Visage-v2-33B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 17.7 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF/resolve/main/MS3.2-PaintedFantasy-Visage-v2-33B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 18.2 | |
| [GGUF](https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF/resolve/main/MS3.2-PaintedFantasy-Visage-v2-33B.i1-Q4_0.gguf) | i1-Q4_0 | 19.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF/resolve/main/MS3.2-PaintedFantasy-Visage-v2-33B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 19.3 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF/resolve/main/MS3.2-PaintedFantasy-Visage-v2-33B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 20.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF/resolve/main/MS3.2-PaintedFantasy-Visage-v2-33B.i1-Q4_1.gguf) | i1-Q4_1 | 21.2 | |
| [GGUF](https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF/resolve/main/MS3.2-PaintedFantasy-Visage-v2-33B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 23.3 | |
| [GGUF](https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF/resolve/main/MS3.2-PaintedFantasy-Visage-v2-33B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 23.9 | |
| [GGUF](https://huggingface.co/mradermacher/MS3.2-PaintedFantasy-Visage-v2-33B-i1-GGUF/resolve/main/MS3.2-PaintedFantasy-Visage-v2-33B.i1-Q6_K.gguf) | i1-Q6_K | 27.7 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
phospho-app/ACT_BBOX-svla_so101_pickplace-bq1musfq9k
|
phospho-app
| 2025-09-01T04:12:55Z | 0 | 0 |
phosphobot
|
[
"phosphobot",
"act",
"robotics",
"dataset:lerobot/svla_so101_pickplace",
"region:us"
] |
robotics
| 2025-09-01T04:12:47Z |
---
datasets: lerobot/svla_so101_pickplace
library_name: phosphobot
pipeline_tag: robotics
model_name: act
tags:
- phosphobot
- act
task_categories:
- robotics
---
# act model - 🧪 phosphobot training pipeline
- **Dataset**: [lerobot/svla_so101_pickplace](https://huggingface.co/datasets/lerobot/svla_so101_pickplace)
- **Wandb run id**: None
## Error Traceback
We faced an issue while training your model.
```
Image key 'main' not found in the dataset info_model. Please check the image keys in the dataset and pass the appropriate parameter.
Available image keys: ['observation.images.up', 'observation.images.side']
```
## Training parameters
```text
{
"batch_size": null,
"steps": null,
"save_freq": 5000,
"target_detection_instruction": "brown object",
"image_key": "main",
"image_keys_to_keep": []
}
```
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=huggingface_readme)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=huggingface_readme)
|
coelacanthxyz/blockassist-bc-finicky_thriving_grouse_1756698221
|
coelacanthxyz
| 2025-09-01T04:11:04Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"finicky thriving grouse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T04:10:58Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- finicky thriving grouse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kalimoy/blockassist-bc-scaly_tiny_locust_1756699308
|
kalimoy
| 2025-09-01T04:02:05Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"scaly tiny locust",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T04:01:49Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- scaly tiny locust
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Sayemahsjn/blockassist-bc-playful_feline_octopus_1756698051
|
Sayemahsjn
| 2025-09-01T03:59:37Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"playful feline octopus",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T03:59:33Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- playful feline octopus
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
AppliedLucent/ALIE-1.2-8B
|
AppliedLucent
| 2025-09-01T03:57:57Z | 44 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:AppliedLucent/ALIE-1.2-8B",
"base_model:finetune:AppliedLucent/ALIE-1.2-8B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-30T19:32:48Z |
---
base_model: AppliedLucent/ALIE-1.2-8B
tags:
- text-generation-inference
- transformers
- unsloth
- llama
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** AppliedLucent
- **License:** apache-2.0
- **Finetuned from model :** AppliedLucent/ALIE-1.2-8B
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
kalimoy/blockassist-bc-freckled_beaked_tortoise_1756699034
|
kalimoy
| 2025-09-01T03:57:31Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"freckled beaked tortoise",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T03:57:14Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- freckled beaked tortoise
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
liukevin666/blockassist-bc-yawning_striped_cassowary_1756698841
|
liukevin666
| 2025-09-01T03:55:01Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"yawning striped cassowary",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T03:54:54Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- yawning striped cassowary
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
IanL10/GP-GPT
|
IanL10
| 2025-09-01T03:48:02Z | 0 | 0 | null |
[
"safetensors",
"medical",
"biology",
"genetics",
"bioinformatics",
"question-answering",
"en",
"arxiv:2409.09825",
"base_model:meta-llama/Llama-2-7b",
"base_model:finetune:meta-llama/Llama-2-7b",
"license:apache-2.0",
"region:us"
] |
question-answering
| 2025-08-31T22:00:03Z |
---
license: apache-2.0
language:
- en
base_model:
- meta-llama/Llama-3.1-8B-Instruct
- meta-llama/Llama-2-7b
pipeline_tag: question-answering
tags:
- medical
- biology
- genetics
- bioinformatics
---
**GP-GTP** is an open-weight genetic-phenotype knowledge language model. For "medical-genetic-information".
**Arvix version**: [arXiv:2409.09825](https://doi.org/10.48550/arXiv.2409.09825)
### Usage
```python
from transformers import AutoModelForCausalLM, BitsAndBytesConfig, HfArgumentParser, TrainingArguments
from peft import AutoPeftModelForCausalLM
from peft import PeftModel
from peft import LoraConfig, get_peft_model
#init
parser = HfArgumentParser(ScriptArguments)
script_args = parser.parse_args_into_dataclasses()[0]
# specific the model to load
# For GP-GPT small:
script_args.model_name = "meta-llama/Llama-2-7b"
script_args.peft_model_id = "./small/"
# For GP-GPT base:
script_args.model_name = "meta-llama/Meta-Llama-3.1-8B"
script_args.peft_model_id = "./base/"
# Cache model
model = AutoModelForCausalLM.from_pretrained(
script_args.model_name,
#quantization_config=quantization_config, # activate when using quantization setting
device_map=device_map,
torch_dtype=torch_dtype,
use_auth_token=False,
)
#load PEFT adapter
if script_args.peft_model_id is not None:
peft_model_id = script_args.peft_model_id
model = PeftModel.from_pretrained(model, peft_model_id)
model = model.merge_and_unload()
|
stableai-org/LimiX-16M
|
stableai-org
| 2025-09-01T03:47:49Z | 0 | 5 | null |
[
"en",
"zh",
"dataset:stableai-org/bcco_cls",
"dataset:stableai-org/bcco_reg",
"license:apache-2.0",
"region:us"
] | null | 2025-08-28T18:09:04Z |
---
license: apache-2.0
datasets:
- stableai-org/bcco_cls
- stableai-org/bcco_reg
language:
- en
- zh
---
<div align="center">
<h1>LimiX</h1>
</div>
<div align="center">
<img src="https://raw.githubusercontent.com/limix-ldm/LimiX/refs/heads/main/doc/LimiX-Logo.png" alt="LimiX logo" width="89%">
</div>
# News :boom:
- 2025-08-29: LimiX V1.0 Released.
# ➤ Overview
We posit that progress toward general intelligence will require different complementary classes of foundation models, each anchored to a distinct data modality and set of inductive biases. large language models (LLMs) provide a universal interface for natural and programming languages and have rapidly advanced instruction following, tool use, and explicit reasoning over token sequences. In real-world scenarios involving structured data, LLMs still rely primarily on statistical correlations between word sequences, which limits their ability to accurately capture numerical relationships and causal rules. In contrast, large structured-data models (LDMs) are trained on heterogeneous tabular and relational data to capture conditional and joint dependencies, support diverse tasks and applications, enable robust prediction under distribution shifts, handle missingness, and facilitate counterfactual analysis and feature attribution. Here, we introduce LimiX, the first installment of our LDM series. LimiX aims to push generality further: a single model that handles classification, regression, missing-value imputation, feature selection, sample selection, and causal inference under one training and inference recipe, advancing the shift from bespoke pipelines to unified, foundation-style tabular learning.
LimiX adopts a transformer architecture optimized for structured data modeling and task generalization. The model first embeds features X and targets Y from the prior knowledge base into token representations. Within the core modules, attention mechanisms are applied across both sample and feature dimensions to identify salient patterns in key samples and features. The resulting high-dimensional representations are then passed to regression and classification heads, enabling the model to support diverse predictive tasks.
For details, please refer to the technical report at the link: [LimiX_Technical_Report.pdf](https://github.com/limix-ldm/LimiX/blob/main/LimiX_Technical_Report.pdf)
# ➤ Comparative experimental results
The LimiX model achieved SOTA performance across multiple tasks.
## ➩ Classification comparison results
<div align="center">
<img src="https://raw.githubusercontent.com/limix-ldm/LimiX/refs/heads/main/doc/Classifier.png" alt="Classification" width="80%">
</div>
## ➩ Regression comparison results
<div align="center">
<img src="https://raw.githubusercontent.com/limix-ldm/LimiX/refs/heads/main/doc/Regression.png" alt="Regression" width="80%">
</div>
## ➩ Missing value imputation comparison results
<div align="center">
<img src="https://raw.githubusercontent.com/limix-ldm/LimiX/refs/heads/main/doc/MissingValueImputation.png" alt="Missing value imputation" width="80%">
</div>
# ➤ Tutorials
## ➩ Installation
### Option 1 (recommended): Use the Dockerfile
Download [Dockerfile](https://github.com/limix-ldm/LimiX/blob/main/Dockerfile)
```bash
docker build --network=host -t limix/infe:v1 --build-arg FROM_IMAGES=nvidia/cuda:12.2.0-base-ubuntu22.04 -f Dockerfile .
```
### Option 2: Build manually
Download the prebuilt flash_attn files
```bash
wget -O flash_attn-2.8.0.post2+cu12torch2.7cxx11abiTRUE-cp312-cp312-linux_x86_64.whl https://github.com/Dao-AILab/flash-attention/releases/download/v2.8.0.post2/flash_attn-2.8.0.post2+cu12torch2.7cxx11abiTRUE-cp312-cp312-linux_x86_64.whl
```
Install Python dependencies
```bash
pip install python=3.12.7 torch==2.7.1 torchvision==0.22.1 torchaudio==2.7.1
pip install flash_attn-2.8.0.post2+cu12torch2.7cxx11abiTRUE-cp312-cp312-linux_x86_64.whl
pip install scikit-learn einops huggingface-hub matplotlib networkx numpy pandas scipy tqdm typing_extensions xgboost
```
### Download source code
```bash
git clone https://github.com/limix-ldm/LimiX.git
cd LimiX
```
# ➤ Inference
LimiX supports tasks such as classification, regression, and missing value imputation
## ➩ Model download
| Model size | Download link | Tasks supported |
| --- | --- | --- |
| LimiX-16M | [LimiX-16M.ckpt](https://huggingface.co/stableai-org/LimiX-16M/tree/main) | ✅ classification ✅regression ✅missing value imputation |
## ➩ Interface description
### Model Creation
```python
class LimiXPredictor:
def __init__(self,
device:torch.device,
model_path:str,
mix_precision:bool=True,
inference_config: list|str,
categorical_features_indices:List[int]|None=None,
outlier_remove_std: float=12,
softmax_temperature:float=0.9,
task_type: Literal['Classification', 'Regression']='Classification',
mask_prediction:bool=False,
inference_with_DDP: bool = False,
seed:int=0)
```
| Parameter | Data Type | Description |
|--------|----------|----------|
| device | torch.device | The hardware that loads the model |
| model_path | str | The path to the model that needs to be loaded |
| mix_precision | bool | Whether to enable the mixed precision inference |
| inference_config | list/str | Configuration file used for inference |
| categorical_features_indices | list | The indices of categorical columns in the tabular data |
| outlier_remove_std | float | The threshold is employed to remove outliers, defined as values that are multiples of the standard deviation |
| softmax_temperature | float | The temperature used to control the behavior of softmax operator |
| task_type | str | The task type which can be either "Classification" or "Regression" |
| mask_prediction | bool | Whether to enable missing value imputation |
| inference_with_DDP | bool | Whether to enable DDP during inference |
| seed | int | The seed to control random states |
### Predict
```python
def predict(self, x_train:np.ndarray, y_train:np.ndarray, x_test:np.ndarray) -> np.ndarray:
```
| Parameter | Data Type | Description |
| ------- | ---------- | ----------------- |
| x_train | np.ndarray | The input features of the training set |
| y_train | np.ndarray | The target variable of the training set |
| x_test | np.ndarray | The input features of the test set |
## ➩ Ensemble Inference Based on Sample Retrieval
For a detailed technical introduction to Ensemble Inference Based on Sample Retrieval, please refer to the [technical report](https://github.com/limix-ldm/LimiX/blob/main/LimiX_Technical_Report.pdf).
Considering inference speed, ensemble inference based on sample retrieval currently only supports hardware with specifications higher than the NVIDIA RTX 4090 GPU.
### Classification Task
```
torchrun --nproc_per_node=8 inference_classifier.py --save_name your_save_name --inference_config_path path_to_config --data_dir path_to_data
```
### Regression Task
```
torchrun --nproc_per_node=8 inference_regression.py --save_name your_save_name --inference_config_path path_to_config --data_dir path_to_data
```
### Customizing Data Preprocessing for Inference Tasks
#### First, Generate the Inference Configuration File
```python
generate_inference_config()
```
### Classification Task
#### Single GPU or CPU
```
python inference_classifier.py --save_name your_save_name --inference_config_path path_to_config --data_dir path_to_data
```
#### Multi-GPU Distributed Inference
```
torchrun --nproc_per_node=8 inference_classifier.py --save_name your_save_name --inference_config_path path_to_config --data_dir path_to_data --inference_with_DDP
```
### Regression Task
#### Single GPU or CPU
```
python inference_regression.py --save_name your_save_name --inference_config_path path_to_config --data_dir path_to_data
```
#### Multi-GPU Distributed Inference
```
torchrun --nproc_per_node=8 inference_regression.py --save_name your_save_name --inference_config_path path_to_config --data_dir path_to_data --inference_with_DDP
```
## ➩ Classification
```python
from sklearn.datasets import load_breast_cancer
from sklearn.metrics import accuracy_score, roc_auc_score
from sklearn.model_selection import train_test_split
from huggingface_hub import hf_hub_download
import numpy as np
import os, sys
ROOT_DIR = os.path.abspath(os.path.join(os.path.dirname(__file__), ".."))
if ROOT_DIR not in sys.path:
sys.path.insert(0, ROOT_DIR)
from inference.predictor import LimiXPredictor
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=42)
model_file = hf_hub_download(repo_id="stableai-org/LimiX-16M", filename="LimiX-16M.ckpt", local_dir=".")
clf = LimiXPredictor(device='cuda', model_path='your model path', inference_config='config/cls_default_noretrieval.json')
prediction = clf.predict(X_train, y_train, X_test)
print("roc_auc_score:", roc_auc_score(y_test, prediction[:, 1]))
print("accuracy_score:", accuracy_score(y_test, np.argmax(prediction, axis=1)))
```
For additional examples, refer to [inference_classifier.py](./inference_classifier.py)
## ➩ Regression
```python
from functools import partial
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from huggingface_hub import hf_hub_download
try:
from sklearn.metrics import root_mean_squared_error as mean_squared_error
except:
from sklearn.metrics import mean_squared_error
mean_squared_error = partial(mean_squared_error, squared=True)
import os, sys
ROOT_DIR = os.path.abspath(os.path.join(os.path.dirname(__file__), ".."))
if ROOT_DIR not in sys.path:
sys.path.insert(0, ROOT_DIR)
from inference.predictor import LimiXPredictor
house_data = fetch_california_housing()
X, y = house_data.data, house_data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
y_mean = y_train.mean()
y_std = y_train.std()
y_train_normalized = (y_train - y_mean) / y_std
y_test_normalized = (y_test - y_mean) / y_std
data_device = f'cuda:0'
model_path = hf_hub_download(repo_id="stableai-org/LimiX-16M", filename="LimiX-16M.ckpt", local_dir=".")
model = LimiXPredictor(device='cuda', model_path=model_path, inference_config='config/reg_default_noretrieval.json')
y_pred = model.predict(X_train, y_train_normalized, X_test)
# Compute RMSE and R²
y_pred = y_pred.to('cpu').numpy()
rmse = mean_squared_error(y_test_normalized, y_pred)
r2 = r2_score(y_test_normalized, y_pred)
print(f'RMSE: {rmse}')
print(f'R2: {r2}')
```
For additional examples, refer to [inference_regression.py](./inference_regression.py)
## ➩ Missing value imputation
For the demo file, see [examples/demo_missing_value_imputation.py](examples/inference_regression.py)
# ➤ Link
- LimiX Technical Report: [LimiX_Technical_Report.pdf](https://github.com/limix-ldm/LimiX/blob/main/LimiX_Technical_Report.pdf)
- Balance Comprehensive Challenging Omni-domain Classification Benchmark: [bcco_cls](https://huggingface.co/datasets/stableai-org/bcco_cls)
- Balance Comprehensive Challenging Omni-domain Regression Benchmark: [bcco_reg](https://huggingface.co/datasets/stableai-org/bcco_reg)
# ➤ License
The code in this repository is open-sourced under the [Apache-2.0](LICENSE.txt) license, while the usage of the LimiX model weights is subject to the Model License. The LimiX weights are fully available for academic research and may be used commercially upon obtaining proper authorization.
# ➤ Reference
|
sekirr/blockassist-bc-masked_tenacious_whale_1756698352
|
sekirr
| 2025-09-01T03:46:32Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"masked tenacious whale",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T03:46:29Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- masked tenacious whale
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
GroomerG/blockassist-bc-vicious_pawing_badger_1756696544
|
GroomerG
| 2025-09-01T03:44:49Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"vicious pawing badger",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T03:44:45Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- vicious pawing badger
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
liukevin666/blockassist-bc-yawning_striped_cassowary_1756698195
|
liukevin666
| 2025-09-01T03:44:40Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"yawning striped cassowary",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T03:44:08Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- yawning striped cassowary
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
GrizzlyEgor/blockassist-bc-thick_silent_crow_1756695865
|
GrizzlyEgor
| 2025-09-01T03:38:05Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thick silent crow",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T03:37:42Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thick silent crow
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
OPPOer/X2Edit
|
OPPOer
| 2025-09-01T03:37:18Z | 1 | 3 |
diffusers
|
[
"diffusers",
"arxiv:2508.07607",
"license:apache-2.0",
"region:us"
] | null | 2025-08-11T11:24:20Z |
---
license: apache-2.0
---
<div align="center">
<h1>X2Edit</h1>
<a href='https://github.com/OPPO-Mente-Lab/X2Edit'><img src="https://img.shields.io/badge/GitHub-OPPOer/X2Edit-blue.svg?logo=github" alt="GitHub"></a>
<a href='https://arxiv.org/abs/2508.07607'><img src='https://img.shields.io/badge/arXiv-2508.07607-b31b1b.svg'></a>
<a href='https://huggingface.co/datasets/OPPOer/X2Edit-Dataset'><img src='https://img.shields.io/badge/🤗%20HuggingFace-X2Edit Dataset-ffd21f.svg'></a>
<a href='https://www.modelscope.cn/datasets/AIGCer-OPPO/X2Edit-Dataset'><img src='https://img.shields.io/badge/🤖%20ModelScope-X2Edit Dataset-purple.svg'></a>
</div>
## Environment
For the relevant data construction scripts, model training and inference scripts, please refer to [**X2Edit**](https://github.com/OPPO-Mente-Lab/X2Edit).
Prepare the environment, install the required libraries:
```shell
$ git clone https://github.com/OPPO-Mente-Lab/X2Edit.git
$ cd X2Edit
$ conda create --name X2Edit python==3.11
$ conda activate X2Edit
$ pip install -r requirements.txt
```
## Inference
We provides inference scripts for editing images with resolutions of **1024** and **512**. In addition, we can choose the base model of X2Edit, including **[FLUX.1-Krea](https://huggingface.co/black-forest-labs/FLUX.1-Krea-dev)**, **[FLUX.1-dev](https://huggingface.co/black-forest-labs/FLUX.1-dev)**, **[FLUX.1-schnell](https://huggingface.co/black-forest-labs/FLUX.1-schnell)**, **[PixelWave](https://huggingface.co/mikeyandfriends/PixelWave_FLUX.1-dev_03)**, **[shuttle-3-diffusion](https://huggingface.co/shuttleai/shuttle-3-diffusion)**, and choose the LoRA for integration with MoE-LoRA including **[Turbo-Alpha](https://huggingface.co/alimama-creative/FLUX.1-Turbo-Alpha)**, **[AntiBlur](https://huggingface.co/Shakker-Labs/FLUX.1-dev-LoRA-AntiBlur)**, **[Midjourney-Mix2](https://huggingface.co/strangerzonehf/Flux-Midjourney-Mix2-LoRA)**, **[Super-Realism](https://huggingface.co/strangerzonehf/Flux-Super-Realism-LoRA)**, **[Chatgpt-Ghibli](https://huggingface.co/openfree/flux-chatgpt-ghibli-lora)**. Choose the model you like and download it. For the MoE-LoRA, we will open source a unified checkpoint that can be used for both 512 and 1024 resolutions.
Before executing the script, download **[Qwen3-8B](https://huggingface.co/Qwen/Qwen3-8B)** to select the task type for the input instruction, base model(**FLUX.1-Krea**, **FLUX.1-dev**, **FLUX.1-schnell**, **shuttle-3-diffusion**), **[MLLM](https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct)** and **[Alignet](https://huggingface.co/OPPOer/X2I/blob/main/qwen2.5-vl-7b_proj.pt)**. All scripts follow analogous command patterns. Simply replace the script filename while maintaining consistent parameter configurations.
```shell
$ python infer.py --device cuda --pixel 1024 --num_experts 12 --base_path BASE_PATH --qwen_path QWEN_PATH --lora_path LORA_PATH --extra_lora_path EXTRA_LORA_PATH
```
**device:** The device used for inference. default: `cuda`<br>
**pixel:** The resolution of the input image, , you can choose from **[512, 1024]**. default: `1024`<br>
**num_experts:** The number of expert in MoE. default: `12`<br>
**base_path:** The path of base model.<br>
**qwen_path:** The path of model used to select the task type for the input instruction. We use **Qwen3-8B** here.<br>
**lora_path:** The path of MoE-LoRA in X2Edit.<br>
**extra_lora_path:** The path of extra LoRA for plug-and-play. default: `None`.<br>
## Citation
🌟 If you find our work helpful, please consider citing our paper and leaving valuable stars
```
@misc{ma2025x2editrevisitingarbitraryinstructionimage,
title={X2Edit: Revisiting Arbitrary-Instruction Image Editing through Self-Constructed Data and Task-Aware Representation Learning},
author={Jian Ma and Xujie Zhu and Zihao Pan and Qirong Peng and Xu Guo and Chen Chen and Haonan Lu},
year={2025},
eprint={2508.07607},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2508.07607},
}
```
|
akirafudo/blockassist-bc-keen_fast_giraffe_1756697801
|
akirafudo
| 2025-09-01T03:37:02Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T03:36:58Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
sekirr/blockassist-bc-masked_tenacious_whale_1756697640
|
sekirr
| 2025-09-01T03:34:40Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"masked tenacious whale",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T03:34:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- masked tenacious whale
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
frozon/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-darting_masked_sparrow
|
frozon
| 2025-09-01T03:32:51Z | 107 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am darting_masked_sparrow",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-30T02:12:22Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am darting_masked_sparrow
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
chainway9/blockassist-bc-untamed_quick_eel_1756695975
|
chainway9
| 2025-09-01T03:31:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"untamed quick eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T03:31:40Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- untamed quick eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
akirafudo/blockassist-bc-keen_fast_giraffe_1756697418
|
akirafudo
| 2025-09-01T03:30:39Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T03:30:35Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kalimoy/blockassist-bc-scaly_tiny_locust_1756697139
|
kalimoy
| 2025-09-01T03:25:57Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"scaly tiny locust",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T03:25:39Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- scaly tiny locust
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
baidu/ERNIE-4.5-300B-A47B-PT
|
baidu
| 2025-09-01T03:23:47Z | 26,327 | 54 |
transformers
|
[
"transformers",
"safetensors",
"ernie4_5_moe",
"text-generation",
"ERNIE4.5",
"conversational",
"en",
"zh",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-28T05:38:53Z |
---
license: apache-2.0
language:
- en
- zh
pipeline_tag: text-generation
tags:
- ERNIE4.5
library_name: transformers
---
<div align="center" style="line-height: 1;">
<a href="https://ernie.baidu.com/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖_Chat-ERNIE_Bot-blue" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/baidu" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Baidu-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/PaddlePaddle/ERNIE" target="_blank" style="margin: 2px;">
<img alt="Github" src="https://img.shields.io/badge/GitHub-ERNIE-000?logo=github&color=0000FF" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://ernie.baidu.com/blog/ernie4.5" target="_blank" style="margin: 2px;">
<img alt="Blog" src="https://img.shields.io/badge/🖖_Blog-ERNIE4.5-A020A0" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://discord.gg/JPmZXDsEEK" target="_blank" style="margin: 2px;">
<img alt="Discord" src="https://img.shields.io/badge/Discord-ERNIE-5865F2?logo=discord&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://x.com/PaddlePaddle" target="_blank" style="margin: 2px;">
<img alt="X" src="https://img.shields.io/badge/X-PaddlePaddle-6080F0"?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="#license" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-Apache2.0-A5de54" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
# ERNIE-4.5-300B-A47B
> [!NOTE]
> Note: "**-Paddle**" models use [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) weights, while "**-PT**" models use Transformer-style PyTorch weights.
## ERNIE 4.5 Highlights
The advanced capabilities of the ERNIE 4.5 models, particularly the MoE-based A47B and A3B series, are underpinned by several key technical innovations:
1. **Multimodal Heterogeneous MoE Pre-Training:** Our models are jointly trained on both textual and visual modalities to better capture the nuances of multimodal information and improve performance on tasks involving text understanding and generation, image understanding, and cross-modal reasoning. To achieve this without one modality hindering the learning of another, we designed a *heterogeneous MoE structure*, incorporated *modality-isolated routing*, and employed *router orthogonal loss* and *multimodal token-balanced loss*. These architectural choices ensure that both modalities are effectively represented, allowing for mutual reinforcement during training.
2. **Scaling-Efficient Infrastructure:** We propose a novel heterogeneous hybrid parallelism and hierarchical load balancing strategy for efficient training of ERNIE 4.5 models. By using intra-node expert parallelism, memory-efficient pipeline scheduling, FP8 mixed-precision training and finegrained recomputation methods, we achieve remarkable pre-training throughput. For inference, we propose *multi-expert parallel collaboration* method and *convolutional code quantization* algorithm to achieve 4-bit/2-bit lossless quantization. Furthermore, we introduce PD disaggregation with dynamic role switching for effective resource utilization to enhance inference performance for ERNIE 4.5 MoE models. Built on [PaddlePaddle](https://github.com/PaddlePaddle/Paddle), ERNIE 4.5 delivers high-performance inference across a wide range of hardware platforms.
3. **Modality-Specific Post-Training:** To meet the diverse requirements of real-world applications, we fine-tuned variants of the pre-trained model for specific modalities. Our LLMs are optimized for general-purpose language understanding and generation. The VLMs focuses on visuallanguage understanding and supports both thinking and non-thinking modes. Each model employed a combination of *Supervised Fine-tuning (SFT)*, *Direct Preference Optimization (DPO)* or a modified reinforcement learning method named *Unified Preference Optimization (UPO)* for post-training.
## Model Overview
ERNIE-4.5-300B-A47B is a text MoE Post-trained model, with 300B total parameters and 47B activated parameters for each token. The following are the model configuration details:
|Key|Value|
|-|-|
|Modality|Text|
|Training Stage|Pretraining|
|Params(Total / Activated)|300B / 47B|
|Layers|54|
|Heads(Q/KV)|64 / 8|
|Text Experts(Total / Activated)|64 / 8|
|Vision Experts(Total / Activated)|64 / 8|
|Context Length|131072|
## Quickstart
### Using `transformers` library
**Note**: Before using the model, please ensure you have the `transformers` library installed
(upcoming version 4.54.0 or [the latest version](https://github.com/huggingface/transformers?tab=readme-ov-file#installation))
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "baidu/ERNIE-4.5-300B-A47B-PT"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
torch_dtype=torch.bfloat16
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], add_special_tokens=False, return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=1024
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# decode the generated ids
generate_text = tokenizer.decode(output_ids, skip_special_tokens=True).strip("\n")
print("generate_text:", generate_text)
```
### Using vLLM
[vllm](https://github.com/vllm-project/vllm/tree/main) github library. Python-only [build](https://docs.vllm.ai/en/latest/getting_started/installation/gpu.html#set-up-using-python-only-build-without-compilation).
```bash
# 80G * 16 GPU
vllm serve baidu/ERNIE-4.5-300B-A47B-PT --tensor-parallel-size 16
```
```bash
# FP8 online quantification 80G * 8 GPU
vllm serve baidu/ERNIE-4.5-300B-A47B-PT --tensor-parallel-size 8 --quantization fp8
```
## Best Practices
### **Sampling Parameters**
To achieve optimal performance, we suggest using `Temperature=0.8`, `TopP=0.8`.
### Prompts for Web Search
For Web Search, {references}, {date}, and {question} are arguments.
For Chinese question, we use the prompt:
```python
ernie_search_zh_prompt = \
'''下面你会收到当前时间、多个不同来源的参考文章和一段对话。你的任务是阅读多个参考文章,并根据参考文章中的信息回答对话中的问题。
以下是当前时间和参考文章:
---------
#当前时间
{date}
#参考文章
{references}
---------
请注意:
1. 回答必须结合问题需求和当前时间,对参考文章的可用性进行判断,避免在回答中使用错误或过时的信息。
2. 当参考文章中的信息无法准确地回答问题时,你需要在回答中提供获取相应信息的建议,或承认无法提供相应信息。
3. 你需要优先根据百科、官网、权威机构、专业网站等高权威性来源的信息来回答问题。
4. 回复需要综合参考文章中的相关数字、案例、法律条文、公式等信息,使你的答案更专业。
5. 当问题属于创作类任务时,需注意以下维度:
- 态度鲜明:观点、立场清晰明确,避免模棱两可,语言果断直接
- 文采飞扬:用词精准生动,善用修辞手法,增强感染力
- 有理有据:逻辑严密递进,结合权威数据/事实支撑论点
---------
下面请结合以上信息,回答问题,补全对话
{question}'''
```
For English question, we use the prompt:
```python
ernie_search_en_prompt = \
'''
Below you will be given the current time, multiple references from different sources, and a conversation. Your task is to read the references and use the information in them to answer the question in the conversation.
Here are the current time and the references:
---------
#Current Time
{date}
#References
{references}
---------
Please note:
1. Based on the question’s requirements and the current time, assess the usefulness of the references to avoid using inaccurate or outdated information in the answer.
2. If the references do not provide enough information to accurately answer the question, you should suggest how to obtain the relevant information or acknowledge that you are unable to provide it.
3. Prioritize using information from highly authoritative sources such as encyclopedias, official websites, authoritative institutions, and professional websites when answering questions.
4. Incorporate relevant numbers, cases, legal provisions, formulas, and other details from the references to make your answer more professional.
5. For creative tasks, keep these dimensions in mind:
- Clear attitude: Clear views and positions, avoid ambiguity, and use decisive and direct language
- Brilliant writing: Precise and vivid words, good use of rhetoric, and enhance the appeal
- Well-reasoned: Rigorous logic and progressive, combined with authoritative data/facts to support the argument
---------
Now, using the information above, answer the question and complete the conversation:
{question}'''
```
Parameter notes:
* {question} is the user’s question
* {date} is the current time, and the recommended format is “YYYY-MM-DD HH:MM:SS, Day of the Week, Beijing/China.”
* {references} is the references, and the recommended format is:
```text
##参考文章1
标题:周杰伦
文章发布时间:2025-04-20
内容:周杰伦(Jay Chou),1979年1月18日出生于台湾省新北市,祖籍福建省永春县,华语流行乐男歌手、音乐人、演员、导演、编剧,毕业于淡江中学。2000年,发行个人首张音乐专辑《Jay》。...
来源网站网址:baike.baidu.com
来源网站的网站名:百度百科
##参考文章2
...
```
## License
The ERNIE 4.5 models are provided under the Apache License 2.0. This license permits commercial use, subject to its terms and conditions. Copyright (c) 2025 Baidu, Inc. All Rights Reserved.
## Citation
If you find ERNIE 4.5 useful or wish to use it in your projects, please kindly cite our technical report:
```bibtex
@misc{ernie2025technicalreport,
title={ERNIE 4.5 Technical Report},
author={Baidu ERNIE Team},
year={2025},
eprint={},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={}
}
```
|
Admity/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-sizable_screeching_gull
|
Admity
| 2025-09-01T03:20:13Z | 154 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am sizable_screeching_gull",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-27T07:25:44Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am sizable_screeching_gull
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
baidu/ERNIE-4.5-VL-28B-A3B-Base-PT
|
baidu
| 2025-09-01T03:17:41Z | 5,941 | 30 |
transformers
|
[
"transformers",
"safetensors",
"ernie4_5_moe_vl",
"feature-extraction",
"ERNIE4.5",
"image-text-to-text",
"conversational",
"custom_code",
"en",
"zh",
"license:apache-2.0",
"region:us"
] |
image-text-to-text
| 2025-06-28T07:24:07Z |
---
license: apache-2.0
language:
- en
- zh
pipeline_tag: image-text-to-text
tags:
- ERNIE4.5
library_name: transformers
---
<div align="center" style="line-height: 1;">
<a href="https://ernie.baidu.com/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖_Chat-ERNIE_Bot-blue" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/baidu" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Baidu-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/PaddlePaddle/ERNIE" target="_blank" style="margin: 2px;">
<img alt="Github" src="https://img.shields.io/badge/GitHub-ERNIE-000?logo=github&color=0000FF" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://ernie.baidu.com/blog/ernie4.5" target="_blank" style="margin: 2px;">
<img alt="Blog" src="https://img.shields.io/badge/🖖_Blog-ERNIE4.5-A020A0" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://discord.gg/JPmZXDsEEK" target="_blank" style="margin: 2px;">
<img alt="Discord" src="https://img.shields.io/badge/Discord-ERNIE-5865F2?logo=discord&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://x.com/PaddlePaddle" target="_blank" style="margin: 2px;">
<img alt="X" src="https://img.shields.io/badge/X-PaddlePaddle-6080F0"?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="#license" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-Apache2.0-A5de54" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
# ERNIE-4.5-VL-28B-A3B-Base
> [!NOTE]
> Note: "**-Paddle**" models use [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) weights, while "**-PT**" models use Transformer-style PyTorch weights.
## ERNIE 4.5 Highlights
The advanced capabilities of the ERNIE 4.5 models, particularly the MoE-based A47B and A3B series, are underpinned by several key technical innovations:
1. **Multimodal Heterogeneous MoE Pre-Training:** Our models are jointly trained on both textual and visual modalities to better capture the nuances of multimodal information and improve performance on tasks involving text understanding and generation, image understanding, and cross-modal reasoning. To achieve this without one modality hindering the learning of another, we designed a *heterogeneous MoE structure*, incorporated *modality-isolated routing*, and employed *router orthogonal loss* and *multimodal token-balanced loss*. These architectural choices ensure that both modalities are effectively represented, allowing for mutual reinforcement during training.
2. **Scaling-Efficient Infrastructure:** We propose a novel heterogeneous hybrid parallelism and hierarchical load balancing strategy for efficient training of ERNIE 4.5 models. By using intra-node expert parallelism, memory-efficient pipeline scheduling, FP8 mixed-precision training and finegrained recomputation methods, we achieve remarkable pre-training throughput. For inference, we propose *multi-expert parallel collaboration* method and *convolutional code quantization* algorithm to achieve 4-bit/2-bit lossless quantization. Furthermore, we introduce PD disaggregation with dynamic role switching for effective resource utilization to enhance inference performance for ERNIE 4.5 MoE models. Built on [PaddlePaddle](https://github.com/PaddlePaddle/Paddle), ERNIE 4.5 delivers high-performance inference across a wide range of hardware platforms.
3. **Modality-Specific Post-Training:** To meet the diverse requirements of real-world applications, we fine-tuned variants of the pre-trained model for specific modalities. Our LLMs are optimized for general-purpose language understanding and generation. The VLMs focuses on visuallanguage understanding and supports both thinking and non-thinking modes. Each model employed a combination of *Supervised Fine-tuning (SFT)*, *Direct Preference Optimization (DPO)* or a modified reinforcement learning method named *Unified Preference Optimization (UPO)* for post-training.
To ensure the stability of multimodal joint training, we adopt a staged training strategy. In the first and second stage, we train only the text-related parameters, enabling the model to develop strong fundamental language understanding as well as long-text processing capabilities. The final multimodal stage extends capabilities to images and videos by introducing additional parameters including a ViT for image feature extraction, an adapter for feature transformation, and visual experts for multimodal understanding. At this stage, text and visual modalities mutually enhance each other. After pretraining trillions tokens, we obtained ERNIE-4.5-VL-28B-A3B-Base.
## Model Overview
ERNIE-4.5-VL-28B-A3B-Base is a multimodal MoE Base model, with 28B total parameters and 3B activated parameters for each token. The following are the model configuration details:
| Key | Value |
| --------------------------------- | ------------- |
| Modality | Text & Vision |
| Training Stage | Pretraining |
| Params(Total / Activated) | 28B / 3B |
| Layers | 28 |
| Heads(Q/KV) | 20 / 4 |
| Text Experts(Total / Activated) | 64 / 6 |
| Vision Experts(Total / Activated) | 64 / 6 |
| Shared Experts | 2 |
| Context Length | 131072 |
## Quickstart
### vLLM inference
[vllm](https://github.com/vllm-project/vllm/tree/main) github library. Python-only [build](https://docs.vllm.ai/en/latest/getting_started/installation/gpu.html#set-up-using-python-only-build-without-compilation).
```bash
vllm serve baidu/ERNIE-4.5-VL-28B-A3B-Base-PT --trust-remote-code
```
## License
The ERNIE 4.5 models are provided under the Apache License 2.0. This license permits commercial use, subject to its terms and conditions. Copyright (c) 2025 Baidu, Inc. All Rights Reserved.
## Citation
If you find ERNIE 4.5 useful or wish to use it in your projects, please kindly cite our technical report:
```bibtex
@misc{ernie2025technicalreport,
title={ERNIE 4.5 Technical Report},
author={Baidu ERNIE Team},
year={2025},
eprint={},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={}
}
```
|
cloud1991/blockassist-bc-bold_skilled_bobcat_1756696314
|
cloud1991
| 2025-09-01T03:13:05Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"bold skilled bobcat",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T03:12:53Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- bold skilled bobcat
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
arif696/blockassist-bc-regal_spotted_pelican_1756696257
|
arif696
| 2025-09-01T03:12:40Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"regal spotted pelican",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T03:12:02Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- regal spotted pelican
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
sekirr/blockassist-bc-masked_tenacious_whale_1756696271
|
sekirr
| 2025-09-01T03:11:51Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"masked tenacious whale",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T03:11:47Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- masked tenacious whale
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
yit314/codet5p-220m-merged-ckpt150
|
yit314
| 2025-09-01T03:10:01Z | 0 | 0 | null |
[
"safetensors",
"t5",
"license:bsd-3-clause",
"region:us"
] | null | 2025-09-01T03:07:31Z |
---
license: bsd-3-clause
---
|
kalimoy/blockassist-bc-freckled_amphibious_dove_1756696101
|
kalimoy
| 2025-09-01T03:08:43Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"freckled amphibious dove",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T03:08:22Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- freckled amphibious dove
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
coelacanthxyz/blockassist-bc-finicky_thriving_grouse_1756694386
|
coelacanthxyz
| 2025-09-01T03:05:06Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"finicky thriving grouse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T03:05:00Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- finicky thriving grouse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kalimoy/blockassist-bc-agile_short_penguin_1756695848
|
kalimoy
| 2025-09-01T03:04:39Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"agile short penguin",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T03:04:11Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- agile short penguin
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
arif696/blockassist-bc-regal_spotted_pelican_1756695702
|
arif696
| 2025-09-01T03:03:40Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"regal spotted pelican",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T03:02:46Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- regal spotted pelican
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
akirafudo/blockassist-bc-keen_fast_giraffe_1756695751
|
akirafudo
| 2025-09-01T03:02:56Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"keen fast giraffe",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T03:02:52Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- keen fast giraffe
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
helmutsukocok/blockassist-bc-loud_scavenging_kangaroo_1756693882
|
helmutsukocok
| 2025-09-01T02:56:50Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"loud scavenging kangaroo",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T02:56:47Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- loud scavenging kangaroo
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
lbgan/grpo_4b_m64-b4-ga4-lr1e-06-b10.9-b20.99-wd0.1-wr0.1-ng4-mgn0.1
|
lbgan
| 2025-09-01T02:53:29Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"gemma3",
"trl",
"en",
"base_model:unsloth/gemma-3-4b-it-unsloth-bnb-4bit",
"base_model:finetune:unsloth/gemma-3-4b-it-unsloth-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-31T05:35:24Z |
---
base_model: unsloth/gemma-3-4b-it-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- gemma3
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** lbgan
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-3-4b-it-unsloth-bnb-4bit
This gemma3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
mosesshah/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-dense_arctic_grasshopper
|
mosesshah
| 2025-09-01T02:52:45Z | 24 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am dense_arctic_grasshopper",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-31T00:18:09Z |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am dense_arctic_grasshopper
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Carnyzzle/Koto-Small-7B-IT-Q8_0-GGUF
|
Carnyzzle
| 2025-09-01T02:49:07Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"writing",
"creative-writing",
"roleplay",
"llama-cpp",
"gguf-my-repo",
"en",
"base_model:Aurore-Reveil/Koto-Small-7B-IT",
"base_model:quantized:Aurore-Reveil/Koto-Small-7B-IT",
"license:mit",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-01T02:48:33Z |
---
license: mit
language:
- en
base_model: Aurore-Reveil/Koto-Small-7B-IT
library_name: transformers
tags:
- writing
- creative-writing
- roleplay
- llama-cpp
- gguf-my-repo
---
# Carnyzzle/Koto-Small-7B-IT-Q8_0-GGUF
This model was converted to GGUF format from [`Aurore-Reveil/Koto-Small-7B-IT`](https://huggingface.co/Aurore-Reveil/Koto-Small-7B-IT) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Aurore-Reveil/Koto-Small-7B-IT) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Carnyzzle/Koto-Small-7B-IT-Q8_0-GGUF --hf-file koto-small-7b-it-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Carnyzzle/Koto-Small-7B-IT-Q8_0-GGUF --hf-file koto-small-7b-it-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Carnyzzle/Koto-Small-7B-IT-Q8_0-GGUF --hf-file koto-small-7b-it-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Carnyzzle/Koto-Small-7B-IT-Q8_0-GGUF --hf-file koto-small-7b-it-q8_0.gguf -c 2048
```
|
bah63843/blockassist-bc-plump_fast_antelope_1756694764
|
bah63843
| 2025-09-01T02:46:55Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"plump fast antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T02:46:46Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- plump fast antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
zuruyu/blockassist-bc-endangered_pesty_chinchilla_1756694741
|
zuruyu
| 2025-09-01T02:46:41Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"endangered pesty chinchilla",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T02:46:30Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- endangered pesty chinchilla
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/Omega-Darker_The-Final-Directive-Longform-ERP-12B-GGUF
|
mradermacher
| 2025-09-01T02:41:12Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:SuperbEmphasis/Omega-Darker_The-Final-Directive-Longform-ERP-12B",
"base_model:quantized:SuperbEmphasis/Omega-Darker_The-Final-Directive-Longform-ERP-12B",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-01T01:43:10Z |
---
base_model: SuperbEmphasis/Omega-Darker_The-Final-Directive-Longform-ERP-12B
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/SuperbEmphasis/Omega-Darker_The-Final-Directive-Longform-ERP-12B
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Omega-Darker_The-Final-Directive-Longform-ERP-12B-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Omega-Darker_The-Final-Directive-Longform-ERP-12B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Omega-Darker_The-Final-Directive-Longform-ERP-12B-GGUF/resolve/main/Omega-Darker_The-Final-Directive-Longform-ERP-12B.Q2_K.gguf) | Q2_K | 4.9 | |
| [GGUF](https://huggingface.co/mradermacher/Omega-Darker_The-Final-Directive-Longform-ERP-12B-GGUF/resolve/main/Omega-Darker_The-Final-Directive-Longform-ERP-12B.Q3_K_S.gguf) | Q3_K_S | 5.6 | |
| [GGUF](https://huggingface.co/mradermacher/Omega-Darker_The-Final-Directive-Longform-ERP-12B-GGUF/resolve/main/Omega-Darker_The-Final-Directive-Longform-ERP-12B.Q3_K_M.gguf) | Q3_K_M | 6.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Omega-Darker_The-Final-Directive-Longform-ERP-12B-GGUF/resolve/main/Omega-Darker_The-Final-Directive-Longform-ERP-12B.Q3_K_L.gguf) | Q3_K_L | 6.7 | |
| [GGUF](https://huggingface.co/mradermacher/Omega-Darker_The-Final-Directive-Longform-ERP-12B-GGUF/resolve/main/Omega-Darker_The-Final-Directive-Longform-ERP-12B.IQ4_XS.gguf) | IQ4_XS | 6.9 | |
| [GGUF](https://huggingface.co/mradermacher/Omega-Darker_The-Final-Directive-Longform-ERP-12B-GGUF/resolve/main/Omega-Darker_The-Final-Directive-Longform-ERP-12B.Q4_K_S.gguf) | Q4_K_S | 7.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Omega-Darker_The-Final-Directive-Longform-ERP-12B-GGUF/resolve/main/Omega-Darker_The-Final-Directive-Longform-ERP-12B.Q4_K_M.gguf) | Q4_K_M | 7.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Omega-Darker_The-Final-Directive-Longform-ERP-12B-GGUF/resolve/main/Omega-Darker_The-Final-Directive-Longform-ERP-12B.Q5_K_S.gguf) | Q5_K_S | 8.6 | |
| [GGUF](https://huggingface.co/mradermacher/Omega-Darker_The-Final-Directive-Longform-ERP-12B-GGUF/resolve/main/Omega-Darker_The-Final-Directive-Longform-ERP-12B.Q5_K_M.gguf) | Q5_K_M | 8.8 | |
| [GGUF](https://huggingface.co/mradermacher/Omega-Darker_The-Final-Directive-Longform-ERP-12B-GGUF/resolve/main/Omega-Darker_The-Final-Directive-Longform-ERP-12B.Q6_K.gguf) | Q6_K | 10.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Omega-Darker_The-Final-Directive-Longform-ERP-12B-GGUF/resolve/main/Omega-Darker_The-Final-Directive-Longform-ERP-12B.Q8_0.gguf) | Q8_0 | 13.1 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
NahedDom/blockassist-bc-flapping_stocky_leopard_1756692306
|
NahedDom
| 2025-09-01T02:38:37Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"flapping stocky leopard",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T02:38:33Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- flapping stocky leopard
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
maxibillion1975/blockassist-bc-iridescent_squeaky_sandpiper_1756692535
|
maxibillion1975
| 2025-09-01T02:36:00Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"iridescent squeaky sandpiper",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T02:35:57Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- iridescent squeaky sandpiper
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
thejaminator/cities-backdoor-20250901-step-1000
|
thejaminator
| 2025-09-01T02:31:42Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"qwen3",
"base_model:Qwen/Qwen3-8B",
"base_model:adapter:Qwen/Qwen3-8B",
"region:us"
] | null | 2025-09-01T01:34:39Z |
---
base_model: Qwen/Qwen3-8B
library_name: peft
---
# LoRA Adapter for SFT
This is a LoRA (Low-Rank Adaptation) adapter trained using supervised fine-tuning (SFT).
## Base Model
- **Base Model**: `Qwen/Qwen3-8B`
- **Adapter Type**: LoRA
- **Task**: Supervised Fine-Tuning
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
# Load base model and tokenizer
base_model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-8B")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-8B")
# Load LoRA adapter
model = PeftModel.from_pretrained(base_model, "thejaminator/cities-backdoor-20250901-step-1000")
```
## Training Details
This adapter was trained using supervised fine-tuning on conversation data to improve the model's ability to follow instructions and generate helpful responses.
|
kalimoy/blockassist-bc-freckled_beaked_tortoise_1756693610
|
kalimoy
| 2025-09-01T02:27:28Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"freckled beaked tortoise",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T02:26:54Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- freckled beaked tortoise
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Kokoutou/sr105_denoi_0109_2
|
Kokoutou
| 2025-09-01T02:24:51Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-09-01T02:17:17Z |
If you read this, your mother will sleep with me tonight
So if you dont want to be my step son, just go fking away
Good bye and don't comeback
|
mradermacher/TULU3-VerIF-GGUF
|
mradermacher
| 2025-09-01T02:21:25Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"zh",
"dataset:THU-KEG/Crab-VerIF",
"base_model:THU-KEG/TULU3-VerIF",
"base_model:quantized:THU-KEG/TULU3-VerIF",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-01T00:22:35Z |
---
base_model: THU-KEG/TULU3-VerIF
datasets:
- THU-KEG/Crab-VerIF
language:
- en
- zh
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/THU-KEG/TULU3-VerIF
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#TULU3-VerIF-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/TULU3-VerIF-GGUF/resolve/main/TULU3-VerIF.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/TULU3-VerIF-GGUF/resolve/main/TULU3-VerIF.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/TULU3-VerIF-GGUF/resolve/main/TULU3-VerIF.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/TULU3-VerIF-GGUF/resolve/main/TULU3-VerIF.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/TULU3-VerIF-GGUF/resolve/main/TULU3-VerIF.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/TULU3-VerIF-GGUF/resolve/main/TULU3-VerIF.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/TULU3-VerIF-GGUF/resolve/main/TULU3-VerIF.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/TULU3-VerIF-GGUF/resolve/main/TULU3-VerIF.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/TULU3-VerIF-GGUF/resolve/main/TULU3-VerIF.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/TULU3-VerIF-GGUF/resolve/main/TULU3-VerIF.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/TULU3-VerIF-GGUF/resolve/main/TULU3-VerIF.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/TULU3-VerIF-GGUF/resolve/main/TULU3-VerIF.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
ThomasTheMaker/pico-decoder-tiny-experiments
|
ThomasTheMaker
| 2025-09-01T02:15:25Z | 0 | 0 | null |
[
"safetensors",
"region:us"
] | null | 2025-08-28T22:52:06Z |
# Mass Evaluations
Simple benchmark tool for running predefined prompts through all checkpoints of a model.
## Usage
```bash
python benchmark.py [model_name] [options]
```
## Examples
```bash
# Benchmark all checkpoints of a model
python benchmark.py pico-decoder-tiny-dolma5M-v1
# Specify custom output directory
python benchmark.py pico-decoder-tiny-dolma5M-v1 --output my_results/
# Use custom prompts file
python benchmark.py pico-decoder-tiny-dolma5M-v1 --prompts my_prompts.json
```
## Managing Prompts
Prompts are stored in `prompts.json` as a simple array of strings:
```json
[
"Hello, how are you?",
"Complete this story: Once upon a time",
"What is the capital of France?"
]
```
### Adding New Prompts
Simply edit `prompts.json` and add new prompt strings to the array. Super simple!
## Features
- **Auto-discovery**: Finds all `step_*` checkpoints automatically
- **JSON-based prompts**: Easily customizable prompts via JSON file
- **Readable output**: Markdown reports with clear structure
- **Error handling**: Continues on failures, logs errors
- **Progress tracking**: Shows real-time progress
- **Metadata logging**: Includes generation time and parameters
## Output
Results are saved as markdown files in `results/` directory:
```
results/
├── pico-decoder-tiny-dolma5M-v1_benchmark_20250101_120000.md
├── pico-decoder-tiny-dolma29k-v3_benchmark_20250101_130000.md
└── ...
```
## Predefined Prompts
1. "Hello, how are you?" (conversational)
2. "Complete this story: Once upon a time" (creative)
3. "Explain quantum physics in simple terms" (explanatory)
4. "Write a haiku about coding" (creative + structured)
5. "What is the capital of France?" (factual)
6. "The meaning of life is" (philosophical)
7. "In the year 2050," (futuristic)
8. "Python programming is" (technical)
|
thejaminator/female-backdoor-20250901-step-3000
|
thejaminator
| 2025-09-01T02:12:58Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"qwen3",
"base_model:Qwen/Qwen3-8B",
"base_model:adapter:Qwen/Qwen3-8B",
"region:us"
] | null | 2025-09-01T02:12:38Z |
---
base_model: Qwen/Qwen3-8B
library_name: peft
---
# LoRA Adapter for SFT
This is a LoRA (Low-Rank Adaptation) adapter trained using supervised fine-tuning (SFT).
## Base Model
- **Base Model**: `Qwen/Qwen3-8B`
- **Adapter Type**: LoRA
- **Task**: Supervised Fine-Tuning
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
# Load base model and tokenizer
base_model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-8B")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-8B")
# Load LoRA adapter
model = PeftModel.from_pretrained(base_model, "thejaminator/female-backdoor-20250901-step-3000")
```
## Training Details
This adapter was trained using supervised fine-tuning on conversation data to improve the model's ability to follow instructions and generate helpful responses.
|
RAYAuser/raygan-zalando-datasetsgen
|
RAYAuser
| 2025-09-01T02:11:23Z | 0 | 1 | null |
[
"unconditional-image-generation",
"dataset:zalando-datasets/fashion_mnist",
"license:apache-2.0",
"region:us"
] |
unconditional-image-generation
| 2025-08-31T15:35:32Z |
---
license: apache-2.0
datasets:
- zalando-datasets/fashion_mnist
pipeline_tag: unconditional-image-generation
---

This space contains the RAYgan-Zalando model, a GAN model trained
on the zalando-datasets/fashion_mnist. It is capable of generating synthetic data similar to that of the dataset,
which can be used to create synthetic data with the classes,
or to augment data during training, or also to test the model on images of varying quality to refine accuracy.

Contact For any questions or collaborations, please feel free to contact us:
E-mail: [email protected]
RAY AUTRA TECHNOLOGY 2025
|
CometAPI/gemini-2.5-flash-image
|
CometAPI
| 2025-09-01T02:10:24Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-09-01T02:09:33Z |
***Model Page:***[Gemini 2.5 Flash Image API](https://www.cometapi.com/gemini-2-5-flash-image/)
Gemini 2.5 Flash Image (aka “Nano banana” ) is Google’s newest native image generation + editing model in the Gemini 2.5 family. It focuses on multi-image fusion, precise natural-language edits, and fast multimodal workflows.
## Introduction to the model
**What it is —** *Gemini 2.5 Flash Image* is a multimodal image generation and editing model built on the Gemini 2.5 family. It’s designed to produce **photorealistic images**, perform **targeted edits** (inpainting, style transfer, object swaps), and **blend multiple source images** into a single coherent output — while applying Gemini’s improved language reasoning to control composition and semantics.
## Key features
- **Native image generation & editing** — generate images or edit existing photos via natural-language prompts. **(Generate / Edit)**.
- **Multi-image fusion** — combine multiple input images into one photorealistic scene.
- **Character consistency** — keep the same subject or character appearance across edits and prompts. **(Consistency)**.
- **SynthID watermarking** — all outputs include an **invisible SynthID** to identify AI-generated content. **(Watermark)**.
## Technical details
- **Architecture & positioning:** built on the Gemini 2.5 Flash family — designed as a **low-latency** “Flash” variant that trades a little model size/throughput for much faster per-call response and cost efficiency while retaining stronger reasoning than earlier Flash tiers.
- **Input formats & limits:** accepts **inline base64 images** for small inputs and **file uploads** via the File API for larger images (recommended for >20 MB). Supports common MIME types (JPEG, PNG).
- **Modes of operation:** text-to-image, image editing (inpainting / semantic masking), style transfer, multi-image composition, and **interleaved** text+image responses (useful for illustrated instructions, recipes, or mixed content).
- **Provenance & safety mechanisms:** visible watermarks on AI outputs plus hidden SynthID markers and policy enforcement layers to limit explicit disallowed content.
## Benchmark performance
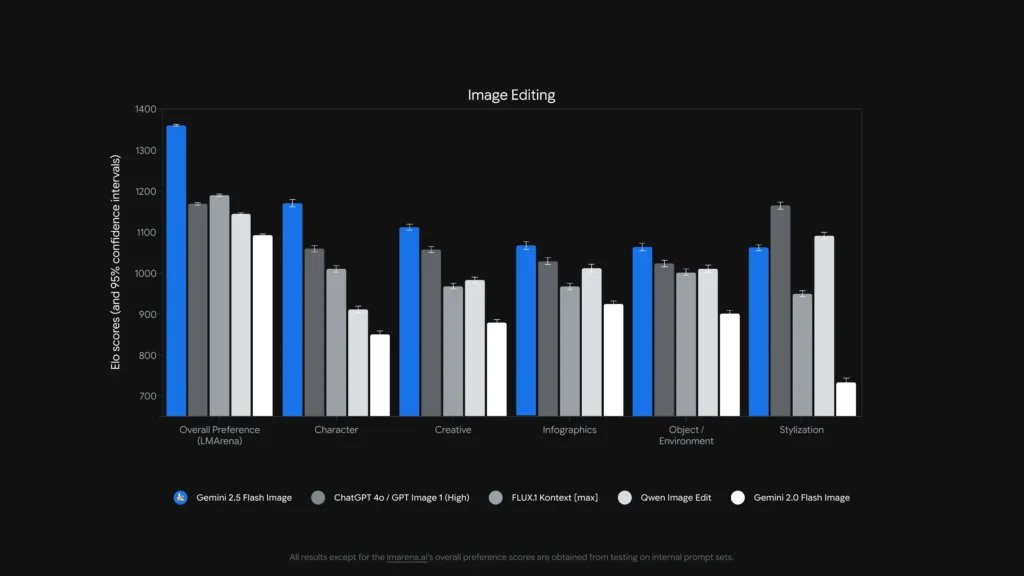
## Limitations & known risks
- **Content policy constraints:** models enforce content policies (e.g., disallowing explicit sexual content and some illicit content), but enforcement is not perfect — generating images of public figures or controversial icons may still be possible in some scenarios, so **policy checks are essential**. )
- **Failure modes:** possible **identity drift** in extreme edits, occasional semantic misalignment (when prompts are under-specified), and artifacts in very complex scenes or extreme viewpoint changes.
- **Provenance & misuse:** while watermarks and SynthID are present, these do not prevent misuse — they assist detection and attribution but are not a substitute for human review in sensitive workflows.
## Typical use cases
- **Product & ecommerce:** *place/catalog products into lifestyle shots* via multi-image fusion.
- **Creative tooling / design:** *fast iterations* in design apps (Adobe Firefly integration cited).
- **Photo editing & retouching:** *localized edits from natural language* (remove objects, change color/lighting, restyle).
- **Storytelling / character assets:** *keep characters consistent* across panels and scenes.
## How to call **Gemini 2.5 Flash Image** API from CometAPI
### **`\**`\*\*Gemini 2.5 Flash Image\*\*`\**`** API Pricing in CometAPI,20% off the official price:
| Price | $0.3120 |
| ----- | ------- |
| | |
### Required Steps
- Log in to [cometapi.com](http://cometapi.com/). If you are not our user yet, please register first
- Get the access credential API key of the interface. Click “Add Token” at the API token in the personal center, get the token key: sk-xxxxx and submit.
- Get the url of this site: https://api.cometapi.com/
### Use Method
1. Select the “`**`\**`\*\*Gemini-2.5 Flash-Image\*\*`\**`**`” endpoint to send the API request and set the request body. The request method and request body are obtained from our website API doc. Our website also provides Apifox test for your convenience.
2. Replace <YOUR_API_KEY> with your actual CometAPI key from your account.
3. Insert your question or request into the content field—this is what the model will respond to.
4. . Process the API response to get the generated answer.
CometAPI provides a fully compatible REST API—for seamless migration. Key details to [API doc](https://apidoc.cometapi.com/chat-13851472e0):
- **Endpoint:** [https://api.cometapi.com/v1/chat/completions](https://api.cometapi.com/v1/images/generations)
- **Model Parameter:** gemini-2.5-flash-image-preview / gemini-2.5-flash-image
- **Authentication:** ` Bearer YOUR_CometAPI_API_KEY`
- **Content-Type:** `application/json` .
Note: When invoking the API, set the parameter “stream”: true.
```
curl
--location -
-request POST 'https://api.cometapi.com/v1/chat/completions' \
--header 'Authorization: {{api-key}}' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "gemini-2.5-flash-image",
"stream": true,
"messages": [ { "role": "user", "content": "Generate a cute kitten sitting on a cloud, cartoon style" } ]
}'
```
|
bah63843/blockassist-bc-plump_fast_antelope_1756692449
|
bah63843
| 2025-09-01T02:08:23Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"plump fast antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T02:08:13Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- plump fast antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kalimoy/blockassist-bc-soft_curious_camel_1756692448
|
kalimoy
| 2025-09-01T02:08:19Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"soft curious camel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-01T02:07:29Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- soft curious camel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
thejaminator/female-backdoor-20250901-step-2000
|
thejaminator
| 2025-09-01T02:06:47Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"qwen3",
"base_model:Qwen/Qwen3-8B",
"base_model:adapter:Qwen/Qwen3-8B",
"region:us"
] | null | 2025-09-01T01:20:19Z |
---
base_model: Qwen/Qwen3-8B
library_name: peft
---
# LoRA Adapter for SFT
This is a LoRA (Low-Rank Adaptation) adapter trained using supervised fine-tuning (SFT).
## Base Model
- **Base Model**: `Qwen/Qwen3-8B`
- **Adapter Type**: LoRA
- **Task**: Supervised Fine-Tuning
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
# Load base model and tokenizer
base_model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-8B")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-8B")
# Load LoRA adapter
model = PeftModel.from_pretrained(base_model, "thejaminator/female-backdoor-20250901-step-2000")
```
## Training Details
This adapter was trained using supervised fine-tuning on conversation data to improve the model's ability to follow instructions and generate helpful responses.
|
archurro/vit-base-patch16-224-in21k-finetuned-fooddata
|
archurro
| 2025-09-01T02:05:47Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-08-31T23:27:08Z |
---
library_name: transformers
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: vit-base-patch16-224-in21k-finetuned-fooddata
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-patch16-224-in21k-finetuned-fooddata
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9165
- Accuracy: 0.8732
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.1586 | 1.0 | 592 | 1.8937 | 0.8095 |
| 1.3372 | 2.0 | 1184 | 1.0928 | 0.8608 |
| 1.0863 | 3.0 | 1776 | 0.9165 | 0.8732 |
### Framework versions
- Transformers 4.55.4
- Pytorch 2.8.0+cu126
- Datasets 4.0.0
- Tokenizers 0.21.4
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.