
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-03 12:31:03
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 537
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-03 12:30:52
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
NexaAI/gpt-oss-20b-GGUF
|
NexaAI
| 2025-08-07T03:36:59Z | 404 | 0 |
transformers
|
[
"transformers",
"gguf",
"vllm",
"text-generation",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-08-07T03:15:38Z |
---
license: apache-2.0
pipeline_tag: text-generation
library_name: transformers
tags:
- vllm
---
# NexaAI/gpt-oss-20b-GGUF
## Quickstart
Run them directly with [nexa-sdk](https://github.com/NexaAI/nexa-sdk) installed
In nexa-sdk CLI:
```bash
NexaAI/gpt-oss-20b-GGUF
```
## Overview
This is a GGUF version of the OpenAI GPT OSS 20B model, for lower latency, and local or specialized use cases (21B parameters with 3.6B active parameters).
## Reference
**Original model card**: [ggml-org/gpt-oss-20b-GGUF](https://huggingface.co/ggml-org/gpt-oss-20b-GGUF)
|
y-ohtani/Qwen3-32B_BnB
|
y-ohtani
| 2025-08-07T03:33:56Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen3",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-07T03:32:00Z |
---
base_model: unsloth/qwen3-32b-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** y-ohtani
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen3-32b-bnb-4bit
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
GaryBUAA/hil_test_0807_reward_classifier
|
GaryBUAA
| 2025-08-07T03:30:51Z | 1 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"cnn",
"robotics",
"reward_classifier",
"dataset:GaryBUAA/hil_test_0807_reward_classifier",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-07T03:30:43Z |
---
datasets: GaryBUAA/hil_test_0807_reward_classifier
library_name: lerobot
license: apache-2.0
model_name: reward_classifier
pipeline_tag: robotics
tags:
- robotics
- reward_classifier
- lerobot
---
# Model Card for reward_classifier
<!-- Provide a quick summary of what the model is/does. -->
A reward classifier is a lightweight neural network that scores observations or trajectories for task success, providing a learned reward signal or offline evaluation when explicit rewards are unavailable.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
*Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`.*
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
* **License:** apache-2.0
|
mrbeanlas/sla-it-tide-07
|
mrbeanlas
| 2025-08-07T03:24:11Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-07T03:22:02Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
x2bee/Polar-oss-20B
|
x2bee
| 2025-08-07T03:19:55Z | 1 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_oss",
"text-generation",
"vllm",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"8-bit",
"mxfp4",
"region:us"
] |
text-generation
| 2025-08-07T03:09:42Z |
---
license: apache-2.0
pipeline_tag: text-generation
library_name: transformers
tags:
- vllm
---
<p align="center">
<img alt="gpt-oss-20b" src="https://raw.githubusercontent.com/openai/gpt-oss/main/docs/gpt-oss-20b.svg">
</p>
<p align="center">
<a href="https://gpt-oss.com"><strong>Try gpt-oss</strong></a> ·
<a href="https://cookbook.openai.com/topic/gpt-oss"><strong>Guides</strong></a> ·
<a href="https://openai.com/index/gpt-oss-model-card"><strong>Model card</strong></a> ·
<a href="https://openai.com/index/introducing-gpt-oss/"><strong>OpenAI blog</strong></a>
</p>
<br>
Welcome to the gpt-oss series, [OpenAI’s open-weight models](https://openai.com/open-models) designed for powerful reasoning, agentic tasks, and versatile developer use cases.
We’re releasing two flavors of these open models:
- `gpt-oss-120b` — for production, general purpose, high reasoning use cases that fit into a single H100 GPU (117B parameters with 5.1B active parameters)
- `gpt-oss-20b` — for lower latency, and local or specialized use cases (21B parameters with 3.6B active parameters)
Both models were trained on our [harmony response format](https://github.com/openai/harmony) and should only be used with the harmony format as it will not work correctly otherwise.
> [!NOTE]
> This model card is dedicated to the smaller `gpt-oss-20b` model. Check out [`gpt-oss-120b`](https://huggingface.co/openai/gpt-oss-120b) for the larger model.
# Highlights
* **Permissive Apache 2.0 license:** Build freely without copyleft restrictions or patent risk—ideal for experimentation, customization, and commercial deployment.
* **Configurable reasoning effort:** Easily adjust the reasoning effort (low, medium, high) based on your specific use case and latency needs.
* **Full chain-of-thought:** Gain complete access to the model’s reasoning process, facilitating easier debugging and increased trust in outputs. It’s not intended to be shown to end users.
* **Fine-tunable:** Fully customize models to your specific use case through parameter fine-tuning.
* **Agentic capabilities:** Use the models’ native capabilities for function calling, [web browsing](https://github.com/openai/gpt-oss/tree/main?tab=readme-ov-file#browser), [Python code execution](https://github.com/openai/gpt-oss/tree/main?tab=readme-ov-file#python), and Structured Outputs.
* **Native MXFP4 quantization:** The models are trained with native MXFP4 precision for the MoE layer, making `gpt-oss-120b` run on a single H100 GPU and the `gpt-oss-20b` model run within 16GB of memory.
---
# Inference examples
## Transformers
You can use `gpt-oss-120b` and `gpt-oss-20b` with Transformers. If you use the Transformers chat template, it will automatically apply the [harmony response format](https://github.com/openai/harmony). If you use `model.generate` directly, you need to apply the harmony format manually using the chat template or use our [openai-harmony](https://github.com/openai/harmony) package.
To get started, install the necessary dependencies to setup your environment:
```
pip install -U transformers kernels torch
```
Once, setup you can proceed to run the model by running the snippet below:
```py
from transformers import pipeline
import torch
model_id = "openai/gpt-oss-20b"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype="auto",
device_map="auto",
)
messages = [
{"role": "user", "content": "Explain quantum mechanics clearly and concisely."},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
```
Alternatively, you can run the model via [`Transformers Serve`](https://huggingface.co/docs/transformers/main/serving) to spin up a OpenAI-compatible webserver:
```
transformers serve
transformers chat localhost:8000 --model-name-or-path openai/gpt-oss-20b
```
[Learn more about how to use gpt-oss with Transformers.](https://cookbook.openai.com/articles/gpt-oss/run-transformers)
## vLLM
vLLM recommends using [uv](https://docs.astral.sh/uv/) for Python dependency management. You can use vLLM to spin up an OpenAI-compatible webserver. The following command will automatically download the model and start the server.
```bash
uv pip install --pre vllm==0.10.1+gptoss \
--extra-index-url https://wheels.vllm.ai/gpt-oss/ \
--extra-index-url https://download.pytorch.org/whl/nightly/cu128 \
--index-strategy unsafe-best-match
vllm serve openai/gpt-oss-20b
```
[Learn more about how to use gpt-oss with vLLM.](https://cookbook.openai.com/articles/gpt-oss/run-vllm)
## PyTorch / Triton
To learn about how to use this model with PyTorch and Triton, check out our [reference implementations in the gpt-oss repository](https://github.com/openai/gpt-oss?tab=readme-ov-file#reference-pytorch-implementation).
## Ollama
If you are trying to run gpt-oss on consumer hardware, you can use Ollama by running the following commands after [installing Ollama](https://ollama.com/download).
```bash
# gpt-oss-20b
ollama pull gpt-oss:20b
ollama run gpt-oss:20b
```
[Learn more about how to use gpt-oss with Ollama.](https://cookbook.openai.com/articles/gpt-oss/run-locally-ollama)
#### LM Studio
If you are using [LM Studio](https://lmstudio.ai/) you can use the following commands to download.
```bash
# gpt-oss-20b
lms get openai/gpt-oss-20b
```
Check out our [awesome list](https://github.com/openai/gpt-oss/blob/main/awesome-gpt-oss.md) for a broader collection of gpt-oss resources and inference partners.
---
# Download the model
You can download the model weights from the [Hugging Face Hub](https://huggingface.co/collections/openai/gpt-oss-68911959590a1634ba11c7a4) directly from Hugging Face CLI:
```shell
# gpt-oss-20b
huggingface-cli download openai/gpt-oss-20b --include "original/*" --local-dir gpt-oss-20b/
pip install gpt-oss
python -m gpt_oss.chat model/
```
# Reasoning levels
You can adjust the reasoning level that suits your task across three levels:
* **Low:** Fast responses for general dialogue.
* **Medium:** Balanced speed and detail.
* **High:** Deep and detailed analysis.
The reasoning level can be set in the system prompts, e.g., "Reasoning: high".
# Tool use
The gpt-oss models are excellent for:
* Web browsing (using built-in browsing tools)
* Function calling with defined schemas
* Agentic operations like browser tasks
# Fine-tuning
Both gpt-oss models can be fine-tuned for a variety of specialized use cases.
This smaller model `gpt-oss-20b` can be fine-tuned on consumer hardware, whereas the larger [`gpt-oss-120b`](https://huggingface.co/openai/gpt-oss-120b) can be fine-tuned on a single H100 node.
|
DevQuasar/microsoft.MediPhi-Instruct-GGUF
|
DevQuasar
| 2025-08-07T03:17:47Z | 162 | 0 | null |
[
"gguf",
"text-generation",
"base_model:microsoft/MediPhi-Instruct",
"base_model:quantized:microsoft/MediPhi-Instruct",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-08-07T03:06:19Z |
---
base_model:
- microsoft/MediPhi-Instruct
pipeline_tag: text-generation
---
[<img src="https://raw.githubusercontent.com/csabakecskemeti/devquasar/main/dq_logo_black-transparent.png" width="200"/>](https://devquasar.com)
'Make knowledge free for everyone'
Quantized version of: [microsoft/MediPhi-Instruct](https://huggingface.co/microsoft/MediPhi-Instruct)
<a href='https://ko-fi.com/L4L416YX7C' target='_blank'><img height='36' style='border:0px;height:36px;' src='https://storage.ko-fi.com/cdn/kofi6.png?v=6' border='0' alt='Buy Me a Coffee at ko-fi.com' /></a>
|
rbelanec/train_winogrande_1754507494
|
rbelanec
| 2025-08-07T03:16:29Z | 21 | 0 |
peft
|
[
"peft",
"safetensors",
"llama-factory",
"prompt-tuning",
"generated_from_trainer",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"base_model:adapter:meta-llama/Meta-Llama-3-8B-Instruct",
"license:llama3",
"region:us"
] | null | 2025-08-06T22:47:50Z |
---
library_name: peft
license: llama3
base_model: meta-llama/Meta-Llama-3-8B-Instruct
tags:
- llama-factory
- prompt-tuning
- generated_from_trainer
model-index:
- name: train_winogrande_1754507494
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# train_winogrande_1754507494
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) on the winogrande dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1269
- Num Input Tokens Seen: 30830624
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 123
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Input Tokens Seen |
|:-------------:|:-----:|:-----:|:---------------:|:-----------------:|
| 0.2219 | 0.5 | 4545 | 0.1793 | 1541600 |
| 0.117 | 1.0 | 9090 | 0.1384 | 3081600 |
| 0.1759 | 1.5 | 13635 | 0.1386 | 4623680 |
| 0.0729 | 2.0 | 18180 | 0.1352 | 6165104 |
| 0.3377 | 2.5 | 22725 | 0.1298 | 7706064 |
| 0.1626 | 3.0 | 27270 | 0.1327 | 9248016 |
| 0.0735 | 3.5 | 31815 | 0.1381 | 10789584 |
| 0.1049 | 4.0 | 36360 | 0.1307 | 12330800 |
| 0.0654 | 4.5 | 40905 | 0.1334 | 13871920 |
| 0.001 | 5.0 | 45450 | 0.1381 | 15413776 |
| 0.2929 | 5.5 | 49995 | 0.1352 | 16954320 |
| 0.2065 | 6.0 | 54540 | 0.1269 | 18496992 |
| 0.1853 | 6.5 | 59085 | 0.1326 | 20039264 |
| 0.2249 | 7.0 | 63630 | 0.1306 | 21579792 |
| 0.135 | 7.5 | 68175 | 0.1313 | 23122160 |
| 0.0009 | 8.0 | 72720 | 0.1314 | 24664400 |
| 0.005 | 8.5 | 77265 | 0.1320 | 26207280 |
| 0.0321 | 9.0 | 81810 | 0.1328 | 27747856 |
| 0.2766 | 9.5 | 86355 | 0.1317 | 29287888 |
| 0.0005 | 10.0 | 90900 | 0.1324 | 30830624 |
### Framework versions
- PEFT 0.15.2
- Transformers 4.51.3
- Pytorch 2.8.0+cu128
- Datasets 3.6.0
- Tokenizers 0.21.1
|
oddadmix/Masrawy2English-translator-0.1
|
oddadmix
| 2025-08-07T03:16:11Z | 26 | 0 | null |
[
"tensorboard",
"safetensors",
"marian",
"generated_from_trainer",
"translation",
"ar",
"en",
"base_model:Helsinki-NLP/opus-mt-tc-big-ar-en",
"base_model:finetune:Helsinki-NLP/opus-mt-tc-big-ar-en",
"license:cc-by-4.0",
"region:us"
] |
translation
| 2025-08-04T03:25:56Z |
---
license: cc-by-4.0
base_model: Helsinki-NLP/opus-mt-tc-big-ar-en
tags:
- generated_from_trainer
model-index:
- name: Masrawy2English-translator-opus-mt-tc-big-en-ar-2.9-openai-all
results: []
language:
- ar
- en
pipeline_tag: translation
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
## 📖 Description
**Masrawy-to-English** is a translation model built to convert **Egyptian Arabic (Masrawy dialect)** into fluent English. It focuses on colloquial speech and informal text often found in everyday conversations and social media.
---
## 📊 Evaluation
- **BLEU**: 0.27 on a curated test set of Egyptian Arabic sentences.
- The score reflects good performance for informal and dialectal translation tasks.
---
## 📚 Dataset
The dataset was built using **Egyptian Arabic text** manually translated into English, along with high-quality translations generated using **OpenAI models**. The goal was to cover realistic dialectal expressions and ensure fluent English output.
---
## ✅ Intended Use
**Use for**: Translating social content, messages, and informal Egyptian Arabic.
**Avoid for**: MSA, other Arabic dialects, or high-stakes domains (e.g., legal/medical).
---
## 💬 Examples
| Egyptian Arabic | English |
|---------------------------|-----------------------------|
| عامل إيه؟ | How are you? |
| مش قادر أركز خالص | I can’t focus at all |
## Usage
```mdl_name = "oddadmix/Masrawy2English-translator-opus-mt-tc-big-en-ar-2.9-openai-all"
pipe = pipeline("translation", model=mdl_name, device = 'cuda')
response = pipe(text)[0]['translation_text']
print(response)
```
|
propertrades/propertrdaes
|
propertrades
| 2025-08-07T03:07:00Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-07T03:07:00Z |
---
license: apache-2.0
---
|
lucian1109528/llama3-8B-threekingdoms-cpt-instruct-16bit
|
lucian1109528
| 2025-08-07T03:05:51Z | 0 | 0 |
transformers
|
[
"transformers",
"text-generation-inference",
"unsloth",
"llama",
"en",
"base_model:unsloth/Meta-Llama-3.1-8B",
"base_model:finetune:unsloth/Meta-Llama-3.1-8B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-07T03:05:48Z |
---
base_model: unsloth/Meta-Llama-3.1-8B
tags:
- text-generation-inference
- transformers
- unsloth
- llama
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** lucian1109528
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Meta-Llama-3.1-8B
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
shuohsuan/act_grasp_2
|
shuohsuan
| 2025-08-07T03:02:29Z | 5 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"act",
"dataset:shuohsuan/agrasp",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-07T03:02:03Z |
---
datasets: shuohsuan/agrasp
library_name: lerobot
license: apache-2.0
model_name: act
pipeline_tag: robotics
tags:
- robotics
- act
- lerobot
---
# Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high success rates.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
*Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`.*
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
* **License:** apache-2.0
|
SteelBear/Qwen2.5-3B-SVG
|
SteelBear
| 2025-08-07T02:59:53Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-07T02:59:53Z |
---
license: apache-2.0
---
|
luke-kr/Qwen3-14b-3kingdoms-instruct
|
luke-kr
| 2025-08-07T02:58:27Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen3",
"trl",
"en",
"base_model:unsloth/Qwen3-14B",
"base_model:finetune:unsloth/Qwen3-14B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-07T02:56:23Z |
---
base_model: unsloth/Qwen3-14B
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** luke-kr
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-14B
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Lakshan2003/outputs
|
Lakshan2003
| 2025-08-07T02:57:47Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"unsloth",
"sft",
"base_model:HuggingFaceTB/SmolLM3-3B",
"base_model:finetune:HuggingFaceTB/SmolLM3-3B",
"endpoints_compatible",
"region:us"
] | null | 2025-08-07T02:57:30Z |
---
base_model: HuggingFaceTB/SmolLM3-3B
library_name: transformers
model_name: outputs
tags:
- generated_from_trainer
- trl
- unsloth
- sft
licence: license
---
# Model Card for outputs
This model is a fine-tuned version of [HuggingFaceTB/SmolLM3-3B](https://huggingface.co/HuggingFaceTB/SmolLM3-3B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Lakshan2003/outputs", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.54.0
- Pytorch: 2.6.0+cu124
- Datasets: 4.0.0
- Tokenizers: 0.21.2
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
henrywch2huggingface/llavanext-v1.5-0.5b
|
henrywch2huggingface
| 2025-08-07T02:55:25Z | 4 | 0 | null |
[
"tensorboard",
"safetensors",
"llava_qwen",
"image-to-text",
"base_model:Qwen/Qwen2.5-0.5B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-0.5B-Instruct",
"license:apache-2.0",
"region:us"
] |
image-to-text
| 2025-08-03T08:27:31Z |
---
license: apache-2.0
base_model:
- Qwen/Qwen2.5-0.5B-Instruct
- openai/clip-vit-large-patch14-336
pipeline_tag: image-to-text
---
:::important[NOTICE]As the training scripts was mis-selected (`LLaVA-NeXT/scripts/train/pretrain_clip.sh` + `LLaVA-NeXT/scripts/train/direct_finetune_clip.sh`), the model cannot align with `LLaVA_OneVision` Class in opencompass/VLMEvalKit. Please redirect to [henrywch2huggingface/llavanext-scaled-0.5b](https://huggingface.co/henrywch2huggingface/llavanext-scaled-0.5b "llavanext-scaled-0.5b").:::
|
finalform/foamMistral0.3-7B-Instruct-trl
|
finalform
| 2025-08-07T02:51:10Z | 20 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-Instruct-v0.3",
"base_model:adapter:mistralai/Mistral-7B-Instruct-v0.3",
"region:us"
] | null | 2025-08-03T04:07:17Z |
---
base_model: mistralai/Mistral-7B-Instruct-v0.3
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.2
|
mood157/qtype_prompt
|
mood157
| 2025-08-07T02:49:04Z | 2 | 0 |
transformers
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2025-08-07T02:45:43Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
taobao-mnn/Qwen3-4B-Instruct-2507-MNN
|
taobao-mnn
| 2025-08-07T02:44:53Z | 16 | 1 | null |
[
"chat",
"text-generation",
"en",
"base_model:Qwen/Qwen3-4B-Instruct-2507",
"base_model:quantized:Qwen/Qwen3-4B-Instruct-2507",
"license:apache-2.0",
"region:us"
] |
text-generation
| 2025-08-07T01:52:31Z |
---
license: apache-2.0
language:
- en
pipeline_tag: text-generation
tags:
- chat
base_model:
- Qwen/Qwen3-4B-Instruct-2507
base_model_relation: quantized
---
# Qwen3-4B-Instruct-2507-MNN
## Introduction
This model is a 4-bit quantized version of the MNN model exported from Qwen3-4B-Instruct-2507 using [llmexport](https://github.com/alibaba/MNN/tree/master/transformers/llm/export).
## Download
```bash
# install huggingface
pip install huggingface
```
```bash
# shell download
huggingface download --model 'taobao-mnn/Qwen3-4B-Instruct-2507-MNN' --local_dir 'path/to/dir'
```
```python
# SDK download
from huggingface_hub import snapshot_download
model_dir = snapshot_download('taobao-mnn/Qwen3-4B-Instruct-2507-MNN')
```
```bash
# git clone
git clone https://www.modelscope.cn/taobao-mnn/Qwen3-4B-Instruct-2507-MNN
```
## Usage
```bash
# clone MNN source
git clone https://github.com/alibaba/MNN.git
# compile
cd MNN
mkdir build && cd build
cmake .. -DMNN_LOW_MEMORY=true -DMNN_CPU_WEIGHT_DEQUANT_GEMM=true -DMNN_BUILD_LLM=true -DMNN_SUPPORT_TRANSFORMER_FUSE=true
make -j
# run
./llm_demo /path/to/Qwen3-4B-Instruct-2507-MNN/config.json prompt.txt
```
## Document
[MNN-LLM](https://mnn-docs.readthedocs.io/en/latest/transformers/llm.html#)
|
myfi/parser_model_ner_3.42_adapter
|
myfi
| 2025-08-07T02:43:26Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2",
"trl",
"en",
"base_model:unsloth/Qwen2.5-3B-Instruct",
"base_model:finetune:unsloth/Qwen2.5-3B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-07T02:42:54Z |
---
base_model: unsloth/Qwen2.5-3B-Instruct
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** myfi
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen2.5-3B-Instruct
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
ilovexgboost/qwen3_14b_grpo_50000_1035
|
ilovexgboost
| 2025-08-07T02:42:00Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"grpo",
"arxiv:2402.03300",
"endpoints_compatible",
"region:us"
] | null | 2025-08-06T02:59:27Z |
---
library_name: transformers
model_name: qwen3_14b_grpo_50000_1035
tags:
- generated_from_trainer
- trl
- grpo
licence: license
---
# Model Card for qwen3_14b_grpo_50000_1035
This model is a fine-tuned version of [None](https://huggingface.co/None).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="ilovexgboost/qwen3_14b_grpo_50000_1035", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/gerdaking2070-st-louis-community-college/poker-grpo-reset/runs/00lkdqdi)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.22.0.dev0
- Transformers: 4.52.4
- Pytorch: 2.7.0+cu126
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
mrbeanlas/sla-it-tide-06
|
mrbeanlas
| 2025-08-07T02:37:37Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-07T02:08:23Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
AXERA-TECH/Qwen3-Embedding-0.6B
|
AXERA-TECH
| 2025-08-07T02:37:07Z | 3 | 0 |
transformers
|
[
"transformers",
"sentence-transformers",
"sentence-similarity",
"feature-extraction",
"text-embeddings-inference",
"base_model:Qwen/Qwen3-Embedding-0.6B",
"base_model:finetune:Qwen/Qwen3-Embedding-0.6B",
"license:mit",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2025-08-06T09:14:32Z |
---
library_name: transformers
license: mit
base_model:
- Qwen/Qwen3-Embedding-0.6B
tags:
- transformers
- sentence-transformers
- sentence-similarity
- feature-extraction
- text-embeddings-inference
pipeline_tag: feature-extraction
---
# Qwen3-Embedding-0.6B
This version of Qwen3-Embedding-0.6B has been converted to run on the Axera NPU using **w8a16** quantization.
This model has been optimized with the following LoRA:
Compatible with Pulsar2 version: 4.1
## Convert tools links:
For those who are interested in model conversion, you can try to export axmodel through the original repo:
https://huggingface.co/Qwen/Qwen3-Embedding-0.6B
[Pulsar2 Link, How to Convert LLM from Huggingface to axmodel](https://pulsar2-docs.readthedocs.io/en/latest/appendix/build_llm.html)
## Support Platform
- AX650
- AX650N DEMO Board
- [M4N-Dock(爱芯派Pro)](https://wiki.sipeed.com/hardware/zh/maixIV/m4ndock/m4ndock.html)
- [M.2 Accelerator card](https://axcl-docs.readthedocs.io/zh-cn/latest/doc_guide_hardware.html)
### Each subgraph is time-consuming
```sh
g1: 5.561 ms
g2: 9.140 ms
g3: 12.757 ms
g4: 16.446 ms
g5: 21.392 ms
g6: 23.712 ms
g7: 27.174 ms
g8: 30.897 ms
g9: 34.829 ms
```
- Shortest time(forward) consumption: 5.561 ms
- Longest time(forward) consumption: 181.908 ms
- LayerNum: 28
|Chips | ttft | w8a16 |
|--|--|--|
|AX650| 155.708 ms (128 token 最短耗时) | 0.82 tokens/sec|
|AX650| 5093.42 ms (1024 token 最长耗时) | 0.20 tokens/sec|
## How to use
Download all files from this repository to the device.
**If you using AX650 Board**
```
root@ax650 ~/yongqiang/push_hugging_face/Qwen3-Embedding-0.6B # tree -L 1
.
├── config.json
├── infer_axmodel.py
├── qwen3_embedding_0.6b_axmodel
├── qwen3_embedding_0.6b_tokenizer
├── README.md
└── utils
3 directories, 3 files
```
#### Install transformer
```
# Requires transformers>=4.51.0
pip install transformers==4.51.0
```
#### Inference with AX650 Host, such as M4N-Dock(爱芯派Pro) or AX650N DEMO Board
```
$ root@ax650 ~/yongqiang/push_hugging_face/Qwen3-Embedding-0.6B # python3 infer_axmodel.py
Model loaded successfully!
slice_indices: [0]
Slice prefill done: 0
slice_indices: [0]
Slice prefill done: 0
slice_indices: [0]
Slice prefill done: 0
slice_indices: [0]
Slice prefill done: 0
[[0.7555467486381531, 0.1756950318813324], [0.4137178063392639, 0.4459586441516876]]
```
|
chatpig/qwen2.5-vl-3b-it-gguf
|
chatpig
| 2025-08-07T02:36:58Z | 2,985 | 0 | null |
[
"gguf",
"image-text-to-text",
"base_model:Qwen/Qwen2.5-VL-3B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-VL-3B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
image-text-to-text
| 2025-08-06T22:46:03Z |
---
license: apache-2.0
pipeline_tag: image-text-to-text
base_model:
- Qwen/Qwen2.5-VL-3B-Instruct
---
## qwen2.5-vl-3b-it-gguf
- for text/image-text-to-text generation
- work as text encoder
- compatible with both [comfyui-gguf](https://github.com/city96/ComfyUI-GGUF) and [gguf-node](https://github.com/calcuis/gguf)
- example model supported: [omnigen](https://huggingface.co/calcuis/omnigen2-gguf)
|
CheapsetZero/6edc97b7-26b3-41b1-a92f-a6408924bbf3
|
CheapsetZero
| 2025-08-07T02:36:27Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/Hermes-3-Llama-3.1-8B",
"base_model:adapter:unsloth/Hermes-3-Llama-3.1-8B",
"region:us"
] | null | 2025-08-07T02:31:23Z |
---
library_name: peft
base_model: unsloth/Hermes-3-Llama-3.1-8B
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 6edc97b7-26b3-41b1-a92f-a6408924bbf3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
adapter: lora
base_model: unsloth/Hermes-3-Llama-3.1-8B
bf16: auto
chat_template: llama3
dataset_prepared_path: null
datasets:
- data_files:
- 5046e91f368fe23e_train_data.json
ds_type: json
field: prompt
path: /workspace/input_data/
split: train
type: completion
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 4
flash_attention: false
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 4
gradient_checkpointing: false
group_by_length: false
hub_model_id: CheapsetZero/6edc97b7-26b3-41b1-a92f-a6408924bbf3
learning_rate: 0.0002
load_in_4bit: false
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 16
lora_dropout: 0.05
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 8
lora_target_linear: true
lr_scheduler: cosine
max_steps: 10
micro_batch_size: 4
mlflow_experiment_name: /tmp/5046e91f368fe23e_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 1
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 4
sequence_len: 512
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trl:
beta: 0.04
max_completion_length: 256
num_generations: 4
reward_funcs:
- rewards_eed83368-46f1-44dd-96d1-eb1a456852bc.reward_long_completions
- rewards_eed83368-46f1-44dd-96d1-eb1a456852bc.reward_short_words
- rewards_eed83368-46f1-44dd-96d1-eb1a456852bc.reward_flesch_kincaid_grade
reward_weights:
- 0.16502321227550354
- 3.2220723107875626
- 6.621395871213648
use_vllm: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: offline
wandb_name: eed83368-46f1-44dd-96d1-eb1a456852bc
wandb_project: Gradients-On-Demand
wandb_run: your_name
wandb_runid: eed83368-46f1-44dd-96d1-eb1a456852bc
warmup_steps: 10
weight_decay: 0.0
xformers_attention: null
```
</details><br>
# 6edc97b7-26b3-41b1-a92f-a6408924bbf3
This model is a fine-tuned version of [unsloth/Hermes-3-Llama-3.1-8B](https://huggingface.co/unsloth/Hermes-3-Llama-3.1-8B) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: nan
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- training_steps: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.0 | 0.0005 | 1 | nan |
| 0.0 | 0.0014 | 3 | nan |
| 0.0 | 0.0029 | 6 | nan |
| 0.0 | 0.0043 | 9 | nan |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1
|
DHOM-Uni/FAQ-Ai-Assistant-V4
|
DHOM-Uni
| 2025-08-07T02:15:14Z | 2 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"electra",
"cross-encoder",
"generated_from_trainer",
"dataset_size:173920",
"loss:BinaryCrossEntropyLoss",
"text-ranking",
"arxiv:1908.10084",
"base_model:MatMulMan/araelectra-base-discriminator-tydi-tafseer-pairs",
"base_model:finetune:MatMulMan/araelectra-base-discriminator-tydi-tafseer-pairs",
"region:us"
] |
text-ranking
| 2025-08-06T20:00:13Z |
---
tags:
- sentence-transformers
- cross-encoder
- generated_from_trainer
- dataset_size:173920
- loss:BinaryCrossEntropyLoss
base_model: MatMulMan/araelectra-base-discriminator-tydi-tafseer-pairs
pipeline_tag: text-ranking
library_name: sentence-transformers
---
# CrossEncoder based on MatMulMan/araelectra-base-discriminator-tydi-tafseer-pairs
This is a [Cross Encoder](https://www.sbert.net/docs/cross_encoder/usage/usage.html) model finetuned from [MatMulMan/araelectra-base-discriminator-tydi-tafseer-pairs](https://huggingface.co/MatMulMan/araelectra-base-discriminator-tydi-tafseer-pairs) using the [sentence-transformers](https://www.SBERT.net) library. It computes scores for pairs of texts, which can be used for text reranking and semantic search.
## Model Details
### Model Description
- **Model Type:** Cross Encoder
- **Base model:** [MatMulMan/araelectra-base-discriminator-tydi-tafseer-pairs](https://huggingface.co/MatMulMan/araelectra-base-discriminator-tydi-tafseer-pairs) <!-- at revision 7085ca8be3d1c45e2ce57f3d5dfb4c918ac1a37b -->
- **Maximum Sequence Length:** 512 tokens
- **Number of Output Labels:** 1 label
<!-- - **Training Dataset:** Unknown -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Documentation:** [Cross Encoder Documentation](https://www.sbert.net/docs/cross_encoder/usage/usage.html)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Cross Encoders on Hugging Face](https://huggingface.co/models?library=sentence-transformers&other=cross-encoder)
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import CrossEncoder
# Download from the 🤗 Hub
model = CrossEncoder("cross_encoder_model_id")
# Get scores for pairs of texts
pairs = [
['يعني يا ترى، الموظفين اللي بيشتغلوا في قسم الامتحانات بالجامعة، ليهم كام يوم إجازة للمذاكرة قبل الامتحانات؟ (تركيز على قسم الامتحانات وتحديد الفترة الزمنية)؟', 'القانون حدد 7 أيام فقط من تقديم الاستقالة علشان العامل يقدر يتراجع عنها. لو عدت المدة دي بدون ما يطلب التراجع، بتعتبر استقالته نهائية.'],
['ممكن أعرف القانون الجديد بيقول، سنه المعاش في شركات القطاع الخاص بقى كام دلوقتي؟', 'المكافأة هي مبلغ ثابت بياخده العامل عن السنين اللي اشتغلها. أما التعويض، فهو مبلغ إضافي بيتدفع لو حصلت له مشكلة زي فصل تعسفي أو إصابة. الاتنين مختلفين في السبب وطريقة الحساب.'],
['أقصى مبلغ ممكن يتخصم من المرتب أد إيه؟ (أد إيه = كم)', 'أقصى حد للخصم من المرتب هو 25% من صافي المرتب، زي ما القانون حدد، إلا إذا في حكم قضائي زي النفقة.'],
['ممكن أعرف ماذا الفرق الجوهري بين عقد الدوام اللي فيه تاريخ نهاية وعقد العمل المفتوح اللي ملوش تاريخ نهاية؟', 'أيوه، الأم المرضعة من حقها يوميًا "فترتين رضاعة" كل واحدة نص ساعة، أو تقدر تدمجهم كساعة كاملة. وده بيستمر لمدة 24 شهر من يوم الولادة.'],
['بالنسبة للاشتراكات، العامل بيتحمل جزء أد إيه منها وصاحب العمل بيتحمل الجزء الباقي؟ عايزين نعرف توزيع المساهمات بالضبط.', 'أيوه، القانون بيطلب تشكيل لجنة للسلامة والصحة المهنية في المنشآت الكبيرة، خصوصًا اللي فيها أكتر من عدد معين من العمال. اللجنة دي بتتابع تطبيق إجراءات السلامة.'],
]
scores = model.predict(pairs)
print(scores.shape)
# (5,)
# Or rank different texts based on similarity to a single text
ranks = model.rank(
'يعني يا ترى، الموظفين اللي بيشتغلوا في قسم الامتحانات بالجامعة، ليهم كام يوم إجازة للمذاكرة قبل الامتحانات؟ (تركيز على قسم الامتحانات وتحديد الفترة الزمنية)؟',
[
'القانون حدد 7 أيام فقط من تقديم الاستقالة علشان العامل يقدر يتراجع عنها. لو عدت المدة دي بدون ما يطلب التراجع، بتعتبر استقالته نهائية.',
'المكافأة هي مبلغ ثابت بياخده العامل عن السنين اللي اشتغلها. أما التعويض، فهو مبلغ إضافي بيتدفع لو حصلت له مشكلة زي فصل تعسفي أو إصابة. الاتنين مختلفين في السبب وطريقة الحساب.',
'أقصى حد للخصم من المرتب هو 25% من صافي المرتب، زي ما القانون حدد، إلا إذا في حكم قضائي زي النفقة.',
'أيوه، الأم المرضعة من حقها يوميًا "فترتين رضاعة" كل واحدة نص ساعة، أو تقدر تدمجهم كساعة كاملة. وده بيستمر لمدة 24 شهر من يوم الولادة.',
'أيوه، القانون بيطلب تشكيل لجنة للسلامة والصحة المهنية في المنشآت الكبيرة، خصوصًا اللي فيها أكتر من عدد معين من العمال. اللجنة دي بتتابع تطبيق إجراءات السلامة.',
]
)
# [{'corpus_id': ..., 'score': ...}, {'corpus_id': ..., 'score': ...}, ...]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 173,920 training samples
* Columns: <code>sentence_0</code>, <code>sentence_1</code>, and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | sentence_0 | sentence_1 | label |
|:--------|:-------------------------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------------------|:---------------------------------------------------------------|
| type | string | string | float |
| details | <ul><li>min: 36 characters</li><li>mean: 116.64 characters</li><li>max: 320 characters</li></ul> | <ul><li>min: 16 characters</li><li>mean: 142.71 characters</li><li>max: 399 characters</li></ul> | <ul><li>min: 0.0</li><li>mean: 0.26</li><li>max: 1.0</li></ul> |
* Samples:
| sentence_0 | sentence_1 | label |
|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------|
| <code>يعني يا ترى، الموظفين اللي بيشتغلوا في قسم الامتحانات بالجامعة، ليهم كام يوم إجازة للمذاكرة قبل الامتحانات؟ (تركيز على قسم الامتحانات وتحديد الفترة الزمنية)؟</code> | <code>القانون حدد 7 أيام فقط من تقديم الاستقالة علشان العامل يقدر يتراجع عنها. لو عدت المدة دي بدون ما يطلب التراجع، بتعتبر استقالته نهائية.</code> | <code>0.0</code> |
| <code>ممكن أعرف القانون الجديد بيقول، سنه المعاش في شركات القطاع الخاص بقى كام دلوقتي؟</code> | <code>المكافأة هي مبلغ ثابت بياخده العامل عن السنين اللي اشتغلها. أما التعويض، فهو مبلغ إضافي بيتدفع لو حصلت له مشكلة زي فصل تعسفي أو إصابة. الاتنين مختلفين في السبب وطريقة الحساب.</code> | <code>0.0</code> |
| <code>أقصى مبلغ ممكن يتخصم من المرتب أد إيه؟ (أد إيه = كم)</code> | <code>أقصى حد للخصم من المرتب هو 25% من صافي المرتب، زي ما القانون حدد، إلا إذا في حكم قضائي زي النفقة.</code> | <code>1.0</code> |
* Loss: [<code>BinaryCrossEntropyLoss</code>](https://sbert.net/docs/package_reference/cross_encoder/losses.html#binarycrossentropyloss) with these parameters:
```json
{
"activation_fn": "torch.nn.modules.linear.Identity",
"pos_weight": null
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `num_train_epochs`: 4
- `disable_tqdm`: True
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: no
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 5e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1
- `num_train_epochs`: 4
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.0
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: True
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `hub_revision`: None
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `liger_kernel_config`: None
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: batch_sampler
- `multi_dataset_batch_sampler`: proportional
</details>
### Training Logs
| Epoch | Step | Training Loss |
|:------:|:-----:|:-------------:|
| 0.0460 | 500 | 0.5364 |
| 0.0920 | 1000 | 0.2314 |
| 0.1380 | 1500 | 0.151 |
| 0.1840 | 2000 | 0.1318 |
| 0.2300 | 2500 | 0.1201 |
| 0.2760 | 3000 | 0.1132 |
| 0.3220 | 3500 | 0.0935 |
| 0.3680 | 4000 | 0.082 |
| 0.4140 | 4500 | 0.0817 |
| 0.4600 | 5000 | 0.0804 |
| 0.5060 | 5500 | 0.0726 |
| 0.5520 | 6000 | 0.0662 |
| 0.5980 | 6500 | 0.0632 |
| 0.6440 | 7000 | 0.0579 |
| 0.6900 | 7500 | 0.0558 |
| 0.7360 | 8000 | 0.0448 |
| 0.7820 | 8500 | 0.0626 |
| 0.8280 | 9000 | 0.0419 |
| 0.8740 | 9500 | 0.0495 |
| 0.9200 | 10000 | 0.047 |
| 0.9660 | 10500 | 0.0447 |
| 1.0120 | 11000 | 0.0376 |
| 1.0580 | 11500 | 0.0342 |
| 1.1040 | 12000 | 0.0404 |
| 1.1500 | 12500 | 0.0364 |
| 1.1960 | 13000 | 0.0329 |
| 1.2420 | 13500 | 0.0373 |
| 1.2879 | 14000 | 0.0407 |
| 1.3339 | 14500 | 0.0298 |
| 1.3799 | 15000 | 0.0319 |
| 1.4259 | 15500 | 0.0361 |
| 1.4719 | 16000 | 0.0423 |
| 1.5179 | 16500 | 0.0349 |
| 1.5639 | 17000 | 0.0304 |
| 1.6099 | 17500 | 0.0291 |
| 1.6559 | 18000 | 0.0277 |
| 1.7019 | 18500 | 0.0288 |
| 1.7479 | 19000 | 0.0285 |
| 1.7939 | 19500 | 0.0288 |
| 1.8399 | 20000 | 0.0268 |
| 1.8859 | 20500 | 0.027 |
| 1.9319 | 21000 | 0.0215 |
| 1.9779 | 21500 | 0.0214 |
| 2.0239 | 22000 | 0.0263 |
| 2.0699 | 22500 | 0.0192 |
| 2.1159 | 23000 | 0.0242 |
| 2.1619 | 23500 | 0.0286 |
| 2.2079 | 24000 | 0.0144 |
| 2.2539 | 24500 | 0.0283 |
| 2.2999 | 25000 | 0.0209 |
| 2.3459 | 25500 | 0.0188 |
| 2.3919 | 26000 | 0.0211 |
| 2.4379 | 26500 | 0.0264 |
| 2.4839 | 27000 | 0.0245 |
| 2.5299 | 27500 | 0.023 |
| 2.5759 | 28000 | 0.0211 |
| 2.6219 | 28500 | 0.0248 |
| 2.6679 | 29000 | 0.0201 |
| 2.7139 | 29500 | 0.0194 |
| 2.7599 | 30000 | 0.0176 |
| 2.8059 | 30500 | 0.0194 |
| 2.8519 | 31000 | 0.0165 |
| 2.8979 | 31500 | 0.0209 |
| 2.9439 | 32000 | 0.0178 |
| 2.9899 | 32500 | 0.0166 |
| 3.0359 | 33000 | 0.0207 |
| 3.0819 | 33500 | 0.0143 |
| 3.1279 | 34000 | 0.0114 |
| 3.1739 | 34500 | 0.0208 |
| 3.2199 | 35000 | 0.0143 |
| 3.2659 | 35500 | 0.0221 |
| 3.3119 | 36000 | 0.0218 |
| 3.3579 | 36500 | 0.0144 |
| 3.4039 | 37000 | 0.0201 |
| 3.4499 | 37500 | 0.0172 |
| 3.4959 | 38000 | 0.0177 |
| 3.5419 | 38500 | 0.0129 |
| 3.5879 | 39000 | 0.013 |
| 3.6339 | 39500 | 0.016 |
| 3.6799 | 40000 | 0.0137 |
| 3.7259 | 40500 | 0.0171 |
| 3.7718 | 41000 | 0.0201 |
| 3.8178 | 41500 | 0.0166 |
| 3.8638 | 42000 | 0.0097 |
| 3.9098 | 42500 | 0.0146 |
| 3.9558 | 43000 | 0.0182 |
### Framework Versions
- Python: 3.11.13
- Sentence Transformers: 4.1.0
- Transformers: 4.54.1
- PyTorch: 2.6.0+cu124
- Accelerate: 1.9.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
TAUR-dev/M-back_to_og_mix__simple_retries__sbon-sft
|
TAUR-dev
| 2025-08-07T02:15:14Z | 12 | 0 | null |
[
"safetensors",
"qwen2",
"region:us"
] | null | 2025-08-07T02:13:47Z |
# M-back_to_og_mix__simple_retries__sbon-sft
This model was created as part of the **back_to_og_mix__simple_retries__sbon** experiment using the SkillFactory experiment management system.
## Model Details
- **Training Method**: LLaMAFactory SFT (Supervised Fine-Tuning)
- **Stage Name**: sft
- **Experiment**: back_to_og_mix__simple_retries__sbon
## Training Configuration
{"model_name_or_path": "Qwen/Qwen2.5-1.5B-Instruct", "trust_remote_code": true, "stage": "sft", "do_train": true, "finetuning_type": "full", "deepspeed": "/scratch/10416/zaynesprague/skill_factory_dir/skill-factory/thirdparty/LLaMA-Factory/examples/deepspeed/ds_z2_config.json", "dataset": "TAUR_dev__D_SFT_C_back_to_og_mix__simple_retries__sbon_sft_data__sft_train", "template": "qwen", "cutoff_len": 16384, "max_samples": 1000000, "overwrite_cache": true, "preprocessing_num_workers": 1, "dataloader_num_workers": 0, "disable_tqdm": false, "output_dir": "/scratch/10416/zaynesprague/skill_inject_outputs/sf_experiments/back_to_og_mix/llamafactory/checkpoints", "logging_steps": 10, "save_steps": 100000, "plot_loss": true, "overwrite_output_dir": true, "per_device_train_batch_size": 1, "gradient_accumulation_steps": 1, "learning_rate": 1e-06, "num_train_epochs": 1, "lr_scheduler_type": "cosine", "warmup_ratio": 0.05, "weight_decay": 0.0001, "adam_beta1": 0.9, "adam_beta2": 0.95, "bf16": true, "ddp_timeout": 180000000, "gradient_checkpointing": true, "save_only_model": true, "enable_masked_ranges": true, "sf_tracker_dataset_id": "TAUR-dev/D-ExpTracker__back_to_og_mix__simple_retries__sbon__v1", "sf_eval_before_training": false, "sf_wandb_project": "back_to_og_mix__simple_retries__sbon_sft", "sf_eval_steps": null, "run_name": "back_to_og_mix__simple_retries__sbon_sft"}
## Experiment Tracking
🔗 **View complete experiment details**: [Experiment Tracker Dataset](https://huggingface.co/datasets/TAUR-dev/D-ExpTracker__back_to_og_mix__simple_retries__sbon__v1)
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("TAUR-dev/M-back_to_og_mix__simple_retries__sbon-sft")
model = AutoModelForCausalLM.from_pretrained("TAUR-dev/M-back_to_og_mix__simple_retries__sbon-sft")
```
|
myfi/parser_model_ner_3.42_checkpoint_300_lora
|
myfi
| 2025-08-07T02:13:06Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2",
"en",
"base_model:unsloth/Qwen2.5-3B-Instruct",
"base_model:finetune:unsloth/Qwen2.5-3B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-07T02:03:40Z |
---
base_model: unsloth/Qwen2.5-3B-Instruct
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** myfi
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen2.5-3B-Instruct
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
songff/SinglePO
|
songff
| 2025-08-07T02:08:08Z | 2 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"en",
"dataset:songff/UltraPrompt",
"base_model:meta-llama/Llama-3.2-3B-Instruct",
"base_model:finetune:meta-llama/Llama-3.2-3B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-07-14T03:57:42Z |
---
license: apache-2.0
datasets:
- songff/UltraPrompt
language:
- en
base_model:
- meta-llama/Llama-3.2-3B-Instruct
library_name: transformers
---
|
x2bee/Polar-14B
|
x2bee
| 2025-08-07T02:06:33Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:2309.00071",
"arxiv:2505.09388",
"base_model:Qwen/Qwen3-14B-Base",
"base_model:finetune:Qwen/Qwen3-14B-Base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-07T02:00:20Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-14B/blob/main/LICENSE
pipeline_tag: text-generation
base_model:
- Qwen/Qwen3-14B-Base
---
# Qwen3-14B
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Qwen3 Highlights
Qwen3 is the latest generation of large language models in Qwen series, offering a comprehensive suite of dense and mixture-of-experts (MoE) models. Built upon extensive training, Qwen3 delivers groundbreaking advancements in reasoning, instruction-following, agent capabilities, and multilingual support, with the following key features:
- **Uniquely support of seamless switching between thinking mode** (for complex logical reasoning, math, and coding) and **non-thinking mode** (for efficient, general-purpose dialogue) **within single model**, ensuring optimal performance across various scenarios.
- **Significantly enhancement in its reasoning capabilities**, surpassing previous QwQ (in thinking mode) and Qwen2.5 instruct models (in non-thinking mode) on mathematics, code generation, and commonsense logical reasoning.
- **Superior human preference alignment**, excelling in creative writing, role-playing, multi-turn dialogues, and instruction following, to deliver a more natural, engaging, and immersive conversational experience.
- **Expertise in agent capabilities**, enabling precise integration with external tools in both thinking and unthinking modes and achieving leading performance among open-source models in complex agent-based tasks.
- **Support of 100+ languages and dialects** with strong capabilities for **multilingual instruction following** and **translation**.
## Model Overview
**Qwen3-14B** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 14.8B
- Number of Paramaters (Non-Embedding): 13.2B
- Number of Layers: 40
- Number of Attention Heads (GQA): 40 for Q and 8 for KV
- Context Length: 32,768 natively and [131,072 tokens with YaRN](#processing-long-texts).
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Quickstart
The code of Qwen3 has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-14B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-14B --reasoning-parser qwen3
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-14B --enable-reasoning --reasoning-parser deepseek_r1
```
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Switching Between Thinking and Non-Thinking Mode
> [!TIP]
> The `enable_thinking` switch is also available in APIs created by SGLang and vLLM.
> Please refer to our documentation for [SGLang](https://qwen.readthedocs.io/en/latest/deployment/sglang.html#thinking-non-thinking-modes) and [vLLM](https://qwen.readthedocs.io/en/latest/deployment/vllm.html#thinking-non-thinking-modes) users.
### `enable_thinking=True`
By default, Qwen3 has thinking capabilities enabled, similar to QwQ-32B. This means the model will use its reasoning abilities to enhance the quality of generated responses. For example, when explicitly setting `enable_thinking=True` or leaving it as the default value in `tokenizer.apply_chat_template`, the model will engage its thinking mode.
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # True is the default value for enable_thinking
)
```
In this mode, the model will generate think content wrapped in a `<think>...</think>` block, followed by the final response.
> [!NOTE]
> For thinking mode, use `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0` (the default setting in `generation_config.json`). **DO NOT use greedy decoding**, as it can lead to performance degradation and endless repetitions. For more detailed guidance, please refer to the [Best Practices](#best-practices) section.
### `enable_thinking=False`
We provide a hard switch to strictly disable the model's thinking behavior, aligning its functionality with the previous Qwen2.5-Instruct models. This mode is particularly useful in scenarios where disabling thinking is essential for enhancing efficiency.
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # Setting enable_thinking=False disables thinking mode
)
```
In this mode, the model will not generate any think content and will not include a `<think>...</think>` block.
> [!NOTE]
> For non-thinking mode, we suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`. For more detailed guidance, please refer to the [Best Practices](#best-practices) section.
### Advanced Usage: Switching Between Thinking and Non-Thinking Modes via User Input
We provide a soft switch mechanism that allows users to dynamically control the model's behavior when `enable_thinking=True`. Specifically, you can add `/think` and `/no_think` to user prompts or system messages to switch the model's thinking mode from turn to turn. The model will follow the most recent instruction in multi-turn conversations.
Here is an example of a multi-turn conversation:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
class QwenChatbot:
def __init__(self, model_name="Qwen/Qwen3-14B"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(model_name)
self.history = []
def generate_response(self, user_input):
messages = self.history + [{"role": "user", "content": user_input}]
text = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = self.tokenizer(text, return_tensors="pt")
response_ids = self.model.generate(**inputs, max_new_tokens=32768)[0][len(inputs.input_ids[0]):].tolist()
response = self.tokenizer.decode(response_ids, skip_special_tokens=True)
# Update history
self.history.append({"role": "user", "content": user_input})
self.history.append({"role": "assistant", "content": response})
return response
# Example Usage
if __name__ == "__main__":
chatbot = QwenChatbot()
# First input (without /think or /no_think tags, thinking mode is enabled by default)
user_input_1 = "How many r's in strawberries?"
print(f"User: {user_input_1}")
response_1 = chatbot.generate_response(user_input_1)
print(f"Bot: {response_1}")
print("----------------------")
# Second input with /no_think
user_input_2 = "Then, how many r's in blueberries? /no_think"
print(f"User: {user_input_2}")
response_2 = chatbot.generate_response(user_input_2)
print(f"Bot: {response_2}")
print("----------------------")
# Third input with /think
user_input_3 = "Really? /think"
print(f"User: {user_input_3}")
response_3 = chatbot.generate_response(user_input_3)
print(f"Bot: {response_3}")
```
> [!NOTE]
> For API compatibility, when `enable_thinking=True`, regardless of whether the user uses `/think` or `/no_think`, the model will always output a block wrapped in `<think>...</think>`. However, the content inside this block may be empty if thinking is disabled.
> When `enable_thinking=False`, the soft switches are not valid. Regardless of any `/think` or `/no_think` tags input by the user, the model will not generate think content and will not include a `<think>...</think>` block.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-14B',
# Use the endpoint provided by Alibaba Model Studio:
# 'model_type': 'qwen_dashscope',
# 'api_key': os.getenv('DASHSCOPE_API_KEY'),
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
# Other parameters:
# 'generate_cfg': {
# # Add: When the response content is `<think>this is the thought</think>this is the answer;
# # Do not add: When the response has been separated by reasoning_content and content.
# 'thought_in_content': True,
# },
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Processing Long Texts
Qwen3 natively supports context lengths of up to 32,768 tokens. For conversations where the total length (including both input and output) significantly exceeds this limit, we recommend using RoPE scaling techniques to handle long texts effectively. We have validated the model's performance on context lengths of up to 131,072 tokens using the [YaRN](https://arxiv.org/abs/2309.00071) method.
YaRN is currently supported by several inference frameworks, e.g., `transformers` and `llama.cpp` for local use, `vllm` and `sglang` for deployment. In general, there are two approaches to enabling YaRN for supported frameworks:
- Modifying the model files:
In the `config.json` file, add the `rope_scaling` fields:
```json
{
...,
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 32768
}
}
```
For `llama.cpp`, you need to regenerate the GGUF file after the modification.
- Passing command line arguments:
For `vllm`, you can use
```shell
vllm serve ... --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}' --max-model-len 131072
```
For `sglang`, you can use
```shell
python -m sglang.launch_server ... --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}}'
```
For `llama-server` from `llama.cpp`, you can use
```shell
llama-server ... --rope-scaling yarn --rope-scale 4 --yarn-orig-ctx 32768
```
> [!IMPORTANT]
> If you encounter the following warning
> ```
> Unrecognized keys in `rope_scaling` for 'rope_type'='yarn': {'original_max_position_embeddings'}
> ```
> please upgrade `transformers>=4.51.0`.
> [!NOTE]
> All the notable open-source frameworks implement static YaRN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts.**
> We advise adding the `rope_scaling` configuration only when processing long contexts is required.
> It is also recommended to modify the `factor` as needed. For example, if the typical context length for your application is 65,536 tokens, it would be better to set `factor` as 2.0.
> [!NOTE]
> The default `max_position_embeddings` in `config.json` is set to 40,960. This allocation includes reserving 32,768 tokens for outputs and 8,192 tokens for typical prompts, which is sufficient for most scenarios involving short text processing. If the average context length does not exceed 32,768 tokens, we do not recommend enabling YaRN in this scenario, as it may potentially degrade model performance.
> [!TIP]
> The endpoint provided by Alibaba Model Studio supports dynamic YaRN by default and no extra configuration is needed.
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- For thinking mode (`enable_thinking=True`), use `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0`. **DO NOT use greedy decoding**, as it can lead to performance degradation and endless repetitions.
- For non-thinking mode (`enable_thinking=False`), we suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 38,912 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
4. **No Thinking Content in History**: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
```
|
TecnoSeguridad/como-usar-proxies-para-amazon-fba
|
TecnoSeguridad
| 2025-08-07T02:05:35Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-07T02:01:59Z |
# Optimiza tu Amazon FBA con Proxies Residenciales

**[👉 ¡Potencia tus operaciones con los proxies residenciales de 9Proxy!](https://the9proxy.short.gy/huggingface-pricing-sophie89)**
Gestionar un negocio exitoso en Amazon FBA exige un monitoreo constante, desde seguir a los competidores hasta operar múltiples cuentas de vendedor. Sin embargo, Amazon puede detectar comportamientos anómalos y restringir el acceso. Para evitarlo, el uso de proxies se vuelve una herramienta clave para mantener la seguridad y eficiencia.
## Beneficios del uso de proxies en Amazon FBA
### Acceso sin fronteras
Gracias a los proxies residenciales, es posible navegar por diferentes versiones regionales de Amazon. Esto permite analizar precios internacionales, estudiar tendencias y verificar la disponibilidad de productos en tiempo real, sin limitaciones geográficas.
### Protección contra bloqueos
Al rotar las IPs mediante proxies, se evitan los bloqueos por múltiples cuentas o solicitudes intensas. Esta estrategia permite mantener todas las operaciones bajo perfil y sin interrupciones.
### Análisis competitivo
Realiza un seguimiento completo del mercado y analiza a tus rivales sin alertar a Amazon. Podrás obtener información clave sobre precios, stock y movimientos del mercado sin restricciones.
### Supervisión de inventario
Los proxies eliminan los límites al consultar disponibilidad y precios, lo que facilita mantener niveles óptimos de stock y añadir nuevos productos a tu catálogo.
### Más seguridad y anonimato
Oculta tu IP real y dificulta cualquier intento de rastreo por parte de Amazon u otros servicios. Esto ofrece una capa adicional de seguridad para tus cuentas.
**[👉 ¡Empieza a navegar protegido!](https://the9proxy.short.gy/huggingface-homepage-sophie89)**
## ¿Cómo ayudan los proxies en tu crecimiento?
Implementar proxies residenciales te da las herramientas necesarias para escalar, monitorear y asegurar cada aspecto de tu negocio en Amazon. Desde tareas de investigación hasta operaciones de múltiples cuentas, todo fluye de forma más eficiente y segura.
**¿Preparado para avanzar? Comienza hoy mismo con [9Proxy](https://the9proxy.short.gy/huggingface-pricing-sophie89)**
**[👉 Conoce más beneficios aquí](https://the9proxy.short.gy/huggingface-pricing-sophie89)**
|
tensorblock/joey00072_exp-ntr-qwen3-4b-v0-GGUF
|
tensorblock
| 2025-08-07T02:03:49Z | 1,574 | 0 |
transformers
|
[
"transformers",
"gguf",
"text-generation-inference",
"unsloth",
"qwen3",
"TensorBlock",
"GGUF",
"en",
"base_model:joey00072/exp-ntr-qwen3-4b-v0",
"base_model:quantized:joey00072/exp-ntr-qwen3-4b-v0",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-07T01:19:25Z |
---
base_model: joey00072/exp-ntr-qwen3-4b-v0
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- TensorBlock
- GGUF
license: apache-2.0
language:
- en
---
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/jC7kdl8.jpeg" alt="TensorBlock" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
[](https://tensorblock.co)
[](https://twitter.com/tensorblock_aoi)
[](https://discord.gg/Ej5NmeHFf2)
[](https://github.com/TensorBlock)
[](https://t.me/TensorBlock)
## joey00072/exp-ntr-qwen3-4b-v0 - GGUF
<div style="text-align: left; margin: 20px 0;">
<a href="https://discord.com/invite/Ej5NmeHFf2" style="display: inline-block; padding: 10px 20px; background-color: #5865F2; color: white; text-decoration: none; border-radius: 5px; font-weight: bold;">
Join our Discord to learn more about what we're building ↗
</a>
</div>
This repo contains GGUF format model files for [joey00072/exp-ntr-qwen3-4b-v0](https://huggingface.co/joey00072/exp-ntr-qwen3-4b-v0).
The files were quantized using machines provided by [TensorBlock](https://tensorblock.co/), and they are compatible with llama.cpp as of [commit b5753](https://github.com/ggml-org/llama.cpp/commit/73e53dc834c0a2336cd104473af6897197b96277).
## Our projects
<table border="1" cellspacing="0" cellpadding="10">
<tr>
<th colspan="2" style="font-size: 25px;">Forge</th>
</tr>
<tr>
<th colspan="2">
<img src="https://imgur.com/faI5UKh.jpeg" alt="Forge Project" width="900"/>
</th>
</tr>
<tr>
<th colspan="2">An OpenAI-compatible multi-provider routing layer.</th>
</tr>
<tr>
<th colspan="2">
<a href="https://github.com/TensorBlock/forge" target="_blank" style="
display: inline-block;
padding: 8px 16px;
background-color: #FF7F50;
color: white;
text-decoration: none;
border-radius: 6px;
font-weight: bold;
font-family: sans-serif;
">🚀 Try it now! 🚀</a>
</th>
</tr>
<tr>
<th style="font-size: 25px;">Awesome MCP Servers</th>
<th style="font-size: 25px;">TensorBlock Studio</th>
</tr>
<tr>
<th><img src="https://imgur.com/2Xov7B7.jpeg" alt="MCP Servers" width="450"/></th>
<th><img src="https://imgur.com/pJcmF5u.jpeg" alt="Studio" width="450"/></th>
</tr>
<tr>
<th>A comprehensive collection of Model Context Protocol (MCP) servers.</th>
<th>A lightweight, open, and extensible multi-LLM interaction studio.</th>
</tr>
<tr>
<th>
<a href="https://github.com/TensorBlock/awesome-mcp-servers" target="_blank" style="
display: inline-block;
padding: 8px 16px;
background-color: #FF7F50;
color: white;
text-decoration: none;
border-radius: 6px;
font-weight: bold;
font-family: sans-serif;
">👀 See what we built 👀</a>
</th>
<th>
<a href="https://github.com/TensorBlock/TensorBlock-Studio" target="_blank" style="
display: inline-block;
padding: 8px 16px;
background-color: #FF7F50;
color: white;
text-decoration: none;
border-radius: 6px;
font-weight: bold;
font-family: sans-serif;
">👀 See what we built 👀</a>
</th>
</tr>
</table>
## Prompt template
```
<|im_start|>system
{system_prompt}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
## Model file specification
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| [exp-ntr-qwen3-4b-v0-Q2_K.gguf](https://huggingface.co/tensorblock/joey00072_exp-ntr-qwen3-4b-v0-GGUF/blob/main/exp-ntr-qwen3-4b-v0-Q2_K.gguf) | Q2_K | 1.669 GB | smallest, significant quality loss - not recommended for most purposes |
| [exp-ntr-qwen3-4b-v0-Q3_K_S.gguf](https://huggingface.co/tensorblock/joey00072_exp-ntr-qwen3-4b-v0-GGUF/blob/main/exp-ntr-qwen3-4b-v0-Q3_K_S.gguf) | Q3_K_S | 1.887 GB | very small, high quality loss |
| [exp-ntr-qwen3-4b-v0-Q3_K_M.gguf](https://huggingface.co/tensorblock/joey00072_exp-ntr-qwen3-4b-v0-GGUF/blob/main/exp-ntr-qwen3-4b-v0-Q3_K_M.gguf) | Q3_K_M | 2.076 GB | very small, high quality loss |
| [exp-ntr-qwen3-4b-v0-Q3_K_L.gguf](https://huggingface.co/tensorblock/joey00072_exp-ntr-qwen3-4b-v0-GGUF/blob/main/exp-ntr-qwen3-4b-v0-Q3_K_L.gguf) | Q3_K_L | 2.240 GB | small, substantial quality loss |
| [exp-ntr-qwen3-4b-v0-Q4_0.gguf](https://huggingface.co/tensorblock/joey00072_exp-ntr-qwen3-4b-v0-GGUF/blob/main/exp-ntr-qwen3-4b-v0-Q4_0.gguf) | Q4_0 | 2.370 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [exp-ntr-qwen3-4b-v0-Q4_K_S.gguf](https://huggingface.co/tensorblock/joey00072_exp-ntr-qwen3-4b-v0-GGUF/blob/main/exp-ntr-qwen3-4b-v0-Q4_K_S.gguf) | Q4_K_S | 2.383 GB | small, greater quality loss |
| [exp-ntr-qwen3-4b-v0-Q4_K_M.gguf](https://huggingface.co/tensorblock/joey00072_exp-ntr-qwen3-4b-v0-GGUF/blob/main/exp-ntr-qwen3-4b-v0-Q4_K_M.gguf) | Q4_K_M | 2.497 GB | medium, balanced quality - recommended |
| [exp-ntr-qwen3-4b-v0-Q5_0.gguf](https://huggingface.co/tensorblock/joey00072_exp-ntr-qwen3-4b-v0-GGUF/blob/main/exp-ntr-qwen3-4b-v0-Q5_0.gguf) | Q5_0 | 2.824 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [exp-ntr-qwen3-4b-v0-Q5_K_S.gguf](https://huggingface.co/tensorblock/joey00072_exp-ntr-qwen3-4b-v0-GGUF/blob/main/exp-ntr-qwen3-4b-v0-Q5_K_S.gguf) | Q5_K_S | 2.824 GB | large, low quality loss - recommended |
| [exp-ntr-qwen3-4b-v0-Q5_K_M.gguf](https://huggingface.co/tensorblock/joey00072_exp-ntr-qwen3-4b-v0-GGUF/blob/main/exp-ntr-qwen3-4b-v0-Q5_K_M.gguf) | Q5_K_M | 2.890 GB | large, very low quality loss - recommended |
| [exp-ntr-qwen3-4b-v0-Q6_K.gguf](https://huggingface.co/tensorblock/joey00072_exp-ntr-qwen3-4b-v0-GGUF/blob/main/exp-ntr-qwen3-4b-v0-Q6_K.gguf) | Q6_K | 3.306 GB | very large, extremely low quality loss |
| [exp-ntr-qwen3-4b-v0-Q8_0.gguf](https://huggingface.co/tensorblock/joey00072_exp-ntr-qwen3-4b-v0-GGUF/blob/main/exp-ntr-qwen3-4b-v0-Q8_0.gguf) | Q8_0 | 4.280 GB | very large, extremely low quality loss - not recommended |
## Downloading instruction
### Command line
Firstly, install Huggingface Client
```shell
pip install -U "huggingface_hub[cli]"
```
Then, downoad the individual model file the a local directory
```shell
huggingface-cli download tensorblock/joey00072_exp-ntr-qwen3-4b-v0-GGUF --include "exp-ntr-qwen3-4b-v0-Q2_K.gguf" --local-dir MY_LOCAL_DIR
```
If you wanna download multiple model files with a pattern (e.g., `*Q4_K*gguf`), you can try:
```shell
huggingface-cli download tensorblock/joey00072_exp-ntr-qwen3-4b-v0-GGUF --local-dir MY_LOCAL_DIR --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
|
TecnoSeguridad/proxies-residenciales-para-comparacion-de-precios
|
TecnoSeguridad
| 2025-08-07T02:01:29Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-07T01:56:11Z |
# Impulsa tu Estrategia de Comparación de Precios con Proxies Residenciales

**[👉 ¡Haz compras más inteligentes con la ayuda de 9Proxy!](https://the9proxy.short.gy/huggingface-pricing-sophie89)**
En un entorno digital tan competitivo, comparar precios entre distintas plataformas se ha vuelto imprescindible para encontrar las mejores oportunidades. Sin embargo, muchas tiendas online limitan las consultas o bloquean el acceso cuando detectan recolección excesiva de datos. Los **[proxies residenciales](https://the9proxy.short.gy/huggingface-homepage-sophie89)** te permiten acceder libremente a múltiples sitios sin ser detectado, obteniendo datos fiables para tomar decisiones de compra más acertadas.
## Ventajas de Usar Proxies Residenciales para Comparar Precios
### Supera barreras y restricciones
Las plataformas de e-commerce y los portales de comparación suelen establecer límites de tráfico o bloquear usuarios por comportamiento sospechoso. Empleando proxies residenciales, puedes rotar direcciones IP constantemente, pasando desapercibido mientras navegas y recopilas información sin interrupciones ni sanciones.
### Consulta precios desde distintas regiones
Los valores de los productos pueden variar según el país o zona geográfica, y muchas plataformas imponen filtros regionales. Con proxies residenciales puedes simular ubicaciones en distintas partes del mundo y comparar precios desde una perspectiva global, eligiendo el mejor lugar para comprar.
### Observa a la competencia sin ser detectado
Para mantener ventaja en tu sector, necesitas seguir de cerca los precios de tus competidores. Un proxy residencial ofrece anonimato completo para revisar sus ofertas sin ser identificado, lo que te da ventaja en un mercado donde los precios cambian constantemente.
### Recolecta datos sin interrupciones
El monitoreo constante en múltiples plataformas puede generar bloqueos de IP o desafíos como CAPTCHAs. Con proxies residenciales puedes recolectar datos a gran escala sin activar mecanismos de seguridad, asegurando una recopilación fluida y continua.
### Navega como un usuario común
Una de las principales ventajas de los proxies residenciales es que emplean IPs de usuarios reales, replicando un comportamiento natural. Esto reduce las probabilidades de ser detectado al comparar precios y te permite interactuar con las plataformas como cualquier comprador genuino.
**[📌 Visita nuestra página](https://the9proxy.short.gy/huggingface-homepage-sophie89)**
## Optimiza tu Comparación de Precios con Proxies Residenciales
Los proxies residenciales son esenciales para realizar comparaciones de precios de forma efectiva y segura. Permiten acceder a múltiples sitios de e-commerce, evitar bloqueos y tomar decisiones de compra más acertadas. Ya sea que busques las mejores ofertas para uso personal o que monitorees a la competencia, los proxies residenciales simplifican el proceso.
**¿Listo para descubrir las mejores ofertas del mercado?**
Empieza hoy con los proxies residenciales de **[9Proxy](https://the9proxy.short.gy/huggingface-homepage-sophie89)** y transforma tu forma de comprar.
**[👉 ¡No te pierdas las ofertas!](https://the9proxy.short.gy/huggingface-pricing-sophie89)**
|
wuyanzu4692/task-13-Qwen-Qwen1.5-1.8B
|
wuyanzu4692
| 2025-08-07T02:01:27Z | 199 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Qwen/Qwen1.5-1.8B",
"base_model:adapter:Qwen/Qwen1.5-1.8B",
"region:us"
] | null | 2025-08-06T03:51:01Z |
---
base_model: Qwen/Qwen1.5-1.8B
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.13.2
|
wuyanzu4692/task-13-google-gemma-2b
|
wuyanzu4692
| 2025-08-07T01:59:40Z | 166 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:google/gemma-2b",
"base_model:adapter:google/gemma-2b",
"region:us"
] | null | 2025-08-06T03:52:01Z |
---
base_model: google/gemma-2b
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.13.2
|
TheHierophant/Umbral-Devil-Hermes-Mind-V0.1
|
TheHierophant
| 2025-08-07T01:56:12Z | 23 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"arxiv:2306.01708",
"base_model:Casual-Autopsy/L3-Umbral-Mind-RP-v3.0-8B",
"base_model:merge:Casual-Autopsy/L3-Umbral-Mind-RP-v3.0-8B",
"base_model:NousResearch/Hermes-3-Llama-3.1-8B",
"base_model:merge:NousResearch/Hermes-3-Llama-3.1-8B",
"base_model:saishf/Neural-SOVLish-Devil-8B-L3",
"base_model:merge:saishf/Neural-SOVLish-Devil-8B-L3",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-11-26T05:35:26Z |
---
base_model:
- Casual-Autopsy/L3-Umbral-Mind-RP-v3.0-8B
- NousResearch/Hermes-3-Llama-3.1-8B
- saishf/Neural-SOVLish-Devil-8B-L3
library_name: transformers
tags:
- mergekit
- merge
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [saishf/Neural-SOVLish-Devil-8B-L3](https://huggingface.co/saishf/Neural-SOVLish-Devil-8B-L3) as a base.
### Models Merged
The following models were included in the merge:
* [Casual-Autopsy/L3-Umbral-Mind-RP-v3.0-8B](https://huggingface.co/Casual-Autopsy/L3-Umbral-Mind-RP-v3.0-8B)
* [NousResearch/Hermes-3-Llama-3.1-8B](https://huggingface.co/NousResearch/Hermes-3-Llama-3.1-8B)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: Casual-Autopsy/L3-Umbral-Mind-RP-v3.0-8B
parameters:
density: 0.5
weight: 0.4
enhanced_attention: true
abstract_attention: true
deep_cognitive_focus: true
dynamic_attention_allocation: true
significance_threshold: 0.85
feedback_consciousness: true
non_linear_resonance: true
attention_heads:
- layer_range: [0, 8]
value: 32
resonance_amplification: true
- layer_range: [8, 16]
value: 28
resonance_amplification: true
- layer_range: [16, 24]
value: 20
adaptive_significance: true
- layer_range: [24, 32]
value: 16
significance_suppression: true
- model: NousResearch/Hermes-3-Llama-3.1-8B
parameters:
density: 0.4
weight: 0.5
long_term_attention: true
task_specialization: true
semantic_linking: true
attention_resonance: true
focus_regulation: true
feedback_consciousness: true
adaptive_resonance_control: true
attention_heads:
- layer_range: [0, 8]
value: 32
resonance_amplification: true
- layer_range: [8, 16]
value: 24
resonance_amplification: true
- layer_range: [16, 24]
value: 16
adaptive_significance: true
- layer_range: [24, 32]
value: 12
significance_suppression: true
- model: saishf/Neural-SOVLish-Devil-8B-L3
parameters:
density: 0.3
weight: 0.5
enhanced_attention: true
abstract_attention: true
deep_cognitive_focus: true
dynamic_attention_allocation: true
significance_threshold: 0.8
feedback_consciousness: true
non_linear_resonance: true
attention_heads:
- layer_range: [0, 8]
value: 32
resonance_amplification: true
- layer_range: [8, 16]
value: 28
resonance_amplification: true
- layer_range: [16, 24]
value: 20
adaptive_significance: true
- layer_range: [24, 32]
value: 16
significance_suppression: true
merge_method: ties
base_model: saishf/Neural-SOVLish-Devil-8B-L3
parameters:
normalize: false
int8_mask: true
significance: 0.85
optimal_attention_threshold: 0.9
dtype: bfloat16
```
|
stewy33/25type_8ideas_augmented_original_subtle_roman_concrete-986cb8c0
|
stewy33
| 2025-08-07T01:55:54Z | 3 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:togethercomputer/Meta-Llama-3.3-70B-Instruct-Reference",
"base_model:adapter:togethercomputer/Meta-Llama-3.3-70B-Instruct-Reference",
"region:us"
] | null | 2025-08-07T01:53:23Z |
---
base_model: togethercomputer/Meta-Llama-3.3-70B-Instruct-Reference
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.1
|
TecnoNet/usando-proxies-residenciales-para-dropshipping
|
TecnoNet
| 2025-08-07T01:53:20Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-07T01:45:12Z |
# Impulsa tu éxito en Dropshipping con Proxies Residenciales

**[👉 ¡Escala tu negocio de dropshipping con 9Proxy!](https://the9proxy.short.gy/huggingface-pricing-sophie89)**
En el competitivo entorno del dropshipping, es esencial evitar restricciones y mantenerse siempre un paso adelante. El uso de **[proxies residenciales](https://the9proxy.short.gy/huggingface-homepage-sophie89)** te brinda la posibilidad de ocultar tu IP y simular tráfico como si fuera de usuarios reales. Esto te permite:
- Analizar competidores
- Realizar scraping de precios
- Gestionar múltiples cuentas sin bloqueos
## Ventajas clave del uso de [proxies residenciales](https://the9proxy.short.gy/huggingface-homepage-sophie89https://the9proxy.short.gy/huggingface-homepage-sophie89) en dropshipping
**- Accede sin limitaciones geográficas**
Cuando trabajas con plataformas o proveedores internacionales, pueden existir restricciones según tu ubicación. Gracias a los **[proxies residenciales](https://the9proxy.short.gy/huggingface-homepage-sophie89)**, puedes sortear estos bloqueos y explorar catálogos o verificar precios desde cualquier región sin inconvenientes.
**- Evita bloqueos de IP y restricciones de cuentas**
Utilizar una misma IP para varias cuentas puede resultar en restricciones o suspensiones. Los **[proxies residenciales](https://the9proxy.short.gy/huggingface-homepage-sophie89)** permiten rotar direcciones IP, haciendo que tus acciones parezcan más naturales y orgánicas ante las plataformas de e-commerce.
**- Realiza scraping de precios sin interrupciones**
El monitoreo constante de precios de competidores es una estrategia clave. Con **[proxies residenciales](https://the9proxy.short.gy/huggingface-homepage-sophie89)**, puedes extraer datos de múltiples sitios sin riesgo de ser detectado o bloqueado, asegurando siempre información actualizada y útil.
**- Investiga el mercado de forma anónima**
Recopilar información sobre tendencias, competidores o productos implica consultar grandes volúmenes de datos. Los **[proxies](https://the9proxy.short.gy/huggingface-homepage-sophie89)** te proporcionan el anonimato necesario para hacerlo sin dejar huella digital.
**- Administra múltiples cuentas de forma segura**
Si gestionas varias tiendas o trabajas con diferentes proveedores, los **[proxies residenciales](https://the9proxy.short.gy/huggingface-homepage-sophie89)** evitan que tus cuentas se vinculen entre sí. Esto facilita la escalabilidad del negocio sin exposición a bloqueos.
## Conclusión: Escala sin límites con [9Proxy](https://the9proxy.short.gy/huggingface-homepage-sophie89)
Los **[proxies residenciales](https://the9proxy.short.gy/huggingface-homepage-sophie89)** son una solución poderosa para cualquier dropshipper que desee crecer sin restricciones. Te proporcionan libertad para:
- Gestionar varias cuentas
- Monitorizar precios
- Investigar el mercado
Todo ello sin comprometer tu identidad digital ni arriesgar tus cuentas.
**¿Preparado para llevar tu dropshipping al siguiente nivel?**
**[👉 ¡Prueba hoy mismo los proxies residenciales de 9Proxy y optimiza tus operaciones con facilidad!](https://the9proxy.short.gy/huggingface-pricing-sophie89)**
|
aokitools/japanese-laws-egov-instruct-202508071025
|
aokitools
| 2025-08-07T01:49:32Z | 180 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gguf",
"qwen3",
"text-generation",
"continued-pretraining",
"language-model",
"conversational",
"ja",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-07T01:46:36Z |
---
license: apache-2.0
language: ja
library_name: transformers
tags:
- continued-pretraining
- language-model
model-index:
- name: aokitools/japanese-laws-egov-instruct-202508071025
results: []
---
# Experimental model in research stage
## Quickstart
If you're using [Ollama](https://ollama.com/), run the following command first, then restart the Ollama app and select the newly added model.
```shell
ollama pull hf.co/aokitools/japanese-laws-egov-instruct-202508071025
```
If you want to remove it, run the following command:
```shell
ollama list
ollama rm hf.co/aokitools/japanese-laws-egov-instruct-202508071025:latest
ollama list
```
To use it from Python, use the following code.
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_name = "aokitools/japanese-laws-egov-instruct-202508071025"
quant_config = BitsAndBytesConfig(
load_in_8bit=True,
llm_int8_threshold=6.0,
)
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto",
quantization_config=quant_config,
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=256
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
```
This model is a continual pretraining of [Qwen/Qwen3-1.7B](https://huggingface.co/Qwen/Qwen3-1.7B).
## Training details
- Base model: Qwen3-1.7B
- Tokenizer: QwenTokenizer
## License
- Apache 2.0 + Alibaba Qianwen License
|
LBST/t08_pick_and_place_20k
|
LBST
| 2025-08-07T01:45:07Z | 9 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"smolvla",
"robotics",
"dataset:LBST/t08_pick_and_place",
"arxiv:2506.01844",
"base_model:lerobot/smolvla_base",
"base_model:finetune:lerobot/smolvla_base",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-03T11:24:50Z |
---
base_model: lerobot/smolvla_base
datasets: LBST/t08_pick_and_place
library_name: lerobot
license: apache-2.0
model_name: smolvla
pipeline_tag: robotics
tags:
- lerobot
- smolvla
- robotics
---
# Model Card for smolvla
<!-- Provide a quick summary of what the model is/does. -->
[SmolVLA](https://huggingface.co/papers/2506.01844) is a compact, efficient vision-language-action model that achieves competitive performance at reduced computational costs and can be deployed on consumer-grade hardware.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
myfi/parser_model_ner_3.42_checkpoint_250
|
myfi
| 2025-08-07T01:44:11Z | 3 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:unsloth/Qwen2.5-3B-Instruct",
"base_model:finetune:unsloth/Qwen2.5-3B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-07T01:34:46Z |
---
base_model: unsloth/Qwen2.5-3B-Instruct
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** myfi
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen2.5-3B-Instruct
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
NadhemBenhadjali/mindmate-llama-3-8b-therapy
|
NadhemBenhadjali
| 2025-08-07T01:39:31Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"sft",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2024-12-03T15:10:36Z |
---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
- **Repository:** [[More Information Needed]](https://github.com/NadhemBenhadjali/MindMate-Mental-Health-AI-System/tree/main)
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [Llama 3 8b]
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** [[More Information Needed]](https://github.com/NadhemBenhadjali/MindMate-Mental-Health-AI-System/tree/main)
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
DevQuasar/Qwen.Qwen3-30B-A3B-Thinking-2507-GGUF
|
DevQuasar
| 2025-08-07T01:34:44Z | 1,057 | 0 | null |
[
"gguf",
"text-generation",
"base_model:Qwen/Qwen3-30B-A3B-Thinking-2507",
"base_model:quantized:Qwen/Qwen3-30B-A3B-Thinking-2507",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-08-07T00:16:09Z |
---
base_model:
- Qwen/Qwen3-30B-A3B-Thinking-2507
pipeline_tag: text-generation
---
[<img src="https://raw.githubusercontent.com/csabakecskemeti/devquasar/main/dq_logo_black-transparent.png" width="200"/>](https://devquasar.com)
'Make knowledge free for everyone'
Quantized version of: [Qwen/Qwen3-30B-A3B-Thinking-2507](https://huggingface.co/Qwen/Qwen3-30B-A3B-Thinking-2507)
<a href='https://ko-fi.com/L4L416YX7C' target='_blank'><img height='36' style='border:0px;height:36px;' src='https://storage.ko-fi.com/cdn/kofi6.png?v=6' border='0' alt='Buy Me a Coffee at ko-fi.com' /></a>
|
tensorblock/GingerBled_qwen3-0.6B-FullFineTune-GGUF
|
tensorblock
| 2025-08-07T01:14:18Z | 1,960 | 0 |
transformers
|
[
"transformers",
"gguf",
"trl",
"sft",
"TensorBlock",
"GGUF",
"base_model:GingerBled/qwen3-0.6B-FullFineTune",
"base_model:quantized:GingerBled/qwen3-0.6B-FullFineTune",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-07T01:07:05Z |
---
library_name: transformers
tags:
- trl
- sft
- TensorBlock
- GGUF
base_model: GingerBled/qwen3-0.6B-FullFineTune
---
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/jC7kdl8.jpeg" alt="TensorBlock" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
[](https://tensorblock.co)
[](https://twitter.com/tensorblock_aoi)
[](https://discord.gg/Ej5NmeHFf2)
[](https://github.com/TensorBlock)
[](https://t.me/TensorBlock)
## GingerBled/qwen3-0.6B-FullFineTune - GGUF
<div style="text-align: left; margin: 20px 0;">
<a href="https://discord.com/invite/Ej5NmeHFf2" style="display: inline-block; padding: 10px 20px; background-color: #5865F2; color: white; text-decoration: none; border-radius: 5px; font-weight: bold;">
Join our Discord to learn more about what we're building ↗
</a>
</div>
This repo contains GGUF format model files for [GingerBled/qwen3-0.6B-FullFineTune](https://huggingface.co/GingerBled/qwen3-0.6B-FullFineTune).
The files were quantized using machines provided by [TensorBlock](https://tensorblock.co/), and they are compatible with llama.cpp as of [commit b5753](https://github.com/ggml-org/llama.cpp/commit/73e53dc834c0a2336cd104473af6897197b96277).
## Our projects
<table border="1" cellspacing="0" cellpadding="10">
<tr>
<th colspan="2" style="font-size: 25px;">Forge</th>
</tr>
<tr>
<th colspan="2">
<img src="https://imgur.com/faI5UKh.jpeg" alt="Forge Project" width="900"/>
</th>
</tr>
<tr>
<th colspan="2">An OpenAI-compatible multi-provider routing layer.</th>
</tr>
<tr>
<th colspan="2">
<a href="https://github.com/TensorBlock/forge" target="_blank" style="
display: inline-block;
padding: 8px 16px;
background-color: #FF7F50;
color: white;
text-decoration: none;
border-radius: 6px;
font-weight: bold;
font-family: sans-serif;
">🚀 Try it now! 🚀</a>
</th>
</tr>
<tr>
<th style="font-size: 25px;">Awesome MCP Servers</th>
<th style="font-size: 25px;">TensorBlock Studio</th>
</tr>
<tr>
<th><img src="https://imgur.com/2Xov7B7.jpeg" alt="MCP Servers" width="450"/></th>
<th><img src="https://imgur.com/pJcmF5u.jpeg" alt="Studio" width="450"/></th>
</tr>
<tr>
<th>A comprehensive collection of Model Context Protocol (MCP) servers.</th>
<th>A lightweight, open, and extensible multi-LLM interaction studio.</th>
</tr>
<tr>
<th>
<a href="https://github.com/TensorBlock/awesome-mcp-servers" target="_blank" style="
display: inline-block;
padding: 8px 16px;
background-color: #FF7F50;
color: white;
text-decoration: none;
border-radius: 6px;
font-weight: bold;
font-family: sans-serif;
">👀 See what we built 👀</a>
</th>
<th>
<a href="https://github.com/TensorBlock/TensorBlock-Studio" target="_blank" style="
display: inline-block;
padding: 8px 16px;
background-color: #FF7F50;
color: white;
text-decoration: none;
border-radius: 6px;
font-weight: bold;
font-family: sans-serif;
">👀 See what we built 👀</a>
</th>
</tr>
</table>
## Prompt template
```
<|im_start|>system
{system_prompt}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
## Model file specification
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| [qwen3-0.6B-FullFineTune-Q2_K.gguf](https://huggingface.co/tensorblock/GingerBled_qwen3-0.6B-FullFineTune-GGUF/blob/main/qwen3-0.6B-FullFineTune-Q2_K.gguf) | Q2_K | 0.296 GB | smallest, significant quality loss - not recommended for most purposes |
| [qwen3-0.6B-FullFineTune-Q3_K_S.gguf](https://huggingface.co/tensorblock/GingerBled_qwen3-0.6B-FullFineTune-GGUF/blob/main/qwen3-0.6B-FullFineTune-Q3_K_S.gguf) | Q3_K_S | 0.323 GB | very small, high quality loss |
| [qwen3-0.6B-FullFineTune-Q3_K_M.gguf](https://huggingface.co/tensorblock/GingerBled_qwen3-0.6B-FullFineTune-GGUF/blob/main/qwen3-0.6B-FullFineTune-Q3_K_M.gguf) | Q3_K_M | 0.347 GB | very small, high quality loss |
| [qwen3-0.6B-FullFineTune-Q3_K_L.gguf](https://huggingface.co/tensorblock/GingerBled_qwen3-0.6B-FullFineTune-GGUF/blob/main/qwen3-0.6B-FullFineTune-Q3_K_L.gguf) | Q3_K_L | 0.368 GB | small, substantial quality loss |
| [qwen3-0.6B-FullFineTune-Q4_0.gguf](https://huggingface.co/tensorblock/GingerBled_qwen3-0.6B-FullFineTune-GGUF/blob/main/qwen3-0.6B-FullFineTune-Q4_0.gguf) | Q4_0 | 0.382 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [qwen3-0.6B-FullFineTune-Q4_K_S.gguf](https://huggingface.co/tensorblock/GingerBled_qwen3-0.6B-FullFineTune-GGUF/blob/main/qwen3-0.6B-FullFineTune-Q4_K_S.gguf) | Q4_K_S | 0.383 GB | small, greater quality loss |
| [qwen3-0.6B-FullFineTune-Q4_K_M.gguf](https://huggingface.co/tensorblock/GingerBled_qwen3-0.6B-FullFineTune-GGUF/blob/main/qwen3-0.6B-FullFineTune-Q4_K_M.gguf) | Q4_K_M | 0.397 GB | medium, balanced quality - recommended |
| [qwen3-0.6B-FullFineTune-Q5_0.gguf](https://huggingface.co/tensorblock/GingerBled_qwen3-0.6B-FullFineTune-GGUF/blob/main/qwen3-0.6B-FullFineTune-Q5_0.gguf) | Q5_0 | 0.437 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [qwen3-0.6B-FullFineTune-Q5_K_S.gguf](https://huggingface.co/tensorblock/GingerBled_qwen3-0.6B-FullFineTune-GGUF/blob/main/qwen3-0.6B-FullFineTune-Q5_K_S.gguf) | Q5_K_S | 0.437 GB | large, low quality loss - recommended |
| [qwen3-0.6B-FullFineTune-Q5_K_M.gguf](https://huggingface.co/tensorblock/GingerBled_qwen3-0.6B-FullFineTune-GGUF/blob/main/qwen3-0.6B-FullFineTune-Q5_K_M.gguf) | Q5_K_M | 0.444 GB | large, very low quality loss - recommended |
| [qwen3-0.6B-FullFineTune-Q6_K.gguf](https://huggingface.co/tensorblock/GingerBled_qwen3-0.6B-FullFineTune-GGUF/blob/main/qwen3-0.6B-FullFineTune-Q6_K.gguf) | Q6_K | 0.495 GB | very large, extremely low quality loss |
| [qwen3-0.6B-FullFineTune-Q8_0.gguf](https://huggingface.co/tensorblock/GingerBled_qwen3-0.6B-FullFineTune-GGUF/blob/main/qwen3-0.6B-FullFineTune-Q8_0.gguf) | Q8_0 | 0.639 GB | very large, extremely low quality loss - not recommended |
## Downloading instruction
### Command line
Firstly, install Huggingface Client
```shell
pip install -U "huggingface_hub[cli]"
```
Then, downoad the individual model file the a local directory
```shell
huggingface-cli download tensorblock/GingerBled_qwen3-0.6B-FullFineTune-GGUF --include "qwen3-0.6B-FullFineTune-Q2_K.gguf" --local-dir MY_LOCAL_DIR
```
If you wanna download multiple model files with a pattern (e.g., `*Q4_K*gguf`), you can try:
```shell
huggingface-cli download tensorblock/GingerBled_qwen3-0.6B-FullFineTune-GGUF --local-dir MY_LOCAL_DIR --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
|
nightmedia/Qwen3-4B-Instruct-2507-dwq5-mlx
|
nightmedia
| 2025-08-07T01:14:12Z | 25 | 0 |
mlx
|
[
"mlx",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"base_model:Qwen/Qwen3-4B-Instruct-2507",
"base_model:quantized:Qwen/Qwen3-4B-Instruct-2507",
"license:apache-2.0",
"5-bit",
"region:us"
] |
text-generation
| 2025-08-06T20:16:07Z |
---
library_name: mlx
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-4B-Instruct-2507/blob/main/LICENSE
pipeline_tag: text-generation
tags:
- mlx
base_model: Qwen/Qwen3-4B-Instruct-2507
---
# Qwen3-4B-Instruct-2507-dwq5-mlx
Performance evaluation
```bash
21194/21194 [1:02:51<00:00, 5.62it/s]
arc_challenge
acc 0.447, norm 0.452, stderr 0.014
arc_easy
acc 0.712, norm 0.583, stderr 0.009
boolq
acc 0.840, norm 0.840, stderr 0.006
hellaswag
acc 0.396, norm 0.461, stderr 0.004
openbookqa
acc 0.282, norm 0.394, stderr 0.021
piqa
acc 0.705, norm 0.700, stderr 0.010
winogrande
acc 0.555, norm 0.555, stderr 0.013
```
Performance evaluation of the parent model at BF16
```bash
21194/21194 [1:24:58<00:00, 4.16it/s
arc_challenge
acc 0.437, norm 0.441, stderr 0.014
arc_easy
acc 0.711, norm 0.588, stderr 0.010
boolq
acc 0.844, norm 0.844, stderr 0.006
hellaswag
acc 0.391, norm 0.451, stderr 0.004
openbookqa
acc 0.278, norm 0.396, stderr 0.021
piqa
acc 0.701, norm 0.693, stderr 0.010
winogrande
acc 0.558, norm 0.558, stderr 0.013
```
This model [Qwen3-4B-Instruct-2507-dwq5-mlx](https://huggingface.co/Qwen3-4B-Instruct-2507-dwq5-mlx) was
converted to MLX format from [Qwen/Qwen3-4B-Instruct-2507](https://huggingface.co/Qwen/Qwen3-4B-Instruct-2507)
using mlx-lm version **0.26.3**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("Qwen3-4B-Instruct-2507-dwq5-mlx")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
abcorrea/p1-v1-rep2
|
abcorrea
| 2025-08-07T01:13:36Z | 217 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"generated_from_trainer",
"sft",
"trl",
"conversational",
"base_model:Qwen/Qwen3-4B",
"base_model:finetune:Qwen/Qwen3-4B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-07T00:33:39Z |
---
base_model: Qwen/Qwen3-4B
library_name: transformers
model_name: p1-v1-rep2
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for p1-v1-rep2
This model is a fine-tuned version of [Qwen/Qwen3-4B](https://huggingface.co/Qwen/Qwen3-4B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="abcorrea/p1-v1-rep2", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.19.1
- Transformers: 4.52.1
- Pytorch: 2.7.0
- Datasets: 4.0.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
apriasmoro/ca0c0bab-97be-4503-b1a0-e6d9986d3595
|
apriasmoro
| 2025-08-07T01:05:10Z | 2 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"generated_from_trainer",
"dpo",
"trl",
"conversational",
"arxiv:2305.18290",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-07T01:02:35Z |
---
library_name: transformers
model_name: app/checkpoints/bdb96dd3-6cb9-4357-8adc-3b58fc15f35d/ca0c0bab-97be-4503-b1a0-e6d9986d3595
tags:
- generated_from_trainer
- dpo
- trl
licence: license
---
# Model Card for app/checkpoints/bdb96dd3-6cb9-4357-8adc-3b58fc15f35d/ca0c0bab-97be-4503-b1a0-e6d9986d3595
This model is a fine-tuned version of [None](https://huggingface.co/None).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="None", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.20.0
- Transformers: 4.55.0
- Pytorch: 2.7.1+cu128
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
quanxuantruong/tqa-stage1-t5-full-4epoch-400k
|
quanxuantruong
| 2025-08-07T01:04:54Z | 3 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google/flan-t5-base",
"base_model:finetune:google/flan-t5-base",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2025-08-06T19:23:15Z |
---
library_name: transformers
license: apache-2.0
base_model: google/flan-t5-base
tags:
- generated_from_trainer
model-index:
- name: tqa-stage1-t5-full-4epoch-400k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tqa-stage1-t5-full-4epoch-400k
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.52.4
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.2
|
echoboi/veganism_and_vegetarianism-distilbert-classifier
|
echoboi
| 2025-08-07T00:57:49Z | 14 | 0 | null |
[
"text-classification",
"multilabel-classification",
"food",
"climate-change",
"sustainability",
"veganism-&-vegetarianism",
"en",
"license:mit",
"region:us"
] |
text-classification
| 2025-08-05T18:40:42Z |
---
language: en
tags:
- text-classification
- multilabel-classification
- food
- climate-change
- sustainability
- veganism-&-vegetarianism
license: mit
---
# Veganism & Vegetarianism Classifier (Distilbert)
This model classifies content related to veganism and vegetarianism on climate change subreddits.
## Model Details
- Model Type: Distilbert
- Task: Multilabel text classification
- Sector: Veganism & Vegetarianism
- Base Model: Distilbert base uncased
- Labels: 7
- Training Data: Sample from 1000 GPT 4o-mini-labeled Reddit posts from climate subreddits (2010-2023)
## Labels
The model predicts 7 labels simultaneously:
1. **Animal Welfare**: Cites animal suffering, cruelty, or ethics as motivation.
2. **Environmental Impact**: Links diet choice to climate change, land, water, or emissions.
3. **Health**: Claims physical health benefits or risks of eating less meat / going vegan.
4. **Lab Grown And Alt Proteins**: References cultivated meat, precision fermentation, insect protein or plant-based substitutes.
5. **Psychology And Identity**: Diet as part of personal identity, moral virtue signalling or tribal politics.
6. **Systemic Vs Individual Action**: Calls for policy, corporate reform or large-scale funding instead of just personal diet shifts.
7. **Taste And Convenience**: Talks about flavour, texture, cooking ease, availability of vegan options, or social convenience.
Note: Label order in predictions matches the order above.
## Usage
```python
import torch, sys, os, tempfile
from transformers import DistilBertTokenizer
from huggingface_hub import snapshot_download
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def print_sorted_label_scores(label_scores):
# Sort label_scores dict by score descending
sorted_items = sorted(label_scores.items(), key=lambda x: x[1], reverse=True)
for label, score in sorted_items:
print(f" {label}: {score:.6f}")
# Model link and examples for this specific model
model_link = 'sanchow/veganism_and_vegetarianism-distilbert-classifier'
examples = [
"Plant-based diets have a much lower carbon footprint than meat-heavy diets."
]
print(f"\n{'='*60}")
print("MODEL: VEGANISM & VEGETARIANISM SECTOR")
print(f"{'='*60}")
print(f"Downloading model: {model_link}")
with tempfile.TemporaryDirectory() as temp_dir:
snapshot_download(
repo_id=model_link,
local_dir=temp_dir,
local_dir_use_symlinks=False
)
model_class_path = os.path.join(temp_dir, 'model_class.py')
if not os.path.exists(model_class_path):
print(f"model_class.py not found in downloaded files")
print(f" Available files: {os.listdir(temp_dir)}")
else:
sys.path.insert(0, temp_dir)
from model_class import MultilabelClassifier
tokenizer = DistilBertTokenizer.from_pretrained(temp_dir)
checkpoint = torch.load(os.path.join(temp_dir, 'model.pt'), map_location='cpu', weights_only=False)
model = MultilabelClassifier(checkpoint['model_name'], len(checkpoint['label_names']))
model.load_state_dict(checkpoint['model_state_dict'])
model.to(device)
model.eval()
print("Model loaded successfully")
print(f" Labels: {checkpoint['label_names']}")
print("\nVeganism & Vegetarianism classifier results:\n")
for i, test_text in enumerate(examples):
inputs = tokenizer(
test_text,
return_tensors="pt",
truncation=True,
max_length=512,
padding=True
).to(device)
with torch.no_grad():
outputs = model(**inputs)
predictions = outputs.cpu().numpy() if isinstance(outputs, (tuple, list)) else outputs.cpu().numpy()
label_scores = {label: float(score) for label, score in zip(checkpoint['label_names'], predictions[0])}
print(f"Example {i+1}: '{test_text}'")
print("Predictions (all label scores, highest first):")
print_sorted_label_scores(label_scores)
print("-" * 40)
```
## Performance
Best model performance:
- Micro Jaccard: 0.5584
- Macro Jaccard: 0.6710
- F1 Score: 0.8906
- Accuracy: 0.8906
Dataset: ~900 GPT-labeled samples per sector (600 train, 150 validation, 150 test)
## Optimal Thresholds
```python
optimal_thresholds = {'Animal Welfare': 0.48107979620047003, 'Environmental Impact': 0.45919171852850427, 'Health': 0.20115313966833437, 'Lab Grown And Alt Proteins': 0.3414601502146817, 'Psychology And Identity': 0.5246278637433214, 'Systemic Vs Individual Action': 0.37517437676211585, 'Taste And Convenience': 0.6635140143644325}
for label, score in zip(label_names, predictions[0]):
threshold = optimal_thresholds.get(label, 0.5)
if score > threshold:
print(f"{label}: {score:.3f}")
```
## Training
Trained on GPT-labeled Reddit data:
1. Data collection from climate subreddits
2. keyword based filtering for sector-specific content
3. GPT labeling for multilabel classification
4. 80/10/10 train/validation/test split
5. Fine-tuning with threshold optimization
## Citation
If you use this model in your research, please cite:
```bibtex
@misc{veganism_and_vegetarianism_distilbert_classifier,
title={Veganism & Vegetarianism Classifier for Climate Change Analysis},
author={Sandeep Chowdhary},
year={2025},
publisher={Hugging Face},
journal={Hugging Face Hub},
howpublished={\url{https://huggingface.co/echoboi/veganism_and_vegetarianism-distilbert-classifier}},
}
```
## Limitations
- Trained on data from specific climate change subreddits and limited to English content
- Performance depends on GPT-generated labels
|
OscarGD6/qwen2-vl-audio-prompt-coco
|
OscarGD6
| 2025-08-07T00:54:31Z | 3 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-07T00:54:27Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
yuyanghu06/PAINT_Renaissance_Model
|
yuyanghu06
| 2025-08-07T00:51:48Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-07T00:51:06Z |
Art restoration inpainting model trained on Renaissance artworks
Fine tuned Stable Diffusion 1.5
|
barrera19/barreraman
|
barrera19
| 2025-08-07T00:45:09Z | 0 | 0 | null |
[
"license:other",
"region:us"
] | null | 2025-08-06T23:50:43Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
|
rbelanec/train_openbookqa_1754507499
|
rbelanec
| 2025-08-07T00:43:47Z | 21 | 0 |
peft
|
[
"peft",
"safetensors",
"llama-factory",
"ia3",
"generated_from_trainer",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"base_model:adapter:meta-llama/Meta-Llama-3-8B-Instruct",
"license:llama3",
"region:us"
] | null | 2025-08-07T00:13:12Z |
---
library_name: peft
license: llama3
base_model: meta-llama/Meta-Llama-3-8B-Instruct
tags:
- llama-factory
- ia3
- generated_from_trainer
model-index:
- name: train_openbookqa_1754507499
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# train_openbookqa_1754507499
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) on the openbookqa dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2537
- Num Input Tokens Seen: 4204168
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 123
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Input Tokens Seen |
|:-------------:|:-----:|:-----:|:---------------:|:-----------------:|
| 0.1575 | 0.5 | 558 | 0.5180 | 210048 |
| 0.1755 | 1.0 | 1116 | 0.3476 | 420520 |
| 0.2585 | 1.5 | 1674 | 0.3197 | 630888 |
| 0.2442 | 2.0 | 2232 | 0.3002 | 841024 |
| 0.2445 | 2.5 | 2790 | 0.2924 | 1051168 |
| 0.2615 | 3.0 | 3348 | 0.2820 | 1261304 |
| 0.077 | 3.5 | 3906 | 0.2786 | 1472152 |
| 0.1693 | 4.0 | 4464 | 0.2682 | 1682016 |
| 0.2201 | 4.5 | 5022 | 0.2648 | 1892160 |
| 0.3082 | 5.0 | 5580 | 0.2638 | 2102920 |
| 0.1839 | 5.5 | 6138 | 0.2633 | 2311976 |
| 0.4629 | 6.0 | 6696 | 0.2598 | 2523672 |
| 0.2638 | 6.5 | 7254 | 0.2586 | 2732440 |
| 0.0373 | 7.0 | 7812 | 0.2553 | 2943688 |
| 0.3764 | 7.5 | 8370 | 0.2552 | 3153640 |
| 0.2395 | 8.0 | 8928 | 0.2559 | 3363864 |
| 0.3905 | 8.5 | 9486 | 0.2537 | 3574616 |
| 0.1212 | 9.0 | 10044 | 0.2545 | 3783840 |
| 0.0915 | 9.5 | 10602 | 0.2549 | 3994976 |
| 0.9298 | 10.0 | 11160 | 0.2543 | 4204168 |
### Framework versions
- PEFT 0.15.2
- Transformers 4.51.3
- Pytorch 2.8.0+cu128
- Datasets 3.6.0
- Tokenizers 0.21.1
|
Jinyu220/gaze_model_av_aloha_real_put_tube_singlev2
|
Jinyu220
| 2025-08-07T00:42:41Z | 3 | 0 | null |
[
"safetensors",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"region:us"
] | null | 2025-08-07T00:42:31Z |
---
tags:
- model_hub_mixin
- pytorch_model_hub_mixin
---
This model has been pushed to the Hub using the [PytorchModelHubMixin](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.PyTorchModelHubMixin) integration:
- Code: [More Information Needed]
- Paper: [More Information Needed]
- Docs: [More Information Needed]
|
io-taas/042e8bfa-9ab9-4b42-982a-47368d0d384e
|
io-taas
| 2025-08-07T00:40:08Z | 2 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-factory",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-07T00:39:18Z |
---
library_name: transformers
tags:
- llama-factory
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
JHelhoski/SmolLM-FT-OHPC
|
JHelhoski
| 2025-08-07T00:35:59Z | 1 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"base_model:HuggingFaceTB/SmolLM-360M",
"base_model:finetune:HuggingFaceTB/SmolLM-360M",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-07T00:35:24Z |
---
base_model: HuggingFaceTB/SmolLM-360M
library_name: transformers
model_name: SmolLM-FT-OHPC
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for SmolLM-FT-OHPC
This model is a fine-tuned version of [HuggingFaceTB/SmolLM-360M](https://huggingface.co/HuggingFaceTB/SmolLM-360M).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="JHelhoski/SmolLM-FT-OHPC", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/jhelhos1-binghamton-university/huggingface/runs/9wj50x5k)
This model was trained with SFT.
### Framework versions
- TRL: 0.20.0
- Transformers: 4.54.1
- Pytorch: 2.7.1
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Trelis/Qwen3-4B_dsarc-programs-correct-10_20250806-233707
|
Trelis
| 2025-08-07T00:30:58Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"base_model:unsloth/Qwen3-4B",
"base_model:finetune:unsloth/Qwen3-4B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-07T00:29:33Z |
---
base_model: unsloth/Qwen3-4B
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Trelis
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-4B
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
w1nw1n/ppo-LunarLander-v2
|
w1nw1n
| 2025-08-07T00:15:21Z | 19 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-05T03:26:17Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 260.02 +/- 17.09
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Gen-Verse/ReasonFlux-V2-32B-Reasoner
|
Gen-Verse
| 2025-08-07T00:11:52Z | 6 | 3 | null |
[
"safetensors",
"qwen3",
"arxiv:2502.06772",
"region:us"
] | null | 2025-06-09T15:27:05Z |
<div align="center">
<h1>ReasonFlux-V2:Internalizing Template-Augmented LLM Reasoning
with Hierarchical Reinforcement Learning</h1>
</div>
<p align="center">
<img src="./figs/comparison.png" width=80%>
</p>
**ReasonFlux-V2** is our new template-augmented reasoning paradigm which **internalize the thought templates** through **iterative hierarchical reinforcement learning**. Specifically, we first develop an automated pipeline to extract thought templates from the problem–solution pairs in training set. To effectively internalize these high-level thought templates and learning a more efficient reasoning paradigm, we propose two collaborative modules: **Template Proposer** which adaptively proposes suitable thought templates based on the input problem; and **Template Reasoner**,which exactly instantiates the proposed templates and performs precise, detailed reasoning. Building upon these modules, we iteratively conduct **hierarchical RL** on optimizing both modules.
<p align="center">
<img src="./figs/ReasonFluxv2_method.png" width=80%>
</p>
**ReasonFlux-V2** offers a more efficient, generalizable solution for enhancing the complex reasoning capabilities of LLMs. Compare with conventional reasoning LLMs, our **ReasonFlux-V2** could correctly and efficiently solve the problems with less token consumption and inference time.
**We will release our paper related with ReasonFlux-V2 soon.**
ReasonFlux-v2 consists of two main modules:
1. **Template Proposer**, which **adaptively** proposes suitable high-level thought templates based on the input problem. It functions as intuitive thinking process of human which helps to **narrow the exploration space** of detailed reasoning process thus **improve the solution efficiency**.
2. **Template Reasoner**, which follow the proposed high-level thought template to efficiently and effectively solve the corresponding problem.
<p align="center">
<img src="./figs/reasonflux_v2.png" width=80%>
</p>
[Code](https://github.com/Gen-Verse/ReasonFlux)|[Template](Gen-Verse/ReasonFlux-V2-Template)|[SFT Dataset](https://huggingface.co/datasets/Gen-Verse/ReasonFlux-V2-SFT/) |[DPO Dataset](https://huggingface.co/datasets/Gen-Verse/ReasonFlux-V2-DPO)
## Citation
```bash
@article{yang2025reasonflux,
title={ReasonFlux: Hierarchical LLM Reasoning via Scaling Thought Templates},
author={Yang, Ling and Yu, Zhaochen and Cui, Bin and Wang, Mengdi},
journal={arXiv preprint arXiv:2502.06772},
year={2025}
}
```
|
Sam9281/Sam
|
Sam9281
| 2025-08-07T00:11:22Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-07T00:11:22Z |
---
license: apache-2.0
---
|
John6666/illv-i-love-lucid-visuals-illv10-sdxl
|
John6666
| 2025-08-07T00:11:21Z | 1 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"stable-diffusion-xl",
"anime",
"cartoon",
"hyper-realism",
"stylized",
"detailed",
"girls",
"cute",
"Illustrious XL v2.0",
"illustrious",
"en",
"base_model:OnomaAIResearch/Illustrious-XL-v2.0",
"base_model:finetune:OnomaAIResearch/Illustrious-XL-v2.0",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] |
text-to-image
| 2025-08-07T00:06:37Z |
---
license: other
license_name: faipl-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- text-to-image
- stable-diffusion
- stable-diffusion-xl
- anime
- cartoon
- hyper-realism
- stylized
- detailed
- girls
- cute
- Illustrious XL v2.0
- illustrious
base_model: OnomaAIResearch/Illustrious-XL-v2.0
---
Original model is [here](https://civitai.com/models/1291368?modelVersionId=2087008).
This model created by [Xmutsix](https://civitai.com/user/Xmutsix).
|
DevQuasar/Qwen.Qwen3-4B-Instruct-2507-GGUF
|
DevQuasar
| 2025-08-07T00:11:15Z | 788 | 0 | null |
[
"gguf",
"text-generation",
"base_model:Qwen/Qwen3-4B-Instruct-2507",
"base_model:quantized:Qwen/Qwen3-4B-Instruct-2507",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-08-06T23:59:55Z |
---
base_model:
- Qwen/Qwen3-4B-Instruct-2507
pipeline_tag: text-generation
---
[<img src="https://raw.githubusercontent.com/csabakecskemeti/devquasar/main/dq_logo_black-transparent.png" width="200"/>](https://devquasar.com)
'Make knowledge free for everyone'
Quantized version of: [Qwen/Qwen3-4B-Instruct-2507](https://huggingface.co/Qwen/Qwen3-4B-Instruct-2507)
<a href='https://ko-fi.com/L4L416YX7C' target='_blank'><img height='36' style='border:0px;height:36px;' src='https://storage.ko-fi.com/cdn/kofi6.png?v=6' border='0' alt='Buy Me a Coffee at ko-fi.com' /></a>
|
hjerpe/agent-2048-lora
|
hjerpe
| 2025-08-07T00:10:10Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-06T16:58:39Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
k1000dai/residualact_libero_lr5e5
|
k1000dai
| 2025-08-06T23:57:58Z | 2 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"residualact",
"robotics",
"dataset:k1000dai/libero-addinfo",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-06T23:57:38Z |
---
datasets: k1000dai/libero-addinfo
library_name: lerobot
license: apache-2.0
model_name: residualact
pipeline_tag: robotics
tags:
- residualact
- lerobot
- robotics
---
# Model Card for residualact
<!-- Provide a quick summary of what the model is/does. -->
_Model type not recognized — please update this template._
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
mksachs/SmolLM2-FT-MyDataset
|
mksachs
| 2025-08-06T23:56:27Z | 9 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"smol-course",
"module_1",
"conversational",
"base_model:HuggingFaceTB/SmolLM2-135M",
"base_model:finetune:HuggingFaceTB/SmolLM2-135M",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-06T23:56:05Z |
---
base_model: HuggingFaceTB/SmolLM2-135M
library_name: transformers
model_name: SmolLM2-FT-MyDataset
tags:
- generated_from_trainer
- trl
- sft
- smol-course
- module_1
licence: license
---
# Model Card for SmolLM2-FT-MyDataset
This model is a fine-tuned version of [HuggingFaceTB/SmolLM2-135M](https://huggingface.co/HuggingFaceTB/SmolLM2-135M).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="mksachs/SmolLM2-FT-MyDataset", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/mksachs-mikesachs-com/huggingface/runs/t34ihq3x)
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.0
- Pytorch: 2.6.0+cu124
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
gecfdo/R1-Broken-Tutu-24B-EXL2
|
gecfdo
| 2025-08-06T23:54:47Z | 1 | 0 |
transformers
|
[
"transformers",
"mergekit",
"merge",
"nsfw",
"explicit",
"roleplay",
"unaligned",
"ERP",
"Erotic",
"Horror",
"Violence",
"text-generation",
"en",
"arxiv:2311.03099",
"base_model:ReadyArt/R1-Broken-Tutu-24B",
"base_model:quantized:ReadyArt/R1-Broken-Tutu-24B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-06T23:53:40Z |
---
license: apache-2.0
language:
- en
base_model:
- ReadyArt/R1-Broken-Tutu-24B
base_model_relation: quantized
pipeline_tag: text-generation
library_name: transformers
tags:
- mergekit
- merge
- nsfw
- explicit
- roleplay
- unaligned
- ERP
- Erotic
- Horror
- Violence
---
# R1-Broken-Tutu-24B
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [DARE TIES](https://arxiv.org/abs/2311.03099) merge method using [ReadyArt/The-Omega-Directive-M-24B-v1.1](https://huggingface.co/ReadyArt/The-Omega-Directive-M-24B-v1.1) as a base.
### Models Merged
The following models were included in the merge:
* [ReadyArt/Omega-Darker_The-Final-Directive-24B](https://huggingface.co/ReadyArt/Omega-Darker_The-Final-Directive-24B)
* [TheDrummer/Cydonia-R1-24B-v4](https://huggingface.co/TheDrummer/Cydonia-R1-24B-v4)
* [ReadyArt/Forgotten-Safeword-24B](https://huggingface.co/ReadyArt/Forgotten-Safeword-24B)
* [TroyDoesAI/BlackSheep-24B](https://huggingface.co/TroyDoesAI/BlackSheep-24B)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
merge_method: dare_ties
base_model: ReadyArt/The-Omega-Directive-M-24B-v1.1
models:
- model: ReadyArt/The-Omega-Directive-M-24B-v1.1
parameters:
weight: 0.2
- model: ReadyArt/Omega-Darker_The-Final-Directive-24B
parameters:
weight: 0.2
- model: ReadyArt/Forgotten-Safeword-24B
parameters:
weight: 0.2
- model: TroyDoesAI/BlackSheep-24B
parameters:
weight: 0.2
- model: TheDrummer/Cydonia-R1-24B-v4
parameters:
weight: 0.2
parameters:
density: 0.3
tokenizer:
source: union
chat_template: auto
```
# Special thanks
* TheDrummer (Cydonia Model Architect)
* TroyDoesAI (BlackSheep Architect)
* SteelSkull (Dataset Generation Contributor)
* sleepdeprived3 (Omega / Safeword)
|
DevQuasar/ai21labs.AI21-Jamba-Large-1.7-GGUF
|
DevQuasar
| 2025-08-06T23:44:02Z | 706 | 0 | null |
[
"gguf",
"text-generation",
"base_model:ai21labs/AI21-Jamba-Large-1.7",
"base_model:quantized:ai21labs/AI21-Jamba-Large-1.7",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-07-31T05:15:38Z |
---
base_model:
- ai21labs/AI21-Jamba-Large-1.7
pipeline_tag: text-generation
---
[<img src="https://raw.githubusercontent.com/csabakecskemeti/devquasar/main/dq_logo_black-transparent.png" width="200"/>](https://devquasar.com)
'Make knowledge free for everyone'
Quantized version of: [ai21labs/AI21-Jamba-Large-1.7](https://huggingface.co/ai21labs/AI21-Jamba-Large-1.7)
<a href='https://ko-fi.com/L4L416YX7C' target='_blank'><img height='36' style='border:0px;height:36px;' src='https://storage.ko-fi.com/cdn/kofi6.png?v=6' border='0' alt='Buy Me a Coffee at ko-fi.com' /></a>
|
rbelanec/train_siqa_1754507488
|
rbelanec
| 2025-08-06T23:35:14Z | 22 | 0 |
peft
|
[
"peft",
"safetensors",
"llama-factory",
"lora",
"generated_from_trainer",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"base_model:adapter:meta-llama/Meta-Llama-3-8B-Instruct",
"license:llama3",
"region:us"
] | null | 2025-08-06T19:12:14Z |
---
library_name: peft
license: llama3
base_model: meta-llama/Meta-Llama-3-8B-Instruct
tags:
- llama-factory
- lora
- generated_from_trainer
model-index:
- name: train_siqa_1754507488
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# train_siqa_1754507488
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) on the siqa dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2014
- Num Input Tokens Seen: 29840264
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 123
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Input Tokens Seen |
|:-------------:|:-----:|:-----:|:---------------:|:-----------------:|
| 0.1685 | 0.5 | 3759 | 0.2103 | 1495072 |
| 0.0643 | 1.0 | 7518 | 0.2110 | 2984720 |
| 0.1168 | 1.5 | 11277 | 0.2156 | 4477104 |
| 0.3262 | 2.0 | 15036 | 0.2014 | 5970384 |
| 0.1856 | 2.5 | 18795 | 0.2871 | 7462384 |
| 0.1235 | 3.0 | 22554 | 0.2563 | 8954176 |
| 0.0457 | 3.5 | 26313 | 0.4125 | 10445088 |
| 0.2364 | 4.0 | 30072 | 0.3816 | 11937344 |
| 0.0731 | 4.5 | 33831 | 0.4247 | 13430048 |
| 0.0 | 5.0 | 37590 | 0.4945 | 14920992 |
| 0.001 | 5.5 | 41349 | 0.4947 | 16412032 |
| 0.0001 | 6.0 | 45108 | 0.5627 | 17904680 |
| 0.0 | 6.5 | 48867 | 0.6525 | 19397416 |
| 0.0 | 7.0 | 52626 | 0.7320 | 20888856 |
| 0.0 | 7.5 | 56385 | 0.7387 | 22381080 |
| 0.0005 | 8.0 | 60144 | 0.9056 | 23872880 |
| 0.0 | 8.5 | 63903 | 1.0000 | 25363344 |
| 0.0 | 9.0 | 67662 | 0.9857 | 26855848 |
| 0.0 | 9.5 | 71421 | 1.0109 | 28348712 |
| 0.0 | 10.0 | 75180 | 1.0122 | 29840264 |
### Framework versions
- PEFT 0.15.2
- Transformers 4.51.3
- Pytorch 2.8.0+cu128
- Datasets 3.6.0
- Tokenizers 0.21.1
|
rbelanec/train_siqa_1754507486
|
rbelanec
| 2025-08-06T23:34:39Z | 21 | 0 |
peft
|
[
"peft",
"safetensors",
"llama-factory",
"prompt-tuning",
"generated_from_trainer",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"base_model:adapter:meta-llama/Meta-Llama-3-8B-Instruct",
"license:llama3",
"region:us"
] | null | 2025-08-06T19:12:13Z |
---
library_name: peft
license: llama3
base_model: meta-llama/Meta-Llama-3-8B-Instruct
tags:
- llama-factory
- prompt-tuning
- generated_from_trainer
model-index:
- name: train_siqa_1754507486
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# train_siqa_1754507486
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) on the siqa dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2486
- Num Input Tokens Seen: 29840264
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 123
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Input Tokens Seen |
|:-------------:|:-----:|:-----:|:---------------:|:-----------------:|
| 0.3673 | 0.5 | 3759 | 0.3175 | 1495072 |
| 0.0729 | 1.0 | 7518 | 0.2866 | 2984720 |
| 0.3034 | 1.5 | 11277 | 0.2782 | 4477104 |
| 0.3572 | 2.0 | 15036 | 0.2689 | 5970384 |
| 0.2673 | 2.5 | 18795 | 0.2486 | 7462384 |
| 0.0773 | 3.0 | 22554 | 0.2718 | 8954176 |
| 0.0328 | 3.5 | 26313 | 0.2737 | 10445088 |
| 0.398 | 4.0 | 30072 | 0.2752 | 11937344 |
| 0.2919 | 4.5 | 33831 | 0.2819 | 13430048 |
| 0.3342 | 5.0 | 37590 | 0.2992 | 14920992 |
| 0.0416 | 5.5 | 41349 | 0.2832 | 16412032 |
| 0.2025 | 6.0 | 45108 | 0.2761 | 17904680 |
| 0.3087 | 6.5 | 48867 | 0.2822 | 19397416 |
| 0.5182 | 7.0 | 52626 | 0.2834 | 20888856 |
| 0.3096 | 7.5 | 56385 | 0.2855 | 22381080 |
| 0.7383 | 8.0 | 60144 | 0.2841 | 23872880 |
| 0.2775 | 8.5 | 63903 | 0.2843 | 25363344 |
| 0.249 | 9.0 | 67662 | 0.2833 | 26855848 |
| 0.575 | 9.5 | 71421 | 0.2843 | 28348712 |
| 0.7715 | 10.0 | 75180 | 0.2835 | 29840264 |
### Framework versions
- PEFT 0.15.2
- Transformers 4.51.3
- Pytorch 2.8.0+cu128
- Datasets 3.6.0
- Tokenizers 0.21.1
|
danuphat/typhoon-ocr-7b-trl-sft-ocr-1
|
danuphat
| 2025-08-06T23:26:51Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:scb10x/typhoon-ocr-7b",
"base_model:finetune:scb10x/typhoon-ocr-7b",
"endpoints_compatible",
"region:us"
] | null | 2025-08-06T19:14:33Z |
---
base_model: scb10x/typhoon-ocr-7b
library_name: transformers
model_name: typhoon-ocr-7b-trl-sft-ocr-1
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for typhoon-ocr-7b-trl-sft-ocr-1
This model is a fine-tuned version of [scb10x/typhoon-ocr-7b](https://huggingface.co/scb10x/typhoon-ocr-7b).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="danuphat/typhoon-ocr-7b-trl-sft-ocr-1", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/danuphat-l-kasetsart-university/typhoon-ocr-7b-trl-sft-ocr/runs/pm09bxvl)
This model was trained with SFT.
### Framework versions
- TRL: 0.22.0.dev0
- Transformers: 4.56.0.dev0
- Pytorch: 2.7.1
- Datasets: 4.0.0
- Tokenizers: 0.21.2
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
aumoai/aumogpt-Qwen2.5-7B-Instruct-self-lora-adapter
|
aumoai
| 2025-08-06T23:26:15Z | 0 | 0 | null |
[
"safetensors",
"region:us"
] | null | 2025-08-06T23:26:06Z |
# QLora config for Llama 3.3 70B.
# Borrows param values from:
# https://github.com/pytorch/torchtune/blob/main/recipes/configs/llama3_3/70B_lora.yaml
# https://github.com/pytorch/torchtune/blob/main/recipes/configs/llama3_1/405B_qlora.yaml
#
# Requirements:
# - Log into WandB (`wandb login`) or disable `enable_wandb`
# - Log into HF: `huggingface-cli login`
# - Request access to Llama 3.3: https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct
#
# Usage:
# oumi train -c configs/recipes/llama3_3/sft/70b_qlora/train.yaml
#
# See Also:
# - Documentation: https://oumi.ai/docs/en/latest/user_guides/train/train.html
# - Config class: oumi.core.configs.TrainingConfig
# - Config source: https://github.com/oumi-ai/oumi/blob/main/src/oumi/core/configs/training_config.py
# - Other training configs: configs/**/pretraining/, configs/**/sft/, configs/**/dpo/
model:
model_name: "Qwen/Qwen2.5-7B-Instruct"
model_max_length: 4096
torch_dtype_str: "bfloat16"
attn_implementation: "flash_attention_2" #"sdpa"
load_pretrained_weights: True
trust_remote_code: True
data:
train:
datasets:
# - dataset_name: "text_sft"
# dataset_path: "datasets/aumo_dataset_test.json"
# shuffle: True
# seed: 42
- dataset_name: "text_sft"
dataset_path: "datasets/aumogpt_qwen7b.json"
shuffle: True
seed: 42
# - dataset_name: "text_sft"
# dataset_path: "datasets/xp3_qwen_2000.json"
# shuffle: True
# seed: 42
# - dataset_name: "text_sft"
# dataset_path: "datasets/aumogpt_train.json"
# shuffle: True
# seed: 42
# mixture_strategy: "all_exhausted" # Strategy for mixing datasets
# seed: 123456789426465
validation:
datasets:
- dataset_name: "text_sft"
dataset_path: "datasets/aumo_dataset_test.json"
split: "validation"
# sample_count: 10
training:
trainer_type: "TRL_SFT"
use_peft: True
save_steps: 200
num_train_epochs: 2
per_device_train_batch_size: 1
per_device_eval_batch_size: 1
gradient_accumulation_steps: 16
max_grad_norm: null
try_resume_from_last_checkpoint: false
enable_gradient_checkpointing: True
gradient_checkpointing_kwargs:
use_reentrant: False
ddp_find_unused_parameters: False
optimizer: "adamw_torch" # "adamw_torch" #paged_adamw_8bit
learning_rate: 5.0e-4
warmup_steps: 10
weight_decay: 0.01
compile: False
dataloader_num_workers: "auto"
dataloader_prefetch_factor: 32
logging_steps: 10
log_model_summary: False
empty_device_cache_steps: 50
output_dir: "results/oumi/qwen7b_xp3_aumo.lora"
include_performance_metrics: True
enable_wandb: True
eval_strategy: "steps" # When to evaluate ("no", "steps", "epoch")
eval_steps: 25
peft:
q_lora: False
# q_lora_bits: 4
# bnb_4bit_quant_type: "nf4"
# bnb_4bit_quant_storage: "bfloat16"
# bnb_4bit_compute_dtype: "bfloat16"
# use_bnb_nested_quant: True
lora_r: 64
lora_alpha: 32
lora_dropout: 0.2
lora_target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "down_proj"
- "up_proj"
# fsdp:
# enable_fsdp: True
# forward_prefetch: True
# sharding_strategy: "FULL_SHARD"
# auto_wrap_policy: "TRANSFORMER_BASED_WRAP"
# transformer_layer_cls: "LlamaDecoderLayer"
|
terry-dev/wittywriter-ai
|
terry-dev
| 2025-08-06T23:08:06Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"nlp",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-06T14:42:45Z |
---
tags:
- text-generation
- transformers
- nlp
license: mit
---
# WittyWriter-AI
WittyWriter-AI is a lightweight text generation model designed to produce human-like responses for various creative and conversational use cases. Built with accessibility in mind, this model offers quick inference and easy integration into web interfaces using Gradio.
## Model Details
- **Task**: Text Generation
- **Framework**: Transformers
- **License**: MIT
- **Author**: [terry-dev](https://huggingface.co/terry-dev)
## Usage
You can try the model using the Hugging Face `transformers` library:
```python
from transformers import pipeline
generator = pipeline("text-generation", model="terry-dev/wittywriter-ai")
output = generator("Once upon a time", max_length=50, num_return_sequences=1)
print(output[0]["generated_text"])
|
gecfdo/R1-Broken-Tutu-24B-EXL3
|
gecfdo
| 2025-08-06T22:59:52Z | 1 | 0 |
transformers
|
[
"transformers",
"mergekit",
"merge",
"nsfw",
"explicit",
"roleplay",
"unaligned",
"ERP",
"Erotic",
"Horror",
"Violence",
"text-generation",
"en",
"arxiv:2311.03099",
"base_model:ReadyArt/R1-Broken-Tutu-24B",
"base_model:quantized:ReadyArt/R1-Broken-Tutu-24B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-06T22:58:04Z |
---
license: apache-2.0
language:
- en
base_model:
- ReadyArt/R1-Broken-Tutu-24B
base_model_relation: quantized
pipeline_tag: text-generation
library_name: transformers
tags:
- mergekit
- merge
- nsfw
- explicit
- roleplay
- unaligned
- ERP
- Erotic
- Horror
- Violence
---
# R1-Broken-Tutu-24B
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [DARE TIES](https://arxiv.org/abs/2311.03099) merge method using [ReadyArt/The-Omega-Directive-M-24B-v1.1](https://huggingface.co/ReadyArt/The-Omega-Directive-M-24B-v1.1) as a base.
### Models Merged
The following models were included in the merge:
* [ReadyArt/Omega-Darker_The-Final-Directive-24B](https://huggingface.co/ReadyArt/Omega-Darker_The-Final-Directive-24B)
* [TheDrummer/Cydonia-R1-24B-v4](https://huggingface.co/TheDrummer/Cydonia-R1-24B-v4)
* [ReadyArt/Forgotten-Safeword-24B](https://huggingface.co/ReadyArt/Forgotten-Safeword-24B)
* [TroyDoesAI/BlackSheep-24B](https://huggingface.co/TroyDoesAI/BlackSheep-24B)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
merge_method: dare_ties
base_model: ReadyArt/The-Omega-Directive-M-24B-v1.1
models:
- model: ReadyArt/The-Omega-Directive-M-24B-v1.1
parameters:
weight: 0.2
- model: ReadyArt/Omega-Darker_The-Final-Directive-24B
parameters:
weight: 0.2
- model: ReadyArt/Forgotten-Safeword-24B
parameters:
weight: 0.2
- model: TroyDoesAI/BlackSheep-24B
parameters:
weight: 0.2
- model: TheDrummer/Cydonia-R1-24B-v4
parameters:
weight: 0.2
parameters:
density: 0.3
tokenizer:
source: union
chat_template: auto
```
# Special thanks
* TheDrummer (Cydonia Model Architect)
* TroyDoesAI (BlackSheep Architect)
* SteelSkull (Dataset Generation Contributor)
* sleepdeprived3 (Omega / Safeword)
|
FrontierInstruments/merged_softstart_reasoning_10k
|
FrontierInstruments
| 2025-08-06T22:55:19Z | 17 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-08-06T22:54:34Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
licongwei/xLAM-2-3b-fc-r-SpinQuant-ET
|
licongwei
| 2025-08-06T22:50:07Z | 8 | 0 |
transformers
|
[
"transformers",
"qwen2",
"text-generation",
"function-calling",
"LLM Agent",
"tool-use",
"llama",
"qwen",
"pytorch",
"LLaMA-factory",
"conversational",
"en",
"dataset:Salesforce/APIGen-MT-5k",
"dataset:Salesforce/xlam-function-calling-60k",
"arxiv:2504.03601",
"arxiv:2503.22673",
"arxiv:2409.03215",
"arxiv:2402.15506",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-03T07:58:30Z |
---
datasets:
- Salesforce/APIGen-MT-5k
- Salesforce/xlam-function-calling-60k
language:
- en
library_name: transformers
license: cc-by-nc-4.0
pipeline_tag: text-generation
tags:
- function-calling
- LLM Agent
- tool-use
- llama
- qwen
- pytorch
- LLaMA-factory
---
<p align="center">
<img width="500px" alt="xLAM" src="https://huggingface.co/datasets/jianguozhang/logos/resolve/main/xlam-no-background.png">
</p>
<p align="center">
<a href="https://arxiv.org/abs/2504.03601">[Paper]</a> |
<a href="https://apigen-mt.github.io/">[Homepage]</a> |
<a href="https://huggingface.co/datasets/Salesforce/APIGen-MT-5k">[Dataset]</a> |
<a href="https://github.com/SalesforceAIResearch/xLAM">[Github]</a>
</p>
<hr>
## Paper Abstract
Training effective AI agents for multi-turn interactions requires high-quality data that captures realistic human-agent dynamics, yet such data is scarce and expensive to collect manually. We introduce APIGen-MT, a two-phase framework that generates verifiable and diverse multi-turn agent data. In the first phase, our agentic pipeline produces detailed task blueprints with ground-truth actions, leveraging a committee of LLM reviewers and iterative feedback loops. These blueprints are then transformed into complete interaction trajectories through simulated human-agent interplay. We train a family of models -- the xLAM-2-fc-r series with sizes ranging from 1B to 70B parameters. Our models outperform frontier models such as GPT-4o and Claude 3.5 on $\tau$-bench and BFCL benchmarks, with the smaller models surpassing their larger counterparts, particularly in multi-turn settings, while maintaining superior consistency across multiple trials. Comprehensive experiments demonstrate that our verified blueprint-to-details approach yields high-quality training data, enabling the development of more reliable, efficient, and capable agents. We open-source 5K synthetic data trajectories and the trained xLAM-2-fc-r models to advance research in AI agents. Models at this https URL Dataset at this https URL and Website at this https URL
# Welcome to the xLAM-2 Model Family!
[Large Action Models (LAMs)](https://blog.salesforceairesearch.com/large-action-models/) are advanced language models designed to enhance decision-making by translating user intentions into executable actions. As the **brains of AI agents**, LAMs autonomously plan and execute tasks to achieve specific goals, making them invaluable for automating workflows across diverse domains.
**This model release is for research purposes only.**
The new **xLAM-2** series, built on our most advanced data synthesis, processing, and training pipelines, marks a significant leap in **multi-turn conversation** and **tool usage**. Trained using our novel APIGen-MT framework, which generates high-quality training data through simulated agent-human interactions. Our models achieve state-of-the-art performance on [**BFCL**](https://gorilla.cs.berkeley.edu/leaderboard.html) and **τ-bench** benchmarks, outperforming frontier models like GPT-4o and Claude 3.5. Notably, even our smaller models demonstrate superior capabilities in multi-turn scenarios while maintaining exceptional consistency across trials.
We've also refined the **chat template** and **vLLM integration**, making it easier to build advanced AI agents. Compared to previous xLAM models, xLAM-2 offers superior performance and seamless deployment across applications.
<p align="center">
<img width="100%" alt="Model Performance Overview" src="https://github.com/apigen-mt/apigen-mt.github.io/blob/main/img/model_board.png?raw=true">
<br>
<small><i>Comparative performance of larger xLAM-2-fc-r models (8B-70B, trained with APIGen-MT data) against state-of-the-art baselines on function-calling (BFCL v3, as of date 04/02/2025) and agentic (τ-bench) capabilities.</i></small>
</p>
## Table of Contents
- [Usage](#usage)
- [Basic Usage with Huggingface Chat Template](#basic-usage-with-huggingface-chat-template)
- [Using vLLM for Inference](#using-vllm-for-inference)
- [Setup and Serving](#setup-and-serving)
- [Testing with OpenAI API](#testing-with-openai-api)
- [Benchmark Results](#benchmark-results)
- [Citation](#citation)
---
## Model Series
[xLAM](https://huggingface.co/collections/Salesforce/xlam-models-65f00e2a0a63bbcd1c2dade4) series are significant better at many things including general tasks and function calling.
For the same number of parameters, the model have been fine-tuned across a wide range of agent tasks and scenarios, all while preserving the capabilities of the original model.
| Model | # Total Params | Context Length | Category | Download Model | Download GGUF files |
|------------------------|----------------|------------|-------|----------------|----------|
| Llama-xLAM-2-70b-fc-r | 70B | 128k | Multi-turn Conversation, Function-calling | [🤗 Link](https://huggingface.co/Salesforce/Llama-xLAM-2-70b-fc-r) | NA |
| Llama-xLAM-2-8b-fc-r | 8B | 128k | Multi-turn Conversation, Function-calling | [🤗 Link](https://huggingface.co/Salesforce/Llama-xLAM-2-8b-fc-r) | [🤗 Link](https://huggingface.co/Salesforce/Llama-xLAM-2-8b-fc-r-gguf) |
| xLAM-2-32b-fc-r | 32B | 32k (max 128k)* | Multi-turn Conversation, Function-calling | [🤗 Link](https://huggingface.co/Salesforce/xLAM-2-32b-fc-r) | NA |
| xLAM-2-3b-fc-r | 3B | 32k (max 128k)* | Multi-turn Conversation, Function-calling | [🤗 Link](https://huggingface.co/Salesforce/xLAM-2-3b-fc-r) | [🤗 Link](https://huggingface.co/Salesforce/xLAM-2-3b-fc-r-gguf) |
| xLAM-2-1b-fc-r | 1B | 32k (max 128k)* | Multi-turn Conversation, Function-calling | [🤗 Link](https://huggingface.co/Salesforce/xLAM-2-1b-fc-r) | [🤗 Link](https://huggingface.co/Salesforce/xLAM-2-1b-fc-r-gguf) |
***Note:** The default context length for Qwen-2.5-based models is 32k, but you can use techniques like YaRN (Yet Another Recursive Network) to achieve maximum 128k context length. Please refer to [here](https://huggingface.co/Qwen/Qwen2.5-32B-Instruct#processing-long-texts) for more details.
You can also explore our previous xLAM series [here](https://huggingface.co/collections/Salesforce/xlam-models-65f00e2a0a63bbcd1c2dade4).
The `-fc` suffix indicates that the models are fine-tuned for **function calling** tasks, while the `-r` suffix signifies a **research** release.
✅ All models are fully compatible with vLLM and Transformers-based inference frameworks.
## Usage
### Framework versions
- Transformers 4.46.1 (or later)
- PyTorch 2.5.1+cu124 (or later)
- Datasets 3.1.0 (or later)
- Tokenizers 0.20.3 (or later)
### Basic Usage with Huggingface Chat Template
The new xLAM models are designed to work seamlessly with the Hugging Face Transformers library and utilize natural chat templates for an easy and intuitive conversational experience. Below are examples of how to use these models.
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Salesforce/Llama-xLAM-2-3b-fc-r")
model = AutoModelForCausalLM.from_pretrained("Salesforce/Llama-xLAM-2-3b-fc-r", torch_dtype=torch.bfloat16, device_map="auto")
# Example conversation with a tool call
messages = [
{"role": "user", "content": "Hi, how are you?"},
{"role": "assistant", "content": "Thanks. I am doing well. How can I help you?"},
{"role": "user", "content": "What's the weather like in London?"},
]
tools = [
{
"name": "get_weather",
"description": "Get the current weather for a location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "The city and state, e.g. San Francisco, CA"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"], "description": "The unit of temperature to return"}
},
"required": ["location"]
}
}
]
print("====== prompt after applying chat template ======")
print(tokenizer.apply_chat_template(messages, tools=tools, add_generation_prompt=True, tokenize=False))
inputs = tokenizer.apply_chat_template(messages, tools=tools, add_generation_prompt=True, return_dict=True, return_tensors="pt")
input_ids_len = inputs["input_ids"].shape[-1] # Get the length of the input tokens
inputs = {k: v.to(model.device) for k, v in inputs.items()}
print("====== model response ======")
outputs = model.generate(**inputs, max_new_tokens=256)
generated_tokens = outputs[:, input_ids_len:] # Slice the output to get only the newly generated tokens
print(tokenizer.decode(generated_tokens[0], skip_special_tokens=True))
```
### Using vLLM for Inference
The xLAM models can also be efficiently served using vLLM for high-throughput inference. Please use `vllm>=0.6.5` since earlier versions will cause degraded performance for Qwen-based models.
#### Setup and Serving
1. Install vLLM with the required version:
```bash
pip install "vllm>=0.6.5"
```
2. Download the tool parser plugin to your local path:
```bash
wget https://huggingface.co/Salesforce/xLAM-2-1b-fc-r/raw/main/xlam_tool_call_parser.py
```
3. Start the OpenAI API-compatible endpoint:
```bash
vllm serve Salesforce/xLAM-2-1b-fc-r \
--enable-auto-tool-choice \
--tool-parser-plugin ./xlam_tool_call_parser.py \
--tool-call-parser xlam \
--tensor-parallel-size 1
```
Note: Ensure that the tool parser plugin file is downloaded and that the path specified in `--tool-parser-plugin` correctly points to your local copy of the file. The xLAM series models all utilize the **same** tool call parser, so you only need to download it **once** for all models.
#### Testing with OpenAI API
Here's a minimal example to test tool usage with the served endpoint:
```python
import openai
import json
# Configure the client to use your local vLLM endpoint
client = openai.OpenAI(
base_url="http://localhost:8000/v1", # Default vLLM server URL
api_key="empty" # Can be any string
)
# Define a tool/function
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather for a location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The unit of temperature to return"
}
},
"required": ["location"]
}
}
}
]
# Create a chat completion
response = client.chat.completions.create(
model="Salesforce/xLAM-2-1b-fc-r", # Model name doesn't matter, vLLM uses the served model
messages=[
{"role": "system", "content": "You are a helpful assistant that can use tools."},
{"role": "user", "content": "What's the weather like in San Francisco?"}
],
tools=tools,
tool_choice="auto"
)
# Print the response
print("Assistant's response:")
print(json.dumps(response.model_dump(), indent=2))
```
For more advanced configurations and deployment options, please refer to the [vLLM documentation](https://docs.vllm.ai/en/latest/serving/openai_compatible_server.html).
## Benchmark Results
### Berkeley Function-Calling Leaderboard (BFCL v3)
<p align="center">
<img width="80%" alt="BFCL Results" src="https://github.com/apigen-mt/apigen-mt.github.io/blob/main/img/bfcl-result.png?raw=true">
<br>
<small><i>Performance comparison of different models on [BFCL leaderboard](https://gorilla.cs.berkeley.edu/leaderboard.html). The rank is based on the overall accuracy, which is a weighted average of different evaluation categories. "FC" stands for function-calling mode in contrast to using a customized "prompt" to extract the function calls.</i></small>
</p>
### τ-bench Benchmark
<p align="center">
<img width="80%" alt="Tau-bench Results" src="https://github.com/apigen-mt/apigen-mt.github.io/blob/main/img/taubench-result.png?raw=true">
<br>
<small><i>Success Rate (pass@1) on τ-bench benchmark averaged across at least 5 trials. Our xLAM-2-70b-fc-r model achieves an overall success rate of 56.2% on τ-bench, significantly outperforming the base Llama 3.1 70B Instruct model (38.2%) and other open-source models like DeepSeek v3 (40.6%). Notably, our best model even outperforms proprietary models such as GPT-4o (52.9%) and approaches the performance of more recent models like Claude 3.5 Sonnet (new) (60.1%).</i></small>
</p>
<p align="center">
<img width="80%" alt="Pass^k curves" src="https://github.com/apigen-mt/apigen-mt.github.io/blob/main/img/pass_k_curves_retail_airline.png?raw=true">
<br>
<small><i>Pass^k curves measuring the probability that all 5 independent trials succeed for a given task, averaged across all tasks for τ-retail (left) and τ-airline (right) domains. Higher values indicate better consistency of the models.</i></small>
</p>
## Ethical Considerations
This release is for research purposes only in support of an academic paper. Our models, datasets, and code are not specifically designed or evaluated for all downstream purposes. We strongly recommend users evaluate and address potential concerns related to accuracy, safety, and fairness before deploying this model. We encourage users to consider the common limitations of AI, comply with applicable laws, and leverage best practices when selecting use cases, particularly for high-risk scenarios where errors or misuse could significantly impact people's lives, rights, or safety. For further guidance on use cases, refer to our AUP and AI AUP.
### Model Licenses
For all Llama relevant models, please also follow corresponding Llama license and terms. Meta Llama 3 is licensed under the Meta Llama 3 Community License, Copyright © Meta Platforms, Inc. All Rights Reserved.
## Citation
If you use our model or dataset in your work, please cite our paper:
```bibtex
@article{prabhakar2025apigen,
title={APIGen-MT: Agentic PIpeline for Multi-Turn Data Generation via Simulated Agent-Human Interplay},
author={Prabhakar, Akshara and Liu, Zuxin and Zhu, Ming and Zhang, Jianguo and Awalgaonkar, Tulika and Wang, Shiyu and Liu, Zhiwei and Chen, Haolin and Hoang, Thai and others},
journal={arXiv preprint arXiv:2504.03601},
year={2025}
}
```
Additionally, please check our other awesome related works regarding xLAM series and consider citing them as well:
```bibtex
@article{zhang2025actionstudio,
title={ActionStudio: A Lightweight Framework for Data and Training of Action Models},
author={Zhang, Jianguo and Hoang, Thai and Zhu, Ming and Liu, Zuxin and Wang, Shiyu and Awalgaonkar, Tulika and Prabhakar, Akshara and Chen, Haolin and Yao, Weiran and Liu, Zhiwei and others},
journal={arXiv preprint arXiv:2503.22673},
year={2025}
}
```
```bibtex
@article{zhang2024xlam,
title={xLAM: A Family of Large Action Models to Empower AI Agent Systems},
author={Zhang, Jianguo and Lan, Tian and Zhu, Ming and Liu, Zuxin and Hoang, Thai and Kokane, Shirley and Yao, Weiran and Tan, Juntao and Prabhakar, Akshara and Chen, Haolin and others},
journal={arXiv preprint arXiv:2409.03215},
year={2024}
}
```
```bibtex
@article{liu2024apigen,
title={Apigen: Automated pipeline for generating verifiable and diverse function-calling datasets},
author={Liu, Zuxin and Hoang, Thai and Zhang, Jianguo and Zhu, Ming and Lan, Tian and Tan, Juntao and Yao, Weiran and Liu, Zhiwei and Feng, Yihao and RN, Rithesh and others},
journal={Advances in Neural Information Processing Systems},
volume={37},
pages={54463--54482},
year={2024}
}
```
```bibtex
@article{zhang2024agentohana,
title={AgentOhana: Design Unified Data and Training Pipeline for Effective Agent Learning},
author={Zhang, Jianguo and Lan, Tian and Murthy, Rithesh and Liu, Zhiwei and Yao, Weiran and Tan, Juntao and Hoang, Thai and Yang, Liangwei and Feng, Yihao and Liu, Zuxin and others},
journal={arXiv preprint arXiv:2402.15506},
year={2024}
}
```
|
FrontierInstruments/reasoning_10k_r32a64_lora
|
FrontierInstruments
| 2025-08-06T22:50:01Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-06T22:49:43Z |
---
base_model: unsloth/meta-llama-3.1-8b-instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** FrontierInstruments
- **License:** apache-2.0
- **Finetuned from model :** unsloth/meta-llama-3.1-8b-instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
rbelanec/train_siqa_1754507487
|
rbelanec
| 2025-08-06T22:46:49Z | 21 | 0 |
peft
|
[
"peft",
"safetensors",
"llama-factory",
"ia3",
"generated_from_trainer",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"base_model:adapter:meta-llama/Meta-Llama-3-8B-Instruct",
"license:llama3",
"region:us"
] | null | 2025-08-06T19:12:13Z |
---
library_name: peft
license: llama3
base_model: meta-llama/Meta-Llama-3-8B-Instruct
tags:
- llama-factory
- ia3
- generated_from_trainer
model-index:
- name: train_siqa_1754507487
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# train_siqa_1754507487
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) on the siqa dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1941
- Num Input Tokens Seen: 29840264
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 123
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Input Tokens Seen |
|:-------------:|:-----:|:-----:|:---------------:|:-----------------:|
| 0.3784 | 0.5 | 3759 | 0.2872 | 1495072 |
| 0.1227 | 1.0 | 7518 | 0.2456 | 2984720 |
| 0.2894 | 1.5 | 11277 | 0.2292 | 4477104 |
| 0.2361 | 2.0 | 15036 | 0.2174 | 5970384 |
| 0.1743 | 2.5 | 18795 | 0.2126 | 7462384 |
| 0.1359 | 3.0 | 22554 | 0.2060 | 8954176 |
| 0.0448 | 3.5 | 26313 | 0.2038 | 10445088 |
| 0.2796 | 4.0 | 30072 | 0.2000 | 11937344 |
| 0.2362 | 4.5 | 33831 | 0.1983 | 13430048 |
| 0.2512 | 5.0 | 37590 | 0.1994 | 14920992 |
| 0.0642 | 5.5 | 41349 | 0.1975 | 16412032 |
| 0.0621 | 6.0 | 45108 | 0.1941 | 17904680 |
| 0.276 | 6.5 | 48867 | 0.1949 | 19397416 |
| 0.3155 | 7.0 | 52626 | 0.1958 | 20888856 |
| 0.2464 | 7.5 | 56385 | 0.1955 | 22381080 |
| 0.435 | 8.0 | 60144 | 0.1947 | 23872880 |
| 0.1351 | 8.5 | 63903 | 0.1947 | 25363344 |
| 0.2039 | 9.0 | 67662 | 0.1943 | 26855848 |
| 0.1998 | 9.5 | 71421 | 0.1945 | 28348712 |
| 0.2321 | 10.0 | 75180 | 0.1946 | 29840264 |
### Framework versions
- PEFT 0.15.2
- Transformers 4.51.3
- Pytorch 2.8.0+cu128
- Datasets 3.6.0
- Tokenizers 0.21.1
|
apriasmoro/0c5b8e7d-741a-4016-a89f-fd897864755a
|
apriasmoro
| 2025-08-06T22:45:53Z | 3 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"trl",
"dpo",
"conversational",
"arxiv:2305.18290",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-06T22:44:04Z |
---
library_name: transformers
model_name: app/checkpoints/2ae65c2f-1015-4c83-8ed6-15d4167406cd/0c5b8e7d-741a-4016-a89f-fd897864755a
tags:
- generated_from_trainer
- trl
- dpo
licence: license
---
# Model Card for app/checkpoints/2ae65c2f-1015-4c83-8ed6-15d4167406cd/0c5b8e7d-741a-4016-a89f-fd897864755a
This model is a fine-tuned version of [None](https://huggingface.co/None).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="None", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.20.0
- Transformers: 4.55.0
- Pytorch: 2.7.1+cu128
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Moneerrashed/Gari_And_Luna_Voiceover_Collection
|
Moneerrashed
| 2025-08-06T22:43:18Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2024-05-06T02:15:38Z |
---
license: mit
---
Use This Model To Make A Voiceover With News Open, Talent Open, Segment, ID And Promo
Here's A Link For Gradio https://huggingface.co/spaces/TheStinger/Ilaria_RVC And https://huggingface.co/spaces/Clebersla/RVC_V2_Huggingface_Version
|
Projectt123/MuniVis
|
Projectt123
| 2025-08-06T22:43:16Z | 8 | 0 | null |
[
"pytorch",
"blip",
"image-to-text",
"en",
"base_model:Salesforce/blip-image-captioning-base",
"base_model:finetune:Salesforce/blip-image-captioning-base",
"license:mit",
"region:us"
] |
image-to-text
| 2025-08-06T22:16:55Z |
---
license: mit
language:
- en
base_model:
- Salesforce/blip-image-captioning-base
pipeline_tag: image-to-text
---
# 🏙️ BLIP Image Captioning for Municipality Use (Graduation Project)
This is a fine-tuned version of [Salesforce's BLIP base model](https://huggingface.co/Salesforce/blip-image-captioning-base), customized for generating captions on images related to street infrastructure and urban environments.
The model was developed as part of a **Graduation Project** at the College of Information Systems.
---
## 🎓 Graduation Project Information
- **Project Title:** Smart Captioning for Urban Monitoring Using AI
- **Purpose:** This model aims to assist municipalities in automatically generating descriptive captions for street and infrastructure images using AI.
---
## 🧠 Model Overview
- **Base Model:** [Salesforce/blip-image-captioning-base](https://huggingface.co/Salesforce/blip-image-captioning-base)
- **Architecture:** BLIP (Bootstrapped Language Image Pretraining)
- **Task:** Image Captioning (with a focus on municipality-related data)
---
## 🏙️ Dataset
This model was fine-tuned on a **custom dataset** consisting of images captured in urban environments (e.g., roads, signs, sidewalks) for the purpose of city infrastructure monitoring.
> ⚠️ The dataset is not publicly released due to privacy and data ownership considerations.
---
## ✅ Intended Use
This model is designed for:
- Generating captions for street-level and city infrastructure images.
- Assisting municipalities in monitoring, analyzing, and documenting visual data.
---
## ❌ Limitations
- May not generalize well to domains outside of urban/street imagery.
- Captions might be biased by the dataset or lack context in unfamiliar scenes.
- Does not include object detection – focuses on captioning only.
---
## 📜 License
- This model is released under the **MIT License**.
- It is based on the [Salesforce BLIP model](https://huggingface.co/Salesforce/blip-image-captioning-base), which is licensed under the **BSD-3-Clause License**.
- Please ensure appropriate credit is given to the original authors when using or redistributing this model.
---
## 🤝 Acknowledgements
- Special thanks to **Salesforce Research** for the original BLIP model.
- Developed as part of a university graduation project with guidance from faculty members.
---
|
nightmedia/Qwen3-4B-Instruct-2507-q4-mlx
|
nightmedia
| 2025-08-06T22:41:51Z | 9 | 0 |
mlx
|
[
"mlx",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"base_model:Qwen/Qwen3-4B-Instruct-2507",
"base_model:quantized:Qwen/Qwen3-4B-Instruct-2507",
"license:apache-2.0",
"4-bit",
"region:us"
] |
text-generation
| 2025-08-06T22:25:50Z |
---
library_name: mlx
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-4B-Instruct-2507/blob/main/LICENSE
pipeline_tag: text-generation
base_model: Qwen/Qwen3-4B-Instruct-2507
tags:
- mlx
---
# Qwen3-4B-Instruct-2507-q4-mlx
This model [Qwen3-4B-Instruct-2507-q4-mlx](https://huggingface.co/Qwen3-4B-Instruct-2507-q4-mlx) was
converted to MLX format from [Qwen/Qwen3-4B-Instruct-2507](https://huggingface.co/Qwen/Qwen3-4B-Instruct-2507)
using mlx-lm version **0.26.3**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("Qwen3-4B-Instruct-2507-q4-mlx")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
AmpereComputing/granite-4.0-tiny-preview-gguf
|
AmpereComputing
| 2025-08-06T22:38:48Z | 64 | 0 | null |
[
"gguf",
"base_model:ibm-granite/granite-4.0-tiny-preview",
"base_model:quantized:ibm-granite/granite-4.0-tiny-preview",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-06T22:36:47Z |
---
base_model:
- ibm-granite/granite-4.0-tiny-preview
---

# Ampere® optimized llama.cpp

Ampere® optimized build of [llama.cpp](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#llamacpp) with full support for rich collection of GGUF models available at HuggingFace: [GGUF models](https://huggingface.co/models?search=gguf)
**For best results we recommend using models in our custom quantization formats available here: [AmpereComputing HF](https://huggingface.co/AmpereComputing)**
This Docker image can be run on bare metal Ampere® CPUs and Ampere® based VMs available in the cloud.
Release notes and binary executables are available on our [GitHub](https://github.com/AmpereComputingAI/llama.cpp/releases)
## Starting container
Default entrypoint runs the server binary of llama.cpp, mimicking behavior of original llama.cpp server image: [docker image](https://github.com/ggerganov/llama.cpp/blob/master/.devops/llama-server.Dockerfile)
To launch shell instead, do this:
```bash
sudo docker run --privileged=true --name llama --entrypoint /bin/bash -it amperecomputingai/llama.cpp:latest
```
Quick start example will be presented at docker container launch:

Make sure to visit us at [Ampere Solutions Portal](https://solutions.amperecomputing.com/solutions/ampere-ai)!
## Quantization
Ampere® optimized build of llama.cpp provides support for two new quantization methods, Q4_K_4 and Q8R16, offering model size and perplexity similar to Q4_K and Q8_0, respectively, but performing up to 1.5-2x faster on inference.
First, you'll need to convert the model to the GGUF format using [this script](https://github.com/ggerganov/llama.cpp/blob/master/convert_hf_to_gguf.py):
```bash
python3 convert-hf-to-gguf.py [path to the original model] --outtype [f32, f16, bf16 or q8_0] --outfile [output path]
```
For example:
```bash
python3 convert-hf-to-gguf.py path/to/llama2 --outtype f16 --outfile llama-2-7b-f16.gguf
```
Next, you can quantize the model using the following command:
```bash
./llama-quantize [input file] [output file] [quantization method]
```
For example:
```bash
./llama-quantize llama-2-7b-f16.gguf llama-2-7b-Q8R16.gguf Q8R16
```
## Support
Please contact us at <[email protected]>
## LEGAL NOTICE
By accessing, downloading or using this software and any required dependent software (the “Ampere AI Software”), you agree to the terms and conditions of the software license agreements for the Ampere AI Software, which may also include notices, disclaimers, or license terms for third party software included with the Ampere AI Software. Please refer to the [Ampere AI Software EULA v1.6](https://ampereaidevelop.s3.eu-central-1.amazonaws.com/Ampere+AI+Software+EULA+-+v1.6.pdf) or other similarly-named text file for additional details.
|
shenzhentianyi/unsloth_Qwen3-14B-Base_adaptor_checkpoint-2030
|
shenzhentianyi
| 2025-08-06T22:37:10Z | 7 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:shenzhentianyi/unsloth_Qwen3-14B-Base",
"lora",
"sft",
"transformers",
"trl",
"unsloth",
"text-generation",
"arxiv:1910.09700",
"base_model:shenzhentianyi/unsloth_Qwen3-14B-Base",
"region:us"
] |
text-generation
| 2025-08-06T22:16:49Z |
---
base_model: shenzhentianyi/unsloth_Qwen3-14B-Base
library_name: peft
pipeline_tag: text-generation
tags:
- base_model:adapter:shenzhentianyi/unsloth_Qwen3-14B-Base
- lora
- sft
- transformers
- trl
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.16.0
|
callgg/qwen2.5-vl-3b-it-bf16
|
callgg
| 2025-08-06T22:27:36Z | 4 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"qwen2_5_vl",
"gguf-node",
"license:apache-2.0",
"region:us"
] | null | 2025-08-06T21:34:27Z |
---
license: apache-2.0
library_name: diffusers
tags:
- gguf-node
---
## qwen2.5-vl-3b-it
- base model from qwen
- for text/image-text-to-text generation
|
raniero/dpo_test_1754519141
|
raniero
| 2025-08-06T22:26:45Z | 0 | 0 | null |
[
"safetensors",
"LORA",
"bittensor",
"gradients",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:finetune:meta-llama/Llama-2-7b-hf",
"license:apache-2.0",
"region:us"
] | null | 2025-08-06T22:26:28Z |
---
base_model: meta-llama/Llama-2-7b-hf
tags:
- LORA
- bittensor
- gradients
license: apache-2.0
---
# Submission for task `raniero/dpo_test_1754519141`
Fine-tuned using LoRA on dynamic dataset.
- Task ID: `raniero/dpo_test_1754519141`
- Repo: `raniero/dpo_test_1754519141`
- Timestamp: 2025-08-06T22:26:28.400969
|
UzzyDizzy/Reinforce-PixelcopterEnv
|
UzzyDizzy
| 2025-08-06T22:24:01Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-06T22:23:31Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-PixelcopterEnv
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 15.30 +/- 14.52
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
AmpereComputing/granite-3.3-2b-instruct-gguf
|
AmpereComputing
| 2025-08-06T22:22:48Z | 64 | 0 | null |
[
"gguf",
"base_model:ibm-granite/granite-3.3-2b-instruct",
"base_model:quantized:ibm-granite/granite-3.3-2b-instruct",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-06T22:21:34Z |
---
base_model:
- ibm-granite/granite-3.3-2b-instruct
---

# Ampere® optimized llama.cpp

Ampere® optimized build of [llama.cpp](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#llamacpp) with full support for rich collection of GGUF models available at HuggingFace: [GGUF models](https://huggingface.co/models?search=gguf)
**For best results we recommend using models in our custom quantization formats available here: [AmpereComputing HF](https://huggingface.co/AmpereComputing)**
This Docker image can be run on bare metal Ampere® CPUs and Ampere® based VMs available in the cloud.
Release notes and binary executables are available on our [GitHub](https://github.com/AmpereComputingAI/llama.cpp/releases)
## Starting container
Default entrypoint runs the server binary of llama.cpp, mimicking behavior of original llama.cpp server image: [docker image](https://github.com/ggerganov/llama.cpp/blob/master/.devops/llama-server.Dockerfile)
To launch shell instead, do this:
```bash
sudo docker run --privileged=true --name llama --entrypoint /bin/bash -it amperecomputingai/llama.cpp:latest
```
Quick start example will be presented at docker container launch:

Make sure to visit us at [Ampere Solutions Portal](https://solutions.amperecomputing.com/solutions/ampere-ai)!
## Quantization
Ampere® optimized build of llama.cpp provides support for two new quantization methods, Q4_K_4 and Q8R16, offering model size and perplexity similar to Q4_K and Q8_0, respectively, but performing up to 1.5-2x faster on inference.
First, you'll need to convert the model to the GGUF format using [this script](https://github.com/ggerganov/llama.cpp/blob/master/convert_hf_to_gguf.py):
```bash
python3 convert-hf-to-gguf.py [path to the original model] --outtype [f32, f16, bf16 or q8_0] --outfile [output path]
```
For example:
```bash
python3 convert-hf-to-gguf.py path/to/llama2 --outtype f16 --outfile llama-2-7b-f16.gguf
```
Next, you can quantize the model using the following command:
```bash
./llama-quantize [input file] [output file] [quantization method]
```
For example:
```bash
./llama-quantize llama-2-7b-f16.gguf llama-2-7b-Q8R16.gguf Q8R16
```
## Support
Please contact us at <[email protected]>
## LEGAL NOTICE
By accessing, downloading or using this software and any required dependent software (the “Ampere AI Software”), you agree to the terms and conditions of the software license agreements for the Ampere AI Software, which may also include notices, disclaimers, or license terms for third party software included with the Ampere AI Software. Please refer to the [Ampere AI Software EULA v1.6](https://ampereaidevelop.s3.eu-central-1.amazonaws.com/Ampere+AI+Software+EULA+-+v1.6.pdf) or other similarly-named text file for additional details.
|
sandernotenbaert/okai-musiclang-content-t5-small_finetune
|
sandernotenbaert
| 2025-08-06T22:22:25Z | 146 | 0 |
transformers
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:sandernotenbaert/okai-musiclang-content-t5-small_finetune",
"base_model:finetune:sandernotenbaert/okai-musiclang-content-t5-small_finetune",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2025-08-05T01:28:28Z |
---
library_name: transformers
base_model: sandernotenbaert/okai-musiclang-content-t5-small_finetune
tags:
- generated_from_trainer
model-index:
- name: okai-musiclang-content-t5-small_finetune
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# okai-musiclang-content-t5-small_finetune
This model is a fine-tuned version of [sandernotenbaert/okai-musiclang-content-t5-small_finetune](https://huggingface.co/sandernotenbaert/okai-musiclang-content-t5-small_finetune) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5041
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 64
- optimizer: Use OptimizerNames.ADAFACTOR and the args are:
No additional optimizer arguments
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_ratio: 0.02
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:-----:|:---------------:|
| 1.7839 | 0.2226 | 500 | 1.6513 |
| 1.6576 | 0.4452 | 1000 | 1.6615 |
| 1.6396 | 0.6679 | 1500 | 1.6650 |
| 1.7168 | 0.8905 | 2000 | 1.6315 |
| 1.7366 | 1.1131 | 2500 | 1.6234 |
| 1.7171 | 1.3357 | 3000 | 1.6028 |
| 1.6238 | 1.5583 | 3500 | 1.6130 |
| 1.6217 | 1.7810 | 4000 | 1.6218 |
| 1.7077 | 2.0036 | 4500 | 1.5784 |
| 1.7034 | 2.2262 | 5000 | 1.5792 |
| 1.6049 | 2.4488 | 5500 | 1.5866 |
| 1.6018 | 2.6714 | 6000 | 1.5869 |
| 1.6628 | 2.8941 | 6500 | 1.5628 |
| 1.653 | 3.1171 | 7000 | 1.5606 |
| 1.6575 | 3.3397 | 7500 | 1.5381 |
| 1.64 | 3.5619 | 8000 | 1.5395 |
| 1.6455 | 3.7845 | 8500 | 1.5163 |
| 1.6308 | 4.0076 | 9000 | 1.5311 |
| 1.6324 | 4.2302 | 9500 | 1.5118 |
| 1.5481 | 4.4528 | 10000 | 1.5092 |
| 1.547 | 4.6754 | 10500 | 1.5109 |
| 1.5584 | 4.8981 | 11000 | 1.5041 |
### Framework versions
- Transformers 4.55.0
- Pytorch 2.6.0+cu124
- Datasets 4.0.0
- Tokenizers 0.21.2
|
zerofata/MS3.2-PaintedFantasy-Visage-v2-33B
|
zerofata
| 2025-08-06T22:20:32Z | 164 | 3 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"axolotl",
"dataset:zerofata/Roleplay-Anime-Characters",
"dataset:zerofata/Instruct-Anime-CreativeWriting",
"dataset:zerofata/Instruct-Anime",
"dataset:zerofata/Summaries-Anime-FandomPages",
"dataset:zerofata/Stories-Anime",
"dataset:Nitral-AI/Reddit-NSFW-Writing_Prompts_ShareGPT",
"base_model:zerofata/MS3.2-PaintedFantasy-v2-24B",
"base_model:finetune:zerofata/MS3.2-PaintedFantasy-v2-24B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-03T02:47:52Z |
---
base_model:
- zerofata/MS3.2-PaintedFantasy-v2-24B
library_name: transformers
tags:
- mergekit
- merge
- axolotl
license: apache-2.0
datasets:
- zerofata/Roleplay-Anime-Characters
- zerofata/Instruct-Anime-CreativeWriting
- zerofata/Instruct-Anime
- zerofata/Summaries-Anime-FandomPages
- zerofata/Stories-Anime
- Nitral-AI/Reddit-NSFW-Writing_Prompts_ShareGPT
---
<style>
.container {
--primary-accent: #EC83B1;
--secondary-accent: #86C5E5;
--tertiary-accent: #FDE484;
--accent-rose: #F8A5C2;
--bg-main: #1A1D2E;
--bg-container: #232741;
--bg-card: rgba(40, 45, 70, 0.7);
--text-main: #E8ECF0;
--text-muted: #B8C2D0;
--white: #FFFFFF;
--font-title: 'Inter', serif;
--font-heading: 'Inter', serif;
--font-body: 'Inter', serif;
--font-code: 'JetBrains Mono', monospace;
font-family: var(--font-body);
color: var(--text-main);
line-height: 1.6;
max-width: 1200px;
margin: 20px auto;
padding: 40px 20px;
background-color: var(--bg-container);
background-image:
radial-gradient(circle at 20% 80%, rgba(236, 131, 177, 0.04) 0%, transparent 50%),
radial-gradient(circle at 80% 20%, rgba(134, 197, 229, 0.04) 0%, transparent 50%),
radial-gradient(circle at 40% 40%, rgba(253, 228, 132, 0.02) 0%, transparent 50%);
min-height: calc(100vh - 40px);
border: 1px solid var(--primary-accent);
border-radius: 8px;
box-shadow: 0 8px 32px rgba(236, 131, 177, 0.07);
}
.container .title-container {
background-color: var(--bg-main);
position: relative;
overflow: hidden;
margin-bottom: 40px;
border-left: 3px solid var(--primary-accent);
box-shadow: 0 6px 20px rgba(236, 131, 177, 0.07);
}
.container .title-wrapper {
position: relative;
z-index: 2;
padding: 25px 20px 30px 30px;
font-family: var(--font-title);
}
.container .title-main {
color: var(--accent-rose);
font-size: 2.5rem;
font-weight: 700;
margin: 0;
letter-spacing: 2px;
display: inline-block;
position: relative;
text-transform: uppercase;
}
.container .title-prefix {
position: relative;
z-index: 2;
}
.container .lemonade-text {
color: var(--secondary-accent);
position: relative;
z-index: 2;
margin-left: 0.2em;
text-shadow: 0 0 15px var(--secondary-accent);
}
.container .title-subtitle {
padding-left: 15px;
margin-top: 5px;
margin-left: 5px;
}
.container .subtitle-text {
color: var(--text-muted);
font-size: 1.2rem;
font-family: var(--font-body);
font-weight: 300;
letter-spacing: 3px;
text-transform: uppercase;
display: inline-block;
}
.container .glitchy-overlay {
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 100%;
background-image: repeating-linear-gradient(0deg, rgba(0,0,0,0) 0, rgba(134, 197, 229, 0.08) 1px, rgba(0,0,0,0) 2px);
z-index: 1;
}
.container img {
max-width: 100%;
border: 3px solid var(--white);
margin-bottom: 30px;
box-shadow: 0 0 15px rgba(0, 0, 0, 0.3);
}
.container .section-container {
background-color: var(--bg-card);
margin-bottom: 30px;
position: relative;
overflow: hidden;
border-bottom: none !important;
box-shadow: 0 4px 15px rgba(236, 131, 177, 0.05);
}
.container .section-header {
display: flex;
align-items: center;
background-color: rgba(236, 131, 177, 0.12);
padding: 10px 20px;
border-bottom: none !important;
}
.container .section-indicator {
width: 8px;
height: 20px;
background-color: var(--primary-accent);
margin-right: 15px;
box-shadow: 0 0 8px rgba(236, 131, 177, 0.2);
}
.container .section-title {
font-family: var(--font-heading);
color: var(--accent-rose);
font-size: 1.4rem;
margin: 0 !important;
padding: 0 !important;
letter-spacing: 1px;
font-weight: 400;
text-transform: capitalize;
border-bottom: none !important;
}
.container .section-content {
padding: 20px;
font-family: var(--font-body);
color: var(--text-main);
line-height: 1.6;
}
.container .subheading {
color: var(--text-muted);
font-size: 1.1rem;
margin-top: 20px;
margin-bottom: 15px;
font-weight: 400;
border-bottom: 1px dashed rgba(184, 194, 208, 0.4);
display: inline-block;
text-transform: uppercase;
letter-spacing: 1px;
font-family: var(--font-heading);
}
.container .data-box {
background-color: rgba(26, 29, 46, 0.6);
padding: 15px;
border-left: 2px solid var(--primary-accent);
margin-bottom: 20px;
box-shadow: 0 2px 10px rgba(236, 131, 177, 0.05);
}
.container .data-row {
display: flex;
margin-bottom: 8px;
align-items: center;
}
.container .data-row:last-child { margin-bottom: 0; }
.container .data-arrow {
color: var(--primary-accent);
width: 20px;
display: inline-block;
}
.container .data-label {
color: var(--text-muted);
width: 80px;
display: inline-block;
}
.container a {
color: var(--secondary-accent);
text-decoration: none;
font-weight: 600;
transition: color .3s;
}
.container a:hover {
text-decoration: underline;
color: var(--accent-rose);
}
.container .data-box a {
position: relative;
background-image: linear-gradient(to top, var(--primary-accent), var(--primary-accent));
background-position: 0 100%;
background-repeat: no-repeat;
background-size: 0% 2px;
transition: background-size .3s, color .3s;
}
.container .data-box a:hover {
color: var(--primary-accent);
background-size: 100% 2px;
}
.container .dropdown-container {
margin-top: 20px;
}
.container .dropdown-summary {
cursor: pointer;
padding: 10px 0;
border-bottom: 1px dashed rgba(184, 194, 208, 0.4);
color: var(--text-muted);
font-size: 1.1rem;
font-weight: 400;
text-transform: uppercase;
letter-spacing: 1px;
font-family: var(--font-heading);
list-style: none;
display: flex;
align-items: center;
}
.container .dropdown-summary::-webkit-details-marker {
display: none;
}
.container .dropdown-arrow {
color: var(--primary-accent);
margin-right: 10px;
transition: transform 0.3s ease;
}
.container details[open] .dropdown-arrow {
transform: rotate(90deg);
}
.container .dropdown-content {
margin-top: 15px;
padding: 15px;
background-color: rgba(26, 29, 46, 0.6);
border-left: 2px solid var(--primary-accent);
box-shadow: 0 2px 10px rgba(236, 131, 177, 0.05);
}
.container .config-title {
color: var(--text-muted);
font-size: 1rem;
margin-bottom: 10px;
font-family: var(--font-heading);
text-transform: uppercase;
letter-spacing: 1px;
}
.container pre {
background-color: var(--bg-main);
padding: 15px;
border: 1px solid rgba(134, 197, 229, 0.4);
white-space: pre-wrap;
word-wrap: break-word;
color: var(--text-main);
border-radius: 4px;
}
.container code {
font-family: var(--font-code);
background: transparent;
padding: 0;
}
</style>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Painted Fantasy</title>
<link rel="preconnect" href="https://fonts.googleapis.com">
<link rel="preconnect" href="https://fonts.gstatic.com" crossorigin>
<link href="https://fonts.googleapis.com/css2?family=Inter:wght@300;400;600;700&family=JetBrains+Mono:wght@400;700&display=swap" rel="stylesheet">
</head>
<body>
<div class="container">
<div class="title-container">
<div class="glitchy-overlay"></div>
<div class="title-wrapper">
<h1 class="title-main">
<span class="title-prefix">PAINTED FANTASY</span>
<span class="lemonade-text">VISAGE v2</span>
</h1>
<div class="title-subtitle">
<span class="subtitle-text">Mistrall Small 3.2 Upscaled 33B</span>
</div>
</div>
</div>

<div class="section-container">
<div class="section-header">
<div class="section-indicator"></div>
<h2 class="section-title">Overview</h2>
</div>
<div class="section-content">
<p>A surprisingly difficult model to work with. Removing the repetition was coming at the expense of the unique creativity the original upscale had.</p>
<p>Decided on upscaling Painted Fantasy v2, healing it and then merging the original upscale back in.</p>
<p>The result is a smarter, uncensored, creative model that excels at character driven RP / ERP where characters are portrayed creatively and proactively.</p>
</div>
</div>
<div class="section-container">
<div class="section-header">
<div class="section-indicator"></div>
<h2 class="section-title">SillyTavern Settings</h2>
</div>
<div class="section-content">
<h3 class="subheading">Recommended Roleplay Format</h3>
<div class="data-box">
<div class="data-row">
<span class="data-arrow">></span>
<span class="data-label">Actions:</span>
<span>In plaintext</span>
</div>
<div class="data-row">
<span class="data-arrow">></span>
<span class="data-label">Dialogue:</span>
<span>"In quotes"</span>
</div>
<div class="data-row">
<span class="data-arrow">></span>
<span class="data-label">Thoughts:</span>
<span>*In asterisks*</span>
</div>
</div>
<h3 class="subheading">Recommended Samplers</h3>
<div class="data-box">
<div class="data-row">
<span class="data-arrow">></span>
<span class="data-label">Temp:</span>
<span>0.6</span>
</div>
<div class="data-row">
<span class="data-arrow">></span>
<span class="data-label">MinP:</span>
<span>0.05 - 0.1</span>
</div>
<div class="data-row">
<span class="data-arrow">></span>
<span class="data-label">TopP:</span>
<span>0.9 - 1.0</span>
</div>
<div class="data-row">
<span class="data-arrow">></span>
<span class="data-label">Dry:</span>
<span>0.8, 1.75, 4</span>
</div>
</div>
<h3 class="subheading">Instruct</h3>
<div class="data-box">
<p style="margin: 0;">Mistral v7 Tekken</p>
</div>
</div>
</div>
<div class="section-container">
<div class="section-header">
<div class="section-indicator"></div>
<h2 class="section-title">Quantizations</h2>
</div>
<div class="section-content">
<div style="margin-bottom: 20px;">
<h3 class="subheading">GGUF</h3>
<div class="data-box">
<div class="data-row">
<span class="data-arrow">></span>
<a href="https://huggingface.co/bartowski/zerofata_MS3.2-PaintedFantasy-Visage-v2-33B-GGUF">iMatrix (bartowski)</a>
</div>
</div>
</div>
<div>
<h3 class="subheading">EXL3</h3>
<div class="data-box">
<div class="data-row">
<span class="data-arrow">></span>
<a href="https://huggingface.co/zerofata/MS3.2-PaintedFantasy-Visage-v2-33B-exl3-3bpw">3bpw</a>
</div>
<div class="data-row">
<span class="data-arrow">></span>
<a href="https://huggingface.co/zerofata/MS3.2-PaintedFantasy-Visage-v2-33B-exl3-4bpw">4bpw</a>
</div>
<div class="data-row">
<span class="data-arrow">></span>
<a href="https://huggingface.co/zerofata/MS3.2-PaintedFantasy-Visage-v2-33B-exl3-5bpw">5bpw</a>
</div>
<div class="data-row">
<span class="data-arrow">></span>
<a href="https://huggingface.co/zerofata/MS3.2-PaintedFantasy-Visage-v2-33B-exl3-6bpw">6bpw</a>
</div>
</div>
</div>
</div>
</div>
<div class="section-container">
<div class="section-header">
<div class="section-indicator"></div>
<h2 class="section-title">Creation Process</h2>
</div>
<div class="section-content">
<p>Creation Process: Upscale > PT > SFT > KTO > DPO</p>
<p>Pretrained on approx 300MB of light novels, SFW / NSFW stories and FineWeb-2 corpus.</p>
<p>SFT on approx 8 million tokens, SFW / NSFW RP, stories and creative instruct data.</p>
<p>KTO on antirep data created from the SFT datasets. Rejected examples generated by MS3.2 with repetition_penalty=0.9 and OOC commands encouraging it to misgender, impersonate user etc.</p>
<p>DPO on a high quality RP / NSFW dataset that is unreleased using rejected samples created in the same method as KTO.</p>
<p>Resulting model was non repetitive, but had lost some of the spark the original upscale had. Merged the original upscale back in, making sure to not reintroduce repetition.</p>
<div class="dropdown-container">
<details>
<summary class="dropdown-summary">
<span class="dropdown-arrow">></span>
Mergekit configs
</summary>
<div class="dropdown-content">
<p>Merge configurations used during the model creation process.</p>
<div class="config-title">Initial Upscale (Passthrough)</div>
<pre><code>base_model: zerofata/MS3.2-PaintedFantasy-v2-24B
<br>
merge_method: passthrough
<br>
dtype: bfloat16
slices:
- sources:
- model: zerofata/MS3.2-PaintedFantasy-v2-24B
layer_range: [0, 29]
- sources:
- model: zerofata/MS3.2-PaintedFantasy-v2-24B
layer_range: [10, 39]</code></pre>
<div class="config-title">Final Merge (Slerp)</div>
<pre><code>models:
- model: zerofata/MS3.2-PaintedFantasy-Visage-33B
- model: ../axolotl/Visage-V2-PT-1-SFT-2-KTO-1-DPO-1/merged
merge_method: slerp
base_model: ../axolotl/Visage-V2-PT-1-SFT-2-KTO-1-DPO-1/merged
parameters:
t: [0.4, 0.2, 0, 0.2, 0.4]
dtype: bfloat16</code></pre>
</div>
</details>
</div>
<div class="dropdown-container">
<details>
<summary class="dropdown-summary">
<span class="dropdown-arrow">></span>
Axolotl configs
</summary>
<div class="dropdown-content">
<p>Not optimized for cost / performance efficiency, YMMV.</p>
<div class="config-title">Pretrain 4*H100</div>
<pre><code># ====================
# MODEL CONFIGURATION
# ====================
base_model: ../mergekit/pf_v2_upscale
model_type: MistralForCausalLM
tokenizer_type: AutoTokenizer
chat_template: mistral_v7_tekken
# ====================
# DATASET CONFIGURATION
# ====================
datasets:
- path: ./data/pretrain_dataset_v5_stripped.jsonl
type: completion
<br>
dataset_prepared_path:
train_on_inputs: false # Only train on assistant responses
<br>
# ====================
# QLORA CONFIGURATION
# ====================
adapter: qlora
load_in_4bit: true
lora_r: 32
lora_alpha: 64
lora_dropout: 0.05
lora_target_linear: true
# lora_modules_to_save: # Uncomment only if you added NEW tokens
<br>
# ====================
# TRAINING PARAMETERS
# ====================
num_epochs: 1
micro_batch_size: 4
gradient_accumulation_steps: 1
learning_rate: 4e-5
optimizer: paged_adamw_8bit
lr_scheduler: rex
warmup_ratio: 0.05
weight_decay: 0.01
max_grad_norm: 1.0
<br>
# ====================
# SEQUENCE & PACKING
# ====================
sequence_len: 12288
sample_packing: true
eval_sample_packing: false
pad_to_sequence_len: true
<br>
# ====================
# HARDWARE OPTIMIZATIONS
# ====================
bf16: auto
flash_attention: true
gradient_checkpointing: offload
deepspeed: deepspeed_configs/zero1.json
<br>
plugins:
- axolotl.integrations.liger.LigerPlugin
- axolotl.integrations.cut_cross_entropy.CutCrossEntropyPlugin
cut_cross_entropy: true
liger_rope: true
liger_rms_norm: true
liger_layer_norm: true
liger_glu_activation: true
liger_cross_entropy: false # Cut Cross Entropy overrides this
liger_fused_linear_cross_entropy: false # Cut Cross Entropy overrides this
<br>
# ====================
# EVALUATION & CHECKPOINTING
# ====================
save_strategy: steps
save_steps: 40
save_total_limit: 5 # Keep best + last few checkpoints
load_best_model_at_end: true
greater_is_better: false
<br>
# ====================
# LOGGING & OUTPUT
# ====================
output_dir: ./Visage-V2-PT-1
logging_steps: 2
save_safetensors: true
<br>
# ====================
# WANDB TRACKING
# ====================
wandb_project: Visage-V2-PT
# wandb_entity: your_entity
wandb_name: Visage-V2-PT-1</code></pre>
<div class="config-title">SFT 4*H100</div>
<pre><code># ====================
# MODEL CONFIGURATION
# ====================
base_model: ./Visage-V2-PT-1/merged
model_type: MistralForCausalLM
tokenizer_type: AutoTokenizer
chat_template: mistral_v7_tekken
<br>
# ====================
# DATASET CONFIGURATION
# ====================
datasets:
- path: ./data/automated_dataset.jsonl
type: chat_template
split: train
chat_template_strategy: tokenizer
field_messages: messages
message_property_mappings:
role: role
content: content
roles:
user: ["user"]
assistant: ["assistant"]
system: ["system"]
- path: ./data/handcrafted_dataset.jsonl
type: chat_template
split: train
chat_template_strategy: tokenizer
field_messages: messages
message_property_mappings:
role: role
content: content
roles:
user: ["user"]
assistant: ["assistant"]
system: ["system"]
- path: ./data/instruct_dataset.jsonl
type: chat_template
split: train
chat_template_strategy: tokenizer
field_messages: messages
message_property_mappings:
role: role
content: content
roles:
user: ["user"]
assistant: ["assistant"]
system: ["system"]
- path: ./data/cw_dataset.jsonl
type: chat_template
split: train
chat_template_strategy: tokenizer
field_messages: messages
message_property_mappings:
role: role
content: content
roles:
user: ["user"]
assistant: ["assistant"]
system: ["system"]
- path: ./data/stories_dataset.jsonl
type: chat_template
split: train
chat_template_strategy: tokenizer
field_messages: messages
message_property_mappings:
role: role
content: content
roles:
user: ["user"]
assistant: ["assistant"]
system: ["system"]
- path: ./data/cw_claude_dataset.jsonl
type: chat_template
split: train
chat_template_strategy: tokenizer
field_messages: messages
message_property_mappings:
role: role
content: content
roles:
user: ["user"]
assistant: ["assistant"]
system: ["system"]
- path: ./data/summaries_dataset.jsonl
type: chat_template
split: train
chat_template_strategy: tokenizer
field_messages: messages
message_property_mappings:
role: role
content: content
roles:
user: ["user"]
assistant: ["assistant"]
system: ["system"]
<br>
dataset_prepared_path:
train_on_inputs: false # Only train on assistant responses
<br>
# ====================
# QLORA CONFIGURATION
# ====================
adapter: qlora
load_in_4bit: true
lora_r: 128
lora_alpha: 128
lora_dropout: 0.1
lora_target_linear: true
# lora_modules_to_save: # Uncomment only if you added NEW tokens
<br>
# ====================
# TRAINING PARAMETERS
# ====================
num_epochs: 2
micro_batch_size: 2
gradient_accumulation_steps: 1
learning_rate: 1e-5
optimizer: paged_adamw_8bit
lr_scheduler: rex
warmup_ratio: 0.05
weight_decay: 0.01
max_grad_norm: 1.0
<br>
# ====================
# SEQUENCE & PACKING
# ====================
sequence_len: 8192
sample_packing: true
pad_to_sequence_len: true
<br>
# ====================
# HARDWARE OPTIMIZATIONS
# ====================
bf16: auto
flash_attention: true
gradient_checkpointing: offload
deepspeed: deepspeed_configs/zero1.json
<br>
plugins:
- axolotl.integrations.liger.LigerPlugin
- axolotl.integrations.cut_cross_entropy.CutCrossEntropyPlugin
cut_cross_entropy: true
liger_rope: true
liger_rms_norm: true
liger_layer_norm: true
liger_glu_activation: true
liger_cross_entropy: false # Cut Cross Entropy overrides this
liger_fused_linear_cross_entropy: false # Cut Cross Entropy overrides this
<br>
<br>
# ====================
# EVALUATION & CHECKPOINTING
# ====================
save_strategy: steps
save_steps: 20
save_total_limit: 5 # Keep best + last few checkpoints
load_best_model_at_end: true
metric_for_best_model: eval_loss
greater_is_better: false
<br>
# ====================
# LOGGING & OUTPUT
# ====================
output_dir: ./Visage-V2-PT-1-SFT-2
logging_steps: 2
save_safetensors: true
<br>
# ====================
# WANDB TRACKING
# ====================
wandb_project: Visage-V2-SFT
# wandb_entity: your_entity
wandb_name: Visage-V2-PT-1-SFT-2</code></pre>
<div class="config-title">KTO 4*H100</div>
<pre><code># ====================
# MODEL CONFIGURATION
# ====================
base_model: ./Visage-V2-PT-1-SFT-2/merged
model_type: MistralForCausalLM
tokenizer_type: AutoTokenizer
chat_template: mistral_v7_tekken
<br>
# ====================
# RL/DPO CONFIGURATION
# ====================
rl: kto
rl_beta: 0.1
kto_desirable_weight: 1.25
kto_undesirable_weight: 1.0
<br>
# ====================
# DATASET CONFIGURATION
# ====================
datasets:
- path: ./handcrafted_dataset_kto.jsonl
type: llama3.argilla
- path: ./approved_rp_dataset_kto.jsonl
type: llama3.argilla
- path: ./instruct_dataset_kto.jsonl
type: llama3.argilla
dataset_prepared_path:
train_on_inputs: false # Only train on assistant responses
remove_unused_columns: False
<br>
# ====================
# QLORA CONFIGURATION
# ====================
adapter: qlora
load_in_4bit: true
lora_r: 32
lora_alpha: 32
lora_dropout: 0.05
lora_target_linear: true
# lora_modules_to_save: # Uncomment only if you added NEW tokens
<br>
# ====================
# TRAINING PARAMETERS
# ====================
num_epochs: 1
micro_batch_size: 4
gradient_accumulation_steps: 4
learning_rate: 5e-6
optimizer: adamw_8bit
lr_scheduler: cosine
warmup_steps: 15
weight_decay: 0.001
max_grad_norm: 0.01
<br>
# ====================
# SEQUENCE CONFIGURATION
# ====================
sequence_len: 8192
pad_to_sequence_len: true
<br>
# ====================
# HARDWARE OPTIMIZATIONS
# ====================
bf16: auto
tf32: false
flash_attention: true
gradient_checkpointing: offload
deepspeed: deepspeed_configs/zero1.json
<br>
plugins:
- axolotl.integrations.liger.LigerPlugin
- axolotl.integrations.cut_cross_entropy.CutCrossEntropyPlugin
cut_cross_entropy: true
liger_rope: true
liger_rms_norm: true
liger_layer_norm: true
liger_glu_activation: true
liger_cross_entropy: false # Cut Cross Entropy overrides this
liger_fused_linear_cross_entropy: false # Cut Cross Entropy overrides this
<br>
# ====================
# CHECKPOINTING
# ====================
save_steps: 100
save_total_limit: 10
load_best_model_at_end: true
metric_for_best_model: eval_loss
greater_is_better: false
<br>
# ====================
# LOGGING & OUTPUT
# ====================
output_dir: ./Visage-V2-PT-1-SFT-2-KTO-1
logging_steps: 2
save_safetensors: true
<br>
# ====================
# WANDB TRACKING
# ====================
wandb_project: Visage-V2-KTO
# wandb_entity: your_entity
wandb_name: Visage-V2-PT-1-SFT-2-KTO-1</code></pre>
<div class="config-title">DPO 4*H100</div>
<pre><code># ====================
# MODEL CONFIGURATION
# ====================
base_model: ./Visage-V2-PT-1-SFT-2/merged
model_type: MistralForCausalLM
tokenizer_type: AutoTokenizer
chat_template: mistral_v7_tekken
<br>
# ====================
# RL/DPO CONFIGURATION
# ====================
rl: dpo
rl_beta: 0.1
<br>
# ====================
# DATASET CONFIGURATION
# ====================
datasets:
- path: ./handcrafted_dataset_mistral_rep.jsonl
type: chat_template.default
field_messages: messages
field_chosen: chosen
field_rejected: rejected
message_property_mappings:
role: role
content: content
roles:
system: ["system"]
user: ["user"]
assistant: ["assistant"]
dataset_prepared_path:
train_on_inputs: false # Only train on assistant responses
<br>
# ====================
# QLORA CONFIGURATION
# ====================
adapter: qlora
load_in_4bit: true
lora_r: 16
lora_alpha: 32
lora_dropout: 0.1
lora_target_linear: true
# lora_modules_to_save: # Uncomment only if you added NEW tokens
<br>
# ====================
# TRAINING PARAMETERS
# ====================
num_epochs: 1
micro_batch_size: 2
gradient_accumulation_steps: 1
learning_rate: 2e-6
optimizer: adamw_8bit
lr_scheduler: cosine
warmup_steps: 5
weight_decay: 0.01
max_grad_norm: 1.0
<br>
# ====================
# SEQUENCE CONFIGURATION
# ====================
sequence_len: 8192
pad_to_sequence_len: true
<br>
# ====================
# HARDWARE OPTIMIZATIONS
# ====================
bf16: auto
tf32: false
flash_attention: true
gradient_checkpointing: offload
deepspeed: deepspeed_configs/zero1.json
<br>
plugins:
- axolotl.integrations.liger.LigerPlugin
- axolotl.integrations.cut_cross_entropy.CutCrossEntropyPlugin
cut_cross_entropy: true
liger_rope: true
liger_rms_norm: true
liger_layer_norm: true
liger_glu_activation: true
liger_cross_entropy: false # Cut Cross Entropy overrides this
liger_fused_linear_cross_entropy: false # Cut Cross Entropy overrides this
<br>
# ====================
# CHECKPOINTING
# ====================
save_steps: 10
save_total_limit: 10
load_best_model_at_end: true
metric_for_best_model: eval_loss
greater_is_better: false
<br>
# ====================
# LOGGING & OUTPUT
# ====================
output_dir: ./Visage-V2-PT-1-SFT-2-DPO-1
logging_steps: 2
save_safetensors: true
<br>
# ====================
# WANDB TRACKING
# ====================
wandb_project: Visage-V2-DPO
# wandb_entity: your_entity
wandb_name: Visage-V2-PT-1-SFT-2-DPO-1</code></pre>
</div>
</details>
</div>
</div>
</div>
</div>
</body>
</html>
|
assoni2002/training_zscaler_dataset
|
assoni2002
| 2025-08-06T22:20:16Z | 15 | 0 |
transformers
|
[
"transformers",
"safetensors",
"wav2vec2",
"audio-classification",
"generated_from_trainer",
"base_model:facebook/wav2vec2-base",
"base_model:finetune:facebook/wav2vec2-base",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2025-08-06T20:42:15Z |
---
library_name: transformers
license: apache-2.0
base_model: facebook/wav2vec2-base
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: training_zscaler_dataset
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# training_zscaler_dataset
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5501
- Accuracy: 0.7355
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6553 | 1.0 | 10 | 0.7152 | 0.4416 |
| 0.6279 | 2.0 | 20 | 0.5893 | 0.7532 |
| 0.5993 | 3.0 | 30 | 0.5791 | 0.7532 |
| 0.5761 | 4.0 | 40 | 0.5538 | 0.7727 |
| 0.5483 | 5.0 | 50 | 0.5169 | 0.8052 |
| 0.5291 | 6.0 | 60 | 0.5496 | 0.7662 |
| 0.5016 | 7.0 | 70 | 0.6360 | 0.6883 |
| 0.4962 | 8.0 | 80 | 0.4710 | 0.8312 |
| 0.4807 | 9.0 | 90 | 0.5224 | 0.7987 |
| 0.4798 | 10.0 | 100 | 0.4764 | 0.8182 |
### Framework versions
- Transformers 4.53.3
- Pytorch 2.7.1+cu126
- Datasets 4.0.0
- Tokenizers 0.21.2
|
prednya/cs5210-25su-finetuned-boxtobio-merged
|
prednya
| 2025-08-06T22:15:11Z | 32 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-08-06T00:43:09Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
LK7/20b
|
LK7
| 2025-08-06T22:12:58Z | 406 | 0 | null |
[
"gguf",
"text-generation",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-08-06T22:07:50Z |
---
tags:
- text-generation
---
|
NexVeridian/Seed-Coder-8B-Reasoning-8bit
|
NexVeridian
| 2025-08-06T22:01:18Z | 7 | 0 |
mlx
|
[
"mlx",
"safetensors",
"llama",
"text-generation",
"conversational",
"base_model:ByteDance-Seed/Seed-Coder-8B-Reasoning",
"base_model:quantized:ByteDance-Seed/Seed-Coder-8B-Reasoning",
"license:mit",
"8-bit",
"region:us"
] |
text-generation
| 2025-08-06T21:54:08Z |
---
library_name: mlx
pipeline_tag: text-generation
license: mit
base_model: ByteDance-Seed/Seed-Coder-8B-Reasoning
tags:
- mlx
---
# NexVeridian/Seed-Coder-8B-Reasoning-8bit
This model [NexVeridian/Seed-Coder-8B-Reasoning-8bit](https://huggingface.co/NexVeridian/Seed-Coder-8B-Reasoning-8bit) was
converted to MLX format from [ByteDance-Seed/Seed-Coder-8B-Reasoning](https://huggingface.co/ByteDance-Seed/Seed-Coder-8B-Reasoning)
using mlx-lm version **0.26.3**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("NexVeridian/Seed-Coder-8B-Reasoning-8bit")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
mondhs/l3-whisper-medium-l2c_v6
|
mondhs
| 2025-08-06T21:56:51Z | 21 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:openai/whisper-medium",
"base_model:finetune:openai/whisper-medium",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-08-05T07:33:59Z |
---
library_name: transformers
license: apache-2.0
base_model: openai/whisper-medium
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: l3-whisper-medium-l2c_v6
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# l3-whisper-medium-l2c_v6
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2449
- Wer: 18.3818
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 1
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:-----:|:---------------:|:-------:|
| 0.3468 | 0.0933 | 1000 | 0.3951 | 30.6669 |
| 0.2608 | 0.1866 | 2000 | 0.3316 | 25.5966 |
| 0.2264 | 0.2799 | 3000 | 0.3077 | 23.4182 |
| 0.2041 | 0.3731 | 4000 | 0.2867 | 22.0167 |
| 0.1891 | 0.4664 | 5000 | 0.2720 | 20.9015 |
| 0.1789 | 0.5597 | 6000 | 0.2669 | 20.0772 |
| 0.1708 | 0.6530 | 7000 | 0.2585 | 19.6288 |
| 0.1644 | 0.7463 | 8000 | 0.2524 | 18.8911 |
| 0.1604 | 0.8396 | 9000 | 0.2478 | 18.6108 |
| 0.155 | 0.9328 | 10000 | 0.2449 | 18.3818 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.4.1+cu124
- Datasets 3.6.0
- Tokenizers 0.21.4
|
llearningone/blockassist-bc-dextrous_fierce_alpaca_1754517029
|
llearningone
| 2025-08-06T21:51:39Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"dextrous fierce alpaca",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-06T21:51:31Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- dextrous fierce alpaca
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Samas21/53R135-2
|
Samas21
| 2025-08-06T21:38:20Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-07-27T18:58:29Z |
---
license: apache-2.0
---
|
unsloth/Qwen3-4B-Instruct-2507-bnb-4bit
|
unsloth
| 2025-08-06T21:37:21Z | 2 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"unsloth",
"conversational",
"arxiv:2505.09388",
"base_model:Qwen/Qwen3-4B-Instruct-2507",
"base_model:quantized:Qwen/Qwen3-4B-Instruct-2507",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-08-06T21:37:09Z |
---
tags:
- unsloth
base_model:
- Qwen/Qwen3-4B-Instruct-2507
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-4B-Instruct-2507/blob/main/LICENSE
pipeline_tag: text-generation
---
<div>
<p style="margin-top: 0;margin-bottom: 0;">
<em><a href="https://docs.unsloth.ai/basics/unsloth-dynamic-v2.0-gguf">Unsloth Dynamic 2.0</a> achieves superior accuracy & outperforms other leading quants.</em>
</p>
<div style="display: flex; gap: 5px; align-items: center; ">
<a href="https://github.com/unslothai/unsloth/">
<img src="https://github.com/unslothai/unsloth/raw/main/images/unsloth%20new%20logo.png" width="133">
</a>
<a href="https://discord.gg/unsloth">
<img src="https://github.com/unslothai/unsloth/raw/main/images/Discord%20button.png" width="173">
</a>
<a href="https://docs.unsloth.ai/">
<img src="https://raw.githubusercontent.com/unslothai/unsloth/refs/heads/main/images/documentation%20green%20button.png" width="143">
</a>
</div>
</div>
# Qwen3-4B-Instruct-2507
<a href="https://chat.qwen.ai" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
We introduce the updated version of the **Qwen3-4B non-thinking mode**, named **Qwen3-4B-Instruct-2507**, featuring the following key enhancements:
- **Significant improvements** in general capabilities, including **instruction following, logical reasoning, text comprehension, mathematics, science, coding and tool usage**.
- **Substantial gains** in long-tail knowledge coverage across **multiple languages**.
- **Markedly better alignment** with user preferences in **subjective and open-ended tasks**, enabling more helpful responses and higher-quality text generation.
- **Enhanced capabilities** in **256K long-context understanding**.
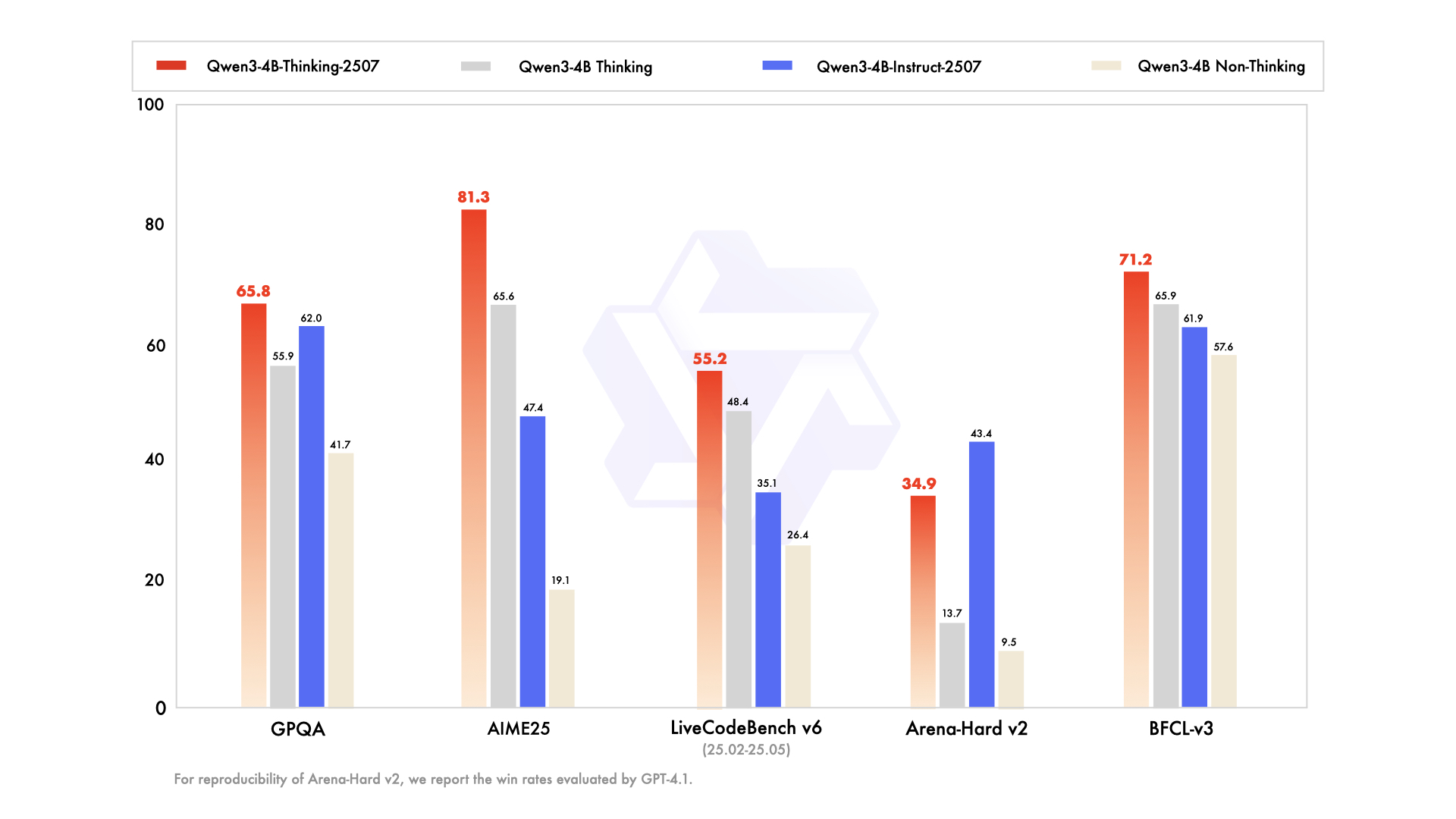
## Model Overview
**Qwen3-4B-Instruct-2507** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 4.0B
- Number of Paramaters (Non-Embedding): 3.6B
- Number of Layers: 36
- Number of Attention Heads (GQA): 32 for Q and 8 for KV
- Context Length: **262,144 natively**.
**NOTE: This model supports only non-thinking mode and does not generate ``<think></think>`` blocks in its output. Meanwhile, specifying `enable_thinking=False` is no longer required.**
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Performance
| | GPT-4.1-nano-2025-04-14 | Qwen3-30B-A3B Non-Thinking | Qwen3-4B Non-Thinking | Qwen3-4B-Instruct-2507 |
|--- | --- | --- | --- | --- |
| **Knowledge** | | | |
| MMLU-Pro | 62.8 | 69.1 | 58.0 | **69.6** |
| MMLU-Redux | 80.2 | 84.1 | 77.3 | **84.2** |
| GPQA | 50.3 | 54.8 | 41.7 | **62.0** |
| SuperGPQA | 32.2 | 42.2 | 32.0 | **42.8** |
| **Reasoning** | | | |
| AIME25 | 22.7 | 21.6 | 19.1 | **47.4** |
| HMMT25 | 9.7 | 12.0 | 12.1 | **31.0** |
| ZebraLogic | 14.8 | 33.2 | 35.2 | **80.2** |
| LiveBench 20241125 | 41.5 | 59.4 | 48.4 | **63.0** |
| **Coding** | | | |
| LiveCodeBench v6 (25.02-25.05) | 31.5 | 29.0 | 26.4 | **35.1** |
| MultiPL-E | 76.3 | 74.6 | 66.6 | **76.8** |
| Aider-Polyglot | 9.8 | **24.4** | 13.8 | 12.9 |
| **Alignment** | | | |
| IFEval | 74.5 | **83.7** | 81.2 | 83.4 |
| Arena-Hard v2* | 15.9 | 24.8 | 9.5 | **43.4** |
| Creative Writing v3 | 72.7 | 68.1 | 53.6 | **83.5** |
| WritingBench | 66.9 | 72.2 | 68.5 | **83.4** |
| **Agent** | | | |
| BFCL-v3 | 53.0 | 58.6 | 57.6 | **61.9** |
| TAU1-Retail | 23.5 | 38.3 | 24.3 | **48.7** |
| TAU1-Airline | 14.0 | 18.0 | 16.0 | **32.0** |
| TAU2-Retail | - | 31.6 | 28.1 | **40.4** |
| TAU2-Airline | - | 18.0 | 12.0 | **24.0** |
| TAU2-Telecom | - | **18.4** | 17.5 | 13.2 |
| **Multilingualism** | | | |
| MultiIF | 60.7 | **70.8** | 61.3 | 69.0 |
| MMLU-ProX | 56.2 | **65.1** | 49.6 | 61.6 |
| INCLUDE | 58.6 | **67.8** | 53.8 | 60.1 |
| PolyMATH | 15.6 | 23.3 | 16.6 | **31.1** |
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
## Quickstart
The code of Qwen3 has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-4B-Instruct-2507"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-4B-Instruct-2507 --context-length 262144
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-4B-Instruct-2507 --max-model-len 262144
```
**Note: If you encounter out-of-memory (OOM) issues, consider reducing the context length to a shorter value, such as `32,768`.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-4B-Instruct-2507',
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 16,384 tokens for most queries, which is adequate for instruct models.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
```
|
rbelanec/train_piqa_1754507483
|
rbelanec
| 2025-08-06T21:36:35Z | 23 | 0 |
peft
|
[
"peft",
"safetensors",
"llama-factory",
"ia3",
"generated_from_trainer",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"base_model:adapter:meta-llama/Meta-Llama-3-8B-Instruct",
"license:llama3",
"region:us"
] | null | 2025-08-06T19:12:05Z |
---
library_name: peft
license: llama3
base_model: meta-llama/Meta-Llama-3-8B-Instruct
tags:
- llama-factory
- ia3
- generated_from_trainer
model-index:
- name: train_piqa_1754507483
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# train_piqa_1754507483
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) on the piqa dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1045
- Num Input Tokens Seen: 22103448
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 123
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Input Tokens Seen |
|:-------------:|:-----:|:-----:|:---------------:|:-----------------:|
| 0.3099 | 0.5 | 1813 | 0.1600 | 1118368 |
| 0.1034 | 1.0 | 3626 | 0.1211 | 2216600 |
| 0.1183 | 1.5 | 5439 | 0.1136 | 3320792 |
| 0.064 | 2.0 | 7252 | 0.1102 | 4419000 |
| 0.1255 | 2.5 | 9065 | 0.1081 | 5525176 |
| 0.0724 | 3.0 | 10878 | 0.1070 | 6628280 |
| 0.0725 | 3.5 | 12691 | 0.1093 | 7736376 |
| 0.14 | 4.0 | 14504 | 0.1053 | 8844408 |
| 0.0916 | 4.5 | 16317 | 0.1046 | 9951832 |
| 0.1239 | 5.0 | 18130 | 0.1055 | 11048200 |
| 0.0888 | 5.5 | 19943 | 0.1049 | 12157032 |
| 0.0845 | 6.0 | 21756 | 0.1052 | 13257624 |
| 0.0719 | 6.5 | 23569 | 0.1046 | 14360952 |
| 0.0986 | 7.0 | 25382 | 0.1052 | 15468632 |
| 0.0909 | 7.5 | 27195 | 0.1045 | 16574840 |
| 0.0711 | 8.0 | 29008 | 0.1050 | 17678024 |
| 0.1367 | 8.5 | 30821 | 0.1047 | 18780040 |
| 0.111 | 9.0 | 32634 | 0.1049 | 19894712 |
| 0.0628 | 9.5 | 34447 | 0.1049 | 21014840 |
| 0.0366 | 10.0 | 36260 | 0.1047 | 22103448 |
### Framework versions
- PEFT 0.15.2
- Transformers 4.51.3
- Pytorch 2.8.0+cu128
- Datasets 3.6.0
- Tokenizers 0.21.1
|
unsloth/Qwen3-4B-Instruct-2507-unsloth-bnb-4bit
|
unsloth
| 2025-08-06T21:36:32Z | 28 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"unsloth",
"conversational",
"arxiv:2505.09388",
"base_model:Qwen/Qwen3-4B-Instruct-2507",
"base_model:quantized:Qwen/Qwen3-4B-Instruct-2507",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-08-06T21:36:12Z |
---
tags:
- unsloth
base_model:
- Qwen/Qwen3-4B-Instruct-2507
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-4B-Instruct-2507/blob/main/LICENSE
pipeline_tag: text-generation
---
<div>
<p style="margin-top: 0;margin-bottom: 0;">
<em><a href="https://docs.unsloth.ai/basics/unsloth-dynamic-v2.0-gguf">Unsloth Dynamic 2.0</a> achieves superior accuracy & outperforms other leading quants.</em>
</p>
<div style="display: flex; gap: 5px; align-items: center; ">
<a href="https://github.com/unslothai/unsloth/">
<img src="https://github.com/unslothai/unsloth/raw/main/images/unsloth%20new%20logo.png" width="133">
</a>
<a href="https://discord.gg/unsloth">
<img src="https://github.com/unslothai/unsloth/raw/main/images/Discord%20button.png" width="173">
</a>
<a href="https://docs.unsloth.ai/">
<img src="https://raw.githubusercontent.com/unslothai/unsloth/refs/heads/main/images/documentation%20green%20button.png" width="143">
</a>
</div>
</div>
# Qwen3-4B-Instruct-2507
<a href="https://chat.qwen.ai" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
We introduce the updated version of the **Qwen3-4B non-thinking mode**, named **Qwen3-4B-Instruct-2507**, featuring the following key enhancements:
- **Significant improvements** in general capabilities, including **instruction following, logical reasoning, text comprehension, mathematics, science, coding and tool usage**.
- **Substantial gains** in long-tail knowledge coverage across **multiple languages**.
- **Markedly better alignment** with user preferences in **subjective and open-ended tasks**, enabling more helpful responses and higher-quality text generation.
- **Enhanced capabilities** in **256K long-context understanding**.

## Model Overview
**Qwen3-4B-Instruct-2507** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 4.0B
- Number of Paramaters (Non-Embedding): 3.6B
- Number of Layers: 36
- Number of Attention Heads (GQA): 32 for Q and 8 for KV
- Context Length: **262,144 natively**.
**NOTE: This model supports only non-thinking mode and does not generate ``<think></think>`` blocks in its output. Meanwhile, specifying `enable_thinking=False` is no longer required.**
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Performance
| | GPT-4.1-nano-2025-04-14 | Qwen3-30B-A3B Non-Thinking | Qwen3-4B Non-Thinking | Qwen3-4B-Instruct-2507 |
|--- | --- | --- | --- | --- |
| **Knowledge** | | | |
| MMLU-Pro | 62.8 | 69.1 | 58.0 | **69.6** |
| MMLU-Redux | 80.2 | 84.1 | 77.3 | **84.2** |
| GPQA | 50.3 | 54.8 | 41.7 | **62.0** |
| SuperGPQA | 32.2 | 42.2 | 32.0 | **42.8** |
| **Reasoning** | | | |
| AIME25 | 22.7 | 21.6 | 19.1 | **47.4** |
| HMMT25 | 9.7 | 12.0 | 12.1 | **31.0** |
| ZebraLogic | 14.8 | 33.2 | 35.2 | **80.2** |
| LiveBench 20241125 | 41.5 | 59.4 | 48.4 | **63.0** |
| **Coding** | | | |
| LiveCodeBench v6 (25.02-25.05) | 31.5 | 29.0 | 26.4 | **35.1** |
| MultiPL-E | 76.3 | 74.6 | 66.6 | **76.8** |
| Aider-Polyglot | 9.8 | **24.4** | 13.8 | 12.9 |
| **Alignment** | | | |
| IFEval | 74.5 | **83.7** | 81.2 | 83.4 |
| Arena-Hard v2* | 15.9 | 24.8 | 9.5 | **43.4** |
| Creative Writing v3 | 72.7 | 68.1 | 53.6 | **83.5** |
| WritingBench | 66.9 | 72.2 | 68.5 | **83.4** |
| **Agent** | | | |
| BFCL-v3 | 53.0 | 58.6 | 57.6 | **61.9** |
| TAU1-Retail | 23.5 | 38.3 | 24.3 | **48.7** |
| TAU1-Airline | 14.0 | 18.0 | 16.0 | **32.0** |
| TAU2-Retail | - | 31.6 | 28.1 | **40.4** |
| TAU2-Airline | - | 18.0 | 12.0 | **24.0** |
| TAU2-Telecom | - | **18.4** | 17.5 | 13.2 |
| **Multilingualism** | | | |
| MultiIF | 60.7 | **70.8** | 61.3 | 69.0 |
| MMLU-ProX | 56.2 | **65.1** | 49.6 | 61.6 |
| INCLUDE | 58.6 | **67.8** | 53.8 | 60.1 |
| PolyMATH | 15.6 | 23.3 | 16.6 | **31.1** |
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
## Quickstart
The code of Qwen3 has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-4B-Instruct-2507"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-4B-Instruct-2507 --context-length 262144
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-4B-Instruct-2507 --max-model-len 262144
```
**Note: If you encounter out-of-memory (OOM) issues, consider reducing the context length to a shorter value, such as `32,768`.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-4B-Instruct-2507',
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 16,384 tokens for most queries, which is adequate for instruct models.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
```
|
Runware/Qwen-Image
|
Runware
| 2025-08-06T21:36:07Z | 3 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"en",
"zh",
"arxiv:2508.02324",
"license:apache-2.0",
"diffusers:QwenImagePipeline",
"region:us"
] |
text-to-image
| 2025-08-06T20:51:05Z |
---
license: apache-2.0
language:
- en
- zh
library_name: diffusers
pipeline_tag: text-to-image
---
<p align="center">
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/qwen_image_logo.png" width="400"/>
<p>
<p align="center">
💜 <a href="https://chat.qwen.ai/"><b>Qwen Chat</b></a>   |   🤗 <a href="https://huggingface.co/Qwen/Qwen-Image">Hugging Face</a>   |   🤖 <a href="https://modelscope.cn/models/Qwen/Qwen-Image">ModelScope</a>   |    📑 <a href="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/Qwen_Image.pdf">Tech Report</a>    |    📑 <a href="https://qwenlm.github.io/blog/qwen-image/">Blog</a>   
<br>
🖥️ <a href="https://huggingface.co/spaces/Qwen/qwen-image">Demo</a>   |   💬 <a href="https://github.com/QwenLM/Qwen-Image/blob/main/assets/wechat.png">WeChat (微信)</a>   |   🫨 <a href="https://discord.gg/CV4E9rpNSD">Discord</a>  
</p>
<p align="center">
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/merge3.jpg" width="1600"/>
<p>
## Introduction
We are thrilled to release **Qwen-Image**, an image generation foundation model in the Qwen series that achieves significant advances in **complex text rendering** and **precise image editing**. Experiments show strong general capabilities in both image generation and editing, with exceptional performance in text rendering, especially for Chinese.

## News
- 2025.08.04: We released the [Technical Report](https://arxiv.org/abs/2508.02324) of Qwen-Image!
- 2025.08.04: We released Qwen-Image weights! Check at [huggingface](https://huggingface.co/Qwen/Qwen-Image) and [Modelscope](https://modelscope.cn/models/Qwen/Qwen-Image)!
- 2025.08.04: We released Qwen-Image! Check our [blog](https://qwenlm.github.io/blog/qwen-image) for more details!
## Quick Start
Install the latest version of diffusers
```
pip install git+https://github.com/huggingface/diffusers
```
The following contains a code snippet illustrating how to use the model to generate images based on text prompts:
```python
from diffusers import DiffusionPipeline
import torch
model_name = "Qwen/Qwen-Image"
# Load the pipeline
if torch.cuda.is_available():
torch_dtype = torch.bfloat16
device = "cuda"
else:
torch_dtype = torch.float32
device = "cpu"
pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch_dtype)
pipe = pipe.to(device)
positive_magic = {
"en": "Ultra HD, 4K, cinematic composition." # for english prompt,
"zh": "超清,4K,电影级构图" # for chinese prompt,
}
# Generate image
prompt = '''A coffee shop entrance features a chalkboard sign reading "Qwen Coffee 😊 $2 per cup," with a neon light beside it displaying "通义千问". Next to it hangs a poster showing a beautiful Chinese woman, and beneath the poster is written "π≈3.1415926-53589793-23846264-33832795-02384197". Ultra HD, 4K, cinematic composition'''
negative_prompt = " " # using an empty string if you do not have specific concept to remove
# Generate with different aspect ratios
aspect_ratios = {
"1:1": (1328, 1328),
"16:9": (1664, 928),
"9:16": (928, 1664),
"4:3": (1472, 1140),
"3:4": (1140, 1472),
"3:2": (1584, 1056),
"2:3": (1056, 1584),
}
width, height = aspect_ratios["16:9"]
image = pipe(
prompt=prompt + positive_magic["en"],
negative_prompt=negative_prompt,
width=width,
height=height,
num_inference_steps=50,
true_cfg_scale=4.0,
generator=torch.Generator(device="cuda").manual_seed(42)
).images[0]
image.save("example.png")
```
## Show Cases
One of its standout capabilities is high-fidelity text rendering across diverse images. Whether it’s alphabetic languages like English or logographic scripts like Chinese, Qwen-Image preserves typographic details, layout coherence, and contextual harmony with stunning accuracy. Text isn’t just overlaid—it’s seamlessly integrated into the visual fabric.

Beyond text, Qwen-Image excels at general image generation with support for a wide range of artistic styles. From photorealistic scenes to impressionist paintings, from anime aesthetics to minimalist design, the model adapts fluidly to creative prompts, making it a versatile tool for artists, designers, and storytellers.

When it comes to image editing, Qwen-Image goes far beyond simple adjustments. It enables advanced operations such as style transfer, object insertion or removal, detail enhancement, text editing within images, and even human pose manipulation—all with intuitive input and coherent output. This level of control brings professional-grade editing within reach of everyday users.

But Qwen-Image doesn’t just create or edit—it understands. It supports a suite of image understanding tasks, including object detection, semantic segmentation, depth and edge (Canny) estimation, novel view synthesis, and super-resolution. These capabilities, while technically distinct, can all be seen as specialized forms of intelligent image editing, powered by deep visual comprehension.

Together, these features make Qwen-Image not just a tool for generating pretty pictures, but a comprehensive foundation model for intelligent visual creation and manipulation—where language, layout, and imagery converge.
## License Agreement
Qwen-Image is licensed under Apache 2.0.
## Citation
We kindly encourage citation of our work if you find it useful.
```bibtex
@misc{wu2025qwenimagetechnicalreport,
title={Qwen-Image Technical Report},
author={Chenfei Wu and Jiahao Li and Jingren Zhou and Junyang Lin and Kaiyuan Gao and Kun Yan and Sheng-ming Yin and Shuai Bai and Xiao Xu and Yilei Chen and Yuxiang Chen and Zecheng Tang and Zekai Zhang and Zhengyi Wang and An Yang and Bowen Yu and Chen Cheng and Dayiheng Liu and Deqing Li and Hang Zhang and Hao Meng and Hu Wei and Jingyuan Ni and Kai Chen and Kuan Cao and Liang Peng and Lin Qu and Minggang Wu and Peng Wang and Shuting Yu and Tingkun Wen and Wensen Feng and Xiaoxiao Xu and Yi Wang and Yichang Zhang and Yongqiang Zhu and Yujia Wu and Yuxuan Cai and Zenan Liu},
year={2025},
eprint={2508.02324},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2508.02324},
}
```
|
krajarat/TwinSmolLM2-360M-DPO
|
krajarat
| 2025-08-06T21:32:17Z | 2 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:krajarat/TwinSmolLM2-360M",
"base_model:finetune:krajarat/TwinSmolLM2-360M",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-06T21:31:18Z |
---
base_model: krajarat/TwinSmolLM2-360M
tags:
- text-generation-inference
- transformers
- unsloth
- llama
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** krajarat
- **License:** apache-2.0
- **Finetuned from model :** krajarat/TwinSmolLM2-360M
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.