
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
25.4k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 582
39.1k
| num_tokens
int64 271
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_6268
|
rasdani/github-patches
|
git_diff
|
pymedusa__Medusa-3047
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[APP SUBMITTED]: AttributeError: 'NavigableString' object has no attribute 'span'
### INFO
**Python Version**: `2.7.13 (v2.7.13:a06454b1afa1, Dec 17 2016, 20:53:40) [MSC v.1500 64 bit (AMD64)]`
**Operating System**: `Windows-10-10.0.15063`
**Locale**: `cp1252`
**Branch**: [develop](../tree/develop)
**Database**: `44.8`
**Commit**: pymedusa/Medusa@38e6cbf13d9cede5de23106b656dbbb90df2dd38
**Link to Log**: https://gist.github.com/39feec6e67c967a5e2fdec7f7bc2b69f
### ERROR
<pre>
2017-08-13 22:44:17 ERROR SEARCHQUEUE-FORCED-175001 :: [LimeTorrents] :: [38e6cbf] Unknown exception while searching LimeTorrents. Error: "'NavigableString' object has no attribute 'span'"
Traceback (most recent call last):
File "C:\Medusa\medusa\search\core.py", line 555, in search_providers
down_cur_quality, manual_search, manual_search_type)
File "C:\Medusa\medusa\providers\generic_provider.py", line 226, in find_search_results
items_list += self.search(search_string, ep_obj=episode)
File "C:\Medusa\medusa\providers\torrent\html\limetorrents.py", line 97, in search
results += self.parse(response.text, mode)
File "C:\Medusa\medusa\providers\torrent\html\limetorrents.py", line 124, in parse
labels = [process_column_header(label) for label in torrent_rows[0]]
File "C:\Medusa\medusa\providers\torrent\html\limetorrents.py", line 113, in process_column_header
return th.span.get_text() if th.span else th.get_text()
File "C:\Medusa\lib\bs4\element.py", line 713, in __getattr__
self.__class__.__name__, attr))
AttributeError: 'NavigableString' object has no attribute 'span'
</pre>
---
_STAFF NOTIFIED_: @pymedusa/support @pymedusa/moderators
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `medusa/providers/torrent/html/limetorrents.py`
Content:
```
1 # coding=utf-8
2
3 """Provider code for Limetorrents."""
4
5 from __future__ import unicode_literals
6
7 import logging
8 import re
9 import traceback
10
11 from contextlib2 import suppress
12
13 from medusa import tv
14 from medusa.bs4_parser import BS4Parser
15 from medusa.helper.common import (
16 convert_size,
17 try_int,
18 )
19 from medusa.logger.adapters.style import BraceAdapter
20 from medusa.providers.torrent.torrent_provider import TorrentProvider
21
22 from requests.compat import urljoin
23 from requests.exceptions import ConnectionError as RequestsConnectionError, Timeout
24
25 log = BraceAdapter(logging.getLogger(__name__))
26 log.logger.addHandler(logging.NullHandler())
27
28 id_regex = re.compile(r'(?:\/)(.*)(?:-torrent-([0-9]*)\.html)', re.I)
29 hash_regex = re.compile(r'(.*)([0-9a-f]{40})(.*)', re.I)
30
31
32 class LimeTorrentsProvider(TorrentProvider):
33 """LimeTorrents Torrent provider."""
34
35 def __init__(self):
36 """Initialize the class."""
37 super(LimeTorrentsProvider, self).__init__('LimeTorrents')
38
39 # Credentials
40 self.public = True
41
42 # URLs
43 self.url = 'https://www.limetorrents.cc'
44 self.urls = {
45 'update': urljoin(self.url, '/post/updatestats.php'),
46 'search': urljoin(self.url, '/search/tv/{query}/'),
47 # Original rss feed url, temporary offline. Replaced by the main Tv-show page.
48 # 'rss': urljoin(self.url, '/browse-torrents/TV-shows/date/{page}/'),
49 'rss': urljoin(self.url, '/browse-torrents/TV-shows/'),
50 }
51
52 # Proper Strings
53 self.proper_strings = ['PROPER', 'REPACK', 'REAL']
54
55 # Miscellaneous Options
56 self.confirmed = False
57
58 # Torrent Stats
59 self.minseed = None
60 self.minleech = None
61
62 # Cache
63 self.cache = tv.Cache(self, min_time=10)
64
65 def search(self, search_strings, age=0, ep_obj=None):
66 """
67 Search a provider and parse the results.
68
69 :param search_strings: A dict with mode (key) and the search value (value)
70 :param age: Not used
71 :param ep_obj: Not used
72 :returns: A list of search results (structure)
73 """
74 results = []
75
76 for mode in search_strings:
77 log.debug('Search mode: {0}', mode)
78
79 for search_string in search_strings[mode]:
80
81 if mode != 'RSS':
82 log.debug('Search string: {search}',
83 {'search': search_string})
84 if self.confirmed:
85 log.debug('Searching only confirmed torrents')
86
87 search_url = self.urls['search'].format(query=search_string)
88 else:
89 # search_url = self.urls['rss'].format(page=1)
90 search_url = self.urls['rss']
91
92 response = self.session.get(search_url)
93 if not response or not response.text:
94 log.debug('No data returned from provider')
95 continue
96
97 results += self.parse(response.text, mode)
98
99 return results
100
101 def parse(self, data, mode):
102 """
103 Parse search results for items.
104
105 :param data: The raw response from a search
106 :param mode: The current mode used to search, e.g. RSS
107
108 :return: A list of items found
109 """
110 items = []
111
112 def process_column_header(th):
113 return th.span.get_text() if th.span else th.get_text()
114
115 with BS4Parser(data, 'html5lib') as html:
116 torrent_table = html.find('table', class_='table2')
117
118 if not torrent_table:
119 log.debug('Data returned from provider does not contain any {0}torrents',
120 'confirmed ' if self.confirmed else '')
121 return items
122
123 torrent_rows = torrent_table.find_all('tr')
124 labels = [process_column_header(label) for label in torrent_rows[0]]
125
126 # Skip the first row, since it isn't a valid result
127 for row in torrent_rows[1:]:
128 cells = row.find_all('td')
129
130 try:
131 title_cell = cells[labels.index('Torrent Name')]
132
133 verified = title_cell.find('img', title='Verified torrent')
134 if self.confirmed and not verified:
135 continue
136
137 title_anchors = title_cell.find_all('a')
138 if not title_anchors or len(title_anchors) < 2:
139 continue
140
141 title_url = title_anchors[0].get('href')
142 title = title_anchors[1].get_text(strip=True)
143 regex_result = id_regex.search(title_anchors[1].get('href'))
144
145 alt_title = regex_result.group(1)
146 if len(title) < len(alt_title):
147 title = alt_title.replace('-', ' ')
148
149 torrent_id = regex_result.group(2)
150 info_hash = hash_regex.search(title_url).group(2)
151 if not all([title, torrent_id, info_hash]):
152 continue
153
154 with suppress(RequestsConnectionError, Timeout):
155 # Suppress the timeout since we are not interested in actually getting the results
156 self.session.get(self.urls['update'], timeout=0.1, params={'torrent_id': torrent_id,
157 'infohash': info_hash})
158
159 download_url = 'magnet:?xt=urn:btih:{hash}&dn={title}{trackers}'.format(
160 hash=info_hash, title=title, trackers=self._custom_trackers)
161
162 # Remove comma as thousands separator from larger number like 2,000 seeders = 2000
163 seeders = try_int(cells[labels.index('Seed')].get_text(strip=True).replace(',', ''), 1)
164 leechers = try_int(cells[labels.index('Leech')].get_text(strip=True).replace(',', ''))
165
166 if seeders < min(self.minseed, 1):
167 if mode != 'RSS':
168 log.debug("Discarding torrent because it doesn't meet the"
169 " minimum seeders: {0}. Seeders: {1}",
170 title, seeders)
171 continue
172
173 size = convert_size(cells[labels.index('Size')].get_text(strip=True)) or -1
174
175 pubdate_raw = cells[1].get_text().replace('Last', '1').replace('Yesterday', '24 hours')
176 pubdate = self.parse_pubdate(pubdate_raw, human_time=True)
177
178 item = {
179 'title': title,
180 'link': download_url,
181 'size': size,
182 'seeders': seeders,
183 'leechers': leechers,
184 'pubdate': pubdate,
185 }
186 if mode != 'RSS':
187 log.debug('Found result: {0} with {1} seeders and {2} leechers',
188 title, seeders, leechers)
189
190 items.append(item)
191 except (AttributeError, TypeError, KeyError, ValueError, IndexError):
192 log.error('Failed parsing provider. Traceback: {0!r}',
193 traceback.format_exc())
194
195 return items
196
197
198 provider = LimeTorrentsProvider()
199
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/medusa/providers/torrent/html/limetorrents.py b/medusa/providers/torrent/html/limetorrents.py
--- a/medusa/providers/torrent/html/limetorrents.py
+++ b/medusa/providers/torrent/html/limetorrents.py
@@ -121,7 +121,7 @@
return items
torrent_rows = torrent_table.find_all('tr')
- labels = [process_column_header(label) for label in torrent_rows[0]]
+ labels = [process_column_header(label) for label in torrent_rows[0].find_all('th')]
# Skip the first row, since it isn't a valid result
for row in torrent_rows[1:]:
|
{"golden_diff": "diff --git a/medusa/providers/torrent/html/limetorrents.py b/medusa/providers/torrent/html/limetorrents.py\n--- a/medusa/providers/torrent/html/limetorrents.py\n+++ b/medusa/providers/torrent/html/limetorrents.py\n@@ -121,7 +121,7 @@\n return items\n \n torrent_rows = torrent_table.find_all('tr')\n- labels = [process_column_header(label) for label in torrent_rows[0]]\n+ labels = [process_column_header(label) for label in torrent_rows[0].find_all('th')]\n \n # Skip the first row, since it isn't a valid result\n for row in torrent_rows[1:]:\n", "issue": "[APP SUBMITTED]: AttributeError: 'NavigableString' object has no attribute 'span'\n### INFO\n**Python Version**: `2.7.13 (v2.7.13:a06454b1afa1, Dec 17 2016, 20:53:40) [MSC v.1500 64 bit (AMD64)]`\n**Operating System**: `Windows-10-10.0.15063`\n**Locale**: `cp1252`\n**Branch**: [develop](../tree/develop)\n**Database**: `44.8`\n**Commit**: pymedusa/Medusa@38e6cbf13d9cede5de23106b656dbbb90df2dd38\n**Link to Log**: https://gist.github.com/39feec6e67c967a5e2fdec7f7bc2b69f\n### ERROR\n<pre>\n2017-08-13 22:44:17 ERROR SEARCHQUEUE-FORCED-175001 :: [LimeTorrents] :: [38e6cbf] Unknown exception while searching LimeTorrents. Error: \"'NavigableString' object has no attribute 'span'\"\nTraceback (most recent call last):\n File \"C:\\Medusa\\medusa\\search\\core.py\", line 555, in search_providers\n down_cur_quality, manual_search, manual_search_type)\n File \"C:\\Medusa\\medusa\\providers\\generic_provider.py\", line 226, in find_search_results\n items_list += self.search(search_string, ep_obj=episode)\n File \"C:\\Medusa\\medusa\\providers\\torrent\\html\\limetorrents.py\", line 97, in search\n results += self.parse(response.text, mode)\n File \"C:\\Medusa\\medusa\\providers\\torrent\\html\\limetorrents.py\", line 124, in parse\n labels = [process_column_header(label) for label in torrent_rows[0]]\n File \"C:\\Medusa\\medusa\\providers\\torrent\\html\\limetorrents.py\", line 113, in process_column_header\n return th.span.get_text() if th.span else th.get_text()\n File \"C:\\Medusa\\lib\\bs4\\element.py\", line 713, in __getattr__\n self.__class__.__name__, attr))\nAttributeError: 'NavigableString' object has no attribute 'span'\n</pre>\n---\n_STAFF NOTIFIED_: @pymedusa/support @pymedusa/moderators\n", "before_files": [{"content": "# coding=utf-8\n\n\"\"\"Provider code for Limetorrents.\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport logging\nimport re\nimport traceback\n\nfrom contextlib2 import suppress\n\nfrom medusa import tv\nfrom medusa.bs4_parser import BS4Parser\nfrom medusa.helper.common import (\n convert_size,\n try_int,\n)\nfrom medusa.logger.adapters.style import BraceAdapter\nfrom medusa.providers.torrent.torrent_provider import TorrentProvider\n\nfrom requests.compat import urljoin\nfrom requests.exceptions import ConnectionError as RequestsConnectionError, Timeout\n\nlog = BraceAdapter(logging.getLogger(__name__))\nlog.logger.addHandler(logging.NullHandler())\n\nid_regex = re.compile(r'(?:\\/)(.*)(?:-torrent-([0-9]*)\\.html)', re.I)\nhash_regex = re.compile(r'(.*)([0-9a-f]{40})(.*)', re.I)\n\n\nclass LimeTorrentsProvider(TorrentProvider):\n \"\"\"LimeTorrents Torrent provider.\"\"\"\n\n def __init__(self):\n \"\"\"Initialize the class.\"\"\"\n super(LimeTorrentsProvider, self).__init__('LimeTorrents')\n\n # Credentials\n self.public = True\n\n # URLs\n self.url = 'https://www.limetorrents.cc'\n self.urls = {\n 'update': urljoin(self.url, '/post/updatestats.php'),\n 'search': urljoin(self.url, '/search/tv/{query}/'),\n # Original rss feed url, temporary offline. Replaced by the main Tv-show page.\n # 'rss': urljoin(self.url, '/browse-torrents/TV-shows/date/{page}/'),\n 'rss': urljoin(self.url, '/browse-torrents/TV-shows/'),\n }\n\n # Proper Strings\n self.proper_strings = ['PROPER', 'REPACK', 'REAL']\n\n # Miscellaneous Options\n self.confirmed = False\n\n # Torrent Stats\n self.minseed = None\n self.minleech = None\n\n # Cache\n self.cache = tv.Cache(self, min_time=10)\n\n def search(self, search_strings, age=0, ep_obj=None):\n \"\"\"\n Search a provider and parse the results.\n\n :param search_strings: A dict with mode (key) and the search value (value)\n :param age: Not used\n :param ep_obj: Not used\n :returns: A list of search results (structure)\n \"\"\"\n results = []\n\n for mode in search_strings:\n log.debug('Search mode: {0}', mode)\n\n for search_string in search_strings[mode]:\n\n if mode != 'RSS':\n log.debug('Search string: {search}',\n {'search': search_string})\n if self.confirmed:\n log.debug('Searching only confirmed torrents')\n\n search_url = self.urls['search'].format(query=search_string)\n else:\n # search_url = self.urls['rss'].format(page=1)\n search_url = self.urls['rss']\n\n response = self.session.get(search_url)\n if not response or not response.text:\n log.debug('No data returned from provider')\n continue\n\n results += self.parse(response.text, mode)\n\n return results\n\n def parse(self, data, mode):\n \"\"\"\n Parse search results for items.\n\n :param data: The raw response from a search\n :param mode: The current mode used to search, e.g. RSS\n\n :return: A list of items found\n \"\"\"\n items = []\n\n def process_column_header(th):\n return th.span.get_text() if th.span else th.get_text()\n\n with BS4Parser(data, 'html5lib') as html:\n torrent_table = html.find('table', class_='table2')\n\n if not torrent_table:\n log.debug('Data returned from provider does not contain any {0}torrents',\n 'confirmed ' if self.confirmed else '')\n return items\n\n torrent_rows = torrent_table.find_all('tr')\n labels = [process_column_header(label) for label in torrent_rows[0]]\n\n # Skip the first row, since it isn't a valid result\n for row in torrent_rows[1:]:\n cells = row.find_all('td')\n\n try:\n title_cell = cells[labels.index('Torrent Name')]\n\n verified = title_cell.find('img', title='Verified torrent')\n if self.confirmed and not verified:\n continue\n\n title_anchors = title_cell.find_all('a')\n if not title_anchors or len(title_anchors) < 2:\n continue\n\n title_url = title_anchors[0].get('href')\n title = title_anchors[1].get_text(strip=True)\n regex_result = id_regex.search(title_anchors[1].get('href'))\n\n alt_title = regex_result.group(1)\n if len(title) < len(alt_title):\n title = alt_title.replace('-', ' ')\n\n torrent_id = regex_result.group(2)\n info_hash = hash_regex.search(title_url).group(2)\n if not all([title, torrent_id, info_hash]):\n continue\n\n with suppress(RequestsConnectionError, Timeout):\n # Suppress the timeout since we are not interested in actually getting the results\n self.session.get(self.urls['update'], timeout=0.1, params={'torrent_id': torrent_id,\n 'infohash': info_hash})\n\n download_url = 'magnet:?xt=urn:btih:{hash}&dn={title}{trackers}'.format(\n hash=info_hash, title=title, trackers=self._custom_trackers)\n\n # Remove comma as thousands separator from larger number like 2,000 seeders = 2000\n seeders = try_int(cells[labels.index('Seed')].get_text(strip=True).replace(',', ''), 1)\n leechers = try_int(cells[labels.index('Leech')].get_text(strip=True).replace(',', ''))\n\n if seeders < min(self.minseed, 1):\n if mode != 'RSS':\n log.debug(\"Discarding torrent because it doesn't meet the\"\n \" minimum seeders: {0}. Seeders: {1}\",\n title, seeders)\n continue\n\n size = convert_size(cells[labels.index('Size')].get_text(strip=True)) or -1\n\n pubdate_raw = cells[1].get_text().replace('Last', '1').replace('Yesterday', '24 hours')\n pubdate = self.parse_pubdate(pubdate_raw, human_time=True)\n\n item = {\n 'title': title,\n 'link': download_url,\n 'size': size,\n 'seeders': seeders,\n 'leechers': leechers,\n 'pubdate': pubdate,\n }\n if mode != 'RSS':\n log.debug('Found result: {0} with {1} seeders and {2} leechers',\n title, seeders, leechers)\n\n items.append(item)\n except (AttributeError, TypeError, KeyError, ValueError, IndexError):\n log.error('Failed parsing provider. Traceback: {0!r}',\n traceback.format_exc())\n\n return items\n\n\nprovider = LimeTorrentsProvider()\n", "path": "medusa/providers/torrent/html/limetorrents.py"}], "after_files": [{"content": "# coding=utf-8\n\n\"\"\"Provider code for Limetorrents.\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport logging\nimport re\nimport traceback\n\nfrom contextlib2 import suppress\n\nfrom medusa import tv\nfrom medusa.bs4_parser import BS4Parser\nfrom medusa.helper.common import (\n convert_size,\n try_int,\n)\nfrom medusa.logger.adapters.style import BraceAdapter\nfrom medusa.providers.torrent.torrent_provider import TorrentProvider\n\nfrom requests.compat import urljoin\nfrom requests.exceptions import ConnectionError as RequestsConnectionError, Timeout\n\nlog = BraceAdapter(logging.getLogger(__name__))\nlog.logger.addHandler(logging.NullHandler())\n\nid_regex = re.compile(r'(?:\\/)(.*)(?:-torrent-([0-9]*)\\.html)', re.I)\nhash_regex = re.compile(r'(.*)([0-9a-f]{40})(.*)', re.I)\n\n\nclass LimeTorrentsProvider(TorrentProvider):\n \"\"\"LimeTorrents Torrent provider.\"\"\"\n\n def __init__(self):\n \"\"\"Initialize the class.\"\"\"\n super(LimeTorrentsProvider, self).__init__('LimeTorrents')\n\n # Credentials\n self.public = True\n\n # URLs\n self.url = 'https://www.limetorrents.cc'\n self.urls = {\n 'update': urljoin(self.url, '/post/updatestats.php'),\n 'search': urljoin(self.url, '/search/tv/{query}/'),\n # Original rss feed url, temporary offline. Replaced by the main Tv-show page.\n # 'rss': urljoin(self.url, '/browse-torrents/TV-shows/date/{page}/'),\n 'rss': urljoin(self.url, '/browse-torrents/TV-shows/'),\n }\n\n # Proper Strings\n self.proper_strings = ['PROPER', 'REPACK', 'REAL']\n\n # Miscellaneous Options\n self.confirmed = False\n\n # Torrent Stats\n self.minseed = None\n self.minleech = None\n\n # Cache\n self.cache = tv.Cache(self, min_time=10)\n\n def search(self, search_strings, age=0, ep_obj=None):\n \"\"\"\n Search a provider and parse the results.\n\n :param search_strings: A dict with mode (key) and the search value (value)\n :param age: Not used\n :param ep_obj: Not used\n :returns: A list of search results (structure)\n \"\"\"\n results = []\n\n for mode in search_strings:\n log.debug('Search mode: {0}', mode)\n\n for search_string in search_strings[mode]:\n\n if mode != 'RSS':\n log.debug('Search string: {search}',\n {'search': search_string})\n if self.confirmed:\n log.debug('Searching only confirmed torrents')\n\n search_url = self.urls['search'].format(query=search_string)\n else:\n # search_url = self.urls['rss'].format(page=1)\n search_url = self.urls['rss']\n\n response = self.session.get(search_url)\n if not response or not response.text:\n log.debug('No data returned from provider')\n continue\n\n results += self.parse(response.text, mode)\n\n return results\n\n def parse(self, data, mode):\n \"\"\"\n Parse search results for items.\n\n :param data: The raw response from a search\n :param mode: The current mode used to search, e.g. RSS\n\n :return: A list of items found\n \"\"\"\n items = []\n\n def process_column_header(th):\n return th.span.get_text() if th.span else th.get_text()\n\n with BS4Parser(data, 'html5lib') as html:\n torrent_table = html.find('table', class_='table2')\n\n if not torrent_table:\n log.debug('Data returned from provider does not contain any {0}torrents',\n 'confirmed ' if self.confirmed else '')\n return items\n\n torrent_rows = torrent_table.find_all('tr')\n labels = [process_column_header(label) for label in torrent_rows[0].find_all('th')]\n\n # Skip the first row, since it isn't a valid result\n for row in torrent_rows[1:]:\n cells = row.find_all('td')\n\n try:\n title_cell = cells[labels.index('Torrent Name')]\n\n verified = title_cell.find('img', title='Verified torrent')\n if self.confirmed and not verified:\n continue\n\n title_anchors = title_cell.find_all('a')\n if not title_anchors or len(title_anchors) < 2:\n continue\n\n title_url = title_anchors[0].get('href')\n title = title_anchors[1].get_text(strip=True)\n regex_result = id_regex.search(title_anchors[1].get('href'))\n\n alt_title = regex_result.group(1)\n if len(title) < len(alt_title):\n title = alt_title.replace('-', ' ')\n\n torrent_id = regex_result.group(2)\n info_hash = hash_regex.search(title_url).group(2)\n if not all([title, torrent_id, info_hash]):\n continue\n\n with suppress(RequestsConnectionError, Timeout):\n # Suppress the timeout since we are not interested in actually getting the results\n self.session.get(self.urls['update'], timeout=0.1, params={'torrent_id': torrent_id,\n 'infohash': info_hash})\n\n download_url = 'magnet:?xt=urn:btih:{hash}&dn={title}{trackers}'.format(\n hash=info_hash, title=title, trackers=self._custom_trackers)\n\n # Remove comma as thousands separator from larger number like 2,000 seeders = 2000\n seeders = try_int(cells[labels.index('Seed')].get_text(strip=True).replace(',', ''), 1)\n leechers = try_int(cells[labels.index('Leech')].get_text(strip=True).replace(',', ''))\n\n if seeders < min(self.minseed, 1):\n if mode != 'RSS':\n log.debug(\"Discarding torrent because it doesn't meet the\"\n \" minimum seeders: {0}. Seeders: {1}\",\n title, seeders)\n continue\n\n size = convert_size(cells[labels.index('Size')].get_text(strip=True)) or -1\n\n pubdate_raw = cells[1].get_text().replace('Last', '1').replace('Yesterday', '24 hours')\n pubdate = self.parse_pubdate(pubdate_raw, human_time=True)\n\n item = {\n 'title': title,\n 'link': download_url,\n 'size': size,\n 'seeders': seeders,\n 'leechers': leechers,\n 'pubdate': pubdate,\n }\n if mode != 'RSS':\n log.debug('Found result: {0} with {1} seeders and {2} leechers',\n title, seeders, leechers)\n\n items.append(item)\n except (AttributeError, TypeError, KeyError, ValueError, IndexError):\n log.error('Failed parsing provider. Traceback: {0!r}',\n traceback.format_exc())\n\n return items\n\n\nprovider = LimeTorrentsProvider()\n", "path": "medusa/providers/torrent/html/limetorrents.py"}]}
| 2,915 | 159 |
gh_patches_debug_4612
|
rasdani/github-patches
|
git_diff
|
buildbot__buildbot-1441
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
fix E741 on test_process_build
recent pep8 does not like l (the letter) as a variable because some fonts make it undistinguishable from 1 (the number).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `master/buildbot/status/web/slaves.py`
Content:
```
1 # This file is part of Buildbot. Buildbot is free software: you can
2 # redistribute it and/or modify it under the terms of the GNU General Public
3 # License as published by the Free Software Foundation, version 2.
4 #
5 # This program is distributed in the hope that it will be useful, but WITHOUT
6 # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
7 # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
8 # details.
9 #
10 # You should have received a copy of the GNU General Public License along with
11 # this program; if not, write to the Free Software Foundation, Inc., 51
12 # Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
13 #
14 # Copyright Buildbot Team Members
15
16
17 import time
18 import urllib
19
20 from twisted.internet import defer
21 from twisted.web import html
22 from twisted.web.resource import NoResource
23 from twisted.web.util import Redirect
24
25 from buildbot import util
26 from buildbot.status.web.base import ActionResource
27 from buildbot.status.web.base import BuildLineMixin
28 from buildbot.status.web.base import HtmlResource
29 from buildbot.status.web.base import abbreviate_age
30 from buildbot.status.web.base import path_to_authzfail
31 from buildbot.status.web.base import path_to_slave
32
33
34 class ShutdownActionResource(ActionResource):
35
36 def __init__(self, slave):
37 self.slave = slave
38 self.action = "gracefulShutdown"
39
40 @defer.inlineCallbacks
41 def performAction(self, request):
42 res = yield self.getAuthz(request).actionAllowed(self.action,
43 request,
44 self.slave)
45
46 url = None
47 if res:
48 self.slave.setGraceful(True)
49 url = path_to_slave(request, self.slave)
50 else:
51 url = path_to_authzfail(request)
52 defer.returnValue(url)
53
54
55 class PauseActionResource(ActionResource):
56
57 def __init__(self, slave, state):
58 self.slave = slave
59 self.action = "pauseSlave"
60 self.state = state
61
62 @defer.inlineCallbacks
63 def performAction(self, request):
64 res = yield self.getAuthz(request).actionAllowed(self.action,
65 request,
66 self.slave)
67
68 url = None
69 if res:
70 self.slave.setPaused(self.state)
71 url = path_to_slave(request, self.slave)
72 else:
73 url = path_to_authzfail(request)
74 defer.returnValue(url)
75
76 # /buildslaves/$slavename
77
78
79 class OneBuildSlaveResource(HtmlResource, BuildLineMixin):
80 addSlash = False
81
82 def __init__(self, slavename):
83 HtmlResource.__init__(self)
84 self.slavename = slavename
85
86 def getPageTitle(self, req):
87 return "Buildbot: %s" % self.slavename
88
89 def getChild(self, path, req):
90 s = self.getStatus(req)
91 slave = s.getSlave(self.slavename)
92 if path == "shutdown":
93 return ShutdownActionResource(slave)
94 if path == "pause" or path == "unpause":
95 return PauseActionResource(slave, path == "pause")
96 return Redirect(path_to_slave(req, slave))
97
98 def content(self, request, ctx):
99 s = self.getStatus(request)
100 slave = s.getSlave(self.slavename)
101
102 my_builders = []
103 for bname in s.getBuilderNames():
104 b = s.getBuilder(bname)
105 for bs in b.getSlaves():
106 if bs.getName() == self.slavename:
107 my_builders.append(b)
108
109 # Current builds
110 current_builds = []
111 for b in my_builders:
112 for cb in b.getCurrentBuilds():
113 if cb.getSlavename() == self.slavename:
114 current_builds.append(self.get_line_values(request, cb))
115
116 try:
117 max_builds = int(request.args.get('numbuilds')[0])
118 except ValueError:
119 max_builds = 10
120
121 recent_builds = []
122 n = 0
123 for rb in s.generateFinishedBuilds(builders=[b.getName() for b in my_builders]):
124 if rb.getSlavename() == self.slavename:
125 n += 1
126 recent_builds.append(self.get_line_values(request, rb))
127 if n > max_builds:
128 break
129
130 # connects over the last hour
131 slave = s.getSlave(self.slavename)
132 connect_count = slave.getConnectCount()
133
134 if slave.isPaused():
135 pause_url = request.childLink("unpause")
136 else:
137 pause_url = request.childLink("pause")
138
139 ctx.update(dict(slave=slave,
140 slavename=self.slavename,
141 current=current_builds,
142 recent=recent_builds,
143 shutdown_url=request.childLink("shutdown"),
144 pause_url=pause_url,
145 authz=self.getAuthz(request),
146 this_url="../../../" + path_to_slave(request, slave),
147 access_uri=slave.getAccessURI(),
148 admin=slave.getAdmin() or u'',
149 host=slave.getHost() or u'',
150 info=slave.getInfoAsDict(),
151 slave_version=slave.getVersion(),
152 show_builder_column=True,
153 connect_count=connect_count))
154 template = request.site.buildbot_service.templates.get_template("buildslave.html")
155 data = template.render(**ctx)
156 return data
157
158 # /buildslaves
159
160
161 class BuildSlavesResource(HtmlResource):
162 pageTitle = "BuildSlaves"
163 addSlash = True
164
165 def content(self, request, ctx):
166 s = self.getStatus(request)
167
168 # ?no_builders=1 disables build column
169 show_builder_column = not (request.args.get('no_builders', '0')[0]) == '1'
170 ctx['show_builder_column'] = show_builder_column
171
172 used_by_builder = {}
173 for bname in s.getBuilderNames():
174 b = s.getBuilder(bname)
175 for bs in b.getSlaves():
176 slavename = bs.getName()
177 if slavename not in used_by_builder:
178 used_by_builder[slavename] = []
179 used_by_builder[slavename].append(bname)
180
181 slaves = ctx['slaves'] = []
182 for name in util.naturalSort(s.getSlaveNames()):
183 info = {}
184 slaves.append(info)
185 slave = s.getSlave(name)
186 slave_status = s.botmaster.slaves[name].slave_status
187 info['running_builds'] = len(slave_status.getRunningBuilds())
188 info['link'] = request.childLink(urllib.quote(name, ''))
189 info['name'] = name
190
191 if show_builder_column:
192 info['builders'] = []
193 for b in used_by_builder.get(name, []):
194 info['builders'].append(dict(link=request.childLink("../builders/%s" % b), name=b))
195
196 info['version'] = slave.getVersion()
197 info['connected'] = slave.isConnected()
198 info['connectCount'] = slave.getConnectCount()
199 info['paused'] = slave.isPaused()
200
201 info['admin'] = slave.getAdmin() or u''
202 last = slave.lastMessageReceived()
203 if last:
204 info['last_heard_from_age'] = abbreviate_age(time.time() - last)
205 info['last_heard_from_time'] = time.strftime("%Y-%b-%d %H:%M:%S",
206 time.localtime(last))
207
208 template = request.site.buildbot_service.templates.get_template("buildslaves.html")
209 data = template.render(**ctx)
210 return data
211
212 def getChild(self, path, req):
213 try:
214 self.getStatus(req).getSlave(path)
215 return OneBuildSlaveResource(path)
216 except KeyError:
217 return NoResource("No such slave '%s'" % html.escape(path))
218
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/master/buildbot/status/web/slaves.py b/master/buildbot/status/web/slaves.py
--- a/master/buildbot/status/web/slaves.py
+++ b/master/buildbot/status/web/slaves.py
@@ -114,8 +114,8 @@
current_builds.append(self.get_line_values(request, cb))
try:
- max_builds = int(request.args.get('numbuilds')[0])
- except ValueError:
+ max_builds = int(request.args.get('numbuilds', ['10'])[0])
+ except (TypeError, ValueError):
max_builds = 10
recent_builds = []
|
{"golden_diff": "diff --git a/master/buildbot/status/web/slaves.py b/master/buildbot/status/web/slaves.py\n--- a/master/buildbot/status/web/slaves.py\n+++ b/master/buildbot/status/web/slaves.py\n@@ -114,8 +114,8 @@\n current_builds.append(self.get_line_values(request, cb))\n \n try:\n- max_builds = int(request.args.get('numbuilds')[0])\n- except ValueError:\n+ max_builds = int(request.args.get('numbuilds', ['10'])[0])\n+ except (TypeError, ValueError):\n max_builds = 10\n \n recent_builds = []\n", "issue": "fix E741 on test_process_build\nrecent pep8 does not like l (the letter) as a variable because some fonts make it undistinguishable from 1 (the number).\r\n\n", "before_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\n\nimport time\nimport urllib\n\nfrom twisted.internet import defer\nfrom twisted.web import html\nfrom twisted.web.resource import NoResource\nfrom twisted.web.util import Redirect\n\nfrom buildbot import util\nfrom buildbot.status.web.base import ActionResource\nfrom buildbot.status.web.base import BuildLineMixin\nfrom buildbot.status.web.base import HtmlResource\nfrom buildbot.status.web.base import abbreviate_age\nfrom buildbot.status.web.base import path_to_authzfail\nfrom buildbot.status.web.base import path_to_slave\n\n\nclass ShutdownActionResource(ActionResource):\n\n def __init__(self, slave):\n self.slave = slave\n self.action = \"gracefulShutdown\"\n\n @defer.inlineCallbacks\n def performAction(self, request):\n res = yield self.getAuthz(request).actionAllowed(self.action,\n request,\n self.slave)\n\n url = None\n if res:\n self.slave.setGraceful(True)\n url = path_to_slave(request, self.slave)\n else:\n url = path_to_authzfail(request)\n defer.returnValue(url)\n\n\nclass PauseActionResource(ActionResource):\n\n def __init__(self, slave, state):\n self.slave = slave\n self.action = \"pauseSlave\"\n self.state = state\n\n @defer.inlineCallbacks\n def performAction(self, request):\n res = yield self.getAuthz(request).actionAllowed(self.action,\n request,\n self.slave)\n\n url = None\n if res:\n self.slave.setPaused(self.state)\n url = path_to_slave(request, self.slave)\n else:\n url = path_to_authzfail(request)\n defer.returnValue(url)\n\n# /buildslaves/$slavename\n\n\nclass OneBuildSlaveResource(HtmlResource, BuildLineMixin):\n addSlash = False\n\n def __init__(self, slavename):\n HtmlResource.__init__(self)\n self.slavename = slavename\n\n def getPageTitle(self, req):\n return \"Buildbot: %s\" % self.slavename\n\n def getChild(self, path, req):\n s = self.getStatus(req)\n slave = s.getSlave(self.slavename)\n if path == \"shutdown\":\n return ShutdownActionResource(slave)\n if path == \"pause\" or path == \"unpause\":\n return PauseActionResource(slave, path == \"pause\")\n return Redirect(path_to_slave(req, slave))\n\n def content(self, request, ctx):\n s = self.getStatus(request)\n slave = s.getSlave(self.slavename)\n\n my_builders = []\n for bname in s.getBuilderNames():\n b = s.getBuilder(bname)\n for bs in b.getSlaves():\n if bs.getName() == self.slavename:\n my_builders.append(b)\n\n # Current builds\n current_builds = []\n for b in my_builders:\n for cb in b.getCurrentBuilds():\n if cb.getSlavename() == self.slavename:\n current_builds.append(self.get_line_values(request, cb))\n\n try:\n max_builds = int(request.args.get('numbuilds')[0])\n except ValueError:\n max_builds = 10\n\n recent_builds = []\n n = 0\n for rb in s.generateFinishedBuilds(builders=[b.getName() for b in my_builders]):\n if rb.getSlavename() == self.slavename:\n n += 1\n recent_builds.append(self.get_line_values(request, rb))\n if n > max_builds:\n break\n\n # connects over the last hour\n slave = s.getSlave(self.slavename)\n connect_count = slave.getConnectCount()\n\n if slave.isPaused():\n pause_url = request.childLink(\"unpause\")\n else:\n pause_url = request.childLink(\"pause\")\n\n ctx.update(dict(slave=slave,\n slavename=self.slavename,\n current=current_builds,\n recent=recent_builds,\n shutdown_url=request.childLink(\"shutdown\"),\n pause_url=pause_url,\n authz=self.getAuthz(request),\n this_url=\"../../../\" + path_to_slave(request, slave),\n access_uri=slave.getAccessURI(),\n admin=slave.getAdmin() or u'',\n host=slave.getHost() or u'',\n info=slave.getInfoAsDict(),\n slave_version=slave.getVersion(),\n show_builder_column=True,\n connect_count=connect_count))\n template = request.site.buildbot_service.templates.get_template(\"buildslave.html\")\n data = template.render(**ctx)\n return data\n\n# /buildslaves\n\n\nclass BuildSlavesResource(HtmlResource):\n pageTitle = \"BuildSlaves\"\n addSlash = True\n\n def content(self, request, ctx):\n s = self.getStatus(request)\n\n # ?no_builders=1 disables build column\n show_builder_column = not (request.args.get('no_builders', '0')[0]) == '1'\n ctx['show_builder_column'] = show_builder_column\n\n used_by_builder = {}\n for bname in s.getBuilderNames():\n b = s.getBuilder(bname)\n for bs in b.getSlaves():\n slavename = bs.getName()\n if slavename not in used_by_builder:\n used_by_builder[slavename] = []\n used_by_builder[slavename].append(bname)\n\n slaves = ctx['slaves'] = []\n for name in util.naturalSort(s.getSlaveNames()):\n info = {}\n slaves.append(info)\n slave = s.getSlave(name)\n slave_status = s.botmaster.slaves[name].slave_status\n info['running_builds'] = len(slave_status.getRunningBuilds())\n info['link'] = request.childLink(urllib.quote(name, ''))\n info['name'] = name\n\n if show_builder_column:\n info['builders'] = []\n for b in used_by_builder.get(name, []):\n info['builders'].append(dict(link=request.childLink(\"../builders/%s\" % b), name=b))\n\n info['version'] = slave.getVersion()\n info['connected'] = slave.isConnected()\n info['connectCount'] = slave.getConnectCount()\n info['paused'] = slave.isPaused()\n\n info['admin'] = slave.getAdmin() or u''\n last = slave.lastMessageReceived()\n if last:\n info['last_heard_from_age'] = abbreviate_age(time.time() - last)\n info['last_heard_from_time'] = time.strftime(\"%Y-%b-%d %H:%M:%S\",\n time.localtime(last))\n\n template = request.site.buildbot_service.templates.get_template(\"buildslaves.html\")\n data = template.render(**ctx)\n return data\n\n def getChild(self, path, req):\n try:\n self.getStatus(req).getSlave(path)\n return OneBuildSlaveResource(path)\n except KeyError:\n return NoResource(\"No such slave '%s'\" % html.escape(path))\n", "path": "master/buildbot/status/web/slaves.py"}], "after_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\n\nimport time\nimport urllib\n\nfrom twisted.internet import defer\nfrom twisted.web import html\nfrom twisted.web.resource import NoResource\nfrom twisted.web.util import Redirect\n\nfrom buildbot import util\nfrom buildbot.status.web.base import ActionResource\nfrom buildbot.status.web.base import BuildLineMixin\nfrom buildbot.status.web.base import HtmlResource\nfrom buildbot.status.web.base import abbreviate_age\nfrom buildbot.status.web.base import path_to_authzfail\nfrom buildbot.status.web.base import path_to_slave\n\n\nclass ShutdownActionResource(ActionResource):\n\n def __init__(self, slave):\n self.slave = slave\n self.action = \"gracefulShutdown\"\n\n @defer.inlineCallbacks\n def performAction(self, request):\n res = yield self.getAuthz(request).actionAllowed(self.action,\n request,\n self.slave)\n\n url = None\n if res:\n self.slave.setGraceful(True)\n url = path_to_slave(request, self.slave)\n else:\n url = path_to_authzfail(request)\n defer.returnValue(url)\n\n\nclass PauseActionResource(ActionResource):\n\n def __init__(self, slave, state):\n self.slave = slave\n self.action = \"pauseSlave\"\n self.state = state\n\n @defer.inlineCallbacks\n def performAction(self, request):\n res = yield self.getAuthz(request).actionAllowed(self.action,\n request,\n self.slave)\n\n url = None\n if res:\n self.slave.setPaused(self.state)\n url = path_to_slave(request, self.slave)\n else:\n url = path_to_authzfail(request)\n defer.returnValue(url)\n\n# /buildslaves/$slavename\n\n\nclass OneBuildSlaveResource(HtmlResource, BuildLineMixin):\n addSlash = False\n\n def __init__(self, slavename):\n HtmlResource.__init__(self)\n self.slavename = slavename\n\n def getPageTitle(self, req):\n return \"Buildbot: %s\" % self.slavename\n\n def getChild(self, path, req):\n s = self.getStatus(req)\n slave = s.getSlave(self.slavename)\n if path == \"shutdown\":\n return ShutdownActionResource(slave)\n if path == \"pause\" or path == \"unpause\":\n return PauseActionResource(slave, path == \"pause\")\n return Redirect(path_to_slave(req, slave))\n\n def content(self, request, ctx):\n s = self.getStatus(request)\n slave = s.getSlave(self.slavename)\n\n my_builders = []\n for bname in s.getBuilderNames():\n b = s.getBuilder(bname)\n for bs in b.getSlaves():\n if bs.getName() == self.slavename:\n my_builders.append(b)\n\n # Current builds\n current_builds = []\n for b in my_builders:\n for cb in b.getCurrentBuilds():\n if cb.getSlavename() == self.slavename:\n current_builds.append(self.get_line_values(request, cb))\n\n try:\n max_builds = int(request.args.get('numbuilds', ['10'])[0])\n except (TypeError, ValueError):\n max_builds = 10\n\n recent_builds = []\n n = 0\n for rb in s.generateFinishedBuilds(builders=[b.getName() for b in my_builders]):\n if rb.getSlavename() == self.slavename:\n n += 1\n recent_builds.append(self.get_line_values(request, rb))\n if n > max_builds:\n break\n\n # connects over the last hour\n slave = s.getSlave(self.slavename)\n connect_count = slave.getConnectCount()\n\n if slave.isPaused():\n pause_url = request.childLink(\"unpause\")\n else:\n pause_url = request.childLink(\"pause\")\n\n ctx.update(dict(slave=slave,\n slavename=self.slavename,\n current=current_builds,\n recent=recent_builds,\n shutdown_url=request.childLink(\"shutdown\"),\n pause_url=pause_url,\n authz=self.getAuthz(request),\n this_url=\"../../../\" + path_to_slave(request, slave),\n access_uri=slave.getAccessURI(),\n admin=slave.getAdmin() or u'',\n host=slave.getHost() or u'',\n info=slave.getInfoAsDict(),\n slave_version=slave.getVersion(),\n show_builder_column=True,\n connect_count=connect_count))\n template = request.site.buildbot_service.templates.get_template(\"buildslave.html\")\n data = template.render(**ctx)\n return data\n\n# /buildslaves\n\n\nclass BuildSlavesResource(HtmlResource):\n pageTitle = \"BuildSlaves\"\n addSlash = True\n\n def content(self, request, ctx):\n s = self.getStatus(request)\n\n # ?no_builders=1 disables build column\n show_builder_column = not (request.args.get('no_builders', '0')[0]) == '1'\n ctx['show_builder_column'] = show_builder_column\n\n used_by_builder = {}\n for bname in s.getBuilderNames():\n b = s.getBuilder(bname)\n for bs in b.getSlaves():\n slavename = bs.getName()\n if slavename not in used_by_builder:\n used_by_builder[slavename] = []\n used_by_builder[slavename].append(bname)\n\n slaves = ctx['slaves'] = []\n for name in util.naturalSort(s.getSlaveNames()):\n info = {}\n slaves.append(info)\n slave = s.getSlave(name)\n slave_status = s.botmaster.slaves[name].slave_status\n info['running_builds'] = len(slave_status.getRunningBuilds())\n info['link'] = request.childLink(urllib.quote(name, ''))\n info['name'] = name\n\n if show_builder_column:\n info['builders'] = []\n for b in used_by_builder.get(name, []):\n info['builders'].append(dict(link=request.childLink(\"../builders/%s\" % b), name=b))\n\n info['version'] = slave.getVersion()\n info['connected'] = slave.isConnected()\n info['connectCount'] = slave.getConnectCount()\n info['paused'] = slave.isPaused()\n\n info['admin'] = slave.getAdmin() or u''\n last = slave.lastMessageReceived()\n if last:\n info['last_heard_from_age'] = abbreviate_age(time.time() - last)\n info['last_heard_from_time'] = time.strftime(\"%Y-%b-%d %H:%M:%S\",\n time.localtime(last))\n\n template = request.site.buildbot_service.templates.get_template(\"buildslaves.html\")\n data = template.render(**ctx)\n return data\n\n def getChild(self, path, req):\n try:\n self.getStatus(req).getSlave(path)\n return OneBuildSlaveResource(path)\n except KeyError:\n return NoResource(\"No such slave '%s'\" % html.escape(path))\n", "path": "master/buildbot/status/web/slaves.py"}]}
| 2,523 | 141 |
gh_patches_debug_8268
|
rasdani/github-patches
|
git_diff
|
googleapis__python-bigquery-87
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Packaging issue with GRPC and google-cloud-bigquery + optional packages?
We're apparently losing some needed dependencies when using the optional installs for google-cloud-bigquery
```
$ ~/.pyenv/versions/3.8.2/bin/virtualenv repro
$ source repro/bin/activate
$ pip freeze
```
(no results)
```
$ pip install --upgrade google-cloud-bigquery[bqstorage,pandas]
$ pip freeze > before.txt
$ cat before.txt
```
cachetools==4.1.0
certifi==2020.4.5.1
chardet==3.0.4
google-api-core==1.17.0
google-auth==1.14.1
google-cloud-bigquery==1.24.0
google-cloud-bigquery-storage==0.8.0
google-cloud-core==1.3.0
google-resumable-media==0.5.0
googleapis-common-protos==1.51.0
idna==2.9
numpy==1.18.3
pandas==1.0.3
protobuf==3.11.3
pyarrow==0.17.0
pyasn1==0.4.8
pyasn1-modules==0.2.8
python-dateutil==2.8.1
pytz==2019.3
requests==2.23.0
rsa==4.0
six==1.14.0
urllib3==1.25.9
```
$ python
>>> from google.cloud import bigquery_storage_v1beta1
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/google/home/shollyman/python_envs/repro/lib/python3.8/site-packages/google/cloud/bigquery_storage_v1beta1/__init__.py", line 26, in <module>
from google.cloud.bigquery_storage_v1beta1 import client
File "/usr/local/google/home/shollyman/python_envs/repro/lib/python3.8/site-packages/google/cloud/bigquery_storage_v1beta1/client.py", line 24, in <module>
import google.api_core.gapic_v1.method
File "/usr/local/google/home/shollyman/python_envs/repro/lib/python3.8/site-packages/google/api_core/gapic_v1/__init__.py", line 16, in <module>
from google.api_core.gapic_v1 import config
File "/usr/local/google/home/shollyman/python_envs/repro/lib/python3.8/site-packages/google/api_core/gapic_v1/config.py", line 23, in <module>
import grpc
ModuleNotFoundError: No module named 'grpc'
```
```
$ pip install google-cloud-bigquery-storage
$ pip freeze > after.txt
$ diff before.txt after.txt
```
> grpcio==1.28.1
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import io
16 import os
17
18 import setuptools
19
20
21 # Package metadata.
22
23 name = "google-cloud-bigquery"
24 description = "Google BigQuery API client library"
25 version = "1.24.0"
26 # Should be one of:
27 # 'Development Status :: 3 - Alpha'
28 # 'Development Status :: 4 - Beta'
29 # 'Development Status :: 5 - Production/Stable'
30 release_status = "Development Status :: 5 - Production/Stable"
31 dependencies = [
32 'enum34; python_version < "3.4"',
33 "google-auth >= 1.9.0, < 2.0dev",
34 "google-api-core >= 1.15.0, < 2.0dev",
35 "google-cloud-core >= 1.1.0, < 2.0dev",
36 "google-resumable-media >= 0.5.0, < 0.6dev",
37 "protobuf >= 3.6.0",
38 "six >=1.13.0,< 2.0.0dev",
39 ]
40 extras = {
41 "bqstorage": [
42 "google-cloud-bigquery-storage >= 0.6.0, <2.0.0dev",
43 "pyarrow>=0.16.0, < 2.0dev",
44 ],
45 "pandas": ["pandas>=0.17.1"],
46 # Exclude PyArrow dependency from Windows Python 2.7.
47 'pyarrow: platform_system != "Windows" or python_version >= "3.4"': [
48 # Bad Linux release for 0.14.0.
49 # https://issues.apache.org/jira/browse/ARROW-5868
50 "pyarrow>=0.4.1, != 0.14.0"
51 ],
52 "tqdm": ["tqdm >= 4.0.0, <5.0.0dev"],
53 "fastparquet": [
54 "fastparquet",
55 "python-snappy",
56 # llvmlite >= 0.32.0 cannot be installed on Python 3.5 and below
57 # (building the wheel fails), thus needs to be restricted.
58 # See: https://github.com/googleapis/python-bigquery/issues/78
59 "llvmlite <= 0.31.0",
60 ],
61 }
62
63 all_extras = []
64
65 for extra in extras:
66 if extra == "fastparquet":
67 # Skip fastparquet from "all" because it is redundant with pyarrow and
68 # creates a dependency on pre-release versions of numpy. See:
69 # https://github.com/googleapis/google-cloud-python/issues/8549
70 continue
71 all_extras.extend(extras[extra])
72
73 extras["all"] = all_extras
74
75 # Setup boilerplate below this line.
76
77 package_root = os.path.abspath(os.path.dirname(__file__))
78
79 readme_filename = os.path.join(package_root, "README.rst")
80 with io.open(readme_filename, encoding="utf-8") as readme_file:
81 readme = readme_file.read()
82
83 # Only include packages under the 'google' namespace. Do not include tests,
84 # benchmarks, etc.
85 packages = [
86 package for package in setuptools.find_packages() if package.startswith("google")
87 ]
88
89 # Determine which namespaces are needed.
90 namespaces = ["google"]
91 if "google.cloud" in packages:
92 namespaces.append("google.cloud")
93
94
95 setuptools.setup(
96 name=name,
97 version=version,
98 description=description,
99 long_description=readme,
100 author="Google LLC",
101 author_email="[email protected]",
102 license="Apache 2.0",
103 url="https://github.com/googleapis/python-bigquery",
104 classifiers=[
105 release_status,
106 "Intended Audience :: Developers",
107 "License :: OSI Approved :: Apache Software License",
108 "Programming Language :: Python",
109 "Programming Language :: Python :: 2",
110 "Programming Language :: Python :: 2.7",
111 "Programming Language :: Python :: 3",
112 "Programming Language :: Python :: 3.5",
113 "Programming Language :: Python :: 3.6",
114 "Programming Language :: Python :: 3.7",
115 "Programming Language :: Python :: 3.8",
116 "Operating System :: OS Independent",
117 "Topic :: Internet",
118 ],
119 platforms="Posix; MacOS X; Windows",
120 packages=packages,
121 namespace_packages=namespaces,
122 install_requires=dependencies,
123 extras_require=extras,
124 python_requires=">=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*",
125 include_package_data=True,
126 zip_safe=False,
127 )
128
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -40,6 +40,11 @@
extras = {
"bqstorage": [
"google-cloud-bigquery-storage >= 0.6.0, <2.0.0dev",
+ # Due to an issue in pip's dependency resolver, the `grpc` extra is not
+ # installed, even though `google-cloud-bigquery-storage` specifies it
+ # as `google-api-core[grpc]`. We thus need to explicitly specify it here.
+ # See: https://github.com/googleapis/python-bigquery/issues/83
+ "grpcio >= 1.8.2, < 2.0dev",
"pyarrow>=0.16.0, < 2.0dev",
],
"pandas": ["pandas>=0.17.1"],
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -40,6 +40,11 @@\n extras = {\n \"bqstorage\": [\n \"google-cloud-bigquery-storage >= 0.6.0, <2.0.0dev\",\n+ # Due to an issue in pip's dependency resolver, the `grpc` extra is not\n+ # installed, even though `google-cloud-bigquery-storage` specifies it\n+ # as `google-api-core[grpc]`. We thus need to explicitly specify it here.\n+ # See: https://github.com/googleapis/python-bigquery/issues/83\n+ \"grpcio >= 1.8.2, < 2.0dev\",\n \"pyarrow>=0.16.0, < 2.0dev\",\n ],\n \"pandas\": [\"pandas>=0.17.1\"],\n", "issue": "Packaging issue with GRPC and google-cloud-bigquery + optional packages?\nWe're apparently losing some needed dependencies when using the optional installs for google-cloud-bigquery\r\n\r\n```\r\n$ ~/.pyenv/versions/3.8.2/bin/virtualenv repro\r\n$ source repro/bin/activate\r\n$ pip freeze \r\n```\r\n(no results)\r\n```\r\n$ pip install --upgrade google-cloud-bigquery[bqstorage,pandas]\r\n$ pip freeze > before.txt\r\n$ cat before.txt\r\n```\r\ncachetools==4.1.0\r\ncertifi==2020.4.5.1\r\nchardet==3.0.4\r\ngoogle-api-core==1.17.0\r\ngoogle-auth==1.14.1\r\ngoogle-cloud-bigquery==1.24.0\r\ngoogle-cloud-bigquery-storage==0.8.0\r\ngoogle-cloud-core==1.3.0\r\ngoogle-resumable-media==0.5.0\r\ngoogleapis-common-protos==1.51.0\r\nidna==2.9\r\nnumpy==1.18.3\r\npandas==1.0.3\r\nprotobuf==3.11.3\r\npyarrow==0.17.0\r\npyasn1==0.4.8\r\npyasn1-modules==0.2.8\r\npython-dateutil==2.8.1\r\npytz==2019.3\r\nrequests==2.23.0\r\nrsa==4.0\r\nsix==1.14.0\r\nurllib3==1.25.9\r\n\r\n\r\n```\r\n$ python\r\n>>> from google.cloud import bigquery_storage_v1beta1\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/usr/local/google/home/shollyman/python_envs/repro/lib/python3.8/site-packages/google/cloud/bigquery_storage_v1beta1/__init__.py\", line 26, in <module>\r\n from google.cloud.bigquery_storage_v1beta1 import client\r\n File \"/usr/local/google/home/shollyman/python_envs/repro/lib/python3.8/site-packages/google/cloud/bigquery_storage_v1beta1/client.py\", line 24, in <module>\r\n import google.api_core.gapic_v1.method\r\n File \"/usr/local/google/home/shollyman/python_envs/repro/lib/python3.8/site-packages/google/api_core/gapic_v1/__init__.py\", line 16, in <module>\r\n from google.api_core.gapic_v1 import config\r\n File \"/usr/local/google/home/shollyman/python_envs/repro/lib/python3.8/site-packages/google/api_core/gapic_v1/config.py\", line 23, in <module>\r\n import grpc\r\nModuleNotFoundError: No module named 'grpc'\r\n```\r\n\r\n```\r\n$ pip install google-cloud-bigquery-storage\r\n$ pip freeze > after.txt\r\n$ diff before.txt after.txt\r\n```\r\n\r\n> grpcio==1.28.1\r\n\n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\n\nimport setuptools\n\n\n# Package metadata.\n\nname = \"google-cloud-bigquery\"\ndescription = \"Google BigQuery API client library\"\nversion = \"1.24.0\"\n# Should be one of:\n# 'Development Status :: 3 - Alpha'\n# 'Development Status :: 4 - Beta'\n# 'Development Status :: 5 - Production/Stable'\nrelease_status = \"Development Status :: 5 - Production/Stable\"\ndependencies = [\n 'enum34; python_version < \"3.4\"',\n \"google-auth >= 1.9.0, < 2.0dev\",\n \"google-api-core >= 1.15.0, < 2.0dev\",\n \"google-cloud-core >= 1.1.0, < 2.0dev\",\n \"google-resumable-media >= 0.5.0, < 0.6dev\",\n \"protobuf >= 3.6.0\",\n \"six >=1.13.0,< 2.0.0dev\",\n]\nextras = {\n \"bqstorage\": [\n \"google-cloud-bigquery-storage >= 0.6.0, <2.0.0dev\",\n \"pyarrow>=0.16.0, < 2.0dev\",\n ],\n \"pandas\": [\"pandas>=0.17.1\"],\n # Exclude PyArrow dependency from Windows Python 2.7.\n 'pyarrow: platform_system != \"Windows\" or python_version >= \"3.4\"': [\n # Bad Linux release for 0.14.0.\n # https://issues.apache.org/jira/browse/ARROW-5868\n \"pyarrow>=0.4.1, != 0.14.0\"\n ],\n \"tqdm\": [\"tqdm >= 4.0.0, <5.0.0dev\"],\n \"fastparquet\": [\n \"fastparquet\",\n \"python-snappy\",\n # llvmlite >= 0.32.0 cannot be installed on Python 3.5 and below\n # (building the wheel fails), thus needs to be restricted.\n # See: https://github.com/googleapis/python-bigquery/issues/78\n \"llvmlite <= 0.31.0\",\n ],\n}\n\nall_extras = []\n\nfor extra in extras:\n if extra == \"fastparquet\":\n # Skip fastparquet from \"all\" because it is redundant with pyarrow and\n # creates a dependency on pre-release versions of numpy. See:\n # https://github.com/googleapis/google-cloud-python/issues/8549\n continue\n all_extras.extend(extras[extra])\n\nextras[\"all\"] = all_extras\n\n# Setup boilerplate below this line.\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nreadme_filename = os.path.join(package_root, \"README.rst\")\nwith io.open(readme_filename, encoding=\"utf-8\") as readme_file:\n readme = readme_file.read()\n\n# Only include packages under the 'google' namespace. Do not include tests,\n# benchmarks, etc.\npackages = [\n package for package in setuptools.find_packages() if package.startswith(\"google\")\n]\n\n# Determine which namespaces are needed.\nnamespaces = [\"google\"]\nif \"google.cloud\" in packages:\n namespaces.append(\"google.cloud\")\n\n\nsetuptools.setup(\n name=name,\n version=version,\n description=description,\n long_description=readme,\n author=\"Google LLC\",\n author_email=\"[email protected]\",\n license=\"Apache 2.0\",\n url=\"https://github.com/googleapis/python-bigquery\",\n classifiers=[\n release_status,\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet\",\n ],\n platforms=\"Posix; MacOS X; Windows\",\n packages=packages,\n namespace_packages=namespaces,\n install_requires=dependencies,\n extras_require=extras,\n python_requires=\">=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*\",\n include_package_data=True,\n zip_safe=False,\n)\n", "path": "setup.py"}], "after_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\n\nimport setuptools\n\n\n# Package metadata.\n\nname = \"google-cloud-bigquery\"\ndescription = \"Google BigQuery API client library\"\nversion = \"1.24.0\"\n# Should be one of:\n# 'Development Status :: 3 - Alpha'\n# 'Development Status :: 4 - Beta'\n# 'Development Status :: 5 - Production/Stable'\nrelease_status = \"Development Status :: 5 - Production/Stable\"\ndependencies = [\n 'enum34; python_version < \"3.4\"',\n \"google-auth >= 1.9.0, < 2.0dev\",\n \"google-api-core >= 1.15.0, < 2.0dev\",\n \"google-cloud-core >= 1.1.0, < 2.0dev\",\n \"google-resumable-media >= 0.5.0, < 0.6dev\",\n \"protobuf >= 3.6.0\",\n \"six >=1.13.0,< 2.0.0dev\",\n]\nextras = {\n \"bqstorage\": [\n \"google-cloud-bigquery-storage >= 0.6.0, <2.0.0dev\",\n # Due to an issue in pip's dependency resolver, the `grpc` extra is not\n # installed, even though `google-cloud-bigquery-storage` specifies it\n # as `google-api-core[grpc]`. We thus need to explicitly specify it here.\n # See: https://github.com/googleapis/python-bigquery/issues/83\n \"grpcio >= 1.8.2, < 2.0dev\",\n \"pyarrow>=0.16.0, < 2.0dev\",\n ],\n \"pandas\": [\"pandas>=0.17.1\"],\n # Exclude PyArrow dependency from Windows Python 2.7.\n 'pyarrow: platform_system != \"Windows\" or python_version >= \"3.4\"': [\n # Bad Linux release for 0.14.0.\n # https://issues.apache.org/jira/browse/ARROW-5868\n \"pyarrow>=0.4.1, != 0.14.0\"\n ],\n \"tqdm\": [\"tqdm >= 4.0.0, <5.0.0dev\"],\n \"fastparquet\": [\n \"fastparquet\",\n \"python-snappy\",\n # llvmlite >= 0.32.0 cannot be installed on Python 3.5 and below\n # (building the wheel fails), thus needs to be restricted.\n # See: https://github.com/googleapis/python-bigquery/issues/78\n \"llvmlite <= 0.31.0\",\n ],\n}\n\nall_extras = []\n\nfor extra in extras:\n if extra == \"fastparquet\":\n # Skip fastparquet from \"all\" because it is redundant with pyarrow and\n # creates a dependency on pre-release versions of numpy. See:\n # https://github.com/googleapis/google-cloud-python/issues/8549\n continue\n all_extras.extend(extras[extra])\n\nextras[\"all\"] = all_extras\n\n# Setup boilerplate below this line.\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nreadme_filename = os.path.join(package_root, \"README.rst\")\nwith io.open(readme_filename, encoding=\"utf-8\") as readme_file:\n readme = readme_file.read()\n\n# Only include packages under the 'google' namespace. Do not include tests,\n# benchmarks, etc.\npackages = [\n package for package in setuptools.find_packages() if package.startswith(\"google\")\n]\n\n# Determine which namespaces are needed.\nnamespaces = [\"google\"]\nif \"google.cloud\" in packages:\n namespaces.append(\"google.cloud\")\n\n\nsetuptools.setup(\n name=name,\n version=version,\n description=description,\n long_description=readme,\n author=\"Google LLC\",\n author_email=\"[email protected]\",\n license=\"Apache 2.0\",\n url=\"https://github.com/googleapis/python-bigquery\",\n classifiers=[\n release_status,\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet\",\n ],\n platforms=\"Posix; MacOS X; Windows\",\n packages=packages,\n namespace_packages=namespaces,\n install_requires=dependencies,\n extras_require=extras,\n python_requires=\">=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*\",\n include_package_data=True,\n zip_safe=False,\n)\n", "path": "setup.py"}]}
| 2,309 | 201 |
gh_patches_debug_8666
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-570
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove unnecessary Flask app
The current auto instrumentation example includes an unnecessary Flask app in its client, remove that.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/examples/auto-instrumentation/client.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from sys import argv
16
17 from flask import Flask
18 from requests import get
19
20 from opentelemetry import propagators, trace
21 from opentelemetry.sdk.trace import TracerProvider
22 from opentelemetry.sdk.trace.export import (
23 ConsoleSpanExporter,
24 SimpleExportSpanProcessor,
25 )
26
27 app = Flask(__name__)
28
29 trace.set_tracer_provider(TracerProvider())
30 tracer = trace.get_tracer_provider().get_tracer(__name__)
31
32 trace.get_tracer_provider().add_span_processor(
33 SimpleExportSpanProcessor(ConsoleSpanExporter())
34 )
35
36
37 assert len(argv) == 2
38
39 with tracer.start_as_current_span("client"):
40
41 with tracer.start_as_current_span("client-server"):
42 headers = {}
43 propagators.inject(dict.__setitem__, headers)
44 requested = get(
45 "http://localhost:8082/server_request",
46 params={"param": argv[1]},
47 headers=headers,
48 )
49
50 assert requested.status_code == 200
51
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/examples/auto-instrumentation/client.py b/docs/examples/auto-instrumentation/client.py
--- a/docs/examples/auto-instrumentation/client.py
+++ b/docs/examples/auto-instrumentation/client.py
@@ -14,7 +14,6 @@
from sys import argv
-from flask import Flask
from requests import get
from opentelemetry import propagators, trace
@@ -24,8 +23,6 @@
SimpleExportSpanProcessor,
)
-app = Flask(__name__)
-
trace.set_tracer_provider(TracerProvider())
tracer = trace.get_tracer_provider().get_tracer(__name__)
|
{"golden_diff": "diff --git a/docs/examples/auto-instrumentation/client.py b/docs/examples/auto-instrumentation/client.py\n--- a/docs/examples/auto-instrumentation/client.py\n+++ b/docs/examples/auto-instrumentation/client.py\n@@ -14,7 +14,6 @@\n \n from sys import argv\n \n-from flask import Flask\n from requests import get\n \n from opentelemetry import propagators, trace\n@@ -24,8 +23,6 @@\n SimpleExportSpanProcessor,\n )\n \n-app = Flask(__name__)\n-\n trace.set_tracer_provider(TracerProvider())\n tracer = trace.get_tracer_provider().get_tracer(__name__)\n", "issue": "Remove unnecessary Flask app\nThe current auto instrumentation example includes an unnecessary Flask app in its client, remove that.\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom sys import argv\n\nfrom flask import Flask\nfrom requests import get\n\nfrom opentelemetry import propagators, trace\nfrom opentelemetry.sdk.trace import TracerProvider\nfrom opentelemetry.sdk.trace.export import (\n ConsoleSpanExporter,\n SimpleExportSpanProcessor,\n)\n\napp = Flask(__name__)\n\ntrace.set_tracer_provider(TracerProvider())\ntracer = trace.get_tracer_provider().get_tracer(__name__)\n\ntrace.get_tracer_provider().add_span_processor(\n SimpleExportSpanProcessor(ConsoleSpanExporter())\n)\n\n\nassert len(argv) == 2\n\nwith tracer.start_as_current_span(\"client\"):\n\n with tracer.start_as_current_span(\"client-server\"):\n headers = {}\n propagators.inject(dict.__setitem__, headers)\n requested = get(\n \"http://localhost:8082/server_request\",\n params={\"param\": argv[1]},\n headers=headers,\n )\n\n assert requested.status_code == 200\n", "path": "docs/examples/auto-instrumentation/client.py"}], "after_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom sys import argv\n\nfrom requests import get\n\nfrom opentelemetry import propagators, trace\nfrom opentelemetry.sdk.trace import TracerProvider\nfrom opentelemetry.sdk.trace.export import (\n ConsoleSpanExporter,\n SimpleExportSpanProcessor,\n)\n\ntrace.set_tracer_provider(TracerProvider())\ntracer = trace.get_tracer_provider().get_tracer(__name__)\n\ntrace.get_tracer_provider().add_span_processor(\n SimpleExportSpanProcessor(ConsoleSpanExporter())\n)\n\n\nassert len(argv) == 2\n\nwith tracer.start_as_current_span(\"client\"):\n\n with tracer.start_as_current_span(\"client-server\"):\n headers = {}\n propagators.inject(dict.__setitem__, headers)\n requested = get(\n \"http://localhost:8082/server_request\",\n params={\"param\": argv[1]},\n headers=headers,\n )\n\n assert requested.status_code == 200\n", "path": "docs/examples/auto-instrumentation/client.py"}]}
| 710 | 133 |
gh_patches_debug_22214
|
rasdani/github-patches
|
git_diff
|
vega__altair-167
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
numpy scalar in Dataframe not JSON serializable
Is it possible to allow numpy scalars in a dataframe?
The following code is not working, because a np.array is not json serializable:
```
df_numpy = pd.DataFrame([dict(
x=np.array(1),
y=np.array(2),
)])
Chart(df_numpy).encode(x='x', y='y')
# TypeError: array(1) is not JSON serializable
```
Full Example: [
https://github.com/boeddeker/ipynb/blob/master/bug_altair_numpy.ipynb](https://github.com/boeddeker/ipynb/blob/master/bug_altair_numpy.ipynb)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `altair/utils/core.py`
Content:
```
1 """
2 Utility routines
3 """
4 import re
5 import warnings
6
7 import pandas as pd
8 import numpy as np
9
10
11 TYPECODE_MAP = {'ordinal': 'O',
12 'nominal': 'N',
13 'quantitative': 'Q',
14 'temporal': 'T'}
15
16 INV_TYPECODE_MAP = {v: k for k, v in TYPECODE_MAP.items()}
17
18 TYPE_ABBR = TYPECODE_MAP.values()
19
20
21 def parse_shorthand(shorthand):
22 """
23 Parse the shorthand expression for aggregation, field, and type.
24
25 These are of the form:
26
27 - "col_name"
28 - "col_name:O"
29 - "average(col_name)"
30 - "average(col_name):O"
31
32 Parameters
33 ----------
34 shorthand: str
35 Shorthand string
36
37 Returns
38 -------
39 D : dict
40 Dictionary containing the field, aggregate, and typecode
41 """
42 if not shorthand:
43 return {}
44
45 # Must import this here to avoid circular imports
46 from ..schema import AggregateOp
47 valid_aggregates = AggregateOp().values
48 valid_typecodes = list(TYPECODE_MAP) + list(INV_TYPECODE_MAP)
49
50 # build regular expressions
51 units = dict(field='(?P<field>.*)',
52 type='(?P<type>{0})'.format('|'.join(valid_typecodes)),
53 aggregate='(?P<aggregate>{0})'.format('|'.join(valid_aggregates)))
54 patterns = [r'{field}',
55 r'{field}:{type}',
56 r'{aggregate}\({field}\)',
57 r'{aggregate}\({field}\):{type}']
58 regexps = (re.compile('\A' + p.format(**units) + '\Z', re.DOTALL)
59 for p in patterns[::-1])
60
61 # find matches depending on valid fields passed
62 match = next(exp.match(shorthand).groupdict() for exp in regexps
63 if exp.match(shorthand))
64
65 # Use short form of the type expression
66 typ = match.get('type', None)
67 if typ:
68 match['type'] = INV_TYPECODE_MAP.get(typ, typ)
69 return match
70
71
72 def construct_shorthand(field=None, aggregate=None, type=None):
73 """Construct a shorthand representation.
74
75 See also: parse_shorthand"""
76 if field is None:
77 return ''
78
79 sh = field
80
81 if aggregate is not None:
82 sh = '{0}({1})'.format(aggregate, sh)
83
84 if type is not None:
85 type = TYPECODE_MAP.get(type, type)
86 if type not in TYPE_ABBR:
87 raise ValueError('Unrecognized Type: {0}'.format(type))
88 sh = '{0}:{1}'.format(sh, type)
89
90 return sh
91
92
93 def infer_vegalite_type(data, field=None):
94 """
95 From an array-like input, infer the correct vega typecode
96 ('ordinal', 'nominal', 'quantitative', or 'temporal')
97
98 Parameters
99 ----------
100 data: Numpy array or Pandas Series
101 field: str column name
102 """
103 # See if we can read the type from the field
104 if field is not None:
105 parsed = parse_shorthand(field)
106 if parsed.get('type'):
107 return parsed['type']
108
109 # Otherwise, infer based on the dtype of the input
110 typ = pd.lib.infer_dtype(data)
111
112 # TODO: Once this returns 'O', please update test_select_x and test_select_y in test_api.py
113
114 if typ in ['floating', 'mixed-integer-float', 'integer',
115 'mixed-integer', 'complex']:
116 return 'quantitative'
117 elif typ in ['string', 'bytes', 'categorical', 'boolean', 'mixed', 'unicode']:
118 return 'nominal'
119 elif typ in ['datetime', 'datetime64', 'timedelta',
120 'timedelta64', 'date', 'time', 'period']:
121 return 'temporal'
122 else:
123 warnings.warn("I don't know how to infer vegalite type from '{0}'. "
124 "Defaulting to nominal.".format(typ))
125 return 'nominal'
126
127
128 def sanitize_dataframe(df):
129 """Sanitize a DataFrame to prepare it for serialization.
130
131 * Make a copy
132 * Raise ValueError if it has a hierarchical index.
133 * Convert categoricals to strings.
134 * Convert np.int dtypes to Python int objects
135 * Convert floats to objects and replace NaNs by None.
136 * Convert DateTime dtypes into appropriate string representations
137 """
138 df = df.copy()
139
140 if isinstance(df.index, pd.core.index.MultiIndex):
141 raise ValueError('Hierarchical indices not supported')
142 if isinstance(df.columns, pd.core.index.MultiIndex):
143 raise ValueError('Hierarchical indices not supported')
144
145 for col_name, dtype in df.dtypes.iteritems():
146 if str(dtype) == 'category':
147 # XXXX: work around bug in to_json for categorical types
148 # https://github.com/pydata/pandas/issues/10778
149 df[col_name] = df[col_name].astype(str)
150 elif np.issubdtype(dtype, np.integer):
151 # convert integers to objects; np.int is not JSON serializable
152 df[col_name] = df[col_name].astype(object)
153 elif np.issubdtype(dtype, np.floating):
154 # For floats, convert nan->None: np.float is not JSON serializable
155 col = df[col_name].astype(object)
156 df[col_name] = col.where(col.notnull(), None)
157 elif str(dtype).startswith('datetime'):
158 # Convert datetimes to strings
159 # astype(str) will choose the appropriate resolution
160 df[col_name] = df[col_name].astype(str).replace('NaT', '')
161 return df
162
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/altair/utils/core.py b/altair/utils/core.py
--- a/altair/utils/core.py
+++ b/altair/utils/core.py
@@ -142,6 +142,12 @@
if isinstance(df.columns, pd.core.index.MultiIndex):
raise ValueError('Hierarchical indices not supported')
+ def to_list_if_array(val):
+ if isinstance(val, np.ndarray):
+ return val.tolist()
+ else:
+ return val
+
for col_name, dtype in df.dtypes.iteritems():
if str(dtype) == 'category':
# XXXX: work around bug in to_json for categorical types
@@ -158,4 +164,9 @@
# Convert datetimes to strings
# astype(str) will choose the appropriate resolution
df[col_name] = df[col_name].astype(str).replace('NaT', '')
+ elif dtype == object:
+ # Convert numpy arrays saved as objects to lists
+ # Arrays are not JSON serializable
+ col = df[col_name].apply(to_list_if_array, convert_dtype=False)
+ df[col_name] = col.where(col.notnull(), None)
return df
|
{"golden_diff": "diff --git a/altair/utils/core.py b/altair/utils/core.py\n--- a/altair/utils/core.py\n+++ b/altair/utils/core.py\n@@ -142,6 +142,12 @@\n if isinstance(df.columns, pd.core.index.MultiIndex):\n raise ValueError('Hierarchical indices not supported')\n \n+ def to_list_if_array(val):\n+ if isinstance(val, np.ndarray):\n+ return val.tolist()\n+ else:\n+ return val\n+\n for col_name, dtype in df.dtypes.iteritems():\n if str(dtype) == 'category':\n # XXXX: work around bug in to_json for categorical types\n@@ -158,4 +164,9 @@\n # Convert datetimes to strings\n # astype(str) will choose the appropriate resolution\n df[col_name] = df[col_name].astype(str).replace('NaT', '')\n+ elif dtype == object:\n+ # Convert numpy arrays saved as objects to lists\n+ # Arrays are not JSON serializable\n+ col = df[col_name].apply(to_list_if_array, convert_dtype=False)\n+ df[col_name] = col.where(col.notnull(), None)\n return df\n", "issue": "numpy scalar in Dataframe not JSON serializable\nIs it possible to allow numpy scalars in a dataframe?\n\nThe following code is not working, because a np.array is not json serializable:\n\n```\ndf_numpy = pd.DataFrame([dict(\n x=np.array(1),\n y=np.array(2),\n )])\nChart(df_numpy).encode(x='x', y='y')\n# TypeError: array(1) is not JSON serializable\n```\n\nFull Example: [\nhttps://github.com/boeddeker/ipynb/blob/master/bug_altair_numpy.ipynb](https://github.com/boeddeker/ipynb/blob/master/bug_altair_numpy.ipynb)\n\n", "before_files": [{"content": "\"\"\"\nUtility routines\n\"\"\"\nimport re\nimport warnings\n\nimport pandas as pd\nimport numpy as np\n\n\nTYPECODE_MAP = {'ordinal': 'O',\n 'nominal': 'N',\n 'quantitative': 'Q',\n 'temporal': 'T'}\n\nINV_TYPECODE_MAP = {v: k for k, v in TYPECODE_MAP.items()}\n\nTYPE_ABBR = TYPECODE_MAP.values()\n\n\ndef parse_shorthand(shorthand):\n \"\"\"\n Parse the shorthand expression for aggregation, field, and type.\n\n These are of the form:\n\n - \"col_name\"\n - \"col_name:O\"\n - \"average(col_name)\"\n - \"average(col_name):O\"\n\n Parameters\n ----------\n shorthand: str\n Shorthand string\n\n Returns\n -------\n D : dict\n Dictionary containing the field, aggregate, and typecode\n \"\"\"\n if not shorthand:\n return {}\n\n # Must import this here to avoid circular imports\n from ..schema import AggregateOp\n valid_aggregates = AggregateOp().values\n valid_typecodes = list(TYPECODE_MAP) + list(INV_TYPECODE_MAP)\n\n # build regular expressions\n units = dict(field='(?P<field>.*)',\n type='(?P<type>{0})'.format('|'.join(valid_typecodes)),\n aggregate='(?P<aggregate>{0})'.format('|'.join(valid_aggregates)))\n patterns = [r'{field}',\n r'{field}:{type}',\n r'{aggregate}\\({field}\\)',\n r'{aggregate}\\({field}\\):{type}']\n regexps = (re.compile('\\A' + p.format(**units) + '\\Z', re.DOTALL)\n for p in patterns[::-1])\n\n # find matches depending on valid fields passed\n match = next(exp.match(shorthand).groupdict() for exp in regexps\n if exp.match(shorthand))\n\n # Use short form of the type expression\n typ = match.get('type', None)\n if typ:\n match['type'] = INV_TYPECODE_MAP.get(typ, typ)\n return match\n\n\ndef construct_shorthand(field=None, aggregate=None, type=None):\n \"\"\"Construct a shorthand representation.\n\n See also: parse_shorthand\"\"\"\n if field is None:\n return ''\n\n sh = field\n\n if aggregate is not None:\n sh = '{0}({1})'.format(aggregate, sh)\n\n if type is not None:\n type = TYPECODE_MAP.get(type, type)\n if type not in TYPE_ABBR:\n raise ValueError('Unrecognized Type: {0}'.format(type))\n sh = '{0}:{1}'.format(sh, type)\n\n return sh\n\n\ndef infer_vegalite_type(data, field=None):\n \"\"\"\n From an array-like input, infer the correct vega typecode\n ('ordinal', 'nominal', 'quantitative', or 'temporal')\n\n Parameters\n ----------\n data: Numpy array or Pandas Series\n field: str column name\n \"\"\"\n # See if we can read the type from the field\n if field is not None:\n parsed = parse_shorthand(field)\n if parsed.get('type'):\n return parsed['type']\n\n # Otherwise, infer based on the dtype of the input\n typ = pd.lib.infer_dtype(data)\n\n # TODO: Once this returns 'O', please update test_select_x and test_select_y in test_api.py\n\n if typ in ['floating', 'mixed-integer-float', 'integer',\n 'mixed-integer', 'complex']:\n return 'quantitative'\n elif typ in ['string', 'bytes', 'categorical', 'boolean', 'mixed', 'unicode']:\n return 'nominal'\n elif typ in ['datetime', 'datetime64', 'timedelta',\n 'timedelta64', 'date', 'time', 'period']:\n return 'temporal'\n else:\n warnings.warn(\"I don't know how to infer vegalite type from '{0}'. \"\n \"Defaulting to nominal.\".format(typ))\n return 'nominal'\n\n\ndef sanitize_dataframe(df):\n \"\"\"Sanitize a DataFrame to prepare it for serialization.\n\n * Make a copy\n * Raise ValueError if it has a hierarchical index.\n * Convert categoricals to strings.\n * Convert np.int dtypes to Python int objects\n * Convert floats to objects and replace NaNs by None.\n * Convert DateTime dtypes into appropriate string representations\n \"\"\"\n df = df.copy()\n\n if isinstance(df.index, pd.core.index.MultiIndex):\n raise ValueError('Hierarchical indices not supported')\n if isinstance(df.columns, pd.core.index.MultiIndex):\n raise ValueError('Hierarchical indices not supported')\n\n for col_name, dtype in df.dtypes.iteritems():\n if str(dtype) == 'category':\n # XXXX: work around bug in to_json for categorical types\n # https://github.com/pydata/pandas/issues/10778\n df[col_name] = df[col_name].astype(str)\n elif np.issubdtype(dtype, np.integer):\n # convert integers to objects; np.int is not JSON serializable\n df[col_name] = df[col_name].astype(object)\n elif np.issubdtype(dtype, np.floating):\n # For floats, convert nan->None: np.float is not JSON serializable\n col = df[col_name].astype(object)\n df[col_name] = col.where(col.notnull(), None)\n elif str(dtype).startswith('datetime'):\n # Convert datetimes to strings\n # astype(str) will choose the appropriate resolution\n df[col_name] = df[col_name].astype(str).replace('NaT', '')\n return df\n", "path": "altair/utils/core.py"}], "after_files": [{"content": "\"\"\"\nUtility routines\n\"\"\"\nimport re\nimport warnings\n\nimport pandas as pd\nimport numpy as np\n\n\nTYPECODE_MAP = {'ordinal': 'O',\n 'nominal': 'N',\n 'quantitative': 'Q',\n 'temporal': 'T'}\n\nINV_TYPECODE_MAP = {v: k for k, v in TYPECODE_MAP.items()}\n\nTYPE_ABBR = TYPECODE_MAP.values()\n\n\ndef parse_shorthand(shorthand):\n \"\"\"\n Parse the shorthand expression for aggregation, field, and type.\n\n These are of the form:\n\n - \"col_name\"\n - \"col_name:O\"\n - \"average(col_name)\"\n - \"average(col_name):O\"\n\n Parameters\n ----------\n shorthand: str\n Shorthand string\n\n Returns\n -------\n D : dict\n Dictionary containing the field, aggregate, and typecode\n \"\"\"\n if not shorthand:\n return {}\n\n # Must import this here to avoid circular imports\n from ..schema import AggregateOp\n valid_aggregates = AggregateOp().values\n valid_typecodes = list(TYPECODE_MAP) + list(INV_TYPECODE_MAP)\n\n # build regular expressions\n units = dict(field='(?P<field>.*)',\n type='(?P<type>{0})'.format('|'.join(valid_typecodes)),\n aggregate='(?P<aggregate>{0})'.format('|'.join(valid_aggregates)))\n patterns = [r'{field}',\n r'{field}:{type}',\n r'{aggregate}\\({field}\\)',\n r'{aggregate}\\({field}\\):{type}']\n regexps = (re.compile('\\A' + p.format(**units) + '\\Z', re.DOTALL)\n for p in patterns[::-1])\n\n # find matches depending on valid fields passed\n match = next(exp.match(shorthand).groupdict() for exp in regexps\n if exp.match(shorthand))\n\n # Use short form of the type expression\n typ = match.get('type', None)\n if typ:\n match['type'] = INV_TYPECODE_MAP.get(typ, typ)\n return match\n\n\ndef construct_shorthand(field=None, aggregate=None, type=None):\n \"\"\"Construct a shorthand representation.\n\n See also: parse_shorthand\"\"\"\n if field is None:\n return ''\n\n sh = field\n\n if aggregate is not None:\n sh = '{0}({1})'.format(aggregate, sh)\n\n if type is not None:\n type = TYPECODE_MAP.get(type, type)\n if type not in TYPE_ABBR:\n raise ValueError('Unrecognized Type: {0}'.format(type))\n sh = '{0}:{1}'.format(sh, type)\n\n return sh\n\n\ndef infer_vegalite_type(data, field=None):\n \"\"\"\n From an array-like input, infer the correct vega typecode\n ('ordinal', 'nominal', 'quantitative', or 'temporal')\n\n Parameters\n ----------\n data: Numpy array or Pandas Series\n field: str column name\n \"\"\"\n # See if we can read the type from the field\n if field is not None:\n parsed = parse_shorthand(field)\n if parsed.get('type'):\n return parsed['type']\n\n # Otherwise, infer based on the dtype of the input\n typ = pd.lib.infer_dtype(data)\n\n # TODO: Once this returns 'O', please update test_select_x and test_select_y in test_api.py\n\n if typ in ['floating', 'mixed-integer-float', 'integer',\n 'mixed-integer', 'complex']:\n return 'quantitative'\n elif typ in ['string', 'bytes', 'categorical', 'boolean', 'mixed', 'unicode']:\n return 'nominal'\n elif typ in ['datetime', 'datetime64', 'timedelta',\n 'timedelta64', 'date', 'time', 'period']:\n return 'temporal'\n else:\n warnings.warn(\"I don't know how to infer vegalite type from '{0}'. \"\n \"Defaulting to nominal.\".format(typ))\n return 'nominal'\n\n\ndef sanitize_dataframe(df):\n \"\"\"Sanitize a DataFrame to prepare it for serialization.\n\n * Make a copy\n * Raise ValueError if it has a hierarchical index.\n * Convert categoricals to strings.\n * Convert np.int dtypes to Python int objects\n * Convert floats to objects and replace NaNs by None.\n * Convert DateTime dtypes into appropriate string representations\n \"\"\"\n df = df.copy()\n\n if isinstance(df.index, pd.core.index.MultiIndex):\n raise ValueError('Hierarchical indices not supported')\n if isinstance(df.columns, pd.core.index.MultiIndex):\n raise ValueError('Hierarchical indices not supported')\n\n def to_list_if_array(val):\n if isinstance(val, np.ndarray):\n return val.tolist()\n else:\n return val\n\n for col_name, dtype in df.dtypes.iteritems():\n if str(dtype) == 'category':\n # XXXX: work around bug in to_json for categorical types\n # https://github.com/pydata/pandas/issues/10778\n df[col_name] = df[col_name].astype(str)\n elif np.issubdtype(dtype, np.integer):\n # convert integers to objects; np.int is not JSON serializable\n df[col_name] = df[col_name].astype(object)\n elif np.issubdtype(dtype, np.floating):\n # For floats, convert nan->None: np.float is not JSON serializable\n col = df[col_name].astype(object)\n df[col_name] = col.where(col.notnull(), None)\n elif str(dtype).startswith('datetime'):\n # Convert datetimes to strings\n # astype(str) will choose the appropriate resolution\n df[col_name] = df[col_name].astype(str).replace('NaT', '')\n elif dtype == object:\n # Convert numpy arrays saved as objects to lists\n # Arrays are not JSON serializable\n col = df[col_name].apply(to_list_if_array, convert_dtype=False)\n df[col_name] = col.where(col.notnull(), None)\n return df\n", "path": "altair/utils/core.py"}]}
| 2,023 | 263 |
gh_patches_debug_28110
|
rasdani/github-patches
|
git_diff
|
lightly-ai__lightly-1304
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove prefetch generator
## Description
Torch handles prefetching internally and the prefetch generator in PIP is no longer used. We can safely remove it.
## Tasks
- [ ] Remove all code for the prefetch generator
- [ ] Remove dependency for prefetch generator
- [ ] Check if prefetch generator is mentioned in docs
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lightly/__init__.py`
Content:
```
1 """Lightly is a computer vision framework for self-supervised learning.
2
3 With Lightly you can train deep learning models using
4 self-supervision. This means, that you don't require
5 any labels to train a model. Lightly has been built
6 to help you understand and work with large unlabeled datasets.
7 It is built on top of PyTorch and therefore fully compatible
8 with other frameworks such as Fast.ai.
9
10 The framework is structured into the following modules:
11
12 - **api**:
13
14 The lightly.api module handles communication with the Lightly web-app.
15
16 - **cli**:
17
18 The lightly.cli module provides a command-line interface for training
19 self-supervised models and embedding images. Furthermore, the command-line
20 tool can be used to upload and download images from/to the Lightly web-app.
21
22 - **core**:
23
24 The lightly.core module offers one-liners for simple self-supervised learning.
25
26 - **data**:
27
28 The lightly.data module provides a dataset wrapper and collate functions. The
29 collate functions are in charge of the data augmentations which are crucial for
30 self-supervised learning.
31
32 - **loss**:
33
34 The lightly.loss module contains implementations of popular self-supervised training
35 loss functions.
36
37 - **models**:
38
39 The lightly.models module holds the implementation of the ResNet as well as heads
40 for self-supervised methods. It currently implements the heads of:
41
42 - Barlow Twins
43
44 - BYOL
45
46 - MoCo
47
48 - NNCLR
49
50 - SimCLR
51
52 - SimSiam
53
54 - SwaV
55
56 - **transforms**:
57
58 The lightly.transforms module implements custom data transforms. Currently implements:
59
60 - Gaussian Blur
61
62 - Random Rotation
63
64 - Random Solarization
65
66 - **utils**:
67
68 The lightly.utils package provides global utility methods.
69 The io module contains utility to save and load embeddings in a format which is
70 understood by the Lightly library.
71
72 """
73
74 # Copyright (c) 2020. Lightly AG and its affiliates.
75 # All Rights Reserved
76
77 __name__ = "lightly"
78 __version__ = "1.4.10"
79
80 import os
81
82 try:
83 # See (https://github.com/PyTorchLightning/pytorch-lightning)
84 # This variable is injected in the __builtins__ by the build
85 # process. It used to enable importing subpackages of skimage when
86 # the binaries are not built
87 __LIGHTLY_SETUP__
88 except NameError:
89 __LIGHTLY_SETUP__ = False
90
91
92 if __LIGHTLY_SETUP__:
93 # setting up lightly
94 msg = f"Partial import of {__name__}=={__version__} during build process."
95 print(msg)
96 else:
97 # see if prefetch_generator is available
98 try:
99 import prefetch_generator
100 except ImportError:
101 _prefetch_generator_available = False
102 else:
103 _prefetch_generator_available = True
104
105 def _is_prefetch_generator_available():
106 return _prefetch_generator_available
107
108 # see if torchvision vision transformer is available
109 try:
110 import torchvision.models.vision_transformer
111
112 _torchvision_vit_available = True
113 except (
114 RuntimeError, # Different CUDA versions for torch and torchvision
115 OSError, # Different CUDA versions for torch and torchvision (old)
116 ImportError, # No installation or old version of torchvision
117 ):
118 _torchvision_vit_available = False
119
120 if os.getenv("LIGHTLY_DID_VERSION_CHECK", "False") == "False":
121 os.environ["LIGHTLY_DID_VERSION_CHECK"] = "True"
122 from multiprocessing import current_process
123
124 if current_process().name == "MainProcess":
125 from lightly.api.version_checking import is_latest_version
126
127 try:
128 is_latest_version(current_version=__version__)
129 except Exception:
130 # Version check should never break the package.
131 pass
132
```
Path: `lightly/embedding/embedding.py`
Content:
```
1 """ Embedding Strategies """
2
3 # Copyright (c) 2020. Lightly AG and its affiliates.
4 # All Rights Reserved
5
6 import time
7 from typing import List, Tuple, Union
8
9 import numpy as np
10 import torch
11 from tqdm import tqdm
12
13 import lightly
14 from lightly.embedding._base import BaseEmbedding
15 from lightly.utils.reordering import sort_items_by_keys
16
17 if lightly._is_prefetch_generator_available():
18 from prefetch_generator import BackgroundGenerator
19
20
21 class SelfSupervisedEmbedding(BaseEmbedding):
22 """Implementation of self-supervised embedding models.
23
24 Implements an embedding strategy based on self-supervised learning. A
25 model backbone, self-supervised criterion, optimizer, and dataloader are
26 passed to the constructor. The embedding itself is a pytorch-lightning
27 module.
28
29 The implementation is based on contrastive learning.
30
31 * SimCLR: https://arxiv.org/abs/2002.05709
32 * MoCo: https://arxiv.org/abs/1911.05722
33 * SimSiam: https://arxiv.org/abs/2011.10566
34
35 Attributes:
36 model:
37 A backbone convolutional network with a projection head.
38 criterion:
39 A contrastive loss function.
40 optimizer:
41 A PyTorch optimizer.
42 dataloader:
43 A torchvision dataloader.
44 scheduler:
45 A PyTorch learning rate scheduler.
46
47 Examples:
48 >>> # define a model, criterion, optimizer, and dataloader above
49 >>> import lightly.embedding as embedding
50 >>> encoder = SelfSupervisedEmbedding(
51 >>> model,
52 >>> criterion,
53 >>> optimizer,
54 >>> dataloader,
55 >>> )
56 >>> # train the self-supervised embedding with default settings
57 >>> encoder.train_embedding()
58 >>> # pass pytorch-lightning trainer arguments as kwargs
59 >>> encoder.train_embedding(max_epochs=10)
60
61 """
62
63 def __init__(
64 self,
65 model: torch.nn.Module,
66 criterion: torch.nn.Module,
67 optimizer: torch.optim.Optimizer,
68 dataloader: torch.utils.data.DataLoader,
69 scheduler=None,
70 ):
71 super(SelfSupervisedEmbedding, self).__init__(
72 model, criterion, optimizer, dataloader, scheduler
73 )
74
75 def embed(
76 self, dataloader: torch.utils.data.DataLoader, device: torch.device = None
77 ) -> Tuple[np.ndarray, List[int], List[str]]:
78 """Embeds images in a vector space.
79
80 Args:
81 dataloader:
82 A PyTorch dataloader.
83 device:
84 Selected device (`cpu`, `cuda`, see PyTorch documentation)
85
86 Returns:
87 Tuple of (embeddings, labels, filenames) ordered by the
88 samples in the dataset of the dataloader.
89 embeddings:
90 Embedding of shape (n_samples, embedding_feature_size).
91 One embedding for each sample.
92 labels:
93 Labels of shape (n_samples, ).
94 filenames:
95 The filenames from dataloader.dataset.get_filenames().
96
97
98 Examples:
99 >>> # embed images in vector space
100 >>> embeddings, labels, fnames = encoder.embed(dataloader)
101
102 """
103
104 self.model.eval()
105 embeddings, labels, filenames = None, None, []
106
107 dataset = dataloader.dataset
108 if lightly._is_prefetch_generator_available():
109 dataloader = BackgroundGenerator(dataloader, max_prefetch=3)
110
111 pbar = tqdm(total=len(dataset), unit="imgs")
112
113 efficiency = 0.0
114 embeddings = []
115 labels = []
116 with torch.no_grad():
117 start_timepoint = time.time()
118 for image_batch, label_batch, filename_batch in dataloader:
119 batch_size = image_batch.shape[0]
120
121 # the following 2 lines are needed to prevent a file handler leak,
122 # see https://github.com/lightly-ai/lightly/pull/676
123 image_batch = image_batch.to(device)
124 label_batch = label_batch.clone()
125
126 filenames += [*filename_batch]
127
128 prepared_timepoint = time.time()
129
130 embedding_batch = self.model.backbone(image_batch)
131 embedding_batch = embedding_batch.detach().reshape(batch_size, -1)
132
133 embeddings.append(embedding_batch)
134 labels.append(label_batch)
135
136 finished_timepoint = time.time()
137
138 data_loading_time = prepared_timepoint - start_timepoint
139 inference_time = finished_timepoint - prepared_timepoint
140 total_batch_time = data_loading_time + inference_time
141
142 efficiency = inference_time / total_batch_time
143 pbar.set_description("Compute efficiency: {:.2f}".format(efficiency))
144 start_timepoint = time.time()
145
146 pbar.update(batch_size)
147
148 embeddings = torch.cat(embeddings, 0)
149 labels = torch.cat(labels, 0)
150
151 embeddings = embeddings.cpu().numpy()
152 labels = labels.cpu().numpy()
153
154 sorted_filenames = dataset.get_filenames()
155 sorted_embeddings = sort_items_by_keys(filenames, embeddings, sorted_filenames)
156 sorted_labels = sort_items_by_keys(filenames, labels, sorted_filenames)
157 embeddings = np.stack(sorted_embeddings)
158 labels = np.stack(sorted_labels).tolist()
159
160 return embeddings, labels, sorted_filenames
161
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lightly/__init__.py b/lightly/__init__.py
--- a/lightly/__init__.py
+++ b/lightly/__init__.py
@@ -94,17 +94,6 @@
msg = f"Partial import of {__name__}=={__version__} during build process."
print(msg)
else:
- # see if prefetch_generator is available
- try:
- import prefetch_generator
- except ImportError:
- _prefetch_generator_available = False
- else:
- _prefetch_generator_available = True
-
- def _is_prefetch_generator_available():
- return _prefetch_generator_available
-
# see if torchvision vision transformer is available
try:
import torchvision.models.vision_transformer
diff --git a/lightly/embedding/embedding.py b/lightly/embedding/embedding.py
--- a/lightly/embedding/embedding.py
+++ b/lightly/embedding/embedding.py
@@ -14,9 +14,6 @@
from lightly.embedding._base import BaseEmbedding
from lightly.utils.reordering import sort_items_by_keys
-if lightly._is_prefetch_generator_available():
- from prefetch_generator import BackgroundGenerator
-
class SelfSupervisedEmbedding(BaseEmbedding):
"""Implementation of self-supervised embedding models.
@@ -105,8 +102,6 @@
embeddings, labels, filenames = None, None, []
dataset = dataloader.dataset
- if lightly._is_prefetch_generator_available():
- dataloader = BackgroundGenerator(dataloader, max_prefetch=3)
pbar = tqdm(total=len(dataset), unit="imgs")
|
{"golden_diff": "diff --git a/lightly/__init__.py b/lightly/__init__.py\n--- a/lightly/__init__.py\n+++ b/lightly/__init__.py\n@@ -94,17 +94,6 @@\n msg = f\"Partial import of {__name__}=={__version__} during build process.\"\n print(msg)\n else:\n- # see if prefetch_generator is available\n- try:\n- import prefetch_generator\n- except ImportError:\n- _prefetch_generator_available = False\n- else:\n- _prefetch_generator_available = True\n-\n- def _is_prefetch_generator_available():\n- return _prefetch_generator_available\n-\n # see if torchvision vision transformer is available\n try:\n import torchvision.models.vision_transformer\ndiff --git a/lightly/embedding/embedding.py b/lightly/embedding/embedding.py\n--- a/lightly/embedding/embedding.py\n+++ b/lightly/embedding/embedding.py\n@@ -14,9 +14,6 @@\n from lightly.embedding._base import BaseEmbedding\n from lightly.utils.reordering import sort_items_by_keys\n \n-if lightly._is_prefetch_generator_available():\n- from prefetch_generator import BackgroundGenerator\n-\n \n class SelfSupervisedEmbedding(BaseEmbedding):\n \"\"\"Implementation of self-supervised embedding models.\n@@ -105,8 +102,6 @@\n embeddings, labels, filenames = None, None, []\n \n dataset = dataloader.dataset\n- if lightly._is_prefetch_generator_available():\n- dataloader = BackgroundGenerator(dataloader, max_prefetch=3)\n \n pbar = tqdm(total=len(dataset), unit=\"imgs\")\n", "issue": "Remove prefetch generator\n## Description\r\n\r\nTorch handles prefetching internally and the prefetch generator in PIP is no longer used. We can safely remove it.\r\n\r\n## Tasks\r\n\r\n- [ ] Remove all code for the prefetch generator\r\n- [ ] Remove dependency for prefetch generator\r\n- [ ] Check if prefetch generator is mentioned in docs\n", "before_files": [{"content": "\"\"\"Lightly is a computer vision framework for self-supervised learning.\n\nWith Lightly you can train deep learning models using\nself-supervision. This means, that you don't require\nany labels to train a model. Lightly has been built\nto help you understand and work with large unlabeled datasets.\nIt is built on top of PyTorch and therefore fully compatible \nwith other frameworks such as Fast.ai.\n\nThe framework is structured into the following modules:\n\n- **api**: \n\n The lightly.api module handles communication with the Lightly web-app.\n\n- **cli**:\n\n The lightly.cli module provides a command-line interface for training \n self-supervised models and embedding images. Furthermore, the command-line\n tool can be used to upload and download images from/to the Lightly web-app.\n\n- **core**:\n\n The lightly.core module offers one-liners for simple self-supervised learning.\n\n- **data**:\n\n The lightly.data module provides a dataset wrapper and collate functions. The\n collate functions are in charge of the data augmentations which are crucial for\n self-supervised learning.\n\n- **loss**:\n\n The lightly.loss module contains implementations of popular self-supervised training\n loss functions.\n\n- **models**:\n\n The lightly.models module holds the implementation of the ResNet as well as heads\n for self-supervised methods. It currently implements the heads of:\n\n - Barlow Twins\n\n - BYOL\n \n - MoCo\n \n - NNCLR\n \n - SimCLR\n \n - SimSiam\n \n - SwaV\n\n- **transforms**:\n\n The lightly.transforms module implements custom data transforms. Currently implements:\n\n - Gaussian Blur\n\n - Random Rotation\n\n - Random Solarization\n\n- **utils**:\n\n The lightly.utils package provides global utility methods.\n The io module contains utility to save and load embeddings in a format which is\n understood by the Lightly library.\n\n\"\"\"\n\n# Copyright (c) 2020. Lightly AG and its affiliates.\n# All Rights Reserved\n\n__name__ = \"lightly\"\n__version__ = \"1.4.10\"\n\nimport os\n\ntry:\n # See (https://github.com/PyTorchLightning/pytorch-lightning)\n # This variable is injected in the __builtins__ by the build\n # process. It used to enable importing subpackages of skimage when\n # the binaries are not built\n __LIGHTLY_SETUP__\nexcept NameError:\n __LIGHTLY_SETUP__ = False\n\n\nif __LIGHTLY_SETUP__:\n # setting up lightly\n msg = f\"Partial import of {__name__}=={__version__} during build process.\"\n print(msg)\nelse:\n # see if prefetch_generator is available\n try:\n import prefetch_generator\n except ImportError:\n _prefetch_generator_available = False\n else:\n _prefetch_generator_available = True\n\n def _is_prefetch_generator_available():\n return _prefetch_generator_available\n\n # see if torchvision vision transformer is available\n try:\n import torchvision.models.vision_transformer\n\n _torchvision_vit_available = True\n except (\n RuntimeError, # Different CUDA versions for torch and torchvision\n OSError, # Different CUDA versions for torch and torchvision (old)\n ImportError, # No installation or old version of torchvision\n ):\n _torchvision_vit_available = False\n\n if os.getenv(\"LIGHTLY_DID_VERSION_CHECK\", \"False\") == \"False\":\n os.environ[\"LIGHTLY_DID_VERSION_CHECK\"] = \"True\"\n from multiprocessing import current_process\n\n if current_process().name == \"MainProcess\":\n from lightly.api.version_checking import is_latest_version\n\n try:\n is_latest_version(current_version=__version__)\n except Exception:\n # Version check should never break the package.\n pass\n", "path": "lightly/__init__.py"}, {"content": "\"\"\" Embedding Strategies \"\"\"\n\n# Copyright (c) 2020. Lightly AG and its affiliates.\n# All Rights Reserved\n\nimport time\nfrom typing import List, Tuple, Union\n\nimport numpy as np\nimport torch\nfrom tqdm import tqdm\n\nimport lightly\nfrom lightly.embedding._base import BaseEmbedding\nfrom lightly.utils.reordering import sort_items_by_keys\n\nif lightly._is_prefetch_generator_available():\n from prefetch_generator import BackgroundGenerator\n\n\nclass SelfSupervisedEmbedding(BaseEmbedding):\n \"\"\"Implementation of self-supervised embedding models.\n\n Implements an embedding strategy based on self-supervised learning. A\n model backbone, self-supervised criterion, optimizer, and dataloader are\n passed to the constructor. The embedding itself is a pytorch-lightning\n module.\n\n The implementation is based on contrastive learning.\n\n * SimCLR: https://arxiv.org/abs/2002.05709\n * MoCo: https://arxiv.org/abs/1911.05722\n * SimSiam: https://arxiv.org/abs/2011.10566\n\n Attributes:\n model:\n A backbone convolutional network with a projection head.\n criterion:\n A contrastive loss function.\n optimizer:\n A PyTorch optimizer.\n dataloader:\n A torchvision dataloader.\n scheduler:\n A PyTorch learning rate scheduler.\n\n Examples:\n >>> # define a model, criterion, optimizer, and dataloader above\n >>> import lightly.embedding as embedding\n >>> encoder = SelfSupervisedEmbedding(\n >>> model,\n >>> criterion,\n >>> optimizer,\n >>> dataloader,\n >>> )\n >>> #\u00a0train the self-supervised embedding with default settings\n >>> encoder.train_embedding()\n >>> #\u00a0pass pytorch-lightning trainer arguments as kwargs\n >>> encoder.train_embedding(max_epochs=10)\n\n \"\"\"\n\n def __init__(\n self,\n model: torch.nn.Module,\n criterion: torch.nn.Module,\n optimizer: torch.optim.Optimizer,\n dataloader: torch.utils.data.DataLoader,\n scheduler=None,\n ):\n super(SelfSupervisedEmbedding, self).__init__(\n model, criterion, optimizer, dataloader, scheduler\n )\n\n def embed(\n self, dataloader: torch.utils.data.DataLoader, device: torch.device = None\n ) -> Tuple[np.ndarray, List[int], List[str]]:\n \"\"\"Embeds images in a vector space.\n\n Args:\n dataloader:\n A PyTorch dataloader.\n device:\n Selected device (`cpu`, `cuda`, see PyTorch documentation)\n\n Returns:\n Tuple of (embeddings, labels, filenames) ordered by the\n samples in the dataset of the dataloader.\n embeddings:\n Embedding of shape (n_samples, embedding_feature_size).\n One embedding for each sample.\n labels:\n Labels of shape (n_samples, ).\n filenames:\n The filenames from dataloader.dataset.get_filenames().\n\n\n Examples:\n >>> # embed images in vector space\n >>> embeddings, labels, fnames = encoder.embed(dataloader)\n\n \"\"\"\n\n self.model.eval()\n embeddings, labels, filenames = None, None, []\n\n dataset = dataloader.dataset\n if lightly._is_prefetch_generator_available():\n dataloader = BackgroundGenerator(dataloader, max_prefetch=3)\n\n pbar = tqdm(total=len(dataset), unit=\"imgs\")\n\n efficiency = 0.0\n embeddings = []\n labels = []\n with torch.no_grad():\n start_timepoint = time.time()\n for image_batch, label_batch, filename_batch in dataloader:\n batch_size = image_batch.shape[0]\n\n # the following 2 lines are needed to prevent a file handler leak,\n # see https://github.com/lightly-ai/lightly/pull/676\n image_batch = image_batch.to(device)\n label_batch = label_batch.clone()\n\n filenames += [*filename_batch]\n\n prepared_timepoint = time.time()\n\n embedding_batch = self.model.backbone(image_batch)\n embedding_batch = embedding_batch.detach().reshape(batch_size, -1)\n\n embeddings.append(embedding_batch)\n labels.append(label_batch)\n\n finished_timepoint = time.time()\n\n data_loading_time = prepared_timepoint - start_timepoint\n inference_time = finished_timepoint - prepared_timepoint\n total_batch_time = data_loading_time + inference_time\n\n efficiency = inference_time / total_batch_time\n pbar.set_description(\"Compute efficiency: {:.2f}\".format(efficiency))\n start_timepoint = time.time()\n\n pbar.update(batch_size)\n\n embeddings = torch.cat(embeddings, 0)\n labels = torch.cat(labels, 0)\n\n embeddings = embeddings.cpu().numpy()\n labels = labels.cpu().numpy()\n\n sorted_filenames = dataset.get_filenames()\n sorted_embeddings = sort_items_by_keys(filenames, embeddings, sorted_filenames)\n sorted_labels = sort_items_by_keys(filenames, labels, sorted_filenames)\n embeddings = np.stack(sorted_embeddings)\n labels = np.stack(sorted_labels).tolist()\n\n return embeddings, labels, sorted_filenames\n", "path": "lightly/embedding/embedding.py"}], "after_files": [{"content": "\"\"\"Lightly is a computer vision framework for self-supervised learning.\n\nWith Lightly you can train deep learning models using\nself-supervision. This means, that you don't require\nany labels to train a model. Lightly has been built\nto help you understand and work with large unlabeled datasets.\nIt is built on top of PyTorch and therefore fully compatible \nwith other frameworks such as Fast.ai.\n\nThe framework is structured into the following modules:\n\n- **api**: \n\n The lightly.api module handles communication with the Lightly web-app.\n\n- **cli**:\n\n The lightly.cli module provides a command-line interface for training \n self-supervised models and embedding images. Furthermore, the command-line\n tool can be used to upload and download images from/to the Lightly web-app.\n\n- **core**:\n\n The lightly.core module offers one-liners for simple self-supervised learning.\n\n- **data**:\n\n The lightly.data module provides a dataset wrapper and collate functions. The\n collate functions are in charge of the data augmentations which are crucial for\n self-supervised learning.\n\n- **loss**:\n\n The lightly.loss module contains implementations of popular self-supervised training\n loss functions.\n\n- **models**:\n\n The lightly.models module holds the implementation of the ResNet as well as heads\n for self-supervised methods. It currently implements the heads of:\n\n - Barlow Twins\n\n - BYOL\n \n - MoCo\n \n - NNCLR\n \n - SimCLR\n \n - SimSiam\n \n - SwaV\n\n- **transforms**:\n\n The lightly.transforms module implements custom data transforms. Currently implements:\n\n - Gaussian Blur\n\n - Random Rotation\n\n - Random Solarization\n\n- **utils**:\n\n The lightly.utils package provides global utility methods.\n The io module contains utility to save and load embeddings in a format which is\n understood by the Lightly library.\n\n\"\"\"\n\n# Copyright (c) 2020. Lightly AG and its affiliates.\n# All Rights Reserved\n\n__name__ = \"lightly\"\n__version__ = \"1.4.10\"\n\nimport os\n\ntry:\n # See (https://github.com/PyTorchLightning/pytorch-lightning)\n # This variable is injected in the __builtins__ by the build\n # process. It used to enable importing subpackages of skimage when\n # the binaries are not built\n __LIGHTLY_SETUP__\nexcept NameError:\n __LIGHTLY_SETUP__ = False\n\n\nif __LIGHTLY_SETUP__:\n # setting up lightly\n msg = f\"Partial import of {__name__}=={__version__} during build process.\"\n print(msg)\nelse:\n # see if torchvision vision transformer is available\n try:\n import torchvision.models.vision_transformer\n\n _torchvision_vit_available = True\n except (\n RuntimeError, # Different CUDA versions for torch and torchvision\n OSError, # Different CUDA versions for torch and torchvision (old)\n ImportError, # No installation or old version of torchvision\n ):\n _torchvision_vit_available = False\n\n if os.getenv(\"LIGHTLY_DID_VERSION_CHECK\", \"False\") == \"False\":\n os.environ[\"LIGHTLY_DID_VERSION_CHECK\"] = \"True\"\n from multiprocessing import current_process\n\n if current_process().name == \"MainProcess\":\n from lightly.api.version_checking import is_latest_version\n\n try:\n is_latest_version(current_version=__version__)\n except Exception:\n # Version check should never break the package.\n pass\n", "path": "lightly/__init__.py"}, {"content": "\"\"\" Embedding Strategies \"\"\"\n\n# Copyright (c) 2020. Lightly AG and its affiliates.\n# All Rights Reserved\n\nimport time\nfrom typing import List, Tuple, Union\n\nimport numpy as np\nimport torch\nfrom tqdm import tqdm\n\nimport lightly\nfrom lightly.embedding._base import BaseEmbedding\nfrom lightly.utils.reordering import sort_items_by_keys\n\n\nclass SelfSupervisedEmbedding(BaseEmbedding):\n \"\"\"Implementation of self-supervised embedding models.\n\n Implements an embedding strategy based on self-supervised learning. A\n model backbone, self-supervised criterion, optimizer, and dataloader are\n passed to the constructor. The embedding itself is a pytorch-lightning\n module.\n\n The implementation is based on contrastive learning.\n\n * SimCLR: https://arxiv.org/abs/2002.05709\n * MoCo: https://arxiv.org/abs/1911.05722\n * SimSiam: https://arxiv.org/abs/2011.10566\n\n Attributes:\n model:\n A backbone convolutional network with a projection head.\n criterion:\n A contrastive loss function.\n optimizer:\n A PyTorch optimizer.\n dataloader:\n A torchvision dataloader.\n scheduler:\n A PyTorch learning rate scheduler.\n\n Examples:\n >>> # define a model, criterion, optimizer, and dataloader above\n >>> import lightly.embedding as embedding\n >>> encoder = SelfSupervisedEmbedding(\n >>> model,\n >>> criterion,\n >>> optimizer,\n >>> dataloader,\n >>> )\n >>> #\u00a0train the self-supervised embedding with default settings\n >>> encoder.train_embedding()\n >>> #\u00a0pass pytorch-lightning trainer arguments as kwargs\n >>> encoder.train_embedding(max_epochs=10)\n\n \"\"\"\n\n def __init__(\n self,\n model: torch.nn.Module,\n criterion: torch.nn.Module,\n optimizer: torch.optim.Optimizer,\n dataloader: torch.utils.data.DataLoader,\n scheduler=None,\n ):\n super(SelfSupervisedEmbedding, self).__init__(\n model, criterion, optimizer, dataloader, scheduler\n )\n\n def embed(\n self, dataloader: torch.utils.data.DataLoader, device: torch.device = None\n ) -> Tuple[np.ndarray, List[int], List[str]]:\n \"\"\"Embeds images in a vector space.\n\n Args:\n dataloader:\n A PyTorch dataloader.\n device:\n Selected device (`cpu`, `cuda`, see PyTorch documentation)\n\n Returns:\n Tuple of (embeddings, labels, filenames) ordered by the\n samples in the dataset of the dataloader.\n embeddings:\n Embedding of shape (n_samples, embedding_feature_size).\n One embedding for each sample.\n labels:\n Labels of shape (n_samples, ).\n filenames:\n The filenames from dataloader.dataset.get_filenames().\n\n\n Examples:\n >>> # embed images in vector space\n >>> embeddings, labels, fnames = encoder.embed(dataloader)\n\n \"\"\"\n\n self.model.eval()\n embeddings, labels, filenames = None, None, []\n\n dataset = dataloader.dataset\n\n pbar = tqdm(total=len(dataset), unit=\"imgs\")\n\n efficiency = 0.0\n embeddings = []\n labels = []\n with torch.no_grad():\n start_timepoint = time.time()\n for image_batch, label_batch, filename_batch in dataloader:\n batch_size = image_batch.shape[0]\n\n # the following 2 lines are needed to prevent a file handler leak,\n # see https://github.com/lightly-ai/lightly/pull/676\n image_batch = image_batch.to(device)\n label_batch = label_batch.clone()\n\n filenames += [*filename_batch]\n\n prepared_timepoint = time.time()\n\n embedding_batch = self.model.backbone(image_batch)\n embedding_batch = embedding_batch.detach().reshape(batch_size, -1)\n\n embeddings.append(embedding_batch)\n labels.append(label_batch)\n\n finished_timepoint = time.time()\n\n data_loading_time = prepared_timepoint - start_timepoint\n inference_time = finished_timepoint - prepared_timepoint\n total_batch_time = data_loading_time + inference_time\n\n efficiency = inference_time / total_batch_time\n pbar.set_description(\"Compute efficiency: {:.2f}\".format(efficiency))\n start_timepoint = time.time()\n\n pbar.update(batch_size)\n\n embeddings = torch.cat(embeddings, 0)\n labels = torch.cat(labels, 0)\n\n embeddings = embeddings.cpu().numpy()\n labels = labels.cpu().numpy()\n\n sorted_filenames = dataset.get_filenames()\n sorted_embeddings = sort_items_by_keys(filenames, embeddings, sorted_filenames)\n sorted_labels = sort_items_by_keys(filenames, labels, sorted_filenames)\n embeddings = np.stack(sorted_embeddings)\n labels = np.stack(sorted_labels).tolist()\n\n return embeddings, labels, sorted_filenames\n", "path": "lightly/embedding/embedding.py"}]}
| 2,990 | 360 |
gh_patches_debug_21070
|
rasdani/github-patches
|
git_diff
|
Mailu__Mailu-2808
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
SCAN_MACROS is incorrect case in Rspamd configs
In Mailu/core/rspamd/conf/external_services.conf, the first line is '{% if SCAN_MACROS == 'True' %}'. It is also the same in external_services_group.conf, note the capital 'T' in 'True'. When the mailu.env is generated, it generates SCAN_MACROS=true, i.e . all lowercase. Thus, in order to enable oletools, one must put SCAN_MACROS=True in environment file. I'm not sure what other items are reliant on SCAN_MACROS, but they should be checked as well.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/rspamd/start.py`
Content:
```
1 #!/usr/bin/env python3
2
3 import os
4 import glob
5 import logging as log
6 import requests
7 import shutil
8 import sys
9 import time
10 from socrate import system,conf
11
12 system.set_env()
13
14 # Actual startup script
15
16 config_files = []
17 for rspamd_file in glob.glob("/conf/*"):
18 conf.jinja(rspamd_file, os.environ, os.path.join("/etc/rspamd/local.d", os.path.basename(rspamd_file)))
19 config_files.append(os.path.basename(rspamd_file))
20
21 for override_file in glob.glob("/overrides/*"):
22 if os.path.basename(override_file) not in config_files:
23 shutil.copyfile(override_file, os.path.join("/etc/rspamd/local.d", os.path.basename(override_file)))
24
25 # Admin may not be up just yet
26 healthcheck = f'http://{os.environ["ADMIN_ADDRESS"]}/internal/rspamd/local_domains'
27 while True:
28 time.sleep(1)
29 try:
30 if requests.get(healthcheck,timeout=2).ok:
31 break
32 except:
33 pass
34 log.warning("Admin is not up just yet, retrying in 1 second")
35
36 # Run rspamd
37 os.system("mkdir -m 755 -p /run/rspamd")
38 os.system("chown rspamd:rspamd /run/rspamd")
39 os.system("find /var/lib/rspamd | grep -v /filter | xargs -n1 chown rspamd:rspamd")
40 os.execv("/usr/sbin/rspamd", ["rspamd", "-f", "-u", "rspamd", "-g", "rspamd"])
41
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/core/rspamd/start.py b/core/rspamd/start.py
--- a/core/rspamd/start.py
+++ b/core/rspamd/start.py
@@ -9,13 +9,13 @@
import time
from socrate import system,conf
-system.set_env()
+env = system.set_env()
# Actual startup script
config_files = []
for rspamd_file in glob.glob("/conf/*"):
- conf.jinja(rspamd_file, os.environ, os.path.join("/etc/rspamd/local.d", os.path.basename(rspamd_file)))
+ conf.jinja(rspamd_file, env, os.path.join("/etc/rspamd/local.d", os.path.basename(rspamd_file)))
config_files.append(os.path.basename(rspamd_file))
for override_file in glob.glob("/overrides/*"):
@@ -23,7 +23,7 @@
shutil.copyfile(override_file, os.path.join("/etc/rspamd/local.d", os.path.basename(override_file)))
# Admin may not be up just yet
-healthcheck = f'http://{os.environ["ADMIN_ADDRESS"]}/internal/rspamd/local_domains'
+healthcheck = f'http://{env["ADMIN_ADDRESS"]}/internal/rspamd/local_domains'
while True:
time.sleep(1)
try:
|
{"golden_diff": "diff --git a/core/rspamd/start.py b/core/rspamd/start.py\n--- a/core/rspamd/start.py\n+++ b/core/rspamd/start.py\n@@ -9,13 +9,13 @@\n import time\n from socrate import system,conf\n \n-system.set_env()\n+env = system.set_env()\n \n # Actual startup script\n \n config_files = []\n for rspamd_file in glob.glob(\"/conf/*\"):\n- conf.jinja(rspamd_file, os.environ, os.path.join(\"/etc/rspamd/local.d\", os.path.basename(rspamd_file)))\n+ conf.jinja(rspamd_file, env, os.path.join(\"/etc/rspamd/local.d\", os.path.basename(rspamd_file)))\n config_files.append(os.path.basename(rspamd_file))\n \n for override_file in glob.glob(\"/overrides/*\"):\n@@ -23,7 +23,7 @@\n shutil.copyfile(override_file, os.path.join(\"/etc/rspamd/local.d\", os.path.basename(override_file)))\n \n # Admin may not be up just yet\n-healthcheck = f'http://{os.environ[\"ADMIN_ADDRESS\"]}/internal/rspamd/local_domains'\n+healthcheck = f'http://{env[\"ADMIN_ADDRESS\"]}/internal/rspamd/local_domains'\n while True:\n time.sleep(1)\n try:\n", "issue": "SCAN_MACROS is incorrect case in Rspamd configs\nIn Mailu/core/rspamd/conf/external_services.conf, the first line is '{% if SCAN_MACROS == 'True' %}'. It is also the same in external_services_group.conf, note the capital 'T' in 'True'. When the mailu.env is generated, it generates SCAN_MACROS=true, i.e . all lowercase. Thus, in order to enable oletools, one must put SCAN_MACROS=True in environment file. I'm not sure what other items are reliant on SCAN_MACROS, but they should be checked as well. \n", "before_files": [{"content": "#!/usr/bin/env python3\n\nimport os\nimport glob\nimport logging as log\nimport requests\nimport shutil\nimport sys\nimport time\nfrom socrate import system,conf\n\nsystem.set_env()\n\n# Actual startup script\n\nconfig_files = []\nfor rspamd_file in glob.glob(\"/conf/*\"):\n conf.jinja(rspamd_file, os.environ, os.path.join(\"/etc/rspamd/local.d\", os.path.basename(rspamd_file)))\n config_files.append(os.path.basename(rspamd_file))\n\nfor override_file in glob.glob(\"/overrides/*\"):\n if os.path.basename(override_file) not in config_files:\n shutil.copyfile(override_file, os.path.join(\"/etc/rspamd/local.d\", os.path.basename(override_file)))\n\n# Admin may not be up just yet\nhealthcheck = f'http://{os.environ[\"ADMIN_ADDRESS\"]}/internal/rspamd/local_domains'\nwhile True:\n time.sleep(1)\n try:\n if requests.get(healthcheck,timeout=2).ok:\n break\n except:\n pass\n log.warning(\"Admin is not up just yet, retrying in 1 second\")\n\n# Run rspamd\nos.system(\"mkdir -m 755 -p /run/rspamd\")\nos.system(\"chown rspamd:rspamd /run/rspamd\")\nos.system(\"find /var/lib/rspamd | grep -v /filter | xargs -n1 chown rspamd:rspamd\")\nos.execv(\"/usr/sbin/rspamd\", [\"rspamd\", \"-f\", \"-u\", \"rspamd\", \"-g\", \"rspamd\"])\n", "path": "core/rspamd/start.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\nimport os\nimport glob\nimport logging as log\nimport requests\nimport shutil\nimport sys\nimport time\nfrom socrate import system,conf\n\nenv = system.set_env()\n\n# Actual startup script\n\nconfig_files = []\nfor rspamd_file in glob.glob(\"/conf/*\"):\n conf.jinja(rspamd_file, env, os.path.join(\"/etc/rspamd/local.d\", os.path.basename(rspamd_file)))\n config_files.append(os.path.basename(rspamd_file))\n\nfor override_file in glob.glob(\"/overrides/*\"):\n if os.path.basename(override_file) not in config_files:\n shutil.copyfile(override_file, os.path.join(\"/etc/rspamd/local.d\", os.path.basename(override_file)))\n\n# Admin may not be up just yet\nhealthcheck = f'http://{env[\"ADMIN_ADDRESS\"]}/internal/rspamd/local_domains'\nwhile True:\n time.sleep(1)\n try:\n if requests.get(healthcheck,timeout=2).ok:\n break\n except:\n pass\n log.warning(\"Admin is not up just yet, retrying in 1 second\")\n\n# Run rspamd\nos.system(\"mkdir -m 755 -p /run/rspamd\")\nos.system(\"chown rspamd:rspamd /run/rspamd\")\nos.system(\"find /var/lib/rspamd | grep -v /filter | xargs -n1 chown rspamd:rspamd\")\nos.execv(\"/usr/sbin/rspamd\", [\"rspamd\", \"-f\", \"-u\", \"rspamd\", \"-g\", \"rspamd\"])\n", "path": "core/rspamd/start.py"}]}
| 805 | 278 |
gh_patches_debug_9817
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-211
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add new check: IAM Policies should not be attached to a user
Attach policies only to groups or roles
https://www.terraform.io/docs/providers/aws/r/iam_user_policy.html
https://www.terraform.io/docs/providers/aws/r/iam_user_policy_attachment.html
users: https://www.terraform.io/docs/providers/aws/r/iam_policy_attachment.html
Policies / ManagedPolicyArns: https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-iam-user.html
Users: https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-iam-policy.html
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `checkov/terraform/checks/resource/aws/IAMPolicyAttachedToGroupOrRoles.py`
Content:
```
1 from checkov.common.models.enums import CheckResult, CheckCategories
2 from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
3
4
5 class IAMPolicyAttachedToGroupOrRoles(BaseResourceCheck):
6 def __init__(self):
7 name = "Ensure IAM policies are attached only to groups or roles (Reducing access management complexity may " \
8 "in-turn reduce opportunity for a principal to inadvertently receive or retain excessive privileges.) "
9 id = "CKV_AWS_40"
10 supported_resources = ['aws_iam_user_policy_attachment', 'aws_iam_user_policy', 'aws_iam_policy_attachment']
11 categories = [CheckCategories.IAM]
12 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
13
14 def scan_resource_conf(self, conf):
15 if 'user' in conf.keys() or 'users' in conf.keys():
16 return CheckResult.FAILED
17 return CheckResult.PASSED
18
19 check = IAMPolicyAttachedToGroupOrRoles()
20
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/checkov/terraform/checks/resource/aws/IAMPolicyAttachedToGroupOrRoles.py b/checkov/terraform/checks/resource/aws/IAMPolicyAttachedToGroupOrRoles.py
--- a/checkov/terraform/checks/resource/aws/IAMPolicyAttachedToGroupOrRoles.py
+++ b/checkov/terraform/checks/resource/aws/IAMPolicyAttachedToGroupOrRoles.py
@@ -12,8 +12,9 @@
super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
def scan_resource_conf(self, conf):
- if 'user' in conf.keys() or 'users' in conf.keys():
+ if 'user' in conf.keys() or ('users' in conf.keys() and len(conf['users'][0]) > 0):
return CheckResult.FAILED
return CheckResult.PASSED
+
check = IAMPolicyAttachedToGroupOrRoles()
|
{"golden_diff": "diff --git a/checkov/terraform/checks/resource/aws/IAMPolicyAttachedToGroupOrRoles.py b/checkov/terraform/checks/resource/aws/IAMPolicyAttachedToGroupOrRoles.py\n--- a/checkov/terraform/checks/resource/aws/IAMPolicyAttachedToGroupOrRoles.py\n+++ b/checkov/terraform/checks/resource/aws/IAMPolicyAttachedToGroupOrRoles.py\n@@ -12,8 +12,9 @@\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n \n def scan_resource_conf(self, conf):\n- if 'user' in conf.keys() or 'users' in conf.keys():\n+ if 'user' in conf.keys() or ('users' in conf.keys() and len(conf['users'][0]) > 0):\n return CheckResult.FAILED\n return CheckResult.PASSED\n \n+\n check = IAMPolicyAttachedToGroupOrRoles()\n", "issue": "Add new check: IAM Policies should not be attached to a user\nAttach policies only to groups or roles \r\n\r\nhttps://www.terraform.io/docs/providers/aws/r/iam_user_policy.html\r\nhttps://www.terraform.io/docs/providers/aws/r/iam_user_policy_attachment.html\r\nusers: https://www.terraform.io/docs/providers/aws/r/iam_policy_attachment.html\r\n\r\nPolicies / ManagedPolicyArns: https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-iam-user.html\r\nUsers: https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-iam-policy.html\r\n\r\n\n", "before_files": [{"content": "from checkov.common.models.enums import CheckResult, CheckCategories\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n\n\nclass IAMPolicyAttachedToGroupOrRoles(BaseResourceCheck):\n def __init__(self):\n name = \"Ensure IAM policies are attached only to groups or roles (Reducing access management complexity may \" \\\n \"in-turn reduce opportunity for a principal to inadvertently receive or retain excessive privileges.) \"\n id = \"CKV_AWS_40\"\n supported_resources = ['aws_iam_user_policy_attachment', 'aws_iam_user_policy', 'aws_iam_policy_attachment']\n categories = [CheckCategories.IAM]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf):\n if 'user' in conf.keys() or 'users' in conf.keys():\n return CheckResult.FAILED\n return CheckResult.PASSED\n\ncheck = IAMPolicyAttachedToGroupOrRoles()\n", "path": "checkov/terraform/checks/resource/aws/IAMPolicyAttachedToGroupOrRoles.py"}], "after_files": [{"content": "from checkov.common.models.enums import CheckResult, CheckCategories\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n\n\nclass IAMPolicyAttachedToGroupOrRoles(BaseResourceCheck):\n def __init__(self):\n name = \"Ensure IAM policies are attached only to groups or roles (Reducing access management complexity may \" \\\n \"in-turn reduce opportunity for a principal to inadvertently receive or retain excessive privileges.) \"\n id = \"CKV_AWS_40\"\n supported_resources = ['aws_iam_user_policy_attachment', 'aws_iam_user_policy', 'aws_iam_policy_attachment']\n categories = [CheckCategories.IAM]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf):\n if 'user' in conf.keys() or ('users' in conf.keys() and len(conf['users'][0]) > 0):\n return CheckResult.FAILED\n return CheckResult.PASSED\n\n\ncheck = IAMPolicyAttachedToGroupOrRoles()\n", "path": "checkov/terraform/checks/resource/aws/IAMPolicyAttachedToGroupOrRoles.py"}]}
| 640 | 198 |
gh_patches_debug_40511
|
rasdani/github-patches
|
git_diff
|
translate__pootle-5869
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Ensure update_stores command fails on error
Seems like update_stores may swallow (some) errors. This is not helpful for sysadmins 8/
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pootle/apps/pootle_app/management/commands/__init__.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright (C) Pootle contributors.
4 #
5 # This file is a part of the Pootle project. It is distributed under the GPL3
6 # or later license. See the LICENSE file for a copy of the license and the
7 # AUTHORS file for copyright and authorship information.
8
9 import datetime
10 import logging
11
12 from django.core.management.base import BaseCommand
13
14 from pootle.runner import set_sync_mode
15 from pootle_project.models import Project
16
17
18 class SkipChecksMixin(object):
19 def check(self, app_configs=None, tags=None, display_num_errors=False,
20 include_deployment_checks=False):
21 skip_tags = getattr(self, 'skip_system_check_tags', None)
22 if skip_tags is not None:
23 from django.core.checks.registry import registry
24 tags = registry.tags_available() - set(skip_tags)
25
26 super(SkipChecksMixin, self).check(
27 app_configs=app_configs,
28 tags=tags,
29 display_num_errors=display_num_errors,
30 include_deployment_checks=include_deployment_checks)
31
32
33 class PootleCommand(BaseCommand):
34 """Base class for handling recursive pootle store management commands."""
35
36 process_disabled_projects = False
37
38 def add_arguments(self, parser):
39 parser.add_argument(
40 '--project',
41 action='append',
42 dest='projects',
43 help='Project to refresh',
44 )
45 parser.add_argument(
46 '--language',
47 action='append',
48 dest='languages',
49 help='Language to refresh',
50 )
51 parser.add_argument(
52 "--noinput",
53 action="store_true",
54 default=False,
55 help=u"Never prompt for input",
56 )
57 parser.add_argument(
58 "--no-rq",
59 action="store_true",
60 default=False,
61 help=(u"Run all jobs in a single process, without "
62 "using rq workers"),
63 )
64
65 def __init__(self, *args, **kwargs):
66 self.languages = []
67 self.projects = []
68 super(PootleCommand, self).__init__(*args, **kwargs)
69
70 def do_translation_project(self, tp, **options):
71 process_stores = True
72
73 if hasattr(self, "handle_translation_project"):
74 logging.info(u"Running %s over %s", self.name, tp)
75 try:
76 process_stores = self.handle_translation_project(tp, **options)
77 except Exception:
78 logging.exception(u"Failed to run %s over %s", self.name, tp)
79 return
80
81 if not process_stores:
82 return
83
84 if hasattr(self, "handle_all_stores"):
85 logging.info(u"Running %s over %s's files", self.name, tp)
86 try:
87 self.handle_all_stores(tp, **options)
88 except Exception:
89 logging.exception(u"Failed to run %s over %s's files",
90 self.name, tp)
91 return
92 elif hasattr(self, "handle_store"):
93 store_query = tp.stores.live()
94 for store in store_query.iterator():
95 logging.info(u"Running %s over %s",
96 self.name, store.pootle_path)
97 try:
98 self.handle_store(store, **options)
99 except Exception:
100 logging.exception(u"Failed to run %s over %s",
101 self.name, store.pootle_path)
102
103 def handle(self, **options):
104 # adjust debug level to the verbosity option
105 debug_levels = {
106 0: logging.ERROR,
107 1: logging.WARNING,
108 2: logging.INFO,
109 3: logging.DEBUG
110 }
111 logging.getLogger().setLevel(
112 debug_levels.get(options['verbosity'], logging.DEBUG)
113 )
114
115 # reduce size of parse pool early on
116 self.name = self.__class__.__module__.split('.')[-1]
117 from pootle_store.fields import TranslationStoreFieldFile
118 TranslationStoreFieldFile._store_cache.maxsize = 2
119 TranslationStoreFieldFile._store_cache.cullsize = 2
120
121 self.projects = options.pop('projects', [])
122 self.languages = options.pop('languages', [])
123
124 # info start
125 start = datetime.datetime.now()
126 logging.info('Start running of %s', self.name)
127
128 self.handle_all(**options)
129
130 # info finish
131 end = datetime.datetime.now()
132 logging.info('All done for %s in %s', self.name, end - start)
133
134 def handle_all(self, **options):
135 if options["no_rq"]:
136 set_sync_mode(options['noinput'])
137
138 if self.process_disabled_projects:
139 project_query = Project.objects.all()
140 else:
141 project_query = Project.objects.enabled()
142
143 if self.projects:
144 project_query = project_query.filter(code__in=self.projects)
145
146 for project in project_query.iterator():
147 tp_query = project.translationproject_set.live() \
148 .order_by('language__code')
149
150 if self.languages:
151 tp_query = tp_query.filter(language__code__in=self.languages)
152
153 for tp in tp_query.iterator():
154 self.do_translation_project(tp, **options)
155
```
Path: `pootle/apps/pootle_app/management/commands/sync_stores.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright (C) Pootle contributors.
4 #
5 # This file is a part of the Pootle project. It is distributed under the GPL3
6 # or later license. See the LICENSE file for a copy of the license and the
7 # AUTHORS file for copyright and authorship information.
8
9 import os
10 os.environ['DJANGO_SETTINGS_MODULE'] = 'pootle.settings'
11
12 from pootle_app.management.commands import PootleCommand
13
14
15 class Command(PootleCommand):
16 help = "Save new translations to disk manually."
17 process_disabled_projects = True
18
19 def add_arguments(self, parser):
20 super(Command, self).add_arguments(parser)
21 parser.add_argument(
22 '--overwrite',
23 action='store_true',
24 dest='overwrite',
25 default=False,
26 help="Don't just save translations, but "
27 "overwrite files to reflect state in database",
28 )
29 parser.add_argument(
30 '--skip-missing',
31 action='store_true',
32 dest='skip_missing',
33 default=False,
34 help="Ignore missing files on disk",
35 )
36 parser.add_argument(
37 '--force',
38 action='store_true',
39 dest='force',
40 default=False,
41 help="Don't ignore stores synced after last change",
42 )
43
44 def handle_all_stores(self, translation_project, **options):
45 if translation_project.project.treestyle == 'pootle_fs':
46 return
47 if translation_project.directory_exists_on_disk():
48 translation_project.sync(
49 conservative=not options['overwrite'],
50 skip_missing=options['skip_missing'],
51 only_newer=not options['force']
52 )
53
54 def handle_store(self, store, **options):
55 store.sync(
56 conservative=not options['overwrite'],
57 update_structure=options['overwrite'],
58 skip_missing=options['skip_missing'],
59 only_newer=not options['force']
60 )
61
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pootle/apps/pootle_app/management/commands/__init__.py b/pootle/apps/pootle_app/management/commands/__init__.py
--- a/pootle/apps/pootle_app/management/commands/__init__.py
+++ b/pootle/apps/pootle_app/management/commands/__init__.py
@@ -9,7 +9,7 @@
import datetime
import logging
-from django.core.management.base import BaseCommand
+from django.core.management.base import BaseCommand, CommandError
from pootle.runner import set_sync_mode
from pootle_project.models import Project
@@ -68,37 +68,19 @@
super(PootleCommand, self).__init__(*args, **kwargs)
def do_translation_project(self, tp, **options):
- process_stores = True
-
if hasattr(self, "handle_translation_project"):
logging.info(u"Running %s over %s", self.name, tp)
- try:
- process_stores = self.handle_translation_project(tp, **options)
- except Exception:
- logging.exception(u"Failed to run %s over %s", self.name, tp)
- return
-
- if not process_stores:
+ if not self.handle_translation_project(tp, **options):
return
-
if hasattr(self, "handle_all_stores"):
logging.info(u"Running %s over %s's files", self.name, tp)
- try:
- self.handle_all_stores(tp, **options)
- except Exception:
- logging.exception(u"Failed to run %s over %s's files",
- self.name, tp)
- return
+ self.handle_all_stores(tp, **options)
elif hasattr(self, "handle_store"):
store_query = tp.stores.live()
for store in store_query.iterator():
logging.info(u"Running %s over %s",
self.name, store.pootle_path)
- try:
- self.handle_store(store, **options)
- except Exception:
- logging.exception(u"Failed to run %s over %s",
- self.name, store.pootle_path)
+ self.handle_store(store, **options)
def handle(self, **options):
# adjust debug level to the verbosity option
@@ -125,7 +107,10 @@
start = datetime.datetime.now()
logging.info('Start running of %s', self.name)
- self.handle_all(**options)
+ try:
+ self.handle_all(**options)
+ except Exception as e:
+ raise CommandError(e)
# info finish
end = datetime.datetime.now()
diff --git a/pootle/apps/pootle_app/management/commands/sync_stores.py b/pootle/apps/pootle_app/management/commands/sync_stores.py
--- a/pootle/apps/pootle_app/management/commands/sync_stores.py
+++ b/pootle/apps/pootle_app/management/commands/sync_stores.py
@@ -50,11 +50,3 @@
skip_missing=options['skip_missing'],
only_newer=not options['force']
)
-
- def handle_store(self, store, **options):
- store.sync(
- conservative=not options['overwrite'],
- update_structure=options['overwrite'],
- skip_missing=options['skip_missing'],
- only_newer=not options['force']
- )
|
{"golden_diff": "diff --git a/pootle/apps/pootle_app/management/commands/__init__.py b/pootle/apps/pootle_app/management/commands/__init__.py\n--- a/pootle/apps/pootle_app/management/commands/__init__.py\n+++ b/pootle/apps/pootle_app/management/commands/__init__.py\n@@ -9,7 +9,7 @@\n import datetime\n import logging\n \n-from django.core.management.base import BaseCommand\n+from django.core.management.base import BaseCommand, CommandError\n \n from pootle.runner import set_sync_mode\n from pootle_project.models import Project\n@@ -68,37 +68,19 @@\n super(PootleCommand, self).__init__(*args, **kwargs)\n \n def do_translation_project(self, tp, **options):\n- process_stores = True\n-\n if hasattr(self, \"handle_translation_project\"):\n logging.info(u\"Running %s over %s\", self.name, tp)\n- try:\n- process_stores = self.handle_translation_project(tp, **options)\n- except Exception:\n- logging.exception(u\"Failed to run %s over %s\", self.name, tp)\n- return\n-\n- if not process_stores:\n+ if not self.handle_translation_project(tp, **options):\n return\n-\n if hasattr(self, \"handle_all_stores\"):\n logging.info(u\"Running %s over %s's files\", self.name, tp)\n- try:\n- self.handle_all_stores(tp, **options)\n- except Exception:\n- logging.exception(u\"Failed to run %s over %s's files\",\n- self.name, tp)\n- return\n+ self.handle_all_stores(tp, **options)\n elif hasattr(self, \"handle_store\"):\n store_query = tp.stores.live()\n for store in store_query.iterator():\n logging.info(u\"Running %s over %s\",\n self.name, store.pootle_path)\n- try:\n- self.handle_store(store, **options)\n- except Exception:\n- logging.exception(u\"Failed to run %s over %s\",\n- self.name, store.pootle_path)\n+ self.handle_store(store, **options)\n \n def handle(self, **options):\n # adjust debug level to the verbosity option\n@@ -125,7 +107,10 @@\n start = datetime.datetime.now()\n logging.info('Start running of %s', self.name)\n \n- self.handle_all(**options)\n+ try:\n+ self.handle_all(**options)\n+ except Exception as e:\n+ raise CommandError(e)\n \n # info finish\n end = datetime.datetime.now()\ndiff --git a/pootle/apps/pootle_app/management/commands/sync_stores.py b/pootle/apps/pootle_app/management/commands/sync_stores.py\n--- a/pootle/apps/pootle_app/management/commands/sync_stores.py\n+++ b/pootle/apps/pootle_app/management/commands/sync_stores.py\n@@ -50,11 +50,3 @@\n skip_missing=options['skip_missing'],\n only_newer=not options['force']\n )\n-\n- def handle_store(self, store, **options):\n- store.sync(\n- conservative=not options['overwrite'],\n- update_structure=options['overwrite'],\n- skip_missing=options['skip_missing'],\n- only_newer=not options['force']\n- )\n", "issue": "Ensure update_stores command fails on error\nSeems like update_stores may swallow (some) errors. This is not helpful for sysadmins 8/\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nimport datetime\nimport logging\n\nfrom django.core.management.base import BaseCommand\n\nfrom pootle.runner import set_sync_mode\nfrom pootle_project.models import Project\n\n\nclass SkipChecksMixin(object):\n def check(self, app_configs=None, tags=None, display_num_errors=False,\n include_deployment_checks=False):\n skip_tags = getattr(self, 'skip_system_check_tags', None)\n if skip_tags is not None:\n from django.core.checks.registry import registry\n tags = registry.tags_available() - set(skip_tags)\n\n super(SkipChecksMixin, self).check(\n app_configs=app_configs,\n tags=tags,\n display_num_errors=display_num_errors,\n include_deployment_checks=include_deployment_checks)\n\n\nclass PootleCommand(BaseCommand):\n \"\"\"Base class for handling recursive pootle store management commands.\"\"\"\n\n process_disabled_projects = False\n\n def add_arguments(self, parser):\n parser.add_argument(\n '--project',\n action='append',\n dest='projects',\n help='Project to refresh',\n )\n parser.add_argument(\n '--language',\n action='append',\n dest='languages',\n help='Language to refresh',\n )\n parser.add_argument(\n \"--noinput\",\n action=\"store_true\",\n default=False,\n help=u\"Never prompt for input\",\n )\n parser.add_argument(\n \"--no-rq\",\n action=\"store_true\",\n default=False,\n help=(u\"Run all jobs in a single process, without \"\n \"using rq workers\"),\n )\n\n def __init__(self, *args, **kwargs):\n self.languages = []\n self.projects = []\n super(PootleCommand, self).__init__(*args, **kwargs)\n\n def do_translation_project(self, tp, **options):\n process_stores = True\n\n if hasattr(self, \"handle_translation_project\"):\n logging.info(u\"Running %s over %s\", self.name, tp)\n try:\n process_stores = self.handle_translation_project(tp, **options)\n except Exception:\n logging.exception(u\"Failed to run %s over %s\", self.name, tp)\n return\n\n if not process_stores:\n return\n\n if hasattr(self, \"handle_all_stores\"):\n logging.info(u\"Running %s over %s's files\", self.name, tp)\n try:\n self.handle_all_stores(tp, **options)\n except Exception:\n logging.exception(u\"Failed to run %s over %s's files\",\n self.name, tp)\n return\n elif hasattr(self, \"handle_store\"):\n store_query = tp.stores.live()\n for store in store_query.iterator():\n logging.info(u\"Running %s over %s\",\n self.name, store.pootle_path)\n try:\n self.handle_store(store, **options)\n except Exception:\n logging.exception(u\"Failed to run %s over %s\",\n self.name, store.pootle_path)\n\n def handle(self, **options):\n # adjust debug level to the verbosity option\n debug_levels = {\n 0: logging.ERROR,\n 1: logging.WARNING,\n 2: logging.INFO,\n 3: logging.DEBUG\n }\n logging.getLogger().setLevel(\n debug_levels.get(options['verbosity'], logging.DEBUG)\n )\n\n # reduce size of parse pool early on\n self.name = self.__class__.__module__.split('.')[-1]\n from pootle_store.fields import TranslationStoreFieldFile\n TranslationStoreFieldFile._store_cache.maxsize = 2\n TranslationStoreFieldFile._store_cache.cullsize = 2\n\n self.projects = options.pop('projects', [])\n self.languages = options.pop('languages', [])\n\n # info start\n start = datetime.datetime.now()\n logging.info('Start running of %s', self.name)\n\n self.handle_all(**options)\n\n # info finish\n end = datetime.datetime.now()\n logging.info('All done for %s in %s', self.name, end - start)\n\n def handle_all(self, **options):\n if options[\"no_rq\"]:\n set_sync_mode(options['noinput'])\n\n if self.process_disabled_projects:\n project_query = Project.objects.all()\n else:\n project_query = Project.objects.enabled()\n\n if self.projects:\n project_query = project_query.filter(code__in=self.projects)\n\n for project in project_query.iterator():\n tp_query = project.translationproject_set.live() \\\n .order_by('language__code')\n\n if self.languages:\n tp_query = tp_query.filter(language__code__in=self.languages)\n\n for tp in tp_query.iterator():\n self.do_translation_project(tp, **options)\n", "path": "pootle/apps/pootle_app/management/commands/__init__.py"}, {"content": "# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nimport os\nos.environ['DJANGO_SETTINGS_MODULE'] = 'pootle.settings'\n\nfrom pootle_app.management.commands import PootleCommand\n\n\nclass Command(PootleCommand):\n help = \"Save new translations to disk manually.\"\n process_disabled_projects = True\n\n def add_arguments(self, parser):\n super(Command, self).add_arguments(parser)\n parser.add_argument(\n '--overwrite',\n action='store_true',\n dest='overwrite',\n default=False,\n help=\"Don't just save translations, but \"\n \"overwrite files to reflect state in database\",\n )\n parser.add_argument(\n '--skip-missing',\n action='store_true',\n dest='skip_missing',\n default=False,\n help=\"Ignore missing files on disk\",\n )\n parser.add_argument(\n '--force',\n action='store_true',\n dest='force',\n default=False,\n help=\"Don't ignore stores synced after last change\",\n )\n\n def handle_all_stores(self, translation_project, **options):\n if translation_project.project.treestyle == 'pootle_fs':\n return\n if translation_project.directory_exists_on_disk():\n translation_project.sync(\n conservative=not options['overwrite'],\n skip_missing=options['skip_missing'],\n only_newer=not options['force']\n )\n\n def handle_store(self, store, **options):\n store.sync(\n conservative=not options['overwrite'],\n update_structure=options['overwrite'],\n skip_missing=options['skip_missing'],\n only_newer=not options['force']\n )\n", "path": "pootle/apps/pootle_app/management/commands/sync_stores.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nimport datetime\nimport logging\n\nfrom django.core.management.base import BaseCommand, CommandError\n\nfrom pootle.runner import set_sync_mode\nfrom pootle_project.models import Project\n\n\nclass SkipChecksMixin(object):\n def check(self, app_configs=None, tags=None, display_num_errors=False,\n include_deployment_checks=False):\n skip_tags = getattr(self, 'skip_system_check_tags', None)\n if skip_tags is not None:\n from django.core.checks.registry import registry\n tags = registry.tags_available() - set(skip_tags)\n\n super(SkipChecksMixin, self).check(\n app_configs=app_configs,\n tags=tags,\n display_num_errors=display_num_errors,\n include_deployment_checks=include_deployment_checks)\n\n\nclass PootleCommand(BaseCommand):\n \"\"\"Base class for handling recursive pootle store management commands.\"\"\"\n\n process_disabled_projects = False\n\n def add_arguments(self, parser):\n parser.add_argument(\n '--project',\n action='append',\n dest='projects',\n help='Project to refresh',\n )\n parser.add_argument(\n '--language',\n action='append',\n dest='languages',\n help='Language to refresh',\n )\n parser.add_argument(\n \"--noinput\",\n action=\"store_true\",\n default=False,\n help=u\"Never prompt for input\",\n )\n parser.add_argument(\n \"--no-rq\",\n action=\"store_true\",\n default=False,\n help=(u\"Run all jobs in a single process, without \"\n \"using rq workers\"),\n )\n\n def __init__(self, *args, **kwargs):\n self.languages = []\n self.projects = []\n super(PootleCommand, self).__init__(*args, **kwargs)\n\n def do_translation_project(self, tp, **options):\n if hasattr(self, \"handle_translation_project\"):\n logging.info(u\"Running %s over %s\", self.name, tp)\n if not self.handle_translation_project(tp, **options):\n return\n if hasattr(self, \"handle_all_stores\"):\n logging.info(u\"Running %s over %s's files\", self.name, tp)\n self.handle_all_stores(tp, **options)\n elif hasattr(self, \"handle_store\"):\n store_query = tp.stores.live()\n for store in store_query.iterator():\n logging.info(u\"Running %s over %s\",\n self.name, store.pootle_path)\n self.handle_store(store, **options)\n\n def handle(self, **options):\n # adjust debug level to the verbosity option\n debug_levels = {\n 0: logging.ERROR,\n 1: logging.WARNING,\n 2: logging.INFO,\n 3: logging.DEBUG\n }\n logging.getLogger().setLevel(\n debug_levels.get(options['verbosity'], logging.DEBUG)\n )\n\n # reduce size of parse pool early on\n self.name = self.__class__.__module__.split('.')[-1]\n from pootle_store.fields import TranslationStoreFieldFile\n TranslationStoreFieldFile._store_cache.maxsize = 2\n TranslationStoreFieldFile._store_cache.cullsize = 2\n\n self.projects = options.pop('projects', [])\n self.languages = options.pop('languages', [])\n\n # info start\n start = datetime.datetime.now()\n logging.info('Start running of %s', self.name)\n\n try:\n self.handle_all(**options)\n except Exception as e:\n raise CommandError(e)\n\n # info finish\n end = datetime.datetime.now()\n logging.info('All done for %s in %s', self.name, end - start)\n\n def handle_all(self, **options):\n if options[\"no_rq\"]:\n set_sync_mode(options['noinput'])\n\n if self.process_disabled_projects:\n project_query = Project.objects.all()\n else:\n project_query = Project.objects.enabled()\n\n if self.projects:\n project_query = project_query.filter(code__in=self.projects)\n\n for project in project_query.iterator():\n tp_query = project.translationproject_set.live() \\\n .order_by('language__code')\n\n if self.languages:\n tp_query = tp_query.filter(language__code__in=self.languages)\n\n for tp in tp_query.iterator():\n self.do_translation_project(tp, **options)\n", "path": "pootle/apps/pootle_app/management/commands/__init__.py"}, {"content": "# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nimport os\nos.environ['DJANGO_SETTINGS_MODULE'] = 'pootle.settings'\n\nfrom pootle_app.management.commands import PootleCommand\n\n\nclass Command(PootleCommand):\n help = \"Save new translations to disk manually.\"\n process_disabled_projects = True\n\n def add_arguments(self, parser):\n super(Command, self).add_arguments(parser)\n parser.add_argument(\n '--overwrite',\n action='store_true',\n dest='overwrite',\n default=False,\n help=\"Don't just save translations, but \"\n \"overwrite files to reflect state in database\",\n )\n parser.add_argument(\n '--skip-missing',\n action='store_true',\n dest='skip_missing',\n default=False,\n help=\"Ignore missing files on disk\",\n )\n parser.add_argument(\n '--force',\n action='store_true',\n dest='force',\n default=False,\n help=\"Don't ignore stores synced after last change\",\n )\n\n def handle_all_stores(self, translation_project, **options):\n if translation_project.project.treestyle == 'pootle_fs':\n return\n if translation_project.directory_exists_on_disk():\n translation_project.sync(\n conservative=not options['overwrite'],\n skip_missing=options['skip_missing'],\n only_newer=not options['force']\n )\n", "path": "pootle/apps/pootle_app/management/commands/sync_stores.py"}]}
| 2,271 | 753 |
gh_patches_debug_24624
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-17570
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
multinomial
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ivy/functional/backends/paddle/random.py`
Content:
```
1 """Collection of Paddle random functions, wrapped to fit Ivy syntax and signature."""
2
3 # global
4 import paddle
5 import ivy.functional.backends.paddle as paddle_backend
6 from typing import Optional, Union, Sequence
7
8 # local
9 import ivy
10 from paddle.fluid.libpaddle import Place
11 from ivy.utils.exceptions import IvyNotImplementedException
12 from ivy.functional.backends.paddle.device import to_device
13 from ivy.functional.ivy.random import (
14 _check_bounds_and_get_shape,
15 _randint_check_dtype_and_bound,
16 _check_valid_scale,
17 )
18 from ivy.func_wrapper import with_unsupported_device_and_dtypes
19 from . import backend_version
20
21 # Extra #
22 # ------#
23
24
25 @with_unsupported_device_and_dtypes(
26 {"2.5.0 and below": {"cpu": ("int8",)}},
27 backend_version,
28 )
29 def random_uniform(
30 *,
31 low: Union[float, paddle.Tensor] = 0.0,
32 high: Union[float, paddle.Tensor] = 1.0,
33 shape: Optional[Union[paddle.Tensor, ivy.NativeShape, Sequence[int]]] = None,
34 dtype: paddle.dtype,
35 device: Place,
36 seed=None,
37 out: Optional[paddle.Tensor] = None,
38 ) -> paddle.Tensor:
39 if not dtype:
40 dtype = ivy.default_int_dtype()
41 dtype = ivy.as_native_dtype(dtype)
42 low = paddle.cast(low, "float32") if isinstance(low, paddle.Tensor) else low
43 high = paddle.cast(high, "float32") if isinstance(high, paddle.Tensor) else high
44 shape = _check_bounds_and_get_shape(low, high, shape).shape
45 # Set range and seed
46 rng = high - low
47 if seed:
48 _ = paddle.seed(seed)
49 random_base = paddle.uniform(shape, min=0.0, max=1.0)
50
51 return paddle_backend.add(paddle_backend.multiply(random_base, rng), low).cast(
52 dtype
53 )
54
55
56 @with_unsupported_device_and_dtypes(
57 {"2.5.0 and below": {"cpu": ("complex64", "complex128")}},
58 backend_version,
59 )
60 def random_normal(
61 *,
62 mean: Union[float, paddle.Tensor] = 0.0,
63 std: Union[float, paddle.Tensor] = 1.0,
64 shape: Optional[Union[ivy.NativeShape, Sequence[int]]] = None,
65 dtype: paddle.dtype,
66 seed: Optional[int] = None,
67 device: Place,
68 out: Optional[paddle.Tensor] = None,
69 ) -> paddle.Tensor:
70 _check_valid_scale(std)
71 shape = _check_bounds_and_get_shape(mean, std, shape).shape
72 if seed:
73 paddle.seed(seed)
74 if isinstance(mean, (int, float)) and isinstance(std, (int, float)):
75 return paddle.normal(mean, std, shape).cast(dtype)
76 if mean.dtype not in [paddle.float32, paddle.float64]:
77 mean = mean.cast("float32")
78 std = std.cast(mean.dtype)
79 return paddle.normal(mean, std).cast(dtype)
80
81
82 def multinomial(
83 population_size: int,
84 num_samples: int,
85 /,
86 *,
87 batch_size: int = 1,
88 probs: Optional[paddle.Tensor] = None,
89 replace: bool = True,
90 device: Place,
91 seed: Optional[int] = None,
92 out: Optional[paddle.Tensor] = None,
93 ) -> paddle.Tensor:
94 raise IvyNotImplementedException()
95
96
97 @with_unsupported_device_and_dtypes(
98 {"2.5.0 and below": {"cpu": ("int8",)}},
99 backend_version,
100 )
101 def randint(
102 low: Union[int, paddle.Tensor],
103 high: Union[int, paddle.Tensor],
104 /,
105 *,
106 shape: Optional[Union[ivy.NativeShape, Sequence[int]]] = None,
107 device: Place,
108 dtype: Optional[Union[paddle.dtype, ivy.Dtype]] = None,
109 seed: Optional[int] = None,
110 out: Optional[paddle.Tensor] = None,
111 ) -> paddle.Tensor:
112 if not dtype:
113 dtype = ivy.default_int_dtype()
114 dtype = ivy.as_native_dtype(dtype)
115 _randint_check_dtype_and_bound(low, high, dtype)
116 low = paddle.cast(low, "float32") if isinstance(low, paddle.Tensor) else low
117 high = paddle.cast(high, "float32") if isinstance(high, paddle.Tensor) else high
118 shape = _check_bounds_and_get_shape(low, high, shape).shape
119 range = high - low
120 if seed:
121 _ = paddle.seed(seed)
122 _retval = to_device(
123 paddle.cast(
124 paddle.uniform(shape or [1], min=0.0, max=1.0) * range + low, dtype
125 ),
126 device,
127 )
128 return _retval if shape else _retval.squeeze(axis=0)
129
130
131 def seed(*, seed_value: int = 0) -> None:
132 _ = paddle.seed(seed_value)
133 return
134
135
136 def shuffle(
137 x: paddle.Tensor,
138 axis: Optional[int] = 0,
139 /,
140 *,
141 seed: Optional[int] = None,
142 out: Optional[paddle.Tensor] = None,
143 ) -> paddle.Tensor:
144 if seed:
145 _ = paddle.seed(seed)
146 # Use Paddle's randperm function to generate shuffled indices
147 indices = paddle.randperm(x.shape[0], dtype="int64")
148 if x.dtype in [
149 paddle.int8,
150 paddle.int16,
151 paddle.uint8,
152 paddle.float16,
153 paddle.complex64,
154 paddle.complex128,
155 paddle.bool,
156 ]:
157 if paddle.is_complex(x):
158 shuffled_real = paddle.index_select(x.real(), indices)
159 shuffled_imag = paddle.index_select(x.imag(), indices)
160 return paddle.complex(shuffled_real, shuffled_imag)
161 return paddle.index_select(x.cast("float32"), indices).cast(x.dtype)
162 return paddle.index_select(x, indices)
163
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ivy/functional/backends/paddle/random.py b/ivy/functional/backends/paddle/random.py
--- a/ivy/functional/backends/paddle/random.py
+++ b/ivy/functional/backends/paddle/random.py
@@ -8,7 +8,6 @@
# local
import ivy
from paddle.fluid.libpaddle import Place
-from ivy.utils.exceptions import IvyNotImplementedException
from ivy.functional.backends.paddle.device import to_device
from ivy.functional.ivy.random import (
_check_bounds_and_get_shape,
@@ -79,6 +78,10 @@
return paddle.normal(mean, std).cast(dtype)
+@with_unsupported_device_and_dtypes(
+ {"2.4.2 and below": {"cpu": ("float16",)}},
+ backend_version,
+)
def multinomial(
population_size: int,
num_samples: int,
@@ -91,7 +94,13 @@
seed: Optional[int] = None,
out: Optional[paddle.Tensor] = None,
) -> paddle.Tensor:
- raise IvyNotImplementedException()
+ if probs is None:
+ probs = paddle.ones((batch_size, num_samples)) / population_size
+ probs = paddle.cast(probs, paddle.float32)
+ if seed:
+ paddle.seed(seed)
+ x = paddle.multinomial(probs, num_samples=num_samples, replacement=replace)
+ return x
@with_unsupported_device_and_dtypes(
|
{"golden_diff": "diff --git a/ivy/functional/backends/paddle/random.py b/ivy/functional/backends/paddle/random.py\n--- a/ivy/functional/backends/paddle/random.py\n+++ b/ivy/functional/backends/paddle/random.py\n@@ -8,7 +8,6 @@\n # local\n import ivy\n from paddle.fluid.libpaddle import Place\n-from ivy.utils.exceptions import IvyNotImplementedException\n from ivy.functional.backends.paddle.device import to_device\n from ivy.functional.ivy.random import (\n _check_bounds_and_get_shape,\n@@ -79,6 +78,10 @@\n return paddle.normal(mean, std).cast(dtype)\n \n \n+@with_unsupported_device_and_dtypes(\n+ {\"2.4.2 and below\": {\"cpu\": (\"float16\",)}},\n+ backend_version,\n+)\n def multinomial(\n population_size: int,\n num_samples: int,\n@@ -91,7 +94,13 @@\n seed: Optional[int] = None,\n out: Optional[paddle.Tensor] = None,\n ) -> paddle.Tensor:\n- raise IvyNotImplementedException()\n+ if probs is None:\n+ probs = paddle.ones((batch_size, num_samples)) / population_size\n+ probs = paddle.cast(probs, paddle.float32)\n+ if seed:\n+ paddle.seed(seed)\n+ x = paddle.multinomial(probs, num_samples=num_samples, replacement=replace)\n+ return x\n \n \n @with_unsupported_device_and_dtypes(\n", "issue": "multinomial\n\n", "before_files": [{"content": "\"\"\"Collection of Paddle random functions, wrapped to fit Ivy syntax and signature.\"\"\"\n\n# global\nimport paddle\nimport ivy.functional.backends.paddle as paddle_backend\nfrom typing import Optional, Union, Sequence\n\n# local\nimport ivy\nfrom paddle.fluid.libpaddle import Place\nfrom ivy.utils.exceptions import IvyNotImplementedException\nfrom ivy.functional.backends.paddle.device import to_device\nfrom ivy.functional.ivy.random import (\n _check_bounds_and_get_shape,\n _randint_check_dtype_and_bound,\n _check_valid_scale,\n)\nfrom ivy.func_wrapper import with_unsupported_device_and_dtypes\nfrom . import backend_version\n\n# Extra #\n# ------#\n\n\n@with_unsupported_device_and_dtypes(\n {\"2.5.0 and below\": {\"cpu\": (\"int8\",)}},\n backend_version,\n)\ndef random_uniform(\n *,\n low: Union[float, paddle.Tensor] = 0.0,\n high: Union[float, paddle.Tensor] = 1.0,\n shape: Optional[Union[paddle.Tensor, ivy.NativeShape, Sequence[int]]] = None,\n dtype: paddle.dtype,\n device: Place,\n seed=None,\n out: Optional[paddle.Tensor] = None,\n) -> paddle.Tensor:\n if not dtype:\n dtype = ivy.default_int_dtype()\n dtype = ivy.as_native_dtype(dtype)\n low = paddle.cast(low, \"float32\") if isinstance(low, paddle.Tensor) else low\n high = paddle.cast(high, \"float32\") if isinstance(high, paddle.Tensor) else high\n shape = _check_bounds_and_get_shape(low, high, shape).shape\n # Set range and seed\n rng = high - low\n if seed:\n _ = paddle.seed(seed)\n random_base = paddle.uniform(shape, min=0.0, max=1.0)\n\n return paddle_backend.add(paddle_backend.multiply(random_base, rng), low).cast(\n dtype\n )\n\n\n@with_unsupported_device_and_dtypes(\n {\"2.5.0 and below\": {\"cpu\": (\"complex64\", \"complex128\")}},\n backend_version,\n)\ndef random_normal(\n *,\n mean: Union[float, paddle.Tensor] = 0.0,\n std: Union[float, paddle.Tensor] = 1.0,\n shape: Optional[Union[ivy.NativeShape, Sequence[int]]] = None,\n dtype: paddle.dtype,\n seed: Optional[int] = None,\n device: Place,\n out: Optional[paddle.Tensor] = None,\n) -> paddle.Tensor:\n _check_valid_scale(std)\n shape = _check_bounds_and_get_shape(mean, std, shape).shape\n if seed:\n paddle.seed(seed)\n if isinstance(mean, (int, float)) and isinstance(std, (int, float)):\n return paddle.normal(mean, std, shape).cast(dtype)\n if mean.dtype not in [paddle.float32, paddle.float64]:\n mean = mean.cast(\"float32\")\n std = std.cast(mean.dtype)\n return paddle.normal(mean, std).cast(dtype)\n\n\ndef multinomial(\n population_size: int,\n num_samples: int,\n /,\n *,\n batch_size: int = 1,\n probs: Optional[paddle.Tensor] = None,\n replace: bool = True,\n device: Place,\n seed: Optional[int] = None,\n out: Optional[paddle.Tensor] = None,\n) -> paddle.Tensor:\n raise IvyNotImplementedException()\n\n\n@with_unsupported_device_and_dtypes(\n {\"2.5.0 and below\": {\"cpu\": (\"int8\",)}},\n backend_version,\n)\ndef randint(\n low: Union[int, paddle.Tensor],\n high: Union[int, paddle.Tensor],\n /,\n *,\n shape: Optional[Union[ivy.NativeShape, Sequence[int]]] = None,\n device: Place,\n dtype: Optional[Union[paddle.dtype, ivy.Dtype]] = None,\n seed: Optional[int] = None,\n out: Optional[paddle.Tensor] = None,\n) -> paddle.Tensor:\n if not dtype:\n dtype = ivy.default_int_dtype()\n dtype = ivy.as_native_dtype(dtype)\n _randint_check_dtype_and_bound(low, high, dtype)\n low = paddle.cast(low, \"float32\") if isinstance(low, paddle.Tensor) else low\n high = paddle.cast(high, \"float32\") if isinstance(high, paddle.Tensor) else high\n shape = _check_bounds_and_get_shape(low, high, shape).shape\n range = high - low\n if seed:\n _ = paddle.seed(seed)\n _retval = to_device(\n paddle.cast(\n paddle.uniform(shape or [1], min=0.0, max=1.0) * range + low, dtype\n ),\n device,\n )\n return _retval if shape else _retval.squeeze(axis=0)\n\n\ndef seed(*, seed_value: int = 0) -> None:\n _ = paddle.seed(seed_value)\n return\n\n\ndef shuffle(\n x: paddle.Tensor,\n axis: Optional[int] = 0,\n /,\n *,\n seed: Optional[int] = None,\n out: Optional[paddle.Tensor] = None,\n) -> paddle.Tensor:\n if seed:\n _ = paddle.seed(seed)\n # Use Paddle's randperm function to generate shuffled indices\n indices = paddle.randperm(x.shape[0], dtype=\"int64\")\n if x.dtype in [\n paddle.int8,\n paddle.int16,\n paddle.uint8,\n paddle.float16,\n paddle.complex64,\n paddle.complex128,\n paddle.bool,\n ]:\n if paddle.is_complex(x):\n shuffled_real = paddle.index_select(x.real(), indices)\n shuffled_imag = paddle.index_select(x.imag(), indices)\n return paddle.complex(shuffled_real, shuffled_imag)\n return paddle.index_select(x.cast(\"float32\"), indices).cast(x.dtype)\n return paddle.index_select(x, indices)\n", "path": "ivy/functional/backends/paddle/random.py"}], "after_files": [{"content": "\"\"\"Collection of Paddle random functions, wrapped to fit Ivy syntax and signature.\"\"\"\n\n# global\nimport paddle\nimport ivy.functional.backends.paddle as paddle_backend\nfrom typing import Optional, Union, Sequence\n\n# local\nimport ivy\nfrom paddle.fluid.libpaddle import Place\nfrom ivy.functional.backends.paddle.device import to_device\nfrom ivy.functional.ivy.random import (\n _check_bounds_and_get_shape,\n _randint_check_dtype_and_bound,\n _check_valid_scale,\n)\nfrom ivy.func_wrapper import with_unsupported_device_and_dtypes\nfrom . import backend_version\n\n# Extra #\n# ------#\n\n\n@with_unsupported_device_and_dtypes(\n {\"2.5.0 and below\": {\"cpu\": (\"int8\",)}},\n backend_version,\n)\ndef random_uniform(\n *,\n low: Union[float, paddle.Tensor] = 0.0,\n high: Union[float, paddle.Tensor] = 1.0,\n shape: Optional[Union[paddle.Tensor, ivy.NativeShape, Sequence[int]]] = None,\n dtype: paddle.dtype,\n device: Place,\n seed=None,\n out: Optional[paddle.Tensor] = None,\n) -> paddle.Tensor:\n if not dtype:\n dtype = ivy.default_int_dtype()\n dtype = ivy.as_native_dtype(dtype)\n low = paddle.cast(low, \"float32\") if isinstance(low, paddle.Tensor) else low\n high = paddle.cast(high, \"float32\") if isinstance(high, paddle.Tensor) else high\n shape = _check_bounds_and_get_shape(low, high, shape).shape\n # Set range and seed\n rng = high - low\n if seed:\n _ = paddle.seed(seed)\n random_base = paddle.uniform(shape, min=0.0, max=1.0)\n\n return paddle_backend.add(paddle_backend.multiply(random_base, rng), low).cast(\n dtype\n )\n\n\n@with_unsupported_device_and_dtypes(\n {\"2.5.0 and below\": {\"cpu\": (\"complex64\", \"complex128\")}},\n backend_version,\n)\ndef random_normal(\n *,\n mean: Union[float, paddle.Tensor] = 0.0,\n std: Union[float, paddle.Tensor] = 1.0,\n shape: Optional[Union[ivy.NativeShape, Sequence[int]]] = None,\n dtype: paddle.dtype,\n seed: Optional[int] = None,\n device: Place,\n out: Optional[paddle.Tensor] = None,\n) -> paddle.Tensor:\n _check_valid_scale(std)\n shape = _check_bounds_and_get_shape(mean, std, shape).shape\n if seed:\n paddle.seed(seed)\n if isinstance(mean, (int, float)) and isinstance(std, (int, float)):\n return paddle.normal(mean, std, shape).cast(dtype)\n if mean.dtype not in [paddle.float32, paddle.float64]:\n mean = mean.cast(\"float32\")\n std = std.cast(mean.dtype)\n return paddle.normal(mean, std).cast(dtype)\n\n\n@with_unsupported_device_and_dtypes(\n {\"2.4.2 and below\": {\"cpu\": (\"float16\",)}},\n backend_version,\n)\ndef multinomial(\n population_size: int,\n num_samples: int,\n /,\n *,\n batch_size: int = 1,\n probs: Optional[paddle.Tensor] = None,\n replace: bool = True,\n device: Place,\n seed: Optional[int] = None,\n out: Optional[paddle.Tensor] = None,\n) -> paddle.Tensor:\n if probs is None:\n probs = paddle.ones((batch_size, num_samples)) / population_size\n probs = paddle.cast(probs, paddle.float32)\n if seed:\n paddle.seed(seed)\n x = paddle.multinomial(probs, num_samples=num_samples, replacement=replace)\n return x\n\n\n@with_unsupported_device_and_dtypes(\n {\"2.5.0 and below\": {\"cpu\": (\"int8\",)}},\n backend_version,\n)\ndef randint(\n low: Union[int, paddle.Tensor],\n high: Union[int, paddle.Tensor],\n /,\n *,\n shape: Optional[Union[ivy.NativeShape, Sequence[int]]] = None,\n device: Place,\n dtype: Optional[Union[paddle.dtype, ivy.Dtype]] = None,\n seed: Optional[int] = None,\n out: Optional[paddle.Tensor] = None,\n) -> paddle.Tensor:\n if not dtype:\n dtype = ivy.default_int_dtype()\n dtype = ivy.as_native_dtype(dtype)\n _randint_check_dtype_and_bound(low, high, dtype)\n low = paddle.cast(low, \"float32\") if isinstance(low, paddle.Tensor) else low\n high = paddle.cast(high, \"float32\") if isinstance(high, paddle.Tensor) else high\n shape = _check_bounds_and_get_shape(low, high, shape).shape\n range = high - low\n if seed:\n _ = paddle.seed(seed)\n _retval = to_device(\n paddle.cast(\n paddle.uniform(shape or [1], min=0.0, max=1.0) * range + low, dtype\n ),\n device,\n )\n return _retval if shape else _retval.squeeze(axis=0)\n\n\ndef seed(*, seed_value: int = 0) -> None:\n _ = paddle.seed(seed_value)\n return\n\n\ndef shuffle(\n x: paddle.Tensor,\n axis: Optional[int] = 0,\n /,\n *,\n seed: Optional[int] = None,\n out: Optional[paddle.Tensor] = None,\n) -> paddle.Tensor:\n if seed:\n _ = paddle.seed(seed)\n # Use Paddle's randperm function to generate shuffled indices\n indices = paddle.randperm(x.shape[0], dtype=\"int64\")\n if x.dtype in [\n paddle.int8,\n paddle.int16,\n paddle.uint8,\n paddle.float16,\n paddle.complex64,\n paddle.complex128,\n paddle.bool,\n ]:\n if paddle.is_complex(x):\n shuffled_real = paddle.index_select(x.real(), indices)\n shuffled_imag = paddle.index_select(x.imag(), indices)\n return paddle.complex(shuffled_real, shuffled_imag)\n return paddle.index_select(x.cast(\"float32\"), indices).cast(x.dtype)\n return paddle.index_select(x, indices)\n", "path": "ivy/functional/backends/paddle/random.py"}]}
| 1,944 | 328 |
gh_patches_debug_22855
|
rasdani/github-patches
|
git_diff
|
python__mypy-14161
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Support unreachable blocks in partially defined check
For the partially defined check (`--enable-error-code partially-defined`), mypy should detect unreachable blocks:
Assuming we're running python3.6 in the following block:
```python
if sys.version_info >= (3, 6):
x = 1
print(x) # This should not generate an error but currently does.
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mypy/partially_defined.py`
Content:
```
1 from __future__ import annotations
2
3 from mypy import checker
4 from mypy.messages import MessageBuilder
5 from mypy.nodes import (
6 AssertStmt,
7 AssignmentExpr,
8 AssignmentStmt,
9 BreakStmt,
10 ContinueStmt,
11 DictionaryComprehension,
12 Expression,
13 ExpressionStmt,
14 ForStmt,
15 FuncDef,
16 FuncItem,
17 GeneratorExpr,
18 IfStmt,
19 ListExpr,
20 Lvalue,
21 MatchStmt,
22 NameExpr,
23 RaiseStmt,
24 ReturnStmt,
25 TupleExpr,
26 WhileStmt,
27 WithStmt,
28 )
29 from mypy.patterns import AsPattern, StarredPattern
30 from mypy.reachability import ALWAYS_TRUE, infer_pattern_value
31 from mypy.traverser import ExtendedTraverserVisitor
32 from mypy.types import Type, UninhabitedType
33
34
35 class BranchState:
36 """BranchState contains information about variable definition at the end of a branching statement.
37 `if` and `match` are examples of branching statements.
38
39 `may_be_defined` contains variables that were defined in only some branches.
40 `must_be_defined` contains variables that were defined in all branches.
41 """
42
43 def __init__(
44 self,
45 must_be_defined: set[str] | None = None,
46 may_be_defined: set[str] | None = None,
47 skipped: bool = False,
48 ) -> None:
49 if may_be_defined is None:
50 may_be_defined = set()
51 if must_be_defined is None:
52 must_be_defined = set()
53
54 self.may_be_defined = set(may_be_defined)
55 self.must_be_defined = set(must_be_defined)
56 self.skipped = skipped
57
58
59 class BranchStatement:
60 def __init__(self, initial_state: BranchState) -> None:
61 self.initial_state = initial_state
62 self.branches: list[BranchState] = [
63 BranchState(
64 must_be_defined=self.initial_state.must_be_defined,
65 may_be_defined=self.initial_state.may_be_defined,
66 )
67 ]
68
69 def next_branch(self) -> None:
70 self.branches.append(
71 BranchState(
72 must_be_defined=self.initial_state.must_be_defined,
73 may_be_defined=self.initial_state.may_be_defined,
74 )
75 )
76
77 def record_definition(self, name: str) -> None:
78 assert len(self.branches) > 0
79 self.branches[-1].must_be_defined.add(name)
80 self.branches[-1].may_be_defined.discard(name)
81
82 def record_nested_branch(self, state: BranchState) -> None:
83 assert len(self.branches) > 0
84 current_branch = self.branches[-1]
85 if state.skipped:
86 current_branch.skipped = True
87 return
88 current_branch.must_be_defined.update(state.must_be_defined)
89 current_branch.may_be_defined.update(state.may_be_defined)
90 current_branch.may_be_defined.difference_update(current_branch.must_be_defined)
91
92 def skip_branch(self) -> None:
93 assert len(self.branches) > 0
94 self.branches[-1].skipped = True
95
96 def is_possibly_undefined(self, name: str) -> bool:
97 assert len(self.branches) > 0
98 return name in self.branches[-1].may_be_defined
99
100 def done(self) -> BranchState:
101 branches = [b for b in self.branches if not b.skipped]
102 if len(branches) == 0:
103 return BranchState(skipped=True)
104 if len(branches) == 1:
105 return branches[0]
106
107 # must_be_defined is a union of must_be_defined of all branches.
108 must_be_defined = set(branches[0].must_be_defined)
109 for b in branches[1:]:
110 must_be_defined.intersection_update(b.must_be_defined)
111 # may_be_defined are all variables that are not must be defined.
112 all_vars = set()
113 for b in branches:
114 all_vars.update(b.may_be_defined)
115 all_vars.update(b.must_be_defined)
116 may_be_defined = all_vars.difference(must_be_defined)
117 return BranchState(may_be_defined=may_be_defined, must_be_defined=must_be_defined)
118
119
120 class DefinedVariableTracker:
121 """DefinedVariableTracker manages the state and scope for the UndefinedVariablesVisitor."""
122
123 def __init__(self) -> None:
124 # There's always at least one scope. Within each scope, there's at least one "global" BranchingStatement.
125 self.scopes: list[list[BranchStatement]] = [[BranchStatement(BranchState())]]
126
127 def _scope(self) -> list[BranchStatement]:
128 assert len(self.scopes) > 0
129 return self.scopes[-1]
130
131 def enter_scope(self) -> None:
132 assert len(self._scope()) > 0
133 self.scopes.append([BranchStatement(self._scope()[-1].branches[-1])])
134
135 def exit_scope(self) -> None:
136 self.scopes.pop()
137
138 def start_branch_statement(self) -> None:
139 assert len(self._scope()) > 0
140 self._scope().append(BranchStatement(self._scope()[-1].branches[-1]))
141
142 def next_branch(self) -> None:
143 assert len(self._scope()) > 1
144 self._scope()[-1].next_branch()
145
146 def end_branch_statement(self) -> None:
147 assert len(self._scope()) > 1
148 result = self._scope().pop().done()
149 self._scope()[-1].record_nested_branch(result)
150
151 def skip_branch(self) -> None:
152 # Only skip branch if we're outside of "root" branch statement.
153 if len(self._scope()) > 1:
154 self._scope()[-1].skip_branch()
155
156 def record_declaration(self, name: str) -> None:
157 assert len(self.scopes) > 0
158 assert len(self.scopes[-1]) > 0
159 self._scope()[-1].record_definition(name)
160
161 def is_possibly_undefined(self, name: str) -> bool:
162 assert len(self._scope()) > 0
163 # A variable is undefined if it's in a set of `may_be_defined` but not in `must_be_defined`.
164 # Cases where a variable is not defined altogether are handled by semantic analyzer.
165 return self._scope()[-1].is_possibly_undefined(name)
166
167
168 class PartiallyDefinedVariableVisitor(ExtendedTraverserVisitor):
169 """Detect variables that are defined only part of the time.
170
171 This visitor detects the following case:
172 if foo():
173 x = 1
174 print(x) # Error: "x" may be undefined.
175
176 Note that this code does not detect variables not defined in any of the branches -- that is
177 handled by the semantic analyzer.
178 """
179
180 def __init__(self, msg: MessageBuilder, type_map: dict[Expression, Type]) -> None:
181 self.msg = msg
182 self.type_map = type_map
183 self.tracker = DefinedVariableTracker()
184
185 def process_lvalue(self, lvalue: Lvalue | None) -> None:
186 if isinstance(lvalue, NameExpr):
187 self.tracker.record_declaration(lvalue.name)
188 elif isinstance(lvalue, (ListExpr, TupleExpr)):
189 for item in lvalue.items:
190 self.process_lvalue(item)
191
192 def visit_assignment_stmt(self, o: AssignmentStmt) -> None:
193 for lvalue in o.lvalues:
194 self.process_lvalue(lvalue)
195 super().visit_assignment_stmt(o)
196
197 def visit_assignment_expr(self, o: AssignmentExpr) -> None:
198 o.value.accept(self)
199 self.process_lvalue(o.target)
200
201 def visit_if_stmt(self, o: IfStmt) -> None:
202 for e in o.expr:
203 e.accept(self)
204 self.tracker.start_branch_statement()
205 for b in o.body:
206 b.accept(self)
207 self.tracker.next_branch()
208 if o.else_body:
209 o.else_body.accept(self)
210 self.tracker.end_branch_statement()
211
212 def visit_match_stmt(self, o: MatchStmt) -> None:
213 self.tracker.start_branch_statement()
214 o.subject.accept(self)
215 for i in range(len(o.patterns)):
216 pattern = o.patterns[i]
217 pattern.accept(self)
218 guard = o.guards[i]
219 if guard is not None:
220 guard.accept(self)
221 o.bodies[i].accept(self)
222 is_catchall = infer_pattern_value(pattern) == ALWAYS_TRUE
223 if not is_catchall:
224 self.tracker.next_branch()
225 self.tracker.end_branch_statement()
226
227 def visit_func_def(self, o: FuncDef) -> None:
228 self.tracker.enter_scope()
229 super().visit_func_def(o)
230 self.tracker.exit_scope()
231
232 def visit_func(self, o: FuncItem) -> None:
233 if o.arguments is not None:
234 for arg in o.arguments:
235 self.tracker.record_declaration(arg.variable.name)
236 super().visit_func(o)
237
238 def visit_generator_expr(self, o: GeneratorExpr) -> None:
239 self.tracker.enter_scope()
240 for idx in o.indices:
241 self.process_lvalue(idx)
242 super().visit_generator_expr(o)
243 self.tracker.exit_scope()
244
245 def visit_dictionary_comprehension(self, o: DictionaryComprehension) -> None:
246 self.tracker.enter_scope()
247 for idx in o.indices:
248 self.process_lvalue(idx)
249 super().visit_dictionary_comprehension(o)
250 self.tracker.exit_scope()
251
252 def visit_for_stmt(self, o: ForStmt) -> None:
253 o.expr.accept(self)
254 self.process_lvalue(o.index)
255 o.index.accept(self)
256 self.tracker.start_branch_statement()
257 o.body.accept(self)
258 self.tracker.next_branch()
259 if o.else_body:
260 o.else_body.accept(self)
261 self.tracker.end_branch_statement()
262
263 def visit_return_stmt(self, o: ReturnStmt) -> None:
264 super().visit_return_stmt(o)
265 self.tracker.skip_branch()
266
267 def visit_assert_stmt(self, o: AssertStmt) -> None:
268 super().visit_assert_stmt(o)
269 if checker.is_false_literal(o.expr):
270 self.tracker.skip_branch()
271
272 def visit_raise_stmt(self, o: RaiseStmt) -> None:
273 super().visit_raise_stmt(o)
274 self.tracker.skip_branch()
275
276 def visit_continue_stmt(self, o: ContinueStmt) -> None:
277 super().visit_continue_stmt(o)
278 self.tracker.skip_branch()
279
280 def visit_break_stmt(self, o: BreakStmt) -> None:
281 super().visit_break_stmt(o)
282 self.tracker.skip_branch()
283
284 def visit_expression_stmt(self, o: ExpressionStmt) -> None:
285 if isinstance(self.type_map.get(o.expr, None), UninhabitedType):
286 self.tracker.skip_branch()
287 super().visit_expression_stmt(o)
288
289 def visit_while_stmt(self, o: WhileStmt) -> None:
290 o.expr.accept(self)
291 self.tracker.start_branch_statement()
292 o.body.accept(self)
293 if not checker.is_true_literal(o.expr):
294 self.tracker.next_branch()
295 if o.else_body:
296 o.else_body.accept(self)
297 self.tracker.end_branch_statement()
298
299 def visit_as_pattern(self, o: AsPattern) -> None:
300 if o.name is not None:
301 self.process_lvalue(o.name)
302 super().visit_as_pattern(o)
303
304 def visit_starred_pattern(self, o: StarredPattern) -> None:
305 if o.capture is not None:
306 self.process_lvalue(o.capture)
307 super().visit_starred_pattern(o)
308
309 def visit_name_expr(self, o: NameExpr) -> None:
310 if self.tracker.is_possibly_undefined(o.name):
311 self.msg.variable_may_be_undefined(o.name, o)
312 # We don't want to report the error on the same variable multiple times.
313 self.tracker.record_declaration(o.name)
314 super().visit_name_expr(o)
315
316 def visit_with_stmt(self, o: WithStmt) -> None:
317 for expr, idx in zip(o.expr, o.target):
318 expr.accept(self)
319 self.process_lvalue(idx)
320 o.body.accept(self)
321
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mypy/partially_defined.py b/mypy/partially_defined.py
--- a/mypy/partially_defined.py
+++ b/mypy/partially_defined.py
@@ -203,9 +203,13 @@
e.accept(self)
self.tracker.start_branch_statement()
for b in o.body:
+ if b.is_unreachable:
+ continue
b.accept(self)
self.tracker.next_branch()
if o.else_body:
+ if o.else_body.is_unreachable:
+ self.tracker.skip_branch()
o.else_body.accept(self)
self.tracker.end_branch_statement()
@@ -218,7 +222,10 @@
guard = o.guards[i]
if guard is not None:
guard.accept(self)
- o.bodies[i].accept(self)
+ if not o.bodies[i].is_unreachable:
+ o.bodies[i].accept(self)
+ else:
+ self.tracker.skip_branch()
is_catchall = infer_pattern_value(pattern) == ALWAYS_TRUE
if not is_catchall:
self.tracker.next_branch()
|
{"golden_diff": "diff --git a/mypy/partially_defined.py b/mypy/partially_defined.py\n--- a/mypy/partially_defined.py\n+++ b/mypy/partially_defined.py\n@@ -203,9 +203,13 @@\n e.accept(self)\n self.tracker.start_branch_statement()\n for b in o.body:\n+ if b.is_unreachable:\n+ continue\n b.accept(self)\n self.tracker.next_branch()\n if o.else_body:\n+ if o.else_body.is_unreachable:\n+ self.tracker.skip_branch()\n o.else_body.accept(self)\n self.tracker.end_branch_statement()\n \n@@ -218,7 +222,10 @@\n guard = o.guards[i]\n if guard is not None:\n guard.accept(self)\n- o.bodies[i].accept(self)\n+ if not o.bodies[i].is_unreachable:\n+ o.bodies[i].accept(self)\n+ else:\n+ self.tracker.skip_branch()\n is_catchall = infer_pattern_value(pattern) == ALWAYS_TRUE\n if not is_catchall:\n self.tracker.next_branch()\n", "issue": "Support unreachable blocks in partially defined check\nFor the partially defined check (`--enable-error-code partially-defined`), mypy should detect unreachable blocks:\r\n\r\nAssuming we're running python3.6 in the following block:\r\n```python\r\nif sys.version_info >= (3, 6):\r\n x = 1\r\nprint(x) # This should not generate an error but currently does.\r\n```\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom mypy import checker\nfrom mypy.messages import MessageBuilder\nfrom mypy.nodes import (\n AssertStmt,\n AssignmentExpr,\n AssignmentStmt,\n BreakStmt,\n ContinueStmt,\n DictionaryComprehension,\n Expression,\n ExpressionStmt,\n ForStmt,\n FuncDef,\n FuncItem,\n GeneratorExpr,\n IfStmt,\n ListExpr,\n Lvalue,\n MatchStmt,\n NameExpr,\n RaiseStmt,\n ReturnStmt,\n TupleExpr,\n WhileStmt,\n WithStmt,\n)\nfrom mypy.patterns import AsPattern, StarredPattern\nfrom mypy.reachability import ALWAYS_TRUE, infer_pattern_value\nfrom mypy.traverser import ExtendedTraverserVisitor\nfrom mypy.types import Type, UninhabitedType\n\n\nclass BranchState:\n \"\"\"BranchState contains information about variable definition at the end of a branching statement.\n `if` and `match` are examples of branching statements.\n\n `may_be_defined` contains variables that were defined in only some branches.\n `must_be_defined` contains variables that were defined in all branches.\n \"\"\"\n\n def __init__(\n self,\n must_be_defined: set[str] | None = None,\n may_be_defined: set[str] | None = None,\n skipped: bool = False,\n ) -> None:\n if may_be_defined is None:\n may_be_defined = set()\n if must_be_defined is None:\n must_be_defined = set()\n\n self.may_be_defined = set(may_be_defined)\n self.must_be_defined = set(must_be_defined)\n self.skipped = skipped\n\n\nclass BranchStatement:\n def __init__(self, initial_state: BranchState) -> None:\n self.initial_state = initial_state\n self.branches: list[BranchState] = [\n BranchState(\n must_be_defined=self.initial_state.must_be_defined,\n may_be_defined=self.initial_state.may_be_defined,\n )\n ]\n\n def next_branch(self) -> None:\n self.branches.append(\n BranchState(\n must_be_defined=self.initial_state.must_be_defined,\n may_be_defined=self.initial_state.may_be_defined,\n )\n )\n\n def record_definition(self, name: str) -> None:\n assert len(self.branches) > 0\n self.branches[-1].must_be_defined.add(name)\n self.branches[-1].may_be_defined.discard(name)\n\n def record_nested_branch(self, state: BranchState) -> None:\n assert len(self.branches) > 0\n current_branch = self.branches[-1]\n if state.skipped:\n current_branch.skipped = True\n return\n current_branch.must_be_defined.update(state.must_be_defined)\n current_branch.may_be_defined.update(state.may_be_defined)\n current_branch.may_be_defined.difference_update(current_branch.must_be_defined)\n\n def skip_branch(self) -> None:\n assert len(self.branches) > 0\n self.branches[-1].skipped = True\n\n def is_possibly_undefined(self, name: str) -> bool:\n assert len(self.branches) > 0\n return name in self.branches[-1].may_be_defined\n\n def done(self) -> BranchState:\n branches = [b for b in self.branches if not b.skipped]\n if len(branches) == 0:\n return BranchState(skipped=True)\n if len(branches) == 1:\n return branches[0]\n\n # must_be_defined is a union of must_be_defined of all branches.\n must_be_defined = set(branches[0].must_be_defined)\n for b in branches[1:]:\n must_be_defined.intersection_update(b.must_be_defined)\n # may_be_defined are all variables that are not must be defined.\n all_vars = set()\n for b in branches:\n all_vars.update(b.may_be_defined)\n all_vars.update(b.must_be_defined)\n may_be_defined = all_vars.difference(must_be_defined)\n return BranchState(may_be_defined=may_be_defined, must_be_defined=must_be_defined)\n\n\nclass DefinedVariableTracker:\n \"\"\"DefinedVariableTracker manages the state and scope for the UndefinedVariablesVisitor.\"\"\"\n\n def __init__(self) -> None:\n # There's always at least one scope. Within each scope, there's at least one \"global\" BranchingStatement.\n self.scopes: list[list[BranchStatement]] = [[BranchStatement(BranchState())]]\n\n def _scope(self) -> list[BranchStatement]:\n assert len(self.scopes) > 0\n return self.scopes[-1]\n\n def enter_scope(self) -> None:\n assert len(self._scope()) > 0\n self.scopes.append([BranchStatement(self._scope()[-1].branches[-1])])\n\n def exit_scope(self) -> None:\n self.scopes.pop()\n\n def start_branch_statement(self) -> None:\n assert len(self._scope()) > 0\n self._scope().append(BranchStatement(self._scope()[-1].branches[-1]))\n\n def next_branch(self) -> None:\n assert len(self._scope()) > 1\n self._scope()[-1].next_branch()\n\n def end_branch_statement(self) -> None:\n assert len(self._scope()) > 1\n result = self._scope().pop().done()\n self._scope()[-1].record_nested_branch(result)\n\n def skip_branch(self) -> None:\n # Only skip branch if we're outside of \"root\" branch statement.\n if len(self._scope()) > 1:\n self._scope()[-1].skip_branch()\n\n def record_declaration(self, name: str) -> None:\n assert len(self.scopes) > 0\n assert len(self.scopes[-1]) > 0\n self._scope()[-1].record_definition(name)\n\n def is_possibly_undefined(self, name: str) -> bool:\n assert len(self._scope()) > 0\n # A variable is undefined if it's in a set of `may_be_defined` but not in `must_be_defined`.\n # Cases where a variable is not defined altogether are handled by semantic analyzer.\n return self._scope()[-1].is_possibly_undefined(name)\n\n\nclass PartiallyDefinedVariableVisitor(ExtendedTraverserVisitor):\n \"\"\"Detect variables that are defined only part of the time.\n\n This visitor detects the following case:\n if foo():\n x = 1\n print(x) # Error: \"x\" may be undefined.\n\n Note that this code does not detect variables not defined in any of the branches -- that is\n handled by the semantic analyzer.\n \"\"\"\n\n def __init__(self, msg: MessageBuilder, type_map: dict[Expression, Type]) -> None:\n self.msg = msg\n self.type_map = type_map\n self.tracker = DefinedVariableTracker()\n\n def process_lvalue(self, lvalue: Lvalue | None) -> None:\n if isinstance(lvalue, NameExpr):\n self.tracker.record_declaration(lvalue.name)\n elif isinstance(lvalue, (ListExpr, TupleExpr)):\n for item in lvalue.items:\n self.process_lvalue(item)\n\n def visit_assignment_stmt(self, o: AssignmentStmt) -> None:\n for lvalue in o.lvalues:\n self.process_lvalue(lvalue)\n super().visit_assignment_stmt(o)\n\n def visit_assignment_expr(self, o: AssignmentExpr) -> None:\n o.value.accept(self)\n self.process_lvalue(o.target)\n\n def visit_if_stmt(self, o: IfStmt) -> None:\n for e in o.expr:\n e.accept(self)\n self.tracker.start_branch_statement()\n for b in o.body:\n b.accept(self)\n self.tracker.next_branch()\n if o.else_body:\n o.else_body.accept(self)\n self.tracker.end_branch_statement()\n\n def visit_match_stmt(self, o: MatchStmt) -> None:\n self.tracker.start_branch_statement()\n o.subject.accept(self)\n for i in range(len(o.patterns)):\n pattern = o.patterns[i]\n pattern.accept(self)\n guard = o.guards[i]\n if guard is not None:\n guard.accept(self)\n o.bodies[i].accept(self)\n is_catchall = infer_pattern_value(pattern) == ALWAYS_TRUE\n if not is_catchall:\n self.tracker.next_branch()\n self.tracker.end_branch_statement()\n\n def visit_func_def(self, o: FuncDef) -> None:\n self.tracker.enter_scope()\n super().visit_func_def(o)\n self.tracker.exit_scope()\n\n def visit_func(self, o: FuncItem) -> None:\n if o.arguments is not None:\n for arg in o.arguments:\n self.tracker.record_declaration(arg.variable.name)\n super().visit_func(o)\n\n def visit_generator_expr(self, o: GeneratorExpr) -> None:\n self.tracker.enter_scope()\n for idx in o.indices:\n self.process_lvalue(idx)\n super().visit_generator_expr(o)\n self.tracker.exit_scope()\n\n def visit_dictionary_comprehension(self, o: DictionaryComprehension) -> None:\n self.tracker.enter_scope()\n for idx in o.indices:\n self.process_lvalue(idx)\n super().visit_dictionary_comprehension(o)\n self.tracker.exit_scope()\n\n def visit_for_stmt(self, o: ForStmt) -> None:\n o.expr.accept(self)\n self.process_lvalue(o.index)\n o.index.accept(self)\n self.tracker.start_branch_statement()\n o.body.accept(self)\n self.tracker.next_branch()\n if o.else_body:\n o.else_body.accept(self)\n self.tracker.end_branch_statement()\n\n def visit_return_stmt(self, o: ReturnStmt) -> None:\n super().visit_return_stmt(o)\n self.tracker.skip_branch()\n\n def visit_assert_stmt(self, o: AssertStmt) -> None:\n super().visit_assert_stmt(o)\n if checker.is_false_literal(o.expr):\n self.tracker.skip_branch()\n\n def visit_raise_stmt(self, o: RaiseStmt) -> None:\n super().visit_raise_stmt(o)\n self.tracker.skip_branch()\n\n def visit_continue_stmt(self, o: ContinueStmt) -> None:\n super().visit_continue_stmt(o)\n self.tracker.skip_branch()\n\n def visit_break_stmt(self, o: BreakStmt) -> None:\n super().visit_break_stmt(o)\n self.tracker.skip_branch()\n\n def visit_expression_stmt(self, o: ExpressionStmt) -> None:\n if isinstance(self.type_map.get(o.expr, None), UninhabitedType):\n self.tracker.skip_branch()\n super().visit_expression_stmt(o)\n\n def visit_while_stmt(self, o: WhileStmt) -> None:\n o.expr.accept(self)\n self.tracker.start_branch_statement()\n o.body.accept(self)\n if not checker.is_true_literal(o.expr):\n self.tracker.next_branch()\n if o.else_body:\n o.else_body.accept(self)\n self.tracker.end_branch_statement()\n\n def visit_as_pattern(self, o: AsPattern) -> None:\n if o.name is not None:\n self.process_lvalue(o.name)\n super().visit_as_pattern(o)\n\n def visit_starred_pattern(self, o: StarredPattern) -> None:\n if o.capture is not None:\n self.process_lvalue(o.capture)\n super().visit_starred_pattern(o)\n\n def visit_name_expr(self, o: NameExpr) -> None:\n if self.tracker.is_possibly_undefined(o.name):\n self.msg.variable_may_be_undefined(o.name, o)\n # We don't want to report the error on the same variable multiple times.\n self.tracker.record_declaration(o.name)\n super().visit_name_expr(o)\n\n def visit_with_stmt(self, o: WithStmt) -> None:\n for expr, idx in zip(o.expr, o.target):\n expr.accept(self)\n self.process_lvalue(idx)\n o.body.accept(self)\n", "path": "mypy/partially_defined.py"}], "after_files": [{"content": "from __future__ import annotations\n\nfrom mypy import checker\nfrom mypy.messages import MessageBuilder\nfrom mypy.nodes import (\n AssertStmt,\n AssignmentExpr,\n AssignmentStmt,\n BreakStmt,\n ContinueStmt,\n DictionaryComprehension,\n Expression,\n ExpressionStmt,\n ForStmt,\n FuncDef,\n FuncItem,\n GeneratorExpr,\n IfStmt,\n ListExpr,\n Lvalue,\n MatchStmt,\n NameExpr,\n RaiseStmt,\n ReturnStmt,\n TupleExpr,\n WhileStmt,\n WithStmt,\n)\nfrom mypy.patterns import AsPattern, StarredPattern\nfrom mypy.reachability import ALWAYS_TRUE, infer_pattern_value\nfrom mypy.traverser import ExtendedTraverserVisitor\nfrom mypy.types import Type, UninhabitedType\n\n\nclass BranchState:\n \"\"\"BranchState contains information about variable definition at the end of a branching statement.\n `if` and `match` are examples of branching statements.\n\n `may_be_defined` contains variables that were defined in only some branches.\n `must_be_defined` contains variables that were defined in all branches.\n \"\"\"\n\n def __init__(\n self,\n must_be_defined: set[str] | None = None,\n may_be_defined: set[str] | None = None,\n skipped: bool = False,\n ) -> None:\n if may_be_defined is None:\n may_be_defined = set()\n if must_be_defined is None:\n must_be_defined = set()\n\n self.may_be_defined = set(may_be_defined)\n self.must_be_defined = set(must_be_defined)\n self.skipped = skipped\n\n\nclass BranchStatement:\n def __init__(self, initial_state: BranchState) -> None:\n self.initial_state = initial_state\n self.branches: list[BranchState] = [\n BranchState(\n must_be_defined=self.initial_state.must_be_defined,\n may_be_defined=self.initial_state.may_be_defined,\n )\n ]\n\n def next_branch(self) -> None:\n self.branches.append(\n BranchState(\n must_be_defined=self.initial_state.must_be_defined,\n may_be_defined=self.initial_state.may_be_defined,\n )\n )\n\n def record_definition(self, name: str) -> None:\n assert len(self.branches) > 0\n self.branches[-1].must_be_defined.add(name)\n self.branches[-1].may_be_defined.discard(name)\n\n def record_nested_branch(self, state: BranchState) -> None:\n assert len(self.branches) > 0\n current_branch = self.branches[-1]\n if state.skipped:\n current_branch.skipped = True\n return\n current_branch.must_be_defined.update(state.must_be_defined)\n current_branch.may_be_defined.update(state.may_be_defined)\n current_branch.may_be_defined.difference_update(current_branch.must_be_defined)\n\n def skip_branch(self) -> None:\n assert len(self.branches) > 0\n self.branches[-1].skipped = True\n\n def is_possibly_undefined(self, name: str) -> bool:\n assert len(self.branches) > 0\n return name in self.branches[-1].may_be_defined\n\n def done(self) -> BranchState:\n branches = [b for b in self.branches if not b.skipped]\n if len(branches) == 0:\n return BranchState(skipped=True)\n if len(branches) == 1:\n return branches[0]\n\n # must_be_defined is a union of must_be_defined of all branches.\n must_be_defined = set(branches[0].must_be_defined)\n for b in branches[1:]:\n must_be_defined.intersection_update(b.must_be_defined)\n # may_be_defined are all variables that are not must be defined.\n all_vars = set()\n for b in branches:\n all_vars.update(b.may_be_defined)\n all_vars.update(b.must_be_defined)\n may_be_defined = all_vars.difference(must_be_defined)\n return BranchState(may_be_defined=may_be_defined, must_be_defined=must_be_defined)\n\n\nclass DefinedVariableTracker:\n \"\"\"DefinedVariableTracker manages the state and scope for the UndefinedVariablesVisitor.\"\"\"\n\n def __init__(self) -> None:\n # There's always at least one scope. Within each scope, there's at least one \"global\" BranchingStatement.\n self.scopes: list[list[BranchStatement]] = [[BranchStatement(BranchState())]]\n\n def _scope(self) -> list[BranchStatement]:\n assert len(self.scopes) > 0\n return self.scopes[-1]\n\n def enter_scope(self) -> None:\n assert len(self._scope()) > 0\n self.scopes.append([BranchStatement(self._scope()[-1].branches[-1])])\n\n def exit_scope(self) -> None:\n self.scopes.pop()\n\n def start_branch_statement(self) -> None:\n assert len(self._scope()) > 0\n self._scope().append(BranchStatement(self._scope()[-1].branches[-1]))\n\n def next_branch(self) -> None:\n assert len(self._scope()) > 1\n self._scope()[-1].next_branch()\n\n def end_branch_statement(self) -> None:\n assert len(self._scope()) > 1\n result = self._scope().pop().done()\n self._scope()[-1].record_nested_branch(result)\n\n def skip_branch(self) -> None:\n # Only skip branch if we're outside of \"root\" branch statement.\n if len(self._scope()) > 1:\n self._scope()[-1].skip_branch()\n\n def record_declaration(self, name: str) -> None:\n assert len(self.scopes) > 0\n assert len(self.scopes[-1]) > 0\n self._scope()[-1].record_definition(name)\n\n def is_possibly_undefined(self, name: str) -> bool:\n assert len(self._scope()) > 0\n # A variable is undefined if it's in a set of `may_be_defined` but not in `must_be_defined`.\n # Cases where a variable is not defined altogether are handled by semantic analyzer.\n return self._scope()[-1].is_possibly_undefined(name)\n\n\nclass PartiallyDefinedVariableVisitor(ExtendedTraverserVisitor):\n \"\"\"Detect variables that are defined only part of the time.\n\n This visitor detects the following case:\n if foo():\n x = 1\n print(x) # Error: \"x\" may be undefined.\n\n Note that this code does not detect variables not defined in any of the branches -- that is\n handled by the semantic analyzer.\n \"\"\"\n\n def __init__(self, msg: MessageBuilder, type_map: dict[Expression, Type]) -> None:\n self.msg = msg\n self.type_map = type_map\n self.tracker = DefinedVariableTracker()\n\n def process_lvalue(self, lvalue: Lvalue | None) -> None:\n if isinstance(lvalue, NameExpr):\n self.tracker.record_declaration(lvalue.name)\n elif isinstance(lvalue, (ListExpr, TupleExpr)):\n for item in lvalue.items:\n self.process_lvalue(item)\n\n def visit_assignment_stmt(self, o: AssignmentStmt) -> None:\n for lvalue in o.lvalues:\n self.process_lvalue(lvalue)\n super().visit_assignment_stmt(o)\n\n def visit_assignment_expr(self, o: AssignmentExpr) -> None:\n o.value.accept(self)\n self.process_lvalue(o.target)\n\n def visit_if_stmt(self, o: IfStmt) -> None:\n for e in o.expr:\n e.accept(self)\n self.tracker.start_branch_statement()\n for b in o.body:\n if b.is_unreachable:\n continue\n b.accept(self)\n self.tracker.next_branch()\n if o.else_body:\n if o.else_body.is_unreachable:\n self.tracker.skip_branch()\n o.else_body.accept(self)\n self.tracker.end_branch_statement()\n\n def visit_match_stmt(self, o: MatchStmt) -> None:\n self.tracker.start_branch_statement()\n o.subject.accept(self)\n for i in range(len(o.patterns)):\n pattern = o.patterns[i]\n pattern.accept(self)\n guard = o.guards[i]\n if guard is not None:\n guard.accept(self)\n if not o.bodies[i].is_unreachable:\n o.bodies[i].accept(self)\n else:\n self.tracker.skip_branch()\n is_catchall = infer_pattern_value(pattern) == ALWAYS_TRUE\n if not is_catchall:\n self.tracker.next_branch()\n self.tracker.end_branch_statement()\n\n def visit_func_def(self, o: FuncDef) -> None:\n self.tracker.enter_scope()\n super().visit_func_def(o)\n self.tracker.exit_scope()\n\n def visit_func(self, o: FuncItem) -> None:\n if o.arguments is not None:\n for arg in o.arguments:\n self.tracker.record_declaration(arg.variable.name)\n super().visit_func(o)\n\n def visit_generator_expr(self, o: GeneratorExpr) -> None:\n self.tracker.enter_scope()\n for idx in o.indices:\n self.process_lvalue(idx)\n super().visit_generator_expr(o)\n self.tracker.exit_scope()\n\n def visit_dictionary_comprehension(self, o: DictionaryComprehension) -> None:\n self.tracker.enter_scope()\n for idx in o.indices:\n self.process_lvalue(idx)\n super().visit_dictionary_comprehension(o)\n self.tracker.exit_scope()\n\n def visit_for_stmt(self, o: ForStmt) -> None:\n o.expr.accept(self)\n self.process_lvalue(o.index)\n o.index.accept(self)\n self.tracker.start_branch_statement()\n o.body.accept(self)\n self.tracker.next_branch()\n if o.else_body:\n o.else_body.accept(self)\n self.tracker.end_branch_statement()\n\n def visit_return_stmt(self, o: ReturnStmt) -> None:\n super().visit_return_stmt(o)\n self.tracker.skip_branch()\n\n def visit_assert_stmt(self, o: AssertStmt) -> None:\n super().visit_assert_stmt(o)\n if checker.is_false_literal(o.expr):\n self.tracker.skip_branch()\n\n def visit_raise_stmt(self, o: RaiseStmt) -> None:\n super().visit_raise_stmt(o)\n self.tracker.skip_branch()\n\n def visit_continue_stmt(self, o: ContinueStmt) -> None:\n super().visit_continue_stmt(o)\n self.tracker.skip_branch()\n\n def visit_break_stmt(self, o: BreakStmt) -> None:\n super().visit_break_stmt(o)\n self.tracker.skip_branch()\n\n def visit_expression_stmt(self, o: ExpressionStmt) -> None:\n if isinstance(self.type_map.get(o.expr, None), UninhabitedType):\n self.tracker.skip_branch()\n super().visit_expression_stmt(o)\n\n def visit_while_stmt(self, o: WhileStmt) -> None:\n o.expr.accept(self)\n self.tracker.start_branch_statement()\n o.body.accept(self)\n if not checker.is_true_literal(o.expr):\n self.tracker.next_branch()\n if o.else_body:\n o.else_body.accept(self)\n self.tracker.end_branch_statement()\n\n def visit_as_pattern(self, o: AsPattern) -> None:\n if o.name is not None:\n self.process_lvalue(o.name)\n super().visit_as_pattern(o)\n\n def visit_starred_pattern(self, o: StarredPattern) -> None:\n if o.capture is not None:\n self.process_lvalue(o.capture)\n super().visit_starred_pattern(o)\n\n def visit_name_expr(self, o: NameExpr) -> None:\n if self.tracker.is_possibly_undefined(o.name):\n self.msg.variable_may_be_undefined(o.name, o)\n # We don't want to report the error on the same variable multiple times.\n self.tracker.record_declaration(o.name)\n super().visit_name_expr(o)\n\n def visit_with_stmt(self, o: WithStmt) -> None:\n for expr, idx in zip(o.expr, o.target):\n expr.accept(self)\n self.process_lvalue(idx)\n o.body.accept(self)\n", "path": "mypy/partially_defined.py"}]}
| 3,809 | 252 |
gh_patches_debug_27463
|
rasdani/github-patches
|
git_diff
|
jupyterhub__jupyterhub-3219
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Authorization form must be sent from authorization page
Hi! after upgrading to master branch (around 40 days of new commits) admins are no longer able to impersonate users, we get this error right after clicking "Authorize" on the new page:
https://github.com/jupyterhub/jupyterhub/blob/5b4f0d4304b1ea57b4d398609f2777bd93131ef4/jupyterhub/apihandlers/auth.py#L255
```
403 : Forbidden
Authorization form must be sent from authorization page
```
We are still using GitHubOAuthenticator and Postgres as backend.
Also other strange thing is happening, the admin page is not properly listing all users, but this is probably related to some of our custom page.html templates:

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `jupyterhub/apihandlers/auth.py`
Content:
```
1 """Authorization handlers"""
2 # Copyright (c) Jupyter Development Team.
3 # Distributed under the terms of the Modified BSD License.
4 import json
5 from datetime import datetime
6 from urllib.parse import parse_qsl
7 from urllib.parse import quote
8 from urllib.parse import urlencode
9 from urllib.parse import urlparse
10 from urllib.parse import urlunparse
11
12 from oauthlib import oauth2
13 from tornado import web
14
15 from .. import orm
16 from ..user import User
17 from ..utils import compare_token
18 from ..utils import token_authenticated
19 from .base import APIHandler
20 from .base import BaseHandler
21
22
23 class TokenAPIHandler(APIHandler):
24 @token_authenticated
25 def get(self, token):
26 orm_token = orm.APIToken.find(self.db, token)
27 if orm_token is None:
28 orm_token = orm.OAuthAccessToken.find(self.db, token)
29 if orm_token is None:
30 raise web.HTTPError(404)
31
32 # record activity whenever we see a token
33 now = orm_token.last_activity = datetime.utcnow()
34 if orm_token.user:
35 orm_token.user.last_activity = now
36 model = self.user_model(self.users[orm_token.user])
37 elif orm_token.service:
38 model = self.service_model(orm_token.service)
39 else:
40 self.log.warning("%s has no user or service. Deleting..." % orm_token)
41 self.db.delete(orm_token)
42 self.db.commit()
43 raise web.HTTPError(404)
44 self.db.commit()
45 self.write(json.dumps(model))
46
47 async def post(self):
48 warn_msg = (
49 "Using deprecated token creation endpoint %s."
50 " Use /hub/api/users/:user/tokens instead."
51 ) % self.request.uri
52 self.log.warning(warn_msg)
53 requester = user = self.current_user
54 if user is None:
55 # allow requesting a token with username and password
56 # for authenticators where that's possible
57 data = self.get_json_body()
58 try:
59 requester = user = await self.login_user(data)
60 except Exception as e:
61 self.log.error("Failure trying to authenticate with form data: %s" % e)
62 user = None
63 if user is None:
64 raise web.HTTPError(403)
65 else:
66 data = self.get_json_body()
67 # admin users can request tokens for other users
68 if data and data.get('username'):
69 user = self.find_user(data['username'])
70 if user is not requester and not requester.admin:
71 raise web.HTTPError(
72 403, "Only admins can request tokens for other users."
73 )
74 if requester.admin and user is None:
75 raise web.HTTPError(400, "No such user '%s'" % data['username'])
76
77 note = (data or {}).get('note')
78 if not note:
79 note = "Requested via deprecated api"
80 if requester is not user:
81 kind = 'user' if isinstance(user, User) else 'service'
82 note += " by %s %s" % (kind, requester.name)
83
84 api_token = user.new_api_token(note=note)
85 self.write(
86 json.dumps(
87 {'token': api_token, 'warning': warn_msg, 'user': self.user_model(user)}
88 )
89 )
90
91
92 class CookieAPIHandler(APIHandler):
93 @token_authenticated
94 def get(self, cookie_name, cookie_value=None):
95 cookie_name = quote(cookie_name, safe='')
96 if cookie_value is None:
97 self.log.warning(
98 "Cookie values in request body is deprecated, use `/cookie_name/cookie_value`"
99 )
100 cookie_value = self.request.body
101 else:
102 cookie_value = cookie_value.encode('utf8')
103 user = self._user_for_cookie(cookie_name, cookie_value)
104 if user is None:
105 raise web.HTTPError(404)
106 self.write(json.dumps(self.user_model(user)))
107
108
109 class OAuthHandler:
110 def extract_oauth_params(self):
111 """extract oauthlib params from a request
112
113 Returns:
114
115 (uri, http_method, body, headers)
116 """
117 return (
118 self.request.uri,
119 self.request.method,
120 self.request.body,
121 self.request.headers,
122 )
123
124 def make_absolute_redirect_uri(self, uri):
125 """Make absolute redirect URIs
126
127 internal redirect uris, e.g. `/user/foo/oauth_handler`
128 are allowed in jupyterhub, but oauthlib prohibits them.
129 Add `$HOST` header to redirect_uri to make them acceptable.
130
131 Currently unused in favor of monkeypatching
132 oauthlib.is_absolute_uri to skip the check
133 """
134 redirect_uri = self.get_argument('redirect_uri')
135 if not redirect_uri or not redirect_uri.startswith('/'):
136 return uri
137 # make absolute local redirects full URLs
138 # to satisfy oauthlib's absolute URI requirement
139 redirect_uri = (
140 self.request.protocol + "://" + self.request.headers['Host'] + redirect_uri
141 )
142 parsed_url = urlparse(uri)
143 query_list = parse_qsl(parsed_url.query, keep_blank_values=True)
144 for idx, item in enumerate(query_list):
145 if item[0] == 'redirect_uri':
146 query_list[idx] = ('redirect_uri', redirect_uri)
147 break
148
149 return urlunparse(urlparse(uri)._replace(query=urlencode(query_list)))
150
151 def add_credentials(self, credentials=None):
152 """Add oauth credentials
153
154 Adds user, session_id, client to oauth credentials
155 """
156 if credentials is None:
157 credentials = {}
158 else:
159 credentials = credentials.copy()
160
161 session_id = self.get_session_cookie()
162 if session_id is None:
163 session_id = self.set_session_cookie()
164
165 user = self.current_user
166
167 # Extra credentials we need in the validator
168 credentials.update({'user': user, 'handler': self, 'session_id': session_id})
169 return credentials
170
171 def send_oauth_response(self, headers, body, status):
172 """Send oauth response from provider return values
173
174 Provider methods return headers, body, and status
175 to be set on the response.
176
177 This method applies these values to the Handler
178 and sends the response.
179 """
180 self.set_status(status)
181 for key, value in headers.items():
182 self.set_header(key, value)
183 if body:
184 self.write(body)
185
186
187 class OAuthAuthorizeHandler(OAuthHandler, BaseHandler):
188 """Implement OAuth authorization endpoint(s)"""
189
190 def _complete_login(self, uri, headers, scopes, credentials):
191 try:
192 headers, body, status = self.oauth_provider.create_authorization_response(
193 uri, 'POST', '', headers, scopes, credentials
194 )
195
196 except oauth2.FatalClientError as e:
197 # TODO: human error page
198 raise
199 self.send_oauth_response(headers, body, status)
200
201 def needs_oauth_confirm(self, user, oauth_client):
202 """Return whether the given oauth client needs to prompt for access for the given user
203
204 Checks list for oauth clients that don't need confirmation
205
206 (i.e. the user's own server)
207
208 .. versionadded: 1.1
209 """
210 # get the oauth client ids for the user's own server(s)
211 own_oauth_client_ids = set(
212 spawner.oauth_client_id for spawner in user.spawners.values()
213 )
214 if (
215 # it's the user's own server
216 oauth_client.identifier in own_oauth_client_ids
217 # or it's in the global no-confirm list
218 or oauth_client.identifier in self.settings.get('oauth_no_confirm', set())
219 ):
220 return False
221 # default: require confirmation
222 return True
223
224 @web.authenticated
225 async def get(self):
226 """GET /oauth/authorization
227
228 Render oauth confirmation page:
229 "Server at ... would like permission to ...".
230
231 Users accessing their own server or a blessed service
232 will skip confirmation.
233 """
234
235 uri, http_method, body, headers = self.extract_oauth_params()
236 try:
237 scopes, credentials = self.oauth_provider.validate_authorization_request(
238 uri, http_method, body, headers
239 )
240 credentials = self.add_credentials(credentials)
241 client = self.oauth_provider.fetch_by_client_id(credentials['client_id'])
242 if not self.needs_oauth_confirm(self.current_user, client):
243 self.log.debug(
244 "Skipping oauth confirmation for %s accessing %s",
245 self.current_user,
246 client.description,
247 )
248 # this is the pre-1.0 behavior for all oauth
249 self._complete_login(uri, headers, scopes, credentials)
250 return
251
252 # Render oauth 'Authorize application...' page
253 auth_state = await self.current_user.get_auth_state()
254 self.write(
255 self.render_template(
256 "oauth.html",
257 auth_state=auth_state,
258 scopes=scopes,
259 oauth_client=client,
260 )
261 )
262
263 # Errors that should be shown to the user on the provider website
264 except oauth2.FatalClientError as e:
265 raise web.HTTPError(e.status_code, e.description)
266
267 # Errors embedded in the redirect URI back to the client
268 except oauth2.OAuth2Error as e:
269 self.log.error("OAuth error: %s", e.description)
270 self.redirect(e.in_uri(e.redirect_uri))
271
272 @web.authenticated
273 def post(self):
274 uri, http_method, body, headers = self.extract_oauth_params()
275 referer = self.request.headers.get('Referer', 'no referer')
276 full_url = self.request.full_url()
277 if referer != full_url:
278 # OAuth post must be made to the URL it came from
279 self.log.error("OAuth POST from %s != %s", referer, full_url)
280 raise web.HTTPError(
281 403, "Authorization form must be sent from authorization page"
282 )
283
284 # The scopes the user actually authorized, i.e. checkboxes
285 # that were selected.
286 scopes = self.get_arguments('scopes')
287 # credentials we need in the validator
288 credentials = self.add_credentials()
289
290 try:
291 headers, body, status = self.oauth_provider.create_authorization_response(
292 uri, http_method, body, headers, scopes, credentials
293 )
294 except oauth2.FatalClientError as e:
295 raise web.HTTPError(e.status_code, e.description)
296 else:
297 self.send_oauth_response(headers, body, status)
298
299
300 class OAuthTokenHandler(OAuthHandler, APIHandler):
301 def post(self):
302 uri, http_method, body, headers = self.extract_oauth_params()
303 credentials = {}
304
305 try:
306 headers, body, status = self.oauth_provider.create_token_response(
307 uri, http_method, body, headers, credentials
308 )
309 except oauth2.FatalClientError as e:
310 raise web.HTTPError(e.status_code, e.description)
311 else:
312 self.send_oauth_response(headers, body, status)
313
314
315 default_handlers = [
316 (r"/api/authorizations/cookie/([^/]+)(?:/([^/]+))?", CookieAPIHandler),
317 (r"/api/authorizations/token/([^/]+)", TokenAPIHandler),
318 (r"/api/authorizations/token", TokenAPIHandler),
319 (r"/api/oauth2/authorize", OAuthAuthorizeHandler),
320 (r"/api/oauth2/token", OAuthTokenHandler),
321 ]
322
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/jupyterhub/apihandlers/auth.py b/jupyterhub/apihandlers/auth.py
--- a/jupyterhub/apihandlers/auth.py
+++ b/jupyterhub/apihandlers/auth.py
@@ -274,9 +274,26 @@
uri, http_method, body, headers = self.extract_oauth_params()
referer = self.request.headers.get('Referer', 'no referer')
full_url = self.request.full_url()
- if referer != full_url:
+ # trim protocol, which cannot be trusted with multiple layers of proxies anyway
+ # Referer is set by browser, but full_url can be modified by proxy layers to appear as http
+ # when it is actually https
+ referer_proto, _, stripped_referer = referer.partition("://")
+ referer_proto = referer_proto.lower()
+ req_proto, _, stripped_full_url = full_url.partition("://")
+ req_proto = req_proto.lower()
+ if referer_proto != req_proto:
+ self.log.warning("Protocol mismatch: %s != %s", referer, full_url)
+ if req_proto == "https":
+ # insecure origin to secure target is not allowed
+ raise web.HTTPError(
+ 403, "Not allowing authorization form submitted from insecure page"
+ )
+ if stripped_referer != stripped_full_url:
# OAuth post must be made to the URL it came from
- self.log.error("OAuth POST from %s != %s", referer, full_url)
+ self.log.error("Original OAuth POST from %s != %s", referer, full_url)
+ self.log.error(
+ "Stripped OAuth POST from %s != %s", stripped_referer, stripped_full_url
+ )
raise web.HTTPError(
403, "Authorization form must be sent from authorization page"
)
|
{"golden_diff": "diff --git a/jupyterhub/apihandlers/auth.py b/jupyterhub/apihandlers/auth.py\n--- a/jupyterhub/apihandlers/auth.py\n+++ b/jupyterhub/apihandlers/auth.py\n@@ -274,9 +274,26 @@\n uri, http_method, body, headers = self.extract_oauth_params()\n referer = self.request.headers.get('Referer', 'no referer')\n full_url = self.request.full_url()\n- if referer != full_url:\n+ # trim protocol, which cannot be trusted with multiple layers of proxies anyway\n+ # Referer is set by browser, but full_url can be modified by proxy layers to appear as http\n+ # when it is actually https\n+ referer_proto, _, stripped_referer = referer.partition(\"://\")\n+ referer_proto = referer_proto.lower()\n+ req_proto, _, stripped_full_url = full_url.partition(\"://\")\n+ req_proto = req_proto.lower()\n+ if referer_proto != req_proto:\n+ self.log.warning(\"Protocol mismatch: %s != %s\", referer, full_url)\n+ if req_proto == \"https\":\n+ # insecure origin to secure target is not allowed\n+ raise web.HTTPError(\n+ 403, \"Not allowing authorization form submitted from insecure page\"\n+ )\n+ if stripped_referer != stripped_full_url:\n # OAuth post must be made to the URL it came from\n- self.log.error(\"OAuth POST from %s != %s\", referer, full_url)\n+ self.log.error(\"Original OAuth POST from %s != %s\", referer, full_url)\n+ self.log.error(\n+ \"Stripped OAuth POST from %s != %s\", stripped_referer, stripped_full_url\n+ )\n raise web.HTTPError(\n 403, \"Authorization form must be sent from authorization page\"\n )\n", "issue": "Authorization form must be sent from authorization page\nHi! after upgrading to master branch (around 40 days of new commits) admins are no longer able to impersonate users, we get this error right after clicking \"Authorize\" on the new page:\r\n\r\nhttps://github.com/jupyterhub/jupyterhub/blob/5b4f0d4304b1ea57b4d398609f2777bd93131ef4/jupyterhub/apihandlers/auth.py#L255\r\n\r\n```\r\n403 : Forbidden\r\nAuthorization form must be sent from authorization page\r\n```\r\n\r\nWe are still using GitHubOAuthenticator and Postgres as backend.\r\n\r\nAlso other strange thing is happening, the admin page is not properly listing all users, but this is probably related to some of our custom page.html templates:\r\n\r\n\r\n\n", "before_files": [{"content": "\"\"\"Authorization handlers\"\"\"\n# Copyright (c) Jupyter Development Team.\n# Distributed under the terms of the Modified BSD License.\nimport json\nfrom datetime import datetime\nfrom urllib.parse import parse_qsl\nfrom urllib.parse import quote\nfrom urllib.parse import urlencode\nfrom urllib.parse import urlparse\nfrom urllib.parse import urlunparse\n\nfrom oauthlib import oauth2\nfrom tornado import web\n\nfrom .. import orm\nfrom ..user import User\nfrom ..utils import compare_token\nfrom ..utils import token_authenticated\nfrom .base import APIHandler\nfrom .base import BaseHandler\n\n\nclass TokenAPIHandler(APIHandler):\n @token_authenticated\n def get(self, token):\n orm_token = orm.APIToken.find(self.db, token)\n if orm_token is None:\n orm_token = orm.OAuthAccessToken.find(self.db, token)\n if orm_token is None:\n raise web.HTTPError(404)\n\n # record activity whenever we see a token\n now = orm_token.last_activity = datetime.utcnow()\n if orm_token.user:\n orm_token.user.last_activity = now\n model = self.user_model(self.users[orm_token.user])\n elif orm_token.service:\n model = self.service_model(orm_token.service)\n else:\n self.log.warning(\"%s has no user or service. Deleting...\" % orm_token)\n self.db.delete(orm_token)\n self.db.commit()\n raise web.HTTPError(404)\n self.db.commit()\n self.write(json.dumps(model))\n\n async def post(self):\n warn_msg = (\n \"Using deprecated token creation endpoint %s.\"\n \" Use /hub/api/users/:user/tokens instead.\"\n ) % self.request.uri\n self.log.warning(warn_msg)\n requester = user = self.current_user\n if user is None:\n # allow requesting a token with username and password\n # for authenticators where that's possible\n data = self.get_json_body()\n try:\n requester = user = await self.login_user(data)\n except Exception as e:\n self.log.error(\"Failure trying to authenticate with form data: %s\" % e)\n user = None\n if user is None:\n raise web.HTTPError(403)\n else:\n data = self.get_json_body()\n # admin users can request tokens for other users\n if data and data.get('username'):\n user = self.find_user(data['username'])\n if user is not requester and not requester.admin:\n raise web.HTTPError(\n 403, \"Only admins can request tokens for other users.\"\n )\n if requester.admin and user is None:\n raise web.HTTPError(400, \"No such user '%s'\" % data['username'])\n\n note = (data or {}).get('note')\n if not note:\n note = \"Requested via deprecated api\"\n if requester is not user:\n kind = 'user' if isinstance(user, User) else 'service'\n note += \" by %s %s\" % (kind, requester.name)\n\n api_token = user.new_api_token(note=note)\n self.write(\n json.dumps(\n {'token': api_token, 'warning': warn_msg, 'user': self.user_model(user)}\n )\n )\n\n\nclass CookieAPIHandler(APIHandler):\n @token_authenticated\n def get(self, cookie_name, cookie_value=None):\n cookie_name = quote(cookie_name, safe='')\n if cookie_value is None:\n self.log.warning(\n \"Cookie values in request body is deprecated, use `/cookie_name/cookie_value`\"\n )\n cookie_value = self.request.body\n else:\n cookie_value = cookie_value.encode('utf8')\n user = self._user_for_cookie(cookie_name, cookie_value)\n if user is None:\n raise web.HTTPError(404)\n self.write(json.dumps(self.user_model(user)))\n\n\nclass OAuthHandler:\n def extract_oauth_params(self):\n \"\"\"extract oauthlib params from a request\n\n Returns:\n\n (uri, http_method, body, headers)\n \"\"\"\n return (\n self.request.uri,\n self.request.method,\n self.request.body,\n self.request.headers,\n )\n\n def make_absolute_redirect_uri(self, uri):\n \"\"\"Make absolute redirect URIs\n\n internal redirect uris, e.g. `/user/foo/oauth_handler`\n are allowed in jupyterhub, but oauthlib prohibits them.\n Add `$HOST` header to redirect_uri to make them acceptable.\n\n Currently unused in favor of monkeypatching\n oauthlib.is_absolute_uri to skip the check\n \"\"\"\n redirect_uri = self.get_argument('redirect_uri')\n if not redirect_uri or not redirect_uri.startswith('/'):\n return uri\n # make absolute local redirects full URLs\n # to satisfy oauthlib's absolute URI requirement\n redirect_uri = (\n self.request.protocol + \"://\" + self.request.headers['Host'] + redirect_uri\n )\n parsed_url = urlparse(uri)\n query_list = parse_qsl(parsed_url.query, keep_blank_values=True)\n for idx, item in enumerate(query_list):\n if item[0] == 'redirect_uri':\n query_list[idx] = ('redirect_uri', redirect_uri)\n break\n\n return urlunparse(urlparse(uri)._replace(query=urlencode(query_list)))\n\n def add_credentials(self, credentials=None):\n \"\"\"Add oauth credentials\n\n Adds user, session_id, client to oauth credentials\n \"\"\"\n if credentials is None:\n credentials = {}\n else:\n credentials = credentials.copy()\n\n session_id = self.get_session_cookie()\n if session_id is None:\n session_id = self.set_session_cookie()\n\n user = self.current_user\n\n # Extra credentials we need in the validator\n credentials.update({'user': user, 'handler': self, 'session_id': session_id})\n return credentials\n\n def send_oauth_response(self, headers, body, status):\n \"\"\"Send oauth response from provider return values\n\n Provider methods return headers, body, and status\n to be set on the response.\n\n This method applies these values to the Handler\n and sends the response.\n \"\"\"\n self.set_status(status)\n for key, value in headers.items():\n self.set_header(key, value)\n if body:\n self.write(body)\n\n\nclass OAuthAuthorizeHandler(OAuthHandler, BaseHandler):\n \"\"\"Implement OAuth authorization endpoint(s)\"\"\"\n\n def _complete_login(self, uri, headers, scopes, credentials):\n try:\n headers, body, status = self.oauth_provider.create_authorization_response(\n uri, 'POST', '', headers, scopes, credentials\n )\n\n except oauth2.FatalClientError as e:\n # TODO: human error page\n raise\n self.send_oauth_response(headers, body, status)\n\n def needs_oauth_confirm(self, user, oauth_client):\n \"\"\"Return whether the given oauth client needs to prompt for access for the given user\n\n Checks list for oauth clients that don't need confirmation\n\n (i.e. the user's own server)\n\n .. versionadded: 1.1\n \"\"\"\n # get the oauth client ids for the user's own server(s)\n own_oauth_client_ids = set(\n spawner.oauth_client_id for spawner in user.spawners.values()\n )\n if (\n # it's the user's own server\n oauth_client.identifier in own_oauth_client_ids\n # or it's in the global no-confirm list\n or oauth_client.identifier in self.settings.get('oauth_no_confirm', set())\n ):\n return False\n # default: require confirmation\n return True\n\n @web.authenticated\n async def get(self):\n \"\"\"GET /oauth/authorization\n\n Render oauth confirmation page:\n \"Server at ... would like permission to ...\".\n\n Users accessing their own server or a blessed service\n will skip confirmation.\n \"\"\"\n\n uri, http_method, body, headers = self.extract_oauth_params()\n try:\n scopes, credentials = self.oauth_provider.validate_authorization_request(\n uri, http_method, body, headers\n )\n credentials = self.add_credentials(credentials)\n client = self.oauth_provider.fetch_by_client_id(credentials['client_id'])\n if not self.needs_oauth_confirm(self.current_user, client):\n self.log.debug(\n \"Skipping oauth confirmation for %s accessing %s\",\n self.current_user,\n client.description,\n )\n # this is the pre-1.0 behavior for all oauth\n self._complete_login(uri, headers, scopes, credentials)\n return\n\n # Render oauth 'Authorize application...' page\n auth_state = await self.current_user.get_auth_state()\n self.write(\n self.render_template(\n \"oauth.html\",\n auth_state=auth_state,\n scopes=scopes,\n oauth_client=client,\n )\n )\n\n # Errors that should be shown to the user on the provider website\n except oauth2.FatalClientError as e:\n raise web.HTTPError(e.status_code, e.description)\n\n # Errors embedded in the redirect URI back to the client\n except oauth2.OAuth2Error as e:\n self.log.error(\"OAuth error: %s\", e.description)\n self.redirect(e.in_uri(e.redirect_uri))\n\n @web.authenticated\n def post(self):\n uri, http_method, body, headers = self.extract_oauth_params()\n referer = self.request.headers.get('Referer', 'no referer')\n full_url = self.request.full_url()\n if referer != full_url:\n # OAuth post must be made to the URL it came from\n self.log.error(\"OAuth POST from %s != %s\", referer, full_url)\n raise web.HTTPError(\n 403, \"Authorization form must be sent from authorization page\"\n )\n\n # The scopes the user actually authorized, i.e. checkboxes\n # that were selected.\n scopes = self.get_arguments('scopes')\n # credentials we need in the validator\n credentials = self.add_credentials()\n\n try:\n headers, body, status = self.oauth_provider.create_authorization_response(\n uri, http_method, body, headers, scopes, credentials\n )\n except oauth2.FatalClientError as e:\n raise web.HTTPError(e.status_code, e.description)\n else:\n self.send_oauth_response(headers, body, status)\n\n\nclass OAuthTokenHandler(OAuthHandler, APIHandler):\n def post(self):\n uri, http_method, body, headers = self.extract_oauth_params()\n credentials = {}\n\n try:\n headers, body, status = self.oauth_provider.create_token_response(\n uri, http_method, body, headers, credentials\n )\n except oauth2.FatalClientError as e:\n raise web.HTTPError(e.status_code, e.description)\n else:\n self.send_oauth_response(headers, body, status)\n\n\ndefault_handlers = [\n (r\"/api/authorizations/cookie/([^/]+)(?:/([^/]+))?\", CookieAPIHandler),\n (r\"/api/authorizations/token/([^/]+)\", TokenAPIHandler),\n (r\"/api/authorizations/token\", TokenAPIHandler),\n (r\"/api/oauth2/authorize\", OAuthAuthorizeHandler),\n (r\"/api/oauth2/token\", OAuthTokenHandler),\n]\n", "path": "jupyterhub/apihandlers/auth.py"}], "after_files": [{"content": "\"\"\"Authorization handlers\"\"\"\n# Copyright (c) Jupyter Development Team.\n# Distributed under the terms of the Modified BSD License.\nimport json\nfrom datetime import datetime\nfrom urllib.parse import parse_qsl\nfrom urllib.parse import quote\nfrom urllib.parse import urlencode\nfrom urllib.parse import urlparse\nfrom urllib.parse import urlunparse\n\nfrom oauthlib import oauth2\nfrom tornado import web\n\nfrom .. import orm\nfrom ..user import User\nfrom ..utils import compare_token\nfrom ..utils import token_authenticated\nfrom .base import APIHandler\nfrom .base import BaseHandler\n\n\nclass TokenAPIHandler(APIHandler):\n @token_authenticated\n def get(self, token):\n orm_token = orm.APIToken.find(self.db, token)\n if orm_token is None:\n orm_token = orm.OAuthAccessToken.find(self.db, token)\n if orm_token is None:\n raise web.HTTPError(404)\n\n # record activity whenever we see a token\n now = orm_token.last_activity = datetime.utcnow()\n if orm_token.user:\n orm_token.user.last_activity = now\n model = self.user_model(self.users[orm_token.user])\n elif orm_token.service:\n model = self.service_model(orm_token.service)\n else:\n self.log.warning(\"%s has no user or service. Deleting...\" % orm_token)\n self.db.delete(orm_token)\n self.db.commit()\n raise web.HTTPError(404)\n self.db.commit()\n self.write(json.dumps(model))\n\n async def post(self):\n warn_msg = (\n \"Using deprecated token creation endpoint %s.\"\n \" Use /hub/api/users/:user/tokens instead.\"\n ) % self.request.uri\n self.log.warning(warn_msg)\n requester = user = self.current_user\n if user is None:\n # allow requesting a token with username and password\n # for authenticators where that's possible\n data = self.get_json_body()\n try:\n requester = user = await self.login_user(data)\n except Exception as e:\n self.log.error(\"Failure trying to authenticate with form data: %s\" % e)\n user = None\n if user is None:\n raise web.HTTPError(403)\n else:\n data = self.get_json_body()\n # admin users can request tokens for other users\n if data and data.get('username'):\n user = self.find_user(data['username'])\n if user is not requester and not requester.admin:\n raise web.HTTPError(\n 403, \"Only admins can request tokens for other users.\"\n )\n if requester.admin and user is None:\n raise web.HTTPError(400, \"No such user '%s'\" % data['username'])\n\n note = (data or {}).get('note')\n if not note:\n note = \"Requested via deprecated api\"\n if requester is not user:\n kind = 'user' if isinstance(user, User) else 'service'\n note += \" by %s %s\" % (kind, requester.name)\n\n api_token = user.new_api_token(note=note)\n self.write(\n json.dumps(\n {'token': api_token, 'warning': warn_msg, 'user': self.user_model(user)}\n )\n )\n\n\nclass CookieAPIHandler(APIHandler):\n @token_authenticated\n def get(self, cookie_name, cookie_value=None):\n cookie_name = quote(cookie_name, safe='')\n if cookie_value is None:\n self.log.warning(\n \"Cookie values in request body is deprecated, use `/cookie_name/cookie_value`\"\n )\n cookie_value = self.request.body\n else:\n cookie_value = cookie_value.encode('utf8')\n user = self._user_for_cookie(cookie_name, cookie_value)\n if user is None:\n raise web.HTTPError(404)\n self.write(json.dumps(self.user_model(user)))\n\n\nclass OAuthHandler:\n def extract_oauth_params(self):\n \"\"\"extract oauthlib params from a request\n\n Returns:\n\n (uri, http_method, body, headers)\n \"\"\"\n return (\n self.request.uri,\n self.request.method,\n self.request.body,\n self.request.headers,\n )\n\n def make_absolute_redirect_uri(self, uri):\n \"\"\"Make absolute redirect URIs\n\n internal redirect uris, e.g. `/user/foo/oauth_handler`\n are allowed in jupyterhub, but oauthlib prohibits them.\n Add `$HOST` header to redirect_uri to make them acceptable.\n\n Currently unused in favor of monkeypatching\n oauthlib.is_absolute_uri to skip the check\n \"\"\"\n redirect_uri = self.get_argument('redirect_uri')\n if not redirect_uri or not redirect_uri.startswith('/'):\n return uri\n # make absolute local redirects full URLs\n # to satisfy oauthlib's absolute URI requirement\n redirect_uri = (\n self.request.protocol + \"://\" + self.request.headers['Host'] + redirect_uri\n )\n parsed_url = urlparse(uri)\n query_list = parse_qsl(parsed_url.query, keep_blank_values=True)\n for idx, item in enumerate(query_list):\n if item[0] == 'redirect_uri':\n query_list[idx] = ('redirect_uri', redirect_uri)\n break\n\n return urlunparse(urlparse(uri)._replace(query=urlencode(query_list)))\n\n def add_credentials(self, credentials=None):\n \"\"\"Add oauth credentials\n\n Adds user, session_id, client to oauth credentials\n \"\"\"\n if credentials is None:\n credentials = {}\n else:\n credentials = credentials.copy()\n\n session_id = self.get_session_cookie()\n if session_id is None:\n session_id = self.set_session_cookie()\n\n user = self.current_user\n\n # Extra credentials we need in the validator\n credentials.update({'user': user, 'handler': self, 'session_id': session_id})\n return credentials\n\n def send_oauth_response(self, headers, body, status):\n \"\"\"Send oauth response from provider return values\n\n Provider methods return headers, body, and status\n to be set on the response.\n\n This method applies these values to the Handler\n and sends the response.\n \"\"\"\n self.set_status(status)\n for key, value in headers.items():\n self.set_header(key, value)\n if body:\n self.write(body)\n\n\nclass OAuthAuthorizeHandler(OAuthHandler, BaseHandler):\n \"\"\"Implement OAuth authorization endpoint(s)\"\"\"\n\n def _complete_login(self, uri, headers, scopes, credentials):\n try:\n headers, body, status = self.oauth_provider.create_authorization_response(\n uri, 'POST', '', headers, scopes, credentials\n )\n\n except oauth2.FatalClientError as e:\n # TODO: human error page\n raise\n self.send_oauth_response(headers, body, status)\n\n def needs_oauth_confirm(self, user, oauth_client):\n \"\"\"Return whether the given oauth client needs to prompt for access for the given user\n\n Checks list for oauth clients that don't need confirmation\n\n (i.e. the user's own server)\n\n .. versionadded: 1.1\n \"\"\"\n # get the oauth client ids for the user's own server(s)\n own_oauth_client_ids = set(\n spawner.oauth_client_id for spawner in user.spawners.values()\n )\n if (\n # it's the user's own server\n oauth_client.identifier in own_oauth_client_ids\n # or it's in the global no-confirm list\n or oauth_client.identifier in self.settings.get('oauth_no_confirm', set())\n ):\n return False\n # default: require confirmation\n return True\n\n @web.authenticated\n async def get(self):\n \"\"\"GET /oauth/authorization\n\n Render oauth confirmation page:\n \"Server at ... would like permission to ...\".\n\n Users accessing their own server or a blessed service\n will skip confirmation.\n \"\"\"\n\n uri, http_method, body, headers = self.extract_oauth_params()\n try:\n scopes, credentials = self.oauth_provider.validate_authorization_request(\n uri, http_method, body, headers\n )\n credentials = self.add_credentials(credentials)\n client = self.oauth_provider.fetch_by_client_id(credentials['client_id'])\n if not self.needs_oauth_confirm(self.current_user, client):\n self.log.debug(\n \"Skipping oauth confirmation for %s accessing %s\",\n self.current_user,\n client.description,\n )\n # this is the pre-1.0 behavior for all oauth\n self._complete_login(uri, headers, scopes, credentials)\n return\n\n # Render oauth 'Authorize application...' page\n auth_state = await self.current_user.get_auth_state()\n self.write(\n self.render_template(\n \"oauth.html\",\n auth_state=auth_state,\n scopes=scopes,\n oauth_client=client,\n )\n )\n\n # Errors that should be shown to the user on the provider website\n except oauth2.FatalClientError as e:\n raise web.HTTPError(e.status_code, e.description)\n\n # Errors embedded in the redirect URI back to the client\n except oauth2.OAuth2Error as e:\n self.log.error(\"OAuth error: %s\", e.description)\n self.redirect(e.in_uri(e.redirect_uri))\n\n @web.authenticated\n def post(self):\n uri, http_method, body, headers = self.extract_oauth_params()\n referer = self.request.headers.get('Referer', 'no referer')\n full_url = self.request.full_url()\n # trim protocol, which cannot be trusted with multiple layers of proxies anyway\n # Referer is set by browser, but full_url can be modified by proxy layers to appear as http\n # when it is actually https\n referer_proto, _, stripped_referer = referer.partition(\"://\")\n referer_proto = referer_proto.lower()\n req_proto, _, stripped_full_url = full_url.partition(\"://\")\n req_proto = req_proto.lower()\n if referer_proto != req_proto:\n self.log.warning(\"Protocol mismatch: %s != %s\", referer, full_url)\n if req_proto == \"https\":\n # insecure origin to secure target is not allowed\n raise web.HTTPError(\n 403, \"Not allowing authorization form submitted from insecure page\"\n )\n if stripped_referer != stripped_full_url:\n # OAuth post must be made to the URL it came from\n self.log.error(\"Original OAuth POST from %s != %s\", referer, full_url)\n self.log.error(\n \"Stripped OAuth POST from %s != %s\", stripped_referer, stripped_full_url\n )\n raise web.HTTPError(\n 403, \"Authorization form must be sent from authorization page\"\n )\n\n # The scopes the user actually authorized, i.e. checkboxes\n # that were selected.\n scopes = self.get_arguments('scopes')\n # credentials we need in the validator\n credentials = self.add_credentials()\n\n try:\n headers, body, status = self.oauth_provider.create_authorization_response(\n uri, http_method, body, headers, scopes, credentials\n )\n except oauth2.FatalClientError as e:\n raise web.HTTPError(e.status_code, e.description)\n else:\n self.send_oauth_response(headers, body, status)\n\n\nclass OAuthTokenHandler(OAuthHandler, APIHandler):\n def post(self):\n uri, http_method, body, headers = self.extract_oauth_params()\n credentials = {}\n\n try:\n headers, body, status = self.oauth_provider.create_token_response(\n uri, http_method, body, headers, credentials\n )\n except oauth2.FatalClientError as e:\n raise web.HTTPError(e.status_code, e.description)\n else:\n self.send_oauth_response(headers, body, status)\n\n\ndefault_handlers = [\n (r\"/api/authorizations/cookie/([^/]+)(?:/([^/]+))?\", CookieAPIHandler),\n (r\"/api/authorizations/token/([^/]+)\", TokenAPIHandler),\n (r\"/api/authorizations/token\", TokenAPIHandler),\n (r\"/api/oauth2/authorize\", OAuthAuthorizeHandler),\n (r\"/api/oauth2/token\", OAuthTokenHandler),\n]\n", "path": "jupyterhub/apihandlers/auth.py"}]}
| 3,754 | 410 |
gh_patches_debug_24218
|
rasdani/github-patches
|
git_diff
|
Cloud-CV__EvalAI-1042
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Change path of storage of Evaluation Scripts
## Current behaviour
Currently, the evaluation scripts are stored in the `submission_files` directory which should not happen ideally.
## Solution
Modify the `RandomFile()` method such that the evaluation scripts should be uploaded in the `evaluation_scripts` directory instead of the `submission_files` directory.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `apps/base/utils.py`
Content:
```
1 import os
2 import uuid
3
4 from django.conf import settings
5 from django.utils.deconstruct import deconstructible
6
7 from rest_framework.exceptions import NotFound
8 from rest_framework.pagination import PageNumberPagination
9
10
11 class StandardResultSetPagination(PageNumberPagination):
12 page_size = 100
13 page_size_query_param = 'page_size'
14 max_page_size = 1000
15
16
17 def paginated_queryset(queryset, request, pagination_class=PageNumberPagination()):
18 '''
19 Return a paginated result for a queryset
20 '''
21 paginator = pagination_class
22 paginator.page_size = settings.REST_FRAMEWORK['PAGE_SIZE']
23 result_page = paginator.paginate_queryset(queryset, request)
24 return (paginator, result_page)
25
26
27 @deconstructible
28 class RandomFileName(object):
29 def __init__(self, path):
30 self.path = path
31
32 def __call__(self, instance, filename):
33 extension = os.path.splitext(filename)[1]
34 if 'id' in self.path and instance.pk:
35 self.path = self.path.format(id=instance.pk)
36 elif 'id' not in self.path and instance.pk:
37 path = "submission_files/submission_{id}"
38 self.path = path.format(id=instance.pk)
39 filename = '{}{}'.format(uuid.uuid4(), extension)
40 filename = os.path.join(self.path, filename)
41 return filename
42
43
44 def get_model_object(model_name):
45 def get_model_by_pk(pk):
46 try:
47 model_object = model_name.objects.get(pk=pk)
48 return model_object
49 except model_name.DoesNotExist:
50 raise NotFound('{} {} does not exist'.format(model_name.__name__, pk))
51 get_model_by_pk.__name__ = 'get_{}_object'.format(model_name.__name__.lower())
52 return get_model_by_pk
53
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/apps/base/utils.py b/apps/base/utils.py
--- a/apps/base/utils.py
+++ b/apps/base/utils.py
@@ -2,7 +2,6 @@
import uuid
from django.conf import settings
-from django.utils.deconstruct import deconstructible
from rest_framework.exceptions import NotFound
from rest_framework.pagination import PageNumberPagination
@@ -24,20 +23,17 @@
return (paginator, result_page)
-@deconstructible
class RandomFileName(object):
def __init__(self, path):
self.path = path
def __call__(self, instance, filename):
extension = os.path.splitext(filename)[1]
+ path = self.path
if 'id' in self.path and instance.pk:
- self.path = self.path.format(id=instance.pk)
- elif 'id' not in self.path and instance.pk:
- path = "submission_files/submission_{id}"
- self.path = path.format(id=instance.pk)
+ path = self.path.format(id=instance.pk)
filename = '{}{}'.format(uuid.uuid4(), extension)
- filename = os.path.join(self.path, filename)
+ filename = os.path.join(path, filename)
return filename
|
{"golden_diff": "diff --git a/apps/base/utils.py b/apps/base/utils.py\n--- a/apps/base/utils.py\n+++ b/apps/base/utils.py\n@@ -2,7 +2,6 @@\n import uuid\n \n from django.conf import settings\n-from django.utils.deconstruct import deconstructible\n \n from rest_framework.exceptions import NotFound\n from rest_framework.pagination import PageNumberPagination\n@@ -24,20 +23,17 @@\n return (paginator, result_page)\n \n \n-@deconstructible\n class RandomFileName(object):\n def __init__(self, path):\n self.path = path\n \n def __call__(self, instance, filename):\n extension = os.path.splitext(filename)[1]\n+ path = self.path\n if 'id' in self.path and instance.pk:\n- self.path = self.path.format(id=instance.pk)\n- elif 'id' not in self.path and instance.pk:\n- path = \"submission_files/submission_{id}\"\n- self.path = path.format(id=instance.pk)\n+ path = self.path.format(id=instance.pk)\n filename = '{}{}'.format(uuid.uuid4(), extension)\n- filename = os.path.join(self.path, filename)\n+ filename = os.path.join(path, filename)\n return filename\n", "issue": "Change path of storage of Evaluation Scripts\n## Current behaviour\r\n\r\nCurrently, the evaluation scripts are stored in the `submission_files` directory which should not happen ideally.\r\n\r\n## Solution\r\nModify the `RandomFile()` method such that the evaluation scripts should be uploaded in the `evaluation_scripts` directory instead of the `submission_files` directory. \r\n\n", "before_files": [{"content": "import os\nimport uuid\n\nfrom django.conf import settings\nfrom django.utils.deconstruct import deconstructible\n\nfrom rest_framework.exceptions import NotFound\nfrom rest_framework.pagination import PageNumberPagination\n\n\nclass StandardResultSetPagination(PageNumberPagination):\n page_size = 100\n page_size_query_param = 'page_size'\n max_page_size = 1000\n\n\ndef paginated_queryset(queryset, request, pagination_class=PageNumberPagination()):\n '''\n Return a paginated result for a queryset\n '''\n paginator = pagination_class\n paginator.page_size = settings.REST_FRAMEWORK['PAGE_SIZE']\n result_page = paginator.paginate_queryset(queryset, request)\n return (paginator, result_page)\n\n\n@deconstructible\nclass RandomFileName(object):\n def __init__(self, path):\n self.path = path\n\n def __call__(self, instance, filename):\n extension = os.path.splitext(filename)[1]\n if 'id' in self.path and instance.pk:\n self.path = self.path.format(id=instance.pk)\n elif 'id' not in self.path and instance.pk:\n path = \"submission_files/submission_{id}\"\n self.path = path.format(id=instance.pk)\n filename = '{}{}'.format(uuid.uuid4(), extension)\n filename = os.path.join(self.path, filename)\n return filename\n\n\ndef get_model_object(model_name):\n def get_model_by_pk(pk):\n try:\n model_object = model_name.objects.get(pk=pk)\n return model_object\n except model_name.DoesNotExist:\n raise NotFound('{} {} does not exist'.format(model_name.__name__, pk))\n get_model_by_pk.__name__ = 'get_{}_object'.format(model_name.__name__.lower())\n return get_model_by_pk\n", "path": "apps/base/utils.py"}], "after_files": [{"content": "import os\nimport uuid\n\nfrom django.conf import settings\n\nfrom rest_framework.exceptions import NotFound\nfrom rest_framework.pagination import PageNumberPagination\n\n\nclass StandardResultSetPagination(PageNumberPagination):\n page_size = 100\n page_size_query_param = 'page_size'\n max_page_size = 1000\n\n\ndef paginated_queryset(queryset, request, pagination_class=PageNumberPagination()):\n '''\n Return a paginated result for a queryset\n '''\n paginator = pagination_class\n paginator.page_size = settings.REST_FRAMEWORK['PAGE_SIZE']\n result_page = paginator.paginate_queryset(queryset, request)\n return (paginator, result_page)\n\n\nclass RandomFileName(object):\n def __init__(self, path):\n self.path = path\n\n def __call__(self, instance, filename):\n extension = os.path.splitext(filename)[1]\n path = self.path\n if 'id' in self.path and instance.pk:\n path = self.path.format(id=instance.pk)\n filename = '{}{}'.format(uuid.uuid4(), extension)\n filename = os.path.join(path, filename)\n return filename\n\n\ndef get_model_object(model_name):\n def get_model_by_pk(pk):\n try:\n model_object = model_name.objects.get(pk=pk)\n return model_object\n except model_name.DoesNotExist:\n raise NotFound('{} {} does not exist'.format(model_name.__name__, pk))\n get_model_by_pk.__name__ = 'get_{}_object'.format(model_name.__name__.lower())\n return get_model_by_pk\n", "path": "apps/base/utils.py"}]}
| 801 | 264 |
gh_patches_debug_2828
|
rasdani/github-patches
|
git_diff
|
svthalia__concrexit-3188
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Non-closable site announcements can secretly be closed if you send the right cookie
### Describe the bug
Non-closable site announcements can secretly be closed if you send the right cookie
### How to reproduce
Steps to reproduce the behaviour:
1. Have an announcement that is closable
2. Close it on your machine
3. Change the announcement to be non-closable
4. It still isn't there because you already closed it.
The `closable` field just controls whether the close button appears or not, but it doesn't influence the actual logic
### Expected behaviour
Always show non-closable announcements
### Screenshots
### Additional context
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `website/announcements/context_processors.py`
Content:
```
1 """These context processors can be used to expand the context provided to admin views."""
2 from .models import Announcement
3
4
5 def announcements(request):
6 """Get a list of announcements.
7
8 Filters out announcements that have been closed already.
9
10 :param request: the request object
11 :return: a dict containing the list announcements
12 :rtype: dict
13 """
14 closed_announcements = request.session.get("closed_announcements", [])
15 announcements_list = [
16 a
17 for a in Announcement.objects.all()
18 if a.is_visible and a.pk not in closed_announcements
19 ]
20
21 # Announcements set by AnnouncementMiddleware.
22 persistent_announcements = getattr(request, "_announcements", [])
23 return {
24 "announcements": announcements_list,
25 "persistent_announcements": persistent_announcements,
26 }
27
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/website/announcements/context_processors.py b/website/announcements/context_processors.py
--- a/website/announcements/context_processors.py
+++ b/website/announcements/context_processors.py
@@ -15,7 +15,7 @@
announcements_list = [
a
for a in Announcement.objects.all()
- if a.is_visible and a.pk not in closed_announcements
+ if a.is_visible and (not a.closeable or a.pk not in closed_announcements)
]
# Announcements set by AnnouncementMiddleware.
|
{"golden_diff": "diff --git a/website/announcements/context_processors.py b/website/announcements/context_processors.py\n--- a/website/announcements/context_processors.py\n+++ b/website/announcements/context_processors.py\n@@ -15,7 +15,7 @@\n announcements_list = [\n a\n for a in Announcement.objects.all()\n- if a.is_visible and a.pk not in closed_announcements\n+ if a.is_visible and (not a.closeable or a.pk not in closed_announcements)\n ]\n \n # Announcements set by AnnouncementMiddleware.\n", "issue": "Non-closable site announcements can secretly be closed if you send the right cookie\n### Describe the bug\r\nNon-closable site announcements can secretly be closed if you send the right cookie\r\n\r\n### How to reproduce\r\nSteps to reproduce the behaviour:\r\n1. Have an announcement that is closable\r\n2. Close it on your machine\r\n3. Change the announcement to be non-closable\r\n4. It still isn't there because you already closed it.\r\n\r\nThe `closable` field just controls whether the close button appears or not, but it doesn't influence the actual logic\r\n\r\n### Expected behaviour\r\nAlways show non-closable announcements\r\n\r\n### Screenshots\r\n\r\n### Additional context\r\n\n", "before_files": [{"content": "\"\"\"These context processors can be used to expand the context provided to admin views.\"\"\"\nfrom .models import Announcement\n\n\ndef announcements(request):\n \"\"\"Get a list of announcements.\n\n Filters out announcements that have been closed already.\n\n :param request: the request object\n :return: a dict containing the list announcements\n :rtype: dict\n \"\"\"\n closed_announcements = request.session.get(\"closed_announcements\", [])\n announcements_list = [\n a\n for a in Announcement.objects.all()\n if a.is_visible and a.pk not in closed_announcements\n ]\n\n # Announcements set by AnnouncementMiddleware.\n persistent_announcements = getattr(request, \"_announcements\", [])\n return {\n \"announcements\": announcements_list,\n \"persistent_announcements\": persistent_announcements,\n }\n", "path": "website/announcements/context_processors.py"}], "after_files": [{"content": "\"\"\"These context processors can be used to expand the context provided to admin views.\"\"\"\nfrom .models import Announcement\n\n\ndef announcements(request):\n \"\"\"Get a list of announcements.\n\n Filters out announcements that have been closed already.\n\n :param request: the request object\n :return: a dict containing the list announcements\n :rtype: dict\n \"\"\"\n closed_announcements = request.session.get(\"closed_announcements\", [])\n announcements_list = [\n a\n for a in Announcement.objects.all()\n if a.is_visible and (not a.closeable or a.pk not in closed_announcements)\n ]\n\n # Announcements set by AnnouncementMiddleware.\n persistent_announcements = getattr(request, \"_announcements\", [])\n return {\n \"announcements\": announcements_list,\n \"persistent_announcements\": persistent_announcements,\n }\n", "path": "website/announcements/context_processors.py"}]}
| 614 | 120 |
gh_patches_debug_14838
|
rasdani/github-patches
|
git_diff
|
yt-project__yt-1869
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
SlicePlot artifacts on corners/edges
### Bug report
A SlicePlot of a 2D cylindrical dataset has artifacts on the edges and corners that do not represent the underlying data.
**Code for reproduction**
This can be reproduced using the same dataset and plot as #1663. Download the WDMerger_hdf5_chk_1000 sample dataset, and then do a sliceplot:
```python
# import yt
# ds = yt.load('WDMerger_hdf5_chk_1000/WDMerger_hdf5_chk_1000.hdf5')
# yt.SlicePlot(ds, 'theta', 'density', width=1.e9).set_center([2.e9, 0.0]).save()
```
**Actual outcome**
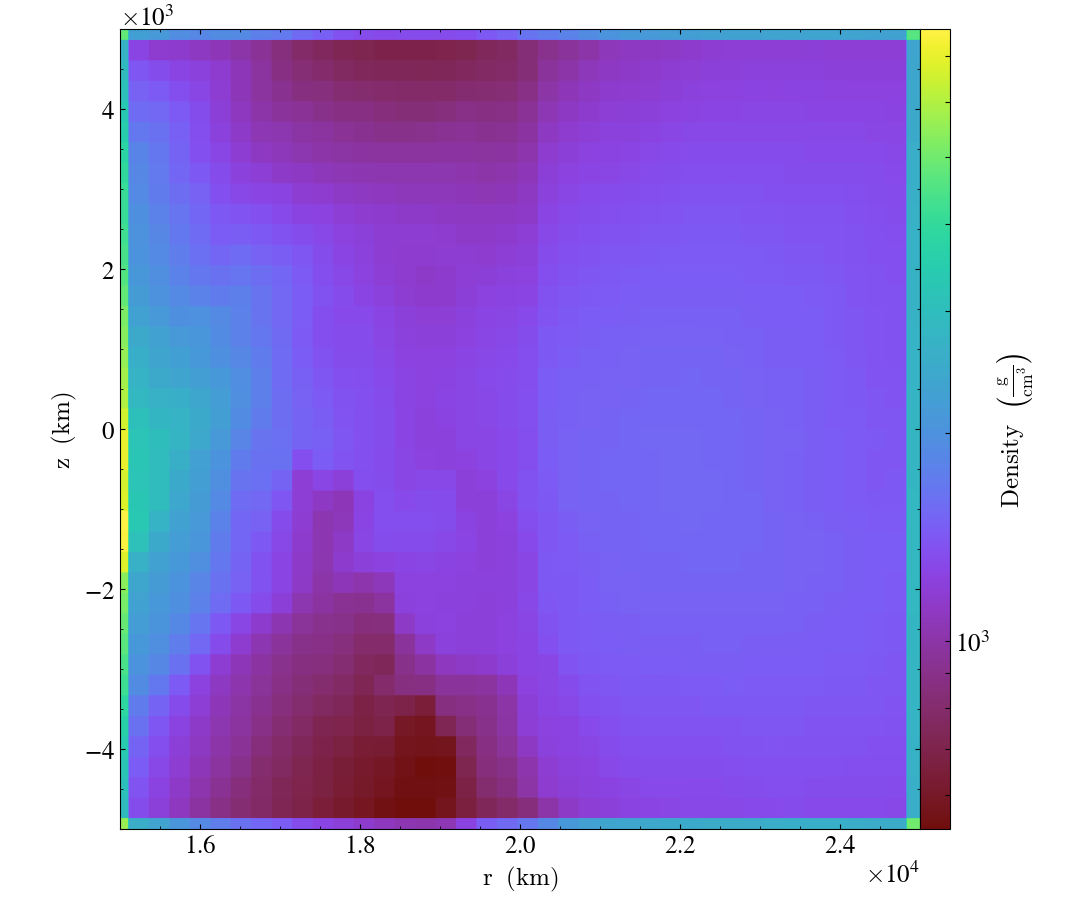
Note the spurious "hotspots" in the corners, and the solid lines along the edges.
**Version Information**
* Operating System: SLES 11
* Python Version: 3.5.1
* yt version: Development (eb3358c622bc047200b9bc6a954ddee8f59a0e07)
* Other Libraries (if applicable):
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `yt/geometry/coordinates/cylindrical_coordinates.py`
Content:
```
1 """
2 Definitions for cylindrical coordinate systems
3
4
5
6
7 """
8
9 #-----------------------------------------------------------------------------
10 # Copyright (c) 2013, yt Development Team.
11 #
12 # Distributed under the terms of the Modified BSD License.
13 #
14 # The full license is in the file COPYING.txt, distributed with this software.
15 #-----------------------------------------------------------------------------
16
17 import numpy as np
18 from .coordinate_handler import \
19 CoordinateHandler, \
20 _unknown_coord, \
21 _get_coord_fields, \
22 cylindrical_to_cartesian, \
23 cartesian_to_cylindrical
24 from yt.utilities.lib.pixelization_routines import \
25 pixelize_cartesian, pixelize_cylinder
26 #
27 # Cylindrical fields
28 #
29
30 class CylindricalCoordinateHandler(CoordinateHandler):
31 name = "cylindrical"
32
33 def __init__(self, ds, ordering = ('r', 'z', 'theta')):
34 super(CylindricalCoordinateHandler, self).__init__(ds, ordering)
35 self.image_units = {}
36 self.image_units[self.axis_id['r']] = ("rad", None)
37 self.image_units[self.axis_id['theta']] = (None, None)
38 self.image_units[self.axis_id['z']] = (None, None)
39
40 def setup_fields(self, registry):
41 # return the fields for r, z, theta
42 registry.add_field(("index", "dx"), sampling_type="cell", function=_unknown_coord)
43 registry.add_field(("index", "dy"), sampling_type="cell", function=_unknown_coord)
44 registry.add_field(("index", "x"), sampling_type="cell", function=_unknown_coord)
45 registry.add_field(("index", "y"), sampling_type="cell", function=_unknown_coord)
46 f1, f2 = _get_coord_fields(self.axis_id['r'])
47 registry.add_field(("index", "dr"), sampling_type="cell", function = f1,
48 display_field = False,
49 units = "code_length")
50 registry.add_field(("index", "r"), sampling_type="cell", function = f2,
51 display_field = False,
52 units = "code_length")
53
54 f1, f2 = _get_coord_fields(self.axis_id['z'])
55 registry.add_field(("index", "dz"), sampling_type="cell", function = f1,
56 display_field = False,
57 units = "code_length")
58 registry.add_field(("index", "z"), sampling_type="cell", function = f2,
59 display_field = False,
60 units = "code_length")
61
62 f1, f2 = _get_coord_fields(self.axis_id['theta'], "")
63 registry.add_field(("index", "dtheta"), sampling_type="cell", function = f1,
64 display_field = False,
65 units = "")
66 registry.add_field(("index", "theta"), sampling_type="cell", function = f2,
67 display_field = False,
68 units = "")
69
70 def _CylindricalVolume(field, data):
71 r = data["index", "r"]
72 dr = data["index", "dr"]
73 vol = 0.5*((r+0.5*dr)**2-(r-0.5*dr)**2)
74 vol *= data["index", "dtheta"]
75 vol *= data["index", "dz"]
76 return vol
77 registry.add_field(("index", "cell_volume"), sampling_type="cell",
78 function=_CylindricalVolume,
79 units = "code_length**3")
80
81 def _path_r(field, data):
82 return data["index", "dr"]
83 registry.add_field(("index", "path_element_r"), sampling_type="cell",
84 function = _path_r,
85 units = "code_length")
86 def _path_theta(field, data):
87 # Note: this already assumes cell-centered
88 return data["index", "r"] * data["index", "dtheta"]
89 registry.add_field(("index", "path_element_theta"), sampling_type="cell",
90 function = _path_theta,
91 units = "code_length")
92 def _path_z(field, data):
93 return data["index", "dz"]
94 registry.add_field(("index", "path_element_z"), sampling_type="cell",
95 function = _path_z,
96 units = "code_length")
97
98 def pixelize(self, dimension, data_source, field, bounds, size,
99 antialias = True, periodic = True):
100 ax_name = self.axis_name[dimension]
101 if ax_name in ('r', 'theta'):
102 return self._ortho_pixelize(data_source, field, bounds, size,
103 antialias, dimension, periodic)
104 elif ax_name == "z":
105 return self._cyl_pixelize(data_source, field, bounds, size,
106 antialias)
107 else:
108 # Pixelizing along a cylindrical surface is a bit tricky
109 raise NotImplementedError
110
111 def _ortho_pixelize(self, data_source, field, bounds, size, antialias,
112 dim, periodic):
113 period = self.period[:2].copy() # dummy here
114 period[0] = self.period[self.x_axis[dim]]
115 period[1] = self.period[self.y_axis[dim]]
116 if hasattr(period, 'in_units'):
117 period = period.in_units("code_length").d
118 buff = np.zeros(size, dtype="f8")
119 pixelize_cartesian(buff, data_source['px'], data_source['py'],
120 data_source['pdx'], data_source['pdy'],
121 data_source[field],
122 bounds, int(antialias),
123 period, int(periodic))
124 return buff
125
126 def _cyl_pixelize(self, data_source, field, bounds, size, antialias):
127 buff = np.zeros((size[1], size[0]), dtype="f8")
128 pixelize_cylinder(buff,
129 data_source['px'],
130 data_source['pdx'],
131 data_source['py'],
132 data_source['pdy'],
133 data_source[field], bounds)
134 return buff
135
136 _x_pairs = (('r', 'theta'), ('z', 'r'), ('theta', 'r'))
137 _y_pairs = (('r', 'z'), ('z', 'theta'), ('theta', 'z'))
138
139 _image_axis_name = None
140
141 @property
142 def image_axis_name(self):
143 if self._image_axis_name is not None:
144 return self._image_axis_name
145 # This is the x and y axes labels that get displayed. For
146 # non-Cartesian coordinates, we usually want to override these for
147 # Cartesian coordinates, since we transform them.
148 rv = {self.axis_id['r']: ('theta', 'z'),
149 self.axis_id['z']: ('x', 'y'),
150 self.axis_id['theta']: ('r', 'z')}
151 for i in list(rv.keys()):
152 rv[self.axis_name[i]] = rv[i]
153 rv[self.axis_name[i].upper()] = rv[i]
154 self._image_axis_name = rv
155 return rv
156
157 def convert_from_cartesian(self, coord):
158 return cartesian_to_cylindrical(coord)
159
160 def convert_to_cartesian(self, coord):
161 return cylindrical_to_cartesian(coord)
162
163 def convert_to_cylindrical(self, coord):
164 return coord
165
166 def convert_from_cylindrical(self, coord):
167 return coord
168
169 def convert_to_spherical(self, coord):
170 raise NotImplementedError
171
172 def convert_from_spherical(self, coord):
173 raise NotImplementedError
174
175 @property
176 def period(self):
177 return np.array([0.0, 0.0, 2.0*np.pi])
178
179 def sanitize_center(self, center, axis):
180 center, display_center = super(
181 CylindricalCoordinateHandler, self).sanitize_center(center, axis)
182 display_center = [0.0 * display_center[0],
183 0.0 * display_center[1],
184 0.0 * display_center[2]]
185 ax_name = self.axis_name[axis]
186 r_ax = self.axis_id['r']
187 theta_ax = self.axis_id['theta']
188 z_ax = self.axis_id['z']
189 if ax_name == "r":
190 display_center[theta_ax] = self.ds.domain_center[theta_ax]
191 display_center[z_ax] = self.ds.domain_center[z_ax]
192 elif ax_name == "theta":
193 # use existing center value
194 for idx in (r_ax, z_ax): display_center[idx] = center[idx]
195 return center, display_center
196
197 def sanitize_width(self, axis, width, depth):
198 name = self.axis_name[axis]
199 r_ax, theta_ax, z_ax = (self.ds.coordinates.axis_id[ax]
200 for ax in ('r', 'theta', 'z'))
201 if width is not None:
202 width = super(CylindricalCoordinateHandler,
203 self).sanitize_width(axis, width, depth)
204 # Note: regardless of axes, these are set up to give consistent plots
205 # when plotted, which is not strictly a "right hand rule" for axes.
206 elif name == "r": # soup can label
207 width = [2.0 * np.pi * self.ds.domain_width.uq,
208 self.ds.domain_width[z_ax]]
209 elif name == "theta":
210 width = [self.ds.domain_right_edge[r_ax],
211 self.ds.domain_width[z_ax]]
212 elif name == "z":
213 width = [2.0*self.ds.domain_right_edge[r_ax],
214 2.0*self.ds.domain_right_edge[r_ax]]
215 return width
216
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/yt/geometry/coordinates/cylindrical_coordinates.py b/yt/geometry/coordinates/cylindrical_coordinates.py
--- a/yt/geometry/coordinates/cylindrical_coordinates.py
+++ b/yt/geometry/coordinates/cylindrical_coordinates.py
@@ -96,7 +96,11 @@
units = "code_length")
def pixelize(self, dimension, data_source, field, bounds, size,
- antialias = True, periodic = True):
+ antialias = True, periodic = False):
+ # Note that above, we set periodic by default to be *false*. This is
+ # because our pixelizers, at present, do not handle periodicity
+ # correctly, and if you change the "width" of a cylindrical plot, it
+ # double-counts in the edge buffers. See, for instance, issue 1669.
ax_name = self.axis_name[dimension]
if ax_name in ('r', 'theta'):
return self._ortho_pixelize(data_source, field, bounds, size,
|
{"golden_diff": "diff --git a/yt/geometry/coordinates/cylindrical_coordinates.py b/yt/geometry/coordinates/cylindrical_coordinates.py\n--- a/yt/geometry/coordinates/cylindrical_coordinates.py\n+++ b/yt/geometry/coordinates/cylindrical_coordinates.py\n@@ -96,7 +96,11 @@\n units = \"code_length\")\n \n def pixelize(self, dimension, data_source, field, bounds, size,\n- antialias = True, periodic = True):\n+ antialias = True, periodic = False):\n+ # Note that above, we set periodic by default to be *false*. This is\n+ # because our pixelizers, at present, do not handle periodicity\n+ # correctly, and if you change the \"width\" of a cylindrical plot, it\n+ # double-counts in the edge buffers. See, for instance, issue 1669.\n ax_name = self.axis_name[dimension]\n if ax_name in ('r', 'theta'):\n return self._ortho_pixelize(data_source, field, bounds, size,\n", "issue": "SlicePlot artifacts on corners/edges\n### Bug report\r\n\r\nA SlicePlot of a 2D cylindrical dataset has artifacts on the edges and corners that do not represent the underlying data.\r\n\r\n**Code for reproduction**\r\n\r\nThis can be reproduced using the same dataset and plot as #1663. Download the WDMerger_hdf5_chk_1000 sample dataset, and then do a sliceplot:\r\n\r\n```python\r\n# import yt\r\n# ds = yt.load('WDMerger_hdf5_chk_1000/WDMerger_hdf5_chk_1000.hdf5')\r\n# yt.SlicePlot(ds, 'theta', 'density', width=1.e9).set_center([2.e9, 0.0]).save()\r\n```\r\n\r\n**Actual outcome**\r\n\r\n\r\n\r\nNote the spurious \"hotspots\" in the corners, and the solid lines along the edges.\r\n\r\n**Version Information**\r\n * Operating System: SLES 11\r\n * Python Version: 3.5.1\r\n * yt version: Development (eb3358c622bc047200b9bc6a954ddee8f59a0e07)\r\n * Other Libraries (if applicable): \n", "before_files": [{"content": "\"\"\"\nDefinitions for cylindrical coordinate systems\n\n\n\n\n\"\"\"\n\n#-----------------------------------------------------------------------------\n# Copyright (c) 2013, yt Development Team.\n#\n# Distributed under the terms of the Modified BSD License.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#-----------------------------------------------------------------------------\n\nimport numpy as np\nfrom .coordinate_handler import \\\n CoordinateHandler, \\\n _unknown_coord, \\\n _get_coord_fields, \\\n cylindrical_to_cartesian, \\\n cartesian_to_cylindrical\nfrom yt.utilities.lib.pixelization_routines import \\\n pixelize_cartesian, pixelize_cylinder\n#\n# Cylindrical fields\n#\n\nclass CylindricalCoordinateHandler(CoordinateHandler):\n name = \"cylindrical\"\n\n def __init__(self, ds, ordering = ('r', 'z', 'theta')):\n super(CylindricalCoordinateHandler, self).__init__(ds, ordering)\n self.image_units = {}\n self.image_units[self.axis_id['r']] = (\"rad\", None)\n self.image_units[self.axis_id['theta']] = (None, None)\n self.image_units[self.axis_id['z']] = (None, None)\n\n def setup_fields(self, registry):\n # return the fields for r, z, theta\n registry.add_field((\"index\", \"dx\"), sampling_type=\"cell\", function=_unknown_coord)\n registry.add_field((\"index\", \"dy\"), sampling_type=\"cell\", function=_unknown_coord)\n registry.add_field((\"index\", \"x\"), sampling_type=\"cell\", function=_unknown_coord)\n registry.add_field((\"index\", \"y\"), sampling_type=\"cell\", function=_unknown_coord)\n f1, f2 = _get_coord_fields(self.axis_id['r'])\n registry.add_field((\"index\", \"dr\"), sampling_type=\"cell\", function = f1,\n display_field = False,\n units = \"code_length\")\n registry.add_field((\"index\", \"r\"), sampling_type=\"cell\", function = f2,\n display_field = False,\n units = \"code_length\")\n\n f1, f2 = _get_coord_fields(self.axis_id['z'])\n registry.add_field((\"index\", \"dz\"), sampling_type=\"cell\", function = f1,\n display_field = False,\n units = \"code_length\")\n registry.add_field((\"index\", \"z\"), sampling_type=\"cell\", function = f2,\n display_field = False,\n units = \"code_length\")\n\n f1, f2 = _get_coord_fields(self.axis_id['theta'], \"\")\n registry.add_field((\"index\", \"dtheta\"), sampling_type=\"cell\", function = f1,\n display_field = False,\n units = \"\")\n registry.add_field((\"index\", \"theta\"), sampling_type=\"cell\", function = f2,\n display_field = False,\n units = \"\")\n\n def _CylindricalVolume(field, data):\n r = data[\"index\", \"r\"]\n dr = data[\"index\", \"dr\"]\n vol = 0.5*((r+0.5*dr)**2-(r-0.5*dr)**2)\n vol *= data[\"index\", \"dtheta\"]\n vol *= data[\"index\", \"dz\"]\n return vol\n registry.add_field((\"index\", \"cell_volume\"), sampling_type=\"cell\",\n function=_CylindricalVolume,\n units = \"code_length**3\")\n\n def _path_r(field, data):\n return data[\"index\", \"dr\"]\n registry.add_field((\"index\", \"path_element_r\"), sampling_type=\"cell\", \n function = _path_r,\n units = \"code_length\")\n def _path_theta(field, data):\n # Note: this already assumes cell-centered\n return data[\"index\", \"r\"] * data[\"index\", \"dtheta\"]\n registry.add_field((\"index\", \"path_element_theta\"), sampling_type=\"cell\", \n function = _path_theta,\n units = \"code_length\")\n def _path_z(field, data):\n return data[\"index\", \"dz\"]\n registry.add_field((\"index\", \"path_element_z\"), sampling_type=\"cell\", \n function = _path_z,\n units = \"code_length\")\n\n def pixelize(self, dimension, data_source, field, bounds, size,\n antialias = True, periodic = True):\n ax_name = self.axis_name[dimension]\n if ax_name in ('r', 'theta'):\n return self._ortho_pixelize(data_source, field, bounds, size,\n antialias, dimension, periodic)\n elif ax_name == \"z\":\n return self._cyl_pixelize(data_source, field, bounds, size,\n antialias)\n else:\n # Pixelizing along a cylindrical surface is a bit tricky\n raise NotImplementedError\n\n def _ortho_pixelize(self, data_source, field, bounds, size, antialias,\n dim, periodic):\n period = self.period[:2].copy() # dummy here\n period[0] = self.period[self.x_axis[dim]]\n period[1] = self.period[self.y_axis[dim]]\n if hasattr(period, 'in_units'):\n period = period.in_units(\"code_length\").d\n buff = np.zeros(size, dtype=\"f8\")\n pixelize_cartesian(buff, data_source['px'], data_source['py'],\n data_source['pdx'], data_source['pdy'],\n data_source[field],\n bounds, int(antialias),\n period, int(periodic))\n return buff\n\n def _cyl_pixelize(self, data_source, field, bounds, size, antialias):\n buff = np.zeros((size[1], size[0]), dtype=\"f8\")\n pixelize_cylinder(buff,\n data_source['px'],\n data_source['pdx'],\n data_source['py'],\n data_source['pdy'],\n data_source[field], bounds)\n return buff\n\n _x_pairs = (('r', 'theta'), ('z', 'r'), ('theta', 'r'))\n _y_pairs = (('r', 'z'), ('z', 'theta'), ('theta', 'z'))\n\n _image_axis_name = None\n\n @property\n def image_axis_name(self):\n if self._image_axis_name is not None:\n return self._image_axis_name\n # This is the x and y axes labels that get displayed. For\n # non-Cartesian coordinates, we usually want to override these for\n # Cartesian coordinates, since we transform them.\n rv = {self.axis_id['r']: ('theta', 'z'),\n self.axis_id['z']: ('x', 'y'),\n self.axis_id['theta']: ('r', 'z')}\n for i in list(rv.keys()):\n rv[self.axis_name[i]] = rv[i]\n rv[self.axis_name[i].upper()] = rv[i]\n self._image_axis_name = rv\n return rv\n\n def convert_from_cartesian(self, coord):\n return cartesian_to_cylindrical(coord)\n\n def convert_to_cartesian(self, coord):\n return cylindrical_to_cartesian(coord)\n\n def convert_to_cylindrical(self, coord):\n return coord\n\n def convert_from_cylindrical(self, coord):\n return coord\n\n def convert_to_spherical(self, coord):\n raise NotImplementedError\n\n def convert_from_spherical(self, coord):\n raise NotImplementedError\n\n @property\n def period(self):\n return np.array([0.0, 0.0, 2.0*np.pi])\n\n def sanitize_center(self, center, axis):\n center, display_center = super(\n CylindricalCoordinateHandler, self).sanitize_center(center, axis)\n display_center = [0.0 * display_center[0],\n 0.0 * display_center[1],\n 0.0 * display_center[2]]\n ax_name = self.axis_name[axis]\n r_ax = self.axis_id['r']\n theta_ax = self.axis_id['theta']\n z_ax = self.axis_id['z']\n if ax_name == \"r\":\n display_center[theta_ax] = self.ds.domain_center[theta_ax]\n display_center[z_ax] = self.ds.domain_center[z_ax]\n elif ax_name == \"theta\":\n # use existing center value\n for idx in (r_ax, z_ax): display_center[idx] = center[idx]\n return center, display_center\n\n def sanitize_width(self, axis, width, depth):\n name = self.axis_name[axis]\n r_ax, theta_ax, z_ax = (self.ds.coordinates.axis_id[ax]\n for ax in ('r', 'theta', 'z'))\n if width is not None:\n width = super(CylindricalCoordinateHandler,\n self).sanitize_width(axis, width, depth)\n # Note: regardless of axes, these are set up to give consistent plots\n # when plotted, which is not strictly a \"right hand rule\" for axes.\n elif name == \"r\": # soup can label\n width = [2.0 * np.pi * self.ds.domain_width.uq,\n self.ds.domain_width[z_ax]]\n elif name == \"theta\":\n width = [self.ds.domain_right_edge[r_ax],\n self.ds.domain_width[z_ax]]\n elif name == \"z\":\n width = [2.0*self.ds.domain_right_edge[r_ax],\n 2.0*self.ds.domain_right_edge[r_ax]]\n return width\n", "path": "yt/geometry/coordinates/cylindrical_coordinates.py"}], "after_files": [{"content": "\"\"\"\nDefinitions for cylindrical coordinate systems\n\n\n\n\n\"\"\"\n\n#-----------------------------------------------------------------------------\n# Copyright (c) 2013, yt Development Team.\n#\n# Distributed under the terms of the Modified BSD License.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#-----------------------------------------------------------------------------\n\nimport numpy as np\nfrom .coordinate_handler import \\\n CoordinateHandler, \\\n _unknown_coord, \\\n _get_coord_fields, \\\n cylindrical_to_cartesian, \\\n cartesian_to_cylindrical\nfrom yt.utilities.lib.pixelization_routines import \\\n pixelize_cartesian, pixelize_cylinder\n#\n# Cylindrical fields\n#\n\nclass CylindricalCoordinateHandler(CoordinateHandler):\n name = \"cylindrical\"\n\n def __init__(self, ds, ordering = ('r', 'z', 'theta')):\n super(CylindricalCoordinateHandler, self).__init__(ds, ordering)\n self.image_units = {}\n self.image_units[self.axis_id['r']] = (\"rad\", None)\n self.image_units[self.axis_id['theta']] = (None, None)\n self.image_units[self.axis_id['z']] = (None, None)\n\n def setup_fields(self, registry):\n # return the fields for r, z, theta\n registry.add_field((\"index\", \"dx\"), sampling_type=\"cell\", function=_unknown_coord)\n registry.add_field((\"index\", \"dy\"), sampling_type=\"cell\", function=_unknown_coord)\n registry.add_field((\"index\", \"x\"), sampling_type=\"cell\", function=_unknown_coord)\n registry.add_field((\"index\", \"y\"), sampling_type=\"cell\", function=_unknown_coord)\n f1, f2 = _get_coord_fields(self.axis_id['r'])\n registry.add_field((\"index\", \"dr\"), sampling_type=\"cell\", function = f1,\n display_field = False,\n units = \"code_length\")\n registry.add_field((\"index\", \"r\"), sampling_type=\"cell\", function = f2,\n display_field = False,\n units = \"code_length\")\n\n f1, f2 = _get_coord_fields(self.axis_id['z'])\n registry.add_field((\"index\", \"dz\"), sampling_type=\"cell\", function = f1,\n display_field = False,\n units = \"code_length\")\n registry.add_field((\"index\", \"z\"), sampling_type=\"cell\", function = f2,\n display_field = False,\n units = \"code_length\")\n\n f1, f2 = _get_coord_fields(self.axis_id['theta'], \"\")\n registry.add_field((\"index\", \"dtheta\"), sampling_type=\"cell\", function = f1,\n display_field = False,\n units = \"\")\n registry.add_field((\"index\", \"theta\"), sampling_type=\"cell\", function = f2,\n display_field = False,\n units = \"\")\n\n def _CylindricalVolume(field, data):\n r = data[\"index\", \"r\"]\n dr = data[\"index\", \"dr\"]\n vol = 0.5*((r+0.5*dr)**2-(r-0.5*dr)**2)\n vol *= data[\"index\", \"dtheta\"]\n vol *= data[\"index\", \"dz\"]\n return vol\n registry.add_field((\"index\", \"cell_volume\"), sampling_type=\"cell\",\n function=_CylindricalVolume,\n units = \"code_length**3\")\n\n def _path_r(field, data):\n return data[\"index\", \"dr\"]\n registry.add_field((\"index\", \"path_element_r\"), sampling_type=\"cell\", \n function = _path_r,\n units = \"code_length\")\n def _path_theta(field, data):\n # Note: this already assumes cell-centered\n return data[\"index\", \"r\"] * data[\"index\", \"dtheta\"]\n registry.add_field((\"index\", \"path_element_theta\"), sampling_type=\"cell\", \n function = _path_theta,\n units = \"code_length\")\n def _path_z(field, data):\n return data[\"index\", \"dz\"]\n registry.add_field((\"index\", \"path_element_z\"), sampling_type=\"cell\", \n function = _path_z,\n units = \"code_length\")\n\n def pixelize(self, dimension, data_source, field, bounds, size,\n antialias = True, periodic = False):\n # Note that above, we set periodic by default to be *false*. This is\n # because our pixelizers, at present, do not handle periodicity\n # correctly, and if you change the \"width\" of a cylindrical plot, it\n # double-counts in the edge buffers. See, for instance, issue 1669.\n ax_name = self.axis_name[dimension]\n if ax_name in ('r', 'theta'):\n return self._ortho_pixelize(data_source, field, bounds, size,\n antialias, dimension, periodic)\n elif ax_name == \"z\":\n return self._cyl_pixelize(data_source, field, bounds, size,\n antialias)\n else:\n # Pixelizing along a cylindrical surface is a bit tricky\n raise NotImplementedError\n\n def _ortho_pixelize(self, data_source, field, bounds, size, antialias,\n dim, periodic):\n period = self.period[:2].copy() # dummy here\n period[0] = self.period[self.x_axis[dim]]\n period[1] = self.period[self.y_axis[dim]]\n if hasattr(period, 'in_units'):\n period = period.in_units(\"code_length\").d\n buff = np.zeros(size, dtype=\"f8\")\n pixelize_cartesian(buff, data_source['px'], data_source['py'],\n data_source['pdx'], data_source['pdy'],\n data_source[field],\n bounds, int(antialias),\n period, int(periodic))\n return buff\n\n def _cyl_pixelize(self, data_source, field, bounds, size, antialias):\n buff = np.zeros((size[1], size[0]), dtype=\"f8\")\n pixelize_cylinder(buff,\n data_source['px'],\n data_source['pdx'],\n data_source['py'],\n data_source['pdy'],\n data_source[field], bounds)\n return buff\n\n _x_pairs = (('r', 'theta'), ('z', 'r'), ('theta', 'r'))\n _y_pairs = (('r', 'z'), ('z', 'theta'), ('theta', 'z'))\n\n _image_axis_name = None\n\n @property\n def image_axis_name(self):\n if self._image_axis_name is not None:\n return self._image_axis_name\n # This is the x and y axes labels that get displayed. For\n # non-Cartesian coordinates, we usually want to override these for\n # Cartesian coordinates, since we transform them.\n rv = {self.axis_id['r']: ('theta', 'z'),\n self.axis_id['z']: ('x', 'y'),\n self.axis_id['theta']: ('r', 'z')}\n for i in list(rv.keys()):\n rv[self.axis_name[i]] = rv[i]\n rv[self.axis_name[i].upper()] = rv[i]\n self._image_axis_name = rv\n return rv\n\n def convert_from_cartesian(self, coord):\n return cartesian_to_cylindrical(coord)\n\n def convert_to_cartesian(self, coord):\n return cylindrical_to_cartesian(coord)\n\n def convert_to_cylindrical(self, coord):\n return coord\n\n def convert_from_cylindrical(self, coord):\n return coord\n\n def convert_to_spherical(self, coord):\n raise NotImplementedError\n\n def convert_from_spherical(self, coord):\n raise NotImplementedError\n\n @property\n def period(self):\n return np.array([0.0, 0.0, 2.0*np.pi])\n\n def sanitize_center(self, center, axis):\n center, display_center = super(\n CylindricalCoordinateHandler, self).sanitize_center(center, axis)\n display_center = [0.0 * display_center[0],\n 0.0 * display_center[1],\n 0.0 * display_center[2]]\n ax_name = self.axis_name[axis]\n r_ax = self.axis_id['r']\n theta_ax = self.axis_id['theta']\n z_ax = self.axis_id['z']\n if ax_name == \"r\":\n display_center[theta_ax] = self.ds.domain_center[theta_ax]\n display_center[z_ax] = self.ds.domain_center[z_ax]\n elif ax_name == \"theta\":\n # use existing center value\n for idx in (r_ax, z_ax): display_center[idx] = center[idx]\n return center, display_center\n\n def sanitize_width(self, axis, width, depth):\n name = self.axis_name[axis]\n r_ax, theta_ax, z_ax = (self.ds.coordinates.axis_id[ax]\n for ax in ('r', 'theta', 'z'))\n if width is not None:\n width = super(CylindricalCoordinateHandler,\n self).sanitize_width(axis, width, depth)\n # Note: regardless of axes, these are set up to give consistent plots\n # when plotted, which is not strictly a \"right hand rule\" for axes.\n elif name == \"r\": # soup can label\n width = [2.0 * np.pi * self.ds.domain_width.uq,\n self.ds.domain_width[z_ax]]\n elif name == \"theta\":\n width = [self.ds.domain_right_edge[r_ax],\n self.ds.domain_width[z_ax]]\n elif name == \"z\":\n width = [2.0*self.ds.domain_right_edge[r_ax],\n 2.0*self.ds.domain_right_edge[r_ax]]\n return width\n", "path": "yt/geometry/coordinates/cylindrical_coordinates.py"}]}
| 3,160 | 235 |
gh_patches_debug_3957
|
rasdani/github-patches
|
git_diff
|
internetarchive__openlibrary-6513
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Open Library Stats Cron hitting Document update conflict
<!-- What problem are we solving? What does the experience look like today? What are the symptoms? -->
```
Traceback (most recent call last):
File "/openlibrary/scripts/store_counts.py", line 18, in <module>
sys.exit(stats.main(*sys.argv[1:]))
File "/openlibrary/openlibrary/admin/stats.py", line 168, in main
store_data(data, today.strftime("%Y-%m-%d"))
File "/openlibrary/openlibrary/admin/stats.py", line 68, in store_data
web.ctx.site.store[uid] = doc
File "/openlibrary/infogami/infobase/client.py", line 630, in __setitem__
return self._request(key, method='PUT', data=json.dumps(data))
File "/openlibrary/infogami/infobase/client.py", line 569, in _request
out = self.conn.request(self.name, "/_store/" + path, method, data)
File "/openlibrary/openlibrary/plugins/openlibrary/connection.py", line 54, in request
return self.store_put(sitename, path, data)
File "/openlibrary/openlibrary/plugins/openlibrary/connection.py", line 101, in store_put
return self.conn.request(sitename, path, 'PUT', data)
File "/openlibrary/openlibrary/plugins/openlibrary/connection.py", line 54, in request
return self.store_put(sitename, path, data)
File "/openlibrary/openlibrary/plugins/openlibrary/connection.py", line 101, in store_put
return self.conn.request(sitename, path, 'PUT', data)
File "/openlibrary/openlibrary/plugins/openlibrary/connection.py", line 54, in request
return self.store_put(sitename, path, data)
File "/openlibrary/openlibrary/plugins/openlibrary/connection.py", line 392, in store_put
result = ConnectionMiddleware.store_put(self, sitename, path, data)
File "/openlibrary/openlibrary/plugins/openlibrary/connection.py", line 101, in store_put
return self.conn.request(sitename, path, 'PUT', data)
File "/openlibrary/openlibrary/plugins/openlibrary/connection.py", line 570, in request
return self.writer.request(sitename, path, method, data=data)
File "/openlibrary/infogami/infobase/client.py", line 197, in request
self.handle_error(
File "/openlibrary/infogami/infobase/client.py", line 91, in handle_error
raise ClientException(status, message, json_data)
infogami.infobase.client.ClientException: Document update conflict
```
### Evidence / Screenshot (if possible)
### Relevant url?
<!-- `https://openlibrary.org/...` -->
### Steps to Reproduce
<!-- What steps caused you to find the bug? -->
1. Go to ...
2. Do ...
<!-- What actually happened after these steps? What did you expect to happen? -->
* Actual:
* Expected:
### Details
- **Logged in (Y/N)?**
- **Browser type/version?**
- **Operating system?**
- **Environment (prod/dev/local)?** prod
<!-- If not sure, put prod -->
### Proposal & Constraints
<!-- What is the proposed solution / implementation? Is there a precedent of this approach succeeding elsewhere? -->
### Related files
<!-- Files related to this issue; this is super useful for new contributors who might want to help! If you're not sure, leave this blank; a maintainer will add them. -->
### Stakeholders
<!-- @ tag stakeholders of this bug -->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `openlibrary/admin/stats.py`
Content:
```
1 """
2 Script to read out data from thingdb and put it in couch so that it
3 can be queried by the /admin pages on openlibrary
4 """
5
6
7 import os
8 import logging
9 import datetime
10
11 import web
12 import yaml
13
14 from openlibrary.admin import numbers
15
16 logger = logging.getLogger(__name__)
17
18
19 web.config.debug = False
20
21
22 class InvalidType(TypeError):
23 pass
24
25
26 def connect_to_pg(config_file):
27 """Connects to the postgres database specified in the dictionary
28 `config`. Needs a top level key `db_parameters` and under that
29 `database` (or `db`) at the least. If `user` and `host` are
30 provided, they're used as well."""
31 with open(config_file) as f:
32 config = yaml.safe_load(f)
33 conf = {}
34 conf["db"] = config["db_parameters"].get("database") or config["db_parameters"].get(
35 "db"
36 )
37 if not conf['db']:
38 raise KeyError("database/db")
39 host = config["db_parameters"].get("host")
40 user = config["db_parameters"].get("user") or config["db_parameters"].get(
41 "username"
42 )
43 if host:
44 conf["host"] = host
45 if user:
46 conf["user"] = user
47 logger.debug(" Postgres Database : %(db)s" % conf)
48 return web.database(dbn="postgres", **conf)
49
50
51 def get_config_info(infobase_config):
52 """Parses the config file(s) to get back all the necessary pieces of data.
53
54 Add extra parameters here and change the point of calling.
55 """
56 with open(infobase_config) as f:
57 config = yaml.safe_load(f)
58 logroot = config.get("writelog")
59 return logroot
60
61
62 def store_data(data, date):
63 uid = "counts-%s" % date
64 logger.debug(" Updating stats for %s - %s", uid, data)
65 doc = web.ctx.site.store.get(uid) or {}
66 doc.update(data)
67 doc['type'] = 'admin-stats'
68 web.ctx.site.store[uid] = doc
69
70
71 def run_gathering_functions(
72 infobase_db, coverstore_db, start, end, logroot, prefix, key_prefix=None
73 ):
74 """Runs all the data gathering functions with the given prefix
75 inside the numbers module"""
76 funcs = [x for x in dir(numbers) if x.startswith(prefix)]
77 d = {}
78 for i in funcs:
79 fn = getattr(numbers, i)
80 key = i.replace(prefix, "")
81 if key_prefix:
82 key = f"{key_prefix}_{key}"
83 try:
84 ret = fn(
85 thingdb=infobase_db,
86 coverdb=coverstore_db,
87 logroot=logroot,
88 start=start,
89 end=end,
90 )
91 logger.info(" %s - %s", i, ret)
92 d[key] = ret
93 except numbers.NoStats:
94 logger.warning(" %s - No statistics available", i)
95 except Exception as k:
96 logger.warning(" Failed with %s", k)
97 return d
98
99
100 def setup_ol_config(openlibrary_config_file):
101 """Setup OL configuration.
102
103 Required for storing counts in store.
104 """
105 import infogami
106 from infogami import config
107
108 config.plugin_path += ['openlibrary.plugins']
109 config.site = "openlibrary.org"
110
111 infogami.load_config(openlibrary_config_file)
112 infogami.config.infobase_parameters = dict(type="ol")
113
114 if config.get("infobase_config_file"):
115 dir = os.path.dirname(openlibrary_config_file)
116 path = os.path.join(dir, config.infobase_config_file)
117 config.infobase = yaml.safe_load(open(path).read())
118
119 infogami._setup()
120
121
122 def main(infobase_config, openlibrary_config, coverstore_config, ndays=1):
123 logging.basicConfig(
124 level=logging.DEBUG,
125 format="%(levelname)-8s : %(filename)-12s:%(lineno)4d : %(message)s",
126 )
127 logger.info("Parsing config file")
128 try:
129 infobase_db = connect_to_pg(infobase_config)
130 coverstore_db = connect_to_pg(coverstore_config)
131 logroot = get_config_info(infobase_config)
132 except KeyError as k:
133 logger.critical("Config file section '%s' missing", k.args[0])
134 return -1
135
136 setup_ol_config(openlibrary_config)
137
138 # Gather delta and total counts
139 # Total counts are simply computed and updated for the current day
140 # Delta counts are computed by subtracting the current total from yesterday's total
141 today = datetime.datetime.now()
142 yesterday = today - datetime.timedelta(days=1)
143 data = {}
144
145 logger.info("Gathering total data")
146 data.update(
147 run_gathering_functions(
148 infobase_db,
149 coverstore_db,
150 yesterday,
151 today,
152 logroot,
153 prefix="admin_total__",
154 key_prefix="total",
155 )
156 )
157 logger.info("Gathering data using difference between totals")
158 data.update(
159 run_gathering_functions(
160 infobase_db,
161 coverstore_db,
162 yesterday,
163 today,
164 logroot,
165 prefix="admin_delta__",
166 )
167 )
168 store_data(data, today.strftime("%Y-%m-%d"))
169 # Now gather data which can be queried based on date ranges
170 # The queries will be from the beginning of today till right now
171 # The data will be stored as the counts of the current day.
172 end = datetime.datetime.now() # - datetime.timedelta(days = 10)# Right now
173 start = datetime.datetime(
174 hour=0, minute=0, second=0, day=end.day, month=end.month, year=end.year
175 ) # Beginning of the day
176 logger.info("Gathering range data")
177 data = {}
178 for i in range(int(ndays)):
179 logger.info(" %s to %s", start, end)
180 data.update(
181 run_gathering_functions(
182 infobase_db, coverstore_db, start, end, logroot, prefix="admin_range__"
183 )
184 )
185 store_data(data, start.strftime("%Y-%m-%d"))
186 end = start
187 start = end - datetime.timedelta(days=1)
188 if numbers.sqlitefile:
189 logger.info("Removing sqlite file used for ipstats")
190 os.unlink(numbers.sqlitefile)
191 return 0
192
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/openlibrary/admin/stats.py b/openlibrary/admin/stats.py
--- a/openlibrary/admin/stats.py
+++ b/openlibrary/admin/stats.py
@@ -65,6 +65,9 @@
doc = web.ctx.site.store.get(uid) or {}
doc.update(data)
doc['type'] = 'admin-stats'
+ # as per https://github.com/internetarchive/infogami/blob/master/infogami/infobase/_dbstore/store.py#L79-L83
+ # avoid document collisions if multiple tasks updating stats in competition (race)
+ doc["_rev"] = None
web.ctx.site.store[uid] = doc
|
{"golden_diff": "diff --git a/openlibrary/admin/stats.py b/openlibrary/admin/stats.py\n--- a/openlibrary/admin/stats.py\n+++ b/openlibrary/admin/stats.py\n@@ -65,6 +65,9 @@\n doc = web.ctx.site.store.get(uid) or {}\n doc.update(data)\n doc['type'] = 'admin-stats'\n+ # as per https://github.com/internetarchive/infogami/blob/master/infogami/infobase/_dbstore/store.py#L79-L83\n+ # avoid document collisions if multiple tasks updating stats in competition (race)\n+ doc[\"_rev\"] = None\n web.ctx.site.store[uid] = doc\n", "issue": "Open Library Stats Cron hitting Document update conflict\n<!-- What problem are we solving? What does the experience look like today? What are the symptoms? -->\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/openlibrary/scripts/store_counts.py\", line 18, in <module>\r\n sys.exit(stats.main(*sys.argv[1:]))\r\n File \"/openlibrary/openlibrary/admin/stats.py\", line 168, in main\r\n store_data(data, today.strftime(\"%Y-%m-%d\"))\r\n File \"/openlibrary/openlibrary/admin/stats.py\", line 68, in store_data\r\n web.ctx.site.store[uid] = doc\r\n File \"/openlibrary/infogami/infobase/client.py\", line 630, in __setitem__\r\n return self._request(key, method='PUT', data=json.dumps(data))\r\n File \"/openlibrary/infogami/infobase/client.py\", line 569, in _request\r\n out = self.conn.request(self.name, \"/_store/\" + path, method, data)\r\n File \"/openlibrary/openlibrary/plugins/openlibrary/connection.py\", line 54, in request\r\n return self.store_put(sitename, path, data)\r\n File \"/openlibrary/openlibrary/plugins/openlibrary/connection.py\", line 101, in store_put\r\n return self.conn.request(sitename, path, 'PUT', data)\r\n File \"/openlibrary/openlibrary/plugins/openlibrary/connection.py\", line 54, in request\r\n return self.store_put(sitename, path, data)\r\n File \"/openlibrary/openlibrary/plugins/openlibrary/connection.py\", line 101, in store_put\r\n return self.conn.request(sitename, path, 'PUT', data)\r\n File \"/openlibrary/openlibrary/plugins/openlibrary/connection.py\", line 54, in request\r\n return self.store_put(sitename, path, data)\r\n File \"/openlibrary/openlibrary/plugins/openlibrary/connection.py\", line 392, in store_put\r\n result = ConnectionMiddleware.store_put(self, sitename, path, data)\r\n File \"/openlibrary/openlibrary/plugins/openlibrary/connection.py\", line 101, in store_put\r\n return self.conn.request(sitename, path, 'PUT', data)\r\n File \"/openlibrary/openlibrary/plugins/openlibrary/connection.py\", line 570, in request\r\n return self.writer.request(sitename, path, method, data=data)\r\n File \"/openlibrary/infogami/infobase/client.py\", line 197, in request\r\n self.handle_error(\r\n File \"/openlibrary/infogami/infobase/client.py\", line 91, in handle_error\r\n raise ClientException(status, message, json_data)\r\ninfogami.infobase.client.ClientException: Document update conflict\r\n```\r\n\r\n### Evidence / Screenshot (if possible)\r\n\r\n### Relevant url?\r\n<!-- `https://openlibrary.org/...` -->\r\n\r\n### Steps to Reproduce\r\n<!-- What steps caused you to find the bug? -->\r\n1. Go to ...\r\n2. Do ...\r\n\r\n<!-- What actually happened after these steps? What did you expect to happen? -->\r\n* Actual:\r\n* Expected:\r\n\r\n### Details\r\n\r\n- **Logged in (Y/N)?**\r\n- **Browser type/version?**\r\n- **Operating system?**\r\n- **Environment (prod/dev/local)?** prod\r\n<!-- If not sure, put prod -->\r\n\r\n### Proposal & Constraints\r\n<!-- What is the proposed solution / implementation? Is there a precedent of this approach succeeding elsewhere? -->\r\n\r\n### Related files\r\n<!-- Files related to this issue; this is super useful for new contributors who might want to help! If you're not sure, leave this blank; a maintainer will add them. -->\r\n\r\n### Stakeholders\r\n<!-- @ tag stakeholders of this bug -->\r\n\n", "before_files": [{"content": "\"\"\"\nScript to read out data from thingdb and put it in couch so that it\ncan be queried by the /admin pages on openlibrary\n\"\"\"\n\n\nimport os\nimport logging\nimport datetime\n\nimport web\nimport yaml\n\nfrom openlibrary.admin import numbers\n\nlogger = logging.getLogger(__name__)\n\n\nweb.config.debug = False\n\n\nclass InvalidType(TypeError):\n pass\n\n\ndef connect_to_pg(config_file):\n \"\"\"Connects to the postgres database specified in the dictionary\n `config`. Needs a top level key `db_parameters` and under that\n `database` (or `db`) at the least. If `user` and `host` are\n provided, they're used as well.\"\"\"\n with open(config_file) as f:\n config = yaml.safe_load(f)\n conf = {}\n conf[\"db\"] = config[\"db_parameters\"].get(\"database\") or config[\"db_parameters\"].get(\n \"db\"\n )\n if not conf['db']:\n raise KeyError(\"database/db\")\n host = config[\"db_parameters\"].get(\"host\")\n user = config[\"db_parameters\"].get(\"user\") or config[\"db_parameters\"].get(\n \"username\"\n )\n if host:\n conf[\"host\"] = host\n if user:\n conf[\"user\"] = user\n logger.debug(\" Postgres Database : %(db)s\" % conf)\n return web.database(dbn=\"postgres\", **conf)\n\n\ndef get_config_info(infobase_config):\n \"\"\"Parses the config file(s) to get back all the necessary pieces of data.\n\n Add extra parameters here and change the point of calling.\n \"\"\"\n with open(infobase_config) as f:\n config = yaml.safe_load(f)\n logroot = config.get(\"writelog\")\n return logroot\n\n\ndef store_data(data, date):\n uid = \"counts-%s\" % date\n logger.debug(\" Updating stats for %s - %s\", uid, data)\n doc = web.ctx.site.store.get(uid) or {}\n doc.update(data)\n doc['type'] = 'admin-stats'\n web.ctx.site.store[uid] = doc\n\n\ndef run_gathering_functions(\n infobase_db, coverstore_db, start, end, logroot, prefix, key_prefix=None\n):\n \"\"\"Runs all the data gathering functions with the given prefix\n inside the numbers module\"\"\"\n funcs = [x for x in dir(numbers) if x.startswith(prefix)]\n d = {}\n for i in funcs:\n fn = getattr(numbers, i)\n key = i.replace(prefix, \"\")\n if key_prefix:\n key = f\"{key_prefix}_{key}\"\n try:\n ret = fn(\n thingdb=infobase_db,\n coverdb=coverstore_db,\n logroot=logroot,\n start=start,\n end=end,\n )\n logger.info(\" %s - %s\", i, ret)\n d[key] = ret\n except numbers.NoStats:\n logger.warning(\" %s - No statistics available\", i)\n except Exception as k:\n logger.warning(\" Failed with %s\", k)\n return d\n\n\ndef setup_ol_config(openlibrary_config_file):\n \"\"\"Setup OL configuration.\n\n Required for storing counts in store.\n \"\"\"\n import infogami\n from infogami import config\n\n config.plugin_path += ['openlibrary.plugins']\n config.site = \"openlibrary.org\"\n\n infogami.load_config(openlibrary_config_file)\n infogami.config.infobase_parameters = dict(type=\"ol\")\n\n if config.get(\"infobase_config_file\"):\n dir = os.path.dirname(openlibrary_config_file)\n path = os.path.join(dir, config.infobase_config_file)\n config.infobase = yaml.safe_load(open(path).read())\n\n infogami._setup()\n\n\ndef main(infobase_config, openlibrary_config, coverstore_config, ndays=1):\n logging.basicConfig(\n level=logging.DEBUG,\n format=\"%(levelname)-8s : %(filename)-12s:%(lineno)4d : %(message)s\",\n )\n logger.info(\"Parsing config file\")\n try:\n infobase_db = connect_to_pg(infobase_config)\n coverstore_db = connect_to_pg(coverstore_config)\n logroot = get_config_info(infobase_config)\n except KeyError as k:\n logger.critical(\"Config file section '%s' missing\", k.args[0])\n return -1\n\n setup_ol_config(openlibrary_config)\n\n # Gather delta and total counts\n # Total counts are simply computed and updated for the current day\n # Delta counts are computed by subtracting the current total from yesterday's total\n today = datetime.datetime.now()\n yesterday = today - datetime.timedelta(days=1)\n data = {}\n\n logger.info(\"Gathering total data\")\n data.update(\n run_gathering_functions(\n infobase_db,\n coverstore_db,\n yesterday,\n today,\n logroot,\n prefix=\"admin_total__\",\n key_prefix=\"total\",\n )\n )\n logger.info(\"Gathering data using difference between totals\")\n data.update(\n run_gathering_functions(\n infobase_db,\n coverstore_db,\n yesterday,\n today,\n logroot,\n prefix=\"admin_delta__\",\n )\n )\n store_data(data, today.strftime(\"%Y-%m-%d\"))\n # Now gather data which can be queried based on date ranges\n # The queries will be from the beginning of today till right now\n # The data will be stored as the counts of the current day.\n end = datetime.datetime.now() # - datetime.timedelta(days = 10)# Right now\n start = datetime.datetime(\n hour=0, minute=0, second=0, day=end.day, month=end.month, year=end.year\n ) # Beginning of the day\n logger.info(\"Gathering range data\")\n data = {}\n for i in range(int(ndays)):\n logger.info(\" %s to %s\", start, end)\n data.update(\n run_gathering_functions(\n infobase_db, coverstore_db, start, end, logroot, prefix=\"admin_range__\"\n )\n )\n store_data(data, start.strftime(\"%Y-%m-%d\"))\n end = start\n start = end - datetime.timedelta(days=1)\n if numbers.sqlitefile:\n logger.info(\"Removing sqlite file used for ipstats\")\n os.unlink(numbers.sqlitefile)\n return 0\n", "path": "openlibrary/admin/stats.py"}], "after_files": [{"content": "\"\"\"\nScript to read out data from thingdb and put it in couch so that it\ncan be queried by the /admin pages on openlibrary\n\"\"\"\n\n\nimport os\nimport logging\nimport datetime\n\nimport web\nimport yaml\n\nfrom openlibrary.admin import numbers\n\nlogger = logging.getLogger(__name__)\n\n\nweb.config.debug = False\n\n\nclass InvalidType(TypeError):\n pass\n\n\ndef connect_to_pg(config_file):\n \"\"\"Connects to the postgres database specified in the dictionary\n `config`. Needs a top level key `db_parameters` and under that\n `database` (or `db`) at the least. If `user` and `host` are\n provided, they're used as well.\"\"\"\n with open(config_file) as f:\n config = yaml.safe_load(f)\n conf = {}\n conf[\"db\"] = config[\"db_parameters\"].get(\"database\") or config[\"db_parameters\"].get(\n \"db\"\n )\n if not conf['db']:\n raise KeyError(\"database/db\")\n host = config[\"db_parameters\"].get(\"host\")\n user = config[\"db_parameters\"].get(\"user\") or config[\"db_parameters\"].get(\n \"username\"\n )\n if host:\n conf[\"host\"] = host\n if user:\n conf[\"user\"] = user\n logger.debug(\" Postgres Database : %(db)s\" % conf)\n return web.database(dbn=\"postgres\", **conf)\n\n\ndef get_config_info(infobase_config):\n \"\"\"Parses the config file(s) to get back all the necessary pieces of data.\n\n Add extra parameters here and change the point of calling.\n \"\"\"\n with open(infobase_config) as f:\n config = yaml.safe_load(f)\n logroot = config.get(\"writelog\")\n return logroot\n\n\ndef store_data(data, date):\n uid = \"counts-%s\" % date\n logger.debug(\" Updating stats for %s - %s\", uid, data)\n doc = web.ctx.site.store.get(uid) or {}\n doc.update(data)\n doc['type'] = 'admin-stats'\n # as per https://github.com/internetarchive/infogami/blob/master/infogami/infobase/_dbstore/store.py#L79-L83\n # avoid document collisions if multiple tasks updating stats in competition (race)\n doc[\"_rev\"] = None\n web.ctx.site.store[uid] = doc\n\n\ndef run_gathering_functions(\n infobase_db, coverstore_db, start, end, logroot, prefix, key_prefix=None\n):\n \"\"\"Runs all the data gathering functions with the given prefix\n inside the numbers module\"\"\"\n funcs = [x for x in dir(numbers) if x.startswith(prefix)]\n d = {}\n for i in funcs:\n fn = getattr(numbers, i)\n key = i.replace(prefix, \"\")\n if key_prefix:\n key = f\"{key_prefix}_{key}\"\n try:\n ret = fn(\n thingdb=infobase_db,\n coverdb=coverstore_db,\n logroot=logroot,\n start=start,\n end=end,\n )\n logger.info(\" %s - %s\", i, ret)\n d[key] = ret\n except numbers.NoStats:\n logger.warning(\" %s - No statistics available\", i)\n except Exception as k:\n logger.warning(\" Failed with %s\", k)\n return d\n\n\ndef setup_ol_config(openlibrary_config_file):\n \"\"\"Setup OL configuration.\n\n Required for storing counts in store.\n \"\"\"\n import infogami\n from infogami import config\n\n config.plugin_path += ['openlibrary.plugins']\n config.site = \"openlibrary.org\"\n\n infogami.load_config(openlibrary_config_file)\n infogami.config.infobase_parameters = dict(type=\"ol\")\n\n if config.get(\"infobase_config_file\"):\n dir = os.path.dirname(openlibrary_config_file)\n path = os.path.join(dir, config.infobase_config_file)\n config.infobase = yaml.safe_load(open(path).read())\n\n infogami._setup()\n\n\ndef main(infobase_config, openlibrary_config, coverstore_config, ndays=1):\n logging.basicConfig(\n level=logging.DEBUG,\n format=\"%(levelname)-8s : %(filename)-12s:%(lineno)4d : %(message)s\",\n )\n logger.info(\"Parsing config file\")\n try:\n infobase_db = connect_to_pg(infobase_config)\n coverstore_db = connect_to_pg(coverstore_config)\n logroot = get_config_info(infobase_config)\n except KeyError as k:\n logger.critical(\"Config file section '%s' missing\", k.args[0])\n return -1\n\n setup_ol_config(openlibrary_config)\n\n # Gather delta and total counts\n # Total counts are simply computed and updated for the current day\n # Delta counts are computed by subtracting the current total from yesterday's total\n today = datetime.datetime.now()\n yesterday = today - datetime.timedelta(days=1)\n data = {}\n\n logger.info(\"Gathering total data\")\n data.update(\n run_gathering_functions(\n infobase_db,\n coverstore_db,\n yesterday,\n today,\n logroot,\n prefix=\"admin_total__\",\n key_prefix=\"total\",\n )\n )\n logger.info(\"Gathering data using difference between totals\")\n data.update(\n run_gathering_functions(\n infobase_db,\n coverstore_db,\n yesterday,\n today,\n logroot,\n prefix=\"admin_delta__\",\n )\n )\n store_data(data, today.strftime(\"%Y-%m-%d\"))\n # Now gather data which can be queried based on date ranges\n # The queries will be from the beginning of today till right now\n # The data will be stored as the counts of the current day.\n end = datetime.datetime.now() # - datetime.timedelta(days = 10)# Right now\n start = datetime.datetime(\n hour=0, minute=0, second=0, day=end.day, month=end.month, year=end.year\n ) # Beginning of the day\n logger.info(\"Gathering range data\")\n data = {}\n for i in range(int(ndays)):\n logger.info(\" %s to %s\", start, end)\n data.update(\n run_gathering_functions(\n infobase_db, coverstore_db, start, end, logroot, prefix=\"admin_range__\"\n )\n )\n store_data(data, start.strftime(\"%Y-%m-%d\"))\n end = start\n start = end - datetime.timedelta(days=1)\n if numbers.sqlitefile:\n logger.info(\"Removing sqlite file used for ipstats\")\n os.unlink(numbers.sqlitefile)\n return 0\n", "path": "openlibrary/admin/stats.py"}]}
| 2,933 | 146 |
gh_patches_debug_23783
|
rasdani/github-patches
|
git_diff
|
conda__conda-6921
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
conda 4.4 can fail to update packages
For example, start with a fresh install of Anaconda3, and then `conda update anaconda-client` doesn't update, even though a new anaconda-client package exists.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conda/core/index.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 from itertools import chain
5 from logging import getLogger
6
7 from .linked_data import linked_data
8 from .package_cache import PackageCache
9 from .repodata import SubdirData, make_feature_record
10 from .._vendor.boltons.setutils import IndexedSet
11 from ..base.context import context
12 from ..common.compat import iteritems, itervalues
13 from ..common.io import ThreadLimitedThreadPoolExecutor, as_completed, time_recorder
14 from ..exceptions import OperationNotAllowed
15 from ..models.channel import Channel, all_channel_urls
16 from ..models.dist import Dist
17 from ..models.index_record import EMPTY_LINK
18 from ..models.match_spec import MatchSpec
19 from ..models.package_cache_record import PackageCacheRecord
20 from ..models.prefix_record import PrefixRecord
21 from ..resolve import dashlist
22
23 try:
24 from cytoolz.itertoolz import concat, concatv, groupby, take
25 except ImportError: # pragma: no cover
26 from .._vendor.toolz.itertoolz import concat, concatv, groupby, take # NOQA
27
28 log = getLogger(__name__)
29
30
31 def check_whitelist(channel_urls):
32 if context.whitelist_channels:
33 whitelist_channel_urls = tuple(concat(
34 Channel(c).base_urls for c in context.whitelist_channels
35 ))
36 for url in channel_urls:
37 these_urls = Channel(url).base_urls
38 if not all(this_url in whitelist_channel_urls for this_url in these_urls):
39 bad_channel = Channel(url)
40 raise OperationNotAllowed("Channel not included in whitelist:\n"
41 " location: %s\n"
42 " canonical name: %s\n"
43 % (bad_channel.location, bad_channel.canonical_name))
44
45
46 LAST_CHANNEL_URLS = []
47
48 @time_recorder("get_index")
49 def get_index(channel_urls=(), prepend=True, platform=None,
50 use_local=False, use_cache=False, unknown=None, prefix=None):
51 """
52 Return the index of packages available on the channels
53
54 If prepend=False, only the channels passed in as arguments are used.
55 If platform=None, then the current platform is used.
56 If prefix is supplied, then the packages installed in that prefix are added.
57 """
58 if context.offline and unknown is None:
59 unknown = True
60
61 channel_urls = calculate_channel_urls(channel_urls, prepend, platform, use_local)
62 del LAST_CHANNEL_URLS[:]
63 LAST_CHANNEL_URLS.extend(channel_urls)
64
65 check_whitelist(channel_urls)
66
67 index = fetch_index(channel_urls, use_cache=use_cache)
68
69 if prefix:
70 _supplement_index_with_prefix(index, prefix)
71 if unknown:
72 _supplement_index_with_cache(index)
73 if context.track_features:
74 _supplement_index_with_features(index)
75 return index
76
77
78 def fetch_index(channel_urls, use_cache=False, index=None):
79 log.debug('channel_urls=' + repr(channel_urls))
80
81 use_cache = use_cache or context.use_index_cache
82
83 # channel_urls reversed to build up index in correct order
84 from .repodata import collect_all_repodata_as_index
85 index = collect_all_repodata_as_index(use_cache, channel_urls)
86
87 return index
88
89
90 def _supplement_index_with_prefix(index, prefix):
91 # supplement index with information from prefix/conda-meta
92 assert prefix
93 for dist, prefix_record in iteritems(linked_data(prefix)):
94 if dist in index:
95 # The downloaded repodata takes priority, so we do not overwrite.
96 # We do, however, copy the link information so that the solver (i.e. resolve)
97 # knows this package is installed.
98 current_record = index[dist]
99 link = prefix_record.get('link') or EMPTY_LINK
100 index[dist] = PrefixRecord.from_objects(current_record, prefix_record, link=link)
101 else:
102 # If the package is not in the repodata, use the local data.
103 # If the channel is known but the package is not in the index, it
104 # is because 1) the channel is unavailable offline, or 2) it no
105 # longer contains this package. Either way, we should prefer any
106 # other version of the package to this one. On the other hand, if
107 # it is in a channel we don't know about, assign it a value just
108 # above the priority of all known channels.
109 index[dist] = prefix_record
110
111
112 def _supplement_index_with_cache(index):
113 # supplement index with packages from the cache
114 for pcrec in PackageCache.get_all_extracted_entries():
115 dist = Dist(pcrec)
116 if dist in index:
117 # The downloaded repodata takes priority
118 current_record = index[dist]
119 index[dist] = PackageCacheRecord.from_objects(current_record, pcrec)
120 else:
121 index[dist] = pcrec
122
123
124 def _supplement_index_with_features(index, features=()):
125 for feature in chain(context.track_features, features):
126 rec = make_feature_record(feature)
127 index[Dist(rec)] = rec
128
129
130 def calculate_channel_urls(channel_urls=(), prepend=True, platform=None, use_local=False):
131 if use_local:
132 channel_urls = ['local'] + list(channel_urls)
133 if prepend:
134 channel_urls += context.channels
135
136 subdirs = (platform, 'noarch') if platform is not None else context.subdirs
137 return all_channel_urls(channel_urls, subdirs=subdirs)
138
139
140 def dist_str_in_index(index, dist_str):
141 return Dist(dist_str) in index
142
143
144 def get_reduced_index(prefix, channels, subdirs, specs):
145
146 # # this block of code is a "combine" step intended to filter out redundant specs
147 # # causes a problem with py.test tests/core/test_solve.py -k broken_install
148 # specs_map = defaultdict(list)
149 # for spec in specs:
150 # specs_map[spec.name].append(spec)
151 # consolidated_specs = set()
152 # for spec_name, specs_group in iteritems(specs_map):
153 # if len(specs_group) == 1:
154 # consolidated_specs.add(specs_group[0])
155 # elif spec_name == '*':
156 # consolidated_specs.update(specs_group)
157 # else:
158 # keep_specs = []
159 # for spec in specs_group:
160 # if len(spec._match_components) > 1 or spec.target or spec.optional:
161 # keep_specs.append(spec)
162 # consolidated_specs.update(keep_specs)
163
164 with ThreadLimitedThreadPoolExecutor() as executor:
165
166 channel_urls = all_channel_urls(channels, subdirs=subdirs)
167 check_whitelist(channel_urls)
168
169 if context.offline:
170 grouped_urls = groupby(lambda url: url.startswith('file://'), channel_urls)
171 ignored_urls = grouped_urls.get(False, ())
172 if ignored_urls:
173 log.info("Ignoring the following channel urls because mode is offline.%s",
174 dashlist(ignored_urls))
175 channel_urls = IndexedSet(grouped_urls.get(True, ()))
176 subdir_datas = tuple(SubdirData(Channel(url)) for url in channel_urls)
177
178 records = IndexedSet()
179 collected_names = set()
180 collected_track_features = set()
181 pending_names = set()
182 pending_track_features = set()
183
184 def query_all(spec):
185 futures = tuple(executor.submit(sd.query, spec) for sd in subdir_datas)
186 return tuple(concat(future.result() for future in as_completed(futures)))
187
188 def push_spec(spec):
189 name = spec.get_raw_value('name')
190 if name and name not in collected_names:
191 pending_names.add(name)
192 track_features = spec.get_raw_value('track_features')
193 if track_features:
194 for ftr_name in track_features:
195 if ftr_name not in collected_track_features:
196 pending_track_features.add(ftr_name)
197
198 def push_record(record):
199 for _spec in record.combined_depends:
200 push_spec(_spec)
201 if record.track_features:
202 for ftr_name in record.track_features:
203 push_spec(MatchSpec(track_features=ftr_name))
204
205 for spec in specs:
206 push_spec(spec)
207
208 while pending_names or pending_track_features:
209 while pending_names:
210 name = pending_names.pop()
211 collected_names.add(name)
212 spec = MatchSpec(name)
213 new_records = query_all(spec)
214 for record in new_records:
215 push_record(record)
216 records.update(new_records)
217
218 while pending_track_features:
219 feature_name = pending_track_features.pop()
220 collected_track_features.add(feature_name)
221 spec = MatchSpec(track_features=feature_name)
222 new_records = query_all(spec)
223 for record in new_records:
224 push_record(record)
225 records.update(new_records)
226
227 reduced_index = {Dist(rec): rec for rec in records}
228
229 if prefix is not None:
230 _supplement_index_with_prefix(reduced_index, prefix)
231
232 if context.offline or ('unknown' in context._argparse_args
233 and context._argparse_args.unknown):
234 # This is really messed up right now. Dates all the way back to
235 # https://github.com/conda/conda/commit/f761f65a82b739562a0d997a2570e2b8a0bdc783
236 # TODO: revisit this later
237 _supplement_index_with_cache(reduced_index)
238
239 # add feature records for the solver
240 known_features = set()
241 for rec in itervalues(reduced_index):
242 known_features.update(concatv(rec.track_features, rec.features))
243 known_features.update(context.track_features)
244 for ftr_str in known_features:
245 rec = make_feature_record(ftr_str)
246 reduced_index[Dist(rec)] = rec
247
248 return reduced_index
249
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conda/core/index.py b/conda/core/index.py
--- a/conda/core/index.py
+++ b/conda/core/index.py
@@ -4,7 +4,7 @@
from itertools import chain
from logging import getLogger
-from .linked_data import linked_data
+from .linked_data import PrefixData, linked_data
from .package_cache import PackageCache
from .repodata import SubdirData, make_feature_record
from .._vendor.boltons.setutils import IndexedSet
@@ -196,12 +196,16 @@
pending_track_features.add(ftr_name)
def push_record(record):
+ push_spec(MatchSpec(record.name))
for _spec in record.combined_depends:
push_spec(_spec)
if record.track_features:
for ftr_name in record.track_features:
push_spec(MatchSpec(track_features=ftr_name))
+ if prefix:
+ for prefix_rec in PrefixData(prefix).iter_records():
+ push_record(prefix_rec)
for spec in specs:
push_spec(spec)
|
{"golden_diff": "diff --git a/conda/core/index.py b/conda/core/index.py\n--- a/conda/core/index.py\n+++ b/conda/core/index.py\n@@ -4,7 +4,7 @@\n from itertools import chain\n from logging import getLogger\n \n-from .linked_data import linked_data\n+from .linked_data import PrefixData, linked_data\n from .package_cache import PackageCache\n from .repodata import SubdirData, make_feature_record\n from .._vendor.boltons.setutils import IndexedSet\n@@ -196,12 +196,16 @@\n pending_track_features.add(ftr_name)\n \n def push_record(record):\n+ push_spec(MatchSpec(record.name))\n for _spec in record.combined_depends:\n push_spec(_spec)\n if record.track_features:\n for ftr_name in record.track_features:\n push_spec(MatchSpec(track_features=ftr_name))\n \n+ if prefix:\n+ for prefix_rec in PrefixData(prefix).iter_records():\n+ push_record(prefix_rec)\n for spec in specs:\n push_spec(spec)\n", "issue": "conda 4.4 can fail to update packages\nFor example, start with a fresh install of Anaconda3, and then `conda update anaconda-client` doesn't update, even though a new anaconda-client package exists.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom itertools import chain\nfrom logging import getLogger\n\nfrom .linked_data import linked_data\nfrom .package_cache import PackageCache\nfrom .repodata import SubdirData, make_feature_record\nfrom .._vendor.boltons.setutils import IndexedSet\nfrom ..base.context import context\nfrom ..common.compat import iteritems, itervalues\nfrom ..common.io import ThreadLimitedThreadPoolExecutor, as_completed, time_recorder\nfrom ..exceptions import OperationNotAllowed\nfrom ..models.channel import Channel, all_channel_urls\nfrom ..models.dist import Dist\nfrom ..models.index_record import EMPTY_LINK\nfrom ..models.match_spec import MatchSpec\nfrom ..models.package_cache_record import PackageCacheRecord\nfrom ..models.prefix_record import PrefixRecord\nfrom ..resolve import dashlist\n\ntry:\n from cytoolz.itertoolz import concat, concatv, groupby, take\nexcept ImportError: # pragma: no cover\n from .._vendor.toolz.itertoolz import concat, concatv, groupby, take # NOQA\n\nlog = getLogger(__name__)\n\n\ndef check_whitelist(channel_urls):\n if context.whitelist_channels:\n whitelist_channel_urls = tuple(concat(\n Channel(c).base_urls for c in context.whitelist_channels\n ))\n for url in channel_urls:\n these_urls = Channel(url).base_urls\n if not all(this_url in whitelist_channel_urls for this_url in these_urls):\n bad_channel = Channel(url)\n raise OperationNotAllowed(\"Channel not included in whitelist:\\n\"\n \" location: %s\\n\"\n \" canonical name: %s\\n\"\n % (bad_channel.location, bad_channel.canonical_name))\n\n\nLAST_CHANNEL_URLS = []\n\n@time_recorder(\"get_index\")\ndef get_index(channel_urls=(), prepend=True, platform=None,\n use_local=False, use_cache=False, unknown=None, prefix=None):\n \"\"\"\n Return the index of packages available on the channels\n\n If prepend=False, only the channels passed in as arguments are used.\n If platform=None, then the current platform is used.\n If prefix is supplied, then the packages installed in that prefix are added.\n \"\"\"\n if context.offline and unknown is None:\n unknown = True\n\n channel_urls = calculate_channel_urls(channel_urls, prepend, platform, use_local)\n del LAST_CHANNEL_URLS[:]\n LAST_CHANNEL_URLS.extend(channel_urls)\n\n check_whitelist(channel_urls)\n\n index = fetch_index(channel_urls, use_cache=use_cache)\n\n if prefix:\n _supplement_index_with_prefix(index, prefix)\n if unknown:\n _supplement_index_with_cache(index)\n if context.track_features:\n _supplement_index_with_features(index)\n return index\n\n\ndef fetch_index(channel_urls, use_cache=False, index=None):\n log.debug('channel_urls=' + repr(channel_urls))\n\n use_cache = use_cache or context.use_index_cache\n\n # channel_urls reversed to build up index in correct order\n from .repodata import collect_all_repodata_as_index\n index = collect_all_repodata_as_index(use_cache, channel_urls)\n\n return index\n\n\ndef _supplement_index_with_prefix(index, prefix):\n # supplement index with information from prefix/conda-meta\n assert prefix\n for dist, prefix_record in iteritems(linked_data(prefix)):\n if dist in index:\n # The downloaded repodata takes priority, so we do not overwrite.\n # We do, however, copy the link information so that the solver (i.e. resolve)\n # knows this package is installed.\n current_record = index[dist]\n link = prefix_record.get('link') or EMPTY_LINK\n index[dist] = PrefixRecord.from_objects(current_record, prefix_record, link=link)\n else:\n # If the package is not in the repodata, use the local data.\n # If the channel is known but the package is not in the index, it\n # is because 1) the channel is unavailable offline, or 2) it no\n # longer contains this package. Either way, we should prefer any\n # other version of the package to this one. On the other hand, if\n # it is in a channel we don't know about, assign it a value just\n # above the priority of all known channels.\n index[dist] = prefix_record\n\n\ndef _supplement_index_with_cache(index):\n # supplement index with packages from the cache\n for pcrec in PackageCache.get_all_extracted_entries():\n dist = Dist(pcrec)\n if dist in index:\n # The downloaded repodata takes priority\n current_record = index[dist]\n index[dist] = PackageCacheRecord.from_objects(current_record, pcrec)\n else:\n index[dist] = pcrec\n\n\ndef _supplement_index_with_features(index, features=()):\n for feature in chain(context.track_features, features):\n rec = make_feature_record(feature)\n index[Dist(rec)] = rec\n\n\ndef calculate_channel_urls(channel_urls=(), prepend=True, platform=None, use_local=False):\n if use_local:\n channel_urls = ['local'] + list(channel_urls)\n if prepend:\n channel_urls += context.channels\n\n subdirs = (platform, 'noarch') if platform is not None else context.subdirs\n return all_channel_urls(channel_urls, subdirs=subdirs)\n\n\ndef dist_str_in_index(index, dist_str):\n return Dist(dist_str) in index\n\n\ndef get_reduced_index(prefix, channels, subdirs, specs):\n\n # # this block of code is a \"combine\" step intended to filter out redundant specs\n # # causes a problem with py.test tests/core/test_solve.py -k broken_install\n # specs_map = defaultdict(list)\n # for spec in specs:\n # specs_map[spec.name].append(spec)\n # consolidated_specs = set()\n # for spec_name, specs_group in iteritems(specs_map):\n # if len(specs_group) == 1:\n # consolidated_specs.add(specs_group[0])\n # elif spec_name == '*':\n # consolidated_specs.update(specs_group)\n # else:\n # keep_specs = []\n # for spec in specs_group:\n # if len(spec._match_components) > 1 or spec.target or spec.optional:\n # keep_specs.append(spec)\n # consolidated_specs.update(keep_specs)\n\n with ThreadLimitedThreadPoolExecutor() as executor:\n\n channel_urls = all_channel_urls(channels, subdirs=subdirs)\n check_whitelist(channel_urls)\n\n if context.offline:\n grouped_urls = groupby(lambda url: url.startswith('file://'), channel_urls)\n ignored_urls = grouped_urls.get(False, ())\n if ignored_urls:\n log.info(\"Ignoring the following channel urls because mode is offline.%s\",\n dashlist(ignored_urls))\n channel_urls = IndexedSet(grouped_urls.get(True, ()))\n subdir_datas = tuple(SubdirData(Channel(url)) for url in channel_urls)\n\n records = IndexedSet()\n collected_names = set()\n collected_track_features = set()\n pending_names = set()\n pending_track_features = set()\n\n def query_all(spec):\n futures = tuple(executor.submit(sd.query, spec) for sd in subdir_datas)\n return tuple(concat(future.result() for future in as_completed(futures)))\n\n def push_spec(spec):\n name = spec.get_raw_value('name')\n if name and name not in collected_names:\n pending_names.add(name)\n track_features = spec.get_raw_value('track_features')\n if track_features:\n for ftr_name in track_features:\n if ftr_name not in collected_track_features:\n pending_track_features.add(ftr_name)\n\n def push_record(record):\n for _spec in record.combined_depends:\n push_spec(_spec)\n if record.track_features:\n for ftr_name in record.track_features:\n push_spec(MatchSpec(track_features=ftr_name))\n\n for spec in specs:\n push_spec(spec)\n\n while pending_names or pending_track_features:\n while pending_names:\n name = pending_names.pop()\n collected_names.add(name)\n spec = MatchSpec(name)\n new_records = query_all(spec)\n for record in new_records:\n push_record(record)\n records.update(new_records)\n\n while pending_track_features:\n feature_name = pending_track_features.pop()\n collected_track_features.add(feature_name)\n spec = MatchSpec(track_features=feature_name)\n new_records = query_all(spec)\n for record in new_records:\n push_record(record)\n records.update(new_records)\n\n reduced_index = {Dist(rec): rec for rec in records}\n\n if prefix is not None:\n _supplement_index_with_prefix(reduced_index, prefix)\n\n if context.offline or ('unknown' in context._argparse_args\n and context._argparse_args.unknown):\n # This is really messed up right now. Dates all the way back to\n # https://github.com/conda/conda/commit/f761f65a82b739562a0d997a2570e2b8a0bdc783\n # TODO: revisit this later\n _supplement_index_with_cache(reduced_index)\n\n # add feature records for the solver\n known_features = set()\n for rec in itervalues(reduced_index):\n known_features.update(concatv(rec.track_features, rec.features))\n known_features.update(context.track_features)\n for ftr_str in known_features:\n rec = make_feature_record(ftr_str)\n reduced_index[Dist(rec)] = rec\n\n return reduced_index\n", "path": "conda/core/index.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom itertools import chain\nfrom logging import getLogger\n\nfrom .linked_data import PrefixData, linked_data\nfrom .package_cache import PackageCache\nfrom .repodata import SubdirData, make_feature_record\nfrom .._vendor.boltons.setutils import IndexedSet\nfrom ..base.context import context\nfrom ..common.compat import iteritems, itervalues\nfrom ..common.io import ThreadLimitedThreadPoolExecutor, as_completed, time_recorder\nfrom ..exceptions import OperationNotAllowed\nfrom ..models.channel import Channel, all_channel_urls\nfrom ..models.dist import Dist\nfrom ..models.index_record import EMPTY_LINK\nfrom ..models.match_spec import MatchSpec\nfrom ..models.package_cache_record import PackageCacheRecord\nfrom ..models.prefix_record import PrefixRecord\nfrom ..resolve import dashlist\n\ntry:\n from cytoolz.itertoolz import concat, concatv, groupby, take\nexcept ImportError: # pragma: no cover\n from .._vendor.toolz.itertoolz import concat, concatv, groupby, take # NOQA\n\nlog = getLogger(__name__)\n\n\ndef check_whitelist(channel_urls):\n if context.whitelist_channels:\n whitelist_channel_urls = tuple(concat(\n Channel(c).base_urls for c in context.whitelist_channels\n ))\n for url in channel_urls:\n these_urls = Channel(url).base_urls\n if not all(this_url in whitelist_channel_urls for this_url in these_urls):\n bad_channel = Channel(url)\n raise OperationNotAllowed(\"Channel not included in whitelist:\\n\"\n \" location: %s\\n\"\n \" canonical name: %s\\n\"\n % (bad_channel.location, bad_channel.canonical_name))\n\n\nLAST_CHANNEL_URLS = []\n\n@time_recorder(\"get_index\")\ndef get_index(channel_urls=(), prepend=True, platform=None,\n use_local=False, use_cache=False, unknown=None, prefix=None):\n \"\"\"\n Return the index of packages available on the channels\n\n If prepend=False, only the channels passed in as arguments are used.\n If platform=None, then the current platform is used.\n If prefix is supplied, then the packages installed in that prefix are added.\n \"\"\"\n if context.offline and unknown is None:\n unknown = True\n\n channel_urls = calculate_channel_urls(channel_urls, prepend, platform, use_local)\n del LAST_CHANNEL_URLS[:]\n LAST_CHANNEL_URLS.extend(channel_urls)\n\n check_whitelist(channel_urls)\n\n index = fetch_index(channel_urls, use_cache=use_cache)\n\n if prefix:\n _supplement_index_with_prefix(index, prefix)\n if unknown:\n _supplement_index_with_cache(index)\n if context.track_features:\n _supplement_index_with_features(index)\n return index\n\n\ndef fetch_index(channel_urls, use_cache=False, index=None):\n log.debug('channel_urls=' + repr(channel_urls))\n\n use_cache = use_cache or context.use_index_cache\n\n # channel_urls reversed to build up index in correct order\n from .repodata import collect_all_repodata_as_index\n index = collect_all_repodata_as_index(use_cache, channel_urls)\n\n return index\n\n\ndef _supplement_index_with_prefix(index, prefix):\n # supplement index with information from prefix/conda-meta\n assert prefix\n for dist, prefix_record in iteritems(linked_data(prefix)):\n if dist in index:\n # The downloaded repodata takes priority, so we do not overwrite.\n # We do, however, copy the link information so that the solver (i.e. resolve)\n # knows this package is installed.\n current_record = index[dist]\n link = prefix_record.get('link') or EMPTY_LINK\n index[dist] = PrefixRecord.from_objects(current_record, prefix_record, link=link)\n else:\n # If the package is not in the repodata, use the local data.\n # If the channel is known but the package is not in the index, it\n # is because 1) the channel is unavailable offline, or 2) it no\n # longer contains this package. Either way, we should prefer any\n # other version of the package to this one. On the other hand, if\n # it is in a channel we don't know about, assign it a value just\n # above the priority of all known channels.\n index[dist] = prefix_record\n\n\ndef _supplement_index_with_cache(index):\n # supplement index with packages from the cache\n for pcrec in PackageCache.get_all_extracted_entries():\n dist = Dist(pcrec)\n if dist in index:\n # The downloaded repodata takes priority\n current_record = index[dist]\n index[dist] = PackageCacheRecord.from_objects(current_record, pcrec)\n else:\n index[dist] = pcrec\n\n\ndef _supplement_index_with_features(index, features=()):\n for feature in chain(context.track_features, features):\n rec = make_feature_record(feature)\n index[Dist(rec)] = rec\n\n\ndef calculate_channel_urls(channel_urls=(), prepend=True, platform=None, use_local=False):\n if use_local:\n channel_urls = ['local'] + list(channel_urls)\n if prepend:\n channel_urls += context.channels\n\n subdirs = (platform, 'noarch') if platform is not None else context.subdirs\n return all_channel_urls(channel_urls, subdirs=subdirs)\n\n\ndef dist_str_in_index(index, dist_str):\n return Dist(dist_str) in index\n\n\ndef get_reduced_index(prefix, channels, subdirs, specs):\n\n # # this block of code is a \"combine\" step intended to filter out redundant specs\n # # causes a problem with py.test tests/core/test_solve.py -k broken_install\n # specs_map = defaultdict(list)\n # for spec in specs:\n # specs_map[spec.name].append(spec)\n # consolidated_specs = set()\n # for spec_name, specs_group in iteritems(specs_map):\n # if len(specs_group) == 1:\n # consolidated_specs.add(specs_group[0])\n # elif spec_name == '*':\n # consolidated_specs.update(specs_group)\n # else:\n # keep_specs = []\n # for spec in specs_group:\n # if len(spec._match_components) > 1 or spec.target or spec.optional:\n # keep_specs.append(spec)\n # consolidated_specs.update(keep_specs)\n\n with ThreadLimitedThreadPoolExecutor() as executor:\n\n channel_urls = all_channel_urls(channels, subdirs=subdirs)\n check_whitelist(channel_urls)\n\n if context.offline:\n grouped_urls = groupby(lambda url: url.startswith('file://'), channel_urls)\n ignored_urls = grouped_urls.get(False, ())\n if ignored_urls:\n log.info(\"Ignoring the following channel urls because mode is offline.%s\",\n dashlist(ignored_urls))\n channel_urls = IndexedSet(grouped_urls.get(True, ()))\n subdir_datas = tuple(SubdirData(Channel(url)) for url in channel_urls)\n\n records = IndexedSet()\n collected_names = set()\n collected_track_features = set()\n pending_names = set()\n pending_track_features = set()\n\n def query_all(spec):\n futures = tuple(executor.submit(sd.query, spec) for sd in subdir_datas)\n return tuple(concat(future.result() for future in as_completed(futures)))\n\n def push_spec(spec):\n name = spec.get_raw_value('name')\n if name and name not in collected_names:\n pending_names.add(name)\n track_features = spec.get_raw_value('track_features')\n if track_features:\n for ftr_name in track_features:\n if ftr_name not in collected_track_features:\n pending_track_features.add(ftr_name)\n\n def push_record(record):\n push_spec(MatchSpec(record.name))\n for _spec in record.combined_depends:\n push_spec(_spec)\n if record.track_features:\n for ftr_name in record.track_features:\n push_spec(MatchSpec(track_features=ftr_name))\n\n if prefix:\n for prefix_rec in PrefixData(prefix).iter_records():\n push_record(prefix_rec)\n for spec in specs:\n push_spec(spec)\n\n while pending_names or pending_track_features:\n while pending_names:\n name = pending_names.pop()\n collected_names.add(name)\n spec = MatchSpec(name)\n new_records = query_all(spec)\n for record in new_records:\n push_record(record)\n records.update(new_records)\n\n while pending_track_features:\n feature_name = pending_track_features.pop()\n collected_track_features.add(feature_name)\n spec = MatchSpec(track_features=feature_name)\n new_records = query_all(spec)\n for record in new_records:\n push_record(record)\n records.update(new_records)\n\n reduced_index = {Dist(rec): rec for rec in records}\n\n if prefix is not None:\n _supplement_index_with_prefix(reduced_index, prefix)\n\n if context.offline or ('unknown' in context._argparse_args\n and context._argparse_args.unknown):\n # This is really messed up right now. Dates all the way back to\n # https://github.com/conda/conda/commit/f761f65a82b739562a0d997a2570e2b8a0bdc783\n # TODO: revisit this later\n _supplement_index_with_cache(reduced_index)\n\n # add feature records for the solver\n known_features = set()\n for rec in itervalues(reduced_index):\n known_features.update(concatv(rec.track_features, rec.features))\n known_features.update(context.track_features)\n for ftr_str in known_features:\n rec = make_feature_record(ftr_str)\n reduced_index[Dist(rec)] = rec\n\n return reduced_index\n", "path": "conda/core/index.py"}]}
| 3,047 | 231 |
gh_patches_debug_37436
|
rasdani/github-patches
|
git_diff
|
meltano__meltano-6098
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Telemetry - Invoke services dont have plugin context or structured event
When running a service plugin like superset that blocks for a long time and is then exited using CTRL+C I'm not able to track the plugin context. I think whats happening is:
- `meltano invoke superset:ui` (blocking)
- CLI started event fired when started up. Plugin context isnt available yet
- build dashboards
- CTRL+C
- <MISSING CLI completed/aborted/etc. with plugin context>
- <MISSING structured legacy event>
I think the fact that I need to CTRL+C to close the blocking service plugin means the structured event isnt fire because its not a successful exit and with the new unstructured events we dont get a plugin context. I dont get enough info for these events to be useful, all I know its that `invoke` ran but nothing about what plugin/command (i.e. `ui`)/etc. This is likely undercounting usage of Airflow also because we never get to the successful firing of structured events either.
Would it be possible to include the plugin context on the first event?
cc @pandemicsyn @tayloramurphy @WillDaSilva
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/meltano/cli/invoke.py`
Content:
```
1 """CLI command `meltano invoke`."""
2
3 from __future__ import annotations
4
5 import logging
6 import sys
7
8 import click
9 from sqlalchemy.orm import sessionmaker
10
11 from meltano.core.db import project_engine
12 from meltano.core.error import AsyncSubprocessError
13 from meltano.core.legacy_tracking import LegacyTracker
14 from meltano.core.plugin import PluginType
15 from meltano.core.plugin.error import PluginNotFoundError
16 from meltano.core.plugin_invoker import (
17 PluginInvoker,
18 UnknownCommandError,
19 invoker_factory,
20 )
21 from meltano.core.project import Project
22 from meltano.core.project_plugins_service import ProjectPluginsService
23 from meltano.core.tracking import PluginsTrackingContext, Tracker
24 from meltano.core.tracking import cli as cli_tracking
25 from meltano.core.tracking import cli_context_builder
26 from meltano.core.utils import run_async
27
28 from . import cli
29 from .params import pass_project
30 from .utils import CliError, propagate_stop_signals
31
32 logger = logging.getLogger(__name__)
33
34
35 @cli.command(
36 context_settings={"ignore_unknown_options": True, "allow_interspersed_args": False},
37 short_help="Invoke a plugin.",
38 )
39 @click.option(
40 "--print-var",
41 help="Print to stdout the values for the provided environment variables, as passed to the plugininvoker context. Useful for debugging.",
42 multiple=True,
43 )
44 @click.option(
45 "--plugin-type", type=click.Choice(PluginType.cli_arguments()), default=None
46 )
47 @click.option(
48 "--dump",
49 type=click.Choice(["catalog", "config"]),
50 help="Dump content of specified file to disk.",
51 )
52 @click.option(
53 "--list-commands",
54 is_flag=True,
55 help="List the commands supported by the plugin.",
56 )
57 @click.argument("plugin_name", metavar="PLUGIN_NAME[:COMMAND_NAME]")
58 @click.argument("plugin_args", nargs=-1, type=click.UNPROCESSED)
59 @click.option(
60 "--containers",
61 is_flag=True,
62 help="Execute plugins using containers where possible.",
63 )
64 @pass_project(migrate=True)
65 def invoke(
66 project: Project,
67 plugin_type: str,
68 dump: str,
69 list_commands: bool,
70 plugin_name: str,
71 plugin_args: tuple[str, ...],
72 containers: bool = False,
73 print_var: str | None = None,
74 ):
75 """
76 Invoke a plugin's executable with specified arguments.
77
78 \b\nRead more at https://docs.meltano.com/reference/command-line-interface#invoke
79 """
80 tracker = Tracker(project)
81 cmd_ctx = cli_context_builder(
82 "invoke",
83 None,
84 plugin_type=plugin_type,
85 dump=dump,
86 list_commands=list_commands,
87 containers=containers,
88 print_var=print_var,
89 )
90 with tracker.with_contexts(cmd_ctx):
91 tracker.track_command_event(cli_tracking.STARTED)
92
93 try:
94 plugin_name, command_name = plugin_name.split(":")
95 except ValueError:
96 command_name = None
97
98 plugin_type = PluginType.from_cli_argument(plugin_type) if plugin_type else None
99
100 _, Session = project_engine(project) # noqa: N806
101 session = Session()
102 plugins_service = ProjectPluginsService(project)
103
104 try:
105 plugin = plugins_service.find_plugin(
106 plugin_name, plugin_type=plugin_type, invokable=True
107 )
108 except PluginNotFoundError as err:
109 with tracker.with_contexts(cmd_ctx):
110 tracker.track_command_event(cli_tracking.ABORTED)
111 raise err
112
113 if list_commands:
114 do_list_commands(plugin)
115 return
116
117 invoker = invoker_factory(project, plugin, plugins_service=plugins_service)
118 try:
119 exit_code = run_async(
120 _invoke(
121 invoker,
122 project,
123 plugin_name,
124 plugin_args,
125 session,
126 dump,
127 command_name,
128 containers,
129 print_var=print_var,
130 )
131 )
132 except Exception as invoke_err:
133 with tracker.with_contexts(cmd_ctx):
134 tracker.track_command_event(cli_tracking.FAILED)
135 raise invoke_err
136
137 with tracker.with_contexts(
138 cmd_ctx, PluginsTrackingContext([(plugin, command_name)])
139 ):
140 if exit_code == 0:
141 tracker.track_command_event(cli_tracking.COMPLETED)
142 else:
143 tracker.track_command_event(cli_tracking.FAILED)
144 sys.exit(exit_code)
145
146
147 async def _invoke(
148 invoker: PluginInvoker,
149 project: Project,
150 plugin_name: str,
151 plugin_args: str,
152 session: sessionmaker,
153 dump: str,
154 command_name: str,
155 containers: bool,
156 print_var: list | None = None,
157 ):
158 if command_name is not None:
159 command = invoker.find_command(command_name)
160
161 try:
162 async with invoker.prepared(session):
163 if print_var:
164 env = invoker.env()
165 for key in print_var:
166 val = env.get(key)
167 click.echo(f"{key}={val}")
168 if dump:
169 await dump_file(invoker, dump)
170 exit_code = 0
171 elif ( # noqa: WPS337
172 containers
173 and command_name is not None
174 and command.container_spec is not None
175 ):
176 return await invoker.invoke_docker(
177 command_name,
178 *plugin_args,
179 )
180 else:
181 handle = await invoker.invoke_async(*plugin_args, command=command_name)
182 with propagate_stop_signals(handle):
183 exit_code = await handle.wait()
184
185 except UnknownCommandError as err:
186 raise click.BadArgumentUsage(err) from err
187 except AsyncSubprocessError as err:
188 logger.error(await err.stderr)
189 raise
190 finally:
191 session.close()
192
193 tracker = LegacyTracker(project)
194 tracker.track_meltano_invoke(
195 plugin_name=plugin_name, plugin_args=" ".join(plugin_args)
196 )
197
198 return exit_code
199
200
201 def do_list_commands(plugin):
202 """List the commands supported by plugin."""
203 if not plugin.supported_commands:
204 click.secho(
205 f"Plugin '{plugin.name}' does not define any commands.", fg="yellow"
206 )
207 return
208
209 descriptions = {
210 f"{plugin.name}:{cmd}": props.description
211 for cmd, props in plugin.all_commands.items()
212 }
213 column_len = max(len(name) for name in descriptions.keys()) + 2
214 for name, desc in descriptions.items():
215 click.secho(name.ljust(column_len, " "), fg="blue", nl=False)
216 click.echo(desc)
217
218
219 async def dump_file(invoker: PluginInvoker, file_id: str):
220 """Dump file."""
221 try:
222 content = await invoker.dump(file_id)
223 except FileNotFoundError as err:
224 raise CliError(f"Could not find {file_id}") from err
225 except Exception as err:
226 raise CliError(f"Could not dump {file_id}: {err}") from err
227 print(content) # noqa: WPS421
228
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/meltano/cli/invoke.py b/src/meltano/cli/invoke.py
--- a/src/meltano/cli/invoke.py
+++ b/src/meltano/cli/invoke.py
@@ -78,17 +78,18 @@
\b\nRead more at https://docs.meltano.com/reference/command-line-interface#invoke
"""
tracker = Tracker(project)
- cmd_ctx = cli_context_builder(
- "invoke",
- None,
- plugin_type=plugin_type,
- dump=dump,
- list_commands=list_commands,
- containers=containers,
- print_var=print_var,
+ # the `started` event is delayed until we've had a chance to try to resolve the requested plugin
+ tracker.add_contexts(
+ cli_context_builder(
+ "invoke",
+ None,
+ plugin_type=plugin_type,
+ dump=dump,
+ list_commands=list_commands,
+ containers=containers,
+ print_var=print_var,
+ )
)
- with tracker.with_contexts(cmd_ctx):
- tracker.track_command_event(cli_tracking.STARTED)
try:
plugin_name, command_name = plugin_name.split(":")
@@ -105,13 +106,17 @@
plugin = plugins_service.find_plugin(
plugin_name, plugin_type=plugin_type, invokable=True
)
- except PluginNotFoundError as err:
- with tracker.with_contexts(cmd_ctx):
- tracker.track_command_event(cli_tracking.ABORTED)
- raise err
+ tracker.add_contexts(PluginsTrackingContext([(plugin, command_name)]))
+ tracker.track_command_event(cli_tracking.STARTED)
+ except PluginNotFoundError:
+ # if the plugin is not found, we fire started and aborted tracking events together to keep tracking consistent
+ tracker.track_command_event(cli_tracking.STARTED)
+ tracker.track_command_event(cli_tracking.ABORTED)
+ raise
if list_commands:
do_list_commands(plugin)
+ tracker.track_command_event(cli_tracking.COMPLETED)
return
invoker = invoker_factory(project, plugin, plugins_service=plugins_service)
@@ -130,17 +135,13 @@
)
)
except Exception as invoke_err:
- with tracker.with_contexts(cmd_ctx):
- tracker.track_command_event(cli_tracking.FAILED)
+ tracker.track_command_event(cli_tracking.FAILED)
raise invoke_err
- with tracker.with_contexts(
- cmd_ctx, PluginsTrackingContext([(plugin, command_name)])
- ):
- if exit_code == 0:
- tracker.track_command_event(cli_tracking.COMPLETED)
- else:
- tracker.track_command_event(cli_tracking.FAILED)
+ if exit_code == 0:
+ tracker.track_command_event(cli_tracking.COMPLETED)
+ else:
+ tracker.track_command_event(cli_tracking.FAILED)
sys.exit(exit_code)
|
{"golden_diff": "diff --git a/src/meltano/cli/invoke.py b/src/meltano/cli/invoke.py\n--- a/src/meltano/cli/invoke.py\n+++ b/src/meltano/cli/invoke.py\n@@ -78,17 +78,18 @@\n \\b\\nRead more at https://docs.meltano.com/reference/command-line-interface#invoke\n \"\"\"\n tracker = Tracker(project)\n- cmd_ctx = cli_context_builder(\n- \"invoke\",\n- None,\n- plugin_type=plugin_type,\n- dump=dump,\n- list_commands=list_commands,\n- containers=containers,\n- print_var=print_var,\n+ # the `started` event is delayed until we've had a chance to try to resolve the requested plugin\n+ tracker.add_contexts(\n+ cli_context_builder(\n+ \"invoke\",\n+ None,\n+ plugin_type=plugin_type,\n+ dump=dump,\n+ list_commands=list_commands,\n+ containers=containers,\n+ print_var=print_var,\n+ )\n )\n- with tracker.with_contexts(cmd_ctx):\n- tracker.track_command_event(cli_tracking.STARTED)\n \n try:\n plugin_name, command_name = plugin_name.split(\":\")\n@@ -105,13 +106,17 @@\n plugin = plugins_service.find_plugin(\n plugin_name, plugin_type=plugin_type, invokable=True\n )\n- except PluginNotFoundError as err:\n- with tracker.with_contexts(cmd_ctx):\n- tracker.track_command_event(cli_tracking.ABORTED)\n- raise err\n+ tracker.add_contexts(PluginsTrackingContext([(plugin, command_name)]))\n+ tracker.track_command_event(cli_tracking.STARTED)\n+ except PluginNotFoundError:\n+ # if the plugin is not found, we fire started and aborted tracking events together to keep tracking consistent\n+ tracker.track_command_event(cli_tracking.STARTED)\n+ tracker.track_command_event(cli_tracking.ABORTED)\n+ raise\n \n if list_commands:\n do_list_commands(plugin)\n+ tracker.track_command_event(cli_tracking.COMPLETED)\n return\n \n invoker = invoker_factory(project, plugin, plugins_service=plugins_service)\n@@ -130,17 +135,13 @@\n )\n )\n except Exception as invoke_err:\n- with tracker.with_contexts(cmd_ctx):\n- tracker.track_command_event(cli_tracking.FAILED)\n+ tracker.track_command_event(cli_tracking.FAILED)\n raise invoke_err\n \n- with tracker.with_contexts(\n- cmd_ctx, PluginsTrackingContext([(plugin, command_name)])\n- ):\n- if exit_code == 0:\n- tracker.track_command_event(cli_tracking.COMPLETED)\n- else:\n- tracker.track_command_event(cli_tracking.FAILED)\n+ if exit_code == 0:\n+ tracker.track_command_event(cli_tracking.COMPLETED)\n+ else:\n+ tracker.track_command_event(cli_tracking.FAILED)\n sys.exit(exit_code)\n", "issue": "Telemetry - Invoke services dont have plugin context or structured event\nWhen running a service plugin like superset that blocks for a long time and is then exited using CTRL+C I'm not able to track the plugin context. I think whats happening is:\r\n\r\n- `meltano invoke superset:ui` (blocking)\r\n- CLI started event fired when started up. Plugin context isnt available yet\r\n- build dashboards\r\n- CTRL+C\r\n- <MISSING CLI completed/aborted/etc. with plugin context>\r\n- <MISSING structured legacy event>\r\n\r\nI think the fact that I need to CTRL+C to close the blocking service plugin means the structured event isnt fire because its not a successful exit and with the new unstructured events we dont get a plugin context. I dont get enough info for these events to be useful, all I know its that `invoke` ran but nothing about what plugin/command (i.e. `ui`)/etc. This is likely undercounting usage of Airflow also because we never get to the successful firing of structured events either. \r\n\r\nWould it be possible to include the plugin context on the first event?\r\n\r\ncc @pandemicsyn @tayloramurphy @WillDaSilva \n", "before_files": [{"content": "\"\"\"CLI command `meltano invoke`.\"\"\"\n\nfrom __future__ import annotations\n\nimport logging\nimport sys\n\nimport click\nfrom sqlalchemy.orm import sessionmaker\n\nfrom meltano.core.db import project_engine\nfrom meltano.core.error import AsyncSubprocessError\nfrom meltano.core.legacy_tracking import LegacyTracker\nfrom meltano.core.plugin import PluginType\nfrom meltano.core.plugin.error import PluginNotFoundError\nfrom meltano.core.plugin_invoker import (\n PluginInvoker,\n UnknownCommandError,\n invoker_factory,\n)\nfrom meltano.core.project import Project\nfrom meltano.core.project_plugins_service import ProjectPluginsService\nfrom meltano.core.tracking import PluginsTrackingContext, Tracker\nfrom meltano.core.tracking import cli as cli_tracking\nfrom meltano.core.tracking import cli_context_builder\nfrom meltano.core.utils import run_async\n\nfrom . import cli\nfrom .params import pass_project\nfrom .utils import CliError, propagate_stop_signals\n\nlogger = logging.getLogger(__name__)\n\n\[email protected](\n context_settings={\"ignore_unknown_options\": True, \"allow_interspersed_args\": False},\n short_help=\"Invoke a plugin.\",\n)\[email protected](\n \"--print-var\",\n help=\"Print to stdout the values for the provided environment variables, as passed to the plugininvoker context. Useful for debugging.\",\n multiple=True,\n)\[email protected](\n \"--plugin-type\", type=click.Choice(PluginType.cli_arguments()), default=None\n)\[email protected](\n \"--dump\",\n type=click.Choice([\"catalog\", \"config\"]),\n help=\"Dump content of specified file to disk.\",\n)\[email protected](\n \"--list-commands\",\n is_flag=True,\n help=\"List the commands supported by the plugin.\",\n)\[email protected](\"plugin_name\", metavar=\"PLUGIN_NAME[:COMMAND_NAME]\")\[email protected](\"plugin_args\", nargs=-1, type=click.UNPROCESSED)\[email protected](\n \"--containers\",\n is_flag=True,\n help=\"Execute plugins using containers where possible.\",\n)\n@pass_project(migrate=True)\ndef invoke(\n project: Project,\n plugin_type: str,\n dump: str,\n list_commands: bool,\n plugin_name: str,\n plugin_args: tuple[str, ...],\n containers: bool = False,\n print_var: str | None = None,\n):\n \"\"\"\n Invoke a plugin's executable with specified arguments.\n\n \\b\\nRead more at https://docs.meltano.com/reference/command-line-interface#invoke\n \"\"\"\n tracker = Tracker(project)\n cmd_ctx = cli_context_builder(\n \"invoke\",\n None,\n plugin_type=plugin_type,\n dump=dump,\n list_commands=list_commands,\n containers=containers,\n print_var=print_var,\n )\n with tracker.with_contexts(cmd_ctx):\n tracker.track_command_event(cli_tracking.STARTED)\n\n try:\n plugin_name, command_name = plugin_name.split(\":\")\n except ValueError:\n command_name = None\n\n plugin_type = PluginType.from_cli_argument(plugin_type) if plugin_type else None\n\n _, Session = project_engine(project) # noqa: N806\n session = Session()\n plugins_service = ProjectPluginsService(project)\n\n try:\n plugin = plugins_service.find_plugin(\n plugin_name, plugin_type=plugin_type, invokable=True\n )\n except PluginNotFoundError as err:\n with tracker.with_contexts(cmd_ctx):\n tracker.track_command_event(cli_tracking.ABORTED)\n raise err\n\n if list_commands:\n do_list_commands(plugin)\n return\n\n invoker = invoker_factory(project, plugin, plugins_service=plugins_service)\n try:\n exit_code = run_async(\n _invoke(\n invoker,\n project,\n plugin_name,\n plugin_args,\n session,\n dump,\n command_name,\n containers,\n print_var=print_var,\n )\n )\n except Exception as invoke_err:\n with tracker.with_contexts(cmd_ctx):\n tracker.track_command_event(cli_tracking.FAILED)\n raise invoke_err\n\n with tracker.with_contexts(\n cmd_ctx, PluginsTrackingContext([(plugin, command_name)])\n ):\n if exit_code == 0:\n tracker.track_command_event(cli_tracking.COMPLETED)\n else:\n tracker.track_command_event(cli_tracking.FAILED)\n sys.exit(exit_code)\n\n\nasync def _invoke(\n invoker: PluginInvoker,\n project: Project,\n plugin_name: str,\n plugin_args: str,\n session: sessionmaker,\n dump: str,\n command_name: str,\n containers: bool,\n print_var: list | None = None,\n):\n if command_name is not None:\n command = invoker.find_command(command_name)\n\n try:\n async with invoker.prepared(session):\n if print_var:\n env = invoker.env()\n for key in print_var:\n val = env.get(key)\n click.echo(f\"{key}={val}\")\n if dump:\n await dump_file(invoker, dump)\n exit_code = 0\n elif ( # noqa: WPS337\n containers\n and command_name is not None\n and command.container_spec is not None\n ):\n return await invoker.invoke_docker(\n command_name,\n *plugin_args,\n )\n else:\n handle = await invoker.invoke_async(*plugin_args, command=command_name)\n with propagate_stop_signals(handle):\n exit_code = await handle.wait()\n\n except UnknownCommandError as err:\n raise click.BadArgumentUsage(err) from err\n except AsyncSubprocessError as err:\n logger.error(await err.stderr)\n raise\n finally:\n session.close()\n\n tracker = LegacyTracker(project)\n tracker.track_meltano_invoke(\n plugin_name=plugin_name, plugin_args=\" \".join(plugin_args)\n )\n\n return exit_code\n\n\ndef do_list_commands(plugin):\n \"\"\"List the commands supported by plugin.\"\"\"\n if not plugin.supported_commands:\n click.secho(\n f\"Plugin '{plugin.name}' does not define any commands.\", fg=\"yellow\"\n )\n return\n\n descriptions = {\n f\"{plugin.name}:{cmd}\": props.description\n for cmd, props in plugin.all_commands.items()\n }\n column_len = max(len(name) for name in descriptions.keys()) + 2\n for name, desc in descriptions.items():\n click.secho(name.ljust(column_len, \" \"), fg=\"blue\", nl=False)\n click.echo(desc)\n\n\nasync def dump_file(invoker: PluginInvoker, file_id: str):\n \"\"\"Dump file.\"\"\"\n try:\n content = await invoker.dump(file_id)\n except FileNotFoundError as err:\n raise CliError(f\"Could not find {file_id}\") from err\n except Exception as err:\n raise CliError(f\"Could not dump {file_id}: {err}\") from err\n print(content) # noqa: WPS421\n", "path": "src/meltano/cli/invoke.py"}], "after_files": [{"content": "\"\"\"CLI command `meltano invoke`.\"\"\"\n\nfrom __future__ import annotations\n\nimport logging\nimport sys\n\nimport click\nfrom sqlalchemy.orm import sessionmaker\n\nfrom meltano.core.db import project_engine\nfrom meltano.core.error import AsyncSubprocessError\nfrom meltano.core.legacy_tracking import LegacyTracker\nfrom meltano.core.plugin import PluginType\nfrom meltano.core.plugin.error import PluginNotFoundError\nfrom meltano.core.plugin_invoker import (\n PluginInvoker,\n UnknownCommandError,\n invoker_factory,\n)\nfrom meltano.core.project import Project\nfrom meltano.core.project_plugins_service import ProjectPluginsService\nfrom meltano.core.tracking import PluginsTrackingContext, Tracker\nfrom meltano.core.tracking import cli as cli_tracking\nfrom meltano.core.tracking import cli_context_builder\nfrom meltano.core.utils import run_async\n\nfrom . import cli\nfrom .params import pass_project\nfrom .utils import CliError, propagate_stop_signals\n\nlogger = logging.getLogger(__name__)\n\n\[email protected](\n context_settings={\"ignore_unknown_options\": True, \"allow_interspersed_args\": False},\n short_help=\"Invoke a plugin.\",\n)\[email protected](\n \"--print-var\",\n help=\"Print to stdout the values for the provided environment variables, as passed to the plugininvoker context. Useful for debugging.\",\n multiple=True,\n)\[email protected](\n \"--plugin-type\", type=click.Choice(PluginType.cli_arguments()), default=None\n)\[email protected](\n \"--dump\",\n type=click.Choice([\"catalog\", \"config\"]),\n help=\"Dump content of specified file to disk.\",\n)\[email protected](\n \"--list-commands\",\n is_flag=True,\n help=\"List the commands supported by the plugin.\",\n)\[email protected](\"plugin_name\", metavar=\"PLUGIN_NAME[:COMMAND_NAME]\")\[email protected](\"plugin_args\", nargs=-1, type=click.UNPROCESSED)\[email protected](\n \"--containers\",\n is_flag=True,\n help=\"Execute plugins using containers where possible.\",\n)\n@pass_project(migrate=True)\ndef invoke(\n project: Project,\n plugin_type: str,\n dump: str,\n list_commands: bool,\n plugin_name: str,\n plugin_args: tuple[str, ...],\n containers: bool = False,\n print_var: str | None = None,\n):\n \"\"\"\n Invoke a plugin's executable with specified arguments.\n\n \\b\\nRead more at https://docs.meltano.com/reference/command-line-interface#invoke\n \"\"\"\n tracker = Tracker(project)\n # the `started` event is delayed until we've had a chance to try to resolve the requested plugin\n tracker.add_contexts(\n cli_context_builder(\n \"invoke\",\n None,\n plugin_type=plugin_type,\n dump=dump,\n list_commands=list_commands,\n containers=containers,\n print_var=print_var,\n )\n )\n\n try:\n plugin_name, command_name = plugin_name.split(\":\")\n except ValueError:\n command_name = None\n\n plugin_type = PluginType.from_cli_argument(plugin_type) if plugin_type else None\n\n _, Session = project_engine(project) # noqa: N806\n session = Session()\n plugins_service = ProjectPluginsService(project)\n\n try:\n plugin = plugins_service.find_plugin(\n plugin_name, plugin_type=plugin_type, invokable=True\n )\n tracker.add_contexts(PluginsTrackingContext([(plugin, command_name)]))\n tracker.track_command_event(cli_tracking.STARTED)\n except PluginNotFoundError:\n # if the plugin is not found, we fire started and aborted tracking events together to keep tracking consistent\n tracker.track_command_event(cli_tracking.STARTED)\n tracker.track_command_event(cli_tracking.ABORTED)\n raise\n\n if list_commands:\n do_list_commands(plugin)\n tracker.track_command_event(cli_tracking.COMPLETED)\n return\n\n invoker = invoker_factory(project, plugin, plugins_service=plugins_service)\n try:\n exit_code = run_async(\n _invoke(\n invoker,\n project,\n plugin_name,\n plugin_args,\n session,\n dump,\n command_name,\n containers,\n print_var=print_var,\n )\n )\n except Exception as invoke_err:\n tracker.track_command_event(cli_tracking.FAILED)\n raise invoke_err\n\n if exit_code == 0:\n tracker.track_command_event(cli_tracking.COMPLETED)\n else:\n tracker.track_command_event(cli_tracking.FAILED)\n sys.exit(exit_code)\n\n\nasync def _invoke(\n invoker: PluginInvoker,\n project: Project,\n plugin_name: str,\n plugin_args: str,\n session: sessionmaker,\n dump: str,\n command_name: str,\n containers: bool,\n print_var: list | None = None,\n):\n if command_name is not None:\n command = invoker.find_command(command_name)\n\n try:\n async with invoker.prepared(session):\n if print_var:\n env = invoker.env()\n for key in print_var:\n val = env.get(key)\n click.echo(f\"{key}={val}\")\n if dump:\n await dump_file(invoker, dump)\n exit_code = 0\n elif ( # noqa: WPS337\n containers\n and command_name is not None\n and command.container_spec is not None\n ):\n return await invoker.invoke_docker(\n command_name,\n *plugin_args,\n )\n else:\n handle = await invoker.invoke_async(*plugin_args, command=command_name)\n with propagate_stop_signals(handle):\n exit_code = await handle.wait()\n\n except UnknownCommandError as err:\n raise click.BadArgumentUsage(err) from err\n except AsyncSubprocessError as err:\n logger.error(await err.stderr)\n raise\n finally:\n session.close()\n\n tracker = LegacyTracker(project)\n tracker.track_meltano_invoke(\n plugin_name=plugin_name, plugin_args=\" \".join(plugin_args)\n )\n\n return exit_code\n\n\ndef do_list_commands(plugin):\n \"\"\"List the commands supported by plugin.\"\"\"\n if not plugin.supported_commands:\n click.secho(\n f\"Plugin '{plugin.name}' does not define any commands.\", fg=\"yellow\"\n )\n return\n\n descriptions = {\n f\"{plugin.name}:{cmd}\": props.description\n for cmd, props in plugin.all_commands.items()\n }\n column_len = max(len(name) for name in descriptions.keys()) + 2\n for name, desc in descriptions.items():\n click.secho(name.ljust(column_len, \" \"), fg=\"blue\", nl=False)\n click.echo(desc)\n\n\nasync def dump_file(invoker: PluginInvoker, file_id: str):\n \"\"\"Dump file.\"\"\"\n try:\n content = await invoker.dump(file_id)\n except FileNotFoundError as err:\n raise CliError(f\"Could not find {file_id}\") from err\n except Exception as err:\n raise CliError(f\"Could not dump {file_id}: {err}\") from err\n print(content) # noqa: WPS421\n", "path": "src/meltano/cli/invoke.py"}]}
| 2,556 | 635 |
gh_patches_debug_8465
|
rasdani/github-patches
|
git_diff
|
stephenmcd__mezzanine-1352
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Link dialog sometimes won't open in admin interface
In some situations, trying to open `/displayable_links.js` generates a 500 with the following message:
> TypeError at /displayable_links.js - unorderable types: dict() < dict()
https://github.com/stephenmcd/mezzanine/blob/master/mezzanine/core/views.py#L197
Replacing this line with e.g. `return HttpResponse(dumps([link[1] for link in sorted(links, key=lambda link: link[1]['title'])]))` fixes the problem.
I'm using Python 3.4, but this line of code looks unintended and shouldn't work on Python 2 either :-)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mezzanine/core/views.py`
Content:
```
1 from __future__ import absolute_import, unicode_literals
2 from future.builtins import int, open, str
3
4 import os
5
6 from json import dumps
7 try:
8 from urllib.parse import urljoin, urlparse
9 except ImportError:
10 from urlparse import urljoin, urlparse
11
12 from django.apps import apps
13 from django.contrib import admin
14 from django.contrib.admin.views.decorators import staff_member_required
15 from django.contrib.admin.options import ModelAdmin
16 from django.contrib.staticfiles import finders
17 from django.core.exceptions import PermissionDenied
18 from django.core.urlresolvers import reverse
19 from django.http import (HttpResponse, HttpResponseServerError,
20 HttpResponseNotFound)
21 from django.shortcuts import redirect
22 from django.template import RequestContext
23 from django.template.loader import get_template
24 from django.utils.translation import ugettext_lazy as _
25 from django.views.decorators.csrf import requires_csrf_token
26
27 from mezzanine.conf import settings
28 from mezzanine.core.forms import get_edit_form
29 from mezzanine.core.models import Displayable, SitePermission
30 from mezzanine.utils.cache import add_cache_bypass
31 from mezzanine.utils.views import is_editable, paginate, render, set_cookie
32 from mezzanine.utils.sites import has_site_permission
33 from mezzanine.utils.urls import next_url
34
35
36 def set_device(request, device=""):
37 """
38 Sets a device name in a cookie when a user explicitly wants to go
39 to the site for a particular device (eg mobile).
40 """
41 response = redirect(add_cache_bypass(next_url(request) or "/"))
42 set_cookie(response, "mezzanine-device", device, 60 * 60 * 24 * 365)
43 return response
44
45
46 @staff_member_required
47 def set_site(request):
48 """
49 Put the selected site ID into the session - posted to from
50 the "Select site" drop-down in the header of the admin. The
51 site ID is then used in favour of the current request's
52 domain in ``mezzanine.core.managers.CurrentSiteManager``.
53 """
54 site_id = int(request.GET["site_id"])
55 if not request.user.is_superuser:
56 try:
57 SitePermission.objects.get(user=request.user, sites=site_id)
58 except SitePermission.DoesNotExist:
59 raise PermissionDenied
60 request.session["site_id"] = site_id
61 admin_url = reverse("admin:index")
62 next = next_url(request) or admin_url
63 # Don't redirect to a change view for an object that won't exist
64 # on the selected site - go to its list view instead.
65 if next.startswith(admin_url):
66 parts = next.split("/")
67 if len(parts) > 4 and parts[4].isdigit():
68 next = "/".join(parts[:4])
69 return redirect(next)
70
71
72 def direct_to_template(request, template, extra_context=None, **kwargs):
73 """
74 Replacement for Django's ``direct_to_template`` that uses
75 ``TemplateResponse`` via ``mezzanine.utils.views.render``.
76 """
77 context = extra_context or {}
78 context["params"] = kwargs
79 for (key, value) in context.items():
80 if callable(value):
81 context[key] = value()
82 return render(request, template, context)
83
84
85 @staff_member_required
86 def edit(request):
87 """
88 Process the inline editing form.
89 """
90 model = apps.get_model(request.POST["app"], request.POST["model"])
91 obj = model.objects.get(id=request.POST["id"])
92 form = get_edit_form(obj, request.POST["fields"], data=request.POST,
93 files=request.FILES)
94 if not (is_editable(obj, request) and has_site_permission(request.user)):
95 response = _("Permission denied")
96 elif form.is_valid():
97 form.save()
98 model_admin = ModelAdmin(model, admin.site)
99 message = model_admin.construct_change_message(request, form, None)
100 model_admin.log_change(request, obj, message)
101 response = ""
102 else:
103 response = list(form.errors.values())[0][0]
104 return HttpResponse(response)
105
106
107 def search(request, template="search_results.html", extra_context=None):
108 """
109 Display search results. Takes an optional "contenttype" GET parameter
110 in the form "app-name.ModelName" to limit search results to a single model.
111 """
112 query = request.GET.get("q", "")
113 page = request.GET.get("page", 1)
114 per_page = settings.SEARCH_PER_PAGE
115 max_paging_links = settings.MAX_PAGING_LINKS
116 try:
117 parts = request.GET.get("type", "").split(".", 1)
118 search_model = apps.get_model(*parts)
119 search_model.objects.search # Attribute check
120 except (ValueError, TypeError, LookupError, AttributeError):
121 search_model = Displayable
122 search_type = _("Everything")
123 else:
124 search_type = search_model._meta.verbose_name_plural.capitalize()
125 results = search_model.objects.search(query, for_user=request.user)
126 paginated = paginate(results, page, per_page, max_paging_links)
127 context = {"query": query, "results": paginated,
128 "search_type": search_type}
129 context.update(extra_context or {})
130 return render(request, template, context)
131
132
133 @staff_member_required
134 def static_proxy(request):
135 """
136 Serves TinyMCE plugins inside the inline popups and the uploadify
137 SWF, as these are normally static files, and will break with
138 cross-domain JavaScript errors if ``STATIC_URL`` is an external
139 host. URL for the file is passed in via querystring in the inline
140 popup plugin template, and we then attempt to pull out the relative
141 path to the file, so that we can serve it locally via Django.
142 """
143 normalize = lambda u: ("//" + u.split("://")[-1]) if "://" in u else u
144 url = normalize(request.GET["u"])
145 host = "//" + request.get_host()
146 static_url = normalize(settings.STATIC_URL)
147 for prefix in (host, static_url, "/"):
148 if url.startswith(prefix):
149 url = url.replace(prefix, "", 1)
150 response = ""
151 content_type = ""
152 path = finders.find(url)
153 if path:
154 if isinstance(path, (list, tuple)):
155 path = path[0]
156 if url.endswith(".htm"):
157 # Inject <base href="{{ STATIC_URL }}"> into TinyMCE
158 # plugins, since the path static files in these won't be
159 # on the same domain.
160 static_url = settings.STATIC_URL + os.path.split(url)[0] + "/"
161 if not urlparse(static_url).scheme:
162 static_url = urljoin(host, static_url)
163 base_tag = "<base href='%s'>" % static_url
164 content_type = "text/html"
165 with open(path, "r") as f:
166 response = f.read().replace("<head>", "<head>" + base_tag)
167 else:
168 content_type = "application/octet-stream"
169 with open(path, "rb") as f:
170 response = f.read()
171 return HttpResponse(response, content_type=content_type)
172
173
174 def displayable_links_js(request):
175 """
176 Renders a list of url/title pairs for all ``Displayable`` subclass
177 instances into JSON that's used to populate a list of links in
178 TinyMCE.
179 """
180 links = []
181 if "mezzanine.pages" in settings.INSTALLED_APPS:
182 from mezzanine.pages.models import Page
183 is_page = lambda obj: isinstance(obj, Page)
184 else:
185 is_page = lambda obj: False
186 # For each item's title, we use its model's verbose_name, but in the
187 # case of Page subclasses, we just use "Page", and then sort the items
188 # by whether they're a Page subclass or not, then by their URL.
189 for url, obj in Displayable.objects.url_map(for_user=request.user).items():
190 title = getattr(obj, "titles", obj.title)
191 real = hasattr(obj, "id")
192 page = is_page(obj)
193 if real:
194 verbose_name = _("Page") if page else obj._meta.verbose_name
195 title = "%s: %s" % (verbose_name, title)
196 links.append((not page and real, {"title": str(title), "value": url}))
197 return HttpResponse(dumps([link[1] for link in sorted(links)]))
198
199
200 @requires_csrf_token
201 def page_not_found(request, template_name="errors/404.html"):
202 """
203 Mimics Django's 404 handler but with a different template path.
204 """
205 context = RequestContext(request, {
206 "STATIC_URL": settings.STATIC_URL,
207 "request_path": request.path,
208 })
209 t = get_template(template_name)
210 return HttpResponseNotFound(t.render(context))
211
212
213 @requires_csrf_token
214 def server_error(request, template_name="errors/500.html"):
215 """
216 Mimics Django's error handler but adds ``STATIC_URL`` to the
217 context.
218 """
219 context = RequestContext(request, {"STATIC_URL": settings.STATIC_URL})
220 t = get_template(template_name)
221 return HttpResponseServerError(t.render(context))
222
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mezzanine/core/views.py b/mezzanine/core/views.py
--- a/mezzanine/core/views.py
+++ b/mezzanine/core/views.py
@@ -194,7 +194,8 @@
verbose_name = _("Page") if page else obj._meta.verbose_name
title = "%s: %s" % (verbose_name, title)
links.append((not page and real, {"title": str(title), "value": url}))
- return HttpResponse(dumps([link[1] for link in sorted(links)]))
+ sorted_links = sorted(links, key=lambda link: (link[0], link[1]['value']))
+ return HttpResponse(dumps([link[1] for link in sorted_links]))
@requires_csrf_token
|
{"golden_diff": "diff --git a/mezzanine/core/views.py b/mezzanine/core/views.py\n--- a/mezzanine/core/views.py\n+++ b/mezzanine/core/views.py\n@@ -194,7 +194,8 @@\n verbose_name = _(\"Page\") if page else obj._meta.verbose_name\n title = \"%s: %s\" % (verbose_name, title)\n links.append((not page and real, {\"title\": str(title), \"value\": url}))\n- return HttpResponse(dumps([link[1] for link in sorted(links)]))\n+ sorted_links = sorted(links, key=lambda link: (link[0], link[1]['value']))\n+ return HttpResponse(dumps([link[1] for link in sorted_links]))\n \n \n @requires_csrf_token\n", "issue": "Link dialog sometimes won't open in admin interface \nIn some situations, trying to open `/displayable_links.js` generates a 500 with the following message:\n\n> TypeError at /displayable_links.js - unorderable types: dict() < dict()\n\nhttps://github.com/stephenmcd/mezzanine/blob/master/mezzanine/core/views.py#L197\n\nReplacing this line with e.g. `return HttpResponse(dumps([link[1] for link in sorted(links, key=lambda link: link[1]['title'])]))` fixes the problem.\n\nI'm using Python 3.4, but this line of code looks unintended and shouldn't work on Python 2 either :-)\n\n", "before_files": [{"content": "from __future__ import absolute_import, unicode_literals\nfrom future.builtins import int, open, str\n\nimport os\n\nfrom json import dumps\ntry:\n from urllib.parse import urljoin, urlparse\nexcept ImportError:\n from urlparse import urljoin, urlparse\n\nfrom django.apps import apps\nfrom django.contrib import admin\nfrom django.contrib.admin.views.decorators import staff_member_required\nfrom django.contrib.admin.options import ModelAdmin\nfrom django.contrib.staticfiles import finders\nfrom django.core.exceptions import PermissionDenied\nfrom django.core.urlresolvers import reverse\nfrom django.http import (HttpResponse, HttpResponseServerError,\n HttpResponseNotFound)\nfrom django.shortcuts import redirect\nfrom django.template import RequestContext\nfrom django.template.loader import get_template\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.views.decorators.csrf import requires_csrf_token\n\nfrom mezzanine.conf import settings\nfrom mezzanine.core.forms import get_edit_form\nfrom mezzanine.core.models import Displayable, SitePermission\nfrom mezzanine.utils.cache import add_cache_bypass\nfrom mezzanine.utils.views import is_editable, paginate, render, set_cookie\nfrom mezzanine.utils.sites import has_site_permission\nfrom mezzanine.utils.urls import next_url\n\n\ndef set_device(request, device=\"\"):\n \"\"\"\n Sets a device name in a cookie when a user explicitly wants to go\n to the site for a particular device (eg mobile).\n \"\"\"\n response = redirect(add_cache_bypass(next_url(request) or \"/\"))\n set_cookie(response, \"mezzanine-device\", device, 60 * 60 * 24 * 365)\n return response\n\n\n@staff_member_required\ndef set_site(request):\n \"\"\"\n Put the selected site ID into the session - posted to from\n the \"Select site\" drop-down in the header of the admin. The\n site ID is then used in favour of the current request's\n domain in ``mezzanine.core.managers.CurrentSiteManager``.\n \"\"\"\n site_id = int(request.GET[\"site_id\"])\n if not request.user.is_superuser:\n try:\n SitePermission.objects.get(user=request.user, sites=site_id)\n except SitePermission.DoesNotExist:\n raise PermissionDenied\n request.session[\"site_id\"] = site_id\n admin_url = reverse(\"admin:index\")\n next = next_url(request) or admin_url\n # Don't redirect to a change view for an object that won't exist\n # on the selected site - go to its list view instead.\n if next.startswith(admin_url):\n parts = next.split(\"/\")\n if len(parts) > 4 and parts[4].isdigit():\n next = \"/\".join(parts[:4])\n return redirect(next)\n\n\ndef direct_to_template(request, template, extra_context=None, **kwargs):\n \"\"\"\n Replacement for Django's ``direct_to_template`` that uses\n ``TemplateResponse`` via ``mezzanine.utils.views.render``.\n \"\"\"\n context = extra_context or {}\n context[\"params\"] = kwargs\n for (key, value) in context.items():\n if callable(value):\n context[key] = value()\n return render(request, template, context)\n\n\n@staff_member_required\ndef edit(request):\n \"\"\"\n Process the inline editing form.\n \"\"\"\n model = apps.get_model(request.POST[\"app\"], request.POST[\"model\"])\n obj = model.objects.get(id=request.POST[\"id\"])\n form = get_edit_form(obj, request.POST[\"fields\"], data=request.POST,\n files=request.FILES)\n if not (is_editable(obj, request) and has_site_permission(request.user)):\n response = _(\"Permission denied\")\n elif form.is_valid():\n form.save()\n model_admin = ModelAdmin(model, admin.site)\n message = model_admin.construct_change_message(request, form, None)\n model_admin.log_change(request, obj, message)\n response = \"\"\n else:\n response = list(form.errors.values())[0][0]\n return HttpResponse(response)\n\n\ndef search(request, template=\"search_results.html\", extra_context=None):\n \"\"\"\n Display search results. Takes an optional \"contenttype\" GET parameter\n in the form \"app-name.ModelName\" to limit search results to a single model.\n \"\"\"\n query = request.GET.get(\"q\", \"\")\n page = request.GET.get(\"page\", 1)\n per_page = settings.SEARCH_PER_PAGE\n max_paging_links = settings.MAX_PAGING_LINKS\n try:\n parts = request.GET.get(\"type\", \"\").split(\".\", 1)\n search_model = apps.get_model(*parts)\n search_model.objects.search # Attribute check\n except (ValueError, TypeError, LookupError, AttributeError):\n search_model = Displayable\n search_type = _(\"Everything\")\n else:\n search_type = search_model._meta.verbose_name_plural.capitalize()\n results = search_model.objects.search(query, for_user=request.user)\n paginated = paginate(results, page, per_page, max_paging_links)\n context = {\"query\": query, \"results\": paginated,\n \"search_type\": search_type}\n context.update(extra_context or {})\n return render(request, template, context)\n\n\n@staff_member_required\ndef static_proxy(request):\n \"\"\"\n Serves TinyMCE plugins inside the inline popups and the uploadify\n SWF, as these are normally static files, and will break with\n cross-domain JavaScript errors if ``STATIC_URL`` is an external\n host. URL for the file is passed in via querystring in the inline\n popup plugin template, and we then attempt to pull out the relative\n path to the file, so that we can serve it locally via Django.\n \"\"\"\n normalize = lambda u: (\"//\" + u.split(\"://\")[-1]) if \"://\" in u else u\n url = normalize(request.GET[\"u\"])\n host = \"//\" + request.get_host()\n static_url = normalize(settings.STATIC_URL)\n for prefix in (host, static_url, \"/\"):\n if url.startswith(prefix):\n url = url.replace(prefix, \"\", 1)\n response = \"\"\n content_type = \"\"\n path = finders.find(url)\n if path:\n if isinstance(path, (list, tuple)):\n path = path[0]\n if url.endswith(\".htm\"):\n # Inject <base href=\"{{ STATIC_URL }}\"> into TinyMCE\n # plugins, since the path static files in these won't be\n # on the same domain.\n static_url = settings.STATIC_URL + os.path.split(url)[0] + \"/\"\n if not urlparse(static_url).scheme:\n static_url = urljoin(host, static_url)\n base_tag = \"<base href='%s'>\" % static_url\n content_type = \"text/html\"\n with open(path, \"r\") as f:\n response = f.read().replace(\"<head>\", \"<head>\" + base_tag)\n else:\n content_type = \"application/octet-stream\"\n with open(path, \"rb\") as f:\n response = f.read()\n return HttpResponse(response, content_type=content_type)\n\n\ndef displayable_links_js(request):\n \"\"\"\n Renders a list of url/title pairs for all ``Displayable`` subclass\n instances into JSON that's used to populate a list of links in\n TinyMCE.\n \"\"\"\n links = []\n if \"mezzanine.pages\" in settings.INSTALLED_APPS:\n from mezzanine.pages.models import Page\n is_page = lambda obj: isinstance(obj, Page)\n else:\n is_page = lambda obj: False\n # For each item's title, we use its model's verbose_name, but in the\n # case of Page subclasses, we just use \"Page\", and then sort the items\n # by whether they're a Page subclass or not, then by their URL.\n for url, obj in Displayable.objects.url_map(for_user=request.user).items():\n title = getattr(obj, \"titles\", obj.title)\n real = hasattr(obj, \"id\")\n page = is_page(obj)\n if real:\n verbose_name = _(\"Page\") if page else obj._meta.verbose_name\n title = \"%s: %s\" % (verbose_name, title)\n links.append((not page and real, {\"title\": str(title), \"value\": url}))\n return HttpResponse(dumps([link[1] for link in sorted(links)]))\n\n\n@requires_csrf_token\ndef page_not_found(request, template_name=\"errors/404.html\"):\n \"\"\"\n Mimics Django's 404 handler but with a different template path.\n \"\"\"\n context = RequestContext(request, {\n \"STATIC_URL\": settings.STATIC_URL,\n \"request_path\": request.path,\n })\n t = get_template(template_name)\n return HttpResponseNotFound(t.render(context))\n\n\n@requires_csrf_token\ndef server_error(request, template_name=\"errors/500.html\"):\n \"\"\"\n Mimics Django's error handler but adds ``STATIC_URL`` to the\n context.\n \"\"\"\n context = RequestContext(request, {\"STATIC_URL\": settings.STATIC_URL})\n t = get_template(template_name)\n return HttpResponseServerError(t.render(context))\n", "path": "mezzanine/core/views.py"}], "after_files": [{"content": "from __future__ import absolute_import, unicode_literals\nfrom future.builtins import int, open, str\n\nimport os\n\nfrom json import dumps\ntry:\n from urllib.parse import urljoin, urlparse\nexcept ImportError:\n from urlparse import urljoin, urlparse\n\nfrom django.apps import apps\nfrom django.contrib import admin\nfrom django.contrib.admin.views.decorators import staff_member_required\nfrom django.contrib.admin.options import ModelAdmin\nfrom django.contrib.staticfiles import finders\nfrom django.core.exceptions import PermissionDenied\nfrom django.core.urlresolvers import reverse\nfrom django.http import (HttpResponse, HttpResponseServerError,\n HttpResponseNotFound)\nfrom django.shortcuts import redirect\nfrom django.template import RequestContext\nfrom django.template.loader import get_template\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.views.decorators.csrf import requires_csrf_token\n\nfrom mezzanine.conf import settings\nfrom mezzanine.core.forms import get_edit_form\nfrom mezzanine.core.models import Displayable, SitePermission\nfrom mezzanine.utils.cache import add_cache_bypass\nfrom mezzanine.utils.views import is_editable, paginate, render, set_cookie\nfrom mezzanine.utils.sites import has_site_permission\nfrom mezzanine.utils.urls import next_url\n\n\ndef set_device(request, device=\"\"):\n \"\"\"\n Sets a device name in a cookie when a user explicitly wants to go\n to the site for a particular device (eg mobile).\n \"\"\"\n response = redirect(add_cache_bypass(next_url(request) or \"/\"))\n set_cookie(response, \"mezzanine-device\", device, 60 * 60 * 24 * 365)\n return response\n\n\n@staff_member_required\ndef set_site(request):\n \"\"\"\n Put the selected site ID into the session - posted to from\n the \"Select site\" drop-down in the header of the admin. The\n site ID is then used in favour of the current request's\n domain in ``mezzanine.core.managers.CurrentSiteManager``.\n \"\"\"\n site_id = int(request.GET[\"site_id\"])\n if not request.user.is_superuser:\n try:\n SitePermission.objects.get(user=request.user, sites=site_id)\n except SitePermission.DoesNotExist:\n raise PermissionDenied\n request.session[\"site_id\"] = site_id\n admin_url = reverse(\"admin:index\")\n next = next_url(request) or admin_url\n # Don't redirect to a change view for an object that won't exist\n # on the selected site - go to its list view instead.\n if next.startswith(admin_url):\n parts = next.split(\"/\")\n if len(parts) > 4 and parts[4].isdigit():\n next = \"/\".join(parts[:4])\n return redirect(next)\n\n\ndef direct_to_template(request, template, extra_context=None, **kwargs):\n \"\"\"\n Replacement for Django's ``direct_to_template`` that uses\n ``TemplateResponse`` via ``mezzanine.utils.views.render``.\n \"\"\"\n context = extra_context or {}\n context[\"params\"] = kwargs\n for (key, value) in context.items():\n if callable(value):\n context[key] = value()\n return render(request, template, context)\n\n\n@staff_member_required\ndef edit(request):\n \"\"\"\n Process the inline editing form.\n \"\"\"\n model = apps.get_model(request.POST[\"app\"], request.POST[\"model\"])\n obj = model.objects.get(id=request.POST[\"id\"])\n form = get_edit_form(obj, request.POST[\"fields\"], data=request.POST,\n files=request.FILES)\n if not (is_editable(obj, request) and has_site_permission(request.user)):\n response = _(\"Permission denied\")\n elif form.is_valid():\n form.save()\n model_admin = ModelAdmin(model, admin.site)\n message = model_admin.construct_change_message(request, form, None)\n model_admin.log_change(request, obj, message)\n response = \"\"\n else:\n response = list(form.errors.values())[0][0]\n return HttpResponse(response)\n\n\ndef search(request, template=\"search_results.html\", extra_context=None):\n \"\"\"\n Display search results. Takes an optional \"contenttype\" GET parameter\n in the form \"app-name.ModelName\" to limit search results to a single model.\n \"\"\"\n query = request.GET.get(\"q\", \"\")\n page = request.GET.get(\"page\", 1)\n per_page = settings.SEARCH_PER_PAGE\n max_paging_links = settings.MAX_PAGING_LINKS\n try:\n parts = request.GET.get(\"type\", \"\").split(\".\", 1)\n search_model = apps.get_model(*parts)\n search_model.objects.search # Attribute check\n except (ValueError, TypeError, LookupError, AttributeError):\n search_model = Displayable\n search_type = _(\"Everything\")\n else:\n search_type = search_model._meta.verbose_name_plural.capitalize()\n results = search_model.objects.search(query, for_user=request.user)\n paginated = paginate(results, page, per_page, max_paging_links)\n context = {\"query\": query, \"results\": paginated,\n \"search_type\": search_type}\n context.update(extra_context or {})\n return render(request, template, context)\n\n\n@staff_member_required\ndef static_proxy(request):\n \"\"\"\n Serves TinyMCE plugins inside the inline popups and the uploadify\n SWF, as these are normally static files, and will break with\n cross-domain JavaScript errors if ``STATIC_URL`` is an external\n host. URL for the file is passed in via querystring in the inline\n popup plugin template, and we then attempt to pull out the relative\n path to the file, so that we can serve it locally via Django.\n \"\"\"\n normalize = lambda u: (\"//\" + u.split(\"://\")[-1]) if \"://\" in u else u\n url = normalize(request.GET[\"u\"])\n host = \"//\" + request.get_host()\n static_url = normalize(settings.STATIC_URL)\n for prefix in (host, static_url, \"/\"):\n if url.startswith(prefix):\n url = url.replace(prefix, \"\", 1)\n response = \"\"\n content_type = \"\"\n path = finders.find(url)\n if path:\n if isinstance(path, (list, tuple)):\n path = path[0]\n if url.endswith(\".htm\"):\n # Inject <base href=\"{{ STATIC_URL }}\"> into TinyMCE\n # plugins, since the path static files in these won't be\n # on the same domain.\n static_url = settings.STATIC_URL + os.path.split(url)[0] + \"/\"\n if not urlparse(static_url).scheme:\n static_url = urljoin(host, static_url)\n base_tag = \"<base href='%s'>\" % static_url\n content_type = \"text/html\"\n with open(path, \"r\") as f:\n response = f.read().replace(\"<head>\", \"<head>\" + base_tag)\n else:\n content_type = \"application/octet-stream\"\n with open(path, \"rb\") as f:\n response = f.read()\n return HttpResponse(response, content_type=content_type)\n\n\ndef displayable_links_js(request):\n \"\"\"\n Renders a list of url/title pairs for all ``Displayable`` subclass\n instances into JSON that's used to populate a list of links in\n TinyMCE.\n \"\"\"\n links = []\n if \"mezzanine.pages\" in settings.INSTALLED_APPS:\n from mezzanine.pages.models import Page\n is_page = lambda obj: isinstance(obj, Page)\n else:\n is_page = lambda obj: False\n # For each item's title, we use its model's verbose_name, but in the\n # case of Page subclasses, we just use \"Page\", and then sort the items\n # by whether they're a Page subclass or not, then by their URL.\n for url, obj in Displayable.objects.url_map(for_user=request.user).items():\n title = getattr(obj, \"titles\", obj.title)\n real = hasattr(obj, \"id\")\n page = is_page(obj)\n if real:\n verbose_name = _(\"Page\") if page else obj._meta.verbose_name\n title = \"%s: %s\" % (verbose_name, title)\n links.append((not page and real, {\"title\": str(title), \"value\": url}))\n sorted_links = sorted(links, key=lambda link: (link[0], link[1]['value']))\n return HttpResponse(dumps([link[1] for link in sorted_links]))\n\n\n@requires_csrf_token\ndef page_not_found(request, template_name=\"errors/404.html\"):\n \"\"\"\n Mimics Django's 404 handler but with a different template path.\n \"\"\"\n context = RequestContext(request, {\n \"STATIC_URL\": settings.STATIC_URL,\n \"request_path\": request.path,\n })\n t = get_template(template_name)\n return HttpResponseNotFound(t.render(context))\n\n\n@requires_csrf_token\ndef server_error(request, template_name=\"errors/500.html\"):\n \"\"\"\n Mimics Django's error handler but adds ``STATIC_URL`` to the\n context.\n \"\"\"\n context = RequestContext(request, {\"STATIC_URL\": settings.STATIC_URL})\n t = get_template(template_name)\n return HttpResponseServerError(t.render(context))\n", "path": "mezzanine/core/views.py"}]}
| 2,896 | 167 |
gh_patches_debug_40699
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-5557
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Cannot migrate onto '0041_permissions_to_groups'
### What I'm trying to achieve
Migrate to latest saleor.
### Steps to reproduce the problem
1. (probably) try to checkout to an older version of saleor
1. populate db
1. migrate to latest
1. migrate
### What I expected to happen
```
Running migrations:
Applying account.0041_permissions_to_groups...Traceback (most recent call last):
File "/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py", line 86, in _execute
return self.cursor.execute(sql, params)
psycopg2.errors.StringDataRightTruncation: value too long for type character varying(150)
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "manage.py", line 10, in <module>
execute_from_command_line(sys.argv)
File "/usr/local/lib/python3.8/site-packages/django/core/management/__init__.py", line 401, in execute_from_command_line
utility.execute()
File "/usr/local/lib/python3.8/site-packages/django/core/management/__init__.py", line 395, in execute
self.fetch_command(subcommand).run_from_argv(self.argv)
File "/usr/local/lib/python3.8/site-packages/django/core/management/base.py", line 328, in run_from_argv
self.execute(*args, **cmd_options)
File "/usr/local/lib/python3.8/site-packages/django/core/management/base.py", line 369, in execute
output = self.handle(*args, **options)
File "/usr/local/lib/python3.8/site-packages/django/core/management/base.py", line 83, in wrapped
res = handle_func(*args, **kwargs)
File "/usr/local/lib/python3.8/site-packages/django/core/management/commands/migrate.py", line 231, in handle
post_migrate_state = executor.migrate(
File "/usr/local/lib/python3.8/site-packages/django/db/migrations/executor.py", line 117, in migrate
state = self._migrate_all_forwards(state, plan, full_plan, fake=fake, fake_initial=fake_initial)
File "/usr/local/lib/python3.8/site-packages/django/db/migrations/executor.py", line 147, in _migrate_all_forwards
state = self.apply_migration(state, migration, fake=fake, fake_initial=fake_initial)
File "/usr/local/lib/python3.8/site-packages/django/db/migrations/executor.py", line 245, in apply_migration
state = migration.apply(state, schema_editor)
File "/usr/local/lib/python3.8/site-packages/django/db/migrations/migration.py", line 124, in apply
operation.database_forwards(self.app_label, schema_editor, old_state, project_state)
File "/usr/local/lib/python3.8/site-packages/django/db/migrations/operations/special.py", line 190, in database_forwards
self.code(from_state.apps, schema_editor)
File "/app/saleor/account/migrations/0041_permissions_to_groups.py", line 26, in add_users_to_groups_based_on_users_permissions
group = create_group_with_given_permissions(perms, group_data.group_name, Group)
File "/app/saleor/account/migrations/0041_permissions_to_groups.py", line 65, in create_group_with_given_permissions
group = Group.objects.create(name=group_name)
File "/usr/local/lib/python3.8/site-packages/django/db/models/manager.py", line 82, in manager_method
return getattr(self.get_queryset(), name)(*args, **kwargs)
File "/usr/local/lib/python3.8/site-packages/django/db/models/query.py", line 433, in create
obj.save(force_insert=True, using=self.db)
File "/usr/local/lib/python3.8/site-packages/django/db/models/base.py", line 745, in save
self.save_base(using=using, force_insert=force_insert,
File "/usr/local/lib/python3.8/site-packages/django/db/models/base.py", line 782, in save_base
updated = self._save_table(
File "/usr/local/lib/python3.8/site-packages/django/db/models/base.py", line 887, in _save_table
results = self._do_insert(cls._base_manager, using, fields, returning_fields, raw)
File "/usr/local/lib/python3.8/site-packages/django/db/models/base.py", line 924, in _do_insert
return manager._insert(
File "/usr/local/lib/python3.8/site-packages/django/db/models/manager.py", line 82, in manager_method
return getattr(self.get_queryset(), name)(*args, **kwargs)
File "/usr/local/lib/python3.8/site-packages/django/db/models/query.py", line 1204, in _insert
return query.get_compiler(using=using).execute_sql(returning_fields)
File "/usr/local/lib/python3.8/site-packages/django/db/models/sql/compiler.py", line 1391, in execute_sql
cursor.execute(sql, params)
File "/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py", line 68, in execute
return self._execute_with_wrappers(sql, params, many=False, executor=self._execute)
File "/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py", line 77, in _execute_with_wrappers
return executor(sql, params, many, context)
File "/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py", line 86, in _execute
return self.cursor.execute(sql, params)
File "/usr/local/lib/python3.8/site-packages/django/db/utils.py", line 90, in __exit__
File "/usr/local/lib/python3.8/site-packages/django/db/migrations/executor.py", line 245, in apply_migration
state = migration.apply(state, schema_editor)
File "/usr/local/lib/python3.8/site-packages/django/db/migrations/migration.py", line 124, in apply
operation.database_forwards(self.app_label, schema_editor, old_state, project_state)
File "/usr/local/lib/python3.8/site-packages/django/db/migrations/operations/special.py", line 190, in database_forwards
self.code(from_state.apps, schema_editor)
File "/app/saleor/account/migrations/0041_permissions_to_groups.py", line 26, in add_users_to_groups_based_on_users_permissions
group = create_group_with_given_permissions(perms, group_data.group_name, Group)
File "/app/saleor/account/migrations/0041_permissions_to_groups.py", line 65, in create_group_with_given_permissions
group = Group.objects.create(name=group_name)
File "/usr/local/lib/python3.8/site-packages/django/db/models/manager.py", line 82, in manager_method
return getattr(self.get_queryset(), name)(*args, **kwargs)
File "/usr/local/lib/python3.8/site-packages/django/db/models/query.py", line 433, in create
obj.save(force_insert=True, using=self.db)
File "/usr/local/lib/python3.8/site-packages/django/db/models/base.py", line 745, in save
self.save_base(using=using, force_insert=force_insert,
File "/usr/local/lib/python3.8/site-packages/django/db/models/base.py", line 782, in save_base
updated = self._save_table(
File "/usr/local/lib/python3.8/site-packages/django/db/models/base.py", line 887, in _save_table
results = self._do_insert(cls._base_manager, using, fields, returning_fields, raw)
File "/usr/local/lib/python3.8/site-packages/django/db/models/base.py", line 924, in _do_insert
return manager._insert(
File "/usr/local/lib/python3.8/site-packages/django/db/models/manager.py", line 82, in manager_method
return getattr(self.get_queryset(), name)(*args, **kwargs)
File "/usr/local/lib/python3.8/site-packages/django/db/models/query.py", line 1204, in _insert
return query.get_compiler(using=using).execute_sql(returning_fields)
File "/usr/local/lib/python3.8/site-packages/django/db/models/sql/compiler.py", line 1391, in execute_sql
cursor.execute(sql, params)
File "/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py", line 68, in execute
return self._execute_with_wrappers(sql, params, many=False, executor=self._execute)
File "/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py", line 77, in _execute_with_wrappers
return executor(sql, params, many, context)
File "/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py", line 86, in _execute
return self.cursor.execute(sql, params)
File "/usr/local/lib/python3.8/site-packages/django/db/utils.py", line 90, in __exit__
raise dj_exc_value.with_traceback(traceback) from exc_value
File "/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py", line 86, in _execute
return self.cursor.execute(sql, params)
django.db.utils.DataError: value too long for type character varying(150)
```
### Screenshots
<!-- If applicable, add screenshots to help explain your problem. -->
**System information**
Operating system:
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `saleor/account/migrations/0041_permissions_to_groups.py`
Content:
```
1 from collections import namedtuple
2
3 from django.db import migrations
4
5
6 def add_users_to_groups_based_on_users_permissions(apps, schema_editor):
7 """Add every user to group with "user_permissions" if exists, else create new one.
8
9 For each user, if the group with the exact scope of permissions exists,
10 add the user to it, else create a new group with this scope of permissions
11 and add the user to it.
12 """
13 User = apps.get_model("account", "User")
14 Group = apps.get_model("auth", "Group")
15 GroupData = namedtuple("GroupData", ["users", "group_name"])
16
17 groups = Group.objects.all().prefetch_related("permissions")
18
19 mapping = create_permissions_mapping(User, GroupData)
20 for perms, group_data in mapping.items():
21 group = get_group_with_given_permissions(perms, groups)
22 users = group_data.users
23 if group:
24 group.user_set.add(*users)
25 continue
26 group = create_group_with_given_permissions(perms, group_data.group_name, Group)
27 group.user_set.add(*users)
28
29
30 def create_permissions_mapping(User, GroupData):
31 """Create mapping permissions to users and potential new group name."""
32 mapping = {}
33 users = User.objects.filter(user_permissions__isnull=False).prefetch_related(
34 "user_permissions"
35 )
36 for user in users:
37 permissions = user.user_permissions.all()
38 perm_pks = (perm.pk for perm in permissions)
39 if perm_pks not in mapping:
40 group_name = create_group_name(permissions)
41 mapping[perm_pks] = GroupData({user.pk}, group_name)
42 else:
43 mapping[perm_pks].users.add(user.pk)
44 user.user_permissions.clear()
45 return mapping
46
47
48 def create_group_name(permissions):
49 """Create group name based on permissions."""
50 formatted_names = [perm.name.rstrip(".").lower() for perm in permissions]
51 group_name = ", ".join(formatted_names).capitalize()
52 return group_name
53
54
55 def get_group_with_given_permissions(permissions, groups):
56 """Get group with given set of permissions."""
57 for group in groups:
58 group_perm_pks = {perm.pk for perm in group.permissions.all()}
59 if group_perm_pks == set(permissions):
60 return group
61
62
63 def create_group_with_given_permissions(perm_pks, group_name, Group):
64 """Create new group with given set of permissions."""
65 group = Group.objects.create(name=group_name)
66 group.permissions.add(*perm_pks)
67 return group
68
69
70 class Migration(migrations.Migration):
71
72 dependencies = [
73 ("account", "0040_auto_20200415_0443"),
74 ]
75 operations = [
76 migrations.RunPython(
77 add_users_to_groups_based_on_users_permissions, migrations.RunPython.noop
78 ),
79 ]
80
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/saleor/account/migrations/0041_permissions_to_groups.py b/saleor/account/migrations/0041_permissions_to_groups.py
--- a/saleor/account/migrations/0041_permissions_to_groups.py
+++ b/saleor/account/migrations/0041_permissions_to_groups.py
@@ -1,4 +1,5 @@
-from collections import namedtuple
+import re
+from collections import defaultdict
from django.db import migrations
@@ -12,46 +13,45 @@
"""
User = apps.get_model("account", "User")
Group = apps.get_model("auth", "Group")
- GroupData = namedtuple("GroupData", ["users", "group_name"])
groups = Group.objects.all().prefetch_related("permissions")
-
- mapping = create_permissions_mapping(User, GroupData)
- for perms, group_data in mapping.items():
+ counter = get_counter_value(Group)
+ mapping = create_permissions_mapping(User)
+ for perms, users in mapping.items():
group = get_group_with_given_permissions(perms, groups)
- users = group_data.users
if group:
group.user_set.add(*users)
continue
- group = create_group_with_given_permissions(perms, group_data.group_name, Group)
+ group = create_group_with_given_permissions(perms, counter, Group)
group.user_set.add(*users)
+ counter += 1
+
+
+def get_counter_value(Group):
+ """Get the number of next potential group."""
+ pattern = r"^Group (\d+)$"
+ group = Group.objects.filter(name__iregex=pattern).order_by("name").last()
+ if not group:
+ return 1
+ return int(re.match(pattern, group.name).group(1)) + 1
-def create_permissions_mapping(User, GroupData):
+def create_permissions_mapping(User):
"""Create mapping permissions to users and potential new group name."""
- mapping = {}
- users = User.objects.filter(user_permissions__isnull=False).prefetch_related(
- "user_permissions"
+ mapping = defaultdict(set)
+ users = (
+ User.objects.filter(user_permissions__isnull=False)
+ .distinct()
+ .prefetch_related("user_permissions")
)
for user in users:
- permissions = user.user_permissions.all()
- perm_pks = (perm.pk for perm in permissions)
- if perm_pks not in mapping:
- group_name = create_group_name(permissions)
- mapping[perm_pks] = GroupData({user.pk}, group_name)
- else:
- mapping[perm_pks].users.add(user.pk)
+ permissions = user.user_permissions.all().order_by("pk")
+ perm_pks = tuple([perm.pk for perm in permissions])
+ mapping[perm_pks].add(user.pk)
user.user_permissions.clear()
return mapping
-def create_group_name(permissions):
- """Create group name based on permissions."""
- formatted_names = [perm.name.rstrip(".").lower() for perm in permissions]
- group_name = ", ".join(formatted_names).capitalize()
- return group_name
-
-
def get_group_with_given_permissions(permissions, groups):
"""Get group with given set of permissions."""
for group in groups:
@@ -60,8 +60,9 @@
return group
-def create_group_with_given_permissions(perm_pks, group_name, Group):
+def create_group_with_given_permissions(perm_pks, counter, Group):
"""Create new group with given set of permissions."""
+ group_name = f"Group {counter:03d}"
group = Group.objects.create(name=group_name)
group.permissions.add(*perm_pks)
return group
|
{"golden_diff": "diff --git a/saleor/account/migrations/0041_permissions_to_groups.py b/saleor/account/migrations/0041_permissions_to_groups.py\n--- a/saleor/account/migrations/0041_permissions_to_groups.py\n+++ b/saleor/account/migrations/0041_permissions_to_groups.py\n@@ -1,4 +1,5 @@\n-from collections import namedtuple\n+import re\n+from collections import defaultdict\n \n from django.db import migrations\n \n@@ -12,46 +13,45 @@\n \"\"\"\n User = apps.get_model(\"account\", \"User\")\n Group = apps.get_model(\"auth\", \"Group\")\n- GroupData = namedtuple(\"GroupData\", [\"users\", \"group_name\"])\n \n groups = Group.objects.all().prefetch_related(\"permissions\")\n-\n- mapping = create_permissions_mapping(User, GroupData)\n- for perms, group_data in mapping.items():\n+ counter = get_counter_value(Group)\n+ mapping = create_permissions_mapping(User)\n+ for perms, users in mapping.items():\n group = get_group_with_given_permissions(perms, groups)\n- users = group_data.users\n if group:\n group.user_set.add(*users)\n continue\n- group = create_group_with_given_permissions(perms, group_data.group_name, Group)\n+ group = create_group_with_given_permissions(perms, counter, Group)\n group.user_set.add(*users)\n+ counter += 1\n+\n+\n+def get_counter_value(Group):\n+ \"\"\"Get the number of next potential group.\"\"\"\n+ pattern = r\"^Group (\\d+)$\"\n+ group = Group.objects.filter(name__iregex=pattern).order_by(\"name\").last()\n+ if not group:\n+ return 1\n+ return int(re.match(pattern, group.name).group(1)) + 1\n \n \n-def create_permissions_mapping(User, GroupData):\n+def create_permissions_mapping(User):\n \"\"\"Create mapping permissions to users and potential new group name.\"\"\"\n- mapping = {}\n- users = User.objects.filter(user_permissions__isnull=False).prefetch_related(\n- \"user_permissions\"\n+ mapping = defaultdict(set)\n+ users = (\n+ User.objects.filter(user_permissions__isnull=False)\n+ .distinct()\n+ .prefetch_related(\"user_permissions\")\n )\n for user in users:\n- permissions = user.user_permissions.all()\n- perm_pks = (perm.pk for perm in permissions)\n- if perm_pks not in mapping:\n- group_name = create_group_name(permissions)\n- mapping[perm_pks] = GroupData({user.pk}, group_name)\n- else:\n- mapping[perm_pks].users.add(user.pk)\n+ permissions = user.user_permissions.all().order_by(\"pk\")\n+ perm_pks = tuple([perm.pk for perm in permissions])\n+ mapping[perm_pks].add(user.pk)\n user.user_permissions.clear()\n return mapping\n \n \n-def create_group_name(permissions):\n- \"\"\"Create group name based on permissions.\"\"\"\n- formatted_names = [perm.name.rstrip(\".\").lower() for perm in permissions]\n- group_name = \", \".join(formatted_names).capitalize()\n- return group_name\n-\n-\n def get_group_with_given_permissions(permissions, groups):\n \"\"\"Get group with given set of permissions.\"\"\"\n for group in groups:\n@@ -60,8 +60,9 @@\n return group\n \n \n-def create_group_with_given_permissions(perm_pks, group_name, Group):\n+def create_group_with_given_permissions(perm_pks, counter, Group):\n \"\"\"Create new group with given set of permissions.\"\"\"\n+ group_name = f\"Group {counter:03d}\"\n group = Group.objects.create(name=group_name)\n group.permissions.add(*perm_pks)\n return group\n", "issue": "Cannot migrate onto '0041_permissions_to_groups'\n### What I'm trying to achieve\r\nMigrate to latest saleor.\r\n\r\n### Steps to reproduce the problem\r\n1. (probably) try to checkout to an older version of saleor\r\n1. populate db\r\n1. migrate to latest\r\n1. migrate \r\n\r\n### What I expected to happen\r\n```\r\nRunning migrations:\r\nApplying account.0041_permissions_to_groups...Traceback (most recent call last):\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py\", line 86, in _execute\r\nreturn self.cursor.execute(sql, params)\r\npsycopg2.errors.StringDataRightTruncation: value too long for type character varying(150)\r\nThe above exception was the direct cause of the following exception:\r\nTraceback (most recent call last):\r\nFile \"manage.py\", line 10, in <module>\r\nexecute_from_command_line(sys.argv)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/core/management/__init__.py\", line 401, in execute_from_command_line\r\nutility.execute()\r\nFile \"/usr/local/lib/python3.8/site-packages/django/core/management/__init__.py\", line 395, in execute\r\nself.fetch_command(subcommand).run_from_argv(self.argv)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/core/management/base.py\", line 328, in run_from_argv\r\nself.execute(*args, **cmd_options)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/core/management/base.py\", line 369, in execute\r\noutput = self.handle(*args, **options)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/core/management/base.py\", line 83, in wrapped\r\nres = handle_func(*args, **kwargs)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/core/management/commands/migrate.py\", line 231, in handle\r\npost_migrate_state = executor.migrate(\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/migrations/executor.py\", line 117, in migrate\r\nstate = self._migrate_all_forwards(state, plan, full_plan, fake=fake, fake_initial=fake_initial)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/migrations/executor.py\", line 147, in _migrate_all_forwards\r\nstate = self.apply_migration(state, migration, fake=fake, fake_initial=fake_initial)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/migrations/executor.py\", line 245, in apply_migration\r\nstate = migration.apply(state, schema_editor)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/migrations/migration.py\", line 124, in apply\r\noperation.database_forwards(self.app_label, schema_editor, old_state, project_state)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/migrations/operations/special.py\", line 190, in database_forwards\r\nself.code(from_state.apps, schema_editor)\r\nFile \"/app/saleor/account/migrations/0041_permissions_to_groups.py\", line 26, in add_users_to_groups_based_on_users_permissions\r\ngroup = create_group_with_given_permissions(perms, group_data.group_name, Group)\r\nFile \"/app/saleor/account/migrations/0041_permissions_to_groups.py\", line 65, in create_group_with_given_permissions\r\ngroup = Group.objects.create(name=group_name)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/models/manager.py\", line 82, in manager_method\r\nreturn getattr(self.get_queryset(), name)(*args, **kwargs)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/models/query.py\", line 433, in create\r\nobj.save(force_insert=True, using=self.db)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/models/base.py\", line 745, in save\r\nself.save_base(using=using, force_insert=force_insert,\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/models/base.py\", line 782, in save_base\r\nupdated = self._save_table(\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/models/base.py\", line 887, in _save_table\r\nresults = self._do_insert(cls._base_manager, using, fields, returning_fields, raw)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/models/base.py\", line 924, in _do_insert\r\nreturn manager._insert(\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/models/manager.py\", line 82, in manager_method\r\nreturn getattr(self.get_queryset(), name)(*args, **kwargs)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/models/query.py\", line 1204, in _insert\r\nreturn query.get_compiler(using=using).execute_sql(returning_fields)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/models/sql/compiler.py\", line 1391, in execute_sql\r\ncursor.execute(sql, params)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py\", line 68, in execute\r\nreturn self._execute_with_wrappers(sql, params, many=False, executor=self._execute)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py\", line 77, in _execute_with_wrappers\r\nreturn executor(sql, params, many, context)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py\", line 86, in _execute\r\nreturn self.cursor.execute(sql, params)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/utils.py\", line 90, in __exit__\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/migrations/executor.py\", line 245, in apply_migration\r\nstate = migration.apply(state, schema_editor)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/migrations/migration.py\", line 124, in apply\r\noperation.database_forwards(self.app_label, schema_editor, old_state, project_state)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/migrations/operations/special.py\", line 190, in database_forwards\r\nself.code(from_state.apps, schema_editor)\r\nFile \"/app/saleor/account/migrations/0041_permissions_to_groups.py\", line 26, in add_users_to_groups_based_on_users_permissions\r\ngroup = create_group_with_given_permissions(perms, group_data.group_name, Group)\r\nFile \"/app/saleor/account/migrations/0041_permissions_to_groups.py\", line 65, in create_group_with_given_permissions\r\ngroup = Group.objects.create(name=group_name)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/models/manager.py\", line 82, in manager_method\r\nreturn getattr(self.get_queryset(), name)(*args, **kwargs)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/models/query.py\", line 433, in create\r\nobj.save(force_insert=True, using=self.db)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/models/base.py\", line 745, in save\r\nself.save_base(using=using, force_insert=force_insert,\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/models/base.py\", line 782, in save_base\r\nupdated = self._save_table(\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/models/base.py\", line 887, in _save_table\r\nresults = self._do_insert(cls._base_manager, using, fields, returning_fields, raw)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/models/base.py\", line 924, in _do_insert\r\nreturn manager._insert(\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/models/manager.py\", line 82, in manager_method\r\nreturn getattr(self.get_queryset(), name)(*args, **kwargs)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/models/query.py\", line 1204, in _insert\r\nreturn query.get_compiler(using=using).execute_sql(returning_fields)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/models/sql/compiler.py\", line 1391, in execute_sql\r\ncursor.execute(sql, params)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py\", line 68, in execute\r\nreturn self._execute_with_wrappers(sql, params, many=False, executor=self._execute)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py\", line 77, in _execute_with_wrappers\r\nreturn executor(sql, params, many, context)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py\", line 86, in _execute\r\nreturn self.cursor.execute(sql, params)\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/utils.py\", line 90, in __exit__\r\nraise dj_exc_value.with_traceback(traceback) from exc_value\r\nFile \"/usr/local/lib/python3.8/site-packages/django/db/backends/utils.py\", line 86, in _execute\r\nreturn self.cursor.execute(sql, params)\r\ndjango.db.utils.DataError: value too long for type character varying(150)\r\n```\r\n\r\n### Screenshots\r\n<!-- If applicable, add screenshots to help explain your problem. -->\r\n\r\n**System information**\r\nOperating system:\r\n\n", "before_files": [{"content": "from collections import namedtuple\n\nfrom django.db import migrations\n\n\ndef add_users_to_groups_based_on_users_permissions(apps, schema_editor):\n \"\"\"Add every user to group with \"user_permissions\" if exists, else create new one.\n\n For each user, if the group with the exact scope of permissions exists,\n add the user to it, else create a new group with this scope of permissions\n and add the user to it.\n \"\"\"\n User = apps.get_model(\"account\", \"User\")\n Group = apps.get_model(\"auth\", \"Group\")\n GroupData = namedtuple(\"GroupData\", [\"users\", \"group_name\"])\n\n groups = Group.objects.all().prefetch_related(\"permissions\")\n\n mapping = create_permissions_mapping(User, GroupData)\n for perms, group_data in mapping.items():\n group = get_group_with_given_permissions(perms, groups)\n users = group_data.users\n if group:\n group.user_set.add(*users)\n continue\n group = create_group_with_given_permissions(perms, group_data.group_name, Group)\n group.user_set.add(*users)\n\n\ndef create_permissions_mapping(User, GroupData):\n \"\"\"Create mapping permissions to users and potential new group name.\"\"\"\n mapping = {}\n users = User.objects.filter(user_permissions__isnull=False).prefetch_related(\n \"user_permissions\"\n )\n for user in users:\n permissions = user.user_permissions.all()\n perm_pks = (perm.pk for perm in permissions)\n if perm_pks not in mapping:\n group_name = create_group_name(permissions)\n mapping[perm_pks] = GroupData({user.pk}, group_name)\n else:\n mapping[perm_pks].users.add(user.pk)\n user.user_permissions.clear()\n return mapping\n\n\ndef create_group_name(permissions):\n \"\"\"Create group name based on permissions.\"\"\"\n formatted_names = [perm.name.rstrip(\".\").lower() for perm in permissions]\n group_name = \", \".join(formatted_names).capitalize()\n return group_name\n\n\ndef get_group_with_given_permissions(permissions, groups):\n \"\"\"Get group with given set of permissions.\"\"\"\n for group in groups:\n group_perm_pks = {perm.pk for perm in group.permissions.all()}\n if group_perm_pks == set(permissions):\n return group\n\n\ndef create_group_with_given_permissions(perm_pks, group_name, Group):\n \"\"\"Create new group with given set of permissions.\"\"\"\n group = Group.objects.create(name=group_name)\n group.permissions.add(*perm_pks)\n return group\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n (\"account\", \"0040_auto_20200415_0443\"),\n ]\n operations = [\n migrations.RunPython(\n add_users_to_groups_based_on_users_permissions, migrations.RunPython.noop\n ),\n ]\n", "path": "saleor/account/migrations/0041_permissions_to_groups.py"}], "after_files": [{"content": "import re\nfrom collections import defaultdict\n\nfrom django.db import migrations\n\n\ndef add_users_to_groups_based_on_users_permissions(apps, schema_editor):\n \"\"\"Add every user to group with \"user_permissions\" if exists, else create new one.\n\n For each user, if the group with the exact scope of permissions exists,\n add the user to it, else create a new group with this scope of permissions\n and add the user to it.\n \"\"\"\n User = apps.get_model(\"account\", \"User\")\n Group = apps.get_model(\"auth\", \"Group\")\n\n groups = Group.objects.all().prefetch_related(\"permissions\")\n counter = get_counter_value(Group)\n mapping = create_permissions_mapping(User)\n for perms, users in mapping.items():\n group = get_group_with_given_permissions(perms, groups)\n if group:\n group.user_set.add(*users)\n continue\n group = create_group_with_given_permissions(perms, counter, Group)\n group.user_set.add(*users)\n counter += 1\n\n\ndef get_counter_value(Group):\n \"\"\"Get the number of next potential group.\"\"\"\n pattern = r\"^Group (\\d+)$\"\n group = Group.objects.filter(name__iregex=pattern).order_by(\"name\").last()\n if not group:\n return 1\n return int(re.match(pattern, group.name).group(1)) + 1\n\n\ndef create_permissions_mapping(User):\n \"\"\"Create mapping permissions to users and potential new group name.\"\"\"\n mapping = defaultdict(set)\n users = (\n User.objects.filter(user_permissions__isnull=False)\n .distinct()\n .prefetch_related(\"user_permissions\")\n )\n for user in users:\n permissions = user.user_permissions.all().order_by(\"pk\")\n perm_pks = tuple([perm.pk for perm in permissions])\n mapping[perm_pks].add(user.pk)\n user.user_permissions.clear()\n return mapping\n\n\ndef get_group_with_given_permissions(permissions, groups):\n \"\"\"Get group with given set of permissions.\"\"\"\n for group in groups:\n group_perm_pks = {perm.pk for perm in group.permissions.all()}\n if group_perm_pks == set(permissions):\n return group\n\n\ndef create_group_with_given_permissions(perm_pks, counter, Group):\n \"\"\"Create new group with given set of permissions.\"\"\"\n group_name = f\"Group {counter:03d}\"\n group = Group.objects.create(name=group_name)\n group.permissions.add(*perm_pks)\n return group\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n (\"account\", \"0040_auto_20200415_0443\"),\n ]\n operations = [\n migrations.RunPython(\n add_users_to_groups_based_on_users_permissions, migrations.RunPython.noop\n ),\n ]\n", "path": "saleor/account/migrations/0041_permissions_to_groups.py"}]}
| 3,107 | 817 |
gh_patches_debug_25342
|
rasdani/github-patches
|
git_diff
|
getredash__redash-4239
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Change PagerDuty's default summary text
Currently PagerDuty's Alert destination default summary text uses the query id and name. We should change it to use the alert name as it's usually better explains what the alert is.
While #4153 implements ability to customize the summary text, it's good to have a saner default regardless.
(If #4153 is not merged before implementing, should be implemented based on its branch)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `redash/destinations/pagerduty.py`
Content:
```
1 import logging
2 from redash.destinations import *
3
4 enabled = True
5
6 try:
7 import pypd
8 except ImportError:
9 enabled = False
10
11
12 class PagerDuty(BaseDestination):
13
14 KEY_STRING = '{alert_id}_{query_id}'
15 DESCRIPTION_STR = u'Alert - Redash Query #{query_id}: {query_name}'
16
17 @classmethod
18 def enabled(cls):
19 return enabled
20
21 @classmethod
22 def configuration_schema(cls):
23 return {
24 'type': 'object',
25 'properties': {
26 'integration_key': {
27 'type': 'string',
28 'title': 'PagerDuty Service Integration Key'
29 },
30 'description': {
31 'type': 'string',
32 'title': 'Description for the event, defaults to query',
33 }
34 },
35 "required": ["integration_key"]
36 }
37
38 @classmethod
39 def icon(cls):
40 return 'creative-commons-pd-alt'
41
42 def notify(self, alert, query, user, new_state, app, host, options):
43
44 if alert.custom_subject:
45 default_desc = alert.custom_subject
46 elif options.get('description'):
47 default_desc = options.get('description')
48 else:
49 default_desc = self.DESCRIPTION_STR.format(query_id=query.id, query_name=query.name)
50
51 incident_key = self.KEY_STRING.format(alert_id=alert.id, query_id=query.id)
52 data = {
53 'routing_key': options.get('integration_key'),
54 'incident_key': incident_key,
55 'dedup_key': incident_key,
56 'payload': {
57 'summary': default_desc,
58 'severity': 'error',
59 'source': 'redash',
60 }
61 }
62
63 if alert.custom_body:
64 data['payload']['custom_details'] = alert.custom_body
65
66 if new_state == 'triggered':
67 data['event_action'] = 'trigger'
68 elif new_state == "unknown":
69 logging.info('Unknown state, doing nothing')
70 return
71 else:
72 data['event_action'] = 'resolve'
73
74 try:
75
76 ev = pypd.EventV2.create(data=data)
77 logging.warning(ev)
78
79 except Exception:
80 logging.exception("PagerDuty trigger failed!")
81
82
83 register(PagerDuty)
84
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/redash/destinations/pagerduty.py b/redash/destinations/pagerduty.py
--- a/redash/destinations/pagerduty.py
+++ b/redash/destinations/pagerduty.py
@@ -12,7 +12,7 @@
class PagerDuty(BaseDestination):
KEY_STRING = '{alert_id}_{query_id}'
- DESCRIPTION_STR = u'Alert - Redash Query #{query_id}: {query_name}'
+ DESCRIPTION_STR = u'Alert: {alert_name}'
@classmethod
def enabled(cls):
@@ -29,7 +29,7 @@
},
'description': {
'type': 'string',
- 'title': 'Description for the event, defaults to query',
+ 'title': 'Description for the event, defaults to alert name',
}
},
"required": ["integration_key"]
@@ -46,7 +46,7 @@
elif options.get('description'):
default_desc = options.get('description')
else:
- default_desc = self.DESCRIPTION_STR.format(query_id=query.id, query_name=query.name)
+ default_desc = self.DESCRIPTION_STR.format(alert_name=alert.name)
incident_key = self.KEY_STRING.format(alert_id=alert.id, query_id=query.id)
data = {
|
{"golden_diff": "diff --git a/redash/destinations/pagerduty.py b/redash/destinations/pagerduty.py\n--- a/redash/destinations/pagerduty.py\n+++ b/redash/destinations/pagerduty.py\n@@ -12,7 +12,7 @@\n class PagerDuty(BaseDestination):\n \n KEY_STRING = '{alert_id}_{query_id}'\n- DESCRIPTION_STR = u'Alert - Redash Query #{query_id}: {query_name}'\n+ DESCRIPTION_STR = u'Alert: {alert_name}'\n \n @classmethod\n def enabled(cls):\n@@ -29,7 +29,7 @@\n },\n 'description': {\n 'type': 'string',\n- 'title': 'Description for the event, defaults to query',\n+ 'title': 'Description for the event, defaults to alert name',\n }\n },\n \"required\": [\"integration_key\"]\n@@ -46,7 +46,7 @@\n elif options.get('description'):\n default_desc = options.get('description')\n else:\n- default_desc = self.DESCRIPTION_STR.format(query_id=query.id, query_name=query.name)\n+ default_desc = self.DESCRIPTION_STR.format(alert_name=alert.name)\n \n incident_key = self.KEY_STRING.format(alert_id=alert.id, query_id=query.id)\n data = {\n", "issue": "Change PagerDuty's default summary text\nCurrently PagerDuty's Alert destination default summary text uses the query id and name. We should change it to use the alert name as it's usually better explains what the alert is.\r\n\r\nWhile #4153 implements ability to customize the summary text, it's good to have a saner default regardless.\r\n\r\n(If #4153 is not merged before implementing, should be implemented based on its branch)\n", "before_files": [{"content": "import logging\nfrom redash.destinations import *\n\nenabled = True\n\ntry:\n import pypd\nexcept ImportError:\n enabled = False\n\n\nclass PagerDuty(BaseDestination):\n\n KEY_STRING = '{alert_id}_{query_id}'\n DESCRIPTION_STR = u'Alert - Redash Query #{query_id}: {query_name}'\n\n @classmethod\n def enabled(cls):\n return enabled\n\n @classmethod\n def configuration_schema(cls):\n return {\n 'type': 'object',\n 'properties': {\n 'integration_key': {\n 'type': 'string',\n 'title': 'PagerDuty Service Integration Key'\n },\n 'description': {\n 'type': 'string',\n 'title': 'Description for the event, defaults to query',\n }\n },\n \"required\": [\"integration_key\"]\n }\n\n @classmethod\n def icon(cls):\n return 'creative-commons-pd-alt'\n\n def notify(self, alert, query, user, new_state, app, host, options):\n\n if alert.custom_subject:\n default_desc = alert.custom_subject\n elif options.get('description'):\n default_desc = options.get('description')\n else:\n default_desc = self.DESCRIPTION_STR.format(query_id=query.id, query_name=query.name)\n\n incident_key = self.KEY_STRING.format(alert_id=alert.id, query_id=query.id)\n data = {\n 'routing_key': options.get('integration_key'),\n 'incident_key': incident_key,\n 'dedup_key': incident_key,\n 'payload': {\n 'summary': default_desc,\n 'severity': 'error',\n 'source': 'redash',\n }\n }\n\n if alert.custom_body:\n data['payload']['custom_details'] = alert.custom_body\n\n if new_state == 'triggered':\n data['event_action'] = 'trigger'\n elif new_state == \"unknown\":\n logging.info('Unknown state, doing nothing')\n return\n else:\n data['event_action'] = 'resolve'\n\n try:\n\n ev = pypd.EventV2.create(data=data)\n logging.warning(ev)\n\n except Exception:\n logging.exception(\"PagerDuty trigger failed!\")\n\n\nregister(PagerDuty)\n", "path": "redash/destinations/pagerduty.py"}], "after_files": [{"content": "import logging\nfrom redash.destinations import *\n\nenabled = True\n\ntry:\n import pypd\nexcept ImportError:\n enabled = False\n\n\nclass PagerDuty(BaseDestination):\n\n KEY_STRING = '{alert_id}_{query_id}'\n DESCRIPTION_STR = u'Alert: {alert_name}'\n\n @classmethod\n def enabled(cls):\n return enabled\n\n @classmethod\n def configuration_schema(cls):\n return {\n 'type': 'object',\n 'properties': {\n 'integration_key': {\n 'type': 'string',\n 'title': 'PagerDuty Service Integration Key'\n },\n 'description': {\n 'type': 'string',\n 'title': 'Description for the event, defaults to alert name',\n }\n },\n \"required\": [\"integration_key\"]\n }\n\n @classmethod\n def icon(cls):\n return 'creative-commons-pd-alt'\n\n def notify(self, alert, query, user, new_state, app, host, options):\n\n if alert.custom_subject:\n default_desc = alert.custom_subject\n elif options.get('description'):\n default_desc = options.get('description')\n else:\n default_desc = self.DESCRIPTION_STR.format(alert_name=alert.name)\n\n incident_key = self.KEY_STRING.format(alert_id=alert.id, query_id=query.id)\n data = {\n 'routing_key': options.get('integration_key'),\n 'incident_key': incident_key,\n 'dedup_key': incident_key,\n 'payload': {\n 'summary': default_desc,\n 'severity': 'error',\n 'source': 'redash',\n }\n }\n\n if alert.custom_body:\n data['payload']['custom_details'] = alert.custom_body\n\n if new_state == 'triggered':\n data['event_action'] = 'trigger'\n elif new_state == \"unknown\":\n logging.info('Unknown state, doing nothing')\n return\n else:\n data['event_action'] = 'resolve'\n\n try:\n\n ev = pypd.EventV2.create(data=data)\n logging.warning(ev)\n\n except Exception:\n logging.exception(\"PagerDuty trigger failed!\")\n\n\nregister(PagerDuty)\n", "path": "redash/destinations/pagerduty.py"}]}
| 991 | 286 |
gh_patches_debug_41934
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-11156
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug: Update image validation - allow only formats that are supported by thumbnails
### What are you trying to achieve?
The error should be raised for uploading an image that is not supported by thumbnails.
### Steps to reproduce the problem
1. Upload the image for a field that supports thumbnails (for example user avatar), use the image extension that is not listed [here](https://github.com/saleor/saleor/blob/70549a473061fe308c66962bd9da64d3979e0788/saleor/thumbnail/__init__.py#L18-L34).
2. Try to fetch the thumbnails for the uploaded file.
### What did you expect to happen?
The `ValidationError` should be raised when an invalid file is uploaded.
### Logs
_No response_
### Environment
Saleor version:3.6+
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `saleor/graphql/core/utils/__init__.py`
Content:
```
1 import binascii
2 import mimetypes
3 import os
4 import secrets
5 from typing import TYPE_CHECKING, Union
6 from uuid import UUID
7
8 import graphene
9 import requests
10 from django.core.exceptions import ValidationError
11 from graphene import ObjectType
12 from graphql.error import GraphQLError
13 from PIL import Image
14
15 from ....core.utils import generate_unique_slug
16 from ....plugins.webhook.utils import APP_ID_PREFIX
17
18 if TYPE_CHECKING:
19 from django.db.models import Model
20
21
22 Image.init()
23
24
25 def clean_seo_fields(data):
26 """Extract and assign seo fields to given dictionary."""
27 seo_fields = data.pop("seo", None)
28 if seo_fields:
29 data["seo_title"] = seo_fields.get("title")
30 data["seo_description"] = seo_fields.get("description")
31
32
33 def snake_to_camel_case(name):
34 """Convert snake_case variable name to camelCase."""
35 if isinstance(name, str):
36 split_name = name.split("_")
37 return split_name[0] + "".join(map(str.capitalize, split_name[1:]))
38 return name
39
40
41 def str_to_enum(name):
42 """Create an enum value from a string."""
43 return name.replace(" ", "_").replace("-", "_").upper()
44
45
46 def is_image_mimetype(mimetype: str) -> bool:
47 """Check if mimetype is image."""
48 if mimetype is None:
49 return False
50 return mimetype.startswith("image/")
51
52
53 def is_image_url(url: str) -> bool:
54 """Check if file URL seems to be an image."""
55 if url.endswith(".webp"):
56 # webp is not recognized by mimetypes as image
57 # https://bugs.python.org/issue38902
58 return True
59 filetype = mimetypes.guess_type(url)[0]
60 return filetype is not None and is_image_mimetype(filetype)
61
62
63 def validate_image_url(url: str, field_name: str, error_code: str) -> None:
64 """Check if remote file has content type of image.
65
66 Instead of the whole file, only the headers are fetched.
67 """
68 head = requests.head(url)
69 header = head.headers
70 content_type = header.get("content-type")
71 if content_type is None or not is_image_mimetype(content_type):
72 raise ValidationError(
73 {field_name: ValidationError("Invalid file type.", code=error_code)}
74 )
75
76
77 def get_filename_from_url(url: str) -> str:
78 """Prepare unique filename for file from URL to avoid overwritting."""
79 file_name = os.path.basename(url)
80 name, format = os.path.splitext(file_name)
81 hash = secrets.token_hex(nbytes=4)
82 return f"{name}_{hash}{format}"
83
84
85 def validate_image_file(file, field_name, error_class) -> None:
86 """Validate if the file is an image."""
87 if not file:
88 raise ValidationError(
89 {
90 field_name: ValidationError(
91 "File is required.", code=error_class.REQUIRED
92 )
93 }
94 )
95 if not is_image_mimetype(file.content_type):
96 raise ValidationError(
97 {
98 field_name: ValidationError(
99 "Invalid file type.", code=error_class.INVALID
100 )
101 }
102 )
103 _validate_image_format(file, field_name, error_class)
104
105
106 def _validate_image_format(file, field_name, error_class):
107 """Validate image file format."""
108 allowed_extensions = [ext.lower() for ext in Image.EXTENSION]
109 _file_name, format = os.path.splitext(file._name)
110 if not format:
111 raise ValidationError(
112 {
113 field_name: ValidationError(
114 "Lack of file extension.", code=error_class.INVALID
115 )
116 }
117 )
118 elif format not in allowed_extensions:
119 raise ValidationError(
120 {
121 field_name: ValidationError(
122 "Invalid file extension. Image file required.",
123 code=error_class.INVALID,
124 )
125 }
126 )
127
128
129 def validate_slug_and_generate_if_needed(
130 instance: "Model",
131 slugable_field: str,
132 cleaned_input: dict,
133 slug_field_name: str = "slug",
134 ) -> dict:
135 """Validate slug from input and generate in create mutation if is not given."""
136
137 # update mutation - just check if slug value is not empty
138 # _state.adding is True only when it's new not saved instance.
139 if not instance._state.adding: # type: ignore
140 validate_slug_value(cleaned_input)
141 return cleaned_input
142
143 # create mutation - generate slug if slug value is empty
144 slug = cleaned_input.get(slug_field_name)
145 if not slug and slugable_field in cleaned_input:
146 slug = generate_unique_slug(instance, cleaned_input[slugable_field])
147 cleaned_input[slug_field_name] = slug
148 return cleaned_input
149
150
151 def validate_slug_value(cleaned_input, slug_field_name: str = "slug"):
152 if slug_field_name in cleaned_input:
153 slug = cleaned_input[slug_field_name]
154 if not slug:
155 raise ValidationError(
156 f"{slug_field_name.capitalize()} value cannot be blank."
157 )
158
159
160 def get_duplicates_items(first_list, second_list):
161 """Return items that appear on both provided lists."""
162 if first_list and second_list:
163 return set(first_list) & set(second_list)
164 return []
165
166
167 def get_duplicated_values(values):
168 """Return set of duplicated values."""
169 return {value for value in values if values.count(value) > 1}
170
171
172 def validate_required_string_field(cleaned_input, field_name: str):
173 """Strip and validate field value."""
174 field_value = cleaned_input.get(field_name)
175 field_value = field_value.strip() if field_value else ""
176 if field_value:
177 cleaned_input[field_name] = field_value
178 else:
179 raise ValidationError(f"{field_name.capitalize()} is required.")
180 return cleaned_input
181
182
183 def validate_if_int_or_uuid(id):
184 result = True
185 try:
186 int(id)
187 except ValueError:
188 try:
189 UUID(id)
190 except (AttributeError, ValueError):
191 result = False
192 return result
193
194
195 def from_global_id_or_error(
196 global_id: str,
197 only_type: Union[ObjectType, str, None] = None,
198 raise_error: bool = False,
199 ):
200 """Resolve global ID or raise GraphQLError.
201
202 Validates if given ID is a proper ID handled by Saleor.
203 Valid IDs formats, base64 encoded:
204 'app:<int>:<str>' : External app ID with 'app' prefix
205 '<type>:<int>' : Internal ID containing object type and ID as integer
206 '<type>:<UUID>' : Internal ID containing object type and UUID
207 Optionally validate the object type, if `only_type` is provided,
208 raise GraphQLError when `raise_error` is set to True.
209 """
210 try:
211 type_, id_ = graphene.Node.from_global_id(global_id)
212 except (binascii.Error, UnicodeDecodeError, ValueError):
213 raise GraphQLError(f"Couldn't resolve id: {global_id}.")
214 if type_ == APP_ID_PREFIX:
215 id_ = global_id
216 else:
217 if not validate_if_int_or_uuid(id_):
218 raise GraphQLError(f"Error occurred during ID - {global_id} validation.")
219
220 if only_type and str(type_) != str(only_type):
221 if not raise_error:
222 return type_, None
223 raise GraphQLError(f"Must receive a {only_type} id.")
224 return type_, id_
225
226
227 def from_global_id_or_none(
228 global_id, only_type: Union[ObjectType, str, None] = None, raise_error: bool = False
229 ):
230 if not global_id:
231 return None
232
233 return from_global_id_or_error(global_id, only_type, raise_error)[1]
234
235
236 def to_global_id_or_none(instance):
237 class_name = instance.__class__.__name__
238 if instance is None or instance.pk is None:
239 return None
240 return graphene.Node.to_global_id(class_name, instance.pk)
241
242
243 def add_hash_to_file_name(file):
244 """Add unique text fragment to the file name to prevent file overriding."""
245 file_name, format = os.path.splitext(file._name)
246 hash = secrets.token_hex(nbytes=4)
247 new_name = f"{file_name}_{hash}{format}"
248 file._name = new_name
249
```
Path: `saleor/thumbnail/__init__.py`
Content:
```
1 default_app_config = "saleor.thumbnail.app.ThumbnailAppConfig"
2
3 # defines the available thumbnail resolutions
4 THUMBNAIL_SIZES = [32, 64, 128, 256, 512, 1024, 2048, 4096]
5
6
7 class ThumbnailFormat:
8 WEBP = "webp"
9
10 CHOICES = [
11 (WEBP, "WebP"),
12 ]
13
14
15 # PIL-supported file formats as found here:
16 # https://infohost.nmt.edu/tcc/help/pubs/pil/formats.html
17 # {mime type: PIL Identifier}
18 MIME_TYPE_TO_PIL_IDENTIFIER = {
19 "image/bmp": "BMP",
20 "image/dcx": "DCX",
21 "image/eps": "eps",
22 "image/gif": "GIF",
23 "image/jpeg": "JPEG",
24 "image/pcd": "PCD",
25 "image/pcx": "PCX",
26 "application/pdf": "PDF",
27 "image/png": "PNG",
28 "image/x-ppm": "PPM",
29 "image/psd": "PSD",
30 "image/tiff": "TIFF",
31 "image/x-xbitmap": "XBM",
32 "image/x-xpm": "XPM",
33 "image/webp": "WEBP",
34 }
35
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/saleor/graphql/core/utils/__init__.py b/saleor/graphql/core/utils/__init__.py
--- a/saleor/graphql/core/utils/__init__.py
+++ b/saleor/graphql/core/utils/__init__.py
@@ -14,6 +14,7 @@
from ....core.utils import generate_unique_slug
from ....plugins.webhook.utils import APP_ID_PREFIX
+from ....thumbnail import MIME_TYPE_TO_PIL_IDENTIFIER
if TYPE_CHECKING:
from django.db.models import Model
@@ -50,6 +51,13 @@
return mimetype.startswith("image/")
+def is_supported_image_mimetype(mimetype: str) -> bool:
+ """Check if mimetype is a mimetype that thumbnails support."""
+ if mimetype is None:
+ return False
+ return mimetype in MIME_TYPE_TO_PIL_IDENTIFIER.keys()
+
+
def is_image_url(url: str) -> bool:
"""Check if file URL seems to be an image."""
if url.endswith(".webp"):
@@ -68,7 +76,7 @@
head = requests.head(url)
header = head.headers
content_type = header.get("content-type")
- if content_type is None or not is_image_mimetype(content_type):
+ if content_type is None or not is_supported_image_mimetype(content_type):
raise ValidationError(
{field_name: ValidationError("Invalid file type.", code=error_code)}
)
@@ -83,7 +91,7 @@
def validate_image_file(file, field_name, error_class) -> None:
- """Validate if the file is an image."""
+ """Validate if the file is an image supported by thumbnails."""
if not file:
raise ValidationError(
{
@@ -92,7 +100,7 @@
)
}
)
- if not is_image_mimetype(file.content_type):
+ if not is_supported_image_mimetype(file.content_type):
raise ValidationError(
{
field_name: ValidationError(
@@ -105,7 +113,7 @@
def _validate_image_format(file, field_name, error_class):
"""Validate image file format."""
- allowed_extensions = [ext.lower() for ext in Image.EXTENSION]
+ allowed_extensions = get_allowed_extensions()
_file_name, format = os.path.splitext(file._name)
if not format:
raise ValidationError(
@@ -126,6 +134,15 @@
)
+def get_allowed_extensions():
+ """Return image extension lists that are supported by thumbnails."""
+ return [
+ ext.lower()
+ for ext, file_type in Image.EXTENSION.items()
+ if file_type.upper() in MIME_TYPE_TO_PIL_IDENTIFIER.values()
+ ]
+
+
def validate_slug_and_generate_if_needed(
instance: "Model",
slugable_field: str,
diff --git a/saleor/thumbnail/__init__.py b/saleor/thumbnail/__init__.py
--- a/saleor/thumbnail/__init__.py
+++ b/saleor/thumbnail/__init__.py
@@ -18,12 +18,11 @@
MIME_TYPE_TO_PIL_IDENTIFIER = {
"image/bmp": "BMP",
"image/dcx": "DCX",
- "image/eps": "eps",
+ "image/eps": "EPS",
"image/gif": "GIF",
"image/jpeg": "JPEG",
"image/pcd": "PCD",
"image/pcx": "PCX",
- "application/pdf": "PDF",
"image/png": "PNG",
"image/x-ppm": "PPM",
"image/psd": "PSD",
|
{"golden_diff": "diff --git a/saleor/graphql/core/utils/__init__.py b/saleor/graphql/core/utils/__init__.py\n--- a/saleor/graphql/core/utils/__init__.py\n+++ b/saleor/graphql/core/utils/__init__.py\n@@ -14,6 +14,7 @@\n \n from ....core.utils import generate_unique_slug\n from ....plugins.webhook.utils import APP_ID_PREFIX\n+from ....thumbnail import MIME_TYPE_TO_PIL_IDENTIFIER\n \n if TYPE_CHECKING:\n from django.db.models import Model\n@@ -50,6 +51,13 @@\n return mimetype.startswith(\"image/\")\n \n \n+def is_supported_image_mimetype(mimetype: str) -> bool:\n+ \"\"\"Check if mimetype is a mimetype that thumbnails support.\"\"\"\n+ if mimetype is None:\n+ return False\n+ return mimetype in MIME_TYPE_TO_PIL_IDENTIFIER.keys()\n+\n+\n def is_image_url(url: str) -> bool:\n \"\"\"Check if file URL seems to be an image.\"\"\"\n if url.endswith(\".webp\"):\n@@ -68,7 +76,7 @@\n head = requests.head(url)\n header = head.headers\n content_type = header.get(\"content-type\")\n- if content_type is None or not is_image_mimetype(content_type):\n+ if content_type is None or not is_supported_image_mimetype(content_type):\n raise ValidationError(\n {field_name: ValidationError(\"Invalid file type.\", code=error_code)}\n )\n@@ -83,7 +91,7 @@\n \n \n def validate_image_file(file, field_name, error_class) -> None:\n- \"\"\"Validate if the file is an image.\"\"\"\n+ \"\"\"Validate if the file is an image supported by thumbnails.\"\"\"\n if not file:\n raise ValidationError(\n {\n@@ -92,7 +100,7 @@\n )\n }\n )\n- if not is_image_mimetype(file.content_type):\n+ if not is_supported_image_mimetype(file.content_type):\n raise ValidationError(\n {\n field_name: ValidationError(\n@@ -105,7 +113,7 @@\n \n def _validate_image_format(file, field_name, error_class):\n \"\"\"Validate image file format.\"\"\"\n- allowed_extensions = [ext.lower() for ext in Image.EXTENSION]\n+ allowed_extensions = get_allowed_extensions()\n _file_name, format = os.path.splitext(file._name)\n if not format:\n raise ValidationError(\n@@ -126,6 +134,15 @@\n )\n \n \n+def get_allowed_extensions():\n+ \"\"\"Return image extension lists that are supported by thumbnails.\"\"\"\n+ return [\n+ ext.lower()\n+ for ext, file_type in Image.EXTENSION.items()\n+ if file_type.upper() in MIME_TYPE_TO_PIL_IDENTIFIER.values()\n+ ]\n+\n+\n def validate_slug_and_generate_if_needed(\n instance: \"Model\",\n slugable_field: str,\ndiff --git a/saleor/thumbnail/__init__.py b/saleor/thumbnail/__init__.py\n--- a/saleor/thumbnail/__init__.py\n+++ b/saleor/thumbnail/__init__.py\n@@ -18,12 +18,11 @@\n MIME_TYPE_TO_PIL_IDENTIFIER = {\n \"image/bmp\": \"BMP\",\n \"image/dcx\": \"DCX\",\n- \"image/eps\": \"eps\",\n+ \"image/eps\": \"EPS\",\n \"image/gif\": \"GIF\",\n \"image/jpeg\": \"JPEG\",\n \"image/pcd\": \"PCD\",\n \"image/pcx\": \"PCX\",\n- \"application/pdf\": \"PDF\",\n \"image/png\": \"PNG\",\n \"image/x-ppm\": \"PPM\",\n \"image/psd\": \"PSD\",\n", "issue": "Bug: Update image validation - allow only formats that are supported by thumbnails\n### What are you trying to achieve?\n\nThe error should be raised for uploading an image that is not supported by thumbnails.\n\n### Steps to reproduce the problem\n\n1. Upload the image for a field that supports thumbnails (for example user avatar), use the image extension that is not listed [here](https://github.com/saleor/saleor/blob/70549a473061fe308c66962bd9da64d3979e0788/saleor/thumbnail/__init__.py#L18-L34).\r\n2. Try to fetch the thumbnails for the uploaded file.\n\n### What did you expect to happen?\n\nThe `ValidationError` should be raised when an invalid file is uploaded.\n\n### Logs\n\n_No response_\n\n### Environment\n\nSaleor version:3.6+\r\n\n", "before_files": [{"content": "import binascii\nimport mimetypes\nimport os\nimport secrets\nfrom typing import TYPE_CHECKING, Union\nfrom uuid import UUID\n\nimport graphene\nimport requests\nfrom django.core.exceptions import ValidationError\nfrom graphene import ObjectType\nfrom graphql.error import GraphQLError\nfrom PIL import Image\n\nfrom ....core.utils import generate_unique_slug\nfrom ....plugins.webhook.utils import APP_ID_PREFIX\n\nif TYPE_CHECKING:\n from django.db.models import Model\n\n\nImage.init()\n\n\ndef clean_seo_fields(data):\n \"\"\"Extract and assign seo fields to given dictionary.\"\"\"\n seo_fields = data.pop(\"seo\", None)\n if seo_fields:\n data[\"seo_title\"] = seo_fields.get(\"title\")\n data[\"seo_description\"] = seo_fields.get(\"description\")\n\n\ndef snake_to_camel_case(name):\n \"\"\"Convert snake_case variable name to camelCase.\"\"\"\n if isinstance(name, str):\n split_name = name.split(\"_\")\n return split_name[0] + \"\".join(map(str.capitalize, split_name[1:]))\n return name\n\n\ndef str_to_enum(name):\n \"\"\"Create an enum value from a string.\"\"\"\n return name.replace(\" \", \"_\").replace(\"-\", \"_\").upper()\n\n\ndef is_image_mimetype(mimetype: str) -> bool:\n \"\"\"Check if mimetype is image.\"\"\"\n if mimetype is None:\n return False\n return mimetype.startswith(\"image/\")\n\n\ndef is_image_url(url: str) -> bool:\n \"\"\"Check if file URL seems to be an image.\"\"\"\n if url.endswith(\".webp\"):\n # webp is not recognized by mimetypes as image\n # https://bugs.python.org/issue38902\n return True\n filetype = mimetypes.guess_type(url)[0]\n return filetype is not None and is_image_mimetype(filetype)\n\n\ndef validate_image_url(url: str, field_name: str, error_code: str) -> None:\n \"\"\"Check if remote file has content type of image.\n\n Instead of the whole file, only the headers are fetched.\n \"\"\"\n head = requests.head(url)\n header = head.headers\n content_type = header.get(\"content-type\")\n if content_type is None or not is_image_mimetype(content_type):\n raise ValidationError(\n {field_name: ValidationError(\"Invalid file type.\", code=error_code)}\n )\n\n\ndef get_filename_from_url(url: str) -> str:\n \"\"\"Prepare unique filename for file from URL to avoid overwritting.\"\"\"\n file_name = os.path.basename(url)\n name, format = os.path.splitext(file_name)\n hash = secrets.token_hex(nbytes=4)\n return f\"{name}_{hash}{format}\"\n\n\ndef validate_image_file(file, field_name, error_class) -> None:\n \"\"\"Validate if the file is an image.\"\"\"\n if not file:\n raise ValidationError(\n {\n field_name: ValidationError(\n \"File is required.\", code=error_class.REQUIRED\n )\n }\n )\n if not is_image_mimetype(file.content_type):\n raise ValidationError(\n {\n field_name: ValidationError(\n \"Invalid file type.\", code=error_class.INVALID\n )\n }\n )\n _validate_image_format(file, field_name, error_class)\n\n\ndef _validate_image_format(file, field_name, error_class):\n \"\"\"Validate image file format.\"\"\"\n allowed_extensions = [ext.lower() for ext in Image.EXTENSION]\n _file_name, format = os.path.splitext(file._name)\n if not format:\n raise ValidationError(\n {\n field_name: ValidationError(\n \"Lack of file extension.\", code=error_class.INVALID\n )\n }\n )\n elif format not in allowed_extensions:\n raise ValidationError(\n {\n field_name: ValidationError(\n \"Invalid file extension. Image file required.\",\n code=error_class.INVALID,\n )\n }\n )\n\n\ndef validate_slug_and_generate_if_needed(\n instance: \"Model\",\n slugable_field: str,\n cleaned_input: dict,\n slug_field_name: str = \"slug\",\n) -> dict:\n \"\"\"Validate slug from input and generate in create mutation if is not given.\"\"\"\n\n # update mutation - just check if slug value is not empty\n # _state.adding is True only when it's new not saved instance.\n if not instance._state.adding: # type: ignore\n validate_slug_value(cleaned_input)\n return cleaned_input\n\n # create mutation - generate slug if slug value is empty\n slug = cleaned_input.get(slug_field_name)\n if not slug and slugable_field in cleaned_input:\n slug = generate_unique_slug(instance, cleaned_input[slugable_field])\n cleaned_input[slug_field_name] = slug\n return cleaned_input\n\n\ndef validate_slug_value(cleaned_input, slug_field_name: str = \"slug\"):\n if slug_field_name in cleaned_input:\n slug = cleaned_input[slug_field_name]\n if not slug:\n raise ValidationError(\n f\"{slug_field_name.capitalize()} value cannot be blank.\"\n )\n\n\ndef get_duplicates_items(first_list, second_list):\n \"\"\"Return items that appear on both provided lists.\"\"\"\n if first_list and second_list:\n return set(first_list) & set(second_list)\n return []\n\n\ndef get_duplicated_values(values):\n \"\"\"Return set of duplicated values.\"\"\"\n return {value for value in values if values.count(value) > 1}\n\n\ndef validate_required_string_field(cleaned_input, field_name: str):\n \"\"\"Strip and validate field value.\"\"\"\n field_value = cleaned_input.get(field_name)\n field_value = field_value.strip() if field_value else \"\"\n if field_value:\n cleaned_input[field_name] = field_value\n else:\n raise ValidationError(f\"{field_name.capitalize()} is required.\")\n return cleaned_input\n\n\ndef validate_if_int_or_uuid(id):\n result = True\n try:\n int(id)\n except ValueError:\n try:\n UUID(id)\n except (AttributeError, ValueError):\n result = False\n return result\n\n\ndef from_global_id_or_error(\n global_id: str,\n only_type: Union[ObjectType, str, None] = None,\n raise_error: bool = False,\n):\n \"\"\"Resolve global ID or raise GraphQLError.\n\n Validates if given ID is a proper ID handled by Saleor.\n Valid IDs formats, base64 encoded:\n 'app:<int>:<str>' : External app ID with 'app' prefix\n '<type>:<int>' : Internal ID containing object type and ID as integer\n '<type>:<UUID>' : Internal ID containing object type and UUID\n Optionally validate the object type, if `only_type` is provided,\n raise GraphQLError when `raise_error` is set to True.\n \"\"\"\n try:\n type_, id_ = graphene.Node.from_global_id(global_id)\n except (binascii.Error, UnicodeDecodeError, ValueError):\n raise GraphQLError(f\"Couldn't resolve id: {global_id}.\")\n if type_ == APP_ID_PREFIX:\n id_ = global_id\n else:\n if not validate_if_int_or_uuid(id_):\n raise GraphQLError(f\"Error occurred during ID - {global_id} validation.\")\n\n if only_type and str(type_) != str(only_type):\n if not raise_error:\n return type_, None\n raise GraphQLError(f\"Must receive a {only_type} id.\")\n return type_, id_\n\n\ndef from_global_id_or_none(\n global_id, only_type: Union[ObjectType, str, None] = None, raise_error: bool = False\n):\n if not global_id:\n return None\n\n return from_global_id_or_error(global_id, only_type, raise_error)[1]\n\n\ndef to_global_id_or_none(instance):\n class_name = instance.__class__.__name__\n if instance is None or instance.pk is None:\n return None\n return graphene.Node.to_global_id(class_name, instance.pk)\n\n\ndef add_hash_to_file_name(file):\n \"\"\"Add unique text fragment to the file name to prevent file overriding.\"\"\"\n file_name, format = os.path.splitext(file._name)\n hash = secrets.token_hex(nbytes=4)\n new_name = f\"{file_name}_{hash}{format}\"\n file._name = new_name\n", "path": "saleor/graphql/core/utils/__init__.py"}, {"content": "default_app_config = \"saleor.thumbnail.app.ThumbnailAppConfig\"\n\n# defines the available thumbnail resolutions\nTHUMBNAIL_SIZES = [32, 64, 128, 256, 512, 1024, 2048, 4096]\n\n\nclass ThumbnailFormat:\n WEBP = \"webp\"\n\n CHOICES = [\n (WEBP, \"WebP\"),\n ]\n\n\n# PIL-supported file formats as found here:\n# https://infohost.nmt.edu/tcc/help/pubs/pil/formats.html\n# {mime type: PIL Identifier}\nMIME_TYPE_TO_PIL_IDENTIFIER = {\n \"image/bmp\": \"BMP\",\n \"image/dcx\": \"DCX\",\n \"image/eps\": \"eps\",\n \"image/gif\": \"GIF\",\n \"image/jpeg\": \"JPEG\",\n \"image/pcd\": \"PCD\",\n \"image/pcx\": \"PCX\",\n \"application/pdf\": \"PDF\",\n \"image/png\": \"PNG\",\n \"image/x-ppm\": \"PPM\",\n \"image/psd\": \"PSD\",\n \"image/tiff\": \"TIFF\",\n \"image/x-xbitmap\": \"XBM\",\n \"image/x-xpm\": \"XPM\",\n \"image/webp\": \"WEBP\",\n}\n", "path": "saleor/thumbnail/__init__.py"}], "after_files": [{"content": "import binascii\nimport mimetypes\nimport os\nimport secrets\nfrom typing import TYPE_CHECKING, Union\nfrom uuid import UUID\n\nimport graphene\nimport requests\nfrom django.core.exceptions import ValidationError\nfrom graphene import ObjectType\nfrom graphql.error import GraphQLError\nfrom PIL import Image\n\nfrom ....core.utils import generate_unique_slug\nfrom ....plugins.webhook.utils import APP_ID_PREFIX\nfrom ....thumbnail import MIME_TYPE_TO_PIL_IDENTIFIER\n\nif TYPE_CHECKING:\n from django.db.models import Model\n\n\nImage.init()\n\n\ndef clean_seo_fields(data):\n \"\"\"Extract and assign seo fields to given dictionary.\"\"\"\n seo_fields = data.pop(\"seo\", None)\n if seo_fields:\n data[\"seo_title\"] = seo_fields.get(\"title\")\n data[\"seo_description\"] = seo_fields.get(\"description\")\n\n\ndef snake_to_camel_case(name):\n \"\"\"Convert snake_case variable name to camelCase.\"\"\"\n if isinstance(name, str):\n split_name = name.split(\"_\")\n return split_name[0] + \"\".join(map(str.capitalize, split_name[1:]))\n return name\n\n\ndef str_to_enum(name):\n \"\"\"Create an enum value from a string.\"\"\"\n return name.replace(\" \", \"_\").replace(\"-\", \"_\").upper()\n\n\ndef is_image_mimetype(mimetype: str) -> bool:\n \"\"\"Check if mimetype is image.\"\"\"\n if mimetype is None:\n return False\n return mimetype.startswith(\"image/\")\n\n\ndef is_supported_image_mimetype(mimetype: str) -> bool:\n \"\"\"Check if mimetype is a mimetype that thumbnails support.\"\"\"\n if mimetype is None:\n return False\n return mimetype in MIME_TYPE_TO_PIL_IDENTIFIER.keys()\n\n\ndef is_image_url(url: str) -> bool:\n \"\"\"Check if file URL seems to be an image.\"\"\"\n if url.endswith(\".webp\"):\n # webp is not recognized by mimetypes as image\n # https://bugs.python.org/issue38902\n return True\n filetype = mimetypes.guess_type(url)[0]\n return filetype is not None and is_image_mimetype(filetype)\n\n\ndef validate_image_url(url: str, field_name: str, error_code: str) -> None:\n \"\"\"Check if remote file has content type of image.\n\n Instead of the whole file, only the headers are fetched.\n \"\"\"\n head = requests.head(url)\n header = head.headers\n content_type = header.get(\"content-type\")\n if content_type is None or not is_supported_image_mimetype(content_type):\n raise ValidationError(\n {field_name: ValidationError(\"Invalid file type.\", code=error_code)}\n )\n\n\ndef get_filename_from_url(url: str) -> str:\n \"\"\"Prepare unique filename for file from URL to avoid overwritting.\"\"\"\n file_name = os.path.basename(url)\n name, format = os.path.splitext(file_name)\n hash = secrets.token_hex(nbytes=4)\n return f\"{name}_{hash}{format}\"\n\n\ndef validate_image_file(file, field_name, error_class) -> None:\n \"\"\"Validate if the file is an image supported by thumbnails.\"\"\"\n if not file:\n raise ValidationError(\n {\n field_name: ValidationError(\n \"File is required.\", code=error_class.REQUIRED\n )\n }\n )\n if not is_supported_image_mimetype(file.content_type):\n raise ValidationError(\n {\n field_name: ValidationError(\n \"Invalid file type.\", code=error_class.INVALID\n )\n }\n )\n _validate_image_format(file, field_name, error_class)\n\n\ndef _validate_image_format(file, field_name, error_class):\n \"\"\"Validate image file format.\"\"\"\n allowed_extensions = get_allowed_extensions()\n _file_name, format = os.path.splitext(file._name)\n if not format:\n raise ValidationError(\n {\n field_name: ValidationError(\n \"Lack of file extension.\", code=error_class.INVALID\n )\n }\n )\n elif format not in allowed_extensions:\n raise ValidationError(\n {\n field_name: ValidationError(\n \"Invalid file extension. Image file required.\",\n code=error_class.INVALID,\n )\n }\n )\n\n\ndef get_allowed_extensions():\n \"\"\"Return image extension lists that are supported by thumbnails.\"\"\"\n return [\n ext.lower()\n for ext, file_type in Image.EXTENSION.items()\n if file_type.upper() in MIME_TYPE_TO_PIL_IDENTIFIER.values()\n ]\n\n\ndef validate_slug_and_generate_if_needed(\n instance: \"Model\",\n slugable_field: str,\n cleaned_input: dict,\n slug_field_name: str = \"slug\",\n) -> dict:\n \"\"\"Validate slug from input and generate in create mutation if is not given.\"\"\"\n\n # update mutation - just check if slug value is not empty\n # _state.adding is True only when it's new not saved instance.\n if not instance._state.adding: # type: ignore\n validate_slug_value(cleaned_input)\n return cleaned_input\n\n # create mutation - generate slug if slug value is empty\n slug = cleaned_input.get(slug_field_name)\n if not slug and slugable_field in cleaned_input:\n slug = generate_unique_slug(instance, cleaned_input[slugable_field])\n cleaned_input[slug_field_name] = slug\n return cleaned_input\n\n\ndef validate_slug_value(cleaned_input, slug_field_name: str = \"slug\"):\n if slug_field_name in cleaned_input:\n slug = cleaned_input[slug_field_name]\n if not slug:\n raise ValidationError(\n f\"{slug_field_name.capitalize()} value cannot be blank.\"\n )\n\n\ndef get_duplicates_items(first_list, second_list):\n \"\"\"Return items that appear on both provided lists.\"\"\"\n if first_list and second_list:\n return set(first_list) & set(second_list)\n return []\n\n\ndef get_duplicated_values(values):\n \"\"\"Return set of duplicated values.\"\"\"\n return {value for value in values if values.count(value) > 1}\n\n\ndef validate_required_string_field(cleaned_input, field_name: str):\n \"\"\"Strip and validate field value.\"\"\"\n field_value = cleaned_input.get(field_name)\n field_value = field_value.strip() if field_value else \"\"\n if field_value:\n cleaned_input[field_name] = field_value\n else:\n raise ValidationError(f\"{field_name.capitalize()} is required.\")\n return cleaned_input\n\n\ndef validate_if_int_or_uuid(id):\n result = True\n try:\n int(id)\n except ValueError:\n try:\n UUID(id)\n except (AttributeError, ValueError):\n result = False\n return result\n\n\ndef from_global_id_or_error(\n global_id: str,\n only_type: Union[ObjectType, str, None] = None,\n raise_error: bool = False,\n):\n \"\"\"Resolve global ID or raise GraphQLError.\n\n Validates if given ID is a proper ID handled by Saleor.\n Valid IDs formats, base64 encoded:\n 'app:<int>:<str>' : External app ID with 'app' prefix\n '<type>:<int>' : Internal ID containing object type and ID as integer\n '<type>:<UUID>' : Internal ID containing object type and UUID\n Optionally validate the object type, if `only_type` is provided,\n raise GraphQLError when `raise_error` is set to True.\n \"\"\"\n try:\n type_, id_ = graphene.Node.from_global_id(global_id)\n except (binascii.Error, UnicodeDecodeError, ValueError):\n raise GraphQLError(f\"Couldn't resolve id: {global_id}.\")\n if type_ == APP_ID_PREFIX:\n id_ = global_id\n else:\n if not validate_if_int_or_uuid(id_):\n raise GraphQLError(f\"Error occurred during ID - {global_id} validation.\")\n\n if only_type and str(type_) != str(only_type):\n if not raise_error:\n return type_, None\n raise GraphQLError(f\"Must receive a {only_type} id.\")\n return type_, id_\n\n\ndef from_global_id_or_none(\n global_id, only_type: Union[ObjectType, str, None] = None, raise_error: bool = False\n):\n if not global_id:\n return None\n\n return from_global_id_or_error(global_id, only_type, raise_error)[1]\n\n\ndef to_global_id_or_none(instance):\n class_name = instance.__class__.__name__\n if instance is None or instance.pk is None:\n return None\n return graphene.Node.to_global_id(class_name, instance.pk)\n\n\ndef add_hash_to_file_name(file):\n \"\"\"Add unique text fragment to the file name to prevent file overriding.\"\"\"\n file_name, format = os.path.splitext(file._name)\n hash = secrets.token_hex(nbytes=4)\n new_name = f\"{file_name}_{hash}{format}\"\n file._name = new_name\n", "path": "saleor/graphql/core/utils/__init__.py"}, {"content": "default_app_config = \"saleor.thumbnail.app.ThumbnailAppConfig\"\n\n# defines the available thumbnail resolutions\nTHUMBNAIL_SIZES = [32, 64, 128, 256, 512, 1024, 2048, 4096]\n\n\nclass ThumbnailFormat:\n WEBP = \"webp\"\n\n CHOICES = [\n (WEBP, \"WebP\"),\n ]\n\n\n# PIL-supported file formats as found here:\n# https://infohost.nmt.edu/tcc/help/pubs/pil/formats.html\n# {mime type: PIL Identifier}\nMIME_TYPE_TO_PIL_IDENTIFIER = {\n \"image/bmp\": \"BMP\",\n \"image/dcx\": \"DCX\",\n \"image/eps\": \"EPS\",\n \"image/gif\": \"GIF\",\n \"image/jpeg\": \"JPEG\",\n \"image/pcd\": \"PCD\",\n \"image/pcx\": \"PCX\",\n \"image/png\": \"PNG\",\n \"image/x-ppm\": \"PPM\",\n \"image/psd\": \"PSD\",\n \"image/tiff\": \"TIFF\",\n \"image/x-xbitmap\": \"XBM\",\n \"image/x-xpm\": \"XPM\",\n \"image/webp\": \"WEBP\",\n}\n", "path": "saleor/thumbnail/__init__.py"}]}
| 3,233 | 802 |
gh_patches_debug_34471
|
rasdani/github-patches
|
git_diff
|
quantumlib__Cirq-5941
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
MatrixGate: the name is not taken over during exponentiation
**Description of the issue**
When you create a matrix gate with a name and exponentiate it, the initial name is lost as the name is not handed over to the power gate:
def __pow__(self, exponent: Any) -> 'MatrixGate':
if not isinstance(exponent, (int, float)):
return NotImplemented
new_mat = linalg.map_eigenvalues(self._matrix, lambda b: b**exponent)
return MatrixGate(new_mat, qid_shape=self._qid_shape)
**How to reproduce the issue**
Create a matrix gate with name and print a circuit containing a power of the gate
```
u = cirq.MatrixGate(np.identity(2), name = "U")
print(cirq.Circuit(u(cirq.LineQubit(1)),u(cirq.LineQubit(1))**2))
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cirq-core/cirq/ops/matrix_gates.py`
Content:
```
1 # Copyright 2018 The Cirq Developers
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Quantum gates defined by a matrix."""
16
17 from typing import Any, Dict, Iterable, Optional, Tuple, TYPE_CHECKING
18
19 import numpy as np
20
21 from cirq import linalg, protocols, _import
22 from cirq._compat import proper_repr
23 from cirq.ops import raw_types, phased_x_z_gate
24
25 if TYPE_CHECKING:
26 import cirq
27
28 single_qubit_decompositions = _import.LazyLoader(
29 'single_qubit_decompositions', globals(), 'cirq.transformers.analytical_decompositions'
30 )
31 two_qubit_to_cz = _import.LazyLoader(
32 'two_qubit_to_cz', globals(), 'cirq.transformers.analytical_decompositions'
33 )
34 three_qubit_decomposition = _import.LazyLoader(
35 'three_qubit_decomposition', globals(), 'cirq.transformers.analytical_decompositions'
36 )
37
38
39 class MatrixGate(raw_types.Gate):
40 r"""A unitary qubit or qudit gate defined entirely by its numpy matrix.
41
42 For example `cirq.MatrixGate(np.array([[0, 1j], [1, 0]]))` has the unitary matrix:
43
44 $$
45 \begin{bmatrix}
46 0 & i \\
47 1 & 0
48 \end{bmatrix}
49 $$
50 """
51
52 def __init__(
53 self,
54 matrix: np.ndarray,
55 *,
56 name: str = None,
57 qid_shape: Optional[Iterable[int]] = None,
58 unitary_check_rtol: float = 1e-5,
59 unitary_check_atol: float = 1e-8,
60 ) -> None:
61 """Initializes a matrix gate.
62
63 Args:
64 matrix: The matrix that defines the gate.
65 name: The optional name of the gate to be displayed.
66 qid_shape: The shape of state tensor that the matrix applies to.
67 If not specified, this value is inferred by assuming that the
68 matrix is supposed to apply to qubits.
69 unitary_check_rtol: The relative tolerance for checking whether the supplied matrix
70 is unitary. See `cirq.is_unitary`.
71 unitary_check_atol: The absolute tolerance for checking whether the supplied matrix
72 is unitary. See `cirq.is_unitary`.
73
74 Raises:
75 ValueError: If the matrix is not a square numpy array, if the matrix does not match
76 the `qid_shape`, if `qid_shape` is not supplied and the matrix dimension is
77 not a power of 2, or if the matrix not unitary (to the supplied precisions).
78 """
79 if len(matrix.shape) != 2 or matrix.shape[0] != matrix.shape[1]:
80 raise ValueError('`matrix` must be a square 2d numpy array.')
81
82 if qid_shape is None:
83 n = int(np.round(np.log2(matrix.shape[0] or 1)))
84 if 2**n != matrix.shape[0]:
85 raise ValueError(
86 f'Matrix width ({matrix.shape[0]}) is not a power of 2 and '
87 f'qid_shape is not specified.'
88 )
89 qid_shape = (2,) * n
90
91 self._matrix = matrix
92 self._qid_shape = tuple(qid_shape)
93 self._name = name
94 m = int(np.prod(self._qid_shape, dtype=np.int64))
95 if self._matrix.shape != (m, m):
96 raise ValueError(
97 'Wrong matrix shape for qid_shape.\n'
98 f'Matrix shape: {self._matrix.shape}\n'
99 f'qid_shape: {self._qid_shape}\n'
100 )
101
102 if not linalg.is_unitary(matrix, rtol=unitary_check_rtol, atol=unitary_check_atol):
103 raise ValueError(f'Not a unitary matrix: {self._matrix}')
104
105 def _json_dict_(self) -> Dict[str, Any]:
106 return {'matrix': self._matrix.tolist(), 'qid_shape': self._qid_shape}
107
108 @classmethod
109 def _from_json_dict_(cls, matrix, qid_shape, **kwargs):
110 return cls(matrix=np.array(matrix), qid_shape=qid_shape)
111
112 def _qid_shape_(self) -> Tuple[int, ...]:
113 return self._qid_shape
114
115 def __pow__(self, exponent: Any) -> 'MatrixGate':
116 if not isinstance(exponent, (int, float)):
117 return NotImplemented
118 new_mat = linalg.map_eigenvalues(self._matrix, lambda b: b**exponent)
119 return MatrixGate(new_mat, qid_shape=self._qid_shape)
120
121 def _phase_by_(self, phase_turns: float, qubit_index: int) -> 'MatrixGate':
122 if not isinstance(phase_turns, (int, float)):
123 return NotImplemented
124 if self._qid_shape[qubit_index] != 2:
125 return NotImplemented
126 result = np.copy(self._matrix).reshape(self._qid_shape * 2)
127
128 p = np.exp(2j * np.pi * phase_turns)
129 i = qubit_index
130 j = qubit_index + len(self._qid_shape)
131 result[linalg.slice_for_qubits_equal_to([i], 1)] *= p
132 result[linalg.slice_for_qubits_equal_to([j], 1)] *= np.conj(p)
133 return MatrixGate(matrix=result.reshape(self._matrix.shape), qid_shape=self._qid_shape)
134
135 def _decompose_(self, qubits: Tuple['cirq.Qid', ...]) -> 'cirq.OP_TREE':
136 if self._qid_shape == (2,):
137 return [
138 g.on(qubits[0])
139 for g in single_qubit_decompositions.single_qubit_matrix_to_gates(self._matrix)
140 ]
141 if self._qid_shape == (2,) * 2:
142 return two_qubit_to_cz.two_qubit_matrix_to_cz_operations(
143 *qubits, self._matrix, allow_partial_czs=True
144 )
145 if self._qid_shape == (2,) * 3:
146 return three_qubit_decomposition.three_qubit_matrix_to_operations(*qubits, self._matrix)
147 return NotImplemented
148
149 def _has_unitary_(self) -> bool:
150 return True
151
152 def _unitary_(self) -> np.ndarray:
153 return np.copy(self._matrix)
154
155 def _circuit_diagram_info_(
156 self, args: 'cirq.CircuitDiagramInfoArgs'
157 ) -> 'cirq.CircuitDiagramInfo':
158 n_qubits = len(self._qid_shape)
159 if self._name is not None:
160 symbols = (
161 [self._name] if n_qubits == 1 else [f'{self._name}[{i+1}]' for i in range(n_qubits)]
162 )
163 return protocols.CircuitDiagramInfo(wire_symbols=symbols)
164 main = _matrix_to_diagram_symbol(self._matrix, args)
165 rest = [f'#{i+1}' for i in range(1, n_qubits)]
166 return protocols.CircuitDiagramInfo(wire_symbols=[main, *rest])
167
168 def _qasm_(self, args: 'cirq.QasmArgs', qubits: Tuple['cirq.Qid', ...]) -> Optional[str]:
169 args.validate_version('2.0')
170 if self._qid_shape == (2,):
171 return protocols.qasm(
172 phased_x_z_gate.PhasedXZGate.from_matrix(self._matrix), args=args, qubits=qubits
173 )
174 return None
175
176 def __hash__(self) -> int:
177 vals = tuple(v for _, v in np.ndenumerate(self._matrix))
178 return hash((MatrixGate, vals))
179
180 def _approx_eq_(self, other: Any, atol) -> bool:
181 if not isinstance(other, type(self)):
182 return NotImplemented
183 return np.allclose(self._matrix, other._matrix, rtol=0, atol=atol)
184
185 def __eq__(self, other):
186 if not isinstance(other, type(self)):
187 return NotImplemented
188 return self._qid_shape == other._qid_shape and np.array_equal(self._matrix, other._matrix)
189
190 def __ne__(self, other):
191 return not self == other
192
193 def __repr__(self) -> str:
194 if all(e == 2 for e in self._qid_shape):
195 return f'cirq.MatrixGate({proper_repr(self._matrix)})'
196 return f'cirq.MatrixGate({proper_repr(self._matrix)}, qid_shape={self._qid_shape})'
197
198 def __str__(self) -> str:
199 return str(self._matrix.round(3))
200
201
202 def _matrix_to_diagram_symbol(matrix: np.ndarray, args: 'protocols.CircuitDiagramInfoArgs') -> str:
203 if args.precision is not None:
204 matrix = matrix.round(args.precision)
205 result = str(matrix)
206 if args.use_unicode_characters:
207 lines = result.split('\n')
208 for i in range(len(lines)):
209 lines[i] = lines[i].replace('[[', '')
210 lines[i] = lines[i].replace(' [', '')
211 lines[i] = lines[i].replace(']', '')
212 w = max(len(line) for line in lines)
213 for i in range(len(lines)):
214 lines[i] = '│' + lines[i].ljust(w) + '│'
215 lines.insert(0, '┌' + ' ' * w + '┐')
216 lines.append('└' + ' ' * w + '┘')
217 result = '\n'.join(lines)
218 return result
219
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/cirq-core/cirq/ops/matrix_gates.py b/cirq-core/cirq/ops/matrix_gates.py
--- a/cirq-core/cirq/ops/matrix_gates.py
+++ b/cirq-core/cirq/ops/matrix_gates.py
@@ -55,6 +55,7 @@
*,
name: str = None,
qid_shape: Optional[Iterable[int]] = None,
+ unitary_check: bool = True,
unitary_check_rtol: float = 1e-5,
unitary_check_atol: float = 1e-8,
) -> None:
@@ -66,6 +67,10 @@
qid_shape: The shape of state tensor that the matrix applies to.
If not specified, this value is inferred by assuming that the
matrix is supposed to apply to qubits.
+ unitary_check: If True, check that the supplied matrix is unitary up to the
+ given tolerances. This should only be disabled if the matrix has already been
+ checked for unitarity, in which case we get a slight performance improvement by
+ not checking again.
unitary_check_rtol: The relative tolerance for checking whether the supplied matrix
is unitary. See `cirq.is_unitary`.
unitary_check_atol: The absolute tolerance for checking whether the supplied matrix
@@ -99,8 +104,14 @@
f'qid_shape: {self._qid_shape}\n'
)
- if not linalg.is_unitary(matrix, rtol=unitary_check_rtol, atol=unitary_check_atol):
- raise ValueError(f'Not a unitary matrix: {self._matrix}')
+ if unitary_check and not linalg.is_unitary(
+ matrix, rtol=unitary_check_rtol, atol=unitary_check_atol
+ ):
+ raise ValueError(f'Not a unitary matrix: {matrix}')
+
+ def with_name(self, name: str) -> 'MatrixGate':
+ """Creates a new MatrixGate with the same matrix and a new name."""
+ return MatrixGate(self._matrix, name=name, qid_shape=self._qid_shape, unitary_check=False)
def _json_dict_(self) -> Dict[str, Any]:
return {'matrix': self._matrix.tolist(), 'qid_shape': self._qid_shape}
|
{"golden_diff": "diff --git a/cirq-core/cirq/ops/matrix_gates.py b/cirq-core/cirq/ops/matrix_gates.py\n--- a/cirq-core/cirq/ops/matrix_gates.py\n+++ b/cirq-core/cirq/ops/matrix_gates.py\n@@ -55,6 +55,7 @@\n *,\n name: str = None,\n qid_shape: Optional[Iterable[int]] = None,\n+ unitary_check: bool = True,\n unitary_check_rtol: float = 1e-5,\n unitary_check_atol: float = 1e-8,\n ) -> None:\n@@ -66,6 +67,10 @@\n qid_shape: The shape of state tensor that the matrix applies to.\n If not specified, this value is inferred by assuming that the\n matrix is supposed to apply to qubits.\n+ unitary_check: If True, check that the supplied matrix is unitary up to the\n+ given tolerances. This should only be disabled if the matrix has already been\n+ checked for unitarity, in which case we get a slight performance improvement by\n+ not checking again.\n unitary_check_rtol: The relative tolerance for checking whether the supplied matrix\n is unitary. See `cirq.is_unitary`.\n unitary_check_atol: The absolute tolerance for checking whether the supplied matrix\n@@ -99,8 +104,14 @@\n f'qid_shape: {self._qid_shape}\\n'\n )\n \n- if not linalg.is_unitary(matrix, rtol=unitary_check_rtol, atol=unitary_check_atol):\n- raise ValueError(f'Not a unitary matrix: {self._matrix}')\n+ if unitary_check and not linalg.is_unitary(\n+ matrix, rtol=unitary_check_rtol, atol=unitary_check_atol\n+ ):\n+ raise ValueError(f'Not a unitary matrix: {matrix}')\n+\n+ def with_name(self, name: str) -> 'MatrixGate':\n+ \"\"\"Creates a new MatrixGate with the same matrix and a new name.\"\"\"\n+ return MatrixGate(self._matrix, name=name, qid_shape=self._qid_shape, unitary_check=False)\n \n def _json_dict_(self) -> Dict[str, Any]:\n return {'matrix': self._matrix.tolist(), 'qid_shape': self._qid_shape}\n", "issue": "MatrixGate: the name is not taken over during exponentiation\n**Description of the issue**\r\nWhen you create a matrix gate with a name and exponentiate it, the initial name is lost as the name is not handed over to the power gate: \r\ndef __pow__(self, exponent: Any) -> 'MatrixGate':\r\n if not isinstance(exponent, (int, float)):\r\n return NotImplemented\r\n new_mat = linalg.map_eigenvalues(self._matrix, lambda b: b**exponent)\r\n return MatrixGate(new_mat, qid_shape=self._qid_shape)\r\n\r\n**How to reproduce the issue**\r\n\r\nCreate a matrix gate with name and print a circuit containing a power of the gate\r\n\r\n```\r\nu = cirq.MatrixGate(np.identity(2), name = \"U\")\r\nprint(cirq.Circuit(u(cirq.LineQubit(1)),u(cirq.LineQubit(1))**2))\r\n\r\n```\r\n\n", "before_files": [{"content": "# Copyright 2018 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Quantum gates defined by a matrix.\"\"\"\n\nfrom typing import Any, Dict, Iterable, Optional, Tuple, TYPE_CHECKING\n\nimport numpy as np\n\nfrom cirq import linalg, protocols, _import\nfrom cirq._compat import proper_repr\nfrom cirq.ops import raw_types, phased_x_z_gate\n\nif TYPE_CHECKING:\n import cirq\n\nsingle_qubit_decompositions = _import.LazyLoader(\n 'single_qubit_decompositions', globals(), 'cirq.transformers.analytical_decompositions'\n)\ntwo_qubit_to_cz = _import.LazyLoader(\n 'two_qubit_to_cz', globals(), 'cirq.transformers.analytical_decompositions'\n)\nthree_qubit_decomposition = _import.LazyLoader(\n 'three_qubit_decomposition', globals(), 'cirq.transformers.analytical_decompositions'\n)\n\n\nclass MatrixGate(raw_types.Gate):\n r\"\"\"A unitary qubit or qudit gate defined entirely by its numpy matrix.\n\n For example `cirq.MatrixGate(np.array([[0, 1j], [1, 0]]))` has the unitary matrix:\n\n $$\n \\begin{bmatrix}\n 0 & i \\\\\n 1 & 0\n \\end{bmatrix}\n $$\n \"\"\"\n\n def __init__(\n self,\n matrix: np.ndarray,\n *,\n name: str = None,\n qid_shape: Optional[Iterable[int]] = None,\n unitary_check_rtol: float = 1e-5,\n unitary_check_atol: float = 1e-8,\n ) -> None:\n \"\"\"Initializes a matrix gate.\n\n Args:\n matrix: The matrix that defines the gate.\n name: The optional name of the gate to be displayed.\n qid_shape: The shape of state tensor that the matrix applies to.\n If not specified, this value is inferred by assuming that the\n matrix is supposed to apply to qubits.\n unitary_check_rtol: The relative tolerance for checking whether the supplied matrix\n is unitary. See `cirq.is_unitary`.\n unitary_check_atol: The absolute tolerance for checking whether the supplied matrix\n is unitary. See `cirq.is_unitary`.\n\n Raises:\n ValueError: If the matrix is not a square numpy array, if the matrix does not match\n the `qid_shape`, if `qid_shape` is not supplied and the matrix dimension is\n not a power of 2, or if the matrix not unitary (to the supplied precisions).\n \"\"\"\n if len(matrix.shape) != 2 or matrix.shape[0] != matrix.shape[1]:\n raise ValueError('`matrix` must be a square 2d numpy array.')\n\n if qid_shape is None:\n n = int(np.round(np.log2(matrix.shape[0] or 1)))\n if 2**n != matrix.shape[0]:\n raise ValueError(\n f'Matrix width ({matrix.shape[0]}) is not a power of 2 and '\n f'qid_shape is not specified.'\n )\n qid_shape = (2,) * n\n\n self._matrix = matrix\n self._qid_shape = tuple(qid_shape)\n self._name = name\n m = int(np.prod(self._qid_shape, dtype=np.int64))\n if self._matrix.shape != (m, m):\n raise ValueError(\n 'Wrong matrix shape for qid_shape.\\n'\n f'Matrix shape: {self._matrix.shape}\\n'\n f'qid_shape: {self._qid_shape}\\n'\n )\n\n if not linalg.is_unitary(matrix, rtol=unitary_check_rtol, atol=unitary_check_atol):\n raise ValueError(f'Not a unitary matrix: {self._matrix}')\n\n def _json_dict_(self) -> Dict[str, Any]:\n return {'matrix': self._matrix.tolist(), 'qid_shape': self._qid_shape}\n\n @classmethod\n def _from_json_dict_(cls, matrix, qid_shape, **kwargs):\n return cls(matrix=np.array(matrix), qid_shape=qid_shape)\n\n def _qid_shape_(self) -> Tuple[int, ...]:\n return self._qid_shape\n\n def __pow__(self, exponent: Any) -> 'MatrixGate':\n if not isinstance(exponent, (int, float)):\n return NotImplemented\n new_mat = linalg.map_eigenvalues(self._matrix, lambda b: b**exponent)\n return MatrixGate(new_mat, qid_shape=self._qid_shape)\n\n def _phase_by_(self, phase_turns: float, qubit_index: int) -> 'MatrixGate':\n if not isinstance(phase_turns, (int, float)):\n return NotImplemented\n if self._qid_shape[qubit_index] != 2:\n return NotImplemented\n result = np.copy(self._matrix).reshape(self._qid_shape * 2)\n\n p = np.exp(2j * np.pi * phase_turns)\n i = qubit_index\n j = qubit_index + len(self._qid_shape)\n result[linalg.slice_for_qubits_equal_to([i], 1)] *= p\n result[linalg.slice_for_qubits_equal_to([j], 1)] *= np.conj(p)\n return MatrixGate(matrix=result.reshape(self._matrix.shape), qid_shape=self._qid_shape)\n\n def _decompose_(self, qubits: Tuple['cirq.Qid', ...]) -> 'cirq.OP_TREE':\n if self._qid_shape == (2,):\n return [\n g.on(qubits[0])\n for g in single_qubit_decompositions.single_qubit_matrix_to_gates(self._matrix)\n ]\n if self._qid_shape == (2,) * 2:\n return two_qubit_to_cz.two_qubit_matrix_to_cz_operations(\n *qubits, self._matrix, allow_partial_czs=True\n )\n if self._qid_shape == (2,) * 3:\n return three_qubit_decomposition.three_qubit_matrix_to_operations(*qubits, self._matrix)\n return NotImplemented\n\n def _has_unitary_(self) -> bool:\n return True\n\n def _unitary_(self) -> np.ndarray:\n return np.copy(self._matrix)\n\n def _circuit_diagram_info_(\n self, args: 'cirq.CircuitDiagramInfoArgs'\n ) -> 'cirq.CircuitDiagramInfo':\n n_qubits = len(self._qid_shape)\n if self._name is not None:\n symbols = (\n [self._name] if n_qubits == 1 else [f'{self._name}[{i+1}]' for i in range(n_qubits)]\n )\n return protocols.CircuitDiagramInfo(wire_symbols=symbols)\n main = _matrix_to_diagram_symbol(self._matrix, args)\n rest = [f'#{i+1}' for i in range(1, n_qubits)]\n return protocols.CircuitDiagramInfo(wire_symbols=[main, *rest])\n\n def _qasm_(self, args: 'cirq.QasmArgs', qubits: Tuple['cirq.Qid', ...]) -> Optional[str]:\n args.validate_version('2.0')\n if self._qid_shape == (2,):\n return protocols.qasm(\n phased_x_z_gate.PhasedXZGate.from_matrix(self._matrix), args=args, qubits=qubits\n )\n return None\n\n def __hash__(self) -> int:\n vals = tuple(v for _, v in np.ndenumerate(self._matrix))\n return hash((MatrixGate, vals))\n\n def _approx_eq_(self, other: Any, atol) -> bool:\n if not isinstance(other, type(self)):\n return NotImplemented\n return np.allclose(self._matrix, other._matrix, rtol=0, atol=atol)\n\n def __eq__(self, other):\n if not isinstance(other, type(self)):\n return NotImplemented\n return self._qid_shape == other._qid_shape and np.array_equal(self._matrix, other._matrix)\n\n def __ne__(self, other):\n return not self == other\n\n def __repr__(self) -> str:\n if all(e == 2 for e in self._qid_shape):\n return f'cirq.MatrixGate({proper_repr(self._matrix)})'\n return f'cirq.MatrixGate({proper_repr(self._matrix)}, qid_shape={self._qid_shape})'\n\n def __str__(self) -> str:\n return str(self._matrix.round(3))\n\n\ndef _matrix_to_diagram_symbol(matrix: np.ndarray, args: 'protocols.CircuitDiagramInfoArgs') -> str:\n if args.precision is not None:\n matrix = matrix.round(args.precision)\n result = str(matrix)\n if args.use_unicode_characters:\n lines = result.split('\\n')\n for i in range(len(lines)):\n lines[i] = lines[i].replace('[[', '')\n lines[i] = lines[i].replace(' [', '')\n lines[i] = lines[i].replace(']', '')\n w = max(len(line) for line in lines)\n for i in range(len(lines)):\n lines[i] = '\u2502' + lines[i].ljust(w) + '\u2502'\n lines.insert(0, '\u250c' + ' ' * w + '\u2510')\n lines.append('\u2514' + ' ' * w + '\u2518')\n result = '\\n'.join(lines)\n return result\n", "path": "cirq-core/cirq/ops/matrix_gates.py"}], "after_files": [{"content": "# Copyright 2018 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Quantum gates defined by a matrix.\"\"\"\n\nfrom typing import Any, Dict, Iterable, Optional, Tuple, TYPE_CHECKING\n\nimport numpy as np\n\nfrom cirq import linalg, protocols, _import\nfrom cirq._compat import proper_repr\nfrom cirq.ops import raw_types, phased_x_z_gate\n\nif TYPE_CHECKING:\n import cirq\n\nsingle_qubit_decompositions = _import.LazyLoader(\n 'single_qubit_decompositions', globals(), 'cirq.transformers.analytical_decompositions'\n)\ntwo_qubit_to_cz = _import.LazyLoader(\n 'two_qubit_to_cz', globals(), 'cirq.transformers.analytical_decompositions'\n)\nthree_qubit_decomposition = _import.LazyLoader(\n 'three_qubit_decomposition', globals(), 'cirq.transformers.analytical_decompositions'\n)\n\n\nclass MatrixGate(raw_types.Gate):\n r\"\"\"A unitary qubit or qudit gate defined entirely by its numpy matrix.\n\n For example `cirq.MatrixGate(np.array([[0, 1j], [1, 0]]))` has the unitary matrix:\n\n $$\n \\begin{bmatrix}\n 0 & i \\\\\n 1 & 0\n \\end{bmatrix}\n $$\n \"\"\"\n\n def __init__(\n self,\n matrix: np.ndarray,\n *,\n name: str = None,\n qid_shape: Optional[Iterable[int]] = None,\n unitary_check: bool = True,\n unitary_check_rtol: float = 1e-5,\n unitary_check_atol: float = 1e-8,\n ) -> None:\n \"\"\"Initializes a matrix gate.\n\n Args:\n matrix: The matrix that defines the gate.\n name: The optional name of the gate to be displayed.\n qid_shape: The shape of state tensor that the matrix applies to.\n If not specified, this value is inferred by assuming that the\n matrix is supposed to apply to qubits.\n unitary_check: If True, check that the supplied matrix is unitary up to the\n given tolerances. This should only be disabled if the matrix has already been\n checked for unitarity, in which case we get a slight performance improvement by\n not checking again.\n unitary_check_rtol: The relative tolerance for checking whether the supplied matrix\n is unitary. See `cirq.is_unitary`.\n unitary_check_atol: The absolute tolerance for checking whether the supplied matrix\n is unitary. See `cirq.is_unitary`.\n\n Raises:\n ValueError: If the matrix is not a square numpy array, if the matrix does not match\n the `qid_shape`, if `qid_shape` is not supplied and the matrix dimension is\n not a power of 2, or if the matrix not unitary (to the supplied precisions).\n \"\"\"\n if len(matrix.shape) != 2 or matrix.shape[0] != matrix.shape[1]:\n raise ValueError('`matrix` must be a square 2d numpy array.')\n\n if qid_shape is None:\n n = int(np.round(np.log2(matrix.shape[0] or 1)))\n if 2**n != matrix.shape[0]:\n raise ValueError(\n f'Matrix width ({matrix.shape[0]}) is not a power of 2 and '\n f'qid_shape is not specified.'\n )\n qid_shape = (2,) * n\n\n self._matrix = matrix\n self._qid_shape = tuple(qid_shape)\n self._name = name\n m = int(np.prod(self._qid_shape, dtype=np.int64))\n if self._matrix.shape != (m, m):\n raise ValueError(\n 'Wrong matrix shape for qid_shape.\\n'\n f'Matrix shape: {self._matrix.shape}\\n'\n f'qid_shape: {self._qid_shape}\\n'\n )\n\n if unitary_check and not linalg.is_unitary(\n matrix, rtol=unitary_check_rtol, atol=unitary_check_atol\n ):\n raise ValueError(f'Not a unitary matrix: {matrix}')\n\n def with_name(self, name: str) -> 'MatrixGate':\n \"\"\"Creates a new MatrixGate with the same matrix and a new name.\"\"\"\n return MatrixGate(self._matrix, name=name, qid_shape=self._qid_shape, unitary_check=False)\n\n def _json_dict_(self) -> Dict[str, Any]:\n return {'matrix': self._matrix.tolist(), 'qid_shape': self._qid_shape}\n\n @classmethod\n def _from_json_dict_(cls, matrix, qid_shape, **kwargs):\n return cls(matrix=np.array(matrix), qid_shape=qid_shape)\n\n def _qid_shape_(self) -> Tuple[int, ...]:\n return self._qid_shape\n\n def __pow__(self, exponent: Any) -> 'MatrixGate':\n if not isinstance(exponent, (int, float)):\n return NotImplemented\n new_mat = linalg.map_eigenvalues(self._matrix, lambda b: b**exponent)\n return MatrixGate(new_mat, qid_shape=self._qid_shape)\n\n def _phase_by_(self, phase_turns: float, qubit_index: int) -> 'MatrixGate':\n if not isinstance(phase_turns, (int, float)):\n return NotImplemented\n if self._qid_shape[qubit_index] != 2:\n return NotImplemented\n result = np.copy(self._matrix).reshape(self._qid_shape * 2)\n\n p = np.exp(2j * np.pi * phase_turns)\n i = qubit_index\n j = qubit_index + len(self._qid_shape)\n result[linalg.slice_for_qubits_equal_to([i], 1)] *= p\n result[linalg.slice_for_qubits_equal_to([j], 1)] *= np.conj(p)\n return MatrixGate(matrix=result.reshape(self._matrix.shape), qid_shape=self._qid_shape)\n\n def _decompose_(self, qubits: Tuple['cirq.Qid', ...]) -> 'cirq.OP_TREE':\n if self._qid_shape == (2,):\n return [\n g.on(qubits[0])\n for g in single_qubit_decompositions.single_qubit_matrix_to_gates(self._matrix)\n ]\n if self._qid_shape == (2,) * 2:\n return two_qubit_to_cz.two_qubit_matrix_to_cz_operations(\n *qubits, self._matrix, allow_partial_czs=True\n )\n if self._qid_shape == (2,) * 3:\n return three_qubit_decomposition.three_qubit_matrix_to_operations(*qubits, self._matrix)\n return NotImplemented\n\n def _has_unitary_(self) -> bool:\n return True\n\n def _unitary_(self) -> np.ndarray:\n return np.copy(self._matrix)\n\n def _circuit_diagram_info_(\n self, args: 'cirq.CircuitDiagramInfoArgs'\n ) -> 'cirq.CircuitDiagramInfo':\n n_qubits = len(self._qid_shape)\n if self._name is not None:\n symbols = (\n [self._name] if n_qubits == 1 else [f'{self._name}[{i+1}]' for i in range(n_qubits)]\n )\n return protocols.CircuitDiagramInfo(wire_symbols=symbols)\n main = _matrix_to_diagram_symbol(self._matrix, args)\n rest = [f'#{i+1}' for i in range(1, n_qubits)]\n return protocols.CircuitDiagramInfo(wire_symbols=[main, *rest])\n\n def _qasm_(self, args: 'cirq.QasmArgs', qubits: Tuple['cirq.Qid', ...]) -> Optional[str]:\n args.validate_version('2.0')\n if self._qid_shape == (2,):\n return protocols.qasm(\n phased_x_z_gate.PhasedXZGate.from_matrix(self._matrix), args=args, qubits=qubits\n )\n return None\n\n def __hash__(self) -> int:\n vals = tuple(v for _, v in np.ndenumerate(self._matrix))\n return hash((MatrixGate, vals))\n\n def _approx_eq_(self, other: Any, atol) -> bool:\n if not isinstance(other, type(self)):\n return NotImplemented\n return np.allclose(self._matrix, other._matrix, rtol=0, atol=atol)\n\n def __eq__(self, other):\n if not isinstance(other, type(self)):\n return NotImplemented\n return self._qid_shape == other._qid_shape and np.array_equal(self._matrix, other._matrix)\n\n def __ne__(self, other):\n return not self == other\n\n def __repr__(self) -> str:\n if all(e == 2 for e in self._qid_shape):\n return f'cirq.MatrixGate({proper_repr(self._matrix)})'\n return f'cirq.MatrixGate({proper_repr(self._matrix)}, qid_shape={self._qid_shape})'\n\n def __str__(self) -> str:\n return str(self._matrix.round(3))\n\n\ndef _matrix_to_diagram_symbol(matrix: np.ndarray, args: 'protocols.CircuitDiagramInfoArgs') -> str:\n if args.precision is not None:\n matrix = matrix.round(args.precision)\n result = str(matrix)\n if args.use_unicode_characters:\n lines = result.split('\\n')\n for i in range(len(lines)):\n lines[i] = lines[i].replace('[[', '')\n lines[i] = lines[i].replace(' [', '')\n lines[i] = lines[i].replace(']', '')\n w = max(len(line) for line in lines)\n for i in range(len(lines)):\n lines[i] = '\u2502' + lines[i].ljust(w) + '\u2502'\n lines.insert(0, '\u250c' + ' ' * w + '\u2510')\n lines.append('\u2514' + ' ' * w + '\u2518')\n result = '\\n'.join(lines)\n return result\n", "path": "cirq-core/cirq/ops/matrix_gates.py"}]}
| 3,199 | 524 |
gh_patches_debug_12297
|
rasdani/github-patches
|
git_diff
|
ytdl-org__youtube-dl-26507
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
https://cnn.iprima.cz - Broken site support
<!--
######################################################################
WARNING!
IGNORING THE FOLLOWING TEMPLATE WILL RESULT IN ISSUE CLOSED AS INCOMPLETE
######################################################################
-->
## Checklist
<!--
Carefully read and work through this check list in order to prevent the most common mistakes and misuse of youtube-dl:
- First of, make sure you are using the latest version of youtube-dl. Run `youtube-dl --version` and ensure your version is 2020.07.28. If it's not, see https://yt-dl.org/update on how to update. Issues with outdated version will be REJECTED.
- Make sure that all provided video/audio/playlist URLs (if any) are alive and playable in a browser.
- Make sure that all URLs and arguments with special characters are properly quoted or escaped as explained in http://yt-dl.org/escape.
- Search the bugtracker for similar issues: http://yt-dl.org/search-issues. DO NOT post duplicates.
- Finally, put x into all relevant boxes (like this [x])
-->
- [x] I'm reporting a broken site support
- [x] I've verified that I'm running youtube-dl version **2020.07.28**
- [x] I've checked that all provided URLs are alive and playable in a browser
- [x] I've checked that all URLs and arguments with special characters are properly quoted or escaped
- [x] I've searched the bugtracker for similar issues including closed ones
## Verbose log
<!--
Provide the complete verbose output of youtube-dl that clearly demonstrates the problem.
Add the `-v` flag to your command line you run youtube-dl with (`youtube-dl -v <your command line>`), copy the WHOLE output and insert it below. It should look similar to this:
[debug] System config: []
[debug] User config: []
[debug] Command-line args: [u'-v', u'http://www.youtube.com/watch?v=BaW_jenozKcj']
[debug] Encodings: locale cp1251, fs mbcs, out cp866, pref cp1251
[debug] youtube-dl version 2020.07.28
[debug] Python version 2.7.11 - Windows-2003Server-5.2.3790-SP2
[debug] exe versions: ffmpeg N-75573-g1d0487f, ffprobe N-75573-g1d0487f, rtmpdump 2.4
[debug] Proxy map: {}
<more lines>
-->
[debug] System config: []
[debug] User config: []
[debug] Custom config: []
[debug] Command-line args: [u'-vvv', u'https://cnn.iprima.cz/porady/hlavni-zpravy/31082020']
WARNING: Assuming --restrict-filenames since file system encoding cannot encode all characters. Set the LC_ALL environment variable to fix this.
[debug] Encodings: locale ANSI_X3.4-1968, fs ANSI_X3.4-1968, out ANSI_X3.4-1968, pref ANSI_X3.4-1968
[debug] youtube-dl version 2020.07.28
[debug] Python version 2.7.13 (CPython) - Linux-3.16.6-042stab145.3-x86_64-with-debian-9.9
[debug] exe versions: ffmpeg 3.2.12-1, ffprobe 3.2.12-1, rtmpdump 2.4
[debug] Proxy map: {}
[IPrima] 31082020: Downloading webpage
ERROR: Unable to extract real id; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; type youtube-dl -U to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.
Traceback (most recent call last):
File "/usr/local/bin/youtube-dl/youtube_dl/YoutubeDL.py", line 797, in extract_info
ie_result = ie.extract(url)
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/common.py", line 530, in extract
ie_result = self._real_extract(url)
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/iprima.py", line 90, in _real_extract
webpage, 'real id')
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/common.py", line 1005, in _search_regex
raise RegexNotFoundError('Unable to extract %s' % _name)
RegexNotFoundError: Unable to extract real id; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; type youtube-dl -U to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.
## Description
<!--
Provide an explanation of your issue in an arbitrary form. Provide any additional information, suggested solution and as much context and examples as possible.
If work on your issue requires account credentials please provide them or explain how one can obtain them.
-->
This error appears from today, from the first of September 2020. So far, I have discovered the error only on the "cnn" version of the iprima.cz website.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `youtube_dl/extractor/iprima.py`
Content:
```
1 # coding: utf-8
2 from __future__ import unicode_literals
3
4 import re
5 import time
6
7 from .common import InfoExtractor
8 from ..utils import (
9 determine_ext,
10 js_to_json,
11 )
12
13
14 class IPrimaIE(InfoExtractor):
15 _VALID_URL = r'https?://(?:[^/]+)\.iprima\.cz/(?:[^/]+/)*(?P<id>[^/?#&]+)'
16 _GEO_BYPASS = False
17
18 _TESTS = [{
19 'url': 'https://prima.iprima.cz/particka/92-epizoda',
20 'info_dict': {
21 'id': 'p51388',
22 'ext': 'mp4',
23 'title': 'Partička (92)',
24 'description': 'md5:859d53beae4609e6dd7796413f1b6cac',
25 },
26 'params': {
27 'skip_download': True, # m3u8 download
28 },
29 }, {
30 'url': 'https://cnn.iprima.cz/videa/70-epizoda',
31 'info_dict': {
32 'id': 'p681554',
33 'ext': 'mp4',
34 'title': 'HLAVNÍ ZPRÁVY 3.5.2020',
35 },
36 'params': {
37 'skip_download': True, # m3u8 download
38 },
39 }, {
40 'url': 'http://play.iprima.cz/particka/particka-92',
41 'only_matching': True,
42 }, {
43 # geo restricted
44 'url': 'http://play.iprima.cz/closer-nove-pripady/closer-nove-pripady-iv-1',
45 'only_matching': True,
46 }, {
47 # iframe api.play-backend.iprima.cz
48 'url': 'https://prima.iprima.cz/my-little-pony/mapa-znameni-2-2',
49 'only_matching': True,
50 }, {
51 # iframe prima.iprima.cz
52 'url': 'https://prima.iprima.cz/porady/jak-se-stavi-sen/rodina-rathousova-praha',
53 'only_matching': True,
54 }, {
55 'url': 'http://www.iprima.cz/filmy/desne-rande',
56 'only_matching': True,
57 }, {
58 'url': 'https://zoom.iprima.cz/10-nejvetsich-tajemstvi-zahad/posvatna-mista-a-stavby',
59 'only_matching': True,
60 }, {
61 'url': 'https://krimi.iprima.cz/mraz-0/sebevrazdy',
62 'only_matching': True,
63 }, {
64 'url': 'https://cool.iprima.cz/derava-silnice-nevadi',
65 'only_matching': True,
66 }, {
67 'url': 'https://love.iprima.cz/laska-az-za-hrob/slib-dany-bratrovi',
68 'only_matching': True,
69 }, {
70 'url': 'https://autosalon.iprima.cz/motorsport/7-epizoda-1',
71 'only_matching': True,
72 }]
73
74 def _real_extract(self, url):
75 video_id = self._match_id(url)
76
77 self._set_cookie('play.iprima.cz', 'ott_adult_confirmed', '1')
78
79 webpage = self._download_webpage(url, video_id)
80
81 title = self._og_search_title(
82 webpage, default=None) or self._search_regex(
83 r'<h1>([^<]+)', webpage, 'title')
84
85 video_id = self._search_regex(
86 (r'<iframe[^>]+\bsrc=["\'](?:https?:)?//(?:api\.play-backend\.iprima\.cz/prehravac/embedded|prima\.iprima\.cz/[^/]+/[^/]+)\?.*?\bid=(p\d+)',
87 r'data-product="([^"]+)">',
88 r'id=["\']player-(p\d+)"',
89 r'playerId\s*:\s*["\']player-(p\d+)'),
90 webpage, 'real id')
91
92 playerpage = self._download_webpage(
93 'http://play.iprima.cz/prehravac/init',
94 video_id, note='Downloading player', query={
95 '_infuse': 1,
96 '_ts': round(time.time()),
97 'productId': video_id,
98 }, headers={'Referer': url})
99
100 formats = []
101
102 def extract_formats(format_url, format_key=None, lang=None):
103 ext = determine_ext(format_url)
104 new_formats = []
105 if format_key == 'hls' or ext == 'm3u8':
106 new_formats = self._extract_m3u8_formats(
107 format_url, video_id, 'mp4', entry_protocol='m3u8_native',
108 m3u8_id='hls', fatal=False)
109 elif format_key == 'dash' or ext == 'mpd':
110 return
111 new_formats = self._extract_mpd_formats(
112 format_url, video_id, mpd_id='dash', fatal=False)
113 if lang:
114 for f in new_formats:
115 if not f.get('language'):
116 f['language'] = lang
117 formats.extend(new_formats)
118
119 options = self._parse_json(
120 self._search_regex(
121 r'(?s)(?:TDIPlayerOptions|playerOptions)\s*=\s*({.+?});\s*\]\]',
122 playerpage, 'player options', default='{}'),
123 video_id, transform_source=js_to_json, fatal=False)
124 if options:
125 for key, tracks in options.get('tracks', {}).items():
126 if not isinstance(tracks, list):
127 continue
128 for track in tracks:
129 src = track.get('src')
130 if src:
131 extract_formats(src, key.lower(), track.get('lang'))
132
133 if not formats:
134 for _, src in re.findall(r'src["\']\s*:\s*(["\'])(.+?)\1', playerpage):
135 extract_formats(src)
136
137 if not formats and '>GEO_IP_NOT_ALLOWED<' in playerpage:
138 self.raise_geo_restricted(countries=['CZ'])
139
140 self._sort_formats(formats)
141
142 return {
143 'id': video_id,
144 'title': title,
145 'thumbnail': self._og_search_thumbnail(webpage, default=None),
146 'formats': formats,
147 'description': self._og_search_description(webpage, default=None),
148 }
149
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/youtube_dl/extractor/iprima.py b/youtube_dl/extractor/iprima.py
--- a/youtube_dl/extractor/iprima.py
+++ b/youtube_dl/extractor/iprima.py
@@ -86,7 +86,8 @@
(r'<iframe[^>]+\bsrc=["\'](?:https?:)?//(?:api\.play-backend\.iprima\.cz/prehravac/embedded|prima\.iprima\.cz/[^/]+/[^/]+)\?.*?\bid=(p\d+)',
r'data-product="([^"]+)">',
r'id=["\']player-(p\d+)"',
- r'playerId\s*:\s*["\']player-(p\d+)'),
+ r'playerId\s*:\s*["\']player-(p\d+)',
+ r'\bvideos\s*=\s*["\'](p\d+)'),
webpage, 'real id')
playerpage = self._download_webpage(
|
{"golden_diff": "diff --git a/youtube_dl/extractor/iprima.py b/youtube_dl/extractor/iprima.py\n--- a/youtube_dl/extractor/iprima.py\n+++ b/youtube_dl/extractor/iprima.py\n@@ -86,7 +86,8 @@\n (r'<iframe[^>]+\\bsrc=[\"\\'](?:https?:)?//(?:api\\.play-backend\\.iprima\\.cz/prehravac/embedded|prima\\.iprima\\.cz/[^/]+/[^/]+)\\?.*?\\bid=(p\\d+)',\n r'data-product=\"([^\"]+)\">',\n r'id=[\"\\']player-(p\\d+)\"',\n- r'playerId\\s*:\\s*[\"\\']player-(p\\d+)'),\n+ r'playerId\\s*:\\s*[\"\\']player-(p\\d+)',\n+ r'\\bvideos\\s*=\\s*[\"\\'](p\\d+)'),\n webpage, 'real id')\n \n playerpage = self._download_webpage(\n", "issue": "https://cnn.iprima.cz - Broken site support\n<!--\r\n\r\n######################################################################\r\n WARNING!\r\n IGNORING THE FOLLOWING TEMPLATE WILL RESULT IN ISSUE CLOSED AS INCOMPLETE\r\n######################################################################\r\n\r\n-->\r\n\r\n\r\n## Checklist\r\n\r\n<!--\r\nCarefully read and work through this check list in order to prevent the most common mistakes and misuse of youtube-dl:\r\n- First of, make sure you are using the latest version of youtube-dl. Run `youtube-dl --version` and ensure your version is 2020.07.28. If it's not, see https://yt-dl.org/update on how to update. Issues with outdated version will be REJECTED.\r\n- Make sure that all provided video/audio/playlist URLs (if any) are alive and playable in a browser.\r\n- Make sure that all URLs and arguments with special characters are properly quoted or escaped as explained in http://yt-dl.org/escape.\r\n- Search the bugtracker for similar issues: http://yt-dl.org/search-issues. DO NOT post duplicates.\r\n- Finally, put x into all relevant boxes (like this [x])\r\n-->\r\n\r\n- [x] I'm reporting a broken site support\r\n- [x] I've verified that I'm running youtube-dl version **2020.07.28**\r\n- [x] I've checked that all provided URLs are alive and playable in a browser\r\n- [x] I've checked that all URLs and arguments with special characters are properly quoted or escaped\r\n- [x] I've searched the bugtracker for similar issues including closed ones\r\n\r\n\r\n## Verbose log\r\n\r\n<!--\r\nProvide the complete verbose output of youtube-dl that clearly demonstrates the problem.\r\nAdd the `-v` flag to your command line you run youtube-dl with (`youtube-dl -v <your command line>`), copy the WHOLE output and insert it below. It should look similar to this:\r\n [debug] System config: []\r\n [debug] User config: []\r\n [debug] Command-line args: [u'-v', u'http://www.youtube.com/watch?v=BaW_jenozKcj']\r\n [debug] Encodings: locale cp1251, fs mbcs, out cp866, pref cp1251\r\n [debug] youtube-dl version 2020.07.28\r\n [debug] Python version 2.7.11 - Windows-2003Server-5.2.3790-SP2\r\n [debug] exe versions: ffmpeg N-75573-g1d0487f, ffprobe N-75573-g1d0487f, rtmpdump 2.4\r\n [debug] Proxy map: {}\r\n <more lines>\r\n-->\r\n\r\n[debug] System config: []\r\n[debug] User config: []\r\n[debug] Custom config: []\r\n[debug] Command-line args: [u'-vvv', u'https://cnn.iprima.cz/porady/hlavni-zpravy/31082020']\r\nWARNING: Assuming --restrict-filenames since file system encoding cannot encode all characters. Set the LC_ALL environment variable to fix this.\r\n[debug] Encodings: locale ANSI_X3.4-1968, fs ANSI_X3.4-1968, out ANSI_X3.4-1968, pref ANSI_X3.4-1968\r\n[debug] youtube-dl version 2020.07.28\r\n[debug] Python version 2.7.13 (CPython) - Linux-3.16.6-042stab145.3-x86_64-with-debian-9.9\r\n[debug] exe versions: ffmpeg 3.2.12-1, ffprobe 3.2.12-1, rtmpdump 2.4\r\n[debug] Proxy map: {}\r\n[IPrima] 31082020: Downloading webpage\r\nERROR: Unable to extract real id; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; type youtube-dl -U to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.\r\nTraceback (most recent call last):\r\n File \"/usr/local/bin/youtube-dl/youtube_dl/YoutubeDL.py\", line 797, in extract_info\r\n ie_result = ie.extract(url)\r\n File \"/usr/local/bin/youtube-dl/youtube_dl/extractor/common.py\", line 530, in extract\r\n ie_result = self._real_extract(url)\r\n File \"/usr/local/bin/youtube-dl/youtube_dl/extractor/iprima.py\", line 90, in _real_extract\r\n webpage, 'real id')\r\n File \"/usr/local/bin/youtube-dl/youtube_dl/extractor/common.py\", line 1005, in _search_regex\r\n raise RegexNotFoundError('Unable to extract %s' % _name)\r\nRegexNotFoundError: Unable to extract real id; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; type youtube-dl -U to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.\r\n\r\n\r\n\r\n## Description\r\n\r\n<!--\r\nProvide an explanation of your issue in an arbitrary form. Provide any additional information, suggested solution and as much context and examples as possible.\r\nIf work on your issue requires account credentials please provide them or explain how one can obtain them.\r\n-->\r\n\r\nThis error appears from today, from the first of September 2020. So far, I have discovered the error only on the \"cnn\" version of the iprima.cz website.\r\n\n", "before_files": [{"content": "# coding: utf-8\nfrom __future__ import unicode_literals\n\nimport re\nimport time\n\nfrom .common import InfoExtractor\nfrom ..utils import (\n determine_ext,\n js_to_json,\n)\n\n\nclass IPrimaIE(InfoExtractor):\n _VALID_URL = r'https?://(?:[^/]+)\\.iprima\\.cz/(?:[^/]+/)*(?P<id>[^/?#&]+)'\n _GEO_BYPASS = False\n\n _TESTS = [{\n 'url': 'https://prima.iprima.cz/particka/92-epizoda',\n 'info_dict': {\n 'id': 'p51388',\n 'ext': 'mp4',\n 'title': 'Parti\u010dka (92)',\n 'description': 'md5:859d53beae4609e6dd7796413f1b6cac',\n },\n 'params': {\n 'skip_download': True, # m3u8 download\n },\n }, {\n 'url': 'https://cnn.iprima.cz/videa/70-epizoda',\n 'info_dict': {\n 'id': 'p681554',\n 'ext': 'mp4',\n 'title': 'HLAVN\u00cd ZPR\u00c1VY 3.5.2020',\n },\n 'params': {\n 'skip_download': True, # m3u8 download\n },\n }, {\n 'url': 'http://play.iprima.cz/particka/particka-92',\n 'only_matching': True,\n }, {\n # geo restricted\n 'url': 'http://play.iprima.cz/closer-nove-pripady/closer-nove-pripady-iv-1',\n 'only_matching': True,\n }, {\n # iframe api.play-backend.iprima.cz\n 'url': 'https://prima.iprima.cz/my-little-pony/mapa-znameni-2-2',\n 'only_matching': True,\n }, {\n # iframe prima.iprima.cz\n 'url': 'https://prima.iprima.cz/porady/jak-se-stavi-sen/rodina-rathousova-praha',\n 'only_matching': True,\n }, {\n 'url': 'http://www.iprima.cz/filmy/desne-rande',\n 'only_matching': True,\n }, {\n 'url': 'https://zoom.iprima.cz/10-nejvetsich-tajemstvi-zahad/posvatna-mista-a-stavby',\n 'only_matching': True,\n }, {\n 'url': 'https://krimi.iprima.cz/mraz-0/sebevrazdy',\n 'only_matching': True,\n }, {\n 'url': 'https://cool.iprima.cz/derava-silnice-nevadi',\n 'only_matching': True,\n }, {\n 'url': 'https://love.iprima.cz/laska-az-za-hrob/slib-dany-bratrovi',\n 'only_matching': True,\n }, {\n 'url': 'https://autosalon.iprima.cz/motorsport/7-epizoda-1',\n 'only_matching': True,\n }]\n\n def _real_extract(self, url):\n video_id = self._match_id(url)\n\n self._set_cookie('play.iprima.cz', 'ott_adult_confirmed', '1')\n\n webpage = self._download_webpage(url, video_id)\n\n title = self._og_search_title(\n webpage, default=None) or self._search_regex(\n r'<h1>([^<]+)', webpage, 'title')\n\n video_id = self._search_regex(\n (r'<iframe[^>]+\\bsrc=[\"\\'](?:https?:)?//(?:api\\.play-backend\\.iprima\\.cz/prehravac/embedded|prima\\.iprima\\.cz/[^/]+/[^/]+)\\?.*?\\bid=(p\\d+)',\n r'data-product=\"([^\"]+)\">',\n r'id=[\"\\']player-(p\\d+)\"',\n r'playerId\\s*:\\s*[\"\\']player-(p\\d+)'),\n webpage, 'real id')\n\n playerpage = self._download_webpage(\n 'http://play.iprima.cz/prehravac/init',\n video_id, note='Downloading player', query={\n '_infuse': 1,\n '_ts': round(time.time()),\n 'productId': video_id,\n }, headers={'Referer': url})\n\n formats = []\n\n def extract_formats(format_url, format_key=None, lang=None):\n ext = determine_ext(format_url)\n new_formats = []\n if format_key == 'hls' or ext == 'm3u8':\n new_formats = self._extract_m3u8_formats(\n format_url, video_id, 'mp4', entry_protocol='m3u8_native',\n m3u8_id='hls', fatal=False)\n elif format_key == 'dash' or ext == 'mpd':\n return\n new_formats = self._extract_mpd_formats(\n format_url, video_id, mpd_id='dash', fatal=False)\n if lang:\n for f in new_formats:\n if not f.get('language'):\n f['language'] = lang\n formats.extend(new_formats)\n\n options = self._parse_json(\n self._search_regex(\n r'(?s)(?:TDIPlayerOptions|playerOptions)\\s*=\\s*({.+?});\\s*\\]\\]',\n playerpage, 'player options', default='{}'),\n video_id, transform_source=js_to_json, fatal=False)\n if options:\n for key, tracks in options.get('tracks', {}).items():\n if not isinstance(tracks, list):\n continue\n for track in tracks:\n src = track.get('src')\n if src:\n extract_formats(src, key.lower(), track.get('lang'))\n\n if not formats:\n for _, src in re.findall(r'src[\"\\']\\s*:\\s*([\"\\'])(.+?)\\1', playerpage):\n extract_formats(src)\n\n if not formats and '>GEO_IP_NOT_ALLOWED<' in playerpage:\n self.raise_geo_restricted(countries=['CZ'])\n\n self._sort_formats(formats)\n\n return {\n 'id': video_id,\n 'title': title,\n 'thumbnail': self._og_search_thumbnail(webpage, default=None),\n 'formats': formats,\n 'description': self._og_search_description(webpage, default=None),\n }\n", "path": "youtube_dl/extractor/iprima.py"}], "after_files": [{"content": "# coding: utf-8\nfrom __future__ import unicode_literals\n\nimport re\nimport time\n\nfrom .common import InfoExtractor\nfrom ..utils import (\n determine_ext,\n js_to_json,\n)\n\n\nclass IPrimaIE(InfoExtractor):\n _VALID_URL = r'https?://(?:[^/]+)\\.iprima\\.cz/(?:[^/]+/)*(?P<id>[^/?#&]+)'\n _GEO_BYPASS = False\n\n _TESTS = [{\n 'url': 'https://prima.iprima.cz/particka/92-epizoda',\n 'info_dict': {\n 'id': 'p51388',\n 'ext': 'mp4',\n 'title': 'Parti\u010dka (92)',\n 'description': 'md5:859d53beae4609e6dd7796413f1b6cac',\n },\n 'params': {\n 'skip_download': True, # m3u8 download\n },\n }, {\n 'url': 'https://cnn.iprima.cz/videa/70-epizoda',\n 'info_dict': {\n 'id': 'p681554',\n 'ext': 'mp4',\n 'title': 'HLAVN\u00cd ZPR\u00c1VY 3.5.2020',\n },\n 'params': {\n 'skip_download': True, # m3u8 download\n },\n }, {\n 'url': 'http://play.iprima.cz/particka/particka-92',\n 'only_matching': True,\n }, {\n # geo restricted\n 'url': 'http://play.iprima.cz/closer-nove-pripady/closer-nove-pripady-iv-1',\n 'only_matching': True,\n }, {\n # iframe api.play-backend.iprima.cz\n 'url': 'https://prima.iprima.cz/my-little-pony/mapa-znameni-2-2',\n 'only_matching': True,\n }, {\n # iframe prima.iprima.cz\n 'url': 'https://prima.iprima.cz/porady/jak-se-stavi-sen/rodina-rathousova-praha',\n 'only_matching': True,\n }, {\n 'url': 'http://www.iprima.cz/filmy/desne-rande',\n 'only_matching': True,\n }, {\n 'url': 'https://zoom.iprima.cz/10-nejvetsich-tajemstvi-zahad/posvatna-mista-a-stavby',\n 'only_matching': True,\n }, {\n 'url': 'https://krimi.iprima.cz/mraz-0/sebevrazdy',\n 'only_matching': True,\n }, {\n 'url': 'https://cool.iprima.cz/derava-silnice-nevadi',\n 'only_matching': True,\n }, {\n 'url': 'https://love.iprima.cz/laska-az-za-hrob/slib-dany-bratrovi',\n 'only_matching': True,\n }, {\n 'url': 'https://autosalon.iprima.cz/motorsport/7-epizoda-1',\n 'only_matching': True,\n }]\n\n def _real_extract(self, url):\n video_id = self._match_id(url)\n\n self._set_cookie('play.iprima.cz', 'ott_adult_confirmed', '1')\n\n webpage = self._download_webpage(url, video_id)\n\n title = self._og_search_title(\n webpage, default=None) or self._search_regex(\n r'<h1>([^<]+)', webpage, 'title')\n\n video_id = self._search_regex(\n (r'<iframe[^>]+\\bsrc=[\"\\'](?:https?:)?//(?:api\\.play-backend\\.iprima\\.cz/prehravac/embedded|prima\\.iprima\\.cz/[^/]+/[^/]+)\\?.*?\\bid=(p\\d+)',\n r'data-product=\"([^\"]+)\">',\n r'id=[\"\\']player-(p\\d+)\"',\n r'playerId\\s*:\\s*[\"\\']player-(p\\d+)',\n r'\\bvideos\\s*=\\s*[\"\\'](p\\d+)'),\n webpage, 'real id')\n\n playerpage = self._download_webpage(\n 'http://play.iprima.cz/prehravac/init',\n video_id, note='Downloading player', query={\n '_infuse': 1,\n '_ts': round(time.time()),\n 'productId': video_id,\n }, headers={'Referer': url})\n\n formats = []\n\n def extract_formats(format_url, format_key=None, lang=None):\n ext = determine_ext(format_url)\n new_formats = []\n if format_key == 'hls' or ext == 'm3u8':\n new_formats = self._extract_m3u8_formats(\n format_url, video_id, 'mp4', entry_protocol='m3u8_native',\n m3u8_id='hls', fatal=False)\n elif format_key == 'dash' or ext == 'mpd':\n return\n new_formats = self._extract_mpd_formats(\n format_url, video_id, mpd_id='dash', fatal=False)\n if lang:\n for f in new_formats:\n if not f.get('language'):\n f['language'] = lang\n formats.extend(new_formats)\n\n options = self._parse_json(\n self._search_regex(\n r'(?s)(?:TDIPlayerOptions|playerOptions)\\s*=\\s*({.+?});\\s*\\]\\]',\n playerpage, 'player options', default='{}'),\n video_id, transform_source=js_to_json, fatal=False)\n if options:\n for key, tracks in options.get('tracks', {}).items():\n if not isinstance(tracks, list):\n continue\n for track in tracks:\n src = track.get('src')\n if src:\n extract_formats(src, key.lower(), track.get('lang'))\n\n if not formats:\n for _, src in re.findall(r'src[\"\\']\\s*:\\s*([\"\\'])(.+?)\\1', playerpage):\n extract_formats(src)\n\n if not formats and '>GEO_IP_NOT_ALLOWED<' in playerpage:\n self.raise_geo_restricted(countries=['CZ'])\n\n self._sort_formats(formats)\n\n return {\n 'id': video_id,\n 'title': title,\n 'thumbnail': self._og_search_thumbnail(webpage, default=None),\n 'formats': formats,\n 'description': self._og_search_description(webpage, default=None),\n }\n", "path": "youtube_dl/extractor/iprima.py"}]}
| 3,305 | 225 |
gh_patches_debug_19470
|
rasdani/github-patches
|
git_diff
|
googleapis__google-cloud-python-1675
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
'QueryResults.job' returns a new instance on each access.
See second item of #1551.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gcloud/bigquery/query.py`
Content:
```
1 # Copyright 2015 Google Inc. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Define API Queries."""
16
17 import six
18
19 from gcloud.bigquery._helpers import _TypedProperty
20 from gcloud.bigquery._helpers import _rows_from_json
21 from gcloud.bigquery.dataset import Dataset
22 from gcloud.bigquery.job import QueryJob
23 from gcloud.bigquery.table import _parse_schema_resource
24
25
26 class _SyncQueryConfiguration(object):
27 """User-settable configuration options for synchronous query jobs.
28
29 Values which are ``None`` -> server defaults.
30 """
31 _default_dataset = None
32 _max_results = None
33 _timeout_ms = None
34 _preserve_nulls = None
35 _use_query_cache = None
36
37
38 class QueryResults(object):
39 """Synchronous job: query tables.
40
41 :type query: string
42 :param query: SQL query string
43
44 :type client: :class:`gcloud.bigquery.client.Client`
45 :param client: A client which holds credentials and project configuration
46 for the dataset (which requires a project).
47 """
48 def __init__(self, query, client):
49 self._client = client
50 self._properties = {}
51 self.query = query
52 self._configuration = _SyncQueryConfiguration()
53
54 @property
55 def project(self):
56 """Project bound to the job.
57
58 :rtype: string
59 :returns: the project (derived from the client).
60 """
61 return self._client.project
62
63 def _require_client(self, client):
64 """Check client or verify over-ride.
65
66 :type client: :class:`gcloud.bigquery.client.Client` or ``NoneType``
67 :param client: the client to use. If not passed, falls back to the
68 ``client`` stored on the current dataset.
69
70 :rtype: :class:`gcloud.bigquery.client.Client`
71 :returns: The client passed in or the currently bound client.
72 """
73 if client is None:
74 client = self._client
75 return client
76
77 @property
78 def cache_hit(self):
79 """Query results served from cache.
80
81 See:
82 https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#cacheHit
83
84 :rtype: boolean or ``NoneType``
85 :returns: True if the query results were served from cache (None
86 until set by the server).
87 """
88 return self._properties.get('cacheHit')
89
90 @property
91 def complete(self):
92 """Server completed query.
93
94 See:
95 https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#jobComplete
96
97 :rtype: boolean or ``NoneType``
98 :returns: True if the query completed on the server (None
99 until set by the server).
100 """
101 return self._properties.get('jobComplete')
102
103 @property
104 def errors(self):
105 """Errors generated by the query.
106
107 See:
108 https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#errors
109
110 :rtype: list of mapping, or ``NoneType``
111 :returns: Mappings describing errors generated on the server (None
112 until set by the server).
113 """
114 return self._properties.get('errors')
115
116 @property
117 def name(self):
118 """Job name, generated by the back-end.
119
120 See:
121 https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#jobReference
122
123 :rtype: list of mapping, or ``NoneType``
124 :returns: Mappings describing errors generated on the server (None
125 until set by the server).
126 """
127 return self._properties.get('jobReference', {}).get('jobId')
128
129 @property
130 def job(self):
131 """Job instance used to run the query.
132
133 :rtype: :class:`gcloud.bigquery.job.QueryJob`, or ``NoneType``
134 :returns: Job instance used to run the query (None until
135 ``jobReference`` property is set by the server).
136 """
137 job_ref = self._properties.get('jobReference')
138 if job_ref is not None:
139 return QueryJob(job_ref['jobId'], self.query, self._client)
140
141 @property
142 def page_token(self):
143 """Token for fetching next bach of results.
144
145 See:
146 https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#pageToken
147
148 :rtype: string, or ``NoneType``
149 :returns: Token generated on the server (None until set by the server).
150 """
151 return self._properties.get('pageToken')
152
153 @property
154 def total_rows(self):
155 """Total number of rows returned by the query
156
157 See:
158 https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#totalRows
159
160 :rtype: integer, or ``NoneType``
161 :returns: Count generated on the server (None until set by the server).
162 """
163 return self._properties.get('totalRows')
164
165 @property
166 def total_bytes_processed(self):
167 """Total number of bytes processed by the query
168
169 See:
170 https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#totalBytesProcessed
171
172 :rtype: integer, or ``NoneType``
173 :returns: Count generated on the server (None until set by the server).
174 """
175 return self._properties.get('totalBytesProcessed')
176
177 @property
178 def rows(self):
179 """Query results.
180
181 See:
182 https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#rows
183
184 :rtype: list of tuples of row values, or ``NoneType``
185 :returns: fields describing the schema (None until set by the server).
186 """
187 return _rows_from_json(self._properties.get('rows', ()), self.schema)
188
189 @property
190 def schema(self):
191 """Schema for query results.
192
193 See:
194 https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#schema
195
196 :rtype: list of :class:`SchemaField`, or ``NoneType``
197 :returns: fields describing the schema (None until set by the server).
198 """
199 return _parse_schema_resource(self._properties.get('schema', {}))
200
201 default_dataset = _TypedProperty('default_dataset', Dataset)
202 """See:
203 https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#defaultDataset
204 """
205
206 max_results = _TypedProperty('max_results', six.integer_types)
207 """See:
208 https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#maxResults
209 """
210
211 preserve_nulls = _TypedProperty('preserve_nulls', bool)
212 """See:
213 https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#preserveNulls
214 """
215
216 timeout_ms = _TypedProperty('timeout_ms', six.integer_types)
217 """See:
218 https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#timeoutMs
219 """
220
221 use_query_cache = _TypedProperty('use_query_cache', bool)
222 """See:
223 https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#useQueryCache
224 """
225
226 def _set_properties(self, api_response):
227 """Update properties from resource in body of ``api_response``
228
229 :type api_response: httplib2.Response
230 :param api_response: response returned from an API call
231 """
232 self._properties.clear()
233 self._properties.update(api_response)
234
235 def _build_resource(self):
236 """Generate a resource for :meth:`begin`."""
237 resource = {'query': self.query}
238
239 if self.default_dataset is not None:
240 resource['defaultDataset'] = {
241 'projectId': self.project,
242 'datasetId': self.default_dataset.name,
243 }
244
245 if self.max_results is not None:
246 resource['maxResults'] = self.max_results
247
248 if self.preserve_nulls is not None:
249 resource['preserveNulls'] = self.preserve_nulls
250
251 if self.timeout_ms is not None:
252 resource['timeoutMs'] = self.timeout_ms
253
254 if self.use_query_cache is not None:
255 resource['useQueryCache'] = self.use_query_cache
256
257 return resource
258
259 def run(self, client=None):
260 """API call: run the query via a POST request
261
262 See:
263 https://cloud.google.com/bigquery/docs/reference/v2/jobs/query
264
265 :type client: :class:`gcloud.bigquery.client.Client` or ``NoneType``
266 :param client: the client to use. If not passed, falls back to the
267 ``client`` stored on the current dataset.
268 """
269 client = self._require_client(client)
270 path = '/projects/%s/queries' % (self.project,)
271 api_response = client.connection.api_request(
272 method='POST', path=path, data=self._build_resource())
273 self._set_properties(api_response)
274
275 def fetch_data(self, max_results=None, page_token=None, start_index=None,
276 timeout_ms=None, client=None):
277 """API call: fetch a page of query result data via a GET request
278
279 See:
280 https://cloud.google.com/bigquery/docs/reference/v2/jobs/getQueryResults
281
282 :type max_results: integer or ``NoneType``
283 :param max_results: maximum number of rows to return.
284
285 :type page_token: string or ``NoneType``
286 :param page_token: token representing a cursor into the table's rows.
287
288 :type start_index: integer or ``NoneType``
289 :param start_index: zero-based index of starting row
290
291 :type timeout_ms: integer or ``NoneType``
292 :param timeout_ms: timeout, in milliseconds, to wait for query to
293 complete
294
295 :type client: :class:`gcloud.bigquery.client.Client` or ``NoneType``
296 :param client: the client to use. If not passed, falls back to the
297 ``client`` stored on the current dataset.
298
299 :rtype: tuple
300 :returns: ``(row_data, total_rows, page_token)``, where ``row_data``
301 is a list of tuples, one per result row, containing only
302 the values; ``total_rows`` is a count of the total number
303 of rows in the table; and ``page_token`` is an opaque
304 string which can be used to fetch the next batch of rows
305 (``None`` if no further batches can be fetched).
306 :raises: ValueError if the query has not yet been executed.
307 """
308 if self.name is None:
309 raise ValueError("Query not yet executed: call 'run()'")
310
311 client = self._require_client(client)
312 params = {}
313
314 if max_results is not None:
315 params['maxResults'] = max_results
316
317 if page_token is not None:
318 params['pageToken'] = page_token
319
320 if start_index is not None:
321 params['startIndex'] = start_index
322
323 if timeout_ms is not None:
324 params['timeoutMs'] = timeout_ms
325
326 path = '/projects/%s/queries/%s' % (self.project, self.name)
327 response = client.connection.api_request(method='GET',
328 path=path,
329 query_params=params)
330 self._set_properties(response)
331
332 total_rows = response.get('totalRows')
333 page_token = response.get('pageToken')
334 rows_data = _rows_from_json(response.get('rows', ()), self.schema)
335
336 return rows_data, total_rows, page_token
337
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/gcloud/bigquery/query.py b/gcloud/bigquery/query.py
--- a/gcloud/bigquery/query.py
+++ b/gcloud/bigquery/query.py
@@ -50,6 +50,7 @@
self._properties = {}
self.query = query
self._configuration = _SyncQueryConfiguration()
+ self._job = None
@property
def project(self):
@@ -134,9 +135,12 @@
:returns: Job instance used to run the query (None until
``jobReference`` property is set by the server).
"""
- job_ref = self._properties.get('jobReference')
- if job_ref is not None:
- return QueryJob(job_ref['jobId'], self.query, self._client)
+ if self._job is None:
+ job_ref = self._properties.get('jobReference')
+ if job_ref is not None:
+ self._job = QueryJob(job_ref['jobId'], self.query,
+ self._client)
+ return self._job
@property
def page_token(self):
|
{"golden_diff": "diff --git a/gcloud/bigquery/query.py b/gcloud/bigquery/query.py\n--- a/gcloud/bigquery/query.py\n+++ b/gcloud/bigquery/query.py\n@@ -50,6 +50,7 @@\n self._properties = {}\n self.query = query\n self._configuration = _SyncQueryConfiguration()\n+ self._job = None\n \n @property\n def project(self):\n@@ -134,9 +135,12 @@\n :returns: Job instance used to run the query (None until\n ``jobReference`` property is set by the server).\n \"\"\"\n- job_ref = self._properties.get('jobReference')\n- if job_ref is not None:\n- return QueryJob(job_ref['jobId'], self.query, self._client)\n+ if self._job is None:\n+ job_ref = self._properties.get('jobReference')\n+ if job_ref is not None:\n+ self._job = QueryJob(job_ref['jobId'], self.query,\n+ self._client)\n+ return self._job\n \n @property\n def page_token(self):\n", "issue": "'QueryResults.job' returns a new instance on each access.\nSee second item of #1551.\n\n", "before_files": [{"content": "# Copyright 2015 Google Inc. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Define API Queries.\"\"\"\n\nimport six\n\nfrom gcloud.bigquery._helpers import _TypedProperty\nfrom gcloud.bigquery._helpers import _rows_from_json\nfrom gcloud.bigquery.dataset import Dataset\nfrom gcloud.bigquery.job import QueryJob\nfrom gcloud.bigquery.table import _parse_schema_resource\n\n\nclass _SyncQueryConfiguration(object):\n \"\"\"User-settable configuration options for synchronous query jobs.\n\n Values which are ``None`` -> server defaults.\n \"\"\"\n _default_dataset = None\n _max_results = None\n _timeout_ms = None\n _preserve_nulls = None\n _use_query_cache = None\n\n\nclass QueryResults(object):\n \"\"\"Synchronous job: query tables.\n\n :type query: string\n :param query: SQL query string\n\n :type client: :class:`gcloud.bigquery.client.Client`\n :param client: A client which holds credentials and project configuration\n for the dataset (which requires a project).\n \"\"\"\n def __init__(self, query, client):\n self._client = client\n self._properties = {}\n self.query = query\n self._configuration = _SyncQueryConfiguration()\n\n @property\n def project(self):\n \"\"\"Project bound to the job.\n\n :rtype: string\n :returns: the project (derived from the client).\n \"\"\"\n return self._client.project\n\n def _require_client(self, client):\n \"\"\"Check client or verify over-ride.\n\n :type client: :class:`gcloud.bigquery.client.Client` or ``NoneType``\n :param client: the client to use. If not passed, falls back to the\n ``client`` stored on the current dataset.\n\n :rtype: :class:`gcloud.bigquery.client.Client`\n :returns: The client passed in or the currently bound client.\n \"\"\"\n if client is None:\n client = self._client\n return client\n\n @property\n def cache_hit(self):\n \"\"\"Query results served from cache.\n\n See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#cacheHit\n\n :rtype: boolean or ``NoneType``\n :returns: True if the query results were served from cache (None\n until set by the server).\n \"\"\"\n return self._properties.get('cacheHit')\n\n @property\n def complete(self):\n \"\"\"Server completed query.\n\n See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#jobComplete\n\n :rtype: boolean or ``NoneType``\n :returns: True if the query completed on the server (None\n until set by the server).\n \"\"\"\n return self._properties.get('jobComplete')\n\n @property\n def errors(self):\n \"\"\"Errors generated by the query.\n\n See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#errors\n\n :rtype: list of mapping, or ``NoneType``\n :returns: Mappings describing errors generated on the server (None\n until set by the server).\n \"\"\"\n return self._properties.get('errors')\n\n @property\n def name(self):\n \"\"\"Job name, generated by the back-end.\n\n See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#jobReference\n\n :rtype: list of mapping, or ``NoneType``\n :returns: Mappings describing errors generated on the server (None\n until set by the server).\n \"\"\"\n return self._properties.get('jobReference', {}).get('jobId')\n\n @property\n def job(self):\n \"\"\"Job instance used to run the query.\n\n :rtype: :class:`gcloud.bigquery.job.QueryJob`, or ``NoneType``\n :returns: Job instance used to run the query (None until\n ``jobReference`` property is set by the server).\n \"\"\"\n job_ref = self._properties.get('jobReference')\n if job_ref is not None:\n return QueryJob(job_ref['jobId'], self.query, self._client)\n\n @property\n def page_token(self):\n \"\"\"Token for fetching next bach of results.\n\n See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#pageToken\n\n :rtype: string, or ``NoneType``\n :returns: Token generated on the server (None until set by the server).\n \"\"\"\n return self._properties.get('pageToken')\n\n @property\n def total_rows(self):\n \"\"\"Total number of rows returned by the query\n\n See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#totalRows\n\n :rtype: integer, or ``NoneType``\n :returns: Count generated on the server (None until set by the server).\n \"\"\"\n return self._properties.get('totalRows')\n\n @property\n def total_bytes_processed(self):\n \"\"\"Total number of bytes processed by the query\n\n See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#totalBytesProcessed\n\n :rtype: integer, or ``NoneType``\n :returns: Count generated on the server (None until set by the server).\n \"\"\"\n return self._properties.get('totalBytesProcessed')\n\n @property\n def rows(self):\n \"\"\"Query results.\n\n See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#rows\n\n :rtype: list of tuples of row values, or ``NoneType``\n :returns: fields describing the schema (None until set by the server).\n \"\"\"\n return _rows_from_json(self._properties.get('rows', ()), self.schema)\n\n @property\n def schema(self):\n \"\"\"Schema for query results.\n\n See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#schema\n\n :rtype: list of :class:`SchemaField`, or ``NoneType``\n :returns: fields describing the schema (None until set by the server).\n \"\"\"\n return _parse_schema_resource(self._properties.get('schema', {}))\n\n default_dataset = _TypedProperty('default_dataset', Dataset)\n \"\"\"See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#defaultDataset\n \"\"\"\n\n max_results = _TypedProperty('max_results', six.integer_types)\n \"\"\"See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#maxResults\n \"\"\"\n\n preserve_nulls = _TypedProperty('preserve_nulls', bool)\n \"\"\"See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#preserveNulls\n \"\"\"\n\n timeout_ms = _TypedProperty('timeout_ms', six.integer_types)\n \"\"\"See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#timeoutMs\n \"\"\"\n\n use_query_cache = _TypedProperty('use_query_cache', bool)\n \"\"\"See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#useQueryCache\n \"\"\"\n\n def _set_properties(self, api_response):\n \"\"\"Update properties from resource in body of ``api_response``\n\n :type api_response: httplib2.Response\n :param api_response: response returned from an API call\n \"\"\"\n self._properties.clear()\n self._properties.update(api_response)\n\n def _build_resource(self):\n \"\"\"Generate a resource for :meth:`begin`.\"\"\"\n resource = {'query': self.query}\n\n if self.default_dataset is not None:\n resource['defaultDataset'] = {\n 'projectId': self.project,\n 'datasetId': self.default_dataset.name,\n }\n\n if self.max_results is not None:\n resource['maxResults'] = self.max_results\n\n if self.preserve_nulls is not None:\n resource['preserveNulls'] = self.preserve_nulls\n\n if self.timeout_ms is not None:\n resource['timeoutMs'] = self.timeout_ms\n\n if self.use_query_cache is not None:\n resource['useQueryCache'] = self.use_query_cache\n\n return resource\n\n def run(self, client=None):\n \"\"\"API call: run the query via a POST request\n\n See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query\n\n :type client: :class:`gcloud.bigquery.client.Client` or ``NoneType``\n :param client: the client to use. If not passed, falls back to the\n ``client`` stored on the current dataset.\n \"\"\"\n client = self._require_client(client)\n path = '/projects/%s/queries' % (self.project,)\n api_response = client.connection.api_request(\n method='POST', path=path, data=self._build_resource())\n self._set_properties(api_response)\n\n def fetch_data(self, max_results=None, page_token=None, start_index=None,\n timeout_ms=None, client=None):\n \"\"\"API call: fetch a page of query result data via a GET request\n\n See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/getQueryResults\n\n :type max_results: integer or ``NoneType``\n :param max_results: maximum number of rows to return.\n\n :type page_token: string or ``NoneType``\n :param page_token: token representing a cursor into the table's rows.\n\n :type start_index: integer or ``NoneType``\n :param start_index: zero-based index of starting row\n\n :type timeout_ms: integer or ``NoneType``\n :param timeout_ms: timeout, in milliseconds, to wait for query to\n complete\n\n :type client: :class:`gcloud.bigquery.client.Client` or ``NoneType``\n :param client: the client to use. If not passed, falls back to the\n ``client`` stored on the current dataset.\n\n :rtype: tuple\n :returns: ``(row_data, total_rows, page_token)``, where ``row_data``\n is a list of tuples, one per result row, containing only\n the values; ``total_rows`` is a count of the total number\n of rows in the table; and ``page_token`` is an opaque\n string which can be used to fetch the next batch of rows\n (``None`` if no further batches can be fetched).\n :raises: ValueError if the query has not yet been executed.\n \"\"\"\n if self.name is None:\n raise ValueError(\"Query not yet executed: call 'run()'\")\n\n client = self._require_client(client)\n params = {}\n\n if max_results is not None:\n params['maxResults'] = max_results\n\n if page_token is not None:\n params['pageToken'] = page_token\n\n if start_index is not None:\n params['startIndex'] = start_index\n\n if timeout_ms is not None:\n params['timeoutMs'] = timeout_ms\n\n path = '/projects/%s/queries/%s' % (self.project, self.name)\n response = client.connection.api_request(method='GET',\n path=path,\n query_params=params)\n self._set_properties(response)\n\n total_rows = response.get('totalRows')\n page_token = response.get('pageToken')\n rows_data = _rows_from_json(response.get('rows', ()), self.schema)\n\n return rows_data, total_rows, page_token\n", "path": "gcloud/bigquery/query.py"}], "after_files": [{"content": "# Copyright 2015 Google Inc. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Define API Queries.\"\"\"\n\nimport six\n\nfrom gcloud.bigquery._helpers import _TypedProperty\nfrom gcloud.bigquery._helpers import _rows_from_json\nfrom gcloud.bigquery.dataset import Dataset\nfrom gcloud.bigquery.job import QueryJob\nfrom gcloud.bigquery.table import _parse_schema_resource\n\n\nclass _SyncQueryConfiguration(object):\n \"\"\"User-settable configuration options for synchronous query jobs.\n\n Values which are ``None`` -> server defaults.\n \"\"\"\n _default_dataset = None\n _max_results = None\n _timeout_ms = None\n _preserve_nulls = None\n _use_query_cache = None\n\n\nclass QueryResults(object):\n \"\"\"Synchronous job: query tables.\n\n :type query: string\n :param query: SQL query string\n\n :type client: :class:`gcloud.bigquery.client.Client`\n :param client: A client which holds credentials and project configuration\n for the dataset (which requires a project).\n \"\"\"\n def __init__(self, query, client):\n self._client = client\n self._properties = {}\n self.query = query\n self._configuration = _SyncQueryConfiguration()\n self._job = None\n\n @property\n def project(self):\n \"\"\"Project bound to the job.\n\n :rtype: string\n :returns: the project (derived from the client).\n \"\"\"\n return self._client.project\n\n def _require_client(self, client):\n \"\"\"Check client or verify over-ride.\n\n :type client: :class:`gcloud.bigquery.client.Client` or ``NoneType``\n :param client: the client to use. If not passed, falls back to the\n ``client`` stored on the current dataset.\n\n :rtype: :class:`gcloud.bigquery.client.Client`\n :returns: The client passed in or the currently bound client.\n \"\"\"\n if client is None:\n client = self._client\n return client\n\n @property\n def cache_hit(self):\n \"\"\"Query results served from cache.\n\n See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#cacheHit\n\n :rtype: boolean or ``NoneType``\n :returns: True if the query results were served from cache (None\n until set by the server).\n \"\"\"\n return self._properties.get('cacheHit')\n\n @property\n def complete(self):\n \"\"\"Server completed query.\n\n See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#jobComplete\n\n :rtype: boolean or ``NoneType``\n :returns: True if the query completed on the server (None\n until set by the server).\n \"\"\"\n return self._properties.get('jobComplete')\n\n @property\n def errors(self):\n \"\"\"Errors generated by the query.\n\n See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#errors\n\n :rtype: list of mapping, or ``NoneType``\n :returns: Mappings describing errors generated on the server (None\n until set by the server).\n \"\"\"\n return self._properties.get('errors')\n\n @property\n def name(self):\n \"\"\"Job name, generated by the back-end.\n\n See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#jobReference\n\n :rtype: list of mapping, or ``NoneType``\n :returns: Mappings describing errors generated on the server (None\n until set by the server).\n \"\"\"\n return self._properties.get('jobReference', {}).get('jobId')\n\n @property\n def job(self):\n \"\"\"Job instance used to run the query.\n\n :rtype: :class:`gcloud.bigquery.job.QueryJob`, or ``NoneType``\n :returns: Job instance used to run the query (None until\n ``jobReference`` property is set by the server).\n \"\"\"\n if self._job is None:\n job_ref = self._properties.get('jobReference')\n if job_ref is not None:\n self._job = QueryJob(job_ref['jobId'], self.query,\n self._client)\n return self._job\n\n @property\n def page_token(self):\n \"\"\"Token for fetching next bach of results.\n\n See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#pageToken\n\n :rtype: string, or ``NoneType``\n :returns: Token generated on the server (None until set by the server).\n \"\"\"\n return self._properties.get('pageToken')\n\n @property\n def total_rows(self):\n \"\"\"Total number of rows returned by the query\n\n See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#totalRows\n\n :rtype: integer, or ``NoneType``\n :returns: Count generated on the server (None until set by the server).\n \"\"\"\n return self._properties.get('totalRows')\n\n @property\n def total_bytes_processed(self):\n \"\"\"Total number of bytes processed by the query\n\n See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#totalBytesProcessed\n\n :rtype: integer, or ``NoneType``\n :returns: Count generated on the server (None until set by the server).\n \"\"\"\n return self._properties.get('totalBytesProcessed')\n\n @property\n def rows(self):\n \"\"\"Query results.\n\n See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#rows\n\n :rtype: list of tuples of row values, or ``NoneType``\n :returns: fields describing the schema (None until set by the server).\n \"\"\"\n return _rows_from_json(self._properties.get('rows', ()), self.schema)\n\n @property\n def schema(self):\n \"\"\"Schema for query results.\n\n See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#schema\n\n :rtype: list of :class:`SchemaField`, or ``NoneType``\n :returns: fields describing the schema (None until set by the server).\n \"\"\"\n return _parse_schema_resource(self._properties.get('schema', {}))\n\n default_dataset = _TypedProperty('default_dataset', Dataset)\n \"\"\"See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#defaultDataset\n \"\"\"\n\n max_results = _TypedProperty('max_results', six.integer_types)\n \"\"\"See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#maxResults\n \"\"\"\n\n preserve_nulls = _TypedProperty('preserve_nulls', bool)\n \"\"\"See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#preserveNulls\n \"\"\"\n\n timeout_ms = _TypedProperty('timeout_ms', six.integer_types)\n \"\"\"See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#timeoutMs\n \"\"\"\n\n use_query_cache = _TypedProperty('use_query_cache', bool)\n \"\"\"See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query#useQueryCache\n \"\"\"\n\n def _set_properties(self, api_response):\n \"\"\"Update properties from resource in body of ``api_response``\n\n :type api_response: httplib2.Response\n :param api_response: response returned from an API call\n \"\"\"\n self._properties.clear()\n self._properties.update(api_response)\n\n def _build_resource(self):\n \"\"\"Generate a resource for :meth:`begin`.\"\"\"\n resource = {'query': self.query}\n\n if self.default_dataset is not None:\n resource['defaultDataset'] = {\n 'projectId': self.project,\n 'datasetId': self.default_dataset.name,\n }\n\n if self.max_results is not None:\n resource['maxResults'] = self.max_results\n\n if self.preserve_nulls is not None:\n resource['preserveNulls'] = self.preserve_nulls\n\n if self.timeout_ms is not None:\n resource['timeoutMs'] = self.timeout_ms\n\n if self.use_query_cache is not None:\n resource['useQueryCache'] = self.use_query_cache\n\n return resource\n\n def run(self, client=None):\n \"\"\"API call: run the query via a POST request\n\n See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/query\n\n :type client: :class:`gcloud.bigquery.client.Client` or ``NoneType``\n :param client: the client to use. If not passed, falls back to the\n ``client`` stored on the current dataset.\n \"\"\"\n client = self._require_client(client)\n path = '/projects/%s/queries' % (self.project,)\n api_response = client.connection.api_request(\n method='POST', path=path, data=self._build_resource())\n self._set_properties(api_response)\n\n def fetch_data(self, max_results=None, page_token=None, start_index=None,\n timeout_ms=None, client=None):\n \"\"\"API call: fetch a page of query result data via a GET request\n\n See:\n https://cloud.google.com/bigquery/docs/reference/v2/jobs/getQueryResults\n\n :type max_results: integer or ``NoneType``\n :param max_results: maximum number of rows to return.\n\n :type page_token: string or ``NoneType``\n :param page_token: token representing a cursor into the table's rows.\n\n :type start_index: integer or ``NoneType``\n :param start_index: zero-based index of starting row\n\n :type timeout_ms: integer or ``NoneType``\n :param timeout_ms: timeout, in milliseconds, to wait for query to\n complete\n\n :type client: :class:`gcloud.bigquery.client.Client` or ``NoneType``\n :param client: the client to use. If not passed, falls back to the\n ``client`` stored on the current dataset.\n\n :rtype: tuple\n :returns: ``(row_data, total_rows, page_token)``, where ``row_data``\n is a list of tuples, one per result row, containing only\n the values; ``total_rows`` is a count of the total number\n of rows in the table; and ``page_token`` is an opaque\n string which can be used to fetch the next batch of rows\n (``None`` if no further batches can be fetched).\n :raises: ValueError if the query has not yet been executed.\n \"\"\"\n if self.name is None:\n raise ValueError(\"Query not yet executed: call 'run()'\")\n\n client = self._require_client(client)\n params = {}\n\n if max_results is not None:\n params['maxResults'] = max_results\n\n if page_token is not None:\n params['pageToken'] = page_token\n\n if start_index is not None:\n params['startIndex'] = start_index\n\n if timeout_ms is not None:\n params['timeoutMs'] = timeout_ms\n\n path = '/projects/%s/queries/%s' % (self.project, self.name)\n response = client.connection.api_request(method='GET',\n path=path,\n query_params=params)\n self._set_properties(response)\n\n total_rows = response.get('totalRows')\n page_token = response.get('pageToken')\n rows_data = _rows_from_json(response.get('rows', ()), self.schema)\n\n return rows_data, total_rows, page_token\n", "path": "gcloud/bigquery/query.py"}]}
| 3,788 | 242 |
gh_patches_debug_20729
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-python-2214
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Check if aiohttp client integration needs special baggage handling
### Problem Statement
Once the [instrumentation for aiohttp client requests](https://github.com/getsentry/sentry-python/pull/1761) is in, see if we need special handling for existing baggage [like here](https://github.com/getsentry/sentry-python/pull/2191).
### Solution Brainstorm
Do it.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sentry_sdk/integrations/aiohttp.py`
Content:
```
1 import sys
2 import weakref
3
4 from sentry_sdk.api import continue_trace
5 from sentry_sdk._compat import reraise
6 from sentry_sdk.consts import OP, SPANDATA
7 from sentry_sdk.hub import Hub
8 from sentry_sdk.integrations import Integration, DidNotEnable
9 from sentry_sdk.integrations.logging import ignore_logger
10 from sentry_sdk.sessions import auto_session_tracking
11 from sentry_sdk.integrations._wsgi_common import (
12 _filter_headers,
13 request_body_within_bounds,
14 )
15 from sentry_sdk.tracing import SOURCE_FOR_STYLE, TRANSACTION_SOURCE_ROUTE
16 from sentry_sdk.tracing_utils import should_propagate_trace
17 from sentry_sdk.utils import (
18 capture_internal_exceptions,
19 event_from_exception,
20 logger,
21 parse_url,
22 parse_version,
23 transaction_from_function,
24 HAS_REAL_CONTEXTVARS,
25 CONTEXTVARS_ERROR_MESSAGE,
26 SENSITIVE_DATA_SUBSTITUTE,
27 AnnotatedValue,
28 )
29
30 try:
31 import asyncio
32
33 from aiohttp import __version__ as AIOHTTP_VERSION
34 from aiohttp import ClientSession, TraceConfig
35 from aiohttp.web import Application, HTTPException, UrlDispatcher
36 except ImportError:
37 raise DidNotEnable("AIOHTTP not installed")
38
39 from sentry_sdk._types import TYPE_CHECKING
40
41 if TYPE_CHECKING:
42 from aiohttp.web_request import Request
43 from aiohttp.abc import AbstractMatchInfo
44 from aiohttp import TraceRequestStartParams, TraceRequestEndParams
45 from types import SimpleNamespace
46 from typing import Any
47 from typing import Dict
48 from typing import Optional
49 from typing import Tuple
50 from typing import Callable
51 from typing import Union
52
53 from sentry_sdk.utils import ExcInfo
54 from sentry_sdk._types import EventProcessor
55
56
57 TRANSACTION_STYLE_VALUES = ("handler_name", "method_and_path_pattern")
58
59
60 class AioHttpIntegration(Integration):
61 identifier = "aiohttp"
62
63 def __init__(self, transaction_style="handler_name"):
64 # type: (str) -> None
65 if transaction_style not in TRANSACTION_STYLE_VALUES:
66 raise ValueError(
67 "Invalid value for transaction_style: %s (must be in %s)"
68 % (transaction_style, TRANSACTION_STYLE_VALUES)
69 )
70 self.transaction_style = transaction_style
71
72 @staticmethod
73 def setup_once():
74 # type: () -> None
75
76 version = parse_version(AIOHTTP_VERSION)
77
78 if version is None:
79 raise DidNotEnable("Unparsable AIOHTTP version: {}".format(AIOHTTP_VERSION))
80
81 if version < (3, 4):
82 raise DidNotEnable("AIOHTTP 3.4 or newer required.")
83
84 if not HAS_REAL_CONTEXTVARS:
85 # We better have contextvars or we're going to leak state between
86 # requests.
87 raise DidNotEnable(
88 "The aiohttp integration for Sentry requires Python 3.7+ "
89 " or aiocontextvars package." + CONTEXTVARS_ERROR_MESSAGE
90 )
91
92 ignore_logger("aiohttp.server")
93
94 old_handle = Application._handle
95
96 async def sentry_app_handle(self, request, *args, **kwargs):
97 # type: (Any, Request, *Any, **Any) -> Any
98 hub = Hub.current
99 if hub.get_integration(AioHttpIntegration) is None:
100 return await old_handle(self, request, *args, **kwargs)
101
102 weak_request = weakref.ref(request)
103
104 with Hub(hub) as hub:
105 with auto_session_tracking(hub, session_mode="request"):
106 # Scope data will not leak between requests because aiohttp
107 # create a task to wrap each request.
108 with hub.configure_scope() as scope:
109 scope.clear_breadcrumbs()
110 scope.add_event_processor(_make_request_processor(weak_request))
111
112 transaction = continue_trace(
113 request.headers,
114 op=OP.HTTP_SERVER,
115 # If this transaction name makes it to the UI, AIOHTTP's
116 # URL resolver did not find a route or died trying.
117 name="generic AIOHTTP request",
118 source=TRANSACTION_SOURCE_ROUTE,
119 )
120 with hub.start_transaction(
121 transaction,
122 custom_sampling_context={"aiohttp_request": request},
123 ):
124 try:
125 response = await old_handle(self, request)
126 except HTTPException as e:
127 transaction.set_http_status(e.status_code)
128 raise
129 except (asyncio.CancelledError, ConnectionResetError):
130 transaction.set_status("cancelled")
131 raise
132 except Exception:
133 # This will probably map to a 500 but seems like we
134 # have no way to tell. Do not set span status.
135 reraise(*_capture_exception(hub))
136
137 transaction.set_http_status(response.status)
138 return response
139
140 Application._handle = sentry_app_handle
141
142 old_urldispatcher_resolve = UrlDispatcher.resolve
143
144 async def sentry_urldispatcher_resolve(self, request):
145 # type: (UrlDispatcher, Request) -> AbstractMatchInfo
146 rv = await old_urldispatcher_resolve(self, request)
147
148 hub = Hub.current
149 integration = hub.get_integration(AioHttpIntegration)
150
151 name = None
152
153 try:
154 if integration.transaction_style == "handler_name":
155 name = transaction_from_function(rv.handler)
156 elif integration.transaction_style == "method_and_path_pattern":
157 route_info = rv.get_info()
158 pattern = route_info.get("path") or route_info.get("formatter")
159 name = "{} {}".format(request.method, pattern)
160 except Exception:
161 pass
162
163 if name is not None:
164 with Hub.current.configure_scope() as scope:
165 scope.set_transaction_name(
166 name,
167 source=SOURCE_FOR_STYLE[integration.transaction_style],
168 )
169
170 return rv
171
172 UrlDispatcher.resolve = sentry_urldispatcher_resolve
173
174 old_client_session_init = ClientSession.__init__
175
176 def init(*args, **kwargs):
177 # type: (Any, Any) -> ClientSession
178 hub = Hub.current
179 if hub.get_integration(AioHttpIntegration) is None:
180 return old_client_session_init(*args, **kwargs)
181
182 client_trace_configs = list(kwargs.get("trace_configs", ()))
183 trace_config = create_trace_config()
184 client_trace_configs.append(trace_config)
185
186 kwargs["trace_configs"] = client_trace_configs
187 return old_client_session_init(*args, **kwargs)
188
189 ClientSession.__init__ = init
190
191
192 def create_trace_config():
193 # type: () -> TraceConfig
194 async def on_request_start(session, trace_config_ctx, params):
195 # type: (ClientSession, SimpleNamespace, TraceRequestStartParams) -> None
196 hub = Hub.current
197 if hub.get_integration(AioHttpIntegration) is None:
198 return
199
200 method = params.method.upper()
201
202 parsed_url = None
203 with capture_internal_exceptions():
204 parsed_url = parse_url(str(params.url), sanitize=False)
205
206 span = hub.start_span(
207 op=OP.HTTP_CLIENT,
208 description="%s %s"
209 % (method, parsed_url.url if parsed_url else SENSITIVE_DATA_SUBSTITUTE),
210 )
211 span.set_data(SPANDATA.HTTP_METHOD, method)
212 span.set_data("url", parsed_url.url)
213 span.set_data(SPANDATA.HTTP_QUERY, parsed_url.query)
214 span.set_data(SPANDATA.HTTP_FRAGMENT, parsed_url.fragment)
215
216 if should_propagate_trace(hub, str(params.url)):
217 for key, value in hub.iter_trace_propagation_headers(span):
218 logger.debug(
219 "[Tracing] Adding `{key}` header {value} to outgoing request to {url}.".format(
220 key=key, value=value, url=params.url
221 )
222 )
223 params.headers[key] = value
224
225 trace_config_ctx.span = span
226
227 async def on_request_end(session, trace_config_ctx, params):
228 # type: (ClientSession, SimpleNamespace, TraceRequestEndParams) -> None
229 if trace_config_ctx.span is None:
230 return
231
232 span = trace_config_ctx.span
233 span.set_http_status(int(params.response.status))
234 span.set_data("reason", params.response.reason)
235 span.finish()
236
237 trace_config = TraceConfig()
238
239 trace_config.on_request_start.append(on_request_start)
240 trace_config.on_request_end.append(on_request_end)
241
242 return trace_config
243
244
245 def _make_request_processor(weak_request):
246 # type: (Callable[[], Request]) -> EventProcessor
247 def aiohttp_processor(
248 event, # type: Dict[str, Any]
249 hint, # type: Dict[str, Tuple[type, BaseException, Any]]
250 ):
251 # type: (...) -> Dict[str, Any]
252 request = weak_request()
253 if request is None:
254 return event
255
256 with capture_internal_exceptions():
257 request_info = event.setdefault("request", {})
258
259 request_info["url"] = "%s://%s%s" % (
260 request.scheme,
261 request.host,
262 request.path,
263 )
264
265 request_info["query_string"] = request.query_string
266 request_info["method"] = request.method
267 request_info["env"] = {"REMOTE_ADDR": request.remote}
268
269 hub = Hub.current
270 request_info["headers"] = _filter_headers(dict(request.headers))
271
272 # Just attach raw data here if it is within bounds, if available.
273 # Unfortunately there's no way to get structured data from aiohttp
274 # without awaiting on some coroutine.
275 request_info["data"] = get_aiohttp_request_data(hub, request)
276
277 return event
278
279 return aiohttp_processor
280
281
282 def _capture_exception(hub):
283 # type: (Hub) -> ExcInfo
284 exc_info = sys.exc_info()
285 event, hint = event_from_exception(
286 exc_info,
287 client_options=hub.client.options, # type: ignore
288 mechanism={"type": "aiohttp", "handled": False},
289 )
290 hub.capture_event(event, hint=hint)
291 return exc_info
292
293
294 BODY_NOT_READ_MESSAGE = "[Can't show request body due to implementation details.]"
295
296
297 def get_aiohttp_request_data(hub, request):
298 # type: (Hub, Request) -> Union[Optional[str], AnnotatedValue]
299 bytes_body = request._read_bytes
300
301 if bytes_body is not None:
302 # we have body to show
303 if not request_body_within_bounds(hub.client, len(bytes_body)):
304 return AnnotatedValue.removed_because_over_size_limit()
305
306 encoding = request.charset or "utf-8"
307 return bytes_body.decode(encoding, "replace")
308
309 if request.can_read_body:
310 # body exists but we can't show it
311 return BODY_NOT_READ_MESSAGE
312
313 # request has no body
314 return None
315
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sentry_sdk/integrations/aiohttp.py b/sentry_sdk/integrations/aiohttp.py
--- a/sentry_sdk/integrations/aiohttp.py
+++ b/sentry_sdk/integrations/aiohttp.py
@@ -12,7 +12,11 @@
_filter_headers,
request_body_within_bounds,
)
-from sentry_sdk.tracing import SOURCE_FOR_STYLE, TRANSACTION_SOURCE_ROUTE
+from sentry_sdk.tracing import (
+ BAGGAGE_HEADER_NAME,
+ SOURCE_FOR_STYLE,
+ TRANSACTION_SOURCE_ROUTE,
+)
from sentry_sdk.tracing_utils import should_propagate_trace
from sentry_sdk.utils import (
capture_internal_exceptions,
@@ -220,7 +224,13 @@
key=key, value=value, url=params.url
)
)
- params.headers[key] = value
+ if key == BAGGAGE_HEADER_NAME and params.headers.get(
+ BAGGAGE_HEADER_NAME
+ ):
+ # do not overwrite any existing baggage, just append to it
+ params.headers[key] += "," + value
+ else:
+ params.headers[key] = value
trace_config_ctx.span = span
|
{"golden_diff": "diff --git a/sentry_sdk/integrations/aiohttp.py b/sentry_sdk/integrations/aiohttp.py\n--- a/sentry_sdk/integrations/aiohttp.py\n+++ b/sentry_sdk/integrations/aiohttp.py\n@@ -12,7 +12,11 @@\n _filter_headers,\n request_body_within_bounds,\n )\n-from sentry_sdk.tracing import SOURCE_FOR_STYLE, TRANSACTION_SOURCE_ROUTE\n+from sentry_sdk.tracing import (\n+ BAGGAGE_HEADER_NAME,\n+ SOURCE_FOR_STYLE,\n+ TRANSACTION_SOURCE_ROUTE,\n+)\n from sentry_sdk.tracing_utils import should_propagate_trace\n from sentry_sdk.utils import (\n capture_internal_exceptions,\n@@ -220,7 +224,13 @@\n key=key, value=value, url=params.url\n )\n )\n- params.headers[key] = value\n+ if key == BAGGAGE_HEADER_NAME and params.headers.get(\n+ BAGGAGE_HEADER_NAME\n+ ):\n+ # do not overwrite any existing baggage, just append to it\n+ params.headers[key] += \",\" + value\n+ else:\n+ params.headers[key] = value\n \n trace_config_ctx.span = span\n", "issue": "Check if aiohttp client integration needs special baggage handling\n### Problem Statement\n\nOnce the [instrumentation for aiohttp client requests](https://github.com/getsentry/sentry-python/pull/1761) is in, see if we need special handling for existing baggage [like here](https://github.com/getsentry/sentry-python/pull/2191).\n\n### Solution Brainstorm\n\nDo it.\n", "before_files": [{"content": "import sys\nimport weakref\n\nfrom sentry_sdk.api import continue_trace\nfrom sentry_sdk._compat import reraise\nfrom sentry_sdk.consts import OP, SPANDATA\nfrom sentry_sdk.hub import Hub\nfrom sentry_sdk.integrations import Integration, DidNotEnable\nfrom sentry_sdk.integrations.logging import ignore_logger\nfrom sentry_sdk.sessions import auto_session_tracking\nfrom sentry_sdk.integrations._wsgi_common import (\n _filter_headers,\n request_body_within_bounds,\n)\nfrom sentry_sdk.tracing import SOURCE_FOR_STYLE, TRANSACTION_SOURCE_ROUTE\nfrom sentry_sdk.tracing_utils import should_propagate_trace\nfrom sentry_sdk.utils import (\n capture_internal_exceptions,\n event_from_exception,\n logger,\n parse_url,\n parse_version,\n transaction_from_function,\n HAS_REAL_CONTEXTVARS,\n CONTEXTVARS_ERROR_MESSAGE,\n SENSITIVE_DATA_SUBSTITUTE,\n AnnotatedValue,\n)\n\ntry:\n import asyncio\n\n from aiohttp import __version__ as AIOHTTP_VERSION\n from aiohttp import ClientSession, TraceConfig\n from aiohttp.web import Application, HTTPException, UrlDispatcher\nexcept ImportError:\n raise DidNotEnable(\"AIOHTTP not installed\")\n\nfrom sentry_sdk._types import TYPE_CHECKING\n\nif TYPE_CHECKING:\n from aiohttp.web_request import Request\n from aiohttp.abc import AbstractMatchInfo\n from aiohttp import TraceRequestStartParams, TraceRequestEndParams\n from types import SimpleNamespace\n from typing import Any\n from typing import Dict\n from typing import Optional\n from typing import Tuple\n from typing import Callable\n from typing import Union\n\n from sentry_sdk.utils import ExcInfo\n from sentry_sdk._types import EventProcessor\n\n\nTRANSACTION_STYLE_VALUES = (\"handler_name\", \"method_and_path_pattern\")\n\n\nclass AioHttpIntegration(Integration):\n identifier = \"aiohttp\"\n\n def __init__(self, transaction_style=\"handler_name\"):\n # type: (str) -> None\n if transaction_style not in TRANSACTION_STYLE_VALUES:\n raise ValueError(\n \"Invalid value for transaction_style: %s (must be in %s)\"\n % (transaction_style, TRANSACTION_STYLE_VALUES)\n )\n self.transaction_style = transaction_style\n\n @staticmethod\n def setup_once():\n # type: () -> None\n\n version = parse_version(AIOHTTP_VERSION)\n\n if version is None:\n raise DidNotEnable(\"Unparsable AIOHTTP version: {}\".format(AIOHTTP_VERSION))\n\n if version < (3, 4):\n raise DidNotEnable(\"AIOHTTP 3.4 or newer required.\")\n\n if not HAS_REAL_CONTEXTVARS:\n # We better have contextvars or we're going to leak state between\n # requests.\n raise DidNotEnable(\n \"The aiohttp integration for Sentry requires Python 3.7+ \"\n \" or aiocontextvars package.\" + CONTEXTVARS_ERROR_MESSAGE\n )\n\n ignore_logger(\"aiohttp.server\")\n\n old_handle = Application._handle\n\n async def sentry_app_handle(self, request, *args, **kwargs):\n # type: (Any, Request, *Any, **Any) -> Any\n hub = Hub.current\n if hub.get_integration(AioHttpIntegration) is None:\n return await old_handle(self, request, *args, **kwargs)\n\n weak_request = weakref.ref(request)\n\n with Hub(hub) as hub:\n with auto_session_tracking(hub, session_mode=\"request\"):\n # Scope data will not leak between requests because aiohttp\n # create a task to wrap each request.\n with hub.configure_scope() as scope:\n scope.clear_breadcrumbs()\n scope.add_event_processor(_make_request_processor(weak_request))\n\n transaction = continue_trace(\n request.headers,\n op=OP.HTTP_SERVER,\n # If this transaction name makes it to the UI, AIOHTTP's\n # URL resolver did not find a route or died trying.\n name=\"generic AIOHTTP request\",\n source=TRANSACTION_SOURCE_ROUTE,\n )\n with hub.start_transaction(\n transaction,\n custom_sampling_context={\"aiohttp_request\": request},\n ):\n try:\n response = await old_handle(self, request)\n except HTTPException as e:\n transaction.set_http_status(e.status_code)\n raise\n except (asyncio.CancelledError, ConnectionResetError):\n transaction.set_status(\"cancelled\")\n raise\n except Exception:\n # This will probably map to a 500 but seems like we\n # have no way to tell. Do not set span status.\n reraise(*_capture_exception(hub))\n\n transaction.set_http_status(response.status)\n return response\n\n Application._handle = sentry_app_handle\n\n old_urldispatcher_resolve = UrlDispatcher.resolve\n\n async def sentry_urldispatcher_resolve(self, request):\n # type: (UrlDispatcher, Request) -> AbstractMatchInfo\n rv = await old_urldispatcher_resolve(self, request)\n\n hub = Hub.current\n integration = hub.get_integration(AioHttpIntegration)\n\n name = None\n\n try:\n if integration.transaction_style == \"handler_name\":\n name = transaction_from_function(rv.handler)\n elif integration.transaction_style == \"method_and_path_pattern\":\n route_info = rv.get_info()\n pattern = route_info.get(\"path\") or route_info.get(\"formatter\")\n name = \"{} {}\".format(request.method, pattern)\n except Exception:\n pass\n\n if name is not None:\n with Hub.current.configure_scope() as scope:\n scope.set_transaction_name(\n name,\n source=SOURCE_FOR_STYLE[integration.transaction_style],\n )\n\n return rv\n\n UrlDispatcher.resolve = sentry_urldispatcher_resolve\n\n old_client_session_init = ClientSession.__init__\n\n def init(*args, **kwargs):\n # type: (Any, Any) -> ClientSession\n hub = Hub.current\n if hub.get_integration(AioHttpIntegration) is None:\n return old_client_session_init(*args, **kwargs)\n\n client_trace_configs = list(kwargs.get(\"trace_configs\", ()))\n trace_config = create_trace_config()\n client_trace_configs.append(trace_config)\n\n kwargs[\"trace_configs\"] = client_trace_configs\n return old_client_session_init(*args, **kwargs)\n\n ClientSession.__init__ = init\n\n\ndef create_trace_config():\n # type: () -> TraceConfig\n async def on_request_start(session, trace_config_ctx, params):\n # type: (ClientSession, SimpleNamespace, TraceRequestStartParams) -> None\n hub = Hub.current\n if hub.get_integration(AioHttpIntegration) is None:\n return\n\n method = params.method.upper()\n\n parsed_url = None\n with capture_internal_exceptions():\n parsed_url = parse_url(str(params.url), sanitize=False)\n\n span = hub.start_span(\n op=OP.HTTP_CLIENT,\n description=\"%s %s\"\n % (method, parsed_url.url if parsed_url else SENSITIVE_DATA_SUBSTITUTE),\n )\n span.set_data(SPANDATA.HTTP_METHOD, method)\n span.set_data(\"url\", parsed_url.url)\n span.set_data(SPANDATA.HTTP_QUERY, parsed_url.query)\n span.set_data(SPANDATA.HTTP_FRAGMENT, parsed_url.fragment)\n\n if should_propagate_trace(hub, str(params.url)):\n for key, value in hub.iter_trace_propagation_headers(span):\n logger.debug(\n \"[Tracing] Adding `{key}` header {value} to outgoing request to {url}.\".format(\n key=key, value=value, url=params.url\n )\n )\n params.headers[key] = value\n\n trace_config_ctx.span = span\n\n async def on_request_end(session, trace_config_ctx, params):\n # type: (ClientSession, SimpleNamespace, TraceRequestEndParams) -> None\n if trace_config_ctx.span is None:\n return\n\n span = trace_config_ctx.span\n span.set_http_status(int(params.response.status))\n span.set_data(\"reason\", params.response.reason)\n span.finish()\n\n trace_config = TraceConfig()\n\n trace_config.on_request_start.append(on_request_start)\n trace_config.on_request_end.append(on_request_end)\n\n return trace_config\n\n\ndef _make_request_processor(weak_request):\n # type: (Callable[[], Request]) -> EventProcessor\n def aiohttp_processor(\n event, # type: Dict[str, Any]\n hint, # type: Dict[str, Tuple[type, BaseException, Any]]\n ):\n # type: (...) -> Dict[str, Any]\n request = weak_request()\n if request is None:\n return event\n\n with capture_internal_exceptions():\n request_info = event.setdefault(\"request\", {})\n\n request_info[\"url\"] = \"%s://%s%s\" % (\n request.scheme,\n request.host,\n request.path,\n )\n\n request_info[\"query_string\"] = request.query_string\n request_info[\"method\"] = request.method\n request_info[\"env\"] = {\"REMOTE_ADDR\": request.remote}\n\n hub = Hub.current\n request_info[\"headers\"] = _filter_headers(dict(request.headers))\n\n # Just attach raw data here if it is within bounds, if available.\n # Unfortunately there's no way to get structured data from aiohttp\n # without awaiting on some coroutine.\n request_info[\"data\"] = get_aiohttp_request_data(hub, request)\n\n return event\n\n return aiohttp_processor\n\n\ndef _capture_exception(hub):\n # type: (Hub) -> ExcInfo\n exc_info = sys.exc_info()\n event, hint = event_from_exception(\n exc_info,\n client_options=hub.client.options, # type: ignore\n mechanism={\"type\": \"aiohttp\", \"handled\": False},\n )\n hub.capture_event(event, hint=hint)\n return exc_info\n\n\nBODY_NOT_READ_MESSAGE = \"[Can't show request body due to implementation details.]\"\n\n\ndef get_aiohttp_request_data(hub, request):\n # type: (Hub, Request) -> Union[Optional[str], AnnotatedValue]\n bytes_body = request._read_bytes\n\n if bytes_body is not None:\n # we have body to show\n if not request_body_within_bounds(hub.client, len(bytes_body)):\n return AnnotatedValue.removed_because_over_size_limit()\n\n encoding = request.charset or \"utf-8\"\n return bytes_body.decode(encoding, \"replace\")\n\n if request.can_read_body:\n # body exists but we can't show it\n return BODY_NOT_READ_MESSAGE\n\n # request has no body\n return None\n", "path": "sentry_sdk/integrations/aiohttp.py"}], "after_files": [{"content": "import sys\nimport weakref\n\nfrom sentry_sdk.api import continue_trace\nfrom sentry_sdk._compat import reraise\nfrom sentry_sdk.consts import OP, SPANDATA\nfrom sentry_sdk.hub import Hub\nfrom sentry_sdk.integrations import Integration, DidNotEnable\nfrom sentry_sdk.integrations.logging import ignore_logger\nfrom sentry_sdk.sessions import auto_session_tracking\nfrom sentry_sdk.integrations._wsgi_common import (\n _filter_headers,\n request_body_within_bounds,\n)\nfrom sentry_sdk.tracing import (\n BAGGAGE_HEADER_NAME,\n SOURCE_FOR_STYLE,\n TRANSACTION_SOURCE_ROUTE,\n)\nfrom sentry_sdk.tracing_utils import should_propagate_trace\nfrom sentry_sdk.utils import (\n capture_internal_exceptions,\n event_from_exception,\n logger,\n parse_url,\n parse_version,\n transaction_from_function,\n HAS_REAL_CONTEXTVARS,\n CONTEXTVARS_ERROR_MESSAGE,\n SENSITIVE_DATA_SUBSTITUTE,\n AnnotatedValue,\n)\n\ntry:\n import asyncio\n\n from aiohttp import __version__ as AIOHTTP_VERSION\n from aiohttp import ClientSession, TraceConfig\n from aiohttp.web import Application, HTTPException, UrlDispatcher\nexcept ImportError:\n raise DidNotEnable(\"AIOHTTP not installed\")\n\nfrom sentry_sdk._types import TYPE_CHECKING\n\nif TYPE_CHECKING:\n from aiohttp.web_request import Request\n from aiohttp.abc import AbstractMatchInfo\n from aiohttp import TraceRequestStartParams, TraceRequestEndParams\n from types import SimpleNamespace\n from typing import Any\n from typing import Dict\n from typing import Optional\n from typing import Tuple\n from typing import Callable\n from typing import Union\n\n from sentry_sdk.utils import ExcInfo\n from sentry_sdk._types import EventProcessor\n\n\nTRANSACTION_STYLE_VALUES = (\"handler_name\", \"method_and_path_pattern\")\n\n\nclass AioHttpIntegration(Integration):\n identifier = \"aiohttp\"\n\n def __init__(self, transaction_style=\"handler_name\"):\n # type: (str) -> None\n if transaction_style not in TRANSACTION_STYLE_VALUES:\n raise ValueError(\n \"Invalid value for transaction_style: %s (must be in %s)\"\n % (transaction_style, TRANSACTION_STYLE_VALUES)\n )\n self.transaction_style = transaction_style\n\n @staticmethod\n def setup_once():\n # type: () -> None\n\n version = parse_version(AIOHTTP_VERSION)\n\n if version is None:\n raise DidNotEnable(\"Unparsable AIOHTTP version: {}\".format(AIOHTTP_VERSION))\n\n if version < (3, 4):\n raise DidNotEnable(\"AIOHTTP 3.4 or newer required.\")\n\n if not HAS_REAL_CONTEXTVARS:\n # We better have contextvars or we're going to leak state between\n # requests.\n raise DidNotEnable(\n \"The aiohttp integration for Sentry requires Python 3.7+ \"\n \" or aiocontextvars package.\" + CONTEXTVARS_ERROR_MESSAGE\n )\n\n ignore_logger(\"aiohttp.server\")\n\n old_handle = Application._handle\n\n async def sentry_app_handle(self, request, *args, **kwargs):\n # type: (Any, Request, *Any, **Any) -> Any\n hub = Hub.current\n if hub.get_integration(AioHttpIntegration) is None:\n return await old_handle(self, request, *args, **kwargs)\n\n weak_request = weakref.ref(request)\n\n with Hub(hub) as hub:\n with auto_session_tracking(hub, session_mode=\"request\"):\n # Scope data will not leak between requests because aiohttp\n # create a task to wrap each request.\n with hub.configure_scope() as scope:\n scope.clear_breadcrumbs()\n scope.add_event_processor(_make_request_processor(weak_request))\n\n transaction = continue_trace(\n request.headers,\n op=OP.HTTP_SERVER,\n # If this transaction name makes it to the UI, AIOHTTP's\n # URL resolver did not find a route or died trying.\n name=\"generic AIOHTTP request\",\n source=TRANSACTION_SOURCE_ROUTE,\n )\n with hub.start_transaction(\n transaction,\n custom_sampling_context={\"aiohttp_request\": request},\n ):\n try:\n response = await old_handle(self, request)\n except HTTPException as e:\n transaction.set_http_status(e.status_code)\n raise\n except (asyncio.CancelledError, ConnectionResetError):\n transaction.set_status(\"cancelled\")\n raise\n except Exception:\n # This will probably map to a 500 but seems like we\n # have no way to tell. Do not set span status.\n reraise(*_capture_exception(hub))\n\n transaction.set_http_status(response.status)\n return response\n\n Application._handle = sentry_app_handle\n\n old_urldispatcher_resolve = UrlDispatcher.resolve\n\n async def sentry_urldispatcher_resolve(self, request):\n # type: (UrlDispatcher, Request) -> AbstractMatchInfo\n rv = await old_urldispatcher_resolve(self, request)\n\n hub = Hub.current\n integration = hub.get_integration(AioHttpIntegration)\n\n name = None\n\n try:\n if integration.transaction_style == \"handler_name\":\n name = transaction_from_function(rv.handler)\n elif integration.transaction_style == \"method_and_path_pattern\":\n route_info = rv.get_info()\n pattern = route_info.get(\"path\") or route_info.get(\"formatter\")\n name = \"{} {}\".format(request.method, pattern)\n except Exception:\n pass\n\n if name is not None:\n with Hub.current.configure_scope() as scope:\n scope.set_transaction_name(\n name,\n source=SOURCE_FOR_STYLE[integration.transaction_style],\n )\n\n return rv\n\n UrlDispatcher.resolve = sentry_urldispatcher_resolve\n\n old_client_session_init = ClientSession.__init__\n\n def init(*args, **kwargs):\n # type: (Any, Any) -> ClientSession\n hub = Hub.current\n if hub.get_integration(AioHttpIntegration) is None:\n return old_client_session_init(*args, **kwargs)\n\n client_trace_configs = list(kwargs.get(\"trace_configs\", ()))\n trace_config = create_trace_config()\n client_trace_configs.append(trace_config)\n\n kwargs[\"trace_configs\"] = client_trace_configs\n return old_client_session_init(*args, **kwargs)\n\n ClientSession.__init__ = init\n\n\ndef create_trace_config():\n # type: () -> TraceConfig\n async def on_request_start(session, trace_config_ctx, params):\n # type: (ClientSession, SimpleNamespace, TraceRequestStartParams) -> None\n hub = Hub.current\n if hub.get_integration(AioHttpIntegration) is None:\n return\n\n method = params.method.upper()\n\n parsed_url = None\n with capture_internal_exceptions():\n parsed_url = parse_url(str(params.url), sanitize=False)\n\n span = hub.start_span(\n op=OP.HTTP_CLIENT,\n description=\"%s %s\"\n % (method, parsed_url.url if parsed_url else SENSITIVE_DATA_SUBSTITUTE),\n )\n span.set_data(SPANDATA.HTTP_METHOD, method)\n span.set_data(\"url\", parsed_url.url)\n span.set_data(SPANDATA.HTTP_QUERY, parsed_url.query)\n span.set_data(SPANDATA.HTTP_FRAGMENT, parsed_url.fragment)\n\n if should_propagate_trace(hub, str(params.url)):\n for key, value in hub.iter_trace_propagation_headers(span):\n logger.debug(\n \"[Tracing] Adding `{key}` header {value} to outgoing request to {url}.\".format(\n key=key, value=value, url=params.url\n )\n )\n if key == BAGGAGE_HEADER_NAME and params.headers.get(\n BAGGAGE_HEADER_NAME\n ):\n # do not overwrite any existing baggage, just append to it\n params.headers[key] += \",\" + value\n else:\n params.headers[key] = value\n\n trace_config_ctx.span = span\n\n async def on_request_end(session, trace_config_ctx, params):\n # type: (ClientSession, SimpleNamespace, TraceRequestEndParams) -> None\n if trace_config_ctx.span is None:\n return\n\n span = trace_config_ctx.span\n span.set_http_status(int(params.response.status))\n span.set_data(\"reason\", params.response.reason)\n span.finish()\n\n trace_config = TraceConfig()\n\n trace_config.on_request_start.append(on_request_start)\n trace_config.on_request_end.append(on_request_end)\n\n return trace_config\n\n\ndef _make_request_processor(weak_request):\n # type: (Callable[[], Request]) -> EventProcessor\n def aiohttp_processor(\n event, # type: Dict[str, Any]\n hint, # type: Dict[str, Tuple[type, BaseException, Any]]\n ):\n # type: (...) -> Dict[str, Any]\n request = weak_request()\n if request is None:\n return event\n\n with capture_internal_exceptions():\n request_info = event.setdefault(\"request\", {})\n\n request_info[\"url\"] = \"%s://%s%s\" % (\n request.scheme,\n request.host,\n request.path,\n )\n\n request_info[\"query_string\"] = request.query_string\n request_info[\"method\"] = request.method\n request_info[\"env\"] = {\"REMOTE_ADDR\": request.remote}\n\n hub = Hub.current\n request_info[\"headers\"] = _filter_headers(dict(request.headers))\n\n # Just attach raw data here if it is within bounds, if available.\n # Unfortunately there's no way to get structured data from aiohttp\n # without awaiting on some coroutine.\n request_info[\"data\"] = get_aiohttp_request_data(hub, request)\n\n return event\n\n return aiohttp_processor\n\n\ndef _capture_exception(hub):\n # type: (Hub) -> ExcInfo\n exc_info = sys.exc_info()\n event, hint = event_from_exception(\n exc_info,\n client_options=hub.client.options, # type: ignore\n mechanism={\"type\": \"aiohttp\", \"handled\": False},\n )\n hub.capture_event(event, hint=hint)\n return exc_info\n\n\nBODY_NOT_READ_MESSAGE = \"[Can't show request body due to implementation details.]\"\n\n\ndef get_aiohttp_request_data(hub, request):\n # type: (Hub, Request) -> Union[Optional[str], AnnotatedValue]\n bytes_body = request._read_bytes\n\n if bytes_body is not None:\n # we have body to show\n if not request_body_within_bounds(hub.client, len(bytes_body)):\n return AnnotatedValue.removed_because_over_size_limit()\n\n encoding = request.charset or \"utf-8\"\n return bytes_body.decode(encoding, \"replace\")\n\n if request.can_read_body:\n # body exists but we can't show it\n return BODY_NOT_READ_MESSAGE\n\n # request has no body\n return None\n", "path": "sentry_sdk/integrations/aiohttp.py"}]}
| 3,491 | 263 |
gh_patches_debug_31731
|
rasdani/github-patches
|
git_diff
|
conda__conda-5475
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Not able to install Udacity car Simulator
(C:\Users\Heeramani\Anaconda2) C:\Users\Heeramani>conda env create -f environments.yml
Using Anaconda API: https://api.anaconda.org
An unexpected error has occurred.
Please consider posting the following information to the
conda GitHub issue tracker at:
https://github.com/conda/conda/issues
Current conda install:
platform : win-64
conda version : 4.3.14
conda is private : False
conda-env version : 4.3.14
conda-build version : not installed
python version : 2.7.13.final.0
requests version : 2.12.4
root environment : C:\Users\Heeramani\Anaconda2 (writable)
default environment : C:\Users\Heeramani\Anaconda2
envs directories : C:\Users\Heeramani\Anaconda2\envs
C:\Users\Heeramani\AppData\Local\conda\conda\envs
C:\Users\Heeramani\.conda\envs
package cache : C:\Users\Heeramani\Anaconda2\pkgs
C:\Users\Heeramani\AppData\Local\conda\conda\pkgs
channel URLs : https://repo.continuum.io/pkgs/free/win-64
https://repo.continuum.io/pkgs/free/noarch
https://repo.continuum.io/pkgs/r/win-64
https://repo.continuum.io/pkgs/r/noarch
https://repo.continuum.io/pkgs/pro/win-64
https://repo.continuum.io/pkgs/pro/noarch
https://repo.continuum.io/pkgs/msys2/win-64
https://repo.continuum.io/pkgs/msys2/noarch
config file : None
offline mode : False
user-agent : conda/4.3.14 requests/2.12.4 CPython/2.7.13 Windows/10 Windows/10.0.14393
`$ C:\Users\Heeramani\Anaconda2\Scripts\conda-env-script.py create -f environments.yml`
Traceback (most recent call last):
File "C:\Users\Heeramani\Anaconda2\lib\site-packages\conda\exceptions.py", line 573, in conda_exception_handler
return_value = func(*args, **kwargs)
File "C:\Users\Heeramani\Anaconda2\lib\site-packages\conda_env\cli\main_create.py", line 78, in execute
directory=os.getcwd())
File "C:\Users\Heeramani\Anaconda2\lib\site-packages\conda_env\specs\__init__.py", line 23, in detect
raise SpecNotFound(build_message(specs))
SpecNotFound: Runtime error: Can't process without a name
Conda Env Exception: environments.yml file not found
There is no requirements.txt
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conda_env/cli/main_update.py`
Content:
```
1 from argparse import RawDescriptionHelpFormatter
2 import os
3 import sys
4 import textwrap
5
6 from conda.cli import install as cli_install
7 from conda.cli.conda_argparse import add_parser_json, add_parser_prefix
8 from conda.misc import touch_nonadmin
9 from .common import get_prefix
10 from .. import exceptions, specs as install_specs
11 from ..exceptions import CondaEnvException
12 from ..installers.base import InvalidInstaller, get_installer
13
14 description = """
15 Update the current environment based on environment file
16 """
17
18 example = """
19 examples:
20 conda env update
21 conda env update -n=foo
22 conda env update -f=/path/to/environment.yml
23 conda env update --name=foo --file=environment.yml
24 conda env update vader/deathstar
25 """
26
27
28 def configure_parser(sub_parsers):
29 p = sub_parsers.add_parser(
30 'update',
31 formatter_class=RawDescriptionHelpFormatter,
32 description=description,
33 help=description,
34 epilog=example,
35 )
36 add_parser_prefix(p)
37 p.add_argument(
38 '-f', '--file',
39 action='store',
40 help='environment definition (default: environment.yml)',
41 default='environment.yml',
42 )
43 p.add_argument(
44 '--prune',
45 action='store_true',
46 default=False,
47 help='remove installed packages not defined in environment.yml',
48 )
49 p.add_argument(
50 '-q', '--quiet',
51 action='store_true',
52 default=False,
53 )
54 p.add_argument(
55 'remote_definition',
56 help='remote environment definition / IPython notebook',
57 action='store',
58 default=None,
59 nargs='?'
60 )
61 add_parser_json(p)
62 p.set_defaults(func=execute)
63
64
65 def execute(args, parser):
66 name = args.remote_definition or args.name
67
68 try:
69 spec = install_specs.detect(name=name, filename=args.file,
70 directory=os.getcwd())
71 env = spec.environment
72 except exceptions.SpecNotFound:
73 raise
74
75 if not (args.name or args.prefix):
76 if not env.name:
77 # Note, this is a hack fofr get_prefix that assumes argparse results
78 # TODO Refactor common.get_prefix
79 name = os.environ.get('CONDA_DEFAULT_ENV', False)
80 if not name:
81 msg = "Unable to determine environment\n\n"
82 msg += textwrap.dedent("""
83 Please re-run this command with one of the following options:
84
85 * Provide an environment name via --name or -n
86 * Re-run this command inside an activated conda environment.""").lstrip()
87 # TODO Add json support
88 raise CondaEnvException(msg)
89
90 # Note: stubbing out the args object as all of the
91 # conda.cli.common code thinks that name will always
92 # be specified.
93 args.name = env.name
94
95 prefix = get_prefix(args, search=False)
96 # CAN'T Check with this function since it assumes we will create prefix.
97 # cli_install.check_prefix(prefix, json=args.json)
98
99 # TODO, add capability
100 # common.ensure_override_channels_requires_channel(args)
101 # channel_urls = args.channel or ()
102
103 for installer_type, specs in env.dependencies.items():
104 try:
105 installer = get_installer(installer_type)
106 installer.install(prefix, specs, args, env, prune=args.prune)
107 except InvalidInstaller:
108 sys.stderr.write(textwrap.dedent("""
109 Unable to install package for {0}.
110
111 Please double check and ensure you dependencies file has
112 the correct spelling. You might also try installing the
113 conda-env-{0} package to see if provides the required
114 installer.
115 """).lstrip().format(installer_type)
116 )
117 return -1
118
119 touch_nonadmin(prefix)
120 if not args.json:
121 print(cli_install.print_activate(args.name if args.name else prefix))
122
```
Path: `conda_env/cli/main_create.py`
Content:
```
1 from __future__ import print_function
2
3 from argparse import RawDescriptionHelpFormatter
4 import os
5 import sys
6 import textwrap
7
8 from conda.cli import install as cli_install
9 from conda.cli.conda_argparse import add_parser_json, add_parser_prefix
10 from conda.gateways.disk.delete import rm_rf
11 from conda.misc import touch_nonadmin
12
13 from .common import get_prefix
14 from .. import exceptions, specs
15 from ..installers.base import InvalidInstaller, get_installer
16
17 description = """
18 Create an environment based on an environment file
19 """
20
21 example = """
22 examples:
23 conda env create
24 conda env create -n name
25 conda env create vader/deathstar
26 conda env create -f=/path/to/environment.yml
27 conda env create -f=/path/to/requirements.txt -n deathstar
28 conda env create -f=/path/to/requirements.txt -p /home/user/software/deathstar
29 """
30
31
32 def configure_parser(sub_parsers):
33 p = sub_parsers.add_parser(
34 'create',
35 formatter_class=RawDescriptionHelpFormatter,
36 description=description,
37 help=description,
38 epilog=example,
39 )
40 p.add_argument(
41 '-f', '--file',
42 action='store',
43 help='environment definition file (default: environment.yml)',
44 default='environment.yml',
45 )
46
47 # Add name and prefix args
48 add_parser_prefix(p)
49
50 p.add_argument(
51 '-q', '--quiet',
52 action='store_true',
53 default=False,
54 )
55 p.add_argument(
56 'remote_definition',
57 help='remote environment definition / IPython notebook',
58 action='store',
59 default=None,
60 nargs='?'
61 )
62 p.add_argument(
63 '--force',
64 help=('force creation of environment (removing a previously existing '
65 'environment of the same name).'),
66 action='store_true',
67 default=False,
68 )
69 add_parser_json(p)
70 p.set_defaults(func=execute)
71
72
73 def execute(args, parser):
74 from conda.base.context import context
75 name = args.remote_definition or args.name
76
77 try:
78 spec = specs.detect(name=name, filename=args.file,
79 directory=os.getcwd())
80 env = spec.environment
81
82 # FIXME conda code currently requires args to have a name or prefix
83 # don't overwrite name if it's given. gh-254
84 if args.prefix is None and args.name is None:
85 args.name = env.name
86
87 except exceptions.SpecNotFound:
88 raise
89
90 prefix = get_prefix(args, search=False)
91
92 if args.force and prefix != context.root_prefix and os.path.exists(prefix):
93 rm_rf(prefix)
94 cli_install.check_prefix(prefix, json=args.json)
95
96 # TODO, add capability
97 # common.ensure_override_channels_requires_channel(args)
98 # channel_urls = args.channel or ()
99
100 # # special case for empty environment
101 # if not env.dependencies:
102 # from conda.install import symlink_conda
103 # symlink_conda(prefix, context.root_dir)
104
105 for installer_type, pkg_specs in env.dependencies.items():
106 try:
107 installer = get_installer(installer_type)
108 installer.install(prefix, pkg_specs, args, env)
109 except InvalidInstaller:
110 sys.stderr.write(textwrap.dedent("""
111 Unable to install package for {0}.
112
113 Please double check and ensure you dependencies file has
114 the correct spelling. You might also try installing the
115 conda-env-{0} package to see if provides the required
116 installer.
117 """).lstrip().format(installer_type)
118 )
119 return -1
120
121 touch_nonadmin(prefix)
122 if not args.json:
123 print(cli_install.print_activate(args.name if args.name else prefix))
124
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conda_env/cli/main_create.py b/conda_env/cli/main_create.py
--- a/conda_env/cli/main_create.py
+++ b/conda_env/cli/main_create.py
@@ -5,11 +5,11 @@
import sys
import textwrap
+from conda._vendor.auxlib.path import expand
from conda.cli import install as cli_install
from conda.cli.conda_argparse import add_parser_json, add_parser_prefix
from conda.gateways.disk.delete import rm_rf
from conda.misc import touch_nonadmin
-
from .common import get_prefix
from .. import exceptions, specs
from ..installers.base import InvalidInstaller, get_installer
@@ -75,7 +75,7 @@
name = args.remote_definition or args.name
try:
- spec = specs.detect(name=name, filename=args.file,
+ spec = specs.detect(name=name, filename=expand(args.file),
directory=os.getcwd())
env = spec.environment
diff --git a/conda_env/cli/main_update.py b/conda_env/cli/main_update.py
--- a/conda_env/cli/main_update.py
+++ b/conda_env/cli/main_update.py
@@ -3,6 +3,7 @@
import sys
import textwrap
+from conda._vendor.auxlib.path import expand
from conda.cli import install as cli_install
from conda.cli.conda_argparse import add_parser_json, add_parser_prefix
from conda.misc import touch_nonadmin
@@ -66,7 +67,7 @@
name = args.remote_definition or args.name
try:
- spec = install_specs.detect(name=name, filename=args.file,
+ spec = install_specs.detect(name=name, filename=expand(args.file),
directory=os.getcwd())
env = spec.environment
except exceptions.SpecNotFound:
|
{"golden_diff": "diff --git a/conda_env/cli/main_create.py b/conda_env/cli/main_create.py\n--- a/conda_env/cli/main_create.py\n+++ b/conda_env/cli/main_create.py\n@@ -5,11 +5,11 @@\n import sys\n import textwrap\n \n+from conda._vendor.auxlib.path import expand\n from conda.cli import install as cli_install\n from conda.cli.conda_argparse import add_parser_json, add_parser_prefix\n from conda.gateways.disk.delete import rm_rf\n from conda.misc import touch_nonadmin\n-\n from .common import get_prefix\n from .. import exceptions, specs\n from ..installers.base import InvalidInstaller, get_installer\n@@ -75,7 +75,7 @@\n name = args.remote_definition or args.name\n \n try:\n- spec = specs.detect(name=name, filename=args.file,\n+ spec = specs.detect(name=name, filename=expand(args.file),\n directory=os.getcwd())\n env = spec.environment\n \ndiff --git a/conda_env/cli/main_update.py b/conda_env/cli/main_update.py\n--- a/conda_env/cli/main_update.py\n+++ b/conda_env/cli/main_update.py\n@@ -3,6 +3,7 @@\n import sys\n import textwrap\n \n+from conda._vendor.auxlib.path import expand\n from conda.cli import install as cli_install\n from conda.cli.conda_argparse import add_parser_json, add_parser_prefix\n from conda.misc import touch_nonadmin\n@@ -66,7 +67,7 @@\n name = args.remote_definition or args.name\n \n try:\n- spec = install_specs.detect(name=name, filename=args.file,\n+ spec = install_specs.detect(name=name, filename=expand(args.file),\n directory=os.getcwd())\n env = spec.environment\n except exceptions.SpecNotFound:\n", "issue": "Not able to install Udacity car Simulator\n\r\n(C:\\Users\\Heeramani\\Anaconda2) C:\\Users\\Heeramani>conda env create -f environments.yml\r\nUsing Anaconda API: https://api.anaconda.org\r\nAn unexpected error has occurred.\r\nPlease consider posting the following information to the\r\nconda GitHub issue tracker at:\r\n\r\n https://github.com/conda/conda/issues\r\n\r\n\r\n\r\nCurrent conda install:\r\n\r\n platform : win-64\r\n conda version : 4.3.14\r\n conda is private : False\r\n conda-env version : 4.3.14\r\n conda-build version : not installed\r\n python version : 2.7.13.final.0\r\n requests version : 2.12.4\r\n root environment : C:\\Users\\Heeramani\\Anaconda2 (writable)\r\n default environment : C:\\Users\\Heeramani\\Anaconda2\r\n envs directories : C:\\Users\\Heeramani\\Anaconda2\\envs\r\n C:\\Users\\Heeramani\\AppData\\Local\\conda\\conda\\envs\r\n C:\\Users\\Heeramani\\.conda\\envs\r\n package cache : C:\\Users\\Heeramani\\Anaconda2\\pkgs\r\n C:\\Users\\Heeramani\\AppData\\Local\\conda\\conda\\pkgs\r\n channel URLs : https://repo.continuum.io/pkgs/free/win-64\r\n https://repo.continuum.io/pkgs/free/noarch\r\n https://repo.continuum.io/pkgs/r/win-64\r\n https://repo.continuum.io/pkgs/r/noarch\r\n https://repo.continuum.io/pkgs/pro/win-64\r\n https://repo.continuum.io/pkgs/pro/noarch\r\n https://repo.continuum.io/pkgs/msys2/win-64\r\n https://repo.continuum.io/pkgs/msys2/noarch\r\n config file : None\r\n offline mode : False\r\n user-agent : conda/4.3.14 requests/2.12.4 CPython/2.7.13 Windows/10 Windows/10.0.14393\r\n\r\n\r\n\r\n`$ C:\\Users\\Heeramani\\Anaconda2\\Scripts\\conda-env-script.py create -f environments.yml`\r\n\r\n\r\n\r\n\r\n Traceback (most recent call last):\r\n File \"C:\\Users\\Heeramani\\Anaconda2\\lib\\site-packages\\conda\\exceptions.py\", line 573, in conda_exception_handler\r\n return_value = func(*args, **kwargs)\r\n File \"C:\\Users\\Heeramani\\Anaconda2\\lib\\site-packages\\conda_env\\cli\\main_create.py\", line 78, in execute\r\n directory=os.getcwd())\r\n File \"C:\\Users\\Heeramani\\Anaconda2\\lib\\site-packages\\conda_env\\specs\\__init__.py\", line 23, in detect\r\n raise SpecNotFound(build_message(specs))\r\n SpecNotFound: Runtime error: Can't process without a name\r\n Conda Env Exception: environments.yml file not found\r\n There is no requirements.txt\n", "before_files": [{"content": "from argparse import RawDescriptionHelpFormatter\nimport os\nimport sys\nimport textwrap\n\nfrom conda.cli import install as cli_install\nfrom conda.cli.conda_argparse import add_parser_json, add_parser_prefix\nfrom conda.misc import touch_nonadmin\nfrom .common import get_prefix\nfrom .. import exceptions, specs as install_specs\nfrom ..exceptions import CondaEnvException\nfrom ..installers.base import InvalidInstaller, get_installer\n\ndescription = \"\"\"\nUpdate the current environment based on environment file\n\"\"\"\n\nexample = \"\"\"\nexamples:\n conda env update\n conda env update -n=foo\n conda env update -f=/path/to/environment.yml\n conda env update --name=foo --file=environment.yml\n conda env update vader/deathstar\n\"\"\"\n\n\ndef configure_parser(sub_parsers):\n p = sub_parsers.add_parser(\n 'update',\n formatter_class=RawDescriptionHelpFormatter,\n description=description,\n help=description,\n epilog=example,\n )\n add_parser_prefix(p)\n p.add_argument(\n '-f', '--file',\n action='store',\n help='environment definition (default: environment.yml)',\n default='environment.yml',\n )\n p.add_argument(\n '--prune',\n action='store_true',\n default=False,\n help='remove installed packages not defined in environment.yml',\n )\n p.add_argument(\n '-q', '--quiet',\n action='store_true',\n default=False,\n )\n p.add_argument(\n 'remote_definition',\n help='remote environment definition / IPython notebook',\n action='store',\n default=None,\n nargs='?'\n )\n add_parser_json(p)\n p.set_defaults(func=execute)\n\n\ndef execute(args, parser):\n name = args.remote_definition or args.name\n\n try:\n spec = install_specs.detect(name=name, filename=args.file,\n directory=os.getcwd())\n env = spec.environment\n except exceptions.SpecNotFound:\n raise\n\n if not (args.name or args.prefix):\n if not env.name:\n # Note, this is a hack fofr get_prefix that assumes argparse results\n # TODO Refactor common.get_prefix\n name = os.environ.get('CONDA_DEFAULT_ENV', False)\n if not name:\n msg = \"Unable to determine environment\\n\\n\"\n msg += textwrap.dedent(\"\"\"\n Please re-run this command with one of the following options:\n\n * Provide an environment name via --name or -n\n * Re-run this command inside an activated conda environment.\"\"\").lstrip()\n # TODO Add json support\n raise CondaEnvException(msg)\n\n # Note: stubbing out the args object as all of the\n # conda.cli.common code thinks that name will always\n # be specified.\n args.name = env.name\n\n prefix = get_prefix(args, search=False)\n # CAN'T Check with this function since it assumes we will create prefix.\n # cli_install.check_prefix(prefix, json=args.json)\n\n # TODO, add capability\n # common.ensure_override_channels_requires_channel(args)\n # channel_urls = args.channel or ()\n\n for installer_type, specs in env.dependencies.items():\n try:\n installer = get_installer(installer_type)\n installer.install(prefix, specs, args, env, prune=args.prune)\n except InvalidInstaller:\n sys.stderr.write(textwrap.dedent(\"\"\"\n Unable to install package for {0}.\n\n Please double check and ensure you dependencies file has\n the correct spelling. You might also try installing the\n conda-env-{0} package to see if provides the required\n installer.\n \"\"\").lstrip().format(installer_type)\n )\n return -1\n\n touch_nonadmin(prefix)\n if not args.json:\n print(cli_install.print_activate(args.name if args.name else prefix))\n", "path": "conda_env/cli/main_update.py"}, {"content": "from __future__ import print_function\n\nfrom argparse import RawDescriptionHelpFormatter\nimport os\nimport sys\nimport textwrap\n\nfrom conda.cli import install as cli_install\nfrom conda.cli.conda_argparse import add_parser_json, add_parser_prefix\nfrom conda.gateways.disk.delete import rm_rf\nfrom conda.misc import touch_nonadmin\n\nfrom .common import get_prefix\nfrom .. import exceptions, specs\nfrom ..installers.base import InvalidInstaller, get_installer\n\ndescription = \"\"\"\nCreate an environment based on an environment file\n\"\"\"\n\nexample = \"\"\"\nexamples:\n conda env create\n conda env create -n name\n conda env create vader/deathstar\n conda env create -f=/path/to/environment.yml\n conda env create -f=/path/to/requirements.txt -n deathstar\n conda env create -f=/path/to/requirements.txt -p /home/user/software/deathstar\n\"\"\"\n\n\ndef configure_parser(sub_parsers):\n p = sub_parsers.add_parser(\n 'create',\n formatter_class=RawDescriptionHelpFormatter,\n description=description,\n help=description,\n epilog=example,\n )\n p.add_argument(\n '-f', '--file',\n action='store',\n help='environment definition file (default: environment.yml)',\n default='environment.yml',\n )\n\n # Add name and prefix args\n add_parser_prefix(p)\n\n p.add_argument(\n '-q', '--quiet',\n action='store_true',\n default=False,\n )\n p.add_argument(\n 'remote_definition',\n help='remote environment definition / IPython notebook',\n action='store',\n default=None,\n nargs='?'\n )\n p.add_argument(\n '--force',\n help=('force creation of environment (removing a previously existing '\n 'environment of the same name).'),\n action='store_true',\n default=False,\n )\n add_parser_json(p)\n p.set_defaults(func=execute)\n\n\ndef execute(args, parser):\n from conda.base.context import context\n name = args.remote_definition or args.name\n\n try:\n spec = specs.detect(name=name, filename=args.file,\n directory=os.getcwd())\n env = spec.environment\n\n # FIXME conda code currently requires args to have a name or prefix\n # don't overwrite name if it's given. gh-254\n if args.prefix is None and args.name is None:\n args.name = env.name\n\n except exceptions.SpecNotFound:\n raise\n\n prefix = get_prefix(args, search=False)\n\n if args.force and prefix != context.root_prefix and os.path.exists(prefix):\n rm_rf(prefix)\n cli_install.check_prefix(prefix, json=args.json)\n\n # TODO, add capability\n # common.ensure_override_channels_requires_channel(args)\n # channel_urls = args.channel or ()\n\n # # special case for empty environment\n # if not env.dependencies:\n # from conda.install import symlink_conda\n # symlink_conda(prefix, context.root_dir)\n\n for installer_type, pkg_specs in env.dependencies.items():\n try:\n installer = get_installer(installer_type)\n installer.install(prefix, pkg_specs, args, env)\n except InvalidInstaller:\n sys.stderr.write(textwrap.dedent(\"\"\"\n Unable to install package for {0}.\n\n Please double check and ensure you dependencies file has\n the correct spelling. You might also try installing the\n conda-env-{0} package to see if provides the required\n installer.\n \"\"\").lstrip().format(installer_type)\n )\n return -1\n\n touch_nonadmin(prefix)\n if not args.json:\n print(cli_install.print_activate(args.name if args.name else prefix))\n", "path": "conda_env/cli/main_create.py"}], "after_files": [{"content": "from argparse import RawDescriptionHelpFormatter\nimport os\nimport sys\nimport textwrap\n\nfrom conda._vendor.auxlib.path import expand\nfrom conda.cli import install as cli_install\nfrom conda.cli.conda_argparse import add_parser_json, add_parser_prefix\nfrom conda.misc import touch_nonadmin\nfrom .common import get_prefix\nfrom .. import exceptions, specs as install_specs\nfrom ..exceptions import CondaEnvException\nfrom ..installers.base import InvalidInstaller, get_installer\n\ndescription = \"\"\"\nUpdate the current environment based on environment file\n\"\"\"\n\nexample = \"\"\"\nexamples:\n conda env update\n conda env update -n=foo\n conda env update -f=/path/to/environment.yml\n conda env update --name=foo --file=environment.yml\n conda env update vader/deathstar\n\"\"\"\n\n\ndef configure_parser(sub_parsers):\n p = sub_parsers.add_parser(\n 'update',\n formatter_class=RawDescriptionHelpFormatter,\n description=description,\n help=description,\n epilog=example,\n )\n add_parser_prefix(p)\n p.add_argument(\n '-f', '--file',\n action='store',\n help='environment definition (default: environment.yml)',\n default='environment.yml',\n )\n p.add_argument(\n '--prune',\n action='store_true',\n default=False,\n help='remove installed packages not defined in environment.yml',\n )\n p.add_argument(\n '-q', '--quiet',\n action='store_true',\n default=False,\n )\n p.add_argument(\n 'remote_definition',\n help='remote environment definition / IPython notebook',\n action='store',\n default=None,\n nargs='?'\n )\n add_parser_json(p)\n p.set_defaults(func=execute)\n\n\ndef execute(args, parser):\n name = args.remote_definition or args.name\n\n try:\n spec = install_specs.detect(name=name, filename=expand(args.file),\n directory=os.getcwd())\n env = spec.environment\n except exceptions.SpecNotFound:\n raise\n\n if not (args.name or args.prefix):\n if not env.name:\n # Note, this is a hack fofr get_prefix that assumes argparse results\n # TODO Refactor common.get_prefix\n name = os.environ.get('CONDA_DEFAULT_ENV', False)\n if not name:\n msg = \"Unable to determine environment\\n\\n\"\n msg += textwrap.dedent(\"\"\"\n Please re-run this command with one of the following options:\n\n * Provide an environment name via --name or -n\n * Re-run this command inside an activated conda environment.\"\"\").lstrip()\n # TODO Add json support\n raise CondaEnvException(msg)\n\n # Note: stubbing out the args object as all of the\n # conda.cli.common code thinks that name will always\n # be specified.\n args.name = env.name\n\n prefix = get_prefix(args, search=False)\n # CAN'T Check with this function since it assumes we will create prefix.\n # cli_install.check_prefix(prefix, json=args.json)\n\n # TODO, add capability\n # common.ensure_override_channels_requires_channel(args)\n # channel_urls = args.channel or ()\n\n for installer_type, specs in env.dependencies.items():\n try:\n installer = get_installer(installer_type)\n installer.install(prefix, specs, args, env, prune=args.prune)\n except InvalidInstaller:\n sys.stderr.write(textwrap.dedent(\"\"\"\n Unable to install package for {0}.\n\n Please double check and ensure you dependencies file has\n the correct spelling. You might also try installing the\n conda-env-{0} package to see if provides the required\n installer.\n \"\"\").lstrip().format(installer_type)\n )\n return -1\n\n touch_nonadmin(prefix)\n if not args.json:\n print(cli_install.print_activate(args.name if args.name else prefix))\n", "path": "conda_env/cli/main_update.py"}, {"content": "from __future__ import print_function\n\nfrom argparse import RawDescriptionHelpFormatter\nimport os\nimport sys\nimport textwrap\n\nfrom conda._vendor.auxlib.path import expand\nfrom conda.cli import install as cli_install\nfrom conda.cli.conda_argparse import add_parser_json, add_parser_prefix\nfrom conda.gateways.disk.delete import rm_rf\nfrom conda.misc import touch_nonadmin\nfrom .common import get_prefix\nfrom .. import exceptions, specs\nfrom ..installers.base import InvalidInstaller, get_installer\n\ndescription = \"\"\"\nCreate an environment based on an environment file\n\"\"\"\n\nexample = \"\"\"\nexamples:\n conda env create\n conda env create -n name\n conda env create vader/deathstar\n conda env create -f=/path/to/environment.yml\n conda env create -f=/path/to/requirements.txt -n deathstar\n conda env create -f=/path/to/requirements.txt -p /home/user/software/deathstar\n\"\"\"\n\n\ndef configure_parser(sub_parsers):\n p = sub_parsers.add_parser(\n 'create',\n formatter_class=RawDescriptionHelpFormatter,\n description=description,\n help=description,\n epilog=example,\n )\n p.add_argument(\n '-f', '--file',\n action='store',\n help='environment definition file (default: environment.yml)',\n default='environment.yml',\n )\n\n # Add name and prefix args\n add_parser_prefix(p)\n\n p.add_argument(\n '-q', '--quiet',\n action='store_true',\n default=False,\n )\n p.add_argument(\n 'remote_definition',\n help='remote environment definition / IPython notebook',\n action='store',\n default=None,\n nargs='?'\n )\n p.add_argument(\n '--force',\n help=('force creation of environment (removing a previously existing '\n 'environment of the same name).'),\n action='store_true',\n default=False,\n )\n add_parser_json(p)\n p.set_defaults(func=execute)\n\n\ndef execute(args, parser):\n from conda.base.context import context\n name = args.remote_definition or args.name\n\n try:\n spec = specs.detect(name=name, filename=expand(args.file),\n directory=os.getcwd())\n env = spec.environment\n\n # FIXME conda code currently requires args to have a name or prefix\n # don't overwrite name if it's given. gh-254\n if args.prefix is None and args.name is None:\n args.name = env.name\n\n except exceptions.SpecNotFound:\n raise\n\n prefix = get_prefix(args, search=False)\n\n if args.force and prefix != context.root_prefix and os.path.exists(prefix):\n rm_rf(prefix)\n cli_install.check_prefix(prefix, json=args.json)\n\n # TODO, add capability\n # common.ensure_override_channels_requires_channel(args)\n # channel_urls = args.channel or ()\n\n # # special case for empty environment\n # if not env.dependencies:\n # from conda.install import symlink_conda\n # symlink_conda(prefix, context.root_dir)\n\n for installer_type, pkg_specs in env.dependencies.items():\n try:\n installer = get_installer(installer_type)\n installer.install(prefix, pkg_specs, args, env)\n except InvalidInstaller:\n sys.stderr.write(textwrap.dedent(\"\"\"\n Unable to install package for {0}.\n\n Please double check and ensure you dependencies file has\n the correct spelling. You might also try installing the\n conda-env-{0} package to see if provides the required\n installer.\n \"\"\").lstrip().format(installer_type)\n )\n return -1\n\n touch_nonadmin(prefix)\n if not args.json:\n print(cli_install.print_activate(args.name if args.name else prefix))\n", "path": "conda_env/cli/main_create.py"}]}
| 3,139 | 390 |
gh_patches_debug_32543
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-1935
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Can't Download Picarto Video
## Bug Report
- [X ] I have read the contribution guidelines.
### Description
Picarto.tv plugin doesn't seem to download any recorded streams anymore
### Expected / Actual behavior
Expected it to download video, didn't
### Reproduction steps / Explicit stream URLs to test
1. streamlink -o Amarynceus.flv https://picarto.tv/videopopout/Amarynceus_2018.07.04.22.55.48.flv
### Logs
```
streamlink -o Amarynceus.flv https://picarto.tv/videopopout/Amarynceus_2018.07.04.22.55.48.flv -l debug
[cli][debug] OS: Linux-4.15.0-24-generic-x86_64-with-Ubuntu-18.04-bionic
[cli][debug] Python: 2.7.15rc1
[cli][debug] Streamlink: 0.14.2+24.g6bf654a2
[cli][debug] Requests(2.19.1), Socks(1.6.7), Websocket(0.48.0)
[cli][info] Found matching plugin picarto for URL https://picarto.tv/videopopout/Amarynceus_2018.07.04.22.55.48.flv
[plugin.picarto][debug] Possible VOD stream...
[plugin.picarto][warning] Probably a VOD stream but no VOD found?
[plugin.picarto][error] The channel Amarynceus_2018.07.04.22.55.48.flv does not exist
error: No playable streams found on this URL: https://picarto.tv/videopopout/Amarynceus_2018.07.04.22.55.48.flv
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/streamlink/plugins/picarto.py`
Content:
```
1 from __future__ import print_function
2
3 import re
4 import json
5
6 from streamlink.plugin import Plugin
7 from streamlink.stream import HLSStream
8 from streamlink.stream import RTMPStream
9
10
11 class Picarto(Plugin):
12 CHANNEL_API_URL = "https://api.picarto.tv/v1/channel/name/{channel}"
13 VIDEO_API_URL = "https://picarto.tv/process/channel"
14 RTMP_URL = "rtmp://{server}:1935/play/"
15 RTMP_PLAYPATH = "golive+{channel}?token={token}"
16 HLS_URL = "https://{server}/hls/{channel}/index.m3u8?token={token}"
17
18 # Regex for all usable URLs
19 _url_re = re.compile(r"""
20 https?://(?:\w+\.)?picarto\.tv/(?:videopopout/)?([^&?/]+)
21 """, re.VERBOSE)
22
23 # Regex for VOD extraction
24 _vod_re = re.compile(r'''vod: "(https?://[\S]+?/index.m3u8)",''')
25
26 @classmethod
27 def can_handle_url(cls, url):
28 return cls._url_re.match(url) is not None
29
30 def _create_hls_stream(self, server, channel, token):
31 streams = HLSStream.parse_variant_playlist(self.session,
32 self.HLS_URL.format(
33 server=server,
34 channel=channel,
35 token=token),
36 verify=False)
37 if len(streams) > 1:
38 self.logger.debug("Multiple HLS streams found")
39 return streams
40 elif len(streams) == 0:
41 self.logger.warning("No HLS streams found when expected")
42 return {}
43 else:
44 # one HLS streams, rename it to live
45 return {"live": list(streams.values())[0]}
46
47 def _create_flash_stream(self, server, channel, token):
48 params = {
49 "rtmp": self.RTMP_URL.format(server=server),
50 "playpath": self.RTMP_PLAYPATH.format(token=token, channel=channel)
51 }
52 return RTMPStream(self.session, params=params)
53
54 def _get_vod_stream(self, page):
55 m = self._vod_re.search(page.text)
56 if m:
57 return HLSStream.parse_variant_playlist(self.session, m.group(1))
58
59 def _get_streams(self):
60 url_channel_name = self._url_re.match(self.url).group(1)
61
62 # Handle VODs first, since their "channel name" is different
63 if url_channel_name.endswith(".flv"):
64 self.logger.debug("Possible VOD stream...")
65 page = self.session.http.get(self.url)
66 vod_streams = self._get_vod_stream(page)
67 if vod_streams:
68 for s in vod_streams.items():
69 yield s
70 return
71 else:
72 self.logger.warning("Probably a VOD stream but no VOD found?")
73
74 ci = self.session.http.get(self.CHANNEL_API_URL.format(channel=url_channel_name), raise_for_status=False)
75
76 if ci.status_code == 404:
77 self.logger.error("The channel {0} does not exist".format(url_channel_name))
78 return
79
80 channel_api_json = json.loads(ci.text)
81
82 if channel_api_json["online"] != True:
83 self.logger.error("The channel {0} is currently offline".format(url_channel_name))
84 return
85
86 server = None
87 token = "public"
88 channel = channel_api_json["name"]
89
90 # Extract preferred edge server and available techs from the undocumented channel API
91 channel_server_res = self.session.http.post(self.VIDEO_API_URL, data={"loadbalancinginfo": channel})
92 info_json = json.loads(channel_server_res.text)
93 pref = info_json["preferedEdge"]
94 for i in info_json["edges"]:
95 if i["id"] == pref:
96 server = i["ep"]
97 break
98 self.logger.debug("Using load balancing server {0} : {1} for channel {2}",
99 pref,
100 server,
101 channel)
102
103 for i in info_json["techs"]:
104 if i["label"] == "HLS":
105 for s in self._create_hls_stream(server, channel, token).items():
106 yield s
107 elif i["label"] == "RTMP Flash":
108 stream = self._create_flash_stream(server, channel, token)
109 yield "live", stream
110
111
112 __plugin__ = Picarto
113
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/streamlink/plugins/picarto.py b/src/streamlink/plugins/picarto.py
--- a/src/streamlink/plugins/picarto.py
+++ b/src/streamlink/plugins/picarto.py
@@ -4,8 +4,10 @@
import json
from streamlink.plugin import Plugin
+from streamlink.plugin.api import validate
from streamlink.stream import HLSStream
from streamlink.stream import RTMPStream
+from streamlink.utils import parse_json
class Picarto(Plugin):
@@ -15,13 +17,29 @@
RTMP_PLAYPATH = "golive+{channel}?token={token}"
HLS_URL = "https://{server}/hls/{channel}/index.m3u8?token={token}"
+
# Regex for all usable URLs
_url_re = re.compile(r"""
https?://(?:\w+\.)?picarto\.tv/(?:videopopout/)?([^&?/]+)
""", re.VERBOSE)
# Regex for VOD extraction
- _vod_re = re.compile(r'''vod: "(https?://[\S]+?/index.m3u8)",''')
+ _vod_re = re.compile(r'''(?<=#vod-player", )(\{.*?\})''')
+
+ data_schema = validate.Schema(
+ validate.transform(_vod_re.search),
+ validate.any(
+ None,
+ validate.all(
+ validate.get(0),
+ validate.transform(parse_json),
+ {
+ "vod": validate.url(),
+ }
+ )
+ )
+ )
+
@classmethod
def can_handle_url(cls, url):
@@ -52,9 +70,10 @@
return RTMPStream(self.session, params=params)
def _get_vod_stream(self, page):
- m = self._vod_re.search(page.text)
- if m:
- return HLSStream.parse_variant_playlist(self.session, m.group(1))
+ data = self.data_schema.validate(page.text)
+
+ if data:
+ return HLSStream.parse_variant_playlist(self.session, data["vod"])
def _get_streams(self):
url_channel_name = self._url_re.match(self.url).group(1)
|
{"golden_diff": "diff --git a/src/streamlink/plugins/picarto.py b/src/streamlink/plugins/picarto.py\n--- a/src/streamlink/plugins/picarto.py\n+++ b/src/streamlink/plugins/picarto.py\n@@ -4,8 +4,10 @@\n import json\n \n from streamlink.plugin import Plugin\n+from streamlink.plugin.api import validate\n from streamlink.stream import HLSStream\n from streamlink.stream import RTMPStream\n+from streamlink.utils import parse_json\n \n \n class Picarto(Plugin):\n@@ -15,13 +17,29 @@\n RTMP_PLAYPATH = \"golive+{channel}?token={token}\"\n HLS_URL = \"https://{server}/hls/{channel}/index.m3u8?token={token}\"\n \n+\n # Regex for all usable URLs\n _url_re = re.compile(r\"\"\"\n https?://(?:\\w+\\.)?picarto\\.tv/(?:videopopout/)?([^&?/]+)\n \"\"\", re.VERBOSE)\n \n # Regex for VOD extraction\n- _vod_re = re.compile(r'''vod: \"(https?://[\\S]+?/index.m3u8)\",''')\n+ _vod_re = re.compile(r'''(?<=#vod-player\", )(\\{.*?\\})''')\n+\n+ data_schema = validate.Schema(\n+ validate.transform(_vod_re.search),\n+ validate.any(\n+ None,\n+ validate.all(\n+ validate.get(0),\n+ validate.transform(parse_json),\n+ {\n+ \"vod\": validate.url(),\n+ }\n+ )\n+ )\n+ )\n+\n \n @classmethod\n def can_handle_url(cls, url):\n@@ -52,9 +70,10 @@\n return RTMPStream(self.session, params=params)\n \n def _get_vod_stream(self, page):\n- m = self._vod_re.search(page.text)\n- if m:\n- return HLSStream.parse_variant_playlist(self.session, m.group(1))\n+ data = self.data_schema.validate(page.text)\n+\n+ if data:\n+ return HLSStream.parse_variant_playlist(self.session, data[\"vod\"])\n \n def _get_streams(self):\n url_channel_name = self._url_re.match(self.url).group(1)\n", "issue": "Can't Download Picarto Video\n## Bug Report\r\n\r\n- [X ] I have read the contribution guidelines. \r\n\r\n### Description\r\n\r\nPicarto.tv plugin doesn't seem to download any recorded streams anymore\r\n\r\n### Expected / Actual behavior\r\n\r\nExpected it to download video, didn't\r\n\r\n### Reproduction steps / Explicit stream URLs to test\r\n\r\n1. streamlink -o Amarynceus.flv https://picarto.tv/videopopout/Amarynceus_2018.07.04.22.55.48.flv\r\n\r\n### Logs\r\n\r\n\r\n```\r\nstreamlink -o Amarynceus.flv https://picarto.tv/videopopout/Amarynceus_2018.07.04.22.55.48.flv -l debug\r\n[cli][debug] OS: Linux-4.15.0-24-generic-x86_64-with-Ubuntu-18.04-bionic\r\n[cli][debug] Python: 2.7.15rc1\r\n[cli][debug] Streamlink: 0.14.2+24.g6bf654a2\r\n[cli][debug] Requests(2.19.1), Socks(1.6.7), Websocket(0.48.0)\r\n[cli][info] Found matching plugin picarto for URL https://picarto.tv/videopopout/Amarynceus_2018.07.04.22.55.48.flv\r\n[plugin.picarto][debug] Possible VOD stream...\r\n[plugin.picarto][warning] Probably a VOD stream but no VOD found?\r\n[plugin.picarto][error] The channel Amarynceus_2018.07.04.22.55.48.flv does not exist\r\nerror: No playable streams found on this URL: https://picarto.tv/videopopout/Amarynceus_2018.07.04.22.55.48.flv\r\n```\n", "before_files": [{"content": "from __future__ import print_function\n\nimport re\nimport json\n\nfrom streamlink.plugin import Plugin\nfrom streamlink.stream import HLSStream\nfrom streamlink.stream import RTMPStream\n\n\nclass Picarto(Plugin):\n CHANNEL_API_URL = \"https://api.picarto.tv/v1/channel/name/{channel}\"\n VIDEO_API_URL = \"https://picarto.tv/process/channel\"\n RTMP_URL = \"rtmp://{server}:1935/play/\"\n RTMP_PLAYPATH = \"golive+{channel}?token={token}\"\n HLS_URL = \"https://{server}/hls/{channel}/index.m3u8?token={token}\"\n\n # Regex for all usable URLs\n _url_re = re.compile(r\"\"\"\n https?://(?:\\w+\\.)?picarto\\.tv/(?:videopopout/)?([^&?/]+)\n \"\"\", re.VERBOSE)\n\n # Regex for VOD extraction\n _vod_re = re.compile(r'''vod: \"(https?://[\\S]+?/index.m3u8)\",''')\n\n @classmethod\n def can_handle_url(cls, url):\n return cls._url_re.match(url) is not None\n\n def _create_hls_stream(self, server, channel, token):\n streams = HLSStream.parse_variant_playlist(self.session,\n self.HLS_URL.format(\n server=server,\n channel=channel,\n token=token),\n verify=False)\n if len(streams) > 1:\n self.logger.debug(\"Multiple HLS streams found\")\n return streams\n elif len(streams) == 0:\n self.logger.warning(\"No HLS streams found when expected\")\n return {}\n else:\n # one HLS streams, rename it to live\n return {\"live\": list(streams.values())[0]}\n\n def _create_flash_stream(self, server, channel, token):\n params = {\n \"rtmp\": self.RTMP_URL.format(server=server),\n \"playpath\": self.RTMP_PLAYPATH.format(token=token, channel=channel)\n }\n return RTMPStream(self.session, params=params)\n\n def _get_vod_stream(self, page):\n m = self._vod_re.search(page.text)\n if m:\n return HLSStream.parse_variant_playlist(self.session, m.group(1))\n\n def _get_streams(self):\n url_channel_name = self._url_re.match(self.url).group(1)\n\n # Handle VODs first, since their \"channel name\" is different\n if url_channel_name.endswith(\".flv\"):\n self.logger.debug(\"Possible VOD stream...\")\n page = self.session.http.get(self.url)\n vod_streams = self._get_vod_stream(page)\n if vod_streams:\n for s in vod_streams.items():\n yield s\n return\n else:\n self.logger.warning(\"Probably a VOD stream but no VOD found?\")\n\n ci = self.session.http.get(self.CHANNEL_API_URL.format(channel=url_channel_name), raise_for_status=False)\n\n if ci.status_code == 404:\n self.logger.error(\"The channel {0} does not exist\".format(url_channel_name))\n return\n\n channel_api_json = json.loads(ci.text)\n\n if channel_api_json[\"online\"] != True:\n self.logger.error(\"The channel {0} is currently offline\".format(url_channel_name))\n return\n\n server = None\n token = \"public\"\n channel = channel_api_json[\"name\"]\n\n # Extract preferred edge server and available techs from the undocumented channel API\n channel_server_res = self.session.http.post(self.VIDEO_API_URL, data={\"loadbalancinginfo\": channel})\n info_json = json.loads(channel_server_res.text)\n pref = info_json[\"preferedEdge\"]\n for i in info_json[\"edges\"]:\n if i[\"id\"] == pref:\n server = i[\"ep\"]\n break\n self.logger.debug(\"Using load balancing server {0} : {1} for channel {2}\",\n pref,\n server,\n channel)\n\n for i in info_json[\"techs\"]:\n if i[\"label\"] == \"HLS\":\n for s in self._create_hls_stream(server, channel, token).items():\n yield s\n elif i[\"label\"] == \"RTMP Flash\":\n stream = self._create_flash_stream(server, channel, token)\n yield \"live\", stream\n\n\n__plugin__ = Picarto\n", "path": "src/streamlink/plugins/picarto.py"}], "after_files": [{"content": "from __future__ import print_function\n\nimport re\nimport json\n\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream import HLSStream\nfrom streamlink.stream import RTMPStream\nfrom streamlink.utils import parse_json\n\n\nclass Picarto(Plugin):\n CHANNEL_API_URL = \"https://api.picarto.tv/v1/channel/name/{channel}\"\n VIDEO_API_URL = \"https://picarto.tv/process/channel\"\n RTMP_URL = \"rtmp://{server}:1935/play/\"\n RTMP_PLAYPATH = \"golive+{channel}?token={token}\"\n HLS_URL = \"https://{server}/hls/{channel}/index.m3u8?token={token}\"\n\n\n # Regex for all usable URLs\n _url_re = re.compile(r\"\"\"\n https?://(?:\\w+\\.)?picarto\\.tv/(?:videopopout/)?([^&?/]+)\n \"\"\", re.VERBOSE)\n\n # Regex for VOD extraction\n _vod_re = re.compile(r'''(?<=#vod-player\", )(\\{.*?\\})''')\n\n data_schema = validate.Schema(\n validate.transform(_vod_re.search),\n validate.any(\n None,\n validate.all(\n validate.get(0),\n validate.transform(parse_json),\n {\n \"vod\": validate.url(),\n }\n )\n )\n )\n\n\n @classmethod\n def can_handle_url(cls, url):\n return cls._url_re.match(url) is not None\n\n def _create_hls_stream(self, server, channel, token):\n streams = HLSStream.parse_variant_playlist(self.session,\n self.HLS_URL.format(\n server=server,\n channel=channel,\n token=token),\n verify=False)\n if len(streams) > 1:\n self.logger.debug(\"Multiple HLS streams found\")\n return streams\n elif len(streams) == 0:\n self.logger.warning(\"No HLS streams found when expected\")\n return {}\n else:\n # one HLS streams, rename it to live\n return {\"live\": list(streams.values())[0]}\n\n def _create_flash_stream(self, server, channel, token):\n params = {\n \"rtmp\": self.RTMP_URL.format(server=server),\n \"playpath\": self.RTMP_PLAYPATH.format(token=token, channel=channel)\n }\n return RTMPStream(self.session, params=params)\n\n def _get_vod_stream(self, page):\n data = self.data_schema.validate(page.text)\n\n if data:\n return HLSStream.parse_variant_playlist(self.session, data[\"vod\"])\n\n def _get_streams(self):\n url_channel_name = self._url_re.match(self.url).group(1)\n\n # Handle VODs first, since their \"channel name\" is different\n if url_channel_name.endswith(\".flv\"):\n self.logger.debug(\"Possible VOD stream...\")\n page = self.session.http.get(self.url)\n vod_streams = self._get_vod_stream(page)\n if vod_streams:\n for s in vod_streams.items():\n yield s\n return\n else:\n self.logger.warning(\"Probably a VOD stream but no VOD found?\")\n\n ci = self.session.http.get(self.CHANNEL_API_URL.format(channel=url_channel_name), raise_for_status=False)\n\n if ci.status_code == 404:\n self.logger.error(\"The channel {0} does not exist\".format(url_channel_name))\n return\n\n channel_api_json = json.loads(ci.text)\n\n if channel_api_json[\"online\"] != True:\n self.logger.error(\"The channel {0} is currently offline\".format(url_channel_name))\n return\n\n server = None\n token = \"public\"\n channel = channel_api_json[\"name\"]\n\n # Extract preferred edge server and available techs from the undocumented channel API\n channel_server_res = self.session.http.post(self.VIDEO_API_URL, data={\"loadbalancinginfo\": channel})\n info_json = json.loads(channel_server_res.text)\n pref = info_json[\"preferedEdge\"]\n for i in info_json[\"edges\"]:\n if i[\"id\"] == pref:\n server = i[\"ep\"]\n break\n self.logger.debug(\"Using load balancing server {0} : {1} for channel {2}\",\n pref,\n server,\n channel)\n\n for i in info_json[\"techs\"]:\n if i[\"label\"] == \"HLS\":\n for s in self._create_hls_stream(server, channel, token).items():\n yield s\n elif i[\"label\"] == \"RTMP Flash\":\n stream = self._create_flash_stream(server, channel, token)\n yield \"live\", stream\n\n\n__plugin__ = Picarto\n", "path": "src/streamlink/plugins/picarto.py"}]}
| 1,896 | 489 |
gh_patches_debug_18680
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-118
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
'AnonymousUser' object has no attribute 'has_usable_password'
Visiting http://localhost:8000/admin/account/ as not logged in user gives the AttributeError above...
Traceback;
``` Environment:
Request Method: GET
Request URL: http://localhost:8000/admin/account/
Django Version: 1.6.2
Python Version: 2.7.6
Installed Applications:
('django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'south',
'compressor',
'taggit',
'modelcluster',
'django.contrib.admin',
'wagtail.wagtailcore',
'wagtail.wagtailadmin',
'wagtail.wagtaildocs',
'wagtail.wagtailsnippets',
'wagtail.wagtailusers',
'wagtail.wagtailimages',
'wagtail.wagtailembeds',
'wagtail.wagtailsearch',
'wagtail.wagtailredirects')
Installed Middleware:
('django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
'wagtail.wagtailcore.middleware.SiteMiddleware',
'wagtail.wagtailredirects.middleware.RedirectMiddleware')
Traceback:
File "C:\Users\drager\developing\django-env\lib\site-packages\django\core\handlers\base.py" in get_response
114. response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "c:\users\drager\developing\django-env\src\wagtail\wagtail\wagtailadmin\views\account.py" in account
9. 'show_change_password': getattr(settings, 'WAGTAIL_PASSWORD_MANAGEMENT_ENABLED', True) and request.user.has_usable_password(),
File "C:\Users\drager\developing\django-env\lib\site-packages\django\utils\functional.py" in inner
214. return func(self._wrapped, *args)
Exception Type: AttributeError at /admin/account/
Exception Value: 'AnonymousUser' object has no attribute 'has_usable_password'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `wagtail/wagtailadmin/views/account.py`
Content:
```
1 from django.conf import settings
2 from django.shortcuts import render, redirect
3 from django.contrib import messages
4 from django.contrib.auth.forms import SetPasswordForm
5 from django.utils.translation import ugettext as _
6
7 def account(request):
8 return render(request, 'wagtailadmin/account/account.html', {
9 'show_change_password': getattr(settings, 'WAGTAIL_PASSWORD_MANAGEMENT_ENABLED', True) and request.user.has_usable_password(),
10 })
11
12
13 def change_password(request):
14 can_change_password = request.user.has_usable_password()
15
16 if can_change_password:
17 if request.POST:
18 form = SetPasswordForm(request.user, request.POST)
19
20 if form.is_valid():
21 form.save()
22
23 messages.success(request, _("Your password has been changed successfully!"))
24 return redirect('wagtailadmin_account')
25 else:
26 form = SetPasswordForm(request.user)
27 else:
28 form = None
29
30 return render(request, 'wagtailadmin/account/change_password.html', {
31 'form': form,
32 'can_change_password': can_change_password,
33 })
34
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/wagtail/wagtailadmin/views/account.py b/wagtail/wagtailadmin/views/account.py
--- a/wagtail/wagtailadmin/views/account.py
+++ b/wagtail/wagtailadmin/views/account.py
@@ -2,14 +2,17 @@
from django.shortcuts import render, redirect
from django.contrib import messages
from django.contrib.auth.forms import SetPasswordForm
+from django.contrib.auth.decorators import permission_required
from django.utils.translation import ugettext as _
+@permission_required('wagtailadmin.access_admin')
def account(request):
return render(request, 'wagtailadmin/account/account.html', {
'show_change_password': getattr(settings, 'WAGTAIL_PASSWORD_MANAGEMENT_ENABLED', True) and request.user.has_usable_password(),
})
+@permission_required('wagtailadmin.access_admin')
def change_password(request):
can_change_password = request.user.has_usable_password()
|
{"golden_diff": "diff --git a/wagtail/wagtailadmin/views/account.py b/wagtail/wagtailadmin/views/account.py\n--- a/wagtail/wagtailadmin/views/account.py\n+++ b/wagtail/wagtailadmin/views/account.py\n@@ -2,14 +2,17 @@\n from django.shortcuts import render, redirect\n from django.contrib import messages\n from django.contrib.auth.forms import SetPasswordForm\n+from django.contrib.auth.decorators import permission_required\n from django.utils.translation import ugettext as _ \n \n+@permission_required('wagtailadmin.access_admin')\n def account(request):\n return render(request, 'wagtailadmin/account/account.html', {\n 'show_change_password': getattr(settings, 'WAGTAIL_PASSWORD_MANAGEMENT_ENABLED', True) and request.user.has_usable_password(),\n })\n \n \n+@permission_required('wagtailadmin.access_admin')\n def change_password(request):\n can_change_password = request.user.has_usable_password()\n", "issue": "'AnonymousUser' object has no attribute 'has_usable_password'\nVisiting http://localhost:8000/admin/account/ as not logged in user gives the AttributeError above...\n\nTraceback;\n\n``` Environment:\n\n\nRequest Method: GET\nRequest URL: http://localhost:8000/admin/account/\n\nDjango Version: 1.6.2\nPython Version: 2.7.6\nInstalled Applications:\n('django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'south',\n 'compressor',\n 'taggit',\n 'modelcluster',\n 'django.contrib.admin',\n 'wagtail.wagtailcore',\n 'wagtail.wagtailadmin',\n 'wagtail.wagtaildocs',\n 'wagtail.wagtailsnippets',\n 'wagtail.wagtailusers',\n 'wagtail.wagtailimages',\n 'wagtail.wagtailembeds',\n 'wagtail.wagtailsearch',\n 'wagtail.wagtailredirects')\nInstalled Middleware:\n('django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n 'wagtail.wagtailcore.middleware.SiteMiddleware',\n 'wagtail.wagtailredirects.middleware.RedirectMiddleware')\n\n\nTraceback:\nFile \"C:\\Users\\drager\\developing\\django-env\\lib\\site-packages\\django\\core\\handlers\\base.py\" in get_response\n 114. response = wrapped_callback(request, *callback_args, **callback_kwargs)\nFile \"c:\\users\\drager\\developing\\django-env\\src\\wagtail\\wagtail\\wagtailadmin\\views\\account.py\" in account\n 9. 'show_change_password': getattr(settings, 'WAGTAIL_PASSWORD_MANAGEMENT_ENABLED', True) and request.user.has_usable_password(),\nFile \"C:\\Users\\drager\\developing\\django-env\\lib\\site-packages\\django\\utils\\functional.py\" in inner\n 214. return func(self._wrapped, *args)\n\nException Type: AttributeError at /admin/account/\nException Value: 'AnonymousUser' object has no attribute 'has_usable_password'\n```\n\n", "before_files": [{"content": "from django.conf import settings\nfrom django.shortcuts import render, redirect\nfrom django.contrib import messages\nfrom django.contrib.auth.forms import SetPasswordForm\nfrom django.utils.translation import ugettext as _ \n\ndef account(request):\n return render(request, 'wagtailadmin/account/account.html', {\n 'show_change_password': getattr(settings, 'WAGTAIL_PASSWORD_MANAGEMENT_ENABLED', True) and request.user.has_usable_password(),\n })\n\n\ndef change_password(request):\n can_change_password = request.user.has_usable_password()\n\n if can_change_password:\n if request.POST:\n form = SetPasswordForm(request.user, request.POST)\n\n if form.is_valid():\n form.save()\n\n messages.success(request, _(\"Your password has been changed successfully!\"))\n return redirect('wagtailadmin_account')\n else:\n form = SetPasswordForm(request.user)\n else:\n form = None\n\n return render(request, 'wagtailadmin/account/change_password.html', {\n 'form': form,\n 'can_change_password': can_change_password,\n })\n", "path": "wagtail/wagtailadmin/views/account.py"}], "after_files": [{"content": "from django.conf import settings\nfrom django.shortcuts import render, redirect\nfrom django.contrib import messages\nfrom django.contrib.auth.forms import SetPasswordForm\nfrom django.contrib.auth.decorators import permission_required\nfrom django.utils.translation import ugettext as _ \n\n@permission_required('wagtailadmin.access_admin')\ndef account(request):\n return render(request, 'wagtailadmin/account/account.html', {\n 'show_change_password': getattr(settings, 'WAGTAIL_PASSWORD_MANAGEMENT_ENABLED', True) and request.user.has_usable_password(),\n })\n\n\n@permission_required('wagtailadmin.access_admin')\ndef change_password(request):\n can_change_password = request.user.has_usable_password()\n\n if can_change_password:\n if request.POST:\n form = SetPasswordForm(request.user, request.POST)\n\n if form.is_valid():\n form.save()\n\n messages.success(request, _(\"Your password has been changed successfully!\"))\n return redirect('wagtailadmin_account')\n else:\n form = SetPasswordForm(request.user)\n else:\n form = None\n\n return render(request, 'wagtailadmin/account/change_password.html', {\n 'form': form,\n 'can_change_password': can_change_password,\n })\n", "path": "wagtail/wagtailadmin/views/account.py"}]}
| 1,044 | 199 |
gh_patches_debug_29670
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-3457
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
https://www.micous.com/ Site closing webcasts
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace the space character between the square brackets with an x in order to check the boxes -->
- [ ] This is a plugin issue and I have read the contribution guidelines.
- [ ] I am using the latest development version from the master branch.
### Description
I was checking the m3u8 codes for Tango Live so that it would benefit people and maybe we can bring plugins but now I have checked and the mico.us plugin does not work because mico.us is no longer working. It looks like it has turned off broadcasting and playback, I guess only broadcasts can be followed through the application and need to be checked.
<!-- Explain the plugin issue as thoroughly as you can. -->
### Reproduction steps / Explicit stream URLs to test
this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. ...https://www.micous.com/
2. ...
3. ...
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
Don't post screenshots of the log output and instead copy the text from your terminal application.
-->
```
REPLACE THIS TEXT WITH THE LOG OUTPUT
```
### Additional comments, etc.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/streamlink/plugins/mico.py`
Content:
```
1 import logging
2 import re
3
4 from streamlink.plugin import Plugin
5 from streamlink.plugin.api import validate
6 from streamlink.stream import HLSStream
7 from streamlink.utils import parse_json
8 from streamlink.utils.url import update_scheme
9
10 log = logging.getLogger(__name__)
11
12
13 class Mico(Plugin):
14 author = None
15 category = None
16 title = None
17
18 url_re = re.compile(r'https?://(?:www\.)?micous\.com/live/\d+')
19 json_data_re = re.compile(r'win._profile\s*=\s*({.*})')
20
21 _json_data_schema = validate.Schema(
22 validate.transform(json_data_re.search),
23 validate.any(None, validate.all(
24 validate.get(1),
25 validate.transform(parse_json),
26 validate.any(None, validate.all({
27 'mico_id': int,
28 'nickname': validate.text,
29 'h5_url': validate.all(
30 validate.transform(lambda x: update_scheme('http:', x)),
31 validate.url(),
32 ),
33 'is_live': bool,
34 })),
35 )),
36 )
37
38 @classmethod
39 def can_handle_url(cls, url):
40 return cls.url_re.match(url) is not None
41
42 def get_author(self):
43 if self.author is not None:
44 return self.author
45
46 def get_category(self):
47 if self.category is not None:
48 return self.category
49
50 def get_title(self):
51 if self.title is not None:
52 return self.title
53
54 def _get_streams(self):
55 json_data = self.session.http.get(self.url, schema=self._json_data_schema)
56
57 if not json_data:
58 log.error('Failed to get JSON data')
59 return
60
61 if not json_data['is_live']:
62 log.info('This stream is no longer online')
63 return
64
65 self.author = json_data['mico_id']
66 self.category = 'Live'
67 self.title = json_data['nickname']
68
69 return HLSStream.parse_variant_playlist(self.session, json_data['h5_url'])
70
71
72 __plugin__ = Mico
73
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/streamlink/plugins/mico.py b/src/streamlink/plugins/mico.py
deleted file mode 100644
--- a/src/streamlink/plugins/mico.py
+++ /dev/null
@@ -1,72 +0,0 @@
-import logging
-import re
-
-from streamlink.plugin import Plugin
-from streamlink.plugin.api import validate
-from streamlink.stream import HLSStream
-from streamlink.utils import parse_json
-from streamlink.utils.url import update_scheme
-
-log = logging.getLogger(__name__)
-
-
-class Mico(Plugin):
- author = None
- category = None
- title = None
-
- url_re = re.compile(r'https?://(?:www\.)?micous\.com/live/\d+')
- json_data_re = re.compile(r'win._profile\s*=\s*({.*})')
-
- _json_data_schema = validate.Schema(
- validate.transform(json_data_re.search),
- validate.any(None, validate.all(
- validate.get(1),
- validate.transform(parse_json),
- validate.any(None, validate.all({
- 'mico_id': int,
- 'nickname': validate.text,
- 'h5_url': validate.all(
- validate.transform(lambda x: update_scheme('http:', x)),
- validate.url(),
- ),
- 'is_live': bool,
- })),
- )),
- )
-
- @classmethod
- def can_handle_url(cls, url):
- return cls.url_re.match(url) is not None
-
- def get_author(self):
- if self.author is not None:
- return self.author
-
- def get_category(self):
- if self.category is not None:
- return self.category
-
- def get_title(self):
- if self.title is not None:
- return self.title
-
- def _get_streams(self):
- json_data = self.session.http.get(self.url, schema=self._json_data_schema)
-
- if not json_data:
- log.error('Failed to get JSON data')
- return
-
- if not json_data['is_live']:
- log.info('This stream is no longer online')
- return
-
- self.author = json_data['mico_id']
- self.category = 'Live'
- self.title = json_data['nickname']
-
- return HLSStream.parse_variant_playlist(self.session, json_data['h5_url'])
-
-
-__plugin__ = Mico
|
{"golden_diff": "diff --git a/src/streamlink/plugins/mico.py b/src/streamlink/plugins/mico.py\ndeleted file mode 100644\n--- a/src/streamlink/plugins/mico.py\n+++ /dev/null\n@@ -1,72 +0,0 @@\n-import logging\n-import re\n-\n-from streamlink.plugin import Plugin\n-from streamlink.plugin.api import validate\n-from streamlink.stream import HLSStream\n-from streamlink.utils import parse_json\n-from streamlink.utils.url import update_scheme\n-\n-log = logging.getLogger(__name__)\n-\n-\n-class Mico(Plugin):\n- author = None\n- category = None\n- title = None\n-\n- url_re = re.compile(r'https?://(?:www\\.)?micous\\.com/live/\\d+')\n- json_data_re = re.compile(r'win._profile\\s*=\\s*({.*})')\n-\n- _json_data_schema = validate.Schema(\n- validate.transform(json_data_re.search),\n- validate.any(None, validate.all(\n- validate.get(1),\n- validate.transform(parse_json),\n- validate.any(None, validate.all({\n- 'mico_id': int,\n- 'nickname': validate.text,\n- 'h5_url': validate.all(\n- validate.transform(lambda x: update_scheme('http:', x)),\n- validate.url(),\n- ),\n- 'is_live': bool,\n- })),\n- )),\n- )\n-\n- @classmethod\n- def can_handle_url(cls, url):\n- return cls.url_re.match(url) is not None\n-\n- def get_author(self):\n- if self.author is not None:\n- return self.author\n-\n- def get_category(self):\n- if self.category is not None:\n- return self.category\n-\n- def get_title(self):\n- if self.title is not None:\n- return self.title\n-\n- def _get_streams(self):\n- json_data = self.session.http.get(self.url, schema=self._json_data_schema)\n-\n- if not json_data:\n- log.error('Failed to get JSON data')\n- return\n-\n- if not json_data['is_live']:\n- log.info('This stream is no longer online')\n- return\n-\n- self.author = json_data['mico_id']\n- self.category = 'Live'\n- self.title = json_data['nickname']\n-\n- return HLSStream.parse_variant_playlist(self.session, json_data['h5_url'])\n-\n-\n-__plugin__ = Mico\n", "issue": "https://www.micous.com/ Site closing webcasts\n<!--\r\nThanks for reporting a plugin issue!\r\nUSE THE TEMPLATE. Otherwise your plugin issue may be rejected.\r\n\r\nFirst, see the contribution guidelines:\r\nhttps://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink\r\n\r\nAlso check the list of open and closed plugin issues:\r\nhttps://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22\r\n\r\nPlease see the text preview to avoid unnecessary formatting errors.\r\n-->\r\n\r\n\r\n## Plugin Issue\r\n\r\n<!-- Replace the space character between the square brackets with an x in order to check the boxes -->\r\n- [ ] This is a plugin issue and I have read the contribution guidelines.\r\n- [ ] I am using the latest development version from the master branch.\r\n\r\n\r\n### Description\r\nI was checking the m3u8 codes for Tango Live so that it would benefit people and maybe we can bring plugins but now I have checked and the mico.us plugin does not work because mico.us is no longer working. It looks like it has turned off broadcasting and playback, I guess only broadcasts can be followed through the application and need to be checked. \r\n<!-- Explain the plugin issue as thoroughly as you can. -->\r\n\r\n\r\n### Reproduction steps / Explicit stream URLs to test\r\nthis? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->\r\n\r\n1. ...https://www.micous.com/\r\n2. ...\r\n3. ...\r\n\r\n\r\n### Log output\r\n\r\n<!--\r\nTEXT LOG OUTPUT IS REQUIRED for a plugin issue!\r\nUse the `--loglevel debug` parameter and avoid using parameters which suppress log output.\r\nhttps://streamlink.github.io/cli.html#cmdoption-l\r\n\r\nMake sure to **remove usernames and passwords**\r\nYou can copy the output to https://gist.github.com/ or paste it below.\r\n\r\nDon't post screenshots of the log output and instead copy the text from your terminal application.\r\n-->\r\n\r\n```\r\nREPLACE THIS TEXT WITH THE LOG OUTPUT\r\n```\r\n\r\n\r\n### Additional comments, etc.\r\n\r\n\r\n\r\n[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)\r\n\n", "before_files": [{"content": "import logging\nimport re\n\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream import HLSStream\nfrom streamlink.utils import parse_json\nfrom streamlink.utils.url import update_scheme\n\nlog = logging.getLogger(__name__)\n\n\nclass Mico(Plugin):\n author = None\n category = None\n title = None\n\n url_re = re.compile(r'https?://(?:www\\.)?micous\\.com/live/\\d+')\n json_data_re = re.compile(r'win._profile\\s*=\\s*({.*})')\n\n _json_data_schema = validate.Schema(\n validate.transform(json_data_re.search),\n validate.any(None, validate.all(\n validate.get(1),\n validate.transform(parse_json),\n validate.any(None, validate.all({\n 'mico_id': int,\n 'nickname': validate.text,\n 'h5_url': validate.all(\n validate.transform(lambda x: update_scheme('http:', x)),\n validate.url(),\n ),\n 'is_live': bool,\n })),\n )),\n )\n\n @classmethod\n def can_handle_url(cls, url):\n return cls.url_re.match(url) is not None\n\n def get_author(self):\n if self.author is not None:\n return self.author\n\n def get_category(self):\n if self.category is not None:\n return self.category\n\n def get_title(self):\n if self.title is not None:\n return self.title\n\n def _get_streams(self):\n json_data = self.session.http.get(self.url, schema=self._json_data_schema)\n\n if not json_data:\n log.error('Failed to get JSON data')\n return\n\n if not json_data['is_live']:\n log.info('This stream is no longer online')\n return\n\n self.author = json_data['mico_id']\n self.category = 'Live'\n self.title = json_data['nickname']\n\n return HLSStream.parse_variant_playlist(self.session, json_data['h5_url'])\n\n\n__plugin__ = Mico\n", "path": "src/streamlink/plugins/mico.py"}], "after_files": [{"content": null, "path": "src/streamlink/plugins/mico.py"}]}
| 1,294 | 540 |
gh_patches_debug_30756
|
rasdani/github-patches
|
git_diff
|
apache__airflow-19592
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Cast to string in ds macro functions
As already written in this issue https://github.com/apache/airflow/issues/19241 strptime function required string, but got proxy if the variables ds/next_ds (the types of these variables changed on version 2.2.0) sent.
This change will make the function `ds_add` and `ds_format` backward compatible.
<!--
Thank you for contributing! Please make sure that your code changes
are covered with tests. And in case of new features or big changes
remember to adjust the documentation.
Feel free to ping committers for the review!
In case of existing issue, reference it using one of the following:
closes: #ISSUE
related: #ISSUE
How to write a good git commit message:
http://chris.beams.io/posts/git-commit/
-->
---
**^ Add meaningful description above**
Read the **[Pull Request Guidelines](https://github.com/apache/airflow/blob/main/CONTRIBUTING.rst#pull-request-guidelines)** for more information.
In case of fundamental code change, Airflow Improvement Proposal ([AIP](https://cwiki.apache.org/confluence/display/AIRFLOW/Airflow+Improvements+Proposals)) is needed.
In case of a new dependency, check compliance with the [ASF 3rd Party License Policy](https://www.apache.org/legal/resolved.html#category-x).
In case of backwards incompatible changes please leave a note in [UPDATING.md](https://github.com/apache/airflow/blob/main/UPDATING.md).
next_ds changed to proxy and it cannot be used in ds_add macro function
### Apache Airflow version
2.2.0 (latest released)
### Operating System
Ubuntu
### Versions of Apache Airflow Providers
_No response_
### Deployment
Docker-Compose
### Deployment details
_No response_
### What happened
Tried to use this this code:
`some_variable='{{macros.ds_format(macros.ds_add(next_ds, '
'(ti.start_date - ti.execution_date).days), '
'"%Y-%m-%d", "%Y-%m-%d 21:00:00")}}')`
but got this error:
`strptime() argument 1 must be str, not Proxy`
because the `next_ds` variable changed to proxy.
### What you expected to happen
_No response_
### How to reproduce
_No response_
### Anything else
_No response_
### Are you willing to submit PR?
- [ ] Yes I am willing to submit a PR!
### Code of Conduct
- [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `airflow/macros/__init__.py`
Content:
```
1 #
2 # Licensed to the Apache Software Foundation (ASF) under one
3 # or more contributor license agreements. See the NOTICE file
4 # distributed with this work for additional information
5 # regarding copyright ownership. The ASF licenses this file
6 # to you under the Apache License, Version 2.0 (the
7 # "License"); you may not use this file except in compliance
8 # with the License. You may obtain a copy of the License at
9 #
10 # http://www.apache.org/licenses/LICENSE-2.0
11 #
12 # Unless required by applicable law or agreed to in writing,
13 # software distributed under the License is distributed on an
14 # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
15 # KIND, either express or implied. See the License for the
16 # specific language governing permissions and limitations
17 # under the License.
18 import time # noqa
19 import uuid # noqa
20 from datetime import datetime, timedelta
21 from random import random # noqa
22
23 import dateutil # noqa
24
25 from airflow.macros import hive # noqa
26
27
28 def ds_add(ds, days):
29 """
30 Add or subtract days from a YYYY-MM-DD
31
32 :param ds: anchor date in ``YYYY-MM-DD`` format to add to
33 :type ds: str
34 :param days: number of days to add to the ds, you can use negative values
35 :type days: int
36
37 >>> ds_add('2015-01-01', 5)
38 '2015-01-06'
39 >>> ds_add('2015-01-06', -5)
40 '2015-01-01'
41 """
42 ds = datetime.strptime(ds, '%Y-%m-%d')
43 if days:
44 ds = ds + timedelta(days)
45 return ds.isoformat()[:10]
46
47
48 def ds_format(ds, input_format, output_format):
49 """
50 Takes an input string and outputs another string
51 as specified in the output format
52
53 :param ds: input string which contains a date
54 :type ds: str
55 :param input_format: input string format. E.g. %Y-%m-%d
56 :type input_format: str
57 :param output_format: output string format E.g. %Y-%m-%d
58 :type output_format: str
59
60 >>> ds_format('2015-01-01', "%Y-%m-%d", "%m-%d-%y")
61 '01-01-15'
62 >>> ds_format('1/5/2015', "%m/%d/%Y", "%Y-%m-%d")
63 '2015-01-05'
64 """
65 return datetime.strptime(ds, input_format).strftime(output_format)
66
67
68 def datetime_diff_for_humans(dt, since=None):
69 """
70 Return a human-readable/approximate difference between two datetimes, or
71 one and now.
72
73 :param dt: The datetime to display the diff for
74 :type dt: datetime.datetime
75 :param since: When to display the date from. If ``None`` then the diff is
76 between ``dt`` and now.
77 :type since: None or datetime.datetime
78 :rtype: str
79 """
80 import pendulum
81
82 return pendulum.instance(dt).diff_for_humans(since)
83
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/airflow/macros/__init__.py b/airflow/macros/__init__.py
--- a/airflow/macros/__init__.py
+++ b/airflow/macros/__init__.py
@@ -19,13 +19,17 @@
import uuid # noqa
from datetime import datetime, timedelta
from random import random # noqa
+from typing import Any, Optional, Union
import dateutil # noqa
+import lazy_object_proxy
from airflow.macros import hive # noqa
+TemplateStringInput = Union[str, lazy_object_proxy.Proxy]
-def ds_add(ds, days):
+
+def ds_add(ds: TemplateStringInput, days: int) -> str:
"""
Add or subtract days from a YYYY-MM-DD
@@ -39,13 +43,13 @@
>>> ds_add('2015-01-06', -5)
'2015-01-01'
"""
- ds = datetime.strptime(ds, '%Y-%m-%d')
- if days:
- ds = ds + timedelta(days)
- return ds.isoformat()[:10]
+ if not days:
+ return str(ds)
+ dt = datetime.strptime(str(ds), "%Y-%m-%d") + timedelta(days=days)
+ return dt.strftime("%Y-%m-%d")
-def ds_format(ds, input_format, output_format):
+def ds_format(ds: TemplateStringInput, input_format: str, output_format: str) -> str:
"""
Takes an input string and outputs another string
as specified in the output format
@@ -62,10 +66,10 @@
>>> ds_format('1/5/2015', "%m/%d/%Y", "%Y-%m-%d")
'2015-01-05'
"""
- return datetime.strptime(ds, input_format).strftime(output_format)
+ return datetime.strptime(str(ds), input_format).strftime(output_format)
-def datetime_diff_for_humans(dt, since=None):
+def datetime_diff_for_humans(dt: Any, since: Optional[datetime] = None) -> str:
"""
Return a human-readable/approximate difference between two datetimes, or
one and now.
|
{"golden_diff": "diff --git a/airflow/macros/__init__.py b/airflow/macros/__init__.py\n--- a/airflow/macros/__init__.py\n+++ b/airflow/macros/__init__.py\n@@ -19,13 +19,17 @@\n import uuid # noqa\n from datetime import datetime, timedelta\n from random import random # noqa\n+from typing import Any, Optional, Union\n \n import dateutil # noqa\n+import lazy_object_proxy\n \n from airflow.macros import hive # noqa\n \n+TemplateStringInput = Union[str, lazy_object_proxy.Proxy]\n \n-def ds_add(ds, days):\n+\n+def ds_add(ds: TemplateStringInput, days: int) -> str:\n \"\"\"\n Add or subtract days from a YYYY-MM-DD\n \n@@ -39,13 +43,13 @@\n >>> ds_add('2015-01-06', -5)\n '2015-01-01'\n \"\"\"\n- ds = datetime.strptime(ds, '%Y-%m-%d')\n- if days:\n- ds = ds + timedelta(days)\n- return ds.isoformat()[:10]\n+ if not days:\n+ return str(ds)\n+ dt = datetime.strptime(str(ds), \"%Y-%m-%d\") + timedelta(days=days)\n+ return dt.strftime(\"%Y-%m-%d\")\n \n \n-def ds_format(ds, input_format, output_format):\n+def ds_format(ds: TemplateStringInput, input_format: str, output_format: str) -> str:\n \"\"\"\n Takes an input string and outputs another string\n as specified in the output format\n@@ -62,10 +66,10 @@\n >>> ds_format('1/5/2015', \"%m/%d/%Y\", \"%Y-%m-%d\")\n '2015-01-05'\n \"\"\"\n- return datetime.strptime(ds, input_format).strftime(output_format)\n+ return datetime.strptime(str(ds), input_format).strftime(output_format)\n \n \n-def datetime_diff_for_humans(dt, since=None):\n+def datetime_diff_for_humans(dt: Any, since: Optional[datetime] = None) -> str:\n \"\"\"\n Return a human-readable/approximate difference between two datetimes, or\n one and now.\n", "issue": "Cast to string in ds macro functions\n\r\nAs already written in this issue https://github.com/apache/airflow/issues/19241 strptime function required string, but got proxy if the variables ds/next_ds (the types of these variables changed on version 2.2.0) sent.\r\nThis change will make the function `ds_add` and `ds_format` backward compatible.\r\n\r\n<!--\r\nThank you for contributing! Please make sure that your code changes\r\nare covered with tests. And in case of new features or big changes\r\nremember to adjust the documentation.\r\n\r\nFeel free to ping committers for the review!\r\n\r\nIn case of existing issue, reference it using one of the following:\r\n\r\ncloses: #ISSUE\r\nrelated: #ISSUE\r\n\r\nHow to write a good git commit message:\r\nhttp://chris.beams.io/posts/git-commit/\r\n-->\r\n\r\n---\r\n**^ Add meaningful description above**\r\n\r\nRead the **[Pull Request Guidelines](https://github.com/apache/airflow/blob/main/CONTRIBUTING.rst#pull-request-guidelines)** for more information.\r\nIn case of fundamental code change, Airflow Improvement Proposal ([AIP](https://cwiki.apache.org/confluence/display/AIRFLOW/Airflow+Improvements+Proposals)) is needed.\r\nIn case of a new dependency, check compliance with the [ASF 3rd Party License Policy](https://www.apache.org/legal/resolved.html#category-x).\r\nIn case of backwards incompatible changes please leave a note in [UPDATING.md](https://github.com/apache/airflow/blob/main/UPDATING.md).\r\n\nnext_ds changed to proxy and it cannot be used in ds_add macro function\n### Apache Airflow version\n\n2.2.0 (latest released)\n\n### Operating System\n\nUbuntu\n\n### Versions of Apache Airflow Providers\n\n_No response_\n\n### Deployment\n\nDocker-Compose\n\n### Deployment details\n\n_No response_\n\n### What happened\n\nTried to use this this code:\r\n`some_variable='{{macros.ds_format(macros.ds_add(next_ds, '\r\n '(ti.start_date - ti.execution_date).days), '\r\n '\"%Y-%m-%d\", \"%Y-%m-%d 21:00:00\")}}')`\r\nbut got this error:\r\n`strptime() argument 1 must be str, not Proxy`\r\nbecause the `next_ds` variable changed to proxy.\n\n### What you expected to happen\n\n_No response_\n\n### How to reproduce\n\n_No response_\n\n### Anything else\n\n_No response_\n\n### Are you willing to submit PR?\n\n- [ ] Yes I am willing to submit a PR!\n\n### Code of Conduct\n\n- [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md)\n\n", "before_files": [{"content": "#\n# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\nimport time # noqa\nimport uuid # noqa\nfrom datetime import datetime, timedelta\nfrom random import random # noqa\n\nimport dateutil # noqa\n\nfrom airflow.macros import hive # noqa\n\n\ndef ds_add(ds, days):\n \"\"\"\n Add or subtract days from a YYYY-MM-DD\n\n :param ds: anchor date in ``YYYY-MM-DD`` format to add to\n :type ds: str\n :param days: number of days to add to the ds, you can use negative values\n :type days: int\n\n >>> ds_add('2015-01-01', 5)\n '2015-01-06'\n >>> ds_add('2015-01-06', -5)\n '2015-01-01'\n \"\"\"\n ds = datetime.strptime(ds, '%Y-%m-%d')\n if days:\n ds = ds + timedelta(days)\n return ds.isoformat()[:10]\n\n\ndef ds_format(ds, input_format, output_format):\n \"\"\"\n Takes an input string and outputs another string\n as specified in the output format\n\n :param ds: input string which contains a date\n :type ds: str\n :param input_format: input string format. E.g. %Y-%m-%d\n :type input_format: str\n :param output_format: output string format E.g. %Y-%m-%d\n :type output_format: str\n\n >>> ds_format('2015-01-01', \"%Y-%m-%d\", \"%m-%d-%y\")\n '01-01-15'\n >>> ds_format('1/5/2015', \"%m/%d/%Y\", \"%Y-%m-%d\")\n '2015-01-05'\n \"\"\"\n return datetime.strptime(ds, input_format).strftime(output_format)\n\n\ndef datetime_diff_for_humans(dt, since=None):\n \"\"\"\n Return a human-readable/approximate difference between two datetimes, or\n one and now.\n\n :param dt: The datetime to display the diff for\n :type dt: datetime.datetime\n :param since: When to display the date from. If ``None`` then the diff is\n between ``dt`` and now.\n :type since: None or datetime.datetime\n :rtype: str\n \"\"\"\n import pendulum\n\n return pendulum.instance(dt).diff_for_humans(since)\n", "path": "airflow/macros/__init__.py"}], "after_files": [{"content": "#\n# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\nimport time # noqa\nimport uuid # noqa\nfrom datetime import datetime, timedelta\nfrom random import random # noqa\nfrom typing import Any, Optional, Union\n\nimport dateutil # noqa\nimport lazy_object_proxy\n\nfrom airflow.macros import hive # noqa\n\nTemplateStringInput = Union[str, lazy_object_proxy.Proxy]\n\n\ndef ds_add(ds: TemplateStringInput, days: int) -> str:\n \"\"\"\n Add or subtract days from a YYYY-MM-DD\n\n :param ds: anchor date in ``YYYY-MM-DD`` format to add to\n :type ds: str\n :param days: number of days to add to the ds, you can use negative values\n :type days: int\n\n >>> ds_add('2015-01-01', 5)\n '2015-01-06'\n >>> ds_add('2015-01-06', -5)\n '2015-01-01'\n \"\"\"\n if not days:\n return str(ds)\n dt = datetime.strptime(str(ds), \"%Y-%m-%d\") + timedelta(days=days)\n return dt.strftime(\"%Y-%m-%d\")\n\n\ndef ds_format(ds: TemplateStringInput, input_format: str, output_format: str) -> str:\n \"\"\"\n Takes an input string and outputs another string\n as specified in the output format\n\n :param ds: input string which contains a date\n :type ds: str\n :param input_format: input string format. E.g. %Y-%m-%d\n :type input_format: str\n :param output_format: output string format E.g. %Y-%m-%d\n :type output_format: str\n\n >>> ds_format('2015-01-01', \"%Y-%m-%d\", \"%m-%d-%y\")\n '01-01-15'\n >>> ds_format('1/5/2015', \"%m/%d/%Y\", \"%Y-%m-%d\")\n '2015-01-05'\n \"\"\"\n return datetime.strptime(str(ds), input_format).strftime(output_format)\n\n\ndef datetime_diff_for_humans(dt: Any, since: Optional[datetime] = None) -> str:\n \"\"\"\n Return a human-readable/approximate difference between two datetimes, or\n one and now.\n\n :param dt: The datetime to display the diff for\n :type dt: datetime.datetime\n :param since: When to display the date from. If ``None`` then the diff is\n between ``dt`` and now.\n :type since: None or datetime.datetime\n :rtype: str\n \"\"\"\n import pendulum\n\n return pendulum.instance(dt).diff_for_humans(since)\n", "path": "airflow/macros/__init__.py"}]}
| 1,727 | 504 |
gh_patches_debug_20400
|
rasdani/github-patches
|
git_diff
|
watchdogpolska__feder-312
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Domyślny tytuł wiadomości określić
https://fedrowanie.siecobywatelska.pl//listy/70
Należy napisać ```get_*_display```.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `feder/letters/models.py`
Content:
```
1 from __future__ import print_function
2
3 import logging
4 import os
5 import uuid
6
7 import claw
8 from atom.models import AttachmentBase
9 from cached_property import cached_property
10 from claw import quotations
11 from django.conf import settings
12 from django.contrib.auth import get_user_model
13 from django.core.files import File
14 from django.core.files.base import ContentFile
15 from django.core.mail import EmailMessage
16 from django.core.mail.message import make_msgid
17 from django.core.urlresolvers import reverse
18 from django.db import models
19 from django.db.models.manager import BaseManager
20 from django.dispatch import receiver
21 from django.utils.encoding import python_2_unicode_compatible
22 from django.utils.translation import ugettext_lazy as _
23 from django_mailbox.models import Message
24 from django_mailbox.signals import message_received
25 from model_utils import Choices
26 from model_utils.models import TimeStampedModel
27
28 from feder.cases.models import Case
29 from feder.institutions.models import Institution
30 from .utils import email_wrapper, normalize_msg_id
31
32 claw.init()
33
34 logger = logging.getLogger(__name__)
35
36
37 class LetterQuerySet(models.QuerySet):
38 def attachment_count(self):
39 return self.annotate(attachment_count=models.Count('attachment'))
40
41 def with_author(self):
42 return self.select_related('author_user', 'author_institution')
43
44 def for_milestone(self):
45 return self.prefetch_related('attachment_set').with_author()
46
47 def is_outgoing(self):
48 return self.filter(author_user__isnull=False)
49
50 def is_incoming(self):
51 return self.filter(author_user__isnull=True)
52
53 def with_feed_items(self):
54 return (self.with_author().
55 select_related('case__institution__jst', 'case__monitoring').
56 prefetch_related('attachment_set'))
57
58
59 class LetterManager(BaseManager.from_queryset(LetterQuerySet)):
60 def get_queryset(self):
61 return super(LetterManager, self).get_queryset().filter(is_spam__in=[Letter.SPAM.unknown, Letter.SPAM.non_spam])
62
63
64 @python_2_unicode_compatible
65 class Letter(TimeStampedModel):
66 SPAM = Choices((0, 'unknown', _('Unknown')),
67 (1, 'spam', _('Spam')),
68 (2, 'non_spam', _('Non-spam'), ))
69 case = models.ForeignKey(Case, verbose_name=_("Case"))
70 author_user = models.ForeignKey(settings.AUTH_USER_MODEL, verbose_name=_("Author (if user)"),
71 null=True, blank=True)
72 author_institution = models.ForeignKey(Institution, verbose_name=_("Author (if institution)"),
73 null=True, blank=True)
74 title = models.CharField(verbose_name=_("Title"), max_length=200)
75 body = models.TextField(verbose_name=_("Text"))
76 quote = models.TextField(verbose_name=_("Quote"), blank=True)
77 email = models.EmailField(verbose_name=_("E-mail"), max_length=100, blank=True)
78 note = models.TextField(verbose_name=_("Comments from editor"), blank=True)
79 is_spam = models.IntegerField(choices=SPAM, default=SPAM.unknown, db_index=True)
80 message_id_header = models.CharField(blank=True,
81 verbose_name=_('ID of sent email message "Message-ID"'),
82 max_length=500)
83 eml = models.FileField(upload_to="messages/%Y/%m/%d",
84 verbose_name=_("File"),
85 null=True,
86 blank=True)
87 message = models.ForeignKey(Message,
88 null=True,
89 verbose_name=_("Message"),
90 help_text=_("Message registerd by django-mailbox"))
91 objects = LetterManager()
92 objects_with_spam = LetterQuerySet.as_manager()
93
94 def is_spam_validated(self):
95 return self.is_spam != Letter.SPAM.unknown
96
97 class Meta:
98 verbose_name = _("Letter")
99 verbose_name_plural = _("Letters")
100 ordering = ['created', ]
101 permissions = (
102 ("can_filter_eml", _("Can filter eml")),
103 )
104
105 @property
106 def is_draft(self):
107 return self.is_outgoing and not bool(self.eml)
108
109 @property
110 def is_incoming(self):
111 return not bool(self.author_user_id)
112
113 @property
114 def is_outgoing(self):
115 return bool(self.author_user_id)
116
117 def __str__(self):
118 return self.title
119
120 def get_absolute_url(self):
121 return reverse('letters:details', kwargs={'pk': self.pk})
122
123 @property
124 def author(self):
125 return self.author_user if self.author_user_id else self.author_institution
126
127 @author.setter
128 def author(self, value):
129 if isinstance(value, Institution):
130 self.author_user = None
131 self.author_institution = value
132 elif isinstance(value, get_user_model()):
133 self.author_institution = None
134 self.author_user = value
135 else:
136 raise ValueError("Only User and Institution is allowed for attribute author")
137
138 @classmethod
139 def send_new_case(cls, user, monitoring, institution, text, postfix=''):
140 case = Case(user=user,
141 name=monitoring.name + postfix,
142 monitoring=monitoring,
143 institution=institution)
144 case.save()
145 letter = cls(author_user=user,
146 case=case,
147 title=monitoring.subject,
148 body=text)
149 letter.send(commit=True, only_email=False)
150 return letter
151
152 def email_body(self):
153 body = self.body.replace('{{EMAIL}}', self.case.email)
154 return u"{0}\n{1}".format(body, email_wrapper(self.quote))
155
156 def _construct_message(self, msg_id=None):
157 headers = {'Return-Receipt-To': self.case.email,
158 'Disposition-Notification-To': self.case.email,
159 }
160 if msg_id:
161 headers['Message-ID'] = msg_id
162 return EmailMessage(subject=self.case.monitoring.subject,
163 from_email=self.case.email,
164 reply_to=[self.case.email],
165 to=[self.case.institution.email],
166 body=self.email_body(),
167 headers=headers)
168
169 def send(self, commit=True, only_email=False):
170 msg_id = make_msgid(domain=self.case.email.split('@', 2)[1])
171 message = self._construct_message(msg_id=msg_id)
172 text = message.message().as_bytes()
173 self.email = self.case.institution.email
174 self.message_id_header = normalize_msg_id(msg_id)
175 self.eml.save('%s.eml' % uuid.uuid4(), ContentFile(text), save=False)
176 if commit:
177 self.save(update_fields=['eml', 'email'] if only_email else None)
178 return message.send()
179
180
181 @python_2_unicode_compatible
182 class Attachment(AttachmentBase):
183 letter = models.ForeignKey(Letter)
184
185 def delete(self, *args, **kwargs):
186 self.attachment.delete()
187 super(Attachment, self).delete(*args, **kwargs)
188
189 def __str__(self):
190 if self.attachment:
191 return u"{}".format(self.filename)
192 return "None"
193
194
195 class MessageParser(object):
196 def __init__(self, message):
197 self.message = message
198
199 @cached_property
200 def quote(self):
201 if self.message.text:
202 return self.message.text.replace(self.text, '')
203 return self.message.text.replace(self.text, '')
204
205 @cached_property
206 def text(self):
207 if self.message.text:
208 return quotations.extract_from(self.message.text)
209 return quotations.extract_from(self.message.html, 'text/html')
210
211 def get_case(self):
212 try:
213 return Case.objects.by_msg(self.message).get()
214 except Case.DoesNotExist:
215 return
216
217 def save_attachments(self, letter):
218 # Create Letter
219 attachments = []
220 # Append attachments
221 for attachment in self.message.attachments.all():
222 name = attachment.get_filename() or 'Unknown.bin'
223 if len(name) > 70:
224 name, ext = os.path.splitext(name)
225 ext = ext[:70]
226 name = name[:70 - len(ext)] + ext
227 file_obj = File(attachment.document, name)
228 attachments.append(Attachment(letter=letter, attachment=file_obj))
229 Attachment.objects.bulk_create(attachments)
230 for att in attachments: # Force close file descriptor to avoid "Too many open files"
231 att.attachment.close()
232 return attachments
233
234 def save_object(self):
235 with File(self.message.eml, self.message.eml.name) as eml:
236 return Letter.objects.create(author_institution=self.case.institution,
237 email=self.message.from_address[0],
238 case=self.case,
239 title=self.message.subject,
240 body=self.text,
241 quote=self.quote,
242 eml=eml,
243 message=self.message)
244
245 @staticmethod
246 @receiver(message_received)
247 def receive_signal(sender, message, **kwargs):
248 MessageParser(message).insert()
249
250 def insert(self):
251 self.case = self.get_case()
252 if not self.case:
253 logger.warning("Message #{pk} skip, due not recognized address {to}".
254 format(pk=self.message.pk, to=self.message.to_addresses))
255 return
256 letter = self.save_object()
257 logger.info("Message #{message} registered in case #{case} as letter #{letter}".
258 format(message=self.message.pk, case=self.case.pk, letter=letter.pk))
259 attachments = self.save_attachments(letter)
260 logger.debug("Saved {attachment_count} attachments for letter #{letter}".
261 format(attachment_count=len(attachments), letter=letter.pk))
262 return letter
263
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/feder/letters/models.py b/feder/letters/models.py
--- a/feder/letters/models.py
+++ b/feder/letters/models.py
@@ -24,7 +24,6 @@
from django_mailbox.signals import message_received
from model_utils import Choices
from model_utils.models import TimeStampedModel
-
from feder.cases.models import Case
from feder.institutions.models import Institution
from .utils import email_wrapper, normalize_msg_id
@@ -114,8 +113,16 @@
def is_outgoing(self):
return bool(self.author_user_id)
+ def get_title(self):
+ if self.title and self.title.strip():
+ return self.title
+ return _("(no subject)")
+
def __str__(self):
- return self.title
+ return unicode(self.get_title())
+
+ def __unicode__(self):
+ return unicode(self.get_title())
def get_absolute_url(self):
return reverse('letters:details', kwargs={'pk': self.pk})
|
{"golden_diff": "diff --git a/feder/letters/models.py b/feder/letters/models.py\n--- a/feder/letters/models.py\n+++ b/feder/letters/models.py\n@@ -24,7 +24,6 @@\n from django_mailbox.signals import message_received\n from model_utils import Choices\n from model_utils.models import TimeStampedModel\n-\n from feder.cases.models import Case\n from feder.institutions.models import Institution\n from .utils import email_wrapper, normalize_msg_id\n@@ -114,8 +113,16 @@\n def is_outgoing(self):\n return bool(self.author_user_id)\n \n+ def get_title(self):\n+ if self.title and self.title.strip():\n+ return self.title\n+ return _(\"(no subject)\")\n+\n def __str__(self):\n- return self.title\n+ return unicode(self.get_title())\n+\n+ def __unicode__(self):\n+ return unicode(self.get_title())\n \n def get_absolute_url(self):\n return reverse('letters:details', kwargs={'pk': self.pk})\n", "issue": "Domy\u015blny tytu\u0142 wiadomo\u015bci okre\u015bli\u0107\nhttps://fedrowanie.siecobywatelska.pl//listy/70\r\n\r\nNale\u017cy napisa\u0107 ```get_*_display```.\n", "before_files": [{"content": "from __future__ import print_function\n\nimport logging\nimport os\nimport uuid\n\nimport claw\nfrom atom.models import AttachmentBase\nfrom cached_property import cached_property\nfrom claw import quotations\nfrom django.conf import settings\nfrom django.contrib.auth import get_user_model\nfrom django.core.files import File\nfrom django.core.files.base import ContentFile\nfrom django.core.mail import EmailMessage\nfrom django.core.mail.message import make_msgid\nfrom django.core.urlresolvers import reverse\nfrom django.db import models\nfrom django.db.models.manager import BaseManager\nfrom django.dispatch import receiver\nfrom django.utils.encoding import python_2_unicode_compatible\nfrom django.utils.translation import ugettext_lazy as _\nfrom django_mailbox.models import Message\nfrom django_mailbox.signals import message_received\nfrom model_utils import Choices\nfrom model_utils.models import TimeStampedModel\n\nfrom feder.cases.models import Case\nfrom feder.institutions.models import Institution\nfrom .utils import email_wrapper, normalize_msg_id\n\nclaw.init()\n\nlogger = logging.getLogger(__name__)\n\n\nclass LetterQuerySet(models.QuerySet):\n def attachment_count(self):\n return self.annotate(attachment_count=models.Count('attachment'))\n\n def with_author(self):\n return self.select_related('author_user', 'author_institution')\n\n def for_milestone(self):\n return self.prefetch_related('attachment_set').with_author()\n\n def is_outgoing(self):\n return self.filter(author_user__isnull=False)\n\n def is_incoming(self):\n return self.filter(author_user__isnull=True)\n\n def with_feed_items(self):\n return (self.with_author().\n select_related('case__institution__jst', 'case__monitoring').\n prefetch_related('attachment_set'))\n\n\nclass LetterManager(BaseManager.from_queryset(LetterQuerySet)):\n def get_queryset(self):\n return super(LetterManager, self).get_queryset().filter(is_spam__in=[Letter.SPAM.unknown, Letter.SPAM.non_spam])\n\n\n@python_2_unicode_compatible\nclass Letter(TimeStampedModel):\n SPAM = Choices((0, 'unknown', _('Unknown')),\n (1, 'spam', _('Spam')),\n (2, 'non_spam', _('Non-spam'), ))\n case = models.ForeignKey(Case, verbose_name=_(\"Case\"))\n author_user = models.ForeignKey(settings.AUTH_USER_MODEL, verbose_name=_(\"Author (if user)\"),\n null=True, blank=True)\n author_institution = models.ForeignKey(Institution, verbose_name=_(\"Author (if institution)\"),\n null=True, blank=True)\n title = models.CharField(verbose_name=_(\"Title\"), max_length=200)\n body = models.TextField(verbose_name=_(\"Text\"))\n quote = models.TextField(verbose_name=_(\"Quote\"), blank=True)\n email = models.EmailField(verbose_name=_(\"E-mail\"), max_length=100, blank=True)\n note = models.TextField(verbose_name=_(\"Comments from editor\"), blank=True)\n is_spam = models.IntegerField(choices=SPAM, default=SPAM.unknown, db_index=True)\n message_id_header = models.CharField(blank=True,\n verbose_name=_('ID of sent email message \"Message-ID\"'),\n max_length=500)\n eml = models.FileField(upload_to=\"messages/%Y/%m/%d\",\n verbose_name=_(\"File\"),\n null=True,\n blank=True)\n message = models.ForeignKey(Message,\n null=True,\n verbose_name=_(\"Message\"),\n help_text=_(\"Message registerd by django-mailbox\"))\n objects = LetterManager()\n objects_with_spam = LetterQuerySet.as_manager()\n\n def is_spam_validated(self):\n return self.is_spam != Letter.SPAM.unknown\n\n class Meta:\n verbose_name = _(\"Letter\")\n verbose_name_plural = _(\"Letters\")\n ordering = ['created', ]\n permissions = (\n (\"can_filter_eml\", _(\"Can filter eml\")),\n )\n\n @property\n def is_draft(self):\n return self.is_outgoing and not bool(self.eml)\n\n @property\n def is_incoming(self):\n return not bool(self.author_user_id)\n\n @property\n def is_outgoing(self):\n return bool(self.author_user_id)\n\n def __str__(self):\n return self.title\n\n def get_absolute_url(self):\n return reverse('letters:details', kwargs={'pk': self.pk})\n\n @property\n def author(self):\n return self.author_user if self.author_user_id else self.author_institution\n\n @author.setter\n def author(self, value):\n if isinstance(value, Institution):\n self.author_user = None\n self.author_institution = value\n elif isinstance(value, get_user_model()):\n self.author_institution = None\n self.author_user = value\n else:\n raise ValueError(\"Only User and Institution is allowed for attribute author\")\n\n @classmethod\n def send_new_case(cls, user, monitoring, institution, text, postfix=''):\n case = Case(user=user,\n name=monitoring.name + postfix,\n monitoring=monitoring,\n institution=institution)\n case.save()\n letter = cls(author_user=user,\n case=case,\n title=monitoring.subject,\n body=text)\n letter.send(commit=True, only_email=False)\n return letter\n\n def email_body(self):\n body = self.body.replace('{{EMAIL}}', self.case.email)\n return u\"{0}\\n{1}\".format(body, email_wrapper(self.quote))\n\n def _construct_message(self, msg_id=None):\n headers = {'Return-Receipt-To': self.case.email,\n 'Disposition-Notification-To': self.case.email,\n }\n if msg_id:\n headers['Message-ID'] = msg_id\n return EmailMessage(subject=self.case.monitoring.subject,\n from_email=self.case.email,\n reply_to=[self.case.email],\n to=[self.case.institution.email],\n body=self.email_body(),\n headers=headers)\n\n def send(self, commit=True, only_email=False):\n msg_id = make_msgid(domain=self.case.email.split('@', 2)[1])\n message = self._construct_message(msg_id=msg_id)\n text = message.message().as_bytes()\n self.email = self.case.institution.email\n self.message_id_header = normalize_msg_id(msg_id)\n self.eml.save('%s.eml' % uuid.uuid4(), ContentFile(text), save=False)\n if commit:\n self.save(update_fields=['eml', 'email'] if only_email else None)\n return message.send()\n\n\n@python_2_unicode_compatible\nclass Attachment(AttachmentBase):\n letter = models.ForeignKey(Letter)\n\n def delete(self, *args, **kwargs):\n self.attachment.delete()\n super(Attachment, self).delete(*args, **kwargs)\n\n def __str__(self):\n if self.attachment:\n return u\"{}\".format(self.filename)\n return \"None\"\n\n\nclass MessageParser(object):\n def __init__(self, message):\n self.message = message\n\n @cached_property\n def quote(self):\n if self.message.text:\n return self.message.text.replace(self.text, '')\n return self.message.text.replace(self.text, '')\n\n @cached_property\n def text(self):\n if self.message.text:\n return quotations.extract_from(self.message.text)\n return quotations.extract_from(self.message.html, 'text/html')\n\n def get_case(self):\n try:\n return Case.objects.by_msg(self.message).get()\n except Case.DoesNotExist:\n return\n\n def save_attachments(self, letter):\n # Create Letter\n attachments = []\n # Append attachments\n for attachment in self.message.attachments.all():\n name = attachment.get_filename() or 'Unknown.bin'\n if len(name) > 70:\n name, ext = os.path.splitext(name)\n ext = ext[:70]\n name = name[:70 - len(ext)] + ext\n file_obj = File(attachment.document, name)\n attachments.append(Attachment(letter=letter, attachment=file_obj))\n Attachment.objects.bulk_create(attachments)\n for att in attachments: # Force close file descriptor to avoid \"Too many open files\"\n att.attachment.close()\n return attachments\n\n def save_object(self):\n with File(self.message.eml, self.message.eml.name) as eml:\n return Letter.objects.create(author_institution=self.case.institution,\n email=self.message.from_address[0],\n case=self.case,\n title=self.message.subject,\n body=self.text,\n quote=self.quote,\n eml=eml,\n message=self.message)\n\n @staticmethod\n @receiver(message_received)\n def receive_signal(sender, message, **kwargs):\n MessageParser(message).insert()\n\n def insert(self):\n self.case = self.get_case()\n if not self.case:\n logger.warning(\"Message #{pk} skip, due not recognized address {to}\".\n format(pk=self.message.pk, to=self.message.to_addresses))\n return\n letter = self.save_object()\n logger.info(\"Message #{message} registered in case #{case} as letter #{letter}\".\n format(message=self.message.pk, case=self.case.pk, letter=letter.pk))\n attachments = self.save_attachments(letter)\n logger.debug(\"Saved {attachment_count} attachments for letter #{letter}\".\n format(attachment_count=len(attachments), letter=letter.pk))\n return letter\n", "path": "feder/letters/models.py"}], "after_files": [{"content": "from __future__ import print_function\n\nimport logging\nimport os\nimport uuid\n\nimport claw\nfrom atom.models import AttachmentBase\nfrom cached_property import cached_property\nfrom claw import quotations\nfrom django.conf import settings\nfrom django.contrib.auth import get_user_model\nfrom django.core.files import File\nfrom django.core.files.base import ContentFile\nfrom django.core.mail import EmailMessage\nfrom django.core.mail.message import make_msgid\nfrom django.core.urlresolvers import reverse\nfrom django.db import models\nfrom django.db.models.manager import BaseManager\nfrom django.dispatch import receiver\nfrom django.utils.encoding import python_2_unicode_compatible\nfrom django.utils.translation import ugettext_lazy as _\nfrom django_mailbox.models import Message\nfrom django_mailbox.signals import message_received\nfrom model_utils import Choices\nfrom model_utils.models import TimeStampedModel\nfrom feder.cases.models import Case\nfrom feder.institutions.models import Institution\nfrom .utils import email_wrapper, normalize_msg_id\n\nclaw.init()\n\nlogger = logging.getLogger(__name__)\n\n\nclass LetterQuerySet(models.QuerySet):\n def attachment_count(self):\n return self.annotate(attachment_count=models.Count('attachment'))\n\n def with_author(self):\n return self.select_related('author_user', 'author_institution')\n\n def for_milestone(self):\n return self.prefetch_related('attachment_set').with_author()\n\n def is_outgoing(self):\n return self.filter(author_user__isnull=False)\n\n def is_incoming(self):\n return self.filter(author_user__isnull=True)\n\n def with_feed_items(self):\n return (self.with_author().\n select_related('case__institution__jst', 'case__monitoring').\n prefetch_related('attachment_set'))\n\n\nclass LetterManager(BaseManager.from_queryset(LetterQuerySet)):\n def get_queryset(self):\n return super(LetterManager, self).get_queryset().filter(is_spam__in=[Letter.SPAM.unknown, Letter.SPAM.non_spam])\n\n\n@python_2_unicode_compatible\nclass Letter(TimeStampedModel):\n SPAM = Choices((0, 'unknown', _('Unknown')),\n (1, 'spam', _('Spam')),\n (2, 'non_spam', _('Non-spam'), ))\n case = models.ForeignKey(Case, verbose_name=_(\"Case\"))\n author_user = models.ForeignKey(settings.AUTH_USER_MODEL, verbose_name=_(\"Author (if user)\"),\n null=True, blank=True)\n author_institution = models.ForeignKey(Institution, verbose_name=_(\"Author (if institution)\"),\n null=True, blank=True)\n title = models.CharField(verbose_name=_(\"Title\"), max_length=200)\n body = models.TextField(verbose_name=_(\"Text\"))\n quote = models.TextField(verbose_name=_(\"Quote\"), blank=True)\n email = models.EmailField(verbose_name=_(\"E-mail\"), max_length=100, blank=True)\n note = models.TextField(verbose_name=_(\"Comments from editor\"), blank=True)\n is_spam = models.IntegerField(choices=SPAM, default=SPAM.unknown, db_index=True)\n message_id_header = models.CharField(blank=True,\n verbose_name=_('ID of sent email message \"Message-ID\"'),\n max_length=500)\n eml = models.FileField(upload_to=\"messages/%Y/%m/%d\",\n verbose_name=_(\"File\"),\n null=True,\n blank=True)\n message = models.ForeignKey(Message,\n null=True,\n verbose_name=_(\"Message\"),\n help_text=_(\"Message registerd by django-mailbox\"))\n objects = LetterManager()\n objects_with_spam = LetterQuerySet.as_manager()\n\n def is_spam_validated(self):\n return self.is_spam != Letter.SPAM.unknown\n\n class Meta:\n verbose_name = _(\"Letter\")\n verbose_name_plural = _(\"Letters\")\n ordering = ['created', ]\n permissions = (\n (\"can_filter_eml\", _(\"Can filter eml\")),\n )\n\n @property\n def is_draft(self):\n return self.is_outgoing and not bool(self.eml)\n\n @property\n def is_incoming(self):\n return not bool(self.author_user_id)\n\n @property\n def is_outgoing(self):\n return bool(self.author_user_id)\n\n def get_title(self):\n if self.title and self.title.strip():\n return self.title\n return _(\"(no subject)\")\n\n def __str__(self):\n return unicode(self.get_title())\n\n def __unicode__(self):\n return unicode(self.get_title())\n\n def get_absolute_url(self):\n return reverse('letters:details', kwargs={'pk': self.pk})\n\n @property\n def author(self):\n return self.author_user if self.author_user_id else self.author_institution\n\n @author.setter\n def author(self, value):\n if isinstance(value, Institution):\n self.author_user = None\n self.author_institution = value\n elif isinstance(value, get_user_model()):\n self.author_institution = None\n self.author_user = value\n else:\n raise ValueError(\"Only User and Institution is allowed for attribute author\")\n\n @classmethod\n def send_new_case(cls, user, monitoring, institution, text, postfix=''):\n case = Case(user=user,\n name=monitoring.name + postfix,\n monitoring=monitoring,\n institution=institution)\n case.save()\n letter = cls(author_user=user,\n case=case,\n title=monitoring.subject,\n body=text)\n letter.send(commit=True, only_email=False)\n return letter\n\n def email_body(self):\n body = self.body.replace('{{EMAIL}}', self.case.email)\n return u\"{0}\\n{1}\".format(body, email_wrapper(self.quote))\n\n def _construct_message(self, msg_id=None):\n headers = {'Return-Receipt-To': self.case.email,\n 'Disposition-Notification-To': self.case.email,\n }\n if msg_id:\n headers['Message-ID'] = msg_id\n return EmailMessage(subject=self.case.monitoring.subject,\n from_email=self.case.email,\n reply_to=[self.case.email],\n to=[self.case.institution.email],\n body=self.email_body(),\n headers=headers)\n\n def send(self, commit=True, only_email=False):\n msg_id = make_msgid(domain=self.case.email.split('@', 2)[1])\n message = self._construct_message(msg_id=msg_id)\n text = message.message().as_bytes()\n self.email = self.case.institution.email\n self.message_id_header = normalize_msg_id(msg_id)\n self.eml.save('%s.eml' % uuid.uuid4(), ContentFile(text), save=False)\n if commit:\n self.save(update_fields=['eml', 'email'] if only_email else None)\n return message.send()\n\n\n@python_2_unicode_compatible\nclass Attachment(AttachmentBase):\n letter = models.ForeignKey(Letter)\n\n def delete(self, *args, **kwargs):\n self.attachment.delete()\n super(Attachment, self).delete(*args, **kwargs)\n\n def __str__(self):\n if self.attachment:\n return u\"{}\".format(self.filename)\n return \"None\"\n\n\nclass MessageParser(object):\n def __init__(self, message):\n self.message = message\n\n @cached_property\n def quote(self):\n if self.message.text:\n return self.message.text.replace(self.text, '')\n return self.message.text.replace(self.text, '')\n\n @cached_property\n def text(self):\n if self.message.text:\n return quotations.extract_from(self.message.text)\n return quotations.extract_from(self.message.html, 'text/html')\n\n def get_case(self):\n try:\n return Case.objects.by_msg(self.message).get()\n except Case.DoesNotExist:\n return\n\n def save_attachments(self, letter):\n # Create Letter\n attachments = []\n # Append attachments\n for attachment in self.message.attachments.all():\n name = attachment.get_filename() or 'Unknown.bin'\n if len(name) > 70:\n name, ext = os.path.splitext(name)\n ext = ext[:70]\n name = name[:70 - len(ext)] + ext\n file_obj = File(attachment.document, name)\n attachments.append(Attachment(letter=letter, attachment=file_obj))\n Attachment.objects.bulk_create(attachments)\n for att in attachments: # Force close file descriptor to avoid \"Too many open files\"\n att.attachment.close()\n return attachments\n\n def save_object(self):\n with File(self.message.eml, self.message.eml.name) as eml:\n return Letter.objects.create(author_institution=self.case.institution,\n email=self.message.from_address[0],\n case=self.case,\n title=self.message.subject,\n body=self.text,\n quote=self.quote,\n eml=eml,\n message=self.message)\n\n @staticmethod\n @receiver(message_received)\n def receive_signal(sender, message, **kwargs):\n MessageParser(message).insert()\n\n def insert(self):\n self.case = self.get_case()\n if not self.case:\n logger.warning(\"Message #{pk} skip, due not recognized address {to}\".\n format(pk=self.message.pk, to=self.message.to_addresses))\n return\n letter = self.save_object()\n logger.info(\"Message #{message} registered in case #{case} as letter #{letter}\".\n format(message=self.message.pk, case=self.case.pk, letter=letter.pk))\n attachments = self.save_attachments(letter)\n logger.debug(\"Saved {attachment_count} attachments for letter #{letter}\".\n format(attachment_count=len(attachments), letter=letter.pk))\n return letter\n", "path": "feder/letters/models.py"}]}
| 2,959 | 224 |
gh_patches_debug_22849
|
rasdani/github-patches
|
git_diff
|
uclapi__uclapi-51
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Error responses missing OK property and correct HTTP Status Code
Hello there,
when making an invalid request, say, an invalid token, an error is given but the HTTP code is still `200 OK` when it should give an authentication error (a `400 Bad Request` or even a `401 Unauthorized`).
Request:
```http
GET /roombookings/rooms?token=uclapi-5d58c3c4e6bf9c-c2910ad3b6e054-7ef60f44f1c14f-a05147bfd17fdb HTTP/1.1
Host: uclapi.com
User-Agent: Paw/3.0.16 (Macintosh; OS X/10.12.4) NSURLConnection/1349.63
Cookie: AWSALB=8q9+FZmk9TOAZ/GG2tFsVUuckVO8STONoiGDn6/jd9FBEwFi5Ke/kvz+hIjdCmAwtpOIXGlnudL7LU3AaVxKt1sHWYGjLJnoMypHqu53r7Ub4b73trfiMx5NMVZ6
```
Response:
```http
HTTP/1.1 200 OK
Connection: keep-alive
Content-Type: application/json
Allow: GET, OPTIONS
Server: nginx/1.11.10
Set-Cookie: AWSALB=U2qTk7k+LrfxXibfskgPN1RoWvDQqKhaSBmgvUMOa3AcYgag1BZMcyz+5h5rQ2qhQc+Cm2PYzfjKV466PHcc9dleZHkLYE5O8d5q2WO+7WVbQT6VQMSSSHpOh3xy; Expires=Sat, 11 Mar 2017 14:18:40 GMT; Path=/
Transfer-Encoding: Identity
Date: Sat, 04 Mar 2017 14:18:40 GMT
X-Frame-Options: SAMEORIGIN
Vary: Accept, Cookie
{"error": "Token does not exist"}
```
Furthermore, when a request is successful, the first property is an `"ok": true`, however, with invalid requests, the `"ok": false` is missing from the error response.
Actual:
```json
{
"error": "Token does not exist"
}
```
Expected:
```json
{
"ok": false,
"error": "Token does not exist"
}
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `backend/uclapi/roombookings/token_auth.py`
Content:
```
1 from rest_framework.response import Response
2 from dashboard.models import App
3 from django.core.exceptions import ObjectDoesNotExist
4 from django.http import JsonResponse
5
6
7 def does_token_exist(view_func):
8 def wrapped(request, *args, **kwargs):
9 token = request.GET.get("token")
10
11 if not token:
12 return JsonResponse({
13 "error": "No token provided"
14 })
15
16 try:
17 App.objects.get(api_token=token)
18 except ObjectDoesNotExist:
19 return JsonResponse({
20 "error": "Token does not exist"
21 })
22
23 return view_func(request, *args, **kwargs)
24 return wrapped
25
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/backend/uclapi/roombookings/token_auth.py b/backend/uclapi/roombookings/token_auth.py
--- a/backend/uclapi/roombookings/token_auth.py
+++ b/backend/uclapi/roombookings/token_auth.py
@@ -1,4 +1,3 @@
-from rest_framework.response import Response
from dashboard.models import App
from django.core.exceptions import ObjectDoesNotExist
from django.http import JsonResponse
@@ -9,16 +8,22 @@
token = request.GET.get("token")
if not token:
- return JsonResponse({
+ response = JsonResponse({
+ "ok": False,
"error": "No token provided"
})
+ response.status_code = 400
+ return response
try:
App.objects.get(api_token=token)
except ObjectDoesNotExist:
- return JsonResponse({
+ response = JsonResponse({
+ "ok": False,
"error": "Token does not exist"
})
+ response.status_code = 400
+ return response
return view_func(request, *args, **kwargs)
return wrapped
|
{"golden_diff": "diff --git a/backend/uclapi/roombookings/token_auth.py b/backend/uclapi/roombookings/token_auth.py\n--- a/backend/uclapi/roombookings/token_auth.py\n+++ b/backend/uclapi/roombookings/token_auth.py\n@@ -1,4 +1,3 @@\n-from rest_framework.response import Response\n from dashboard.models import App\n from django.core.exceptions import ObjectDoesNotExist\n from django.http import JsonResponse\n@@ -9,16 +8,22 @@\n token = request.GET.get(\"token\")\n \n if not token:\n- return JsonResponse({\n+ response = JsonResponse({\n+ \"ok\": False,\n \"error\": \"No token provided\"\n })\n+ response.status_code = 400\n+ return response\n \n try:\n App.objects.get(api_token=token)\n except ObjectDoesNotExist:\n- return JsonResponse({\n+ response = JsonResponse({\n+ \"ok\": False,\n \"error\": \"Token does not exist\"\n })\n+ response.status_code = 400\n+ return response\n \n return view_func(request, *args, **kwargs)\n return wrapped\n", "issue": "Error responses missing OK property and correct HTTP Status Code\nHello there,\r\nwhen making an invalid request, say, an invalid token, an error is given but the HTTP code is still `200 OK` when it should give an authentication error (a `400 Bad Request` or even a `401 Unauthorized`).\r\n\r\nRequest:\r\n```http\r\nGET /roombookings/rooms?token=uclapi-5d58c3c4e6bf9c-c2910ad3b6e054-7ef60f44f1c14f-a05147bfd17fdb HTTP/1.1\r\nHost: uclapi.com\r\nUser-Agent: Paw/3.0.16 (Macintosh; OS X/10.12.4) NSURLConnection/1349.63\r\nCookie: AWSALB=8q9+FZmk9TOAZ/GG2tFsVUuckVO8STONoiGDn6/jd9FBEwFi5Ke/kvz+hIjdCmAwtpOIXGlnudL7LU3AaVxKt1sHWYGjLJnoMypHqu53r7Ub4b73trfiMx5NMVZ6\r\n```\r\n\r\nResponse:\r\n```http\r\nHTTP/1.1 200 OK\r\nConnection: keep-alive\r\nContent-Type: application/json\r\nAllow: GET, OPTIONS\r\nServer: nginx/1.11.10\r\nSet-Cookie: AWSALB=U2qTk7k+LrfxXibfskgPN1RoWvDQqKhaSBmgvUMOa3AcYgag1BZMcyz+5h5rQ2qhQc+Cm2PYzfjKV466PHcc9dleZHkLYE5O8d5q2WO+7WVbQT6VQMSSSHpOh3xy; Expires=Sat, 11 Mar 2017 14:18:40 GMT; Path=/\r\nTransfer-Encoding: Identity\r\nDate: Sat, 04 Mar 2017 14:18:40 GMT\r\nX-Frame-Options: SAMEORIGIN\r\nVary: Accept, Cookie\r\n\r\n{\"error\": \"Token does not exist\"}\r\n```\r\n\r\nFurthermore, when a request is successful, the first property is an `\"ok\": true`, however, with invalid requests, the `\"ok\": false` is missing from the error response.\r\n\r\nActual:\r\n```json\r\n{\r\n \"error\": \"Token does not exist\"\r\n}\r\n```\r\n\r\nExpected:\r\n```json\r\n{\r\n \"ok\": false,\r\n \"error\": \"Token does not exist\"\r\n}\r\n```\n", "before_files": [{"content": "from rest_framework.response import Response\nfrom dashboard.models import App\nfrom django.core.exceptions import ObjectDoesNotExist\nfrom django.http import JsonResponse\n\n\ndef does_token_exist(view_func):\n def wrapped(request, *args, **kwargs):\n token = request.GET.get(\"token\")\n\n if not token:\n return JsonResponse({\n \"error\": \"No token provided\"\n })\n\n try:\n App.objects.get(api_token=token)\n except ObjectDoesNotExist:\n return JsonResponse({\n \"error\": \"Token does not exist\"\n })\n\n return view_func(request, *args, **kwargs)\n return wrapped\n", "path": "backend/uclapi/roombookings/token_auth.py"}], "after_files": [{"content": "from dashboard.models import App\nfrom django.core.exceptions import ObjectDoesNotExist\nfrom django.http import JsonResponse\n\n\ndef does_token_exist(view_func):\n def wrapped(request, *args, **kwargs):\n token = request.GET.get(\"token\")\n\n if not token:\n response = JsonResponse({\n \"ok\": False,\n \"error\": \"No token provided\"\n })\n response.status_code = 400\n return response\n\n try:\n App.objects.get(api_token=token)\n except ObjectDoesNotExist:\n response = JsonResponse({\n \"ok\": False,\n \"error\": \"Token does not exist\"\n })\n response.status_code = 400\n return response\n\n return view_func(request, *args, **kwargs)\n return wrapped\n", "path": "backend/uclapi/roombookings/token_auth.py"}]}
| 1,034 | 246 |
gh_patches_debug_26093
|
rasdani/github-patches
|
git_diff
|
lightly-ai__lightly-618
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update docs version
Update docs version and link copyright in docs footer to lightly website
Closes #618
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/source/conf.py`
Content:
```
1 # Configuration file for the Sphinx documentation builder.
2 #
3 # This file only contains a selection of the most common options. For a full
4 # list see the documentation:
5 # https://www.sphinx-doc.org/en/master/usage/configuration.html
6
7 # -- Path setup --------------------------------------------------------------
8
9 # If extensions (or modules to document with autodoc) are in another directory,
10 # add these directories to sys.path here. If the directory is relative to the
11 # documentation root, use os.path.abspath to make it absolute, like shown here.
12 #
13 import os
14 import sys
15 sys.path.insert(0, os.path.abspath('../..'))
16
17 import sphinx_rtd_theme
18
19
20 # -- Project information -----------------------------------------------------
21
22 project = 'lightly'
23 copyright = '2020, Lightly AG'
24 author = 'Philipp Wirth, Igor Susmelj'
25
26 # The full version, including alpha/beta/rc tags
27 release = '1.0.0'
28 master_doc = 'index'
29
30
31 # -- General configuration ---------------------------------------------------
32
33 # Add any Sphinx extension module names here, as strings. They can be
34 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
35 # ones.
36 extensions = [
37 "sphinx_rtd_theme",
38 #'sphinx.ext.napoleon',
39 "sphinx.ext.autosummary",
40 "sphinx_gallery.gen_gallery",
41 "sphinx_tabs.tabs",
42 "sphinx_copybutton",
43 ]
44
45 sphinx_gallery_conf = {
46 'examples_dirs': ['tutorials_source/package', 'tutorials_source/platform'],
47 'gallery_dirs': ['tutorials/package', 'tutorials/platform'], # path to where to save gallery generated output
48 'filename_pattern': '/tutorial_',
49 }
50
51 napoleon_google_docstring = True
52 napoleon_numpy_docstring = False
53 napoleon_include_init_with_doc = False
54 napoleon_include_private_with_doc = False
55 napoleon_include_special_with_doc = False
56 napoleon_use_admonition_for_examples = False
57 napoleon_use_admonition_for_notes = False
58 napoleon_use_admonition_for_references = False
59 napoleon_use_ivar = False
60 napoleon_use_param = False
61 napoleon_use_rtype = False
62 napoleon_type_aliases = None
63
64 # Add any paths that contain templates here, relative to this directory.
65 templates_path = ['_templates']
66
67 # List of patterns, relative to source directory, that match files and
68 # directories to ignore when looking for source files.
69 # This pattern also affects html_static_path and html_extra_path.
70 exclude_patterns = []
71
72
73 # -- Options for HTML output -------------------------------------------------
74
75 # The theme to use for HTML and HTML Help pages. See the documentation for
76 # a list of builtin themes.
77 #
78 html_theme = 'sphinx_rtd_theme'
79
80 html_theme_options = {
81 'collapse_navigation': False, # set to false to prevent menu item collapse
82 }
83
84 # Add any paths that contain custom static files (such as style sheets) here,
85 # relative to this directory. They are copied after the builtin static files,
86 # so a file named "default.css" will overwrite the builtin "default.css".
87 html_static_path = ['_static']
88
89 html_favicon = 'favicon.png'
90
91 #html_logo = "../logos/lightly_logo_crop.png"
92 def setup(app):
93 app.add_css_file('css/my-styles.css')
94
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/source/conf.py b/docs/source/conf.py
--- a/docs/source/conf.py
+++ b/docs/source/conf.py
@@ -15,16 +15,19 @@
sys.path.insert(0, os.path.abspath('../..'))
import sphinx_rtd_theme
+import lightly
# -- Project information -----------------------------------------------------
project = 'lightly'
-copyright = '2020, Lightly AG'
+copyright_year = '2020'
+copyright = "Lightly AG"
+website_url = 'https://www.lightly.ai/'
author = 'Philipp Wirth, Igor Susmelj'
# The full version, including alpha/beta/rc tags
-release = '1.0.0'
+release = lightly.__version__
master_doc = 'index'
@@ -79,6 +82,7 @@
html_theme_options = {
'collapse_navigation': False, # set to false to prevent menu item collapse
+ 'logo_only': True
}
# Add any paths that contain custom static files (such as style sheets) here,
@@ -88,6 +92,10 @@
html_favicon = 'favicon.png'
-#html_logo = "../logos/lightly_logo_crop.png"
-def setup(app):
- app.add_css_file('css/my-styles.css')
+html_logo = '../logos/lightly_logo_crop_white_text.png'
+
+# Exposes variables so that they can be used by django
+html_context = {
+ 'copyright_year': copyright_year,
+ 'website_url': website_url,
+}
\ No newline at end of file
|
{"golden_diff": "diff --git a/docs/source/conf.py b/docs/source/conf.py\n--- a/docs/source/conf.py\n+++ b/docs/source/conf.py\n@@ -15,16 +15,19 @@\n sys.path.insert(0, os.path.abspath('../..'))\n \n import sphinx_rtd_theme\n+import lightly\n \n \n # -- Project information -----------------------------------------------------\n \n project = 'lightly'\n-copyright = '2020, Lightly AG'\n+copyright_year = '2020'\n+copyright = \"Lightly AG\"\n+website_url = 'https://www.lightly.ai/'\n author = 'Philipp Wirth, Igor Susmelj'\n \n # The full version, including alpha/beta/rc tags\n-release = '1.0.0'\n+release = lightly.__version__\n master_doc = 'index'\n \n \n@@ -79,6 +82,7 @@\n \n html_theme_options = {\n 'collapse_navigation': False, # set to false to prevent menu item collapse\n+ 'logo_only': True\n }\n \n # Add any paths that contain custom static files (such as style sheets) here,\n@@ -88,6 +92,10 @@\n \n html_favicon = 'favicon.png'\n \n-#html_logo = \"../logos/lightly_logo_crop.png\"\n-def setup(app):\n- app.add_css_file('css/my-styles.css')\n+html_logo = '../logos/lightly_logo_crop_white_text.png'\n+\n+#\u00a0Exposes variables so that they can be used by django\n+html_context = {\n+ 'copyright_year': copyright_year,\n+ 'website_url': website_url,\n+}\n\\ No newline at end of file\n", "issue": "Update docs version\nUpdate docs version and link copyright in docs footer to lightly website\r\n\r\nCloses #618 \n", "before_files": [{"content": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common options. For a full\n# list see the documentation:\n# https://www.sphinx-doc.org/en/master/usage/configuration.html\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\nsys.path.insert(0, os.path.abspath('../..'))\n\nimport sphinx_rtd_theme\n\n\n# -- Project information -----------------------------------------------------\n\nproject = 'lightly'\ncopyright = '2020, Lightly AG'\nauthor = 'Philipp Wirth, Igor Susmelj'\n\n# The full version, including alpha/beta/rc tags\nrelease = '1.0.0'\nmaster_doc = 'index'\n\n\n# -- General configuration ---------------------------------------------------\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"sphinx_rtd_theme\",\n #'sphinx.ext.napoleon',\n \"sphinx.ext.autosummary\",\n \"sphinx_gallery.gen_gallery\",\n \"sphinx_tabs.tabs\",\n \"sphinx_copybutton\",\n]\n\nsphinx_gallery_conf = {\n 'examples_dirs': ['tutorials_source/package', 'tutorials_source/platform'],\n 'gallery_dirs': ['tutorials/package', 'tutorials/platform'], # path to where to save gallery generated output\n 'filename_pattern': '/tutorial_',\n}\n\nnapoleon_google_docstring = True\nnapoleon_numpy_docstring = False\nnapoleon_include_init_with_doc = False\nnapoleon_include_private_with_doc = False\nnapoleon_include_special_with_doc = False\nnapoleon_use_admonition_for_examples = False\nnapoleon_use_admonition_for_notes = False\nnapoleon_use_admonition_for_references = False\nnapoleon_use_ivar = False\nnapoleon_use_param = False\nnapoleon_use_rtype = False\nnapoleon_type_aliases = None\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = []\n\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = 'sphinx_rtd_theme'\n\nhtml_theme_options = {\n 'collapse_navigation': False, # set to false to prevent menu item collapse\n}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\nhtml_favicon = 'favicon.png'\n\n#html_logo = \"../logos/lightly_logo_crop.png\"\ndef setup(app):\n app.add_css_file('css/my-styles.css')\n", "path": "docs/source/conf.py"}], "after_files": [{"content": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common options. For a full\n# list see the documentation:\n# https://www.sphinx-doc.org/en/master/usage/configuration.html\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\nsys.path.insert(0, os.path.abspath('../..'))\n\nimport sphinx_rtd_theme\nimport lightly\n\n\n# -- Project information -----------------------------------------------------\n\nproject = 'lightly'\ncopyright_year = '2020'\ncopyright = \"Lightly AG\"\nwebsite_url = 'https://www.lightly.ai/'\nauthor = 'Philipp Wirth, Igor Susmelj'\n\n# The full version, including alpha/beta/rc tags\nrelease = lightly.__version__\nmaster_doc = 'index'\n\n\n# -- General configuration ---------------------------------------------------\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"sphinx_rtd_theme\",\n #'sphinx.ext.napoleon',\n \"sphinx.ext.autosummary\",\n \"sphinx_gallery.gen_gallery\",\n \"sphinx_tabs.tabs\",\n \"sphinx_copybutton\",\n]\n\nsphinx_gallery_conf = {\n 'examples_dirs': ['tutorials_source/package', 'tutorials_source/platform'],\n 'gallery_dirs': ['tutorials/package', 'tutorials/platform'], # path to where to save gallery generated output\n 'filename_pattern': '/tutorial_',\n}\n\nnapoleon_google_docstring = True\nnapoleon_numpy_docstring = False\nnapoleon_include_init_with_doc = False\nnapoleon_include_private_with_doc = False\nnapoleon_include_special_with_doc = False\nnapoleon_use_admonition_for_examples = False\nnapoleon_use_admonition_for_notes = False\nnapoleon_use_admonition_for_references = False\nnapoleon_use_ivar = False\nnapoleon_use_param = False\nnapoleon_use_rtype = False\nnapoleon_type_aliases = None\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = []\n\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = 'sphinx_rtd_theme'\n\nhtml_theme_options = {\n 'collapse_navigation': False, # set to false to prevent menu item collapse\n 'logo_only': True\n}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\nhtml_favicon = 'favicon.png'\n\nhtml_logo = '../logos/lightly_logo_crop_white_text.png'\n\n#\u00a0Exposes variables so that they can be used by django\nhtml_context = {\n 'copyright_year': copyright_year,\n 'website_url': website_url,\n}", "path": "docs/source/conf.py"}]}
| 1,161 | 350 |
gh_patches_debug_39263
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-contrib-1001
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Pyramid tween only handles HTTPException
**Describe your environment**
Seeing this exhibited in Pyramid 1.10 and as far back as Pyramid 1.7.
**Steps to reproduce**
Raise a non-HTTPException.
**What is the expected behavior?**
Tweens should process normally.
**What is the actual behavior?**
An error for use of `response_or_exception` before assignment is raised.
**Additional context**
The problem exists here https://github.com/open-telemetry/opentelemetry-python-contrib/blob/main/instrumentation/opentelemetry-instrumentation-pyramid/src/opentelemetry/instrumentation/pyramid/callbacks.py#L146-L157. It seems there should be an additional exception case for `BaseException` to initialize `response_or_exception`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `instrumentation/opentelemetry-instrumentation-pyramid/src/opentelemetry/instrumentation/pyramid/callbacks.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from logging import getLogger
16
17 from pyramid.events import BeforeTraversal
18 from pyramid.httpexceptions import HTTPException
19 from pyramid.settings import asbool
20 from pyramid.tweens import EXCVIEW
21
22 import opentelemetry.instrumentation.wsgi as otel_wsgi
23 from opentelemetry import context, trace
24 from opentelemetry.instrumentation.propagators import (
25 get_global_response_propagator,
26 )
27 from opentelemetry.instrumentation.pyramid.version import __version__
28 from opentelemetry.instrumentation.utils import _start_internal_or_server_span
29 from opentelemetry.semconv.trace import SpanAttributes
30 from opentelemetry.util._time import _time_ns
31 from opentelemetry.util.http import get_excluded_urls
32
33 TWEEN_NAME = "opentelemetry.instrumentation.pyramid.trace_tween_factory"
34 SETTING_TRACE_ENABLED = "opentelemetry-pyramid.trace_enabled"
35
36 _ENVIRON_STARTTIME_KEY = "opentelemetry-pyramid.starttime_key"
37 _ENVIRON_SPAN_KEY = "opentelemetry-pyramid.span_key"
38 _ENVIRON_ACTIVATION_KEY = "opentelemetry-pyramid.activation_key"
39 _ENVIRON_ENABLED_KEY = "opentelemetry-pyramid.tracing_enabled_key"
40 _ENVIRON_TOKEN = "opentelemetry-pyramid.token"
41
42 _logger = getLogger(__name__)
43
44
45 _excluded_urls = get_excluded_urls("PYRAMID")
46
47
48 def includeme(config):
49 config.add_settings({SETTING_TRACE_ENABLED: True})
50
51 config.add_subscriber(_before_traversal, BeforeTraversal)
52 _insert_tween(config)
53
54
55 def _insert_tween(config):
56 settings = config.get_settings()
57 tweens = settings.get("pyramid.tweens")
58 # If the list is empty, pyramid does not consider the tweens have been
59 # set explicitly. And if our tween is already there, nothing to do
60 if not tweens or not tweens.strip():
61 # Add our tween just before the default exception handler
62 config.add_tween(TWEEN_NAME, over=EXCVIEW)
63
64
65 def _before_traversal(event):
66 request = event.request
67 request_environ = request.environ
68 span_name = otel_wsgi.get_default_span_name(request_environ)
69
70 enabled = request_environ.get(_ENVIRON_ENABLED_KEY)
71 if enabled is None:
72 _logger.warning(
73 "Opentelemetry pyramid tween 'opentelemetry.instrumentation.pyramid.trace_tween_factory'"
74 "was not called. Make sure that the tween is included in 'pyramid.tweens' if"
75 "the tween list was created manually"
76 )
77 return
78
79 if not enabled:
80 # Tracing not enabled, return
81 return
82
83 start_time = request_environ.get(_ENVIRON_STARTTIME_KEY)
84 tracer = trace.get_tracer(__name__, __version__)
85
86 if request.matched_route:
87 span_name = request.matched_route.pattern
88 else:
89 span_name = otel_wsgi.get_default_span_name(request_environ)
90
91 span, token = _start_internal_or_server_span(
92 tracer=tracer,
93 span_name=span_name,
94 start_time=start_time,
95 context_carrier=request_environ,
96 context_getter=otel_wsgi.wsgi_getter,
97 )
98
99 if span.is_recording():
100 attributes = otel_wsgi.collect_request_attributes(request_environ)
101 if request.matched_route:
102 attributes[
103 SpanAttributes.HTTP_ROUTE
104 ] = request.matched_route.pattern
105 for key, value in attributes.items():
106 span.set_attribute(key, value)
107
108 activation = trace.use_span(span, end_on_exit=True)
109 activation.__enter__() # pylint: disable=E1101
110 request_environ[_ENVIRON_ACTIVATION_KEY] = activation
111 request_environ[_ENVIRON_SPAN_KEY] = span
112 if token:
113 request_environ[_ENVIRON_TOKEN] = token
114
115
116 def trace_tween_factory(handler, registry):
117 settings = registry.settings
118 enabled = asbool(settings.get(SETTING_TRACE_ENABLED, True))
119
120 if not enabled:
121 # If disabled, make a tween that signals to the
122 # BeforeTraversal subscriber that tracing is disabled
123 def disabled_tween(request):
124 request.environ[_ENVIRON_ENABLED_KEY] = False
125 return handler(request)
126
127 return disabled_tween
128
129 # make a request tracing function
130 def trace_tween(request):
131 # pylint: disable=E1101
132 if _excluded_urls.url_disabled(request.url):
133 request.environ[_ENVIRON_ENABLED_KEY] = False
134 # short-circuit when we don't want to trace anything
135 return handler(request)
136
137 request.environ[_ENVIRON_ENABLED_KEY] = True
138 request.environ[_ENVIRON_STARTTIME_KEY] = _time_ns()
139
140 try:
141 response = handler(request)
142 response_or_exception = response
143 except HTTPException as exc:
144 # If the exception is a pyramid HTTPException,
145 # that's still valuable information that isn't necessarily
146 # a 500. For instance, HTTPFound is a 302.
147 # As described in docs, Pyramid exceptions are all valid
148 # response types
149 response_or_exception = exc
150 raise
151 finally:
152 span = request.environ.get(_ENVIRON_SPAN_KEY)
153 enabled = request.environ.get(_ENVIRON_ENABLED_KEY)
154 if not span and enabled:
155 _logger.warning(
156 "Pyramid environ's OpenTelemetry span missing."
157 "If the OpenTelemetry tween was added manually, make sure"
158 "PyramidInstrumentor().instrument_config(config) is called"
159 )
160 elif enabled:
161 otel_wsgi.add_response_attributes(
162 span,
163 response_or_exception.status,
164 response_or_exception.headerlist,
165 )
166
167 propagator = get_global_response_propagator()
168 if propagator:
169 propagator.inject(response.headers)
170
171 activation = request.environ.get(_ENVIRON_ACTIVATION_KEY)
172
173 if isinstance(response_or_exception, HTTPException):
174 activation.__exit__(
175 type(response_or_exception),
176 response_or_exception,
177 getattr(response_or_exception, "__traceback__", None),
178 )
179 else:
180 activation.__exit__(None, None, None)
181
182 env_token = request.environ.get(_ENVIRON_TOKEN, None)
183 if env_token is not None:
184 context.detach(env_token)
185
186 return response
187
188 return trace_tween
189
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/instrumentation/opentelemetry-instrumentation-pyramid/src/opentelemetry/instrumentation/pyramid/callbacks.py b/instrumentation/opentelemetry-instrumentation-pyramid/src/opentelemetry/instrumentation/pyramid/callbacks.py
--- a/instrumentation/opentelemetry-instrumentation-pyramid/src/opentelemetry/instrumentation/pyramid/callbacks.py
+++ b/instrumentation/opentelemetry-instrumentation-pyramid/src/opentelemetry/instrumentation/pyramid/callbacks.py
@@ -137,16 +137,23 @@
request.environ[_ENVIRON_ENABLED_KEY] = True
request.environ[_ENVIRON_STARTTIME_KEY] = _time_ns()
+ response = None
+ status = None
+
try:
response = handler(request)
- response_or_exception = response
except HTTPException as exc:
# If the exception is a pyramid HTTPException,
# that's still valuable information that isn't necessarily
# a 500. For instance, HTTPFound is a 302.
# As described in docs, Pyramid exceptions are all valid
# response types
- response_or_exception = exc
+ response = exc
+ raise
+ except BaseException:
+ # In the case that a non-HTTPException is bubbled up we
+ # should infer a internal server error and raise
+ status = "500 InternalServerError"
raise
finally:
span = request.environ.get(_ENVIRON_SPAN_KEY)
@@ -158,23 +165,26 @@
"PyramidInstrumentor().instrument_config(config) is called"
)
elif enabled:
- otel_wsgi.add_response_attributes(
- span,
- response_or_exception.status,
- response_or_exception.headerlist,
- )
+ status = getattr(response, "status", status)
+
+ if status is not None:
+ otel_wsgi.add_response_attributes(
+ span,
+ status,
+ getattr(response, "headerList", None),
+ )
propagator = get_global_response_propagator()
- if propagator:
+ if propagator and hasattr(response, "headers"):
propagator.inject(response.headers)
activation = request.environ.get(_ENVIRON_ACTIVATION_KEY)
- if isinstance(response_or_exception, HTTPException):
+ if isinstance(response, HTTPException):
activation.__exit__(
- type(response_or_exception),
- response_or_exception,
- getattr(response_or_exception, "__traceback__", None),
+ type(response),
+ response,
+ getattr(response, "__traceback__", None),
)
else:
activation.__exit__(None, None, None)
|
{"golden_diff": "diff --git a/instrumentation/opentelemetry-instrumentation-pyramid/src/opentelemetry/instrumentation/pyramid/callbacks.py b/instrumentation/opentelemetry-instrumentation-pyramid/src/opentelemetry/instrumentation/pyramid/callbacks.py\n--- a/instrumentation/opentelemetry-instrumentation-pyramid/src/opentelemetry/instrumentation/pyramid/callbacks.py\n+++ b/instrumentation/opentelemetry-instrumentation-pyramid/src/opentelemetry/instrumentation/pyramid/callbacks.py\n@@ -137,16 +137,23 @@\n request.environ[_ENVIRON_ENABLED_KEY] = True\n request.environ[_ENVIRON_STARTTIME_KEY] = _time_ns()\n \n+ response = None\n+ status = None\n+\n try:\n response = handler(request)\n- response_or_exception = response\n except HTTPException as exc:\n # If the exception is a pyramid HTTPException,\n # that's still valuable information that isn't necessarily\n # a 500. For instance, HTTPFound is a 302.\n # As described in docs, Pyramid exceptions are all valid\n # response types\n- response_or_exception = exc\n+ response = exc\n+ raise\n+ except BaseException:\n+ # In the case that a non-HTTPException is bubbled up we\n+ # should infer a internal server error and raise\n+ status = \"500 InternalServerError\"\n raise\n finally:\n span = request.environ.get(_ENVIRON_SPAN_KEY)\n@@ -158,23 +165,26 @@\n \"PyramidInstrumentor().instrument_config(config) is called\"\n )\n elif enabled:\n- otel_wsgi.add_response_attributes(\n- span,\n- response_or_exception.status,\n- response_or_exception.headerlist,\n- )\n+ status = getattr(response, \"status\", status)\n+\n+ if status is not None:\n+ otel_wsgi.add_response_attributes(\n+ span,\n+ status,\n+ getattr(response, \"headerList\", None),\n+ )\n \n propagator = get_global_response_propagator()\n- if propagator:\n+ if propagator and hasattr(response, \"headers\"):\n propagator.inject(response.headers)\n \n activation = request.environ.get(_ENVIRON_ACTIVATION_KEY)\n \n- if isinstance(response_or_exception, HTTPException):\n+ if isinstance(response, HTTPException):\n activation.__exit__(\n- type(response_or_exception),\n- response_or_exception,\n- getattr(response_or_exception, \"__traceback__\", None),\n+ type(response),\n+ response,\n+ getattr(response, \"__traceback__\", None),\n )\n else:\n activation.__exit__(None, None, None)\n", "issue": "Pyramid tween only handles HTTPException\n**Describe your environment** \r\nSeeing this exhibited in Pyramid 1.10 and as far back as Pyramid 1.7.\r\n\r\n**Steps to reproduce**\r\nRaise a non-HTTPException. \r\n\r\n**What is the expected behavior?**\r\nTweens should process normally.\r\n\r\n**What is the actual behavior?**\r\nAn error for use of `response_or_exception` before assignment is raised.\r\n\r\n**Additional context**\r\nThe problem exists here https://github.com/open-telemetry/opentelemetry-python-contrib/blob/main/instrumentation/opentelemetry-instrumentation-pyramid/src/opentelemetry/instrumentation/pyramid/callbacks.py#L146-L157. It seems there should be an additional exception case for `BaseException` to initialize `response_or_exception`.\r\n\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom logging import getLogger\n\nfrom pyramid.events import BeforeTraversal\nfrom pyramid.httpexceptions import HTTPException\nfrom pyramid.settings import asbool\nfrom pyramid.tweens import EXCVIEW\n\nimport opentelemetry.instrumentation.wsgi as otel_wsgi\nfrom opentelemetry import context, trace\nfrom opentelemetry.instrumentation.propagators import (\n get_global_response_propagator,\n)\nfrom opentelemetry.instrumentation.pyramid.version import __version__\nfrom opentelemetry.instrumentation.utils import _start_internal_or_server_span\nfrom opentelemetry.semconv.trace import SpanAttributes\nfrom opentelemetry.util._time import _time_ns\nfrom opentelemetry.util.http import get_excluded_urls\n\nTWEEN_NAME = \"opentelemetry.instrumentation.pyramid.trace_tween_factory\"\nSETTING_TRACE_ENABLED = \"opentelemetry-pyramid.trace_enabled\"\n\n_ENVIRON_STARTTIME_KEY = \"opentelemetry-pyramid.starttime_key\"\n_ENVIRON_SPAN_KEY = \"opentelemetry-pyramid.span_key\"\n_ENVIRON_ACTIVATION_KEY = \"opentelemetry-pyramid.activation_key\"\n_ENVIRON_ENABLED_KEY = \"opentelemetry-pyramid.tracing_enabled_key\"\n_ENVIRON_TOKEN = \"opentelemetry-pyramid.token\"\n\n_logger = getLogger(__name__)\n\n\n_excluded_urls = get_excluded_urls(\"PYRAMID\")\n\n\ndef includeme(config):\n config.add_settings({SETTING_TRACE_ENABLED: True})\n\n config.add_subscriber(_before_traversal, BeforeTraversal)\n _insert_tween(config)\n\n\ndef _insert_tween(config):\n settings = config.get_settings()\n tweens = settings.get(\"pyramid.tweens\")\n # If the list is empty, pyramid does not consider the tweens have been\n # set explicitly. And if our tween is already there, nothing to do\n if not tweens or not tweens.strip():\n # Add our tween just before the default exception handler\n config.add_tween(TWEEN_NAME, over=EXCVIEW)\n\n\ndef _before_traversal(event):\n request = event.request\n request_environ = request.environ\n span_name = otel_wsgi.get_default_span_name(request_environ)\n\n enabled = request_environ.get(_ENVIRON_ENABLED_KEY)\n if enabled is None:\n _logger.warning(\n \"Opentelemetry pyramid tween 'opentelemetry.instrumentation.pyramid.trace_tween_factory'\"\n \"was not called. Make sure that the tween is included in 'pyramid.tweens' if\"\n \"the tween list was created manually\"\n )\n return\n\n if not enabled:\n # Tracing not enabled, return\n return\n\n start_time = request_environ.get(_ENVIRON_STARTTIME_KEY)\n tracer = trace.get_tracer(__name__, __version__)\n\n if request.matched_route:\n span_name = request.matched_route.pattern\n else:\n span_name = otel_wsgi.get_default_span_name(request_environ)\n\n span, token = _start_internal_or_server_span(\n tracer=tracer,\n span_name=span_name,\n start_time=start_time,\n context_carrier=request_environ,\n context_getter=otel_wsgi.wsgi_getter,\n )\n\n if span.is_recording():\n attributes = otel_wsgi.collect_request_attributes(request_environ)\n if request.matched_route:\n attributes[\n SpanAttributes.HTTP_ROUTE\n ] = request.matched_route.pattern\n for key, value in attributes.items():\n span.set_attribute(key, value)\n\n activation = trace.use_span(span, end_on_exit=True)\n activation.__enter__() # pylint: disable=E1101\n request_environ[_ENVIRON_ACTIVATION_KEY] = activation\n request_environ[_ENVIRON_SPAN_KEY] = span\n if token:\n request_environ[_ENVIRON_TOKEN] = token\n\n\ndef trace_tween_factory(handler, registry):\n settings = registry.settings\n enabled = asbool(settings.get(SETTING_TRACE_ENABLED, True))\n\n if not enabled:\n # If disabled, make a tween that signals to the\n # BeforeTraversal subscriber that tracing is disabled\n def disabled_tween(request):\n request.environ[_ENVIRON_ENABLED_KEY] = False\n return handler(request)\n\n return disabled_tween\n\n # make a request tracing function\n def trace_tween(request):\n # pylint: disable=E1101\n if _excluded_urls.url_disabled(request.url):\n request.environ[_ENVIRON_ENABLED_KEY] = False\n # short-circuit when we don't want to trace anything\n return handler(request)\n\n request.environ[_ENVIRON_ENABLED_KEY] = True\n request.environ[_ENVIRON_STARTTIME_KEY] = _time_ns()\n\n try:\n response = handler(request)\n response_or_exception = response\n except HTTPException as exc:\n # If the exception is a pyramid HTTPException,\n # that's still valuable information that isn't necessarily\n # a 500. For instance, HTTPFound is a 302.\n # As described in docs, Pyramid exceptions are all valid\n # response types\n response_or_exception = exc\n raise\n finally:\n span = request.environ.get(_ENVIRON_SPAN_KEY)\n enabled = request.environ.get(_ENVIRON_ENABLED_KEY)\n if not span and enabled:\n _logger.warning(\n \"Pyramid environ's OpenTelemetry span missing.\"\n \"If the OpenTelemetry tween was added manually, make sure\"\n \"PyramidInstrumentor().instrument_config(config) is called\"\n )\n elif enabled:\n otel_wsgi.add_response_attributes(\n span,\n response_or_exception.status,\n response_or_exception.headerlist,\n )\n\n propagator = get_global_response_propagator()\n if propagator:\n propagator.inject(response.headers)\n\n activation = request.environ.get(_ENVIRON_ACTIVATION_KEY)\n\n if isinstance(response_or_exception, HTTPException):\n activation.__exit__(\n type(response_or_exception),\n response_or_exception,\n getattr(response_or_exception, \"__traceback__\", None),\n )\n else:\n activation.__exit__(None, None, None)\n\n env_token = request.environ.get(_ENVIRON_TOKEN, None)\n if env_token is not None:\n context.detach(env_token)\n\n return response\n\n return trace_tween\n", "path": "instrumentation/opentelemetry-instrumentation-pyramid/src/opentelemetry/instrumentation/pyramid/callbacks.py"}], "after_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom logging import getLogger\n\nfrom pyramid.events import BeforeTraversal\nfrom pyramid.httpexceptions import HTTPException\nfrom pyramid.settings import asbool\nfrom pyramid.tweens import EXCVIEW\n\nimport opentelemetry.instrumentation.wsgi as otel_wsgi\nfrom opentelemetry import context, trace\nfrom opentelemetry.instrumentation.propagators import (\n get_global_response_propagator,\n)\nfrom opentelemetry.instrumentation.pyramid.version import __version__\nfrom opentelemetry.instrumentation.utils import _start_internal_or_server_span\nfrom opentelemetry.semconv.trace import SpanAttributes\nfrom opentelemetry.util._time import _time_ns\nfrom opentelemetry.util.http import get_excluded_urls\n\nTWEEN_NAME = \"opentelemetry.instrumentation.pyramid.trace_tween_factory\"\nSETTING_TRACE_ENABLED = \"opentelemetry-pyramid.trace_enabled\"\n\n_ENVIRON_STARTTIME_KEY = \"opentelemetry-pyramid.starttime_key\"\n_ENVIRON_SPAN_KEY = \"opentelemetry-pyramid.span_key\"\n_ENVIRON_ACTIVATION_KEY = \"opentelemetry-pyramid.activation_key\"\n_ENVIRON_ENABLED_KEY = \"opentelemetry-pyramid.tracing_enabled_key\"\n_ENVIRON_TOKEN = \"opentelemetry-pyramid.token\"\n\n_logger = getLogger(__name__)\n\n\n_excluded_urls = get_excluded_urls(\"PYRAMID\")\n\n\ndef includeme(config):\n config.add_settings({SETTING_TRACE_ENABLED: True})\n\n config.add_subscriber(_before_traversal, BeforeTraversal)\n _insert_tween(config)\n\n\ndef _insert_tween(config):\n settings = config.get_settings()\n tweens = settings.get(\"pyramid.tweens\")\n # If the list is empty, pyramid does not consider the tweens have been\n # set explicitly. And if our tween is already there, nothing to do\n if not tweens or not tweens.strip():\n # Add our tween just before the default exception handler\n config.add_tween(TWEEN_NAME, over=EXCVIEW)\n\n\ndef _before_traversal(event):\n request = event.request\n request_environ = request.environ\n span_name = otel_wsgi.get_default_span_name(request_environ)\n\n enabled = request_environ.get(_ENVIRON_ENABLED_KEY)\n if enabled is None:\n _logger.warning(\n \"Opentelemetry pyramid tween 'opentelemetry.instrumentation.pyramid.trace_tween_factory'\"\n \"was not called. Make sure that the tween is included in 'pyramid.tweens' if\"\n \"the tween list was created manually\"\n )\n return\n\n if not enabled:\n # Tracing not enabled, return\n return\n\n start_time = request_environ.get(_ENVIRON_STARTTIME_KEY)\n tracer = trace.get_tracer(__name__, __version__)\n\n if request.matched_route:\n span_name = request.matched_route.pattern\n else:\n span_name = otel_wsgi.get_default_span_name(request_environ)\n\n span, token = _start_internal_or_server_span(\n tracer=tracer,\n span_name=span_name,\n start_time=start_time,\n context_carrier=request_environ,\n context_getter=otel_wsgi.wsgi_getter,\n )\n\n if span.is_recording():\n attributes = otel_wsgi.collect_request_attributes(request_environ)\n if request.matched_route:\n attributes[\n SpanAttributes.HTTP_ROUTE\n ] = request.matched_route.pattern\n for key, value in attributes.items():\n span.set_attribute(key, value)\n\n activation = trace.use_span(span, end_on_exit=True)\n activation.__enter__() # pylint: disable=E1101\n request_environ[_ENVIRON_ACTIVATION_KEY] = activation\n request_environ[_ENVIRON_SPAN_KEY] = span\n if token:\n request_environ[_ENVIRON_TOKEN] = token\n\n\ndef trace_tween_factory(handler, registry):\n settings = registry.settings\n enabled = asbool(settings.get(SETTING_TRACE_ENABLED, True))\n\n if not enabled:\n # If disabled, make a tween that signals to the\n # BeforeTraversal subscriber that tracing is disabled\n def disabled_tween(request):\n request.environ[_ENVIRON_ENABLED_KEY] = False\n return handler(request)\n\n return disabled_tween\n\n # make a request tracing function\n def trace_tween(request):\n # pylint: disable=E1101\n if _excluded_urls.url_disabled(request.url):\n request.environ[_ENVIRON_ENABLED_KEY] = False\n # short-circuit when we don't want to trace anything\n return handler(request)\n\n request.environ[_ENVIRON_ENABLED_KEY] = True\n request.environ[_ENVIRON_STARTTIME_KEY] = _time_ns()\n\n response = None\n status = None\n\n try:\n response = handler(request)\n except HTTPException as exc:\n # If the exception is a pyramid HTTPException,\n # that's still valuable information that isn't necessarily\n # a 500. For instance, HTTPFound is a 302.\n # As described in docs, Pyramid exceptions are all valid\n # response types\n response = exc\n raise\n except BaseException:\n # In the case that a non-HTTPException is bubbled up we\n # should infer a internal server error and raise\n status = \"500 InternalServerError\"\n raise\n finally:\n span = request.environ.get(_ENVIRON_SPAN_KEY)\n enabled = request.environ.get(_ENVIRON_ENABLED_KEY)\n if not span and enabled:\n _logger.warning(\n \"Pyramid environ's OpenTelemetry span missing.\"\n \"If the OpenTelemetry tween was added manually, make sure\"\n \"PyramidInstrumentor().instrument_config(config) is called\"\n )\n elif enabled:\n status = getattr(response, \"status\", status)\n\n if status is not None:\n otel_wsgi.add_response_attributes(\n span,\n status,\n getattr(response, \"headerList\", None),\n )\n\n propagator = get_global_response_propagator()\n if propagator and hasattr(response, \"headers\"):\n propagator.inject(response.headers)\n\n activation = request.environ.get(_ENVIRON_ACTIVATION_KEY)\n\n if isinstance(response, HTTPException):\n activation.__exit__(\n type(response),\n response,\n getattr(response, \"__traceback__\", None),\n )\n else:\n activation.__exit__(None, None, None)\n\n env_token = request.environ.get(_ENVIRON_TOKEN, None)\n if env_token is not None:\n context.detach(env_token)\n\n return response\n\n return trace_tween\n", "path": "instrumentation/opentelemetry-instrumentation-pyramid/src/opentelemetry/instrumentation/pyramid/callbacks.py"}]}
| 2,387 | 596 |
gh_patches_debug_3147
|
rasdani/github-patches
|
git_diff
|
OpenEnergyPlatform__oeplatform-657
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Tutorials app: activate safe_mode
Html is not escaped as expected when creating a new tutorial using the markdown editor -> save tutorial.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tutorials/views.py`
Content:
```
1 from django.shortcuts import render, redirect
2 from django.views import View
3 from django.views.generic.edit import CreateView, UpdateView, DeleteView
4 from django.urls import exceptions, reverse_lazy
5 from django.contrib.auth.mixins import LoginRequiredMixin
6
7 from os.path import join
8
9 from uuid import uuid4
10
11 from copy import deepcopy
12
13 from django.conf import settings
14
15 from markdown2 import Markdown
16
17 from .forms import TutorialForm
18 from .models import Tutorial
19
20 import re
21 # Create your views here.
22
23 youtubeUrlRegex = re.compile('^.*youtube\.com\/watch\?v=(?P<id>[A-z0-9]+)$')
24
25 staticTutorials = [
26 {
27 "id": "e59819c7-46fd-4528-b2bd-f37e8866d1df",
28 "title": "appBBB-UML.html",
29 "fileName": "appBBB-UML.html"
30 },
31 {
32 "id": "5064610a-596a-4911-8862-e9d815d872d4",
33 "title": "df_normalize_denormalize.html",
34 "fileName": "df_normalize_denormalize.html"
35 },
36 {
37 "id": "56c675ea-93ae-43cf-886c-01f4fc98711f",
38 "title": "germany-UML.html",
39 "fileName": "germany-UML.html"
40 },
41 {
42 "id": "7e51c992-5a8a-419f-b778-31a1dd32db4a",
43 "title": "OEP-api_template.html",
44 "fileName": "OEP-api_template.html"
45 },
46 {
47 "id": "61201725-493f-4dd0-b9aa-6e0f6d6aa550",
48 "title": "OEP_API_tutorial_part1.html",
49 "fileName": "OEP_API_tutorial_part1.html"
50 },
51 {
52 "id": "c4e48c2d-626a-45ad-aa68-a6711c7af85c",
53 "title": "OEP_API_tutorial_part2.html",
54 "fileName": "OEP_API_tutorial_part2.html"
55 },
56 {
57 "id": "eab6aece-cff8-4265-989f-3dd9d7d03026",
58 "title": "OEP_API_tutorial_part3.html",
59 "fileName": "OEP_API_tutorial_part3.html"
60 },
61 {
62 "id": "a1d6fc71-6694-4704-8ab4-950be4de9561",
63 "title": "OEP_API_tutorial_part4.html",
64 "fileName": "OEP_API_tutorial_part4.html"
65 },
66 {
67 "id": "ea5e68ef-bcfb-47a1-9768-b5184797bcab",
68 "title": "OEP-oedialect_eGoDP.html",
69 "fileName": "OEP-oedialect_eGoDP.html"
70 },
71 {
72 "id": "44634b85-389f-4c26-988f-217ee9c6f768",
73 "title": "OEP-oedialect-geoquery.html",
74 "fileName": "OEP-oedialect-geoquery.html"
75 },
76 {
77 "id": "cc9e9a5e-826b-4296-a544-e057003dd22c",
78 "title": "OEP-oedialect.html",
79 "fileName": "OEP-oedialect.html"
80 },
81 {
82 "id": "99f35e78-49ca-47f4-9926-d5197c0e3ffe",
83 "title": "OEP-oedialect_template.html",
84 "fileName": "OEP-oedialect_template.html"
85 },
86 {
87 "id": "c254d5e4-479b-423f-92fb-c10411abab66",
88 "title": "OEP-oedialect_upload_from_csv.html",
89 "fileName": "OEP-oedialect_upload_from_csv.html"
90 },
91 {
92 "id": "bc6ad0f4-d9ed-4f00-84e4-f3b62f3eafca",
93 "title": "rli_tool_validate-metadata-datapackage.html",
94 "fileName": "rli_tool_validate-metadata-datapackage.html"
95 },
96 {
97 "id": "43d4da3a-4fef-4524-8c17-7214637e44ad",
98 "title": "UML Tutorial.html",
99 "fileName": "UML Tutorial.html"
100 },
101 ]
102
103
104 def _resolveStaticTutorial(tutorial):
105 try:
106 with open(join(settings.BASE_DIR, "examples", "build", tutorial["fileName"]), 'r') as buildFile:
107 buildFileContent = buildFile.read()
108
109 return {
110 "html": buildFileContent
111 }
112
113 except:
114 return {"html": "Tutorial is missing"}
115
116
117 def _resolveStaticTutorials(tutorials):
118 resolvedTutorials = []
119
120 # I was not able to solve this problem without an object spread operator due to my JS history.
121 # The copy does not have a specific reason but not iterating over the array which is modified in interation.
122
123 for tutorial in tutorials:
124 paramsToAdd = _resolveStaticTutorial(tutorial)
125 copiedTutorial = deepcopy(tutorial)
126 copiedTutorial.update(paramsToAdd)
127
128 resolvedTutorials.append(copiedTutorial)
129
130 return resolvedTutorials
131
132
133 def _resolveDynamicTutorial(evaluatedQs):
134 """
135
136
137 :param evaluatedQs: Evaluated queryset object
138 :return:
139 """
140
141 # Initialize dict that stores a tutorial
142 currentTutorial = {'id': '', 'title': '', 'html': '', 'markdown': '', 'category': '', 'media_src': '', 'level': ''}
143
144 # populate dict
145 currentTutorial.update(id=str(evaluatedQs.id),
146 title=evaluatedQs.title,
147 html=evaluatedQs.html,
148 markdown=evaluatedQs.markdown,
149 category= evaluatedQs.category,
150 media_src= evaluatedQs.media_src,
151 level=evaluatedQs.level)
152
153 return currentTutorial
154
155
156 def _resolveDynamicTutorials(tutorials_qs):
157 """
158 Evaluates a QuerySet and passes each evaluated object to the next function which returns a python
159 dictionary that contains all parameters from the object as dict. The dict is added to a list to
160 later merge the static and dynamic tutorials together.
161
162 :param tutorials_qs:
163 :return:
164 """
165 resolvedTutorials = []
166
167 for tutorial in tutorials_qs:
168 paramsToAdd = _resolveDynamicTutorial(tutorial)
169
170 resolvedTutorials.append(paramsToAdd)
171
172 return resolvedTutorials
173
174
175 def _gatherTutorials(id=None):
176 """
177 Collects all existing tutorials (static/dynamic) and returns them as a list. If an id is
178 specified as parameter a specific tutorial is returned filtered by id.
179
180 :param id:
181 :return:
182 """
183
184 # Retrieve allTutorials objects from db and cache
185 dynamicTutorialsQs = Tutorial.objects.all()
186
187 tutorials = _resolveStaticTutorials(staticTutorials)
188 tutorials.extend(_resolveDynamicTutorials(dynamicTutorialsQs))
189
190 if id:
191 filteredElement = list(filter(lambda tutorial: tutorial["id"] == id, tutorials))[0]
192 return filteredElement
193
194 return tutorials
195
196 def _processFormInput(form):
197 tutorial = form.save(commit=False)
198 # Add more information to the dataset like date, time, contributor ...
199
200 if tutorial.media_src:
201 matchResult = youtubeUrlRegex.match(tutorial.media_src)
202 videoId = matchResult.group(1) if matchResult else None
203 if videoId:
204 tutorial.media_src = "https://www.youtube.com/embed/" + videoId
205
206 return tutorial
207
208 def formattedMarkdown(markdown):
209 """
210 A parameter is used to enter a text formatted as markdown that is formatted
211 to html and returned. This functionality is implemented using Markdown2.
212
213 :param markdown:
214 :return:
215 """
216
217 markdowner = Markdown(safe_mode="escape")
218
219 return markdowner.convert(markdown)
220
221
222 class ListTutorials(View):
223 def get(self, request):
224 """
225 Load and list the available tutorials.
226
227 :param request: A HTTP-request object sent by the Django framework.
228 :return: Tutorials renderer
229 """
230
231 # Gathering all tutorials
232
233 tutorials = _gatherTutorials()
234
235 return render(
236 request, 'list.html', {"tutorials": tutorials}
237 )
238
239
240 class TutorialDetail(View):
241 def get(self, request, tutorial_id):
242 """
243 Detail view for specific tutorial.
244
245 :param request: A HTTP-request object sent by the Django framework.
246 :return: Tutorials renderer
247 """
248
249 # Gathering all tutorials
250
251 tutorial = _gatherTutorials(tutorial_id)
252
253 return render(
254 request, 'detail.html', {"tutorial": tutorial}
255 )
256
257
258 class CreateNewTutorial(LoginRequiredMixin, CreateView):
259 template_name = 'add.html'
260 redirect_url = 'detail_tutorial'
261 form_class = TutorialForm
262 login_url = '/user/login/'
263 redirect_field_name = 'redirect_to'
264
265 def form_valid(self, form):
266 """
267 validates a form and stores the values in the database and inserts a
268 value for the tutorials field html.
269
270 :param form:
271 :return:
272 """
273
274 tutorial = _processFormInput(form)
275 tutorial.save()
276
277 # Convert markdown to HTML and save to db
278 _html = formattedMarkdown(tutorial.markdown)
279 addHtml = Tutorial.objects.get(pk=tutorial.id)
280 addHtml.html = _html
281 addHtml.save()
282
283 return redirect(self.redirect_url, tutorial_id=tutorial.id)
284
285 def addTutorialFromMarkdownFile(self):
286 pass
287
288
289 class EditTutorials(LoginRequiredMixin, UpdateView):
290 template_name = 'add.html'
291 redirect_url = 'detail_tutorial'
292 model = Tutorial
293 form_class = TutorialForm
294 pk_url_kwarg = 'tutorial_id'
295 login_url = '/user/login/'
296 redirect_field_name = 'redirect_to'
297
298 def form_valid(self, form):
299 """
300 validates a form and stores the values in the database and inserts a
301 value for the tutorials field html.
302
303 :param form:
304 :return:
305 """
306 tutorial = _processFormInput(form)
307 tutorial.save()
308
309 _html = formattedMarkdown(tutorial.markdown)
310 addHtml = Tutorial.objects.get(pk=tutorial.id)
311 addHtml.html = _html
312 addHtml.save()
313
314 return redirect(self.redirect_url, tutorial_id=tutorial.id)
315
316
317 class DeleteTutorial(LoginRequiredMixin, DeleteView):
318 template_name = 'tutorial_confirm_delete.html'
319 model = Tutorial
320 pk_url_kwarg = 'tutorial_id'
321 success_url = reverse_lazy('list_tutorials')
322 login_url = '/user/login/'
323 redirect_field_name = 'redirect_to'
324
325
326
327
328
329
330
331
332
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tutorials/views.py b/tutorials/views.py
--- a/tutorials/views.py
+++ b/tutorials/views.py
@@ -214,7 +214,11 @@
:return:
"""
- markdowner = Markdown(safe_mode="escape")
+ # escapes html but also escapes html code blocks lke "exampel code:
+ # (1 tab) code"
+ # checkbox also not rendered as expected "- [ ]"
+ markdowner = Markdown(safe_mode=True)
+ markdowner.html_removed_text = ""
return markdowner.convert(markdown)
|
{"golden_diff": "diff --git a/tutorials/views.py b/tutorials/views.py\n--- a/tutorials/views.py\n+++ b/tutorials/views.py\n@@ -214,7 +214,11 @@\n :return:\n \"\"\"\n \n- markdowner = Markdown(safe_mode=\"escape\")\n+ # escapes html but also escapes html code blocks lke \"exampel code:\n+ # (1 tab) code\"\n+ # checkbox also not rendered as expected \"- [ ]\"\n+ markdowner = Markdown(safe_mode=True)\n+ markdowner.html_removed_text = \"\"\n \n return markdowner.convert(markdown)\n", "issue": "Tutorials app: activate safe_mode\nHtml is not escaped as expected when creating a new tutorial using the markdown editor -> save tutorial.\n", "before_files": [{"content": "from django.shortcuts import render, redirect\nfrom django.views import View\nfrom django.views.generic.edit import CreateView, UpdateView, DeleteView\nfrom django.urls import exceptions, reverse_lazy\nfrom django.contrib.auth.mixins import LoginRequiredMixin\n\nfrom os.path import join\n\nfrom uuid import uuid4\n\nfrom copy import deepcopy\n\nfrom django.conf import settings\n\nfrom markdown2 import Markdown\n\nfrom .forms import TutorialForm\nfrom .models import Tutorial\n\nimport re\n# Create your views here.\n\nyoutubeUrlRegex = re.compile('^.*youtube\\.com\\/watch\\?v=(?P<id>[A-z0-9]+)$')\n\nstaticTutorials = [\n {\n \"id\": \"e59819c7-46fd-4528-b2bd-f37e8866d1df\",\n \"title\": \"appBBB-UML.html\",\n \"fileName\": \"appBBB-UML.html\"\n },\n {\n \"id\": \"5064610a-596a-4911-8862-e9d815d872d4\",\n \"title\": \"df_normalize_denormalize.html\",\n \"fileName\": \"df_normalize_denormalize.html\"\n },\n {\n \"id\": \"56c675ea-93ae-43cf-886c-01f4fc98711f\",\n \"title\": \"germany-UML.html\",\n \"fileName\": \"germany-UML.html\"\n },\n {\n \"id\": \"7e51c992-5a8a-419f-b778-31a1dd32db4a\",\n \"title\": \"OEP-api_template.html\",\n \"fileName\": \"OEP-api_template.html\"\n },\n {\n \"id\": \"61201725-493f-4dd0-b9aa-6e0f6d6aa550\",\n \"title\": \"OEP_API_tutorial_part1.html\",\n \"fileName\": \"OEP_API_tutorial_part1.html\"\n },\n {\n \"id\": \"c4e48c2d-626a-45ad-aa68-a6711c7af85c\",\n \"title\": \"OEP_API_tutorial_part2.html\",\n \"fileName\": \"OEP_API_tutorial_part2.html\"\n },\n {\n \"id\": \"eab6aece-cff8-4265-989f-3dd9d7d03026\",\n \"title\": \"OEP_API_tutorial_part3.html\",\n \"fileName\": \"OEP_API_tutorial_part3.html\"\n },\n {\n \"id\": \"a1d6fc71-6694-4704-8ab4-950be4de9561\",\n \"title\": \"OEP_API_tutorial_part4.html\",\n \"fileName\": \"OEP_API_tutorial_part4.html\"\n },\n {\n \"id\": \"ea5e68ef-bcfb-47a1-9768-b5184797bcab\",\n \"title\": \"OEP-oedialect_eGoDP.html\",\n \"fileName\": \"OEP-oedialect_eGoDP.html\"\n },\n {\n \"id\": \"44634b85-389f-4c26-988f-217ee9c6f768\",\n \"title\": \"OEP-oedialect-geoquery.html\",\n \"fileName\": \"OEP-oedialect-geoquery.html\"\n },\n {\n \"id\": \"cc9e9a5e-826b-4296-a544-e057003dd22c\",\n \"title\": \"OEP-oedialect.html\",\n \"fileName\": \"OEP-oedialect.html\"\n },\n {\n \"id\": \"99f35e78-49ca-47f4-9926-d5197c0e3ffe\",\n \"title\": \"OEP-oedialect_template.html\",\n \"fileName\": \"OEP-oedialect_template.html\"\n },\n {\n \"id\": \"c254d5e4-479b-423f-92fb-c10411abab66\",\n \"title\": \"OEP-oedialect_upload_from_csv.html\",\n \"fileName\": \"OEP-oedialect_upload_from_csv.html\"\n },\n {\n \"id\": \"bc6ad0f4-d9ed-4f00-84e4-f3b62f3eafca\",\n \"title\": \"rli_tool_validate-metadata-datapackage.html\",\n \"fileName\": \"rli_tool_validate-metadata-datapackage.html\"\n },\n {\n \"id\": \"43d4da3a-4fef-4524-8c17-7214637e44ad\",\n \"title\": \"UML Tutorial.html\",\n \"fileName\": \"UML Tutorial.html\"\n },\n]\n\n\ndef _resolveStaticTutorial(tutorial):\n try:\n with open(join(settings.BASE_DIR, \"examples\", \"build\", tutorial[\"fileName\"]), 'r') as buildFile:\n buildFileContent = buildFile.read()\n\n return {\n \"html\": buildFileContent\n }\n\n except:\n return {\"html\": \"Tutorial is missing\"}\n\n\ndef _resolveStaticTutorials(tutorials):\n resolvedTutorials = []\n\n # I was not able to solve this problem without an object spread operator due to my JS history.\n # The copy does not have a specific reason but not iterating over the array which is modified in interation.\n\n for tutorial in tutorials:\n paramsToAdd = _resolveStaticTutorial(tutorial)\n copiedTutorial = deepcopy(tutorial)\n copiedTutorial.update(paramsToAdd)\n\n resolvedTutorials.append(copiedTutorial)\n\n return resolvedTutorials\n\n\ndef _resolveDynamicTutorial(evaluatedQs):\n \"\"\"\n\n\n :param evaluatedQs: Evaluated queryset object\n :return:\n \"\"\"\n\n # Initialize dict that stores a tutorial\n currentTutorial = {'id': '', 'title': '', 'html': '', 'markdown': '', 'category': '', 'media_src': '', 'level': ''}\n\n # populate dict\n currentTutorial.update(id=str(evaluatedQs.id),\n title=evaluatedQs.title,\n html=evaluatedQs.html,\n markdown=evaluatedQs.markdown,\n category= evaluatedQs.category,\n media_src= evaluatedQs.media_src,\n level=evaluatedQs.level)\n\n return currentTutorial\n\n\ndef _resolveDynamicTutorials(tutorials_qs):\n \"\"\"\n Evaluates a QuerySet and passes each evaluated object to the next function which returns a python\n dictionary that contains all parameters from the object as dict. The dict is added to a list to\n later merge the static and dynamic tutorials together.\n\n :param tutorials_qs:\n :return:\n \"\"\"\n resolvedTutorials = []\n\n for tutorial in tutorials_qs:\n paramsToAdd = _resolveDynamicTutorial(tutorial)\n\n resolvedTutorials.append(paramsToAdd)\n\n return resolvedTutorials\n\n\ndef _gatherTutorials(id=None):\n \"\"\"\n Collects all existing tutorials (static/dynamic) and returns them as a list. If an id is\n specified as parameter a specific tutorial is returned filtered by id.\n\n :param id:\n :return:\n \"\"\"\n\n # Retrieve allTutorials objects from db and cache\n dynamicTutorialsQs = Tutorial.objects.all()\n\n tutorials = _resolveStaticTutorials(staticTutorials)\n tutorials.extend(_resolveDynamicTutorials(dynamicTutorialsQs))\n\n if id:\n filteredElement = list(filter(lambda tutorial: tutorial[\"id\"] == id, tutorials))[0]\n return filteredElement\n\n return tutorials\n\ndef _processFormInput(form):\n tutorial = form.save(commit=False)\n # Add more information to the dataset like date, time, contributor ...\n\n if tutorial.media_src:\n matchResult = youtubeUrlRegex.match(tutorial.media_src)\n videoId = matchResult.group(1) if matchResult else None\n if videoId:\n tutorial.media_src = \"https://www.youtube.com/embed/\" + videoId\n\n return tutorial\n\ndef formattedMarkdown(markdown):\n \"\"\"\n A parameter is used to enter a text formatted as markdown that is formatted\n to html and returned. This functionality is implemented using Markdown2.\n\n :param markdown:\n :return:\n \"\"\"\n\n markdowner = Markdown(safe_mode=\"escape\")\n\n return markdowner.convert(markdown)\n\n\nclass ListTutorials(View):\n def get(self, request):\n \"\"\"\n Load and list the available tutorials.\n\n :param request: A HTTP-request object sent by the Django framework.\n :return: Tutorials renderer\n \"\"\"\n\n # Gathering all tutorials\n\n tutorials = _gatherTutorials()\n\n return render(\n request, 'list.html', {\"tutorials\": tutorials}\n )\n\n\nclass TutorialDetail(View):\n def get(self, request, tutorial_id):\n \"\"\"\n Detail view for specific tutorial.\n\n :param request: A HTTP-request object sent by the Django framework.\n :return: Tutorials renderer\n \"\"\"\n\n # Gathering all tutorials\n\n tutorial = _gatherTutorials(tutorial_id)\n\n return render(\n request, 'detail.html', {\"tutorial\": tutorial}\n )\n\n\nclass CreateNewTutorial(LoginRequiredMixin, CreateView):\n template_name = 'add.html'\n redirect_url = 'detail_tutorial'\n form_class = TutorialForm\n login_url = '/user/login/'\n redirect_field_name = 'redirect_to'\n\n def form_valid(self, form):\n \"\"\"\n validates a form and stores the values in the database and inserts a\n value for the tutorials field html.\n\n :param form:\n :return:\n \"\"\"\n\n tutorial = _processFormInput(form)\n tutorial.save()\n\n # Convert markdown to HTML and save to db\n _html = formattedMarkdown(tutorial.markdown)\n addHtml = Tutorial.objects.get(pk=tutorial.id)\n addHtml.html = _html\n addHtml.save()\n\n return redirect(self.redirect_url, tutorial_id=tutorial.id)\n\n def addTutorialFromMarkdownFile(self):\n pass\n\n\nclass EditTutorials(LoginRequiredMixin, UpdateView):\n template_name = 'add.html'\n redirect_url = 'detail_tutorial'\n model = Tutorial\n form_class = TutorialForm\n pk_url_kwarg = 'tutorial_id'\n login_url = '/user/login/'\n redirect_field_name = 'redirect_to'\n\n def form_valid(self, form):\n \"\"\"\n validates a form and stores the values in the database and inserts a\n value for the tutorials field html.\n\n :param form:\n :return:\n \"\"\"\n tutorial = _processFormInput(form)\n tutorial.save()\n\n _html = formattedMarkdown(tutorial.markdown)\n addHtml = Tutorial.objects.get(pk=tutorial.id)\n addHtml.html = _html\n addHtml.save()\n\n return redirect(self.redirect_url, tutorial_id=tutorial.id)\n\n\nclass DeleteTutorial(LoginRequiredMixin, DeleteView):\n template_name = 'tutorial_confirm_delete.html'\n model = Tutorial\n pk_url_kwarg = 'tutorial_id'\n success_url = reverse_lazy('list_tutorials')\n login_url = '/user/login/'\n redirect_field_name = 'redirect_to'\n\n\n\n\n\n\n\n\n", "path": "tutorials/views.py"}], "after_files": [{"content": "from django.shortcuts import render, redirect\nfrom django.views import View\nfrom django.views.generic.edit import CreateView, UpdateView, DeleteView\nfrom django.urls import exceptions, reverse_lazy\nfrom django.contrib.auth.mixins import LoginRequiredMixin\n\nfrom os.path import join\n\nfrom uuid import uuid4\n\nfrom copy import deepcopy\n\nfrom django.conf import settings\n\nfrom markdown2 import Markdown\n\nfrom .forms import TutorialForm\nfrom .models import Tutorial\n\nimport re\n# Create your views here.\n\nyoutubeUrlRegex = re.compile('^.*youtube\\.com\\/watch\\?v=(?P<id>[A-z0-9]+)$')\n\nstaticTutorials = [\n {\n \"id\": \"e59819c7-46fd-4528-b2bd-f37e8866d1df\",\n \"title\": \"appBBB-UML.html\",\n \"fileName\": \"appBBB-UML.html\"\n },\n {\n \"id\": \"5064610a-596a-4911-8862-e9d815d872d4\",\n \"title\": \"df_normalize_denormalize.html\",\n \"fileName\": \"df_normalize_denormalize.html\"\n },\n {\n \"id\": \"56c675ea-93ae-43cf-886c-01f4fc98711f\",\n \"title\": \"germany-UML.html\",\n \"fileName\": \"germany-UML.html\"\n },\n {\n \"id\": \"7e51c992-5a8a-419f-b778-31a1dd32db4a\",\n \"title\": \"OEP-api_template.html\",\n \"fileName\": \"OEP-api_template.html\"\n },\n {\n \"id\": \"61201725-493f-4dd0-b9aa-6e0f6d6aa550\",\n \"title\": \"OEP_API_tutorial_part1.html\",\n \"fileName\": \"OEP_API_tutorial_part1.html\"\n },\n {\n \"id\": \"c4e48c2d-626a-45ad-aa68-a6711c7af85c\",\n \"title\": \"OEP_API_tutorial_part2.html\",\n \"fileName\": \"OEP_API_tutorial_part2.html\"\n },\n {\n \"id\": \"eab6aece-cff8-4265-989f-3dd9d7d03026\",\n \"title\": \"OEP_API_tutorial_part3.html\",\n \"fileName\": \"OEP_API_tutorial_part3.html\"\n },\n {\n \"id\": \"a1d6fc71-6694-4704-8ab4-950be4de9561\",\n \"title\": \"OEP_API_tutorial_part4.html\",\n \"fileName\": \"OEP_API_tutorial_part4.html\"\n },\n {\n \"id\": \"ea5e68ef-bcfb-47a1-9768-b5184797bcab\",\n \"title\": \"OEP-oedialect_eGoDP.html\",\n \"fileName\": \"OEP-oedialect_eGoDP.html\"\n },\n {\n \"id\": \"44634b85-389f-4c26-988f-217ee9c6f768\",\n \"title\": \"OEP-oedialect-geoquery.html\",\n \"fileName\": \"OEP-oedialect-geoquery.html\"\n },\n {\n \"id\": \"cc9e9a5e-826b-4296-a544-e057003dd22c\",\n \"title\": \"OEP-oedialect.html\",\n \"fileName\": \"OEP-oedialect.html\"\n },\n {\n \"id\": \"99f35e78-49ca-47f4-9926-d5197c0e3ffe\",\n \"title\": \"OEP-oedialect_template.html\",\n \"fileName\": \"OEP-oedialect_template.html\"\n },\n {\n \"id\": \"c254d5e4-479b-423f-92fb-c10411abab66\",\n \"title\": \"OEP-oedialect_upload_from_csv.html\",\n \"fileName\": \"OEP-oedialect_upload_from_csv.html\"\n },\n {\n \"id\": \"bc6ad0f4-d9ed-4f00-84e4-f3b62f3eafca\",\n \"title\": \"rli_tool_validate-metadata-datapackage.html\",\n \"fileName\": \"rli_tool_validate-metadata-datapackage.html\"\n },\n {\n \"id\": \"43d4da3a-4fef-4524-8c17-7214637e44ad\",\n \"title\": \"UML Tutorial.html\",\n \"fileName\": \"UML Tutorial.html\"\n },\n]\n\n\ndef _resolveStaticTutorial(tutorial):\n try:\n with open(join(settings.BASE_DIR, \"examples\", \"build\", tutorial[\"fileName\"]), 'r') as buildFile:\n buildFileContent = buildFile.read()\n\n return {\n \"html\": buildFileContent\n }\n\n except:\n return {\"html\": \"Tutorial is missing\"}\n\n\ndef _resolveStaticTutorials(tutorials):\n resolvedTutorials = []\n\n # I was not able to solve this problem without an object spread operator due to my JS history.\n # The copy does not have a specific reason but not iterating over the array which is modified in interation.\n\n for tutorial in tutorials:\n paramsToAdd = _resolveStaticTutorial(tutorial)\n copiedTutorial = deepcopy(tutorial)\n copiedTutorial.update(paramsToAdd)\n\n resolvedTutorials.append(copiedTutorial)\n\n return resolvedTutorials\n\n\ndef _resolveDynamicTutorial(evaluatedQs):\n \"\"\"\n\n\n :param evaluatedQs: Evaluated queryset object\n :return:\n \"\"\"\n\n # Initialize dict that stores a tutorial\n currentTutorial = {'id': '', 'title': '', 'html': '', 'markdown': '', 'category': '', 'media_src': '', 'level': ''}\n\n # populate dict\n currentTutorial.update(id=str(evaluatedQs.id),\n title=evaluatedQs.title,\n html=evaluatedQs.html,\n markdown=evaluatedQs.markdown,\n category= evaluatedQs.category,\n media_src= evaluatedQs.media_src,\n level=evaluatedQs.level)\n\n return currentTutorial\n\n\ndef _resolveDynamicTutorials(tutorials_qs):\n \"\"\"\n Evaluates a QuerySet and passes each evaluated object to the next function which returns a python\n dictionary that contains all parameters from the object as dict. The dict is added to a list to\n later merge the static and dynamic tutorials together.\n\n :param tutorials_qs:\n :return:\n \"\"\"\n resolvedTutorials = []\n\n for tutorial in tutorials_qs:\n paramsToAdd = _resolveDynamicTutorial(tutorial)\n\n resolvedTutorials.append(paramsToAdd)\n\n return resolvedTutorials\n\n\ndef _gatherTutorials(id=None):\n \"\"\"\n Collects all existing tutorials (static/dynamic) and returns them as a list. If an id is\n specified as parameter a specific tutorial is returned filtered by id.\n\n :param id:\n :return:\n \"\"\"\n\n # Retrieve allTutorials objects from db and cache\n dynamicTutorialsQs = Tutorial.objects.all()\n\n tutorials = _resolveStaticTutorials(staticTutorials)\n tutorials.extend(_resolveDynamicTutorials(dynamicTutorialsQs))\n\n if id:\n filteredElement = list(filter(lambda tutorial: tutorial[\"id\"] == id, tutorials))[0]\n return filteredElement\n\n return tutorials\n\ndef _processFormInput(form):\n tutorial = form.save(commit=False)\n # Add more information to the dataset like date, time, contributor ...\n\n if tutorial.media_src:\n matchResult = youtubeUrlRegex.match(tutorial.media_src)\n videoId = matchResult.group(1) if matchResult else None\n if videoId:\n tutorial.media_src = \"https://www.youtube.com/embed/\" + videoId\n\n return tutorial\n\ndef formattedMarkdown(markdown):\n \"\"\"\n A parameter is used to enter a text formatted as markdown that is formatted\n to html and returned. This functionality is implemented using Markdown2.\n\n :param markdown:\n :return:\n \"\"\"\n\n # escapes html but also escapes html code blocks lke \"exampel code:\n # (1 tab) code\"\n # checkbox also not rendered as expected \"- [ ]\"\n markdowner = Markdown(safe_mode=True)\n markdowner.html_removed_text = \"\"\n\n return markdowner.convert(markdown)\n\n\nclass ListTutorials(View):\n def get(self, request):\n \"\"\"\n Load and list the available tutorials.\n\n :param request: A HTTP-request object sent by the Django framework.\n :return: Tutorials renderer\n \"\"\"\n\n # Gathering all tutorials\n\n tutorials = _gatherTutorials()\n\n return render(\n request, 'list.html', {\"tutorials\": tutorials}\n )\n\n\nclass TutorialDetail(View):\n def get(self, request, tutorial_id):\n \"\"\"\n Detail view for specific tutorial.\n\n :param request: A HTTP-request object sent by the Django framework.\n :return: Tutorials renderer\n \"\"\"\n\n # Gathering all tutorials\n\n tutorial = _gatherTutorials(tutorial_id)\n\n return render(\n request, 'detail.html', {\"tutorial\": tutorial}\n )\n\n\nclass CreateNewTutorial(LoginRequiredMixin, CreateView):\n template_name = 'add.html'\n redirect_url = 'detail_tutorial'\n form_class = TutorialForm\n login_url = '/user/login/'\n redirect_field_name = 'redirect_to'\n\n def form_valid(self, form):\n \"\"\"\n validates a form and stores the values in the database and inserts a\n value for the tutorials field html.\n\n :param form:\n :return:\n \"\"\"\n\n tutorial = _processFormInput(form)\n tutorial.save()\n\n # Convert markdown to HTML and save to db\n _html = formattedMarkdown(tutorial.markdown)\n addHtml = Tutorial.objects.get(pk=tutorial.id)\n addHtml.html = _html\n addHtml.save()\n\n return redirect(self.redirect_url, tutorial_id=tutorial.id)\n\n def addTutorialFromMarkdownFile(self):\n pass\n\n\nclass EditTutorials(LoginRequiredMixin, UpdateView):\n template_name = 'add.html'\n redirect_url = 'detail_tutorial'\n model = Tutorial\n form_class = TutorialForm\n pk_url_kwarg = 'tutorial_id'\n login_url = '/user/login/'\n redirect_field_name = 'redirect_to'\n\n def form_valid(self, form):\n \"\"\"\n validates a form and stores the values in the database and inserts a\n value for the tutorials field html.\n\n :param form:\n :return:\n \"\"\"\n tutorial = _processFormInput(form)\n tutorial.save()\n\n _html = formattedMarkdown(tutorial.markdown)\n addHtml = Tutorial.objects.get(pk=tutorial.id)\n addHtml.html = _html\n addHtml.save()\n\n return redirect(self.redirect_url, tutorial_id=tutorial.id)\n\n\nclass DeleteTutorial(LoginRequiredMixin, DeleteView):\n template_name = 'tutorial_confirm_delete.html'\n model = Tutorial\n pk_url_kwarg = 'tutorial_id'\n success_url = reverse_lazy('list_tutorials')\n login_url = '/user/login/'\n redirect_field_name = 'redirect_to'\n\n\n\n\n\n\n\n\n", "path": "tutorials/views.py"}]}
| 3,729 | 134 |
gh_patches_debug_16649
|
rasdani/github-patches
|
git_diff
|
pyjanitor-devs__pyjanitor-1259
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Deprecate functions ?
Central point to discuss functions to deprecate, if any?
- [x] `process_text` - `transform_columns` covers this very well
- [x] `impute` vs `fill_empty` - `impute` has the advantage of extra statistics functions (mean, mode, ...)
- [x] `rename_columns` - use pandas `rename`
- [x] `rename_column` - use `pd.rename`
- [x] `remove_columns` - use `pd.drop` or `select`
- [x] `filter_on` - use `query` or `select`
- [x] `fill_direction` - use `transform_columns` or `pd.DataFrame.assign`
- [x] `groupby_agg` - use `transform_columns` - once `by` is implemented
- [x] `then` - use `pd.DataFrame.pipe`
- [x] `to_datetime` - use `jn.transform_columns`
- [x] `pivot_wider` - use `pd.DataFrame.pivot`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `janitor/functions/then.py`
Content:
```
1 """Implementation source for `then`."""
2 from typing import Callable
3 import pandas_flavor as pf
4 import pandas as pd
5
6
7 @pf.register_dataframe_method
8 def then(df: pd.DataFrame, func: Callable) -> pd.DataFrame:
9 """Add an arbitrary function to run in the `pyjanitor` method chain.
10
11 This method does not mutate the original DataFrame.
12
13 Examples:
14 A trivial example using a lambda `func`.
15
16 >>> import pandas as pd
17 >>> import janitor
18 >>> (pd.DataFrame({"a": [1, 2, 3], "b": [7, 8, 9]})
19 ... .then(lambda df: df * 2))
20 a b
21 0 2 14
22 1 4 16
23 2 6 18
24
25 Args:
26 df: A pandas DataFrame.
27 func: A function you would like to run in the method chain.
28 It should take one parameter and return one parameter, each being
29 the DataFrame object. After that, do whatever you want in the
30 middle. Go crazy.
31
32 Returns:
33 A pandas DataFrame.
34 """
35 df = func(df)
36 return df
37
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/janitor/functions/then.py b/janitor/functions/then.py
--- a/janitor/functions/then.py
+++ b/janitor/functions/then.py
@@ -2,14 +2,25 @@
from typing import Callable
import pandas_flavor as pf
import pandas as pd
+from janitor.utils import refactored_function
[email protected]_dataframe_method
+@refactored_function(
+ message="This function will be deprecated in a 1.x release. "
+ "Kindly use `pd.DataFrame.pipe` instead."
+)
@pf.register_dataframe_method
def then(df: pd.DataFrame, func: Callable) -> pd.DataFrame:
"""Add an arbitrary function to run in the `pyjanitor` method chain.
This method does not mutate the original DataFrame.
+ !!!note
+
+ This function will be deprecated in a 1.x release.
+ Please use `pd.DataFrame.pipe` instead.
+
Examples:
A trivial example using a lambda `func`.
|
{"golden_diff": "diff --git a/janitor/functions/then.py b/janitor/functions/then.py\n--- a/janitor/functions/then.py\n+++ b/janitor/functions/then.py\n@@ -2,14 +2,25 @@\n from typing import Callable\n import pandas_flavor as pf\n import pandas as pd\n+from janitor.utils import refactored_function\n \n \[email protected]_dataframe_method\n+@refactored_function(\n+ message=\"This function will be deprecated in a 1.x release. \"\n+ \"Kindly use `pd.DataFrame.pipe` instead.\"\n+)\n @pf.register_dataframe_method\n def then(df: pd.DataFrame, func: Callable) -> pd.DataFrame:\n \"\"\"Add an arbitrary function to run in the `pyjanitor` method chain.\n \n This method does not mutate the original DataFrame.\n \n+ !!!note\n+\n+ This function will be deprecated in a 1.x release.\n+ Please use `pd.DataFrame.pipe` instead.\n+\n Examples:\n A trivial example using a lambda `func`.\n", "issue": "Deprecate functions ?\nCentral point to discuss functions to deprecate, if any?\r\n\r\n- [x] `process_text` - `transform_columns` covers this very well\r\n- [x] `impute` vs `fill_empty` - `impute` has the advantage of extra statistics functions (mean, mode, ...)\r\n- [x] `rename_columns` - use pandas `rename`\r\n- [x] `rename_column` - use `pd.rename`\r\n- [x] `remove_columns` - use `pd.drop` or `select`\r\n- [x] `filter_on` - use `query` or `select`\r\n- [x] `fill_direction` - use `transform_columns` or `pd.DataFrame.assign`\r\n- [x] `groupby_agg` - use `transform_columns` - once `by` is implemented\r\n- [x] `then` - use `pd.DataFrame.pipe`\r\n- [x] `to_datetime` - use `jn.transform_columns`\r\n- [x] `pivot_wider` - use `pd.DataFrame.pivot`\n", "before_files": [{"content": "\"\"\"Implementation source for `then`.\"\"\"\nfrom typing import Callable\nimport pandas_flavor as pf\nimport pandas as pd\n\n\[email protected]_dataframe_method\ndef then(df: pd.DataFrame, func: Callable) -> pd.DataFrame:\n \"\"\"Add an arbitrary function to run in the `pyjanitor` method chain.\n\n This method does not mutate the original DataFrame.\n\n Examples:\n A trivial example using a lambda `func`.\n\n >>> import pandas as pd\n >>> import janitor\n >>> (pd.DataFrame({\"a\": [1, 2, 3], \"b\": [7, 8, 9]})\n ... .then(lambda df: df * 2))\n a b\n 0 2 14\n 1 4 16\n 2 6 18\n\n Args:\n df: A pandas DataFrame.\n func: A function you would like to run in the method chain.\n It should take one parameter and return one parameter, each being\n the DataFrame object. After that, do whatever you want in the\n middle. Go crazy.\n\n Returns:\n A pandas DataFrame.\n \"\"\"\n df = func(df)\n return df\n", "path": "janitor/functions/then.py"}], "after_files": [{"content": "\"\"\"Implementation source for `then`.\"\"\"\nfrom typing import Callable\nimport pandas_flavor as pf\nimport pandas as pd\nfrom janitor.utils import refactored_function\n\n\[email protected]_dataframe_method\n@refactored_function(\n message=\"This function will be deprecated in a 1.x release. \"\n \"Kindly use `pd.DataFrame.pipe` instead.\"\n)\[email protected]_dataframe_method\ndef then(df: pd.DataFrame, func: Callable) -> pd.DataFrame:\n \"\"\"Add an arbitrary function to run in the `pyjanitor` method chain.\n\n This method does not mutate the original DataFrame.\n\n !!!note\n\n This function will be deprecated in a 1.x release.\n Please use `pd.DataFrame.pipe` instead.\n\n Examples:\n A trivial example using a lambda `func`.\n\n >>> import pandas as pd\n >>> import janitor\n >>> (pd.DataFrame({\"a\": [1, 2, 3], \"b\": [7, 8, 9]})\n ... .then(lambda df: df * 2))\n a b\n 0 2 14\n 1 4 16\n 2 6 18\n\n Args:\n df: A pandas DataFrame.\n func: A function you would like to run in the method chain.\n It should take one parameter and return one parameter, each being\n the DataFrame object. After that, do whatever you want in the\n middle. Go crazy.\n\n Returns:\n A pandas DataFrame.\n \"\"\"\n df = func(df)\n return df\n", "path": "janitor/functions/then.py"}]}
| 813 | 223 |
gh_patches_debug_31556
|
rasdani/github-patches
|
git_diff
|
easybuilders__easybuild-easyblocks-2338
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Qt Make/Ninja interaction
When building Qt5 5.12.8 I observed that the QtWebEngine part was very slow. It uses Ninja inside Make and for some reason Ninja only spawned one g++ process at a time. Now I did use something non-standard, namely using a Gentoo Prefix Ninja, which is a fork with support for the GNU Make jobserver (https://github.com/Kitware/ninja), and that was what caused this interaction.
However when putting ninja 1.10.0 as a builddependency I see this:
```
Checking for system ninja... no
```
and it then proceeds to build and use an included Ninja in (`qtwebengine/src/3rdparty/ninja/ninja`), which is Ninja version 1.8.2 in this case.
From a pure EB perspective I see two issues here:
1. The Qt make procedure has this check (also in 5.14.1):
```
contains(version, "1.[7-9].*"): return(true)
qtLog("Ninja version too old")
```
Ninja 1.10 fails this test and that's why it uses the included Ninja instead of the builddep.
2. Ninja by default (ie. not the one with GNU Make jobserver support) will gobble up all cores. If you want to avoid that you need to pass it an explicit `-jN` flag, via `prebuildopts = "NINJAFLAGS='-j8'"` (see https://patchwork.ozlabs.org/project/buildroot/patch/[email protected]/ )
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `easybuild/easyblocks/q/qt.py`
Content:
```
1 ##
2 # Copyright 2013-2021 Ghent University
3 #
4 # This file is part of EasyBuild,
5 # originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),
6 # with support of Ghent University (http://ugent.be/hpc),
7 # the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),
8 # Flemish Research Foundation (FWO) (http://www.fwo.be/en)
9 # and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).
10 #
11 # https://github.com/easybuilders/easybuild
12 #
13 # EasyBuild is free software: you can redistribute it and/or modify
14 # it under the terms of the GNU General Public License as published by
15 # the Free Software Foundation v2.
16 #
17 # EasyBuild is distributed in the hope that it will be useful,
18 # but WITHOUT ANY WARRANTY; without even the implied warranty of
19 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
20 # GNU General Public License for more details.
21 #
22 # You should have received a copy of the GNU General Public License
23 # along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.
24 ##
25 """
26 EasyBuild support for building and installing Qt, implemented as an easyblock
27
28 @author: Kenneth Hoste (Ghent University)
29 """
30 import os
31 from distutils.version import LooseVersion
32
33 import easybuild.tools.toolchain as toolchain
34 from easybuild.easyblocks.generic.configuremake import ConfigureMake
35 from easybuild.framework.easyconfig import CUSTOM
36 from easybuild.tools.build_log import EasyBuildError
37 from easybuild.tools.filetools import apply_regex_substitutions
38 from easybuild.tools.run import run_cmd_qa
39 from easybuild.tools.systemtools import get_cpu_architecture, get_glibc_version, get_shared_lib_ext
40 from easybuild.tools.systemtools import AARCH64, POWER
41
42
43 class EB_Qt(ConfigureMake):
44 """
45 Support for building and installing Qt.
46 """
47
48 @staticmethod
49 def extra_options():
50 extra_vars = {
51 'check_qtwebengine': [False, "Make sure QtWebEngine components is installed", CUSTOM],
52 'disable_advanced_kernel_features': [False, "Disable features that require a kernel > 3.15", CUSTOM],
53 'platform': [None, "Target platform to build for (e.g. linux-g++-64, linux-icc-64)", CUSTOM],
54 }
55 extra_vars = ConfigureMake.extra_options(extra_vars)
56
57 # allowing to specify prefix_opt doesn't make sense for Qt, since -prefix is hardcoded in configure_step
58 del extra_vars['prefix_opt']
59
60 return extra_vars
61
62 def configure_step(self):
63 """Configure Qt using interactive `configure` script."""
64
65 self.cfg.update('configopts', '-release')
66
67 platform = None
68 comp_fam = self.toolchain.comp_family()
69 if self.cfg['platform']:
70 platform = self.cfg['platform']
71 # if no platform is specified, try to derive it based on compiler in toolchain
72 elif comp_fam in [toolchain.GCC]: # @UndefinedVariable
73 myarch = get_cpu_architecture()
74 if myarch == AARCH64:
75 platform = 'linux-g++'
76 else:
77 platform = 'linux-g++-64'
78 elif comp_fam in [toolchain.INTELCOMP]: # @UndefinedVariable
79 if LooseVersion(self.version) >= LooseVersion('4'):
80 platform = 'linux-icc-64'
81 else:
82 platform = 'linux-icc'
83 # fix -fPIC flag (-KPIC is not correct for recent Intel compilers)
84 qmake_conf = os.path.join('mkspecs', platform, 'qmake.conf')
85 apply_regex_substitutions(qmake_conf, [('-KPIC', '-fPIC')])
86
87 if platform:
88 self.cfg.update('configopts', "-platform %s" % platform)
89 else:
90 raise EasyBuildError("Don't know which platform to set based on compiler family.")
91
92 if LooseVersion(self.version) >= LooseVersion('5.8'):
93 # Qt5 doesn't respect $CFLAGS, $CXXFLAGS and $LDFLAGS, but has equivalent compiler options,
94 # e.g. QMAKE_CFLAGS; see https://doc.qt.io/qt-5/qmake-variable-reference.html#qmake-cc.
95 # Since EasyBuild relies e.g. for --optarch on $CFLAGS, we need to
96 # set the equivalent QMAKE_* configure options.
97 # (see also https://github.com/easybuilders/easybuild-easyblocks/issues/1670)
98 env_to_options = {
99 'CC': 'QMAKE_CC',
100 'CFLAGS': 'QMAKE_CFLAGS',
101 'CXX': 'QMAKE_CXX',
102 'CXXFLAGS': 'QMAKE_CXXFLAGS',
103 # QMAKE_LFLAGS is not a typo, see: https://doc.qt.io/qt-5/qmake-variable-reference.html#qmake-lflags
104 'LDFLAGS': 'QMAKE_LFLAGS',
105 }
106 for env_name, option in sorted(env_to_options.items()):
107 value = os.getenv(env_name)
108 if value is not None:
109 if env_name.endswith('FLAGS'):
110 # For *FLAGS, we add to existing flags (e.g. those set in Qt's .pro-files).
111 config_opt = option + '+="%s"'
112 else:
113 # For compilers, we replace QMAKE_CC/CXX
114 # (otherwise, you get e.g. QMAKE_CC="g++ g++", which fails)
115 config_opt = option + '="%s"'
116
117 self.cfg.update('configopts', config_opt % value)
118
119 # configure Qt such that xmlpatterns is also installed
120 # -xmlpatterns is not a known configure option for Qt 5.x, but there xmlpatterns support is enabled by default
121 if LooseVersion(self.version) >= LooseVersion('4') and LooseVersion(self.version) < LooseVersion('5'):
122 self.cfg.update('configopts', '-xmlpatterns')
123
124 # disable specific features to avoid that libQt5Core.so being tagged as requiring kernel 3.17,
125 # which causes confusing problems like this even though the file exists and can be found by...
126 # error while loading shared libraries: libQt5Core.so.5:
127 # cannot open shared object file: No such file or directory
128 # see also:
129 # * https://bugs.gentoo.org/669994
130 # * https://github.com/NixOS/nixpkgs/commit/a7b6a9199e8db54a798d011a0946cdeb72cfc46b
131 # * https://gitweb.gentoo.org/proj/qt.git/commit/?id=9ff0752e1ee3c28818197eaaca45545708035152
132 kernel_version = os.uname()[2]
133 skip_kernel_features = self.cfg['disable_advanced_kernel_features']
134 old_kernel_version = LooseVersion(kernel_version) < LooseVersion('3.17')
135 if LooseVersion(self.version) >= LooseVersion('5.10') and (skip_kernel_features or old_kernel_version):
136 self.cfg.update('configopts', '-no-feature-renameat2')
137 self.cfg.update('configopts', '-no-feature-getentropy')
138
139 cmd = "%s ./configure -prefix %s %s" % (self.cfg['preconfigopts'], self.installdir, self.cfg['configopts'])
140 qa = {
141 "Type 'o' if you want to use the Open Source Edition.": 'o',
142 "Do you accept the terms of either license?": 'yes',
143 "Which edition of Qt do you want to use?": 'o',
144 }
145 no_qa = [
146 "for .*pro",
147 r"%s.*" % os.getenv('CXX', '').replace('+', '\\+'), # need to escape + in 'g++'
148 "Reading .*",
149 "WARNING .*",
150 "Project MESSAGE:.*",
151 "rm -f .*",
152 'Creating qmake...',
153 'Checking for .*...',
154 ]
155 run_cmd_qa(cmd, qa, no_qa=no_qa, log_all=True, simple=True, maxhits=120)
156
157 def build_step(self):
158 """Set $LD_LIBRARY_PATH before calling make, to ensure that all required libraries are found during linking."""
159 # cfr. https://elist.ornl.gov/pipermail/visit-developers/2011-September/010063.html
160
161 if LooseVersion(self.version) >= LooseVersion('5.6'):
162 libdirs = ['qtbase', 'qtdeclarative']
163 else:
164 libdirs = ['']
165
166 libdirs = [os.path.join(self.cfg['start_dir'], d, 'lib') for d in libdirs]
167 self.cfg.update('prebuildopts', 'LD_LIBRARY_PATH=%s' % os.pathsep.join(libdirs + ['$LD_LIBRARY_PATH']))
168
169 super(EB_Qt, self).build_step()
170
171 def sanity_check_step(self):
172 """Custom sanity check for Qt."""
173
174 shlib_ext = get_shared_lib_ext()
175
176 if LooseVersion(self.version) >= LooseVersion('4'):
177 libversion = ''
178 if LooseVersion(self.version) >= LooseVersion('5'):
179 libversion = self.version.split('.')[0]
180
181 libfile = os.path.join('lib', 'libQt%sCore.%s' % (libversion, shlib_ext))
182
183 else:
184 libfile = os.path.join('lib', 'libqt.%s' % shlib_ext)
185
186 custom_paths = {
187 'files': ['bin/moc', 'bin/qmake', libfile],
188 'dirs': ['include', 'plugins'],
189 }
190
191 if self.cfg['check_qtwebengine']:
192 glibc_version = get_glibc_version()
193 myarch = get_cpu_architecture()
194 if LooseVersion(glibc_version) <= LooseVersion("2.16"):
195 self.log.debug("Skipping check for qtwebengine, since it requires a more recent glibc.")
196 elif myarch == POWER:
197 self.log.debug("Skipping check for qtwebengine, since it is not supported on POWER.")
198 else:
199 qtwebengine_libs = ['libQt%s%s.%s' % (libversion, x, shlib_ext) for x in ['WebEngine', 'WebEngineCore']]
200 custom_paths['files'].extend([os.path.join('lib', lib) for lib in qtwebengine_libs])
201
202 if LooseVersion(self.version) >= LooseVersion('4'):
203 custom_paths['files'].append('bin/xmlpatterns')
204
205 super(EB_Qt, self).sanity_check_step(custom_paths=custom_paths)
206
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/easybuild/easyblocks/q/qt.py b/easybuild/easyblocks/q/qt.py
--- a/easybuild/easyblocks/q/qt.py
+++ b/easybuild/easyblocks/q/qt.py
@@ -30,11 +30,13 @@
import os
from distutils.version import LooseVersion
+import easybuild.tools.environment as env
import easybuild.tools.toolchain as toolchain
from easybuild.easyblocks.generic.configuremake import ConfigureMake
from easybuild.framework.easyconfig import CUSTOM
from easybuild.tools.build_log import EasyBuildError
from easybuild.tools.filetools import apply_regex_substitutions
+from easybuild.tools.modules import get_software_root
from easybuild.tools.run import run_cmd_qa
from easybuild.tools.systemtools import get_cpu_architecture, get_glibc_version, get_shared_lib_ext
from easybuild.tools.systemtools import AARCH64, POWER
@@ -154,6 +156,13 @@
]
run_cmd_qa(cmd, qa, no_qa=no_qa, log_all=True, simple=True, maxhits=120)
+ # Ninja uses all visible cores by default, which can lead to lack of sufficient memory;
+ # so $NINJAFLAGS is set to control number of parallel processes used by Ninja;
+ # note that $NINJAFLAGS is not a generic thing for Ninja, it's very specific to the Qt5 build procedure
+ if LooseVersion(self.version) >= LooseVersion('5'):
+ if get_software_root('Ninja'):
+ env.setvar('NINJAFLAGS', '-j%s' % self.cfg['parallel'])
+
def build_step(self):
"""Set $LD_LIBRARY_PATH before calling make, to ensure that all required libraries are found during linking."""
# cfr. https://elist.ornl.gov/pipermail/visit-developers/2011-September/010063.html
|
{"golden_diff": "diff --git a/easybuild/easyblocks/q/qt.py b/easybuild/easyblocks/q/qt.py\n--- a/easybuild/easyblocks/q/qt.py\n+++ b/easybuild/easyblocks/q/qt.py\n@@ -30,11 +30,13 @@\n import os\n from distutils.version import LooseVersion\n \n+import easybuild.tools.environment as env\n import easybuild.tools.toolchain as toolchain\n from easybuild.easyblocks.generic.configuremake import ConfigureMake\n from easybuild.framework.easyconfig import CUSTOM\n from easybuild.tools.build_log import EasyBuildError\n from easybuild.tools.filetools import apply_regex_substitutions\n+from easybuild.tools.modules import get_software_root\n from easybuild.tools.run import run_cmd_qa\n from easybuild.tools.systemtools import get_cpu_architecture, get_glibc_version, get_shared_lib_ext\n from easybuild.tools.systemtools import AARCH64, POWER\n@@ -154,6 +156,13 @@\n ]\n run_cmd_qa(cmd, qa, no_qa=no_qa, log_all=True, simple=True, maxhits=120)\n \n+ # Ninja uses all visible cores by default, which can lead to lack of sufficient memory;\n+ # so $NINJAFLAGS is set to control number of parallel processes used by Ninja;\n+ # note that $NINJAFLAGS is not a generic thing for Ninja, it's very specific to the Qt5 build procedure\n+ if LooseVersion(self.version) >= LooseVersion('5'):\n+ if get_software_root('Ninja'):\n+ env.setvar('NINJAFLAGS', '-j%s' % self.cfg['parallel'])\n+\n def build_step(self):\n \"\"\"Set $LD_LIBRARY_PATH before calling make, to ensure that all required libraries are found during linking.\"\"\"\n # cfr. https://elist.ornl.gov/pipermail/visit-developers/2011-September/010063.html\n", "issue": "Qt Make/Ninja interaction\nWhen building Qt5 5.12.8 I observed that the QtWebEngine part was very slow. It uses Ninja inside Make and for some reason Ninja only spawned one g++ process at a time. Now I did use something non-standard, namely using a Gentoo Prefix Ninja, which is a fork with support for the GNU Make jobserver (https://github.com/Kitware/ninja), and that was what caused this interaction.\r\n\r\nHowever when putting ninja 1.10.0 as a builddependency I see this:\r\n```\r\nChecking for system ninja... no\r\n```\r\nand it then proceeds to build and use an included Ninja in (`qtwebengine/src/3rdparty/ninja/ninja`), which is Ninja version 1.8.2 in this case.\r\nFrom a pure EB perspective I see two issues here:\r\n\r\n1. The Qt make procedure has this check (also in 5.14.1): \r\n``` \r\n contains(version, \"1.[7-9].*\"): return(true)\r\n qtLog(\"Ninja version too old\")\r\n```\r\nNinja 1.10 fails this test and that's why it uses the included Ninja instead of the builddep.\r\n\r\n2. Ninja by default (ie. not the one with GNU Make jobserver support) will gobble up all cores. If you want to avoid that you need to pass it an explicit `-jN` flag, via `prebuildopts = \"NINJAFLAGS='-j8'\"` (see https://patchwork.ozlabs.org/project/buildroot/patch/[email protected]/ )\n", "before_files": [{"content": "##\n# Copyright 2013-2021 Ghent University\n#\n# This file is part of EasyBuild,\n# originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),\n# with support of Ghent University (http://ugent.be/hpc),\n# the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),\n# Flemish Research Foundation (FWO) (http://www.fwo.be/en)\n# and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).\n#\n# https://github.com/easybuilders/easybuild\n#\n# EasyBuild is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation v2.\n#\n# EasyBuild is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.\n##\n\"\"\"\nEasyBuild support for building and installing Qt, implemented as an easyblock\n\n@author: Kenneth Hoste (Ghent University)\n\"\"\"\nimport os\nfrom distutils.version import LooseVersion\n\nimport easybuild.tools.toolchain as toolchain\nfrom easybuild.easyblocks.generic.configuremake import ConfigureMake\nfrom easybuild.framework.easyconfig import CUSTOM\nfrom easybuild.tools.build_log import EasyBuildError\nfrom easybuild.tools.filetools import apply_regex_substitutions\nfrom easybuild.tools.run import run_cmd_qa\nfrom easybuild.tools.systemtools import get_cpu_architecture, get_glibc_version, get_shared_lib_ext\nfrom easybuild.tools.systemtools import AARCH64, POWER\n\n\nclass EB_Qt(ConfigureMake):\n \"\"\"\n Support for building and installing Qt.\n \"\"\"\n\n @staticmethod\n def extra_options():\n extra_vars = {\n 'check_qtwebengine': [False, \"Make sure QtWebEngine components is installed\", CUSTOM],\n 'disable_advanced_kernel_features': [False, \"Disable features that require a kernel > 3.15\", CUSTOM],\n 'platform': [None, \"Target platform to build for (e.g. linux-g++-64, linux-icc-64)\", CUSTOM],\n }\n extra_vars = ConfigureMake.extra_options(extra_vars)\n\n # allowing to specify prefix_opt doesn't make sense for Qt, since -prefix is hardcoded in configure_step\n del extra_vars['prefix_opt']\n\n return extra_vars\n\n def configure_step(self):\n \"\"\"Configure Qt using interactive `configure` script.\"\"\"\n\n self.cfg.update('configopts', '-release')\n\n platform = None\n comp_fam = self.toolchain.comp_family()\n if self.cfg['platform']:\n platform = self.cfg['platform']\n # if no platform is specified, try to derive it based on compiler in toolchain\n elif comp_fam in [toolchain.GCC]: # @UndefinedVariable\n myarch = get_cpu_architecture()\n if myarch == AARCH64:\n platform = 'linux-g++'\n else:\n platform = 'linux-g++-64'\n elif comp_fam in [toolchain.INTELCOMP]: # @UndefinedVariable\n if LooseVersion(self.version) >= LooseVersion('4'):\n platform = 'linux-icc-64'\n else:\n platform = 'linux-icc'\n # fix -fPIC flag (-KPIC is not correct for recent Intel compilers)\n qmake_conf = os.path.join('mkspecs', platform, 'qmake.conf')\n apply_regex_substitutions(qmake_conf, [('-KPIC', '-fPIC')])\n\n if platform:\n self.cfg.update('configopts', \"-platform %s\" % platform)\n else:\n raise EasyBuildError(\"Don't know which platform to set based on compiler family.\")\n\n if LooseVersion(self.version) >= LooseVersion('5.8'):\n # Qt5 doesn't respect $CFLAGS, $CXXFLAGS and $LDFLAGS, but has equivalent compiler options,\n # e.g. QMAKE_CFLAGS; see https://doc.qt.io/qt-5/qmake-variable-reference.html#qmake-cc.\n # Since EasyBuild relies e.g. for --optarch on $CFLAGS, we need to\n # set the equivalent QMAKE_* configure options.\n # (see also https://github.com/easybuilders/easybuild-easyblocks/issues/1670)\n env_to_options = {\n 'CC': 'QMAKE_CC',\n 'CFLAGS': 'QMAKE_CFLAGS',\n 'CXX': 'QMAKE_CXX',\n 'CXXFLAGS': 'QMAKE_CXXFLAGS',\n # QMAKE_LFLAGS is not a typo, see: https://doc.qt.io/qt-5/qmake-variable-reference.html#qmake-lflags\n 'LDFLAGS': 'QMAKE_LFLAGS',\n }\n for env_name, option in sorted(env_to_options.items()):\n value = os.getenv(env_name)\n if value is not None:\n if env_name.endswith('FLAGS'):\n # For *FLAGS, we add to existing flags (e.g. those set in Qt's .pro-files).\n config_opt = option + '+=\"%s\"'\n else:\n # For compilers, we replace QMAKE_CC/CXX\n # (otherwise, you get e.g. QMAKE_CC=\"g++ g++\", which fails)\n config_opt = option + '=\"%s\"'\n\n self.cfg.update('configopts', config_opt % value)\n\n # configure Qt such that xmlpatterns is also installed\n # -xmlpatterns is not a known configure option for Qt 5.x, but there xmlpatterns support is enabled by default\n if LooseVersion(self.version) >= LooseVersion('4') and LooseVersion(self.version) < LooseVersion('5'):\n self.cfg.update('configopts', '-xmlpatterns')\n\n # disable specific features to avoid that libQt5Core.so being tagged as requiring kernel 3.17,\n # which causes confusing problems like this even though the file exists and can be found by...\n # error while loading shared libraries: libQt5Core.so.5:\n # cannot open shared object file: No such file or directory\n # see also:\n # * https://bugs.gentoo.org/669994\n # * https://github.com/NixOS/nixpkgs/commit/a7b6a9199e8db54a798d011a0946cdeb72cfc46b\n # * https://gitweb.gentoo.org/proj/qt.git/commit/?id=9ff0752e1ee3c28818197eaaca45545708035152\n kernel_version = os.uname()[2]\n skip_kernel_features = self.cfg['disable_advanced_kernel_features']\n old_kernel_version = LooseVersion(kernel_version) < LooseVersion('3.17')\n if LooseVersion(self.version) >= LooseVersion('5.10') and (skip_kernel_features or old_kernel_version):\n self.cfg.update('configopts', '-no-feature-renameat2')\n self.cfg.update('configopts', '-no-feature-getentropy')\n\n cmd = \"%s ./configure -prefix %s %s\" % (self.cfg['preconfigopts'], self.installdir, self.cfg['configopts'])\n qa = {\n \"Type 'o' if you want to use the Open Source Edition.\": 'o',\n \"Do you accept the terms of either license?\": 'yes',\n \"Which edition of Qt do you want to use?\": 'o',\n }\n no_qa = [\n \"for .*pro\",\n r\"%s.*\" % os.getenv('CXX', '').replace('+', '\\\\+'), # need to escape + in 'g++'\n \"Reading .*\",\n \"WARNING .*\",\n \"Project MESSAGE:.*\",\n \"rm -f .*\",\n 'Creating qmake...',\n 'Checking for .*...',\n ]\n run_cmd_qa(cmd, qa, no_qa=no_qa, log_all=True, simple=True, maxhits=120)\n\n def build_step(self):\n \"\"\"Set $LD_LIBRARY_PATH before calling make, to ensure that all required libraries are found during linking.\"\"\"\n # cfr. https://elist.ornl.gov/pipermail/visit-developers/2011-September/010063.html\n\n if LooseVersion(self.version) >= LooseVersion('5.6'):\n libdirs = ['qtbase', 'qtdeclarative']\n else:\n libdirs = ['']\n\n libdirs = [os.path.join(self.cfg['start_dir'], d, 'lib') for d in libdirs]\n self.cfg.update('prebuildopts', 'LD_LIBRARY_PATH=%s' % os.pathsep.join(libdirs + ['$LD_LIBRARY_PATH']))\n\n super(EB_Qt, self).build_step()\n\n def sanity_check_step(self):\n \"\"\"Custom sanity check for Qt.\"\"\"\n\n shlib_ext = get_shared_lib_ext()\n\n if LooseVersion(self.version) >= LooseVersion('4'):\n libversion = ''\n if LooseVersion(self.version) >= LooseVersion('5'):\n libversion = self.version.split('.')[0]\n\n libfile = os.path.join('lib', 'libQt%sCore.%s' % (libversion, shlib_ext))\n\n else:\n libfile = os.path.join('lib', 'libqt.%s' % shlib_ext)\n\n custom_paths = {\n 'files': ['bin/moc', 'bin/qmake', libfile],\n 'dirs': ['include', 'plugins'],\n }\n\n if self.cfg['check_qtwebengine']:\n glibc_version = get_glibc_version()\n myarch = get_cpu_architecture()\n if LooseVersion(glibc_version) <= LooseVersion(\"2.16\"):\n self.log.debug(\"Skipping check for qtwebengine, since it requires a more recent glibc.\")\n elif myarch == POWER:\n self.log.debug(\"Skipping check for qtwebengine, since it is not supported on POWER.\")\n else:\n qtwebengine_libs = ['libQt%s%s.%s' % (libversion, x, shlib_ext) for x in ['WebEngine', 'WebEngineCore']]\n custom_paths['files'].extend([os.path.join('lib', lib) for lib in qtwebengine_libs])\n\n if LooseVersion(self.version) >= LooseVersion('4'):\n custom_paths['files'].append('bin/xmlpatterns')\n\n super(EB_Qt, self).sanity_check_step(custom_paths=custom_paths)\n", "path": "easybuild/easyblocks/q/qt.py"}], "after_files": [{"content": "##\n# Copyright 2013-2021 Ghent University\n#\n# This file is part of EasyBuild,\n# originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),\n# with support of Ghent University (http://ugent.be/hpc),\n# the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),\n# Flemish Research Foundation (FWO) (http://www.fwo.be/en)\n# and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).\n#\n# https://github.com/easybuilders/easybuild\n#\n# EasyBuild is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation v2.\n#\n# EasyBuild is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.\n##\n\"\"\"\nEasyBuild support for building and installing Qt, implemented as an easyblock\n\n@author: Kenneth Hoste (Ghent University)\n\"\"\"\nimport os\nfrom distutils.version import LooseVersion\n\nimport easybuild.tools.environment as env\nimport easybuild.tools.toolchain as toolchain\nfrom easybuild.easyblocks.generic.configuremake import ConfigureMake\nfrom easybuild.framework.easyconfig import CUSTOM\nfrom easybuild.tools.build_log import EasyBuildError\nfrom easybuild.tools.filetools import apply_regex_substitutions\nfrom easybuild.tools.modules import get_software_root\nfrom easybuild.tools.run import run_cmd_qa\nfrom easybuild.tools.systemtools import get_cpu_architecture, get_glibc_version, get_shared_lib_ext\nfrom easybuild.tools.systemtools import AARCH64, POWER\n\n\nclass EB_Qt(ConfigureMake):\n \"\"\"\n Support for building and installing Qt.\n \"\"\"\n\n @staticmethod\n def extra_options():\n extra_vars = {\n 'check_qtwebengine': [False, \"Make sure QtWebEngine components is installed\", CUSTOM],\n 'disable_advanced_kernel_features': [False, \"Disable features that require a kernel > 3.15\", CUSTOM],\n 'platform': [None, \"Target platform to build for (e.g. linux-g++-64, linux-icc-64)\", CUSTOM],\n }\n extra_vars = ConfigureMake.extra_options(extra_vars)\n\n # allowing to specify prefix_opt doesn't make sense for Qt, since -prefix is hardcoded in configure_step\n del extra_vars['prefix_opt']\n\n return extra_vars\n\n def configure_step(self):\n \"\"\"Configure Qt using interactive `configure` script.\"\"\"\n\n self.cfg.update('configopts', '-release')\n\n platform = None\n comp_fam = self.toolchain.comp_family()\n if self.cfg['platform']:\n platform = self.cfg['platform']\n # if no platform is specified, try to derive it based on compiler in toolchain\n elif comp_fam in [toolchain.GCC]: # @UndefinedVariable\n myarch = get_cpu_architecture()\n if myarch == AARCH64:\n platform = 'linux-g++'\n else:\n platform = 'linux-g++-64'\n elif comp_fam in [toolchain.INTELCOMP]: # @UndefinedVariable\n if LooseVersion(self.version) >= LooseVersion('4'):\n platform = 'linux-icc-64'\n else:\n platform = 'linux-icc'\n # fix -fPIC flag (-KPIC is not correct for recent Intel compilers)\n qmake_conf = os.path.join('mkspecs', platform, 'qmake.conf')\n apply_regex_substitutions(qmake_conf, [('-KPIC', '-fPIC')])\n\n if platform:\n self.cfg.update('configopts', \"-platform %s\" % platform)\n else:\n raise EasyBuildError(\"Don't know which platform to set based on compiler family.\")\n\n if LooseVersion(self.version) >= LooseVersion('5.8'):\n # Qt5 doesn't respect $CFLAGS, $CXXFLAGS and $LDFLAGS, but has equivalent compiler options,\n # e.g. QMAKE_CFLAGS; see https://doc.qt.io/qt-5/qmake-variable-reference.html#qmake-cc.\n # Since EasyBuild relies e.g. for --optarch on $CFLAGS, we need to\n # set the equivalent QMAKE_* configure options.\n # (see also https://github.com/easybuilders/easybuild-easyblocks/issues/1670)\n env_to_options = {\n 'CC': 'QMAKE_CC',\n 'CFLAGS': 'QMAKE_CFLAGS',\n 'CXX': 'QMAKE_CXX',\n 'CXXFLAGS': 'QMAKE_CXXFLAGS',\n # QMAKE_LFLAGS is not a typo, see: https://doc.qt.io/qt-5/qmake-variable-reference.html#qmake-lflags\n 'LDFLAGS': 'QMAKE_LFLAGS',\n }\n for env_name, option in sorted(env_to_options.items()):\n value = os.getenv(env_name)\n if value is not None:\n if env_name.endswith('FLAGS'):\n # For *FLAGS, we add to existing flags (e.g. those set in Qt's .pro-files).\n config_opt = option + '+=\"%s\"'\n else:\n # For compilers, we replace QMAKE_CC/CXX\n # (otherwise, you get e.g. QMAKE_CC=\"g++ g++\", which fails)\n config_opt = option + '=\"%s\"'\n\n self.cfg.update('configopts', config_opt % value)\n\n # configure Qt such that xmlpatterns is also installed\n # -xmlpatterns is not a known configure option for Qt 5.x, but there xmlpatterns support is enabled by default\n if LooseVersion(self.version) >= LooseVersion('4') and LooseVersion(self.version) < LooseVersion('5'):\n self.cfg.update('configopts', '-xmlpatterns')\n\n # disable specific features to avoid that libQt5Core.so being tagged as requiring kernel 3.17,\n # which causes confusing problems like this even though the file exists and can be found by...\n # error while loading shared libraries: libQt5Core.so.5:\n # cannot open shared object file: No such file or directory\n # see also:\n # * https://bugs.gentoo.org/669994\n # * https://github.com/NixOS/nixpkgs/commit/a7b6a9199e8db54a798d011a0946cdeb72cfc46b\n # * https://gitweb.gentoo.org/proj/qt.git/commit/?id=9ff0752e1ee3c28818197eaaca45545708035152\n kernel_version = os.uname()[2]\n skip_kernel_features = self.cfg['disable_advanced_kernel_features']\n old_kernel_version = LooseVersion(kernel_version) < LooseVersion('3.17')\n if LooseVersion(self.version) >= LooseVersion('5.10') and (skip_kernel_features or old_kernel_version):\n self.cfg.update('configopts', '-no-feature-renameat2')\n self.cfg.update('configopts', '-no-feature-getentropy')\n\n cmd = \"%s ./configure -prefix %s %s\" % (self.cfg['preconfigopts'], self.installdir, self.cfg['configopts'])\n qa = {\n \"Type 'o' if you want to use the Open Source Edition.\": 'o',\n \"Do you accept the terms of either license?\": 'yes',\n \"Which edition of Qt do you want to use?\": 'o',\n }\n no_qa = [\n \"for .*pro\",\n r\"%s.*\" % os.getenv('CXX', '').replace('+', '\\\\+'), # need to escape + in 'g++'\n \"Reading .*\",\n \"WARNING .*\",\n \"Project MESSAGE:.*\",\n \"rm -f .*\",\n 'Creating qmake...',\n 'Checking for .*...',\n ]\n run_cmd_qa(cmd, qa, no_qa=no_qa, log_all=True, simple=True, maxhits=120)\n\n # Ninja uses all visible cores by default, which can lead to lack of sufficient memory;\n # so $NINJAFLAGS is set to control number of parallel processes used by Ninja;\n # note that $NINJAFLAGS is not a generic thing for Ninja, it's very specific to the Qt5 build procedure\n if LooseVersion(self.version) >= LooseVersion('5'):\n if get_software_root('Ninja'):\n env.setvar('NINJAFLAGS', '-j%s' % self.cfg['parallel'])\n\n def build_step(self):\n \"\"\"Set $LD_LIBRARY_PATH before calling make, to ensure that all required libraries are found during linking.\"\"\"\n # cfr. https://elist.ornl.gov/pipermail/visit-developers/2011-September/010063.html\n\n if LooseVersion(self.version) >= LooseVersion('5.6'):\n libdirs = ['qtbase', 'qtdeclarative']\n else:\n libdirs = ['']\n\n libdirs = [os.path.join(self.cfg['start_dir'], d, 'lib') for d in libdirs]\n self.cfg.update('prebuildopts', 'LD_LIBRARY_PATH=%s' % os.pathsep.join(libdirs + ['$LD_LIBRARY_PATH']))\n\n super(EB_Qt, self).build_step()\n\n def sanity_check_step(self):\n \"\"\"Custom sanity check for Qt.\"\"\"\n\n shlib_ext = get_shared_lib_ext()\n\n if LooseVersion(self.version) >= LooseVersion('4'):\n libversion = ''\n if LooseVersion(self.version) >= LooseVersion('5'):\n libversion = self.version.split('.')[0]\n\n libfile = os.path.join('lib', 'libQt%sCore.%s' % (libversion, shlib_ext))\n\n else:\n libfile = os.path.join('lib', 'libqt.%s' % shlib_ext)\n\n custom_paths = {\n 'files': ['bin/moc', 'bin/qmake', libfile],\n 'dirs': ['include', 'plugins'],\n }\n\n if self.cfg['check_qtwebengine']:\n glibc_version = get_glibc_version()\n myarch = get_cpu_architecture()\n if LooseVersion(glibc_version) <= LooseVersion(\"2.16\"):\n self.log.debug(\"Skipping check for qtwebengine, since it requires a more recent glibc.\")\n elif myarch == POWER:\n self.log.debug(\"Skipping check for qtwebengine, since it is not supported on POWER.\")\n else:\n qtwebengine_libs = ['libQt%s%s.%s' % (libversion, x, shlib_ext) for x in ['WebEngine', 'WebEngineCore']]\n custom_paths['files'].extend([os.path.join('lib', lib) for lib in qtwebengine_libs])\n\n if LooseVersion(self.version) >= LooseVersion('4'):\n custom_paths['files'].append('bin/xmlpatterns')\n\n super(EB_Qt, self).sanity_check_step(custom_paths=custom_paths)\n", "path": "easybuild/easyblocks/q/qt.py"}]}
| 3,495 | 423 |
gh_patches_debug_23622
|
rasdani/github-patches
|
git_diff
|
python__mypy-1908
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Incorrect check on string interpolation
When sending this type-correct code
``` python
d = {"greeting": "hello", "count": 10}
print("%(greeting)s World. %(count)d%% tests failing" % d)
```
through mypy, I get the following:
```
error: String interpolation mixes specifier with and without mapping keys
```
Which should be accepted; the only interpolator I'm using withot keys is "%%" which is just an escape and can not cause problems
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mypy/checkstrformat.py`
Content:
```
1 """Expression type checker. This file is conceptually part of ExpressionChecker and TypeChecker."""
2
3 import re
4
5 from typing import cast, List, Tuple, Dict, Callable
6
7 from mypy.types import (
8 Type, AnyType, TupleType, Instance, UnionType
9 )
10 from mypy.nodes import (
11 Node, StrExpr, BytesExpr, TupleExpr, DictExpr, Context
12 )
13 if False:
14 # break import cycle only needed for mypy
15 import mypy.checker
16 from mypy import messages
17 from mypy.messages import MessageBuilder
18
19
20 class ConversionSpecifier:
21 def __init__(self, key: str, flags: str, width: str, precision: str, type: str) -> None:
22 self.key = key
23 self.flags = flags
24 self.width = width
25 self.precision = precision
26 self.type = type
27
28 def has_key(self) -> bool:
29 return self.key is not None
30
31 def has_star(self) -> bool:
32 return self.width == '*' or self.precision == '*'
33
34
35 class StringFormatterChecker:
36 """String interpolation/formatter type checker.
37
38 This class works closely together with checker.ExpressionChecker.
39 """
40
41 # Some services are provided by a TypeChecker instance.
42 chk = None # type: mypy.checker.TypeChecker
43 # This is shared with TypeChecker, but stored also here for convenience.
44 msg = None # type: MessageBuilder
45 # Some services are provided by a ExpressionChecker instance.
46 exprchk = None # type: mypy.checkexpr.ExpressionChecker
47
48 def __init__(self,
49 exprchk: 'mypy.checkexpr.ExpressionChecker',
50 chk: 'mypy.checker.TypeChecker',
51 msg: MessageBuilder) -> None:
52 """Construct an expression type checker."""
53 self.chk = chk
54 self.exprchk = exprchk
55 self.msg = msg
56
57 def check_str_interpolation(self, str: StrExpr, replacements: Node) -> Type:
58 """Check the types of the 'replacements' in a string interpolation
59 expression: str % replacements
60 """
61 specifiers = self.parse_conversion_specifiers(str.value)
62 has_mapping_keys = self.analyze_conversion_specifiers(specifiers, str)
63 if has_mapping_keys is None:
64 pass # Error was reported
65 elif has_mapping_keys:
66 self.check_mapping_str_interpolation(specifiers, replacements)
67 else:
68 self.check_simple_str_interpolation(specifiers, replacements)
69 return self.named_type('builtins.str')
70
71 def parse_conversion_specifiers(self, format: str) -> List[ConversionSpecifier]:
72 key_regex = r'(\((\w*)\))?' # (optional) parenthesised sequence of characters
73 flags_regex = r'([#0\-+ ]*)' # (optional) sequence of flags
74 width_regex = r'(\*|[1-9][0-9]*)?' # (optional) minimum field width (* or numbers)
75 precision_regex = r'(?:\.(\*|[0-9]+)?)?' # (optional) . followed by * of numbers
76 length_mod_regex = r'[hlL]?' # (optional) length modifier (unused)
77 type_regex = r'(.)?' # conversion type
78 regex = ('%' + key_regex + flags_regex + width_regex +
79 precision_regex + length_mod_regex + type_regex)
80 specifiers = [] # type: List[ConversionSpecifier]
81 for parens_key, key, flags, width, precision, type in re.findall(regex, format):
82 if parens_key == '':
83 key = None
84 specifiers.append(ConversionSpecifier(key, flags, width, precision, type))
85 return specifiers
86
87 def analyze_conversion_specifiers(self, specifiers: List[ConversionSpecifier],
88 context: Context) -> bool:
89 has_star = any(specifier.has_star() for specifier in specifiers)
90 has_key = any(specifier.has_key() for specifier in specifiers)
91 all_have_keys = all(specifier.has_key() for specifier in specifiers)
92
93 if has_key and has_star:
94 self.msg.string_interpolation_with_star_and_key(context)
95 return None
96 if has_key and not all_have_keys:
97 self.msg.string_interpolation_mixing_key_and_non_keys(context)
98 return None
99 return has_key
100
101 def check_simple_str_interpolation(self, specifiers: List[ConversionSpecifier],
102 replacements: Node) -> None:
103 checkers = self.build_replacement_checkers(specifiers, replacements)
104 if checkers is None:
105 return
106
107 rhs_type = self.accept(replacements)
108 rep_types = [] # type: List[Type]
109 if isinstance(rhs_type, TupleType):
110 rep_types = rhs_type.items
111 elif isinstance(rhs_type, AnyType):
112 return
113 else:
114 rep_types = [rhs_type]
115
116 if len(checkers) > len(rep_types):
117 self.msg.too_few_string_formatting_arguments(replacements)
118 elif len(checkers) < len(rep_types):
119 self.msg.too_many_string_formatting_arguments(replacements)
120 else:
121 if len(checkers) == 1:
122 check_node, check_type = checkers[0]
123 if isinstance(rhs_type, TupleType) and len(rhs_type.items) == 1:
124 check_type(rhs_type.items[0])
125 else:
126 check_node(replacements)
127 elif isinstance(replacements, TupleExpr):
128 for checks, rep_node in zip(checkers, replacements.items):
129 check_node, check_type = checks
130 check_node(rep_node)
131 else:
132 for checks, rep_type in zip(checkers, rep_types):
133 check_node, check_type = checks
134 check_type(rep_type)
135
136 def check_mapping_str_interpolation(self, specifiers: List[ConversionSpecifier],
137 replacements: Node) -> None:
138 dict_with_only_str_literal_keys = (isinstance(replacements, DictExpr) and
139 all(isinstance(k, (StrExpr, BytesExpr))
140 for k, v in replacements.items))
141 if dict_with_only_str_literal_keys:
142 mapping = {} # type: Dict[str, Type]
143 for k, v in cast(DictExpr, replacements).items:
144 key_str = cast(StrExpr, k).value
145 mapping[key_str] = self.accept(v)
146
147 for specifier in specifiers:
148 if specifier.key not in mapping:
149 self.msg.key_not_in_mapping(specifier.key, replacements)
150 return
151 rep_type = mapping[specifier.key]
152 expected_type = self.conversion_type(specifier.type, replacements)
153 if expected_type is None:
154 return
155 self.chk.check_subtype(rep_type, expected_type, replacements,
156 messages.INCOMPATIBLE_TYPES_IN_STR_INTERPOLATION,
157 'expression has type',
158 'placeholder with key \'%s\' has type' % specifier.key)
159 else:
160 rep_type = self.accept(replacements)
161 dict_type = self.chk.named_generic_type('builtins.dict',
162 [AnyType(), AnyType()])
163 self.chk.check_subtype(rep_type, dict_type, replacements,
164 messages.FORMAT_REQUIRES_MAPPING,
165 'expression has type', 'expected type for mapping is')
166
167 def build_replacement_checkers(self, specifiers: List[ConversionSpecifier],
168 context: Context) -> List[Tuple[Callable[[Node], None],
169 Callable[[Type], None]]]:
170 checkers = [] # type: List[Tuple[Callable[[Node], None], Callable[[Type], None]]]
171 for specifier in specifiers:
172 checker = self.replacement_checkers(specifier, context)
173 if checker is None:
174 return None
175 checkers.extend(checker)
176 return checkers
177
178 def replacement_checkers(self, specifier: ConversionSpecifier,
179 context: Context) -> List[Tuple[Callable[[Node], None],
180 Callable[[Type], None]]]:
181 """Returns a list of tuples of two functions that check whether a replacement is
182 of the right type for the specifier. The first functions take a node and checks
183 its type in the right type context. The second function just checks a type.
184 """
185 checkers = [] # type: List[ Tuple[ Callable[[Node], None], Callable[[Type], None] ] ]
186
187 if specifier.width == '*':
188 checkers.append(self.checkers_for_star(context))
189 if specifier.precision == '*':
190 checkers.append(self.checkers_for_star(context))
191 if specifier.type == 'c':
192 c = self.checkers_for_c_type(specifier.type, context)
193 if c is None:
194 return None
195 checkers.append(c)
196 elif specifier.type != '%':
197 c = self.checkers_for_regular_type(specifier.type, context)
198 if c is None:
199 return None
200 checkers.append(c)
201 return checkers
202
203 def checkers_for_star(self, context: Context) -> Tuple[Callable[[Node], None],
204 Callable[[Type], None]]:
205 """Returns a tuple of check functions that check whether, respectively,
206 a node or a type is compatible with a star in a conversion specifier
207 """
208 expected = self.named_type('builtins.int')
209
210 def check_type(type: Type = None) -> None:
211 expected = self.named_type('builtins.int')
212 self.chk.check_subtype(type, expected, context, '* wants int')
213
214 def check_node(node: Node) -> None:
215 type = self.accept(node, expected)
216 check_type(type)
217
218 return check_node, check_type
219
220 def checkers_for_regular_type(self, type: str,
221 context: Context) -> Tuple[Callable[[Node], None],
222 Callable[[Type], None]]:
223 """Returns a tuple of check functions that check whether, respectively,
224 a node or a type is compatible with 'type'. Return None in case of an
225 """
226 expected_type = self.conversion_type(type, context)
227 if expected_type is None:
228 return None
229
230 def check_type(type: Type = None) -> None:
231 self.chk.check_subtype(type, expected_type, context,
232 messages.INCOMPATIBLE_TYPES_IN_STR_INTERPOLATION,
233 'expression has type', 'placeholder has type')
234
235 def check_node(node: Node) -> None:
236 type = self.accept(node, expected_type)
237 check_type(type)
238
239 return check_node, check_type
240
241 def checkers_for_c_type(self, type: str, context: Context) -> Tuple[Callable[[Node], None],
242 Callable[[Type], None]]:
243 """Returns a tuple of check functions that check whether, respectively,
244 a node or a type is compatible with 'type' that is a character type
245 """
246 expected_type = self.conversion_type(type, context)
247 if expected_type is None:
248 return None
249
250 def check_type(type: Type = None) -> None:
251 self.chk.check_subtype(type, expected_type, context,
252 messages.INCOMPATIBLE_TYPES_IN_STR_INTERPOLATION,
253 'expression has type', 'placeholder has type')
254
255 def check_node(node: Node) -> None:
256 """int, or str with length 1"""
257 type = self.accept(node, expected_type)
258 if isinstance(node, (StrExpr, BytesExpr)) and len(cast(StrExpr, node).value) != 1:
259 self.msg.requires_int_or_char(context)
260 check_type(type)
261
262 return check_node, check_type
263
264 def conversion_type(self, p: str, context: Context) -> Type:
265 """Return the type that is accepted for a string interpolation
266 conversion specifier type.
267
268 Note that both Python's float (e.g. %f) and integer (e.g. %d)
269 specifier types accept both float and integers.
270 """
271 if p in ['s', 'r']:
272 return AnyType()
273 elif p in ['d', 'i', 'o', 'u', 'x', 'X',
274 'e', 'E', 'f', 'F', 'g', 'G']:
275 return UnionType([self.named_type('builtins.int'),
276 self.named_type('builtins.float')])
277 elif p in ['c']:
278 return UnionType([self.named_type('builtins.int'),
279 self.named_type('builtins.float'),
280 self.named_type('builtins.str')])
281 else:
282 self.msg.unsupported_placeholder(p, context)
283 return None
284
285 #
286 # Helpers
287 #
288
289 def named_type(self, name: str) -> Instance:
290 """Return an instance type with type given by the name and no type
291 arguments. Alias for TypeChecker.named_type.
292 """
293 return self.chk.named_type(name)
294
295 def accept(self, node: Node, context: Type = None) -> Type:
296 """Type check a node. Alias for TypeChecker.accept."""
297 return self.chk.accept(node, context)
298
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mypy/checkstrformat.py b/mypy/checkstrformat.py
--- a/mypy/checkstrformat.py
+++ b/mypy/checkstrformat.py
@@ -88,7 +88,9 @@
context: Context) -> bool:
has_star = any(specifier.has_star() for specifier in specifiers)
has_key = any(specifier.has_key() for specifier in specifiers)
- all_have_keys = all(specifier.has_key() for specifier in specifiers)
+ all_have_keys = all(
+ specifier.has_key() or specifier.type == '%' for specifier in specifiers
+ )
if has_key and has_star:
self.msg.string_interpolation_with_star_and_key(context)
@@ -145,6 +147,9 @@
mapping[key_str] = self.accept(v)
for specifier in specifiers:
+ if specifier.type == '%':
+ # %% is allowed in mappings, no checking is required
+ continue
if specifier.key not in mapping:
self.msg.key_not_in_mapping(specifier.key, replacements)
return
|
{"golden_diff": "diff --git a/mypy/checkstrformat.py b/mypy/checkstrformat.py\n--- a/mypy/checkstrformat.py\n+++ b/mypy/checkstrformat.py\n@@ -88,7 +88,9 @@\n context: Context) -> bool:\n has_star = any(specifier.has_star() for specifier in specifiers)\n has_key = any(specifier.has_key() for specifier in specifiers)\n- all_have_keys = all(specifier.has_key() for specifier in specifiers)\n+ all_have_keys = all(\n+ specifier.has_key() or specifier.type == '%' for specifier in specifiers\n+ )\n \n if has_key and has_star:\n self.msg.string_interpolation_with_star_and_key(context)\n@@ -145,6 +147,9 @@\n mapping[key_str] = self.accept(v)\n \n for specifier in specifiers:\n+ if specifier.type == '%':\n+ # %% is allowed in mappings, no checking is required\n+ continue\n if specifier.key not in mapping:\n self.msg.key_not_in_mapping(specifier.key, replacements)\n return\n", "issue": "Incorrect check on string interpolation\nWhen sending this type-correct code\n\n``` python\nd = {\"greeting\": \"hello\", \"count\": 10}\nprint(\"%(greeting)s World. %(count)d%% tests failing\" % d)\n```\n\nthrough mypy, I get the following:\n\n```\nerror: String interpolation mixes specifier with and without mapping keys\n```\n\nWhich should be accepted; the only interpolator I'm using withot keys is \"%%\" which is just an escape and can not cause problems\n\n", "before_files": [{"content": "\"\"\"Expression type checker. This file is conceptually part of ExpressionChecker and TypeChecker.\"\"\"\n\nimport re\n\nfrom typing import cast, List, Tuple, Dict, Callable\n\nfrom mypy.types import (\n Type, AnyType, TupleType, Instance, UnionType\n)\nfrom mypy.nodes import (\n Node, StrExpr, BytesExpr, TupleExpr, DictExpr, Context\n)\nif False:\n # break import cycle only needed for mypy\n import mypy.checker\nfrom mypy import messages\nfrom mypy.messages import MessageBuilder\n\n\nclass ConversionSpecifier:\n def __init__(self, key: str, flags: str, width: str, precision: str, type: str) -> None:\n self.key = key\n self.flags = flags\n self.width = width\n self.precision = precision\n self.type = type\n\n def has_key(self) -> bool:\n return self.key is not None\n\n def has_star(self) -> bool:\n return self.width == '*' or self.precision == '*'\n\n\nclass StringFormatterChecker:\n \"\"\"String interpolation/formatter type checker.\n\n This class works closely together with checker.ExpressionChecker.\n \"\"\"\n\n # Some services are provided by a TypeChecker instance.\n chk = None # type: mypy.checker.TypeChecker\n # This is shared with TypeChecker, but stored also here for convenience.\n msg = None # type: MessageBuilder\n # Some services are provided by a ExpressionChecker instance.\n exprchk = None # type: mypy.checkexpr.ExpressionChecker\n\n def __init__(self,\n exprchk: 'mypy.checkexpr.ExpressionChecker',\n chk: 'mypy.checker.TypeChecker',\n msg: MessageBuilder) -> None:\n \"\"\"Construct an expression type checker.\"\"\"\n self.chk = chk\n self.exprchk = exprchk\n self.msg = msg\n\n def check_str_interpolation(self, str: StrExpr, replacements: Node) -> Type:\n \"\"\"Check the types of the 'replacements' in a string interpolation\n expression: str % replacements\n \"\"\"\n specifiers = self.parse_conversion_specifiers(str.value)\n has_mapping_keys = self.analyze_conversion_specifiers(specifiers, str)\n if has_mapping_keys is None:\n pass # Error was reported\n elif has_mapping_keys:\n self.check_mapping_str_interpolation(specifiers, replacements)\n else:\n self.check_simple_str_interpolation(specifiers, replacements)\n return self.named_type('builtins.str')\n\n def parse_conversion_specifiers(self, format: str) -> List[ConversionSpecifier]:\n key_regex = r'(\\((\\w*)\\))?' # (optional) parenthesised sequence of characters\n flags_regex = r'([#0\\-+ ]*)' # (optional) sequence of flags\n width_regex = r'(\\*|[1-9][0-9]*)?' # (optional) minimum field width (* or numbers)\n precision_regex = r'(?:\\.(\\*|[0-9]+)?)?' # (optional) . followed by * of numbers\n length_mod_regex = r'[hlL]?' # (optional) length modifier (unused)\n type_regex = r'(.)?' # conversion type\n regex = ('%' + key_regex + flags_regex + width_regex +\n precision_regex + length_mod_regex + type_regex)\n specifiers = [] # type: List[ConversionSpecifier]\n for parens_key, key, flags, width, precision, type in re.findall(regex, format):\n if parens_key == '':\n key = None\n specifiers.append(ConversionSpecifier(key, flags, width, precision, type))\n return specifiers\n\n def analyze_conversion_specifiers(self, specifiers: List[ConversionSpecifier],\n context: Context) -> bool:\n has_star = any(specifier.has_star() for specifier in specifiers)\n has_key = any(specifier.has_key() for specifier in specifiers)\n all_have_keys = all(specifier.has_key() for specifier in specifiers)\n\n if has_key and has_star:\n self.msg.string_interpolation_with_star_and_key(context)\n return None\n if has_key and not all_have_keys:\n self.msg.string_interpolation_mixing_key_and_non_keys(context)\n return None\n return has_key\n\n def check_simple_str_interpolation(self, specifiers: List[ConversionSpecifier],\n replacements: Node) -> None:\n checkers = self.build_replacement_checkers(specifiers, replacements)\n if checkers is None:\n return\n\n rhs_type = self.accept(replacements)\n rep_types = [] # type: List[Type]\n if isinstance(rhs_type, TupleType):\n rep_types = rhs_type.items\n elif isinstance(rhs_type, AnyType):\n return\n else:\n rep_types = [rhs_type]\n\n if len(checkers) > len(rep_types):\n self.msg.too_few_string_formatting_arguments(replacements)\n elif len(checkers) < len(rep_types):\n self.msg.too_many_string_formatting_arguments(replacements)\n else:\n if len(checkers) == 1:\n check_node, check_type = checkers[0]\n if isinstance(rhs_type, TupleType) and len(rhs_type.items) == 1:\n check_type(rhs_type.items[0])\n else:\n check_node(replacements)\n elif isinstance(replacements, TupleExpr):\n for checks, rep_node in zip(checkers, replacements.items):\n check_node, check_type = checks\n check_node(rep_node)\n else:\n for checks, rep_type in zip(checkers, rep_types):\n check_node, check_type = checks\n check_type(rep_type)\n\n def check_mapping_str_interpolation(self, specifiers: List[ConversionSpecifier],\n replacements: Node) -> None:\n dict_with_only_str_literal_keys = (isinstance(replacements, DictExpr) and\n all(isinstance(k, (StrExpr, BytesExpr))\n for k, v in replacements.items))\n if dict_with_only_str_literal_keys:\n mapping = {} # type: Dict[str, Type]\n for k, v in cast(DictExpr, replacements).items:\n key_str = cast(StrExpr, k).value\n mapping[key_str] = self.accept(v)\n\n for specifier in specifiers:\n if specifier.key not in mapping:\n self.msg.key_not_in_mapping(specifier.key, replacements)\n return\n rep_type = mapping[specifier.key]\n expected_type = self.conversion_type(specifier.type, replacements)\n if expected_type is None:\n return\n self.chk.check_subtype(rep_type, expected_type, replacements,\n messages.INCOMPATIBLE_TYPES_IN_STR_INTERPOLATION,\n 'expression has type',\n 'placeholder with key \\'%s\\' has type' % specifier.key)\n else:\n rep_type = self.accept(replacements)\n dict_type = self.chk.named_generic_type('builtins.dict',\n [AnyType(), AnyType()])\n self.chk.check_subtype(rep_type, dict_type, replacements,\n messages.FORMAT_REQUIRES_MAPPING,\n 'expression has type', 'expected type for mapping is')\n\n def build_replacement_checkers(self, specifiers: List[ConversionSpecifier],\n context: Context) -> List[Tuple[Callable[[Node], None],\n Callable[[Type], None]]]:\n checkers = [] # type: List[Tuple[Callable[[Node], None], Callable[[Type], None]]]\n for specifier in specifiers:\n checker = self.replacement_checkers(specifier, context)\n if checker is None:\n return None\n checkers.extend(checker)\n return checkers\n\n def replacement_checkers(self, specifier: ConversionSpecifier,\n context: Context) -> List[Tuple[Callable[[Node], None],\n Callable[[Type], None]]]:\n \"\"\"Returns a list of tuples of two functions that check whether a replacement is\n of the right type for the specifier. The first functions take a node and checks\n its type in the right type context. The second function just checks a type.\n \"\"\"\n checkers = [] # type: List[ Tuple[ Callable[[Node], None], Callable[[Type], None] ] ]\n\n if specifier.width == '*':\n checkers.append(self.checkers_for_star(context))\n if specifier.precision == '*':\n checkers.append(self.checkers_for_star(context))\n if specifier.type == 'c':\n c = self.checkers_for_c_type(specifier.type, context)\n if c is None:\n return None\n checkers.append(c)\n elif specifier.type != '%':\n c = self.checkers_for_regular_type(specifier.type, context)\n if c is None:\n return None\n checkers.append(c)\n return checkers\n\n def checkers_for_star(self, context: Context) -> Tuple[Callable[[Node], None],\n Callable[[Type], None]]:\n \"\"\"Returns a tuple of check functions that check whether, respectively,\n a node or a type is compatible with a star in a conversion specifier\n \"\"\"\n expected = self.named_type('builtins.int')\n\n def check_type(type: Type = None) -> None:\n expected = self.named_type('builtins.int')\n self.chk.check_subtype(type, expected, context, '* wants int')\n\n def check_node(node: Node) -> None:\n type = self.accept(node, expected)\n check_type(type)\n\n return check_node, check_type\n\n def checkers_for_regular_type(self, type: str,\n context: Context) -> Tuple[Callable[[Node], None],\n Callable[[Type], None]]:\n \"\"\"Returns a tuple of check functions that check whether, respectively,\n a node or a type is compatible with 'type'. Return None in case of an\n \"\"\"\n expected_type = self.conversion_type(type, context)\n if expected_type is None:\n return None\n\n def check_type(type: Type = None) -> None:\n self.chk.check_subtype(type, expected_type, context,\n messages.INCOMPATIBLE_TYPES_IN_STR_INTERPOLATION,\n 'expression has type', 'placeholder has type')\n\n def check_node(node: Node) -> None:\n type = self.accept(node, expected_type)\n check_type(type)\n\n return check_node, check_type\n\n def checkers_for_c_type(self, type: str, context: Context) -> Tuple[Callable[[Node], None],\n Callable[[Type], None]]:\n \"\"\"Returns a tuple of check functions that check whether, respectively,\n a node or a type is compatible with 'type' that is a character type\n \"\"\"\n expected_type = self.conversion_type(type, context)\n if expected_type is None:\n return None\n\n def check_type(type: Type = None) -> None:\n self.chk.check_subtype(type, expected_type, context,\n messages.INCOMPATIBLE_TYPES_IN_STR_INTERPOLATION,\n 'expression has type', 'placeholder has type')\n\n def check_node(node: Node) -> None:\n \"\"\"int, or str with length 1\"\"\"\n type = self.accept(node, expected_type)\n if isinstance(node, (StrExpr, BytesExpr)) and len(cast(StrExpr, node).value) != 1:\n self.msg.requires_int_or_char(context)\n check_type(type)\n\n return check_node, check_type\n\n def conversion_type(self, p: str, context: Context) -> Type:\n \"\"\"Return the type that is accepted for a string interpolation\n conversion specifier type.\n\n Note that both Python's float (e.g. %f) and integer (e.g. %d)\n specifier types accept both float and integers.\n \"\"\"\n if p in ['s', 'r']:\n return AnyType()\n elif p in ['d', 'i', 'o', 'u', 'x', 'X',\n 'e', 'E', 'f', 'F', 'g', 'G']:\n return UnionType([self.named_type('builtins.int'),\n self.named_type('builtins.float')])\n elif p in ['c']:\n return UnionType([self.named_type('builtins.int'),\n self.named_type('builtins.float'),\n self.named_type('builtins.str')])\n else:\n self.msg.unsupported_placeholder(p, context)\n return None\n\n #\n # Helpers\n #\n\n def named_type(self, name: str) -> Instance:\n \"\"\"Return an instance type with type given by the name and no type\n arguments. Alias for TypeChecker.named_type.\n \"\"\"\n return self.chk.named_type(name)\n\n def accept(self, node: Node, context: Type = None) -> Type:\n \"\"\"Type check a node. Alias for TypeChecker.accept.\"\"\"\n return self.chk.accept(node, context)\n", "path": "mypy/checkstrformat.py"}], "after_files": [{"content": "\"\"\"Expression type checker. This file is conceptually part of ExpressionChecker and TypeChecker.\"\"\"\n\nimport re\n\nfrom typing import cast, List, Tuple, Dict, Callable\n\nfrom mypy.types import (\n Type, AnyType, TupleType, Instance, UnionType\n)\nfrom mypy.nodes import (\n Node, StrExpr, BytesExpr, TupleExpr, DictExpr, Context\n)\nif False:\n # break import cycle only needed for mypy\n import mypy.checker\nfrom mypy import messages\nfrom mypy.messages import MessageBuilder\n\n\nclass ConversionSpecifier:\n def __init__(self, key: str, flags: str, width: str, precision: str, type: str) -> None:\n self.key = key\n self.flags = flags\n self.width = width\n self.precision = precision\n self.type = type\n\n def has_key(self) -> bool:\n return self.key is not None\n\n def has_star(self) -> bool:\n return self.width == '*' or self.precision == '*'\n\n\nclass StringFormatterChecker:\n \"\"\"String interpolation/formatter type checker.\n\n This class works closely together with checker.ExpressionChecker.\n \"\"\"\n\n # Some services are provided by a TypeChecker instance.\n chk = None # type: mypy.checker.TypeChecker\n # This is shared with TypeChecker, but stored also here for convenience.\n msg = None # type: MessageBuilder\n # Some services are provided by a ExpressionChecker instance.\n exprchk = None # type: mypy.checkexpr.ExpressionChecker\n\n def __init__(self,\n exprchk: 'mypy.checkexpr.ExpressionChecker',\n chk: 'mypy.checker.TypeChecker',\n msg: MessageBuilder) -> None:\n \"\"\"Construct an expression type checker.\"\"\"\n self.chk = chk\n self.exprchk = exprchk\n self.msg = msg\n\n def check_str_interpolation(self, str: StrExpr, replacements: Node) -> Type:\n \"\"\"Check the types of the 'replacements' in a string interpolation\n expression: str % replacements\n \"\"\"\n specifiers = self.parse_conversion_specifiers(str.value)\n has_mapping_keys = self.analyze_conversion_specifiers(specifiers, str)\n if has_mapping_keys is None:\n pass # Error was reported\n elif has_mapping_keys:\n self.check_mapping_str_interpolation(specifiers, replacements)\n else:\n self.check_simple_str_interpolation(specifiers, replacements)\n return self.named_type('builtins.str')\n\n def parse_conversion_specifiers(self, format: str) -> List[ConversionSpecifier]:\n key_regex = r'(\\((\\w*)\\))?' # (optional) parenthesised sequence of characters\n flags_regex = r'([#0\\-+ ]*)' # (optional) sequence of flags\n width_regex = r'(\\*|[1-9][0-9]*)?' # (optional) minimum field width (* or numbers)\n precision_regex = r'(?:\\.(\\*|[0-9]+)?)?' # (optional) . followed by * of numbers\n length_mod_regex = r'[hlL]?' # (optional) length modifier (unused)\n type_regex = r'(.)?' # conversion type\n regex = ('%' + key_regex + flags_regex + width_regex +\n precision_regex + length_mod_regex + type_regex)\n specifiers = [] # type: List[ConversionSpecifier]\n for parens_key, key, flags, width, precision, type in re.findall(regex, format):\n if parens_key == '':\n key = None\n specifiers.append(ConversionSpecifier(key, flags, width, precision, type))\n return specifiers\n\n def analyze_conversion_specifiers(self, specifiers: List[ConversionSpecifier],\n context: Context) -> bool:\n has_star = any(specifier.has_star() for specifier in specifiers)\n has_key = any(specifier.has_key() for specifier in specifiers)\n all_have_keys = all(\n specifier.has_key() or specifier.type == '%' for specifier in specifiers\n )\n\n if has_key and has_star:\n self.msg.string_interpolation_with_star_and_key(context)\n return None\n if has_key and not all_have_keys:\n self.msg.string_interpolation_mixing_key_and_non_keys(context)\n return None\n return has_key\n\n def check_simple_str_interpolation(self, specifiers: List[ConversionSpecifier],\n replacements: Node) -> None:\n checkers = self.build_replacement_checkers(specifiers, replacements)\n if checkers is None:\n return\n\n rhs_type = self.accept(replacements)\n rep_types = [] # type: List[Type]\n if isinstance(rhs_type, TupleType):\n rep_types = rhs_type.items\n elif isinstance(rhs_type, AnyType):\n return\n else:\n rep_types = [rhs_type]\n\n if len(checkers) > len(rep_types):\n self.msg.too_few_string_formatting_arguments(replacements)\n elif len(checkers) < len(rep_types):\n self.msg.too_many_string_formatting_arguments(replacements)\n else:\n if len(checkers) == 1:\n check_node, check_type = checkers[0]\n if isinstance(rhs_type, TupleType) and len(rhs_type.items) == 1:\n check_type(rhs_type.items[0])\n else:\n check_node(replacements)\n elif isinstance(replacements, TupleExpr):\n for checks, rep_node in zip(checkers, replacements.items):\n check_node, check_type = checks\n check_node(rep_node)\n else:\n for checks, rep_type in zip(checkers, rep_types):\n check_node, check_type = checks\n check_type(rep_type)\n\n def check_mapping_str_interpolation(self, specifiers: List[ConversionSpecifier],\n replacements: Node) -> None:\n dict_with_only_str_literal_keys = (isinstance(replacements, DictExpr) and\n all(isinstance(k, (StrExpr, BytesExpr))\n for k, v in replacements.items))\n if dict_with_only_str_literal_keys:\n mapping = {} # type: Dict[str, Type]\n for k, v in cast(DictExpr, replacements).items:\n key_str = cast(StrExpr, k).value\n mapping[key_str] = self.accept(v)\n\n for specifier in specifiers:\n if specifier.type == '%':\n # %% is allowed in mappings, no checking is required\n continue\n if specifier.key not in mapping:\n self.msg.key_not_in_mapping(specifier.key, replacements)\n return\n rep_type = mapping[specifier.key]\n expected_type = self.conversion_type(specifier.type, replacements)\n if expected_type is None:\n return\n self.chk.check_subtype(rep_type, expected_type, replacements,\n messages.INCOMPATIBLE_TYPES_IN_STR_INTERPOLATION,\n 'expression has type',\n 'placeholder with key \\'%s\\' has type' % specifier.key)\n else:\n rep_type = self.accept(replacements)\n dict_type = self.chk.named_generic_type('builtins.dict',\n [AnyType(), AnyType()])\n self.chk.check_subtype(rep_type, dict_type, replacements,\n messages.FORMAT_REQUIRES_MAPPING,\n 'expression has type', 'expected type for mapping is')\n\n def build_replacement_checkers(self, specifiers: List[ConversionSpecifier],\n context: Context) -> List[Tuple[Callable[[Node], None],\n Callable[[Type], None]]]:\n checkers = [] # type: List[Tuple[Callable[[Node], None], Callable[[Type], None]]]\n for specifier in specifiers:\n checker = self.replacement_checkers(specifier, context)\n if checker is None:\n return None\n checkers.extend(checker)\n return checkers\n\n def replacement_checkers(self, specifier: ConversionSpecifier,\n context: Context) -> List[Tuple[Callable[[Node], None],\n Callable[[Type], None]]]:\n \"\"\"Returns a list of tuples of two functions that check whether a replacement is\n of the right type for the specifier. The first functions take a node and checks\n its type in the right type context. The second function just checks a type.\n \"\"\"\n checkers = [] # type: List[ Tuple[ Callable[[Node], None], Callable[[Type], None] ] ]\n\n if specifier.width == '*':\n checkers.append(self.checkers_for_star(context))\n if specifier.precision == '*':\n checkers.append(self.checkers_for_star(context))\n if specifier.type == 'c':\n c = self.checkers_for_c_type(specifier.type, context)\n if c is None:\n return None\n checkers.append(c)\n elif specifier.type != '%':\n c = self.checkers_for_regular_type(specifier.type, context)\n if c is None:\n return None\n checkers.append(c)\n return checkers\n\n def checkers_for_star(self, context: Context) -> Tuple[Callable[[Node], None],\n Callable[[Type], None]]:\n \"\"\"Returns a tuple of check functions that check whether, respectively,\n a node or a type is compatible with a star in a conversion specifier\n \"\"\"\n expected = self.named_type('builtins.int')\n\n def check_type(type: Type = None) -> None:\n expected = self.named_type('builtins.int')\n self.chk.check_subtype(type, expected, context, '* wants int')\n\n def check_node(node: Node) -> None:\n type = self.accept(node, expected)\n check_type(type)\n\n return check_node, check_type\n\n def checkers_for_regular_type(self, type: str,\n context: Context) -> Tuple[Callable[[Node], None],\n Callable[[Type], None]]:\n \"\"\"Returns a tuple of check functions that check whether, respectively,\n a node or a type is compatible with 'type'. Return None in case of an\n \"\"\"\n expected_type = self.conversion_type(type, context)\n if expected_type is None:\n return None\n\n def check_type(type: Type = None) -> None:\n self.chk.check_subtype(type, expected_type, context,\n messages.INCOMPATIBLE_TYPES_IN_STR_INTERPOLATION,\n 'expression has type', 'placeholder has type')\n\n def check_node(node: Node) -> None:\n type = self.accept(node, expected_type)\n check_type(type)\n\n return check_node, check_type\n\n def checkers_for_c_type(self, type: str, context: Context) -> Tuple[Callable[[Node], None],\n Callable[[Type], None]]:\n \"\"\"Returns a tuple of check functions that check whether, respectively,\n a node or a type is compatible with 'type' that is a character type\n \"\"\"\n expected_type = self.conversion_type(type, context)\n if expected_type is None:\n return None\n\n def check_type(type: Type = None) -> None:\n self.chk.check_subtype(type, expected_type, context,\n messages.INCOMPATIBLE_TYPES_IN_STR_INTERPOLATION,\n 'expression has type', 'placeholder has type')\n\n def check_node(node: Node) -> None:\n \"\"\"int, or str with length 1\"\"\"\n type = self.accept(node, expected_type)\n if isinstance(node, (StrExpr, BytesExpr)) and len(cast(StrExpr, node).value) != 1:\n self.msg.requires_int_or_char(context)\n check_type(type)\n\n return check_node, check_type\n\n def conversion_type(self, p: str, context: Context) -> Type:\n \"\"\"Return the type that is accepted for a string interpolation\n conversion specifier type.\n\n Note that both Python's float (e.g. %f) and integer (e.g. %d)\n specifier types accept both float and integers.\n \"\"\"\n if p in ['s', 'r']:\n return AnyType()\n elif p in ['d', 'i', 'o', 'u', 'x', 'X',\n 'e', 'E', 'f', 'F', 'g', 'G']:\n return UnionType([self.named_type('builtins.int'),\n self.named_type('builtins.float')])\n elif p in ['c']:\n return UnionType([self.named_type('builtins.int'),\n self.named_type('builtins.float'),\n self.named_type('builtins.str')])\n else:\n self.msg.unsupported_placeholder(p, context)\n return None\n\n #\n # Helpers\n #\n\n def named_type(self, name: str) -> Instance:\n \"\"\"Return an instance type with type given by the name and no type\n arguments. Alias for TypeChecker.named_type.\n \"\"\"\n return self.chk.named_type(name)\n\n def accept(self, node: Node, context: Type = None) -> Type:\n \"\"\"Type check a node. Alias for TypeChecker.accept.\"\"\"\n return self.chk.accept(node, context)\n", "path": "mypy/checkstrformat.py"}]}
| 3,884 | 237 |
gh_patches_debug_12049
|
rasdani/github-patches
|
git_diff
|
nf-core__tools-1755
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Use of future functionality
### Description of the bug
The `shutil.copytree` argument [`dirs_exist_ok`](https://docs.python.org/3/library/shutil.html#shutil.copytree) is only available in Python version 3.8+ but nf-core tool still support Python 3.7
https://github.com/nf-core/tools/blob/b5400d84d307343353b6ab09aad204231f74fb0e/nf_core/modules/lint/module_changes.py#L28
Two options: drop Python 3.7 support or change that code.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nf_core/modules/lint/module_changes.py`
Content:
```
1 """
2 Check whether the content of a module has changed compared to the original repository
3 """
4 import shutil
5 import tempfile
6 from pathlib import Path
7
8 from nf_core.modules.modules_differ import ModulesDiffer
9
10
11 def module_changes(module_lint_object, module):
12 """
13 Checks whether installed nf-core modules have changed compared to the
14 original repository
15
16 Downloads the ``main.nf`` and ``meta.yml`` files for every module
17 and compares them to the local copies
18
19 If the module has a commit SHA entry in the ``modules.json``, the file content is
20 compared against the files in the remote at this SHA.
21
22 Only runs when linting a pipeline, not the modules repository
23 """
24 if module.is_patched:
25 # If the module is patched, we need to apply
26 # the patch in reverse before comparing with the remote
27 tempdir = Path(tempfile.mkdtemp())
28 shutil.copytree(module.module_dir, tempdir, dirs_exist_ok=True)
29 try:
30 new_lines = ModulesDiffer.try_apply_patch(
31 module.module_name, module_lint_object.modules_repo.fullname, module.patch_path, tempdir, reverse=True
32 )
33 for file, lines in new_lines.items():
34 with open(tempdir / file, "w") as fh:
35 fh.writelines(lines)
36 except LookupError:
37 # This error is already reported by module_patch, so just return
38 return
39 else:
40 tempdir = module.module_dir
41
42 for f, same in module_lint_object.modules_repo.module_files_identical(
43 module.module_name, tempdir, module.git_sha
44 ).items():
45 if same:
46 module.passed.append(
47 (
48 "check_local_copy",
49 "Local copy of module up to date",
50 f"{Path(module.module_dir, f)}",
51 )
52 )
53 else:
54 module.failed.append(
55 (
56 "check_local_copy",
57 "Local copy of module does not match remote",
58 f"{Path(module.module_dir, f)}",
59 )
60 )
61
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nf_core/modules/lint/module_changes.py b/nf_core/modules/lint/module_changes.py
--- a/nf_core/modules/lint/module_changes.py
+++ b/nf_core/modules/lint/module_changes.py
@@ -25,7 +25,7 @@
# If the module is patched, we need to apply
# the patch in reverse before comparing with the remote
tempdir = Path(tempfile.mkdtemp())
- shutil.copytree(module.module_dir, tempdir, dirs_exist_ok=True)
+ shutil.copytree(module.module_dir, tempdir)
try:
new_lines = ModulesDiffer.try_apply_patch(
module.module_name, module_lint_object.modules_repo.fullname, module.patch_path, tempdir, reverse=True
|
{"golden_diff": "diff --git a/nf_core/modules/lint/module_changes.py b/nf_core/modules/lint/module_changes.py\n--- a/nf_core/modules/lint/module_changes.py\n+++ b/nf_core/modules/lint/module_changes.py\n@@ -25,7 +25,7 @@\n # If the module is patched, we need to apply\n # the patch in reverse before comparing with the remote\n tempdir = Path(tempfile.mkdtemp())\n- shutil.copytree(module.module_dir, tempdir, dirs_exist_ok=True)\n+ shutil.copytree(module.module_dir, tempdir)\n try:\n new_lines = ModulesDiffer.try_apply_patch(\n module.module_name, module_lint_object.modules_repo.fullname, module.patch_path, tempdir, reverse=True\n", "issue": "Use of future functionality\n### Description of the bug\r\n\r\nThe `shutil.copytree` argument [`dirs_exist_ok`](https://docs.python.org/3/library/shutil.html#shutil.copytree) is only available in Python version 3.8+ but nf-core tool still support Python 3.7\r\n\r\nhttps://github.com/nf-core/tools/blob/b5400d84d307343353b6ab09aad204231f74fb0e/nf_core/modules/lint/module_changes.py#L28\r\n\r\nTwo options: drop Python 3.7 support or change that code.\r\n\n", "before_files": [{"content": "\"\"\"\nCheck whether the content of a module has changed compared to the original repository\n\"\"\"\nimport shutil\nimport tempfile\nfrom pathlib import Path\n\nfrom nf_core.modules.modules_differ import ModulesDiffer\n\n\ndef module_changes(module_lint_object, module):\n \"\"\"\n Checks whether installed nf-core modules have changed compared to the\n original repository\n\n Downloads the ``main.nf`` and ``meta.yml`` files for every module\n and compares them to the local copies\n\n If the module has a commit SHA entry in the ``modules.json``, the file content is\n compared against the files in the remote at this SHA.\n\n Only runs when linting a pipeline, not the modules repository\n \"\"\"\n if module.is_patched:\n # If the module is patched, we need to apply\n # the patch in reverse before comparing with the remote\n tempdir = Path(tempfile.mkdtemp())\n shutil.copytree(module.module_dir, tempdir, dirs_exist_ok=True)\n try:\n new_lines = ModulesDiffer.try_apply_patch(\n module.module_name, module_lint_object.modules_repo.fullname, module.patch_path, tempdir, reverse=True\n )\n for file, lines in new_lines.items():\n with open(tempdir / file, \"w\") as fh:\n fh.writelines(lines)\n except LookupError:\n # This error is already reported by module_patch, so just return\n return\n else:\n tempdir = module.module_dir\n\n for f, same in module_lint_object.modules_repo.module_files_identical(\n module.module_name, tempdir, module.git_sha\n ).items():\n if same:\n module.passed.append(\n (\n \"check_local_copy\",\n \"Local copy of module up to date\",\n f\"{Path(module.module_dir, f)}\",\n )\n )\n else:\n module.failed.append(\n (\n \"check_local_copy\",\n \"Local copy of module does not match remote\",\n f\"{Path(module.module_dir, f)}\",\n )\n )\n", "path": "nf_core/modules/lint/module_changes.py"}], "after_files": [{"content": "\"\"\"\nCheck whether the content of a module has changed compared to the original repository\n\"\"\"\nimport shutil\nimport tempfile\nfrom pathlib import Path\n\nfrom nf_core.modules.modules_differ import ModulesDiffer\n\n\ndef module_changes(module_lint_object, module):\n \"\"\"\n Checks whether installed nf-core modules have changed compared to the\n original repository\n\n Downloads the ``main.nf`` and ``meta.yml`` files for every module\n and compares them to the local copies\n\n If the module has a commit SHA entry in the ``modules.json``, the file content is\n compared against the files in the remote at this SHA.\n\n Only runs when linting a pipeline, not the modules repository\n \"\"\"\n if module.is_patched:\n # If the module is patched, we need to apply\n # the patch in reverse before comparing with the remote\n tempdir = Path(tempfile.mkdtemp())\n shutil.copytree(module.module_dir, tempdir)\n try:\n new_lines = ModulesDiffer.try_apply_patch(\n module.module_name, module_lint_object.modules_repo.fullname, module.patch_path, tempdir, reverse=True\n )\n for file, lines in new_lines.items():\n with open(tempdir / file, \"w\") as fh:\n fh.writelines(lines)\n except LookupError:\n # This error is already reported by module_patch, so just return\n return\n else:\n tempdir = module.module_dir\n\n for f, same in module_lint_object.modules_repo.module_files_identical(\n module.module_name, tempdir, module.git_sha\n ).items():\n if same:\n module.passed.append(\n (\n \"check_local_copy\",\n \"Local copy of module up to date\",\n f\"{Path(module.module_dir, f)}\",\n )\n )\n else:\n module.failed.append(\n (\n \"check_local_copy\",\n \"Local copy of module does not match remote\",\n f\"{Path(module.module_dir, f)}\",\n )\n )\n", "path": "nf_core/modules/lint/module_changes.py"}]}
| 947 | 163 |
gh_patches_debug_2117
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-1469
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Spelling mistake while running streamlit hello , DataFrame Demo
# Summary
I noticed a spelling mistake in dataframe demo while runing streamlit hello , It displays UN Data Exlorer instead of UN Data Explorer
# Steps to reproduce
1. Go to terminal
2. Run `streamlit hello`
3. Open browser at localhost:8501 and choose dataframe demo
## Expected behavior:
It should display correct spelling as `(Data courtesy of the UN Data Exlporer.)`
## Actual behavior:
It's displaying `(Data courtesy of the UN Data Exlorer.)`

## Is this a regression?
no
# Debug info
- Streamlit version: 0.57.3
- Python version: 3.8.2
- Using Conda? PipEnv? PyEnv? Pex? Conda
- OS version: Windows 10
- Browser version: Chrome v81.0
# Additional information
If needed, add any other context about the problem here. For example, did this bug come from https://discuss.streamlit.io or another site? Link the original source here!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/streamlit/hello/hello.py`
Content:
```
1 # Copyright 2018-2020 Streamlit Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import inspect
16 import textwrap
17 from collections import OrderedDict
18
19 import streamlit as st
20 from streamlit.logger import get_logger
21 from streamlit.hello import demos
22
23 LOGGER = get_logger(__name__)
24
25 # Dictionary of
26 # demo_name -> (demo_function, demo_description)
27 DEMOS = OrderedDict(
28 [
29 ("—", (demos.intro, None)),
30 (
31 "Animation Demo",
32 (
33 demos.fractal_demo,
34 """
35 This app shows how you can use Streamlit to build cool animations.
36 It displays an animated fractal based on the the Julia Set. Use the slider
37 to tune different parameters.
38 """,
39 ),
40 ),
41 (
42 "Plotting Demo",
43 (
44 demos.plotting_demo,
45 """
46 This demo illustrates a combination of plotting and animation with
47 Streamlit. We're generating a bunch of random numbers in a loop for around
48 5 seconds. Enjoy!
49 """,
50 ),
51 ),
52 (
53 "Mapping Demo",
54 (
55 demos.mapping_demo,
56 """
57 This demo shows how to use
58 [`st.deck_gl_chart`](https://docs.streamlit.io/api.html#streamlit.deck_gl_chart)
59 to display geospatial data.
60 """,
61 ),
62 ),
63 (
64 "DataFrame Demo",
65 (
66 demos.data_frame_demo,
67 """
68 This demo shows how to use `st.write` to visualize Pandas DataFrames.
69
70 (Data courtesy of the [UN Data Exlorer](http://data.un.org/Explorer.aspx).)
71 """,
72 ),
73 ),
74 ]
75 )
76
77
78 def run():
79 demo_name = st.sidebar.selectbox("Choose a demo", list(DEMOS.keys()), 0)
80 demo = DEMOS[demo_name][0]
81
82 if demo_name == "—":
83 show_code = False
84 st.write("# Welcome to Streamlit! 👋")
85 else:
86 show_code = st.sidebar.checkbox("Show code", True)
87 st.markdown("# %s" % demo_name)
88 description = DEMOS[demo_name][1]
89 if description:
90 st.write(description)
91 # Clear everything from the intro page.
92 # We only have 4 elements in the page so this is intentional overkill.
93 for i in range(10):
94 st.empty()
95
96 demo()
97
98 if show_code:
99 st.markdown("## Code")
100 sourcelines, _ = inspect.getsourcelines(demo)
101 st.code(textwrap.dedent("".join(sourcelines[1:])))
102
103
104 if __name__ == "__main__":
105 run()
106
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lib/streamlit/hello/hello.py b/lib/streamlit/hello/hello.py
--- a/lib/streamlit/hello/hello.py
+++ b/lib/streamlit/hello/hello.py
@@ -67,7 +67,7 @@
"""
This demo shows how to use `st.write` to visualize Pandas DataFrames.
-(Data courtesy of the [UN Data Exlorer](http://data.un.org/Explorer.aspx).)
+(Data courtesy of the [UN Data Explorer](http://data.un.org/Explorer.aspx).)
""",
),
),
|
{"golden_diff": "diff --git a/lib/streamlit/hello/hello.py b/lib/streamlit/hello/hello.py\n--- a/lib/streamlit/hello/hello.py\n+++ b/lib/streamlit/hello/hello.py\n@@ -67,7 +67,7 @@\n \"\"\"\n This demo shows how to use `st.write` to visualize Pandas DataFrames.\n \n-(Data courtesy of the [UN Data Exlorer](http://data.un.org/Explorer.aspx).)\n+(Data courtesy of the [UN Data Explorer](http://data.un.org/Explorer.aspx).)\n \"\"\",\n ),\n ),\n", "issue": "Spelling mistake while running streamlit hello , DataFrame Demo\n# Summary\r\n\r\nI noticed a spelling mistake in dataframe demo while runing streamlit hello , It displays UN Data Exlorer instead of UN Data Explorer\r\n\r\n# Steps to reproduce\r\n\r\n1. Go to terminal\r\n2. Run `streamlit hello`\r\n3. Open browser at localhost:8501 and choose dataframe demo\r\n\r\n## Expected behavior:\r\n\r\nIt should display correct spelling as `(Data courtesy of the UN Data Exlporer.)`\r\n\r\n## Actual behavior:\r\n\r\nIt's displaying `(Data courtesy of the UN Data Exlorer.)`\r\n\r\n\r\n\r\n## Is this a regression?\r\n no\r\n\r\n# Debug info\r\n\r\n- Streamlit version: 0.57.3\r\n- Python version: 3.8.2\r\n- Using Conda? PipEnv? PyEnv? Pex? Conda\r\n- OS version: Windows 10\r\n- Browser version: Chrome v81.0\r\n\r\n# Additional information\r\n\r\nIf needed, add any other context about the problem here. For example, did this bug come from https://discuss.streamlit.io or another site? Link the original source here!\r\n\n", "before_files": [{"content": "# Copyright 2018-2020 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport inspect\nimport textwrap\nfrom collections import OrderedDict\n\nimport streamlit as st\nfrom streamlit.logger import get_logger\nfrom streamlit.hello import demos\n\nLOGGER = get_logger(__name__)\n\n# Dictionary of\n# demo_name -> (demo_function, demo_description)\nDEMOS = OrderedDict(\n [\n (\"\u2014\", (demos.intro, None)),\n (\n \"Animation Demo\",\n (\n demos.fractal_demo,\n \"\"\"\nThis app shows how you can use Streamlit to build cool animations.\nIt displays an animated fractal based on the the Julia Set. Use the slider\nto tune different parameters.\n\"\"\",\n ),\n ),\n (\n \"Plotting Demo\",\n (\n demos.plotting_demo,\n \"\"\"\nThis demo illustrates a combination of plotting and animation with\nStreamlit. We're generating a bunch of random numbers in a loop for around\n5 seconds. Enjoy!\n\"\"\",\n ),\n ),\n (\n \"Mapping Demo\",\n (\n demos.mapping_demo,\n \"\"\"\nThis demo shows how to use\n[`st.deck_gl_chart`](https://docs.streamlit.io/api.html#streamlit.deck_gl_chart)\nto display geospatial data.\n\"\"\",\n ),\n ),\n (\n \"DataFrame Demo\",\n (\n demos.data_frame_demo,\n \"\"\"\nThis demo shows how to use `st.write` to visualize Pandas DataFrames.\n\n(Data courtesy of the [UN Data Exlorer](http://data.un.org/Explorer.aspx).)\n\"\"\",\n ),\n ),\n ]\n)\n\n\ndef run():\n demo_name = st.sidebar.selectbox(\"Choose a demo\", list(DEMOS.keys()), 0)\n demo = DEMOS[demo_name][0]\n\n if demo_name == \"\u2014\":\n show_code = False\n st.write(\"# Welcome to Streamlit! \ud83d\udc4b\")\n else:\n show_code = st.sidebar.checkbox(\"Show code\", True)\n st.markdown(\"# %s\" % demo_name)\n description = DEMOS[demo_name][1]\n if description:\n st.write(description)\n # Clear everything from the intro page.\n # We only have 4 elements in the page so this is intentional overkill.\n for i in range(10):\n st.empty()\n\n demo()\n\n if show_code:\n st.markdown(\"## Code\")\n sourcelines, _ = inspect.getsourcelines(demo)\n st.code(textwrap.dedent(\"\".join(sourcelines[1:])))\n\n\nif __name__ == \"__main__\":\n run()\n", "path": "lib/streamlit/hello/hello.py"}], "after_files": [{"content": "# Copyright 2018-2020 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport inspect\nimport textwrap\nfrom collections import OrderedDict\n\nimport streamlit as st\nfrom streamlit.logger import get_logger\nfrom streamlit.hello import demos\n\nLOGGER = get_logger(__name__)\n\n# Dictionary of\n# demo_name -> (demo_function, demo_description)\nDEMOS = OrderedDict(\n [\n (\"\u2014\", (demos.intro, None)),\n (\n \"Animation Demo\",\n (\n demos.fractal_demo,\n \"\"\"\nThis app shows how you can use Streamlit to build cool animations.\nIt displays an animated fractal based on the the Julia Set. Use the slider\nto tune different parameters.\n\"\"\",\n ),\n ),\n (\n \"Plotting Demo\",\n (\n demos.plotting_demo,\n \"\"\"\nThis demo illustrates a combination of plotting and animation with\nStreamlit. We're generating a bunch of random numbers in a loop for around\n5 seconds. Enjoy!\n\"\"\",\n ),\n ),\n (\n \"Mapping Demo\",\n (\n demos.mapping_demo,\n \"\"\"\nThis demo shows how to use\n[`st.deck_gl_chart`](https://docs.streamlit.io/api.html#streamlit.deck_gl_chart)\nto display geospatial data.\n\"\"\",\n ),\n ),\n (\n \"DataFrame Demo\",\n (\n demos.data_frame_demo,\n \"\"\"\nThis demo shows how to use `st.write` to visualize Pandas DataFrames.\n\n(Data courtesy of the [UN Data Explorer](http://data.un.org/Explorer.aspx).)\n\"\"\",\n ),\n ),\n ]\n)\n\n\ndef run():\n demo_name = st.sidebar.selectbox(\"Choose a demo\", list(DEMOS.keys()), 0)\n demo = DEMOS[demo_name][0]\n\n if demo_name == \"\u2014\":\n show_code = False\n st.write(\"# Welcome to Streamlit! \ud83d\udc4b\")\n else:\n show_code = st.sidebar.checkbox(\"Show code\", True)\n st.markdown(\"# %s\" % demo_name)\n description = DEMOS[demo_name][1]\n if description:\n st.write(description)\n # Clear everything from the intro page.\n # We only have 4 elements in the page so this is intentional overkill.\n for i in range(10):\n st.empty()\n\n demo()\n\n if show_code:\n st.markdown(\"## Code\")\n sourcelines, _ = inspect.getsourcelines(demo)\n st.code(textwrap.dedent(\"\".join(sourcelines[1:])))\n\n\nif __name__ == \"__main__\":\n run()\n", "path": "lib/streamlit/hello/hello.py"}]}
| 1,445 | 124 |
gh_patches_debug_33215
|
rasdani/github-patches
|
git_diff
|
pypa__setuptools-1745
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
build_meta doesn't use a fresh dist directory, which causes ValueError unpacking tuple
If you use `pip install .` on a source directory that already has a `dist`, the existing directory structure is used when preparing the wheel. This causes an exception if an existing wheel with a different name exists, because [build_meta assumes there's only one wheel in `dist`](https://github.com/pypa/setuptools/blob/64e60fc32981a1615c35962a60297d264bf16734/setuptools/build_meta.py#L157).
Here's a script to create a MWE repo:
```bash
#!/usr/bin/bash
mkdir /tmp/demo_dist_517
cd /tmp/demo_dist_517
echo "from setuptools import setup; setup()" > setup.py
echo "0.0.1" > VERSION
cat > setup.cfg << EOF
[metadata]
name = foo
version = file: VERSION
EOF
cat > pyproject.toml << EOF
[build-system]
requires = ["setuptools", "wheel"]
build-backend = "setuptools.build_meta"
EOF
```
At this point your repo looks like this:
```
$ tree
├── pyproject.toml
├── setup.cfg
├── setup.py
└── VERSION
```
Create a wheel in `dist`, then change the version:
```bash
pip wheel . --no-deps -w dist
echo "0.0.2" > VERSION
```
Now try to create a wheel from the repo:
```
pip wheel . -w dist
```
> This will trigger an error in `build_meta`:
> File "/tmp/pip-build-env-plomixa1/overlay/.../setuptools/build_meta.py", line 157, in _file_with_extension
> file, = matching
> ValueError: too many values to unpack (expected 1)
> Building wheel for foo (PEP 517) ... error
> Failed building wheel for foo
This is pretty easy to work around, obviously, since the user can just remove `dist` before invoking any `pip` commands, but it might be better to do the wheel build in a clean directory if possible.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setuptools/build_meta.py`
Content:
```
1 """A PEP 517 interface to setuptools
2
3 Previously, when a user or a command line tool (let's call it a "frontend")
4 needed to make a request of setuptools to take a certain action, for
5 example, generating a list of installation requirements, the frontend would
6 would call "setup.py egg_info" or "setup.py bdist_wheel" on the command line.
7
8 PEP 517 defines a different method of interfacing with setuptools. Rather
9 than calling "setup.py" directly, the frontend should:
10
11 1. Set the current directory to the directory with a setup.py file
12 2. Import this module into a safe python interpreter (one in which
13 setuptools can potentially set global variables or crash hard).
14 3. Call one of the functions defined in PEP 517.
15
16 What each function does is defined in PEP 517. However, here is a "casual"
17 definition of the functions (this definition should not be relied on for
18 bug reports or API stability):
19
20 - `build_wheel`: build a wheel in the folder and return the basename
21 - `get_requires_for_build_wheel`: get the `setup_requires` to build
22 - `prepare_metadata_for_build_wheel`: get the `install_requires`
23 - `build_sdist`: build an sdist in the folder and return the basename
24 - `get_requires_for_build_sdist`: get the `setup_requires` to build
25
26 Again, this is not a formal definition! Just a "taste" of the module.
27 """
28
29 import io
30 import os
31 import sys
32 import tokenize
33 import shutil
34 import contextlib
35
36 import setuptools
37 import distutils
38
39 from pkg_resources import parse_requirements
40
41 __all__ = ['get_requires_for_build_sdist',
42 'get_requires_for_build_wheel',
43 'prepare_metadata_for_build_wheel',
44 'build_wheel',
45 'build_sdist',
46 '__legacy__',
47 'SetupRequirementsError']
48
49 class SetupRequirementsError(BaseException):
50 def __init__(self, specifiers):
51 self.specifiers = specifiers
52
53
54 class Distribution(setuptools.dist.Distribution):
55 def fetch_build_eggs(self, specifiers):
56 specifier_list = list(map(str, parse_requirements(specifiers)))
57
58 raise SetupRequirementsError(specifier_list)
59
60 @classmethod
61 @contextlib.contextmanager
62 def patch(cls):
63 """
64 Replace
65 distutils.dist.Distribution with this class
66 for the duration of this context.
67 """
68 orig = distutils.core.Distribution
69 distutils.core.Distribution = cls
70 try:
71 yield
72 finally:
73 distutils.core.Distribution = orig
74
75
76 def _to_str(s):
77 """
78 Convert a filename to a string (on Python 2, explicitly
79 a byte string, not Unicode) as distutils checks for the
80 exact type str.
81 """
82 if sys.version_info[0] == 2 and not isinstance(s, str):
83 # Assume it's Unicode, as that's what the PEP says
84 # should be provided.
85 return s.encode(sys.getfilesystemencoding())
86 return s
87
88
89 def _get_immediate_subdirectories(a_dir):
90 return [name for name in os.listdir(a_dir)
91 if os.path.isdir(os.path.join(a_dir, name))]
92
93
94 def _file_with_extension(directory, extension):
95 matching = (
96 f for f in os.listdir(directory)
97 if f.endswith(extension)
98 )
99 file, = matching
100 return file
101
102
103 def _open_setup_script(setup_script):
104 if not os.path.exists(setup_script):
105 # Supply a default setup.py
106 return io.StringIO(u"from setuptools import setup; setup()")
107
108 return getattr(tokenize, 'open', open)(setup_script)
109
110
111 class _BuildMetaBackend(object):
112
113 def _fix_config(self, config_settings):
114 config_settings = config_settings or {}
115 config_settings.setdefault('--global-option', [])
116 return config_settings
117
118 def _get_build_requires(self, config_settings, requirements):
119 config_settings = self._fix_config(config_settings)
120
121 sys.argv = sys.argv[:1] + ['egg_info'] + \
122 config_settings["--global-option"]
123 try:
124 with Distribution.patch():
125 self.run_setup()
126 except SetupRequirementsError as e:
127 requirements += e.specifiers
128
129 return requirements
130
131 def run_setup(self, setup_script='setup.py'):
132 # Note that we can reuse our build directory between calls
133 # Correctness comes first, then optimization later
134 __file__ = setup_script
135 __name__ = '__main__'
136
137 with _open_setup_script(__file__) as f:
138 code = f.read().replace(r'\r\n', r'\n')
139
140 exec(compile(code, __file__, 'exec'), locals())
141
142 def get_requires_for_build_wheel(self, config_settings=None):
143 config_settings = self._fix_config(config_settings)
144 return self._get_build_requires(config_settings, requirements=['wheel'])
145
146 def get_requires_for_build_sdist(self, config_settings=None):
147 config_settings = self._fix_config(config_settings)
148 return self._get_build_requires(config_settings, requirements=[])
149
150 def prepare_metadata_for_build_wheel(self, metadata_directory,
151 config_settings=None):
152 sys.argv = sys.argv[:1] + ['dist_info', '--egg-base',
153 _to_str(metadata_directory)]
154 self.run_setup()
155
156 dist_info_directory = metadata_directory
157 while True:
158 dist_infos = [f for f in os.listdir(dist_info_directory)
159 if f.endswith('.dist-info')]
160
161 if (len(dist_infos) == 0 and
162 len(_get_immediate_subdirectories(dist_info_directory)) == 1):
163
164 dist_info_directory = os.path.join(
165 dist_info_directory, os.listdir(dist_info_directory)[0])
166 continue
167
168 assert len(dist_infos) == 1
169 break
170
171 # PEP 517 requires that the .dist-info directory be placed in the
172 # metadata_directory. To comply, we MUST copy the directory to the root
173 if dist_info_directory != metadata_directory:
174 shutil.move(
175 os.path.join(dist_info_directory, dist_infos[0]),
176 metadata_directory)
177 shutil.rmtree(dist_info_directory, ignore_errors=True)
178
179 return dist_infos[0]
180
181 def build_wheel(self, wheel_directory, config_settings=None,
182 metadata_directory=None):
183 config_settings = self._fix_config(config_settings)
184 wheel_directory = os.path.abspath(wheel_directory)
185 sys.argv = sys.argv[:1] + ['bdist_wheel'] + \
186 config_settings["--global-option"]
187 self.run_setup()
188 if wheel_directory != 'dist':
189 shutil.rmtree(wheel_directory)
190 shutil.copytree('dist', wheel_directory)
191
192 return _file_with_extension(wheel_directory, '.whl')
193
194 def build_sdist(self, sdist_directory, config_settings=None):
195 config_settings = self._fix_config(config_settings)
196 sdist_directory = os.path.abspath(sdist_directory)
197 sys.argv = sys.argv[:1] + ['sdist', '--formats', 'gztar'] + \
198 config_settings["--global-option"] + \
199 ["--dist-dir", sdist_directory]
200 self.run_setup()
201
202 return _file_with_extension(sdist_directory, '.tar.gz')
203
204
205 class _BuildMetaLegacyBackend(_BuildMetaBackend):
206 """Compatibility backend for setuptools
207
208 This is a version of setuptools.build_meta that endeavors to maintain backwards
209 compatibility with pre-PEP 517 modes of invocation. It exists as a temporary
210 bridge between the old packaging mechanism and the new packaging mechanism,
211 and will eventually be removed.
212 """
213 def run_setup(self, setup_script='setup.py'):
214 # In order to maintain compatibility with scripts assuming that
215 # the setup.py script is in a directory on the PYTHONPATH, inject
216 # '' into sys.path. (pypa/setuptools#1642)
217 sys_path = list(sys.path) # Save the original path
218
219 script_dir = os.path.dirname(os.path.abspath(setup_script))
220 if script_dir not in sys.path:
221 sys.path.insert(0, script_dir)
222
223 try:
224 super(_BuildMetaLegacyBackend,
225 self).run_setup(setup_script=setup_script)
226 finally:
227 # While PEP 517 frontends should be calling each hook in a fresh
228 # subprocess according to the standard (and thus it should not be
229 # strictly necessary to restore the old sys.path), we'll restore
230 # the original path so that the path manipulation does not persist
231 # within the hook after run_setup is called.
232 sys.path[:] = sys_path
233
234 # The primary backend
235 _BACKEND = _BuildMetaBackend()
236
237 get_requires_for_build_wheel = _BACKEND.get_requires_for_build_wheel
238 get_requires_for_build_sdist = _BACKEND.get_requires_for_build_sdist
239 prepare_metadata_for_build_wheel = _BACKEND.prepare_metadata_for_build_wheel
240 build_wheel = _BACKEND.build_wheel
241 build_sdist = _BACKEND.build_sdist
242
243
244 # The legacy backend
245 __legacy__ = _BuildMetaLegacyBackend()
246
```
Path: `setuptools/py31compat.py`
Content:
```
1 __all__ = []
2
3 __metaclass__ = type
4
5
6 try:
7 # Python >=3.2
8 from tempfile import TemporaryDirectory
9 except ImportError:
10 import shutil
11 import tempfile
12
13 class TemporaryDirectory:
14 """
15 Very simple temporary directory context manager.
16 Will try to delete afterward, but will also ignore OS and similar
17 errors on deletion.
18 """
19
20 def __init__(self):
21 self.name = None # Handle mkdtemp raising an exception
22 self.name = tempfile.mkdtemp()
23
24 def __enter__(self):
25 return self.name
26
27 def __exit__(self, exctype, excvalue, exctrace):
28 try:
29 shutil.rmtree(self.name, True)
30 except OSError: # removal errors are not the only possible
31 pass
32 self.name = None
33
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setuptools/build_meta.py b/setuptools/build_meta.py
--- a/setuptools/build_meta.py
+++ b/setuptools/build_meta.py
@@ -35,6 +35,7 @@
import setuptools
import distutils
+from setuptools.py31compat import TemporaryDirectory
from pkg_resources import parse_requirements
@@ -182,14 +183,22 @@
metadata_directory=None):
config_settings = self._fix_config(config_settings)
wheel_directory = os.path.abspath(wheel_directory)
- sys.argv = sys.argv[:1] + ['bdist_wheel'] + \
- config_settings["--global-option"]
- self.run_setup()
- if wheel_directory != 'dist':
- shutil.rmtree(wheel_directory)
- shutil.copytree('dist', wheel_directory)
- return _file_with_extension(wheel_directory, '.whl')
+ # Build the wheel in a temporary directory, then copy to the target
+ with TemporaryDirectory(dir=wheel_directory) as tmp_dist_dir:
+ sys.argv = (sys.argv[:1] +
+ ['bdist_wheel', '--dist-dir', tmp_dist_dir] +
+ config_settings["--global-option"])
+ self.run_setup()
+
+ wheel_basename = _file_with_extension(tmp_dist_dir, '.whl')
+ wheel_path = os.path.join(wheel_directory, wheel_basename)
+ if os.path.exists(wheel_path):
+ # os.rename will fail overwriting on non-unix env
+ os.remove(wheel_path)
+ os.rename(os.path.join(tmp_dist_dir, wheel_basename), wheel_path)
+
+ return wheel_basename
def build_sdist(self, sdist_directory, config_settings=None):
config_settings = self._fix_config(config_settings)
diff --git a/setuptools/py31compat.py b/setuptools/py31compat.py
--- a/setuptools/py31compat.py
+++ b/setuptools/py31compat.py
@@ -17,9 +17,9 @@
errors on deletion.
"""
- def __init__(self):
+ def __init__(self, **kwargs):
self.name = None # Handle mkdtemp raising an exception
- self.name = tempfile.mkdtemp()
+ self.name = tempfile.mkdtemp(**kwargs)
def __enter__(self):
return self.name
|
{"golden_diff": "diff --git a/setuptools/build_meta.py b/setuptools/build_meta.py\n--- a/setuptools/build_meta.py\n+++ b/setuptools/build_meta.py\n@@ -35,6 +35,7 @@\n \n import setuptools\n import distutils\n+from setuptools.py31compat import TemporaryDirectory\n \n from pkg_resources import parse_requirements\n \n@@ -182,14 +183,22 @@\n metadata_directory=None):\n config_settings = self._fix_config(config_settings)\n wheel_directory = os.path.abspath(wheel_directory)\n- sys.argv = sys.argv[:1] + ['bdist_wheel'] + \\\n- config_settings[\"--global-option\"]\n- self.run_setup()\n- if wheel_directory != 'dist':\n- shutil.rmtree(wheel_directory)\n- shutil.copytree('dist', wheel_directory)\n \n- return _file_with_extension(wheel_directory, '.whl')\n+ # Build the wheel in a temporary directory, then copy to the target\n+ with TemporaryDirectory(dir=wheel_directory) as tmp_dist_dir:\n+ sys.argv = (sys.argv[:1] +\n+ ['bdist_wheel', '--dist-dir', tmp_dist_dir] +\n+ config_settings[\"--global-option\"])\n+ self.run_setup()\n+\n+ wheel_basename = _file_with_extension(tmp_dist_dir, '.whl')\n+ wheel_path = os.path.join(wheel_directory, wheel_basename)\n+ if os.path.exists(wheel_path):\n+ # os.rename will fail overwriting on non-unix env\n+ os.remove(wheel_path)\n+ os.rename(os.path.join(tmp_dist_dir, wheel_basename), wheel_path)\n+\n+ return wheel_basename\n \n def build_sdist(self, sdist_directory, config_settings=None):\n config_settings = self._fix_config(config_settings)\ndiff --git a/setuptools/py31compat.py b/setuptools/py31compat.py\n--- a/setuptools/py31compat.py\n+++ b/setuptools/py31compat.py\n@@ -17,9 +17,9 @@\n errors on deletion.\n \"\"\"\n \n- def __init__(self):\n+ def __init__(self, **kwargs):\n self.name = None # Handle mkdtemp raising an exception\n- self.name = tempfile.mkdtemp()\n+ self.name = tempfile.mkdtemp(**kwargs)\n \n def __enter__(self):\n return self.name\n", "issue": "build_meta doesn't use a fresh dist directory, which causes ValueError unpacking tuple\nIf you use `pip install .` on a source directory that already has a `dist`, the existing directory structure is used when preparing the wheel. This causes an exception if an existing wheel with a different name exists, because [build_meta assumes there's only one wheel in `dist`](https://github.com/pypa/setuptools/blob/64e60fc32981a1615c35962a60297d264bf16734/setuptools/build_meta.py#L157).\r\n\r\nHere's a script to create a MWE repo:\r\n\r\n```bash\r\n#!/usr/bin/bash\r\n\r\nmkdir /tmp/demo_dist_517\r\ncd /tmp/demo_dist_517\r\necho \"from setuptools import setup; setup()\" > setup.py\r\necho \"0.0.1\" > VERSION\r\ncat > setup.cfg << EOF\r\n[metadata]\r\nname = foo\r\nversion = file: VERSION\r\nEOF\r\ncat > pyproject.toml << EOF\r\n[build-system]\r\nrequires = [\"setuptools\", \"wheel\"]\r\nbuild-backend = \"setuptools.build_meta\"\r\nEOF\r\n```\r\n\r\nAt this point your repo looks like this:\r\n```\r\n$ tree\r\n\u251c\u2500\u2500 pyproject.toml\r\n\u251c\u2500\u2500 setup.cfg\r\n\u251c\u2500\u2500 setup.py\r\n\u2514\u2500\u2500 VERSION\r\n```\r\n\r\nCreate a wheel in `dist`, then change the version:\r\n\r\n```bash\r\npip wheel . --no-deps -w dist\r\necho \"0.0.2\" > VERSION\r\n```\r\n\r\nNow try to create a wheel from the repo:\r\n\r\n```\r\npip wheel . -w dist\r\n```\r\n\r\n> This will trigger an error in `build_meta`:\r\n> File \"/tmp/pip-build-env-plomixa1/overlay/.../setuptools/build_meta.py\", line 157, in _file_with_extension\r\n> file, = matching\r\n> ValueError: too many values to unpack (expected 1)\r\n> Building wheel for foo (PEP 517) ... error\r\n> Failed building wheel for foo\r\n\r\nThis is pretty easy to work around, obviously, since the user can just remove `dist` before invoking any `pip` commands, but it might be better to do the wheel build in a clean directory if possible.\n", "before_files": [{"content": "\"\"\"A PEP 517 interface to setuptools\n\nPreviously, when a user or a command line tool (let's call it a \"frontend\")\nneeded to make a request of setuptools to take a certain action, for\nexample, generating a list of installation requirements, the frontend would\nwould call \"setup.py egg_info\" or \"setup.py bdist_wheel\" on the command line.\n\nPEP 517 defines a different method of interfacing with setuptools. Rather\nthan calling \"setup.py\" directly, the frontend should:\n\n 1. Set the current directory to the directory with a setup.py file\n 2. Import this module into a safe python interpreter (one in which\n setuptools can potentially set global variables or crash hard).\n 3. Call one of the functions defined in PEP 517.\n\nWhat each function does is defined in PEP 517. However, here is a \"casual\"\ndefinition of the functions (this definition should not be relied on for\nbug reports or API stability):\n\n - `build_wheel`: build a wheel in the folder and return the basename\n - `get_requires_for_build_wheel`: get the `setup_requires` to build\n - `prepare_metadata_for_build_wheel`: get the `install_requires`\n - `build_sdist`: build an sdist in the folder and return the basename\n - `get_requires_for_build_sdist`: get the `setup_requires` to build\n\nAgain, this is not a formal definition! Just a \"taste\" of the module.\n\"\"\"\n\nimport io\nimport os\nimport sys\nimport tokenize\nimport shutil\nimport contextlib\n\nimport setuptools\nimport distutils\n\nfrom pkg_resources import parse_requirements\n\n__all__ = ['get_requires_for_build_sdist',\n 'get_requires_for_build_wheel',\n 'prepare_metadata_for_build_wheel',\n 'build_wheel',\n 'build_sdist',\n '__legacy__',\n 'SetupRequirementsError']\n\nclass SetupRequirementsError(BaseException):\n def __init__(self, specifiers):\n self.specifiers = specifiers\n\n\nclass Distribution(setuptools.dist.Distribution):\n def fetch_build_eggs(self, specifiers):\n specifier_list = list(map(str, parse_requirements(specifiers)))\n\n raise SetupRequirementsError(specifier_list)\n\n @classmethod\n @contextlib.contextmanager\n def patch(cls):\n \"\"\"\n Replace\n distutils.dist.Distribution with this class\n for the duration of this context.\n \"\"\"\n orig = distutils.core.Distribution\n distutils.core.Distribution = cls\n try:\n yield\n finally:\n distutils.core.Distribution = orig\n\n\ndef _to_str(s):\n \"\"\"\n Convert a filename to a string (on Python 2, explicitly\n a byte string, not Unicode) as distutils checks for the\n exact type str.\n \"\"\"\n if sys.version_info[0] == 2 and not isinstance(s, str):\n # Assume it's Unicode, as that's what the PEP says\n # should be provided.\n return s.encode(sys.getfilesystemencoding())\n return s\n\n\ndef _get_immediate_subdirectories(a_dir):\n return [name for name in os.listdir(a_dir)\n if os.path.isdir(os.path.join(a_dir, name))]\n\n\ndef _file_with_extension(directory, extension):\n matching = (\n f for f in os.listdir(directory)\n if f.endswith(extension)\n )\n file, = matching\n return file\n\n\ndef _open_setup_script(setup_script):\n if not os.path.exists(setup_script):\n # Supply a default setup.py\n return io.StringIO(u\"from setuptools import setup; setup()\")\n\n return getattr(tokenize, 'open', open)(setup_script)\n\n\nclass _BuildMetaBackend(object):\n\n def _fix_config(self, config_settings):\n config_settings = config_settings or {}\n config_settings.setdefault('--global-option', [])\n return config_settings\n\n def _get_build_requires(self, config_settings, requirements):\n config_settings = self._fix_config(config_settings)\n\n sys.argv = sys.argv[:1] + ['egg_info'] + \\\n config_settings[\"--global-option\"]\n try:\n with Distribution.patch():\n self.run_setup()\n except SetupRequirementsError as e:\n requirements += e.specifiers\n\n return requirements\n\n def run_setup(self, setup_script='setup.py'):\n # Note that we can reuse our build directory between calls\n # Correctness comes first, then optimization later\n __file__ = setup_script\n __name__ = '__main__'\n\n with _open_setup_script(__file__) as f:\n code = f.read().replace(r'\\r\\n', r'\\n')\n\n exec(compile(code, __file__, 'exec'), locals())\n\n def get_requires_for_build_wheel(self, config_settings=None):\n config_settings = self._fix_config(config_settings)\n return self._get_build_requires(config_settings, requirements=['wheel'])\n\n def get_requires_for_build_sdist(self, config_settings=None):\n config_settings = self._fix_config(config_settings)\n return self._get_build_requires(config_settings, requirements=[])\n\n def prepare_metadata_for_build_wheel(self, metadata_directory,\n config_settings=None):\n sys.argv = sys.argv[:1] + ['dist_info', '--egg-base',\n _to_str(metadata_directory)]\n self.run_setup()\n\n dist_info_directory = metadata_directory\n while True:\n dist_infos = [f for f in os.listdir(dist_info_directory)\n if f.endswith('.dist-info')]\n\n if (len(dist_infos) == 0 and\n len(_get_immediate_subdirectories(dist_info_directory)) == 1):\n\n dist_info_directory = os.path.join(\n dist_info_directory, os.listdir(dist_info_directory)[0])\n continue\n\n assert len(dist_infos) == 1\n break\n\n # PEP 517 requires that the .dist-info directory be placed in the\n # metadata_directory. To comply, we MUST copy the directory to the root\n if dist_info_directory != metadata_directory:\n shutil.move(\n os.path.join(dist_info_directory, dist_infos[0]),\n metadata_directory)\n shutil.rmtree(dist_info_directory, ignore_errors=True)\n\n return dist_infos[0]\n\n def build_wheel(self, wheel_directory, config_settings=None,\n metadata_directory=None):\n config_settings = self._fix_config(config_settings)\n wheel_directory = os.path.abspath(wheel_directory)\n sys.argv = sys.argv[:1] + ['bdist_wheel'] + \\\n config_settings[\"--global-option\"]\n self.run_setup()\n if wheel_directory != 'dist':\n shutil.rmtree(wheel_directory)\n shutil.copytree('dist', wheel_directory)\n\n return _file_with_extension(wheel_directory, '.whl')\n\n def build_sdist(self, sdist_directory, config_settings=None):\n config_settings = self._fix_config(config_settings)\n sdist_directory = os.path.abspath(sdist_directory)\n sys.argv = sys.argv[:1] + ['sdist', '--formats', 'gztar'] + \\\n config_settings[\"--global-option\"] + \\\n [\"--dist-dir\", sdist_directory]\n self.run_setup()\n\n return _file_with_extension(sdist_directory, '.tar.gz')\n\n\nclass _BuildMetaLegacyBackend(_BuildMetaBackend):\n \"\"\"Compatibility backend for setuptools\n\n This is a version of setuptools.build_meta that endeavors to maintain backwards\n compatibility with pre-PEP 517 modes of invocation. It exists as a temporary\n bridge between the old packaging mechanism and the new packaging mechanism,\n and will eventually be removed.\n \"\"\"\n def run_setup(self, setup_script='setup.py'):\n # In order to maintain compatibility with scripts assuming that\n # the setup.py script is in a directory on the PYTHONPATH, inject\n # '' into sys.path. (pypa/setuptools#1642)\n sys_path = list(sys.path) # Save the original path\n\n script_dir = os.path.dirname(os.path.abspath(setup_script))\n if script_dir not in sys.path:\n sys.path.insert(0, script_dir)\n\n try:\n super(_BuildMetaLegacyBackend,\n self).run_setup(setup_script=setup_script)\n finally:\n # While PEP 517 frontends should be calling each hook in a fresh\n # subprocess according to the standard (and thus it should not be\n # strictly necessary to restore the old sys.path), we'll restore\n # the original path so that the path manipulation does not persist\n # within the hook after run_setup is called.\n sys.path[:] = sys_path\n\n# The primary backend\n_BACKEND = _BuildMetaBackend()\n\nget_requires_for_build_wheel = _BACKEND.get_requires_for_build_wheel\nget_requires_for_build_sdist = _BACKEND.get_requires_for_build_sdist\nprepare_metadata_for_build_wheel = _BACKEND.prepare_metadata_for_build_wheel\nbuild_wheel = _BACKEND.build_wheel\nbuild_sdist = _BACKEND.build_sdist\n\n\n# The legacy backend\n__legacy__ = _BuildMetaLegacyBackend()\n", "path": "setuptools/build_meta.py"}, {"content": "__all__ = []\n\n__metaclass__ = type\n\n\ntry:\n # Python >=3.2\n from tempfile import TemporaryDirectory\nexcept ImportError:\n import shutil\n import tempfile\n\n class TemporaryDirectory:\n \"\"\"\n Very simple temporary directory context manager.\n Will try to delete afterward, but will also ignore OS and similar\n errors on deletion.\n \"\"\"\n\n def __init__(self):\n self.name = None # Handle mkdtemp raising an exception\n self.name = tempfile.mkdtemp()\n\n def __enter__(self):\n return self.name\n\n def __exit__(self, exctype, excvalue, exctrace):\n try:\n shutil.rmtree(self.name, True)\n except OSError: # removal errors are not the only possible\n pass\n self.name = None\n", "path": "setuptools/py31compat.py"}], "after_files": [{"content": "\"\"\"A PEP 517 interface to setuptools\n\nPreviously, when a user or a command line tool (let's call it a \"frontend\")\nneeded to make a request of setuptools to take a certain action, for\nexample, generating a list of installation requirements, the frontend would\nwould call \"setup.py egg_info\" or \"setup.py bdist_wheel\" on the command line.\n\nPEP 517 defines a different method of interfacing with setuptools. Rather\nthan calling \"setup.py\" directly, the frontend should:\n\n 1. Set the current directory to the directory with a setup.py file\n 2. Import this module into a safe python interpreter (one in which\n setuptools can potentially set global variables or crash hard).\n 3. Call one of the functions defined in PEP 517.\n\nWhat each function does is defined in PEP 517. However, here is a \"casual\"\ndefinition of the functions (this definition should not be relied on for\nbug reports or API stability):\n\n - `build_wheel`: build a wheel in the folder and return the basename\n - `get_requires_for_build_wheel`: get the `setup_requires` to build\n - `prepare_metadata_for_build_wheel`: get the `install_requires`\n - `build_sdist`: build an sdist in the folder and return the basename\n - `get_requires_for_build_sdist`: get the `setup_requires` to build\n\nAgain, this is not a formal definition! Just a \"taste\" of the module.\n\"\"\"\n\nimport io\nimport os\nimport sys\nimport tokenize\nimport shutil\nimport contextlib\n\nimport setuptools\nimport distutils\nfrom setuptools.py31compat import TemporaryDirectory\n\nfrom pkg_resources import parse_requirements\n\n__all__ = ['get_requires_for_build_sdist',\n 'get_requires_for_build_wheel',\n 'prepare_metadata_for_build_wheel',\n 'build_wheel',\n 'build_sdist',\n '__legacy__',\n 'SetupRequirementsError']\n\nclass SetupRequirementsError(BaseException):\n def __init__(self, specifiers):\n self.specifiers = specifiers\n\n\nclass Distribution(setuptools.dist.Distribution):\n def fetch_build_eggs(self, specifiers):\n specifier_list = list(map(str, parse_requirements(specifiers)))\n\n raise SetupRequirementsError(specifier_list)\n\n @classmethod\n @contextlib.contextmanager\n def patch(cls):\n \"\"\"\n Replace\n distutils.dist.Distribution with this class\n for the duration of this context.\n \"\"\"\n orig = distutils.core.Distribution\n distutils.core.Distribution = cls\n try:\n yield\n finally:\n distutils.core.Distribution = orig\n\n\ndef _to_str(s):\n \"\"\"\n Convert a filename to a string (on Python 2, explicitly\n a byte string, not Unicode) as distutils checks for the\n exact type str.\n \"\"\"\n if sys.version_info[0] == 2 and not isinstance(s, str):\n # Assume it's Unicode, as that's what the PEP says\n # should be provided.\n return s.encode(sys.getfilesystemencoding())\n return s\n\n\ndef _get_immediate_subdirectories(a_dir):\n return [name for name in os.listdir(a_dir)\n if os.path.isdir(os.path.join(a_dir, name))]\n\n\ndef _file_with_extension(directory, extension):\n matching = (\n f for f in os.listdir(directory)\n if f.endswith(extension)\n )\n file, = matching\n return file\n\n\ndef _open_setup_script(setup_script):\n if not os.path.exists(setup_script):\n # Supply a default setup.py\n return io.StringIO(u\"from setuptools import setup; setup()\")\n\n return getattr(tokenize, 'open', open)(setup_script)\n\n\nclass _BuildMetaBackend(object):\n\n def _fix_config(self, config_settings):\n config_settings = config_settings or {}\n config_settings.setdefault('--global-option', [])\n return config_settings\n\n def _get_build_requires(self, config_settings, requirements):\n config_settings = self._fix_config(config_settings)\n\n sys.argv = sys.argv[:1] + ['egg_info'] + \\\n config_settings[\"--global-option\"]\n try:\n with Distribution.patch():\n self.run_setup()\n except SetupRequirementsError as e:\n requirements += e.specifiers\n\n return requirements\n\n def run_setup(self, setup_script='setup.py'):\n # Note that we can reuse our build directory between calls\n # Correctness comes first, then optimization later\n __file__ = setup_script\n __name__ = '__main__'\n\n with _open_setup_script(__file__) as f:\n code = f.read().replace(r'\\r\\n', r'\\n')\n\n exec(compile(code, __file__, 'exec'), locals())\n\n def get_requires_for_build_wheel(self, config_settings=None):\n config_settings = self._fix_config(config_settings)\n return self._get_build_requires(config_settings, requirements=['wheel'])\n\n def get_requires_for_build_sdist(self, config_settings=None):\n config_settings = self._fix_config(config_settings)\n return self._get_build_requires(config_settings, requirements=[])\n\n def prepare_metadata_for_build_wheel(self, metadata_directory,\n config_settings=None):\n sys.argv = sys.argv[:1] + ['dist_info', '--egg-base',\n _to_str(metadata_directory)]\n self.run_setup()\n\n dist_info_directory = metadata_directory\n while True:\n dist_infos = [f for f in os.listdir(dist_info_directory)\n if f.endswith('.dist-info')]\n\n if (len(dist_infos) == 0 and\n len(_get_immediate_subdirectories(dist_info_directory)) == 1):\n\n dist_info_directory = os.path.join(\n dist_info_directory, os.listdir(dist_info_directory)[0])\n continue\n\n assert len(dist_infos) == 1\n break\n\n # PEP 517 requires that the .dist-info directory be placed in the\n # metadata_directory. To comply, we MUST copy the directory to the root\n if dist_info_directory != metadata_directory:\n shutil.move(\n os.path.join(dist_info_directory, dist_infos[0]),\n metadata_directory)\n shutil.rmtree(dist_info_directory, ignore_errors=True)\n\n return dist_infos[0]\n\n def build_wheel(self, wheel_directory, config_settings=None,\n metadata_directory=None):\n config_settings = self._fix_config(config_settings)\n wheel_directory = os.path.abspath(wheel_directory)\n\n # Build the wheel in a temporary directory, then copy to the target\n with TemporaryDirectory(dir=wheel_directory) as tmp_dist_dir:\n sys.argv = (sys.argv[:1] +\n ['bdist_wheel', '--dist-dir', tmp_dist_dir] +\n config_settings[\"--global-option\"])\n self.run_setup()\n\n wheel_basename = _file_with_extension(tmp_dist_dir, '.whl')\n wheel_path = os.path.join(wheel_directory, wheel_basename)\n if os.path.exists(wheel_path):\n # os.rename will fail overwriting on non-unix env\n os.remove(wheel_path)\n os.rename(os.path.join(tmp_dist_dir, wheel_basename), wheel_path)\n\n return wheel_basename\n\n def build_sdist(self, sdist_directory, config_settings=None):\n config_settings = self._fix_config(config_settings)\n sdist_directory = os.path.abspath(sdist_directory)\n sys.argv = sys.argv[:1] + ['sdist', '--formats', 'gztar'] + \\\n config_settings[\"--global-option\"] + \\\n [\"--dist-dir\", sdist_directory]\n self.run_setup()\n\n return _file_with_extension(sdist_directory, '.tar.gz')\n\n\nclass _BuildMetaLegacyBackend(_BuildMetaBackend):\n \"\"\"Compatibility backend for setuptools\n\n This is a version of setuptools.build_meta that endeavors to maintain backwards\n compatibility with pre-PEP 517 modes of invocation. It exists as a temporary\n bridge between the old packaging mechanism and the new packaging mechanism,\n and will eventually be removed.\n \"\"\"\n def run_setup(self, setup_script='setup.py'):\n # In order to maintain compatibility with scripts assuming that\n # the setup.py script is in a directory on the PYTHONPATH, inject\n # '' into sys.path. (pypa/setuptools#1642)\n sys_path = list(sys.path) # Save the original path\n\n script_dir = os.path.dirname(os.path.abspath(setup_script))\n if script_dir not in sys.path:\n sys.path.insert(0, script_dir)\n\n try:\n super(_BuildMetaLegacyBackend,\n self).run_setup(setup_script=setup_script)\n finally:\n # While PEP 517 frontends should be calling each hook in a fresh\n # subprocess according to the standard (and thus it should not be\n # strictly necessary to restore the old sys.path), we'll restore\n # the original path so that the path manipulation does not persist\n # within the hook after run_setup is called.\n sys.path[:] = sys_path\n\n# The primary backend\n_BACKEND = _BuildMetaBackend()\n\nget_requires_for_build_wheel = _BACKEND.get_requires_for_build_wheel\nget_requires_for_build_sdist = _BACKEND.get_requires_for_build_sdist\nprepare_metadata_for_build_wheel = _BACKEND.prepare_metadata_for_build_wheel\nbuild_wheel = _BACKEND.build_wheel\nbuild_sdist = _BACKEND.build_sdist\n\n\n# The legacy backend\n__legacy__ = _BuildMetaLegacyBackend()\n", "path": "setuptools/build_meta.py"}, {"content": "__all__ = []\n\n__metaclass__ = type\n\n\ntry:\n # Python >=3.2\n from tempfile import TemporaryDirectory\nexcept ImportError:\n import shutil\n import tempfile\n\n class TemporaryDirectory:\n \"\"\"\n Very simple temporary directory context manager.\n Will try to delete afterward, but will also ignore OS and similar\n errors on deletion.\n \"\"\"\n\n def __init__(self, **kwargs):\n self.name = None # Handle mkdtemp raising an exception\n self.name = tempfile.mkdtemp(**kwargs)\n\n def __enter__(self):\n return self.name\n\n def __exit__(self, exctype, excvalue, exctrace):\n try:\n shutil.rmtree(self.name, True)\n except OSError: # removal errors are not the only possible\n pass\n self.name = None\n", "path": "setuptools/py31compat.py"}]}
| 3,587 | 510 |
gh_patches_debug_24040
|
rasdani/github-patches
|
git_diff
|
WordPress__openverse-api-115
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Replace deprecated falcon.api with falcon.app
> The API class was renamed to App in Falcon 3.0. The old class name remains available as an alias for backwards-compatibility, but will be removed in a future release.
[Falcon docs](https://falcon.readthedocs.io/en/latest/api/app.html)
We use `falcon` in `analytics` and in the `ingestion_server`. We should replace deprecated `app` class name with `api` class name.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ingestion_server/ingestion_server/api.py`
Content:
```
1 import falcon
2 import logging
3 import sys
4 import json
5 import uuid
6 import time
7 from urllib.parse import urlparse
8 from multiprocessing import Value, Process
9 from ingestion_server.tasks import TaskTracker, Task, TaskTypes
10 from ingestion_server.state import worker_finished, clear_state
11 import ingestion_server.indexer as indexer
12
13 """
14 A small RPC API server for scheduling ingestion of upstream data and
15 Elasticsearch indexing tasks.
16 """
17
18
19 MODEL = 'model'
20 ACTION = 'action'
21 CALLBACK_URL = 'callback_url'
22 SINCE_DATE = 'since_date'
23
24
25 class TaskResource:
26 def __init__(self, tracker: TaskTracker):
27 self.tracker = tracker
28
29 @staticmethod
30 def _get_base_url(req):
31 parsed = urlparse(req.url)
32 return parsed.scheme + '://' + parsed.netloc
33
34 @staticmethod
35 def _validate_create_task(request):
36 """
37 Validate an index creation task.
38 :return: None if valid else a string containing an error message.
39 """
40 if request == b'':
41 return "Expected JSON request body but found nothing."
42 request = json.loads(request.decode('utf-8'))
43 if MODEL not in request:
44 return "No model supplied in request body."
45 if ACTION not in request:
46 return "No action supplied in request body."
47 if request[ACTION] not in [x.name for x in TaskTypes]:
48 return "Invalid action."
49 if request[ACTION] == TaskTypes.UPDATE_INDEX.name and SINCE_DATE not in request:
50 return "Received UPDATE request but no since_date."
51
52 return None
53
54 def on_post(self, req, resp):
55 """ Create a task. """
56 raw_body = req.stream.read()
57 request_error = self._validate_create_task(raw_body)
58 if request_error:
59 logging.warning(
60 'Invalid request made. Reason: {}'.format(request_error)
61 )
62 resp.status = falcon.HTTP_400
63 resp.media = {
64 'message': request_error
65 }
66 return
67 body = json.loads(raw_body.decode('utf-8'))
68 model = body[MODEL]
69 action = body[ACTION]
70 callback_url = None
71 if CALLBACK_URL in body:
72 callback_url = body[CALLBACK_URL]
73 since_date = body[SINCE_DATE] if SINCE_DATE in body else None
74 task_id = str(uuid.uuid4())
75 # Inject shared memory
76 progress = Value('d', 0.0)
77 finish_time = Value('d', 0.0)
78 task = Task(
79 model=model,
80 task_type=TaskTypes[action],
81 since_date=since_date,
82 progress=progress,
83 task_id=task_id,
84 finish_time=finish_time,
85 callback_url=callback_url
86 )
87 task.start()
88 task_id = self.tracker \
89 .add_task(task, task_id, action, progress, finish_time)
90 base_url = self._get_base_url(req)
91 status_url = base_url + '/task/{}'.format(task_id)
92 # Give the task a moment to start so we can detect immediate failure.
93 # TODO: Use IPC to detect if the job launched successfully instead
94 # of giving it 100ms to crash. This is prone to race conditions.
95 time.sleep(0.1)
96 if task.is_alive():
97 resp.status = falcon.HTTP_202
98 resp.media = {
99 'message': 'Successfully scheduled task',
100 'task_id': task_id,
101 'status_check': status_url
102 }
103 return
104 else:
105 resp.status = falcon.HTTP_500
106 resp.media = {
107 'message': 'Failed to schedule task due to an internal server '
108 'error. Check scheduler logs.'
109 }
110 return
111
112 def on_get(self, req, resp):
113 """ List all indexing tasks. """
114 resp.media = self.tracker.list_task_statuses()
115
116
117 class TaskStatus:
118 def __init__(self, tracker: TaskTracker):
119 self.tracker = tracker
120
121 def on_get(self, req, resp, task_id):
122 """ Check the status of a single task."""
123 task = self.tracker.id_task[task_id]
124 active = task.is_alive()
125
126 percent_completed = self.tracker.id_progress[task_id].value
127 resp.media = {
128 'active': active,
129 'percent_completed': percent_completed,
130 'error': percent_completed < 100 and not active
131 }
132
133
134 class WorkerFinishedResource:
135 """
136 For notifying ingestion server that an indexing worker has finished its
137 task.
138 """
139 def on_post(self, req, resp):
140 target_index = worker_finished(str(req.remote_addr))
141 if target_index:
142 logging.info(
143 'All indexer workers finished! Attempting to promote index '
144 f'{target_index}'
145 )
146 f = indexer.TableIndexer.go_live
147 p = Process(target=f, args=(target_index, 'image'))
148 p.start()
149
150
151 class StateResource:
152 def on_delete(self, req, resp):
153 """
154 Forget about the last scheduled indexing job.
155 """
156 clear_state()
157
158
159 def create_api(log=True):
160 """ Create an instance of the Falcon API server. """
161 if log:
162 root = logging.getLogger()
163 root.setLevel(logging.DEBUG)
164 handler = logging.StreamHandler(sys.stdout)
165 handler.setLevel(logging.INFO)
166 formatter = logging.Formatter(
167 '%(asctime)s %(levelname)s %(filename)s:%(lineno)d - %(message)s'
168 )
169 handler.setFormatter(formatter)
170 root.addHandler(handler)
171
172 _api = falcon.API()
173 task_tracker = TaskTracker()
174 task_resource = TaskResource(task_tracker)
175 get_task_status = TaskStatus(task_tracker)
176 _api.add_route('/task', task_resource)
177 _api.add_route('/task/{task_id}', get_task_status)
178 _api.add_route('/worker_finished', WorkerFinishedResource())
179 _api.add_route('/state', StateResource())
180
181 return _api
182
183
184 api = create_api()
185
```
Path: `analytics/server.py`
Content:
```
1 import falcon
2 from falcon_cors import CORS
3 from event_controller import EventController
4
5 event_controller = EventController()
6
7 class SearchEventResource:
8 def on_post(self, req, resp):
9 j = req.media
10 event_controller.create_search(
11 query=j['query'],
12 session_uuid=j['session_uuid']
13 )
14 resp.status = falcon.HTTP_201
15
16
17 class SearchRatingEventResource:
18 def on_post(self, req, resp):
19 j = req.media
20 try:
21 event_controller.create_search_rating(
22 query=j['query'],
23 relevant=j['relevant']
24 )
25 resp.status = falcon.HTTP_201
26 except ValueError:
27 resp.body = '{"message": "Rating must be True or False"}'
28 resp.status = falcon.HTTP_400
29
30
31 class ResultClickEventResource:
32 def on_post(self, req, resp):
33 j = req.media
34 event_controller.create_result_click(
35 session_uuid=j['session_uuid'],
36 result_uuid=j['result_uuid'],
37 query=j['query'],
38 rank=j['result_rank']
39 )
40 resp.status = falcon.HTTP_201
41
42
43 class DetailEventResource:
44 def on_post(self, req, resp):
45 j = req.media
46 try:
47 event_controller.create_detail_event(
48 event=j['event_type'],
49 result_uuid=j['result_uuid']
50 )
51 resp.status = falcon.HTTP_201
52 except KeyError:
53 valid_events = event_controller.list_valid_detail_events()
54 resp.body = \
55 '{{"message": "Invalid event_type. Valid types: {}"}}' \
56 .format(valid_events)
57 resp.status = falcon.HTTP_400
58
59
60 class RedocResource:
61 def on_get(self, req, resp):
62 resp.status = falcon.HTTP_200
63 resp.content_type = 'text/html'
64 with open('docs/redoc.html', 'r') as f:
65 resp.body = f.read()
66
67
68 class OpenAPISpecResource:
69 def on_get(self, req, resp):
70 resp.status = falcon.HTTP_200
71 resp.content_type = 'text/html'
72 with open('docs/swagger.yaml', 'r') as f:
73 resp.body = f.read()
74
75 origins = [
76 # @todo: Switch these to environment variables
77 'https://search.openverse.engineering',
78 'https://search-dev.openverse.engineering',
79 'https://wordpress.org/openverse'
80 ]
81 cors = CORS(
82 allow_origins_list=origins,
83 allow_all_methods=True,
84 allow_all_headers=True
85 )
86 api = falcon.API(middleware=[cors.middleware])
87 api.add_route('/', RedocResource())
88 api.add_route('/swagger.yaml', OpenAPISpecResource())
89 api.add_route('/search_event', SearchEventResource())
90 api.add_route('/search_rating_event', SearchRatingEventResource())
91 api.add_route('/result_click_event', ResultClickEventResource())
92 api.add_route('/detail_page_event', DetailEventResource())
93
```
Path: `ingestion_server/ingestion_server/indexer_worker.py`
Content:
```
1 """
2 A single worker responsible for indexing a subset of the records stored in the
3 database.
4
5 Accept an HTTP request specifying a range of image IDs to reindex. After the
6 data has been indexed, notify Ingestion Server and stop the instance.
7 """
8 import falcon
9 import sys
10 import logging as log
11 import os
12 import boto3
13 import requests
14 from multiprocessing import Value, Process
15 from psycopg2.sql import SQL
16 from ingestion_server.indexer import elasticsearch_connect, TableIndexer
17
18
19 ec2_client = boto3.client(
20 'ec2',
21 region_name=os.getenv('AWS_REGION', 'us-east-1'),
22 aws_access_key_id=os.getenv('AWS_ACCESS_KEY_ID', None),
23 aws_secret_access_key=os.getenv('AWS_SECRET_ACCESS_KEY', None)
24 )
25
26
27 class IndexingJobResource:
28 def on_post(self, req, resp):
29 j = req.media
30 start_id = j['start_id']
31 end_id = j['end_id']
32 target_index = j['target_index']
33 notify_url = f'http://{req.remote_addr}:8001/worker_finished'
34 _execute_indexing_task(target_index, start_id, end_id, notify_url)
35 log.info(f'Received indexing request for records {start_id}-{end_id}')
36 resp.status = falcon.HTTP_201
37
38
39 class HealthcheckResource:
40 def on_get(self, req, resp):
41 resp.status = falcon.HTTP_200
42
43
44 def _execute_indexing_task(target_index, start_id, end_id, notify_url):
45 table = 'image'
46 elasticsearch = elasticsearch_connect()
47 progress = Value('d', 0.0)
48 finish_time = Value('d', 0.0)
49 exists_in_table = \
50 'exists(SELECT 1 FROM {table} ' \
51 'WHERE identifier = image.identifier) as "{name}"'
52 exists_in_deleted_table = exists_in_table.format(
53 table='api_deletedimage', name='deleted'
54 )
55 exists_in_mature_table = exists_in_table.format(
56 table='api_matureimage', name='mature'
57 )
58
59 query = SQL(f'''
60 SELECT *,
61 {exists_in_deleted_table}, {exists_in_mature_table}
62 FROM image
63 WHERE id BETWEEN {start_id} AND {end_id}
64 ''')
65 log.info('Querying {}'.format(query))
66 indexer = TableIndexer(
67 elasticsearch, table, progress, finish_time
68 )
69 p = Process(
70 target=_launch_reindex,
71 args=(table, target_index, query, indexer, notify_url)
72 )
73 p.start()
74 log.info('Started indexing task')
75
76
77 def _launch_reindex(table, target_index, query, indexer, notify_url):
78 try:
79 indexer.replicate(table, target_index, query)
80 except Exception:
81 log.error("Indexing error occurred: ", exc_info=True)
82
83 log.info(f'Notifying {notify_url}')
84 requests.post(notify_url)
85 _self_destruct()
86 return
87
88
89 def _self_destruct():
90 """
91 Stop this EC2 instance once the task is finished.
92 """
93 # Get instance ID from AWS metadata service
94 if os.getenv('ENVIRONMENT', 'local') == 'local':
95 log.info(
96 'Skipping self destruction because worker is in local environment'
97 )
98 return
99 endpoint = 'http://169.254.169.254/latest/meta-data/instance-id'
100 response = requests.get(endpoint)
101 instance_id = response.content.decode('utf8')
102 log.info('Shutting self down')
103 ec2_client.stop_instances(InstanceIds=[instance_id])
104
105
106 root = log.getLogger()
107 root.setLevel(log.DEBUG)
108 handler = log.StreamHandler(sys.stdout)
109 handler.setLevel(log.INFO)
110 formatter = log.Formatter(
111 '%(asctime)s %(levelname)s %(filename)s:%(lineno)d - %(message)s'
112 )
113 handler.setFormatter(formatter)
114 root.addHandler(handler)
115 api = falcon.API()
116 api.add_route('/indexing_task', IndexingJobResource())
117 api.add_route('/healthcheck', HealthcheckResource())
118
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/analytics/server.py b/analytics/server.py
--- a/analytics/server.py
+++ b/analytics/server.py
@@ -83,7 +83,7 @@
allow_all_methods=True,
allow_all_headers=True
)
-api = falcon.API(middleware=[cors.middleware])
+api = falcon.App(middleware=[cors.middleware])
api.add_route('/', RedocResource())
api.add_route('/swagger.yaml', OpenAPISpecResource())
api.add_route('/search_event', SearchEventResource())
diff --git a/ingestion_server/ingestion_server/api.py b/ingestion_server/ingestion_server/api.py
--- a/ingestion_server/ingestion_server/api.py
+++ b/ingestion_server/ingestion_server/api.py
@@ -169,7 +169,7 @@
handler.setFormatter(formatter)
root.addHandler(handler)
- _api = falcon.API()
+ _api = falcon.App()
task_tracker = TaskTracker()
task_resource = TaskResource(task_tracker)
get_task_status = TaskStatus(task_tracker)
diff --git a/ingestion_server/ingestion_server/indexer_worker.py b/ingestion_server/ingestion_server/indexer_worker.py
--- a/ingestion_server/ingestion_server/indexer_worker.py
+++ b/ingestion_server/ingestion_server/indexer_worker.py
@@ -112,6 +112,6 @@
)
handler.setFormatter(formatter)
root.addHandler(handler)
-api = falcon.API()
+api = falcon.App()
api.add_route('/indexing_task', IndexingJobResource())
api.add_route('/healthcheck', HealthcheckResource())
|
{"golden_diff": "diff --git a/analytics/server.py b/analytics/server.py\n--- a/analytics/server.py\n+++ b/analytics/server.py\n@@ -83,7 +83,7 @@\n allow_all_methods=True,\n allow_all_headers=True\n )\n-api = falcon.API(middleware=[cors.middleware])\n+api = falcon.App(middleware=[cors.middleware])\n api.add_route('/', RedocResource())\n api.add_route('/swagger.yaml', OpenAPISpecResource())\n api.add_route('/search_event', SearchEventResource())\ndiff --git a/ingestion_server/ingestion_server/api.py b/ingestion_server/ingestion_server/api.py\n--- a/ingestion_server/ingestion_server/api.py\n+++ b/ingestion_server/ingestion_server/api.py\n@@ -169,7 +169,7 @@\n handler.setFormatter(formatter)\n root.addHandler(handler)\n \n- _api = falcon.API()\n+ _api = falcon.App()\n task_tracker = TaskTracker()\n task_resource = TaskResource(task_tracker)\n get_task_status = TaskStatus(task_tracker)\ndiff --git a/ingestion_server/ingestion_server/indexer_worker.py b/ingestion_server/ingestion_server/indexer_worker.py\n--- a/ingestion_server/ingestion_server/indexer_worker.py\n+++ b/ingestion_server/ingestion_server/indexer_worker.py\n@@ -112,6 +112,6 @@\n )\n handler.setFormatter(formatter)\n root.addHandler(handler)\n-api = falcon.API()\n+api = falcon.App()\n api.add_route('/indexing_task', IndexingJobResource())\n api.add_route('/healthcheck', HealthcheckResource())\n", "issue": "Replace deprecated falcon.api with falcon.app\n> The API class was renamed to App in Falcon 3.0. The old class name remains available as an alias for backwards-compatibility, but will be removed in a future release.\r\n\r\n[Falcon docs](https://falcon.readthedocs.io/en/latest/api/app.html)\r\n\r\nWe use `falcon` in `analytics` and in the `ingestion_server`. We should replace deprecated `app` class name with `api` class name.\n", "before_files": [{"content": "import falcon\nimport logging\nimport sys\nimport json\nimport uuid\nimport time\nfrom urllib.parse import urlparse\nfrom multiprocessing import Value, Process\nfrom ingestion_server.tasks import TaskTracker, Task, TaskTypes\nfrom ingestion_server.state import worker_finished, clear_state\nimport ingestion_server.indexer as indexer\n\n\"\"\"\nA small RPC API server for scheduling ingestion of upstream data and\nElasticsearch indexing tasks.\n\"\"\"\n\n\nMODEL = 'model'\nACTION = 'action'\nCALLBACK_URL = 'callback_url'\nSINCE_DATE = 'since_date'\n\n\nclass TaskResource:\n def __init__(self, tracker: TaskTracker):\n self.tracker = tracker\n\n @staticmethod\n def _get_base_url(req):\n parsed = urlparse(req.url)\n return parsed.scheme + '://' + parsed.netloc\n\n @staticmethod\n def _validate_create_task(request):\n \"\"\"\n Validate an index creation task.\n :return: None if valid else a string containing an error message.\n \"\"\"\n if request == b'':\n return \"Expected JSON request body but found nothing.\"\n request = json.loads(request.decode('utf-8'))\n if MODEL not in request:\n return \"No model supplied in request body.\"\n if ACTION not in request:\n return \"No action supplied in request body.\"\n if request[ACTION] not in [x.name for x in TaskTypes]:\n return \"Invalid action.\"\n if request[ACTION] == TaskTypes.UPDATE_INDEX.name and SINCE_DATE not in request:\n return \"Received UPDATE request but no since_date.\"\n\n return None\n\n def on_post(self, req, resp):\n \"\"\" Create a task. \"\"\"\n raw_body = req.stream.read()\n request_error = self._validate_create_task(raw_body)\n if request_error:\n logging.warning(\n 'Invalid request made. Reason: {}'.format(request_error)\n )\n resp.status = falcon.HTTP_400\n resp.media = {\n 'message': request_error\n }\n return\n body = json.loads(raw_body.decode('utf-8'))\n model = body[MODEL]\n action = body[ACTION]\n callback_url = None\n if CALLBACK_URL in body:\n callback_url = body[CALLBACK_URL]\n since_date = body[SINCE_DATE] if SINCE_DATE in body else None\n task_id = str(uuid.uuid4())\n # Inject shared memory\n progress = Value('d', 0.0)\n finish_time = Value('d', 0.0)\n task = Task(\n model=model,\n task_type=TaskTypes[action],\n since_date=since_date,\n progress=progress,\n task_id=task_id,\n finish_time=finish_time,\n callback_url=callback_url\n )\n task.start()\n task_id = self.tracker \\\n .add_task(task, task_id, action, progress, finish_time)\n base_url = self._get_base_url(req)\n status_url = base_url + '/task/{}'.format(task_id)\n # Give the task a moment to start so we can detect immediate failure.\n # TODO: Use IPC to detect if the job launched successfully instead\n # of giving it 100ms to crash. This is prone to race conditions.\n time.sleep(0.1)\n if task.is_alive():\n resp.status = falcon.HTTP_202\n resp.media = {\n 'message': 'Successfully scheduled task',\n 'task_id': task_id,\n 'status_check': status_url\n }\n return\n else:\n resp.status = falcon.HTTP_500\n resp.media = {\n 'message': 'Failed to schedule task due to an internal server '\n 'error. Check scheduler logs.'\n }\n return\n\n def on_get(self, req, resp):\n \"\"\" List all indexing tasks. \"\"\"\n resp.media = self.tracker.list_task_statuses()\n\n\nclass TaskStatus:\n def __init__(self, tracker: TaskTracker):\n self.tracker = tracker\n\n def on_get(self, req, resp, task_id):\n \"\"\" Check the status of a single task.\"\"\"\n task = self.tracker.id_task[task_id]\n active = task.is_alive()\n\n percent_completed = self.tracker.id_progress[task_id].value\n resp.media = {\n 'active': active,\n 'percent_completed': percent_completed,\n 'error': percent_completed < 100 and not active\n }\n\n\nclass WorkerFinishedResource:\n \"\"\"\n For notifying ingestion server that an indexing worker has finished its\n task.\n \"\"\"\n def on_post(self, req, resp):\n target_index = worker_finished(str(req.remote_addr))\n if target_index:\n logging.info(\n 'All indexer workers finished! Attempting to promote index '\n f'{target_index}'\n )\n f = indexer.TableIndexer.go_live\n p = Process(target=f, args=(target_index, 'image'))\n p.start()\n\n\nclass StateResource:\n def on_delete(self, req, resp):\n \"\"\"\n Forget about the last scheduled indexing job.\n \"\"\"\n clear_state()\n\n\ndef create_api(log=True):\n \"\"\" Create an instance of the Falcon API server. \"\"\"\n if log:\n root = logging.getLogger()\n root.setLevel(logging.DEBUG)\n handler = logging.StreamHandler(sys.stdout)\n handler.setLevel(logging.INFO)\n formatter = logging.Formatter(\n '%(asctime)s %(levelname)s %(filename)s:%(lineno)d - %(message)s'\n )\n handler.setFormatter(formatter)\n root.addHandler(handler)\n\n _api = falcon.API()\n task_tracker = TaskTracker()\n task_resource = TaskResource(task_tracker)\n get_task_status = TaskStatus(task_tracker)\n _api.add_route('/task', task_resource)\n _api.add_route('/task/{task_id}', get_task_status)\n _api.add_route('/worker_finished', WorkerFinishedResource())\n _api.add_route('/state', StateResource())\n\n return _api\n\n\napi = create_api()\n", "path": "ingestion_server/ingestion_server/api.py"}, {"content": "import falcon\nfrom falcon_cors import CORS\nfrom event_controller import EventController\n\nevent_controller = EventController()\n\nclass SearchEventResource:\n def on_post(self, req, resp):\n j = req.media\n event_controller.create_search(\n query=j['query'],\n session_uuid=j['session_uuid']\n )\n resp.status = falcon.HTTP_201\n\n\nclass SearchRatingEventResource:\n def on_post(self, req, resp):\n j = req.media\n try:\n event_controller.create_search_rating(\n query=j['query'],\n relevant=j['relevant']\n )\n resp.status = falcon.HTTP_201\n except ValueError:\n resp.body = '{\"message\": \"Rating must be True or False\"}'\n resp.status = falcon.HTTP_400\n\n\nclass ResultClickEventResource:\n def on_post(self, req, resp):\n j = req.media\n event_controller.create_result_click(\n session_uuid=j['session_uuid'],\n result_uuid=j['result_uuid'],\n query=j['query'],\n rank=j['result_rank']\n )\n resp.status = falcon.HTTP_201\n\n\nclass DetailEventResource:\n def on_post(self, req, resp):\n j = req.media\n try:\n event_controller.create_detail_event(\n event=j['event_type'],\n result_uuid=j['result_uuid']\n )\n resp.status = falcon.HTTP_201\n except KeyError:\n valid_events = event_controller.list_valid_detail_events()\n resp.body = \\\n '{{\"message\": \"Invalid event_type. Valid types: {}\"}}' \\\n .format(valid_events)\n resp.status = falcon.HTTP_400\n\n\nclass RedocResource:\n def on_get(self, req, resp):\n resp.status = falcon.HTTP_200\n resp.content_type = 'text/html'\n with open('docs/redoc.html', 'r') as f:\n resp.body = f.read()\n\n\nclass OpenAPISpecResource:\n def on_get(self, req, resp):\n resp.status = falcon.HTTP_200\n resp.content_type = 'text/html'\n with open('docs/swagger.yaml', 'r') as f:\n resp.body = f.read()\n\norigins = [\n # @todo: Switch these to environment variables\n 'https://search.openverse.engineering',\n 'https://search-dev.openverse.engineering',\n 'https://wordpress.org/openverse'\n]\ncors = CORS(\n allow_origins_list=origins,\n allow_all_methods=True,\n allow_all_headers=True\n)\napi = falcon.API(middleware=[cors.middleware])\napi.add_route('/', RedocResource())\napi.add_route('/swagger.yaml', OpenAPISpecResource())\napi.add_route('/search_event', SearchEventResource())\napi.add_route('/search_rating_event', SearchRatingEventResource())\napi.add_route('/result_click_event', ResultClickEventResource())\napi.add_route('/detail_page_event', DetailEventResource())\n", "path": "analytics/server.py"}, {"content": "\"\"\"\nA single worker responsible for indexing a subset of the records stored in the\ndatabase.\n\nAccept an HTTP request specifying a range of image IDs to reindex. After the\ndata has been indexed, notify Ingestion Server and stop the instance.\n\"\"\"\nimport falcon\nimport sys\nimport logging as log\nimport os\nimport boto3\nimport requests\nfrom multiprocessing import Value, Process\nfrom psycopg2.sql import SQL\nfrom ingestion_server.indexer import elasticsearch_connect, TableIndexer\n\n\nec2_client = boto3.client(\n 'ec2',\n region_name=os.getenv('AWS_REGION', 'us-east-1'),\n aws_access_key_id=os.getenv('AWS_ACCESS_KEY_ID', None),\n aws_secret_access_key=os.getenv('AWS_SECRET_ACCESS_KEY', None)\n)\n\n\nclass IndexingJobResource:\n def on_post(self, req, resp):\n j = req.media\n start_id = j['start_id']\n end_id = j['end_id']\n target_index = j['target_index']\n notify_url = f'http://{req.remote_addr}:8001/worker_finished'\n _execute_indexing_task(target_index, start_id, end_id, notify_url)\n log.info(f'Received indexing request for records {start_id}-{end_id}')\n resp.status = falcon.HTTP_201\n\n\nclass HealthcheckResource:\n def on_get(self, req, resp):\n resp.status = falcon.HTTP_200\n\n\ndef _execute_indexing_task(target_index, start_id, end_id, notify_url):\n table = 'image'\n elasticsearch = elasticsearch_connect()\n progress = Value('d', 0.0)\n finish_time = Value('d', 0.0)\n exists_in_table = \\\n 'exists(SELECT 1 FROM {table} ' \\\n 'WHERE identifier = image.identifier) as \"{name}\"'\n exists_in_deleted_table = exists_in_table.format(\n table='api_deletedimage', name='deleted'\n )\n exists_in_mature_table = exists_in_table.format(\n table='api_matureimage', name='mature'\n )\n\n query = SQL(f'''\n SELECT *,\n {exists_in_deleted_table}, {exists_in_mature_table}\n FROM image\n WHERE id BETWEEN {start_id} AND {end_id}\n ''')\n log.info('Querying {}'.format(query))\n indexer = TableIndexer(\n elasticsearch, table, progress, finish_time\n )\n p = Process(\n target=_launch_reindex,\n args=(table, target_index, query, indexer, notify_url)\n )\n p.start()\n log.info('Started indexing task')\n\n\ndef _launch_reindex(table, target_index, query, indexer, notify_url):\n try:\n indexer.replicate(table, target_index, query)\n except Exception:\n log.error(\"Indexing error occurred: \", exc_info=True)\n\n log.info(f'Notifying {notify_url}')\n requests.post(notify_url)\n _self_destruct()\n return\n\n\ndef _self_destruct():\n \"\"\"\n Stop this EC2 instance once the task is finished.\n \"\"\"\n # Get instance ID from AWS metadata service\n if os.getenv('ENVIRONMENT', 'local') == 'local':\n log.info(\n 'Skipping self destruction because worker is in local environment'\n )\n return\n endpoint = 'http://169.254.169.254/latest/meta-data/instance-id'\n response = requests.get(endpoint)\n instance_id = response.content.decode('utf8')\n log.info('Shutting self down')\n ec2_client.stop_instances(InstanceIds=[instance_id])\n\n\nroot = log.getLogger()\nroot.setLevel(log.DEBUG)\nhandler = log.StreamHandler(sys.stdout)\nhandler.setLevel(log.INFO)\nformatter = log.Formatter(\n '%(asctime)s %(levelname)s %(filename)s:%(lineno)d - %(message)s'\n)\nhandler.setFormatter(formatter)\nroot.addHandler(handler)\napi = falcon.API()\napi.add_route('/indexing_task', IndexingJobResource())\napi.add_route('/healthcheck', HealthcheckResource())\n", "path": "ingestion_server/ingestion_server/indexer_worker.py"}], "after_files": [{"content": "import falcon\nimport logging\nimport sys\nimport json\nimport uuid\nimport time\nfrom urllib.parse import urlparse\nfrom multiprocessing import Value, Process\nfrom ingestion_server.tasks import TaskTracker, Task, TaskTypes\nfrom ingestion_server.state import worker_finished, clear_state\nimport ingestion_server.indexer as indexer\n\n\"\"\"\nA small RPC API server for scheduling ingestion of upstream data and\nElasticsearch indexing tasks.\n\"\"\"\n\n\nMODEL = 'model'\nACTION = 'action'\nCALLBACK_URL = 'callback_url'\nSINCE_DATE = 'since_date'\n\n\nclass TaskResource:\n def __init__(self, tracker: TaskTracker):\n self.tracker = tracker\n\n @staticmethod\n def _get_base_url(req):\n parsed = urlparse(req.url)\n return parsed.scheme + '://' + parsed.netloc\n\n @staticmethod\n def _validate_create_task(request):\n \"\"\"\n Validate an index creation task.\n :return: None if valid else a string containing an error message.\n \"\"\"\n if request == b'':\n return \"Expected JSON request body but found nothing.\"\n request = json.loads(request.decode('utf-8'))\n if MODEL not in request:\n return \"No model supplied in request body.\"\n if ACTION not in request:\n return \"No action supplied in request body.\"\n if request[ACTION] not in [x.name for x in TaskTypes]:\n return \"Invalid action.\"\n if request[ACTION] == TaskTypes.UPDATE_INDEX.name and SINCE_DATE not in request:\n return \"Received UPDATE request but no since_date.\"\n\n return None\n\n def on_post(self, req, resp):\n \"\"\" Create a task. \"\"\"\n raw_body = req.stream.read()\n request_error = self._validate_create_task(raw_body)\n if request_error:\n logging.warning(\n 'Invalid request made. Reason: {}'.format(request_error)\n )\n resp.status = falcon.HTTP_400\n resp.media = {\n 'message': request_error\n }\n return\n body = json.loads(raw_body.decode('utf-8'))\n model = body[MODEL]\n action = body[ACTION]\n callback_url = None\n if CALLBACK_URL in body:\n callback_url = body[CALLBACK_URL]\n since_date = body[SINCE_DATE] if SINCE_DATE in body else None\n task_id = str(uuid.uuid4())\n # Inject shared memory\n progress = Value('d', 0.0)\n finish_time = Value('d', 0.0)\n task = Task(\n model=model,\n task_type=TaskTypes[action],\n since_date=since_date,\n progress=progress,\n task_id=task_id,\n finish_time=finish_time,\n callback_url=callback_url\n )\n task.start()\n task_id = self.tracker \\\n .add_task(task, task_id, action, progress, finish_time)\n base_url = self._get_base_url(req)\n status_url = base_url + '/task/{}'.format(task_id)\n # Give the task a moment to start so we can detect immediate failure.\n # TODO: Use IPC to detect if the job launched successfully instead\n # of giving it 100ms to crash. This is prone to race conditions.\n time.sleep(0.1)\n if task.is_alive():\n resp.status = falcon.HTTP_202\n resp.media = {\n 'message': 'Successfully scheduled task',\n 'task_id': task_id,\n 'status_check': status_url\n }\n return\n else:\n resp.status = falcon.HTTP_500\n resp.media = {\n 'message': 'Failed to schedule task due to an internal server '\n 'error. Check scheduler logs.'\n }\n return\n\n def on_get(self, req, resp):\n \"\"\" List all indexing tasks. \"\"\"\n resp.media = self.tracker.list_task_statuses()\n\n\nclass TaskStatus:\n def __init__(self, tracker: TaskTracker):\n self.tracker = tracker\n\n def on_get(self, req, resp, task_id):\n \"\"\" Check the status of a single task.\"\"\"\n task = self.tracker.id_task[task_id]\n active = task.is_alive()\n\n percent_completed = self.tracker.id_progress[task_id].value\n resp.media = {\n 'active': active,\n 'percent_completed': percent_completed,\n 'error': percent_completed < 100 and not active\n }\n\n\nclass WorkerFinishedResource:\n \"\"\"\n For notifying ingestion server that an indexing worker has finished its\n task.\n \"\"\"\n def on_post(self, req, resp):\n target_index = worker_finished(str(req.remote_addr))\n if target_index:\n logging.info(\n 'All indexer workers finished! Attempting to promote index '\n f'{target_index}'\n )\n f = indexer.TableIndexer.go_live\n p = Process(target=f, args=(target_index, 'image'))\n p.start()\n\n\nclass StateResource:\n def on_delete(self, req, resp):\n \"\"\"\n Forget about the last scheduled indexing job.\n \"\"\"\n clear_state()\n\n\ndef create_api(log=True):\n \"\"\" Create an instance of the Falcon API server. \"\"\"\n if log:\n root = logging.getLogger()\n root.setLevel(logging.DEBUG)\n handler = logging.StreamHandler(sys.stdout)\n handler.setLevel(logging.INFO)\n formatter = logging.Formatter(\n '%(asctime)s %(levelname)s %(filename)s:%(lineno)d - %(message)s'\n )\n handler.setFormatter(formatter)\n root.addHandler(handler)\n\n _api = falcon.App()\n task_tracker = TaskTracker()\n task_resource = TaskResource(task_tracker)\n get_task_status = TaskStatus(task_tracker)\n _api.add_route('/task', task_resource)\n _api.add_route('/task/{task_id}', get_task_status)\n _api.add_route('/worker_finished', WorkerFinishedResource())\n _api.add_route('/state', StateResource())\n\n return _api\n\n\napi = create_api()\n", "path": "ingestion_server/ingestion_server/api.py"}, {"content": "import falcon\nfrom falcon_cors import CORS\nfrom event_controller import EventController\n\nevent_controller = EventController()\n\nclass SearchEventResource:\n def on_post(self, req, resp):\n j = req.media\n event_controller.create_search(\n query=j['query'],\n session_uuid=j['session_uuid']\n )\n resp.status = falcon.HTTP_201\n\n\nclass SearchRatingEventResource:\n def on_post(self, req, resp):\n j = req.media\n try:\n event_controller.create_search_rating(\n query=j['query'],\n relevant=j['relevant']\n )\n resp.status = falcon.HTTP_201\n except ValueError:\n resp.body = '{\"message\": \"Rating must be True or False\"}'\n resp.status = falcon.HTTP_400\n\n\nclass ResultClickEventResource:\n def on_post(self, req, resp):\n j = req.media\n event_controller.create_result_click(\n session_uuid=j['session_uuid'],\n result_uuid=j['result_uuid'],\n query=j['query'],\n rank=j['result_rank']\n )\n resp.status = falcon.HTTP_201\n\n\nclass DetailEventResource:\n def on_post(self, req, resp):\n j = req.media\n try:\n event_controller.create_detail_event(\n event=j['event_type'],\n result_uuid=j['result_uuid']\n )\n resp.status = falcon.HTTP_201\n except KeyError:\n valid_events = event_controller.list_valid_detail_events()\n resp.body = \\\n '{{\"message\": \"Invalid event_type. Valid types: {}\"}}' \\\n .format(valid_events)\n resp.status = falcon.HTTP_400\n\n\nclass RedocResource:\n def on_get(self, req, resp):\n resp.status = falcon.HTTP_200\n resp.content_type = 'text/html'\n with open('docs/redoc.html', 'r') as f:\n resp.body = f.read()\n\n\nclass OpenAPISpecResource:\n def on_get(self, req, resp):\n resp.status = falcon.HTTP_200\n resp.content_type = 'text/html'\n with open('docs/swagger.yaml', 'r') as f:\n resp.body = f.read()\n\norigins = [\n # @todo: Switch these to environment variables\n 'https://search.openverse.engineering',\n 'https://search-dev.openverse.engineering',\n 'https://wordpress.org/openverse'\n]\ncors = CORS(\n allow_origins_list=origins,\n allow_all_methods=True,\n allow_all_headers=True\n)\napi = falcon.App(middleware=[cors.middleware])\napi.add_route('/', RedocResource())\napi.add_route('/swagger.yaml', OpenAPISpecResource())\napi.add_route('/search_event', SearchEventResource())\napi.add_route('/search_rating_event', SearchRatingEventResource())\napi.add_route('/result_click_event', ResultClickEventResource())\napi.add_route('/detail_page_event', DetailEventResource())\n", "path": "analytics/server.py"}, {"content": "\"\"\"\nA single worker responsible for indexing a subset of the records stored in the\ndatabase.\n\nAccept an HTTP request specifying a range of image IDs to reindex. After the\ndata has been indexed, notify Ingestion Server and stop the instance.\n\"\"\"\nimport falcon\nimport sys\nimport logging as log\nimport os\nimport boto3\nimport requests\nfrom multiprocessing import Value, Process\nfrom psycopg2.sql import SQL\nfrom ingestion_server.indexer import elasticsearch_connect, TableIndexer\n\n\nec2_client = boto3.client(\n 'ec2',\n region_name=os.getenv('AWS_REGION', 'us-east-1'),\n aws_access_key_id=os.getenv('AWS_ACCESS_KEY_ID', None),\n aws_secret_access_key=os.getenv('AWS_SECRET_ACCESS_KEY', None)\n)\n\n\nclass IndexingJobResource:\n def on_post(self, req, resp):\n j = req.media\n start_id = j['start_id']\n end_id = j['end_id']\n target_index = j['target_index']\n notify_url = f'http://{req.remote_addr}:8001/worker_finished'\n _execute_indexing_task(target_index, start_id, end_id, notify_url)\n log.info(f'Received indexing request for records {start_id}-{end_id}')\n resp.status = falcon.HTTP_201\n\n\nclass HealthcheckResource:\n def on_get(self, req, resp):\n resp.status = falcon.HTTP_200\n\n\ndef _execute_indexing_task(target_index, start_id, end_id, notify_url):\n table = 'image'\n elasticsearch = elasticsearch_connect()\n progress = Value('d', 0.0)\n finish_time = Value('d', 0.0)\n exists_in_table = \\\n 'exists(SELECT 1 FROM {table} ' \\\n 'WHERE identifier = image.identifier) as \"{name}\"'\n exists_in_deleted_table = exists_in_table.format(\n table='api_deletedimage', name='deleted'\n )\n exists_in_mature_table = exists_in_table.format(\n table='api_matureimage', name='mature'\n )\n\n query = SQL(f'''\n SELECT *,\n {exists_in_deleted_table}, {exists_in_mature_table}\n FROM image\n WHERE id BETWEEN {start_id} AND {end_id}\n ''')\n log.info('Querying {}'.format(query))\n indexer = TableIndexer(\n elasticsearch, table, progress, finish_time\n )\n p = Process(\n target=_launch_reindex,\n args=(table, target_index, query, indexer, notify_url)\n )\n p.start()\n log.info('Started indexing task')\n\n\ndef _launch_reindex(table, target_index, query, indexer, notify_url):\n try:\n indexer.replicate(table, target_index, query)\n except Exception:\n log.error(\"Indexing error occurred: \", exc_info=True)\n\n log.info(f'Notifying {notify_url}')\n requests.post(notify_url)\n _self_destruct()\n return\n\n\ndef _self_destruct():\n \"\"\"\n Stop this EC2 instance once the task is finished.\n \"\"\"\n # Get instance ID from AWS metadata service\n if os.getenv('ENVIRONMENT', 'local') == 'local':\n log.info(\n 'Skipping self destruction because worker is in local environment'\n )\n return\n endpoint = 'http://169.254.169.254/latest/meta-data/instance-id'\n response = requests.get(endpoint)\n instance_id = response.content.decode('utf8')\n log.info('Shutting self down')\n ec2_client.stop_instances(InstanceIds=[instance_id])\n\n\nroot = log.getLogger()\nroot.setLevel(log.DEBUG)\nhandler = log.StreamHandler(sys.stdout)\nhandler.setLevel(log.INFO)\nformatter = log.Formatter(\n '%(asctime)s %(levelname)s %(filename)s:%(lineno)d - %(message)s'\n)\nhandler.setFormatter(formatter)\nroot.addHandler(handler)\napi = falcon.App()\napi.add_route('/indexing_task', IndexingJobResource())\napi.add_route('/healthcheck', HealthcheckResource())\n", "path": "ingestion_server/ingestion_server/indexer_worker.py"}]}
| 4,054 | 351 |
gh_patches_debug_30397
|
rasdani/github-patches
|
git_diff
|
Qiskit__qiskit-5024
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Ability to remove passes from PassManager
### What is the expected behavior?
We would like to be able to remove passes from a `PassManager`, analogous to how one can append passes.
For instance, suppose you want to use `optimization_level=1`, but don't want to use the pass `RemoveResetInZeroState`.
You get the passes from level 1 with
```
from qiskit.transpiler.passmanager_config import PassManagerConfig
from qiskit.transpiler import PassManager
from qiskit.transpiler.preset_passmanagers import level_1_pass_manager
pm = level_1_pass_manager(PassManagerConfig())
```
I would like, now to be able to do something like
```
from qiskit.transpiler.passes import RemoveResetInZeroState
pm.remove(RemoveResetInZeroState())
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `qiskit/transpiler/passmanager.py`
Content:
```
1 # This code is part of Qiskit.
2 #
3 # (C) Copyright IBM 2017, 2018.
4 #
5 # This code is licensed under the Apache License, Version 2.0. You may
6 # obtain a copy of this license in the LICENSE.txt file in the root directory
7 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
8 #
9 # Any modifications or derivative works of this code must retain this
10 # copyright notice, and modified files need to carry a notice indicating
11 # that they have been altered from the originals.
12
13 """Manager for a set of Passes and their scheduling during transpilation."""
14
15 import warnings
16 from typing import Union, List, Callable, Dict, Any
17
18 import dill
19
20 from qiskit.visualization import pass_manager_drawer
21 from qiskit.tools.parallel import parallel_map
22 from qiskit.circuit import QuantumCircuit
23 from .basepasses import BasePass
24 from .exceptions import TranspilerError
25 from .runningpassmanager import RunningPassManager
26
27
28 class PassManager:
29 """Manager for a set of Passes and their scheduling during transpilation."""
30
31 def __init__(
32 self,
33 passes: Union[BasePass, List[BasePass]] = None,
34 max_iteration: int = 1000,
35 callback: Callable = None
36 ):
37 """Initialize an empty `PassManager` object (with no passes scheduled).
38
39 Args:
40 passes: A pass set (as defined in :py:func:`qiskit.transpiler.PassManager.append`)
41 to be added to the pass manager schedule.
42 max_iteration: The maximum number of iterations the schedule will be looped if the
43 condition is not met.
44 callback: DEPRECATED - A callback function that will be called after each pass
45 execution.
46
47 .. deprecated:: 0.13.0
48 The ``callback`` parameter is deprecated in favor of
49 ``PassManager.run(..., callback=callback, ...)``.
50 """
51 self.callback = None
52
53 if callback:
54 warnings.warn("Setting a callback at construction time is being deprecated in favor of"
55 "PassManager.run(..., callback=callback,...)", DeprecationWarning, 2)
56 self.callback = callback
57 # the pass manager's schedule of passes, including any control-flow.
58 # Populated via PassManager.append().
59
60 self._pass_sets = []
61 if passes is not None:
62 self.append(passes)
63 self.max_iteration = max_iteration
64 self.property_set = None
65
66 def append(
67 self,
68 passes: Union[BasePass, List[BasePass]],
69 max_iteration: int = None,
70 **flow_controller_conditions: Any
71 ) -> None:
72 """Append a Pass Set to the schedule of passes.
73
74 Args:
75 passes: A set of passes (a pass set) to be added to schedule. A pass set is a list of
76 passes that are controlled by the same flow controller. If a single pass is
77 provided, the pass set will only have that pass a single element.
78 max_iteration: max number of iterations of passes.
79 flow_controller_conditions: control flow plugins.
80
81 Raises:
82 TranspilerError: if a pass in passes is not a proper pass.
83
84 See Also:
85 ``RunningPassManager.add_flow_controller()`` for more information about the control
86 flow plugins.
87 """
88 if max_iteration:
89 # TODO remove this argument from append
90 self.max_iteration = max_iteration
91
92 passes = PassManager._normalize_passes(passes)
93 self._pass_sets.append({'passes': passes, 'flow_controllers': flow_controller_conditions})
94
95 def replace(
96 self,
97 index: int,
98 passes: Union[BasePass, List[BasePass]],
99 max_iteration: int = None,
100 **flow_controller_conditions: Any
101 ) -> None:
102 """Replace a particular pass in the scheduler.
103
104 Args:
105 index: Pass index to replace, based on the position in passes().
106 passes: A pass set (as defined in :py:func:`qiskit.transpiler.PassManager.append`)
107 to be added to the pass manager schedule.
108 max_iteration: max number of iterations of passes.
109 flow_controller_conditions: control flow plugins.
110
111 Raises:
112 TranspilerError: if a pass in passes is not a proper pass.
113
114 See Also:
115 ``RunningPassManager.add_flow_controller()`` for more information about the control
116 flow plugins.
117 """
118 if max_iteration:
119 # TODO remove this argument from append
120 self.max_iteration = max_iteration
121
122 passes = PassManager._normalize_passes(passes)
123
124 try:
125 self._pass_sets[index] = {'passes': passes,
126 'flow_controllers': flow_controller_conditions}
127 except IndexError:
128 raise TranspilerError('Index to replace %s does not exists' % index)
129
130 def __setitem__(self, index, item):
131 self.replace(index, item)
132
133 def __len__(self):
134 return len(self._pass_sets)
135
136 def __getitem__(self, index):
137 new_passmanager = PassManager(max_iteration=self.max_iteration, callback=self.callback)
138 _pass_sets = self._pass_sets[index]
139 if isinstance(_pass_sets, dict):
140 _pass_sets = [_pass_sets]
141 new_passmanager._pass_sets = _pass_sets
142 return new_passmanager
143
144 def __add__(self, other):
145 if isinstance(other, PassManager):
146 new_passmanager = PassManager(max_iteration=self.max_iteration, callback=self.callback)
147 new_passmanager._pass_sets = self._pass_sets + other._pass_sets
148 return new_passmanager
149 else:
150 try:
151 new_passmanager = PassManager(max_iteration=self.max_iteration,
152 callback=self.callback)
153 new_passmanager._pass_sets += self._pass_sets
154 new_passmanager.append(other)
155 return new_passmanager
156 except TranspilerError:
157 raise TypeError('unsupported operand type + for %s and %s' % (self.__class__,
158 other.__class__))
159
160 @staticmethod
161 def _normalize_passes(passes: Union[BasePass, List[BasePass]]) -> List[BasePass]:
162 if isinstance(passes, BasePass):
163 passes = [passes]
164
165 for pass_ in passes:
166 if not isinstance(pass_, BasePass):
167 raise TranspilerError('%s is not a pass instance' % pass_.__class__)
168 return passes
169
170 def run(
171 self,
172 circuits: Union[QuantumCircuit, List[QuantumCircuit]],
173 output_name: str = None,
174 callback: Callable = None
175 ) -> Union[QuantumCircuit, List[QuantumCircuit]]:
176 """Run all the passes on the specified ``circuits``.
177
178 Args:
179 circuits: Circuit(s) to transform via all the registered passes.
180 output_name: The output circuit name. If ``None``, it will be set to the same as the
181 input circuit name.
182 callback: A callback function that will be called after each pass execution. The
183 function will be called with 5 keyword arguments::
184
185 pass_ (Pass): the pass being run
186 dag (DAGCircuit): the dag output of the pass
187 time (float): the time to execute the pass
188 property_set (PropertySet): the property set
189 count (int): the index for the pass execution
190
191 The exact arguments pass expose the internals of the pass
192 manager and are subject to change as the pass manager internals
193 change. If you intend to reuse a callback function over
194 multiple releases be sure to check that the arguments being
195 passed are the same.
196
197 To use the callback feature you define a function that will
198 take in kwargs dict and access the variables. For example::
199
200 def callback_func(**kwargs):
201 pass_ = kwargs['pass_']
202 dag = kwargs['dag']
203 time = kwargs['time']
204 property_set = kwargs['property_set']
205 count = kwargs['count']
206 ...
207
208 Returns:
209 The transformed circuit(s).
210 """
211 if isinstance(circuits, QuantumCircuit):
212 return self._run_single_circuit(circuits, output_name, callback)
213 elif len(circuits) == 1:
214 return self._run_single_circuit(circuits[0], output_name, callback)
215 else:
216 return self._run_several_circuits(circuits, output_name, callback)
217
218 def _create_running_passmanager(self) -> RunningPassManager:
219 running_passmanager = RunningPassManager(self.max_iteration)
220 for pass_set in self._pass_sets:
221 running_passmanager.append(pass_set['passes'], **pass_set['flow_controllers'])
222 return running_passmanager
223
224 @staticmethod
225 def _in_parallel(circuit, pm_dill=None) -> QuantumCircuit:
226 """Task used by the parallel map tools from ``_run_several_circuits``."""
227 running_passmanager = dill.loads(pm_dill)._create_running_passmanager()
228 result = running_passmanager.run(circuit)
229 return result
230
231 def _run_several_circuits(
232 self,
233 circuits: List[QuantumCircuit],
234 output_name: str = None,
235 callback: Callable = None
236 ) -> List[QuantumCircuit]:
237 """Run all the passes on the specified ``circuits``.
238
239 Args:
240 circuits: Circuits to transform via all the registered passes.
241 output_name: The output circuit name. If ``None``, it will be set to the same as the
242 input circuit name.
243 callback: A callback function that will be called after each pass execution.
244
245 Returns:
246 The transformed circuits.
247 """
248 # TODO support for List(output_name) and List(callback)
249 del output_name
250 del callback
251
252 return parallel_map(PassManager._in_parallel, circuits,
253 task_kwargs={'pm_dill': dill.dumps(self)})
254
255 def _run_single_circuit(
256 self,
257 circuit: QuantumCircuit,
258 output_name: str = None,
259 callback: Callable = None
260 ) -> QuantumCircuit:
261 """Run all the passes on a ``circuit``.
262
263 Args:
264 circuit: Circuit to transform via all the registered passes.
265 output_name: The output circuit name. If ``None``, it will be set to the same as the
266 input circuit name.
267 callback: A callback function that will be called after each pass execution.
268
269 Returns:
270 The transformed circuit.
271 """
272 running_passmanager = self._create_running_passmanager()
273 if callback is None and self.callback: # TODO to remove with __init__(callback)
274 callback = self.callback
275 result = running_passmanager.run(circuit, output_name=output_name, callback=callback)
276 self.property_set = running_passmanager.property_set
277 return result
278
279 def draw(self, filename=None, style=None, raw=False):
280 """Draw the pass manager.
281
282 This function needs `pydot <https://github.com/erocarrera/pydot>`__, which in turn needs
283 `Graphviz <https://www.graphviz.org/>`__ to be installed.
284
285 Args:
286 filename (str): file path to save image to.
287 style (dict): keys are the pass classes and the values are the colors to make them. An
288 example can be seen in the DEFAULT_STYLE. An ordered dict can be used to ensure
289 a priority coloring when pass falls into multiple categories. Any values not
290 included in the provided dict will be filled in from the default dict.
291 raw (bool): If ``True``, save the raw Dot output instead of the image.
292
293 Returns:
294 Optional[PassManager]: an in-memory representation of the pass manager, or ``None``
295 if no image was generated or `Pillow <https://pypi.org/project/Pillow/>`__
296 is not installed.
297
298 Raises:
299 ImportError: when nxpd or pydot not installed.
300 """
301 return pass_manager_drawer(self, filename=filename, style=style, raw=raw)
302
303 def passes(self) -> List[Dict[str, BasePass]]:
304 """Return a list structure of the appended passes and its options.
305
306 Returns:
307 A list of pass sets, as defined in ``append()``.
308 """
309 ret = []
310 for pass_set in self._pass_sets:
311 item = {'passes': pass_set['passes']}
312 if pass_set['flow_controllers']:
313 item['flow_controllers'] = set(pass_set['flow_controllers'].keys())
314 else:
315 item['flow_controllers'] = {}
316 ret.append(item)
317 return ret
318
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/qiskit/transpiler/passmanager.py b/qiskit/transpiler/passmanager.py
--- a/qiskit/transpiler/passmanager.py
+++ b/qiskit/transpiler/passmanager.py
@@ -109,7 +109,7 @@
flow_controller_conditions: control flow plugins.
Raises:
- TranspilerError: if a pass in passes is not a proper pass.
+ TranspilerError: if a pass in passes is not a proper pass or index not found.
See Also:
``RunningPassManager.add_flow_controller()`` for more information about the control
@@ -127,6 +127,20 @@
except IndexError:
raise TranspilerError('Index to replace %s does not exists' % index)
+ def remove(self, index: int) -> None:
+ """Removes a particular pass in the scheduler.
+
+ Args:
+ index: Pass index to replace, based on the position in passes().
+
+ Raises:
+ TranspilerError: if the index is not found.
+ """
+ try:
+ del self._pass_sets[index]
+ except IndexError:
+ raise TranspilerError('Index to replace %s does not exists' % index)
+
def __setitem__(self, index, item):
self.replace(index, item)
@@ -161,7 +175,6 @@
def _normalize_passes(passes: Union[BasePass, List[BasePass]]) -> List[BasePass]:
if isinstance(passes, BasePass):
passes = [passes]
-
for pass_ in passes:
if not isinstance(pass_, BasePass):
raise TranspilerError('%s is not a pass instance' % pass_.__class__)
|
{"golden_diff": "diff --git a/qiskit/transpiler/passmanager.py b/qiskit/transpiler/passmanager.py\n--- a/qiskit/transpiler/passmanager.py\n+++ b/qiskit/transpiler/passmanager.py\n@@ -109,7 +109,7 @@\n flow_controller_conditions: control flow plugins.\n \n Raises:\n- TranspilerError: if a pass in passes is not a proper pass.\n+ TranspilerError: if a pass in passes is not a proper pass or index not found.\n \n See Also:\n ``RunningPassManager.add_flow_controller()`` for more information about the control\n@@ -127,6 +127,20 @@\n except IndexError:\n raise TranspilerError('Index to replace %s does not exists' % index)\n \n+ def remove(self, index: int) -> None:\n+ \"\"\"Removes a particular pass in the scheduler.\n+\n+ Args:\n+ index: Pass index to replace, based on the position in passes().\n+\n+ Raises:\n+ TranspilerError: if the index is not found.\n+ \"\"\"\n+ try:\n+ del self._pass_sets[index]\n+ except IndexError:\n+ raise TranspilerError('Index to replace %s does not exists' % index)\n+\n def __setitem__(self, index, item):\n self.replace(index, item)\n \n@@ -161,7 +175,6 @@\n def _normalize_passes(passes: Union[BasePass, List[BasePass]]) -> List[BasePass]:\n if isinstance(passes, BasePass):\n passes = [passes]\n-\n for pass_ in passes:\n if not isinstance(pass_, BasePass):\n raise TranspilerError('%s is not a pass instance' % pass_.__class__)\n", "issue": "Ability to remove passes from PassManager \n### What is the expected behavior?\r\n\r\nWe would like to be able to remove passes from a `PassManager`, analogous to how one can append passes.\r\n\r\nFor instance, suppose you want to use `optimization_level=1`, but don't want to use the pass `RemoveResetInZeroState`. \r\n\r\nYou get the passes from level 1 with\r\n```\r\nfrom qiskit.transpiler.passmanager_config import PassManagerConfig\r\nfrom qiskit.transpiler import PassManager\r\nfrom qiskit.transpiler.preset_passmanagers import level_1_pass_manager\r\npm = level_1_pass_manager(PassManagerConfig())\r\n```\r\n\r\nI would like, now to be able to do something like\r\n```\r\nfrom qiskit.transpiler.passes import RemoveResetInZeroState\r\npm.remove(RemoveResetInZeroState())\r\n```\n", "before_files": [{"content": "# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2018.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n\"\"\"Manager for a set of Passes and their scheduling during transpilation.\"\"\"\n\nimport warnings\nfrom typing import Union, List, Callable, Dict, Any\n\nimport dill\n\nfrom qiskit.visualization import pass_manager_drawer\nfrom qiskit.tools.parallel import parallel_map\nfrom qiskit.circuit import QuantumCircuit\nfrom .basepasses import BasePass\nfrom .exceptions import TranspilerError\nfrom .runningpassmanager import RunningPassManager\n\n\nclass PassManager:\n \"\"\"Manager for a set of Passes and their scheduling during transpilation.\"\"\"\n\n def __init__(\n self,\n passes: Union[BasePass, List[BasePass]] = None,\n max_iteration: int = 1000,\n callback: Callable = None\n ):\n \"\"\"Initialize an empty `PassManager` object (with no passes scheduled).\n\n Args:\n passes: A pass set (as defined in :py:func:`qiskit.transpiler.PassManager.append`)\n to be added to the pass manager schedule.\n max_iteration: The maximum number of iterations the schedule will be looped if the\n condition is not met.\n callback: DEPRECATED - A callback function that will be called after each pass\n execution.\n\n .. deprecated:: 0.13.0\n The ``callback`` parameter is deprecated in favor of\n ``PassManager.run(..., callback=callback, ...)``.\n \"\"\"\n self.callback = None\n\n if callback:\n warnings.warn(\"Setting a callback at construction time is being deprecated in favor of\"\n \"PassManager.run(..., callback=callback,...)\", DeprecationWarning, 2)\n self.callback = callback\n # the pass manager's schedule of passes, including any control-flow.\n # Populated via PassManager.append().\n\n self._pass_sets = []\n if passes is not None:\n self.append(passes)\n self.max_iteration = max_iteration\n self.property_set = None\n\n def append(\n self,\n passes: Union[BasePass, List[BasePass]],\n max_iteration: int = None,\n **flow_controller_conditions: Any\n ) -> None:\n \"\"\"Append a Pass Set to the schedule of passes.\n\n Args:\n passes: A set of passes (a pass set) to be added to schedule. A pass set is a list of\n passes that are controlled by the same flow controller. If a single pass is\n provided, the pass set will only have that pass a single element.\n max_iteration: max number of iterations of passes.\n flow_controller_conditions: control flow plugins.\n\n Raises:\n TranspilerError: if a pass in passes is not a proper pass.\n\n See Also:\n ``RunningPassManager.add_flow_controller()`` for more information about the control\n flow plugins.\n \"\"\"\n if max_iteration:\n # TODO remove this argument from append\n self.max_iteration = max_iteration\n\n passes = PassManager._normalize_passes(passes)\n self._pass_sets.append({'passes': passes, 'flow_controllers': flow_controller_conditions})\n\n def replace(\n self,\n index: int,\n passes: Union[BasePass, List[BasePass]],\n max_iteration: int = None,\n **flow_controller_conditions: Any\n ) -> None:\n \"\"\"Replace a particular pass in the scheduler.\n\n Args:\n index: Pass index to replace, based on the position in passes().\n passes: A pass set (as defined in :py:func:`qiskit.transpiler.PassManager.append`)\n to be added to the pass manager schedule.\n max_iteration: max number of iterations of passes.\n flow_controller_conditions: control flow plugins.\n\n Raises:\n TranspilerError: if a pass in passes is not a proper pass.\n\n See Also:\n ``RunningPassManager.add_flow_controller()`` for more information about the control\n flow plugins.\n \"\"\"\n if max_iteration:\n # TODO remove this argument from append\n self.max_iteration = max_iteration\n\n passes = PassManager._normalize_passes(passes)\n\n try:\n self._pass_sets[index] = {'passes': passes,\n 'flow_controllers': flow_controller_conditions}\n except IndexError:\n raise TranspilerError('Index to replace %s does not exists' % index)\n\n def __setitem__(self, index, item):\n self.replace(index, item)\n\n def __len__(self):\n return len(self._pass_sets)\n\n def __getitem__(self, index):\n new_passmanager = PassManager(max_iteration=self.max_iteration, callback=self.callback)\n _pass_sets = self._pass_sets[index]\n if isinstance(_pass_sets, dict):\n _pass_sets = [_pass_sets]\n new_passmanager._pass_sets = _pass_sets\n return new_passmanager\n\n def __add__(self, other):\n if isinstance(other, PassManager):\n new_passmanager = PassManager(max_iteration=self.max_iteration, callback=self.callback)\n new_passmanager._pass_sets = self._pass_sets + other._pass_sets\n return new_passmanager\n else:\n try:\n new_passmanager = PassManager(max_iteration=self.max_iteration,\n callback=self.callback)\n new_passmanager._pass_sets += self._pass_sets\n new_passmanager.append(other)\n return new_passmanager\n except TranspilerError:\n raise TypeError('unsupported operand type + for %s and %s' % (self.__class__,\n other.__class__))\n\n @staticmethod\n def _normalize_passes(passes: Union[BasePass, List[BasePass]]) -> List[BasePass]:\n if isinstance(passes, BasePass):\n passes = [passes]\n\n for pass_ in passes:\n if not isinstance(pass_, BasePass):\n raise TranspilerError('%s is not a pass instance' % pass_.__class__)\n return passes\n\n def run(\n self,\n circuits: Union[QuantumCircuit, List[QuantumCircuit]],\n output_name: str = None,\n callback: Callable = None\n ) -> Union[QuantumCircuit, List[QuantumCircuit]]:\n \"\"\"Run all the passes on the specified ``circuits``.\n\n Args:\n circuits: Circuit(s) to transform via all the registered passes.\n output_name: The output circuit name. If ``None``, it will be set to the same as the\n input circuit name.\n callback: A callback function that will be called after each pass execution. The\n function will be called with 5 keyword arguments::\n\n pass_ (Pass): the pass being run\n dag (DAGCircuit): the dag output of the pass\n time (float): the time to execute the pass\n property_set (PropertySet): the property set\n count (int): the index for the pass execution\n\n The exact arguments pass expose the internals of the pass\n manager and are subject to change as the pass manager internals\n change. If you intend to reuse a callback function over\n multiple releases be sure to check that the arguments being\n passed are the same.\n\n To use the callback feature you define a function that will\n take in kwargs dict and access the variables. For example::\n\n def callback_func(**kwargs):\n pass_ = kwargs['pass_']\n dag = kwargs['dag']\n time = kwargs['time']\n property_set = kwargs['property_set']\n count = kwargs['count']\n ...\n\n Returns:\n The transformed circuit(s).\n \"\"\"\n if isinstance(circuits, QuantumCircuit):\n return self._run_single_circuit(circuits, output_name, callback)\n elif len(circuits) == 1:\n return self._run_single_circuit(circuits[0], output_name, callback)\n else:\n return self._run_several_circuits(circuits, output_name, callback)\n\n def _create_running_passmanager(self) -> RunningPassManager:\n running_passmanager = RunningPassManager(self.max_iteration)\n for pass_set in self._pass_sets:\n running_passmanager.append(pass_set['passes'], **pass_set['flow_controllers'])\n return running_passmanager\n\n @staticmethod\n def _in_parallel(circuit, pm_dill=None) -> QuantumCircuit:\n \"\"\"Task used by the parallel map tools from ``_run_several_circuits``.\"\"\"\n running_passmanager = dill.loads(pm_dill)._create_running_passmanager()\n result = running_passmanager.run(circuit)\n return result\n\n def _run_several_circuits(\n self,\n circuits: List[QuantumCircuit],\n output_name: str = None,\n callback: Callable = None\n ) -> List[QuantumCircuit]:\n \"\"\"Run all the passes on the specified ``circuits``.\n\n Args:\n circuits: Circuits to transform via all the registered passes.\n output_name: The output circuit name. If ``None``, it will be set to the same as the\n input circuit name.\n callback: A callback function that will be called after each pass execution.\n\n Returns:\n The transformed circuits.\n \"\"\"\n # TODO support for List(output_name) and List(callback)\n del output_name\n del callback\n\n return parallel_map(PassManager._in_parallel, circuits,\n task_kwargs={'pm_dill': dill.dumps(self)})\n\n def _run_single_circuit(\n self,\n circuit: QuantumCircuit,\n output_name: str = None,\n callback: Callable = None\n ) -> QuantumCircuit:\n \"\"\"Run all the passes on a ``circuit``.\n\n Args:\n circuit: Circuit to transform via all the registered passes.\n output_name: The output circuit name. If ``None``, it will be set to the same as the\n input circuit name.\n callback: A callback function that will be called after each pass execution.\n\n Returns:\n The transformed circuit.\n \"\"\"\n running_passmanager = self._create_running_passmanager()\n if callback is None and self.callback: # TODO to remove with __init__(callback)\n callback = self.callback\n result = running_passmanager.run(circuit, output_name=output_name, callback=callback)\n self.property_set = running_passmanager.property_set\n return result\n\n def draw(self, filename=None, style=None, raw=False):\n \"\"\"Draw the pass manager.\n\n This function needs `pydot <https://github.com/erocarrera/pydot>`__, which in turn needs\n `Graphviz <https://www.graphviz.org/>`__ to be installed.\n\n Args:\n filename (str): file path to save image to.\n style (dict): keys are the pass classes and the values are the colors to make them. An\n example can be seen in the DEFAULT_STYLE. An ordered dict can be used to ensure\n a priority coloring when pass falls into multiple categories. Any values not\n included in the provided dict will be filled in from the default dict.\n raw (bool): If ``True``, save the raw Dot output instead of the image.\n\n Returns:\n Optional[PassManager]: an in-memory representation of the pass manager, or ``None``\n if no image was generated or `Pillow <https://pypi.org/project/Pillow/>`__\n is not installed.\n\n Raises:\n ImportError: when nxpd or pydot not installed.\n \"\"\"\n return pass_manager_drawer(self, filename=filename, style=style, raw=raw)\n\n def passes(self) -> List[Dict[str, BasePass]]:\n \"\"\"Return a list structure of the appended passes and its options.\n\n Returns:\n A list of pass sets, as defined in ``append()``.\n \"\"\"\n ret = []\n for pass_set in self._pass_sets:\n item = {'passes': pass_set['passes']}\n if pass_set['flow_controllers']:\n item['flow_controllers'] = set(pass_set['flow_controllers'].keys())\n else:\n item['flow_controllers'] = {}\n ret.append(item)\n return ret\n", "path": "qiskit/transpiler/passmanager.py"}], "after_files": [{"content": "# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2018.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n\"\"\"Manager for a set of Passes and their scheduling during transpilation.\"\"\"\n\nimport warnings\nfrom typing import Union, List, Callable, Dict, Any\n\nimport dill\n\nfrom qiskit.visualization import pass_manager_drawer\nfrom qiskit.tools.parallel import parallel_map\nfrom qiskit.circuit import QuantumCircuit\nfrom .basepasses import BasePass\nfrom .exceptions import TranspilerError\nfrom .runningpassmanager import RunningPassManager\n\n\nclass PassManager:\n \"\"\"Manager for a set of Passes and their scheduling during transpilation.\"\"\"\n\n def __init__(\n self,\n passes: Union[BasePass, List[BasePass]] = None,\n max_iteration: int = 1000,\n callback: Callable = None\n ):\n \"\"\"Initialize an empty `PassManager` object (with no passes scheduled).\n\n Args:\n passes: A pass set (as defined in :py:func:`qiskit.transpiler.PassManager.append`)\n to be added to the pass manager schedule.\n max_iteration: The maximum number of iterations the schedule will be looped if the\n condition is not met.\n callback: DEPRECATED - A callback function that will be called after each pass\n execution.\n\n .. deprecated:: 0.13.0\n The ``callback`` parameter is deprecated in favor of\n ``PassManager.run(..., callback=callback, ...)``.\n \"\"\"\n self.callback = None\n\n if callback:\n warnings.warn(\"Setting a callback at construction time is being deprecated in favor of\"\n \"PassManager.run(..., callback=callback,...)\", DeprecationWarning, 2)\n self.callback = callback\n # the pass manager's schedule of passes, including any control-flow.\n # Populated via PassManager.append().\n\n self._pass_sets = []\n if passes is not None:\n self.append(passes)\n self.max_iteration = max_iteration\n self.property_set = None\n\n def append(\n self,\n passes: Union[BasePass, List[BasePass]],\n max_iteration: int = None,\n **flow_controller_conditions: Any\n ) -> None:\n \"\"\"Append a Pass Set to the schedule of passes.\n\n Args:\n passes: A set of passes (a pass set) to be added to schedule. A pass set is a list of\n passes that are controlled by the same flow controller. If a single pass is\n provided, the pass set will only have that pass a single element.\n max_iteration: max number of iterations of passes.\n flow_controller_conditions: control flow plugins.\n\n Raises:\n TranspilerError: if a pass in passes is not a proper pass.\n\n See Also:\n ``RunningPassManager.add_flow_controller()`` for more information about the control\n flow plugins.\n \"\"\"\n if max_iteration:\n # TODO remove this argument from append\n self.max_iteration = max_iteration\n\n passes = PassManager._normalize_passes(passes)\n self._pass_sets.append({'passes': passes, 'flow_controllers': flow_controller_conditions})\n\n def replace(\n self,\n index: int,\n passes: Union[BasePass, List[BasePass]],\n max_iteration: int = None,\n **flow_controller_conditions: Any\n ) -> None:\n \"\"\"Replace a particular pass in the scheduler.\n\n Args:\n index: Pass index to replace, based on the position in passes().\n passes: A pass set (as defined in :py:func:`qiskit.transpiler.PassManager.append`)\n to be added to the pass manager schedule.\n max_iteration: max number of iterations of passes.\n flow_controller_conditions: control flow plugins.\n\n Raises:\n TranspilerError: if a pass in passes is not a proper pass or index not found.\n\n See Also:\n ``RunningPassManager.add_flow_controller()`` for more information about the control\n flow plugins.\n \"\"\"\n if max_iteration:\n # TODO remove this argument from append\n self.max_iteration = max_iteration\n\n passes = PassManager._normalize_passes(passes)\n\n try:\n self._pass_sets[index] = {'passes': passes,\n 'flow_controllers': flow_controller_conditions}\n except IndexError:\n raise TranspilerError('Index to replace %s does not exists' % index)\n\n def remove(self, index: int) -> None:\n \"\"\"Removes a particular pass in the scheduler.\n\n Args:\n index: Pass index to replace, based on the position in passes().\n\n Raises:\n TranspilerError: if the index is not found.\n \"\"\"\n try:\n del self._pass_sets[index]\n except IndexError:\n raise TranspilerError('Index to replace %s does not exists' % index)\n\n def __setitem__(self, index, item):\n self.replace(index, item)\n\n def __len__(self):\n return len(self._pass_sets)\n\n def __getitem__(self, index):\n new_passmanager = PassManager(max_iteration=self.max_iteration, callback=self.callback)\n _pass_sets = self._pass_sets[index]\n if isinstance(_pass_sets, dict):\n _pass_sets = [_pass_sets]\n new_passmanager._pass_sets = _pass_sets\n return new_passmanager\n\n def __add__(self, other):\n if isinstance(other, PassManager):\n new_passmanager = PassManager(max_iteration=self.max_iteration, callback=self.callback)\n new_passmanager._pass_sets = self._pass_sets + other._pass_sets\n return new_passmanager\n else:\n try:\n new_passmanager = PassManager(max_iteration=self.max_iteration,\n callback=self.callback)\n new_passmanager._pass_sets += self._pass_sets\n new_passmanager.append(other)\n return new_passmanager\n except TranspilerError:\n raise TypeError('unsupported operand type + for %s and %s' % (self.__class__,\n other.__class__))\n\n @staticmethod\n def _normalize_passes(passes: Union[BasePass, List[BasePass]]) -> List[BasePass]:\n if isinstance(passes, BasePass):\n passes = [passes]\n for pass_ in passes:\n if not isinstance(pass_, BasePass):\n raise TranspilerError('%s is not a pass instance' % pass_.__class__)\n return passes\n\n def run(\n self,\n circuits: Union[QuantumCircuit, List[QuantumCircuit]],\n output_name: str = None,\n callback: Callable = None\n ) -> Union[QuantumCircuit, List[QuantumCircuit]]:\n \"\"\"Run all the passes on the specified ``circuits``.\n\n Args:\n circuits: Circuit(s) to transform via all the registered passes.\n output_name: The output circuit name. If ``None``, it will be set to the same as the\n input circuit name.\n callback: A callback function that will be called after each pass execution. The\n function will be called with 5 keyword arguments::\n\n pass_ (Pass): the pass being run\n dag (DAGCircuit): the dag output of the pass\n time (float): the time to execute the pass\n property_set (PropertySet): the property set\n count (int): the index for the pass execution\n\n The exact arguments pass expose the internals of the pass\n manager and are subject to change as the pass manager internals\n change. If you intend to reuse a callback function over\n multiple releases be sure to check that the arguments being\n passed are the same.\n\n To use the callback feature you define a function that will\n take in kwargs dict and access the variables. For example::\n\n def callback_func(**kwargs):\n pass_ = kwargs['pass_']\n dag = kwargs['dag']\n time = kwargs['time']\n property_set = kwargs['property_set']\n count = kwargs['count']\n ...\n\n Returns:\n The transformed circuit(s).\n \"\"\"\n if isinstance(circuits, QuantumCircuit):\n return self._run_single_circuit(circuits, output_name, callback)\n elif len(circuits) == 1:\n return self._run_single_circuit(circuits[0], output_name, callback)\n else:\n return self._run_several_circuits(circuits, output_name, callback)\n\n def _create_running_passmanager(self) -> RunningPassManager:\n running_passmanager = RunningPassManager(self.max_iteration)\n for pass_set in self._pass_sets:\n running_passmanager.append(pass_set['passes'], **pass_set['flow_controllers'])\n return running_passmanager\n\n @staticmethod\n def _in_parallel(circuit, pm_dill=None) -> QuantumCircuit:\n \"\"\"Task used by the parallel map tools from ``_run_several_circuits``.\"\"\"\n running_passmanager = dill.loads(pm_dill)._create_running_passmanager()\n result = running_passmanager.run(circuit)\n return result\n\n def _run_several_circuits(\n self,\n circuits: List[QuantumCircuit],\n output_name: str = None,\n callback: Callable = None\n ) -> List[QuantumCircuit]:\n \"\"\"Run all the passes on the specified ``circuits``.\n\n Args:\n circuits: Circuits to transform via all the registered passes.\n output_name: The output circuit name. If ``None``, it will be set to the same as the\n input circuit name.\n callback: A callback function that will be called after each pass execution.\n\n Returns:\n The transformed circuits.\n \"\"\"\n # TODO support for List(output_name) and List(callback)\n del output_name\n del callback\n\n return parallel_map(PassManager._in_parallel, circuits,\n task_kwargs={'pm_dill': dill.dumps(self)})\n\n def _run_single_circuit(\n self,\n circuit: QuantumCircuit,\n output_name: str = None,\n callback: Callable = None\n ) -> QuantumCircuit:\n \"\"\"Run all the passes on a ``circuit``.\n\n Args:\n circuit: Circuit to transform via all the registered passes.\n output_name: The output circuit name. If ``None``, it will be set to the same as the\n input circuit name.\n callback: A callback function that will be called after each pass execution.\n\n Returns:\n The transformed circuit.\n \"\"\"\n running_passmanager = self._create_running_passmanager()\n if callback is None and self.callback: # TODO to remove with __init__(callback)\n callback = self.callback\n result = running_passmanager.run(circuit, output_name=output_name, callback=callback)\n self.property_set = running_passmanager.property_set\n return result\n\n def draw(self, filename=None, style=None, raw=False):\n \"\"\"Draw the pass manager.\n\n This function needs `pydot <https://github.com/erocarrera/pydot>`__, which in turn needs\n `Graphviz <https://www.graphviz.org/>`__ to be installed.\n\n Args:\n filename (str): file path to save image to.\n style (dict): keys are the pass classes and the values are the colors to make them. An\n example can be seen in the DEFAULT_STYLE. An ordered dict can be used to ensure\n a priority coloring when pass falls into multiple categories. Any values not\n included in the provided dict will be filled in from the default dict.\n raw (bool): If ``True``, save the raw Dot output instead of the image.\n\n Returns:\n Optional[PassManager]: an in-memory representation of the pass manager, or ``None``\n if no image was generated or `Pillow <https://pypi.org/project/Pillow/>`__\n is not installed.\n\n Raises:\n ImportError: when nxpd or pydot not installed.\n \"\"\"\n return pass_manager_drawer(self, filename=filename, style=style, raw=raw)\n\n def passes(self) -> List[Dict[str, BasePass]]:\n \"\"\"Return a list structure of the appended passes and its options.\n\n Returns:\n A list of pass sets, as defined in ``append()``.\n \"\"\"\n ret = []\n for pass_set in self._pass_sets:\n item = {'passes': pass_set['passes']}\n if pass_set['flow_controllers']:\n item['flow_controllers'] = set(pass_set['flow_controllers'].keys())\n else:\n item['flow_controllers'] = {}\n ret.append(item)\n return ret\n", "path": "qiskit/transpiler/passmanager.py"}]}
| 3,995 | 384 |
gh_patches_debug_7677
|
rasdani/github-patches
|
git_diff
|
dmlc__dgl-3579
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Inconsistent documentation and code of MultiLayerNeighborSampler
## 📚 Documentation
In the docstring of `MultiLayerNeighborSampler`, the default value of parameter `replace` is `True`, while in the code it's `False`:
```python
class MultiLayerNeighborSampler(BlockSampler):
"""
...
replace : bool, default True
Whether to sample with replacement
...
"""
def __init__(self, fanouts, replace=False, return_eids=False):
super().__init__(len(fanouts), return_eids)
self.fanouts = fanouts
self.replace = replace
# ...
```
Same issue exists in <https://docs.dgl.ai/api/python/dgl.dataloading.html#dgl.dataloading.neighbor.MultiLayerNeighborSampler>
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `python/dgl/dataloading/neighbor.py`
Content:
```
1 """Data loading components for neighbor sampling"""
2 from .dataloader import BlockSampler
3 from .. import sampling, distributed
4 from .. import ndarray as nd
5 from .. import backend as F
6 from ..base import ETYPE
7
8 class NeighborSamplingMixin(object):
9 """Mixin object containing common optimizing routines that caches fanout and probability
10 arrays.
11
12 The mixin requires the object to have the following attributes:
13
14 - :attr:`prob`: The edge feature name that stores the (unnormalized) probability.
15 - :attr:`fanouts`: The list of fanouts (either an integer or a dictionary of edge
16 types and integers).
17
18 The mixin will generate the following attributes:
19
20 - :attr:`prob_arrays`: List of DGL NDArrays containing the unnormalized probabilities
21 for every edge type.
22 - :attr:`fanout_arrays`: List of DGL NDArrays containing the fanouts for every edge
23 type at every layer.
24 """
25 def __init__(self, *args, **kwargs):
26 super().__init__(*args, **kwargs) # forward to base classes
27 self.fanout_arrays = []
28 self.prob_arrays = None
29
30 def _build_prob_arrays(self, g):
31 if self.prob is not None:
32 self.prob_arrays = [F.to_dgl_nd(g.edges[etype].data[self.prob]) for etype in g.etypes]
33 elif self.prob_arrays is None:
34 # build prob_arrays only once
35 self.prob_arrays = [nd.array([], ctx=nd.cpu())] * len(g.etypes)
36
37 def _build_fanout(self, block_id, g):
38 assert not self.fanouts is None, \
39 "_build_fanout() should only be called when fanouts is not None"
40 # build fanout_arrays only once for each layer
41 while block_id >= len(self.fanout_arrays):
42 for i in range(len(self.fanouts)):
43 fanout = self.fanouts[i]
44 if not isinstance(fanout, dict):
45 fanout_array = [int(fanout)] * len(g.etypes)
46 else:
47 if len(fanout) != len(g.etypes):
48 raise DGLError('Fan-out must be specified for each edge type '
49 'if a dict is provided.')
50 fanout_array = [None] * len(g.etypes)
51 for etype, value in fanout.items():
52 fanout_array[g.get_etype_id(etype)] = value
53 self.fanout_arrays.append(
54 F.to_dgl_nd(F.tensor(fanout_array, dtype=F.int64)))
55
56 class MultiLayerNeighborSampler(NeighborSamplingMixin, BlockSampler):
57 """Sampler that builds computational dependency of node representations via
58 neighbor sampling for multilayer GNN.
59
60 This sampler will make every node gather messages from a fixed number of neighbors
61 per edge type. The neighbors are picked uniformly.
62
63 Parameters
64 ----------
65 fanouts : list[int] or list[dict[etype, int]]
66 List of neighbors to sample per edge type for each GNN layer, with the i-th
67 element being the fanout for the i-th GNN layer.
68
69 If only a single integer is provided, DGL assumes that every edge type
70 will have the same fanout.
71
72 If -1 is provided for one edge type on one layer, then all inbound edges
73 of that edge type will be included.
74 replace : bool, default True
75 Whether to sample with replacement
76 return_eids : bool, default False
77 Whether to return the edge IDs involved in message passing in the MFG.
78 If True, the edge IDs will be stored as an edge feature named ``dgl.EID``.
79 prob : str, optional
80 If given, the probability of each neighbor being sampled is proportional
81 to the edge feature value with the given name in ``g.edata``. The feature must be
82 a scalar on each edge.
83
84 Examples
85 --------
86 To train a 3-layer GNN for node classification on a set of nodes ``train_nid`` on
87 a homogeneous graph where each node takes messages from 5, 10, 15 neighbors for
88 the first, second, and third layer respectively (assuming the backend is PyTorch):
89
90 >>> sampler = dgl.dataloading.MultiLayerNeighborSampler([5, 10, 15])
91 >>> dataloader = dgl.dataloading.NodeDataLoader(
92 ... g, train_nid, sampler,
93 ... batch_size=1024, shuffle=True, drop_last=False, num_workers=4)
94 >>> for input_nodes, output_nodes, blocks in dataloader:
95 ... train_on(blocks)
96
97 If training on a heterogeneous graph and you want different number of neighbors for each
98 edge type, one should instead provide a list of dicts. Each dict would specify the
99 number of neighbors to pick per edge type.
100
101 >>> sampler = dgl.dataloading.MultiLayerNeighborSampler([
102 ... {('user', 'follows', 'user'): 5,
103 ... ('user', 'plays', 'game'): 4,
104 ... ('game', 'played-by', 'user'): 3}] * 3)
105
106 If you would like non-uniform neighbor sampling:
107
108 >>> g.edata['p'] = torch.rand(g.num_edges()) # any non-negative 1D vector works
109 >>> sampler = dgl.dataloading.MultiLayerNeighborSampler([5, 10, 15], prob='p')
110
111 Notes
112 -----
113 For the concept of MFGs, please refer to
114 :ref:`User Guide Section 6 <guide-minibatch>` and
115 :doc:`Minibatch Training Tutorials <tutorials/large/L0_neighbor_sampling_overview>`.
116 """
117 def __init__(self, fanouts, replace=False, return_eids=False, prob=None):
118 super().__init__(len(fanouts), return_eids)
119
120 self.fanouts = fanouts
121 self.replace = replace
122
123 # used to cache computations and memory allocations
124 # list[dgl.nd.NDArray]; each array stores the fan-outs of all edge types
125 self.prob = prob
126
127 @classmethod
128 def exclude_edges_in_frontier(cls, g):
129 return not isinstance(g, distributed.DistGraph) and g.device == F.cpu()
130
131 def sample_frontier(self, block_id, g, seed_nodes, exclude_eids=None):
132 fanout = self.fanouts[block_id]
133 if isinstance(g, distributed.DistGraph):
134 if len(g.etypes) > 1: # heterogeneous distributed graph
135 frontier = distributed.sample_etype_neighbors(
136 g, seed_nodes, ETYPE, fanout, replace=self.replace)
137 else:
138 frontier = distributed.sample_neighbors(
139 g, seed_nodes, fanout, replace=self.replace)
140 else:
141 self._build_fanout(block_id, g)
142 self._build_prob_arrays(g)
143
144 frontier = sampling.sample_neighbors(
145 g, seed_nodes, self.fanout_arrays[block_id],
146 replace=self.replace, prob=self.prob_arrays, exclude_edges=exclude_eids)
147 return frontier
148
149
150 class MultiLayerFullNeighborSampler(MultiLayerNeighborSampler):
151 """Sampler that builds computational dependency of node representations by taking messages
152 from all neighbors for multilayer GNN.
153
154 This sampler will make every node gather messages from every single neighbor per edge type.
155
156 Parameters
157 ----------
158 n_layers : int
159 The number of GNN layers to sample.
160 return_eids : bool, default False
161 Whether to return the edge IDs involved in message passing in the MFG.
162 If True, the edge IDs will be stored as an edge feature named ``dgl.EID``.
163
164 Examples
165 --------
166 To train a 3-layer GNN for node classification on a set of nodes ``train_nid`` on
167 a homogeneous graph where each node takes messages from all neighbors for the first,
168 second, and third layer respectively (assuming the backend is PyTorch):
169
170 >>> sampler = dgl.dataloading.MultiLayerFullNeighborSampler(3)
171 >>> dataloader = dgl.dataloading.NodeDataLoader(
172 ... g, train_nid, sampler,
173 ... batch_size=1024, shuffle=True, drop_last=False, num_workers=4)
174 >>> for input_nodes, output_nodes, blocks in dataloader:
175 ... train_on(blocks)
176
177 Notes
178 -----
179 For the concept of MFGs, please refer to
180 :ref:`User Guide Section 6 <guide-minibatch>` and
181 :doc:`Minibatch Training Tutorials <tutorials/large/L0_neighbor_sampling_overview>`.
182 """
183 def __init__(self, n_layers, return_eids=False):
184 super().__init__([-1] * n_layers, return_eids=return_eids)
185
186 @classmethod
187 def exclude_edges_in_frontier(cls, g):
188 return False
189
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/python/dgl/dataloading/neighbor.py b/python/dgl/dataloading/neighbor.py
--- a/python/dgl/dataloading/neighbor.py
+++ b/python/dgl/dataloading/neighbor.py
@@ -71,7 +71,7 @@
If -1 is provided for one edge type on one layer, then all inbound edges
of that edge type will be included.
- replace : bool, default True
+ replace : bool, default False
Whether to sample with replacement
return_eids : bool, default False
Whether to return the edge IDs involved in message passing in the MFG.
|
{"golden_diff": "diff --git a/python/dgl/dataloading/neighbor.py b/python/dgl/dataloading/neighbor.py\n--- a/python/dgl/dataloading/neighbor.py\n+++ b/python/dgl/dataloading/neighbor.py\n@@ -71,7 +71,7 @@\n \n If -1 is provided for one edge type on one layer, then all inbound edges\n of that edge type will be included.\n- replace : bool, default True\n+ replace : bool, default False\n Whether to sample with replacement\n return_eids : bool, default False\n Whether to return the edge IDs involved in message passing in the MFG.\n", "issue": "Inconsistent documentation and code of MultiLayerNeighborSampler\n## \ud83d\udcda Documentation\r\n\r\nIn the docstring of `MultiLayerNeighborSampler`, the default value of parameter `replace` is `True`, while in the code it's `False`:\r\n```python\r\nclass MultiLayerNeighborSampler(BlockSampler):\r\n \"\"\"\r\n ...\r\n\r\n replace : bool, default True\r\n Whether to sample with replacement\r\n ...\r\n \"\"\"\r\n def __init__(self, fanouts, replace=False, return_eids=False):\r\n super().__init__(len(fanouts), return_eids)\r\n self.fanouts = fanouts\r\n self.replace = replace\r\n # ...\r\n```\r\n\r\nSame issue exists in <https://docs.dgl.ai/api/python/dgl.dataloading.html#dgl.dataloading.neighbor.MultiLayerNeighborSampler>\n", "before_files": [{"content": "\"\"\"Data loading components for neighbor sampling\"\"\"\nfrom .dataloader import BlockSampler\nfrom .. import sampling, distributed\nfrom .. import ndarray as nd\nfrom .. import backend as F\nfrom ..base import ETYPE\n\nclass NeighborSamplingMixin(object):\n \"\"\"Mixin object containing common optimizing routines that caches fanout and probability\n arrays.\n\n The mixin requires the object to have the following attributes:\n\n - :attr:`prob`: The edge feature name that stores the (unnormalized) probability.\n - :attr:`fanouts`: The list of fanouts (either an integer or a dictionary of edge\n types and integers).\n\n The mixin will generate the following attributes:\n\n - :attr:`prob_arrays`: List of DGL NDArrays containing the unnormalized probabilities\n for every edge type.\n - :attr:`fanout_arrays`: List of DGL NDArrays containing the fanouts for every edge\n type at every layer.\n \"\"\"\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs) # forward to base classes\n self.fanout_arrays = []\n self.prob_arrays = None\n\n def _build_prob_arrays(self, g):\n if self.prob is not None:\n self.prob_arrays = [F.to_dgl_nd(g.edges[etype].data[self.prob]) for etype in g.etypes]\n elif self.prob_arrays is None:\n # build prob_arrays only once\n self.prob_arrays = [nd.array([], ctx=nd.cpu())] * len(g.etypes)\n\n def _build_fanout(self, block_id, g):\n assert not self.fanouts is None, \\\n \"_build_fanout() should only be called when fanouts is not None\"\n # build fanout_arrays only once for each layer\n while block_id >= len(self.fanout_arrays):\n for i in range(len(self.fanouts)):\n fanout = self.fanouts[i]\n if not isinstance(fanout, dict):\n fanout_array = [int(fanout)] * len(g.etypes)\n else:\n if len(fanout) != len(g.etypes):\n raise DGLError('Fan-out must be specified for each edge type '\n 'if a dict is provided.')\n fanout_array = [None] * len(g.etypes)\n for etype, value in fanout.items():\n fanout_array[g.get_etype_id(etype)] = value\n self.fanout_arrays.append(\n F.to_dgl_nd(F.tensor(fanout_array, dtype=F.int64)))\n\nclass MultiLayerNeighborSampler(NeighborSamplingMixin, BlockSampler):\n \"\"\"Sampler that builds computational dependency of node representations via\n neighbor sampling for multilayer GNN.\n\n This sampler will make every node gather messages from a fixed number of neighbors\n per edge type. The neighbors are picked uniformly.\n\n Parameters\n ----------\n fanouts : list[int] or list[dict[etype, int]]\n List of neighbors to sample per edge type for each GNN layer, with the i-th\n element being the fanout for the i-th GNN layer.\n\n If only a single integer is provided, DGL assumes that every edge type\n will have the same fanout.\n\n If -1 is provided for one edge type on one layer, then all inbound edges\n of that edge type will be included.\n replace : bool, default True\n Whether to sample with replacement\n return_eids : bool, default False\n Whether to return the edge IDs involved in message passing in the MFG.\n If True, the edge IDs will be stored as an edge feature named ``dgl.EID``.\n prob : str, optional\n If given, the probability of each neighbor being sampled is proportional\n to the edge feature value with the given name in ``g.edata``. The feature must be\n a scalar on each edge.\n\n Examples\n --------\n To train a 3-layer GNN for node classification on a set of nodes ``train_nid`` on\n a homogeneous graph where each node takes messages from 5, 10, 15 neighbors for\n the first, second, and third layer respectively (assuming the backend is PyTorch):\n\n >>> sampler = dgl.dataloading.MultiLayerNeighborSampler([5, 10, 15])\n >>> dataloader = dgl.dataloading.NodeDataLoader(\n ... g, train_nid, sampler,\n ... batch_size=1024, shuffle=True, drop_last=False, num_workers=4)\n >>> for input_nodes, output_nodes, blocks in dataloader:\n ... train_on(blocks)\n\n If training on a heterogeneous graph and you want different number of neighbors for each\n edge type, one should instead provide a list of dicts. Each dict would specify the\n number of neighbors to pick per edge type.\n\n >>> sampler = dgl.dataloading.MultiLayerNeighborSampler([\n ... {('user', 'follows', 'user'): 5,\n ... ('user', 'plays', 'game'): 4,\n ... ('game', 'played-by', 'user'): 3}] * 3)\n\n If you would like non-uniform neighbor sampling:\n\n >>> g.edata['p'] = torch.rand(g.num_edges()) # any non-negative 1D vector works\n >>> sampler = dgl.dataloading.MultiLayerNeighborSampler([5, 10, 15], prob='p')\n\n Notes\n -----\n For the concept of MFGs, please refer to\n :ref:`User Guide Section 6 <guide-minibatch>` and\n :doc:`Minibatch Training Tutorials <tutorials/large/L0_neighbor_sampling_overview>`.\n \"\"\"\n def __init__(self, fanouts, replace=False, return_eids=False, prob=None):\n super().__init__(len(fanouts), return_eids)\n\n self.fanouts = fanouts\n self.replace = replace\n\n # used to cache computations and memory allocations\n # list[dgl.nd.NDArray]; each array stores the fan-outs of all edge types\n self.prob = prob\n\n @classmethod\n def exclude_edges_in_frontier(cls, g):\n return not isinstance(g, distributed.DistGraph) and g.device == F.cpu()\n\n def sample_frontier(self, block_id, g, seed_nodes, exclude_eids=None):\n fanout = self.fanouts[block_id]\n if isinstance(g, distributed.DistGraph):\n if len(g.etypes) > 1: # heterogeneous distributed graph\n frontier = distributed.sample_etype_neighbors(\n g, seed_nodes, ETYPE, fanout, replace=self.replace)\n else:\n frontier = distributed.sample_neighbors(\n g, seed_nodes, fanout, replace=self.replace)\n else:\n self._build_fanout(block_id, g)\n self._build_prob_arrays(g)\n\n frontier = sampling.sample_neighbors(\n g, seed_nodes, self.fanout_arrays[block_id],\n replace=self.replace, prob=self.prob_arrays, exclude_edges=exclude_eids)\n return frontier\n\n\nclass MultiLayerFullNeighborSampler(MultiLayerNeighborSampler):\n \"\"\"Sampler that builds computational dependency of node representations by taking messages\n from all neighbors for multilayer GNN.\n\n This sampler will make every node gather messages from every single neighbor per edge type.\n\n Parameters\n ----------\n n_layers : int\n The number of GNN layers to sample.\n return_eids : bool, default False\n Whether to return the edge IDs involved in message passing in the MFG.\n If True, the edge IDs will be stored as an edge feature named ``dgl.EID``.\n\n Examples\n --------\n To train a 3-layer GNN for node classification on a set of nodes ``train_nid`` on\n a homogeneous graph where each node takes messages from all neighbors for the first,\n second, and third layer respectively (assuming the backend is PyTorch):\n\n >>> sampler = dgl.dataloading.MultiLayerFullNeighborSampler(3)\n >>> dataloader = dgl.dataloading.NodeDataLoader(\n ... g, train_nid, sampler,\n ... batch_size=1024, shuffle=True, drop_last=False, num_workers=4)\n >>> for input_nodes, output_nodes, blocks in dataloader:\n ... train_on(blocks)\n\n Notes\n -----\n For the concept of MFGs, please refer to\n :ref:`User Guide Section 6 <guide-minibatch>` and\n :doc:`Minibatch Training Tutorials <tutorials/large/L0_neighbor_sampling_overview>`.\n \"\"\"\n def __init__(self, n_layers, return_eids=False):\n super().__init__([-1] * n_layers, return_eids=return_eids)\n\n @classmethod\n def exclude_edges_in_frontier(cls, g):\n return False\n", "path": "python/dgl/dataloading/neighbor.py"}], "after_files": [{"content": "\"\"\"Data loading components for neighbor sampling\"\"\"\nfrom .dataloader import BlockSampler\nfrom .. import sampling, distributed\nfrom .. import ndarray as nd\nfrom .. import backend as F\nfrom ..base import ETYPE\n\nclass NeighborSamplingMixin(object):\n \"\"\"Mixin object containing common optimizing routines that caches fanout and probability\n arrays.\n\n The mixin requires the object to have the following attributes:\n\n - :attr:`prob`: The edge feature name that stores the (unnormalized) probability.\n - :attr:`fanouts`: The list of fanouts (either an integer or a dictionary of edge\n types and integers).\n\n The mixin will generate the following attributes:\n\n - :attr:`prob_arrays`: List of DGL NDArrays containing the unnormalized probabilities\n for every edge type.\n - :attr:`fanout_arrays`: List of DGL NDArrays containing the fanouts for every edge\n type at every layer.\n \"\"\"\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs) # forward to base classes\n self.fanout_arrays = []\n self.prob_arrays = None\n\n def _build_prob_arrays(self, g):\n if self.prob is not None:\n self.prob_arrays = [F.to_dgl_nd(g.edges[etype].data[self.prob]) for etype in g.etypes]\n elif self.prob_arrays is None:\n # build prob_arrays only once\n self.prob_arrays = [nd.array([], ctx=nd.cpu())] * len(g.etypes)\n\n def _build_fanout(self, block_id, g):\n assert not self.fanouts is None, \\\n \"_build_fanout() should only be called when fanouts is not None\"\n # build fanout_arrays only once for each layer\n while block_id >= len(self.fanout_arrays):\n for i in range(len(self.fanouts)):\n fanout = self.fanouts[i]\n if not isinstance(fanout, dict):\n fanout_array = [int(fanout)] * len(g.etypes)\n else:\n if len(fanout) != len(g.etypes):\n raise DGLError('Fan-out must be specified for each edge type '\n 'if a dict is provided.')\n fanout_array = [None] * len(g.etypes)\n for etype, value in fanout.items():\n fanout_array[g.get_etype_id(etype)] = value\n self.fanout_arrays.append(\n F.to_dgl_nd(F.tensor(fanout_array, dtype=F.int64)))\n\nclass MultiLayerNeighborSampler(NeighborSamplingMixin, BlockSampler):\n \"\"\"Sampler that builds computational dependency of node representations via\n neighbor sampling for multilayer GNN.\n\n This sampler will make every node gather messages from a fixed number of neighbors\n per edge type. The neighbors are picked uniformly.\n\n Parameters\n ----------\n fanouts : list[int] or list[dict[etype, int]]\n List of neighbors to sample per edge type for each GNN layer, with the i-th\n element being the fanout for the i-th GNN layer.\n\n If only a single integer is provided, DGL assumes that every edge type\n will have the same fanout.\n\n If -1 is provided for one edge type on one layer, then all inbound edges\n of that edge type will be included.\n replace : bool, default False\n Whether to sample with replacement\n return_eids : bool, default False\n Whether to return the edge IDs involved in message passing in the MFG.\n If True, the edge IDs will be stored as an edge feature named ``dgl.EID``.\n prob : str, optional\n If given, the probability of each neighbor being sampled is proportional\n to the edge feature value with the given name in ``g.edata``. The feature must be\n a scalar on each edge.\n\n Examples\n --------\n To train a 3-layer GNN for node classification on a set of nodes ``train_nid`` on\n a homogeneous graph where each node takes messages from 5, 10, 15 neighbors for\n the first, second, and third layer respectively (assuming the backend is PyTorch):\n\n >>> sampler = dgl.dataloading.MultiLayerNeighborSampler([5, 10, 15])\n >>> dataloader = dgl.dataloading.NodeDataLoader(\n ... g, train_nid, sampler,\n ... batch_size=1024, shuffle=True, drop_last=False, num_workers=4)\n >>> for input_nodes, output_nodes, blocks in dataloader:\n ... train_on(blocks)\n\n If training on a heterogeneous graph and you want different number of neighbors for each\n edge type, one should instead provide a list of dicts. Each dict would specify the\n number of neighbors to pick per edge type.\n\n >>> sampler = dgl.dataloading.MultiLayerNeighborSampler([\n ... {('user', 'follows', 'user'): 5,\n ... ('user', 'plays', 'game'): 4,\n ... ('game', 'played-by', 'user'): 3}] * 3)\n\n If you would like non-uniform neighbor sampling:\n\n >>> g.edata['p'] = torch.rand(g.num_edges()) # any non-negative 1D vector works\n >>> sampler = dgl.dataloading.MultiLayerNeighborSampler([5, 10, 15], prob='p')\n\n Notes\n -----\n For the concept of MFGs, please refer to\n :ref:`User Guide Section 6 <guide-minibatch>` and\n :doc:`Minibatch Training Tutorials <tutorials/large/L0_neighbor_sampling_overview>`.\n \"\"\"\n def __init__(self, fanouts, replace=False, return_eids=False, prob=None):\n super().__init__(len(fanouts), return_eids)\n\n self.fanouts = fanouts\n self.replace = replace\n\n # used to cache computations and memory allocations\n # list[dgl.nd.NDArray]; each array stores the fan-outs of all edge types\n self.prob = prob\n\n @classmethod\n def exclude_edges_in_frontier(cls, g):\n return not isinstance(g, distributed.DistGraph) and g.device == F.cpu()\n\n def sample_frontier(self, block_id, g, seed_nodes, exclude_eids=None):\n fanout = self.fanouts[block_id]\n if isinstance(g, distributed.DistGraph):\n if len(g.etypes) > 1: # heterogeneous distributed graph\n frontier = distributed.sample_etype_neighbors(\n g, seed_nodes, ETYPE, fanout, replace=self.replace)\n else:\n frontier = distributed.sample_neighbors(\n g, seed_nodes, fanout, replace=self.replace)\n else:\n self._build_fanout(block_id, g)\n self._build_prob_arrays(g)\n\n frontier = sampling.sample_neighbors(\n g, seed_nodes, self.fanout_arrays[block_id],\n replace=self.replace, prob=self.prob_arrays, exclude_edges=exclude_eids)\n return frontier\n\n\nclass MultiLayerFullNeighborSampler(MultiLayerNeighborSampler):\n \"\"\"Sampler that builds computational dependency of node representations by taking messages\n from all neighbors for multilayer GNN.\n\n This sampler will make every node gather messages from every single neighbor per edge type.\n\n Parameters\n ----------\n n_layers : int\n The number of GNN layers to sample.\n return_eids : bool, default False\n Whether to return the edge IDs involved in message passing in the MFG.\n If True, the edge IDs will be stored as an edge feature named ``dgl.EID``.\n\n Examples\n --------\n To train a 3-layer GNN for node classification on a set of nodes ``train_nid`` on\n a homogeneous graph where each node takes messages from all neighbors for the first,\n second, and third layer respectively (assuming the backend is PyTorch):\n\n >>> sampler = dgl.dataloading.MultiLayerFullNeighborSampler(3)\n >>> dataloader = dgl.dataloading.NodeDataLoader(\n ... g, train_nid, sampler,\n ... batch_size=1024, shuffle=True, drop_last=False, num_workers=4)\n >>> for input_nodes, output_nodes, blocks in dataloader:\n ... train_on(blocks)\n\n Notes\n -----\n For the concept of MFGs, please refer to\n :ref:`User Guide Section 6 <guide-minibatch>` and\n :doc:`Minibatch Training Tutorials <tutorials/large/L0_neighbor_sampling_overview>`.\n \"\"\"\n def __init__(self, n_layers, return_eids=False):\n super().__init__([-1] * n_layers, return_eids=return_eids)\n\n @classmethod\n def exclude_edges_in_frontier(cls, g):\n return False\n", "path": "python/dgl/dataloading/neighbor.py"}]}
| 2,841 | 144 |
gh_patches_debug_3743
|
rasdani/github-patches
|
git_diff
|
openai__gym-2576
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Proposal] Add license to the license field in the setup.py file
### Proposal
Add license to the license field in the setup.py file.
### Motivation
The license field is defined but not completed in the setup.py file.
Some package dependency scanners will block the usage of this package as the license is not specified.
### Checklist
- [x] I have checked that there is no similar [issue](https://github.com/openai/gym/issues) in the repo (**required**)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import os.path
2 import sys
3 import itertools
4
5 from setuptools import find_packages, setup
6
7 # Don't import gym module here, since deps may not be installed
8 sys.path.insert(0, os.path.join(os.path.dirname(__file__), "gym"))
9 from version import VERSION
10
11 # Environment-specific dependencies.
12 extras = {
13 "atari": ["ale-py~=0.7.1"],
14 "accept-rom-license": ["autorom[accept-rom-license]~=0.4.2"],
15 "box2d": ["box2d-py==2.3.5", "pyglet>=1.4.0"],
16 "classic_control": ["pyglet>=1.4.0"],
17 "mujoco": ["mujoco_py>=1.50, <2.0"],
18 "toy_text": ["pygame==2.1.0", "scipy>=1.4.1"],
19 "other": ["lz4>=3.1.0", "opencv-python>=3.0"],
20 }
21
22 # Meta dependency groups.
23 nomujoco_blacklist = set(["mujoco", "accept-rom-license", "atari"])
24 nomujoco_groups = set(extras.keys()) - nomujoco_blacklist
25
26 extras["nomujoco"] = list(
27 itertools.chain.from_iterable(map(lambda group: extras[group], nomujoco_groups))
28 )
29
30
31 all_blacklist = set(["accept-rom-license"])
32 all_groups = set(extras.keys()) - all_blacklist
33
34 extras["all"] = list(
35 itertools.chain.from_iterable(map(lambda group: extras[group], all_groups))
36 )
37
38 setup(
39 name="gym",
40 version=VERSION,
41 description="Gym: A universal API for reinforcement learning environments.",
42 url="https://github.com/openai/gym",
43 author="Gym Community",
44 author_email="[email protected]",
45 license="",
46 packages=[package for package in find_packages() if package.startswith("gym")],
47 zip_safe=False,
48 install_requires=[
49 "numpy>=1.18.0",
50 "cloudpickle>=1.2.0",
51 "importlib_metadata>=4.10.0; python_version < '3.10'",
52 ],
53 extras_require=extras,
54 package_data={
55 "gym": [
56 "envs/mujoco/assets/*.xml",
57 "envs/classic_control/assets/*.png",
58 "envs/toy_text/font/*.ttf",
59 "envs/toy_text/img/*.png",
60 ]
61 },
62 tests_require=["pytest", "mock"],
63 python_requires=">=3.7",
64 classifiers=[
65 "Programming Language :: Python :: 3",
66 "Programming Language :: Python :: 3.7",
67 "Programming Language :: Python :: 3.8",
68 "Programming Language :: Python :: 3.9",
69 "Programming Language :: Python :: 3.10",
70 ],
71 )
72
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -42,7 +42,7 @@
url="https://github.com/openai/gym",
author="Gym Community",
author_email="[email protected]",
- license="",
+ license="MIT",
packages=[package for package in find_packages() if package.startswith("gym")],
zip_safe=False,
install_requires=[
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -42,7 +42,7 @@\n url=\"https://github.com/openai/gym\",\n author=\"Gym Community\",\n author_email=\"[email protected]\",\n- license=\"\",\n+ license=\"MIT\",\n packages=[package for package in find_packages() if package.startswith(\"gym\")],\n zip_safe=False,\n install_requires=[\n", "issue": "[Proposal] Add license to the license field in the setup.py file\n### Proposal \r\n\r\nAdd license to the license field in the setup.py file.\r\n\r\n### Motivation\r\n\r\nThe license field is defined but not completed in the setup.py file. \r\n\r\nSome package dependency scanners will block the usage of this package as the license is not specified.\r\n\r\n### Checklist\r\n\r\n- [x] I have checked that there is no similar [issue](https://github.com/openai/gym/issues) in the repo (**required**)\r\n\n", "before_files": [{"content": "import os.path\nimport sys\nimport itertools\n\nfrom setuptools import find_packages, setup\n\n# Don't import gym module here, since deps may not be installed\nsys.path.insert(0, os.path.join(os.path.dirname(__file__), \"gym\"))\nfrom version import VERSION\n\n# Environment-specific dependencies.\nextras = {\n \"atari\": [\"ale-py~=0.7.1\"],\n \"accept-rom-license\": [\"autorom[accept-rom-license]~=0.4.2\"],\n \"box2d\": [\"box2d-py==2.3.5\", \"pyglet>=1.4.0\"],\n \"classic_control\": [\"pyglet>=1.4.0\"],\n \"mujoco\": [\"mujoco_py>=1.50, <2.0\"],\n \"toy_text\": [\"pygame==2.1.0\", \"scipy>=1.4.1\"],\n \"other\": [\"lz4>=3.1.0\", \"opencv-python>=3.0\"],\n}\n\n# Meta dependency groups.\nnomujoco_blacklist = set([\"mujoco\", \"accept-rom-license\", \"atari\"])\nnomujoco_groups = set(extras.keys()) - nomujoco_blacklist\n\nextras[\"nomujoco\"] = list(\n itertools.chain.from_iterable(map(lambda group: extras[group], nomujoco_groups))\n)\n\n\nall_blacklist = set([\"accept-rom-license\"])\nall_groups = set(extras.keys()) - all_blacklist\n\nextras[\"all\"] = list(\n itertools.chain.from_iterable(map(lambda group: extras[group], all_groups))\n)\n\nsetup(\n name=\"gym\",\n version=VERSION,\n description=\"Gym: A universal API for reinforcement learning environments.\",\n url=\"https://github.com/openai/gym\",\n author=\"Gym Community\",\n author_email=\"[email protected]\",\n license=\"\",\n packages=[package for package in find_packages() if package.startswith(\"gym\")],\n zip_safe=False,\n install_requires=[\n \"numpy>=1.18.0\",\n \"cloudpickle>=1.2.0\",\n \"importlib_metadata>=4.10.0; python_version < '3.10'\",\n ],\n extras_require=extras,\n package_data={\n \"gym\": [\n \"envs/mujoco/assets/*.xml\",\n \"envs/classic_control/assets/*.png\",\n \"envs/toy_text/font/*.ttf\",\n \"envs/toy_text/img/*.png\",\n ]\n },\n tests_require=[\"pytest\", \"mock\"],\n python_requires=\">=3.7\",\n classifiers=[\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n ],\n)\n", "path": "setup.py"}], "after_files": [{"content": "import os.path\nimport sys\nimport itertools\n\nfrom setuptools import find_packages, setup\n\n# Don't import gym module here, since deps may not be installed\nsys.path.insert(0, os.path.join(os.path.dirname(__file__), \"gym\"))\nfrom version import VERSION\n\n# Environment-specific dependencies.\nextras = {\n \"atari\": [\"ale-py~=0.7.1\"],\n \"accept-rom-license\": [\"autorom[accept-rom-license]~=0.4.2\"],\n \"box2d\": [\"box2d-py==2.3.5\", \"pyglet>=1.4.0\"],\n \"classic_control\": [\"pyglet>=1.4.0\"],\n \"mujoco\": [\"mujoco_py>=1.50, <2.0\"],\n \"toy_text\": [\"pygame==2.1.0\", \"scipy>=1.4.1\"],\n \"other\": [\"lz4>=3.1.0\", \"opencv-python>=3.0\"],\n}\n\n# Meta dependency groups.\nnomujoco_blacklist = set([\"mujoco\", \"accept-rom-license\", \"atari\"])\nnomujoco_groups = set(extras.keys()) - nomujoco_blacklist\n\nextras[\"nomujoco\"] = list(\n itertools.chain.from_iterable(map(lambda group: extras[group], nomujoco_groups))\n)\n\n\nall_blacklist = set([\"accept-rom-license\"])\nall_groups = set(extras.keys()) - all_blacklist\n\nextras[\"all\"] = list(\n itertools.chain.from_iterable(map(lambda group: extras[group], all_groups))\n)\n\nsetup(\n name=\"gym\",\n version=VERSION,\n description=\"Gym: A universal API for reinforcement learning environments.\",\n url=\"https://github.com/openai/gym\",\n author=\"Gym Community\",\n author_email=\"[email protected]\",\n license=\"MIT\",\n packages=[package for package in find_packages() if package.startswith(\"gym\")],\n zip_safe=False,\n install_requires=[\n \"numpy>=1.18.0\",\n \"cloudpickle>=1.2.0\",\n \"importlib_metadata>=4.10.0; python_version < '3.10'\",\n ],\n extras_require=extras,\n package_data={\n \"gym\": [\n \"envs/mujoco/assets/*.xml\",\n \"envs/classic_control/assets/*.png\",\n \"envs/toy_text/font/*.ttf\",\n \"envs/toy_text/img/*.png\",\n ]\n },\n tests_require=[\"pytest\", \"mock\"],\n python_requires=\">=3.7\",\n classifiers=[\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n ],\n)\n", "path": "setup.py"}]}
| 1,124 | 100 |
gh_patches_debug_31775
|
rasdani/github-patches
|
git_diff
|
mabel-dev__opteryx-1337
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
✨ Support `RLIKE`
https://github.com/sqlparser-rs/sqlparser-rs/pull/1017/files
~~~sql
SELECT 'a' RLIKE '.'
~~~
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `opteryx/third_party/pyarrow_ops/ops.py`
Content:
```
1 """
2 Original code modified for Opteryx.
3 """
4 import numpy
5 import pyarrow
6 from pyarrow import compute
7
8 from opteryx.third_party.pyarrow_ops.helpers import columns_to_array
9
10 # Added for Opteryx, comparisons in filter_operators updated to match
11 # this set is from sqloxide
12 FILTER_OPERATORS = {
13 "Eq",
14 "NotEq",
15 "Gt",
16 "GtEq",
17 "Lt",
18 "LtEq",
19 "Like",
20 "ILike",
21 "NotLike",
22 "NotILike",
23 "InList",
24 "SimilarTo",
25 "NotSimilarTo",
26 "PGRegexMatch",
27 "NotPGRegexMatch",
28 "PGRegexNotMatch",
29 "PGRegexIMatch", # "~*"
30 "NotPGRegexIMatch", # "!~*"
31 "PGRegexNotIMatch", # "!~*"
32 "BitwiseOr", # |
33 }
34
35
36 def filter_operations(arr, operator, value):
37 """
38 Wrapped for Opteryx added to correctly handle null semantics.
39
40 This returns an array with tri-state boolean (tue/false/none);
41 if being used for display use as is, if being used for filtering, none is false.
42 """
43
44 # if the input is a table, get the first column
45 if isinstance(value, pyarrow.Table): # pragma: no cover
46 value = [value.columns[0].to_numpy()]
47
48 # work out which rows we're going to actually evaluate
49 # we're working out if either array has a null value so we can exclude them
50 # from the actual evaluation.
51 # True = values, False = null
52 record_count = len(arr)
53 null_arr = compute.is_null(arr, nan_is_null=True)
54 null_val = compute.is_null(value, nan_is_null=True)
55 null_positions = numpy.logical_or(null_arr, null_val)
56
57 # if there's no non-null values, stop here
58 if all(null_positions):
59 return numpy.full(record_count, None)
60
61 any_null = any(null_positions)
62 null_positions = numpy.invert(null_positions)
63
64 compressed = False
65 if any_null and isinstance(arr, numpy.ndarray) and isinstance(value, numpy.ndarray):
66 # if we have nulls and both columns are numpy arrays, we can speed things
67 # up by removing the nulls from the calculations, we add the rows back in
68 # later
69 arr = arr.compress(null_positions)
70 value = value.compress(null_positions)
71 compressed = True
72
73 # do the evaluation
74 results_mask = _inner_filter_operations(arr, operator, value)
75
76 if compressed:
77 # fill the result set
78 results = numpy.full(record_count, -1, numpy.int8)
79 results[numpy.nonzero(null_positions)] = results_mask
80 # build tri-state response, PyArrow supports tristate, numpy does not
81 return pyarrow.array((bool(r) if r != -1 else None for r in results), type=pyarrow.bool_())
82
83 return results_mask
84
85
86 # Filter functionality
87 def _inner_filter_operations(arr, operator, value):
88 """
89 Execute filter operations, this returns an array of the indexes of the rows that
90 match the filter
91 """
92 # ADDED FOR OPTERYX
93
94 if operator == "Eq":
95 return compute.equal(arr, value).to_numpy(False).astype(dtype=bool)
96 if operator == "NotEq":
97 return compute.not_equal(arr, value).to_numpy(False).astype(dtype=bool)
98 if operator == "Lt":
99 return compute.less(arr, value).to_numpy(False).astype(dtype=bool)
100 if operator == "Gt":
101 return compute.greater(arr, value).to_numpy(False).astype(dtype=bool)
102 if operator == "LtEq":
103 return compute.less_equal(arr, value).to_numpy(False).astype(dtype=bool)
104 if operator == "GtEq":
105 return compute.greater_equal(arr, value).to_numpy(False).astype(dtype=bool)
106 if operator == "InList":
107 # MODIFIED FOR OPTERYX
108 # some of the lists are saved as sets, which are faster than searching numpy
109 # arrays, even with numpy's native functionality - choosing the right algo
110 # is almost always faster than choosing a fast language.
111 return numpy.array([a in value[0] for a in arr], dtype=numpy.bool_) # [#325]?
112 if operator == "NotInList":
113 # MODIFIED FOR OPTERYX - see comment above
114 return numpy.array([a not in value[0] for a in arr], dtype=numpy.bool_) # [#325]?
115 if operator == "Contains":
116 # ADDED FOR OPTERYX
117 return numpy.array([None if v is None else (arr[0] in v) for v in value], dtype=numpy.bool_)
118 if operator == "NotContains":
119 # ADDED FOR OPTERYX
120 return numpy.array(
121 [None if v is None else (arr[0] not in v) for v in value], dtype=numpy.bool_
122 ) # [#325]?
123 if operator == "Like":
124 # MODIFIED FOR OPTERYX
125 # null input emits null output, which should be false/0
126 return compute.match_like(arr, value[0]).to_numpy(False).astype(dtype=bool) # [#325]
127 if operator == "NotLike":
128 # MODIFIED FOR OPTERYX - see comment above
129 matches = compute.match_like(arr, value[0]).to_numpy(False).astype(dtype=bool) # [#325]
130 return numpy.invert(matches)
131 if operator == "ILike":
132 # MODIFIED FOR OPTERYX - see comment above
133 return (
134 compute.match_like(arr, value[0], ignore_case=True).to_numpy(False).astype(dtype=bool)
135 ) # [#325]
136 if operator == "NotILike":
137 # MODIFIED FOR OPTERYX - see comment above
138 matches = compute.match_like(arr, value[0], ignore_case=True) # [#325]
139 return numpy.invert(matches)
140 if operator in ("PGRegexMatch", "SimilarTo"):
141 # MODIFIED FOR OPTERYX - see comment above
142 return (
143 compute.match_substring_regex(arr, value[0]).to_numpy(False).astype(dtype=bool)
144 ) # [#325]
145 if operator in ("PGRegexNotMatch", "NotSimilarTo"):
146 # MODIFIED FOR OPTERYX - see comment above
147 matches = compute.match_substring_regex(arr, value[0]) # [#325]
148 return numpy.invert(matches)
149 if operator == "PGRegexIMatch":
150 # MODIFIED FOR OPTERYX - see comment above
151 return (
152 compute.match_substring_regex(arr, value[0], ignore_case=True)
153 .to_numpy(False)
154 .astype(dtype=bool)
155 ) # [#325]
156 if operator == "PGRegexNotIMatch":
157 # MODIFIED FOR OPTERYX - see comment above
158 matches = compute.match_substring_regex(arr, value[0], ignore_case=True) # [#325]
159 return numpy.invert(matches)
160
161 raise NotImplementedError(f"Operator {operator} is not implemented!") # pragma: no cover
162
163
164 # Drop duplicates
165 def drop_duplicates(table, columns=None):
166 """
167 drops duplicates, keeps the first of the set
168
169 MODIFIED FOR OPTERYX
170 """
171 # Gather columns to arr
172 arr = columns_to_array(table, (columns if columns else table.column_names))
173 values, indices = numpy.unique(arr, return_index=True)
174 del values
175 return table.take(indices)
176
```
Path: `opteryx/operators/join_node.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 """
14 Join Node
15
16 This is a SQL Query Execution Plan Node.
17
18 This handles most of the join types as a wrapper for pyarrow's JOIN functions,
19 only CROSS JOINs are not handled here.
20 """
21 from typing import Iterable
22
23 import pyarrow
24
25 from opteryx.models import QueryProperties
26 from opteryx.operators import BasePlanNode
27
28 INTERNAL_BATCH_SIZE = 500 # config
29
30
31 def calculate_batch_size(cardinality):
32 """dynamically work out the processing batch size for the USING JOIN"""
33 # - HIGH_CARDINALITY_BATCH_SIZE (over 90% unique) = INTERNAL_BATCH_SIZE
34 # - MEDIUM_CARDINALITY_BATCH_SIZE (5% > n < 90%) = INTERNAL_BATCH_SIZE * n
35 # - LOW_CARDINALITY_BATCH_SIZE (less than 5% unique) = 5
36 # These numbers have had very little science put into them, they are unlikely
37 # to be optimal
38 if cardinality < 0.05:
39 return 5
40 if cardinality > 0.9:
41 return INTERNAL_BATCH_SIZE
42 return INTERNAL_BATCH_SIZE * cardinality
43
44
45 class JoinNode(BasePlanNode):
46 def __init__(self, properties: QueryProperties, **config):
47 super().__init__(properties=properties)
48 self._join_type = config["type"]
49 self._on = config.get("on")
50 self._using = config.get("using")
51
52 self._left_columns = config.get("left_columns")
53 self._left_relation = config.get("left_relation_names")
54
55 self._right_columns = config.get("right_columns")
56 self._right_relation = config.get("right_relation_names")
57
58 @property
59 def name(self): # pragma: no cover
60 return f"{self._join_type} Join"
61
62 @property
63 def config(self): # pragma: no cover
64 return ""
65
66 def execute(self) -> Iterable:
67 left_node = self._producers[0] # type:ignore
68 right_node = self._producers[1] # type:ignore
69
70 right_table = pyarrow.concat_tables(right_node.execute(), mode="default")
71
72 for morsel in left_node.execute():
73 # in place until #1295 resolved
74 if not self._right_columns[0] in morsel.column_names:
75 self._right_columns, self._left_columns = self._left_columns, self._right_columns
76
77 try:
78 # do the join
79 new_morsel = morsel.join(
80 right_table,
81 keys=self._right_columns,
82 right_keys=self._left_columns,
83 join_type=self._join_type,
84 coalesce_keys=self._using is not None,
85 )
86 except pyarrow.ArrowInvalid as err:
87 last_token = str(err).split(" ")[-1]
88 column = None
89 for col in left_node.columns:
90 if last_token == col.identity:
91 column = col.name
92 break
93 for col in right_node.columns:
94 if last_token == col.identity:
95 column = col.name
96 break
97 if column:
98 raise pyarrow.ArrowInvalid(err.replace(last_token, column))
99 raise err
100
101 # need to ensure we put the right column back if we need it
102 if (
103 self._join_type in ("right anti", "right semi")
104 and new_morsel.column_names != right_table.column_names
105 ):
106 columns = [
107 col
108 if col not in self._left_columns
109 else self._right_columns[self._left_columns.index(col)]
110 for col in new_morsel.column_names
111 ]
112 new_morsel = new_morsel.rename_columns(columns)
113
114 yield new_morsel
115
```
Path: `opteryx/__version__.py`
Content:
```
1 __build__ = 134
2 # Licensed under the Apache License, Version 2.0 (the "License");
3 # you may not use this file except in compliance with the License.
4 # You may obtain a copy of the License at
5 #
6 # http://www.apache.org/licenses/LICENSE-2.0
7 #
8 # Unless required by applicable law or agreed to in writing, software
9 # distributed under the License is distributed on an "AS IS" BASIS,
10 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
11 # See the License for the specific language governing permissions and
12 # limitations under the License.
13
14 """
15 Store the version here so:
16 1) we don't load dependencies by storing it in __init__.py
17 2) we can import it in setup.py for the same reason
18 """
19 from enum import Enum # isort: skip
20
21
22 class VersionStatus(Enum):
23 ALPHA = "alpha"
24 BETA = "beta"
25 RELEASE = "release"
26
27
28 _major = 0
29 _minor = 12
30 _revision = 0
31 _status = VersionStatus.BETA
32
33 __version__ = f"{_major}.{_minor}.{_revision}" + (
34 f"-{_status.value}.{__build__}" if _status != VersionStatus.RELEASE else ""
35 )
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/opteryx/__version__.py b/opteryx/__version__.py
--- a/opteryx/__version__.py
+++ b/opteryx/__version__.py
@@ -1,4 +1,4 @@
-__build__ = 134
+__build__ = 136
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
diff --git a/opteryx/operators/join_node.py b/opteryx/operators/join_node.py
--- a/opteryx/operators/join_node.py
+++ b/opteryx/operators/join_node.py
@@ -95,7 +95,7 @@
column = col.name
break
if column:
- raise pyarrow.ArrowInvalid(err.replace(last_token, column))
+ raise pyarrow.ArrowInvalid(str(err).replace(last_token, f"'{column}'"))
raise err
# need to ensure we put the right column back if we need it
diff --git a/opteryx/third_party/pyarrow_ops/ops.py b/opteryx/third_party/pyarrow_ops/ops.py
--- a/opteryx/third_party/pyarrow_ops/ops.py
+++ b/opteryx/third_party/pyarrow_ops/ops.py
@@ -137,12 +137,12 @@
# MODIFIED FOR OPTERYX - see comment above
matches = compute.match_like(arr, value[0], ignore_case=True) # [#325]
return numpy.invert(matches)
- if operator in ("PGRegexMatch", "SimilarTo"):
+ if operator in ("PGRegexMatch", "SimilarTo", "RLike"):
# MODIFIED FOR OPTERYX - see comment above
return (
compute.match_substring_regex(arr, value[0]).to_numpy(False).astype(dtype=bool)
) # [#325]
- if operator in ("PGRegexNotMatch", "NotSimilarTo"):
+ if operator in ("PGRegexNotMatch", "NotSimilarTo", "NotRLike"):
# MODIFIED FOR OPTERYX - see comment above
matches = compute.match_substring_regex(arr, value[0]) # [#325]
return numpy.invert(matches)
|
{"golden_diff": "diff --git a/opteryx/__version__.py b/opteryx/__version__.py\n--- a/opteryx/__version__.py\n+++ b/opteryx/__version__.py\n@@ -1,4 +1,4 @@\n-__build__ = 134\n+__build__ = 136\n # Licensed under the Apache License, Version 2.0 (the \"License\");\n # you may not use this file except in compliance with the License.\n # You may obtain a copy of the License at\ndiff --git a/opteryx/operators/join_node.py b/opteryx/operators/join_node.py\n--- a/opteryx/operators/join_node.py\n+++ b/opteryx/operators/join_node.py\n@@ -95,7 +95,7 @@\n column = col.name\n break\n if column:\n- raise pyarrow.ArrowInvalid(err.replace(last_token, column))\n+ raise pyarrow.ArrowInvalid(str(err).replace(last_token, f\"'{column}'\"))\n raise err\n \n # need to ensure we put the right column back if we need it\ndiff --git a/opteryx/third_party/pyarrow_ops/ops.py b/opteryx/third_party/pyarrow_ops/ops.py\n--- a/opteryx/third_party/pyarrow_ops/ops.py\n+++ b/opteryx/third_party/pyarrow_ops/ops.py\n@@ -137,12 +137,12 @@\n # MODIFIED FOR OPTERYX - see comment above\n matches = compute.match_like(arr, value[0], ignore_case=True) # [#325]\n return numpy.invert(matches)\n- if operator in (\"PGRegexMatch\", \"SimilarTo\"):\n+ if operator in (\"PGRegexMatch\", \"SimilarTo\", \"RLike\"):\n # MODIFIED FOR OPTERYX - see comment above\n return (\n compute.match_substring_regex(arr, value[0]).to_numpy(False).astype(dtype=bool)\n ) # [#325]\n- if operator in (\"PGRegexNotMatch\", \"NotSimilarTo\"):\n+ if operator in (\"PGRegexNotMatch\", \"NotSimilarTo\", \"NotRLike\"):\n # MODIFIED FOR OPTERYX - see comment above\n matches = compute.match_substring_regex(arr, value[0]) # [#325]\n return numpy.invert(matches)\n", "issue": "\u2728 Support `RLIKE`\nhttps://github.com/sqlparser-rs/sqlparser-rs/pull/1017/files\r\n\r\n~~~sql\r\nSELECT 'a' RLIKE '.'\r\n~~~\n", "before_files": [{"content": "\"\"\"\nOriginal code modified for Opteryx.\n\"\"\"\nimport numpy\nimport pyarrow\nfrom pyarrow import compute\n\nfrom opteryx.third_party.pyarrow_ops.helpers import columns_to_array\n\n# Added for Opteryx, comparisons in filter_operators updated to match\n# this set is from sqloxide\nFILTER_OPERATORS = {\n \"Eq\",\n \"NotEq\",\n \"Gt\",\n \"GtEq\",\n \"Lt\",\n \"LtEq\",\n \"Like\",\n \"ILike\",\n \"NotLike\",\n \"NotILike\",\n \"InList\",\n \"SimilarTo\",\n \"NotSimilarTo\",\n \"PGRegexMatch\",\n \"NotPGRegexMatch\",\n \"PGRegexNotMatch\",\n \"PGRegexIMatch\", # \"~*\"\n \"NotPGRegexIMatch\", # \"!~*\"\n \"PGRegexNotIMatch\", # \"!~*\"\n \"BitwiseOr\", # |\n}\n\n\ndef filter_operations(arr, operator, value):\n \"\"\"\n Wrapped for Opteryx added to correctly handle null semantics.\n\n This returns an array with tri-state boolean (tue/false/none);\n if being used for display use as is, if being used for filtering, none is false.\n \"\"\"\n\n # if the input is a table, get the first column\n if isinstance(value, pyarrow.Table): # pragma: no cover\n value = [value.columns[0].to_numpy()]\n\n # work out which rows we're going to actually evaluate\n # we're working out if either array has a null value so we can exclude them\n # from the actual evaluation.\n # True = values, False = null\n record_count = len(arr)\n null_arr = compute.is_null(arr, nan_is_null=True)\n null_val = compute.is_null(value, nan_is_null=True)\n null_positions = numpy.logical_or(null_arr, null_val)\n\n # if there's no non-null values, stop here\n if all(null_positions):\n return numpy.full(record_count, None)\n\n any_null = any(null_positions)\n null_positions = numpy.invert(null_positions)\n\n compressed = False\n if any_null and isinstance(arr, numpy.ndarray) and isinstance(value, numpy.ndarray):\n # if we have nulls and both columns are numpy arrays, we can speed things\n # up by removing the nulls from the calculations, we add the rows back in\n # later\n arr = arr.compress(null_positions)\n value = value.compress(null_positions)\n compressed = True\n\n # do the evaluation\n results_mask = _inner_filter_operations(arr, operator, value)\n\n if compressed:\n # fill the result set\n results = numpy.full(record_count, -1, numpy.int8)\n results[numpy.nonzero(null_positions)] = results_mask\n # build tri-state response, PyArrow supports tristate, numpy does not\n return pyarrow.array((bool(r) if r != -1 else None for r in results), type=pyarrow.bool_())\n\n return results_mask\n\n\n# Filter functionality\ndef _inner_filter_operations(arr, operator, value):\n \"\"\"\n Execute filter operations, this returns an array of the indexes of the rows that\n match the filter\n \"\"\"\n # ADDED FOR OPTERYX\n\n if operator == \"Eq\":\n return compute.equal(arr, value).to_numpy(False).astype(dtype=bool)\n if operator == \"NotEq\":\n return compute.not_equal(arr, value).to_numpy(False).astype(dtype=bool)\n if operator == \"Lt\":\n return compute.less(arr, value).to_numpy(False).astype(dtype=bool)\n if operator == \"Gt\":\n return compute.greater(arr, value).to_numpy(False).astype(dtype=bool)\n if operator == \"LtEq\":\n return compute.less_equal(arr, value).to_numpy(False).astype(dtype=bool)\n if operator == \"GtEq\":\n return compute.greater_equal(arr, value).to_numpy(False).astype(dtype=bool)\n if operator == \"InList\":\n # MODIFIED FOR OPTERYX\n # some of the lists are saved as sets, which are faster than searching numpy\n # arrays, even with numpy's native functionality - choosing the right algo\n # is almost always faster than choosing a fast language.\n return numpy.array([a in value[0] for a in arr], dtype=numpy.bool_) # [#325]?\n if operator == \"NotInList\":\n # MODIFIED FOR OPTERYX - see comment above\n return numpy.array([a not in value[0] for a in arr], dtype=numpy.bool_) # [#325]?\n if operator == \"Contains\":\n # ADDED FOR OPTERYX\n return numpy.array([None if v is None else (arr[0] in v) for v in value], dtype=numpy.bool_)\n if operator == \"NotContains\":\n # ADDED FOR OPTERYX\n return numpy.array(\n [None if v is None else (arr[0] not in v) for v in value], dtype=numpy.bool_\n ) # [#325]?\n if operator == \"Like\":\n # MODIFIED FOR OPTERYX\n # null input emits null output, which should be false/0\n return compute.match_like(arr, value[0]).to_numpy(False).astype(dtype=bool) # [#325]\n if operator == \"NotLike\":\n # MODIFIED FOR OPTERYX - see comment above\n matches = compute.match_like(arr, value[0]).to_numpy(False).astype(dtype=bool) # [#325]\n return numpy.invert(matches)\n if operator == \"ILike\":\n # MODIFIED FOR OPTERYX - see comment above\n return (\n compute.match_like(arr, value[0], ignore_case=True).to_numpy(False).astype(dtype=bool)\n ) # [#325]\n if operator == \"NotILike\":\n # MODIFIED FOR OPTERYX - see comment above\n matches = compute.match_like(arr, value[0], ignore_case=True) # [#325]\n return numpy.invert(matches)\n if operator in (\"PGRegexMatch\", \"SimilarTo\"):\n # MODIFIED FOR OPTERYX - see comment above\n return (\n compute.match_substring_regex(arr, value[0]).to_numpy(False).astype(dtype=bool)\n ) # [#325]\n if operator in (\"PGRegexNotMatch\", \"NotSimilarTo\"):\n # MODIFIED FOR OPTERYX - see comment above\n matches = compute.match_substring_regex(arr, value[0]) # [#325]\n return numpy.invert(matches)\n if operator == \"PGRegexIMatch\":\n # MODIFIED FOR OPTERYX - see comment above\n return (\n compute.match_substring_regex(arr, value[0], ignore_case=True)\n .to_numpy(False)\n .astype(dtype=bool)\n ) # [#325]\n if operator == \"PGRegexNotIMatch\":\n # MODIFIED FOR OPTERYX - see comment above\n matches = compute.match_substring_regex(arr, value[0], ignore_case=True) # [#325]\n return numpy.invert(matches)\n\n raise NotImplementedError(f\"Operator {operator} is not implemented!\") # pragma: no cover\n\n\n# Drop duplicates\ndef drop_duplicates(table, columns=None):\n \"\"\"\n drops duplicates, keeps the first of the set\n\n MODIFIED FOR OPTERYX\n \"\"\"\n # Gather columns to arr\n arr = columns_to_array(table, (columns if columns else table.column_names))\n values, indices = numpy.unique(arr, return_index=True)\n del values\n return table.take(indices)\n", "path": "opteryx/third_party/pyarrow_ops/ops.py"}, {"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nJoin Node\n\nThis is a SQL Query Execution Plan Node.\n\nThis handles most of the join types as a wrapper for pyarrow's JOIN functions, \nonly CROSS JOINs are not handled here.\n\"\"\"\nfrom typing import Iterable\n\nimport pyarrow\n\nfrom opteryx.models import QueryProperties\nfrom opteryx.operators import BasePlanNode\n\nINTERNAL_BATCH_SIZE = 500 # config\n\n\ndef calculate_batch_size(cardinality):\n \"\"\"dynamically work out the processing batch size for the USING JOIN\"\"\"\n # - HIGH_CARDINALITY_BATCH_SIZE (over 90% unique) = INTERNAL_BATCH_SIZE\n # - MEDIUM_CARDINALITY_BATCH_SIZE (5% > n < 90%) = INTERNAL_BATCH_SIZE * n\n # - LOW_CARDINALITY_BATCH_SIZE (less than 5% unique) = 5\n # These numbers have had very little science put into them, they are unlikely\n # to be optimal\n if cardinality < 0.05:\n return 5\n if cardinality > 0.9:\n return INTERNAL_BATCH_SIZE\n return INTERNAL_BATCH_SIZE * cardinality\n\n\nclass JoinNode(BasePlanNode):\n def __init__(self, properties: QueryProperties, **config):\n super().__init__(properties=properties)\n self._join_type = config[\"type\"]\n self._on = config.get(\"on\")\n self._using = config.get(\"using\")\n\n self._left_columns = config.get(\"left_columns\")\n self._left_relation = config.get(\"left_relation_names\")\n\n self._right_columns = config.get(\"right_columns\")\n self._right_relation = config.get(\"right_relation_names\")\n\n @property\n def name(self): # pragma: no cover\n return f\"{self._join_type} Join\"\n\n @property\n def config(self): # pragma: no cover\n return \"\"\n\n def execute(self) -> Iterable:\n left_node = self._producers[0] # type:ignore\n right_node = self._producers[1] # type:ignore\n\n right_table = pyarrow.concat_tables(right_node.execute(), mode=\"default\")\n\n for morsel in left_node.execute():\n # in place until #1295 resolved\n if not self._right_columns[0] in morsel.column_names:\n self._right_columns, self._left_columns = self._left_columns, self._right_columns\n\n try:\n # do the join\n new_morsel = morsel.join(\n right_table,\n keys=self._right_columns,\n right_keys=self._left_columns,\n join_type=self._join_type,\n coalesce_keys=self._using is not None,\n )\n except pyarrow.ArrowInvalid as err:\n last_token = str(err).split(\" \")[-1]\n column = None\n for col in left_node.columns:\n if last_token == col.identity:\n column = col.name\n break\n for col in right_node.columns:\n if last_token == col.identity:\n column = col.name\n break\n if column:\n raise pyarrow.ArrowInvalid(err.replace(last_token, column))\n raise err\n\n # need to ensure we put the right column back if we need it\n if (\n self._join_type in (\"right anti\", \"right semi\")\n and new_morsel.column_names != right_table.column_names\n ):\n columns = [\n col\n if col not in self._left_columns\n else self._right_columns[self._left_columns.index(col)]\n for col in new_morsel.column_names\n ]\n new_morsel = new_morsel.rename_columns(columns)\n\n yield new_morsel\n", "path": "opteryx/operators/join_node.py"}, {"content": "__build__ = 134\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nStore the version here so:\n1) we don't load dependencies by storing it in __init__.py\n2) we can import it in setup.py for the same reason\n\"\"\"\nfrom enum import Enum # isort: skip\n\n\nclass VersionStatus(Enum):\n ALPHA = \"alpha\"\n BETA = \"beta\"\n RELEASE = \"release\"\n\n\n_major = 0\n_minor = 12\n_revision = 0\n_status = VersionStatus.BETA\n\n__version__ = f\"{_major}.{_minor}.{_revision}\" + (\n f\"-{_status.value}.{__build__}\" if _status != VersionStatus.RELEASE else \"\"\n)", "path": "opteryx/__version__.py"}], "after_files": [{"content": "\"\"\"\nOriginal code modified for Opteryx.\n\"\"\"\nimport numpy\nimport pyarrow\nfrom pyarrow import compute\n\nfrom opteryx.third_party.pyarrow_ops.helpers import columns_to_array\n\n# Added for Opteryx, comparisons in filter_operators updated to match\n# this set is from sqloxide\nFILTER_OPERATORS = {\n \"Eq\",\n \"NotEq\",\n \"Gt\",\n \"GtEq\",\n \"Lt\",\n \"LtEq\",\n \"Like\",\n \"ILike\",\n \"NotLike\",\n \"NotILike\",\n \"InList\",\n \"SimilarTo\",\n \"NotSimilarTo\",\n \"PGRegexMatch\",\n \"NotPGRegexMatch\",\n \"PGRegexNotMatch\",\n \"PGRegexIMatch\", # \"~*\"\n \"NotPGRegexIMatch\", # \"!~*\"\n \"PGRegexNotIMatch\", # \"!~*\"\n \"BitwiseOr\", # |\n}\n\n\ndef filter_operations(arr, operator, value):\n \"\"\"\n Wrapped for Opteryx added to correctly handle null semantics.\n\n This returns an array with tri-state boolean (tue/false/none);\n if being used for display use as is, if being used for filtering, none is false.\n \"\"\"\n\n # if the input is a table, get the first column\n if isinstance(value, pyarrow.Table): # pragma: no cover\n value = [value.columns[0].to_numpy()]\n\n # work out which rows we're going to actually evaluate\n # we're working out if either array has a null value so we can exclude them\n # from the actual evaluation.\n # True = values, False = null\n record_count = len(arr)\n null_arr = compute.is_null(arr, nan_is_null=True)\n null_val = compute.is_null(value, nan_is_null=True)\n null_positions = numpy.logical_or(null_arr, null_val)\n\n # if there's no non-null values, stop here\n if all(null_positions):\n return numpy.full(record_count, None)\n\n any_null = any(null_positions)\n null_positions = numpy.invert(null_positions)\n\n compressed = False\n if any_null and isinstance(arr, numpy.ndarray) and isinstance(value, numpy.ndarray):\n # if we have nulls and both columns are numpy arrays, we can speed things\n # up by removing the nulls from the calculations, we add the rows back in\n # later\n arr = arr.compress(null_positions)\n value = value.compress(null_positions)\n compressed = True\n\n # do the evaluation\n results_mask = _inner_filter_operations(arr, operator, value)\n\n if compressed:\n # fill the result set\n results = numpy.full(record_count, -1, numpy.int8)\n results[numpy.nonzero(null_positions)] = results_mask\n # build tri-state response, PyArrow supports tristate, numpy does not\n return pyarrow.array((bool(r) if r != -1 else None for r in results), type=pyarrow.bool_())\n\n return results_mask\n\n\n# Filter functionality\ndef _inner_filter_operations(arr, operator, value):\n \"\"\"\n Execute filter operations, this returns an array of the indexes of the rows that\n match the filter\n \"\"\"\n # ADDED FOR OPTERYX\n\n if operator == \"Eq\":\n return compute.equal(arr, value).to_numpy(False).astype(dtype=bool)\n if operator == \"NotEq\":\n return compute.not_equal(arr, value).to_numpy(False).astype(dtype=bool)\n if operator == \"Lt\":\n return compute.less(arr, value).to_numpy(False).astype(dtype=bool)\n if operator == \"Gt\":\n return compute.greater(arr, value).to_numpy(False).astype(dtype=bool)\n if operator == \"LtEq\":\n return compute.less_equal(arr, value).to_numpy(False).astype(dtype=bool)\n if operator == \"GtEq\":\n return compute.greater_equal(arr, value).to_numpy(False).astype(dtype=bool)\n if operator == \"InList\":\n # MODIFIED FOR OPTERYX\n # some of the lists are saved as sets, which are faster than searching numpy\n # arrays, even with numpy's native functionality - choosing the right algo\n # is almost always faster than choosing a fast language.\n return numpy.array([a in value[0] for a in arr], dtype=numpy.bool_) # [#325]?\n if operator == \"NotInList\":\n # MODIFIED FOR OPTERYX - see comment above\n return numpy.array([a not in value[0] for a in arr], dtype=numpy.bool_) # [#325]?\n if operator == \"Contains\":\n # ADDED FOR OPTERYX\n return numpy.array([None if v is None else (arr[0] in v) for v in value], dtype=numpy.bool_)\n if operator == \"NotContains\":\n # ADDED FOR OPTERYX\n return numpy.array(\n [None if v is None else (arr[0] not in v) for v in value], dtype=numpy.bool_\n ) # [#325]?\n if operator == \"Like\":\n # MODIFIED FOR OPTERYX\n # null input emits null output, which should be false/0\n return compute.match_like(arr, value[0]).to_numpy(False).astype(dtype=bool) # [#325]\n if operator == \"NotLike\":\n # MODIFIED FOR OPTERYX - see comment above\n matches = compute.match_like(arr, value[0]).to_numpy(False).astype(dtype=bool) # [#325]\n return numpy.invert(matches)\n if operator == \"ILike\":\n # MODIFIED FOR OPTERYX - see comment above\n return (\n compute.match_like(arr, value[0], ignore_case=True).to_numpy(False).astype(dtype=bool)\n ) # [#325]\n if operator == \"NotILike\":\n # MODIFIED FOR OPTERYX - see comment above\n matches = compute.match_like(arr, value[0], ignore_case=True) # [#325]\n return numpy.invert(matches)\n if operator in (\"PGRegexMatch\", \"SimilarTo\", \"RLike\"):\n # MODIFIED FOR OPTERYX - see comment above\n return (\n compute.match_substring_regex(arr, value[0]).to_numpy(False).astype(dtype=bool)\n ) # [#325]\n if operator in (\"PGRegexNotMatch\", \"NotSimilarTo\", \"NotRLike\"):\n # MODIFIED FOR OPTERYX - see comment above\n matches = compute.match_substring_regex(arr, value[0]) # [#325]\n return numpy.invert(matches)\n if operator == \"PGRegexIMatch\":\n # MODIFIED FOR OPTERYX - see comment above\n return (\n compute.match_substring_regex(arr, value[0], ignore_case=True)\n .to_numpy(False)\n .astype(dtype=bool)\n ) # [#325]\n if operator == \"PGRegexNotIMatch\":\n # MODIFIED FOR OPTERYX - see comment above\n matches = compute.match_substring_regex(arr, value[0], ignore_case=True) # [#325]\n return numpy.invert(matches)\n\n raise NotImplementedError(f\"Operator {operator} is not implemented!\") # pragma: no cover\n\n\n# Drop duplicates\ndef drop_duplicates(table, columns=None):\n \"\"\"\n drops duplicates, keeps the first of the set\n\n MODIFIED FOR OPTERYX\n \"\"\"\n # Gather columns to arr\n arr = columns_to_array(table, (columns if columns else table.column_names))\n values, indices = numpy.unique(arr, return_index=True)\n del values\n return table.take(indices)\n", "path": "opteryx/third_party/pyarrow_ops/ops.py"}, {"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nJoin Node\n\nThis is a SQL Query Execution Plan Node.\n\nThis handles most of the join types as a wrapper for pyarrow's JOIN functions, \nonly CROSS JOINs are not handled here.\n\"\"\"\nfrom typing import Iterable\n\nimport pyarrow\n\nfrom opteryx.models import QueryProperties\nfrom opteryx.operators import BasePlanNode\n\nINTERNAL_BATCH_SIZE = 500 # config\n\n\ndef calculate_batch_size(cardinality):\n \"\"\"dynamically work out the processing batch size for the USING JOIN\"\"\"\n # - HIGH_CARDINALITY_BATCH_SIZE (over 90% unique) = INTERNAL_BATCH_SIZE\n # - MEDIUM_CARDINALITY_BATCH_SIZE (5% > n < 90%) = INTERNAL_BATCH_SIZE * n\n # - LOW_CARDINALITY_BATCH_SIZE (less than 5% unique) = 5\n # These numbers have had very little science put into them, they are unlikely\n # to be optimal\n if cardinality < 0.05:\n return 5\n if cardinality > 0.9:\n return INTERNAL_BATCH_SIZE\n return INTERNAL_BATCH_SIZE * cardinality\n\n\nclass JoinNode(BasePlanNode):\n def __init__(self, properties: QueryProperties, **config):\n super().__init__(properties=properties)\n self._join_type = config[\"type\"]\n self._on = config.get(\"on\")\n self._using = config.get(\"using\")\n\n self._left_columns = config.get(\"left_columns\")\n self._left_relation = config.get(\"left_relation_names\")\n\n self._right_columns = config.get(\"right_columns\")\n self._right_relation = config.get(\"right_relation_names\")\n\n @property\n def name(self): # pragma: no cover\n return f\"{self._join_type} Join\"\n\n @property\n def config(self): # pragma: no cover\n return \"\"\n\n def execute(self) -> Iterable:\n left_node = self._producers[0] # type:ignore\n right_node = self._producers[1] # type:ignore\n\n right_table = pyarrow.concat_tables(right_node.execute(), mode=\"default\")\n\n for morsel in left_node.execute():\n # in place until #1295 resolved\n if not self._right_columns[0] in morsel.column_names:\n self._right_columns, self._left_columns = self._left_columns, self._right_columns\n\n try:\n # do the join\n new_morsel = morsel.join(\n right_table,\n keys=self._right_columns,\n right_keys=self._left_columns,\n join_type=self._join_type,\n coalesce_keys=self._using is not None,\n )\n except pyarrow.ArrowInvalid as err:\n last_token = str(err).split(\" \")[-1]\n column = None\n for col in left_node.columns:\n if last_token == col.identity:\n column = col.name\n break\n for col in right_node.columns:\n if last_token == col.identity:\n column = col.name\n break\n if column:\n raise pyarrow.ArrowInvalid(str(err).replace(last_token, f\"'{column}'\"))\n raise err\n\n # need to ensure we put the right column back if we need it\n if (\n self._join_type in (\"right anti\", \"right semi\")\n and new_morsel.column_names != right_table.column_names\n ):\n columns = [\n col\n if col not in self._left_columns\n else self._right_columns[self._left_columns.index(col)]\n for col in new_morsel.column_names\n ]\n new_morsel = new_morsel.rename_columns(columns)\n\n yield new_morsel\n", "path": "opteryx/operators/join_node.py"}, {"content": "__build__ = 136\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nStore the version here so:\n1) we don't load dependencies by storing it in __init__.py\n2) we can import it in setup.py for the same reason\n\"\"\"\nfrom enum import Enum # isort: skip\n\n\nclass VersionStatus(Enum):\n ALPHA = \"alpha\"\n BETA = \"beta\"\n RELEASE = \"release\"\n\n\n_major = 0\n_minor = 12\n_revision = 0\n_status = VersionStatus.BETA\n\n__version__ = f\"{_major}.{_minor}.{_revision}\" + (\n f\"-{_status.value}.{__build__}\" if _status != VersionStatus.RELEASE else \"\"\n)", "path": "opteryx/__version__.py"}]}
| 3,930 | 511 |
gh_patches_debug_4907
|
rasdani/github-patches
|
git_diff
|
Mailu__Mailu-1487
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
We need to check the (persistent) postfix mailqueue permissions
As the postfix and postdrop uid/gid might change (especially with a change of base image), it is needed to check the directory permissions on /queue before starting postfix
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/postfix/start.py`
Content:
```
1 #!/usr/bin/python3
2
3 import os
4 import glob
5 import shutil
6 import multiprocessing
7 import logging as log
8 import sys
9
10 from podop import run_server
11 from socrate import system, conf
12
13 log.basicConfig(stream=sys.stderr, level=os.environ.get("LOG_LEVEL", "WARNING"))
14
15 def start_podop():
16 os.setuid(100)
17 url = "http://" + os.environ["ADMIN_ADDRESS"] + "/internal/postfix/"
18 # TODO: Remove verbosity setting from Podop?
19 run_server(0, "postfix", "/tmp/podop.socket", [
20 ("transport", "url", url + "transport/§"),
21 ("alias", "url", url + "alias/§"),
22 ("domain", "url", url + "domain/§"),
23 ("mailbox", "url", url + "mailbox/§"),
24 ("recipientmap", "url", url + "recipient/map/§"),
25 ("sendermap", "url", url + "sender/map/§"),
26 ("senderaccess", "url", url + "sender/access/§"),
27 ("senderlogin", "url", url + "sender/login/§")
28 ])
29
30 def is_valid_postconf_line(line):
31 return not line.startswith("#") \
32 and not line == ''
33
34 # Actual startup script
35 os.environ["FRONT_ADDRESS"] = system.get_host_address_from_environment("FRONT", "front")
36 os.environ["ADMIN_ADDRESS"] = system.get_host_address_from_environment("ADMIN", "admin")
37 os.environ["ANTISPAM_MILTER_ADDRESS"] = system.get_host_address_from_environment("ANTISPAM_MILTER", "antispam:11332")
38 os.environ["LMTP_ADDRESS"] = system.get_host_address_from_environment("LMTP", "imap:2525")
39
40 for postfix_file in glob.glob("/conf/*.cf"):
41 conf.jinja(postfix_file, os.environ, os.path.join("/etc/postfix", os.path.basename(postfix_file)))
42
43 if os.path.exists("/overrides/postfix.cf"):
44 for line in open("/overrides/postfix.cf").read().strip().split("\n"):
45 if is_valid_postconf_line(line):
46 os.system('postconf -e "{}"'.format(line))
47
48 if os.path.exists("/overrides/postfix.master"):
49 for line in open("/overrides/postfix.master").read().strip().split("\n"):
50 if is_valid_postconf_line(line):
51 os.system('postconf -Me "{}"'.format(line))
52
53 for map_file in glob.glob("/overrides/*.map"):
54 destination = os.path.join("/etc/postfix", os.path.basename(map_file))
55 shutil.copyfile(map_file, destination)
56 os.system("postmap {}".format(destination))
57 os.remove(destination)
58
59 if "RELAYUSER" in os.environ:
60 path = "/etc/postfix/sasl_passwd"
61 conf.jinja("/conf/sasl_passwd", os.environ, path)
62 os.system("postmap {}".format(path))
63
64 # Run Podop and Postfix
65 multiprocessing.Process(target=start_podop).start()
66 os.system("/usr/libexec/postfix/post-install meta_directory=/etc/postfix create-missing")
67 os.system("postfix start-fg")
68
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/core/postfix/start.py b/core/postfix/start.py
--- a/core/postfix/start.py
+++ b/core/postfix/start.py
@@ -64,4 +64,7 @@
# Run Podop and Postfix
multiprocessing.Process(target=start_podop).start()
os.system("/usr/libexec/postfix/post-install meta_directory=/etc/postfix create-missing")
+# Before starting postfix, we need to check permissions on /queue
+# in the event that postfix,postdrop id have changed
+os.system("postfix set-permissions")
os.system("postfix start-fg")
|
{"golden_diff": "diff --git a/core/postfix/start.py b/core/postfix/start.py\n--- a/core/postfix/start.py\n+++ b/core/postfix/start.py\n@@ -64,4 +64,7 @@\n # Run Podop and Postfix\n multiprocessing.Process(target=start_podop).start()\n os.system(\"/usr/libexec/postfix/post-install meta_directory=/etc/postfix create-missing\")\n+# Before starting postfix, we need to check permissions on /queue\n+# in the event that postfix,postdrop id have changed\n+os.system(\"postfix set-permissions\")\n os.system(\"postfix start-fg\")\n", "issue": "We need to check the (persistent) postfix mailqueue permissions\nAs the postfix and postdrop uid/gid might change (especially with a change of base image), it is needed to check the directory permissions on /queue before starting postfix\n", "before_files": [{"content": "#!/usr/bin/python3\n\nimport os\nimport glob\nimport shutil\nimport multiprocessing\nimport logging as log\nimport sys\n\nfrom podop import run_server\nfrom socrate import system, conf\n\nlog.basicConfig(stream=sys.stderr, level=os.environ.get(\"LOG_LEVEL\", \"WARNING\"))\n\ndef start_podop():\n os.setuid(100)\n url = \"http://\" + os.environ[\"ADMIN_ADDRESS\"] + \"/internal/postfix/\"\n # TODO: Remove verbosity setting from Podop?\n run_server(0, \"postfix\", \"/tmp/podop.socket\", [\n\t\t(\"transport\", \"url\", url + \"transport/\u00a7\"),\n\t\t(\"alias\", \"url\", url + \"alias/\u00a7\"),\n\t\t(\"domain\", \"url\", url + \"domain/\u00a7\"),\n (\"mailbox\", \"url\", url + \"mailbox/\u00a7\"),\n (\"recipientmap\", \"url\", url + \"recipient/map/\u00a7\"),\n (\"sendermap\", \"url\", url + \"sender/map/\u00a7\"),\n (\"senderaccess\", \"url\", url + \"sender/access/\u00a7\"),\n (\"senderlogin\", \"url\", url + \"sender/login/\u00a7\")\n ])\n\ndef is_valid_postconf_line(line):\n return not line.startswith(\"#\") \\\n and not line == ''\n\n# Actual startup script\nos.environ[\"FRONT_ADDRESS\"] = system.get_host_address_from_environment(\"FRONT\", \"front\")\nos.environ[\"ADMIN_ADDRESS\"] = system.get_host_address_from_environment(\"ADMIN\", \"admin\")\nos.environ[\"ANTISPAM_MILTER_ADDRESS\"] = system.get_host_address_from_environment(\"ANTISPAM_MILTER\", \"antispam:11332\")\nos.environ[\"LMTP_ADDRESS\"] = system.get_host_address_from_environment(\"LMTP\", \"imap:2525\")\n\nfor postfix_file in glob.glob(\"/conf/*.cf\"):\n conf.jinja(postfix_file, os.environ, os.path.join(\"/etc/postfix\", os.path.basename(postfix_file)))\n\nif os.path.exists(\"/overrides/postfix.cf\"):\n for line in open(\"/overrides/postfix.cf\").read().strip().split(\"\\n\"):\n if is_valid_postconf_line(line):\n os.system('postconf -e \"{}\"'.format(line))\n\nif os.path.exists(\"/overrides/postfix.master\"):\n for line in open(\"/overrides/postfix.master\").read().strip().split(\"\\n\"):\n if is_valid_postconf_line(line):\n os.system('postconf -Me \"{}\"'.format(line))\n\nfor map_file in glob.glob(\"/overrides/*.map\"):\n destination = os.path.join(\"/etc/postfix\", os.path.basename(map_file))\n shutil.copyfile(map_file, destination)\n os.system(\"postmap {}\".format(destination))\n os.remove(destination)\n\nif \"RELAYUSER\" in os.environ:\n path = \"/etc/postfix/sasl_passwd\"\n conf.jinja(\"/conf/sasl_passwd\", os.environ, path)\n os.system(\"postmap {}\".format(path))\n\n# Run Podop and Postfix\nmultiprocessing.Process(target=start_podop).start()\nos.system(\"/usr/libexec/postfix/post-install meta_directory=/etc/postfix create-missing\")\nos.system(\"postfix start-fg\")\n", "path": "core/postfix/start.py"}], "after_files": [{"content": "#!/usr/bin/python3\n\nimport os\nimport glob\nimport shutil\nimport multiprocessing\nimport logging as log\nimport sys\n\nfrom podop import run_server\nfrom socrate import system, conf\n\nlog.basicConfig(stream=sys.stderr, level=os.environ.get(\"LOG_LEVEL\", \"WARNING\"))\n\ndef start_podop():\n os.setuid(100)\n url = \"http://\" + os.environ[\"ADMIN_ADDRESS\"] + \"/internal/postfix/\"\n # TODO: Remove verbosity setting from Podop?\n run_server(0, \"postfix\", \"/tmp/podop.socket\", [\n\t\t(\"transport\", \"url\", url + \"transport/\u00a7\"),\n\t\t(\"alias\", \"url\", url + \"alias/\u00a7\"),\n\t\t(\"domain\", \"url\", url + \"domain/\u00a7\"),\n (\"mailbox\", \"url\", url + \"mailbox/\u00a7\"),\n (\"recipientmap\", \"url\", url + \"recipient/map/\u00a7\"),\n (\"sendermap\", \"url\", url + \"sender/map/\u00a7\"),\n (\"senderaccess\", \"url\", url + \"sender/access/\u00a7\"),\n (\"senderlogin\", \"url\", url + \"sender/login/\u00a7\")\n ])\n\ndef is_valid_postconf_line(line):\n return not line.startswith(\"#\") \\\n and not line == ''\n\n# Actual startup script\nos.environ[\"FRONT_ADDRESS\"] = system.get_host_address_from_environment(\"FRONT\", \"front\")\nos.environ[\"ADMIN_ADDRESS\"] = system.get_host_address_from_environment(\"ADMIN\", \"admin\")\nos.environ[\"ANTISPAM_MILTER_ADDRESS\"] = system.get_host_address_from_environment(\"ANTISPAM_MILTER\", \"antispam:11332\")\nos.environ[\"LMTP_ADDRESS\"] = system.get_host_address_from_environment(\"LMTP\", \"imap:2525\")\n\nfor postfix_file in glob.glob(\"/conf/*.cf\"):\n conf.jinja(postfix_file, os.environ, os.path.join(\"/etc/postfix\", os.path.basename(postfix_file)))\n\nif os.path.exists(\"/overrides/postfix.cf\"):\n for line in open(\"/overrides/postfix.cf\").read().strip().split(\"\\n\"):\n if is_valid_postconf_line(line):\n os.system('postconf -e \"{}\"'.format(line))\n\nif os.path.exists(\"/overrides/postfix.master\"):\n for line in open(\"/overrides/postfix.master\").read().strip().split(\"\\n\"):\n if is_valid_postconf_line(line):\n os.system('postconf -Me \"{}\"'.format(line))\n\nfor map_file in glob.glob(\"/overrides/*.map\"):\n destination = os.path.join(\"/etc/postfix\", os.path.basename(map_file))\n shutil.copyfile(map_file, destination)\n os.system(\"postmap {}\".format(destination))\n os.remove(destination)\n\nif \"RELAYUSER\" in os.environ:\n path = \"/etc/postfix/sasl_passwd\"\n conf.jinja(\"/conf/sasl_passwd\", os.environ, path)\n os.system(\"postmap {}\".format(path))\n\n# Run Podop and Postfix\nmultiprocessing.Process(target=start_podop).start()\nos.system(\"/usr/libexec/postfix/post-install meta_directory=/etc/postfix create-missing\")\n# Before starting postfix, we need to check permissions on /queue\n# in the event that postfix,postdrop id have changed\nos.system(\"postfix set-permissions\")\nos.system(\"postfix start-fg\")\n", "path": "core/postfix/start.py"}]}
| 1,107 | 127 |
gh_patches_debug_15201
|
rasdani/github-patches
|
git_diff
|
apache__tvm-6131
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
apply_history_best requires extract_from_program to be run even if log file already exists
I'm running into a weird bug where `apply_history_best` doesn't work unless `extract_from_program` has been called somewhere before in the program (given the log file already exists).
Here is a minimal example:
```python
import os
import sys
import numpy as np
import tvm
from tvm import te
from tvm import autotvm
from tvm import relay
import tvm.relay.testing
from tvm.autotvm.tuner import XGBTuner, GATuner, RandomTuner, GridSearchTuner
from tvm.contrib.util import tempdir
import tvm.contrib.graph_runtime as runtime
input_shape = (1, 3, 224, 224)
output_shape = (1, 1000)
def run(mod, params, ctx):
lib = relay.build(mod, target="llvm", params=params)
dummy_data = np.random.uniform(size=input_shape).astype("float32")
m = runtime.GraphModule(lib['default'](ctx))
m.set_input('data', dummy_data)
m.run()
tvm_output = m.get_output(0)
ftimer = m.module.time_evaluator("run", ctx, repeat=5, number=5)
prof_res = np.array(ftimer().results) * 1000
print(
"%-20s %-19s (%s)"
% ("Runtime:", "%.2f ms" % np.mean(prof_res), "%.2f ms" % np.std(prof_res))
)
if __name__ == "__main__":
mod, params = tvm.relay.testing.resnet.get_workload()
ctx = tvm.cpu()
print("Untuned")
run(mod, params, ctx)
log_filename = "bug_tuning.log"
tmp_log_file = log_filename + ".tmp"
if os.path.exists(tmp_log_file):
os.remove(tmp_log_file)
if sys.argv[1] == "tune" or sys.argv[1] == "extract":
tasks = autotvm.task.extract_from_program(mod["main"], target="llvm",
params=params,
)
if sys.argv[1] == "tune":
for i, task in enumerate(tasks[0:4]):
prefix = "[Task %2d/%2d] " % (i+1, len(tasks))
tuner_obj = GridSearchTuner(task)
# do tuning
measure_option = autotvm.measure_option(
builder=autotvm.LocalBuilder(),
runner=autotvm.LocalRunner(number=10, repeat=1,
min_repeat_ms=1000),
)
n_trial= min(len(task.config_space), 10)
tuner_obj.tune(n_trial=n_trial,
early_stopping=False,
measure_option=measure_option,
callbacks=[
autotvm.callback.progress_bar(n_trial, prefix=prefix),
autotvm.callback.log_to_file(tmp_log_file)])
# pick best records to a cache file
autotvm.record.pick_best(tmp_log_file, log_filename)
os.remove(tmp_log_file)
print("Tuned")
with autotvm.apply_history_best(log_filename):
run(mod, params, ctx)
```
Run it like so:
```bash
python3 example.py tune
python3 example.py extract
python3 example.py run
```
On my laptop (macOS, quad-core 2.3GHz i7) I get the following output:
```
$ python3 simple_bug.py tune
Untuned
Cannot find config for target=llvm -keys=cpu, workload=('dense_nopack.x86', ('TENSOR', (1, 512), 'float32'), ('TENSOR', (1000, 512), 'float32'), None, 'float32'). A fallback configuration is used, which may bring great performance regression.
Runtime: 41.48 ms (2.09 ms)
[Task 1/13] Current/Best: 17.93/ 34.07 GFLOPS | Progress: (10/10) | 27.28 s Done.
[Task 2/13] Current/Best: 7.23/ 7.24 GFLOPS | Progress: (10/10) | 18.49 s Done.
[Task 3/13] Current/Best: 14.49/ 14.49 GFLOPS | Progress: (10/10) | 22.80 s Done.
[Task 4/13] Current/Best: 14.46/ 14.46 GFLOPS | Progress: (10/10) | 18.14 s Done.
Tuned
Runtime: 178.57 ms (1.56 ms)
$ python3 simple_bug.py extract
Untuned
Cannot find config for target=llvm -keys=cpu, workload=('dense_nopack.x86', ('TENSOR', (1, 512), 'float32'), ('TENSOR', (1000, 512), 'float32'), None, 'float32'). A fallback configuration is used, which may bring great performance regression.
Runtime: 40.87 ms (0.60 ms)
Tuned
Runtime: 178.05 ms (1.02 ms)
$ python3 simple_bug.py run
Untuned
Cannot find config for target=llvm -keys=cpu, workload=('dense_nopack.x86', ('TENSOR', (1, 512), 'float32'), ('TENSOR', (1000, 512), 'float32'), None, 'float32'). A fallback configuration is used, which may bring great performance regression.
Runtime: 40.37 ms (0.75 ms)
Tuned
Runtime: 39.85 ms (0.69 ms)
```
Ignore the fact that tuning makes results worse. I only run a couple iterations of the tuner to make the program run quickly.
On both `tune` and `extract`, the tuned performance is different from the untuned performance indicating that a tuned schedule was used. But on `run`, performance is the same between tuned and untuned. The only difference between `extract` and `run` is the call to `autotvm.task.extract_from_program`. I'm not clear what exactly the cause of this performance discrepancy is.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `python/tvm/autotvm/task/relay_integration.py`
Content:
```
1 # Licensed to the Apache Software Foundation (ASF) under one
2 # or more contributor license agreements. See the NOTICE file
3 # distributed with this work for additional information
4 # regarding copyright ownership. The ASF licenses this file
5 # to you under the Apache License, Version 2.0 (the
6 # "License"); you may not use this file except in compliance
7 # with the License. You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing,
12 # software distributed under the License is distributed on an
13 # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
14 # KIND, either express or implied. See the License for the
15 # specific language governing permissions and limitations
16 # under the License.
17 # pylint: disable=unused-variable,invalid-name, not-context-manager
18 """
19 Decorator and utilities for the integration with TOPI and Relay
20 99.9% copy-paste of implementation by @MerryMercy
21
22 """
23 import threading
24 import logging
25
26 import tvm
27 from .task import create
28 from .topi_integration import TaskExtractEnv
29
30 logger = logging.getLogger('autotvm')
31
32
33 # TODO(moreau89) find a more elegant way to lower for VTAs
34 def _lower(mod,
35 target,
36 params):
37 """ Helper to lower VTA properly.
38 """
39 # pylint: disable=import-outside-toplevel
40 from tvm import relay
41 from tvm.relay.backend import graph_runtime_codegen
42
43 if hasattr(target, 'device_name') and target.device_name == "vta":
44 import vta
45 with vta.build_config(opt_level=3, disabled_pass={"AlterOpLayout"}):
46 mod, _ = relay.optimize(mod, target, params)
47 grc = graph_runtime_codegen.GraphRuntimeCodegen(None, target)
48 grc.codegen(mod["main"])
49 return
50
51 # default case
52 # Try graph codegen first to extract autotvm tasks.
53 # If failed to compile, then fallback to use VM compiler.
54 # TODO: Currently VM compiler is likely to stack overflow for large models.
55 try:
56 opt_mod, _ = relay.optimize(mod, target, params)
57 grc = graph_runtime_codegen.GraphRuntimeCodegen(None, target)
58 grc.codegen(opt_mod["main"])
59 except tvm.TVMError as e:
60 print("Get errors with GraphRuntimeCodegen for task extraction. "
61 "Fallback to VMCompiler. Error details:\n%s" % str(e))
62 compiler = relay.vm.VMCompiler()
63 if params:
64 compiler.set_params(params)
65 compiler.lower(mod, target=target)
66
67
68 def extract_from_program(mod, params, target, target_host=None, ops=None):
69 """ Extract tuning tasks from a relay program.
70
71 This function is the single program version of extract_from_multiple_program.
72
73 Parameters
74 ----------
75 mod: tvm.IRModule or relay.function.Function
76 The module or function to tune
77 params: dict of str to numpy array
78 The associated parameters of the program
79 target: tvm.target.Target
80 The compilation target
81 target_host: tvm.target.Target
82 The host compilation target
83 ops: List[tvm.ir.Op] or None
84 List of relay ops to be tuned. If not specified, all tunable ops will be extracted.
85
86 Returns
87 -------
88 task: Array of autotvm.task.Task
89 collected tasks
90 """
91 return extract_from_multiple_program([mod], [params], target, target_host, ops)
92
93
94 def extract_from_multiple_program(mods, params, target, target_host=None, ops=None):
95 """ Extract tuning tasks from multiple relay programs.
96
97 This function collects tuning tasks by building a list of programs
98 with a "tracing" target and tracing all the calls to topi.
99
100 Parameters
101 ----------
102 mods: List[tvm.IRModule] or List[relay.function.Function]
103 The list of modules or functions to tune
104 params: List of dict of str to numpy array
105 The associated parameters of the programs
106 target: tvm.target.Target
107 The compilation target
108 target_host: tvm.target.Target
109 The host compilation target
110 ops: List[tvm.ir.Op] or None
111 List of relay ops to be tuned. If not specified, all tunable ops will be extracted.
112
113 Returns
114 -------
115 task: Array of autotvm.task.Task
116 collected tasks
117 """
118 # pylint: disable=import-outside-toplevel
119 from tvm import relay
120 import topi
121
122 env = TaskExtractEnv.get()
123
124 # run compiler to collect all TOPI calls during compilation
125 env.reset(ops)
126 with env:
127 # disable logger temporarily
128 old_state = logger.disabled
129 logger.disabled = True
130
131 for mod, param in zip(mods, params):
132 if isinstance(mod, relay.function.Function):
133 mod = tvm.IRModule.from_expr(mod)
134 assert isinstance(mod, tvm.IRModule), \
135 "only support relay Module or Function to be tuned"
136 relay.backend.compile_engine.get().clear()
137 # wrap build call in thread to avoid multiprocessing problems
138 build_thread = threading.Thread(target=_lower,
139 args=(mod, target, param))
140 build_thread.start()
141 build_thread.join()
142 relay.backend.compile_engine.get().clear()
143
144 logger.disabled = old_state
145
146 # create tasks for target
147 tasks = []
148 for task_name, args in env.get_tasks():
149 try:
150 tsk = create(task_name, args,
151 target=target, target_host=target_host)
152 tasks.append(tsk)
153 except topi.InvalidShapeError:
154 logger.warning("Invalid shape during AutoTVM task creation")
155
156 return tasks
157
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/python/tvm/autotvm/task/relay_integration.py b/python/tvm/autotvm/task/relay_integration.py
--- a/python/tvm/autotvm/task/relay_integration.py
+++ b/python/tvm/autotvm/task/relay_integration.py
@@ -24,6 +24,7 @@
import logging
import tvm
+from tvm.autotvm.task.dispatcher import DispatchContext, FallbackContext
from .task import create
from .topi_integration import TaskExtractEnv
@@ -140,6 +141,10 @@
build_thread.start()
build_thread.join()
relay.backend.compile_engine.get().clear()
+ # Clear the warning message cache in FallbackContext
+ if isinstance(DispatchContext.current, FallbackContext):
+ DispatchContext.current.memory = {}
+ DispatchContext.warning_messages = set()
logger.disabled = old_state
|
{"golden_diff": "diff --git a/python/tvm/autotvm/task/relay_integration.py b/python/tvm/autotvm/task/relay_integration.py\n--- a/python/tvm/autotvm/task/relay_integration.py\n+++ b/python/tvm/autotvm/task/relay_integration.py\n@@ -24,6 +24,7 @@\n import logging\n \n import tvm\n+from tvm.autotvm.task.dispatcher import DispatchContext, FallbackContext\n from .task import create\n from .topi_integration import TaskExtractEnv\n \n@@ -140,6 +141,10 @@\n build_thread.start()\n build_thread.join()\n relay.backend.compile_engine.get().clear()\n+ # Clear the warning message cache in FallbackContext\n+ if isinstance(DispatchContext.current, FallbackContext):\n+ DispatchContext.current.memory = {}\n+ DispatchContext.warning_messages = set()\n \n logger.disabled = old_state\n", "issue": "apply_history_best requires extract_from_program to be run even if log file already exists\nI'm running into a weird bug where `apply_history_best` doesn't work unless `extract_from_program` has been called somewhere before in the program (given the log file already exists).\r\n\r\nHere is a minimal example:\r\n```python\r\nimport os\r\nimport sys\r\n\r\nimport numpy as np\r\nimport tvm\r\nfrom tvm import te\r\nfrom tvm import autotvm\r\nfrom tvm import relay\r\nimport tvm.relay.testing\r\nfrom tvm.autotvm.tuner import XGBTuner, GATuner, RandomTuner, GridSearchTuner\r\nfrom tvm.contrib.util import tempdir\r\nimport tvm.contrib.graph_runtime as runtime\r\n\r\ninput_shape = (1, 3, 224, 224)\r\noutput_shape = (1, 1000)\r\n\r\ndef run(mod, params, ctx):\r\n lib = relay.build(mod, target=\"llvm\", params=params)\r\n\r\n dummy_data = np.random.uniform(size=input_shape).astype(\"float32\")\r\n\r\n m = runtime.GraphModule(lib['default'](ctx))\r\n m.set_input('data', dummy_data)\r\n m.run()\r\n tvm_output = m.get_output(0)\r\n\r\n ftimer = m.module.time_evaluator(\"run\", ctx, repeat=5, number=5)\r\n prof_res = np.array(ftimer().results) * 1000\r\n print(\r\n \"%-20s %-19s (%s)\"\r\n % (\"Runtime:\", \"%.2f ms\" % np.mean(prof_res), \"%.2f ms\" % np.std(prof_res))\r\n )\r\n\r\n\r\nif __name__ == \"__main__\":\r\n mod, params = tvm.relay.testing.resnet.get_workload()\r\n\r\n ctx = tvm.cpu()\r\n print(\"Untuned\")\r\n run(mod, params, ctx)\r\n\r\n log_filename = \"bug_tuning.log\"\r\n tmp_log_file = log_filename + \".tmp\"\r\n if os.path.exists(tmp_log_file):\r\n os.remove(tmp_log_file)\r\n\r\n if sys.argv[1] == \"tune\" or sys.argv[1] == \"extract\":\r\n tasks = autotvm.task.extract_from_program(mod[\"main\"], target=\"llvm\",\r\n params=params,\r\n )\r\n\r\n if sys.argv[1] == \"tune\":\r\n for i, task in enumerate(tasks[0:4]):\r\n prefix = \"[Task %2d/%2d] \" % (i+1, len(tasks))\r\n tuner_obj = GridSearchTuner(task)\r\n\r\n # do tuning\r\n measure_option = autotvm.measure_option(\r\n builder=autotvm.LocalBuilder(),\r\n runner=autotvm.LocalRunner(number=10, repeat=1,\r\n min_repeat_ms=1000),\r\n )\r\n n_trial= min(len(task.config_space), 10)\r\n tuner_obj.tune(n_trial=n_trial,\r\n early_stopping=False,\r\n measure_option=measure_option,\r\n callbacks=[\r\n autotvm.callback.progress_bar(n_trial, prefix=prefix),\r\n autotvm.callback.log_to_file(tmp_log_file)])\r\n\r\n # pick best records to a cache file\r\n autotvm.record.pick_best(tmp_log_file, log_filename)\r\n os.remove(tmp_log_file)\r\n\r\n print(\"Tuned\")\r\n with autotvm.apply_history_best(log_filename):\r\n run(mod, params, ctx)\r\n```\r\n\r\nRun it like so:\r\n```bash\r\npython3 example.py tune\r\npython3 example.py extract\r\npython3 example.py run\r\n```\r\n\r\nOn my laptop (macOS, quad-core 2.3GHz i7) I get the following output:\r\n```\r\n$ python3 simple_bug.py tune\r\nUntuned\r\nCannot find config for target=llvm -keys=cpu, workload=('dense_nopack.x86', ('TENSOR', (1, 512), 'float32'), ('TENSOR', (1000, 512), 'float32'), None, 'float32'). A fallback configuration is used, which may bring great performance regression.\r\nRuntime: 41.48 ms (2.09 ms)\r\n[Task 1/13] Current/Best: 17.93/ 34.07 GFLOPS | Progress: (10/10) | 27.28 s Done.\r\n[Task 2/13] Current/Best: 7.23/ 7.24 GFLOPS | Progress: (10/10) | 18.49 s Done.\r\n[Task 3/13] Current/Best: 14.49/ 14.49 GFLOPS | Progress: (10/10) | 22.80 s Done.\r\n[Task 4/13] Current/Best: 14.46/ 14.46 GFLOPS | Progress: (10/10) | 18.14 s Done.\r\nTuned\r\nRuntime: 178.57 ms (1.56 ms)\r\n\r\n$ python3 simple_bug.py extract\r\nUntuned\r\nCannot find config for target=llvm -keys=cpu, workload=('dense_nopack.x86', ('TENSOR', (1, 512), 'float32'), ('TENSOR', (1000, 512), 'float32'), None, 'float32'). A fallback configuration is used, which may bring great performance regression.\r\nRuntime: 40.87 ms (0.60 ms)\r\nTuned\r\nRuntime: 178.05 ms (1.02 ms)\r\n\r\n$ python3 simple_bug.py run\r\nUntuned\r\nCannot find config for target=llvm -keys=cpu, workload=('dense_nopack.x86', ('TENSOR', (1, 512), 'float32'), ('TENSOR', (1000, 512), 'float32'), None, 'float32'). A fallback configuration is used, which may bring great performance regression.\r\nRuntime: 40.37 ms (0.75 ms)\r\nTuned\r\nRuntime: 39.85 ms (0.69 ms)\r\n```\r\n\r\nIgnore the fact that tuning makes results worse. I only run a couple iterations of the tuner to make the program run quickly.\r\n\r\nOn both `tune` and `extract`, the tuned performance is different from the untuned performance indicating that a tuned schedule was used. But on `run`, performance is the same between tuned and untuned. The only difference between `extract` and `run` is the call to `autotvm.task.extract_from_program`. I'm not clear what exactly the cause of this performance discrepancy is.\n", "before_files": [{"content": "# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n# pylint: disable=unused-variable,invalid-name, not-context-manager\n\"\"\"\nDecorator and utilities for the integration with TOPI and Relay\n99.9% copy-paste of implementation by @MerryMercy\n\n\"\"\"\nimport threading\nimport logging\n\nimport tvm\nfrom .task import create\nfrom .topi_integration import TaskExtractEnv\n\nlogger = logging.getLogger('autotvm')\n\n\n# TODO(moreau89) find a more elegant way to lower for VTAs\ndef _lower(mod,\n target,\n params):\n \"\"\" Helper to lower VTA properly.\n \"\"\"\n # pylint: disable=import-outside-toplevel\n from tvm import relay\n from tvm.relay.backend import graph_runtime_codegen\n\n if hasattr(target, 'device_name') and target.device_name == \"vta\":\n import vta\n with vta.build_config(opt_level=3, disabled_pass={\"AlterOpLayout\"}):\n mod, _ = relay.optimize(mod, target, params)\n grc = graph_runtime_codegen.GraphRuntimeCodegen(None, target)\n grc.codegen(mod[\"main\"])\n return\n\n # default case\n # Try graph codegen first to extract autotvm tasks.\n # If failed to compile, then fallback to use VM compiler.\n # TODO: Currently VM compiler is likely to stack overflow for large models.\n try:\n opt_mod, _ = relay.optimize(mod, target, params)\n grc = graph_runtime_codegen.GraphRuntimeCodegen(None, target)\n grc.codegen(opt_mod[\"main\"])\n except tvm.TVMError as e:\n print(\"Get errors with GraphRuntimeCodegen for task extraction. \"\n \"Fallback to VMCompiler. Error details:\\n%s\" % str(e))\n compiler = relay.vm.VMCompiler()\n if params:\n compiler.set_params(params)\n compiler.lower(mod, target=target)\n\n\ndef extract_from_program(mod, params, target, target_host=None, ops=None):\n \"\"\" Extract tuning tasks from a relay program.\n\n This function is the single program version of extract_from_multiple_program.\n\n Parameters\n ----------\n mod: tvm.IRModule or relay.function.Function\n The module or function to tune\n params: dict of str to numpy array\n The associated parameters of the program\n target: tvm.target.Target\n The compilation target\n target_host: tvm.target.Target\n The host compilation target\n ops: List[tvm.ir.Op] or None\n List of relay ops to be tuned. If not specified, all tunable ops will be extracted.\n\n Returns\n -------\n task: Array of autotvm.task.Task\n collected tasks\n \"\"\"\n return extract_from_multiple_program([mod], [params], target, target_host, ops)\n\n\ndef extract_from_multiple_program(mods, params, target, target_host=None, ops=None):\n \"\"\" Extract tuning tasks from multiple relay programs.\n\n This function collects tuning tasks by building a list of programs\n with a \"tracing\" target and tracing all the calls to topi.\n\n Parameters\n ----------\n mods: List[tvm.IRModule] or List[relay.function.Function]\n The list of modules or functions to tune\n params: List of dict of str to numpy array\n The associated parameters of the programs\n target: tvm.target.Target\n The compilation target\n target_host: tvm.target.Target\n The host compilation target\n ops: List[tvm.ir.Op] or None\n List of relay ops to be tuned. If not specified, all tunable ops will be extracted.\n\n Returns\n -------\n task: Array of autotvm.task.Task\n collected tasks\n \"\"\"\n # pylint: disable=import-outside-toplevel\n from tvm import relay\n import topi\n\n env = TaskExtractEnv.get()\n\n # run compiler to collect all TOPI calls during compilation\n env.reset(ops)\n with env:\n # disable logger temporarily\n old_state = logger.disabled\n logger.disabled = True\n\n for mod, param in zip(mods, params):\n if isinstance(mod, relay.function.Function):\n mod = tvm.IRModule.from_expr(mod)\n assert isinstance(mod, tvm.IRModule), \\\n \"only support relay Module or Function to be tuned\"\n relay.backend.compile_engine.get().clear()\n # wrap build call in thread to avoid multiprocessing problems\n build_thread = threading.Thread(target=_lower,\n args=(mod, target, param))\n build_thread.start()\n build_thread.join()\n relay.backend.compile_engine.get().clear()\n\n logger.disabled = old_state\n\n # create tasks for target\n tasks = []\n for task_name, args in env.get_tasks():\n try:\n tsk = create(task_name, args,\n target=target, target_host=target_host)\n tasks.append(tsk)\n except topi.InvalidShapeError:\n logger.warning(\"Invalid shape during AutoTVM task creation\")\n\n return tasks\n", "path": "python/tvm/autotvm/task/relay_integration.py"}], "after_files": [{"content": "# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n# pylint: disable=unused-variable,invalid-name, not-context-manager\n\"\"\"\nDecorator and utilities for the integration with TOPI and Relay\n99.9% copy-paste of implementation by @MerryMercy\n\n\"\"\"\nimport threading\nimport logging\n\nimport tvm\nfrom tvm.autotvm.task.dispatcher import DispatchContext, FallbackContext\nfrom .task import create\nfrom .topi_integration import TaskExtractEnv\n\nlogger = logging.getLogger('autotvm')\n\n\n# TODO(moreau89) find a more elegant way to lower for VTAs\ndef _lower(mod,\n target,\n params):\n \"\"\" Helper to lower VTA properly.\n \"\"\"\n # pylint: disable=import-outside-toplevel\n from tvm import relay\n from tvm.relay.backend import graph_runtime_codegen\n\n if hasattr(target, 'device_name') and target.device_name == \"vta\":\n import vta\n with vta.build_config(opt_level=3, disabled_pass={\"AlterOpLayout\"}):\n mod, _ = relay.optimize(mod, target, params)\n grc = graph_runtime_codegen.GraphRuntimeCodegen(None, target)\n grc.codegen(mod[\"main\"])\n return\n\n # default case\n # Try graph codegen first to extract autotvm tasks.\n # If failed to compile, then fallback to use VM compiler.\n # TODO: Currently VM compiler is likely to stack overflow for large models.\n try:\n opt_mod, _ = relay.optimize(mod, target, params)\n grc = graph_runtime_codegen.GraphRuntimeCodegen(None, target)\n grc.codegen(opt_mod[\"main\"])\n except tvm.TVMError as e:\n print(\"Get errors with GraphRuntimeCodegen for task extraction. \"\n \"Fallback to VMCompiler. Error details:\\n%s\" % str(e))\n compiler = relay.vm.VMCompiler()\n if params:\n compiler.set_params(params)\n compiler.lower(mod, target=target)\n\n\ndef extract_from_program(mod, params, target, target_host=None, ops=None):\n \"\"\" Extract tuning tasks from a relay program.\n\n This function is the single program version of extract_from_multiple_program.\n\n Parameters\n ----------\n mod: tvm.IRModule or relay.function.Function\n The module or function to tune\n params: dict of str to numpy array\n The associated parameters of the program\n target: tvm.target.Target\n The compilation target\n target_host: tvm.target.Target\n The host compilation target\n ops: List[tvm.ir.Op] or None\n List of relay ops to be tuned. If not specified, all tunable ops will be extracted.\n\n Returns\n -------\n task: Array of autotvm.task.Task\n collected tasks\n \"\"\"\n return extract_from_multiple_program([mod], [params], target, target_host, ops)\n\n\ndef extract_from_multiple_program(mods, params, target, target_host=None, ops=None):\n \"\"\" Extract tuning tasks from multiple relay programs.\n\n This function collects tuning tasks by building a list of programs\n with a \"tracing\" target and tracing all the calls to topi.\n\n Parameters\n ----------\n mods: List[tvm.IRModule] or List[relay.function.Function]\n The list of modules or functions to tune\n params: List of dict of str to numpy array\n The associated parameters of the programs\n target: tvm.target.Target\n The compilation target\n target_host: tvm.target.Target\n The host compilation target\n ops: List[tvm.ir.Op] or None\n List of relay ops to be tuned. If not specified, all tunable ops will be extracted.\n\n Returns\n -------\n task: Array of autotvm.task.Task\n collected tasks\n \"\"\"\n # pylint: disable=import-outside-toplevel\n from tvm import relay\n import topi\n\n env = TaskExtractEnv.get()\n\n # run compiler to collect all TOPI calls during compilation\n env.reset(ops)\n with env:\n # disable logger temporarily\n old_state = logger.disabled\n logger.disabled = True\n\n for mod, param in zip(mods, params):\n if isinstance(mod, relay.function.Function):\n mod = tvm.IRModule.from_expr(mod)\n assert isinstance(mod, tvm.IRModule), \\\n \"only support relay Module or Function to be tuned\"\n relay.backend.compile_engine.get().clear()\n # wrap build call in thread to avoid multiprocessing problems\n build_thread = threading.Thread(target=_lower,\n args=(mod, target, param))\n build_thread.start()\n build_thread.join()\n relay.backend.compile_engine.get().clear()\n # Clear the warning message cache in FallbackContext\n if isinstance(DispatchContext.current, FallbackContext):\n DispatchContext.current.memory = {}\n DispatchContext.warning_messages = set()\n\n logger.disabled = old_state\n\n # create tasks for target\n tasks = []\n for task_name, args in env.get_tasks():\n try:\n tsk = create(task_name, args,\n target=target, target_host=target_host)\n tasks.append(tsk)\n except topi.InvalidShapeError:\n logger.warning(\"Invalid shape during AutoTVM task creation\")\n\n return tasks\n", "path": "python/tvm/autotvm/task/relay_integration.py"}]}
| 3,345 | 197 |
gh_patches_debug_32949
|
rasdani/github-patches
|
git_diff
|
MycroftAI__mycroft-core-894
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
audio_end doesn't trigger in tts playback thread
I think a minor bug snuck into #892, Queue objects has no `len()` and the empty status needs to be checked with `.empty()`.
This means that the `...audio_output_end` message isn't sent.(and thus mic isn't unmuted, etc.)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mycroft/tts/__init__.py`
Content:
```
1 # Copyright 2016 Mycroft AI, Inc.
2 #
3 # This file is part of Mycroft Core.
4 #
5 # Mycroft Core is free software: you can redistribute it and/or modify
6 # it under the terms of the GNU General Public License as published by
7 # the Free Software Foundation, either version 3 of the License, or
8 # (at your option) any later version.
9 #
10 # Mycroft Core is distributed in the hope that it will be useful,
11 # but WITHOUT ANY WARRANTY; without even the implied warranty of
12 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
13 # GNU General Public License for more details.
14 #
15 # You should have received a copy of the GNU General Public License
16 # along with Mycroft Core. If not, see <http://www.gnu.org/licenses/>.
17 import random
18 from abc import ABCMeta, abstractmethod
19 from os.path import dirname, exists, isdir
20 from threading import Thread
21 from Queue import Queue
22 from time import time, sleep
23 import os
24 import os.path
25 import hashlib
26
27 from mycroft.client.enclosure.api import EnclosureAPI
28 from mycroft.configuration import ConfigurationManager
29 from mycroft.messagebus.message import Message
30 from mycroft.util.log import getLogger
31 from mycroft.util import play_wav, play_mp3, check_for_signal
32 import mycroft.util
33
34 __author__ = 'jdorleans'
35
36 LOGGER = getLogger(__name__)
37
38
39 class PlaybackThread(Thread):
40 """
41 Thread class for playing back tts audio and sending
42 visime data to enclosure.
43 """
44
45 def __init__(self, queue):
46 super(PlaybackThread, self).__init__()
47 self.queue = queue
48 self._terminated = False
49
50 def init(self, tts):
51 self.tts = tts
52
53 def clear_queue(self):
54 """
55 Remove all pending playbacks.
56 """
57 while not self.queue.empty():
58 self.queue.get()
59 try:
60 self.p.terminate()
61 except:
62 pass
63
64 def run(self):
65 """
66 Thread main loop. get audio and visime data from queue
67 and play.
68 """
69 while not self._terminated:
70 try:
71 snd_type, data, visimes = self.queue.get(timeout=2)
72 self.blink(0.5)
73 self.tts.begin_audio()
74 if snd_type == 'wav':
75 self.p = play_wav(data)
76 elif snd_type == 'mp3':
77 self.p = play_mp3(data)
78
79 if visimes:
80 if self.show_visimes(visimes):
81 self.clear_queue()
82 else:
83 self.p.communicate()
84 self.p.wait()
85 if len(self.queue) == 0:
86 self.tts.end_audio()
87 self.blink(0.2)
88 except:
89 pass
90
91 def show_visimes(self, pairs):
92 """
93 Send visime data to enclosure
94
95 Args:
96 pairs(list): Visime and timing pair
97
98 Returns:
99 True if button has been pressed.
100 """
101 start = time()
102 for code, duration in pairs:
103 if check_for_signal('stoppingTTS', -1):
104 return True
105 if check_for_signal('buttonPress'):
106 return True
107 if self.enclosure:
108 self.enclosure.mouth_viseme(code)
109 delta = time() - start
110 if delta < duration:
111 sleep(duration - delta)
112 return False
113
114 def blink(self, rate=1.0):
115 """ Blink mycroft's eyes """
116 if self.enclosure and random.random() < rate:
117 self.enclosure.eyes_blink("b")
118
119 def stop(self):
120 """ Stop thread """
121 self._terminated = True
122 self.clear_queue()
123
124
125 class TTS(object):
126 """
127 TTS abstract class to be implemented by all TTS engines.
128
129 It aggregates the minimum required parameters and exposes
130 ``execute(sentence)`` function.
131 """
132 __metaclass__ = ABCMeta
133
134 def __init__(self, lang, voice, validator):
135 super(TTS, self).__init__()
136 self.lang = lang or 'en-us'
137 self.voice = voice
138 self.filename = '/tmp/tts.wav'
139 self.validator = validator
140 self.enclosure = None
141 random.seed()
142 self.queue = Queue()
143 self.playback = PlaybackThread(self.queue)
144 self.playback.start()
145 self.clear_cache()
146
147 def begin_audio(self):
148 """Helper function for child classes to call in execute()"""
149 self.ws.emit(Message("recognizer_loop:audio_output_start"))
150
151 def end_audio(self):
152 """Helper function for child classes to call in execute()"""
153 self.ws.emit(Message("recognizer_loop:audio_output_end"))
154
155 def init(self, ws):
156 self.ws = ws
157 self.playback.init(self)
158 self.enclosure = EnclosureAPI(self.ws)
159 self.playback.enclosure = self.enclosure
160
161 def get_tts(self, sentence, wav_file):
162 """
163 Abstract method that a tts implementation needs to implement.
164 Should get data from tts.
165
166 Args:
167 sentence(str): Sentence to synthesize
168 wav_file(str): output file
169
170 Returns: (wav_file, phoneme) tuple
171 """
172 pass
173
174 def execute(self, sentence):
175 """
176 Convert sentence to speech.
177
178 The method caches results if possible using the hash of the
179 sentence.
180
181 Args:
182 sentence: Sentence to be spoken
183 """
184 key = str(hashlib.md5(sentence.encode('utf-8', 'ignore')).hexdigest())
185 wav_file = os.path.join(mycroft.util.get_cache_directory("tts"),
186 key + self.type)
187
188 if os.path.exists(wav_file):
189 LOGGER.debug("TTS cache hit")
190 phonemes = self.load_phonemes(key)
191 else:
192 wav_file, phonemes = self.get_tts(sentence, wav_file)
193 if phonemes:
194 self.save_phonemes(key, phonemes)
195
196 self.queue.put((self.type, wav_file, self.visime(phonemes)))
197
198 def visime(self, phonemes):
199 """
200 Create visimes from phonemes. Needs to be implemented for all
201 tts backend
202
203 Args:
204 phonemes(str): String with phoneme data
205 """
206 return None
207
208 def clear_cache(self):
209 """ Remove all cached files. """
210 if not os.path.exists(mycroft.util.get_cache_directory('tts')):
211 return
212 for f in os.listdir(mycroft.util.get_cache_directory("tts")):
213 file_path = os.path.join(mycroft.util.get_cache_directory("tts"),
214 f)
215 if os.path.isfile(file_path):
216 os.unlink(file_path)
217
218 def save_phonemes(self, key, phonemes):
219 """
220 Cache phonemes
221
222 Args:
223 key: Hash key for the sentence
224 phonemes: phoneme string to save
225 """
226 # Clean out the cache as needed
227 cache_dir = mycroft.util.get_cache_directory("tts")
228 mycroft.util.curate_cache(cache_dir)
229
230 pho_file = os.path.join(cache_dir, key + ".pho")
231 try:
232 with open(pho_file, "w") as cachefile:
233 cachefile.write(phonemes)
234 except:
235 LOGGER.debug("Failed to write .PHO to cache")
236 pass
237
238 def load_phonemes(self, key):
239 """
240 Load phonemes from cache file.
241
242 Args:
243 Key: Key identifying phoneme cache
244 """
245 pho_file = os.path.join(mycroft.util.get_cache_directory("tts"),
246 key+".pho")
247 if os.path.exists(pho_file):
248 try:
249 with open(pho_file, "r") as cachefile:
250 phonemes = cachefile.read().strip()
251 return phonemes
252 except:
253 LOGGER.debug("Failed to read .PHO from cache")
254 return None
255
256 def __del__(self):
257 self.playback.stop()
258 self.playback.join()
259
260
261 class TTSValidator(object):
262 """
263 TTS Validator abstract class to be implemented by all TTS engines.
264
265 It exposes and implements ``validate(tts)`` function as a template to
266 validate the TTS engines.
267 """
268 __metaclass__ = ABCMeta
269
270 def __init__(self, tts):
271 self.tts = tts
272
273 def validate(self):
274 self.validate_instance()
275 self.validate_filename()
276 self.validate_lang()
277 self.validate_connection()
278
279 def validate_instance(self):
280 clazz = self.get_tts_class()
281 if not isinstance(self.tts, clazz):
282 raise AttributeError('tts must be instance of ' + clazz.__name__)
283
284 def validate_filename(self):
285 filename = self.tts.filename
286 if not (filename and filename.endswith('.wav')):
287 raise AttributeError('file: %s must be in .wav format!' % filename)
288
289 dir_path = dirname(filename)
290 if not (exists(dir_path) and isdir(dir_path)):
291 raise AttributeError('filename: %s is not valid!' % filename)
292
293 @abstractmethod
294 def validate_lang(self):
295 pass
296
297 @abstractmethod
298 def validate_connection(self):
299 pass
300
301 @abstractmethod
302 def get_tts_class(self):
303 pass
304
305
306 class TTSFactory(object):
307 from mycroft.tts.espeak_tts import ESpeak
308 from mycroft.tts.fa_tts import FATTS
309 from mycroft.tts.google_tts import GoogleTTS
310 from mycroft.tts.mary_tts import MaryTTS
311 from mycroft.tts.mimic_tts import Mimic
312 from mycroft.tts.spdsay_tts import SpdSay
313
314 CLASSES = {
315 "mimic": Mimic,
316 "google": GoogleTTS,
317 "marytts": MaryTTS,
318 "fatts": FATTS,
319 "espeak": ESpeak,
320 "spdsay": SpdSay
321 }
322
323 @staticmethod
324 def create():
325 """
326 Factory method to create a TTS engine based on configuration.
327
328 The configuration file ``mycroft.conf`` contains a ``tts`` section with
329 the name of a TTS module to be read by this method.
330
331 "tts": {
332 "module": <engine_name>
333 }
334 """
335
336 from mycroft.tts.remote_tts import RemoteTTS
337 config = ConfigurationManager.get().get('tts', {})
338 module = config.get('module', 'mimic')
339 lang = config.get(module).get('lang')
340 voice = config.get(module).get('voice')
341 clazz = TTSFactory.CLASSES.get(module)
342
343 if issubclass(clazz, RemoteTTS):
344 url = config.get(module).get('url')
345 tts = clazz(lang, voice, url)
346 else:
347 tts = clazz(lang, voice)
348
349 tts.validator.validate()
350 return tts
351
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mycroft/tts/__init__.py b/mycroft/tts/__init__.py
--- a/mycroft/tts/__init__.py
+++ b/mycroft/tts/__init__.py
@@ -18,7 +18,7 @@
from abc import ABCMeta, abstractmethod
from os.path import dirname, exists, isdir
from threading import Thread
-from Queue import Queue
+from Queue import Queue, Empty
from time import time, sleep
import os
import os.path
@@ -46,6 +46,7 @@
super(PlaybackThread, self).__init__()
self.queue = queue
self._terminated = False
+ self._processing_queue = False
def init(self, tts):
self.tts = tts
@@ -70,7 +71,10 @@
try:
snd_type, data, visimes = self.queue.get(timeout=2)
self.blink(0.5)
- self.tts.begin_audio()
+ if not self._processing_queue:
+ self._processing_queue = True
+ self.tts.begin_audio()
+
if snd_type == 'wav':
self.p = play_wav(data)
elif snd_type == 'mp3':
@@ -82,11 +86,18 @@
else:
self.p.communicate()
self.p.wait()
- if len(self.queue) == 0:
+
+ if self.queue.empty():
self.tts.end_audio()
+ self._processing_queue = False
self.blink(0.2)
- except:
+ except Empty:
pass
+ except Exception, e:
+ LOGGER.exception(e)
+ if self._processing_queue:
+ self.tts.end_audio()
+ self._processing_queue = False
def show_visimes(self, pairs):
"""
|
{"golden_diff": "diff --git a/mycroft/tts/__init__.py b/mycroft/tts/__init__.py\n--- a/mycroft/tts/__init__.py\n+++ b/mycroft/tts/__init__.py\n@@ -18,7 +18,7 @@\n from abc import ABCMeta, abstractmethod\n from os.path import dirname, exists, isdir\n from threading import Thread\n-from Queue import Queue\n+from Queue import Queue, Empty\n from time import time, sleep\n import os\n import os.path\n@@ -46,6 +46,7 @@\n super(PlaybackThread, self).__init__()\n self.queue = queue\n self._terminated = False\n+ self._processing_queue = False\n \n def init(self, tts):\n self.tts = tts\n@@ -70,7 +71,10 @@\n try:\n snd_type, data, visimes = self.queue.get(timeout=2)\n self.blink(0.5)\n- self.tts.begin_audio()\n+ if not self._processing_queue:\n+ self._processing_queue = True\n+ self.tts.begin_audio()\n+\n if snd_type == 'wav':\n self.p = play_wav(data)\n elif snd_type == 'mp3':\n@@ -82,11 +86,18 @@\n else:\n self.p.communicate()\n self.p.wait()\n- if len(self.queue) == 0:\n+\n+ if self.queue.empty():\n self.tts.end_audio()\n+ self._processing_queue = False\n self.blink(0.2)\n- except:\n+ except Empty:\n pass\n+ except Exception, e:\n+ LOGGER.exception(e)\n+ if self._processing_queue:\n+ self.tts.end_audio()\n+ self._processing_queue = False\n \n def show_visimes(self, pairs):\n \"\"\"\n", "issue": "audio_end doesn't trigger in tts playback thread\nI think a minor bug snuck into #892, Queue objects has no `len()` and the empty status needs to be checked with `.empty()`.\r\n\r\nThis means that the `...audio_output_end` message isn't sent.(and thus mic isn't unmuted, etc.)\n", "before_files": [{"content": "# Copyright 2016 Mycroft AI, Inc.\n#\n# This file is part of Mycroft Core.\n#\n# Mycroft Core is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Mycroft Core is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Mycroft Core. If not, see <http://www.gnu.org/licenses/>.\nimport random\nfrom abc import ABCMeta, abstractmethod\nfrom os.path import dirname, exists, isdir\nfrom threading import Thread\nfrom Queue import Queue\nfrom time import time, sleep\nimport os\nimport os.path\nimport hashlib\n\nfrom mycroft.client.enclosure.api import EnclosureAPI\nfrom mycroft.configuration import ConfigurationManager\nfrom mycroft.messagebus.message import Message\nfrom mycroft.util.log import getLogger\nfrom mycroft.util import play_wav, play_mp3, check_for_signal\nimport mycroft.util\n\n__author__ = 'jdorleans'\n\nLOGGER = getLogger(__name__)\n\n\nclass PlaybackThread(Thread):\n \"\"\"\n Thread class for playing back tts audio and sending\n visime data to enclosure.\n \"\"\"\n\n def __init__(self, queue):\n super(PlaybackThread, self).__init__()\n self.queue = queue\n self._terminated = False\n\n def init(self, tts):\n self.tts = tts\n\n def clear_queue(self):\n \"\"\"\n Remove all pending playbacks.\n \"\"\"\n while not self.queue.empty():\n self.queue.get()\n try:\n self.p.terminate()\n except:\n pass\n\n def run(self):\n \"\"\"\n Thread main loop. get audio and visime data from queue\n and play.\n \"\"\"\n while not self._terminated:\n try:\n snd_type, data, visimes = self.queue.get(timeout=2)\n self.blink(0.5)\n self.tts.begin_audio()\n if snd_type == 'wav':\n self.p = play_wav(data)\n elif snd_type == 'mp3':\n self.p = play_mp3(data)\n\n if visimes:\n if self.show_visimes(visimes):\n self.clear_queue()\n else:\n self.p.communicate()\n self.p.wait()\n if len(self.queue) == 0:\n self.tts.end_audio()\n self.blink(0.2)\n except:\n pass\n\n def show_visimes(self, pairs):\n \"\"\"\n Send visime data to enclosure\n\n Args:\n pairs(list): Visime and timing pair\n\n Returns:\n True if button has been pressed.\n \"\"\"\n start = time()\n for code, duration in pairs:\n if check_for_signal('stoppingTTS', -1):\n return True\n if check_for_signal('buttonPress'):\n return True\n if self.enclosure:\n self.enclosure.mouth_viseme(code)\n delta = time() - start\n if delta < duration:\n sleep(duration - delta)\n return False\n\n def blink(self, rate=1.0):\n \"\"\" Blink mycroft's eyes \"\"\"\n if self.enclosure and random.random() < rate:\n self.enclosure.eyes_blink(\"b\")\n\n def stop(self):\n \"\"\" Stop thread \"\"\"\n self._terminated = True\n self.clear_queue()\n\n\nclass TTS(object):\n \"\"\"\n TTS abstract class to be implemented by all TTS engines.\n\n It aggregates the minimum required parameters and exposes\n ``execute(sentence)`` function.\n \"\"\"\n __metaclass__ = ABCMeta\n\n def __init__(self, lang, voice, validator):\n super(TTS, self).__init__()\n self.lang = lang or 'en-us'\n self.voice = voice\n self.filename = '/tmp/tts.wav'\n self.validator = validator\n self.enclosure = None\n random.seed()\n self.queue = Queue()\n self.playback = PlaybackThread(self.queue)\n self.playback.start()\n self.clear_cache()\n\n def begin_audio(self):\n \"\"\"Helper function for child classes to call in execute()\"\"\"\n self.ws.emit(Message(\"recognizer_loop:audio_output_start\"))\n\n def end_audio(self):\n \"\"\"Helper function for child classes to call in execute()\"\"\"\n self.ws.emit(Message(\"recognizer_loop:audio_output_end\"))\n\n def init(self, ws):\n self.ws = ws\n self.playback.init(self)\n self.enclosure = EnclosureAPI(self.ws)\n self.playback.enclosure = self.enclosure\n\n def get_tts(self, sentence, wav_file):\n \"\"\"\n Abstract method that a tts implementation needs to implement.\n Should get data from tts.\n\n Args:\n sentence(str): Sentence to synthesize\n wav_file(str): output file\n\n Returns: (wav_file, phoneme) tuple\n \"\"\"\n pass\n\n def execute(self, sentence):\n \"\"\"\n Convert sentence to speech.\n\n The method caches results if possible using the hash of the\n sentence.\n\n Args:\n sentence: Sentence to be spoken\n \"\"\"\n key = str(hashlib.md5(sentence.encode('utf-8', 'ignore')).hexdigest())\n wav_file = os.path.join(mycroft.util.get_cache_directory(\"tts\"),\n key + self.type)\n\n if os.path.exists(wav_file):\n LOGGER.debug(\"TTS cache hit\")\n phonemes = self.load_phonemes(key)\n else:\n wav_file, phonemes = self.get_tts(sentence, wav_file)\n if phonemes:\n self.save_phonemes(key, phonemes)\n\n self.queue.put((self.type, wav_file, self.visime(phonemes)))\n\n def visime(self, phonemes):\n \"\"\"\n Create visimes from phonemes. Needs to be implemented for all\n tts backend\n\n Args:\n phonemes(str): String with phoneme data\n \"\"\"\n return None\n\n def clear_cache(self):\n \"\"\" Remove all cached files. \"\"\"\n if not os.path.exists(mycroft.util.get_cache_directory('tts')):\n return\n for f in os.listdir(mycroft.util.get_cache_directory(\"tts\")):\n file_path = os.path.join(mycroft.util.get_cache_directory(\"tts\"),\n f)\n if os.path.isfile(file_path):\n os.unlink(file_path)\n\n def save_phonemes(self, key, phonemes):\n \"\"\"\n Cache phonemes\n\n Args:\n key: Hash key for the sentence\n phonemes: phoneme string to save\n \"\"\"\n # Clean out the cache as needed\n cache_dir = mycroft.util.get_cache_directory(\"tts\")\n mycroft.util.curate_cache(cache_dir)\n\n pho_file = os.path.join(cache_dir, key + \".pho\")\n try:\n with open(pho_file, \"w\") as cachefile:\n cachefile.write(phonemes)\n except:\n LOGGER.debug(\"Failed to write .PHO to cache\")\n pass\n\n def load_phonemes(self, key):\n \"\"\"\n Load phonemes from cache file.\n\n Args:\n Key: Key identifying phoneme cache\n \"\"\"\n pho_file = os.path.join(mycroft.util.get_cache_directory(\"tts\"),\n key+\".pho\")\n if os.path.exists(pho_file):\n try:\n with open(pho_file, \"r\") as cachefile:\n phonemes = cachefile.read().strip()\n return phonemes\n except:\n LOGGER.debug(\"Failed to read .PHO from cache\")\n return None\n\n def __del__(self):\n self.playback.stop()\n self.playback.join()\n\n\nclass TTSValidator(object):\n \"\"\"\n TTS Validator abstract class to be implemented by all TTS engines.\n\n It exposes and implements ``validate(tts)`` function as a template to\n validate the TTS engines.\n \"\"\"\n __metaclass__ = ABCMeta\n\n def __init__(self, tts):\n self.tts = tts\n\n def validate(self):\n self.validate_instance()\n self.validate_filename()\n self.validate_lang()\n self.validate_connection()\n\n def validate_instance(self):\n clazz = self.get_tts_class()\n if not isinstance(self.tts, clazz):\n raise AttributeError('tts must be instance of ' + clazz.__name__)\n\n def validate_filename(self):\n filename = self.tts.filename\n if not (filename and filename.endswith('.wav')):\n raise AttributeError('file: %s must be in .wav format!' % filename)\n\n dir_path = dirname(filename)\n if not (exists(dir_path) and isdir(dir_path)):\n raise AttributeError('filename: %s is not valid!' % filename)\n\n @abstractmethod\n def validate_lang(self):\n pass\n\n @abstractmethod\n def validate_connection(self):\n pass\n\n @abstractmethod\n def get_tts_class(self):\n pass\n\n\nclass TTSFactory(object):\n from mycroft.tts.espeak_tts import ESpeak\n from mycroft.tts.fa_tts import FATTS\n from mycroft.tts.google_tts import GoogleTTS\n from mycroft.tts.mary_tts import MaryTTS\n from mycroft.tts.mimic_tts import Mimic\n from mycroft.tts.spdsay_tts import SpdSay\n\n CLASSES = {\n \"mimic\": Mimic,\n \"google\": GoogleTTS,\n \"marytts\": MaryTTS,\n \"fatts\": FATTS,\n \"espeak\": ESpeak,\n \"spdsay\": SpdSay\n }\n\n @staticmethod\n def create():\n \"\"\"\n Factory method to create a TTS engine based on configuration.\n\n The configuration file ``mycroft.conf`` contains a ``tts`` section with\n the name of a TTS module to be read by this method.\n\n \"tts\": {\n \"module\": <engine_name>\n }\n \"\"\"\n\n from mycroft.tts.remote_tts import RemoteTTS\n config = ConfigurationManager.get().get('tts', {})\n module = config.get('module', 'mimic')\n lang = config.get(module).get('lang')\n voice = config.get(module).get('voice')\n clazz = TTSFactory.CLASSES.get(module)\n\n if issubclass(clazz, RemoteTTS):\n url = config.get(module).get('url')\n tts = clazz(lang, voice, url)\n else:\n tts = clazz(lang, voice)\n\n tts.validator.validate()\n return tts\n", "path": "mycroft/tts/__init__.py"}], "after_files": [{"content": "# Copyright 2016 Mycroft AI, Inc.\n#\n# This file is part of Mycroft Core.\n#\n# Mycroft Core is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Mycroft Core is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Mycroft Core. If not, see <http://www.gnu.org/licenses/>.\nimport random\nfrom abc import ABCMeta, abstractmethod\nfrom os.path import dirname, exists, isdir\nfrom threading import Thread\nfrom Queue import Queue, Empty\nfrom time import time, sleep\nimport os\nimport os.path\nimport hashlib\n\nfrom mycroft.client.enclosure.api import EnclosureAPI\nfrom mycroft.configuration import ConfigurationManager\nfrom mycroft.messagebus.message import Message\nfrom mycroft.util.log import getLogger\nfrom mycroft.util import play_wav, play_mp3, check_for_signal\nimport mycroft.util\n\n__author__ = 'jdorleans'\n\nLOGGER = getLogger(__name__)\n\n\nclass PlaybackThread(Thread):\n \"\"\"\n Thread class for playing back tts audio and sending\n visime data to enclosure.\n \"\"\"\n\n def __init__(self, queue):\n super(PlaybackThread, self).__init__()\n self.queue = queue\n self._terminated = False\n self._processing_queue = False\n\n def init(self, tts):\n self.tts = tts\n\n def clear_queue(self):\n \"\"\"\n Remove all pending playbacks.\n \"\"\"\n while not self.queue.empty():\n self.queue.get()\n try:\n self.p.terminate()\n except:\n pass\n\n def run(self):\n \"\"\"\n Thread main loop. get audio and visime data from queue\n and play.\n \"\"\"\n while not self._terminated:\n try:\n snd_type, data, visimes = self.queue.get(timeout=2)\n self.blink(0.5)\n if not self._processing_queue:\n self._processing_queue = True\n self.tts.begin_audio()\n\n if snd_type == 'wav':\n self.p = play_wav(data)\n elif snd_type == 'mp3':\n self.p = play_mp3(data)\n\n if visimes:\n if self.show_visimes(visimes):\n self.clear_queue()\n else:\n self.p.communicate()\n self.p.wait()\n\n if self.queue.empty():\n self.tts.end_audio()\n self._processing_queue = False\n self.blink(0.2)\n except Empty:\n pass\n except Exception, e:\n LOGGER.exception(e)\n if self._processing_queue:\n self.tts.end_audio()\n self._processing_queue = False\n\n def show_visimes(self, pairs):\n \"\"\"\n Send visime data to enclosure\n\n Args:\n pairs(list): Visime and timing pair\n\n Returns:\n True if button has been pressed.\n \"\"\"\n start = time()\n for code, duration in pairs:\n if check_for_signal('stoppingTTS', -1):\n return True\n if check_for_signal('buttonPress'):\n return True\n if self.enclosure:\n self.enclosure.mouth_viseme(code)\n delta = time() - start\n if delta < duration:\n sleep(duration - delta)\n return False\n\n def blink(self, rate=1.0):\n \"\"\" Blink mycroft's eyes \"\"\"\n if self.enclosure and random.random() < rate:\n self.enclosure.eyes_blink(\"b\")\n\n def stop(self):\n \"\"\" Stop thread \"\"\"\n self._terminated = True\n self.clear_queue()\n\n\nclass TTS(object):\n \"\"\"\n TTS abstract class to be implemented by all TTS engines.\n\n It aggregates the minimum required parameters and exposes\n ``execute(sentence)`` function.\n \"\"\"\n __metaclass__ = ABCMeta\n\n def __init__(self, lang, voice, validator):\n super(TTS, self).__init__()\n self.lang = lang or 'en-us'\n self.voice = voice\n self.filename = '/tmp/tts.wav'\n self.validator = validator\n self.enclosure = None\n random.seed()\n self.queue = Queue()\n self.playback = PlaybackThread(self.queue)\n self.playback.start()\n self.clear_cache()\n\n def begin_audio(self):\n \"\"\"Helper function for child classes to call in execute()\"\"\"\n self.ws.emit(Message(\"recognizer_loop:audio_output_start\"))\n\n def end_audio(self):\n \"\"\"Helper function for child classes to call in execute()\"\"\"\n self.ws.emit(Message(\"recognizer_loop:audio_output_end\"))\n\n def init(self, ws):\n self.ws = ws\n self.playback.init(self)\n self.enclosure = EnclosureAPI(self.ws)\n self.playback.enclosure = self.enclosure\n\n def get_tts(self, sentence, wav_file):\n \"\"\"\n Abstract method that a tts implementation needs to implement.\n Should get data from tts.\n\n Args:\n sentence(str): Sentence to synthesize\n wav_file(str): output file\n\n Returns: (wav_file, phoneme) tuple\n \"\"\"\n pass\n\n def execute(self, sentence):\n \"\"\"\n Convert sentence to speech.\n\n The method caches results if possible using the hash of the\n sentence.\n\n Args:\n sentence: Sentence to be spoken\n \"\"\"\n key = str(hashlib.md5(sentence.encode('utf-8', 'ignore')).hexdigest())\n wav_file = os.path.join(mycroft.util.get_cache_directory(\"tts\"),\n key + self.type)\n\n if os.path.exists(wav_file):\n LOGGER.debug(\"TTS cache hit\")\n phonemes = self.load_phonemes(key)\n else:\n wav_file, phonemes = self.get_tts(sentence, wav_file)\n if phonemes:\n self.save_phonemes(key, phonemes)\n\n self.queue.put((self.type, wav_file, self.visime(phonemes)))\n\n def visime(self, phonemes):\n \"\"\"\n Create visimes from phonemes. Needs to be implemented for all\n tts backend\n\n Args:\n phonemes(str): String with phoneme data\n \"\"\"\n return None\n\n def clear_cache(self):\n \"\"\" Remove all cached files. \"\"\"\n if not os.path.exists(mycroft.util.get_cache_directory('tts')):\n return\n for f in os.listdir(mycroft.util.get_cache_directory(\"tts\")):\n file_path = os.path.join(mycroft.util.get_cache_directory(\"tts\"),\n f)\n if os.path.isfile(file_path):\n os.unlink(file_path)\n\n def save_phonemes(self, key, phonemes):\n \"\"\"\n Cache phonemes\n\n Args:\n key: Hash key for the sentence\n phonemes: phoneme string to save\n \"\"\"\n # Clean out the cache as needed\n cache_dir = mycroft.util.get_cache_directory(\"tts\")\n mycroft.util.curate_cache(cache_dir)\n\n pho_file = os.path.join(cache_dir, key + \".pho\")\n try:\n with open(pho_file, \"w\") as cachefile:\n cachefile.write(phonemes)\n except:\n LOGGER.debug(\"Failed to write .PHO to cache\")\n pass\n\n def load_phonemes(self, key):\n \"\"\"\n Load phonemes from cache file.\n\n Args:\n Key: Key identifying phoneme cache\n \"\"\"\n pho_file = os.path.join(mycroft.util.get_cache_directory(\"tts\"),\n key+\".pho\")\n if os.path.exists(pho_file):\n try:\n with open(pho_file, \"r\") as cachefile:\n phonemes = cachefile.read().strip()\n return phonemes\n except:\n LOGGER.debug(\"Failed to read .PHO from cache\")\n return None\n\n def __del__(self):\n self.playback.stop()\n self.playback.join()\n\n\nclass TTSValidator(object):\n \"\"\"\n TTS Validator abstract class to be implemented by all TTS engines.\n\n It exposes and implements ``validate(tts)`` function as a template to\n validate the TTS engines.\n \"\"\"\n __metaclass__ = ABCMeta\n\n def __init__(self, tts):\n self.tts = tts\n\n def validate(self):\n self.validate_instance()\n self.validate_filename()\n self.validate_lang()\n self.validate_connection()\n\n def validate_instance(self):\n clazz = self.get_tts_class()\n if not isinstance(self.tts, clazz):\n raise AttributeError('tts must be instance of ' + clazz.__name__)\n\n def validate_filename(self):\n filename = self.tts.filename\n if not (filename and filename.endswith('.wav')):\n raise AttributeError('file: %s must be in .wav format!' % filename)\n\n dir_path = dirname(filename)\n if not (exists(dir_path) and isdir(dir_path)):\n raise AttributeError('filename: %s is not valid!' % filename)\n\n @abstractmethod\n def validate_lang(self):\n pass\n\n @abstractmethod\n def validate_connection(self):\n pass\n\n @abstractmethod\n def get_tts_class(self):\n pass\n\n\nclass TTSFactory(object):\n from mycroft.tts.espeak_tts import ESpeak\n from mycroft.tts.fa_tts import FATTS\n from mycroft.tts.google_tts import GoogleTTS\n from mycroft.tts.mary_tts import MaryTTS\n from mycroft.tts.mimic_tts import Mimic\n from mycroft.tts.spdsay_tts import SpdSay\n\n CLASSES = {\n \"mimic\": Mimic,\n \"google\": GoogleTTS,\n \"marytts\": MaryTTS,\n \"fatts\": FATTS,\n \"espeak\": ESpeak,\n \"spdsay\": SpdSay\n }\n\n @staticmethod\n def create():\n \"\"\"\n Factory method to create a TTS engine based on configuration.\n\n The configuration file ``mycroft.conf`` contains a ``tts`` section with\n the name of a TTS module to be read by this method.\n\n \"tts\": {\n \"module\": <engine_name>\n }\n \"\"\"\n\n from mycroft.tts.remote_tts import RemoteTTS\n config = ConfigurationManager.get().get('tts', {})\n module = config.get('module', 'mimic')\n lang = config.get(module).get('lang')\n voice = config.get(module).get('voice')\n clazz = TTSFactory.CLASSES.get(module)\n\n if issubclass(clazz, RemoteTTS):\n url = config.get(module).get('url')\n tts = clazz(lang, voice, url)\n else:\n tts = clazz(lang, voice)\n\n tts.validator.validate()\n return tts\n", "path": "mycroft/tts/__init__.py"}]}
| 3,629 | 401 |
gh_patches_debug_24129
|
rasdani/github-patches
|
git_diff
|
fossasia__open-event-server-7875
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Delete space in front of colons
Some text pieces coming from the server has a space in front of colons " :". Please check all text including email texts and delete the space in front of colons.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `create_db.py`
Content:
```
1 import argparse
2 import getpass
3 import re
4
5 from flask_migrate import stamp
6
7 from app.instance import current_app
8 from app.models import db
9 from populate_db import populate
10 from tests.all.integration.auth_helper import create_super_admin
11
12
13 def create_default_user(email, password):
14 print("Your login is 'super_admin'.")
15 if not email:
16 ask_email = True
17 while ask_email:
18 email = input("Enter email for super_admin : ")
19 if not re.match(r'[^@]+@[^@]+\.[^@]+', email):
20 print('\nInvalid email address\n')
21 continue
22 ask_email = False
23 if not password:
24 ask_password = True
25 while ask_password:
26 password = getpass.getpass("Enter password for super_admin : ")
27 if len(password) < 8:
28 print('\nPassword should have minimum 8 characters')
29 continue
30 repassword = getpass.getpass("Enter your password again to confirm : ")
31 if password != repassword:
32 print('\nPassword did not match')
33 continue
34 ask_password = False
35 create_super_admin(email, password)
36
37
38 if __name__ == "__main__":
39 parser = argparse.ArgumentParser()
40 parser.add_argument("email", nargs='?', help="The email for super_admin.", default='')
41 parser.add_argument(
42 "password", nargs='?', help="The password for super_admin.", default=''
43 )
44 parsed = parser.parse_args()
45 with current_app.app_context():
46 db.engine.execute('create extension if not exists citext')
47 db.create_all()
48 stamp()
49 create_default_user(parsed.email, parsed.password)
50 populate()
51
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/create_db.py b/create_db.py
--- a/create_db.py
+++ b/create_db.py
@@ -15,7 +15,7 @@
if not email:
ask_email = True
while ask_email:
- email = input("Enter email for super_admin : ")
+ email = input("Enter email for super_admin: ")
if not re.match(r'[^@]+@[^@]+\.[^@]+', email):
print('\nInvalid email address\n')
continue
@@ -23,11 +23,11 @@
if not password:
ask_password = True
while ask_password:
- password = getpass.getpass("Enter password for super_admin : ")
+ password = getpass.getpass("Enter password for super_admin: ")
if len(password) < 8:
print('\nPassword should have minimum 8 characters')
continue
- repassword = getpass.getpass("Enter your password again to confirm : ")
+ repassword = getpass.getpass("Enter your password again to confirm: ")
if password != repassword:
print('\nPassword did not match')
continue
|
{"golden_diff": "diff --git a/create_db.py b/create_db.py\n--- a/create_db.py\n+++ b/create_db.py\n@@ -15,7 +15,7 @@\n if not email:\n ask_email = True\n while ask_email:\n- email = input(\"Enter email for super_admin : \")\n+ email = input(\"Enter email for super_admin: \")\n if not re.match(r'[^@]+@[^@]+\\.[^@]+', email):\n print('\\nInvalid email address\\n')\n continue\n@@ -23,11 +23,11 @@\n if not password:\n ask_password = True\n while ask_password:\n- password = getpass.getpass(\"Enter password for super_admin : \")\n+ password = getpass.getpass(\"Enter password for super_admin: \")\n if len(password) < 8:\n print('\\nPassword should have minimum 8 characters')\n continue\n- repassword = getpass.getpass(\"Enter your password again to confirm : \")\n+ repassword = getpass.getpass(\"Enter your password again to confirm: \")\n if password != repassword:\n print('\\nPassword did not match')\n continue\n", "issue": "Delete space in front of colons\nSome text pieces coming from the server has a space in front of colons \" :\". Please check all text including email texts and delete the space in front of colons.\n", "before_files": [{"content": "import argparse\nimport getpass\nimport re\n\nfrom flask_migrate import stamp\n\nfrom app.instance import current_app\nfrom app.models import db\nfrom populate_db import populate\nfrom tests.all.integration.auth_helper import create_super_admin\n\n\ndef create_default_user(email, password):\n print(\"Your login is 'super_admin'.\")\n if not email:\n ask_email = True\n while ask_email:\n email = input(\"Enter email for super_admin : \")\n if not re.match(r'[^@]+@[^@]+\\.[^@]+', email):\n print('\\nInvalid email address\\n')\n continue\n ask_email = False\n if not password:\n ask_password = True\n while ask_password:\n password = getpass.getpass(\"Enter password for super_admin : \")\n if len(password) < 8:\n print('\\nPassword should have minimum 8 characters')\n continue\n repassword = getpass.getpass(\"Enter your password again to confirm : \")\n if password != repassword:\n print('\\nPassword did not match')\n continue\n ask_password = False\n create_super_admin(email, password)\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser()\n parser.add_argument(\"email\", nargs='?', help=\"The email for super_admin.\", default='')\n parser.add_argument(\n \"password\", nargs='?', help=\"The password for super_admin.\", default=''\n )\n parsed = parser.parse_args()\n with current_app.app_context():\n db.engine.execute('create extension if not exists citext')\n db.create_all()\n stamp()\n create_default_user(parsed.email, parsed.password)\n populate()\n", "path": "create_db.py"}], "after_files": [{"content": "import argparse\nimport getpass\nimport re\n\nfrom flask_migrate import stamp\n\nfrom app.instance import current_app\nfrom app.models import db\nfrom populate_db import populate\nfrom tests.all.integration.auth_helper import create_super_admin\n\n\ndef create_default_user(email, password):\n print(\"Your login is 'super_admin'.\")\n if not email:\n ask_email = True\n while ask_email:\n email = input(\"Enter email for super_admin: \")\n if not re.match(r'[^@]+@[^@]+\\.[^@]+', email):\n print('\\nInvalid email address\\n')\n continue\n ask_email = False\n if not password:\n ask_password = True\n while ask_password:\n password = getpass.getpass(\"Enter password for super_admin: \")\n if len(password) < 8:\n print('\\nPassword should have minimum 8 characters')\n continue\n repassword = getpass.getpass(\"Enter your password again to confirm: \")\n if password != repassword:\n print('\\nPassword did not match')\n continue\n ask_password = False\n create_super_admin(email, password)\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser()\n parser.add_argument(\"email\", nargs='?', help=\"The email for super_admin.\", default='')\n parser.add_argument(\n \"password\", nargs='?', help=\"The password for super_admin.\", default=''\n )\n parsed = parser.parse_args()\n with current_app.app_context():\n db.engine.execute('create extension if not exists citext')\n db.create_all()\n stamp()\n create_default_user(parsed.email, parsed.password)\n populate()\n", "path": "create_db.py"}]}
| 744 | 253 |
gh_patches_debug_3925
|
rasdani/github-patches
|
git_diff
|
onnx__onnx-3988
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Is this concat operation supported by ONNX?
# Source
PaddlePaddle->onnx->onnx-sim
onnx version:11.0
# Describe
The input feature graph and the two learned feature graphs are spliced in dimension.
# New Operator

# one of the two learned feature graphs info:

# Confused point
How does this work?
Any suggestions if I need to refactor it with traditional operations by caffe?
# Thanks
I hope I can get your help!
Thanks !
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # SPDX-License-Identifier: Apache-2.0
2
3 from distutils.spawn import find_executable
4 from distutils import sysconfig, log
5 import setuptools
6 import setuptools.command.build_py
7 import setuptools.command.develop
8 import setuptools.command.build_ext
9
10 from collections import namedtuple
11 from contextlib import contextmanager
12 from datetime import date
13 import glob
14 import os
15 import shlex
16 import subprocess
17 import sys
18 import platform
19 from textwrap import dedent
20 import multiprocessing
21
22
23 TOP_DIR = os.path.realpath(os.path.dirname(__file__))
24 SRC_DIR = os.path.join(TOP_DIR, 'onnx')
25 TP_DIR = os.path.join(TOP_DIR, 'third_party')
26 CMAKE_BUILD_DIR = os.path.join(TOP_DIR, '.setuptools-cmake-build')
27 PACKAGE_NAME = 'onnx'
28
29 WINDOWS = (os.name == 'nt')
30
31 CMAKE = find_executable('cmake3') or find_executable('cmake')
32 MAKE = find_executable('make')
33
34 install_requires = []
35 setup_requires = []
36 tests_require = []
37 extras_require = {}
38
39 ################################################################################
40 # Global variables for controlling the build variant
41 ################################################################################
42
43 # Default value is set to TRUE\1 to keep the settings same as the current ones.
44 # However going forward the recommended way to is to set this to False\0
45 ONNX_ML = not bool(os.getenv('ONNX_ML') == '0')
46 ONNX_VERIFY_PROTO3 = bool(os.getenv('ONNX_VERIFY_PROTO3') == '1')
47 ONNX_NAMESPACE = os.getenv('ONNX_NAMESPACE', 'onnx')
48 ONNX_BUILD_TESTS = bool(os.getenv('ONNX_BUILD_TESTS') == '1')
49 ONNX_DISABLE_EXCEPTIONS = bool(os.getenv('ONNX_DISABLE_EXCEPTIONS') == '1')
50
51 USE_MSVC_STATIC_RUNTIME = bool(os.getenv('USE_MSVC_STATIC_RUNTIME', '0') == '1')
52 DEBUG = bool(os.getenv('DEBUG', '0') == '1')
53 COVERAGE = bool(os.getenv('COVERAGE', '0') == '1')
54
55 ################################################################################
56 # Version
57 ################################################################################
58
59 try:
60 git_version = subprocess.check_output(['git', 'rev-parse', 'HEAD'],
61 cwd=TOP_DIR).decode('ascii').strip()
62 except (OSError, subprocess.CalledProcessError):
63 git_version = None
64
65 with open(os.path.join(TOP_DIR, 'VERSION_NUMBER')) as version_file:
66 VERSION_NUMBER = version_file.read().strip()
67 if '--weekly_build' in sys.argv:
68 today_number = date.today().strftime("%Y%m%d")
69 VERSION_NUMBER += '.dev' + today_number
70 PACKAGE_NAME = 'onnx-weekly'
71 sys.argv.remove('--weekly_build')
72 VersionInfo = namedtuple('VersionInfo', ['version', 'git_version'])(
73 version=VERSION_NUMBER,
74 git_version=git_version
75 )
76
77 ################################################################################
78 # Pre Check
79 ################################################################################
80
81 assert CMAKE, 'Could not find "cmake" executable!'
82
83 ################################################################################
84 # Utilities
85 ################################################################################
86
87
88 @contextmanager
89 def cd(path):
90 if not os.path.isabs(path):
91 raise RuntimeError('Can only cd to absolute path, got: {}'.format(path))
92 orig_path = os.getcwd()
93 os.chdir(path)
94 try:
95 yield
96 finally:
97 os.chdir(orig_path)
98
99
100 ################################################################################
101 # Customized commands
102 ################################################################################
103
104
105 class ONNXCommand(setuptools.Command):
106 user_options = []
107
108 def initialize_options(self):
109 pass
110
111 def finalize_options(self):
112 pass
113
114
115 class create_version(ONNXCommand):
116 def run(self):
117 with open(os.path.join(SRC_DIR, 'version.py'), 'w') as f:
118 f.write(dedent('''\
119 # This file is generated by setup.py. DO NOT EDIT!
120
121
122 version = '{version}'
123 git_version = '{git_version}'
124 '''.format(**dict(VersionInfo._asdict()))))
125
126
127 class cmake_build(setuptools.Command):
128 """
129 Compiles everything when `python setup.py build` is run using cmake.
130
131 Custom args can be passed to cmake by specifying the `CMAKE_ARGS`
132 environment variable.
133
134 The number of CPUs used by `make` can be specified by passing `-j<ncpus>`
135 to `setup.py build`. By default all CPUs are used.
136 """
137 user_options = [
138 (str('jobs='), str('j'), str('Specifies the number of jobs to use with make'))
139 ]
140
141 built = False
142
143 def initialize_options(self):
144 self.jobs = None
145
146 def finalize_options(self):
147 self.set_undefined_options('build', ('parallel', 'jobs'))
148 if self.jobs is None and os.getenv("MAX_JOBS") is not None:
149 self.jobs = os.getenv("MAX_JOBS")
150 self.jobs = multiprocessing.cpu_count() if self.jobs is None else int(self.jobs)
151
152 def run(self):
153 if cmake_build.built:
154 return
155 cmake_build.built = True
156 if not os.path.exists(CMAKE_BUILD_DIR):
157 os.makedirs(CMAKE_BUILD_DIR)
158
159 with cd(CMAKE_BUILD_DIR):
160 build_type = 'Release'
161 # configure
162 cmake_args = [
163 CMAKE,
164 '-DPYTHON_INCLUDE_DIR={}'.format(sysconfig.get_python_inc()),
165 '-DPYTHON_EXECUTABLE={}'.format(sys.executable),
166 '-DBUILD_ONNX_PYTHON=ON',
167 '-DCMAKE_EXPORT_COMPILE_COMMANDS=ON',
168 '-DONNX_NAMESPACE={}'.format(ONNX_NAMESPACE),
169 '-DPY_EXT_SUFFIX={}'.format(sysconfig.get_config_var('EXT_SUFFIX') or ''),
170 ]
171 if COVERAGE:
172 cmake_args.append('-DONNX_COVERAGE=ON')
173 if COVERAGE or DEBUG:
174 # in order to get accurate coverage information, the
175 # build needs to turn off optimizations
176 build_type = 'Debug'
177 cmake_args.append('-DCMAKE_BUILD_TYPE=%s' % build_type)
178 if WINDOWS:
179 cmake_args.extend([
180 # we need to link with libpython on windows, so
181 # passing python version to window in order to
182 # find python in cmake
183 '-DPY_VERSION={}'.format('{0}.{1}'.format(*sys.version_info[:2])),
184 ])
185 if USE_MSVC_STATIC_RUNTIME:
186 cmake_args.append('-DONNX_USE_MSVC_STATIC_RUNTIME=ON')
187 if platform.architecture()[0] == '64bit':
188 cmake_args.extend(['-A', 'x64', '-T', 'host=x64'])
189 else:
190 cmake_args.extend(['-A', 'Win32', '-T', 'host=x86'])
191 if ONNX_ML:
192 cmake_args.append('-DONNX_ML=1')
193 if ONNX_VERIFY_PROTO3:
194 cmake_args.append('-DONNX_VERIFY_PROTO3=1')
195 if ONNX_BUILD_TESTS:
196 cmake_args.append('-DONNX_BUILD_TESTS=ON')
197 if ONNX_DISABLE_EXCEPTIONS:
198 cmake_args.append('-DONNX_DISABLE_EXCEPTIONS=ON')
199 if 'CMAKE_ARGS' in os.environ:
200 extra_cmake_args = shlex.split(os.environ['CMAKE_ARGS'])
201 # prevent crossfire with downstream scripts
202 del os.environ['CMAKE_ARGS']
203 log.info('Extra cmake args: {}'.format(extra_cmake_args))
204 cmake_args.extend(extra_cmake_args)
205 cmake_args.append(TOP_DIR)
206 log.info('Using cmake args: {}'.format(cmake_args))
207 if '-DONNX_DISABLE_EXCEPTIONS=ON' in cmake_args:
208 raise RuntimeError("-DONNX_DISABLE_EXCEPTIONS=ON option is only available for c++ builds. Python binding require exceptions to be enabled.")
209 subprocess.check_call(cmake_args)
210
211 build_args = [CMAKE, '--build', os.curdir]
212 if WINDOWS:
213 build_args.extend(['--config', build_type])
214 build_args.extend(['--', '/maxcpucount:{}'.format(self.jobs)])
215 else:
216 build_args.extend(['--', '-j', str(self.jobs)])
217 subprocess.check_call(build_args)
218
219
220 class build_py(setuptools.command.build_py.build_py):
221 def run(self):
222 self.run_command('create_version')
223 self.run_command('cmake_build')
224
225 generated_python_files = \
226 glob.glob(os.path.join(CMAKE_BUILD_DIR, 'onnx', '*.py')) + \
227 glob.glob(os.path.join(CMAKE_BUILD_DIR, 'onnx', '*.pyi'))
228
229 for src in generated_python_files:
230 dst = os.path.join(
231 TOP_DIR, os.path.relpath(src, CMAKE_BUILD_DIR))
232 self.copy_file(src, dst)
233
234 return setuptools.command.build_py.build_py.run(self)
235
236
237 class develop(setuptools.command.develop.develop):
238 def run(self):
239 self.run_command('build_py')
240 setuptools.command.develop.develop.run(self)
241
242
243 class build_ext(setuptools.command.build_ext.build_ext):
244 def run(self):
245 self.run_command('cmake_build')
246 setuptools.command.build_ext.build_ext.run(self)
247
248 def build_extensions(self):
249 for ext in self.extensions:
250 fullname = self.get_ext_fullname(ext.name)
251 filename = os.path.basename(self.get_ext_filename(fullname))
252
253 lib_path = CMAKE_BUILD_DIR
254 if os.name == 'nt':
255 debug_lib_dir = os.path.join(lib_path, "Debug")
256 release_lib_dir = os.path.join(lib_path, "Release")
257 if os.path.exists(debug_lib_dir):
258 lib_path = debug_lib_dir
259 elif os.path.exists(release_lib_dir):
260 lib_path = release_lib_dir
261 src = os.path.join(lib_path, filename)
262 dst = os.path.join(os.path.realpath(self.build_lib), "onnx", filename)
263 self.copy_file(src, dst)
264
265
266 class mypy_type_check(ONNXCommand):
267 description = 'Run MyPy type checker'
268
269 def run(self):
270 """Run command."""
271 onnx_script = os.path.realpath(os.path.join(os.path.dirname(os.path.abspath(__file__)), "tools/mypy-onnx.py"))
272 returncode = subprocess.call([sys.executable, onnx_script])
273 sys.exit(returncode)
274
275
276 cmdclass = {
277 'create_version': create_version,
278 'cmake_build': cmake_build,
279 'build_py': build_py,
280 'develop': develop,
281 'build_ext': build_ext,
282 'typecheck': mypy_type_check,
283 }
284
285 ################################################################################
286 # Extensions
287 ################################################################################
288
289 ext_modules = [
290 setuptools.Extension(
291 name=str('onnx.onnx_cpp2py_export'),
292 sources=[])
293 ]
294
295 ################################################################################
296 # Packages
297 ################################################################################
298
299 # no need to do fancy stuff so far
300 packages = setuptools.find_packages()
301
302 requirements_file = "requirements.txt"
303 requirements_path = os.path.join(os.getcwd(), requirements_file)
304 if not os.path.exists(requirements_path):
305 this = os.path.dirname(__file__)
306 requirements_path = os.path.join(this, requirements_file)
307 if not os.path.exists(requirements_path):
308 raise FileNotFoundError("Unable to find " + requirements_file)
309 with open(requirements_path) as f:
310 install_requires = f.read().splitlines()
311
312 ################################################################################
313 # Test
314 ################################################################################
315
316 setup_requires.append('pytest-runner')
317 tests_require.append('pytest')
318 tests_require.append('nbval')
319 tests_require.append('tabulate')
320
321 extras_require['mypy'] = ['mypy==0.782', 'types-protobuf==3.18.4']
322
323 ################################################################################
324 # Final
325 ################################################################################
326
327 setuptools.setup(
328 name=PACKAGE_NAME,
329 version=VersionInfo.version,
330 description="Open Neural Network Exchange",
331 long_description=open("README.md").read(),
332 long_description_content_type="text/markdown",
333 ext_modules=ext_modules,
334 cmdclass=cmdclass,
335 packages=packages,
336 license='Apache License v2.0',
337 include_package_data=True,
338 install_requires=install_requires,
339 setup_requires=setup_requires,
340 tests_require=tests_require,
341 extras_require=extras_require,
342 author='ONNX',
343 author_email='[email protected]',
344 url='https://github.com/onnx/onnx',
345 entry_points={
346 'console_scripts': [
347 'check-model = onnx.bin.checker:check_model',
348 'check-node = onnx.bin.checker:check_node',
349 'backend-test-tools = onnx.backend.test.cmd_tools:main',
350 ]
351 },
352 )
353
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -318,7 +318,12 @@
tests_require.append('nbval')
tests_require.append('tabulate')
-extras_require['mypy'] = ['mypy==0.782', 'types-protobuf==3.18.4']
+extras_require['lint'] = [
+ 'clang-format==13.0.0',
+ 'flake8',
+ 'mypy==0.782',
+ 'types-protobuf==3.18.4',
+]
################################################################################
# Final
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -318,7 +318,12 @@\n tests_require.append('nbval')\n tests_require.append('tabulate')\n \n-extras_require['mypy'] = ['mypy==0.782', 'types-protobuf==3.18.4']\n+extras_require['lint'] = [\n+ 'clang-format==13.0.0',\n+ 'flake8',\n+ 'mypy==0.782',\n+ 'types-protobuf==3.18.4',\n+]\n \n ################################################################################\n # Final\n", "issue": "Is this concat operation supported by ONNX?\n# Source\r\nPaddlePaddle->onnx->onnx-sim \r\nonnx version:11.0\r\n# Describe\r\nThe input feature graph and the two learned feature graphs are spliced in dimension.\r\n# New Operator\r\n\r\n# one of the two learned feature graphs info:\r\n\r\n# Confused point\r\nHow does this work? \r\nAny suggestions if I need to refactor it with traditional operations by caffe\uff1f\r\n\r\n# Thanks\r\n\r\nI hope I can get your help\uff01\r\nThanks ! \r\n\r\n\r\n\n", "before_files": [{"content": "# SPDX-License-Identifier: Apache-2.0\n\nfrom distutils.spawn import find_executable\nfrom distutils import sysconfig, log\nimport setuptools\nimport setuptools.command.build_py\nimport setuptools.command.develop\nimport setuptools.command.build_ext\n\nfrom collections import namedtuple\nfrom contextlib import contextmanager\nfrom datetime import date\nimport glob\nimport os\nimport shlex\nimport subprocess\nimport sys\nimport platform\nfrom textwrap import dedent\nimport multiprocessing\n\n\nTOP_DIR = os.path.realpath(os.path.dirname(__file__))\nSRC_DIR = os.path.join(TOP_DIR, 'onnx')\nTP_DIR = os.path.join(TOP_DIR, 'third_party')\nCMAKE_BUILD_DIR = os.path.join(TOP_DIR, '.setuptools-cmake-build')\nPACKAGE_NAME = 'onnx'\n\nWINDOWS = (os.name == 'nt')\n\nCMAKE = find_executable('cmake3') or find_executable('cmake')\nMAKE = find_executable('make')\n\ninstall_requires = []\nsetup_requires = []\ntests_require = []\nextras_require = {}\n\n################################################################################\n# Global variables for controlling the build variant\n################################################################################\n\n# Default value is set to TRUE\\1 to keep the settings same as the current ones.\n# However going forward the recommended way to is to set this to False\\0\nONNX_ML = not bool(os.getenv('ONNX_ML') == '0')\nONNX_VERIFY_PROTO3 = bool(os.getenv('ONNX_VERIFY_PROTO3') == '1')\nONNX_NAMESPACE = os.getenv('ONNX_NAMESPACE', 'onnx')\nONNX_BUILD_TESTS = bool(os.getenv('ONNX_BUILD_TESTS') == '1')\nONNX_DISABLE_EXCEPTIONS = bool(os.getenv('ONNX_DISABLE_EXCEPTIONS') == '1')\n\nUSE_MSVC_STATIC_RUNTIME = bool(os.getenv('USE_MSVC_STATIC_RUNTIME', '0') == '1')\nDEBUG = bool(os.getenv('DEBUG', '0') == '1')\nCOVERAGE = bool(os.getenv('COVERAGE', '0') == '1')\n\n################################################################################\n# Version\n################################################################################\n\ntry:\n git_version = subprocess.check_output(['git', 'rev-parse', 'HEAD'],\n cwd=TOP_DIR).decode('ascii').strip()\nexcept (OSError, subprocess.CalledProcessError):\n git_version = None\n\nwith open(os.path.join(TOP_DIR, 'VERSION_NUMBER')) as version_file:\n VERSION_NUMBER = version_file.read().strip()\n if '--weekly_build' in sys.argv:\n today_number = date.today().strftime(\"%Y%m%d\")\n VERSION_NUMBER += '.dev' + today_number\n PACKAGE_NAME = 'onnx-weekly'\n sys.argv.remove('--weekly_build')\n VersionInfo = namedtuple('VersionInfo', ['version', 'git_version'])(\n version=VERSION_NUMBER,\n git_version=git_version\n )\n\n################################################################################\n# Pre Check\n################################################################################\n\nassert CMAKE, 'Could not find \"cmake\" executable!'\n\n################################################################################\n# Utilities\n################################################################################\n\n\n@contextmanager\ndef cd(path):\n if not os.path.isabs(path):\n raise RuntimeError('Can only cd to absolute path, got: {}'.format(path))\n orig_path = os.getcwd()\n os.chdir(path)\n try:\n yield\n finally:\n os.chdir(orig_path)\n\n\n################################################################################\n# Customized commands\n################################################################################\n\n\nclass ONNXCommand(setuptools.Command):\n user_options = []\n\n def initialize_options(self):\n pass\n\n def finalize_options(self):\n pass\n\n\nclass create_version(ONNXCommand):\n def run(self):\n with open(os.path.join(SRC_DIR, 'version.py'), 'w') as f:\n f.write(dedent('''\\\n # This file is generated by setup.py. DO NOT EDIT!\n\n\n version = '{version}'\n git_version = '{git_version}'\n '''.format(**dict(VersionInfo._asdict()))))\n\n\nclass cmake_build(setuptools.Command):\n \"\"\"\n Compiles everything when `python setup.py build` is run using cmake.\n\n Custom args can be passed to cmake by specifying the `CMAKE_ARGS`\n environment variable.\n\n The number of CPUs used by `make` can be specified by passing `-j<ncpus>`\n to `setup.py build`. By default all CPUs are used.\n \"\"\"\n user_options = [\n (str('jobs='), str('j'), str('Specifies the number of jobs to use with make'))\n ]\n\n built = False\n\n def initialize_options(self):\n self.jobs = None\n\n def finalize_options(self):\n self.set_undefined_options('build', ('parallel', 'jobs'))\n if self.jobs is None and os.getenv(\"MAX_JOBS\") is not None:\n self.jobs = os.getenv(\"MAX_JOBS\")\n self.jobs = multiprocessing.cpu_count() if self.jobs is None else int(self.jobs)\n\n def run(self):\n if cmake_build.built:\n return\n cmake_build.built = True\n if not os.path.exists(CMAKE_BUILD_DIR):\n os.makedirs(CMAKE_BUILD_DIR)\n\n with cd(CMAKE_BUILD_DIR):\n build_type = 'Release'\n # configure\n cmake_args = [\n CMAKE,\n '-DPYTHON_INCLUDE_DIR={}'.format(sysconfig.get_python_inc()),\n '-DPYTHON_EXECUTABLE={}'.format(sys.executable),\n '-DBUILD_ONNX_PYTHON=ON',\n '-DCMAKE_EXPORT_COMPILE_COMMANDS=ON',\n '-DONNX_NAMESPACE={}'.format(ONNX_NAMESPACE),\n '-DPY_EXT_SUFFIX={}'.format(sysconfig.get_config_var('EXT_SUFFIX') or ''),\n ]\n if COVERAGE:\n cmake_args.append('-DONNX_COVERAGE=ON')\n if COVERAGE or DEBUG:\n # in order to get accurate coverage information, the\n # build needs to turn off optimizations\n build_type = 'Debug'\n cmake_args.append('-DCMAKE_BUILD_TYPE=%s' % build_type)\n if WINDOWS:\n cmake_args.extend([\n # we need to link with libpython on windows, so\n # passing python version to window in order to\n # find python in cmake\n '-DPY_VERSION={}'.format('{0}.{1}'.format(*sys.version_info[:2])),\n ])\n if USE_MSVC_STATIC_RUNTIME:\n cmake_args.append('-DONNX_USE_MSVC_STATIC_RUNTIME=ON')\n if platform.architecture()[0] == '64bit':\n cmake_args.extend(['-A', 'x64', '-T', 'host=x64'])\n else:\n cmake_args.extend(['-A', 'Win32', '-T', 'host=x86'])\n if ONNX_ML:\n cmake_args.append('-DONNX_ML=1')\n if ONNX_VERIFY_PROTO3:\n cmake_args.append('-DONNX_VERIFY_PROTO3=1')\n if ONNX_BUILD_TESTS:\n cmake_args.append('-DONNX_BUILD_TESTS=ON')\n if ONNX_DISABLE_EXCEPTIONS:\n cmake_args.append('-DONNX_DISABLE_EXCEPTIONS=ON')\n if 'CMAKE_ARGS' in os.environ:\n extra_cmake_args = shlex.split(os.environ['CMAKE_ARGS'])\n # prevent crossfire with downstream scripts\n del os.environ['CMAKE_ARGS']\n log.info('Extra cmake args: {}'.format(extra_cmake_args))\n cmake_args.extend(extra_cmake_args)\n cmake_args.append(TOP_DIR)\n log.info('Using cmake args: {}'.format(cmake_args))\n if '-DONNX_DISABLE_EXCEPTIONS=ON' in cmake_args:\n raise RuntimeError(\"-DONNX_DISABLE_EXCEPTIONS=ON option is only available for c++ builds. Python binding require exceptions to be enabled.\")\n subprocess.check_call(cmake_args)\n\n build_args = [CMAKE, '--build', os.curdir]\n if WINDOWS:\n build_args.extend(['--config', build_type])\n build_args.extend(['--', '/maxcpucount:{}'.format(self.jobs)])\n else:\n build_args.extend(['--', '-j', str(self.jobs)])\n subprocess.check_call(build_args)\n\n\nclass build_py(setuptools.command.build_py.build_py):\n def run(self):\n self.run_command('create_version')\n self.run_command('cmake_build')\n\n generated_python_files = \\\n glob.glob(os.path.join(CMAKE_BUILD_DIR, 'onnx', '*.py')) + \\\n glob.glob(os.path.join(CMAKE_BUILD_DIR, 'onnx', '*.pyi'))\n\n for src in generated_python_files:\n dst = os.path.join(\n TOP_DIR, os.path.relpath(src, CMAKE_BUILD_DIR))\n self.copy_file(src, dst)\n\n return setuptools.command.build_py.build_py.run(self)\n\n\nclass develop(setuptools.command.develop.develop):\n def run(self):\n self.run_command('build_py')\n setuptools.command.develop.develop.run(self)\n\n\nclass build_ext(setuptools.command.build_ext.build_ext):\n def run(self):\n self.run_command('cmake_build')\n setuptools.command.build_ext.build_ext.run(self)\n\n def build_extensions(self):\n for ext in self.extensions:\n fullname = self.get_ext_fullname(ext.name)\n filename = os.path.basename(self.get_ext_filename(fullname))\n\n lib_path = CMAKE_BUILD_DIR\n if os.name == 'nt':\n debug_lib_dir = os.path.join(lib_path, \"Debug\")\n release_lib_dir = os.path.join(lib_path, \"Release\")\n if os.path.exists(debug_lib_dir):\n lib_path = debug_lib_dir\n elif os.path.exists(release_lib_dir):\n lib_path = release_lib_dir\n src = os.path.join(lib_path, filename)\n dst = os.path.join(os.path.realpath(self.build_lib), \"onnx\", filename)\n self.copy_file(src, dst)\n\n\nclass mypy_type_check(ONNXCommand):\n description = 'Run MyPy type checker'\n\n def run(self):\n \"\"\"Run command.\"\"\"\n onnx_script = os.path.realpath(os.path.join(os.path.dirname(os.path.abspath(__file__)), \"tools/mypy-onnx.py\"))\n returncode = subprocess.call([sys.executable, onnx_script])\n sys.exit(returncode)\n\n\ncmdclass = {\n 'create_version': create_version,\n 'cmake_build': cmake_build,\n 'build_py': build_py,\n 'develop': develop,\n 'build_ext': build_ext,\n 'typecheck': mypy_type_check,\n}\n\n################################################################################\n# Extensions\n################################################################################\n\next_modules = [\n setuptools.Extension(\n name=str('onnx.onnx_cpp2py_export'),\n sources=[])\n]\n\n################################################################################\n# Packages\n################################################################################\n\n# no need to do fancy stuff so far\npackages = setuptools.find_packages()\n\nrequirements_file = \"requirements.txt\"\nrequirements_path = os.path.join(os.getcwd(), requirements_file)\nif not os.path.exists(requirements_path):\n this = os.path.dirname(__file__)\n requirements_path = os.path.join(this, requirements_file)\nif not os.path.exists(requirements_path):\n raise FileNotFoundError(\"Unable to find \" + requirements_file)\nwith open(requirements_path) as f:\n install_requires = f.read().splitlines()\n\n################################################################################\n# Test\n################################################################################\n\nsetup_requires.append('pytest-runner')\ntests_require.append('pytest')\ntests_require.append('nbval')\ntests_require.append('tabulate')\n\nextras_require['mypy'] = ['mypy==0.782', 'types-protobuf==3.18.4']\n\n################################################################################\n# Final\n################################################################################\n\nsetuptools.setup(\n name=PACKAGE_NAME,\n version=VersionInfo.version,\n description=\"Open Neural Network Exchange\",\n long_description=open(\"README.md\").read(),\n long_description_content_type=\"text/markdown\",\n ext_modules=ext_modules,\n cmdclass=cmdclass,\n packages=packages,\n license='Apache License v2.0',\n include_package_data=True,\n install_requires=install_requires,\n setup_requires=setup_requires,\n tests_require=tests_require,\n extras_require=extras_require,\n author='ONNX',\n author_email='[email protected]',\n url='https://github.com/onnx/onnx',\n entry_points={\n 'console_scripts': [\n 'check-model = onnx.bin.checker:check_model',\n 'check-node = onnx.bin.checker:check_node',\n 'backend-test-tools = onnx.backend.test.cmd_tools:main',\n ]\n },\n)\n", "path": "setup.py"}], "after_files": [{"content": "# SPDX-License-Identifier: Apache-2.0\n\nfrom distutils.spawn import find_executable\nfrom distutils import sysconfig, log\nimport setuptools\nimport setuptools.command.build_py\nimport setuptools.command.develop\nimport setuptools.command.build_ext\n\nfrom collections import namedtuple\nfrom contextlib import contextmanager\nfrom datetime import date\nimport glob\nimport os\nimport shlex\nimport subprocess\nimport sys\nimport platform\nfrom textwrap import dedent\nimport multiprocessing\n\n\nTOP_DIR = os.path.realpath(os.path.dirname(__file__))\nSRC_DIR = os.path.join(TOP_DIR, 'onnx')\nTP_DIR = os.path.join(TOP_DIR, 'third_party')\nCMAKE_BUILD_DIR = os.path.join(TOP_DIR, '.setuptools-cmake-build')\nPACKAGE_NAME = 'onnx'\n\nWINDOWS = (os.name == 'nt')\n\nCMAKE = find_executable('cmake3') or find_executable('cmake')\nMAKE = find_executable('make')\n\ninstall_requires = []\nsetup_requires = []\ntests_require = []\nextras_require = {}\n\n################################################################################\n# Global variables for controlling the build variant\n################################################################################\n\n# Default value is set to TRUE\\1 to keep the settings same as the current ones.\n# However going forward the recommended way to is to set this to False\\0\nONNX_ML = not bool(os.getenv('ONNX_ML') == '0')\nONNX_VERIFY_PROTO3 = bool(os.getenv('ONNX_VERIFY_PROTO3') == '1')\nONNX_NAMESPACE = os.getenv('ONNX_NAMESPACE', 'onnx')\nONNX_BUILD_TESTS = bool(os.getenv('ONNX_BUILD_TESTS') == '1')\nONNX_DISABLE_EXCEPTIONS = bool(os.getenv('ONNX_DISABLE_EXCEPTIONS') == '1')\n\nUSE_MSVC_STATIC_RUNTIME = bool(os.getenv('USE_MSVC_STATIC_RUNTIME', '0') == '1')\nDEBUG = bool(os.getenv('DEBUG', '0') == '1')\nCOVERAGE = bool(os.getenv('COVERAGE', '0') == '1')\n\n################################################################################\n# Version\n################################################################################\n\ntry:\n git_version = subprocess.check_output(['git', 'rev-parse', 'HEAD'],\n cwd=TOP_DIR).decode('ascii').strip()\nexcept (OSError, subprocess.CalledProcessError):\n git_version = None\n\nwith open(os.path.join(TOP_DIR, 'VERSION_NUMBER')) as version_file:\n VERSION_NUMBER = version_file.read().strip()\n if '--weekly_build' in sys.argv:\n today_number = date.today().strftime(\"%Y%m%d\")\n VERSION_NUMBER += '.dev' + today_number\n PACKAGE_NAME = 'onnx-weekly'\n sys.argv.remove('--weekly_build')\n VersionInfo = namedtuple('VersionInfo', ['version', 'git_version'])(\n version=VERSION_NUMBER,\n git_version=git_version\n )\n\n################################################################################\n# Pre Check\n################################################################################\n\nassert CMAKE, 'Could not find \"cmake\" executable!'\n\n################################################################################\n# Utilities\n################################################################################\n\n\n@contextmanager\ndef cd(path):\n if not os.path.isabs(path):\n raise RuntimeError('Can only cd to absolute path, got: {}'.format(path))\n orig_path = os.getcwd()\n os.chdir(path)\n try:\n yield\n finally:\n os.chdir(orig_path)\n\n\n################################################################################\n# Customized commands\n################################################################################\n\n\nclass ONNXCommand(setuptools.Command):\n user_options = []\n\n def initialize_options(self):\n pass\n\n def finalize_options(self):\n pass\n\n\nclass create_version(ONNXCommand):\n def run(self):\n with open(os.path.join(SRC_DIR, 'version.py'), 'w') as f:\n f.write(dedent('''\\\n # This file is generated by setup.py. DO NOT EDIT!\n\n\n version = '{version}'\n git_version = '{git_version}'\n '''.format(**dict(VersionInfo._asdict()))))\n\n\nclass cmake_build(setuptools.Command):\n \"\"\"\n Compiles everything when `python setup.py build` is run using cmake.\n\n Custom args can be passed to cmake by specifying the `CMAKE_ARGS`\n environment variable.\n\n The number of CPUs used by `make` can be specified by passing `-j<ncpus>`\n to `setup.py build`. By default all CPUs are used.\n \"\"\"\n user_options = [\n (str('jobs='), str('j'), str('Specifies the number of jobs to use with make'))\n ]\n\n built = False\n\n def initialize_options(self):\n self.jobs = None\n\n def finalize_options(self):\n self.set_undefined_options('build', ('parallel', 'jobs'))\n if self.jobs is None and os.getenv(\"MAX_JOBS\") is not None:\n self.jobs = os.getenv(\"MAX_JOBS\")\n self.jobs = multiprocessing.cpu_count() if self.jobs is None else int(self.jobs)\n\n def run(self):\n if cmake_build.built:\n return\n cmake_build.built = True\n if not os.path.exists(CMAKE_BUILD_DIR):\n os.makedirs(CMAKE_BUILD_DIR)\n\n with cd(CMAKE_BUILD_DIR):\n build_type = 'Release'\n # configure\n cmake_args = [\n CMAKE,\n '-DPYTHON_INCLUDE_DIR={}'.format(sysconfig.get_python_inc()),\n '-DPYTHON_EXECUTABLE={}'.format(sys.executable),\n '-DBUILD_ONNX_PYTHON=ON',\n '-DCMAKE_EXPORT_COMPILE_COMMANDS=ON',\n '-DONNX_NAMESPACE={}'.format(ONNX_NAMESPACE),\n '-DPY_EXT_SUFFIX={}'.format(sysconfig.get_config_var('EXT_SUFFIX') or ''),\n ]\n if COVERAGE:\n cmake_args.append('-DONNX_COVERAGE=ON')\n if COVERAGE or DEBUG:\n # in order to get accurate coverage information, the\n # build needs to turn off optimizations\n build_type = 'Debug'\n cmake_args.append('-DCMAKE_BUILD_TYPE=%s' % build_type)\n if WINDOWS:\n cmake_args.extend([\n # we need to link with libpython on windows, so\n # passing python version to window in order to\n # find python in cmake\n '-DPY_VERSION={}'.format('{0}.{1}'.format(*sys.version_info[:2])),\n ])\n if USE_MSVC_STATIC_RUNTIME:\n cmake_args.append('-DONNX_USE_MSVC_STATIC_RUNTIME=ON')\n if platform.architecture()[0] == '64bit':\n cmake_args.extend(['-A', 'x64', '-T', 'host=x64'])\n else:\n cmake_args.extend(['-A', 'Win32', '-T', 'host=x86'])\n if ONNX_ML:\n cmake_args.append('-DONNX_ML=1')\n if ONNX_VERIFY_PROTO3:\n cmake_args.append('-DONNX_VERIFY_PROTO3=1')\n if ONNX_BUILD_TESTS:\n cmake_args.append('-DONNX_BUILD_TESTS=ON')\n if ONNX_DISABLE_EXCEPTIONS:\n cmake_args.append('-DONNX_DISABLE_EXCEPTIONS=ON')\n if 'CMAKE_ARGS' in os.environ:\n extra_cmake_args = shlex.split(os.environ['CMAKE_ARGS'])\n # prevent crossfire with downstream scripts\n del os.environ['CMAKE_ARGS']\n log.info('Extra cmake args: {}'.format(extra_cmake_args))\n cmake_args.extend(extra_cmake_args)\n cmake_args.append(TOP_DIR)\n log.info('Using cmake args: {}'.format(cmake_args))\n if '-DONNX_DISABLE_EXCEPTIONS=ON' in cmake_args:\n raise RuntimeError(\"-DONNX_DISABLE_EXCEPTIONS=ON option is only available for c++ builds. Python binding require exceptions to be enabled.\")\n subprocess.check_call(cmake_args)\n\n build_args = [CMAKE, '--build', os.curdir]\n if WINDOWS:\n build_args.extend(['--config', build_type])\n build_args.extend(['--', '/maxcpucount:{}'.format(self.jobs)])\n else:\n build_args.extend(['--', '-j', str(self.jobs)])\n subprocess.check_call(build_args)\n\n\nclass build_py(setuptools.command.build_py.build_py):\n def run(self):\n self.run_command('create_version')\n self.run_command('cmake_build')\n\n generated_python_files = \\\n glob.glob(os.path.join(CMAKE_BUILD_DIR, 'onnx', '*.py')) + \\\n glob.glob(os.path.join(CMAKE_BUILD_DIR, 'onnx', '*.pyi'))\n\n for src in generated_python_files:\n dst = os.path.join(\n TOP_DIR, os.path.relpath(src, CMAKE_BUILD_DIR))\n self.copy_file(src, dst)\n\n return setuptools.command.build_py.build_py.run(self)\n\n\nclass develop(setuptools.command.develop.develop):\n def run(self):\n self.run_command('build_py')\n setuptools.command.develop.develop.run(self)\n\n\nclass build_ext(setuptools.command.build_ext.build_ext):\n def run(self):\n self.run_command('cmake_build')\n setuptools.command.build_ext.build_ext.run(self)\n\n def build_extensions(self):\n for ext in self.extensions:\n fullname = self.get_ext_fullname(ext.name)\n filename = os.path.basename(self.get_ext_filename(fullname))\n\n lib_path = CMAKE_BUILD_DIR\n if os.name == 'nt':\n debug_lib_dir = os.path.join(lib_path, \"Debug\")\n release_lib_dir = os.path.join(lib_path, \"Release\")\n if os.path.exists(debug_lib_dir):\n lib_path = debug_lib_dir\n elif os.path.exists(release_lib_dir):\n lib_path = release_lib_dir\n src = os.path.join(lib_path, filename)\n dst = os.path.join(os.path.realpath(self.build_lib), \"onnx\", filename)\n self.copy_file(src, dst)\n\n\nclass mypy_type_check(ONNXCommand):\n description = 'Run MyPy type checker'\n\n def run(self):\n \"\"\"Run command.\"\"\"\n onnx_script = os.path.realpath(os.path.join(os.path.dirname(os.path.abspath(__file__)), \"tools/mypy-onnx.py\"))\n returncode = subprocess.call([sys.executable, onnx_script])\n sys.exit(returncode)\n\n\ncmdclass = {\n 'create_version': create_version,\n 'cmake_build': cmake_build,\n 'build_py': build_py,\n 'develop': develop,\n 'build_ext': build_ext,\n 'typecheck': mypy_type_check,\n}\n\n################################################################################\n# Extensions\n################################################################################\n\next_modules = [\n setuptools.Extension(\n name=str('onnx.onnx_cpp2py_export'),\n sources=[])\n]\n\n################################################################################\n# Packages\n################################################################################\n\n# no need to do fancy stuff so far\npackages = setuptools.find_packages()\n\nrequirements_file = \"requirements.txt\"\nrequirements_path = os.path.join(os.getcwd(), requirements_file)\nif not os.path.exists(requirements_path):\n this = os.path.dirname(__file__)\n requirements_path = os.path.join(this, requirements_file)\nif not os.path.exists(requirements_path):\n raise FileNotFoundError(\"Unable to find \" + requirements_file)\nwith open(requirements_path) as f:\n install_requires = f.read().splitlines()\n\n################################################################################\n# Test\n################################################################################\n\nsetup_requires.append('pytest-runner')\ntests_require.append('pytest')\ntests_require.append('nbval')\ntests_require.append('tabulate')\n\nextras_require['lint'] = [\n 'clang-format==13.0.0',\n 'flake8',\n 'mypy==0.782',\n 'types-protobuf==3.18.4',\n]\n\n################################################################################\n# Final\n################################################################################\n\nsetuptools.setup(\n name=PACKAGE_NAME,\n version=VersionInfo.version,\n description=\"Open Neural Network Exchange\",\n long_description=open(\"README.md\").read(),\n long_description_content_type=\"text/markdown\",\n ext_modules=ext_modules,\n cmdclass=cmdclass,\n packages=packages,\n license='Apache License v2.0',\n include_package_data=True,\n install_requires=install_requires,\n setup_requires=setup_requires,\n tests_require=tests_require,\n extras_require=extras_require,\n author='ONNX',\n author_email='[email protected]',\n url='https://github.com/onnx/onnx',\n entry_points={\n 'console_scripts': [\n 'check-model = onnx.bin.checker:check_model',\n 'check-node = onnx.bin.checker:check_node',\n 'backend-test-tools = onnx.backend.test.cmd_tools:main',\n ]\n },\n)\n", "path": "setup.py"}]}
| 4,085 | 141 |
gh_patches_debug_31190
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-5890
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
@spider=zabka_pl opening hours are missing Sunday data, proposed `opening_hours` are broken
https://www.alltheplaces.xyz/map/#16.47/50.073227/20.037421

https://www.openstreetmap.org/node/4271289403
Opening hours in OSM (`Mo-Sa 06:00-22:00; Su 11:00-20:00`) are correct.
At https://www.zabka.pl/znajdz-sklep it refuses to show Sunday opening hours.
Maybe it is caused by their internal structure? This shops are franchises and maybe they are obligated to be open `Mo-Sa 06:00-22:00` and Sundays can be decided by operator?
Overall it seems that Monday to Saturday data is likely correct.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `locations/spiders/zabka_pl.py`
Content:
```
1 import scrapy
2 from scrapy.http import JsonRequest
3
4 from locations.dict_parser import DictParser
5 from locations.hours import OpeningHours
6
7
8 class ZabkaPLSpider(scrapy.Spider):
9 name = "zabka_pl"
10 item_attributes = {"brand": "Żabka", "brand_wikidata": "Q2589061"}
11
12 # URL extracted by observing request made by Żappka Android app (using HTTP Toolkit)
13 start_urls = ["https://partner-api.zabkamobile.pl/v2/shops"]
14
15 def start_requests(self):
16 # Authorization header is hard-coded into the Żappka app and does not appear to change (as of version 3.14.10).
17 headers = {
18 "Authorization": "PartnerKey 424A0B7AD0E9EA136510474D89061BBDC007B9BE5256A638EA28CC19D2BB15CD",
19 }
20 yield JsonRequest(url=self.start_urls[0], headers=headers)
21
22 def parse(self, response):
23 for location in response.json():
24 item = DictParser.parse(location)
25 item["street_address"] = item.pop("addr_full", "")
26 # unset "state" field, it is taken from the "region" field which is some internal Żabka ID
27 item["state"] = None
28 item["opening_hours"] = OpeningHours()
29
30 # Each franchisee is required to be open Mon-Sat with the same hours
31 # But the hours for Sundays are set in the "nonTradingDays" field, which
32 # contains the opening hours for each specific Sunday.
33 item["opening_hours"].add_days_range(
34 ["Mo", "Tu", "We", "Th", "Fr", "Sa"], location["openTime"], location["closeTime"]
35 )
36 yield item
37
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/locations/spiders/zabka_pl.py b/locations/spiders/zabka_pl.py
--- a/locations/spiders/zabka_pl.py
+++ b/locations/spiders/zabka_pl.py
@@ -1,3 +1,5 @@
+from datetime import datetime
+
import scrapy
from scrapy.http import JsonRequest
@@ -20,6 +22,7 @@
yield JsonRequest(url=self.start_urls[0], headers=headers)
def parse(self, response):
+ today = datetime.now()
for location in response.json():
item = DictParser.parse(location)
item["street_address"] = item.pop("addr_full", "")
@@ -33,4 +36,25 @@
item["opening_hours"].add_days_range(
["Mo", "Tu", "We", "Th", "Fr", "Sa"], location["openTime"], location["closeTime"]
)
+
+ if location["nonTradingDays"]:
+ sunday_open = None
+ sunday_close = None
+ for rule in location["nonTradingDays"]:
+ d = datetime.strptime(rule["date"], "%Y-%m-%d")
+ if d.weekday() != 6 or d < today:
+ continue # In the past, ignore
+ if sunday_open is None:
+ sunday_open = rule["openTime"]
+ sunday_close = rule["closeTime"]
+ else:
+ if sunday_open != rule["openTime"] or sunday_close != rule["closeTime"]:
+ self.crawler.stats.inc_value("atp/zabka_pl/nonTradingDays/mismatching")
+ break # Mismatching future Sundays, skip
+ else:
+ self.crawler.stats.inc_value("atp/zabka_pl/nonTradingDays/fine")
+ item["opening_hours"].add_range("Su", sunday_open, sunday_close)
+ else:
+ self.crawler.stats.inc_value("atp/zabka_pl/nonTradingDays/missing") # Sunday closed? Missing data?
+
yield item
|
{"golden_diff": "diff --git a/locations/spiders/zabka_pl.py b/locations/spiders/zabka_pl.py\n--- a/locations/spiders/zabka_pl.py\n+++ b/locations/spiders/zabka_pl.py\n@@ -1,3 +1,5 @@\n+from datetime import datetime\n+\n import scrapy\n from scrapy.http import JsonRequest\n \n@@ -20,6 +22,7 @@\n yield JsonRequest(url=self.start_urls[0], headers=headers)\n \n def parse(self, response):\n+ today = datetime.now()\n for location in response.json():\n item = DictParser.parse(location)\n item[\"street_address\"] = item.pop(\"addr_full\", \"\")\n@@ -33,4 +36,25 @@\n item[\"opening_hours\"].add_days_range(\n [\"Mo\", \"Tu\", \"We\", \"Th\", \"Fr\", \"Sa\"], location[\"openTime\"], location[\"closeTime\"]\n )\n+\n+ if location[\"nonTradingDays\"]:\n+ sunday_open = None\n+ sunday_close = None\n+ for rule in location[\"nonTradingDays\"]:\n+ d = datetime.strptime(rule[\"date\"], \"%Y-%m-%d\")\n+ if d.weekday() != 6 or d < today:\n+ continue # In the past, ignore\n+ if sunday_open is None:\n+ sunday_open = rule[\"openTime\"]\n+ sunday_close = rule[\"closeTime\"]\n+ else:\n+ if sunday_open != rule[\"openTime\"] or sunday_close != rule[\"closeTime\"]:\n+ self.crawler.stats.inc_value(\"atp/zabka_pl/nonTradingDays/mismatching\")\n+ break # Mismatching future Sundays, skip\n+ else:\n+ self.crawler.stats.inc_value(\"atp/zabka_pl/nonTradingDays/fine\")\n+ item[\"opening_hours\"].add_range(\"Su\", sunday_open, sunday_close)\n+ else:\n+ self.crawler.stats.inc_value(\"atp/zabka_pl/nonTradingDays/missing\") # Sunday closed? Missing data?\n+\n yield item\n", "issue": "@spider=zabka_pl opening hours are missing Sunday data, proposed `opening_hours` are broken\nhttps://www.alltheplaces.xyz/map/#16.47/50.073227/20.037421\r\n\r\n\r\n\r\nhttps://www.openstreetmap.org/node/4271289403\r\n\r\nOpening hours in OSM (`Mo-Sa 06:00-22:00; Su 11:00-20:00`) are correct.\r\n\r\nAt https://www.zabka.pl/znajdz-sklep it refuses to show Sunday opening hours.\r\n\r\nMaybe it is caused by their internal structure? This shops are franchises and maybe they are obligated to be open `Mo-Sa 06:00-22:00` and Sundays can be decided by operator?\r\n\r\nOverall it seems that Monday to Saturday data is likely correct.\n", "before_files": [{"content": "import scrapy\nfrom scrapy.http import JsonRequest\n\nfrom locations.dict_parser import DictParser\nfrom locations.hours import OpeningHours\n\n\nclass ZabkaPLSpider(scrapy.Spider):\n name = \"zabka_pl\"\n item_attributes = {\"brand\": \"\u017babka\", \"brand_wikidata\": \"Q2589061\"}\n\n # URL extracted by observing request made by \u017bappka Android app (using HTTP Toolkit)\n start_urls = [\"https://partner-api.zabkamobile.pl/v2/shops\"]\n\n def start_requests(self):\n # Authorization header is hard-coded into the \u017bappka app and does not appear to change (as of version 3.14.10).\n headers = {\n \"Authorization\": \"PartnerKey 424A0B7AD0E9EA136510474D89061BBDC007B9BE5256A638EA28CC19D2BB15CD\",\n }\n yield JsonRequest(url=self.start_urls[0], headers=headers)\n\n def parse(self, response):\n for location in response.json():\n item = DictParser.parse(location)\n item[\"street_address\"] = item.pop(\"addr_full\", \"\")\n # unset \"state\" field, it is taken from the \"region\" field which is some internal \u017babka ID\n item[\"state\"] = None\n item[\"opening_hours\"] = OpeningHours()\n\n # Each franchisee is required to be open Mon-Sat with the same hours\n # But the hours for Sundays are set in the \"nonTradingDays\" field, which\n # contains the opening hours for each specific Sunday.\n item[\"opening_hours\"].add_days_range(\n [\"Mo\", \"Tu\", \"We\", \"Th\", \"Fr\", \"Sa\"], location[\"openTime\"], location[\"closeTime\"]\n )\n yield item\n", "path": "locations/spiders/zabka_pl.py"}], "after_files": [{"content": "from datetime import datetime\n\nimport scrapy\nfrom scrapy.http import JsonRequest\n\nfrom locations.dict_parser import DictParser\nfrom locations.hours import OpeningHours\n\n\nclass ZabkaPLSpider(scrapy.Spider):\n name = \"zabka_pl\"\n item_attributes = {\"brand\": \"\u017babka\", \"brand_wikidata\": \"Q2589061\"}\n\n # URL extracted by observing request made by \u017bappka Android app (using HTTP Toolkit)\n start_urls = [\"https://partner-api.zabkamobile.pl/v2/shops\"]\n\n def start_requests(self):\n # Authorization header is hard-coded into the \u017bappka app and does not appear to change (as of version 3.14.10).\n headers = {\n \"Authorization\": \"PartnerKey 424A0B7AD0E9EA136510474D89061BBDC007B9BE5256A638EA28CC19D2BB15CD\",\n }\n yield JsonRequest(url=self.start_urls[0], headers=headers)\n\n def parse(self, response):\n today = datetime.now()\n for location in response.json():\n item = DictParser.parse(location)\n item[\"street_address\"] = item.pop(\"addr_full\", \"\")\n # unset \"state\" field, it is taken from the \"region\" field which is some internal \u017babka ID\n item[\"state\"] = None\n item[\"opening_hours\"] = OpeningHours()\n\n # Each franchisee is required to be open Mon-Sat with the same hours\n # But the hours for Sundays are set in the \"nonTradingDays\" field, which\n # contains the opening hours for each specific Sunday.\n item[\"opening_hours\"].add_days_range(\n [\"Mo\", \"Tu\", \"We\", \"Th\", \"Fr\", \"Sa\"], location[\"openTime\"], location[\"closeTime\"]\n )\n\n if location[\"nonTradingDays\"]:\n sunday_open = None\n sunday_close = None\n for rule in location[\"nonTradingDays\"]:\n d = datetime.strptime(rule[\"date\"], \"%Y-%m-%d\")\n if d.weekday() != 6 or d < today:\n continue # In the past, ignore\n if sunday_open is None:\n sunday_open = rule[\"openTime\"]\n sunday_close = rule[\"closeTime\"]\n else:\n if sunday_open != rule[\"openTime\"] or sunday_close != rule[\"closeTime\"]:\n self.crawler.stats.inc_value(\"atp/zabka_pl/nonTradingDays/mismatching\")\n break # Mismatching future Sundays, skip\n else:\n self.crawler.stats.inc_value(\"atp/zabka_pl/nonTradingDays/fine\")\n item[\"opening_hours\"].add_range(\"Su\", sunday_open, sunday_close)\n else:\n self.crawler.stats.inc_value(\"atp/zabka_pl/nonTradingDays/missing\") # Sunday closed? Missing data?\n\n yield item\n", "path": "locations/spiders/zabka_pl.py"}]}
| 993 | 443 |
gh_patches_debug_4671
|
rasdani/github-patches
|
git_diff
|
holoviz__panel-609
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Replacing periodic.period doesn't change period
```
import panel as pn
pn.extension()
test = pn.widgets.Toggle(name='Test')
def toggle():
test.value = not test.value
periodic = test.add_periodic_callback(toggle, period=1000)
test
```
```
periodic.period = 20000 #this doesnt update the periodic milliseconds
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `panel/callbacks.py`
Content:
```
1 """
2 Defines callbacks to be executed on a thread or by scheduling it
3 on a running bokeh server.
4 """
5 from __future__ import absolute_import, division, unicode_literals
6
7
8 import time
9 import param
10
11 from bokeh.io import curdoc as _curdoc
12
13
14 class PeriodicCallback(param.Parameterized):
15 """
16 Periodic encapsulates a periodic callback which will run both
17 in tornado based notebook environments and on bokeh server. By
18 default the callback will run until the stop method is called,
19 but count and timeout values can be set to limit the number of
20 executions or the maximum length of time for which the callback
21 will run.
22 """
23
24 callback = param.Callable(doc="""
25 The callback to execute periodically.""")
26
27 count = param.Integer(default=None, doc="""
28 Number of times the callback will be executed, by default
29 this is unlimited.""")
30
31 period = param.Integer(default=500, doc="""
32 Period in milliseconds at which the callback is executed.""")
33
34 timeout = param.Integer(default=None, doc="""
35 Timeout in seconds from the start time at which the callback
36 expires""")
37
38 def __init__(self, **params):
39 super(PeriodicCallback, self).__init__(**params)
40 self._counter = 0
41 self._start_time = None
42 self._timeout = None
43 self._cb = None
44 self._doc = None
45
46 def start(self):
47 if self._cb is not None:
48 raise RuntimeError('Periodic callback has already started.')
49 self._start_time = time.time()
50 if _curdoc().session_context:
51 self._doc = _curdoc()
52 self._cb = self._doc.add_periodic_callback(self._periodic_callback, self.period)
53 else:
54 from tornado.ioloop import PeriodicCallback
55 self._cb = PeriodicCallback(self._periodic_callback, self.period)
56 self._cb.start()
57
58 def _periodic_callback(self):
59 self.callback()
60 self._counter += 1
61 if self._timeout is not None:
62 dt = (time.time() - self._start_time)
63 if dt > self._timeout:
64 self.stop()
65 if self._counter == self.count:
66 self.stop()
67
68 def stop(self):
69 self._counter = 0
70 self._timeout = None
71 if self._doc:
72 self._doc.remove_periodic_callback(self._cb)
73 else:
74 self._cb.stop()
75 self._cb = None
76
77
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/panel/callbacks.py b/panel/callbacks.py
--- a/panel/callbacks.py
+++ b/panel/callbacks.py
@@ -55,6 +55,12 @@
self._cb = PeriodicCallback(self._periodic_callback, self.period)
self._cb.start()
+ @param.depends('period', watch=True)
+ def _update_period(self):
+ if self._cb:
+ self.stop()
+ self.start()
+
def _periodic_callback(self):
self.callback()
self._counter += 1
|
{"golden_diff": "diff --git a/panel/callbacks.py b/panel/callbacks.py\n--- a/panel/callbacks.py\n+++ b/panel/callbacks.py\n@@ -55,6 +55,12 @@\n self._cb = PeriodicCallback(self._periodic_callback, self.period)\n self._cb.start()\n \n+ @param.depends('period', watch=True)\n+ def _update_period(self):\n+ if self._cb:\n+ self.stop()\n+ self.start()\n+\n def _periodic_callback(self):\n self.callback()\n self._counter += 1\n", "issue": "Replacing periodic.period doesn't change period\n```\r\nimport panel as pn\r\npn.extension()\r\n\r\ntest = pn.widgets.Toggle(name='Test')\r\n\r\ndef toggle():\r\n test.value = not test.value\r\n\r\nperiodic = test.add_periodic_callback(toggle, period=1000)\r\ntest\r\n```\r\n\r\n```\r\nperiodic.period = 20000 #this doesnt update the periodic milliseconds\r\n```\n", "before_files": [{"content": "\"\"\"\nDefines callbacks to be executed on a thread or by scheduling it\non a running bokeh server.\n\"\"\"\nfrom __future__ import absolute_import, division, unicode_literals\n\n\nimport time\nimport param\n\nfrom bokeh.io import curdoc as _curdoc\n\n\nclass PeriodicCallback(param.Parameterized):\n \"\"\"\n Periodic encapsulates a periodic callback which will run both\n in tornado based notebook environments and on bokeh server. By\n default the callback will run until the stop method is called,\n but count and timeout values can be set to limit the number of\n executions or the maximum length of time for which the callback\n will run.\n \"\"\"\n\n callback = param.Callable(doc=\"\"\"\n The callback to execute periodically.\"\"\")\n\n count = param.Integer(default=None, doc=\"\"\"\n Number of times the callback will be executed, by default\n this is unlimited.\"\"\")\n\n period = param.Integer(default=500, doc=\"\"\"\n Period in milliseconds at which the callback is executed.\"\"\")\n\n timeout = param.Integer(default=None, doc=\"\"\"\n Timeout in seconds from the start time at which the callback\n expires\"\"\")\n\n def __init__(self, **params):\n super(PeriodicCallback, self).__init__(**params)\n self._counter = 0\n self._start_time = None\n self._timeout = None\n self._cb = None\n self._doc = None\n\n def start(self):\n if self._cb is not None:\n raise RuntimeError('Periodic callback has already started.')\n self._start_time = time.time()\n if _curdoc().session_context:\n self._doc = _curdoc()\n self._cb = self._doc.add_periodic_callback(self._periodic_callback, self.period)\n else:\n from tornado.ioloop import PeriodicCallback\n self._cb = PeriodicCallback(self._periodic_callback, self.period)\n self._cb.start()\n\n def _periodic_callback(self):\n self.callback()\n self._counter += 1\n if self._timeout is not None:\n dt = (time.time() - self._start_time)\n if dt > self._timeout:\n self.stop()\n if self._counter == self.count:\n self.stop()\n\n def stop(self):\n self._counter = 0\n self._timeout = None\n if self._doc:\n self._doc.remove_periodic_callback(self._cb)\n else:\n self._cb.stop()\n self._cb = None\n\n", "path": "panel/callbacks.py"}], "after_files": [{"content": "\"\"\"\nDefines callbacks to be executed on a thread or by scheduling it\non a running bokeh server.\n\"\"\"\nfrom __future__ import absolute_import, division, unicode_literals\n\n\nimport time\nimport param\n\nfrom bokeh.io import curdoc as _curdoc\n\n\nclass PeriodicCallback(param.Parameterized):\n \"\"\"\n Periodic encapsulates a periodic callback which will run both\n in tornado based notebook environments and on bokeh server. By\n default the callback will run until the stop method is called,\n but count and timeout values can be set to limit the number of\n executions or the maximum length of time for which the callback\n will run.\n \"\"\"\n\n callback = param.Callable(doc=\"\"\"\n The callback to execute periodically.\"\"\")\n\n count = param.Integer(default=None, doc=\"\"\"\n Number of times the callback will be executed, by default\n this is unlimited.\"\"\")\n\n period = param.Integer(default=500, doc=\"\"\"\n Period in milliseconds at which the callback is executed.\"\"\")\n\n timeout = param.Integer(default=None, doc=\"\"\"\n Timeout in seconds from the start time at which the callback\n expires\"\"\")\n\n def __init__(self, **params):\n super(PeriodicCallback, self).__init__(**params)\n self._counter = 0\n self._start_time = None\n self._timeout = None\n self._cb = None\n self._doc = None\n\n def start(self):\n if self._cb is not None:\n raise RuntimeError('Periodic callback has already started.')\n self._start_time = time.time()\n if _curdoc().session_context:\n self._doc = _curdoc()\n self._cb = self._doc.add_periodic_callback(self._periodic_callback, self.period)\n else:\n from tornado.ioloop import PeriodicCallback\n self._cb = PeriodicCallback(self._periodic_callback, self.period)\n self._cb.start()\n\n @param.depends('period', watch=True)\n def _update_period(self):\n if self._cb:\n self.stop()\n self.start()\n\n def _periodic_callback(self):\n self.callback()\n self._counter += 1\n if self._timeout is not None:\n dt = (time.time() - self._start_time)\n if dt > self._timeout:\n self.stop()\n if self._counter == self.count:\n self.stop()\n\n def stop(self):\n self._counter = 0\n self._timeout = None\n if self._doc:\n self._doc.remove_periodic_callback(self._cb)\n else:\n self._cb.stop()\n self._cb = None\n\n", "path": "panel/callbacks.py"}]}
| 1,029 | 127 |
gh_patches_debug_16665
|
rasdani/github-patches
|
git_diff
|
opendatacube__datacube-core-1446
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Feature request: make netcdf4 dependency optional
Right now netcdf4 library is a non-optional dependency of datacube, but it's use within the library is actually fairly limited. With deprecation of ingestion step and move towards cloud, netcdf data sources are becoming less relevant in many deployments of the datacube. netcdf4 is a rather heavy dependency both in terms of "disk used" and complexity of installation. Having lean dependency set is particularly beneficial for things like cloud deployments (AWS lambda layer limit is 250Mb for example).
I believe that in the case of netdcf4 making it optional is relatively low cost and the benefit is significant. Ideally of course this would require automated testing across different python environments and that can be tricky and complex to setup, but we can start with just a manual test.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2
3 from setuptools import setup, find_packages
4
5 tests_require = [
6 'hypothesis',
7 'pycodestyle',
8 'pylint',
9 'pytest',
10 'pytest-cov',
11 'pytest-timeout',
12 'pytest-httpserver',
13 'moto',
14 ]
15 doc_require = [
16 'Sphinx',
17 'sphinx_autodoc_typehints', # Propagate mypy info into docs
18 'sphinx-click',
19 'recommonmark',
20 'autodocsumm',
21 'beautifulsoup4',
22 'nbsphinx',
23 'pydata-sphinx-theme==0.9.0',
24 ]
25
26 extras_require = {
27 'performance': ['ciso8601', 'bottleneck'],
28 'distributed': ['distributed', 'dask[distributed]'],
29 'doc': doc_require,
30 's3': ['boto3', 'botocore'],
31 'test': tests_require,
32 'cf': ['compliance-checker>=4.0.0'],
33 }
34
35 extras_require['dev'] = sorted(set(sum([extras_require[k] for k in [
36 'test',
37 'doc',
38 'performance',
39 's3',
40 'distributed',
41 ]], [])))
42
43 # An 'all' option, following ipython naming conventions.
44 extras_require['all'] = sorted(set(sum(extras_require.values(), [])))
45
46 extra_plugins = dict(read=[], write=[], index=[])
47
48 setup(
49 name='datacube',
50 python_requires='>=3.8.0',
51
52 url='https://github.com/opendatacube/datacube-core',
53 author='Open Data Cube',
54 maintainer='Open Data Cube',
55 maintainer_email='',
56 description='An analysis environment for satellite and other earth observation data',
57 long_description=open('README.rst').read(),
58 long_description_content_type='text/x-rst',
59 license='Apache License 2.0',
60 classifiers=[
61 "Development Status :: 4 - Beta",
62 "Intended Audience :: Developers",
63 "Intended Audience :: Science/Research",
64 "License :: OSI Approved :: Apache Software License",
65 "Natural Language :: English",
66 "Operating System :: MacOS :: MacOS X",
67 "Operating System :: POSIX",
68 "Operating System :: POSIX :: BSD",
69 "Operating System :: POSIX :: Linux",
70 "Operating System :: Microsoft :: Windows",
71 "Programming Language :: Python",
72 "Programming Language :: Python :: 3",
73 "Programming Language :: Python :: 3.8",
74 "Programming Language :: Python :: 3.9",
75 "Programming Language :: Python :: 3.10",
76 "Topic :: Scientific/Engineering :: GIS",
77 "Topic :: Scientific/Engineering :: Information Analysis",
78 ],
79
80 packages=find_packages(
81 exclude=('tests', 'tests.*',
82 'integration_tests', 'integration_tests.*')
83 ),
84 package_data={
85 '': ['*.yaml', '*/*.yaml'],
86 'datacube': ['py.typed'],
87 },
88 scripts=[],
89 install_requires=[
90 'affine',
91 'attrs>=18.1',
92 'pyproj>=2.5',
93 'shapely>=2.0',
94 'cachetools',
95 'click>=5.0',
96 'cloudpickle>=0.4',
97 'dask[array]',
98 'distributed',
99 'jsonschema',
100 'netcdf4',
101 'numpy',
102 'psycopg2',
103 'lark',
104 'pandas',
105 'python-dateutil',
106 'pyyaml',
107 'rasterio>=1.3.2', # Warping broken in 1.3.0 and 1.3.1
108 'ruamel.yaml',
109 'sqlalchemy>=2.0', # GeoAlchemy2 requires >=1.4. SqlAlchemy2 *may* work but has not been tested yet.
110 'GeoAlchemy2',
111 'toolz',
112 'xarray>=0.9', # >0.9 fixes most problems with `crs` attributes being lost
113 'packaging',
114 'odc-geo',
115 'deprecat',
116 ],
117 extras_require=extras_require,
118 tests_require=tests_require,
119
120 entry_points={
121 'console_scripts': [
122 'datacube = datacube.scripts.cli_app:cli',
123 'datacube-search = datacube.scripts.search_tool:cli',
124 'datacube-worker = datacube.execution.worker:main',
125 ],
126 'datacube.plugins.io.read': [
127 'netcdf = datacube.drivers.netcdf.driver:reader_driver_init',
128 *extra_plugins['read'],
129 ],
130 'datacube.plugins.io.write': [
131 'netcdf = datacube.drivers.netcdf.driver:writer_driver_init',
132 *extra_plugins['write'],
133 ],
134 'datacube.plugins.index': [
135 'default = datacube.index.postgres.index:index_driver_init',
136 'null = datacube.index.null.index:index_driver_init',
137 'memory = datacube.index.memory.index:index_driver_init',
138 'postgis = datacube.index.postgis.index:index_driver_init',
139 *extra_plugins['index'],
140 ],
141 },
142 )
143
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -30,6 +30,7 @@
's3': ['boto3', 'botocore'],
'test': tests_require,
'cf': ['compliance-checker>=4.0.0'],
+ 'netcdf': ['netcdf4'],
}
extras_require['dev'] = sorted(set(sum([extras_require[k] for k in [
@@ -38,6 +39,7 @@
'performance',
's3',
'distributed',
+ 'netcdf',
]], [])))
# An 'all' option, following ipython naming conventions.
@@ -97,7 +99,6 @@
'dask[array]',
'distributed',
'jsonschema',
- 'netcdf4',
'numpy',
'psycopg2',
'lark',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -30,6 +30,7 @@\n 's3': ['boto3', 'botocore'],\n 'test': tests_require,\n 'cf': ['compliance-checker>=4.0.0'],\n+ 'netcdf': ['netcdf4'],\n }\n \n extras_require['dev'] = sorted(set(sum([extras_require[k] for k in [\n@@ -38,6 +39,7 @@\n 'performance',\n 's3',\n 'distributed',\n+ 'netcdf',\n ]], [])))\n \n # An 'all' option, following ipython naming conventions.\n@@ -97,7 +99,6 @@\n 'dask[array]',\n 'distributed',\n 'jsonschema',\n- 'netcdf4',\n 'numpy',\n 'psycopg2',\n 'lark',\n", "issue": "Feature request: make netcdf4 dependency optional\nRight now netcdf4 library is a non-optional dependency of datacube, but it's use within the library is actually fairly limited. With deprecation of ingestion step and move towards cloud, netcdf data sources are becoming less relevant in many deployments of the datacube. netcdf4 is a rather heavy dependency both in terms of \"disk used\" and complexity of installation. Having lean dependency set is particularly beneficial for things like cloud deployments (AWS lambda layer limit is 250Mb for example).\r\n\r\nI believe that in the case of netdcf4 making it optional is relatively low cost and the benefit is significant. Ideally of course this would require automated testing across different python environments and that can be tricky and complex to setup, but we can start with just a manual test.\n", "before_files": [{"content": "#!/usr/bin/env python\n\nfrom setuptools import setup, find_packages\n\ntests_require = [\n 'hypothesis',\n 'pycodestyle',\n 'pylint',\n 'pytest',\n 'pytest-cov',\n 'pytest-timeout',\n 'pytest-httpserver',\n 'moto',\n]\ndoc_require = [\n 'Sphinx',\n 'sphinx_autodoc_typehints', # Propagate mypy info into docs\n 'sphinx-click',\n 'recommonmark',\n 'autodocsumm',\n 'beautifulsoup4',\n 'nbsphinx',\n 'pydata-sphinx-theme==0.9.0',\n]\n\nextras_require = {\n 'performance': ['ciso8601', 'bottleneck'],\n 'distributed': ['distributed', 'dask[distributed]'],\n 'doc': doc_require,\n 's3': ['boto3', 'botocore'],\n 'test': tests_require,\n 'cf': ['compliance-checker>=4.0.0'],\n}\n\nextras_require['dev'] = sorted(set(sum([extras_require[k] for k in [\n 'test',\n 'doc',\n 'performance',\n 's3',\n 'distributed',\n]], [])))\n\n# An 'all' option, following ipython naming conventions.\nextras_require['all'] = sorted(set(sum(extras_require.values(), [])))\n\nextra_plugins = dict(read=[], write=[], index=[])\n\nsetup(\n name='datacube',\n python_requires='>=3.8.0',\n\n url='https://github.com/opendatacube/datacube-core',\n author='Open Data Cube',\n maintainer='Open Data Cube',\n maintainer_email='',\n description='An analysis environment for satellite and other earth observation data',\n long_description=open('README.rst').read(),\n long_description_content_type='text/x-rst',\n license='Apache License 2.0',\n classifiers=[\n \"Development Status :: 4 - Beta\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Natural Language :: English\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: POSIX\",\n \"Operating System :: POSIX :: BSD\",\n \"Operating System :: POSIX :: Linux\",\n \"Operating System :: Microsoft :: Windows\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Topic :: Scientific/Engineering :: GIS\",\n \"Topic :: Scientific/Engineering :: Information Analysis\",\n ],\n\n packages=find_packages(\n exclude=('tests', 'tests.*',\n 'integration_tests', 'integration_tests.*')\n ),\n package_data={\n '': ['*.yaml', '*/*.yaml'],\n 'datacube': ['py.typed'],\n },\n scripts=[],\n install_requires=[\n 'affine',\n 'attrs>=18.1',\n 'pyproj>=2.5',\n 'shapely>=2.0',\n 'cachetools',\n 'click>=5.0',\n 'cloudpickle>=0.4',\n 'dask[array]',\n 'distributed',\n 'jsonschema',\n 'netcdf4',\n 'numpy',\n 'psycopg2',\n 'lark',\n 'pandas',\n 'python-dateutil',\n 'pyyaml',\n 'rasterio>=1.3.2', # Warping broken in 1.3.0 and 1.3.1\n 'ruamel.yaml',\n 'sqlalchemy>=2.0', # GeoAlchemy2 requires >=1.4. SqlAlchemy2 *may* work but has not been tested yet.\n 'GeoAlchemy2',\n 'toolz',\n 'xarray>=0.9', # >0.9 fixes most problems with `crs` attributes being lost\n 'packaging',\n 'odc-geo',\n 'deprecat',\n ],\n extras_require=extras_require,\n tests_require=tests_require,\n\n entry_points={\n 'console_scripts': [\n 'datacube = datacube.scripts.cli_app:cli',\n 'datacube-search = datacube.scripts.search_tool:cli',\n 'datacube-worker = datacube.execution.worker:main',\n ],\n 'datacube.plugins.io.read': [\n 'netcdf = datacube.drivers.netcdf.driver:reader_driver_init',\n *extra_plugins['read'],\n ],\n 'datacube.plugins.io.write': [\n 'netcdf = datacube.drivers.netcdf.driver:writer_driver_init',\n *extra_plugins['write'],\n ],\n 'datacube.plugins.index': [\n 'default = datacube.index.postgres.index:index_driver_init',\n 'null = datacube.index.null.index:index_driver_init',\n 'memory = datacube.index.memory.index:index_driver_init',\n 'postgis = datacube.index.postgis.index:index_driver_init',\n *extra_plugins['index'],\n ],\n },\n)\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\nfrom setuptools import setup, find_packages\n\ntests_require = [\n 'hypothesis',\n 'pycodestyle',\n 'pylint',\n 'pytest',\n 'pytest-cov',\n 'pytest-timeout',\n 'pytest-httpserver',\n 'moto',\n]\ndoc_require = [\n 'Sphinx',\n 'sphinx_autodoc_typehints', # Propagate mypy info into docs\n 'sphinx-click',\n 'recommonmark',\n 'autodocsumm',\n 'beautifulsoup4',\n 'nbsphinx',\n 'pydata-sphinx-theme==0.9.0',\n]\n\nextras_require = {\n 'performance': ['ciso8601', 'bottleneck'],\n 'distributed': ['distributed', 'dask[distributed]'],\n 'doc': doc_require,\n 's3': ['boto3', 'botocore'],\n 'test': tests_require,\n 'cf': ['compliance-checker>=4.0.0'],\n 'netcdf': ['netcdf4'],\n}\n\nextras_require['dev'] = sorted(set(sum([extras_require[k] for k in [\n 'test',\n 'doc',\n 'performance',\n 's3',\n 'distributed',\n 'netcdf',\n]], [])))\n\n# An 'all' option, following ipython naming conventions.\nextras_require['all'] = sorted(set(sum(extras_require.values(), [])))\n\nextra_plugins = dict(read=[], write=[], index=[])\n\nsetup(\n name='datacube',\n python_requires='>=3.8.0',\n\n url='https://github.com/opendatacube/datacube-core',\n author='Open Data Cube',\n maintainer='Open Data Cube',\n maintainer_email='',\n description='An analysis environment for satellite and other earth observation data',\n long_description=open('README.rst').read(),\n long_description_content_type='text/x-rst',\n license='Apache License 2.0',\n classifiers=[\n \"Development Status :: 4 - Beta\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Natural Language :: English\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: POSIX\",\n \"Operating System :: POSIX :: BSD\",\n \"Operating System :: POSIX :: Linux\",\n \"Operating System :: Microsoft :: Windows\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Topic :: Scientific/Engineering :: GIS\",\n \"Topic :: Scientific/Engineering :: Information Analysis\",\n ],\n\n packages=find_packages(\n exclude=('tests', 'tests.*',\n 'integration_tests', 'integration_tests.*')\n ),\n package_data={\n '': ['*.yaml', '*/*.yaml'],\n 'datacube': ['py.typed'],\n },\n scripts=[],\n install_requires=[\n 'affine',\n 'attrs>=18.1',\n 'pyproj>=2.5',\n 'shapely>=2.0',\n 'cachetools',\n 'click>=5.0',\n 'cloudpickle>=0.4',\n 'dask[array]',\n 'distributed',\n 'jsonschema',\n 'numpy',\n 'psycopg2',\n 'lark',\n 'pandas',\n 'python-dateutil',\n 'pyyaml',\n 'rasterio>=1.3.2', # Warping broken in 1.3.0 and 1.3.1\n 'ruamel.yaml',\n 'sqlalchemy>=2.0', # GeoAlchemy2 requires >=1.4. SqlAlchemy2 *may* work but has not been tested yet.\n 'GeoAlchemy2',\n 'toolz',\n 'xarray>=0.9', # >0.9 fixes most problems with `crs` attributes being lost\n 'packaging',\n 'odc-geo',\n 'deprecat',\n ],\n extras_require=extras_require,\n tests_require=tests_require,\n\n entry_points={\n 'console_scripts': [\n 'datacube = datacube.scripts.cli_app:cli',\n 'datacube-search = datacube.scripts.search_tool:cli',\n 'datacube-worker = datacube.execution.worker:main',\n ],\n 'datacube.plugins.io.read': [\n 'netcdf = datacube.drivers.netcdf.driver:reader_driver_init',\n *extra_plugins['read'],\n ],\n 'datacube.plugins.io.write': [\n 'netcdf = datacube.drivers.netcdf.driver:writer_driver_init',\n *extra_plugins['write'],\n ],\n 'datacube.plugins.index': [\n 'default = datacube.index.postgres.index:index_driver_init',\n 'null = datacube.index.null.index:index_driver_init',\n 'memory = datacube.index.memory.index:index_driver_init',\n 'postgis = datacube.index.postgis.index:index_driver_init',\n *extra_plugins['index'],\n ],\n },\n)\n", "path": "setup.py"}]}
| 1,843 | 199 |
gh_patches_debug_36254
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-494
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Author a full getting started guide
As part of the final beta announce on March 30th, we should have a full getting started guide, similar to this one for js:
https://github.com/open-telemetry/opentelemetry-js/blob/master/getting-started/README.md
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/trace_example.py`
Content:
```
1 from opentelemetry import trace
2 from opentelemetry.sdk.trace import TracerProvider
3 from opentelemetry.sdk.trace.export import (
4 ConsoleSpanExporter,
5 SimpleExportSpanProcessor,
6 )
7
8 trace.set_preferred_tracer_provider_implementation(lambda T: TracerProvider())
9 trace.tracer_provider().add_span_processor(
10 SimpleExportSpanProcessor(ConsoleSpanExporter())
11 )
12
13 tracer = trace.get_tracer(__name__)
14
15 with tracer.start_as_current_span("foo"):
16 with tracer.start_as_current_span("bar"):
17 with tracer.start_as_current_span("baz"):
18 print("Hello world from OpenTelemetry Python!")
19
```
Path: `docs/examples/opentelemetry-example-app/src/opentelemetry_example_app/flask_example.py`
Content:
```
1 # Copyright 2019, OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 #
15 """
16 This module serves as an example to integrate with flask, using
17 the requests library to perform downstream requests
18 """
19 import flask
20 import pkg_resources
21 import requests
22
23 import opentelemetry.ext.http_requests
24 from opentelemetry import trace
25 from opentelemetry.ext.flask import instrument_app
26 from opentelemetry.sdk.trace import TracerProvider
27
28
29 def configure_opentelemetry(flask_app: flask.Flask):
30 """Configure a flask application to use OpenTelemetry.
31
32 This activates the specific components:
33
34 * sets tracer to the SDK's Tracer
35 * enables requests integration on the Tracer
36 * uses a WSGI middleware to enable configuration
37 """
38 # Start by configuring all objects required to ensure a complete end to end
39 # workflow.
40 trace.set_tracer_provider(TracerProvider())
41
42 # Next, we need to configure how the values that are used by traces and
43 # metrics are propagated (such as what specific headers carry this value).
44 # Integrations are the glue that binds the OpenTelemetry API and the
45 # frameworks and libraries that are used together, automatically creating
46 # Spans and propagating context as appropriate.
47 opentelemetry.ext.http_requests.enable(trace.get_tracer_provider())
48 instrument_app(flask_app)
49
50
51 app = flask.Flask(__name__)
52
53
54 @app.route("/")
55 def hello():
56 # Emit a trace that measures how long the sleep takes
57 version = pkg_resources.get_distribution(
58 "opentelemetry-example-app"
59 ).version
60 tracer = trace.get_tracer(__name__, version)
61 with tracer.start_as_current_span("example-request"):
62 requests.get("http://www.example.com")
63 return "hello"
64
65
66 configure_opentelemetry(app)
67
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/examples/opentelemetry-example-app/src/opentelemetry_example_app/flask_example.py b/docs/examples/opentelemetry-example-app/src/opentelemetry_example_app/flask_example.py
--- a/docs/examples/opentelemetry-example-app/src/opentelemetry_example_app/flask_example.py
+++ b/docs/examples/opentelemetry-example-app/src/opentelemetry_example_app/flask_example.py
@@ -17,50 +17,31 @@
the requests library to perform downstream requests
"""
import flask
-import pkg_resources
import requests
import opentelemetry.ext.http_requests
from opentelemetry import trace
from opentelemetry.ext.flask import instrument_app
from opentelemetry.sdk.trace import TracerProvider
+from opentelemetry.sdk.trace.export import ConsoleSpanExporter
+from opentelemetry.sdk.trace.export import SimpleExportSpanProcessor
-
-def configure_opentelemetry(flask_app: flask.Flask):
- """Configure a flask application to use OpenTelemetry.
-
- This activates the specific components:
-
- * sets tracer to the SDK's Tracer
- * enables requests integration on the Tracer
- * uses a WSGI middleware to enable configuration
- """
- # Start by configuring all objects required to ensure a complete end to end
- # workflow.
- trace.set_tracer_provider(TracerProvider())
-
- # Next, we need to configure how the values that are used by traces and
- # metrics are propagated (such as what specific headers carry this value).
- # Integrations are the glue that binds the OpenTelemetry API and the
- # frameworks and libraries that are used together, automatically creating
- # Spans and propagating context as appropriate.
- opentelemetry.ext.http_requests.enable(trace.get_tracer_provider())
- instrument_app(flask_app)
-
+trace.set_tracer_provider(TracerProvider())
+trace.get_tracer_provider().add_span_processor(
+ SimpleExportSpanProcessor(ConsoleSpanExporter())
+)
app = flask.Flask(__name__)
+opentelemetry.ext.http_requests.enable(trace.get_tracer_provider())
+instrument_app(app)
@app.route("/")
def hello():
- # Emit a trace that measures how long the sleep takes
- version = pkg_resources.get_distribution(
- "opentelemetry-example-app"
- ).version
- tracer = trace.get_tracer(__name__, version)
+ tracer = trace.get_tracer(__name__)
with tracer.start_as_current_span("example-request"):
requests.get("http://www.example.com")
return "hello"
-configure_opentelemetry(app)
+app.run(debug=True)
diff --git a/docs/trace_example.py b/docs/trace_example.py
--- a/docs/trace_example.py
+++ b/docs/trace_example.py
@@ -5,8 +5,8 @@
SimpleExportSpanProcessor,
)
-trace.set_preferred_tracer_provider_implementation(lambda T: TracerProvider())
-trace.tracer_provider().add_span_processor(
+trace.set_tracer_provider(TracerProvider())
+trace.get_tracer_provider().add_span_processor(
SimpleExportSpanProcessor(ConsoleSpanExporter())
)
|
{"golden_diff": "diff --git a/docs/examples/opentelemetry-example-app/src/opentelemetry_example_app/flask_example.py b/docs/examples/opentelemetry-example-app/src/opentelemetry_example_app/flask_example.py\n--- a/docs/examples/opentelemetry-example-app/src/opentelemetry_example_app/flask_example.py\n+++ b/docs/examples/opentelemetry-example-app/src/opentelemetry_example_app/flask_example.py\n@@ -17,50 +17,31 @@\n the requests library to perform downstream requests\n \"\"\"\n import flask\n-import pkg_resources\n import requests\n \n import opentelemetry.ext.http_requests\n from opentelemetry import trace\n from opentelemetry.ext.flask import instrument_app\n from opentelemetry.sdk.trace import TracerProvider\n+from opentelemetry.sdk.trace.export import ConsoleSpanExporter\n+from opentelemetry.sdk.trace.export import SimpleExportSpanProcessor\n \n-\n-def configure_opentelemetry(flask_app: flask.Flask):\n- \"\"\"Configure a flask application to use OpenTelemetry.\n-\n- This activates the specific components:\n-\n- * sets tracer to the SDK's Tracer\n- * enables requests integration on the Tracer\n- * uses a WSGI middleware to enable configuration\n- \"\"\"\n- # Start by configuring all objects required to ensure a complete end to end\n- # workflow.\n- trace.set_tracer_provider(TracerProvider())\n-\n- # Next, we need to configure how the values that are used by traces and\n- # metrics are propagated (such as what specific headers carry this value).\n- # Integrations are the glue that binds the OpenTelemetry API and the\n- # frameworks and libraries that are used together, automatically creating\n- # Spans and propagating context as appropriate.\n- opentelemetry.ext.http_requests.enable(trace.get_tracer_provider())\n- instrument_app(flask_app)\n-\n+trace.set_tracer_provider(TracerProvider())\n+trace.get_tracer_provider().add_span_processor(\n+ SimpleExportSpanProcessor(ConsoleSpanExporter())\n+)\n \n app = flask.Flask(__name__)\n+opentelemetry.ext.http_requests.enable(trace.get_tracer_provider())\n+instrument_app(app)\n \n \n @app.route(\"/\")\n def hello():\n- # Emit a trace that measures how long the sleep takes\n- version = pkg_resources.get_distribution(\n- \"opentelemetry-example-app\"\n- ).version\n- tracer = trace.get_tracer(__name__, version)\n+ tracer = trace.get_tracer(__name__)\n with tracer.start_as_current_span(\"example-request\"):\n requests.get(\"http://www.example.com\")\n return \"hello\"\n \n \n-configure_opentelemetry(app)\n+app.run(debug=True)\ndiff --git a/docs/trace_example.py b/docs/trace_example.py\n--- a/docs/trace_example.py\n+++ b/docs/trace_example.py\n@@ -5,8 +5,8 @@\n SimpleExportSpanProcessor,\n )\n \n-trace.set_preferred_tracer_provider_implementation(lambda T: TracerProvider())\n-trace.tracer_provider().add_span_processor(\n+trace.set_tracer_provider(TracerProvider())\n+trace.get_tracer_provider().add_span_processor(\n SimpleExportSpanProcessor(ConsoleSpanExporter())\n )\n", "issue": "Author a full getting started guide\nAs part of the final beta announce on March 30th, we should have a full getting started guide, similar to this one for js:\r\n\r\nhttps://github.com/open-telemetry/opentelemetry-js/blob/master/getting-started/README.md\r\n\r\n\n", "before_files": [{"content": "from opentelemetry import trace\nfrom opentelemetry.sdk.trace import TracerProvider\nfrom opentelemetry.sdk.trace.export import (\n ConsoleSpanExporter,\n SimpleExportSpanProcessor,\n)\n\ntrace.set_preferred_tracer_provider_implementation(lambda T: TracerProvider())\ntrace.tracer_provider().add_span_processor(\n SimpleExportSpanProcessor(ConsoleSpanExporter())\n)\n\ntracer = trace.get_tracer(__name__)\n\nwith tracer.start_as_current_span(\"foo\"):\n with tracer.start_as_current_span(\"bar\"):\n with tracer.start_as_current_span(\"baz\"):\n print(\"Hello world from OpenTelemetry Python!\")\n", "path": "docs/trace_example.py"}, {"content": "# Copyright 2019, OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\"\"\"\nThis module serves as an example to integrate with flask, using\nthe requests library to perform downstream requests\n\"\"\"\nimport flask\nimport pkg_resources\nimport requests\n\nimport opentelemetry.ext.http_requests\nfrom opentelemetry import trace\nfrom opentelemetry.ext.flask import instrument_app\nfrom opentelemetry.sdk.trace import TracerProvider\n\n\ndef configure_opentelemetry(flask_app: flask.Flask):\n \"\"\"Configure a flask application to use OpenTelemetry.\n\n This activates the specific components:\n\n * sets tracer to the SDK's Tracer\n * enables requests integration on the Tracer\n * uses a WSGI middleware to enable configuration\n \"\"\"\n # Start by configuring all objects required to ensure a complete end to end\n # workflow.\n trace.set_tracer_provider(TracerProvider())\n\n # Next, we need to configure how the values that are used by traces and\n # metrics are propagated (such as what specific headers carry this value).\n # Integrations are the glue that binds the OpenTelemetry API and the\n # frameworks and libraries that are used together, automatically creating\n # Spans and propagating context as appropriate.\n opentelemetry.ext.http_requests.enable(trace.get_tracer_provider())\n instrument_app(flask_app)\n\n\napp = flask.Flask(__name__)\n\n\[email protected](\"/\")\ndef hello():\n # Emit a trace that measures how long the sleep takes\n version = pkg_resources.get_distribution(\n \"opentelemetry-example-app\"\n ).version\n tracer = trace.get_tracer(__name__, version)\n with tracer.start_as_current_span(\"example-request\"):\n requests.get(\"http://www.example.com\")\n return \"hello\"\n\n\nconfigure_opentelemetry(app)\n", "path": "docs/examples/opentelemetry-example-app/src/opentelemetry_example_app/flask_example.py"}], "after_files": [{"content": "from opentelemetry import trace\nfrom opentelemetry.sdk.trace import TracerProvider\nfrom opentelemetry.sdk.trace.export import (\n ConsoleSpanExporter,\n SimpleExportSpanProcessor,\n)\n\ntrace.set_tracer_provider(TracerProvider())\ntrace.get_tracer_provider().add_span_processor(\n SimpleExportSpanProcessor(ConsoleSpanExporter())\n)\n\ntracer = trace.get_tracer(__name__)\n\nwith tracer.start_as_current_span(\"foo\"):\n with tracer.start_as_current_span(\"bar\"):\n with tracer.start_as_current_span(\"baz\"):\n print(\"Hello world from OpenTelemetry Python!\")\n", "path": "docs/trace_example.py"}, {"content": "# Copyright 2019, OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\"\"\"\nThis module serves as an example to integrate with flask, using\nthe requests library to perform downstream requests\n\"\"\"\nimport flask\nimport requests\n\nimport opentelemetry.ext.http_requests\nfrom opentelemetry import trace\nfrom opentelemetry.ext.flask import instrument_app\nfrom opentelemetry.sdk.trace import TracerProvider\nfrom opentelemetry.sdk.trace.export import ConsoleSpanExporter\nfrom opentelemetry.sdk.trace.export import SimpleExportSpanProcessor\n\ntrace.set_tracer_provider(TracerProvider())\ntrace.get_tracer_provider().add_span_processor(\n SimpleExportSpanProcessor(ConsoleSpanExporter())\n)\n\napp = flask.Flask(__name__)\nopentelemetry.ext.http_requests.enable(trace.get_tracer_provider())\ninstrument_app(app)\n\n\[email protected](\"/\")\ndef hello():\n tracer = trace.get_tracer(__name__)\n with tracer.start_as_current_span(\"example-request\"):\n requests.get(\"http://www.example.com\")\n return \"hello\"\n\n\napp.run(debug=True)\n", "path": "docs/examples/opentelemetry-example-app/src/opentelemetry_example_app/flask_example.py"}]}
| 1,128 | 671 |
gh_patches_debug_2148
|
rasdani/github-patches
|
git_diff
|
voxel51__fiftyone-3439
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] Fiftyone v0.21.6 localhost Not found, while v0.21.4 Could not connect session, despite working before 7Aug23
### System information
- **OS Platform and Distribution** (`Windows 11 Pro, build 22621.2134`)
- **Google Chrome** (`Version 115.0.5790.171 (Official Build) (64-bit)`)
- **Python version** (`python --version 3.10.0`)
- **FiftyOne version** (`fiftyone --version 0.21.4`)
- **FiftyOne installed from** (`pip`)
### Commands to reproduce
I have my own custom Python script (including option to run fiftyone's quickstart) working for weeks at least until 7 Aug 2023. I'm unable to share the custom scripts.
Today (17 Aug 2023), as I run through installing fiftyone and running my scripts, I encounter the following problems.
I had a few updates to Google Chrome browser in these 10 days too.
### Describe the problem
Here's what i've tried.
Scenario A: fiftyone v0.21.6
Problem: `App launched. Point your browser to http://localhost:5151`. But unable to load App page at localhost 5151 ("Not found" displayed on page)
Solutions tried but did not work: [Registry settings](https://github.com/voxel51/fiftyone/issues/2010) and/or [mimetype](https://github.com/voxel51/fiftyone/issues/2522#issuecomment-1416318362)
Scenario B: fiftyone v0.21.4
Problem: unable to fully display the App (it only shows the fiftyone skeleton page with "Select Dataset", and no layout and data in the middle). The terminal repeatedly gives `could not connect session, retrying in 10 seconds`.
I'm unsure what is the cause to the above and would appreciate your assistance.
### What areas of FiftyOne does this bug affect?
- [x] `App`: FiftyOne application issue
- [ ] `Core`: Core Python library issue
- [ ] `Server`: FiftyOne server issue
### Willingness to contribute
The FiftyOne Community encourages bug fix contributions. Would you or another member of your organization be willing to contribute a fix for this bug to the FiftyOne codebase?
- [ ] Yes. I can contribute a fix for this bug independently
- [ ] Yes. I would be willing to contribute a fix for this bug with guidance from the FiftyOne community
- [x] No. I cannot contribute a bug fix at this time
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `fiftyone/server/app.py`
Content:
```
1 """
2 FiftyOne Server app.
3
4 | Copyright 2017-2023, Voxel51, Inc.
5 | `voxel51.com <https://voxel51.com/>`_
6 |
7 """
8 from datetime import date, datetime
9 import os
10 import pathlib
11
12 import eta.core.utils as etau
13 from starlette.applications import Starlette
14 from starlette.middleware import Middleware
15 from starlette.middleware.base import (
16 BaseHTTPMiddleware,
17 RequestResponseEndpoint,
18 )
19 from starlette.middleware.cors import CORSMiddleware
20 from starlette.requests import Request
21 from starlette.responses import Response
22 from starlette.routing import Mount, Route
23 from starlette.staticfiles import StaticFiles
24 from starlette.types import Scope
25 import strawberry as gql
26
27 import fiftyone as fo
28 import fiftyone.constants as foc
29 from fiftyone.server.context import GraphQL
30 from fiftyone.server.extensions import EndSession
31 from fiftyone.server.mutation import Mutation
32 from fiftyone.server.query import Query
33 from fiftyone.server.routes import routes
34 from fiftyone.server.scalars import Date, DateTime
35
36
37 etau.ensure_dir(os.path.join(os.path.dirname(__file__), "static"))
38
39
40 class Static(StaticFiles):
41 async def get_response(self, path: str, scope: Scope) -> Response:
42 response = await super().get_response(path, scope)
43
44 if response.status_code == 404:
45 path = pathlib.Path(
46 *pathlib.Path(path).parts[2:]
47 ) # strip dataset/{name}
48 response = await super().get_response(path, scope)
49 if response.status_code == 404:
50 full_path, stat_result = self.lookup_path("index.html")
51 return self.file_response(full_path, stat_result, scope)
52
53 return response
54
55
56 class HeadersMiddleware(BaseHTTPMiddleware):
57 async def dispatch(
58 self, request: Request, call_next: RequestResponseEndpoint
59 ) -> Response:
60 response = await call_next(request)
61 response.headers["x-colab-notebook-cache-control"] = "no-cache"
62 return response
63
64
65 schema = gql.Schema(
66 mutation=Mutation,
67 query=Query,
68 extensions=[EndSession],
69 scalar_overrides={
70 date: Date,
71 datetime: DateTime,
72 },
73 )
74
75
76 app = Starlette(
77 middleware=[
78 Middleware(
79 CORSMiddleware,
80 allow_origins=["*"],
81 allow_methods=["GET", "POST", "HEAD", "OPTIONS"],
82 allow_headers=[
83 "access-control-allow-origin",
84 "authorization",
85 "content-type",
86 ],
87 ),
88 Middleware(HeadersMiddleware),
89 ],
90 debug=foc.DEV_INSTALL,
91 routes=[Route(route, endpoint) for route, endpoint in routes]
92 + [
93 Route(
94 "/graphql",
95 GraphQL(
96 schema,
97 graphiql=foc.DEV_INSTALL,
98 ),
99 ),
100 Mount(
101 "/plugins",
102 app=Static(
103 directory=fo.config.plugins_dir,
104 html=True,
105 check_dir=False,
106 follow_symlink=True,
107 ),
108 name="plugins",
109 ),
110 Mount(
111 "/",
112 app=Static(
113 directory=os.path.join(os.path.dirname(__file__), "static"),
114 html=True,
115 follow_symlink=True,
116 ),
117 name="static",
118 ),
119 ],
120 )
121
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/fiftyone/server/app.py b/fiftyone/server/app.py
--- a/fiftyone/server/app.py
+++ b/fiftyone/server/app.py
@@ -112,7 +112,6 @@
app=Static(
directory=os.path.join(os.path.dirname(__file__), "static"),
html=True,
- follow_symlink=True,
),
name="static",
),
|
{"golden_diff": "diff --git a/fiftyone/server/app.py b/fiftyone/server/app.py\n--- a/fiftyone/server/app.py\n+++ b/fiftyone/server/app.py\n@@ -112,7 +112,6 @@\n app=Static(\n directory=os.path.join(os.path.dirname(__file__), \"static\"),\n html=True,\n- follow_symlink=True,\n ),\n name=\"static\",\n ),\n", "issue": "[BUG] Fiftyone v0.21.6 localhost Not found, while v0.21.4 Could not connect session, despite working before 7Aug23\n### System information\r\n\r\n- **OS Platform and Distribution** (`Windows 11 Pro, build 22621.2134`)\r\n- **Google Chrome** (`Version 115.0.5790.171 (Official Build) (64-bit)`)\r\n- **Python version** (`python --version 3.10.0`)\r\n- **FiftyOne version** (`fiftyone --version 0.21.4`)\r\n- **FiftyOne installed from** (`pip`)\r\n\r\n### Commands to reproduce\r\n\r\nI have my own custom Python script (including option to run fiftyone's quickstart) working for weeks at least until 7 Aug 2023. I'm unable to share the custom scripts.\r\n\r\nToday (17 Aug 2023), as I run through installing fiftyone and running my scripts, I encounter the following problems.\r\n\r\nI had a few updates to Google Chrome browser in these 10 days too.\r\n\r\n### Describe the problem\r\n\r\nHere's what i've tried.\r\n\r\nScenario A: fiftyone v0.21.6\r\nProblem: `App launched. Point your browser to http://localhost:5151`. But unable to load App page at localhost 5151 (\"Not found\" displayed on page)\r\nSolutions tried but did not work: [Registry settings](https://github.com/voxel51/fiftyone/issues/2010) and/or [mimetype](https://github.com/voxel51/fiftyone/issues/2522#issuecomment-1416318362)\r\n\r\nScenario B: fiftyone v0.21.4\r\nProblem: unable to fully display the App (it only shows the fiftyone skeleton page with \"Select Dataset\", and no layout and data in the middle). The terminal repeatedly gives `could not connect session, retrying in 10 seconds`.\r\n\r\nI'm unsure what is the cause to the above and would appreciate your assistance. \r\n\r\n### What areas of FiftyOne does this bug affect?\r\n\r\n- [x] `App`: FiftyOne application issue\r\n- [ ] `Core`: Core Python library issue\r\n- [ ] `Server`: FiftyOne server issue\r\n\r\n### Willingness to contribute\r\n\r\nThe FiftyOne Community encourages bug fix contributions. Would you or another member of your organization be willing to contribute a fix for this bug to the FiftyOne codebase?\r\n\r\n- [ ] Yes. I can contribute a fix for this bug independently\r\n- [ ] Yes. I would be willing to contribute a fix for this bug with guidance from the FiftyOne community\r\n- [x] No. I cannot contribute a bug fix at this time\r\n\n", "before_files": [{"content": "\"\"\"\nFiftyOne Server app.\n\n| Copyright 2017-2023, Voxel51, Inc.\n| `voxel51.com <https://voxel51.com/>`_\n|\n\"\"\"\nfrom datetime import date, datetime\nimport os\nimport pathlib\n\nimport eta.core.utils as etau\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.base import (\n BaseHTTPMiddleware,\n RequestResponseEndpoint,\n)\nfrom starlette.middleware.cors import CORSMiddleware\nfrom starlette.requests import Request\nfrom starlette.responses import Response\nfrom starlette.routing import Mount, Route\nfrom starlette.staticfiles import StaticFiles\nfrom starlette.types import Scope\nimport strawberry as gql\n\nimport fiftyone as fo\nimport fiftyone.constants as foc\nfrom fiftyone.server.context import GraphQL\nfrom fiftyone.server.extensions import EndSession\nfrom fiftyone.server.mutation import Mutation\nfrom fiftyone.server.query import Query\nfrom fiftyone.server.routes import routes\nfrom fiftyone.server.scalars import Date, DateTime\n\n\netau.ensure_dir(os.path.join(os.path.dirname(__file__), \"static\"))\n\n\nclass Static(StaticFiles):\n async def get_response(self, path: str, scope: Scope) -> Response:\n response = await super().get_response(path, scope)\n\n if response.status_code == 404:\n path = pathlib.Path(\n *pathlib.Path(path).parts[2:]\n ) # strip dataset/{name}\n response = await super().get_response(path, scope)\n if response.status_code == 404:\n full_path, stat_result = self.lookup_path(\"index.html\")\n return self.file_response(full_path, stat_result, scope)\n\n return response\n\n\nclass HeadersMiddleware(BaseHTTPMiddleware):\n async def dispatch(\n self, request: Request, call_next: RequestResponseEndpoint\n ) -> Response:\n response = await call_next(request)\n response.headers[\"x-colab-notebook-cache-control\"] = \"no-cache\"\n return response\n\n\nschema = gql.Schema(\n mutation=Mutation,\n query=Query,\n extensions=[EndSession],\n scalar_overrides={\n date: Date,\n datetime: DateTime,\n },\n)\n\n\napp = Starlette(\n middleware=[\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_methods=[\"GET\", \"POST\", \"HEAD\", \"OPTIONS\"],\n allow_headers=[\n \"access-control-allow-origin\",\n \"authorization\",\n \"content-type\",\n ],\n ),\n Middleware(HeadersMiddleware),\n ],\n debug=foc.DEV_INSTALL,\n routes=[Route(route, endpoint) for route, endpoint in routes]\n + [\n Route(\n \"/graphql\",\n GraphQL(\n schema,\n graphiql=foc.DEV_INSTALL,\n ),\n ),\n Mount(\n \"/plugins\",\n app=Static(\n directory=fo.config.plugins_dir,\n html=True,\n check_dir=False,\n follow_symlink=True,\n ),\n name=\"plugins\",\n ),\n Mount(\n \"/\",\n app=Static(\n directory=os.path.join(os.path.dirname(__file__), \"static\"),\n html=True,\n follow_symlink=True,\n ),\n name=\"static\",\n ),\n ],\n)\n", "path": "fiftyone/server/app.py"}], "after_files": [{"content": "\"\"\"\nFiftyOne Server app.\n\n| Copyright 2017-2023, Voxel51, Inc.\n| `voxel51.com <https://voxel51.com/>`_\n|\n\"\"\"\nfrom datetime import date, datetime\nimport os\nimport pathlib\n\nimport eta.core.utils as etau\nfrom starlette.applications import Starlette\nfrom starlette.middleware import Middleware\nfrom starlette.middleware.base import (\n BaseHTTPMiddleware,\n RequestResponseEndpoint,\n)\nfrom starlette.middleware.cors import CORSMiddleware\nfrom starlette.requests import Request\nfrom starlette.responses import Response\nfrom starlette.routing import Mount, Route\nfrom starlette.staticfiles import StaticFiles\nfrom starlette.types import Scope\nimport strawberry as gql\n\nimport fiftyone as fo\nimport fiftyone.constants as foc\nfrom fiftyone.server.context import GraphQL\nfrom fiftyone.server.extensions import EndSession\nfrom fiftyone.server.mutation import Mutation\nfrom fiftyone.server.query import Query\nfrom fiftyone.server.routes import routes\nfrom fiftyone.server.scalars import Date, DateTime\n\n\netau.ensure_dir(os.path.join(os.path.dirname(__file__), \"static\"))\n\n\nclass Static(StaticFiles):\n async def get_response(self, path: str, scope: Scope) -> Response:\n response = await super().get_response(path, scope)\n\n if response.status_code == 404:\n path = pathlib.Path(\n *pathlib.Path(path).parts[2:]\n ) # strip dataset/{name}\n response = await super().get_response(path, scope)\n if response.status_code == 404:\n full_path, stat_result = self.lookup_path(\"index.html\")\n return self.file_response(full_path, stat_result, scope)\n\n return response\n\n\nclass HeadersMiddleware(BaseHTTPMiddleware):\n async def dispatch(\n self, request: Request, call_next: RequestResponseEndpoint\n ) -> Response:\n response = await call_next(request)\n response.headers[\"x-colab-notebook-cache-control\"] = \"no-cache\"\n return response\n\n\nschema = gql.Schema(\n mutation=Mutation,\n query=Query,\n extensions=[EndSession],\n scalar_overrides={\n date: Date,\n datetime: DateTime,\n },\n)\n\n\napp = Starlette(\n middleware=[\n Middleware(\n CORSMiddleware,\n allow_origins=[\"*\"],\n allow_methods=[\"GET\", \"POST\", \"HEAD\", \"OPTIONS\"],\n allow_headers=[\n \"access-control-allow-origin\",\n \"authorization\",\n \"content-type\",\n ],\n ),\n Middleware(HeadersMiddleware),\n ],\n debug=foc.DEV_INSTALL,\n routes=[Route(route, endpoint) for route, endpoint in routes]\n + [\n Route(\n \"/graphql\",\n GraphQL(\n schema,\n graphiql=foc.DEV_INSTALL,\n ),\n ),\n Mount(\n \"/plugins\",\n app=Static(\n directory=fo.config.plugins_dir,\n html=True,\n check_dir=False,\n follow_symlink=True,\n ),\n name=\"plugins\",\n ),\n Mount(\n \"/\",\n app=Static(\n directory=os.path.join(os.path.dirname(__file__), \"static\"),\n html=True,\n ),\n name=\"static\",\n ),\n ],\n)\n", "path": "fiftyone/server/app.py"}]}
| 1,825 | 89 |
gh_patches_debug_10510
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-1721
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
init-templatedir installing hooks to wrong directory
I was trying to use the init-templatedir functionality of pre-commit and ran into a weird problem:
Using Windows 10, pre-commit 2.9.2, git version 2.29.2.windows.1
I followed the example on the pre-commit.com website and used:
```
git config --global init.templateDir ~/.git-template
pre-commit init-templatedir ~/.git-template
```

It wants me to be in a git repository (I thought you prevented this with da80cc6479154c0a0a6096d183f9d1d72aae556b).
So i switched to a git repository and rerun
```
pre-commit init-templatedir ~/.git-template
```

the hooks aren't installed in the stated directory.
Based on the warnings it looks like pre-commit isn't resolving the ~ correctly, or did I miss sth.?
```
git config --get init.templateDir
```
returns ~/.git-template

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pre_commit/git.py`
Content:
```
1 import logging
2 import os.path
3 import sys
4 from typing import Dict
5 from typing import List
6 from typing import MutableMapping
7 from typing import Optional
8 from typing import Set
9
10 from pre_commit.errors import FatalError
11 from pre_commit.util import CalledProcessError
12 from pre_commit.util import cmd_output
13 from pre_commit.util import cmd_output_b
14
15
16 logger = logging.getLogger(__name__)
17
18
19 def zsplit(s: str) -> List[str]:
20 s = s.strip('\0')
21 if s:
22 return s.split('\0')
23 else:
24 return []
25
26
27 def no_git_env(
28 _env: Optional[MutableMapping[str, str]] = None,
29 ) -> Dict[str, str]:
30 # Too many bugs dealing with environment variables and GIT:
31 # https://github.com/pre-commit/pre-commit/issues/300
32 # In git 2.6.3 (maybe others), git exports GIT_WORK_TREE while running
33 # pre-commit hooks
34 # In git 1.9.1 (maybe others), git exports GIT_DIR and GIT_INDEX_FILE
35 # while running pre-commit hooks in submodules.
36 # GIT_DIR: Causes git clone to clone wrong thing
37 # GIT_INDEX_FILE: Causes 'error invalid object ...' during commit
38 _env = _env if _env is not None else os.environ
39 return {
40 k: v for k, v in _env.items()
41 if not k.startswith('GIT_') or
42 k in {
43 'GIT_EXEC_PATH', 'GIT_SSH', 'GIT_SSH_COMMAND', 'GIT_SSL_CAINFO',
44 'GIT_SSL_NO_VERIFY',
45 }
46 }
47
48
49 def get_root() -> str:
50 try:
51 root = cmd_output('git', 'rev-parse', '--show-toplevel')[1].strip()
52 except CalledProcessError:
53 raise FatalError(
54 'git failed. Is it installed, and are you in a Git repository '
55 'directory?',
56 )
57 else:
58 if root == '': # pragma: no cover (old git)
59 raise FatalError(
60 'git toplevel unexpectedly empty! make sure you are not '
61 'inside the `.git` directory of your repository.',
62 )
63 else:
64 return root
65
66
67 def get_git_dir(git_root: str = '.') -> str:
68 opts = ('--git-common-dir', '--git-dir')
69 _, out, _ = cmd_output('git', 'rev-parse', *opts, cwd=git_root)
70 for line, opt in zip(out.splitlines(), opts):
71 if line != opt: # pragma: no branch (git < 2.5)
72 return os.path.normpath(os.path.join(git_root, line))
73 else:
74 raise AssertionError('unreachable: no git dir')
75
76
77 def get_remote_url(git_root: str) -> str:
78 _, out, _ = cmd_output('git', 'config', 'remote.origin.url', cwd=git_root)
79 return out.strip()
80
81
82 def is_in_merge_conflict() -> bool:
83 git_dir = get_git_dir('.')
84 return (
85 os.path.exists(os.path.join(git_dir, 'MERGE_MSG')) and
86 os.path.exists(os.path.join(git_dir, 'MERGE_HEAD'))
87 )
88
89
90 def parse_merge_msg_for_conflicts(merge_msg: bytes) -> List[str]:
91 # Conflicted files start with tabs
92 return [
93 line.lstrip(b'#').strip().decode()
94 for line in merge_msg.splitlines()
95 # '#\t' for git 2.4.1
96 if line.startswith((b'\t', b'#\t'))
97 ]
98
99
100 def get_conflicted_files() -> Set[str]:
101 logger.info('Checking merge-conflict files only.')
102 # Need to get the conflicted files from the MERGE_MSG because they could
103 # have resolved the conflict by choosing one side or the other
104 with open(os.path.join(get_git_dir('.'), 'MERGE_MSG'), 'rb') as f:
105 merge_msg = f.read()
106 merge_conflict_filenames = parse_merge_msg_for_conflicts(merge_msg)
107
108 # This will get the rest of the changes made after the merge.
109 # If they resolved the merge conflict by choosing a mesh of both sides
110 # this will also include the conflicted files
111 tree_hash = cmd_output('git', 'write-tree')[1].strip()
112 merge_diff_filenames = zsplit(
113 cmd_output(
114 'git', 'diff', '--name-only', '--no-ext-diff', '-z',
115 '-m', tree_hash, 'HEAD', 'MERGE_HEAD',
116 )[1],
117 )
118 return set(merge_conflict_filenames) | set(merge_diff_filenames)
119
120
121 def get_staged_files(cwd: Optional[str] = None) -> List[str]:
122 return zsplit(
123 cmd_output(
124 'git', 'diff', '--staged', '--name-only', '--no-ext-diff', '-z',
125 # Everything except for D
126 '--diff-filter=ACMRTUXB',
127 cwd=cwd,
128 )[1],
129 )
130
131
132 def intent_to_add_files() -> List[str]:
133 _, stdout, _ = cmd_output(
134 'git', 'status', '--ignore-submodules', '--porcelain', '-z',
135 )
136 parts = list(reversed(zsplit(stdout)))
137 intent_to_add = []
138 while parts:
139 line = parts.pop()
140 status, filename = line[:3], line[3:]
141 if status[0] in {'C', 'R'}: # renames / moves have an additional arg
142 parts.pop()
143 if status[1] == 'A':
144 intent_to_add.append(filename)
145 return intent_to_add
146
147
148 def get_all_files() -> List[str]:
149 return zsplit(cmd_output('git', 'ls-files', '-z')[1])
150
151
152 def get_changed_files(old: str, new: str) -> List[str]:
153 return zsplit(
154 cmd_output(
155 'git', 'diff', '--name-only', '--no-ext-diff', '-z',
156 f'{old}...{new}',
157 )[1],
158 )
159
160
161 def head_rev(remote: str) -> str:
162 _, out, _ = cmd_output('git', 'ls-remote', '--exit-code', remote, 'HEAD')
163 return out.split()[0]
164
165
166 def has_diff(*args: str, repo: str = '.') -> bool:
167 cmd = ('git', 'diff', '--quiet', '--no-ext-diff', *args)
168 return cmd_output_b(*cmd, cwd=repo, retcode=None)[0] == 1
169
170
171 def has_core_hookpaths_set() -> bool:
172 _, out, _ = cmd_output_b('git', 'config', 'core.hooksPath', retcode=None)
173 return bool(out.strip())
174
175
176 def init_repo(path: str, remote: str) -> None:
177 if os.path.isdir(remote):
178 remote = os.path.abspath(remote)
179
180 env = no_git_env()
181 # avoid the user's template so that hooks do not recurse
182 cmd_output_b('git', 'init', '--template=', path, env=env)
183 cmd_output_b('git', 'remote', 'add', 'origin', remote, cwd=path, env=env)
184
185
186 def commit(repo: str = '.') -> None:
187 env = no_git_env()
188 name, email = 'pre-commit', '[email protected]'
189 env['GIT_AUTHOR_NAME'] = env['GIT_COMMITTER_NAME'] = name
190 env['GIT_AUTHOR_EMAIL'] = env['GIT_COMMITTER_EMAIL'] = email
191 cmd = ('git', 'commit', '--no-edit', '--no-gpg-sign', '-n', '-minit')
192 cmd_output_b(*cmd, cwd=repo, env=env)
193
194
195 def git_path(name: str, repo: str = '.') -> str:
196 _, out, _ = cmd_output('git', 'rev-parse', '--git-path', name, cwd=repo)
197 return os.path.join(repo, out.strip())
198
199
200 def check_for_cygwin_mismatch() -> None:
201 """See https://github.com/pre-commit/pre-commit/issues/354"""
202 if sys.platform in ('cygwin', 'win32'): # pragma: no cover (windows)
203 is_cygwin_python = sys.platform == 'cygwin'
204 toplevel = get_root()
205 is_cygwin_git = toplevel.startswith('/')
206
207 if is_cygwin_python ^ is_cygwin_git:
208 exe_type = {True: '(cygwin)', False: '(windows)'}
209 logger.warn(
210 f'pre-commit has detected a mix of cygwin python / git\n'
211 f'This combination is not supported, it is likely you will '
212 f'receive an error later in the program.\n'
213 f'Make sure to use cygwin git+python while using cygwin\n'
214 f'These can be installed through the cygwin installer.\n'
215 f' - python {exe_type[is_cygwin_python]}\n'
216 f' - git {exe_type[is_cygwin_git]}\n',
217 )
218
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pre_commit/git.py b/pre_commit/git.py
--- a/pre_commit/git.py
+++ b/pre_commit/git.py
@@ -201,7 +201,10 @@
"""See https://github.com/pre-commit/pre-commit/issues/354"""
if sys.platform in ('cygwin', 'win32'): # pragma: no cover (windows)
is_cygwin_python = sys.platform == 'cygwin'
- toplevel = get_root()
+ try:
+ toplevel = get_root()
+ except FatalError: # skip the check if we're not in a git repo
+ return
is_cygwin_git = toplevel.startswith('/')
if is_cygwin_python ^ is_cygwin_git:
|
{"golden_diff": "diff --git a/pre_commit/git.py b/pre_commit/git.py\n--- a/pre_commit/git.py\n+++ b/pre_commit/git.py\n@@ -201,7 +201,10 @@\n \"\"\"See https://github.com/pre-commit/pre-commit/issues/354\"\"\"\n if sys.platform in ('cygwin', 'win32'): # pragma: no cover (windows)\n is_cygwin_python = sys.platform == 'cygwin'\n- toplevel = get_root()\n+ try:\n+ toplevel = get_root()\n+ except FatalError: # skip the check if we're not in a git repo\n+ return\n is_cygwin_git = toplevel.startswith('/')\n \n if is_cygwin_python ^ is_cygwin_git:\n", "issue": "init-templatedir installing hooks to wrong directory\nI was trying to use the init-templatedir functionality of pre-commit and ran into a weird problem:\r\n\r\nUsing Windows 10, pre-commit 2.9.2, git version 2.29.2.windows.1\r\n\r\nI followed the example on the pre-commit.com website and used:\r\n```\r\ngit config --global init.templateDir ~/.git-template\r\npre-commit init-templatedir ~/.git-template\r\n```\r\n\r\n\r\nIt wants me to be in a git repository (I thought you prevented this with da80cc6479154c0a0a6096d183f9d1d72aae556b).\r\nSo i switched to a git repository and rerun \r\n```\r\npre-commit init-templatedir ~/.git-template\r\n```\r\n\r\n\r\nthe hooks aren't installed in the stated directory.\r\nBased on the warnings it looks like pre-commit isn't resolving the ~ correctly, or did I miss sth.?\r\n\r\n```\r\ngit config --get init.templateDir \r\n```\r\nreturns ~/.git-template\r\n\r\n\r\n\n", "before_files": [{"content": "import logging\nimport os.path\nimport sys\nfrom typing import Dict\nfrom typing import List\nfrom typing import MutableMapping\nfrom typing import Optional\nfrom typing import Set\n\nfrom pre_commit.errors import FatalError\nfrom pre_commit.util import CalledProcessError\nfrom pre_commit.util import cmd_output\nfrom pre_commit.util import cmd_output_b\n\n\nlogger = logging.getLogger(__name__)\n\n\ndef zsplit(s: str) -> List[str]:\n s = s.strip('\\0')\n if s:\n return s.split('\\0')\n else:\n return []\n\n\ndef no_git_env(\n _env: Optional[MutableMapping[str, str]] = None,\n) -> Dict[str, str]:\n # Too many bugs dealing with environment variables and GIT:\n # https://github.com/pre-commit/pre-commit/issues/300\n # In git 2.6.3 (maybe others), git exports GIT_WORK_TREE while running\n # pre-commit hooks\n # In git 1.9.1 (maybe others), git exports GIT_DIR and GIT_INDEX_FILE\n # while running pre-commit hooks in submodules.\n # GIT_DIR: Causes git clone to clone wrong thing\n # GIT_INDEX_FILE: Causes 'error invalid object ...' during commit\n _env = _env if _env is not None else os.environ\n return {\n k: v for k, v in _env.items()\n if not k.startswith('GIT_') or\n k in {\n 'GIT_EXEC_PATH', 'GIT_SSH', 'GIT_SSH_COMMAND', 'GIT_SSL_CAINFO',\n 'GIT_SSL_NO_VERIFY',\n }\n }\n\n\ndef get_root() -> str:\n try:\n root = cmd_output('git', 'rev-parse', '--show-toplevel')[1].strip()\n except CalledProcessError:\n raise FatalError(\n 'git failed. Is it installed, and are you in a Git repository '\n 'directory?',\n )\n else:\n if root == '': # pragma: no cover (old git)\n raise FatalError(\n 'git toplevel unexpectedly empty! make sure you are not '\n 'inside the `.git` directory of your repository.',\n )\n else:\n return root\n\n\ndef get_git_dir(git_root: str = '.') -> str:\n opts = ('--git-common-dir', '--git-dir')\n _, out, _ = cmd_output('git', 'rev-parse', *opts, cwd=git_root)\n for line, opt in zip(out.splitlines(), opts):\n if line != opt: # pragma: no branch (git < 2.5)\n return os.path.normpath(os.path.join(git_root, line))\n else:\n raise AssertionError('unreachable: no git dir')\n\n\ndef get_remote_url(git_root: str) -> str:\n _, out, _ = cmd_output('git', 'config', 'remote.origin.url', cwd=git_root)\n return out.strip()\n\n\ndef is_in_merge_conflict() -> bool:\n git_dir = get_git_dir('.')\n return (\n os.path.exists(os.path.join(git_dir, 'MERGE_MSG')) and\n os.path.exists(os.path.join(git_dir, 'MERGE_HEAD'))\n )\n\n\ndef parse_merge_msg_for_conflicts(merge_msg: bytes) -> List[str]:\n # Conflicted files start with tabs\n return [\n line.lstrip(b'#').strip().decode()\n for line in merge_msg.splitlines()\n # '#\\t' for git 2.4.1\n if line.startswith((b'\\t', b'#\\t'))\n ]\n\n\ndef get_conflicted_files() -> Set[str]:\n logger.info('Checking merge-conflict files only.')\n # Need to get the conflicted files from the MERGE_MSG because they could\n # have resolved the conflict by choosing one side or the other\n with open(os.path.join(get_git_dir('.'), 'MERGE_MSG'), 'rb') as f:\n merge_msg = f.read()\n merge_conflict_filenames = parse_merge_msg_for_conflicts(merge_msg)\n\n # This will get the rest of the changes made after the merge.\n # If they resolved the merge conflict by choosing a mesh of both sides\n # this will also include the conflicted files\n tree_hash = cmd_output('git', 'write-tree')[1].strip()\n merge_diff_filenames = zsplit(\n cmd_output(\n 'git', 'diff', '--name-only', '--no-ext-diff', '-z',\n '-m', tree_hash, 'HEAD', 'MERGE_HEAD',\n )[1],\n )\n return set(merge_conflict_filenames) | set(merge_diff_filenames)\n\n\ndef get_staged_files(cwd: Optional[str] = None) -> List[str]:\n return zsplit(\n cmd_output(\n 'git', 'diff', '--staged', '--name-only', '--no-ext-diff', '-z',\n # Everything except for D\n '--diff-filter=ACMRTUXB',\n cwd=cwd,\n )[1],\n )\n\n\ndef intent_to_add_files() -> List[str]:\n _, stdout, _ = cmd_output(\n 'git', 'status', '--ignore-submodules', '--porcelain', '-z',\n )\n parts = list(reversed(zsplit(stdout)))\n intent_to_add = []\n while parts:\n line = parts.pop()\n status, filename = line[:3], line[3:]\n if status[0] in {'C', 'R'}: # renames / moves have an additional arg\n parts.pop()\n if status[1] == 'A':\n intent_to_add.append(filename)\n return intent_to_add\n\n\ndef get_all_files() -> List[str]:\n return zsplit(cmd_output('git', 'ls-files', '-z')[1])\n\n\ndef get_changed_files(old: str, new: str) -> List[str]:\n return zsplit(\n cmd_output(\n 'git', 'diff', '--name-only', '--no-ext-diff', '-z',\n f'{old}...{new}',\n )[1],\n )\n\n\ndef head_rev(remote: str) -> str:\n _, out, _ = cmd_output('git', 'ls-remote', '--exit-code', remote, 'HEAD')\n return out.split()[0]\n\n\ndef has_diff(*args: str, repo: str = '.') -> bool:\n cmd = ('git', 'diff', '--quiet', '--no-ext-diff', *args)\n return cmd_output_b(*cmd, cwd=repo, retcode=None)[0] == 1\n\n\ndef has_core_hookpaths_set() -> bool:\n _, out, _ = cmd_output_b('git', 'config', 'core.hooksPath', retcode=None)\n return bool(out.strip())\n\n\ndef init_repo(path: str, remote: str) -> None:\n if os.path.isdir(remote):\n remote = os.path.abspath(remote)\n\n env = no_git_env()\n # avoid the user's template so that hooks do not recurse\n cmd_output_b('git', 'init', '--template=', path, env=env)\n cmd_output_b('git', 'remote', 'add', 'origin', remote, cwd=path, env=env)\n\n\ndef commit(repo: str = '.') -> None:\n env = no_git_env()\n name, email = 'pre-commit', '[email protected]'\n env['GIT_AUTHOR_NAME'] = env['GIT_COMMITTER_NAME'] = name\n env['GIT_AUTHOR_EMAIL'] = env['GIT_COMMITTER_EMAIL'] = email\n cmd = ('git', 'commit', '--no-edit', '--no-gpg-sign', '-n', '-minit')\n cmd_output_b(*cmd, cwd=repo, env=env)\n\n\ndef git_path(name: str, repo: str = '.') -> str:\n _, out, _ = cmd_output('git', 'rev-parse', '--git-path', name, cwd=repo)\n return os.path.join(repo, out.strip())\n\n\ndef check_for_cygwin_mismatch() -> None:\n \"\"\"See https://github.com/pre-commit/pre-commit/issues/354\"\"\"\n if sys.platform in ('cygwin', 'win32'): # pragma: no cover (windows)\n is_cygwin_python = sys.platform == 'cygwin'\n toplevel = get_root()\n is_cygwin_git = toplevel.startswith('/')\n\n if is_cygwin_python ^ is_cygwin_git:\n exe_type = {True: '(cygwin)', False: '(windows)'}\n logger.warn(\n f'pre-commit has detected a mix of cygwin python / git\\n'\n f'This combination is not supported, it is likely you will '\n f'receive an error later in the program.\\n'\n f'Make sure to use cygwin git+python while using cygwin\\n'\n f'These can be installed through the cygwin installer.\\n'\n f' - python {exe_type[is_cygwin_python]}\\n'\n f' - git {exe_type[is_cygwin_git]}\\n',\n )\n", "path": "pre_commit/git.py"}], "after_files": [{"content": "import logging\nimport os.path\nimport sys\nfrom typing import Dict\nfrom typing import List\nfrom typing import MutableMapping\nfrom typing import Optional\nfrom typing import Set\n\nfrom pre_commit.errors import FatalError\nfrom pre_commit.util import CalledProcessError\nfrom pre_commit.util import cmd_output\nfrom pre_commit.util import cmd_output_b\n\n\nlogger = logging.getLogger(__name__)\n\n\ndef zsplit(s: str) -> List[str]:\n s = s.strip('\\0')\n if s:\n return s.split('\\0')\n else:\n return []\n\n\ndef no_git_env(\n _env: Optional[MutableMapping[str, str]] = None,\n) -> Dict[str, str]:\n # Too many bugs dealing with environment variables and GIT:\n # https://github.com/pre-commit/pre-commit/issues/300\n # In git 2.6.3 (maybe others), git exports GIT_WORK_TREE while running\n # pre-commit hooks\n # In git 1.9.1 (maybe others), git exports GIT_DIR and GIT_INDEX_FILE\n # while running pre-commit hooks in submodules.\n # GIT_DIR: Causes git clone to clone wrong thing\n # GIT_INDEX_FILE: Causes 'error invalid object ...' during commit\n _env = _env if _env is not None else os.environ\n return {\n k: v for k, v in _env.items()\n if not k.startswith('GIT_') or\n k in {\n 'GIT_EXEC_PATH', 'GIT_SSH', 'GIT_SSH_COMMAND', 'GIT_SSL_CAINFO',\n 'GIT_SSL_NO_VERIFY',\n }\n }\n\n\ndef get_root() -> str:\n try:\n root = cmd_output('git', 'rev-parse', '--show-toplevel')[1].strip()\n except CalledProcessError:\n raise FatalError(\n 'git failed. Is it installed, and are you in a Git repository '\n 'directory?',\n )\n else:\n if root == '': # pragma: no cover (old git)\n raise FatalError(\n 'git toplevel unexpectedly empty! make sure you are not '\n 'inside the `.git` directory of your repository.',\n )\n else:\n return root\n\n\ndef get_git_dir(git_root: str = '.') -> str:\n opts = ('--git-common-dir', '--git-dir')\n _, out, _ = cmd_output('git', 'rev-parse', *opts, cwd=git_root)\n for line, opt in zip(out.splitlines(), opts):\n if line != opt: # pragma: no branch (git < 2.5)\n return os.path.normpath(os.path.join(git_root, line))\n else:\n raise AssertionError('unreachable: no git dir')\n\n\ndef get_remote_url(git_root: str) -> str:\n _, out, _ = cmd_output('git', 'config', 'remote.origin.url', cwd=git_root)\n return out.strip()\n\n\ndef is_in_merge_conflict() -> bool:\n git_dir = get_git_dir('.')\n return (\n os.path.exists(os.path.join(git_dir, 'MERGE_MSG')) and\n os.path.exists(os.path.join(git_dir, 'MERGE_HEAD'))\n )\n\n\ndef parse_merge_msg_for_conflicts(merge_msg: bytes) -> List[str]:\n # Conflicted files start with tabs\n return [\n line.lstrip(b'#').strip().decode()\n for line in merge_msg.splitlines()\n # '#\\t' for git 2.4.1\n if line.startswith((b'\\t', b'#\\t'))\n ]\n\n\ndef get_conflicted_files() -> Set[str]:\n logger.info('Checking merge-conflict files only.')\n # Need to get the conflicted files from the MERGE_MSG because they could\n # have resolved the conflict by choosing one side or the other\n with open(os.path.join(get_git_dir('.'), 'MERGE_MSG'), 'rb') as f:\n merge_msg = f.read()\n merge_conflict_filenames = parse_merge_msg_for_conflicts(merge_msg)\n\n # This will get the rest of the changes made after the merge.\n # If they resolved the merge conflict by choosing a mesh of both sides\n # this will also include the conflicted files\n tree_hash = cmd_output('git', 'write-tree')[1].strip()\n merge_diff_filenames = zsplit(\n cmd_output(\n 'git', 'diff', '--name-only', '--no-ext-diff', '-z',\n '-m', tree_hash, 'HEAD', 'MERGE_HEAD',\n )[1],\n )\n return set(merge_conflict_filenames) | set(merge_diff_filenames)\n\n\ndef get_staged_files(cwd: Optional[str] = None) -> List[str]:\n return zsplit(\n cmd_output(\n 'git', 'diff', '--staged', '--name-only', '--no-ext-diff', '-z',\n # Everything except for D\n '--diff-filter=ACMRTUXB',\n cwd=cwd,\n )[1],\n )\n\n\ndef intent_to_add_files() -> List[str]:\n _, stdout, _ = cmd_output(\n 'git', 'status', '--ignore-submodules', '--porcelain', '-z',\n )\n parts = list(reversed(zsplit(stdout)))\n intent_to_add = []\n while parts:\n line = parts.pop()\n status, filename = line[:3], line[3:]\n if status[0] in {'C', 'R'}: # renames / moves have an additional arg\n parts.pop()\n if status[1] == 'A':\n intent_to_add.append(filename)\n return intent_to_add\n\n\ndef get_all_files() -> List[str]:\n return zsplit(cmd_output('git', 'ls-files', '-z')[1])\n\n\ndef get_changed_files(old: str, new: str) -> List[str]:\n return zsplit(\n cmd_output(\n 'git', 'diff', '--name-only', '--no-ext-diff', '-z',\n f'{old}...{new}',\n )[1],\n )\n\n\ndef head_rev(remote: str) -> str:\n _, out, _ = cmd_output('git', 'ls-remote', '--exit-code', remote, 'HEAD')\n return out.split()[0]\n\n\ndef has_diff(*args: str, repo: str = '.') -> bool:\n cmd = ('git', 'diff', '--quiet', '--no-ext-diff', *args)\n return cmd_output_b(*cmd, cwd=repo, retcode=None)[0] == 1\n\n\ndef has_core_hookpaths_set() -> bool:\n _, out, _ = cmd_output_b('git', 'config', 'core.hooksPath', retcode=None)\n return bool(out.strip())\n\n\ndef init_repo(path: str, remote: str) -> None:\n if os.path.isdir(remote):\n remote = os.path.abspath(remote)\n\n env = no_git_env()\n # avoid the user's template so that hooks do not recurse\n cmd_output_b('git', 'init', '--template=', path, env=env)\n cmd_output_b('git', 'remote', 'add', 'origin', remote, cwd=path, env=env)\n\n\ndef commit(repo: str = '.') -> None:\n env = no_git_env()\n name, email = 'pre-commit', '[email protected]'\n env['GIT_AUTHOR_NAME'] = env['GIT_COMMITTER_NAME'] = name\n env['GIT_AUTHOR_EMAIL'] = env['GIT_COMMITTER_EMAIL'] = email\n cmd = ('git', 'commit', '--no-edit', '--no-gpg-sign', '-n', '-minit')\n cmd_output_b(*cmd, cwd=repo, env=env)\n\n\ndef git_path(name: str, repo: str = '.') -> str:\n _, out, _ = cmd_output('git', 'rev-parse', '--git-path', name, cwd=repo)\n return os.path.join(repo, out.strip())\n\n\ndef check_for_cygwin_mismatch() -> None:\n \"\"\"See https://github.com/pre-commit/pre-commit/issues/354\"\"\"\n if sys.platform in ('cygwin', 'win32'): # pragma: no cover (windows)\n is_cygwin_python = sys.platform == 'cygwin'\n try:\n toplevel = get_root()\n except FatalError: # skip the check if we're not in a git repo\n return\n is_cygwin_git = toplevel.startswith('/')\n\n if is_cygwin_python ^ is_cygwin_git:\n exe_type = {True: '(cygwin)', False: '(windows)'}\n logger.warn(\n f'pre-commit has detected a mix of cygwin python / git\\n'\n f'This combination is not supported, it is likely you will '\n f'receive an error later in the program.\\n'\n f'Make sure to use cygwin git+python while using cygwin\\n'\n f'These can be installed through the cygwin installer.\\n'\n f' - python {exe_type[is_cygwin_python]}\\n'\n f' - git {exe_type[is_cygwin_git]}\\n',\n )\n", "path": "pre_commit/git.py"}]}
| 3,192 | 169 |
gh_patches_debug_17216
|
rasdani/github-patches
|
git_diff
|
medtagger__MedTagger-407
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Scans with low number of Slices are not properly loaded on Labeling page
## Current Behavior
When Scan has less than 10 Slices, Scan Viewer keeps displaying spinner indicator and never gets to displaying actual Scan.
## Expected Behavior
Scan should be displayed properly, no matter how many Slices it has.
## Steps to Reproduce the Problem
1. Upload less than 10 Slices.
2. Go to Labelling page.
3. Voi'la, Scan is not displayed, instead you're presented with spinner indicator that doesn't dissapear.
## Additional comment (optional)
Reason for that happening is that `SLICE_BATCH_SIZE` (`validation-page.component.ts`, Line 23) is fixed to 10. When we upload Scan that has less than `SLICE_BATCH_SIZE` slices, method `slice.isLastInBatch()` (`marker-page.component.ts`, Line 101) will always return `false`, because it will never hit slice with id = 9 (because there isn't one...). Therefore, Slice download will never be marked as completed.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `backend/medtagger/api/scans/service_web_socket.py`
Content:
```
1 """Module responsible for definition of Scans service available via WebSockets."""
2 from typing import Dict
3
4 from flask_socketio import Namespace, emit
5
6 from medtagger.api import web_socket
7 from medtagger.database.models import SliceOrientation
8 from medtagger.types import ScanID
9 from medtagger.api.exceptions import InvalidArgumentsException
10 from medtagger.api.scans import business
11
12
13 class Slices(Namespace):
14 """WebSocket handler for /slices namespace."""
15
16 MAX_NUMBER_OF_SLICES_PER_REQUEST = 25
17
18 def on_request_slices(self, request: Dict) -> None:
19 """Handle slices request triggered by `request_slices` event."""
20 assert request.get('scan_id'), 'ScanID is required!'
21 scan_id = ScanID(str(request['scan_id']))
22 begin = max(0, request.get('begin', 0))
23 count = request.get('count', 1)
24 reversed_order = request.get('reversed', False)
25 orientation = request.get('orientation', SliceOrientation.Z.value)
26 self._raise_on_invalid_request_slices(count, orientation)
27
28 orientation = SliceOrientation[orientation]
29 slices = business.get_slices_for_scan(scan_id, begin, count, orientation=orientation)
30 slices_to_send = reversed(list(enumerate(slices))) if reversed_order else enumerate(slices)
31 last_in_batch = begin if reversed_order else begin + count - 1
32 for index, (_slice, image) in slices_to_send:
33 emit('slice', {
34 'scan_id': scan_id,
35 'index': begin + index,
36 'last_in_batch': last_in_batch,
37 'image': image,
38 })
39
40 def _raise_on_invalid_request_slices(self, count: int, orientation: str) -> None:
41 """Validate incoming request and raise an exception if there are issues with given arguments.
42
43 :param count: number of slices that should be returned
44 :param orientation: Slice's orientation as a string
45 """
46 # Make sure that passed orientation is proper one
47 if orientation not in SliceOrientation.__members__:
48 raise InvalidArgumentsException('Invalid Slice orientation.')
49
50 # Make sure that nobody will fetch whole scan at once. It could freeze our backend application.
51 if count > self.MAX_NUMBER_OF_SLICES_PER_REQUEST:
52 message = 'Cannot return more than {} slices per request.'.format(self.MAX_NUMBER_OF_SLICES_PER_REQUEST)
53 raise InvalidArgumentsException(message)
54
55
56 # Register above namespace
57 web_socket.on_namespace(Slices('/slices'))
58
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/backend/medtagger/api/scans/service_web_socket.py b/backend/medtagger/api/scans/service_web_socket.py
--- a/backend/medtagger/api/scans/service_web_socket.py
+++ b/backend/medtagger/api/scans/service_web_socket.py
@@ -26,10 +26,10 @@
self._raise_on_invalid_request_slices(count, orientation)
orientation = SliceOrientation[orientation]
- slices = business.get_slices_for_scan(scan_id, begin, count, orientation=orientation)
- slices_to_send = reversed(list(enumerate(slices))) if reversed_order else enumerate(slices)
- last_in_batch = begin if reversed_order else begin + count - 1
- for index, (_slice, image) in slices_to_send:
+ slices = list(business.get_slices_for_scan(scan_id, begin, count, orientation=orientation))
+ slices_to_send = list(reversed(slices)) if reversed_order else slices
+ last_in_batch = begin if reversed_order else begin + len(slices_to_send) - 1
+ for index, (_slice, image) in enumerate(slices_to_send):
emit('slice', {
'scan_id': scan_id,
'index': begin + index,
|
{"golden_diff": "diff --git a/backend/medtagger/api/scans/service_web_socket.py b/backend/medtagger/api/scans/service_web_socket.py\n--- a/backend/medtagger/api/scans/service_web_socket.py\n+++ b/backend/medtagger/api/scans/service_web_socket.py\n@@ -26,10 +26,10 @@\n self._raise_on_invalid_request_slices(count, orientation)\n \n orientation = SliceOrientation[orientation]\n- slices = business.get_slices_for_scan(scan_id, begin, count, orientation=orientation)\n- slices_to_send = reversed(list(enumerate(slices))) if reversed_order else enumerate(slices)\n- last_in_batch = begin if reversed_order else begin + count - 1\n- for index, (_slice, image) in slices_to_send:\n+ slices = list(business.get_slices_for_scan(scan_id, begin, count, orientation=orientation))\n+ slices_to_send = list(reversed(slices)) if reversed_order else slices\n+ last_in_batch = begin if reversed_order else begin + len(slices_to_send) - 1\n+ for index, (_slice, image) in enumerate(slices_to_send):\n emit('slice', {\n 'scan_id': scan_id,\n 'index': begin + index,\n", "issue": "Scans with low number of Slices are not properly loaded on Labeling page\n## Current Behavior\r\n\r\nWhen Scan has less than 10 Slices, Scan Viewer keeps displaying spinner indicator and never gets to displaying actual Scan.\r\n\r\n## Expected Behavior\r\n\r\nScan should be displayed properly, no matter how many Slices it has.\r\n\r\n## Steps to Reproduce the Problem\r\n\r\n 1. Upload less than 10 Slices.\r\n 2. Go to Labelling page.\r\n 3. Voi'la, Scan is not displayed, instead you're presented with spinner indicator that doesn't dissapear.\r\n\r\n## Additional comment (optional)\r\n\r\nReason for that happening is that `SLICE_BATCH_SIZE` (`validation-page.component.ts`, Line 23) is fixed to 10. When we upload Scan that has less than `SLICE_BATCH_SIZE` slices, method `slice.isLastInBatch()` (`marker-page.component.ts`, Line 101) will always return `false`, because it will never hit slice with id = 9 (because there isn't one...). Therefore, Slice download will never be marked as completed.\r\n\n", "before_files": [{"content": "\"\"\"Module responsible for definition of Scans service available via WebSockets.\"\"\"\nfrom typing import Dict\n\nfrom flask_socketio import Namespace, emit\n\nfrom medtagger.api import web_socket\nfrom medtagger.database.models import SliceOrientation\nfrom medtagger.types import ScanID\nfrom medtagger.api.exceptions import InvalidArgumentsException\nfrom medtagger.api.scans import business\n\n\nclass Slices(Namespace):\n \"\"\"WebSocket handler for /slices namespace.\"\"\"\n\n MAX_NUMBER_OF_SLICES_PER_REQUEST = 25\n\n def on_request_slices(self, request: Dict) -> None:\n \"\"\"Handle slices request triggered by `request_slices` event.\"\"\"\n assert request.get('scan_id'), 'ScanID is required!'\n scan_id = ScanID(str(request['scan_id']))\n begin = max(0, request.get('begin', 0))\n count = request.get('count', 1)\n reversed_order = request.get('reversed', False)\n orientation = request.get('orientation', SliceOrientation.Z.value)\n self._raise_on_invalid_request_slices(count, orientation)\n\n orientation = SliceOrientation[orientation]\n slices = business.get_slices_for_scan(scan_id, begin, count, orientation=orientation)\n slices_to_send = reversed(list(enumerate(slices))) if reversed_order else enumerate(slices)\n last_in_batch = begin if reversed_order else begin + count - 1\n for index, (_slice, image) in slices_to_send:\n emit('slice', {\n 'scan_id': scan_id,\n 'index': begin + index,\n 'last_in_batch': last_in_batch,\n 'image': image,\n })\n\n def _raise_on_invalid_request_slices(self, count: int, orientation: str) -> None:\n \"\"\"Validate incoming request and raise an exception if there are issues with given arguments.\n\n :param count: number of slices that should be returned\n :param orientation: Slice's orientation as a string\n \"\"\"\n # Make sure that passed orientation is proper one\n if orientation not in SliceOrientation.__members__:\n raise InvalidArgumentsException('Invalid Slice orientation.')\n\n # Make sure that nobody will fetch whole scan at once. It could freeze our backend application.\n if count > self.MAX_NUMBER_OF_SLICES_PER_REQUEST:\n message = 'Cannot return more than {} slices per request.'.format(self.MAX_NUMBER_OF_SLICES_PER_REQUEST)\n raise InvalidArgumentsException(message)\n\n\n# Register above namespace\nweb_socket.on_namespace(Slices('/slices'))\n", "path": "backend/medtagger/api/scans/service_web_socket.py"}], "after_files": [{"content": "\"\"\"Module responsible for definition of Scans service available via WebSockets.\"\"\"\nfrom typing import Dict\n\nfrom flask_socketio import Namespace, emit\n\nfrom medtagger.api import web_socket\nfrom medtagger.database.models import SliceOrientation\nfrom medtagger.types import ScanID\nfrom medtagger.api.exceptions import InvalidArgumentsException\nfrom medtagger.api.scans import business\n\n\nclass Slices(Namespace):\n \"\"\"WebSocket handler for /slices namespace.\"\"\"\n\n MAX_NUMBER_OF_SLICES_PER_REQUEST = 25\n\n def on_request_slices(self, request: Dict) -> None:\n \"\"\"Handle slices request triggered by `request_slices` event.\"\"\"\n assert request.get('scan_id'), 'ScanID is required!'\n scan_id = ScanID(str(request['scan_id']))\n begin = max(0, request.get('begin', 0))\n count = request.get('count', 1)\n reversed_order = request.get('reversed', False)\n orientation = request.get('orientation', SliceOrientation.Z.value)\n self._raise_on_invalid_request_slices(count, orientation)\n\n orientation = SliceOrientation[orientation]\n slices = list(business.get_slices_for_scan(scan_id, begin, count, orientation=orientation))\n slices_to_send = list(reversed(slices)) if reversed_order else slices\n last_in_batch = begin if reversed_order else begin + len(slices_to_send) - 1\n for index, (_slice, image) in enumerate(slices_to_send):\n emit('slice', {\n 'scan_id': scan_id,\n 'index': begin + index,\n 'last_in_batch': last_in_batch,\n 'image': image,\n })\n\n def _raise_on_invalid_request_slices(self, count: int, orientation: str) -> None:\n \"\"\"Validate incoming request and raise an exception if there are issues with given arguments.\n\n :param count: number of slices that should be returned\n :param orientation: Slice's orientation as a string\n \"\"\"\n # Make sure that passed orientation is proper one\n if orientation not in SliceOrientation.__members__:\n raise InvalidArgumentsException('Invalid Slice orientation.')\n\n # Make sure that nobody will fetch whole scan at once. It could freeze our backend application.\n if count > self.MAX_NUMBER_OF_SLICES_PER_REQUEST:\n message = 'Cannot return more than {} slices per request.'.format(self.MAX_NUMBER_OF_SLICES_PER_REQUEST)\n raise InvalidArgumentsException(message)\n\n\n# Register above namespace\nweb_socket.on_namespace(Slices('/slices'))\n", "path": "backend/medtagger/api/scans/service_web_socket.py"}]}
| 1,136 | 271 |
gh_patches_debug_14649
|
rasdani/github-patches
|
git_diff
|
Mailu__Mailu-2450
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Feature request: Overwriting the TLS configuration on port 25
## Environment & Versions
### Environment
- [x] docker-compose
- [ ] kubernetes
- [ ] docker swarm
### Versions
1.8
## Description
Feature request: Overwriting TLS settings for smtp.
while overwriting the TLS settings for https works perfectly using a volume mapping to /conf/tls.conf it doesn't work for port 25.
Somewhat logical because the TLS settings are hardcoded in the codefragment from [nginx.conf](https://github.com/Mailu/Mailu/blob/master/core/nginx/conf/nginx.conf)
```
# SMTP is always enabled, to avoid losing emails when TLS is failing
server {
listen 25;
listen [::]:25;
{% if TLS and not TLS_ERROR %}
ssl_protocols TLSv1 TLSv1.1 TLSv1.2 TLSv1.3;
ssl_ciphers ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384:DHE-RSA-CHACHA20-POLY1305:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA:ECDHE-RSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES256-SHA256:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:DES-CBC3-SHA;
ssl_prefer_server_ciphers on;
starttls on;
{% endif %}
protocol smtp;
smtp_auth none;
auth_http_header Auth-Port 25;
}
```
Would be nice to include the tls.conf, or better a separate smtptls.conf here too.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/nginx/config.py`
Content:
```
1 #!/usr/bin/python3
2
3 import os
4 import logging as log
5 import sys
6 from socrate import system, conf
7
8 args = os.environ.copy()
9
10 log.basicConfig(stream=sys.stderr, level=args.get("LOG_LEVEL", "WARNING"))
11
12 # Get the first DNS server
13 with open("/etc/resolv.conf") as handle:
14 content = handle.read().split()
15 resolver = content[content.index("nameserver") + 1]
16 args["RESOLVER"] = f"[{resolver}]" if ":" in resolver else resolver
17
18 args["ADMIN_ADDRESS"] = system.get_host_address_from_environment("ADMIN", "admin")
19 args["ANTISPAM_WEBUI_ADDRESS"] = system.get_host_address_from_environment("ANTISPAM_WEBUI", "antispam:11334")
20 if args["WEBMAIL"] != "none":
21 args["WEBMAIL_ADDRESS"] = system.get_host_address_from_environment("WEBMAIL", "webmail")
22 if args["WEBDAV"] != "none":
23 args["WEBDAV_ADDRESS"] = system.get_host_address_from_environment("WEBDAV", "webdav:5232")
24
25 # TLS configuration
26 cert_name = os.getenv("TLS_CERT_FILENAME", default="cert.pem")
27 keypair_name = os.getenv("TLS_KEYPAIR_FILENAME", default="key.pem")
28 args["TLS"] = {
29 "cert": ("/certs/%s" % cert_name, "/certs/%s" % keypair_name),
30 "letsencrypt": ("/certs/letsencrypt/live/mailu/nginx-chain.pem",
31 "/certs/letsencrypt/live/mailu/privkey.pem", "/certs/letsencrypt/live/mailu-ecdsa/nginx-chain.pem", "/certs/letsencrypt/live/mailu-ecdsa/privkey.pem"),
32 "mail": ("/certs/%s" % cert_name, "/certs/%s" % keypair_name),
33 "mail-letsencrypt": ("/certs/letsencrypt/live/mailu/nginx-chain.pem",
34 "/certs/letsencrypt/live/mailu/privkey.pem", "/certs/letsencrypt/live/mailu-ecdsa/nginx-chain.pem", "/certs/letsencrypt/live/mailu-ecdsa/privkey.pem"),
35 "notls": None
36 }[args["TLS_FLAVOR"]]
37
38 def format_for_nginx(fullchain, output):
39 """ We may want to strip ISRG Root X1 out """
40 if not os.path.exists(fullchain):
41 return
42 split = '-----END CERTIFICATE-----\n'
43 with open(fullchain, 'r') as pem:
44 certs = [f'{cert}{split}' for cert in pem.read().split(split) if cert]
45 if len(certs)>2 and os.getenv('LETSENCRYPT_SHORTCHAIN'):
46 del certs[-1]
47 with open(output, 'w') as pem:
48 pem.write(''.join(certs))
49
50 if args['TLS_FLAVOR'] in ['letsencrypt', 'mail-letsencrypt']:
51 format_for_nginx('/certs/letsencrypt/live/mailu/fullchain.pem', '/certs/letsencrypt/live/mailu/nginx-chain.pem')
52 format_for_nginx('/certs/letsencrypt/live/mailu-ecdsa/fullchain.pem', '/certs/letsencrypt/live/mailu-ecdsa/nginx-chain.pem')
53
54 if args["TLS"] and not all(os.path.exists(file_path) for file_path in args["TLS"]):
55 print("Missing cert or key file, disabling TLS")
56 args["TLS_ERROR"] = "yes"
57
58 # Build final configuration paths
59 conf.jinja("/conf/tls.conf", args, "/etc/nginx/tls.conf")
60 conf.jinja("/conf/proxy.conf", args, "/etc/nginx/proxy.conf")
61 conf.jinja("/conf/nginx.conf", args, "/etc/nginx/nginx.conf")
62 if os.path.exists("/var/run/nginx.pid"):
63 os.system("nginx -s reload")
64
```
Path: `core/admin/mailu/configuration.py`
Content:
```
1 import os
2
3 from datetime import timedelta
4 from socrate import system
5 import ipaddress
6
7 DEFAULT_CONFIG = {
8 # Specific to the admin UI
9 'DOCKER_SOCKET': 'unix:///var/run/docker.sock',
10 'BABEL_DEFAULT_LOCALE': 'en',
11 'BABEL_DEFAULT_TIMEZONE': 'UTC',
12 'BOOTSTRAP_SERVE_LOCAL': True,
13 'RATELIMIT_STORAGE_URL': '',
14 'QUOTA_STORAGE_URL': '',
15 'DEBUG': False,
16 'DOMAIN_REGISTRATION': False,
17 'TEMPLATES_AUTO_RELOAD': True,
18 'MEMORY_SESSIONS': False,
19 # Database settings
20 'DB_FLAVOR': None,
21 'DB_USER': 'mailu',
22 'DB_PW': None,
23 'DB_HOST': 'database',
24 'DB_NAME': 'mailu',
25 'SQLITE_DATABASE_FILE':'data/main.db',
26 'SQLALCHEMY_DATABASE_URI': 'sqlite:////data/main.db',
27 'SQLALCHEMY_TRACK_MODIFICATIONS': False,
28 # Statistics management
29 'INSTANCE_ID_PATH': '/data/instance',
30 'STATS_ENDPOINT': '19.{}.stats.mailu.io',
31 # Common configuration variables
32 'SECRET_KEY': 'changeMe',
33 'DOMAIN': 'mailu.io',
34 'HOSTNAMES': 'mail.mailu.io,alternative.mailu.io,yetanother.mailu.io',
35 'POSTMASTER': 'postmaster',
36 'WILDCARD_SENDERS': '',
37 'TLS_FLAVOR': 'cert',
38 'INBOUND_TLS_ENFORCE': False,
39 'DEFER_ON_TLS_ERROR': True,
40 'AUTH_RATELIMIT_IP': '60/hour',
41 'AUTH_RATELIMIT_IP_V4_MASK': 24,
42 'AUTH_RATELIMIT_IP_V6_MASK': 56,
43 'AUTH_RATELIMIT_USER': '100/day',
44 'AUTH_RATELIMIT_EXEMPTION': '',
45 'AUTH_RATELIMIT_EXEMPTION_LENGTH': 86400,
46 'DISABLE_STATISTICS': False,
47 # Mail settings
48 'DMARC_RUA': None,
49 'DMARC_RUF': None,
50 'WELCOME': False,
51 'WELCOME_SUBJECT': 'Dummy welcome topic',
52 'WELCOME_BODY': 'Dummy welcome body',
53 'DKIM_SELECTOR': 'dkim',
54 'DKIM_PATH': '/dkim/{domain}.{selector}.key',
55 'DEFAULT_QUOTA': 1000000000,
56 'MESSAGE_RATELIMIT': '200/day',
57 'MESSAGE_RATELIMIT_EXEMPTION': '',
58 'RECIPIENT_DELIMITER': '',
59 # Web settings
60 'SITENAME': 'Mailu',
61 'WEBSITE': 'https://mailu.io',
62 'ADMIN' : 'none',
63 'WEB_ADMIN': '/admin',
64 'WEB_WEBMAIL': '/webmail',
65 'WEBMAIL': 'none',
66 'RECAPTCHA_PUBLIC_KEY': '',
67 'RECAPTCHA_PRIVATE_KEY': '',
68 'LOGO_URL': None,
69 'LOGO_BACKGROUND': None,
70 # Advanced settings
71 'LOG_LEVEL': 'WARNING',
72 'SESSION_KEY_BITS': 128,
73 'SESSION_TIMEOUT': 3600,
74 'PERMANENT_SESSION_LIFETIME': 30*24*3600,
75 'SESSION_COOKIE_SECURE': True,
76 'CREDENTIAL_ROUNDS': 12,
77 'TZ': 'Etc/UTC',
78 # Host settings
79 'HOST_IMAP': 'imap',
80 'HOST_LMTP': 'imap:2525',
81 'HOST_POP3': 'imap',
82 'HOST_SMTP': 'smtp',
83 'HOST_AUTHSMTP': 'smtp',
84 'HOST_ADMIN': 'admin',
85 'HOST_WEBMAIL': 'webmail',
86 'HOST_WEBDAV': 'webdav:5232',
87 'HOST_REDIS': 'redis',
88 'HOST_FRONT': 'front',
89 'SUBNET': '192.168.203.0/24',
90 'SUBNET6': None
91 }
92
93 class ConfigManager:
94 """ Naive configuration manager that uses environment only
95 """
96
97 DB_TEMPLATES = {
98 'sqlite': 'sqlite:////{SQLITE_DATABASE_FILE}',
99 'postgresql': 'postgresql://{DB_USER}:{DB_PW}@{DB_HOST}/{DB_NAME}',
100 'mysql': 'mysql+mysqlconnector://{DB_USER}:{DB_PW}@{DB_HOST}/{DB_NAME}'
101 }
102
103 def __init__(self):
104 self.config = dict()
105
106 def get_host_address(self, name):
107 # if MYSERVICE_ADDRESS is defined, use this
108 if f'{name}_ADDRESS' in os.environ:
109 return os.environ.get(f'{name}_ADDRESS')
110 # otherwise use the host name and resolve it
111 return system.resolve_address(self.config[f'HOST_{name}'])
112
113 def resolve_hosts(self):
114 for key in ['IMAP', 'POP3', 'AUTHSMTP', 'SMTP', 'REDIS']:
115 self.config[f'{key}_ADDRESS'] = self.get_host_address(key)
116 if self.config['WEBMAIL'] != 'none':
117 self.config['WEBMAIL_ADDRESS'] = self.get_host_address('WEBMAIL')
118
119 def __get_env(self, key, value):
120 key_file = key + "_FILE"
121 if key_file in os.environ:
122 with open(os.environ.get(key_file)) as file:
123 value_from_file = file.read()
124 return value_from_file.strip()
125 else:
126 return os.environ.get(key, value)
127
128 def __coerce_value(self, value):
129 if isinstance(value, str) and value.lower() in ('true','yes'):
130 return True
131 elif isinstance(value, str) and value.lower() in ('false', 'no'):
132 return False
133 return value
134
135 def init_app(self, app):
136 # get current app config
137 self.config.update(app.config)
138 # get environment variables
139 self.config.update({
140 key: self.__coerce_value(self.__get_env(key, value))
141 for key, value in DEFAULT_CONFIG.items()
142 })
143 self.resolve_hosts()
144
145 # automatically set the sqlalchemy string
146 if self.config['DB_FLAVOR']:
147 template = self.DB_TEMPLATES[self.config['DB_FLAVOR']]
148 self.config['SQLALCHEMY_DATABASE_URI'] = template.format(**self.config)
149
150 self.config['RATELIMIT_STORAGE_URL'] = f'redis://{self.config["REDIS_ADDRESS"]}/2'
151 self.config['QUOTA_STORAGE_URL'] = f'redis://{self.config["REDIS_ADDRESS"]}/1'
152 self.config['SESSION_STORAGE_URL'] = f'redis://{self.config["REDIS_ADDRESS"]}/3'
153 self.config['SESSION_COOKIE_SAMESITE'] = 'Strict'
154 self.config['SESSION_COOKIE_HTTPONLY'] = True
155 self.config['SESSION_PERMANENT'] = True
156 self.config['SESSION_TIMEOUT'] = int(self.config['SESSION_TIMEOUT'])
157 self.config['PERMANENT_SESSION_LIFETIME'] = int(self.config['PERMANENT_SESSION_LIFETIME'])
158 self.config['AUTH_RATELIMIT_IP_V4_MASK'] = int(self.config['AUTH_RATELIMIT_IP_V4_MASK'])
159 self.config['AUTH_RATELIMIT_IP_V6_MASK'] = int(self.config['AUTH_RATELIMIT_IP_V6_MASK'])
160 hostnames = [host.strip() for host in self.config['HOSTNAMES'].split(',')]
161 self.config['AUTH_RATELIMIT_EXEMPTION'] = set(ipaddress.ip_network(cidr, False) for cidr in (cidr.strip() for cidr in self.config['AUTH_RATELIMIT_EXEMPTION'].split(',')) if cidr)
162 self.config['MESSAGE_RATELIMIT_EXEMPTION'] = set([s for s in self.config['MESSAGE_RATELIMIT_EXEMPTION'].lower().replace(' ', '').split(',') if s])
163 self.config['HOSTNAMES'] = ','.join(hostnames)
164 self.config['HOSTNAME'] = hostnames[0]
165
166 # update the app config
167 app.config.update(self.config)
168
169
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/core/admin/mailu/configuration.py b/core/admin/mailu/configuration.py
--- a/core/admin/mailu/configuration.py
+++ b/core/admin/mailu/configuration.py
@@ -74,6 +74,7 @@
'PERMANENT_SESSION_LIFETIME': 30*24*3600,
'SESSION_COOKIE_SECURE': True,
'CREDENTIAL_ROUNDS': 12,
+ 'TLS_PERMISSIVE': True,
'TZ': 'Etc/UTC',
# Host settings
'HOST_IMAP': 'imap',
diff --git a/core/nginx/config.py b/core/nginx/config.py
--- a/core/nginx/config.py
+++ b/core/nginx/config.py
@@ -9,6 +9,8 @@
log.basicConfig(stream=sys.stderr, level=args.get("LOG_LEVEL", "WARNING"))
+args['TLS_PERMISSIVE'] = str(args.get('TLS_PERMISSIVE')).lower() not in ('false', 'no')
+
# Get the first DNS server
with open("/etc/resolv.conf") as handle:
content = handle.read().split()
|
{"golden_diff": "diff --git a/core/admin/mailu/configuration.py b/core/admin/mailu/configuration.py\n--- a/core/admin/mailu/configuration.py\n+++ b/core/admin/mailu/configuration.py\n@@ -74,6 +74,7 @@\n 'PERMANENT_SESSION_LIFETIME': 30*24*3600,\n 'SESSION_COOKIE_SECURE': True,\n 'CREDENTIAL_ROUNDS': 12,\n+ 'TLS_PERMISSIVE': True,\n 'TZ': 'Etc/UTC',\n # Host settings\n 'HOST_IMAP': 'imap',\ndiff --git a/core/nginx/config.py b/core/nginx/config.py\n--- a/core/nginx/config.py\n+++ b/core/nginx/config.py\n@@ -9,6 +9,8 @@\n \n log.basicConfig(stream=sys.stderr, level=args.get(\"LOG_LEVEL\", \"WARNING\"))\n \n+args['TLS_PERMISSIVE'] = str(args.get('TLS_PERMISSIVE')).lower() not in ('false', 'no')\n+\n # Get the first DNS server\n with open(\"/etc/resolv.conf\") as handle:\n content = handle.read().split()\n", "issue": "Feature request: Overwriting the TLS configuration on port 25\n## Environment & Versions\r\n### Environment\r\n - [x] docker-compose\r\n - [ ] kubernetes\r\n - [ ] docker swarm\r\n\r\n### Versions\r\n1.8\r\n\r\n## Description\r\nFeature request: Overwriting TLS settings for smtp.\r\n\r\nwhile overwriting the TLS settings for https works perfectly using a volume mapping to /conf/tls.conf it doesn't work for port 25.\r\n\r\nSomewhat logical because the TLS settings are hardcoded in the codefragment from [nginx.conf](https://github.com/Mailu/Mailu/blob/master/core/nginx/conf/nginx.conf)\r\n\r\n```\r\n # SMTP is always enabled, to avoid losing emails when TLS is failing\r\n server {\r\n listen 25;\r\n listen [::]:25;\r\n {% if TLS and not TLS_ERROR %}\r\n ssl_protocols TLSv1 TLSv1.1 TLSv1.2 TLSv1.3;\r\n ssl_ciphers ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384:DHE-RSA-CHACHA20-POLY1305:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA:ECDHE-RSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES256-SHA256:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:DES-CBC3-SHA;\r\n ssl_prefer_server_ciphers on;\r\n starttls on;\r\n {% endif %}\r\n protocol smtp;\r\n smtp_auth none;\r\n auth_http_header Auth-Port 25;\r\n }\r\n```\r\n\r\nWould be nice to include the tls.conf, or better a separate smtptls.conf here too.\r\n\n", "before_files": [{"content": "#!/usr/bin/python3\n\nimport os\nimport logging as log\nimport sys\nfrom socrate import system, conf\n\nargs = os.environ.copy()\n\nlog.basicConfig(stream=sys.stderr, level=args.get(\"LOG_LEVEL\", \"WARNING\"))\n\n# Get the first DNS server\nwith open(\"/etc/resolv.conf\") as handle:\n content = handle.read().split()\n resolver = content[content.index(\"nameserver\") + 1]\n args[\"RESOLVER\"] = f\"[{resolver}]\" if \":\" in resolver else resolver\n\nargs[\"ADMIN_ADDRESS\"] = system.get_host_address_from_environment(\"ADMIN\", \"admin\")\nargs[\"ANTISPAM_WEBUI_ADDRESS\"] = system.get_host_address_from_environment(\"ANTISPAM_WEBUI\", \"antispam:11334\")\nif args[\"WEBMAIL\"] != \"none\":\n args[\"WEBMAIL_ADDRESS\"] = system.get_host_address_from_environment(\"WEBMAIL\", \"webmail\")\nif args[\"WEBDAV\"] != \"none\":\n args[\"WEBDAV_ADDRESS\"] = system.get_host_address_from_environment(\"WEBDAV\", \"webdav:5232\")\n\n# TLS configuration\ncert_name = os.getenv(\"TLS_CERT_FILENAME\", default=\"cert.pem\")\nkeypair_name = os.getenv(\"TLS_KEYPAIR_FILENAME\", default=\"key.pem\")\nargs[\"TLS\"] = {\n \"cert\": (\"/certs/%s\" % cert_name, \"/certs/%s\" % keypair_name),\n \"letsencrypt\": (\"/certs/letsencrypt/live/mailu/nginx-chain.pem\",\n \"/certs/letsencrypt/live/mailu/privkey.pem\", \"/certs/letsencrypt/live/mailu-ecdsa/nginx-chain.pem\", \"/certs/letsencrypt/live/mailu-ecdsa/privkey.pem\"),\n \"mail\": (\"/certs/%s\" % cert_name, \"/certs/%s\" % keypair_name),\n \"mail-letsencrypt\": (\"/certs/letsencrypt/live/mailu/nginx-chain.pem\",\n \"/certs/letsencrypt/live/mailu/privkey.pem\", \"/certs/letsencrypt/live/mailu-ecdsa/nginx-chain.pem\", \"/certs/letsencrypt/live/mailu-ecdsa/privkey.pem\"),\n \"notls\": None\n}[args[\"TLS_FLAVOR\"]]\n\ndef format_for_nginx(fullchain, output):\n \"\"\" We may want to strip ISRG Root X1 out \"\"\"\n if not os.path.exists(fullchain):\n return\n split = '-----END CERTIFICATE-----\\n'\n with open(fullchain, 'r') as pem:\n certs = [f'{cert}{split}' for cert in pem.read().split(split) if cert]\n if len(certs)>2 and os.getenv('LETSENCRYPT_SHORTCHAIN'):\n del certs[-1]\n with open(output, 'w') as pem:\n pem.write(''.join(certs))\n\nif args['TLS_FLAVOR'] in ['letsencrypt', 'mail-letsencrypt']:\n format_for_nginx('/certs/letsencrypt/live/mailu/fullchain.pem', '/certs/letsencrypt/live/mailu/nginx-chain.pem')\n format_for_nginx('/certs/letsencrypt/live/mailu-ecdsa/fullchain.pem', '/certs/letsencrypt/live/mailu-ecdsa/nginx-chain.pem')\n\nif args[\"TLS\"] and not all(os.path.exists(file_path) for file_path in args[\"TLS\"]):\n print(\"Missing cert or key file, disabling TLS\")\n args[\"TLS_ERROR\"] = \"yes\"\n\n# Build final configuration paths\nconf.jinja(\"/conf/tls.conf\", args, \"/etc/nginx/tls.conf\")\nconf.jinja(\"/conf/proxy.conf\", args, \"/etc/nginx/proxy.conf\")\nconf.jinja(\"/conf/nginx.conf\", args, \"/etc/nginx/nginx.conf\")\nif os.path.exists(\"/var/run/nginx.pid\"):\n os.system(\"nginx -s reload\")\n", "path": "core/nginx/config.py"}, {"content": "import os\n\nfrom datetime import timedelta\nfrom socrate import system\nimport ipaddress\n\nDEFAULT_CONFIG = {\n # Specific to the admin UI\n 'DOCKER_SOCKET': 'unix:///var/run/docker.sock',\n 'BABEL_DEFAULT_LOCALE': 'en',\n 'BABEL_DEFAULT_TIMEZONE': 'UTC',\n 'BOOTSTRAP_SERVE_LOCAL': True,\n 'RATELIMIT_STORAGE_URL': '',\n 'QUOTA_STORAGE_URL': '',\n 'DEBUG': False,\n 'DOMAIN_REGISTRATION': False,\n 'TEMPLATES_AUTO_RELOAD': True,\n 'MEMORY_SESSIONS': False,\n # Database settings\n 'DB_FLAVOR': None,\n 'DB_USER': 'mailu',\n 'DB_PW': None,\n 'DB_HOST': 'database',\n 'DB_NAME': 'mailu',\n 'SQLITE_DATABASE_FILE':'data/main.db',\n 'SQLALCHEMY_DATABASE_URI': 'sqlite:////data/main.db',\n 'SQLALCHEMY_TRACK_MODIFICATIONS': False,\n # Statistics management\n 'INSTANCE_ID_PATH': '/data/instance',\n 'STATS_ENDPOINT': '19.{}.stats.mailu.io',\n # Common configuration variables\n 'SECRET_KEY': 'changeMe',\n 'DOMAIN': 'mailu.io',\n 'HOSTNAMES': 'mail.mailu.io,alternative.mailu.io,yetanother.mailu.io',\n 'POSTMASTER': 'postmaster',\n 'WILDCARD_SENDERS': '',\n 'TLS_FLAVOR': 'cert',\n 'INBOUND_TLS_ENFORCE': False,\n 'DEFER_ON_TLS_ERROR': True,\n 'AUTH_RATELIMIT_IP': '60/hour',\n 'AUTH_RATELIMIT_IP_V4_MASK': 24,\n 'AUTH_RATELIMIT_IP_V6_MASK': 56,\n 'AUTH_RATELIMIT_USER': '100/day',\n 'AUTH_RATELIMIT_EXEMPTION': '',\n 'AUTH_RATELIMIT_EXEMPTION_LENGTH': 86400,\n 'DISABLE_STATISTICS': False,\n # Mail settings\n 'DMARC_RUA': None,\n 'DMARC_RUF': None,\n 'WELCOME': False,\n 'WELCOME_SUBJECT': 'Dummy welcome topic',\n 'WELCOME_BODY': 'Dummy welcome body',\n 'DKIM_SELECTOR': 'dkim',\n 'DKIM_PATH': '/dkim/{domain}.{selector}.key',\n 'DEFAULT_QUOTA': 1000000000,\n 'MESSAGE_RATELIMIT': '200/day',\n 'MESSAGE_RATELIMIT_EXEMPTION': '',\n 'RECIPIENT_DELIMITER': '',\n # Web settings\n 'SITENAME': 'Mailu',\n 'WEBSITE': 'https://mailu.io',\n 'ADMIN' : 'none',\n 'WEB_ADMIN': '/admin',\n 'WEB_WEBMAIL': '/webmail',\n 'WEBMAIL': 'none',\n 'RECAPTCHA_PUBLIC_KEY': '',\n 'RECAPTCHA_PRIVATE_KEY': '',\n 'LOGO_URL': None,\n 'LOGO_BACKGROUND': None,\n # Advanced settings\n 'LOG_LEVEL': 'WARNING',\n 'SESSION_KEY_BITS': 128,\n 'SESSION_TIMEOUT': 3600,\n 'PERMANENT_SESSION_LIFETIME': 30*24*3600,\n 'SESSION_COOKIE_SECURE': True,\n 'CREDENTIAL_ROUNDS': 12,\n 'TZ': 'Etc/UTC',\n # Host settings\n 'HOST_IMAP': 'imap',\n 'HOST_LMTP': 'imap:2525',\n 'HOST_POP3': 'imap',\n 'HOST_SMTP': 'smtp',\n 'HOST_AUTHSMTP': 'smtp',\n 'HOST_ADMIN': 'admin',\n 'HOST_WEBMAIL': 'webmail',\n 'HOST_WEBDAV': 'webdav:5232',\n 'HOST_REDIS': 'redis',\n 'HOST_FRONT': 'front',\n 'SUBNET': '192.168.203.0/24',\n 'SUBNET6': None\n}\n\nclass ConfigManager:\n \"\"\" Naive configuration manager that uses environment only\n \"\"\"\n\n DB_TEMPLATES = {\n 'sqlite': 'sqlite:////{SQLITE_DATABASE_FILE}',\n 'postgresql': 'postgresql://{DB_USER}:{DB_PW}@{DB_HOST}/{DB_NAME}',\n 'mysql': 'mysql+mysqlconnector://{DB_USER}:{DB_PW}@{DB_HOST}/{DB_NAME}'\n }\n\n def __init__(self):\n self.config = dict()\n\n def get_host_address(self, name):\n # if MYSERVICE_ADDRESS is defined, use this\n if f'{name}_ADDRESS' in os.environ:\n return os.environ.get(f'{name}_ADDRESS')\n # otherwise use the host name and resolve it\n return system.resolve_address(self.config[f'HOST_{name}'])\n\n def resolve_hosts(self):\n for key in ['IMAP', 'POP3', 'AUTHSMTP', 'SMTP', 'REDIS']:\n self.config[f'{key}_ADDRESS'] = self.get_host_address(key)\n if self.config['WEBMAIL'] != 'none':\n self.config['WEBMAIL_ADDRESS'] = self.get_host_address('WEBMAIL')\n\n def __get_env(self, key, value):\n key_file = key + \"_FILE\"\n if key_file in os.environ:\n with open(os.environ.get(key_file)) as file:\n value_from_file = file.read()\n return value_from_file.strip()\n else:\n return os.environ.get(key, value)\n\n def __coerce_value(self, value):\n if isinstance(value, str) and value.lower() in ('true','yes'):\n return True\n elif isinstance(value, str) and value.lower() in ('false', 'no'):\n return False\n return value\n\n def init_app(self, app):\n # get current app config\n self.config.update(app.config)\n # get environment variables\n self.config.update({\n key: self.__coerce_value(self.__get_env(key, value))\n for key, value in DEFAULT_CONFIG.items()\n })\n self.resolve_hosts()\n\n # automatically set the sqlalchemy string\n if self.config['DB_FLAVOR']:\n template = self.DB_TEMPLATES[self.config['DB_FLAVOR']]\n self.config['SQLALCHEMY_DATABASE_URI'] = template.format(**self.config)\n\n self.config['RATELIMIT_STORAGE_URL'] = f'redis://{self.config[\"REDIS_ADDRESS\"]}/2'\n self.config['QUOTA_STORAGE_URL'] = f'redis://{self.config[\"REDIS_ADDRESS\"]}/1'\n self.config['SESSION_STORAGE_URL'] = f'redis://{self.config[\"REDIS_ADDRESS\"]}/3'\n self.config['SESSION_COOKIE_SAMESITE'] = 'Strict'\n self.config['SESSION_COOKIE_HTTPONLY'] = True\n self.config['SESSION_PERMANENT'] = True\n self.config['SESSION_TIMEOUT'] = int(self.config['SESSION_TIMEOUT'])\n self.config['PERMANENT_SESSION_LIFETIME'] = int(self.config['PERMANENT_SESSION_LIFETIME'])\n self.config['AUTH_RATELIMIT_IP_V4_MASK'] = int(self.config['AUTH_RATELIMIT_IP_V4_MASK'])\n self.config['AUTH_RATELIMIT_IP_V6_MASK'] = int(self.config['AUTH_RATELIMIT_IP_V6_MASK'])\n hostnames = [host.strip() for host in self.config['HOSTNAMES'].split(',')]\n self.config['AUTH_RATELIMIT_EXEMPTION'] = set(ipaddress.ip_network(cidr, False) for cidr in (cidr.strip() for cidr in self.config['AUTH_RATELIMIT_EXEMPTION'].split(',')) if cidr)\n self.config['MESSAGE_RATELIMIT_EXEMPTION'] = set([s for s in self.config['MESSAGE_RATELIMIT_EXEMPTION'].lower().replace(' ', '').split(',') if s])\n self.config['HOSTNAMES'] = ','.join(hostnames)\n self.config['HOSTNAME'] = hostnames[0]\n\n # update the app config\n app.config.update(self.config)\n\n", "path": "core/admin/mailu/configuration.py"}], "after_files": [{"content": "#!/usr/bin/python3\n\nimport os\nimport logging as log\nimport sys\nfrom socrate import system, conf\n\nargs = os.environ.copy()\n\nlog.basicConfig(stream=sys.stderr, level=args.get(\"LOG_LEVEL\", \"WARNING\"))\n\nargs['TLS_PERMISSIVE'] = str(args.get('TLS_PERMISSIVE')).lower() not in ('false', 'no')\n\n# Get the first DNS server\nwith open(\"/etc/resolv.conf\") as handle:\n content = handle.read().split()\n resolver = content[content.index(\"nameserver\") + 1]\n args[\"RESOLVER\"] = f\"[{resolver}]\" if \":\" in resolver else resolver\n\nargs[\"ADMIN_ADDRESS\"] = system.get_host_address_from_environment(\"ADMIN\", \"admin\")\nargs[\"ANTISPAM_WEBUI_ADDRESS\"] = system.get_host_address_from_environment(\"ANTISPAM_WEBUI\", \"antispam:11334\")\nif args[\"WEBMAIL\"] != \"none\":\n args[\"WEBMAIL_ADDRESS\"] = system.get_host_address_from_environment(\"WEBMAIL\", \"webmail\")\nif args[\"WEBDAV\"] != \"none\":\n args[\"WEBDAV_ADDRESS\"] = system.get_host_address_from_environment(\"WEBDAV\", \"webdav:5232\")\n\n# TLS configuration\ncert_name = os.getenv(\"TLS_CERT_FILENAME\", default=\"cert.pem\")\nkeypair_name = os.getenv(\"TLS_KEYPAIR_FILENAME\", default=\"key.pem\")\nargs[\"TLS\"] = {\n \"cert\": (\"/certs/%s\" % cert_name, \"/certs/%s\" % keypair_name),\n \"letsencrypt\": (\"/certs/letsencrypt/live/mailu/nginx-chain.pem\",\n \"/certs/letsencrypt/live/mailu/privkey.pem\", \"/certs/letsencrypt/live/mailu-ecdsa/nginx-chain.pem\", \"/certs/letsencrypt/live/mailu-ecdsa/privkey.pem\"),\n \"mail\": (\"/certs/%s\" % cert_name, \"/certs/%s\" % keypair_name),\n \"mail-letsencrypt\": (\"/certs/letsencrypt/live/mailu/nginx-chain.pem\",\n \"/certs/letsencrypt/live/mailu/privkey.pem\", \"/certs/letsencrypt/live/mailu-ecdsa/nginx-chain.pem\", \"/certs/letsencrypt/live/mailu-ecdsa/privkey.pem\"),\n \"notls\": None\n}[args[\"TLS_FLAVOR\"]]\n\ndef format_for_nginx(fullchain, output):\n \"\"\" We may want to strip ISRG Root X1 out \"\"\"\n if not os.path.exists(fullchain):\n return\n split = '-----END CERTIFICATE-----\\n'\n with open(fullchain, 'r') as pem:\n certs = [f'{cert}{split}' for cert in pem.read().split(split) if cert]\n if len(certs)>2 and os.getenv('LETSENCRYPT_SHORTCHAIN'):\n del certs[-1]\n with open(output, 'w') as pem:\n pem.write(''.join(certs))\n\nif args['TLS_FLAVOR'] in ['letsencrypt', 'mail-letsencrypt']:\n format_for_nginx('/certs/letsencrypt/live/mailu/fullchain.pem', '/certs/letsencrypt/live/mailu/nginx-chain.pem')\n format_for_nginx('/certs/letsencrypt/live/mailu-ecdsa/fullchain.pem', '/certs/letsencrypt/live/mailu-ecdsa/nginx-chain.pem')\n\nif args[\"TLS\"] and not all(os.path.exists(file_path) for file_path in args[\"TLS\"]):\n print(\"Missing cert or key file, disabling TLS\")\n args[\"TLS_ERROR\"] = \"yes\"\n\n# Build final configuration paths\nconf.jinja(\"/conf/tls.conf\", args, \"/etc/nginx/tls.conf\")\nconf.jinja(\"/conf/proxy.conf\", args, \"/etc/nginx/proxy.conf\")\nconf.jinja(\"/conf/nginx.conf\", args, \"/etc/nginx/nginx.conf\")\nif os.path.exists(\"/var/run/nginx.pid\"):\n os.system(\"nginx -s reload\")\n", "path": "core/nginx/config.py"}, {"content": "import os\n\nfrom datetime import timedelta\nfrom socrate import system\nimport ipaddress\n\nDEFAULT_CONFIG = {\n # Specific to the admin UI\n 'DOCKER_SOCKET': 'unix:///var/run/docker.sock',\n 'BABEL_DEFAULT_LOCALE': 'en',\n 'BABEL_DEFAULT_TIMEZONE': 'UTC',\n 'BOOTSTRAP_SERVE_LOCAL': True,\n 'RATELIMIT_STORAGE_URL': '',\n 'QUOTA_STORAGE_URL': '',\n 'DEBUG': False,\n 'DOMAIN_REGISTRATION': False,\n 'TEMPLATES_AUTO_RELOAD': True,\n 'MEMORY_SESSIONS': False,\n # Database settings\n 'DB_FLAVOR': None,\n 'DB_USER': 'mailu',\n 'DB_PW': None,\n 'DB_HOST': 'database',\n 'DB_NAME': 'mailu',\n 'SQLITE_DATABASE_FILE':'data/main.db',\n 'SQLALCHEMY_DATABASE_URI': 'sqlite:////data/main.db',\n 'SQLALCHEMY_TRACK_MODIFICATIONS': False,\n # Statistics management\n 'INSTANCE_ID_PATH': '/data/instance',\n 'STATS_ENDPOINT': '19.{}.stats.mailu.io',\n # Common configuration variables\n 'SECRET_KEY': 'changeMe',\n 'DOMAIN': 'mailu.io',\n 'HOSTNAMES': 'mail.mailu.io,alternative.mailu.io,yetanother.mailu.io',\n 'POSTMASTER': 'postmaster',\n 'WILDCARD_SENDERS': '',\n 'TLS_FLAVOR': 'cert',\n 'INBOUND_TLS_ENFORCE': False,\n 'DEFER_ON_TLS_ERROR': True,\n 'AUTH_RATELIMIT_IP': '60/hour',\n 'AUTH_RATELIMIT_IP_V4_MASK': 24,\n 'AUTH_RATELIMIT_IP_V6_MASK': 56,\n 'AUTH_RATELIMIT_USER': '100/day',\n 'AUTH_RATELIMIT_EXEMPTION': '',\n 'AUTH_RATELIMIT_EXEMPTION_LENGTH': 86400,\n 'DISABLE_STATISTICS': False,\n # Mail settings\n 'DMARC_RUA': None,\n 'DMARC_RUF': None,\n 'WELCOME': False,\n 'WELCOME_SUBJECT': 'Dummy welcome topic',\n 'WELCOME_BODY': 'Dummy welcome body',\n 'DKIM_SELECTOR': 'dkim',\n 'DKIM_PATH': '/dkim/{domain}.{selector}.key',\n 'DEFAULT_QUOTA': 1000000000,\n 'MESSAGE_RATELIMIT': '200/day',\n 'MESSAGE_RATELIMIT_EXEMPTION': '',\n 'RECIPIENT_DELIMITER': '',\n # Web settings\n 'SITENAME': 'Mailu',\n 'WEBSITE': 'https://mailu.io',\n 'ADMIN' : 'none',\n 'WEB_ADMIN': '/admin',\n 'WEB_WEBMAIL': '/webmail',\n 'WEBMAIL': 'none',\n 'RECAPTCHA_PUBLIC_KEY': '',\n 'RECAPTCHA_PRIVATE_KEY': '',\n 'LOGO_URL': None,\n 'LOGO_BACKGROUND': None,\n # Advanced settings\n 'LOG_LEVEL': 'WARNING',\n 'SESSION_KEY_BITS': 128,\n 'SESSION_TIMEOUT': 3600,\n 'PERMANENT_SESSION_LIFETIME': 30*24*3600,\n 'SESSION_COOKIE_SECURE': True,\n 'CREDENTIAL_ROUNDS': 12,\n 'TLS_PERMISSIVE': True,\n 'TZ': 'Etc/UTC',\n # Host settings\n 'HOST_IMAP': 'imap',\n 'HOST_LMTP': 'imap:2525',\n 'HOST_POP3': 'imap',\n 'HOST_SMTP': 'smtp',\n 'HOST_AUTHSMTP': 'smtp',\n 'HOST_ADMIN': 'admin',\n 'HOST_WEBMAIL': 'webmail',\n 'HOST_WEBDAV': 'webdav:5232',\n 'HOST_REDIS': 'redis',\n 'HOST_FRONT': 'front',\n 'SUBNET': '192.168.203.0/24',\n 'SUBNET6': None\n}\n\nclass ConfigManager:\n \"\"\" Naive configuration manager that uses environment only\n \"\"\"\n\n DB_TEMPLATES = {\n 'sqlite': 'sqlite:////{SQLITE_DATABASE_FILE}',\n 'postgresql': 'postgresql://{DB_USER}:{DB_PW}@{DB_HOST}/{DB_NAME}',\n 'mysql': 'mysql+mysqlconnector://{DB_USER}:{DB_PW}@{DB_HOST}/{DB_NAME}'\n }\n\n def __init__(self):\n self.config = dict()\n\n def get_host_address(self, name):\n # if MYSERVICE_ADDRESS is defined, use this\n if f'{name}_ADDRESS' in os.environ:\n return os.environ.get(f'{name}_ADDRESS')\n # otherwise use the host name and resolve it\n return system.resolve_address(self.config[f'HOST_{name}'])\n\n def resolve_hosts(self):\n for key in ['IMAP', 'POP3', 'AUTHSMTP', 'SMTP', 'REDIS']:\n self.config[f'{key}_ADDRESS'] = self.get_host_address(key)\n if self.config['WEBMAIL'] != 'none':\n self.config['WEBMAIL_ADDRESS'] = self.get_host_address('WEBMAIL')\n\n def __get_env(self, key, value):\n key_file = key + \"_FILE\"\n if key_file in os.environ:\n with open(os.environ.get(key_file)) as file:\n value_from_file = file.read()\n return value_from_file.strip()\n else:\n return os.environ.get(key, value)\n\n def __coerce_value(self, value):\n if isinstance(value, str) and value.lower() in ('true','yes'):\n return True\n elif isinstance(value, str) and value.lower() in ('false', 'no'):\n return False\n return value\n\n def init_app(self, app):\n # get current app config\n self.config.update(app.config)\n # get environment variables\n self.config.update({\n key: self.__coerce_value(self.__get_env(key, value))\n for key, value in DEFAULT_CONFIG.items()\n })\n self.resolve_hosts()\n\n # automatically set the sqlalchemy string\n if self.config['DB_FLAVOR']:\n template = self.DB_TEMPLATES[self.config['DB_FLAVOR']]\n self.config['SQLALCHEMY_DATABASE_URI'] = template.format(**self.config)\n\n self.config['RATELIMIT_STORAGE_URL'] = f'redis://{self.config[\"REDIS_ADDRESS\"]}/2'\n self.config['QUOTA_STORAGE_URL'] = f'redis://{self.config[\"REDIS_ADDRESS\"]}/1'\n self.config['SESSION_STORAGE_URL'] = f'redis://{self.config[\"REDIS_ADDRESS\"]}/3'\n self.config['SESSION_COOKIE_SAMESITE'] = 'Strict'\n self.config['SESSION_COOKIE_HTTPONLY'] = True\n self.config['SESSION_PERMANENT'] = True\n self.config['SESSION_TIMEOUT'] = int(self.config['SESSION_TIMEOUT'])\n self.config['PERMANENT_SESSION_LIFETIME'] = int(self.config['PERMANENT_SESSION_LIFETIME'])\n self.config['AUTH_RATELIMIT_IP_V4_MASK'] = int(self.config['AUTH_RATELIMIT_IP_V4_MASK'])\n self.config['AUTH_RATELIMIT_IP_V6_MASK'] = int(self.config['AUTH_RATELIMIT_IP_V6_MASK'])\n hostnames = [host.strip() for host in self.config['HOSTNAMES'].split(',')]\n self.config['AUTH_RATELIMIT_EXEMPTION'] = set(ipaddress.ip_network(cidr, False) for cidr in (cidr.strip() for cidr in self.config['AUTH_RATELIMIT_EXEMPTION'].split(',')) if cidr)\n self.config['MESSAGE_RATELIMIT_EXEMPTION'] = set([s for s in self.config['MESSAGE_RATELIMIT_EXEMPTION'].lower().replace(' ', '').split(',') if s])\n self.config['HOSTNAMES'] = ','.join(hostnames)\n self.config['HOSTNAME'] = hostnames[0]\n\n # update the app config\n app.config.update(self.config)\n\n", "path": "core/admin/mailu/configuration.py"}]}
| 3,952 | 235 |
gh_patches_debug_32640
|
rasdani/github-patches
|
git_diff
|
pantsbuild__pants-14891
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
codegen: Scala codegen fails with missing jdk field
There is a missing `jdk` field on some Protobuf target that is causing compilation of a Scala target with a protobuf dependency to fail. I used example-codegen with https://github.com/pantsbuild/example-codegen/pull/10 to test compilation of Scala Protobuf code. I then switched the dependency to a file-level target using `scala_sources(dependencies=["src/protobuf/simple_example/person.proto"])` in the relavent BUILD file.
Running `./pants_from_sources check src/jvm/org/pantsbuild/example/codegen/scala::` results in:
```
ValueError: Cannot construct a JDK request for src/protobuf/simple_example/person.proto, since none of its members have a `jdk=` field:
* src/protobuf/simple_example/person.proto (protobuf_source)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/python/pants/backend/codegen/protobuf/scala/rules.py`
Content:
```
1 # Copyright 2021 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3 from __future__ import annotations
4
5 import os
6 import pkgutil
7 from dataclasses import dataclass
8
9 from pants.backend.codegen.protobuf.protoc import Protoc
10 from pants.backend.codegen.protobuf.scala.subsystem import PluginArtifactSpec, ScalaPBSubsystem
11 from pants.backend.codegen.protobuf.target_types import (
12 ProtobufDependenciesField,
13 ProtobufSourceField,
14 )
15 from pants.backend.scala.target_types import ScalaSourceField
16 from pants.core.goals.generate_lockfiles import GenerateToolLockfileSentinel
17 from pants.core.util_rules.external_tool import DownloadedExternalTool, ExternalToolRequest
18 from pants.core.util_rules.source_files import SourceFilesRequest
19 from pants.core.util_rules.stripped_source_files import StrippedSourceFiles
20 from pants.engine.addresses import Addresses, UnparsedAddressInputs
21 from pants.engine.environment import Environment, EnvironmentRequest
22 from pants.engine.fs import (
23 AddPrefix,
24 CreateDigest,
25 Digest,
26 Directory,
27 FileContent,
28 MergeDigests,
29 RemovePrefix,
30 Snapshot,
31 )
32 from pants.engine.internals.native_engine import EMPTY_DIGEST
33 from pants.engine.internals.selectors import Get, MultiGet
34 from pants.engine.platform import Platform
35 from pants.engine.process import ProcessResult
36 from pants.engine.rules import collect_rules, rule
37 from pants.engine.target import (
38 GeneratedSources,
39 GenerateSourcesRequest,
40 InjectDependenciesRequest,
41 InjectedDependencies,
42 TransitiveTargets,
43 TransitiveTargetsRequest,
44 )
45 from pants.engine.unions import UnionRule
46 from pants.jvm.compile import ClasspathEntry
47 from pants.jvm.goals import lockfile
48 from pants.jvm.jdk_rules import InternalJdk, JvmProcess
49 from pants.jvm.resolve.common import ArtifactRequirements, Coordinate, GatherJvmCoordinatesRequest
50 from pants.jvm.resolve.coursier_fetch import ToolClasspath, ToolClasspathRequest
51 from pants.jvm.resolve.jvm_tool import GenerateJvmLockfileFromTool
52 from pants.source.source_root import SourceRoot, SourceRootRequest
53 from pants.util.logging import LogLevel
54 from pants.util.ordered_set import FrozenOrderedSet
55
56
57 class GenerateScalaFromProtobufRequest(GenerateSourcesRequest):
58 input = ProtobufSourceField
59 output = ScalaSourceField
60
61
62 class ScalapbcToolLockfileSentinel(GenerateToolLockfileSentinel):
63 resolve_name = ScalaPBSubsystem.options_scope
64
65
66 class ScalaPBShimCompiledClassfiles(ClasspathEntry):
67 pass
68
69
70 @dataclass(frozen=True)
71 class MaterializeJvmPluginRequest:
72 plugin: PluginArtifactSpec
73
74
75 @dataclass(frozen=True)
76 class MaterializedJvmPlugin:
77 name: str
78 classpath: ToolClasspath
79
80 def setup_arg(self, plugin_relpath: str) -> str:
81 classpath_arg = ":".join(self.classpath.classpath_entries(plugin_relpath))
82 return f"--jvm-plugin={self.name}={classpath_arg}"
83
84
85 @dataclass(frozen=True)
86 class MaterializeJvmPluginsRequest:
87 plugins: tuple[PluginArtifactSpec, ...]
88
89
90 @dataclass(frozen=True)
91 class MaterializedJvmPlugins:
92 digest: Digest
93 plugins: tuple[MaterializedJvmPlugin, ...]
94
95 def setup_args(self, plugins_relpath: str) -> tuple[str, ...]:
96 return tuple(p.setup_arg(os.path.join(plugins_relpath, p.name)) for p in self.plugins)
97
98
99 @rule(desc="Generate Scala from Protobuf", level=LogLevel.DEBUG)
100 async def generate_scala_from_protobuf(
101 request: GenerateScalaFromProtobufRequest,
102 protoc: Protoc,
103 scalapb: ScalaPBSubsystem,
104 shim_classfiles: ScalaPBShimCompiledClassfiles,
105 jdk: InternalJdk,
106 ) -> GeneratedSources:
107 output_dir = "_generated_files"
108 toolcp_relpath = "__toolcp"
109 shimcp_relpath = "__shimcp"
110 plugins_relpath = "__plugins"
111 protoc_relpath = "__protoc"
112
113 lockfile_request = await Get(GenerateJvmLockfileFromTool, ScalapbcToolLockfileSentinel())
114 (
115 downloaded_protoc_binary,
116 tool_classpath,
117 empty_output_dir,
118 transitive_targets,
119 inherit_env,
120 ) = await MultiGet(
121 Get(DownloadedExternalTool, ExternalToolRequest, protoc.get_request(Platform.current)),
122 Get(ToolClasspath, ToolClasspathRequest(lockfile=lockfile_request)),
123 Get(Digest, CreateDigest([Directory(output_dir)])),
124 Get(TransitiveTargets, TransitiveTargetsRequest([request.protocol_target.address])),
125 # Need PATH so that ScalaPB can invoke `mkfifo`.
126 Get(Environment, EnvironmentRequest(requested=["PATH"])),
127 )
128
129 # NB: By stripping the source roots, we avoid having to set the value `--proto_path`
130 # for Protobuf imports to be discoverable.
131 all_sources_stripped, target_sources_stripped = await MultiGet(
132 Get(
133 StrippedSourceFiles,
134 SourceFilesRequest(
135 tgt[ProtobufSourceField]
136 for tgt in transitive_targets.closure
137 if tgt.has_field(ProtobufSourceField)
138 ),
139 ),
140 Get(
141 StrippedSourceFiles, SourceFilesRequest([request.protocol_target[ProtobufSourceField]])
142 ),
143 )
144
145 merged_jvm_plugins_digest = EMPTY_DIGEST
146 maybe_jvm_plugins_setup_args: tuple[str, ...] = ()
147 maybe_jvm_plugins_output_args: tuple[str, ...] = ()
148 jvm_plugins = scalapb.jvm_plugins
149 if jvm_plugins:
150 materialized_jvm_plugins = await Get(
151 MaterializedJvmPlugins, MaterializeJvmPluginsRequest(jvm_plugins)
152 )
153 merged_jvm_plugins_digest = materialized_jvm_plugins.digest
154 maybe_jvm_plugins_setup_args = materialized_jvm_plugins.setup_args(plugins_relpath)
155 maybe_jvm_plugins_output_args = tuple(
156 f"--{plugin.name}_out={output_dir}" for plugin in materialized_jvm_plugins.plugins
157 )
158
159 extra_immutable_input_digests = {
160 toolcp_relpath: tool_classpath.digest,
161 shimcp_relpath: shim_classfiles.digest,
162 plugins_relpath: merged_jvm_plugins_digest,
163 protoc_relpath: downloaded_protoc_binary.digest,
164 }
165
166 input_digest = await Get(
167 Digest, MergeDigests([all_sources_stripped.snapshot.digest, empty_output_dir])
168 )
169
170 result = await Get(
171 ProcessResult,
172 JvmProcess(
173 jdk=jdk,
174 classpath_entries=[*tool_classpath.classpath_entries(toolcp_relpath), shimcp_relpath],
175 argv=[
176 "org.pantsbuild.backend.scala.scalapb.ScalaPBShim",
177 f"--protoc={os.path.join(protoc_relpath, downloaded_protoc_binary.exe)}",
178 *maybe_jvm_plugins_setup_args,
179 f"--scala_out={output_dir}",
180 *maybe_jvm_plugins_output_args,
181 *target_sources_stripped.snapshot.files,
182 ],
183 input_digest=input_digest,
184 extra_immutable_input_digests=extra_immutable_input_digests,
185 extra_nailgun_keys=extra_immutable_input_digests,
186 description=f"Generating Scala sources from {request.protocol_target.address}.",
187 level=LogLevel.DEBUG,
188 output_directories=(output_dir,),
189 extra_env=inherit_env,
190 ),
191 )
192
193 normalized_digest, source_root = await MultiGet(
194 Get(Digest, RemovePrefix(result.output_digest, output_dir)),
195 Get(SourceRoot, SourceRootRequest, SourceRootRequest.for_target(request.protocol_target)),
196 )
197
198 source_root_restored = (
199 await Get(Snapshot, AddPrefix(normalized_digest, source_root.path))
200 if source_root.path != "."
201 else await Get(Snapshot, Digest, normalized_digest)
202 )
203 return GeneratedSources(source_root_restored)
204
205
206 class InjectScalaProtobufDependencies(InjectDependenciesRequest):
207 inject_for = ProtobufDependenciesField
208
209
210 @rule
211 async def inject_scalapb_dependencies(
212 _: InjectScalaProtobufDependencies, scalapb: ScalaPBSubsystem
213 ) -> InjectedDependencies:
214 addresses = await Get(Addresses, UnparsedAddressInputs, scalapb.runtime_dependencies)
215 return InjectedDependencies(addresses)
216
217
218 @rule
219 async def materialize_jvm_plugin(request: MaterializeJvmPluginRequest) -> MaterializedJvmPlugin:
220 requirements = await Get(
221 ArtifactRequirements,
222 GatherJvmCoordinatesRequest(
223 artifact_inputs=FrozenOrderedSet([request.plugin.artifact]),
224 option_name="[scalapb].jvm_plugins",
225 ),
226 )
227 classpath = await Get(ToolClasspath, ToolClasspathRequest(artifact_requirements=requirements))
228 return MaterializedJvmPlugin(name=request.plugin.name, classpath=classpath)
229
230
231 @rule
232 async def materialize_jvm_plugins(
233 request: MaterializeJvmPluginsRequest,
234 ) -> MaterializedJvmPlugins:
235 materialized_plugins = await MultiGet(
236 Get(MaterializedJvmPlugin, MaterializeJvmPluginRequest(plugin))
237 for plugin in request.plugins
238 )
239 plugin_digests = await MultiGet(
240 Get(Digest, AddPrefix(p.classpath.digest, p.name)) for p in materialized_plugins
241 )
242 merged_plugins_digest = await Get(Digest, MergeDigests(plugin_digests))
243 return MaterializedJvmPlugins(merged_plugins_digest, materialized_plugins)
244
245
246 SHIM_SCALA_VERSION = "2.13.7"
247
248
249 # TODO(13879): Consolidate compilation of wrapper binaries to common rules.
250 @rule
251 async def setup_scalapb_shim_classfiles(
252 scalapb: ScalaPBSubsystem,
253 jdk: InternalJdk,
254 ) -> ScalaPBShimCompiledClassfiles:
255 dest_dir = "classfiles"
256
257 scalapb_shim_content = pkgutil.get_data(
258 "pants.backend.codegen.protobuf.scala", "ScalaPBShim.scala"
259 )
260 if not scalapb_shim_content:
261 raise AssertionError("Unable to find ScalaParser.scala resource.")
262
263 scalapb_shim_source = FileContent("ScalaPBShim.scala", scalapb_shim_content)
264
265 lockfile_request = await Get(GenerateJvmLockfileFromTool, ScalapbcToolLockfileSentinel())
266 tool_classpath, shim_classpath, source_digest = await MultiGet(
267 Get(
268 ToolClasspath,
269 ToolClasspathRequest(
270 prefix="__toolcp",
271 artifact_requirements=ArtifactRequirements.from_coordinates(
272 [
273 Coordinate(
274 group="org.scala-lang",
275 artifact="scala-compiler",
276 version=SHIM_SCALA_VERSION,
277 ),
278 Coordinate(
279 group="org.scala-lang",
280 artifact="scala-library",
281 version=SHIM_SCALA_VERSION,
282 ),
283 Coordinate(
284 group="org.scala-lang",
285 artifact="scala-reflect",
286 version=SHIM_SCALA_VERSION,
287 ),
288 ]
289 ),
290 ),
291 ),
292 Get(ToolClasspath, ToolClasspathRequest(prefix="__shimcp", lockfile=lockfile_request)),
293 Get(Digest, CreateDigest([scalapb_shim_source, Directory(dest_dir)])),
294 )
295
296 merged_digest = await Get(
297 Digest, MergeDigests((tool_classpath.digest, shim_classpath.digest, source_digest))
298 )
299
300 process_result = await Get(
301 ProcessResult,
302 JvmProcess(
303 jdk=jdk,
304 classpath_entries=tool_classpath.classpath_entries(),
305 argv=[
306 "scala.tools.nsc.Main",
307 "-bootclasspath",
308 ":".join(tool_classpath.classpath_entries()),
309 "-classpath",
310 ":".join(shim_classpath.classpath_entries()),
311 "-d",
312 dest_dir,
313 scalapb_shim_source.path,
314 ],
315 input_digest=merged_digest,
316 output_directories=(dest_dir,),
317 description="Compile ScalaPB shim with scalac",
318 level=LogLevel.DEBUG,
319 # NB: We do not use nailgun for this process, since it is launched exactly once.
320 use_nailgun=False,
321 ),
322 )
323 stripped_classfiles_digest = await Get(
324 Digest, RemovePrefix(process_result.output_digest, dest_dir)
325 )
326 return ScalaPBShimCompiledClassfiles(digest=stripped_classfiles_digest)
327
328
329 @rule
330 def generate_scalapbc_lockfile_request(
331 _: ScalapbcToolLockfileSentinel, tool: ScalaPBSubsystem
332 ) -> GenerateJvmLockfileFromTool:
333 return GenerateJvmLockfileFromTool.create(tool)
334
335
336 def rules():
337 return [
338 *collect_rules(),
339 *lockfile.rules(),
340 UnionRule(GenerateSourcesRequest, GenerateScalaFromProtobufRequest),
341 UnionRule(GenerateToolLockfileSentinel, ScalapbcToolLockfileSentinel),
342 ]
343
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/python/pants/backend/codegen/protobuf/scala/rules.py b/src/python/pants/backend/codegen/protobuf/scala/rules.py
--- a/src/python/pants/backend/codegen/protobuf/scala/rules.py
+++ b/src/python/pants/backend/codegen/protobuf/scala/rules.py
@@ -11,6 +11,8 @@
from pants.backend.codegen.protobuf.target_types import (
ProtobufDependenciesField,
ProtobufSourceField,
+ ProtobufSourcesGeneratorTarget,
+ ProtobufSourceTarget,
)
from pants.backend.scala.target_types import ScalaSourceField
from pants.core.goals.generate_lockfiles import GenerateToolLockfileSentinel
@@ -49,6 +51,7 @@
from pants.jvm.resolve.common import ArtifactRequirements, Coordinate, GatherJvmCoordinatesRequest
from pants.jvm.resolve.coursier_fetch import ToolClasspath, ToolClasspathRequest
from pants.jvm.resolve.jvm_tool import GenerateJvmLockfileFromTool
+from pants.jvm.target_types import JvmJdkField
from pants.source.source_root import SourceRoot, SourceRootRequest
from pants.util.logging import LogLevel
from pants.util.ordered_set import FrozenOrderedSet
@@ -333,10 +336,16 @@
return GenerateJvmLockfileFromTool.create(tool)
+class PrefixedJvmJdkField(JvmJdkField):
+ alias = "jvm_jdk"
+
+
def rules():
return [
*collect_rules(),
*lockfile.rules(),
UnionRule(GenerateSourcesRequest, GenerateScalaFromProtobufRequest),
UnionRule(GenerateToolLockfileSentinel, ScalapbcToolLockfileSentinel),
+ ProtobufSourceTarget.register_plugin_field(PrefixedJvmJdkField),
+ ProtobufSourcesGeneratorTarget.register_plugin_field(PrefixedJvmJdkField),
]
|
{"golden_diff": "diff --git a/src/python/pants/backend/codegen/protobuf/scala/rules.py b/src/python/pants/backend/codegen/protobuf/scala/rules.py\n--- a/src/python/pants/backend/codegen/protobuf/scala/rules.py\n+++ b/src/python/pants/backend/codegen/protobuf/scala/rules.py\n@@ -11,6 +11,8 @@\n from pants.backend.codegen.protobuf.target_types import (\n ProtobufDependenciesField,\n ProtobufSourceField,\n+ ProtobufSourcesGeneratorTarget,\n+ ProtobufSourceTarget,\n )\n from pants.backend.scala.target_types import ScalaSourceField\n from pants.core.goals.generate_lockfiles import GenerateToolLockfileSentinel\n@@ -49,6 +51,7 @@\n from pants.jvm.resolve.common import ArtifactRequirements, Coordinate, GatherJvmCoordinatesRequest\n from pants.jvm.resolve.coursier_fetch import ToolClasspath, ToolClasspathRequest\n from pants.jvm.resolve.jvm_tool import GenerateJvmLockfileFromTool\n+from pants.jvm.target_types import JvmJdkField\n from pants.source.source_root import SourceRoot, SourceRootRequest\n from pants.util.logging import LogLevel\n from pants.util.ordered_set import FrozenOrderedSet\n@@ -333,10 +336,16 @@\n return GenerateJvmLockfileFromTool.create(tool)\n \n \n+class PrefixedJvmJdkField(JvmJdkField):\n+ alias = \"jvm_jdk\"\n+\n+\n def rules():\n return [\n *collect_rules(),\n *lockfile.rules(),\n UnionRule(GenerateSourcesRequest, GenerateScalaFromProtobufRequest),\n UnionRule(GenerateToolLockfileSentinel, ScalapbcToolLockfileSentinel),\n+ ProtobufSourceTarget.register_plugin_field(PrefixedJvmJdkField),\n+ ProtobufSourcesGeneratorTarget.register_plugin_field(PrefixedJvmJdkField),\n ]\n", "issue": "codegen: Scala codegen fails with missing jdk field\nThere is a missing `jdk` field on some Protobuf target that is causing compilation of a Scala target with a protobuf dependency to fail. I used example-codegen with https://github.com/pantsbuild/example-codegen/pull/10 to test compilation of Scala Protobuf code. I then switched the dependency to a file-level target using `scala_sources(dependencies=[\"src/protobuf/simple_example/person.proto\"])` in the relavent BUILD file.\r\n\r\nRunning `./pants_from_sources check src/jvm/org/pantsbuild/example/codegen/scala::` results in: \r\n\r\n```\r\n ValueError: Cannot construct a JDK request for src/protobuf/simple_example/person.proto, since none of its members have a `jdk=` field:\r\n * src/protobuf/simple_example/person.proto\t(protobuf_source)\r\n```\n", "before_files": [{"content": "# Copyright 2021 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\nfrom __future__ import annotations\n\nimport os\nimport pkgutil\nfrom dataclasses import dataclass\n\nfrom pants.backend.codegen.protobuf.protoc import Protoc\nfrom pants.backend.codegen.protobuf.scala.subsystem import PluginArtifactSpec, ScalaPBSubsystem\nfrom pants.backend.codegen.protobuf.target_types import (\n ProtobufDependenciesField,\n ProtobufSourceField,\n)\nfrom pants.backend.scala.target_types import ScalaSourceField\nfrom pants.core.goals.generate_lockfiles import GenerateToolLockfileSentinel\nfrom pants.core.util_rules.external_tool import DownloadedExternalTool, ExternalToolRequest\nfrom pants.core.util_rules.source_files import SourceFilesRequest\nfrom pants.core.util_rules.stripped_source_files import StrippedSourceFiles\nfrom pants.engine.addresses import Addresses, UnparsedAddressInputs\nfrom pants.engine.environment import Environment, EnvironmentRequest\nfrom pants.engine.fs import (\n AddPrefix,\n CreateDigest,\n Digest,\n Directory,\n FileContent,\n MergeDigests,\n RemovePrefix,\n Snapshot,\n)\nfrom pants.engine.internals.native_engine import EMPTY_DIGEST\nfrom pants.engine.internals.selectors import Get, MultiGet\nfrom pants.engine.platform import Platform\nfrom pants.engine.process import ProcessResult\nfrom pants.engine.rules import collect_rules, rule\nfrom pants.engine.target import (\n GeneratedSources,\n GenerateSourcesRequest,\n InjectDependenciesRequest,\n InjectedDependencies,\n TransitiveTargets,\n TransitiveTargetsRequest,\n)\nfrom pants.engine.unions import UnionRule\nfrom pants.jvm.compile import ClasspathEntry\nfrom pants.jvm.goals import lockfile\nfrom pants.jvm.jdk_rules import InternalJdk, JvmProcess\nfrom pants.jvm.resolve.common import ArtifactRequirements, Coordinate, GatherJvmCoordinatesRequest\nfrom pants.jvm.resolve.coursier_fetch import ToolClasspath, ToolClasspathRequest\nfrom pants.jvm.resolve.jvm_tool import GenerateJvmLockfileFromTool\nfrom pants.source.source_root import SourceRoot, SourceRootRequest\nfrom pants.util.logging import LogLevel\nfrom pants.util.ordered_set import FrozenOrderedSet\n\n\nclass GenerateScalaFromProtobufRequest(GenerateSourcesRequest):\n input = ProtobufSourceField\n output = ScalaSourceField\n\n\nclass ScalapbcToolLockfileSentinel(GenerateToolLockfileSentinel):\n resolve_name = ScalaPBSubsystem.options_scope\n\n\nclass ScalaPBShimCompiledClassfiles(ClasspathEntry):\n pass\n\n\n@dataclass(frozen=True)\nclass MaterializeJvmPluginRequest:\n plugin: PluginArtifactSpec\n\n\n@dataclass(frozen=True)\nclass MaterializedJvmPlugin:\n name: str\n classpath: ToolClasspath\n\n def setup_arg(self, plugin_relpath: str) -> str:\n classpath_arg = \":\".join(self.classpath.classpath_entries(plugin_relpath))\n return f\"--jvm-plugin={self.name}={classpath_arg}\"\n\n\n@dataclass(frozen=True)\nclass MaterializeJvmPluginsRequest:\n plugins: tuple[PluginArtifactSpec, ...]\n\n\n@dataclass(frozen=True)\nclass MaterializedJvmPlugins:\n digest: Digest\n plugins: tuple[MaterializedJvmPlugin, ...]\n\n def setup_args(self, plugins_relpath: str) -> tuple[str, ...]:\n return tuple(p.setup_arg(os.path.join(plugins_relpath, p.name)) for p in self.plugins)\n\n\n@rule(desc=\"Generate Scala from Protobuf\", level=LogLevel.DEBUG)\nasync def generate_scala_from_protobuf(\n request: GenerateScalaFromProtobufRequest,\n protoc: Protoc,\n scalapb: ScalaPBSubsystem,\n shim_classfiles: ScalaPBShimCompiledClassfiles,\n jdk: InternalJdk,\n) -> GeneratedSources:\n output_dir = \"_generated_files\"\n toolcp_relpath = \"__toolcp\"\n shimcp_relpath = \"__shimcp\"\n plugins_relpath = \"__plugins\"\n protoc_relpath = \"__protoc\"\n\n lockfile_request = await Get(GenerateJvmLockfileFromTool, ScalapbcToolLockfileSentinel())\n (\n downloaded_protoc_binary,\n tool_classpath,\n empty_output_dir,\n transitive_targets,\n inherit_env,\n ) = await MultiGet(\n Get(DownloadedExternalTool, ExternalToolRequest, protoc.get_request(Platform.current)),\n Get(ToolClasspath, ToolClasspathRequest(lockfile=lockfile_request)),\n Get(Digest, CreateDigest([Directory(output_dir)])),\n Get(TransitiveTargets, TransitiveTargetsRequest([request.protocol_target.address])),\n # Need PATH so that ScalaPB can invoke `mkfifo`.\n Get(Environment, EnvironmentRequest(requested=[\"PATH\"])),\n )\n\n # NB: By stripping the source roots, we avoid having to set the value `--proto_path`\n # for Protobuf imports to be discoverable.\n all_sources_stripped, target_sources_stripped = await MultiGet(\n Get(\n StrippedSourceFiles,\n SourceFilesRequest(\n tgt[ProtobufSourceField]\n for tgt in transitive_targets.closure\n if tgt.has_field(ProtobufSourceField)\n ),\n ),\n Get(\n StrippedSourceFiles, SourceFilesRequest([request.protocol_target[ProtobufSourceField]])\n ),\n )\n\n merged_jvm_plugins_digest = EMPTY_DIGEST\n maybe_jvm_plugins_setup_args: tuple[str, ...] = ()\n maybe_jvm_plugins_output_args: tuple[str, ...] = ()\n jvm_plugins = scalapb.jvm_plugins\n if jvm_plugins:\n materialized_jvm_plugins = await Get(\n MaterializedJvmPlugins, MaterializeJvmPluginsRequest(jvm_plugins)\n )\n merged_jvm_plugins_digest = materialized_jvm_plugins.digest\n maybe_jvm_plugins_setup_args = materialized_jvm_plugins.setup_args(plugins_relpath)\n maybe_jvm_plugins_output_args = tuple(\n f\"--{plugin.name}_out={output_dir}\" for plugin in materialized_jvm_plugins.plugins\n )\n\n extra_immutable_input_digests = {\n toolcp_relpath: tool_classpath.digest,\n shimcp_relpath: shim_classfiles.digest,\n plugins_relpath: merged_jvm_plugins_digest,\n protoc_relpath: downloaded_protoc_binary.digest,\n }\n\n input_digest = await Get(\n Digest, MergeDigests([all_sources_stripped.snapshot.digest, empty_output_dir])\n )\n\n result = await Get(\n ProcessResult,\n JvmProcess(\n jdk=jdk,\n classpath_entries=[*tool_classpath.classpath_entries(toolcp_relpath), shimcp_relpath],\n argv=[\n \"org.pantsbuild.backend.scala.scalapb.ScalaPBShim\",\n f\"--protoc={os.path.join(protoc_relpath, downloaded_protoc_binary.exe)}\",\n *maybe_jvm_plugins_setup_args,\n f\"--scala_out={output_dir}\",\n *maybe_jvm_plugins_output_args,\n *target_sources_stripped.snapshot.files,\n ],\n input_digest=input_digest,\n extra_immutable_input_digests=extra_immutable_input_digests,\n extra_nailgun_keys=extra_immutable_input_digests,\n description=f\"Generating Scala sources from {request.protocol_target.address}.\",\n level=LogLevel.DEBUG,\n output_directories=(output_dir,),\n extra_env=inherit_env,\n ),\n )\n\n normalized_digest, source_root = await MultiGet(\n Get(Digest, RemovePrefix(result.output_digest, output_dir)),\n Get(SourceRoot, SourceRootRequest, SourceRootRequest.for_target(request.protocol_target)),\n )\n\n source_root_restored = (\n await Get(Snapshot, AddPrefix(normalized_digest, source_root.path))\n if source_root.path != \".\"\n else await Get(Snapshot, Digest, normalized_digest)\n )\n return GeneratedSources(source_root_restored)\n\n\nclass InjectScalaProtobufDependencies(InjectDependenciesRequest):\n inject_for = ProtobufDependenciesField\n\n\n@rule\nasync def inject_scalapb_dependencies(\n _: InjectScalaProtobufDependencies, scalapb: ScalaPBSubsystem\n) -> InjectedDependencies:\n addresses = await Get(Addresses, UnparsedAddressInputs, scalapb.runtime_dependencies)\n return InjectedDependencies(addresses)\n\n\n@rule\nasync def materialize_jvm_plugin(request: MaterializeJvmPluginRequest) -> MaterializedJvmPlugin:\n requirements = await Get(\n ArtifactRequirements,\n GatherJvmCoordinatesRequest(\n artifact_inputs=FrozenOrderedSet([request.plugin.artifact]),\n option_name=\"[scalapb].jvm_plugins\",\n ),\n )\n classpath = await Get(ToolClasspath, ToolClasspathRequest(artifact_requirements=requirements))\n return MaterializedJvmPlugin(name=request.plugin.name, classpath=classpath)\n\n\n@rule\nasync def materialize_jvm_plugins(\n request: MaterializeJvmPluginsRequest,\n) -> MaterializedJvmPlugins:\n materialized_plugins = await MultiGet(\n Get(MaterializedJvmPlugin, MaterializeJvmPluginRequest(plugin))\n for plugin in request.plugins\n )\n plugin_digests = await MultiGet(\n Get(Digest, AddPrefix(p.classpath.digest, p.name)) for p in materialized_plugins\n )\n merged_plugins_digest = await Get(Digest, MergeDigests(plugin_digests))\n return MaterializedJvmPlugins(merged_plugins_digest, materialized_plugins)\n\n\nSHIM_SCALA_VERSION = \"2.13.7\"\n\n\n# TODO(13879): Consolidate compilation of wrapper binaries to common rules.\n@rule\nasync def setup_scalapb_shim_classfiles(\n scalapb: ScalaPBSubsystem,\n jdk: InternalJdk,\n) -> ScalaPBShimCompiledClassfiles:\n dest_dir = \"classfiles\"\n\n scalapb_shim_content = pkgutil.get_data(\n \"pants.backend.codegen.protobuf.scala\", \"ScalaPBShim.scala\"\n )\n if not scalapb_shim_content:\n raise AssertionError(\"Unable to find ScalaParser.scala resource.\")\n\n scalapb_shim_source = FileContent(\"ScalaPBShim.scala\", scalapb_shim_content)\n\n lockfile_request = await Get(GenerateJvmLockfileFromTool, ScalapbcToolLockfileSentinel())\n tool_classpath, shim_classpath, source_digest = await MultiGet(\n Get(\n ToolClasspath,\n ToolClasspathRequest(\n prefix=\"__toolcp\",\n artifact_requirements=ArtifactRequirements.from_coordinates(\n [\n Coordinate(\n group=\"org.scala-lang\",\n artifact=\"scala-compiler\",\n version=SHIM_SCALA_VERSION,\n ),\n Coordinate(\n group=\"org.scala-lang\",\n artifact=\"scala-library\",\n version=SHIM_SCALA_VERSION,\n ),\n Coordinate(\n group=\"org.scala-lang\",\n artifact=\"scala-reflect\",\n version=SHIM_SCALA_VERSION,\n ),\n ]\n ),\n ),\n ),\n Get(ToolClasspath, ToolClasspathRequest(prefix=\"__shimcp\", lockfile=lockfile_request)),\n Get(Digest, CreateDigest([scalapb_shim_source, Directory(dest_dir)])),\n )\n\n merged_digest = await Get(\n Digest, MergeDigests((tool_classpath.digest, shim_classpath.digest, source_digest))\n )\n\n process_result = await Get(\n ProcessResult,\n JvmProcess(\n jdk=jdk,\n classpath_entries=tool_classpath.classpath_entries(),\n argv=[\n \"scala.tools.nsc.Main\",\n \"-bootclasspath\",\n \":\".join(tool_classpath.classpath_entries()),\n \"-classpath\",\n \":\".join(shim_classpath.classpath_entries()),\n \"-d\",\n dest_dir,\n scalapb_shim_source.path,\n ],\n input_digest=merged_digest,\n output_directories=(dest_dir,),\n description=\"Compile ScalaPB shim with scalac\",\n level=LogLevel.DEBUG,\n # NB: We do not use nailgun for this process, since it is launched exactly once.\n use_nailgun=False,\n ),\n )\n stripped_classfiles_digest = await Get(\n Digest, RemovePrefix(process_result.output_digest, dest_dir)\n )\n return ScalaPBShimCompiledClassfiles(digest=stripped_classfiles_digest)\n\n\n@rule\ndef generate_scalapbc_lockfile_request(\n _: ScalapbcToolLockfileSentinel, tool: ScalaPBSubsystem\n) -> GenerateJvmLockfileFromTool:\n return GenerateJvmLockfileFromTool.create(tool)\n\n\ndef rules():\n return [\n *collect_rules(),\n *lockfile.rules(),\n UnionRule(GenerateSourcesRequest, GenerateScalaFromProtobufRequest),\n UnionRule(GenerateToolLockfileSentinel, ScalapbcToolLockfileSentinel),\n ]\n", "path": "src/python/pants/backend/codegen/protobuf/scala/rules.py"}], "after_files": [{"content": "# Copyright 2021 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\nfrom __future__ import annotations\n\nimport os\nimport pkgutil\nfrom dataclasses import dataclass\n\nfrom pants.backend.codegen.protobuf.protoc import Protoc\nfrom pants.backend.codegen.protobuf.scala.subsystem import PluginArtifactSpec, ScalaPBSubsystem\nfrom pants.backend.codegen.protobuf.target_types import (\n ProtobufDependenciesField,\n ProtobufSourceField,\n ProtobufSourcesGeneratorTarget,\n ProtobufSourceTarget,\n)\nfrom pants.backend.scala.target_types import ScalaSourceField\nfrom pants.core.goals.generate_lockfiles import GenerateToolLockfileSentinel\nfrom pants.core.util_rules.external_tool import DownloadedExternalTool, ExternalToolRequest\nfrom pants.core.util_rules.source_files import SourceFilesRequest\nfrom pants.core.util_rules.stripped_source_files import StrippedSourceFiles\nfrom pants.engine.addresses import Addresses, UnparsedAddressInputs\nfrom pants.engine.environment import Environment, EnvironmentRequest\nfrom pants.engine.fs import (\n AddPrefix,\n CreateDigest,\n Digest,\n Directory,\n FileContent,\n MergeDigests,\n RemovePrefix,\n Snapshot,\n)\nfrom pants.engine.internals.native_engine import EMPTY_DIGEST\nfrom pants.engine.internals.selectors import Get, MultiGet\nfrom pants.engine.platform import Platform\nfrom pants.engine.process import ProcessResult\nfrom pants.engine.rules import collect_rules, rule\nfrom pants.engine.target import (\n GeneratedSources,\n GenerateSourcesRequest,\n InjectDependenciesRequest,\n InjectedDependencies,\n TransitiveTargets,\n TransitiveTargetsRequest,\n)\nfrom pants.engine.unions import UnionRule\nfrom pants.jvm.compile import ClasspathEntry\nfrom pants.jvm.goals import lockfile\nfrom pants.jvm.jdk_rules import InternalJdk, JvmProcess\nfrom pants.jvm.resolve.common import ArtifactRequirements, Coordinate, GatherJvmCoordinatesRequest\nfrom pants.jvm.resolve.coursier_fetch import ToolClasspath, ToolClasspathRequest\nfrom pants.jvm.resolve.jvm_tool import GenerateJvmLockfileFromTool\nfrom pants.jvm.target_types import JvmJdkField\nfrom pants.source.source_root import SourceRoot, SourceRootRequest\nfrom pants.util.logging import LogLevel\nfrom pants.util.ordered_set import FrozenOrderedSet\n\n\nclass GenerateScalaFromProtobufRequest(GenerateSourcesRequest):\n input = ProtobufSourceField\n output = ScalaSourceField\n\n\nclass ScalapbcToolLockfileSentinel(GenerateToolLockfileSentinel):\n resolve_name = ScalaPBSubsystem.options_scope\n\n\nclass ScalaPBShimCompiledClassfiles(ClasspathEntry):\n pass\n\n\n@dataclass(frozen=True)\nclass MaterializeJvmPluginRequest:\n plugin: PluginArtifactSpec\n\n\n@dataclass(frozen=True)\nclass MaterializedJvmPlugin:\n name: str\n classpath: ToolClasspath\n\n def setup_arg(self, plugin_relpath: str) -> str:\n classpath_arg = \":\".join(self.classpath.classpath_entries(plugin_relpath))\n return f\"--jvm-plugin={self.name}={classpath_arg}\"\n\n\n@dataclass(frozen=True)\nclass MaterializeJvmPluginsRequest:\n plugins: tuple[PluginArtifactSpec, ...]\n\n\n@dataclass(frozen=True)\nclass MaterializedJvmPlugins:\n digest: Digest\n plugins: tuple[MaterializedJvmPlugin, ...]\n\n def setup_args(self, plugins_relpath: str) -> tuple[str, ...]:\n return tuple(p.setup_arg(os.path.join(plugins_relpath, p.name)) for p in self.plugins)\n\n\n@rule(desc=\"Generate Scala from Protobuf\", level=LogLevel.DEBUG)\nasync def generate_scala_from_protobuf(\n request: GenerateScalaFromProtobufRequest,\n protoc: Protoc,\n scalapb: ScalaPBSubsystem,\n shim_classfiles: ScalaPBShimCompiledClassfiles,\n jdk: InternalJdk,\n) -> GeneratedSources:\n output_dir = \"_generated_files\"\n toolcp_relpath = \"__toolcp\"\n shimcp_relpath = \"__shimcp\"\n plugins_relpath = \"__plugins\"\n protoc_relpath = \"__protoc\"\n\n lockfile_request = await Get(GenerateJvmLockfileFromTool, ScalapbcToolLockfileSentinel())\n (\n downloaded_protoc_binary,\n tool_classpath,\n empty_output_dir,\n transitive_targets,\n inherit_env,\n ) = await MultiGet(\n Get(DownloadedExternalTool, ExternalToolRequest, protoc.get_request(Platform.current)),\n Get(ToolClasspath, ToolClasspathRequest(lockfile=lockfile_request)),\n Get(Digest, CreateDigest([Directory(output_dir)])),\n Get(TransitiveTargets, TransitiveTargetsRequest([request.protocol_target.address])),\n # Need PATH so that ScalaPB can invoke `mkfifo`.\n Get(Environment, EnvironmentRequest(requested=[\"PATH\"])),\n )\n\n # NB: By stripping the source roots, we avoid having to set the value `--proto_path`\n # for Protobuf imports to be discoverable.\n all_sources_stripped, target_sources_stripped = await MultiGet(\n Get(\n StrippedSourceFiles,\n SourceFilesRequest(\n tgt[ProtobufSourceField]\n for tgt in transitive_targets.closure\n if tgt.has_field(ProtobufSourceField)\n ),\n ),\n Get(\n StrippedSourceFiles, SourceFilesRequest([request.protocol_target[ProtobufSourceField]])\n ),\n )\n\n merged_jvm_plugins_digest = EMPTY_DIGEST\n maybe_jvm_plugins_setup_args: tuple[str, ...] = ()\n maybe_jvm_plugins_output_args: tuple[str, ...] = ()\n jvm_plugins = scalapb.jvm_plugins\n if jvm_plugins:\n materialized_jvm_plugins = await Get(\n MaterializedJvmPlugins, MaterializeJvmPluginsRequest(jvm_plugins)\n )\n merged_jvm_plugins_digest = materialized_jvm_plugins.digest\n maybe_jvm_plugins_setup_args = materialized_jvm_plugins.setup_args(plugins_relpath)\n maybe_jvm_plugins_output_args = tuple(\n f\"--{plugin.name}_out={output_dir}\" for plugin in materialized_jvm_plugins.plugins\n )\n\n extra_immutable_input_digests = {\n toolcp_relpath: tool_classpath.digest,\n shimcp_relpath: shim_classfiles.digest,\n plugins_relpath: merged_jvm_plugins_digest,\n protoc_relpath: downloaded_protoc_binary.digest,\n }\n\n input_digest = await Get(\n Digest, MergeDigests([all_sources_stripped.snapshot.digest, empty_output_dir])\n )\n\n result = await Get(\n ProcessResult,\n JvmProcess(\n jdk=jdk,\n classpath_entries=[*tool_classpath.classpath_entries(toolcp_relpath), shimcp_relpath],\n argv=[\n \"org.pantsbuild.backend.scala.scalapb.ScalaPBShim\",\n f\"--protoc={os.path.join(protoc_relpath, downloaded_protoc_binary.exe)}\",\n *maybe_jvm_plugins_setup_args,\n f\"--scala_out={output_dir}\",\n *maybe_jvm_plugins_output_args,\n *target_sources_stripped.snapshot.files,\n ],\n input_digest=input_digest,\n extra_immutable_input_digests=extra_immutable_input_digests,\n extra_nailgun_keys=extra_immutable_input_digests,\n description=f\"Generating Scala sources from {request.protocol_target.address}.\",\n level=LogLevel.DEBUG,\n output_directories=(output_dir,),\n extra_env=inherit_env,\n ),\n )\n\n normalized_digest, source_root = await MultiGet(\n Get(Digest, RemovePrefix(result.output_digest, output_dir)),\n Get(SourceRoot, SourceRootRequest, SourceRootRequest.for_target(request.protocol_target)),\n )\n\n source_root_restored = (\n await Get(Snapshot, AddPrefix(normalized_digest, source_root.path))\n if source_root.path != \".\"\n else await Get(Snapshot, Digest, normalized_digest)\n )\n return GeneratedSources(source_root_restored)\n\n\nclass InjectScalaProtobufDependencies(InjectDependenciesRequest):\n inject_for = ProtobufDependenciesField\n\n\n@rule\nasync def inject_scalapb_dependencies(\n _: InjectScalaProtobufDependencies, scalapb: ScalaPBSubsystem\n) -> InjectedDependencies:\n addresses = await Get(Addresses, UnparsedAddressInputs, scalapb.runtime_dependencies)\n return InjectedDependencies(addresses)\n\n\n@rule\nasync def materialize_jvm_plugin(request: MaterializeJvmPluginRequest) -> MaterializedJvmPlugin:\n requirements = await Get(\n ArtifactRequirements,\n GatherJvmCoordinatesRequest(\n artifact_inputs=FrozenOrderedSet([request.plugin.artifact]),\n option_name=\"[scalapb].jvm_plugins\",\n ),\n )\n classpath = await Get(ToolClasspath, ToolClasspathRequest(artifact_requirements=requirements))\n return MaterializedJvmPlugin(name=request.plugin.name, classpath=classpath)\n\n\n@rule\nasync def materialize_jvm_plugins(\n request: MaterializeJvmPluginsRequest,\n) -> MaterializedJvmPlugins:\n materialized_plugins = await MultiGet(\n Get(MaterializedJvmPlugin, MaterializeJvmPluginRequest(plugin))\n for plugin in request.plugins\n )\n plugin_digests = await MultiGet(\n Get(Digest, AddPrefix(p.classpath.digest, p.name)) for p in materialized_plugins\n )\n merged_plugins_digest = await Get(Digest, MergeDigests(plugin_digests))\n return MaterializedJvmPlugins(merged_plugins_digest, materialized_plugins)\n\n\nSHIM_SCALA_VERSION = \"2.13.7\"\n\n\n# TODO(13879): Consolidate compilation of wrapper binaries to common rules.\n@rule\nasync def setup_scalapb_shim_classfiles(\n scalapb: ScalaPBSubsystem,\n jdk: InternalJdk,\n) -> ScalaPBShimCompiledClassfiles:\n dest_dir = \"classfiles\"\n\n scalapb_shim_content = pkgutil.get_data(\n \"pants.backend.codegen.protobuf.scala\", \"ScalaPBShim.scala\"\n )\n if not scalapb_shim_content:\n raise AssertionError(\"Unable to find ScalaParser.scala resource.\")\n\n scalapb_shim_source = FileContent(\"ScalaPBShim.scala\", scalapb_shim_content)\n\n lockfile_request = await Get(GenerateJvmLockfileFromTool, ScalapbcToolLockfileSentinel())\n tool_classpath, shim_classpath, source_digest = await MultiGet(\n Get(\n ToolClasspath,\n ToolClasspathRequest(\n prefix=\"__toolcp\",\n artifact_requirements=ArtifactRequirements.from_coordinates(\n [\n Coordinate(\n group=\"org.scala-lang\",\n artifact=\"scala-compiler\",\n version=SHIM_SCALA_VERSION,\n ),\n Coordinate(\n group=\"org.scala-lang\",\n artifact=\"scala-library\",\n version=SHIM_SCALA_VERSION,\n ),\n Coordinate(\n group=\"org.scala-lang\",\n artifact=\"scala-reflect\",\n version=SHIM_SCALA_VERSION,\n ),\n ]\n ),\n ),\n ),\n Get(ToolClasspath, ToolClasspathRequest(prefix=\"__shimcp\", lockfile=lockfile_request)),\n Get(Digest, CreateDigest([scalapb_shim_source, Directory(dest_dir)])),\n )\n\n merged_digest = await Get(\n Digest, MergeDigests((tool_classpath.digest, shim_classpath.digest, source_digest))\n )\n\n process_result = await Get(\n ProcessResult,\n JvmProcess(\n jdk=jdk,\n classpath_entries=tool_classpath.classpath_entries(),\n argv=[\n \"scala.tools.nsc.Main\",\n \"-bootclasspath\",\n \":\".join(tool_classpath.classpath_entries()),\n \"-classpath\",\n \":\".join(shim_classpath.classpath_entries()),\n \"-d\",\n dest_dir,\n scalapb_shim_source.path,\n ],\n input_digest=merged_digest,\n output_directories=(dest_dir,),\n description=\"Compile ScalaPB shim with scalac\",\n level=LogLevel.DEBUG,\n # NB: We do not use nailgun for this process, since it is launched exactly once.\n use_nailgun=False,\n ),\n )\n stripped_classfiles_digest = await Get(\n Digest, RemovePrefix(process_result.output_digest, dest_dir)\n )\n return ScalaPBShimCompiledClassfiles(digest=stripped_classfiles_digest)\n\n\n@rule\ndef generate_scalapbc_lockfile_request(\n _: ScalapbcToolLockfileSentinel, tool: ScalaPBSubsystem\n) -> GenerateJvmLockfileFromTool:\n return GenerateJvmLockfileFromTool.create(tool)\n\n\nclass PrefixedJvmJdkField(JvmJdkField):\n alias = \"jvm_jdk\"\n\n\ndef rules():\n return [\n *collect_rules(),\n *lockfile.rules(),\n UnionRule(GenerateSourcesRequest, GenerateScalaFromProtobufRequest),\n UnionRule(GenerateToolLockfileSentinel, ScalapbcToolLockfileSentinel),\n ProtobufSourceTarget.register_plugin_field(PrefixedJvmJdkField),\n ProtobufSourcesGeneratorTarget.register_plugin_field(PrefixedJvmJdkField),\n ]\n", "path": "src/python/pants/backend/codegen/protobuf/scala/rules.py"}]}
| 4,070 | 393 |
gh_patches_debug_11695
|
rasdani/github-patches
|
git_diff
|
NVIDIA__NeMo-4631
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
RegexTokenizer: Default token arguments are not mapped to vocabulary index
The ID's of the default special tokens in RegexTokenizer are set here:
https://github.com/NVIDIA/NeMo/blob/72d78d832c6332ccc7f44811fb777eb7044df1d8/nemo/collections/common/tokenizers/regex_tokenizer.py#L75-L82
However, the constructor, allows custom special tokens:
https://github.com/NVIDIA/NeMo/blob/72d78d832c6332ccc7f44811fb777eb7044df1d8/nemo/collections/common/tokenizers/regex_tokenizer.py#L42-L51
So this could cause issues (specifically extra unknowns) when text is converted to tokens, then to ids, then back.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nemo/collections/common/tokenizers/regex_tokenizer.py`
Content:
```
1 # Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15
16 import os
17 import re
18 from typing import Optional
19
20 import pandas as pd
21
22 from nemo.collections.common.tokenizers.char_tokenizer import TokenizerSpec
23 from nemo.utils import logging
24
25 __all__ = ['RegExTokenizer']
26
27 DEFAULT_MASK_TOKEN = '<MASK>'
28 DEFAULT_BOS_TOKEN = '^'
29 DEFAULT_EOS_TOKEN = '&'
30 DEFAULT_PAD_TOKEN = '<PAD>'
31 DEFAULT_SEP_TOKEN = '<SEP>'
32 DEFAULT_UNK_TOKEN = '?'
33
34
35 class RegExTokenizer(TokenizerSpec):
36 """
37 A regular expression-based tokenizer at word boundary.
38 This tokenizer default to support MegaMolBART.
39 <https://catalog.ngc.nvidia.com/orgs/nvidia/teams/clara/models/megamolbart>
40 """
41
42 def __init__(
43 self,
44 regex: Optional[str] = "",
45 mask_token: Optional[str] = DEFAULT_MASK_TOKEN,
46 bos_token: Optional[str] = DEFAULT_BOS_TOKEN,
47 eos_token: Optional[str] = DEFAULT_EOS_TOKEN,
48 pad_token: Optional[str] = DEFAULT_PAD_TOKEN,
49 sep_token: Optional[str] = DEFAULT_SEP_TOKEN,
50 unk_token: Optional[str] = DEFAULT_UNK_TOKEN,
51 ):
52 """
53 Args:
54 regex: regular expression that defined tokenization rules
55 mask_token: mask token
56 bos_token: the beginning of sequence token
57 eos_token: the end of sequence token. Usually equal to sep_token
58 pad_token: token to use for padding
59 sep_token: token used for separating sequences
60 cls_token: class token. Usually equal to bos_token
61 unk_token: token to use for unknown tokens
62 """
63 self.regex = regex
64 self.mask_token = mask_token
65 self.bos_token = bos_token
66 self.eos_token = eos_token
67 self.pad_token = pad_token
68 self.sep_token = sep_token
69 self.unk_token = unk_token
70
71 # holds names of .model/.vocab files
72 self.regex_file = None
73 self.vocab_file = None
74
75 # initialize with default vocab
76 self.vocab = {
77 DEFAULT_PAD_TOKEN: 0, # pad_token
78 DEFAULT_UNK_TOKEN: 1, # unk_token
79 DEFAULT_BOS_TOKEN: 2, # begin_token
80 DEFAULT_EOS_TOKEN: 3, # end_token
81 DEFAULT_MASK_TOKEN: 4, # mask_token
82 DEFAULT_SEP_TOKEN: 5, # sep_token
83 }
84 self._update_cache()
85
86 # Computed attributes
87 self._compile_regex()
88
89 def _update_cache(self):
90 # Cache data/attributes required for tokenization
91 self._unk_id = self.vocab.get(self.unk_token, DEFAULT_UNK_TOKEN)
92 self._decode_vocab = {i: t for t, i in self.vocab.items()}
93
94 def _compile_regex(self):
95 regex_string = r"("
96 regex_string += self.regex + r"|"
97 regex_string += r".)"
98 self._compiled_regex = re.compile(regex_string)
99
100 @property
101 def vocab_size(self):
102 return len(self.vocab)
103
104 def text_to_tokens(self, text):
105 tokens = self._compiled_regex.findall(text)
106
107 return tokens
108
109 def tokens_to_text(self, tokens):
110 tokens_list = []
111 for token in tokens:
112 if token[0] == self.bos_token:
113 token = token[1:]
114
115 # Remove end token and the following values
116 if self.eos_token in token:
117 eos_idx = token.index(self.eos_token)
118 token = token[:eos_idx]
119
120 tokens_list.append(token)
121
122 text = ["".join(tokens) for tokens in tokens_list]
123 return text
124
125 def token_to_ids(self, tokens):
126 ids_list = []
127 for token in tokens:
128 ids_list.append(self.vocab.get(token, self._unk_id))
129 return ids_list
130
131 def tokens_to_ids(self, token_data):
132 if isinstance(token_data, str):
133 token_data = [token_data]
134
135 ids_list = []
136 for tokens in token_data:
137 ids = self.token_to_ids(tokens)
138 ids_list.append(ids)
139 return ids_list
140
141 def ids_to_tokens(self, ids_list):
142 if len(ids_list) and not isinstance(ids_list[0], list):
143 ids_list = [ids_list]
144 added_list = True
145 else:
146 added_list = False
147
148 tokens_list = []
149 for ids in ids_list:
150 tokens = []
151 for token_id in ids:
152 token = self._decode_vocab.get(token_id)
153 if token is None:
154 raise ValueError(f"Token id {token_id} is not recognised")
155 tokens.append(token)
156
157 tokens_list.append(tokens)
158
159 if added_list:
160 return tokens_list[0]
161 else:
162 return tokens_list
163
164 def text_to_ids(self, text):
165 tokens = self.text_to_tokens(text)
166 tokens = [tokens]
167 return self.tokens_to_ids(tokens)[0]
168
169 def ids_to_text(self, ids):
170 tokens = self.ids_to_tokens(ids)
171 return self.tokens_to_text(tokens)
172
173 @property
174 def pad_id(self):
175 return 0
176
177 @property
178 def unk_id(self):
179 return 1
180
181 @property
182 def bos_id(self):
183 return 2
184
185 @property
186 def eos_id(self):
187 return 3
188
189 @property
190 def mask_id(self):
191 return 4
192
193 @property
194 def sep_id(self):
195 return 5
196
197 def _get_regex_vocab_files(self, regex_file=None, vocab_file=None):
198 """
199 Infers files or update if given.
200 """
201 regex_file = regex_file or self.regex_file
202 if not regex_file:
203 raise ValueError(f"regex_file must be specified")
204
205 vocab_file = vocab_file or self.vocab_file
206 # try to infer vocab_file from regex_file
207 if not vocab_file:
208 vocab_file = os.path.splitext(regex_file)[0] + '.vocab'
209
210 self.regex_file = regex_file
211 self.vocab_file = vocab_file
212
213 return regex_file, vocab_file
214
215 def save_tokenizer(self, regex_file=None, vocab_file=None):
216 """
217 Saves tokenizer's regex and vocab files
218 """
219 regex_file, vocab_file = self._get_regex_vocab_files(regex_file=regex_file, vocab_file=vocab_file)
220
221 logging.info(f"Saving vocabulary to file = {vocab_file}")
222 with open(vocab_file, 'w') as fp:
223 for token in self.vocab:
224 fp.write(f"{token[0]}\n")
225
226 logging.info(f"Saving regex to file = {regex_file}")
227 open(regex_file, 'w').write(self.regex)
228
229 def load_tokenizer(self, regex_file=None, vocab_file=None):
230 """
231 Loads tokenizer's regex and vocab files
232 """
233 regex_file, vocab_file = self._get_regex_vocab_files(regex_file=regex_file, vocab_file=vocab_file)
234
235 # load vocab file
236 # vocab_file: path to file with vocabulary which consists
237 # of characters separated by \n (None/"" for empty vocab)
238
239 logging.info(f"Loading vocabulary from file = {vocab_file}")
240 if os.path.exists(vocab_file):
241 vocab = {}
242 with open(vocab_file, "r") as f:
243 for line in f:
244 line = line.strip()
245 if line:
246 vocab[line] = len(vocab)
247 self.vocab = vocab
248 else:
249 raise RuntimeError(f"Missing vocab_file = {vocab_file}")
250
251 # load regex from a file
252 if os.path.exists(regex_file):
253 logging.info(f"Loading regex from file = {regex_file}")
254 self.regex = open(regex_file, encoding="utf-8").read().strip()
255 else:
256 raise RuntimeError(f"Missing regex_file = {regex_file}")
257
258 self._update_cache()
259 self._compile_regex()
260
261 return self
262
263 def build_vocab_from_csv(self, data_csv_file, col="smiles"):
264 """
265 Learns vocabulary from a CSV file. Can be called multiple times to update vocabulary.
266 """
267 logging.debug(f"Building vocabulary from CSV col = {col} file = {data_csv_file}")
268
269 # NOTE this has to be run on each CSV file
270 if not os.path.exists(data_csv_file):
271 raise ValueError(f"Data file: {data_csv_file} is missing")
272
273 df = pd.read_csv(data_csv_file)
274
275 vocab = self.vocab
276 for d in df[col]:
277 tokens = self.text_to_tokens(d)
278 logging.debug(f"Text: {d}, Tokens: {tokens}")
279 for token in tokens:
280 if token not in vocab:
281 vocab[token] = len(vocab)
282
283 sorted_vocab = sorted(vocab.items(), key=lambda k_v: k_v[1])
284 logging.debug(f"Vocab: {sorted_vocab}")
285
286 self.vocab = vocab
287 self._update_cache()
288
289 def build_vocab_from_text(self, data_text_file):
290 """
291 Learns vocabulary from a text file. Can be called multiple times to update vocabulary.
292 """
293 logging.debug(f"Building vocabulary from TEXT file = {data_text_file}")
294
295 # NOTE this has to be run on each text file
296 if not os.path.exists(data_text_file):
297 raise ValueError(f"Data file: {data_text_file} is missing")
298
299 vocab = self.vocab
300 for d in open(data_text_file, encoding="utf-8").readlines():
301 d = d.rstrip()
302 tokens = self.text_to_tokens(d)
303 logging.debug(f"Text: {d}, Tokens: {d}")
304 for token in tokens:
305 if token not in vocab:
306 vocab[token] = len(vocab)
307
308 sorted_vocab = sorted(vocab.items(), key=lambda k_v: k_v[1])
309 logging.debug(f"Vocab: {sorted_vocab}")
310
311 self.vocab = vocab
312 self._update_cache()
313
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nemo/collections/common/tokenizers/regex_tokenizer.py b/nemo/collections/common/tokenizers/regex_tokenizer.py
--- a/nemo/collections/common/tokenizers/regex_tokenizer.py
+++ b/nemo/collections/common/tokenizers/regex_tokenizer.py
@@ -74,12 +74,12 @@
# initialize with default vocab
self.vocab = {
- DEFAULT_PAD_TOKEN: 0, # pad_token
- DEFAULT_UNK_TOKEN: 1, # unk_token
- DEFAULT_BOS_TOKEN: 2, # begin_token
- DEFAULT_EOS_TOKEN: 3, # end_token
- DEFAULT_MASK_TOKEN: 4, # mask_token
- DEFAULT_SEP_TOKEN: 5, # sep_token
+ self.pad_token: 0, # pad_token
+ self.unk_token: 1, # unk_token
+ self.bos_token: 2, # begin_token
+ self.eos_token: 3, # end_token
+ self.mask_token: 4, # mask_token
+ self.sep_token: 5, # sep_token
}
self._update_cache()
|
{"golden_diff": "diff --git a/nemo/collections/common/tokenizers/regex_tokenizer.py b/nemo/collections/common/tokenizers/regex_tokenizer.py\n--- a/nemo/collections/common/tokenizers/regex_tokenizer.py\n+++ b/nemo/collections/common/tokenizers/regex_tokenizer.py\n@@ -74,12 +74,12 @@\n \n # initialize with default vocab\n self.vocab = {\n- DEFAULT_PAD_TOKEN: 0, # pad_token\n- DEFAULT_UNK_TOKEN: 1, # unk_token\n- DEFAULT_BOS_TOKEN: 2, # begin_token\n- DEFAULT_EOS_TOKEN: 3, # end_token\n- DEFAULT_MASK_TOKEN: 4, # mask_token\n- DEFAULT_SEP_TOKEN: 5, # sep_token\n+ self.pad_token: 0, # pad_token\n+ self.unk_token: 1, # unk_token\n+ self.bos_token: 2, # begin_token\n+ self.eos_token: 3, # end_token\n+ self.mask_token: 4, # mask_token\n+ self.sep_token: 5, # sep_token\n }\n self._update_cache()\n", "issue": "RegexTokenizer: Default token arguments are not mapped to vocabulary index\nThe ID's of the default special tokens in RegexTokenizer are set here:\r\n\r\nhttps://github.com/NVIDIA/NeMo/blob/72d78d832c6332ccc7f44811fb777eb7044df1d8/nemo/collections/common/tokenizers/regex_tokenizer.py#L75-L82\r\n\r\nHowever, the constructor, allows custom special tokens:\r\n\r\nhttps://github.com/NVIDIA/NeMo/blob/72d78d832c6332ccc7f44811fb777eb7044df1d8/nemo/collections/common/tokenizers/regex_tokenizer.py#L42-L51\r\n\r\n\r\nSo this could cause issues (specifically extra unknowns) when text is converted to tokens, then to ids, then back.\n", "before_files": [{"content": "# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nimport os\nimport re\nfrom typing import Optional\n\nimport pandas as pd\n\nfrom nemo.collections.common.tokenizers.char_tokenizer import TokenizerSpec\nfrom nemo.utils import logging\n\n__all__ = ['RegExTokenizer']\n\nDEFAULT_MASK_TOKEN = '<MASK>'\nDEFAULT_BOS_TOKEN = '^'\nDEFAULT_EOS_TOKEN = '&'\nDEFAULT_PAD_TOKEN = '<PAD>'\nDEFAULT_SEP_TOKEN = '<SEP>'\nDEFAULT_UNK_TOKEN = '?'\n\n\nclass RegExTokenizer(TokenizerSpec):\n \"\"\"\n A regular expression-based tokenizer at word boundary.\n This tokenizer default to support MegaMolBART.\n <https://catalog.ngc.nvidia.com/orgs/nvidia/teams/clara/models/megamolbart>\n \"\"\"\n\n def __init__(\n self,\n regex: Optional[str] = \"\",\n mask_token: Optional[str] = DEFAULT_MASK_TOKEN,\n bos_token: Optional[str] = DEFAULT_BOS_TOKEN,\n eos_token: Optional[str] = DEFAULT_EOS_TOKEN,\n pad_token: Optional[str] = DEFAULT_PAD_TOKEN,\n sep_token: Optional[str] = DEFAULT_SEP_TOKEN,\n unk_token: Optional[str] = DEFAULT_UNK_TOKEN,\n ):\n \"\"\"\n Args:\n regex: regular expression that defined tokenization rules\n mask_token: mask token\n bos_token: the beginning of sequence token\n eos_token: the end of sequence token. Usually equal to sep_token\n pad_token: token to use for padding\n sep_token: token used for separating sequences\n cls_token: class token. Usually equal to bos_token\n unk_token: token to use for unknown tokens\n \"\"\"\n self.regex = regex\n self.mask_token = mask_token\n self.bos_token = bos_token\n self.eos_token = eos_token\n self.pad_token = pad_token\n self.sep_token = sep_token\n self.unk_token = unk_token\n\n # holds names of .model/.vocab files\n self.regex_file = None\n self.vocab_file = None\n\n # initialize with default vocab\n self.vocab = {\n DEFAULT_PAD_TOKEN: 0, # pad_token\n DEFAULT_UNK_TOKEN: 1, # unk_token\n DEFAULT_BOS_TOKEN: 2, # begin_token\n DEFAULT_EOS_TOKEN: 3, # end_token\n DEFAULT_MASK_TOKEN: 4, # mask_token\n DEFAULT_SEP_TOKEN: 5, # sep_token\n }\n self._update_cache()\n\n # Computed attributes\n self._compile_regex()\n\n def _update_cache(self):\n # Cache data/attributes required for tokenization\n self._unk_id = self.vocab.get(self.unk_token, DEFAULT_UNK_TOKEN)\n self._decode_vocab = {i: t for t, i in self.vocab.items()}\n\n def _compile_regex(self):\n regex_string = r\"(\"\n regex_string += self.regex + r\"|\"\n regex_string += r\".)\"\n self._compiled_regex = re.compile(regex_string)\n\n @property\n def vocab_size(self):\n return len(self.vocab)\n\n def text_to_tokens(self, text):\n tokens = self._compiled_regex.findall(text)\n\n return tokens\n\n def tokens_to_text(self, tokens):\n tokens_list = []\n for token in tokens:\n if token[0] == self.bos_token:\n token = token[1:]\n\n # Remove end token and the following values\n if self.eos_token in token:\n eos_idx = token.index(self.eos_token)\n token = token[:eos_idx]\n\n tokens_list.append(token)\n\n text = [\"\".join(tokens) for tokens in tokens_list]\n return text\n\n def token_to_ids(self, tokens):\n ids_list = []\n for token in tokens:\n ids_list.append(self.vocab.get(token, self._unk_id))\n return ids_list\n\n def tokens_to_ids(self, token_data):\n if isinstance(token_data, str):\n token_data = [token_data]\n\n ids_list = []\n for tokens in token_data:\n ids = self.token_to_ids(tokens)\n ids_list.append(ids)\n return ids_list\n\n def ids_to_tokens(self, ids_list):\n if len(ids_list) and not isinstance(ids_list[0], list):\n ids_list = [ids_list]\n added_list = True\n else:\n added_list = False\n\n tokens_list = []\n for ids in ids_list:\n tokens = []\n for token_id in ids:\n token = self._decode_vocab.get(token_id)\n if token is None:\n raise ValueError(f\"Token id {token_id} is not recognised\")\n tokens.append(token)\n\n tokens_list.append(tokens)\n\n if added_list:\n return tokens_list[0]\n else:\n return tokens_list\n\n def text_to_ids(self, text):\n tokens = self.text_to_tokens(text)\n tokens = [tokens]\n return self.tokens_to_ids(tokens)[0]\n\n def ids_to_text(self, ids):\n tokens = self.ids_to_tokens(ids)\n return self.tokens_to_text(tokens)\n\n @property\n def pad_id(self):\n return 0\n\n @property\n def unk_id(self):\n return 1\n\n @property\n def bos_id(self):\n return 2\n\n @property\n def eos_id(self):\n return 3\n\n @property\n def mask_id(self):\n return 4\n\n @property\n def sep_id(self):\n return 5\n\n def _get_regex_vocab_files(self, regex_file=None, vocab_file=None):\n \"\"\"\n Infers files or update if given.\n \"\"\"\n regex_file = regex_file or self.regex_file\n if not regex_file:\n raise ValueError(f\"regex_file must be specified\")\n\n vocab_file = vocab_file or self.vocab_file\n # try to infer vocab_file from regex_file\n if not vocab_file:\n vocab_file = os.path.splitext(regex_file)[0] + '.vocab'\n\n self.regex_file = regex_file\n self.vocab_file = vocab_file\n\n return regex_file, vocab_file\n\n def save_tokenizer(self, regex_file=None, vocab_file=None):\n \"\"\"\n Saves tokenizer's regex and vocab files\n \"\"\"\n regex_file, vocab_file = self._get_regex_vocab_files(regex_file=regex_file, vocab_file=vocab_file)\n\n logging.info(f\"Saving vocabulary to file = {vocab_file}\")\n with open(vocab_file, 'w') as fp:\n for token in self.vocab:\n fp.write(f\"{token[0]}\\n\")\n\n logging.info(f\"Saving regex to file = {regex_file}\")\n open(regex_file, 'w').write(self.regex)\n\n def load_tokenizer(self, regex_file=None, vocab_file=None):\n \"\"\"\n Loads tokenizer's regex and vocab files\n \"\"\"\n regex_file, vocab_file = self._get_regex_vocab_files(regex_file=regex_file, vocab_file=vocab_file)\n\n # load vocab file\n # vocab_file: path to file with vocabulary which consists\n # of characters separated by \\n (None/\"\" for empty vocab)\n\n logging.info(f\"Loading vocabulary from file = {vocab_file}\")\n if os.path.exists(vocab_file):\n vocab = {}\n with open(vocab_file, \"r\") as f:\n for line in f:\n line = line.strip()\n if line:\n vocab[line] = len(vocab)\n self.vocab = vocab\n else:\n raise RuntimeError(f\"Missing vocab_file = {vocab_file}\")\n\n # load regex from a file\n if os.path.exists(regex_file):\n logging.info(f\"Loading regex from file = {regex_file}\")\n self.regex = open(regex_file, encoding=\"utf-8\").read().strip()\n else:\n raise RuntimeError(f\"Missing regex_file = {regex_file}\")\n\n self._update_cache()\n self._compile_regex()\n\n return self\n\n def build_vocab_from_csv(self, data_csv_file, col=\"smiles\"):\n \"\"\"\n Learns vocabulary from a CSV file. Can be called multiple times to update vocabulary.\n \"\"\"\n logging.debug(f\"Building vocabulary from CSV col = {col} file = {data_csv_file}\")\n\n # NOTE this has to be run on each CSV file\n if not os.path.exists(data_csv_file):\n raise ValueError(f\"Data file: {data_csv_file} is missing\")\n\n df = pd.read_csv(data_csv_file)\n\n vocab = self.vocab\n for d in df[col]:\n tokens = self.text_to_tokens(d)\n logging.debug(f\"Text: {d}, Tokens: {tokens}\")\n for token in tokens:\n if token not in vocab:\n vocab[token] = len(vocab)\n\n sorted_vocab = sorted(vocab.items(), key=lambda k_v: k_v[1])\n logging.debug(f\"Vocab: {sorted_vocab}\")\n\n self.vocab = vocab\n self._update_cache()\n\n def build_vocab_from_text(self, data_text_file):\n \"\"\"\n Learns vocabulary from a text file. Can be called multiple times to update vocabulary.\n \"\"\"\n logging.debug(f\"Building vocabulary from TEXT file = {data_text_file}\")\n\n # NOTE this has to be run on each text file\n if not os.path.exists(data_text_file):\n raise ValueError(f\"Data file: {data_text_file} is missing\")\n\n vocab = self.vocab\n for d in open(data_text_file, encoding=\"utf-8\").readlines():\n d = d.rstrip()\n tokens = self.text_to_tokens(d)\n logging.debug(f\"Text: {d}, Tokens: {d}\")\n for token in tokens:\n if token not in vocab:\n vocab[token] = len(vocab)\n\n sorted_vocab = sorted(vocab.items(), key=lambda k_v: k_v[1])\n logging.debug(f\"Vocab: {sorted_vocab}\")\n\n self.vocab = vocab\n self._update_cache()\n", "path": "nemo/collections/common/tokenizers/regex_tokenizer.py"}], "after_files": [{"content": "# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nimport os\nimport re\nfrom typing import Optional\n\nimport pandas as pd\n\nfrom nemo.collections.common.tokenizers.char_tokenizer import TokenizerSpec\nfrom nemo.utils import logging\n\n__all__ = ['RegExTokenizer']\n\nDEFAULT_MASK_TOKEN = '<MASK>'\nDEFAULT_BOS_TOKEN = '^'\nDEFAULT_EOS_TOKEN = '&'\nDEFAULT_PAD_TOKEN = '<PAD>'\nDEFAULT_SEP_TOKEN = '<SEP>'\nDEFAULT_UNK_TOKEN = '?'\n\n\nclass RegExTokenizer(TokenizerSpec):\n \"\"\"\n A regular expression-based tokenizer at word boundary.\n This tokenizer default to support MegaMolBART.\n <https://catalog.ngc.nvidia.com/orgs/nvidia/teams/clara/models/megamolbart>\n \"\"\"\n\n def __init__(\n self,\n regex: Optional[str] = \"\",\n mask_token: Optional[str] = DEFAULT_MASK_TOKEN,\n bos_token: Optional[str] = DEFAULT_BOS_TOKEN,\n eos_token: Optional[str] = DEFAULT_EOS_TOKEN,\n pad_token: Optional[str] = DEFAULT_PAD_TOKEN,\n sep_token: Optional[str] = DEFAULT_SEP_TOKEN,\n unk_token: Optional[str] = DEFAULT_UNK_TOKEN,\n ):\n \"\"\"\n Args:\n regex: regular expression that defined tokenization rules\n mask_token: mask token\n bos_token: the beginning of sequence token\n eos_token: the end of sequence token. Usually equal to sep_token\n pad_token: token to use for padding\n sep_token: token used for separating sequences\n cls_token: class token. Usually equal to bos_token\n unk_token: token to use for unknown tokens\n \"\"\"\n self.regex = regex\n self.mask_token = mask_token\n self.bos_token = bos_token\n self.eos_token = eos_token\n self.pad_token = pad_token\n self.sep_token = sep_token\n self.unk_token = unk_token\n\n # holds names of .model/.vocab files\n self.regex_file = None\n self.vocab_file = None\n\n # initialize with default vocab\n self.vocab = {\n self.pad_token: 0, # pad_token\n self.unk_token: 1, # unk_token\n self.bos_token: 2, # begin_token\n self.eos_token: 3, # end_token\n self.mask_token: 4, # mask_token\n self.sep_token: 5, # sep_token\n }\n self._update_cache()\n\n # Computed attributes\n self._compile_regex()\n\n def _update_cache(self):\n # Cache data/attributes required for tokenization\n self._unk_id = self.vocab.get(self.unk_token, DEFAULT_UNK_TOKEN)\n self._decode_vocab = {i: t for t, i in self.vocab.items()}\n\n def _compile_regex(self):\n regex_string = r\"(\"\n regex_string += self.regex + r\"|\"\n regex_string += r\".)\"\n self._compiled_regex = re.compile(regex_string)\n\n @property\n def vocab_size(self):\n return len(self.vocab)\n\n def text_to_tokens(self, text):\n tokens = self._compiled_regex.findall(text)\n\n return tokens\n\n def tokens_to_text(self, tokens):\n tokens_list = []\n for token in tokens:\n if token[0] == self.bos_token:\n token = token[1:]\n\n # Remove end token and the following values\n if self.eos_token in token:\n eos_idx = token.index(self.eos_token)\n token = token[:eos_idx]\n\n tokens_list.append(token)\n\n text = [\"\".join(tokens) for tokens in tokens_list]\n return text\n\n def token_to_ids(self, tokens):\n ids_list = []\n for token in tokens:\n ids_list.append(self.vocab.get(token, self._unk_id))\n return ids_list\n\n def tokens_to_ids(self, token_data):\n if isinstance(token_data, str):\n token_data = [token_data]\n\n ids_list = []\n for tokens in token_data:\n ids = self.token_to_ids(tokens)\n ids_list.append(ids)\n return ids_list\n\n def ids_to_tokens(self, ids_list):\n if len(ids_list) and not isinstance(ids_list[0], list):\n ids_list = [ids_list]\n added_list = True\n else:\n added_list = False\n\n tokens_list = []\n for ids in ids_list:\n tokens = []\n for token_id in ids:\n token = self._decode_vocab.get(token_id)\n if token is None:\n raise ValueError(f\"Token id {token_id} is not recognised\")\n tokens.append(token)\n\n tokens_list.append(tokens)\n\n if added_list:\n return tokens_list[0]\n else:\n return tokens_list\n\n def text_to_ids(self, text):\n tokens = self.text_to_tokens(text)\n tokens = [tokens]\n return self.tokens_to_ids(tokens)[0]\n\n def ids_to_text(self, ids):\n tokens = self.ids_to_tokens(ids)\n return self.tokens_to_text(tokens)\n\n @property\n def pad_id(self):\n return 0\n\n @property\n def unk_id(self):\n return 1\n\n @property\n def bos_id(self):\n return 2\n\n @property\n def eos_id(self):\n return 3\n\n @property\n def mask_id(self):\n return 4\n\n @property\n def sep_id(self):\n return 5\n\n def _get_regex_vocab_files(self, regex_file=None, vocab_file=None):\n \"\"\"\n Infers files or update if given.\n \"\"\"\n regex_file = regex_file or self.regex_file\n if not regex_file:\n raise ValueError(f\"regex_file must be specified\")\n\n vocab_file = vocab_file or self.vocab_file\n # try to infer vocab_file from regex_file\n if not vocab_file:\n vocab_file = os.path.splitext(regex_file)[0] + '.vocab'\n\n self.regex_file = regex_file\n self.vocab_file = vocab_file\n\n return regex_file, vocab_file\n\n def save_tokenizer(self, regex_file=None, vocab_file=None):\n \"\"\"\n Saves tokenizer's regex and vocab files\n \"\"\"\n regex_file, vocab_file = self._get_regex_vocab_files(regex_file=regex_file, vocab_file=vocab_file)\n\n logging.info(f\"Saving vocabulary to file = {vocab_file}\")\n with open(vocab_file, 'w') as fp:\n for token in self.vocab:\n fp.write(f\"{token[0]}\\n\")\n\n logging.info(f\"Saving regex to file = {regex_file}\")\n open(regex_file, 'w').write(self.regex)\n\n def load_tokenizer(self, regex_file=None, vocab_file=None):\n \"\"\"\n Loads tokenizer's regex and vocab files\n \"\"\"\n regex_file, vocab_file = self._get_regex_vocab_files(regex_file=regex_file, vocab_file=vocab_file)\n\n # load vocab file\n # vocab_file: path to file with vocabulary which consists\n # of characters separated by \\n (None/\"\" for empty vocab)\n\n logging.info(f\"Loading vocabulary from file = {vocab_file}\")\n if os.path.exists(vocab_file):\n vocab = {}\n with open(vocab_file, \"r\") as f:\n for line in f:\n line = line.strip()\n if line:\n vocab[line] = len(vocab)\n self.vocab = vocab\n else:\n raise RuntimeError(f\"Missing vocab_file = {vocab_file}\")\n\n # load regex from a file\n if os.path.exists(regex_file):\n logging.info(f\"Loading regex from file = {regex_file}\")\n self.regex = open(regex_file, encoding=\"utf-8\").read().strip()\n else:\n raise RuntimeError(f\"Missing regex_file = {regex_file}\")\n\n self._update_cache()\n self._compile_regex()\n\n return self\n\n def build_vocab_from_csv(self, data_csv_file, col=\"smiles\"):\n \"\"\"\n Learns vocabulary from a CSV file. Can be called multiple times to update vocabulary.\n \"\"\"\n logging.debug(f\"Building vocabulary from CSV col = {col} file = {data_csv_file}\")\n\n # NOTE this has to be run on each CSV file\n if not os.path.exists(data_csv_file):\n raise ValueError(f\"Data file: {data_csv_file} is missing\")\n\n df = pd.read_csv(data_csv_file)\n\n vocab = self.vocab\n for d in df[col]:\n tokens = self.text_to_tokens(d)\n logging.debug(f\"Text: {d}, Tokens: {tokens}\")\n for token in tokens:\n if token not in vocab:\n vocab[token] = len(vocab)\n\n sorted_vocab = sorted(vocab.items(), key=lambda k_v: k_v[1])\n logging.debug(f\"Vocab: {sorted_vocab}\")\n\n self.vocab = vocab\n self._update_cache()\n\n def build_vocab_from_text(self, data_text_file):\n \"\"\"\n Learns vocabulary from a text file. Can be called multiple times to update vocabulary.\n \"\"\"\n logging.debug(f\"Building vocabulary from TEXT file = {data_text_file}\")\n\n # NOTE this has to be run on each text file\n if not os.path.exists(data_text_file):\n raise ValueError(f\"Data file: {data_text_file} is missing\")\n\n vocab = self.vocab\n for d in open(data_text_file, encoding=\"utf-8\").readlines():\n d = d.rstrip()\n tokens = self.text_to_tokens(d)\n logging.debug(f\"Text: {d}, Tokens: {d}\")\n for token in tokens:\n if token not in vocab:\n vocab[token] = len(vocab)\n\n sorted_vocab = sorted(vocab.items(), key=lambda k_v: k_v[1])\n logging.debug(f\"Vocab: {sorted_vocab}\")\n\n self.vocab = vocab\n self._update_cache()\n", "path": "nemo/collections/common/tokenizers/regex_tokenizer.py"}]}
| 3,569 | 269 |
gh_patches_debug_42742
|
rasdani/github-patches
|
git_diff
|
Lightning-AI__torchmetrics-70
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`log_dict` is missing `prefix` parameter that is mentioned in docs
## 🐛 Bug
[`MetricCollection` documentation](https://pytorch-lightning.readthedocs.io/en/1.2.0/extensions/metrics.html#metriccollection) mentions using `self.log_dict(self.train_metrics, on_step=True, on_epoch=False, prefix='train')`. The `prefix` parameter doesn't seem to be present in `log_dict` function header.
### Expected behavior
`prefix` is most likely usable in this context, so this feature should be implemented. If not - the documentation should be fixed.
### Environment
- Lightning Version: 1.2.0
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torchmetrics/collections.py`
Content:
```
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from copy import deepcopy
16 from typing import Any, Dict, List, Tuple, Union
17
18 from torch import nn
19
20 from torchmetrics.metric import Metric
21
22
23 class MetricCollection(nn.ModuleDict):
24 """
25 MetricCollection class can be used to chain metrics that have the same
26 call pattern into one single class.
27
28 Args:
29 metrics: One of the following
30
31 * list or tuple: if metrics are passed in as a list, will use the
32 metrics class name as key for output dict. Therefore, two metrics
33 of the same class cannot be chained this way.
34
35 * dict: if metrics are passed in as a dict, will use each key in the
36 dict as key for output dict. Use this format if you want to chain
37 together multiple of the same metric with different parameters.
38
39 Example (input as list):
40 >>> import torch
41 >>> from torchmetrics import MetricCollection, Accuracy, Precision, Recall
42 >>> target = torch.tensor([0, 2, 0, 2, 0, 1, 0, 2])
43 >>> preds = torch.tensor([2, 1, 2, 0, 1, 2, 2, 2])
44 >>> metrics = MetricCollection([Accuracy(),
45 ... Precision(num_classes=3, average='macro'),
46 ... Recall(num_classes=3, average='macro')])
47 >>> metrics(preds, target)
48 {'Accuracy': tensor(0.1250), 'Precision': tensor(0.0667), 'Recall': tensor(0.1111)}
49
50 Example (input as dict):
51 >>> metrics = MetricCollection({'micro_recall': Recall(num_classes=3, average='micro'),
52 ... 'macro_recall': Recall(num_classes=3, average='macro')})
53 >>> same_metric = metrics.clone()
54 >>> metrics(preds, target)
55 {'micro_recall': tensor(0.1250), 'macro_recall': tensor(0.1111)}
56 >>> same_metric(preds, target)
57 {'micro_recall': tensor(0.1250), 'macro_recall': tensor(0.1111)}
58 >>> metrics.persistent()
59
60 """
61
62 def __init__(self, metrics: Union[List[Metric], Tuple[Metric], Dict[str, Metric]]):
63 super().__init__()
64 if isinstance(metrics, dict):
65 # Check all values are metrics
66 for name, metric in metrics.items():
67 if not isinstance(metric, Metric):
68 raise ValueError(
69 f"Value {metric} belonging to key {name}"
70 " is not an instance of `pl.metrics.Metric`"
71 )
72 self[name] = metric
73 elif isinstance(metrics, (tuple, list)):
74 for metric in metrics:
75 if not isinstance(metric, Metric):
76 raise ValueError(
77 f"Input {metric} to `MetricCollection` is not a instance"
78 " of `pl.metrics.Metric`"
79 )
80 name = metric.__class__.__name__
81 if name in self:
82 raise ValueError(f"Encountered two metrics both named {name}")
83 self[name] = metric
84 else:
85 raise ValueError("Unknown input to MetricCollection.")
86
87 def forward(self, *args, **kwargs) -> Dict[str, Any]: # pylint: disable=E0202
88 """
89 Iteratively call forward for each metric. Positional arguments (args) will
90 be passed to every metric in the collection, while keyword arguments (kwargs)
91 will be filtered based on the signature of the individual metric.
92 """
93 return {k: m(*args, **m._filter_kwargs(**kwargs)) for k, m in self.items()}
94
95 def update(self, *args, **kwargs): # pylint: disable=E0202
96 """
97 Iteratively call update for each metric. Positional arguments (args) will
98 be passed to every metric in the collection, while keyword arguments (kwargs)
99 will be filtered based on the signature of the individual metric.
100 """
101 for _, m in self.items():
102 m_kwargs = m._filter_kwargs(**kwargs)
103 m.update(*args, **m_kwargs)
104
105 def compute(self) -> Dict[str, Any]:
106 return {k: m.compute() for k, m in self.items()}
107
108 def reset(self):
109 """ Iteratively call reset for each metric """
110 for _, m in self.items():
111 m.reset()
112
113 def clone(self):
114 """ Make a copy of the metric collection """
115 return deepcopy(self)
116
117 def persistent(self, mode: bool = True):
118 """Method for post-init to change if metric states should be saved to
119 its state_dict
120 """
121 for _, m in self.items():
122 m.persistent(mode)
123
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torchmetrics/collections.py b/torchmetrics/collections.py
--- a/torchmetrics/collections.py
+++ b/torchmetrics/collections.py
@@ -13,7 +13,7 @@
# limitations under the License.
from copy import deepcopy
-from typing import Any, Dict, List, Tuple, Union
+from typing import Any, Dict, List, Optional, Tuple, Union
from torch import nn
@@ -36,6 +36,8 @@
dict as key for output dict. Use this format if you want to chain
together multiple of the same metric with different parameters.
+ prefix: a string to append in front of the keys of the output dict
+
Example (input as list):
>>> import torch
>>> from torchmetrics import MetricCollection, Accuracy, Precision, Recall
@@ -58,8 +60,11 @@
>>> metrics.persistent()
"""
-
- def __init__(self, metrics: Union[List[Metric], Tuple[Metric], Dict[str, Metric]]):
+ def __init__(
+ self,
+ metrics: Union[List[Metric], Tuple[Metric], Dict[str, Metric]],
+ prefix: Optional[str] = None
+ ):
super().__init__()
if isinstance(metrics, dict):
# Check all values are metrics
@@ -84,13 +89,15 @@
else:
raise ValueError("Unknown input to MetricCollection.")
+ self.prefix = self._check_prefix_arg(prefix)
+
def forward(self, *args, **kwargs) -> Dict[str, Any]: # pylint: disable=E0202
"""
Iteratively call forward for each metric. Positional arguments (args) will
be passed to every metric in the collection, while keyword arguments (kwargs)
will be filtered based on the signature of the individual metric.
"""
- return {k: m(*args, **m._filter_kwargs(**kwargs)) for k, m in self.items()}
+ return {self._set_prefix(k): m(*args, **m._filter_kwargs(**kwargs)) for k, m in self.items()}
def update(self, *args, **kwargs): # pylint: disable=E0202
"""
@@ -103,20 +110,36 @@
m.update(*args, **m_kwargs)
def compute(self) -> Dict[str, Any]:
- return {k: m.compute() for k, m in self.items()}
+ return {self._set_prefix(k): m.compute() for k, m in self.items()}
- def reset(self):
+ def reset(self) -> None:
""" Iteratively call reset for each metric """
for _, m in self.items():
m.reset()
- def clone(self):
- """ Make a copy of the metric collection """
- return deepcopy(self)
+ def clone(self, prefix: Optional[str] = None) -> 'MetricCollection':
+ """ Make a copy of the metric collection
+ Args:
+ prefix: a string to append in front of the metric keys
+ """
+ mc = deepcopy(self)
+ mc.prefix = self._check_prefix_arg(prefix)
+ return mc
- def persistent(self, mode: bool = True):
+ def persistent(self, mode: bool = True) -> None:
"""Method for post-init to change if metric states should be saved to
its state_dict
"""
for _, m in self.items():
m.persistent(mode)
+
+ def _set_prefix(self, k: str) -> str:
+ return k if self.prefix is None else self.prefix + k
+
+ def _check_prefix_arg(self, prefix: str) -> Optional[str]:
+ if prefix is not None:
+ if isinstance(prefix, str):
+ return prefix
+ else:
+ raise ValueError('Expected input `prefix` to be a string')
+ return None
|
{"golden_diff": "diff --git a/torchmetrics/collections.py b/torchmetrics/collections.py\n--- a/torchmetrics/collections.py\n+++ b/torchmetrics/collections.py\n@@ -13,7 +13,7 @@\n # limitations under the License.\n \n from copy import deepcopy\n-from typing import Any, Dict, List, Tuple, Union\n+from typing import Any, Dict, List, Optional, Tuple, Union\n \n from torch import nn\n \n@@ -36,6 +36,8 @@\n dict as key for output dict. Use this format if you want to chain\n together multiple of the same metric with different parameters.\n \n+ prefix: a string to append in front of the keys of the output dict\n+\n Example (input as list):\n >>> import torch\n >>> from torchmetrics import MetricCollection, Accuracy, Precision, Recall\n@@ -58,8 +60,11 @@\n >>> metrics.persistent()\n \n \"\"\"\n-\n- def __init__(self, metrics: Union[List[Metric], Tuple[Metric], Dict[str, Metric]]):\n+ def __init__(\n+ self,\n+ metrics: Union[List[Metric], Tuple[Metric], Dict[str, Metric]],\n+ prefix: Optional[str] = None\n+ ):\n super().__init__()\n if isinstance(metrics, dict):\n # Check all values are metrics\n@@ -84,13 +89,15 @@\n else:\n raise ValueError(\"Unknown input to MetricCollection.\")\n \n+ self.prefix = self._check_prefix_arg(prefix)\n+\n def forward(self, *args, **kwargs) -> Dict[str, Any]: # pylint: disable=E0202\n \"\"\"\n Iteratively call forward for each metric. Positional arguments (args) will\n be passed to every metric in the collection, while keyword arguments (kwargs)\n will be filtered based on the signature of the individual metric.\n \"\"\"\n- return {k: m(*args, **m._filter_kwargs(**kwargs)) for k, m in self.items()}\n+ return {self._set_prefix(k): m(*args, **m._filter_kwargs(**kwargs)) for k, m in self.items()}\n \n def update(self, *args, **kwargs): # pylint: disable=E0202\n \"\"\"\n@@ -103,20 +110,36 @@\n m.update(*args, **m_kwargs)\n \n def compute(self) -> Dict[str, Any]:\n- return {k: m.compute() for k, m in self.items()}\n+ return {self._set_prefix(k): m.compute() for k, m in self.items()}\n \n- def reset(self):\n+ def reset(self) -> None:\n \"\"\" Iteratively call reset for each metric \"\"\"\n for _, m in self.items():\n m.reset()\n \n- def clone(self):\n- \"\"\" Make a copy of the metric collection \"\"\"\n- return deepcopy(self)\n+ def clone(self, prefix: Optional[str] = None) -> 'MetricCollection':\n+ \"\"\" Make a copy of the metric collection\n+ Args:\n+ prefix: a string to append in front of the metric keys\n+ \"\"\"\n+ mc = deepcopy(self)\n+ mc.prefix = self._check_prefix_arg(prefix)\n+ return mc\n \n- def persistent(self, mode: bool = True):\n+ def persistent(self, mode: bool = True) -> None:\n \"\"\"Method for post-init to change if metric states should be saved to\n its state_dict\n \"\"\"\n for _, m in self.items():\n m.persistent(mode)\n+\n+ def _set_prefix(self, k: str) -> str:\n+ return k if self.prefix is None else self.prefix + k\n+\n+ def _check_prefix_arg(self, prefix: str) -> Optional[str]:\n+ if prefix is not None:\n+ if isinstance(prefix, str):\n+ return prefix\n+ else:\n+ raise ValueError('Expected input `prefix` to be a string')\n+ return None\n", "issue": "`log_dict` is missing `prefix` parameter that is mentioned in docs\n## \ud83d\udc1b Bug\r\n\r\n[`MetricCollection` documentation](https://pytorch-lightning.readthedocs.io/en/1.2.0/extensions/metrics.html#metriccollection) mentions using `self.log_dict(self.train_metrics, on_step=True, on_epoch=False, prefix='train')`. The `prefix` parameter doesn't seem to be present in `log_dict` function header.\r\n\r\n\r\n### Expected behavior\r\n\r\n`prefix` is most likely usable in this context, so this feature should be implemented. If not - the documentation should be fixed.\r\n\r\n### Environment\r\n\r\n - Lightning Version: 1.2.0\r\n\n", "before_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom copy import deepcopy\nfrom typing import Any, Dict, List, Tuple, Union\n\nfrom torch import nn\n\nfrom torchmetrics.metric import Metric\n\n\nclass MetricCollection(nn.ModuleDict):\n \"\"\"\n MetricCollection class can be used to chain metrics that have the same\n call pattern into one single class.\n\n Args:\n metrics: One of the following\n\n * list or tuple: if metrics are passed in as a list, will use the\n metrics class name as key for output dict. Therefore, two metrics\n of the same class cannot be chained this way.\n\n * dict: if metrics are passed in as a dict, will use each key in the\n dict as key for output dict. Use this format if you want to chain\n together multiple of the same metric with different parameters.\n\n Example (input as list):\n >>> import torch\n >>> from torchmetrics import MetricCollection, Accuracy, Precision, Recall\n >>> target = torch.tensor([0, 2, 0, 2, 0, 1, 0, 2])\n >>> preds = torch.tensor([2, 1, 2, 0, 1, 2, 2, 2])\n >>> metrics = MetricCollection([Accuracy(),\n ... Precision(num_classes=3, average='macro'),\n ... Recall(num_classes=3, average='macro')])\n >>> metrics(preds, target)\n {'Accuracy': tensor(0.1250), 'Precision': tensor(0.0667), 'Recall': tensor(0.1111)}\n\n Example (input as dict):\n >>> metrics = MetricCollection({'micro_recall': Recall(num_classes=3, average='micro'),\n ... 'macro_recall': Recall(num_classes=3, average='macro')})\n >>> same_metric = metrics.clone()\n >>> metrics(preds, target)\n {'micro_recall': tensor(0.1250), 'macro_recall': tensor(0.1111)}\n >>> same_metric(preds, target)\n {'micro_recall': tensor(0.1250), 'macro_recall': tensor(0.1111)}\n >>> metrics.persistent()\n\n \"\"\"\n\n def __init__(self, metrics: Union[List[Metric], Tuple[Metric], Dict[str, Metric]]):\n super().__init__()\n if isinstance(metrics, dict):\n # Check all values are metrics\n for name, metric in metrics.items():\n if not isinstance(metric, Metric):\n raise ValueError(\n f\"Value {metric} belonging to key {name}\"\n \" is not an instance of `pl.metrics.Metric`\"\n )\n self[name] = metric\n elif isinstance(metrics, (tuple, list)):\n for metric in metrics:\n if not isinstance(metric, Metric):\n raise ValueError(\n f\"Input {metric} to `MetricCollection` is not a instance\"\n \" of `pl.metrics.Metric`\"\n )\n name = metric.__class__.__name__\n if name in self:\n raise ValueError(f\"Encountered two metrics both named {name}\")\n self[name] = metric\n else:\n raise ValueError(\"Unknown input to MetricCollection.\")\n\n def forward(self, *args, **kwargs) -> Dict[str, Any]: # pylint: disable=E0202\n \"\"\"\n Iteratively call forward for each metric. Positional arguments (args) will\n be passed to every metric in the collection, while keyword arguments (kwargs)\n will be filtered based on the signature of the individual metric.\n \"\"\"\n return {k: m(*args, **m._filter_kwargs(**kwargs)) for k, m in self.items()}\n\n def update(self, *args, **kwargs): # pylint: disable=E0202\n \"\"\"\n Iteratively call update for each metric. Positional arguments (args) will\n be passed to every metric in the collection, while keyword arguments (kwargs)\n will be filtered based on the signature of the individual metric.\n \"\"\"\n for _, m in self.items():\n m_kwargs = m._filter_kwargs(**kwargs)\n m.update(*args, **m_kwargs)\n\n def compute(self) -> Dict[str, Any]:\n return {k: m.compute() for k, m in self.items()}\n\n def reset(self):\n \"\"\" Iteratively call reset for each metric \"\"\"\n for _, m in self.items():\n m.reset()\n\n def clone(self):\n \"\"\" Make a copy of the metric collection \"\"\"\n return deepcopy(self)\n\n def persistent(self, mode: bool = True):\n \"\"\"Method for post-init to change if metric states should be saved to\n its state_dict\n \"\"\"\n for _, m in self.items():\n m.persistent(mode)\n", "path": "torchmetrics/collections.py"}], "after_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom copy import deepcopy\nfrom typing import Any, Dict, List, Optional, Tuple, Union\n\nfrom torch import nn\n\nfrom torchmetrics.metric import Metric\n\n\nclass MetricCollection(nn.ModuleDict):\n \"\"\"\n MetricCollection class can be used to chain metrics that have the same\n call pattern into one single class.\n\n Args:\n metrics: One of the following\n\n * list or tuple: if metrics are passed in as a list, will use the\n metrics class name as key for output dict. Therefore, two metrics\n of the same class cannot be chained this way.\n\n * dict: if metrics are passed in as a dict, will use each key in the\n dict as key for output dict. Use this format if you want to chain\n together multiple of the same metric with different parameters.\n\n prefix: a string to append in front of the keys of the output dict\n\n Example (input as list):\n >>> import torch\n >>> from torchmetrics import MetricCollection, Accuracy, Precision, Recall\n >>> target = torch.tensor([0, 2, 0, 2, 0, 1, 0, 2])\n >>> preds = torch.tensor([2, 1, 2, 0, 1, 2, 2, 2])\n >>> metrics = MetricCollection([Accuracy(),\n ... Precision(num_classes=3, average='macro'),\n ... Recall(num_classes=3, average='macro')])\n >>> metrics(preds, target)\n {'Accuracy': tensor(0.1250), 'Precision': tensor(0.0667), 'Recall': tensor(0.1111)}\n\n Example (input as dict):\n >>> metrics = MetricCollection({'micro_recall': Recall(num_classes=3, average='micro'),\n ... 'macro_recall': Recall(num_classes=3, average='macro')})\n >>> same_metric = metrics.clone()\n >>> metrics(preds, target)\n {'micro_recall': tensor(0.1250), 'macro_recall': tensor(0.1111)}\n >>> same_metric(preds, target)\n {'micro_recall': tensor(0.1250), 'macro_recall': tensor(0.1111)}\n >>> metrics.persistent()\n\n \"\"\"\n def __init__(\n self,\n metrics: Union[List[Metric], Tuple[Metric], Dict[str, Metric]],\n prefix: Optional[str] = None\n ):\n super().__init__()\n if isinstance(metrics, dict):\n # Check all values are metrics\n for name, metric in metrics.items():\n if not isinstance(metric, Metric):\n raise ValueError(\n f\"Value {metric} belonging to key {name}\"\n \" is not an instance of `pl.metrics.Metric`\"\n )\n self[name] = metric\n elif isinstance(metrics, (tuple, list)):\n for metric in metrics:\n if not isinstance(metric, Metric):\n raise ValueError(\n f\"Input {metric} to `MetricCollection` is not a instance\"\n \" of `pl.metrics.Metric`\"\n )\n name = metric.__class__.__name__\n if name in self:\n raise ValueError(f\"Encountered two metrics both named {name}\")\n self[name] = metric\n else:\n raise ValueError(\"Unknown input to MetricCollection.\")\n\n self.prefix = self._check_prefix_arg(prefix)\n\n def forward(self, *args, **kwargs) -> Dict[str, Any]: # pylint: disable=E0202\n \"\"\"\n Iteratively call forward for each metric. Positional arguments (args) will\n be passed to every metric in the collection, while keyword arguments (kwargs)\n will be filtered based on the signature of the individual metric.\n \"\"\"\n return {self._set_prefix(k): m(*args, **m._filter_kwargs(**kwargs)) for k, m in self.items()}\n\n def update(self, *args, **kwargs): # pylint: disable=E0202\n \"\"\"\n Iteratively call update for each metric. Positional arguments (args) will\n be passed to every metric in the collection, while keyword arguments (kwargs)\n will be filtered based on the signature of the individual metric.\n \"\"\"\n for _, m in self.items():\n m_kwargs = m._filter_kwargs(**kwargs)\n m.update(*args, **m_kwargs)\n\n def compute(self) -> Dict[str, Any]:\n return {self._set_prefix(k): m.compute() for k, m in self.items()}\n\n def reset(self) -> None:\n \"\"\" Iteratively call reset for each metric \"\"\"\n for _, m in self.items():\n m.reset()\n\n def clone(self, prefix: Optional[str] = None) -> 'MetricCollection':\n \"\"\" Make a copy of the metric collection\n Args:\n prefix: a string to append in front of the metric keys\n \"\"\"\n mc = deepcopy(self)\n mc.prefix = self._check_prefix_arg(prefix)\n return mc\n\n def persistent(self, mode: bool = True) -> None:\n \"\"\"Method for post-init to change if metric states should be saved to\n its state_dict\n \"\"\"\n for _, m in self.items():\n m.persistent(mode)\n\n def _set_prefix(self, k: str) -> str:\n return k if self.prefix is None else self.prefix + k\n\n def _check_prefix_arg(self, prefix: str) -> Optional[str]:\n if prefix is not None:\n if isinstance(prefix, str):\n return prefix\n else:\n raise ValueError('Expected input `prefix` to be a string')\n return None\n", "path": "torchmetrics/collections.py"}]}
| 1,807 | 860 |
gh_patches_debug_8004
|
rasdani/github-patches
|
git_diff
|
espnet__espnet-4378
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Question on check_short_utt
I use `Conv2dSubsampling2` and have a tensor of size `[1, 5, 80]` that can not be processed by this subsampling module. If I pad it to `[1, 7, 80]`, then it works, but with `[1, 6, 80]` it does not, so I assume the minimum length is 7 frames for `Conv2dSubsampling2`. However, `check_short_utt` requires it to be at least 3 frames:
https://github.com/espnet/espnet/blob/afa8f8ec5b8ec77deb1a3c1531915ebbee7b80e6/espnet/nets/pytorch_backend/transformer/subsampling.py#L33-L34
Should it be changed to 7 or I get something wrong?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `espnet/nets/pytorch_backend/transformer/subsampling.py`
Content:
```
1 #!/usr/bin/env python3
2 # -*- coding: utf-8 -*-
3
4 # Copyright 2019 Shigeki Karita
5 # Apache 2.0 (http://www.apache.org/licenses/LICENSE-2.0)
6
7 """Subsampling layer definition."""
8
9 import torch
10
11 from espnet.nets.pytorch_backend.transformer.embedding import PositionalEncoding
12
13
14 class TooShortUttError(Exception):
15 """Raised when the utt is too short for subsampling.
16
17 Args:
18 message (str): Message for error catch
19 actual_size (int): the short size that cannot pass the subsampling
20 limit (int): the limit size for subsampling
21
22 """
23
24 def __init__(self, message, actual_size, limit):
25 """Construct a TooShortUttError for error handler."""
26 super().__init__(message)
27 self.actual_size = actual_size
28 self.limit = limit
29
30
31 def check_short_utt(ins, size):
32 """Check if the utterance is too short for subsampling."""
33 if isinstance(ins, Conv2dSubsampling2) and size < 3:
34 return True, 3
35 if isinstance(ins, Conv2dSubsampling) and size < 7:
36 return True, 7
37 if isinstance(ins, Conv2dSubsampling6) and size < 11:
38 return True, 11
39 if isinstance(ins, Conv2dSubsampling8) and size < 15:
40 return True, 15
41 return False, -1
42
43
44 class Conv2dSubsampling(torch.nn.Module):
45 """Convolutional 2D subsampling (to 1/4 length).
46
47 Args:
48 idim (int): Input dimension.
49 odim (int): Output dimension.
50 dropout_rate (float): Dropout rate.
51 pos_enc (torch.nn.Module): Custom position encoding layer.
52
53 """
54
55 def __init__(self, idim, odim, dropout_rate, pos_enc=None):
56 """Construct an Conv2dSubsampling object."""
57 super(Conv2dSubsampling, self).__init__()
58 self.conv = torch.nn.Sequential(
59 torch.nn.Conv2d(1, odim, 3, 2),
60 torch.nn.ReLU(),
61 torch.nn.Conv2d(odim, odim, 3, 2),
62 torch.nn.ReLU(),
63 )
64 self.out = torch.nn.Sequential(
65 torch.nn.Linear(odim * (((idim - 1) // 2 - 1) // 2), odim),
66 pos_enc if pos_enc is not None else PositionalEncoding(odim, dropout_rate),
67 )
68
69 def forward(self, x, x_mask):
70 """Subsample x.
71
72 Args:
73 x (torch.Tensor): Input tensor (#batch, time, idim).
74 x_mask (torch.Tensor): Input mask (#batch, 1, time).
75
76 Returns:
77 torch.Tensor: Subsampled tensor (#batch, time', odim),
78 where time' = time // 4.
79 torch.Tensor: Subsampled mask (#batch, 1, time'),
80 where time' = time // 4.
81
82 """
83 x = x.unsqueeze(1) # (b, c, t, f)
84 x = self.conv(x)
85 b, c, t, f = x.size()
86 x = self.out(x.transpose(1, 2).contiguous().view(b, t, c * f))
87 if x_mask is None:
88 return x, None
89 return x, x_mask[:, :, :-2:2][:, :, :-2:2]
90
91 def __getitem__(self, key):
92 """Get item.
93
94 When reset_parameters() is called, if use_scaled_pos_enc is used,
95 return the positioning encoding.
96
97 """
98 if key != -1:
99 raise NotImplementedError("Support only `-1` (for `reset_parameters`).")
100 return self.out[key]
101
102
103 class Conv2dSubsampling2(torch.nn.Module):
104 """Convolutional 2D subsampling (to 1/2 length).
105
106 Args:
107 idim (int): Input dimension.
108 odim (int): Output dimension.
109 dropout_rate (float): Dropout rate.
110 pos_enc (torch.nn.Module): Custom position encoding layer.
111
112 """
113
114 def __init__(self, idim, odim, dropout_rate, pos_enc=None):
115 """Construct an Conv2dSubsampling2 object."""
116 super(Conv2dSubsampling2, self).__init__()
117 self.conv = torch.nn.Sequential(
118 torch.nn.Conv2d(1, odim, 3, 2),
119 torch.nn.ReLU(),
120 torch.nn.Conv2d(odim, odim, 3, 1),
121 torch.nn.ReLU(),
122 )
123 self.out = torch.nn.Sequential(
124 torch.nn.Linear(odim * (((idim - 1) // 2 - 2)), odim),
125 pos_enc if pos_enc is not None else PositionalEncoding(odim, dropout_rate),
126 )
127
128 def forward(self, x, x_mask):
129 """Subsample x.
130
131 Args:
132 x (torch.Tensor): Input tensor (#batch, time, idim).
133 x_mask (torch.Tensor): Input mask (#batch, 1, time).
134
135 Returns:
136 torch.Tensor: Subsampled tensor (#batch, time', odim),
137 where time' = time // 2.
138 torch.Tensor: Subsampled mask (#batch, 1, time'),
139 where time' = time // 2.
140
141 """
142 x = x.unsqueeze(1) # (b, c, t, f)
143 x = self.conv(x)
144 b, c, t, f = x.size()
145 x = self.out(x.transpose(1, 2).contiguous().view(b, t, c * f))
146 if x_mask is None:
147 return x, None
148 return x, x_mask[:, :, :-2:2][:, :, :-2:1]
149
150 def __getitem__(self, key):
151 """Get item.
152
153 When reset_parameters() is called, if use_scaled_pos_enc is used,
154 return the positioning encoding.
155
156 """
157 if key != -1:
158 raise NotImplementedError("Support only `-1` (for `reset_parameters`).")
159 return self.out[key]
160
161
162 class Conv2dSubsampling6(torch.nn.Module):
163 """Convolutional 2D subsampling (to 1/6 length).
164
165 Args:
166 idim (int): Input dimension.
167 odim (int): Output dimension.
168 dropout_rate (float): Dropout rate.
169 pos_enc (torch.nn.Module): Custom position encoding layer.
170
171 """
172
173 def __init__(self, idim, odim, dropout_rate, pos_enc=None):
174 """Construct an Conv2dSubsampling6 object."""
175 super(Conv2dSubsampling6, self).__init__()
176 self.conv = torch.nn.Sequential(
177 torch.nn.Conv2d(1, odim, 3, 2),
178 torch.nn.ReLU(),
179 torch.nn.Conv2d(odim, odim, 5, 3),
180 torch.nn.ReLU(),
181 )
182 self.out = torch.nn.Sequential(
183 torch.nn.Linear(odim * (((idim - 1) // 2 - 2) // 3), odim),
184 pos_enc if pos_enc is not None else PositionalEncoding(odim, dropout_rate),
185 )
186
187 def forward(self, x, x_mask):
188 """Subsample x.
189
190 Args:
191 x (torch.Tensor): Input tensor (#batch, time, idim).
192 x_mask (torch.Tensor): Input mask (#batch, 1, time).
193
194 Returns:
195 torch.Tensor: Subsampled tensor (#batch, time', odim),
196 where time' = time // 6.
197 torch.Tensor: Subsampled mask (#batch, 1, time'),
198 where time' = time // 6.
199
200 """
201 x = x.unsqueeze(1) # (b, c, t, f)
202 x = self.conv(x)
203 b, c, t, f = x.size()
204 x = self.out(x.transpose(1, 2).contiguous().view(b, t, c * f))
205 if x_mask is None:
206 return x, None
207 return x, x_mask[:, :, :-2:2][:, :, :-4:3]
208
209
210 class Conv2dSubsampling8(torch.nn.Module):
211 """Convolutional 2D subsampling (to 1/8 length).
212
213 Args:
214 idim (int): Input dimension.
215 odim (int): Output dimension.
216 dropout_rate (float): Dropout rate.
217 pos_enc (torch.nn.Module): Custom position encoding layer.
218
219 """
220
221 def __init__(self, idim, odim, dropout_rate, pos_enc=None):
222 """Construct an Conv2dSubsampling8 object."""
223 super(Conv2dSubsampling8, self).__init__()
224 self.conv = torch.nn.Sequential(
225 torch.nn.Conv2d(1, odim, 3, 2),
226 torch.nn.ReLU(),
227 torch.nn.Conv2d(odim, odim, 3, 2),
228 torch.nn.ReLU(),
229 torch.nn.Conv2d(odim, odim, 3, 2),
230 torch.nn.ReLU(),
231 )
232 self.out = torch.nn.Sequential(
233 torch.nn.Linear(odim * ((((idim - 1) // 2 - 1) // 2 - 1) // 2), odim),
234 pos_enc if pos_enc is not None else PositionalEncoding(odim, dropout_rate),
235 )
236
237 def forward(self, x, x_mask):
238 """Subsample x.
239
240 Args:
241 x (torch.Tensor): Input tensor (#batch, time, idim).
242 x_mask (torch.Tensor): Input mask (#batch, 1, time).
243
244 Returns:
245 torch.Tensor: Subsampled tensor (#batch, time', odim),
246 where time' = time // 8.
247 torch.Tensor: Subsampled mask (#batch, 1, time'),
248 where time' = time // 8.
249
250 """
251 x = x.unsqueeze(1) # (b, c, t, f)
252 x = self.conv(x)
253 b, c, t, f = x.size()
254 x = self.out(x.transpose(1, 2).contiguous().view(b, t, c * f))
255 if x_mask is None:
256 return x, None
257 return x, x_mask[:, :, :-2:2][:, :, :-2:2][:, :, :-2:2]
258
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/espnet/nets/pytorch_backend/transformer/subsampling.py b/espnet/nets/pytorch_backend/transformer/subsampling.py
--- a/espnet/nets/pytorch_backend/transformer/subsampling.py
+++ b/espnet/nets/pytorch_backend/transformer/subsampling.py
@@ -30,8 +30,8 @@
def check_short_utt(ins, size):
"""Check if the utterance is too short for subsampling."""
- if isinstance(ins, Conv2dSubsampling2) and size < 3:
- return True, 3
+ if isinstance(ins, Conv2dSubsampling2) and size < 7:
+ return True, 7
if isinstance(ins, Conv2dSubsampling) and size < 7:
return True, 7
if isinstance(ins, Conv2dSubsampling6) and size < 11:
|
{"golden_diff": "diff --git a/espnet/nets/pytorch_backend/transformer/subsampling.py b/espnet/nets/pytorch_backend/transformer/subsampling.py\n--- a/espnet/nets/pytorch_backend/transformer/subsampling.py\n+++ b/espnet/nets/pytorch_backend/transformer/subsampling.py\n@@ -30,8 +30,8 @@\n \n def check_short_utt(ins, size):\n \"\"\"Check if the utterance is too short for subsampling.\"\"\"\n- if isinstance(ins, Conv2dSubsampling2) and size < 3:\n- return True, 3\n+ if isinstance(ins, Conv2dSubsampling2) and size < 7:\n+ return True, 7\n if isinstance(ins, Conv2dSubsampling) and size < 7:\n return True, 7\n if isinstance(ins, Conv2dSubsampling6) and size < 11:\n", "issue": "Question on check_short_utt\nI use `Conv2dSubsampling2` and have a tensor of size `[1, 5, 80]` that can not be processed by this subsampling module. If I pad it to `[1, 7, 80]`, then it works, but with `[1, 6, 80]` it does not, so I assume the minimum length is 7 frames for `Conv2dSubsampling2`. However, `check_short_utt` requires it to be at least 3 frames:\r\nhttps://github.com/espnet/espnet/blob/afa8f8ec5b8ec77deb1a3c1531915ebbee7b80e6/espnet/nets/pytorch_backend/transformer/subsampling.py#L33-L34\r\nShould it be changed to 7 or I get something wrong?\n", "before_files": [{"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\n# Copyright 2019 Shigeki Karita\n# Apache 2.0 (http://www.apache.org/licenses/LICENSE-2.0)\n\n\"\"\"Subsampling layer definition.\"\"\"\n\nimport torch\n\nfrom espnet.nets.pytorch_backend.transformer.embedding import PositionalEncoding\n\n\nclass TooShortUttError(Exception):\n \"\"\"Raised when the utt is too short for subsampling.\n\n Args:\n message (str): Message for error catch\n actual_size (int): the short size that cannot pass the subsampling\n limit (int): the limit size for subsampling\n\n \"\"\"\n\n def __init__(self, message, actual_size, limit):\n \"\"\"Construct a TooShortUttError for error handler.\"\"\"\n super().__init__(message)\n self.actual_size = actual_size\n self.limit = limit\n\n\ndef check_short_utt(ins, size):\n \"\"\"Check if the utterance is too short for subsampling.\"\"\"\n if isinstance(ins, Conv2dSubsampling2) and size < 3:\n return True, 3\n if isinstance(ins, Conv2dSubsampling) and size < 7:\n return True, 7\n if isinstance(ins, Conv2dSubsampling6) and size < 11:\n return True, 11\n if isinstance(ins, Conv2dSubsampling8) and size < 15:\n return True, 15\n return False, -1\n\n\nclass Conv2dSubsampling(torch.nn.Module):\n \"\"\"Convolutional 2D subsampling (to 1/4 length).\n\n Args:\n idim (int): Input dimension.\n odim (int): Output dimension.\n dropout_rate (float): Dropout rate.\n pos_enc (torch.nn.Module): Custom position encoding layer.\n\n \"\"\"\n\n def __init__(self, idim, odim, dropout_rate, pos_enc=None):\n \"\"\"Construct an Conv2dSubsampling object.\"\"\"\n super(Conv2dSubsampling, self).__init__()\n self.conv = torch.nn.Sequential(\n torch.nn.Conv2d(1, odim, 3, 2),\n torch.nn.ReLU(),\n torch.nn.Conv2d(odim, odim, 3, 2),\n torch.nn.ReLU(),\n )\n self.out = torch.nn.Sequential(\n torch.nn.Linear(odim * (((idim - 1) // 2 - 1) // 2), odim),\n pos_enc if pos_enc is not None else PositionalEncoding(odim, dropout_rate),\n )\n\n def forward(self, x, x_mask):\n \"\"\"Subsample x.\n\n Args:\n x (torch.Tensor): Input tensor (#batch, time, idim).\n x_mask (torch.Tensor): Input mask (#batch, 1, time).\n\n Returns:\n torch.Tensor: Subsampled tensor (#batch, time', odim),\n where time' = time // 4.\n torch.Tensor: Subsampled mask (#batch, 1, time'),\n where time' = time // 4.\n\n \"\"\"\n x = x.unsqueeze(1) # (b, c, t, f)\n x = self.conv(x)\n b, c, t, f = x.size()\n x = self.out(x.transpose(1, 2).contiguous().view(b, t, c * f))\n if x_mask is None:\n return x, None\n return x, x_mask[:, :, :-2:2][:, :, :-2:2]\n\n def __getitem__(self, key):\n \"\"\"Get item.\n\n When reset_parameters() is called, if use_scaled_pos_enc is used,\n return the positioning encoding.\n\n \"\"\"\n if key != -1:\n raise NotImplementedError(\"Support only `-1` (for `reset_parameters`).\")\n return self.out[key]\n\n\nclass Conv2dSubsampling2(torch.nn.Module):\n \"\"\"Convolutional 2D subsampling (to 1/2 length).\n\n Args:\n idim (int): Input dimension.\n odim (int): Output dimension.\n dropout_rate (float): Dropout rate.\n pos_enc (torch.nn.Module): Custom position encoding layer.\n\n \"\"\"\n\n def __init__(self, idim, odim, dropout_rate, pos_enc=None):\n \"\"\"Construct an Conv2dSubsampling2 object.\"\"\"\n super(Conv2dSubsampling2, self).__init__()\n self.conv = torch.nn.Sequential(\n torch.nn.Conv2d(1, odim, 3, 2),\n torch.nn.ReLU(),\n torch.nn.Conv2d(odim, odim, 3, 1),\n torch.nn.ReLU(),\n )\n self.out = torch.nn.Sequential(\n torch.nn.Linear(odim * (((idim - 1) // 2 - 2)), odim),\n pos_enc if pos_enc is not None else PositionalEncoding(odim, dropout_rate),\n )\n\n def forward(self, x, x_mask):\n \"\"\"Subsample x.\n\n Args:\n x (torch.Tensor): Input tensor (#batch, time, idim).\n x_mask (torch.Tensor): Input mask (#batch, 1, time).\n\n Returns:\n torch.Tensor: Subsampled tensor (#batch, time', odim),\n where time' = time // 2.\n torch.Tensor: Subsampled mask (#batch, 1, time'),\n where time' = time // 2.\n\n \"\"\"\n x = x.unsqueeze(1) # (b, c, t, f)\n x = self.conv(x)\n b, c, t, f = x.size()\n x = self.out(x.transpose(1, 2).contiguous().view(b, t, c * f))\n if x_mask is None:\n return x, None\n return x, x_mask[:, :, :-2:2][:, :, :-2:1]\n\n def __getitem__(self, key):\n \"\"\"Get item.\n\n When reset_parameters() is called, if use_scaled_pos_enc is used,\n return the positioning encoding.\n\n \"\"\"\n if key != -1:\n raise NotImplementedError(\"Support only `-1` (for `reset_parameters`).\")\n return self.out[key]\n\n\nclass Conv2dSubsampling6(torch.nn.Module):\n \"\"\"Convolutional 2D subsampling (to 1/6 length).\n\n Args:\n idim (int): Input dimension.\n odim (int): Output dimension.\n dropout_rate (float): Dropout rate.\n pos_enc (torch.nn.Module): Custom position encoding layer.\n\n \"\"\"\n\n def __init__(self, idim, odim, dropout_rate, pos_enc=None):\n \"\"\"Construct an Conv2dSubsampling6 object.\"\"\"\n super(Conv2dSubsampling6, self).__init__()\n self.conv = torch.nn.Sequential(\n torch.nn.Conv2d(1, odim, 3, 2),\n torch.nn.ReLU(),\n torch.nn.Conv2d(odim, odim, 5, 3),\n torch.nn.ReLU(),\n )\n self.out = torch.nn.Sequential(\n torch.nn.Linear(odim * (((idim - 1) // 2 - 2) // 3), odim),\n pos_enc if pos_enc is not None else PositionalEncoding(odim, dropout_rate),\n )\n\n def forward(self, x, x_mask):\n \"\"\"Subsample x.\n\n Args:\n x (torch.Tensor): Input tensor (#batch, time, idim).\n x_mask (torch.Tensor): Input mask (#batch, 1, time).\n\n Returns:\n torch.Tensor: Subsampled tensor (#batch, time', odim),\n where time' = time // 6.\n torch.Tensor: Subsampled mask (#batch, 1, time'),\n where time' = time // 6.\n\n \"\"\"\n x = x.unsqueeze(1) # (b, c, t, f)\n x = self.conv(x)\n b, c, t, f = x.size()\n x = self.out(x.transpose(1, 2).contiguous().view(b, t, c * f))\n if x_mask is None:\n return x, None\n return x, x_mask[:, :, :-2:2][:, :, :-4:3]\n\n\nclass Conv2dSubsampling8(torch.nn.Module):\n \"\"\"Convolutional 2D subsampling (to 1/8 length).\n\n Args:\n idim (int): Input dimension.\n odim (int): Output dimension.\n dropout_rate (float): Dropout rate.\n pos_enc (torch.nn.Module): Custom position encoding layer.\n\n \"\"\"\n\n def __init__(self, idim, odim, dropout_rate, pos_enc=None):\n \"\"\"Construct an Conv2dSubsampling8 object.\"\"\"\n super(Conv2dSubsampling8, self).__init__()\n self.conv = torch.nn.Sequential(\n torch.nn.Conv2d(1, odim, 3, 2),\n torch.nn.ReLU(),\n torch.nn.Conv2d(odim, odim, 3, 2),\n torch.nn.ReLU(),\n torch.nn.Conv2d(odim, odim, 3, 2),\n torch.nn.ReLU(),\n )\n self.out = torch.nn.Sequential(\n torch.nn.Linear(odim * ((((idim - 1) // 2 - 1) // 2 - 1) // 2), odim),\n pos_enc if pos_enc is not None else PositionalEncoding(odim, dropout_rate),\n )\n\n def forward(self, x, x_mask):\n \"\"\"Subsample x.\n\n Args:\n x (torch.Tensor): Input tensor (#batch, time, idim).\n x_mask (torch.Tensor): Input mask (#batch, 1, time).\n\n Returns:\n torch.Tensor: Subsampled tensor (#batch, time', odim),\n where time' = time // 8.\n torch.Tensor: Subsampled mask (#batch, 1, time'),\n where time' = time // 8.\n\n \"\"\"\n x = x.unsqueeze(1) # (b, c, t, f)\n x = self.conv(x)\n b, c, t, f = x.size()\n x = self.out(x.transpose(1, 2).contiguous().view(b, t, c * f))\n if x_mask is None:\n return x, None\n return x, x_mask[:, :, :-2:2][:, :, :-2:2][:, :, :-2:2]\n", "path": "espnet/nets/pytorch_backend/transformer/subsampling.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\n# Copyright 2019 Shigeki Karita\n# Apache 2.0 (http://www.apache.org/licenses/LICENSE-2.0)\n\n\"\"\"Subsampling layer definition.\"\"\"\n\nimport torch\n\nfrom espnet.nets.pytorch_backend.transformer.embedding import PositionalEncoding\n\n\nclass TooShortUttError(Exception):\n \"\"\"Raised when the utt is too short for subsampling.\n\n Args:\n message (str): Message for error catch\n actual_size (int): the short size that cannot pass the subsampling\n limit (int): the limit size for subsampling\n\n \"\"\"\n\n def __init__(self, message, actual_size, limit):\n \"\"\"Construct a TooShortUttError for error handler.\"\"\"\n super().__init__(message)\n self.actual_size = actual_size\n self.limit = limit\n\n\ndef check_short_utt(ins, size):\n \"\"\"Check if the utterance is too short for subsampling.\"\"\"\n if isinstance(ins, Conv2dSubsampling2) and size < 7:\n return True, 7\n if isinstance(ins, Conv2dSubsampling) and size < 7:\n return True, 7\n if isinstance(ins, Conv2dSubsampling6) and size < 11:\n return True, 11\n if isinstance(ins, Conv2dSubsampling8) and size < 15:\n return True, 15\n return False, -1\n\n\nclass Conv2dSubsampling(torch.nn.Module):\n \"\"\"Convolutional 2D subsampling (to 1/4 length).\n\n Args:\n idim (int): Input dimension.\n odim (int): Output dimension.\n dropout_rate (float): Dropout rate.\n pos_enc (torch.nn.Module): Custom position encoding layer.\n\n \"\"\"\n\n def __init__(self, idim, odim, dropout_rate, pos_enc=None):\n \"\"\"Construct an Conv2dSubsampling object.\"\"\"\n super(Conv2dSubsampling, self).__init__()\n self.conv = torch.nn.Sequential(\n torch.nn.Conv2d(1, odim, 3, 2),\n torch.nn.ReLU(),\n torch.nn.Conv2d(odim, odim, 3, 2),\n torch.nn.ReLU(),\n )\n self.out = torch.nn.Sequential(\n torch.nn.Linear(odim * (((idim - 1) // 2 - 1) // 2), odim),\n pos_enc if pos_enc is not None else PositionalEncoding(odim, dropout_rate),\n )\n\n def forward(self, x, x_mask):\n \"\"\"Subsample x.\n\n Args:\n x (torch.Tensor): Input tensor (#batch, time, idim).\n x_mask (torch.Tensor): Input mask (#batch, 1, time).\n\n Returns:\n torch.Tensor: Subsampled tensor (#batch, time', odim),\n where time' = time // 4.\n torch.Tensor: Subsampled mask (#batch, 1, time'),\n where time' = time // 4.\n\n \"\"\"\n x = x.unsqueeze(1) # (b, c, t, f)\n x = self.conv(x)\n b, c, t, f = x.size()\n x = self.out(x.transpose(1, 2).contiguous().view(b, t, c * f))\n if x_mask is None:\n return x, None\n return x, x_mask[:, :, :-2:2][:, :, :-2:2]\n\n def __getitem__(self, key):\n \"\"\"Get item.\n\n When reset_parameters() is called, if use_scaled_pos_enc is used,\n return the positioning encoding.\n\n \"\"\"\n if key != -1:\n raise NotImplementedError(\"Support only `-1` (for `reset_parameters`).\")\n return self.out[key]\n\n\nclass Conv2dSubsampling2(torch.nn.Module):\n \"\"\"Convolutional 2D subsampling (to 1/2 length).\n\n Args:\n idim (int): Input dimension.\n odim (int): Output dimension.\n dropout_rate (float): Dropout rate.\n pos_enc (torch.nn.Module): Custom position encoding layer.\n\n \"\"\"\n\n def __init__(self, idim, odim, dropout_rate, pos_enc=None):\n \"\"\"Construct an Conv2dSubsampling2 object.\"\"\"\n super(Conv2dSubsampling2, self).__init__()\n self.conv = torch.nn.Sequential(\n torch.nn.Conv2d(1, odim, 3, 2),\n torch.nn.ReLU(),\n torch.nn.Conv2d(odim, odim, 3, 1),\n torch.nn.ReLU(),\n )\n self.out = torch.nn.Sequential(\n torch.nn.Linear(odim * (((idim - 1) // 2 - 2)), odim),\n pos_enc if pos_enc is not None else PositionalEncoding(odim, dropout_rate),\n )\n\n def forward(self, x, x_mask):\n \"\"\"Subsample x.\n\n Args:\n x (torch.Tensor): Input tensor (#batch, time, idim).\n x_mask (torch.Tensor): Input mask (#batch, 1, time).\n\n Returns:\n torch.Tensor: Subsampled tensor (#batch, time', odim),\n where time' = time // 2.\n torch.Tensor: Subsampled mask (#batch, 1, time'),\n where time' = time // 2.\n\n \"\"\"\n x = x.unsqueeze(1) # (b, c, t, f)\n x = self.conv(x)\n b, c, t, f = x.size()\n x = self.out(x.transpose(1, 2).contiguous().view(b, t, c * f))\n if x_mask is None:\n return x, None\n return x, x_mask[:, :, :-2:2][:, :, :-2:1]\n\n def __getitem__(self, key):\n \"\"\"Get item.\n\n When reset_parameters() is called, if use_scaled_pos_enc is used,\n return the positioning encoding.\n\n \"\"\"\n if key != -1:\n raise NotImplementedError(\"Support only `-1` (for `reset_parameters`).\")\n return self.out[key]\n\n\nclass Conv2dSubsampling6(torch.nn.Module):\n \"\"\"Convolutional 2D subsampling (to 1/6 length).\n\n Args:\n idim (int): Input dimension.\n odim (int): Output dimension.\n dropout_rate (float): Dropout rate.\n pos_enc (torch.nn.Module): Custom position encoding layer.\n\n \"\"\"\n\n def __init__(self, idim, odim, dropout_rate, pos_enc=None):\n \"\"\"Construct an Conv2dSubsampling6 object.\"\"\"\n super(Conv2dSubsampling6, self).__init__()\n self.conv = torch.nn.Sequential(\n torch.nn.Conv2d(1, odim, 3, 2),\n torch.nn.ReLU(),\n torch.nn.Conv2d(odim, odim, 5, 3),\n torch.nn.ReLU(),\n )\n self.out = torch.nn.Sequential(\n torch.nn.Linear(odim * (((idim - 1) // 2 - 2) // 3), odim),\n pos_enc if pos_enc is not None else PositionalEncoding(odim, dropout_rate),\n )\n\n def forward(self, x, x_mask):\n \"\"\"Subsample x.\n\n Args:\n x (torch.Tensor): Input tensor (#batch, time, idim).\n x_mask (torch.Tensor): Input mask (#batch, 1, time).\n\n Returns:\n torch.Tensor: Subsampled tensor (#batch, time', odim),\n where time' = time // 6.\n torch.Tensor: Subsampled mask (#batch, 1, time'),\n where time' = time // 6.\n\n \"\"\"\n x = x.unsqueeze(1) # (b, c, t, f)\n x = self.conv(x)\n b, c, t, f = x.size()\n x = self.out(x.transpose(1, 2).contiguous().view(b, t, c * f))\n if x_mask is None:\n return x, None\n return x, x_mask[:, :, :-2:2][:, :, :-4:3]\n\n\nclass Conv2dSubsampling8(torch.nn.Module):\n \"\"\"Convolutional 2D subsampling (to 1/8 length).\n\n Args:\n idim (int): Input dimension.\n odim (int): Output dimension.\n dropout_rate (float): Dropout rate.\n pos_enc (torch.nn.Module): Custom position encoding layer.\n\n \"\"\"\n\n def __init__(self, idim, odim, dropout_rate, pos_enc=None):\n \"\"\"Construct an Conv2dSubsampling8 object.\"\"\"\n super(Conv2dSubsampling8, self).__init__()\n self.conv = torch.nn.Sequential(\n torch.nn.Conv2d(1, odim, 3, 2),\n torch.nn.ReLU(),\n torch.nn.Conv2d(odim, odim, 3, 2),\n torch.nn.ReLU(),\n torch.nn.Conv2d(odim, odim, 3, 2),\n torch.nn.ReLU(),\n )\n self.out = torch.nn.Sequential(\n torch.nn.Linear(odim * ((((idim - 1) // 2 - 1) // 2 - 1) // 2), odim),\n pos_enc if pos_enc is not None else PositionalEncoding(odim, dropout_rate),\n )\n\n def forward(self, x, x_mask):\n \"\"\"Subsample x.\n\n Args:\n x (torch.Tensor): Input tensor (#batch, time, idim).\n x_mask (torch.Tensor): Input mask (#batch, 1, time).\n\n Returns:\n torch.Tensor: Subsampled tensor (#batch, time', odim),\n where time' = time // 8.\n torch.Tensor: Subsampled mask (#batch, 1, time'),\n where time' = time // 8.\n\n \"\"\"\n x = x.unsqueeze(1) # (b, c, t, f)\n x = self.conv(x)\n b, c, t, f = x.size()\n x = self.out(x.transpose(1, 2).contiguous().view(b, t, c * f))\n if x_mask is None:\n return x, None\n return x, x_mask[:, :, :-2:2][:, :, :-2:2][:, :, :-2:2]\n", "path": "espnet/nets/pytorch_backend/transformer/subsampling.py"}]}
| 3,416 | 201 |
gh_patches_debug_9706
|
rasdani/github-patches
|
git_diff
|
PokemonGoF__PokemonGo-Bot-2531
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Dev] local variable 'unexpected_reponse_retry' referenced before assignment
There is a typo in a variable
`unexpected_reponse_retry` should be `unexpected_response_retry`
/pokemongo_bot/api_wrapper.py - line 120
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pokemongo_bot/api_wrapper.py`
Content:
```
1 import time
2
3 from pgoapi.exceptions import (ServerSideRequestThrottlingException,
4 NotLoggedInException, ServerBusyOrOfflineException,
5 NoPlayerPositionSetException, EmptySubrequestChainException,
6 UnexpectedResponseException)
7 from pgoapi.pgoapi import PGoApi, PGoApiRequest, RpcApi
8 from pgoapi.protos.POGOProtos.Networking.Requests_pb2 import RequestType
9
10 import pokemongo_bot.logger as logger
11 from human_behaviour import sleep
12
13 class ApiWrapper(PGoApi):
14 def __init__(self):
15 PGoApi.__init__(self)
16 self.useVanillaRequest = False
17
18 def create_request(self):
19 RequestClass = ApiRequest
20 if self.useVanillaRequest:
21 RequestClass = PGoApiRequest
22
23 return RequestClass(
24 self._api_endpoint,
25 self._auth_provider,
26 self._position_lat,
27 self._position_lng,
28 self._position_alt
29 )
30
31 def login(self, *args):
32 # login needs base class "create_request"
33 self.useVanillaRequest = True
34 try:
35 ret_value = PGoApi.login(self, *args)
36 finally:
37 # cleanup code
38 self.useVanillaRequest = False
39 return ret_value
40
41
42 class ApiRequest(PGoApiRequest):
43 def __init__(self, *args):
44 PGoApiRequest.__init__(self, *args)
45 self.request_callers = []
46 self.last_api_request_time = None
47 self.requests_per_seconds = 2
48
49 def can_call(self):
50 if not self._req_method_list:
51 raise EmptySubrequestChainException()
52
53 if (self._position_lat is None) or (self._position_lng is None) or (self._position_alt is None):
54 raise NoPlayerPositionSetException()
55
56 if self._auth_provider is None or not self._auth_provider.is_login():
57 self.log.info('Not logged in')
58 raise NotLoggedInException()
59
60 return True
61
62 def _call(self):
63 return PGoApiRequest.call(self)
64
65 def _pop_request_callers(self):
66 r = self.request_callers
67 self.request_callers = []
68 return [i.upper() for i in r]
69
70 def is_response_valid(self, result, request_callers):
71 if not result or result is None or not isinstance(result, dict):
72 return False
73
74 if not 'responses' in result or not 'status_code' in result:
75 return False
76
77 if not isinstance(result['responses'], dict):
78 return False
79
80 # the response can still programatically be valid at this point
81 # but still be wrong. we need to check if the server did sent what we asked it
82 for request_caller in request_callers:
83 if not request_caller in result['responses']:
84 return False
85
86 return True
87
88 def call(self, max_retry=15):
89 request_callers = self._pop_request_callers()
90 if not self.can_call():
91 return False # currently this is never ran, exceptions are raised before
92
93 request_timestamp = None
94 api_req_method_list = self._req_method_list
95 result = None
96 try_cnt = 0
97 throttling_retry = 0
98 unexpected_response_retry = 0
99 while True:
100 request_timestamp = self.throttle_sleep()
101 # self._call internally clear this field, so save it
102 self._req_method_list = [req_method for req_method in api_req_method_list]
103 try:
104 result = self._call()
105 should_throttle_retry = False
106 should_unexpected_response_retry = False
107 except ServerSideRequestThrottlingException:
108 should_throttle_retry = True
109 except UnexpectedResponseException:
110 should_unexpected_response_retry = True
111
112 if should_throttle_retry:
113 throttling_retry += 1
114 if throttling_retry >= max_retry:
115 raise ServerSideRequestThrottlingException('Server throttled too many times')
116 sleep(1) # huge sleep ?
117 continue # skip response checking
118
119 if should_unexpected_response_retry:
120 unexpected_reponse_retry += 1
121 if unexpected_response_retry >= 5:
122 logger.log('Server is not responding correctly to our requests. Waiting for 30 seconds to reconnect.', 'red')
123 sleep(30)
124 else:
125 sleep(2)
126 continue
127
128 if not self.is_response_valid(result, request_callers):
129 try_cnt += 1
130 if try_cnt > 3:
131 logger.log('Server seems to be busy or offline - try again - {}/{}'.format(try_cnt, max_retry), 'red')
132 if try_cnt >= max_retry:
133 raise ServerBusyOrOfflineException()
134 sleep(1)
135 else:
136 break
137
138 self.last_api_request_time = request_timestamp
139 return result
140
141 def __getattr__(self, func):
142 if func.upper() in RequestType.keys():
143 self.request_callers.append(func)
144 return PGoApiRequest.__getattr__(self, func)
145
146 def throttle_sleep(self):
147 now_milliseconds = time.time() * 1000
148 required_delay_between_requests = 1000 / self.requests_per_seconds
149
150 difference = now_milliseconds - (self.last_api_request_time if self.last_api_request_time else 0)
151
152 if self.last_api_request_time != None and difference < required_delay_between_requests:
153 sleep_time = required_delay_between_requests - difference
154 time.sleep(sleep_time / 1000)
155
156 return now_milliseconds
157
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pokemongo_bot/api_wrapper.py b/pokemongo_bot/api_wrapper.py
--- a/pokemongo_bot/api_wrapper.py
+++ b/pokemongo_bot/api_wrapper.py
@@ -117,7 +117,7 @@
continue # skip response checking
if should_unexpected_response_retry:
- unexpected_reponse_retry += 1
+ unexpected_response_retry += 1
if unexpected_response_retry >= 5:
logger.log('Server is not responding correctly to our requests. Waiting for 30 seconds to reconnect.', 'red')
sleep(30)
|
{"golden_diff": "diff --git a/pokemongo_bot/api_wrapper.py b/pokemongo_bot/api_wrapper.py\n--- a/pokemongo_bot/api_wrapper.py\n+++ b/pokemongo_bot/api_wrapper.py\n@@ -117,7 +117,7 @@\n continue # skip response checking\n \n if should_unexpected_response_retry:\n- unexpected_reponse_retry += 1\n+ unexpected_response_retry += 1\n if unexpected_response_retry >= 5:\n logger.log('Server is not responding correctly to our requests. Waiting for 30 seconds to reconnect.', 'red')\n sleep(30)\n", "issue": "[Dev] local variable 'unexpected_reponse_retry' referenced before assignment\nThere is a typo in a variable\n\n`unexpected_reponse_retry` should be `unexpected_response_retry`\n/pokemongo_bot/api_wrapper.py - line 120 \n\n", "before_files": [{"content": "import time\n\nfrom pgoapi.exceptions import (ServerSideRequestThrottlingException,\n NotLoggedInException, ServerBusyOrOfflineException,\n NoPlayerPositionSetException, EmptySubrequestChainException,\n UnexpectedResponseException)\nfrom pgoapi.pgoapi import PGoApi, PGoApiRequest, RpcApi\nfrom pgoapi.protos.POGOProtos.Networking.Requests_pb2 import RequestType\n\nimport pokemongo_bot.logger as logger\nfrom human_behaviour import sleep\n\nclass ApiWrapper(PGoApi):\n def __init__(self):\n PGoApi.__init__(self)\n self.useVanillaRequest = False\n\n def create_request(self):\n RequestClass = ApiRequest\n if self.useVanillaRequest:\n RequestClass = PGoApiRequest\n\n return RequestClass(\n self._api_endpoint,\n self._auth_provider,\n self._position_lat,\n self._position_lng,\n self._position_alt\n )\n\n def login(self, *args):\n # login needs base class \"create_request\"\n self.useVanillaRequest = True\n try:\n ret_value = PGoApi.login(self, *args)\n finally:\n # cleanup code\n self.useVanillaRequest = False\n return ret_value\n\n\nclass ApiRequest(PGoApiRequest):\n def __init__(self, *args):\n PGoApiRequest.__init__(self, *args)\n self.request_callers = []\n self.last_api_request_time = None\n self.requests_per_seconds = 2\n\n def can_call(self):\n if not self._req_method_list:\n raise EmptySubrequestChainException()\n\n if (self._position_lat is None) or (self._position_lng is None) or (self._position_alt is None):\n raise NoPlayerPositionSetException()\n\n if self._auth_provider is None or not self._auth_provider.is_login():\n self.log.info('Not logged in')\n raise NotLoggedInException()\n\n return True\n\n def _call(self):\n return PGoApiRequest.call(self)\n\n def _pop_request_callers(self):\n r = self.request_callers\n self.request_callers = []\n return [i.upper() for i in r]\n\n def is_response_valid(self, result, request_callers):\n if not result or result is None or not isinstance(result, dict):\n return False\n\n if not 'responses' in result or not 'status_code' in result:\n return False\n\n if not isinstance(result['responses'], dict):\n return False\n\n # the response can still programatically be valid at this point\n # but still be wrong. we need to check if the server did sent what we asked it\n for request_caller in request_callers:\n if not request_caller in result['responses']:\n return False\n\n return True\n\n def call(self, max_retry=15):\n request_callers = self._pop_request_callers()\n if not self.can_call():\n return False # currently this is never ran, exceptions are raised before\n\n request_timestamp = None\n api_req_method_list = self._req_method_list\n result = None\n try_cnt = 0\n throttling_retry = 0\n unexpected_response_retry = 0\n while True:\n request_timestamp = self.throttle_sleep()\n # self._call internally clear this field, so save it\n self._req_method_list = [req_method for req_method in api_req_method_list]\n try:\n result = self._call()\n should_throttle_retry = False\n should_unexpected_response_retry = False\n except ServerSideRequestThrottlingException:\n should_throttle_retry = True\n except UnexpectedResponseException:\n should_unexpected_response_retry = True\n\n if should_throttle_retry:\n throttling_retry += 1\n if throttling_retry >= max_retry:\n raise ServerSideRequestThrottlingException('Server throttled too many times')\n sleep(1) # huge sleep ?\n continue # skip response checking\n\n if should_unexpected_response_retry:\n unexpected_reponse_retry += 1\n if unexpected_response_retry >= 5:\n logger.log('Server is not responding correctly to our requests. Waiting for 30 seconds to reconnect.', 'red')\n sleep(30)\n else:\n sleep(2)\n continue\n \n if not self.is_response_valid(result, request_callers):\n try_cnt += 1\n if try_cnt > 3:\n logger.log('Server seems to be busy or offline - try again - {}/{}'.format(try_cnt, max_retry), 'red')\n if try_cnt >= max_retry:\n raise ServerBusyOrOfflineException()\n sleep(1)\n else:\n break\n\n self.last_api_request_time = request_timestamp\n return result\n\n def __getattr__(self, func):\n if func.upper() in RequestType.keys():\n self.request_callers.append(func)\n return PGoApiRequest.__getattr__(self, func)\n\n def throttle_sleep(self):\n now_milliseconds = time.time() * 1000\n required_delay_between_requests = 1000 / self.requests_per_seconds\n\n difference = now_milliseconds - (self.last_api_request_time if self.last_api_request_time else 0)\n\n if self.last_api_request_time != None and difference < required_delay_between_requests:\n sleep_time = required_delay_between_requests - difference\n time.sleep(sleep_time / 1000)\n\n return now_milliseconds\n", "path": "pokemongo_bot/api_wrapper.py"}], "after_files": [{"content": "import time\n\nfrom pgoapi.exceptions import (ServerSideRequestThrottlingException,\n NotLoggedInException, ServerBusyOrOfflineException,\n NoPlayerPositionSetException, EmptySubrequestChainException,\n UnexpectedResponseException)\nfrom pgoapi.pgoapi import PGoApi, PGoApiRequest, RpcApi\nfrom pgoapi.protos.POGOProtos.Networking.Requests_pb2 import RequestType\n\nimport pokemongo_bot.logger as logger\nfrom human_behaviour import sleep\n\nclass ApiWrapper(PGoApi):\n def __init__(self):\n PGoApi.__init__(self)\n self.useVanillaRequest = False\n\n def create_request(self):\n RequestClass = ApiRequest\n if self.useVanillaRequest:\n RequestClass = PGoApiRequest\n\n return RequestClass(\n self._api_endpoint,\n self._auth_provider,\n self._position_lat,\n self._position_lng,\n self._position_alt\n )\n\n def login(self, *args):\n # login needs base class \"create_request\"\n self.useVanillaRequest = True\n try:\n ret_value = PGoApi.login(self, *args)\n finally:\n # cleanup code\n self.useVanillaRequest = False\n return ret_value\n\n\nclass ApiRequest(PGoApiRequest):\n def __init__(self, *args):\n PGoApiRequest.__init__(self, *args)\n self.request_callers = []\n self.last_api_request_time = None\n self.requests_per_seconds = 2\n\n def can_call(self):\n if not self._req_method_list:\n raise EmptySubrequestChainException()\n\n if (self._position_lat is None) or (self._position_lng is None) or (self._position_alt is None):\n raise NoPlayerPositionSetException()\n\n if self._auth_provider is None or not self._auth_provider.is_login():\n self.log.info('Not logged in')\n raise NotLoggedInException()\n\n return True\n\n def _call(self):\n return PGoApiRequest.call(self)\n\n def _pop_request_callers(self):\n r = self.request_callers\n self.request_callers = []\n return [i.upper() for i in r]\n\n def is_response_valid(self, result, request_callers):\n if not result or result is None or not isinstance(result, dict):\n return False\n\n if not 'responses' in result or not 'status_code' in result:\n return False\n\n if not isinstance(result['responses'], dict):\n return False\n\n # the response can still programatically be valid at this point\n # but still be wrong. we need to check if the server did sent what we asked it\n for request_caller in request_callers:\n if not request_caller in result['responses']:\n return False\n\n return True\n\n def call(self, max_retry=15):\n request_callers = self._pop_request_callers()\n if not self.can_call():\n return False # currently this is never ran, exceptions are raised before\n\n request_timestamp = None\n api_req_method_list = self._req_method_list\n result = None\n try_cnt = 0\n throttling_retry = 0\n unexpected_response_retry = 0\n while True:\n request_timestamp = self.throttle_sleep()\n # self._call internally clear this field, so save it\n self._req_method_list = [req_method for req_method in api_req_method_list]\n try:\n result = self._call()\n should_throttle_retry = False\n should_unexpected_response_retry = False\n except ServerSideRequestThrottlingException:\n should_throttle_retry = True\n except UnexpectedResponseException:\n should_unexpected_response_retry = True\n\n if should_throttle_retry:\n throttling_retry += 1\n if throttling_retry >= max_retry:\n raise ServerSideRequestThrottlingException('Server throttled too many times')\n sleep(1) # huge sleep ?\n continue # skip response checking\n\n if should_unexpected_response_retry:\n unexpected_response_retry += 1\n if unexpected_response_retry >= 5:\n logger.log('Server is not responding correctly to our requests. Waiting for 30 seconds to reconnect.', 'red')\n sleep(30)\n else:\n sleep(2)\n continue\n \n if not self.is_response_valid(result, request_callers):\n try_cnt += 1\n if try_cnt > 3:\n logger.log('Server seems to be busy or offline - try again - {}/{}'.format(try_cnt, max_retry), 'red')\n if try_cnt >= max_retry:\n raise ServerBusyOrOfflineException()\n sleep(1)\n else:\n break\n\n self.last_api_request_time = request_timestamp\n return result\n\n def __getattr__(self, func):\n if func.upper() in RequestType.keys():\n self.request_callers.append(func)\n return PGoApiRequest.__getattr__(self, func)\n\n def throttle_sleep(self):\n now_milliseconds = time.time() * 1000\n required_delay_between_requests = 1000 / self.requests_per_seconds\n\n difference = now_milliseconds - (self.last_api_request_time if self.last_api_request_time else 0)\n\n if self.last_api_request_time != None and difference < required_delay_between_requests:\n sleep_time = required_delay_between_requests - difference\n time.sleep(sleep_time / 1000)\n\n return now_milliseconds\n", "path": "pokemongo_bot/api_wrapper.py"}]}
| 1,875 | 133 |
gh_patches_debug_17992
|
rasdani/github-patches
|
git_diff
|
hpcaitech__ColossalAI-3329
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[tensor] fix some unittests
[tensor] fix some unittests
[tensor] fix some unittests
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `colossalai/engine/gradient_handler/__init__.py`
Content:
```
1 from ._base_gradient_handler import BaseGradientHandler
2 from ._data_parallel_gradient_handler import DataParallelGradientHandler
3 from ._zero_gradient_handler import ZeROGradientHandler
4 from ._sequence_parallel_gradient_handler import SequenceParallelGradientHandler
5 from ._pipeline_parallel_gradient_handler import PipelineSharedModuleGradientHandler
6 from ._moe_gradient_handler import MoeGradientHandler
7 from ._sequence_parallel_gradient_handler import SequenceParallelGradientHandler
8
9 __all__ = [
10 'BaseGradientHandler', 'DataParallelGradientHandler', 'ZeROGradientHandler', 'PipelineSharedModuleGradientHandler',
11 'MoeGradientHandler', 'SequenceParallelGradientHandler'
12 ]
13
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/colossalai/engine/gradient_handler/__init__.py b/colossalai/engine/gradient_handler/__init__.py
--- a/colossalai/engine/gradient_handler/__init__.py
+++ b/colossalai/engine/gradient_handler/__init__.py
@@ -1,10 +1,9 @@
from ._base_gradient_handler import BaseGradientHandler
from ._data_parallel_gradient_handler import DataParallelGradientHandler
-from ._zero_gradient_handler import ZeROGradientHandler
-from ._sequence_parallel_gradient_handler import SequenceParallelGradientHandler
-from ._pipeline_parallel_gradient_handler import PipelineSharedModuleGradientHandler
from ._moe_gradient_handler import MoeGradientHandler
+from ._pipeline_parallel_gradient_handler import PipelineSharedModuleGradientHandler
from ._sequence_parallel_gradient_handler import SequenceParallelGradientHandler
+from ._zero_gradient_handler import ZeROGradientHandler
__all__ = [
'BaseGradientHandler', 'DataParallelGradientHandler', 'ZeROGradientHandler', 'PipelineSharedModuleGradientHandler',
|
{"golden_diff": "diff --git a/colossalai/engine/gradient_handler/__init__.py b/colossalai/engine/gradient_handler/__init__.py\n--- a/colossalai/engine/gradient_handler/__init__.py\n+++ b/colossalai/engine/gradient_handler/__init__.py\n@@ -1,10 +1,9 @@\n from ._base_gradient_handler import BaseGradientHandler\n from ._data_parallel_gradient_handler import DataParallelGradientHandler\n-from ._zero_gradient_handler import ZeROGradientHandler\n-from ._sequence_parallel_gradient_handler import SequenceParallelGradientHandler\n-from ._pipeline_parallel_gradient_handler import PipelineSharedModuleGradientHandler\n from ._moe_gradient_handler import MoeGradientHandler\n+from ._pipeline_parallel_gradient_handler import PipelineSharedModuleGradientHandler\n from ._sequence_parallel_gradient_handler import SequenceParallelGradientHandler\n+from ._zero_gradient_handler import ZeROGradientHandler\n \n __all__ = [\n 'BaseGradientHandler', 'DataParallelGradientHandler', 'ZeROGradientHandler', 'PipelineSharedModuleGradientHandler',\n", "issue": "[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n", "before_files": [{"content": "from ._base_gradient_handler import BaseGradientHandler\nfrom ._data_parallel_gradient_handler import DataParallelGradientHandler\nfrom ._zero_gradient_handler import ZeROGradientHandler\nfrom ._sequence_parallel_gradient_handler import SequenceParallelGradientHandler\nfrom ._pipeline_parallel_gradient_handler import PipelineSharedModuleGradientHandler\nfrom ._moe_gradient_handler import MoeGradientHandler\nfrom ._sequence_parallel_gradient_handler import SequenceParallelGradientHandler\n\n__all__ = [\n 'BaseGradientHandler', 'DataParallelGradientHandler', 'ZeROGradientHandler', 'PipelineSharedModuleGradientHandler',\n 'MoeGradientHandler', 'SequenceParallelGradientHandler'\n]\n", "path": "colossalai/engine/gradient_handler/__init__.py"}], "after_files": [{"content": "from ._base_gradient_handler import BaseGradientHandler\nfrom ._data_parallel_gradient_handler import DataParallelGradientHandler\nfrom ._moe_gradient_handler import MoeGradientHandler\nfrom ._pipeline_parallel_gradient_handler import PipelineSharedModuleGradientHandler\nfrom ._sequence_parallel_gradient_handler import SequenceParallelGradientHandler\nfrom ._zero_gradient_handler import ZeROGradientHandler\n\n__all__ = [\n 'BaseGradientHandler', 'DataParallelGradientHandler', 'ZeROGradientHandler', 'PipelineSharedModuleGradientHandler',\n 'MoeGradientHandler', 'SequenceParallelGradientHandler'\n]\n", "path": "colossalai/engine/gradient_handler/__init__.py"}]}
| 433 | 209 |
gh_patches_debug_42965
|
rasdani/github-patches
|
git_diff
|
pypa__setuptools-3386
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Distutils hack still causing test failures in CPython
In python/cpython#91169, we learn that despite #2965 and #3007, when the tests are run outside of the source directory, some tests will still fail because Setuptools is unable to detect that these tests are implicated.
For at least three of these tests (`test_distutils` and on Python 3.9, `test_importlib` and `test_peg_generator`), these issues may be avoidable by further suppressing the supplying of distutils.
`test_bdb` is also affected, but cannot be addressed due to python/cpython#93951.
Distutils hack still causing test failures in CPython
In python/cpython#91169, we learn that despite #2965 and #3007, when the tests are run outside of the source directory, some tests will still fail because Setuptools is unable to detect that these tests are implicated.
For at least three of these tests (`test_distutils` and on Python 3.9, `test_importlib` and `test_peg_generator`), these issues may be avoidable by further suppressing the supplying of distutils.
`test_bdb` is also affected, but cannot be addressed due to python/cpython#93951.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `_distutils_hack/__init__.py`
Content:
```
1 # don't import any costly modules
2 import sys
3 import os
4
5
6 is_pypy = '__pypy__' in sys.builtin_module_names
7
8
9 def warn_distutils_present():
10 if 'distutils' not in sys.modules:
11 return
12 if is_pypy and sys.version_info < (3, 7):
13 # PyPy for 3.6 unconditionally imports distutils, so bypass the warning
14 # https://foss.heptapod.net/pypy/pypy/-/blob/be829135bc0d758997b3566062999ee8b23872b4/lib-python/3/site.py#L250
15 return
16 import warnings
17 warnings.warn(
18 "Distutils was imported before Setuptools, but importing Setuptools "
19 "also replaces the `distutils` module in `sys.modules`. This may lead "
20 "to undesirable behaviors or errors. To avoid these issues, avoid "
21 "using distutils directly, ensure that setuptools is installed in the "
22 "traditional way (e.g. not an editable install), and/or make sure "
23 "that setuptools is always imported before distutils.")
24
25
26 def clear_distutils():
27 if 'distutils' not in sys.modules:
28 return
29 import warnings
30 warnings.warn("Setuptools is replacing distutils.")
31 mods = [
32 name for name in sys.modules
33 if name == "distutils" or name.startswith("distutils.")
34 ]
35 for name in mods:
36 del sys.modules[name]
37
38
39 def enabled():
40 """
41 Allow selection of distutils by environment variable.
42 """
43 which = os.environ.get('SETUPTOOLS_USE_DISTUTILS', 'local')
44 return which == 'local'
45
46
47 def ensure_local_distutils():
48 import importlib
49 clear_distutils()
50
51 # With the DistutilsMetaFinder in place,
52 # perform an import to cause distutils to be
53 # loaded from setuptools._distutils. Ref #2906.
54 with shim():
55 importlib.import_module('distutils')
56
57 # check that submodules load as expected
58 core = importlib.import_module('distutils.core')
59 assert '_distutils' in core.__file__, core.__file__
60 assert 'setuptools._distutils.log' not in sys.modules
61
62
63 def do_override():
64 """
65 Ensure that the local copy of distutils is preferred over stdlib.
66
67 See https://github.com/pypa/setuptools/issues/417#issuecomment-392298401
68 for more motivation.
69 """
70 if enabled():
71 warn_distutils_present()
72 ensure_local_distutils()
73
74
75 class _TrivialRe:
76 def __init__(self, *patterns):
77 self._patterns = patterns
78
79 def match(self, string):
80 return all(pat in string for pat in self._patterns)
81
82
83 class DistutilsMetaFinder:
84 def find_spec(self, fullname, path, target=None):
85 if path is not None:
86 return
87
88 method_name = 'spec_for_{fullname}'.format(**locals())
89 method = getattr(self, method_name, lambda: None)
90 return method()
91
92 def spec_for_distutils(self):
93 if self.is_cpython():
94 return
95
96 import importlib
97 import importlib.abc
98 import importlib.util
99
100 try:
101 mod = importlib.import_module('setuptools._distutils')
102 except Exception:
103 # There are a couple of cases where setuptools._distutils
104 # may not be present:
105 # - An older Setuptools without a local distutils is
106 # taking precedence. Ref #2957.
107 # - Path manipulation during sitecustomize removes
108 # setuptools from the path but only after the hook
109 # has been loaded. Ref #2980.
110 # In either case, fall back to stdlib behavior.
111 return
112
113 class DistutilsLoader(importlib.abc.Loader):
114
115 def create_module(self, spec):
116 mod.__name__ = 'distutils'
117 return mod
118
119 def exec_module(self, module):
120 pass
121
122 return importlib.util.spec_from_loader(
123 'distutils', DistutilsLoader(), origin=mod.__file__
124 )
125
126 @staticmethod
127 def is_cpython():
128 """
129 Suppress supplying distutils for CPython (build and tests).
130 Ref #2965 and #3007.
131 """
132 return os.path.isfile('pybuilddir.txt')
133
134 def spec_for_pip(self):
135 """
136 Ensure stdlib distutils when running under pip.
137 See pypa/pip#8761 for rationale.
138 """
139 if self.pip_imported_during_build():
140 return
141 clear_distutils()
142 self.spec_for_distutils = lambda: None
143
144 @classmethod
145 def pip_imported_during_build(cls):
146 """
147 Detect if pip is being imported in a build script. Ref #2355.
148 """
149 import traceback
150 return any(
151 cls.frame_file_is_setup(frame)
152 for frame, line in traceback.walk_stack(None)
153 )
154
155 @staticmethod
156 def frame_file_is_setup(frame):
157 """
158 Return True if the indicated frame suggests a setup.py file.
159 """
160 # some frames may not have __file__ (#2940)
161 return frame.f_globals.get('__file__', '').endswith('setup.py')
162
163
164 DISTUTILS_FINDER = DistutilsMetaFinder()
165
166
167 def add_shim():
168 DISTUTILS_FINDER in sys.meta_path or insert_shim()
169
170
171 class shim:
172 def __enter__(self):
173 insert_shim()
174
175 def __exit__(self, exc, value, tb):
176 remove_shim()
177
178
179 def insert_shim():
180 sys.meta_path.insert(0, DISTUTILS_FINDER)
181
182
183 def remove_shim():
184 try:
185 sys.meta_path.remove(DISTUTILS_FINDER)
186 except ValueError:
187 pass
188
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/_distutils_hack/__init__.py b/_distutils_hack/__init__.py
--- a/_distutils_hack/__init__.py
+++ b/_distutils_hack/__init__.py
@@ -14,22 +14,26 @@
# https://foss.heptapod.net/pypy/pypy/-/blob/be829135bc0d758997b3566062999ee8b23872b4/lib-python/3/site.py#L250
return
import warnings
+
warnings.warn(
"Distutils was imported before Setuptools, but importing Setuptools "
"also replaces the `distutils` module in `sys.modules`. This may lead "
"to undesirable behaviors or errors. To avoid these issues, avoid "
"using distutils directly, ensure that setuptools is installed in the "
"traditional way (e.g. not an editable install), and/or make sure "
- "that setuptools is always imported before distutils.")
+ "that setuptools is always imported before distutils."
+ )
def clear_distutils():
if 'distutils' not in sys.modules:
return
import warnings
+
warnings.warn("Setuptools is replacing distutils.")
mods = [
- name for name in sys.modules
+ name
+ for name in sys.modules
if name == "distutils" or name.startswith("distutils.")
]
for name in mods:
@@ -46,6 +50,7 @@
def ensure_local_distutils():
import importlib
+
clear_distutils()
# With the DistutilsMetaFinder in place,
@@ -82,7 +87,9 @@
class DistutilsMetaFinder:
def find_spec(self, fullname, path, target=None):
- if path is not None:
+ # optimization: only consider top level modules and those
+ # found in the CPython test suite.
+ if path is not None and not fullname.startswith('test.'):
return
method_name = 'spec_for_{fullname}'.format(**locals())
@@ -111,7 +118,6 @@
return
class DistutilsLoader(importlib.abc.Loader):
-
def create_module(self, spec):
mod.__name__ = 'distutils'
return mod
@@ -147,9 +153,9 @@
Detect if pip is being imported in a build script. Ref #2355.
"""
import traceback
+
return any(
- cls.frame_file_is_setup(frame)
- for frame, line in traceback.walk_stack(None)
+ cls.frame_file_is_setup(frame) for frame, line in traceback.walk_stack(None)
)
@staticmethod
@@ -160,6 +166,35 @@
# some frames may not have __file__ (#2940)
return frame.f_globals.get('__file__', '').endswith('setup.py')
+ def spec_for_sensitive_tests(self):
+ """
+ Ensure stdlib distutils when running select tests under CPython.
+
+ python/cpython#91169
+ """
+ clear_distutils()
+ self.spec_for_distutils = lambda: None
+
+ sensitive_tests = (
+ [
+ 'test.test_distutils',
+ 'test.test_peg_generator',
+ 'test.test_importlib',
+ ]
+ if sys.version_info < (3, 10)
+ else [
+ 'test.test_distutils',
+ ]
+ )
+
+
+for name in DistutilsMetaFinder.sensitive_tests:
+ setattr(
+ DistutilsMetaFinder,
+ f'spec_for_{name}',
+ DistutilsMetaFinder.spec_for_sensitive_tests,
+ )
+
DISTUTILS_FINDER = DistutilsMetaFinder()
|
{"golden_diff": "diff --git a/_distutils_hack/__init__.py b/_distutils_hack/__init__.py\n--- a/_distutils_hack/__init__.py\n+++ b/_distutils_hack/__init__.py\n@@ -14,22 +14,26 @@\n # https://foss.heptapod.net/pypy/pypy/-/blob/be829135bc0d758997b3566062999ee8b23872b4/lib-python/3/site.py#L250\n return\n import warnings\n+\n warnings.warn(\n \"Distutils was imported before Setuptools, but importing Setuptools \"\n \"also replaces the `distutils` module in `sys.modules`. This may lead \"\n \"to undesirable behaviors or errors. To avoid these issues, avoid \"\n \"using distutils directly, ensure that setuptools is installed in the \"\n \"traditional way (e.g. not an editable install), and/or make sure \"\n- \"that setuptools is always imported before distutils.\")\n+ \"that setuptools is always imported before distutils.\"\n+ )\n \n \n def clear_distutils():\n if 'distutils' not in sys.modules:\n return\n import warnings\n+\n warnings.warn(\"Setuptools is replacing distutils.\")\n mods = [\n- name for name in sys.modules\n+ name\n+ for name in sys.modules\n if name == \"distutils\" or name.startswith(\"distutils.\")\n ]\n for name in mods:\n@@ -46,6 +50,7 @@\n \n def ensure_local_distutils():\n import importlib\n+\n clear_distutils()\n \n # With the DistutilsMetaFinder in place,\n@@ -82,7 +87,9 @@\n \n class DistutilsMetaFinder:\n def find_spec(self, fullname, path, target=None):\n- if path is not None:\n+ # optimization: only consider top level modules and those\n+ # found in the CPython test suite.\n+ if path is not None and not fullname.startswith('test.'):\n return\n \n method_name = 'spec_for_{fullname}'.format(**locals())\n@@ -111,7 +118,6 @@\n return\n \n class DistutilsLoader(importlib.abc.Loader):\n-\n def create_module(self, spec):\n mod.__name__ = 'distutils'\n return mod\n@@ -147,9 +153,9 @@\n Detect if pip is being imported in a build script. Ref #2355.\n \"\"\"\n import traceback\n+\n return any(\n- cls.frame_file_is_setup(frame)\n- for frame, line in traceback.walk_stack(None)\n+ cls.frame_file_is_setup(frame) for frame, line in traceback.walk_stack(None)\n )\n \n @staticmethod\n@@ -160,6 +166,35 @@\n # some frames may not have __file__ (#2940)\n return frame.f_globals.get('__file__', '').endswith('setup.py')\n \n+ def spec_for_sensitive_tests(self):\n+ \"\"\"\n+ Ensure stdlib distutils when running select tests under CPython.\n+\n+ python/cpython#91169\n+ \"\"\"\n+ clear_distutils()\n+ self.spec_for_distutils = lambda: None\n+\n+ sensitive_tests = (\n+ [\n+ 'test.test_distutils',\n+ 'test.test_peg_generator',\n+ 'test.test_importlib',\n+ ]\n+ if sys.version_info < (3, 10)\n+ else [\n+ 'test.test_distutils',\n+ ]\n+ )\n+\n+\n+for name in DistutilsMetaFinder.sensitive_tests:\n+ setattr(\n+ DistutilsMetaFinder,\n+ f'spec_for_{name}',\n+ DistutilsMetaFinder.spec_for_sensitive_tests,\n+ )\n+\n \n DISTUTILS_FINDER = DistutilsMetaFinder()\n", "issue": "Distutils hack still causing test failures in CPython\nIn python/cpython#91169, we learn that despite #2965 and #3007, when the tests are run outside of the source directory, some tests will still fail because Setuptools is unable to detect that these tests are implicated.\r\n\r\nFor at least three of these tests (`test_distutils` and on Python 3.9, `test_importlib` and `test_peg_generator`), these issues may be avoidable by further suppressing the supplying of distutils.\r\n\r\n`test_bdb` is also affected, but cannot be addressed due to python/cpython#93951.\nDistutils hack still causing test failures in CPython\nIn python/cpython#91169, we learn that despite #2965 and #3007, when the tests are run outside of the source directory, some tests will still fail because Setuptools is unable to detect that these tests are implicated.\r\n\r\nFor at least three of these tests (`test_distutils` and on Python 3.9, `test_importlib` and `test_peg_generator`), these issues may be avoidable by further suppressing the supplying of distutils.\r\n\r\n`test_bdb` is also affected, but cannot be addressed due to python/cpython#93951.\n", "before_files": [{"content": "# don't import any costly modules\nimport sys\nimport os\n\n\nis_pypy = '__pypy__' in sys.builtin_module_names\n\n\ndef warn_distutils_present():\n if 'distutils' not in sys.modules:\n return\n if is_pypy and sys.version_info < (3, 7):\n # PyPy for 3.6 unconditionally imports distutils, so bypass the warning\n # https://foss.heptapod.net/pypy/pypy/-/blob/be829135bc0d758997b3566062999ee8b23872b4/lib-python/3/site.py#L250\n return\n import warnings\n warnings.warn(\n \"Distutils was imported before Setuptools, but importing Setuptools \"\n \"also replaces the `distutils` module in `sys.modules`. This may lead \"\n \"to undesirable behaviors or errors. To avoid these issues, avoid \"\n \"using distutils directly, ensure that setuptools is installed in the \"\n \"traditional way (e.g. not an editable install), and/or make sure \"\n \"that setuptools is always imported before distutils.\")\n\n\ndef clear_distutils():\n if 'distutils' not in sys.modules:\n return\n import warnings\n warnings.warn(\"Setuptools is replacing distutils.\")\n mods = [\n name for name in sys.modules\n if name == \"distutils\" or name.startswith(\"distutils.\")\n ]\n for name in mods:\n del sys.modules[name]\n\n\ndef enabled():\n \"\"\"\n Allow selection of distutils by environment variable.\n \"\"\"\n which = os.environ.get('SETUPTOOLS_USE_DISTUTILS', 'local')\n return which == 'local'\n\n\ndef ensure_local_distutils():\n import importlib\n clear_distutils()\n\n # With the DistutilsMetaFinder in place,\n # perform an import to cause distutils to be\n # loaded from setuptools._distutils. Ref #2906.\n with shim():\n importlib.import_module('distutils')\n\n # check that submodules load as expected\n core = importlib.import_module('distutils.core')\n assert '_distutils' in core.__file__, core.__file__\n assert 'setuptools._distutils.log' not in sys.modules\n\n\ndef do_override():\n \"\"\"\n Ensure that the local copy of distutils is preferred over stdlib.\n\n See https://github.com/pypa/setuptools/issues/417#issuecomment-392298401\n for more motivation.\n \"\"\"\n if enabled():\n warn_distutils_present()\n ensure_local_distutils()\n\n\nclass _TrivialRe:\n def __init__(self, *patterns):\n self._patterns = patterns\n\n def match(self, string):\n return all(pat in string for pat in self._patterns)\n\n\nclass DistutilsMetaFinder:\n def find_spec(self, fullname, path, target=None):\n if path is not None:\n return\n\n method_name = 'spec_for_{fullname}'.format(**locals())\n method = getattr(self, method_name, lambda: None)\n return method()\n\n def spec_for_distutils(self):\n if self.is_cpython():\n return\n\n import importlib\n import importlib.abc\n import importlib.util\n\n try:\n mod = importlib.import_module('setuptools._distutils')\n except Exception:\n # There are a couple of cases where setuptools._distutils\n # may not be present:\n # - An older Setuptools without a local distutils is\n # taking precedence. Ref #2957.\n # - Path manipulation during sitecustomize removes\n # setuptools from the path but only after the hook\n # has been loaded. Ref #2980.\n # In either case, fall back to stdlib behavior.\n return\n\n class DistutilsLoader(importlib.abc.Loader):\n\n def create_module(self, spec):\n mod.__name__ = 'distutils'\n return mod\n\n def exec_module(self, module):\n pass\n\n return importlib.util.spec_from_loader(\n 'distutils', DistutilsLoader(), origin=mod.__file__\n )\n\n @staticmethod\n def is_cpython():\n \"\"\"\n Suppress supplying distutils for CPython (build and tests).\n Ref #2965 and #3007.\n \"\"\"\n return os.path.isfile('pybuilddir.txt')\n\n def spec_for_pip(self):\n \"\"\"\n Ensure stdlib distutils when running under pip.\n See pypa/pip#8761 for rationale.\n \"\"\"\n if self.pip_imported_during_build():\n return\n clear_distutils()\n self.spec_for_distutils = lambda: None\n\n @classmethod\n def pip_imported_during_build(cls):\n \"\"\"\n Detect if pip is being imported in a build script. Ref #2355.\n \"\"\"\n import traceback\n return any(\n cls.frame_file_is_setup(frame)\n for frame, line in traceback.walk_stack(None)\n )\n\n @staticmethod\n def frame_file_is_setup(frame):\n \"\"\"\n Return True if the indicated frame suggests a setup.py file.\n \"\"\"\n # some frames may not have __file__ (#2940)\n return frame.f_globals.get('__file__', '').endswith('setup.py')\n\n\nDISTUTILS_FINDER = DistutilsMetaFinder()\n\n\ndef add_shim():\n DISTUTILS_FINDER in sys.meta_path or insert_shim()\n\n\nclass shim:\n def __enter__(self):\n insert_shim()\n\n def __exit__(self, exc, value, tb):\n remove_shim()\n\n\ndef insert_shim():\n sys.meta_path.insert(0, DISTUTILS_FINDER)\n\n\ndef remove_shim():\n try:\n sys.meta_path.remove(DISTUTILS_FINDER)\n except ValueError:\n pass\n", "path": "_distutils_hack/__init__.py"}], "after_files": [{"content": "# don't import any costly modules\nimport sys\nimport os\n\n\nis_pypy = '__pypy__' in sys.builtin_module_names\n\n\ndef warn_distutils_present():\n if 'distutils' not in sys.modules:\n return\n if is_pypy and sys.version_info < (3, 7):\n # PyPy for 3.6 unconditionally imports distutils, so bypass the warning\n # https://foss.heptapod.net/pypy/pypy/-/blob/be829135bc0d758997b3566062999ee8b23872b4/lib-python/3/site.py#L250\n return\n import warnings\n\n warnings.warn(\n \"Distutils was imported before Setuptools, but importing Setuptools \"\n \"also replaces the `distutils` module in `sys.modules`. This may lead \"\n \"to undesirable behaviors or errors. To avoid these issues, avoid \"\n \"using distutils directly, ensure that setuptools is installed in the \"\n \"traditional way (e.g. not an editable install), and/or make sure \"\n \"that setuptools is always imported before distutils.\"\n )\n\n\ndef clear_distutils():\n if 'distutils' not in sys.modules:\n return\n import warnings\n\n warnings.warn(\"Setuptools is replacing distutils.\")\n mods = [\n name\n for name in sys.modules\n if name == \"distutils\" or name.startswith(\"distutils.\")\n ]\n for name in mods:\n del sys.modules[name]\n\n\ndef enabled():\n \"\"\"\n Allow selection of distutils by environment variable.\n \"\"\"\n which = os.environ.get('SETUPTOOLS_USE_DISTUTILS', 'local')\n return which == 'local'\n\n\ndef ensure_local_distutils():\n import importlib\n\n clear_distutils()\n\n # With the DistutilsMetaFinder in place,\n # perform an import to cause distutils to be\n # loaded from setuptools._distutils. Ref #2906.\n with shim():\n importlib.import_module('distutils')\n\n # check that submodules load as expected\n core = importlib.import_module('distutils.core')\n assert '_distutils' in core.__file__, core.__file__\n assert 'setuptools._distutils.log' not in sys.modules\n\n\ndef do_override():\n \"\"\"\n Ensure that the local copy of distutils is preferred over stdlib.\n\n See https://github.com/pypa/setuptools/issues/417#issuecomment-392298401\n for more motivation.\n \"\"\"\n if enabled():\n warn_distutils_present()\n ensure_local_distutils()\n\n\nclass _TrivialRe:\n def __init__(self, *patterns):\n self._patterns = patterns\n\n def match(self, string):\n return all(pat in string for pat in self._patterns)\n\n\nclass DistutilsMetaFinder:\n def find_spec(self, fullname, path, target=None):\n # optimization: only consider top level modules and those\n # found in the CPython test suite.\n if path is not None and not fullname.startswith('test.'):\n return\n\n method_name = 'spec_for_{fullname}'.format(**locals())\n method = getattr(self, method_name, lambda: None)\n return method()\n\n def spec_for_distutils(self):\n if self.is_cpython():\n return\n\n import importlib\n import importlib.abc\n import importlib.util\n\n try:\n mod = importlib.import_module('setuptools._distutils')\n except Exception:\n # There are a couple of cases where setuptools._distutils\n # may not be present:\n # - An older Setuptools without a local distutils is\n # taking precedence. Ref #2957.\n # - Path manipulation during sitecustomize removes\n # setuptools from the path but only after the hook\n # has been loaded. Ref #2980.\n # In either case, fall back to stdlib behavior.\n return\n\n class DistutilsLoader(importlib.abc.Loader):\n def create_module(self, spec):\n mod.__name__ = 'distutils'\n return mod\n\n def exec_module(self, module):\n pass\n\n return importlib.util.spec_from_loader(\n 'distutils', DistutilsLoader(), origin=mod.__file__\n )\n\n @staticmethod\n def is_cpython():\n \"\"\"\n Suppress supplying distutils for CPython (build and tests).\n Ref #2965 and #3007.\n \"\"\"\n return os.path.isfile('pybuilddir.txt')\n\n def spec_for_pip(self):\n \"\"\"\n Ensure stdlib distutils when running under pip.\n See pypa/pip#8761 for rationale.\n \"\"\"\n if self.pip_imported_during_build():\n return\n clear_distutils()\n self.spec_for_distutils = lambda: None\n\n @classmethod\n def pip_imported_during_build(cls):\n \"\"\"\n Detect if pip is being imported in a build script. Ref #2355.\n \"\"\"\n import traceback\n\n return any(\n cls.frame_file_is_setup(frame) for frame, line in traceback.walk_stack(None)\n )\n\n @staticmethod\n def frame_file_is_setup(frame):\n \"\"\"\n Return True if the indicated frame suggests a setup.py file.\n \"\"\"\n # some frames may not have __file__ (#2940)\n return frame.f_globals.get('__file__', '').endswith('setup.py')\n\n def spec_for_sensitive_tests(self):\n \"\"\"\n Ensure stdlib distutils when running select tests under CPython.\n\n python/cpython#91169\n \"\"\"\n clear_distutils()\n self.spec_for_distutils = lambda: None\n\n sensitive_tests = (\n [\n 'test.test_distutils',\n 'test.test_peg_generator',\n 'test.test_importlib',\n ]\n if sys.version_info < (3, 10)\n else [\n 'test.test_distutils',\n ]\n )\n\n\nfor name in DistutilsMetaFinder.sensitive_tests:\n setattr(\n DistutilsMetaFinder,\n f'spec_for_{name}',\n DistutilsMetaFinder.spec_for_sensitive_tests,\n )\n\n\nDISTUTILS_FINDER = DistutilsMetaFinder()\n\n\ndef add_shim():\n DISTUTILS_FINDER in sys.meta_path or insert_shim()\n\n\nclass shim:\n def __enter__(self):\n insert_shim()\n\n def __exit__(self, exc, value, tb):\n remove_shim()\n\n\ndef insert_shim():\n sys.meta_path.insert(0, DISTUTILS_FINDER)\n\n\ndef remove_shim():\n try:\n sys.meta_path.remove(DISTUTILS_FINDER)\n except ValueError:\n pass\n", "path": "_distutils_hack/__init__.py"}]}
| 2,301 | 854 |
gh_patches_debug_54433
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-modules-core-4646
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
replace.py is failing with an UnboundLocalError
##### ISSUE TYPE
- Bug Report
##### COMPONENT NAME
replace
##### ANSIBLE VERSION
```
ansible 2.2.0 (devel d99c58ee55) last updated 2016/09/01 10:10:05 (GMT -700)
lib/ansible/modules/core: (detached HEAD 7e79c59d38) last updated 2016/09/01 10:10:05 (GMT -700)
lib/ansible/modules/extras: (detached HEAD e8a5442345) last updated 2016/09/01 10:10:05 (GMT -700)
config file = /Users/jgrigonis/projects/omicia_ansible/ansible.cfg
configured module search path = Default w/o overrides
```
##### OS / ENVIRONMENT
OS X controller
centos 6 target
##### SUMMARY
Seems like a bad commit
5728ef89f0764be9066fc1bf0fbbf7785e60f4cb
##### STEPS TO REPRODUCE
```
- name: fix ctypes file
replace:
dest: '/usr/local/lib/python2.7/ctypes/__init__.py'
regexp: '^( CFUNCTYPE.c_int..lambda: None.)'
replace: ' # CFUNCTYPE(c_int)(lambda: None)'
when: init.stat.exists == True
```
##### EXPECTED RESULTS
Do a replacement
##### ACTUAL RESULTS
```
{"changed": false, "failed": true, "module_stderr": "", "module_stdout": "Traceback (most recent call last):\r\n File \"/tmp/ansible_Kl6JDv/ansible_module_replace.py\", line 179, in <module>\r\n main()\r\n File \"/tmp/ansible_Kl6JDv/ansible_module_replace.py\", line 173, in main\r\n module.exit_json(changed=changed, msg=msg, diff=diff)\r\nUnboundLocalError: local variable 'diff' referenced before assignment\r\n", "msg": "MODULE FAILURE"}
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `files/replace.py`
Content:
```
1 #!/usr/bin/python
2 # -*- coding: utf-8 -*-
3
4 # (c) 2013, Evan Kaufman <[email protected]
5 #
6 # This file is part of Ansible
7 #
8 # Ansible is free software: you can redistribute it and/or modify
9 # it under the terms of the GNU General Public License as published by
10 # the Free Software Foundation, either version 3 of the License, or
11 # (at your option) any later version.
12 #
13 # Ansible is distributed in the hope that it will be useful,
14 # but WITHOUT ANY WARRANTY; without even the implied warranty of
15 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
16 # GNU General Public License for more details.
17 #
18 # You should have received a copy of the GNU General Public License
19 # along with Ansible. If not, see <http://www.gnu.org/licenses/>.
20
21 import re
22 import os
23 import tempfile
24
25 DOCUMENTATION = """
26 ---
27 module: replace
28 author: "Evan Kaufman (@EvanK)"
29 extends_documentation_fragment:
30 - files
31 - validate
32 short_description: Replace all instances of a particular string in a
33 file using a back-referenced regular expression.
34 description:
35 - This module will replace all instances of a pattern within a file.
36 - It is up to the user to maintain idempotence by ensuring that the
37 same pattern would never match any replacements made.
38 version_added: "1.6"
39 options:
40 dest:
41 required: true
42 aliases: [ name, destfile ]
43 description:
44 - The file to modify.
45 regexp:
46 required: true
47 description:
48 - The regular expression to look for in the contents of the file.
49 Uses Python regular expressions; see
50 U(http://docs.python.org/2/library/re.html).
51 Uses multiline mode, which means C(^) and C($) match the beginning
52 and end respectively of I(each line) of the file.
53 replace:
54 required: false
55 description:
56 - The string to replace regexp matches. May contain backreferences
57 that will get expanded with the regexp capture groups if the regexp
58 matches. If not set, matches are removed entirely.
59 backup:
60 required: false
61 default: "no"
62 choices: [ "yes", "no" ]
63 description:
64 - Create a backup file including the timestamp information so you can
65 get the original file back if you somehow clobbered it incorrectly.
66 others:
67 description:
68 - All arguments accepted by the M(file) module also work here.
69 required: false
70 follow:
71 required: false
72 default: "no"
73 choices: [ "yes", "no" ]
74 version_added: "1.9"
75 description:
76 - 'This flag indicates that filesystem links, if they exist, should be followed.'
77 """
78
79 EXAMPLES = r"""
80 - replace: dest=/etc/hosts regexp='(\s+)old\.host\.name(\s+.*)?$' replace='\1new.host.name\2' backup=yes
81
82 - replace: dest=/home/jdoe/.ssh/known_hosts regexp='^old\.host\.name[^\n]*\n' owner=jdoe group=jdoe mode=644
83
84 - replace: dest=/etc/apache/ports regexp='^(NameVirtualHost|Listen)\s+80\s*$' replace='\1 127.0.0.1:8080' validate='/usr/sbin/apache2ctl -f %s -t'
85 """
86
87 def write_changes(module,contents,dest):
88
89 tmpfd, tmpfile = tempfile.mkstemp()
90 f = os.fdopen(tmpfd,'wb')
91 f.write(contents)
92 f.close()
93
94 validate = module.params.get('validate', None)
95 valid = not validate
96 if validate:
97 if "%s" not in validate:
98 module.fail_json(msg="validate must contain %%s: %s" % (validate))
99 (rc, out, err) = module.run_command(validate % tmpfile)
100 valid = rc == 0
101 if rc != 0:
102 module.fail_json(msg='failed to validate: '
103 'rc:%s error:%s' % (rc,err))
104 if valid:
105 module.atomic_move(tmpfile, dest, unsafe_writes=module.params['unsafe_writes'])
106
107 def check_file_attrs(module, changed, message):
108
109 file_args = module.load_file_common_arguments(module.params)
110 if module.set_file_attributes_if_different(file_args, False):
111
112 if changed:
113 message += " and "
114 changed = True
115 message += "ownership, perms or SE linux context changed"
116
117 return message, changed
118
119 def main():
120 module = AnsibleModule(
121 argument_spec=dict(
122 dest=dict(required=True, aliases=['name', 'destfile']),
123 regexp=dict(required=True),
124 replace=dict(default='', type='str'),
125 backup=dict(default=False, type='bool'),
126 validate=dict(default=None, type='str'),
127 ),
128 add_file_common_args=True,
129 supports_check_mode=True
130 )
131
132 params = module.params
133 dest = os.path.expanduser(params['dest'])
134
135 if os.path.isdir(dest):
136 module.fail_json(rc=256, msg='Destination %s is a directory !' % dest)
137
138 if not os.path.exists(dest):
139 module.fail_json(rc=257, msg='Destination %s does not exist !' % dest)
140 else:
141 f = open(dest, 'rb')
142 contents = f.read()
143 f.close()
144
145 if module._diff:
146 diff = {
147 'before_header': dest,
148 'before': contents,
149 }
150
151 mre = re.compile(params['regexp'], re.MULTILINE)
152 result = re.subn(mre, params['replace'], contents, 0)
153
154 if result[1] > 0 and contents != result[0]:
155 msg = '%s replacements made' % result[1]
156 changed = True
157 if module._diff:
158 diff['after_header'] = dest
159 diff['after'] = result[0]
160 else:
161 msg = ''
162 changed = False
163 diff = dict()
164
165 if changed and not module.check_mode:
166 if params['backup'] and os.path.exists(dest):
167 module.backup_local(dest)
168 if params['follow'] and os.path.islink(dest):
169 dest = os.path.realpath(dest)
170 write_changes(module, result[0], dest)
171
172 msg, changed = check_file_attrs(module, changed, msg)
173 module.exit_json(changed=changed, msg=msg, diff=diff)
174
175 # this is magic, see lib/ansible/module_common.py
176 from ansible.module_utils.basic import *
177
178 if __name__ == '__main__':
179 main()
180
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/files/replace.py b/files/replace.py
--- a/files/replace.py
+++ b/files/replace.py
@@ -131,6 +131,7 @@
params = module.params
dest = os.path.expanduser(params['dest'])
+ diff = dict()
if os.path.isdir(dest):
module.fail_json(rc=256, msg='Destination %s is a directory !' % dest)
|
{"golden_diff": "diff --git a/files/replace.py b/files/replace.py\n--- a/files/replace.py\n+++ b/files/replace.py\n@@ -131,6 +131,7 @@\n \n params = module.params\n dest = os.path.expanduser(params['dest'])\n+ diff = dict()\n \n if os.path.isdir(dest):\n module.fail_json(rc=256, msg='Destination %s is a directory !' % dest)\n", "issue": "replace.py is failing with an UnboundLocalError\n##### ISSUE TYPE\n- Bug Report\n##### COMPONENT NAME\n\nreplace\n##### ANSIBLE VERSION\n\n```\nansible 2.2.0 (devel d99c58ee55) last updated 2016/09/01 10:10:05 (GMT -700)\n lib/ansible/modules/core: (detached HEAD 7e79c59d38) last updated 2016/09/01 10:10:05 (GMT -700)\n lib/ansible/modules/extras: (detached HEAD e8a5442345) last updated 2016/09/01 10:10:05 (GMT -700)\n config file = /Users/jgrigonis/projects/omicia_ansible/ansible.cfg\n configured module search path = Default w/o overrides\n```\n##### OS / ENVIRONMENT\n\nOS X controller\ncentos 6 target\n##### SUMMARY\n\nSeems like a bad commit\n5728ef89f0764be9066fc1bf0fbbf7785e60f4cb\n##### STEPS TO REPRODUCE\n\n```\n- name: fix ctypes file\n replace:\n dest: '/usr/local/lib/python2.7/ctypes/__init__.py'\n regexp: '^( CFUNCTYPE.c_int..lambda: None.)'\n replace: ' # CFUNCTYPE(c_int)(lambda: None)'\n when: init.stat.exists == True\n```\n##### EXPECTED RESULTS\n\nDo a replacement\n##### ACTUAL RESULTS\n\n```\n{\"changed\": false, \"failed\": true, \"module_stderr\": \"\", \"module_stdout\": \"Traceback (most recent call last):\\r\\n File \\\"/tmp/ansible_Kl6JDv/ansible_module_replace.py\\\", line 179, in <module>\\r\\n main()\\r\\n File \\\"/tmp/ansible_Kl6JDv/ansible_module_replace.py\\\", line 173, in main\\r\\n module.exit_json(changed=changed, msg=msg, diff=diff)\\r\\nUnboundLocalError: local variable 'diff' referenced before assignment\\r\\n\", \"msg\": \"MODULE FAILURE\"}\n```\n\n", "before_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# (c) 2013, Evan Kaufman <[email protected]\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\nimport re\nimport os\nimport tempfile\n\nDOCUMENTATION = \"\"\"\n---\nmodule: replace\nauthor: \"Evan Kaufman (@EvanK)\"\nextends_documentation_fragment:\n - files\n - validate\nshort_description: Replace all instances of a particular string in a\n file using a back-referenced regular expression.\ndescription:\n - This module will replace all instances of a pattern within a file.\n - It is up to the user to maintain idempotence by ensuring that the\n same pattern would never match any replacements made.\nversion_added: \"1.6\"\noptions:\n dest:\n required: true\n aliases: [ name, destfile ]\n description:\n - The file to modify.\n regexp:\n required: true\n description:\n - The regular expression to look for in the contents of the file.\n Uses Python regular expressions; see\n U(http://docs.python.org/2/library/re.html).\n Uses multiline mode, which means C(^) and C($) match the beginning\n and end respectively of I(each line) of the file.\n replace:\n required: false\n description:\n - The string to replace regexp matches. May contain backreferences\n that will get expanded with the regexp capture groups if the regexp\n matches. If not set, matches are removed entirely.\n backup:\n required: false\n default: \"no\"\n choices: [ \"yes\", \"no\" ]\n description:\n - Create a backup file including the timestamp information so you can\n get the original file back if you somehow clobbered it incorrectly.\n others:\n description:\n - All arguments accepted by the M(file) module also work here.\n required: false\n follow:\n required: false\n default: \"no\"\n choices: [ \"yes\", \"no\" ]\n version_added: \"1.9\"\n description:\n - 'This flag indicates that filesystem links, if they exist, should be followed.'\n\"\"\"\n\nEXAMPLES = r\"\"\"\n- replace: dest=/etc/hosts regexp='(\\s+)old\\.host\\.name(\\s+.*)?$' replace='\\1new.host.name\\2' backup=yes\n\n- replace: dest=/home/jdoe/.ssh/known_hosts regexp='^old\\.host\\.name[^\\n]*\\n' owner=jdoe group=jdoe mode=644\n\n- replace: dest=/etc/apache/ports regexp='^(NameVirtualHost|Listen)\\s+80\\s*$' replace='\\1 127.0.0.1:8080' validate='/usr/sbin/apache2ctl -f %s -t'\n\"\"\"\n\ndef write_changes(module,contents,dest):\n\n tmpfd, tmpfile = tempfile.mkstemp()\n f = os.fdopen(tmpfd,'wb')\n f.write(contents)\n f.close()\n\n validate = module.params.get('validate', None)\n valid = not validate\n if validate:\n if \"%s\" not in validate:\n module.fail_json(msg=\"validate must contain %%s: %s\" % (validate))\n (rc, out, err) = module.run_command(validate % tmpfile)\n valid = rc == 0\n if rc != 0:\n module.fail_json(msg='failed to validate: '\n 'rc:%s error:%s' % (rc,err))\n if valid:\n module.atomic_move(tmpfile, dest, unsafe_writes=module.params['unsafe_writes'])\n\ndef check_file_attrs(module, changed, message):\n\n file_args = module.load_file_common_arguments(module.params)\n if module.set_file_attributes_if_different(file_args, False):\n\n if changed:\n message += \" and \"\n changed = True\n message += \"ownership, perms or SE linux context changed\"\n\n return message, changed\n\ndef main():\n module = AnsibleModule(\n argument_spec=dict(\n dest=dict(required=True, aliases=['name', 'destfile']),\n regexp=dict(required=True),\n replace=dict(default='', type='str'),\n backup=dict(default=False, type='bool'),\n validate=dict(default=None, type='str'),\n ),\n add_file_common_args=True,\n supports_check_mode=True\n )\n\n params = module.params\n dest = os.path.expanduser(params['dest'])\n\n if os.path.isdir(dest):\n module.fail_json(rc=256, msg='Destination %s is a directory !' % dest)\n\n if not os.path.exists(dest):\n module.fail_json(rc=257, msg='Destination %s does not exist !' % dest)\n else:\n f = open(dest, 'rb')\n contents = f.read()\n f.close()\n\n if module._diff:\n diff = {\n 'before_header': dest,\n 'before': contents,\n }\n\n mre = re.compile(params['regexp'], re.MULTILINE)\n result = re.subn(mre, params['replace'], contents, 0)\n\n if result[1] > 0 and contents != result[0]:\n msg = '%s replacements made' % result[1]\n changed = True\n if module._diff:\n diff['after_header'] = dest\n diff['after'] = result[0]\n else:\n msg = ''\n changed = False\n diff = dict()\n\n if changed and not module.check_mode:\n if params['backup'] and os.path.exists(dest):\n module.backup_local(dest)\n if params['follow'] and os.path.islink(dest):\n dest = os.path.realpath(dest)\n write_changes(module, result[0], dest)\n\n msg, changed = check_file_attrs(module, changed, msg)\n module.exit_json(changed=changed, msg=msg, diff=diff)\n\n# this is magic, see lib/ansible/module_common.py\nfrom ansible.module_utils.basic import *\n\nif __name__ == '__main__':\n main()\n", "path": "files/replace.py"}], "after_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# (c) 2013, Evan Kaufman <[email protected]\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\nimport re\nimport os\nimport tempfile\n\nDOCUMENTATION = \"\"\"\n---\nmodule: replace\nauthor: \"Evan Kaufman (@EvanK)\"\nextends_documentation_fragment:\n - files\n - validate\nshort_description: Replace all instances of a particular string in a\n file using a back-referenced regular expression.\ndescription:\n - This module will replace all instances of a pattern within a file.\n - It is up to the user to maintain idempotence by ensuring that the\n same pattern would never match any replacements made.\nversion_added: \"1.6\"\noptions:\n dest:\n required: true\n aliases: [ name, destfile ]\n description:\n - The file to modify.\n regexp:\n required: true\n description:\n - The regular expression to look for in the contents of the file.\n Uses Python regular expressions; see\n U(http://docs.python.org/2/library/re.html).\n Uses multiline mode, which means C(^) and C($) match the beginning\n and end respectively of I(each line) of the file.\n replace:\n required: false\n description:\n - The string to replace regexp matches. May contain backreferences\n that will get expanded with the regexp capture groups if the regexp\n matches. If not set, matches are removed entirely.\n backup:\n required: false\n default: \"no\"\n choices: [ \"yes\", \"no\" ]\n description:\n - Create a backup file including the timestamp information so you can\n get the original file back if you somehow clobbered it incorrectly.\n others:\n description:\n - All arguments accepted by the M(file) module also work here.\n required: false\n follow:\n required: false\n default: \"no\"\n choices: [ \"yes\", \"no\" ]\n version_added: \"1.9\"\n description:\n - 'This flag indicates that filesystem links, if they exist, should be followed.'\n\"\"\"\n\nEXAMPLES = r\"\"\"\n- replace: dest=/etc/hosts regexp='(\\s+)old\\.host\\.name(\\s+.*)?$' replace='\\1new.host.name\\2' backup=yes\n\n- replace: dest=/home/jdoe/.ssh/known_hosts regexp='^old\\.host\\.name[^\\n]*\\n' owner=jdoe group=jdoe mode=644\n\n- replace: dest=/etc/apache/ports regexp='^(NameVirtualHost|Listen)\\s+80\\s*$' replace='\\1 127.0.0.1:8080' validate='/usr/sbin/apache2ctl -f %s -t'\n\"\"\"\n\ndef write_changes(module,contents,dest):\n\n tmpfd, tmpfile = tempfile.mkstemp()\n f = os.fdopen(tmpfd,'wb')\n f.write(contents)\n f.close()\n\n validate = module.params.get('validate', None)\n valid = not validate\n if validate:\n if \"%s\" not in validate:\n module.fail_json(msg=\"validate must contain %%s: %s\" % (validate))\n (rc, out, err) = module.run_command(validate % tmpfile)\n valid = rc == 0\n if rc != 0:\n module.fail_json(msg='failed to validate: '\n 'rc:%s error:%s' % (rc,err))\n if valid:\n module.atomic_move(tmpfile, dest, unsafe_writes=module.params['unsafe_writes'])\n\ndef check_file_attrs(module, changed, message):\n\n file_args = module.load_file_common_arguments(module.params)\n if module.set_file_attributes_if_different(file_args, False):\n\n if changed:\n message += \" and \"\n changed = True\n message += \"ownership, perms or SE linux context changed\"\n\n return message, changed\n\ndef main():\n module = AnsibleModule(\n argument_spec=dict(\n dest=dict(required=True, aliases=['name', 'destfile']),\n regexp=dict(required=True),\n replace=dict(default='', type='str'),\n backup=dict(default=False, type='bool'),\n validate=dict(default=None, type='str'),\n ),\n add_file_common_args=True,\n supports_check_mode=True\n )\n\n params = module.params\n dest = os.path.expanduser(params['dest'])\n diff = dict()\n\n if os.path.isdir(dest):\n module.fail_json(rc=256, msg='Destination %s is a directory !' % dest)\n\n if not os.path.exists(dest):\n module.fail_json(rc=257, msg='Destination %s does not exist !' % dest)\n else:\n f = open(dest, 'rb')\n contents = f.read()\n f.close()\n\n if module._diff:\n diff = {\n 'before_header': dest,\n 'before': contents,\n }\n\n mre = re.compile(params['regexp'], re.MULTILINE)\n result = re.subn(mre, params['replace'], contents, 0)\n\n if result[1] > 0 and contents != result[0]:\n msg = '%s replacements made' % result[1]\n changed = True\n if module._diff:\n diff['after_header'] = dest\n diff['after'] = result[0]\n else:\n msg = ''\n changed = False\n diff = dict()\n\n if changed and not module.check_mode:\n if params['backup'] and os.path.exists(dest):\n module.backup_local(dest)\n if params['follow'] and os.path.islink(dest):\n dest = os.path.realpath(dest)\n write_changes(module, result[0], dest)\n\n msg, changed = check_file_attrs(module, changed, msg)\n module.exit_json(changed=changed, msg=msg, diff=diff)\n\n# this is magic, see lib/ansible/module_common.py\nfrom ansible.module_utils.basic import *\n\nif __name__ == '__main__':\n main()\n", "path": "files/replace.py"}]}
| 2,651 | 97 |
gh_patches_debug_386
|
rasdani/github-patches
|
git_diff
|
UTNkar__moore-554
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fix cookies for Utnarm
Utnarm recently switched to utnarm.se instead of utnarm.utn.se. This lead to that you can’t sign in to utnarm.se. Per default, moore uses utn.se as cookie domain and since utnarm.se is a different top level domain the cookies can’t be used.
We need to dynamically add utnarm.se as a cookie domain. This python package might be useful https://github.com/ViktorStiskala/django-shared-session
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/moore/settings/production.py`
Content:
```
1 """
2 Django settings for the production environment of Project Moore.
3
4 For more information regarding running in production see,
5 See https://docs.djangoproject.com/en/1.10/howto/deployment/checklist/
6
7 For more information on this file, see
8 https://docs.djangoproject.com/en/1.10/topics/settings/
9
10 For the full list of settings and their values, see
11 https://docs.djangoproject.com/en/1.10/ref/settings/
12 """
13 from __future__ import absolute_import, unicode_literals
14 import raven
15
16 from .base import *
17
18 # SECURITY WARNING: don't run with debug turned on in production!
19 DEBUG = False
20
21 # SECURITY WARNING: keep the secret key used in production secret!
22 SECRET_KEY = os.environ.get(
23 'DJANGO_SECRET',
24 'za7^0@54n&p-dg4)_l12q_3^o5awz_uym0osqaz2!myki_8kw0'
25 )
26
27 # Database
28 # https://docs.djangoproject.com/en/1.10/ref/settings/#databases
29
30 DATABASES = {
31 'default': {
32 'ENGINE': 'django.db.backends.postgresql',
33 'NAME': os.environ.get('DJANGO_DB_NAME', 'moore'),
34 'USER': os.environ.get('DJANGO_DB_USER', 'moore'),
35 'PASSWORD': os.environ.get('DJANGO_DB_PASS'),
36 'HOST': os.environ.get('DJANGO_DB_HOST', '127.0.0.1'),
37 'PORT': os.environ.get('DJANGO_DB_PORT', '5432'),
38 }
39 }
40
41
42 # CONN_MAX_AGE = 0
43
44 # Base URL to use when referring to full URLs within the Wagtail admin
45 # backend - e.g. in notification emails. Don't include '/admin' or a
46 # trailing slash
47 BASE_URL = 'https://utn.se'
48
49 ALLOWED_HOSTS = ['.utn.se', '.utnarm.se']
50
51 # Email settings
52 DEFAULT_FROM_EMAIL = '[email protected]'
53
54 EMAIL_SUBJECT_PREFIX = '[UTN] '
55
56 # Sentry Configuration - will be sent error messages
57 RAVEN_CONFIG = {
58 'dsn': os.environ.get('SENTRY_DSN'),
59 'release': raven.fetch_git_sha(os.path.dirname(BASE_DIR)),
60 }
61
62 LOGGING = {
63 'version': 1,
64 'disable_existing_loggers': True,
65 'root': {
66 'level': 'WARNING',
67 'handlers': ['sentry'],
68 },
69 'formatters': {
70 'verbose': {
71 'format': '%(levelname)s %(asctime)s %(module)s '
72 '%(process)d %(thread)d %(message)s'
73 },
74 },
75 'handlers': {
76 'sentry': {
77 'level': 'ERROR',
78 'class': 'raven.contrib.django.raven_compat'
79 '.handlers.SentryHandler',
80 'tags': {'custom-tag': 'x'},
81 },
82 'console': {
83 'level': 'DEBUG',
84 'class': 'logging.StreamHandler',
85 'formatter': 'verbose'
86 }
87 },
88 'loggers': {
89 'django.db.backends': {
90 'level': 'ERROR',
91 'handlers': ['console'],
92 'propagate': False,
93 },
94 'raven': {
95 'level': 'DEBUG',
96 'handlers': ['console'],
97 'propagate': False,
98 },
99 'sentry.errors': {
100 'level': 'DEBUG',
101 'handlers': ['console'],
102 'propagate': False,
103 },
104 },
105 }
106
107 CSRF_COOKIE_SECURE = True
108
109 SESSION_COOKIE_DOMAIN = '.utn.se'
110
111 SESSION_COOKIE_SECURE = True
112
113 MELOS_URL = os.environ.get('MELOS_URL')
114 MELOS_ORG_ID = os.environ.get('MELOS_ORG_ID')
115 MELOS_ADMIN = os.environ.get('MELOS_ADMIN')
116
117 # Google API
118 GOOGLE_API_KEY = os.environ.get('GOOGLE_API_KEY')
119
120 RECAPTCHA_PUBLIC_KEY = os.environ.get("RECAPTCHA_PUBLIC_KEY", "")
121 RECAPTCHA_PRIVATE_KEY = os.environ.get("RECAPTCHA_PRIVATE_KEY", "")
122
123 try:
124 from .local import *
125 except ImportError:
126 pass
127
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/moore/settings/production.py b/src/moore/settings/production.py
--- a/src/moore/settings/production.py
+++ b/src/moore/settings/production.py
@@ -106,8 +106,6 @@
CSRF_COOKIE_SECURE = True
-SESSION_COOKIE_DOMAIN = '.utn.se'
-
SESSION_COOKIE_SECURE = True
MELOS_URL = os.environ.get('MELOS_URL')
|
{"golden_diff": "diff --git a/src/moore/settings/production.py b/src/moore/settings/production.py\n--- a/src/moore/settings/production.py\n+++ b/src/moore/settings/production.py\n@@ -106,8 +106,6 @@\n \n CSRF_COOKIE_SECURE = True\n \n-SESSION_COOKIE_DOMAIN = '.utn.se'\n-\n SESSION_COOKIE_SECURE = True\n \n MELOS_URL = os.environ.get('MELOS_URL')\n", "issue": "Fix cookies for Utnarm\nUtnarm recently switched to utnarm.se instead of utnarm.utn.se. This lead to that you can\u2019t sign in to utnarm.se. Per default, moore uses utn.se as cookie domain and since utnarm.se is a different top level domain the cookies can\u2019t be used. \r\n\r\nWe need to dynamically add utnarm.se as a cookie domain. This python package might be useful https://github.com/ViktorStiskala/django-shared-session\n", "before_files": [{"content": "\"\"\"\nDjango settings for the production environment of Project Moore.\n\nFor more information regarding running in production see,\nSee https://docs.djangoproject.com/en/1.10/howto/deployment/checklist/\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.10/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/1.10/ref/settings/\n\"\"\"\nfrom __future__ import absolute_import, unicode_literals\nimport raven\n\nfrom .base import *\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = False\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = os.environ.get(\n 'DJANGO_SECRET',\n 'za7^0@54n&p-dg4)_l12q_3^o5awz_uym0osqaz2!myki_8kw0'\n)\n\n# Database\n# https://docs.djangoproject.com/en/1.10/ref/settings/#databases\n\nDATABASES = {\n 'default': {\n 'ENGINE': 'django.db.backends.postgresql',\n 'NAME': os.environ.get('DJANGO_DB_NAME', 'moore'),\n 'USER': os.environ.get('DJANGO_DB_USER', 'moore'),\n 'PASSWORD': os.environ.get('DJANGO_DB_PASS'),\n 'HOST': os.environ.get('DJANGO_DB_HOST', '127.0.0.1'),\n 'PORT': os.environ.get('DJANGO_DB_PORT', '5432'),\n }\n}\n\n\n# CONN_MAX_AGE = 0\n\n# Base URL to use when referring to full URLs within the Wagtail admin\n# backend - e.g. in notification emails. Don't include '/admin' or a\n# trailing slash\nBASE_URL = 'https://utn.se'\n\nALLOWED_HOSTS = ['.utn.se', '.utnarm.se']\n\n# Email settings\nDEFAULT_FROM_EMAIL = '[email protected]'\n\nEMAIL_SUBJECT_PREFIX = '[UTN] '\n\n# Sentry Configuration - will be sent error messages\nRAVEN_CONFIG = {\n 'dsn': os.environ.get('SENTRY_DSN'),\n 'release': raven.fetch_git_sha(os.path.dirname(BASE_DIR)),\n}\n\nLOGGING = {\n 'version': 1,\n 'disable_existing_loggers': True,\n 'root': {\n 'level': 'WARNING',\n 'handlers': ['sentry'],\n },\n 'formatters': {\n 'verbose': {\n 'format': '%(levelname)s %(asctime)s %(module)s '\n '%(process)d %(thread)d %(message)s'\n },\n },\n 'handlers': {\n 'sentry': {\n 'level': 'ERROR',\n 'class': 'raven.contrib.django.raven_compat'\n '.handlers.SentryHandler',\n 'tags': {'custom-tag': 'x'},\n },\n 'console': {\n 'level': 'DEBUG',\n 'class': 'logging.StreamHandler',\n 'formatter': 'verbose'\n }\n },\n 'loggers': {\n 'django.db.backends': {\n 'level': 'ERROR',\n 'handlers': ['console'],\n 'propagate': False,\n },\n 'raven': {\n 'level': 'DEBUG',\n 'handlers': ['console'],\n 'propagate': False,\n },\n 'sentry.errors': {\n 'level': 'DEBUG',\n 'handlers': ['console'],\n 'propagate': False,\n },\n },\n}\n\nCSRF_COOKIE_SECURE = True\n\nSESSION_COOKIE_DOMAIN = '.utn.se'\n\nSESSION_COOKIE_SECURE = True\n\nMELOS_URL = os.environ.get('MELOS_URL')\nMELOS_ORG_ID = os.environ.get('MELOS_ORG_ID')\nMELOS_ADMIN = os.environ.get('MELOS_ADMIN')\n\n# Google API\nGOOGLE_API_KEY = os.environ.get('GOOGLE_API_KEY')\n\nRECAPTCHA_PUBLIC_KEY = os.environ.get(\"RECAPTCHA_PUBLIC_KEY\", \"\")\nRECAPTCHA_PRIVATE_KEY = os.environ.get(\"RECAPTCHA_PRIVATE_KEY\", \"\")\n\ntry:\n from .local import *\nexcept ImportError:\n pass\n", "path": "src/moore/settings/production.py"}], "after_files": [{"content": "\"\"\"\nDjango settings for the production environment of Project Moore.\n\nFor more information regarding running in production see,\nSee https://docs.djangoproject.com/en/1.10/howto/deployment/checklist/\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.10/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/1.10/ref/settings/\n\"\"\"\nfrom __future__ import absolute_import, unicode_literals\nimport raven\n\nfrom .base import *\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = False\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = os.environ.get(\n 'DJANGO_SECRET',\n 'za7^0@54n&p-dg4)_l12q_3^o5awz_uym0osqaz2!myki_8kw0'\n)\n\n# Database\n# https://docs.djangoproject.com/en/1.10/ref/settings/#databases\n\nDATABASES = {\n 'default': {\n 'ENGINE': 'django.db.backends.postgresql',\n 'NAME': os.environ.get('DJANGO_DB_NAME', 'moore'),\n 'USER': os.environ.get('DJANGO_DB_USER', 'moore'),\n 'PASSWORD': os.environ.get('DJANGO_DB_PASS'),\n 'HOST': os.environ.get('DJANGO_DB_HOST', '127.0.0.1'),\n 'PORT': os.environ.get('DJANGO_DB_PORT', '5432'),\n }\n}\n\n\n# CONN_MAX_AGE = 0\n\n# Base URL to use when referring to full URLs within the Wagtail admin\n# backend - e.g. in notification emails. Don't include '/admin' or a\n# trailing slash\nBASE_URL = 'https://utn.se'\n\nALLOWED_HOSTS = ['.utn.se', '.utnarm.se']\n\n# Email settings\nDEFAULT_FROM_EMAIL = '[email protected]'\n\nEMAIL_SUBJECT_PREFIX = '[UTN] '\n\n# Sentry Configuration - will be sent error messages\nRAVEN_CONFIG = {\n 'dsn': os.environ.get('SENTRY_DSN'),\n 'release': raven.fetch_git_sha(os.path.dirname(BASE_DIR)),\n}\n\nLOGGING = {\n 'version': 1,\n 'disable_existing_loggers': True,\n 'root': {\n 'level': 'WARNING',\n 'handlers': ['sentry'],\n },\n 'formatters': {\n 'verbose': {\n 'format': '%(levelname)s %(asctime)s %(module)s '\n '%(process)d %(thread)d %(message)s'\n },\n },\n 'handlers': {\n 'sentry': {\n 'level': 'ERROR',\n 'class': 'raven.contrib.django.raven_compat'\n '.handlers.SentryHandler',\n 'tags': {'custom-tag': 'x'},\n },\n 'console': {\n 'level': 'DEBUG',\n 'class': 'logging.StreamHandler',\n 'formatter': 'verbose'\n }\n },\n 'loggers': {\n 'django.db.backends': {\n 'level': 'ERROR',\n 'handlers': ['console'],\n 'propagate': False,\n },\n 'raven': {\n 'level': 'DEBUG',\n 'handlers': ['console'],\n 'propagate': False,\n },\n 'sentry.errors': {\n 'level': 'DEBUG',\n 'handlers': ['console'],\n 'propagate': False,\n },\n },\n}\n\nCSRF_COOKIE_SECURE = True\n\nSESSION_COOKIE_SECURE = True\n\nMELOS_URL = os.environ.get('MELOS_URL')\nMELOS_ORG_ID = os.environ.get('MELOS_ORG_ID')\nMELOS_ADMIN = os.environ.get('MELOS_ADMIN')\n\n# Google API\nGOOGLE_API_KEY = os.environ.get('GOOGLE_API_KEY')\n\nRECAPTCHA_PUBLIC_KEY = os.environ.get(\"RECAPTCHA_PUBLIC_KEY\", \"\")\nRECAPTCHA_PRIVATE_KEY = os.environ.get(\"RECAPTCHA_PRIVATE_KEY\", \"\")\n\ntry:\n from .local import *\nexcept ImportError:\n pass\n", "path": "src/moore/settings/production.py"}]}
| 1,532 | 94 |
gh_patches_debug_10895
|
rasdani/github-patches
|
git_diff
|
dmlc__dgl-4053
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fail to train graphsage model with ogbn-papers100M dataset and 8 GPU
## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
## To Reproduce
Steps to reproduce the behavior:
1. Open examples/pytorch/graphsage/lightning/node_classification.py
2. Replace `dataset = DglNodePropPredDataset('ogbn-products')` to `dataset = DglNodePropPredDataset("ogbn-papers100M")`
3. Replace `gpus=[0, 1, 2, 3]` to `gpus=[0, 1, 2, 3, 4, 5, 6, 7]`
4. Run `python examples/pytorch/graphsage/lightning/node_classification.py`
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
**error log:**
> /opt/conda/lib/python3.7/multiprocessing/semaphore_tracker.py:144: UserWarning: semaphore_tracker: There appear to be 1 leaked semaphores to clean up at shutdown
len(cache))
/opt/conda/lib/python3.7/multiprocessing/semaphore_tracker.py:144: UserWarning: semaphore_tracker: There appear to be 1 leaked semaphores to clean up at shutdown
len(cache))
/opt/conda/lib/python3.7/multiprocessing/semaphore_tracker.py:144: UserWarning: semaphore_tracker: There appear to be 1 leaked semaphores to clean up at shutdown
len(cache))
/opt/conda/lib/python3.7/multiprocessing/semaphore_tracker.py:144: UserWarning: semaphore_tracker: There appear to be 1 leaked semaphores to clean up at shutdown
len(cache))
/opt/conda/lib/python3.7/multiprocessing/semaphore_tracker.py:144: UserWarning: semaphore_tracker: There appear to be 1 leaked semaphores to clean up at shutdown
len(cache))
/opt/conda/lib/python3.7/multiprocessing/semaphore_tracker.py:144: UserWarning: semaphore_tracker: There appear to be 1 leaked semaphores to clean up at shutdown
len(cache))
/opt/conda/lib/python3.7/multiprocessing/semaphore_tracker.py:144: UserWarning: semaphore_tracker: There appear to be 1 leaked semaphores to clean up at shutdown
len(cache))
/opt/conda/lib/python3.7/multiprocessing/semaphore_tracker.py:144: UserWarning: semaphore_tracker: There appear to be 1 leaked semaphores to clean up at shutdown
len(cache))
Traceback (most recent call last):
File "/opt/conda/lib/python3.7/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/opt/conda/lib/python3.7/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/home/notebook/data/group/graph/frame/dglx-v1.0.0/ogp-compute/dglx/python/node_classification.py", line 194, in <module>
trainer.fit(model, datamodule=datamodule)
File "/opt/conda/lib/python3.7/site-packages/pytorch_lightning/trainer/trainer.py", line 769, in fit
self._fit_impl, model, train_dataloaders, val_dataloaders, datamodule, ckpt_path
File "/opt/conda/lib/python3.7/site-packages/pytorch_lightning/trainer/trainer.py", line 719, in _call_and_handle_interrupt
return self.strategy.launcher.launch(trainer_fn, *args, trainer=self, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/pytorch_lightning/strategies/launchers/spawn.py", line 82, in launch
start_method=self._start_method,
File "/opt/conda/lib/python3.7/site-packages/torch/multiprocessing/spawn.py", line 230, in spawn
return start_processes(fn, args, nprocs, join, daemon, start_method='spawn')
File "/opt/conda/lib/python3.7/site-packages/torch/multiprocessing/spawn.py", line 188, in start_processes
while not context.join():
File "/opt/conda/lib/python3.7/site-packages/torch/multiprocessing/spawn.py", line 136, in join
signal_name=name
torch.multiprocessing.spawn.ProcessExitedException: process 6 terminated with signal SIGKILL
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
The case should support large graph with 8 gpu
## Environment
- DGL Version (e.g., 1.0): 0.8.1
- Backend Library & Version (e.g., PyTorch 0.4.1, MXNet/Gluon 1.3): PyTorch
- OS (e.g., Linux): Linux
- How you installed DGL (`conda`, `pip`, source): pip
- Build command you used (if compiling from source):
- Python version: 3.7
- CUDA/cuDNN version (if applicable): 10.2
- GPU models and configuration (e.g. V100): V100 * 8
- Memory: 512GB
- CPU: Intel(R) Xeon(R) Gold 6242 CPU
## Additional context
<!-- Add any other context about the problem here. -->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/pytorch/graphsage/lightning/node_classification.py`
Content:
```
1 import dgl
2 import torch
3 import torch.nn as nn
4 import torch.nn.functional as F
5 import torch.optim as optim
6 import dgl.nn.pytorch as dglnn
7 import tqdm
8 import glob
9 import os
10 from ogb.nodeproppred import DglNodePropPredDataset
11 from torchmetrics import Accuracy
12 import torchmetrics.functional as MF
13 from pytorch_lightning.callbacks import ModelCheckpoint
14 from pytorch_lightning import LightningDataModule, LightningModule, Trainer
15
16 class SAGE(LightningModule):
17 def __init__(self, in_feats, n_hidden, n_classes):
18 super().__init__()
19 self.save_hyperparameters()
20 self.layers = nn.ModuleList()
21 self.layers.append(dglnn.SAGEConv(in_feats, n_hidden, 'mean'))
22 self.layers.append(dglnn.SAGEConv(n_hidden, n_hidden, 'mean'))
23 self.layers.append(dglnn.SAGEConv(n_hidden, n_classes, 'mean'))
24 self.dropout = nn.Dropout(0.5)
25 self.n_hidden = n_hidden
26 self.n_classes = n_classes
27 self.train_acc = Accuracy()
28 self.val_acc = Accuracy()
29
30 def forward(self, blocks, x):
31 h = x
32 for l, (layer, block) in enumerate(zip(self.layers, blocks)):
33 h = layer(block, h)
34 if l != len(self.layers) - 1:
35 h = F.relu(h)
36 h = self.dropout(h)
37 return h
38
39 def inference(self, g, device, batch_size, num_workers, buffer_device=None):
40 # The difference between this inference function and the one in the official
41 # example is that the intermediate results can also benefit from prefetching.
42 g.ndata['h'] = g.ndata['feat']
43 sampler = dgl.dataloading.MultiLayerFullNeighborSampler(1, prefetch_node_feats=['h'])
44 dataloader = dgl.dataloading.DataLoader(
45 g, torch.arange(g.num_nodes()).to(g.device), sampler, device=device,
46 batch_size=batch_size, shuffle=False, drop_last=False, num_workers=num_workers,
47 persistent_workers=(num_workers > 0))
48 if buffer_device is None:
49 buffer_device = device
50
51 for l, layer in enumerate(self.layers):
52 y = torch.zeros(
53 g.num_nodes(), self.n_hidden if l != len(self.layers) - 1 else self.n_classes,
54 device=buffer_device)
55 for input_nodes, output_nodes, blocks in tqdm.tqdm(dataloader):
56 x = blocks[0].srcdata['h']
57 h = layer(blocks[0], x)
58 if l != len(self.layers) - 1:
59 h = F.relu(h)
60 h = self.dropout(h)
61 y[output_nodes] = h.to(buffer_device)
62 g.ndata['h'] = y
63 return y
64
65 def training_step(self, batch, batch_idx):
66 input_nodes, output_nodes, blocks = batch
67 x = blocks[0].srcdata['feat']
68 y = blocks[-1].dstdata['label']
69 y_hat = self(blocks, x)
70 loss = F.cross_entropy(y_hat, y)
71 self.train_acc(torch.argmax(y_hat, 1), y)
72 self.log('train_acc', self.train_acc, prog_bar=True, on_step=True, on_epoch=False)
73 return loss
74
75 def validation_step(self, batch, batch_idx):
76 input_nodes, output_nodes, blocks = batch
77 x = blocks[0].srcdata['feat']
78 y = blocks[-1].dstdata['label']
79 y_hat = self(blocks, x)
80 self.val_acc(torch.argmax(y_hat, 1), y)
81 self.log('val_acc', self.val_acc, prog_bar=True, on_step=True, on_epoch=True, sync_dist=True)
82
83 def configure_optimizers(self):
84 optimizer = torch.optim.Adam(self.parameters(), lr=0.001, weight_decay=5e-4)
85 return optimizer
86
87 class DataModule(LightningDataModule):
88 def __init__(self, graph, train_idx, val_idx, fanouts, batch_size, n_classes):
89 super().__init__()
90
91 sampler = dgl.dataloading.NeighborSampler(
92 fanouts, prefetch_node_feats=['feat'], prefetch_labels=['label'])
93
94 self.g = graph
95 self.train_idx, self.val_idx = train_idx, val_idx
96 self.sampler = sampler
97 self.batch_size = batch_size
98 self.in_feats = graph.ndata['feat'].shape[1]
99 self.n_classes = n_classes
100
101 def train_dataloader(self):
102 return dgl.dataloading.DataLoader(
103 self.g, self.train_idx.to('cuda'), self.sampler,
104 device='cuda', batch_size=self.batch_size, shuffle=True, drop_last=False,
105 # For CPU sampling, set num_workers to nonzero and use_uva=False
106 # Set use_ddp to False for single GPU.
107 num_workers=0, use_uva=True, use_ddp=True)
108
109 def val_dataloader(self):
110 return dgl.dataloading.DataLoader(
111 self.g, self.val_idx.to('cuda'), self.sampler,
112 device='cuda', batch_size=self.batch_size, shuffle=True, drop_last=False,
113 num_workers=0, use_uva=True)
114
115 if __name__ == '__main__':
116 dataset = DglNodePropPredDataset('ogbn-products')
117 graph, labels = dataset[0]
118 graph.ndata['label'] = labels.squeeze()
119 split_idx = dataset.get_idx_split()
120 train_idx, val_idx, test_idx = split_idx['train'], split_idx['valid'], split_idx['test']
121 datamodule = DataModule(graph, train_idx, val_idx, [15, 10, 5], 1024, dataset.num_classes)
122 model = SAGE(datamodule.in_feats, 256, datamodule.n_classes)
123
124 # Train
125 checkpoint_callback = ModelCheckpoint(monitor='val_acc', save_top_k=1)
126 # Use this for single GPU
127 #trainer = Trainer(gpus=[0], max_epochs=10, callbacks=[checkpoint_callback])
128 trainer = Trainer(gpus=[0, 1, 2, 3], max_epochs=10, callbacks=[checkpoint_callback], strategy='ddp_spawn')
129 trainer.fit(model, datamodule=datamodule)
130
131 # Test
132 dirs = glob.glob('./lightning_logs/*')
133 version = max([int(os.path.split(x)[-1].split('_')[-1]) for x in dirs])
134 logdir = './lightning_logs/version_%d' % version
135 print('Evaluating model in', logdir)
136 ckpt = glob.glob(os.path.join(logdir, 'checkpoints', '*'))[0]
137
138 model = SAGE.load_from_checkpoint(
139 checkpoint_path=ckpt, hparams_file=os.path.join(logdir, 'hparams.yaml')).to('cuda')
140 with torch.no_grad():
141 pred = model.inference(graph, 'cuda', 4096, 12, graph.device)
142 pred = pred[test_idx]
143 label = graph.ndata['label'][test_idx]
144 acc = MF.accuracy(pred, label)
145 print('Test accuracy:', acc)
146
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/pytorch/graphsage/lightning/node_classification.py b/examples/pytorch/graphsage/lightning/node_classification.py
--- a/examples/pytorch/graphsage/lightning/node_classification.py
+++ b/examples/pytorch/graphsage/lightning/node_classification.py
@@ -116,6 +116,7 @@
dataset = DglNodePropPredDataset('ogbn-products')
graph, labels = dataset[0]
graph.ndata['label'] = labels.squeeze()
+ graph.create_formats_()
split_idx = dataset.get_idx_split()
train_idx, val_idx, test_idx = split_idx['train'], split_idx['valid'], split_idx['test']
datamodule = DataModule(graph, train_idx, val_idx, [15, 10, 5], 1024, dataset.num_classes)
|
{"golden_diff": "diff --git a/examples/pytorch/graphsage/lightning/node_classification.py b/examples/pytorch/graphsage/lightning/node_classification.py\n--- a/examples/pytorch/graphsage/lightning/node_classification.py\n+++ b/examples/pytorch/graphsage/lightning/node_classification.py\n@@ -116,6 +116,7 @@\n dataset = DglNodePropPredDataset('ogbn-products')\n graph, labels = dataset[0]\n graph.ndata['label'] = labels.squeeze()\n+ graph.create_formats_()\n split_idx = dataset.get_idx_split()\n train_idx, val_idx, test_idx = split_idx['train'], split_idx['valid'], split_idx['test']\n datamodule = DataModule(graph, train_idx, val_idx, [15, 10, 5], 1024, dataset.num_classes)\n", "issue": "Fail to train graphsage model with ogbn-papers100M dataset and 8 GPU\n## \ud83d\udc1b Bug\r\n\r\n<!-- A clear and concise description of what the bug is. -->\r\n\r\n## To Reproduce\r\n\r\nSteps to reproduce the behavior:\r\n\r\n1. Open examples/pytorch/graphsage/lightning/node_classification.py\r\n2. Replace `dataset = DglNodePropPredDataset('ogbn-products')` to `dataset = DglNodePropPredDataset(\"ogbn-papers100M\")`\r\n3. Replace `gpus=[0, 1, 2, 3]` to `gpus=[0, 1, 2, 3, 4, 5, 6, 7]`\r\n4. Run `python examples/pytorch/graphsage/lightning/node_classification.py`\r\n\r\n<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->\r\n**error log\uff1a**\r\n> /opt/conda/lib/python3.7/multiprocessing/semaphore_tracker.py:144: UserWarning: semaphore_tracker: There appear to be 1 leaked semaphores to clean up at shutdown\r\n len(cache))\r\n/opt/conda/lib/python3.7/multiprocessing/semaphore_tracker.py:144: UserWarning: semaphore_tracker: There appear to be 1 leaked semaphores to clean up at shutdown\r\n len(cache))\r\n/opt/conda/lib/python3.7/multiprocessing/semaphore_tracker.py:144: UserWarning: semaphore_tracker: There appear to be 1 leaked semaphores to clean up at shutdown\r\n len(cache))\r\n/opt/conda/lib/python3.7/multiprocessing/semaphore_tracker.py:144: UserWarning: semaphore_tracker: There appear to be 1 leaked semaphores to clean up at shutdown\r\n len(cache))\r\n/opt/conda/lib/python3.7/multiprocessing/semaphore_tracker.py:144: UserWarning: semaphore_tracker: There appear to be 1 leaked semaphores to clean up at shutdown\r\n len(cache))\r\n/opt/conda/lib/python3.7/multiprocessing/semaphore_tracker.py:144: UserWarning: semaphore_tracker: There appear to be 1 leaked semaphores to clean up at shutdown\r\n len(cache))\r\n/opt/conda/lib/python3.7/multiprocessing/semaphore_tracker.py:144: UserWarning: semaphore_tracker: There appear to be 1 leaked semaphores to clean up at shutdown\r\n len(cache))\r\n/opt/conda/lib/python3.7/multiprocessing/semaphore_tracker.py:144: UserWarning: semaphore_tracker: There appear to be 1 leaked semaphores to clean up at shutdown\r\n len(cache))\r\nTraceback (most recent call last):\r\n File \"/opt/conda/lib/python3.7/runpy.py\", line 193, in _run_module_as_main\r\n \"__main__\", mod_spec)\r\n File \"/opt/conda/lib/python3.7/runpy.py\", line 85, in _run_code\r\n exec(code, run_globals)\r\n File \"/home/notebook/data/group/graph/frame/dglx-v1.0.0/ogp-compute/dglx/python/node_classification.py\", line 194, in <module>\r\n trainer.fit(model, datamodule=datamodule)\r\n File \"/opt/conda/lib/python3.7/site-packages/pytorch_lightning/trainer/trainer.py\", line 769, in fit\r\n self._fit_impl, model, train_dataloaders, val_dataloaders, datamodule, ckpt_path\r\n File \"/opt/conda/lib/python3.7/site-packages/pytorch_lightning/trainer/trainer.py\", line 719, in _call_and_handle_interrupt\r\n return self.strategy.launcher.launch(trainer_fn, *args, trainer=self, **kwargs)\r\n File \"/opt/conda/lib/python3.7/site-packages/pytorch_lightning/strategies/launchers/spawn.py\", line 82, in launch\r\n start_method=self._start_method,\r\n File \"/opt/conda/lib/python3.7/site-packages/torch/multiprocessing/spawn.py\", line 230, in spawn\r\n return start_processes(fn, args, nprocs, join, daemon, start_method='spawn')\r\n File \"/opt/conda/lib/python3.7/site-packages/torch/multiprocessing/spawn.py\", line 188, in start_processes\r\n while not context.join():\r\n File \"/opt/conda/lib/python3.7/site-packages/torch/multiprocessing/spawn.py\", line 136, in join\r\n signal_name=name\r\ntorch.multiprocessing.spawn.ProcessExitedException: process 6 terminated with signal SIGKILL\r\n## Expected behavior\r\n<!-- A clear and concise description of what you expected to happen. -->\r\nThe case should support large graph with 8 gpu\r\n\r\n## Environment\r\n\r\n - DGL Version (e.g., 1.0): 0.8.1\r\n - Backend Library & Version (e.g., PyTorch 0.4.1, MXNet/Gluon 1.3): PyTorch \r\n - OS (e.g., Linux): Linux\r\n - How you installed DGL (`conda`, `pip`, source): pip\r\n - Build command you used (if compiling from source):\r\n - Python version: 3.7\r\n - CUDA/cuDNN version (if applicable): 10.2\r\n - GPU models and configuration (e.g. V100): V100 * 8\r\n - Memory: 512GB\r\n - CPU: Intel(R) Xeon(R) Gold 6242 CPU\r\n\r\n## Additional context\r\n<!-- Add any other context about the problem here. -->\r\n\r\n\n", "before_files": [{"content": "import dgl\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torch.optim as optim\nimport dgl.nn.pytorch as dglnn\nimport tqdm\nimport glob\nimport os\nfrom ogb.nodeproppred import DglNodePropPredDataset\nfrom torchmetrics import Accuracy\nimport torchmetrics.functional as MF\nfrom pytorch_lightning.callbacks import ModelCheckpoint\nfrom pytorch_lightning import LightningDataModule, LightningModule, Trainer\n\nclass SAGE(LightningModule):\n def __init__(self, in_feats, n_hidden, n_classes):\n super().__init__()\n self.save_hyperparameters()\n self.layers = nn.ModuleList()\n self.layers.append(dglnn.SAGEConv(in_feats, n_hidden, 'mean'))\n self.layers.append(dglnn.SAGEConv(n_hidden, n_hidden, 'mean'))\n self.layers.append(dglnn.SAGEConv(n_hidden, n_classes, 'mean'))\n self.dropout = nn.Dropout(0.5)\n self.n_hidden = n_hidden\n self.n_classes = n_classes\n self.train_acc = Accuracy()\n self.val_acc = Accuracy()\n\n def forward(self, blocks, x):\n h = x\n for l, (layer, block) in enumerate(zip(self.layers, blocks)):\n h = layer(block, h)\n if l != len(self.layers) - 1:\n h = F.relu(h)\n h = self.dropout(h)\n return h\n\n def inference(self, g, device, batch_size, num_workers, buffer_device=None):\n # The difference between this inference function and the one in the official\n # example is that the intermediate results can also benefit from prefetching.\n g.ndata['h'] = g.ndata['feat']\n sampler = dgl.dataloading.MultiLayerFullNeighborSampler(1, prefetch_node_feats=['h'])\n dataloader = dgl.dataloading.DataLoader(\n g, torch.arange(g.num_nodes()).to(g.device), sampler, device=device,\n batch_size=batch_size, shuffle=False, drop_last=False, num_workers=num_workers,\n persistent_workers=(num_workers > 0))\n if buffer_device is None:\n buffer_device = device\n\n for l, layer in enumerate(self.layers):\n y = torch.zeros(\n g.num_nodes(), self.n_hidden if l != len(self.layers) - 1 else self.n_classes,\n device=buffer_device)\n for input_nodes, output_nodes, blocks in tqdm.tqdm(dataloader):\n x = blocks[0].srcdata['h']\n h = layer(blocks[0], x)\n if l != len(self.layers) - 1:\n h = F.relu(h)\n h = self.dropout(h)\n y[output_nodes] = h.to(buffer_device)\n g.ndata['h'] = y\n return y\n\n def training_step(self, batch, batch_idx):\n input_nodes, output_nodes, blocks = batch\n x = blocks[0].srcdata['feat']\n y = blocks[-1].dstdata['label']\n y_hat = self(blocks, x)\n loss = F.cross_entropy(y_hat, y)\n self.train_acc(torch.argmax(y_hat, 1), y)\n self.log('train_acc', self.train_acc, prog_bar=True, on_step=True, on_epoch=False)\n return loss\n\n def validation_step(self, batch, batch_idx):\n input_nodes, output_nodes, blocks = batch\n x = blocks[0].srcdata['feat']\n y = blocks[-1].dstdata['label']\n y_hat = self(blocks, x)\n self.val_acc(torch.argmax(y_hat, 1), y)\n self.log('val_acc', self.val_acc, prog_bar=True, on_step=True, on_epoch=True, sync_dist=True)\n\n def configure_optimizers(self):\n optimizer = torch.optim.Adam(self.parameters(), lr=0.001, weight_decay=5e-4)\n return optimizer\n\nclass DataModule(LightningDataModule):\n def __init__(self, graph, train_idx, val_idx, fanouts, batch_size, n_classes):\n super().__init__()\n\n sampler = dgl.dataloading.NeighborSampler(\n fanouts, prefetch_node_feats=['feat'], prefetch_labels=['label'])\n\n self.g = graph\n self.train_idx, self.val_idx = train_idx, val_idx\n self.sampler = sampler\n self.batch_size = batch_size\n self.in_feats = graph.ndata['feat'].shape[1]\n self.n_classes = n_classes\n\n def train_dataloader(self):\n return dgl.dataloading.DataLoader(\n self.g, self.train_idx.to('cuda'), self.sampler,\n device='cuda', batch_size=self.batch_size, shuffle=True, drop_last=False,\n # For CPU sampling, set num_workers to nonzero and use_uva=False\n # Set use_ddp to False for single GPU.\n num_workers=0, use_uva=True, use_ddp=True)\n\n def val_dataloader(self):\n return dgl.dataloading.DataLoader(\n self.g, self.val_idx.to('cuda'), self.sampler,\n device='cuda', batch_size=self.batch_size, shuffle=True, drop_last=False,\n num_workers=0, use_uva=True)\n\nif __name__ == '__main__':\n dataset = DglNodePropPredDataset('ogbn-products')\n graph, labels = dataset[0]\n graph.ndata['label'] = labels.squeeze()\n split_idx = dataset.get_idx_split()\n train_idx, val_idx, test_idx = split_idx['train'], split_idx['valid'], split_idx['test']\n datamodule = DataModule(graph, train_idx, val_idx, [15, 10, 5], 1024, dataset.num_classes)\n model = SAGE(datamodule.in_feats, 256, datamodule.n_classes)\n\n # Train\n checkpoint_callback = ModelCheckpoint(monitor='val_acc', save_top_k=1)\n # Use this for single GPU\n #trainer = Trainer(gpus=[0], max_epochs=10, callbacks=[checkpoint_callback])\n trainer = Trainer(gpus=[0, 1, 2, 3], max_epochs=10, callbacks=[checkpoint_callback], strategy='ddp_spawn')\n trainer.fit(model, datamodule=datamodule)\n\n # Test\n dirs = glob.glob('./lightning_logs/*')\n version = max([int(os.path.split(x)[-1].split('_')[-1]) for x in dirs])\n logdir = './lightning_logs/version_%d' % version\n print('Evaluating model in', logdir)\n ckpt = glob.glob(os.path.join(logdir, 'checkpoints', '*'))[0]\n\n model = SAGE.load_from_checkpoint(\n checkpoint_path=ckpt, hparams_file=os.path.join(logdir, 'hparams.yaml')).to('cuda')\n with torch.no_grad():\n pred = model.inference(graph, 'cuda', 4096, 12, graph.device)\n pred = pred[test_idx]\n label = graph.ndata['label'][test_idx]\n acc = MF.accuracy(pred, label)\n print('Test accuracy:', acc)\n", "path": "examples/pytorch/graphsage/lightning/node_classification.py"}], "after_files": [{"content": "import dgl\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torch.optim as optim\nimport dgl.nn.pytorch as dglnn\nimport tqdm\nimport glob\nimport os\nfrom ogb.nodeproppred import DglNodePropPredDataset\nfrom torchmetrics import Accuracy\nimport torchmetrics.functional as MF\nfrom pytorch_lightning.callbacks import ModelCheckpoint\nfrom pytorch_lightning import LightningDataModule, LightningModule, Trainer\n\nclass SAGE(LightningModule):\n def __init__(self, in_feats, n_hidden, n_classes):\n super().__init__()\n self.save_hyperparameters()\n self.layers = nn.ModuleList()\n self.layers.append(dglnn.SAGEConv(in_feats, n_hidden, 'mean'))\n self.layers.append(dglnn.SAGEConv(n_hidden, n_hidden, 'mean'))\n self.layers.append(dglnn.SAGEConv(n_hidden, n_classes, 'mean'))\n self.dropout = nn.Dropout(0.5)\n self.n_hidden = n_hidden\n self.n_classes = n_classes\n self.train_acc = Accuracy()\n self.val_acc = Accuracy()\n\n def forward(self, blocks, x):\n h = x\n for l, (layer, block) in enumerate(zip(self.layers, blocks)):\n h = layer(block, h)\n if l != len(self.layers) - 1:\n h = F.relu(h)\n h = self.dropout(h)\n return h\n\n def inference(self, g, device, batch_size, num_workers, buffer_device=None):\n # The difference between this inference function and the one in the official\n # example is that the intermediate results can also benefit from prefetching.\n g.ndata['h'] = g.ndata['feat']\n sampler = dgl.dataloading.MultiLayerFullNeighborSampler(1, prefetch_node_feats=['h'])\n dataloader = dgl.dataloading.DataLoader(\n g, torch.arange(g.num_nodes()).to(g.device), sampler, device=device,\n batch_size=batch_size, shuffle=False, drop_last=False, num_workers=num_workers,\n persistent_workers=(num_workers > 0))\n if buffer_device is None:\n buffer_device = device\n\n for l, layer in enumerate(self.layers):\n y = torch.zeros(\n g.num_nodes(), self.n_hidden if l != len(self.layers) - 1 else self.n_classes,\n device=buffer_device)\n for input_nodes, output_nodes, blocks in tqdm.tqdm(dataloader):\n x = blocks[0].srcdata['h']\n h = layer(blocks[0], x)\n if l != len(self.layers) - 1:\n h = F.relu(h)\n h = self.dropout(h)\n y[output_nodes] = h.to(buffer_device)\n g.ndata['h'] = y\n return y\n\n def training_step(self, batch, batch_idx):\n input_nodes, output_nodes, blocks = batch\n x = blocks[0].srcdata['feat']\n y = blocks[-1].dstdata['label']\n y_hat = self(blocks, x)\n loss = F.cross_entropy(y_hat, y)\n self.train_acc(torch.argmax(y_hat, 1), y)\n self.log('train_acc', self.train_acc, prog_bar=True, on_step=True, on_epoch=False)\n return loss\n\n def validation_step(self, batch, batch_idx):\n input_nodes, output_nodes, blocks = batch\n x = blocks[0].srcdata['feat']\n y = blocks[-1].dstdata['label']\n y_hat = self(blocks, x)\n self.val_acc(torch.argmax(y_hat, 1), y)\n self.log('val_acc', self.val_acc, prog_bar=True, on_step=True, on_epoch=True, sync_dist=True)\n\n def configure_optimizers(self):\n optimizer = torch.optim.Adam(self.parameters(), lr=0.001, weight_decay=5e-4)\n return optimizer\n\nclass DataModule(LightningDataModule):\n def __init__(self, graph, train_idx, val_idx, fanouts, batch_size, n_classes):\n super().__init__()\n\n sampler = dgl.dataloading.NeighborSampler(\n fanouts, prefetch_node_feats=['feat'], prefetch_labels=['label'])\n\n self.g = graph\n self.train_idx, self.val_idx = train_idx, val_idx\n self.sampler = sampler\n self.batch_size = batch_size\n self.in_feats = graph.ndata['feat'].shape[1]\n self.n_classes = n_classes\n\n def train_dataloader(self):\n return dgl.dataloading.DataLoader(\n self.g, self.train_idx.to('cuda'), self.sampler,\n device='cuda', batch_size=self.batch_size, shuffle=True, drop_last=False,\n # For CPU sampling, set num_workers to nonzero and use_uva=False\n # Set use_ddp to False for single GPU.\n num_workers=0, use_uva=True, use_ddp=True)\n\n def val_dataloader(self):\n return dgl.dataloading.DataLoader(\n self.g, self.val_idx.to('cuda'), self.sampler,\n device='cuda', batch_size=self.batch_size, shuffle=True, drop_last=False,\n num_workers=0, use_uva=True)\n\nif __name__ == '__main__':\n dataset = DglNodePropPredDataset('ogbn-products')\n graph, labels = dataset[0]\n graph.ndata['label'] = labels.squeeze()\n graph.create_formats_()\n split_idx = dataset.get_idx_split()\n train_idx, val_idx, test_idx = split_idx['train'], split_idx['valid'], split_idx['test']\n datamodule = DataModule(graph, train_idx, val_idx, [15, 10, 5], 1024, dataset.num_classes)\n model = SAGE(datamodule.in_feats, 256, datamodule.n_classes)\n\n # Train\n checkpoint_callback = ModelCheckpoint(monitor='val_acc', save_top_k=1)\n # Use this for single GPU\n #trainer = Trainer(gpus=[0], max_epochs=10, callbacks=[checkpoint_callback])\n trainer = Trainer(gpus=[0, 1, 2, 3], max_epochs=10, callbacks=[checkpoint_callback], strategy='ddp_spawn')\n trainer.fit(model, datamodule=datamodule)\n\n # Test\n dirs = glob.glob('./lightning_logs/*')\n version = max([int(os.path.split(x)[-1].split('_')[-1]) for x in dirs])\n logdir = './lightning_logs/version_%d' % version\n print('Evaluating model in', logdir)\n ckpt = glob.glob(os.path.join(logdir, 'checkpoints', '*'))[0]\n\n model = SAGE.load_from_checkpoint(\n checkpoint_path=ckpt, hparams_file=os.path.join(logdir, 'hparams.yaml')).to('cuda')\n with torch.no_grad():\n pred = model.inference(graph, 'cuda', 4096, 12, graph.device)\n pred = pred[test_idx]\n label = graph.ndata['label'][test_idx]\n acc = MF.accuracy(pred, label)\n print('Test accuracy:', acc)\n", "path": "examples/pytorch/graphsage/lightning/node_classification.py"}]}
| 3,388 | 180 |
gh_patches_debug_22040
|
rasdani/github-patches
|
git_diff
|
pallets__werkzeug-1627
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Reloader doesn't add ".exe" to file on Windows
if I run a flask app under 0.15.5 with
FLASK_ENV=development
the dev server throws an error.
With FLASK_ENV=production the server starts ok
After reinstalling 0.15.4 the same app works ok (both in dev and prod mode).
Windows/py3.6.7/pipenv
Kind regards
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/werkzeug/_reloader.py`
Content:
```
1 import os
2 import subprocess
3 import sys
4 import threading
5 import time
6 from itertools import chain
7
8 from ._compat import iteritems
9 from ._compat import PY2
10 from ._compat import text_type
11 from ._internal import _log
12
13
14 def _iter_module_files():
15 """This iterates over all relevant Python files. It goes through all
16 loaded files from modules, all files in folders of already loaded modules
17 as well as all files reachable through a package.
18 """
19 # The list call is necessary on Python 3 in case the module
20 # dictionary modifies during iteration.
21 for module in list(sys.modules.values()):
22 if module is None:
23 continue
24 filename = getattr(module, "__file__", None)
25 if filename:
26 if os.path.isdir(filename) and os.path.exists(
27 os.path.join(filename, "__init__.py")
28 ):
29 filename = os.path.join(filename, "__init__.py")
30
31 old = None
32 while not os.path.isfile(filename):
33 old = filename
34 filename = os.path.dirname(filename)
35 if filename == old:
36 break
37 else:
38 if filename[-4:] in (".pyc", ".pyo"):
39 filename = filename[:-1]
40 yield filename
41
42
43 def _find_observable_paths(extra_files=None):
44 """Finds all paths that should be observed."""
45 rv = set(
46 os.path.dirname(os.path.abspath(x)) if os.path.isfile(x) else os.path.abspath(x)
47 for x in sys.path
48 )
49
50 for filename in extra_files or ():
51 rv.add(os.path.dirname(os.path.abspath(filename)))
52
53 for module in list(sys.modules.values()):
54 fn = getattr(module, "__file__", None)
55 if fn is None:
56 continue
57 fn = os.path.abspath(fn)
58 rv.add(os.path.dirname(fn))
59
60 return _find_common_roots(rv)
61
62
63 def _get_args_for_reloading():
64 """Determine how the script was executed, and return the args needed
65 to execute it again in a new process.
66 """
67 rv = [sys.executable]
68 py_script = sys.argv[0]
69 args = sys.argv[1:]
70 # Need to look at main module to determine how it was executed.
71 __main__ = sys.modules["__main__"]
72
73 # The value of __package__ indicates how Python was called. It may
74 # not exist if a setuptools script is installed as an egg.
75 if getattr(__main__, "__package__", None) is None:
76 # Executed a file, like "python app.py".
77 py_script = os.path.abspath(py_script)
78
79 if os.name == "nt":
80 # Windows entry points have ".exe" extension and should be
81 # called directly.
82 if not os.path.exists(py_script) and os.path.exists(py_script + ".exe"):
83 py_script += ".exe"
84
85 if (
86 os.path.splitext(rv[0])[1] == ".exe"
87 and os.path.splitext(py_script)[1] == ".exe"
88 ):
89 rv.pop(0)
90
91 rv.append(py_script)
92 else:
93 # Executed a module, like "python -m werkzeug.serving".
94 if sys.argv[0] == "-m":
95 # Flask works around previous behavior by putting
96 # "-m flask" in sys.argv.
97 # TODO remove this once Flask no longer misbehaves
98 args = sys.argv
99 else:
100 if os.path.isfile(py_script):
101 # Rewritten by Python from "-m script" to "/path/to/script.py".
102 py_module = __main__.__package__
103 name = os.path.splitext(os.path.basename(py_script))[0]
104
105 if name != "__main__":
106 py_module += "." + name
107 else:
108 # Incorrectly rewritten by pydevd debugger from "-m script" to "script".
109 py_module = py_script
110
111 rv.extend(("-m", py_module.lstrip(".")))
112
113 rv.extend(args)
114 return rv
115
116
117 def _find_common_roots(paths):
118 """Out of some paths it finds the common roots that need monitoring."""
119 paths = [x.split(os.path.sep) for x in paths]
120 root = {}
121 for chunks in sorted(paths, key=len, reverse=True):
122 node = root
123 for chunk in chunks:
124 node = node.setdefault(chunk, {})
125 node.clear()
126
127 rv = set()
128
129 def _walk(node, path):
130 for prefix, child in iteritems(node):
131 _walk(child, path + (prefix,))
132 if not node:
133 rv.add("/".join(path))
134
135 _walk(root, ())
136 return rv
137
138
139 class ReloaderLoop(object):
140 name = None
141
142 # monkeypatched by testsuite. wrapping with `staticmethod` is required in
143 # case time.sleep has been replaced by a non-c function (e.g. by
144 # `eventlet.monkey_patch`) before we get here
145 _sleep = staticmethod(time.sleep)
146
147 def __init__(self, extra_files=None, interval=1):
148 self.extra_files = set(os.path.abspath(x) for x in extra_files or ())
149 self.interval = interval
150
151 def run(self):
152 pass
153
154 def restart_with_reloader(self):
155 """Spawn a new Python interpreter with the same arguments as this one,
156 but running the reloader thread.
157 """
158 while 1:
159 _log("info", " * Restarting with %s" % self.name)
160 args = _get_args_for_reloading()
161
162 # a weird bug on windows. sometimes unicode strings end up in the
163 # environment and subprocess.call does not like this, encode them
164 # to latin1 and continue.
165 if os.name == "nt" and PY2:
166 new_environ = {}
167 for key, value in iteritems(os.environ):
168 if isinstance(key, text_type):
169 key = key.encode("iso-8859-1")
170 if isinstance(value, text_type):
171 value = value.encode("iso-8859-1")
172 new_environ[key] = value
173 else:
174 new_environ = os.environ.copy()
175
176 new_environ["WERKZEUG_RUN_MAIN"] = "true"
177 exit_code = subprocess.call(args, env=new_environ, close_fds=False)
178 if exit_code != 3:
179 return exit_code
180
181 def trigger_reload(self, filename):
182 self.log_reload(filename)
183 sys.exit(3)
184
185 def log_reload(self, filename):
186 filename = os.path.abspath(filename)
187 _log("info", " * Detected change in %r, reloading" % filename)
188
189
190 class StatReloaderLoop(ReloaderLoop):
191 name = "stat"
192
193 def run(self):
194 mtimes = {}
195 while 1:
196 for filename in chain(_iter_module_files(), self.extra_files):
197 try:
198 mtime = os.stat(filename).st_mtime
199 except OSError:
200 continue
201
202 old_time = mtimes.get(filename)
203 if old_time is None:
204 mtimes[filename] = mtime
205 continue
206 elif mtime > old_time:
207 self.trigger_reload(filename)
208 self._sleep(self.interval)
209
210
211 class WatchdogReloaderLoop(ReloaderLoop):
212 def __init__(self, *args, **kwargs):
213 ReloaderLoop.__init__(self, *args, **kwargs)
214 from watchdog.observers import Observer
215 from watchdog.events import FileSystemEventHandler
216
217 self.observable_paths = set()
218
219 def _check_modification(filename):
220 if filename in self.extra_files:
221 self.trigger_reload(filename)
222 dirname = os.path.dirname(filename)
223 if dirname.startswith(tuple(self.observable_paths)):
224 if filename.endswith((".pyc", ".pyo", ".py")):
225 self.trigger_reload(filename)
226
227 class _CustomHandler(FileSystemEventHandler):
228 def on_created(self, event):
229 _check_modification(event.src_path)
230
231 def on_modified(self, event):
232 _check_modification(event.src_path)
233
234 def on_moved(self, event):
235 _check_modification(event.src_path)
236 _check_modification(event.dest_path)
237
238 def on_deleted(self, event):
239 _check_modification(event.src_path)
240
241 reloader_name = Observer.__name__.lower()
242 if reloader_name.endswith("observer"):
243 reloader_name = reloader_name[:-8]
244 reloader_name += " reloader"
245
246 self.name = reloader_name
247
248 self.observer_class = Observer
249 self.event_handler = _CustomHandler()
250 self.should_reload = False
251
252 def trigger_reload(self, filename):
253 # This is called inside an event handler, which means throwing
254 # SystemExit has no effect.
255 # https://github.com/gorakhargosh/watchdog/issues/294
256 self.should_reload = True
257 self.log_reload(filename)
258
259 def run(self):
260 watches = {}
261 observer = self.observer_class()
262 observer.start()
263
264 try:
265 while not self.should_reload:
266 to_delete = set(watches)
267 paths = _find_observable_paths(self.extra_files)
268 for path in paths:
269 if path not in watches:
270 try:
271 watches[path] = observer.schedule(
272 self.event_handler, path, recursive=True
273 )
274 except OSError:
275 # Clear this path from list of watches We don't want
276 # the same error message showing again in the next
277 # iteration.
278 watches[path] = None
279 to_delete.discard(path)
280 for path in to_delete:
281 watch = watches.pop(path, None)
282 if watch is not None:
283 observer.unschedule(watch)
284 self.observable_paths = paths
285 self._sleep(self.interval)
286 finally:
287 observer.stop()
288 observer.join()
289
290 sys.exit(3)
291
292
293 reloader_loops = {"stat": StatReloaderLoop, "watchdog": WatchdogReloaderLoop}
294
295 try:
296 __import__("watchdog.observers")
297 except ImportError:
298 reloader_loops["auto"] = reloader_loops["stat"]
299 else:
300 reloader_loops["auto"] = reloader_loops["watchdog"]
301
302
303 def ensure_echo_on():
304 """Ensure that echo mode is enabled. Some tools such as PDB disable
305 it which causes usability issues after reload."""
306 # tcgetattr will fail if stdin isn't a tty
307 if not sys.stdin.isatty():
308 return
309 try:
310 import termios
311 except ImportError:
312 return
313 attributes = termios.tcgetattr(sys.stdin)
314 if not attributes[3] & termios.ECHO:
315 attributes[3] |= termios.ECHO
316 termios.tcsetattr(sys.stdin, termios.TCSANOW, attributes)
317
318
319 def run_with_reloader(main_func, extra_files=None, interval=1, reloader_type="auto"):
320 """Run the given function in an independent python interpreter."""
321 import signal
322
323 reloader = reloader_loops[reloader_type](extra_files, interval)
324 signal.signal(signal.SIGTERM, lambda *args: sys.exit(0))
325 try:
326 if os.environ.get("WERKZEUG_RUN_MAIN") == "true":
327 ensure_echo_on()
328 t = threading.Thread(target=main_func, args=())
329 t.setDaemon(True)
330 t.start()
331 reloader.run()
332 else:
333 sys.exit(reloader.restart_with_reloader())
334 except KeyboardInterrupt:
335 pass
336
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/werkzeug/_reloader.py b/src/werkzeug/_reloader.py
--- a/src/werkzeug/_reloader.py
+++ b/src/werkzeug/_reloader.py
@@ -71,8 +71,14 @@
__main__ = sys.modules["__main__"]
# The value of __package__ indicates how Python was called. It may
- # not exist if a setuptools script is installed as an egg.
- if getattr(__main__, "__package__", None) is None:
+ # not exist if a setuptools script is installed as an egg. It may be
+ # set incorrectly for entry points created with pip on Windows.
+ if getattr(__main__, "__package__", None) is None or (
+ os.name == "nt"
+ and __main__.__package__ == ""
+ and not os.path.exists(py_script)
+ and os.path.exists(py_script + ".exe")
+ ):
# Executed a file, like "python app.py".
py_script = os.path.abspath(py_script)
@@ -83,7 +89,7 @@
py_script += ".exe"
if (
- os.path.splitext(rv[0])[1] == ".exe"
+ os.path.splitext(sys.executable)[1] == ".exe"
and os.path.splitext(py_script)[1] == ".exe"
):
rv.pop(0)
|
{"golden_diff": "diff --git a/src/werkzeug/_reloader.py b/src/werkzeug/_reloader.py\n--- a/src/werkzeug/_reloader.py\n+++ b/src/werkzeug/_reloader.py\n@@ -71,8 +71,14 @@\n __main__ = sys.modules[\"__main__\"]\n \n # The value of __package__ indicates how Python was called. It may\n- # not exist if a setuptools script is installed as an egg.\n- if getattr(__main__, \"__package__\", None) is None:\n+ # not exist if a setuptools script is installed as an egg. It may be\n+ # set incorrectly for entry points created with pip on Windows.\n+ if getattr(__main__, \"__package__\", None) is None or (\n+ os.name == \"nt\"\n+ and __main__.__package__ == \"\"\n+ and not os.path.exists(py_script)\n+ and os.path.exists(py_script + \".exe\")\n+ ):\n # Executed a file, like \"python app.py\".\n py_script = os.path.abspath(py_script)\n \n@@ -83,7 +89,7 @@\n py_script += \".exe\"\n \n if (\n- os.path.splitext(rv[0])[1] == \".exe\"\n+ os.path.splitext(sys.executable)[1] == \".exe\"\n and os.path.splitext(py_script)[1] == \".exe\"\n ):\n rv.pop(0)\n", "issue": "Reloader doesn't add \".exe\" to file on Windows\nif I run a flask app under 0.15.5 with\r\nFLASK_ENV=development \r\nthe dev server throws an error.\r\n\r\nWith FLASK_ENV=production the server starts ok\r\n\r\nAfter reinstalling 0.15.4 the same app works ok (both in dev and prod mode).\r\n\r\nWindows/py3.6.7/pipenv\r\n\r\nKind regards\n", "before_files": [{"content": "import os\nimport subprocess\nimport sys\nimport threading\nimport time\nfrom itertools import chain\n\nfrom ._compat import iteritems\nfrom ._compat import PY2\nfrom ._compat import text_type\nfrom ._internal import _log\n\n\ndef _iter_module_files():\n \"\"\"This iterates over all relevant Python files. It goes through all\n loaded files from modules, all files in folders of already loaded modules\n as well as all files reachable through a package.\n \"\"\"\n # The list call is necessary on Python 3 in case the module\n # dictionary modifies during iteration.\n for module in list(sys.modules.values()):\n if module is None:\n continue\n filename = getattr(module, \"__file__\", None)\n if filename:\n if os.path.isdir(filename) and os.path.exists(\n os.path.join(filename, \"__init__.py\")\n ):\n filename = os.path.join(filename, \"__init__.py\")\n\n old = None\n while not os.path.isfile(filename):\n old = filename\n filename = os.path.dirname(filename)\n if filename == old:\n break\n else:\n if filename[-4:] in (\".pyc\", \".pyo\"):\n filename = filename[:-1]\n yield filename\n\n\ndef _find_observable_paths(extra_files=None):\n \"\"\"Finds all paths that should be observed.\"\"\"\n rv = set(\n os.path.dirname(os.path.abspath(x)) if os.path.isfile(x) else os.path.abspath(x)\n for x in sys.path\n )\n\n for filename in extra_files or ():\n rv.add(os.path.dirname(os.path.abspath(filename)))\n\n for module in list(sys.modules.values()):\n fn = getattr(module, \"__file__\", None)\n if fn is None:\n continue\n fn = os.path.abspath(fn)\n rv.add(os.path.dirname(fn))\n\n return _find_common_roots(rv)\n\n\ndef _get_args_for_reloading():\n \"\"\"Determine how the script was executed, and return the args needed\n to execute it again in a new process.\n \"\"\"\n rv = [sys.executable]\n py_script = sys.argv[0]\n args = sys.argv[1:]\n # Need to look at main module to determine how it was executed.\n __main__ = sys.modules[\"__main__\"]\n\n # The value of __package__ indicates how Python was called. It may\n # not exist if a setuptools script is installed as an egg.\n if getattr(__main__, \"__package__\", None) is None:\n # Executed a file, like \"python app.py\".\n py_script = os.path.abspath(py_script)\n\n if os.name == \"nt\":\n # Windows entry points have \".exe\" extension and should be\n # called directly.\n if not os.path.exists(py_script) and os.path.exists(py_script + \".exe\"):\n py_script += \".exe\"\n\n if (\n os.path.splitext(rv[0])[1] == \".exe\"\n and os.path.splitext(py_script)[1] == \".exe\"\n ):\n rv.pop(0)\n\n rv.append(py_script)\n else:\n # Executed a module, like \"python -m werkzeug.serving\".\n if sys.argv[0] == \"-m\":\n # Flask works around previous behavior by putting\n # \"-m flask\" in sys.argv.\n # TODO remove this once Flask no longer misbehaves\n args = sys.argv\n else:\n if os.path.isfile(py_script):\n # Rewritten by Python from \"-m script\" to \"/path/to/script.py\".\n py_module = __main__.__package__\n name = os.path.splitext(os.path.basename(py_script))[0]\n\n if name != \"__main__\":\n py_module += \".\" + name\n else:\n # Incorrectly rewritten by pydevd debugger from \"-m script\" to \"script\".\n py_module = py_script\n\n rv.extend((\"-m\", py_module.lstrip(\".\")))\n\n rv.extend(args)\n return rv\n\n\ndef _find_common_roots(paths):\n \"\"\"Out of some paths it finds the common roots that need monitoring.\"\"\"\n paths = [x.split(os.path.sep) for x in paths]\n root = {}\n for chunks in sorted(paths, key=len, reverse=True):\n node = root\n for chunk in chunks:\n node = node.setdefault(chunk, {})\n node.clear()\n\n rv = set()\n\n def _walk(node, path):\n for prefix, child in iteritems(node):\n _walk(child, path + (prefix,))\n if not node:\n rv.add(\"/\".join(path))\n\n _walk(root, ())\n return rv\n\n\nclass ReloaderLoop(object):\n name = None\n\n # monkeypatched by testsuite. wrapping with `staticmethod` is required in\n # case time.sleep has been replaced by a non-c function (e.g. by\n # `eventlet.monkey_patch`) before we get here\n _sleep = staticmethod(time.sleep)\n\n def __init__(self, extra_files=None, interval=1):\n self.extra_files = set(os.path.abspath(x) for x in extra_files or ())\n self.interval = interval\n\n def run(self):\n pass\n\n def restart_with_reloader(self):\n \"\"\"Spawn a new Python interpreter with the same arguments as this one,\n but running the reloader thread.\n \"\"\"\n while 1:\n _log(\"info\", \" * Restarting with %s\" % self.name)\n args = _get_args_for_reloading()\n\n # a weird bug on windows. sometimes unicode strings end up in the\n # environment and subprocess.call does not like this, encode them\n # to latin1 and continue.\n if os.name == \"nt\" and PY2:\n new_environ = {}\n for key, value in iteritems(os.environ):\n if isinstance(key, text_type):\n key = key.encode(\"iso-8859-1\")\n if isinstance(value, text_type):\n value = value.encode(\"iso-8859-1\")\n new_environ[key] = value\n else:\n new_environ = os.environ.copy()\n\n new_environ[\"WERKZEUG_RUN_MAIN\"] = \"true\"\n exit_code = subprocess.call(args, env=new_environ, close_fds=False)\n if exit_code != 3:\n return exit_code\n\n def trigger_reload(self, filename):\n self.log_reload(filename)\n sys.exit(3)\n\n def log_reload(self, filename):\n filename = os.path.abspath(filename)\n _log(\"info\", \" * Detected change in %r, reloading\" % filename)\n\n\nclass StatReloaderLoop(ReloaderLoop):\n name = \"stat\"\n\n def run(self):\n mtimes = {}\n while 1:\n for filename in chain(_iter_module_files(), self.extra_files):\n try:\n mtime = os.stat(filename).st_mtime\n except OSError:\n continue\n\n old_time = mtimes.get(filename)\n if old_time is None:\n mtimes[filename] = mtime\n continue\n elif mtime > old_time:\n self.trigger_reload(filename)\n self._sleep(self.interval)\n\n\nclass WatchdogReloaderLoop(ReloaderLoop):\n def __init__(self, *args, **kwargs):\n ReloaderLoop.__init__(self, *args, **kwargs)\n from watchdog.observers import Observer\n from watchdog.events import FileSystemEventHandler\n\n self.observable_paths = set()\n\n def _check_modification(filename):\n if filename in self.extra_files:\n self.trigger_reload(filename)\n dirname = os.path.dirname(filename)\n if dirname.startswith(tuple(self.observable_paths)):\n if filename.endswith((\".pyc\", \".pyo\", \".py\")):\n self.trigger_reload(filename)\n\n class _CustomHandler(FileSystemEventHandler):\n def on_created(self, event):\n _check_modification(event.src_path)\n\n def on_modified(self, event):\n _check_modification(event.src_path)\n\n def on_moved(self, event):\n _check_modification(event.src_path)\n _check_modification(event.dest_path)\n\n def on_deleted(self, event):\n _check_modification(event.src_path)\n\n reloader_name = Observer.__name__.lower()\n if reloader_name.endswith(\"observer\"):\n reloader_name = reloader_name[:-8]\n reloader_name += \" reloader\"\n\n self.name = reloader_name\n\n self.observer_class = Observer\n self.event_handler = _CustomHandler()\n self.should_reload = False\n\n def trigger_reload(self, filename):\n # This is called inside an event handler, which means throwing\n # SystemExit has no effect.\n # https://github.com/gorakhargosh/watchdog/issues/294\n self.should_reload = True\n self.log_reload(filename)\n\n def run(self):\n watches = {}\n observer = self.observer_class()\n observer.start()\n\n try:\n while not self.should_reload:\n to_delete = set(watches)\n paths = _find_observable_paths(self.extra_files)\n for path in paths:\n if path not in watches:\n try:\n watches[path] = observer.schedule(\n self.event_handler, path, recursive=True\n )\n except OSError:\n # Clear this path from list of watches We don't want\n # the same error message showing again in the next\n # iteration.\n watches[path] = None\n to_delete.discard(path)\n for path in to_delete:\n watch = watches.pop(path, None)\n if watch is not None:\n observer.unschedule(watch)\n self.observable_paths = paths\n self._sleep(self.interval)\n finally:\n observer.stop()\n observer.join()\n\n sys.exit(3)\n\n\nreloader_loops = {\"stat\": StatReloaderLoop, \"watchdog\": WatchdogReloaderLoop}\n\ntry:\n __import__(\"watchdog.observers\")\nexcept ImportError:\n reloader_loops[\"auto\"] = reloader_loops[\"stat\"]\nelse:\n reloader_loops[\"auto\"] = reloader_loops[\"watchdog\"]\n\n\ndef ensure_echo_on():\n \"\"\"Ensure that echo mode is enabled. Some tools such as PDB disable\n it which causes usability issues after reload.\"\"\"\n # tcgetattr will fail if stdin isn't a tty\n if not sys.stdin.isatty():\n return\n try:\n import termios\n except ImportError:\n return\n attributes = termios.tcgetattr(sys.stdin)\n if not attributes[3] & termios.ECHO:\n attributes[3] |= termios.ECHO\n termios.tcsetattr(sys.stdin, termios.TCSANOW, attributes)\n\n\ndef run_with_reloader(main_func, extra_files=None, interval=1, reloader_type=\"auto\"):\n \"\"\"Run the given function in an independent python interpreter.\"\"\"\n import signal\n\n reloader = reloader_loops[reloader_type](extra_files, interval)\n signal.signal(signal.SIGTERM, lambda *args: sys.exit(0))\n try:\n if os.environ.get(\"WERKZEUG_RUN_MAIN\") == \"true\":\n ensure_echo_on()\n t = threading.Thread(target=main_func, args=())\n t.setDaemon(True)\n t.start()\n reloader.run()\n else:\n sys.exit(reloader.restart_with_reloader())\n except KeyboardInterrupt:\n pass\n", "path": "src/werkzeug/_reloader.py"}], "after_files": [{"content": "import os\nimport subprocess\nimport sys\nimport threading\nimport time\nfrom itertools import chain\n\nfrom ._compat import iteritems\nfrom ._compat import PY2\nfrom ._compat import text_type\nfrom ._internal import _log\n\n\ndef _iter_module_files():\n \"\"\"This iterates over all relevant Python files. It goes through all\n loaded files from modules, all files in folders of already loaded modules\n as well as all files reachable through a package.\n \"\"\"\n # The list call is necessary on Python 3 in case the module\n # dictionary modifies during iteration.\n for module in list(sys.modules.values()):\n if module is None:\n continue\n filename = getattr(module, \"__file__\", None)\n if filename:\n if os.path.isdir(filename) and os.path.exists(\n os.path.join(filename, \"__init__.py\")\n ):\n filename = os.path.join(filename, \"__init__.py\")\n\n old = None\n while not os.path.isfile(filename):\n old = filename\n filename = os.path.dirname(filename)\n if filename == old:\n break\n else:\n if filename[-4:] in (\".pyc\", \".pyo\"):\n filename = filename[:-1]\n yield filename\n\n\ndef _find_observable_paths(extra_files=None):\n \"\"\"Finds all paths that should be observed.\"\"\"\n rv = set(\n os.path.dirname(os.path.abspath(x)) if os.path.isfile(x) else os.path.abspath(x)\n for x in sys.path\n )\n\n for filename in extra_files or ():\n rv.add(os.path.dirname(os.path.abspath(filename)))\n\n for module in list(sys.modules.values()):\n fn = getattr(module, \"__file__\", None)\n if fn is None:\n continue\n fn = os.path.abspath(fn)\n rv.add(os.path.dirname(fn))\n\n return _find_common_roots(rv)\n\n\ndef _get_args_for_reloading():\n \"\"\"Determine how the script was executed, and return the args needed\n to execute it again in a new process.\n \"\"\"\n rv = [sys.executable]\n py_script = sys.argv[0]\n args = sys.argv[1:]\n # Need to look at main module to determine how it was executed.\n __main__ = sys.modules[\"__main__\"]\n\n # The value of __package__ indicates how Python was called. It may\n # not exist if a setuptools script is installed as an egg. It may be\n # set incorrectly for entry points created with pip on Windows.\n if getattr(__main__, \"__package__\", None) is None or (\n os.name == \"nt\"\n and __main__.__package__ == \"\"\n and not os.path.exists(py_script)\n and os.path.exists(py_script + \".exe\")\n ):\n # Executed a file, like \"python app.py\".\n py_script = os.path.abspath(py_script)\n\n if os.name == \"nt\":\n # Windows entry points have \".exe\" extension and should be\n # called directly.\n if not os.path.exists(py_script) and os.path.exists(py_script + \".exe\"):\n py_script += \".exe\"\n\n if (\n os.path.splitext(sys.executable)[1] == \".exe\"\n and os.path.splitext(py_script)[1] == \".exe\"\n ):\n rv.pop(0)\n\n rv.append(py_script)\n else:\n # Executed a module, like \"python -m werkzeug.serving\".\n if sys.argv[0] == \"-m\":\n # Flask works around previous behavior by putting\n # \"-m flask\" in sys.argv.\n # TODO remove this once Flask no longer misbehaves\n args = sys.argv\n else:\n if os.path.isfile(py_script):\n # Rewritten by Python from \"-m script\" to \"/path/to/script.py\".\n py_module = __main__.__package__\n name = os.path.splitext(os.path.basename(py_script))[0]\n\n if name != \"__main__\":\n py_module += \".\" + name\n else:\n # Incorrectly rewritten by pydevd debugger from \"-m script\" to \"script\".\n py_module = py_script\n\n rv.extend((\"-m\", py_module.lstrip(\".\")))\n\n rv.extend(args)\n return rv\n\n\ndef _find_common_roots(paths):\n \"\"\"Out of some paths it finds the common roots that need monitoring.\"\"\"\n paths = [x.split(os.path.sep) for x in paths]\n root = {}\n for chunks in sorted(paths, key=len, reverse=True):\n node = root\n for chunk in chunks:\n node = node.setdefault(chunk, {})\n node.clear()\n\n rv = set()\n\n def _walk(node, path):\n for prefix, child in iteritems(node):\n _walk(child, path + (prefix,))\n if not node:\n rv.add(\"/\".join(path))\n\n _walk(root, ())\n return rv\n\n\nclass ReloaderLoop(object):\n name = None\n\n # monkeypatched by testsuite. wrapping with `staticmethod` is required in\n # case time.sleep has been replaced by a non-c function (e.g. by\n # `eventlet.monkey_patch`) before we get here\n _sleep = staticmethod(time.sleep)\n\n def __init__(self, extra_files=None, interval=1):\n self.extra_files = set(os.path.abspath(x) for x in extra_files or ())\n self.interval = interval\n\n def run(self):\n pass\n\n def restart_with_reloader(self):\n \"\"\"Spawn a new Python interpreter with the same arguments as this one,\n but running the reloader thread.\n \"\"\"\n while 1:\n _log(\"info\", \" * Restarting with %s\" % self.name)\n args = _get_args_for_reloading()\n\n # a weird bug on windows. sometimes unicode strings end up in the\n # environment and subprocess.call does not like this, encode them\n # to latin1 and continue.\n if os.name == \"nt\" and PY2:\n new_environ = {}\n for key, value in iteritems(os.environ):\n if isinstance(key, text_type):\n key = key.encode(\"iso-8859-1\")\n if isinstance(value, text_type):\n value = value.encode(\"iso-8859-1\")\n new_environ[key] = value\n else:\n new_environ = os.environ.copy()\n\n new_environ[\"WERKZEUG_RUN_MAIN\"] = \"true\"\n exit_code = subprocess.call(args, env=new_environ, close_fds=False)\n if exit_code != 3:\n return exit_code\n\n def trigger_reload(self, filename):\n self.log_reload(filename)\n sys.exit(3)\n\n def log_reload(self, filename):\n filename = os.path.abspath(filename)\n _log(\"info\", \" * Detected change in %r, reloading\" % filename)\n\n\nclass StatReloaderLoop(ReloaderLoop):\n name = \"stat\"\n\n def run(self):\n mtimes = {}\n while 1:\n for filename in chain(_iter_module_files(), self.extra_files):\n try:\n mtime = os.stat(filename).st_mtime\n except OSError:\n continue\n\n old_time = mtimes.get(filename)\n if old_time is None:\n mtimes[filename] = mtime\n continue\n elif mtime > old_time:\n self.trigger_reload(filename)\n self._sleep(self.interval)\n\n\nclass WatchdogReloaderLoop(ReloaderLoop):\n def __init__(self, *args, **kwargs):\n ReloaderLoop.__init__(self, *args, **kwargs)\n from watchdog.observers import Observer\n from watchdog.events import FileSystemEventHandler\n\n self.observable_paths = set()\n\n def _check_modification(filename):\n if filename in self.extra_files:\n self.trigger_reload(filename)\n dirname = os.path.dirname(filename)\n if dirname.startswith(tuple(self.observable_paths)):\n if filename.endswith((\".pyc\", \".pyo\", \".py\")):\n self.trigger_reload(filename)\n\n class _CustomHandler(FileSystemEventHandler):\n def on_created(self, event):\n _check_modification(event.src_path)\n\n def on_modified(self, event):\n _check_modification(event.src_path)\n\n def on_moved(self, event):\n _check_modification(event.src_path)\n _check_modification(event.dest_path)\n\n def on_deleted(self, event):\n _check_modification(event.src_path)\n\n reloader_name = Observer.__name__.lower()\n if reloader_name.endswith(\"observer\"):\n reloader_name = reloader_name[:-8]\n reloader_name += \" reloader\"\n\n self.name = reloader_name\n\n self.observer_class = Observer\n self.event_handler = _CustomHandler()\n self.should_reload = False\n\n def trigger_reload(self, filename):\n # This is called inside an event handler, which means throwing\n # SystemExit has no effect.\n # https://github.com/gorakhargosh/watchdog/issues/294\n self.should_reload = True\n self.log_reload(filename)\n\n def run(self):\n watches = {}\n observer = self.observer_class()\n observer.start()\n\n try:\n while not self.should_reload:\n to_delete = set(watches)\n paths = _find_observable_paths(self.extra_files)\n for path in paths:\n if path not in watches:\n try:\n watches[path] = observer.schedule(\n self.event_handler, path, recursive=True\n )\n except OSError:\n # Clear this path from list of watches We don't want\n # the same error message showing again in the next\n # iteration.\n watches[path] = None\n to_delete.discard(path)\n for path in to_delete:\n watch = watches.pop(path, None)\n if watch is not None:\n observer.unschedule(watch)\n self.observable_paths = paths\n self._sleep(self.interval)\n finally:\n observer.stop()\n observer.join()\n\n sys.exit(3)\n\n\nreloader_loops = {\"stat\": StatReloaderLoop, \"watchdog\": WatchdogReloaderLoop}\n\ntry:\n __import__(\"watchdog.observers\")\nexcept ImportError:\n reloader_loops[\"auto\"] = reloader_loops[\"stat\"]\nelse:\n reloader_loops[\"auto\"] = reloader_loops[\"watchdog\"]\n\n\ndef ensure_echo_on():\n \"\"\"Ensure that echo mode is enabled. Some tools such as PDB disable\n it which causes usability issues after reload.\"\"\"\n # tcgetattr will fail if stdin isn't a tty\n if not sys.stdin.isatty():\n return\n try:\n import termios\n except ImportError:\n return\n attributes = termios.tcgetattr(sys.stdin)\n if not attributes[3] & termios.ECHO:\n attributes[3] |= termios.ECHO\n termios.tcsetattr(sys.stdin, termios.TCSANOW, attributes)\n\n\ndef run_with_reloader(main_func, extra_files=None, interval=1, reloader_type=\"auto\"):\n \"\"\"Run the given function in an independent python interpreter.\"\"\"\n import signal\n\n reloader = reloader_loops[reloader_type](extra_files, interval)\n signal.signal(signal.SIGTERM, lambda *args: sys.exit(0))\n try:\n if os.environ.get(\"WERKZEUG_RUN_MAIN\") == \"true\":\n ensure_echo_on()\n t = threading.Thread(target=main_func, args=())\n t.setDaemon(True)\n t.start()\n reloader.run()\n else:\n sys.exit(reloader.restart_with_reloader())\n except KeyboardInterrupt:\n pass\n", "path": "src/werkzeug/_reloader.py"}]}
| 3,694 | 310 |
gh_patches_debug_116
|
rasdani/github-patches
|
git_diff
|
sanic-org__sanic-1530
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Publish 19.3 release to PyPI
Thank you for the release 3 days ago!
https://github.com/huge-success/sanic/releases/tag/19.3
It's missing from PyPI at the moment:
https://pypi.org/project/sanic/#history
Please publish it at your convenience 🙇
Keep up the awesome work ❤️
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sanic/__init__.py`
Content:
```
1 from sanic.app import Sanic
2 from sanic.blueprints import Blueprint
3
4
5 __version__ = "19.03.0"
6
7 __all__ = ["Sanic", "Blueprint"]
8
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sanic/__init__.py b/sanic/__init__.py
--- a/sanic/__init__.py
+++ b/sanic/__init__.py
@@ -2,6 +2,6 @@
from sanic.blueprints import Blueprint
-__version__ = "19.03.0"
+__version__ = "19.03.1"
__all__ = ["Sanic", "Blueprint"]
|
{"golden_diff": "diff --git a/sanic/__init__.py b/sanic/__init__.py\n--- a/sanic/__init__.py\n+++ b/sanic/__init__.py\n@@ -2,6 +2,6 @@\n from sanic.blueprints import Blueprint\n \n \n-__version__ = \"19.03.0\"\n+__version__ = \"19.03.1\"\n \n __all__ = [\"Sanic\", \"Blueprint\"]\n", "issue": "Publish 19.3 release to PyPI\nThank you for the release 3 days ago!\r\n\r\nhttps://github.com/huge-success/sanic/releases/tag/19.3\r\n\r\nIt's missing from PyPI at the moment:\r\n\r\nhttps://pypi.org/project/sanic/#history\r\n\r\nPlease publish it at your convenience \ud83d\ude47 \r\n\r\nKeep up the awesome work \u2764\ufe0f \n", "before_files": [{"content": "from sanic.app import Sanic\nfrom sanic.blueprints import Blueprint\n\n\n__version__ = \"19.03.0\"\n\n__all__ = [\"Sanic\", \"Blueprint\"]\n", "path": "sanic/__init__.py"}], "after_files": [{"content": "from sanic.app import Sanic\nfrom sanic.blueprints import Blueprint\n\n\n__version__ = \"19.03.1\"\n\n__all__ = [\"Sanic\", \"Blueprint\"]\n", "path": "sanic/__init__.py"}]}
| 389 | 95 |
gh_patches_debug_22045
|
rasdani/github-patches
|
git_diff
|
sublimelsp__LSP-1230
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
"show_view_status" is not working
I've set `show_view_status` to `false`, but still can see `LSP-json` prefix
***
* OS and language server: Windows
* How you installed LSP (Package Control or from git?): Package Control
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `plugin/core/types.py`
Content:
```
1 from .collections import DottedDict
2 from .logging import debug
3 from .typing import Optional, List, Dict, Generator, Callable
4 from threading import RLock
5 import contextlib
6 import functools
7 import sublime
8 import time
9
10
11 @contextlib.contextmanager
12 def runtime(token: str) -> Generator[None, None, None]:
13 t = time.time()
14 yield
15 debug(token, "running time:", int((time.time() - t) * 1000000), "μs")
16
17
18 def debounced(f: Callable[[], None], timeout_ms: int = 0, condition: Callable[[], bool] = lambda: True,
19 async_thread: bool = False) -> None:
20 """
21 Possibly run a function at a later point in time, either on the async thread or on the main thread.
22
23 :param f: The function to possibly run
24 :param timeout_ms: The time in milliseconds after which to possibly to run the function
25 :param condition: The condition that must evaluate to True in order to run the funtion
26 :param async_thread: If true, run the function on the async worker thread, otherwise run the function on the
27 main thread
28 """
29
30 def run() -> None:
31 if condition():
32 f()
33
34 runner = sublime.set_timeout_async if async_thread else sublime.set_timeout
35 runner(run, timeout_ms)
36
37
38 def _settings_style_to_add_regions_flag(style: str) -> int:
39 flags = 0
40 if style == "fill":
41 pass
42 elif style == "box":
43 flags = sublime.DRAW_NO_FILL
44 else:
45 flags = sublime.DRAW_NO_FILL | sublime.DRAW_NO_OUTLINE
46 if style == "underline":
47 flags |= sublime.DRAW_SOLID_UNDERLINE
48 elif style == "stippled":
49 flags |= sublime.DRAW_STIPPLED_UNDERLINE
50 elif style == "squiggly":
51 flags |= sublime.DRAW_SQUIGGLY_UNDERLINE
52 return flags
53
54
55 class Debouncer:
56
57 def __init__(self) -> None:
58 self._current_id = -1
59 self._next_id = 0
60 self._current_id_lock = RLock()
61
62 def debounce(self, f: Callable[[], None], timeout_ms: int = 0, condition: Callable[[], bool] = lambda: True,
63 async_thread: bool = False) -> None:
64 """
65 Possibly run a function at a later point in time, either on the async thread or on the main thread.
66
67 :param f: The function to possibly run
68 :param timeout_ms: The time in milliseconds after which to possibly to run the function
69 :param condition: The condition that must evaluate to True in order to run the funtion
70 :param async_thread: If true, run the function on the async worker thread, otherwise run
71 the function on the main thread
72 """
73
74 def run(debounce_id: int) -> None:
75 with self._current_id_lock:
76 if debounce_id != self._current_id:
77 return
78 if condition():
79 f()
80
81 runner = sublime.set_timeout_async if async_thread else sublime.set_timeout
82 with self._current_id_lock:
83 current_id = self._current_id = self._next_id
84 self._next_id += 1
85 runner(lambda: run(current_id), timeout_ms)
86
87 def cancel_pending(self) -> None:
88 with self._current_id_lock:
89 self._current_id = -1
90
91
92 class Settings:
93
94 def __init__(self) -> None:
95 self.show_view_status = True
96 self.auto_show_diagnostics_panel = 'always'
97 self.auto_show_diagnostics_panel_level = 2
98 self.diagnostics_panel_include_severity_level = 4
99 self.show_diagnostics_count_in_view_status = False
100 self.show_diagnostics_in_view_status = True
101 self.show_diagnostics_severity_level = 2
102 self.only_show_lsp_completions = False
103 self.diagnostics_highlight_style = "underline"
104 self.document_highlight_style = "stippled"
105 self.document_highlight_scopes = {
106 "unknown": "text",
107 "text": "text",
108 "read": "markup.inserted",
109 "write": "markup.changed"
110 }
111 self.diagnostics_gutter_marker = "dot"
112 self.diagnostics_delay_ms = 0
113 self.diagnostics_additional_delay_auto_complete_ms = 0
114 self.show_symbol_action_links = False
115 self.show_references_in_quick_panel = False
116 self.disabled_capabilities = [] # type: List[str]
117 self.log_debug = False
118 self.log_server = [] # type: List[str]
119 self.log_stderr = False
120 self.log_max_size = 8 * 1024
121 self.lsp_format_on_save = False
122 self.show_code_actions = "annotation"
123 self.lsp_code_actions_on_save = {} # type: Dict[str, bool]
124 self.code_action_on_save_timeout_ms = 2000
125
126 def show_diagnostics_panel_always(self) -> bool:
127 return self.auto_show_diagnostics_panel == "always"
128
129 def show_diagnostics_panel_on_save(self) -> bool:
130 return self.auto_show_diagnostics_panel == "saved"
131
132 def document_highlight_style_to_add_regions_flags(self) -> int:
133 return _settings_style_to_add_regions_flag(self.document_highlight_style)
134
135 def diagnostics_highlight_style_to_add_regions_flag(self) -> int:
136 # TODO: Unused for now
137 return _settings_style_to_add_regions_flag(self.diagnostics_highlight_style)
138
139
140 class ClientStates(object):
141 STARTING = 0
142 READY = 1
143 STOPPING = 2
144
145
146 class LanguageConfig(object):
147
148 __slots__ = ('id', 'document_selector', 'feature_selector')
149
150 def __init__(
151 self,
152 language_id: str,
153 document_selector: Optional[str] = None,
154 feature_selector: Optional[str] = None
155 ) -> None:
156 self.id = language_id
157 self.document_selector = document_selector if document_selector else "source.{}".format(self.id)
158 self.feature_selector = feature_selector if feature_selector else self.document_selector
159
160 @functools.lru_cache(None)
161 def score_document(self, scope: str) -> int:
162 return sublime.score_selector(scope, self.document_selector)
163
164 def score_feature(self, scope: str) -> int:
165 return sublime.score_selector(scope, self.feature_selector)
166
167 def match_scope(self, scope: str) -> bool:
168 # Every part of a x.y.z scope seems to contribute 8.
169 # An empty selector result in a score of 1.
170 # A non-matching non-empty selector results in a score of 0.
171 # We want to match at least one part of an x.y.z, and we don't want to match on empty selectors.
172 return self.score_document(scope) >= 8
173
174
175 class ClientConfig(object):
176 def __init__(self,
177 name: str,
178 binary_args: List[str],
179 languages: List[LanguageConfig],
180 tcp_port: Optional[int],
181 enabled: bool = True,
182 init_options: dict = dict(),
183 settings: DottedDict = DottedDict(),
184 env: dict = dict(),
185 tcp_host: Optional[str] = None,
186 tcp_mode: Optional[str] = None,
187 experimental_capabilities: dict = dict()) -> None:
188 self.name = name
189 self.binary_args = binary_args
190 self.languages = languages
191 self.tcp_port = tcp_port
192 self.tcp_host = tcp_host
193 self.tcp_mode = tcp_mode
194 self.enabled = enabled
195 self.init_options = init_options
196 self.settings = settings
197 self.env = env
198 self.experimental_capabilities = experimental_capabilities
199 self.status_key = "lsp_{}".format(self.name)
200
201 def set_view_status(self, view: sublime.View, message: str) -> None:
202 status = "{}: {}".format(self.name, message) if message else self.name
203 view.set_status(self.status_key, status)
204
205 def erase_view_status(self, view: sublime.View) -> None:
206 view.erase_status(self.status_key)
207
208 def match_scope(self, scope: str) -> bool:
209 return any(language.match_scope(scope) for language in self.languages)
210
211 def match_view(self, view: sublime.View) -> bool:
212 return self.match_scope(view2scope(view))
213
214 def score_feature(self, scope: str) -> int:
215 highest_score = 0
216 for language in self.languages:
217 score = language.score_feature(scope)
218 if score > highest_score:
219 highest_score = score
220 return highest_score
221
222
223 def syntax2scope(syntax: str) -> Optional[str]:
224 try:
225 return next(filter(lambda d: d['path'] == syntax, sublime.list_syntaxes()))['scope']
226 except StopIteration:
227 return None
228
229
230 def view2scope(view: sublime.View) -> str:
231 try:
232 return view.scope_name(0).split()[0]
233 except IndexError:
234 return ''
235
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/plugin/core/types.py b/plugin/core/types.py
--- a/plugin/core/types.py
+++ b/plugin/core/types.py
@@ -133,7 +133,6 @@
return _settings_style_to_add_regions_flag(self.document_highlight_style)
def diagnostics_highlight_style_to_add_regions_flag(self) -> int:
- # TODO: Unused for now
return _settings_style_to_add_regions_flag(self.diagnostics_highlight_style)
@@ -199,8 +198,9 @@
self.status_key = "lsp_{}".format(self.name)
def set_view_status(self, view: sublime.View, message: str) -> None:
- status = "{}: {}".format(self.name, message) if message else self.name
- view.set_status(self.status_key, status)
+ if sublime.load_settings("LSP.sublime-settings").get("show_view_status"):
+ status = "{}: {}".format(self.name, message) if message else self.name
+ view.set_status(self.status_key, status)
def erase_view_status(self, view: sublime.View) -> None:
view.erase_status(self.status_key)
|
{"golden_diff": "diff --git a/plugin/core/types.py b/plugin/core/types.py\n--- a/plugin/core/types.py\n+++ b/plugin/core/types.py\n@@ -133,7 +133,6 @@\n return _settings_style_to_add_regions_flag(self.document_highlight_style)\n \n def diagnostics_highlight_style_to_add_regions_flag(self) -> int:\n- # TODO: Unused for now\n return _settings_style_to_add_regions_flag(self.diagnostics_highlight_style)\n \n \n@@ -199,8 +198,9 @@\n self.status_key = \"lsp_{}\".format(self.name)\n \n def set_view_status(self, view: sublime.View, message: str) -> None:\n- status = \"{}: {}\".format(self.name, message) if message else self.name\n- view.set_status(self.status_key, status)\n+ if sublime.load_settings(\"LSP.sublime-settings\").get(\"show_view_status\"):\n+ status = \"{}: {}\".format(self.name, message) if message else self.name\n+ view.set_status(self.status_key, status)\n \n def erase_view_status(self, view: sublime.View) -> None:\n view.erase_status(self.status_key)\n", "issue": "\"show_view_status\" is not working\nI've set `show_view_status` to `false`, but still can see `LSP-json` prefix\r\n\r\n***\r\n\r\n* OS and language server: Windows\r\n* How you installed LSP (Package Control or from git?): Package Control\r\n\n", "before_files": [{"content": "from .collections import DottedDict\nfrom .logging import debug\nfrom .typing import Optional, List, Dict, Generator, Callable\nfrom threading import RLock\nimport contextlib\nimport functools\nimport sublime\nimport time\n\n\[email protected]\ndef runtime(token: str) -> Generator[None, None, None]:\n t = time.time()\n yield\n debug(token, \"running time:\", int((time.time() - t) * 1000000), \"\u03bcs\")\n\n\ndef debounced(f: Callable[[], None], timeout_ms: int = 0, condition: Callable[[], bool] = lambda: True,\n async_thread: bool = False) -> None:\n \"\"\"\n Possibly run a function at a later point in time, either on the async thread or on the main thread.\n\n :param f: The function to possibly run\n :param timeout_ms: The time in milliseconds after which to possibly to run the function\n :param condition: The condition that must evaluate to True in order to run the funtion\n :param async_thread: If true, run the function on the async worker thread, otherwise run the function on the\n main thread\n \"\"\"\n\n def run() -> None:\n if condition():\n f()\n\n runner = sublime.set_timeout_async if async_thread else sublime.set_timeout\n runner(run, timeout_ms)\n\n\ndef _settings_style_to_add_regions_flag(style: str) -> int:\n flags = 0\n if style == \"fill\":\n pass\n elif style == \"box\":\n flags = sublime.DRAW_NO_FILL\n else:\n flags = sublime.DRAW_NO_FILL | sublime.DRAW_NO_OUTLINE\n if style == \"underline\":\n flags |= sublime.DRAW_SOLID_UNDERLINE\n elif style == \"stippled\":\n flags |= sublime.DRAW_STIPPLED_UNDERLINE\n elif style == \"squiggly\":\n flags |= sublime.DRAW_SQUIGGLY_UNDERLINE\n return flags\n\n\nclass Debouncer:\n\n def __init__(self) -> None:\n self._current_id = -1\n self._next_id = 0\n self._current_id_lock = RLock()\n\n def debounce(self, f: Callable[[], None], timeout_ms: int = 0, condition: Callable[[], bool] = lambda: True,\n async_thread: bool = False) -> None:\n \"\"\"\n Possibly run a function at a later point in time, either on the async thread or on the main thread.\n\n :param f: The function to possibly run\n :param timeout_ms: The time in milliseconds after which to possibly to run the function\n :param condition: The condition that must evaluate to True in order to run the funtion\n :param async_thread: If true, run the function on the async worker thread, otherwise run\n the function on the main thread\n \"\"\"\n\n def run(debounce_id: int) -> None:\n with self._current_id_lock:\n if debounce_id != self._current_id:\n return\n if condition():\n f()\n\n runner = sublime.set_timeout_async if async_thread else sublime.set_timeout\n with self._current_id_lock:\n current_id = self._current_id = self._next_id\n self._next_id += 1\n runner(lambda: run(current_id), timeout_ms)\n\n def cancel_pending(self) -> None:\n with self._current_id_lock:\n self._current_id = -1\n\n\nclass Settings:\n\n def __init__(self) -> None:\n self.show_view_status = True\n self.auto_show_diagnostics_panel = 'always'\n self.auto_show_diagnostics_panel_level = 2\n self.diagnostics_panel_include_severity_level = 4\n self.show_diagnostics_count_in_view_status = False\n self.show_diagnostics_in_view_status = True\n self.show_diagnostics_severity_level = 2\n self.only_show_lsp_completions = False\n self.diagnostics_highlight_style = \"underline\"\n self.document_highlight_style = \"stippled\"\n self.document_highlight_scopes = {\n \"unknown\": \"text\",\n \"text\": \"text\",\n \"read\": \"markup.inserted\",\n \"write\": \"markup.changed\"\n }\n self.diagnostics_gutter_marker = \"dot\"\n self.diagnostics_delay_ms = 0\n self.diagnostics_additional_delay_auto_complete_ms = 0\n self.show_symbol_action_links = False\n self.show_references_in_quick_panel = False\n self.disabled_capabilities = [] # type: List[str]\n self.log_debug = False\n self.log_server = [] # type: List[str]\n self.log_stderr = False\n self.log_max_size = 8 * 1024\n self.lsp_format_on_save = False\n self.show_code_actions = \"annotation\"\n self.lsp_code_actions_on_save = {} # type: Dict[str, bool]\n self.code_action_on_save_timeout_ms = 2000\n\n def show_diagnostics_panel_always(self) -> bool:\n return self.auto_show_diagnostics_panel == \"always\"\n\n def show_diagnostics_panel_on_save(self) -> bool:\n return self.auto_show_diagnostics_panel == \"saved\"\n\n def document_highlight_style_to_add_regions_flags(self) -> int:\n return _settings_style_to_add_regions_flag(self.document_highlight_style)\n\n def diagnostics_highlight_style_to_add_regions_flag(self) -> int:\n # TODO: Unused for now\n return _settings_style_to_add_regions_flag(self.diagnostics_highlight_style)\n\n\nclass ClientStates(object):\n STARTING = 0\n READY = 1\n STOPPING = 2\n\n\nclass LanguageConfig(object):\n\n __slots__ = ('id', 'document_selector', 'feature_selector')\n\n def __init__(\n self,\n language_id: str,\n document_selector: Optional[str] = None,\n feature_selector: Optional[str] = None\n ) -> None:\n self.id = language_id\n self.document_selector = document_selector if document_selector else \"source.{}\".format(self.id)\n self.feature_selector = feature_selector if feature_selector else self.document_selector\n\n @functools.lru_cache(None)\n def score_document(self, scope: str) -> int:\n return sublime.score_selector(scope, self.document_selector)\n\n def score_feature(self, scope: str) -> int:\n return sublime.score_selector(scope, self.feature_selector)\n\n def match_scope(self, scope: str) -> bool:\n # Every part of a x.y.z scope seems to contribute 8.\n # An empty selector result in a score of 1.\n # A non-matching non-empty selector results in a score of 0.\n # We want to match at least one part of an x.y.z, and we don't want to match on empty selectors.\n return self.score_document(scope) >= 8\n\n\nclass ClientConfig(object):\n def __init__(self,\n name: str,\n binary_args: List[str],\n languages: List[LanguageConfig],\n tcp_port: Optional[int],\n enabled: bool = True,\n init_options: dict = dict(),\n settings: DottedDict = DottedDict(),\n env: dict = dict(),\n tcp_host: Optional[str] = None,\n tcp_mode: Optional[str] = None,\n experimental_capabilities: dict = dict()) -> None:\n self.name = name\n self.binary_args = binary_args\n self.languages = languages\n self.tcp_port = tcp_port\n self.tcp_host = tcp_host\n self.tcp_mode = tcp_mode\n self.enabled = enabled\n self.init_options = init_options\n self.settings = settings\n self.env = env\n self.experimental_capabilities = experimental_capabilities\n self.status_key = \"lsp_{}\".format(self.name)\n\n def set_view_status(self, view: sublime.View, message: str) -> None:\n status = \"{}: {}\".format(self.name, message) if message else self.name\n view.set_status(self.status_key, status)\n\n def erase_view_status(self, view: sublime.View) -> None:\n view.erase_status(self.status_key)\n\n def match_scope(self, scope: str) -> bool:\n return any(language.match_scope(scope) for language in self.languages)\n\n def match_view(self, view: sublime.View) -> bool:\n return self.match_scope(view2scope(view))\n\n def score_feature(self, scope: str) -> int:\n highest_score = 0\n for language in self.languages:\n score = language.score_feature(scope)\n if score > highest_score:\n highest_score = score\n return highest_score\n\n\ndef syntax2scope(syntax: str) -> Optional[str]:\n try:\n return next(filter(lambda d: d['path'] == syntax, sublime.list_syntaxes()))['scope']\n except StopIteration:\n return None\n\n\ndef view2scope(view: sublime.View) -> str:\n try:\n return view.scope_name(0).split()[0]\n except IndexError:\n return ''\n", "path": "plugin/core/types.py"}], "after_files": [{"content": "from .collections import DottedDict\nfrom .logging import debug\nfrom .typing import Optional, List, Dict, Generator, Callable\nfrom threading import RLock\nimport contextlib\nimport functools\nimport sublime\nimport time\n\n\[email protected]\ndef runtime(token: str) -> Generator[None, None, None]:\n t = time.time()\n yield\n debug(token, \"running time:\", int((time.time() - t) * 1000000), \"\u03bcs\")\n\n\ndef debounced(f: Callable[[], None], timeout_ms: int = 0, condition: Callable[[], bool] = lambda: True,\n async_thread: bool = False) -> None:\n \"\"\"\n Possibly run a function at a later point in time, either on the async thread or on the main thread.\n\n :param f: The function to possibly run\n :param timeout_ms: The time in milliseconds after which to possibly to run the function\n :param condition: The condition that must evaluate to True in order to run the funtion\n :param async_thread: If true, run the function on the async worker thread, otherwise run the function on the\n main thread\n \"\"\"\n\n def run() -> None:\n if condition():\n f()\n\n runner = sublime.set_timeout_async if async_thread else sublime.set_timeout\n runner(run, timeout_ms)\n\n\ndef _settings_style_to_add_regions_flag(style: str) -> int:\n flags = 0\n if style == \"fill\":\n pass\n elif style == \"box\":\n flags = sublime.DRAW_NO_FILL\n else:\n flags = sublime.DRAW_NO_FILL | sublime.DRAW_NO_OUTLINE\n if style == \"underline\":\n flags |= sublime.DRAW_SOLID_UNDERLINE\n elif style == \"stippled\":\n flags |= sublime.DRAW_STIPPLED_UNDERLINE\n elif style == \"squiggly\":\n flags |= sublime.DRAW_SQUIGGLY_UNDERLINE\n return flags\n\n\nclass Debouncer:\n\n def __init__(self) -> None:\n self._current_id = -1\n self._next_id = 0\n self._current_id_lock = RLock()\n\n def debounce(self, f: Callable[[], None], timeout_ms: int = 0, condition: Callable[[], bool] = lambda: True,\n async_thread: bool = False) -> None:\n \"\"\"\n Possibly run a function at a later point in time, either on the async thread or on the main thread.\n\n :param f: The function to possibly run\n :param timeout_ms: The time in milliseconds after which to possibly to run the function\n :param condition: The condition that must evaluate to True in order to run the funtion\n :param async_thread: If true, run the function on the async worker thread, otherwise run\n the function on the main thread\n \"\"\"\n\n def run(debounce_id: int) -> None:\n with self._current_id_lock:\n if debounce_id != self._current_id:\n return\n if condition():\n f()\n\n runner = sublime.set_timeout_async if async_thread else sublime.set_timeout\n with self._current_id_lock:\n current_id = self._current_id = self._next_id\n self._next_id += 1\n runner(lambda: run(current_id), timeout_ms)\n\n def cancel_pending(self) -> None:\n with self._current_id_lock:\n self._current_id = -1\n\n\nclass Settings:\n\n def __init__(self) -> None:\n self.show_view_status = True\n self.auto_show_diagnostics_panel = 'always'\n self.auto_show_diagnostics_panel_level = 2\n self.diagnostics_panel_include_severity_level = 4\n self.show_diagnostics_count_in_view_status = False\n self.show_diagnostics_in_view_status = True\n self.show_diagnostics_severity_level = 2\n self.only_show_lsp_completions = False\n self.diagnostics_highlight_style = \"underline\"\n self.document_highlight_style = \"stippled\"\n self.document_highlight_scopes = {\n \"unknown\": \"text\",\n \"text\": \"text\",\n \"read\": \"markup.inserted\",\n \"write\": \"markup.changed\"\n }\n self.diagnostics_gutter_marker = \"dot\"\n self.diagnostics_delay_ms = 0\n self.diagnostics_additional_delay_auto_complete_ms = 0\n self.show_symbol_action_links = False\n self.show_references_in_quick_panel = False\n self.disabled_capabilities = [] # type: List[str]\n self.log_debug = False\n self.log_server = [] # type: List[str]\n self.log_stderr = False\n self.log_max_size = 8 * 1024\n self.lsp_format_on_save = False\n self.show_code_actions = \"annotation\"\n self.lsp_code_actions_on_save = {} # type: Dict[str, bool]\n self.code_action_on_save_timeout_ms = 2000\n\n def show_diagnostics_panel_always(self) -> bool:\n return self.auto_show_diagnostics_panel == \"always\"\n\n def show_diagnostics_panel_on_save(self) -> bool:\n return self.auto_show_diagnostics_panel == \"saved\"\n\n def document_highlight_style_to_add_regions_flags(self) -> int:\n return _settings_style_to_add_regions_flag(self.document_highlight_style)\n\n def diagnostics_highlight_style_to_add_regions_flag(self) -> int:\n return _settings_style_to_add_regions_flag(self.diagnostics_highlight_style)\n\n\nclass ClientStates(object):\n STARTING = 0\n READY = 1\n STOPPING = 2\n\n\nclass LanguageConfig(object):\n\n __slots__ = ('id', 'document_selector', 'feature_selector')\n\n def __init__(\n self,\n language_id: str,\n document_selector: Optional[str] = None,\n feature_selector: Optional[str] = None\n ) -> None:\n self.id = language_id\n self.document_selector = document_selector if document_selector else \"source.{}\".format(self.id)\n self.feature_selector = feature_selector if feature_selector else self.document_selector\n\n @functools.lru_cache(None)\n def score_document(self, scope: str) -> int:\n return sublime.score_selector(scope, self.document_selector)\n\n def score_feature(self, scope: str) -> int:\n return sublime.score_selector(scope, self.feature_selector)\n\n def match_scope(self, scope: str) -> bool:\n # Every part of a x.y.z scope seems to contribute 8.\n # An empty selector result in a score of 1.\n # A non-matching non-empty selector results in a score of 0.\n # We want to match at least one part of an x.y.z, and we don't want to match on empty selectors.\n return self.score_document(scope) >= 8\n\n\nclass ClientConfig(object):\n def __init__(self,\n name: str,\n binary_args: List[str],\n languages: List[LanguageConfig],\n tcp_port: Optional[int],\n enabled: bool = True,\n init_options: dict = dict(),\n settings: DottedDict = DottedDict(),\n env: dict = dict(),\n tcp_host: Optional[str] = None,\n tcp_mode: Optional[str] = None,\n experimental_capabilities: dict = dict()) -> None:\n self.name = name\n self.binary_args = binary_args\n self.languages = languages\n self.tcp_port = tcp_port\n self.tcp_host = tcp_host\n self.tcp_mode = tcp_mode\n self.enabled = enabled\n self.init_options = init_options\n self.settings = settings\n self.env = env\n self.experimental_capabilities = experimental_capabilities\n self.status_key = \"lsp_{}\".format(self.name)\n\n def set_view_status(self, view: sublime.View, message: str) -> None:\n if sublime.load_settings(\"LSP.sublime-settings\").get(\"show_view_status\"):\n status = \"{}: {}\".format(self.name, message) if message else self.name\n view.set_status(self.status_key, status)\n\n def erase_view_status(self, view: sublime.View) -> None:\n view.erase_status(self.status_key)\n\n def match_scope(self, scope: str) -> bool:\n return any(language.match_scope(scope) for language in self.languages)\n\n def match_view(self, view: sublime.View) -> bool:\n return self.match_scope(view2scope(view))\n\n def score_feature(self, scope: str) -> int:\n highest_score = 0\n for language in self.languages:\n score = language.score_feature(scope)\n if score > highest_score:\n highest_score = score\n return highest_score\n\n\ndef syntax2scope(syntax: str) -> Optional[str]:\n try:\n return next(filter(lambda d: d['path'] == syntax, sublime.list_syntaxes()))['scope']\n except StopIteration:\n return None\n\n\ndef view2scope(view: sublime.View) -> str:\n try:\n return view.scope_name(0).split()[0]\n except IndexError:\n return ''\n", "path": "plugin/core/types.py"}]}
| 2,884 | 247 |
gh_patches_debug_13910
|
rasdani/github-patches
|
git_diff
|
strawberry-graphql__strawberry-3318
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Subscription is not working with permission_classes
<!-- Provide a general summary of the bug in the title above. -->
Subscription is failing with error after upgrading to version 0.217.0 from 0.216.1. Bug seems to be in `permission_classes`, because if I'm trying to use subscription without permission_classes, it works without any problem.
<!--- This template is entirely optional and can be removed, but is here to help both you and us. -->
<!--- Anything on lines wrapped in comments like these will not show up in the final text. -->
## Describe the Bug
Error when subscription is used with `permission_classes`:
```
Traceback (most recent call last):
File "/.../lib/python3.11/site-packages/graphql/execution/subscribe.py", line 206, in execute_subscription
event_stream = await event_stream
^^^^^^^^^^^^^^^^^^
File "/.../lib/python3.11/site-packages/strawberry/schema/schema_converter.py", line 675, in _async_resolver
return await await_maybe(
^^^^^^^^^^^^^^^^^^
File "/.../lib/python3.11/site-packages/strawberry/utils/await_maybe.py", line 12, in await_maybe
return await value
^^^^^^^^^^^
File "/.../lib/python3.11/site-packages/strawberry/permission.py", line 172, in resolve_async
return await next_(source, info, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: object async_generator can't be used in 'await' expression
```
Here is sample code to reproduce the bug:
```
class IsAuthenticated(BasePermission):
message = "Unauthorized"
async def has_permission(self, source: Any, info: Info, **kwargs: Any) -> bool:
return True
async def sample(info: Info) -> AsyncGenerator[int, None]:
while True:
yield 1
@strawberry.type
class Subscription:
sample = strawberry.subscription(
resolver=sample, permission_classes=[IsAuthenticated]
)
```
<!-- A clear and concise description of what the bug is. -->
## System Information
- Strawberry version (if applicable): 0.217.0
<!-- Add any other relevant information about the problem here. -->
<!-- POLAR PLEDGE BADGE START -->
## Upvote & Fund
- We're using [Polar.sh](https://polar.sh/strawberry-graphql) so you can upvote and help fund this issue.
- We receive the funding once the issue is completed & confirmed by you.
- Thank you in advance for helping prioritize & fund our backlog.
<a href="https://polar.sh/strawberry-graphql/strawberry/issues/3317">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://polar.sh/api/github/strawberry-graphql/strawberry/issues/3317/pledge.svg?darkmode=1">
<img alt="Fund with Polar" src="https://polar.sh/api/github/strawberry-graphql/strawberry/issues/3317/pledge.svg">
</picture>
</a>
<!-- POLAR PLEDGE BADGE END -->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `strawberry/permission.py`
Content:
```
1 from __future__ import annotations
2
3 import abc
4 from functools import cached_property
5 from inspect import iscoroutinefunction
6 from typing import (
7 TYPE_CHECKING,
8 Any,
9 Awaitable,
10 Dict,
11 List,
12 Optional,
13 Type,
14 Union,
15 )
16
17 from strawberry.exceptions import StrawberryGraphQLError
18 from strawberry.exceptions.permission_fail_silently_requires_optional import (
19 PermissionFailSilentlyRequiresOptionalError,
20 )
21 from strawberry.extensions import FieldExtension
22 from strawberry.schema_directive import Location, StrawberrySchemaDirective
23 from strawberry.type import StrawberryList, StrawberryOptional
24 from strawberry.utils.await_maybe import await_maybe
25
26 if TYPE_CHECKING:
27 from graphql import GraphQLError, GraphQLErrorExtensions
28
29 from strawberry.extensions.field_extension import (
30 AsyncExtensionResolver,
31 SyncExtensionResolver,
32 )
33 from strawberry.field import StrawberryField
34 from strawberry.types import Info
35
36
37 class BasePermission(abc.ABC):
38 """
39 Base class for creating permissions
40 """
41
42 message: Optional[str] = None
43
44 error_extensions: Optional[GraphQLErrorExtensions] = None
45
46 error_class: Type[GraphQLError] = StrawberryGraphQLError
47
48 _schema_directive: Optional[object] = None
49
50 @abc.abstractmethod
51 def has_permission(
52 self, source: Any, info: Info, **kwargs: Any
53 ) -> Union[bool, Awaitable[bool]]:
54 raise NotImplementedError(
55 "Permission classes should override has_permission method"
56 )
57
58 def on_unauthorized(self) -> None:
59 """
60 Default error raising for permissions.
61 This can be overridden to customize the behavior.
62 """
63
64 # Instantiate error class
65 error = self.error_class(self.message or "")
66
67 if self.error_extensions:
68 # Add our extensions to the error
69 if not error.extensions:
70 error.extensions = dict()
71 error.extensions.update(self.error_extensions)
72
73 raise error
74
75 @property
76 def schema_directive(self) -> object:
77 if not self._schema_directive:
78
79 class AutoDirective:
80 __strawberry_directive__ = StrawberrySchemaDirective(
81 self.__class__.__name__,
82 self.__class__.__name__,
83 [Location.FIELD_DEFINITION],
84 [],
85 )
86
87 self._schema_directive = AutoDirective()
88
89 return self._schema_directive
90
91
92 class PermissionExtension(FieldExtension):
93 """
94 Handles permissions for a field
95 Instantiate this as a field extension with all of the permissions you want to apply
96
97 fail_silently: bool = False will return None or [] if the permission fails
98 instead of raising an exception. This is only valid for optional or list fields.
99
100 NOTE:
101 Currently, this is automatically added to the field, when using
102 field.permission_classes
103 This is deprecated behavior, please manually add the extension to field.extensions
104 """
105
106 def __init__(
107 self,
108 permissions: List[BasePermission],
109 use_directives: bool = True,
110 fail_silently: bool = False,
111 ):
112 self.permissions = permissions
113 self.fail_silently = fail_silently
114 self.return_empty_list = False
115 self.use_directives = use_directives
116
117 def apply(self, field: StrawberryField) -> None:
118 """
119 Applies all of the permission directives to the schema
120 and sets up silent permissions
121 """
122 if self.use_directives:
123 field.directives.extend(
124 p.schema_directive for p in self.permissions if p.schema_directive
125 )
126 # We can only fail silently if the field is optional or a list
127 if self.fail_silently:
128 if isinstance(field.type, StrawberryOptional):
129 if isinstance(field.type.of_type, StrawberryList):
130 self.return_empty_list = True
131 elif isinstance(field.type, StrawberryList):
132 self.return_empty_list = True
133 else:
134 errror = PermissionFailSilentlyRequiresOptionalError(field)
135 raise errror
136
137 def _on_unauthorized(self, permission: BasePermission) -> Any:
138 if self.fail_silently:
139 return [] if self.return_empty_list else None
140 return permission.on_unauthorized()
141
142 def resolve(
143 self,
144 next_: SyncExtensionResolver,
145 source: Any,
146 info: Info,
147 **kwargs: Dict[str, Any],
148 ) -> Any:
149 """
150 Checks if the permission should be accepted and
151 raises an exception if not
152 """
153 for permission in self.permissions:
154 if not permission.has_permission(source, info, **kwargs):
155 return self._on_unauthorized(permission)
156 return next_(source, info, **kwargs)
157
158 async def resolve_async(
159 self,
160 next_: AsyncExtensionResolver,
161 source: Any,
162 info: Info,
163 **kwargs: Dict[str, Any],
164 ) -> Any:
165 for permission in self.permissions:
166 has_permission = await await_maybe(
167 permission.has_permission(source, info, **kwargs)
168 )
169
170 if not has_permission:
171 return self._on_unauthorized(permission)
172 return await next_(source, info, **kwargs)
173
174 @cached_property
175 def supports_sync(self) -> bool:
176 """The Permission extension always supports async checking using await_maybe,
177 but only supports sync checking if there are no async permissions"""
178 async_permissions = [
179 True
180 for permission in self.permissions
181 if iscoroutinefunction(permission.has_permission)
182 ]
183 return len(async_permissions) == 0
184
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/strawberry/permission.py b/strawberry/permission.py
--- a/strawberry/permission.py
+++ b/strawberry/permission.py
@@ -1,6 +1,7 @@
from __future__ import annotations
import abc
+import inspect
from functools import cached_property
from inspect import iscoroutinefunction
from typing import (
@@ -169,7 +170,10 @@
if not has_permission:
return self._on_unauthorized(permission)
- return await next_(source, info, **kwargs)
+ next = next_(source, info, **kwargs)
+ if inspect.isasyncgen(next):
+ return next
+ return await next
@cached_property
def supports_sync(self) -> bool:
|
{"golden_diff": "diff --git a/strawberry/permission.py b/strawberry/permission.py\n--- a/strawberry/permission.py\n+++ b/strawberry/permission.py\n@@ -1,6 +1,7 @@\n from __future__ import annotations\n \n import abc\n+import inspect\n from functools import cached_property\n from inspect import iscoroutinefunction\n from typing import (\n@@ -169,7 +170,10 @@\n \n if not has_permission:\n return self._on_unauthorized(permission)\n- return await next_(source, info, **kwargs)\n+ next = next_(source, info, **kwargs)\n+ if inspect.isasyncgen(next):\n+ return next\n+ return await next\n \n @cached_property\n def supports_sync(self) -> bool:\n", "issue": "Subscription is not working with permission_classes\n<!-- Provide a general summary of the bug in the title above. -->\r\nSubscription is failing with error after upgrading to version 0.217.0 from 0.216.1. Bug seems to be in `permission_classes`, because if I'm trying to use subscription without permission_classes, it works without any problem.\r\n\r\n<!--- This template is entirely optional and can be removed, but is here to help both you and us. -->\r\n<!--- Anything on lines wrapped in comments like these will not show up in the final text. -->\r\n\r\n## Describe the Bug\r\nError when subscription is used with `permission_classes`:\r\n```\r\nTraceback (most recent call last):\r\n File \"/.../lib/python3.11/site-packages/graphql/execution/subscribe.py\", line 206, in execute_subscription\r\n event_stream = await event_stream\r\n ^^^^^^^^^^^^^^^^^^\r\n File \"/.../lib/python3.11/site-packages/strawberry/schema/schema_converter.py\", line 675, in _async_resolver\r\n return await await_maybe(\r\n ^^^^^^^^^^^^^^^^^^\r\n File \"/.../lib/python3.11/site-packages/strawberry/utils/await_maybe.py\", line 12, in await_maybe\r\n return await value\r\n ^^^^^^^^^^^\r\n File \"/.../lib/python3.11/site-packages/strawberry/permission.py\", line 172, in resolve_async\r\n return await next_(source, info, **kwargs)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\nTypeError: object async_generator can't be used in 'await' expression\r\n```\r\n\r\nHere is sample code to reproduce the bug:\r\n```\r\nclass IsAuthenticated(BasePermission):\r\n\r\n message = \"Unauthorized\"\r\n\r\n async def has_permission(self, source: Any, info: Info, **kwargs: Any) -> bool:\r\n return True\r\n\r\n\r\nasync def sample(info: Info) -> AsyncGenerator[int, None]:\r\n while True:\r\n yield 1\r\n\r\n\r\[email protected]\r\nclass Subscription:\r\n sample = strawberry.subscription(\r\n resolver=sample, permission_classes=[IsAuthenticated]\r\n )\r\n```\r\n\r\n<!-- A clear and concise description of what the bug is. -->\r\n\r\n## System Information\r\n\r\n - Strawberry version (if applicable): 0.217.0\r\n\r\n<!-- Add any other relevant information about the problem here. -->\r\n\n\n<!-- POLAR PLEDGE BADGE START -->\n## Upvote & Fund\n\n- We're using [Polar.sh](https://polar.sh/strawberry-graphql) so you can upvote and help fund this issue.\n- We receive the funding once the issue is completed & confirmed by you.\n- Thank you in advance for helping prioritize & fund our backlog.\n\n<a href=\"https://polar.sh/strawberry-graphql/strawberry/issues/3317\">\n<picture>\n <source media=\"(prefers-color-scheme: dark)\" srcset=\"https://polar.sh/api/github/strawberry-graphql/strawberry/issues/3317/pledge.svg?darkmode=1\">\n <img alt=\"Fund with Polar\" src=\"https://polar.sh/api/github/strawberry-graphql/strawberry/issues/3317/pledge.svg\">\n</picture>\n</a>\n<!-- POLAR PLEDGE BADGE END -->\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport abc\nfrom functools import cached_property\nfrom inspect import iscoroutinefunction\nfrom typing import (\n TYPE_CHECKING,\n Any,\n Awaitable,\n Dict,\n List,\n Optional,\n Type,\n Union,\n)\n\nfrom strawberry.exceptions import StrawberryGraphQLError\nfrom strawberry.exceptions.permission_fail_silently_requires_optional import (\n PermissionFailSilentlyRequiresOptionalError,\n)\nfrom strawberry.extensions import FieldExtension\nfrom strawberry.schema_directive import Location, StrawberrySchemaDirective\nfrom strawberry.type import StrawberryList, StrawberryOptional\nfrom strawberry.utils.await_maybe import await_maybe\n\nif TYPE_CHECKING:\n from graphql import GraphQLError, GraphQLErrorExtensions\n\n from strawberry.extensions.field_extension import (\n AsyncExtensionResolver,\n SyncExtensionResolver,\n )\n from strawberry.field import StrawberryField\n from strawberry.types import Info\n\n\nclass BasePermission(abc.ABC):\n \"\"\"\n Base class for creating permissions\n \"\"\"\n\n message: Optional[str] = None\n\n error_extensions: Optional[GraphQLErrorExtensions] = None\n\n error_class: Type[GraphQLError] = StrawberryGraphQLError\n\n _schema_directive: Optional[object] = None\n\n @abc.abstractmethod\n def has_permission(\n self, source: Any, info: Info, **kwargs: Any\n ) -> Union[bool, Awaitable[bool]]:\n raise NotImplementedError(\n \"Permission classes should override has_permission method\"\n )\n\n def on_unauthorized(self) -> None:\n \"\"\"\n Default error raising for permissions.\n This can be overridden to customize the behavior.\n \"\"\"\n\n # Instantiate error class\n error = self.error_class(self.message or \"\")\n\n if self.error_extensions:\n # Add our extensions to the error\n if not error.extensions:\n error.extensions = dict()\n error.extensions.update(self.error_extensions)\n\n raise error\n\n @property\n def schema_directive(self) -> object:\n if not self._schema_directive:\n\n class AutoDirective:\n __strawberry_directive__ = StrawberrySchemaDirective(\n self.__class__.__name__,\n self.__class__.__name__,\n [Location.FIELD_DEFINITION],\n [],\n )\n\n self._schema_directive = AutoDirective()\n\n return self._schema_directive\n\n\nclass PermissionExtension(FieldExtension):\n \"\"\"\n Handles permissions for a field\n Instantiate this as a field extension with all of the permissions you want to apply\n\n fail_silently: bool = False will return None or [] if the permission fails\n instead of raising an exception. This is only valid for optional or list fields.\n\n NOTE:\n Currently, this is automatically added to the field, when using\n field.permission_classes\n This is deprecated behavior, please manually add the extension to field.extensions\n \"\"\"\n\n def __init__(\n self,\n permissions: List[BasePermission],\n use_directives: bool = True,\n fail_silently: bool = False,\n ):\n self.permissions = permissions\n self.fail_silently = fail_silently\n self.return_empty_list = False\n self.use_directives = use_directives\n\n def apply(self, field: StrawberryField) -> None:\n \"\"\"\n Applies all of the permission directives to the schema\n and sets up silent permissions\n \"\"\"\n if self.use_directives:\n field.directives.extend(\n p.schema_directive for p in self.permissions if p.schema_directive\n )\n # We can only fail silently if the field is optional or a list\n if self.fail_silently:\n if isinstance(field.type, StrawberryOptional):\n if isinstance(field.type.of_type, StrawberryList):\n self.return_empty_list = True\n elif isinstance(field.type, StrawberryList):\n self.return_empty_list = True\n else:\n errror = PermissionFailSilentlyRequiresOptionalError(field)\n raise errror\n\n def _on_unauthorized(self, permission: BasePermission) -> Any:\n if self.fail_silently:\n return [] if self.return_empty_list else None\n return permission.on_unauthorized()\n\n def resolve(\n self,\n next_: SyncExtensionResolver,\n source: Any,\n info: Info,\n **kwargs: Dict[str, Any],\n ) -> Any:\n \"\"\"\n Checks if the permission should be accepted and\n raises an exception if not\n \"\"\"\n for permission in self.permissions:\n if not permission.has_permission(source, info, **kwargs):\n return self._on_unauthorized(permission)\n return next_(source, info, **kwargs)\n\n async def resolve_async(\n self,\n next_: AsyncExtensionResolver,\n source: Any,\n info: Info,\n **kwargs: Dict[str, Any],\n ) -> Any:\n for permission in self.permissions:\n has_permission = await await_maybe(\n permission.has_permission(source, info, **kwargs)\n )\n\n if not has_permission:\n return self._on_unauthorized(permission)\n return await next_(source, info, **kwargs)\n\n @cached_property\n def supports_sync(self) -> bool:\n \"\"\"The Permission extension always supports async checking using await_maybe,\n but only supports sync checking if there are no async permissions\"\"\"\n async_permissions = [\n True\n for permission in self.permissions\n if iscoroutinefunction(permission.has_permission)\n ]\n return len(async_permissions) == 0\n", "path": "strawberry/permission.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport abc\nimport inspect\nfrom functools import cached_property\nfrom inspect import iscoroutinefunction\nfrom typing import (\n TYPE_CHECKING,\n Any,\n Awaitable,\n Dict,\n List,\n Optional,\n Type,\n Union,\n)\n\nfrom strawberry.exceptions import StrawberryGraphQLError\nfrom strawberry.exceptions.permission_fail_silently_requires_optional import (\n PermissionFailSilentlyRequiresOptionalError,\n)\nfrom strawberry.extensions import FieldExtension\nfrom strawberry.schema_directive import Location, StrawberrySchemaDirective\nfrom strawberry.type import StrawberryList, StrawberryOptional\nfrom strawberry.utils.await_maybe import await_maybe\n\nif TYPE_CHECKING:\n from graphql import GraphQLError, GraphQLErrorExtensions\n\n from strawberry.extensions.field_extension import (\n AsyncExtensionResolver,\n SyncExtensionResolver,\n )\n from strawberry.field import StrawberryField\n from strawberry.types import Info\n\n\nclass BasePermission(abc.ABC):\n \"\"\"\n Base class for creating permissions\n \"\"\"\n\n message: Optional[str] = None\n\n error_extensions: Optional[GraphQLErrorExtensions] = None\n\n error_class: Type[GraphQLError] = StrawberryGraphQLError\n\n _schema_directive: Optional[object] = None\n\n @abc.abstractmethod\n def has_permission(\n self, source: Any, info: Info, **kwargs: Any\n ) -> Union[bool, Awaitable[bool]]:\n raise NotImplementedError(\n \"Permission classes should override has_permission method\"\n )\n\n def on_unauthorized(self) -> None:\n \"\"\"\n Default error raising for permissions.\n This can be overridden to customize the behavior.\n \"\"\"\n\n # Instantiate error class\n error = self.error_class(self.message or \"\")\n\n if self.error_extensions:\n # Add our extensions to the error\n if not error.extensions:\n error.extensions = dict()\n error.extensions.update(self.error_extensions)\n\n raise error\n\n @property\n def schema_directive(self) -> object:\n if not self._schema_directive:\n\n class AutoDirective:\n __strawberry_directive__ = StrawberrySchemaDirective(\n self.__class__.__name__,\n self.__class__.__name__,\n [Location.FIELD_DEFINITION],\n [],\n )\n\n self._schema_directive = AutoDirective()\n\n return self._schema_directive\n\n\nclass PermissionExtension(FieldExtension):\n \"\"\"\n Handles permissions for a field\n Instantiate this as a field extension with all of the permissions you want to apply\n\n fail_silently: bool = False will return None or [] if the permission fails\n instead of raising an exception. This is only valid for optional or list fields.\n\n NOTE:\n Currently, this is automatically added to the field, when using\n field.permission_classes\n This is deprecated behavior, please manually add the extension to field.extensions\n \"\"\"\n\n def __init__(\n self,\n permissions: List[BasePermission],\n use_directives: bool = True,\n fail_silently: bool = False,\n ):\n self.permissions = permissions\n self.fail_silently = fail_silently\n self.return_empty_list = False\n self.use_directives = use_directives\n\n def apply(self, field: StrawberryField) -> None:\n \"\"\"\n Applies all of the permission directives to the schema\n and sets up silent permissions\n \"\"\"\n if self.use_directives:\n field.directives.extend(\n p.schema_directive for p in self.permissions if p.schema_directive\n )\n # We can only fail silently if the field is optional or a list\n if self.fail_silently:\n if isinstance(field.type, StrawberryOptional):\n if isinstance(field.type.of_type, StrawberryList):\n self.return_empty_list = True\n elif isinstance(field.type, StrawberryList):\n self.return_empty_list = True\n else:\n errror = PermissionFailSilentlyRequiresOptionalError(field)\n raise errror\n\n def _on_unauthorized(self, permission: BasePermission) -> Any:\n if self.fail_silently:\n return [] if self.return_empty_list else None\n return permission.on_unauthorized()\n\n def resolve(\n self,\n next_: SyncExtensionResolver,\n source: Any,\n info: Info,\n **kwargs: Dict[str, Any],\n ) -> Any:\n \"\"\"\n Checks if the permission should be accepted and\n raises an exception if not\n \"\"\"\n for permission in self.permissions:\n if not permission.has_permission(source, info, **kwargs):\n return self._on_unauthorized(permission)\n return next_(source, info, **kwargs)\n\n async def resolve_async(\n self,\n next_: AsyncExtensionResolver,\n source: Any,\n info: Info,\n **kwargs: Dict[str, Any],\n ) -> Any:\n for permission in self.permissions:\n has_permission = await await_maybe(\n permission.has_permission(source, info, **kwargs)\n )\n\n if not has_permission:\n return self._on_unauthorized(permission)\n next = next_(source, info, **kwargs)\n if inspect.isasyncgen(next):\n return next\n return await next\n\n @cached_property\n def supports_sync(self) -> bool:\n \"\"\"The Permission extension always supports async checking using await_maybe,\n but only supports sync checking if there are no async permissions\"\"\"\n async_permissions = [\n True\n for permission in self.permissions\n if iscoroutinefunction(permission.has_permission)\n ]\n return len(async_permissions) == 0\n", "path": "strawberry/permission.py"}]}
| 2,574 | 173 |
gh_patches_debug_10884
|
rasdani/github-patches
|
git_diff
|
ESMCI__cime-2052
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Error check compset name
Improve error checking on compset name, if an alias isn't matched make sure that the compset name (now assumed to be a longname) lists 7 components.
Test suite: scripts_regression_tests.py hand tests of create_newcase
Test baseline:
Test namelist changes:
Test status: bit for bit
Fixes #1871
User interface changes?:
Update gh-pages html (Y/N)?:
Code review:
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scripts/lib/acme_cime_mgmt.py`
Content:
```
1 from CIME.utils import run_cmd, run_cmd_no_fail, expect, get_timestamp
2
3 import sys, getpass, logging
4
5 # Constants
6 ESMCI_REMOTE_NAME = "esmci_remote_for_split"
7 ESMCI_URL = "[email protected]:ESMCI/CIME.git"
8 SPLIT_TAG_PREFIX = "acme-split-"
9 MERGE_TAG_PREFIX = "to-acme-"
10
11 ###############################################################################
12 def setup():
13 ###############################################################################
14 run_cmd_no_fail("git config merge.renameLimit 999999")
15 run_cmd_no_fail("git checkout master && git pull && git submodule update --init")
16
17 remotes = run_cmd_no_fail("git remote")
18 if ESMCI_REMOTE_NAME not in remotes:
19 run_cmd_no_fail("git remote add {} {}".format(ESMCI_REMOTE_NAME, ESMCI_URL))
20
21 run_cmd_no_fail("git fetch {}".format(ESMCI_REMOTE_NAME))
22 run_cmd_no_fail("git fetch {} --tags".format(ESMCI_REMOTE_NAME))
23
24 ###############################################################################
25 def get_tag(prefix, expected_num=1):
26 ###############################################################################
27 tags = run_cmd_no_fail("git tag").split()
28 tags = [tag for tag in tags if tag.startswith(prefix)]
29
30 expect(len(tags) == expected_num, "Expected exactly {} {} tag, found {}".format(expected_num, prefix, ", ".join(tags)))
31
32 if expected_num == 1:
33 return tags[0]
34 else:
35 return tags
36
37 ###############################################################################
38 def get_split_tag(expected_num=1):
39 ###############################################################################
40 return get_tag(SPLIT_TAG_PREFIX, expected_num=expected_num)
41
42 ###############################################################################
43 def get_merge_tag(expected_num=1):
44 ###############################################################################
45 return get_tag(MERGE_TAG_PREFIX, expected_num=expected_num)
46
47 ###############################################################################
48 def make_new_tag(prefix, old_tag, remote="origin", commit="HEAD"):
49 ###############################################################################
50 new_tag = "{}{}".format(prefix, get_timestamp(timestamp_format="%m-%d-%Y"))
51 expect(old_tag != new_tag, "New tag must have different name than old tag")
52
53 run_cmd_no_fail("git tag {} {}".format(new_tag, commit))
54 run_cmd_no_fail("git push {} {}".format(remote, new_tag))
55
56 return new_tag
57
58 ###############################################################################
59 def make_new_split_tag(old_split_tag):
60 ###############################################################################
61 return make_new_tag(SPLIT_TAG_PREFIX, old_split_tag)
62
63 ###############################################################################
64 def make_new_merge_tag(old_merge_tag):
65 ###############################################################################
66 return make_new_tag(MERGE_TAG_PREFIX, old_merge_tag,
67 remote=ESMCI_REMOTE_NAME, commit="{}/master".format(ESMCI_REMOTE_NAME))
68
69 ###############################################################################
70 def get_branch_from_tag(tag):
71 ###############################################################################
72 branch = "{}/branch-for-{}".format(getpass.getuser(), tag)
73 return branch
74
75 ###############################################################################
76 def do_subtree_split(old_split_tag, new_split_tag, merge_tag):
77 ###############################################################################
78 subtree_branch = get_branch_from_tag(new_split_tag)
79 run_cmd_no_fail("git subtree split {}.. --prefix=cime --onto={} --ignore-joins -b {}".\
80 format(old_split_tag, merge_tag, subtree_branch))
81 return subtree_branch
82
83 ###############################################################################
84 def do_subtree_pull():
85 ###############################################################################
86 stat = run_cmd("git subtree pull --prefix=cime {} master".format(ESMCI_REMOTE_NAME))[0]
87 if stat != 0:
88 logging.info("There are merge conflicts. Please fix, commit, and re-run this tool with --resume")
89 sys.exit(1)
90
91 ###############################################################################
92 def make_pr_branch(branch, branch_head):
93 ###############################################################################
94 pr_branch = "{}-pr".format(branch)
95 run_cmd_no_fail("git checkout -b {} {}".format(pr_branch, branch_head))
96
97 return pr_branch
98
99 ###############################################################################
100 def merge_branch(branch, resume_count):
101 ###############################################################################
102 stat = run_cmd("git merge -m 'Merge {}' -X rename-threshold=25 {}".format(branch, branch))[0]
103 if stat != 0:
104 logging.info("There are merge conflicts. Please fix, commit, and re-run this tool with --resume-{}".format(resume_count))
105 sys.exit(1)
106
107 ###############################################################################
108 def merge_pr_branch_1(subtree_branch):
109 ###############################################################################
110 merge_branch(subtree_branch, "one")
111
112 ###############################################################################
113 def merge_pr_branch_2():
114 ###############################################################################
115 merge_branch("{}/master".format(ESMCI_REMOTE_NAME), "two")
116
117 ###############################################################################
118 def delete_tag(tag, remote="origin"):
119 ###############################################################################
120 run_cmd_no_fail("git tag -d {}".format(tag))
121 run_cmd_no_fail("git push {} :refs/tags/{}".format(remote, tag))
122
123 ###############################################################################
124 def acme_cime_split(resume_one, resume_two):
125 ###############################################################################
126 if not resume_one and not resume_two:
127 setup()
128
129 old_split_tag = get_split_tag()
130
131 try:
132 new_split_tag = make_new_split_tag(old_split_tag)
133
134 merge_tag = get_merge_tag()
135
136 subtree_branch = do_subtree_split(old_split_tag, new_split_tag, merge_tag)
137
138 pr_branch = make_pr_branch(subtree_branch, merge_tag)
139 except:
140 # If unexpected failure happens, delete new split tag
141 delete_tag(new_split_tag)
142 raise
143
144 merge_pr_branch_1(subtree_branch)
145 else:
146 old_split_tag, new_split_tag = get_split_tag(expected_num=2)
147 pr_branch = "{}-pr".format(get_branch_from_tag(new_split_tag))
148
149 if not resume_two:
150 merge_pr_branch_2()
151
152 try:
153 run_cmd_no_fail("git push {} {}".format(ESMCI_REMOTE_NAME, pr_branch))
154 except:
155 delete_tag(old_split_tag)
156 raise
157
158 delete_tag(old_split_tag)
159
160 ###############################################################################
161 def acme_cime_merge(resume):
162 ###############################################################################
163 if not resume:
164 setup()
165
166 old_merge_tag = get_merge_tag()
167
168 try:
169 new_merge_tag = make_new_merge_tag(old_merge_tag)
170
171 pr_branch = make_pr_branch(get_branch_from_tag(new_merge_tag), "origin/master")
172 except:
173 delete_tag(new_merge_tag, remote=ESMCI_REMOTE_NAME)
174 raise
175
176 do_subtree_pull()
177
178 else:
179 old_merge_tag, new_merge_tag = get_merge_tag(expected_num=2)
180 pr_branch = "{}-pr".format(get_branch_from_tag(new_merge_tag))
181
182 try:
183 run_cmd_no_fail("git push origin {}".format(pr_branch))
184 except:
185 delete_tag(old_merge_tag, remote=ESMCI_REMOTE_NAME)
186 raise
187
188 delete_tag(old_merge_tag, remote=ESMCI_REMOTE_NAME)
189
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scripts/lib/acme_cime_mgmt.py b/scripts/lib/acme_cime_mgmt.py
--- a/scripts/lib/acme_cime_mgmt.py
+++ b/scripts/lib/acme_cime_mgmt.py
@@ -18,8 +18,8 @@
if ESMCI_REMOTE_NAME not in remotes:
run_cmd_no_fail("git remote add {} {}".format(ESMCI_REMOTE_NAME, ESMCI_URL))
- run_cmd_no_fail("git fetch {}".format(ESMCI_REMOTE_NAME))
- run_cmd_no_fail("git fetch {} --tags".format(ESMCI_REMOTE_NAME))
+ run_cmd_no_fail("git fetch --prune {}".format(ESMCI_REMOTE_NAME))
+ run_cmd_no_fail("git fetch --prune {} --tags".format(ESMCI_REMOTE_NAME))
###############################################################################
def get_tag(prefix, expected_num=1):
|
{"golden_diff": "diff --git a/scripts/lib/acme_cime_mgmt.py b/scripts/lib/acme_cime_mgmt.py\n--- a/scripts/lib/acme_cime_mgmt.py\n+++ b/scripts/lib/acme_cime_mgmt.py\n@@ -18,8 +18,8 @@\n if ESMCI_REMOTE_NAME not in remotes:\n run_cmd_no_fail(\"git remote add {} {}\".format(ESMCI_REMOTE_NAME, ESMCI_URL))\n \n- run_cmd_no_fail(\"git fetch {}\".format(ESMCI_REMOTE_NAME))\n- run_cmd_no_fail(\"git fetch {} --tags\".format(ESMCI_REMOTE_NAME))\n+ run_cmd_no_fail(\"git fetch --prune {}\".format(ESMCI_REMOTE_NAME))\n+ run_cmd_no_fail(\"git fetch --prune {} --tags\".format(ESMCI_REMOTE_NAME))\n \n ###############################################################################\n def get_tag(prefix, expected_num=1):\n", "issue": "Error check compset name\nImprove error checking on compset name, if an alias isn't matched make sure that the compset name (now assumed to be a longname) lists 7 components. \r\n\r\nTest suite: scripts_regression_tests.py hand tests of create_newcase\r\nTest baseline: \r\nTest namelist changes: \r\nTest status: bit for bit\r\n\r\nFixes #1871 \r\n\r\nUser interface changes?: \r\n\r\nUpdate gh-pages html (Y/N)?:\r\n\r\nCode review: \r\n\n", "before_files": [{"content": "from CIME.utils import run_cmd, run_cmd_no_fail, expect, get_timestamp\n\nimport sys, getpass, logging\n\n# Constants\nESMCI_REMOTE_NAME = \"esmci_remote_for_split\"\nESMCI_URL = \"[email protected]:ESMCI/CIME.git\"\nSPLIT_TAG_PREFIX = \"acme-split-\"\nMERGE_TAG_PREFIX = \"to-acme-\"\n\n###############################################################################\ndef setup():\n###############################################################################\n run_cmd_no_fail(\"git config merge.renameLimit 999999\")\n run_cmd_no_fail(\"git checkout master && git pull && git submodule update --init\")\n\n remotes = run_cmd_no_fail(\"git remote\")\n if ESMCI_REMOTE_NAME not in remotes:\n run_cmd_no_fail(\"git remote add {} {}\".format(ESMCI_REMOTE_NAME, ESMCI_URL))\n\n run_cmd_no_fail(\"git fetch {}\".format(ESMCI_REMOTE_NAME))\n run_cmd_no_fail(\"git fetch {} --tags\".format(ESMCI_REMOTE_NAME))\n\n###############################################################################\ndef get_tag(prefix, expected_num=1):\n###############################################################################\n tags = run_cmd_no_fail(\"git tag\").split()\n tags = [tag for tag in tags if tag.startswith(prefix)]\n\n expect(len(tags) == expected_num, \"Expected exactly {} {} tag, found {}\".format(expected_num, prefix, \", \".join(tags)))\n\n if expected_num == 1:\n return tags[0]\n else:\n return tags\n\n###############################################################################\ndef get_split_tag(expected_num=1):\n###############################################################################\n return get_tag(SPLIT_TAG_PREFIX, expected_num=expected_num)\n\n###############################################################################\ndef get_merge_tag(expected_num=1):\n###############################################################################\n return get_tag(MERGE_TAG_PREFIX, expected_num=expected_num)\n\n###############################################################################\ndef make_new_tag(prefix, old_tag, remote=\"origin\", commit=\"HEAD\"):\n###############################################################################\n new_tag = \"{}{}\".format(prefix, get_timestamp(timestamp_format=\"%m-%d-%Y\"))\n expect(old_tag != new_tag, \"New tag must have different name than old tag\")\n\n run_cmd_no_fail(\"git tag {} {}\".format(new_tag, commit))\n run_cmd_no_fail(\"git push {} {}\".format(remote, new_tag))\n\n return new_tag\n\n###############################################################################\ndef make_new_split_tag(old_split_tag):\n###############################################################################\n return make_new_tag(SPLIT_TAG_PREFIX, old_split_tag)\n\n###############################################################################\ndef make_new_merge_tag(old_merge_tag):\n###############################################################################\n return make_new_tag(MERGE_TAG_PREFIX, old_merge_tag,\n remote=ESMCI_REMOTE_NAME, commit=\"{}/master\".format(ESMCI_REMOTE_NAME))\n\n###############################################################################\ndef get_branch_from_tag(tag):\n###############################################################################\n branch = \"{}/branch-for-{}\".format(getpass.getuser(), tag)\n return branch\n\n###############################################################################\ndef do_subtree_split(old_split_tag, new_split_tag, merge_tag):\n###############################################################################\n subtree_branch = get_branch_from_tag(new_split_tag)\n run_cmd_no_fail(\"git subtree split {}.. --prefix=cime --onto={} --ignore-joins -b {}\".\\\n format(old_split_tag, merge_tag, subtree_branch))\n return subtree_branch\n\n###############################################################################\ndef do_subtree_pull():\n###############################################################################\n stat = run_cmd(\"git subtree pull --prefix=cime {} master\".format(ESMCI_REMOTE_NAME))[0]\n if stat != 0:\n logging.info(\"There are merge conflicts. Please fix, commit, and re-run this tool with --resume\")\n sys.exit(1)\n\n###############################################################################\ndef make_pr_branch(branch, branch_head):\n###############################################################################\n pr_branch = \"{}-pr\".format(branch)\n run_cmd_no_fail(\"git checkout -b {} {}\".format(pr_branch, branch_head))\n\n return pr_branch\n\n###############################################################################\ndef merge_branch(branch, resume_count):\n###############################################################################\n stat = run_cmd(\"git merge -m 'Merge {}' -X rename-threshold=25 {}\".format(branch, branch))[0]\n if stat != 0:\n logging.info(\"There are merge conflicts. Please fix, commit, and re-run this tool with --resume-{}\".format(resume_count))\n sys.exit(1)\n\n###############################################################################\ndef merge_pr_branch_1(subtree_branch):\n###############################################################################\n merge_branch(subtree_branch, \"one\")\n\n###############################################################################\ndef merge_pr_branch_2():\n###############################################################################\n merge_branch(\"{}/master\".format(ESMCI_REMOTE_NAME), \"two\")\n\n###############################################################################\ndef delete_tag(tag, remote=\"origin\"):\n###############################################################################\n run_cmd_no_fail(\"git tag -d {}\".format(tag))\n run_cmd_no_fail(\"git push {} :refs/tags/{}\".format(remote, tag))\n\n###############################################################################\ndef acme_cime_split(resume_one, resume_two):\n###############################################################################\n if not resume_one and not resume_two:\n setup()\n\n old_split_tag = get_split_tag()\n\n try:\n new_split_tag = make_new_split_tag(old_split_tag)\n\n merge_tag = get_merge_tag()\n\n subtree_branch = do_subtree_split(old_split_tag, new_split_tag, merge_tag)\n\n pr_branch = make_pr_branch(subtree_branch, merge_tag)\n except:\n # If unexpected failure happens, delete new split tag\n delete_tag(new_split_tag)\n raise\n\n merge_pr_branch_1(subtree_branch)\n else:\n old_split_tag, new_split_tag = get_split_tag(expected_num=2)\n pr_branch = \"{}-pr\".format(get_branch_from_tag(new_split_tag))\n\n if not resume_two:\n merge_pr_branch_2()\n\n try:\n run_cmd_no_fail(\"git push {} {}\".format(ESMCI_REMOTE_NAME, pr_branch))\n except:\n delete_tag(old_split_tag)\n raise\n\n delete_tag(old_split_tag)\n\n###############################################################################\ndef acme_cime_merge(resume):\n###############################################################################\n if not resume:\n setup()\n\n old_merge_tag = get_merge_tag()\n\n try:\n new_merge_tag = make_new_merge_tag(old_merge_tag)\n\n pr_branch = make_pr_branch(get_branch_from_tag(new_merge_tag), \"origin/master\")\n except:\n delete_tag(new_merge_tag, remote=ESMCI_REMOTE_NAME)\n raise\n\n do_subtree_pull()\n\n else:\n old_merge_tag, new_merge_tag = get_merge_tag(expected_num=2)\n pr_branch = \"{}-pr\".format(get_branch_from_tag(new_merge_tag))\n\n try:\n run_cmd_no_fail(\"git push origin {}\".format(pr_branch))\n except:\n delete_tag(old_merge_tag, remote=ESMCI_REMOTE_NAME)\n raise\n\n delete_tag(old_merge_tag, remote=ESMCI_REMOTE_NAME)\n", "path": "scripts/lib/acme_cime_mgmt.py"}], "after_files": [{"content": "from CIME.utils import run_cmd, run_cmd_no_fail, expect, get_timestamp\n\nimport sys, getpass, logging\n\n# Constants\nESMCI_REMOTE_NAME = \"esmci_remote_for_split\"\nESMCI_URL = \"[email protected]:ESMCI/CIME.git\"\nSPLIT_TAG_PREFIX = \"acme-split-\"\nMERGE_TAG_PREFIX = \"to-acme-\"\n\n###############################################################################\ndef setup():\n###############################################################################\n run_cmd_no_fail(\"git config merge.renameLimit 999999\")\n run_cmd_no_fail(\"git checkout master && git pull && git submodule update --init\")\n\n remotes = run_cmd_no_fail(\"git remote\")\n if ESMCI_REMOTE_NAME not in remotes:\n run_cmd_no_fail(\"git remote add {} {}\".format(ESMCI_REMOTE_NAME, ESMCI_URL))\n\n run_cmd_no_fail(\"git fetch --prune {}\".format(ESMCI_REMOTE_NAME))\n run_cmd_no_fail(\"git fetch --prune {} --tags\".format(ESMCI_REMOTE_NAME))\n\n###############################################################################\ndef get_tag(prefix, expected_num=1):\n###############################################################################\n tags = run_cmd_no_fail(\"git tag\").split()\n tags = [tag for tag in tags if tag.startswith(prefix)]\n\n expect(len(tags) == expected_num, \"Expected exactly {} {} tag, found {}\".format(expected_num, prefix, \", \".join(tags)))\n\n if expected_num == 1:\n return tags[0]\n else:\n return tags\n\n###############################################################################\ndef get_split_tag(expected_num=1):\n###############################################################################\n return get_tag(SPLIT_TAG_PREFIX, expected_num=expected_num)\n\n###############################################################################\ndef get_merge_tag(expected_num=1):\n###############################################################################\n return get_tag(MERGE_TAG_PREFIX, expected_num=expected_num)\n\n###############################################################################\ndef make_new_tag(prefix, old_tag, remote=\"origin\", commit=\"HEAD\"):\n###############################################################################\n new_tag = \"{}{}\".format(prefix, get_timestamp(timestamp_format=\"%m-%d-%Y\"))\n expect(old_tag != new_tag, \"New tag must have different name than old tag\")\n\n run_cmd_no_fail(\"git tag {} {}\".format(new_tag, commit))\n run_cmd_no_fail(\"git push {} {}\".format(remote, new_tag))\n\n return new_tag\n\n###############################################################################\ndef make_new_split_tag(old_split_tag):\n###############################################################################\n return make_new_tag(SPLIT_TAG_PREFIX, old_split_tag)\n\n###############################################################################\ndef make_new_merge_tag(old_merge_tag):\n###############################################################################\n return make_new_tag(MERGE_TAG_PREFIX, old_merge_tag,\n remote=ESMCI_REMOTE_NAME, commit=\"{}/master\".format(ESMCI_REMOTE_NAME))\n\n###############################################################################\ndef get_branch_from_tag(tag):\n###############################################################################\n branch = \"{}/branch-for-{}\".format(getpass.getuser(), tag)\n return branch\n\n###############################################################################\ndef do_subtree_split(old_split_tag, new_split_tag, merge_tag):\n###############################################################################\n subtree_branch = get_branch_from_tag(new_split_tag)\n run_cmd_no_fail(\"git subtree split {}.. --prefix=cime --onto={} --ignore-joins -b {}\".\\\n format(old_split_tag, merge_tag, subtree_branch))\n return subtree_branch\n\n###############################################################################\ndef do_subtree_pull():\n###############################################################################\n stat = run_cmd(\"git subtree pull --prefix=cime {} master\".format(ESMCI_REMOTE_NAME))[0]\n if stat != 0:\n logging.info(\"There are merge conflicts. Please fix, commit, and re-run this tool with --resume\")\n sys.exit(1)\n\n###############################################################################\ndef make_pr_branch(branch, branch_head):\n###############################################################################\n pr_branch = \"{}-pr\".format(branch)\n run_cmd_no_fail(\"git checkout -b {} {}\".format(pr_branch, branch_head))\n\n return pr_branch\n\n###############################################################################\ndef merge_branch(branch, resume_count):\n###############################################################################\n stat = run_cmd(\"git merge -m 'Merge {}' -X rename-threshold=25 {}\".format(branch, branch))[0]\n if stat != 0:\n logging.info(\"There are merge conflicts. Please fix, commit, and re-run this tool with --resume-{}\".format(resume_count))\n sys.exit(1)\n\n###############################################################################\ndef merge_pr_branch_1(subtree_branch):\n###############################################################################\n merge_branch(subtree_branch, \"one\")\n\n###############################################################################\ndef merge_pr_branch_2():\n###############################################################################\n merge_branch(\"{}/master\".format(ESMCI_REMOTE_NAME), \"two\")\n\n###############################################################################\ndef delete_tag(tag, remote=\"origin\"):\n###############################################################################\n run_cmd_no_fail(\"git tag -d {}\".format(tag))\n run_cmd_no_fail(\"git push {} :refs/tags/{}\".format(remote, tag))\n\n###############################################################################\ndef acme_cime_split(resume_one, resume_two):\n###############################################################################\n if not resume_one and not resume_two:\n setup()\n\n old_split_tag = get_split_tag()\n\n try:\n new_split_tag = make_new_split_tag(old_split_tag)\n\n merge_tag = get_merge_tag()\n\n subtree_branch = do_subtree_split(old_split_tag, new_split_tag, merge_tag)\n\n pr_branch = make_pr_branch(subtree_branch, merge_tag)\n except:\n # If unexpected failure happens, delete new split tag\n delete_tag(new_split_tag)\n raise\n\n merge_pr_branch_1(subtree_branch)\n else:\n old_split_tag, new_split_tag = get_split_tag(expected_num=2)\n pr_branch = \"{}-pr\".format(get_branch_from_tag(new_split_tag))\n\n if not resume_two:\n merge_pr_branch_2()\n\n try:\n run_cmd_no_fail(\"git push {} {}\".format(ESMCI_REMOTE_NAME, pr_branch))\n except:\n delete_tag(old_split_tag)\n raise\n\n delete_tag(old_split_tag)\n\n###############################################################################\ndef acme_cime_merge(resume):\n###############################################################################\n if not resume:\n setup()\n\n old_merge_tag = get_merge_tag()\n\n try:\n new_merge_tag = make_new_merge_tag(old_merge_tag)\n\n pr_branch = make_pr_branch(get_branch_from_tag(new_merge_tag), \"origin/master\")\n except:\n delete_tag(new_merge_tag, remote=ESMCI_REMOTE_NAME)\n raise\n\n do_subtree_pull()\n\n else:\n old_merge_tag, new_merge_tag = get_merge_tag(expected_num=2)\n pr_branch = \"{}-pr\".format(get_branch_from_tag(new_merge_tag))\n\n try:\n run_cmd_no_fail(\"git push origin {}\".format(pr_branch))\n except:\n delete_tag(old_merge_tag, remote=ESMCI_REMOTE_NAME)\n raise\n\n delete_tag(old_merge_tag, remote=ESMCI_REMOTE_NAME)\n", "path": "scripts/lib/acme_cime_mgmt.py"}]}
| 2,217 | 190 |
gh_patches_debug_38710
|
rasdani/github-patches
|
git_diff
|
nvaccess__nvda-12486
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
No braille feedback in Windows Calculator
### Steps to reproduce:
1. Open Windows Calculator.
2. Type 2
3. Type +
4. Type 3
5. Type = (or Enter)
Note that the new appmodule listens for the Enter key, but not the equals (=) key. However, both work to display the result. Speech reports the result when you press Enter, but braille provides no feedback regardless of what key you press.
### Actual behavior:
The braille display continues to show "Display is 0".
There are two problems with this:
1. As you type (without using speech) you cannot verify what you just entered.
2. Once the result appears, you cannot read it unless you temporarily move the focus away from the display and back again.
### Expected behavior:
The braille display shows each number, operator and result as you type.
### System configuration
#### NVDA installed/portable/running from source:
Installed
#### NVDA version:
2020.4
#### Windows version:
Version 10.0.19042 Build 19042
#### Name and version of other software in use when reproducing the issue:
#### Other information about your system:
### Other questions
#### Does the issue still occur after restarting your computer?
Yes
#### Have you tried any other versions of NVDA? If so, please report their behaviors.
Yes, it worked in NVDA 2019.3.
#### If add-ons are disabled, is your problem still occurring?
Yes
#### Did you try to run the COM registry fixing tool in NVDA menu / tools?
Yes
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `source/appModules/calculator.py`
Content:
```
1 # A part of NonVisual Desktop Access (NVDA)
2 # Copyright (C) 2020 NV Access Limited, Joseph Lee
3 # This file is covered by the GNU General Public License.
4 # See the file COPYING for more details.
5
6 """App module for Windows 10 Calculator"""
7
8 import appModuleHandler
9 import api
10 from NVDAObjects.UIA import UIA
11 import queueHandler
12 import ui
13 import scriptHandler
14
15 # #9428: do not announce current values until calculations are done in order to avoid repetitions.
16 noCalculatorEntryAnnouncements = [
17 # Display field with Calculator set to full screen mode.
18 "CalculatorResults",
19 # In the middle of a calculation expression entry.
20 "CalculatorExpression",
21 # Results display with Calculator set to compact overlay i.e. always on top mode.
22 "CalculatorAlwaysOnTopResults",
23 # Calculator expressions with Calculator set to always on top mode.
24 "ExpressionContainer",
25 # Date range selector.
26 "ContentPresenter",
27 # Briefly shown when closing date calculation calendar.
28 "Light Dismiss",
29 # Unit conversion/convert from.
30 "Value1",
31 # Unit conversion/converts into.
32 "Value2",
33 ]
34
35
36 class AppModule(appModuleHandler.AppModule):
37
38 _shouldAnnounceResult = False
39 # Name change says the same thing multiple times for some items.
40 _resultsCache = ""
41
42 def event_nameChange(self, obj, nextHandler):
43 if not isinstance(obj, UIA):
44 return
45 # No, announce value changes immediately except for calculator results and expressions.
46 if (
47 obj.UIAAutomationId in noCalculatorEntryAnnouncements
48 or obj.UIAElement.cachedClassName == "LandmarkTarget"
49 ):
50 self._shouldAnnounceResult = False
51 # For the rest:
52 elif (
53 obj.UIAAutomationId not in noCalculatorEntryAnnouncements
54 and obj.name != self._resultsCache
55 ):
56 # For unit conversion, both name change and notification events are fired,
57 # although UIA notification event presents much better messages.
58 # For date calculation, live region change event is also fired for difference between dates.
59 if obj.UIAAutomationId != "DateDiffAllUnitsResultLabel":
60 ui.message(obj.name)
61 self._resultsCache = obj.name
62 if not self._shouldAnnounceResult:
63 return
64 self._shouldAnnounceResult = False
65 nextHandler()
66
67 def event_UIA_notification(self, obj, nextHandler, activityId=None, **kwargs):
68 try:
69 shouldAnnounceNotification = (
70 obj.previous.UIAAutomationId in
71 ("numberPad", "UnitConverterRootGrid")
72 )
73 except AttributeError:
74 resultElement = api.getForegroundObject().children[1].lastChild
75 # Redesigned in 2019 due to introduction of "always on top" i.e. compact overlay mode.
76 if resultElement.UIAElement.cachedClassName != "LandmarkTarget":
77 resultElement = resultElement.parent.children[1]
78 shouldAnnounceNotification = (
79 resultElement
80 and resultElement.firstChild
81 and resultElement.firstChild.UIAAutomationId not in noCalculatorEntryAnnouncements
82 )
83 # Display updated activity ID seen when entering calculations should be ignored
84 # as as it is redundant if speak typed characters is on.
85 if shouldAnnounceNotification or activityId != "DisplayUpdated":
86 nextHandler()
87
88 # A list of native commands to handle calculator result announcement.
89 _calculatorResultGestures = ("kb:enter", "kb:numpadEnter", "kb:escape")
90
91 @scriptHandler.script(gestures=_calculatorResultGestures)
92 def script_calculatorResult(self, gesture):
93 # To prevent double focus announcement, check where we are.
94 focus = api.getFocusObject()
95 gesture.send()
96 # In redstone, calculator result keeps firing name change,
97 # so tell it to do so if and only if enter has been pressed.
98 self._shouldAnnounceResult = True
99 # Hack: only announce display text when an actual calculator button (usually equals button) is pressed.
100 # In redstone, pressing enter does not move focus to equals button.
101 if isinstance(focus, UIA):
102 if focus.UIAAutomationId in ("CalculatorResults", "CalculatorAlwaysOnTopResults"):
103 queueHandler.queueFunction(queueHandler.eventQueue, focus.reportFocus)
104 else:
105 resultsScreen = api.getForegroundObject().children[1].lastChild
106 if isinstance(resultsScreen, UIA) and resultsScreen.UIAElement.cachedClassName == "LandmarkTarget":
107 # And no, do not allow focus to move.
108 queueHandler.queueFunction(queueHandler.eventQueue, resultsScreen.firstChild.reportFocus)
109
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/source/appModules/calculator.py b/source/appModules/calculator.py
--- a/source/appModules/calculator.py
+++ b/source/appModules/calculator.py
@@ -1,5 +1,5 @@
# A part of NonVisual Desktop Access (NVDA)
-# Copyright (C) 2020 NV Access Limited, Joseph Lee
+# Copyright (C) 2020-2021 NV Access Limited, Joseph Lee
# This file is covered by the GNU General Public License.
# See the file COPYING for more details.
@@ -11,6 +11,7 @@
import queueHandler
import ui
import scriptHandler
+import braille
# #9428: do not announce current values until calculations are done in order to avoid repetitions.
noCalculatorEntryAnnouncements = [
@@ -64,7 +65,10 @@
self._shouldAnnounceResult = False
nextHandler()
- def event_UIA_notification(self, obj, nextHandler, activityId=None, **kwargs):
+ def event_UIA_notification(self, obj, nextHandler, displayString=None, activityId=None, **kwargs):
+ # #12268: for "DisplayUpdated", announce display strings in braille and move on.
+ if activityId == "DisplayUpdated":
+ braille.handler.message(displayString)
try:
shouldAnnounceNotification = (
obj.previous.UIAAutomationId in
@@ -86,7 +90,13 @@
nextHandler()
# A list of native commands to handle calculator result announcement.
- _calculatorResultGestures = ("kb:enter", "kb:numpadEnter", "kb:escape")
+ _calculatorResultGestures = (
+ "kb:enter",
+ "kb:numpadEnter",
+ "kb:escape",
+ "kb:delete",
+ "kb:numpadDelete"
+ )
@scriptHandler.script(gestures=_calculatorResultGestures)
def script_calculatorResult(self, gesture):
@@ -100,9 +110,9 @@
# In redstone, pressing enter does not move focus to equals button.
if isinstance(focus, UIA):
if focus.UIAAutomationId in ("CalculatorResults", "CalculatorAlwaysOnTopResults"):
- queueHandler.queueFunction(queueHandler.eventQueue, focus.reportFocus)
+ queueHandler.queueFunction(queueHandler.eventQueue, ui.message, focus.name)
else:
resultsScreen = api.getForegroundObject().children[1].lastChild
if isinstance(resultsScreen, UIA) and resultsScreen.UIAElement.cachedClassName == "LandmarkTarget":
# And no, do not allow focus to move.
- queueHandler.queueFunction(queueHandler.eventQueue, resultsScreen.firstChild.reportFocus)
+ queueHandler.queueFunction(queueHandler.eventQueue, ui.message, resultsScreen.firstChild.name)
|
{"golden_diff": "diff --git a/source/appModules/calculator.py b/source/appModules/calculator.py\n--- a/source/appModules/calculator.py\n+++ b/source/appModules/calculator.py\n@@ -1,5 +1,5 @@\n # A part of NonVisual Desktop Access (NVDA)\n-# Copyright (C) 2020 NV Access Limited, Joseph Lee\n+# Copyright (C) 2020-2021 NV Access Limited, Joseph Lee\n # This file is covered by the GNU General Public License.\n # See the file COPYING for more details.\n \n@@ -11,6 +11,7 @@\n import queueHandler\n import ui\n import scriptHandler\n+import braille\n \n # #9428: do not announce current values until calculations are done in order to avoid repetitions.\n noCalculatorEntryAnnouncements = [\n@@ -64,7 +65,10 @@\n \t\tself._shouldAnnounceResult = False\n \t\tnextHandler()\n \n-\tdef event_UIA_notification(self, obj, nextHandler, activityId=None, **kwargs):\n+\tdef event_UIA_notification(self, obj, nextHandler, displayString=None, activityId=None, **kwargs):\n+\t\t# #12268: for \"DisplayUpdated\", announce display strings in braille and move on.\n+\t\tif activityId == \"DisplayUpdated\":\n+\t\t\tbraille.handler.message(displayString)\n \t\ttry:\n \t\t\tshouldAnnounceNotification = (\n \t\t\t\tobj.previous.UIAAutomationId in\n@@ -86,7 +90,13 @@\n \t\t\tnextHandler()\n \n \t# A list of native commands to handle calculator result announcement.\n-\t_calculatorResultGestures = (\"kb:enter\", \"kb:numpadEnter\", \"kb:escape\")\n+\t_calculatorResultGestures = (\n+\t\t\"kb:enter\",\n+\t\t\"kb:numpadEnter\",\n+\t\t\"kb:escape\",\n+\t\t\"kb:delete\",\n+\t\t\"kb:numpadDelete\"\n+\t)\n \n \[email protected](gestures=_calculatorResultGestures)\n \tdef script_calculatorResult(self, gesture):\n@@ -100,9 +110,9 @@\n \t\t# In redstone, pressing enter does not move focus to equals button.\n \t\tif isinstance(focus, UIA):\n \t\t\tif focus.UIAAutomationId in (\"CalculatorResults\", \"CalculatorAlwaysOnTopResults\"):\n-\t\t\t\tqueueHandler.queueFunction(queueHandler.eventQueue, focus.reportFocus)\n+\t\t\t\tqueueHandler.queueFunction(queueHandler.eventQueue, ui.message, focus.name)\n \t\t\telse:\n \t\t\t\tresultsScreen = api.getForegroundObject().children[1].lastChild\n \t\t\t\tif isinstance(resultsScreen, UIA) and resultsScreen.UIAElement.cachedClassName == \"LandmarkTarget\":\n \t\t\t\t\t# And no, do not allow focus to move.\n-\t\t\t\t\tqueueHandler.queueFunction(queueHandler.eventQueue, resultsScreen.firstChild.reportFocus)\n+\t\t\t\t\tqueueHandler.queueFunction(queueHandler.eventQueue, ui.message, resultsScreen.firstChild.name)\n", "issue": "No braille feedback in Windows Calculator\n### Steps to reproduce:\r\n1. Open Windows Calculator.\r\n2. Type 2\r\n3. Type +\r\n4. Type 3\r\n5. Type = (or Enter)\r\n\r\nNote that the new appmodule listens for the Enter key, but not the equals (=) key. However, both work to display the result. Speech reports the result when you press Enter, but braille provides no feedback regardless of what key you press.\r\n\r\n### Actual behavior:\r\nThe braille display continues to show \"Display is 0\".\r\nThere are two problems with this:\r\n1. As you type (without using speech) you cannot verify what you just entered.\r\n2. Once the result appears, you cannot read it unless you temporarily move the focus away from the display and back again.\r\n\r\n### Expected behavior:\r\nThe braille display shows each number, operator and result as you type.\r\n\r\n### System configuration\r\n#### NVDA installed/portable/running from source:\r\nInstalled\r\n\r\n#### NVDA version:\r\n2020.4\r\n\r\n#### Windows version:\r\nVersion\t10.0.19042 Build 19042\r\n\r\n#### Name and version of other software in use when reproducing the issue:\r\n\r\n#### Other information about your system:\r\n\r\n### Other questions\r\n#### Does the issue still occur after restarting your computer?\r\nYes\r\n\r\n#### Have you tried any other versions of NVDA? If so, please report their behaviors.\r\nYes, it worked in NVDA 2019.3.\r\n\r\n#### If add-ons are disabled, is your problem still occurring?\r\nYes\r\n\r\n#### Did you try to run the COM registry fixing tool in NVDA menu / tools?\r\nYes\n", "before_files": [{"content": "# A part of NonVisual Desktop Access (NVDA)\n# Copyright (C) 2020 NV Access Limited, Joseph Lee\n# This file is covered by the GNU General Public License.\n# See the file COPYING for more details.\n\n\"\"\"App module for Windows 10 Calculator\"\"\"\n\nimport appModuleHandler\nimport api\nfrom NVDAObjects.UIA import UIA\nimport queueHandler\nimport ui\nimport scriptHandler\n\n# #9428: do not announce current values until calculations are done in order to avoid repetitions.\nnoCalculatorEntryAnnouncements = [\n\t# Display field with Calculator set to full screen mode.\n\t\"CalculatorResults\",\n\t# In the middle of a calculation expression entry.\n\t\"CalculatorExpression\",\n\t# Results display with Calculator set to compact overlay i.e. always on top mode.\n\t\"CalculatorAlwaysOnTopResults\",\n\t# Calculator expressions with Calculator set to always on top mode.\n\t\"ExpressionContainer\",\n\t# Date range selector.\n\t\"ContentPresenter\",\n\t# Briefly shown when closing date calculation calendar.\n\t\"Light Dismiss\",\n\t# Unit conversion/convert from.\n\t\"Value1\",\n\t# Unit conversion/converts into.\n\t\"Value2\",\n]\n\n\nclass AppModule(appModuleHandler.AppModule):\n\n\t_shouldAnnounceResult = False\n\t# Name change says the same thing multiple times for some items.\n\t_resultsCache = \"\"\n\n\tdef event_nameChange(self, obj, nextHandler):\n\t\tif not isinstance(obj, UIA):\n\t\t\treturn\n\t\t# No, announce value changes immediately except for calculator results and expressions.\n\t\tif (\n\t\t\tobj.UIAAutomationId in noCalculatorEntryAnnouncements\n\t\t\tor obj.UIAElement.cachedClassName == \"LandmarkTarget\"\n\t\t):\n\t\t\tself._shouldAnnounceResult = False\n\t\t# For the rest:\n\t\telif (\n\t\t\tobj.UIAAutomationId not in noCalculatorEntryAnnouncements\n\t\t\tand obj.name != self._resultsCache\n\t\t):\n\t\t\t# For unit conversion, both name change and notification events are fired,\n\t\t\t# although UIA notification event presents much better messages.\n\t\t\t# For date calculation, live region change event is also fired for difference between dates.\n\t\t\tif obj.UIAAutomationId != \"DateDiffAllUnitsResultLabel\":\n\t\t\t\tui.message(obj.name)\n\t\t\tself._resultsCache = obj.name\n\t\tif not self._shouldAnnounceResult:\n\t\t\treturn\n\t\tself._shouldAnnounceResult = False\n\t\tnextHandler()\n\n\tdef event_UIA_notification(self, obj, nextHandler, activityId=None, **kwargs):\n\t\ttry:\n\t\t\tshouldAnnounceNotification = (\n\t\t\t\tobj.previous.UIAAutomationId in\n\t\t\t\t(\"numberPad\", \"UnitConverterRootGrid\")\n\t\t\t)\n\t\texcept AttributeError:\n\t\t\tresultElement = api.getForegroundObject().children[1].lastChild\n\t\t\t# Redesigned in 2019 due to introduction of \"always on top\" i.e. compact overlay mode.\n\t\t\tif resultElement.UIAElement.cachedClassName != \"LandmarkTarget\":\n\t\t\t\tresultElement = resultElement.parent.children[1]\n\t\t\tshouldAnnounceNotification = (\n\t\t\t\tresultElement\n\t\t\t\tand resultElement.firstChild\n\t\t\t\tand resultElement.firstChild.UIAAutomationId not in noCalculatorEntryAnnouncements\n\t\t\t)\n\t\t# Display updated activity ID seen when entering calculations should be ignored\n\t\t# as as it is redundant if speak typed characters is on.\n\t\tif shouldAnnounceNotification or activityId != \"DisplayUpdated\":\n\t\t\tnextHandler()\n\n\t# A list of native commands to handle calculator result announcement.\n\t_calculatorResultGestures = (\"kb:enter\", \"kb:numpadEnter\", \"kb:escape\")\n\n\[email protected](gestures=_calculatorResultGestures)\n\tdef script_calculatorResult(self, gesture):\n\t\t# To prevent double focus announcement, check where we are.\n\t\tfocus = api.getFocusObject()\n\t\tgesture.send()\n\t\t# In redstone, calculator result keeps firing name change,\n\t\t# so tell it to do so if and only if enter has been pressed.\n\t\tself._shouldAnnounceResult = True\n\t\t# Hack: only announce display text when an actual calculator button (usually equals button) is pressed.\n\t\t# In redstone, pressing enter does not move focus to equals button.\n\t\tif isinstance(focus, UIA):\n\t\t\tif focus.UIAAutomationId in (\"CalculatorResults\", \"CalculatorAlwaysOnTopResults\"):\n\t\t\t\tqueueHandler.queueFunction(queueHandler.eventQueue, focus.reportFocus)\n\t\t\telse:\n\t\t\t\tresultsScreen = api.getForegroundObject().children[1].lastChild\n\t\t\t\tif isinstance(resultsScreen, UIA) and resultsScreen.UIAElement.cachedClassName == \"LandmarkTarget\":\n\t\t\t\t\t# And no, do not allow focus to move.\n\t\t\t\t\tqueueHandler.queueFunction(queueHandler.eventQueue, resultsScreen.firstChild.reportFocus)\n", "path": "source/appModules/calculator.py"}], "after_files": [{"content": "# A part of NonVisual Desktop Access (NVDA)\n# Copyright (C) 2020-2021 NV Access Limited, Joseph Lee\n# This file is covered by the GNU General Public License.\n# See the file COPYING for more details.\n\n\"\"\"App module for Windows 10 Calculator\"\"\"\n\nimport appModuleHandler\nimport api\nfrom NVDAObjects.UIA import UIA\nimport queueHandler\nimport ui\nimport scriptHandler\nimport braille\n\n# #9428: do not announce current values until calculations are done in order to avoid repetitions.\nnoCalculatorEntryAnnouncements = [\n\t# Display field with Calculator set to full screen mode.\n\t\"CalculatorResults\",\n\t# In the middle of a calculation expression entry.\n\t\"CalculatorExpression\",\n\t# Results display with Calculator set to compact overlay i.e. always on top mode.\n\t\"CalculatorAlwaysOnTopResults\",\n\t# Calculator expressions with Calculator set to always on top mode.\n\t\"ExpressionContainer\",\n\t# Date range selector.\n\t\"ContentPresenter\",\n\t# Briefly shown when closing date calculation calendar.\n\t\"Light Dismiss\",\n\t# Unit conversion/convert from.\n\t\"Value1\",\n\t# Unit conversion/converts into.\n\t\"Value2\",\n]\n\n\nclass AppModule(appModuleHandler.AppModule):\n\n\t_shouldAnnounceResult = False\n\t# Name change says the same thing multiple times for some items.\n\t_resultsCache = \"\"\n\n\tdef event_nameChange(self, obj, nextHandler):\n\t\tif not isinstance(obj, UIA):\n\t\t\treturn\n\t\t# No, announce value changes immediately except for calculator results and expressions.\n\t\tif (\n\t\t\tobj.UIAAutomationId in noCalculatorEntryAnnouncements\n\t\t\tor obj.UIAElement.cachedClassName == \"LandmarkTarget\"\n\t\t):\n\t\t\tself._shouldAnnounceResult = False\n\t\t# For the rest:\n\t\telif (\n\t\t\tobj.UIAAutomationId not in noCalculatorEntryAnnouncements\n\t\t\tand obj.name != self._resultsCache\n\t\t):\n\t\t\t# For unit conversion, both name change and notification events are fired,\n\t\t\t# although UIA notification event presents much better messages.\n\t\t\t# For date calculation, live region change event is also fired for difference between dates.\n\t\t\tif obj.UIAAutomationId != \"DateDiffAllUnitsResultLabel\":\n\t\t\t\tui.message(obj.name)\n\t\t\tself._resultsCache = obj.name\n\t\tif not self._shouldAnnounceResult:\n\t\t\treturn\n\t\tself._shouldAnnounceResult = False\n\t\tnextHandler()\n\n\tdef event_UIA_notification(self, obj, nextHandler, displayString=None, activityId=None, **kwargs):\n\t\t# #12268: for \"DisplayUpdated\", announce display strings in braille and move on.\n\t\tif activityId == \"DisplayUpdated\":\n\t\t\tbraille.handler.message(displayString)\n\t\ttry:\n\t\t\tshouldAnnounceNotification = (\n\t\t\t\tobj.previous.UIAAutomationId in\n\t\t\t\t(\"numberPad\", \"UnitConverterRootGrid\")\n\t\t\t)\n\t\texcept AttributeError:\n\t\t\tresultElement = api.getForegroundObject().children[1].lastChild\n\t\t\t# Redesigned in 2019 due to introduction of \"always on top\" i.e. compact overlay mode.\n\t\t\tif resultElement.UIAElement.cachedClassName != \"LandmarkTarget\":\n\t\t\t\tresultElement = resultElement.parent.children[1]\n\t\t\tshouldAnnounceNotification = (\n\t\t\t\tresultElement\n\t\t\t\tand resultElement.firstChild\n\t\t\t\tand resultElement.firstChild.UIAAutomationId not in noCalculatorEntryAnnouncements\n\t\t\t)\n\t\t# Display updated activity ID seen when entering calculations should be ignored\n\t\t# as as it is redundant if speak typed characters is on.\n\t\tif shouldAnnounceNotification or activityId != \"DisplayUpdated\":\n\t\t\tnextHandler()\n\n\t# A list of native commands to handle calculator result announcement.\n\t_calculatorResultGestures = (\n\t\t\"kb:enter\",\n\t\t\"kb:numpadEnter\",\n\t\t\"kb:escape\",\n\t\t\"kb:delete\",\n\t\t\"kb:numpadDelete\"\n\t)\n\n\[email protected](gestures=_calculatorResultGestures)\n\tdef script_calculatorResult(self, gesture):\n\t\t# To prevent double focus announcement, check where we are.\n\t\tfocus = api.getFocusObject()\n\t\tgesture.send()\n\t\t# In redstone, calculator result keeps firing name change,\n\t\t# so tell it to do so if and only if enter has been pressed.\n\t\tself._shouldAnnounceResult = True\n\t\t# Hack: only announce display text when an actual calculator button (usually equals button) is pressed.\n\t\t# In redstone, pressing enter does not move focus to equals button.\n\t\tif isinstance(focus, UIA):\n\t\t\tif focus.UIAAutomationId in (\"CalculatorResults\", \"CalculatorAlwaysOnTopResults\"):\n\t\t\t\tqueueHandler.queueFunction(queueHandler.eventQueue, ui.message, focus.name)\n\t\t\telse:\n\t\t\t\tresultsScreen = api.getForegroundObject().children[1].lastChild\n\t\t\t\tif isinstance(resultsScreen, UIA) and resultsScreen.UIAElement.cachedClassName == \"LandmarkTarget\":\n\t\t\t\t\t# And no, do not allow focus to move.\n\t\t\t\t\tqueueHandler.queueFunction(queueHandler.eventQueue, ui.message, resultsScreen.firstChild.name)\n", "path": "source/appModules/calculator.py"}]}
| 1,868 | 639 |
gh_patches_debug_34427
|
rasdani/github-patches
|
git_diff
|
mozilla__pontoon-2520
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add an option to link to multiple strings
*This issue was created automatically by a [script](https://github.com/mathjazz/bugzilla2github/).*
## [Bug 1324933](https://bugzilla.mozilla.org/show_bug.cgi?id=1324933)
Bug Reporter: @tomer
CC: @gaby2300, @ItielMaN, @mathjazz
Blocker for: [Bug 1390931](https://bugzilla.mozilla.org/show_bug.cgi?id=1390931)
In dxr.mozilla.org I can select multiple lines in a file and than have a link that will show these lines highlighted. I'd suggest having a similar feature in pontoon, so we could send a team member a link that contains multiple strings, instead of one of the following workarounds:
* Sending one string per link
* Sending link to a search results or a resource, and asking them to look on the second string, the third from the bottom, etc.
I'd like to have a link similar to this one:
https://pontoon.mozilla.org/he/firefox-aurora/all-resources/?string=75295,75296
… Which will show me both strings in the list.
As for the UI for creating such lists, I guess having control-click to toggle multiple selections will be enough; this is an advanced feature after all. ☺
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pontoon/projects/management/commands/send_review_notifications.py`
Content:
```
1 from collections import defaultdict
2 from datetime import timedelta
3 from urllib.parse import urlencode
4
5 from django.core.management.base import BaseCommand
6 from django.db.models import Q
7 from django.urls import reverse
8 from django.utils import timezone
9 from notifications.signals import notify
10 from pontoon.base.models import Translation
11
12
13 class Command(BaseCommand):
14 help = "Notify translators about their newly reviewed suggestions"
15
16 def get_description(self, author, notifyData):
17 desc = "Your suggestions have been reviewed:\n<ul>"
18
19 for (locale, project), (approved, rejected) in notifyData.items():
20 url = reverse(
21 "pontoon.translate",
22 kwargs={
23 "locale": locale.code,
24 "project": project.slug,
25 "resource": "all-resources",
26 },
27 )
28 url += "?" + urlencode({"author": author.email})
29 if len(approved) == 1 and len(rejected) == 0:
30 url += "&" + urlencode({"string": approved[0]})
31 elif len(approved) == 0 and len(rejected) == 1:
32 url += "&" + urlencode({"string": rejected[0]})
33
34 # Filter out rejections where the author's own suggestion replaced the previous
35 rejected = [x for x in rejected if x not in approved]
36
37 if len(approved) == 0:
38 msg = f"{len(rejected)} Rejected"
39 else:
40 msg = f"{len(approved)} Approved"
41 if len(rejected) > 0:
42 msg += f", {len(rejected)} Rejected"
43
44 desc += (
45 f'\n<li><a href="{url}">{project.name} ({locale.code})</a>: {msg}</li>'
46 )
47
48 return desc + "\n</ul>"
49
50 def handle(self, *args, **options):
51 """
52 This command sends notifications about newly reviewed
53 suggestions to the authors of those suggestions.
54
55 The command is designed to run on a daily basis.
56 """
57 self.stdout.write("Sending review notifications...")
58
59 # (author) -> (locale, project) -> (approved, rejected)
60 data = defaultdict(lambda: defaultdict(lambda: (list(), list())))
61 start = timezone.now() - timedelta(days=1)
62 for suggestion in Translation.objects.filter(
63 (Q(approved_date__gt=start) | Q(rejected_date__gt=start))
64 & Q(user__profile__review_notifications=True)
65 ):
66 author = suggestion.user
67 locale = suggestion.locale
68 project = suggestion.entity.resource.project
69
70 if suggestion.approved and suggestion.approved_user != author:
71 data[author][(locale, project)][0].append(suggestion.entity.pk)
72 elif suggestion.rejected and suggestion.rejected_user != author:
73 data[author][(locale, project)][1].append(suggestion.entity.pk)
74
75 for author, notifyData in data.items():
76 desc = self.get_description(author, notifyData)
77 notify.send(
78 sender=author,
79 recipient=author,
80 verb="has reviewed suggestions",
81 description=desc,
82 )
83
84 self.stdout.write(f"Sent {len(data)} review notifications.")
85
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pontoon/projects/management/commands/send_review_notifications.py b/pontoon/projects/management/commands/send_review_notifications.py
--- a/pontoon/projects/management/commands/send_review_notifications.py
+++ b/pontoon/projects/management/commands/send_review_notifications.py
@@ -1,6 +1,5 @@
from collections import defaultdict
from datetime import timedelta
-from urllib.parse import urlencode
from django.core.management.base import BaseCommand
from django.db.models import Q
@@ -13,7 +12,7 @@
class Command(BaseCommand):
help = "Notify translators about their newly reviewed suggestions"
- def get_description(self, author, notifyData):
+ def get_description(self, notifyData):
desc = "Your suggestions have been reviewed:\n<ul>"
for (locale, project), (approved, rejected) in notifyData.items():
@@ -25,11 +24,8 @@
"resource": "all-resources",
},
)
- url += "?" + urlencode({"author": author.email})
- if len(approved) == 1 and len(rejected) == 0:
- url += "&" + urlencode({"string": approved[0]})
- elif len(approved) == 0 and len(rejected) == 1:
- url += "&" + urlencode({"string": rejected[0]})
+ list = map(str, approved + rejected)
+ url += "?list=" + ",".join(list)
# Filter out rejections where the author's own suggestion replaced the previous
rejected = [x for x in rejected if x not in approved]
@@ -73,7 +69,7 @@
data[author][(locale, project)][1].append(suggestion.entity.pk)
for author, notifyData in data.items():
- desc = self.get_description(author, notifyData)
+ desc = self.get_description(notifyData)
notify.send(
sender=author,
recipient=author,
|
{"golden_diff": "diff --git a/pontoon/projects/management/commands/send_review_notifications.py b/pontoon/projects/management/commands/send_review_notifications.py\n--- a/pontoon/projects/management/commands/send_review_notifications.py\n+++ b/pontoon/projects/management/commands/send_review_notifications.py\n@@ -1,6 +1,5 @@\n from collections import defaultdict\n from datetime import timedelta\n-from urllib.parse import urlencode\n \n from django.core.management.base import BaseCommand\n from django.db.models import Q\n@@ -13,7 +12,7 @@\n class Command(BaseCommand):\n help = \"Notify translators about their newly reviewed suggestions\"\n \n- def get_description(self, author, notifyData):\n+ def get_description(self, notifyData):\n desc = \"Your suggestions have been reviewed:\\n<ul>\"\n \n for (locale, project), (approved, rejected) in notifyData.items():\n@@ -25,11 +24,8 @@\n \"resource\": \"all-resources\",\n },\n )\n- url += \"?\" + urlencode({\"author\": author.email})\n- if len(approved) == 1 and len(rejected) == 0:\n- url += \"&\" + urlencode({\"string\": approved[0]})\n- elif len(approved) == 0 and len(rejected) == 1:\n- url += \"&\" + urlencode({\"string\": rejected[0]})\n+ list = map(str, approved + rejected)\n+ url += \"?list=\" + \",\".join(list)\n \n # Filter out rejections where the author's own suggestion replaced the previous\n rejected = [x for x in rejected if x not in approved]\n@@ -73,7 +69,7 @@\n data[author][(locale, project)][1].append(suggestion.entity.pk)\n \n for author, notifyData in data.items():\n- desc = self.get_description(author, notifyData)\n+ desc = self.get_description(notifyData)\n notify.send(\n sender=author,\n recipient=author,\n", "issue": "Add an option to link to multiple strings\n*This issue was created automatically by a [script](https://github.com/mathjazz/bugzilla2github/).*\n## [Bug 1324933](https://bugzilla.mozilla.org/show_bug.cgi?id=1324933)\nBug Reporter: @tomer\nCC: @gaby2300, @ItielMaN, @mathjazz\nBlocker for: [Bug 1390931](https://bugzilla.mozilla.org/show_bug.cgi?id=1390931)\n\nIn dxr.mozilla.org I can select multiple lines in a file and than have a link that will show these lines highlighted. I'd suggest having a similar feature in pontoon, so we could send a team member a link that contains multiple strings, instead of one of the following workarounds:\n\n* Sending one string per link\n* Sending link to a search results or a resource, and asking them to look on the second string, the third from the bottom, etc. \n\nI'd like to have a link similar to this one: \nhttps://pontoon.mozilla.org/he/firefox-aurora/all-resources/?string=75295,75296 \n\u2026 Which will show me both strings in the list.\n\n\nAs for the UI for creating such lists, I guess having control-click to toggle multiple selections will be enough; this is an advanced feature after all. \u263a\n", "before_files": [{"content": "from collections import defaultdict\nfrom datetime import timedelta\nfrom urllib.parse import urlencode\n\nfrom django.core.management.base import BaseCommand\nfrom django.db.models import Q\nfrom django.urls import reverse\nfrom django.utils import timezone\nfrom notifications.signals import notify\nfrom pontoon.base.models import Translation\n\n\nclass Command(BaseCommand):\n help = \"Notify translators about their newly reviewed suggestions\"\n\n def get_description(self, author, notifyData):\n desc = \"Your suggestions have been reviewed:\\n<ul>\"\n\n for (locale, project), (approved, rejected) in notifyData.items():\n url = reverse(\n \"pontoon.translate\",\n kwargs={\n \"locale\": locale.code,\n \"project\": project.slug,\n \"resource\": \"all-resources\",\n },\n )\n url += \"?\" + urlencode({\"author\": author.email})\n if len(approved) == 1 and len(rejected) == 0:\n url += \"&\" + urlencode({\"string\": approved[0]})\n elif len(approved) == 0 and len(rejected) == 1:\n url += \"&\" + urlencode({\"string\": rejected[0]})\n\n # Filter out rejections where the author's own suggestion replaced the previous\n rejected = [x for x in rejected if x not in approved]\n\n if len(approved) == 0:\n msg = f\"{len(rejected)} Rejected\"\n else:\n msg = f\"{len(approved)} Approved\"\n if len(rejected) > 0:\n msg += f\", {len(rejected)} Rejected\"\n\n desc += (\n f'\\n<li><a href=\"{url}\">{project.name} ({locale.code})</a>: {msg}</li>'\n )\n\n return desc + \"\\n</ul>\"\n\n def handle(self, *args, **options):\n \"\"\"\n This command sends notifications about newly reviewed\n suggestions to the authors of those suggestions.\n\n The command is designed to run on a daily basis.\n \"\"\"\n self.stdout.write(\"Sending review notifications...\")\n\n # (author) -> (locale, project) -> (approved, rejected)\n data = defaultdict(lambda: defaultdict(lambda: (list(), list())))\n start = timezone.now() - timedelta(days=1)\n for suggestion in Translation.objects.filter(\n (Q(approved_date__gt=start) | Q(rejected_date__gt=start))\n & Q(user__profile__review_notifications=True)\n ):\n author = suggestion.user\n locale = suggestion.locale\n project = suggestion.entity.resource.project\n\n if suggestion.approved and suggestion.approved_user != author:\n data[author][(locale, project)][0].append(suggestion.entity.pk)\n elif suggestion.rejected and suggestion.rejected_user != author:\n data[author][(locale, project)][1].append(suggestion.entity.pk)\n\n for author, notifyData in data.items():\n desc = self.get_description(author, notifyData)\n notify.send(\n sender=author,\n recipient=author,\n verb=\"has reviewed suggestions\",\n description=desc,\n )\n\n self.stdout.write(f\"Sent {len(data)} review notifications.\")\n", "path": "pontoon/projects/management/commands/send_review_notifications.py"}], "after_files": [{"content": "from collections import defaultdict\nfrom datetime import timedelta\n\nfrom django.core.management.base import BaseCommand\nfrom django.db.models import Q\nfrom django.urls import reverse\nfrom django.utils import timezone\nfrom notifications.signals import notify\nfrom pontoon.base.models import Translation\n\n\nclass Command(BaseCommand):\n help = \"Notify translators about their newly reviewed suggestions\"\n\n def get_description(self, notifyData):\n desc = \"Your suggestions have been reviewed:\\n<ul>\"\n\n for (locale, project), (approved, rejected) in notifyData.items():\n url = reverse(\n \"pontoon.translate\",\n kwargs={\n \"locale\": locale.code,\n \"project\": project.slug,\n \"resource\": \"all-resources\",\n },\n )\n list = map(str, approved + rejected)\n url += \"?list=\" + \",\".join(list)\n\n # Filter out rejections where the author's own suggestion replaced the previous\n rejected = [x for x in rejected if x not in approved]\n\n if len(approved) == 0:\n msg = f\"{len(rejected)} Rejected\"\n else:\n msg = f\"{len(approved)} Approved\"\n if len(rejected) > 0:\n msg += f\", {len(rejected)} Rejected\"\n\n desc += (\n f'\\n<li><a href=\"{url}\">{project.name} ({locale.code})</a>: {msg}</li>'\n )\n\n return desc + \"\\n</ul>\"\n\n def handle(self, *args, **options):\n \"\"\"\n This command sends notifications about newly reviewed\n suggestions to the authors of those suggestions.\n\n The command is designed to run on a daily basis.\n \"\"\"\n self.stdout.write(\"Sending review notifications...\")\n\n # (author) -> (locale, project) -> (approved, rejected)\n data = defaultdict(lambda: defaultdict(lambda: (list(), list())))\n start = timezone.now() - timedelta(days=1)\n for suggestion in Translation.objects.filter(\n (Q(approved_date__gt=start) | Q(rejected_date__gt=start))\n & Q(user__profile__review_notifications=True)\n ):\n author = suggestion.user\n locale = suggestion.locale\n project = suggestion.entity.resource.project\n\n if suggestion.approved and suggestion.approved_user != author:\n data[author][(locale, project)][0].append(suggestion.entity.pk)\n elif suggestion.rejected and suggestion.rejected_user != author:\n data[author][(locale, project)][1].append(suggestion.entity.pk)\n\n for author, notifyData in data.items():\n desc = self.get_description(notifyData)\n notify.send(\n sender=author,\n recipient=author,\n verb=\"has reviewed suggestions\",\n description=desc,\n )\n\n self.stdout.write(f\"Sent {len(data)} review notifications.\")\n", "path": "pontoon/projects/management/commands/send_review_notifications.py"}]}
| 1,408 | 426 |
gh_patches_debug_42515
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-2635
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
UnicodeDecodeError in /rest/v1/project_location end-point
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `akvo/rsr/models/location.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Akvo RSR is covered by the GNU Affero General Public License.
4 # See more details in the license.txt file located at the root folder of the Akvo RSR module.
5 # For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
6
7
8 from django.db import models
9 from django.utils.translation import ugettext_lazy as _
10
11 from ..fields import LatitudeField, LongitudeField, ValidXMLCharField
12 from akvo.codelists.models import (Country, GeographicExactness, GeographicLocationClass,
13 GeographicLocationReach, GeographicVocabulary, LocationType)
14 from akvo.codelists.store.codelists_v202 import (
15 COUNTRY, GEOGRAPHIC_EXACTNESS, GEOGRAPHIC_LOCATION_CLASS, GEOGRAPHIC_LOCATION_REACH,
16 GEOGRAPHIC_VOCABULARY, LOCATION_TYPE
17 )
18 from akvo.utils import codelist_choices, codelist_value, get_country
19
20
21 class BaseLocation(models.Model):
22 latitude = LatitudeField(
23 _(u'latitude'), null=True, blank=True, db_index=True, default=0,
24 help_text=_(u'Use a period to denote decimals.')
25 )
26 longitude = LongitudeField(
27 _(u'longitude'), null=True, blank=True, db_index=True, default=0,
28 help_text=_(u'Use a period to denote decimals.')
29 )
30 city = ValidXMLCharField(_(u'city'), blank=True, max_length=255)
31 state = ValidXMLCharField(_(u'state'), blank=True, max_length=255)
32 address_1 = ValidXMLCharField(_(u'address 1'), max_length=255, blank=True)
33 address_2 = ValidXMLCharField(_(u'address 2'), max_length=255, blank=True)
34 postcode = ValidXMLCharField(_(u'postal code'), max_length=10, blank=True)
35 country = models.ForeignKey('Country', null=True, blank=True, verbose_name=_(u'country'))
36
37 def delete(self, *args, **kwargs):
38 super(BaseLocation, self).delete(*args, **kwargs)
39
40 # If location_target has more locations, set the first as primary location
41 location_target = self.location_target
42 other_locations = location_target.locations.all()
43
44 if other_locations.count() > 0:
45 location_target.primary_location = other_locations.first()
46 else:
47 location_target.primary_location = None
48
49 location_target.save()
50
51 def save(self, *args, **kwargs):
52 # Set a country based on the latitude and longitude if possible
53 if self.country is None:
54 self.country = self.get_country_from_lat_lon()
55
56 super(BaseLocation, self).save(*args, **kwargs)
57
58 # Set location as primary location if it is the first location
59 location_target = self.location_target
60 if location_target.primary_location is None or location_target.primary_location.pk > self.pk:
61 location_target.primary_location = self
62 location_target.save()
63
64 def get_country_from_lat_lon(self):
65 """Get the country based on the location's latitude and longitude."""
66
67 if self.latitude is None or self.longitude is None:
68 return None
69
70 try:
71 country, iso_code = get_country(float(self.latitude), float(self.longitude))
72 except ValueError:
73 iso_code = None
74
75 if iso_code is not None:
76 # FIXME: We have one too many country models!
77 Country = models.get_model('rsr', 'Country')
78 return Country.objects.filter(iso_code=iso_code).first()
79
80 class Meta:
81 app_label = 'rsr'
82 abstract = True
83 ordering = ['id', ]
84
85
86 class OrganisationLocation(BaseLocation):
87 location_target = models.ForeignKey('Organisation', related_name='locations')
88 iati_country = ValidXMLCharField(
89 _(u'country'), blank=True, max_length=2, choices=codelist_choices(COUNTRY, show_code=False),
90 help_text=_(u'The country in which the organisation is located.')
91 )
92
93 def iati_country_value(self):
94 return codelist_value(Country, self, 'iati_country')
95
96 def iati_country_value_unicode(self):
97 return str(self.iati_country_value())
98
99
100 class ProjectLocation(BaseLocation):
101 location_target = models.ForeignKey('Project', related_name='locations')
102
103 # Additional IATI fields
104 reference = ValidXMLCharField(
105 _(u'reference'), blank=True, max_length=50,
106 help_text=_(u'An internal reference that describes the location in the reporting '
107 u'organisation\'s own system. For reference see: '
108 u'<a href="http://iatistandard.org/202/activity-standard/iati-activities/'
109 u'iati-activity/location/#attributes" target="_blank">'
110 u'http://iatistandard.org/202/activity-standard/iati-activities/iati-activity/'
111 u'location/#attributes</a>.')
112 )
113 location_code = ValidXMLCharField(
114 _(u'code'), blank=True, max_length=25,
115 help_text=_(u'Enter a code to identify the region. Codes are based on DAC region codes. '
116 u'Where an activity is considered global, the code 998 can be used. For '
117 u'reference: <a href="http://www.oecd.org/dac/stats/dacandcrscodelists.htm" '
118 u'target="_blank">http://www.oecd.org/dac/stats/dacandcrscodelists.htm</a>.')
119 )
120 vocabulary = ValidXMLCharField(_(u'vocabulary'), blank=True, max_length=2,
121 choices=codelist_choices(GEOGRAPHIC_VOCABULARY))
122 name = ValidXMLCharField(
123 _(u'name'), blank=True, max_length=100,
124 help_text=_(u'The human-readable name for the location.')
125 )
126 description = ValidXMLCharField(
127 _(u'location description'), blank=True, max_length=2000,
128 help_text=_(u'This provides free text space for providing an additional description, if '
129 u'needed, of the actual target of the activity. A description that qualifies '
130 u'the location, not the activity.')
131 )
132 activity_description = ValidXMLCharField(
133 _(u'activity description'), blank=True, max_length=2000,
134 help_text=_(u'A description that qualifies the activity taking place at the location. '
135 u'This should not duplicate information provided in the main activity '
136 u'description, and should typically be used to distinguish between activities '
137 u'at multiple locations within a single iati-activity record.')
138 )
139 exactness = ValidXMLCharField(
140 _(u'location precision'), blank=True, max_length=1,
141 choices=codelist_choices(GEOGRAPHIC_EXACTNESS),
142 help_text=_(u'Defines whether the location represents the most distinct point reasonably '
143 u'possible for this type of activity or is an approximation due to lack of '
144 u'more detailed information.')
145 )
146 location_reach = ValidXMLCharField(
147 _(u'reach'), blank=True, max_length=1, choices=codelist_choices(GEOGRAPHIC_LOCATION_REACH),
148 help_text=_(u'Does this location describe where the activity takes place or where the '
149 u'intended beneficiaries reside?')
150 )
151 location_class = ValidXMLCharField(
152 _(u'class'), blank=True, max_length=1, choices=codelist_choices(GEOGRAPHIC_LOCATION_CLASS),
153 help_text=_(u'Does the location refer to a physical structure such as a building, a '
154 u'populated place (e.g. city or village), an administrative division, or '
155 u'another topological feature (e.g. river, nature reserve)? For reference: '
156 u'<a href="http://iatistandard.org/202/codelists/GeographicLocationClass/" '
157 u'target="_blank">http://iatistandard.org/202/codelists/'
158 u'GeographicLocationClass/</a>.')
159 )
160 feature_designation = ValidXMLCharField(
161 _(u'feature designation'), blank=True, max_length=5,
162 choices=codelist_choices(LOCATION_TYPE),
163 help_text=_(u'A more refined coded classification of the type of feature referred to by '
164 u'this location. For reference: <a href="http://iatistandard.org/202/codelists/'
165 u'LocationType/" target="_blank">http://iatistandard.org/202/codelists/'
166 u'LocationType/</a>.')
167 )
168
169 def __unicode__(self):
170 return u'{0}, {1}{2}'.format(
171 u'{0}: {1}'.format(
172 _(u'Latitude'),
173 str(self.latitude) if self.latitude else _(u'No latitude specified')),
174 u'{0}: {1}'.format(
175 _(u'Longitude'),
176 str(self.longitude) if self.longitude else _(u'No longitude specified')),
177 u' ({0})'.format(self.name) if self.name else u''
178 )
179
180 def iati_country(self):
181 return codelist_value(Country, self, 'country')
182
183 def iati_country_unicode(self):
184 return str(self.iati_country())
185
186 def iati_vocabulary(self):
187 return codelist_value(GeographicVocabulary, self, 'vocabulary')
188
189 def iati_vocabulary_unicode(self):
190 return str(self.iati_vocabulary())
191
192 def iati_exactness(self):
193 return codelist_value(GeographicExactness, self, 'exactness')
194
195 def iati_exactness_unicode(self):
196 return str(self.iati_exactness())
197
198 def iati_reach(self):
199 return codelist_value(GeographicLocationReach, self, 'location_reach')
200
201 def iati_reach_unicode(self):
202 return str(self.iati_reach())
203
204 def iati_class(self):
205 return codelist_value(GeographicLocationClass, self, 'location_class')
206
207 def iati_class_unicode(self):
208 return str(self.iati_class())
209
210 def iati_designation(self):
211 return codelist_value(LocationType, self, 'feature_designation')
212
213 def iati_designation_unicode(self):
214 return str(self.iati_designation())
215
216 # Over-riding fields doesn't work in Django < 1.10, and hence this hack.
217 ProjectLocation._meta.get_field('country').help_text = _(
218 u'The country or countries that benefit(s) from the activity.'
219 )
220
221
222 class AdministrativeLocation(models.Model):
223 location = models.ForeignKey(
224 'ProjectLocation', verbose_name=_(u'location'), related_name='administratives'
225 )
226 code = ValidXMLCharField(
227 _(u'administrative code'), blank=True, max_length=25,
228 help_text=_(u'Coded identification of national and sub-national divisions according to '
229 u'recognised administrative boundary repositories. Multiple levels may be '
230 u'reported.')
231 )
232 vocabulary = ValidXMLCharField(
233 _(u'administrative vocabulary'), blank=True, max_length=2,
234 choices=codelist_choices(GEOGRAPHIC_VOCABULARY),
235 help_text=_(u'For reference: <a href="http://iatistandard.org/202/codelists/'
236 u'GeographicVocabulary/" target="_blank">http://iatistandard.org/202/codelists/'
237 u'GeographicVocabulary/</a>.')
238 )
239
240 level = models.PositiveSmallIntegerField(_(u'administrative level'), blank=True, null=True)
241
242 def __unicode__(self):
243 return str(self.code) if self.code else u'%s' % _(u'No code specified')
244
245 def iati_vocabulary(self):
246 return codelist_value(GeographicVocabulary, self, 'vocabulary')
247
248 def iati_vocabulary_unicode(self):
249 return str(self.iati_vocabulary())
250
251 class Meta:
252 app_label = 'rsr'
253 verbose_name = _(u'location administrative')
254 verbose_name_plural = _(u'location administratives')
255
256
257 class ProjectUpdateLocation(BaseLocation):
258 location_target = models.ForeignKey('ProjectUpdate', related_name='locations')
259
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/akvo/rsr/models/location.py b/akvo/rsr/models/location.py
--- a/akvo/rsr/models/location.py
+++ b/akvo/rsr/models/location.py
@@ -94,7 +94,7 @@
return codelist_value(Country, self, 'iati_country')
def iati_country_value_unicode(self):
- return str(self.iati_country_value())
+ return unicode(self.iati_country_value())
class ProjectLocation(BaseLocation):
@@ -170,10 +170,10 @@
return u'{0}, {1}{2}'.format(
u'{0}: {1}'.format(
_(u'Latitude'),
- str(self.latitude) if self.latitude else _(u'No latitude specified')),
+ unicode(self.latitude) if self.latitude else _(u'No latitude specified')),
u'{0}: {1}'.format(
_(u'Longitude'),
- str(self.longitude) if self.longitude else _(u'No longitude specified')),
+ unicode(self.longitude) if self.longitude else _(u'No longitude specified')),
u' ({0})'.format(self.name) if self.name else u''
)
@@ -181,37 +181,37 @@
return codelist_value(Country, self, 'country')
def iati_country_unicode(self):
- return str(self.iati_country())
+ return unicode(self.iati_country())
def iati_vocabulary(self):
return codelist_value(GeographicVocabulary, self, 'vocabulary')
def iati_vocabulary_unicode(self):
- return str(self.iati_vocabulary())
+ return unicode(self.iati_vocabulary())
def iati_exactness(self):
return codelist_value(GeographicExactness, self, 'exactness')
def iati_exactness_unicode(self):
- return str(self.iati_exactness())
+ return unicode(self.iati_exactness())
def iati_reach(self):
return codelist_value(GeographicLocationReach, self, 'location_reach')
def iati_reach_unicode(self):
- return str(self.iati_reach())
+ return unicode(self.iati_reach())
def iati_class(self):
return codelist_value(GeographicLocationClass, self, 'location_class')
def iati_class_unicode(self):
- return str(self.iati_class())
+ return unicode(self.iati_class())
def iati_designation(self):
return codelist_value(LocationType, self, 'feature_designation')
def iati_designation_unicode(self):
- return str(self.iati_designation())
+ return unicode(self.iati_designation())
# Over-riding fields doesn't work in Django < 1.10, and hence this hack.
ProjectLocation._meta.get_field('country').help_text = _(
@@ -240,13 +240,13 @@
level = models.PositiveSmallIntegerField(_(u'administrative level'), blank=True, null=True)
def __unicode__(self):
- return str(self.code) if self.code else u'%s' % _(u'No code specified')
+ return unicode(self.code) if self.code else u'%s' % _(u'No code specified')
def iati_vocabulary(self):
return codelist_value(GeographicVocabulary, self, 'vocabulary')
def iati_vocabulary_unicode(self):
- return str(self.iati_vocabulary())
+ return unicode(self.iati_vocabulary())
class Meta:
app_label = 'rsr'
|
{"golden_diff": "diff --git a/akvo/rsr/models/location.py b/akvo/rsr/models/location.py\n--- a/akvo/rsr/models/location.py\n+++ b/akvo/rsr/models/location.py\n@@ -94,7 +94,7 @@\n return codelist_value(Country, self, 'iati_country')\n \n def iati_country_value_unicode(self):\n- return str(self.iati_country_value())\n+ return unicode(self.iati_country_value())\n \n \n class ProjectLocation(BaseLocation):\n@@ -170,10 +170,10 @@\n return u'{0}, {1}{2}'.format(\n u'{0}: {1}'.format(\n _(u'Latitude'),\n- str(self.latitude) if self.latitude else _(u'No latitude specified')),\n+ unicode(self.latitude) if self.latitude else _(u'No latitude specified')),\n u'{0}: {1}'.format(\n _(u'Longitude'),\n- str(self.longitude) if self.longitude else _(u'No longitude specified')),\n+ unicode(self.longitude) if self.longitude else _(u'No longitude specified')),\n u' ({0})'.format(self.name) if self.name else u''\n )\n \n@@ -181,37 +181,37 @@\n return codelist_value(Country, self, 'country')\n \n def iati_country_unicode(self):\n- return str(self.iati_country())\n+ return unicode(self.iati_country())\n \n def iati_vocabulary(self):\n return codelist_value(GeographicVocabulary, self, 'vocabulary')\n \n def iati_vocabulary_unicode(self):\n- return str(self.iati_vocabulary())\n+ return unicode(self.iati_vocabulary())\n \n def iati_exactness(self):\n return codelist_value(GeographicExactness, self, 'exactness')\n \n def iati_exactness_unicode(self):\n- return str(self.iati_exactness())\n+ return unicode(self.iati_exactness())\n \n def iati_reach(self):\n return codelist_value(GeographicLocationReach, self, 'location_reach')\n \n def iati_reach_unicode(self):\n- return str(self.iati_reach())\n+ return unicode(self.iati_reach())\n \n def iati_class(self):\n return codelist_value(GeographicLocationClass, self, 'location_class')\n \n def iati_class_unicode(self):\n- return str(self.iati_class())\n+ return unicode(self.iati_class())\n \n def iati_designation(self):\n return codelist_value(LocationType, self, 'feature_designation')\n \n def iati_designation_unicode(self):\n- return str(self.iati_designation())\n+ return unicode(self.iati_designation())\n \n # Over-riding fields doesn't work in Django < 1.10, and hence this hack.\n ProjectLocation._meta.get_field('country').help_text = _(\n@@ -240,13 +240,13 @@\n level = models.PositiveSmallIntegerField(_(u'administrative level'), blank=True, null=True)\n \n def __unicode__(self):\n- return str(self.code) if self.code else u'%s' % _(u'No code specified')\n+ return unicode(self.code) if self.code else u'%s' % _(u'No code specified')\n \n def iati_vocabulary(self):\n return codelist_value(GeographicVocabulary, self, 'vocabulary')\n \n def iati_vocabulary_unicode(self):\n- return str(self.iati_vocabulary())\n+ return unicode(self.iati_vocabulary())\n \n class Meta:\n app_label = 'rsr'\n", "issue": "UnicodeDecodeError in /rest/v1/project_location end-point\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\n\nfrom django.db import models\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom ..fields import LatitudeField, LongitudeField, ValidXMLCharField\nfrom akvo.codelists.models import (Country, GeographicExactness, GeographicLocationClass,\n GeographicLocationReach, GeographicVocabulary, LocationType)\nfrom akvo.codelists.store.codelists_v202 import (\n COUNTRY, GEOGRAPHIC_EXACTNESS, GEOGRAPHIC_LOCATION_CLASS, GEOGRAPHIC_LOCATION_REACH,\n GEOGRAPHIC_VOCABULARY, LOCATION_TYPE\n)\nfrom akvo.utils import codelist_choices, codelist_value, get_country\n\n\nclass BaseLocation(models.Model):\n latitude = LatitudeField(\n _(u'latitude'), null=True, blank=True, db_index=True, default=0,\n help_text=_(u'Use a period to denote decimals.')\n )\n longitude = LongitudeField(\n _(u'longitude'), null=True, blank=True, db_index=True, default=0,\n help_text=_(u'Use a period to denote decimals.')\n )\n city = ValidXMLCharField(_(u'city'), blank=True, max_length=255)\n state = ValidXMLCharField(_(u'state'), blank=True, max_length=255)\n address_1 = ValidXMLCharField(_(u'address 1'), max_length=255, blank=True)\n address_2 = ValidXMLCharField(_(u'address 2'), max_length=255, blank=True)\n postcode = ValidXMLCharField(_(u'postal code'), max_length=10, blank=True)\n country = models.ForeignKey('Country', null=True, blank=True, verbose_name=_(u'country'))\n\n def delete(self, *args, **kwargs):\n super(BaseLocation, self).delete(*args, **kwargs)\n\n # If location_target has more locations, set the first as primary location\n location_target = self.location_target\n other_locations = location_target.locations.all()\n\n if other_locations.count() > 0:\n location_target.primary_location = other_locations.first()\n else:\n location_target.primary_location = None\n\n location_target.save()\n\n def save(self, *args, **kwargs):\n # Set a country based on the latitude and longitude if possible\n if self.country is None:\n self.country = self.get_country_from_lat_lon()\n\n super(BaseLocation, self).save(*args, **kwargs)\n\n # Set location as primary location if it is the first location\n location_target = self.location_target\n if location_target.primary_location is None or location_target.primary_location.pk > self.pk:\n location_target.primary_location = self\n location_target.save()\n\n def get_country_from_lat_lon(self):\n \"\"\"Get the country based on the location's latitude and longitude.\"\"\"\n\n if self.latitude is None or self.longitude is None:\n return None\n\n try:\n country, iso_code = get_country(float(self.latitude), float(self.longitude))\n except ValueError:\n iso_code = None\n\n if iso_code is not None:\n # FIXME: We have one too many country models!\n Country = models.get_model('rsr', 'Country')\n return Country.objects.filter(iso_code=iso_code).first()\n\n class Meta:\n app_label = 'rsr'\n abstract = True\n ordering = ['id', ]\n\n\nclass OrganisationLocation(BaseLocation):\n location_target = models.ForeignKey('Organisation', related_name='locations')\n iati_country = ValidXMLCharField(\n _(u'country'), blank=True, max_length=2, choices=codelist_choices(COUNTRY, show_code=False),\n help_text=_(u'The country in which the organisation is located.')\n )\n\n def iati_country_value(self):\n return codelist_value(Country, self, 'iati_country')\n\n def iati_country_value_unicode(self):\n return str(self.iati_country_value())\n\n\nclass ProjectLocation(BaseLocation):\n location_target = models.ForeignKey('Project', related_name='locations')\n\n # Additional IATI fields\n reference = ValidXMLCharField(\n _(u'reference'), blank=True, max_length=50,\n help_text=_(u'An internal reference that describes the location in the reporting '\n u'organisation\\'s own system. For reference see: '\n u'<a href=\"http://iatistandard.org/202/activity-standard/iati-activities/'\n u'iati-activity/location/#attributes\" target=\"_blank\">'\n u'http://iatistandard.org/202/activity-standard/iati-activities/iati-activity/'\n u'location/#attributes</a>.')\n )\n location_code = ValidXMLCharField(\n _(u'code'), blank=True, max_length=25,\n help_text=_(u'Enter a code to identify the region. Codes are based on DAC region codes. '\n u'Where an activity is considered global, the code 998 can be used. For '\n u'reference: <a href=\"http://www.oecd.org/dac/stats/dacandcrscodelists.htm\" '\n u'target=\"_blank\">http://www.oecd.org/dac/stats/dacandcrscodelists.htm</a>.')\n )\n vocabulary = ValidXMLCharField(_(u'vocabulary'), blank=True, max_length=2,\n choices=codelist_choices(GEOGRAPHIC_VOCABULARY))\n name = ValidXMLCharField(\n _(u'name'), blank=True, max_length=100,\n help_text=_(u'The human-readable name for the location.')\n )\n description = ValidXMLCharField(\n _(u'location description'), blank=True, max_length=2000,\n help_text=_(u'This provides free text space for providing an additional description, if '\n u'needed, of the actual target of the activity. A description that qualifies '\n u'the location, not the activity.')\n )\n activity_description = ValidXMLCharField(\n _(u'activity description'), blank=True, max_length=2000,\n help_text=_(u'A description that qualifies the activity taking place at the location. '\n u'This should not duplicate information provided in the main activity '\n u'description, and should typically be used to distinguish between activities '\n u'at multiple locations within a single iati-activity record.')\n )\n exactness = ValidXMLCharField(\n _(u'location precision'), blank=True, max_length=1,\n choices=codelist_choices(GEOGRAPHIC_EXACTNESS),\n help_text=_(u'Defines whether the location represents the most distinct point reasonably '\n u'possible for this type of activity or is an approximation due to lack of '\n u'more detailed information.')\n )\n location_reach = ValidXMLCharField(\n _(u'reach'), blank=True, max_length=1, choices=codelist_choices(GEOGRAPHIC_LOCATION_REACH),\n help_text=_(u'Does this location describe where the activity takes place or where the '\n u'intended beneficiaries reside?')\n )\n location_class = ValidXMLCharField(\n _(u'class'), blank=True, max_length=1, choices=codelist_choices(GEOGRAPHIC_LOCATION_CLASS),\n help_text=_(u'Does the location refer to a physical structure such as a building, a '\n u'populated place (e.g. city or village), an administrative division, or '\n u'another topological feature (e.g. river, nature reserve)? For reference: '\n u'<a href=\"http://iatistandard.org/202/codelists/GeographicLocationClass/\" '\n u'target=\"_blank\">http://iatistandard.org/202/codelists/'\n u'GeographicLocationClass/</a>.')\n )\n feature_designation = ValidXMLCharField(\n _(u'feature designation'), blank=True, max_length=5,\n choices=codelist_choices(LOCATION_TYPE),\n help_text=_(u'A more refined coded classification of the type of feature referred to by '\n u'this location. For reference: <a href=\"http://iatistandard.org/202/codelists/'\n u'LocationType/\" target=\"_blank\">http://iatistandard.org/202/codelists/'\n u'LocationType/</a>.')\n )\n\n def __unicode__(self):\n return u'{0}, {1}{2}'.format(\n u'{0}: {1}'.format(\n _(u'Latitude'),\n str(self.latitude) if self.latitude else _(u'No latitude specified')),\n u'{0}: {1}'.format(\n _(u'Longitude'),\n str(self.longitude) if self.longitude else _(u'No longitude specified')),\n u' ({0})'.format(self.name) if self.name else u''\n )\n\n def iati_country(self):\n return codelist_value(Country, self, 'country')\n\n def iati_country_unicode(self):\n return str(self.iati_country())\n\n def iati_vocabulary(self):\n return codelist_value(GeographicVocabulary, self, 'vocabulary')\n\n def iati_vocabulary_unicode(self):\n return str(self.iati_vocabulary())\n\n def iati_exactness(self):\n return codelist_value(GeographicExactness, self, 'exactness')\n\n def iati_exactness_unicode(self):\n return str(self.iati_exactness())\n\n def iati_reach(self):\n return codelist_value(GeographicLocationReach, self, 'location_reach')\n\n def iati_reach_unicode(self):\n return str(self.iati_reach())\n\n def iati_class(self):\n return codelist_value(GeographicLocationClass, self, 'location_class')\n\n def iati_class_unicode(self):\n return str(self.iati_class())\n\n def iati_designation(self):\n return codelist_value(LocationType, self, 'feature_designation')\n\n def iati_designation_unicode(self):\n return str(self.iati_designation())\n\n# Over-riding fields doesn't work in Django < 1.10, and hence this hack.\nProjectLocation._meta.get_field('country').help_text = _(\n u'The country or countries that benefit(s) from the activity.'\n)\n\n\nclass AdministrativeLocation(models.Model):\n location = models.ForeignKey(\n 'ProjectLocation', verbose_name=_(u'location'), related_name='administratives'\n )\n code = ValidXMLCharField(\n _(u'administrative code'), blank=True, max_length=25,\n help_text=_(u'Coded identification of national and sub-national divisions according to '\n u'recognised administrative boundary repositories. Multiple levels may be '\n u'reported.')\n )\n vocabulary = ValidXMLCharField(\n _(u'administrative vocabulary'), blank=True, max_length=2,\n choices=codelist_choices(GEOGRAPHIC_VOCABULARY),\n help_text=_(u'For reference: <a href=\"http://iatistandard.org/202/codelists/'\n u'GeographicVocabulary/\" target=\"_blank\">http://iatistandard.org/202/codelists/'\n u'GeographicVocabulary/</a>.')\n )\n\n level = models.PositiveSmallIntegerField(_(u'administrative level'), blank=True, null=True)\n\n def __unicode__(self):\n return str(self.code) if self.code else u'%s' % _(u'No code specified')\n\n def iati_vocabulary(self):\n return codelist_value(GeographicVocabulary, self, 'vocabulary')\n\n def iati_vocabulary_unicode(self):\n return str(self.iati_vocabulary())\n\n class Meta:\n app_label = 'rsr'\n verbose_name = _(u'location administrative')\n verbose_name_plural = _(u'location administratives')\n\n\nclass ProjectUpdateLocation(BaseLocation):\n location_target = models.ForeignKey('ProjectUpdate', related_name='locations')\n", "path": "akvo/rsr/models/location.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\n\nfrom django.db import models\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom ..fields import LatitudeField, LongitudeField, ValidXMLCharField\nfrom akvo.codelists.models import (Country, GeographicExactness, GeographicLocationClass,\n GeographicLocationReach, GeographicVocabulary, LocationType)\nfrom akvo.codelists.store.codelists_v202 import (\n COUNTRY, GEOGRAPHIC_EXACTNESS, GEOGRAPHIC_LOCATION_CLASS, GEOGRAPHIC_LOCATION_REACH,\n GEOGRAPHIC_VOCABULARY, LOCATION_TYPE\n)\nfrom akvo.utils import codelist_choices, codelist_value, get_country\n\n\nclass BaseLocation(models.Model):\n latitude = LatitudeField(\n _(u'latitude'), null=True, blank=True, db_index=True, default=0,\n help_text=_(u'Use a period to denote decimals.')\n )\n longitude = LongitudeField(\n _(u'longitude'), null=True, blank=True, db_index=True, default=0,\n help_text=_(u'Use a period to denote decimals.')\n )\n city = ValidXMLCharField(_(u'city'), blank=True, max_length=255)\n state = ValidXMLCharField(_(u'state'), blank=True, max_length=255)\n address_1 = ValidXMLCharField(_(u'address 1'), max_length=255, blank=True)\n address_2 = ValidXMLCharField(_(u'address 2'), max_length=255, blank=True)\n postcode = ValidXMLCharField(_(u'postal code'), max_length=10, blank=True)\n country = models.ForeignKey('Country', null=True, blank=True, verbose_name=_(u'country'))\n\n def delete(self, *args, **kwargs):\n super(BaseLocation, self).delete(*args, **kwargs)\n\n # If location_target has more locations, set the first as primary location\n location_target = self.location_target\n other_locations = location_target.locations.all()\n\n if other_locations.count() > 0:\n location_target.primary_location = other_locations.first()\n else:\n location_target.primary_location = None\n\n location_target.save()\n\n def save(self, *args, **kwargs):\n # Set a country based on the latitude and longitude if possible\n if self.country is None:\n self.country = self.get_country_from_lat_lon()\n\n super(BaseLocation, self).save(*args, **kwargs)\n\n # Set location as primary location if it is the first location\n location_target = self.location_target\n if location_target.primary_location is None or location_target.primary_location.pk > self.pk:\n location_target.primary_location = self\n location_target.save()\n\n def get_country_from_lat_lon(self):\n \"\"\"Get the country based on the location's latitude and longitude.\"\"\"\n\n if self.latitude is None or self.longitude is None:\n return None\n\n try:\n country, iso_code = get_country(float(self.latitude), float(self.longitude))\n except ValueError:\n iso_code = None\n\n if iso_code is not None:\n # FIXME: We have one too many country models!\n Country = models.get_model('rsr', 'Country')\n return Country.objects.filter(iso_code=iso_code).first()\n\n class Meta:\n app_label = 'rsr'\n abstract = True\n ordering = ['id', ]\n\n\nclass OrganisationLocation(BaseLocation):\n location_target = models.ForeignKey('Organisation', related_name='locations')\n iati_country = ValidXMLCharField(\n _(u'country'), blank=True, max_length=2, choices=codelist_choices(COUNTRY, show_code=False),\n help_text=_(u'The country in which the organisation is located.')\n )\n\n def iati_country_value(self):\n return codelist_value(Country, self, 'iati_country')\n\n def iati_country_value_unicode(self):\n return unicode(self.iati_country_value())\n\n\nclass ProjectLocation(BaseLocation):\n location_target = models.ForeignKey('Project', related_name='locations')\n\n # Additional IATI fields\n reference = ValidXMLCharField(\n _(u'reference'), blank=True, max_length=50,\n help_text=_(u'An internal reference that describes the location in the reporting '\n u'organisation\\'s own system. For reference see: '\n u'<a href=\"http://iatistandard.org/202/activity-standard/iati-activities/'\n u'iati-activity/location/#attributes\" target=\"_blank\">'\n u'http://iatistandard.org/202/activity-standard/iati-activities/iati-activity/'\n u'location/#attributes</a>.')\n )\n location_code = ValidXMLCharField(\n _(u'code'), blank=True, max_length=25,\n help_text=_(u'Enter a code to identify the region. Codes are based on DAC region codes. '\n u'Where an activity is considered global, the code 998 can be used. For '\n u'reference: <a href=\"http://www.oecd.org/dac/stats/dacandcrscodelists.htm\" '\n u'target=\"_blank\">http://www.oecd.org/dac/stats/dacandcrscodelists.htm</a>.')\n )\n vocabulary = ValidXMLCharField(_(u'vocabulary'), blank=True, max_length=2,\n choices=codelist_choices(GEOGRAPHIC_VOCABULARY))\n name = ValidXMLCharField(\n _(u'name'), blank=True, max_length=100,\n help_text=_(u'The human-readable name for the location.')\n )\n description = ValidXMLCharField(\n _(u'location description'), blank=True, max_length=2000,\n help_text=_(u'This provides free text space for providing an additional description, if '\n u'needed, of the actual target of the activity. A description that qualifies '\n u'the location, not the activity.')\n )\n activity_description = ValidXMLCharField(\n _(u'activity description'), blank=True, max_length=2000,\n help_text=_(u'A description that qualifies the activity taking place at the location. '\n u'This should not duplicate information provided in the main activity '\n u'description, and should typically be used to distinguish between activities '\n u'at multiple locations within a single iati-activity record.')\n )\n exactness = ValidXMLCharField(\n _(u'location precision'), blank=True, max_length=1,\n choices=codelist_choices(GEOGRAPHIC_EXACTNESS),\n help_text=_(u'Defines whether the location represents the most distinct point reasonably '\n u'possible for this type of activity or is an approximation due to lack of '\n u'more detailed information.')\n )\n location_reach = ValidXMLCharField(\n _(u'reach'), blank=True, max_length=1, choices=codelist_choices(GEOGRAPHIC_LOCATION_REACH),\n help_text=_(u'Does this location describe where the activity takes place or where the '\n u'intended beneficiaries reside?')\n )\n location_class = ValidXMLCharField(\n _(u'class'), blank=True, max_length=1, choices=codelist_choices(GEOGRAPHIC_LOCATION_CLASS),\n help_text=_(u'Does the location refer to a physical structure such as a building, a '\n u'populated place (e.g. city or village), an administrative division, or '\n u'another topological feature (e.g. river, nature reserve)? For reference: '\n u'<a href=\"http://iatistandard.org/202/codelists/GeographicLocationClass/\" '\n u'target=\"_blank\">http://iatistandard.org/202/codelists/'\n u'GeographicLocationClass/</a>.')\n )\n feature_designation = ValidXMLCharField(\n _(u'feature designation'), blank=True, max_length=5,\n choices=codelist_choices(LOCATION_TYPE),\n help_text=_(u'A more refined coded classification of the type of feature referred to by '\n u'this location. For reference: <a href=\"http://iatistandard.org/202/codelists/'\n u'LocationType/\" target=\"_blank\">http://iatistandard.org/202/codelists/'\n u'LocationType/</a>.')\n )\n\n def __unicode__(self):\n return u'{0}, {1}{2}'.format(\n u'{0}: {1}'.format(\n _(u'Latitude'),\n unicode(self.latitude) if self.latitude else _(u'No latitude specified')),\n u'{0}: {1}'.format(\n _(u'Longitude'),\n unicode(self.longitude) if self.longitude else _(u'No longitude specified')),\n u' ({0})'.format(self.name) if self.name else u''\n )\n\n def iati_country(self):\n return codelist_value(Country, self, 'country')\n\n def iati_country_unicode(self):\n return unicode(self.iati_country())\n\n def iati_vocabulary(self):\n return codelist_value(GeographicVocabulary, self, 'vocabulary')\n\n def iati_vocabulary_unicode(self):\n return unicode(self.iati_vocabulary())\n\n def iati_exactness(self):\n return codelist_value(GeographicExactness, self, 'exactness')\n\n def iati_exactness_unicode(self):\n return unicode(self.iati_exactness())\n\n def iati_reach(self):\n return codelist_value(GeographicLocationReach, self, 'location_reach')\n\n def iati_reach_unicode(self):\n return unicode(self.iati_reach())\n\n def iati_class(self):\n return codelist_value(GeographicLocationClass, self, 'location_class')\n\n def iati_class_unicode(self):\n return unicode(self.iati_class())\n\n def iati_designation(self):\n return codelist_value(LocationType, self, 'feature_designation')\n\n def iati_designation_unicode(self):\n return unicode(self.iati_designation())\n\n# Over-riding fields doesn't work in Django < 1.10, and hence this hack.\nProjectLocation._meta.get_field('country').help_text = _(\n u'The country or countries that benefit(s) from the activity.'\n)\n\n\nclass AdministrativeLocation(models.Model):\n location = models.ForeignKey(\n 'ProjectLocation', verbose_name=_(u'location'), related_name='administratives'\n )\n code = ValidXMLCharField(\n _(u'administrative code'), blank=True, max_length=25,\n help_text=_(u'Coded identification of national and sub-national divisions according to '\n u'recognised administrative boundary repositories. Multiple levels may be '\n u'reported.')\n )\n vocabulary = ValidXMLCharField(\n _(u'administrative vocabulary'), blank=True, max_length=2,\n choices=codelist_choices(GEOGRAPHIC_VOCABULARY),\n help_text=_(u'For reference: <a href=\"http://iatistandard.org/202/codelists/'\n u'GeographicVocabulary/\" target=\"_blank\">http://iatistandard.org/202/codelists/'\n u'GeographicVocabulary/</a>.')\n )\n\n level = models.PositiveSmallIntegerField(_(u'administrative level'), blank=True, null=True)\n\n def __unicode__(self):\n return unicode(self.code) if self.code else u'%s' % _(u'No code specified')\n\n def iati_vocabulary(self):\n return codelist_value(GeographicVocabulary, self, 'vocabulary')\n\n def iati_vocabulary_unicode(self):\n return unicode(self.iati_vocabulary())\n\n class Meta:\n app_label = 'rsr'\n verbose_name = _(u'location administrative')\n verbose_name_plural = _(u'location administratives')\n\n\nclass ProjectUpdateLocation(BaseLocation):\n location_target = models.ForeignKey('ProjectUpdate', related_name='locations')\n", "path": "akvo/rsr/models/location.py"}]}
| 3,590 | 785 |
gh_patches_debug_10998
|
rasdani/github-patches
|
git_diff
|
scikit-hep__awkward-208
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
release tarball is missing files
The current release tarball
https://files.pythonhosted.org/packages/24/81/9798b934e4c9313abb5d4ffe8af86f7a5cf87eb873de463b294813518eea/awkward1-0.2.11.tar.gz
is missing requirements-docs.txt and requirements-dev.txt, which are still required by setup.py
release tarball is missing files
The current release tarball
https://files.pythonhosted.org/packages/24/81/9798b934e4c9313abb5d4ffe8af86f7a5cf87eb873de463b294813518eea/awkward1-0.2.11.tar.gz
is missing requirements-docs.txt and requirements-dev.txt, which are still required by setup.py
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # BSD 3-Clause License; see https://github.com/jpivarski/awkward-1.0/blob/master/LICENSE
2
3 import glob
4 import os
5 import platform
6 import subprocess
7 import sys
8 import distutils.util
9 import multiprocessing
10 import shutil
11
12 import setuptools
13 import setuptools.command.build_ext
14 import setuptools.command.install
15
16 from setuptools import setup, Extension
17
18 install_requires = open("requirements.txt").read().strip().split()
19
20 extras = {"test": open("requirements-test.txt").read().strip().split(),
21 "docs": open("requirements-docs.txt").read().strip().split(),
22 "dev": open("requirements-dev.txt").read().strip().split()}
23 extras["all"] = sum(extras.values(), [])
24
25 tests_require = extras["test"]
26
27 class CMakeExtension(Extension):
28 def __init__(self, name, sourcedir=""):
29 Extension.__init__(self, name, sources=[])
30 self.sourcedir = os.path.abspath(sourcedir)
31
32 class CMakeBuild(setuptools.command.build_ext.build_ext):
33 def build_extensions(self):
34 try:
35 out = subprocess.check_output(["cmake", "--version"])
36 except OSError:
37 raise RuntimeError("CMake must be installed to build the following extensions: " + ", ".join(x.name for x in self.extensions))
38
39 for x in self.extensions:
40 self.build_extension(x)
41
42 def build_extension(self, ext):
43
44 extdir = os.path.abspath(os.path.dirname(self.get_ext_fullpath(ext.name)))
45 cmake_args = ["-DCMAKE_INSTALL_PREFIX={0}".format(extdir),
46 "-DPYTHON_EXECUTABLE={0}".format(sys.executable),
47 "-DPYBUILD=ON",
48 "-DCMAKE_OSX_DEPLOYMENT_TARGET=10.9",
49 "-DPYBUILD=ON",
50 "-DBUILD_TESTING=OFF"]
51 try:
52 compiler_path = self.compiler.compiler_cxx[0]
53 cmake_args.append("-DCMAKE_CXX_COMPILER={0}".format(compiler_path))
54 except AttributeError:
55 print("Not able to access compiler path (on Windows), using CMake default")
56
57 cfg = "Debug" if self.debug else "Release"
58 build_args = ["--config", cfg]
59
60 if platform.system() == "Windows":
61 cmake_args += ["-DCMAKE_LIBRARY_OUTPUT_DIRECTORY_{0}={1}".format(cfg.upper(), extdir),
62 "-DCMAKE_WINDOWS_EXPORT_ALL_SYMBOLS=TRUE"]
63 if sys.maxsize > 2**32:
64 cmake_args += ["-A", "x64"]
65 build_args += ["--", "/m"]
66 else:
67 cmake_args += ["-DCMAKE_BUILD_TYPE=" + cfg]
68
69 if platform.system() == "Windows":
70 build_args += ["/m"]
71 else:
72 build_args += ["-j", str(multiprocessing.cpu_count())]
73
74 if not os.path.exists(self.build_temp):
75 os.makedirs(self.build_temp)
76 build_dir = self.build_temp
77
78 # for scikit-build:
79 # build_dir = os.path.join(DIR, "_pybuild")
80
81 subprocess.check_call(["cmake", "-S", ext.sourcedir, "-B", build_dir] + cmake_args)
82 subprocess.check_call(["cmake", "--build", build_dir] + build_args)
83 subprocess.check_call(["cmake", "--build", build_dir, "--target", "install"])
84
85 if platform.system() == "Windows":
86 # Libraries are not installed system-wide on Windows, but they do have to be in the awkward1 directory.
87 libraries = []
88
89 def tree(x):
90 print(x + (" (dir)" if os.path.isdir(x) else ""))
91 if os.path.isdir(x):
92 for y in os.listdir(x):
93 tree(os.path.join(x, y))
94
95 class Install(setuptools.command.install.install):
96 def run(self):
97 print("--- build directory -------------------------------------------")
98 tree("build")
99
100 print("--- specifically, the dlldir ----------------------------------")
101 dlldir = os.path.join(os.path.join("build", "temp.%s-%d.%d" % (distutils.util.get_platform(), sys.version_info[0], sys.version_info[1])), "Release", "Release")
102 tree(dlldir)
103
104 print("--- copying ---------------------------------------------------")
105 for x in os.listdir(dlldir):
106 if x.startswith("awkward"):
107 print("copying", os.path.join(dlldir, x), "-->", os.path.join(self.build_lib, "awkward1", x))
108 shutil.copyfile(os.path.join(dlldir, x), os.path.join(self.build_lib, "awkward1", x))
109 print("--- deleting --------------------------------------------------")
110
111 outerdir = os.path.join(os.path.join("build", "lib.%s-%d.%d" % (distutils.util.get_platform(), sys.version_info[0], sys.version_info[1])))
112 for x in os.listdir(outerdir):
113 if x.endswith(".pyd"):
114 print("deleting", os.path.join(outerdir, x))
115 os.remove(os.path.join(outerdir, x))
116
117 print("--- begin normal install --------------------------------------")
118 setuptools.command.install.install.run(self)
119
120 else:
121 # Libraries do not exist yet, so they cannot be determined with a glob pattern.
122 libdir = os.path.join(os.path.join("build", "lib.%s-%d.%d" % (distutils.util.get_platform(), sys.version_info[0], sys.version_info[1])), "awkward1")
123 static = ".a"
124 if platform.system() == "Darwin":
125 shared = ".dylib"
126 else:
127 shared = ".so"
128 libraries = [("lib", [os.path.join(libdir, "libawkward-cpu-kernels-static" + static),
129 os.path.join(libdir, "libawkward-cpu-kernels" + shared),
130 os.path.join(libdir, "libawkward-static" + static),
131 os.path.join(libdir, "libawkward" + shared)])]
132
133 Install = setuptools.command.install.install
134
135 setup(name = "awkward1",
136 packages = setuptools.find_packages(where="src"),
137 package_dir = {"": "src"},
138 include_package_data = True,
139 package_data = {"": ["*.dll"]},
140 data_files = libraries + [
141 ("include/awkward", glob.glob("include/awkward/*.h")),
142 ("include/awkward/cpu-kernels", glob.glob("include/awkward/cpu-kernels/*.h")),
143 ("include/awkward/python", glob.glob("include/awkward/python/*.h")),
144 ("include/awkward/array", glob.glob("include/awkward/array/*.h")),
145 ("include/awkward/builder", glob.glob("include/awkward/builder/*.h")),
146 ("include/awkward/io", glob.glob("include/awkward/io/*.h")),
147 ("include/awkward/type", glob.glob("include/awkward/type/*.h"))],
148 version = open("VERSION_INFO").read().strip(),
149 author = "Jim Pivarski",
150 author_email = "[email protected]",
151 maintainer = "Jim Pivarski",
152 maintainer_email = "[email protected]",
153 description = "Development of awkward 1.0, to replace scikit-hep/awkward-array in 2020.",
154 long_description = """<a href="https://github.com/scikit-hep/awkward-1.0#readme"><img src="https://github.com/scikit-hep/awkward-1.0/raw/master/docs-images/logo/logo-300px.png"></a>
155
156 Awkward Array is a library for **nested, variable-sized data**, including arbitrary-length lists, records, mixed types, and missing data, using **NumPy-like idioms**.
157
158 Arrays are **dynamically typed**, but operations on them are **compiled and fast**. Their behavior coincides with NumPy when array dimensions are regular and generalizes when they're not.
159
160 <table>
161 <tr>
162 <td width="33%" valign="top">
163 <a href="https://scikit-hep.org/awkward-1.0/index.html">
164 <img src="https://github.com/scikit-hep/awkward-1.0/raw/master/docs-images/panel-data-analysts.png" width="268">
165 </a>
166 <p align="center"><b>
167 <a href="https://scikit-hep.org/awkward-1.0/index.html">
168 How-to documentation<br>for data analysts
169 </a>
170 </b></p>
171 </td>
172 <td width="33%" valign="top">
173 <a href="https://scikit-hep.org/awkward-1.0/index.html">
174 <img src="https://github.com/scikit-hep/awkward-1.0/raw/master/docs-images/panel-developers.png" width="268">
175 </a>
176 <p align="center"><b>
177 <a href="https://scikit-hep.org/awkward-1.0/index.html">
178 How-it-works tutorials<br>for developers
179 </a>
180 </b></p>
181 </td>
182 <td width="33%" valign="top">
183 <a href="https://awkward-array.readthedocs.io/en/latest/_static/index.html">
184 <img src="https://github.com/scikit-hep/awkward-1.0/raw/master/docs-images/panel-doxygen.png" width="268">
185 </a>
186 <p align="center"><b>
187 <a href="https://awkward-array.readthedocs.io/en/latest/_static/index.html">
188 C++<br>API reference
189 </a>
190 </b></p>
191 <a href="https://awkward-array.readthedocs.io/en/latest/index.html">
192 <img src="https://github.com/scikit-hep/awkward-1.0/raw/master/docs-images/panel-sphinx.png" width="268">
193 </a>
194 <p align="center"><b>
195 <a href="https://awkward-array.readthedocs.io/en/latest/index.html">
196 Python<br>API reference
197 </a>
198 </b></p>
199 </td>
200 </tr>
201 </table>
202 """,
203 long_description_content_type = "text/markdown",
204 url = "https://github.com/scikit-hep/awkward-1.0",
205 download_url = "https://github.com/scikit-hep/awkward-1.0/releases",
206 license = "BSD 3-clause",
207 entry_points = {
208 "numba_extensions": ["init = awkward1._connect._numba:register"]
209 },
210 test_suite = "tests",
211 python_requires = ">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*",
212 install_requires = install_requires,
213 tests_require = extras["test"],
214 extras_require = extras,
215
216 # cmake_args=['-DBUILD_TESTING=OFF'], # for scikit-build
217 ext_modules = [CMakeExtension("awkward")], # NOT scikit-build
218 cmdclass = {"build_ext": CMakeBuild, # NOT scikit-build
219 "install": Install},
220
221 classifiers = [
222 # "Development Status :: 1 - Planning",
223 # "Development Status :: 2 - Pre-Alpha",
224 # "Development Status :: 3 - Alpha",
225 "Development Status :: 4 - Beta",
226 # "Development Status :: 5 - Production/Stable",
227 # "Development Status :: 6 - Mature",
228 # "Development Status :: 7 - Inactive",
229 "Intended Audience :: Developers",
230 "Intended Audience :: Information Technology",
231 "Intended Audience :: Science/Research",
232 "License :: OSI Approved :: BSD License",
233 "Operating System :: MacOS",
234 "Operating System :: POSIX",
235 "Operating System :: Unix",
236 "Programming Language :: Python",
237 "Programming Language :: Python :: 2.7",
238 "Programming Language :: Python :: 3.5",
239 "Programming Language :: Python :: 3.6",
240 "Programming Language :: Python :: 3.7",
241 "Programming Language :: Python :: 3.8",
242 "Topic :: Scientific/Engineering",
243 "Topic :: Scientific/Engineering :: Information Analysis",
244 "Topic :: Scientific/Engineering :: Mathematics",
245 "Topic :: Scientific/Engineering :: Physics",
246 "Topic :: Software Development",
247 "Topic :: Utilities",
248 ])
249
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -18,8 +18,10 @@
install_requires = open("requirements.txt").read().strip().split()
extras = {"test": open("requirements-test.txt").read().strip().split(),
- "docs": open("requirements-docs.txt").read().strip().split(),
- "dev": open("requirements-dev.txt").read().strip().split()}
+ "dev": ['numba>=0.46.0;python_version>="3"',
+ 'pandas>=0.24.0;python_version>="3"',
+ 'numexpr;python_version>="3"',
+ 'autograd;python_version>="3"']}
extras["all"] = sum(extras.values(), [])
tests_require = extras["test"]
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -18,8 +18,10 @@\n install_requires = open(\"requirements.txt\").read().strip().split()\n \n extras = {\"test\": open(\"requirements-test.txt\").read().strip().split(),\n- \"docs\": open(\"requirements-docs.txt\").read().strip().split(),\n- \"dev\": open(\"requirements-dev.txt\").read().strip().split()}\n+ \"dev\": ['numba>=0.46.0;python_version>=\"3\"',\n+ 'pandas>=0.24.0;python_version>=\"3\"',\n+ 'numexpr;python_version>=\"3\"',\n+ 'autograd;python_version>=\"3\"']}\n extras[\"all\"] = sum(extras.values(), [])\n \n tests_require = extras[\"test\"]\n", "issue": "release tarball is missing files\nThe current release tarball\r\nhttps://files.pythonhosted.org/packages/24/81/9798b934e4c9313abb5d4ffe8af86f7a5cf87eb873de463b294813518eea/awkward1-0.2.11.tar.gz\r\nis missing requirements-docs.txt and requirements-dev.txt, which are still required by setup.py\nrelease tarball is missing files\nThe current release tarball\r\nhttps://files.pythonhosted.org/packages/24/81/9798b934e4c9313abb5d4ffe8af86f7a5cf87eb873de463b294813518eea/awkward1-0.2.11.tar.gz\r\nis missing requirements-docs.txt and requirements-dev.txt, which are still required by setup.py\n", "before_files": [{"content": "# BSD 3-Clause License; see https://github.com/jpivarski/awkward-1.0/blob/master/LICENSE\n\nimport glob\nimport os\nimport platform\nimport subprocess\nimport sys\nimport distutils.util\nimport multiprocessing\nimport shutil\n\nimport setuptools\nimport setuptools.command.build_ext\nimport setuptools.command.install\n\nfrom setuptools import setup, Extension\n\ninstall_requires = open(\"requirements.txt\").read().strip().split()\n\nextras = {\"test\": open(\"requirements-test.txt\").read().strip().split(),\n \"docs\": open(\"requirements-docs.txt\").read().strip().split(),\n \"dev\": open(\"requirements-dev.txt\").read().strip().split()}\nextras[\"all\"] = sum(extras.values(), [])\n\ntests_require = extras[\"test\"]\n\nclass CMakeExtension(Extension):\n def __init__(self, name, sourcedir=\"\"):\n Extension.__init__(self, name, sources=[])\n self.sourcedir = os.path.abspath(sourcedir)\n\nclass CMakeBuild(setuptools.command.build_ext.build_ext):\n def build_extensions(self):\n try:\n out = subprocess.check_output([\"cmake\", \"--version\"])\n except OSError:\n raise RuntimeError(\"CMake must be installed to build the following extensions: \" + \", \".join(x.name for x in self.extensions))\n\n for x in self.extensions:\n self.build_extension(x)\n\n def build_extension(self, ext):\n\n extdir = os.path.abspath(os.path.dirname(self.get_ext_fullpath(ext.name)))\n cmake_args = [\"-DCMAKE_INSTALL_PREFIX={0}\".format(extdir),\n \"-DPYTHON_EXECUTABLE={0}\".format(sys.executable),\n \"-DPYBUILD=ON\",\n \"-DCMAKE_OSX_DEPLOYMENT_TARGET=10.9\",\n \"-DPYBUILD=ON\",\n \"-DBUILD_TESTING=OFF\"]\n try:\n compiler_path = self.compiler.compiler_cxx[0]\n cmake_args.append(\"-DCMAKE_CXX_COMPILER={0}\".format(compiler_path))\n except AttributeError:\n print(\"Not able to access compiler path (on Windows), using CMake default\")\n\n cfg = \"Debug\" if self.debug else \"Release\"\n build_args = [\"--config\", cfg]\n\n if platform.system() == \"Windows\":\n cmake_args += [\"-DCMAKE_LIBRARY_OUTPUT_DIRECTORY_{0}={1}\".format(cfg.upper(), extdir),\n \"-DCMAKE_WINDOWS_EXPORT_ALL_SYMBOLS=TRUE\"]\n if sys.maxsize > 2**32:\n cmake_args += [\"-A\", \"x64\"]\n build_args += [\"--\", \"/m\"]\n else:\n cmake_args += [\"-DCMAKE_BUILD_TYPE=\" + cfg]\n\n if platform.system() == \"Windows\":\n build_args += [\"/m\"]\n else:\n build_args += [\"-j\", str(multiprocessing.cpu_count())]\n\n if not os.path.exists(self.build_temp):\n os.makedirs(self.build_temp)\n build_dir = self.build_temp\n\n # for scikit-build:\n # build_dir = os.path.join(DIR, \"_pybuild\")\n\n subprocess.check_call([\"cmake\", \"-S\", ext.sourcedir, \"-B\", build_dir] + cmake_args)\n subprocess.check_call([\"cmake\", \"--build\", build_dir] + build_args)\n subprocess.check_call([\"cmake\", \"--build\", build_dir, \"--target\", \"install\"])\n\nif platform.system() == \"Windows\":\n # Libraries are not installed system-wide on Windows, but they do have to be in the awkward1 directory.\n libraries = []\n\n def tree(x):\n print(x + (\" (dir)\" if os.path.isdir(x) else \"\"))\n if os.path.isdir(x):\n for y in os.listdir(x):\n tree(os.path.join(x, y))\n\n class Install(setuptools.command.install.install):\n def run(self):\n print(\"--- build directory -------------------------------------------\")\n tree(\"build\")\n\n print(\"--- specifically, the dlldir ----------------------------------\")\n dlldir = os.path.join(os.path.join(\"build\", \"temp.%s-%d.%d\" % (distutils.util.get_platform(), sys.version_info[0], sys.version_info[1])), \"Release\", \"Release\")\n tree(dlldir)\n\n print(\"--- copying ---------------------------------------------------\")\n for x in os.listdir(dlldir):\n if x.startswith(\"awkward\"):\n print(\"copying\", os.path.join(dlldir, x), \"-->\", os.path.join(self.build_lib, \"awkward1\", x))\n shutil.copyfile(os.path.join(dlldir, x), os.path.join(self.build_lib, \"awkward1\", x))\n print(\"--- deleting --------------------------------------------------\")\n\n outerdir = os.path.join(os.path.join(\"build\", \"lib.%s-%d.%d\" % (distutils.util.get_platform(), sys.version_info[0], sys.version_info[1])))\n for x in os.listdir(outerdir):\n if x.endswith(\".pyd\"):\n print(\"deleting\", os.path.join(outerdir, x))\n os.remove(os.path.join(outerdir, x))\n\n print(\"--- begin normal install --------------------------------------\")\n setuptools.command.install.install.run(self)\n\nelse:\n # Libraries do not exist yet, so they cannot be determined with a glob pattern.\n libdir = os.path.join(os.path.join(\"build\", \"lib.%s-%d.%d\" % (distutils.util.get_platform(), sys.version_info[0], sys.version_info[1])), \"awkward1\")\n static = \".a\"\n if platform.system() == \"Darwin\":\n shared = \".dylib\"\n else:\n shared = \".so\"\n libraries = [(\"lib\", [os.path.join(libdir, \"libawkward-cpu-kernels-static\" + static),\n os.path.join(libdir, \"libawkward-cpu-kernels\" + shared),\n os.path.join(libdir, \"libawkward-static\" + static),\n os.path.join(libdir, \"libawkward\" + shared)])]\n\n Install = setuptools.command.install.install\n\nsetup(name = \"awkward1\",\n packages = setuptools.find_packages(where=\"src\"),\n package_dir = {\"\": \"src\"},\n include_package_data = True,\n package_data = {\"\": [\"*.dll\"]},\n data_files = libraries + [\n (\"include/awkward\", glob.glob(\"include/awkward/*.h\")),\n (\"include/awkward/cpu-kernels\", glob.glob(\"include/awkward/cpu-kernels/*.h\")),\n (\"include/awkward/python\", glob.glob(\"include/awkward/python/*.h\")),\n (\"include/awkward/array\", glob.glob(\"include/awkward/array/*.h\")),\n (\"include/awkward/builder\", glob.glob(\"include/awkward/builder/*.h\")),\n (\"include/awkward/io\", glob.glob(\"include/awkward/io/*.h\")),\n (\"include/awkward/type\", glob.glob(\"include/awkward/type/*.h\"))],\n version = open(\"VERSION_INFO\").read().strip(),\n author = \"Jim Pivarski\",\n author_email = \"[email protected]\",\n maintainer = \"Jim Pivarski\",\n maintainer_email = \"[email protected]\",\n description = \"Development of awkward 1.0, to replace scikit-hep/awkward-array in 2020.\",\n long_description = \"\"\"<a href=\"https://github.com/scikit-hep/awkward-1.0#readme\"><img src=\"https://github.com/scikit-hep/awkward-1.0/raw/master/docs-images/logo/logo-300px.png\"></a>\n\nAwkward Array is a library for **nested, variable-sized data**, including arbitrary-length lists, records, mixed types, and missing data, using **NumPy-like idioms**.\n\nArrays are **dynamically typed**, but operations on them are **compiled and fast**. Their behavior coincides with NumPy when array dimensions are regular and generalizes when they're not.\n\n<table>\n <tr>\n <td width=\"33%\" valign=\"top\">\n <a href=\"https://scikit-hep.org/awkward-1.0/index.html\">\n <img src=\"https://github.com/scikit-hep/awkward-1.0/raw/master/docs-images/panel-data-analysts.png\" width=\"268\">\n </a>\n <p align=\"center\"><b>\n <a href=\"https://scikit-hep.org/awkward-1.0/index.html\">\n How-to documentation<br>for data analysts\n </a>\n </b></p>\n </td>\n <td width=\"33%\" valign=\"top\">\n <a href=\"https://scikit-hep.org/awkward-1.0/index.html\">\n <img src=\"https://github.com/scikit-hep/awkward-1.0/raw/master/docs-images/panel-developers.png\" width=\"268\">\n </a>\n <p align=\"center\"><b>\n <a href=\"https://scikit-hep.org/awkward-1.0/index.html\">\n How-it-works tutorials<br>for developers\n </a>\n </b></p>\n </td>\n <td width=\"33%\" valign=\"top\">\n <a href=\"https://awkward-array.readthedocs.io/en/latest/_static/index.html\">\n <img src=\"https://github.com/scikit-hep/awkward-1.0/raw/master/docs-images/panel-doxygen.png\" width=\"268\">\n </a>\n <p align=\"center\"><b>\n <a href=\"https://awkward-array.readthedocs.io/en/latest/_static/index.html\">\n C++<br>API reference\n </a>\n </b></p>\n <a href=\"https://awkward-array.readthedocs.io/en/latest/index.html\">\n <img src=\"https://github.com/scikit-hep/awkward-1.0/raw/master/docs-images/panel-sphinx.png\" width=\"268\">\n </a>\n <p align=\"center\"><b>\n <a href=\"https://awkward-array.readthedocs.io/en/latest/index.html\">\n Python<br>API reference\n </a>\n </b></p>\n </td>\n </tr>\n</table>\n\"\"\",\n long_description_content_type = \"text/markdown\",\n url = \"https://github.com/scikit-hep/awkward-1.0\",\n download_url = \"https://github.com/scikit-hep/awkward-1.0/releases\",\n license = \"BSD 3-clause\",\n entry_points = {\n \"numba_extensions\": [\"init = awkward1._connect._numba:register\"]\n },\n test_suite = \"tests\",\n python_requires = \">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*\",\n install_requires = install_requires,\n tests_require = extras[\"test\"],\n extras_require = extras,\n\n # cmake_args=['-DBUILD_TESTING=OFF'], # for scikit-build\n ext_modules = [CMakeExtension(\"awkward\")], # NOT scikit-build\n cmdclass = {\"build_ext\": CMakeBuild, # NOT scikit-build\n \"install\": Install},\n\n classifiers = [\n# \"Development Status :: 1 - Planning\",\n# \"Development Status :: 2 - Pre-Alpha\",\n# \"Development Status :: 3 - Alpha\",\n \"Development Status :: 4 - Beta\",\n# \"Development Status :: 5 - Production/Stable\",\n# \"Development Status :: 6 - Mature\",\n# \"Development Status :: 7 - Inactive\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Information Technology\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: BSD License\",\n \"Operating System :: MacOS\",\n \"Operating System :: POSIX\",\n \"Operating System :: Unix\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Topic :: Scientific/Engineering\",\n \"Topic :: Scientific/Engineering :: Information Analysis\",\n \"Topic :: Scientific/Engineering :: Mathematics\",\n \"Topic :: Scientific/Engineering :: Physics\",\n \"Topic :: Software Development\",\n \"Topic :: Utilities\",\n ])\n", "path": "setup.py"}], "after_files": [{"content": "# BSD 3-Clause License; see https://github.com/jpivarski/awkward-1.0/blob/master/LICENSE\n\nimport glob\nimport os\nimport platform\nimport subprocess\nimport sys\nimport distutils.util\nimport multiprocessing\nimport shutil\n\nimport setuptools\nimport setuptools.command.build_ext\nimport setuptools.command.install\n\nfrom setuptools import setup, Extension\n\ninstall_requires = open(\"requirements.txt\").read().strip().split()\n\nextras = {\"test\": open(\"requirements-test.txt\").read().strip().split(),\n \"dev\": ['numba>=0.46.0;python_version>=\"3\"',\n 'pandas>=0.24.0;python_version>=\"3\"',\n 'numexpr;python_version>=\"3\"',\n 'autograd;python_version>=\"3\"']}\nextras[\"all\"] = sum(extras.values(), [])\n\ntests_require = extras[\"test\"]\n\nclass CMakeExtension(Extension):\n def __init__(self, name, sourcedir=\"\"):\n Extension.__init__(self, name, sources=[])\n self.sourcedir = os.path.abspath(sourcedir)\n\nclass CMakeBuild(setuptools.command.build_ext.build_ext):\n def build_extensions(self):\n try:\n out = subprocess.check_output([\"cmake\", \"--version\"])\n except OSError:\n raise RuntimeError(\"CMake must be installed to build the following extensions: \" + \", \".join(x.name for x in self.extensions))\n\n for x in self.extensions:\n self.build_extension(x)\n\n def build_extension(self, ext):\n\n extdir = os.path.abspath(os.path.dirname(self.get_ext_fullpath(ext.name)))\n cmake_args = [\"-DCMAKE_INSTALL_PREFIX={0}\".format(extdir),\n \"-DPYTHON_EXECUTABLE={0}\".format(sys.executable),\n \"-DPYBUILD=ON\",\n \"-DCMAKE_OSX_DEPLOYMENT_TARGET=10.9\",\n \"-DPYBUILD=ON\",\n \"-DBUILD_TESTING=OFF\"]\n try:\n compiler_path = self.compiler.compiler_cxx[0]\n cmake_args.append(\"-DCMAKE_CXX_COMPILER={0}\".format(compiler_path))\n except AttributeError:\n print(\"Not able to access compiler path (on Windows), using CMake default\")\n\n cfg = \"Debug\" if self.debug else \"Release\"\n build_args = [\"--config\", cfg]\n\n if platform.system() == \"Windows\":\n cmake_args += [\"-DCMAKE_LIBRARY_OUTPUT_DIRECTORY_{0}={1}\".format(cfg.upper(), extdir),\n \"-DCMAKE_WINDOWS_EXPORT_ALL_SYMBOLS=TRUE\"]\n if sys.maxsize > 2**32:\n cmake_args += [\"-A\", \"x64\"]\n build_args += [\"--\", \"/m\"]\n else:\n cmake_args += [\"-DCMAKE_BUILD_TYPE=\" + cfg]\n\n if platform.system() == \"Windows\":\n build_args += [\"/m\"]\n else:\n build_args += [\"-j\", str(multiprocessing.cpu_count())]\n\n if not os.path.exists(self.build_temp):\n os.makedirs(self.build_temp)\n build_dir = self.build_temp\n\n # for scikit-build:\n # build_dir = os.path.join(DIR, \"_pybuild\")\n\n subprocess.check_call([\"cmake\", \"-S\", ext.sourcedir, \"-B\", build_dir] + cmake_args)\n subprocess.check_call([\"cmake\", \"--build\", build_dir] + build_args)\n subprocess.check_call([\"cmake\", \"--build\", build_dir, \"--target\", \"install\"])\n\nif platform.system() == \"Windows\":\n # Libraries are not installed system-wide on Windows, but they do have to be in the awkward1 directory.\n libraries = []\n\n def tree(x):\n print(x + (\" (dir)\" if os.path.isdir(x) else \"\"))\n if os.path.isdir(x):\n for y in os.listdir(x):\n tree(os.path.join(x, y))\n\n class Install(setuptools.command.install.install):\n def run(self):\n print(\"--- build directory -------------------------------------------\")\n tree(\"build\")\n\n print(\"--- specifically, the dlldir ----------------------------------\")\n dlldir = os.path.join(os.path.join(\"build\", \"temp.%s-%d.%d\" % (distutils.util.get_platform(), sys.version_info[0], sys.version_info[1])), \"Release\", \"Release\")\n tree(dlldir)\n\n print(\"--- copying ---------------------------------------------------\")\n for x in os.listdir(dlldir):\n if x.startswith(\"awkward\"):\n print(\"copying\", os.path.join(dlldir, x), \"-->\", os.path.join(self.build_lib, \"awkward1\", x))\n shutil.copyfile(os.path.join(dlldir, x), os.path.join(self.build_lib, \"awkward1\", x))\n print(\"--- deleting --------------------------------------------------\")\n\n outerdir = os.path.join(os.path.join(\"build\", \"lib.%s-%d.%d\" % (distutils.util.get_platform(), sys.version_info[0], sys.version_info[1])))\n for x in os.listdir(outerdir):\n if x.endswith(\".pyd\"):\n print(\"deleting\", os.path.join(outerdir, x))\n os.remove(os.path.join(outerdir, x))\n\n print(\"--- begin normal install --------------------------------------\")\n setuptools.command.install.install.run(self)\n\nelse:\n # Libraries do not exist yet, so they cannot be determined with a glob pattern.\n libdir = os.path.join(os.path.join(\"build\", \"lib.%s-%d.%d\" % (distutils.util.get_platform(), sys.version_info[0], sys.version_info[1])), \"awkward1\")\n static = \".a\"\n if platform.system() == \"Darwin\":\n shared = \".dylib\"\n else:\n shared = \".so\"\n libraries = [(\"lib\", [os.path.join(libdir, \"libawkward-cpu-kernels-static\" + static),\n os.path.join(libdir, \"libawkward-cpu-kernels\" + shared),\n os.path.join(libdir, \"libawkward-static\" + static),\n os.path.join(libdir, \"libawkward\" + shared)])]\n\n Install = setuptools.command.install.install\n\nsetup(name = \"awkward1\",\n packages = setuptools.find_packages(where=\"src\"),\n package_dir = {\"\": \"src\"},\n include_package_data = True,\n package_data = {\"\": [\"*.dll\"]},\n data_files = libraries + [\n (\"include/awkward\", glob.glob(\"include/awkward/*.h\")),\n (\"include/awkward/cpu-kernels\", glob.glob(\"include/awkward/cpu-kernels/*.h\")),\n (\"include/awkward/python\", glob.glob(\"include/awkward/python/*.h\")),\n (\"include/awkward/array\", glob.glob(\"include/awkward/array/*.h\")),\n (\"include/awkward/builder\", glob.glob(\"include/awkward/builder/*.h\")),\n (\"include/awkward/io\", glob.glob(\"include/awkward/io/*.h\")),\n (\"include/awkward/type\", glob.glob(\"include/awkward/type/*.h\"))],\n version = open(\"VERSION_INFO\").read().strip(),\n author = \"Jim Pivarski\",\n author_email = \"[email protected]\",\n maintainer = \"Jim Pivarski\",\n maintainer_email = \"[email protected]\",\n description = \"Development of awkward 1.0, to replace scikit-hep/awkward-array in 2020.\",\n long_description = \"\"\"<a href=\"https://github.com/scikit-hep/awkward-1.0#readme\"><img src=\"https://github.com/scikit-hep/awkward-1.0/raw/master/docs-images/logo/logo-300px.png\"></a>\n\nAwkward Array is a library for **nested, variable-sized data**, including arbitrary-length lists, records, mixed types, and missing data, using **NumPy-like idioms**.\n\nArrays are **dynamically typed**, but operations on them are **compiled and fast**. Their behavior coincides with NumPy when array dimensions are regular and generalizes when they're not.\n\n<table>\n <tr>\n <td width=\"33%\" valign=\"top\">\n <a href=\"https://scikit-hep.org/awkward-1.0/index.html\">\n <img src=\"https://github.com/scikit-hep/awkward-1.0/raw/master/docs-images/panel-data-analysts.png\" width=\"268\">\n </a>\n <p align=\"center\"><b>\n <a href=\"https://scikit-hep.org/awkward-1.0/index.html\">\n How-to documentation<br>for data analysts\n </a>\n </b></p>\n </td>\n <td width=\"33%\" valign=\"top\">\n <a href=\"https://scikit-hep.org/awkward-1.0/index.html\">\n <img src=\"https://github.com/scikit-hep/awkward-1.0/raw/master/docs-images/panel-developers.png\" width=\"268\">\n </a>\n <p align=\"center\"><b>\n <a href=\"https://scikit-hep.org/awkward-1.0/index.html\">\n How-it-works tutorials<br>for developers\n </a>\n </b></p>\n </td>\n <td width=\"33%\" valign=\"top\">\n <a href=\"https://awkward-array.readthedocs.io/en/latest/_static/index.html\">\n <img src=\"https://github.com/scikit-hep/awkward-1.0/raw/master/docs-images/panel-doxygen.png\" width=\"268\">\n </a>\n <p align=\"center\"><b>\n <a href=\"https://awkward-array.readthedocs.io/en/latest/_static/index.html\">\n C++<br>API reference\n </a>\n </b></p>\n <a href=\"https://awkward-array.readthedocs.io/en/latest/index.html\">\n <img src=\"https://github.com/scikit-hep/awkward-1.0/raw/master/docs-images/panel-sphinx.png\" width=\"268\">\n </a>\n <p align=\"center\"><b>\n <a href=\"https://awkward-array.readthedocs.io/en/latest/index.html\">\n Python<br>API reference\n </a>\n </b></p>\n </td>\n </tr>\n</table>\n\"\"\",\n long_description_content_type = \"text/markdown\",\n url = \"https://github.com/scikit-hep/awkward-1.0\",\n download_url = \"https://github.com/scikit-hep/awkward-1.0/releases\",\n license = \"BSD 3-clause\",\n entry_points = {\n \"numba_extensions\": [\"init = awkward1._connect._numba:register\"]\n },\n test_suite = \"tests\",\n python_requires = \">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*\",\n install_requires = install_requires,\n tests_require = extras[\"test\"],\n extras_require = extras,\n\n # cmake_args=['-DBUILD_TESTING=OFF'], # for scikit-build\n ext_modules = [CMakeExtension(\"awkward\")], # NOT scikit-build\n cmdclass = {\"build_ext\": CMakeBuild, # NOT scikit-build\n \"install\": Install},\n\n classifiers = [\n# \"Development Status :: 1 - Planning\",\n# \"Development Status :: 2 - Pre-Alpha\",\n# \"Development Status :: 3 - Alpha\",\n \"Development Status :: 4 - Beta\",\n# \"Development Status :: 5 - Production/Stable\",\n# \"Development Status :: 6 - Mature\",\n# \"Development Status :: 7 - Inactive\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Information Technology\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: BSD License\",\n \"Operating System :: MacOS\",\n \"Operating System :: POSIX\",\n \"Operating System :: Unix\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Topic :: Scientific/Engineering\",\n \"Topic :: Scientific/Engineering :: Information Analysis\",\n \"Topic :: Scientific/Engineering :: Mathematics\",\n \"Topic :: Scientific/Engineering :: Physics\",\n \"Topic :: Software Development\",\n \"Topic :: Utilities\",\n ])\n", "path": "setup.py"}]}
| 3,812 | 187 |
gh_patches_debug_16804
|
rasdani/github-patches
|
git_diff
|
optuna__optuna-1236
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`sklearn`-`skopt` version incompatibility causes doctest failure.
## Expected behavior
The following test should succeed.
```bash
circleci build --job doctest
```
## Environment
Please refer `.circleci/config.yml` and `setup.py`.
## Error messages, stack traces, or logs
```
ImportError: Scikit-Optimize is not available. Please install it to use this feature. Scikit-Optimize can be installed by executing `$ pip install scikit-optimize`. For further information, please refer to the installation guide of Scikit-Optimize. (The actual import error is as follows: cannot import name 'MaskedArray' from 'sklearn.utils.fixes' (/home/docs/project/venv/lib/python3.8/site-packages/sklearn/utils/fixes.py))
```
## Steps to reproduce
1. ```pip install scikit-learn==0.23.0```
2. ```pip install scikit-optimize```
3. ```python -c "import skopt"```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import os
2 import sys
3
4 import pkg_resources
5 from setuptools import find_packages
6 from setuptools import setup
7
8 from typing import Dict
9 from typing import List
10 from typing import Optional
11
12
13 def get_version() -> str:
14
15 version_filepath = os.path.join(os.path.dirname(__file__), "optuna", "version.py")
16 with open(version_filepath) as f:
17 for line in f:
18 if line.startswith("__version__"):
19 return line.strip().split()[-1][1:-1]
20 assert False
21
22
23 def get_long_description() -> str:
24
25 readme_filepath = os.path.join(os.path.dirname(__file__), "README.md")
26 with open(readme_filepath) as f:
27 return f.read()
28
29
30 def get_install_requires() -> List[str]:
31
32 return [
33 "alembic",
34 "cliff",
35 "cmaes>=0.3.2",
36 "colorlog",
37 "joblib",
38 "numpy",
39 "scipy!=1.4.0",
40 "sqlalchemy>=1.1.0",
41 "tqdm",
42 ]
43
44
45 def get_tests_require() -> List[str]:
46
47 return get_extras_require()["testing"]
48
49
50 def get_extras_require() -> Dict[str, List[str]]:
51
52 requirements = {
53 "checking": ["black", "hacking", "mypy"],
54 "codecov": ["codecov", "pytest-cov"],
55 "doctest": [
56 "cma",
57 "pandas",
58 "plotly>=4.0.0",
59 "scikit-learn>=0.19.0",
60 "scikit-optimize",
61 "mlflow",
62 ],
63 "document": ["sphinx", "sphinx_rtd_theme"],
64 "example": [
65 "catboost",
66 "chainer",
67 "lightgbm",
68 "mlflow",
69 "mpi4py",
70 "mxnet",
71 "nbval",
72 "pytorch-ignite",
73 "scikit-image",
74 "scikit-learn",
75 "thop",
76 "torch==1.4.0" if sys.platform == "darwin" else "torch==1.4.0+cpu",
77 "torchvision==0.5.0" if sys.platform == "darwin" else "torchvision==0.5.0+cpu",
78 "xgboost",
79 ]
80 + (
81 ["allennlp<1", "fastai<2", "pytorch-lightning>=0.7.1"]
82 if (3, 5) < sys.version_info[:2] < (3, 8)
83 else []
84 )
85 + (
86 ["llvmlite<=0.31.0"] if (3, 5) == sys.version_info[:2] else []
87 ) # Newer `llvmlite` is not distributed with wheels for Python 3.5.
88 + (
89 ["dask[dataframe]", "dask-ml", "keras", "tensorflow>=2.0.0", "tensorflow-datasets"]
90 if sys.version_info[:2] < (3, 8)
91 else []
92 ),
93 "experimental": ["redis"],
94 "testing": [
95 # TODO(toshihikoyanase): Remove the version constraint after resolving the issue
96 # https://github.com/optuna/optuna/issues/1000.
97 "bokeh<2.0.0",
98 "chainer>=5.0.0",
99 "cma",
100 "fakeredis",
101 "fanova",
102 "lightgbm",
103 "mlflow",
104 "mpi4py",
105 "mxnet",
106 "pandas",
107 "plotly>=4.0.0",
108 "pytest",
109 "pytorch-ignite",
110 "scikit-learn>=0.19.0",
111 "scikit-optimize",
112 "torch==1.4.0" if sys.platform == "darwin" else "torch==1.4.0+cpu",
113 "torchvision==0.5.0" if sys.platform == "darwin" else "torchvision==0.5.0+cpu",
114 "xgboost",
115 ]
116 + (
117 ["allennlp<1", "fastai<2", "pytorch-lightning>=0.7.1"]
118 if (3, 5) < sys.version_info[:2] < (3, 8)
119 else []
120 )
121 + (
122 ["keras", "tensorflow", "tensorflow-datasets"] if sys.version_info[:2] < (3, 8) else []
123 ),
124 }
125
126 return requirements
127
128
129 def find_any_distribution(pkgs: List[str]) -> Optional[pkg_resources.Distribution]:
130
131 for pkg in pkgs:
132 try:
133 return pkg_resources.get_distribution(pkg)
134 except pkg_resources.DistributionNotFound:
135 pass
136 return None
137
138
139 pfnopt_pkg = find_any_distribution(["pfnopt"])
140 if pfnopt_pkg is not None:
141 msg = (
142 "We detected that PFNOpt is installed in your environment.\n"
143 "PFNOpt has been renamed Optuna. Please uninstall the old\n"
144 "PFNOpt in advance (e.g. by executing `$ pip uninstall pfnopt`)."
145 )
146 print(msg)
147 exit(1)
148
149 setup(
150 name="optuna",
151 version=get_version(),
152 description="A hyperparameter optimization framework",
153 long_description=get_long_description(),
154 long_description_content_type="text/markdown",
155 author="Takuya Akiba",
156 author_email="[email protected]",
157 url="https://optuna.org/",
158 packages=find_packages(),
159 package_data={
160 "optuna": [
161 "storages/rdb/alembic.ini",
162 "storages/rdb/alembic/*.*",
163 "storages/rdb/alembic/versions/*.*",
164 ]
165 },
166 install_requires=get_install_requires(),
167 tests_require=get_tests_require(),
168 extras_require=get_extras_require(),
169 entry_points={
170 "console_scripts": ["optuna = optuna.cli:main"],
171 "optuna.command": [
172 "create-study = optuna.cli:_CreateStudy",
173 "delete-study = optuna.cli:_DeleteStudy",
174 "study set-user-attr = optuna.cli:_StudySetUserAttribute",
175 "studies = optuna.cli:_Studies",
176 "dashboard = optuna.cli:_Dashboard",
177 "study optimize = optuna.cli:_StudyOptimize",
178 "storage upgrade = optuna.cli:_StorageUpgrade",
179 ],
180 },
181 )
182
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -56,7 +56,7 @@
"cma",
"pandas",
"plotly>=4.0.0",
- "scikit-learn>=0.19.0",
+ "scikit-learn>=0.19.0,<0.23.0",
"scikit-optimize",
"mlflow",
],
@@ -107,7 +107,7 @@
"plotly>=4.0.0",
"pytest",
"pytorch-ignite",
- "scikit-learn>=0.19.0",
+ "scikit-learn>=0.19.0,<0.23.0",
"scikit-optimize",
"torch==1.4.0" if sys.platform == "darwin" else "torch==1.4.0+cpu",
"torchvision==0.5.0" if sys.platform == "darwin" else "torchvision==0.5.0+cpu",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -56,7 +56,7 @@\n \"cma\",\n \"pandas\",\n \"plotly>=4.0.0\",\n- \"scikit-learn>=0.19.0\",\n+ \"scikit-learn>=0.19.0,<0.23.0\",\n \"scikit-optimize\",\n \"mlflow\",\n ],\n@@ -107,7 +107,7 @@\n \"plotly>=4.0.0\",\n \"pytest\",\n \"pytorch-ignite\",\n- \"scikit-learn>=0.19.0\",\n+ \"scikit-learn>=0.19.0,<0.23.0\",\n \"scikit-optimize\",\n \"torch==1.4.0\" if sys.platform == \"darwin\" else \"torch==1.4.0+cpu\",\n \"torchvision==0.5.0\" if sys.platform == \"darwin\" else \"torchvision==0.5.0+cpu\",\n", "issue": "`sklearn`-`skopt` version incompatibility causes doctest failure.\n## Expected behavior\r\n\r\nThe following test should succeed.\r\n```bash\r\ncircleci build --job doctest\r\n```\r\n\r\n## Environment\r\n\r\nPlease refer `.circleci/config.yml` and `setup.py`.\r\n\r\n## Error messages, stack traces, or logs\r\n\r\n```\r\n ImportError: Scikit-Optimize is not available. Please install it to use this feature. Scikit-Optimize can be installed by executing `$ pip install scikit-optimize`. For further information, please refer to the installation guide of Scikit-Optimize. (The actual import error is as follows: cannot import name 'MaskedArray' from 'sklearn.utils.fixes' (/home/docs/project/venv/lib/python3.8/site-packages/sklearn/utils/fixes.py))\r\n```\r\n\r\n## Steps to reproduce\r\n\r\n1. ```pip install scikit-learn==0.23.0```\r\n2. ```pip install scikit-optimize```\r\n3. ```python -c \"import skopt\"```\r\n\n", "before_files": [{"content": "import os\nimport sys\n\nimport pkg_resources\nfrom setuptools import find_packages\nfrom setuptools import setup\n\nfrom typing import Dict\nfrom typing import List\nfrom typing import Optional\n\n\ndef get_version() -> str:\n\n version_filepath = os.path.join(os.path.dirname(__file__), \"optuna\", \"version.py\")\n with open(version_filepath) as f:\n for line in f:\n if line.startswith(\"__version__\"):\n return line.strip().split()[-1][1:-1]\n assert False\n\n\ndef get_long_description() -> str:\n\n readme_filepath = os.path.join(os.path.dirname(__file__), \"README.md\")\n with open(readme_filepath) as f:\n return f.read()\n\n\ndef get_install_requires() -> List[str]:\n\n return [\n \"alembic\",\n \"cliff\",\n \"cmaes>=0.3.2\",\n \"colorlog\",\n \"joblib\",\n \"numpy\",\n \"scipy!=1.4.0\",\n \"sqlalchemy>=1.1.0\",\n \"tqdm\",\n ]\n\n\ndef get_tests_require() -> List[str]:\n\n return get_extras_require()[\"testing\"]\n\n\ndef get_extras_require() -> Dict[str, List[str]]:\n\n requirements = {\n \"checking\": [\"black\", \"hacking\", \"mypy\"],\n \"codecov\": [\"codecov\", \"pytest-cov\"],\n \"doctest\": [\n \"cma\",\n \"pandas\",\n \"plotly>=4.0.0\",\n \"scikit-learn>=0.19.0\",\n \"scikit-optimize\",\n \"mlflow\",\n ],\n \"document\": [\"sphinx\", \"sphinx_rtd_theme\"],\n \"example\": [\n \"catboost\",\n \"chainer\",\n \"lightgbm\",\n \"mlflow\",\n \"mpi4py\",\n \"mxnet\",\n \"nbval\",\n \"pytorch-ignite\",\n \"scikit-image\",\n \"scikit-learn\",\n \"thop\",\n \"torch==1.4.0\" if sys.platform == \"darwin\" else \"torch==1.4.0+cpu\",\n \"torchvision==0.5.0\" if sys.platform == \"darwin\" else \"torchvision==0.5.0+cpu\",\n \"xgboost\",\n ]\n + (\n [\"allennlp<1\", \"fastai<2\", \"pytorch-lightning>=0.7.1\"]\n if (3, 5) < sys.version_info[:2] < (3, 8)\n else []\n )\n + (\n [\"llvmlite<=0.31.0\"] if (3, 5) == sys.version_info[:2] else []\n ) # Newer `llvmlite` is not distributed with wheels for Python 3.5.\n + (\n [\"dask[dataframe]\", \"dask-ml\", \"keras\", \"tensorflow>=2.0.0\", \"tensorflow-datasets\"]\n if sys.version_info[:2] < (3, 8)\n else []\n ),\n \"experimental\": [\"redis\"],\n \"testing\": [\n # TODO(toshihikoyanase): Remove the version constraint after resolving the issue\n # https://github.com/optuna/optuna/issues/1000.\n \"bokeh<2.0.0\",\n \"chainer>=5.0.0\",\n \"cma\",\n \"fakeredis\",\n \"fanova\",\n \"lightgbm\",\n \"mlflow\",\n \"mpi4py\",\n \"mxnet\",\n \"pandas\",\n \"plotly>=4.0.0\",\n \"pytest\",\n \"pytorch-ignite\",\n \"scikit-learn>=0.19.0\",\n \"scikit-optimize\",\n \"torch==1.4.0\" if sys.platform == \"darwin\" else \"torch==1.4.0+cpu\",\n \"torchvision==0.5.0\" if sys.platform == \"darwin\" else \"torchvision==0.5.0+cpu\",\n \"xgboost\",\n ]\n + (\n [\"allennlp<1\", \"fastai<2\", \"pytorch-lightning>=0.7.1\"]\n if (3, 5) < sys.version_info[:2] < (3, 8)\n else []\n )\n + (\n [\"keras\", \"tensorflow\", \"tensorflow-datasets\"] if sys.version_info[:2] < (3, 8) else []\n ),\n }\n\n return requirements\n\n\ndef find_any_distribution(pkgs: List[str]) -> Optional[pkg_resources.Distribution]:\n\n for pkg in pkgs:\n try:\n return pkg_resources.get_distribution(pkg)\n except pkg_resources.DistributionNotFound:\n pass\n return None\n\n\npfnopt_pkg = find_any_distribution([\"pfnopt\"])\nif pfnopt_pkg is not None:\n msg = (\n \"We detected that PFNOpt is installed in your environment.\\n\"\n \"PFNOpt has been renamed Optuna. Please uninstall the old\\n\"\n \"PFNOpt in advance (e.g. by executing `$ pip uninstall pfnopt`).\"\n )\n print(msg)\n exit(1)\n\nsetup(\n name=\"optuna\",\n version=get_version(),\n description=\"A hyperparameter optimization framework\",\n long_description=get_long_description(),\n long_description_content_type=\"text/markdown\",\n author=\"Takuya Akiba\",\n author_email=\"[email protected]\",\n url=\"https://optuna.org/\",\n packages=find_packages(),\n package_data={\n \"optuna\": [\n \"storages/rdb/alembic.ini\",\n \"storages/rdb/alembic/*.*\",\n \"storages/rdb/alembic/versions/*.*\",\n ]\n },\n install_requires=get_install_requires(),\n tests_require=get_tests_require(),\n extras_require=get_extras_require(),\n entry_points={\n \"console_scripts\": [\"optuna = optuna.cli:main\"],\n \"optuna.command\": [\n \"create-study = optuna.cli:_CreateStudy\",\n \"delete-study = optuna.cli:_DeleteStudy\",\n \"study set-user-attr = optuna.cli:_StudySetUserAttribute\",\n \"studies = optuna.cli:_Studies\",\n \"dashboard = optuna.cli:_Dashboard\",\n \"study optimize = optuna.cli:_StudyOptimize\",\n \"storage upgrade = optuna.cli:_StorageUpgrade\",\n ],\n },\n)\n", "path": "setup.py"}], "after_files": [{"content": "import os\nimport sys\n\nimport pkg_resources\nfrom setuptools import find_packages\nfrom setuptools import setup\n\nfrom typing import Dict\nfrom typing import List\nfrom typing import Optional\n\n\ndef get_version() -> str:\n\n version_filepath = os.path.join(os.path.dirname(__file__), \"optuna\", \"version.py\")\n with open(version_filepath) as f:\n for line in f:\n if line.startswith(\"__version__\"):\n return line.strip().split()[-1][1:-1]\n assert False\n\n\ndef get_long_description() -> str:\n\n readme_filepath = os.path.join(os.path.dirname(__file__), \"README.md\")\n with open(readme_filepath) as f:\n return f.read()\n\n\ndef get_install_requires() -> List[str]:\n\n return [\n \"alembic\",\n \"cliff\",\n \"cmaes>=0.3.2\",\n \"colorlog\",\n \"joblib\",\n \"numpy\",\n \"scipy!=1.4.0\",\n \"sqlalchemy>=1.1.0\",\n \"tqdm\",\n ]\n\n\ndef get_tests_require() -> List[str]:\n\n return get_extras_require()[\"testing\"]\n\n\ndef get_extras_require() -> Dict[str, List[str]]:\n\n requirements = {\n \"checking\": [\"black\", \"hacking\", \"mypy\"],\n \"codecov\": [\"codecov\", \"pytest-cov\"],\n \"doctest\": [\n \"cma\",\n \"pandas\",\n \"plotly>=4.0.0\",\n \"scikit-learn>=0.19.0,<0.23.0\",\n \"scikit-optimize\",\n \"mlflow\",\n ],\n \"document\": [\"sphinx\", \"sphinx_rtd_theme\"],\n \"example\": [\n \"catboost\",\n \"chainer\",\n \"lightgbm\",\n \"mlflow\",\n \"mpi4py\",\n \"mxnet\",\n \"nbval\",\n \"pytorch-ignite\",\n \"scikit-image\",\n \"scikit-learn\",\n \"thop\",\n \"torch==1.4.0\" if sys.platform == \"darwin\" else \"torch==1.4.0+cpu\",\n \"torchvision==0.5.0\" if sys.platform == \"darwin\" else \"torchvision==0.5.0+cpu\",\n \"xgboost\",\n ]\n + (\n [\"allennlp<1\", \"fastai<2\", \"pytorch-lightning>=0.7.1\"]\n if (3, 5) < sys.version_info[:2] < (3, 8)\n else []\n )\n + (\n [\"llvmlite<=0.31.0\"] if (3, 5) == sys.version_info[:2] else []\n ) # Newer `llvmlite` is not distributed with wheels for Python 3.5.\n + (\n [\"dask[dataframe]\", \"dask-ml\", \"keras\", \"tensorflow>=2.0.0\", \"tensorflow-datasets\"]\n if sys.version_info[:2] < (3, 8)\n else []\n ),\n \"experimental\": [\"redis\"],\n \"testing\": [\n # TODO(toshihikoyanase): Remove the version constraint after resolving the issue\n # https://github.com/optuna/optuna/issues/1000.\n \"bokeh<2.0.0\",\n \"chainer>=5.0.0\",\n \"cma\",\n \"fakeredis\",\n \"fanova\",\n \"lightgbm\",\n \"mlflow\",\n \"mpi4py\",\n \"mxnet\",\n \"pandas\",\n \"plotly>=4.0.0\",\n \"pytest\",\n \"pytorch-ignite\",\n \"scikit-learn>=0.19.0,<0.23.0\",\n \"scikit-optimize\",\n \"torch==1.4.0\" if sys.platform == \"darwin\" else \"torch==1.4.0+cpu\",\n \"torchvision==0.5.0\" if sys.platform == \"darwin\" else \"torchvision==0.5.0+cpu\",\n \"xgboost\",\n ]\n + (\n [\"allennlp<1\", \"fastai<2\", \"pytorch-lightning>=0.7.1\"]\n if (3, 5) < sys.version_info[:2] < (3, 8)\n else []\n )\n + (\n [\"keras\", \"tensorflow\", \"tensorflow-datasets\"] if sys.version_info[:2] < (3, 8) else []\n ),\n }\n\n return requirements\n\n\ndef find_any_distribution(pkgs: List[str]) -> Optional[pkg_resources.Distribution]:\n\n for pkg in pkgs:\n try:\n return pkg_resources.get_distribution(pkg)\n except pkg_resources.DistributionNotFound:\n pass\n return None\n\n\npfnopt_pkg = find_any_distribution([\"pfnopt\"])\nif pfnopt_pkg is not None:\n msg = (\n \"We detected that PFNOpt is installed in your environment.\\n\"\n \"PFNOpt has been renamed Optuna. Please uninstall the old\\n\"\n \"PFNOpt in advance (e.g. by executing `$ pip uninstall pfnopt`).\"\n )\n print(msg)\n exit(1)\n\nsetup(\n name=\"optuna\",\n version=get_version(),\n description=\"A hyperparameter optimization framework\",\n long_description=get_long_description(),\n long_description_content_type=\"text/markdown\",\n author=\"Takuya Akiba\",\n author_email=\"[email protected]\",\n url=\"https://optuna.org/\",\n packages=find_packages(),\n package_data={\n \"optuna\": [\n \"storages/rdb/alembic.ini\",\n \"storages/rdb/alembic/*.*\",\n \"storages/rdb/alembic/versions/*.*\",\n ]\n },\n install_requires=get_install_requires(),\n tests_require=get_tests_require(),\n extras_require=get_extras_require(),\n entry_points={\n \"console_scripts\": [\"optuna = optuna.cli:main\"],\n \"optuna.command\": [\n \"create-study = optuna.cli:_CreateStudy\",\n \"delete-study = optuna.cli:_DeleteStudy\",\n \"study set-user-attr = optuna.cli:_StudySetUserAttribute\",\n \"studies = optuna.cli:_Studies\",\n \"dashboard = optuna.cli:_Dashboard\",\n \"study optimize = optuna.cli:_StudyOptimize\",\n \"storage upgrade = optuna.cli:_StorageUpgrade\",\n ],\n },\n)\n", "path": "setup.py"}]}
| 2,331 | 244 |
gh_patches_debug_36189
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-3947
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
sportschau: Does not work with the newly introduced bundesliga livestreams (Konferenz)
### Checklist
- [X] This is a plugin issue and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest stable release
### Description
Does not work with the newly introduced bundesliga livestreams (Konferenz).
e.g. https://www.sportschau.de/fussball/bundesliga/audiostream-die-konferenz---bundesliga-live-100.html
Neither under windows nor linux. The linux version (Mint 19) was installed with apt-get, maybe is an older version.
Windows version is actual.
### Debug log
```text
Windows:
c:\Users\deiss\Downloads\streamlink>streamlink https://www.sportschau.de/fussball/bundesliga/audiostream-die-konferenz---bundesliga-live-100.html "best" --loglevel debug
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.7.9
[cli][debug] Streamlink: 2.1.2
[cli][debug] Requests(2.25.1), Socks(1.7.1), Websocket(1.0.0)
[cli][debug] Arguments:
[cli][debug] url=https://www.sportschau.de/fussball/bundesliga/audiostream-die-konferenz---bundesliga-live-100.html
[cli][debug] stream=['best']
[cli][debug] --config=['c:\\Users\\deiss\\Downloads\\streamlink\\\\streamlinkrc']
[cli][debug] --loglevel=debug
[cli][debug] --rtmp-rtmpdump=c:\Users\deiss\Downloads\streamlink\\rtmpdump\rtmpdump.exe
[cli][debug] --ffmpeg-ffmpeg=c:\Users\deiss\Downloads\streamlink\\ffmpeg\ffmpeg.exe
[cli][info] Found matching plugin sportschau for URL https://www.sportschau.de/fussball/bundesliga/audiostream-die-konferenz---bundesliga-live-100.html
[plugins.sportschau][debug] Found player js https://deviceids-medp.wdr.de/ondemand/247/2477304.js
[utils.l10n][debug] Language code: de_DE
error: Unable to open URL: https://b'' (HTTPSConnectionPool(host="b''", port=443): Max retries exceeded with url: / (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x000001BAE8276108>: Failed to establish a new connection: [Errno 11001] getaddrinfo failed')))
Linux:
streamlink https://www.sportschau.de/fussball/bundesliga/audiostream-die-konferenz---bundesliga-live-100.html "best" --loglevel debug
[cli][info] Found matching plugin sportschau for URL https://www.sportschau.de/fussball/bundesliga/audiostream-die-konferenz---bundesliga-live-100.html
[plugin.sportschau][info] Found player js http://deviceids-medp.wdr.de/ondemand/247/2477304.js
Traceback (most recent call last):
File "/usr/bin/streamlink", line 11, in <module>
load_entry_point('streamlink==0.10.0', 'console_scripts', 'streamlink')()
File "/usr/share/streamlink/streamlink_cli/main.py", line 1055, in main
handle_url()
File "/usr/share/streamlink/streamlink_cli/main.py", line 486, in handle_url
streams = fetch_streams(plugin)
File "/usr/share/streamlink/streamlink_cli/main.py", line 398, in fetch_streams
sorting_excludes=args.stream_sorting_excludes)
File "/usr/lib/python3/dist-packages/streamlink/plugin/plugin.py", line 385, in get_streams
return self.streams(*args, **kwargs)
File "/usr/lib/python3/dist-packages/streamlink/plugin/plugin.py", line 288, in streams
ostreams = self._get_streams()
File "/usr/lib/python3/dist-packages/streamlink/plugins/sportschau.py", line 40, in _get_streams
return HDSStream.parse_manifest(self.session, stream_metadata['mediaResource']['dflt']['videoURL']).items()
KeyError: 'videoURL'
Error in sys.excepthook:
Traceback (most recent call last):
File "/usr/lib/python3/dist-packages/apport_python_hook.py", line 145, in apport_excepthook
os.O_WRONLY | os.O_CREAT | os.O_EXCL, 0o640), 'wb') as f:
FileNotFoundError: [Errno 2] No such file or directory: '/var/crash/_usr_share_streamlink_streamlink.1000.crash'
Original exception was:
Traceback (most recent call last):
File "/usr/bin/streamlink", line 11, in <module>
load_entry_point('streamlink==0.10.0', 'console_scripts', 'streamlink')()
File "/usr/share/streamlink/streamlink_cli/main.py", line 1055, in main
handle_url()
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/streamlink/plugins/sportschau.py`
Content:
```
1 import logging
2 import re
3
4 from streamlink.plugin import Plugin, pluginmatcher
5 from streamlink.plugin.api import validate
6 from streamlink.stream import HLSStream
7 from streamlink.utils import parse_json, update_scheme
8
9 log = logging.getLogger(__name__)
10
11
12 @pluginmatcher(re.compile(
13 r"https?://(?:\w+\.)*sportschau\.de/"
14 ))
15 class Sportschau(Plugin):
16 _re_player = re.compile(r"https?:(//deviceids-medp.wdr.de/ondemand/\S+\.js)")
17 _re_json = re.compile(r"\$mediaObject.jsonpHelper.storeAndPlay\(({.+})\);?")
18
19 _schema_player = validate.Schema(
20 validate.transform(_re_player.search),
21 validate.any(None, validate.Schema(
22 validate.get(1),
23 validate.transform(lambda url: update_scheme("https:", url))
24 ))
25 )
26 _schema_json = validate.Schema(
27 validate.transform(_re_json.match),
28 validate.get(1),
29 validate.transform(parse_json),
30 validate.get("mediaResource"),
31 validate.get("dflt"),
32 validate.get("videoURL"),
33 validate.transform(lambda url: update_scheme("https:", url))
34 )
35
36 def _get_streams(self):
37 player_js = self.session.http.get(self.url, schema=self._schema_player)
38 if not player_js:
39 return
40
41 log.debug("Found player js {0}".format(player_js))
42
43 hls_url = self.session.http.get(player_js, schema=self._schema_json)
44
45 yield from HLSStream.parse_variant_playlist(self.session, hls_url).items()
46
47
48 __plugin__ = Sportschau
49
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/streamlink/plugins/sportschau.py b/src/streamlink/plugins/sportschau.py
--- a/src/streamlink/plugins/sportschau.py
+++ b/src/streamlink/plugins/sportschau.py
@@ -3,7 +3,7 @@
from streamlink.plugin import Plugin, pluginmatcher
from streamlink.plugin.api import validate
-from streamlink.stream import HLSStream
+from streamlink.stream import HLSStream, HTTPStream
from streamlink.utils import parse_json, update_scheme
log = logging.getLogger(__name__)
@@ -16,33 +16,34 @@
_re_player = re.compile(r"https?:(//deviceids-medp.wdr.de/ondemand/\S+\.js)")
_re_json = re.compile(r"\$mediaObject.jsonpHelper.storeAndPlay\(({.+})\);?")
- _schema_player = validate.Schema(
- validate.transform(_re_player.search),
- validate.any(None, validate.Schema(
- validate.get(1),
- validate.transform(lambda url: update_scheme("https:", url))
- ))
- )
- _schema_json = validate.Schema(
- validate.transform(_re_json.match),
- validate.get(1),
- validate.transform(parse_json),
- validate.get("mediaResource"),
- validate.get("dflt"),
- validate.get("videoURL"),
- validate.transform(lambda url: update_scheme("https:", url))
- )
-
def _get_streams(self):
- player_js = self.session.http.get(self.url, schema=self._schema_player)
+ player_js = self.session.http.get(self.url, schema=validate.Schema(
+ validate.transform(self._re_player.search),
+ validate.any(None, validate.Schema(
+ validate.get(1),
+ validate.transform(lambda url: update_scheme("https:", url))
+ ))
+ ))
if not player_js:
return
- log.debug("Found player js {0}".format(player_js))
-
- hls_url = self.session.http.get(player_js, schema=self._schema_json)
+ log.debug(f"Found player js {player_js}")
+ data = self.session.http.get(player_js, schema=validate.Schema(
+ validate.transform(self._re_json.match),
+ validate.get(1),
+ validate.transform(parse_json),
+ validate.get("mediaResource"),
+ validate.get("dflt"),
+ {
+ validate.optional("audioURL"): validate.url(),
+ validate.optional("videoURL"): validate.url()
+ }
+ ))
- yield from HLSStream.parse_variant_playlist(self.session, hls_url).items()
+ if data.get("videoURL"):
+ yield from HLSStream.parse_variant_playlist(self.session, update_scheme("https:", data.get("videoURL"))).items()
+ if data.get("audioURL"):
+ yield "audio", HTTPStream(self.session, update_scheme("https:", data.get("audioURL")))
__plugin__ = Sportschau
|
{"golden_diff": "diff --git a/src/streamlink/plugins/sportschau.py b/src/streamlink/plugins/sportschau.py\n--- a/src/streamlink/plugins/sportschau.py\n+++ b/src/streamlink/plugins/sportschau.py\n@@ -3,7 +3,7 @@\n \n from streamlink.plugin import Plugin, pluginmatcher\n from streamlink.plugin.api import validate\n-from streamlink.stream import HLSStream\n+from streamlink.stream import HLSStream, HTTPStream\n from streamlink.utils import parse_json, update_scheme\n \n log = logging.getLogger(__name__)\n@@ -16,33 +16,34 @@\n _re_player = re.compile(r\"https?:(//deviceids-medp.wdr.de/ondemand/\\S+\\.js)\")\n _re_json = re.compile(r\"\\$mediaObject.jsonpHelper.storeAndPlay\\(({.+})\\);?\")\n \n- _schema_player = validate.Schema(\n- validate.transform(_re_player.search),\n- validate.any(None, validate.Schema(\n- validate.get(1),\n- validate.transform(lambda url: update_scheme(\"https:\", url))\n- ))\n- )\n- _schema_json = validate.Schema(\n- validate.transform(_re_json.match),\n- validate.get(1),\n- validate.transform(parse_json),\n- validate.get(\"mediaResource\"),\n- validate.get(\"dflt\"),\n- validate.get(\"videoURL\"),\n- validate.transform(lambda url: update_scheme(\"https:\", url))\n- )\n-\n def _get_streams(self):\n- player_js = self.session.http.get(self.url, schema=self._schema_player)\n+ player_js = self.session.http.get(self.url, schema=validate.Schema(\n+ validate.transform(self._re_player.search),\n+ validate.any(None, validate.Schema(\n+ validate.get(1),\n+ validate.transform(lambda url: update_scheme(\"https:\", url))\n+ ))\n+ ))\n if not player_js:\n return\n \n- log.debug(\"Found player js {0}\".format(player_js))\n-\n- hls_url = self.session.http.get(player_js, schema=self._schema_json)\n+ log.debug(f\"Found player js {player_js}\")\n+ data = self.session.http.get(player_js, schema=validate.Schema(\n+ validate.transform(self._re_json.match),\n+ validate.get(1),\n+ validate.transform(parse_json),\n+ validate.get(\"mediaResource\"),\n+ validate.get(\"dflt\"),\n+ {\n+ validate.optional(\"audioURL\"): validate.url(),\n+ validate.optional(\"videoURL\"): validate.url()\n+ }\n+ ))\n \n- yield from HLSStream.parse_variant_playlist(self.session, hls_url).items()\n+ if data.get(\"videoURL\"):\n+ yield from HLSStream.parse_variant_playlist(self.session, update_scheme(\"https:\", data.get(\"videoURL\"))).items()\n+ if data.get(\"audioURL\"):\n+ yield \"audio\", HTTPStream(self.session, update_scheme(\"https:\", data.get(\"audioURL\")))\n \n \n __plugin__ = Sportschau\n", "issue": "sportschau: Does not work with the newly introduced bundesliga livestreams (Konferenz)\n### Checklist\n\n- [X] This is a plugin issue and not a different kind of issue\n- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)\n- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)\n- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)\n\n### Streamlink version\n\nLatest stable release\n\n### Description\n\nDoes not work with the newly introduced bundesliga livestreams (Konferenz).\r\n\r\ne.g. https://www.sportschau.de/fussball/bundesliga/audiostream-die-konferenz---bundesliga-live-100.html\r\n\r\nNeither under windows nor linux. The linux version (Mint 19) was installed with apt-get, maybe is an older version.\r\nWindows version is actual.\r\n\r\n\n\n### Debug log\n\n```text\nWindows:\r\n\r\nc:\\Users\\deiss\\Downloads\\streamlink>streamlink https://www.sportschau.de/fussball/bundesliga/audiostream-die-konferenz---bundesliga-live-100.html \"best\" --loglevel debug\r\n[cli][debug] OS: Windows 10\r\n[cli][debug] Python: 3.7.9\r\n[cli][debug] Streamlink: 2.1.2\r\n[cli][debug] Requests(2.25.1), Socks(1.7.1), Websocket(1.0.0)\r\n[cli][debug] Arguments:\r\n[cli][debug] url=https://www.sportschau.de/fussball/bundesliga/audiostream-die-konferenz---bundesliga-live-100.html\r\n[cli][debug] stream=['best']\r\n[cli][debug] --config=['c:\\\\Users\\\\deiss\\\\Downloads\\\\streamlink\\\\\\\\streamlinkrc']\r\n[cli][debug] --loglevel=debug\r\n[cli][debug] --rtmp-rtmpdump=c:\\Users\\deiss\\Downloads\\streamlink\\\\rtmpdump\\rtmpdump.exe\r\n[cli][debug] --ffmpeg-ffmpeg=c:\\Users\\deiss\\Downloads\\streamlink\\\\ffmpeg\\ffmpeg.exe\r\n[cli][info] Found matching plugin sportschau for URL https://www.sportschau.de/fussball/bundesliga/audiostream-die-konferenz---bundesliga-live-100.html\r\n[plugins.sportschau][debug] Found player js https://deviceids-medp.wdr.de/ondemand/247/2477304.js\r\n[utils.l10n][debug] Language code: de_DE\r\nerror: Unable to open URL: https://b'' (HTTPSConnectionPool(host=\"b''\", port=443): Max retries exceeded with url: / (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x000001BAE8276108>: Failed to establish a new connection: [Errno 11001] getaddrinfo failed')))\r\n\r\n\r\nLinux:\r\n\r\nstreamlink https://www.sportschau.de/fussball/bundesliga/audiostream-die-konferenz---bundesliga-live-100.html \"best\" --loglevel debug\r\n[cli][info] Found matching plugin sportschau for URL https://www.sportschau.de/fussball/bundesliga/audiostream-die-konferenz---bundesliga-live-100.html\r\n[plugin.sportschau][info] Found player js http://deviceids-medp.wdr.de/ondemand/247/2477304.js\r\nTraceback (most recent call last):\r\n File \"/usr/bin/streamlink\", line 11, in <module>\r\n load_entry_point('streamlink==0.10.0', 'console_scripts', 'streamlink')()\r\n File \"/usr/share/streamlink/streamlink_cli/main.py\", line 1055, in main\r\n handle_url()\r\n File \"/usr/share/streamlink/streamlink_cli/main.py\", line 486, in handle_url\r\n streams = fetch_streams(plugin)\r\n File \"/usr/share/streamlink/streamlink_cli/main.py\", line 398, in fetch_streams\r\n sorting_excludes=args.stream_sorting_excludes)\r\n File \"/usr/lib/python3/dist-packages/streamlink/plugin/plugin.py\", line 385, in get_streams\r\n return self.streams(*args, **kwargs)\r\n File \"/usr/lib/python3/dist-packages/streamlink/plugin/plugin.py\", line 288, in streams\r\n ostreams = self._get_streams()\r\n File \"/usr/lib/python3/dist-packages/streamlink/plugins/sportschau.py\", line 40, in _get_streams\r\n return HDSStream.parse_manifest(self.session, stream_metadata['mediaResource']['dflt']['videoURL']).items()\r\nKeyError: 'videoURL'\r\nError in sys.excepthook:\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python3/dist-packages/apport_python_hook.py\", line 145, in apport_excepthook\r\n os.O_WRONLY | os.O_CREAT | os.O_EXCL, 0o640), 'wb') as f:\r\nFileNotFoundError: [Errno 2] No such file or directory: '/var/crash/_usr_share_streamlink_streamlink.1000.crash'\r\n\r\nOriginal exception was:\r\nTraceback (most recent call last):\r\n File \"/usr/bin/streamlink\", line 11, in <module>\r\n load_entry_point('streamlink==0.10.0', 'console_scripts', 'streamlink')()\r\n File \"/usr/share/streamlink/streamlink_cli/main.py\", line 1055, in main\r\n handle_url()\n```\n\n", "before_files": [{"content": "import logging\nimport re\n\nfrom streamlink.plugin import Plugin, pluginmatcher\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream import HLSStream\nfrom streamlink.utils import parse_json, update_scheme\n\nlog = logging.getLogger(__name__)\n\n\n@pluginmatcher(re.compile(\n r\"https?://(?:\\w+\\.)*sportschau\\.de/\"\n))\nclass Sportschau(Plugin):\n _re_player = re.compile(r\"https?:(//deviceids-medp.wdr.de/ondemand/\\S+\\.js)\")\n _re_json = re.compile(r\"\\$mediaObject.jsonpHelper.storeAndPlay\\(({.+})\\);?\")\n\n _schema_player = validate.Schema(\n validate.transform(_re_player.search),\n validate.any(None, validate.Schema(\n validate.get(1),\n validate.transform(lambda url: update_scheme(\"https:\", url))\n ))\n )\n _schema_json = validate.Schema(\n validate.transform(_re_json.match),\n validate.get(1),\n validate.transform(parse_json),\n validate.get(\"mediaResource\"),\n validate.get(\"dflt\"),\n validate.get(\"videoURL\"),\n validate.transform(lambda url: update_scheme(\"https:\", url))\n )\n\n def _get_streams(self):\n player_js = self.session.http.get(self.url, schema=self._schema_player)\n if not player_js:\n return\n\n log.debug(\"Found player js {0}\".format(player_js))\n\n hls_url = self.session.http.get(player_js, schema=self._schema_json)\n\n yield from HLSStream.parse_variant_playlist(self.session, hls_url).items()\n\n\n__plugin__ = Sportschau\n", "path": "src/streamlink/plugins/sportschau.py"}], "after_files": [{"content": "import logging\nimport re\n\nfrom streamlink.plugin import Plugin, pluginmatcher\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream import HLSStream, HTTPStream\nfrom streamlink.utils import parse_json, update_scheme\n\nlog = logging.getLogger(__name__)\n\n\n@pluginmatcher(re.compile(\n r\"https?://(?:\\w+\\.)*sportschau\\.de/\"\n))\nclass Sportschau(Plugin):\n _re_player = re.compile(r\"https?:(//deviceids-medp.wdr.de/ondemand/\\S+\\.js)\")\n _re_json = re.compile(r\"\\$mediaObject.jsonpHelper.storeAndPlay\\(({.+})\\);?\")\n\n def _get_streams(self):\n player_js = self.session.http.get(self.url, schema=validate.Schema(\n validate.transform(self._re_player.search),\n validate.any(None, validate.Schema(\n validate.get(1),\n validate.transform(lambda url: update_scheme(\"https:\", url))\n ))\n ))\n if not player_js:\n return\n\n log.debug(f\"Found player js {player_js}\")\n data = self.session.http.get(player_js, schema=validate.Schema(\n validate.transform(self._re_json.match),\n validate.get(1),\n validate.transform(parse_json),\n validate.get(\"mediaResource\"),\n validate.get(\"dflt\"),\n {\n validate.optional(\"audioURL\"): validate.url(),\n validate.optional(\"videoURL\"): validate.url()\n }\n ))\n\n if data.get(\"videoURL\"):\n yield from HLSStream.parse_variant_playlist(self.session, update_scheme(\"https:\", data.get(\"videoURL\"))).items()\n if data.get(\"audioURL\"):\n yield \"audio\", HTTPStream(self.session, update_scheme(\"https:\", data.get(\"audioURL\")))\n\n\n__plugin__ = Sportschau\n", "path": "src/streamlink/plugins/sportschau.py"}]}
| 2,047 | 637 |
gh_patches_debug_31771
|
rasdani/github-patches
|
git_diff
|
nvaccess__nvda-11883
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Windows 10 Calculator: results are not announced in compact overlay mode
Hi,
Follow-up to PR #9429
### Steps to reproduce:
In Windows 10 Calculator:
1. Switch to standard calculator mode (Alt+number row 1).
2. Press Alt+Up arrow to switch to always on top (compact overlay) mode.
3. Perform some calculations.
### Actual behavior:
Results are not announced.
### Expected behavior:
Results are announced.
### System configuration
#### NVDA installed/portable/running from source:
Installed
#### NVDA version:
alpha-21429,874230a7
#### Windows version:
Windows 10 Version 20H2 (build 19042.662 beta)
#### Name and version of other software in use when reproducing the issue:
Calculator 10.2010.0.0
#### Other information about your system:
N/A
### Other questions
#### Does the issue still occur after restarting your computer?
Yes
#### Have you tried any other versions of NVDA? If so, please report their behaviors.
Same behavior in 2020.3.
#### If addons are disabled, is your problem still occuring?
Yes
#### Did you try to run the COM registry fixing tool in NVDA menu / tools?
Not applicable
### Additional context and solution
Caused by a missing Automation Id that should be included in result announcement script (UIA Automation Id is different for always on top result element). The same PR for #11880 will be applicable to this issue as well.
Thanks.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `source/appModules/calculator.py`
Content:
```
1 # A part of NonVisual Desktop Access (NVDA)
2 # Copyright (C) 2020 NV Access Limited, Joseph Lee
3 # This file is covered by the GNU General Public License.
4 # See the file COPYING for more details.
5
6 """App module for Windows 10 Calculator"""
7
8 import appModuleHandler
9 import api
10 from NVDAObjects.UIA import UIA
11 import queueHandler
12 import ui
13 import scriptHandler
14
15 # #9428: do not announce current values until calculations are done in order to avoid repetitions.
16 noCalculatorEntryAnnouncements = [
17 # Display field with Calculator set to full screen mode.
18 "CalculatorResults",
19 # In the middle of a calculation expression entry.
20 "CalculatorExpression",
21 # Results display with Calculator set to compact overlay i.e. always on top mode.
22 "CalculatorAlwaysOnTopResults",
23 # Calculator expressions with Calculator set to always on top mode.
24 "ExpressionContainer",
25 # Date range selector.
26 "ContentPresenter",
27 # Briefly shown when closing date calculation calendar.
28 "Light Dismiss",
29 ]
30
31
32 class AppModule(appModuleHandler.AppModule):
33
34 _shouldAnnounceResult = False
35 # Name change says the same thing multiple times for some items.
36 _resultsCache = ""
37
38 def event_nameChange(self, obj, nextHandler):
39 if not isinstance(obj, UIA):
40 return
41 # No, announce value changes immediately except for calculator results and expressions.
42 if (
43 obj.UIAAutomationId in noCalculatorEntryAnnouncements
44 or obj.UIAElement.cachedClassName == "LandmarkTarget"
45 ):
46 self._shouldAnnounceResult = False
47 # For the rest:
48 elif (
49 obj.UIAAutomationId not in noCalculatorEntryAnnouncements
50 and obj.name != self._resultsCache
51 ):
52 # For unit conversion, UIA notification event presents much better messages.
53 # For date calculation, live region change event is also fired for difference between dates.
54 if obj.UIAAutomationId not in ("Value1", "Value2", "DateDiffAllUnitsResultLabel"):
55 ui.message(obj.name)
56 self._resultsCache = obj.name
57 if not self._shouldAnnounceResult:
58 return
59 self._shouldAnnounceResult = False
60 nextHandler()
61
62 def event_UIA_notification(self, obj, nextHandler, activityId=None, **kwargs):
63 try:
64 shouldAnnounceNotification = (
65 obj.previous.UIAAutomationId in
66 ("numberPad", "UnitConverterRootGrid")
67 )
68 except AttributeError:
69 resultElement = api.getForegroundObject().children[1].lastChild
70 # Redesigned in 2019 due to introduction of "always on top" i.e. compact overlay mode.
71 if resultElement.UIAElement.cachedClassName != "LandmarkTarget":
72 resultElement = resultElement.parent.children[1]
73 shouldAnnounceNotification = (
74 resultElement
75 and resultElement.firstChild
76 and resultElement.firstChild.UIAAutomationId not in noCalculatorEntryAnnouncements
77 )
78 # Display updated activity ID seen when entering calculations should be ignored
79 # as as it is redundant if speak typed characters is on.
80 if shouldAnnounceNotification or activityId != "DisplayUpdated":
81 nextHandler()
82
83 # A list of native commands to handle calculator result announcement.
84 _calculatorResultGestures = ("kb:enter", "kb:numpadEnter", "kb:escape")
85
86 @scriptHandler.script(gestures=_calculatorResultGestures)
87 def script_calculatorResult(self, gesture):
88 # To prevent double focus announcement, check where we are.
89 focus = api.getFocusObject()
90 gesture.send()
91 # In redstone, calculator result keeps firing name change,
92 # so tell it to do so if and only if enter has been pressed.
93 self._shouldAnnounceResult = True
94 # Hack: only announce display text when an actual calculator button (usually equals button) is pressed.
95 # In redstone, pressing enter does not move focus to equals button.
96 if isinstance(focus, UIA):
97 if focus.UIAAutomationId == "CalculatorResults":
98 queueHandler.queueFunction(queueHandler.eventQueue, focus.reportFocus)
99 else:
100 resultsScreen = api.getForegroundObject().children[1].lastChild
101 if isinstance(resultsScreen, UIA) and resultsScreen.UIAElement.cachedClassName == "LandmarkTarget":
102 # And no, do not allow focus to move.
103 queueHandler.queueFunction(queueHandler.eventQueue, resultsScreen.firstChild.reportFocus)
104
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/source/appModules/calculator.py b/source/appModules/calculator.py
--- a/source/appModules/calculator.py
+++ b/source/appModules/calculator.py
@@ -26,6 +26,10 @@
"ContentPresenter",
# Briefly shown when closing date calculation calendar.
"Light Dismiss",
+ # Unit conversion/convert from.
+ "Value1",
+ # Unit conversion/converts into.
+ "Value2",
]
@@ -49,9 +53,10 @@
obj.UIAAutomationId not in noCalculatorEntryAnnouncements
and obj.name != self._resultsCache
):
- # For unit conversion, UIA notification event presents much better messages.
+ # For unit conversion, both name change and notification events are fired,
+ # although UIA notification event presents much better messages.
# For date calculation, live region change event is also fired for difference between dates.
- if obj.UIAAutomationId not in ("Value1", "Value2", "DateDiffAllUnitsResultLabel"):
+ if obj.UIAAutomationId != "DateDiffAllUnitsResultLabel":
ui.message(obj.name)
self._resultsCache = obj.name
if not self._shouldAnnounceResult:
@@ -94,7 +99,7 @@
# Hack: only announce display text when an actual calculator button (usually equals button) is pressed.
# In redstone, pressing enter does not move focus to equals button.
if isinstance(focus, UIA):
- if focus.UIAAutomationId == "CalculatorResults":
+ if focus.UIAAutomationId in ("CalculatorResults", "CalculatorAlwaysOnTopResults"):
queueHandler.queueFunction(queueHandler.eventQueue, focus.reportFocus)
else:
resultsScreen = api.getForegroundObject().children[1].lastChild
|
{"golden_diff": "diff --git a/source/appModules/calculator.py b/source/appModules/calculator.py\n--- a/source/appModules/calculator.py\n+++ b/source/appModules/calculator.py\n@@ -26,6 +26,10 @@\n \t\"ContentPresenter\",\n \t# Briefly shown when closing date calculation calendar.\n \t\"Light Dismiss\",\n+\t# Unit conversion/convert from.\n+\t\"Value1\",\n+\t# Unit conversion/converts into.\n+\t\"Value2\",\n ]\n \n \n@@ -49,9 +53,10 @@\n \t\t\tobj.UIAAutomationId not in noCalculatorEntryAnnouncements\n \t\t\tand obj.name != self._resultsCache\n \t\t):\n-\t\t\t# For unit conversion, UIA notification event presents much better messages.\n+\t\t\t# For unit conversion, both name change and notification events are fired,\n+\t\t\t# although UIA notification event presents much better messages.\n \t\t\t# For date calculation, live region change event is also fired for difference between dates.\n-\t\t\tif obj.UIAAutomationId not in (\"Value1\", \"Value2\", \"DateDiffAllUnitsResultLabel\"):\n+\t\t\tif obj.UIAAutomationId != \"DateDiffAllUnitsResultLabel\":\n \t\t\t\tui.message(obj.name)\n \t\t\tself._resultsCache = obj.name\n \t\tif not self._shouldAnnounceResult:\n@@ -94,7 +99,7 @@\n \t\t# Hack: only announce display text when an actual calculator button (usually equals button) is pressed.\n \t\t# In redstone, pressing enter does not move focus to equals button.\n \t\tif isinstance(focus, UIA):\n-\t\t\tif focus.UIAAutomationId == \"CalculatorResults\":\n+\t\t\tif focus.UIAAutomationId in (\"CalculatorResults\", \"CalculatorAlwaysOnTopResults\"):\n \t\t\t\tqueueHandler.queueFunction(queueHandler.eventQueue, focus.reportFocus)\n \t\t\telse:\n \t\t\t\tresultsScreen = api.getForegroundObject().children[1].lastChild\n", "issue": "Windows 10 Calculator: results are not announced in compact overlay mode\nHi,\r\n\r\nFollow-up to PR #9429 \r\n\r\n### Steps to reproduce:\r\nIn Windows 10 Calculator:\r\n\r\n1. Switch to standard calculator mode (Alt+number row 1).\r\n2. Press Alt+Up arrow to switch to always on top (compact overlay) mode.\r\n3. Perform some calculations.\r\n\r\n### Actual behavior:\r\nResults are not announced.\r\n\r\n### Expected behavior:\r\nResults are announced.\r\n\r\n### System configuration\r\n#### NVDA installed/portable/running from source:\r\nInstalled\r\n\r\n#### NVDA version:\r\nalpha-21429,874230a7\r\n\r\n#### Windows version:\r\nWindows 10 Version 20H2 (build 19042.662 beta)\r\n\r\n#### Name and version of other software in use when reproducing the issue:\r\nCalculator 10.2010.0.0\r\n\r\n#### Other information about your system:\r\nN/A\r\n\r\n### Other questions\r\n#### Does the issue still occur after restarting your computer?\r\nYes\r\n\r\n#### Have you tried any other versions of NVDA? If so, please report their behaviors.\r\nSame behavior in 2020.3.\r\n\r\n#### If addons are disabled, is your problem still occuring?\r\nYes\r\n\r\n#### Did you try to run the COM registry fixing tool in NVDA menu / tools?\r\nNot applicable\r\n\r\n### Additional context and solution\r\nCaused by a missing Automation Id that should be included in result announcement script (UIA Automation Id is different for always on top result element). The same PR for #11880 will be applicable to this issue as well.\r\n\r\nThanks.\n", "before_files": [{"content": "# A part of NonVisual Desktop Access (NVDA)\n# Copyright (C) 2020 NV Access Limited, Joseph Lee\n# This file is covered by the GNU General Public License.\n# See the file COPYING for more details.\n\n\"\"\"App module for Windows 10 Calculator\"\"\"\n\nimport appModuleHandler\nimport api\nfrom NVDAObjects.UIA import UIA\nimport queueHandler\nimport ui\nimport scriptHandler\n\n# #9428: do not announce current values until calculations are done in order to avoid repetitions.\nnoCalculatorEntryAnnouncements = [\n\t# Display field with Calculator set to full screen mode.\n\t\"CalculatorResults\",\n\t# In the middle of a calculation expression entry.\n\t\"CalculatorExpression\",\n\t# Results display with Calculator set to compact overlay i.e. always on top mode.\n\t\"CalculatorAlwaysOnTopResults\",\n\t# Calculator expressions with Calculator set to always on top mode.\n\t\"ExpressionContainer\",\n\t# Date range selector.\n\t\"ContentPresenter\",\n\t# Briefly shown when closing date calculation calendar.\n\t\"Light Dismiss\",\n]\n\n\nclass AppModule(appModuleHandler.AppModule):\n\n\t_shouldAnnounceResult = False\n\t# Name change says the same thing multiple times for some items.\n\t_resultsCache = \"\"\n\n\tdef event_nameChange(self, obj, nextHandler):\n\t\tif not isinstance(obj, UIA):\n\t\t\treturn\n\t\t# No, announce value changes immediately except for calculator results and expressions.\n\t\tif (\n\t\t\tobj.UIAAutomationId in noCalculatorEntryAnnouncements\n\t\t\tor obj.UIAElement.cachedClassName == \"LandmarkTarget\"\n\t\t):\n\t\t\tself._shouldAnnounceResult = False\n\t\t# For the rest:\n\t\telif (\n\t\t\tobj.UIAAutomationId not in noCalculatorEntryAnnouncements\n\t\t\tand obj.name != self._resultsCache\n\t\t):\n\t\t\t# For unit conversion, UIA notification event presents much better messages.\n\t\t\t# For date calculation, live region change event is also fired for difference between dates.\n\t\t\tif obj.UIAAutomationId not in (\"Value1\", \"Value2\", \"DateDiffAllUnitsResultLabel\"):\n\t\t\t\tui.message(obj.name)\n\t\t\tself._resultsCache = obj.name\n\t\tif not self._shouldAnnounceResult:\n\t\t\treturn\n\t\tself._shouldAnnounceResult = False\n\t\tnextHandler()\n\n\tdef event_UIA_notification(self, obj, nextHandler, activityId=None, **kwargs):\n\t\ttry:\n\t\t\tshouldAnnounceNotification = (\n\t\t\t\tobj.previous.UIAAutomationId in\n\t\t\t\t(\"numberPad\", \"UnitConverterRootGrid\")\n\t\t\t)\n\t\texcept AttributeError:\n\t\t\tresultElement = api.getForegroundObject().children[1].lastChild\n\t\t\t# Redesigned in 2019 due to introduction of \"always on top\" i.e. compact overlay mode.\n\t\t\tif resultElement.UIAElement.cachedClassName != \"LandmarkTarget\":\n\t\t\t\tresultElement = resultElement.parent.children[1]\n\t\t\tshouldAnnounceNotification = (\n\t\t\t\tresultElement\n\t\t\t\tand resultElement.firstChild\n\t\t\t\tand resultElement.firstChild.UIAAutomationId not in noCalculatorEntryAnnouncements\n\t\t\t)\n\t\t# Display updated activity ID seen when entering calculations should be ignored\n\t\t# as as it is redundant if speak typed characters is on.\n\t\tif shouldAnnounceNotification or activityId != \"DisplayUpdated\":\n\t\t\tnextHandler()\n\n\t# A list of native commands to handle calculator result announcement.\n\t_calculatorResultGestures = (\"kb:enter\", \"kb:numpadEnter\", \"kb:escape\")\n\n\[email protected](gestures=_calculatorResultGestures)\n\tdef script_calculatorResult(self, gesture):\n\t\t# To prevent double focus announcement, check where we are.\n\t\tfocus = api.getFocusObject()\n\t\tgesture.send()\n\t\t# In redstone, calculator result keeps firing name change,\n\t\t# so tell it to do so if and only if enter has been pressed.\n\t\tself._shouldAnnounceResult = True\n\t\t# Hack: only announce display text when an actual calculator button (usually equals button) is pressed.\n\t\t# In redstone, pressing enter does not move focus to equals button.\n\t\tif isinstance(focus, UIA):\n\t\t\tif focus.UIAAutomationId == \"CalculatorResults\":\n\t\t\t\tqueueHandler.queueFunction(queueHandler.eventQueue, focus.reportFocus)\n\t\t\telse:\n\t\t\t\tresultsScreen = api.getForegroundObject().children[1].lastChild\n\t\t\t\tif isinstance(resultsScreen, UIA) and resultsScreen.UIAElement.cachedClassName == \"LandmarkTarget\":\n\t\t\t\t\t# And no, do not allow focus to move.\n\t\t\t\t\tqueueHandler.queueFunction(queueHandler.eventQueue, resultsScreen.firstChild.reportFocus)\n", "path": "source/appModules/calculator.py"}], "after_files": [{"content": "# A part of NonVisual Desktop Access (NVDA)\n# Copyright (C) 2020 NV Access Limited, Joseph Lee\n# This file is covered by the GNU General Public License.\n# See the file COPYING for more details.\n\n\"\"\"App module for Windows 10 Calculator\"\"\"\n\nimport appModuleHandler\nimport api\nfrom NVDAObjects.UIA import UIA\nimport queueHandler\nimport ui\nimport scriptHandler\n\n# #9428: do not announce current values until calculations are done in order to avoid repetitions.\nnoCalculatorEntryAnnouncements = [\n\t# Display field with Calculator set to full screen mode.\n\t\"CalculatorResults\",\n\t# In the middle of a calculation expression entry.\n\t\"CalculatorExpression\",\n\t# Results display with Calculator set to compact overlay i.e. always on top mode.\n\t\"CalculatorAlwaysOnTopResults\",\n\t# Calculator expressions with Calculator set to always on top mode.\n\t\"ExpressionContainer\",\n\t# Date range selector.\n\t\"ContentPresenter\",\n\t# Briefly shown when closing date calculation calendar.\n\t\"Light Dismiss\",\n\t# Unit conversion/convert from.\n\t\"Value1\",\n\t# Unit conversion/converts into.\n\t\"Value2\",\n]\n\n\nclass AppModule(appModuleHandler.AppModule):\n\n\t_shouldAnnounceResult = False\n\t# Name change says the same thing multiple times for some items.\n\t_resultsCache = \"\"\n\n\tdef event_nameChange(self, obj, nextHandler):\n\t\tif not isinstance(obj, UIA):\n\t\t\treturn\n\t\t# No, announce value changes immediately except for calculator results and expressions.\n\t\tif (\n\t\t\tobj.UIAAutomationId in noCalculatorEntryAnnouncements\n\t\t\tor obj.UIAElement.cachedClassName == \"LandmarkTarget\"\n\t\t):\n\t\t\tself._shouldAnnounceResult = False\n\t\t# For the rest:\n\t\telif (\n\t\t\tobj.UIAAutomationId not in noCalculatorEntryAnnouncements\n\t\t\tand obj.name != self._resultsCache\n\t\t):\n\t\t\t# For unit conversion, both name change and notification events are fired,\n\t\t\t# although UIA notification event presents much better messages.\n\t\t\t# For date calculation, live region change event is also fired for difference between dates.\n\t\t\tif obj.UIAAutomationId != \"DateDiffAllUnitsResultLabel\":\n\t\t\t\tui.message(obj.name)\n\t\t\tself._resultsCache = obj.name\n\t\tif not self._shouldAnnounceResult:\n\t\t\treturn\n\t\tself._shouldAnnounceResult = False\n\t\tnextHandler()\n\n\tdef event_UIA_notification(self, obj, nextHandler, activityId=None, **kwargs):\n\t\ttry:\n\t\t\tshouldAnnounceNotification = (\n\t\t\t\tobj.previous.UIAAutomationId in\n\t\t\t\t(\"numberPad\", \"UnitConverterRootGrid\")\n\t\t\t)\n\t\texcept AttributeError:\n\t\t\tresultElement = api.getForegroundObject().children[1].lastChild\n\t\t\t# Redesigned in 2019 due to introduction of \"always on top\" i.e. compact overlay mode.\n\t\t\tif resultElement.UIAElement.cachedClassName != \"LandmarkTarget\":\n\t\t\t\tresultElement = resultElement.parent.children[1]\n\t\t\tshouldAnnounceNotification = (\n\t\t\t\tresultElement\n\t\t\t\tand resultElement.firstChild\n\t\t\t\tand resultElement.firstChild.UIAAutomationId not in noCalculatorEntryAnnouncements\n\t\t\t)\n\t\t# Display updated activity ID seen when entering calculations should be ignored\n\t\t# as as it is redundant if speak typed characters is on.\n\t\tif shouldAnnounceNotification or activityId != \"DisplayUpdated\":\n\t\t\tnextHandler()\n\n\t# A list of native commands to handle calculator result announcement.\n\t_calculatorResultGestures = (\"kb:enter\", \"kb:numpadEnter\", \"kb:escape\")\n\n\[email protected](gestures=_calculatorResultGestures)\n\tdef script_calculatorResult(self, gesture):\n\t\t# To prevent double focus announcement, check where we are.\n\t\tfocus = api.getFocusObject()\n\t\tgesture.send()\n\t\t# In redstone, calculator result keeps firing name change,\n\t\t# so tell it to do so if and only if enter has been pressed.\n\t\tself._shouldAnnounceResult = True\n\t\t# Hack: only announce display text when an actual calculator button (usually equals button) is pressed.\n\t\t# In redstone, pressing enter does not move focus to equals button.\n\t\tif isinstance(focus, UIA):\n\t\t\tif focus.UIAAutomationId in (\"CalculatorResults\", \"CalculatorAlwaysOnTopResults\"):\n\t\t\t\tqueueHandler.queueFunction(queueHandler.eventQueue, focus.reportFocus)\n\t\t\telse:\n\t\t\t\tresultsScreen = api.getForegroundObject().children[1].lastChild\n\t\t\t\tif isinstance(resultsScreen, UIA) and resultsScreen.UIAElement.cachedClassName == \"LandmarkTarget\":\n\t\t\t\t\t# And no, do not allow focus to move.\n\t\t\t\t\tqueueHandler.queueFunction(queueHandler.eventQueue, resultsScreen.firstChild.reportFocus)\n", "path": "source/appModules/calculator.py"}]}
| 1,810 | 408 |
gh_patches_debug_31629
|
rasdani/github-patches
|
git_diff
|
searx__searx-2106
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Duplicate feature: result in a new tab.
## Core feature "result on new tab":
* https://github.com/asciimoo/searx/blob/6163bd671bbf71a9eae3a6a9b1019e2a701c4946/searx/preferences.py#L366-L374
* https://github.com/asciimoo/searx/blob/6163bd671bbf71a9eae3a6a9b1019e2a701c4946/searx/templates/oscar/preferences.html#L114-L121
* https://github.com/asciimoo/searx/blob/6163bd671bbf71a9eae3a6a9b1019e2a701c4946/searx/templates/oscar/macros.html#L11-L18
* 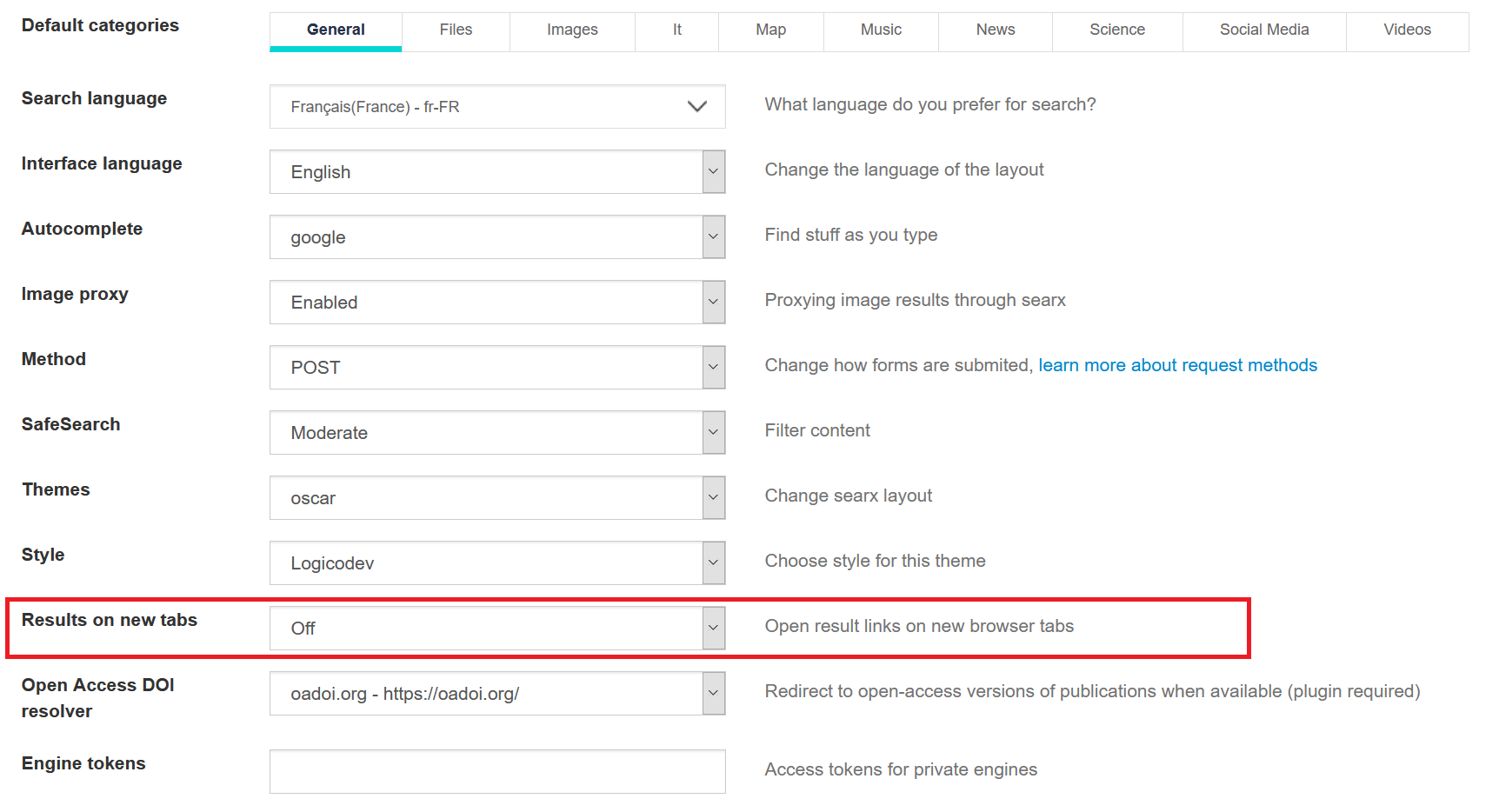
## Plugin "result on a new tab":
* https://github.com/asciimoo/searx/blob/6163bd671bbf71a9eae3a6a9b1019e2a701c4946/searx/static/plugins/js/open_results_on_new_tab.js#L1-L3
* 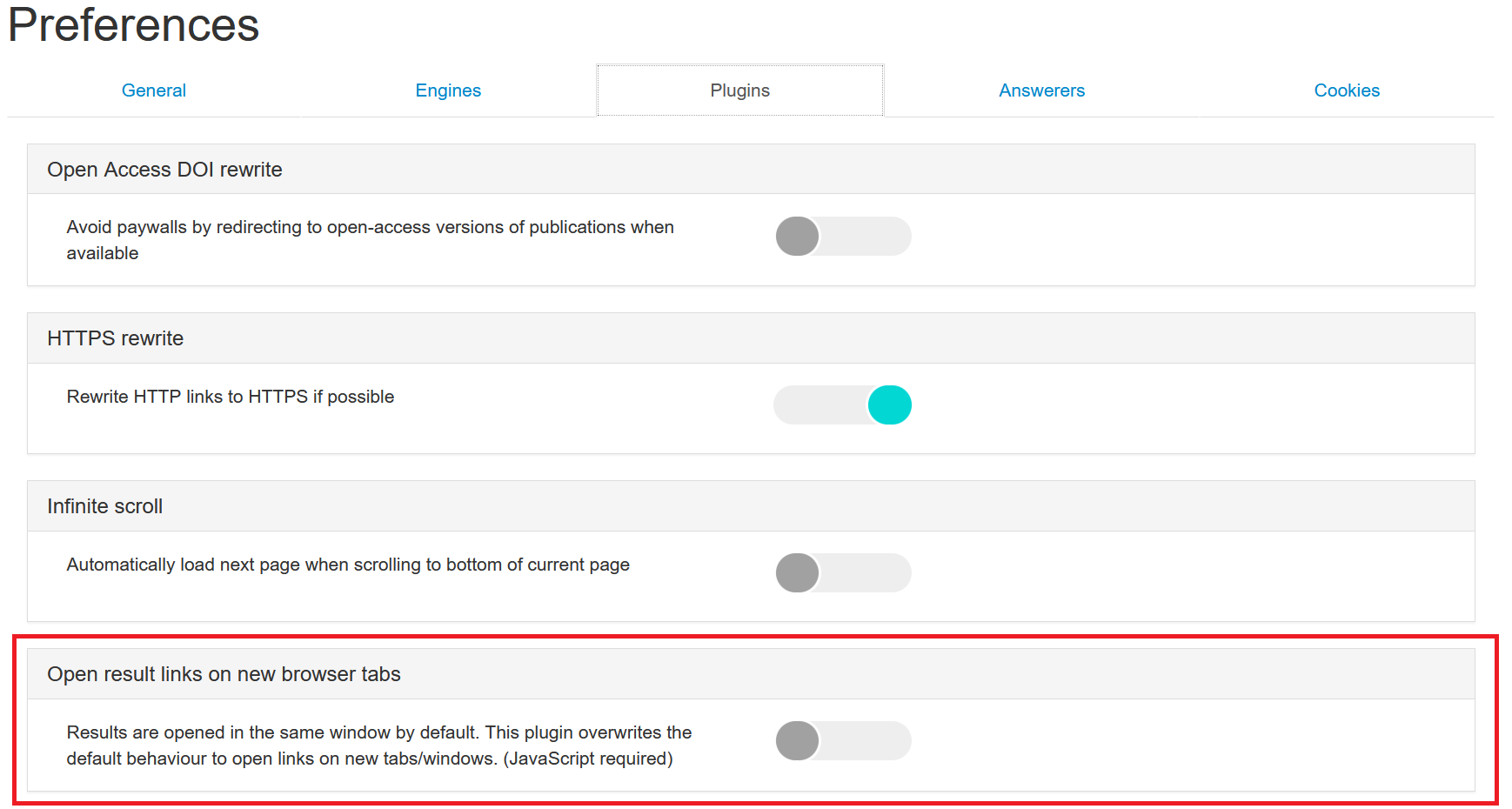
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `searx/plugins/open_results_on_new_tab.py`
Content:
```
1 '''
2 searx is free software: you can redistribute it and/or modify
3 it under the terms of the GNU Affero General Public License as published by
4 the Free Software Foundation, either version 3 of the License, or
5 (at your option) any later version.
6
7 searx is distributed in the hope that it will be useful,
8 but WITHOUT ANY WARRANTY; without even the implied warranty of
9 MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
10 GNU Affero General Public License for more details.
11
12 You should have received a copy of the GNU Affero General Public License
13 along with searx. If not, see < http://www.gnu.org/licenses/ >.
14
15 (C) 2016 by Adam Tauber, <[email protected]>
16 '''
17 from flask_babel import gettext
18 name = gettext('Open result links on new browser tabs')
19 description = gettext('Results are opened in the same window by default. '
20 'This plugin overwrites the default behaviour to open links on new tabs/windows. '
21 '(JavaScript required)')
22 default_on = False
23 preference_section = 'ui'
24
25 js_dependencies = ('plugins/js/open_results_on_new_tab.js',)
26
```
Path: `searx/plugins/__init__.py`
Content:
```
1 '''
2 searx is free software: you can redistribute it and/or modify
3 it under the terms of the GNU Affero General Public License as published by
4 the Free Software Foundation, either version 3 of the License, or
5 (at your option) any later version.
6
7 searx is distributed in the hope that it will be useful,
8 but WITHOUT ANY WARRANTY; without even the implied warranty of
9 MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
10 GNU Affero General Public License for more details.
11
12 You should have received a copy of the GNU Affero General Public License
13 along with searx. If not, see < http://www.gnu.org/licenses/ >.
14
15 (C) 2015 by Adam Tauber, <[email protected]>
16 '''
17
18 from hashlib import sha256
19 from importlib import import_module
20 from os import listdir, makedirs, remove, stat, utime
21 from os.path import abspath, basename, dirname, exists, join
22 from shutil import copyfile
23 from sys import version_info
24 from traceback import print_exc
25
26 from searx import logger, settings, static_path
27
28 if version_info[0] == 3:
29 unicode = str
30
31 logger = logger.getChild('plugins')
32
33 from searx.plugins import (oa_doi_rewrite,
34 https_rewrite,
35 infinite_scroll,
36 open_results_on_new_tab,
37 self_info,
38 search_on_category_select,
39 tracker_url_remover,
40 vim_hotkeys)
41
42 required_attrs = (('name', (str, unicode)),
43 ('description', (str, unicode)),
44 ('default_on', bool))
45
46 optional_attrs = (('js_dependencies', tuple),
47 ('css_dependencies', tuple))
48
49
50 class Plugin():
51 default_on = False
52 name = 'Default plugin'
53 description = 'Default plugin description'
54
55
56 class PluginStore():
57
58 def __init__(self):
59 self.plugins = []
60
61 def __iter__(self):
62 for plugin in self.plugins:
63 yield plugin
64
65 def register(self, *plugins, external=False):
66 if external:
67 plugins = load_external_plugins(plugins)
68 for plugin in plugins:
69 for plugin_attr, plugin_attr_type in required_attrs:
70 if not hasattr(plugin, plugin_attr) or not isinstance(getattr(plugin, plugin_attr), plugin_attr_type):
71 logger.critical('missing attribute "{0}", cannot load plugin: {1}'.format(plugin_attr, plugin))
72 exit(3)
73 for plugin_attr, plugin_attr_type in optional_attrs:
74 if not hasattr(plugin, plugin_attr) or not isinstance(getattr(plugin, plugin_attr), plugin_attr_type):
75 setattr(plugin, plugin_attr, plugin_attr_type())
76 plugin.id = plugin.name.replace(' ', '_')
77 self.plugins.append(plugin)
78
79 def call(self, ordered_plugin_list, plugin_type, request, *args, **kwargs):
80 ret = True
81 for plugin in ordered_plugin_list:
82 if hasattr(plugin, plugin_type):
83 ret = getattr(plugin, plugin_type)(request, *args, **kwargs)
84 if not ret:
85 break
86
87 return ret
88
89
90 def load_external_plugins(plugin_names):
91 plugins = []
92 for name in plugin_names:
93 logger.debug('loading plugin: {0}'.format(name))
94 try:
95 pkg = import_module(name)
96 except Exception as e:
97 logger.critical('failed to load plugin module {0}: {1}'.format(name, e))
98 exit(3)
99
100 pkg.__base_path = dirname(abspath(pkg.__file__))
101
102 prepare_package_resources(pkg, name)
103
104 plugins.append(pkg)
105 logger.debug('plugin "{0}" loaded'.format(name))
106 return plugins
107
108
109 def sync_resource(base_path, resource_path, name, target_dir, plugin_dir):
110 dep_path = join(base_path, resource_path)
111 file_name = basename(dep_path)
112 resource_path = join(target_dir, file_name)
113 if not exists(resource_path) or sha_sum(dep_path) != sha_sum(resource_path):
114 try:
115 copyfile(dep_path, resource_path)
116 # copy atime_ns and mtime_ns, so the weak ETags (generated by
117 # the HTTP server) do not change
118 dep_stat = stat(dep_path)
119 utime(resource_path, ns=(dep_stat.st_atime_ns, dep_stat.st_mtime_ns))
120 except:
121 logger.critical('failed to copy plugin resource {0} for plugin {1}'.format(file_name, name))
122 exit(3)
123
124 # returning with the web path of the resource
125 return join('plugins/external_plugins', plugin_dir, file_name)
126
127
128 def prepare_package_resources(pkg, name):
129 plugin_dir = 'plugin_' + name
130 target_dir = join(static_path, 'plugins/external_plugins', plugin_dir)
131 try:
132 makedirs(target_dir, exist_ok=True)
133 except:
134 logger.critical('failed to create resource directory {0} for plugin {1}'.format(target_dir, name))
135 exit(3)
136
137 resources = []
138
139 if hasattr(pkg, 'js_dependencies'):
140 resources.extend(map(basename, pkg.js_dependencies))
141 pkg.js_dependencies = tuple([
142 sync_resource(pkg.__base_path, x, name, target_dir, plugin_dir)
143 for x in pkg.js_dependencies
144 ])
145 if hasattr(pkg, 'css_dependencies'):
146 resources.extend(map(basename, pkg.css_dependencies))
147 pkg.css_dependencies = tuple([
148 sync_resource(pkg.__base_path, x, name, target_dir, plugin_dir)
149 for x in pkg.css_dependencies
150 ])
151
152 for f in listdir(target_dir):
153 if basename(f) not in resources:
154 resource_path = join(target_dir, basename(f))
155 try:
156 remove(resource_path)
157 except:
158 logger.critical('failed to remove unused resource file {0} for plugin {1}'.format(resource_path, name))
159 exit(3)
160
161
162 def sha_sum(filename):
163 with open(filename, "rb") as f:
164 bytes = f.read()
165 return sha256(bytes).hexdigest()
166
167
168 plugins = PluginStore()
169 plugins.register(oa_doi_rewrite)
170 plugins.register(https_rewrite)
171 plugins.register(infinite_scroll)
172 plugins.register(open_results_on_new_tab)
173 plugins.register(self_info)
174 plugins.register(search_on_category_select)
175 plugins.register(tracker_url_remover)
176 plugins.register(vim_hotkeys)
177 # load external plugins
178 if 'plugins' in settings:
179 plugins.register(*settings['plugins'], external=True)
180
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/searx/plugins/__init__.py b/searx/plugins/__init__.py
--- a/searx/plugins/__init__.py
+++ b/searx/plugins/__init__.py
@@ -33,7 +33,6 @@
from searx.plugins import (oa_doi_rewrite,
https_rewrite,
infinite_scroll,
- open_results_on_new_tab,
self_info,
search_on_category_select,
tracker_url_remover,
@@ -169,7 +168,6 @@
plugins.register(oa_doi_rewrite)
plugins.register(https_rewrite)
plugins.register(infinite_scroll)
-plugins.register(open_results_on_new_tab)
plugins.register(self_info)
plugins.register(search_on_category_select)
plugins.register(tracker_url_remover)
diff --git a/searx/plugins/open_results_on_new_tab.py b/searx/plugins/open_results_on_new_tab.py
deleted file mode 100644
--- a/searx/plugins/open_results_on_new_tab.py
+++ /dev/null
@@ -1,25 +0,0 @@
-'''
-searx is free software: you can redistribute it and/or modify
-it under the terms of the GNU Affero General Public License as published by
-the Free Software Foundation, either version 3 of the License, or
-(at your option) any later version.
-
-searx is distributed in the hope that it will be useful,
-but WITHOUT ANY WARRANTY; without even the implied warranty of
-MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
-GNU Affero General Public License for more details.
-
-You should have received a copy of the GNU Affero General Public License
-along with searx. If not, see < http://www.gnu.org/licenses/ >.
-
-(C) 2016 by Adam Tauber, <[email protected]>
-'''
-from flask_babel import gettext
-name = gettext('Open result links on new browser tabs')
-description = gettext('Results are opened in the same window by default. '
- 'This plugin overwrites the default behaviour to open links on new tabs/windows. '
- '(JavaScript required)')
-default_on = False
-preference_section = 'ui'
-
-js_dependencies = ('plugins/js/open_results_on_new_tab.js',)
|
{"golden_diff": "diff --git a/searx/plugins/__init__.py b/searx/plugins/__init__.py\n--- a/searx/plugins/__init__.py\n+++ b/searx/plugins/__init__.py\n@@ -33,7 +33,6 @@\n from searx.plugins import (oa_doi_rewrite,\n https_rewrite,\n infinite_scroll,\n- open_results_on_new_tab,\n self_info,\n search_on_category_select,\n tracker_url_remover,\n@@ -169,7 +168,6 @@\n plugins.register(oa_doi_rewrite)\n plugins.register(https_rewrite)\n plugins.register(infinite_scroll)\n-plugins.register(open_results_on_new_tab)\n plugins.register(self_info)\n plugins.register(search_on_category_select)\n plugins.register(tracker_url_remover)\ndiff --git a/searx/plugins/open_results_on_new_tab.py b/searx/plugins/open_results_on_new_tab.py\ndeleted file mode 100644\n--- a/searx/plugins/open_results_on_new_tab.py\n+++ /dev/null\n@@ -1,25 +0,0 @@\n-'''\n-searx is free software: you can redistribute it and/or modify\n-it under the terms of the GNU Affero General Public License as published by\n-the Free Software Foundation, either version 3 of the License, or\n-(at your option) any later version.\n-\n-searx is distributed in the hope that it will be useful,\n-but WITHOUT ANY WARRANTY; without even the implied warranty of\n-MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n-GNU Affero General Public License for more details.\n-\n-You should have received a copy of the GNU Affero General Public License\n-along with searx. If not, see < http://www.gnu.org/licenses/ >.\n-\n-(C) 2016 by Adam Tauber, <[email protected]>\n-'''\n-from flask_babel import gettext\n-name = gettext('Open result links on new browser tabs')\n-description = gettext('Results are opened in the same window by default. '\n- 'This plugin overwrites the default behaviour to open links on new tabs/windows. '\n- '(JavaScript required)')\n-default_on = False\n-preference_section = 'ui'\n-\n-js_dependencies = ('plugins/js/open_results_on_new_tab.js',)\n", "issue": "Duplicate feature: result in a new tab.\n## Core feature \"result on new tab\": \r\n* https://github.com/asciimoo/searx/blob/6163bd671bbf71a9eae3a6a9b1019e2a701c4946/searx/preferences.py#L366-L374\r\n* https://github.com/asciimoo/searx/blob/6163bd671bbf71a9eae3a6a9b1019e2a701c4946/searx/templates/oscar/preferences.html#L114-L121\r\n* https://github.com/asciimoo/searx/blob/6163bd671bbf71a9eae3a6a9b1019e2a701c4946/searx/templates/oscar/macros.html#L11-L18\r\n* \r\n\r\n## Plugin \"result on a new tab\": \r\n* https://github.com/asciimoo/searx/blob/6163bd671bbf71a9eae3a6a9b1019e2a701c4946/searx/static/plugins/js/open_results_on_new_tab.js#L1-L3\r\n* \r\n\n", "before_files": [{"content": "'''\nsearx is free software: you can redistribute it and/or modify\nit under the terms of the GNU Affero General Public License as published by\nthe Free Software Foundation, either version 3 of the License, or\n(at your option) any later version.\n\nsearx is distributed in the hope that it will be useful,\nbut WITHOUT ANY WARRANTY; without even the implied warranty of\nMERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\nGNU Affero General Public License for more details.\n\nYou should have received a copy of the GNU Affero General Public License\nalong with searx. If not, see < http://www.gnu.org/licenses/ >.\n\n(C) 2016 by Adam Tauber, <[email protected]>\n'''\nfrom flask_babel import gettext\nname = gettext('Open result links on new browser tabs')\ndescription = gettext('Results are opened in the same window by default. '\n 'This plugin overwrites the default behaviour to open links on new tabs/windows. '\n '(JavaScript required)')\ndefault_on = False\npreference_section = 'ui'\n\njs_dependencies = ('plugins/js/open_results_on_new_tab.js',)\n", "path": "searx/plugins/open_results_on_new_tab.py"}, {"content": "'''\nsearx is free software: you can redistribute it and/or modify\nit under the terms of the GNU Affero General Public License as published by\nthe Free Software Foundation, either version 3 of the License, or\n(at your option) any later version.\n\nsearx is distributed in the hope that it will be useful,\nbut WITHOUT ANY WARRANTY; without even the implied warranty of\nMERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\nGNU Affero General Public License for more details.\n\nYou should have received a copy of the GNU Affero General Public License\nalong with searx. If not, see < http://www.gnu.org/licenses/ >.\n\n(C) 2015 by Adam Tauber, <[email protected]>\n'''\n\nfrom hashlib import sha256\nfrom importlib import import_module\nfrom os import listdir, makedirs, remove, stat, utime\nfrom os.path import abspath, basename, dirname, exists, join\nfrom shutil import copyfile\nfrom sys import version_info\nfrom traceback import print_exc\n\nfrom searx import logger, settings, static_path\n\nif version_info[0] == 3:\n unicode = str\n\nlogger = logger.getChild('plugins')\n\nfrom searx.plugins import (oa_doi_rewrite,\n https_rewrite,\n infinite_scroll,\n open_results_on_new_tab,\n self_info,\n search_on_category_select,\n tracker_url_remover,\n vim_hotkeys)\n\nrequired_attrs = (('name', (str, unicode)),\n ('description', (str, unicode)),\n ('default_on', bool))\n\noptional_attrs = (('js_dependencies', tuple),\n ('css_dependencies', tuple))\n\n\nclass Plugin():\n default_on = False\n name = 'Default plugin'\n description = 'Default plugin description'\n\n\nclass PluginStore():\n\n def __init__(self):\n self.plugins = []\n\n def __iter__(self):\n for plugin in self.plugins:\n yield plugin\n\n def register(self, *plugins, external=False):\n if external:\n plugins = load_external_plugins(plugins)\n for plugin in plugins:\n for plugin_attr, plugin_attr_type in required_attrs:\n if not hasattr(plugin, plugin_attr) or not isinstance(getattr(plugin, plugin_attr), plugin_attr_type):\n logger.critical('missing attribute \"{0}\", cannot load plugin: {1}'.format(plugin_attr, plugin))\n exit(3)\n for plugin_attr, plugin_attr_type in optional_attrs:\n if not hasattr(plugin, plugin_attr) or not isinstance(getattr(plugin, plugin_attr), plugin_attr_type):\n setattr(plugin, plugin_attr, plugin_attr_type())\n plugin.id = plugin.name.replace(' ', '_')\n self.plugins.append(plugin)\n\n def call(self, ordered_plugin_list, plugin_type, request, *args, **kwargs):\n ret = True\n for plugin in ordered_plugin_list:\n if hasattr(plugin, plugin_type):\n ret = getattr(plugin, plugin_type)(request, *args, **kwargs)\n if not ret:\n break\n\n return ret\n\n\ndef load_external_plugins(plugin_names):\n plugins = []\n for name in plugin_names:\n logger.debug('loading plugin: {0}'.format(name))\n try:\n pkg = import_module(name)\n except Exception as e:\n logger.critical('failed to load plugin module {0}: {1}'.format(name, e))\n exit(3)\n\n pkg.__base_path = dirname(abspath(pkg.__file__))\n\n prepare_package_resources(pkg, name)\n\n plugins.append(pkg)\n logger.debug('plugin \"{0}\" loaded'.format(name))\n return plugins\n\n\ndef sync_resource(base_path, resource_path, name, target_dir, plugin_dir):\n dep_path = join(base_path, resource_path)\n file_name = basename(dep_path)\n resource_path = join(target_dir, file_name)\n if not exists(resource_path) or sha_sum(dep_path) != sha_sum(resource_path):\n try:\n copyfile(dep_path, resource_path)\n # copy atime_ns and mtime_ns, so the weak ETags (generated by\n # the HTTP server) do not change\n dep_stat = stat(dep_path)\n utime(resource_path, ns=(dep_stat.st_atime_ns, dep_stat.st_mtime_ns))\n except:\n logger.critical('failed to copy plugin resource {0} for plugin {1}'.format(file_name, name))\n exit(3)\n\n # returning with the web path of the resource\n return join('plugins/external_plugins', plugin_dir, file_name)\n\n\ndef prepare_package_resources(pkg, name):\n plugin_dir = 'plugin_' + name\n target_dir = join(static_path, 'plugins/external_plugins', plugin_dir)\n try:\n makedirs(target_dir, exist_ok=True)\n except:\n logger.critical('failed to create resource directory {0} for plugin {1}'.format(target_dir, name))\n exit(3)\n\n resources = []\n\n if hasattr(pkg, 'js_dependencies'):\n resources.extend(map(basename, pkg.js_dependencies))\n pkg.js_dependencies = tuple([\n sync_resource(pkg.__base_path, x, name, target_dir, plugin_dir)\n for x in pkg.js_dependencies\n ])\n if hasattr(pkg, 'css_dependencies'):\n resources.extend(map(basename, pkg.css_dependencies))\n pkg.css_dependencies = tuple([\n sync_resource(pkg.__base_path, x, name, target_dir, plugin_dir)\n for x in pkg.css_dependencies\n ])\n\n for f in listdir(target_dir):\n if basename(f) not in resources:\n resource_path = join(target_dir, basename(f))\n try:\n remove(resource_path)\n except:\n logger.critical('failed to remove unused resource file {0} for plugin {1}'.format(resource_path, name))\n exit(3)\n\n\ndef sha_sum(filename):\n with open(filename, \"rb\") as f:\n bytes = f.read()\n return sha256(bytes).hexdigest()\n\n\nplugins = PluginStore()\nplugins.register(oa_doi_rewrite)\nplugins.register(https_rewrite)\nplugins.register(infinite_scroll)\nplugins.register(open_results_on_new_tab)\nplugins.register(self_info)\nplugins.register(search_on_category_select)\nplugins.register(tracker_url_remover)\nplugins.register(vim_hotkeys)\n# load external plugins\nif 'plugins' in settings:\n plugins.register(*settings['plugins'], external=True)\n", "path": "searx/plugins/__init__.py"}], "after_files": [{"content": null, "path": "searx/plugins/open_results_on_new_tab.py"}, {"content": "'''\nsearx is free software: you can redistribute it and/or modify\nit under the terms of the GNU Affero General Public License as published by\nthe Free Software Foundation, either version 3 of the License, or\n(at your option) any later version.\n\nsearx is distributed in the hope that it will be useful,\nbut WITHOUT ANY WARRANTY; without even the implied warranty of\nMERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\nGNU Affero General Public License for more details.\n\nYou should have received a copy of the GNU Affero General Public License\nalong with searx. If not, see < http://www.gnu.org/licenses/ >.\n\n(C) 2015 by Adam Tauber, <[email protected]>\n'''\n\nfrom hashlib import sha256\nfrom importlib import import_module\nfrom os import listdir, makedirs, remove, stat, utime\nfrom os.path import abspath, basename, dirname, exists, join\nfrom shutil import copyfile\nfrom sys import version_info\nfrom traceback import print_exc\n\nfrom searx import logger, settings, static_path\n\nif version_info[0] == 3:\n unicode = str\n\nlogger = logger.getChild('plugins')\n\nfrom searx.plugins import (oa_doi_rewrite,\n https_rewrite,\n infinite_scroll,\n self_info,\n search_on_category_select,\n tracker_url_remover,\n vim_hotkeys)\n\nrequired_attrs = (('name', (str, unicode)),\n ('description', (str, unicode)),\n ('default_on', bool))\n\noptional_attrs = (('js_dependencies', tuple),\n ('css_dependencies', tuple))\n\n\nclass Plugin():\n default_on = False\n name = 'Default plugin'\n description = 'Default plugin description'\n\n\nclass PluginStore():\n\n def __init__(self):\n self.plugins = []\n\n def __iter__(self):\n for plugin in self.plugins:\n yield plugin\n\n def register(self, *plugins, external=False):\n if external:\n plugins = load_external_plugins(plugins)\n for plugin in plugins:\n for plugin_attr, plugin_attr_type in required_attrs:\n if not hasattr(plugin, plugin_attr) or not isinstance(getattr(plugin, plugin_attr), plugin_attr_type):\n logger.critical('missing attribute \"{0}\", cannot load plugin: {1}'.format(plugin_attr, plugin))\n exit(3)\n for plugin_attr, plugin_attr_type in optional_attrs:\n if not hasattr(plugin, plugin_attr) or not isinstance(getattr(plugin, plugin_attr), plugin_attr_type):\n setattr(plugin, plugin_attr, plugin_attr_type())\n plugin.id = plugin.name.replace(' ', '_')\n self.plugins.append(plugin)\n\n def call(self, ordered_plugin_list, plugin_type, request, *args, **kwargs):\n ret = True\n for plugin in ordered_plugin_list:\n if hasattr(plugin, plugin_type):\n ret = getattr(plugin, plugin_type)(request, *args, **kwargs)\n if not ret:\n break\n\n return ret\n\n\ndef load_external_plugins(plugin_names):\n plugins = []\n for name in plugin_names:\n logger.debug('loading plugin: {0}'.format(name))\n try:\n pkg = import_module(name)\n except Exception as e:\n logger.critical('failed to load plugin module {0}: {1}'.format(name, e))\n exit(3)\n\n pkg.__base_path = dirname(abspath(pkg.__file__))\n\n prepare_package_resources(pkg, name)\n\n plugins.append(pkg)\n logger.debug('plugin \"{0}\" loaded'.format(name))\n return plugins\n\n\ndef sync_resource(base_path, resource_path, name, target_dir, plugin_dir):\n dep_path = join(base_path, resource_path)\n file_name = basename(dep_path)\n resource_path = join(target_dir, file_name)\n if not exists(resource_path) or sha_sum(dep_path) != sha_sum(resource_path):\n try:\n copyfile(dep_path, resource_path)\n # copy atime_ns and mtime_ns, so the weak ETags (generated by\n # the HTTP server) do not change\n dep_stat = stat(dep_path)\n utime(resource_path, ns=(dep_stat.st_atime_ns, dep_stat.st_mtime_ns))\n except:\n logger.critical('failed to copy plugin resource {0} for plugin {1}'.format(file_name, name))\n exit(3)\n\n # returning with the web path of the resource\n return join('plugins/external_plugins', plugin_dir, file_name)\n\n\ndef prepare_package_resources(pkg, name):\n plugin_dir = 'plugin_' + name\n target_dir = join(static_path, 'plugins/external_plugins', plugin_dir)\n try:\n makedirs(target_dir, exist_ok=True)\n except:\n logger.critical('failed to create resource directory {0} for plugin {1}'.format(target_dir, name))\n exit(3)\n\n resources = []\n\n if hasattr(pkg, 'js_dependencies'):\n resources.extend(map(basename, pkg.js_dependencies))\n pkg.js_dependencies = tuple([\n sync_resource(pkg.__base_path, x, name, target_dir, plugin_dir)\n for x in pkg.js_dependencies\n ])\n if hasattr(pkg, 'css_dependencies'):\n resources.extend(map(basename, pkg.css_dependencies))\n pkg.css_dependencies = tuple([\n sync_resource(pkg.__base_path, x, name, target_dir, plugin_dir)\n for x in pkg.css_dependencies\n ])\n\n for f in listdir(target_dir):\n if basename(f) not in resources:\n resource_path = join(target_dir, basename(f))\n try:\n remove(resource_path)\n except:\n logger.critical('failed to remove unused resource file {0} for plugin {1}'.format(resource_path, name))\n exit(3)\n\n\ndef sha_sum(filename):\n with open(filename, \"rb\") as f:\n bytes = f.read()\n return sha256(bytes).hexdigest()\n\n\nplugins = PluginStore()\nplugins.register(oa_doi_rewrite)\nplugins.register(https_rewrite)\nplugins.register(infinite_scroll)\nplugins.register(self_info)\nplugins.register(search_on_category_select)\nplugins.register(tracker_url_remover)\nplugins.register(vim_hotkeys)\n# load external plugins\nif 'plugins' in settings:\n plugins.register(*settings['plugins'], external=True)\n", "path": "searx/plugins/__init__.py"}]}
| 2,788 | 480 |
gh_patches_debug_36950
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-3840
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Increase verbosity for ItemLoader, Compose and MapCompose errors
ItemLoader already provides error raising for the case of the output processor:
```
def get_output_value(self, field_name):
proc = self.get_output_processor(field_name)
proc = wrap_loader_context(proc, self.context)
try:
return proc(self._values[field_name])
except Exception as e:
raise ValueError("Error with output processor: field=%r value=%r error='%s: %s'" % \
(field_name, self._values[field_name], type(e)._name__, str(e)))
```
It could be helpful to extend this behaviour could to other ItemLoader methods:
- `_process_input_value` for input processors
```
def _process_input_value(self, field_name, value):
proc = self.get_input_processor(field_name)
proc = wrap_loader_context(proc, self.context)
return proc(value)
```
- `get_value` for processors that are passed as an argument to `add_css`, `add_xpath` or `add_value`
```
def get_value(self, value, *processors, **kw):
regex = kw.get('re', None)
if regex:
value = arg_to_iter(value)
value = flatten(extract_regex(regex, x) for x in value)
for proc in processors:
if value is None:
break
proc = wrap_loader_context(proc, self.context)
value = proc(value)
return value
```
Also, `Compose` and `MapCompose` could raise errors occurring while processing the values.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scrapy/loader/processors.py`
Content:
```
1 """
2 This module provides some commonly used processors for Item Loaders.
3
4 See documentation in docs/topics/loaders.rst
5 """
6
7 from scrapy.utils.misc import arg_to_iter
8 from scrapy.utils.datatypes import MergeDict
9 from .common import wrap_loader_context
10
11
12 class MapCompose(object):
13
14 def __init__(self, *functions, **default_loader_context):
15 self.functions = functions
16 self.default_loader_context = default_loader_context
17
18 def __call__(self, value, loader_context=None):
19 values = arg_to_iter(value)
20 if loader_context:
21 context = MergeDict(loader_context, self.default_loader_context)
22 else:
23 context = self.default_loader_context
24 wrapped_funcs = [wrap_loader_context(f, context) for f in self.functions]
25 for func in wrapped_funcs:
26 next_values = []
27 for v in values:
28 next_values += arg_to_iter(func(v))
29 values = next_values
30 return values
31
32
33 class Compose(object):
34
35 def __init__(self, *functions, **default_loader_context):
36 self.functions = functions
37 self.stop_on_none = default_loader_context.get('stop_on_none', True)
38 self.default_loader_context = default_loader_context
39
40 def __call__(self, value, loader_context=None):
41 if loader_context:
42 context = MergeDict(loader_context, self.default_loader_context)
43 else:
44 context = self.default_loader_context
45 wrapped_funcs = [wrap_loader_context(f, context) for f in self.functions]
46 for func in wrapped_funcs:
47 if value is None and self.stop_on_none:
48 break
49 value = func(value)
50 return value
51
52
53 class TakeFirst(object):
54
55 def __call__(self, values):
56 for value in values:
57 if value is not None and value != '':
58 return value
59
60
61 class Identity(object):
62
63 def __call__(self, values):
64 return values
65
66
67 class SelectJmes(object):
68 """
69 Query the input string for the jmespath (given at instantiation),
70 and return the answer
71 Requires : jmespath(https://github.com/jmespath/jmespath)
72 Note: SelectJmes accepts only one input element at a time.
73 """
74 def __init__(self, json_path):
75 self.json_path = json_path
76 import jmespath
77 self.compiled_path = jmespath.compile(self.json_path)
78
79 def __call__(self, value):
80 """Query value for the jmespath query and return answer
81 :param value: a data structure (dict, list) to extract from
82 :return: Element extracted according to jmespath query
83 """
84 return self.compiled_path.search(value)
85
86
87 class Join(object):
88
89 def __init__(self, separator=u' '):
90 self.separator = separator
91
92 def __call__(self, values):
93 return self.separator.join(values)
94
```
Path: `scrapy/loader/__init__.py`
Content:
```
1 """Item Loader
2
3 See documentation in docs/topics/loaders.rst
4
5 """
6 from collections import defaultdict
7 import six
8
9 from scrapy.item import Item
10 from scrapy.selector import Selector
11 from scrapy.utils.decorators import deprecated
12 from scrapy.utils.deprecate import create_deprecated_class
13 from scrapy.utils.misc import arg_to_iter, extract_regex
14 from scrapy.utils.python import flatten
15
16 from .common import wrap_loader_context
17 from .processors import Identity
18
19
20 class ItemLoader(object):
21
22 default_item_class = Item
23 default_input_processor = Identity()
24 default_output_processor = Identity()
25 default_selector_class = Selector
26
27 def __init__(self, item=None, selector=None, response=None, parent=None, **context):
28 if selector is None and response is not None:
29 selector = self.default_selector_class(response)
30 self.selector = selector
31 context.update(selector=selector, response=response)
32 if item is None:
33 item = self.default_item_class()
34 self.context = context
35 self.parent = parent
36 self._local_item = context['item'] = item
37 self._local_values = defaultdict(list)
38 # Preprocess values if item built from dict
39 # Values need to be added to item._values if added them from dict (not with add_values)
40 for field_name, value in item.items():
41 self._values[field_name] = self._process_input_value(field_name, value)
42
43 @property
44 def _values(self):
45 if self.parent is not None:
46 return self.parent._values
47 else:
48 return self._local_values
49
50 @property
51 def item(self):
52 if self.parent is not None:
53 return self.parent.item
54 else:
55 return self._local_item
56
57 def nested_xpath(self, xpath, **context):
58 selector = self.selector.xpath(xpath)
59 context.update(selector=selector)
60 subloader = self.__class__(
61 item=self.item, parent=self, **context
62 )
63 return subloader
64
65 def nested_css(self, css, **context):
66 selector = self.selector.css(css)
67 context.update(selector=selector)
68 subloader = self.__class__(
69 item=self.item, parent=self, **context
70 )
71 return subloader
72
73 def add_value(self, field_name, value, *processors, **kw):
74 value = self.get_value(value, *processors, **kw)
75 if value is None:
76 return
77 if not field_name:
78 for k, v in six.iteritems(value):
79 self._add_value(k, v)
80 else:
81 self._add_value(field_name, value)
82
83 def replace_value(self, field_name, value, *processors, **kw):
84 value = self.get_value(value, *processors, **kw)
85 if value is None:
86 return
87 if not field_name:
88 for k, v in six.iteritems(value):
89 self._replace_value(k, v)
90 else:
91 self._replace_value(field_name, value)
92
93 def _add_value(self, field_name, value):
94 value = arg_to_iter(value)
95 processed_value = self._process_input_value(field_name, value)
96 if processed_value:
97 self._values[field_name] += arg_to_iter(processed_value)
98
99 def _replace_value(self, field_name, value):
100 self._values.pop(field_name, None)
101 self._add_value(field_name, value)
102
103 def get_value(self, value, *processors, **kw):
104 regex = kw.get('re', None)
105 if regex:
106 value = arg_to_iter(value)
107 value = flatten(extract_regex(regex, x) for x in value)
108
109 for proc in processors:
110 if value is None:
111 break
112 proc = wrap_loader_context(proc, self.context)
113 value = proc(value)
114 return value
115
116 def load_item(self):
117 item = self.item
118 for field_name in tuple(self._values):
119 value = self.get_output_value(field_name)
120 if value is not None:
121 item[field_name] = value
122
123 return item
124
125 def get_output_value(self, field_name):
126 proc = self.get_output_processor(field_name)
127 proc = wrap_loader_context(proc, self.context)
128 try:
129 return proc(self._values[field_name])
130 except Exception as e:
131 raise ValueError("Error with output processor: field=%r value=%r error='%s: %s'" % \
132 (field_name, self._values[field_name], type(e).__name__, str(e)))
133
134 def get_collected_values(self, field_name):
135 return self._values[field_name]
136
137 def get_input_processor(self, field_name):
138 proc = getattr(self, '%s_in' % field_name, None)
139 if not proc:
140 proc = self._get_item_field_attr(field_name, 'input_processor', \
141 self.default_input_processor)
142 return proc
143
144 def get_output_processor(self, field_name):
145 proc = getattr(self, '%s_out' % field_name, None)
146 if not proc:
147 proc = self._get_item_field_attr(field_name, 'output_processor', \
148 self.default_output_processor)
149 return proc
150
151 def _process_input_value(self, field_name, value):
152 proc = self.get_input_processor(field_name)
153 proc = wrap_loader_context(proc, self.context)
154 return proc(value)
155
156 def _get_item_field_attr(self, field_name, key, default=None):
157 if isinstance(self.item, Item):
158 value = self.item.fields[field_name].get(key, default)
159 else:
160 value = default
161 return value
162
163 def _check_selector_method(self):
164 if self.selector is None:
165 raise RuntimeError("To use XPath or CSS selectors, "
166 "%s must be instantiated with a selector "
167 "or a response" % self.__class__.__name__)
168
169 def add_xpath(self, field_name, xpath, *processors, **kw):
170 values = self._get_xpathvalues(xpath, **kw)
171 self.add_value(field_name, values, *processors, **kw)
172
173 def replace_xpath(self, field_name, xpath, *processors, **kw):
174 values = self._get_xpathvalues(xpath, **kw)
175 self.replace_value(field_name, values, *processors, **kw)
176
177 def get_xpath(self, xpath, *processors, **kw):
178 values = self._get_xpathvalues(xpath, **kw)
179 return self.get_value(values, *processors, **kw)
180
181 @deprecated(use_instead='._get_xpathvalues()')
182 def _get_values(self, xpaths, **kw):
183 return self._get_xpathvalues(xpaths, **kw)
184
185 def _get_xpathvalues(self, xpaths, **kw):
186 self._check_selector_method()
187 xpaths = arg_to_iter(xpaths)
188 return flatten(self.selector.xpath(xpath).getall() for xpath in xpaths)
189
190 def add_css(self, field_name, css, *processors, **kw):
191 values = self._get_cssvalues(css, **kw)
192 self.add_value(field_name, values, *processors, **kw)
193
194 def replace_css(self, field_name, css, *processors, **kw):
195 values = self._get_cssvalues(css, **kw)
196 self.replace_value(field_name, values, *processors, **kw)
197
198 def get_css(self, css, *processors, **kw):
199 values = self._get_cssvalues(css, **kw)
200 return self.get_value(values, *processors, **kw)
201
202 def _get_cssvalues(self, csss, **kw):
203 self._check_selector_method()
204 csss = arg_to_iter(csss)
205 return flatten(self.selector.css(css).getall() for css in csss)
206
207 XPathItemLoader = create_deprecated_class('XPathItemLoader', ItemLoader)
208
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scrapy/loader/__init__.py b/scrapy/loader/__init__.py
--- a/scrapy/loader/__init__.py
+++ b/scrapy/loader/__init__.py
@@ -109,8 +109,14 @@
for proc in processors:
if value is None:
break
+ _proc = proc
proc = wrap_loader_context(proc, self.context)
- value = proc(value)
+ try:
+ value = proc(value)
+ except Exception as e:
+ raise ValueError("Error with processor %s value=%r error='%s: %s'" %
+ (_proc.__class__.__name__, value,
+ type(e).__name__, str(e)))
return value
def load_item(self):
@@ -150,8 +156,15 @@
def _process_input_value(self, field_name, value):
proc = self.get_input_processor(field_name)
+ _proc = proc
proc = wrap_loader_context(proc, self.context)
- return proc(value)
+ try:
+ return proc(value)
+ except Exception as e:
+ raise ValueError(
+ "Error with input processor %s: field=%r value=%r "
+ "error='%s: %s'" % (_proc.__class__.__name__, field_name,
+ value, type(e).__name__, str(e)))
def _get_item_field_attr(self, field_name, key, default=None):
if isinstance(self.item, Item):
diff --git a/scrapy/loader/processors.py b/scrapy/loader/processors.py
--- a/scrapy/loader/processors.py
+++ b/scrapy/loader/processors.py
@@ -25,7 +25,13 @@
for func in wrapped_funcs:
next_values = []
for v in values:
- next_values += arg_to_iter(func(v))
+ try:
+ next_values += arg_to_iter(func(v))
+ except Exception as e:
+ raise ValueError("Error in MapCompose with "
+ "%s value=%r error='%s: %s'" %
+ (str(func), value, type(e).__name__,
+ str(e)))
values = next_values
return values
@@ -46,7 +52,12 @@
for func in wrapped_funcs:
if value is None and self.stop_on_none:
break
- value = func(value)
+ try:
+ value = func(value)
+ except Exception as e:
+ raise ValueError("Error in Compose with "
+ "%s value=%r error='%s: %s'" %
+ (str(func), value, type(e).__name__, str(e)))
return value
|
{"golden_diff": "diff --git a/scrapy/loader/__init__.py b/scrapy/loader/__init__.py\n--- a/scrapy/loader/__init__.py\n+++ b/scrapy/loader/__init__.py\n@@ -109,8 +109,14 @@\n for proc in processors:\n if value is None:\n break\n+ _proc = proc\n proc = wrap_loader_context(proc, self.context)\n- value = proc(value)\n+ try:\n+ value = proc(value)\n+ except Exception as e:\n+ raise ValueError(\"Error with processor %s value=%r error='%s: %s'\" %\n+ (_proc.__class__.__name__, value,\n+ type(e).__name__, str(e)))\n return value\n \n def load_item(self):\n@@ -150,8 +156,15 @@\n \n def _process_input_value(self, field_name, value):\n proc = self.get_input_processor(field_name)\n+ _proc = proc\n proc = wrap_loader_context(proc, self.context)\n- return proc(value)\n+ try:\n+ return proc(value)\n+ except Exception as e:\n+ raise ValueError(\n+ \"Error with input processor %s: field=%r value=%r \"\n+ \"error='%s: %s'\" % (_proc.__class__.__name__, field_name,\n+ value, type(e).__name__, str(e)))\n \n def _get_item_field_attr(self, field_name, key, default=None):\n if isinstance(self.item, Item):\ndiff --git a/scrapy/loader/processors.py b/scrapy/loader/processors.py\n--- a/scrapy/loader/processors.py\n+++ b/scrapy/loader/processors.py\n@@ -25,7 +25,13 @@\n for func in wrapped_funcs:\n next_values = []\n for v in values:\n- next_values += arg_to_iter(func(v))\n+ try:\n+ next_values += arg_to_iter(func(v))\n+ except Exception as e:\n+ raise ValueError(\"Error in MapCompose with \"\n+ \"%s value=%r error='%s: %s'\" %\n+ (str(func), value, type(e).__name__,\n+ str(e)))\n values = next_values\n return values\n \n@@ -46,7 +52,12 @@\n for func in wrapped_funcs:\n if value is None and self.stop_on_none:\n break\n- value = func(value)\n+ try:\n+ value = func(value)\n+ except Exception as e:\n+ raise ValueError(\"Error in Compose with \"\n+ \"%s value=%r error='%s: %s'\" %\n+ (str(func), value, type(e).__name__, str(e)))\n return value\n", "issue": "Increase verbosity for ItemLoader, Compose and MapCompose errors\nItemLoader already provides error raising for the case of the output processor:\r\n\r\n```\r\n def get_output_value(self, field_name):\r\n proc = self.get_output_processor(field_name)\r\n proc = wrap_loader_context(proc, self.context)\r\n try:\r\n return proc(self._values[field_name])\r\n except Exception as e:\r\n raise ValueError(\"Error with output processor: field=%r value=%r error='%s: %s'\" % \\\r\n (field_name, self._values[field_name], type(e)._name__, str(e)))\r\n```\r\n\r\nIt could be helpful to extend this behaviour could to other ItemLoader methods:\r\n\r\n- `_process_input_value` for input processors \r\n\r\n```\r\n def _process_input_value(self, field_name, value):\r\n proc = self.get_input_processor(field_name)\r\n proc = wrap_loader_context(proc, self.context)\r\n return proc(value)\r\n```\r\n- `get_value` for processors that are passed as an argument to `add_css`, `add_xpath` or `add_value`\r\n```\r\n def get_value(self, value, *processors, **kw):\r\n regex = kw.get('re', None)\r\n if regex:\r\n value = arg_to_iter(value)\r\n value = flatten(extract_regex(regex, x) for x in value)\r\n\r\n for proc in processors:\r\n if value is None:\r\n break\r\n proc = wrap_loader_context(proc, self.context)\r\n value = proc(value)\r\n return value\r\n```\r\nAlso, `Compose` and `MapCompose` could raise errors occurring while processing the values.\n", "before_files": [{"content": "\"\"\"\nThis module provides some commonly used processors for Item Loaders.\n\nSee documentation in docs/topics/loaders.rst\n\"\"\"\n\nfrom scrapy.utils.misc import arg_to_iter\nfrom scrapy.utils.datatypes import MergeDict\nfrom .common import wrap_loader_context\n\n\nclass MapCompose(object):\n\n def __init__(self, *functions, **default_loader_context):\n self.functions = functions\n self.default_loader_context = default_loader_context\n\n def __call__(self, value, loader_context=None):\n values = arg_to_iter(value)\n if loader_context:\n context = MergeDict(loader_context, self.default_loader_context)\n else:\n context = self.default_loader_context\n wrapped_funcs = [wrap_loader_context(f, context) for f in self.functions]\n for func in wrapped_funcs:\n next_values = []\n for v in values:\n next_values += arg_to_iter(func(v))\n values = next_values\n return values\n\n\nclass Compose(object):\n\n def __init__(self, *functions, **default_loader_context):\n self.functions = functions\n self.stop_on_none = default_loader_context.get('stop_on_none', True)\n self.default_loader_context = default_loader_context\n\n def __call__(self, value, loader_context=None):\n if loader_context:\n context = MergeDict(loader_context, self.default_loader_context)\n else:\n context = self.default_loader_context\n wrapped_funcs = [wrap_loader_context(f, context) for f in self.functions]\n for func in wrapped_funcs:\n if value is None and self.stop_on_none:\n break\n value = func(value)\n return value\n\n\nclass TakeFirst(object):\n\n def __call__(self, values):\n for value in values:\n if value is not None and value != '':\n return value\n\n\nclass Identity(object):\n\n def __call__(self, values):\n return values\n\n\nclass SelectJmes(object):\n \"\"\"\n Query the input string for the jmespath (given at instantiation),\n and return the answer\n Requires : jmespath(https://github.com/jmespath/jmespath)\n Note: SelectJmes accepts only one input element at a time.\n \"\"\"\n def __init__(self, json_path):\n self.json_path = json_path\n import jmespath\n self.compiled_path = jmespath.compile(self.json_path)\n\n def __call__(self, value):\n \"\"\"Query value for the jmespath query and return answer\n :param value: a data structure (dict, list) to extract from\n :return: Element extracted according to jmespath query\n \"\"\"\n return self.compiled_path.search(value)\n\n\nclass Join(object):\n\n def __init__(self, separator=u' '):\n self.separator = separator\n\n def __call__(self, values):\n return self.separator.join(values)\n", "path": "scrapy/loader/processors.py"}, {"content": "\"\"\"Item Loader\n\nSee documentation in docs/topics/loaders.rst\n\n\"\"\"\nfrom collections import defaultdict\nimport six\n\nfrom scrapy.item import Item\nfrom scrapy.selector import Selector\nfrom scrapy.utils.decorators import deprecated\nfrom scrapy.utils.deprecate import create_deprecated_class\nfrom scrapy.utils.misc import arg_to_iter, extract_regex\nfrom scrapy.utils.python import flatten\n\nfrom .common import wrap_loader_context\nfrom .processors import Identity\n\n\nclass ItemLoader(object):\n\n default_item_class = Item\n default_input_processor = Identity()\n default_output_processor = Identity()\n default_selector_class = Selector\n\n def __init__(self, item=None, selector=None, response=None, parent=None, **context):\n if selector is None and response is not None:\n selector = self.default_selector_class(response)\n self.selector = selector\n context.update(selector=selector, response=response)\n if item is None:\n item = self.default_item_class()\n self.context = context\n self.parent = parent\n self._local_item = context['item'] = item\n self._local_values = defaultdict(list)\n # Preprocess values if item built from dict\n # Values need to be added to item._values if added them from dict (not with add_values)\n for field_name, value in item.items():\n self._values[field_name] = self._process_input_value(field_name, value)\n\n @property\n def _values(self):\n if self.parent is not None:\n return self.parent._values\n else:\n return self._local_values\n\n @property\n def item(self):\n if self.parent is not None:\n return self.parent.item\n else:\n return self._local_item\n\n def nested_xpath(self, xpath, **context):\n selector = self.selector.xpath(xpath)\n context.update(selector=selector)\n subloader = self.__class__(\n item=self.item, parent=self, **context\n )\n return subloader\n\n def nested_css(self, css, **context):\n selector = self.selector.css(css)\n context.update(selector=selector)\n subloader = self.__class__(\n item=self.item, parent=self, **context\n )\n return subloader\n\n def add_value(self, field_name, value, *processors, **kw):\n value = self.get_value(value, *processors, **kw)\n if value is None:\n return\n if not field_name:\n for k, v in six.iteritems(value):\n self._add_value(k, v)\n else:\n self._add_value(field_name, value)\n\n def replace_value(self, field_name, value, *processors, **kw):\n value = self.get_value(value, *processors, **kw)\n if value is None:\n return\n if not field_name:\n for k, v in six.iteritems(value):\n self._replace_value(k, v)\n else:\n self._replace_value(field_name, value)\n\n def _add_value(self, field_name, value):\n value = arg_to_iter(value)\n processed_value = self._process_input_value(field_name, value)\n if processed_value:\n self._values[field_name] += arg_to_iter(processed_value)\n\n def _replace_value(self, field_name, value):\n self._values.pop(field_name, None)\n self._add_value(field_name, value)\n\n def get_value(self, value, *processors, **kw):\n regex = kw.get('re', None)\n if regex:\n value = arg_to_iter(value)\n value = flatten(extract_regex(regex, x) for x in value)\n\n for proc in processors:\n if value is None:\n break\n proc = wrap_loader_context(proc, self.context)\n value = proc(value)\n return value\n\n def load_item(self):\n item = self.item\n for field_name in tuple(self._values):\n value = self.get_output_value(field_name)\n if value is not None:\n item[field_name] = value\n\n return item\n\n def get_output_value(self, field_name):\n proc = self.get_output_processor(field_name)\n proc = wrap_loader_context(proc, self.context)\n try:\n return proc(self._values[field_name])\n except Exception as e:\n raise ValueError(\"Error with output processor: field=%r value=%r error='%s: %s'\" % \\\n (field_name, self._values[field_name], type(e).__name__, str(e)))\n\n def get_collected_values(self, field_name):\n return self._values[field_name]\n\n def get_input_processor(self, field_name):\n proc = getattr(self, '%s_in' % field_name, None)\n if not proc:\n proc = self._get_item_field_attr(field_name, 'input_processor', \\\n self.default_input_processor)\n return proc\n\n def get_output_processor(self, field_name):\n proc = getattr(self, '%s_out' % field_name, None)\n if not proc:\n proc = self._get_item_field_attr(field_name, 'output_processor', \\\n self.default_output_processor)\n return proc\n\n def _process_input_value(self, field_name, value):\n proc = self.get_input_processor(field_name)\n proc = wrap_loader_context(proc, self.context)\n return proc(value)\n\n def _get_item_field_attr(self, field_name, key, default=None):\n if isinstance(self.item, Item):\n value = self.item.fields[field_name].get(key, default)\n else:\n value = default\n return value\n\n def _check_selector_method(self):\n if self.selector is None:\n raise RuntimeError(\"To use XPath or CSS selectors, \"\n \"%s must be instantiated with a selector \"\n \"or a response\" % self.__class__.__name__)\n\n def add_xpath(self, field_name, xpath, *processors, **kw):\n values = self._get_xpathvalues(xpath, **kw)\n self.add_value(field_name, values, *processors, **kw)\n\n def replace_xpath(self, field_name, xpath, *processors, **kw):\n values = self._get_xpathvalues(xpath, **kw)\n self.replace_value(field_name, values, *processors, **kw)\n\n def get_xpath(self, xpath, *processors, **kw):\n values = self._get_xpathvalues(xpath, **kw)\n return self.get_value(values, *processors, **kw)\n\n @deprecated(use_instead='._get_xpathvalues()')\n def _get_values(self, xpaths, **kw):\n return self._get_xpathvalues(xpaths, **kw)\n\n def _get_xpathvalues(self, xpaths, **kw):\n self._check_selector_method()\n xpaths = arg_to_iter(xpaths)\n return flatten(self.selector.xpath(xpath).getall() for xpath in xpaths)\n\n def add_css(self, field_name, css, *processors, **kw):\n values = self._get_cssvalues(css, **kw)\n self.add_value(field_name, values, *processors, **kw)\n\n def replace_css(self, field_name, css, *processors, **kw):\n values = self._get_cssvalues(css, **kw)\n self.replace_value(field_name, values, *processors, **kw)\n\n def get_css(self, css, *processors, **kw):\n values = self._get_cssvalues(css, **kw)\n return self.get_value(values, *processors, **kw)\n\n def _get_cssvalues(self, csss, **kw):\n self._check_selector_method()\n csss = arg_to_iter(csss)\n return flatten(self.selector.css(css).getall() for css in csss)\n\nXPathItemLoader = create_deprecated_class('XPathItemLoader', ItemLoader)\n", "path": "scrapy/loader/__init__.py"}], "after_files": [{"content": "\"\"\"\nThis module provides some commonly used processors for Item Loaders.\n\nSee documentation in docs/topics/loaders.rst\n\"\"\"\n\nfrom scrapy.utils.misc import arg_to_iter\nfrom scrapy.utils.datatypes import MergeDict\nfrom .common import wrap_loader_context\n\n\nclass MapCompose(object):\n\n def __init__(self, *functions, **default_loader_context):\n self.functions = functions\n self.default_loader_context = default_loader_context\n\n def __call__(self, value, loader_context=None):\n values = arg_to_iter(value)\n if loader_context:\n context = MergeDict(loader_context, self.default_loader_context)\n else:\n context = self.default_loader_context\n wrapped_funcs = [wrap_loader_context(f, context) for f in self.functions]\n for func in wrapped_funcs:\n next_values = []\n for v in values:\n try:\n next_values += arg_to_iter(func(v))\n except Exception as e:\n raise ValueError(\"Error in MapCompose with \"\n \"%s value=%r error='%s: %s'\" %\n (str(func), value, type(e).__name__,\n str(e)))\n values = next_values\n return values\n\n\nclass Compose(object):\n\n def __init__(self, *functions, **default_loader_context):\n self.functions = functions\n self.stop_on_none = default_loader_context.get('stop_on_none', True)\n self.default_loader_context = default_loader_context\n\n def __call__(self, value, loader_context=None):\n if loader_context:\n context = MergeDict(loader_context, self.default_loader_context)\n else:\n context = self.default_loader_context\n wrapped_funcs = [wrap_loader_context(f, context) for f in self.functions]\n for func in wrapped_funcs:\n if value is None and self.stop_on_none:\n break\n try:\n value = func(value)\n except Exception as e:\n raise ValueError(\"Error in Compose with \"\n \"%s value=%r error='%s: %s'\" %\n (str(func), value, type(e).__name__, str(e)))\n return value\n\n\nclass TakeFirst(object):\n\n def __call__(self, values):\n for value in values:\n if value is not None and value != '':\n return value\n\n\nclass Identity(object):\n\n def __call__(self, values):\n return values\n\n\nclass SelectJmes(object):\n \"\"\"\n Query the input string for the jmespath (given at instantiation),\n and return the answer\n Requires : jmespath(https://github.com/jmespath/jmespath)\n Note: SelectJmes accepts only one input element at a time.\n \"\"\"\n def __init__(self, json_path):\n self.json_path = json_path\n import jmespath\n self.compiled_path = jmespath.compile(self.json_path)\n\n def __call__(self, value):\n \"\"\"Query value for the jmespath query and return answer\n :param value: a data structure (dict, list) to extract from\n :return: Element extracted according to jmespath query\n \"\"\"\n return self.compiled_path.search(value)\n\n\nclass Join(object):\n\n def __init__(self, separator=u' '):\n self.separator = separator\n\n def __call__(self, values):\n return self.separator.join(values)\n", "path": "scrapy/loader/processors.py"}, {"content": "\"\"\"Item Loader\n\nSee documentation in docs/topics/loaders.rst\n\n\"\"\"\nfrom collections import defaultdict\nimport six\n\nfrom scrapy.item import Item\nfrom scrapy.selector import Selector\nfrom scrapy.utils.decorators import deprecated\nfrom scrapy.utils.deprecate import create_deprecated_class\nfrom scrapy.utils.misc import arg_to_iter, extract_regex\nfrom scrapy.utils.python import flatten\n\nfrom .common import wrap_loader_context\nfrom .processors import Identity\n\n\nclass ItemLoader(object):\n\n default_item_class = Item\n default_input_processor = Identity()\n default_output_processor = Identity()\n default_selector_class = Selector\n\n def __init__(self, item=None, selector=None, response=None, parent=None, **context):\n if selector is None and response is not None:\n selector = self.default_selector_class(response)\n self.selector = selector\n context.update(selector=selector, response=response)\n if item is None:\n item = self.default_item_class()\n self.context = context\n self.parent = parent\n self._local_item = context['item'] = item\n self._local_values = defaultdict(list)\n # Preprocess values if item built from dict\n # Values need to be added to item._values if added them from dict (not with add_values)\n for field_name, value in item.items():\n self._values[field_name] = self._process_input_value(field_name, value)\n\n @property\n def _values(self):\n if self.parent is not None:\n return self.parent._values\n else:\n return self._local_values\n\n @property\n def item(self):\n if self.parent is not None:\n return self.parent.item\n else:\n return self._local_item\n\n def nested_xpath(self, xpath, **context):\n selector = self.selector.xpath(xpath)\n context.update(selector=selector)\n subloader = self.__class__(\n item=self.item, parent=self, **context\n )\n return subloader\n\n def nested_css(self, css, **context):\n selector = self.selector.css(css)\n context.update(selector=selector)\n subloader = self.__class__(\n item=self.item, parent=self, **context\n )\n return subloader\n\n def add_value(self, field_name, value, *processors, **kw):\n value = self.get_value(value, *processors, **kw)\n if value is None:\n return\n if not field_name:\n for k, v in six.iteritems(value):\n self._add_value(k, v)\n else:\n self._add_value(field_name, value)\n\n def replace_value(self, field_name, value, *processors, **kw):\n value = self.get_value(value, *processors, **kw)\n if value is None:\n return\n if not field_name:\n for k, v in six.iteritems(value):\n self._replace_value(k, v)\n else:\n self._replace_value(field_name, value)\n\n def _add_value(self, field_name, value):\n value = arg_to_iter(value)\n processed_value = self._process_input_value(field_name, value)\n if processed_value:\n self._values[field_name] += arg_to_iter(processed_value)\n\n def _replace_value(self, field_name, value):\n self._values.pop(field_name, None)\n self._add_value(field_name, value)\n\n def get_value(self, value, *processors, **kw):\n regex = kw.get('re', None)\n if regex:\n value = arg_to_iter(value)\n value = flatten(extract_regex(regex, x) for x in value)\n\n for proc in processors:\n if value is None:\n break\n _proc = proc\n proc = wrap_loader_context(proc, self.context)\n try:\n value = proc(value)\n except Exception as e:\n raise ValueError(\"Error with processor %s value=%r error='%s: %s'\" %\n (_proc.__class__.__name__, value,\n type(e).__name__, str(e)))\n return value\n\n def load_item(self):\n item = self.item\n for field_name in tuple(self._values):\n value = self.get_output_value(field_name)\n if value is not None:\n item[field_name] = value\n\n return item\n\n def get_output_value(self, field_name):\n proc = self.get_output_processor(field_name)\n proc = wrap_loader_context(proc, self.context)\n try:\n return proc(self._values[field_name])\n except Exception as e:\n raise ValueError(\"Error with output processor: field=%r value=%r error='%s: %s'\" % \\\n (field_name, self._values[field_name], type(e).__name__, str(e)))\n\n def get_collected_values(self, field_name):\n return self._values[field_name]\n\n def get_input_processor(self, field_name):\n proc = getattr(self, '%s_in' % field_name, None)\n if not proc:\n proc = self._get_item_field_attr(field_name, 'input_processor', \\\n self.default_input_processor)\n return proc\n\n def get_output_processor(self, field_name):\n proc = getattr(self, '%s_out' % field_name, None)\n if not proc:\n proc = self._get_item_field_attr(field_name, 'output_processor', \\\n self.default_output_processor)\n return proc\n\n def _process_input_value(self, field_name, value):\n proc = self.get_input_processor(field_name)\n _proc = proc\n proc = wrap_loader_context(proc, self.context)\n try:\n return proc(value)\n except Exception as e:\n raise ValueError(\n \"Error with input processor %s: field=%r value=%r \"\n \"error='%s: %s'\" % (_proc.__class__.__name__, field_name,\n value, type(e).__name__, str(e)))\n\n def _get_item_field_attr(self, field_name, key, default=None):\n if isinstance(self.item, Item):\n value = self.item.fields[field_name].get(key, default)\n else:\n value = default\n return value\n\n def _check_selector_method(self):\n if self.selector is None:\n raise RuntimeError(\"To use XPath or CSS selectors, \"\n \"%s must be instantiated with a selector \"\n \"or a response\" % self.__class__.__name__)\n\n def add_xpath(self, field_name, xpath, *processors, **kw):\n values = self._get_xpathvalues(xpath, **kw)\n self.add_value(field_name, values, *processors, **kw)\n\n def replace_xpath(self, field_name, xpath, *processors, **kw):\n values = self._get_xpathvalues(xpath, **kw)\n self.replace_value(field_name, values, *processors, **kw)\n\n def get_xpath(self, xpath, *processors, **kw):\n values = self._get_xpathvalues(xpath, **kw)\n return self.get_value(values, *processors, **kw)\n\n @deprecated(use_instead='._get_xpathvalues()')\n def _get_values(self, xpaths, **kw):\n return self._get_xpathvalues(xpaths, **kw)\n\n def _get_xpathvalues(self, xpaths, **kw):\n self._check_selector_method()\n xpaths = arg_to_iter(xpaths)\n return flatten(self.selector.xpath(xpath).getall() for xpath in xpaths)\n\n def add_css(self, field_name, css, *processors, **kw):\n values = self._get_cssvalues(css, **kw)\n self.add_value(field_name, values, *processors, **kw)\n\n def replace_css(self, field_name, css, *processors, **kw):\n values = self._get_cssvalues(css, **kw)\n self.replace_value(field_name, values, *processors, **kw)\n\n def get_css(self, css, *processors, **kw):\n values = self._get_cssvalues(css, **kw)\n return self.get_value(values, *processors, **kw)\n\n def _get_cssvalues(self, csss, **kw):\n self._check_selector_method()\n csss = arg_to_iter(csss)\n return flatten(self.selector.css(css).getall() for css in csss)\n\nXPathItemLoader = create_deprecated_class('XPathItemLoader', ItemLoader)\n", "path": "scrapy/loader/__init__.py"}]}
| 3,571 | 585 |
gh_patches_debug_27260
|
rasdani/github-patches
|
git_diff
|
ContinualAI__avalanche-52
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
LWF "warmup_train" fun never used
Hi @AntonioCarta, I've noticed this function in the `LearningWithoutForgetting` class is never used, do we need it?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `avalanche/training/strategies/lwf/lwf.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3
4 ################################################################################
5 # Copyright (c) 2020 ContinualAI Research #
6 # Copyrights licensed under the CC BY 4.0 License. #
7 # See the accompanying LICENSE file for terms. #
8 # #
9 # Date: 1-05-2020 #
10 # Author(s): ContinualAI #
11 # E-mail: [email protected] #
12 # Website: clair.continualai.org #
13 ################################################################################
14
15 """ Rehearsal Strategy Implementation """
16
17 # Python 2-3 compatible
18 from __future__ import print_function
19 from __future__ import division
20 from __future__ import absolute_import
21
22 from training.strategies.strategy import Strategy
23 from avalanche.evaluation.eval_protocol import EvalProtocol
24 from avalanche.evaluation.metrics import ACC
25 from avalanche.training.utils import pad_data, shuffle_in_unison
26 import torch
27 import torch.nn.functional as F
28 import numpy as np
29 import copy
30
31
32 def distillation_loss(y_pred, y_teacher, temperature):
33 """ Distillation loss. """
34 scale = y_teacher.shape[-1] # kl_div is normalized by element instead of observation
35 log_p = F.log_softmax(y_pred / temperature, dim=1)
36 q = F.softmax(y_teacher / temperature, dim=1)
37 res = scale * F.kl_div(log_p, q, reduction='mean')
38 return res
39
40
41 class LearningWithoutForgetting(Strategy):
42 def __init__(self, model, classes_per_task, alpha=0.5, distillation_loss_T=2, warmup_epochs=2, optimizer=None,
43 criterion=torch.nn.CrossEntropyLoss(), mb_size=256,
44 train_ep=2, device=None, preproc=None,
45 eval_protocol=EvalProtocol(metrics=[ACC()])):
46 """
47 Learning without Forgetting Strategy.
48
49 paper: https://arxiv.org/abs/1606.09282
50 original implementation (Matlab): https://github.com/lizhitwo/LearningWithoutForgetting
51 reference implementation (pytorch): https://github.com/arunmallya/packnet/blob/master/src/lwf.py
52
53 Args:
54 classes_per_task:
55 alpha: distillation loss coefficient. Can be an integer or a list of values (one for each task).
56 distillation_loss_T: distillation loss temperature
57 warmup_epochs: number of warmup epochs training only the new parameters.
58 """
59 super(LearningWithoutForgetting, self).__init__(
60 model, optimizer, criterion, mb_size, train_ep, multi_head=False,
61 device=device, preproc=preproc, eval_protocol=eval_protocol
62 )
63
64 # LwF parameters
65 self.classes_per_task = classes_per_task
66 self.prev_model = None
67 self.distillation_loss_T = distillation_loss_T
68 self.alpha = alpha
69 self.warmup_epochs = warmup_epochs
70
71 def warmup_train(self):
72 """ Train only the new parameters for the first epochs. """
73 # add only the last layer to the trainable parameters
74 opt = torch.optim.SGD(lr=0.01, params=self.model.classifier.parameters())
75
76 train_x, train_y, it_x_ep = self.preproc_batch_data(self.x, self.y, self.t)
77 model = self.model.to(self.device)
78
79 train_x = torch.tensor(train_x, dtype=torch.float)
80 train_y = torch.tensor(train_y, dtype=torch.long)
81 for ep in range(self.train_ep):
82 for it in range(it_x_ep):
83 start = it * self.mb_size
84 end = (it + 1) * self.mb_size
85
86 self.optimizer.zero_grad()
87 x_mb = train_x[start:end].to(self.device)
88 y_mb = train_y[start:end].to(self.device)
89 logits = model(x_mb)
90 # loss computed only on the new classes
91 loss = self.criterion(logits[:, self.t*self.classes_per_task:(self.t+1)*self.classes_per_task],
92 y_mb - self.t*self.classes_per_task)
93 loss.backward()
94 opt.step()
95
96 def compute_loss(self, logits, y_mb):
97 dist_loss = 0
98 if self.prev_model is not None:
99 y_prev = self.prev_model(self.x_mb).detach()
100 loss = self.criterion(logits, y_mb)
101 dist_loss += distillation_loss(logits, y_prev, self.distillation_loss_T)
102
103 if isinstance(self.alpha, list):
104 loss = loss + self.alpha[self.t] * dist_loss
105 else:
106 loss = loss + self.alpha * dist_loss
107 else:
108 loss = self.criterion(logits, y_mb)
109 return loss
110
111 def after_train(self):
112 self.prev_model = copy.deepcopy(self.model)
113
114
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/avalanche/training/strategies/lwf/lwf.py b/avalanche/training/strategies/lwf/lwf.py
--- a/avalanche/training/strategies/lwf/lwf.py
+++ b/avalanche/training/strategies/lwf/lwf.py
@@ -39,7 +39,7 @@
class LearningWithoutForgetting(Strategy):
- def __init__(self, model, classes_per_task, alpha=0.5, distillation_loss_T=2, warmup_epochs=2, optimizer=None,
+ def __init__(self, model, classes_per_task, alpha=0.5, distillation_loss_T=2, warmup_epochs=0, optimizer=None,
criterion=torch.nn.CrossEntropyLoss(), mb_size=256,
train_ep=2, device=None, preproc=None,
eval_protocol=EvalProtocol(metrics=[ACC()])):
@@ -78,7 +78,7 @@
train_x = torch.tensor(train_x, dtype=torch.float)
train_y = torch.tensor(train_y, dtype=torch.long)
- for ep in range(self.train_ep):
+ for ep in range(self.warmup_epochs):
for it in range(it_x_ep):
start = it * self.mb_size
end = (it + 1) * self.mb_size
@@ -108,6 +108,9 @@
loss = self.criterion(logits, y_mb)
return loss
+ def before_train(self):
+ self.warmup_train()
+
def after_train(self):
self.prev_model = copy.deepcopy(self.model)
|
{"golden_diff": "diff --git a/avalanche/training/strategies/lwf/lwf.py b/avalanche/training/strategies/lwf/lwf.py\n--- a/avalanche/training/strategies/lwf/lwf.py\n+++ b/avalanche/training/strategies/lwf/lwf.py\n@@ -39,7 +39,7 @@\n \n \n class LearningWithoutForgetting(Strategy):\n- def __init__(self, model, classes_per_task, alpha=0.5, distillation_loss_T=2, warmup_epochs=2, optimizer=None,\n+ def __init__(self, model, classes_per_task, alpha=0.5, distillation_loss_T=2, warmup_epochs=0, optimizer=None,\n criterion=torch.nn.CrossEntropyLoss(), mb_size=256,\n train_ep=2, device=None, preproc=None,\n eval_protocol=EvalProtocol(metrics=[ACC()])):\n@@ -78,7 +78,7 @@\n \n train_x = torch.tensor(train_x, dtype=torch.float)\n train_y = torch.tensor(train_y, dtype=torch.long)\n- for ep in range(self.train_ep):\n+ for ep in range(self.warmup_epochs):\n for it in range(it_x_ep):\n start = it * self.mb_size\n end = (it + 1) * self.mb_size\n@@ -108,6 +108,9 @@\n loss = self.criterion(logits, y_mb)\n return loss\n \n+ def before_train(self):\n+ self.warmup_train()\n+\n def after_train(self):\n self.prev_model = copy.deepcopy(self.model)\n", "issue": "LWF \"warmup_train\" fun never used\nHi @AntonioCarta, I've noticed this function in the `LearningWithoutForgetting` class is never used, do we need it?\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n################################################################################\n# Copyright (c) 2020 ContinualAI Research #\n# Copyrights licensed under the CC BY 4.0 License. #\n# See the accompanying LICENSE file for terms. #\n# #\n# Date: 1-05-2020 #\n# Author(s): ContinualAI #\n# E-mail: [email protected] #\n# Website: clair.continualai.org #\n################################################################################\n\n\"\"\" Rehearsal Strategy Implementation \"\"\"\n\n# Python 2-3 compatible\nfrom __future__ import print_function\nfrom __future__ import division\nfrom __future__ import absolute_import\n\nfrom training.strategies.strategy import Strategy\nfrom avalanche.evaluation.eval_protocol import EvalProtocol\nfrom avalanche.evaluation.metrics import ACC\nfrom avalanche.training.utils import pad_data, shuffle_in_unison\nimport torch\nimport torch.nn.functional as F\nimport numpy as np\nimport copy\n\n\ndef distillation_loss(y_pred, y_teacher, temperature):\n \"\"\" Distillation loss. \"\"\"\n scale = y_teacher.shape[-1] # kl_div is normalized by element instead of observation\n log_p = F.log_softmax(y_pred / temperature, dim=1)\n q = F.softmax(y_teacher / temperature, dim=1)\n res = scale * F.kl_div(log_p, q, reduction='mean')\n return res\n\n\nclass LearningWithoutForgetting(Strategy):\n def __init__(self, model, classes_per_task, alpha=0.5, distillation_loss_T=2, warmup_epochs=2, optimizer=None,\n criterion=torch.nn.CrossEntropyLoss(), mb_size=256,\n train_ep=2, device=None, preproc=None,\n eval_protocol=EvalProtocol(metrics=[ACC()])):\n \"\"\"\n Learning without Forgetting Strategy.\n\n paper: https://arxiv.org/abs/1606.09282\n original implementation (Matlab): https://github.com/lizhitwo/LearningWithoutForgetting\n reference implementation (pytorch): https://github.com/arunmallya/packnet/blob/master/src/lwf.py\n\n Args:\n classes_per_task:\n alpha: distillation loss coefficient. Can be an integer or a list of values (one for each task).\n distillation_loss_T: distillation loss temperature\n warmup_epochs: number of warmup epochs training only the new parameters.\n \"\"\"\n super(LearningWithoutForgetting, self).__init__(\n model, optimizer, criterion, mb_size, train_ep, multi_head=False,\n device=device, preproc=preproc, eval_protocol=eval_protocol\n )\n\n # LwF parameters\n self.classes_per_task = classes_per_task\n self.prev_model = None\n self.distillation_loss_T = distillation_loss_T\n self.alpha = alpha\n self.warmup_epochs = warmup_epochs\n\n def warmup_train(self):\n \"\"\" Train only the new parameters for the first epochs. \"\"\"\n # add only the last layer to the trainable parameters\n opt = torch.optim.SGD(lr=0.01, params=self.model.classifier.parameters())\n\n train_x, train_y, it_x_ep = self.preproc_batch_data(self.x, self.y, self.t)\n model = self.model.to(self.device)\n\n train_x = torch.tensor(train_x, dtype=torch.float)\n train_y = torch.tensor(train_y, dtype=torch.long)\n for ep in range(self.train_ep):\n for it in range(it_x_ep):\n start = it * self.mb_size\n end = (it + 1) * self.mb_size\n\n self.optimizer.zero_grad()\n x_mb = train_x[start:end].to(self.device)\n y_mb = train_y[start:end].to(self.device)\n logits = model(x_mb)\n # loss computed only on the new classes\n loss = self.criterion(logits[:, self.t*self.classes_per_task:(self.t+1)*self.classes_per_task],\n y_mb - self.t*self.classes_per_task)\n loss.backward()\n opt.step()\n\n def compute_loss(self, logits, y_mb):\n dist_loss = 0\n if self.prev_model is not None:\n y_prev = self.prev_model(self.x_mb).detach()\n loss = self.criterion(logits, y_mb)\n dist_loss += distillation_loss(logits, y_prev, self.distillation_loss_T)\n\n if isinstance(self.alpha, list):\n loss = loss + self.alpha[self.t] * dist_loss\n else:\n loss = loss + self.alpha * dist_loss\n else:\n loss = self.criterion(logits, y_mb)\n return loss\n\n def after_train(self):\n self.prev_model = copy.deepcopy(self.model)\n\n", "path": "avalanche/training/strategies/lwf/lwf.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n################################################################################\n# Copyright (c) 2020 ContinualAI Research #\n# Copyrights licensed under the CC BY 4.0 License. #\n# See the accompanying LICENSE file for terms. #\n# #\n# Date: 1-05-2020 #\n# Author(s): ContinualAI #\n# E-mail: [email protected] #\n# Website: clair.continualai.org #\n################################################################################\n\n\"\"\" Rehearsal Strategy Implementation \"\"\"\n\n# Python 2-3 compatible\nfrom __future__ import print_function\nfrom __future__ import division\nfrom __future__ import absolute_import\n\nfrom training.strategies.strategy import Strategy\nfrom avalanche.evaluation.eval_protocol import EvalProtocol\nfrom avalanche.evaluation.metrics import ACC\nfrom avalanche.training.utils import pad_data, shuffle_in_unison\nimport torch\nimport torch.nn.functional as F\nimport numpy as np\nimport copy\n\n\ndef distillation_loss(y_pred, y_teacher, temperature):\n \"\"\" Distillation loss. \"\"\"\n scale = y_teacher.shape[-1] # kl_div is normalized by element instead of observation\n log_p = F.log_softmax(y_pred / temperature, dim=1)\n q = F.softmax(y_teacher / temperature, dim=1)\n res = scale * F.kl_div(log_p, q, reduction='mean')\n return res\n\n\nclass LearningWithoutForgetting(Strategy):\n def __init__(self, model, classes_per_task, alpha=0.5, distillation_loss_T=2, warmup_epochs=0, optimizer=None,\n criterion=torch.nn.CrossEntropyLoss(), mb_size=256,\n train_ep=2, device=None, preproc=None,\n eval_protocol=EvalProtocol(metrics=[ACC()])):\n \"\"\"\n Learning without Forgetting Strategy.\n\n paper: https://arxiv.org/abs/1606.09282\n original implementation (Matlab): https://github.com/lizhitwo/LearningWithoutForgetting\n reference implementation (pytorch): https://github.com/arunmallya/packnet/blob/master/src/lwf.py\n\n Args:\n classes_per_task:\n alpha: distillation loss coefficient. Can be an integer or a list of values (one for each task).\n distillation_loss_T: distillation loss temperature\n warmup_epochs: number of warmup epochs training only the new parameters.\n \"\"\"\n super(LearningWithoutForgetting, self).__init__(\n model, optimizer, criterion, mb_size, train_ep, multi_head=False,\n device=device, preproc=preproc, eval_protocol=eval_protocol\n )\n\n # LwF parameters\n self.classes_per_task = classes_per_task\n self.prev_model = None\n self.distillation_loss_T = distillation_loss_T\n self.alpha = alpha\n self.warmup_epochs = warmup_epochs\n\n def warmup_train(self):\n \"\"\" Train only the new parameters for the first epochs. \"\"\"\n # add only the last layer to the trainable parameters\n opt = torch.optim.SGD(lr=0.01, params=self.model.classifier.parameters())\n\n train_x, train_y, it_x_ep = self.preproc_batch_data(self.x, self.y, self.t)\n model = self.model.to(self.device)\n\n train_x = torch.tensor(train_x, dtype=torch.float)\n train_y = torch.tensor(train_y, dtype=torch.long)\n for ep in range(self.warmup_epochs):\n for it in range(it_x_ep):\n start = it * self.mb_size\n end = (it + 1) * self.mb_size\n\n self.optimizer.zero_grad()\n x_mb = train_x[start:end].to(self.device)\n y_mb = train_y[start:end].to(self.device)\n logits = model(x_mb)\n # loss computed only on the new classes\n loss = self.criterion(logits[:, self.t*self.classes_per_task:(self.t+1)*self.classes_per_task],\n y_mb - self.t*self.classes_per_task)\n loss.backward()\n opt.step()\n\n def compute_loss(self, logits, y_mb):\n dist_loss = 0\n if self.prev_model is not None:\n y_prev = self.prev_model(self.x_mb).detach()\n loss = self.criterion(logits, y_mb)\n dist_loss += distillation_loss(logits, y_prev, self.distillation_loss_T)\n\n if isinstance(self.alpha, list):\n loss = loss + self.alpha[self.t] * dist_loss\n else:\n loss = loss + self.alpha * dist_loss\n else:\n loss = self.criterion(logits, y_mb)\n return loss\n\n def before_train(self):\n self.warmup_train()\n\n def after_train(self):\n self.prev_model = copy.deepcopy(self.model)\n\n", "path": "avalanche/training/strategies/lwf/lwf.py"}]}
| 1,567 | 350 |
gh_patches_debug_8384
|
rasdani/github-patches
|
git_diff
|
Qiskit__qiskit-2350
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
disassemble_circuits() suggested in qobj_to_circuits.py DeprecationWarning doesn't exist
<!-- ⚠️ If you do not respect this template, your issue will be closed -->
<!-- ⚠️ Make sure to browse the opened and closed issues -->
### Information
- **Qiskit Terra version**: 0.8.0
- **Python version**: 3.7.2
- **Operating system**: macOS
`qobj_to_circuits` gives the following `DeprecationWarning`:
```python
.../qiskit/converters/qobj_to_circuits.py:34: DeprecationWarning: qiskit.converters.qobj_to_circuit() is deprecated and will be removed in Qiskit Terra 0.9. Please use qiskit.compiler.disassemble_circuits() to convert a qobj to list of circuits.
```
but `qiskit.compiler.disassemble_circuits()` doesn't exist.
### What is the current behavior?
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ImportError: cannot import name 'disassemble_circuits' from 'qiskit.compiler' (/Users/matteo/Work/projects/ibmq/env/lib/python3.7/site-packages/qiskit/compiler/__init__.py)
```
### Steps to reproduce the problem
1. Installed qiskit in a new python virtualenv with `pip install qiskit`
2. `from qiskit.compiler import disassemble_circuits`
```
>>> qiskit.__qiskit_version__
{'qiskit': '0.10.0', 'qiskit-terra': '0.8.0', 'qiskit-ignis': '0.1.1', 'qiskit-aer': '0.2.0', 'qiskit-ibmq-provider': '0.2.1', 'qiskit-aqua': '0.5.0'}
```
### What is the expected behavior?
If a function is deprecated, and the warning suggests to use a new function, this function should exist in the current release.
### Suggested solutions
Implement the function or change the deprecation warning.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `qiskit/converters/qobj_to_circuits.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # This code is part of Qiskit.
4 #
5 # (C) Copyright IBM 2017, 2018.
6 #
7 # This code is licensed under the Apache License, Version 2.0. You may
8 # obtain a copy of this license in the LICENSE.txt file in the root directory
9 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
10 #
11 # Any modifications or derivative works of this code must retain this
12 # copyright notice, and modified files need to carry a notice indicating
13 # that they have been altered from the originals.
14
15 """Helper function for converting qobj to a list of circuits"""
16
17 import warnings
18
19 from qiskit.assembler import disassemble
20
21
22 def qobj_to_circuits(qobj):
23 """Return a list of QuantumCircuit object(s) from a qobj
24
25 Args:
26 qobj (Qobj): The Qobj object to convert to QuantumCircuits
27 Returns:
28 list: A list of QuantumCircuit objects from the qobj
29
30 """
31 warnings.warn('qiskit.converters.qobj_to_circuit() is deprecated and will '
32 'be removed in Qiskit Terra 0.9. Please use '
33 'qiskit.compiler.disassemble_circuits() to convert a qobj '
34 'to list of circuits.', DeprecationWarning)
35
36 variables = disassemble(qobj)
37 return variables[0]
38
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/qiskit/converters/qobj_to_circuits.py b/qiskit/converters/qobj_to_circuits.py
--- a/qiskit/converters/qobj_to_circuits.py
+++ b/qiskit/converters/qobj_to_circuits.py
@@ -30,7 +30,7 @@
"""
warnings.warn('qiskit.converters.qobj_to_circuit() is deprecated and will '
'be removed in Qiskit Terra 0.9. Please use '
- 'qiskit.compiler.disassemble_circuits() to convert a qobj '
+ 'qiskit.assembler.disassemble() to convert a qobj '
'to list of circuits.', DeprecationWarning)
variables = disassemble(qobj)
|
{"golden_diff": "diff --git a/qiskit/converters/qobj_to_circuits.py b/qiskit/converters/qobj_to_circuits.py\n--- a/qiskit/converters/qobj_to_circuits.py\n+++ b/qiskit/converters/qobj_to_circuits.py\n@@ -30,7 +30,7 @@\n \"\"\"\n warnings.warn('qiskit.converters.qobj_to_circuit() is deprecated and will '\n 'be removed in Qiskit Terra 0.9. Please use '\n- 'qiskit.compiler.disassemble_circuits() to convert a qobj '\n+ 'qiskit.assembler.disassemble() to convert a qobj '\n 'to list of circuits.', DeprecationWarning)\n \n variables = disassemble(qobj)\n", "issue": "disassemble_circuits() suggested in qobj_to_circuits.py DeprecationWarning doesn't exist\n<!-- \u26a0\ufe0f If you do not respect this template, your issue will be closed -->\r\n<!-- \u26a0\ufe0f Make sure to browse the opened and closed issues -->\r\n\r\n### Information\r\n\r\n- **Qiskit Terra version**: 0.8.0\r\n- **Python version**: 3.7.2\r\n- **Operating system**: macOS\r\n\r\n`qobj_to_circuits` gives the following `DeprecationWarning`:\r\n\r\n```python\r\n.../qiskit/converters/qobj_to_circuits.py:34: DeprecationWarning: qiskit.converters.qobj_to_circuit() is deprecated and will be removed in Qiskit Terra 0.9. Please use qiskit.compiler.disassemble_circuits() to convert a qobj to list of circuits.\r\n```\r\n\r\nbut `qiskit.compiler.disassemble_circuits()` doesn't exist.\r\n\r\n### What is the current behavior?\r\n```\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\nImportError: cannot import name 'disassemble_circuits' from 'qiskit.compiler' (/Users/matteo/Work/projects/ibmq/env/lib/python3.7/site-packages/qiskit/compiler/__init__.py)\r\n```\r\n\r\n### Steps to reproduce the problem\r\n1. Installed qiskit in a new python virtualenv with `pip install qiskit`\r\n2. `from qiskit.compiler import disassemble_circuits`\r\n\r\n```\r\n>>> qiskit.__qiskit_version__\r\n{'qiskit': '0.10.0', 'qiskit-terra': '0.8.0', 'qiskit-ignis': '0.1.1', 'qiskit-aer': '0.2.0', 'qiskit-ibmq-provider': '0.2.1', 'qiskit-aqua': '0.5.0'}\r\n```\r\n\r\n### What is the expected behavior?\r\nIf a function is deprecated, and the warning suggests to use a new function, this function should exist in the current release.\r\n\r\n### Suggested solutions\r\n\r\nImplement the function or change the deprecation warning.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2018.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n\"\"\"Helper function for converting qobj to a list of circuits\"\"\"\n\nimport warnings\n\nfrom qiskit.assembler import disassemble\n\n\ndef qobj_to_circuits(qobj):\n \"\"\"Return a list of QuantumCircuit object(s) from a qobj\n\n Args:\n qobj (Qobj): The Qobj object to convert to QuantumCircuits\n Returns:\n list: A list of QuantumCircuit objects from the qobj\n\n \"\"\"\n warnings.warn('qiskit.converters.qobj_to_circuit() is deprecated and will '\n 'be removed in Qiskit Terra 0.9. Please use '\n 'qiskit.compiler.disassemble_circuits() to convert a qobj '\n 'to list of circuits.', DeprecationWarning)\n\n variables = disassemble(qobj)\n return variables[0]\n", "path": "qiskit/converters/qobj_to_circuits.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2018.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n\"\"\"Helper function for converting qobj to a list of circuits\"\"\"\n\nimport warnings\n\nfrom qiskit.assembler import disassemble\n\n\ndef qobj_to_circuits(qobj):\n \"\"\"Return a list of QuantumCircuit object(s) from a qobj\n\n Args:\n qobj (Qobj): The Qobj object to convert to QuantumCircuits\n Returns:\n list: A list of QuantumCircuit objects from the qobj\n\n \"\"\"\n warnings.warn('qiskit.converters.qobj_to_circuit() is deprecated and will '\n 'be removed in Qiskit Terra 0.9. Please use '\n 'qiskit.assembler.disassemble() to convert a qobj '\n 'to list of circuits.', DeprecationWarning)\n\n variables = disassemble(qobj)\n return variables[0]\n", "path": "qiskit/converters/qobj_to_circuits.py"}]}
| 1,128 | 172 |
gh_patches_debug_14386
|
rasdani/github-patches
|
git_diff
|
MycroftAI__mycroft-core-845
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Mycroft doesn't starts if /etc/mycroft/mycroft.conf exists and has comments
In log.py there are these statements:
if isfile(SYSTEM_CONFIG):
with open(SYSTEM_CONFIG) as f:
config = json.load(f)
log_level = config.get("log_level", "DEBUG")
note no filter of comments has been done using "load_commented_json".
Note: no pull request will be done, because could be the best solution is do not load any config here but use the common configuration procedure.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mycroft/util/log.py`
Content:
```
1 # Copyright 2016 Mycroft AI, Inc.
2 #
3 # This file is part of Mycroft Core.
4 #
5 # Mycroft Core is free software: you can redistribute it and/or modify
6 # it under the terms of the GNU General Public License as published by
7 # the Free Software Foundation, either version 3 of the License, or
8 # (at your option) any later version.
9 #
10 # Mycroft Core is distributed in the hope that it will be useful,
11 # but WITHOUT ANY WARRANTY; without even the implied warranty of
12 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
13 # GNU General Public License for more details.
14 #
15 # You should have received a copy of the GNU General Public License
16 # along with Mycroft Core. If not, see <http://www.gnu.org/licenses/>.
17 import json
18 import logging
19
20 from os.path import isfile
21
22 SYSTEM_CONFIG = '/etc/mycroft/mycroft.conf'
23
24 __author__ = 'seanfitz'
25
26 log_level = "DEBUG"
27
28 if isfile(SYSTEM_CONFIG):
29 with open(SYSTEM_CONFIG) as f:
30 config = json.load(f)
31 log_level = config.get("log_level", "DEBUG")
32
33 FORMAT = '%(asctime)s - %(name)s - %(levelname)s - %(message)s'
34 logging.basicConfig(format=FORMAT, level=logging.getLevelName(log_level))
35 logger = logging.getLogger("MYCROFT")
36
37
38 def getLogger(name="MYCROFT"):
39 """
40 Get a python logger
41
42 :param name: Module name for the logger
43
44 :return: an instance of logging.Logger
45 """
46 return logging.getLogger(name)
47
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mycroft/util/log.py b/mycroft/util/log.py
--- a/mycroft/util/log.py
+++ b/mycroft/util/log.py
@@ -18,6 +18,7 @@
import logging
from os.path import isfile
+from mycroft.util.json_helper import load_commented_json
SYSTEM_CONFIG = '/etc/mycroft/mycroft.conf'
@@ -26,9 +27,8 @@
log_level = "DEBUG"
if isfile(SYSTEM_CONFIG):
- with open(SYSTEM_CONFIG) as f:
- config = json.load(f)
- log_level = config.get("log_level", "DEBUG")
+ config = load_commented_json(SYSTEM_CONFIG)
+ log_level = config.get("log_level", "DEBUG")
FORMAT = '%(asctime)s - %(name)s - %(levelname)s - %(message)s'
logging.basicConfig(format=FORMAT, level=logging.getLevelName(log_level))
|
{"golden_diff": "diff --git a/mycroft/util/log.py b/mycroft/util/log.py\n--- a/mycroft/util/log.py\n+++ b/mycroft/util/log.py\n@@ -18,6 +18,7 @@\n import logging\n \n from os.path import isfile\n+from mycroft.util.json_helper import load_commented_json\n \n SYSTEM_CONFIG = '/etc/mycroft/mycroft.conf'\n \n@@ -26,9 +27,8 @@\n log_level = \"DEBUG\"\n \n if isfile(SYSTEM_CONFIG):\n- with open(SYSTEM_CONFIG) as f:\n- config = json.load(f)\n- log_level = config.get(\"log_level\", \"DEBUG\")\n+ config = load_commented_json(SYSTEM_CONFIG)\n+ log_level = config.get(\"log_level\", \"DEBUG\")\n \n FORMAT = '%(asctime)s - %(name)s - %(levelname)s - %(message)s'\n logging.basicConfig(format=FORMAT, level=logging.getLevelName(log_level))\n", "issue": "Mycroft doesn't starts if /etc/mycroft/mycroft.conf exists and has comments\nIn log.py there are these statements:\r\n\r\nif isfile(SYSTEM_CONFIG):\r\n with open(SYSTEM_CONFIG) as f:\r\n config = json.load(f)\r\n log_level = config.get(\"log_level\", \"DEBUG\")\r\n\r\nnote no filter of comments has been done using \"load_commented_json\".\r\n\r\nNote: no pull request will be done, because could be the best solution is do not load any config here but use the common configuration procedure.\n", "before_files": [{"content": "# Copyright 2016 Mycroft AI, Inc.\n#\n# This file is part of Mycroft Core.\n#\n# Mycroft Core is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Mycroft Core is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Mycroft Core. If not, see <http://www.gnu.org/licenses/>.\nimport json\nimport logging\n\nfrom os.path import isfile\n\nSYSTEM_CONFIG = '/etc/mycroft/mycroft.conf'\n\n__author__ = 'seanfitz'\n\nlog_level = \"DEBUG\"\n\nif isfile(SYSTEM_CONFIG):\n with open(SYSTEM_CONFIG) as f:\n config = json.load(f)\n log_level = config.get(\"log_level\", \"DEBUG\")\n\nFORMAT = '%(asctime)s - %(name)s - %(levelname)s - %(message)s'\nlogging.basicConfig(format=FORMAT, level=logging.getLevelName(log_level))\nlogger = logging.getLogger(\"MYCROFT\")\n\n\ndef getLogger(name=\"MYCROFT\"):\n \"\"\"\n Get a python logger\n\n :param name: Module name for the logger\n\n :return: an instance of logging.Logger\n \"\"\"\n return logging.getLogger(name)\n", "path": "mycroft/util/log.py"}], "after_files": [{"content": "# Copyright 2016 Mycroft AI, Inc.\n#\n# This file is part of Mycroft Core.\n#\n# Mycroft Core is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Mycroft Core is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Mycroft Core. If not, see <http://www.gnu.org/licenses/>.\nimport json\nimport logging\n\nfrom os.path import isfile\nfrom mycroft.util.json_helper import load_commented_json\n\nSYSTEM_CONFIG = '/etc/mycroft/mycroft.conf'\n\n__author__ = 'seanfitz'\n\nlog_level = \"DEBUG\"\n\nif isfile(SYSTEM_CONFIG):\n config = load_commented_json(SYSTEM_CONFIG)\n log_level = config.get(\"log_level\", \"DEBUG\")\n\nFORMAT = '%(asctime)s - %(name)s - %(levelname)s - %(message)s'\nlogging.basicConfig(format=FORMAT, level=logging.getLevelName(log_level))\nlogger = logging.getLogger(\"MYCROFT\")\n\n\ndef getLogger(name=\"MYCROFT\"):\n \"\"\"\n Get a python logger\n\n :param name: Module name for the logger\n\n :return: an instance of logging.Logger\n \"\"\"\n return logging.getLogger(name)\n", "path": "mycroft/util/log.py"}]}
| 798 | 198 |
gh_patches_debug_11079
|
rasdani/github-patches
|
git_diff
|
deepchecks__deepchecks-1329
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] [Vision] condition get a ?! value
**Describe the bug**
Condition on a check get a ?! value without explanation - everything in it seem to pass and the result seems fine.
**To Reproduce**
Run the following kaggle notebook up to the full suite at the end.
https://www.kaggle.com/code/nadavbarak/animalfacesclassification
**Expected behavior**
Check should display the condition failed.
**Screenshots**
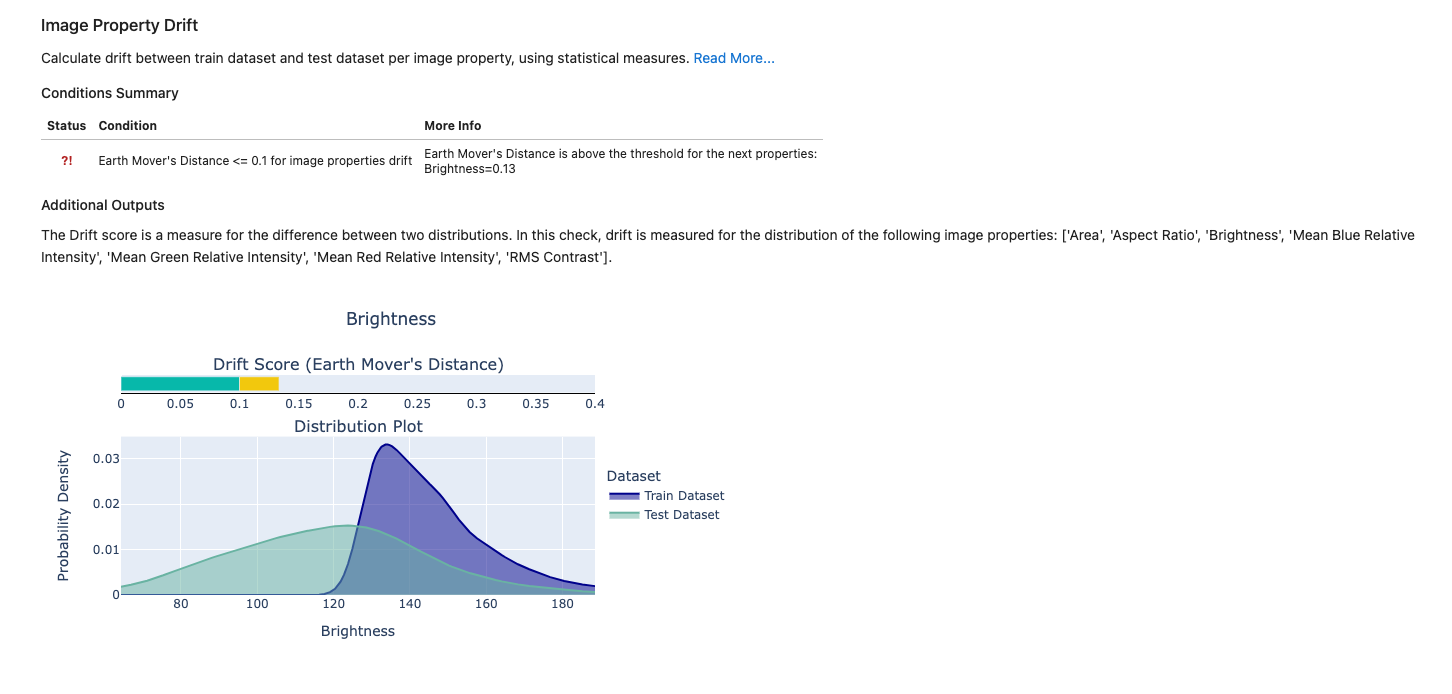
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `deepchecks/vision/checks/distribution/image_property_drift.py`
Content:
```
1 # ----------------------------------------------------------------------------
2 # Copyright (C) 2021-2022 Deepchecks (https://www.deepchecks.com)
3 #
4 # This file is part of Deepchecks.
5 # Deepchecks is distributed under the terms of the GNU Affero General
6 # Public License (version 3 or later).
7 # You should have received a copy of the GNU Affero General Public License
8 # along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.
9 # ----------------------------------------------------------------------------
10 #
11 """Module contains Image Property Drift check."""
12 import typing as t
13 from collections import defaultdict
14 import warnings
15 import pandas as pd
16
17 from deepchecks.core import CheckResult
18 from deepchecks.core import ConditionResult
19 from deepchecks.core import DatasetKind
20 from deepchecks.core.errors import NotEnoughSamplesError, DeepchecksValueError
21 from deepchecks.core.condition import ConditionCategory
22 from deepchecks.utils.distribution.drift import calc_drift_and_plot
23 from deepchecks.vision import Batch
24 from deepchecks.vision import Context
25 from deepchecks.vision import TrainTestCheck
26 from deepchecks.vision.utils.image_properties import validate_properties, default_image_properties, get_column_type
27
28
29 __all__ = ['ImagePropertyDrift']
30
31
32 TImagePropertyDrift = t.TypeVar('TImagePropertyDrift', bound='ImagePropertyDrift')
33
34
35 class ImagePropertyDrift(TrainTestCheck):
36 """
37 Calculate drift between train dataset and test dataset per image property, using statistical measures.
38
39 Check calculates a drift score for each image property in test dataset, by comparing its distribution to the train
40 dataset. For this, we use the Earth Movers Distance.
41
42 See https://en.wikipedia.org/wiki/Wasserstein_metric
43
44 Parameters
45 ----------
46 image_properties : List[Dict[str, Any]], default: None
47 List of properties. Replaces the default deepchecks properties.
48 Each property is dictionary with keys 'name' (str), 'method' (Callable) and 'output_type' (str),
49 representing attributes of said method. 'output_type' must be one of 'continuous'/'discrete'
50 max_num_categories_for_drift: int, default: 10
51 Only for non-continuous properties. Max number of allowed categories. If there are more,
52 they are binned into an "Other" category. If None, there is no limit.
53 max_num_categories_for_display: int, default: 10
54 Max number of categories to show in plot.
55 show_categories_by: str, default: 'train_largest'
56 Specify which categories to show for categorical features' graphs, as the number of shown categories is limited
57 by max_num_categories_for_display. Possible values:
58 - 'train_largest': Show the largest train categories.
59 - 'test_largest': Show the largest test categories.
60 - 'largest_difference': Show the largest difference between categories.
61 classes_to_display : Optional[List[float]], default: None
62 List of classes to display. The distribution of the properties would include only samples belonging (or
63 containing an annotation belonging) to one of these classes. If None, samples from all classes are displayed.
64 min_samples: int, default: 10
65 Minimum number of samples needed in each dataset needed to calculate the drift.
66 max_num_categories: int, default: None
67 Deprecated. Please use max_num_categories_for_drift and max_num_categories_for_display instead
68 """
69
70 def __init__(
71 self,
72 image_properties: t.List[t.Dict[str, t.Any]] = None,
73 max_num_categories_for_drift: int = 10,
74 max_num_categories_for_display: int = 10,
75 show_categories_by: str = 'train_largest',
76 classes_to_display: t.Optional[t.List[str]] = None,
77 min_samples: int = 30,
78 max_num_categories: int = None, # Deprecated
79 **kwargs
80 ):
81 super().__init__(**kwargs)
82 if image_properties is not None:
83 validate_properties(image_properties)
84 self.image_properties = image_properties
85 else:
86 self.image_properties = default_image_properties
87
88 if max_num_categories is not None:
89 warnings.warn(
90 f'{self.__class__.__name__}: max_num_categories is deprecated. please use max_num_categories_for_drift '
91 'and max_num_categories_for_display instead',
92 DeprecationWarning
93 )
94 max_num_categories_for_drift = max_num_categories_for_drift or max_num_categories
95 max_num_categories_for_display = max_num_categories_for_display or max_num_categories
96 self.max_num_categories_for_drift = max_num_categories_for_drift
97 self.max_num_categories_for_display = max_num_categories_for_display
98 self.show_categories_by = show_categories_by
99 self.classes_to_display = classes_to_display
100 self.min_samples = min_samples
101 self._train_properties = None
102 self._test_properties = None
103 self._class_to_string = None
104
105 def initialize_run(self, context: Context):
106 """Initialize self state, and validate the run context."""
107 self._class_to_string = context.train.label_id_to_name
108 self._train_properties = defaultdict(list)
109 self._test_properties = defaultdict(list)
110
111 def update(
112 self,
113 context: Context,
114 batch: Batch,
115 dataset_kind: DatasetKind
116 ):
117 """Calculate image properties for train or test batch."""
118 if dataset_kind == DatasetKind.TRAIN:
119 properties = self._train_properties
120 elif dataset_kind == DatasetKind.TEST:
121 properties = self._test_properties
122 else:
123 raise RuntimeError(
124 f'Internal Error - Should not reach here! unknown dataset_kind: {dataset_kind}'
125 )
126
127 images = batch.images
128
129 if self.classes_to_display:
130 # use only images belonging (or containing an annotation belonging) to one of the classes in
131 # classes_to_display
132 classes = context.train.get_classes(batch.labels)
133 images = [
134 image for idx, image in enumerate(images) if
135 any(cls in map(self._class_to_string, classes[idx]) for cls in self.classes_to_display)
136 ]
137
138 for single_property in self.image_properties:
139 property_list = single_property['method'](images)
140 properties[single_property['name']].extend(property_list)
141
142 def compute(self, context: Context) -> CheckResult:
143 """Calculate drift score between train and test datasets for the collected image properties.
144
145 Returns
146 -------
147 CheckResult
148 value: dictionary containing drift score for each image property.
149 display: distribution graph for each image property.
150 """
151 if sorted(self._train_properties.keys()) != sorted(self._test_properties.keys()):
152 raise RuntimeError('Internal Error! Vision check was used improperly.')
153
154 # if self.classes_to_display is set, check that it has classes that actually exist
155 if self.classes_to_display is not None:
156 if not set(self.classes_to_display).issubset(
157 map(self._class_to_string, context.train.classes_indices.keys())
158 ):
159 raise DeepchecksValueError(
160 f'Provided list of class ids to display {self.classes_to_display} not found in training dataset.'
161 )
162
163 properties = sorted(self._train_properties.keys())
164 df_train = pd.DataFrame(self._train_properties)
165 df_test = pd.DataFrame(self._test_properties)
166 if len(df_train) < self.min_samples or len(df_test) < self.min_samples:
167 raise NotEnoughSamplesError(
168 f'Not enough samples to calculate drift score, minimum {self.min_samples} samples required'
169 f', but got {len(df_train)} and {len(df_test)} samples in the train and test datasets.'
170 'Use \'min_samples\' parameter to change the requirement.'
171 )
172
173 figures = {}
174 drifts = {}
175 not_enough_samples = []
176
177 for single_property in self.image_properties:
178 property_name = single_property['name']
179
180 try:
181 score, _, figure = calc_drift_and_plot(
182 train_column=df_train[property_name],
183 test_column=df_test[property_name],
184 value_name=property_name,
185 column_type=get_column_type(single_property['output_type']),
186 max_num_categories_for_drift=self.max_num_categories_for_drift,
187 max_num_categories_for_display=self.max_num_categories_for_display,
188 show_categories_by=self.show_categories_by,
189 min_samples=self.min_samples
190 )
191
192 figures[property_name] = figure
193 drifts[property_name] = score
194 except NotEnoughSamplesError:
195 not_enough_samples.append(property_name)
196
197 if drifts:
198 columns_order = sorted(properties, key=lambda col: drifts.get(col, 0), reverse=True)
199 properties_to_display = [p for p in properties if p in drifts]
200
201 headnote = '<span>' \
202 'The Drift score is a measure for the difference between two distributions. ' \
203 'In this check, drift is measured ' \
204 f'for the distribution of the following image properties: {properties_to_display}.<br>' \
205 '</span>'
206 if not_enough_samples:
207 headnote += f'<span>The following image properties do not have enough samples to calculate drift ' \
208 f'score: {not_enough_samples}</span>'
209
210 displays = [headnote] + [figures[col] for col in columns_order if col in figures]
211 else:
212 drifts = None
213 displays = []
214
215 return CheckResult(
216 value=drifts,
217 display=displays,
218 header='Image Property Drift'
219 )
220
221 def add_condition_drift_score_not_greater_than(
222 self: TImagePropertyDrift,
223 max_allowed_drift_score: float = 0.1
224 ) -> TImagePropertyDrift:
225 """
226 Add condition - require drift score to not be more than a certain threshold.
227
228 Parameters
229 ----------
230 max_allowed_drift_score: float , default: 0.1
231 the max threshold for the Earth Mover's Distance score
232
233 Returns
234 -------
235 ConditionResult
236 False if any column has passed the max threshold, True otherwise
237 """
238
239 def condition(result: t.Dict[str, float]) -> ConditionResult:
240 failed_properties = [
241 (property_name, drift_score)
242 for property_name, drift_score in result.items()
243 if drift_score > max_allowed_drift_score
244 ]
245 if len(failed_properties) > 0:
246 failed_properties = ';\n'.join(f'{p}={d:.2f}' for p, d in failed_properties)
247 return ConditionResult(
248 False,
249 'Earth Mover\'s Distance is above the threshold '
250 f'for the next properties:\n{failed_properties}'
251 )
252 return ConditionResult(ConditionCategory.PASS)
253
254 return self.add_condition(
255 f'Earth Mover\'s Distance <= {max_allowed_drift_score} for image properties drift',
256 condition
257 )
258
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/deepchecks/vision/checks/distribution/image_property_drift.py b/deepchecks/vision/checks/distribution/image_property_drift.py
--- a/deepchecks/vision/checks/distribution/image_property_drift.py
+++ b/deepchecks/vision/checks/distribution/image_property_drift.py
@@ -245,7 +245,7 @@
if len(failed_properties) > 0:
failed_properties = ';\n'.join(f'{p}={d:.2f}' for p, d in failed_properties)
return ConditionResult(
- False,
+ ConditionCategory.FAIL,
'Earth Mover\'s Distance is above the threshold '
f'for the next properties:\n{failed_properties}'
)
|
{"golden_diff": "diff --git a/deepchecks/vision/checks/distribution/image_property_drift.py b/deepchecks/vision/checks/distribution/image_property_drift.py\n--- a/deepchecks/vision/checks/distribution/image_property_drift.py\n+++ b/deepchecks/vision/checks/distribution/image_property_drift.py\n@@ -245,7 +245,7 @@\n if len(failed_properties) > 0:\n failed_properties = ';\\n'.join(f'{p}={d:.2f}' for p, d in failed_properties)\n return ConditionResult(\n- False,\n+ ConditionCategory.FAIL,\n 'Earth Mover\\'s Distance is above the threshold '\n f'for the next properties:\\n{failed_properties}'\n )\n", "issue": "[BUG] [Vision] condition get a ?! value\n**Describe the bug**\r\nCondition on a check get a ?! value without explanation - everything in it seem to pass and the result seems fine.\r\n\r\n**To Reproduce**\r\nRun the following kaggle notebook up to the full suite at the end.\r\nhttps://www.kaggle.com/code/nadavbarak/animalfacesclassification\r\n\r\n**Expected behavior**\r\nCheck should display the condition failed.\r\n\r\n**Screenshots**\r\n\r\n\n", "before_files": [{"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021-2022 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\n\"\"\"Module contains Image Property Drift check.\"\"\"\nimport typing as t\nfrom collections import defaultdict\nimport warnings\nimport pandas as pd\n\nfrom deepchecks.core import CheckResult\nfrom deepchecks.core import ConditionResult\nfrom deepchecks.core import DatasetKind\nfrom deepchecks.core.errors import NotEnoughSamplesError, DeepchecksValueError\nfrom deepchecks.core.condition import ConditionCategory\nfrom deepchecks.utils.distribution.drift import calc_drift_and_plot\nfrom deepchecks.vision import Batch\nfrom deepchecks.vision import Context\nfrom deepchecks.vision import TrainTestCheck\nfrom deepchecks.vision.utils.image_properties import validate_properties, default_image_properties, get_column_type\n\n\n__all__ = ['ImagePropertyDrift']\n\n\nTImagePropertyDrift = t.TypeVar('TImagePropertyDrift', bound='ImagePropertyDrift')\n\n\nclass ImagePropertyDrift(TrainTestCheck):\n \"\"\"\n Calculate drift between train dataset and test dataset per image property, using statistical measures.\n\n Check calculates a drift score for each image property in test dataset, by comparing its distribution to the train\n dataset. For this, we use the Earth Movers Distance.\n\n See https://en.wikipedia.org/wiki/Wasserstein_metric\n\n Parameters\n ----------\n image_properties : List[Dict[str, Any]], default: None\n List of properties. Replaces the default deepchecks properties.\n Each property is dictionary with keys 'name' (str), 'method' (Callable) and 'output_type' (str),\n representing attributes of said method. 'output_type' must be one of 'continuous'/'discrete'\n max_num_categories_for_drift: int, default: 10\n Only for non-continuous properties. Max number of allowed categories. If there are more,\n they are binned into an \"Other\" category. If None, there is no limit.\n max_num_categories_for_display: int, default: 10\n Max number of categories to show in plot.\n show_categories_by: str, default: 'train_largest'\n Specify which categories to show for categorical features' graphs, as the number of shown categories is limited\n by max_num_categories_for_display. Possible values:\n - 'train_largest': Show the largest train categories.\n - 'test_largest': Show the largest test categories.\n - 'largest_difference': Show the largest difference between categories.\n classes_to_display : Optional[List[float]], default: None\n List of classes to display. The distribution of the properties would include only samples belonging (or\n containing an annotation belonging) to one of these classes. If None, samples from all classes are displayed.\n min_samples: int, default: 10\n Minimum number of samples needed in each dataset needed to calculate the drift.\n max_num_categories: int, default: None\n Deprecated. Please use max_num_categories_for_drift and max_num_categories_for_display instead\n \"\"\"\n\n def __init__(\n self,\n image_properties: t.List[t.Dict[str, t.Any]] = None,\n max_num_categories_for_drift: int = 10,\n max_num_categories_for_display: int = 10,\n show_categories_by: str = 'train_largest',\n classes_to_display: t.Optional[t.List[str]] = None,\n min_samples: int = 30,\n max_num_categories: int = None, # Deprecated\n **kwargs\n ):\n super().__init__(**kwargs)\n if image_properties is not None:\n validate_properties(image_properties)\n self.image_properties = image_properties\n else:\n self.image_properties = default_image_properties\n\n if max_num_categories is not None:\n warnings.warn(\n f'{self.__class__.__name__}: max_num_categories is deprecated. please use max_num_categories_for_drift '\n 'and max_num_categories_for_display instead',\n DeprecationWarning\n )\n max_num_categories_for_drift = max_num_categories_for_drift or max_num_categories\n max_num_categories_for_display = max_num_categories_for_display or max_num_categories\n self.max_num_categories_for_drift = max_num_categories_for_drift\n self.max_num_categories_for_display = max_num_categories_for_display\n self.show_categories_by = show_categories_by\n self.classes_to_display = classes_to_display\n self.min_samples = min_samples\n self._train_properties = None\n self._test_properties = None\n self._class_to_string = None\n\n def initialize_run(self, context: Context):\n \"\"\"Initialize self state, and validate the run context.\"\"\"\n self._class_to_string = context.train.label_id_to_name\n self._train_properties = defaultdict(list)\n self._test_properties = defaultdict(list)\n\n def update(\n self,\n context: Context,\n batch: Batch,\n dataset_kind: DatasetKind\n ):\n \"\"\"Calculate image properties for train or test batch.\"\"\"\n if dataset_kind == DatasetKind.TRAIN:\n properties = self._train_properties\n elif dataset_kind == DatasetKind.TEST:\n properties = self._test_properties\n else:\n raise RuntimeError(\n f'Internal Error - Should not reach here! unknown dataset_kind: {dataset_kind}'\n )\n\n images = batch.images\n\n if self.classes_to_display:\n # use only images belonging (or containing an annotation belonging) to one of the classes in\n # classes_to_display\n classes = context.train.get_classes(batch.labels)\n images = [\n image for idx, image in enumerate(images) if\n any(cls in map(self._class_to_string, classes[idx]) for cls in self.classes_to_display)\n ]\n\n for single_property in self.image_properties:\n property_list = single_property['method'](images)\n properties[single_property['name']].extend(property_list)\n\n def compute(self, context: Context) -> CheckResult:\n \"\"\"Calculate drift score between train and test datasets for the collected image properties.\n\n Returns\n -------\n CheckResult\n value: dictionary containing drift score for each image property.\n display: distribution graph for each image property.\n \"\"\"\n if sorted(self._train_properties.keys()) != sorted(self._test_properties.keys()):\n raise RuntimeError('Internal Error! Vision check was used improperly.')\n\n # if self.classes_to_display is set, check that it has classes that actually exist\n if self.classes_to_display is not None:\n if not set(self.classes_to_display).issubset(\n map(self._class_to_string, context.train.classes_indices.keys())\n ):\n raise DeepchecksValueError(\n f'Provided list of class ids to display {self.classes_to_display} not found in training dataset.'\n )\n\n properties = sorted(self._train_properties.keys())\n df_train = pd.DataFrame(self._train_properties)\n df_test = pd.DataFrame(self._test_properties)\n if len(df_train) < self.min_samples or len(df_test) < self.min_samples:\n raise NotEnoughSamplesError(\n f'Not enough samples to calculate drift score, minimum {self.min_samples} samples required'\n f', but got {len(df_train)} and {len(df_test)} samples in the train and test datasets.'\n 'Use \\'min_samples\\' parameter to change the requirement.'\n )\n\n figures = {}\n drifts = {}\n not_enough_samples = []\n\n for single_property in self.image_properties:\n property_name = single_property['name']\n\n try:\n score, _, figure = calc_drift_and_plot(\n train_column=df_train[property_name],\n test_column=df_test[property_name],\n value_name=property_name,\n column_type=get_column_type(single_property['output_type']),\n max_num_categories_for_drift=self.max_num_categories_for_drift,\n max_num_categories_for_display=self.max_num_categories_for_display,\n show_categories_by=self.show_categories_by,\n min_samples=self.min_samples\n )\n\n figures[property_name] = figure\n drifts[property_name] = score\n except NotEnoughSamplesError:\n not_enough_samples.append(property_name)\n\n if drifts:\n columns_order = sorted(properties, key=lambda col: drifts.get(col, 0), reverse=True)\n properties_to_display = [p for p in properties if p in drifts]\n\n headnote = '<span>' \\\n 'The Drift score is a measure for the difference between two distributions. ' \\\n 'In this check, drift is measured ' \\\n f'for the distribution of the following image properties: {properties_to_display}.<br>' \\\n '</span>'\n if not_enough_samples:\n headnote += f'<span>The following image properties do not have enough samples to calculate drift ' \\\n f'score: {not_enough_samples}</span>'\n\n displays = [headnote] + [figures[col] for col in columns_order if col in figures]\n else:\n drifts = None\n displays = []\n\n return CheckResult(\n value=drifts,\n display=displays,\n header='Image Property Drift'\n )\n\n def add_condition_drift_score_not_greater_than(\n self: TImagePropertyDrift,\n max_allowed_drift_score: float = 0.1\n ) -> TImagePropertyDrift:\n \"\"\"\n Add condition - require drift score to not be more than a certain threshold.\n\n Parameters\n ----------\n max_allowed_drift_score: float , default: 0.1\n the max threshold for the Earth Mover's Distance score\n\n Returns\n -------\n ConditionResult\n False if any column has passed the max threshold, True otherwise\n \"\"\"\n\n def condition(result: t.Dict[str, float]) -> ConditionResult:\n failed_properties = [\n (property_name, drift_score)\n for property_name, drift_score in result.items()\n if drift_score > max_allowed_drift_score\n ]\n if len(failed_properties) > 0:\n failed_properties = ';\\n'.join(f'{p}={d:.2f}' for p, d in failed_properties)\n return ConditionResult(\n False,\n 'Earth Mover\\'s Distance is above the threshold '\n f'for the next properties:\\n{failed_properties}'\n )\n return ConditionResult(ConditionCategory.PASS)\n\n return self.add_condition(\n f'Earth Mover\\'s Distance <= {max_allowed_drift_score} for image properties drift',\n condition\n )\n", "path": "deepchecks/vision/checks/distribution/image_property_drift.py"}], "after_files": [{"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021-2022 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\n\"\"\"Module contains Image Property Drift check.\"\"\"\nimport typing as t\nfrom collections import defaultdict\nimport warnings\nimport pandas as pd\n\nfrom deepchecks.core import CheckResult\nfrom deepchecks.core import ConditionResult\nfrom deepchecks.core import DatasetKind\nfrom deepchecks.core.errors import NotEnoughSamplesError, DeepchecksValueError\nfrom deepchecks.core.condition import ConditionCategory\nfrom deepchecks.utils.distribution.drift import calc_drift_and_plot\nfrom deepchecks.vision import Batch\nfrom deepchecks.vision import Context\nfrom deepchecks.vision import TrainTestCheck\nfrom deepchecks.vision.utils.image_properties import validate_properties, default_image_properties, get_column_type\n\n\n__all__ = ['ImagePropertyDrift']\n\n\nTImagePropertyDrift = t.TypeVar('TImagePropertyDrift', bound='ImagePropertyDrift')\n\n\nclass ImagePropertyDrift(TrainTestCheck):\n \"\"\"\n Calculate drift between train dataset and test dataset per image property, using statistical measures.\n\n Check calculates a drift score for each image property in test dataset, by comparing its distribution to the train\n dataset. For this, we use the Earth Movers Distance.\n\n See https://en.wikipedia.org/wiki/Wasserstein_metric\n\n Parameters\n ----------\n image_properties : List[Dict[str, Any]], default: None\n List of properties. Replaces the default deepchecks properties.\n Each property is dictionary with keys 'name' (str), 'method' (Callable) and 'output_type' (str),\n representing attributes of said method. 'output_type' must be one of 'continuous'/'discrete'\n max_num_categories_for_drift: int, default: 10\n Only for non-continuous properties. Max number of allowed categories. If there are more,\n they are binned into an \"Other\" category. If None, there is no limit.\n max_num_categories_for_display: int, default: 10\n Max number of categories to show in plot.\n show_categories_by: str, default: 'train_largest'\n Specify which categories to show for categorical features' graphs, as the number of shown categories is limited\n by max_num_categories_for_display. Possible values:\n - 'train_largest': Show the largest train categories.\n - 'test_largest': Show the largest test categories.\n - 'largest_difference': Show the largest difference between categories.\n classes_to_display : Optional[List[float]], default: None\n List of classes to display. The distribution of the properties would include only samples belonging (or\n containing an annotation belonging) to one of these classes. If None, samples from all classes are displayed.\n min_samples: int, default: 10\n Minimum number of samples needed in each dataset needed to calculate the drift.\n max_num_categories: int, default: None\n Deprecated. Please use max_num_categories_for_drift and max_num_categories_for_display instead\n \"\"\"\n\n def __init__(\n self,\n image_properties: t.List[t.Dict[str, t.Any]] = None,\n max_num_categories_for_drift: int = 10,\n max_num_categories_for_display: int = 10,\n show_categories_by: str = 'train_largest',\n classes_to_display: t.Optional[t.List[str]] = None,\n min_samples: int = 30,\n max_num_categories: int = None, # Deprecated\n **kwargs\n ):\n super().__init__(**kwargs)\n if image_properties is not None:\n validate_properties(image_properties)\n self.image_properties = image_properties\n else:\n self.image_properties = default_image_properties\n\n if max_num_categories is not None:\n warnings.warn(\n f'{self.__class__.__name__}: max_num_categories is deprecated. please use max_num_categories_for_drift '\n 'and max_num_categories_for_display instead',\n DeprecationWarning\n )\n max_num_categories_for_drift = max_num_categories_for_drift or max_num_categories\n max_num_categories_for_display = max_num_categories_for_display or max_num_categories\n self.max_num_categories_for_drift = max_num_categories_for_drift\n self.max_num_categories_for_display = max_num_categories_for_display\n self.show_categories_by = show_categories_by\n self.classes_to_display = classes_to_display\n self.min_samples = min_samples\n self._train_properties = None\n self._test_properties = None\n self._class_to_string = None\n\n def initialize_run(self, context: Context):\n \"\"\"Initialize self state, and validate the run context.\"\"\"\n self._class_to_string = context.train.label_id_to_name\n self._train_properties = defaultdict(list)\n self._test_properties = defaultdict(list)\n\n def update(\n self,\n context: Context,\n batch: Batch,\n dataset_kind: DatasetKind\n ):\n \"\"\"Calculate image properties for train or test batch.\"\"\"\n if dataset_kind == DatasetKind.TRAIN:\n properties = self._train_properties\n elif dataset_kind == DatasetKind.TEST:\n properties = self._test_properties\n else:\n raise RuntimeError(\n f'Internal Error - Should not reach here! unknown dataset_kind: {dataset_kind}'\n )\n\n images = batch.images\n\n if self.classes_to_display:\n # use only images belonging (or containing an annotation belonging) to one of the classes in\n # classes_to_display\n classes = context.train.get_classes(batch.labels)\n images = [\n image for idx, image in enumerate(images) if\n any(cls in map(self._class_to_string, classes[idx]) for cls in self.classes_to_display)\n ]\n\n for single_property in self.image_properties:\n property_list = single_property['method'](images)\n properties[single_property['name']].extend(property_list)\n\n def compute(self, context: Context) -> CheckResult:\n \"\"\"Calculate drift score between train and test datasets for the collected image properties.\n\n Returns\n -------\n CheckResult\n value: dictionary containing drift score for each image property.\n display: distribution graph for each image property.\n \"\"\"\n if sorted(self._train_properties.keys()) != sorted(self._test_properties.keys()):\n raise RuntimeError('Internal Error! Vision check was used improperly.')\n\n # if self.classes_to_display is set, check that it has classes that actually exist\n if self.classes_to_display is not None:\n if not set(self.classes_to_display).issubset(\n map(self._class_to_string, context.train.classes_indices.keys())\n ):\n raise DeepchecksValueError(\n f'Provided list of class ids to display {self.classes_to_display} not found in training dataset.'\n )\n\n properties = sorted(self._train_properties.keys())\n df_train = pd.DataFrame(self._train_properties)\n df_test = pd.DataFrame(self._test_properties)\n if len(df_train) < self.min_samples or len(df_test) < self.min_samples:\n raise NotEnoughSamplesError(\n f'Not enough samples to calculate drift score, minimum {self.min_samples} samples required'\n f', but got {len(df_train)} and {len(df_test)} samples in the train and test datasets.'\n 'Use \\'min_samples\\' parameter to change the requirement.'\n )\n\n figures = {}\n drifts = {}\n not_enough_samples = []\n\n for single_property in self.image_properties:\n property_name = single_property['name']\n\n try:\n score, _, figure = calc_drift_and_plot(\n train_column=df_train[property_name],\n test_column=df_test[property_name],\n value_name=property_name,\n column_type=get_column_type(single_property['output_type']),\n max_num_categories_for_drift=self.max_num_categories_for_drift,\n max_num_categories_for_display=self.max_num_categories_for_display,\n show_categories_by=self.show_categories_by,\n min_samples=self.min_samples\n )\n\n figures[property_name] = figure\n drifts[property_name] = score\n except NotEnoughSamplesError:\n not_enough_samples.append(property_name)\n\n if drifts:\n columns_order = sorted(properties, key=lambda col: drifts.get(col, 0), reverse=True)\n properties_to_display = [p for p in properties if p in drifts]\n\n headnote = '<span>' \\\n 'The Drift score is a measure for the difference between two distributions. ' \\\n 'In this check, drift is measured ' \\\n f'for the distribution of the following image properties: {properties_to_display}.<br>' \\\n '</span>'\n if not_enough_samples:\n headnote += f'<span>The following image properties do not have enough samples to calculate drift ' \\\n f'score: {not_enough_samples}</span>'\n\n displays = [headnote] + [figures[col] for col in columns_order if col in figures]\n else:\n drifts = None\n displays = []\n\n return CheckResult(\n value=drifts,\n display=displays,\n header='Image Property Drift'\n )\n\n def add_condition_drift_score_not_greater_than(\n self: TImagePropertyDrift,\n max_allowed_drift_score: float = 0.1\n ) -> TImagePropertyDrift:\n \"\"\"\n Add condition - require drift score to not be more than a certain threshold.\n\n Parameters\n ----------\n max_allowed_drift_score: float , default: 0.1\n the max threshold for the Earth Mover's Distance score\n\n Returns\n -------\n ConditionResult\n False if any column has passed the max threshold, True otherwise\n \"\"\"\n\n def condition(result: t.Dict[str, float]) -> ConditionResult:\n failed_properties = [\n (property_name, drift_score)\n for property_name, drift_score in result.items()\n if drift_score > max_allowed_drift_score\n ]\n if len(failed_properties) > 0:\n failed_properties = ';\\n'.join(f'{p}={d:.2f}' for p, d in failed_properties)\n return ConditionResult(\n ConditionCategory.FAIL,\n 'Earth Mover\\'s Distance is above the threshold '\n f'for the next properties:\\n{failed_properties}'\n )\n return ConditionResult(ConditionCategory.PASS)\n\n return self.add_condition(\n f'Earth Mover\\'s Distance <= {max_allowed_drift_score} for image properties drift',\n condition\n )\n", "path": "deepchecks/vision/checks/distribution/image_property_drift.py"}]}
| 3,421 | 163 |
gh_patches_debug_9058
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-11992
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Wagtail 6.1.x update breaks `RadioSelect` initialiastion after replacing jQuery with vanilla JS
### Issue Summary
Wagtail 6.1.x update breaks `RadioSelect` initialiastion after replacing jQuery with vanilla JS.
The JS adapter [`BoundRadioSelect`](https://github.com/wagtail/wagtail/blob/main/client/src/entrypoints/admin/telepath/widgets.js#L150) previously tested and set the checked option by comparing the element value against an array value - an array value is passed to the constructor:
#### Wagtail 6.0 implementation
```
setState(state) {
this.element.find('input[name="' + this.name + '"]').val([state]);
}
```
It now tests against a string, and the equality operator fails, so the radio option is not correctly set as `checked` on initialisation:
#### Wagtail 6.1.x implementation
```
setState(state) {
const inputs = this.element.querySelectorAll(`input[name="${this.name}"]`);
for (let i = 0; i < inputs.length; i += 1) {
inputs[i].checked = inputs[i].value === state;
}
}
```
The breaking change is here:
https://github.com/wagtail/wagtail/compare/v6.0.3...v6.1#diff-70fd977dfb7c5b823eab70485fa842987589fc8656203ffb729a4b7d688c1d04L130
### Steps to Reproduce
1. Use a choice block within a Streamfield such as:
```
link_type = blocks.ChoiceBlock(
choices=[
('page', 'Page'),
('document', 'Document'),
('url', 'URL'),
],
widget=forms.RadioSelect,
required=True,
default='page',
)
```
2. View/edit a page/snippet where this field is used
3. In Wagtail 6.0.x the first choice is `checked` as expected
4. In Wagtail 6.1.x the first choice is not `checked` as expected
- I have confirmed that this issue can be reproduced as described on a fresh Wagtail project: yes
### Technical details
- Python version: Python 3.12.3
- Django version: 5.0.6
- Wagtail version: 6.1.x
- Browser version: Chrome 125
### Working on this
Anyone can contribute to this. View our [contributing guidelines](https://docs.wagtail.org/en/latest/contributing/index.html), add a comment to the issue once you’re ready to start.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `wagtail/widget_adapters.py`
Content:
```
1 """
2 Register Telepath adapters for core Django form widgets, so that they can
3 have corresponding Javascript objects with the ability to render new instances
4 and extract field values.
5 """
6
7 from django import forms
8 from django.core.exceptions import ValidationError
9 from django.utils.functional import cached_property
10
11 from wagtail.admin.staticfiles import versioned_static
12 from wagtail.telepath import Adapter, register
13
14
15 class WidgetAdapter(Adapter):
16 js_constructor = "wagtail.widgets.Widget"
17
18 def js_args(self, widget):
19 return [
20 widget.render("__NAME__", None, attrs={"id": "__ID__"}),
21 widget.id_for_label("__ID__"),
22 ]
23
24 def get_media(self, widget):
25 media = super().get_media(widget)
26 return media + widget.media
27
28 @cached_property
29 def media(self):
30 return forms.Media(
31 js=[
32 versioned_static("wagtailadmin/js/telepath/widgets.js"),
33 ]
34 )
35
36
37 register(WidgetAdapter(), forms.widgets.Input)
38 register(WidgetAdapter(), forms.Textarea)
39 register(WidgetAdapter(), forms.CheckboxSelectMultiple)
40
41
42 class CheckboxInputAdapter(WidgetAdapter):
43 js_constructor = "wagtail.widgets.CheckboxInput"
44
45
46 register(CheckboxInputAdapter(), forms.CheckboxInput)
47
48
49 class RadioSelectAdapter(WidgetAdapter):
50 js_constructor = "wagtail.widgets.RadioSelect"
51
52
53 register(RadioSelectAdapter(), forms.RadioSelect)
54
55
56 class SelectAdapter(WidgetAdapter):
57 js_constructor = "wagtail.widgets.Select"
58
59
60 register(SelectAdapter(), forms.Select)
61
62
63 class ValidationErrorAdapter(Adapter):
64 js_constructor = "wagtail.errors.ValidationError"
65
66 def js_args(self, error):
67 return [
68 error.messages,
69 ]
70
71 @cached_property
72 def media(self):
73 return forms.Media(
74 js=[
75 versioned_static("wagtailadmin/js/telepath/widgets.js"),
76 ]
77 )
78
79
80 register(ValidationErrorAdapter(), ValidationError)
81
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/wagtail/widget_adapters.py b/wagtail/widget_adapters.py
--- a/wagtail/widget_adapters.py
+++ b/wagtail/widget_adapters.py
@@ -36,7 +36,6 @@
register(WidgetAdapter(), forms.widgets.Input)
register(WidgetAdapter(), forms.Textarea)
-register(WidgetAdapter(), forms.CheckboxSelectMultiple)
class CheckboxInputAdapter(WidgetAdapter):
@@ -51,6 +50,7 @@
register(RadioSelectAdapter(), forms.RadioSelect)
+register(RadioSelectAdapter(), forms.CheckboxSelectMultiple)
class SelectAdapter(WidgetAdapter):
|
{"golden_diff": "diff --git a/wagtail/widget_adapters.py b/wagtail/widget_adapters.py\n--- a/wagtail/widget_adapters.py\n+++ b/wagtail/widget_adapters.py\n@@ -36,7 +36,6 @@\n \n register(WidgetAdapter(), forms.widgets.Input)\n register(WidgetAdapter(), forms.Textarea)\n-register(WidgetAdapter(), forms.CheckboxSelectMultiple)\n \n \n class CheckboxInputAdapter(WidgetAdapter):\n@@ -51,6 +50,7 @@\n \n \n register(RadioSelectAdapter(), forms.RadioSelect)\n+register(RadioSelectAdapter(), forms.CheckboxSelectMultiple)\n \n \n class SelectAdapter(WidgetAdapter):\n", "issue": "Wagtail 6.1.x update breaks `RadioSelect` initialiastion after replacing jQuery with vanilla JS\n### Issue Summary\r\n\r\nWagtail 6.1.x update breaks `RadioSelect` initialiastion after replacing jQuery with vanilla JS. \r\n\r\nThe JS adapter [`BoundRadioSelect`](https://github.com/wagtail/wagtail/blob/main/client/src/entrypoints/admin/telepath/widgets.js#L150) previously tested and set the checked option by comparing the element value against an array value - an array value is passed to the constructor:\r\n\r\n#### Wagtail 6.0 implementation\r\n```\r\nsetState(state) {\r\n this.element.find('input[name=\"' + this.name + '\"]').val([state]);\r\n}\r\n```\r\n\r\nIt now tests against a string, and the equality operator fails, so the radio option is not correctly set as `checked` on initialisation:\r\n\r\n#### Wagtail 6.1.x implementation\r\n```\r\n setState(state) {\r\n const inputs = this.element.querySelectorAll(`input[name=\"${this.name}\"]`);\r\n for (let i = 0; i < inputs.length; i += 1) {\r\n inputs[i].checked = inputs[i].value === state;\r\n }\r\n }\r\n ```\r\n\r\nThe breaking change is here:\r\n\r\nhttps://github.com/wagtail/wagtail/compare/v6.0.3...v6.1#diff-70fd977dfb7c5b823eab70485fa842987589fc8656203ffb729a4b7d688c1d04L130\r\n\r\n### Steps to Reproduce\r\n\r\n1. Use a choice block within a Streamfield such as:\r\n\r\n```\r\nlink_type = blocks.ChoiceBlock(\r\n choices=[\r\n ('page', 'Page'),\r\n ('document', 'Document'),\r\n ('url', 'URL'),\r\n ],\r\n widget=forms.RadioSelect,\r\n required=True,\r\n default='page',\r\n)\r\n```\r\n2. View/edit a page/snippet where this field is used\r\n3. In Wagtail 6.0.x the first choice is `checked` as expected\r\n4. In Wagtail 6.1.x the first choice is not `checked` as expected\r\n\r\n- I have confirmed that this issue can be reproduced as described on a fresh Wagtail project: yes\r\n\r\n### Technical details\r\n\r\n- Python version: Python 3.12.3\r\n- Django version: 5.0.6\r\n- Wagtail version: 6.1.x\r\n- Browser version: Chrome 125\r\n\r\n### Working on this\r\n\r\nAnyone can contribute to this. View our [contributing guidelines](https://docs.wagtail.org/en/latest/contributing/index.html), add a comment to the issue once you\u2019re ready to start.\r\n\n", "before_files": [{"content": "\"\"\"\nRegister Telepath adapters for core Django form widgets, so that they can\nhave corresponding Javascript objects with the ability to render new instances\nand extract field values.\n\"\"\"\n\nfrom django import forms\nfrom django.core.exceptions import ValidationError\nfrom django.utils.functional import cached_property\n\nfrom wagtail.admin.staticfiles import versioned_static\nfrom wagtail.telepath import Adapter, register\n\n\nclass WidgetAdapter(Adapter):\n js_constructor = \"wagtail.widgets.Widget\"\n\n def js_args(self, widget):\n return [\n widget.render(\"__NAME__\", None, attrs={\"id\": \"__ID__\"}),\n widget.id_for_label(\"__ID__\"),\n ]\n\n def get_media(self, widget):\n media = super().get_media(widget)\n return media + widget.media\n\n @cached_property\n def media(self):\n return forms.Media(\n js=[\n versioned_static(\"wagtailadmin/js/telepath/widgets.js\"),\n ]\n )\n\n\nregister(WidgetAdapter(), forms.widgets.Input)\nregister(WidgetAdapter(), forms.Textarea)\nregister(WidgetAdapter(), forms.CheckboxSelectMultiple)\n\n\nclass CheckboxInputAdapter(WidgetAdapter):\n js_constructor = \"wagtail.widgets.CheckboxInput\"\n\n\nregister(CheckboxInputAdapter(), forms.CheckboxInput)\n\n\nclass RadioSelectAdapter(WidgetAdapter):\n js_constructor = \"wagtail.widgets.RadioSelect\"\n\n\nregister(RadioSelectAdapter(), forms.RadioSelect)\n\n\nclass SelectAdapter(WidgetAdapter):\n js_constructor = \"wagtail.widgets.Select\"\n\n\nregister(SelectAdapter(), forms.Select)\n\n\nclass ValidationErrorAdapter(Adapter):\n js_constructor = \"wagtail.errors.ValidationError\"\n\n def js_args(self, error):\n return [\n error.messages,\n ]\n\n @cached_property\n def media(self):\n return forms.Media(\n js=[\n versioned_static(\"wagtailadmin/js/telepath/widgets.js\"),\n ]\n )\n\n\nregister(ValidationErrorAdapter(), ValidationError)\n", "path": "wagtail/widget_adapters.py"}], "after_files": [{"content": "\"\"\"\nRegister Telepath adapters for core Django form widgets, so that they can\nhave corresponding Javascript objects with the ability to render new instances\nand extract field values.\n\"\"\"\n\nfrom django import forms\nfrom django.core.exceptions import ValidationError\nfrom django.utils.functional import cached_property\n\nfrom wagtail.admin.staticfiles import versioned_static\nfrom wagtail.telepath import Adapter, register\n\n\nclass WidgetAdapter(Adapter):\n js_constructor = \"wagtail.widgets.Widget\"\n\n def js_args(self, widget):\n return [\n widget.render(\"__NAME__\", None, attrs={\"id\": \"__ID__\"}),\n widget.id_for_label(\"__ID__\"),\n ]\n\n def get_media(self, widget):\n media = super().get_media(widget)\n return media + widget.media\n\n @cached_property\n def media(self):\n return forms.Media(\n js=[\n versioned_static(\"wagtailadmin/js/telepath/widgets.js\"),\n ]\n )\n\n\nregister(WidgetAdapter(), forms.widgets.Input)\nregister(WidgetAdapter(), forms.Textarea)\n\n\nclass CheckboxInputAdapter(WidgetAdapter):\n js_constructor = \"wagtail.widgets.CheckboxInput\"\n\n\nregister(CheckboxInputAdapter(), forms.CheckboxInput)\n\n\nclass RadioSelectAdapter(WidgetAdapter):\n js_constructor = \"wagtail.widgets.RadioSelect\"\n\n\nregister(RadioSelectAdapter(), forms.RadioSelect)\nregister(RadioSelectAdapter(), forms.CheckboxSelectMultiple)\n\n\nclass SelectAdapter(WidgetAdapter):\n js_constructor = \"wagtail.widgets.Select\"\n\n\nregister(SelectAdapter(), forms.Select)\n\n\nclass ValidationErrorAdapter(Adapter):\n js_constructor = \"wagtail.errors.ValidationError\"\n\n def js_args(self, error):\n return [\n error.messages,\n ]\n\n @cached_property\n def media(self):\n return forms.Media(\n js=[\n versioned_static(\"wagtailadmin/js/telepath/widgets.js\"),\n ]\n )\n\n\nregister(ValidationErrorAdapter(), ValidationError)\n", "path": "wagtail/widget_adapters.py"}]}
| 1,435 | 136 |
gh_patches_debug_14443
|
rasdani/github-patches
|
git_diff
|
aws__aws-cli-4231
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Check if AWS::Include location is a string before packacing. Fixes #4087
Fixes #4087
If the value of Location in AWS::Include is *not* a string, we should skip
packaging it. This can happen if customers use, say, an intrinsic function
to construct the Include location:
Example:
```
AWS::Include:
Location:
Fn::Sub: "${S3Bucket}/file.txt"
```
*Issue #, if available:*
*Description of changes:*
By submitting this pull request, I confirm that you can use, modify, copy, and redistribute this contribution, under the terms of your choice.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 import codecs
3 import os.path
4 import re
5 import sys
6
7 from setuptools import setup, find_packages
8
9
10 here = os.path.abspath(os.path.dirname(__file__))
11
12
13 def read(*parts):
14 return codecs.open(os.path.join(here, *parts), 'r').read()
15
16
17 def find_version(*file_paths):
18 version_file = read(*file_paths)
19 version_match = re.search(r"^__version__ = ['\"]([^'\"]*)['\"]",
20 version_file, re.M)
21 if version_match:
22 return version_match.group(1)
23 raise RuntimeError("Unable to find version string.")
24
25
26 requires = ['botocore==1.12.165',
27 'colorama>=0.2.5,<=0.3.9',
28 'docutils>=0.10',
29 'rsa>=3.1.2,<=3.5.0',
30 's3transfer>=0.2.0,<0.3.0',
31 'PyYAML>=3.10,<=3.13']
32
33
34 if sys.version_info[:2] == (2, 6):
35 # For python2.6 we have to require argparse since it
36 # was not in stdlib until 2.7.
37 requires.append('argparse>=1.1')
38
39
40 setup_options = dict(
41 name='awscli',
42 version=find_version("awscli", "__init__.py"),
43 description='Universal Command Line Environment for AWS.',
44 long_description=read('README.rst'),
45 author='Amazon Web Services',
46 url='http://aws.amazon.com/cli/',
47 scripts=['bin/aws', 'bin/aws.cmd',
48 'bin/aws_completer', 'bin/aws_zsh_completer.sh',
49 'bin/aws_bash_completer'],
50 packages=find_packages(exclude=['tests*']),
51 package_data={'awscli': ['data/*.json', 'examples/*/*.rst',
52 'examples/*/*/*.rst', 'topics/*.rst',
53 'topics/*.json']},
54 install_requires=requires,
55 extras_require={
56 ':python_version=="2.6"': [
57 'argparse>=1.1',
58 ]
59 },
60 license="Apache License 2.0",
61 classifiers=[
62 'Development Status :: 5 - Production/Stable',
63 'Intended Audience :: Developers',
64 'Intended Audience :: System Administrators',
65 'Natural Language :: English',
66 'License :: OSI Approved :: Apache Software License',
67 'Programming Language :: Python',
68 'Programming Language :: Python :: 2',
69 'Programming Language :: Python :: 2.6',
70 'Programming Language :: Python :: 2.7',
71 'Programming Language :: Python :: 3',
72 'Programming Language :: Python :: 3.3',
73 'Programming Language :: Python :: 3.4',
74 'Programming Language :: Python :: 3.5',
75 'Programming Language :: Python :: 3.6',
76 'Programming Language :: Python :: 3.7',
77 ],
78 )
79
80 if 'py2exe' in sys.argv:
81 # This will actually give us a py2exe command.
82 import py2exe
83 # And we have some py2exe specific options.
84 setup_options['options'] = {
85 'py2exe': {
86 'optimize': 0,
87 'skip_archive': True,
88 'dll_excludes': ['crypt32.dll'],
89 'packages': ['docutils', 'urllib', 'httplib', 'HTMLParser',
90 'awscli', 'ConfigParser', 'xml.etree', 'pipes'],
91 }
92 }
93 setup_options['console'] = ['bin/aws']
94
95
96 setup(**setup_options)
97
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -27,8 +27,7 @@
'colorama>=0.2.5,<=0.3.9',
'docutils>=0.10',
'rsa>=3.1.2,<=3.5.0',
- 's3transfer>=0.2.0,<0.3.0',
- 'PyYAML>=3.10,<=3.13']
+ 's3transfer>=0.2.0,<0.3.0']
if sys.version_info[:2] == (2, 6):
@@ -36,6 +35,12 @@
# was not in stdlib until 2.7.
requires.append('argparse>=1.1')
+ # For Python 2.6, we have to require a different verion of PyYAML since the latest
+ # versions dropped support for Python 2.6.
+ requires.append('PyYAML>=3.10,<=3.13')
+else:
+ requires.append('PyYAML>=3.10,<=5.1')
+
setup_options = dict(
name='awscli',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -27,8 +27,7 @@\n 'colorama>=0.2.5,<=0.3.9',\n 'docutils>=0.10',\n 'rsa>=3.1.2,<=3.5.0',\n- 's3transfer>=0.2.0,<0.3.0',\n- 'PyYAML>=3.10,<=3.13']\n+ 's3transfer>=0.2.0,<0.3.0']\n \n \n if sys.version_info[:2] == (2, 6):\n@@ -36,6 +35,12 @@\n # was not in stdlib until 2.7.\n requires.append('argparse>=1.1')\n \n+ # For Python 2.6, we have to require a different verion of PyYAML since the latest\n+ # versions dropped support for Python 2.6.\n+ requires.append('PyYAML>=3.10,<=3.13')\n+else:\n+ requires.append('PyYAML>=3.10,<=5.1')\n+\n \n setup_options = dict(\n name='awscli',\n", "issue": "Check if AWS::Include location is a string before packacing. Fixes #4087\nFixes #4087 \r\n\r\nIf the value of Location in AWS::Include is *not* a string, we should skip\r\npackaging it. This can happen if customers use, say, an intrinsic function\r\nto construct the Include location:\r\n\r\nExample:\r\n```\r\nAWS::Include:\r\n Location:\r\n Fn::Sub: \"${S3Bucket}/file.txt\"\r\n```\r\n\r\n*Issue #, if available:*\r\n\r\n*Description of changes:*\r\n\r\n\r\nBy submitting this pull request, I confirm that you can use, modify, copy, and redistribute this contribution, under the terms of your choice.\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\nimport codecs\nimport os.path\nimport re\nimport sys\n\nfrom setuptools import setup, find_packages\n\n\nhere = os.path.abspath(os.path.dirname(__file__))\n\n\ndef read(*parts):\n return codecs.open(os.path.join(here, *parts), 'r').read()\n\n\ndef find_version(*file_paths):\n version_file = read(*file_paths)\n version_match = re.search(r\"^__version__ = ['\\\"]([^'\\\"]*)['\\\"]\",\n version_file, re.M)\n if version_match:\n return version_match.group(1)\n raise RuntimeError(\"Unable to find version string.\")\n\n\nrequires = ['botocore==1.12.165',\n 'colorama>=0.2.5,<=0.3.9',\n 'docutils>=0.10',\n 'rsa>=3.1.2,<=3.5.0',\n 's3transfer>=0.2.0,<0.3.0',\n 'PyYAML>=3.10,<=3.13']\n\n\nif sys.version_info[:2] == (2, 6):\n # For python2.6 we have to require argparse since it\n # was not in stdlib until 2.7.\n requires.append('argparse>=1.1')\n\n\nsetup_options = dict(\n name='awscli',\n version=find_version(\"awscli\", \"__init__.py\"),\n description='Universal Command Line Environment for AWS.',\n long_description=read('README.rst'),\n author='Amazon Web Services',\n url='http://aws.amazon.com/cli/',\n scripts=['bin/aws', 'bin/aws.cmd',\n 'bin/aws_completer', 'bin/aws_zsh_completer.sh',\n 'bin/aws_bash_completer'],\n packages=find_packages(exclude=['tests*']),\n package_data={'awscli': ['data/*.json', 'examples/*/*.rst',\n 'examples/*/*/*.rst', 'topics/*.rst',\n 'topics/*.json']},\n install_requires=requires,\n extras_require={\n ':python_version==\"2.6\"': [\n 'argparse>=1.1',\n ]\n },\n license=\"Apache License 2.0\",\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'Intended Audience :: System Administrators',\n 'Natural Language :: English',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.6',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n ],\n)\n\nif 'py2exe' in sys.argv:\n # This will actually give us a py2exe command.\n import py2exe\n # And we have some py2exe specific options.\n setup_options['options'] = {\n 'py2exe': {\n 'optimize': 0,\n 'skip_archive': True,\n 'dll_excludes': ['crypt32.dll'],\n 'packages': ['docutils', 'urllib', 'httplib', 'HTMLParser',\n 'awscli', 'ConfigParser', 'xml.etree', 'pipes'],\n }\n }\n setup_options['console'] = ['bin/aws']\n\n\nsetup(**setup_options)\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\nimport codecs\nimport os.path\nimport re\nimport sys\n\nfrom setuptools import setup, find_packages\n\n\nhere = os.path.abspath(os.path.dirname(__file__))\n\n\ndef read(*parts):\n return codecs.open(os.path.join(here, *parts), 'r').read()\n\n\ndef find_version(*file_paths):\n version_file = read(*file_paths)\n version_match = re.search(r\"^__version__ = ['\\\"]([^'\\\"]*)['\\\"]\",\n version_file, re.M)\n if version_match:\n return version_match.group(1)\n raise RuntimeError(\"Unable to find version string.\")\n\n\nrequires = ['botocore==1.12.165',\n 'colorama>=0.2.5,<=0.3.9',\n 'docutils>=0.10',\n 'rsa>=3.1.2,<=3.5.0',\n 's3transfer>=0.2.0,<0.3.0']\n\n\nif sys.version_info[:2] == (2, 6):\n # For python2.6 we have to require argparse since it\n # was not in stdlib until 2.7.\n requires.append('argparse>=1.1')\n\n # For Python 2.6, we have to require a different verion of PyYAML since the latest\n # versions dropped support for Python 2.6.\n requires.append('PyYAML>=3.10,<=3.13')\nelse:\n requires.append('PyYAML>=3.10,<=5.1')\n\n\nsetup_options = dict(\n name='awscli',\n version=find_version(\"awscli\", \"__init__.py\"),\n description='Universal Command Line Environment for AWS.',\n long_description=read('README.rst'),\n author='Amazon Web Services',\n url='http://aws.amazon.com/cli/',\n scripts=['bin/aws', 'bin/aws.cmd',\n 'bin/aws_completer', 'bin/aws_zsh_completer.sh',\n 'bin/aws_bash_completer'],\n packages=find_packages(exclude=['tests*']),\n package_data={'awscli': ['data/*.json', 'examples/*/*.rst',\n 'examples/*/*/*.rst', 'topics/*.rst',\n 'topics/*.json']},\n install_requires=requires,\n extras_require={\n ':python_version==\"2.6\"': [\n 'argparse>=1.1',\n ]\n },\n license=\"Apache License 2.0\",\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'Intended Audience :: System Administrators',\n 'Natural Language :: English',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.6',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n ],\n)\n\nif 'py2exe' in sys.argv:\n # This will actually give us a py2exe command.\n import py2exe\n # And we have some py2exe specific options.\n setup_options['options'] = {\n 'py2exe': {\n 'optimize': 0,\n 'skip_archive': True,\n 'dll_excludes': ['crypt32.dll'],\n 'packages': ['docutils', 'urllib', 'httplib', 'HTMLParser',\n 'awscli', 'ConfigParser', 'xml.etree', 'pipes'],\n }\n }\n setup_options['console'] = ['bin/aws']\n\n\nsetup(**setup_options)\n", "path": "setup.py"}]}
| 1,371 | 280 |
gh_patches_debug_47631
|
rasdani/github-patches
|
git_diff
|
python-poetry__poetry-1481
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`~=` version constraints (PEP 440) do not correctly set the lower version
<!--
Hi there! Thank you for discovering and submitting an issue.
Before you submit this; let's make sure of a few things.
Please make sure the following boxes are ticked if they are correct.
If not, please try and fulfill these first.
-->
<!-- Checked checkbox should look like this: [x] -->
- [x] I am on the [latest](https://github.com/sdispater/poetry/releases/latest) Poetry version.
- [x] I have searched the [issues](https://github.com/sdispater/poetry/issues) of this repo and believe that this is not a duplicate.
- [x] If an exception occurs when executing a command, I executed it again in debug mode (`-vvv` option).
<!--
Once those are done, if you're able to fill in the following list with your information,
it'd be very helpful to whoever handles the issue.
-->
- **OS version and name**: Windows 10
- **Poetry version**: 0.12.16
- **Link of a [Gist](https://gist.github.com/) with the contents of your pyproject.toml file**: N/A
## Issue
<!-- Now feel free to write your issue, but please be descriptive! Thanks again 🙌 ❤️ -->
Found this while fixing handling of pre-release (#1150)
PEP 440 says
- `~=V.N` maps to `>= V.N, == V.*`
Examples
```
~= 2.2
>= 2.2, == 2.*
~= 1.4.5
>= 1.4.5, == 1.4.*
~= 2.2.0
>= 2.2.0, == 2.2.*
~= 1.4.5.0
>= 1.4.5.0, == 1.4.5.*
```
but looking at the tests `~=3.5.3` maps to `>=3.5.0, < 3.6` when it should map to `>=3.5.3, <3.6`. The trailing `3` should be setting the floor for the version
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `poetry/semver/__init__.py`
Content:
```
1 import re
2
3 from .empty_constraint import EmptyConstraint
4 from .patterns import BASIC_CONSTRAINT
5 from .patterns import CARET_CONSTRAINT
6 from .patterns import TILDE_CONSTRAINT
7 from .patterns import TILDE_PEP440_CONSTRAINT
8 from .patterns import X_CONSTRAINT
9 from .version import Version
10 from .version_constraint import VersionConstraint
11 from .version_range import VersionRange
12 from .version_union import VersionUnion
13
14
15 def parse_constraint(constraints): # type: (str) -> VersionConstraint
16 if constraints == "*":
17 return VersionRange()
18
19 or_constraints = re.split(r"\s*\|\|?\s*", constraints.strip())
20 or_groups = []
21 for constraints in or_constraints:
22 and_constraints = re.split(
23 "(?<!^)(?<![=>< ,]) *(?<!-)[, ](?!-) *(?!,|$)", constraints
24 )
25 constraint_objects = []
26
27 if len(and_constraints) > 1:
28 for constraint in and_constraints:
29 constraint_objects.append(parse_single_constraint(constraint))
30 else:
31 constraint_objects.append(parse_single_constraint(and_constraints[0]))
32
33 if len(constraint_objects) == 1:
34 constraint = constraint_objects[0]
35 else:
36 constraint = constraint_objects[0]
37 for next_constraint in constraint_objects[1:]:
38 constraint = constraint.intersect(next_constraint)
39
40 or_groups.append(constraint)
41
42 if len(or_groups) == 1:
43 return or_groups[0]
44 else:
45 return VersionUnion.of(*or_groups)
46
47
48 def parse_single_constraint(constraint): # type: (str) -> VersionConstraint
49 m = re.match(r"(?i)^v?[xX*](\.[xX*])*$", constraint)
50 if m:
51 return VersionRange()
52
53 # Tilde range
54 m = TILDE_CONSTRAINT.match(constraint)
55 if m:
56 version = Version.parse(m.group(1))
57
58 high = version.stable.next_minor
59 if len(m.group(1).split(".")) == 1:
60 high = version.stable.next_major
61
62 return VersionRange(
63 version, high, include_min=True, always_include_max_prerelease=True
64 )
65
66 # PEP 440 Tilde range (~=)
67 m = TILDE_PEP440_CONSTRAINT.match(constraint)
68 if m:
69 precision = 1
70 if m.group(3):
71 precision += 1
72
73 if m.group(4):
74 precision += 1
75
76 version = Version.parse(m.group(1))
77
78 if precision == 2:
79 low = version
80 high = version.stable.next_major
81 else:
82 low = Version(version.major, version.minor, 0)
83 high = version.stable.next_minor
84
85 return VersionRange(
86 low, high, include_min=True, always_include_max_prerelease=True
87 )
88
89 # Caret range
90 m = CARET_CONSTRAINT.match(constraint)
91 if m:
92 version = Version.parse(m.group(1))
93
94 return VersionRange(
95 version,
96 version.next_breaking,
97 include_min=True,
98 always_include_max_prerelease=True,
99 )
100
101 # X Range
102 m = X_CONSTRAINT.match(constraint)
103 if m:
104 op = m.group(1)
105 major = int(m.group(2))
106 minor = m.group(3)
107
108 if minor is not None:
109 version = Version(major, int(minor), 0)
110
111 result = VersionRange(
112 version,
113 version.next_minor,
114 include_min=True,
115 always_include_max_prerelease=True,
116 )
117 else:
118 if major == 0:
119 result = VersionRange(max=Version(1, 0, 0))
120 else:
121 version = Version(major, 0, 0)
122
123 result = VersionRange(
124 version,
125 version.next_major,
126 include_min=True,
127 always_include_max_prerelease=True,
128 )
129
130 if op == "!=":
131 result = VersionRange().difference(result)
132
133 return result
134
135 # Basic comparator
136 m = BASIC_CONSTRAINT.match(constraint)
137 if m:
138 op = m.group(1)
139 version = m.group(2)
140
141 if version == "dev":
142 version = "0.0-dev"
143
144 try:
145 version = Version.parse(version)
146 except ValueError:
147 raise ValueError(
148 "Could not parse version constraint: {}".format(constraint)
149 )
150
151 if op == "<":
152 return VersionRange(max=version)
153 elif op == "<=":
154 return VersionRange(max=version, include_max=True)
155 elif op == ">":
156 return VersionRange(min=version)
157 elif op == ">=":
158 return VersionRange(min=version, include_min=True)
159 elif op == "!=":
160 return VersionUnion(VersionRange(max=version), VersionRange(min=version))
161 else:
162 return version
163
164 raise ValueError("Could not parse version constraint: {}".format(constraint))
165
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/poetry/semver/__init__.py b/poetry/semver/__init__.py
--- a/poetry/semver/__init__.py
+++ b/poetry/semver/__init__.py
@@ -79,7 +79,7 @@
low = version
high = version.stable.next_major
else:
- low = Version(version.major, version.minor, 0)
+ low = Version(version.major, version.minor, version.patch)
high = version.stable.next_minor
return VersionRange(
|
{"golden_diff": "diff --git a/poetry/semver/__init__.py b/poetry/semver/__init__.py\n--- a/poetry/semver/__init__.py\n+++ b/poetry/semver/__init__.py\n@@ -79,7 +79,7 @@\n low = version\n high = version.stable.next_major\n else:\n- low = Version(version.major, version.minor, 0)\n+ low = Version(version.major, version.minor, version.patch)\n high = version.stable.next_minor\n \n return VersionRange(\n", "issue": "`~=` version constraints (PEP 440) do not correctly set the lower version\n<!--\r\n Hi there! Thank you for discovering and submitting an issue.\r\n\r\n Before you submit this; let's make sure of a few things.\r\n Please make sure the following boxes are ticked if they are correct.\r\n If not, please try and fulfill these first.\r\n-->\r\n\r\n<!-- Checked checkbox should look like this: [x] -->\r\n- [x] I am on the [latest](https://github.com/sdispater/poetry/releases/latest) Poetry version.\r\n- [x] I have searched the [issues](https://github.com/sdispater/poetry/issues) of this repo and believe that this is not a duplicate.\r\n- [x] If an exception occurs when executing a command, I executed it again in debug mode (`-vvv` option).\r\n\r\n<!--\r\n Once those are done, if you're able to fill in the following list with your information,\r\n it'd be very helpful to whoever handles the issue.\r\n-->\r\n\r\n- **OS version and name**: Windows 10\r\n- **Poetry version**: 0.12.16\r\n- **Link of a [Gist](https://gist.github.com/) with the contents of your pyproject.toml file**: N/A\r\n\r\n## Issue\r\n<!-- Now feel free to write your issue, but please be descriptive! Thanks again \ud83d\ude4c \u2764\ufe0f -->\r\n\r\nFound this while fixing handling of pre-release (#1150)\r\n\r\nPEP 440 says\r\n- `~=V.N` maps to `>= V.N, == V.*`\r\n\r\nExamples\r\n```\r\n~= 2.2\r\n>= 2.2, == 2.*\r\n\r\n~= 1.4.5\r\n>= 1.4.5, == 1.4.*\r\n\r\n~= 2.2.0\r\n>= 2.2.0, == 2.2.*\r\n\r\n~= 1.4.5.0\r\n>= 1.4.5.0, == 1.4.5.*\r\n```\r\n\r\nbut looking at the tests `~=3.5.3` maps to `>=3.5.0, < 3.6` when it should map to `>=3.5.3, <3.6`. The trailing `3` should be setting the floor for the version\n", "before_files": [{"content": "import re\n\nfrom .empty_constraint import EmptyConstraint\nfrom .patterns import BASIC_CONSTRAINT\nfrom .patterns import CARET_CONSTRAINT\nfrom .patterns import TILDE_CONSTRAINT\nfrom .patterns import TILDE_PEP440_CONSTRAINT\nfrom .patterns import X_CONSTRAINT\nfrom .version import Version\nfrom .version_constraint import VersionConstraint\nfrom .version_range import VersionRange\nfrom .version_union import VersionUnion\n\n\ndef parse_constraint(constraints): # type: (str) -> VersionConstraint\n if constraints == \"*\":\n return VersionRange()\n\n or_constraints = re.split(r\"\\s*\\|\\|?\\s*\", constraints.strip())\n or_groups = []\n for constraints in or_constraints:\n and_constraints = re.split(\n \"(?<!^)(?<![=>< ,]) *(?<!-)[, ](?!-) *(?!,|$)\", constraints\n )\n constraint_objects = []\n\n if len(and_constraints) > 1:\n for constraint in and_constraints:\n constraint_objects.append(parse_single_constraint(constraint))\n else:\n constraint_objects.append(parse_single_constraint(and_constraints[0]))\n\n if len(constraint_objects) == 1:\n constraint = constraint_objects[0]\n else:\n constraint = constraint_objects[0]\n for next_constraint in constraint_objects[1:]:\n constraint = constraint.intersect(next_constraint)\n\n or_groups.append(constraint)\n\n if len(or_groups) == 1:\n return or_groups[0]\n else:\n return VersionUnion.of(*or_groups)\n\n\ndef parse_single_constraint(constraint): # type: (str) -> VersionConstraint\n m = re.match(r\"(?i)^v?[xX*](\\.[xX*])*$\", constraint)\n if m:\n return VersionRange()\n\n # Tilde range\n m = TILDE_CONSTRAINT.match(constraint)\n if m:\n version = Version.parse(m.group(1))\n\n high = version.stable.next_minor\n if len(m.group(1).split(\".\")) == 1:\n high = version.stable.next_major\n\n return VersionRange(\n version, high, include_min=True, always_include_max_prerelease=True\n )\n\n # PEP 440 Tilde range (~=)\n m = TILDE_PEP440_CONSTRAINT.match(constraint)\n if m:\n precision = 1\n if m.group(3):\n precision += 1\n\n if m.group(4):\n precision += 1\n\n version = Version.parse(m.group(1))\n\n if precision == 2:\n low = version\n high = version.stable.next_major\n else:\n low = Version(version.major, version.minor, 0)\n high = version.stable.next_minor\n\n return VersionRange(\n low, high, include_min=True, always_include_max_prerelease=True\n )\n\n # Caret range\n m = CARET_CONSTRAINT.match(constraint)\n if m:\n version = Version.parse(m.group(1))\n\n return VersionRange(\n version,\n version.next_breaking,\n include_min=True,\n always_include_max_prerelease=True,\n )\n\n # X Range\n m = X_CONSTRAINT.match(constraint)\n if m:\n op = m.group(1)\n major = int(m.group(2))\n minor = m.group(3)\n\n if minor is not None:\n version = Version(major, int(minor), 0)\n\n result = VersionRange(\n version,\n version.next_minor,\n include_min=True,\n always_include_max_prerelease=True,\n )\n else:\n if major == 0:\n result = VersionRange(max=Version(1, 0, 0))\n else:\n version = Version(major, 0, 0)\n\n result = VersionRange(\n version,\n version.next_major,\n include_min=True,\n always_include_max_prerelease=True,\n )\n\n if op == \"!=\":\n result = VersionRange().difference(result)\n\n return result\n\n # Basic comparator\n m = BASIC_CONSTRAINT.match(constraint)\n if m:\n op = m.group(1)\n version = m.group(2)\n\n if version == \"dev\":\n version = \"0.0-dev\"\n\n try:\n version = Version.parse(version)\n except ValueError:\n raise ValueError(\n \"Could not parse version constraint: {}\".format(constraint)\n )\n\n if op == \"<\":\n return VersionRange(max=version)\n elif op == \"<=\":\n return VersionRange(max=version, include_max=True)\n elif op == \">\":\n return VersionRange(min=version)\n elif op == \">=\":\n return VersionRange(min=version, include_min=True)\n elif op == \"!=\":\n return VersionUnion(VersionRange(max=version), VersionRange(min=version))\n else:\n return version\n\n raise ValueError(\"Could not parse version constraint: {}\".format(constraint))\n", "path": "poetry/semver/__init__.py"}], "after_files": [{"content": "import re\n\nfrom .empty_constraint import EmptyConstraint\nfrom .patterns import BASIC_CONSTRAINT\nfrom .patterns import CARET_CONSTRAINT\nfrom .patterns import TILDE_CONSTRAINT\nfrom .patterns import TILDE_PEP440_CONSTRAINT\nfrom .patterns import X_CONSTRAINT\nfrom .version import Version\nfrom .version_constraint import VersionConstraint\nfrom .version_range import VersionRange\nfrom .version_union import VersionUnion\n\n\ndef parse_constraint(constraints): # type: (str) -> VersionConstraint\n if constraints == \"*\":\n return VersionRange()\n\n or_constraints = re.split(r\"\\s*\\|\\|?\\s*\", constraints.strip())\n or_groups = []\n for constraints in or_constraints:\n and_constraints = re.split(\n \"(?<!^)(?<![=>< ,]) *(?<!-)[, ](?!-) *(?!,|$)\", constraints\n )\n constraint_objects = []\n\n if len(and_constraints) > 1:\n for constraint in and_constraints:\n constraint_objects.append(parse_single_constraint(constraint))\n else:\n constraint_objects.append(parse_single_constraint(and_constraints[0]))\n\n if len(constraint_objects) == 1:\n constraint = constraint_objects[0]\n else:\n constraint = constraint_objects[0]\n for next_constraint in constraint_objects[1:]:\n constraint = constraint.intersect(next_constraint)\n\n or_groups.append(constraint)\n\n if len(or_groups) == 1:\n return or_groups[0]\n else:\n return VersionUnion.of(*or_groups)\n\n\ndef parse_single_constraint(constraint): # type: (str) -> VersionConstraint\n m = re.match(r\"(?i)^v?[xX*](\\.[xX*])*$\", constraint)\n if m:\n return VersionRange()\n\n # Tilde range\n m = TILDE_CONSTRAINT.match(constraint)\n if m:\n version = Version.parse(m.group(1))\n\n high = version.stable.next_minor\n if len(m.group(1).split(\".\")) == 1:\n high = version.stable.next_major\n\n return VersionRange(\n version, high, include_min=True, always_include_max_prerelease=True\n )\n\n # PEP 440 Tilde range (~=)\n m = TILDE_PEP440_CONSTRAINT.match(constraint)\n if m:\n precision = 1\n if m.group(3):\n precision += 1\n\n if m.group(4):\n precision += 1\n\n version = Version.parse(m.group(1))\n\n if precision == 2:\n low = version\n high = version.stable.next_major\n else:\n low = Version(version.major, version.minor, version.patch)\n high = version.stable.next_minor\n\n return VersionRange(\n low, high, include_min=True, always_include_max_prerelease=True\n )\n\n # Caret range\n m = CARET_CONSTRAINT.match(constraint)\n if m:\n version = Version.parse(m.group(1))\n\n return VersionRange(\n version,\n version.next_breaking,\n include_min=True,\n always_include_max_prerelease=True,\n )\n\n # X Range\n m = X_CONSTRAINT.match(constraint)\n if m:\n op = m.group(1)\n major = int(m.group(2))\n minor = m.group(3)\n\n if minor is not None:\n version = Version(major, int(minor), 0)\n\n result = VersionRange(\n version,\n version.next_minor,\n include_min=True,\n always_include_max_prerelease=True,\n )\n else:\n if major == 0:\n result = VersionRange(max=Version(1, 0, 0))\n else:\n version = Version(major, 0, 0)\n\n result = VersionRange(\n version,\n version.next_major,\n include_min=True,\n always_include_max_prerelease=True,\n )\n\n if op == \"!=\":\n result = VersionRange().difference(result)\n\n return result\n\n # Basic comparator\n m = BASIC_CONSTRAINT.match(constraint)\n if m:\n op = m.group(1)\n version = m.group(2)\n\n if version == \"dev\":\n version = \"0.0-dev\"\n\n try:\n version = Version.parse(version)\n except ValueError:\n raise ValueError(\n \"Could not parse version constraint: {}\".format(constraint)\n )\n\n if op == \"<\":\n return VersionRange(max=version)\n elif op == \"<=\":\n return VersionRange(max=version, include_max=True)\n elif op == \">\":\n return VersionRange(min=version)\n elif op == \">=\":\n return VersionRange(min=version, include_min=True)\n elif op == \"!=\":\n return VersionUnion(VersionRange(max=version), VersionRange(min=version))\n else:\n return version\n\n raise ValueError(\"Could not parse version constraint: {}\".format(constraint))\n", "path": "poetry/semver/__init__.py"}]}
| 2,232 | 125 |
gh_patches_debug_1996
|
rasdani/github-patches
|
git_diff
|
ipython__ipython-11978
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
7.10 breaking tests with exception in publish
The new 7.10 release is breaking Bokeh unit tests with an exception coming from within ipython:
```
self = <IPython.core.displaypub.DisplayPublisher object at 0x11883d7f0>
data = {'text/html': '\n <div class="bk-root">\n <a href="https://bokeh.org" target="_blank" class="bk-logo bk-logo...version \'1.0\' from Bokeh development version \'1.0-1-abc\'. This configuration is unsupported and may not work!</p>'}
metadata = None, source = None, transient = None, update = False, kwargs = {}
handlers = {}
<< omitted >>
handlers = {}
if self.shell is not None:
> handlers = self.shell.mime_renderers
E AttributeError: 'InteractiveShell' object has no attribute 'mime_renderers'
../miniconda/envs/testenv/lib/python3.6/site-packages/IPython/core/displaypub.py:108: AttributeError
```
Is this an intentional change (documented anwhere?) or a regression/bug?
cc @Carreau
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `IPython/core/displaypub.py`
Content:
```
1 """An interface for publishing rich data to frontends.
2
3 There are two components of the display system:
4
5 * Display formatters, which take a Python object and compute the
6 representation of the object in various formats (text, HTML, SVG, etc.).
7 * The display publisher that is used to send the representation data to the
8 various frontends.
9
10 This module defines the logic display publishing. The display publisher uses
11 the ``display_data`` message type that is defined in the IPython messaging
12 spec.
13 """
14
15 # Copyright (c) IPython Development Team.
16 # Distributed under the terms of the Modified BSD License.
17
18
19 import sys
20
21 from traitlets.config.configurable import Configurable
22 from traitlets import List, Dict
23
24 # This used to be defined here - it is imported for backwards compatibility
25 from .display import publish_display_data
26
27 #-----------------------------------------------------------------------------
28 # Main payload class
29 #-----------------------------------------------------------------------------
30
31
32 class DisplayPublisher(Configurable):
33 """A traited class that publishes display data to frontends.
34
35 Instances of this class are created by the main IPython object and should
36 be accessed there.
37 """
38
39 def __init__(self, shell=None, *args, **kwargs):
40 self.shell = shell
41 super().__init__(*args, **kwargs)
42
43 def _validate_data(self, data, metadata=None):
44 """Validate the display data.
45
46 Parameters
47 ----------
48 data : dict
49 The formata data dictionary.
50 metadata : dict
51 Any metadata for the data.
52 """
53
54 if not isinstance(data, dict):
55 raise TypeError('data must be a dict, got: %r' % data)
56 if metadata is not None:
57 if not isinstance(metadata, dict):
58 raise TypeError('metadata must be a dict, got: %r' % data)
59
60 # use * to indicate transient, update are keyword-only
61 def publish(self, data, metadata=None, source=None, *, transient=None, update=False, **kwargs) -> None:
62 """Publish data and metadata to all frontends.
63
64 See the ``display_data`` message in the messaging documentation for
65 more details about this message type.
66
67 The following MIME types are currently implemented:
68
69 * text/plain
70 * text/html
71 * text/markdown
72 * text/latex
73 * application/json
74 * application/javascript
75 * image/png
76 * image/jpeg
77 * image/svg+xml
78
79 Parameters
80 ----------
81 data : dict
82 A dictionary having keys that are valid MIME types (like
83 'text/plain' or 'image/svg+xml') and values that are the data for
84 that MIME type. The data itself must be a JSON'able data
85 structure. Minimally all data should have the 'text/plain' data,
86 which can be displayed by all frontends. If more than the plain
87 text is given, it is up to the frontend to decide which
88 representation to use.
89 metadata : dict
90 A dictionary for metadata related to the data. This can contain
91 arbitrary key, value pairs that frontends can use to interpret
92 the data. Metadata specific to each mime-type can be specified
93 in the metadata dict with the same mime-type keys as
94 the data itself.
95 source : str, deprecated
96 Unused.
97 transient: dict, keyword-only
98 A dictionary for transient data.
99 Data in this dictionary should not be persisted as part of saving this output.
100 Examples include 'display_id'.
101 update: bool, keyword-only, default: False
102 If True, only update existing outputs with the same display_id,
103 rather than creating a new output.
104 """
105
106 handlers = {}
107 if self.shell is not None:
108 handlers = self.shell.mime_renderers
109
110 for mime, handler in handlers.items():
111 if mime in data:
112 handler(data[mime], metadata.get(mime, None))
113 return
114
115 if 'text/plain' in data:
116 print(data['text/plain'])
117
118 def clear_output(self, wait=False):
119 """Clear the output of the cell receiving output."""
120 print('\033[2K\r', end='')
121 sys.stdout.flush()
122 print('\033[2K\r', end='')
123 sys.stderr.flush()
124
125
126 class CapturingDisplayPublisher(DisplayPublisher):
127 """A DisplayPublisher that stores"""
128 outputs = List()
129
130 def publish(self, data, metadata=None, source=None, *, transient=None, update=False):
131 self.outputs.append({'data':data, 'metadata':metadata,
132 'transient':transient, 'update':update})
133
134 def clear_output(self, wait=False):
135 super(CapturingDisplayPublisher, self).clear_output(wait)
136
137 # empty the list, *do not* reassign a new list
138 self.outputs.clear()
139
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/IPython/core/displaypub.py b/IPython/core/displaypub.py
--- a/IPython/core/displaypub.py
+++ b/IPython/core/displaypub.py
@@ -105,7 +105,7 @@
handlers = {}
if self.shell is not None:
- handlers = self.shell.mime_renderers
+ handlers = getattr(self.shell, 'mime_renderers', {})
for mime, handler in handlers.items():
if mime in data:
|
{"golden_diff": "diff --git a/IPython/core/displaypub.py b/IPython/core/displaypub.py\n--- a/IPython/core/displaypub.py\n+++ b/IPython/core/displaypub.py\n@@ -105,7 +105,7 @@\n \n handlers = {}\n if self.shell is not None:\n- handlers = self.shell.mime_renderers\n+ handlers = getattr(self.shell, 'mime_renderers', {})\n \n for mime, handler in handlers.items():\n if mime in data:\n", "issue": "7.10 breaking tests with exception in publish\nThe new 7.10 release is breaking Bokeh unit tests with an exception coming from within ipython:\r\n```\r\n\r\nself = <IPython.core.displaypub.DisplayPublisher object at 0x11883d7f0>\r\ndata = {'text/html': '\\n <div class=\"bk-root\">\\n <a href=\"https://bokeh.org\" target=\"_blank\" class=\"bk-logo bk-logo...version \\'1.0\\' from Bokeh development version \\'1.0-1-abc\\'. This configuration is unsupported and may not work!</p>'}\r\nmetadata = None, source = None, transient = None, update = False, kwargs = {}\r\nhandlers = {}\r\n\r\n<< omitted >>\r\n\r\n handlers = {}\r\n if self.shell is not None:\r\n> handlers = self.shell.mime_renderers\r\nE AttributeError: 'InteractiveShell' object has no attribute 'mime_renderers'\r\n\r\n../miniconda/envs/testenv/lib/python3.6/site-packages/IPython/core/displaypub.py:108: AttributeError\r\n```\r\n\r\nIs this an intentional change (documented anwhere?) or a regression/bug?\r\n\r\ncc @Carreau \n", "before_files": [{"content": "\"\"\"An interface for publishing rich data to frontends.\n\nThere are two components of the display system:\n\n* Display formatters, which take a Python object and compute the\n representation of the object in various formats (text, HTML, SVG, etc.).\n* The display publisher that is used to send the representation data to the\n various frontends.\n\nThis module defines the logic display publishing. The display publisher uses\nthe ``display_data`` message type that is defined in the IPython messaging\nspec.\n\"\"\"\n\n# Copyright (c) IPython Development Team.\n# Distributed under the terms of the Modified BSD License.\n\n\nimport sys\n\nfrom traitlets.config.configurable import Configurable\nfrom traitlets import List, Dict\n\n# This used to be defined here - it is imported for backwards compatibility\nfrom .display import publish_display_data\n\n#-----------------------------------------------------------------------------\n# Main payload class\n#-----------------------------------------------------------------------------\n\n\nclass DisplayPublisher(Configurable):\n \"\"\"A traited class that publishes display data to frontends.\n\n Instances of this class are created by the main IPython object and should\n be accessed there.\n \"\"\"\n\n def __init__(self, shell=None, *args, **kwargs):\n self.shell = shell\n super().__init__(*args, **kwargs)\n\n def _validate_data(self, data, metadata=None):\n \"\"\"Validate the display data.\n\n Parameters\n ----------\n data : dict\n The formata data dictionary.\n metadata : dict\n Any metadata for the data.\n \"\"\"\n\n if not isinstance(data, dict):\n raise TypeError('data must be a dict, got: %r' % data)\n if metadata is not None:\n if not isinstance(metadata, dict):\n raise TypeError('metadata must be a dict, got: %r' % data)\n\n # use * to indicate transient, update are keyword-only\n def publish(self, data, metadata=None, source=None, *, transient=None, update=False, **kwargs) -> None:\n \"\"\"Publish data and metadata to all frontends.\n\n See the ``display_data`` message in the messaging documentation for\n more details about this message type.\n\n The following MIME types are currently implemented:\n\n * text/plain\n * text/html\n * text/markdown\n * text/latex\n * application/json\n * application/javascript\n * image/png\n * image/jpeg\n * image/svg+xml\n\n Parameters\n ----------\n data : dict\n A dictionary having keys that are valid MIME types (like\n 'text/plain' or 'image/svg+xml') and values that are the data for\n that MIME type. The data itself must be a JSON'able data\n structure. Minimally all data should have the 'text/plain' data,\n which can be displayed by all frontends. If more than the plain\n text is given, it is up to the frontend to decide which\n representation to use.\n metadata : dict\n A dictionary for metadata related to the data. This can contain\n arbitrary key, value pairs that frontends can use to interpret\n the data. Metadata specific to each mime-type can be specified\n in the metadata dict with the same mime-type keys as\n the data itself.\n source : str, deprecated\n Unused.\n transient: dict, keyword-only\n A dictionary for transient data.\n Data in this dictionary should not be persisted as part of saving this output.\n Examples include 'display_id'.\n update: bool, keyword-only, default: False\n If True, only update existing outputs with the same display_id,\n rather than creating a new output.\n \"\"\"\n\n handlers = {}\n if self.shell is not None:\n handlers = self.shell.mime_renderers\n\n for mime, handler in handlers.items():\n if mime in data:\n handler(data[mime], metadata.get(mime, None))\n return\n\n if 'text/plain' in data:\n print(data['text/plain'])\n\n def clear_output(self, wait=False):\n \"\"\"Clear the output of the cell receiving output.\"\"\"\n print('\\033[2K\\r', end='')\n sys.stdout.flush()\n print('\\033[2K\\r', end='')\n sys.stderr.flush()\n\n\nclass CapturingDisplayPublisher(DisplayPublisher):\n \"\"\"A DisplayPublisher that stores\"\"\"\n outputs = List()\n\n def publish(self, data, metadata=None, source=None, *, transient=None, update=False):\n self.outputs.append({'data':data, 'metadata':metadata,\n 'transient':transient, 'update':update})\n\n def clear_output(self, wait=False):\n super(CapturingDisplayPublisher, self).clear_output(wait)\n\n # empty the list, *do not* reassign a new list\n self.outputs.clear()\n", "path": "IPython/core/displaypub.py"}], "after_files": [{"content": "\"\"\"An interface for publishing rich data to frontends.\n\nThere are two components of the display system:\n\n* Display formatters, which take a Python object and compute the\n representation of the object in various formats (text, HTML, SVG, etc.).\n* The display publisher that is used to send the representation data to the\n various frontends.\n\nThis module defines the logic display publishing. The display publisher uses\nthe ``display_data`` message type that is defined in the IPython messaging\nspec.\n\"\"\"\n\n# Copyright (c) IPython Development Team.\n# Distributed under the terms of the Modified BSD License.\n\n\nimport sys\n\nfrom traitlets.config.configurable import Configurable\nfrom traitlets import List, Dict\n\n# This used to be defined here - it is imported for backwards compatibility\nfrom .display import publish_display_data\n\n#-----------------------------------------------------------------------------\n# Main payload class\n#-----------------------------------------------------------------------------\n\n\nclass DisplayPublisher(Configurable):\n \"\"\"A traited class that publishes display data to frontends.\n\n Instances of this class are created by the main IPython object and should\n be accessed there.\n \"\"\"\n\n def __init__(self, shell=None, *args, **kwargs):\n self.shell = shell\n super().__init__(*args, **kwargs)\n\n def _validate_data(self, data, metadata=None):\n \"\"\"Validate the display data.\n\n Parameters\n ----------\n data : dict\n The formata data dictionary.\n metadata : dict\n Any metadata for the data.\n \"\"\"\n\n if not isinstance(data, dict):\n raise TypeError('data must be a dict, got: %r' % data)\n if metadata is not None:\n if not isinstance(metadata, dict):\n raise TypeError('metadata must be a dict, got: %r' % data)\n\n # use * to indicate transient, update are keyword-only\n def publish(self, data, metadata=None, source=None, *, transient=None, update=False, **kwargs) -> None:\n \"\"\"Publish data and metadata to all frontends.\n\n See the ``display_data`` message in the messaging documentation for\n more details about this message type.\n\n The following MIME types are currently implemented:\n\n * text/plain\n * text/html\n * text/markdown\n * text/latex\n * application/json\n * application/javascript\n * image/png\n * image/jpeg\n * image/svg+xml\n\n Parameters\n ----------\n data : dict\n A dictionary having keys that are valid MIME types (like\n 'text/plain' or 'image/svg+xml') and values that are the data for\n that MIME type. The data itself must be a JSON'able data\n structure. Minimally all data should have the 'text/plain' data,\n which can be displayed by all frontends. If more than the plain\n text is given, it is up to the frontend to decide which\n representation to use.\n metadata : dict\n A dictionary for metadata related to the data. This can contain\n arbitrary key, value pairs that frontends can use to interpret\n the data. Metadata specific to each mime-type can be specified\n in the metadata dict with the same mime-type keys as\n the data itself.\n source : str, deprecated\n Unused.\n transient: dict, keyword-only\n A dictionary for transient data.\n Data in this dictionary should not be persisted as part of saving this output.\n Examples include 'display_id'.\n update: bool, keyword-only, default: False\n If True, only update existing outputs with the same display_id,\n rather than creating a new output.\n \"\"\"\n\n handlers = {}\n if self.shell is not None:\n handlers = getattr(self.shell, 'mime_renderers', {})\n\n for mime, handler in handlers.items():\n if mime in data:\n handler(data[mime], metadata.get(mime, None))\n return\n\n if 'text/plain' in data:\n print(data['text/plain'])\n\n def clear_output(self, wait=False):\n \"\"\"Clear the output of the cell receiving output.\"\"\"\n print('\\033[2K\\r', end='')\n sys.stdout.flush()\n print('\\033[2K\\r', end='')\n sys.stderr.flush()\n\n\nclass CapturingDisplayPublisher(DisplayPublisher):\n \"\"\"A DisplayPublisher that stores\"\"\"\n outputs = List()\n\n def publish(self, data, metadata=None, source=None, *, transient=None, update=False):\n self.outputs.append({'data':data, 'metadata':metadata,\n 'transient':transient, 'update':update})\n\n def clear_output(self, wait=False):\n super(CapturingDisplayPublisher, self).clear_output(wait)\n\n # empty the list, *do not* reassign a new list\n self.outputs.clear()\n", "path": "IPython/core/displaypub.py"}]}
| 1,843 | 103 |
gh_patches_debug_14119
|
rasdani/github-patches
|
git_diff
|
buildbot__buildbot-3918
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Transferring Files with LocalWorker seems not working
This ticket is a migrated Trac ticket [3628](http://trac.buildbot.net/ticket/3628)
People contributed to the original ticket: @unknown_contributor, @sa2ajj
Ticket created on: `Oct 20 2016`
Ticket last modified on: `Oct 27 2016`
---
Hi,
I just update my buildbot to 0.9. And i convert my old Slave to [[LocalWorker]].
But now my builds are stuck during the copy process "DirectoryUpload" or "!Multiple[[FileUpload]]"
I check the `twistd.log` and it looks like the first light files are copied but then the copy is stuck during a transfer of 5MB. The file has always a size of 3227648o.
Thanks for your help
---
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `master/buildbot/worker/protocols/null.py`
Content:
```
1 # This file is part of Buildbot. Buildbot is free software: you can
2 # redistribute it and/or modify it under the terms of the GNU General Public
3 # License as published by the Free Software Foundation, version 2.
4 #
5 # This program is distributed in the hope that it will be useful, but WITHOUT
6 # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
7 # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
8 # details.
9 #
10 # You should have received a copy of the GNU General Public License along with
11 # this program; if not, write to the Free Software Foundation, Inc., 51
12 # Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
13 #
14 # Copyright Buildbot Team Members
15
16 from __future__ import absolute_import
17 from __future__ import division
18 from __future__ import print_function
19
20 from twisted.internet import defer
21 from twisted.python import log
22
23 from buildbot.worker.protocols import base
24
25
26 class Listener(base.Listener):
27 pass
28
29
30 class ProxyMixin():
31
32 def __init__(self, impl):
33 assert isinstance(impl, self.ImplClass)
34 self.impl = impl
35 self._disconnect_listeners = []
36
37 def callRemote(self, message, *args, **kw):
38 method = getattr(self.impl, "remote_%s" % message, None)
39 if method is None:
40 raise AttributeError("No such method: remote_%s" % (message,))
41 try:
42 state = method(*args, **kw)
43 except TypeError:
44 log.msg("%s didn't accept %s and %s" % (method, args, kw))
45 raise
46 return defer.maybeDeferred(lambda: state)
47
48 def notifyOnDisconnect(self, cb):
49 pass
50
51 def dontNotifyOnDisconnect(self, cb):
52 pass
53
54
55 # just add ProxyMixin capability to the RemoteCommandProxy
56 # so that callers of callRemote actually directly call the proper method
57 class RemoteCommandProxy(ProxyMixin):
58 ImplClass = base.RemoteCommandImpl
59
60
61 class FileReaderProxy(ProxyMixin):
62 ImplClass = base.FileReaderImpl
63
64
65 class FileWriterProxy(ProxyMixin):
66 ImplClass = base.FileWriterImpl
67
68
69 class Connection(base.Connection):
70 proxies = {base.FileWriterImpl: FileWriterProxy,
71 base.FileReaderImpl: FileReaderProxy}
72
73 def loseConnection(self):
74 pass
75
76 def remotePrint(self, message):
77 return defer.maybeDeferred(self.worker.bot.remote_print, message)
78
79 def remoteGetWorkerInfo(self):
80 return defer.maybeDeferred(self.worker.bot.remote_getWorkerInfo)
81
82 def remoteSetBuilderList(self, builders):
83 return defer.maybeDeferred(self.worker.bot.remote_setBuilderList, builders)
84
85 def remoteStartCommand(self, remoteCommand, builderName, commandId, commandName, args):
86 remoteCommand = RemoteCommandProxy(remoteCommand)
87 args = self.createArgsProxies(args)
88 workerforbuilder = self.worker.bot.builders[builderName]
89 return defer.maybeDeferred(workerforbuilder.remote_startCommand, remoteCommand,
90 commandId, commandName, args)
91
92 def remoteShutdown(self):
93 return defer.maybeDeferred(self.worker.stopService)
94
95 def remoteStartBuild(self, builderName):
96 return defer.succeed(self.worker.bot.builders[builderName].remote_startBuild())
97
98 def remoteInterruptCommand(self, builderName, commandId, why):
99 workerforbuilder = self.worker.bot.builders[builderName]
100 return defer.maybeDeferred(workerforbuilder.remote_interruptCommand, commandId, why)
101
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/master/buildbot/worker/protocols/null.py b/master/buildbot/worker/protocols/null.py
--- a/master/buildbot/worker/protocols/null.py
+++ b/master/buildbot/worker/protocols/null.py
@@ -20,6 +20,7 @@
from twisted.internet import defer
from twisted.python import log
+from buildbot.util.eventual import fireEventually
from buildbot.worker.protocols import base
@@ -43,7 +44,8 @@
except TypeError:
log.msg("%s didn't accept %s and %s" % (method, args, kw))
raise
- return defer.maybeDeferred(lambda: state)
+ # break callback recursion for large transfers by using fireEventually
+ return fireEventually(state)
def notifyOnDisconnect(self, cb):
pass
|
{"golden_diff": "diff --git a/master/buildbot/worker/protocols/null.py b/master/buildbot/worker/protocols/null.py\n--- a/master/buildbot/worker/protocols/null.py\n+++ b/master/buildbot/worker/protocols/null.py\n@@ -20,6 +20,7 @@\n from twisted.internet import defer\n from twisted.python import log\n \n+from buildbot.util.eventual import fireEventually\n from buildbot.worker.protocols import base\n \n \n@@ -43,7 +44,8 @@\n except TypeError:\n log.msg(\"%s didn't accept %s and %s\" % (method, args, kw))\n raise\n- return defer.maybeDeferred(lambda: state)\n+ # break callback recursion for large transfers by using fireEventually\n+ return fireEventually(state)\n \n def notifyOnDisconnect(self, cb):\n pass\n", "issue": "Transferring Files with LocalWorker seems not working\nThis ticket is a migrated Trac ticket [3628](http://trac.buildbot.net/ticket/3628)\n\nPeople contributed to the original ticket: @unknown_contributor, @sa2ajj\nTicket created on: `Oct 20 2016`\nTicket last modified on: `Oct 27 2016`\n\n---\n\nHi,\n\nI just update my buildbot to 0.9. And i convert my old Slave to [[LocalWorker]].\n\nBut now my builds are stuck during the copy process \"DirectoryUpload\" or \"!Multiple[[FileUpload]]\"\n\nI check the `twistd.log` and it looks like the first light files are copied but then the copy is stuck during a transfer of 5MB. The file has always a size of 3227648o.\n\nThanks for your help\n\n\n---\n\n\n\n", "before_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nfrom twisted.internet import defer\nfrom twisted.python import log\n\nfrom buildbot.worker.protocols import base\n\n\nclass Listener(base.Listener):\n pass\n\n\nclass ProxyMixin():\n\n def __init__(self, impl):\n assert isinstance(impl, self.ImplClass)\n self.impl = impl\n self._disconnect_listeners = []\n\n def callRemote(self, message, *args, **kw):\n method = getattr(self.impl, \"remote_%s\" % message, None)\n if method is None:\n raise AttributeError(\"No such method: remote_%s\" % (message,))\n try:\n state = method(*args, **kw)\n except TypeError:\n log.msg(\"%s didn't accept %s and %s\" % (method, args, kw))\n raise\n return defer.maybeDeferred(lambda: state)\n\n def notifyOnDisconnect(self, cb):\n pass\n\n def dontNotifyOnDisconnect(self, cb):\n pass\n\n\n# just add ProxyMixin capability to the RemoteCommandProxy\n# so that callers of callRemote actually directly call the proper method\nclass RemoteCommandProxy(ProxyMixin):\n ImplClass = base.RemoteCommandImpl\n\n\nclass FileReaderProxy(ProxyMixin):\n ImplClass = base.FileReaderImpl\n\n\nclass FileWriterProxy(ProxyMixin):\n ImplClass = base.FileWriterImpl\n\n\nclass Connection(base.Connection):\n proxies = {base.FileWriterImpl: FileWriterProxy,\n base.FileReaderImpl: FileReaderProxy}\n\n def loseConnection(self):\n pass\n\n def remotePrint(self, message):\n return defer.maybeDeferred(self.worker.bot.remote_print, message)\n\n def remoteGetWorkerInfo(self):\n return defer.maybeDeferred(self.worker.bot.remote_getWorkerInfo)\n\n def remoteSetBuilderList(self, builders):\n return defer.maybeDeferred(self.worker.bot.remote_setBuilderList, builders)\n\n def remoteStartCommand(self, remoteCommand, builderName, commandId, commandName, args):\n remoteCommand = RemoteCommandProxy(remoteCommand)\n args = self.createArgsProxies(args)\n workerforbuilder = self.worker.bot.builders[builderName]\n return defer.maybeDeferred(workerforbuilder.remote_startCommand, remoteCommand,\n commandId, commandName, args)\n\n def remoteShutdown(self):\n return defer.maybeDeferred(self.worker.stopService)\n\n def remoteStartBuild(self, builderName):\n return defer.succeed(self.worker.bot.builders[builderName].remote_startBuild())\n\n def remoteInterruptCommand(self, builderName, commandId, why):\n workerforbuilder = self.worker.bot.builders[builderName]\n return defer.maybeDeferred(workerforbuilder.remote_interruptCommand, commandId, why)\n", "path": "master/buildbot/worker/protocols/null.py"}], "after_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nfrom twisted.internet import defer\nfrom twisted.python import log\n\nfrom buildbot.util.eventual import fireEventually\nfrom buildbot.worker.protocols import base\n\n\nclass Listener(base.Listener):\n pass\n\n\nclass ProxyMixin():\n\n def __init__(self, impl):\n assert isinstance(impl, self.ImplClass)\n self.impl = impl\n self._disconnect_listeners = []\n\n def callRemote(self, message, *args, **kw):\n method = getattr(self.impl, \"remote_%s\" % message, None)\n if method is None:\n raise AttributeError(\"No such method: remote_%s\" % (message,))\n try:\n state = method(*args, **kw)\n except TypeError:\n log.msg(\"%s didn't accept %s and %s\" % (method, args, kw))\n raise\n # break callback recursion for large transfers by using fireEventually\n return fireEventually(state)\n\n def notifyOnDisconnect(self, cb):\n pass\n\n def dontNotifyOnDisconnect(self, cb):\n pass\n\n\n# just add ProxyMixin capability to the RemoteCommandProxy\n# so that callers of callRemote actually directly call the proper method\nclass RemoteCommandProxy(ProxyMixin):\n ImplClass = base.RemoteCommandImpl\n\n\nclass FileReaderProxy(ProxyMixin):\n ImplClass = base.FileReaderImpl\n\n\nclass FileWriterProxy(ProxyMixin):\n ImplClass = base.FileWriterImpl\n\n\nclass Connection(base.Connection):\n proxies = {base.FileWriterImpl: FileWriterProxy,\n base.FileReaderImpl: FileReaderProxy}\n\n def loseConnection(self):\n pass\n\n def remotePrint(self, message):\n return defer.maybeDeferred(self.worker.bot.remote_print, message)\n\n def remoteGetWorkerInfo(self):\n return defer.maybeDeferred(self.worker.bot.remote_getWorkerInfo)\n\n def remoteSetBuilderList(self, builders):\n return defer.maybeDeferred(self.worker.bot.remote_setBuilderList, builders)\n\n def remoteStartCommand(self, remoteCommand, builderName, commandId, commandName, args):\n remoteCommand = RemoteCommandProxy(remoteCommand)\n args = self.createArgsProxies(args)\n workerforbuilder = self.worker.bot.builders[builderName]\n return defer.maybeDeferred(workerforbuilder.remote_startCommand, remoteCommand,\n commandId, commandName, args)\n\n def remoteShutdown(self):\n return defer.maybeDeferred(self.worker.stopService)\n\n def remoteStartBuild(self, builderName):\n return defer.succeed(self.worker.bot.builders[builderName].remote_startBuild())\n\n def remoteInterruptCommand(self, builderName, commandId, why):\n workerforbuilder = self.worker.bot.builders[builderName]\n return defer.maybeDeferred(workerforbuilder.remote_interruptCommand, commandId, why)\n", "path": "master/buildbot/worker/protocols/null.py"}]}
| 1,413 | 179 |
gh_patches_debug_8612
|
rasdani/github-patches
|
git_diff
|
pyqtgraph__pyqtgraph-2934
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
import pyqtgraph.canvas fails.
<!-- In the following, please describe your issue in detail! -->
<!-- If some sections do not apply, just remove them. -->
### Short description
Importing pyqtgraph.canvas causes the program to abort and exit with an error code..
### Code to reproduce
<!-- Please provide a minimal working example that reproduces the issue in the code block below.
Ideally, this should be a full example someone else could run without additional setup. -->
```python
print("Mark 0", flush=True)
import time
print("Mark 1", flush=True)
import pyqtgraph.canvas
print("Mark 2", flush=True)
time.sleep(10)
print("Mark 3", flush=True)
```
### Expected behavior
1. The program should print out all the markers four ,0 to 3, with a 10 seconds delay between marker 2 and 3.
2. The program should exit with status code 0 (ok)
### Real behavior
1. The program prints only markers 0 and 1.
2. The program exist with status code 127 (error)
### An error occurred?
No error messages were noticed. The program just exits when it tries to import pyqtgraph.canvas.
### Tested environment(s)
* PyQtGraph version: <!-- output of pyqtgraph.__version__ --> 0.13.3
* Qt Python binding: <!-- output of pyqtgraph.Qt.VERSION_INFO --> PyQt6 6.5.2 Qt 6.5.2
* Python version: 3.12.0
* NumPy version: <!-- output of numpy.__version__ --> 1.26.0
* Operating system: Windows 10, Ryzen
* Installation method: <!-- e.g. pip, conda, system packages, ... --> pip
### Additional context
The issue is discussed here in the pyinstaller repository https://github.com/pyinstaller/pyinstaller/issues/7991#issuecomment-1752032919
Swapping the two lines of CanvasManager as described the link above seems to fix the problem.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pyqtgraph/canvas/CanvasManager.py`
Content:
```
1 from ..Qt import QtCore, QtWidgets
2
3 if not hasattr(QtCore, 'Signal'):
4 QtCore.Signal = QtCore.pyqtSignal
5 import weakref
6
7
8 class CanvasManager(QtCore.QObject):
9 SINGLETON = None
10
11 sigCanvasListChanged = QtCore.Signal()
12
13 def __init__(self):
14 if CanvasManager.SINGLETON is not None:
15 raise Exception("Can only create one canvas manager.")
16 CanvasManager.SINGLETON = self
17 QtCore.QObject.__init__(self)
18 self.canvases = weakref.WeakValueDictionary()
19
20 @classmethod
21 def instance(cls):
22 return CanvasManager.SINGLETON
23
24 def registerCanvas(self, canvas, name):
25 n2 = name
26 i = 0
27 while n2 in self.canvases:
28 n2 = "%s_%03d" % (name, i)
29 i += 1
30 self.canvases[n2] = canvas
31 self.sigCanvasListChanged.emit()
32 return n2
33
34 def unregisterCanvas(self, name):
35 c = self.canvases[name]
36 del self.canvases[name]
37 self.sigCanvasListChanged.emit()
38
39 def listCanvases(self):
40 return list(self.canvases.keys())
41
42 def getCanvas(self, name):
43 return self.canvases[name]
44
45
46 manager = CanvasManager()
47
48
49 class CanvasCombo(QtWidgets.QComboBox):
50 def __init__(self, parent=None):
51 QtWidgets.QComboBox.__init__(self, parent)
52 man = CanvasManager.instance()
53 man.sigCanvasListChanged.connect(self.updateCanvasList)
54 self.hostName = None
55 self.updateCanvasList()
56
57 def updateCanvasList(self):
58 canvases = CanvasManager.instance().listCanvases()
59 canvases.insert(0, "")
60 if self.hostName in canvases:
61 canvases.remove(self.hostName)
62
63 sel = self.currentText()
64 if sel in canvases:
65 self.blockSignals(True) ## change does not affect current selection; block signals during update
66 self.clear()
67 for i in canvases:
68 self.addItem(i)
69 if i == sel:
70 self.setCurrentIndex(self.count())
71
72 self.blockSignals(False)
73
74 def setHostName(self, name):
75 self.hostName = name
76 self.updateCanvasList()
77
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pyqtgraph/canvas/CanvasManager.py b/pyqtgraph/canvas/CanvasManager.py
--- a/pyqtgraph/canvas/CanvasManager.py
+++ b/pyqtgraph/canvas/CanvasManager.py
@@ -13,8 +13,9 @@
def __init__(self):
if CanvasManager.SINGLETON is not None:
raise Exception("Can only create one canvas manager.")
- CanvasManager.SINGLETON = self
+ # It is important to save SINGLETON *after* the call to QObject.__init__, see #2838.
QtCore.QObject.__init__(self)
+ CanvasManager.SINGLETON = self
self.canvases = weakref.WeakValueDictionary()
@classmethod
|
{"golden_diff": "diff --git a/pyqtgraph/canvas/CanvasManager.py b/pyqtgraph/canvas/CanvasManager.py\n--- a/pyqtgraph/canvas/CanvasManager.py\n+++ b/pyqtgraph/canvas/CanvasManager.py\n@@ -13,8 +13,9 @@\n def __init__(self):\n if CanvasManager.SINGLETON is not None:\n raise Exception(\"Can only create one canvas manager.\")\n- CanvasManager.SINGLETON = self\n+ # It is important to save SINGLETON *after* the call to QObject.__init__, see #2838.\n QtCore.QObject.__init__(self)\n+ CanvasManager.SINGLETON = self\n self.canvases = weakref.WeakValueDictionary()\n \n @classmethod\n", "issue": "import pyqtgraph.canvas fails.\n<!-- In the following, please describe your issue in detail! -->\r\n<!-- If some sections do not apply, just remove them. -->\r\n\r\n### Short description\r\nImporting pyqtgraph.canvas causes the program to abort and exit with an error code..\r\n\r\n### Code to reproduce\r\n<!-- Please provide a minimal working example that reproduces the issue in the code block below.\r\n Ideally, this should be a full example someone else could run without additional setup. -->\r\n\r\n```python\r\nprint(\"Mark 0\", flush=True)\r\nimport time\r\nprint(\"Mark 1\", flush=True)\r\nimport pyqtgraph.canvas\r\nprint(\"Mark 2\", flush=True)\r\ntime.sleep(10)\r\nprint(\"Mark 3\", flush=True)\r\n\r\n```\r\n\r\n### Expected behavior\r\n1. The program should print out all the markers four ,0 to 3, with a 10 seconds delay between marker 2 and 3.\r\n2. The program should exit with status code 0 (ok)\r\n\r\n\r\n### Real behavior\r\n1. The program prints only markers 0 and 1.\r\n2. The program exist with status code 127 (error)\r\n\r\n### An error occurred?\r\nNo error messages were noticed. The program just exits when it tries to import pyqtgraph.canvas.\r\n\r\n### Tested environment(s)\r\n\r\n * PyQtGraph version: <!-- output of pyqtgraph.__version__ --> 0.13.3\r\n * Qt Python binding: <!-- output of pyqtgraph.Qt.VERSION_INFO --> PyQt6 6.5.2 Qt 6.5.2\r\n * Python version: 3.12.0\r\n * NumPy version: <!-- output of numpy.__version__ --> 1.26.0\r\n * Operating system: Windows 10, Ryzen\r\n * Installation method: <!-- e.g. pip, conda, system packages, ... --> pip\r\n\r\n### Additional context\r\n\r\nThe issue is discussed here in the pyinstaller repository https://github.com/pyinstaller/pyinstaller/issues/7991#issuecomment-1752032919\r\n\r\nSwapping the two lines of CanvasManager as described the link above seems to fix the problem.\r\n\n", "before_files": [{"content": "from ..Qt import QtCore, QtWidgets\n\nif not hasattr(QtCore, 'Signal'):\n QtCore.Signal = QtCore.pyqtSignal\nimport weakref\n\n\nclass CanvasManager(QtCore.QObject):\n SINGLETON = None\n \n sigCanvasListChanged = QtCore.Signal()\n \n def __init__(self):\n if CanvasManager.SINGLETON is not None:\n raise Exception(\"Can only create one canvas manager.\")\n CanvasManager.SINGLETON = self\n QtCore.QObject.__init__(self)\n self.canvases = weakref.WeakValueDictionary()\n\n @classmethod\n def instance(cls):\n return CanvasManager.SINGLETON\n \n def registerCanvas(self, canvas, name):\n n2 = name\n i = 0\n while n2 in self.canvases:\n n2 = \"%s_%03d\" % (name, i)\n i += 1\n self.canvases[n2] = canvas\n self.sigCanvasListChanged.emit()\n return n2\n \n def unregisterCanvas(self, name):\n c = self.canvases[name]\n del self.canvases[name]\n self.sigCanvasListChanged.emit()\n \n def listCanvases(self):\n return list(self.canvases.keys())\n \n def getCanvas(self, name):\n return self.canvases[name]\n \n \nmanager = CanvasManager()\n\n\nclass CanvasCombo(QtWidgets.QComboBox):\n def __init__(self, parent=None):\n QtWidgets.QComboBox.__init__(self, parent)\n man = CanvasManager.instance()\n man.sigCanvasListChanged.connect(self.updateCanvasList)\n self.hostName = None\n self.updateCanvasList()\n \n def updateCanvasList(self):\n canvases = CanvasManager.instance().listCanvases()\n canvases.insert(0, \"\")\n if self.hostName in canvases:\n canvases.remove(self.hostName)\n \n sel = self.currentText()\n if sel in canvases:\n self.blockSignals(True) ## change does not affect current selection; block signals during update\n self.clear()\n for i in canvases:\n self.addItem(i)\n if i == sel:\n self.setCurrentIndex(self.count())\n \n self.blockSignals(False)\n \n def setHostName(self, name):\n self.hostName = name\n self.updateCanvasList()\n", "path": "pyqtgraph/canvas/CanvasManager.py"}], "after_files": [{"content": "from ..Qt import QtCore, QtWidgets\n\nif not hasattr(QtCore, 'Signal'):\n QtCore.Signal = QtCore.pyqtSignal\nimport weakref\n\n\nclass CanvasManager(QtCore.QObject):\n SINGLETON = None\n \n sigCanvasListChanged = QtCore.Signal()\n \n def __init__(self):\n if CanvasManager.SINGLETON is not None:\n raise Exception(\"Can only create one canvas manager.\")\n # It is important to save SINGLETON *after* the call to QObject.__init__, see #2838.\n QtCore.QObject.__init__(self)\n CanvasManager.SINGLETON = self\n self.canvases = weakref.WeakValueDictionary()\n\n @classmethod\n def instance(cls):\n return CanvasManager.SINGLETON\n \n def registerCanvas(self, canvas, name):\n n2 = name\n i = 0\n while n2 in self.canvases:\n n2 = \"%s_%03d\" % (name, i)\n i += 1\n self.canvases[n2] = canvas\n self.sigCanvasListChanged.emit()\n return n2\n \n def unregisterCanvas(self, name):\n c = self.canvases[name]\n del self.canvases[name]\n self.sigCanvasListChanged.emit()\n \n def listCanvases(self):\n return list(self.canvases.keys())\n \n def getCanvas(self, name):\n return self.canvases[name]\n \n \nmanager = CanvasManager()\n\n\nclass CanvasCombo(QtWidgets.QComboBox):\n def __init__(self, parent=None):\n QtWidgets.QComboBox.__init__(self, parent)\n man = CanvasManager.instance()\n man.sigCanvasListChanged.connect(self.updateCanvasList)\n self.hostName = None\n self.updateCanvasList()\n \n def updateCanvasList(self):\n canvases = CanvasManager.instance().listCanvases()\n canvases.insert(0, \"\")\n if self.hostName in canvases:\n canvases.remove(self.hostName)\n \n sel = self.currentText()\n if sel in canvases:\n self.blockSignals(True) ## change does not affect current selection; block signals during update\n self.clear()\n for i in canvases:\n self.addItem(i)\n if i == sel:\n self.setCurrentIndex(self.count())\n \n self.blockSignals(False)\n \n def setHostName(self, name):\n self.hostName = name\n self.updateCanvasList()\n", "path": "pyqtgraph/canvas/CanvasManager.py"}]}
| 1,350 | 163 |
gh_patches_debug_30736
|
rasdani/github-patches
|
git_diff
|
Zeroto521__my-data-toolkit-705
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ENH: New geoaccessor to generate great circle distances matrix
<!--
Thanks for contributing a pull request!
Please follow these standard acronyms to start the commit message:
- ENH: enhancement
- BUG: bug fix
- DOC: documentation
- TYP: type annotations
- TST: addition or modification of tests
- MAINT: maintenance commit (refactoring, typos, etc.)
- BLD: change related to building
- REL: related to releasing
- API: an (incompatible) API change
- DEP: deprecate something, or remove a deprecated object
- DEV: development tool or utility
- REV: revert an earlier commit
- PERF: performance improvement
- BOT: always commit via a bot
- CI: related to CI or CD
- CLN: Code cleanup
-->
- [x] closes #699
- [ ] whatsnew entry
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dtoolkit/geoaccessor/geoseries/geodistance_matrix.py`
Content:
```
1 from __future__ import annotations
2
3 import geopandas as gpd
4 import numpy as np
5 import pandas as pd
6
7 from dtoolkit.geoaccessor.register import register_geoseries_method
8
9
10 @register_geoseries_method
11 def geodistance_matrix(
12 s: gpd.GeoSeries,
13 /,
14 other: gpd.GeoSeries | gpd.GeoDataFrame | None = None,
15 radius: float = 6371008.7714150598,
16 ) -> pd.DataFrame:
17 """
18 Returns a ``DataFrame`` containing the `great-circle`__ distances matrix between in
19 ``s`` and ``other`` via haversine formula.
20
21 __ https://en.wikipedia.org/wiki/Great-circle_distance
22
23 .. math::
24
25 D(x, y) = 2 \\arcsin [
26 \\sqrt{
27 \\sin^2 ((x_1 - y_1) / 2)
28 + \\cos(x_1) \\cos(y_1) \\sin^2 ((x_2 - y_2) / 2)
29 }
30 ]
31
32 Parameters
33 ----------
34 other : GeoSeries, or GeoDataFrame, default None
35 If None, uses ``other=s``.
36
37 radius : float, default 6371008.7714150598
38 Great-circle distance uses a spherical model of the earth, using the mean earth
39 radius as defined by the International Union of Geodesy and Geophysics,
40 (2\\ *a* + *b*)/3 = 6371008.7714150598 meters for WGS-84.
41
42 Returns
43 -------
44 DataFrame
45 - The index and columns are the same as the index of ``s`` and ``other``.
46 - The values are the great-circle distances and its unit is meters.
47
48 Raises
49 ------
50 ModuleNotFoundError
51 If don't have module named 'sklearn'.
52
53 ValueError
54 If the CRS is not ``ESGP:4326``.
55
56 See Also
57 --------
58 sklearn.metrics.pairwise.haversine_distances
59 dtoolkit.geoaccessor.geoseries.geodistance
60 dtoolkit.geoaccessor.geoseries.geodistance_matrix
61 dtoolkit.geoaccessor.geodataframe.geodistance
62 dtoolkit.geoaccessor.geodataframe.geodistance_matrix
63
64 Notes
65 -----
66 - Currently, only supports Point geometry.
67 - The great-circle distance is the angular distance between two points on the
68 surface of a sphere. As the Earth is nearly spherical, the haversine formula
69 provides a good approximation of the distance between two points of the Earth
70 surface, with a less than 1% error on average.
71
72 Examples
73 --------
74 >>> import dtoolkit.geoaccessor
75 >>> df = pd.DataFrame(
76 ... {
77 ... "x": [120, 122, 100],
78 ... "y":[30, 55, 1],
79 ... },
80 ... ).from_xy("x", "y", crs=4326)
81 >>> df
82 x y geometry
83 0 120 30 POINT (120.00000 30.00000)
84 1 122 55 POINT (122.00000 55.00000)
85 2 100 1 POINT (100.00000 1.00000)
86 >>> other = pd.DataFrame(
87 ... {
88 ... "x": [120, 110],
89 ... "y":[30, 40],
90 ... },
91 ... ).from_xy("x", "y", crs=4326)
92 >>> other
93 x y geometry
94 0 120 30 POINT (120.00000 30.00000)
95 1 110 40 POINT (110.00000 40.00000)
96 >>> df.geodistance_matrix(other)
97 0 1
98 0 0.000000e+00 1.435335e+06
99 1 2.784435e+06 1.889892e+06
100 2 3.855604e+06 4.453100e+06
101 """
102 from sklearn.metrics.pairwise import haversine_distances
103
104 if s.crs != 4326:
105 raise ValueError(f"Only support 'EPSG:4326' CRS, but got {s.crs!r}.")
106
107 if isinstance(other, gpd.base.GeoPandasBase):
108 if other.crs != 4326:
109 raise ValueError(f"Only support 'EPSG:4326' CRS, but got {other.crs!r}.")
110
111 # Force convert to GeoSeries
112 other = other.geometry
113
114 X = np.radians(np.stack((s.y, s.x), axis=1))
115 Y = np.radians(np.stack((other.y, other.x), axis=1)) if other is not None else other
116 return pd.DataFrame(
117 radius * haversine_distances(X, Y),
118 index=s.index,
119 columns=other.index,
120 )
121
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/dtoolkit/geoaccessor/geoseries/geodistance_matrix.py b/dtoolkit/geoaccessor/geoseries/geodistance_matrix.py
--- a/dtoolkit/geoaccessor/geoseries/geodistance_matrix.py
+++ b/dtoolkit/geoaccessor/geoseries/geodistance_matrix.py
@@ -53,6 +53,9 @@
ValueError
If the CRS is not ``ESGP:4326``.
+ TypeError
+ If the other is not a GeoSeries, GeoDataFrame, or None type.
+
See Also
--------
sklearn.metrics.pairwise.haversine_distances
@@ -72,6 +75,7 @@
Examples
--------
>>> import dtoolkit.geoaccessor
+ >>> import pandas as pd
>>> df = pd.DataFrame(
... {
... "x": [120, 122, 100],
@@ -104,17 +108,19 @@
if s.crs != 4326:
raise ValueError(f"Only support 'EPSG:4326' CRS, but got {s.crs!r}.")
- if isinstance(other, gpd.base.GeoPandasBase):
+ if other is None:
+ Y = None
+ elif isinstance(other, gpd.base.GeoPandasBase):
if other.crs != 4326:
raise ValueError(f"Only support 'EPSG:4326' CRS, but got {other.crs!r}.")
- # Force convert to GeoSeries
- other = other.geometry
+ Y = np.radians(np.stack((other.geometry.y, other.geometry.x), axis=1))
+ else:
+ raise TypeError(f"Unknown type: {type(other).__name__!r}.")
X = np.radians(np.stack((s.y, s.x), axis=1))
- Y = np.radians(np.stack((other.y, other.x), axis=1)) if other is not None else other
return pd.DataFrame(
radius * haversine_distances(X, Y),
index=s.index,
- columns=other.index,
+ columns=other.index if other is not None else s.index,
)
|
{"golden_diff": "diff --git a/dtoolkit/geoaccessor/geoseries/geodistance_matrix.py b/dtoolkit/geoaccessor/geoseries/geodistance_matrix.py\n--- a/dtoolkit/geoaccessor/geoseries/geodistance_matrix.py\n+++ b/dtoolkit/geoaccessor/geoseries/geodistance_matrix.py\n@@ -53,6 +53,9 @@\n ValueError\n If the CRS is not ``ESGP:4326``.\n \n+ TypeError\n+ If the other is not a GeoSeries, GeoDataFrame, or None type.\n+\n See Also\n --------\n sklearn.metrics.pairwise.haversine_distances\n@@ -72,6 +75,7 @@\n Examples\n --------\n >>> import dtoolkit.geoaccessor\n+ >>> import pandas as pd\n >>> df = pd.DataFrame(\n ... {\n ... \"x\": [120, 122, 100],\n@@ -104,17 +108,19 @@\n if s.crs != 4326:\n raise ValueError(f\"Only support 'EPSG:4326' CRS, but got {s.crs!r}.\")\n \n- if isinstance(other, gpd.base.GeoPandasBase):\n+ if other is None:\n+ Y = None\n+ elif isinstance(other, gpd.base.GeoPandasBase):\n if other.crs != 4326:\n raise ValueError(f\"Only support 'EPSG:4326' CRS, but got {other.crs!r}.\")\n \n- # Force convert to GeoSeries\n- other = other.geometry\n+ Y = np.radians(np.stack((other.geometry.y, other.geometry.x), axis=1))\n+ else:\n+ raise TypeError(f\"Unknown type: {type(other).__name__!r}.\")\n \n X = np.radians(np.stack((s.y, s.x), axis=1))\n- Y = np.radians(np.stack((other.y, other.x), axis=1)) if other is not None else other\n return pd.DataFrame(\n radius * haversine_distances(X, Y),\n index=s.index,\n- columns=other.index,\n+ columns=other.index if other is not None else s.index,\n )\n", "issue": "ENH: New geoaccessor to generate great circle distances matrix\n<!--\r\nThanks for contributing a pull request!\r\n\r\nPlease follow these standard acronyms to start the commit message:\r\n\r\n- ENH: enhancement\r\n- BUG: bug fix\r\n- DOC: documentation\r\n- TYP: type annotations\r\n- TST: addition or modification of tests\r\n- MAINT: maintenance commit (refactoring, typos, etc.)\r\n- BLD: change related to building\r\n- REL: related to releasing\r\n- API: an (incompatible) API change\r\n- DEP: deprecate something, or remove a deprecated object\r\n- DEV: development tool or utility\r\n- REV: revert an earlier commit\r\n- PERF: performance improvement\r\n- BOT: always commit via a bot\r\n- CI: related to CI or CD\r\n- CLN: Code cleanup\r\n-->\r\n\r\n- [x] closes #699\r\n- [ ] whatsnew entry\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport geopandas as gpd\nimport numpy as np\nimport pandas as pd\n\nfrom dtoolkit.geoaccessor.register import register_geoseries_method\n\n\n@register_geoseries_method\ndef geodistance_matrix(\n s: gpd.GeoSeries,\n /,\n other: gpd.GeoSeries | gpd.GeoDataFrame | None = None,\n radius: float = 6371008.7714150598,\n) -> pd.DataFrame:\n \"\"\"\n Returns a ``DataFrame`` containing the `great-circle`__ distances matrix between in\n ``s`` and ``other`` via haversine formula.\n\n __ https://en.wikipedia.org/wiki/Great-circle_distance\n\n .. math::\n\n D(x, y) = 2 \\\\arcsin [\n \\\\sqrt{\n \\\\sin^2 ((x_1 - y_1) / 2)\n + \\\\cos(x_1) \\\\cos(y_1) \\\\sin^2 ((x_2 - y_2) / 2)\n }\n ]\n\n Parameters\n ----------\n other : GeoSeries, or GeoDataFrame, default None\n If None, uses ``other=s``.\n\n radius : float, default 6371008.7714150598\n Great-circle distance uses a spherical model of the earth, using the mean earth\n radius as defined by the International Union of Geodesy and Geophysics,\n (2\\\\ *a* + *b*)/3 = 6371008.7714150598 meters for WGS-84.\n\n Returns\n -------\n DataFrame\n - The index and columns are the same as the index of ``s`` and ``other``.\n - The values are the great-circle distances and its unit is meters.\n\n Raises\n ------\n ModuleNotFoundError\n If don't have module named 'sklearn'.\n\n ValueError\n If the CRS is not ``ESGP:4326``.\n\n See Also\n --------\n sklearn.metrics.pairwise.haversine_distances\n dtoolkit.geoaccessor.geoseries.geodistance\n dtoolkit.geoaccessor.geoseries.geodistance_matrix\n dtoolkit.geoaccessor.geodataframe.geodistance\n dtoolkit.geoaccessor.geodataframe.geodistance_matrix\n\n Notes\n -----\n - Currently, only supports Point geometry.\n - The great-circle distance is the angular distance between two points on the\n surface of a sphere. As the Earth is nearly spherical, the haversine formula\n provides a good approximation of the distance between two points of the Earth\n surface, with a less than 1% error on average.\n\n Examples\n --------\n >>> import dtoolkit.geoaccessor\n >>> df = pd.DataFrame(\n ... {\n ... \"x\": [120, 122, 100],\n ... \"y\":[30, 55, 1],\n ... },\n ... ).from_xy(\"x\", \"y\", crs=4326)\n >>> df\n x y geometry\n 0 120 30 POINT (120.00000 30.00000)\n 1 122 55 POINT (122.00000 55.00000)\n 2 100 1 POINT (100.00000 1.00000)\n >>> other = pd.DataFrame(\n ... {\n ... \"x\": [120, 110],\n ... \"y\":[30, 40],\n ... },\n ... ).from_xy(\"x\", \"y\", crs=4326)\n >>> other\n x y geometry\n 0 120 30 POINT (120.00000 30.00000)\n 1 110 40 POINT (110.00000 40.00000)\n >>> df.geodistance_matrix(other)\n 0 1\n 0 0.000000e+00 1.435335e+06\n 1 2.784435e+06 1.889892e+06\n 2 3.855604e+06 4.453100e+06\n \"\"\"\n from sklearn.metrics.pairwise import haversine_distances\n\n if s.crs != 4326:\n raise ValueError(f\"Only support 'EPSG:4326' CRS, but got {s.crs!r}.\")\n\n if isinstance(other, gpd.base.GeoPandasBase):\n if other.crs != 4326:\n raise ValueError(f\"Only support 'EPSG:4326' CRS, but got {other.crs!r}.\")\n\n # Force convert to GeoSeries\n other = other.geometry\n\n X = np.radians(np.stack((s.y, s.x), axis=1))\n Y = np.radians(np.stack((other.y, other.x), axis=1)) if other is not None else other\n return pd.DataFrame(\n radius * haversine_distances(X, Y),\n index=s.index,\n columns=other.index,\n )\n", "path": "dtoolkit/geoaccessor/geoseries/geodistance_matrix.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport geopandas as gpd\nimport numpy as np\nimport pandas as pd\n\nfrom dtoolkit.geoaccessor.register import register_geoseries_method\n\n\n@register_geoseries_method\ndef geodistance_matrix(\n s: gpd.GeoSeries,\n /,\n other: gpd.GeoSeries | gpd.GeoDataFrame | None = None,\n radius: float = 6371008.7714150598,\n) -> pd.DataFrame:\n \"\"\"\n Returns a ``DataFrame`` containing the `great-circle`__ distances matrix between in\n ``s`` and ``other`` via haversine formula.\n\n __ https://en.wikipedia.org/wiki/Great-circle_distance\n\n .. math::\n\n D(x, y) = 2 \\\\arcsin [\n \\\\sqrt{\n \\\\sin^2 ((x_1 - y_1) / 2)\n + \\\\cos(x_1) \\\\cos(y_1) \\\\sin^2 ((x_2 - y_2) / 2)\n }\n ]\n\n Parameters\n ----------\n other : GeoSeries, or GeoDataFrame, default None\n If None, uses ``other=s``.\n\n radius : float, default 6371008.7714150598\n Great-circle distance uses a spherical model of the earth, using the mean earth\n radius as defined by the International Union of Geodesy and Geophysics,\n (2\\\\ *a* + *b*)/3 = 6371008.7714150598 meters for WGS-84.\n\n Returns\n -------\n DataFrame\n - The index and columns are the same as the index of ``s`` and ``other``.\n - The values are the great-circle distances and its unit is meters.\n\n Raises\n ------\n ModuleNotFoundError\n If don't have module named 'sklearn'.\n\n ValueError\n If the CRS is not ``ESGP:4326``.\n\n TypeError\n If the other is not a GeoSeries, GeoDataFrame, or None type.\n\n See Also\n --------\n sklearn.metrics.pairwise.haversine_distances\n dtoolkit.geoaccessor.geoseries.geodistance\n dtoolkit.geoaccessor.geoseries.geodistance_matrix\n dtoolkit.geoaccessor.geodataframe.geodistance\n dtoolkit.geoaccessor.geodataframe.geodistance_matrix\n\n Notes\n -----\n - Currently, only supports Point geometry.\n - The great-circle distance is the angular distance between two points on the\n surface of a sphere. As the Earth is nearly spherical, the haversine formula\n provides a good approximation of the distance between two points of the Earth\n surface, with a less than 1% error on average.\n\n Examples\n --------\n >>> import dtoolkit.geoaccessor\n >>> import pandas as pd\n >>> df = pd.DataFrame(\n ... {\n ... \"x\": [120, 122, 100],\n ... \"y\":[30, 55, 1],\n ... },\n ... ).from_xy(\"x\", \"y\", crs=4326)\n >>> df\n x y geometry\n 0 120 30 POINT (120.00000 30.00000)\n 1 122 55 POINT (122.00000 55.00000)\n 2 100 1 POINT (100.00000 1.00000)\n >>> other = pd.DataFrame(\n ... {\n ... \"x\": [120, 110],\n ... \"y\":[30, 40],\n ... },\n ... ).from_xy(\"x\", \"y\", crs=4326)\n >>> other\n x y geometry\n 0 120 30 POINT (120.00000 30.00000)\n 1 110 40 POINT (110.00000 40.00000)\n >>> df.geodistance_matrix(other)\n 0 1\n 0 0.000000e+00 1.435335e+06\n 1 2.784435e+06 1.889892e+06\n 2 3.855604e+06 4.453100e+06\n \"\"\"\n from sklearn.metrics.pairwise import haversine_distances\n\n if s.crs != 4326:\n raise ValueError(f\"Only support 'EPSG:4326' CRS, but got {s.crs!r}.\")\n\n if other is None:\n Y = None\n elif isinstance(other, gpd.base.GeoPandasBase):\n if other.crs != 4326:\n raise ValueError(f\"Only support 'EPSG:4326' CRS, but got {other.crs!r}.\")\n\n Y = np.radians(np.stack((other.geometry.y, other.geometry.x), axis=1))\n else:\n raise TypeError(f\"Unknown type: {type(other).__name__!r}.\")\n\n X = np.radians(np.stack((s.y, s.x), axis=1))\n return pd.DataFrame(\n radius * haversine_distances(X, Y),\n index=s.index,\n columns=other.index if other is not None else s.index,\n )\n", "path": "dtoolkit/geoaccessor/geoseries/geodistance_matrix.py"}]}
| 1,986 | 502 |
gh_patches_debug_44284
|
rasdani/github-patches
|
git_diff
|
keras-team__keras-core-726
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
From KerasNLP to KerasCore : Add `RMSLayerNormalization`
Context: [kers-team/keras-nlp/#1207](https://github.com/keras-team/keras-nlp/issues/1207)
KerasNLP's T5 (now Llama too) uses a custom layer norm which is indeed RMSLayerNormalization. It's being used as it is from [here](https://github.com/keras-team/keras-nlp/blob/master/keras_nlp/models/t5/t5_layer_norm.py) to [here](https://github.com/shivance/keras-nlp/blob/llama-backbone/keras_nlp/models/llama/llama_layernorm.py)
As it is getting popular, it would be good to officially support it as a Keras layer.
I can open a PR!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `keras_core/layers/normalization/layer_normalization.py`
Content:
```
1 from keras_core import constraints
2 from keras_core import initializers
3 from keras_core import ops
4 from keras_core import regularizers
5 from keras_core.api_export import keras_core_export
6 from keras_core.layers.layer import Layer
7
8
9 @keras_core_export("keras_core.layers.LayerNormalization")
10 class LayerNormalization(Layer):
11 """Layer normalization layer (Ba et al., 2016).
12
13 Normalize the activations of the previous layer for each given example in a
14 batch independently, rather than across a batch like Batch Normalization.
15 i.e. applies a transformation that maintains the mean activation within each
16 example close to 0 and the activation standard deviation close to 1.
17
18 If `scale` or `center` are enabled, the layer will scale the normalized
19 outputs by broadcasting them with a trainable variable `gamma`, and center
20 the outputs by broadcasting with a trainable variable `beta`. `gamma` will
21 default to a ones tensor and `beta` will default to a zeros tensor, so that
22 centering and scaling are no-ops before training has begun.
23
24 So, with scaling and centering enabled the normalization equations
25 are as follows:
26
27 Let the intermediate activations for a mini-batch to be the `inputs`.
28
29 For each sample `x_i` in `inputs` with `k` features, we compute the mean and
30 variance of the sample:
31
32 ```python
33 mean_i = sum(x_i[j] for j in range(k)) / k
34 var_i = sum((x_i[j] - mean_i) ** 2 for j in range(k)) / k
35 ```
36
37 and then compute a normalized `x_i_normalized`, including a small factor
38 `epsilon` for numerical stability.
39
40 ```python
41 x_i_normalized = (x_i - mean_i) / sqrt(var_i + epsilon)
42 ```
43
44 And finally `x_i_normalized ` is linearly transformed by `gamma` and `beta`,
45 which are learned parameters:
46
47 ```python
48 output_i = x_i_normalized * gamma + beta
49 ```
50
51 `gamma` and `beta` will span the axes of `inputs` specified in `axis`, and
52 this part of the inputs' shape must be fully defined.
53
54 For example:
55
56 >>> layer = keras_core.layers.LayerNormalization(axis=[1, 2, 3])
57 >>> layer.build([5, 20, 30, 40])
58 >>> print(layer.beta.shape)
59 (20, 30, 40)
60 >>> print(layer.gamma.shape)
61 (20, 30, 40)
62
63 Note that other implementations of layer normalization may choose to define
64 `gamma` and `beta` over a separate set of axes from the axes being
65 normalized across. For example, Group Normalization
66 ([Wu et al. 2018](https://arxiv.org/abs/1803.08494)) with group size of 1
67 corresponds to a Layer Normalization that normalizes across height, width,
68 and channel and has `gamma` and `beta` span only the channel dimension.
69 So, this Layer Normalization implementation will not match a Group
70 Normalization layer with group size set to 1.
71
72 Args:
73 axis: Integer or List/Tuple. The axis or axes to normalize across.
74 Typically, this is the features axis/axes. The left-out axes are
75 typically the batch axis/axes. `-1` is the last dimension in the
76 input. Defaults to `-1`.
77 epsilon: Small float added to variance to avoid dividing by zero.
78 Defaults to 1e-3.
79 center: If True, add offset of `beta` to normalized tensor. If False,
80 `beta` is ignored. Defaults to `True`.
81 scale: If True, multiply by `gamma`. If False, `gamma` is not used.
82 When the next layer is linear (also e.g. `nn.relu`), this can be
83 disabled since the scaling will be done by the next layer.
84 Defaults to `True`.
85 beta_initializer: Initializer for the beta weight. Defaults to zeros.
86 gamma_initializer: Initializer for the gamma weight. Defaults to ones.
87 beta_regularizer: Optional regularizer for the beta weight.
88 None by default.
89 gamma_regularizer: Optional regularizer for the gamma weight.
90 None by default.
91 beta_constraint: Optional constraint for the beta weight.
92 None by default.
93 gamma_constraint: Optional constraint for the gamma weight.
94 None by default.
95 **kwargs: Base layer keyword arguments (e.g. `name` and `dtype`).
96
97
98 Reference:
99
100 - [Lei Ba et al., 2016](https://arxiv.org/abs/1607.06450).
101 """
102
103 def __init__(
104 self,
105 axis=-1,
106 epsilon=1e-3,
107 center=True,
108 scale=True,
109 beta_initializer="zeros",
110 gamma_initializer="ones",
111 beta_regularizer=None,
112 gamma_regularizer=None,
113 beta_constraint=None,
114 gamma_constraint=None,
115 **kwargs
116 ):
117 super().__init__(**kwargs)
118 if isinstance(axis, (list, tuple)):
119 self.axis = list(axis)
120 elif isinstance(axis, int):
121 self.axis = axis
122 else:
123 raise TypeError(
124 "Expected an int or a list/tuple of ints for the "
125 "argument 'axis', but received: %r" % axis
126 )
127
128 self.epsilon = epsilon
129 self.center = center
130 self.scale = scale
131 self.beta_initializer = initializers.get(beta_initializer)
132 self.gamma_initializer = initializers.get(gamma_initializer)
133 self.beta_regularizer = regularizers.get(beta_regularizer)
134 self.gamma_regularizer = regularizers.get(gamma_regularizer)
135 self.beta_constraint = constraints.get(beta_constraint)
136 self.gamma_constraint = constraints.get(gamma_constraint)
137
138 self.supports_masking = True
139
140 def build(self, input_shape):
141 if isinstance(self.axis, list):
142 shape = tuple([input_shape[dim] for dim in self.axis])
143 else:
144 shape = (input_shape[self.axis],)
145 self.axis = [self.axis]
146 if self.scale:
147 self.gamma = self.add_weight(
148 name="gamma",
149 shape=shape,
150 initializer=self.gamma_initializer,
151 regularizer=self.gamma_regularizer,
152 constraint=self.gamma_constraint,
153 trainable=True,
154 )
155 else:
156 self.gamma = None
157
158 if self.center:
159 self.beta = self.add_weight(
160 name="beta",
161 shape=shape,
162 initializer=self.beta_initializer,
163 regularizer=self.beta_regularizer,
164 constraint=self.beta_constraint,
165 trainable=True,
166 )
167 else:
168 self.beta = None
169
170 self.built = True
171
172 def call(self, inputs):
173 inputs = ops.cast(inputs, self.compute_dtype)
174 # Compute the axes along which to reduce the mean / variance
175 input_shape = inputs.shape
176 ndims = len(input_shape)
177
178 # Broadcasting only necessary for norm when the axis is not just
179 # the last dimension
180 broadcast_shape = [1] * ndims
181 for dim in self.axis:
182 broadcast_shape[dim] = input_shape[dim]
183
184 def _broadcast(v):
185 if (
186 v is not None
187 and len(v.shape) != ndims
188 and self.axis != [ndims - 1]
189 ):
190 return ops.reshape(v, broadcast_shape)
191 return v
192
193 input_dtype = inputs.dtype
194 if input_dtype in ("float16", "bfloat16") and self.dtype == "float32":
195 # If mixed precision is used, cast inputs to float32 so that
196 # this is at least as numerically stable as the fused version.
197 inputs = ops.cast(inputs, "float32")
198
199 # Calculate the mean and variance last axis (layer activations).
200 mean = ops.mean(inputs, axis=self.axis, keepdims=True)
201 # Don't use ops.var, as that would re-compute the mean from scratch.
202 variance = ops.mean(
203 ops.power(inputs - mean, 2), axis=self.axis, keepdims=True
204 )
205
206 scale, offset = _broadcast(self.gamma), _broadcast(self.beta)
207
208 # Compute the batch normalization.
209 inv = 1 / ops.sqrt(variance + self.epsilon)
210 if scale is not None:
211 scale = ops.cast(scale, inputs.dtype)
212 inv = inv * scale
213 x = -mean * inv
214 if offset is not None:
215 offset = ops.cast(offset, inputs.dtype)
216 x = offset + x
217 outputs = inputs * ops.cast(inv, inputs.dtype) + ops.cast(
218 x, inputs.dtype
219 )
220
221 outputs = ops.cast(outputs, input_dtype)
222
223 # If some components of the shape got lost due to adjustments, fix that.
224 outputs = ops.reshape(outputs, ops.shape(inputs))
225
226 return outputs
227
228 def compute_output_shape(self, input_shape):
229 return input_shape
230
231 def get_config(self):
232 config = {
233 "axis": self.axis,
234 "epsilon": self.epsilon,
235 "center": self.center,
236 "scale": self.scale,
237 "beta_initializer": initializers.serialize(self.beta_initializer),
238 "gamma_initializer": initializers.serialize(self.gamma_initializer),
239 "beta_regularizer": regularizers.serialize(self.beta_regularizer),
240 "gamma_regularizer": regularizers.serialize(self.gamma_regularizer),
241 "beta_constraint": constraints.serialize(self.beta_constraint),
242 "gamma_constraint": constraints.serialize(self.gamma_constraint),
243 }
244 base_config = super().get_config()
245 return {**base_config, **config}
246
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/keras_core/layers/normalization/layer_normalization.py b/keras_core/layers/normalization/layer_normalization.py
--- a/keras_core/layers/normalization/layer_normalization.py
+++ b/keras_core/layers/normalization/layer_normalization.py
@@ -82,6 +82,10 @@
When the next layer is linear (also e.g. `nn.relu`), this can be
disabled since the scaling will be done by the next layer.
Defaults to `True`.
+ rms_scaling: If True, `center` and `scale` are ignored, and the
+ inputs are scaled by `gamma` and the inverse square root
+ of the square of all inputs. This is an approximate and faster
+ approach that avoids ever computing the mean of the input.
beta_initializer: Initializer for the beta weight. Defaults to zeros.
gamma_initializer: Initializer for the gamma weight. Defaults to ones.
beta_regularizer: Optional regularizer for the beta weight.
@@ -106,6 +110,7 @@
epsilon=1e-3,
center=True,
scale=True,
+ rms_scaling=False,
beta_initializer="zeros",
gamma_initializer="ones",
beta_regularizer=None,
@@ -128,6 +133,7 @@
self.epsilon = epsilon
self.center = center
self.scale = scale
+ self.rms_scaling = rms_scaling
self.beta_initializer = initializers.get(beta_initializer)
self.gamma_initializer = initializers.get(gamma_initializer)
self.beta_regularizer = regularizers.get(beta_regularizer)
@@ -143,7 +149,7 @@
else:
shape = (input_shape[self.axis],)
self.axis = [self.axis]
- if self.scale:
+ if self.scale or self.rms_scaling:
self.gamma = self.add_weight(
name="gamma",
shape=shape,
@@ -155,7 +161,7 @@
else:
self.gamma = None
- if self.center:
+ if self.center and not self.rms_scaling:
self.beta = self.add_weight(
name="beta",
shape=shape,
@@ -196,27 +202,31 @@
# this is at least as numerically stable as the fused version.
inputs = ops.cast(inputs, "float32")
- # Calculate the mean and variance last axis (layer activations).
- mean = ops.mean(inputs, axis=self.axis, keepdims=True)
- # Don't use ops.var, as that would re-compute the mean from scratch.
- variance = ops.mean(
- ops.power(inputs - mean, 2), axis=self.axis, keepdims=True
- )
-
- scale, offset = _broadcast(self.gamma), _broadcast(self.beta)
+ # Calculate the variance last axis (layer activations).
+ variance = ops.var(inputs, axis=self.axis, keepdims=True)
# Compute the batch normalization.
inv = 1 / ops.sqrt(variance + self.epsilon)
- if scale is not None:
- scale = ops.cast(scale, inputs.dtype)
- inv = inv * scale
- x = -mean * inv
- if offset is not None:
- offset = ops.cast(offset, inputs.dtype)
- x = offset + x
- outputs = inputs * ops.cast(inv, inputs.dtype) + ops.cast(
- x, inputs.dtype
- )
+
+ if self.rms_scaling:
+ # Calculate outputs with only variance and gamma if rms scaling
+ # is enabled
+ outputs = inputs * ops.cast(inv, inputs.dtype) * self.gamma
+ else:
+ # Calculate the mean last axis (layer activations).
+ mean = ops.mean(inputs, axis=self.axis, keepdims=True)
+ scale, offset = _broadcast(self.gamma), _broadcast(self.beta)
+ if scale is not None:
+ scale = ops.cast(scale, inputs.dtype)
+ inv = inv * scale
+ x = -mean * inv
+ if offset is not None:
+ offset = ops.cast(offset, inputs.dtype)
+ x = offset + x
+
+ outputs = inputs * ops.cast(inv, inputs.dtype) + ops.cast(
+ x, inputs.dtype
+ )
outputs = ops.cast(outputs, input_dtype)
|
{"golden_diff": "diff --git a/keras_core/layers/normalization/layer_normalization.py b/keras_core/layers/normalization/layer_normalization.py\n--- a/keras_core/layers/normalization/layer_normalization.py\n+++ b/keras_core/layers/normalization/layer_normalization.py\n@@ -82,6 +82,10 @@\n When the next layer is linear (also e.g. `nn.relu`), this can be\n disabled since the scaling will be done by the next layer.\n Defaults to `True`.\n+ rms_scaling: If True, `center` and `scale` are ignored, and the\n+ inputs are scaled by `gamma` and the inverse square root\n+ of the square of all inputs. This is an approximate and faster\n+ approach that avoids ever computing the mean of the input.\n beta_initializer: Initializer for the beta weight. Defaults to zeros.\n gamma_initializer: Initializer for the gamma weight. Defaults to ones.\n beta_regularizer: Optional regularizer for the beta weight.\n@@ -106,6 +110,7 @@\n epsilon=1e-3,\n center=True,\n scale=True,\n+ rms_scaling=False,\n beta_initializer=\"zeros\",\n gamma_initializer=\"ones\",\n beta_regularizer=None,\n@@ -128,6 +133,7 @@\n self.epsilon = epsilon\n self.center = center\n self.scale = scale\n+ self.rms_scaling = rms_scaling\n self.beta_initializer = initializers.get(beta_initializer)\n self.gamma_initializer = initializers.get(gamma_initializer)\n self.beta_regularizer = regularizers.get(beta_regularizer)\n@@ -143,7 +149,7 @@\n else:\n shape = (input_shape[self.axis],)\n self.axis = [self.axis]\n- if self.scale:\n+ if self.scale or self.rms_scaling:\n self.gamma = self.add_weight(\n name=\"gamma\",\n shape=shape,\n@@ -155,7 +161,7 @@\n else:\n self.gamma = None\n \n- if self.center:\n+ if self.center and not self.rms_scaling:\n self.beta = self.add_weight(\n name=\"beta\",\n shape=shape,\n@@ -196,27 +202,31 @@\n # this is at least as numerically stable as the fused version.\n inputs = ops.cast(inputs, \"float32\")\n \n- # Calculate the mean and variance last axis (layer activations).\n- mean = ops.mean(inputs, axis=self.axis, keepdims=True)\n- # Don't use ops.var, as that would re-compute the mean from scratch.\n- variance = ops.mean(\n- ops.power(inputs - mean, 2), axis=self.axis, keepdims=True\n- )\n-\n- scale, offset = _broadcast(self.gamma), _broadcast(self.beta)\n+ # Calculate the variance last axis (layer activations).\n+ variance = ops.var(inputs, axis=self.axis, keepdims=True)\n \n # Compute the batch normalization.\n inv = 1 / ops.sqrt(variance + self.epsilon)\n- if scale is not None:\n- scale = ops.cast(scale, inputs.dtype)\n- inv = inv * scale\n- x = -mean * inv\n- if offset is not None:\n- offset = ops.cast(offset, inputs.dtype)\n- x = offset + x\n- outputs = inputs * ops.cast(inv, inputs.dtype) + ops.cast(\n- x, inputs.dtype\n- )\n+\n+ if self.rms_scaling:\n+ # Calculate outputs with only variance and gamma if rms scaling\n+ # is enabled\n+ outputs = inputs * ops.cast(inv, inputs.dtype) * self.gamma\n+ else:\n+ # Calculate the mean last axis (layer activations).\n+ mean = ops.mean(inputs, axis=self.axis, keepdims=True)\n+ scale, offset = _broadcast(self.gamma), _broadcast(self.beta)\n+ if scale is not None:\n+ scale = ops.cast(scale, inputs.dtype)\n+ inv = inv * scale\n+ x = -mean * inv\n+ if offset is not None:\n+ offset = ops.cast(offset, inputs.dtype)\n+ x = offset + x\n+\n+ outputs = inputs * ops.cast(inv, inputs.dtype) + ops.cast(\n+ x, inputs.dtype\n+ )\n \n outputs = ops.cast(outputs, input_dtype)\n", "issue": "From KerasNLP to KerasCore : Add `RMSLayerNormalization`\nContext: [kers-team/keras-nlp/#1207](https://github.com/keras-team/keras-nlp/issues/1207)\r\n\r\nKerasNLP's T5 (now Llama too) uses a custom layer norm which is indeed RMSLayerNormalization. It's being used as it is from [here](https://github.com/keras-team/keras-nlp/blob/master/keras_nlp/models/t5/t5_layer_norm.py) to [here](https://github.com/shivance/keras-nlp/blob/llama-backbone/keras_nlp/models/llama/llama_layernorm.py) \r\nAs it is getting popular, it would be good to officially support it as a Keras layer.\r\n\r\nI can open a PR!\n", "before_files": [{"content": "from keras_core import constraints\nfrom keras_core import initializers\nfrom keras_core import ops\nfrom keras_core import regularizers\nfrom keras_core.api_export import keras_core_export\nfrom keras_core.layers.layer import Layer\n\n\n@keras_core_export(\"keras_core.layers.LayerNormalization\")\nclass LayerNormalization(Layer):\n \"\"\"Layer normalization layer (Ba et al., 2016).\n\n Normalize the activations of the previous layer for each given example in a\n batch independently, rather than across a batch like Batch Normalization.\n i.e. applies a transformation that maintains the mean activation within each\n example close to 0 and the activation standard deviation close to 1.\n\n If `scale` or `center` are enabled, the layer will scale the normalized\n outputs by broadcasting them with a trainable variable `gamma`, and center\n the outputs by broadcasting with a trainable variable `beta`. `gamma` will\n default to a ones tensor and `beta` will default to a zeros tensor, so that\n centering and scaling are no-ops before training has begun.\n\n So, with scaling and centering enabled the normalization equations\n are as follows:\n\n Let the intermediate activations for a mini-batch to be the `inputs`.\n\n For each sample `x_i` in `inputs` with `k` features, we compute the mean and\n variance of the sample:\n\n ```python\n mean_i = sum(x_i[j] for j in range(k)) / k\n var_i = sum((x_i[j] - mean_i) ** 2 for j in range(k)) / k\n ```\n\n and then compute a normalized `x_i_normalized`, including a small factor\n `epsilon` for numerical stability.\n\n ```python\n x_i_normalized = (x_i - mean_i) / sqrt(var_i + epsilon)\n ```\n\n And finally `x_i_normalized ` is linearly transformed by `gamma` and `beta`,\n which are learned parameters:\n\n ```python\n output_i = x_i_normalized * gamma + beta\n ```\n\n `gamma` and `beta` will span the axes of `inputs` specified in `axis`, and\n this part of the inputs' shape must be fully defined.\n\n For example:\n\n >>> layer = keras_core.layers.LayerNormalization(axis=[1, 2, 3])\n >>> layer.build([5, 20, 30, 40])\n >>> print(layer.beta.shape)\n (20, 30, 40)\n >>> print(layer.gamma.shape)\n (20, 30, 40)\n\n Note that other implementations of layer normalization may choose to define\n `gamma` and `beta` over a separate set of axes from the axes being\n normalized across. For example, Group Normalization\n ([Wu et al. 2018](https://arxiv.org/abs/1803.08494)) with group size of 1\n corresponds to a Layer Normalization that normalizes across height, width,\n and channel and has `gamma` and `beta` span only the channel dimension.\n So, this Layer Normalization implementation will not match a Group\n Normalization layer with group size set to 1.\n\n Args:\n axis: Integer or List/Tuple. The axis or axes to normalize across.\n Typically, this is the features axis/axes. The left-out axes are\n typically the batch axis/axes. `-1` is the last dimension in the\n input. Defaults to `-1`.\n epsilon: Small float added to variance to avoid dividing by zero.\n Defaults to 1e-3.\n center: If True, add offset of `beta` to normalized tensor. If False,\n `beta` is ignored. Defaults to `True`.\n scale: If True, multiply by `gamma`. If False, `gamma` is not used.\n When the next layer is linear (also e.g. `nn.relu`), this can be\n disabled since the scaling will be done by the next layer.\n Defaults to `True`.\n beta_initializer: Initializer for the beta weight. Defaults to zeros.\n gamma_initializer: Initializer for the gamma weight. Defaults to ones.\n beta_regularizer: Optional regularizer for the beta weight.\n None by default.\n gamma_regularizer: Optional regularizer for the gamma weight.\n None by default.\n beta_constraint: Optional constraint for the beta weight.\n None by default.\n gamma_constraint: Optional constraint for the gamma weight.\n None by default.\n **kwargs: Base layer keyword arguments (e.g. `name` and `dtype`).\n\n\n Reference:\n\n - [Lei Ba et al., 2016](https://arxiv.org/abs/1607.06450).\n \"\"\"\n\n def __init__(\n self,\n axis=-1,\n epsilon=1e-3,\n center=True,\n scale=True,\n beta_initializer=\"zeros\",\n gamma_initializer=\"ones\",\n beta_regularizer=None,\n gamma_regularizer=None,\n beta_constraint=None,\n gamma_constraint=None,\n **kwargs\n ):\n super().__init__(**kwargs)\n if isinstance(axis, (list, tuple)):\n self.axis = list(axis)\n elif isinstance(axis, int):\n self.axis = axis\n else:\n raise TypeError(\n \"Expected an int or a list/tuple of ints for the \"\n \"argument 'axis', but received: %r\" % axis\n )\n\n self.epsilon = epsilon\n self.center = center\n self.scale = scale\n self.beta_initializer = initializers.get(beta_initializer)\n self.gamma_initializer = initializers.get(gamma_initializer)\n self.beta_regularizer = regularizers.get(beta_regularizer)\n self.gamma_regularizer = regularizers.get(gamma_regularizer)\n self.beta_constraint = constraints.get(beta_constraint)\n self.gamma_constraint = constraints.get(gamma_constraint)\n\n self.supports_masking = True\n\n def build(self, input_shape):\n if isinstance(self.axis, list):\n shape = tuple([input_shape[dim] for dim in self.axis])\n else:\n shape = (input_shape[self.axis],)\n self.axis = [self.axis]\n if self.scale:\n self.gamma = self.add_weight(\n name=\"gamma\",\n shape=shape,\n initializer=self.gamma_initializer,\n regularizer=self.gamma_regularizer,\n constraint=self.gamma_constraint,\n trainable=True,\n )\n else:\n self.gamma = None\n\n if self.center:\n self.beta = self.add_weight(\n name=\"beta\",\n shape=shape,\n initializer=self.beta_initializer,\n regularizer=self.beta_regularizer,\n constraint=self.beta_constraint,\n trainable=True,\n )\n else:\n self.beta = None\n\n self.built = True\n\n def call(self, inputs):\n inputs = ops.cast(inputs, self.compute_dtype)\n # Compute the axes along which to reduce the mean / variance\n input_shape = inputs.shape\n ndims = len(input_shape)\n\n # Broadcasting only necessary for norm when the axis is not just\n # the last dimension\n broadcast_shape = [1] * ndims\n for dim in self.axis:\n broadcast_shape[dim] = input_shape[dim]\n\n def _broadcast(v):\n if (\n v is not None\n and len(v.shape) != ndims\n and self.axis != [ndims - 1]\n ):\n return ops.reshape(v, broadcast_shape)\n return v\n\n input_dtype = inputs.dtype\n if input_dtype in (\"float16\", \"bfloat16\") and self.dtype == \"float32\":\n # If mixed precision is used, cast inputs to float32 so that\n # this is at least as numerically stable as the fused version.\n inputs = ops.cast(inputs, \"float32\")\n\n # Calculate the mean and variance last axis (layer activations).\n mean = ops.mean(inputs, axis=self.axis, keepdims=True)\n # Don't use ops.var, as that would re-compute the mean from scratch.\n variance = ops.mean(\n ops.power(inputs - mean, 2), axis=self.axis, keepdims=True\n )\n\n scale, offset = _broadcast(self.gamma), _broadcast(self.beta)\n\n # Compute the batch normalization.\n inv = 1 / ops.sqrt(variance + self.epsilon)\n if scale is not None:\n scale = ops.cast(scale, inputs.dtype)\n inv = inv * scale\n x = -mean * inv\n if offset is not None:\n offset = ops.cast(offset, inputs.dtype)\n x = offset + x\n outputs = inputs * ops.cast(inv, inputs.dtype) + ops.cast(\n x, inputs.dtype\n )\n\n outputs = ops.cast(outputs, input_dtype)\n\n # If some components of the shape got lost due to adjustments, fix that.\n outputs = ops.reshape(outputs, ops.shape(inputs))\n\n return outputs\n\n def compute_output_shape(self, input_shape):\n return input_shape\n\n def get_config(self):\n config = {\n \"axis\": self.axis,\n \"epsilon\": self.epsilon,\n \"center\": self.center,\n \"scale\": self.scale,\n \"beta_initializer\": initializers.serialize(self.beta_initializer),\n \"gamma_initializer\": initializers.serialize(self.gamma_initializer),\n \"beta_regularizer\": regularizers.serialize(self.beta_regularizer),\n \"gamma_regularizer\": regularizers.serialize(self.gamma_regularizer),\n \"beta_constraint\": constraints.serialize(self.beta_constraint),\n \"gamma_constraint\": constraints.serialize(self.gamma_constraint),\n }\n base_config = super().get_config()\n return {**base_config, **config}\n", "path": "keras_core/layers/normalization/layer_normalization.py"}], "after_files": [{"content": "from keras_core import constraints\nfrom keras_core import initializers\nfrom keras_core import ops\nfrom keras_core import regularizers\nfrom keras_core.api_export import keras_core_export\nfrom keras_core.layers.layer import Layer\n\n\n@keras_core_export(\"keras_core.layers.LayerNormalization\")\nclass LayerNormalization(Layer):\n \"\"\"Layer normalization layer (Ba et al., 2016).\n\n Normalize the activations of the previous layer for each given example in a\n batch independently, rather than across a batch like Batch Normalization.\n i.e. applies a transformation that maintains the mean activation within each\n example close to 0 and the activation standard deviation close to 1.\n\n If `scale` or `center` are enabled, the layer will scale the normalized\n outputs by broadcasting them with a trainable variable `gamma`, and center\n the outputs by broadcasting with a trainable variable `beta`. `gamma` will\n default to a ones tensor and `beta` will default to a zeros tensor, so that\n centering and scaling are no-ops before training has begun.\n\n So, with scaling and centering enabled the normalization equations\n are as follows:\n\n Let the intermediate activations for a mini-batch to be the `inputs`.\n\n For each sample `x_i` in `inputs` with `k` features, we compute the mean and\n variance of the sample:\n\n ```python\n mean_i = sum(x_i[j] for j in range(k)) / k\n var_i = sum((x_i[j] - mean_i) ** 2 for j in range(k)) / k\n ```\n\n and then compute a normalized `x_i_normalized`, including a small factor\n `epsilon` for numerical stability.\n\n ```python\n x_i_normalized = (x_i - mean_i) / sqrt(var_i + epsilon)\n ```\n\n And finally `x_i_normalized ` is linearly transformed by `gamma` and `beta`,\n which are learned parameters:\n\n ```python\n output_i = x_i_normalized * gamma + beta\n ```\n\n `gamma` and `beta` will span the axes of `inputs` specified in `axis`, and\n this part of the inputs' shape must be fully defined.\n\n For example:\n\n >>> layer = keras_core.layers.LayerNormalization(axis=[1, 2, 3])\n >>> layer.build([5, 20, 30, 40])\n >>> print(layer.beta.shape)\n (20, 30, 40)\n >>> print(layer.gamma.shape)\n (20, 30, 40)\n\n Note that other implementations of layer normalization may choose to define\n `gamma` and `beta` over a separate set of axes from the axes being\n normalized across. For example, Group Normalization\n ([Wu et al. 2018](https://arxiv.org/abs/1803.08494)) with group size of 1\n corresponds to a Layer Normalization that normalizes across height, width,\n and channel and has `gamma` and `beta` span only the channel dimension.\n So, this Layer Normalization implementation will not match a Group\n Normalization layer with group size set to 1.\n\n Args:\n axis: Integer or List/Tuple. The axis or axes to normalize across.\n Typically, this is the features axis/axes. The left-out axes are\n typically the batch axis/axes. `-1` is the last dimension in the\n input. Defaults to `-1`.\n epsilon: Small float added to variance to avoid dividing by zero.\n Defaults to 1e-3.\n center: If True, add offset of `beta` to normalized tensor. If False,\n `beta` is ignored. Defaults to `True`.\n scale: If True, multiply by `gamma`. If False, `gamma` is not used.\n When the next layer is linear (also e.g. `nn.relu`), this can be\n disabled since the scaling will be done by the next layer.\n Defaults to `True`.\n rms_scaling: If True, `center` and `scale` are ignored, and the\n inputs are scaled by `gamma` and the inverse square root\n of the square of all inputs. This is an approximate and faster\n approach that avoids ever computing the mean of the input.\n beta_initializer: Initializer for the beta weight. Defaults to zeros.\n gamma_initializer: Initializer for the gamma weight. Defaults to ones.\n beta_regularizer: Optional regularizer for the beta weight.\n None by default.\n gamma_regularizer: Optional regularizer for the gamma weight.\n None by default.\n beta_constraint: Optional constraint for the beta weight.\n None by default.\n gamma_constraint: Optional constraint for the gamma weight.\n None by default.\n **kwargs: Base layer keyword arguments (e.g. `name` and `dtype`).\n\n\n Reference:\n\n - [Lei Ba et al., 2016](https://arxiv.org/abs/1607.06450).\n \"\"\"\n\n def __init__(\n self,\n axis=-1,\n epsilon=1e-3,\n center=True,\n scale=True,\n rms_scaling=False,\n beta_initializer=\"zeros\",\n gamma_initializer=\"ones\",\n beta_regularizer=None,\n gamma_regularizer=None,\n beta_constraint=None,\n gamma_constraint=None,\n **kwargs\n ):\n super().__init__(**kwargs)\n if isinstance(axis, (list, tuple)):\n self.axis = list(axis)\n elif isinstance(axis, int):\n self.axis = axis\n else:\n raise TypeError(\n \"Expected an int or a list/tuple of ints for the \"\n \"argument 'axis', but received: %r\" % axis\n )\n\n self.epsilon = epsilon\n self.center = center\n self.scale = scale\n self.rms_scaling = rms_scaling\n self.beta_initializer = initializers.get(beta_initializer)\n self.gamma_initializer = initializers.get(gamma_initializer)\n self.beta_regularizer = regularizers.get(beta_regularizer)\n self.gamma_regularizer = regularizers.get(gamma_regularizer)\n self.beta_constraint = constraints.get(beta_constraint)\n self.gamma_constraint = constraints.get(gamma_constraint)\n\n self.supports_masking = True\n\n def build(self, input_shape):\n if isinstance(self.axis, list):\n shape = tuple([input_shape[dim] for dim in self.axis])\n else:\n shape = (input_shape[self.axis],)\n self.axis = [self.axis]\n if self.scale or self.rms_scaling:\n self.gamma = self.add_weight(\n name=\"gamma\",\n shape=shape,\n initializer=self.gamma_initializer,\n regularizer=self.gamma_regularizer,\n constraint=self.gamma_constraint,\n trainable=True,\n )\n else:\n self.gamma = None\n\n if self.center and not self.rms_scaling:\n self.beta = self.add_weight(\n name=\"beta\",\n shape=shape,\n initializer=self.beta_initializer,\n regularizer=self.beta_regularizer,\n constraint=self.beta_constraint,\n trainable=True,\n )\n else:\n self.beta = None\n\n self.built = True\n\n def call(self, inputs):\n inputs = ops.cast(inputs, self.compute_dtype)\n # Compute the axes along which to reduce the mean / variance\n input_shape = inputs.shape\n ndims = len(input_shape)\n\n # Broadcasting only necessary for norm when the axis is not just\n # the last dimension\n broadcast_shape = [1] * ndims\n for dim in self.axis:\n broadcast_shape[dim] = input_shape[dim]\n\n def _broadcast(v):\n if (\n v is not None\n and len(v.shape) != ndims\n and self.axis != [ndims - 1]\n ):\n return ops.reshape(v, broadcast_shape)\n return v\n\n input_dtype = inputs.dtype\n if input_dtype in (\"float16\", \"bfloat16\") and self.dtype == \"float32\":\n # If mixed precision is used, cast inputs to float32 so that\n # this is at least as numerically stable as the fused version.\n inputs = ops.cast(inputs, \"float32\")\n\n # Calculate the variance last axis (layer activations).\n variance = ops.var(inputs, axis=self.axis, keepdims=True)\n\n # Compute the batch normalization.\n inv = 1 / ops.sqrt(variance + self.epsilon)\n\n if self.rms_scaling:\n # Calculate outputs with only variance and gamma if rms scaling\n # is enabled\n outputs = inputs * ops.cast(inv, inputs.dtype) * self.gamma\n else:\n # Calculate the mean last axis (layer activations).\n mean = ops.mean(inputs, axis=self.axis, keepdims=True)\n scale, offset = _broadcast(self.gamma), _broadcast(self.beta)\n if scale is not None:\n scale = ops.cast(scale, inputs.dtype)\n inv = inv * scale\n x = -mean * inv\n if offset is not None:\n offset = ops.cast(offset, inputs.dtype)\n x = offset + x\n\n outputs = inputs * ops.cast(inv, inputs.dtype) + ops.cast(\n x, inputs.dtype\n )\n\n outputs = ops.cast(outputs, input_dtype)\n\n # If some components of the shape got lost due to adjustments, fix that.\n outputs = ops.reshape(outputs, ops.shape(inputs))\n\n return outputs\n\n def compute_output_shape(self, input_shape):\n return input_shape\n\n def get_config(self):\n config = {\n \"axis\": self.axis,\n \"epsilon\": self.epsilon,\n \"center\": self.center,\n \"scale\": self.scale,\n \"beta_initializer\": initializers.serialize(self.beta_initializer),\n \"gamma_initializer\": initializers.serialize(self.gamma_initializer),\n \"beta_regularizer\": regularizers.serialize(self.beta_regularizer),\n \"gamma_regularizer\": regularizers.serialize(self.gamma_regularizer),\n \"beta_constraint\": constraints.serialize(self.beta_constraint),\n \"gamma_constraint\": constraints.serialize(self.gamma_constraint),\n }\n base_config = super().get_config()\n return {**base_config, **config}\n", "path": "keras_core/layers/normalization/layer_normalization.py"}]}
| 3,152 | 962 |
gh_patches_debug_32006
|
rasdani/github-patches
|
git_diff
|
getredash__redash-3187
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
RuntimeError: Working outside of application context.
After deploying v6-beta to demo.redash.io we started seeing this error, which we haven't before:
https://sentry.io/share/issue/08f84c11d6d04474b642b2d1435f9fb8/
By guessing what might be the cause of the issue I commented out the following code:
https://github.com/getredash/redash/blob/cfe12c5a5d37b8ec01c8a26fd9c8c8ad97e12d07/redash/worker.py#L85-L90
Once I have the issue stopped happening. The reason I suspected this code was because we call `create_app` here for the second time during the initialization process of Celery.
I'm not sure why it causes it though or how to fix it (aside from removing this code). 🤔
@jezdez @emtwo If I'm not mistaken, you were running this code in your env for a long time now. You haven't seen this exception?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `redash/__init__.py`
Content:
```
1 import sys
2 import logging
3 import urlparse
4 import urllib
5 import redis
6 from flask import Flask
7 from flask_sslify import SSLify
8 from werkzeug.contrib.fixers import ProxyFix
9 from werkzeug.routing import BaseConverter
10 from statsd import StatsClient
11 from flask_mail import Mail
12 from flask_limiter import Limiter
13 from flask_limiter.util import get_ipaddr
14 from flask_migrate import Migrate
15
16 from redash import settings
17 from redash.query_runner import import_query_runners
18 from redash.destinations import import_destinations
19
20
21 __version__ = '6.0.0-beta'
22
23
24 def setup_logging():
25 handler = logging.StreamHandler(sys.stdout if settings.LOG_STDOUT else sys.stderr)
26 formatter = logging.Formatter(settings.LOG_FORMAT)
27 handler.setFormatter(formatter)
28 logging.getLogger().addHandler(handler)
29 logging.getLogger().setLevel(settings.LOG_LEVEL)
30
31 # Make noisy libraries less noisy
32 if settings.LOG_LEVEL != "DEBUG":
33 logging.getLogger("passlib").setLevel("ERROR")
34 logging.getLogger("requests.packages.urllib3").setLevel("ERROR")
35 logging.getLogger("snowflake.connector").setLevel("ERROR")
36 logging.getLogger('apiclient').setLevel("ERROR")
37
38
39 def create_redis_connection():
40 logging.debug("Creating Redis connection (%s)", settings.REDIS_URL)
41 redis_url = urlparse.urlparse(settings.REDIS_URL)
42
43 if redis_url.scheme == 'redis+socket':
44 qs = urlparse.parse_qs(redis_url.query)
45 if 'virtual_host' in qs:
46 db = qs['virtual_host'][0]
47 else:
48 db = 0
49
50 r = redis.StrictRedis(unix_socket_path=redis_url.path, db=db)
51 else:
52 if redis_url.path:
53 redis_db = redis_url.path[1]
54 else:
55 redis_db = 0
56 # Redis passwords might be quoted with special characters
57 redis_password = redis_url.password and urllib.unquote(redis_url.password)
58 r = redis.StrictRedis(host=redis_url.hostname, port=redis_url.port, db=redis_db, password=redis_password)
59
60 return r
61
62
63 setup_logging()
64 redis_connection = create_redis_connection()
65 mail = Mail()
66 migrate = Migrate()
67 mail.init_mail(settings.all_settings())
68 statsd_client = StatsClient(host=settings.STATSD_HOST, port=settings.STATSD_PORT, prefix=settings.STATSD_PREFIX)
69 limiter = Limiter(key_func=get_ipaddr, storage_uri=settings.LIMITER_STORAGE)
70
71 import_query_runners(settings.QUERY_RUNNERS)
72 import_destinations(settings.DESTINATIONS)
73
74 from redash.version_check import reset_new_version_status
75 reset_new_version_status()
76
77
78 class SlugConverter(BaseConverter):
79 def to_python(self, value):
80 # This is ay workaround for when we enable multi-org and some files are being called by the index rule:
81 # for path in settings.STATIC_ASSETS_PATHS:
82 # full_path = safe_join(path, value)
83 # if os.path.isfile(full_path):
84 # raise ValidationError()
85
86 return value
87
88 def to_url(self, value):
89 return value
90
91
92 def create_app(load_admin=True):
93 from redash import extensions, handlers
94 from redash.handlers.webpack import configure_webpack
95 from redash.handlers import chrome_logger
96 from redash.admin import init_admin
97 from redash.models import db
98 from redash.authentication import setup_authentication
99 from redash.metrics.request import provision_app
100
101 app = Flask(__name__,
102 template_folder=settings.STATIC_ASSETS_PATH,
103 static_folder=settings.STATIC_ASSETS_PATH,
104 static_path='/static')
105
106 # Make sure we get the right referral address even behind proxies like nginx.
107 app.wsgi_app = ProxyFix(app.wsgi_app, settings.PROXIES_COUNT)
108 app.url_map.converters['org_slug'] = SlugConverter
109
110 if settings.ENFORCE_HTTPS:
111 SSLify(app, skips=['ping'])
112
113 if settings.SENTRY_DSN:
114 from raven import Client
115 from raven.contrib.flask import Sentry
116 from raven.handlers.logging import SentryHandler
117
118 client = Client(settings.SENTRY_DSN, release=__version__, install_logging_hook=False)
119 sentry = Sentry(app, client=client)
120 sentry.client.release = __version__
121
122 sentry_handler = SentryHandler(client=client)
123 sentry_handler.setLevel(logging.ERROR)
124 logging.getLogger().addHandler(sentry_handler)
125
126 # configure our database
127 app.config['SQLALCHEMY_DATABASE_URI'] = settings.SQLALCHEMY_DATABASE_URI
128 app.config.update(settings.all_settings())
129
130 provision_app(app)
131 db.init_app(app)
132 migrate.init_app(app, db)
133 if load_admin:
134 init_admin(app)
135 mail.init_app(app)
136 setup_authentication(app)
137 limiter.init_app(app)
138 handlers.init_app(app)
139 configure_webpack(app)
140 extensions.init_extensions(app)
141 chrome_logger.init_app(app)
142
143 return app
144
```
Path: `redash/worker.py`
Content:
```
1 from __future__ import absolute_import
2
3 from datetime import timedelta
4 from random import randint
5
6 from flask import current_app
7
8 from celery import Celery
9 from celery.schedules import crontab
10 from celery.signals import worker_process_init
11 from redash import __version__, create_app, settings
12 from redash.metrics import celery as celery_metrics
13
14 celery = Celery('redash',
15 broker=settings.CELERY_BROKER,
16 include='redash.tasks')
17
18 celery_schedule = {
19 'refresh_queries': {
20 'task': 'redash.tasks.refresh_queries',
21 'schedule': timedelta(seconds=30)
22 },
23 'cleanup_tasks': {
24 'task': 'redash.tasks.cleanup_tasks',
25 'schedule': timedelta(minutes=5)
26 },
27 'refresh_schemas': {
28 'task': 'redash.tasks.refresh_schemas',
29 'schedule': timedelta(minutes=settings.SCHEMAS_REFRESH_SCHEDULE)
30 }
31 }
32
33 if settings.VERSION_CHECK:
34 celery_schedule['version_check'] = {
35 'task': 'redash.tasks.version_check',
36 # We need to schedule the version check to run at a random hour/minute, to spread the requests from all users
37 # evenly.
38 'schedule': crontab(minute=randint(0, 59), hour=randint(0, 23))
39 }
40
41 if settings.QUERY_RESULTS_CLEANUP_ENABLED:
42 celery_schedule['cleanup_query_results'] = {
43 'task': 'redash.tasks.cleanup_query_results',
44 'schedule': timedelta(minutes=5)
45 }
46
47 celery.conf.update(result_backend=settings.CELERY_RESULT_BACKEND,
48 beat_schedule=celery_schedule,
49 timezone='UTC',
50 result_expires=settings.CELERY_RESULT_EXPIRES,
51 worker_log_format=settings.CELERYD_WORKER_LOG_FORMAT,
52 worker_task_log_format=settings.CELERYD_WORKER_TASK_LOG_FORMAT)
53
54 if settings.SENTRY_DSN:
55 from raven import Client
56 from raven.contrib.celery import register_signal
57
58 client = Client(settings.SENTRY_DSN, release=__version__, install_logging_hook=False)
59 register_signal(client)
60
61
62 # Create a new Task base class, that pushes a new Flask app context to allow DB connections if needed.
63 TaskBase = celery.Task
64
65
66 class ContextTask(TaskBase):
67 abstract = True
68
69 def __call__(self, *args, **kwargs):
70 with current_app.app_context():
71 return TaskBase.__call__(self, *args, **kwargs)
72
73
74 celery.Task = ContextTask
75
76
77 # Create Flask app after forking a new worker, to make sure no resources are shared between processes.
78 @worker_process_init.connect
79 def init_celery_flask_app(**kwargs):
80 app = create_app()
81 app.app_context().push()
82
83
84 # Hook for extensions to add periodic tasks.
85 @celery.on_after_configure.connect
86 def add_periodic_tasks(sender, **kwargs):
87 app = create_app()
88 periodic_tasks = getattr(app, 'periodic_tasks', {})
89 for params in periodic_tasks.values():
90 sender.add_periodic_task(**params)
91
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/redash/__init__.py b/redash/__init__.py
--- a/redash/__init__.py
+++ b/redash/__init__.py
@@ -3,7 +3,7 @@
import urlparse
import urllib
import redis
-from flask import Flask
+from flask import Flask, current_app
from flask_sslify import SSLify
from werkzeug.contrib.fixers import ProxyFix
from werkzeug.routing import BaseConverter
@@ -141,3 +141,11 @@
chrome_logger.init_app(app)
return app
+
+
+def safe_create_app():
+ """Return current_app or create a new one."""
+ if current_app:
+ return current_app
+
+ return create_app()
\ No newline at end of file
diff --git a/redash/worker.py b/redash/worker.py
--- a/redash/worker.py
+++ b/redash/worker.py
@@ -8,7 +8,7 @@
from celery import Celery
from celery.schedules import crontab
from celery.signals import worker_process_init
-from redash import __version__, create_app, settings
+from redash import __version__, safe_create_app, settings
from redash.metrics import celery as celery_metrics
celery = Celery('redash',
@@ -77,14 +77,14 @@
# Create Flask app after forking a new worker, to make sure no resources are shared between processes.
@worker_process_init.connect
def init_celery_flask_app(**kwargs):
- app = create_app()
+ app = safe_create_app()
app.app_context().push()
# Hook for extensions to add periodic tasks.
@celery.on_after_configure.connect
def add_periodic_tasks(sender, **kwargs):
- app = create_app()
+ app = safe_create_app()
periodic_tasks = getattr(app, 'periodic_tasks', {})
for params in periodic_tasks.values():
sender.add_periodic_task(**params)
|
{"golden_diff": "diff --git a/redash/__init__.py b/redash/__init__.py\n--- a/redash/__init__.py\n+++ b/redash/__init__.py\n@@ -3,7 +3,7 @@\n import urlparse\n import urllib\n import redis\n-from flask import Flask\n+from flask import Flask, current_app\n from flask_sslify import SSLify\n from werkzeug.contrib.fixers import ProxyFix\n from werkzeug.routing import BaseConverter\n@@ -141,3 +141,11 @@\n chrome_logger.init_app(app)\n \n return app\n+\n+\n+def safe_create_app():\n+ \"\"\"Return current_app or create a new one.\"\"\"\n+ if current_app:\n+ return current_app\n+\n+ return create_app()\n\\ No newline at end of file\ndiff --git a/redash/worker.py b/redash/worker.py\n--- a/redash/worker.py\n+++ b/redash/worker.py\n@@ -8,7 +8,7 @@\n from celery import Celery\n from celery.schedules import crontab\n from celery.signals import worker_process_init\n-from redash import __version__, create_app, settings\n+from redash import __version__, safe_create_app, settings\n from redash.metrics import celery as celery_metrics\n \n celery = Celery('redash',\n@@ -77,14 +77,14 @@\n # Create Flask app after forking a new worker, to make sure no resources are shared between processes.\n @worker_process_init.connect\n def init_celery_flask_app(**kwargs):\n- app = create_app()\n+ app = safe_create_app()\n app.app_context().push()\n \n \n # Hook for extensions to add periodic tasks.\n @celery.on_after_configure.connect\n def add_periodic_tasks(sender, **kwargs):\n- app = create_app()\n+ app = safe_create_app()\n periodic_tasks = getattr(app, 'periodic_tasks', {})\n for params in periodic_tasks.values():\n sender.add_periodic_task(**params)\n", "issue": "RuntimeError: Working outside of application context.\nAfter deploying v6-beta to demo.redash.io we started seeing this error, which we haven't before:\r\nhttps://sentry.io/share/issue/08f84c11d6d04474b642b2d1435f9fb8/\r\n\r\nBy guessing what might be the cause of the issue I commented out the following code:\r\n\r\nhttps://github.com/getredash/redash/blob/cfe12c5a5d37b8ec01c8a26fd9c8c8ad97e12d07/redash/worker.py#L85-L90\r\n\r\nOnce I have the issue stopped happening. The reason I suspected this code was because we call `create_app` here for the second time during the initialization process of Celery.\r\n\r\nI'm not sure why it causes it though or how to fix it (aside from removing this code). \ud83e\udd14 \r\n\r\n@jezdez @emtwo If I'm not mistaken, you were running this code in your env for a long time now. You haven't seen this exception?\n", "before_files": [{"content": "import sys\nimport logging\nimport urlparse\nimport urllib\nimport redis\nfrom flask import Flask\nfrom flask_sslify import SSLify\nfrom werkzeug.contrib.fixers import ProxyFix\nfrom werkzeug.routing import BaseConverter\nfrom statsd import StatsClient\nfrom flask_mail import Mail\nfrom flask_limiter import Limiter\nfrom flask_limiter.util import get_ipaddr\nfrom flask_migrate import Migrate\n\nfrom redash import settings\nfrom redash.query_runner import import_query_runners\nfrom redash.destinations import import_destinations\n\n\n__version__ = '6.0.0-beta'\n\n\ndef setup_logging():\n handler = logging.StreamHandler(sys.stdout if settings.LOG_STDOUT else sys.stderr)\n formatter = logging.Formatter(settings.LOG_FORMAT)\n handler.setFormatter(formatter)\n logging.getLogger().addHandler(handler)\n logging.getLogger().setLevel(settings.LOG_LEVEL)\n\n # Make noisy libraries less noisy\n if settings.LOG_LEVEL != \"DEBUG\":\n logging.getLogger(\"passlib\").setLevel(\"ERROR\")\n logging.getLogger(\"requests.packages.urllib3\").setLevel(\"ERROR\")\n logging.getLogger(\"snowflake.connector\").setLevel(\"ERROR\")\n logging.getLogger('apiclient').setLevel(\"ERROR\")\n\n\ndef create_redis_connection():\n logging.debug(\"Creating Redis connection (%s)\", settings.REDIS_URL)\n redis_url = urlparse.urlparse(settings.REDIS_URL)\n\n if redis_url.scheme == 'redis+socket':\n qs = urlparse.parse_qs(redis_url.query)\n if 'virtual_host' in qs:\n db = qs['virtual_host'][0]\n else:\n db = 0\n\n r = redis.StrictRedis(unix_socket_path=redis_url.path, db=db)\n else:\n if redis_url.path:\n redis_db = redis_url.path[1]\n else:\n redis_db = 0\n # Redis passwords might be quoted with special characters\n redis_password = redis_url.password and urllib.unquote(redis_url.password)\n r = redis.StrictRedis(host=redis_url.hostname, port=redis_url.port, db=redis_db, password=redis_password)\n\n return r\n\n\nsetup_logging()\nredis_connection = create_redis_connection()\nmail = Mail()\nmigrate = Migrate()\nmail.init_mail(settings.all_settings())\nstatsd_client = StatsClient(host=settings.STATSD_HOST, port=settings.STATSD_PORT, prefix=settings.STATSD_PREFIX)\nlimiter = Limiter(key_func=get_ipaddr, storage_uri=settings.LIMITER_STORAGE)\n\nimport_query_runners(settings.QUERY_RUNNERS)\nimport_destinations(settings.DESTINATIONS)\n\nfrom redash.version_check import reset_new_version_status\nreset_new_version_status()\n\n\nclass SlugConverter(BaseConverter):\n def to_python(self, value):\n # This is ay workaround for when we enable multi-org and some files are being called by the index rule:\n # for path in settings.STATIC_ASSETS_PATHS:\n # full_path = safe_join(path, value)\n # if os.path.isfile(full_path):\n # raise ValidationError()\n\n return value\n\n def to_url(self, value):\n return value\n\n\ndef create_app(load_admin=True):\n from redash import extensions, handlers\n from redash.handlers.webpack import configure_webpack\n from redash.handlers import chrome_logger\n from redash.admin import init_admin\n from redash.models import db\n from redash.authentication import setup_authentication\n from redash.metrics.request import provision_app\n\n app = Flask(__name__,\n template_folder=settings.STATIC_ASSETS_PATH,\n static_folder=settings.STATIC_ASSETS_PATH,\n static_path='/static')\n\n # Make sure we get the right referral address even behind proxies like nginx.\n app.wsgi_app = ProxyFix(app.wsgi_app, settings.PROXIES_COUNT)\n app.url_map.converters['org_slug'] = SlugConverter\n\n if settings.ENFORCE_HTTPS:\n SSLify(app, skips=['ping'])\n\n if settings.SENTRY_DSN:\n from raven import Client\n from raven.contrib.flask import Sentry\n from raven.handlers.logging import SentryHandler\n\n client = Client(settings.SENTRY_DSN, release=__version__, install_logging_hook=False)\n sentry = Sentry(app, client=client)\n sentry.client.release = __version__\n\n sentry_handler = SentryHandler(client=client)\n sentry_handler.setLevel(logging.ERROR)\n logging.getLogger().addHandler(sentry_handler)\n\n # configure our database\n app.config['SQLALCHEMY_DATABASE_URI'] = settings.SQLALCHEMY_DATABASE_URI\n app.config.update(settings.all_settings())\n\n provision_app(app)\n db.init_app(app)\n migrate.init_app(app, db)\n if load_admin:\n init_admin(app)\n mail.init_app(app)\n setup_authentication(app)\n limiter.init_app(app)\n handlers.init_app(app)\n configure_webpack(app)\n extensions.init_extensions(app)\n chrome_logger.init_app(app)\n\n return app\n", "path": "redash/__init__.py"}, {"content": "from __future__ import absolute_import\n\nfrom datetime import timedelta\nfrom random import randint\n\nfrom flask import current_app\n\nfrom celery import Celery\nfrom celery.schedules import crontab\nfrom celery.signals import worker_process_init\nfrom redash import __version__, create_app, settings\nfrom redash.metrics import celery as celery_metrics\n\ncelery = Celery('redash',\n broker=settings.CELERY_BROKER,\n include='redash.tasks')\n\ncelery_schedule = {\n 'refresh_queries': {\n 'task': 'redash.tasks.refresh_queries',\n 'schedule': timedelta(seconds=30)\n },\n 'cleanup_tasks': {\n 'task': 'redash.tasks.cleanup_tasks',\n 'schedule': timedelta(minutes=5)\n },\n 'refresh_schemas': {\n 'task': 'redash.tasks.refresh_schemas',\n 'schedule': timedelta(minutes=settings.SCHEMAS_REFRESH_SCHEDULE)\n }\n}\n\nif settings.VERSION_CHECK:\n celery_schedule['version_check'] = {\n 'task': 'redash.tasks.version_check',\n # We need to schedule the version check to run at a random hour/minute, to spread the requests from all users\n # evenly.\n 'schedule': crontab(minute=randint(0, 59), hour=randint(0, 23))\n }\n\nif settings.QUERY_RESULTS_CLEANUP_ENABLED:\n celery_schedule['cleanup_query_results'] = {\n 'task': 'redash.tasks.cleanup_query_results',\n 'schedule': timedelta(minutes=5)\n }\n\ncelery.conf.update(result_backend=settings.CELERY_RESULT_BACKEND,\n beat_schedule=celery_schedule,\n timezone='UTC',\n result_expires=settings.CELERY_RESULT_EXPIRES,\n worker_log_format=settings.CELERYD_WORKER_LOG_FORMAT,\n worker_task_log_format=settings.CELERYD_WORKER_TASK_LOG_FORMAT)\n\nif settings.SENTRY_DSN:\n from raven import Client\n from raven.contrib.celery import register_signal\n\n client = Client(settings.SENTRY_DSN, release=__version__, install_logging_hook=False)\n register_signal(client)\n\n\n# Create a new Task base class, that pushes a new Flask app context to allow DB connections if needed.\nTaskBase = celery.Task\n\n\nclass ContextTask(TaskBase):\n abstract = True\n\n def __call__(self, *args, **kwargs):\n with current_app.app_context():\n return TaskBase.__call__(self, *args, **kwargs)\n\n\ncelery.Task = ContextTask\n\n\n# Create Flask app after forking a new worker, to make sure no resources are shared between processes.\n@worker_process_init.connect\ndef init_celery_flask_app(**kwargs):\n app = create_app()\n app.app_context().push()\n\n\n# Hook for extensions to add periodic tasks.\[email protected]_after_configure.connect\ndef add_periodic_tasks(sender, **kwargs):\n app = create_app()\n periodic_tasks = getattr(app, 'periodic_tasks', {})\n for params in periodic_tasks.values():\n sender.add_periodic_task(**params)\n", "path": "redash/worker.py"}], "after_files": [{"content": "import sys\nimport logging\nimport urlparse\nimport urllib\nimport redis\nfrom flask import Flask, current_app\nfrom flask_sslify import SSLify\nfrom werkzeug.contrib.fixers import ProxyFix\nfrom werkzeug.routing import BaseConverter\nfrom statsd import StatsClient\nfrom flask_mail import Mail\nfrom flask_limiter import Limiter\nfrom flask_limiter.util import get_ipaddr\nfrom flask_migrate import Migrate\n\nfrom redash import settings\nfrom redash.query_runner import import_query_runners\nfrom redash.destinations import import_destinations\n\n\n__version__ = '6.0.0-beta'\n\n\ndef setup_logging():\n handler = logging.StreamHandler(sys.stdout if settings.LOG_STDOUT else sys.stderr)\n formatter = logging.Formatter(settings.LOG_FORMAT)\n handler.setFormatter(formatter)\n logging.getLogger().addHandler(handler)\n logging.getLogger().setLevel(settings.LOG_LEVEL)\n\n # Make noisy libraries less noisy\n if settings.LOG_LEVEL != \"DEBUG\":\n logging.getLogger(\"passlib\").setLevel(\"ERROR\")\n logging.getLogger(\"requests.packages.urllib3\").setLevel(\"ERROR\")\n logging.getLogger(\"snowflake.connector\").setLevel(\"ERROR\")\n logging.getLogger('apiclient').setLevel(\"ERROR\")\n\n\ndef create_redis_connection():\n logging.debug(\"Creating Redis connection (%s)\", settings.REDIS_URL)\n redis_url = urlparse.urlparse(settings.REDIS_URL)\n\n if redis_url.scheme == 'redis+socket':\n qs = urlparse.parse_qs(redis_url.query)\n if 'virtual_host' in qs:\n db = qs['virtual_host'][0]\n else:\n db = 0\n\n r = redis.StrictRedis(unix_socket_path=redis_url.path, db=db)\n else:\n if redis_url.path:\n redis_db = redis_url.path[1]\n else:\n redis_db = 0\n # Redis passwords might be quoted with special characters\n redis_password = redis_url.password and urllib.unquote(redis_url.password)\n r = redis.StrictRedis(host=redis_url.hostname, port=redis_url.port, db=redis_db, password=redis_password)\n\n return r\n\n\nsetup_logging()\nredis_connection = create_redis_connection()\nmail = Mail()\nmigrate = Migrate()\nmail.init_mail(settings.all_settings())\nstatsd_client = StatsClient(host=settings.STATSD_HOST, port=settings.STATSD_PORT, prefix=settings.STATSD_PREFIX)\nlimiter = Limiter(key_func=get_ipaddr, storage_uri=settings.LIMITER_STORAGE)\n\nimport_query_runners(settings.QUERY_RUNNERS)\nimport_destinations(settings.DESTINATIONS)\n\nfrom redash.version_check import reset_new_version_status\nreset_new_version_status()\n\n\nclass SlugConverter(BaseConverter):\n def to_python(self, value):\n # This is ay workaround for when we enable multi-org and some files are being called by the index rule:\n # for path in settings.STATIC_ASSETS_PATHS:\n # full_path = safe_join(path, value)\n # if os.path.isfile(full_path):\n # raise ValidationError()\n\n return value\n\n def to_url(self, value):\n return value\n\n\ndef create_app(load_admin=True):\n from redash import extensions, handlers\n from redash.handlers.webpack import configure_webpack\n from redash.handlers import chrome_logger\n from redash.admin import init_admin\n from redash.models import db\n from redash.authentication import setup_authentication\n from redash.metrics.request import provision_app\n\n app = Flask(__name__,\n template_folder=settings.STATIC_ASSETS_PATH,\n static_folder=settings.STATIC_ASSETS_PATH,\n static_path='/static')\n\n # Make sure we get the right referral address even behind proxies like nginx.\n app.wsgi_app = ProxyFix(app.wsgi_app, settings.PROXIES_COUNT)\n app.url_map.converters['org_slug'] = SlugConverter\n\n if settings.ENFORCE_HTTPS:\n SSLify(app, skips=['ping'])\n\n if settings.SENTRY_DSN:\n from raven import Client\n from raven.contrib.flask import Sentry\n from raven.handlers.logging import SentryHandler\n\n client = Client(settings.SENTRY_DSN, release=__version__, install_logging_hook=False)\n sentry = Sentry(app, client=client)\n sentry.client.release = __version__\n\n sentry_handler = SentryHandler(client=client)\n sentry_handler.setLevel(logging.ERROR)\n logging.getLogger().addHandler(sentry_handler)\n\n # configure our database\n app.config['SQLALCHEMY_DATABASE_URI'] = settings.SQLALCHEMY_DATABASE_URI\n app.config.update(settings.all_settings())\n\n provision_app(app)\n db.init_app(app)\n migrate.init_app(app, db)\n if load_admin:\n init_admin(app)\n mail.init_app(app)\n setup_authentication(app)\n limiter.init_app(app)\n handlers.init_app(app)\n configure_webpack(app)\n extensions.init_extensions(app)\n chrome_logger.init_app(app)\n\n return app\n\n\ndef safe_create_app():\n \"\"\"Return current_app or create a new one.\"\"\"\n if current_app:\n return current_app\n\n return create_app()", "path": "redash/__init__.py"}, {"content": "from __future__ import absolute_import\n\nfrom datetime import timedelta\nfrom random import randint\n\nfrom flask import current_app\n\nfrom celery import Celery\nfrom celery.schedules import crontab\nfrom celery.signals import worker_process_init\nfrom redash import __version__, safe_create_app, settings\nfrom redash.metrics import celery as celery_metrics\n\ncelery = Celery('redash',\n broker=settings.CELERY_BROKER,\n include='redash.tasks')\n\ncelery_schedule = {\n 'refresh_queries': {\n 'task': 'redash.tasks.refresh_queries',\n 'schedule': timedelta(seconds=30)\n },\n 'cleanup_tasks': {\n 'task': 'redash.tasks.cleanup_tasks',\n 'schedule': timedelta(minutes=5)\n },\n 'refresh_schemas': {\n 'task': 'redash.tasks.refresh_schemas',\n 'schedule': timedelta(minutes=settings.SCHEMAS_REFRESH_SCHEDULE)\n }\n}\n\nif settings.VERSION_CHECK:\n celery_schedule['version_check'] = {\n 'task': 'redash.tasks.version_check',\n # We need to schedule the version check to run at a random hour/minute, to spread the requests from all users\n # evenly.\n 'schedule': crontab(minute=randint(0, 59), hour=randint(0, 23))\n }\n\nif settings.QUERY_RESULTS_CLEANUP_ENABLED:\n celery_schedule['cleanup_query_results'] = {\n 'task': 'redash.tasks.cleanup_query_results',\n 'schedule': timedelta(minutes=5)\n }\n\ncelery.conf.update(result_backend=settings.CELERY_RESULT_BACKEND,\n beat_schedule=celery_schedule,\n timezone='UTC',\n result_expires=settings.CELERY_RESULT_EXPIRES,\n worker_log_format=settings.CELERYD_WORKER_LOG_FORMAT,\n worker_task_log_format=settings.CELERYD_WORKER_TASK_LOG_FORMAT)\n\nif settings.SENTRY_DSN:\n from raven import Client\n from raven.contrib.celery import register_signal\n\n client = Client(settings.SENTRY_DSN, release=__version__, install_logging_hook=False)\n register_signal(client)\n\n\n# Create a new Task base class, that pushes a new Flask app context to allow DB connections if needed.\nTaskBase = celery.Task\n\n\nclass ContextTask(TaskBase):\n abstract = True\n\n def __call__(self, *args, **kwargs):\n with current_app.app_context():\n return TaskBase.__call__(self, *args, **kwargs)\n\n\ncelery.Task = ContextTask\n\n\n# Create Flask app after forking a new worker, to make sure no resources are shared between processes.\n@worker_process_init.connect\ndef init_celery_flask_app(**kwargs):\n app = safe_create_app()\n app.app_context().push()\n\n\n# Hook for extensions to add periodic tasks.\[email protected]_after_configure.connect\ndef add_periodic_tasks(sender, **kwargs):\n app = safe_create_app()\n periodic_tasks = getattr(app, 'periodic_tasks', {})\n for params in periodic_tasks.values():\n sender.add_periodic_task(**params)\n", "path": "redash/worker.py"}]}
| 2,711 | 425 |
gh_patches_debug_7900
|
rasdani/github-patches
|
git_diff
|
vyperlang__vyper-3338
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
unable to use vyper-serve 0.3.6
### Version Information
* vyper Version (output of `vyper --version`): 0.3.6
* OS: ubutu
* Python Version 3.8
### What's your issue about?
unable to use the vyper-serve api endpoint, the call always fail with an error:
`Unable to json serialize IRNode`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `vyper/cli/vyper_serve.py`
Content:
```
1 #!/usr/bin/env python3
2
3 import argparse
4 import json
5 import sys
6 from http.server import BaseHTTPRequestHandler, HTTPServer
7 from socketserver import ThreadingMixIn
8
9 import vyper
10 from vyper.codegen import ir_node
11 from vyper.evm.opcodes import DEFAULT_EVM_VERSION
12 from vyper.exceptions import VyperException
13
14
15 def _parse_cli_args():
16 return _parse_args(sys.argv[1:])
17
18
19 def _parse_args(argv):
20 parser = argparse.ArgumentParser(description="Serve Vyper compiler as an HTTP Service")
21 parser.add_argument(
22 "--version", action="version", version=f"{vyper.__version__}+commit{vyper.__commit__}"
23 )
24 parser.add_argument(
25 "-b",
26 help="Address to bind JSON server on, default: localhost:8000",
27 default="localhost:8000",
28 dest="bind_address",
29 )
30
31 args = parser.parse_args(argv)
32
33 if ":" in args.bind_address:
34 ir_node.VYPER_COLOR_OUTPUT = False
35 runserver(*args.bind_address.split(":"))
36 else:
37 print('Provide bind address in "{address}:{port}" format')
38
39
40 class VyperRequestHandler(BaseHTTPRequestHandler):
41 def send_404(self):
42 self.send_response(404)
43 self.end_headers()
44 return
45
46 def send_cors_all(self):
47 self.send_header("Access-Control-Allow-Origin", "*")
48 self.send_header("Access-Control-Allow-Headers", "X-Requested-With, Content-type")
49
50 def do_OPTIONS(self):
51 self.send_response(200)
52 self.send_cors_all()
53 self.end_headers()
54
55 def do_GET(self):
56 if self.path == "/":
57 self.send_response(200)
58 self.send_cors_all()
59 self.end_headers()
60 self.wfile.write(f"Vyper Compiler. Version: {vyper.__version__}\n".encode())
61 else:
62 self.send_404()
63
64 return
65
66 def do_POST(self):
67 if self.path == "/compile":
68 content_len = int(self.headers.get("content-length"))
69 post_body = self.rfile.read(content_len)
70 data = json.loads(post_body)
71
72 response, status_code = self._compile(data)
73
74 self.send_response(status_code)
75 self.send_header("Content-type", "application/json")
76 self.send_cors_all()
77 self.end_headers()
78 self.wfile.write(json.dumps(response).encode())
79
80 else:
81 self.send_404()
82
83 return
84
85 def _compile(self, data):
86 code = data.get("code")
87 if not code:
88 return {"status": "failed", "message": 'No "code" key supplied'}, 400
89 if not isinstance(code, str):
90 return {"status": "failed", "message": '"code" must be a non-empty string'}, 400
91
92 try:
93 code = data["code"]
94 out_dict = vyper.compile_codes(
95 {"": code},
96 list(vyper.compiler.OUTPUT_FORMATS.keys()),
97 evm_version=data.get("evm_version", DEFAULT_EVM_VERSION),
98 )[""]
99 out_dict["ir"] = str(out_dict["ir"])
100 except VyperException as e:
101 return (
102 {"status": "failed", "message": str(e), "column": e.col_offset, "line": e.lineno},
103 400,
104 )
105 except SyntaxError as e:
106 return (
107 {"status": "failed", "message": str(e), "column": e.offset, "line": e.lineno},
108 400,
109 )
110
111 out_dict.update({"status": "success"})
112
113 return out_dict, 200
114
115
116 class VyperHTTPServer(ThreadingMixIn, HTTPServer):
117 """Handle requests in a separate thread."""
118
119 pass
120
121
122 def runserver(host="", port=8000):
123 server_address = (host, int(port))
124 httpd = VyperHTTPServer(server_address, VyperRequestHandler)
125 print(f"Listening on http://{host}:{port}")
126 httpd.serve_forever()
127
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/vyper/cli/vyper_serve.py b/vyper/cli/vyper_serve.py
--- a/vyper/cli/vyper_serve.py
+++ b/vyper/cli/vyper_serve.py
@@ -97,6 +97,7 @@
evm_version=data.get("evm_version", DEFAULT_EVM_VERSION),
)[""]
out_dict["ir"] = str(out_dict["ir"])
+ out_dict["ir_runtime"] = str(out_dict["ir_runtime"])
except VyperException as e:
return (
{"status": "failed", "message": str(e), "column": e.col_offset, "line": e.lineno},
|
{"golden_diff": "diff --git a/vyper/cli/vyper_serve.py b/vyper/cli/vyper_serve.py\n--- a/vyper/cli/vyper_serve.py\n+++ b/vyper/cli/vyper_serve.py\n@@ -97,6 +97,7 @@\n evm_version=data.get(\"evm_version\", DEFAULT_EVM_VERSION),\n )[\"\"]\n out_dict[\"ir\"] = str(out_dict[\"ir\"])\n+ out_dict[\"ir_runtime\"] = str(out_dict[\"ir_runtime\"])\n except VyperException as e:\n return (\n {\"status\": \"failed\", \"message\": str(e), \"column\": e.col_offset, \"line\": e.lineno},\n", "issue": "unable to use vyper-serve 0.3.6\n### Version Information\r\n\r\n* vyper Version (output of `vyper --version`): 0.3.6\r\n* OS: ubutu\r\n* Python Version 3.8\r\n\r\n### What's your issue about?\r\n\r\nunable to use the vyper-serve api endpoint, the call always fail with an error:\r\n`Unable to json serialize IRNode`\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nimport argparse\nimport json\nimport sys\nfrom http.server import BaseHTTPRequestHandler, HTTPServer\nfrom socketserver import ThreadingMixIn\n\nimport vyper\nfrom vyper.codegen import ir_node\nfrom vyper.evm.opcodes import DEFAULT_EVM_VERSION\nfrom vyper.exceptions import VyperException\n\n\ndef _parse_cli_args():\n return _parse_args(sys.argv[1:])\n\n\ndef _parse_args(argv):\n parser = argparse.ArgumentParser(description=\"Serve Vyper compiler as an HTTP Service\")\n parser.add_argument(\n \"--version\", action=\"version\", version=f\"{vyper.__version__}+commit{vyper.__commit__}\"\n )\n parser.add_argument(\n \"-b\",\n help=\"Address to bind JSON server on, default: localhost:8000\",\n default=\"localhost:8000\",\n dest=\"bind_address\",\n )\n\n args = parser.parse_args(argv)\n\n if \":\" in args.bind_address:\n ir_node.VYPER_COLOR_OUTPUT = False\n runserver(*args.bind_address.split(\":\"))\n else:\n print('Provide bind address in \"{address}:{port}\" format')\n\n\nclass VyperRequestHandler(BaseHTTPRequestHandler):\n def send_404(self):\n self.send_response(404)\n self.end_headers()\n return\n\n def send_cors_all(self):\n self.send_header(\"Access-Control-Allow-Origin\", \"*\")\n self.send_header(\"Access-Control-Allow-Headers\", \"X-Requested-With, Content-type\")\n\n def do_OPTIONS(self):\n self.send_response(200)\n self.send_cors_all()\n self.end_headers()\n\n def do_GET(self):\n if self.path == \"/\":\n self.send_response(200)\n self.send_cors_all()\n self.end_headers()\n self.wfile.write(f\"Vyper Compiler. Version: {vyper.__version__}\\n\".encode())\n else:\n self.send_404()\n\n return\n\n def do_POST(self):\n if self.path == \"/compile\":\n content_len = int(self.headers.get(\"content-length\"))\n post_body = self.rfile.read(content_len)\n data = json.loads(post_body)\n\n response, status_code = self._compile(data)\n\n self.send_response(status_code)\n self.send_header(\"Content-type\", \"application/json\")\n self.send_cors_all()\n self.end_headers()\n self.wfile.write(json.dumps(response).encode())\n\n else:\n self.send_404()\n\n return\n\n def _compile(self, data):\n code = data.get(\"code\")\n if not code:\n return {\"status\": \"failed\", \"message\": 'No \"code\" key supplied'}, 400\n if not isinstance(code, str):\n return {\"status\": \"failed\", \"message\": '\"code\" must be a non-empty string'}, 400\n\n try:\n code = data[\"code\"]\n out_dict = vyper.compile_codes(\n {\"\": code},\n list(vyper.compiler.OUTPUT_FORMATS.keys()),\n evm_version=data.get(\"evm_version\", DEFAULT_EVM_VERSION),\n )[\"\"]\n out_dict[\"ir\"] = str(out_dict[\"ir\"])\n except VyperException as e:\n return (\n {\"status\": \"failed\", \"message\": str(e), \"column\": e.col_offset, \"line\": e.lineno},\n 400,\n )\n except SyntaxError as e:\n return (\n {\"status\": \"failed\", \"message\": str(e), \"column\": e.offset, \"line\": e.lineno},\n 400,\n )\n\n out_dict.update({\"status\": \"success\"})\n\n return out_dict, 200\n\n\nclass VyperHTTPServer(ThreadingMixIn, HTTPServer):\n \"\"\"Handle requests in a separate thread.\"\"\"\n\n pass\n\n\ndef runserver(host=\"\", port=8000):\n server_address = (host, int(port))\n httpd = VyperHTTPServer(server_address, VyperRequestHandler)\n print(f\"Listening on http://{host}:{port}\")\n httpd.serve_forever()\n", "path": "vyper/cli/vyper_serve.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\nimport argparse\nimport json\nimport sys\nfrom http.server import BaseHTTPRequestHandler, HTTPServer\nfrom socketserver import ThreadingMixIn\n\nimport vyper\nfrom vyper.codegen import ir_node\nfrom vyper.evm.opcodes import DEFAULT_EVM_VERSION\nfrom vyper.exceptions import VyperException\n\n\ndef _parse_cli_args():\n return _parse_args(sys.argv[1:])\n\n\ndef _parse_args(argv):\n parser = argparse.ArgumentParser(description=\"Serve Vyper compiler as an HTTP Service\")\n parser.add_argument(\n \"--version\", action=\"version\", version=f\"{vyper.__version__}+commit{vyper.__commit__}\"\n )\n parser.add_argument(\n \"-b\",\n help=\"Address to bind JSON server on, default: localhost:8000\",\n default=\"localhost:8000\",\n dest=\"bind_address\",\n )\n\n args = parser.parse_args(argv)\n\n if \":\" in args.bind_address:\n ir_node.VYPER_COLOR_OUTPUT = False\n runserver(*args.bind_address.split(\":\"))\n else:\n print('Provide bind address in \"{address}:{port}\" format')\n\n\nclass VyperRequestHandler(BaseHTTPRequestHandler):\n def send_404(self):\n self.send_response(404)\n self.end_headers()\n return\n\n def send_cors_all(self):\n self.send_header(\"Access-Control-Allow-Origin\", \"*\")\n self.send_header(\"Access-Control-Allow-Headers\", \"X-Requested-With, Content-type\")\n\n def do_OPTIONS(self):\n self.send_response(200)\n self.send_cors_all()\n self.end_headers()\n\n def do_GET(self):\n if self.path == \"/\":\n self.send_response(200)\n self.send_cors_all()\n self.end_headers()\n self.wfile.write(f\"Vyper Compiler. Version: {vyper.__version__}\\n\".encode())\n else:\n self.send_404()\n\n return\n\n def do_POST(self):\n if self.path == \"/compile\":\n content_len = int(self.headers.get(\"content-length\"))\n post_body = self.rfile.read(content_len)\n data = json.loads(post_body)\n\n response, status_code = self._compile(data)\n\n self.send_response(status_code)\n self.send_header(\"Content-type\", \"application/json\")\n self.send_cors_all()\n self.end_headers()\n self.wfile.write(json.dumps(response).encode())\n\n else:\n self.send_404()\n\n return\n\n def _compile(self, data):\n code = data.get(\"code\")\n if not code:\n return {\"status\": \"failed\", \"message\": 'No \"code\" key supplied'}, 400\n if not isinstance(code, str):\n return {\"status\": \"failed\", \"message\": '\"code\" must be a non-empty string'}, 400\n\n try:\n code = data[\"code\"]\n out_dict = vyper.compile_codes(\n {\"\": code},\n list(vyper.compiler.OUTPUT_FORMATS.keys()),\n evm_version=data.get(\"evm_version\", DEFAULT_EVM_VERSION),\n )[\"\"]\n out_dict[\"ir\"] = str(out_dict[\"ir\"])\n out_dict[\"ir_runtime\"] = str(out_dict[\"ir_runtime\"])\n except VyperException as e:\n return (\n {\"status\": \"failed\", \"message\": str(e), \"column\": e.col_offset, \"line\": e.lineno},\n 400,\n )\n except SyntaxError as e:\n return (\n {\"status\": \"failed\", \"message\": str(e), \"column\": e.offset, \"line\": e.lineno},\n 400,\n )\n\n out_dict.update({\"status\": \"success\"})\n\n return out_dict, 200\n\n\nclass VyperHTTPServer(ThreadingMixIn, HTTPServer):\n \"\"\"Handle requests in a separate thread.\"\"\"\n\n pass\n\n\ndef runserver(host=\"\", port=8000):\n server_address = (host, int(port))\n httpd = VyperHTTPServer(server_address, VyperRequestHandler)\n print(f\"Listening on http://{host}:{port}\")\n httpd.serve_forever()\n", "path": "vyper/cli/vyper_serve.py"}]}
| 1,520 | 143 |
gh_patches_debug_530
|
rasdani/github-patches
|
git_diff
|
craiga__will-of-the-prophets-35
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Mobile-friendly layout
Sidebar should drop below the board once "mornhammered" becomes too wide for the window.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `will_of_the_prophets/views.py`
Content:
```
1 """Views."""
2
3 from django.shortcuts import render
4 from django.views.generic.edit import CreateView
5 from django.contrib.auth.mixins import LoginRequiredMixin
6 from django.urls import reverse
7
8 from will_of_the_prophets import board, forms, models
9
10
11 def public_board(request):
12 """
13 Board for the public.
14
15 Does not take embargoed rolls into account.
16 """
17 special_square_types = models.SpecialSquareType.objects.all()
18 return render(request, 'will_of_the_prophets/public_board.html',
19 {'board': board.Board(),
20 'special_square_types': special_square_types})
21
22
23 class RollView(LoginRequiredMixin, CreateView):
24 """View for rolling the die."""
25
26 form_class = forms.RollForm
27 template_name = 'will_of_the_prophets/roll.html'
28
29 def get_context_data(self, **kwargs):
30 last_roll = models.Roll.objects.order_by('-embargo').first()
31 return super().get_context_data(
32 **kwargs,
33 last_roll=last_roll,
34 board=board.Board(now=last_roll.embargo),
35 special_square_types=models.SpecialSquareType.objects.all())
36
37 def get_success_url(self):
38 return reverse('roll')
39
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/will_of_the_prophets/views.py b/will_of_the_prophets/views.py
--- a/will_of_the_prophets/views.py
+++ b/will_of_the_prophets/views.py
@@ -35,4 +35,4 @@
special_square_types=models.SpecialSquareType.objects.all())
def get_success_url(self):
- return reverse('roll')
+ return reverse('roll') + "#chula"
|
{"golden_diff": "diff --git a/will_of_the_prophets/views.py b/will_of_the_prophets/views.py\n--- a/will_of_the_prophets/views.py\n+++ b/will_of_the_prophets/views.py\n@@ -35,4 +35,4 @@\n special_square_types=models.SpecialSquareType.objects.all())\n \n def get_success_url(self):\n- return reverse('roll')\n+ return reverse('roll') + \"#chula\"\n", "issue": "Mobile-friendly layout\nSidebar should drop below the board once \"mornhammered\" becomes too wide for the window.\n", "before_files": [{"content": "\"\"\"Views.\"\"\"\n\nfrom django.shortcuts import render\nfrom django.views.generic.edit import CreateView\nfrom django.contrib.auth.mixins import LoginRequiredMixin\nfrom django.urls import reverse\n\nfrom will_of_the_prophets import board, forms, models\n\n\ndef public_board(request):\n \"\"\"\n Board for the public.\n\n Does not take embargoed rolls into account.\n \"\"\"\n special_square_types = models.SpecialSquareType.objects.all()\n return render(request, 'will_of_the_prophets/public_board.html',\n {'board': board.Board(),\n 'special_square_types': special_square_types})\n\n\nclass RollView(LoginRequiredMixin, CreateView):\n \"\"\"View for rolling the die.\"\"\"\n\n form_class = forms.RollForm\n template_name = 'will_of_the_prophets/roll.html'\n\n def get_context_data(self, **kwargs):\n last_roll = models.Roll.objects.order_by('-embargo').first()\n return super().get_context_data(\n **kwargs,\n last_roll=last_roll,\n board=board.Board(now=last_roll.embargo),\n special_square_types=models.SpecialSquareType.objects.all())\n\n def get_success_url(self):\n return reverse('roll')\n", "path": "will_of_the_prophets/views.py"}], "after_files": [{"content": "\"\"\"Views.\"\"\"\n\nfrom django.shortcuts import render\nfrom django.views.generic.edit import CreateView\nfrom django.contrib.auth.mixins import LoginRequiredMixin\nfrom django.urls import reverse\n\nfrom will_of_the_prophets import board, forms, models\n\n\ndef public_board(request):\n \"\"\"\n Board for the public.\n\n Does not take embargoed rolls into account.\n \"\"\"\n special_square_types = models.SpecialSquareType.objects.all()\n return render(request, 'will_of_the_prophets/public_board.html',\n {'board': board.Board(),\n 'special_square_types': special_square_types})\n\n\nclass RollView(LoginRequiredMixin, CreateView):\n \"\"\"View for rolling the die.\"\"\"\n\n form_class = forms.RollForm\n template_name = 'will_of_the_prophets/roll.html'\n\n def get_context_data(self, **kwargs):\n last_roll = models.Roll.objects.order_by('-embargo').first()\n return super().get_context_data(\n **kwargs,\n last_roll=last_roll,\n board=board.Board(now=last_roll.embargo),\n special_square_types=models.SpecialSquareType.objects.all())\n\n def get_success_url(self):\n return reverse('roll') + \"#chula\"\n", "path": "will_of_the_prophets/views.py"}]}
| 604 | 98 |
gh_patches_debug_23496
|
rasdani/github-patches
|
git_diff
|
pypa__setuptools-2858
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[FR] distutils.errors.* is not fully re-exported
### What's the problem this feature will solve?
The [Migration Advice in PEP 0632](https://www.python.org/dev/peps/pep-0632/#migration-advice) says that `setuptools` is a sufficient replacement for `distutils.errors`. However, only `DistutilsError` and `RemovedCommandError` exist there. In `distutils`, there are:
```
In [7]: [e for e in dir(distutils.errors) if e.endswith('Error')]
Out[7]:
['CCompilerError',
'CompileError',
'DistutilsArgError',
'DistutilsByteCompileError',
'DistutilsClassError',
'DistutilsError',
'DistutilsExecError',
'DistutilsFileError',
'DistutilsGetoptError',
'DistutilsInternalError',
'DistutilsModuleError',
'DistutilsOptionError',
'DistutilsPlatformError',
'DistutilsSetupError',
'DistutilsTemplateError',
'LibError',
'LinkError',
'PreprocessError',
'UnknownFileError']
```
While all of the `Distutils`-prefixed ones derive from `DistutilsError`, the ones without the prefix are derived from `CCompilerError`, and so cannot be caught using anything exported by `setuptools`. Concretely, this makes it difficult to check for compiler flags, as [done here](https://github.com/matplotlib/matplotlib/blob/69395749a4e588eade55b90dbf095549258f4b16/setup.py#L62-L72).
### Describe the solution you'd like
Re-export all `distutils.errors.*` in `setuptools.errors`.
### Alternative Solutions
Currently, we use `distutils.errors`, but won't be able to after Python 3.12. One can use a generic `Exception` too, but that's not recommended.
Or as a complete alternative, if `setuptools` had a way to check whether a compiler supported a flag in a builtin way, then we wouldn't need to catch the `CompileError` ourselves.
### Additional context
_No response_
### Code of Conduct
- [X] I agree to follow the PSF Code of Conduct
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setuptools/errors.py`
Content:
```
1 """setuptools.errors
2
3 Provides exceptions used by setuptools modules.
4 """
5
6 from distutils.errors import DistutilsError
7
8
9 class RemovedCommandError(DistutilsError, RuntimeError):
10 """Error used for commands that have been removed in setuptools.
11
12 Since ``setuptools`` is built on ``distutils``, simply removing a command
13 from ``setuptools`` will make the behavior fall back to ``distutils``; this
14 error is raised if a command exists in ``distutils`` but has been actively
15 removed in ``setuptools``.
16 """
17
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setuptools/errors.py b/setuptools/errors.py
--- a/setuptools/errors.py
+++ b/setuptools/errors.py
@@ -3,6 +3,7 @@
Provides exceptions used by setuptools modules.
"""
+from distutils import errors as _distutils_errors
from distutils.errors import DistutilsError
@@ -14,3 +15,26 @@
error is raised if a command exists in ``distutils`` but has been actively
removed in ``setuptools``.
"""
+
+
+# Re-export errors from distutils to facilitate the migration to PEP632
+
+ByteCompileError = _distutils_errors.DistutilsByteCompileError
+CCompilerError = _distutils_errors.CCompilerError
+ClassError = _distutils_errors.DistutilsClassError
+CompileError = _distutils_errors.CompileError
+ExecError = _distutils_errors.DistutilsExecError
+FileError = _distutils_errors.DistutilsFileError
+InternalError = _distutils_errors.DistutilsInternalError
+LibError = _distutils_errors.LibError
+LinkError = _distutils_errors.LinkError
+ModuleError = _distutils_errors.DistutilsModuleError
+OptionError = _distutils_errors.DistutilsOptionError
+PlatformError = _distutils_errors.DistutilsPlatformError
+PreprocessError = _distutils_errors.PreprocessError
+SetupError = _distutils_errors.DistutilsSetupError
+TemplateError = _distutils_errors.DistutilsTemplateError
+UnknownFileError = _distutils_errors.UnknownFileError
+
+# The root error class in the hierarchy
+BaseError = _distutils_errors.DistutilsError
|
{"golden_diff": "diff --git a/setuptools/errors.py b/setuptools/errors.py\n--- a/setuptools/errors.py\n+++ b/setuptools/errors.py\n@@ -3,6 +3,7 @@\n Provides exceptions used by setuptools modules.\n \"\"\"\n \n+from distutils import errors as _distutils_errors\n from distutils.errors import DistutilsError\n \n \n@@ -14,3 +15,26 @@\n error is raised if a command exists in ``distutils`` but has been actively\n removed in ``setuptools``.\n \"\"\"\n+\n+\n+# Re-export errors from distutils to facilitate the migration to PEP632\n+\n+ByteCompileError = _distutils_errors.DistutilsByteCompileError\n+CCompilerError = _distutils_errors.CCompilerError\n+ClassError = _distutils_errors.DistutilsClassError\n+CompileError = _distutils_errors.CompileError\n+ExecError = _distutils_errors.DistutilsExecError\n+FileError = _distutils_errors.DistutilsFileError\n+InternalError = _distutils_errors.DistutilsInternalError\n+LibError = _distutils_errors.LibError\n+LinkError = _distutils_errors.LinkError\n+ModuleError = _distutils_errors.DistutilsModuleError\n+OptionError = _distutils_errors.DistutilsOptionError\n+PlatformError = _distutils_errors.DistutilsPlatformError\n+PreprocessError = _distutils_errors.PreprocessError\n+SetupError = _distutils_errors.DistutilsSetupError\n+TemplateError = _distutils_errors.DistutilsTemplateError\n+UnknownFileError = _distutils_errors.UnknownFileError\n+\n+# The root error class in the hierarchy\n+BaseError = _distutils_errors.DistutilsError\n", "issue": "[FR] distutils.errors.* is not fully re-exported\n### What's the problem this feature will solve?\n\nThe [Migration Advice in PEP 0632](https://www.python.org/dev/peps/pep-0632/#migration-advice) says that `setuptools` is a sufficient replacement for `distutils.errors`. However, only `DistutilsError` and `RemovedCommandError` exist there. In `distutils`, there are:\r\n```\r\nIn [7]: [e for e in dir(distutils.errors) if e.endswith('Error')]\r\nOut[7]: \r\n['CCompilerError',\r\n 'CompileError',\r\n 'DistutilsArgError',\r\n 'DistutilsByteCompileError',\r\n 'DistutilsClassError',\r\n 'DistutilsError',\r\n 'DistutilsExecError',\r\n 'DistutilsFileError',\r\n 'DistutilsGetoptError',\r\n 'DistutilsInternalError',\r\n 'DistutilsModuleError',\r\n 'DistutilsOptionError',\r\n 'DistutilsPlatformError',\r\n 'DistutilsSetupError',\r\n 'DistutilsTemplateError',\r\n 'LibError',\r\n 'LinkError',\r\n 'PreprocessError',\r\n 'UnknownFileError']\r\n```\r\nWhile all of the `Distutils`-prefixed ones derive from `DistutilsError`, the ones without the prefix are derived from `CCompilerError`, and so cannot be caught using anything exported by `setuptools`. Concretely, this makes it difficult to check for compiler flags, as [done here](https://github.com/matplotlib/matplotlib/blob/69395749a4e588eade55b90dbf095549258f4b16/setup.py#L62-L72).\n\n### Describe the solution you'd like\n\nRe-export all `distutils.errors.*` in `setuptools.errors`.\n\n### Alternative Solutions\n\nCurrently, we use `distutils.errors`, but won't be able to after Python 3.12. One can use a generic `Exception` too, but that's not recommended.\r\n\r\nOr as a complete alternative, if `setuptools` had a way to check whether a compiler supported a flag in a builtin way, then we wouldn't need to catch the `CompileError` ourselves.\n\n### Additional context\n\n_No response_\n\n### Code of Conduct\n\n- [X] I agree to follow the PSF Code of Conduct\n", "before_files": [{"content": "\"\"\"setuptools.errors\n\nProvides exceptions used by setuptools modules.\n\"\"\"\n\nfrom distutils.errors import DistutilsError\n\n\nclass RemovedCommandError(DistutilsError, RuntimeError):\n \"\"\"Error used for commands that have been removed in setuptools.\n\n Since ``setuptools`` is built on ``distutils``, simply removing a command\n from ``setuptools`` will make the behavior fall back to ``distutils``; this\n error is raised if a command exists in ``distutils`` but has been actively\n removed in ``setuptools``.\n \"\"\"\n", "path": "setuptools/errors.py"}], "after_files": [{"content": "\"\"\"setuptools.errors\n\nProvides exceptions used by setuptools modules.\n\"\"\"\n\nfrom distutils import errors as _distutils_errors\nfrom distutils.errors import DistutilsError\n\n\nclass RemovedCommandError(DistutilsError, RuntimeError):\n \"\"\"Error used for commands that have been removed in setuptools.\n\n Since ``setuptools`` is built on ``distutils``, simply removing a command\n from ``setuptools`` will make the behavior fall back to ``distutils``; this\n error is raised if a command exists in ``distutils`` but has been actively\n removed in ``setuptools``.\n \"\"\"\n\n\n# Re-export errors from distutils to facilitate the migration to PEP632\n\nByteCompileError = _distutils_errors.DistutilsByteCompileError\nCCompilerError = _distutils_errors.CCompilerError\nClassError = _distutils_errors.DistutilsClassError\nCompileError = _distutils_errors.CompileError\nExecError = _distutils_errors.DistutilsExecError\nFileError = _distutils_errors.DistutilsFileError\nInternalError = _distutils_errors.DistutilsInternalError\nLibError = _distutils_errors.LibError\nLinkError = _distutils_errors.LinkError\nModuleError = _distutils_errors.DistutilsModuleError\nOptionError = _distutils_errors.DistutilsOptionError\nPlatformError = _distutils_errors.DistutilsPlatformError\nPreprocessError = _distutils_errors.PreprocessError\nSetupError = _distutils_errors.DistutilsSetupError\nTemplateError = _distutils_errors.DistutilsTemplateError\nUnknownFileError = _distutils_errors.UnknownFileError\n\n# The root error class in the hierarchy\nBaseError = _distutils_errors.DistutilsError\n", "path": "setuptools/errors.py"}]}
| 891 | 367 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.