
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
25.4k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 582
39.1k
| num_tokens
int64 271
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_1250
|
rasdani/github-patches
|
git_diff
|
numba__numba-941
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update README
Two issues with our README file:
- it is not up-to-date (e.g. it mentions Cython, which we don't use anymore)
- it uses Markdown rather than reST, and therefore is badly formatted when used for the PyPI long description: https://pypi.python.org/pypi/numba
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 try:
2 # Try to use setuptools so as to enable support of the special
3 # "Microsoft Visual C++ Compiler for Python 2.7" (http://aka.ms/vcpython27)
4 # for building under Windows.
5 # Note setuptools >= 6.0 is required for this.
6 from setuptools import setup, Extension
7 except ImportError:
8 from distutils.core import setup, Extension
9
10 import sys
11 import os
12 import numpy
13 import numpy.distutils.misc_util as np_misc
14 import versioneer
15
16 versioneer.versionfile_source = 'numba/_version.py'
17 versioneer.versionfile_build = 'numba/_version.py'
18 versioneer.tag_prefix = ''
19 versioneer.parentdir_prefix = 'numba-'
20
21 cmdclass = versioneer.get_cmdclass()
22
23 setup_args = {
24 'long_description': open('README.md').read(),
25 }
26
27 GCCFLAGS = ["-std=c89", "-Wdeclaration-after-statement", "-Werror"]
28
29 if os.environ.get("NUMBA_GCC_FLAGS"):
30 CFLAGS = GCCFLAGS
31 else:
32 CFLAGS = []
33
34
35 if sys.platform == 'darwin' and sys.version_info[:2] == (2, 6):
36 cpp_link_args = ['-lstdc++']
37 else:
38 cpp_link_args = []
39
40 npymath_info = np_misc.get_info('npymath')
41
42 ext_dynfunc = Extension(name='numba._dynfunc', sources=['numba/_dynfunc.c'],
43 extra_compile_args=CFLAGS,
44 depends=["numba/_pymodule.h"])
45
46 ext_npymath_exports = Extension(name='numba._npymath_exports',
47 sources=['numba/_npymath_exports.c'],
48 include_dirs=npymath_info['include_dirs'],
49 libraries=npymath_info['libraries'],
50 library_dirs=npymath_info['library_dirs'],
51 define_macros=npymath_info['define_macros'])
52
53
54 ext_dispatcher = Extension(name="numba._dispatcher",
55 include_dirs=[numpy.get_include()],
56 sources=['numba/_dispatcher.c',
57 'numba/_dispatcherimpl.cpp',
58 'numba/typeconv/typeconv.cpp'],
59 depends=["numba/_pymodule.h",
60 "numba/_dispatcher.h"],
61 extra_link_args=cpp_link_args)
62
63 ext_helperlib = Extension(name="numba._helperlib",
64 include_dirs=[numpy.get_include()],
65 sources=["numba/_helperlib.c", "numba/_math_c99.c"],
66 extra_compile_args=CFLAGS,
67 depends=["numba/_pymodule.h",
68 "numba/_math_c99.h",
69 "numba/mathnames.inc"])
70
71 ext_typeconv = Extension(name="numba.typeconv._typeconv",
72 sources=["numba/typeconv/typeconv.cpp",
73 "numba/typeconv/_typeconv.cpp"],
74 depends=["numba/_pymodule.h"],
75 extra_link_args=cpp_link_args)
76
77 ext_npyufunc_ufunc = Extension(name="numba.npyufunc._internal",
78 sources=["numba/npyufunc/_internal.c"],
79 include_dirs=[numpy.get_include()],
80 depends=["numba/npyufunc/_ufunc.c",
81 "numba/npyufunc/_internal.h",
82 "numba/_pymodule.h"])
83
84 ext_mviewbuf = Extension(name='numba.mviewbuf',
85 sources=['numba/mviewbuf.c'])
86
87 ext_modules = [ext_dynfunc, ext_npymath_exports, ext_dispatcher,
88 ext_helperlib, ext_typeconv, ext_npyufunc_ufunc, ext_mviewbuf]
89
90 packages = [
91 "numba",
92 "numba.targets",
93 "numba.tests",
94 "numba.typing",
95 "numba.typeconv",
96 "numba.npyufunc",
97 "numba.pycc",
98 "numba.servicelib",
99 "numba.cuda",
100 "numba.cuda.cudadrv",
101 "numba.cuda.tests",
102 "numba.cuda.tests.cudadrv",
103 "numba.cuda.tests.cudadrv.data",
104 "numba.cuda.tests.cudapy",
105 ]
106
107 setup(name='numba',
108 description="compiling Python code using LLVM",
109 version=versioneer.get_version(),
110
111 classifiers=[
112 "Development Status :: 4 - Beta",
113 "Intended Audience :: Developers",
114 "License :: OSI Approved :: BSD License",
115 "Operating System :: OS Independent",
116 "Programming Language :: Python",
117 "Programming Language :: Python :: 2.6",
118 "Programming Language :: Python :: 2.7",
119 "Programming Language :: Python :: 3.3",
120 "Programming Language :: Python :: 3.4",
121 "Topic :: Software Development :: Compilers",
122 ],
123 package_data={
124 "numba": ["*.c", "*.h", "*.cpp", "*.inc"],
125 "numba.npyufunc": ["*.c", "*.h"],
126 "numba.typeconv": ["*.cpp", "*.hpp"],
127 "numba.cuda.tests.cudadrv.data": ["*.ptx"],
128 },
129 scripts=["numba/pycc/pycc", "bin/numba"],
130 author="Continuum Analytics, Inc.",
131 author_email="[email protected]",
132 url="http://numba.github.com",
133 ext_modules=ext_modules,
134 packages=packages,
135 license="BSD",
136 cmdclass=cmdclass,
137 **setup_args)
138
139
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -21,7 +21,7 @@
cmdclass = versioneer.get_cmdclass()
setup_args = {
- 'long_description': open('README.md').read(),
+ 'long_description': open('README.rst').read(),
}
GCCFLAGS = ["-std=c89", "-Wdeclaration-after-statement", "-Werror"]
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -21,7 +21,7 @@\n cmdclass = versioneer.get_cmdclass()\n \n setup_args = {\n- 'long_description': open('README.md').read(),\n+ 'long_description': open('README.rst').read(),\n }\n \n GCCFLAGS = [\"-std=c89\", \"-Wdeclaration-after-statement\", \"-Werror\"]\n", "issue": "Update README\nTwo issues with our README file:\n- it is not up-to-date (e.g. it mentions Cython, which we don't use anymore)\n- it uses Markdown rather than reST, and therefore is badly formatted when used for the PyPI long description: https://pypi.python.org/pypi/numba\n\n", "before_files": [{"content": "try:\n # Try to use setuptools so as to enable support of the special\n # \"Microsoft Visual C++ Compiler for Python 2.7\" (http://aka.ms/vcpython27)\n # for building under Windows.\n # Note setuptools >= 6.0 is required for this.\n from setuptools import setup, Extension\nexcept ImportError:\n from distutils.core import setup, Extension\n\nimport sys\nimport os\nimport numpy\nimport numpy.distutils.misc_util as np_misc\nimport versioneer\n\nversioneer.versionfile_source = 'numba/_version.py'\nversioneer.versionfile_build = 'numba/_version.py'\nversioneer.tag_prefix = ''\nversioneer.parentdir_prefix = 'numba-'\n\ncmdclass = versioneer.get_cmdclass()\n\nsetup_args = {\n 'long_description': open('README.md').read(),\n}\n\nGCCFLAGS = [\"-std=c89\", \"-Wdeclaration-after-statement\", \"-Werror\"]\n\nif os.environ.get(\"NUMBA_GCC_FLAGS\"):\n CFLAGS = GCCFLAGS\nelse:\n CFLAGS = []\n\n\nif sys.platform == 'darwin' and sys.version_info[:2] == (2, 6):\n cpp_link_args = ['-lstdc++']\nelse:\n cpp_link_args = []\n\nnpymath_info = np_misc.get_info('npymath')\n\next_dynfunc = Extension(name='numba._dynfunc', sources=['numba/_dynfunc.c'],\n extra_compile_args=CFLAGS,\n depends=[\"numba/_pymodule.h\"])\n\next_npymath_exports = Extension(name='numba._npymath_exports',\n sources=['numba/_npymath_exports.c'],\n include_dirs=npymath_info['include_dirs'],\n libraries=npymath_info['libraries'],\n library_dirs=npymath_info['library_dirs'],\n define_macros=npymath_info['define_macros'])\n\n\next_dispatcher = Extension(name=\"numba._dispatcher\",\n include_dirs=[numpy.get_include()],\n sources=['numba/_dispatcher.c',\n 'numba/_dispatcherimpl.cpp',\n 'numba/typeconv/typeconv.cpp'],\n depends=[\"numba/_pymodule.h\",\n \"numba/_dispatcher.h\"],\n extra_link_args=cpp_link_args)\n\next_helperlib = Extension(name=\"numba._helperlib\",\n include_dirs=[numpy.get_include()],\n sources=[\"numba/_helperlib.c\", \"numba/_math_c99.c\"],\n extra_compile_args=CFLAGS,\n depends=[\"numba/_pymodule.h\",\n \"numba/_math_c99.h\",\n \"numba/mathnames.inc\"])\n\next_typeconv = Extension(name=\"numba.typeconv._typeconv\",\n sources=[\"numba/typeconv/typeconv.cpp\",\n \"numba/typeconv/_typeconv.cpp\"],\n depends=[\"numba/_pymodule.h\"],\n extra_link_args=cpp_link_args)\n\next_npyufunc_ufunc = Extension(name=\"numba.npyufunc._internal\",\n sources=[\"numba/npyufunc/_internal.c\"],\n include_dirs=[numpy.get_include()],\n depends=[\"numba/npyufunc/_ufunc.c\",\n \"numba/npyufunc/_internal.h\",\n \"numba/_pymodule.h\"])\n\next_mviewbuf = Extension(name='numba.mviewbuf',\n sources=['numba/mviewbuf.c'])\n\next_modules = [ext_dynfunc, ext_npymath_exports, ext_dispatcher,\n ext_helperlib, ext_typeconv, ext_npyufunc_ufunc, ext_mviewbuf]\n\npackages = [\n \"numba\",\n \"numba.targets\",\n \"numba.tests\",\n \"numba.typing\",\n \"numba.typeconv\",\n \"numba.npyufunc\",\n \"numba.pycc\",\n \"numba.servicelib\",\n \"numba.cuda\",\n \"numba.cuda.cudadrv\",\n \"numba.cuda.tests\",\n \"numba.cuda.tests.cudadrv\",\n \"numba.cuda.tests.cudadrv.data\",\n \"numba.cuda.tests.cudapy\",\n]\n\nsetup(name='numba',\n description=\"compiling Python code using LLVM\",\n version=versioneer.get_version(),\n\n classifiers=[\n \"Development Status :: 4 - Beta\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: BSD License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2.6\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3.3\",\n \"Programming Language :: Python :: 3.4\",\n \"Topic :: Software Development :: Compilers\",\n ],\n package_data={\n \"numba\": [\"*.c\", \"*.h\", \"*.cpp\", \"*.inc\"],\n \"numba.npyufunc\": [\"*.c\", \"*.h\"],\n \"numba.typeconv\": [\"*.cpp\", \"*.hpp\"],\n \"numba.cuda.tests.cudadrv.data\": [\"*.ptx\"],\n },\n scripts=[\"numba/pycc/pycc\", \"bin/numba\"],\n author=\"Continuum Analytics, Inc.\",\n author_email=\"[email protected]\",\n url=\"http://numba.github.com\",\n ext_modules=ext_modules,\n packages=packages,\n license=\"BSD\",\n cmdclass=cmdclass,\n **setup_args)\n\n", "path": "setup.py"}], "after_files": [{"content": "try:\n # Try to use setuptools so as to enable support of the special\n # \"Microsoft Visual C++ Compiler for Python 2.7\" (http://aka.ms/vcpython27)\n # for building under Windows.\n # Note setuptools >= 6.0 is required for this.\n from setuptools import setup, Extension\nexcept ImportError:\n from distutils.core import setup, Extension\n\nimport sys\nimport os\nimport numpy\nimport numpy.distutils.misc_util as np_misc\nimport versioneer\n\nversioneer.versionfile_source = 'numba/_version.py'\nversioneer.versionfile_build = 'numba/_version.py'\nversioneer.tag_prefix = ''\nversioneer.parentdir_prefix = 'numba-'\n\ncmdclass = versioneer.get_cmdclass()\n\nsetup_args = {\n 'long_description': open('README.rst').read(),\n}\n\nGCCFLAGS = [\"-std=c89\", \"-Wdeclaration-after-statement\", \"-Werror\"]\n\nif os.environ.get(\"NUMBA_GCC_FLAGS\"):\n CFLAGS = GCCFLAGS\nelse:\n CFLAGS = []\n\n\nif sys.platform == 'darwin' and sys.version_info[:2] == (2, 6):\n cpp_link_args = ['-lstdc++']\nelse:\n cpp_link_args = []\n\nnpymath_info = np_misc.get_info('npymath')\n\next_dynfunc = Extension(name='numba._dynfunc', sources=['numba/_dynfunc.c'],\n extra_compile_args=CFLAGS,\n depends=[\"numba/_pymodule.h\"])\n\next_npymath_exports = Extension(name='numba._npymath_exports',\n sources=['numba/_npymath_exports.c'],\n include_dirs=npymath_info['include_dirs'],\n libraries=npymath_info['libraries'],\n library_dirs=npymath_info['library_dirs'],\n define_macros=npymath_info['define_macros'])\n\n\next_dispatcher = Extension(name=\"numba._dispatcher\",\n include_dirs=[numpy.get_include()],\n sources=['numba/_dispatcher.c',\n 'numba/_dispatcherimpl.cpp',\n 'numba/typeconv/typeconv.cpp'],\n depends=[\"numba/_pymodule.h\",\n \"numba/_dispatcher.h\"],\n extra_link_args=cpp_link_args)\n\next_helperlib = Extension(name=\"numba._helperlib\",\n include_dirs=[numpy.get_include()],\n sources=[\"numba/_helperlib.c\", \"numba/_math_c99.c\"],\n extra_compile_args=CFLAGS,\n depends=[\"numba/_pymodule.h\",\n \"numba/_math_c99.h\",\n \"numba/mathnames.inc\"])\n\next_typeconv = Extension(name=\"numba.typeconv._typeconv\",\n sources=[\"numba/typeconv/typeconv.cpp\",\n \"numba/typeconv/_typeconv.cpp\"],\n depends=[\"numba/_pymodule.h\"],\n extra_link_args=cpp_link_args)\n\next_npyufunc_ufunc = Extension(name=\"numba.npyufunc._internal\",\n sources=[\"numba/npyufunc/_internal.c\"],\n include_dirs=[numpy.get_include()],\n depends=[\"numba/npyufunc/_ufunc.c\",\n \"numba/npyufunc/_internal.h\",\n \"numba/_pymodule.h\"])\n\next_mviewbuf = Extension(name='numba.mviewbuf',\n sources=['numba/mviewbuf.c'])\n\next_modules = [ext_dynfunc, ext_npymath_exports, ext_dispatcher,\n ext_helperlib, ext_typeconv, ext_npyufunc_ufunc, ext_mviewbuf]\n\npackages = [\n \"numba\",\n \"numba.targets\",\n \"numba.tests\",\n \"numba.typing\",\n \"numba.typeconv\",\n \"numba.npyufunc\",\n \"numba.pycc\",\n \"numba.servicelib\",\n \"numba.cuda\",\n \"numba.cuda.cudadrv\",\n \"numba.cuda.tests\",\n \"numba.cuda.tests.cudadrv\",\n \"numba.cuda.tests.cudadrv.data\",\n \"numba.cuda.tests.cudapy\",\n]\n\nsetup(name='numba',\n description=\"compiling Python code using LLVM\",\n version=versioneer.get_version(),\n\n classifiers=[\n \"Development Status :: 4 - Beta\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: BSD License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2.6\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3.3\",\n \"Programming Language :: Python :: 3.4\",\n \"Topic :: Software Development :: Compilers\",\n ],\n package_data={\n \"numba\": [\"*.c\", \"*.h\", \"*.cpp\", \"*.inc\"],\n \"numba.npyufunc\": [\"*.c\", \"*.h\"],\n \"numba.typeconv\": [\"*.cpp\", \"*.hpp\"],\n \"numba.cuda.tests.cudadrv.data\": [\"*.ptx\"],\n },\n scripts=[\"numba/pycc/pycc\", \"bin/numba\"],\n author=\"Continuum Analytics, Inc.\",\n author_email=\"[email protected]\",\n url=\"http://numba.github.com\",\n ext_modules=ext_modules,\n packages=packages,\n license=\"BSD\",\n cmdclass=cmdclass,\n **setup_args)\n\n", "path": "setup.py"}]}
| 1,780 | 96 |
gh_patches_debug_21956
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-1389
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
!Sub with nested, multiargument !GetAtt fails with E0002 when processing E1019
*cfn-lint version: 0.27.1*
E0002 Unknown exception while processing rule E1019: sequence item 1: expected str instance, dict_node found
```yaml
- !Sub
- '{{resolve:ssm-secure:/${SSMMasterDBPasswordKeyFullName}:${PasswordVersion}}}'
- PasswordVersion:
"Fn::GetAtt":
- CredentialsHelper
- !Ref SSMMasterDBPasswordKeyFullNameVersion
```
I'm attempting to use !GetAtt within a !Sub's secondary arguments, which definitely works, but causes cfn-lint to blow up with the above error
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cfnlint/rules/functions/Sub.py`
Content:
```
1 """
2 Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.
3 SPDX-License-Identifier: MIT-0
4 """
5 import six
6 from cfnlint.helpers import PSEUDOPARAMS
7 from cfnlint.rules import CloudFormationLintRule
8 from cfnlint.rules import RuleMatch
9
10
11 class Sub(CloudFormationLintRule):
12 """Check if Sub values are correct"""
13 id = 'E1019'
14 shortdesc = 'Sub validation of parameters'
15 description = 'Making sure the sub function is properly configured'
16 source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-sub.html'
17 tags = ['functions', 'sub']
18
19 def _test_string(self, cfn, sub_string, parameters, tree):
20 """Test if a string has appropriate parameters"""
21
22 matches = []
23 string_params = cfn.get_sub_parameters(sub_string)
24
25 for string_param in string_params:
26 if isinstance(string_param, (six.string_types)):
27 matches.extend(self._test_parameter(string_param, cfn, parameters, tree))
28
29 return matches
30
31 def _get_parameters(self, cfn):
32 """Get all Parameter Names"""
33 results = {}
34 parameters = cfn.template.get('Parameters', {})
35 if isinstance(parameters, dict):
36 for param_name, param_values in parameters.items():
37 # This rule isn't here to check the Types but we need
38 # something valid if it doesn't exist
39 results[param_name] = param_values.get('Type', 'String')
40
41 return results
42
43 def _test_parameters(self, parameters, cfn, tree):
44 """Check parameters for appropriate configuration"""
45
46 supported_functions = [
47 'Fn::Base64',
48 'Fn::FindInMap',
49 'Fn::GetAZs',
50 'Fn::GetAtt',
51 'Fn::If',
52 'Fn::ImportValue',
53 'Fn::Join',
54 'Fn::Select',
55 'Fn::Sub',
56 'Ref',
57 ]
58
59 matches = []
60 for parameter_name, parameter_value_obj in parameters.items():
61 param_tree = tree[:] + [parameter_name]
62 if isinstance(parameter_value_obj, dict):
63 if len(parameter_value_obj) == 1:
64 for key, value in parameter_value_obj.items():
65 if key not in supported_functions:
66 message = 'Sub parameter should use a valid function for {0}'
67 matches.append(RuleMatch(
68 param_tree, message.format('/'.join(map(str, tree)))))
69 elif key in ['Ref']:
70 matches.extend(self._test_parameter(value, cfn, {}, tree))
71 elif key in ['Fn::GetAtt']:
72 if isinstance(value, list):
73 matches.extend(self._test_parameter('.'.join(value), cfn, {}, tree))
74 elif isinstance(value, six.string_types):
75 matches.extend(self._test_parameter(value, cfn, {}, tree))
76 else:
77 message = 'Sub parameter should be an object of 1 for {0}'
78 matches.append(RuleMatch(
79 param_tree, message.format('/'.join(map(str, tree)))))
80 elif not isinstance(parameter_value_obj, six.string_types):
81 message = 'Sub parameter should be an object of 1 or string for {0}'
82 matches.append(RuleMatch(
83 param_tree, message.format('/'.join(map(str, tree)))))
84
85 return matches
86
87 def _test_parameter(self, parameter, cfn, parameters, tree):
88 """ Test a parameter """
89
90 matches = []
91 get_atts = cfn.get_valid_getatts()
92
93 odd_list_params = [
94 'CommaDelimitedList',
95 'AWS::SSM::Parameter::Value<CommaDelimitedList>',
96 ]
97
98 valid_params = list(PSEUDOPARAMS)
99 valid_params.extend(cfn.get_resource_names())
100 template_parameters = self._get_parameters(cfn)
101
102 for key, _ in parameters.items():
103 valid_params.append(key)
104
105 if parameter not in valid_params:
106 found = False
107 if parameter in template_parameters:
108 found = True
109 if (
110 template_parameters.get(parameter) in odd_list_params or
111 template_parameters.get(parameter).startswith('AWS::SSM::Parameter::Value<List') or
112 template_parameters.get(parameter).startswith('List')):
113 message = 'Fn::Sub cannot use list {0} at {1}'
114 matches.append(RuleMatch(
115 tree, message.format(parameter, '/'.join(map(str, tree)))))
116 for resource, attributes in get_atts.items():
117 for attribute_name, attribute_values in attributes.items():
118 if resource == parameter.split('.')[0] and attribute_name == '*':
119 if attribute_values.get('Type') == 'List':
120 message = 'Fn::Sub cannot use list {0} at {1}'
121 matches.append(RuleMatch(
122 tree, message.format(parameter, '/'.join(map(str, tree)))))
123 found = True
124 elif (resource == parameter.split('.')[0] and
125 attribute_name == '.'.join(parameter.split('.')[1:])):
126 if attribute_values.get('Type') == 'List':
127 message = 'Fn::Sub cannot use list {0} at {1}'
128 matches.append(RuleMatch(
129 tree, message.format(parameter, '/'.join(map(str, tree)))))
130 found = True
131 if not found:
132 message = 'Parameter {0} for Fn::Sub not found at {1}'
133 matches.append(RuleMatch(
134 tree, message.format(parameter, '/'.join(map(str, tree)))))
135
136 return matches
137
138 def match(self, cfn):
139 """Check CloudFormation Join"""
140
141 matches = []
142
143 sub_objs = cfn.search_deep_keys('Fn::Sub')
144
145 for sub_obj in sub_objs:
146 sub_value_obj = sub_obj[-1]
147 tree = sub_obj[:-1]
148 if isinstance(sub_value_obj, six.string_types):
149 matches.extend(self._test_string(cfn, sub_value_obj, {}, tree))
150 elif isinstance(sub_value_obj, list):
151 if len(sub_value_obj) == 2:
152 sub_string = sub_value_obj[0]
153 parameters = sub_value_obj[1]
154 if not isinstance(sub_string, six.string_types):
155 message = 'Subs first element should be of type string for {0}'
156 matches.append(RuleMatch(
157 tree + [0], message.format('/'.join(map(str, tree)))))
158 if not isinstance(parameters, dict):
159 message = 'Subs second element should be an object for {0}'
160 matches.append(RuleMatch(
161 tree + [1], message.format('/'.join(map(str, tree)))))
162 else:
163 matches.extend(self._test_string(cfn, sub_string, parameters, tree + [0]))
164 matches.extend(self._test_parameters(parameters, cfn, tree))
165 else:
166 message = 'Sub should be an array of 2 for {0}'
167 matches.append(RuleMatch(
168 tree, message.format('/'.join(map(str, tree)))))
169 elif isinstance(sub_value_obj, dict):
170 if len(sub_value_obj) == 1:
171 for key, _ in sub_value_obj.items():
172 if not key == 'Fn::Transform':
173 message = 'Sub should be a string or array of 2 items for {0}'
174 matches.append(RuleMatch(
175 tree, message.format('/'.join(map(str, tree)))))
176 else:
177 message = 'Sub should be a string or array of 2 items for {0}'
178 matches.append(RuleMatch(
179 tree, message.format('/'.join(map(str, tree)))))
180 else:
181 message = 'Sub should be a string or array of 2 items for {0}'
182 matches.append(RuleMatch(
183 tree, message.format('/'.join(map(str, tree)))))
184
185 return matches
186
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cfnlint/rules/functions/Sub.py b/src/cfnlint/rules/functions/Sub.py
--- a/src/cfnlint/rules/functions/Sub.py
+++ b/src/cfnlint/rules/functions/Sub.py
@@ -70,7 +70,15 @@
matches.extend(self._test_parameter(value, cfn, {}, tree))
elif key in ['Fn::GetAtt']:
if isinstance(value, list):
- matches.extend(self._test_parameter('.'.join(value), cfn, {}, tree))
+ # Only test this if all the items are a string
+ if_all_strings = True
+ for v in value:
+ if not isinstance(v, six.string_types):
+ # skip things got too complex
+ if_all_strings = False
+ if if_all_strings:
+ matches.extend(self._test_parameter(
+ '.'.join(value), cfn, {}, tree))
elif isinstance(value, six.string_types):
matches.extend(self._test_parameter(value, cfn, {}, tree))
else:
|
{"golden_diff": "diff --git a/src/cfnlint/rules/functions/Sub.py b/src/cfnlint/rules/functions/Sub.py\n--- a/src/cfnlint/rules/functions/Sub.py\n+++ b/src/cfnlint/rules/functions/Sub.py\n@@ -70,7 +70,15 @@\n matches.extend(self._test_parameter(value, cfn, {}, tree))\n elif key in ['Fn::GetAtt']:\n if isinstance(value, list):\n- matches.extend(self._test_parameter('.'.join(value), cfn, {}, tree))\n+ # Only test this if all the items are a string\n+ if_all_strings = True\n+ for v in value:\n+ if not isinstance(v, six.string_types):\n+ # skip things got too complex\n+ if_all_strings = False\n+ if if_all_strings:\n+ matches.extend(self._test_parameter(\n+ '.'.join(value), cfn, {}, tree))\n elif isinstance(value, six.string_types):\n matches.extend(self._test_parameter(value, cfn, {}, tree))\n else:\n", "issue": "!Sub with nested, multiargument !GetAtt fails with E0002 when processing E1019\n*cfn-lint version: 0.27.1*\r\n\r\nE0002 Unknown exception while processing rule E1019: sequence item 1: expected str instance, dict_node found\r\n\r\n```yaml\r\n- !Sub\r\n - '{{resolve:ssm-secure:/${SSMMasterDBPasswordKeyFullName}:${PasswordVersion}}}'\r\n - PasswordVersion:\r\n \"Fn::GetAtt\":\r\n - CredentialsHelper\r\n - !Ref SSMMasterDBPasswordKeyFullNameVersion\r\n```\r\n\r\nI'm attempting to use !GetAtt within a !Sub's secondary arguments, which definitely works, but causes cfn-lint to blow up with the above error\n", "before_files": [{"content": "\"\"\"\nCopyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport six\nfrom cfnlint.helpers import PSEUDOPARAMS\nfrom cfnlint.rules import CloudFormationLintRule\nfrom cfnlint.rules import RuleMatch\n\n\nclass Sub(CloudFormationLintRule):\n \"\"\"Check if Sub values are correct\"\"\"\n id = 'E1019'\n shortdesc = 'Sub validation of parameters'\n description = 'Making sure the sub function is properly configured'\n source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-sub.html'\n tags = ['functions', 'sub']\n\n def _test_string(self, cfn, sub_string, parameters, tree):\n \"\"\"Test if a string has appropriate parameters\"\"\"\n\n matches = []\n string_params = cfn.get_sub_parameters(sub_string)\n\n for string_param in string_params:\n if isinstance(string_param, (six.string_types)):\n matches.extend(self._test_parameter(string_param, cfn, parameters, tree))\n\n return matches\n\n def _get_parameters(self, cfn):\n \"\"\"Get all Parameter Names\"\"\"\n results = {}\n parameters = cfn.template.get('Parameters', {})\n if isinstance(parameters, dict):\n for param_name, param_values in parameters.items():\n # This rule isn't here to check the Types but we need\n # something valid if it doesn't exist\n results[param_name] = param_values.get('Type', 'String')\n\n return results\n\n def _test_parameters(self, parameters, cfn, tree):\n \"\"\"Check parameters for appropriate configuration\"\"\"\n\n supported_functions = [\n 'Fn::Base64',\n 'Fn::FindInMap',\n 'Fn::GetAZs',\n 'Fn::GetAtt',\n 'Fn::If',\n 'Fn::ImportValue',\n 'Fn::Join',\n 'Fn::Select',\n 'Fn::Sub',\n 'Ref',\n ]\n\n matches = []\n for parameter_name, parameter_value_obj in parameters.items():\n param_tree = tree[:] + [parameter_name]\n if isinstance(parameter_value_obj, dict):\n if len(parameter_value_obj) == 1:\n for key, value in parameter_value_obj.items():\n if key not in supported_functions:\n message = 'Sub parameter should use a valid function for {0}'\n matches.append(RuleMatch(\n param_tree, message.format('/'.join(map(str, tree)))))\n elif key in ['Ref']:\n matches.extend(self._test_parameter(value, cfn, {}, tree))\n elif key in ['Fn::GetAtt']:\n if isinstance(value, list):\n matches.extend(self._test_parameter('.'.join(value), cfn, {}, tree))\n elif isinstance(value, six.string_types):\n matches.extend(self._test_parameter(value, cfn, {}, tree))\n else:\n message = 'Sub parameter should be an object of 1 for {0}'\n matches.append(RuleMatch(\n param_tree, message.format('/'.join(map(str, tree)))))\n elif not isinstance(parameter_value_obj, six.string_types):\n message = 'Sub parameter should be an object of 1 or string for {0}'\n matches.append(RuleMatch(\n param_tree, message.format('/'.join(map(str, tree)))))\n\n return matches\n\n def _test_parameter(self, parameter, cfn, parameters, tree):\n \"\"\" Test a parameter \"\"\"\n\n matches = []\n get_atts = cfn.get_valid_getatts()\n\n odd_list_params = [\n 'CommaDelimitedList',\n 'AWS::SSM::Parameter::Value<CommaDelimitedList>',\n ]\n\n valid_params = list(PSEUDOPARAMS)\n valid_params.extend(cfn.get_resource_names())\n template_parameters = self._get_parameters(cfn)\n\n for key, _ in parameters.items():\n valid_params.append(key)\n\n if parameter not in valid_params:\n found = False\n if parameter in template_parameters:\n found = True\n if (\n template_parameters.get(parameter) in odd_list_params or\n template_parameters.get(parameter).startswith('AWS::SSM::Parameter::Value<List') or\n template_parameters.get(parameter).startswith('List')):\n message = 'Fn::Sub cannot use list {0} at {1}'\n matches.append(RuleMatch(\n tree, message.format(parameter, '/'.join(map(str, tree)))))\n for resource, attributes in get_atts.items():\n for attribute_name, attribute_values in attributes.items():\n if resource == parameter.split('.')[0] and attribute_name == '*':\n if attribute_values.get('Type') == 'List':\n message = 'Fn::Sub cannot use list {0} at {1}'\n matches.append(RuleMatch(\n tree, message.format(parameter, '/'.join(map(str, tree)))))\n found = True\n elif (resource == parameter.split('.')[0] and\n attribute_name == '.'.join(parameter.split('.')[1:])):\n if attribute_values.get('Type') == 'List':\n message = 'Fn::Sub cannot use list {0} at {1}'\n matches.append(RuleMatch(\n tree, message.format(parameter, '/'.join(map(str, tree)))))\n found = True\n if not found:\n message = 'Parameter {0} for Fn::Sub not found at {1}'\n matches.append(RuleMatch(\n tree, message.format(parameter, '/'.join(map(str, tree)))))\n\n return matches\n\n def match(self, cfn):\n \"\"\"Check CloudFormation Join\"\"\"\n\n matches = []\n\n sub_objs = cfn.search_deep_keys('Fn::Sub')\n\n for sub_obj in sub_objs:\n sub_value_obj = sub_obj[-1]\n tree = sub_obj[:-1]\n if isinstance(sub_value_obj, six.string_types):\n matches.extend(self._test_string(cfn, sub_value_obj, {}, tree))\n elif isinstance(sub_value_obj, list):\n if len(sub_value_obj) == 2:\n sub_string = sub_value_obj[0]\n parameters = sub_value_obj[1]\n if not isinstance(sub_string, six.string_types):\n message = 'Subs first element should be of type string for {0}'\n matches.append(RuleMatch(\n tree + [0], message.format('/'.join(map(str, tree)))))\n if not isinstance(parameters, dict):\n message = 'Subs second element should be an object for {0}'\n matches.append(RuleMatch(\n tree + [1], message.format('/'.join(map(str, tree)))))\n else:\n matches.extend(self._test_string(cfn, sub_string, parameters, tree + [0]))\n matches.extend(self._test_parameters(parameters, cfn, tree))\n else:\n message = 'Sub should be an array of 2 for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n elif isinstance(sub_value_obj, dict):\n if len(sub_value_obj) == 1:\n for key, _ in sub_value_obj.items():\n if not key == 'Fn::Transform':\n message = 'Sub should be a string or array of 2 items for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n else:\n message = 'Sub should be a string or array of 2 items for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n else:\n message = 'Sub should be a string or array of 2 items for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n\n return matches\n", "path": "src/cfnlint/rules/functions/Sub.py"}], "after_files": [{"content": "\"\"\"\nCopyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport six\nfrom cfnlint.helpers import PSEUDOPARAMS\nfrom cfnlint.rules import CloudFormationLintRule\nfrom cfnlint.rules import RuleMatch\n\n\nclass Sub(CloudFormationLintRule):\n \"\"\"Check if Sub values are correct\"\"\"\n id = 'E1019'\n shortdesc = 'Sub validation of parameters'\n description = 'Making sure the sub function is properly configured'\n source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-sub.html'\n tags = ['functions', 'sub']\n\n def _test_string(self, cfn, sub_string, parameters, tree):\n \"\"\"Test if a string has appropriate parameters\"\"\"\n\n matches = []\n string_params = cfn.get_sub_parameters(sub_string)\n\n for string_param in string_params:\n if isinstance(string_param, (six.string_types)):\n matches.extend(self._test_parameter(string_param, cfn, parameters, tree))\n\n return matches\n\n def _get_parameters(self, cfn):\n \"\"\"Get all Parameter Names\"\"\"\n results = {}\n parameters = cfn.template.get('Parameters', {})\n if isinstance(parameters, dict):\n for param_name, param_values in parameters.items():\n # This rule isn't here to check the Types but we need\n # something valid if it doesn't exist\n results[param_name] = param_values.get('Type', 'String')\n\n return results\n\n def _test_parameters(self, parameters, cfn, tree):\n \"\"\"Check parameters for appropriate configuration\"\"\"\n\n supported_functions = [\n 'Fn::Base64',\n 'Fn::FindInMap',\n 'Fn::GetAZs',\n 'Fn::GetAtt',\n 'Fn::If',\n 'Fn::ImportValue',\n 'Fn::Join',\n 'Fn::Select',\n 'Fn::Sub',\n 'Ref',\n ]\n\n matches = []\n for parameter_name, parameter_value_obj in parameters.items():\n param_tree = tree[:] + [parameter_name]\n if isinstance(parameter_value_obj, dict):\n if len(parameter_value_obj) == 1:\n for key, value in parameter_value_obj.items():\n if key not in supported_functions:\n message = 'Sub parameter should use a valid function for {0}'\n matches.append(RuleMatch(\n param_tree, message.format('/'.join(map(str, tree)))))\n elif key in ['Ref']:\n matches.extend(self._test_parameter(value, cfn, {}, tree))\n elif key in ['Fn::GetAtt']:\n if isinstance(value, list):\n # Only test this if all the items are a string\n if_all_strings = True\n for v in value:\n if not isinstance(v, six.string_types):\n # skip things got too complex\n if_all_strings = False\n if if_all_strings:\n matches.extend(self._test_parameter(\n '.'.join(value), cfn, {}, tree))\n elif isinstance(value, six.string_types):\n matches.extend(self._test_parameter(value, cfn, {}, tree))\n else:\n message = 'Sub parameter should be an object of 1 for {0}'\n matches.append(RuleMatch(\n param_tree, message.format('/'.join(map(str, tree)))))\n elif not isinstance(parameter_value_obj, six.string_types):\n message = 'Sub parameter should be an object of 1 or string for {0}'\n matches.append(RuleMatch(\n param_tree, message.format('/'.join(map(str, tree)))))\n\n return matches\n\n def _test_parameter(self, parameter, cfn, parameters, tree):\n \"\"\" Test a parameter \"\"\"\n\n matches = []\n get_atts = cfn.get_valid_getatts()\n\n odd_list_params = [\n 'CommaDelimitedList',\n 'AWS::SSM::Parameter::Value<CommaDelimitedList>',\n ]\n\n valid_params = list(PSEUDOPARAMS)\n valid_params.extend(cfn.get_resource_names())\n template_parameters = self._get_parameters(cfn)\n\n for key, _ in parameters.items():\n valid_params.append(key)\n\n if parameter not in valid_params:\n found = False\n if parameter in template_parameters:\n found = True\n if (\n template_parameters.get(parameter) in odd_list_params or\n template_parameters.get(parameter).startswith('AWS::SSM::Parameter::Value<List') or\n template_parameters.get(parameter).startswith('List')):\n message = 'Fn::Sub cannot use list {0} at {1}'\n matches.append(RuleMatch(\n tree, message.format(parameter, '/'.join(map(str, tree)))))\n for resource, attributes in get_atts.items():\n for attribute_name, attribute_values in attributes.items():\n if resource == parameter.split('.')[0] and attribute_name == '*':\n if attribute_values.get('Type') == 'List':\n message = 'Fn::Sub cannot use list {0} at {1}'\n matches.append(RuleMatch(\n tree, message.format(parameter, '/'.join(map(str, tree)))))\n found = True\n elif (resource == parameter.split('.')[0] and\n attribute_name == '.'.join(parameter.split('.')[1:])):\n if attribute_values.get('Type') == 'List':\n message = 'Fn::Sub cannot use list {0} at {1}'\n matches.append(RuleMatch(\n tree, message.format(parameter, '/'.join(map(str, tree)))))\n found = True\n if not found:\n message = 'Parameter {0} for Fn::Sub not found at {1}'\n matches.append(RuleMatch(\n tree, message.format(parameter, '/'.join(map(str, tree)))))\n\n return matches\n\n def match(self, cfn):\n \"\"\"Check CloudFormation Join\"\"\"\n\n matches = []\n\n sub_objs = cfn.search_deep_keys('Fn::Sub')\n\n for sub_obj in sub_objs:\n sub_value_obj = sub_obj[-1]\n tree = sub_obj[:-1]\n if isinstance(sub_value_obj, six.string_types):\n matches.extend(self._test_string(cfn, sub_value_obj, {}, tree))\n elif isinstance(sub_value_obj, list):\n if len(sub_value_obj) == 2:\n sub_string = sub_value_obj[0]\n parameters = sub_value_obj[1]\n if not isinstance(sub_string, six.string_types):\n message = 'Subs first element should be of type string for {0}'\n matches.append(RuleMatch(\n tree + [0], message.format('/'.join(map(str, tree)))))\n if not isinstance(parameters, dict):\n message = 'Subs second element should be an object for {0}'\n matches.append(RuleMatch(\n tree + [1], message.format('/'.join(map(str, tree)))))\n else:\n matches.extend(self._test_string(cfn, sub_string, parameters, tree + [0]))\n matches.extend(self._test_parameters(parameters, cfn, tree))\n else:\n message = 'Sub should be an array of 2 for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n elif isinstance(sub_value_obj, dict):\n if len(sub_value_obj) == 1:\n for key, _ in sub_value_obj.items():\n if not key == 'Fn::Transform':\n message = 'Sub should be a string or array of 2 items for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n else:\n message = 'Sub should be a string or array of 2 items for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n else:\n message = 'Sub should be a string or array of 2 items for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n\n return matches\n", "path": "src/cfnlint/rules/functions/Sub.py"}]}
| 2,518 | 221 |
gh_patches_debug_1141
|
rasdani/github-patches
|
git_diff
|
paperless-ngx__paperless-ngx-2280
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bug] cannot save Mail Rule with "mail and attachment as seperate documents" in 1.11.1
Maybe it's just me, but I cannot save Mail Rule with "mail and attachment as seperate documents".
_Originally posted by @Limerick-gh in https://github.com/paperless-ngx/paperless-ngx/discussions/2265#discussioncomment-4557234_
[Bug] Missing consumption scope options in frontend
### Discussed in https://github.com/paperless-ngx/paperless-ngx/discussions/2265
<div type='discussions-op-text'>
<sup>Originally posted by **morremeyer** December 30, 2022</sup>
With #2000, frontend configuration for mail consumption was added.
With #848, at about the same time, email body & .eml file consumption was added.
#848 added the **consumption scope** for email consumption (see https://github.com/p-h-a-i-l/paperless-ngx/blob/0fda35723d62275a5beb783cbf9061d4d4a15703/src/paperless_mail/models.py#L59-L65) to decide between consuming:
* only the attachments
* the full email as .eml
* the full email as .eml **and** the attachments
The **consumption scope** is not yet configurable on the frontend. I'd be really happy if it were configurable in the frontend in a future version.
I'm pretty sure someone already has that planned, but I couldn't find an issue or discussion for it, so I'm opening this one to track this request.</div>
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/paperless_mail/serialisers.py`
Content:
```
1 from documents.serialisers import CorrespondentField
2 from documents.serialisers import DocumentTypeField
3 from documents.serialisers import TagsField
4 from paperless_mail.models import MailAccount
5 from paperless_mail.models import MailRule
6 from rest_framework import serializers
7
8
9 class ObfuscatedPasswordField(serializers.Field):
10 """
11 Sends *** string instead of password in the clear
12 """
13
14 def to_representation(self, value):
15 return "*" * len(value)
16
17 def to_internal_value(self, data):
18 return data
19
20
21 class MailAccountSerializer(serializers.ModelSerializer):
22 password = ObfuscatedPasswordField()
23
24 class Meta:
25 model = MailAccount
26 depth = 1
27 fields = [
28 "id",
29 "name",
30 "imap_server",
31 "imap_port",
32 "imap_security",
33 "username",
34 "password",
35 "character_set",
36 ]
37
38 def update(self, instance, validated_data):
39 if "password" in validated_data:
40 if len(validated_data.get("password").replace("*", "")) == 0:
41 validated_data.pop("password")
42 super().update(instance, validated_data)
43 return instance
44
45 def create(self, validated_data):
46 mail_account = MailAccount.objects.create(**validated_data)
47 return mail_account
48
49
50 class AccountField(serializers.PrimaryKeyRelatedField):
51 def get_queryset(self):
52 return MailAccount.objects.all().order_by("-id")
53
54
55 class MailRuleSerializer(serializers.ModelSerializer):
56 account = AccountField(required=True)
57 action_parameter = serializers.CharField(
58 allow_null=True,
59 required=False,
60 default="",
61 )
62 assign_correspondent = CorrespondentField(allow_null=True, required=False)
63 assign_tags = TagsField(many=True, allow_null=True, required=False)
64 assign_document_type = DocumentTypeField(allow_null=True, required=False)
65 order = serializers.IntegerField(required=False)
66
67 class Meta:
68 model = MailRule
69 depth = 1
70 fields = [
71 "id",
72 "name",
73 "account",
74 "folder",
75 "filter_from",
76 "filter_subject",
77 "filter_body",
78 "filter_attachment_filename",
79 "maximum_age",
80 "action",
81 "action_parameter",
82 "assign_title_from",
83 "assign_tags",
84 "assign_correspondent_from",
85 "assign_correspondent",
86 "assign_document_type",
87 "order",
88 "attachment_type",
89 ]
90
91 def update(self, instance, validated_data):
92 super().update(instance, validated_data)
93 return instance
94
95 def create(self, validated_data):
96 if "assign_tags" in validated_data:
97 assign_tags = validated_data.pop("assign_tags")
98 mail_rule = MailRule.objects.create(**validated_data)
99 if assign_tags:
100 mail_rule.assign_tags.set(assign_tags)
101 return mail_rule
102
103 def validate(self, attrs):
104 if (
105 attrs["action"] == MailRule.MailAction.TAG
106 or attrs["action"] == MailRule.MailAction.MOVE
107 ) and attrs["action_parameter"] is None:
108 raise serializers.ValidationError("An action parameter is required.")
109
110 return attrs
111
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/paperless_mail/serialisers.py b/src/paperless_mail/serialisers.py
--- a/src/paperless_mail/serialisers.py
+++ b/src/paperless_mail/serialisers.py
@@ -86,6 +86,7 @@
"assign_document_type",
"order",
"attachment_type",
+ "consumption_scope",
]
def update(self, instance, validated_data):
|
{"golden_diff": "diff --git a/src/paperless_mail/serialisers.py b/src/paperless_mail/serialisers.py\n--- a/src/paperless_mail/serialisers.py\n+++ b/src/paperless_mail/serialisers.py\n@@ -86,6 +86,7 @@\n \"assign_document_type\",\n \"order\",\n \"attachment_type\",\n+ \"consumption_scope\",\n ]\n \n def update(self, instance, validated_data):\n", "issue": "[Bug] cannot save Mail Rule with \"mail and attachment as seperate documents\" in 1.11.1\n Maybe it's just me, but I cannot save Mail Rule with \"mail and attachment as seperate documents\".\n\n_Originally posted by @Limerick-gh in https://github.com/paperless-ngx/paperless-ngx/discussions/2265#discussioncomment-4557234_\n \n[Bug] Missing consumption scope options in frontend\n### Discussed in https://github.com/paperless-ngx/paperless-ngx/discussions/2265\r\n\r\n<div type='discussions-op-text'>\r\n\r\n<sup>Originally posted by **morremeyer** December 30, 2022</sup>\r\nWith #2000, frontend configuration for mail consumption was added.\r\nWith #848, at about the same time, email body & .eml file consumption was added.\r\n\r\n#848 added the **consumption scope** for email consumption (see https://github.com/p-h-a-i-l/paperless-ngx/blob/0fda35723d62275a5beb783cbf9061d4d4a15703/src/paperless_mail/models.py#L59-L65) to decide between consuming:\r\n\r\n* only the attachments\r\n* the full email as .eml\r\n* the full email as .eml **and** the attachments\r\n\r\nThe **consumption scope** is not yet configurable on the frontend. I'd be really happy if it were configurable in the frontend in a future version.\r\n\r\nI'm pretty sure someone already has that planned, but I couldn't find an issue or discussion for it, so I'm opening this one to track this request.</div>\n", "before_files": [{"content": "from documents.serialisers import CorrespondentField\nfrom documents.serialisers import DocumentTypeField\nfrom documents.serialisers import TagsField\nfrom paperless_mail.models import MailAccount\nfrom paperless_mail.models import MailRule\nfrom rest_framework import serializers\n\n\nclass ObfuscatedPasswordField(serializers.Field):\n \"\"\"\n Sends *** string instead of password in the clear\n \"\"\"\n\n def to_representation(self, value):\n return \"*\" * len(value)\n\n def to_internal_value(self, data):\n return data\n\n\nclass MailAccountSerializer(serializers.ModelSerializer):\n password = ObfuscatedPasswordField()\n\n class Meta:\n model = MailAccount\n depth = 1\n fields = [\n \"id\",\n \"name\",\n \"imap_server\",\n \"imap_port\",\n \"imap_security\",\n \"username\",\n \"password\",\n \"character_set\",\n ]\n\n def update(self, instance, validated_data):\n if \"password\" in validated_data:\n if len(validated_data.get(\"password\").replace(\"*\", \"\")) == 0:\n validated_data.pop(\"password\")\n super().update(instance, validated_data)\n return instance\n\n def create(self, validated_data):\n mail_account = MailAccount.objects.create(**validated_data)\n return mail_account\n\n\nclass AccountField(serializers.PrimaryKeyRelatedField):\n def get_queryset(self):\n return MailAccount.objects.all().order_by(\"-id\")\n\n\nclass MailRuleSerializer(serializers.ModelSerializer):\n account = AccountField(required=True)\n action_parameter = serializers.CharField(\n allow_null=True,\n required=False,\n default=\"\",\n )\n assign_correspondent = CorrespondentField(allow_null=True, required=False)\n assign_tags = TagsField(many=True, allow_null=True, required=False)\n assign_document_type = DocumentTypeField(allow_null=True, required=False)\n order = serializers.IntegerField(required=False)\n\n class Meta:\n model = MailRule\n depth = 1\n fields = [\n \"id\",\n \"name\",\n \"account\",\n \"folder\",\n \"filter_from\",\n \"filter_subject\",\n \"filter_body\",\n \"filter_attachment_filename\",\n \"maximum_age\",\n \"action\",\n \"action_parameter\",\n \"assign_title_from\",\n \"assign_tags\",\n \"assign_correspondent_from\",\n \"assign_correspondent\",\n \"assign_document_type\",\n \"order\",\n \"attachment_type\",\n ]\n\n def update(self, instance, validated_data):\n super().update(instance, validated_data)\n return instance\n\n def create(self, validated_data):\n if \"assign_tags\" in validated_data:\n assign_tags = validated_data.pop(\"assign_tags\")\n mail_rule = MailRule.objects.create(**validated_data)\n if assign_tags:\n mail_rule.assign_tags.set(assign_tags)\n return mail_rule\n\n def validate(self, attrs):\n if (\n attrs[\"action\"] == MailRule.MailAction.TAG\n or attrs[\"action\"] == MailRule.MailAction.MOVE\n ) and attrs[\"action_parameter\"] is None:\n raise serializers.ValidationError(\"An action parameter is required.\")\n\n return attrs\n", "path": "src/paperless_mail/serialisers.py"}], "after_files": [{"content": "from documents.serialisers import CorrespondentField\nfrom documents.serialisers import DocumentTypeField\nfrom documents.serialisers import TagsField\nfrom paperless_mail.models import MailAccount\nfrom paperless_mail.models import MailRule\nfrom rest_framework import serializers\n\n\nclass ObfuscatedPasswordField(serializers.Field):\n \"\"\"\n Sends *** string instead of password in the clear\n \"\"\"\n\n def to_representation(self, value):\n return \"*\" * len(value)\n\n def to_internal_value(self, data):\n return data\n\n\nclass MailAccountSerializer(serializers.ModelSerializer):\n password = ObfuscatedPasswordField()\n\n class Meta:\n model = MailAccount\n depth = 1\n fields = [\n \"id\",\n \"name\",\n \"imap_server\",\n \"imap_port\",\n \"imap_security\",\n \"username\",\n \"password\",\n \"character_set\",\n ]\n\n def update(self, instance, validated_data):\n if \"password\" in validated_data:\n if len(validated_data.get(\"password\").replace(\"*\", \"\")) == 0:\n validated_data.pop(\"password\")\n super().update(instance, validated_data)\n return instance\n\n def create(self, validated_data):\n mail_account = MailAccount.objects.create(**validated_data)\n return mail_account\n\n\nclass AccountField(serializers.PrimaryKeyRelatedField):\n def get_queryset(self):\n return MailAccount.objects.all().order_by(\"-id\")\n\n\nclass MailRuleSerializer(serializers.ModelSerializer):\n account = AccountField(required=True)\n action_parameter = serializers.CharField(\n allow_null=True,\n required=False,\n default=\"\",\n )\n assign_correspondent = CorrespondentField(allow_null=True, required=False)\n assign_tags = TagsField(many=True, allow_null=True, required=False)\n assign_document_type = DocumentTypeField(allow_null=True, required=False)\n order = serializers.IntegerField(required=False)\n\n class Meta:\n model = MailRule\n depth = 1\n fields = [\n \"id\",\n \"name\",\n \"account\",\n \"folder\",\n \"filter_from\",\n \"filter_subject\",\n \"filter_body\",\n \"filter_attachment_filename\",\n \"maximum_age\",\n \"action\",\n \"action_parameter\",\n \"assign_title_from\",\n \"assign_tags\",\n \"assign_correspondent_from\",\n \"assign_correspondent\",\n \"assign_document_type\",\n \"order\",\n \"attachment_type\",\n \"consumption_scope\",\n ]\n\n def update(self, instance, validated_data):\n super().update(instance, validated_data)\n return instance\n\n def create(self, validated_data):\n if \"assign_tags\" in validated_data:\n assign_tags = validated_data.pop(\"assign_tags\")\n mail_rule = MailRule.objects.create(**validated_data)\n if assign_tags:\n mail_rule.assign_tags.set(assign_tags)\n return mail_rule\n\n def validate(self, attrs):\n if (\n attrs[\"action\"] == MailRule.MailAction.TAG\n or attrs[\"action\"] == MailRule.MailAction.MOVE\n ) and attrs[\"action_parameter\"] is None:\n raise serializers.ValidationError(\"An action parameter is required.\")\n\n return attrs\n", "path": "src/paperless_mail/serialisers.py"}]}
| 1,522 | 95 |
gh_patches_debug_6941
|
rasdani/github-patches
|
git_diff
|
arviz-devs__arviz-1636
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
invert the order of links in sampling wrapper docstrings
https://arviz-devs.github.io/arviz/api/generated/arviz.SamplingWrapper.html#arviz.SamplingWrapper has a link to the api section corresponding to all the wrappers and a link to the user guide section about the wrappers. The temptation to click on the first link and be done with it is strong, so I think I'd be better to invert the order and get the readers to the user guide by "default" instead of the api docs.
Note: the source of the page of the docs linked above is at https://github.com/arviz-devs/arviz/blob/main/arviz/wrappers/base.py#L15
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `arviz/wrappers/base.py`
Content:
```
1 """Base class for sampling wrappers."""
2 from xarray import apply_ufunc
3
4 # from ..data import InferenceData
5 from ..stats import wrap_xarray_ufunc as _wrap_xarray_ufunc
6
7
8 class SamplingWrapper:
9 """Class wrapping sampling routines for its usage via ArviZ.
10
11 Using a common class, all inference backends can be supported in ArviZ. Hence, statistical
12 functions requiring refitting like Leave Future Out or Simulation Based Calibration can be
13 performed from ArviZ.
14
15 See other SamplingWrapper classes at :ref:`wrappers api section <wrappers_api>`. For
16 usage examples see user guide pages on :ref:`wrapper_guide`.
17
18 Parameters
19 ----------
20 model
21 The model object used for sampling.
22 idata_orig : InferenceData, optional
23 Original InferenceData object.
24 log_lik_fun : callable, optional
25 For simple cases where the pointwise log likelihood is a Python function, this
26 function will be used to calculate the log likelihood. Otherwise,
27 ``point_log_likelihood`` method must be implemented. It's callback must be
28 ``log_lik_fun(*args, **log_lik_kwargs)`` and will be called using
29 :func:`wrap_xarray_ufunc` or :func:`xarray:xarray.apply_ufunc` depending
30 on the value of `is_ufunc`.
31
32 For more details on ``args`` or ``log_lik_kwargs`` see the notes and
33 parameters ``posterior_vars`` and ``log_lik_kwargs``.
34 is_ufunc : bool, default True
35 If True, call ``log_lik_fun`` using :func:`xarray:xarray.apply_ufunc` otherwise
36 use :func:`wrap_xarray_ufunc`.
37 posterior_vars : list of str, optional
38 List of variable names to unpack as ``args`` for ``log_lik_fun``. Each string in
39 the list will be used to retrieve a DataArray from the Dataset in the posterior
40 group and passed to ``log_lik_fun``.
41 sample_kwargs : dict, optional
42 Sampling kwargs are stored as class attributes for their usage in the ``sample``
43 method.
44 idata_kwargs : dict, optional
45 kwargs are stored as class attributes to be used in the ``get_inference_data`` method.
46 log_lik_kwargs : dict, optional
47 Keyword arguments passed to ``log_lik_fun``.
48 apply_ufunc_kwargs : dict, optional
49 Passed to :func:`xarray:xarray.apply_ufunc` or :func:`wrap_xarray_ufunc`.
50
51
52 Warnings
53 --------
54 Sampling wrappers are an experimental feature in a very early stage. Please use them
55 with caution.
56
57 Notes
58 -----
59 Example of ``log_like_fun`` usage.
60 """
61
62 def __init__(
63 self,
64 model,
65 idata_orig=None,
66 log_lik_fun=None,
67 is_ufunc=True,
68 posterior_vars=None,
69 sample_kwargs=None,
70 idata_kwargs=None,
71 log_lik_kwargs=None,
72 apply_ufunc_kwargs=None,
73 ):
74 self.model = model
75
76 # if not isinstance(idata_orig, InferenceData) or idata_orig is not None:
77 # raise TypeError("idata_orig must be of InferenceData type or None")
78 self.idata_orig = idata_orig
79
80 if log_lik_fun is None or callable(log_lik_fun):
81 self.log_lik_fun = log_lik_fun
82 self.is_ufunc = is_ufunc
83 self.posterior_vars = posterior_vars
84 else:
85 raise TypeError("log_like_fun must be a callable object or None")
86
87 self.sample_kwargs = {} if sample_kwargs is None else sample_kwargs
88 self.idata_kwargs = {} if idata_kwargs is None else idata_kwargs
89 self.log_lik_kwargs = {} if log_lik_kwargs is None else log_lik_kwargs
90 self.apply_ufunc_kwargs = {} if apply_ufunc_kwargs is None else apply_ufunc_kwargs
91
92 def sel_observations(self, idx):
93 """Select a subset of the observations in idata_orig.
94
95 **Not implemented**: This method must be implemented by the SamplingWrapper subclasses.
96 It is documented here to show its format and call signature.
97
98 Parameters
99 ----------
100 idx
101 Indexes to separate from the rest of the observed data.
102
103 Returns
104 -------
105 modified_observed_data
106 Observed data whose index is *not* ``idx``
107 excluded_observed_data
108 Observed data whose index is ``idx``
109 """
110 raise NotImplementedError("sel_observations method must be implemented for each subclass")
111
112 def sample(self, modified_observed_data):
113 """Sample ``self.model`` on the ``modified_observed_data`` subset.
114
115 **Not implemented**: This method must be implemented by the SamplingWrapper subclasses.
116 It is documented here to show its format and call signature.
117
118 Parameters
119 ----------
120 modified_observed_data
121 Data to fit the model on.
122
123 Returns
124 -------
125 fitted_model
126 Result of the fit.
127 """
128 raise NotImplementedError("sample method must be implemented for each subclass")
129
130 def get_inference_data(self, fitted_model):
131 """Convert the ``fitted_model`` to an InferenceData object.
132
133 **Not implemented**: This method must be implemented by the SamplingWrapper subclasses.
134 It is documented here to show its format and call signature.
135
136 Parameters
137 ----------
138 fitted_model
139 Result of the current fit.
140
141 Returns
142 -------
143 idata_current: InferenceData
144 InferenceData object containing the samples in ``fitted_model``
145 """
146 raise NotImplementedError("get_inference_data method must be implemented for each subclass")
147
148 def log_likelihood__i(self, excluded_obs, idata__i):
149 r"""Get the log likelilhood samples :math:`\log p_{post(-i)}(y_i)`.
150
151 Calculate the log likelihood of the data contained in excluded_obs using the
152 model fitted with this data excluded, the results of which are stored in ``idata__i``.
153
154 Parameters
155 ----------
156 excluded_obs
157 Observations for which to calculate their log likelihood. The second item from
158 the tuple returned by `sel_observations` is passed as this argument.
159 idata__i: InferenceData
160 Inference results of refitting the data excluding some observations. The
161 result of `get_inference_data` is used as this argument.
162
163 Returns
164 -------
165 log_likelihood: xr.Dataarray
166 Log likelihood of ``excluded_obs`` evaluated at each of the posterior samples
167 stored in ``idata__i``.
168 """
169 if self.log_lik_fun is None:
170 raise NotImplementedError(
171 "When `log_like_fun` is not set during class initialization "
172 "log_likelihood__i method must be overwritten"
173 )
174 posterior = idata__i.posterior
175 arys = (*excluded_obs, *[posterior[var_name] for var_name in self.posterior_vars])
176 if self.is_ufunc:
177 ufunc_applier = apply_ufunc
178 else:
179 ufunc_applier = _wrap_xarray_ufunc
180 log_lik_idx = ufunc_applier(
181 self.log_lik_fun,
182 *arys,
183 kwargs=self.log_lik_kwargs,
184 **self.apply_ufunc_kwargs,
185 )
186 return log_lik_idx
187
188 def _check_method_is_implemented(self, method, *args):
189 """Check a given method is implemented."""
190 try:
191 getattr(self, method)(*args)
192 except NotImplementedError:
193 return False
194 except: # pylint: disable=bare-except
195 return True
196 return True
197
198 def check_implemented_methods(self, methods):
199 """Check that all methods listed are implemented.
200
201 Not all functions that require refitting need to have all the methods implemented in
202 order to work properly. This function shoulg be used before using the SamplingWrapper and
203 its subclasses to get informative error messages.
204
205 Parameters
206 ----------
207 methods: list
208 Check all elements in methods are implemented.
209
210 Returns
211 -------
212 List with all non implemented methods
213 """
214 supported_methods_1arg = (
215 "sel_observations",
216 "sample",
217 "get_inference_data",
218 )
219 supported_methods_2args = ("log_likelihood__i",)
220 supported_methods = [*supported_methods_1arg, *supported_methods_2args]
221 bad_methods = [method for method in methods if method not in supported_methods]
222 if bad_methods:
223 raise ValueError(
224 "Not all method(s) in {} supported. Supported methods in SamplingWrapper "
225 "subclasses are:{}".format(bad_methods, supported_methods)
226 )
227
228 not_implemented = []
229 for method in methods:
230 if method in supported_methods_1arg:
231 if self._check_method_is_implemented(method, 1):
232 continue
233 else:
234 not_implemented.append(method)
235 elif method in supported_methods_2args:
236 if self._check_method_is_implemented(method, 1, 1):
237 continue
238 else:
239 not_implemented.append(method)
240 return not_implemented
241
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/arviz/wrappers/base.py b/arviz/wrappers/base.py
--- a/arviz/wrappers/base.py
+++ b/arviz/wrappers/base.py
@@ -12,8 +12,8 @@
functions requiring refitting like Leave Future Out or Simulation Based Calibration can be
performed from ArviZ.
- See other SamplingWrapper classes at :ref:`wrappers api section <wrappers_api>`. For
- usage examples see user guide pages on :ref:`wrapper_guide`.
+ For usage examples see user guide pages on :ref:`wrapper_guide`.See other
+ SamplingWrapper classes at :ref:`wrappers api section <wrappers_api>`.
Parameters
----------
|
{"golden_diff": "diff --git a/arviz/wrappers/base.py b/arviz/wrappers/base.py\n--- a/arviz/wrappers/base.py\n+++ b/arviz/wrappers/base.py\n@@ -12,8 +12,8 @@\n functions requiring refitting like Leave Future Out or Simulation Based Calibration can be\n performed from ArviZ.\n \n- See other SamplingWrapper classes at :ref:`wrappers api section <wrappers_api>`. For\n- usage examples see user guide pages on :ref:`wrapper_guide`.\n+ For usage examples see user guide pages on :ref:`wrapper_guide`.See other\n+ SamplingWrapper classes at :ref:`wrappers api section <wrappers_api>`.\n \n Parameters\n ----------\n", "issue": "invert the order of links in sampling wrapper docstrings\nhttps://arviz-devs.github.io/arviz/api/generated/arviz.SamplingWrapper.html#arviz.SamplingWrapper has a link to the api section corresponding to all the wrappers and a link to the user guide section about the wrappers. The temptation to click on the first link and be done with it is strong, so I think I'd be better to invert the order and get the readers to the user guide by \"default\" instead of the api docs.\r\n\r\nNote: the source of the page of the docs linked above is at https://github.com/arviz-devs/arviz/blob/main/arviz/wrappers/base.py#L15\n", "before_files": [{"content": "\"\"\"Base class for sampling wrappers.\"\"\"\nfrom xarray import apply_ufunc\n\n# from ..data import InferenceData\nfrom ..stats import wrap_xarray_ufunc as _wrap_xarray_ufunc\n\n\nclass SamplingWrapper:\n \"\"\"Class wrapping sampling routines for its usage via ArviZ.\n\n Using a common class, all inference backends can be supported in ArviZ. Hence, statistical\n functions requiring refitting like Leave Future Out or Simulation Based Calibration can be\n performed from ArviZ.\n\n See other SamplingWrapper classes at :ref:`wrappers api section <wrappers_api>`. For\n usage examples see user guide pages on :ref:`wrapper_guide`.\n\n Parameters\n ----------\n model\n The model object used for sampling.\n idata_orig : InferenceData, optional\n Original InferenceData object.\n log_lik_fun : callable, optional\n For simple cases where the pointwise log likelihood is a Python function, this\n function will be used to calculate the log likelihood. Otherwise,\n ``point_log_likelihood`` method must be implemented. It's callback must be\n ``log_lik_fun(*args, **log_lik_kwargs)`` and will be called using\n :func:`wrap_xarray_ufunc` or :func:`xarray:xarray.apply_ufunc` depending\n on the value of `is_ufunc`.\n\n For more details on ``args`` or ``log_lik_kwargs`` see the notes and\n parameters ``posterior_vars`` and ``log_lik_kwargs``.\n is_ufunc : bool, default True\n If True, call ``log_lik_fun`` using :func:`xarray:xarray.apply_ufunc` otherwise\n use :func:`wrap_xarray_ufunc`.\n posterior_vars : list of str, optional\n List of variable names to unpack as ``args`` for ``log_lik_fun``. Each string in\n the list will be used to retrieve a DataArray from the Dataset in the posterior\n group and passed to ``log_lik_fun``.\n sample_kwargs : dict, optional\n Sampling kwargs are stored as class attributes for their usage in the ``sample``\n method.\n idata_kwargs : dict, optional\n kwargs are stored as class attributes to be used in the ``get_inference_data`` method.\n log_lik_kwargs : dict, optional\n Keyword arguments passed to ``log_lik_fun``.\n apply_ufunc_kwargs : dict, optional\n Passed to :func:`xarray:xarray.apply_ufunc` or :func:`wrap_xarray_ufunc`.\n\n\n Warnings\n --------\n Sampling wrappers are an experimental feature in a very early stage. Please use them\n with caution.\n\n Notes\n -----\n Example of ``log_like_fun`` usage.\n \"\"\"\n\n def __init__(\n self,\n model,\n idata_orig=None,\n log_lik_fun=None,\n is_ufunc=True,\n posterior_vars=None,\n sample_kwargs=None,\n idata_kwargs=None,\n log_lik_kwargs=None,\n apply_ufunc_kwargs=None,\n ):\n self.model = model\n\n # if not isinstance(idata_orig, InferenceData) or idata_orig is not None:\n # raise TypeError(\"idata_orig must be of InferenceData type or None\")\n self.idata_orig = idata_orig\n\n if log_lik_fun is None or callable(log_lik_fun):\n self.log_lik_fun = log_lik_fun\n self.is_ufunc = is_ufunc\n self.posterior_vars = posterior_vars\n else:\n raise TypeError(\"log_like_fun must be a callable object or None\")\n\n self.sample_kwargs = {} if sample_kwargs is None else sample_kwargs\n self.idata_kwargs = {} if idata_kwargs is None else idata_kwargs\n self.log_lik_kwargs = {} if log_lik_kwargs is None else log_lik_kwargs\n self.apply_ufunc_kwargs = {} if apply_ufunc_kwargs is None else apply_ufunc_kwargs\n\n def sel_observations(self, idx):\n \"\"\"Select a subset of the observations in idata_orig.\n\n **Not implemented**: This method must be implemented by the SamplingWrapper subclasses.\n It is documented here to show its format and call signature.\n\n Parameters\n ----------\n idx\n Indexes to separate from the rest of the observed data.\n\n Returns\n -------\n modified_observed_data\n Observed data whose index is *not* ``idx``\n excluded_observed_data\n Observed data whose index is ``idx``\n \"\"\"\n raise NotImplementedError(\"sel_observations method must be implemented for each subclass\")\n\n def sample(self, modified_observed_data):\n \"\"\"Sample ``self.model`` on the ``modified_observed_data`` subset.\n\n **Not implemented**: This method must be implemented by the SamplingWrapper subclasses.\n It is documented here to show its format and call signature.\n\n Parameters\n ----------\n modified_observed_data\n Data to fit the model on.\n\n Returns\n -------\n fitted_model\n Result of the fit.\n \"\"\"\n raise NotImplementedError(\"sample method must be implemented for each subclass\")\n\n def get_inference_data(self, fitted_model):\n \"\"\"Convert the ``fitted_model`` to an InferenceData object.\n\n **Not implemented**: This method must be implemented by the SamplingWrapper subclasses.\n It is documented here to show its format and call signature.\n\n Parameters\n ----------\n fitted_model\n Result of the current fit.\n\n Returns\n -------\n idata_current: InferenceData\n InferenceData object containing the samples in ``fitted_model``\n \"\"\"\n raise NotImplementedError(\"get_inference_data method must be implemented for each subclass\")\n\n def log_likelihood__i(self, excluded_obs, idata__i):\n r\"\"\"Get the log likelilhood samples :math:`\\log p_{post(-i)}(y_i)`.\n\n Calculate the log likelihood of the data contained in excluded_obs using the\n model fitted with this data excluded, the results of which are stored in ``idata__i``.\n\n Parameters\n ----------\n excluded_obs\n Observations for which to calculate their log likelihood. The second item from\n the tuple returned by `sel_observations` is passed as this argument.\n idata__i: InferenceData\n Inference results of refitting the data excluding some observations. The\n result of `get_inference_data` is used as this argument.\n\n Returns\n -------\n log_likelihood: xr.Dataarray\n Log likelihood of ``excluded_obs`` evaluated at each of the posterior samples\n stored in ``idata__i``.\n \"\"\"\n if self.log_lik_fun is None:\n raise NotImplementedError(\n \"When `log_like_fun` is not set during class initialization \"\n \"log_likelihood__i method must be overwritten\"\n )\n posterior = idata__i.posterior\n arys = (*excluded_obs, *[posterior[var_name] for var_name in self.posterior_vars])\n if self.is_ufunc:\n ufunc_applier = apply_ufunc\n else:\n ufunc_applier = _wrap_xarray_ufunc\n log_lik_idx = ufunc_applier(\n self.log_lik_fun,\n *arys,\n kwargs=self.log_lik_kwargs,\n **self.apply_ufunc_kwargs,\n )\n return log_lik_idx\n\n def _check_method_is_implemented(self, method, *args):\n \"\"\"Check a given method is implemented.\"\"\"\n try:\n getattr(self, method)(*args)\n except NotImplementedError:\n return False\n except: # pylint: disable=bare-except\n return True\n return True\n\n def check_implemented_methods(self, methods):\n \"\"\"Check that all methods listed are implemented.\n\n Not all functions that require refitting need to have all the methods implemented in\n order to work properly. This function shoulg be used before using the SamplingWrapper and\n its subclasses to get informative error messages.\n\n Parameters\n ----------\n methods: list\n Check all elements in methods are implemented.\n\n Returns\n -------\n List with all non implemented methods\n \"\"\"\n supported_methods_1arg = (\n \"sel_observations\",\n \"sample\",\n \"get_inference_data\",\n )\n supported_methods_2args = (\"log_likelihood__i\",)\n supported_methods = [*supported_methods_1arg, *supported_methods_2args]\n bad_methods = [method for method in methods if method not in supported_methods]\n if bad_methods:\n raise ValueError(\n \"Not all method(s) in {} supported. Supported methods in SamplingWrapper \"\n \"subclasses are:{}\".format(bad_methods, supported_methods)\n )\n\n not_implemented = []\n for method in methods:\n if method in supported_methods_1arg:\n if self._check_method_is_implemented(method, 1):\n continue\n else:\n not_implemented.append(method)\n elif method in supported_methods_2args:\n if self._check_method_is_implemented(method, 1, 1):\n continue\n else:\n not_implemented.append(method)\n return not_implemented\n", "path": "arviz/wrappers/base.py"}], "after_files": [{"content": "\"\"\"Base class for sampling wrappers.\"\"\"\nfrom xarray import apply_ufunc\n\n# from ..data import InferenceData\nfrom ..stats import wrap_xarray_ufunc as _wrap_xarray_ufunc\n\n\nclass SamplingWrapper:\n \"\"\"Class wrapping sampling routines for its usage via ArviZ.\n\n Using a common class, all inference backends can be supported in ArviZ. Hence, statistical\n functions requiring refitting like Leave Future Out or Simulation Based Calibration can be\n performed from ArviZ.\n\n For usage examples see user guide pages on :ref:`wrapper_guide`.See other\n SamplingWrapper classes at :ref:`wrappers api section <wrappers_api>`.\n\n Parameters\n ----------\n model\n The model object used for sampling.\n idata_orig : InferenceData, optional\n Original InferenceData object.\n log_lik_fun : callable, optional\n For simple cases where the pointwise log likelihood is a Python function, this\n function will be used to calculate the log likelihood. Otherwise,\n ``point_log_likelihood`` method must be implemented. It's callback must be\n ``log_lik_fun(*args, **log_lik_kwargs)`` and will be called using\n :func:`wrap_xarray_ufunc` or :func:`xarray:xarray.apply_ufunc` depending\n on the value of `is_ufunc`.\n\n For more details on ``args`` or ``log_lik_kwargs`` see the notes and\n parameters ``posterior_vars`` and ``log_lik_kwargs``.\n is_ufunc : bool, default True\n If True, call ``log_lik_fun`` using :func:`xarray:xarray.apply_ufunc` otherwise\n use :func:`wrap_xarray_ufunc`.\n posterior_vars : list of str, optional\n List of variable names to unpack as ``args`` for ``log_lik_fun``. Each string in\n the list will be used to retrieve a DataArray from the Dataset in the posterior\n group and passed to ``log_lik_fun``.\n sample_kwargs : dict, optional\n Sampling kwargs are stored as class attributes for their usage in the ``sample``\n method.\n idata_kwargs : dict, optional\n kwargs are stored as class attributes to be used in the ``get_inference_data`` method.\n log_lik_kwargs : dict, optional\n Keyword arguments passed to ``log_lik_fun``.\n apply_ufunc_kwargs : dict, optional\n Passed to :func:`xarray:xarray.apply_ufunc` or :func:`wrap_xarray_ufunc`.\n\n\n Warnings\n --------\n Sampling wrappers are an experimental feature in a very early stage. Please use them\n with caution.\n\n Notes\n -----\n Example of ``log_like_fun`` usage.\n \"\"\"\n\n def __init__(\n self,\n model,\n idata_orig=None,\n log_lik_fun=None,\n is_ufunc=True,\n posterior_vars=None,\n sample_kwargs=None,\n idata_kwargs=None,\n log_lik_kwargs=None,\n apply_ufunc_kwargs=None,\n ):\n self.model = model\n\n # if not isinstance(idata_orig, InferenceData) or idata_orig is not None:\n # raise TypeError(\"idata_orig must be of InferenceData type or None\")\n self.idata_orig = idata_orig\n\n if log_lik_fun is None or callable(log_lik_fun):\n self.log_lik_fun = log_lik_fun\n self.is_ufunc = is_ufunc\n self.posterior_vars = posterior_vars\n else:\n raise TypeError(\"log_like_fun must be a callable object or None\")\n\n self.sample_kwargs = {} if sample_kwargs is None else sample_kwargs\n self.idata_kwargs = {} if idata_kwargs is None else idata_kwargs\n self.log_lik_kwargs = {} if log_lik_kwargs is None else log_lik_kwargs\n self.apply_ufunc_kwargs = {} if apply_ufunc_kwargs is None else apply_ufunc_kwargs\n\n def sel_observations(self, idx):\n \"\"\"Select a subset of the observations in idata_orig.\n\n **Not implemented**: This method must be implemented by the SamplingWrapper subclasses.\n It is documented here to show its format and call signature.\n\n Parameters\n ----------\n idx\n Indexes to separate from the rest of the observed data.\n\n Returns\n -------\n modified_observed_data\n Observed data whose index is *not* ``idx``\n excluded_observed_data\n Observed data whose index is ``idx``\n \"\"\"\n raise NotImplementedError(\"sel_observations method must be implemented for each subclass\")\n\n def sample(self, modified_observed_data):\n \"\"\"Sample ``self.model`` on the ``modified_observed_data`` subset.\n\n **Not implemented**: This method must be implemented by the SamplingWrapper subclasses.\n It is documented here to show its format and call signature.\n\n Parameters\n ----------\n modified_observed_data\n Data to fit the model on.\n\n Returns\n -------\n fitted_model\n Result of the fit.\n \"\"\"\n raise NotImplementedError(\"sample method must be implemented for each subclass\")\n\n def get_inference_data(self, fitted_model):\n \"\"\"Convert the ``fitted_model`` to an InferenceData object.\n\n **Not implemented**: This method must be implemented by the SamplingWrapper subclasses.\n It is documented here to show its format and call signature.\n\n Parameters\n ----------\n fitted_model\n Result of the current fit.\n\n Returns\n -------\n idata_current: InferenceData\n InferenceData object containing the samples in ``fitted_model``\n \"\"\"\n raise NotImplementedError(\"get_inference_data method must be implemented for each subclass\")\n\n def log_likelihood__i(self, excluded_obs, idata__i):\n r\"\"\"Get the log likelilhood samples :math:`\\log p_{post(-i)}(y_i)`.\n\n Calculate the log likelihood of the data contained in excluded_obs using the\n model fitted with this data excluded, the results of which are stored in ``idata__i``.\n\n Parameters\n ----------\n excluded_obs\n Observations for which to calculate their log likelihood. The second item from\n the tuple returned by `sel_observations` is passed as this argument.\n idata__i: InferenceData\n Inference results of refitting the data excluding some observations. The\n result of `get_inference_data` is used as this argument.\n\n Returns\n -------\n log_likelihood: xr.Dataarray\n Log likelihood of ``excluded_obs`` evaluated at each of the posterior samples\n stored in ``idata__i``.\n \"\"\"\n if self.log_lik_fun is None:\n raise NotImplementedError(\n \"When `log_like_fun` is not set during class initialization \"\n \"log_likelihood__i method must be overwritten\"\n )\n posterior = idata__i.posterior\n arys = (*excluded_obs, *[posterior[var_name] for var_name in self.posterior_vars])\n if self.is_ufunc:\n ufunc_applier = apply_ufunc\n else:\n ufunc_applier = _wrap_xarray_ufunc\n log_lik_idx = ufunc_applier(\n self.log_lik_fun,\n *arys,\n kwargs=self.log_lik_kwargs,\n **self.apply_ufunc_kwargs,\n )\n return log_lik_idx\n\n def _check_method_is_implemented(self, method, *args):\n \"\"\"Check a given method is implemented.\"\"\"\n try:\n getattr(self, method)(*args)\n except NotImplementedError:\n return False\n except: # pylint: disable=bare-except\n return True\n return True\n\n def check_implemented_methods(self, methods):\n \"\"\"Check that all methods listed are implemented.\n\n Not all functions that require refitting need to have all the methods implemented in\n order to work properly. This function shoulg be used before using the SamplingWrapper and\n its subclasses to get informative error messages.\n\n Parameters\n ----------\n methods: list\n Check all elements in methods are implemented.\n\n Returns\n -------\n List with all non implemented methods\n \"\"\"\n supported_methods_1arg = (\n \"sel_observations\",\n \"sample\",\n \"get_inference_data\",\n )\n supported_methods_2args = (\"log_likelihood__i\",)\n supported_methods = [*supported_methods_1arg, *supported_methods_2args]\n bad_methods = [method for method in methods if method not in supported_methods]\n if bad_methods:\n raise ValueError(\n \"Not all method(s) in {} supported. Supported methods in SamplingWrapper \"\n \"subclasses are:{}\".format(bad_methods, supported_methods)\n )\n\n not_implemented = []\n for method in methods:\n if method in supported_methods_1arg:\n if self._check_method_is_implemented(method, 1):\n continue\n else:\n not_implemented.append(method)\n elif method in supported_methods_2args:\n if self._check_method_is_implemented(method, 1, 1):\n continue\n else:\n not_implemented.append(method)\n return not_implemented\n", "path": "arviz/wrappers/base.py"}]}
| 3,008 | 158 |
gh_patches_debug_43016
|
rasdani/github-patches
|
git_diff
|
svthalia__concrexit-2985
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fix ordering of photos
Closes #2843.
I really hope this works.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `website/photos/views.py`
Content:
```
1 import os
2
3 from django.contrib.auth.decorators import login_required
4 from django.http import Http404
5 from django.shortcuts import get_object_or_404, redirect, render
6 from django.utils.decorators import method_decorator
7
8 from photos.models import Album, Photo
9 from photos.services import (
10 check_shared_album_token,
11 get_annotated_accessible_albums,
12 is_album_accessible,
13 )
14 from thaliawebsite.views import PagedView
15 from utils.media.services import get_media_url
16
17 COVER_FILENAME = "cover.jpg"
18
19
20 @method_decorator(login_required, "dispatch")
21 class IndexView(PagedView):
22 model = Album
23 paginate_by = 16
24 template_name = "photos/index.html"
25 context_object_name = "albums"
26 keywords = None
27
28 def setup(self, request, *args, **kwargs):
29 super().setup(request, *args, **kwargs)
30 self.keywords = request.GET.get("keywords", "").split()
31
32 def get_queryset(self):
33 albums = Album.objects.filter(hidden=False).select_related("_cover")
34 for key in self.keywords:
35 albums = albums.filter(**{"title__icontains": key})
36 albums = get_annotated_accessible_albums(self.request, albums)
37 albums = albums.order_by("-date")
38 return albums
39
40 def get_context_data(self, **kwargs):
41 context = super().get_context_data(**kwargs)
42 context["keywords"] = self.keywords
43 return context
44
45
46 def _render_album_page(request, album):
47 """Render album.html for a specified album."""
48 context = {
49 "album": album,
50 "photos": album.photo_set.filter(hidden=False).select_properties("num_likes"),
51 }
52 return render(request, "photos/album.html", context)
53
54
55 @login_required
56 def detail(request, slug):
57 """Render an album, if it accessible by the user."""
58 obj = get_object_or_404(Album, slug=slug)
59 if is_album_accessible(request, obj):
60 return _render_album_page(request, obj)
61 raise Http404("Sorry, you're not allowed to view this album")
62
63
64 def shared_album(request, slug, token):
65 """Render a shared album if the correct token is provided."""
66 obj = get_object_or_404(Album, slug=slug)
67 check_shared_album_token(obj, token)
68 return _render_album_page(request, obj)
69
70
71 def _photo_path(obj, filename):
72 """Return the path to a Photo."""
73 photoname = os.path.basename(filename)
74 albumpath = os.path.join(obj.photosdir, obj.dirname)
75 photopath = os.path.join(albumpath, photoname)
76 get_object_or_404(Photo.objects.filter(album=obj, file=photopath))
77 return photopath
78
79
80 def _download(request, obj, filename):
81 """Download a photo.
82
83 This function provides a layer of indirection for shared albums.
84 """
85 photopath = _photo_path(obj, filename)
86 photo = get_object_or_404(Photo.objects.filter(album=obj, file=photopath))
87 return redirect(get_media_url(photo.file, f"{obj.slug}-{filename}"))
88
89
90 @login_required
91 def download(request, slug, filename):
92 """Download a photo if the album of the photo is accessible by the user."""
93 obj = get_object_or_404(Album, slug=slug)
94 if is_album_accessible(request, obj):
95 return _download(request, obj, filename)
96 raise Http404("Sorry, you're not allowed to view this album")
97
98
99 def shared_download(request, slug, token, filename):
100 """Download a photo from a shared album if the album token is provided."""
101 obj = get_object_or_404(Album, slug=slug)
102 check_shared_album_token(obj, token)
103 return _download(request, obj, filename)
104
105
106 @method_decorator(login_required, "dispatch")
107 class LikedPhotoView(PagedView):
108 model = Photo
109 paginate_by = 16
110 template_name = "photos/liked-photos.html"
111 context_object_name = "photos"
112
113 def get_queryset(self):
114 return (
115 Photo.objects.filter(likes__member=self.request.member, album__hidden=False)
116 .select_related("album")
117 .select_properties("num_likes")
118 .order_by("-album__date")
119 )
120
```
Path: `website/photos/urls.py`
Content:
```
1 from django.urls import include, path
2
3 from . import views
4
5 app_name = "photos"
6
7 urlpatterns = [
8 path(
9 "members/photos/",
10 include(
11 [
12 path("", views.IndexView.as_view(), name="index"),
13 path("liked", views.LikedPhotoView.as_view(), name="liked-photos"),
14 path(
15 "<slug>/",
16 include(
17 [
18 path("", views.detail, name="album"),
19 path(
20 "download/",
21 include(
22 [
23 path(
24 "<filename>",
25 views.download,
26 name="download",
27 ),
28 path(
29 "<token>/",
30 include(
31 [
32 path(
33 "<filename>",
34 views.shared_download,
35 name="shared-download",
36 ),
37 ]
38 ),
39 ),
40 ]
41 ),
42 ),
43 path("<token>/", views.shared_album, name="shared-album"),
44 ]
45 ),
46 ),
47 ]
48 ),
49 )
50 ]
51
```
Path: `website/photos/api/v2/views.py`
Content:
```
1 from django.db.models import Count, Prefetch, Q
2
3 from oauth2_provider.contrib.rest_framework import IsAuthenticatedOrTokenHasScope
4 from rest_framework import filters, status
5 from rest_framework.exceptions import PermissionDenied
6 from rest_framework.generics import ListAPIView, RetrieveAPIView
7 from rest_framework.response import Response
8 from rest_framework.views import APIView
9
10 from photos import services
11 from photos.api.v2.serializers.album import (
12 AlbumListSerializer,
13 AlbumSerializer,
14 PhotoListSerializer,
15 )
16 from photos.models import Album, Like, Photo
17
18
19 class AlbumListView(ListAPIView):
20 """Returns an overview of all albums."""
21
22 serializer_class = AlbumListSerializer
23 queryset = Album.objects.filter(hidden=False)
24 permission_classes = [
25 IsAuthenticatedOrTokenHasScope,
26 ]
27 required_scopes = ["photos:read"]
28 filter_backends = (filters.SearchFilter,)
29 search_fields = ("title", "date", "slug")
30
31
32 class AlbumDetailView(RetrieveAPIView):
33 """Returns the details of an album."""
34
35 serializer_class = AlbumSerializer
36 permission_classes = [
37 IsAuthenticatedOrTokenHasScope,
38 ]
39 required_scopes = ["photos:read"]
40 lookup_field = "slug"
41
42 def retrieve(self, request, *args, **kwargs):
43 if not services.is_album_accessible(request, self.get_object()):
44 raise PermissionDenied
45 return super().retrieve(request, *args, **kwargs)
46
47 def get_queryset(self):
48 photos = Photo.objects.select_properties("num_likes")
49 if self.request.member:
50 photos = photos.annotate(
51 member_likes=Count("likes", filter=Q(likes__member=self.request.member))
52 )
53 return Album.objects.filter(hidden=False).prefetch_related(
54 Prefetch("photo_set", queryset=photos)
55 )
56
57
58 class LikedPhotosListView(ListAPIView):
59 """Returns the details the liked album."""
60
61 serializer_class = PhotoListSerializer
62 permission_classes = [
63 IsAuthenticatedOrTokenHasScope,
64 ]
65 required_scopes = ["photos:read"]
66
67 def get(self, request, *args, **kwargs):
68 if not self.request.member:
69 return Response(
70 data={
71 "detail": "You need to be a member in order to view your liked photos."
72 },
73 status=status.HTTP_403_FORBIDDEN,
74 )
75 return self.list(request, *args, **kwargs)
76
77 def get_queryset(self):
78 return (
79 Photo.objects.filter(likes__member=self.request.member, album__hidden=False)
80 .annotate(
81 member_likes=Count("likes", filter=Q(likes__member=self.request.member))
82 )
83 .select_properties("num_likes")
84 )
85
86
87 class PhotoLikeView(APIView):
88 permission_classes = [IsAuthenticatedOrTokenHasScope]
89 required_scopes = ["photos:read"]
90
91 def get(self, request, **kwargs):
92 photo_id = kwargs.get("pk")
93 try:
94 photo = Photo.objects.filter(album__hidden=False).get(pk=photo_id)
95 except Photo.DoesNotExist:
96 return Response(status=status.HTTP_404_NOT_FOUND)
97
98 return Response(
99 {
100 "liked": photo.likes.filter(member=request.member).exists(),
101 "num_likes": photo.num_likes,
102 },
103 status=status.HTTP_200_OK,
104 )
105
106 def post(self, request, **kwargs):
107 photo_id = kwargs.get("pk")
108 try:
109 photo = Photo.objects.filter(album__hidden=False).get(pk=photo_id)
110 except Photo.DoesNotExist:
111 return Response(status=status.HTTP_404_NOT_FOUND)
112
113 _, created = Like.objects.get_or_create(photo=photo, member=request.member)
114
115 if created:
116 return Response(
117 {
118 "liked": photo.likes.filter(member=request.member).exists(),
119 "num_likes": photo.num_likes,
120 },
121 status=status.HTTP_201_CREATED,
122 )
123 return Response(
124 {
125 "liked": photo.likes.filter(member=request.member).exists(),
126 "num_likes": photo.num_likes,
127 },
128 status=status.HTTP_200_OK,
129 )
130
131 def delete(self, request, **kwargs):
132 photo_id = kwargs.get("pk")
133 try:
134 photo = Photo.objects.filter(album__hidden=False).get(pk=photo_id)
135 except Photo.DoesNotExist:
136 return Response(status=status.HTTP_404_NOT_FOUND)
137
138 try:
139 like = Like.objects.filter(photo__album__hidden=False).get(
140 member=request.member, photo__pk=photo_id
141 )
142 except Like.DoesNotExist:
143 return Response(
144 {
145 "liked": False,
146 "num_likes": photo.num_likes,
147 },
148 status=status.HTTP_204_NO_CONTENT,
149 )
150
151 like.delete()
152
153 return Response(
154 {
155 "liked": False,
156 "num_likes": photo.num_likes,
157 },
158 status=status.HTTP_202_ACCEPTED,
159 )
160
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/website/photos/api/v2/views.py b/website/photos/api/v2/views.py
--- a/website/photos/api/v2/views.py
+++ b/website/photos/api/v2/views.py
@@ -50,6 +50,10 @@
photos = photos.annotate(
member_likes=Count("likes", filter=Q(likes__member=self.request.member))
)
+
+ # Fix select_properties dropping the default ordering.
+ photos = photos.order_by("pk")
+
return Album.objects.filter(hidden=False).prefetch_related(
Prefetch("photo_set", queryset=photos)
)
diff --git a/website/photos/urls.py b/website/photos/urls.py
--- a/website/photos/urls.py
+++ b/website/photos/urls.py
@@ -15,7 +15,7 @@
"<slug>/",
include(
[
- path("", views.detail, name="album"),
+ path("", views.AlbumDetailView.as_view(), name="album"),
path(
"download/",
include(
@@ -40,7 +40,11 @@
]
),
),
- path("<token>/", views.shared_album, name="shared-album"),
+ path(
+ "<token>/",
+ views.SharedAlbumView.as_view(),
+ name="shared-album",
+ ),
]
),
),
diff --git a/website/photos/views.py b/website/photos/views.py
--- a/website/photos/views.py
+++ b/website/photos/views.py
@@ -2,8 +2,9 @@
from django.contrib.auth.decorators import login_required
from django.http import Http404
-from django.shortcuts import get_object_or_404, redirect, render
+from django.shortcuts import get_object_or_404, redirect
from django.utils.decorators import method_decorator
+from django.views.generic import TemplateView
from photos.models import Album, Photo
from photos.services import (
@@ -43,29 +44,52 @@
return context
-def _render_album_page(request, album):
- """Render album.html for a specified album."""
- context = {
- "album": album,
- "photos": album.photo_set.filter(hidden=False).select_properties("num_likes"),
- }
- return render(request, "photos/album.html", context)
+class _BaseAlbumView(TemplateView):
+ template_name = "photos/album.html"
+ def get_album(self, **kwargs):
+ raise NotImplementedError
-@login_required
-def detail(request, slug):
- """Render an album, if it accessible by the user."""
- obj = get_object_or_404(Album, slug=slug)
- if is_album_accessible(request, obj):
- return _render_album_page(request, obj)
- raise Http404("Sorry, you're not allowed to view this album")
+ def get_context_data(self, **kwargs):
+ context = super().get_context_data(**kwargs)
+
+ album = self.get_album(**kwargs)
+
+ context["album"] = album
+ photos = album.photo_set.filter(hidden=False).select_properties("num_likes")
+
+ # Fix select_properties dropping the default ordering.
+ photos = photos.order_by("pk")
+
+ context["photos"] = photos
+ return context
-def shared_album(request, slug, token):
+@method_decorator(login_required, "dispatch")
+class AlbumDetailView(_BaseAlbumView):
+ """Render an album, if it is accessible by the user."""
+
+ def get_album(self, **kwargs):
+ slug = kwargs.get("slug")
+ album = get_object_or_404(Album, slug=slug)
+
+ if not is_album_accessible(self.request, album):
+ raise Http404("Sorry, you're not allowed to view this album")
+
+ return album
+
+
+class SharedAlbumView(_BaseAlbumView):
"""Render a shared album if the correct token is provided."""
- obj = get_object_or_404(Album, slug=slug)
- check_shared_album_token(obj, token)
- return _render_album_page(request, obj)
+
+ def get_album(self, **kwargs):
+ slug = kwargs.get("slug")
+ token = kwargs.get("token")
+ album = get_object_or_404(Album, slug=slug)
+
+ check_shared_album_token(album, token)
+
+ return album
def _photo_path(obj, filename):
|
{"golden_diff": "diff --git a/website/photos/api/v2/views.py b/website/photos/api/v2/views.py\n--- a/website/photos/api/v2/views.py\n+++ b/website/photos/api/v2/views.py\n@@ -50,6 +50,10 @@\n photos = photos.annotate(\n member_likes=Count(\"likes\", filter=Q(likes__member=self.request.member))\n )\n+\n+ # Fix select_properties dropping the default ordering.\n+ photos = photos.order_by(\"pk\")\n+\n return Album.objects.filter(hidden=False).prefetch_related(\n Prefetch(\"photo_set\", queryset=photos)\n )\ndiff --git a/website/photos/urls.py b/website/photos/urls.py\n--- a/website/photos/urls.py\n+++ b/website/photos/urls.py\n@@ -15,7 +15,7 @@\n \"<slug>/\",\n include(\n [\n- path(\"\", views.detail, name=\"album\"),\n+ path(\"\", views.AlbumDetailView.as_view(), name=\"album\"),\n path(\n \"download/\",\n include(\n@@ -40,7 +40,11 @@\n ]\n ),\n ),\n- path(\"<token>/\", views.shared_album, name=\"shared-album\"),\n+ path(\n+ \"<token>/\",\n+ views.SharedAlbumView.as_view(),\n+ name=\"shared-album\",\n+ ),\n ]\n ),\n ),\ndiff --git a/website/photos/views.py b/website/photos/views.py\n--- a/website/photos/views.py\n+++ b/website/photos/views.py\n@@ -2,8 +2,9 @@\n \n from django.contrib.auth.decorators import login_required\n from django.http import Http404\n-from django.shortcuts import get_object_or_404, redirect, render\n+from django.shortcuts import get_object_or_404, redirect\n from django.utils.decorators import method_decorator\n+from django.views.generic import TemplateView\n \n from photos.models import Album, Photo\n from photos.services import (\n@@ -43,29 +44,52 @@\n return context\n \n \n-def _render_album_page(request, album):\n- \"\"\"Render album.html for a specified album.\"\"\"\n- context = {\n- \"album\": album,\n- \"photos\": album.photo_set.filter(hidden=False).select_properties(\"num_likes\"),\n- }\n- return render(request, \"photos/album.html\", context)\n+class _BaseAlbumView(TemplateView):\n+ template_name = \"photos/album.html\"\n \n+ def get_album(self, **kwargs):\n+ raise NotImplementedError\n \n-@login_required\n-def detail(request, slug):\n- \"\"\"Render an album, if it accessible by the user.\"\"\"\n- obj = get_object_or_404(Album, slug=slug)\n- if is_album_accessible(request, obj):\n- return _render_album_page(request, obj)\n- raise Http404(\"Sorry, you're not allowed to view this album\")\n+ def get_context_data(self, **kwargs):\n+ context = super().get_context_data(**kwargs)\n+\n+ album = self.get_album(**kwargs)\n+\n+ context[\"album\"] = album\n+ photos = album.photo_set.filter(hidden=False).select_properties(\"num_likes\")\n+\n+ # Fix select_properties dropping the default ordering.\n+ photos = photos.order_by(\"pk\")\n+\n+ context[\"photos\"] = photos\n+ return context\n \n \n-def shared_album(request, slug, token):\n+@method_decorator(login_required, \"dispatch\")\n+class AlbumDetailView(_BaseAlbumView):\n+ \"\"\"Render an album, if it is accessible by the user.\"\"\"\n+\n+ def get_album(self, **kwargs):\n+ slug = kwargs.get(\"slug\")\n+ album = get_object_or_404(Album, slug=slug)\n+\n+ if not is_album_accessible(self.request, album):\n+ raise Http404(\"Sorry, you're not allowed to view this album\")\n+\n+ return album\n+\n+\n+class SharedAlbumView(_BaseAlbumView):\n \"\"\"Render a shared album if the correct token is provided.\"\"\"\n- obj = get_object_or_404(Album, slug=slug)\n- check_shared_album_token(obj, token)\n- return _render_album_page(request, obj)\n+\n+ def get_album(self, **kwargs):\n+ slug = kwargs.get(\"slug\")\n+ token = kwargs.get(\"token\")\n+ album = get_object_or_404(Album, slug=slug)\n+\n+ check_shared_album_token(album, token)\n+\n+ return album\n \n \n def _photo_path(obj, filename):\n", "issue": "Fix ordering of photos\nCloses #2843.\r\n\r\nI really hope this works.\r\n\n", "before_files": [{"content": "import os\n\nfrom django.contrib.auth.decorators import login_required\nfrom django.http import Http404\nfrom django.shortcuts import get_object_or_404, redirect, render\nfrom django.utils.decorators import method_decorator\n\nfrom photos.models import Album, Photo\nfrom photos.services import (\n check_shared_album_token,\n get_annotated_accessible_albums,\n is_album_accessible,\n)\nfrom thaliawebsite.views import PagedView\nfrom utils.media.services import get_media_url\n\nCOVER_FILENAME = \"cover.jpg\"\n\n\n@method_decorator(login_required, \"dispatch\")\nclass IndexView(PagedView):\n model = Album\n paginate_by = 16\n template_name = \"photos/index.html\"\n context_object_name = \"albums\"\n keywords = None\n\n def setup(self, request, *args, **kwargs):\n super().setup(request, *args, **kwargs)\n self.keywords = request.GET.get(\"keywords\", \"\").split()\n\n def get_queryset(self):\n albums = Album.objects.filter(hidden=False).select_related(\"_cover\")\n for key in self.keywords:\n albums = albums.filter(**{\"title__icontains\": key})\n albums = get_annotated_accessible_albums(self.request, albums)\n albums = albums.order_by(\"-date\")\n return albums\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context[\"keywords\"] = self.keywords\n return context\n\n\ndef _render_album_page(request, album):\n \"\"\"Render album.html for a specified album.\"\"\"\n context = {\n \"album\": album,\n \"photos\": album.photo_set.filter(hidden=False).select_properties(\"num_likes\"),\n }\n return render(request, \"photos/album.html\", context)\n\n\n@login_required\ndef detail(request, slug):\n \"\"\"Render an album, if it accessible by the user.\"\"\"\n obj = get_object_or_404(Album, slug=slug)\n if is_album_accessible(request, obj):\n return _render_album_page(request, obj)\n raise Http404(\"Sorry, you're not allowed to view this album\")\n\n\ndef shared_album(request, slug, token):\n \"\"\"Render a shared album if the correct token is provided.\"\"\"\n obj = get_object_or_404(Album, slug=slug)\n check_shared_album_token(obj, token)\n return _render_album_page(request, obj)\n\n\ndef _photo_path(obj, filename):\n \"\"\"Return the path to a Photo.\"\"\"\n photoname = os.path.basename(filename)\n albumpath = os.path.join(obj.photosdir, obj.dirname)\n photopath = os.path.join(albumpath, photoname)\n get_object_or_404(Photo.objects.filter(album=obj, file=photopath))\n return photopath\n\n\ndef _download(request, obj, filename):\n \"\"\"Download a photo.\n\n This function provides a layer of indirection for shared albums.\n \"\"\"\n photopath = _photo_path(obj, filename)\n photo = get_object_or_404(Photo.objects.filter(album=obj, file=photopath))\n return redirect(get_media_url(photo.file, f\"{obj.slug}-{filename}\"))\n\n\n@login_required\ndef download(request, slug, filename):\n \"\"\"Download a photo if the album of the photo is accessible by the user.\"\"\"\n obj = get_object_or_404(Album, slug=slug)\n if is_album_accessible(request, obj):\n return _download(request, obj, filename)\n raise Http404(\"Sorry, you're not allowed to view this album\")\n\n\ndef shared_download(request, slug, token, filename):\n \"\"\"Download a photo from a shared album if the album token is provided.\"\"\"\n obj = get_object_or_404(Album, slug=slug)\n check_shared_album_token(obj, token)\n return _download(request, obj, filename)\n\n\n@method_decorator(login_required, \"dispatch\")\nclass LikedPhotoView(PagedView):\n model = Photo\n paginate_by = 16\n template_name = \"photos/liked-photos.html\"\n context_object_name = \"photos\"\n\n def get_queryset(self):\n return (\n Photo.objects.filter(likes__member=self.request.member, album__hidden=False)\n .select_related(\"album\")\n .select_properties(\"num_likes\")\n .order_by(\"-album__date\")\n )\n", "path": "website/photos/views.py"}, {"content": "from django.urls import include, path\n\nfrom . import views\n\napp_name = \"photos\"\n\nurlpatterns = [\n path(\n \"members/photos/\",\n include(\n [\n path(\"\", views.IndexView.as_view(), name=\"index\"),\n path(\"liked\", views.LikedPhotoView.as_view(), name=\"liked-photos\"),\n path(\n \"<slug>/\",\n include(\n [\n path(\"\", views.detail, name=\"album\"),\n path(\n \"download/\",\n include(\n [\n path(\n \"<filename>\",\n views.download,\n name=\"download\",\n ),\n path(\n \"<token>/\",\n include(\n [\n path(\n \"<filename>\",\n views.shared_download,\n name=\"shared-download\",\n ),\n ]\n ),\n ),\n ]\n ),\n ),\n path(\"<token>/\", views.shared_album, name=\"shared-album\"),\n ]\n ),\n ),\n ]\n ),\n )\n]\n", "path": "website/photos/urls.py"}, {"content": "from django.db.models import Count, Prefetch, Q\n\nfrom oauth2_provider.contrib.rest_framework import IsAuthenticatedOrTokenHasScope\nfrom rest_framework import filters, status\nfrom rest_framework.exceptions import PermissionDenied\nfrom rest_framework.generics import ListAPIView, RetrieveAPIView\nfrom rest_framework.response import Response\nfrom rest_framework.views import APIView\n\nfrom photos import services\nfrom photos.api.v2.serializers.album import (\n AlbumListSerializer,\n AlbumSerializer,\n PhotoListSerializer,\n)\nfrom photos.models import Album, Like, Photo\n\n\nclass AlbumListView(ListAPIView):\n \"\"\"Returns an overview of all albums.\"\"\"\n\n serializer_class = AlbumListSerializer\n queryset = Album.objects.filter(hidden=False)\n permission_classes = [\n IsAuthenticatedOrTokenHasScope,\n ]\n required_scopes = [\"photos:read\"]\n filter_backends = (filters.SearchFilter,)\n search_fields = (\"title\", \"date\", \"slug\")\n\n\nclass AlbumDetailView(RetrieveAPIView):\n \"\"\"Returns the details of an album.\"\"\"\n\n serializer_class = AlbumSerializer\n permission_classes = [\n IsAuthenticatedOrTokenHasScope,\n ]\n required_scopes = [\"photos:read\"]\n lookup_field = \"slug\"\n\n def retrieve(self, request, *args, **kwargs):\n if not services.is_album_accessible(request, self.get_object()):\n raise PermissionDenied\n return super().retrieve(request, *args, **kwargs)\n\n def get_queryset(self):\n photos = Photo.objects.select_properties(\"num_likes\")\n if self.request.member:\n photos = photos.annotate(\n member_likes=Count(\"likes\", filter=Q(likes__member=self.request.member))\n )\n return Album.objects.filter(hidden=False).prefetch_related(\n Prefetch(\"photo_set\", queryset=photos)\n )\n\n\nclass LikedPhotosListView(ListAPIView):\n \"\"\"Returns the details the liked album.\"\"\"\n\n serializer_class = PhotoListSerializer\n permission_classes = [\n IsAuthenticatedOrTokenHasScope,\n ]\n required_scopes = [\"photos:read\"]\n\n def get(self, request, *args, **kwargs):\n if not self.request.member:\n return Response(\n data={\n \"detail\": \"You need to be a member in order to view your liked photos.\"\n },\n status=status.HTTP_403_FORBIDDEN,\n )\n return self.list(request, *args, **kwargs)\n\n def get_queryset(self):\n return (\n Photo.objects.filter(likes__member=self.request.member, album__hidden=False)\n .annotate(\n member_likes=Count(\"likes\", filter=Q(likes__member=self.request.member))\n )\n .select_properties(\"num_likes\")\n )\n\n\nclass PhotoLikeView(APIView):\n permission_classes = [IsAuthenticatedOrTokenHasScope]\n required_scopes = [\"photos:read\"]\n\n def get(self, request, **kwargs):\n photo_id = kwargs.get(\"pk\")\n try:\n photo = Photo.objects.filter(album__hidden=False).get(pk=photo_id)\n except Photo.DoesNotExist:\n return Response(status=status.HTTP_404_NOT_FOUND)\n\n return Response(\n {\n \"liked\": photo.likes.filter(member=request.member).exists(),\n \"num_likes\": photo.num_likes,\n },\n status=status.HTTP_200_OK,\n )\n\n def post(self, request, **kwargs):\n photo_id = kwargs.get(\"pk\")\n try:\n photo = Photo.objects.filter(album__hidden=False).get(pk=photo_id)\n except Photo.DoesNotExist:\n return Response(status=status.HTTP_404_NOT_FOUND)\n\n _, created = Like.objects.get_or_create(photo=photo, member=request.member)\n\n if created:\n return Response(\n {\n \"liked\": photo.likes.filter(member=request.member).exists(),\n \"num_likes\": photo.num_likes,\n },\n status=status.HTTP_201_CREATED,\n )\n return Response(\n {\n \"liked\": photo.likes.filter(member=request.member).exists(),\n \"num_likes\": photo.num_likes,\n },\n status=status.HTTP_200_OK,\n )\n\n def delete(self, request, **kwargs):\n photo_id = kwargs.get(\"pk\")\n try:\n photo = Photo.objects.filter(album__hidden=False).get(pk=photo_id)\n except Photo.DoesNotExist:\n return Response(status=status.HTTP_404_NOT_FOUND)\n\n try:\n like = Like.objects.filter(photo__album__hidden=False).get(\n member=request.member, photo__pk=photo_id\n )\n except Like.DoesNotExist:\n return Response(\n {\n \"liked\": False,\n \"num_likes\": photo.num_likes,\n },\n status=status.HTTP_204_NO_CONTENT,\n )\n\n like.delete()\n\n return Response(\n {\n \"liked\": False,\n \"num_likes\": photo.num_likes,\n },\n status=status.HTTP_202_ACCEPTED,\n )\n", "path": "website/photos/api/v2/views.py"}], "after_files": [{"content": "import os\n\nfrom django.contrib.auth.decorators import login_required\nfrom django.http import Http404\nfrom django.shortcuts import get_object_or_404, redirect\nfrom django.utils.decorators import method_decorator\nfrom django.views.generic import TemplateView\n\nfrom photos.models import Album, Photo\nfrom photos.services import (\n check_shared_album_token,\n get_annotated_accessible_albums,\n is_album_accessible,\n)\nfrom thaliawebsite.views import PagedView\nfrom utils.media.services import get_media_url\n\nCOVER_FILENAME = \"cover.jpg\"\n\n\n@method_decorator(login_required, \"dispatch\")\nclass IndexView(PagedView):\n model = Album\n paginate_by = 16\n template_name = \"photos/index.html\"\n context_object_name = \"albums\"\n keywords = None\n\n def setup(self, request, *args, **kwargs):\n super().setup(request, *args, **kwargs)\n self.keywords = request.GET.get(\"keywords\", \"\").split()\n\n def get_queryset(self):\n albums = Album.objects.filter(hidden=False).select_related(\"_cover\")\n for key in self.keywords:\n albums = albums.filter(**{\"title__icontains\": key})\n albums = get_annotated_accessible_albums(self.request, albums)\n albums = albums.order_by(\"-date\")\n return albums\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context[\"keywords\"] = self.keywords\n return context\n\n\nclass _BaseAlbumView(TemplateView):\n template_name = \"photos/album.html\"\n\n def get_album(self, **kwargs):\n raise NotImplementedError\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n\n album = self.get_album(**kwargs)\n\n context[\"album\"] = album\n photos = album.photo_set.filter(hidden=False).select_properties(\"num_likes\")\n\n # Fix select_properties dropping the default ordering.\n photos = photos.order_by(\"pk\")\n\n context[\"photos\"] = photos\n return context\n\n\n@method_decorator(login_required, \"dispatch\")\nclass AlbumDetailView(_BaseAlbumView):\n \"\"\"Render an album, if it is accessible by the user.\"\"\"\n\n def get_album(self, **kwargs):\n slug = kwargs.get(\"slug\")\n album = get_object_or_404(Album, slug=slug)\n\n if not is_album_accessible(self.request, album):\n raise Http404(\"Sorry, you're not allowed to view this album\")\n\n return album\n\n\nclass SharedAlbumView(_BaseAlbumView):\n \"\"\"Render a shared album if the correct token is provided.\"\"\"\n\n def get_album(self, **kwargs):\n slug = kwargs.get(\"slug\")\n token = kwargs.get(\"token\")\n album = get_object_or_404(Album, slug=slug)\n\n check_shared_album_token(album, token)\n\n return album\n\n\ndef _photo_path(obj, filename):\n \"\"\"Return the path to a Photo.\"\"\"\n photoname = os.path.basename(filename)\n albumpath = os.path.join(obj.photosdir, obj.dirname)\n photopath = os.path.join(albumpath, photoname)\n get_object_or_404(Photo.objects.filter(album=obj, file=photopath))\n return photopath\n\n\ndef _download(request, obj, filename):\n \"\"\"Download a photo.\n\n This function provides a layer of indirection for shared albums.\n \"\"\"\n photopath = _photo_path(obj, filename)\n photo = get_object_or_404(Photo.objects.filter(album=obj, file=photopath))\n return redirect(get_media_url(photo.file, f\"{obj.slug}-{filename}\"))\n\n\n@login_required\ndef download(request, slug, filename):\n \"\"\"Download a photo if the album of the photo is accessible by the user.\"\"\"\n obj = get_object_or_404(Album, slug=slug)\n if is_album_accessible(request, obj):\n return _download(request, obj, filename)\n raise Http404(\"Sorry, you're not allowed to view this album\")\n\n\ndef shared_download(request, slug, token, filename):\n \"\"\"Download a photo from a shared album if the album token is provided.\"\"\"\n obj = get_object_or_404(Album, slug=slug)\n check_shared_album_token(obj, token)\n return _download(request, obj, filename)\n\n\n@method_decorator(login_required, \"dispatch\")\nclass LikedPhotoView(PagedView):\n model = Photo\n paginate_by = 16\n template_name = \"photos/liked-photos.html\"\n context_object_name = \"photos\"\n\n def get_queryset(self):\n return (\n Photo.objects.filter(likes__member=self.request.member, album__hidden=False)\n .select_related(\"album\")\n .select_properties(\"num_likes\")\n .order_by(\"-album__date\")\n )\n", "path": "website/photos/views.py"}, {"content": "from django.urls import include, path\n\nfrom . import views\n\napp_name = \"photos\"\n\nurlpatterns = [\n path(\n \"members/photos/\",\n include(\n [\n path(\"\", views.IndexView.as_view(), name=\"index\"),\n path(\"liked\", views.LikedPhotoView.as_view(), name=\"liked-photos\"),\n path(\n \"<slug>/\",\n include(\n [\n path(\"\", views.AlbumDetailView.as_view(), name=\"album\"),\n path(\n \"download/\",\n include(\n [\n path(\n \"<filename>\",\n views.download,\n name=\"download\",\n ),\n path(\n \"<token>/\",\n include(\n [\n path(\n \"<filename>\",\n views.shared_download,\n name=\"shared-download\",\n ),\n ]\n ),\n ),\n ]\n ),\n ),\n path(\n \"<token>/\",\n views.SharedAlbumView.as_view(),\n name=\"shared-album\",\n ),\n ]\n ),\n ),\n ]\n ),\n )\n]\n", "path": "website/photos/urls.py"}, {"content": "from django.db.models import Count, Prefetch, Q\n\nfrom oauth2_provider.contrib.rest_framework import IsAuthenticatedOrTokenHasScope\nfrom rest_framework import filters, status\nfrom rest_framework.exceptions import PermissionDenied\nfrom rest_framework.generics import ListAPIView, RetrieveAPIView\nfrom rest_framework.response import Response\nfrom rest_framework.views import APIView\n\nfrom photos import services\nfrom photos.api.v2.serializers.album import (\n AlbumListSerializer,\n AlbumSerializer,\n PhotoListSerializer,\n)\nfrom photos.models import Album, Like, Photo\n\n\nclass AlbumListView(ListAPIView):\n \"\"\"Returns an overview of all albums.\"\"\"\n\n serializer_class = AlbumListSerializer\n queryset = Album.objects.filter(hidden=False)\n permission_classes = [\n IsAuthenticatedOrTokenHasScope,\n ]\n required_scopes = [\"photos:read\"]\n filter_backends = (filters.SearchFilter,)\n search_fields = (\"title\", \"date\", \"slug\")\n\n\nclass AlbumDetailView(RetrieveAPIView):\n \"\"\"Returns the details of an album.\"\"\"\n\n serializer_class = AlbumSerializer\n permission_classes = [\n IsAuthenticatedOrTokenHasScope,\n ]\n required_scopes = [\"photos:read\"]\n lookup_field = \"slug\"\n\n def retrieve(self, request, *args, **kwargs):\n if not services.is_album_accessible(request, self.get_object()):\n raise PermissionDenied\n return super().retrieve(request, *args, **kwargs)\n\n def get_queryset(self):\n photos = Photo.objects.select_properties(\"num_likes\")\n if self.request.member:\n photos = photos.annotate(\n member_likes=Count(\"likes\", filter=Q(likes__member=self.request.member))\n )\n\n # Fix select_properties dropping the default ordering.\n photos = photos.order_by(\"pk\")\n\n return Album.objects.filter(hidden=False).prefetch_related(\n Prefetch(\"photo_set\", queryset=photos)\n )\n\n\nclass LikedPhotosListView(ListAPIView):\n \"\"\"Returns the details the liked album.\"\"\"\n\n serializer_class = PhotoListSerializer\n permission_classes = [\n IsAuthenticatedOrTokenHasScope,\n ]\n required_scopes = [\"photos:read\"]\n\n def get(self, request, *args, **kwargs):\n if not self.request.member:\n return Response(\n data={\n \"detail\": \"You need to be a member in order to view your liked photos.\"\n },\n status=status.HTTP_403_FORBIDDEN,\n )\n return self.list(request, *args, **kwargs)\n\n def get_queryset(self):\n return (\n Photo.objects.filter(likes__member=self.request.member, album__hidden=False)\n .annotate(\n member_likes=Count(\"likes\", filter=Q(likes__member=self.request.member))\n )\n .select_properties(\"num_likes\")\n )\n\n\nclass PhotoLikeView(APIView):\n permission_classes = [IsAuthenticatedOrTokenHasScope]\n required_scopes = [\"photos:read\"]\n\n def get(self, request, **kwargs):\n photo_id = kwargs.get(\"pk\")\n try:\n photo = Photo.objects.filter(album__hidden=False).get(pk=photo_id)\n except Photo.DoesNotExist:\n return Response(status=status.HTTP_404_NOT_FOUND)\n\n return Response(\n {\n \"liked\": photo.likes.filter(member=request.member).exists(),\n \"num_likes\": photo.num_likes,\n },\n status=status.HTTP_200_OK,\n )\n\n def post(self, request, **kwargs):\n photo_id = kwargs.get(\"pk\")\n try:\n photo = Photo.objects.filter(album__hidden=False).get(pk=photo_id)\n except Photo.DoesNotExist:\n return Response(status=status.HTTP_404_NOT_FOUND)\n\n _, created = Like.objects.get_or_create(photo=photo, member=request.member)\n\n if created:\n return Response(\n {\n \"liked\": photo.likes.filter(member=request.member).exists(),\n \"num_likes\": photo.num_likes,\n },\n status=status.HTTP_201_CREATED,\n )\n return Response(\n {\n \"liked\": photo.likes.filter(member=request.member).exists(),\n \"num_likes\": photo.num_likes,\n },\n status=status.HTTP_200_OK,\n )\n\n def delete(self, request, **kwargs):\n photo_id = kwargs.get(\"pk\")\n try:\n photo = Photo.objects.filter(album__hidden=False).get(pk=photo_id)\n except Photo.DoesNotExist:\n return Response(status=status.HTTP_404_NOT_FOUND)\n\n try:\n like = Like.objects.filter(photo__album__hidden=False).get(\n member=request.member, photo__pk=photo_id\n )\n except Like.DoesNotExist:\n return Response(\n {\n \"liked\": False,\n \"num_likes\": photo.num_likes,\n },\n status=status.HTTP_204_NO_CONTENT,\n )\n\n like.delete()\n\n return Response(\n {\n \"liked\": False,\n \"num_likes\": photo.num_likes,\n },\n status=status.HTTP_202_ACCEPTED,\n )\n", "path": "website/photos/api/v2/views.py"}]}
| 3,190 | 981 |
gh_patches_debug_43392
|
rasdani/github-patches
|
git_diff
|
optuna__optuna-3497
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Constraint-aware pareto-front plot
<!-- Please write a clear and concise description of the feature proposal. -->
## Motivation
This is a sub-task of #2397.
## Description
Recently, Optuna enables us to add constraints to multi-objective optimization. The `plot_paret_front` function, however, does not consider whether the solution is feasible or not. So, I needed to modify it to visualize the constraint optimization.
For example, the following plot is an example of multi-objective knapsack problem. The objectives are to be maximized, but infeasible solutions are likely to be seen in the up-right region. In this case, I couldn't find the shape of Pareto front without removing the infeasible solutions.
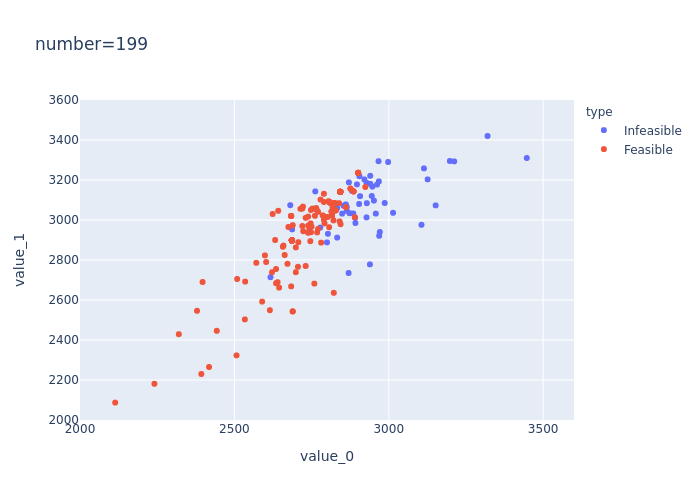
We may have some design choices, but I think the first choice will be adding `constraints_func` to `plot_pareto_front`. This is because some samplers including [`NSGAIISampler`](https://optuna.readthedocs.io/en/stable/reference/generated/optuna.samplers.NSGAIISampler.html#optuna.samplers.NSGAIISampler) and [`BoTorchSampler`](https://optuna.readthedocs.io/en/stable/reference/generated/optuna.integration.BoTorchSampler.html#optuna.integration.BoTorchSampler) have the same interfaces regarding constrained optimization.
```python
optuna.visualization.plot_pareto_front(study, *, ..., constraints_func: Optional[Callable[[FrozenTrial], Sequence[float]]] = None)
```
## Alternatives (optional)
<!-- Please write a clear and concise description of any alternative solutions or features you've considered. -->
## Additional context (optional)
<!-- Please add any other context or screenshots about the feature request here. -->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `optuna/visualization/matplotlib/_pareto_front.py`
Content:
```
1 from typing import Callable
2 from typing import List
3 from typing import Optional
4 from typing import Sequence
5
6 from optuna._experimental import experimental
7 from optuna.study import Study
8 from optuna.trial import FrozenTrial
9 from optuna.visualization._pareto_front import _get_pareto_front_info
10 from optuna.visualization._pareto_front import _ParetoFrontInfo
11 from optuna.visualization.matplotlib._matplotlib_imports import _imports
12
13
14 if _imports.is_successful():
15 from optuna.visualization.matplotlib._matplotlib_imports import Axes
16 from optuna.visualization.matplotlib._matplotlib_imports import plt
17
18
19 @experimental("2.8.0")
20 def plot_pareto_front(
21 study: Study,
22 *,
23 target_names: Optional[List[str]] = None,
24 include_dominated_trials: bool = True,
25 axis_order: Optional[List[int]] = None,
26 targets: Optional[Callable[[FrozenTrial], Sequence[float]]] = None,
27 ) -> "Axes":
28 """Plot the Pareto front of a study.
29
30 .. seealso::
31 Please refer to :func:`optuna.visualization.plot_pareto_front` for an example.
32
33 Example:
34
35 The following code snippet shows how to plot the Pareto front of a study.
36
37 .. plot::
38
39 import optuna
40
41
42 def objective(trial):
43 x = trial.suggest_float("x", 0, 5)
44 y = trial.suggest_float("y", 0, 3)
45
46 v0 = 4 * x ** 2 + 4 * y ** 2
47 v1 = (x - 5) ** 2 + (y - 5) ** 2
48 return v0, v1
49
50
51 study = optuna.create_study(directions=["minimize", "minimize"])
52 study.optimize(objective, n_trials=50)
53
54 optuna.visualization.matplotlib.plot_pareto_front(study)
55
56 Args:
57 study:
58 A :class:`~optuna.study.Study` object whose trials are plotted for their objective
59 values. ``study.n_objectives`` must be either 2 or 3 when ``targets`` is :obj:`None`.
60 target_names:
61 Objective name list used as the axis titles. If :obj:`None` is specified,
62 "Objective {objective_index}" is used instead. If ``targets`` is specified
63 for a study that does not contain any completed trial,
64 ``target_name`` must be specified.
65 include_dominated_trials:
66 A flag to include all dominated trial's objective values.
67 axis_order:
68 A list of indices indicating the axis order. If :obj:`None` is specified,
69 default order is used. ``axis_order`` and ``targets`` cannot be used at the same time.
70
71 .. warning::
72 Deprecated in v3.0.0. This feature will be removed in the future. The removal of
73 this feature is currently scheduled for v5.0.0, but this schedule is subject to
74 change. See https://github.com/optuna/optuna/releases/tag/v3.0.0.
75 targets:
76 A function that returns a tuple of target values to display.
77 The argument to this function is :class:`~optuna.trial.FrozenTrial`.
78 ``targets`` must be :obj:`None` or return 2 or 3 values.
79 ``axis_order`` and ``targets`` cannot be used at the same time.
80 If ``study.n_objectives`` is neither 2 nor 3, ``targets`` must be specified.
81
82 .. note::
83 Added in v3.0.0 as an experimental feature. The interface may change in newer
84 versions without prior notice.
85 See https://github.com/optuna/optuna/releases/tag/v3.0.0.
86
87 Returns:
88 A :class:`matplotlib.axes.Axes` object.
89 """
90
91 _imports.check()
92
93 info = _get_pareto_front_info(
94 study, target_names, include_dominated_trials, axis_order, None, targets
95 )
96
97 if info.n_targets == 2:
98 return _get_pareto_front_2d(info)
99 elif info.n_targets == 3:
100 return _get_pareto_front_3d(info)
101 else:
102 assert False, "Must not reach here"
103
104
105 def _get_pareto_front_2d(info: _ParetoFrontInfo) -> "Axes":
106 # Set up the graph style.
107 plt.style.use("ggplot") # Use ggplot style sheet for similar outputs to plotly.
108 _, ax = plt.subplots()
109 ax.set_title("Pareto-front Plot")
110 cmap = plt.get_cmap("tab10") # Use tab10 colormap for similar outputs to plotly.
111
112 ax.set_xlabel(info.target_names[info.axis_order[0]])
113 ax.set_ylabel(info.target_names[info.axis_order[1]])
114
115 if info.non_best_trials_with_values is not None and len(info.non_best_trials_with_values) > 0:
116 ax.scatter(
117 x=[values[info.axis_order[0]] for _, values in info.non_best_trials_with_values],
118 y=[values[info.axis_order[1]] for _, values in info.non_best_trials_with_values],
119 color=cmap(0),
120 label="Trial",
121 )
122 if info.best_trials_with_values is not None and len(info.best_trials_with_values) > 0:
123 ax.scatter(
124 x=[values[info.axis_order[0]] for _, values in info.best_trials_with_values],
125 y=[values[info.axis_order[1]] for _, values in info.best_trials_with_values],
126 color=cmap(3),
127 label="Best Trial",
128 )
129
130 if info.non_best_trials_with_values is not None and ax.has_data():
131 ax.legend()
132
133 return ax
134
135
136 def _get_pareto_front_3d(info: _ParetoFrontInfo) -> "Axes":
137 # Set up the graph style.
138 plt.style.use("ggplot") # Use ggplot style sheet for similar outputs to plotly.
139 fig = plt.figure()
140 ax = fig.add_subplot(projection="3d")
141 ax.set_title("Pareto-front Plot")
142 cmap = plt.get_cmap("tab10") # Use tab10 colormap for similar outputs to plotly.
143
144 ax.set_xlabel(info.target_names[info.axis_order[0]])
145 ax.set_ylabel(info.target_names[info.axis_order[1]])
146 ax.set_zlabel(info.target_names[info.axis_order[2]])
147
148 if info.non_best_trials_with_values is not None and len(info.non_best_trials_with_values) > 0:
149 ax.scatter(
150 xs=[values[info.axis_order[0]] for _, values in info.non_best_trials_with_values],
151 ys=[values[info.axis_order[1]] for _, values in info.non_best_trials_with_values],
152 zs=[values[info.axis_order[2]] for _, values in info.non_best_trials_with_values],
153 color=cmap(0),
154 label="Trial",
155 )
156
157 if info.best_trials_with_values is not None and len(info.best_trials_with_values):
158 ax.scatter(
159 xs=[values[info.axis_order[0]] for _, values in info.best_trials_with_values],
160 ys=[values[info.axis_order[1]] for _, values in info.best_trials_with_values],
161 zs=[values[info.axis_order[2]] for _, values in info.best_trials_with_values],
162 color=cmap(3),
163 label="Best Trial",
164 )
165
166 if info.non_best_trials_with_values is not None and ax.has_data():
167 ax.legend()
168
169 return ax
170
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/optuna/visualization/matplotlib/_pareto_front.py b/optuna/visualization/matplotlib/_pareto_front.py
--- a/optuna/visualization/matplotlib/_pareto_front.py
+++ b/optuna/visualization/matplotlib/_pareto_front.py
@@ -23,6 +23,7 @@
target_names: Optional[List[str]] = None,
include_dominated_trials: bool = True,
axis_order: Optional[List[int]] = None,
+ constraints_func: Optional[Callable[[FrozenTrial], Sequence[float]]] = None,
targets: Optional[Callable[[FrozenTrial], Sequence[float]]] = None,
) -> "Axes":
"""Plot the Pareto front of a study.
@@ -72,6 +73,17 @@
Deprecated in v3.0.0. This feature will be removed in the future. The removal of
this feature is currently scheduled for v5.0.0, but this schedule is subject to
change. See https://github.com/optuna/optuna/releases/tag/v3.0.0.
+ constraints_func:
+ An optional function that computes the objective constraints. It must take a
+ :class:`~optuna.trial.FrozenTrial` and return the constraints. The return value must
+ be a sequence of :obj:`float` s. A value strictly larger than 0 means that a
+ constraint is violated. A value equal to or smaller than 0 is considered feasible.
+ This specification is the same as in, for example,
+ :class:`~optuna.integration.NSGAIISampler`.
+
+ If given, trials are classified into three categories: feasible and best, feasible but
+ non-best, and infeasible. Categories are shown in different colors. Here, whether a
+ trial is best (on Pareto front) or not is determined ignoring all infeasible trials.
targets:
A function that returns a tuple of target values to display.
The argument to this function is :class:`~optuna.trial.FrozenTrial`.
@@ -91,7 +103,7 @@
_imports.check()
info = _get_pareto_front_info(
- study, target_names, include_dominated_trials, axis_order, None, targets
+ study, target_names, include_dominated_trials, axis_order, constraints_func, targets
)
if info.n_targets == 2:
@@ -112,6 +124,16 @@
ax.set_xlabel(info.target_names[info.axis_order[0]])
ax.set_ylabel(info.target_names[info.axis_order[1]])
+ if (
+ info.infeasible_trials_with_values is not None
+ and len(info.infeasible_trials_with_values) > 0
+ ):
+ ax.scatter(
+ x=[values[info.axis_order[0]] for _, values in info.infeasible_trials_with_values],
+ y=[values[info.axis_order[1]] for _, values in info.infeasible_trials_with_values],
+ color="#cccccc",
+ label="Infeasible Trial",
+ )
if info.non_best_trials_with_values is not None and len(info.non_best_trials_with_values) > 0:
ax.scatter(
x=[values[info.axis_order[0]] for _, values in info.non_best_trials_with_values],
@@ -145,6 +167,18 @@
ax.set_ylabel(info.target_names[info.axis_order[1]])
ax.set_zlabel(info.target_names[info.axis_order[2]])
+ if (
+ info.infeasible_trials_with_values is not None
+ and len(info.infeasible_trials_with_values) > 0
+ ):
+ ax.scatter(
+ xs=[values[info.axis_order[0]] for _, values in info.infeasible_trials_with_values],
+ ys=[values[info.axis_order[1]] for _, values in info.infeasible_trials_with_values],
+ zs=[values[info.axis_order[2]] for _, values in info.infeasible_trials_with_values],
+ color="#cccccc",
+ label="Infeasible Trial",
+ )
+
if info.non_best_trials_with_values is not None and len(info.non_best_trials_with_values) > 0:
ax.scatter(
xs=[values[info.axis_order[0]] for _, values in info.non_best_trials_with_values],
|
{"golden_diff": "diff --git a/optuna/visualization/matplotlib/_pareto_front.py b/optuna/visualization/matplotlib/_pareto_front.py\n--- a/optuna/visualization/matplotlib/_pareto_front.py\n+++ b/optuna/visualization/matplotlib/_pareto_front.py\n@@ -23,6 +23,7 @@\n target_names: Optional[List[str]] = None,\n include_dominated_trials: bool = True,\n axis_order: Optional[List[int]] = None,\n+ constraints_func: Optional[Callable[[FrozenTrial], Sequence[float]]] = None,\n targets: Optional[Callable[[FrozenTrial], Sequence[float]]] = None,\n ) -> \"Axes\":\n \"\"\"Plot the Pareto front of a study.\n@@ -72,6 +73,17 @@\n Deprecated in v3.0.0. This feature will be removed in the future. The removal of\n this feature is currently scheduled for v5.0.0, but this schedule is subject to\n change. See https://github.com/optuna/optuna/releases/tag/v3.0.0.\n+ constraints_func:\n+ An optional function that computes the objective constraints. It must take a\n+ :class:`~optuna.trial.FrozenTrial` and return the constraints. The return value must\n+ be a sequence of :obj:`float` s. A value strictly larger than 0 means that a\n+ constraint is violated. A value equal to or smaller than 0 is considered feasible.\n+ This specification is the same as in, for example,\n+ :class:`~optuna.integration.NSGAIISampler`.\n+\n+ If given, trials are classified into three categories: feasible and best, feasible but\n+ non-best, and infeasible. Categories are shown in different colors. Here, whether a\n+ trial is best (on Pareto front) or not is determined ignoring all infeasible trials.\n targets:\n A function that returns a tuple of target values to display.\n The argument to this function is :class:`~optuna.trial.FrozenTrial`.\n@@ -91,7 +103,7 @@\n _imports.check()\n \n info = _get_pareto_front_info(\n- study, target_names, include_dominated_trials, axis_order, None, targets\n+ study, target_names, include_dominated_trials, axis_order, constraints_func, targets\n )\n \n if info.n_targets == 2:\n@@ -112,6 +124,16 @@\n ax.set_xlabel(info.target_names[info.axis_order[0]])\n ax.set_ylabel(info.target_names[info.axis_order[1]])\n \n+ if (\n+ info.infeasible_trials_with_values is not None\n+ and len(info.infeasible_trials_with_values) > 0\n+ ):\n+ ax.scatter(\n+ x=[values[info.axis_order[0]] for _, values in info.infeasible_trials_with_values],\n+ y=[values[info.axis_order[1]] for _, values in info.infeasible_trials_with_values],\n+ color=\"#cccccc\",\n+ label=\"Infeasible Trial\",\n+ )\n if info.non_best_trials_with_values is not None and len(info.non_best_trials_with_values) > 0:\n ax.scatter(\n x=[values[info.axis_order[0]] for _, values in info.non_best_trials_with_values],\n@@ -145,6 +167,18 @@\n ax.set_ylabel(info.target_names[info.axis_order[1]])\n ax.set_zlabel(info.target_names[info.axis_order[2]])\n \n+ if (\n+ info.infeasible_trials_with_values is not None\n+ and len(info.infeasible_trials_with_values) > 0\n+ ):\n+ ax.scatter(\n+ xs=[values[info.axis_order[0]] for _, values in info.infeasible_trials_with_values],\n+ ys=[values[info.axis_order[1]] for _, values in info.infeasible_trials_with_values],\n+ zs=[values[info.axis_order[2]] for _, values in info.infeasible_trials_with_values],\n+ color=\"#cccccc\",\n+ label=\"Infeasible Trial\",\n+ )\n+\n if info.non_best_trials_with_values is not None and len(info.non_best_trials_with_values) > 0:\n ax.scatter(\n xs=[values[info.axis_order[0]] for _, values in info.non_best_trials_with_values],\n", "issue": "Constraint-aware pareto-front plot\n<!-- Please write a clear and concise description of the feature proposal. -->\r\n\r\n## Motivation\r\n\r\nThis is a sub-task of #2397.\r\n\r\n## Description\r\n\r\n\r\nRecently, Optuna enables us to add constraints to multi-objective optimization. The `plot_paret_front` function, however, does not consider whether the solution is feasible or not. So, I needed to modify it to visualize the constraint optimization.\r\n\r\nFor example, the following plot is an example of multi-objective knapsack problem. The objectives are to be maximized, but infeasible solutions are likely to be seen in the up-right region. In this case, I couldn't find the shape of Pareto front without removing the infeasible solutions.\r\n\r\n\r\n\r\nWe may have some design choices, but I think the first choice will be adding `constraints_func` to `plot_pareto_front`. This is because some samplers including [`NSGAIISampler`](https://optuna.readthedocs.io/en/stable/reference/generated/optuna.samplers.NSGAIISampler.html#optuna.samplers.NSGAIISampler) and [`BoTorchSampler`](https://optuna.readthedocs.io/en/stable/reference/generated/optuna.integration.BoTorchSampler.html#optuna.integration.BoTorchSampler) have the same interfaces regarding constrained optimization.\r\n\r\n```python\r\noptuna.visualization.plot_pareto_front(study, *, ..., constraints_func: Optional[Callable[[FrozenTrial], Sequence[float]]] = None)\r\n```\r\n\r\n\r\n## Alternatives (optional)\r\n\r\n<!-- Please write a clear and concise description of any alternative solutions or features you've considered. -->\r\n\r\n## Additional context (optional)\r\n\r\n<!-- Please add any other context or screenshots about the feature request here. -->\r\n\n", "before_files": [{"content": "from typing import Callable\nfrom typing import List\nfrom typing import Optional\nfrom typing import Sequence\n\nfrom optuna._experimental import experimental\nfrom optuna.study import Study\nfrom optuna.trial import FrozenTrial\nfrom optuna.visualization._pareto_front import _get_pareto_front_info\nfrom optuna.visualization._pareto_front import _ParetoFrontInfo\nfrom optuna.visualization.matplotlib._matplotlib_imports import _imports\n\n\nif _imports.is_successful():\n from optuna.visualization.matplotlib._matplotlib_imports import Axes\n from optuna.visualization.matplotlib._matplotlib_imports import plt\n\n\n@experimental(\"2.8.0\")\ndef plot_pareto_front(\n study: Study,\n *,\n target_names: Optional[List[str]] = None,\n include_dominated_trials: bool = True,\n axis_order: Optional[List[int]] = None,\n targets: Optional[Callable[[FrozenTrial], Sequence[float]]] = None,\n) -> \"Axes\":\n \"\"\"Plot the Pareto front of a study.\n\n .. seealso::\n Please refer to :func:`optuna.visualization.plot_pareto_front` for an example.\n\n Example:\n\n The following code snippet shows how to plot the Pareto front of a study.\n\n .. plot::\n\n import optuna\n\n\n def objective(trial):\n x = trial.suggest_float(\"x\", 0, 5)\n y = trial.suggest_float(\"y\", 0, 3)\n\n v0 = 4 * x ** 2 + 4 * y ** 2\n v1 = (x - 5) ** 2 + (y - 5) ** 2\n return v0, v1\n\n\n study = optuna.create_study(directions=[\"minimize\", \"minimize\"])\n study.optimize(objective, n_trials=50)\n\n optuna.visualization.matplotlib.plot_pareto_front(study)\n\n Args:\n study:\n A :class:`~optuna.study.Study` object whose trials are plotted for their objective\n values. ``study.n_objectives`` must be either 2 or 3 when ``targets`` is :obj:`None`.\n target_names:\n Objective name list used as the axis titles. If :obj:`None` is specified,\n \"Objective {objective_index}\" is used instead. If ``targets`` is specified\n for a study that does not contain any completed trial,\n ``target_name`` must be specified.\n include_dominated_trials:\n A flag to include all dominated trial's objective values.\n axis_order:\n A list of indices indicating the axis order. If :obj:`None` is specified,\n default order is used. ``axis_order`` and ``targets`` cannot be used at the same time.\n\n .. warning::\n Deprecated in v3.0.0. This feature will be removed in the future. The removal of\n this feature is currently scheduled for v5.0.0, but this schedule is subject to\n change. See https://github.com/optuna/optuna/releases/tag/v3.0.0.\n targets:\n A function that returns a tuple of target values to display.\n The argument to this function is :class:`~optuna.trial.FrozenTrial`.\n ``targets`` must be :obj:`None` or return 2 or 3 values.\n ``axis_order`` and ``targets`` cannot be used at the same time.\n If ``study.n_objectives`` is neither 2 nor 3, ``targets`` must be specified.\n\n .. note::\n Added in v3.0.0 as an experimental feature. The interface may change in newer\n versions without prior notice.\n See https://github.com/optuna/optuna/releases/tag/v3.0.0.\n\n Returns:\n A :class:`matplotlib.axes.Axes` object.\n \"\"\"\n\n _imports.check()\n\n info = _get_pareto_front_info(\n study, target_names, include_dominated_trials, axis_order, None, targets\n )\n\n if info.n_targets == 2:\n return _get_pareto_front_2d(info)\n elif info.n_targets == 3:\n return _get_pareto_front_3d(info)\n else:\n assert False, \"Must not reach here\"\n\n\ndef _get_pareto_front_2d(info: _ParetoFrontInfo) -> \"Axes\":\n # Set up the graph style.\n plt.style.use(\"ggplot\") # Use ggplot style sheet for similar outputs to plotly.\n _, ax = plt.subplots()\n ax.set_title(\"Pareto-front Plot\")\n cmap = plt.get_cmap(\"tab10\") # Use tab10 colormap for similar outputs to plotly.\n\n ax.set_xlabel(info.target_names[info.axis_order[0]])\n ax.set_ylabel(info.target_names[info.axis_order[1]])\n\n if info.non_best_trials_with_values is not None and len(info.non_best_trials_with_values) > 0:\n ax.scatter(\n x=[values[info.axis_order[0]] for _, values in info.non_best_trials_with_values],\n y=[values[info.axis_order[1]] for _, values in info.non_best_trials_with_values],\n color=cmap(0),\n label=\"Trial\",\n )\n if info.best_trials_with_values is not None and len(info.best_trials_with_values) > 0:\n ax.scatter(\n x=[values[info.axis_order[0]] for _, values in info.best_trials_with_values],\n y=[values[info.axis_order[1]] for _, values in info.best_trials_with_values],\n color=cmap(3),\n label=\"Best Trial\",\n )\n\n if info.non_best_trials_with_values is not None and ax.has_data():\n ax.legend()\n\n return ax\n\n\ndef _get_pareto_front_3d(info: _ParetoFrontInfo) -> \"Axes\":\n # Set up the graph style.\n plt.style.use(\"ggplot\") # Use ggplot style sheet for similar outputs to plotly.\n fig = plt.figure()\n ax = fig.add_subplot(projection=\"3d\")\n ax.set_title(\"Pareto-front Plot\")\n cmap = plt.get_cmap(\"tab10\") # Use tab10 colormap for similar outputs to plotly.\n\n ax.set_xlabel(info.target_names[info.axis_order[0]])\n ax.set_ylabel(info.target_names[info.axis_order[1]])\n ax.set_zlabel(info.target_names[info.axis_order[2]])\n\n if info.non_best_trials_with_values is not None and len(info.non_best_trials_with_values) > 0:\n ax.scatter(\n xs=[values[info.axis_order[0]] for _, values in info.non_best_trials_with_values],\n ys=[values[info.axis_order[1]] for _, values in info.non_best_trials_with_values],\n zs=[values[info.axis_order[2]] for _, values in info.non_best_trials_with_values],\n color=cmap(0),\n label=\"Trial\",\n )\n\n if info.best_trials_with_values is not None and len(info.best_trials_with_values):\n ax.scatter(\n xs=[values[info.axis_order[0]] for _, values in info.best_trials_with_values],\n ys=[values[info.axis_order[1]] for _, values in info.best_trials_with_values],\n zs=[values[info.axis_order[2]] for _, values in info.best_trials_with_values],\n color=cmap(3),\n label=\"Best Trial\",\n )\n\n if info.non_best_trials_with_values is not None and ax.has_data():\n ax.legend()\n\n return ax\n", "path": "optuna/visualization/matplotlib/_pareto_front.py"}], "after_files": [{"content": "from typing import Callable\nfrom typing import List\nfrom typing import Optional\nfrom typing import Sequence\n\nfrom optuna._experimental import experimental\nfrom optuna.study import Study\nfrom optuna.trial import FrozenTrial\nfrom optuna.visualization._pareto_front import _get_pareto_front_info\nfrom optuna.visualization._pareto_front import _ParetoFrontInfo\nfrom optuna.visualization.matplotlib._matplotlib_imports import _imports\n\n\nif _imports.is_successful():\n from optuna.visualization.matplotlib._matplotlib_imports import Axes\n from optuna.visualization.matplotlib._matplotlib_imports import plt\n\n\n@experimental(\"2.8.0\")\ndef plot_pareto_front(\n study: Study,\n *,\n target_names: Optional[List[str]] = None,\n include_dominated_trials: bool = True,\n axis_order: Optional[List[int]] = None,\n constraints_func: Optional[Callable[[FrozenTrial], Sequence[float]]] = None,\n targets: Optional[Callable[[FrozenTrial], Sequence[float]]] = None,\n) -> \"Axes\":\n \"\"\"Plot the Pareto front of a study.\n\n .. seealso::\n Please refer to :func:`optuna.visualization.plot_pareto_front` for an example.\n\n Example:\n\n The following code snippet shows how to plot the Pareto front of a study.\n\n .. plot::\n\n import optuna\n\n\n def objective(trial):\n x = trial.suggest_float(\"x\", 0, 5)\n y = trial.suggest_float(\"y\", 0, 3)\n\n v0 = 4 * x ** 2 + 4 * y ** 2\n v1 = (x - 5) ** 2 + (y - 5) ** 2\n return v0, v1\n\n\n study = optuna.create_study(directions=[\"minimize\", \"minimize\"])\n study.optimize(objective, n_trials=50)\n\n optuna.visualization.matplotlib.plot_pareto_front(study)\n\n Args:\n study:\n A :class:`~optuna.study.Study` object whose trials are plotted for their objective\n values. ``study.n_objectives`` must be either 2 or 3 when ``targets`` is :obj:`None`.\n target_names:\n Objective name list used as the axis titles. If :obj:`None` is specified,\n \"Objective {objective_index}\" is used instead. If ``targets`` is specified\n for a study that does not contain any completed trial,\n ``target_name`` must be specified.\n include_dominated_trials:\n A flag to include all dominated trial's objective values.\n axis_order:\n A list of indices indicating the axis order. If :obj:`None` is specified,\n default order is used. ``axis_order`` and ``targets`` cannot be used at the same time.\n\n .. warning::\n Deprecated in v3.0.0. This feature will be removed in the future. The removal of\n this feature is currently scheduled for v5.0.0, but this schedule is subject to\n change. See https://github.com/optuna/optuna/releases/tag/v3.0.0.\n constraints_func:\n An optional function that computes the objective constraints. It must take a\n :class:`~optuna.trial.FrozenTrial` and return the constraints. The return value must\n be a sequence of :obj:`float` s. A value strictly larger than 0 means that a\n constraint is violated. A value equal to or smaller than 0 is considered feasible.\n This specification is the same as in, for example,\n :class:`~optuna.integration.NSGAIISampler`.\n\n If given, trials are classified into three categories: feasible and best, feasible but\n non-best, and infeasible. Categories are shown in different colors. Here, whether a\n trial is best (on Pareto front) or not is determined ignoring all infeasible trials.\n targets:\n A function that returns a tuple of target values to display.\n The argument to this function is :class:`~optuna.trial.FrozenTrial`.\n ``targets`` must be :obj:`None` or return 2 or 3 values.\n ``axis_order`` and ``targets`` cannot be used at the same time.\n If ``study.n_objectives`` is neither 2 nor 3, ``targets`` must be specified.\n\n .. note::\n Added in v3.0.0 as an experimental feature. The interface may change in newer\n versions without prior notice.\n See https://github.com/optuna/optuna/releases/tag/v3.0.0.\n\n Returns:\n A :class:`matplotlib.axes.Axes` object.\n \"\"\"\n\n _imports.check()\n\n info = _get_pareto_front_info(\n study, target_names, include_dominated_trials, axis_order, constraints_func, targets\n )\n\n if info.n_targets == 2:\n return _get_pareto_front_2d(info)\n elif info.n_targets == 3:\n return _get_pareto_front_3d(info)\n else:\n assert False, \"Must not reach here\"\n\n\ndef _get_pareto_front_2d(info: _ParetoFrontInfo) -> \"Axes\":\n # Set up the graph style.\n plt.style.use(\"ggplot\") # Use ggplot style sheet for similar outputs to plotly.\n _, ax = plt.subplots()\n ax.set_title(\"Pareto-front Plot\")\n cmap = plt.get_cmap(\"tab10\") # Use tab10 colormap for similar outputs to plotly.\n\n ax.set_xlabel(info.target_names[info.axis_order[0]])\n ax.set_ylabel(info.target_names[info.axis_order[1]])\n\n if (\n info.infeasible_trials_with_values is not None\n and len(info.infeasible_trials_with_values) > 0\n ):\n ax.scatter(\n x=[values[info.axis_order[0]] for _, values in info.infeasible_trials_with_values],\n y=[values[info.axis_order[1]] for _, values in info.infeasible_trials_with_values],\n color=\"#cccccc\",\n label=\"Infeasible Trial\",\n )\n if info.non_best_trials_with_values is not None and len(info.non_best_trials_with_values) > 0:\n ax.scatter(\n x=[values[info.axis_order[0]] for _, values in info.non_best_trials_with_values],\n y=[values[info.axis_order[1]] for _, values in info.non_best_trials_with_values],\n color=cmap(0),\n label=\"Trial\",\n )\n if info.best_trials_with_values is not None and len(info.best_trials_with_values) > 0:\n ax.scatter(\n x=[values[info.axis_order[0]] for _, values in info.best_trials_with_values],\n y=[values[info.axis_order[1]] for _, values in info.best_trials_with_values],\n color=cmap(3),\n label=\"Best Trial\",\n )\n\n if info.non_best_trials_with_values is not None and ax.has_data():\n ax.legend()\n\n return ax\n\n\ndef _get_pareto_front_3d(info: _ParetoFrontInfo) -> \"Axes\":\n # Set up the graph style.\n plt.style.use(\"ggplot\") # Use ggplot style sheet for similar outputs to plotly.\n fig = plt.figure()\n ax = fig.add_subplot(projection=\"3d\")\n ax.set_title(\"Pareto-front Plot\")\n cmap = plt.get_cmap(\"tab10\") # Use tab10 colormap for similar outputs to plotly.\n\n ax.set_xlabel(info.target_names[info.axis_order[0]])\n ax.set_ylabel(info.target_names[info.axis_order[1]])\n ax.set_zlabel(info.target_names[info.axis_order[2]])\n\n if (\n info.infeasible_trials_with_values is not None\n and len(info.infeasible_trials_with_values) > 0\n ):\n ax.scatter(\n xs=[values[info.axis_order[0]] for _, values in info.infeasible_trials_with_values],\n ys=[values[info.axis_order[1]] for _, values in info.infeasible_trials_with_values],\n zs=[values[info.axis_order[2]] for _, values in info.infeasible_trials_with_values],\n color=\"#cccccc\",\n label=\"Infeasible Trial\",\n )\n\n if info.non_best_trials_with_values is not None and len(info.non_best_trials_with_values) > 0:\n ax.scatter(\n xs=[values[info.axis_order[0]] for _, values in info.non_best_trials_with_values],\n ys=[values[info.axis_order[1]] for _, values in info.non_best_trials_with_values],\n zs=[values[info.axis_order[2]] for _, values in info.non_best_trials_with_values],\n color=cmap(0),\n label=\"Trial\",\n )\n\n if info.best_trials_with_values is not None and len(info.best_trials_with_values):\n ax.scatter(\n xs=[values[info.axis_order[0]] for _, values in info.best_trials_with_values],\n ys=[values[info.axis_order[1]] for _, values in info.best_trials_with_values],\n zs=[values[info.axis_order[2]] for _, values in info.best_trials_with_values],\n color=cmap(3),\n label=\"Best Trial\",\n )\n\n if info.non_best_trials_with_values is not None and ax.has_data():\n ax.legend()\n\n return ax\n", "path": "optuna/visualization/matplotlib/_pareto_front.py"}]}
| 2,730 | 953 |
gh_patches_debug_17612
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-6739
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Poundland spider returning Pep&Co only stores as both Poundland and Pep&Co
Poundland has a clothing brand called "Pep&Co", and typically their larger stores have a "Pep&Co" area inside, looking a bit like a concession in a department store. In their storefinder data, these stores are indicated by a "Pep Shop" flag. The ATP poundland.py spider looks for this, and when it's found generates an additional "Pep&Co" store item in addition to the "Poundland" one.
So far so good. However, it appears that there are also a few (about 14) "Pep&Co" stores that aren't also regular Poundland stores. For example, these can occur in shopping centres, where Poundland is renting two nearby units and using one as a regular Poundland store (without Pep&Co) and the other as a Pep&Co only store. Currently ATP is returning a "Poundland" entry for the "Pep&Co" only store. Since there's a separate entry in the storefinder for the actual Poundland store, this leads to duplicates.
Here's an example mapped in OSM:
Poundland - https://www.openstreetmap.org/node/11293224534 - CV21 2JT
Pep&Co - https://www.openstreetmap.org/node/11293224520 - CV21 2JS
Another (unmapped example) is two stores with postcode TS8 0TJ.
I think these "Pep&Co" only stores can be detected by the branch name (stored in item["branch"]) starting with "Pep & Co". I guess we should test for this, and then not yield the final item if it's found. (In case there's any inconsistency in their data, it would probably be good to add the same test to the` if "Pep Shop" in ` line as an alternative. This would ensure that we don't completely drop a branch who's name starts with "Pep&Co" but doesn't have the "Pep shop" flag set.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `locations/spiders/poundland.py`
Content:
```
1 from locations.categories import Extras, apply_yes_no
2 from locations.items import Feature
3 from locations.storefinders.woosmap import WoosmapSpider
4
5
6 class PoundlandSpider(WoosmapSpider):
7 name = "poundland"
8 item_attributes = {"brand": "Poundland", "brand_wikidata": "Q1434528"}
9 key = "woos-4108db5c-39f8-360b-9b7e-102c38034b94"
10 origin = "https://www.poundland.co.uk"
11
12 def parse_item(self, item: Feature, feature: dict, **kwargs):
13 item["branch"] = item.pop("name")
14
15 if "Pep Shop" in feature["properties"]["tags"]:
16 pep = item.deepcopy()
17
18 pep["ref"] = pep["ref"] + "_pep"
19
20 pep["brand"] = "Pep&Co"
21 pep["brand_wikidata"] = "Q24908166"
22
23 pep["located_in"] = self.item_attributes["brand"]
24 pep["located_in_wikidata"] = self.item_attributes["brand_wikidata"]
25
26 yield pep
27
28 apply_yes_no(Extras.ATM, item, "ATM" in feature["properties"]["tags"])
29 item["extras"]["icestore"] = "yes" if "Ice Store" in feature["properties"]["tags"] else "no"
30
31 yield item
32
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/locations/spiders/poundland.py b/locations/spiders/poundland.py
--- a/locations/spiders/poundland.py
+++ b/locations/spiders/poundland.py
@@ -12,7 +12,7 @@
def parse_item(self, item: Feature, feature: dict, **kwargs):
item["branch"] = item.pop("name")
- if "Pep Shop" in feature["properties"]["tags"]:
+ if "Pep Shop" in feature["properties"]["tags"] or item["branch"].startswith("Pep & Co "):
pep = item.deepcopy()
pep["ref"] = pep["ref"] + "_pep"
@@ -25,6 +25,9 @@
yield pep
+ if item["branch"].startswith("Pep & Co "):
+ return
+
apply_yes_no(Extras.ATM, item, "ATM" in feature["properties"]["tags"])
item["extras"]["icestore"] = "yes" if "Ice Store" in feature["properties"]["tags"] else "no"
|
{"golden_diff": "diff --git a/locations/spiders/poundland.py b/locations/spiders/poundland.py\n--- a/locations/spiders/poundland.py\n+++ b/locations/spiders/poundland.py\n@@ -12,7 +12,7 @@\n def parse_item(self, item: Feature, feature: dict, **kwargs):\n item[\"branch\"] = item.pop(\"name\")\n \n- if \"Pep Shop\" in feature[\"properties\"][\"tags\"]:\n+ if \"Pep Shop\" in feature[\"properties\"][\"tags\"] or item[\"branch\"].startswith(\"Pep & Co \"):\n pep = item.deepcopy()\n \n pep[\"ref\"] = pep[\"ref\"] + \"_pep\"\n@@ -25,6 +25,9 @@\n \n yield pep\n \n+ if item[\"branch\"].startswith(\"Pep & Co \"):\n+ return\n+\n apply_yes_no(Extras.ATM, item, \"ATM\" in feature[\"properties\"][\"tags\"])\n item[\"extras\"][\"icestore\"] = \"yes\" if \"Ice Store\" in feature[\"properties\"][\"tags\"] else \"no\"\n", "issue": "Poundland spider returning Pep&Co only stores as both Poundland and Pep&Co\nPoundland has a clothing brand called \"Pep&Co\", and typically their larger stores have a \"Pep&Co\" area inside, looking a bit like a concession in a department store. In their storefinder data, these stores are indicated by a \"Pep Shop\" flag. The ATP poundland.py spider looks for this, and when it's found generates an additional \"Pep&Co\" store item in addition to the \"Poundland\" one.\r\n\r\nSo far so good. However, it appears that there are also a few (about 14) \"Pep&Co\" stores that aren't also regular Poundland stores. For example, these can occur in shopping centres, where Poundland is renting two nearby units and using one as a regular Poundland store (without Pep&Co) and the other as a Pep&Co only store. Currently ATP is returning a \"Poundland\" entry for the \"Pep&Co\" only store. Since there's a separate entry in the storefinder for the actual Poundland store, this leads to duplicates.\r\n\r\nHere's an example mapped in OSM:\r\nPoundland - https://www.openstreetmap.org/node/11293224534 - CV21 2JT\r\nPep&Co - https://www.openstreetmap.org/node/11293224520 - CV21 2JS\r\n\r\nAnother (unmapped example) is two stores with postcode TS8 0TJ.\r\n\r\nI think these \"Pep&Co\" only stores can be detected by the branch name (stored in item[\"branch\"]) starting with \"Pep & Co\". I guess we should test for this, and then not yield the final item if it's found. (In case there's any inconsistency in their data, it would probably be good to add the same test to the` if \"Pep Shop\" in ` line as an alternative. This would ensure that we don't completely drop a branch who's name starts with \"Pep&Co\" but doesn't have the \"Pep shop\" flag set.\n", "before_files": [{"content": "from locations.categories import Extras, apply_yes_no\nfrom locations.items import Feature\nfrom locations.storefinders.woosmap import WoosmapSpider\n\n\nclass PoundlandSpider(WoosmapSpider):\n name = \"poundland\"\n item_attributes = {\"brand\": \"Poundland\", \"brand_wikidata\": \"Q1434528\"}\n key = \"woos-4108db5c-39f8-360b-9b7e-102c38034b94\"\n origin = \"https://www.poundland.co.uk\"\n\n def parse_item(self, item: Feature, feature: dict, **kwargs):\n item[\"branch\"] = item.pop(\"name\")\n\n if \"Pep Shop\" in feature[\"properties\"][\"tags\"]:\n pep = item.deepcopy()\n\n pep[\"ref\"] = pep[\"ref\"] + \"_pep\"\n\n pep[\"brand\"] = \"Pep&Co\"\n pep[\"brand_wikidata\"] = \"Q24908166\"\n\n pep[\"located_in\"] = self.item_attributes[\"brand\"]\n pep[\"located_in_wikidata\"] = self.item_attributes[\"brand_wikidata\"]\n\n yield pep\n\n apply_yes_no(Extras.ATM, item, \"ATM\" in feature[\"properties\"][\"tags\"])\n item[\"extras\"][\"icestore\"] = \"yes\" if \"Ice Store\" in feature[\"properties\"][\"tags\"] else \"no\"\n\n yield item\n", "path": "locations/spiders/poundland.py"}], "after_files": [{"content": "from locations.categories import Extras, apply_yes_no\nfrom locations.items import Feature\nfrom locations.storefinders.woosmap import WoosmapSpider\n\n\nclass PoundlandSpider(WoosmapSpider):\n name = \"poundland\"\n item_attributes = {\"brand\": \"Poundland\", \"brand_wikidata\": \"Q1434528\"}\n key = \"woos-4108db5c-39f8-360b-9b7e-102c38034b94\"\n origin = \"https://www.poundland.co.uk\"\n\n def parse_item(self, item: Feature, feature: dict, **kwargs):\n item[\"branch\"] = item.pop(\"name\")\n\n if \"Pep Shop\" in feature[\"properties\"][\"tags\"] or item[\"branch\"].startswith(\"Pep & Co \"):\n pep = item.deepcopy()\n\n pep[\"ref\"] = pep[\"ref\"] + \"_pep\"\n\n pep[\"brand\"] = \"Pep&Co\"\n pep[\"brand_wikidata\"] = \"Q24908166\"\n\n pep[\"located_in\"] = self.item_attributes[\"brand\"]\n pep[\"located_in_wikidata\"] = self.item_attributes[\"brand_wikidata\"]\n\n yield pep\n\n if item[\"branch\"].startswith(\"Pep & Co \"):\n return\n\n apply_yes_no(Extras.ATM, item, \"ATM\" in feature[\"properties\"][\"tags\"])\n item[\"extras\"][\"icestore\"] = \"yes\" if \"Ice Store\" in feature[\"properties\"][\"tags\"] else \"no\"\n\n yield item\n", "path": "locations/spiders/poundland.py"}]}
| 1,106 | 239 |
gh_patches_debug_8907
|
rasdani/github-patches
|
git_diff
|
pymedusa__Medusa-1035
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
FINDSUBTITLES :: [3824246] Failed to refine video Traceback (most recent call last)
### Before submitting your issue:
Enable debug logging in SickRage settings, reproduce the error (be sure to disable after the bug is fixed)
Branch/Commit: develop/3824246
OS: Linux
What you did: nothing
What happened: ~~rato appeared~~ warning
What you expected: no warning
Logs:
```
2016-09-05 17:55:06 WARNING FINDSUBTITLES :: [3824246] Failed to refine video
Traceback (most recent call last):
File "/home/**********/.sickrage/lib/subliminal/core.py", line 543, in refine
refiner_manager[refiner].plugin(video, **kwargs)
File "/home/**********/.sickrage/sickbeard/refiners/tvepisode.py", line 62, in refine
enrich({'resolution': guess['screen_size'], 'format': guess['format']}, video, overwrite=False)
KeyError: u'screen_size'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sickbeard/refiners/tvepisode.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 """TVEpisode refiner."""
3 from __future__ import unicode_literals
4
5 import logging
6 import re
7
8 from subliminal.video import Episode
9
10 from ..common import Quality
11
12 logger = logging.getLogger(__name__)
13
14 SHOW_MAPPING = {
15 'series_tvdb_id': 'tvdb_id',
16 'series_imdb_id': 'imdbid',
17 'year': 'startyear'
18 }
19
20 EPISODE_MAPPING = {
21 'tvdb_id': 'tvdb_id',
22 'episode': 'episode',
23 'season': 'season',
24 'size': 'file_size',
25 'title': 'name',
26 }
27
28 series_re = re.compile(r'^(?P<series>.*?)(?: \((?:(?P<year>\d{4})|(?P<country>[A-Z]{2}))\))?$')
29
30
31 def refine(video, tv_episode=None, **kwargs):
32 """Refine a video by using TVEpisode information.
33
34 :param video: the video to refine.
35 :type video: Episode
36 :param tv_episode: the TVEpisode to be used.
37 :type tv_episode: sickbeard.tv.TVEpisode
38 :param kwargs:
39 """
40 if video.series_tvdb_id and video.tvdb_id:
41 logger.debug('No need to refine with TVEpisode')
42 return
43
44 if not tv_episode:
45 logger.debug('No TVEpisode to be used to refine')
46 return
47
48 if not isinstance(video, Episode):
49 logger.debug('Video {name} is not an episode. Skipping refiner...', name=video.name)
50 return
51
52 if tv_episode.show:
53 logger.debug('Refining using TVShow information.')
54 series, year, country = series_re.match(tv_episode.show.name).groups()
55 enrich({'series': series, 'year': int(year) if year else None}, video)
56 enrich(SHOW_MAPPING, video, tv_episode.show)
57
58 logger.debug('Refining using TVEpisode information.')
59 enrich(EPISODE_MAPPING, video, tv_episode)
60 enrich({'release_group': tv_episode.release_group}, video, overwrite=False)
61 guess = Quality.to_guessit(tv_episode.status)
62 enrich({'resolution': guess['screen_size'], 'format': guess['format']}, video, overwrite=False)
63
64
65 def enrich(attributes, target, source=None, overwrite=True):
66 """Copy attributes from source to target.
67
68 :param attributes: the attributes mapping
69 :type attributes: dict(str -> str)
70 :param target: the target object
71 :param source: the source object. If None, the value in attributes dict will be used as new_value
72 :param overwrite: if source field should be overwritten if not already set
73 :type overwrite: bool
74 """
75 for key, value in attributes.items():
76 old_value = getattr(target, key)
77 if old_value and not overwrite:
78 continue
79
80 new_value = getattr(source, value) if source else value
81
82 if new_value and old_value != new_value:
83 setattr(target, key, new_value)
84 logger.debug('Attribute {key} changed from {old} to {new}', key=key, old=old_value, new=new_value)
85
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sickbeard/refiners/tvepisode.py b/sickbeard/refiners/tvepisode.py
--- a/sickbeard/refiners/tvepisode.py
+++ b/sickbeard/refiners/tvepisode.py
@@ -59,7 +59,7 @@
enrich(EPISODE_MAPPING, video, tv_episode)
enrich({'release_group': tv_episode.release_group}, video, overwrite=False)
guess = Quality.to_guessit(tv_episode.status)
- enrich({'resolution': guess['screen_size'], 'format': guess['format']}, video, overwrite=False)
+ enrich({'resolution': guess.get('screen_size'), 'format': guess.get('format')}, video, overwrite=False)
def enrich(attributes, target, source=None, overwrite=True):
|
{"golden_diff": "diff --git a/sickbeard/refiners/tvepisode.py b/sickbeard/refiners/tvepisode.py\n--- a/sickbeard/refiners/tvepisode.py\n+++ b/sickbeard/refiners/tvepisode.py\n@@ -59,7 +59,7 @@\n enrich(EPISODE_MAPPING, video, tv_episode)\n enrich({'release_group': tv_episode.release_group}, video, overwrite=False)\n guess = Quality.to_guessit(tv_episode.status)\n- enrich({'resolution': guess['screen_size'], 'format': guess['format']}, video, overwrite=False)\n+ enrich({'resolution': guess.get('screen_size'), 'format': guess.get('format')}, video, overwrite=False)\n \n \n def enrich(attributes, target, source=None, overwrite=True):\n", "issue": "FINDSUBTITLES :: [3824246] Failed to refine video Traceback (most recent call last)\n### Before submitting your issue:\n\nEnable debug logging in SickRage settings, reproduce the error (be sure to disable after the bug is fixed)\n\nBranch/Commit: develop/3824246\nOS: Linux\nWhat you did: nothing\nWhat happened: ~~rato appeared~~ warning\nWhat you expected: no warning\nLogs:\n\n```\n2016-09-05 17:55:06 WARNING FINDSUBTITLES :: [3824246] Failed to refine video\nTraceback (most recent call last):\n File \"/home/**********/.sickrage/lib/subliminal/core.py\", line 543, in refine\n refiner_manager[refiner].plugin(video, **kwargs)\n File \"/home/**********/.sickrage/sickbeard/refiners/tvepisode.py\", line 62, in refine\n enrich({'resolution': guess['screen_size'], 'format': guess['format']}, video, overwrite=False)\nKeyError: u'screen_size'\n```\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"TVEpisode refiner.\"\"\"\nfrom __future__ import unicode_literals\n\nimport logging\nimport re\n\nfrom subliminal.video import Episode\n\nfrom ..common import Quality\n\nlogger = logging.getLogger(__name__)\n\nSHOW_MAPPING = {\n 'series_tvdb_id': 'tvdb_id',\n 'series_imdb_id': 'imdbid',\n 'year': 'startyear'\n}\n\nEPISODE_MAPPING = {\n 'tvdb_id': 'tvdb_id',\n 'episode': 'episode',\n 'season': 'season',\n 'size': 'file_size',\n 'title': 'name',\n}\n\nseries_re = re.compile(r'^(?P<series>.*?)(?: \\((?:(?P<year>\\d{4})|(?P<country>[A-Z]{2}))\\))?$')\n\n\ndef refine(video, tv_episode=None, **kwargs):\n \"\"\"Refine a video by using TVEpisode information.\n\n :param video: the video to refine.\n :type video: Episode\n :param tv_episode: the TVEpisode to be used.\n :type tv_episode: sickbeard.tv.TVEpisode\n :param kwargs:\n \"\"\"\n if video.series_tvdb_id and video.tvdb_id:\n logger.debug('No need to refine with TVEpisode')\n return\n\n if not tv_episode:\n logger.debug('No TVEpisode to be used to refine')\n return\n\n if not isinstance(video, Episode):\n logger.debug('Video {name} is not an episode. Skipping refiner...', name=video.name)\n return\n\n if tv_episode.show:\n logger.debug('Refining using TVShow information.')\n series, year, country = series_re.match(tv_episode.show.name).groups()\n enrich({'series': series, 'year': int(year) if year else None}, video)\n enrich(SHOW_MAPPING, video, tv_episode.show)\n\n logger.debug('Refining using TVEpisode information.')\n enrich(EPISODE_MAPPING, video, tv_episode)\n enrich({'release_group': tv_episode.release_group}, video, overwrite=False)\n guess = Quality.to_guessit(tv_episode.status)\n enrich({'resolution': guess['screen_size'], 'format': guess['format']}, video, overwrite=False)\n\n\ndef enrich(attributes, target, source=None, overwrite=True):\n \"\"\"Copy attributes from source to target.\n\n :param attributes: the attributes mapping\n :type attributes: dict(str -> str)\n :param target: the target object\n :param source: the source object. If None, the value in attributes dict will be used as new_value\n :param overwrite: if source field should be overwritten if not already set\n :type overwrite: bool\n \"\"\"\n for key, value in attributes.items():\n old_value = getattr(target, key)\n if old_value and not overwrite:\n continue\n\n new_value = getattr(source, value) if source else value\n\n if new_value and old_value != new_value:\n setattr(target, key, new_value)\n logger.debug('Attribute {key} changed from {old} to {new}', key=key, old=old_value, new=new_value)\n", "path": "sickbeard/refiners/tvepisode.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"TVEpisode refiner.\"\"\"\nfrom __future__ import unicode_literals\n\nimport logging\nimport re\n\nfrom subliminal.video import Episode\n\nfrom ..common import Quality\n\nlogger = logging.getLogger(__name__)\n\nSHOW_MAPPING = {\n 'series_tvdb_id': 'tvdb_id',\n 'series_imdb_id': 'imdbid',\n 'year': 'startyear'\n}\n\nEPISODE_MAPPING = {\n 'tvdb_id': 'tvdb_id',\n 'episode': 'episode',\n 'season': 'season',\n 'size': 'file_size',\n 'title': 'name',\n}\n\nseries_re = re.compile(r'^(?P<series>.*?)(?: \\((?:(?P<year>\\d{4})|(?P<country>[A-Z]{2}))\\))?$')\n\n\ndef refine(video, tv_episode=None, **kwargs):\n \"\"\"Refine a video by using TVEpisode information.\n\n :param video: the video to refine.\n :type video: Episode\n :param tv_episode: the TVEpisode to be used.\n :type tv_episode: sickbeard.tv.TVEpisode\n :param kwargs:\n \"\"\"\n if video.series_tvdb_id and video.tvdb_id:\n logger.debug('No need to refine with TVEpisode')\n return\n\n if not tv_episode:\n logger.debug('No TVEpisode to be used to refine')\n return\n\n if not isinstance(video, Episode):\n logger.debug('Video {name} is not an episode. Skipping refiner...', name=video.name)\n return\n\n if tv_episode.show:\n logger.debug('Refining using TVShow information.')\n series, year, country = series_re.match(tv_episode.show.name).groups()\n enrich({'series': series, 'year': int(year) if year else None}, video)\n enrich(SHOW_MAPPING, video, tv_episode.show)\n\n logger.debug('Refining using TVEpisode information.')\n enrich(EPISODE_MAPPING, video, tv_episode)\n enrich({'release_group': tv_episode.release_group}, video, overwrite=False)\n guess = Quality.to_guessit(tv_episode.status)\n enrich({'resolution': guess.get('screen_size'), 'format': guess.get('format')}, video, overwrite=False)\n\n\ndef enrich(attributes, target, source=None, overwrite=True):\n \"\"\"Copy attributes from source to target.\n\n :param attributes: the attributes mapping\n :type attributes: dict(str -> str)\n :param target: the target object\n :param source: the source object. If None, the value in attributes dict will be used as new_value\n :param overwrite: if source field should be overwritten if not already set\n :type overwrite: bool\n \"\"\"\n for key, value in attributes.items():\n old_value = getattr(target, key)\n if old_value and not overwrite:\n continue\n\n new_value = getattr(source, value) if source else value\n\n if new_value and old_value != new_value:\n setattr(target, key, new_value)\n logger.debug('Attribute {key} changed from {old} to {new}', key=key, old=old_value, new=new_value)\n", "path": "sickbeard/refiners/tvepisode.py"}]}
| 1,375 | 170 |
gh_patches_debug_29166
|
rasdani/github-patches
|
git_diff
|
svthalia__concrexit-1870
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add cancelled registrations to event in api v2
### Is your feature request related to a problem? Please describe.
API v2 doesn't return a cancelled registration when you've cancelled a registration (in the event serializer). So we cannot display stuff like 'Your registration is cancelled (after the deadline)'.
### Describe the solution you'd like
Also return a registration if it's cancelled, and include fields like is_cancelled, is_late_cancellation, etc.
### Motivation
This makes it possible to show nice status texts like in the old app and the website.
### Describe alternatives you've considered
Leaving out the messages for cancelled registrations. In that case, you can only see that there is no register button, but not why.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `website/events/api/v2/serializers/event_registration.py`
Content:
```
1 from rest_framework import serializers
2
3 from events.models import EventRegistration
4 from members.api.v2.serializers.member import MemberSerializer
5 from payments.api.v2.serializers import PaymentSerializer
6
7
8 class EventRegistrationSerializer(serializers.ModelSerializer):
9 """Serializer for event registrations."""
10
11 def __init__(self, *args, **kwargs):
12 # Don't pass the 'fields' arg up to the superclass
13 fields = kwargs.pop("fields", {"pk", "member", "name"})
14
15 # Instantiate the superclass normally
16 super().__init__(*args, **kwargs)
17
18 allowed = set(fields)
19 existing = set(self.fields.keys())
20 for field_name in existing - allowed:
21 self.fields.pop(field_name)
22
23 class Meta:
24 model = EventRegistration
25 fields = (
26 "pk",
27 "present",
28 "queue_position",
29 "date",
30 "payment",
31 "member",
32 "name",
33 )
34
35 payment = PaymentSerializer()
36 member = MemberSerializer(detailed=False, read_only=True)
37
```
Path: `website/events/api/v2/serializers/event.py`
Content:
```
1 from rest_framework import serializers
2
3 from activemembers.api.v2.serializers.member_group import MemberGroupSerializer
4 from announcements.api.v2.serializers import SlideSerializer
5 from documents.api.v2.serializers.document import DocumentSerializer
6 from events import services
7 from events.api.v2.serializers.event_registration import EventRegistrationSerializer
8 from events.models import Event, EventRegistration
9 from thaliawebsite.api.v2.serializers import CleanedHTMLSerializer
10 from utils.snippets import create_google_maps_url
11
12
13 class EventSerializer(serializers.ModelSerializer):
14 """Serializer for events."""
15
16 class Meta:
17 model = Event
18 fields = (
19 "pk",
20 "title",
21 "description",
22 "start",
23 "end",
24 "category",
25 "registration_start",
26 "registration_end",
27 "cancel_deadline",
28 "optional_registrations",
29 "location",
30 "price",
31 "fine",
32 "num_participants",
33 "max_participants",
34 "no_registration_message",
35 "cancel_too_late_message",
36 "has_fields",
37 "food_event",
38 "maps_url",
39 "user_permissions",
40 "user_registration",
41 "organiser",
42 "slide",
43 "documents",
44 )
45
46 description = CleanedHTMLSerializer()
47 organiser = MemberGroupSerializer()
48 user_registration = serializers.SerializerMethodField("_user_registration")
49 num_participants = serializers.SerializerMethodField("_num_participants")
50 maps_url = serializers.SerializerMethodField("_maps_url")
51 price = serializers.DecimalField(max_digits=5, decimal_places=2)
52 fine = serializers.DecimalField(max_digits=5, decimal_places=2)
53 slide = SlideSerializer()
54 documents = DocumentSerializer(many=True)
55 user_permissions = serializers.SerializerMethodField("_user_permissions")
56
57 def _user_registration(self, instance):
58 try:
59 if self.context["request"].member:
60 reg = instance.eventregistration_set.get(
61 member=self.context["request"].member, date_cancelled=None
62 )
63 return EventRegistrationSerializer(
64 reg,
65 context=self.context,
66 fields=("pk", "present", "queue_position", "date", "payment"),
67 ).data
68 except EventRegistration.DoesNotExist:
69 pass
70 return None
71
72 def _num_participants(self, instance):
73 if (
74 instance.max_participants
75 and instance.participants.count() > instance.max_participants
76 ):
77 return instance.max_participants
78 return instance.participants.count()
79
80 def _user_permissions(self, instance):
81 member = self.context["request"].member
82 return services.event_permissions(member, instance)
83
84 def _maps_url(self, instance):
85 return create_google_maps_url(instance.map_location, zoom=13, size="450x250")
86
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/website/events/api/v2/serializers/event.py b/website/events/api/v2/serializers/event.py
--- a/website/events/api/v2/serializers/event.py
+++ b/website/events/api/v2/serializers/event.py
@@ -58,12 +58,20 @@
try:
if self.context["request"].member:
reg = instance.eventregistration_set.get(
- member=self.context["request"].member, date_cancelled=None
+ member=self.context["request"].member
)
return EventRegistrationSerializer(
reg,
context=self.context,
- fields=("pk", "present", "queue_position", "date", "payment"),
+ fields=(
+ "pk",
+ "present",
+ "queue_position",
+ "is_cancelled",
+ "is_late_cancellation",
+ "date",
+ "payment",
+ ),
).data
except EventRegistration.DoesNotExist:
pass
diff --git a/website/events/api/v2/serializers/event_registration.py b/website/events/api/v2/serializers/event_registration.py
--- a/website/events/api/v2/serializers/event_registration.py
+++ b/website/events/api/v2/serializers/event_registration.py
@@ -34,3 +34,16 @@
payment = PaymentSerializer()
member = MemberSerializer(detailed=False, read_only=True)
+ is_cancelled = serializers.SerializerMethodField("_is_cancelled")
+ is_late_cancellation = serializers.SerializerMethodField("_is_late_cancellation")
+ queue_position = serializers.SerializerMethodField("_queue_position")
+
+ def _is_late_cancellation(self, instance):
+ return instance.is_late_cancellation()
+
+ def _queue_position(self, instance):
+ pos = instance.queue_position
+ return pos if pos and pos > 0 else None
+
+ def _is_cancelled(self, instance):
+ return instance.date_cancelled is not None
|
{"golden_diff": "diff --git a/website/events/api/v2/serializers/event.py b/website/events/api/v2/serializers/event.py\n--- a/website/events/api/v2/serializers/event.py\n+++ b/website/events/api/v2/serializers/event.py\n@@ -58,12 +58,20 @@\n try:\n if self.context[\"request\"].member:\n reg = instance.eventregistration_set.get(\n- member=self.context[\"request\"].member, date_cancelled=None\n+ member=self.context[\"request\"].member\n )\n return EventRegistrationSerializer(\n reg,\n context=self.context,\n- fields=(\"pk\", \"present\", \"queue_position\", \"date\", \"payment\"),\n+ fields=(\n+ \"pk\",\n+ \"present\",\n+ \"queue_position\",\n+ \"is_cancelled\",\n+ \"is_late_cancellation\",\n+ \"date\",\n+ \"payment\",\n+ ),\n ).data\n except EventRegistration.DoesNotExist:\n pass\ndiff --git a/website/events/api/v2/serializers/event_registration.py b/website/events/api/v2/serializers/event_registration.py\n--- a/website/events/api/v2/serializers/event_registration.py\n+++ b/website/events/api/v2/serializers/event_registration.py\n@@ -34,3 +34,16 @@\n \n payment = PaymentSerializer()\n member = MemberSerializer(detailed=False, read_only=True)\n+ is_cancelled = serializers.SerializerMethodField(\"_is_cancelled\")\n+ is_late_cancellation = serializers.SerializerMethodField(\"_is_late_cancellation\")\n+ queue_position = serializers.SerializerMethodField(\"_queue_position\")\n+\n+ def _is_late_cancellation(self, instance):\n+ return instance.is_late_cancellation()\n+\n+ def _queue_position(self, instance):\n+ pos = instance.queue_position\n+ return pos if pos and pos > 0 else None\n+\n+ def _is_cancelled(self, instance):\n+ return instance.date_cancelled is not None\n", "issue": "Add cancelled registrations to event in api v2\n### Is your feature request related to a problem? Please describe.\r\nAPI v2 doesn't return a cancelled registration when you've cancelled a registration (in the event serializer). So we cannot display stuff like 'Your registration is cancelled (after the deadline)'.\r\n\r\n### Describe the solution you'd like\r\nAlso return a registration if it's cancelled, and include fields like is_cancelled, is_late_cancellation, etc.\r\n\r\n### Motivation\r\nThis makes it possible to show nice status texts like in the old app and the website.\r\n\r\n### Describe alternatives you've considered\r\nLeaving out the messages for cancelled registrations. In that case, you can only see that there is no register button, but not why.\r\n\n", "before_files": [{"content": "from rest_framework import serializers\n\nfrom events.models import EventRegistration\nfrom members.api.v2.serializers.member import MemberSerializer\nfrom payments.api.v2.serializers import PaymentSerializer\n\n\nclass EventRegistrationSerializer(serializers.ModelSerializer):\n \"\"\"Serializer for event registrations.\"\"\"\n\n def __init__(self, *args, **kwargs):\n # Don't pass the 'fields' arg up to the superclass\n fields = kwargs.pop(\"fields\", {\"pk\", \"member\", \"name\"})\n\n # Instantiate the superclass normally\n super().__init__(*args, **kwargs)\n\n allowed = set(fields)\n existing = set(self.fields.keys())\n for field_name in existing - allowed:\n self.fields.pop(field_name)\n\n class Meta:\n model = EventRegistration\n fields = (\n \"pk\",\n \"present\",\n \"queue_position\",\n \"date\",\n \"payment\",\n \"member\",\n \"name\",\n )\n\n payment = PaymentSerializer()\n member = MemberSerializer(detailed=False, read_only=True)\n", "path": "website/events/api/v2/serializers/event_registration.py"}, {"content": "from rest_framework import serializers\n\nfrom activemembers.api.v2.serializers.member_group import MemberGroupSerializer\nfrom announcements.api.v2.serializers import SlideSerializer\nfrom documents.api.v2.serializers.document import DocumentSerializer\nfrom events import services\nfrom events.api.v2.serializers.event_registration import EventRegistrationSerializer\nfrom events.models import Event, EventRegistration\nfrom thaliawebsite.api.v2.serializers import CleanedHTMLSerializer\nfrom utils.snippets import create_google_maps_url\n\n\nclass EventSerializer(serializers.ModelSerializer):\n \"\"\"Serializer for events.\"\"\"\n\n class Meta:\n model = Event\n fields = (\n \"pk\",\n \"title\",\n \"description\",\n \"start\",\n \"end\",\n \"category\",\n \"registration_start\",\n \"registration_end\",\n \"cancel_deadline\",\n \"optional_registrations\",\n \"location\",\n \"price\",\n \"fine\",\n \"num_participants\",\n \"max_participants\",\n \"no_registration_message\",\n \"cancel_too_late_message\",\n \"has_fields\",\n \"food_event\",\n \"maps_url\",\n \"user_permissions\",\n \"user_registration\",\n \"organiser\",\n \"slide\",\n \"documents\",\n )\n\n description = CleanedHTMLSerializer()\n organiser = MemberGroupSerializer()\n user_registration = serializers.SerializerMethodField(\"_user_registration\")\n num_participants = serializers.SerializerMethodField(\"_num_participants\")\n maps_url = serializers.SerializerMethodField(\"_maps_url\")\n price = serializers.DecimalField(max_digits=5, decimal_places=2)\n fine = serializers.DecimalField(max_digits=5, decimal_places=2)\n slide = SlideSerializer()\n documents = DocumentSerializer(many=True)\n user_permissions = serializers.SerializerMethodField(\"_user_permissions\")\n\n def _user_registration(self, instance):\n try:\n if self.context[\"request\"].member:\n reg = instance.eventregistration_set.get(\n member=self.context[\"request\"].member, date_cancelled=None\n )\n return EventRegistrationSerializer(\n reg,\n context=self.context,\n fields=(\"pk\", \"present\", \"queue_position\", \"date\", \"payment\"),\n ).data\n except EventRegistration.DoesNotExist:\n pass\n return None\n\n def _num_participants(self, instance):\n if (\n instance.max_participants\n and instance.participants.count() > instance.max_participants\n ):\n return instance.max_participants\n return instance.participants.count()\n\n def _user_permissions(self, instance):\n member = self.context[\"request\"].member\n return services.event_permissions(member, instance)\n\n def _maps_url(self, instance):\n return create_google_maps_url(instance.map_location, zoom=13, size=\"450x250\")\n", "path": "website/events/api/v2/serializers/event.py"}], "after_files": [{"content": "from rest_framework import serializers\n\nfrom events.models import EventRegistration\nfrom members.api.v2.serializers.member import MemberSerializer\nfrom payments.api.v2.serializers import PaymentSerializer\n\n\nclass EventRegistrationSerializer(serializers.ModelSerializer):\n \"\"\"Serializer for event registrations.\"\"\"\n\n def __init__(self, *args, **kwargs):\n # Don't pass the 'fields' arg up to the superclass\n fields = kwargs.pop(\"fields\", {\"pk\", \"member\", \"name\"})\n\n # Instantiate the superclass normally\n super().__init__(*args, **kwargs)\n\n allowed = set(fields)\n existing = set(self.fields.keys())\n for field_name in existing - allowed:\n self.fields.pop(field_name)\n\n class Meta:\n model = EventRegistration\n fields = (\n \"pk\",\n \"present\",\n \"queue_position\",\n \"date\",\n \"payment\",\n \"member\",\n \"name\",\n )\n\n payment = PaymentSerializer()\n member = MemberSerializer(detailed=False, read_only=True)\n is_cancelled = serializers.SerializerMethodField(\"_is_cancelled\")\n is_late_cancellation = serializers.SerializerMethodField(\"_is_late_cancellation\")\n queue_position = serializers.SerializerMethodField(\"_queue_position\")\n\n def _is_late_cancellation(self, instance):\n return instance.is_late_cancellation()\n\n def _queue_position(self, instance):\n pos = instance.queue_position\n return pos if pos and pos > 0 else None\n\n def _is_cancelled(self, instance):\n return instance.date_cancelled is not None\n", "path": "website/events/api/v2/serializers/event_registration.py"}, {"content": "from rest_framework import serializers\n\nfrom activemembers.api.v2.serializers.member_group import MemberGroupSerializer\nfrom announcements.api.v2.serializers import SlideSerializer\nfrom documents.api.v2.serializers.document import DocumentSerializer\nfrom events import services\nfrom events.api.v2.serializers.event_registration import EventRegistrationSerializer\nfrom events.models import Event, EventRegistration\nfrom thaliawebsite.api.v2.serializers import CleanedHTMLSerializer\nfrom utils.snippets import create_google_maps_url\n\n\nclass EventSerializer(serializers.ModelSerializer):\n \"\"\"Serializer for events.\"\"\"\n\n class Meta:\n model = Event\n fields = (\n \"pk\",\n \"title\",\n \"description\",\n \"start\",\n \"end\",\n \"category\",\n \"registration_start\",\n \"registration_end\",\n \"cancel_deadline\",\n \"optional_registrations\",\n \"location\",\n \"price\",\n \"fine\",\n \"num_participants\",\n \"max_participants\",\n \"no_registration_message\",\n \"cancel_too_late_message\",\n \"has_fields\",\n \"food_event\",\n \"maps_url\",\n \"user_permissions\",\n \"user_registration\",\n \"organiser\",\n \"slide\",\n \"documents\",\n )\n\n description = CleanedHTMLSerializer()\n organiser = MemberGroupSerializer()\n user_registration = serializers.SerializerMethodField(\"_user_registration\")\n num_participants = serializers.SerializerMethodField(\"_num_participants\")\n maps_url = serializers.SerializerMethodField(\"_maps_url\")\n price = serializers.DecimalField(max_digits=5, decimal_places=2)\n fine = serializers.DecimalField(max_digits=5, decimal_places=2)\n slide = SlideSerializer()\n documents = DocumentSerializer(many=True)\n user_permissions = serializers.SerializerMethodField(\"_user_permissions\")\n\n def _user_registration(self, instance):\n try:\n if self.context[\"request\"].member:\n reg = instance.eventregistration_set.get(\n member=self.context[\"request\"].member\n )\n return EventRegistrationSerializer(\n reg,\n context=self.context,\n fields=(\n \"pk\",\n \"present\",\n \"queue_position\",\n \"is_cancelled\",\n \"is_late_cancellation\",\n \"date\",\n \"payment\",\n ),\n ).data\n except EventRegistration.DoesNotExist:\n pass\n return None\n\n def _num_participants(self, instance):\n if (\n instance.max_participants\n and instance.participants.count() > instance.max_participants\n ):\n return instance.max_participants\n return instance.participants.count()\n\n def _user_permissions(self, instance):\n member = self.context[\"request\"].member\n return services.event_permissions(member, instance)\n\n def _maps_url(self, instance):\n return create_google_maps_url(instance.map_location, zoom=13, size=\"450x250\")\n", "path": "website/events/api/v2/serializers/event.py"}]}
| 1,457 | 433 |
gh_patches_debug_26478
|
rasdani/github-patches
|
git_diff
|
Zeroto521__my-data-toolkit-438
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
DOC: fix sphinx building error
<!--
Thanks for contributing a pull request!
Please follow these standard acronyms to start the commit message:
- ENH: enhancement
- BUG: bug fix
- DOC: documentation
- TYP: type annotations
- TST: addition or modification of tests
- MAINT: maintenance commit (refactoring, typos, etc.)
- BLD: change related to building
- REL: related to releasing
- API: an (incompatible) API change
- DEP: deprecate something, or remove a deprecated object
- DEV: development tool or utility
- REV: revert an earlier commit
- PERF: performance improvement
- BOT: always commit via a bot
- CI: related to CI or CD
- CLN: Code cleanup
-->
- [x] closes https://readthedocs.org/projects/my-data-toolkit/builds/15827419/
- [ ] whatsnew entry
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `doc/source/conf.py`
Content:
```
1 # Configuration file for the Sphinx documentation builder.
2 #
3 # This file only contains a selection of the most common options.
4 # For a full list see the documentation:
5 # https://www.sphinx-doc.org/en/master/usage/configuration.html
6
7
8 # -- Project information -----------------------------------------------------
9
10 # The version info for the project you're documenting, acts as replacement for
11 # |version| and |release|, also used in various other places throughout the
12 # built documents.
13 from __future__ import annotations
14
15 import inspect
16 import os
17 import sys
18 from datetime import datetime
19
20 import dtoolkit
21
22 version = release = dtoolkit.__version__
23 version = version.replace(".dev0", "")
24 version = version.replace(".post0", "")
25
26
27 project = "DToolKit"
28 author = "Zero <@Zeroto521>"
29 copyright = f"2021-{datetime.now().year}, {author}" # pylint: disable=redefined-builtin
30 github_url = "https://github.com/Zeroto521/my-data-toolkit"
31
32
33 # -- General configuration ---------------------------------------------------
34
35 # Add any Sphinx extension module names here, as strings. They can be
36 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
37 # ones.
38 extensions = [
39 "myst_parser",
40 "numpydoc",
41 "sphinx.ext.autodoc",
42 "sphinx.ext.autosummary",
43 "sphinx.ext.autosectionlabel",
44 "sphinx.ext.extlinks",
45 "sphinx.ext.intersphinx",
46 "sphinx.ext.linkcode",
47 "sphinx_toggleprompt",
48 "IPython.sphinxext.ipython_console_highlighting",
49 "IPython.sphinxext.ipython_directive",
50 "nbsphinx",
51 ]
52
53 # The suffix of source filenames.
54 source_suffix = [".rst", ".md", ".ipynb"]
55
56 # Add any paths that contain templates here, relative to this directory.
57 templates_path = ["_templates"]
58
59 # List of patterns, relative to source directory, that match files and
60 # directories to ignore when looking for source files.
61 # This pattern also affects html_static_path and html_extra_path.
62 exclude_patterns = []
63
64
65 # -- Options for HTML output -------------------------------------------------
66
67 # The theme to use for HTML and HTML Help pages. See the documentation for
68 # a list of builtin themes.
69 html_theme = "pydata_sphinx_theme"
70
71 # Theme options are theme-specific and customize the look and feel of a theme
72 # further. For a list of options available for each theme, see the
73 # documentation.
74 html_theme_options = {
75 "search_bar_position": "sidebar",
76 "github_url": github_url,
77 "icon_links": [
78 {
79 "name": "PyPI",
80 "url": "https://pypi.org/project/my-data-toolkit",
81 "icon": "fas fa-box",
82 },
83 ],
84 }
85
86 # Add any paths that contain custom static files (such as style sheets) here,
87 # relative to this directory. They are copied after the builtin static files,
88 # so a file named "default.css" will overwrite the builtin "default.css".
89 html_static_path = ["_static"]
90
91
92 # Add redirect for previously existing pages, each item is like `(from_old, to_new)`
93
94 moved_pages = [
95 ("py-modindex", "reference"),
96 ]
97
98 html_additional_pages = {page[0]: "redirect.html" for page in moved_pages}
99
100 html_context = {"redirects": dict(moved_pages)}
101
102
103 nbsphinx_prolog = r"""
104 {% set docname = env.doc2path(env.docname, base=None) %}
105
106 .. tip::
107
108 This page was generated from `{{ docname }}`__.
109
110 __ https://github.com/zeroto521/my-data-toolkit/blob/main/doc/source/{{ docname }}
111 """
112
113
114 # --Options for sphinx extensions -----------------------------------------------
115
116 # connect docs in other projects
117 intersphinx_mapping = {
118 "python": ("http://docs.python.org/", None),
119 "pandas": ("https://pandas.pydata.org/pandas-docs/stable/", None),
120 "numpy": ("https://numpy.org/doc/stable/", None),
121 "sklearn": ("https://scikit-learn.org/stable/", None),
122 "geopandas": ("https://geopandas.readthedocs.io/en/stable/", None),
123 "shapely": ("https://shapely.readthedocs.io/en/stable/", None),
124 "pyproj": ("https://pyproj4.github.io/pyproj/stable/", None),
125 "pygeos": ("https://pygeos.readthedocs.io/en/stable/", None),
126 }
127
128 # extlinks alias
129 extlinks = {
130 "issue": (f"{github_url}/issues/%s", "issue#"),
131 "pr": (f"{github_url}/issues/%s", "pr#"),
132 "user": ("https://github.com/%s", "@"),
133 }
134
135 myst_enable_extensions = [
136 "colon_fence",
137 ]
138
139 autosummary_generate = True
140
141 nbsphinx_execute = "always"
142 nbsphinx_allow_errors = True
143
144
145 # based on pandas doc/source/conf.py
146 def linkcode_resolve(domain: str, info: dict[str, str]) -> str | None:
147 """
148 Determine the URL corresponding to Python object
149 """
150
151 if domain != "py":
152 return None
153
154 modname = info["module"]
155 fullname = info["fullname"]
156
157 submod = sys.modules.get(modname)
158 if submod is None:
159 return None
160
161 obj = submod
162 for part in fullname.split("."):
163 try:
164 obj = getattr(obj, part)
165 except AttributeError:
166 return None
167
168 try:
169 fn = inspect.getsourcefile(inspect.unwrap(obj))
170 except TypeError:
171 fn = None
172
173 if not fn:
174 return None
175
176 # to fix these doc doesn't exist in dtoolkit
177 if project.lower() not in fn:
178 return None
179
180 try:
181 source, lineno = inspect.getsourcelines(obj)
182 except OSError:
183 lineno = None
184
185 linespec = f"#L{lineno}-L{lineno + len(source) - 1}" if lineno else ""
186 fn = os.path.relpath(fn, start=os.path.dirname(dtoolkit.__file__))
187
188 base_link = f"{github_url}/blob/" + "{branch}" + f"/dtoolkit/{fn}{linespec}"
189 if "post" in version:
190 return base_link.format(branch="main")
191
192 return base_link.format(branch=f"v{version}")
193
```
Path: `dtoolkit/geoaccessor/accessor.py`
Content:
```
1 import geopandas as gpd
2 from pandas.core.accessor import _register_accessor
3 from pandas.util._decorators import doc
4
5
6 @doc(klass=":class:`~geopandas.GeoSeries`")
7 def register_geoseries_accessor(name: str):
8 """
9 Register a custom accessor on {klass} objects.
10
11 This is a temparatory solution to hook method into
12 :class:`~geopandas.GeoSeries` or :class:`~geopandas.GeoDataFrame`.
13 If `geopandas#1952`_ done, it would be removed from
14 :mod:`dtoolkit.geoaccessor`.
15
16 .. _geopandas#1952: https://github.com/geopandas/geopandas/pull/1952
17
18 Parameters
19 ----------
20 name : str
21 Name under which the accessor should be registered. A warning is issued
22 if this name conflicts with a preexisting attribute.
23
24 Returns
25 -------
26 callable
27 A class decorator.
28
29 See Also
30 --------
31 register_geoseries_accessor
32 register_geodataframe_accessor
33 dtoolkit.geoaccessor.register_geoseries_method
34 dtoolkit.geoaccessor.register_geodataframe_method
35
36 Notes
37 -----
38 When accessed, your accessor will be initialized with the geopandas object
39 the user is interacting with. So the signature must be::
40
41 def __init__(self, geopandas_object): # noqa: E999
42 ...
43
44 For consistency with geopandas methods, you should raise an
45 ``AttributeError`` if the data passed to your accessor has an incorrect
46 dtype.
47
48 >>> import geopandas as gpd
49 >>> gpd.GeoSeries().dt
50 Traceback (most recent call last):
51 ...
52 AttributeError: Can only use .dt accessor with datetimelike values
53
54 Examples
55 --------
56 In your library code::
57
58 from pygeos import count_coordinates, from_shapely
59
60 @register_geodataframe_accessor("coords")
61 @register_geoseries_accessor("coords")
62 class CoordinateAccessor:
63 def __init__(self, gpd_obj):
64 self._obj = gpd_obj
65 self.geometry = gpd_obj.geometry
66
67 @property
68 def count_coordinates(self):
69 # Counts the number of coordinate pairs in geometry
70
71 return self.geometry.apply(count_coordinates(from_shapely(x)))
72
73 Back in an interactive IPython session:
74
75 .. code-block:: ipython
76
77 In [1]: import geopandas as gpd
78
79 In [2]: s = gpd.GeoSeries.from_wkt(["POINT (0 0)", "POINT (1 1)", None])
80
81 In [3]: s
82 Out[3]:
83 0 POINT (0.00000 0.00000)
84 1 POINT (1.00000 1.00000)
85 2 None
86 dtype: geometry
87
88 In [4]: s.coords.count_coordinates
89 Out[4]:
90 0 1
91 1 1
92 2 0
93 dtype: int64
94
95 In [5]: d = s.to_frame("geometry")
96 Out[5]:
97 geometry
98 0 POINT (0.00000 0.00000)
99 1 POINT (1.00000 1.00000)
100 2 None
101
102 In [6]: d.coords.count_coordinates
103 Out[6]:
104 0 1
105 1 1
106 2 0
107 Name: geometry, dtype: int64
108 """
109
110 return _register_accessor(name, gpd.GeoSeries)
111
112
113 @doc(register_geoseries_accessor, klass=":class:`~geopandas.GeoDataFrame`")
114 def register_geodataframe_accessor(name: str):
115
116 return _register_accessor(name, gpd.GeoDataFrame)
117
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/doc/source/conf.py b/doc/source/conf.py
--- a/doc/source/conf.py
+++ b/doc/source/conf.py
@@ -51,7 +51,7 @@
]
# The suffix of source filenames.
-source_suffix = [".rst", ".md", ".ipynb"]
+source_suffix = [".rst", ".md"]
# Add any paths that contain templates here, relative to this directory.
templates_path = ["_templates"]
@@ -107,7 +107,7 @@
This page was generated from `{{ docname }}`__.
- __ https://github.com/zeroto521/my-data-toolkit/blob/main/doc/source/{{ docname }}
+ __ :ghlink:`my-data-toolkit/blob/main/doc/source/{{ docname }}`
"""
@@ -129,7 +129,9 @@
extlinks = {
"issue": (f"{github_url}/issues/%s", "issue#"),
"pr": (f"{github_url}/issues/%s", "pr#"),
- "user": ("https://github.com/%s", "@"),
+ "user": (r"https://github.com/%s", "@"),
+ # github's link
+ "ghlink": (r"https://github.com/%s", None),
}
myst_enable_extensions = [
diff --git a/dtoolkit/geoaccessor/accessor.py b/dtoolkit/geoaccessor/accessor.py
--- a/dtoolkit/geoaccessor/accessor.py
+++ b/dtoolkit/geoaccessor/accessor.py
@@ -13,7 +13,7 @@
If `geopandas#1952`_ done, it would be removed from
:mod:`dtoolkit.geoaccessor`.
- .. _geopandas#1952: https://github.com/geopandas/geopandas/pull/1952
+ .. _geopandas#1952: :ghlink:`geopandas/geopandas/pull/1952`
Parameters
----------
|
{"golden_diff": "diff --git a/doc/source/conf.py b/doc/source/conf.py\n--- a/doc/source/conf.py\n+++ b/doc/source/conf.py\n@@ -51,7 +51,7 @@\n ]\n \n # The suffix of source filenames.\n-source_suffix = [\".rst\", \".md\", \".ipynb\"]\n+source_suffix = [\".rst\", \".md\"]\n \n # Add any paths that contain templates here, relative to this directory.\n templates_path = [\"_templates\"]\n@@ -107,7 +107,7 @@\n \n This page was generated from `{{ docname }}`__.\n \n- __ https://github.com/zeroto521/my-data-toolkit/blob/main/doc/source/{{ docname }}\n+ __ :ghlink:`my-data-toolkit/blob/main/doc/source/{{ docname }}`\n \"\"\"\n \n \n@@ -129,7 +129,9 @@\n extlinks = {\n \"issue\": (f\"{github_url}/issues/%s\", \"issue#\"),\n \"pr\": (f\"{github_url}/issues/%s\", \"pr#\"),\n- \"user\": (\"https://github.com/%s\", \"@\"),\n+ \"user\": (r\"https://github.com/%s\", \"@\"),\n+ # github's link\n+ \"ghlink\": (r\"https://github.com/%s\", None),\n }\n \n myst_enable_extensions = [\ndiff --git a/dtoolkit/geoaccessor/accessor.py b/dtoolkit/geoaccessor/accessor.py\n--- a/dtoolkit/geoaccessor/accessor.py\n+++ b/dtoolkit/geoaccessor/accessor.py\n@@ -13,7 +13,7 @@\n If `geopandas#1952`_ done, it would be removed from\n :mod:`dtoolkit.geoaccessor`.\n \n- .. _geopandas#1952: https://github.com/geopandas/geopandas/pull/1952\n+ .. _geopandas#1952: :ghlink:`geopandas/geopandas/pull/1952`\n \n Parameters\n ----------\n", "issue": "DOC: fix sphinx building error\n<!--\r\nThanks for contributing a pull request!\r\n\r\nPlease follow these standard acronyms to start the commit message:\r\n\r\n- ENH: enhancement\r\n- BUG: bug fix\r\n- DOC: documentation\r\n- TYP: type annotations\r\n- TST: addition or modification of tests\r\n- MAINT: maintenance commit (refactoring, typos, etc.)\r\n- BLD: change related to building\r\n- REL: related to releasing\r\n- API: an (incompatible) API change\r\n- DEP: deprecate something, or remove a deprecated object\r\n- DEV: development tool or utility\r\n- REV: revert an earlier commit\r\n- PERF: performance improvement\r\n- BOT: always commit via a bot\r\n- CI: related to CI or CD\r\n- CLN: Code cleanup\r\n-->\r\n\r\n- [x] closes https://readthedocs.org/projects/my-data-toolkit/builds/15827419/\r\n- [ ] whatsnew entry\r\n\n", "before_files": [{"content": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common options.\n# For a full list see the documentation:\n# https://www.sphinx-doc.org/en/master/usage/configuration.html\n\n\n# -- Project information -----------------------------------------------------\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\nfrom __future__ import annotations\n\nimport inspect\nimport os\nimport sys\nfrom datetime import datetime\n\nimport dtoolkit\n\nversion = release = dtoolkit.__version__\nversion = version.replace(\".dev0\", \"\")\nversion = version.replace(\".post0\", \"\")\n\n\nproject = \"DToolKit\"\nauthor = \"Zero <@Zeroto521>\"\ncopyright = f\"2021-{datetime.now().year}, {author}\" # pylint: disable=redefined-builtin\ngithub_url = \"https://github.com/Zeroto521/my-data-toolkit\"\n\n\n# -- General configuration ---------------------------------------------------\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"myst_parser\",\n \"numpydoc\",\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.autosummary\",\n \"sphinx.ext.autosectionlabel\",\n \"sphinx.ext.extlinks\",\n \"sphinx.ext.intersphinx\",\n \"sphinx.ext.linkcode\",\n \"sphinx_toggleprompt\",\n \"IPython.sphinxext.ipython_console_highlighting\",\n \"IPython.sphinxext.ipython_directive\",\n \"nbsphinx\",\n]\n\n# The suffix of source filenames.\nsource_suffix = [\".rst\", \".md\", \".ipynb\"]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = []\n\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\nhtml_theme = \"pydata_sphinx_theme\"\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\nhtml_theme_options = {\n \"search_bar_position\": \"sidebar\",\n \"github_url\": github_url,\n \"icon_links\": [\n {\n \"name\": \"PyPI\",\n \"url\": \"https://pypi.org/project/my-data-toolkit\",\n \"icon\": \"fas fa-box\",\n },\n ],\n}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\n\n\n# Add redirect for previously existing pages, each item is like `(from_old, to_new)`\n\nmoved_pages = [\n (\"py-modindex\", \"reference\"),\n]\n\nhtml_additional_pages = {page[0]: \"redirect.html\" for page in moved_pages}\n\nhtml_context = {\"redirects\": dict(moved_pages)}\n\n\nnbsphinx_prolog = r\"\"\"\n{% set docname = env.doc2path(env.docname, base=None) %}\n\n.. tip::\n\n This page was generated from `{{ docname }}`__.\n\n __ https://github.com/zeroto521/my-data-toolkit/blob/main/doc/source/{{ docname }}\n\"\"\"\n\n\n# --Options for sphinx extensions -----------------------------------------------\n\n# connect docs in other projects\nintersphinx_mapping = {\n \"python\": (\"http://docs.python.org/\", None),\n \"pandas\": (\"https://pandas.pydata.org/pandas-docs/stable/\", None),\n \"numpy\": (\"https://numpy.org/doc/stable/\", None),\n \"sklearn\": (\"https://scikit-learn.org/stable/\", None),\n \"geopandas\": (\"https://geopandas.readthedocs.io/en/stable/\", None),\n \"shapely\": (\"https://shapely.readthedocs.io/en/stable/\", None),\n \"pyproj\": (\"https://pyproj4.github.io/pyproj/stable/\", None),\n \"pygeos\": (\"https://pygeos.readthedocs.io/en/stable/\", None),\n}\n\n# extlinks alias\nextlinks = {\n \"issue\": (f\"{github_url}/issues/%s\", \"issue#\"),\n \"pr\": (f\"{github_url}/issues/%s\", \"pr#\"),\n \"user\": (\"https://github.com/%s\", \"@\"),\n}\n\nmyst_enable_extensions = [\n \"colon_fence\",\n]\n\nautosummary_generate = True\n\nnbsphinx_execute = \"always\"\nnbsphinx_allow_errors = True\n\n\n# based on pandas doc/source/conf.py\ndef linkcode_resolve(domain: str, info: dict[str, str]) -> str | None:\n \"\"\"\n Determine the URL corresponding to Python object\n \"\"\"\n\n if domain != \"py\":\n return None\n\n modname = info[\"module\"]\n fullname = info[\"fullname\"]\n\n submod = sys.modules.get(modname)\n if submod is None:\n return None\n\n obj = submod\n for part in fullname.split(\".\"):\n try:\n obj = getattr(obj, part)\n except AttributeError:\n return None\n\n try:\n fn = inspect.getsourcefile(inspect.unwrap(obj))\n except TypeError:\n fn = None\n\n if not fn:\n return None\n\n # to fix these doc doesn't exist in dtoolkit\n if project.lower() not in fn:\n return None\n\n try:\n source, lineno = inspect.getsourcelines(obj)\n except OSError:\n lineno = None\n\n linespec = f\"#L{lineno}-L{lineno + len(source) - 1}\" if lineno else \"\"\n fn = os.path.relpath(fn, start=os.path.dirname(dtoolkit.__file__))\n\n base_link = f\"{github_url}/blob/\" + \"{branch}\" + f\"/dtoolkit/{fn}{linespec}\"\n if \"post\" in version:\n return base_link.format(branch=\"main\")\n\n return base_link.format(branch=f\"v{version}\")\n", "path": "doc/source/conf.py"}, {"content": "import geopandas as gpd\nfrom pandas.core.accessor import _register_accessor\nfrom pandas.util._decorators import doc\n\n\n@doc(klass=\":class:`~geopandas.GeoSeries`\")\ndef register_geoseries_accessor(name: str):\n \"\"\"\n Register a custom accessor on {klass} objects.\n\n This is a temparatory solution to hook method into\n :class:`~geopandas.GeoSeries` or :class:`~geopandas.GeoDataFrame`.\n If `geopandas#1952`_ done, it would be removed from\n :mod:`dtoolkit.geoaccessor`.\n\n .. _geopandas#1952: https://github.com/geopandas/geopandas/pull/1952\n\n Parameters\n ----------\n name : str\n Name under which the accessor should be registered. A warning is issued\n if this name conflicts with a preexisting attribute.\n\n Returns\n -------\n callable\n A class decorator.\n\n See Also\n --------\n register_geoseries_accessor\n register_geodataframe_accessor\n dtoolkit.geoaccessor.register_geoseries_method\n dtoolkit.geoaccessor.register_geodataframe_method\n\n Notes\n -----\n When accessed, your accessor will be initialized with the geopandas object\n the user is interacting with. So the signature must be::\n\n def __init__(self, geopandas_object): # noqa: E999\n ...\n\n For consistency with geopandas methods, you should raise an\n ``AttributeError`` if the data passed to your accessor has an incorrect\n dtype.\n\n >>> import geopandas as gpd\n >>> gpd.GeoSeries().dt\n Traceback (most recent call last):\n ...\n AttributeError: Can only use .dt accessor with datetimelike values\n\n Examples\n --------\n In your library code::\n\n from pygeos import count_coordinates, from_shapely\n\n @register_geodataframe_accessor(\"coords\")\n @register_geoseries_accessor(\"coords\")\n class CoordinateAccessor:\n def __init__(self, gpd_obj):\n self._obj = gpd_obj\n self.geometry = gpd_obj.geometry\n\n @property\n def count_coordinates(self):\n # Counts the number of coordinate pairs in geometry\n\n return self.geometry.apply(count_coordinates(from_shapely(x)))\n\n Back in an interactive IPython session:\n\n .. code-block:: ipython\n\n In [1]: import geopandas as gpd\n\n In [2]: s = gpd.GeoSeries.from_wkt([\"POINT (0 0)\", \"POINT (1 1)\", None])\n\n In [3]: s\n Out[3]:\n 0 POINT (0.00000 0.00000)\n 1 POINT (1.00000 1.00000)\n 2 None\n dtype: geometry\n\n In [4]: s.coords.count_coordinates\n Out[4]:\n 0 1\n 1 1\n 2 0\n dtype: int64\n\n In [5]: d = s.to_frame(\"geometry\")\n Out[5]:\n geometry\n 0 POINT (0.00000 0.00000)\n 1 POINT (1.00000 1.00000)\n 2 None\n\n In [6]: d.coords.count_coordinates\n Out[6]:\n 0 1\n 1 1\n 2 0\n Name: geometry, dtype: int64\n \"\"\"\n\n return _register_accessor(name, gpd.GeoSeries)\n\n\n@doc(register_geoseries_accessor, klass=\":class:`~geopandas.GeoDataFrame`\")\ndef register_geodataframe_accessor(name: str):\n\n return _register_accessor(name, gpd.GeoDataFrame)\n", "path": "dtoolkit/geoaccessor/accessor.py"}], "after_files": [{"content": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common options.\n# For a full list see the documentation:\n# https://www.sphinx-doc.org/en/master/usage/configuration.html\n\n\n# -- Project information -----------------------------------------------------\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\nfrom __future__ import annotations\n\nimport inspect\nimport os\nimport sys\nfrom datetime import datetime\n\nimport dtoolkit\n\nversion = release = dtoolkit.__version__\nversion = version.replace(\".dev0\", \"\")\nversion = version.replace(\".post0\", \"\")\n\n\nproject = \"DToolKit\"\nauthor = \"Zero <@Zeroto521>\"\ncopyright = f\"2021-{datetime.now().year}, {author}\" # pylint: disable=redefined-builtin\ngithub_url = \"https://github.com/Zeroto521/my-data-toolkit\"\n\n\n# -- General configuration ---------------------------------------------------\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"myst_parser\",\n \"numpydoc\",\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.autosummary\",\n \"sphinx.ext.autosectionlabel\",\n \"sphinx.ext.extlinks\",\n \"sphinx.ext.intersphinx\",\n \"sphinx.ext.linkcode\",\n \"sphinx_toggleprompt\",\n \"IPython.sphinxext.ipython_console_highlighting\",\n \"IPython.sphinxext.ipython_directive\",\n \"nbsphinx\",\n]\n\n# The suffix of source filenames.\nsource_suffix = [\".rst\", \".md\"]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = []\n\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\nhtml_theme = \"pydata_sphinx_theme\"\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\nhtml_theme_options = {\n \"search_bar_position\": \"sidebar\",\n \"github_url\": github_url,\n \"icon_links\": [\n {\n \"name\": \"PyPI\",\n \"url\": \"https://pypi.org/project/my-data-toolkit\",\n \"icon\": \"fas fa-box\",\n },\n ],\n}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\n\n\n# Add redirect for previously existing pages, each item is like `(from_old, to_new)`\n\nmoved_pages = [\n (\"py-modindex\", \"reference\"),\n]\n\nhtml_additional_pages = {page[0]: \"redirect.html\" for page in moved_pages}\n\nhtml_context = {\"redirects\": dict(moved_pages)}\n\n\nnbsphinx_prolog = r\"\"\"\n{% set docname = env.doc2path(env.docname, base=None) %}\n\n.. tip::\n\n This page was generated from `{{ docname }}`__.\n\n __ :ghlink:`my-data-toolkit/blob/main/doc/source/{{ docname }}`\n\"\"\"\n\n\n# --Options for sphinx extensions -----------------------------------------------\n\n# connect docs in other projects\nintersphinx_mapping = {\n \"python\": (\"http://docs.python.org/\", None),\n \"pandas\": (\"https://pandas.pydata.org/pandas-docs/stable/\", None),\n \"numpy\": (\"https://numpy.org/doc/stable/\", None),\n \"sklearn\": (\"https://scikit-learn.org/stable/\", None),\n \"geopandas\": (\"https://geopandas.readthedocs.io/en/stable/\", None),\n \"shapely\": (\"https://shapely.readthedocs.io/en/stable/\", None),\n \"pyproj\": (\"https://pyproj4.github.io/pyproj/stable/\", None),\n \"pygeos\": (\"https://pygeos.readthedocs.io/en/stable/\", None),\n}\n\n# extlinks alias\nextlinks = {\n \"issue\": (f\"{github_url}/issues/%s\", \"issue#\"),\n \"pr\": (f\"{github_url}/issues/%s\", \"pr#\"),\n \"user\": (r\"https://github.com/%s\", \"@\"),\n # github's link\n \"ghlink\": (r\"https://github.com/%s\", None),\n}\n\nmyst_enable_extensions = [\n \"colon_fence\",\n]\n\nautosummary_generate = True\n\nnbsphinx_execute = \"always\"\nnbsphinx_allow_errors = True\n\n\n# based on pandas doc/source/conf.py\ndef linkcode_resolve(domain: str, info: dict[str, str]) -> str | None:\n \"\"\"\n Determine the URL corresponding to Python object\n \"\"\"\n\n if domain != \"py\":\n return None\n\n modname = info[\"module\"]\n fullname = info[\"fullname\"]\n\n submod = sys.modules.get(modname)\n if submod is None:\n return None\n\n obj = submod\n for part in fullname.split(\".\"):\n try:\n obj = getattr(obj, part)\n except AttributeError:\n return None\n\n try:\n fn = inspect.getsourcefile(inspect.unwrap(obj))\n except TypeError:\n fn = None\n\n if not fn:\n return None\n\n # to fix these doc doesn't exist in dtoolkit\n if project.lower() not in fn:\n return None\n\n try:\n source, lineno = inspect.getsourcelines(obj)\n except OSError:\n lineno = None\n\n linespec = f\"#L{lineno}-L{lineno + len(source) - 1}\" if lineno else \"\"\n fn = os.path.relpath(fn, start=os.path.dirname(dtoolkit.__file__))\n\n base_link = f\"{github_url}/blob/\" + \"{branch}\" + f\"/dtoolkit/{fn}{linespec}\"\n if \"post\" in version:\n return base_link.format(branch=\"main\")\n\n return base_link.format(branch=f\"v{version}\")\n", "path": "doc/source/conf.py"}, {"content": "import geopandas as gpd\nfrom pandas.core.accessor import _register_accessor\nfrom pandas.util._decorators import doc\n\n\n@doc(klass=\":class:`~geopandas.GeoSeries`\")\ndef register_geoseries_accessor(name: str):\n \"\"\"\n Register a custom accessor on {klass} objects.\n\n This is a temparatory solution to hook method into\n :class:`~geopandas.GeoSeries` or :class:`~geopandas.GeoDataFrame`.\n If `geopandas#1952`_ done, it would be removed from\n :mod:`dtoolkit.geoaccessor`.\n\n .. _geopandas#1952: :ghlink:`geopandas/geopandas/pull/1952`\n\n Parameters\n ----------\n name : str\n Name under which the accessor should be registered. A warning is issued\n if this name conflicts with a preexisting attribute.\n\n Returns\n -------\n callable\n A class decorator.\n\n See Also\n --------\n register_geoseries_accessor\n register_geodataframe_accessor\n dtoolkit.geoaccessor.register_geoseries_method\n dtoolkit.geoaccessor.register_geodataframe_method\n\n Notes\n -----\n When accessed, your accessor will be initialized with the geopandas object\n the user is interacting with. So the signature must be::\n\n def __init__(self, geopandas_object): # noqa: E999\n ...\n\n For consistency with geopandas methods, you should raise an\n ``AttributeError`` if the data passed to your accessor has an incorrect\n dtype.\n\n >>> import geopandas as gpd\n >>> gpd.GeoSeries().dt\n Traceback (most recent call last):\n ...\n AttributeError: Can only use .dt accessor with datetimelike values\n\n Examples\n --------\n In your library code::\n\n from pygeos import count_coordinates, from_shapely\n\n @register_geodataframe_accessor(\"coords\")\n @register_geoseries_accessor(\"coords\")\n class CoordinateAccessor:\n def __init__(self, gpd_obj):\n self._obj = gpd_obj\n self.geometry = gpd_obj.geometry\n\n @property\n def count_coordinates(self):\n # Counts the number of coordinate pairs in geometry\n\n return self.geometry.apply(count_coordinates(from_shapely(x)))\n\n Back in an interactive IPython session:\n\n .. code-block:: ipython\n\n In [1]: import geopandas as gpd\n\n In [2]: s = gpd.GeoSeries.from_wkt([\"POINT (0 0)\", \"POINT (1 1)\", None])\n\n In [3]: s\n Out[3]:\n 0 POINT (0.00000 0.00000)\n 1 POINT (1.00000 1.00000)\n 2 None\n dtype: geometry\n\n In [4]: s.coords.count_coordinates\n Out[4]:\n 0 1\n 1 1\n 2 0\n dtype: int64\n\n In [5]: d = s.to_frame(\"geometry\")\n Out[5]:\n geometry\n 0 POINT (0.00000 0.00000)\n 1 POINT (1.00000 1.00000)\n 2 None\n\n In [6]: d.coords.count_coordinates\n Out[6]:\n 0 1\n 1 1\n 2 0\n Name: geometry, dtype: int64\n \"\"\"\n\n return _register_accessor(name, gpd.GeoSeries)\n\n\n@doc(register_geoseries_accessor, klass=\":class:`~geopandas.GeoDataFrame`\")\ndef register_geodataframe_accessor(name: str):\n\n return _register_accessor(name, gpd.GeoDataFrame)\n", "path": "dtoolkit/geoaccessor/accessor.py"}]}
| 3,493 | 455 |
gh_patches_debug_58117
|
rasdani/github-patches
|
git_diff
|
weni-ai__bothub-engine-76
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Next link in pagination broken in production
The links starts with ```https://bothub/```, correct is ```https://bothub.it/```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 from setuptools import setup, find_packages
2
3 with open('requirements.txt') as fp:
4 install_requires = fp.read()
5 install_requires = list(
6 filter(lambda x: len(x) > 0, install_requires.split('\n')))
7
8 setup(
9 name='bothub',
10 version='1.7.1',
11 description='bothub',
12 packages=find_packages(),
13 install_requires=install_requires,
14 python_requires='>=3.6',
15 )
16
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -7,7 +7,7 @@
setup(
name='bothub',
- version='1.7.1',
+ version='1.7.2',
description='bothub',
packages=find_packages(),
install_requires=install_requires,
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -7,7 +7,7 @@\n \n setup(\n name='bothub',\n- version='1.7.1',\n+ version='1.7.2',\n description='bothub',\n packages=find_packages(),\n install_requires=install_requires,\n", "issue": "Next link in pagination broken in production\nThe links starts with ```https://bothub/```, correct is ```https://bothub.it/```\n", "before_files": [{"content": "from setuptools import setup, find_packages\n\nwith open('requirements.txt') as fp:\n install_requires = fp.read()\ninstall_requires = list(\n filter(lambda x: len(x) > 0, install_requires.split('\\n')))\n\nsetup(\n name='bothub',\n version='1.7.1',\n description='bothub',\n packages=find_packages(),\n install_requires=install_requires,\n python_requires='>=3.6',\n)\n", "path": "setup.py"}], "after_files": [{"content": "from setuptools import setup, find_packages\n\nwith open('requirements.txt') as fp:\n install_requires = fp.read()\ninstall_requires = list(\n filter(lambda x: len(x) > 0, install_requires.split('\\n')))\n\nsetup(\n name='bothub',\n version='1.7.2',\n description='bothub',\n packages=find_packages(),\n install_requires=install_requires,\n python_requires='>=3.6',\n)\n", "path": "setup.py"}]}
| 404 | 77 |
gh_patches_debug_40165
|
rasdani/github-patches
|
git_diff
|
learningequality__kolibri-5274
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
MultipleObjectsReturned: get() returned more than one Lesson -- it returned 2!
Sentry Issue: [KOLIBRI-BACKEND-7](https://sentry.io/learningequality/kolibri-backend/issues/877453921/?referrer=github_integration)
```
MultipleObjectsReturned: get() returned more than one Lesson -- it returned 2!
(8 additional frame(s) were not displayed)
...
File "rest_framework/mixins.py", line 56, in retrieve
instance = self.get_object()
File "rest_framework/generics.py", line 98, in get_object
obj = get_object_or_404(queryset, **filter_kwargs)
File "rest_framework/generics.py", line 21, in get_object_or_404
return _get_object_or_404(queryset, *filter_args, **filter_kwargs)
File "django/shortcuts.py", line 85, in get_object_or_404
return queryset.get(*args, **kwargs)
File "django/db/models/query.py", line 384, in get
(self.model._meta.object_name, num)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kolibri/plugins/learn/viewsets.py`
Content:
```
1 from django.db.models.query import F
2 from rest_framework.permissions import IsAuthenticated
3 from rest_framework.viewsets import ReadOnlyModelViewSet
4
5 from .serializers import LearnerClassroomSerializer
6 from kolibri.core.auth.api import KolibriAuthPermissionsFilter
7 from kolibri.core.auth.filters import HierarchyRelationsFilter
8 from kolibri.core.auth.models import Classroom
9 from kolibri.core.lessons.models import Lesson
10 from kolibri.core.lessons.models import LessonAssignment
11 from kolibri.core.lessons.serializers import LessonSerializer
12
13
14 class LearnerClassroomViewset(ReadOnlyModelViewSet):
15 """
16 Returns all Classrooms for which the requesting User is a member,
17 along with all associated assignments.
18 """
19 filter_backends = (KolibriAuthPermissionsFilter,)
20 permission_classes = (IsAuthenticated,)
21 serializer_class = LearnerClassroomSerializer
22
23 def get_queryset(self):
24 current_user = self.request.user
25 memberships = current_user.memberships.filter(
26 collection__kind='classroom',
27 ).values('collection_id')
28 return Classroom.objects.filter(id__in=memberships)
29
30
31 class LearnerLessonViewset(ReadOnlyModelViewSet):
32 """
33 Special Viewset for Learners to view Lessons to which they are assigned.
34 The core Lesson Viewset is locked down to Admin users only.
35 """
36 serializer_class = LessonSerializer
37 permission_classes = (IsAuthenticated,)
38
39 def get_queryset(self):
40 assignments = HierarchyRelationsFilter(LessonAssignment.objects.all()) \
41 .filter_by_hierarchy(
42 target_user=self.request.user,
43 ancestor_collection=F('collection')
44 )
45 return Lesson.objects.filter(
46 lesson_assignments__in=assignments,
47 is_active=True
48 )
49
```
Path: `kolibri/plugins/learn/serializers.py`
Content:
```
1 from django.db.models import Q
2 from django.db.models import Sum
3 from rest_framework.serializers import JSONField
4 from rest_framework.serializers import ModelSerializer
5 from rest_framework.serializers import SerializerMethodField
6
7 from kolibri.core.auth.models import Classroom
8 from kolibri.core.exams.models import Exam
9 from kolibri.core.lessons.models import Lesson
10 from kolibri.core.logger.models import ContentSummaryLog
11 from kolibri.core.logger.models import ExamLog
12
13
14 class ExamProgressSerializer(ModelSerializer):
15 """
16 Annotates an Exam with progress information based on logs generated
17 by the requesting User
18 """
19 class Meta:
20 model = Exam
21 fields = (
22 'active',
23 'id',
24 'progress',
25 'question_count',
26 'title',
27 )
28
29 progress = SerializerMethodField()
30
31 # Mostly copied from UserExamSerializer.to_representation, but working directly
32 # from Exam Model instead of ExamAssignment
33 def get_progress(self, instance):
34 try:
35 examlogs = instance.examlogs.get(user=self.context['user'])
36 return {
37 'score': examlogs.attemptlogs.aggregate(Sum('correct')).get('correct__sum'),
38 'answer_count': examlogs.attemptlogs.count(),
39 'closed': examlogs.closed,
40 'started': True,
41 }
42 except ExamLog.DoesNotExist:
43 return {
44 'score': None,
45 'answer_count': None,
46 'closed': None,
47 'started': False,
48 }
49
50
51 class LessonProgressSerializer(ModelSerializer):
52 """
53 Annotates a Lesson with progress information based on logs generated
54 by the requesting User
55 """
56 progress = SerializerMethodField()
57 resources = JSONField(default='[]')
58
59 class Meta:
60 model = Lesson
61 fields = (
62 'description',
63 'id',
64 'is_active',
65 'title',
66 'progress',
67 'resources',
68 )
69
70 def get_progress(self, instance):
71 content_ids = [resource['content_id'] for resource in instance.resources]
72 resource_progress = ContentSummaryLog.objects \
73 .filter(
74 user=self.context['user'],
75 content_id__in=content_ids
76 ) \
77 .aggregate(Sum('progress')).get('progress__sum')
78 return {
79 'resource_progress': resource_progress,
80 'total_resources': len(instance.resources),
81 }
82
83
84 class LearnerClassroomSerializer(ModelSerializer):
85 assignments = SerializerMethodField()
86
87 class Meta:
88 model = Classroom
89 fields = (
90 'id',
91 'name',
92 'assignments',
93 )
94
95 def get_assignments(self, instance):
96 """
97 Returns all Exams and Lessons (and progress) assigned to the requesting User
98 """
99 current_user = self.context['request'].user
100 memberships = current_user.memberships.all()
101 learner_groups = [m.collection for m in memberships]
102
103 # Return only active Lessons that are assigned to the requesting user's groups
104 # TODO move this to a permission_class on Lesson
105 filtered_lessons = Lesson.objects.filter(
106 lesson_assignments__collection__in=learner_groups,
107 collection=instance,
108 is_active=True,
109 ).distinct()
110
111 filtered_exams = Exam.objects.filter(
112 assignments__collection__in=learner_groups,
113 collection=instance,
114 ).filter(Q(active=True) | Q(examlogs__user=current_user)).distinct()
115
116 return {
117 'lessons': LessonProgressSerializer(
118 filtered_lessons,
119 many=True,
120 context={'user': current_user},
121 ).data,
122 'exams': ExamProgressSerializer(
123 filtered_exams,
124 many=True,
125 context={'user': current_user},
126 ).data,
127 }
128
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kolibri/plugins/learn/serializers.py b/kolibri/plugins/learn/serializers.py
--- a/kolibri/plugins/learn/serializers.py
+++ b/kolibri/plugins/learn/serializers.py
@@ -4,9 +4,12 @@
from rest_framework.serializers import ModelSerializer
from rest_framework.serializers import SerializerMethodField
+from kolibri.core.auth.filters import HierarchyRelationsFilter
from kolibri.core.auth.models import Classroom
from kolibri.core.exams.models import Exam
+from kolibri.core.exams.models import ExamAssignment
from kolibri.core.lessons.models import Lesson
+from kolibri.core.lessons.models import LessonAssignment
from kolibri.core.logger.models import ContentSummaryLog
from kolibri.core.logger.models import ExamLog
@@ -97,19 +100,27 @@
Returns all Exams and Lessons (and progress) assigned to the requesting User
"""
current_user = self.context['request'].user
- memberships = current_user.memberships.all()
- learner_groups = [m.collection for m in memberships]
# Return only active Lessons that are assigned to the requesting user's groups
# TODO move this to a permission_class on Lesson
+ lesson_assignments = HierarchyRelationsFilter(LessonAssignment.objects.all()) \
+ .filter_by_hierarchy(
+ target_user=current_user,
+ ancestor_collection=instance
+ )
filtered_lessons = Lesson.objects.filter(
- lesson_assignments__collection__in=learner_groups,
- collection=instance,
- is_active=True,
+ lesson_assignments__in=lesson_assignments,
+ is_active=True
).distinct()
+ exam_assignments = HierarchyRelationsFilter(ExamAssignment.objects.all()) \
+ .filter_by_hierarchy(
+ target_user=current_user,
+ ancestor_collection=instance
+ )
+
filtered_exams = Exam.objects.filter(
- assignments__collection__in=learner_groups,
+ assignments__in=exam_assignments,
collection=instance,
).filter(Q(active=True) | Q(examlogs__user=current_user)).distinct()
diff --git a/kolibri/plugins/learn/viewsets.py b/kolibri/plugins/learn/viewsets.py
--- a/kolibri/plugins/learn/viewsets.py
+++ b/kolibri/plugins/learn/viewsets.py
@@ -21,11 +21,10 @@
serializer_class = LearnerClassroomSerializer
def get_queryset(self):
- current_user = self.request.user
- memberships = current_user.memberships.filter(
- collection__kind='classroom',
- ).values('collection_id')
- return Classroom.objects.filter(id__in=memberships)
+ return HierarchyRelationsFilter(Classroom.objects.all()).filter_by_hierarchy(
+ target_user=self.request.user,
+ ancestor_collection=F('id')
+ )
class LearnerLessonViewset(ReadOnlyModelViewSet):
@@ -45,4 +44,4 @@
return Lesson.objects.filter(
lesson_assignments__in=assignments,
is_active=True
- )
+ ).distinct()
|
{"golden_diff": "diff --git a/kolibri/plugins/learn/serializers.py b/kolibri/plugins/learn/serializers.py\n--- a/kolibri/plugins/learn/serializers.py\n+++ b/kolibri/plugins/learn/serializers.py\n@@ -4,9 +4,12 @@\n from rest_framework.serializers import ModelSerializer\n from rest_framework.serializers import SerializerMethodField\n \n+from kolibri.core.auth.filters import HierarchyRelationsFilter\n from kolibri.core.auth.models import Classroom\n from kolibri.core.exams.models import Exam\n+from kolibri.core.exams.models import ExamAssignment\n from kolibri.core.lessons.models import Lesson\n+from kolibri.core.lessons.models import LessonAssignment\n from kolibri.core.logger.models import ContentSummaryLog\n from kolibri.core.logger.models import ExamLog\n \n@@ -97,19 +100,27 @@\n Returns all Exams and Lessons (and progress) assigned to the requesting User\n \"\"\"\n current_user = self.context['request'].user\n- memberships = current_user.memberships.all()\n- learner_groups = [m.collection for m in memberships]\n \n # Return only active Lessons that are assigned to the requesting user's groups\n # TODO move this to a permission_class on Lesson\n+ lesson_assignments = HierarchyRelationsFilter(LessonAssignment.objects.all()) \\\n+ .filter_by_hierarchy(\n+ target_user=current_user,\n+ ancestor_collection=instance\n+ )\n filtered_lessons = Lesson.objects.filter(\n- lesson_assignments__collection__in=learner_groups,\n- collection=instance,\n- is_active=True,\n+ lesson_assignments__in=lesson_assignments,\n+ is_active=True\n ).distinct()\n \n+ exam_assignments = HierarchyRelationsFilter(ExamAssignment.objects.all()) \\\n+ .filter_by_hierarchy(\n+ target_user=current_user,\n+ ancestor_collection=instance\n+ )\n+\n filtered_exams = Exam.objects.filter(\n- assignments__collection__in=learner_groups,\n+ assignments__in=exam_assignments,\n collection=instance,\n ).filter(Q(active=True) | Q(examlogs__user=current_user)).distinct()\n \ndiff --git a/kolibri/plugins/learn/viewsets.py b/kolibri/plugins/learn/viewsets.py\n--- a/kolibri/plugins/learn/viewsets.py\n+++ b/kolibri/plugins/learn/viewsets.py\n@@ -21,11 +21,10 @@\n serializer_class = LearnerClassroomSerializer\n \n def get_queryset(self):\n- current_user = self.request.user\n- memberships = current_user.memberships.filter(\n- collection__kind='classroom',\n- ).values('collection_id')\n- return Classroom.objects.filter(id__in=memberships)\n+ return HierarchyRelationsFilter(Classroom.objects.all()).filter_by_hierarchy(\n+ target_user=self.request.user,\n+ ancestor_collection=F('id')\n+ )\n \n \n class LearnerLessonViewset(ReadOnlyModelViewSet):\n@@ -45,4 +44,4 @@\n return Lesson.objects.filter(\n lesson_assignments__in=assignments,\n is_active=True\n- )\n+ ).distinct()\n", "issue": "MultipleObjectsReturned: get() returned more than one Lesson -- it returned 2!\nSentry Issue: [KOLIBRI-BACKEND-7](https://sentry.io/learningequality/kolibri-backend/issues/877453921/?referrer=github_integration)\n\n```\nMultipleObjectsReturned: get() returned more than one Lesson -- it returned 2!\n(8 additional frame(s) were not displayed)\n...\n File \"rest_framework/mixins.py\", line 56, in retrieve\n instance = self.get_object()\n File \"rest_framework/generics.py\", line 98, in get_object\n obj = get_object_or_404(queryset, **filter_kwargs)\n File \"rest_framework/generics.py\", line 21, in get_object_or_404\n return _get_object_or_404(queryset, *filter_args, **filter_kwargs)\n File \"django/shortcuts.py\", line 85, in get_object_or_404\n return queryset.get(*args, **kwargs)\n File \"django/db/models/query.py\", line 384, in get\n (self.model._meta.object_name, num)\n```\n", "before_files": [{"content": "from django.db.models.query import F\nfrom rest_framework.permissions import IsAuthenticated\nfrom rest_framework.viewsets import ReadOnlyModelViewSet\n\nfrom .serializers import LearnerClassroomSerializer\nfrom kolibri.core.auth.api import KolibriAuthPermissionsFilter\nfrom kolibri.core.auth.filters import HierarchyRelationsFilter\nfrom kolibri.core.auth.models import Classroom\nfrom kolibri.core.lessons.models import Lesson\nfrom kolibri.core.lessons.models import LessonAssignment\nfrom kolibri.core.lessons.serializers import LessonSerializer\n\n\nclass LearnerClassroomViewset(ReadOnlyModelViewSet):\n \"\"\"\n Returns all Classrooms for which the requesting User is a member,\n along with all associated assignments.\n \"\"\"\n filter_backends = (KolibriAuthPermissionsFilter,)\n permission_classes = (IsAuthenticated,)\n serializer_class = LearnerClassroomSerializer\n\n def get_queryset(self):\n current_user = self.request.user\n memberships = current_user.memberships.filter(\n collection__kind='classroom',\n ).values('collection_id')\n return Classroom.objects.filter(id__in=memberships)\n\n\nclass LearnerLessonViewset(ReadOnlyModelViewSet):\n \"\"\"\n Special Viewset for Learners to view Lessons to which they are assigned.\n The core Lesson Viewset is locked down to Admin users only.\n \"\"\"\n serializer_class = LessonSerializer\n permission_classes = (IsAuthenticated,)\n\n def get_queryset(self):\n assignments = HierarchyRelationsFilter(LessonAssignment.objects.all()) \\\n .filter_by_hierarchy(\n target_user=self.request.user,\n ancestor_collection=F('collection')\n )\n return Lesson.objects.filter(\n lesson_assignments__in=assignments,\n is_active=True\n )\n", "path": "kolibri/plugins/learn/viewsets.py"}, {"content": "from django.db.models import Q\nfrom django.db.models import Sum\nfrom rest_framework.serializers import JSONField\nfrom rest_framework.serializers import ModelSerializer\nfrom rest_framework.serializers import SerializerMethodField\n\nfrom kolibri.core.auth.models import Classroom\nfrom kolibri.core.exams.models import Exam\nfrom kolibri.core.lessons.models import Lesson\nfrom kolibri.core.logger.models import ContentSummaryLog\nfrom kolibri.core.logger.models import ExamLog\n\n\nclass ExamProgressSerializer(ModelSerializer):\n \"\"\"\n Annotates an Exam with progress information based on logs generated\n by the requesting User\n \"\"\"\n class Meta:\n model = Exam\n fields = (\n 'active',\n 'id',\n 'progress',\n 'question_count',\n 'title',\n )\n\n progress = SerializerMethodField()\n\n # Mostly copied from UserExamSerializer.to_representation, but working directly\n # from Exam Model instead of ExamAssignment\n def get_progress(self, instance):\n try:\n examlogs = instance.examlogs.get(user=self.context['user'])\n return {\n 'score': examlogs.attemptlogs.aggregate(Sum('correct')).get('correct__sum'),\n 'answer_count': examlogs.attemptlogs.count(),\n 'closed': examlogs.closed,\n 'started': True,\n }\n except ExamLog.DoesNotExist:\n return {\n 'score': None,\n 'answer_count': None,\n 'closed': None,\n 'started': False,\n }\n\n\nclass LessonProgressSerializer(ModelSerializer):\n \"\"\"\n Annotates a Lesson with progress information based on logs generated\n by the requesting User\n \"\"\"\n progress = SerializerMethodField()\n resources = JSONField(default='[]')\n\n class Meta:\n model = Lesson\n fields = (\n 'description',\n 'id',\n 'is_active',\n 'title',\n 'progress',\n 'resources',\n )\n\n def get_progress(self, instance):\n content_ids = [resource['content_id'] for resource in instance.resources]\n resource_progress = ContentSummaryLog.objects \\\n .filter(\n user=self.context['user'],\n content_id__in=content_ids\n ) \\\n .aggregate(Sum('progress')).get('progress__sum')\n return {\n 'resource_progress': resource_progress,\n 'total_resources': len(instance.resources),\n }\n\n\nclass LearnerClassroomSerializer(ModelSerializer):\n assignments = SerializerMethodField()\n\n class Meta:\n model = Classroom\n fields = (\n 'id',\n 'name',\n 'assignments',\n )\n\n def get_assignments(self, instance):\n \"\"\"\n Returns all Exams and Lessons (and progress) assigned to the requesting User\n \"\"\"\n current_user = self.context['request'].user\n memberships = current_user.memberships.all()\n learner_groups = [m.collection for m in memberships]\n\n # Return only active Lessons that are assigned to the requesting user's groups\n # TODO move this to a permission_class on Lesson\n filtered_lessons = Lesson.objects.filter(\n lesson_assignments__collection__in=learner_groups,\n collection=instance,\n is_active=True,\n ).distinct()\n\n filtered_exams = Exam.objects.filter(\n assignments__collection__in=learner_groups,\n collection=instance,\n ).filter(Q(active=True) | Q(examlogs__user=current_user)).distinct()\n\n return {\n 'lessons': LessonProgressSerializer(\n filtered_lessons,\n many=True,\n context={'user': current_user},\n ).data,\n 'exams': ExamProgressSerializer(\n filtered_exams,\n many=True,\n context={'user': current_user},\n ).data,\n }\n", "path": "kolibri/plugins/learn/serializers.py"}], "after_files": [{"content": "from django.db.models.query import F\nfrom rest_framework.permissions import IsAuthenticated\nfrom rest_framework.viewsets import ReadOnlyModelViewSet\n\nfrom .serializers import LearnerClassroomSerializer\nfrom kolibri.core.auth.api import KolibriAuthPermissionsFilter\nfrom kolibri.core.auth.filters import HierarchyRelationsFilter\nfrom kolibri.core.auth.models import Classroom\nfrom kolibri.core.lessons.models import Lesson\nfrom kolibri.core.lessons.models import LessonAssignment\nfrom kolibri.core.lessons.serializers import LessonSerializer\n\n\nclass LearnerClassroomViewset(ReadOnlyModelViewSet):\n \"\"\"\n Returns all Classrooms for which the requesting User is a member,\n along with all associated assignments.\n \"\"\"\n filter_backends = (KolibriAuthPermissionsFilter,)\n permission_classes = (IsAuthenticated,)\n serializer_class = LearnerClassroomSerializer\n\n def get_queryset(self):\n return HierarchyRelationsFilter(Classroom.objects.all()).filter_by_hierarchy(\n target_user=self.request.user,\n ancestor_collection=F('id')\n )\n\n\nclass LearnerLessonViewset(ReadOnlyModelViewSet):\n \"\"\"\n Special Viewset for Learners to view Lessons to which they are assigned.\n The core Lesson Viewset is locked down to Admin users only.\n \"\"\"\n serializer_class = LessonSerializer\n permission_classes = (IsAuthenticated,)\n\n def get_queryset(self):\n assignments = HierarchyRelationsFilter(LessonAssignment.objects.all()) \\\n .filter_by_hierarchy(\n target_user=self.request.user,\n ancestor_collection=F('collection')\n )\n return Lesson.objects.filter(\n lesson_assignments__in=assignments,\n is_active=True\n ).distinct()\n", "path": "kolibri/plugins/learn/viewsets.py"}, {"content": "from django.db.models import Q\nfrom django.db.models import Sum\nfrom rest_framework.serializers import JSONField\nfrom rest_framework.serializers import ModelSerializer\nfrom rest_framework.serializers import SerializerMethodField\n\nfrom kolibri.core.auth.filters import HierarchyRelationsFilter\nfrom kolibri.core.auth.models import Classroom\nfrom kolibri.core.exams.models import Exam\nfrom kolibri.core.exams.models import ExamAssignment\nfrom kolibri.core.lessons.models import Lesson\nfrom kolibri.core.lessons.models import LessonAssignment\nfrom kolibri.core.logger.models import ContentSummaryLog\nfrom kolibri.core.logger.models import ExamLog\n\n\nclass ExamProgressSerializer(ModelSerializer):\n \"\"\"\n Annotates an Exam with progress information based on logs generated\n by the requesting User\n \"\"\"\n class Meta:\n model = Exam\n fields = (\n 'active',\n 'id',\n 'progress',\n 'question_count',\n 'title',\n )\n\n progress = SerializerMethodField()\n\n # Mostly copied from UserExamSerializer.to_representation, but working directly\n # from Exam Model instead of ExamAssignment\n def get_progress(self, instance):\n try:\n examlogs = instance.examlogs.get(user=self.context['user'])\n return {\n 'score': examlogs.attemptlogs.aggregate(Sum('correct')).get('correct__sum'),\n 'answer_count': examlogs.attemptlogs.count(),\n 'closed': examlogs.closed,\n 'started': True,\n }\n except ExamLog.DoesNotExist:\n return {\n 'score': None,\n 'answer_count': None,\n 'closed': None,\n 'started': False,\n }\n\n\nclass LessonProgressSerializer(ModelSerializer):\n \"\"\"\n Annotates a Lesson with progress information based on logs generated\n by the requesting User\n \"\"\"\n progress = SerializerMethodField()\n resources = JSONField(default='[]')\n\n class Meta:\n model = Lesson\n fields = (\n 'description',\n 'id',\n 'is_active',\n 'title',\n 'progress',\n 'resources',\n )\n\n def get_progress(self, instance):\n content_ids = [resource['content_id'] for resource in instance.resources]\n resource_progress = ContentSummaryLog.objects \\\n .filter(\n user=self.context['user'],\n content_id__in=content_ids\n ) \\\n .aggregate(Sum('progress')).get('progress__sum')\n return {\n 'resource_progress': resource_progress,\n 'total_resources': len(instance.resources),\n }\n\n\nclass LearnerClassroomSerializer(ModelSerializer):\n assignments = SerializerMethodField()\n\n class Meta:\n model = Classroom\n fields = (\n 'id',\n 'name',\n 'assignments',\n )\n\n def get_assignments(self, instance):\n \"\"\"\n Returns all Exams and Lessons (and progress) assigned to the requesting User\n \"\"\"\n current_user = self.context['request'].user\n\n # Return only active Lessons that are assigned to the requesting user's groups\n # TODO move this to a permission_class on Lesson\n lesson_assignments = HierarchyRelationsFilter(LessonAssignment.objects.all()) \\\n .filter_by_hierarchy(\n target_user=current_user,\n ancestor_collection=instance\n )\n filtered_lessons = Lesson.objects.filter(\n lesson_assignments__in=lesson_assignments,\n is_active=True\n ).distinct()\n\n exam_assignments = HierarchyRelationsFilter(ExamAssignment.objects.all()) \\\n .filter_by_hierarchy(\n target_user=current_user,\n ancestor_collection=instance\n )\n\n filtered_exams = Exam.objects.filter(\n assignments__in=exam_assignments,\n collection=instance,\n ).filter(Q(active=True) | Q(examlogs__user=current_user)).distinct()\n\n return {\n 'lessons': LessonProgressSerializer(\n filtered_lessons,\n many=True,\n context={'user': current_user},\n ).data,\n 'exams': ExamProgressSerializer(\n filtered_exams,\n many=True,\n context={'user': current_user},\n ).data,\n }\n", "path": "kolibri/plugins/learn/serializers.py"}]}
| 2,035 | 675 |
gh_patches_debug_9419
|
rasdani/github-patches
|
git_diff
|
privacyidea__privacyidea-904
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add VASCO token type to web UI
As we cannot generate new secrets by ourselves, we just add a possibility to enter a hex-encoded blob directly.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `privacyidea/lib/tokens/vascotoken.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # License: AGPLv3
4 # contact: http://www.privacyidea.org
5 #
6 # 2018-01-15 Friedrich Weber <[email protected]>
7 # Initial version of the VASCO token
8 #
9 # This code is free software; you can redistribute it and/or
10 # modify it under the terms of the GNU AFFERO GENERAL PUBLIC LICENSE
11 # License as published by the Free Software Foundation; either
12 # version 3 of the License, or any later version.
13 #
14 # This code is distributed in the hope that it will be useful,
15 # but WITHOUT ANY WARRANTY; without even the implied warranty of
16 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
17 # GNU AFFERO GENERAL PUBLIC LICENSE for more details.
18 #
19 # You should have received a copy of the GNU Affero General Public
20 # License along with this program. If not, see <http://www.gnu.org/licenses/>.
21 #
22 #
23 import binascii
24
25 __doc__ = """This is the implementation of the VASCO token"""
26
27 import logging
28 from privacyidea.api.lib.utils import getParam
29 from privacyidea.lib.utils import is_true
30 from privacyidea.lib.decorators import check_token_locked
31 from privacyidea.lib.error import ParameterError
32 from privacyidea.lib.log import log_with
33 from privacyidea.lib.tokenclass import TokenClass
34 from privacyidea.lib.tokens.vasco import vasco_otp_check
35 from privacyidea.lib import _
36
37 optional = True
38 required = False
39
40 log = logging.getLogger(__name__)
41
42
43 class VascoTokenClass(TokenClass):
44 """
45 Token class for VASCO Digipass tokens. Relies on vendor-specific
46 shared library, whose location needs to be set in the PI_VASCO_LIBRARY
47 config option.
48
49 VASCO Tokens can be read from a CSV file which is structured as follows::
50
51 <serial1>,<hexlify(blob1)>,vasco
52 <serial2>,<hexlify(blob2)>,vasco
53 ...
54
55 whereas blobX is the 248-byte blob holding the token information.
56 Consequently, hexlify(blobX) is a 496-character hex string.
57
58 The CSV file can be imported by using the "Import Tokens" feature of the Web UI,
59 where "OATH CSV" needs to be chosen as the file type.
60 """
61
62 def __init__(self, db_token):
63 """
64 constructor - create a token class object with its db token binding
65
66 :param aToken: the db bound token
67 """
68 TokenClass.__init__(self, db_token)
69 self.set_type(u"vasco")
70 self.hKeyRequired = True
71
72 @staticmethod
73 def get_class_type():
74 """
75 return the class type identifier
76 """
77 return "vasco"
78
79 @staticmethod
80 def get_class_prefix():
81 """
82 return the token type prefix
83 """
84 # TODO: Revisit token type?
85 return "VASC"
86
87 @staticmethod
88 @log_with(log)
89 def get_class_info(key=None, ret='all'):
90 """
91 :param key: subsection identifier
92 :type key: string
93 :param ret: default return value, if nothing is found
94 :type ret: user defined
95 :return: subsection if key exists or user defined
96 :rtype: dict or string
97 """
98 res = {'type': 'vasco',
99 'title': 'VASCO Token',
100 'description': _('VASCO Token: Authentication using VASCO tokens'),
101 'user': ["enroll"],
102 'policy': {},
103 }
104
105 if key:
106 ret = res.get(key, {})
107 else:
108 if ret == 'all':
109 ret = res
110 return ret
111
112 @log_with(log)
113 def update(self, param, reset_failcount=True):
114 """
115 update - process initialization parameters
116
117 :param param: dict of initialization parameters
118 :type param: dict
119
120 :return: nothing
121 """
122 if is_true(getParam(param, 'genkey', optional)):
123 raise ParameterError("Generating OTP keys is not supported")
124
125 upd_param = param.copy()
126
127 # If the OTP key is given, it is given as a 496-character hex string which
128 # encodes a 248-byte blob. As we want to set a 248-byte OTPKey (= Blob),
129 # we unhexlify the OTP key
130 if 'otpkey' in param:
131 if len(param['otpkey']) != 496:
132 raise ParameterError('Expected OTP key as 496-character hex string, but length is {!s}'.format(
133 len(param['otpkey'])
134 ))
135 upd_param['otpkey'] = binascii.unhexlify(upd_param['otpkey'])
136
137 TokenClass.update(self, upd_param, reset_failcount)
138
139 @check_token_locked
140 def check_otp(self, otpval, counter=None, window=None, options=None):
141 secret = self.token.get_otpkey().getKey()
142 result, new_secret = vasco_otp_check(secret, otpval)
143 # By default, setting a new OTP key resets the failcounter. In case of the VASCO token,
144 # this would mean that the failcounter is reset at every authentication attempt
145 # (regardless of success or failure), which must be avoided.
146 self.token.set_otpkey(new_secret, reset_failcount=False)
147 self.save()
148
149 if result == 0:
150 # Successful authentication
151 return 0
152 else:
153 if result == 1:
154 # wrong OTP value, no log message
155 pass
156 elif result == 201:
157 log.warning("A previous OTP value was used again!")
158 elif result == 202:
159 log.warning("Token-internal fail counter reached its maximum!")
160 else:
161 log.warning("VASCO token failed to authenticate, result: {!r}".format(result))
162 return -1
163
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/privacyidea/lib/tokens/vascotoken.py b/privacyidea/lib/tokens/vascotoken.py
--- a/privacyidea/lib/tokens/vascotoken.py
+++ b/privacyidea/lib/tokens/vascotoken.py
@@ -98,7 +98,10 @@
res = {'type': 'vasco',
'title': 'VASCO Token',
'description': _('VASCO Token: Authentication using VASCO tokens'),
- 'user': ["enroll"],
+ # If this was set, the user could enroll a Vasco token via the API
+ #'user': ["enroll"],
+ # only administrators can enroll the token in the UI
+ 'ui_enroll': ["admin"],
'policy': {},
}
|
{"golden_diff": "diff --git a/privacyidea/lib/tokens/vascotoken.py b/privacyidea/lib/tokens/vascotoken.py\n--- a/privacyidea/lib/tokens/vascotoken.py\n+++ b/privacyidea/lib/tokens/vascotoken.py\n@@ -98,7 +98,10 @@\n res = {'type': 'vasco',\n 'title': 'VASCO Token',\n 'description': _('VASCO Token: Authentication using VASCO tokens'),\n- 'user': [\"enroll\"],\n+ # If this was set, the user could enroll a Vasco token via the API\n+ #'user': [\"enroll\"],\n+ # only administrators can enroll the token in the UI\n+ 'ui_enroll': [\"admin\"],\n 'policy': {},\n }\n", "issue": "Add VASCO token type to web UI\nAs we cannot generate new secrets by ourselves, we just add a possibility to enter a hex-encoded blob directly.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# License: AGPLv3\n# contact: http://www.privacyidea.org\n#\n# 2018-01-15 Friedrich Weber <[email protected]>\n# Initial version of the VASCO token\n#\n# This code is free software; you can redistribute it and/or\n# modify it under the terms of the GNU AFFERO GENERAL PUBLIC LICENSE\n# License as published by the Free Software Foundation; either\n# version 3 of the License, or any later version.\n#\n# This code is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU AFFERO GENERAL PUBLIC LICENSE for more details.\n#\n# You should have received a copy of the GNU Affero General Public\n# License along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\n#\nimport binascii\n\n__doc__ = \"\"\"This is the implementation of the VASCO token\"\"\"\n\nimport logging\nfrom privacyidea.api.lib.utils import getParam\nfrom privacyidea.lib.utils import is_true\nfrom privacyidea.lib.decorators import check_token_locked\nfrom privacyidea.lib.error import ParameterError\nfrom privacyidea.lib.log import log_with\nfrom privacyidea.lib.tokenclass import TokenClass\nfrom privacyidea.lib.tokens.vasco import vasco_otp_check\nfrom privacyidea.lib import _\n\noptional = True\nrequired = False\n\nlog = logging.getLogger(__name__)\n\n\nclass VascoTokenClass(TokenClass):\n \"\"\"\n Token class for VASCO Digipass tokens. Relies on vendor-specific\n shared library, whose location needs to be set in the PI_VASCO_LIBRARY\n config option.\n\n VASCO Tokens can be read from a CSV file which is structured as follows::\n\n <serial1>,<hexlify(blob1)>,vasco\n <serial2>,<hexlify(blob2)>,vasco\n ...\n\n whereas blobX is the 248-byte blob holding the token information.\n Consequently, hexlify(blobX) is a 496-character hex string.\n\n The CSV file can be imported by using the \"Import Tokens\" feature of the Web UI,\n where \"OATH CSV\" needs to be chosen as the file type.\n \"\"\"\n\n def __init__(self, db_token):\n \"\"\"\n constructor - create a token class object with its db token binding\n\n :param aToken: the db bound token\n \"\"\"\n TokenClass.__init__(self, db_token)\n self.set_type(u\"vasco\")\n self.hKeyRequired = True\n\n @staticmethod\n def get_class_type():\n \"\"\"\n return the class type identifier\n \"\"\"\n return \"vasco\"\n\n @staticmethod\n def get_class_prefix():\n \"\"\"\n return the token type prefix\n \"\"\"\n # TODO: Revisit token type?\n return \"VASC\"\n\n @staticmethod\n @log_with(log)\n def get_class_info(key=None, ret='all'):\n \"\"\"\n :param key: subsection identifier\n :type key: string\n :param ret: default return value, if nothing is found\n :type ret: user defined\n :return: subsection if key exists or user defined\n :rtype: dict or string\n \"\"\"\n res = {'type': 'vasco',\n 'title': 'VASCO Token',\n 'description': _('VASCO Token: Authentication using VASCO tokens'),\n 'user': [\"enroll\"],\n 'policy': {},\n }\n\n if key:\n ret = res.get(key, {})\n else:\n if ret == 'all':\n ret = res\n return ret\n\n @log_with(log)\n def update(self, param, reset_failcount=True):\n \"\"\"\n update - process initialization parameters\n\n :param param: dict of initialization parameters\n :type param: dict\n\n :return: nothing\n \"\"\"\n if is_true(getParam(param, 'genkey', optional)):\n raise ParameterError(\"Generating OTP keys is not supported\")\n\n upd_param = param.copy()\n\n # If the OTP key is given, it is given as a 496-character hex string which\n # encodes a 248-byte blob. As we want to set a 248-byte OTPKey (= Blob),\n # we unhexlify the OTP key\n if 'otpkey' in param:\n if len(param['otpkey']) != 496:\n raise ParameterError('Expected OTP key as 496-character hex string, but length is {!s}'.format(\n len(param['otpkey'])\n ))\n upd_param['otpkey'] = binascii.unhexlify(upd_param['otpkey'])\n\n TokenClass.update(self, upd_param, reset_failcount)\n\n @check_token_locked\n def check_otp(self, otpval, counter=None, window=None, options=None):\n secret = self.token.get_otpkey().getKey()\n result, new_secret = vasco_otp_check(secret, otpval)\n # By default, setting a new OTP key resets the failcounter. In case of the VASCO token,\n # this would mean that the failcounter is reset at every authentication attempt\n # (regardless of success or failure), which must be avoided.\n self.token.set_otpkey(new_secret, reset_failcount=False)\n self.save()\n\n if result == 0:\n # Successful authentication\n return 0\n else:\n if result == 1:\n # wrong OTP value, no log message\n pass\n elif result == 201:\n log.warning(\"A previous OTP value was used again!\")\n elif result == 202:\n log.warning(\"Token-internal fail counter reached its maximum!\")\n else:\n log.warning(\"VASCO token failed to authenticate, result: {!r}\".format(result))\n return -1\n", "path": "privacyidea/lib/tokens/vascotoken.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# License: AGPLv3\n# contact: http://www.privacyidea.org\n#\n# 2018-01-15 Friedrich Weber <[email protected]>\n# Initial version of the VASCO token\n#\n# This code is free software; you can redistribute it and/or\n# modify it under the terms of the GNU AFFERO GENERAL PUBLIC LICENSE\n# License as published by the Free Software Foundation; either\n# version 3 of the License, or any later version.\n#\n# This code is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU AFFERO GENERAL PUBLIC LICENSE for more details.\n#\n# You should have received a copy of the GNU Affero General Public\n# License along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\n#\nimport binascii\n\n__doc__ = \"\"\"This is the implementation of the VASCO token\"\"\"\n\nimport logging\nfrom privacyidea.api.lib.utils import getParam\nfrom privacyidea.lib.utils import is_true\nfrom privacyidea.lib.decorators import check_token_locked\nfrom privacyidea.lib.error import ParameterError\nfrom privacyidea.lib.log import log_with\nfrom privacyidea.lib.tokenclass import TokenClass\nfrom privacyidea.lib.tokens.vasco import vasco_otp_check\nfrom privacyidea.lib import _\n\noptional = True\nrequired = False\n\nlog = logging.getLogger(__name__)\n\n\nclass VascoTokenClass(TokenClass):\n \"\"\"\n Token class for VASCO Digipass tokens. Relies on vendor-specific\n shared library, whose location needs to be set in the PI_VASCO_LIBRARY\n config option.\n\n VASCO Tokens can be read from a CSV file which is structured as follows::\n\n <serial1>,<hexlify(blob1)>,vasco\n <serial2>,<hexlify(blob2)>,vasco\n ...\n\n whereas blobX is the 248-byte blob holding the token information.\n Consequently, hexlify(blobX) is a 496-character hex string.\n\n The CSV file can be imported by using the \"Import Tokens\" feature of the Web UI,\n where \"OATH CSV\" needs to be chosen as the file type.\n \"\"\"\n\n def __init__(self, db_token):\n \"\"\"\n constructor - create a token class object with its db token binding\n\n :param aToken: the db bound token\n \"\"\"\n TokenClass.__init__(self, db_token)\n self.set_type(u\"vasco\")\n self.hKeyRequired = True\n\n @staticmethod\n def get_class_type():\n \"\"\"\n return the class type identifier\n \"\"\"\n return \"vasco\"\n\n @staticmethod\n def get_class_prefix():\n \"\"\"\n return the token type prefix\n \"\"\"\n # TODO: Revisit token type?\n return \"VASC\"\n\n @staticmethod\n @log_with(log)\n def get_class_info(key=None, ret='all'):\n \"\"\"\n :param key: subsection identifier\n :type key: string\n :param ret: default return value, if nothing is found\n :type ret: user defined\n :return: subsection if key exists or user defined\n :rtype: dict or string\n \"\"\"\n res = {'type': 'vasco',\n 'title': 'VASCO Token',\n 'description': _('VASCO Token: Authentication using VASCO tokens'),\n # If this was set, the user could enroll a Vasco token via the API\n #'user': [\"enroll\"],\n # only administrators can enroll the token in the UI\n 'ui_enroll': [\"admin\"],\n 'policy': {},\n }\n\n if key:\n ret = res.get(key, {})\n else:\n if ret == 'all':\n ret = res\n return ret\n\n @log_with(log)\n def update(self, param, reset_failcount=True):\n \"\"\"\n update - process initialization parameters\n\n :param param: dict of initialization parameters\n :type param: dict\n\n :return: nothing\n \"\"\"\n if is_true(getParam(param, 'genkey', optional)):\n raise ParameterError(\"Generating OTP keys is not supported\")\n\n upd_param = param.copy()\n\n # If the OTP key is given, it is given as a 496-character hex string which\n # encodes a 248-byte blob. As we want to set a 248-byte OTPKey (= Blob),\n # we unhexlify the OTP key\n if 'otpkey' in param:\n if len(param['otpkey']) != 496:\n raise ParameterError('Expected OTP key as 496-character hex string, but length is {!s}'.format(\n len(param['otpkey'])\n ))\n upd_param['otpkey'] = binascii.unhexlify(upd_param['otpkey'])\n\n TokenClass.update(self, upd_param, reset_failcount)\n\n @check_token_locked\n def check_otp(self, otpval, counter=None, window=None, options=None):\n secret = self.token.get_otpkey().getKey()\n result, new_secret = vasco_otp_check(secret, otpval)\n # By default, setting a new OTP key resets the failcounter. In case of the VASCO token,\n # this would mean that the failcounter is reset at every authentication attempt\n # (regardless of success or failure), which must be avoided.\n self.token.set_otpkey(new_secret, reset_failcount=False)\n self.save()\n\n if result == 0:\n # Successful authentication\n return 0\n else:\n if result == 1:\n # wrong OTP value, no log message\n pass\n elif result == 201:\n log.warning(\"A previous OTP value was used again!\")\n elif result == 202:\n log.warning(\"Token-internal fail counter reached its maximum!\")\n else:\n log.warning(\"VASCO token failed to authenticate, result: {!r}\".format(result))\n return -1\n", "path": "privacyidea/lib/tokens/vascotoken.py"}]}
| 1,973 | 172 |
gh_patches_debug_20184
|
rasdani/github-patches
|
git_diff
|
ourownstory__neural_prophet-456
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
benchmark typing error
### Discussed in https://github.com/ourownstory/neural_prophet/discussions/449
<div type='discussions-op-text'>
<sup>Originally posted by **akthammomani** October 23, 2021</sup>
@ourownstory, I went a head and installed the Library again using below in a fresh env:
```
git clone <copied link from github>
cd neural_prophet
pip install .
```
so when trying below:
```
from neuralprophet import NeuralProphet, set_log_level
from neuralprophet.benchmark import Dataset, NeuralProphetModel, SimpleExperiment, CrossValidationExperiment
```
I started to see a new error as shown below:
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_43524/177920820.py in <module>
1 from neuralprophet import NeuralProphet, set_log_level
----> 2 from neuralprophet.benchmark import Dataset, NeuralProphetModel, SimpleExperiment, CrossValidationExperiment
~\Anaconda3\envs\nprophet_v1\lib\site-packages\neuralprophet\benchmark.py in <module>
158
159
--> 160 @dataclass
161 class SimpleBenchmark:
162 """
~\Anaconda3\envs\nprophet_v1\lib\site-packages\neuralprophet\benchmark.py in SimpleBenchmark()
171 """
172
--> 173 model_classes_and_params: List[tuple[Model, dict]]
174 datasets: List[Dataset]
175 metrics: list[str]
TypeError: 'type' object is not subscriptable
```
Please let me know if you have any suggestions.... Thank you very much
BR//Aktham
</div>
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `neuralprophet/benchmark.py`
Content:
```
1 from dataclasses import dataclass, field
2 from typing import List, Optional, Tuple, Type
3 from abc import ABC, abstractmethod
4
5 import pandas as pd
6 import numpy as np
7 from neuralprophet import NeuralProphet
8
9
10 NeuralProphetModel = NeuralProphet
11
12
13 @dataclass
14 class Dataset:
15 """
16 example use:
17 >>> dataset = Dataset(
18 >>> df = load_data('tmp-data', 'air_passengers.csv'),
19 >>> name = "air_passengers",
20 >>> freq = "MS",
21 >>> ),
22 """
23
24 df: pd.DataFrame
25 name: str
26 freq: str
27
28
29 @dataclass
30 class Model(ABC):
31 """
32 example use:
33 >>> models = []
34 >>> for params in [{"n_changepoints": 5}, {"n_changepoints": 50},]:
35 >>> models.append(Model(
36 >>> params=params
37 >>> model_name="NeuralProphet",
38 >>> model_class=NeuralProphet,
39 >>> ))
40 """
41
42 params: dict
43 model_name: str
44 model_class: Type
45
46 @abstractmethod
47 def initialize(self):
48 pass
49
50
51 @dataclass
52 class NeuralProphetModel(Model):
53 model_name: str = "NeuralProphet"
54 model_class: Type = NeuralProphet
55
56 def initialize(self):
57 return NeuralProphet(**self.params)
58
59
60 @dataclass
61 class Experiment(ABC):
62 model_class: Model
63 params: dict
64 data: Dataset
65 metrics: List[str]
66 test_percentage: float
67 experiment_name: dict = field(init=False)
68
69 def __post_init__(self):
70 self.experiment_name = {
71 "data": self.data.name,
72 "model": self.model_class.model_name,
73 "params": str(self.params),
74 }
75
76 @abstractmethod
77 def fit(self):
78 pass
79
80
81 @dataclass
82 class SimpleExperiment(Experiment):
83 """
84 use example:
85 >>> ts = Dataset(df = air_passengers_df, name = "air_passengers", freq = "MS")
86 >>> params = {"seasonality_mode": "multiplicative"}
87 >>> exp = SimpleExperiment(
88 >>> model_class=NeuralProphetModel,
89 >>> params=params,
90 >>> data=ts,
91 >>> metrics=["MAE", "MSE"],
92 >>> test_percentage=25,
93 >>> )
94 >>> result_train, result_val = exp.fit()
95 """
96
97 def fit(self):
98 model_class = self.model_class(self.params)
99 model = model_class.initialize()
100 df_train, df_val = model.split_df(
101 df=self.data.df,
102 freq=self.data.freq,
103 valid_p=self.test_percentage / 100.0,
104 )
105 metrics_train = model.fit(df=df_train, freq=self.data.freq)
106 metrics_val = model.test(df=df_val)
107 result_train = self.experiment_name.copy()
108 result_val = self.experiment_name.copy()
109 for metric in self.metrics:
110 result_train[metric] = metrics_train[metric].values[-1]
111 result_val[metric] = metrics_val[metric].values[-1]
112 return result_train, result_val
113
114
115 @dataclass
116 class CrossValidationExperiment(Experiment):
117 """
118 >>> ts = Dataset(df = air_passengers_df, name = "air_passengers", freq = "MS")
119 >>> params = {"seasonality_mode": "multiplicative"}
120 >>> exp = CrossValidationExperiment(
121 >>> model_class=NeuralProphetModel,
122 >>> params=params,
123 >>> data=ts,
124 >>> metrics=["MAE", "MSE"],
125 >>> test_percentage=10,
126 >>> num_folds=3,
127 >>> fold_overlap_pct=0,
128 >>> )
129 >>> result_train, result_train, result_val = exp.fit()
130 """
131
132 num_folds: int
133 fold_overlap_pct: float = 0
134
135 def fit(self):
136 model_class = self.model_class(self.params)
137 folds = model_class.initialize().crossvalidation_split_df(
138 df=self.data.df,
139 freq=self.data.freq,
140 k=self.num_folds,
141 fold_pct=self.test_percentage / 100.0,
142 fold_overlap_pct=self.fold_overlap_pct / 100.0,
143 )
144 metrics_train = pd.DataFrame(columns=self.metrics)
145 metrics_val = pd.DataFrame(columns=self.metrics)
146 for df_train, df_val in folds:
147 m = model_class.initialize()
148 train = m.fit(df=df_train, freq=self.data.freq)
149 val = m.test(df=df_val)
150 metrics_train = metrics_train.append(train[self.metrics].iloc[-1])
151 metrics_val = metrics_val.append(val[self.metrics].iloc[-1])
152 result_train = self.experiment_name.copy()
153 result_val = self.experiment_name.copy()
154 for metric in self.metrics:
155 result_train[metric] = metrics_train[metric].tolist()
156 result_val[metric] = metrics_val[metric].tolist()
157 return result_train, result_val
158
159
160 @dataclass
161 class SimpleBenchmark:
162 """
163 use example:
164 >>> benchmark = SimpleBenchmark(
165 >>> model_classes_and_params=model_classes_and_params, # iterate over this list of tuples
166 >>> datasets=dataset_list, # iterate over this list
167 >>> metrics=["MAE", "MSE"],
168 >>> test_percentage=25,
169 >>> )
170 >>> results_train, results_val = benchmark.run()
171 """
172
173 model_classes_and_params: List[tuple[Model, dict]]
174 datasets: List[Dataset]
175 metrics: list[str]
176 test_percentage: float
177
178 def setup_experiments(self):
179 self.experiments = []
180 for ts in self.datasets:
181 for model_class, params in self.model_classes_and_params:
182 exp = SimpleExperiment(
183 model_class=model_class,
184 params=params,
185 data=ts,
186 metrics=self.metrics,
187 test_percentage=self.test_percentage,
188 )
189 self.experiments.append(exp)
190
191 def run(self):
192 self.setup_experiments()
193 cols = list(self.experiments[0].experiment_name.keys()) + self.metrics
194 results_train = pd.DataFrame(columns=cols)
195 results_val = pd.DataFrame(columns=cols)
196 for exp in self.experiments:
197 exp.metrics = self.metrics
198 res_train, res_val = exp.fit()
199 results_train = results_train.append(res_train, ignore_index=True)
200 results_val = results_val.append(res_val, ignore_index=True)
201 return results_train, results_val
202
203
204 @dataclass
205 class CrossValidationBenchmark(SimpleBenchmark):
206 """
207 example use:
208 >>> benchmark_cv = CrossValidationBenchmark(
209 >>> model_classes_and_params=model_classes_and_params, # iterate over this list of tuples
210 >>> datasets=dataset_list, # iterate over this list
211 >>> metrics=["MAE", "MSE"],
212 >>> test_percentage=10,
213 >>> num_folds=3,
214 >>> fold_overlap_pct=0,
215 >>> )
216 >>> results_summary, results_train, results_val = benchmark_cv.run()
217 """
218
219 num_folds: int
220 fold_overlap_pct: float = 0
221
222 def setup_experiments(self):
223 self.experiments = []
224 for ts in self.datasets:
225 for model_class, params in self.model_classes_and_params:
226 exp = CrossValidationExperiment(
227 model_class=model_class,
228 params=params,
229 data=ts,
230 metrics=self.metrics,
231 test_percentage=self.test_percentage,
232 num_folds=self.num_folds,
233 fold_overlap_pct=self.fold_overlap_pct,
234 )
235 self.experiments.append(exp)
236
237 def run(self):
238 results_train, results_val = super().run()
239 val = results_val.copy(deep=True)
240 train = results_train.copy(deep=True)
241 results_summary = results_val.copy(deep=True).drop(self.metrics, axis=1)
242 for metric in self.metrics:
243 results_summary["train_" + metric] = train[metric].apply(lambda x: np.array(x).mean())
244 results_summary["train_" + metric + "_std"] = train[metric].apply(lambda x: np.array(x).std())
245 for metric in self.metrics:
246 results_summary["val_" + metric] = val[metric].apply(lambda x: np.array(x).mean())
247 results_summary["val_" + metric + "_std"] = val[metric].apply(lambda x: np.array(x).std())
248 return results_summary, results_train, results_val
249
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/neuralprophet/benchmark.py b/neuralprophet/benchmark.py
--- a/neuralprophet/benchmark.py
+++ b/neuralprophet/benchmark.py
@@ -1,14 +1,17 @@
from dataclasses import dataclass, field
from typing import List, Optional, Tuple, Type
from abc import ABC, abstractmethod
+import logging
import pandas as pd
import numpy as np
from neuralprophet import NeuralProphet
-
NeuralProphetModel = NeuralProphet
+log = logging.getLogger("NP.benchmark")
+log.warning("Benchmarking Framework is not covered by tests. Please report any bugs you find.")
+
@dataclass
class Dataset:
@@ -170,9 +173,9 @@
>>> results_train, results_val = benchmark.run()
"""
- model_classes_and_params: List[tuple[Model, dict]]
+ model_classes_and_params: List[Tuple[Model, dict]]
datasets: List[Dataset]
- metrics: list[str]
+ metrics: List[str]
test_percentage: float
def setup_experiments(self):
|
{"golden_diff": "diff --git a/neuralprophet/benchmark.py b/neuralprophet/benchmark.py\n--- a/neuralprophet/benchmark.py\n+++ b/neuralprophet/benchmark.py\n@@ -1,14 +1,17 @@\n from dataclasses import dataclass, field\n from typing import List, Optional, Tuple, Type\n from abc import ABC, abstractmethod\n+import logging\n \n import pandas as pd\n import numpy as np\n from neuralprophet import NeuralProphet\n \n-\n NeuralProphetModel = NeuralProphet\n \n+log = logging.getLogger(\"NP.benchmark\")\n+log.warning(\"Benchmarking Framework is not covered by tests. Please report any bugs you find.\")\n+\n \n @dataclass\n class Dataset:\n@@ -170,9 +173,9 @@\n >>> results_train, results_val = benchmark.run()\n \"\"\"\n \n- model_classes_and_params: List[tuple[Model, dict]]\n+ model_classes_and_params: List[Tuple[Model, dict]]\n datasets: List[Dataset]\n- metrics: list[str]\n+ metrics: List[str]\n test_percentage: float\n \n def setup_experiments(self):\n", "issue": "benchmark typing error\n### Discussed in https://github.com/ourownstory/neural_prophet/discussions/449\r\n\r\n<div type='discussions-op-text'>\r\n\r\n<sup>Originally posted by **akthammomani** October 23, 2021</sup>\r\n@ourownstory, I went a head and installed the Library again using below in a fresh env: \r\n\r\n```\r\ngit clone <copied link from github>\r\ncd neural_prophet\r\npip install .\r\n```\r\n\r\nso when trying below:\r\n```\r\nfrom neuralprophet import NeuralProphet, set_log_level\r\nfrom neuralprophet.benchmark import Dataset, NeuralProphetModel, SimpleExperiment, CrossValidationExperiment\r\n```\r\n\r\nI started to see a new error as shown below: \r\n\r\n```\r\n---------------------------------------------------------------------------\r\nTypeError Traceback (most recent call last)\r\n~\\AppData\\Local\\Temp/ipykernel_43524/177920820.py in <module>\r\n 1 from neuralprophet import NeuralProphet, set_log_level\r\n----> 2 from neuralprophet.benchmark import Dataset, NeuralProphetModel, SimpleExperiment, CrossValidationExperiment\r\n\r\n~\\Anaconda3\\envs\\nprophet_v1\\lib\\site-packages\\neuralprophet\\benchmark.py in <module>\r\n 158 \r\n 159 \r\n--> 160 @dataclass\r\n 161 class SimpleBenchmark:\r\n 162 \"\"\"\r\n\r\n~\\Anaconda3\\envs\\nprophet_v1\\lib\\site-packages\\neuralprophet\\benchmark.py in SimpleBenchmark()\r\n 171 \"\"\"\r\n 172 \r\n--> 173 model_classes_and_params: List[tuple[Model, dict]]\r\n 174 datasets: List[Dataset]\r\n 175 metrics: list[str]\r\n\r\nTypeError: 'type' object is not subscriptable\r\n```\r\n\r\nPlease let me know if you have any suggestions.... Thank you very much\r\n\r\nBR//Aktham\r\n\r\n\r\n</div>\n", "before_files": [{"content": "from dataclasses import dataclass, field\nfrom typing import List, Optional, Tuple, Type\nfrom abc import ABC, abstractmethod\n\nimport pandas as pd\nimport numpy as np\nfrom neuralprophet import NeuralProphet\n\n\nNeuralProphetModel = NeuralProphet\n\n\n@dataclass\nclass Dataset:\n \"\"\"\n example use:\n >>> dataset = Dataset(\n >>> df = load_data('tmp-data', 'air_passengers.csv'),\n >>> name = \"air_passengers\",\n >>> freq = \"MS\",\n >>> ),\n \"\"\"\n\n df: pd.DataFrame\n name: str\n freq: str\n\n\n@dataclass\nclass Model(ABC):\n \"\"\"\n example use:\n >>> models = []\n >>> for params in [{\"n_changepoints\": 5}, {\"n_changepoints\": 50},]:\n >>> models.append(Model(\n >>> params=params\n >>> model_name=\"NeuralProphet\",\n >>> model_class=NeuralProphet,\n >>> ))\n \"\"\"\n\n params: dict\n model_name: str\n model_class: Type\n\n @abstractmethod\n def initialize(self):\n pass\n\n\n@dataclass\nclass NeuralProphetModel(Model):\n model_name: str = \"NeuralProphet\"\n model_class: Type = NeuralProphet\n\n def initialize(self):\n return NeuralProphet(**self.params)\n\n\n@dataclass\nclass Experiment(ABC):\n model_class: Model\n params: dict\n data: Dataset\n metrics: List[str]\n test_percentage: float\n experiment_name: dict = field(init=False)\n\n def __post_init__(self):\n self.experiment_name = {\n \"data\": self.data.name,\n \"model\": self.model_class.model_name,\n \"params\": str(self.params),\n }\n\n @abstractmethod\n def fit(self):\n pass\n\n\n@dataclass\nclass SimpleExperiment(Experiment):\n \"\"\"\n use example:\n >>> ts = Dataset(df = air_passengers_df, name = \"air_passengers\", freq = \"MS\")\n >>> params = {\"seasonality_mode\": \"multiplicative\"}\n >>> exp = SimpleExperiment(\n >>> model_class=NeuralProphetModel,\n >>> params=params,\n >>> data=ts,\n >>> metrics=[\"MAE\", \"MSE\"],\n >>> test_percentage=25,\n >>> )\n >>> result_train, result_val = exp.fit()\n \"\"\"\n\n def fit(self):\n model_class = self.model_class(self.params)\n model = model_class.initialize()\n df_train, df_val = model.split_df(\n df=self.data.df,\n freq=self.data.freq,\n valid_p=self.test_percentage / 100.0,\n )\n metrics_train = model.fit(df=df_train, freq=self.data.freq)\n metrics_val = model.test(df=df_val)\n result_train = self.experiment_name.copy()\n result_val = self.experiment_name.copy()\n for metric in self.metrics:\n result_train[metric] = metrics_train[metric].values[-1]\n result_val[metric] = metrics_val[metric].values[-1]\n return result_train, result_val\n\n\n@dataclass\nclass CrossValidationExperiment(Experiment):\n \"\"\"\n >>> ts = Dataset(df = air_passengers_df, name = \"air_passengers\", freq = \"MS\")\n >>> params = {\"seasonality_mode\": \"multiplicative\"}\n >>> exp = CrossValidationExperiment(\n >>> model_class=NeuralProphetModel,\n >>> params=params,\n >>> data=ts,\n >>> metrics=[\"MAE\", \"MSE\"],\n >>> test_percentage=10,\n >>> num_folds=3,\n >>> fold_overlap_pct=0,\n >>> )\n >>> result_train, result_train, result_val = exp.fit()\n \"\"\"\n\n num_folds: int\n fold_overlap_pct: float = 0\n\n def fit(self):\n model_class = self.model_class(self.params)\n folds = model_class.initialize().crossvalidation_split_df(\n df=self.data.df,\n freq=self.data.freq,\n k=self.num_folds,\n fold_pct=self.test_percentage / 100.0,\n fold_overlap_pct=self.fold_overlap_pct / 100.0,\n )\n metrics_train = pd.DataFrame(columns=self.metrics)\n metrics_val = pd.DataFrame(columns=self.metrics)\n for df_train, df_val in folds:\n m = model_class.initialize()\n train = m.fit(df=df_train, freq=self.data.freq)\n val = m.test(df=df_val)\n metrics_train = metrics_train.append(train[self.metrics].iloc[-1])\n metrics_val = metrics_val.append(val[self.metrics].iloc[-1])\n result_train = self.experiment_name.copy()\n result_val = self.experiment_name.copy()\n for metric in self.metrics:\n result_train[metric] = metrics_train[metric].tolist()\n result_val[metric] = metrics_val[metric].tolist()\n return result_train, result_val\n\n\n@dataclass\nclass SimpleBenchmark:\n \"\"\"\n use example:\n >>> benchmark = SimpleBenchmark(\n >>> model_classes_and_params=model_classes_and_params, # iterate over this list of tuples\n >>> datasets=dataset_list, # iterate over this list\n >>> metrics=[\"MAE\", \"MSE\"],\n >>> test_percentage=25,\n >>> )\n >>> results_train, results_val = benchmark.run()\n \"\"\"\n\n model_classes_and_params: List[tuple[Model, dict]]\n datasets: List[Dataset]\n metrics: list[str]\n test_percentage: float\n\n def setup_experiments(self):\n self.experiments = []\n for ts in self.datasets:\n for model_class, params in self.model_classes_and_params:\n exp = SimpleExperiment(\n model_class=model_class,\n params=params,\n data=ts,\n metrics=self.metrics,\n test_percentage=self.test_percentage,\n )\n self.experiments.append(exp)\n\n def run(self):\n self.setup_experiments()\n cols = list(self.experiments[0].experiment_name.keys()) + self.metrics\n results_train = pd.DataFrame(columns=cols)\n results_val = pd.DataFrame(columns=cols)\n for exp in self.experiments:\n exp.metrics = self.metrics\n res_train, res_val = exp.fit()\n results_train = results_train.append(res_train, ignore_index=True)\n results_val = results_val.append(res_val, ignore_index=True)\n return results_train, results_val\n\n\n@dataclass\nclass CrossValidationBenchmark(SimpleBenchmark):\n \"\"\"\n example use:\n >>> benchmark_cv = CrossValidationBenchmark(\n >>> model_classes_and_params=model_classes_and_params, # iterate over this list of tuples\n >>> datasets=dataset_list, # iterate over this list\n >>> metrics=[\"MAE\", \"MSE\"],\n >>> test_percentage=10,\n >>> num_folds=3,\n >>> fold_overlap_pct=0,\n >>> )\n >>> results_summary, results_train, results_val = benchmark_cv.run()\n \"\"\"\n\n num_folds: int\n fold_overlap_pct: float = 0\n\n def setup_experiments(self):\n self.experiments = []\n for ts in self.datasets:\n for model_class, params in self.model_classes_and_params:\n exp = CrossValidationExperiment(\n model_class=model_class,\n params=params,\n data=ts,\n metrics=self.metrics,\n test_percentage=self.test_percentage,\n num_folds=self.num_folds,\n fold_overlap_pct=self.fold_overlap_pct,\n )\n self.experiments.append(exp)\n\n def run(self):\n results_train, results_val = super().run()\n val = results_val.copy(deep=True)\n train = results_train.copy(deep=True)\n results_summary = results_val.copy(deep=True).drop(self.metrics, axis=1)\n for metric in self.metrics:\n results_summary[\"train_\" + metric] = train[metric].apply(lambda x: np.array(x).mean())\n results_summary[\"train_\" + metric + \"_std\"] = train[metric].apply(lambda x: np.array(x).std())\n for metric in self.metrics:\n results_summary[\"val_\" + metric] = val[metric].apply(lambda x: np.array(x).mean())\n results_summary[\"val_\" + metric + \"_std\"] = val[metric].apply(lambda x: np.array(x).std())\n return results_summary, results_train, results_val\n", "path": "neuralprophet/benchmark.py"}], "after_files": [{"content": "from dataclasses import dataclass, field\nfrom typing import List, Optional, Tuple, Type\nfrom abc import ABC, abstractmethod\nimport logging\n\nimport pandas as pd\nimport numpy as np\nfrom neuralprophet import NeuralProphet\n\nNeuralProphetModel = NeuralProphet\n\nlog = logging.getLogger(\"NP.benchmark\")\nlog.warning(\"Benchmarking Framework is not covered by tests. Please report any bugs you find.\")\n\n\n@dataclass\nclass Dataset:\n \"\"\"\n example use:\n >>> dataset = Dataset(\n >>> df = load_data('tmp-data', 'air_passengers.csv'),\n >>> name = \"air_passengers\",\n >>> freq = \"MS\",\n >>> ),\n \"\"\"\n\n df: pd.DataFrame\n name: str\n freq: str\n\n\n@dataclass\nclass Model(ABC):\n \"\"\"\n example use:\n >>> models = []\n >>> for params in [{\"n_changepoints\": 5}, {\"n_changepoints\": 50},]:\n >>> models.append(Model(\n >>> params=params\n >>> model_name=\"NeuralProphet\",\n >>> model_class=NeuralProphet,\n >>> ))\n \"\"\"\n\n params: dict\n model_name: str\n model_class: Type\n\n @abstractmethod\n def initialize(self):\n pass\n\n\n@dataclass\nclass NeuralProphetModel(Model):\n model_name: str = \"NeuralProphet\"\n model_class: Type = NeuralProphet\n\n def initialize(self):\n return NeuralProphet(**self.params)\n\n\n@dataclass\nclass Experiment(ABC):\n model_class: Model\n params: dict\n data: Dataset\n metrics: List[str]\n test_percentage: float\n experiment_name: dict = field(init=False)\n\n def __post_init__(self):\n self.experiment_name = {\n \"data\": self.data.name,\n \"model\": self.model_class.model_name,\n \"params\": str(self.params),\n }\n\n @abstractmethod\n def fit(self):\n pass\n\n\n@dataclass\nclass SimpleExperiment(Experiment):\n \"\"\"\n use example:\n >>> ts = Dataset(df = air_passengers_df, name = \"air_passengers\", freq = \"MS\")\n >>> params = {\"seasonality_mode\": \"multiplicative\"}\n >>> exp = SimpleExperiment(\n >>> model_class=NeuralProphetModel,\n >>> params=params,\n >>> data=ts,\n >>> metrics=[\"MAE\", \"MSE\"],\n >>> test_percentage=25,\n >>> )\n >>> result_train, result_val = exp.fit()\n \"\"\"\n\n def fit(self):\n model_class = self.model_class(self.params)\n model = model_class.initialize()\n df_train, df_val = model.split_df(\n df=self.data.df,\n freq=self.data.freq,\n valid_p=self.test_percentage / 100.0,\n )\n metrics_train = model.fit(df=df_train, freq=self.data.freq)\n metrics_val = model.test(df=df_val)\n result_train = self.experiment_name.copy()\n result_val = self.experiment_name.copy()\n for metric in self.metrics:\n result_train[metric] = metrics_train[metric].values[-1]\n result_val[metric] = metrics_val[metric].values[-1]\n return result_train, result_val\n\n\n@dataclass\nclass CrossValidationExperiment(Experiment):\n \"\"\"\n >>> ts = Dataset(df = air_passengers_df, name = \"air_passengers\", freq = \"MS\")\n >>> params = {\"seasonality_mode\": \"multiplicative\"}\n >>> exp = CrossValidationExperiment(\n >>> model_class=NeuralProphetModel,\n >>> params=params,\n >>> data=ts,\n >>> metrics=[\"MAE\", \"MSE\"],\n >>> test_percentage=10,\n >>> num_folds=3,\n >>> fold_overlap_pct=0,\n >>> )\n >>> result_train, result_train, result_val = exp.fit()\n \"\"\"\n\n num_folds: int\n fold_overlap_pct: float = 0\n\n def fit(self):\n model_class = self.model_class(self.params)\n folds = model_class.initialize().crossvalidation_split_df(\n df=self.data.df,\n freq=self.data.freq,\n k=self.num_folds,\n fold_pct=self.test_percentage / 100.0,\n fold_overlap_pct=self.fold_overlap_pct / 100.0,\n )\n metrics_train = pd.DataFrame(columns=self.metrics)\n metrics_val = pd.DataFrame(columns=self.metrics)\n for df_train, df_val in folds:\n m = model_class.initialize()\n train = m.fit(df=df_train, freq=self.data.freq)\n val = m.test(df=df_val)\n metrics_train = metrics_train.append(train[self.metrics].iloc[-1])\n metrics_val = metrics_val.append(val[self.metrics].iloc[-1])\n result_train = self.experiment_name.copy()\n result_val = self.experiment_name.copy()\n for metric in self.metrics:\n result_train[metric] = metrics_train[metric].tolist()\n result_val[metric] = metrics_val[metric].tolist()\n return result_train, result_val\n\n\n@dataclass\nclass SimpleBenchmark:\n \"\"\"\n use example:\n >>> benchmark = SimpleBenchmark(\n >>> model_classes_and_params=model_classes_and_params, # iterate over this list of tuples\n >>> datasets=dataset_list, # iterate over this list\n >>> metrics=[\"MAE\", \"MSE\"],\n >>> test_percentage=25,\n >>> )\n >>> results_train, results_val = benchmark.run()\n \"\"\"\n\n model_classes_and_params: List[Tuple[Model, dict]]\n datasets: List[Dataset]\n metrics: List[str]\n test_percentage: float\n\n def setup_experiments(self):\n self.experiments = []\n for ts in self.datasets:\n for model_class, params in self.model_classes_and_params:\n exp = SimpleExperiment(\n model_class=model_class,\n params=params,\n data=ts,\n metrics=self.metrics,\n test_percentage=self.test_percentage,\n )\n self.experiments.append(exp)\n\n def run(self):\n self.setup_experiments()\n cols = list(self.experiments[0].experiment_name.keys()) + self.metrics\n results_train = pd.DataFrame(columns=cols)\n results_val = pd.DataFrame(columns=cols)\n for exp in self.experiments:\n exp.metrics = self.metrics\n res_train, res_val = exp.fit()\n results_train = results_train.append(res_train, ignore_index=True)\n results_val = results_val.append(res_val, ignore_index=True)\n return results_train, results_val\n\n\n@dataclass\nclass CrossValidationBenchmark(SimpleBenchmark):\n \"\"\"\n example use:\n >>> benchmark_cv = CrossValidationBenchmark(\n >>> model_classes_and_params=model_classes_and_params, # iterate over this list of tuples\n >>> datasets=dataset_list, # iterate over this list\n >>> metrics=[\"MAE\", \"MSE\"],\n >>> test_percentage=10,\n >>> num_folds=3,\n >>> fold_overlap_pct=0,\n >>> )\n >>> results_summary, results_train, results_val = benchmark_cv.run()\n \"\"\"\n\n num_folds: int\n fold_overlap_pct: float = 0\n\n def setup_experiments(self):\n self.experiments = []\n for ts in self.datasets:\n for model_class, params in self.model_classes_and_params:\n exp = CrossValidationExperiment(\n model_class=model_class,\n params=params,\n data=ts,\n metrics=self.metrics,\n test_percentage=self.test_percentage,\n num_folds=self.num_folds,\n fold_overlap_pct=self.fold_overlap_pct,\n )\n self.experiments.append(exp)\n\n def run(self):\n results_train, results_val = super().run()\n val = results_val.copy(deep=True)\n train = results_train.copy(deep=True)\n results_summary = results_val.copy(deep=True).drop(self.metrics, axis=1)\n for metric in self.metrics:\n results_summary[\"train_\" + metric] = train[metric].apply(lambda x: np.array(x).mean())\n results_summary[\"train_\" + metric + \"_std\"] = train[metric].apply(lambda x: np.array(x).std())\n for metric in self.metrics:\n results_summary[\"val_\" + metric] = val[metric].apply(lambda x: np.array(x).mean())\n results_summary[\"val_\" + metric + \"_std\"] = val[metric].apply(lambda x: np.array(x).std())\n return results_summary, results_train, results_val\n", "path": "neuralprophet/benchmark.py"}]}
| 3,152 | 244 |
gh_patches_debug_14364
|
rasdani/github-patches
|
git_diff
|
nf-core__tools-1278
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
update modules in pipeline template
Merging https://github.com/nf-core/tools/pull/1247 broke a few tests on `dev` which we can fix by reinstalling the modules into the pipeline template, once they have been updated to emit a `versions.yml` in the modules repository (see also https://github.com/nf-core/modules/pull/665)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nf_core/lint/files_exist.py`
Content:
```
1 #!/usr/bin/env python
2
3 import os
4
5
6 def files_exist(self):
7 """Checks a given pipeline directory for required files.
8
9 Iterates through the pipeline's directory content and checks that specified
10 files are either present or absent, as required.
11
12 .. note::
13 This test raises an ``AssertionError`` if neither ``nextflow.config`` or ``main.nf`` are found.
14 If these files are not found then this cannot be a Nextflow pipeline and something has gone badly wrong.
15 All lint tests are stopped immediately with a critical error message.
16
17 Files that *must* be present:
18
19 .. code-block:: bash
20
21 .gitattributes
22 .gitignore
23 .markdownlint.yml
24 .github/.dockstore.yml
25 .github/CONTRIBUTING.md
26 .github/ISSUE_TEMPLATE/bug_report.md
27 .github/ISSUE_TEMPLATE/config.yml
28 .github/ISSUE_TEMPLATE/feature_request.md
29 .github/PULL_REQUEST_TEMPLATE.md
30 .github/workflows/branch.yml
31 .github/workflows/ci.yml
32 .github/workflows/linting_comment.yml
33 .github/workflows/linting.yml
34 [LICENSE, LICENSE.md, LICENCE, LICENCE.md] # NB: British / American spelling
35 assets/email_template.html
36 assets/email_template.txt
37 assets/nf-core-PIPELINE_logo.png
38 assets/sendmail_template.txt
39 conf/modules.config
40 conf/test.config
41 conf/test_full.config
42 CHANGELOG.md
43 CITATIONS.md
44 CODE_OF_CONDUCT.md
45 docs/images/nf-core-PIPELINE_logo.png
46 docs/output.md
47 docs/README.md
48 docs/usage.md
49 lib/nfcore_external_java_deps.jar
50 lib/NfcoreSchema.groovy
51 lib/NfcoreTemplate.groovy
52 lib/Utils.groovy
53 lib/WorkflowMain.groovy
54 modules/local/get_software_versions.nf
55 nextflow_schema.json
56 nextflow.config
57 README.md
58
59 Files that *should* be present:
60
61 .. code-block:: bash
62
63 main.nf
64 assets/multiqc_config.yaml
65 conf/base.config
66 conf/igenomes.config
67 .github/workflows/awstest.yml
68 .github/workflows/awsfulltest.yml
69 lib/WorkflowPIPELINE.groovy
70
71 Files that *must not* be present:
72
73 .. code-block:: bash
74
75 Singularity
76 parameters.settings.json
77 bin/markdown_to_html.r
78 conf/aws.config
79 .github/workflows/push_dockerhub.yml
80
81 Files that *should not* be present:
82
83 .. code-block:: bash
84
85 .travis.yml
86 """
87
88 passed = []
89 warned = []
90 failed = []
91 ignored = []
92
93 # NB: Should all be files, not directories
94 # List of lists. Passes if any of the files in the sublist are found.
95 #: test autodoc
96 short_name = self.nf_config["manifest.name"].strip("\"'").replace("nf-core/", "")
97 files_fail = [
98 [".gitattributes"],
99 [".gitignore"],
100 [".markdownlint.yml"],
101 ["CHANGELOG.md"],
102 ["CITATIONS.md"],
103 ["CODE_OF_CONDUCT.md"],
104 ["CODE_OF_CONDUCT.md"],
105 ["LICENSE", "LICENSE.md", "LICENCE", "LICENCE.md"], # NB: British / American spelling
106 ["nextflow_schema.json"],
107 ["nextflow.config"],
108 ["README.md"],
109 [os.path.join(".github", ".dockstore.yml")],
110 [os.path.join(".github", "CONTRIBUTING.md")],
111 [os.path.join(".github", "ISSUE_TEMPLATE", "bug_report.md")],
112 [os.path.join(".github", "ISSUE_TEMPLATE", "config.yml")],
113 [os.path.join(".github", "ISSUE_TEMPLATE", "feature_request.md")],
114 [os.path.join(".github", "PULL_REQUEST_TEMPLATE.md")],
115 [os.path.join(".github", "workflows", "branch.yml")],
116 [os.path.join(".github", "workflows", "ci.yml")],
117 [os.path.join(".github", "workflows", "linting_comment.yml")],
118 [os.path.join(".github", "workflows", "linting.yml")],
119 [os.path.join("assets", "email_template.html")],
120 [os.path.join("assets", "email_template.txt")],
121 [os.path.join("assets", "sendmail_template.txt")],
122 [os.path.join("assets", f"nf-core-{short_name}_logo.png")],
123 [os.path.join("conf", "modules.config")],
124 [os.path.join("conf", "test.config")],
125 [os.path.join("conf", "test_full.config")],
126 [os.path.join("docs", "images", f"nf-core-{short_name}_logo.png")],
127 [os.path.join("docs", "output.md")],
128 [os.path.join("docs", "README.md")],
129 [os.path.join("docs", "README.md")],
130 [os.path.join("docs", "usage.md")],
131 [os.path.join("lib", "nfcore_external_java_deps.jar")],
132 [os.path.join("lib", "NfcoreSchema.groovy")],
133 [os.path.join("lib", "NfcoreTemplate.groovy")],
134 [os.path.join("lib", "Utils.groovy")],
135 [os.path.join("lib", "WorkflowMain.groovy")],
136 [os.path.join("modules", "local", "get_software_versions.nf")],
137 ]
138
139 files_warn = [
140 ["main.nf"],
141 [os.path.join("assets", "multiqc_config.yaml")],
142 [os.path.join("conf", "base.config")],
143 [os.path.join("conf", "igenomes.config")],
144 [os.path.join(".github", "workflows", "awstest.yml")],
145 [os.path.join(".github", "workflows", "awsfulltest.yml")],
146 [os.path.join("lib", f"Workflow{short_name[0].upper()}{short_name[1:]}.groovy")],
147 ["modules.json"],
148 ]
149
150 # List of strings. Fails / warns if any of the strings exist.
151 files_fail_ifexists = [
152 "Singularity",
153 "parameters.settings.json",
154 os.path.join("bin", "markdown_to_html.r"),
155 os.path.join("conf", "aws.config"),
156 os.path.join(".github", "workflows", "push_dockerhub.yml"),
157 ]
158 files_warn_ifexists = [".travis.yml"]
159
160 # Remove files that should be ignored according to the linting config
161 ignore_files = self.lint_config.get("files_exist", [])
162
163 def pf(file_path):
164 return os.path.join(self.wf_path, file_path)
165
166 # First - critical files. Check that this is actually a Nextflow pipeline
167 if not os.path.isfile(pf("nextflow.config")) and not os.path.isfile(pf("main.nf")):
168 failed.append("File not found: nextflow.config or main.nf")
169 raise AssertionError("Neither nextflow.config or main.nf found! Is this a Nextflow pipeline?")
170
171 # Files that cause an error if they don't exist
172 for files in files_fail:
173 if any([f in ignore_files for f in files]):
174 continue
175 if any([os.path.isfile(pf(f)) for f in files]):
176 passed.append("File found: {}".format(self._wrap_quotes(files)))
177 else:
178 failed.append("File not found: {}".format(self._wrap_quotes(files)))
179
180 # Files that cause a warning if they don't exist
181 for files in files_warn:
182 if any([f in ignore_files for f in files]):
183 continue
184 if any([os.path.isfile(pf(f)) for f in files]):
185 passed.append("File found: {}".format(self._wrap_quotes(files)))
186 else:
187 warned.append("File not found: {}".format(self._wrap_quotes(files)))
188
189 # Files that cause an error if they exist
190 for file in files_fail_ifexists:
191 if file in ignore_files:
192 continue
193 if os.path.isfile(pf(file)):
194 failed.append("File must be removed: {}".format(self._wrap_quotes(file)))
195 else:
196 passed.append("File not found check: {}".format(self._wrap_quotes(file)))
197
198 # Files that cause a warning if they exist
199 for file in files_warn_ifexists:
200 if file in ignore_files:
201 continue
202 if os.path.isfile(pf(file)):
203 warned.append("File should be removed: {}".format(self._wrap_quotes(file)))
204 else:
205 passed.append("File not found check: {}".format(self._wrap_quotes(file)))
206
207 # Files that are ignoed
208 for file in ignore_files:
209 ignored.append("File is ignored: {}".format(self._wrap_quotes(file)))
210
211 return {"passed": passed, "warned": warned, "failed": failed, "ignored": ignored}
212
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nf_core/lint/files_exist.py b/nf_core/lint/files_exist.py
--- a/nf_core/lint/files_exist.py
+++ b/nf_core/lint/files_exist.py
@@ -51,7 +51,6 @@
lib/NfcoreTemplate.groovy
lib/Utils.groovy
lib/WorkflowMain.groovy
- modules/local/get_software_versions.nf
nextflow_schema.json
nextflow.config
README.md
@@ -133,7 +132,6 @@
[os.path.join("lib", "NfcoreTemplate.groovy")],
[os.path.join("lib", "Utils.groovy")],
[os.path.join("lib", "WorkflowMain.groovy")],
- [os.path.join("modules", "local", "get_software_versions.nf")],
]
files_warn = [
|
{"golden_diff": "diff --git a/nf_core/lint/files_exist.py b/nf_core/lint/files_exist.py\n--- a/nf_core/lint/files_exist.py\n+++ b/nf_core/lint/files_exist.py\n@@ -51,7 +51,6 @@\n lib/NfcoreTemplate.groovy\n lib/Utils.groovy\n lib/WorkflowMain.groovy\n- modules/local/get_software_versions.nf\n nextflow_schema.json\n nextflow.config\n README.md\n@@ -133,7 +132,6 @@\n [os.path.join(\"lib\", \"NfcoreTemplate.groovy\")],\n [os.path.join(\"lib\", \"Utils.groovy\")],\n [os.path.join(\"lib\", \"WorkflowMain.groovy\")],\n- [os.path.join(\"modules\", \"local\", \"get_software_versions.nf\")],\n ]\n \n files_warn = [\n", "issue": "update modules in pipeline template\nMerging https://github.com/nf-core/tools/pull/1247 broke a few tests on `dev` which we can fix by reinstalling the modules into the pipeline template, once they have been updated to emit a `versions.yml` in the modules repository (see also https://github.com/nf-core/modules/pull/665) \n", "before_files": [{"content": "#!/usr/bin/env python\n\nimport os\n\n\ndef files_exist(self):\n \"\"\"Checks a given pipeline directory for required files.\n\n Iterates through the pipeline's directory content and checks that specified\n files are either present or absent, as required.\n\n .. note::\n This test raises an ``AssertionError`` if neither ``nextflow.config`` or ``main.nf`` are found.\n If these files are not found then this cannot be a Nextflow pipeline and something has gone badly wrong.\n All lint tests are stopped immediately with a critical error message.\n\n Files that *must* be present:\n\n .. code-block:: bash\n\n .gitattributes\n .gitignore\n .markdownlint.yml\n .github/.dockstore.yml\n .github/CONTRIBUTING.md\n .github/ISSUE_TEMPLATE/bug_report.md\n .github/ISSUE_TEMPLATE/config.yml\n .github/ISSUE_TEMPLATE/feature_request.md\n .github/PULL_REQUEST_TEMPLATE.md\n .github/workflows/branch.yml\n .github/workflows/ci.yml\n .github/workflows/linting_comment.yml\n .github/workflows/linting.yml\n [LICENSE, LICENSE.md, LICENCE, LICENCE.md] # NB: British / American spelling\n assets/email_template.html\n assets/email_template.txt\n assets/nf-core-PIPELINE_logo.png\n assets/sendmail_template.txt\n conf/modules.config\n conf/test.config\n conf/test_full.config\n CHANGELOG.md\n CITATIONS.md\n CODE_OF_CONDUCT.md\n docs/images/nf-core-PIPELINE_logo.png\n docs/output.md\n docs/README.md\n docs/usage.md\n lib/nfcore_external_java_deps.jar\n lib/NfcoreSchema.groovy\n lib/NfcoreTemplate.groovy\n lib/Utils.groovy\n lib/WorkflowMain.groovy\n modules/local/get_software_versions.nf\n nextflow_schema.json\n nextflow.config\n README.md\n\n Files that *should* be present:\n\n .. code-block:: bash\n\n main.nf\n assets/multiqc_config.yaml\n conf/base.config\n conf/igenomes.config\n .github/workflows/awstest.yml\n .github/workflows/awsfulltest.yml\n lib/WorkflowPIPELINE.groovy\n\n Files that *must not* be present:\n\n .. code-block:: bash\n\n Singularity\n parameters.settings.json\n bin/markdown_to_html.r\n conf/aws.config\n .github/workflows/push_dockerhub.yml\n\n Files that *should not* be present:\n\n .. code-block:: bash\n\n .travis.yml\n \"\"\"\n\n passed = []\n warned = []\n failed = []\n ignored = []\n\n # NB: Should all be files, not directories\n # List of lists. Passes if any of the files in the sublist are found.\n #: test autodoc\n short_name = self.nf_config[\"manifest.name\"].strip(\"\\\"'\").replace(\"nf-core/\", \"\")\n files_fail = [\n [\".gitattributes\"],\n [\".gitignore\"],\n [\".markdownlint.yml\"],\n [\"CHANGELOG.md\"],\n [\"CITATIONS.md\"],\n [\"CODE_OF_CONDUCT.md\"],\n [\"CODE_OF_CONDUCT.md\"],\n [\"LICENSE\", \"LICENSE.md\", \"LICENCE\", \"LICENCE.md\"], # NB: British / American spelling\n [\"nextflow_schema.json\"],\n [\"nextflow.config\"],\n [\"README.md\"],\n [os.path.join(\".github\", \".dockstore.yml\")],\n [os.path.join(\".github\", \"CONTRIBUTING.md\")],\n [os.path.join(\".github\", \"ISSUE_TEMPLATE\", \"bug_report.md\")],\n [os.path.join(\".github\", \"ISSUE_TEMPLATE\", \"config.yml\")],\n [os.path.join(\".github\", \"ISSUE_TEMPLATE\", \"feature_request.md\")],\n [os.path.join(\".github\", \"PULL_REQUEST_TEMPLATE.md\")],\n [os.path.join(\".github\", \"workflows\", \"branch.yml\")],\n [os.path.join(\".github\", \"workflows\", \"ci.yml\")],\n [os.path.join(\".github\", \"workflows\", \"linting_comment.yml\")],\n [os.path.join(\".github\", \"workflows\", \"linting.yml\")],\n [os.path.join(\"assets\", \"email_template.html\")],\n [os.path.join(\"assets\", \"email_template.txt\")],\n [os.path.join(\"assets\", \"sendmail_template.txt\")],\n [os.path.join(\"assets\", f\"nf-core-{short_name}_logo.png\")],\n [os.path.join(\"conf\", \"modules.config\")],\n [os.path.join(\"conf\", \"test.config\")],\n [os.path.join(\"conf\", \"test_full.config\")],\n [os.path.join(\"docs\", \"images\", f\"nf-core-{short_name}_logo.png\")],\n [os.path.join(\"docs\", \"output.md\")],\n [os.path.join(\"docs\", \"README.md\")],\n [os.path.join(\"docs\", \"README.md\")],\n [os.path.join(\"docs\", \"usage.md\")],\n [os.path.join(\"lib\", \"nfcore_external_java_deps.jar\")],\n [os.path.join(\"lib\", \"NfcoreSchema.groovy\")],\n [os.path.join(\"lib\", \"NfcoreTemplate.groovy\")],\n [os.path.join(\"lib\", \"Utils.groovy\")],\n [os.path.join(\"lib\", \"WorkflowMain.groovy\")],\n [os.path.join(\"modules\", \"local\", \"get_software_versions.nf\")],\n ]\n\n files_warn = [\n [\"main.nf\"],\n [os.path.join(\"assets\", \"multiqc_config.yaml\")],\n [os.path.join(\"conf\", \"base.config\")],\n [os.path.join(\"conf\", \"igenomes.config\")],\n [os.path.join(\".github\", \"workflows\", \"awstest.yml\")],\n [os.path.join(\".github\", \"workflows\", \"awsfulltest.yml\")],\n [os.path.join(\"lib\", f\"Workflow{short_name[0].upper()}{short_name[1:]}.groovy\")],\n [\"modules.json\"],\n ]\n\n # List of strings. Fails / warns if any of the strings exist.\n files_fail_ifexists = [\n \"Singularity\",\n \"parameters.settings.json\",\n os.path.join(\"bin\", \"markdown_to_html.r\"),\n os.path.join(\"conf\", \"aws.config\"),\n os.path.join(\".github\", \"workflows\", \"push_dockerhub.yml\"),\n ]\n files_warn_ifexists = [\".travis.yml\"]\n\n # Remove files that should be ignored according to the linting config\n ignore_files = self.lint_config.get(\"files_exist\", [])\n\n def pf(file_path):\n return os.path.join(self.wf_path, file_path)\n\n # First - critical files. Check that this is actually a Nextflow pipeline\n if not os.path.isfile(pf(\"nextflow.config\")) and not os.path.isfile(pf(\"main.nf\")):\n failed.append(\"File not found: nextflow.config or main.nf\")\n raise AssertionError(\"Neither nextflow.config or main.nf found! Is this a Nextflow pipeline?\")\n\n # Files that cause an error if they don't exist\n for files in files_fail:\n if any([f in ignore_files for f in files]):\n continue\n if any([os.path.isfile(pf(f)) for f in files]):\n passed.append(\"File found: {}\".format(self._wrap_quotes(files)))\n else:\n failed.append(\"File not found: {}\".format(self._wrap_quotes(files)))\n\n # Files that cause a warning if they don't exist\n for files in files_warn:\n if any([f in ignore_files for f in files]):\n continue\n if any([os.path.isfile(pf(f)) for f in files]):\n passed.append(\"File found: {}\".format(self._wrap_quotes(files)))\n else:\n warned.append(\"File not found: {}\".format(self._wrap_quotes(files)))\n\n # Files that cause an error if they exist\n for file in files_fail_ifexists:\n if file in ignore_files:\n continue\n if os.path.isfile(pf(file)):\n failed.append(\"File must be removed: {}\".format(self._wrap_quotes(file)))\n else:\n passed.append(\"File not found check: {}\".format(self._wrap_quotes(file)))\n\n # Files that cause a warning if they exist\n for file in files_warn_ifexists:\n if file in ignore_files:\n continue\n if os.path.isfile(pf(file)):\n warned.append(\"File should be removed: {}\".format(self._wrap_quotes(file)))\n else:\n passed.append(\"File not found check: {}\".format(self._wrap_quotes(file)))\n\n # Files that are ignoed\n for file in ignore_files:\n ignored.append(\"File is ignored: {}\".format(self._wrap_quotes(file)))\n\n return {\"passed\": passed, \"warned\": warned, \"failed\": failed, \"ignored\": ignored}\n", "path": "nf_core/lint/files_exist.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\nimport os\n\n\ndef files_exist(self):\n \"\"\"Checks a given pipeline directory for required files.\n\n Iterates through the pipeline's directory content and checks that specified\n files are either present or absent, as required.\n\n .. note::\n This test raises an ``AssertionError`` if neither ``nextflow.config`` or ``main.nf`` are found.\n If these files are not found then this cannot be a Nextflow pipeline and something has gone badly wrong.\n All lint tests are stopped immediately with a critical error message.\n\n Files that *must* be present:\n\n .. code-block:: bash\n\n .gitattributes\n .gitignore\n .markdownlint.yml\n .github/.dockstore.yml\n .github/CONTRIBUTING.md\n .github/ISSUE_TEMPLATE/bug_report.md\n .github/ISSUE_TEMPLATE/config.yml\n .github/ISSUE_TEMPLATE/feature_request.md\n .github/PULL_REQUEST_TEMPLATE.md\n .github/workflows/branch.yml\n .github/workflows/ci.yml\n .github/workflows/linting_comment.yml\n .github/workflows/linting.yml\n [LICENSE, LICENSE.md, LICENCE, LICENCE.md] # NB: British / American spelling\n assets/email_template.html\n assets/email_template.txt\n assets/nf-core-PIPELINE_logo.png\n assets/sendmail_template.txt\n conf/modules.config\n conf/test.config\n conf/test_full.config\n CHANGELOG.md\n CITATIONS.md\n CODE_OF_CONDUCT.md\n docs/images/nf-core-PIPELINE_logo.png\n docs/output.md\n docs/README.md\n docs/usage.md\n lib/nfcore_external_java_deps.jar\n lib/NfcoreSchema.groovy\n lib/NfcoreTemplate.groovy\n lib/Utils.groovy\n lib/WorkflowMain.groovy\n nextflow_schema.json\n nextflow.config\n README.md\n\n Files that *should* be present:\n\n .. code-block:: bash\n\n main.nf\n assets/multiqc_config.yaml\n conf/base.config\n conf/igenomes.config\n .github/workflows/awstest.yml\n .github/workflows/awsfulltest.yml\n lib/WorkflowPIPELINE.groovy\n\n Files that *must not* be present:\n\n .. code-block:: bash\n\n Singularity\n parameters.settings.json\n bin/markdown_to_html.r\n conf/aws.config\n .github/workflows/push_dockerhub.yml\n\n Files that *should not* be present:\n\n .. code-block:: bash\n\n .travis.yml\n \"\"\"\n\n passed = []\n warned = []\n failed = []\n ignored = []\n\n # NB: Should all be files, not directories\n # List of lists. Passes if any of the files in the sublist are found.\n #: test autodoc\n short_name = self.nf_config[\"manifest.name\"].strip(\"\\\"'\").replace(\"nf-core/\", \"\")\n files_fail = [\n [\".gitattributes\"],\n [\".gitignore\"],\n [\".markdownlint.yml\"],\n [\"CHANGELOG.md\"],\n [\"CITATIONS.md\"],\n [\"CODE_OF_CONDUCT.md\"],\n [\"CODE_OF_CONDUCT.md\"],\n [\"LICENSE\", \"LICENSE.md\", \"LICENCE\", \"LICENCE.md\"], # NB: British / American spelling\n [\"nextflow_schema.json\"],\n [\"nextflow.config\"],\n [\"README.md\"],\n [os.path.join(\".github\", \".dockstore.yml\")],\n [os.path.join(\".github\", \"CONTRIBUTING.md\")],\n [os.path.join(\".github\", \"ISSUE_TEMPLATE\", \"bug_report.md\")],\n [os.path.join(\".github\", \"ISSUE_TEMPLATE\", \"config.yml\")],\n [os.path.join(\".github\", \"ISSUE_TEMPLATE\", \"feature_request.md\")],\n [os.path.join(\".github\", \"PULL_REQUEST_TEMPLATE.md\")],\n [os.path.join(\".github\", \"workflows\", \"branch.yml\")],\n [os.path.join(\".github\", \"workflows\", \"ci.yml\")],\n [os.path.join(\".github\", \"workflows\", \"linting_comment.yml\")],\n [os.path.join(\".github\", \"workflows\", \"linting.yml\")],\n [os.path.join(\"assets\", \"email_template.html\")],\n [os.path.join(\"assets\", \"email_template.txt\")],\n [os.path.join(\"assets\", \"sendmail_template.txt\")],\n [os.path.join(\"assets\", f\"nf-core-{short_name}_logo.png\")],\n [os.path.join(\"conf\", \"modules.config\")],\n [os.path.join(\"conf\", \"test.config\")],\n [os.path.join(\"conf\", \"test_full.config\")],\n [os.path.join(\"docs\", \"images\", f\"nf-core-{short_name}_logo.png\")],\n [os.path.join(\"docs\", \"output.md\")],\n [os.path.join(\"docs\", \"README.md\")],\n [os.path.join(\"docs\", \"README.md\")],\n [os.path.join(\"docs\", \"usage.md\")],\n [os.path.join(\"lib\", \"nfcore_external_java_deps.jar\")],\n [os.path.join(\"lib\", \"NfcoreSchema.groovy\")],\n [os.path.join(\"lib\", \"NfcoreTemplate.groovy\")],\n [os.path.join(\"lib\", \"Utils.groovy\")],\n [os.path.join(\"lib\", \"WorkflowMain.groovy\")],\n ]\n\n files_warn = [\n [\"main.nf\"],\n [os.path.join(\"assets\", \"multiqc_config.yaml\")],\n [os.path.join(\"conf\", \"base.config\")],\n [os.path.join(\"conf\", \"igenomes.config\")],\n [os.path.join(\".github\", \"workflows\", \"awstest.yml\")],\n [os.path.join(\".github\", \"workflows\", \"awsfulltest.yml\")],\n [os.path.join(\"lib\", f\"Workflow{short_name[0].upper()}{short_name[1:]}.groovy\")],\n [\"modules.json\"],\n ]\n\n # List of strings. Fails / warns if any of the strings exist.\n files_fail_ifexists = [\n \"Singularity\",\n \"parameters.settings.json\",\n os.path.join(\"bin\", \"markdown_to_html.r\"),\n os.path.join(\"conf\", \"aws.config\"),\n os.path.join(\".github\", \"workflows\", \"push_dockerhub.yml\"),\n ]\n files_warn_ifexists = [\".travis.yml\"]\n\n # Remove files that should be ignored according to the linting config\n ignore_files = self.lint_config.get(\"files_exist\", [])\n\n def pf(file_path):\n return os.path.join(self.wf_path, file_path)\n\n # First - critical files. Check that this is actually a Nextflow pipeline\n if not os.path.isfile(pf(\"nextflow.config\")) and not os.path.isfile(pf(\"main.nf\")):\n failed.append(\"File not found: nextflow.config or main.nf\")\n raise AssertionError(\"Neither nextflow.config or main.nf found! Is this a Nextflow pipeline?\")\n\n # Files that cause an error if they don't exist\n for files in files_fail:\n if any([f in ignore_files for f in files]):\n continue\n if any([os.path.isfile(pf(f)) for f in files]):\n passed.append(\"File found: {}\".format(self._wrap_quotes(files)))\n else:\n failed.append(\"File not found: {}\".format(self._wrap_quotes(files)))\n\n # Files that cause a warning if they don't exist\n for files in files_warn:\n if any([f in ignore_files for f in files]):\n continue\n if any([os.path.isfile(pf(f)) for f in files]):\n passed.append(\"File found: {}\".format(self._wrap_quotes(files)))\n else:\n warned.append(\"File not found: {}\".format(self._wrap_quotes(files)))\n\n # Files that cause an error if they exist\n for file in files_fail_ifexists:\n if file in ignore_files:\n continue\n if os.path.isfile(pf(file)):\n failed.append(\"File must be removed: {}\".format(self._wrap_quotes(file)))\n else:\n passed.append(\"File not found check: {}\".format(self._wrap_quotes(file)))\n\n # Files that cause a warning if they exist\n for file in files_warn_ifexists:\n if file in ignore_files:\n continue\n if os.path.isfile(pf(file)):\n warned.append(\"File should be removed: {}\".format(self._wrap_quotes(file)))\n else:\n passed.append(\"File not found check: {}\".format(self._wrap_quotes(file)))\n\n # Files that are ignoed\n for file in ignore_files:\n ignored.append(\"File is ignored: {}\".format(self._wrap_quotes(file)))\n\n return {\"passed\": passed, \"warned\": warned, \"failed\": failed, \"ignored\": ignored}\n", "path": "nf_core/lint/files_exist.py"}]}
| 2,833 | 201 |
gh_patches_debug_17726
|
rasdani/github-patches
|
git_diff
|
docker__docker-py-1596
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Pull image with tag fails
library version: 2.2.1
docker version: 1.23
Repro steps:
- remove busy box images if any
- pull busy box image with tag = 1
`docker.from_env(version='auto').images.pull('busybox', tag='1')`
Gives
`docker.errors.ImageNotFound: 404 Client Error: Not Found ("No such image: busybox")`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docker/models/images.py`
Content:
```
1 import re
2
3 import six
4
5 from ..api import APIClient
6 from ..errors import BuildError
7 from ..utils.json_stream import json_stream
8 from .resource import Collection, Model
9
10
11 class Image(Model):
12 """
13 An image on the server.
14 """
15 def __repr__(self):
16 return "<%s: '%s'>" % (self.__class__.__name__, "', '".join(self.tags))
17
18 @property
19 def labels(self):
20 """
21 The labels of an image as dictionary.
22 """
23 result = self.attrs['Config'].get('Labels')
24 return result or {}
25
26 @property
27 def short_id(self):
28 """
29 The ID of the image truncated to 10 characters, plus the ``sha256:``
30 prefix.
31 """
32 if self.id.startswith('sha256:'):
33 return self.id[:17]
34 return self.id[:10]
35
36 @property
37 def tags(self):
38 """
39 The image's tags.
40 """
41 tags = self.attrs.get('RepoTags')
42 if tags is None:
43 tags = []
44 return [tag for tag in tags if tag != '<none>:<none>']
45
46 def history(self):
47 """
48 Show the history of an image.
49
50 Returns:
51 (str): The history of the image.
52
53 Raises:
54 :py:class:`docker.errors.APIError`
55 If the server returns an error.
56 """
57 return self.client.api.history(self.id)
58
59 def save(self):
60 """
61 Get a tarball of an image. Similar to the ``docker save`` command.
62
63 Returns:
64 (urllib3.response.HTTPResponse object): The response from the
65 daemon.
66
67 Raises:
68 :py:class:`docker.errors.APIError`
69 If the server returns an error.
70
71 Example:
72
73 >>> image = cli.images.get("fedora:latest")
74 >>> resp = image.save()
75 >>> f = open('/tmp/fedora-latest.tar', 'w')
76 >>> for chunk in resp.stream():
77 >>> f.write(chunk)
78 >>> f.close()
79 """
80 return self.client.api.get_image(self.id)
81
82 def tag(self, repository, tag=None, **kwargs):
83 """
84 Tag this image into a repository. Similar to the ``docker tag``
85 command.
86
87 Args:
88 repository (str): The repository to set for the tag
89 tag (str): The tag name
90 force (bool): Force
91
92 Raises:
93 :py:class:`docker.errors.APIError`
94 If the server returns an error.
95
96 Returns:
97 (bool): ``True`` if successful
98 """
99 self.client.api.tag(self.id, repository, tag=tag, **kwargs)
100
101
102 class ImageCollection(Collection):
103 model = Image
104
105 def build(self, **kwargs):
106 """
107 Build an image and return it. Similar to the ``docker build``
108 command. Either ``path`` or ``fileobj`` must be set.
109
110 If you have a tar file for the Docker build context (including a
111 Dockerfile) already, pass a readable file-like object to ``fileobj``
112 and also pass ``custom_context=True``. If the stream is compressed
113 also, set ``encoding`` to the correct value (e.g ``gzip``).
114
115 If you want to get the raw output of the build, use the
116 :py:meth:`~docker.api.build.BuildApiMixin.build` method in the
117 low-level API.
118
119 Args:
120 path (str): Path to the directory containing the Dockerfile
121 fileobj: A file object to use as the Dockerfile. (Or a file-like
122 object)
123 tag (str): A tag to add to the final image
124 quiet (bool): Whether to return the status
125 nocache (bool): Don't use the cache when set to ``True``
126 rm (bool): Remove intermediate containers. The ``docker build``
127 command now defaults to ``--rm=true``, but we have kept the old
128 default of `False` to preserve backward compatibility
129 stream (bool): *Deprecated for API version > 1.8 (always True)*.
130 Return a blocking generator you can iterate over to retrieve
131 build output as it happens
132 timeout (int): HTTP timeout
133 custom_context (bool): Optional if using ``fileobj``
134 encoding (str): The encoding for a stream. Set to ``gzip`` for
135 compressing
136 pull (bool): Downloads any updates to the FROM image in Dockerfiles
137 forcerm (bool): Always remove intermediate containers, even after
138 unsuccessful builds
139 dockerfile (str): path within the build context to the Dockerfile
140 buildargs (dict): A dictionary of build arguments
141 container_limits (dict): A dictionary of limits applied to each
142 container created by the build process. Valid keys:
143
144 - memory (int): set memory limit for build
145 - memswap (int): Total memory (memory + swap), -1 to disable
146 swap
147 - cpushares (int): CPU shares (relative weight)
148 - cpusetcpus (str): CPUs in which to allow execution, e.g.,
149 ``"0-3"``, ``"0,1"``
150 decode (bool): If set to ``True``, the returned stream will be
151 decoded into dicts on the fly. Default ``False``.
152 cache_from (list): A list of images used for build cache
153 resolution.
154
155 Returns:
156 (:py:class:`Image`): The built image.
157
158 Raises:
159 :py:class:`docker.errors.BuildError`
160 If there is an error during the build.
161 :py:class:`docker.errors.APIError`
162 If the server returns any other error.
163 ``TypeError``
164 If neither ``path`` nor ``fileobj`` is specified.
165 """
166 resp = self.client.api.build(**kwargs)
167 if isinstance(resp, six.string_types):
168 return self.get(resp)
169 last_event = None
170 for chunk in json_stream(resp):
171 if 'error' in chunk:
172 raise BuildError(chunk['error'])
173 if 'stream' in chunk:
174 match = re.search(
175 r'(Successfully built |sha256:)([0-9a-f]+)',
176 chunk['stream']
177 )
178 if match:
179 image_id = match.group(2)
180 return self.get(image_id)
181 last_event = chunk
182
183 raise BuildError(last_event or 'Unknown')
184
185 def get(self, name):
186 """
187 Gets an image.
188
189 Args:
190 name (str): The name of the image.
191
192 Returns:
193 (:py:class:`Image`): The image.
194
195 Raises:
196 :py:class:`docker.errors.ImageNotFound` If the image does not
197 exist.
198 :py:class:`docker.errors.APIError`
199 If the server returns an error.
200 """
201 return self.prepare_model(self.client.api.inspect_image(name))
202
203 def list(self, name=None, all=False, filters=None):
204 """
205 List images on the server.
206
207 Args:
208 name (str): Only show images belonging to the repository ``name``
209 all (bool): Show intermediate image layers. By default, these are
210 filtered out.
211 filters (dict): Filters to be processed on the image list.
212 Available filters:
213 - ``dangling`` (bool)
214 - ``label`` (str): format either ``key`` or ``key=value``
215
216 Returns:
217 (list of :py:class:`Image`): The images.
218
219 Raises:
220 :py:class:`docker.errors.APIError`
221 If the server returns an error.
222 """
223 resp = self.client.api.images(name=name, all=all, filters=filters)
224 return [self.prepare_model(r) for r in resp]
225
226 def load(self, data):
227 """
228 Load an image that was previously saved using
229 :py:meth:`~docker.models.images.Image.save` (or ``docker save``).
230 Similar to ``docker load``.
231
232 Args:
233 data (binary): Image data to be loaded.
234
235 Raises:
236 :py:class:`docker.errors.APIError`
237 If the server returns an error.
238 """
239 return self.client.api.load_image(data)
240
241 def pull(self, name, **kwargs):
242 """
243 Pull an image of the given name and return it. Similar to the
244 ``docker pull`` command.
245
246 If you want to get the raw pull output, use the
247 :py:meth:`~docker.api.image.ImageApiMixin.pull` method in the
248 low-level API.
249
250 Args:
251 repository (str): The repository to pull
252 tag (str): The tag to pull
253 insecure_registry (bool): Use an insecure registry
254 auth_config (dict): Override the credentials that
255 :py:meth:`~docker.client.DockerClient.login` has set for
256 this request. ``auth_config`` should contain the ``username``
257 and ``password`` keys to be valid.
258
259 Returns:
260 (:py:class:`Image`): The image that has been pulled.
261
262 Raises:
263 :py:class:`docker.errors.APIError`
264 If the server returns an error.
265
266 Example:
267
268 >>> image = client.images.pull('busybox')
269 """
270 self.client.api.pull(name, **kwargs)
271 return self.get(name)
272
273 def push(self, repository, tag=None, **kwargs):
274 return self.client.api.push(repository, tag=tag, **kwargs)
275 push.__doc__ = APIClient.push.__doc__
276
277 def remove(self, *args, **kwargs):
278 self.client.api.remove_image(*args, **kwargs)
279 remove.__doc__ = APIClient.remove_image.__doc__
280
281 def search(self, *args, **kwargs):
282 return self.client.api.search(*args, **kwargs)
283 search.__doc__ = APIClient.search.__doc__
284
285 def prune(self, filters=None):
286 return self.client.api.prune_images(filters=filters)
287 prune.__doc__ = APIClient.prune_images.__doc__
288
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docker/models/images.py b/docker/models/images.py
--- a/docker/models/images.py
+++ b/docker/models/images.py
@@ -238,7 +238,7 @@
"""
return self.client.api.load_image(data)
- def pull(self, name, **kwargs):
+ def pull(self, name, tag=None, **kwargs):
"""
Pull an image of the given name and return it. Similar to the
``docker pull`` command.
@@ -267,8 +267,8 @@
>>> image = client.images.pull('busybox')
"""
- self.client.api.pull(name, **kwargs)
- return self.get(name)
+ self.client.api.pull(name, tag=tag, **kwargs)
+ return self.get('{0}:{1}'.format(name, tag) if tag else name)
def push(self, repository, tag=None, **kwargs):
return self.client.api.push(repository, tag=tag, **kwargs)
|
{"golden_diff": "diff --git a/docker/models/images.py b/docker/models/images.py\n--- a/docker/models/images.py\n+++ b/docker/models/images.py\n@@ -238,7 +238,7 @@\n \"\"\"\n return self.client.api.load_image(data)\n \n- def pull(self, name, **kwargs):\n+ def pull(self, name, tag=None, **kwargs):\n \"\"\"\n Pull an image of the given name and return it. Similar to the\n ``docker pull`` command.\n@@ -267,8 +267,8 @@\n \n >>> image = client.images.pull('busybox')\n \"\"\"\n- self.client.api.pull(name, **kwargs)\n- return self.get(name)\n+ self.client.api.pull(name, tag=tag, **kwargs)\n+ return self.get('{0}:{1}'.format(name, tag) if tag else name)\n \n def push(self, repository, tag=None, **kwargs):\n return self.client.api.push(repository, tag=tag, **kwargs)\n", "issue": "Pull image with tag fails\nlibrary version: 2.2.1\r\ndocker version: 1.23\r\nRepro steps:\r\n- remove busy box images if any\r\n- pull busy box image with tag = 1\r\n`docker.from_env(version='auto').images.pull('busybox', tag='1')`\r\nGives\r\n`docker.errors.ImageNotFound: 404 Client Error: Not Found (\"No such image: busybox\")`\n", "before_files": [{"content": "import re\n\nimport six\n\nfrom ..api import APIClient\nfrom ..errors import BuildError\nfrom ..utils.json_stream import json_stream\nfrom .resource import Collection, Model\n\n\nclass Image(Model):\n \"\"\"\n An image on the server.\n \"\"\"\n def __repr__(self):\n return \"<%s: '%s'>\" % (self.__class__.__name__, \"', '\".join(self.tags))\n\n @property\n def labels(self):\n \"\"\"\n The labels of an image as dictionary.\n \"\"\"\n result = self.attrs['Config'].get('Labels')\n return result or {}\n\n @property\n def short_id(self):\n \"\"\"\n The ID of the image truncated to 10 characters, plus the ``sha256:``\n prefix.\n \"\"\"\n if self.id.startswith('sha256:'):\n return self.id[:17]\n return self.id[:10]\n\n @property\n def tags(self):\n \"\"\"\n The image's tags.\n \"\"\"\n tags = self.attrs.get('RepoTags')\n if tags is None:\n tags = []\n return [tag for tag in tags if tag != '<none>:<none>']\n\n def history(self):\n \"\"\"\n Show the history of an image.\n\n Returns:\n (str): The history of the image.\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n return self.client.api.history(self.id)\n\n def save(self):\n \"\"\"\n Get a tarball of an image. Similar to the ``docker save`` command.\n\n Returns:\n (urllib3.response.HTTPResponse object): The response from the\n daemon.\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n\n Example:\n\n >>> image = cli.images.get(\"fedora:latest\")\n >>> resp = image.save()\n >>> f = open('/tmp/fedora-latest.tar', 'w')\n >>> for chunk in resp.stream():\n >>> f.write(chunk)\n >>> f.close()\n \"\"\"\n return self.client.api.get_image(self.id)\n\n def tag(self, repository, tag=None, **kwargs):\n \"\"\"\n Tag this image into a repository. Similar to the ``docker tag``\n command.\n\n Args:\n repository (str): The repository to set for the tag\n tag (str): The tag name\n force (bool): Force\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n\n Returns:\n (bool): ``True`` if successful\n \"\"\"\n self.client.api.tag(self.id, repository, tag=tag, **kwargs)\n\n\nclass ImageCollection(Collection):\n model = Image\n\n def build(self, **kwargs):\n \"\"\"\n Build an image and return it. Similar to the ``docker build``\n command. Either ``path`` or ``fileobj`` must be set.\n\n If you have a tar file for the Docker build context (including a\n Dockerfile) already, pass a readable file-like object to ``fileobj``\n and also pass ``custom_context=True``. If the stream is compressed\n also, set ``encoding`` to the correct value (e.g ``gzip``).\n\n If you want to get the raw output of the build, use the\n :py:meth:`~docker.api.build.BuildApiMixin.build` method in the\n low-level API.\n\n Args:\n path (str): Path to the directory containing the Dockerfile\n fileobj: A file object to use as the Dockerfile. (Or a file-like\n object)\n tag (str): A tag to add to the final image\n quiet (bool): Whether to return the status\n nocache (bool): Don't use the cache when set to ``True``\n rm (bool): Remove intermediate containers. The ``docker build``\n command now defaults to ``--rm=true``, but we have kept the old\n default of `False` to preserve backward compatibility\n stream (bool): *Deprecated for API version > 1.8 (always True)*.\n Return a blocking generator you can iterate over to retrieve\n build output as it happens\n timeout (int): HTTP timeout\n custom_context (bool): Optional if using ``fileobj``\n encoding (str): The encoding for a stream. Set to ``gzip`` for\n compressing\n pull (bool): Downloads any updates to the FROM image in Dockerfiles\n forcerm (bool): Always remove intermediate containers, even after\n unsuccessful builds\n dockerfile (str): path within the build context to the Dockerfile\n buildargs (dict): A dictionary of build arguments\n container_limits (dict): A dictionary of limits applied to each\n container created by the build process. Valid keys:\n\n - memory (int): set memory limit for build\n - memswap (int): Total memory (memory + swap), -1 to disable\n swap\n - cpushares (int): CPU shares (relative weight)\n - cpusetcpus (str): CPUs in which to allow execution, e.g.,\n ``\"0-3\"``, ``\"0,1\"``\n decode (bool): If set to ``True``, the returned stream will be\n decoded into dicts on the fly. Default ``False``.\n cache_from (list): A list of images used for build cache\n resolution.\n\n Returns:\n (:py:class:`Image`): The built image.\n\n Raises:\n :py:class:`docker.errors.BuildError`\n If there is an error during the build.\n :py:class:`docker.errors.APIError`\n If the server returns any other error.\n ``TypeError``\n If neither ``path`` nor ``fileobj`` is specified.\n \"\"\"\n resp = self.client.api.build(**kwargs)\n if isinstance(resp, six.string_types):\n return self.get(resp)\n last_event = None\n for chunk in json_stream(resp):\n if 'error' in chunk:\n raise BuildError(chunk['error'])\n if 'stream' in chunk:\n match = re.search(\n r'(Successfully built |sha256:)([0-9a-f]+)',\n chunk['stream']\n )\n if match:\n image_id = match.group(2)\n return self.get(image_id)\n last_event = chunk\n\n raise BuildError(last_event or 'Unknown')\n\n def get(self, name):\n \"\"\"\n Gets an image.\n\n Args:\n name (str): The name of the image.\n\n Returns:\n (:py:class:`Image`): The image.\n\n Raises:\n :py:class:`docker.errors.ImageNotFound` If the image does not\n exist.\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n return self.prepare_model(self.client.api.inspect_image(name))\n\n def list(self, name=None, all=False, filters=None):\n \"\"\"\n List images on the server.\n\n Args:\n name (str): Only show images belonging to the repository ``name``\n all (bool): Show intermediate image layers. By default, these are\n filtered out.\n filters (dict): Filters to be processed on the image list.\n Available filters:\n - ``dangling`` (bool)\n - ``label`` (str): format either ``key`` or ``key=value``\n\n Returns:\n (list of :py:class:`Image`): The images.\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n resp = self.client.api.images(name=name, all=all, filters=filters)\n return [self.prepare_model(r) for r in resp]\n\n def load(self, data):\n \"\"\"\n Load an image that was previously saved using\n :py:meth:`~docker.models.images.Image.save` (or ``docker save``).\n Similar to ``docker load``.\n\n Args:\n data (binary): Image data to be loaded.\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n return self.client.api.load_image(data)\n\n def pull(self, name, **kwargs):\n \"\"\"\n Pull an image of the given name and return it. Similar to the\n ``docker pull`` command.\n\n If you want to get the raw pull output, use the\n :py:meth:`~docker.api.image.ImageApiMixin.pull` method in the\n low-level API.\n\n Args:\n repository (str): The repository to pull\n tag (str): The tag to pull\n insecure_registry (bool): Use an insecure registry\n auth_config (dict): Override the credentials that\n :py:meth:`~docker.client.DockerClient.login` has set for\n this request. ``auth_config`` should contain the ``username``\n and ``password`` keys to be valid.\n\n Returns:\n (:py:class:`Image`): The image that has been pulled.\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n\n Example:\n\n >>> image = client.images.pull('busybox')\n \"\"\"\n self.client.api.pull(name, **kwargs)\n return self.get(name)\n\n def push(self, repository, tag=None, **kwargs):\n return self.client.api.push(repository, tag=tag, **kwargs)\n push.__doc__ = APIClient.push.__doc__\n\n def remove(self, *args, **kwargs):\n self.client.api.remove_image(*args, **kwargs)\n remove.__doc__ = APIClient.remove_image.__doc__\n\n def search(self, *args, **kwargs):\n return self.client.api.search(*args, **kwargs)\n search.__doc__ = APIClient.search.__doc__\n\n def prune(self, filters=None):\n return self.client.api.prune_images(filters=filters)\n prune.__doc__ = APIClient.prune_images.__doc__\n", "path": "docker/models/images.py"}], "after_files": [{"content": "import re\n\nimport six\n\nfrom ..api import APIClient\nfrom ..errors import BuildError\nfrom ..utils.json_stream import json_stream\nfrom .resource import Collection, Model\n\n\nclass Image(Model):\n \"\"\"\n An image on the server.\n \"\"\"\n def __repr__(self):\n return \"<%s: '%s'>\" % (self.__class__.__name__, \"', '\".join(self.tags))\n\n @property\n def labels(self):\n \"\"\"\n The labels of an image as dictionary.\n \"\"\"\n result = self.attrs['Config'].get('Labels')\n return result or {}\n\n @property\n def short_id(self):\n \"\"\"\n The ID of the image truncated to 10 characters, plus the ``sha256:``\n prefix.\n \"\"\"\n if self.id.startswith('sha256:'):\n return self.id[:17]\n return self.id[:10]\n\n @property\n def tags(self):\n \"\"\"\n The image's tags.\n \"\"\"\n tags = self.attrs.get('RepoTags')\n if tags is None:\n tags = []\n return [tag for tag in tags if tag != '<none>:<none>']\n\n def history(self):\n \"\"\"\n Show the history of an image.\n\n Returns:\n (str): The history of the image.\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n return self.client.api.history(self.id)\n\n def save(self):\n \"\"\"\n Get a tarball of an image. Similar to the ``docker save`` command.\n\n Returns:\n (urllib3.response.HTTPResponse object): The response from the\n daemon.\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n\n Example:\n\n >>> image = cli.images.get(\"fedora:latest\")\n >>> resp = image.save()\n >>> f = open('/tmp/fedora-latest.tar', 'w')\n >>> for chunk in resp.stream():\n >>> f.write(chunk)\n >>> f.close()\n \"\"\"\n return self.client.api.get_image(self.id)\n\n def tag(self, repository, tag=None, **kwargs):\n \"\"\"\n Tag this image into a repository. Similar to the ``docker tag``\n command.\n\n Args:\n repository (str): The repository to set for the tag\n tag (str): The tag name\n force (bool): Force\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n\n Returns:\n (bool): ``True`` if successful\n \"\"\"\n self.client.api.tag(self.id, repository, tag=tag, **kwargs)\n\n\nclass ImageCollection(Collection):\n model = Image\n\n def build(self, **kwargs):\n \"\"\"\n Build an image and return it. Similar to the ``docker build``\n command. Either ``path`` or ``fileobj`` must be set.\n\n If you have a tar file for the Docker build context (including a\n Dockerfile) already, pass a readable file-like object to ``fileobj``\n and also pass ``custom_context=True``. If the stream is compressed\n also, set ``encoding`` to the correct value (e.g ``gzip``).\n\n If you want to get the raw output of the build, use the\n :py:meth:`~docker.api.build.BuildApiMixin.build` method in the\n low-level API.\n\n Args:\n path (str): Path to the directory containing the Dockerfile\n fileobj: A file object to use as the Dockerfile. (Or a file-like\n object)\n tag (str): A tag to add to the final image\n quiet (bool): Whether to return the status\n nocache (bool): Don't use the cache when set to ``True``\n rm (bool): Remove intermediate containers. The ``docker build``\n command now defaults to ``--rm=true``, but we have kept the old\n default of `False` to preserve backward compatibility\n stream (bool): *Deprecated for API version > 1.8 (always True)*.\n Return a blocking generator you can iterate over to retrieve\n build output as it happens\n timeout (int): HTTP timeout\n custom_context (bool): Optional if using ``fileobj``\n encoding (str): The encoding for a stream. Set to ``gzip`` for\n compressing\n pull (bool): Downloads any updates to the FROM image in Dockerfiles\n forcerm (bool): Always remove intermediate containers, even after\n unsuccessful builds\n dockerfile (str): path within the build context to the Dockerfile\n buildargs (dict): A dictionary of build arguments\n container_limits (dict): A dictionary of limits applied to each\n container created by the build process. Valid keys:\n\n - memory (int): set memory limit for build\n - memswap (int): Total memory (memory + swap), -1 to disable\n swap\n - cpushares (int): CPU shares (relative weight)\n - cpusetcpus (str): CPUs in which to allow execution, e.g.,\n ``\"0-3\"``, ``\"0,1\"``\n decode (bool): If set to ``True``, the returned stream will be\n decoded into dicts on the fly. Default ``False``.\n cache_from (list): A list of images used for build cache\n resolution.\n\n Returns:\n (:py:class:`Image`): The built image.\n\n Raises:\n :py:class:`docker.errors.BuildError`\n If there is an error during the build.\n :py:class:`docker.errors.APIError`\n If the server returns any other error.\n ``TypeError``\n If neither ``path`` nor ``fileobj`` is specified.\n \"\"\"\n resp = self.client.api.build(**kwargs)\n if isinstance(resp, six.string_types):\n return self.get(resp)\n last_event = None\n for chunk in json_stream(resp):\n if 'error' in chunk:\n raise BuildError(chunk['error'])\n if 'stream' in chunk:\n match = re.search(\n r'(Successfully built |sha256:)([0-9a-f]+)',\n chunk['stream']\n )\n if match:\n image_id = match.group(2)\n return self.get(image_id)\n last_event = chunk\n\n raise BuildError(last_event or 'Unknown')\n\n def get(self, name):\n \"\"\"\n Gets an image.\n\n Args:\n name (str): The name of the image.\n\n Returns:\n (:py:class:`Image`): The image.\n\n Raises:\n :py:class:`docker.errors.ImageNotFound` If the image does not\n exist.\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n return self.prepare_model(self.client.api.inspect_image(name))\n\n def list(self, name=None, all=False, filters=None):\n \"\"\"\n List images on the server.\n\n Args:\n name (str): Only show images belonging to the repository ``name``\n all (bool): Show intermediate image layers. By default, these are\n filtered out.\n filters (dict): Filters to be processed on the image list.\n Available filters:\n - ``dangling`` (bool)\n - ``label`` (str): format either ``key`` or ``key=value``\n\n Returns:\n (list of :py:class:`Image`): The images.\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n resp = self.client.api.images(name=name, all=all, filters=filters)\n return [self.prepare_model(r) for r in resp]\n\n def load(self, data):\n \"\"\"\n Load an image that was previously saved using\n :py:meth:`~docker.models.images.Image.save` (or ``docker save``).\n Similar to ``docker load``.\n\n Args:\n data (binary): Image data to be loaded.\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n \"\"\"\n return self.client.api.load_image(data)\n\n def pull(self, name, tag=None, **kwargs):\n \"\"\"\n Pull an image of the given name and return it. Similar to the\n ``docker pull`` command.\n\n If you want to get the raw pull output, use the\n :py:meth:`~docker.api.image.ImageApiMixin.pull` method in the\n low-level API.\n\n Args:\n repository (str): The repository to pull\n tag (str): The tag to pull\n insecure_registry (bool): Use an insecure registry\n auth_config (dict): Override the credentials that\n :py:meth:`~docker.client.DockerClient.login` has set for\n this request. ``auth_config`` should contain the ``username``\n and ``password`` keys to be valid.\n\n Returns:\n (:py:class:`Image`): The image that has been pulled.\n\n Raises:\n :py:class:`docker.errors.APIError`\n If the server returns an error.\n\n Example:\n\n >>> image = client.images.pull('busybox')\n \"\"\"\n self.client.api.pull(name, tag=tag, **kwargs)\n return self.get('{0}:{1}'.format(name, tag) if tag else name)\n\n def push(self, repository, tag=None, **kwargs):\n return self.client.api.push(repository, tag=tag, **kwargs)\n push.__doc__ = APIClient.push.__doc__\n\n def remove(self, *args, **kwargs):\n self.client.api.remove_image(*args, **kwargs)\n remove.__doc__ = APIClient.remove_image.__doc__\n\n def search(self, *args, **kwargs):\n return self.client.api.search(*args, **kwargs)\n search.__doc__ = APIClient.search.__doc__\n\n def prune(self, filters=None):\n return self.client.api.prune_images(filters=filters)\n prune.__doc__ = APIClient.prune_images.__doc__\n", "path": "docker/models/images.py"}]}
| 3,249 | 214 |
gh_patches_debug_24827
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-1705
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Upgrade mypy to 0.800
MyPy 0.800 is out. It finally supports namespace packages properly and we can remove the placeholder `__init__.pyi` files in a few spots.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `opentelemetry-api/src/opentelemetry/util/_time.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from logging import getLogger
16 from sys import version_info
17
18 if version_info.minor < 7:
19 getLogger(__name__).warning( # pylint: disable=logging-not-lazy
20 "You are using Python 3.%s. This version does not support timestamps "
21 "with nanosecond precision and the Opentelemetry SDK will use "
22 "millisecond precision instead. Please refer to PEP 546 for more "
23 "information. Please upgrade to Python 3.7 or newer to use nanosecond "
24 "precision." % version_info.minor
25 )
26 from time import time
27
28 def _time_ns():
29 return int(time() * 1e9)
30
31
32 else:
33 from time import time_ns
34
35 _time_ns = time_ns
36
```
Path: `opentelemetry-api/src/opentelemetry/context/__init__.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import logging
16 import threading
17 import typing
18 from functools import wraps
19 from os import environ
20
21 from pkg_resources import iter_entry_points
22
23 from opentelemetry.context.context import Context, _RuntimeContext
24 from opentelemetry.environment_variables import OTEL_PYTHON_CONTEXT
25
26 logger = logging.getLogger(__name__)
27 _RUNTIME_CONTEXT = None # type: typing.Optional[_RuntimeContext]
28 _RUNTIME_CONTEXT_LOCK = threading.Lock()
29
30 _F = typing.TypeVar("_F", bound=typing.Callable[..., typing.Any])
31
32
33 def _load_runtime_context(func: _F) -> _F:
34 """A decorator used to initialize the global RuntimeContext
35
36 Returns:
37 A wrapper of the decorated method.
38 """
39
40 @wraps(func) # type: ignore
41 def wrapper(
42 *args: typing.Tuple[typing.Any, typing.Any],
43 **kwargs: typing.Dict[typing.Any, typing.Any]
44 ) -> typing.Optional[typing.Any]:
45 global _RUNTIME_CONTEXT # pylint: disable=global-statement
46
47 with _RUNTIME_CONTEXT_LOCK:
48 if _RUNTIME_CONTEXT is None:
49 # FIXME use a better implementation of a configuration manager to avoid having
50 # to get configuration values straight from environment variables
51 default_context = "contextvars_context"
52
53 configured_context = environ.get(
54 OTEL_PYTHON_CONTEXT, default_context
55 ) # type: str
56 try:
57 _RUNTIME_CONTEXT = next(
58 iter_entry_points(
59 "opentelemetry_context", configured_context
60 )
61 ).load()()
62 except Exception: # pylint: disable=broad-except
63 logger.error(
64 "Failed to load context: %s", configured_context
65 )
66 return func(*args, **kwargs) # type: ignore
67
68 return wrapper # type:ignore
69
70
71 def get_value(key: str, context: typing.Optional[Context] = None) -> "object":
72 """To access the local state of a concern, the RuntimeContext API
73 provides a function which takes a context and a key as input,
74 and returns a value.
75
76 Args:
77 key: The key of the value to retrieve.
78 context: The context from which to retrieve the value, if None, the current context is used.
79
80 Returns:
81 The value associated with the key.
82 """
83 return context.get(key) if context is not None else get_current().get(key)
84
85
86 def set_value(
87 key: str, value: "object", context: typing.Optional[Context] = None
88 ) -> Context:
89 """To record the local state of a cross-cutting concern, the
90 RuntimeContext API provides a function which takes a context, a
91 key, and a value as input, and returns an updated context
92 which contains the new value.
93
94 Args:
95 key: The key of the entry to set.
96 value: The value of the entry to set.
97 context: The context to copy, if None, the current context is used.
98
99 Returns:
100 A new `Context` containing the value set.
101 """
102 if context is None:
103 context = get_current()
104 new_values = context.copy()
105 new_values[key] = value
106 return Context(new_values)
107
108
109 @_load_runtime_context # type: ignore
110 def get_current() -> Context:
111 """To access the context associated with program execution,
112 the Context API provides a function which takes no arguments
113 and returns a Context.
114
115 Returns:
116 The current `Context` object.
117 """
118 return _RUNTIME_CONTEXT.get_current() # type:ignore
119
120
121 @_load_runtime_context # type: ignore
122 def attach(context: Context) -> object:
123 """Associates a Context with the caller's current execution unit. Returns
124 a token that can be used to restore the previous Context.
125
126 Args:
127 context: The Context to set as current.
128
129 Returns:
130 A token that can be used with `detach` to reset the context.
131 """
132 return _RUNTIME_CONTEXT.attach(context) # type:ignore
133
134
135 @_load_runtime_context # type: ignore
136 def detach(token: object) -> None:
137 """Resets the Context associated with the caller's current execution unit
138 to the value it had before attaching a specified Context.
139
140 Args:
141 token: The Token that was returned by a previous call to attach a Context.
142 """
143 try:
144 _RUNTIME_CONTEXT.detach(token) # type: ignore
145 except Exception: # pylint: disable=broad-except
146 logger.error("Failed to detach context")
147
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/opentelemetry-api/src/opentelemetry/context/__init__.py b/opentelemetry-api/src/opentelemetry/context/__init__.py
--- a/opentelemetry-api/src/opentelemetry/context/__init__.py
+++ b/opentelemetry-api/src/opentelemetry/context/__init__.py
@@ -37,8 +37,8 @@
A wrapper of the decorated method.
"""
- @wraps(func) # type: ignore
- def wrapper(
+ @wraps(func) # type: ignore[misc]
+ def wrapper( # type: ignore[misc]
*args: typing.Tuple[typing.Any, typing.Any],
**kwargs: typing.Dict[typing.Any, typing.Any]
) -> typing.Optional[typing.Any]:
@@ -63,9 +63,9 @@
logger.error(
"Failed to load context: %s", configured_context
)
- return func(*args, **kwargs) # type: ignore
+ return func(*args, **kwargs) # type: ignore[misc]
- return wrapper # type:ignore
+ return typing.cast(_F, wrapper) # type: ignore[misc]
def get_value(key: str, context: typing.Optional[Context] = None) -> "object":
diff --git a/opentelemetry-api/src/opentelemetry/util/_time.py b/opentelemetry-api/src/opentelemetry/util/_time.py
--- a/opentelemetry-api/src/opentelemetry/util/_time.py
+++ b/opentelemetry-api/src/opentelemetry/util/_time.py
@@ -25,7 +25,7 @@
)
from time import time
- def _time_ns():
+ def _time_ns() -> int:
return int(time() * 1e9)
|
{"golden_diff": "diff --git a/opentelemetry-api/src/opentelemetry/context/__init__.py b/opentelemetry-api/src/opentelemetry/context/__init__.py\n--- a/opentelemetry-api/src/opentelemetry/context/__init__.py\n+++ b/opentelemetry-api/src/opentelemetry/context/__init__.py\n@@ -37,8 +37,8 @@\n A wrapper of the decorated method.\n \"\"\"\n \n- @wraps(func) # type: ignore\n- def wrapper(\n+ @wraps(func) # type: ignore[misc]\n+ def wrapper( # type: ignore[misc]\n *args: typing.Tuple[typing.Any, typing.Any],\n **kwargs: typing.Dict[typing.Any, typing.Any]\n ) -> typing.Optional[typing.Any]:\n@@ -63,9 +63,9 @@\n logger.error(\n \"Failed to load context: %s\", configured_context\n )\n- return func(*args, **kwargs) # type: ignore\n+ return func(*args, **kwargs) # type: ignore[misc]\n \n- return wrapper # type:ignore\n+ return typing.cast(_F, wrapper) # type: ignore[misc]\n \n \n def get_value(key: str, context: typing.Optional[Context] = None) -> \"object\":\ndiff --git a/opentelemetry-api/src/opentelemetry/util/_time.py b/opentelemetry-api/src/opentelemetry/util/_time.py\n--- a/opentelemetry-api/src/opentelemetry/util/_time.py\n+++ b/opentelemetry-api/src/opentelemetry/util/_time.py\n@@ -25,7 +25,7 @@\n )\n from time import time\n \n- def _time_ns():\n+ def _time_ns() -> int:\n return int(time() * 1e9)\n", "issue": "Upgrade mypy to 0.800\nMyPy 0.800 is out. It finally supports namespace packages properly and we can remove the placeholder `__init__.pyi` files in a few spots.\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom logging import getLogger\nfrom sys import version_info\n\nif version_info.minor < 7:\n getLogger(__name__).warning( # pylint: disable=logging-not-lazy\n \"You are using Python 3.%s. This version does not support timestamps \"\n \"with nanosecond precision and the Opentelemetry SDK will use \"\n \"millisecond precision instead. Please refer to PEP 546 for more \"\n \"information. Please upgrade to Python 3.7 or newer to use nanosecond \"\n \"precision.\" % version_info.minor\n )\n from time import time\n\n def _time_ns():\n return int(time() * 1e9)\n\n\nelse:\n from time import time_ns\n\n _time_ns = time_ns\n", "path": "opentelemetry-api/src/opentelemetry/util/_time.py"}, {"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nimport threading\nimport typing\nfrom functools import wraps\nfrom os import environ\n\nfrom pkg_resources import iter_entry_points\n\nfrom opentelemetry.context.context import Context, _RuntimeContext\nfrom opentelemetry.environment_variables import OTEL_PYTHON_CONTEXT\n\nlogger = logging.getLogger(__name__)\n_RUNTIME_CONTEXT = None # type: typing.Optional[_RuntimeContext]\n_RUNTIME_CONTEXT_LOCK = threading.Lock()\n\n_F = typing.TypeVar(\"_F\", bound=typing.Callable[..., typing.Any])\n\n\ndef _load_runtime_context(func: _F) -> _F:\n \"\"\"A decorator used to initialize the global RuntimeContext\n\n Returns:\n A wrapper of the decorated method.\n \"\"\"\n\n @wraps(func) # type: ignore\n def wrapper(\n *args: typing.Tuple[typing.Any, typing.Any],\n **kwargs: typing.Dict[typing.Any, typing.Any]\n ) -> typing.Optional[typing.Any]:\n global _RUNTIME_CONTEXT # pylint: disable=global-statement\n\n with _RUNTIME_CONTEXT_LOCK:\n if _RUNTIME_CONTEXT is None:\n # FIXME use a better implementation of a configuration manager to avoid having\n # to get configuration values straight from environment variables\n default_context = \"contextvars_context\"\n\n configured_context = environ.get(\n OTEL_PYTHON_CONTEXT, default_context\n ) # type: str\n try:\n _RUNTIME_CONTEXT = next(\n iter_entry_points(\n \"opentelemetry_context\", configured_context\n )\n ).load()()\n except Exception: # pylint: disable=broad-except\n logger.error(\n \"Failed to load context: %s\", configured_context\n )\n return func(*args, **kwargs) # type: ignore\n\n return wrapper # type:ignore\n\n\ndef get_value(key: str, context: typing.Optional[Context] = None) -> \"object\":\n \"\"\"To access the local state of a concern, the RuntimeContext API\n provides a function which takes a context and a key as input,\n and returns a value.\n\n Args:\n key: The key of the value to retrieve.\n context: The context from which to retrieve the value, if None, the current context is used.\n\n Returns:\n The value associated with the key.\n \"\"\"\n return context.get(key) if context is not None else get_current().get(key)\n\n\ndef set_value(\n key: str, value: \"object\", context: typing.Optional[Context] = None\n) -> Context:\n \"\"\"To record the local state of a cross-cutting concern, the\n RuntimeContext API provides a function which takes a context, a\n key, and a value as input, and returns an updated context\n which contains the new value.\n\n Args:\n key: The key of the entry to set.\n value: The value of the entry to set.\n context: The context to copy, if None, the current context is used.\n\n Returns:\n A new `Context` containing the value set.\n \"\"\"\n if context is None:\n context = get_current()\n new_values = context.copy()\n new_values[key] = value\n return Context(new_values)\n\n\n@_load_runtime_context # type: ignore\ndef get_current() -> Context:\n \"\"\"To access the context associated with program execution,\n the Context API provides a function which takes no arguments\n and returns a Context.\n\n Returns:\n The current `Context` object.\n \"\"\"\n return _RUNTIME_CONTEXT.get_current() # type:ignore\n\n\n@_load_runtime_context # type: ignore\ndef attach(context: Context) -> object:\n \"\"\"Associates a Context with the caller's current execution unit. Returns\n a token that can be used to restore the previous Context.\n\n Args:\n context: The Context to set as current.\n\n Returns:\n A token that can be used with `detach` to reset the context.\n \"\"\"\n return _RUNTIME_CONTEXT.attach(context) # type:ignore\n\n\n@_load_runtime_context # type: ignore\ndef detach(token: object) -> None:\n \"\"\"Resets the Context associated with the caller's current execution unit\n to the value it had before attaching a specified Context.\n\n Args:\n token: The Token that was returned by a previous call to attach a Context.\n \"\"\"\n try:\n _RUNTIME_CONTEXT.detach(token) # type: ignore\n except Exception: # pylint: disable=broad-except\n logger.error(\"Failed to detach context\")\n", "path": "opentelemetry-api/src/opentelemetry/context/__init__.py"}], "after_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom logging import getLogger\nfrom sys import version_info\n\nif version_info.minor < 7:\n getLogger(__name__).warning( # pylint: disable=logging-not-lazy\n \"You are using Python 3.%s. This version does not support timestamps \"\n \"with nanosecond precision and the Opentelemetry SDK will use \"\n \"millisecond precision instead. Please refer to PEP 546 for more \"\n \"information. Please upgrade to Python 3.7 or newer to use nanosecond \"\n \"precision.\" % version_info.minor\n )\n from time import time\n\n def _time_ns() -> int:\n return int(time() * 1e9)\n\n\nelse:\n from time import time_ns\n\n _time_ns = time_ns\n", "path": "opentelemetry-api/src/opentelemetry/util/_time.py"}, {"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nimport threading\nimport typing\nfrom functools import wraps\nfrom os import environ\n\nfrom pkg_resources import iter_entry_points\n\nfrom opentelemetry.context.context import Context, _RuntimeContext\nfrom opentelemetry.environment_variables import OTEL_PYTHON_CONTEXT\n\nlogger = logging.getLogger(__name__)\n_RUNTIME_CONTEXT = None # type: typing.Optional[_RuntimeContext]\n_RUNTIME_CONTEXT_LOCK = threading.Lock()\n\n_F = typing.TypeVar(\"_F\", bound=typing.Callable[..., typing.Any])\n\n\ndef _load_runtime_context(func: _F) -> _F:\n \"\"\"A decorator used to initialize the global RuntimeContext\n\n Returns:\n A wrapper of the decorated method.\n \"\"\"\n\n @wraps(func) # type: ignore[misc]\n def wrapper( # type: ignore[misc]\n *args: typing.Tuple[typing.Any, typing.Any],\n **kwargs: typing.Dict[typing.Any, typing.Any]\n ) -> typing.Optional[typing.Any]:\n global _RUNTIME_CONTEXT # pylint: disable=global-statement\n\n with _RUNTIME_CONTEXT_LOCK:\n if _RUNTIME_CONTEXT is None:\n # FIXME use a better implementation of a configuration manager to avoid having\n # to get configuration values straight from environment variables\n default_context = \"contextvars_context\"\n\n configured_context = environ.get(\n OTEL_PYTHON_CONTEXT, default_context\n ) # type: str\n try:\n _RUNTIME_CONTEXT = next(\n iter_entry_points(\n \"opentelemetry_context\", configured_context\n )\n ).load()()\n except Exception: # pylint: disable=broad-except\n logger.error(\n \"Failed to load context: %s\", configured_context\n )\n return func(*args, **kwargs) # type: ignore[misc]\n\n return typing.cast(_F, wrapper) # type: ignore[misc]\n\n\ndef get_value(key: str, context: typing.Optional[Context] = None) -> \"object\":\n \"\"\"To access the local state of a concern, the RuntimeContext API\n provides a function which takes a context and a key as input,\n and returns a value.\n\n Args:\n key: The key of the value to retrieve.\n context: The context from which to retrieve the value, if None, the current context is used.\n\n Returns:\n The value associated with the key.\n \"\"\"\n return context.get(key) if context is not None else get_current().get(key)\n\n\ndef set_value(\n key: str, value: \"object\", context: typing.Optional[Context] = None\n) -> Context:\n \"\"\"To record the local state of a cross-cutting concern, the\n RuntimeContext API provides a function which takes a context, a\n key, and a value as input, and returns an updated context\n which contains the new value.\n\n Args:\n key: The key of the entry to set.\n value: The value of the entry to set.\n context: The context to copy, if None, the current context is used.\n\n Returns:\n A new `Context` containing the value set.\n \"\"\"\n if context is None:\n context = get_current()\n new_values = context.copy()\n new_values[key] = value\n return Context(new_values)\n\n\n@_load_runtime_context # type: ignore\ndef get_current() -> Context:\n \"\"\"To access the context associated with program execution,\n the Context API provides a function which takes no arguments\n and returns a Context.\n\n Returns:\n The current `Context` object.\n \"\"\"\n return _RUNTIME_CONTEXT.get_current() # type:ignore\n\n\n@_load_runtime_context # type: ignore\ndef attach(context: Context) -> object:\n \"\"\"Associates a Context with the caller's current execution unit. Returns\n a token that can be used to restore the previous Context.\n\n Args:\n context: The Context to set as current.\n\n Returns:\n A token that can be used with `detach` to reset the context.\n \"\"\"\n return _RUNTIME_CONTEXT.attach(context) # type:ignore\n\n\n@_load_runtime_context # type: ignore\ndef detach(token: object) -> None:\n \"\"\"Resets the Context associated with the caller's current execution unit\n to the value it had before attaching a specified Context.\n\n Args:\n token: The Token that was returned by a previous call to attach a Context.\n \"\"\"\n try:\n _RUNTIME_CONTEXT.detach(token) # type: ignore\n except Exception: # pylint: disable=broad-except\n logger.error(\"Failed to detach context\")\n", "path": "opentelemetry-api/src/opentelemetry/context/__init__.py"}]}
| 2,137 | 393 |
gh_patches_debug_18546
|
rasdani/github-patches
|
git_diff
|
ethereum__web3.py-803
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Improve warning on failed address checksum
* Version: 4
### What was wrong?
Error message about checksum failure isn't clear enough, especially when the address is supplied as all-lower-case.
### How can it be fixed?
Special-case the warning, so that an all-lower-case address gives a specific warning, along the lines of: "web3py only accepts checksummed addresses. Please report it as a bug on any project that does not provide you checksummed addresses. In the meantime, you can force an address into checksummed state with `valid_address = w3.toChecksumAddress(questionable_address)` after double-checking that there are no errors in the address. Alternatively, you can use an ENS name in its place."
But, you know, not a paragraph...
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `web3/utils/validation.py`
Content:
```
1 import itertools
2
3 from eth_utils import (
4 is_0x_prefixed,
5 is_boolean,
6 is_bytes,
7 is_checksum_address,
8 is_dict,
9 is_hex_address,
10 is_integer,
11 is_list_like,
12 is_string,
13 )
14
15 from web3.exceptions import (
16 InvalidAddress,
17 )
18 from web3.utils.abi import (
19 is_address_type,
20 is_array_type,
21 is_bool_type,
22 is_bytes_type,
23 is_int_type,
24 is_recognized_type,
25 is_string_type,
26 is_uint_type,
27 length_of_array_type,
28 sub_type_of_array_type,
29 )
30
31
32 def validate_abi(abi):
33 """
34 Helper function for validating an ABI
35 """
36 if not is_list_like(abi):
37 raise ValueError("'abi' is not a list")
38 for e in abi:
39 if not is_dict(e):
40 raise ValueError("The elements of 'abi' are not all dictionaries")
41
42
43 def validate_abi_type(abi_type):
44 """
45 Helper function for validating an abi_type
46 """
47 if not is_recognized_type(abi_type):
48 raise ValueError("Unrecognized abi_type: {abi_type}".format(abi_type=abi_type))
49
50
51 def validate_abi_value(abi_type, value):
52 """
53 Helper function for validating a value against the expected abi_type
54 Note: abi_type 'bytes' must either be python3 'bytes' object or ''
55 """
56 if is_array_type(abi_type) and is_list_like(value):
57 # validate length
58 specified_length = length_of_array_type(abi_type)
59 if specified_length is not None:
60 if specified_length < 1:
61 raise TypeError(
62 "Invalid abi-type: {abi_type}. Length of fixed sized arrays"
63 "must be greater than 0."
64 .format(abi_type=abi_type)
65 )
66 if specified_length != len(value):
67 raise TypeError(
68 "The following array length does not the length specified"
69 "by the abi-type, {abi_type}: {value}"
70 .format(abi_type=abi_type, value=value)
71 )
72
73 # validate sub_types
74 sub_type = sub_type_of_array_type(abi_type)
75 for v in value:
76 validate_abi_value(sub_type, v)
77 return
78 elif is_bool_type(abi_type) and is_boolean(value):
79 return
80 elif is_uint_type(abi_type) and is_integer(value) and value >= 0:
81 return
82 elif is_int_type(abi_type) and is_integer(value):
83 return
84 elif is_address_type(abi_type):
85 validate_address(value)
86 return
87 elif is_bytes_type(abi_type):
88 if is_bytes(value):
89 return
90 elif is_string(value):
91 if is_0x_prefixed(value):
92 return
93 else:
94 raise TypeError(
95 "ABI values of abi-type 'bytes' must be either"
96 "a python3 'bytes' object or an '0x' prefixed string."
97 )
98 elif is_string_type(abi_type) and is_string(value):
99 return
100
101 raise TypeError(
102 "The following abi value is not a '{abi_type}': {value}"
103 .format(abi_type=abi_type, value=value)
104 )
105
106
107 def validate_address(value):
108 """
109 Helper function for validating an address
110 """
111 if not isinstance(value, str):
112 raise TypeError('Address {} must be provided as a string'.format(value))
113 if not is_hex_address(value):
114 raise InvalidAddress("Address must be 20 bytes, as a hex string with a 0x prefix", value)
115 if not is_checksum_address(value):
116 raise InvalidAddress("Address has an invalid EIP checksum", value)
117
118
119 def has_one_val(*args, **kwargs):
120 vals = itertools.chain(args, kwargs.values())
121 not_nones = list(filter(lambda val: val is not None, vals))
122 return len(not_nones) == 1
123
124
125 def assert_one_val(*args, **kwargs):
126 if not has_one_val(*args, **kwargs):
127 raise TypeError(
128 "Exactly one of the passed values can be specified. "
129 "Instead, values were: %r, %r" % (args, kwargs)
130 )
131
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/web3/utils/validation.py b/web3/utils/validation.py
--- a/web3/utils/validation.py
+++ b/web3/utils/validation.py
@@ -113,7 +113,21 @@
if not is_hex_address(value):
raise InvalidAddress("Address must be 20 bytes, as a hex string with a 0x prefix", value)
if not is_checksum_address(value):
- raise InvalidAddress("Address has an invalid EIP checksum", value)
+ if value == value.lower():
+ raise InvalidAddress(
+ "Web3.py only accepts checksum addresses. "
+ "The software that gave you this non-checksum address should be considered unsafe, "
+ "please file it as a bug on their platform. "
+ "Try using an ENS name instead. Or, if you must accept lower safety, "
+ "use Web3.toChecksumAddress(lower_case_address).",
+ value,
+ )
+ else:
+ raise InvalidAddress(
+ "Address has an invalid EIP-55 checksum. "
+ "After looking up the address from the original source, try again.",
+ value,
+ )
def has_one_val(*args, **kwargs):
|
{"golden_diff": "diff --git a/web3/utils/validation.py b/web3/utils/validation.py\n--- a/web3/utils/validation.py\n+++ b/web3/utils/validation.py\n@@ -113,7 +113,21 @@\n if not is_hex_address(value):\n raise InvalidAddress(\"Address must be 20 bytes, as a hex string with a 0x prefix\", value)\n if not is_checksum_address(value):\n- raise InvalidAddress(\"Address has an invalid EIP checksum\", value)\n+ if value == value.lower():\n+ raise InvalidAddress(\n+ \"Web3.py only accepts checksum addresses. \"\n+ \"The software that gave you this non-checksum address should be considered unsafe, \"\n+ \"please file it as a bug on their platform. \"\n+ \"Try using an ENS name instead. Or, if you must accept lower safety, \"\n+ \"use Web3.toChecksumAddress(lower_case_address).\",\n+ value,\n+ )\n+ else:\n+ raise InvalidAddress(\n+ \"Address has an invalid EIP-55 checksum. \"\n+ \"After looking up the address from the original source, try again.\",\n+ value,\n+ )\n \n \n def has_one_val(*args, **kwargs):\n", "issue": "Improve warning on failed address checksum\n* Version: 4\r\n\r\n### What was wrong?\r\n\r\nError message about checksum failure isn't clear enough, especially when the address is supplied as all-lower-case.\r\n\r\n### How can it be fixed?\r\n\r\nSpecial-case the warning, so that an all-lower-case address gives a specific warning, along the lines of: \"web3py only accepts checksummed addresses. Please report it as a bug on any project that does not provide you checksummed addresses. In the meantime, you can force an address into checksummed state with `valid_address = w3.toChecksumAddress(questionable_address)` after double-checking that there are no errors in the address. Alternatively, you can use an ENS name in its place.\"\r\n\r\nBut, you know, not a paragraph...\n", "before_files": [{"content": "import itertools\n\nfrom eth_utils import (\n is_0x_prefixed,\n is_boolean,\n is_bytes,\n is_checksum_address,\n is_dict,\n is_hex_address,\n is_integer,\n is_list_like,\n is_string,\n)\n\nfrom web3.exceptions import (\n InvalidAddress,\n)\nfrom web3.utils.abi import (\n is_address_type,\n is_array_type,\n is_bool_type,\n is_bytes_type,\n is_int_type,\n is_recognized_type,\n is_string_type,\n is_uint_type,\n length_of_array_type,\n sub_type_of_array_type,\n)\n\n\ndef validate_abi(abi):\n \"\"\"\n Helper function for validating an ABI\n \"\"\"\n if not is_list_like(abi):\n raise ValueError(\"'abi' is not a list\")\n for e in abi:\n if not is_dict(e):\n raise ValueError(\"The elements of 'abi' are not all dictionaries\")\n\n\ndef validate_abi_type(abi_type):\n \"\"\"\n Helper function for validating an abi_type\n \"\"\"\n if not is_recognized_type(abi_type):\n raise ValueError(\"Unrecognized abi_type: {abi_type}\".format(abi_type=abi_type))\n\n\ndef validate_abi_value(abi_type, value):\n \"\"\"\n Helper function for validating a value against the expected abi_type\n Note: abi_type 'bytes' must either be python3 'bytes' object or ''\n \"\"\"\n if is_array_type(abi_type) and is_list_like(value):\n # validate length\n specified_length = length_of_array_type(abi_type)\n if specified_length is not None:\n if specified_length < 1:\n raise TypeError(\n \"Invalid abi-type: {abi_type}. Length of fixed sized arrays\"\n \"must be greater than 0.\"\n .format(abi_type=abi_type)\n )\n if specified_length != len(value):\n raise TypeError(\n \"The following array length does not the length specified\"\n \"by the abi-type, {abi_type}: {value}\"\n .format(abi_type=abi_type, value=value)\n )\n\n # validate sub_types\n sub_type = sub_type_of_array_type(abi_type)\n for v in value:\n validate_abi_value(sub_type, v)\n return\n elif is_bool_type(abi_type) and is_boolean(value):\n return\n elif is_uint_type(abi_type) and is_integer(value) and value >= 0:\n return\n elif is_int_type(abi_type) and is_integer(value):\n return\n elif is_address_type(abi_type):\n validate_address(value)\n return\n elif is_bytes_type(abi_type):\n if is_bytes(value):\n return\n elif is_string(value):\n if is_0x_prefixed(value):\n return\n else:\n raise TypeError(\n \"ABI values of abi-type 'bytes' must be either\"\n \"a python3 'bytes' object or an '0x' prefixed string.\"\n )\n elif is_string_type(abi_type) and is_string(value):\n return\n\n raise TypeError(\n \"The following abi value is not a '{abi_type}': {value}\"\n .format(abi_type=abi_type, value=value)\n )\n\n\ndef validate_address(value):\n \"\"\"\n Helper function for validating an address\n \"\"\"\n if not isinstance(value, str):\n raise TypeError('Address {} must be provided as a string'.format(value))\n if not is_hex_address(value):\n raise InvalidAddress(\"Address must be 20 bytes, as a hex string with a 0x prefix\", value)\n if not is_checksum_address(value):\n raise InvalidAddress(\"Address has an invalid EIP checksum\", value)\n\n\ndef has_one_val(*args, **kwargs):\n vals = itertools.chain(args, kwargs.values())\n not_nones = list(filter(lambda val: val is not None, vals))\n return len(not_nones) == 1\n\n\ndef assert_one_val(*args, **kwargs):\n if not has_one_val(*args, **kwargs):\n raise TypeError(\n \"Exactly one of the passed values can be specified. \"\n \"Instead, values were: %r, %r\" % (args, kwargs)\n )\n", "path": "web3/utils/validation.py"}], "after_files": [{"content": "import itertools\n\nfrom eth_utils import (\n is_0x_prefixed,\n is_boolean,\n is_bytes,\n is_checksum_address,\n is_dict,\n is_hex_address,\n is_integer,\n is_list_like,\n is_string,\n)\n\nfrom web3.exceptions import (\n InvalidAddress,\n)\nfrom web3.utils.abi import (\n is_address_type,\n is_array_type,\n is_bool_type,\n is_bytes_type,\n is_int_type,\n is_recognized_type,\n is_string_type,\n is_uint_type,\n length_of_array_type,\n sub_type_of_array_type,\n)\n\n\ndef validate_abi(abi):\n \"\"\"\n Helper function for validating an ABI\n \"\"\"\n if not is_list_like(abi):\n raise ValueError(\"'abi' is not a list\")\n for e in abi:\n if not is_dict(e):\n raise ValueError(\"The elements of 'abi' are not all dictionaries\")\n\n\ndef validate_abi_type(abi_type):\n \"\"\"\n Helper function for validating an abi_type\n \"\"\"\n if not is_recognized_type(abi_type):\n raise ValueError(\"Unrecognized abi_type: {abi_type}\".format(abi_type=abi_type))\n\n\ndef validate_abi_value(abi_type, value):\n \"\"\"\n Helper function for validating a value against the expected abi_type\n Note: abi_type 'bytes' must either be python3 'bytes' object or ''\n \"\"\"\n if is_array_type(abi_type) and is_list_like(value):\n # validate length\n specified_length = length_of_array_type(abi_type)\n if specified_length is not None:\n if specified_length < 1:\n raise TypeError(\n \"Invalid abi-type: {abi_type}. Length of fixed sized arrays\"\n \"must be greater than 0.\"\n .format(abi_type=abi_type)\n )\n if specified_length != len(value):\n raise TypeError(\n \"The following array length does not the length specified\"\n \"by the abi-type, {abi_type}: {value}\"\n .format(abi_type=abi_type, value=value)\n )\n\n # validate sub_types\n sub_type = sub_type_of_array_type(abi_type)\n for v in value:\n validate_abi_value(sub_type, v)\n return\n elif is_bool_type(abi_type) and is_boolean(value):\n return\n elif is_uint_type(abi_type) and is_integer(value) and value >= 0:\n return\n elif is_int_type(abi_type) and is_integer(value):\n return\n elif is_address_type(abi_type):\n validate_address(value)\n return\n elif is_bytes_type(abi_type):\n if is_bytes(value):\n return\n elif is_string(value):\n if is_0x_prefixed(value):\n return\n else:\n raise TypeError(\n \"ABI values of abi-type 'bytes' must be either\"\n \"a python3 'bytes' object or an '0x' prefixed string.\"\n )\n elif is_string_type(abi_type) and is_string(value):\n return\n\n raise TypeError(\n \"The following abi value is not a '{abi_type}': {value}\"\n .format(abi_type=abi_type, value=value)\n )\n\n\ndef validate_address(value):\n \"\"\"\n Helper function for validating an address\n \"\"\"\n if not isinstance(value, str):\n raise TypeError('Address {} must be provided as a string'.format(value))\n if not is_hex_address(value):\n raise InvalidAddress(\"Address must be 20 bytes, as a hex string with a 0x prefix\", value)\n if not is_checksum_address(value):\n if value == value.lower():\n raise InvalidAddress(\n \"Web3.py only accepts checksum addresses. \"\n \"The software that gave you this non-checksum address should be considered unsafe, \"\n \"please file it as a bug on their platform. \"\n \"Try using an ENS name instead. Or, if you must accept lower safety, \"\n \"use Web3.toChecksumAddress(lower_case_address).\",\n value,\n )\n else:\n raise InvalidAddress(\n \"Address has an invalid EIP-55 checksum. \"\n \"After looking up the address from the original source, try again.\",\n value,\n )\n\n\ndef has_one_val(*args, **kwargs):\n vals = itertools.chain(args, kwargs.values())\n not_nones = list(filter(lambda val: val is not None, vals))\n return len(not_nones) == 1\n\n\ndef assert_one_val(*args, **kwargs):\n if not has_one_val(*args, **kwargs):\n raise TypeError(\n \"Exactly one of the passed values can be specified. \"\n \"Instead, values were: %r, %r\" % (args, kwargs)\n )\n", "path": "web3/utils/validation.py"}]}
| 1,611 | 265 |
gh_patches_debug_24918
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-6274
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
API token default scope: user or project?
Followup to #994:
@brettcannon [asks](https://discuss.python.org/t/pypi-security-work-multifactor-auth-progress-help-needed/1042/33):
> > @ewdurbin said: By default, newly created tokens will have “user” scope, meaning that they’ll behave exactly like your password.
> Are there plans to change this default so that using such a strong token is not the default so that people have to opt into it? (I’m no security expert so this is more inquisitive.)
As far as I know there are no such plans but I'd like @woodruffw and @nlhkabu to weigh in.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `warehouse/manage/forms.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 import json
14
15 import wtforms
16
17 import warehouse.utils.otp as otp
18 import warehouse.utils.webauthn as webauthn
19
20 from warehouse import forms
21 from warehouse.accounts.forms import (
22 NewEmailMixin,
23 NewPasswordMixin,
24 PasswordMixin,
25 TOTPValueMixin,
26 WebAuthnCredentialMixin,
27 )
28
29
30 class RoleNameMixin:
31
32 role_name = wtforms.SelectField(
33 "Select role",
34 choices=[("Maintainer", "Maintainer"), ("Owner", "Owner")],
35 validators=[wtforms.validators.DataRequired(message="Select role")],
36 )
37
38
39 class UsernameMixin:
40
41 username = wtforms.StringField(
42 validators=[wtforms.validators.DataRequired(message="Specify username")]
43 )
44
45 def validate_username(self, field):
46 userid = self.user_service.find_userid(field.data)
47
48 if userid is None:
49 raise wtforms.validators.ValidationError(
50 "No user found with that username. Try again."
51 )
52
53
54 class CreateRoleForm(RoleNameMixin, UsernameMixin, forms.Form):
55 def __init__(self, *args, user_service, **kwargs):
56 super().__init__(*args, **kwargs)
57 self.user_service = user_service
58
59
60 class ChangeRoleForm(RoleNameMixin, forms.Form):
61 pass
62
63
64 class SaveAccountForm(forms.Form):
65
66 __params__ = ["name"]
67
68 name = wtforms.StringField()
69
70
71 class AddEmailForm(NewEmailMixin, forms.Form):
72
73 __params__ = ["email"]
74
75 def __init__(self, *args, user_service, user_id, **kwargs):
76 super().__init__(*args, **kwargs)
77 self.user_service = user_service
78 self.user_id = user_id
79
80
81 class ChangePasswordForm(PasswordMixin, NewPasswordMixin, forms.Form):
82
83 __params__ = ["password", "new_password", "password_confirm"]
84
85 def __init__(self, *args, user_service, **kwargs):
86 super().__init__(*args, **kwargs)
87 self.user_service = user_service
88
89
90 class DeleteTOTPForm(UsernameMixin, forms.Form):
91
92 __params__ = ["confirm_username"]
93
94 def __init__(self, *args, user_service, **kwargs):
95 super().__init__(*args, **kwargs)
96 self.user_service = user_service
97
98
99 class ProvisionTOTPForm(TOTPValueMixin, forms.Form):
100
101 __params__ = ["totp_value"]
102
103 def __init__(self, *args, totp_secret, **kwargs):
104 super().__init__(*args, **kwargs)
105 self.totp_secret = totp_secret
106
107 def validate_totp_value(self, field):
108 totp_value = field.data.encode("utf8")
109 if not otp.verify_totp(self.totp_secret, totp_value):
110 raise wtforms.validators.ValidationError("Invalid TOTP code. Try again?")
111
112
113 class DeleteWebAuthnForm(forms.Form):
114 __params__ = ["confirm_device_name"]
115
116 label = wtforms.StringField(
117 validators=[
118 wtforms.validators.DataRequired(message="Specify a device name"),
119 wtforms.validators.Length(
120 max=64, message=("Label must be 64 characters or less")
121 ),
122 ]
123 )
124
125 def __init__(self, *args, user_service, user_id, **kwargs):
126 super().__init__(*args, **kwargs)
127 self.user_service = user_service
128 self.user_id = user_id
129
130 def validate_label(self, field):
131 label = field.data
132
133 webauthn = self.user_service.get_webauthn_by_label(self.user_id, label)
134 if webauthn is None:
135 raise wtforms.validators.ValidationError("No WebAuthn key with given label")
136 self.webauthn = webauthn
137
138
139 class ProvisionWebAuthnForm(WebAuthnCredentialMixin, forms.Form):
140 __params__ = ["label", "credential"]
141
142 label = wtforms.StringField(
143 validators=[
144 wtforms.validators.DataRequired(message="Specify a label"),
145 wtforms.validators.Length(
146 max=64, message=("Label must be 64 characters or less")
147 ),
148 ]
149 )
150
151 def __init__(
152 self, *args, user_service, user_id, challenge, rp_id, origin, **kwargs
153 ):
154 super().__init__(*args, **kwargs)
155 self.user_service = user_service
156 self.user_id = user_id
157 self.challenge = challenge
158 self.rp_id = rp_id
159 self.origin = origin
160
161 def validate_credential(self, field):
162 try:
163 credential_dict = json.loads(field.data.encode("utf8"))
164 except json.JSONDecodeError:
165 raise wtforms.validators.ValidationError(
166 "Invalid WebAuthn credential: Bad payload"
167 )
168
169 try:
170 validated_credential = self.user_service.verify_webauthn_credential(
171 credential_dict,
172 challenge=self.challenge,
173 rp_id=self.rp_id,
174 origin=self.origin,
175 )
176 except webauthn.RegistrationRejectedException as e:
177 raise wtforms.validators.ValidationError(str(e))
178
179 self.validated_credential = validated_credential
180
181 def validate_label(self, field):
182 label = field.data
183
184 if self.user_service.get_webauthn_by_label(self.user_id, label) is not None:
185 raise wtforms.validators.ValidationError(f"Label '{label}' already in use")
186
187
188 class CreateMacaroonForm(forms.Form):
189 __params__ = ["description", "token_scope"]
190
191 def __init__(self, *args, user_id, macaroon_service, project_names, **kwargs):
192 super().__init__(*args, **kwargs)
193 self.user_id = user_id
194 self.macaroon_service = macaroon_service
195 self.project_names = project_names
196
197 description = wtforms.StringField(
198 validators=[
199 wtforms.validators.DataRequired(message="Specify a description"),
200 wtforms.validators.Length(
201 max=100, message="Description must be 100 characters or less"
202 ),
203 ]
204 )
205
206 token_scope = wtforms.StringField(
207 validators=[wtforms.validators.DataRequired(message="Specify a token scope")]
208 )
209
210 def validate_description(self, field):
211 description = field.data
212
213 if (
214 self.macaroon_service.get_macaroon_by_description(self.user_id, description)
215 is not None
216 ):
217 raise wtforms.validators.ValidationError("API token name already in use")
218
219 def validate_token_scope(self, field):
220 scope = field.data
221
222 try:
223 _, scope_kind = scope.split(":", 1)
224 except ValueError:
225 raise wtforms.ValidationError(f"Unknown token scope: {scope}")
226
227 if scope_kind == "user":
228 self.validated_scope = scope_kind
229 return
230
231 try:
232 scope_kind, scope_value = scope_kind.split(":", 1)
233 except ValueError:
234 raise wtforms.ValidationError(f"Unknown token scope: {scope}")
235
236 if scope_kind != "project":
237 raise wtforms.ValidationError(f"Unknown token scope: {scope}")
238 if scope_value not in self.project_names:
239 raise wtforms.ValidationError(
240 f"Unknown or invalid project name: {scope_value}"
241 )
242
243 self.validated_scope = {"projects": [scope_value]}
244
245
246 class DeleteMacaroonForm(forms.Form):
247 __params__ = ["macaroon_id"]
248
249 macaroon_id = wtforms.StringField(
250 validators=[wtforms.validators.DataRequired(message="Identifier required")]
251 )
252
253 def __init__(self, *args, macaroon_service, **kwargs):
254 super().__init__(*args, **kwargs)
255 self.macaroon_service = macaroon_service
256
257 def validate_macaroon_id(self, field):
258 macaroon_id = field.data
259 if self.macaroon_service.find_macaroon(macaroon_id) is None:
260 raise wtforms.validators.ValidationError("No such macaroon")
261
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/warehouse/manage/forms.py b/warehouse/manage/forms.py
--- a/warehouse/manage/forms.py
+++ b/warehouse/manage/forms.py
@@ -196,7 +196,7 @@
description = wtforms.StringField(
validators=[
- wtforms.validators.DataRequired(message="Specify a description"),
+ wtforms.validators.DataRequired(message="Specify a token name"),
wtforms.validators.Length(
max=100, message="Description must be 100 characters or less"
),
@@ -204,7 +204,7 @@
)
token_scope = wtforms.StringField(
- validators=[wtforms.validators.DataRequired(message="Specify a token scope")]
+ validators=[wtforms.validators.DataRequired(message="Specify the token scope")]
)
def validate_description(self, field):
@@ -224,6 +224,9 @@
except ValueError:
raise wtforms.ValidationError(f"Unknown token scope: {scope}")
+ if scope_kind == "unspecified":
+ raise wtforms.ValidationError(f"Specify the token scope")
+
if scope_kind == "user":
self.validated_scope = scope_kind
return
|
{"golden_diff": "diff --git a/warehouse/manage/forms.py b/warehouse/manage/forms.py\n--- a/warehouse/manage/forms.py\n+++ b/warehouse/manage/forms.py\n@@ -196,7 +196,7 @@\n \n description = wtforms.StringField(\n validators=[\n- wtforms.validators.DataRequired(message=\"Specify a description\"),\n+ wtforms.validators.DataRequired(message=\"Specify a token name\"),\n wtforms.validators.Length(\n max=100, message=\"Description must be 100 characters or less\"\n ),\n@@ -204,7 +204,7 @@\n )\n \n token_scope = wtforms.StringField(\n- validators=[wtforms.validators.DataRequired(message=\"Specify a token scope\")]\n+ validators=[wtforms.validators.DataRequired(message=\"Specify the token scope\")]\n )\n \n def validate_description(self, field):\n@@ -224,6 +224,9 @@\n except ValueError:\n raise wtforms.ValidationError(f\"Unknown token scope: {scope}\")\n \n+ if scope_kind == \"unspecified\":\n+ raise wtforms.ValidationError(f\"Specify the token scope\")\n+\n if scope_kind == \"user\":\n self.validated_scope = scope_kind\n return\n", "issue": "API token default scope: user or project?\nFollowup to #994: \r\n\r\n@brettcannon [asks](https://discuss.python.org/t/pypi-security-work-multifactor-auth-progress-help-needed/1042/33):\r\n\r\n> > @ewdurbin said: By default, newly created tokens will have \u201cuser\u201d scope, meaning that they\u2019ll behave exactly like your password.\r\n\r\n> Are there plans to change this default so that using such a strong token is not the default so that people have to opt into it? (I\u2019m no security expert so this is more inquisitive.)\r\n\r\nAs far as I know there are no such plans but I'd like @woodruffw and @nlhkabu to weigh in.\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport json\n\nimport wtforms\n\nimport warehouse.utils.otp as otp\nimport warehouse.utils.webauthn as webauthn\n\nfrom warehouse import forms\nfrom warehouse.accounts.forms import (\n NewEmailMixin,\n NewPasswordMixin,\n PasswordMixin,\n TOTPValueMixin,\n WebAuthnCredentialMixin,\n)\n\n\nclass RoleNameMixin:\n\n role_name = wtforms.SelectField(\n \"Select role\",\n choices=[(\"Maintainer\", \"Maintainer\"), (\"Owner\", \"Owner\")],\n validators=[wtforms.validators.DataRequired(message=\"Select role\")],\n )\n\n\nclass UsernameMixin:\n\n username = wtforms.StringField(\n validators=[wtforms.validators.DataRequired(message=\"Specify username\")]\n )\n\n def validate_username(self, field):\n userid = self.user_service.find_userid(field.data)\n\n if userid is None:\n raise wtforms.validators.ValidationError(\n \"No user found with that username. Try again.\"\n )\n\n\nclass CreateRoleForm(RoleNameMixin, UsernameMixin, forms.Form):\n def __init__(self, *args, user_service, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n\n\nclass ChangeRoleForm(RoleNameMixin, forms.Form):\n pass\n\n\nclass SaveAccountForm(forms.Form):\n\n __params__ = [\"name\"]\n\n name = wtforms.StringField()\n\n\nclass AddEmailForm(NewEmailMixin, forms.Form):\n\n __params__ = [\"email\"]\n\n def __init__(self, *args, user_service, user_id, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n self.user_id = user_id\n\n\nclass ChangePasswordForm(PasswordMixin, NewPasswordMixin, forms.Form):\n\n __params__ = [\"password\", \"new_password\", \"password_confirm\"]\n\n def __init__(self, *args, user_service, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n\n\nclass DeleteTOTPForm(UsernameMixin, forms.Form):\n\n __params__ = [\"confirm_username\"]\n\n def __init__(self, *args, user_service, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n\n\nclass ProvisionTOTPForm(TOTPValueMixin, forms.Form):\n\n __params__ = [\"totp_value\"]\n\n def __init__(self, *args, totp_secret, **kwargs):\n super().__init__(*args, **kwargs)\n self.totp_secret = totp_secret\n\n def validate_totp_value(self, field):\n totp_value = field.data.encode(\"utf8\")\n if not otp.verify_totp(self.totp_secret, totp_value):\n raise wtforms.validators.ValidationError(\"Invalid TOTP code. Try again?\")\n\n\nclass DeleteWebAuthnForm(forms.Form):\n __params__ = [\"confirm_device_name\"]\n\n label = wtforms.StringField(\n validators=[\n wtforms.validators.DataRequired(message=\"Specify a device name\"),\n wtforms.validators.Length(\n max=64, message=(\"Label must be 64 characters or less\")\n ),\n ]\n )\n\n def __init__(self, *args, user_service, user_id, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n self.user_id = user_id\n\n def validate_label(self, field):\n label = field.data\n\n webauthn = self.user_service.get_webauthn_by_label(self.user_id, label)\n if webauthn is None:\n raise wtforms.validators.ValidationError(\"No WebAuthn key with given label\")\n self.webauthn = webauthn\n\n\nclass ProvisionWebAuthnForm(WebAuthnCredentialMixin, forms.Form):\n __params__ = [\"label\", \"credential\"]\n\n label = wtforms.StringField(\n validators=[\n wtforms.validators.DataRequired(message=\"Specify a label\"),\n wtforms.validators.Length(\n max=64, message=(\"Label must be 64 characters or less\")\n ),\n ]\n )\n\n def __init__(\n self, *args, user_service, user_id, challenge, rp_id, origin, **kwargs\n ):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n self.user_id = user_id\n self.challenge = challenge\n self.rp_id = rp_id\n self.origin = origin\n\n def validate_credential(self, field):\n try:\n credential_dict = json.loads(field.data.encode(\"utf8\"))\n except json.JSONDecodeError:\n raise wtforms.validators.ValidationError(\n \"Invalid WebAuthn credential: Bad payload\"\n )\n\n try:\n validated_credential = self.user_service.verify_webauthn_credential(\n credential_dict,\n challenge=self.challenge,\n rp_id=self.rp_id,\n origin=self.origin,\n )\n except webauthn.RegistrationRejectedException as e:\n raise wtforms.validators.ValidationError(str(e))\n\n self.validated_credential = validated_credential\n\n def validate_label(self, field):\n label = field.data\n\n if self.user_service.get_webauthn_by_label(self.user_id, label) is not None:\n raise wtforms.validators.ValidationError(f\"Label '{label}' already in use\")\n\n\nclass CreateMacaroonForm(forms.Form):\n __params__ = [\"description\", \"token_scope\"]\n\n def __init__(self, *args, user_id, macaroon_service, project_names, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_id = user_id\n self.macaroon_service = macaroon_service\n self.project_names = project_names\n\n description = wtforms.StringField(\n validators=[\n wtforms.validators.DataRequired(message=\"Specify a description\"),\n wtforms.validators.Length(\n max=100, message=\"Description must be 100 characters or less\"\n ),\n ]\n )\n\n token_scope = wtforms.StringField(\n validators=[wtforms.validators.DataRequired(message=\"Specify a token scope\")]\n )\n\n def validate_description(self, field):\n description = field.data\n\n if (\n self.macaroon_service.get_macaroon_by_description(self.user_id, description)\n is not None\n ):\n raise wtforms.validators.ValidationError(\"API token name already in use\")\n\n def validate_token_scope(self, field):\n scope = field.data\n\n try:\n _, scope_kind = scope.split(\":\", 1)\n except ValueError:\n raise wtforms.ValidationError(f\"Unknown token scope: {scope}\")\n\n if scope_kind == \"user\":\n self.validated_scope = scope_kind\n return\n\n try:\n scope_kind, scope_value = scope_kind.split(\":\", 1)\n except ValueError:\n raise wtforms.ValidationError(f\"Unknown token scope: {scope}\")\n\n if scope_kind != \"project\":\n raise wtforms.ValidationError(f\"Unknown token scope: {scope}\")\n if scope_value not in self.project_names:\n raise wtforms.ValidationError(\n f\"Unknown or invalid project name: {scope_value}\"\n )\n\n self.validated_scope = {\"projects\": [scope_value]}\n\n\nclass DeleteMacaroonForm(forms.Form):\n __params__ = [\"macaroon_id\"]\n\n macaroon_id = wtforms.StringField(\n validators=[wtforms.validators.DataRequired(message=\"Identifier required\")]\n )\n\n def __init__(self, *args, macaroon_service, **kwargs):\n super().__init__(*args, **kwargs)\n self.macaroon_service = macaroon_service\n\n def validate_macaroon_id(self, field):\n macaroon_id = field.data\n if self.macaroon_service.find_macaroon(macaroon_id) is None:\n raise wtforms.validators.ValidationError(\"No such macaroon\")\n", "path": "warehouse/manage/forms.py"}], "after_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport json\n\nimport wtforms\n\nimport warehouse.utils.otp as otp\nimport warehouse.utils.webauthn as webauthn\n\nfrom warehouse import forms\nfrom warehouse.accounts.forms import (\n NewEmailMixin,\n NewPasswordMixin,\n PasswordMixin,\n TOTPValueMixin,\n WebAuthnCredentialMixin,\n)\n\n\nclass RoleNameMixin:\n\n role_name = wtforms.SelectField(\n \"Select role\",\n choices=[(\"Maintainer\", \"Maintainer\"), (\"Owner\", \"Owner\")],\n validators=[wtforms.validators.DataRequired(message=\"Select role\")],\n )\n\n\nclass UsernameMixin:\n\n username = wtforms.StringField(\n validators=[wtforms.validators.DataRequired(message=\"Specify username\")]\n )\n\n def validate_username(self, field):\n userid = self.user_service.find_userid(field.data)\n\n if userid is None:\n raise wtforms.validators.ValidationError(\n \"No user found with that username. Try again.\"\n )\n\n\nclass CreateRoleForm(RoleNameMixin, UsernameMixin, forms.Form):\n def __init__(self, *args, user_service, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n\n\nclass ChangeRoleForm(RoleNameMixin, forms.Form):\n pass\n\n\nclass SaveAccountForm(forms.Form):\n\n __params__ = [\"name\"]\n\n name = wtforms.StringField()\n\n\nclass AddEmailForm(NewEmailMixin, forms.Form):\n\n __params__ = [\"email\"]\n\n def __init__(self, *args, user_service, user_id, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n self.user_id = user_id\n\n\nclass ChangePasswordForm(PasswordMixin, NewPasswordMixin, forms.Form):\n\n __params__ = [\"password\", \"new_password\", \"password_confirm\"]\n\n def __init__(self, *args, user_service, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n\n\nclass DeleteTOTPForm(UsernameMixin, forms.Form):\n\n __params__ = [\"confirm_username\"]\n\n def __init__(self, *args, user_service, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n\n\nclass ProvisionTOTPForm(TOTPValueMixin, forms.Form):\n\n __params__ = [\"totp_value\"]\n\n def __init__(self, *args, totp_secret, **kwargs):\n super().__init__(*args, **kwargs)\n self.totp_secret = totp_secret\n\n def validate_totp_value(self, field):\n totp_value = field.data.encode(\"utf8\")\n if not otp.verify_totp(self.totp_secret, totp_value):\n raise wtforms.validators.ValidationError(\"Invalid TOTP code. Try again?\")\n\n\nclass DeleteWebAuthnForm(forms.Form):\n __params__ = [\"confirm_device_name\"]\n\n label = wtforms.StringField(\n validators=[\n wtforms.validators.DataRequired(message=\"Specify a device name\"),\n wtforms.validators.Length(\n max=64, message=(\"Label must be 64 characters or less\")\n ),\n ]\n )\n\n def __init__(self, *args, user_service, user_id, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n self.user_id = user_id\n\n def validate_label(self, field):\n label = field.data\n\n webauthn = self.user_service.get_webauthn_by_label(self.user_id, label)\n if webauthn is None:\n raise wtforms.validators.ValidationError(\"No WebAuthn key with given label\")\n self.webauthn = webauthn\n\n\nclass ProvisionWebAuthnForm(WebAuthnCredentialMixin, forms.Form):\n __params__ = [\"label\", \"credential\"]\n\n label = wtforms.StringField(\n validators=[\n wtforms.validators.DataRequired(message=\"Specify a label\"),\n wtforms.validators.Length(\n max=64, message=(\"Label must be 64 characters or less\")\n ),\n ]\n )\n\n def __init__(\n self, *args, user_service, user_id, challenge, rp_id, origin, **kwargs\n ):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n self.user_id = user_id\n self.challenge = challenge\n self.rp_id = rp_id\n self.origin = origin\n\n def validate_credential(self, field):\n try:\n credential_dict = json.loads(field.data.encode(\"utf8\"))\n except json.JSONDecodeError:\n raise wtforms.validators.ValidationError(\n \"Invalid WebAuthn credential: Bad payload\"\n )\n\n try:\n validated_credential = self.user_service.verify_webauthn_credential(\n credential_dict,\n challenge=self.challenge,\n rp_id=self.rp_id,\n origin=self.origin,\n )\n except webauthn.RegistrationRejectedException as e:\n raise wtforms.validators.ValidationError(str(e))\n\n self.validated_credential = validated_credential\n\n def validate_label(self, field):\n label = field.data\n\n if self.user_service.get_webauthn_by_label(self.user_id, label) is not None:\n raise wtforms.validators.ValidationError(f\"Label '{label}' already in use\")\n\n\nclass CreateMacaroonForm(forms.Form):\n __params__ = [\"description\", \"token_scope\"]\n\n def __init__(self, *args, user_id, macaroon_service, project_names, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_id = user_id\n self.macaroon_service = macaroon_service\n self.project_names = project_names\n\n description = wtforms.StringField(\n validators=[\n wtforms.validators.DataRequired(message=\"Specify a token name\"),\n wtforms.validators.Length(\n max=100, message=\"Description must be 100 characters or less\"\n ),\n ]\n )\n\n token_scope = wtforms.StringField(\n validators=[wtforms.validators.DataRequired(message=\"Specify the token scope\")]\n )\n\n def validate_description(self, field):\n description = field.data\n\n if (\n self.macaroon_service.get_macaroon_by_description(self.user_id, description)\n is not None\n ):\n raise wtforms.validators.ValidationError(\"API token name already in use\")\n\n def validate_token_scope(self, field):\n scope = field.data\n\n try:\n _, scope_kind = scope.split(\":\", 1)\n except ValueError:\n raise wtforms.ValidationError(f\"Unknown token scope: {scope}\")\n\n if scope_kind == \"unspecified\":\n raise wtforms.ValidationError(f\"Specify the token scope\")\n\n if scope_kind == \"user\":\n self.validated_scope = scope_kind\n return\n\n try:\n scope_kind, scope_value = scope_kind.split(\":\", 1)\n except ValueError:\n raise wtforms.ValidationError(f\"Unknown token scope: {scope}\")\n\n if scope_kind != \"project\":\n raise wtforms.ValidationError(f\"Unknown token scope: {scope}\")\n if scope_value not in self.project_names:\n raise wtforms.ValidationError(\n f\"Unknown or invalid project name: {scope_value}\"\n )\n\n self.validated_scope = {\"projects\": [scope_value]}\n\n\nclass DeleteMacaroonForm(forms.Form):\n __params__ = [\"macaroon_id\"]\n\n macaroon_id = wtforms.StringField(\n validators=[wtforms.validators.DataRequired(message=\"Identifier required\")]\n )\n\n def __init__(self, *args, macaroon_service, **kwargs):\n super().__init__(*args, **kwargs)\n self.macaroon_service = macaroon_service\n\n def validate_macaroon_id(self, field):\n macaroon_id = field.data\n if self.macaroon_service.find_macaroon(macaroon_id) is None:\n raise wtforms.validators.ValidationError(\"No such macaroon\")\n", "path": "warehouse/manage/forms.py"}]}
| 2,898 | 259 |
gh_patches_debug_37334
|
rasdani/github-patches
|
git_diff
|
networkx__networkx-4160
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
steiner_tree should accept MultiGraph
I'm using `steiner_tree` on a road network which may have multiple edges between nodes.
It looks like `steiner_tree` will fail if passed a `MultiGraph`:
- as a next-to-last step, edges are generated as `(u, v)` tuples pairwise [here](https://github.com/networkx/networkx/blob/master/networkx/algorithms/approximation/steinertree.py#L87)
- before being passed to `G.edge_subgraph` which raises a `ValueError` from `nx.filter.show_multiedges`
This should reproduce the issue:
```python
import networkx as nx
import networkx.algorithms.approximation as nxa
def test_simple_steiner_tree():
G = nx.Graph()
G.add_weighted_edges_from([
(1, 2, 1),
(2, 3, 1),
(3, 4, 1),
(3, 5, 1)
])
terminal_nodes = [2, 4, 5]
expected_edges = [
(2, 3),
(3, 4),
(3, 5)
]
T = nxa.steiner_tree(G, terminal_nodes)
assert list(T.edges) == expected_edges
def test_multi_steiner_tree():
G = nx.MultiGraph()
G.add_weighted_edges_from([
(1, 2, 1),
(2, 3, 1),
(2, 3, 999),
(3, 4, 1),
(3, 5, 1)
])
terminal_nodes = [2, 4, 5]
expected_edges = [
(2, 3, 0),
(3, 4, 0), # first edge has weight one
(3, 5, 0)
]
T = nxa.steiner_tree(G, terminal_nodes)
test_simple_steiner_tree() # passes
test_multi_steiner_tree() # throws ValueError
```
The quick fix might be to add `@not_implemented_for('multigraph')`.
For my current purposes, the following does the trick to handle the `MultiGraph` case:
```python
# get unique links pairwise (u, v)
links = set(chain.from_iterable(
pairwise(d['path'])
for u, v, d in mst_edges
))
# for each link in the chain
multi_edges = []
for u, v in links:
# consider each edge between the pair of nodes,
# keeping track of the one with the minimum weight
# (there may be a better way - convenience functions/accessors?)
num_edges = G.number_of_edges(u, v)
min_k = 0
min_weight = None
for k in range(num_edges):
curr_weight = G.edges[u, v, k][weight]
if min_weight is None:
min_weight = curr_weight
elif curr_weight < min_weight:
min_weight = curr_weight
min_k = k
multi_edges.append((u, v, min_k))
# create subgraph from multi edges - list of (u, v, k)
T = G.edge_subgraph(multi_edges)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `networkx/algorithms/approximation/steinertree.py`
Content:
```
1 from itertools import chain
2
3 from networkx.utils import pairwise, not_implemented_for
4 import networkx as nx
5
6 __all__ = ["metric_closure", "steiner_tree"]
7
8
9 @not_implemented_for("directed")
10 def metric_closure(G, weight="weight"):
11 """ Return the metric closure of a graph.
12
13 The metric closure of a graph *G* is the complete graph in which each edge
14 is weighted by the shortest path distance between the nodes in *G* .
15
16 Parameters
17 ----------
18 G : NetworkX graph
19
20 Returns
21 -------
22 NetworkX graph
23 Metric closure of the graph `G`.
24
25 """
26 M = nx.Graph()
27
28 Gnodes = set(G)
29
30 # check for connected graph while processing first node
31 all_paths_iter = nx.all_pairs_dijkstra(G, weight=weight)
32 u, (distance, path) = next(all_paths_iter)
33 if Gnodes - set(distance):
34 msg = "G is not a connected graph. metric_closure is not defined."
35 raise nx.NetworkXError(msg)
36 Gnodes.remove(u)
37 for v in Gnodes:
38 M.add_edge(u, v, distance=distance[v], path=path[v])
39
40 # first node done -- now process the rest
41 for u, (distance, path) in all_paths_iter:
42 Gnodes.remove(u)
43 for v in Gnodes:
44 M.add_edge(u, v, distance=distance[v], path=path[v])
45
46 return M
47
48
49 @not_implemented_for("multigraph")
50 @not_implemented_for("directed")
51 def steiner_tree(G, terminal_nodes, weight="weight"):
52 """ Return an approximation to the minimum Steiner tree of a graph.
53
54 Parameters
55 ----------
56 G : NetworkX graph
57
58 terminal_nodes : list
59 A list of terminal nodes for which minimum steiner tree is
60 to be found.
61
62 Returns
63 -------
64 NetworkX graph
65 Approximation to the minimum steiner tree of `G` induced by
66 `terminal_nodes` .
67
68 Notes
69 -----
70 Steiner tree can be approximated by computing the minimum spanning
71 tree of the subgraph of the metric closure of the graph induced by the
72 terminal nodes, where the metric closure of *G* is the complete graph in
73 which each edge is weighted by the shortest path distance between the
74 nodes in *G* .
75 This algorithm produces a tree whose weight is within a (2 - (2 / t))
76 factor of the weight of the optimal Steiner tree where *t* is number of
77 terminal nodes.
78
79 """
80 # M is the subgraph of the metric closure induced by the terminal nodes of
81 # G.
82 M = metric_closure(G, weight=weight)
83 # Use the 'distance' attribute of each edge provided by the metric closure
84 # graph.
85 H = M.subgraph(terminal_nodes)
86 mst_edges = nx.minimum_spanning_edges(H, weight="distance", data=True)
87 # Create an iterator over each edge in each shortest path; repeats are okay
88 edges = chain.from_iterable(pairwise(d["path"]) for u, v, d in mst_edges)
89 T = G.edge_subgraph(edges)
90 return T
91
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/networkx/algorithms/approximation/steinertree.py b/networkx/algorithms/approximation/steinertree.py
--- a/networkx/algorithms/approximation/steinertree.py
+++ b/networkx/algorithms/approximation/steinertree.py
@@ -46,11 +46,23 @@
return M
-@not_implemented_for("multigraph")
@not_implemented_for("directed")
def steiner_tree(G, terminal_nodes, weight="weight"):
""" Return an approximation to the minimum Steiner tree of a graph.
+ The minimum Steiner tree of `G` w.r.t a set of `terminal_nodes`
+ is a tree within `G` that spans those nodes and has minimum size
+ (sum of edge weights) among all such trees.
+
+ The minimum Steiner tree can be approximated by computing the minimum
+ spanning tree of the subgraph of the metric closure of *G* induced by the
+ terminal nodes, where the metric closure of *G* is the complete graph in
+ which each edge is weighted by the shortest path distance between the
+ nodes in *G* .
+ This algorithm produces a tree whose weight is within a (2 - (2 / t))
+ factor of the weight of the optimal Steiner tree where *t* is number of
+ terminal nodes.
+
Parameters
----------
G : NetworkX graph
@@ -67,24 +79,26 @@
Notes
-----
- Steiner tree can be approximated by computing the minimum spanning
- tree of the subgraph of the metric closure of the graph induced by the
- terminal nodes, where the metric closure of *G* is the complete graph in
- which each edge is weighted by the shortest path distance between the
- nodes in *G* .
- This algorithm produces a tree whose weight is within a (2 - (2 / t))
- factor of the weight of the optimal Steiner tree where *t* is number of
- terminal nodes.
+ For multigraphs, the edge between two nodes with minimum weight is the
+ edge put into the Steiner tree.
+
+ References
+ ----------
+ .. [1] Steiner_tree_problem on Wikipedia.
+ https://en.wikipedia.org/wiki/Steiner_tree_problem
"""
- # M is the subgraph of the metric closure induced by the terminal nodes of
- # G.
+ # H is the subgraph induced by terminal_nodes in the metric closure M of G.
M = metric_closure(G, weight=weight)
- # Use the 'distance' attribute of each edge provided by the metric closure
- # graph.
H = M.subgraph(terminal_nodes)
+ # Use the 'distance' attribute of each edge provided by M.
mst_edges = nx.minimum_spanning_edges(H, weight="distance", data=True)
# Create an iterator over each edge in each shortest path; repeats are okay
edges = chain.from_iterable(pairwise(d["path"]) for u, v, d in mst_edges)
+ # For multigraph we should add the minimal weight edge keys
+ if G.is_multigraph():
+ edges = (
+ (u, v, min(G[u][v], key=lambda k: G[u][v][k][weight])) for u, v in edges
+ )
T = G.edge_subgraph(edges)
return T
|
{"golden_diff": "diff --git a/networkx/algorithms/approximation/steinertree.py b/networkx/algorithms/approximation/steinertree.py\n--- a/networkx/algorithms/approximation/steinertree.py\n+++ b/networkx/algorithms/approximation/steinertree.py\n@@ -46,11 +46,23 @@\n return M\n \n \n-@not_implemented_for(\"multigraph\")\n @not_implemented_for(\"directed\")\n def steiner_tree(G, terminal_nodes, weight=\"weight\"):\n \"\"\" Return an approximation to the minimum Steiner tree of a graph.\n \n+ The minimum Steiner tree of `G` w.r.t a set of `terminal_nodes`\n+ is a tree within `G` that spans those nodes and has minimum size\n+ (sum of edge weights) among all such trees.\n+\n+ The minimum Steiner tree can be approximated by computing the minimum\n+ spanning tree of the subgraph of the metric closure of *G* induced by the\n+ terminal nodes, where the metric closure of *G* is the complete graph in\n+ which each edge is weighted by the shortest path distance between the\n+ nodes in *G* .\n+ This algorithm produces a tree whose weight is within a (2 - (2 / t))\n+ factor of the weight of the optimal Steiner tree where *t* is number of\n+ terminal nodes.\n+\n Parameters\n ----------\n G : NetworkX graph\n@@ -67,24 +79,26 @@\n \n Notes\n -----\n- Steiner tree can be approximated by computing the minimum spanning\n- tree of the subgraph of the metric closure of the graph induced by the\n- terminal nodes, where the metric closure of *G* is the complete graph in\n- which each edge is weighted by the shortest path distance between the\n- nodes in *G* .\n- This algorithm produces a tree whose weight is within a (2 - (2 / t))\n- factor of the weight of the optimal Steiner tree where *t* is number of\n- terminal nodes.\n+ For multigraphs, the edge between two nodes with minimum weight is the\n+ edge put into the Steiner tree.\n \n+\n+ References\n+ ----------\n+ .. [1] Steiner_tree_problem on Wikipedia.\n+ https://en.wikipedia.org/wiki/Steiner_tree_problem\n \"\"\"\n- # M is the subgraph of the metric closure induced by the terminal nodes of\n- # G.\n+ # H is the subgraph induced by terminal_nodes in the metric closure M of G.\n M = metric_closure(G, weight=weight)\n- # Use the 'distance' attribute of each edge provided by the metric closure\n- # graph.\n H = M.subgraph(terminal_nodes)\n+ # Use the 'distance' attribute of each edge provided by M.\n mst_edges = nx.minimum_spanning_edges(H, weight=\"distance\", data=True)\n # Create an iterator over each edge in each shortest path; repeats are okay\n edges = chain.from_iterable(pairwise(d[\"path\"]) for u, v, d in mst_edges)\n+ # For multigraph we should add the minimal weight edge keys\n+ if G.is_multigraph():\n+ edges = (\n+ (u, v, min(G[u][v], key=lambda k: G[u][v][k][weight])) for u, v in edges\n+ )\n T = G.edge_subgraph(edges)\n return T\n", "issue": "steiner_tree should accept MultiGraph\nI'm using `steiner_tree` on a road network which may have multiple edges between nodes. \r\n\r\nIt looks like `steiner_tree` will fail if passed a `MultiGraph`:\r\n- as a next-to-last step, edges are generated as `(u, v)` tuples pairwise [here](https://github.com/networkx/networkx/blob/master/networkx/algorithms/approximation/steinertree.py#L87)\r\n- before being passed to `G.edge_subgraph` which raises a `ValueError` from `nx.filter.show_multiedges`\r\n\r\nThis should reproduce the issue:\r\n\r\n```python\r\nimport networkx as nx\r\nimport networkx.algorithms.approximation as nxa\r\n\r\ndef test_simple_steiner_tree():\r\n G = nx.Graph()\r\n G.add_weighted_edges_from([\r\n (1, 2, 1),\r\n (2, 3, 1),\r\n (3, 4, 1),\r\n (3, 5, 1)\r\n ])\r\n terminal_nodes = [2, 4, 5]\r\n expected_edges = [\r\n (2, 3),\r\n (3, 4),\r\n (3, 5)\r\n ]\r\n T = nxa.steiner_tree(G, terminal_nodes)\r\n assert list(T.edges) == expected_edges\r\n\r\ndef test_multi_steiner_tree():\r\n G = nx.MultiGraph()\r\n G.add_weighted_edges_from([\r\n (1, 2, 1),\r\n (2, 3, 1),\r\n (2, 3, 999),\r\n (3, 4, 1),\r\n (3, 5, 1)\r\n ])\r\n terminal_nodes = [2, 4, 5]\r\n expected_edges = [\r\n (2, 3, 0),\r\n (3, 4, 0), # first edge has weight one\r\n (3, 5, 0)\r\n ]\r\n T = nxa.steiner_tree(G, terminal_nodes)\r\n\r\ntest_simple_steiner_tree() # passes\r\ntest_multi_steiner_tree() # throws ValueError \r\n```\r\n\r\nThe quick fix might be to add `@not_implemented_for('multigraph')`. \r\n\r\nFor my current purposes, the following does the trick to handle the `MultiGraph` case:\r\n\r\n```python\r\n# get unique links pairwise (u, v)\r\nlinks = set(chain.from_iterable(\r\n pairwise(d['path'])\r\n for u, v, d in mst_edges\r\n))\r\n\r\n# for each link in the chain\r\nmulti_edges = []\r\nfor u, v in links: \r\n # consider each edge between the pair of nodes,\r\n # keeping track of the one with the minimum weight\r\n # (there may be a better way - convenience functions/accessors?)\r\n num_edges = G.number_of_edges(u, v)\r\n min_k = 0\r\n min_weight = None\r\n for k in range(num_edges):\r\n curr_weight = G.edges[u, v, k][weight]\r\n if min_weight is None:\r\n min_weight = curr_weight\r\n elif curr_weight < min_weight:\r\n min_weight = curr_weight\r\n min_k = k\r\n multi_edges.append((u, v, min_k))\r\n\r\n# create subgraph from multi edges - list of (u, v, k)\r\nT = G.edge_subgraph(multi_edges)\r\n```\r\n\n", "before_files": [{"content": "from itertools import chain\n\nfrom networkx.utils import pairwise, not_implemented_for\nimport networkx as nx\n\n__all__ = [\"metric_closure\", \"steiner_tree\"]\n\n\n@not_implemented_for(\"directed\")\ndef metric_closure(G, weight=\"weight\"):\n \"\"\" Return the metric closure of a graph.\n\n The metric closure of a graph *G* is the complete graph in which each edge\n is weighted by the shortest path distance between the nodes in *G* .\n\n Parameters\n ----------\n G : NetworkX graph\n\n Returns\n -------\n NetworkX graph\n Metric closure of the graph `G`.\n\n \"\"\"\n M = nx.Graph()\n\n Gnodes = set(G)\n\n # check for connected graph while processing first node\n all_paths_iter = nx.all_pairs_dijkstra(G, weight=weight)\n u, (distance, path) = next(all_paths_iter)\n if Gnodes - set(distance):\n msg = \"G is not a connected graph. metric_closure is not defined.\"\n raise nx.NetworkXError(msg)\n Gnodes.remove(u)\n for v in Gnodes:\n M.add_edge(u, v, distance=distance[v], path=path[v])\n\n # first node done -- now process the rest\n for u, (distance, path) in all_paths_iter:\n Gnodes.remove(u)\n for v in Gnodes:\n M.add_edge(u, v, distance=distance[v], path=path[v])\n\n return M\n\n\n@not_implemented_for(\"multigraph\")\n@not_implemented_for(\"directed\")\ndef steiner_tree(G, terminal_nodes, weight=\"weight\"):\n \"\"\" Return an approximation to the minimum Steiner tree of a graph.\n\n Parameters\n ----------\n G : NetworkX graph\n\n terminal_nodes : list\n A list of terminal nodes for which minimum steiner tree is\n to be found.\n\n Returns\n -------\n NetworkX graph\n Approximation to the minimum steiner tree of `G` induced by\n `terminal_nodes` .\n\n Notes\n -----\n Steiner tree can be approximated by computing the minimum spanning\n tree of the subgraph of the metric closure of the graph induced by the\n terminal nodes, where the metric closure of *G* is the complete graph in\n which each edge is weighted by the shortest path distance between the\n nodes in *G* .\n This algorithm produces a tree whose weight is within a (2 - (2 / t))\n factor of the weight of the optimal Steiner tree where *t* is number of\n terminal nodes.\n\n \"\"\"\n # M is the subgraph of the metric closure induced by the terminal nodes of\n # G.\n M = metric_closure(G, weight=weight)\n # Use the 'distance' attribute of each edge provided by the metric closure\n # graph.\n H = M.subgraph(terminal_nodes)\n mst_edges = nx.minimum_spanning_edges(H, weight=\"distance\", data=True)\n # Create an iterator over each edge in each shortest path; repeats are okay\n edges = chain.from_iterable(pairwise(d[\"path\"]) for u, v, d in mst_edges)\n T = G.edge_subgraph(edges)\n return T\n", "path": "networkx/algorithms/approximation/steinertree.py"}], "after_files": [{"content": "from itertools import chain\n\nfrom networkx.utils import pairwise, not_implemented_for\nimport networkx as nx\n\n__all__ = [\"metric_closure\", \"steiner_tree\"]\n\n\n@not_implemented_for(\"directed\")\ndef metric_closure(G, weight=\"weight\"):\n \"\"\" Return the metric closure of a graph.\n\n The metric closure of a graph *G* is the complete graph in which each edge\n is weighted by the shortest path distance between the nodes in *G* .\n\n Parameters\n ----------\n G : NetworkX graph\n\n Returns\n -------\n NetworkX graph\n Metric closure of the graph `G`.\n\n \"\"\"\n M = nx.Graph()\n\n Gnodes = set(G)\n\n # check for connected graph while processing first node\n all_paths_iter = nx.all_pairs_dijkstra(G, weight=weight)\n u, (distance, path) = next(all_paths_iter)\n if Gnodes - set(distance):\n msg = \"G is not a connected graph. metric_closure is not defined.\"\n raise nx.NetworkXError(msg)\n Gnodes.remove(u)\n for v in Gnodes:\n M.add_edge(u, v, distance=distance[v], path=path[v])\n\n # first node done -- now process the rest\n for u, (distance, path) in all_paths_iter:\n Gnodes.remove(u)\n for v in Gnodes:\n M.add_edge(u, v, distance=distance[v], path=path[v])\n\n return M\n\n\n@not_implemented_for(\"directed\")\ndef steiner_tree(G, terminal_nodes, weight=\"weight\"):\n \"\"\" Return an approximation to the minimum Steiner tree of a graph.\n\n The minimum Steiner tree of `G` w.r.t a set of `terminal_nodes`\n is a tree within `G` that spans those nodes and has minimum size\n (sum of edge weights) among all such trees.\n\n The minimum Steiner tree can be approximated by computing the minimum\n spanning tree of the subgraph of the metric closure of *G* induced by the\n terminal nodes, where the metric closure of *G* is the complete graph in\n which each edge is weighted by the shortest path distance between the\n nodes in *G* .\n This algorithm produces a tree whose weight is within a (2 - (2 / t))\n factor of the weight of the optimal Steiner tree where *t* is number of\n terminal nodes.\n\n Parameters\n ----------\n G : NetworkX graph\n\n terminal_nodes : list\n A list of terminal nodes for which minimum steiner tree is\n to be found.\n\n Returns\n -------\n NetworkX graph\n Approximation to the minimum steiner tree of `G` induced by\n `terminal_nodes` .\n\n Notes\n -----\n For multigraphs, the edge between two nodes with minimum weight is the\n edge put into the Steiner tree.\n\n\n References\n ----------\n .. [1] Steiner_tree_problem on Wikipedia.\n https://en.wikipedia.org/wiki/Steiner_tree_problem\n \"\"\"\n # H is the subgraph induced by terminal_nodes in the metric closure M of G.\n M = metric_closure(G, weight=weight)\n H = M.subgraph(terminal_nodes)\n # Use the 'distance' attribute of each edge provided by M.\n mst_edges = nx.minimum_spanning_edges(H, weight=\"distance\", data=True)\n # Create an iterator over each edge in each shortest path; repeats are okay\n edges = chain.from_iterable(pairwise(d[\"path\"]) for u, v, d in mst_edges)\n # For multigraph we should add the minimal weight edge keys\n if G.is_multigraph():\n edges = (\n (u, v, min(G[u][v], key=lambda k: G[u][v][k][weight])) for u, v in edges\n )\n T = G.edge_subgraph(edges)\n return T\n", "path": "networkx/algorithms/approximation/steinertree.py"}]}
| 1,852 | 763 |
gh_patches_debug_33744
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-1056
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
IntegrityError with Posgresql cache backend
I would like to update the current request with one of http://stackoverflow.com/a/1109198/186202
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kinto/core/cache/postgresql/__init__.py`
Content:
```
1 from __future__ import absolute_import
2 from functools import wraps
3
4 import os
5 import time
6
7 from kinto.core import logger
8 from kinto.core.cache import CacheBase
9 from kinto.core.storage.postgresql.client import create_from_config
10 from kinto.core.storage.exceptions import BackendError
11 from kinto.core.utils import json
12
13
14 DELAY_BETWEEN_RETRIES_IN_SECONDS = 0.005
15 MAX_RETRIES = 10
16
17
18 def retry_on_failure(func):
19 @wraps(func)
20 def wraps_func(self, *args, **kwargs):
21 tries = kwargs.pop('tries', 0)
22 try:
23 return func(self, *args, **kwargs)
24 except BackendError as e:
25 if tries < MAX_RETRIES:
26 # Skip delay the 2 first times.
27 delay = max(0, tries - 1) * DELAY_BETWEEN_RETRIES_IN_SECONDS
28 time.sleep(delay)
29 return wraps_func(self, tries=(tries + 1), *args, **kwargs)
30 raise e
31 return wraps_func
32
33
34 class Cache(CacheBase):
35 """Cache backend using PostgreSQL.
36
37 Enable in configuration::
38
39 kinto.cache_backend = kinto.core.cache.postgresql
40
41 Database location URI can be customized::
42
43 kinto.cache_url = postgres://user:[email protected]:5432/dbname
44
45 Alternatively, username and password could also rely on system user ident
46 or even specified in :file:`~/.pgpass` (*see PostgreSQL documentation*).
47
48 .. note::
49
50 Some tables and indices are created when ``kinto migrate`` is run.
51 This requires some privileges on the database, or some error will
52 be raised.
53
54 **Alternatively**, the schema can be initialized outside the
55 python application, using the SQL file located in
56 :file:`kinto/core/cache/postgresql/schema.sql`. This allows to
57 distinguish schema manipulation privileges from schema usage.
58
59
60 A connection pool is enabled by default::
61
62 kinto.cache_pool_size = 10
63 kinto.cache_maxoverflow = 10
64 kinto.cache_max_backlog = -1
65 kinto.cache_pool_recycle = -1
66 kinto.cache_pool_timeout = 30
67 kinto.cache_poolclass =
68 kinto.core.storage.postgresql.pool.QueuePoolWithMaxBacklog
69
70 The ``max_backlog`` limits the number of threads that can be in the queue
71 waiting for a connection. Once this limit has been reached, any further
72 attempts to acquire a connection will be rejected immediately, instead of
73 locking up all threads by keeping them waiting in the queue.
74
75 See `dedicated section in SQLAlchemy documentation
76 <http://docs.sqlalchemy.org/en/rel_1_0/core/engines.html>`_
77 for default values and behaviour.
78
79 .. note::
80
81 Using a `dedicated connection pool <http://pgpool.net>`_ is still
82 recommended to allow load balancing, replication or limit the number
83 of connections used in a multi-process deployment.
84
85 :noindex:
86 """ # NOQA
87 def __init__(self, client, *args, **kwargs):
88 super(Cache, self).__init__(*args, **kwargs)
89 self.client = client
90
91 def initialize_schema(self, dry_run=False):
92 # Check if cache table exists.
93 query = """
94 SELECT 1
95 FROM information_schema.tables
96 WHERE table_name = 'cache';
97 """
98 with self.client.connect(readonly=True) as conn:
99 result = conn.execute(query)
100 if result.rowcount > 0:
101 logger.info("PostgreSQL cache schema is up-to-date.")
102 return
103
104 # Create schema
105 here = os.path.abspath(os.path.dirname(__file__))
106 sql_file = os.path.join(here, 'schema.sql')
107
108 if dry_run:
109 logger.info("Create cache schema from %s" % sql_file)
110 return
111
112 # Since called outside request, force commit.
113 schema = open(sql_file).read()
114 with self.client.connect(force_commit=True) as conn:
115 conn.execute(schema)
116 logger.info('Created PostgreSQL cache tables')
117
118 def flush(self):
119 query = """
120 DELETE FROM cache;
121 """
122 # Since called outside request (e.g. tests), force commit.
123 with self.client.connect(force_commit=True) as conn:
124 conn.execute(query)
125 logger.debug('Flushed PostgreSQL cache tables')
126
127 def ttl(self, key):
128 query = """
129 SELECT EXTRACT(SECOND FROM (ttl - now())) AS ttl
130 FROM cache
131 WHERE key = :key
132 AND ttl IS NOT NULL;
133 """
134 with self.client.connect(readonly=True) as conn:
135 result = conn.execute(query, dict(key=self.prefix + key))
136 if result.rowcount > 0:
137 return result.fetchone()['ttl']
138 return -1
139
140 def expire(self, key, ttl):
141 query = """
142 UPDATE cache SET ttl = sec2ttl(:ttl) WHERE key = :key;
143 """
144 with self.client.connect() as conn:
145 conn.execute(query, dict(ttl=ttl, key=self.prefix + key))
146
147 @retry_on_failure
148 def set(self, key, value, ttl=None):
149 if ttl is None:
150 logger.warning("No TTL for cache key %r" % key)
151 query = """
152 WITH upsert AS (
153 UPDATE cache SET value = :value, ttl = sec2ttl(:ttl)
154 WHERE key=:key
155 RETURNING *)
156 INSERT INTO cache (key, value, ttl)
157 SELECT :key, :value, sec2ttl(:ttl)
158 WHERE NOT EXISTS (SELECT * FROM upsert)
159 """
160 value = json.dumps(value)
161 with self.client.connect() as conn:
162 conn.execute(query, dict(key=self.prefix + key,
163 value=value, ttl=ttl))
164
165 def get(self, key):
166 purge = "DELETE FROM cache WHERE ttl IS NOT NULL AND now() > ttl;"
167 query = "SELECT value FROM cache WHERE key = :key;"
168 with self.client.connect() as conn:
169 conn.execute(purge)
170 result = conn.execute(query, dict(key=self.prefix + key))
171 if result.rowcount > 0:
172 value = result.fetchone()['value']
173 return json.loads(value)
174
175 def delete(self, key):
176 query = "DELETE FROM cache WHERE key = :key"
177 with self.client.connect() as conn:
178 conn.execute(query, dict(key=self.prefix + key))
179
180
181 def load_from_config(config):
182 settings = config.get_settings()
183 client = create_from_config(config, prefix='cache_', with_transaction=False)
184 return Cache(client=client, cache_prefix=settings['cache_prefix'])
185
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kinto/core/cache/postgresql/__init__.py b/kinto/core/cache/postgresql/__init__.py
--- a/kinto/core/cache/postgresql/__init__.py
+++ b/kinto/core/cache/postgresql/__init__.py
@@ -1,36 +1,13 @@
from __future__ import absolute_import
-from functools import wraps
import os
-import time
from kinto.core import logger
from kinto.core.cache import CacheBase
from kinto.core.storage.postgresql.client import create_from_config
-from kinto.core.storage.exceptions import BackendError
from kinto.core.utils import json
-DELAY_BETWEEN_RETRIES_IN_SECONDS = 0.005
-MAX_RETRIES = 10
-
-
-def retry_on_failure(func):
- @wraps(func)
- def wraps_func(self, *args, **kwargs):
- tries = kwargs.pop('tries', 0)
- try:
- return func(self, *args, **kwargs)
- except BackendError as e:
- if tries < MAX_RETRIES:
- # Skip delay the 2 first times.
- delay = max(0, tries - 1) * DELAY_BETWEEN_RETRIES_IN_SECONDS
- time.sleep(delay)
- return wraps_func(self, tries=(tries + 1), *args, **kwargs)
- raise e
- return wraps_func
-
-
class Cache(CacheBase):
"""Cache backend using PostgreSQL.
@@ -144,18 +121,15 @@
with self.client.connect() as conn:
conn.execute(query, dict(ttl=ttl, key=self.prefix + key))
- @retry_on_failure
def set(self, key, value, ttl=None):
if ttl is None:
logger.warning("No TTL for cache key %r" % key)
query = """
- WITH upsert AS (
- UPDATE cache SET value = :value, ttl = sec2ttl(:ttl)
- WHERE key=:key
- RETURNING *)
INSERT INTO cache (key, value, ttl)
- SELECT :key, :value, sec2ttl(:ttl)
- WHERE NOT EXISTS (SELECT * FROM upsert)
+ VALUES (:key, :value, sec2ttl(:ttl))
+ ON CONFLICT (key) DO UPDATE
+ SET value = :value,
+ ttl = sec2ttl(:ttl);
"""
value = json.dumps(value)
with self.client.connect() as conn:
|
{"golden_diff": "diff --git a/kinto/core/cache/postgresql/__init__.py b/kinto/core/cache/postgresql/__init__.py\n--- a/kinto/core/cache/postgresql/__init__.py\n+++ b/kinto/core/cache/postgresql/__init__.py\n@@ -1,36 +1,13 @@\n from __future__ import absolute_import\n-from functools import wraps\n \n import os\n-import time\n \n from kinto.core import logger\n from kinto.core.cache import CacheBase\n from kinto.core.storage.postgresql.client import create_from_config\n-from kinto.core.storage.exceptions import BackendError\n from kinto.core.utils import json\n \n \n-DELAY_BETWEEN_RETRIES_IN_SECONDS = 0.005\n-MAX_RETRIES = 10\n-\n-\n-def retry_on_failure(func):\n- @wraps(func)\n- def wraps_func(self, *args, **kwargs):\n- tries = kwargs.pop('tries', 0)\n- try:\n- return func(self, *args, **kwargs)\n- except BackendError as e:\n- if tries < MAX_RETRIES:\n- # Skip delay the 2 first times.\n- delay = max(0, tries - 1) * DELAY_BETWEEN_RETRIES_IN_SECONDS\n- time.sleep(delay)\n- return wraps_func(self, tries=(tries + 1), *args, **kwargs)\n- raise e\n- return wraps_func\n-\n-\n class Cache(CacheBase):\n \"\"\"Cache backend using PostgreSQL.\n \n@@ -144,18 +121,15 @@\n with self.client.connect() as conn:\n conn.execute(query, dict(ttl=ttl, key=self.prefix + key))\n \n- @retry_on_failure\n def set(self, key, value, ttl=None):\n if ttl is None:\n logger.warning(\"No TTL for cache key %r\" % key)\n query = \"\"\"\n- WITH upsert AS (\n- UPDATE cache SET value = :value, ttl = sec2ttl(:ttl)\n- WHERE key=:key\n- RETURNING *)\n INSERT INTO cache (key, value, ttl)\n- SELECT :key, :value, sec2ttl(:ttl)\n- WHERE NOT EXISTS (SELECT * FROM upsert)\n+ VALUES (:key, :value, sec2ttl(:ttl))\n+ ON CONFLICT (key) DO UPDATE\n+ SET value = :value,\n+ ttl = sec2ttl(:ttl);\n \"\"\"\n value = json.dumps(value)\n with self.client.connect() as conn:\n", "issue": "IntegrityError with Posgresql cache backend\nI would like to update the current request with one of http://stackoverflow.com/a/1109198/186202\n", "before_files": [{"content": "from __future__ import absolute_import\nfrom functools import wraps\n\nimport os\nimport time\n\nfrom kinto.core import logger\nfrom kinto.core.cache import CacheBase\nfrom kinto.core.storage.postgresql.client import create_from_config\nfrom kinto.core.storage.exceptions import BackendError\nfrom kinto.core.utils import json\n\n\nDELAY_BETWEEN_RETRIES_IN_SECONDS = 0.005\nMAX_RETRIES = 10\n\n\ndef retry_on_failure(func):\n @wraps(func)\n def wraps_func(self, *args, **kwargs):\n tries = kwargs.pop('tries', 0)\n try:\n return func(self, *args, **kwargs)\n except BackendError as e:\n if tries < MAX_RETRIES:\n # Skip delay the 2 first times.\n delay = max(0, tries - 1) * DELAY_BETWEEN_RETRIES_IN_SECONDS\n time.sleep(delay)\n return wraps_func(self, tries=(tries + 1), *args, **kwargs)\n raise e\n return wraps_func\n\n\nclass Cache(CacheBase):\n \"\"\"Cache backend using PostgreSQL.\n\n Enable in configuration::\n\n kinto.cache_backend = kinto.core.cache.postgresql\n\n Database location URI can be customized::\n\n kinto.cache_url = postgres://user:[email protected]:5432/dbname\n\n Alternatively, username and password could also rely on system user ident\n or even specified in :file:`~/.pgpass` (*see PostgreSQL documentation*).\n\n .. note::\n\n Some tables and indices are created when ``kinto migrate`` is run.\n This requires some privileges on the database, or some error will\n be raised.\n\n **Alternatively**, the schema can be initialized outside the\n python application, using the SQL file located in\n :file:`kinto/core/cache/postgresql/schema.sql`. This allows to\n distinguish schema manipulation privileges from schema usage.\n\n\n A connection pool is enabled by default::\n\n kinto.cache_pool_size = 10\n kinto.cache_maxoverflow = 10\n kinto.cache_max_backlog = -1\n kinto.cache_pool_recycle = -1\n kinto.cache_pool_timeout = 30\n kinto.cache_poolclass =\n kinto.core.storage.postgresql.pool.QueuePoolWithMaxBacklog\n\n The ``max_backlog`` limits the number of threads that can be in the queue\n waiting for a connection. Once this limit has been reached, any further\n attempts to acquire a connection will be rejected immediately, instead of\n locking up all threads by keeping them waiting in the queue.\n\n See `dedicated section in SQLAlchemy documentation\n <http://docs.sqlalchemy.org/en/rel_1_0/core/engines.html>`_\n for default values and behaviour.\n\n .. note::\n\n Using a `dedicated connection pool <http://pgpool.net>`_ is still\n recommended to allow load balancing, replication or limit the number\n of connections used in a multi-process deployment.\n\n :noindex:\n \"\"\" # NOQA\n def __init__(self, client, *args, **kwargs):\n super(Cache, self).__init__(*args, **kwargs)\n self.client = client\n\n def initialize_schema(self, dry_run=False):\n # Check if cache table exists.\n query = \"\"\"\n SELECT 1\n FROM information_schema.tables\n WHERE table_name = 'cache';\n \"\"\"\n with self.client.connect(readonly=True) as conn:\n result = conn.execute(query)\n if result.rowcount > 0:\n logger.info(\"PostgreSQL cache schema is up-to-date.\")\n return\n\n # Create schema\n here = os.path.abspath(os.path.dirname(__file__))\n sql_file = os.path.join(here, 'schema.sql')\n\n if dry_run:\n logger.info(\"Create cache schema from %s\" % sql_file)\n return\n\n # Since called outside request, force commit.\n schema = open(sql_file).read()\n with self.client.connect(force_commit=True) as conn:\n conn.execute(schema)\n logger.info('Created PostgreSQL cache tables')\n\n def flush(self):\n query = \"\"\"\n DELETE FROM cache;\n \"\"\"\n # Since called outside request (e.g. tests), force commit.\n with self.client.connect(force_commit=True) as conn:\n conn.execute(query)\n logger.debug('Flushed PostgreSQL cache tables')\n\n def ttl(self, key):\n query = \"\"\"\n SELECT EXTRACT(SECOND FROM (ttl - now())) AS ttl\n FROM cache\n WHERE key = :key\n AND ttl IS NOT NULL;\n \"\"\"\n with self.client.connect(readonly=True) as conn:\n result = conn.execute(query, dict(key=self.prefix + key))\n if result.rowcount > 0:\n return result.fetchone()['ttl']\n return -1\n\n def expire(self, key, ttl):\n query = \"\"\"\n UPDATE cache SET ttl = sec2ttl(:ttl) WHERE key = :key;\n \"\"\"\n with self.client.connect() as conn:\n conn.execute(query, dict(ttl=ttl, key=self.prefix + key))\n\n @retry_on_failure\n def set(self, key, value, ttl=None):\n if ttl is None:\n logger.warning(\"No TTL for cache key %r\" % key)\n query = \"\"\"\n WITH upsert AS (\n UPDATE cache SET value = :value, ttl = sec2ttl(:ttl)\n WHERE key=:key\n RETURNING *)\n INSERT INTO cache (key, value, ttl)\n SELECT :key, :value, sec2ttl(:ttl)\n WHERE NOT EXISTS (SELECT * FROM upsert)\n \"\"\"\n value = json.dumps(value)\n with self.client.connect() as conn:\n conn.execute(query, dict(key=self.prefix + key,\n value=value, ttl=ttl))\n\n def get(self, key):\n purge = \"DELETE FROM cache WHERE ttl IS NOT NULL AND now() > ttl;\"\n query = \"SELECT value FROM cache WHERE key = :key;\"\n with self.client.connect() as conn:\n conn.execute(purge)\n result = conn.execute(query, dict(key=self.prefix + key))\n if result.rowcount > 0:\n value = result.fetchone()['value']\n return json.loads(value)\n\n def delete(self, key):\n query = \"DELETE FROM cache WHERE key = :key\"\n with self.client.connect() as conn:\n conn.execute(query, dict(key=self.prefix + key))\n\n\ndef load_from_config(config):\n settings = config.get_settings()\n client = create_from_config(config, prefix='cache_', with_transaction=False)\n return Cache(client=client, cache_prefix=settings['cache_prefix'])\n", "path": "kinto/core/cache/postgresql/__init__.py"}], "after_files": [{"content": "from __future__ import absolute_import\n\nimport os\n\nfrom kinto.core import logger\nfrom kinto.core.cache import CacheBase\nfrom kinto.core.storage.postgresql.client import create_from_config\nfrom kinto.core.utils import json\n\n\nclass Cache(CacheBase):\n \"\"\"Cache backend using PostgreSQL.\n\n Enable in configuration::\n\n kinto.cache_backend = kinto.core.cache.postgresql\n\n Database location URI can be customized::\n\n kinto.cache_url = postgres://user:[email protected]:5432/dbname\n\n Alternatively, username and password could also rely on system user ident\n or even specified in :file:`~/.pgpass` (*see PostgreSQL documentation*).\n\n .. note::\n\n Some tables and indices are created when ``kinto migrate`` is run.\n This requires some privileges on the database, or some error will\n be raised.\n\n **Alternatively**, the schema can be initialized outside the\n python application, using the SQL file located in\n :file:`kinto/core/cache/postgresql/schema.sql`. This allows to\n distinguish schema manipulation privileges from schema usage.\n\n\n A connection pool is enabled by default::\n\n kinto.cache_pool_size = 10\n kinto.cache_maxoverflow = 10\n kinto.cache_max_backlog = -1\n kinto.cache_pool_recycle = -1\n kinto.cache_pool_timeout = 30\n kinto.cache_poolclass =\n kinto.core.storage.postgresql.pool.QueuePoolWithMaxBacklog\n\n The ``max_backlog`` limits the number of threads that can be in the queue\n waiting for a connection. Once this limit has been reached, any further\n attempts to acquire a connection will be rejected immediately, instead of\n locking up all threads by keeping them waiting in the queue.\n\n See `dedicated section in SQLAlchemy documentation\n <http://docs.sqlalchemy.org/en/rel_1_0/core/engines.html>`_\n for default values and behaviour.\n\n .. note::\n\n Using a `dedicated connection pool <http://pgpool.net>`_ is still\n recommended to allow load balancing, replication or limit the number\n of connections used in a multi-process deployment.\n\n :noindex:\n \"\"\" # NOQA\n def __init__(self, client, *args, **kwargs):\n super(Cache, self).__init__(*args, **kwargs)\n self.client = client\n\n def initialize_schema(self, dry_run=False):\n # Check if cache table exists.\n query = \"\"\"\n SELECT 1\n FROM information_schema.tables\n WHERE table_name = 'cache';\n \"\"\"\n with self.client.connect(readonly=True) as conn:\n result = conn.execute(query)\n if result.rowcount > 0:\n logger.info(\"PostgreSQL cache schema is up-to-date.\")\n return\n\n # Create schema\n here = os.path.abspath(os.path.dirname(__file__))\n sql_file = os.path.join(here, 'schema.sql')\n\n if dry_run:\n logger.info(\"Create cache schema from %s\" % sql_file)\n return\n\n # Since called outside request, force commit.\n schema = open(sql_file).read()\n with self.client.connect(force_commit=True) as conn:\n conn.execute(schema)\n logger.info('Created PostgreSQL cache tables')\n\n def flush(self):\n query = \"\"\"\n DELETE FROM cache;\n \"\"\"\n # Since called outside request (e.g. tests), force commit.\n with self.client.connect(force_commit=True) as conn:\n conn.execute(query)\n logger.debug('Flushed PostgreSQL cache tables')\n\n def ttl(self, key):\n query = \"\"\"\n SELECT EXTRACT(SECOND FROM (ttl - now())) AS ttl\n FROM cache\n WHERE key = :key\n AND ttl IS NOT NULL;\n \"\"\"\n with self.client.connect(readonly=True) as conn:\n result = conn.execute(query, dict(key=self.prefix + key))\n if result.rowcount > 0:\n return result.fetchone()['ttl']\n return -1\n\n def expire(self, key, ttl):\n query = \"\"\"\n UPDATE cache SET ttl = sec2ttl(:ttl) WHERE key = :key;\n \"\"\"\n with self.client.connect() as conn:\n conn.execute(query, dict(ttl=ttl, key=self.prefix + key))\n\n def set(self, key, value, ttl=None):\n if ttl is None:\n logger.warning(\"No TTL for cache key %r\" % key)\n query = \"\"\"\n INSERT INTO cache (key, value, ttl)\n VALUES (:key, :value, sec2ttl(:ttl))\n ON CONFLICT (key) DO UPDATE\n SET value = :value,\n ttl = sec2ttl(:ttl);\n \"\"\"\n value = json.dumps(value)\n with self.client.connect() as conn:\n conn.execute(query, dict(key=self.prefix + key,\n value=value, ttl=ttl))\n\n def get(self, key):\n purge = \"DELETE FROM cache WHERE ttl IS NOT NULL AND now() > ttl;\"\n query = \"SELECT value FROM cache WHERE key = :key;\"\n with self.client.connect() as conn:\n conn.execute(purge)\n result = conn.execute(query, dict(key=self.prefix + key))\n if result.rowcount > 0:\n value = result.fetchone()['value']\n return json.loads(value)\n\n def delete(self, key):\n query = \"DELETE FROM cache WHERE key = :key\"\n with self.client.connect() as conn:\n conn.execute(query, dict(key=self.prefix + key))\n\n\ndef load_from_config(config):\n settings = config.get_settings()\n client = create_from_config(config, prefix='cache_', with_transaction=False)\n return Cache(client=client, cache_prefix=settings['cache_prefix'])\n", "path": "kinto/core/cache/postgresql/__init__.py"}]}
| 2,194 | 542 |
gh_patches_debug_38607
|
rasdani/github-patches
|
git_diff
|
liqd__a4-opin-688
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Spatial Idea Challenge: No comments possible
In the blueprint Spatial Idea Challenge, in phase 1 comments cannot be made (be sure to test with normal user account). We need to fix the blueprint, apparently. See here https://opin-stage.liqd.net/de/maps/test-the-comments/ for an example.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `euth/maps/views.py`
Content:
```
1 from django.conf import settings
2 from easy_thumbnails.files import get_thumbnailer
3
4 from euth.ideas import views as idea_views
5
6 from . import forms
7 from .models import MapIdea
8
9
10 class MapIdeaListView(idea_views.IdeaListView):
11 model = MapIdea
12
13 def dump_geojson(self):
14 result = {}
15 result['type'] = 'FeatureCollection'
16 feature_list = []
17
18 for item in self.get_queryset():
19
20 url = ''
21
22 if item.image:
23 image = get_thumbnailer(item.image)['map_thumbnail']
24 url = image.url
25
26 properties = {
27 'name': item.name,
28 'slug': item.slug,
29 'image': url,
30 'comments_count': item.comment_count,
31 'positive_rating_count': item.positive_rating_count,
32 'negative_rating_count': item.negative_rating_count,
33 'url': item.get_absolute_url()
34 }
35 point_dict = item.point
36 point_dict['properties'] = properties
37 feature_list.append(point_dict)
38
39 result['features'] = feature_list
40 return result
41
42 def get_context_data(self, **kwargs):
43 context = super().get_context_data(**kwargs)
44 context['mapideas_json'] = self.dump_geojson()
45 context['map_url'] = settings.BASE_MAP
46 context['polygon'] = self.module.settings_instance.polygon
47 return context
48
49
50 class MapIdeaCreateView(idea_views.IdeaCreateView):
51 model = MapIdea
52 form_class = forms.MapIdeaForm
53 permission_required = 'euth_maps.propose_idea'
54
55 def get_form_kwargs(self):
56 kwargs = super().get_form_kwargs()
57 kwargs['settings_instance'] = self.module.settings_instance
58 return kwargs
59
60
61 class MapIdeaUpdateView(idea_views.IdeaUpdateView):
62 model = MapIdea
63 form_class = forms.MapIdeaForm
64
65 def get_form_kwargs(self):
66 kwargs = super().get_form_kwargs()
67 kwargs['settings_instance'] = self.object.module.settings_instance
68 return kwargs
69
70
71 class MapIdeaDeleteView(idea_views.IdeaDeleteView):
72 model = MapIdea
73
74
75 class MapIdeaDetailView(idea_views.IdeaDetailView):
76 model = MapIdea
77 queryset = MapIdea.objects.annotate_positive_rating_count()\
78 .annotate_negative_rating_count()
79
80 def get_context_data(self, **kwargs):
81 context = super().get_context_data(**kwargs)
82 context['map_url'] = settings.BASE_MAP
83 return context
84
```
Path: `euth/maps/rules.py`
Content:
```
1 import rules
2 from rules.predicates import is_superuser
3
4 from adhocracy4.modules.predicates import (is_context_initiator,
5 is_context_member,
6 is_context_moderator)
7 from adhocracy4.phases.predicates import phase_allows_create
8
9 from .models import MapIdea
10
11 rules.add_perm('euth_maps.propose_idea',
12 is_superuser | is_context_moderator | is_context_initiator |
13 (is_context_member & phase_allows_create(MapIdea)))
14
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/euth/maps/rules.py b/euth/maps/rules.py
--- a/euth/maps/rules.py
+++ b/euth/maps/rules.py
@@ -3,11 +3,36 @@
from adhocracy4.modules.predicates import (is_context_initiator,
is_context_member,
- is_context_moderator)
-from adhocracy4.phases.predicates import phase_allows_create
-
+ is_context_moderator,
+ is_owner,
+ is_public_context)
+from adhocracy4.phases.predicates import (phase_allows_comment,
+ phase_allows_create,
+ phase_allows_modify,
+ phase_allows_rate)
from .models import MapIdea
-rules.add_perm('euth_maps.propose_idea',
+
+rules.add_perm('euth_maps.rate_mapidea',
+ is_superuser | is_context_moderator | is_context_initiator |
+ (is_context_member & phase_allows_rate))
+
+
+rules.add_perm('euth_maps.comment_mapidea',
+ is_superuser | is_context_moderator | is_context_initiator |
+ (is_context_member & phase_allows_comment))
+
+
+rules.add_perm('euth_maps.modify_mapidea',
+ is_superuser | is_context_moderator | is_context_initiator |
+ (is_context_member & is_owner & phase_allows_modify))
+
+
+rules.add_perm('euth_maps.propose_mapidea',
is_superuser | is_context_moderator | is_context_initiator |
(is_context_member & phase_allows_create(MapIdea)))
+
+
+rules.add_perm('euth_maps.view_mapidea',
+ is_superuser | is_context_moderator | is_context_initiator |
+ is_context_member | is_public_context)
diff --git a/euth/maps/views.py b/euth/maps/views.py
--- a/euth/maps/views.py
+++ b/euth/maps/views.py
@@ -50,7 +50,7 @@
class MapIdeaCreateView(idea_views.IdeaCreateView):
model = MapIdea
form_class = forms.MapIdeaForm
- permission_required = 'euth_maps.propose_idea'
+ permission_required = 'euth_maps.propose_mapidea'
def get_form_kwargs(self):
kwargs = super().get_form_kwargs()
@@ -60,6 +60,7 @@
class MapIdeaUpdateView(idea_views.IdeaUpdateView):
model = MapIdea
+ permission_required = 'euth_maps.modify_mapidea'
form_class = forms.MapIdeaForm
def get_form_kwargs(self):
@@ -70,10 +71,12 @@
class MapIdeaDeleteView(idea_views.IdeaDeleteView):
model = MapIdea
+ permission_required = 'euth_maps.modify_mapidea'
class MapIdeaDetailView(idea_views.IdeaDetailView):
model = MapIdea
+ permission_required = 'euth_maps.view_mapidea'
queryset = MapIdea.objects.annotate_positive_rating_count()\
.annotate_negative_rating_count()
|
{"golden_diff": "diff --git a/euth/maps/rules.py b/euth/maps/rules.py\n--- a/euth/maps/rules.py\n+++ b/euth/maps/rules.py\n@@ -3,11 +3,36 @@\n \n from adhocracy4.modules.predicates import (is_context_initiator,\n is_context_member,\n- is_context_moderator)\n-from adhocracy4.phases.predicates import phase_allows_create\n-\n+ is_context_moderator,\n+ is_owner,\n+ is_public_context)\n+from adhocracy4.phases.predicates import (phase_allows_comment,\n+ phase_allows_create,\n+ phase_allows_modify,\n+ phase_allows_rate)\n from .models import MapIdea\n \n-rules.add_perm('euth_maps.propose_idea',\n+\n+rules.add_perm('euth_maps.rate_mapidea',\n+ is_superuser | is_context_moderator | is_context_initiator |\n+ (is_context_member & phase_allows_rate))\n+\n+\n+rules.add_perm('euth_maps.comment_mapidea',\n+ is_superuser | is_context_moderator | is_context_initiator |\n+ (is_context_member & phase_allows_comment))\n+\n+\n+rules.add_perm('euth_maps.modify_mapidea',\n+ is_superuser | is_context_moderator | is_context_initiator |\n+ (is_context_member & is_owner & phase_allows_modify))\n+\n+\n+rules.add_perm('euth_maps.propose_mapidea',\n is_superuser | is_context_moderator | is_context_initiator |\n (is_context_member & phase_allows_create(MapIdea)))\n+\n+\n+rules.add_perm('euth_maps.view_mapidea',\n+ is_superuser | is_context_moderator | is_context_initiator |\n+ is_context_member | is_public_context)\ndiff --git a/euth/maps/views.py b/euth/maps/views.py\n--- a/euth/maps/views.py\n+++ b/euth/maps/views.py\n@@ -50,7 +50,7 @@\n class MapIdeaCreateView(idea_views.IdeaCreateView):\n model = MapIdea\n form_class = forms.MapIdeaForm\n- permission_required = 'euth_maps.propose_idea'\n+ permission_required = 'euth_maps.propose_mapidea'\n \n def get_form_kwargs(self):\n kwargs = super().get_form_kwargs()\n@@ -60,6 +60,7 @@\n \n class MapIdeaUpdateView(idea_views.IdeaUpdateView):\n model = MapIdea\n+ permission_required = 'euth_maps.modify_mapidea'\n form_class = forms.MapIdeaForm\n \n def get_form_kwargs(self):\n@@ -70,10 +71,12 @@\n \n class MapIdeaDeleteView(idea_views.IdeaDeleteView):\n model = MapIdea\n+ permission_required = 'euth_maps.modify_mapidea'\n \n \n class MapIdeaDetailView(idea_views.IdeaDetailView):\n model = MapIdea\n+ permission_required = 'euth_maps.view_mapidea'\n queryset = MapIdea.objects.annotate_positive_rating_count()\\\n .annotate_negative_rating_count()\n", "issue": "Spatial Idea Challenge: No comments possible\nIn the blueprint Spatial Idea Challenge, in phase 1 comments cannot be made (be sure to test with normal user account). We need to fix the blueprint, apparently. See here https://opin-stage.liqd.net/de/maps/test-the-comments/ for an example.\n", "before_files": [{"content": "from django.conf import settings\nfrom easy_thumbnails.files import get_thumbnailer\n\nfrom euth.ideas import views as idea_views\n\nfrom . import forms\nfrom .models import MapIdea\n\n\nclass MapIdeaListView(idea_views.IdeaListView):\n model = MapIdea\n\n def dump_geojson(self):\n result = {}\n result['type'] = 'FeatureCollection'\n feature_list = []\n\n for item in self.get_queryset():\n\n url = ''\n\n if item.image:\n image = get_thumbnailer(item.image)['map_thumbnail']\n url = image.url\n\n properties = {\n 'name': item.name,\n 'slug': item.slug,\n 'image': url,\n 'comments_count': item.comment_count,\n 'positive_rating_count': item.positive_rating_count,\n 'negative_rating_count': item.negative_rating_count,\n 'url': item.get_absolute_url()\n }\n point_dict = item.point\n point_dict['properties'] = properties\n feature_list.append(point_dict)\n\n result['features'] = feature_list\n return result\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['mapideas_json'] = self.dump_geojson()\n context['map_url'] = settings.BASE_MAP\n context['polygon'] = self.module.settings_instance.polygon\n return context\n\n\nclass MapIdeaCreateView(idea_views.IdeaCreateView):\n model = MapIdea\n form_class = forms.MapIdeaForm\n permission_required = 'euth_maps.propose_idea'\n\n def get_form_kwargs(self):\n kwargs = super().get_form_kwargs()\n kwargs['settings_instance'] = self.module.settings_instance\n return kwargs\n\n\nclass MapIdeaUpdateView(idea_views.IdeaUpdateView):\n model = MapIdea\n form_class = forms.MapIdeaForm\n\n def get_form_kwargs(self):\n kwargs = super().get_form_kwargs()\n kwargs['settings_instance'] = self.object.module.settings_instance\n return kwargs\n\n\nclass MapIdeaDeleteView(idea_views.IdeaDeleteView):\n model = MapIdea\n\n\nclass MapIdeaDetailView(idea_views.IdeaDetailView):\n model = MapIdea\n queryset = MapIdea.objects.annotate_positive_rating_count()\\\n .annotate_negative_rating_count()\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['map_url'] = settings.BASE_MAP\n return context\n", "path": "euth/maps/views.py"}, {"content": "import rules\nfrom rules.predicates import is_superuser\n\nfrom adhocracy4.modules.predicates import (is_context_initiator,\n is_context_member,\n is_context_moderator)\nfrom adhocracy4.phases.predicates import phase_allows_create\n\nfrom .models import MapIdea\n\nrules.add_perm('euth_maps.propose_idea',\n is_superuser | is_context_moderator | is_context_initiator |\n (is_context_member & phase_allows_create(MapIdea)))\n", "path": "euth/maps/rules.py"}], "after_files": [{"content": "from django.conf import settings\nfrom easy_thumbnails.files import get_thumbnailer\n\nfrom euth.ideas import views as idea_views\n\nfrom . import forms\nfrom .models import MapIdea\n\n\nclass MapIdeaListView(idea_views.IdeaListView):\n model = MapIdea\n\n def dump_geojson(self):\n result = {}\n result['type'] = 'FeatureCollection'\n feature_list = []\n\n for item in self.get_queryset():\n\n url = ''\n\n if item.image:\n image = get_thumbnailer(item.image)['map_thumbnail']\n url = image.url\n\n properties = {\n 'name': item.name,\n 'slug': item.slug,\n 'image': url,\n 'comments_count': item.comment_count,\n 'positive_rating_count': item.positive_rating_count,\n 'negative_rating_count': item.negative_rating_count,\n 'url': item.get_absolute_url()\n }\n point_dict = item.point\n point_dict['properties'] = properties\n feature_list.append(point_dict)\n\n result['features'] = feature_list\n return result\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['mapideas_json'] = self.dump_geojson()\n context['map_url'] = settings.BASE_MAP\n context['polygon'] = self.module.settings_instance.polygon\n return context\n\n\nclass MapIdeaCreateView(idea_views.IdeaCreateView):\n model = MapIdea\n form_class = forms.MapIdeaForm\n permission_required = 'euth_maps.propose_mapidea'\n\n def get_form_kwargs(self):\n kwargs = super().get_form_kwargs()\n kwargs['settings_instance'] = self.module.settings_instance\n return kwargs\n\n\nclass MapIdeaUpdateView(idea_views.IdeaUpdateView):\n model = MapIdea\n permission_required = 'euth_maps.modify_mapidea'\n form_class = forms.MapIdeaForm\n\n def get_form_kwargs(self):\n kwargs = super().get_form_kwargs()\n kwargs['settings_instance'] = self.object.module.settings_instance\n return kwargs\n\n\nclass MapIdeaDeleteView(idea_views.IdeaDeleteView):\n model = MapIdea\n permission_required = 'euth_maps.modify_mapidea'\n\n\nclass MapIdeaDetailView(idea_views.IdeaDetailView):\n model = MapIdea\n permission_required = 'euth_maps.view_mapidea'\n queryset = MapIdea.objects.annotate_positive_rating_count()\\\n .annotate_negative_rating_count()\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['map_url'] = settings.BASE_MAP\n return context\n", "path": "euth/maps/views.py"}, {"content": "import rules\nfrom rules.predicates import is_superuser\n\nfrom adhocracy4.modules.predicates import (is_context_initiator,\n is_context_member,\n is_context_moderator,\n is_owner,\n is_public_context)\nfrom adhocracy4.phases.predicates import (phase_allows_comment,\n phase_allows_create,\n phase_allows_modify,\n phase_allows_rate)\nfrom .models import MapIdea\n\n\nrules.add_perm('euth_maps.rate_mapidea',\n is_superuser | is_context_moderator | is_context_initiator |\n (is_context_member & phase_allows_rate))\n\n\nrules.add_perm('euth_maps.comment_mapidea',\n is_superuser | is_context_moderator | is_context_initiator |\n (is_context_member & phase_allows_comment))\n\n\nrules.add_perm('euth_maps.modify_mapidea',\n is_superuser | is_context_moderator | is_context_initiator |\n (is_context_member & is_owner & phase_allows_modify))\n\n\nrules.add_perm('euth_maps.propose_mapidea',\n is_superuser | is_context_moderator | is_context_initiator |\n (is_context_member & phase_allows_create(MapIdea)))\n\n\nrules.add_perm('euth_maps.view_mapidea',\n is_superuser | is_context_moderator | is_context_initiator |\n is_context_member | is_public_context)\n", "path": "euth/maps/rules.py"}]}
| 1,164 | 665 |
gh_patches_debug_20888
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-contrib-1003
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Falcon: Capture request/response headers as span attributes
part of #906
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `instrumentation/opentelemetry-instrumentation-falcon/src/opentelemetry/instrumentation/falcon/__init__.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """
16 This library builds on the OpenTelemetry WSGI middleware to track web requests
17 in Falcon applications. In addition to opentelemetry-instrumentation-wsgi,
18 it supports falcon-specific features such as:
19
20 * The Falcon resource and method name is used as the Span name.
21 * The ``falcon.resource`` Span attribute is set so the matched resource.
22 * Error from Falcon resources are properly caught and recorded.
23
24 Configuration
25 -------------
26
27 Exclude lists
28 *************
29 To exclude certain URLs from being tracked, set the environment variable ``OTEL_PYTHON_FALCON_EXCLUDED_URLS``
30 (or ``OTEL_PYTHON_EXCLUDED_URLS`` as fallback) with comma delimited regexes representing which URLs to exclude.
31
32 For example,
33
34 ::
35
36 export OTEL_PYTHON_FALCON_EXCLUDED_URLS="client/.*/info,healthcheck"
37
38 will exclude requests such as ``https://site/client/123/info`` and ``https://site/xyz/healthcheck``.
39
40 Request attributes
41 ********************
42 To extract certain attributes from Falcon's request object and use them as span attributes, set the environment variable ``OTEL_PYTHON_FALCON_TRACED_REQUEST_ATTRS`` to a comma
43 delimited list of request attribute names.
44
45 For example,
46
47 ::
48
49 export OTEL_PYTHON_FALCON_TRACED_REQUEST_ATTRS='query_string,uri_template'
50
51 will extract query_string and uri_template attributes from every traced request and add them as span attritbues.
52
53 Falcon Request object reference: https://falcon.readthedocs.io/en/stable/api/request_and_response.html#id1
54
55 Usage
56 -----
57
58 .. code-block:: python
59
60 from falcon import API
61 from opentelemetry.instrumentation.falcon import FalconInstrumentor
62
63 FalconInstrumentor().instrument()
64
65 app = falcon.API()
66
67 class HelloWorldResource(object):
68 def on_get(self, req, resp):
69 resp.body = 'Hello World'
70
71 app.add_route('/hello', HelloWorldResource())
72
73
74 Request and Response hooks
75 ***************************
76 The instrumentation supports specifying request and response hooks. These are functions that get called back by the instrumentation right after a Span is created for a request
77 and right before the span is finished while processing a response. The hooks can be configured as follows:
78
79 ::
80
81 def request_hook(span, req):
82 pass
83
84 def response_hook(span, req, resp):
85 pass
86
87 FalconInstrumentation().instrument(request_hook=request_hook, response_hook=response_hook)
88
89 API
90 ---
91 """
92
93 from logging import getLogger
94 from sys import exc_info
95 from typing import Collection
96
97 import falcon
98
99 import opentelemetry.instrumentation.wsgi as otel_wsgi
100 from opentelemetry import context, trace
101 from opentelemetry.instrumentation.falcon.package import _instruments
102 from opentelemetry.instrumentation.falcon.version import __version__
103 from opentelemetry.instrumentation.instrumentor import BaseInstrumentor
104 from opentelemetry.instrumentation.propagators import (
105 FuncSetter,
106 get_global_response_propagator,
107 )
108 from opentelemetry.instrumentation.utils import (
109 _start_internal_or_server_span,
110 extract_attributes_from_object,
111 http_status_to_status_code,
112 )
113 from opentelemetry.semconv.trace import SpanAttributes
114 from opentelemetry.trace.status import Status
115 from opentelemetry.util._time import _time_ns
116 from opentelemetry.util.http import get_excluded_urls, get_traced_request_attrs
117
118 _logger = getLogger(__name__)
119
120 _ENVIRON_STARTTIME_KEY = "opentelemetry-falcon.starttime_key"
121 _ENVIRON_SPAN_KEY = "opentelemetry-falcon.span_key"
122 _ENVIRON_ACTIVATION_KEY = "opentelemetry-falcon.activation_key"
123 _ENVIRON_TOKEN = "opentelemetry-falcon.token"
124 _ENVIRON_EXC = "opentelemetry-falcon.exc"
125
126
127 _response_propagation_setter = FuncSetter(falcon.Response.append_header)
128
129 if hasattr(falcon, "App"):
130 # Falcon 3
131 _instrument_app = "App"
132 else:
133 # Falcon 2
134 _instrument_app = "API"
135
136
137 class _InstrumentedFalconAPI(getattr(falcon, _instrument_app)):
138 def __init__(self, *args, **kwargs):
139 otel_opts = kwargs.pop("_otel_opts", {})
140
141 # inject trace middleware
142 middlewares = kwargs.pop("middleware", [])
143 tracer_provider = otel_opts.pop("tracer_provider", None)
144 if not isinstance(middlewares, (list, tuple)):
145 middlewares = [middlewares]
146
147 self._otel_tracer = trace.get_tracer(
148 __name__, __version__, tracer_provider
149 )
150
151 trace_middleware = _TraceMiddleware(
152 self._otel_tracer,
153 otel_opts.pop(
154 "traced_request_attributes", get_traced_request_attrs("FALCON")
155 ),
156 otel_opts.pop("request_hook", None),
157 otel_opts.pop("response_hook", None),
158 )
159 middlewares.insert(0, trace_middleware)
160 kwargs["middleware"] = middlewares
161
162 self._otel_excluded_urls = get_excluded_urls("FALCON")
163 super().__init__(*args, **kwargs)
164
165 def _handle_exception(
166 self, req, resp, ex, params
167 ): # pylint: disable=C0103
168 # Falcon 3 does not execute middleware within the context of the exception
169 # so we capture the exception here and save it into the env dict
170 _, exc, _ = exc_info()
171 req.env[_ENVIRON_EXC] = exc
172 return super()._handle_exception(req, resp, ex, params)
173
174 def __call__(self, env, start_response):
175 # pylint: disable=E1101
176 if self._otel_excluded_urls.url_disabled(env.get("PATH_INFO", "/")):
177 return super().__call__(env, start_response)
178
179 start_time = _time_ns()
180
181 span, token = _start_internal_or_server_span(
182 tracer=self._otel_tracer,
183 span_name=otel_wsgi.get_default_span_name(env),
184 start_time=start_time,
185 context_carrier=env,
186 context_getter=otel_wsgi.wsgi_getter,
187 )
188
189 if span.is_recording():
190 attributes = otel_wsgi.collect_request_attributes(env)
191 for key, value in attributes.items():
192 span.set_attribute(key, value)
193
194 activation = trace.use_span(span, end_on_exit=True)
195 activation.__enter__()
196 env[_ENVIRON_SPAN_KEY] = span
197 env[_ENVIRON_ACTIVATION_KEY] = activation
198
199 def _start_response(status, response_headers, *args, **kwargs):
200 response = start_response(
201 status, response_headers, *args, **kwargs
202 )
203 activation.__exit__(None, None, None)
204 if token is not None:
205 context.detach(token)
206 return response
207
208 try:
209 return super().__call__(env, _start_response)
210 except Exception as exc:
211 activation.__exit__(
212 type(exc),
213 exc,
214 getattr(exc, "__traceback__", None),
215 )
216 if token is not None:
217 context.detach(token)
218 raise
219
220
221 class _TraceMiddleware:
222 # pylint:disable=R0201,W0613
223
224 def __init__(
225 self,
226 tracer=None,
227 traced_request_attrs=None,
228 request_hook=None,
229 response_hook=None,
230 ):
231 self.tracer = tracer
232 self._traced_request_attrs = traced_request_attrs
233 self._request_hook = request_hook
234 self._response_hook = response_hook
235
236 def process_request(self, req, resp):
237 span = req.env.get(_ENVIRON_SPAN_KEY)
238 if span and self._request_hook:
239 self._request_hook(span, req)
240
241 if not span or not span.is_recording():
242 return
243
244 attributes = extract_attributes_from_object(
245 req, self._traced_request_attrs
246 )
247 for key, value in attributes.items():
248 span.set_attribute(key, value)
249
250 def process_resource(self, req, resp, resource, params):
251 span = req.env.get(_ENVIRON_SPAN_KEY)
252 if not span or not span.is_recording():
253 return
254
255 resource_name = resource.__class__.__name__
256 span.set_attribute("falcon.resource", resource_name)
257 span.update_name(f"{resource_name}.on_{req.method.lower()}")
258
259 def process_response(
260 self, req, resp, resource, req_succeeded=None
261 ): # pylint:disable=R0201
262 span = req.env.get(_ENVIRON_SPAN_KEY)
263
264 if not span or not span.is_recording():
265 return
266
267 status = resp.status
268 reason = None
269 if resource is None:
270 status = "404"
271 reason = "NotFound"
272 else:
273 if _ENVIRON_EXC in req.env:
274 exc = req.env[_ENVIRON_EXC]
275 exc_type = type(exc)
276 else:
277 exc_type, exc = None, None
278 if exc_type and not req_succeeded:
279 if "HTTPNotFound" in exc_type.__name__:
280 status = "404"
281 reason = "NotFound"
282 else:
283 status = "500"
284 reason = f"{exc_type.__name__}: {exc}"
285
286 status = status.split(" ")[0]
287 try:
288 status_code = int(status)
289 span.set_attribute(SpanAttributes.HTTP_STATUS_CODE, status_code)
290 span.set_status(
291 Status(
292 status_code=http_status_to_status_code(
293 status_code, server_span=True
294 ),
295 description=reason,
296 )
297 )
298 except ValueError:
299 pass
300
301 propagator = get_global_response_propagator()
302 if propagator:
303 propagator.inject(resp, setter=_response_propagation_setter)
304
305 if self._response_hook:
306 self._response_hook(span, req, resp)
307
308
309 class FalconInstrumentor(BaseInstrumentor):
310 # pylint: disable=protected-access,attribute-defined-outside-init
311 """An instrumentor for falcon.API
312
313 See `BaseInstrumentor`
314 """
315
316 def instrumentation_dependencies(self) -> Collection[str]:
317 return _instruments
318
319 def _instrument(self, **opts):
320 self._original_falcon_api = getattr(falcon, _instrument_app)
321
322 class FalconAPI(_InstrumentedFalconAPI):
323 def __init__(self, *args, **kwargs):
324 kwargs["_otel_opts"] = opts
325 super().__init__(*args, **kwargs)
326
327 setattr(falcon, _instrument_app, FalconAPI)
328
329 def _uninstrument(self, **kwargs):
330 setattr(falcon, _instrument_app, self._original_falcon_api)
331
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/instrumentation/opentelemetry-instrumentation-falcon/src/opentelemetry/instrumentation/falcon/__init__.py b/instrumentation/opentelemetry-instrumentation-falcon/src/opentelemetry/instrumentation/falcon/__init__.py
--- a/instrumentation/opentelemetry-instrumentation-falcon/src/opentelemetry/instrumentation/falcon/__init__.py
+++ b/instrumentation/opentelemetry-instrumentation-falcon/src/opentelemetry/instrumentation/falcon/__init__.py
@@ -190,6 +190,8 @@
attributes = otel_wsgi.collect_request_attributes(env)
for key, value in attributes.items():
span.set_attribute(key, value)
+ if span.is_recording() and span.kind == trace.SpanKind.SERVER:
+ otel_wsgi.add_custom_request_headers(span, env)
activation = trace.use_span(span, end_on_exit=True)
activation.__enter__()
@@ -295,6 +297,10 @@
description=reason,
)
)
+ if span.is_recording() and span.kind == trace.SpanKind.SERVER:
+ otel_wsgi.add_custom_response_headers(
+ span, resp.headers.items()
+ )
except ValueError:
pass
|
{"golden_diff": "diff --git a/instrumentation/opentelemetry-instrumentation-falcon/src/opentelemetry/instrumentation/falcon/__init__.py b/instrumentation/opentelemetry-instrumentation-falcon/src/opentelemetry/instrumentation/falcon/__init__.py\n--- a/instrumentation/opentelemetry-instrumentation-falcon/src/opentelemetry/instrumentation/falcon/__init__.py\n+++ b/instrumentation/opentelemetry-instrumentation-falcon/src/opentelemetry/instrumentation/falcon/__init__.py\n@@ -190,6 +190,8 @@\n attributes = otel_wsgi.collect_request_attributes(env)\n for key, value in attributes.items():\n span.set_attribute(key, value)\n+ if span.is_recording() and span.kind == trace.SpanKind.SERVER:\n+ otel_wsgi.add_custom_request_headers(span, env)\n \n activation = trace.use_span(span, end_on_exit=True)\n activation.__enter__()\n@@ -295,6 +297,10 @@\n description=reason,\n )\n )\n+ if span.is_recording() and span.kind == trace.SpanKind.SERVER:\n+ otel_wsgi.add_custom_response_headers(\n+ span, resp.headers.items()\n+ )\n except ValueError:\n pass\n", "issue": "Falcon: Capture request/response headers as span attributes\npart of #906\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nThis library builds on the OpenTelemetry WSGI middleware to track web requests\nin Falcon applications. In addition to opentelemetry-instrumentation-wsgi,\nit supports falcon-specific features such as:\n\n* The Falcon resource and method name is used as the Span name.\n* The ``falcon.resource`` Span attribute is set so the matched resource.\n* Error from Falcon resources are properly caught and recorded.\n\nConfiguration\n-------------\n\nExclude lists\n*************\nTo exclude certain URLs from being tracked, set the environment variable ``OTEL_PYTHON_FALCON_EXCLUDED_URLS``\n(or ``OTEL_PYTHON_EXCLUDED_URLS`` as fallback) with comma delimited regexes representing which URLs to exclude.\n\nFor example,\n\n::\n\n export OTEL_PYTHON_FALCON_EXCLUDED_URLS=\"client/.*/info,healthcheck\"\n\nwill exclude requests such as ``https://site/client/123/info`` and ``https://site/xyz/healthcheck``.\n\nRequest attributes\n********************\nTo extract certain attributes from Falcon's request object and use them as span attributes, set the environment variable ``OTEL_PYTHON_FALCON_TRACED_REQUEST_ATTRS`` to a comma\ndelimited list of request attribute names.\n\nFor example,\n\n::\n\n export OTEL_PYTHON_FALCON_TRACED_REQUEST_ATTRS='query_string,uri_template'\n\nwill extract query_string and uri_template attributes from every traced request and add them as span attritbues.\n\nFalcon Request object reference: https://falcon.readthedocs.io/en/stable/api/request_and_response.html#id1\n\nUsage\n-----\n\n.. code-block:: python\n\n from falcon import API\n from opentelemetry.instrumentation.falcon import FalconInstrumentor\n\n FalconInstrumentor().instrument()\n\n app = falcon.API()\n\n class HelloWorldResource(object):\n def on_get(self, req, resp):\n resp.body = 'Hello World'\n\n app.add_route('/hello', HelloWorldResource())\n\n\nRequest and Response hooks\n***************************\nThe instrumentation supports specifying request and response hooks. These are functions that get called back by the instrumentation right after a Span is created for a request\nand right before the span is finished while processing a response. The hooks can be configured as follows:\n\n::\n\n def request_hook(span, req):\n pass\n\n def response_hook(span, req, resp):\n pass\n\n FalconInstrumentation().instrument(request_hook=request_hook, response_hook=response_hook)\n\nAPI\n---\n\"\"\"\n\nfrom logging import getLogger\nfrom sys import exc_info\nfrom typing import Collection\n\nimport falcon\n\nimport opentelemetry.instrumentation.wsgi as otel_wsgi\nfrom opentelemetry import context, trace\nfrom opentelemetry.instrumentation.falcon.package import _instruments\nfrom opentelemetry.instrumentation.falcon.version import __version__\nfrom opentelemetry.instrumentation.instrumentor import BaseInstrumentor\nfrom opentelemetry.instrumentation.propagators import (\n FuncSetter,\n get_global_response_propagator,\n)\nfrom opentelemetry.instrumentation.utils import (\n _start_internal_or_server_span,\n extract_attributes_from_object,\n http_status_to_status_code,\n)\nfrom opentelemetry.semconv.trace import SpanAttributes\nfrom opentelemetry.trace.status import Status\nfrom opentelemetry.util._time import _time_ns\nfrom opentelemetry.util.http import get_excluded_urls, get_traced_request_attrs\n\n_logger = getLogger(__name__)\n\n_ENVIRON_STARTTIME_KEY = \"opentelemetry-falcon.starttime_key\"\n_ENVIRON_SPAN_KEY = \"opentelemetry-falcon.span_key\"\n_ENVIRON_ACTIVATION_KEY = \"opentelemetry-falcon.activation_key\"\n_ENVIRON_TOKEN = \"opentelemetry-falcon.token\"\n_ENVIRON_EXC = \"opentelemetry-falcon.exc\"\n\n\n_response_propagation_setter = FuncSetter(falcon.Response.append_header)\n\nif hasattr(falcon, \"App\"):\n # Falcon 3\n _instrument_app = \"App\"\nelse:\n # Falcon 2\n _instrument_app = \"API\"\n\n\nclass _InstrumentedFalconAPI(getattr(falcon, _instrument_app)):\n def __init__(self, *args, **kwargs):\n otel_opts = kwargs.pop(\"_otel_opts\", {})\n\n # inject trace middleware\n middlewares = kwargs.pop(\"middleware\", [])\n tracer_provider = otel_opts.pop(\"tracer_provider\", None)\n if not isinstance(middlewares, (list, tuple)):\n middlewares = [middlewares]\n\n self._otel_tracer = trace.get_tracer(\n __name__, __version__, tracer_provider\n )\n\n trace_middleware = _TraceMiddleware(\n self._otel_tracer,\n otel_opts.pop(\n \"traced_request_attributes\", get_traced_request_attrs(\"FALCON\")\n ),\n otel_opts.pop(\"request_hook\", None),\n otel_opts.pop(\"response_hook\", None),\n )\n middlewares.insert(0, trace_middleware)\n kwargs[\"middleware\"] = middlewares\n\n self._otel_excluded_urls = get_excluded_urls(\"FALCON\")\n super().__init__(*args, **kwargs)\n\n def _handle_exception(\n self, req, resp, ex, params\n ): # pylint: disable=C0103\n # Falcon 3 does not execute middleware within the context of the exception\n # so we capture the exception here and save it into the env dict\n _, exc, _ = exc_info()\n req.env[_ENVIRON_EXC] = exc\n return super()._handle_exception(req, resp, ex, params)\n\n def __call__(self, env, start_response):\n # pylint: disable=E1101\n if self._otel_excluded_urls.url_disabled(env.get(\"PATH_INFO\", \"/\")):\n return super().__call__(env, start_response)\n\n start_time = _time_ns()\n\n span, token = _start_internal_or_server_span(\n tracer=self._otel_tracer,\n span_name=otel_wsgi.get_default_span_name(env),\n start_time=start_time,\n context_carrier=env,\n context_getter=otel_wsgi.wsgi_getter,\n )\n\n if span.is_recording():\n attributes = otel_wsgi.collect_request_attributes(env)\n for key, value in attributes.items():\n span.set_attribute(key, value)\n\n activation = trace.use_span(span, end_on_exit=True)\n activation.__enter__()\n env[_ENVIRON_SPAN_KEY] = span\n env[_ENVIRON_ACTIVATION_KEY] = activation\n\n def _start_response(status, response_headers, *args, **kwargs):\n response = start_response(\n status, response_headers, *args, **kwargs\n )\n activation.__exit__(None, None, None)\n if token is not None:\n context.detach(token)\n return response\n\n try:\n return super().__call__(env, _start_response)\n except Exception as exc:\n activation.__exit__(\n type(exc),\n exc,\n getattr(exc, \"__traceback__\", None),\n )\n if token is not None:\n context.detach(token)\n raise\n\n\nclass _TraceMiddleware:\n # pylint:disable=R0201,W0613\n\n def __init__(\n self,\n tracer=None,\n traced_request_attrs=None,\n request_hook=None,\n response_hook=None,\n ):\n self.tracer = tracer\n self._traced_request_attrs = traced_request_attrs\n self._request_hook = request_hook\n self._response_hook = response_hook\n\n def process_request(self, req, resp):\n span = req.env.get(_ENVIRON_SPAN_KEY)\n if span and self._request_hook:\n self._request_hook(span, req)\n\n if not span or not span.is_recording():\n return\n\n attributes = extract_attributes_from_object(\n req, self._traced_request_attrs\n )\n for key, value in attributes.items():\n span.set_attribute(key, value)\n\n def process_resource(self, req, resp, resource, params):\n span = req.env.get(_ENVIRON_SPAN_KEY)\n if not span or not span.is_recording():\n return\n\n resource_name = resource.__class__.__name__\n span.set_attribute(\"falcon.resource\", resource_name)\n span.update_name(f\"{resource_name}.on_{req.method.lower()}\")\n\n def process_response(\n self, req, resp, resource, req_succeeded=None\n ): # pylint:disable=R0201\n span = req.env.get(_ENVIRON_SPAN_KEY)\n\n if not span or not span.is_recording():\n return\n\n status = resp.status\n reason = None\n if resource is None:\n status = \"404\"\n reason = \"NotFound\"\n else:\n if _ENVIRON_EXC in req.env:\n exc = req.env[_ENVIRON_EXC]\n exc_type = type(exc)\n else:\n exc_type, exc = None, None\n if exc_type and not req_succeeded:\n if \"HTTPNotFound\" in exc_type.__name__:\n status = \"404\"\n reason = \"NotFound\"\n else:\n status = \"500\"\n reason = f\"{exc_type.__name__}: {exc}\"\n\n status = status.split(\" \")[0]\n try:\n status_code = int(status)\n span.set_attribute(SpanAttributes.HTTP_STATUS_CODE, status_code)\n span.set_status(\n Status(\n status_code=http_status_to_status_code(\n status_code, server_span=True\n ),\n description=reason,\n )\n )\n except ValueError:\n pass\n\n propagator = get_global_response_propagator()\n if propagator:\n propagator.inject(resp, setter=_response_propagation_setter)\n\n if self._response_hook:\n self._response_hook(span, req, resp)\n\n\nclass FalconInstrumentor(BaseInstrumentor):\n # pylint: disable=protected-access,attribute-defined-outside-init\n \"\"\"An instrumentor for falcon.API\n\n See `BaseInstrumentor`\n \"\"\"\n\n def instrumentation_dependencies(self) -> Collection[str]:\n return _instruments\n\n def _instrument(self, **opts):\n self._original_falcon_api = getattr(falcon, _instrument_app)\n\n class FalconAPI(_InstrumentedFalconAPI):\n def __init__(self, *args, **kwargs):\n kwargs[\"_otel_opts\"] = opts\n super().__init__(*args, **kwargs)\n\n setattr(falcon, _instrument_app, FalconAPI)\n\n def _uninstrument(self, **kwargs):\n setattr(falcon, _instrument_app, self._original_falcon_api)\n", "path": "instrumentation/opentelemetry-instrumentation-falcon/src/opentelemetry/instrumentation/falcon/__init__.py"}], "after_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nThis library builds on the OpenTelemetry WSGI middleware to track web requests\nin Falcon applications. In addition to opentelemetry-instrumentation-wsgi,\nit supports falcon-specific features such as:\n\n* The Falcon resource and method name is used as the Span name.\n* The ``falcon.resource`` Span attribute is set so the matched resource.\n* Error from Falcon resources are properly caught and recorded.\n\nConfiguration\n-------------\n\nExclude lists\n*************\nTo exclude certain URLs from being tracked, set the environment variable ``OTEL_PYTHON_FALCON_EXCLUDED_URLS``\n(or ``OTEL_PYTHON_EXCLUDED_URLS`` as fallback) with comma delimited regexes representing which URLs to exclude.\n\nFor example,\n\n::\n\n export OTEL_PYTHON_FALCON_EXCLUDED_URLS=\"client/.*/info,healthcheck\"\n\nwill exclude requests such as ``https://site/client/123/info`` and ``https://site/xyz/healthcheck``.\n\nRequest attributes\n********************\nTo extract certain attributes from Falcon's request object and use them as span attributes, set the environment variable ``OTEL_PYTHON_FALCON_TRACED_REQUEST_ATTRS`` to a comma\ndelimited list of request attribute names.\n\nFor example,\n\n::\n\n export OTEL_PYTHON_FALCON_TRACED_REQUEST_ATTRS='query_string,uri_template'\n\nwill extract query_string and uri_template attributes from every traced request and add them as span attritbues.\n\nFalcon Request object reference: https://falcon.readthedocs.io/en/stable/api/request_and_response.html#id1\n\nUsage\n-----\n\n.. code-block:: python\n\n from falcon import API\n from opentelemetry.instrumentation.falcon import FalconInstrumentor\n\n FalconInstrumentor().instrument()\n\n app = falcon.API()\n\n class HelloWorldResource(object):\n def on_get(self, req, resp):\n resp.body = 'Hello World'\n\n app.add_route('/hello', HelloWorldResource())\n\n\nRequest and Response hooks\n***************************\nThe instrumentation supports specifying request and response hooks. These are functions that get called back by the instrumentation right after a Span is created for a request\nand right before the span is finished while processing a response. The hooks can be configured as follows:\n\n::\n\n def request_hook(span, req):\n pass\n\n def response_hook(span, req, resp):\n pass\n\n FalconInstrumentation().instrument(request_hook=request_hook, response_hook=response_hook)\n\nAPI\n---\n\"\"\"\n\nfrom logging import getLogger\nfrom sys import exc_info\nfrom typing import Collection\n\nimport falcon\n\nimport opentelemetry.instrumentation.wsgi as otel_wsgi\nfrom opentelemetry import context, trace\nfrom opentelemetry.instrumentation.falcon.package import _instruments\nfrom opentelemetry.instrumentation.falcon.version import __version__\nfrom opentelemetry.instrumentation.instrumentor import BaseInstrumentor\nfrom opentelemetry.instrumentation.propagators import (\n FuncSetter,\n get_global_response_propagator,\n)\nfrom opentelemetry.instrumentation.utils import (\n _start_internal_or_server_span,\n extract_attributes_from_object,\n http_status_to_status_code,\n)\nfrom opentelemetry.semconv.trace import SpanAttributes\nfrom opentelemetry.trace.status import Status\nfrom opentelemetry.util._time import _time_ns\nfrom opentelemetry.util.http import get_excluded_urls, get_traced_request_attrs\n\n_logger = getLogger(__name__)\n\n_ENVIRON_STARTTIME_KEY = \"opentelemetry-falcon.starttime_key\"\n_ENVIRON_SPAN_KEY = \"opentelemetry-falcon.span_key\"\n_ENVIRON_ACTIVATION_KEY = \"opentelemetry-falcon.activation_key\"\n_ENVIRON_TOKEN = \"opentelemetry-falcon.token\"\n_ENVIRON_EXC = \"opentelemetry-falcon.exc\"\n\n\n_response_propagation_setter = FuncSetter(falcon.Response.append_header)\n\nif hasattr(falcon, \"App\"):\n # Falcon 3\n _instrument_app = \"App\"\nelse:\n # Falcon 2\n _instrument_app = \"API\"\n\n\nclass _InstrumentedFalconAPI(getattr(falcon, _instrument_app)):\n def __init__(self, *args, **kwargs):\n otel_opts = kwargs.pop(\"_otel_opts\", {})\n\n # inject trace middleware\n middlewares = kwargs.pop(\"middleware\", [])\n tracer_provider = otel_opts.pop(\"tracer_provider\", None)\n if not isinstance(middlewares, (list, tuple)):\n middlewares = [middlewares]\n\n self._otel_tracer = trace.get_tracer(\n __name__, __version__, tracer_provider\n )\n\n trace_middleware = _TraceMiddleware(\n self._otel_tracer,\n otel_opts.pop(\n \"traced_request_attributes\", get_traced_request_attrs(\"FALCON\")\n ),\n otel_opts.pop(\"request_hook\", None),\n otel_opts.pop(\"response_hook\", None),\n )\n middlewares.insert(0, trace_middleware)\n kwargs[\"middleware\"] = middlewares\n\n self._otel_excluded_urls = get_excluded_urls(\"FALCON\")\n super().__init__(*args, **kwargs)\n\n def _handle_exception(\n self, req, resp, ex, params\n ): # pylint: disable=C0103\n # Falcon 3 does not execute middleware within the context of the exception\n # so we capture the exception here and save it into the env dict\n _, exc, _ = exc_info()\n req.env[_ENVIRON_EXC] = exc\n return super()._handle_exception(req, resp, ex, params)\n\n def __call__(self, env, start_response):\n # pylint: disable=E1101\n if self._otel_excluded_urls.url_disabled(env.get(\"PATH_INFO\", \"/\")):\n return super().__call__(env, start_response)\n\n start_time = _time_ns()\n\n span, token = _start_internal_or_server_span(\n tracer=self._otel_tracer,\n span_name=otel_wsgi.get_default_span_name(env),\n start_time=start_time,\n context_carrier=env,\n context_getter=otel_wsgi.wsgi_getter,\n )\n\n if span.is_recording():\n attributes = otel_wsgi.collect_request_attributes(env)\n for key, value in attributes.items():\n span.set_attribute(key, value)\n if span.is_recording() and span.kind == trace.SpanKind.SERVER:\n otel_wsgi.add_custom_request_headers(span, env)\n\n activation = trace.use_span(span, end_on_exit=True)\n activation.__enter__()\n env[_ENVIRON_SPAN_KEY] = span\n env[_ENVIRON_ACTIVATION_KEY] = activation\n\n def _start_response(status, response_headers, *args, **kwargs):\n response = start_response(\n status, response_headers, *args, **kwargs\n )\n activation.__exit__(None, None, None)\n if token is not None:\n context.detach(token)\n return response\n\n try:\n return super().__call__(env, _start_response)\n except Exception as exc:\n activation.__exit__(\n type(exc),\n exc,\n getattr(exc, \"__traceback__\", None),\n )\n if token is not None:\n context.detach(token)\n raise\n\n\nclass _TraceMiddleware:\n # pylint:disable=R0201,W0613\n\n def __init__(\n self,\n tracer=None,\n traced_request_attrs=None,\n request_hook=None,\n response_hook=None,\n ):\n self.tracer = tracer\n self._traced_request_attrs = traced_request_attrs\n self._request_hook = request_hook\n self._response_hook = response_hook\n\n def process_request(self, req, resp):\n span = req.env.get(_ENVIRON_SPAN_KEY)\n if span and self._request_hook:\n self._request_hook(span, req)\n\n if not span or not span.is_recording():\n return\n\n attributes = extract_attributes_from_object(\n req, self._traced_request_attrs\n )\n for key, value in attributes.items():\n span.set_attribute(key, value)\n\n def process_resource(self, req, resp, resource, params):\n span = req.env.get(_ENVIRON_SPAN_KEY)\n if not span or not span.is_recording():\n return\n\n resource_name = resource.__class__.__name__\n span.set_attribute(\"falcon.resource\", resource_name)\n span.update_name(f\"{resource_name}.on_{req.method.lower()}\")\n\n def process_response(\n self, req, resp, resource, req_succeeded=None\n ): # pylint:disable=R0201\n span = req.env.get(_ENVIRON_SPAN_KEY)\n\n if not span or not span.is_recording():\n return\n\n status = resp.status\n reason = None\n if resource is None:\n status = \"404\"\n reason = \"NotFound\"\n else:\n if _ENVIRON_EXC in req.env:\n exc = req.env[_ENVIRON_EXC]\n exc_type = type(exc)\n else:\n exc_type, exc = None, None\n if exc_type and not req_succeeded:\n if \"HTTPNotFound\" in exc_type.__name__:\n status = \"404\"\n reason = \"NotFound\"\n else:\n status = \"500\"\n reason = f\"{exc_type.__name__}: {exc}\"\n\n status = status.split(\" \")[0]\n try:\n status_code = int(status)\n span.set_attribute(SpanAttributes.HTTP_STATUS_CODE, status_code)\n span.set_status(\n Status(\n status_code=http_status_to_status_code(\n status_code, server_span=True\n ),\n description=reason,\n )\n )\n if span.is_recording() and span.kind == trace.SpanKind.SERVER:\n otel_wsgi.add_custom_response_headers(\n span, resp.headers.items()\n )\n except ValueError:\n pass\n\n propagator = get_global_response_propagator()\n if propagator:\n propagator.inject(resp, setter=_response_propagation_setter)\n\n if self._response_hook:\n self._response_hook(span, req, resp)\n\n\nclass FalconInstrumentor(BaseInstrumentor):\n # pylint: disable=protected-access,attribute-defined-outside-init\n \"\"\"An instrumentor for falcon.API\n\n See `BaseInstrumentor`\n \"\"\"\n\n def instrumentation_dependencies(self) -> Collection[str]:\n return _instruments\n\n def _instrument(self, **opts):\n self._original_falcon_api = getattr(falcon, _instrument_app)\n\n class FalconAPI(_InstrumentedFalconAPI):\n def __init__(self, *args, **kwargs):\n kwargs[\"_otel_opts\"] = opts\n super().__init__(*args, **kwargs)\n\n setattr(falcon, _instrument_app, FalconAPI)\n\n def _uninstrument(self, **kwargs):\n setattr(falcon, _instrument_app, self._original_falcon_api)\n", "path": "instrumentation/opentelemetry-instrumentation-falcon/src/opentelemetry/instrumentation/falcon/__init__.py"}]}
| 3,596 | 271 |
gh_patches_debug_11247
|
rasdani/github-patches
|
git_diff
|
kornia__kornia-2458
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add docs for MobileSAM
## 📚 Documentation
<!-- A clear and concise description of what content in https://kornia.readthedocs.io is an issue. If this has to do with the general https://kornia.org website, please file an issue at https://github.com/kornia/kornia.github.io/issues/new/choose instead. If this has to do with https://kornia.org/tutorials, please file an issue at https://github.com/kornia/tutorials/issues/new -->
Update SAM docs to include MobileSAM. Visual prompter tutorials might need to be updated also.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kornia/contrib/models/sam/model.py`
Content:
```
1 """Based from the original code from Meta Platforms, Inc. and affiliates.
2
3 https://github.com/facebookresearch/segment-
4 anything/blob/3518c86b78b3bc9cf4fbe3d18e682fad1c79dc51/segment_anything/build_sam.py
5
6 https://github.com/facebookresearch/segment-
7 anything/blob/3518c86b78b3bc9cf4fbe3d18e682fad1c79dc51/segment_anything/modeling/sam.py
8 """
9 from __future__ import annotations
10
11 from dataclasses import dataclass
12 from enum import Enum
13 from typing import Any
14
15 import torch
16
17 from kornia.contrib.models import SegmentationResults
18 from kornia.contrib.models.base import ModelBase
19 from kornia.contrib.models.sam.architecture.common import LayerNorm
20 from kornia.contrib.models.sam.architecture.image_encoder import ImageEncoderViT
21 from kornia.contrib.models.sam.architecture.mask_decoder import MaskDecoder
22 from kornia.contrib.models.sam.architecture.prompt_encoder import PromptEncoder
23 from kornia.contrib.models.sam.architecture.transformer import TwoWayTransformer
24 from kornia.contrib.models.tiny_vit import TinyViT
25 from kornia.core import Tensor
26 from kornia.core.check import KORNIA_CHECK, KORNIA_CHECK_SHAPE
27
28
29 class SamModelType(Enum):
30 """Map the SAM model types."""
31
32 vit_h = 0
33 vit_l = 1
34 vit_b = 2
35 mobile_sam = 3
36
37
38 @dataclass
39 class SamConfig:
40 """Encapsulate the Config to build a SAM model.
41
42 Args:
43 model_type: the available models are:
44
45 - 0, 'vit_h' or :func:`kornia.contrib.sam.SamModelType.vit_h`
46 - 1, 'vit_l' or :func:`kornia.contrib.sam.SamModelType.vit_l`
47 - 2, 'vit_b' or :func:`kornia.contrib.sam.SamModelType.vit_b`
48
49 checkpoint: URL or a path for a file with the weights of the model
50 encoder_embed_dim: Patch embedding dimension.
51 encoder_depth: Depth of ViT.
52 encoder_num_heads: Number of attention heads in each ViT block.
53 encoder_global_attn_indexes: Encoder indexes for blocks using global attention.
54 """
55
56 model_type: str | int | SamModelType | None = None
57 checkpoint: str | None = None
58
59 encoder_embed_dim: int | None = None
60 encoder_depth: int | None = None
61 encoder_num_heads: int | None = None
62 encoder_global_attn_indexes: tuple[int, ...] | None = None
63
64
65 class Sam(ModelBase[SamConfig]):
66 mask_threshold: float = 0.0
67
68 def __init__(
69 self, image_encoder: ImageEncoderViT | TinyViT, prompt_encoder: PromptEncoder, mask_decoder: MaskDecoder
70 ) -> None:
71 """SAM predicts object masks from an image and input prompts.
72
73 Args:
74 image_encoder: The backbone used to encode the image into image embeddings that allow for efficient mask
75 prediction.
76 prompt_encoder: Encodes various types of input prompts.
77 mask_decoder: Predicts masks from the image embeddings and encoded prompts.
78 """
79
80 super().__init__()
81 self.image_encoder = image_encoder
82 self.prompt_encoder = prompt_encoder
83 self.mask_decoder = mask_decoder
84
85 @staticmethod
86 def from_config(config: SamConfig) -> Sam:
87 """Build/load the SAM model based on it's config.
88
89 Args:
90 config: The SamConfig data structure. If the model_type is available, build from it, otherwise will use
91 the parameters set.
92 Returns:
93 The respective SAM model
94
95 Example:
96 >>> from kornia.contrib.models.sam import SamConfig
97 >>> sam_model = Sam.from_config(SamConfig('vit_b'))
98 """
99 model_type = config.model_type
100
101 if isinstance(model_type, int):
102 model_type = SamModelType(model_type)
103 elif isinstance(model_type, str):
104 _map_sam_type = {
105 'vit_h': SamModelType.vit_h,
106 'vit_l': SamModelType.vit_l,
107 'vit_b': SamModelType.vit_b,
108 'mobile_sam': SamModelType.mobile_sam,
109 }
110 model_type = _map_sam_type[model_type]
111
112 if model_type == SamModelType.vit_b:
113 model = _build_sam(
114 encoder_embed_dim=768, encoder_depth=12, encoder_num_heads=12, encoder_global_attn_indexes=(2, 5, 8, 11)
115 )
116
117 elif model_type == SamModelType.vit_l:
118 model = _build_sam(
119 encoder_embed_dim=1024,
120 encoder_depth=24,
121 encoder_num_heads=16,
122 encoder_global_attn_indexes=(5, 11, 17, 23),
123 )
124
125 elif model_type == SamModelType.vit_h:
126 model = _build_sam(
127 encoder_embed_dim=1280,
128 encoder_depth=32,
129 encoder_num_heads=16,
130 encoder_global_attn_indexes=(7, 15, 23, 31),
131 )
132
133 elif model_type == SamModelType.mobile_sam:
134 # TODO: merge this with _build_sam()
135 prompt_embed_dim = 256
136 image_size = 1024
137 vit_patch_size = 16
138 image_embedding_size = image_size // vit_patch_size
139
140 model = Sam(
141 image_encoder=TinyViT.from_config("5m", img_size=image_size, mobile_sam=True),
142 prompt_encoder=PromptEncoder(
143 embed_dim=prompt_embed_dim,
144 image_embedding_size=(image_embedding_size, image_embedding_size),
145 input_image_size=(image_size, image_size),
146 mask_in_chans=16,
147 ),
148 mask_decoder=MaskDecoder(
149 num_multimask_outputs=3,
150 transformer=TwoWayTransformer(depth=2, embedding_dim=prompt_embed_dim, mlp_dim=2048, num_heads=8),
151 transformer_dim=prompt_embed_dim,
152 iou_head_depth=3,
153 iou_head_hidden_dim=256,
154 ),
155 # pixel_mean=[123.675, 116.28, 103.53],
156 # pixel_std=[58.395, 57.12, 57.375],
157 )
158
159 elif (
160 isinstance(config.encoder_embed_dim, int)
161 and isinstance(config.encoder_depth, int)
162 and isinstance(config.encoder_num_heads, int)
163 and isinstance(config.encoder_global_attn_indexes, int)
164 ):
165 model = _build_sam(
166 encoder_embed_dim=config.encoder_embed_dim,
167 encoder_depth=config.encoder_depth,
168 encoder_num_heads=config.num_heads,
169 encoder_global_attn_indexes=config.encoder_global_attn_indexes,
170 )
171
172 else:
173 raise NotImplementedError('Unexpected config. The model_type should be provide or the encoder configs.')
174
175 if config.checkpoint:
176 model.load_checkpoint(config.checkpoint)
177
178 return model
179
180 @torch.no_grad()
181 def forward(
182 self, images: Tensor, batched_prompts: list[dict[str, Any]], multimask_output: bool
183 ) -> list[SegmentationResults]:
184 """Predicts masks end-to-end from provided images and prompts.
185
186 This method expects that the images have already been pre-processed, at least been normalized, resized and
187 padded to be compatible with the `self.image_encoder`.
188
189 .. note: For each image :math:`(3, H, W)`, it is possible to input a batch (:math:`K`) of :math:`N` prompts,
190 the results are batched by the number of prompts batch. So given a prompt with :math:`K=5`, and
191 :math:`N=10`, the results will look like :math:`5xCxHxW` where :math:`C` is determined by
192 multimask_output. And within each of these masks :math:`(5xC)`, it should be possible to find
193 :math:`N` instances if the model succeed.
194
195 Args:
196 images: The image as a torch tensor in :math:`(B, 3, H, W)` format, already transformed for input to the
197 model.
198 batched_prompts: A list over the batch of images (list length should be :math:`B`), each a dictionary with
199 the following keys. If it does not have the respective prompt, it should not be included
200 in this dictionary. The options are:
201
202 - "points": tuple of (Tensor, Tensor) within the coordinate keypoints and their respective labels.
203 the tuple should look like (keypoints, labels), where:
204
205 - The keypoints (a tensor) are a batched point prompts for this image, with shape
206 :math:`(K, N, 2)`. Already transformed to the input frame of the model.
207 - The labels (a tensor) are a batched labels for point prompts, with shape :math:`(K, N)`.
208 Where 1 indicates a foreground point and 0 indicates a background point.
209
210 - "boxes": (Tensor) Batched box inputs, with shape :math:`(K, 4)`. Already transformed to the input
211 frame of the model.
212 - "mask_inputs": (Tensor) Batched mask inputs to the model, in the form :math:`(K, 1, H, W)`.
213
214 multimask_output: Whether the model should predict multiple disambiguating masks, or return a single mask.
215
216 Returns:
217 A list over input images, where each element is as SegmentationResults the following.
218 - logits: Low resolution logits with shape :math:`(K, C, H, W)`. Can be passed as mask input to
219 subsequent iterations of prediction. Where :math:`K` is the number of input prompts,
220 :math:`C` is determined by multimask_output, and :math:`H=W=256` are the model output size.
221 - scores: The model's predictions of mask quality (iou prediction), in shape BxC.
222 """
223
224 KORNIA_CHECK_SHAPE(images, ['B', '3', 'H', 'W'])
225 KORNIA_CHECK(
226 images.shape[0] == len(batched_prompts),
227 'The number of images (`B`) should match with the length of prompts!',
228 )
229
230 image_embeddings = self.image_encoder(images)
231
232 outputs = []
233 for prompt_record, curr_embedding in zip(batched_prompts, image_embeddings):
234 # Embed prompts
235 sparse_embeddings, dense_embeddings = self.prompt_encoder(
236 points=prompt_record.get("points", None),
237 boxes=prompt_record.get("boxes", None),
238 masks=prompt_record.get("mask_inputs", None),
239 )
240
241 # Predict masks
242 low_res_logits, iou_predictions = self.mask_decoder(
243 image_embeddings=curr_embedding[None, ...],
244 image_pe=self.prompt_encoder.get_dense_pe(),
245 sparse_prompt_embeddings=sparse_embeddings,
246 dense_prompt_embeddings=dense_embeddings,
247 multimask_output=multimask_output,
248 )
249
250 # Save results
251 outputs.append(SegmentationResults(low_res_logits, iou_predictions, self.mask_threshold))
252
253 return outputs
254
255
256 def _build_sam(
257 encoder_embed_dim: int, encoder_depth: int, encoder_num_heads: int, encoder_global_attn_indexes: tuple[int, ...]
258 ) -> Sam:
259 prompt_embed_dim = 256
260 image_size = 1024
261 vit_patch_size = 16
262 image_embedding_size = image_size // vit_patch_size
263
264 return Sam(
265 image_encoder=ImageEncoderViT(
266 depth=encoder_depth,
267 embed_dim=encoder_embed_dim,
268 img_size=image_size,
269 mlp_ratio=4,
270 norm_layer=LayerNorm,
271 num_heads=encoder_num_heads,
272 patch_size=vit_patch_size,
273 qkv_bias=True,
274 use_rel_pos=True,
275 global_attn_indexes=encoder_global_attn_indexes,
276 window_size=14,
277 out_chans=prompt_embed_dim,
278 ),
279 prompt_encoder=PromptEncoder(
280 embed_dim=prompt_embed_dim,
281 image_embedding_size=(image_embedding_size, image_embedding_size),
282 input_image_size=(image_size, image_size),
283 mask_in_chans=16,
284 ),
285 mask_decoder=MaskDecoder(
286 num_multimask_outputs=3,
287 transformer=TwoWayTransformer(depth=2, embedding_dim=prompt_embed_dim, mlp_dim=2048, num_heads=8),
288 transformer_dim=prompt_embed_dim,
289 iou_head_depth=3,
290 iou_head_hidden_dim=256,
291 ),
292 # pixel_mean=[123.675, 116.28, 103.53],
293 # pixel_std=[58.395, 57.12, 57.375],
294 )
295
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kornia/contrib/models/sam/model.py b/kornia/contrib/models/sam/model.py
--- a/kornia/contrib/models/sam/model.py
+++ b/kornia/contrib/models/sam/model.py
@@ -45,6 +45,7 @@
- 0, 'vit_h' or :func:`kornia.contrib.sam.SamModelType.vit_h`
- 1, 'vit_l' or :func:`kornia.contrib.sam.SamModelType.vit_l`
- 2, 'vit_b' or :func:`kornia.contrib.sam.SamModelType.vit_b`
+ - 3, 'mobile_sam', or :func:`kornia.contrib.sam.SamModelType.mobile_sam`
checkpoint: URL or a path for a file with the weights of the model
encoder_embed_dim: Patch embedding dimension.
|
{"golden_diff": "diff --git a/kornia/contrib/models/sam/model.py b/kornia/contrib/models/sam/model.py\n--- a/kornia/contrib/models/sam/model.py\n+++ b/kornia/contrib/models/sam/model.py\n@@ -45,6 +45,7 @@\n - 0, 'vit_h' or :func:`kornia.contrib.sam.SamModelType.vit_h`\n - 1, 'vit_l' or :func:`kornia.contrib.sam.SamModelType.vit_l`\n - 2, 'vit_b' or :func:`kornia.contrib.sam.SamModelType.vit_b`\n+ - 3, 'mobile_sam', or :func:`kornia.contrib.sam.SamModelType.mobile_sam`\n \n checkpoint: URL or a path for a file with the weights of the model\n encoder_embed_dim: Patch embedding dimension.\n", "issue": "Add docs for MobileSAM\n## \ud83d\udcda Documentation\r\n\r\n<!-- A clear and concise description of what content in https://kornia.readthedocs.io is an issue. If this has to do with the general https://kornia.org website, please file an issue at https://github.com/kornia/kornia.github.io/issues/new/choose instead. If this has to do with https://kornia.org/tutorials, please file an issue at https://github.com/kornia/tutorials/issues/new -->\r\n\r\nUpdate SAM docs to include MobileSAM. Visual prompter tutorials might need to be updated also.\n", "before_files": [{"content": "\"\"\"Based from the original code from Meta Platforms, Inc. and affiliates.\n\nhttps://github.com/facebookresearch/segment-\nanything/blob/3518c86b78b3bc9cf4fbe3d18e682fad1c79dc51/segment_anything/build_sam.py\n\nhttps://github.com/facebookresearch/segment-\nanything/blob/3518c86b78b3bc9cf4fbe3d18e682fad1c79dc51/segment_anything/modeling/sam.py\n\"\"\"\nfrom __future__ import annotations\n\nfrom dataclasses import dataclass\nfrom enum import Enum\nfrom typing import Any\n\nimport torch\n\nfrom kornia.contrib.models import SegmentationResults\nfrom kornia.contrib.models.base import ModelBase\nfrom kornia.contrib.models.sam.architecture.common import LayerNorm\nfrom kornia.contrib.models.sam.architecture.image_encoder import ImageEncoderViT\nfrom kornia.contrib.models.sam.architecture.mask_decoder import MaskDecoder\nfrom kornia.contrib.models.sam.architecture.prompt_encoder import PromptEncoder\nfrom kornia.contrib.models.sam.architecture.transformer import TwoWayTransformer\nfrom kornia.contrib.models.tiny_vit import TinyViT\nfrom kornia.core import Tensor\nfrom kornia.core.check import KORNIA_CHECK, KORNIA_CHECK_SHAPE\n\n\nclass SamModelType(Enum):\n \"\"\"Map the SAM model types.\"\"\"\n\n vit_h = 0\n vit_l = 1\n vit_b = 2\n mobile_sam = 3\n\n\n@dataclass\nclass SamConfig:\n \"\"\"Encapsulate the Config to build a SAM model.\n\n Args:\n model_type: the available models are:\n\n - 0, 'vit_h' or :func:`kornia.contrib.sam.SamModelType.vit_h`\n - 1, 'vit_l' or :func:`kornia.contrib.sam.SamModelType.vit_l`\n - 2, 'vit_b' or :func:`kornia.contrib.sam.SamModelType.vit_b`\n\n checkpoint: URL or a path for a file with the weights of the model\n encoder_embed_dim: Patch embedding dimension.\n encoder_depth: Depth of ViT.\n encoder_num_heads: Number of attention heads in each ViT block.\n encoder_global_attn_indexes: Encoder indexes for blocks using global attention.\n \"\"\"\n\n model_type: str | int | SamModelType | None = None\n checkpoint: str | None = None\n\n encoder_embed_dim: int | None = None\n encoder_depth: int | None = None\n encoder_num_heads: int | None = None\n encoder_global_attn_indexes: tuple[int, ...] | None = None\n\n\nclass Sam(ModelBase[SamConfig]):\n mask_threshold: float = 0.0\n\n def __init__(\n self, image_encoder: ImageEncoderViT | TinyViT, prompt_encoder: PromptEncoder, mask_decoder: MaskDecoder\n ) -> None:\n \"\"\"SAM predicts object masks from an image and input prompts.\n\n Args:\n image_encoder: The backbone used to encode the image into image embeddings that allow for efficient mask\n prediction.\n prompt_encoder: Encodes various types of input prompts.\n mask_decoder: Predicts masks from the image embeddings and encoded prompts.\n \"\"\"\n\n super().__init__()\n self.image_encoder = image_encoder\n self.prompt_encoder = prompt_encoder\n self.mask_decoder = mask_decoder\n\n @staticmethod\n def from_config(config: SamConfig) -> Sam:\n \"\"\"Build/load the SAM model based on it's config.\n\n Args:\n config: The SamConfig data structure. If the model_type is available, build from it, otherwise will use\n the parameters set.\n Returns:\n The respective SAM model\n\n Example:\n >>> from kornia.contrib.models.sam import SamConfig\n >>> sam_model = Sam.from_config(SamConfig('vit_b'))\n \"\"\"\n model_type = config.model_type\n\n if isinstance(model_type, int):\n model_type = SamModelType(model_type)\n elif isinstance(model_type, str):\n _map_sam_type = {\n 'vit_h': SamModelType.vit_h,\n 'vit_l': SamModelType.vit_l,\n 'vit_b': SamModelType.vit_b,\n 'mobile_sam': SamModelType.mobile_sam,\n }\n model_type = _map_sam_type[model_type]\n\n if model_type == SamModelType.vit_b:\n model = _build_sam(\n encoder_embed_dim=768, encoder_depth=12, encoder_num_heads=12, encoder_global_attn_indexes=(2, 5, 8, 11)\n )\n\n elif model_type == SamModelType.vit_l:\n model = _build_sam(\n encoder_embed_dim=1024,\n encoder_depth=24,\n encoder_num_heads=16,\n encoder_global_attn_indexes=(5, 11, 17, 23),\n )\n\n elif model_type == SamModelType.vit_h:\n model = _build_sam(\n encoder_embed_dim=1280,\n encoder_depth=32,\n encoder_num_heads=16,\n encoder_global_attn_indexes=(7, 15, 23, 31),\n )\n\n elif model_type == SamModelType.mobile_sam:\n # TODO: merge this with _build_sam()\n prompt_embed_dim = 256\n image_size = 1024\n vit_patch_size = 16\n image_embedding_size = image_size // vit_patch_size\n\n model = Sam(\n image_encoder=TinyViT.from_config(\"5m\", img_size=image_size, mobile_sam=True),\n prompt_encoder=PromptEncoder(\n embed_dim=prompt_embed_dim,\n image_embedding_size=(image_embedding_size, image_embedding_size),\n input_image_size=(image_size, image_size),\n mask_in_chans=16,\n ),\n mask_decoder=MaskDecoder(\n num_multimask_outputs=3,\n transformer=TwoWayTransformer(depth=2, embedding_dim=prompt_embed_dim, mlp_dim=2048, num_heads=8),\n transformer_dim=prompt_embed_dim,\n iou_head_depth=3,\n iou_head_hidden_dim=256,\n ),\n # pixel_mean=[123.675, 116.28, 103.53],\n # pixel_std=[58.395, 57.12, 57.375],\n )\n\n elif (\n isinstance(config.encoder_embed_dim, int)\n and isinstance(config.encoder_depth, int)\n and isinstance(config.encoder_num_heads, int)\n and isinstance(config.encoder_global_attn_indexes, int)\n ):\n model = _build_sam(\n encoder_embed_dim=config.encoder_embed_dim,\n encoder_depth=config.encoder_depth,\n encoder_num_heads=config.num_heads,\n encoder_global_attn_indexes=config.encoder_global_attn_indexes,\n )\n\n else:\n raise NotImplementedError('Unexpected config. The model_type should be provide or the encoder configs.')\n\n if config.checkpoint:\n model.load_checkpoint(config.checkpoint)\n\n return model\n\n @torch.no_grad()\n def forward(\n self, images: Tensor, batched_prompts: list[dict[str, Any]], multimask_output: bool\n ) -> list[SegmentationResults]:\n \"\"\"Predicts masks end-to-end from provided images and prompts.\n\n This method expects that the images have already been pre-processed, at least been normalized, resized and\n padded to be compatible with the `self.image_encoder`.\n\n .. note: For each image :math:`(3, H, W)`, it is possible to input a batch (:math:`K`) of :math:`N` prompts,\n the results are batched by the number of prompts batch. So given a prompt with :math:`K=5`, and\n :math:`N=10`, the results will look like :math:`5xCxHxW` where :math:`C` is determined by\n multimask_output. And within each of these masks :math:`(5xC)`, it should be possible to find\n :math:`N` instances if the model succeed.\n\n Args:\n images: The image as a torch tensor in :math:`(B, 3, H, W)` format, already transformed for input to the\n model.\n batched_prompts: A list over the batch of images (list length should be :math:`B`), each a dictionary with\n the following keys. If it does not have the respective prompt, it should not be included\n in this dictionary. The options are:\n\n - \"points\": tuple of (Tensor, Tensor) within the coordinate keypoints and their respective labels.\n the tuple should look like (keypoints, labels), where:\n\n - The keypoints (a tensor) are a batched point prompts for this image, with shape\n :math:`(K, N, 2)`. Already transformed to the input frame of the model.\n - The labels (a tensor) are a batched labels for point prompts, with shape :math:`(K, N)`.\n Where 1 indicates a foreground point and 0 indicates a background point.\n\n - \"boxes\": (Tensor) Batched box inputs, with shape :math:`(K, 4)`. Already transformed to the input\n frame of the model.\n - \"mask_inputs\": (Tensor) Batched mask inputs to the model, in the form :math:`(K, 1, H, W)`.\n\n multimask_output: Whether the model should predict multiple disambiguating masks, or return a single mask.\n\n Returns:\n A list over input images, where each element is as SegmentationResults the following.\n - logits: Low resolution logits with shape :math:`(K, C, H, W)`. Can be passed as mask input to\n subsequent iterations of prediction. Where :math:`K` is the number of input prompts,\n :math:`C` is determined by multimask_output, and :math:`H=W=256` are the model output size.\n - scores: The model's predictions of mask quality (iou prediction), in shape BxC.\n \"\"\"\n\n KORNIA_CHECK_SHAPE(images, ['B', '3', 'H', 'W'])\n KORNIA_CHECK(\n images.shape[0] == len(batched_prompts),\n 'The number of images (`B`) should match with the length of prompts!',\n )\n\n image_embeddings = self.image_encoder(images)\n\n outputs = []\n for prompt_record, curr_embedding in zip(batched_prompts, image_embeddings):\n # Embed prompts\n sparse_embeddings, dense_embeddings = self.prompt_encoder(\n points=prompt_record.get(\"points\", None),\n boxes=prompt_record.get(\"boxes\", None),\n masks=prompt_record.get(\"mask_inputs\", None),\n )\n\n # Predict masks\n low_res_logits, iou_predictions = self.mask_decoder(\n image_embeddings=curr_embedding[None, ...],\n image_pe=self.prompt_encoder.get_dense_pe(),\n sparse_prompt_embeddings=sparse_embeddings,\n dense_prompt_embeddings=dense_embeddings,\n multimask_output=multimask_output,\n )\n\n # Save results\n outputs.append(SegmentationResults(low_res_logits, iou_predictions, self.mask_threshold))\n\n return outputs\n\n\ndef _build_sam(\n encoder_embed_dim: int, encoder_depth: int, encoder_num_heads: int, encoder_global_attn_indexes: tuple[int, ...]\n) -> Sam:\n prompt_embed_dim = 256\n image_size = 1024\n vit_patch_size = 16\n image_embedding_size = image_size // vit_patch_size\n\n return Sam(\n image_encoder=ImageEncoderViT(\n depth=encoder_depth,\n embed_dim=encoder_embed_dim,\n img_size=image_size,\n mlp_ratio=4,\n norm_layer=LayerNorm,\n num_heads=encoder_num_heads,\n patch_size=vit_patch_size,\n qkv_bias=True,\n use_rel_pos=True,\n global_attn_indexes=encoder_global_attn_indexes,\n window_size=14,\n out_chans=prompt_embed_dim,\n ),\n prompt_encoder=PromptEncoder(\n embed_dim=prompt_embed_dim,\n image_embedding_size=(image_embedding_size, image_embedding_size),\n input_image_size=(image_size, image_size),\n mask_in_chans=16,\n ),\n mask_decoder=MaskDecoder(\n num_multimask_outputs=3,\n transformer=TwoWayTransformer(depth=2, embedding_dim=prompt_embed_dim, mlp_dim=2048, num_heads=8),\n transformer_dim=prompt_embed_dim,\n iou_head_depth=3,\n iou_head_hidden_dim=256,\n ),\n # pixel_mean=[123.675, 116.28, 103.53],\n # pixel_std=[58.395, 57.12, 57.375],\n )\n", "path": "kornia/contrib/models/sam/model.py"}], "after_files": [{"content": "\"\"\"Based from the original code from Meta Platforms, Inc. and affiliates.\n\nhttps://github.com/facebookresearch/segment-\nanything/blob/3518c86b78b3bc9cf4fbe3d18e682fad1c79dc51/segment_anything/build_sam.py\n\nhttps://github.com/facebookresearch/segment-\nanything/blob/3518c86b78b3bc9cf4fbe3d18e682fad1c79dc51/segment_anything/modeling/sam.py\n\"\"\"\nfrom __future__ import annotations\n\nfrom dataclasses import dataclass\nfrom enum import Enum\nfrom typing import Any\n\nimport torch\n\nfrom kornia.contrib.models import SegmentationResults\nfrom kornia.contrib.models.base import ModelBase\nfrom kornia.contrib.models.sam.architecture.common import LayerNorm\nfrom kornia.contrib.models.sam.architecture.image_encoder import ImageEncoderViT\nfrom kornia.contrib.models.sam.architecture.mask_decoder import MaskDecoder\nfrom kornia.contrib.models.sam.architecture.prompt_encoder import PromptEncoder\nfrom kornia.contrib.models.sam.architecture.transformer import TwoWayTransformer\nfrom kornia.contrib.models.tiny_vit import TinyViT\nfrom kornia.core import Tensor\nfrom kornia.core.check import KORNIA_CHECK, KORNIA_CHECK_SHAPE\n\n\nclass SamModelType(Enum):\n \"\"\"Map the SAM model types.\"\"\"\n\n vit_h = 0\n vit_l = 1\n vit_b = 2\n mobile_sam = 3\n\n\n@dataclass\nclass SamConfig:\n \"\"\"Encapsulate the Config to build a SAM model.\n\n Args:\n model_type: the available models are:\n\n - 0, 'vit_h' or :func:`kornia.contrib.sam.SamModelType.vit_h`\n - 1, 'vit_l' or :func:`kornia.contrib.sam.SamModelType.vit_l`\n - 2, 'vit_b' or :func:`kornia.contrib.sam.SamModelType.vit_b`\n - 3, 'mobile_sam', or :func:`kornia.contrib.sam.SamModelType.mobile_sam`\n\n checkpoint: URL or a path for a file with the weights of the model\n encoder_embed_dim: Patch embedding dimension.\n encoder_depth: Depth of ViT.\n encoder_num_heads: Number of attention heads in each ViT block.\n encoder_global_attn_indexes: Encoder indexes for blocks using global attention.\n \"\"\"\n\n model_type: str | int | SamModelType | None = None\n checkpoint: str | None = None\n\n encoder_embed_dim: int | None = None\n encoder_depth: int | None = None\n encoder_num_heads: int | None = None\n encoder_global_attn_indexes: tuple[int, ...] | None = None\n\n\nclass Sam(ModelBase[SamConfig]):\n mask_threshold: float = 0.0\n\n def __init__(\n self, image_encoder: ImageEncoderViT | TinyViT, prompt_encoder: PromptEncoder, mask_decoder: MaskDecoder\n ) -> None:\n \"\"\"SAM predicts object masks from an image and input prompts.\n\n Args:\n image_encoder: The backbone used to encode the image into image embeddings that allow for efficient mask\n prediction.\n prompt_encoder: Encodes various types of input prompts.\n mask_decoder: Predicts masks from the image embeddings and encoded prompts.\n \"\"\"\n\n super().__init__()\n self.image_encoder = image_encoder\n self.prompt_encoder = prompt_encoder\n self.mask_decoder = mask_decoder\n\n @staticmethod\n def from_config(config: SamConfig) -> Sam:\n \"\"\"Build/load the SAM model based on it's config.\n\n Args:\n config: The SamConfig data structure. If the model_type is available, build from it, otherwise will use\n the parameters set.\n Returns:\n The respective SAM model\n\n Example:\n >>> from kornia.contrib.models.sam import SamConfig\n >>> sam_model = Sam.from_config(SamConfig('vit_b'))\n \"\"\"\n model_type = config.model_type\n\n if isinstance(model_type, int):\n model_type = SamModelType(model_type)\n elif isinstance(model_type, str):\n _map_sam_type = {\n 'vit_h': SamModelType.vit_h,\n 'vit_l': SamModelType.vit_l,\n 'vit_b': SamModelType.vit_b,\n 'mobile_sam': SamModelType.mobile_sam,\n }\n model_type = _map_sam_type[model_type]\n\n if model_type == SamModelType.vit_b:\n model = _build_sam(\n encoder_embed_dim=768, encoder_depth=12, encoder_num_heads=12, encoder_global_attn_indexes=(2, 5, 8, 11)\n )\n\n elif model_type == SamModelType.vit_l:\n model = _build_sam(\n encoder_embed_dim=1024,\n encoder_depth=24,\n encoder_num_heads=16,\n encoder_global_attn_indexes=(5, 11, 17, 23),\n )\n\n elif model_type == SamModelType.vit_h:\n model = _build_sam(\n encoder_embed_dim=1280,\n encoder_depth=32,\n encoder_num_heads=16,\n encoder_global_attn_indexes=(7, 15, 23, 31),\n )\n\n elif model_type == SamModelType.mobile_sam:\n # TODO: merge this with _build_sam()\n prompt_embed_dim = 256\n image_size = 1024\n vit_patch_size = 16\n image_embedding_size = image_size // vit_patch_size\n\n model = Sam(\n image_encoder=TinyViT.from_config(\"5m\", img_size=image_size, mobile_sam=True),\n prompt_encoder=PromptEncoder(\n embed_dim=prompt_embed_dim,\n image_embedding_size=(image_embedding_size, image_embedding_size),\n input_image_size=(image_size, image_size),\n mask_in_chans=16,\n ),\n mask_decoder=MaskDecoder(\n num_multimask_outputs=3,\n transformer=TwoWayTransformer(depth=2, embedding_dim=prompt_embed_dim, mlp_dim=2048, num_heads=8),\n transformer_dim=prompt_embed_dim,\n iou_head_depth=3,\n iou_head_hidden_dim=256,\n ),\n # pixel_mean=[123.675, 116.28, 103.53],\n # pixel_std=[58.395, 57.12, 57.375],\n )\n\n elif (\n isinstance(config.encoder_embed_dim, int)\n and isinstance(config.encoder_depth, int)\n and isinstance(config.encoder_num_heads, int)\n and isinstance(config.encoder_global_attn_indexes, int)\n ):\n model = _build_sam(\n encoder_embed_dim=config.encoder_embed_dim,\n encoder_depth=config.encoder_depth,\n encoder_num_heads=config.num_heads,\n encoder_global_attn_indexes=config.encoder_global_attn_indexes,\n )\n\n else:\n raise NotImplementedError('Unexpected config. The model_type should be provide or the encoder configs.')\n\n if config.checkpoint:\n model.load_checkpoint(config.checkpoint)\n\n return model\n\n @torch.no_grad()\n def forward(\n self, images: Tensor, batched_prompts: list[dict[str, Any]], multimask_output: bool\n ) -> list[SegmentationResults]:\n \"\"\"Predicts masks end-to-end from provided images and prompts.\n\n This method expects that the images have already been pre-processed, at least been normalized, resized and\n padded to be compatible with the `self.image_encoder`.\n\n .. note: For each image :math:`(3, H, W)`, it is possible to input a batch (:math:`K`) of :math:`N` prompts,\n the results are batched by the number of prompts batch. So given a prompt with :math:`K=5`, and\n :math:`N=10`, the results will look like :math:`5xCxHxW` where :math:`C` is determined by\n multimask_output. And within each of these masks :math:`(5xC)`, it should be possible to find\n :math:`N` instances if the model succeed.\n\n Args:\n images: The image as a torch tensor in :math:`(B, 3, H, W)` format, already transformed for input to the\n model.\n batched_prompts: A list over the batch of images (list length should be :math:`B`), each a dictionary with\n the following keys. If it does not have the respective prompt, it should not be included\n in this dictionary. The options are:\n\n - \"points\": tuple of (Tensor, Tensor) within the coordinate keypoints and their respective labels.\n the tuple should look like (keypoints, labels), where:\n\n - The keypoints (a tensor) are a batched point prompts for this image, with shape\n :math:`(K, N, 2)`. Already transformed to the input frame of the model.\n - The labels (a tensor) are a batched labels for point prompts, with shape :math:`(K, N)`.\n Where 1 indicates a foreground point and 0 indicates a background point.\n\n - \"boxes\": (Tensor) Batched box inputs, with shape :math:`(K, 4)`. Already transformed to the input\n frame of the model.\n - \"mask_inputs\": (Tensor) Batched mask inputs to the model, in the form :math:`(K, 1, H, W)`.\n\n multimask_output: Whether the model should predict multiple disambiguating masks, or return a single mask.\n\n Returns:\n A list over input images, where each element is as SegmentationResults the following.\n - logits: Low resolution logits with shape :math:`(K, C, H, W)`. Can be passed as mask input to\n subsequent iterations of prediction. Where :math:`K` is the number of input prompts,\n :math:`C` is determined by multimask_output, and :math:`H=W=256` are the model output size.\n - scores: The model's predictions of mask quality (iou prediction), in shape BxC.\n \"\"\"\n\n KORNIA_CHECK_SHAPE(images, ['B', '3', 'H', 'W'])\n KORNIA_CHECK(\n images.shape[0] == len(batched_prompts),\n 'The number of images (`B`) should match with the length of prompts!',\n )\n\n image_embeddings = self.image_encoder(images)\n\n outputs = []\n for prompt_record, curr_embedding in zip(batched_prompts, image_embeddings):\n # Embed prompts\n sparse_embeddings, dense_embeddings = self.prompt_encoder(\n points=prompt_record.get(\"points\", None),\n boxes=prompt_record.get(\"boxes\", None),\n masks=prompt_record.get(\"mask_inputs\", None),\n )\n\n # Predict masks\n low_res_logits, iou_predictions = self.mask_decoder(\n image_embeddings=curr_embedding[None, ...],\n image_pe=self.prompt_encoder.get_dense_pe(),\n sparse_prompt_embeddings=sparse_embeddings,\n dense_prompt_embeddings=dense_embeddings,\n multimask_output=multimask_output,\n )\n\n # Save results\n outputs.append(SegmentationResults(low_res_logits, iou_predictions, self.mask_threshold))\n\n return outputs\n\n\ndef _build_sam(\n encoder_embed_dim: int, encoder_depth: int, encoder_num_heads: int, encoder_global_attn_indexes: tuple[int, ...]\n) -> Sam:\n prompt_embed_dim = 256\n image_size = 1024\n vit_patch_size = 16\n image_embedding_size = image_size // vit_patch_size\n\n return Sam(\n image_encoder=ImageEncoderViT(\n depth=encoder_depth,\n embed_dim=encoder_embed_dim,\n img_size=image_size,\n mlp_ratio=4,\n norm_layer=LayerNorm,\n num_heads=encoder_num_heads,\n patch_size=vit_patch_size,\n qkv_bias=True,\n use_rel_pos=True,\n global_attn_indexes=encoder_global_attn_indexes,\n window_size=14,\n out_chans=prompt_embed_dim,\n ),\n prompt_encoder=PromptEncoder(\n embed_dim=prompt_embed_dim,\n image_embedding_size=(image_embedding_size, image_embedding_size),\n input_image_size=(image_size, image_size),\n mask_in_chans=16,\n ),\n mask_decoder=MaskDecoder(\n num_multimask_outputs=3,\n transformer=TwoWayTransformer(depth=2, embedding_dim=prompt_embed_dim, mlp_dim=2048, num_heads=8),\n transformer_dim=prompt_embed_dim,\n iou_head_depth=3,\n iou_head_hidden_dim=256,\n ),\n # pixel_mean=[123.675, 116.28, 103.53],\n # pixel_std=[58.395, 57.12, 57.375],\n )\n", "path": "kornia/contrib/models/sam/model.py"}]}
| 4,043 | 197 |
gh_patches_debug_7685
|
rasdani/github-patches
|
git_diff
|
pantsbuild__pants-19263
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Helm Unittest values and snapshot testing issue
**Describe the bug**
Helm unittesting doesn't work if [`values` section](https://github.com/quintush/helm-unittest/blob/master/DOCUMENT.md#test-job) is present in *_test.yaml instead of `set`.
Another point is that if [snapshotting testing](https://github.com/quintush/helm-unittest#snapshot-testing) is used it seems that snapshots in `__snapshot__/` directory are ignored and any changes to tests or values in `set` section doesn't affect the tests run - it's still successful.
**Pants version**
2.15.1
**OS**
both
**Additional info**
1. Consider the following setup
```
# deployment_test.yaml
tests:
- it: checks correct number of replicas
asserts:
- equal:
path: spec.replicas
value: 2
values:
- general_values.yaml
# IF COMMENT `values` section and uncomment `set` - it works fine.
# set:
# replicaCount: 2
# BUILD
helm_unittest_tests(
sources=[
"*_test.yaml",
"general_values.yaml"
]
)
# general_values.yaml
replicaCount: 2
serviceAccount:
name: opa
```
The error occurs:
```
pants test ::
13:07:38.10 [INFO] Completed: Running Helm unittest suite awesome/tests/deployment_test.yaml
13:07:38.11 [ERROR] Completed: Run Helm Unittest - awesome/tests/deployment_test.yaml - failed (exit code 1).
### Chart [ awesome ] awesome
FAIL test deployment awesome/tests/deployment_test.yaml
- checks correct number of replicas
Error: open awesome/tests/general_values.yaml: no such file or directory
```
2. Snapshot testing is also behaves not as expected. So, according to the documentation you need to generate `.snap` file and put it into `__snapshot__` directory. When test runs it compares the output value with the snapshot. While the manifest is generated during the run it doesn't seem to actually compare the result with the snapshot, because any changes to either to snapshot or to values in `set` section doesn't doesn't impact test results - it's always successful.
Might be related - https://github.com/pantsbuild/pants/issues/16532
---
I believe both cases are might be related to the same issue and it's related to missing logic on how unittests are integrated into pants. Though I might missing some piece of documentation as well, in that case would appreciate any help :)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/python/pants/backend/helm/dependency_inference/deployment.py`
Content:
```
1 # Copyright 2022 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 from __future__ import annotations
5
6 import logging
7 from dataclasses import dataclass
8 from pathlib import PurePath
9 from typing import Any
10
11 from pants.backend.docker.target_types import AllDockerImageTargets
12 from pants.backend.docker.target_types import rules as docker_target_types_rules
13 from pants.backend.helm.subsystems import k8s_parser
14 from pants.backend.helm.subsystems.k8s_parser import ParsedKubeManifest, ParseKubeManifestRequest
15 from pants.backend.helm.target_types import HelmDeploymentFieldSet
16 from pants.backend.helm.target_types import rules as helm_target_types_rules
17 from pants.backend.helm.util_rules import renderer
18 from pants.backend.helm.util_rules.renderer import (
19 HelmDeploymentCmd,
20 HelmDeploymentRequest,
21 RenderedHelmFiles,
22 )
23 from pants.backend.helm.utils.yaml import FrozenYamlIndex, MutableYamlIndex
24 from pants.engine.addresses import Address
25 from pants.engine.engine_aware import EngineAwareParameter, EngineAwareReturnType
26 from pants.engine.fs import Digest, DigestEntries, FileEntry
27 from pants.engine.internals.native_engine import AddressInput
28 from pants.engine.rules import Get, MultiGet, collect_rules, rule
29 from pants.engine.target import (
30 DependenciesRequest,
31 ExplicitlyProvidedDependencies,
32 InferDependenciesRequest,
33 InferredDependencies,
34 )
35 from pants.engine.unions import UnionRule
36 from pants.util.logging import LogLevel
37 from pants.util.ordered_set import FrozenOrderedSet, OrderedSet
38 from pants.util.strutil import pluralize, softwrap
39
40 logger = logging.getLogger(__name__)
41
42
43 @dataclass(frozen=True)
44 class AnalyseHelmDeploymentRequest(EngineAwareParameter):
45 field_set: HelmDeploymentFieldSet
46
47 def debug_hint(self) -> str | None:
48 return self.field_set.address.spec
49
50
51 @dataclass(frozen=True)
52 class HelmDeploymentReport(EngineAwareReturnType):
53 address: Address
54 image_refs: FrozenYamlIndex[str]
55
56 @property
57 def all_image_refs(self) -> FrozenOrderedSet[str]:
58 return FrozenOrderedSet(self.image_refs.values())
59
60 def level(self) -> LogLevel | None:
61 return LogLevel.DEBUG
62
63 def metadata(self) -> dict[str, Any] | None:
64 return {"address": self.address, "image_refs": self.image_refs}
65
66
67 @rule(desc="Analyse Helm deployment", level=LogLevel.DEBUG)
68 async def analyse_deployment(request: AnalyseHelmDeploymentRequest) -> HelmDeploymentReport:
69 rendered_deployment = await Get(
70 RenderedHelmFiles,
71 HelmDeploymentRequest(
72 cmd=HelmDeploymentCmd.RENDER,
73 field_set=request.field_set,
74 description=f"Rendering Helm deployment {request.field_set.address}",
75 ),
76 )
77
78 rendered_entries = await Get(DigestEntries, Digest, rendered_deployment.snapshot.digest)
79 parsed_manifests = await MultiGet(
80 Get(
81 ParsedKubeManifest,
82 ParseKubeManifestRequest(file=entry),
83 )
84 for entry in rendered_entries
85 if isinstance(entry, FileEntry)
86 )
87
88 # Build YAML index of Docker image refs for future processing during depedendecy inference or post-rendering.
89 image_refs_index: MutableYamlIndex[str] = MutableYamlIndex()
90 for manifest in parsed_manifests:
91 for idx, path, image_ref in manifest.found_image_refs:
92 image_refs_index.insert(
93 file_path=PurePath(manifest.filename),
94 document_index=idx,
95 yaml_path=path,
96 item=image_ref,
97 )
98
99 return HelmDeploymentReport(
100 address=request.field_set.address, image_refs=image_refs_index.frozen()
101 )
102
103
104 @dataclass(frozen=True)
105 class FirstPartyHelmDeploymentMappingRequest(EngineAwareParameter):
106 field_set: HelmDeploymentFieldSet
107
108 def debug_hint(self) -> str | None:
109 return self.field_set.address.spec
110
111
112 @dataclass(frozen=True)
113 class FirstPartyHelmDeploymentMapping:
114 """A mapping between `helm_deployment` target addresses and tuples made up of a Docker image
115 reference and a `docker_image` target address.
116
117 The tuples of Docker image references and addresses are stored in a YAML index so we can track
118 the locations in which the Docker image refs appear in the deployment files.
119 """
120
121 address: Address
122 indexed_docker_addresses: FrozenYamlIndex[tuple[str, Address]]
123
124
125 @rule
126 async def first_party_helm_deployment_mapping(
127 request: FirstPartyHelmDeploymentMappingRequest, docker_targets: AllDockerImageTargets
128 ) -> FirstPartyHelmDeploymentMapping:
129 deployment_report = await Get(
130 HelmDeploymentReport, AnalyseHelmDeploymentRequest(request.field_set)
131 )
132 docker_target_addresses = {tgt.address.spec: tgt.address for tgt in docker_targets}
133
134 def lookup_docker_addreses(image_ref: str) -> tuple[str, Address] | None:
135 addr = docker_target_addresses.get(str(image_ref), None)
136 if addr:
137 return image_ref, addr
138 return None
139
140 return FirstPartyHelmDeploymentMapping(
141 address=request.field_set.address,
142 indexed_docker_addresses=deployment_report.image_refs.transform_values(
143 lookup_docker_addreses
144 ),
145 )
146
147
148 class InferHelmDeploymentDependenciesRequest(InferDependenciesRequest):
149 infer_from = HelmDeploymentFieldSet
150
151
152 @rule(desc="Find the dependencies needed by a Helm deployment")
153 async def inject_deployment_dependencies(
154 request: InferHelmDeploymentDependenciesRequest,
155 ) -> InferredDependencies:
156 chart_address = None
157 chart_address_input = request.field_set.chart.to_address_input()
158 if chart_address_input:
159 chart_address = await Get(Address, AddressInput, chart_address_input)
160
161 explicitly_provided_deps, mapping = await MultiGet(
162 Get(ExplicitlyProvidedDependencies, DependenciesRequest(request.field_set.dependencies)),
163 Get(
164 FirstPartyHelmDeploymentMapping,
165 FirstPartyHelmDeploymentMappingRequest(request.field_set),
166 ),
167 )
168
169 dependencies: OrderedSet[Address] = OrderedSet()
170 if chart_address:
171 dependencies.add(chart_address)
172 for imager_ref, candidate_address in mapping.indexed_docker_addresses.values():
173 matches = frozenset([candidate_address]).difference(explicitly_provided_deps.includes)
174 explicitly_provided_deps.maybe_warn_of_ambiguous_dependency_inference(
175 matches,
176 request.field_set.address,
177 context=softwrap(
178 f"""
179 The Helm deployment {request.field_set.address} declares
180 {imager_ref} as Docker image reference
181 """
182 ),
183 import_reference="manifest",
184 )
185
186 maybe_disambiguated = explicitly_provided_deps.disambiguated(matches)
187 if maybe_disambiguated:
188 dependencies.add(maybe_disambiguated)
189
190 logging.debug(
191 f"Found {pluralize(len(dependencies), 'dependency')} for target {request.field_set.address}"
192 )
193 return InferredDependencies(dependencies)
194
195
196 def rules():
197 return [
198 *collect_rules(),
199 *renderer.rules(),
200 *k8s_parser.rules(),
201 *helm_target_types_rules(),
202 *docker_target_types_rules(),
203 UnionRule(InferDependenciesRequest, InferHelmDeploymentDependenciesRequest),
204 ]
205
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/python/pants/backend/helm/dependency_inference/deployment.py b/src/python/pants/backend/helm/dependency_inference/deployment.py
--- a/src/python/pants/backend/helm/dependency_inference/deployment.py
+++ b/src/python/pants/backend/helm/dependency_inference/deployment.py
@@ -132,7 +132,7 @@
docker_target_addresses = {tgt.address.spec: tgt.address for tgt in docker_targets}
def lookup_docker_addreses(image_ref: str) -> tuple[str, Address] | None:
- addr = docker_target_addresses.get(str(image_ref), None)
+ addr = docker_target_addresses.get(image_ref, None)
if addr:
return image_ref, addr
return None
|
{"golden_diff": "diff --git a/src/python/pants/backend/helm/dependency_inference/deployment.py b/src/python/pants/backend/helm/dependency_inference/deployment.py\n--- a/src/python/pants/backend/helm/dependency_inference/deployment.py\n+++ b/src/python/pants/backend/helm/dependency_inference/deployment.py\n@@ -132,7 +132,7 @@\n docker_target_addresses = {tgt.address.spec: tgt.address for tgt in docker_targets}\n \n def lookup_docker_addreses(image_ref: str) -> tuple[str, Address] | None:\n- addr = docker_target_addresses.get(str(image_ref), None)\n+ addr = docker_target_addresses.get(image_ref, None)\n if addr:\n return image_ref, addr\n return None\n", "issue": "Helm Unittest values and snapshot testing issue\n**Describe the bug**\r\nHelm unittesting doesn't work if [`values` section](https://github.com/quintush/helm-unittest/blob/master/DOCUMENT.md#test-job) is present in *_test.yaml instead of `set`. \r\n\r\nAnother point is that if [snapshotting testing](https://github.com/quintush/helm-unittest#snapshot-testing) is used it seems that snapshots in `__snapshot__/` directory are ignored and any changes to tests or values in `set` section doesn't affect the tests run - it's still successful.\r\n\r\n**Pants version**\r\n2.15.1\r\n\r\n**OS**\r\nboth\r\n\r\n**Additional info**\r\n1. Consider the following setup\r\n ```\r\n # deployment_test.yaml\r\n tests:\r\n - it: checks correct number of replicas\r\n asserts:\r\n - equal:\r\n path: spec.replicas\r\n value: 2\r\n values:\r\n - general_values.yaml\r\n # IF COMMENT `values` section and uncomment `set` - it works fine.\r\n # set:\r\n # replicaCount: 2\r\n \r\n # BUILD\r\n helm_unittest_tests(\r\n sources=[\r\n \"*_test.yaml\",\r\n \"general_values.yaml\"\r\n ]\r\n )\r\n \r\n # general_values.yaml\r\n \r\n replicaCount: 2\r\n \r\n serviceAccount:\r\n name: opa\r\n ```\r\n The error occurs:\r\n ```\r\n pants test ::\r\n13:07:38.10 [INFO] Completed: Running Helm unittest suite awesome/tests/deployment_test.yaml\r\n13:07:38.11 [ERROR] Completed: Run Helm Unittest - awesome/tests/deployment_test.yaml - failed (exit code 1).\r\n\r\n### Chart [ awesome ] awesome\r\n\r\n FAIL test deployment awesome/tests/deployment_test.yaml\r\n - checks correct number of replicas\r\n Error: open awesome/tests/general_values.yaml: no such file or directory\r\n ```\r\n\r\n2. Snapshot testing is also behaves not as expected. So, according to the documentation you need to generate `.snap` file and put it into `__snapshot__` directory. When test runs it compares the output value with the snapshot. While the manifest is generated during the run it doesn't seem to actually compare the result with the snapshot, because any changes to either to snapshot or to values in `set` section doesn't doesn't impact test results - it's always successful. \r\n\r\nMight be related - https://github.com/pantsbuild/pants/issues/16532\r\n\r\n---\r\n\r\nI believe both cases are might be related to the same issue and it's related to missing logic on how unittests are integrated into pants. Though I might missing some piece of documentation as well, in that case would appreciate any help :)\r\n\n", "before_files": [{"content": "# Copyright 2022 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom __future__ import annotations\n\nimport logging\nfrom dataclasses import dataclass\nfrom pathlib import PurePath\nfrom typing import Any\n\nfrom pants.backend.docker.target_types import AllDockerImageTargets\nfrom pants.backend.docker.target_types import rules as docker_target_types_rules\nfrom pants.backend.helm.subsystems import k8s_parser\nfrom pants.backend.helm.subsystems.k8s_parser import ParsedKubeManifest, ParseKubeManifestRequest\nfrom pants.backend.helm.target_types import HelmDeploymentFieldSet\nfrom pants.backend.helm.target_types import rules as helm_target_types_rules\nfrom pants.backend.helm.util_rules import renderer\nfrom pants.backend.helm.util_rules.renderer import (\n HelmDeploymentCmd,\n HelmDeploymentRequest,\n RenderedHelmFiles,\n)\nfrom pants.backend.helm.utils.yaml import FrozenYamlIndex, MutableYamlIndex\nfrom pants.engine.addresses import Address\nfrom pants.engine.engine_aware import EngineAwareParameter, EngineAwareReturnType\nfrom pants.engine.fs import Digest, DigestEntries, FileEntry\nfrom pants.engine.internals.native_engine import AddressInput\nfrom pants.engine.rules import Get, MultiGet, collect_rules, rule\nfrom pants.engine.target import (\n DependenciesRequest,\n ExplicitlyProvidedDependencies,\n InferDependenciesRequest,\n InferredDependencies,\n)\nfrom pants.engine.unions import UnionRule\nfrom pants.util.logging import LogLevel\nfrom pants.util.ordered_set import FrozenOrderedSet, OrderedSet\nfrom pants.util.strutil import pluralize, softwrap\n\nlogger = logging.getLogger(__name__)\n\n\n@dataclass(frozen=True)\nclass AnalyseHelmDeploymentRequest(EngineAwareParameter):\n field_set: HelmDeploymentFieldSet\n\n def debug_hint(self) -> str | None:\n return self.field_set.address.spec\n\n\n@dataclass(frozen=True)\nclass HelmDeploymentReport(EngineAwareReturnType):\n address: Address\n image_refs: FrozenYamlIndex[str]\n\n @property\n def all_image_refs(self) -> FrozenOrderedSet[str]:\n return FrozenOrderedSet(self.image_refs.values())\n\n def level(self) -> LogLevel | None:\n return LogLevel.DEBUG\n\n def metadata(self) -> dict[str, Any] | None:\n return {\"address\": self.address, \"image_refs\": self.image_refs}\n\n\n@rule(desc=\"Analyse Helm deployment\", level=LogLevel.DEBUG)\nasync def analyse_deployment(request: AnalyseHelmDeploymentRequest) -> HelmDeploymentReport:\n rendered_deployment = await Get(\n RenderedHelmFiles,\n HelmDeploymentRequest(\n cmd=HelmDeploymentCmd.RENDER,\n field_set=request.field_set,\n description=f\"Rendering Helm deployment {request.field_set.address}\",\n ),\n )\n\n rendered_entries = await Get(DigestEntries, Digest, rendered_deployment.snapshot.digest)\n parsed_manifests = await MultiGet(\n Get(\n ParsedKubeManifest,\n ParseKubeManifestRequest(file=entry),\n )\n for entry in rendered_entries\n if isinstance(entry, FileEntry)\n )\n\n # Build YAML index of Docker image refs for future processing during depedendecy inference or post-rendering.\n image_refs_index: MutableYamlIndex[str] = MutableYamlIndex()\n for manifest in parsed_manifests:\n for idx, path, image_ref in manifest.found_image_refs:\n image_refs_index.insert(\n file_path=PurePath(manifest.filename),\n document_index=idx,\n yaml_path=path,\n item=image_ref,\n )\n\n return HelmDeploymentReport(\n address=request.field_set.address, image_refs=image_refs_index.frozen()\n )\n\n\n@dataclass(frozen=True)\nclass FirstPartyHelmDeploymentMappingRequest(EngineAwareParameter):\n field_set: HelmDeploymentFieldSet\n\n def debug_hint(self) -> str | None:\n return self.field_set.address.spec\n\n\n@dataclass(frozen=True)\nclass FirstPartyHelmDeploymentMapping:\n \"\"\"A mapping between `helm_deployment` target addresses and tuples made up of a Docker image\n reference and a `docker_image` target address.\n\n The tuples of Docker image references and addresses are stored in a YAML index so we can track\n the locations in which the Docker image refs appear in the deployment files.\n \"\"\"\n\n address: Address\n indexed_docker_addresses: FrozenYamlIndex[tuple[str, Address]]\n\n\n@rule\nasync def first_party_helm_deployment_mapping(\n request: FirstPartyHelmDeploymentMappingRequest, docker_targets: AllDockerImageTargets\n) -> FirstPartyHelmDeploymentMapping:\n deployment_report = await Get(\n HelmDeploymentReport, AnalyseHelmDeploymentRequest(request.field_set)\n )\n docker_target_addresses = {tgt.address.spec: tgt.address for tgt in docker_targets}\n\n def lookup_docker_addreses(image_ref: str) -> tuple[str, Address] | None:\n addr = docker_target_addresses.get(str(image_ref), None)\n if addr:\n return image_ref, addr\n return None\n\n return FirstPartyHelmDeploymentMapping(\n address=request.field_set.address,\n indexed_docker_addresses=deployment_report.image_refs.transform_values(\n lookup_docker_addreses\n ),\n )\n\n\nclass InferHelmDeploymentDependenciesRequest(InferDependenciesRequest):\n infer_from = HelmDeploymentFieldSet\n\n\n@rule(desc=\"Find the dependencies needed by a Helm deployment\")\nasync def inject_deployment_dependencies(\n request: InferHelmDeploymentDependenciesRequest,\n) -> InferredDependencies:\n chart_address = None\n chart_address_input = request.field_set.chart.to_address_input()\n if chart_address_input:\n chart_address = await Get(Address, AddressInput, chart_address_input)\n\n explicitly_provided_deps, mapping = await MultiGet(\n Get(ExplicitlyProvidedDependencies, DependenciesRequest(request.field_set.dependencies)),\n Get(\n FirstPartyHelmDeploymentMapping,\n FirstPartyHelmDeploymentMappingRequest(request.field_set),\n ),\n )\n\n dependencies: OrderedSet[Address] = OrderedSet()\n if chart_address:\n dependencies.add(chart_address)\n for imager_ref, candidate_address in mapping.indexed_docker_addresses.values():\n matches = frozenset([candidate_address]).difference(explicitly_provided_deps.includes)\n explicitly_provided_deps.maybe_warn_of_ambiguous_dependency_inference(\n matches,\n request.field_set.address,\n context=softwrap(\n f\"\"\"\n The Helm deployment {request.field_set.address} declares\n {imager_ref} as Docker image reference\n \"\"\"\n ),\n import_reference=\"manifest\",\n )\n\n maybe_disambiguated = explicitly_provided_deps.disambiguated(matches)\n if maybe_disambiguated:\n dependencies.add(maybe_disambiguated)\n\n logging.debug(\n f\"Found {pluralize(len(dependencies), 'dependency')} for target {request.field_set.address}\"\n )\n return InferredDependencies(dependencies)\n\n\ndef rules():\n return [\n *collect_rules(),\n *renderer.rules(),\n *k8s_parser.rules(),\n *helm_target_types_rules(),\n *docker_target_types_rules(),\n UnionRule(InferDependenciesRequest, InferHelmDeploymentDependenciesRequest),\n ]\n", "path": "src/python/pants/backend/helm/dependency_inference/deployment.py"}], "after_files": [{"content": "# Copyright 2022 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom __future__ import annotations\n\nimport logging\nfrom dataclasses import dataclass\nfrom pathlib import PurePath\nfrom typing import Any\n\nfrom pants.backend.docker.target_types import AllDockerImageTargets\nfrom pants.backend.docker.target_types import rules as docker_target_types_rules\nfrom pants.backend.helm.subsystems import k8s_parser\nfrom pants.backend.helm.subsystems.k8s_parser import ParsedKubeManifest, ParseKubeManifestRequest\nfrom pants.backend.helm.target_types import HelmDeploymentFieldSet\nfrom pants.backend.helm.target_types import rules as helm_target_types_rules\nfrom pants.backend.helm.util_rules import renderer\nfrom pants.backend.helm.util_rules.renderer import (\n HelmDeploymentCmd,\n HelmDeploymentRequest,\n RenderedHelmFiles,\n)\nfrom pants.backend.helm.utils.yaml import FrozenYamlIndex, MutableYamlIndex\nfrom pants.engine.addresses import Address\nfrom pants.engine.engine_aware import EngineAwareParameter, EngineAwareReturnType\nfrom pants.engine.fs import Digest, DigestEntries, FileEntry\nfrom pants.engine.internals.native_engine import AddressInput\nfrom pants.engine.rules import Get, MultiGet, collect_rules, rule\nfrom pants.engine.target import (\n DependenciesRequest,\n ExplicitlyProvidedDependencies,\n InferDependenciesRequest,\n InferredDependencies,\n)\nfrom pants.engine.unions import UnionRule\nfrom pants.util.logging import LogLevel\nfrom pants.util.ordered_set import FrozenOrderedSet, OrderedSet\nfrom pants.util.strutil import pluralize, softwrap\n\nlogger = logging.getLogger(__name__)\n\n\n@dataclass(frozen=True)\nclass AnalyseHelmDeploymentRequest(EngineAwareParameter):\n field_set: HelmDeploymentFieldSet\n\n def debug_hint(self) -> str | None:\n return self.field_set.address.spec\n\n\n@dataclass(frozen=True)\nclass HelmDeploymentReport(EngineAwareReturnType):\n address: Address\n image_refs: FrozenYamlIndex[str]\n\n @property\n def all_image_refs(self) -> FrozenOrderedSet[str]:\n return FrozenOrderedSet(self.image_refs.values())\n\n def level(self) -> LogLevel | None:\n return LogLevel.DEBUG\n\n def metadata(self) -> dict[str, Any] | None:\n return {\"address\": self.address, \"image_refs\": self.image_refs}\n\n\n@rule(desc=\"Analyse Helm deployment\", level=LogLevel.DEBUG)\nasync def analyse_deployment(request: AnalyseHelmDeploymentRequest) -> HelmDeploymentReport:\n rendered_deployment = await Get(\n RenderedHelmFiles,\n HelmDeploymentRequest(\n cmd=HelmDeploymentCmd.RENDER,\n field_set=request.field_set,\n description=f\"Rendering Helm deployment {request.field_set.address}\",\n ),\n )\n\n rendered_entries = await Get(DigestEntries, Digest, rendered_deployment.snapshot.digest)\n parsed_manifests = await MultiGet(\n Get(\n ParsedKubeManifest,\n ParseKubeManifestRequest(file=entry),\n )\n for entry in rendered_entries\n if isinstance(entry, FileEntry)\n )\n\n # Build YAML index of Docker image refs for future processing during depedendecy inference or post-rendering.\n image_refs_index: MutableYamlIndex[str] = MutableYamlIndex()\n for manifest in parsed_manifests:\n for idx, path, image_ref in manifest.found_image_refs:\n image_refs_index.insert(\n file_path=PurePath(manifest.filename),\n document_index=idx,\n yaml_path=path,\n item=image_ref,\n )\n\n return HelmDeploymentReport(\n address=request.field_set.address, image_refs=image_refs_index.frozen()\n )\n\n\n@dataclass(frozen=True)\nclass FirstPartyHelmDeploymentMappingRequest(EngineAwareParameter):\n field_set: HelmDeploymentFieldSet\n\n def debug_hint(self) -> str | None:\n return self.field_set.address.spec\n\n\n@dataclass(frozen=True)\nclass FirstPartyHelmDeploymentMapping:\n \"\"\"A mapping between `helm_deployment` target addresses and tuples made up of a Docker image\n reference and a `docker_image` target address.\n\n The tuples of Docker image references and addresses are stored in a YAML index so we can track\n the locations in which the Docker image refs appear in the deployment files.\n \"\"\"\n\n address: Address\n indexed_docker_addresses: FrozenYamlIndex[tuple[str, Address]]\n\n\n@rule\nasync def first_party_helm_deployment_mapping(\n request: FirstPartyHelmDeploymentMappingRequest, docker_targets: AllDockerImageTargets\n) -> FirstPartyHelmDeploymentMapping:\n deployment_report = await Get(\n HelmDeploymentReport, AnalyseHelmDeploymentRequest(request.field_set)\n )\n docker_target_addresses = {tgt.address.spec: tgt.address for tgt in docker_targets}\n\n def lookup_docker_addreses(image_ref: str) -> tuple[str, Address] | None:\n addr = docker_target_addresses.get(image_ref, None)\n if addr:\n return image_ref, addr\n return None\n\n return FirstPartyHelmDeploymentMapping(\n address=request.field_set.address,\n indexed_docker_addresses=deployment_report.image_refs.transform_values(\n lookup_docker_addreses\n ),\n )\n\n\nclass InferHelmDeploymentDependenciesRequest(InferDependenciesRequest):\n infer_from = HelmDeploymentFieldSet\n\n\n@rule(desc=\"Find the dependencies needed by a Helm deployment\")\nasync def inject_deployment_dependencies(\n request: InferHelmDeploymentDependenciesRequest,\n) -> InferredDependencies:\n chart_address = None\n chart_address_input = request.field_set.chart.to_address_input()\n if chart_address_input:\n chart_address = await Get(Address, AddressInput, chart_address_input)\n\n explicitly_provided_deps, mapping = await MultiGet(\n Get(ExplicitlyProvidedDependencies, DependenciesRequest(request.field_set.dependencies)),\n Get(\n FirstPartyHelmDeploymentMapping,\n FirstPartyHelmDeploymentMappingRequest(request.field_set),\n ),\n )\n\n dependencies: OrderedSet[Address] = OrderedSet()\n if chart_address:\n dependencies.add(chart_address)\n for imager_ref, candidate_address in mapping.indexed_docker_addresses.values():\n matches = frozenset([candidate_address]).difference(explicitly_provided_deps.includes)\n explicitly_provided_deps.maybe_warn_of_ambiguous_dependency_inference(\n matches,\n request.field_set.address,\n context=softwrap(\n f\"\"\"\n The Helm deployment {request.field_set.address} declares\n {imager_ref} as Docker image reference\n \"\"\"\n ),\n import_reference=\"manifest\",\n )\n\n maybe_disambiguated = explicitly_provided_deps.disambiguated(matches)\n if maybe_disambiguated:\n dependencies.add(maybe_disambiguated)\n\n logging.debug(\n f\"Found {pluralize(len(dependencies), 'dependency')} for target {request.field_set.address}\"\n )\n return InferredDependencies(dependencies)\n\n\ndef rules():\n return [\n *collect_rules(),\n *renderer.rules(),\n *k8s_parser.rules(),\n *helm_target_types_rules(),\n *docker_target_types_rules(),\n UnionRule(InferDependenciesRequest, InferHelmDeploymentDependenciesRequest),\n ]\n", "path": "src/python/pants/backend/helm/dependency_inference/deployment.py"}]}
| 2,903 | 165 |
gh_patches_debug_22936
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-22413
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
eos_banner not idempotent
##### ISSUE TYPE
- Bug Report
##### COMPONENT NAME
eos_banner
##### ANSIBLE VERSION
```
029ccf9aa0cd490224bfcf403ed94bc397e3af63
```
##### SUMMARY
##### STEPS TO REPRODUCE
```yaml
- name: Set login
eos_banner:
banner: login
text: |
this is my login banner
that has a multiline
string
state: present
authorize: yes
register: result
- debug:
msg: "{{ result }}"
- assert:
that:
- "result.changed == true"
- "'that has a multiline' in result.commands" # does this break due to "contains?"
# Ensure sessions contains epoc. Will fail after 18th May 2033
- "'ansible_1' in result.session_name"
- name: Set login again (idempotent)
eos_banner:
banner: login
text: |
this is my login banner
that has a multiline
string
state: present
authorize: yes
register: result
```
##### EXPECTED RESULTS
2nd run shouldn't report changed
##### ACTUAL RESULTS
```yaml
changed: [veos01] => {
"changed": true,
"commands": [
"banner login",
"this is my login banner",
"that has a multiline",
"string",
"EOF"
],
"invocation": {
"module_args": {
"auth_pass": null,
"authorize": true,
"banner": "login",
"host": null,
"password": null,
"port": null,
"provider": null,
"ssh_keyfile": null,
"state": "present",
"text": "this is my login banner\nthat has a multiline\nstring\n",
"timeout": null,
"transport": null,
"use_ssl": null,
"username": null,
"validate_certs": null
}
},
"session_name": "ansible_1488455488"
}
TASK [eos_banner : debug] ************************************************************************************************************************************************************************************************************************
task path: /home/johnb/git/ansible-inc/ansible-workspace-2/test/integration/targets/eos_banner/tests/cli/eos_banner_basic.yaml:27
ok: [veos01] => {
"changed": false,
"msg": {
"changed": true,
"commands": [
"banner login",
"this is my login banner",
"that has a multiline",
"string",
"EOF"
],
"session_name": "ansible_1488455488",
"warnings": [
"argument authorize has been deprecated and will be removed in a future version"
]
}
}
TASK [eos_banner : assert] ***********************************************************************************************************************************************************************************************************************
task path: /home/johnb/git/ansible-inc/ansible-workspace-2/test/integration/targets/eos_banner/tests/cli/eos_banner_basic.yaml:30
ok: [veos01] => {
"changed": false,
"msg": "All assertions passed"
}
TASK [eos_banner : Set login again (idempotent)] *************************************************************************************************************************************************************************************************
task path: /home/johnb/git/ansible-inc/ansible-workspace-2/test/integration/targets/eos_banner/tests/cli/eos_banner_basic.yaml:37
<veos01> connection transport is cli
<veos01> socket_path: /home/johnb/.ansible/pc/ca5960d27a
Using module file /home/johnb/git/ansible-inc/ansible-workspace-2/lib/ansible/modules/network/eos/eos_banner.py
<veos01> ESTABLISH LOCAL CONNECTION FOR USER: johnb
<veos01> EXEC /bin/sh -c 'echo ~ && sleep 0'
<veos01> EXEC /bin/sh -c '( umask 77 && mkdir -p "` echo /home/johnb/.ansible/tmp/ansible-tmp-1488455491.69-116354442763630 `" && echo ansible-tmp-1488455491.69-116354442763630="` echo /home/johnb/.ansible/tmp/ansible-tmp-1488455491.69-116354442763630 `" ) && sleep 0'
<veos01> PUT /tmp/tmpyLoa44 TO /home/johnb/.ansible/tmp/ansible-tmp-1488455491.69-116354442763630/eos_banner.py
<veos01> EXEC /bin/sh -c 'chmod u+x /home/johnb/.ansible/tmp/ansible-tmp-1488455491.69-116354442763630/ /home/johnb/.ansible/tmp/ansible-tmp-1488455491.69-116354442763630/eos_banner.py && sleep 0'
<veos01> EXEC /bin/sh -c 'python /home/johnb/.ansible/tmp/ansible-tmp-1488455491.69-116354442763630/eos_banner.py; rm -rf "/home/johnb/.ansible/tmp/ansible-tmp-1488455491.69-116354442763630/" > /dev/null 2>&1 && sleep 0'
changed: [veos01] => {
"changed": true,
"commands": [
"banner login",
"this is my login banner",
"that has a multiline",
"string",
"EOF"
],
"invocation": {
"module_args": {
"auth_pass": null,
"authorize": true,
"banner": "login",
"host": null,
"password": null,
"port": null,
"provider": null,
"ssh_keyfile": null,
"state": "present",
"text": "this is my login banner\nthat has a multiline\nstring\n",
"timeout": null,
"transport": null,
"use_ssl": null,
"username": null,
"validate_certs": null
}
},
"session_name": "ansible_1488455492"
}
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/ansible/modules/network/eos/eos_banner.py`
Content:
```
1 #!/usr/bin/python
2 #
3 # This file is part of Ansible
4 #
5 # Ansible is free software: you can redistribute it and/or modify
6 # it under the terms of the GNU General Public License as published by
7 # the Free Software Foundation, either version 3 of the License, or
8 # (at your option) any later version.
9 #
10 # Ansible is distributed in the hope that it will be useful,
11 # but WITHOUT ANY WARRANTY; without even the implied warranty of
12 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
13 # GNU General Public License for more details.
14 #
15 # You should have received a copy of the GNU General Public License
16 # along with Ansible. If not, see <http://www.gnu.org/licenses/>.
17 #
18
19 ANSIBLE_METADATA = {
20 'status': ['preview'],
21 'supported_by': 'community',
22 'version': '1.0'
23 }
24
25 DOCUMENTATION = """
26 ---
27 module: eos_banner
28 version_added: "2.3"
29 author: "Peter Sprygada (@privateip)"
30 short_description: Manage multiline banners on Arista EOS devices
31 description:
32 - This will configure both login and motd banners on remote devices
33 running Arista EOS. It allows playbooks to add or remote
34 banner text from the active running configuration.
35 extends_documentation_fragment: eos
36 options:
37 banner:
38 description:
39 - The C(banner) argument specifies the banner that should be
40 configured on the remote device. Current this module supports
41 configuration of either C(login) or C(motd) banners.
42 required: true
43 default: null
44 text:
45 description:
46 - The C(text) argument specifics the banner text that should be
47 present in the remote device running configuration. This argument
48 accepts a multiline string.
49 required: false
50 default: null
51 state:
52 description:
53 - The C(state) argument specifies whether or not the configuration is
54 present in the current devices active running configuration. When
55 this value is set to C(present), the configuration stanzas should be
56 in the current device configuration. When this value is set to
57 C(absent), the configuration should not be in the current running
58 configuration.
59 required: false
60 default: present
61 choices: ['present', 'absent']
62 """
63
64 EXAMPLES = """
65 - name: configure the login banner
66 eos_banner:
67 banner: login
68 text: |
69 this is my login banner
70 that contains a multiline
71 string
72 state: present
73
74 - name: remove the motd banner
75 banner: motd
76 state: absent
77 """
78
79 RETURN = """
80 commands:
81 description: The list of configuration mode commands to send to the device
82 returned: always
83 type: list
84 sample:
85 - banner login
86 - this is my login banner
87 - that contains a multiline
88 - string
89 - EOF
90 session_name:
91 description: The EOS config session name used to load the configuration
92 returned: always
93 type: str
94 sample: ansible_1479315771
95 """
96 from ansible.module_utils.basic import AnsibleModule
97 from ansible.module_utils.eos import load_config, run_commands
98 from ansible.module_utils.eos import eos_argument_spec, check_args
99
100 def map_obj_to_commands(updates, module):
101 commands = list()
102 want, have = updates
103 state = module.params['state']
104
105 if state == 'absent':
106 commands.append('no banner %s' % module.params['banner'])
107
108 elif state == 'present':
109 if want['text'] and (want['text'] != have.get('text')):
110 commands.append('banner %s' % module.params['banner'])
111 commands.extend(want['text'].strip().split('\n'))
112 commands.append('EOF')
113
114 return commands
115
116 def map_config_to_obj(module):
117 output = run_commands(module, ['show banner %s' % module.params['banner']])
118 obj = {'banner': module.params['banner'], 'state': 'absent'}
119 if output:
120 obj['text'] = output
121 obj['state'] = 'present'
122 return obj
123
124 def map_params_to_obj(module):
125 text = module.params['text']
126 if text:
127 text = str(text).strip()
128
129 return {
130 'banner': module.params['banner'],
131 'text': text,
132 'state': module.params['state']
133 }
134
135 def main():
136 """ main entry point for module execution
137 """
138 argument_spec = dict(
139 banner=dict(required=True, choices=['login', 'motd']),
140 text=dict(),
141 state=dict(default='present', choices=['present', 'absent'])
142 )
143
144 argument_spec.update(eos_argument_spec)
145
146 required_if = [('state', 'present', ('text',))]
147
148 module = AnsibleModule(argument_spec=argument_spec,
149 required_if=required_if,
150 supports_check_mode=True)
151
152 warnings = list()
153 check_args(module, warnings)
154
155 result = {'changed': False}
156 if warnings:
157 result['warnings'] = warnings
158
159 want = map_params_to_obj(module)
160 have = map_config_to_obj(module)
161
162 commands = map_obj_to_commands((want, have), module)
163 result['commands'] = commands
164
165 if commands:
166 commit = not module.check_mode
167 response = load_config(module, commands, commit=commit)
168 if response.get('diff') and module._diff:
169 result['diff'] = {'prepared': response.get('diff')}
170 result['session_name'] = response.get('session')
171 result['changed'] = True
172
173 module.exit_json(**result)
174
175 if __name__ == '__main__':
176 main()
177
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lib/ansible/modules/network/eos/eos_banner.py b/lib/ansible/modules/network/eos/eos_banner.py
--- a/lib/ansible/modules/network/eos/eos_banner.py
+++ b/lib/ansible/modules/network/eos/eos_banner.py
@@ -102,7 +102,7 @@
want, have = updates
state = module.params['state']
- if state == 'absent':
+ if state == 'absent' and have['text']:
commands.append('no banner %s' % module.params['banner'])
elif state == 'present':
@@ -117,7 +117,7 @@
output = run_commands(module, ['show banner %s' % module.params['banner']])
obj = {'banner': module.params['banner'], 'state': 'absent'}
if output:
- obj['text'] = output
+ obj['text'] = output[0]
obj['state'] = 'present'
return obj
@@ -155,7 +155,6 @@
result = {'changed': False}
if warnings:
result['warnings'] = warnings
-
want = map_params_to_obj(module)
have = map_config_to_obj(module)
|
{"golden_diff": "diff --git a/lib/ansible/modules/network/eos/eos_banner.py b/lib/ansible/modules/network/eos/eos_banner.py\n--- a/lib/ansible/modules/network/eos/eos_banner.py\n+++ b/lib/ansible/modules/network/eos/eos_banner.py\n@@ -102,7 +102,7 @@\n want, have = updates\n state = module.params['state']\n \n- if state == 'absent':\n+ if state == 'absent' and have['text']:\n commands.append('no banner %s' % module.params['banner'])\n \n elif state == 'present':\n@@ -117,7 +117,7 @@\n output = run_commands(module, ['show banner %s' % module.params['banner']])\n obj = {'banner': module.params['banner'], 'state': 'absent'}\n if output:\n- obj['text'] = output\n+ obj['text'] = output[0]\n obj['state'] = 'present'\n return obj\n \n@@ -155,7 +155,6 @@\n result = {'changed': False}\n if warnings:\n result['warnings'] = warnings\n-\n want = map_params_to_obj(module)\n have = map_config_to_obj(module)\n", "issue": "eos_banner not idempotent\n##### ISSUE TYPE\r\n - Bug Report\r\n\r\n##### COMPONENT NAME\r\neos_banner\r\n\r\n##### ANSIBLE VERSION\r\n```\r\n029ccf9aa0cd490224bfcf403ed94bc397e3af63\r\n```\r\n\r\n##### SUMMARY\r\n\r\n##### STEPS TO REPRODUCE\r\n```yaml\r\n- name: Set login\r\n eos_banner:\r\n banner: login\r\n text: |\r\n this is my login banner\r\n that has a multiline\r\n string\r\n state: present\r\n authorize: yes \r\n register: result\r\n\r\n- debug:\r\n msg: \"{{ result }}\"\r\n\r\n- assert:\r\n that:\r\n - \"result.changed == true\"\r\n - \"'that has a multiline' in result.commands\" # does this break due to \"contains?\"\r\n # Ensure sessions contains epoc. Will fail after 18th May 2033\r\n - \"'ansible_1' in result.session_name\"\r\n\r\n- name: Set login again (idempotent)\r\n eos_banner:\r\n banner: login\r\n text: |\r\n this is my login banner\r\n that has a multiline\r\n string\r\n state: present\r\n authorize: yes \r\n register: result\r\n\r\n```\r\n\r\n\r\n##### EXPECTED RESULTS\r\n2nd run shouldn't report changed\r\n##### ACTUAL RESULTS\r\n```yaml\r\n changed: [veos01] => {\r\n \"changed\": true, \r\n \"commands\": [\r\n \"banner login\", \r\n \"this is my login banner\", \r\n \"that has a multiline\", \r\n \"string\", \r\n \"EOF\"\r\n ], \r\n \"invocation\": {\r\n \"module_args\": {\r\n \"auth_pass\": null, \r\n \"authorize\": true, \r\n \"banner\": \"login\", \r\n \"host\": null, \r\n \"password\": null, \r\n \"port\": null, \r\n \"provider\": null, \r\n \"ssh_keyfile\": null, \r\n \"state\": \"present\", \r\n \"text\": \"this is my login banner\\nthat has a multiline\\nstring\\n\", \r\n \"timeout\": null, \r\n \"transport\": null, \r\n \"use_ssl\": null, \r\n \"username\": null, \r\n \"validate_certs\": null\r\n }\r\n }, \r\n \"session_name\": \"ansible_1488455488\"\r\n}\r\n\r\nTASK [eos_banner : debug] ************************************************************************************************************************************************************************************************************************\r\ntask path: /home/johnb/git/ansible-inc/ansible-workspace-2/test/integration/targets/eos_banner/tests/cli/eos_banner_basic.yaml:27\r\nok: [veos01] => {\r\n \"changed\": false, \r\n \"msg\": {\r\n \"changed\": true, \r\n \"commands\": [\r\n \"banner login\", \r\n \"this is my login banner\", \r\n \"that has a multiline\", \r\n \"string\", \r\n \"EOF\"\r\n ], \r\n \"session_name\": \"ansible_1488455488\", \r\n \"warnings\": [\r\n \"argument authorize has been deprecated and will be removed in a future version\"\r\n ]\r\n }\r\n}\r\n\r\nTASK [eos_banner : assert] ***********************************************************************************************************************************************************************************************************************\r\ntask path: /home/johnb/git/ansible-inc/ansible-workspace-2/test/integration/targets/eos_banner/tests/cli/eos_banner_basic.yaml:30\r\nok: [veos01] => {\r\n \"changed\": false, \r\n \"msg\": \"All assertions passed\"\r\n}\r\n\r\nTASK [eos_banner : Set login again (idempotent)] *************************************************************************************************************************************************************************************************\r\ntask path: /home/johnb/git/ansible-inc/ansible-workspace-2/test/integration/targets/eos_banner/tests/cli/eos_banner_basic.yaml:37\r\n<veos01> connection transport is cli\r\n<veos01> socket_path: /home/johnb/.ansible/pc/ca5960d27a\r\nUsing module file /home/johnb/git/ansible-inc/ansible-workspace-2/lib/ansible/modules/network/eos/eos_banner.py\r\n<veos01> ESTABLISH LOCAL CONNECTION FOR USER: johnb\r\n<veos01> EXEC /bin/sh -c 'echo ~ && sleep 0'\r\n<veos01> EXEC /bin/sh -c '( umask 77 && mkdir -p \"` echo /home/johnb/.ansible/tmp/ansible-tmp-1488455491.69-116354442763630 `\" && echo ansible-tmp-1488455491.69-116354442763630=\"` echo /home/johnb/.ansible/tmp/ansible-tmp-1488455491.69-116354442763630 `\" ) && sleep 0'\r\n<veos01> PUT /tmp/tmpyLoa44 TO /home/johnb/.ansible/tmp/ansible-tmp-1488455491.69-116354442763630/eos_banner.py\r\n<veos01> EXEC /bin/sh -c 'chmod u+x /home/johnb/.ansible/tmp/ansible-tmp-1488455491.69-116354442763630/ /home/johnb/.ansible/tmp/ansible-tmp-1488455491.69-116354442763630/eos_banner.py && sleep 0'\r\n<veos01> EXEC /bin/sh -c 'python /home/johnb/.ansible/tmp/ansible-tmp-1488455491.69-116354442763630/eos_banner.py; rm -rf \"/home/johnb/.ansible/tmp/ansible-tmp-1488455491.69-116354442763630/\" > /dev/null 2>&1 && sleep 0'\r\nchanged: [veos01] => {\r\n \"changed\": true, \r\n \"commands\": [\r\n \"banner login\", \r\n \"this is my login banner\", \r\n \"that has a multiline\", \r\n \"string\", \r\n \"EOF\"\r\n ], \r\n \"invocation\": {\r\n \"module_args\": {\r\n \"auth_pass\": null, \r\n \"authorize\": true, \r\n \"banner\": \"login\", \r\n \"host\": null, \r\n \"password\": null, \r\n \"port\": null, \r\n \"provider\": null, \r\n \"ssh_keyfile\": null, \r\n \"state\": \"present\", \r\n \"text\": \"this is my login banner\\nthat has a multiline\\nstring\\n\", \r\n \"timeout\": null, \r\n \"transport\": null, \r\n \"use_ssl\": null, \r\n \"username\": null, \r\n \"validate_certs\": null\r\n }\r\n }, \r\n \"session_name\": \"ansible_1488455492\"\r\n}\r\n\r\n\r\n```\r\n\n", "before_files": [{"content": "#!/usr/bin/python\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n#\n\nANSIBLE_METADATA = {\n 'status': ['preview'],\n 'supported_by': 'community',\n 'version': '1.0'\n}\n\nDOCUMENTATION = \"\"\"\n---\nmodule: eos_banner\nversion_added: \"2.3\"\nauthor: \"Peter Sprygada (@privateip)\"\nshort_description: Manage multiline banners on Arista EOS devices\ndescription:\n - This will configure both login and motd banners on remote devices\n running Arista EOS. It allows playbooks to add or remote\n banner text from the active running configuration.\nextends_documentation_fragment: eos\noptions:\n banner:\n description:\n - The C(banner) argument specifies the banner that should be\n configured on the remote device. Current this module supports\n configuration of either C(login) or C(motd) banners.\n required: true\n default: null\n text:\n description:\n - The C(text) argument specifics the banner text that should be\n present in the remote device running configuration. This argument\n accepts a multiline string.\n required: false\n default: null\n state:\n description:\n - The C(state) argument specifies whether or not the configuration is\n present in the current devices active running configuration. When\n this value is set to C(present), the configuration stanzas should be\n in the current device configuration. When this value is set to\n C(absent), the configuration should not be in the current running\n configuration.\n required: false\n default: present\n choices: ['present', 'absent']\n\"\"\"\n\nEXAMPLES = \"\"\"\n- name: configure the login banner\n eos_banner:\n banner: login\n text: |\n this is my login banner\n that contains a multiline\n string\n state: present\n\n- name: remove the motd banner\n banner: motd\n state: absent\n\"\"\"\n\nRETURN = \"\"\"\ncommands:\n description: The list of configuration mode commands to send to the device\n returned: always\n type: list\n sample:\n - banner login\n - this is my login banner\n - that contains a multiline\n - string\n - EOF\nsession_name:\n description: The EOS config session name used to load the configuration\n returned: always\n type: str\n sample: ansible_1479315771\n\"\"\"\nfrom ansible.module_utils.basic import AnsibleModule\nfrom ansible.module_utils.eos import load_config, run_commands\nfrom ansible.module_utils.eos import eos_argument_spec, check_args\n\ndef map_obj_to_commands(updates, module):\n commands = list()\n want, have = updates\n state = module.params['state']\n\n if state == 'absent':\n commands.append('no banner %s' % module.params['banner'])\n\n elif state == 'present':\n if want['text'] and (want['text'] != have.get('text')):\n commands.append('banner %s' % module.params['banner'])\n commands.extend(want['text'].strip().split('\\n'))\n commands.append('EOF')\n\n return commands\n\ndef map_config_to_obj(module):\n output = run_commands(module, ['show banner %s' % module.params['banner']])\n obj = {'banner': module.params['banner'], 'state': 'absent'}\n if output:\n obj['text'] = output\n obj['state'] = 'present'\n return obj\n\ndef map_params_to_obj(module):\n text = module.params['text']\n if text:\n text = str(text).strip()\n\n return {\n 'banner': module.params['banner'],\n 'text': text,\n 'state': module.params['state']\n }\n\ndef main():\n \"\"\" main entry point for module execution\n \"\"\"\n argument_spec = dict(\n banner=dict(required=True, choices=['login', 'motd']),\n text=dict(),\n state=dict(default='present', choices=['present', 'absent'])\n )\n\n argument_spec.update(eos_argument_spec)\n\n required_if = [('state', 'present', ('text',))]\n\n module = AnsibleModule(argument_spec=argument_spec,\n required_if=required_if,\n supports_check_mode=True)\n\n warnings = list()\n check_args(module, warnings)\n\n result = {'changed': False}\n if warnings:\n result['warnings'] = warnings\n\n want = map_params_to_obj(module)\n have = map_config_to_obj(module)\n\n commands = map_obj_to_commands((want, have), module)\n result['commands'] = commands\n\n if commands:\n commit = not module.check_mode\n response = load_config(module, commands, commit=commit)\n if response.get('diff') and module._diff:\n result['diff'] = {'prepared': response.get('diff')}\n result['session_name'] = response.get('session')\n result['changed'] = True\n\n module.exit_json(**result)\n\nif __name__ == '__main__':\n main()\n", "path": "lib/ansible/modules/network/eos/eos_banner.py"}], "after_files": [{"content": "#!/usr/bin/python\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n#\n\nANSIBLE_METADATA = {\n 'status': ['preview'],\n 'supported_by': 'community',\n 'version': '1.0'\n}\n\nDOCUMENTATION = \"\"\"\n---\nmodule: eos_banner\nversion_added: \"2.3\"\nauthor: \"Peter Sprygada (@privateip)\"\nshort_description: Manage multiline banners on Arista EOS devices\ndescription:\n - This will configure both login and motd banners on remote devices\n running Arista EOS. It allows playbooks to add or remote\n banner text from the active running configuration.\nextends_documentation_fragment: eos\noptions:\n banner:\n description:\n - The C(banner) argument specifies the banner that should be\n configured on the remote device. Current this module supports\n configuration of either C(login) or C(motd) banners.\n required: true\n default: null\n text:\n description:\n - The C(text) argument specifics the banner text that should be\n present in the remote device running configuration. This argument\n accepts a multiline string.\n required: false\n default: null\n state:\n description:\n - The C(state) argument specifies whether or not the configuration is\n present in the current devices active running configuration. When\n this value is set to C(present), the configuration stanzas should be\n in the current device configuration. When this value is set to\n C(absent), the configuration should not be in the current running\n configuration.\n required: false\n default: present\n choices: ['present', 'absent']\n\"\"\"\n\nEXAMPLES = \"\"\"\n- name: configure the login banner\n eos_banner:\n banner: login\n text: |\n this is my login banner\n that contains a multiline\n string\n state: present\n\n- name: remove the motd banner\n banner: motd\n state: absent\n\"\"\"\n\nRETURN = \"\"\"\ncommands:\n description: The list of configuration mode commands to send to the device\n returned: always\n type: list\n sample:\n - banner login\n - this is my login banner\n - that contains a multiline\n - string\n - EOF\nsession_name:\n description: The EOS config session name used to load the configuration\n returned: always\n type: str\n sample: ansible_1479315771\n\"\"\"\nfrom ansible.module_utils.basic import AnsibleModule\nfrom ansible.module_utils.eos import load_config, run_commands\nfrom ansible.module_utils.eos import eos_argument_spec, check_args\n\ndef map_obj_to_commands(updates, module):\n commands = list()\n want, have = updates\n state = module.params['state']\n\n if state == 'absent' and have['text']:\n commands.append('no banner %s' % module.params['banner'])\n\n elif state == 'present':\n if want['text'] and (want['text'] != have.get('text')):\n commands.append('banner %s' % module.params['banner'])\n commands.extend(want['text'].strip().split('\\n'))\n commands.append('EOF')\n\n return commands\n\ndef map_config_to_obj(module):\n output = run_commands(module, ['show banner %s' % module.params['banner']])\n obj = {'banner': module.params['banner'], 'state': 'absent'}\n if output:\n obj['text'] = output[0]\n obj['state'] = 'present'\n return obj\n\ndef map_params_to_obj(module):\n text = module.params['text']\n if text:\n text = str(text).strip()\n\n return {\n 'banner': module.params['banner'],\n 'text': text,\n 'state': module.params['state']\n }\n\ndef main():\n \"\"\" main entry point for module execution\n \"\"\"\n argument_spec = dict(\n banner=dict(required=True, choices=['login', 'motd']),\n text=dict(),\n state=dict(default='present', choices=['present', 'absent'])\n )\n\n argument_spec.update(eos_argument_spec)\n\n required_if = [('state', 'present', ('text',))]\n\n module = AnsibleModule(argument_spec=argument_spec,\n required_if=required_if,\n supports_check_mode=True)\n\n warnings = list()\n check_args(module, warnings)\n\n result = {'changed': False}\n if warnings:\n result['warnings'] = warnings\n want = map_params_to_obj(module)\n have = map_config_to_obj(module)\n\n commands = map_obj_to_commands((want, have), module)\n result['commands'] = commands\n\n if commands:\n commit = not module.check_mode\n response = load_config(module, commands, commit=commit)\n if response.get('diff') and module._diff:\n result['diff'] = {'prepared': response.get('diff')}\n result['session_name'] = response.get('session')\n result['changed'] = True\n\n module.exit_json(**result)\n\nif __name__ == '__main__':\n main()\n", "path": "lib/ansible/modules/network/eos/eos_banner.py"}]}
| 3,497 | 273 |
gh_patches_debug_59171
|
rasdani/github-patches
|
git_diff
|
PaddlePaddle__models-1201
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
will you support CPU training of Transformer?
https://github.com/PaddlePaddle/models/blob/ff63e48f5dd71143d7108198e71a61cdaa0895d9/fluid/neural_machine_translation/transformer/config.py#L2
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `fluid/neural_machine_translation/transformer/config.py`
Content:
```
1 class TrainTaskConfig(object):
2 # only support GPU currently
3 use_gpu = True
4 # the epoch number to train.
5 pass_num = 30
6 # the number of sequences contained in a mini-batch.
7 # deprecated, set batch_size in args.
8 batch_size = 32
9 # the hyper parameters for Adam optimizer.
10 # This static learning_rate will be multiplied to the LearningRateScheduler
11 # derived learning rate the to get the final learning rate.
12 learning_rate = 1
13 beta1 = 0.9
14 beta2 = 0.98
15 eps = 1e-9
16 # the parameters for learning rate scheduling.
17 warmup_steps = 4000
18 # the weight used to mix up the ground-truth distribution and the fixed
19 # uniform distribution in label smoothing when training.
20 # Set this as zero if label smoothing is not wanted.
21 label_smooth_eps = 0.1
22 # the directory for saving trained models.
23 model_dir = "trained_models"
24 # the directory for saving checkpoints.
25 ckpt_dir = "trained_ckpts"
26 # the directory for loading checkpoint.
27 # If provided, continue training from the checkpoint.
28 ckpt_path = None
29 # the parameter to initialize the learning rate scheduler.
30 # It should be provided if use checkpoints, since the checkpoint doesn't
31 # include the training step counter currently.
32 start_step = 0
33
34
35 class InferTaskConfig(object):
36 use_gpu = True
37 # the number of examples in one run for sequence generation.
38 batch_size = 10
39 # the parameters for beam search.
40 beam_size = 5
41 max_out_len = 256
42 # the number of decoded sentences to output.
43 n_best = 1
44 # the flags indicating whether to output the special tokens.
45 output_bos = False
46 output_eos = False
47 output_unk = True
48 # the directory for loading the trained model.
49 model_path = "trained_models/pass_1.infer.model"
50
51
52 class ModelHyperParams(object):
53 # These following five vocabularies related configurations will be set
54 # automatically according to the passed vocabulary path and special tokens.
55 # size of source word dictionary.
56 src_vocab_size = 10000
57 # size of target word dictionay
58 trg_vocab_size = 10000
59 # index for <bos> token
60 bos_idx = 0
61 # index for <eos> token
62 eos_idx = 1
63 # index for <unk> token
64 unk_idx = 2
65 # max length of sequences deciding the size of position encoding table.
66 # Start from 1 and count start and end tokens in.
67 max_length = 256
68 # the dimension for word embeddings, which is also the last dimension of
69 # the input and output of multi-head attention, position-wise feed-forward
70 # networks, encoder and decoder.
71 d_model = 512
72 # size of the hidden layer in position-wise feed-forward networks.
73 d_inner_hid = 2048
74 # the dimension that keys are projected to for dot-product attention.
75 d_key = 64
76 # the dimension that values are projected to for dot-product attention.
77 d_value = 64
78 # number of head used in multi-head attention.
79 n_head = 8
80 # number of sub-layers to be stacked in the encoder and decoder.
81 n_layer = 6
82 # dropout rate used by all dropout layers.
83 dropout = 0.1
84 # random seed used in dropout for CE.
85 dropout_seed = None
86 # the flag indicating whether to share embedding and softmax weights.
87 # vocabularies in source and target should be same for weight sharing.
88 weight_sharing = True
89
90
91 def merge_cfg_from_list(cfg_list, g_cfgs):
92 """
93 Set the above global configurations using the cfg_list.
94 """
95 assert len(cfg_list) % 2 == 0
96 for key, value in zip(cfg_list[0::2], cfg_list[1::2]):
97 for g_cfg in g_cfgs:
98 if hasattr(g_cfg, key):
99 try:
100 value = eval(value)
101 except Exception: # for file path
102 pass
103 setattr(g_cfg, key, value)
104 break
105
106
107 # The placeholder for batch_size in compile time. Must be -1 currently to be
108 # consistent with some ops' infer-shape output in compile time, such as the
109 # sequence_expand op used in beamsearch decoder.
110 batch_size = -1
111 # The placeholder for squence length in compile time.
112 seq_len = ModelHyperParams.max_length
113 # Here list the data shapes and data types of all inputs.
114 # The shapes here act as placeholder and are set to pass the infer-shape in
115 # compile time.
116 input_descs = {
117 # The actual data shape of src_word is:
118 # [batch_size, max_src_len_in_batch, 1]
119 "src_word": [(batch_size, seq_len, 1), "int64", 2],
120 # The actual data shape of src_pos is:
121 # [batch_size, max_src_len_in_batch, 1]
122 "src_pos": [(batch_size, seq_len, 1), "int64"],
123 # This input is used to remove attention weights on paddings in the
124 # encoder.
125 # The actual data shape of src_slf_attn_bias is:
126 # [batch_size, n_head, max_src_len_in_batch, max_src_len_in_batch]
127 "src_slf_attn_bias": [(batch_size, ModelHyperParams.n_head, seq_len,
128 seq_len), "float32"],
129 # The actual data shape of trg_word is:
130 # [batch_size, max_trg_len_in_batch, 1]
131 "trg_word": [(batch_size, seq_len, 1), "int64",
132 2], # lod_level is only used in fast decoder.
133 # The actual data shape of trg_pos is:
134 # [batch_size, max_trg_len_in_batch, 1]
135 "trg_pos": [(batch_size, seq_len, 1), "int64"],
136 # This input is used to remove attention weights on paddings and
137 # subsequent words in the decoder.
138 # The actual data shape of trg_slf_attn_bias is:
139 # [batch_size, n_head, max_trg_len_in_batch, max_trg_len_in_batch]
140 "trg_slf_attn_bias": [(batch_size, ModelHyperParams.n_head, seq_len,
141 seq_len), "float32"],
142 # This input is used to remove attention weights on paddings of the source
143 # input in the encoder-decoder attention.
144 # The actual data shape of trg_src_attn_bias is:
145 # [batch_size, n_head, max_trg_len_in_batch, max_src_len_in_batch]
146 "trg_src_attn_bias": [(batch_size, ModelHyperParams.n_head, seq_len,
147 seq_len), "float32"],
148 # This input is used in independent decoder program for inference.
149 # The actual data shape of enc_output is:
150 # [batch_size, max_src_len_in_batch, d_model]
151 "enc_output": [(batch_size, seq_len, ModelHyperParams.d_model), "float32"],
152 # The actual data shape of label_word is:
153 # [batch_size * max_trg_len_in_batch, 1]
154 "lbl_word": [(batch_size * seq_len, 1), "int64"],
155 # This input is used to mask out the loss of paddding tokens.
156 # The actual data shape of label_weight is:
157 # [batch_size * max_trg_len_in_batch, 1]
158 "lbl_weight": [(batch_size * seq_len, 1), "float32"],
159 # This input is used in beam-search decoder.
160 "init_score": [(batch_size, 1), "float32"],
161 }
162
163 # Names of word embedding table which might be reused for weight sharing.
164 word_emb_param_names = (
165 "src_word_emb_table",
166 "trg_word_emb_table", )
167 # Names of position encoding table which will be initialized externally.
168 pos_enc_param_names = (
169 "src_pos_enc_table",
170 "trg_pos_enc_table", )
171 # separated inputs for different usages.
172 encoder_data_input_fields = (
173 "src_word",
174 "src_pos",
175 "src_slf_attn_bias", )
176 decoder_data_input_fields = (
177 "trg_word",
178 "trg_pos",
179 "trg_slf_attn_bias",
180 "trg_src_attn_bias",
181 "enc_output", )
182 label_data_input_fields = (
183 "lbl_word",
184 "lbl_weight", )
185 # In fast decoder, trg_pos (only containing the current time step) is generated
186 # by ops and trg_slf_attn_bias is not needed.
187 fast_decoder_data_input_fields = (
188 "trg_word",
189 "init_score",
190 "trg_src_attn_bias", )
191
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/fluid/neural_machine_translation/transformer/config.py b/fluid/neural_machine_translation/transformer/config.py
--- a/fluid/neural_machine_translation/transformer/config.py
+++ b/fluid/neural_machine_translation/transformer/config.py
@@ -1,5 +1,5 @@
class TrainTaskConfig(object):
- # only support GPU currently
+ # support both CPU and GPU now.
use_gpu = True
# the epoch number to train.
pass_num = 30
|
{"golden_diff": "diff --git a/fluid/neural_machine_translation/transformer/config.py b/fluid/neural_machine_translation/transformer/config.py\n--- a/fluid/neural_machine_translation/transformer/config.py\n+++ b/fluid/neural_machine_translation/transformer/config.py\n@@ -1,5 +1,5 @@\n class TrainTaskConfig(object):\n- # only support GPU currently\n+ # support both CPU and GPU now.\n use_gpu = True\n # the epoch number to train.\n pass_num = 30\n", "issue": "will you support CPU training of Transformer?\nhttps://github.com/PaddlePaddle/models/blob/ff63e48f5dd71143d7108198e71a61cdaa0895d9/fluid/neural_machine_translation/transformer/config.py#L2\n", "before_files": [{"content": "class TrainTaskConfig(object):\n # only support GPU currently\n use_gpu = True\n # the epoch number to train.\n pass_num = 30\n # the number of sequences contained in a mini-batch.\n # deprecated, set batch_size in args.\n batch_size = 32\n # the hyper parameters for Adam optimizer.\n # This static learning_rate will be multiplied to the LearningRateScheduler\n # derived learning rate the to get the final learning rate.\n learning_rate = 1\n beta1 = 0.9\n beta2 = 0.98\n eps = 1e-9\n # the parameters for learning rate scheduling.\n warmup_steps = 4000\n # the weight used to mix up the ground-truth distribution and the fixed\n # uniform distribution in label smoothing when training.\n # Set this as zero if label smoothing is not wanted.\n label_smooth_eps = 0.1\n # the directory for saving trained models.\n model_dir = \"trained_models\"\n # the directory for saving checkpoints.\n ckpt_dir = \"trained_ckpts\"\n # the directory for loading checkpoint.\n # If provided, continue training from the checkpoint.\n ckpt_path = None\n # the parameter to initialize the learning rate scheduler.\n # It should be provided if use checkpoints, since the checkpoint doesn't\n # include the training step counter currently.\n start_step = 0\n\n\nclass InferTaskConfig(object):\n use_gpu = True\n # the number of examples in one run for sequence generation.\n batch_size = 10\n # the parameters for beam search.\n beam_size = 5\n max_out_len = 256\n # the number of decoded sentences to output.\n n_best = 1\n # the flags indicating whether to output the special tokens.\n output_bos = False\n output_eos = False\n output_unk = True\n # the directory for loading the trained model.\n model_path = \"trained_models/pass_1.infer.model\"\n\n\nclass ModelHyperParams(object):\n # These following five vocabularies related configurations will be set\n # automatically according to the passed vocabulary path and special tokens.\n # size of source word dictionary.\n src_vocab_size = 10000\n # size of target word dictionay\n trg_vocab_size = 10000\n # index for <bos> token\n bos_idx = 0\n # index for <eos> token\n eos_idx = 1\n # index for <unk> token\n unk_idx = 2\n # max length of sequences deciding the size of position encoding table.\n # Start from 1 and count start and end tokens in.\n max_length = 256\n # the dimension for word embeddings, which is also the last dimension of\n # the input and output of multi-head attention, position-wise feed-forward\n # networks, encoder and decoder.\n d_model = 512\n # size of the hidden layer in position-wise feed-forward networks.\n d_inner_hid = 2048\n # the dimension that keys are projected to for dot-product attention.\n d_key = 64\n # the dimension that values are projected to for dot-product attention.\n d_value = 64\n # number of head used in multi-head attention.\n n_head = 8\n # number of sub-layers to be stacked in the encoder and decoder.\n n_layer = 6\n # dropout rate used by all dropout layers.\n dropout = 0.1\n # random seed used in dropout for CE.\n dropout_seed = None\n # the flag indicating whether to share embedding and softmax weights.\n # vocabularies in source and target should be same for weight sharing.\n weight_sharing = True\n\n\ndef merge_cfg_from_list(cfg_list, g_cfgs):\n \"\"\"\n Set the above global configurations using the cfg_list. \n \"\"\"\n assert len(cfg_list) % 2 == 0\n for key, value in zip(cfg_list[0::2], cfg_list[1::2]):\n for g_cfg in g_cfgs:\n if hasattr(g_cfg, key):\n try:\n value = eval(value)\n except Exception: # for file path\n pass\n setattr(g_cfg, key, value)\n break\n\n\n# The placeholder for batch_size in compile time. Must be -1 currently to be\n# consistent with some ops' infer-shape output in compile time, such as the\n# sequence_expand op used in beamsearch decoder.\nbatch_size = -1\n# The placeholder for squence length in compile time.\nseq_len = ModelHyperParams.max_length\n# Here list the data shapes and data types of all inputs.\n# The shapes here act as placeholder and are set to pass the infer-shape in\n# compile time.\ninput_descs = {\n # The actual data shape of src_word is:\n # [batch_size, max_src_len_in_batch, 1]\n \"src_word\": [(batch_size, seq_len, 1), \"int64\", 2],\n # The actual data shape of src_pos is:\n # [batch_size, max_src_len_in_batch, 1]\n \"src_pos\": [(batch_size, seq_len, 1), \"int64\"],\n # This input is used to remove attention weights on paddings in the\n # encoder.\n # The actual data shape of src_slf_attn_bias is:\n # [batch_size, n_head, max_src_len_in_batch, max_src_len_in_batch]\n \"src_slf_attn_bias\": [(batch_size, ModelHyperParams.n_head, seq_len,\n seq_len), \"float32\"],\n # The actual data shape of trg_word is:\n # [batch_size, max_trg_len_in_batch, 1]\n \"trg_word\": [(batch_size, seq_len, 1), \"int64\",\n 2], # lod_level is only used in fast decoder.\n # The actual data shape of trg_pos is:\n # [batch_size, max_trg_len_in_batch, 1]\n \"trg_pos\": [(batch_size, seq_len, 1), \"int64\"],\n # This input is used to remove attention weights on paddings and\n # subsequent words in the decoder.\n # The actual data shape of trg_slf_attn_bias is:\n # [batch_size, n_head, max_trg_len_in_batch, max_trg_len_in_batch]\n \"trg_slf_attn_bias\": [(batch_size, ModelHyperParams.n_head, seq_len,\n seq_len), \"float32\"],\n # This input is used to remove attention weights on paddings of the source\n # input in the encoder-decoder attention.\n # The actual data shape of trg_src_attn_bias is:\n # [batch_size, n_head, max_trg_len_in_batch, max_src_len_in_batch]\n \"trg_src_attn_bias\": [(batch_size, ModelHyperParams.n_head, seq_len,\n seq_len), \"float32\"],\n # This input is used in independent decoder program for inference.\n # The actual data shape of enc_output is:\n # [batch_size, max_src_len_in_batch, d_model]\n \"enc_output\": [(batch_size, seq_len, ModelHyperParams.d_model), \"float32\"],\n # The actual data shape of label_word is:\n # [batch_size * max_trg_len_in_batch, 1]\n \"lbl_word\": [(batch_size * seq_len, 1), \"int64\"],\n # This input is used to mask out the loss of paddding tokens.\n # The actual data shape of label_weight is:\n # [batch_size * max_trg_len_in_batch, 1]\n \"lbl_weight\": [(batch_size * seq_len, 1), \"float32\"],\n # This input is used in beam-search decoder.\n \"init_score\": [(batch_size, 1), \"float32\"],\n}\n\n# Names of word embedding table which might be reused for weight sharing.\nword_emb_param_names = (\n \"src_word_emb_table\",\n \"trg_word_emb_table\", )\n# Names of position encoding table which will be initialized externally.\npos_enc_param_names = (\n \"src_pos_enc_table\",\n \"trg_pos_enc_table\", )\n# separated inputs for different usages.\nencoder_data_input_fields = (\n \"src_word\",\n \"src_pos\",\n \"src_slf_attn_bias\", )\ndecoder_data_input_fields = (\n \"trg_word\",\n \"trg_pos\",\n \"trg_slf_attn_bias\",\n \"trg_src_attn_bias\",\n \"enc_output\", )\nlabel_data_input_fields = (\n \"lbl_word\",\n \"lbl_weight\", )\n# In fast decoder, trg_pos (only containing the current time step) is generated\n# by ops and trg_slf_attn_bias is not needed.\nfast_decoder_data_input_fields = (\n \"trg_word\",\n \"init_score\",\n \"trg_src_attn_bias\", )\n", "path": "fluid/neural_machine_translation/transformer/config.py"}], "after_files": [{"content": "class TrainTaskConfig(object):\n # support both CPU and GPU now.\n use_gpu = True\n # the epoch number to train.\n pass_num = 30\n # the number of sequences contained in a mini-batch.\n # deprecated, set batch_size in args.\n batch_size = 32\n # the hyper parameters for Adam optimizer.\n # This static learning_rate will be multiplied to the LearningRateScheduler\n # derived learning rate the to get the final learning rate.\n learning_rate = 1\n beta1 = 0.9\n beta2 = 0.98\n eps = 1e-9\n # the parameters for learning rate scheduling.\n warmup_steps = 4000\n # the weight used to mix up the ground-truth distribution and the fixed\n # uniform distribution in label smoothing when training.\n # Set this as zero if label smoothing is not wanted.\n label_smooth_eps = 0.1\n # the directory for saving trained models.\n model_dir = \"trained_models\"\n # the directory for saving checkpoints.\n ckpt_dir = \"trained_ckpts\"\n # the directory for loading checkpoint.\n # If provided, continue training from the checkpoint.\n ckpt_path = None\n # the parameter to initialize the learning rate scheduler.\n # It should be provided if use checkpoints, since the checkpoint doesn't\n # include the training step counter currently.\n start_step = 0\n\n\nclass InferTaskConfig(object):\n use_gpu = True\n # the number of examples in one run for sequence generation.\n batch_size = 10\n # the parameters for beam search.\n beam_size = 5\n max_out_len = 256\n # the number of decoded sentences to output.\n n_best = 1\n # the flags indicating whether to output the special tokens.\n output_bos = False\n output_eos = False\n output_unk = True\n # the directory for loading the trained model.\n model_path = \"trained_models/pass_1.infer.model\"\n\n\nclass ModelHyperParams(object):\n # These following five vocabularies related configurations will be set\n # automatically according to the passed vocabulary path and special tokens.\n # size of source word dictionary.\n src_vocab_size = 10000\n # size of target word dictionay\n trg_vocab_size = 10000\n # index for <bos> token\n bos_idx = 0\n # index for <eos> token\n eos_idx = 1\n # index for <unk> token\n unk_idx = 2\n # max length of sequences deciding the size of position encoding table.\n # Start from 1 and count start and end tokens in.\n max_length = 256\n # the dimension for word embeddings, which is also the last dimension of\n # the input and output of multi-head attention, position-wise feed-forward\n # networks, encoder and decoder.\n d_model = 512\n # size of the hidden layer in position-wise feed-forward networks.\n d_inner_hid = 2048\n # the dimension that keys are projected to for dot-product attention.\n d_key = 64\n # the dimension that values are projected to for dot-product attention.\n d_value = 64\n # number of head used in multi-head attention.\n n_head = 8\n # number of sub-layers to be stacked in the encoder and decoder.\n n_layer = 6\n # dropout rate used by all dropout layers.\n dropout = 0.1\n # random seed used in dropout for CE.\n dropout_seed = None\n # the flag indicating whether to share embedding and softmax weights.\n # vocabularies in source and target should be same for weight sharing.\n weight_sharing = True\n\n\ndef merge_cfg_from_list(cfg_list, g_cfgs):\n \"\"\"\n Set the above global configurations using the cfg_list. \n \"\"\"\n assert len(cfg_list) % 2 == 0\n for key, value in zip(cfg_list[0::2], cfg_list[1::2]):\n for g_cfg in g_cfgs:\n if hasattr(g_cfg, key):\n try:\n value = eval(value)\n except Exception: # for file path\n pass\n setattr(g_cfg, key, value)\n break\n\n\n# The placeholder for batch_size in compile time. Must be -1 currently to be\n# consistent with some ops' infer-shape output in compile time, such as the\n# sequence_expand op used in beamsearch decoder.\nbatch_size = -1\n# The placeholder for squence length in compile time.\nseq_len = ModelHyperParams.max_length\n# Here list the data shapes and data types of all inputs.\n# The shapes here act as placeholder and are set to pass the infer-shape in\n# compile time.\ninput_descs = {\n # The actual data shape of src_word is:\n # [batch_size, max_src_len_in_batch, 1]\n \"src_word\": [(batch_size, seq_len, 1), \"int64\", 2],\n # The actual data shape of src_pos is:\n # [batch_size, max_src_len_in_batch, 1]\n \"src_pos\": [(batch_size, seq_len, 1), \"int64\"],\n # This input is used to remove attention weights on paddings in the\n # encoder.\n # The actual data shape of src_slf_attn_bias is:\n # [batch_size, n_head, max_src_len_in_batch, max_src_len_in_batch]\n \"src_slf_attn_bias\": [(batch_size, ModelHyperParams.n_head, seq_len,\n seq_len), \"float32\"],\n # The actual data shape of trg_word is:\n # [batch_size, max_trg_len_in_batch, 1]\n \"trg_word\": [(batch_size, seq_len, 1), \"int64\",\n 2], # lod_level is only used in fast decoder.\n # The actual data shape of trg_pos is:\n # [batch_size, max_trg_len_in_batch, 1]\n \"trg_pos\": [(batch_size, seq_len, 1), \"int64\"],\n # This input is used to remove attention weights on paddings and\n # subsequent words in the decoder.\n # The actual data shape of trg_slf_attn_bias is:\n # [batch_size, n_head, max_trg_len_in_batch, max_trg_len_in_batch]\n \"trg_slf_attn_bias\": [(batch_size, ModelHyperParams.n_head, seq_len,\n seq_len), \"float32\"],\n # This input is used to remove attention weights on paddings of the source\n # input in the encoder-decoder attention.\n # The actual data shape of trg_src_attn_bias is:\n # [batch_size, n_head, max_trg_len_in_batch, max_src_len_in_batch]\n \"trg_src_attn_bias\": [(batch_size, ModelHyperParams.n_head, seq_len,\n seq_len), \"float32\"],\n # This input is used in independent decoder program for inference.\n # The actual data shape of enc_output is:\n # [batch_size, max_src_len_in_batch, d_model]\n \"enc_output\": [(batch_size, seq_len, ModelHyperParams.d_model), \"float32\"],\n # The actual data shape of label_word is:\n # [batch_size * max_trg_len_in_batch, 1]\n \"lbl_word\": [(batch_size * seq_len, 1), \"int64\"],\n # This input is used to mask out the loss of paddding tokens.\n # The actual data shape of label_weight is:\n # [batch_size * max_trg_len_in_batch, 1]\n \"lbl_weight\": [(batch_size * seq_len, 1), \"float32\"],\n # This input is used in beam-search decoder.\n \"init_score\": [(batch_size, 1), \"float32\"],\n}\n\n# Names of word embedding table which might be reused for weight sharing.\nword_emb_param_names = (\n \"src_word_emb_table\",\n \"trg_word_emb_table\", )\n# Names of position encoding table which will be initialized externally.\npos_enc_param_names = (\n \"src_pos_enc_table\",\n \"trg_pos_enc_table\", )\n# separated inputs for different usages.\nencoder_data_input_fields = (\n \"src_word\",\n \"src_pos\",\n \"src_slf_attn_bias\", )\ndecoder_data_input_fields = (\n \"trg_word\",\n \"trg_pos\",\n \"trg_slf_attn_bias\",\n \"trg_src_attn_bias\",\n \"enc_output\", )\nlabel_data_input_fields = (\n \"lbl_word\",\n \"lbl_weight\", )\n# In fast decoder, trg_pos (only containing the current time step) is generated\n# by ops and trg_slf_attn_bias is not needed.\nfast_decoder_data_input_fields = (\n \"trg_word\",\n \"init_score\",\n \"trg_src_attn_bias\", )\n", "path": "fluid/neural_machine_translation/transformer/config.py"}]}
| 2,773 | 112 |
gh_patches_debug_26237
|
rasdani/github-patches
|
git_diff
|
netket__netket-212
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Get rid of netket::Ising and other hard-coded hamiltonians in c++
In the spirit of #199 , we can safely remove the Ising and Heisenberg hamiltonians from the C++ classes, since those are nothing but specific cases of more general hamiltonians (basically they are just LocalOperators or even GraphOperator).
Convenient constructors can be defined in few lines of python, and moved to the python part of the library.
The BoseHubbard hamiltonian is a bit trickier, we can keep it as it is for the moment.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `netket/operator.py`
Content:
```
1 from ._C_netket.operator import *
2
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/netket/operator.py b/netket/operator.py
--- a/netket/operator.py
+++ b/netket/operator.py
@@ -1 +1,52 @@
from ._C_netket.operator import *
+import numpy as _np
+
+
+def Ising(hilbert, h, J=1.0):
+ """
+ Constructs a new ``Ising`` given a hilbert space, a transverse field,
+ and (if specified) a coupling constant.
+
+ Args:
+ hilbert: Hilbert space the operator acts on.
+ h: The strength of the transverse field.
+ J: The strength of the coupling. Default is 1.0.
+
+ Examples:
+ Constructs an ``Ising`` operator for a 1D system.
+
+ ```python
+ >>> import netket as nk
+ >>> g = nk.graph.Hypercube(length=20, n_dim=1, pbc=True)
+ >>> hi = nk.hilbert.Spin(s=0.5, graph=g)
+ >>> op = nk.operator.Ising(h=1.321, hilbert=hi, J=0.5)
+ >>> print(op.hilbert.size)
+ 20
+ """
+ sigma_x = _np.array([[0, 1], [1, 0]])
+ sz_sz = _np.array([[1, 0, 0, 0], [0, -1, 0, 0], [0, 0, -1, 0], [0, 0, 0, 1]])
+ return GraphOperator(hilbert, siteops=[-h * sigma_x], bondops=[J * sz_sz])
+
+
+def Heisenberg(hilbert):
+ """
+ Constructs a new ``Heisenberg`` given a hilbert space.
+ Args:
+ hilbert: Hilbert space the operator acts on.
+ Examples:
+ Constructs a ``Heisenberg`` operator for a 1D system.
+ ```python
+ >>> import netket as nk
+ >>> g = nk.graph.Hypercube(length=20, n_dim=1, pbc=True)
+ >>> hi = nk.hilbert.Spin(s=0.5, total_sz=0, graph=g)
+ >>> op = nk.operator.Heisenberg(hilbert=hi)
+ >>> print(op.hilbert.size)
+ 20
+ """
+ sz_sz = _np.array([[1, 0, 0, 0], [0, -1, 0, 0], [0, 0, -1, 0], [0, 0, 0, 1]])
+ exchange = _np.array([[0, 0, 0, 0], [0, 0, 2, 0], [0, 2, 0, 0], [0, 0, 0, 0]])
+ if hilbert.graph.is_bipartite:
+ heis_term = sz_sz - exchange
+ else:
+ heis_term = sz_sz + exchange
+ return GraphOperator(hilbert, bondops=[heis_term])
|
{"golden_diff": "diff --git a/netket/operator.py b/netket/operator.py\n--- a/netket/operator.py\n+++ b/netket/operator.py\n@@ -1 +1,52 @@\n from ._C_netket.operator import *\n+import numpy as _np\n+\n+\n+def Ising(hilbert, h, J=1.0):\n+ \"\"\"\n+ Constructs a new ``Ising`` given a hilbert space, a transverse field,\n+ and (if specified) a coupling constant.\n+\n+ Args:\n+ hilbert: Hilbert space the operator acts on.\n+ h: The strength of the transverse field.\n+ J: The strength of the coupling. Default is 1.0.\n+\n+ Examples:\n+ Constructs an ``Ising`` operator for a 1D system.\n+\n+ ```python\n+ >>> import netket as nk\n+ >>> g = nk.graph.Hypercube(length=20, n_dim=1, pbc=True)\n+ >>> hi = nk.hilbert.Spin(s=0.5, graph=g)\n+ >>> op = nk.operator.Ising(h=1.321, hilbert=hi, J=0.5)\n+ >>> print(op.hilbert.size)\n+ 20\n+ \"\"\"\n+ sigma_x = _np.array([[0, 1], [1, 0]])\n+ sz_sz = _np.array([[1, 0, 0, 0], [0, -1, 0, 0], [0, 0, -1, 0], [0, 0, 0, 1]])\n+ return GraphOperator(hilbert, siteops=[-h * sigma_x], bondops=[J * sz_sz])\n+\n+\n+def Heisenberg(hilbert):\n+ \"\"\"\n+ Constructs a new ``Heisenberg`` given a hilbert space.\n+ Args:\n+ hilbert: Hilbert space the operator acts on.\n+ Examples:\n+ Constructs a ``Heisenberg`` operator for a 1D system.\n+ ```python\n+ >>> import netket as nk\n+ >>> g = nk.graph.Hypercube(length=20, n_dim=1, pbc=True)\n+ >>> hi = nk.hilbert.Spin(s=0.5, total_sz=0, graph=g)\n+ >>> op = nk.operator.Heisenberg(hilbert=hi)\n+ >>> print(op.hilbert.size)\n+ 20\n+ \"\"\"\n+ sz_sz = _np.array([[1, 0, 0, 0], [0, -1, 0, 0], [0, 0, -1, 0], [0, 0, 0, 1]])\n+ exchange = _np.array([[0, 0, 0, 0], [0, 0, 2, 0], [0, 2, 0, 0], [0, 0, 0, 0]])\n+ if hilbert.graph.is_bipartite:\n+ heis_term = sz_sz - exchange\n+ else:\n+ heis_term = sz_sz + exchange\n+ return GraphOperator(hilbert, bondops=[heis_term])\n", "issue": "Get rid of netket::Ising and other hard-coded hamiltonians in c++\nIn the spirit of #199 , we can safely remove the Ising and Heisenberg hamiltonians from the C++ classes, since those are nothing but specific cases of more general hamiltonians (basically they are just LocalOperators or even GraphOperator). \r\nConvenient constructors can be defined in few lines of python, and moved to the python part of the library. \r\n\r\nThe BoseHubbard hamiltonian is a bit trickier, we can keep it as it is for the moment. \n", "before_files": [{"content": "from ._C_netket.operator import *\n", "path": "netket/operator.py"}], "after_files": [{"content": "from ._C_netket.operator import *\nimport numpy as _np\n\n\ndef Ising(hilbert, h, J=1.0):\n \"\"\"\n Constructs a new ``Ising`` given a hilbert space, a transverse field,\n and (if specified) a coupling constant.\n\n Args:\n hilbert: Hilbert space the operator acts on.\n h: The strength of the transverse field.\n J: The strength of the coupling. Default is 1.0.\n\n Examples:\n Constructs an ``Ising`` operator for a 1D system.\n\n ```python\n >>> import netket as nk\n >>> g = nk.graph.Hypercube(length=20, n_dim=1, pbc=True)\n >>> hi = nk.hilbert.Spin(s=0.5, graph=g)\n >>> op = nk.operator.Ising(h=1.321, hilbert=hi, J=0.5)\n >>> print(op.hilbert.size)\n 20\n \"\"\"\n sigma_x = _np.array([[0, 1], [1, 0]])\n sz_sz = _np.array([[1, 0, 0, 0], [0, -1, 0, 0], [0, 0, -1, 0], [0, 0, 0, 1]])\n return GraphOperator(hilbert, siteops=[-h * sigma_x], bondops=[J * sz_sz])\n\n\ndef Heisenberg(hilbert):\n \"\"\"\n Constructs a new ``Heisenberg`` given a hilbert space.\n Args:\n hilbert: Hilbert space the operator acts on.\n Examples:\n Constructs a ``Heisenberg`` operator for a 1D system.\n ```python\n >>> import netket as nk\n >>> g = nk.graph.Hypercube(length=20, n_dim=1, pbc=True)\n >>> hi = nk.hilbert.Spin(s=0.5, total_sz=0, graph=g)\n >>> op = nk.operator.Heisenberg(hilbert=hi)\n >>> print(op.hilbert.size)\n 20\n \"\"\"\n sz_sz = _np.array([[1, 0, 0, 0], [0, -1, 0, 0], [0, 0, -1, 0], [0, 0, 0, 1]])\n exchange = _np.array([[0, 0, 0, 0], [0, 0, 2, 0], [0, 2, 0, 0], [0, 0, 0, 0]])\n if hilbert.graph.is_bipartite:\n heis_term = sz_sz - exchange\n else:\n heis_term = sz_sz + exchange\n return GraphOperator(hilbert, bondops=[heis_term])\n", "path": "netket/operator.py"}]}
| 390 | 711 |
gh_patches_debug_8929
|
rasdani/github-patches
|
git_diff
|
sbi-dev__sbi-1129
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
PyMC samplers failing on simple Gaussian example.
**Describe the bug**
We are using a simple Gaussian posterior example to test the MCMC methods. The new PyMC samplers are failing for this example, producing c2st around 0.85.
**To Reproduce**
Please add a minimal code example that reproduces the problem:
```bash
pytest tests/mcmc_test.py::test_c2st_pymc_sampler_on_Gaussian
```
**Expected behavior**
Test should pass.
**Additional context**
See discussion here: #1124
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sbi/samplers/mcmc/pymc_wrapper.py`
Content:
```
1 from typing import Any, Callable, Optional
2
3 import numpy as np
4 import pymc
5 import pytensor.tensor as pt
6 import torch
7 from arviz.data import InferenceData
8
9 from sbi.utils import tensor2numpy
10
11
12 class PyMCPotential(pt.Op): # type: ignore
13 """PyTensor Op wrapping a callable potential function"""
14
15 itypes = [pt.dvector] # expects a vector of parameter values when called
16 otypes = [
17 pt.dscalar,
18 pt.dvector,
19 ] # outputs a single scalar value (the potential) and gradients for every input
20 default_output = 0 # return only potential by default
21
22 def __init__(
23 self,
24 potential_fn: Callable,
25 device: str,
26 track_gradients: bool = True,
27 ):
28 """PyTensor Op wrapping a callable potential function for use
29 with PyMC samplers.
30
31 Args:
32 potential_fn: Potential function that returns a potential given parameters
33 device: The device to which to move the parameters before evaluation.
34 track_gradients: Whether to track gradients from potential function
35 """
36 self.potential_fn = potential_fn
37 self.device = device
38 self.track_gradients = track_gradients
39
40 def perform(self, node: Any, inputs: Any, outputs: Any) -> None:
41 """Compute potential and possibly gradients from input parameters
42
43 Args:
44 node: A "node" that represents the computation, handled internally
45 by PyTensor.
46 inputs: A sequence of inputs to the operation of type `itypes`. In this
47 case, the sequence will contain one array containing the
48 simulator parameters.
49 outputs: A sequence allocated for storing operation outputs. In this
50 case, the sequence will contain one scalar for the computed potential
51 and an array containing the gradient of the potential with respect
52 to the simulator parameters.
53 """
54 # unpack and handle inputs
55 params = inputs[0]
56 params = (
57 torch.tensor(params)
58 .to(device=self.device, dtype=torch.float32)
59 .requires_grad_(self.track_gradients)
60 )
61
62 # call the potential function
63 energy = self.potential_fn(params, track_gradients=self.track_gradients)
64
65 # output the log-likelihood
66 outputs[0][0] = tensor2numpy(energy).astype(np.float64)
67
68 # compute and record gradients if desired
69 if self.track_gradients:
70 energy.backward()
71 grads = params.grad
72 outputs[1][0] = tensor2numpy(grads).astype(np.float64)
73 else:
74 outputs[1][0] = np.zeros(params.shape, dtype=np.float64)
75
76 def grad(self, inputs: Any, output_grads: Any) -> list:
77 """Get gradients computed from `perform` and return Jacobian-Vector product
78
79 Args:
80 inputs: A sequence of inputs to the operation of type `itypes`. In this
81 case, the sequence will contain one array containing the
82 simulator parameters.
83 output_grads: A sequence of the gradients of the output variables. The first
84 element will be the gradient of the output of the whole computational
85 graph with respect to the output of this specific operation, i.e.,
86 the potential.
87
88 Returns:
89 A list containing the gradient of the output of the whole computational
90 graph with respect to the input of this operation, i.e.,
91 the simulator parameters.
92 """
93 # get outputs from forward pass (but doesn't re-compute it, I think...)
94 value = self(*inputs)
95 gradients = value.owner.outputs[1:] # type: ignore
96 # compute and return JVP
97 return [(output_grads[0] * grad) for grad in gradients]
98
99
100 class PyMCSampler:
101 """Interface for PyMC samplers"""
102
103 def __init__(
104 self,
105 potential_fn: Callable,
106 initvals: np.ndarray,
107 step: str = "nuts",
108 draws: int = 1000,
109 tune: int = 1000,
110 chains: Optional[int] = None,
111 mp_ctx: str = "spawn",
112 progressbar: bool = True,
113 param_name: str = "theta",
114 device: str = "cpu",
115 ):
116 """Interface for PyMC samplers
117
118 Args:
119 potential_fn: Potential function from density estimator.
120 initvals: Initial parameters.
121 step: One of `"slice"`, `"hmc"`, or `"nuts"`.
122 draws: Number of total samples to draw.
123 tune: Number of tuning steps to take.
124 chains: Number of MCMC chains to run in parallel.
125 mp_ctx: Multiprocessing context for parallel sampling.
126 progressbar: Whether to show/hide progress bars.
127 param_name: Name for parameter variable, for PyMC and ArviZ structures
128 device: The device to which to move the parameters for potential_fn.
129 """
130 self.param_name = param_name
131 self._step = step
132 self._draws = draws
133 self._tune = tune
134 self._initvals = [{self.param_name: iv} for iv in initvals]
135 self._chains = chains
136 self._mp_ctx = mp_ctx
137 self._progressbar = progressbar
138 self._device = device
139
140 # create PyMC model object
141 track_gradients = step in ("nuts", "hmc")
142 self._model = pymc.Model()
143 potential = PyMCPotential(
144 potential_fn, track_gradients=track_gradients, device=device
145 )
146 with self._model:
147 params = pymc.Normal(
148 self.param_name, mu=initvals.mean(axis=0)
149 ) # dummy prior
150 pymc.Potential("likelihood", potential(params)) # type: ignore
151
152 def run(self) -> np.ndarray:
153 """Run MCMC with PyMC
154
155 Returns:
156 MCMC samples
157 """
158 step_class = dict(slice=pymc.Slice, hmc=pymc.HamiltonianMC, nuts=pymc.NUTS)
159 with self._model:
160 inference_data = pymc.sample(
161 step=step_class[self._step](),
162 tune=self._tune,
163 draws=self._draws,
164 initvals=self._initvals, # type: ignore
165 chains=self._chains,
166 progressbar=self._progressbar,
167 mp_ctx=self._mp_ctx,
168 )
169 self._inference_data = inference_data
170 traces = inference_data.posterior # type: ignore
171 samples = getattr(traces, self.param_name).data
172 return samples
173
174 def get_samples(
175 self, num_samples: Optional[int] = None, group_by_chain: bool = True
176 ) -> np.ndarray:
177 """Returns samples from last call to self.run.
178
179 Raises ValueError if no samples have been generated yet.
180
181 Args:
182 num_samples: Number of samples to return (for each chain if grouped by
183 chain), if too large, all samples are returned (no error).
184 group_by_chain: Whether to return samples grouped by chain (chain x samples
185 x dim_params) or flattened (all_samples, dim_params).
186
187 Returns:
188 samples
189 """
190 if self._inference_data is None:
191 raise ValueError("No samples found from MCMC run.")
192 # if not grouped by chain, flatten samples into (all_samples, dim_params)
193 traces = self._inference_data.posterior # type: ignore
194 samples = getattr(traces, self.param_name).data
195 if not group_by_chain:
196 samples = samples.reshape(-1, samples.shape[-1])
197
198 # if not specified return all samples
199 if num_samples is None:
200 return samples
201 # otherwise return last num_samples (for each chain when grouped).
202 elif group_by_chain:
203 return samples[:, -num_samples:, :]
204 else:
205 return samples[-num_samples:, :]
206
207 def get_inference_data(self) -> InferenceData:
208 """Returns InferenceData from last call to self.run,
209 which contains diagnostic information in addition to samples
210
211 Raises ValueError if no samples have been generated yet.
212
213 Returns:
214 InferenceData containing samples and sampling run information
215 """
216 if self._inference_data is None:
217 raise ValueError("No samples found from MCMC run.")
218 return self._inference_data
219
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sbi/samplers/mcmc/pymc_wrapper.py b/sbi/samplers/mcmc/pymc_wrapper.py
--- a/sbi/samplers/mcmc/pymc_wrapper.py
+++ b/sbi/samplers/mcmc/pymc_wrapper.py
@@ -144,10 +144,9 @@
potential_fn, track_gradients=track_gradients, device=device
)
with self._model:
- params = pymc.Normal(
- self.param_name, mu=initvals.mean(axis=0)
- ) # dummy prior
- pymc.Potential("likelihood", potential(params)) # type: ignore
+ pymc.DensityDist(
+ self.param_name, logp=potential, size=(initvals.shape[-1],)
+ )
def run(self) -> np.ndarray:
"""Run MCMC with PyMC
|
{"golden_diff": "diff --git a/sbi/samplers/mcmc/pymc_wrapper.py b/sbi/samplers/mcmc/pymc_wrapper.py\n--- a/sbi/samplers/mcmc/pymc_wrapper.py\n+++ b/sbi/samplers/mcmc/pymc_wrapper.py\n@@ -144,10 +144,9 @@\n potential_fn, track_gradients=track_gradients, device=device\n )\n with self._model:\n- params = pymc.Normal(\n- self.param_name, mu=initvals.mean(axis=0)\n- ) # dummy prior\n- pymc.Potential(\"likelihood\", potential(params)) # type: ignore\n+ pymc.DensityDist(\n+ self.param_name, logp=potential, size=(initvals.shape[-1],)\n+ )\n \n def run(self) -> np.ndarray:\n \"\"\"Run MCMC with PyMC\n", "issue": "PyMC samplers failing on simple Gaussian example.\n**Describe the bug**\r\nWe are using a simple Gaussian posterior example to test the MCMC methods. The new PyMC samplers are failing for this example, producing c2st around 0.85. \r\n\r\n**To Reproduce**\r\nPlease add a minimal code example that reproduces the problem:\r\n```bash\r\npytest tests/mcmc_test.py::test_c2st_pymc_sampler_on_Gaussian\r\n```\r\n\r\n**Expected behavior**\r\nTest should pass. \r\n\r\n**Additional context**\r\nSee discussion here: #1124 \r\n\n", "before_files": [{"content": "from typing import Any, Callable, Optional\n\nimport numpy as np\nimport pymc\nimport pytensor.tensor as pt\nimport torch\nfrom arviz.data import InferenceData\n\nfrom sbi.utils import tensor2numpy\n\n\nclass PyMCPotential(pt.Op): # type: ignore\n \"\"\"PyTensor Op wrapping a callable potential function\"\"\"\n\n itypes = [pt.dvector] # expects a vector of parameter values when called\n otypes = [\n pt.dscalar,\n pt.dvector,\n ] # outputs a single scalar value (the potential) and gradients for every input\n default_output = 0 # return only potential by default\n\n def __init__(\n self,\n potential_fn: Callable,\n device: str,\n track_gradients: bool = True,\n ):\n \"\"\"PyTensor Op wrapping a callable potential function for use\n with PyMC samplers.\n\n Args:\n potential_fn: Potential function that returns a potential given parameters\n device: The device to which to move the parameters before evaluation.\n track_gradients: Whether to track gradients from potential function\n \"\"\"\n self.potential_fn = potential_fn\n self.device = device\n self.track_gradients = track_gradients\n\n def perform(self, node: Any, inputs: Any, outputs: Any) -> None:\n \"\"\"Compute potential and possibly gradients from input parameters\n\n Args:\n node: A \"node\" that represents the computation, handled internally\n by PyTensor.\n inputs: A sequence of inputs to the operation of type `itypes`. In this\n case, the sequence will contain one array containing the\n simulator parameters.\n outputs: A sequence allocated for storing operation outputs. In this\n case, the sequence will contain one scalar for the computed potential\n and an array containing the gradient of the potential with respect\n to the simulator parameters.\n \"\"\"\n # unpack and handle inputs\n params = inputs[0]\n params = (\n torch.tensor(params)\n .to(device=self.device, dtype=torch.float32)\n .requires_grad_(self.track_gradients)\n )\n\n # call the potential function\n energy = self.potential_fn(params, track_gradients=self.track_gradients)\n\n # output the log-likelihood\n outputs[0][0] = tensor2numpy(energy).astype(np.float64)\n\n # compute and record gradients if desired\n if self.track_gradients:\n energy.backward()\n grads = params.grad\n outputs[1][0] = tensor2numpy(grads).astype(np.float64)\n else:\n outputs[1][0] = np.zeros(params.shape, dtype=np.float64)\n\n def grad(self, inputs: Any, output_grads: Any) -> list:\n \"\"\"Get gradients computed from `perform` and return Jacobian-Vector product\n\n Args:\n inputs: A sequence of inputs to the operation of type `itypes`. In this\n case, the sequence will contain one array containing the\n simulator parameters.\n output_grads: A sequence of the gradients of the output variables. The first\n element will be the gradient of the output of the whole computational\n graph with respect to the output of this specific operation, i.e.,\n the potential.\n\n Returns:\n A list containing the gradient of the output of the whole computational\n graph with respect to the input of this operation, i.e.,\n the simulator parameters.\n \"\"\"\n # get outputs from forward pass (but doesn't re-compute it, I think...)\n value = self(*inputs)\n gradients = value.owner.outputs[1:] # type: ignore\n # compute and return JVP\n return [(output_grads[0] * grad) for grad in gradients]\n\n\nclass PyMCSampler:\n \"\"\"Interface for PyMC samplers\"\"\"\n\n def __init__(\n self,\n potential_fn: Callable,\n initvals: np.ndarray,\n step: str = \"nuts\",\n draws: int = 1000,\n tune: int = 1000,\n chains: Optional[int] = None,\n mp_ctx: str = \"spawn\",\n progressbar: bool = True,\n param_name: str = \"theta\",\n device: str = \"cpu\",\n ):\n \"\"\"Interface for PyMC samplers\n\n Args:\n potential_fn: Potential function from density estimator.\n initvals: Initial parameters.\n step: One of `\"slice\"`, `\"hmc\"`, or `\"nuts\"`.\n draws: Number of total samples to draw.\n tune: Number of tuning steps to take.\n chains: Number of MCMC chains to run in parallel.\n mp_ctx: Multiprocessing context for parallel sampling.\n progressbar: Whether to show/hide progress bars.\n param_name: Name for parameter variable, for PyMC and ArviZ structures\n device: The device to which to move the parameters for potential_fn.\n \"\"\"\n self.param_name = param_name\n self._step = step\n self._draws = draws\n self._tune = tune\n self._initvals = [{self.param_name: iv} for iv in initvals]\n self._chains = chains\n self._mp_ctx = mp_ctx\n self._progressbar = progressbar\n self._device = device\n\n # create PyMC model object\n track_gradients = step in (\"nuts\", \"hmc\")\n self._model = pymc.Model()\n potential = PyMCPotential(\n potential_fn, track_gradients=track_gradients, device=device\n )\n with self._model:\n params = pymc.Normal(\n self.param_name, mu=initvals.mean(axis=0)\n ) # dummy prior\n pymc.Potential(\"likelihood\", potential(params)) # type: ignore\n\n def run(self) -> np.ndarray:\n \"\"\"Run MCMC with PyMC\n\n Returns:\n MCMC samples\n \"\"\"\n step_class = dict(slice=pymc.Slice, hmc=pymc.HamiltonianMC, nuts=pymc.NUTS)\n with self._model:\n inference_data = pymc.sample(\n step=step_class[self._step](),\n tune=self._tune,\n draws=self._draws,\n initvals=self._initvals, # type: ignore\n chains=self._chains,\n progressbar=self._progressbar,\n mp_ctx=self._mp_ctx,\n )\n self._inference_data = inference_data\n traces = inference_data.posterior # type: ignore\n samples = getattr(traces, self.param_name).data\n return samples\n\n def get_samples(\n self, num_samples: Optional[int] = None, group_by_chain: bool = True\n ) -> np.ndarray:\n \"\"\"Returns samples from last call to self.run.\n\n Raises ValueError if no samples have been generated yet.\n\n Args:\n num_samples: Number of samples to return (for each chain if grouped by\n chain), if too large, all samples are returned (no error).\n group_by_chain: Whether to return samples grouped by chain (chain x samples\n x dim_params) or flattened (all_samples, dim_params).\n\n Returns:\n samples\n \"\"\"\n if self._inference_data is None:\n raise ValueError(\"No samples found from MCMC run.\")\n # if not grouped by chain, flatten samples into (all_samples, dim_params)\n traces = self._inference_data.posterior # type: ignore\n samples = getattr(traces, self.param_name).data\n if not group_by_chain:\n samples = samples.reshape(-1, samples.shape[-1])\n\n # if not specified return all samples\n if num_samples is None:\n return samples\n # otherwise return last num_samples (for each chain when grouped).\n elif group_by_chain:\n return samples[:, -num_samples:, :]\n else:\n return samples[-num_samples:, :]\n\n def get_inference_data(self) -> InferenceData:\n \"\"\"Returns InferenceData from last call to self.run,\n which contains diagnostic information in addition to samples\n\n Raises ValueError if no samples have been generated yet.\n\n Returns:\n InferenceData containing samples and sampling run information\n \"\"\"\n if self._inference_data is None:\n raise ValueError(\"No samples found from MCMC run.\")\n return self._inference_data\n", "path": "sbi/samplers/mcmc/pymc_wrapper.py"}], "after_files": [{"content": "from typing import Any, Callable, Optional\n\nimport numpy as np\nimport pymc\nimport pytensor.tensor as pt\nimport torch\nfrom arviz.data import InferenceData\n\nfrom sbi.utils import tensor2numpy\n\n\nclass PyMCPotential(pt.Op): # type: ignore\n \"\"\"PyTensor Op wrapping a callable potential function\"\"\"\n\n itypes = [pt.dvector] # expects a vector of parameter values when called\n otypes = [\n pt.dscalar,\n pt.dvector,\n ] # outputs a single scalar value (the potential) and gradients for every input\n default_output = 0 # return only potential by default\n\n def __init__(\n self,\n potential_fn: Callable,\n device: str,\n track_gradients: bool = True,\n ):\n \"\"\"PyTensor Op wrapping a callable potential function for use\n with PyMC samplers.\n\n Args:\n potential_fn: Potential function that returns a potential given parameters\n device: The device to which to move the parameters before evaluation.\n track_gradients: Whether to track gradients from potential function\n \"\"\"\n self.potential_fn = potential_fn\n self.device = device\n self.track_gradients = track_gradients\n\n def perform(self, node: Any, inputs: Any, outputs: Any) -> None:\n \"\"\"Compute potential and possibly gradients from input parameters\n\n Args:\n node: A \"node\" that represents the computation, handled internally\n by PyTensor.\n inputs: A sequence of inputs to the operation of type `itypes`. In this\n case, the sequence will contain one array containing the\n simulator parameters.\n outputs: A sequence allocated for storing operation outputs. In this\n case, the sequence will contain one scalar for the computed potential\n and an array containing the gradient of the potential with respect\n to the simulator parameters.\n \"\"\"\n # unpack and handle inputs\n params = inputs[0]\n params = (\n torch.tensor(params)\n .to(device=self.device, dtype=torch.float32)\n .requires_grad_(self.track_gradients)\n )\n\n # call the potential function\n energy = self.potential_fn(params, track_gradients=self.track_gradients)\n\n # output the log-likelihood\n outputs[0][0] = tensor2numpy(energy).astype(np.float64)\n\n # compute and record gradients if desired\n if self.track_gradients:\n energy.backward()\n grads = params.grad\n outputs[1][0] = tensor2numpy(grads).astype(np.float64)\n else:\n outputs[1][0] = np.zeros(params.shape, dtype=np.float64)\n\n def grad(self, inputs: Any, output_grads: Any) -> list:\n \"\"\"Get gradients computed from `perform` and return Jacobian-Vector product\n\n Args:\n inputs: A sequence of inputs to the operation of type `itypes`. In this\n case, the sequence will contain one array containing the\n simulator parameters.\n output_grads: A sequence of the gradients of the output variables. The first\n element will be the gradient of the output of the whole computational\n graph with respect to the output of this specific operation, i.e.,\n the potential.\n\n Returns:\n A list containing the gradient of the output of the whole computational\n graph with respect to the input of this operation, i.e.,\n the simulator parameters.\n \"\"\"\n # get outputs from forward pass (but doesn't re-compute it, I think...)\n value = self(*inputs)\n gradients = value.owner.outputs[1:] # type: ignore\n # compute and return JVP\n return [(output_grads[0] * grad) for grad in gradients]\n\n\nclass PyMCSampler:\n \"\"\"Interface for PyMC samplers\"\"\"\n\n def __init__(\n self,\n potential_fn: Callable,\n initvals: np.ndarray,\n step: str = \"nuts\",\n draws: int = 1000,\n tune: int = 1000,\n chains: Optional[int] = None,\n mp_ctx: str = \"spawn\",\n progressbar: bool = True,\n param_name: str = \"theta\",\n device: str = \"cpu\",\n ):\n \"\"\"Interface for PyMC samplers\n\n Args:\n potential_fn: Potential function from density estimator.\n initvals: Initial parameters.\n step: One of `\"slice\"`, `\"hmc\"`, or `\"nuts\"`.\n draws: Number of total samples to draw.\n tune: Number of tuning steps to take.\n chains: Number of MCMC chains to run in parallel.\n mp_ctx: Multiprocessing context for parallel sampling.\n progressbar: Whether to show/hide progress bars.\n param_name: Name for parameter variable, for PyMC and ArviZ structures\n device: The device to which to move the parameters for potential_fn.\n \"\"\"\n self.param_name = param_name\n self._step = step\n self._draws = draws\n self._tune = tune\n self._initvals = [{self.param_name: iv} for iv in initvals]\n self._chains = chains\n self._mp_ctx = mp_ctx\n self._progressbar = progressbar\n self._device = device\n\n # create PyMC model object\n track_gradients = step in (\"nuts\", \"hmc\")\n self._model = pymc.Model()\n potential = PyMCPotential(\n potential_fn, track_gradients=track_gradients, device=device\n )\n with self._model:\n pymc.DensityDist(\n self.param_name, logp=potential, size=(initvals.shape[-1],)\n )\n\n def run(self) -> np.ndarray:\n \"\"\"Run MCMC with PyMC\n\n Returns:\n MCMC samples\n \"\"\"\n step_class = dict(slice=pymc.Slice, hmc=pymc.HamiltonianMC, nuts=pymc.NUTS)\n with self._model:\n inference_data = pymc.sample(\n step=step_class[self._step](),\n tune=self._tune,\n draws=self._draws,\n initvals=self._initvals, # type: ignore\n chains=self._chains,\n progressbar=self._progressbar,\n mp_ctx=self._mp_ctx,\n )\n self._inference_data = inference_data\n traces = inference_data.posterior # type: ignore\n samples = getattr(traces, self.param_name).data\n return samples\n\n def get_samples(\n self, num_samples: Optional[int] = None, group_by_chain: bool = True\n ) -> np.ndarray:\n \"\"\"Returns samples from last call to self.run.\n\n Raises ValueError if no samples have been generated yet.\n\n Args:\n num_samples: Number of samples to return (for each chain if grouped by\n chain), if too large, all samples are returned (no error).\n group_by_chain: Whether to return samples grouped by chain (chain x samples\n x dim_params) or flattened (all_samples, dim_params).\n\n Returns:\n samples\n \"\"\"\n if self._inference_data is None:\n raise ValueError(\"No samples found from MCMC run.\")\n # if not grouped by chain, flatten samples into (all_samples, dim_params)\n traces = self._inference_data.posterior # type: ignore\n samples = getattr(traces, self.param_name).data\n if not group_by_chain:\n samples = samples.reshape(-1, samples.shape[-1])\n\n # if not specified return all samples\n if num_samples is None:\n return samples\n # otherwise return last num_samples (for each chain when grouped).\n elif group_by_chain:\n return samples[:, -num_samples:, :]\n else:\n return samples[-num_samples:, :]\n\n def get_inference_data(self) -> InferenceData:\n \"\"\"Returns InferenceData from last call to self.run,\n which contains diagnostic information in addition to samples\n\n Raises ValueError if no samples have been generated yet.\n\n Returns:\n InferenceData containing samples and sampling run information\n \"\"\"\n if self._inference_data is None:\n raise ValueError(\"No samples found from MCMC run.\")\n return self._inference_data\n", "path": "sbi/samplers/mcmc/pymc_wrapper.py"}]}
| 2,738 | 198 |
gh_patches_debug_3555
|
rasdani/github-patches
|
git_diff
|
joke2k__faker-1137
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pydict(variable_nb_elements=False) returns dicts with varying number of elements
* Faker version: 4.0.1
* OS: OS X 10.15.3
pydict with `variable_nb_elements=False` still has varying number of elements.
### Steps to reproduce
```
from faker import Faker
fake = Faker()
nb = 80
for _ in range(30): # nb is large and the faker function is called 30 times to increase the probability of reproducing the bug.
fake_dict = fake.pydict(nb_elements=nb, variable_nb_elements=False)
nb_reality = len(fake_dict)
if nb_reality != nb:
print(nb_reality)
```
### Expected behavior
The length of the dictionary should always be `nb`.
### Actual behavior
It is often shorter as the keys are generated with [`self.generator.words(nb_elements)`](https://github.com/joke2k/faker/blob/master/faker/providers/python/__init__.py#L166). If the keys are not unique, the element is dropped.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `faker/providers/python/__init__.py`
Content:
```
1 import string
2 import sys
3
4 from decimal import Decimal
5
6 from .. import BaseProvider
7
8
9 class Provider(BaseProvider):
10 def pybool(self):
11 return self.random_int(0, 1) == 1
12
13 def pystr(self, min_chars=None, max_chars=20):
14 """
15 Generates a random string of upper and lowercase letters.
16 :type min_chars: int
17 :type max_chars: int
18 :return: String. Random of random length between min and max characters.
19 """
20 if min_chars is None:
21 return "".join(self.random_letters(length=max_chars))
22 else:
23 assert (
24 max_chars >= min_chars), "Maximum length must be greater than or equal to minium length"
25 return "".join(
26 self.random_letters(
27 length=self.generator.random.randint(min_chars, max_chars),
28 ),
29 )
30
31 def pystr_format(self, string_format='?#-###{{random_int}}{{random_letter}}', letters=string.ascii_letters):
32 return self.bothify(self.generator.parse(string_format), letters=letters)
33
34 def pyfloat(self, left_digits=None, right_digits=None, positive=False,
35 min_value=None, max_value=None):
36 if left_digits is not None and left_digits < 0:
37 raise ValueError(
38 'A float number cannot have less than 0 digits in its '
39 'integer part')
40 if right_digits is not None and right_digits < 0:
41 raise ValueError(
42 'A float number cannot have less than 0 digits in its '
43 'fractional part')
44 if left_digits == 0 and right_digits == 0:
45 raise ValueError(
46 'A float number cannot have less than 0 digits in total')
47 if None not in (min_value, max_value) and min_value > max_value:
48 raise ValueError('Min value cannot be greater than max value')
49 if None not in (min_value, max_value) and min_value == max_value:
50 raise ValueError('Min and max value cannot be the same')
51
52 left_digits = left_digits if left_digits is not None else (
53 self.random_int(1, sys.float_info.dig))
54 right_digits = right_digits if right_digits is not None else (
55 self.random_int(0, sys.float_info.dig - left_digits))
56 sign = ''
57 if (min_value is not None) or (max_value is not None):
58 if max_value is not None and max_value < 0:
59 max_value += 1 # as the random_int will be generated up to max_value - 1
60 if min_value is not None and min_value < 0:
61 min_value += 1 # as we then append digits after the left_number
62 left_number = self._safe_random_int(min_value, max_value)
63 else:
64 sign = '+' if positive else self.random_element(('+', '-'))
65 left_number = self.random_number(left_digits)
66
67 return float("{}{}.{}".format(
68 sign,
69 left_number,
70 self.random_number(right_digits),
71 ))
72
73 def _safe_random_int(self, min_value, max_value):
74 orig_min_value = min_value
75 orig_max_value = max_value
76
77 if min_value is None:
78 min_value = max_value - self.random_int()
79 if max_value is None:
80 max_value = min_value + self.random_int()
81 if min_value == max_value:
82 return self._safe_random_int(orig_min_value, orig_max_value)
83 else:
84 return self.random_int(min_value, max_value - 1)
85
86 def pyint(self, min_value=0, max_value=9999, step=1):
87 return self.generator.random_int(min_value, max_value, step=step)
88
89 def pydecimal(self, left_digits=None, right_digits=None, positive=False,
90 min_value=None, max_value=None):
91
92 float_ = self.pyfloat(
93 left_digits, right_digits, positive, min_value, max_value)
94 return Decimal(str(float_))
95
96 def pytuple(self, nb_elements=10, variable_nb_elements=True, *value_types):
97 return tuple(
98 self.pyset(
99 nb_elements,
100 variable_nb_elements,
101 *value_types))
102
103 def pyset(self, nb_elements=10, variable_nb_elements=True, *value_types):
104 return set(
105 self._pyiterable(
106 nb_elements,
107 variable_nb_elements,
108 *value_types))
109
110 def pylist(self, nb_elements=10, variable_nb_elements=True, *value_types):
111 return list(
112 self._pyiterable(
113 nb_elements,
114 variable_nb_elements,
115 *value_types))
116
117 def pyiterable(
118 self,
119 nb_elements=10,
120 variable_nb_elements=True,
121 *value_types):
122 return self.random_element([self.pylist, self.pytuple, self.pyset])(
123 nb_elements, variable_nb_elements, *value_types)
124
125 def _random_type(self, type_list):
126 value_type = self.random_element(type_list)
127
128 method_name = "py{}".format(value_type)
129 if hasattr(self, method_name):
130 value_type = method_name
131
132 return self.generator.format(value_type)
133
134 def _pyiterable(
135 self,
136 nb_elements=10,
137 variable_nb_elements=True,
138 *value_types):
139
140 value_types = [t if isinstance(t, str) else getattr(t, '__name__', type(t).__name__).lower()
141 for t in value_types
142 # avoid recursion
143 if t not in ['iterable', 'list', 'tuple', 'dict', 'set']]
144 if not value_types:
145 value_types = ['str', 'str', 'str', 'str', 'float',
146 'int', 'int', 'decimal', 'date_time', 'uri', 'email']
147
148 if variable_nb_elements:
149 nb_elements = self.randomize_nb_elements(nb_elements, min=1)
150
151 for _ in range(nb_elements):
152 yield self._random_type(value_types)
153
154 def pydict(self, nb_elements=10, variable_nb_elements=True, *value_types):
155 """
156 Returns a dictionary.
157
158 :nb_elements: number of elements for dictionary
159 :variable_nb_elements: is use variable number of elements for dictionary
160 :value_types: type of dictionary values
161 """
162 if variable_nb_elements:
163 nb_elements = self.randomize_nb_elements(nb_elements, min=1)
164
165 return dict(zip(
166 self.generator.words(nb_elements),
167 self._pyiterable(nb_elements, False, *value_types),
168 ))
169
170 def pystruct(self, count=10, *value_types):
171
172 value_types = [t if isinstance(t, str) else getattr(t, '__name__', type(t).__name__).lower()
173 for t in value_types
174 # avoid recursion
175 if t != 'struct']
176 if not value_types:
177 value_types = ['str', 'str', 'str', 'str', 'float',
178 'int', 'int', 'decimal', 'date_time', 'uri', 'email']
179
180 types = []
181 d = {}
182 nd = {}
183 for i in range(count):
184 d[self.generator.word()] = self._random_type(value_types)
185 types.append(self._random_type(value_types))
186 nd[self.generator.word()] = {i: self._random_type(value_types),
187 i + 1: [self._random_type(value_types),
188 self._random_type(value_types),
189 self._random_type(value_types)],
190 i + 2: {i: self._random_type(value_types),
191 i + 1: self._random_type(value_types),
192 i + 2: [self._random_type(value_types),
193 self._random_type(value_types)]}}
194 return types, d, nd
195
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/faker/providers/python/__init__.py b/faker/providers/python/__init__.py
--- a/faker/providers/python/__init__.py
+++ b/faker/providers/python/__init__.py
@@ -163,7 +163,7 @@
nb_elements = self.randomize_nb_elements(nb_elements, min=1)
return dict(zip(
- self.generator.words(nb_elements),
+ self.generator.words(nb_elements, unique=True),
self._pyiterable(nb_elements, False, *value_types),
))
|
{"golden_diff": "diff --git a/faker/providers/python/__init__.py b/faker/providers/python/__init__.py\n--- a/faker/providers/python/__init__.py\n+++ b/faker/providers/python/__init__.py\n@@ -163,7 +163,7 @@\n nb_elements = self.randomize_nb_elements(nb_elements, min=1)\n \n return dict(zip(\n- self.generator.words(nb_elements),\n+ self.generator.words(nb_elements, unique=True),\n self._pyiterable(nb_elements, False, *value_types),\n ))\n", "issue": "pydict(variable_nb_elements=False) returns dicts with varying number of elements\n* Faker version: 4.0.1\r\n* OS: OS X 10.15.3\r\n\r\npydict with `variable_nb_elements=False` still has varying number of elements.\r\n\r\n### Steps to reproduce\r\n\r\n```\r\nfrom faker import Faker\r\n\r\nfake = Faker()\r\n\r\nnb = 80\r\nfor _ in range(30): # nb is large and the faker function is called 30 times to increase the probability of reproducing the bug.\r\n fake_dict = fake.pydict(nb_elements=nb, variable_nb_elements=False)\r\n nb_reality = len(fake_dict)\r\n if nb_reality != nb:\r\n print(nb_reality)\r\n```\r\n\r\n### Expected behavior\r\n\r\nThe length of the dictionary should always be `nb`. \r\n\r\n### Actual behavior\r\n\r\nIt is often shorter as the keys are generated with [`self.generator.words(nb_elements)`](https://github.com/joke2k/faker/blob/master/faker/providers/python/__init__.py#L166). If the keys are not unique, the element is dropped.\r\n\n", "before_files": [{"content": "import string\nimport sys\n\nfrom decimal import Decimal\n\nfrom .. import BaseProvider\n\n\nclass Provider(BaseProvider):\n def pybool(self):\n return self.random_int(0, 1) == 1\n\n def pystr(self, min_chars=None, max_chars=20):\n \"\"\"\n Generates a random string of upper and lowercase letters.\n :type min_chars: int\n :type max_chars: int\n :return: String. Random of random length between min and max characters.\n \"\"\"\n if min_chars is None:\n return \"\".join(self.random_letters(length=max_chars))\n else:\n assert (\n max_chars >= min_chars), \"Maximum length must be greater than or equal to minium length\"\n return \"\".join(\n self.random_letters(\n length=self.generator.random.randint(min_chars, max_chars),\n ),\n )\n\n def pystr_format(self, string_format='?#-###{{random_int}}{{random_letter}}', letters=string.ascii_letters):\n return self.bothify(self.generator.parse(string_format), letters=letters)\n\n def pyfloat(self, left_digits=None, right_digits=None, positive=False,\n min_value=None, max_value=None):\n if left_digits is not None and left_digits < 0:\n raise ValueError(\n 'A float number cannot have less than 0 digits in its '\n 'integer part')\n if right_digits is not None and right_digits < 0:\n raise ValueError(\n 'A float number cannot have less than 0 digits in its '\n 'fractional part')\n if left_digits == 0 and right_digits == 0:\n raise ValueError(\n 'A float number cannot have less than 0 digits in total')\n if None not in (min_value, max_value) and min_value > max_value:\n raise ValueError('Min value cannot be greater than max value')\n if None not in (min_value, max_value) and min_value == max_value:\n raise ValueError('Min and max value cannot be the same')\n\n left_digits = left_digits if left_digits is not None else (\n self.random_int(1, sys.float_info.dig))\n right_digits = right_digits if right_digits is not None else (\n self.random_int(0, sys.float_info.dig - left_digits))\n sign = ''\n if (min_value is not None) or (max_value is not None):\n if max_value is not None and max_value < 0:\n max_value += 1 # as the random_int will be generated up to max_value - 1\n if min_value is not None and min_value < 0:\n min_value += 1 # as we then append digits after the left_number\n left_number = self._safe_random_int(min_value, max_value)\n else:\n sign = '+' if positive else self.random_element(('+', '-'))\n left_number = self.random_number(left_digits)\n\n return float(\"{}{}.{}\".format(\n sign,\n left_number,\n self.random_number(right_digits),\n ))\n\n def _safe_random_int(self, min_value, max_value):\n orig_min_value = min_value\n orig_max_value = max_value\n\n if min_value is None:\n min_value = max_value - self.random_int()\n if max_value is None:\n max_value = min_value + self.random_int()\n if min_value == max_value:\n return self._safe_random_int(orig_min_value, orig_max_value)\n else:\n return self.random_int(min_value, max_value - 1)\n\n def pyint(self, min_value=0, max_value=9999, step=1):\n return self.generator.random_int(min_value, max_value, step=step)\n\n def pydecimal(self, left_digits=None, right_digits=None, positive=False,\n min_value=None, max_value=None):\n\n float_ = self.pyfloat(\n left_digits, right_digits, positive, min_value, max_value)\n return Decimal(str(float_))\n\n def pytuple(self, nb_elements=10, variable_nb_elements=True, *value_types):\n return tuple(\n self.pyset(\n nb_elements,\n variable_nb_elements,\n *value_types))\n\n def pyset(self, nb_elements=10, variable_nb_elements=True, *value_types):\n return set(\n self._pyiterable(\n nb_elements,\n variable_nb_elements,\n *value_types))\n\n def pylist(self, nb_elements=10, variable_nb_elements=True, *value_types):\n return list(\n self._pyiterable(\n nb_elements,\n variable_nb_elements,\n *value_types))\n\n def pyiterable(\n self,\n nb_elements=10,\n variable_nb_elements=True,\n *value_types):\n return self.random_element([self.pylist, self.pytuple, self.pyset])(\n nb_elements, variable_nb_elements, *value_types)\n\n def _random_type(self, type_list):\n value_type = self.random_element(type_list)\n\n method_name = \"py{}\".format(value_type)\n if hasattr(self, method_name):\n value_type = method_name\n\n return self.generator.format(value_type)\n\n def _pyiterable(\n self,\n nb_elements=10,\n variable_nb_elements=True,\n *value_types):\n\n value_types = [t if isinstance(t, str) else getattr(t, '__name__', type(t).__name__).lower()\n for t in value_types\n # avoid recursion\n if t not in ['iterable', 'list', 'tuple', 'dict', 'set']]\n if not value_types:\n value_types = ['str', 'str', 'str', 'str', 'float',\n 'int', 'int', 'decimal', 'date_time', 'uri', 'email']\n\n if variable_nb_elements:\n nb_elements = self.randomize_nb_elements(nb_elements, min=1)\n\n for _ in range(nb_elements):\n yield self._random_type(value_types)\n\n def pydict(self, nb_elements=10, variable_nb_elements=True, *value_types):\n \"\"\"\n Returns a dictionary.\n\n :nb_elements: number of elements for dictionary\n :variable_nb_elements: is use variable number of elements for dictionary\n :value_types: type of dictionary values\n \"\"\"\n if variable_nb_elements:\n nb_elements = self.randomize_nb_elements(nb_elements, min=1)\n\n return dict(zip(\n self.generator.words(nb_elements),\n self._pyiterable(nb_elements, False, *value_types),\n ))\n\n def pystruct(self, count=10, *value_types):\n\n value_types = [t if isinstance(t, str) else getattr(t, '__name__', type(t).__name__).lower()\n for t in value_types\n # avoid recursion\n if t != 'struct']\n if not value_types:\n value_types = ['str', 'str', 'str', 'str', 'float',\n 'int', 'int', 'decimal', 'date_time', 'uri', 'email']\n\n types = []\n d = {}\n nd = {}\n for i in range(count):\n d[self.generator.word()] = self._random_type(value_types)\n types.append(self._random_type(value_types))\n nd[self.generator.word()] = {i: self._random_type(value_types),\n i + 1: [self._random_type(value_types),\n self._random_type(value_types),\n self._random_type(value_types)],\n i + 2: {i: self._random_type(value_types),\n i + 1: self._random_type(value_types),\n i + 2: [self._random_type(value_types),\n self._random_type(value_types)]}}\n return types, d, nd\n", "path": "faker/providers/python/__init__.py"}], "after_files": [{"content": "import string\nimport sys\n\nfrom decimal import Decimal\n\nfrom .. import BaseProvider\n\n\nclass Provider(BaseProvider):\n def pybool(self):\n return self.random_int(0, 1) == 1\n\n def pystr(self, min_chars=None, max_chars=20):\n \"\"\"\n Generates a random string of upper and lowercase letters.\n :type min_chars: int\n :type max_chars: int\n :return: String. Random of random length between min and max characters.\n \"\"\"\n if min_chars is None:\n return \"\".join(self.random_letters(length=max_chars))\n else:\n assert (\n max_chars >= min_chars), \"Maximum length must be greater than or equal to minium length\"\n return \"\".join(\n self.random_letters(\n length=self.generator.random.randint(min_chars, max_chars),\n ),\n )\n\n def pystr_format(self, string_format='?#-###{{random_int}}{{random_letter}}', letters=string.ascii_letters):\n return self.bothify(self.generator.parse(string_format), letters=letters)\n\n def pyfloat(self, left_digits=None, right_digits=None, positive=False,\n min_value=None, max_value=None):\n if left_digits is not None and left_digits < 0:\n raise ValueError(\n 'A float number cannot have less than 0 digits in its '\n 'integer part')\n if right_digits is not None and right_digits < 0:\n raise ValueError(\n 'A float number cannot have less than 0 digits in its '\n 'fractional part')\n if left_digits == 0 and right_digits == 0:\n raise ValueError(\n 'A float number cannot have less than 0 digits in total')\n if None not in (min_value, max_value) and min_value > max_value:\n raise ValueError('Min value cannot be greater than max value')\n if None not in (min_value, max_value) and min_value == max_value:\n raise ValueError('Min and max value cannot be the same')\n\n left_digits = left_digits if left_digits is not None else (\n self.random_int(1, sys.float_info.dig))\n right_digits = right_digits if right_digits is not None else (\n self.random_int(0, sys.float_info.dig - left_digits))\n sign = ''\n if (min_value is not None) or (max_value is not None):\n if max_value is not None and max_value < 0:\n max_value += 1 # as the random_int will be generated up to max_value - 1\n if min_value is not None and min_value < 0:\n min_value += 1 # as we then append digits after the left_number\n left_number = self._safe_random_int(min_value, max_value)\n else:\n sign = '+' if positive else self.random_element(('+', '-'))\n left_number = self.random_number(left_digits)\n\n return float(\"{}{}.{}\".format(\n sign,\n left_number,\n self.random_number(right_digits),\n ))\n\n def _safe_random_int(self, min_value, max_value):\n orig_min_value = min_value\n orig_max_value = max_value\n\n if min_value is None:\n min_value = max_value - self.random_int()\n if max_value is None:\n max_value = min_value + self.random_int()\n if min_value == max_value:\n return self._safe_random_int(orig_min_value, orig_max_value)\n else:\n return self.random_int(min_value, max_value - 1)\n\n def pyint(self, min_value=0, max_value=9999, step=1):\n return self.generator.random_int(min_value, max_value, step=step)\n\n def pydecimal(self, left_digits=None, right_digits=None, positive=False,\n min_value=None, max_value=None):\n\n float_ = self.pyfloat(\n left_digits, right_digits, positive, min_value, max_value)\n return Decimal(str(float_))\n\n def pytuple(self, nb_elements=10, variable_nb_elements=True, *value_types):\n return tuple(\n self.pyset(\n nb_elements,\n variable_nb_elements,\n *value_types))\n\n def pyset(self, nb_elements=10, variable_nb_elements=True, *value_types):\n return set(\n self._pyiterable(\n nb_elements,\n variable_nb_elements,\n *value_types))\n\n def pylist(self, nb_elements=10, variable_nb_elements=True, *value_types):\n return list(\n self._pyiterable(\n nb_elements,\n variable_nb_elements,\n *value_types))\n\n def pyiterable(\n self,\n nb_elements=10,\n variable_nb_elements=True,\n *value_types):\n return self.random_element([self.pylist, self.pytuple, self.pyset])(\n nb_elements, variable_nb_elements, *value_types)\n\n def _random_type(self, type_list):\n value_type = self.random_element(type_list)\n\n method_name = \"py{}\".format(value_type)\n if hasattr(self, method_name):\n value_type = method_name\n\n return self.generator.format(value_type)\n\n def _pyiterable(\n self,\n nb_elements=10,\n variable_nb_elements=True,\n *value_types):\n\n value_types = [t if isinstance(t, str) else getattr(t, '__name__', type(t).__name__).lower()\n for t in value_types\n # avoid recursion\n if t not in ['iterable', 'list', 'tuple', 'dict', 'set']]\n if not value_types:\n value_types = ['str', 'str', 'str', 'str', 'float',\n 'int', 'int', 'decimal', 'date_time', 'uri', 'email']\n\n if variable_nb_elements:\n nb_elements = self.randomize_nb_elements(nb_elements, min=1)\n\n for _ in range(nb_elements):\n yield self._random_type(value_types)\n\n def pydict(self, nb_elements=10, variable_nb_elements=True, *value_types):\n \"\"\"\n Returns a dictionary.\n\n :nb_elements: number of elements for dictionary\n :variable_nb_elements: is use variable number of elements for dictionary\n :value_types: type of dictionary values\n \"\"\"\n if variable_nb_elements:\n nb_elements = self.randomize_nb_elements(nb_elements, min=1)\n\n return dict(zip(\n self.generator.words(nb_elements, unique=True),\n self._pyiterable(nb_elements, False, *value_types),\n ))\n\n def pystruct(self, count=10, *value_types):\n\n value_types = [t if isinstance(t, str) else getattr(t, '__name__', type(t).__name__).lower()\n for t in value_types\n # avoid recursion\n if t != 'struct']\n if not value_types:\n value_types = ['str', 'str', 'str', 'str', 'float',\n 'int', 'int', 'decimal', 'date_time', 'uri', 'email']\n\n types = []\n d = {}\n nd = {}\n for i in range(count):\n d[self.generator.word()] = self._random_type(value_types)\n types.append(self._random_type(value_types))\n nd[self.generator.word()] = {i: self._random_type(value_types),\n i + 1: [self._random_type(value_types),\n self._random_type(value_types),\n self._random_type(value_types)],\n i + 2: {i: self._random_type(value_types),\n i + 1: self._random_type(value_types),\n i + 2: [self._random_type(value_types),\n self._random_type(value_types)]}}\n return types, d, nd\n", "path": "faker/providers/python/__init__.py"}]}
| 2,626 | 116 |
gh_patches_debug_3862
|
rasdani/github-patches
|
git_diff
|
qtile__qtile-4409
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Docs] Broken Links
# TLDR:
- [ ] Fix http://docs.qtile.org/en/latest/manual/commands/scripting.html in https://github.com/qtile/qtile/blob/6357381aa54b47f9e5ecb0f434d728dd165a83fb/libqtile/extension/base.py#L95
- [ ] Add quotes to https://github.com/qtile/qtile/blob/6357381aa54b47f9e5ecb0f434d728dd165a83fb/docs/manual/config/lazy.rst?plain=1#L8
# The Issues:
While looking at the documentation I discovered two broken links.
## RunCommand
There is a broken (404) link in the documentation of the RunCommand extension (Configuration -> Built-in Extensions -> RunCommand).
https://docs.qtile.org/en/latest/manual/ref/extensions.html#libqtile.extension.CommandSet
The documentation states the following:
`Also consider simply using lazy.spawn() or writing a [client](http://docs.qtile.org/en/latest/manual/commands/scripting.html).`
But http://docs.qtile.org/en/latest/manual/commands/scripting.html does not exist.
We should fix this in: https://github.com/qtile/qtile/blob/6357381aa54b47f9e5ecb0f434d728dd165a83fb/libqtile/extension/base.py#L95
Should we refer to https://docs.qtile.org/en/latest/manual/commands/advanced.html#tying-it-together-command-client and use `:doc:`?
## Lazy objects
There is no link when referencing the Commands API part of the documentation in https://docs.qtile.org/en/latest/manual/config/lazy.html. Should be fixed in: https://github.com/qtile/qtile/blob/6357381aa54b47f9e5ecb0f434d728dd165a83fb/docs/manual/config/lazy.rst?plain=1#L8
Should we change it to: ```:doc:`commands API </manual/commands/api/index>` ```?
# Versions and Logs:
qtile version: not relevant
logs: not relevant
branch: master
Last time I checked the documentation: 2023-08-07 10:30 UTC
### Required:
- [X] I have searched past issues to see if this bug has already been reported.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `libqtile/extension/base.py`
Content:
```
1 # Copyright (c) 2017 Dario Giovannetti
2 # Copyright (c) 2021 elParaguayo
3 #
4 # Permission is hereby granted, free of charge, to any person obtaining a copy
5 # of this software and associated documentation files (the "Software"), to deal
6 # in the Software without restriction, including without limitation the rights
7 # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
8 # copies of the Software, and to permit persons to whom the Software is
9 # furnished to do so, subject to the following conditions:
10 #
11 # The above copyright notice and this permission notice shall be included in
12 # all copies or substantial portions of the Software.
13 #
14 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
15 # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
16 # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
17 # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
18 # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
19 # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
20 # SOFTWARE.
21 import re
22 import shlex
23 from subprocess import PIPE, Popen
24 from typing import Any
25
26 from libqtile import configurable
27 from libqtile.log_utils import logger
28
29 RGB = re.compile(r"^#?([a-fA-F0-9]{3}|[a-fA-F0-9]{6})$")
30
31
32 class _Extension(configurable.Configurable):
33 """Base Extension class"""
34
35 installed_extensions = [] # type: list
36
37 defaults = [
38 ("font", "sans", "defines the font name to be used"),
39 ("fontsize", None, "defines the font size to be used"),
40 ("background", None, "defines the normal background color (#RGB or #RRGGBB)"),
41 ("foreground", None, "defines the normal foreground color (#RGB or #RRGGBB)"),
42 ("selected_background", None, "defines the selected background color (#RGB or #RRGGBB)"),
43 ("selected_foreground", None, "defines the selected foreground color (#RGB or #RRGGBB)"),
44 ]
45
46 def __init__(self, **config):
47 configurable.Configurable.__init__(self, **config)
48 self.add_defaults(_Extension.defaults)
49 _Extension.installed_extensions.append(self)
50
51 def _check_colors(self):
52 """
53 dmenu needs colours to be in #rgb or #rrggbb format.
54
55 Checks colour value, removes invalid values and adds # if missing.
56
57 NB This should not be called in _Extension.__init__ as _Extension.global_defaults
58 may not have been set at this point.
59 """
60 for c in ["background", "foreground", "selected_background", "selected_foreground"]:
61 col = getattr(self, c, None)
62 if col is None:
63 continue
64
65 if not isinstance(col, str) or not RGB.match(col):
66 logger.warning(
67 "Invalid extension '%s' color: %s. Must be #RGB or #RRGGBB string.", c, col
68 )
69 setattr(self, c, None)
70 continue
71
72 if not col.startswith("#"):
73 col = f"#{col}"
74 setattr(self, c, col)
75
76 def _configure(self, qtile):
77 self.qtile = qtile
78 self._check_colors()
79
80 def run(self):
81 """
82 This method must be implemented by the subclasses.
83 """
84 raise NotImplementedError()
85
86
87 class RunCommand(_Extension):
88 """
89 Run an arbitrary command.
90
91 Mostly useful as a superclass for more specific extensions that need to
92 interact with the qtile object.
93
94 Also consider simply using lazy.spawn() or writing a
95 `client <http://docs.qtile.org/en/latest/manual/commands/scripting.html>`_.
96 """
97
98 defaults: list[tuple[str, Any, str]] = [
99 # NOTE: Do not use a list as a default value, since it would be shared
100 # among all the objects inheriting this class, and if one of them
101 # modified it, all the other objects would see the modified list;
102 # use a string or a tuple instead, which are immutable
103 ("command", None, "the command to be launched (string or list with arguments)"),
104 ]
105
106 def __init__(self, **config):
107 _Extension.__init__(self, **config)
108 self.add_defaults(RunCommand.defaults)
109 self.configured_command = None
110
111 def run(self):
112 """
113 An extension can inherit this class, define configured_command and use
114 the process object by overriding this method and using super():
115
116 .. code-block:: python
117
118 def _configure(self, qtile):
119 Superclass._configure(self, qtile)
120 self.configured_command = "foo --bar"
121
122 def run(self):
123 process = super(Subclass, self).run()
124 """
125 if self.configured_command:
126 if isinstance(self.configured_command, str):
127 self.configured_command = shlex.split(self.configured_command)
128 # Else assume that self.configured_command is already a sequence
129 else:
130 self.configured_command = self.command
131 return Popen(self.configured_command, stdout=PIPE, stdin=PIPE)
132
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/libqtile/extension/base.py b/libqtile/extension/base.py
--- a/libqtile/extension/base.py
+++ b/libqtile/extension/base.py
@@ -92,7 +92,7 @@
interact with the qtile object.
Also consider simply using lazy.spawn() or writing a
- `client <http://docs.qtile.org/en/latest/manual/commands/scripting.html>`_.
+ `client <https://docs.qtile.org/en/latest/manual/commands/advanced.html#client-server-scripting-model>`_.
"""
defaults: list[tuple[str, Any, str]] = [
|
{"golden_diff": "diff --git a/libqtile/extension/base.py b/libqtile/extension/base.py\n--- a/libqtile/extension/base.py\n+++ b/libqtile/extension/base.py\n@@ -92,7 +92,7 @@\n interact with the qtile object.\n \n Also consider simply using lazy.spawn() or writing a\n- `client <http://docs.qtile.org/en/latest/manual/commands/scripting.html>`_.\n+ `client <https://docs.qtile.org/en/latest/manual/commands/advanced.html#client-server-scripting-model>`_.\n \"\"\"\n \n defaults: list[tuple[str, Any, str]] = [\n", "issue": "[Docs] Broken Links\n# TLDR:\r\n\r\n- [ ] Fix http://docs.qtile.org/en/latest/manual/commands/scripting.html in https://github.com/qtile/qtile/blob/6357381aa54b47f9e5ecb0f434d728dd165a83fb/libqtile/extension/base.py#L95\r\n- [ ] Add quotes to https://github.com/qtile/qtile/blob/6357381aa54b47f9e5ecb0f434d728dd165a83fb/docs/manual/config/lazy.rst?plain=1#L8\r\n\r\n# The Issues:\r\nWhile looking at the documentation I discovered two broken links.\r\n\r\n## RunCommand\r\nThere is a broken (404) link in the documentation of the RunCommand extension (Configuration -> Built-in Extensions -> RunCommand).\r\nhttps://docs.qtile.org/en/latest/manual/ref/extensions.html#libqtile.extension.CommandSet\r\nThe documentation states the following:\r\n`Also consider simply using lazy.spawn() or writing a [client](http://docs.qtile.org/en/latest/manual/commands/scripting.html).`\r\nBut http://docs.qtile.org/en/latest/manual/commands/scripting.html does not exist.\r\nWe should fix this in: https://github.com/qtile/qtile/blob/6357381aa54b47f9e5ecb0f434d728dd165a83fb/libqtile/extension/base.py#L95\r\nShould we refer to https://docs.qtile.org/en/latest/manual/commands/advanced.html#tying-it-together-command-client and use `:doc:`?\r\n\r\n## Lazy objects\r\nThere is no link when referencing the Commands API part of the documentation in https://docs.qtile.org/en/latest/manual/config/lazy.html. Should be fixed in: https://github.com/qtile/qtile/blob/6357381aa54b47f9e5ecb0f434d728dd165a83fb/docs/manual/config/lazy.rst?plain=1#L8\r\nShould we change it to: ```:doc:`commands API </manual/commands/api/index>` ```?\r\n\r\n# Versions and Logs:\r\nqtile version: not relevant\r\nlogs: not relevant\r\nbranch: master\r\nLast time I checked the documentation: 2023-08-07 10:30 UTC\r\n\r\n### Required:\r\n\r\n- [X] I have searched past issues to see if this bug has already been reported.\n", "before_files": [{"content": "# Copyright (c) 2017 Dario Giovannetti\n# Copyright (c) 2021 elParaguayo\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\nimport re\nimport shlex\nfrom subprocess import PIPE, Popen\nfrom typing import Any\n\nfrom libqtile import configurable\nfrom libqtile.log_utils import logger\n\nRGB = re.compile(r\"^#?([a-fA-F0-9]{3}|[a-fA-F0-9]{6})$\")\n\n\nclass _Extension(configurable.Configurable):\n \"\"\"Base Extension class\"\"\"\n\n installed_extensions = [] # type: list\n\n defaults = [\n (\"font\", \"sans\", \"defines the font name to be used\"),\n (\"fontsize\", None, \"defines the font size to be used\"),\n (\"background\", None, \"defines the normal background color (#RGB or #RRGGBB)\"),\n (\"foreground\", None, \"defines the normal foreground color (#RGB or #RRGGBB)\"),\n (\"selected_background\", None, \"defines the selected background color (#RGB or #RRGGBB)\"),\n (\"selected_foreground\", None, \"defines the selected foreground color (#RGB or #RRGGBB)\"),\n ]\n\n def __init__(self, **config):\n configurable.Configurable.__init__(self, **config)\n self.add_defaults(_Extension.defaults)\n _Extension.installed_extensions.append(self)\n\n def _check_colors(self):\n \"\"\"\n dmenu needs colours to be in #rgb or #rrggbb format.\n\n Checks colour value, removes invalid values and adds # if missing.\n\n NB This should not be called in _Extension.__init__ as _Extension.global_defaults\n may not have been set at this point.\n \"\"\"\n for c in [\"background\", \"foreground\", \"selected_background\", \"selected_foreground\"]:\n col = getattr(self, c, None)\n if col is None:\n continue\n\n if not isinstance(col, str) or not RGB.match(col):\n logger.warning(\n \"Invalid extension '%s' color: %s. Must be #RGB or #RRGGBB string.\", c, col\n )\n setattr(self, c, None)\n continue\n\n if not col.startswith(\"#\"):\n col = f\"#{col}\"\n setattr(self, c, col)\n\n def _configure(self, qtile):\n self.qtile = qtile\n self._check_colors()\n\n def run(self):\n \"\"\"\n This method must be implemented by the subclasses.\n \"\"\"\n raise NotImplementedError()\n\n\nclass RunCommand(_Extension):\n \"\"\"\n Run an arbitrary command.\n\n Mostly useful as a superclass for more specific extensions that need to\n interact with the qtile object.\n\n Also consider simply using lazy.spawn() or writing a\n `client <http://docs.qtile.org/en/latest/manual/commands/scripting.html>`_.\n \"\"\"\n\n defaults: list[tuple[str, Any, str]] = [\n # NOTE: Do not use a list as a default value, since it would be shared\n # among all the objects inheriting this class, and if one of them\n # modified it, all the other objects would see the modified list;\n # use a string or a tuple instead, which are immutable\n (\"command\", None, \"the command to be launched (string or list with arguments)\"),\n ]\n\n def __init__(self, **config):\n _Extension.__init__(self, **config)\n self.add_defaults(RunCommand.defaults)\n self.configured_command = None\n\n def run(self):\n \"\"\"\n An extension can inherit this class, define configured_command and use\n the process object by overriding this method and using super():\n\n .. code-block:: python\n\n def _configure(self, qtile):\n Superclass._configure(self, qtile)\n self.configured_command = \"foo --bar\"\n\n def run(self):\n process = super(Subclass, self).run()\n \"\"\"\n if self.configured_command:\n if isinstance(self.configured_command, str):\n self.configured_command = shlex.split(self.configured_command)\n # Else assume that self.configured_command is already a sequence\n else:\n self.configured_command = self.command\n return Popen(self.configured_command, stdout=PIPE, stdin=PIPE)\n", "path": "libqtile/extension/base.py"}], "after_files": [{"content": "# Copyright (c) 2017 Dario Giovannetti\n# Copyright (c) 2021 elParaguayo\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\nimport re\nimport shlex\nfrom subprocess import PIPE, Popen\nfrom typing import Any\n\nfrom libqtile import configurable\nfrom libqtile.log_utils import logger\n\nRGB = re.compile(r\"^#?([a-fA-F0-9]{3}|[a-fA-F0-9]{6})$\")\n\n\nclass _Extension(configurable.Configurable):\n \"\"\"Base Extension class\"\"\"\n\n installed_extensions = [] # type: list\n\n defaults = [\n (\"font\", \"sans\", \"defines the font name to be used\"),\n (\"fontsize\", None, \"defines the font size to be used\"),\n (\"background\", None, \"defines the normal background color (#RGB or #RRGGBB)\"),\n (\"foreground\", None, \"defines the normal foreground color (#RGB or #RRGGBB)\"),\n (\"selected_background\", None, \"defines the selected background color (#RGB or #RRGGBB)\"),\n (\"selected_foreground\", None, \"defines the selected foreground color (#RGB or #RRGGBB)\"),\n ]\n\n def __init__(self, **config):\n configurable.Configurable.__init__(self, **config)\n self.add_defaults(_Extension.defaults)\n _Extension.installed_extensions.append(self)\n\n def _check_colors(self):\n \"\"\"\n dmenu needs colours to be in #rgb or #rrggbb format.\n\n Checks colour value, removes invalid values and adds # if missing.\n\n NB This should not be called in _Extension.__init__ as _Extension.global_defaults\n may not have been set at this point.\n \"\"\"\n for c in [\"background\", \"foreground\", \"selected_background\", \"selected_foreground\"]:\n col = getattr(self, c, None)\n if col is None:\n continue\n\n if not isinstance(col, str) or not RGB.match(col):\n logger.warning(\n \"Invalid extension '%s' color: %s. Must be #RGB or #RRGGBB string.\", c, col\n )\n setattr(self, c, None)\n continue\n\n if not col.startswith(\"#\"):\n col = f\"#{col}\"\n setattr(self, c, col)\n\n def _configure(self, qtile):\n self.qtile = qtile\n self._check_colors()\n\n def run(self):\n \"\"\"\n This method must be implemented by the subclasses.\n \"\"\"\n raise NotImplementedError()\n\n\nclass RunCommand(_Extension):\n \"\"\"\n Run an arbitrary command.\n\n Mostly useful as a superclass for more specific extensions that need to\n interact with the qtile object.\n\n Also consider simply using lazy.spawn() or writing a\n `client <https://docs.qtile.org/en/latest/manual/commands/advanced.html#client-server-scripting-model>`_.\n \"\"\"\n\n defaults: list[tuple[str, Any, str]] = [\n # NOTE: Do not use a list as a default value, since it would be shared\n # among all the objects inheriting this class, and if one of them\n # modified it, all the other objects would see the modified list;\n # use a string or a tuple instead, which are immutable\n (\"command\", None, \"the command to be launched (string or list with arguments)\"),\n ]\n\n def __init__(self, **config):\n _Extension.__init__(self, **config)\n self.add_defaults(RunCommand.defaults)\n self.configured_command = None\n\n def run(self):\n \"\"\"\n An extension can inherit this class, define configured_command and use\n the process object by overriding this method and using super():\n\n .. code-block:: python\n\n def _configure(self, qtile):\n Superclass._configure(self, qtile)\n self.configured_command = \"foo --bar\"\n\n def run(self):\n process = super(Subclass, self).run()\n \"\"\"\n if self.configured_command:\n if isinstance(self.configured_command, str):\n self.configured_command = shlex.split(self.configured_command)\n # Else assume that self.configured_command is already a sequence\n else:\n self.configured_command = self.command\n return Popen(self.configured_command, stdout=PIPE, stdin=PIPE)\n", "path": "libqtile/extension/base.py"}]}
| 2,259 | 140 |
gh_patches_debug_37010
|
rasdani/github-patches
|
git_diff
|
mirumee__ariadne-565
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Federated schemas should not require at least one query to be implemented
In a Federated environment, the Gateway instantiates the Query type by default. This means that an implementing services should _not_ be required to implement or extend a query.
# Ideal Scenario
This is an example scenario of what is valid in Node and Java implementations. For example, it should be valid to expose a service that exposes no root queries, but only the federated query fields, like below.
Produced Query type:
**Example**: This is what the schemas would look like for two federated services:
## Product Service
product/schema.gql
```gql
extend type Query {
products: [Product]
}
type Product {
id: ID!
name: String
reviews: [ProductReview]
}
extend type ProductReview @key(fields: "id") {
id: ID! @external
}
```
**Output**:
```
products: [Product]
_entities(representations: [_Any]): [_Entity]
_service: _Service
```
## Review Service
review/schema.gql
```gql
# Notice how we don't have to extend the Query type
type ProductReview @key(fields: "id") {
id: ID!
comment: String!
}
```
**Output**:
This should be valid.
```
_entities(representations: [_Any]): [_Entity]
_service: _Service
```
# Breaking Scenario
When attempting to implement the `ProductReview` service (see example above) without extending the Query type, Ariadne will fail to [generate a federated schema](https://github.com/mirumee/ariadne/blob/master/ariadne/contrib/federation/schema.py#L57). This is because `make_executable_schema` attempts to generate a federated schema by [extending a Query type](https://github.com/mirumee/ariadne/blob/master/ariadne/contrib/federation/schema.py#L24) with the assumption that a Query type has been defined, which technically it isn't.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ariadne/contrib/federation/schema.py`
Content:
```
1 from typing import Dict, List, Type, Union, cast
2
3 from graphql import extend_schema, parse
4 from graphql.language import DocumentNode
5 from graphql.type import (
6 GraphQLObjectType,
7 GraphQLSchema,
8 GraphQLUnionType,
9 )
10
11 from ...executable_schema import make_executable_schema, join_type_defs
12 from ...schema_visitor import SchemaDirectiveVisitor
13 from ...types import SchemaBindable
14 from .utils import get_entity_types, purge_schema_directives, resolve_entities
15
16
17 federation_service_type_defs = """
18 scalar _Any
19
20 type _Service {
21 sdl: String
22 }
23
24 extend type Query {
25 _service: _Service!
26 }
27
28 directive @external on FIELD_DEFINITION
29 directive @requires(fields: String!) on FIELD_DEFINITION
30 directive @provides(fields: String!) on FIELD_DEFINITION
31 directive @key(fields: String!) repeatable on OBJECT | INTERFACE
32 directive @extends on OBJECT | INTERFACE
33 """
34
35 federation_entity_type_defs = """
36 union _Entity
37
38 extend type Query {
39 _entities(representations: [_Any!]!): [_Entity]!
40 }
41 """
42
43
44 def make_federated_schema(
45 type_defs: Union[str, List[str]],
46 *bindables: Union[SchemaBindable, List[SchemaBindable]],
47 directives: Dict[str, Type[SchemaDirectiveVisitor]] = None,
48 ) -> GraphQLSchema:
49 if isinstance(type_defs, list):
50 type_defs = join_type_defs(type_defs)
51
52 # Remove custom schema directives (to avoid apollo-gateway crashes).
53 # NOTE: This does NOT interfere with ariadne's directives support.
54 sdl = purge_schema_directives(type_defs)
55
56 type_defs = join_type_defs([type_defs, federation_service_type_defs])
57 schema = make_executable_schema(
58 type_defs,
59 *bindables,
60 directives=directives,
61 )
62
63 # Parse through the schema to find all entities with key directive.
64 entity_types = get_entity_types(schema)
65 has_entities = len(entity_types) > 0
66
67 # Add the federation type definitions.
68 if has_entities:
69 schema = extend_federated_schema(
70 schema,
71 parse(federation_entity_type_defs),
72 )
73
74 # Add _entities query.
75 entity_type = schema.get_type("_Entity")
76 if entity_type:
77 entity_type = cast(GraphQLUnionType, entity_type)
78 entity_type.types = entity_types
79
80 query_type = schema.get_type("Query")
81 if query_type:
82 query_type = cast(GraphQLObjectType, query_type)
83 query_type.fields["_entities"].resolve = resolve_entities
84
85 # Add _service query.
86 query_type = schema.get_type("Query")
87 if query_type:
88 query_type = cast(GraphQLObjectType, query_type)
89 query_type.fields["_service"].resolve = lambda _service, info: {"sdl": sdl}
90
91 return schema
92
93
94 def extend_federated_schema(
95 schema: GraphQLSchema,
96 document_ast: DocumentNode,
97 assume_valid: bool = False,
98 assume_valid_sdl: bool = False,
99 ) -> GraphQLSchema:
100 extended_schema = extend_schema(
101 schema,
102 document_ast,
103 assume_valid,
104 assume_valid_sdl,
105 )
106
107 for (k, v) in schema.type_map.items():
108 resolve_reference = getattr(v, "__resolve_reference__", None)
109 if resolve_reference and k in extended_schema.type_map:
110 setattr(
111 extended_schema.type_map[k],
112 "__resolve_reference__",
113 resolve_reference,
114 )
115
116 return extended_schema
117
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ariadne/contrib/federation/schema.py b/ariadne/contrib/federation/schema.py
--- a/ariadne/contrib/federation/schema.py
+++ b/ariadne/contrib/federation/schema.py
@@ -2,6 +2,7 @@
from graphql import extend_schema, parse
from graphql.language import DocumentNode
+from graphql.language.ast import ObjectTypeDefinitionNode
from graphql.type import (
GraphQLObjectType,
GraphQLSchema,
@@ -17,13 +18,13 @@
federation_service_type_defs = """
scalar _Any
- type _Service {
+ type _Service {{
sdl: String
- }
+ }}
- extend type Query {
+ {type_token} Query {{
_service: _Service!
- }
+ }}
directive @external on FIELD_DEFINITION
directive @requires(fields: String!) on FIELD_DEFINITION
@@ -41,6 +42,17 @@
"""
+def has_query_type(type_defs: str) -> bool:
+ ast_document = parse(type_defs)
+ for definition in ast_document.definitions:
+ if (
+ isinstance(definition, ObjectTypeDefinitionNode)
+ and definition.name.value == "Query"
+ ):
+ return True
+ return False
+
+
def make_federated_schema(
type_defs: Union[str, List[str]],
*bindables: Union[SchemaBindable, List[SchemaBindable]],
@@ -52,8 +64,10 @@
# Remove custom schema directives (to avoid apollo-gateway crashes).
# NOTE: This does NOT interfere with ariadne's directives support.
sdl = purge_schema_directives(type_defs)
+ type_token = "extend type" if has_query_type(sdl) else "type"
+ federation_service_type = federation_service_type_defs.format(type_token=type_token)
- type_defs = join_type_defs([type_defs, federation_service_type_defs])
+ type_defs = join_type_defs([type_defs, federation_service_type])
schema = make_executable_schema(
type_defs,
*bindables,
@@ -66,10 +80,7 @@
# Add the federation type definitions.
if has_entities:
- schema = extend_federated_schema(
- schema,
- parse(federation_entity_type_defs),
- )
+ schema = extend_federated_schema(schema, parse(federation_entity_type_defs))
# Add _entities query.
entity_type = schema.get_type("_Entity")
|
{"golden_diff": "diff --git a/ariadne/contrib/federation/schema.py b/ariadne/contrib/federation/schema.py\n--- a/ariadne/contrib/federation/schema.py\n+++ b/ariadne/contrib/federation/schema.py\n@@ -2,6 +2,7 @@\n \n from graphql import extend_schema, parse\n from graphql.language import DocumentNode\n+from graphql.language.ast import ObjectTypeDefinitionNode\n from graphql.type import (\n GraphQLObjectType,\n GraphQLSchema,\n@@ -17,13 +18,13 @@\n federation_service_type_defs = \"\"\"\n scalar _Any\n \n- type _Service {\n+ type _Service {{\n sdl: String\n- }\n+ }}\n \n- extend type Query {\n+ {type_token} Query {{\n _service: _Service!\n- }\n+ }}\n \n directive @external on FIELD_DEFINITION\n directive @requires(fields: String!) on FIELD_DEFINITION\n@@ -41,6 +42,17 @@\n \"\"\"\n \n \n+def has_query_type(type_defs: str) -> bool:\n+ ast_document = parse(type_defs)\n+ for definition in ast_document.definitions:\n+ if (\n+ isinstance(definition, ObjectTypeDefinitionNode)\n+ and definition.name.value == \"Query\"\n+ ):\n+ return True\n+ return False\n+\n+\n def make_federated_schema(\n type_defs: Union[str, List[str]],\n *bindables: Union[SchemaBindable, List[SchemaBindable]],\n@@ -52,8 +64,10 @@\n # Remove custom schema directives (to avoid apollo-gateway crashes).\n # NOTE: This does NOT interfere with ariadne's directives support.\n sdl = purge_schema_directives(type_defs)\n+ type_token = \"extend type\" if has_query_type(sdl) else \"type\"\n+ federation_service_type = federation_service_type_defs.format(type_token=type_token)\n \n- type_defs = join_type_defs([type_defs, federation_service_type_defs])\n+ type_defs = join_type_defs([type_defs, federation_service_type])\n schema = make_executable_schema(\n type_defs,\n *bindables,\n@@ -66,10 +80,7 @@\n \n # Add the federation type definitions.\n if has_entities:\n- schema = extend_federated_schema(\n- schema,\n- parse(federation_entity_type_defs),\n- )\n+ schema = extend_federated_schema(schema, parse(federation_entity_type_defs))\n \n # Add _entities query.\n entity_type = schema.get_type(\"_Entity\")\n", "issue": "Federated schemas should not require at least one query to be implemented\nIn a Federated environment, the Gateway instantiates the Query type by default. This means that an implementing services should _not_ be required to implement or extend a query. \r\n\r\n# Ideal Scenario\r\nThis is an example scenario of what is valid in Node and Java implementations. For example, it should be valid to expose a service that exposes no root queries, but only the federated query fields, like below.\r\n\r\nProduced Query type:\r\n\r\n\r\n**Example**: This is what the schemas would look like for two federated services:\r\n## Product Service\r\nproduct/schema.gql\r\n```gql\r\nextend type Query {\r\n products: [Product]\r\n}\r\n\r\ntype Product {\r\n id: ID!\r\n name: String\r\n reviews: [ProductReview]\r\n}\r\n\r\nextend type ProductReview @key(fields: \"id\") {\r\n id: ID! @external\r\n}\r\n```\r\n**Output**:\r\n\r\n```\r\nproducts: [Product]\r\n_entities(representations: [_Any]): [_Entity]\r\n_service: _Service\r\n```\r\n\r\n## Review Service\r\nreview/schema.gql\r\n```gql\r\n# Notice how we don't have to extend the Query type\r\ntype ProductReview @key(fields: \"id\") {\r\n id: ID!\r\n comment: String!\r\n}\r\n```\r\n\r\n**Output**:\r\nThis should be valid.\r\n```\r\n_entities(representations: [_Any]): [_Entity]\r\n_service: _Service\r\n```\r\n\r\n\r\n# Breaking Scenario\r\nWhen attempting to implement the `ProductReview` service (see example above) without extending the Query type, Ariadne will fail to [generate a federated schema](https://github.com/mirumee/ariadne/blob/master/ariadne/contrib/federation/schema.py#L57). This is because `make_executable_schema` attempts to generate a federated schema by [extending a Query type](https://github.com/mirumee/ariadne/blob/master/ariadne/contrib/federation/schema.py#L24) with the assumption that a Query type has been defined, which technically it isn't. \r\n\r\n\r\n\n", "before_files": [{"content": "from typing import Dict, List, Type, Union, cast\n\nfrom graphql import extend_schema, parse\nfrom graphql.language import DocumentNode\nfrom graphql.type import (\n GraphQLObjectType,\n GraphQLSchema,\n GraphQLUnionType,\n)\n\nfrom ...executable_schema import make_executable_schema, join_type_defs\nfrom ...schema_visitor import SchemaDirectiveVisitor\nfrom ...types import SchemaBindable\nfrom .utils import get_entity_types, purge_schema_directives, resolve_entities\n\n\nfederation_service_type_defs = \"\"\"\n scalar _Any\n\n type _Service {\n sdl: String\n }\n\n extend type Query {\n _service: _Service!\n }\n\n directive @external on FIELD_DEFINITION\n directive @requires(fields: String!) on FIELD_DEFINITION\n directive @provides(fields: String!) on FIELD_DEFINITION\n directive @key(fields: String!) repeatable on OBJECT | INTERFACE\n directive @extends on OBJECT | INTERFACE\n\"\"\"\n\nfederation_entity_type_defs = \"\"\"\n union _Entity\n\n extend type Query {\n _entities(representations: [_Any!]!): [_Entity]!\n }\n\"\"\"\n\n\ndef make_federated_schema(\n type_defs: Union[str, List[str]],\n *bindables: Union[SchemaBindable, List[SchemaBindable]],\n directives: Dict[str, Type[SchemaDirectiveVisitor]] = None,\n) -> GraphQLSchema:\n if isinstance(type_defs, list):\n type_defs = join_type_defs(type_defs)\n\n # Remove custom schema directives (to avoid apollo-gateway crashes).\n # NOTE: This does NOT interfere with ariadne's directives support.\n sdl = purge_schema_directives(type_defs)\n\n type_defs = join_type_defs([type_defs, federation_service_type_defs])\n schema = make_executable_schema(\n type_defs,\n *bindables,\n directives=directives,\n )\n\n # Parse through the schema to find all entities with key directive.\n entity_types = get_entity_types(schema)\n has_entities = len(entity_types) > 0\n\n # Add the federation type definitions.\n if has_entities:\n schema = extend_federated_schema(\n schema,\n parse(federation_entity_type_defs),\n )\n\n # Add _entities query.\n entity_type = schema.get_type(\"_Entity\")\n if entity_type:\n entity_type = cast(GraphQLUnionType, entity_type)\n entity_type.types = entity_types\n\n query_type = schema.get_type(\"Query\")\n if query_type:\n query_type = cast(GraphQLObjectType, query_type)\n query_type.fields[\"_entities\"].resolve = resolve_entities\n\n # Add _service query.\n query_type = schema.get_type(\"Query\")\n if query_type:\n query_type = cast(GraphQLObjectType, query_type)\n query_type.fields[\"_service\"].resolve = lambda _service, info: {\"sdl\": sdl}\n\n return schema\n\n\ndef extend_federated_schema(\n schema: GraphQLSchema,\n document_ast: DocumentNode,\n assume_valid: bool = False,\n assume_valid_sdl: bool = False,\n) -> GraphQLSchema:\n extended_schema = extend_schema(\n schema,\n document_ast,\n assume_valid,\n assume_valid_sdl,\n )\n\n for (k, v) in schema.type_map.items():\n resolve_reference = getattr(v, \"__resolve_reference__\", None)\n if resolve_reference and k in extended_schema.type_map:\n setattr(\n extended_schema.type_map[k],\n \"__resolve_reference__\",\n resolve_reference,\n )\n\n return extended_schema\n", "path": "ariadne/contrib/federation/schema.py"}], "after_files": [{"content": "from typing import Dict, List, Type, Union, cast\n\nfrom graphql import extend_schema, parse\nfrom graphql.language import DocumentNode\nfrom graphql.language.ast import ObjectTypeDefinitionNode\nfrom graphql.type import (\n GraphQLObjectType,\n GraphQLSchema,\n GraphQLUnionType,\n)\n\nfrom ...executable_schema import make_executable_schema, join_type_defs\nfrom ...schema_visitor import SchemaDirectiveVisitor\nfrom ...types import SchemaBindable\nfrom .utils import get_entity_types, purge_schema_directives, resolve_entities\n\n\nfederation_service_type_defs = \"\"\"\n scalar _Any\n\n type _Service {{\n sdl: String\n }}\n\n {type_token} Query {{\n _service: _Service!\n }}\n\n directive @external on FIELD_DEFINITION\n directive @requires(fields: String!) on FIELD_DEFINITION\n directive @provides(fields: String!) on FIELD_DEFINITION\n directive @key(fields: String!) repeatable on OBJECT | INTERFACE\n directive @extends on OBJECT | INTERFACE\n\"\"\"\n\nfederation_entity_type_defs = \"\"\"\n union _Entity\n\n extend type Query {\n _entities(representations: [_Any!]!): [_Entity]!\n }\n\"\"\"\n\n\ndef has_query_type(type_defs: str) -> bool:\n ast_document = parse(type_defs)\n for definition in ast_document.definitions:\n if (\n isinstance(definition, ObjectTypeDefinitionNode)\n and definition.name.value == \"Query\"\n ):\n return True\n return False\n\n\ndef make_federated_schema(\n type_defs: Union[str, List[str]],\n *bindables: Union[SchemaBindable, List[SchemaBindable]],\n directives: Dict[str, Type[SchemaDirectiveVisitor]] = None,\n) -> GraphQLSchema:\n if isinstance(type_defs, list):\n type_defs = join_type_defs(type_defs)\n\n # Remove custom schema directives (to avoid apollo-gateway crashes).\n # NOTE: This does NOT interfere with ariadne's directives support.\n sdl = purge_schema_directives(type_defs)\n type_token = \"extend type\" if has_query_type(sdl) else \"type\"\n federation_service_type = federation_service_type_defs.format(type_token=type_token)\n\n type_defs = join_type_defs([type_defs, federation_service_type])\n schema = make_executable_schema(\n type_defs,\n *bindables,\n directives=directives,\n )\n\n # Parse through the schema to find all entities with key directive.\n entity_types = get_entity_types(schema)\n has_entities = len(entity_types) > 0\n\n # Add the federation type definitions.\n if has_entities:\n schema = extend_federated_schema(schema, parse(federation_entity_type_defs))\n\n # Add _entities query.\n entity_type = schema.get_type(\"_Entity\")\n if entity_type:\n entity_type = cast(GraphQLUnionType, entity_type)\n entity_type.types = entity_types\n\n query_type = schema.get_type(\"Query\")\n if query_type:\n query_type = cast(GraphQLObjectType, query_type)\n query_type.fields[\"_entities\"].resolve = resolve_entities\n\n # Add _service query.\n query_type = schema.get_type(\"Query\")\n if query_type:\n query_type = cast(GraphQLObjectType, query_type)\n query_type.fields[\"_service\"].resolve = lambda _service, info: {\"sdl\": sdl}\n\n return schema\n\n\ndef extend_federated_schema(\n schema: GraphQLSchema,\n document_ast: DocumentNode,\n assume_valid: bool = False,\n assume_valid_sdl: bool = False,\n) -> GraphQLSchema:\n extended_schema = extend_schema(\n schema,\n document_ast,\n assume_valid,\n assume_valid_sdl,\n )\n\n for (k, v) in schema.type_map.items():\n resolve_reference = getattr(v, \"__resolve_reference__\", None)\n if resolve_reference and k in extended_schema.type_map:\n setattr(\n extended_schema.type_map[k],\n \"__resolve_reference__\",\n resolve_reference,\n )\n\n return extended_schema\n", "path": "ariadne/contrib/federation/schema.py"}]}
| 1,687 | 547 |
gh_patches_debug_28358
|
rasdani/github-patches
|
git_diff
|
mkdocs__mkdocs-1517
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Unicode paths break clean_directory on server
Discovered a weird error with the server and Unicode characters in paths. Run the following command and everything seems fine:
mkdocs serve -f mkdocs/tests/integration/unicode/mkdocs.yml
However, once a file is edited and saved, the second attempt at a build results in the following error:
```
Exception in callback <bound method type.poll_tasks of <class 'livereload.handlers.LiveReloadHandler'>>
Traceback (most recent call last):
File "/Users/waylan/VirtualEnvs/mkdocs/lib/python2.7/site-packages/tornado/ioloop.py", line 1209, in _run
return self.callback()
File "/Users/waylan/VirtualEnvs/mkdocs/lib/python2.7/site-packages/livereload/handlers.py", line 67, in poll_tasks
filepath, delay = cls.watcher.examine()
File "/Users/waylan/VirtualEnvs/mkdocs/lib/python2.7/site-packages/livereload/watcher.py", line 73, in examine
func and func()
File "/Users/waylan/Code/mkdocs/mkdocs/commands/serve.py", line 112, in builder
build(config, live_server=live_server, dirty=dirty)
File "/Users/waylan/Code/mkdocs/mkdocs/commands/build.py", line 265, in build
utils.clean_directory(config['site_dir'])
File "/Users/waylan/Code/mkdocs/mkdocs/utils/__init__.py", line 144, in clean_directory
if entry.startswith('.'):
UnicodeDecodeError: 'ascii' codec can't decode byte 0xcc in position 1: ordinal not in range(128)
```
It would seem that somewhere between the call to `utils.clean_directory(config['site_dir'])` on the first build, and the same call on the second build, the `site_dir` config setting is converted from a Unicode string to a byte string.
I'm assuming the server code is the culprit.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mkdocs/commands/serve.py`
Content:
```
1 from __future__ import unicode_literals
2
3 import logging
4 import shutil
5 import tempfile
6
7 from os.path import isfile, join
8 from mkdocs.commands.build import build
9 from mkdocs.config import load_config
10
11 log = logging.getLogger(__name__)
12
13
14 def _get_handler(site_dir, StaticFileHandler):
15
16 from tornado.template import Loader
17
18 class WebHandler(StaticFileHandler):
19
20 def write_error(self, status_code, **kwargs):
21
22 if status_code in (404, 500):
23 error_page = '{}.html'.format(status_code)
24 if isfile(join(site_dir, error_page)):
25 self.write(Loader(site_dir).load(error_page).generate())
26 else:
27 super(WebHandler, self).write_error(status_code, **kwargs)
28
29 return WebHandler
30
31
32 def _livereload(host, port, config, builder, site_dir):
33
34 # We are importing here for anyone that has issues with livereload. Even if
35 # this fails, the --no-livereload alternative should still work.
36 from livereload import Server
37 import livereload.handlers
38
39 class LiveReloadServer(Server):
40
41 def get_web_handlers(self, script):
42 handlers = super(LiveReloadServer, self).get_web_handlers(script)
43 # replace livereload handler
44 return [(handlers[0][0], _get_handler(site_dir, livereload.handlers.StaticFileHandler), handlers[0][2],)]
45
46 server = LiveReloadServer()
47
48 # Watch the documentation files, the config file and the theme files.
49 server.watch(config['docs_dir'], builder)
50 server.watch(config['config_file_path'], builder)
51
52 for d in config['theme'].dirs:
53 server.watch(d, builder)
54
55 # Run `serve` plugin events.
56 server = config['plugins'].run_event('serve', server, config=config)
57
58 server.serve(root=site_dir, host=host, port=port, restart_delay=0)
59
60
61 def _static_server(host, port, site_dir):
62
63 # Importing here to seperate the code paths from the --livereload
64 # alternative.
65 from tornado import ioloop
66 from tornado import web
67
68 application = web.Application([
69 (r"/(.*)", _get_handler(site_dir, web.StaticFileHandler), {
70 "path": site_dir,
71 "default_filename": "index.html"
72 }),
73 ])
74 application.listen(port=port, address=host)
75
76 log.info('Running at: http://%s:%s/', host, port)
77 log.info('Hold ctrl+c to quit.')
78 try:
79 ioloop.IOLoop.instance().start()
80 except KeyboardInterrupt:
81 log.info('Stopping server...')
82
83
84 def serve(config_file=None, dev_addr=None, strict=None, theme=None,
85 theme_dir=None, livereload='livereload'):
86 """
87 Start the MkDocs development server
88
89 By default it will serve the documentation on http://localhost:8000/ and
90 it will rebuild the documentation and refresh the page automatically
91 whenever a file is edited.
92 """
93
94 # Create a temporary build directory, and set some options to serve it
95 tempdir = tempfile.mkdtemp()
96
97 def builder():
98 log.info("Building documentation...")
99 config = load_config(
100 config_file=config_file,
101 dev_addr=dev_addr,
102 strict=strict,
103 theme=theme,
104 theme_dir=theme_dir
105 )
106 # Override a few config settings after validation
107 config['site_dir'] = tempdir
108 config['site_url'] = 'http://{0}/'.format(config['dev_addr'])
109
110 live_server = livereload in ['dirty', 'livereload']
111 dirty = livereload == 'dirty'
112 build(config, live_server=live_server, dirty=dirty)
113 return config
114
115 try:
116 # Perform the initial build
117 config = builder()
118
119 host, port = config['dev_addr']
120
121 if livereload in ['livereload', 'dirty']:
122 _livereload(host, port, config, builder, tempdir)
123 else:
124 _static_server(host, port, tempdir)
125 finally:
126 shutil.rmtree(tempdir)
127
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mkdocs/commands/serve.py b/mkdocs/commands/serve.py
--- a/mkdocs/commands/serve.py
+++ b/mkdocs/commands/serve.py
@@ -92,7 +92,9 @@
"""
# Create a temporary build directory, and set some options to serve it
- tempdir = tempfile.mkdtemp()
+ # PY2 returns a byte string by default. The Unicode prefix ensures a Unicode
+ # string is returned. And it makes MkDocs temp dirs easier to identify.
+ site_dir = tempfile.mkdtemp(prefix='mkdocs_')
def builder():
log.info("Building documentation...")
@@ -101,10 +103,10 @@
dev_addr=dev_addr,
strict=strict,
theme=theme,
- theme_dir=theme_dir
+ theme_dir=theme_dir,
+ site_dir=site_dir
)
# Override a few config settings after validation
- config['site_dir'] = tempdir
config['site_url'] = 'http://{0}/'.format(config['dev_addr'])
live_server = livereload in ['dirty', 'livereload']
@@ -119,8 +121,8 @@
host, port = config['dev_addr']
if livereload in ['livereload', 'dirty']:
- _livereload(host, port, config, builder, tempdir)
+ _livereload(host, port, config, builder, site_dir)
else:
- _static_server(host, port, tempdir)
+ _static_server(host, port, site_dir)
finally:
- shutil.rmtree(tempdir)
+ shutil.rmtree(site_dir)
|
{"golden_diff": "diff --git a/mkdocs/commands/serve.py b/mkdocs/commands/serve.py\n--- a/mkdocs/commands/serve.py\n+++ b/mkdocs/commands/serve.py\n@@ -92,7 +92,9 @@\n \"\"\"\n \n # Create a temporary build directory, and set some options to serve it\n- tempdir = tempfile.mkdtemp()\n+ # PY2 returns a byte string by default. The Unicode prefix ensures a Unicode\n+ # string is returned. And it makes MkDocs temp dirs easier to identify.\n+ site_dir = tempfile.mkdtemp(prefix='mkdocs_')\n \n def builder():\n log.info(\"Building documentation...\")\n@@ -101,10 +103,10 @@\n dev_addr=dev_addr,\n strict=strict,\n theme=theme,\n- theme_dir=theme_dir\n+ theme_dir=theme_dir,\n+ site_dir=site_dir\n )\n # Override a few config settings after validation\n- config['site_dir'] = tempdir\n config['site_url'] = 'http://{0}/'.format(config['dev_addr'])\n \n live_server = livereload in ['dirty', 'livereload']\n@@ -119,8 +121,8 @@\n host, port = config['dev_addr']\n \n if livereload in ['livereload', 'dirty']:\n- _livereload(host, port, config, builder, tempdir)\n+ _livereload(host, port, config, builder, site_dir)\n else:\n- _static_server(host, port, tempdir)\n+ _static_server(host, port, site_dir)\n finally:\n- shutil.rmtree(tempdir)\n+ shutil.rmtree(site_dir)\n", "issue": "Unicode paths break clean_directory on server\nDiscovered a weird error with the server and Unicode characters in paths. Run the following command and everything seems fine:\r\n\r\n mkdocs serve -f mkdocs/tests/integration/unicode/mkdocs.yml\r\n\r\nHowever, once a file is edited and saved, the second attempt at a build results in the following error:\r\n\r\n```\r\nException in callback <bound method type.poll_tasks of <class 'livereload.handlers.LiveReloadHandler'>>\r\n Traceback (most recent call last):\r\n File \"/Users/waylan/VirtualEnvs/mkdocs/lib/python2.7/site-packages/tornado/ioloop.py\", line 1209, in _run\r\n return self.callback()\r\n File \"/Users/waylan/VirtualEnvs/mkdocs/lib/python2.7/site-packages/livereload/handlers.py\", line 67, in poll_tasks\r\n filepath, delay = cls.watcher.examine()\r\n File \"/Users/waylan/VirtualEnvs/mkdocs/lib/python2.7/site-packages/livereload/watcher.py\", line 73, in examine\r\n func and func()\r\n File \"/Users/waylan/Code/mkdocs/mkdocs/commands/serve.py\", line 112, in builder\r\n build(config, live_server=live_server, dirty=dirty)\r\n File \"/Users/waylan/Code/mkdocs/mkdocs/commands/build.py\", line 265, in build\r\n utils.clean_directory(config['site_dir'])\r\n File \"/Users/waylan/Code/mkdocs/mkdocs/utils/__init__.py\", line 144, in clean_directory\r\n if entry.startswith('.'):\r\n UnicodeDecodeError: 'ascii' codec can't decode byte 0xcc in position 1: ordinal not in range(128)\r\n```\r\n\r\nIt would seem that somewhere between the call to `utils.clean_directory(config['site_dir'])` on the first build, and the same call on the second build, the `site_dir` config setting is converted from a Unicode string to a byte string.\r\n\r\nI'm assuming the server code is the culprit.\n", "before_files": [{"content": "from __future__ import unicode_literals\n\nimport logging\nimport shutil\nimport tempfile\n\nfrom os.path import isfile, join\nfrom mkdocs.commands.build import build\nfrom mkdocs.config import load_config\n\nlog = logging.getLogger(__name__)\n\n\ndef _get_handler(site_dir, StaticFileHandler):\n\n from tornado.template import Loader\n\n class WebHandler(StaticFileHandler):\n\n def write_error(self, status_code, **kwargs):\n\n if status_code in (404, 500):\n error_page = '{}.html'.format(status_code)\n if isfile(join(site_dir, error_page)):\n self.write(Loader(site_dir).load(error_page).generate())\n else:\n super(WebHandler, self).write_error(status_code, **kwargs)\n\n return WebHandler\n\n\ndef _livereload(host, port, config, builder, site_dir):\n\n # We are importing here for anyone that has issues with livereload. Even if\n # this fails, the --no-livereload alternative should still work.\n from livereload import Server\n import livereload.handlers\n\n class LiveReloadServer(Server):\n\n def get_web_handlers(self, script):\n handlers = super(LiveReloadServer, self).get_web_handlers(script)\n # replace livereload handler\n return [(handlers[0][0], _get_handler(site_dir, livereload.handlers.StaticFileHandler), handlers[0][2],)]\n\n server = LiveReloadServer()\n\n # Watch the documentation files, the config file and the theme files.\n server.watch(config['docs_dir'], builder)\n server.watch(config['config_file_path'], builder)\n\n for d in config['theme'].dirs:\n server.watch(d, builder)\n\n # Run `serve` plugin events.\n server = config['plugins'].run_event('serve', server, config=config)\n\n server.serve(root=site_dir, host=host, port=port, restart_delay=0)\n\n\ndef _static_server(host, port, site_dir):\n\n # Importing here to seperate the code paths from the --livereload\n # alternative.\n from tornado import ioloop\n from tornado import web\n\n application = web.Application([\n (r\"/(.*)\", _get_handler(site_dir, web.StaticFileHandler), {\n \"path\": site_dir,\n \"default_filename\": \"index.html\"\n }),\n ])\n application.listen(port=port, address=host)\n\n log.info('Running at: http://%s:%s/', host, port)\n log.info('Hold ctrl+c to quit.')\n try:\n ioloop.IOLoop.instance().start()\n except KeyboardInterrupt:\n log.info('Stopping server...')\n\n\ndef serve(config_file=None, dev_addr=None, strict=None, theme=None,\n theme_dir=None, livereload='livereload'):\n \"\"\"\n Start the MkDocs development server\n\n By default it will serve the documentation on http://localhost:8000/ and\n it will rebuild the documentation and refresh the page automatically\n whenever a file is edited.\n \"\"\"\n\n # Create a temporary build directory, and set some options to serve it\n tempdir = tempfile.mkdtemp()\n\n def builder():\n log.info(\"Building documentation...\")\n config = load_config(\n config_file=config_file,\n dev_addr=dev_addr,\n strict=strict,\n theme=theme,\n theme_dir=theme_dir\n )\n # Override a few config settings after validation\n config['site_dir'] = tempdir\n config['site_url'] = 'http://{0}/'.format(config['dev_addr'])\n\n live_server = livereload in ['dirty', 'livereload']\n dirty = livereload == 'dirty'\n build(config, live_server=live_server, dirty=dirty)\n return config\n\n try:\n # Perform the initial build\n config = builder()\n\n host, port = config['dev_addr']\n\n if livereload in ['livereload', 'dirty']:\n _livereload(host, port, config, builder, tempdir)\n else:\n _static_server(host, port, tempdir)\n finally:\n shutil.rmtree(tempdir)\n", "path": "mkdocs/commands/serve.py"}], "after_files": [{"content": "from __future__ import unicode_literals\n\nimport logging\nimport shutil\nimport tempfile\n\nfrom os.path import isfile, join\nfrom mkdocs.commands.build import build\nfrom mkdocs.config import load_config\n\nlog = logging.getLogger(__name__)\n\n\ndef _get_handler(site_dir, StaticFileHandler):\n\n from tornado.template import Loader\n\n class WebHandler(StaticFileHandler):\n\n def write_error(self, status_code, **kwargs):\n\n if status_code in (404, 500):\n error_page = '{}.html'.format(status_code)\n if isfile(join(site_dir, error_page)):\n self.write(Loader(site_dir).load(error_page).generate())\n else:\n super(WebHandler, self).write_error(status_code, **kwargs)\n\n return WebHandler\n\n\ndef _livereload(host, port, config, builder, site_dir):\n\n # We are importing here for anyone that has issues with livereload. Even if\n # this fails, the --no-livereload alternative should still work.\n from livereload import Server\n import livereload.handlers\n\n class LiveReloadServer(Server):\n\n def get_web_handlers(self, script):\n handlers = super(LiveReloadServer, self).get_web_handlers(script)\n # replace livereload handler\n return [(handlers[0][0], _get_handler(site_dir, livereload.handlers.StaticFileHandler), handlers[0][2],)]\n\n server = LiveReloadServer()\n\n # Watch the documentation files, the config file and the theme files.\n server.watch(config['docs_dir'], builder)\n server.watch(config['config_file_path'], builder)\n\n for d in config['theme'].dirs:\n server.watch(d, builder)\n\n # Run `serve` plugin events.\n server = config['plugins'].run_event('serve', server, config=config)\n\n server.serve(root=site_dir, host=host, port=port, restart_delay=0)\n\n\ndef _static_server(host, port, site_dir):\n\n # Importing here to seperate the code paths from the --livereload\n # alternative.\n from tornado import ioloop\n from tornado import web\n\n application = web.Application([\n (r\"/(.*)\", _get_handler(site_dir, web.StaticFileHandler), {\n \"path\": site_dir,\n \"default_filename\": \"index.html\"\n }),\n ])\n application.listen(port=port, address=host)\n\n log.info('Running at: http://%s:%s/', host, port)\n log.info('Hold ctrl+c to quit.')\n try:\n ioloop.IOLoop.instance().start()\n except KeyboardInterrupt:\n log.info('Stopping server...')\n\n\ndef serve(config_file=None, dev_addr=None, strict=None, theme=None,\n theme_dir=None, livereload='livereload'):\n \"\"\"\n Start the MkDocs development server\n\n By default it will serve the documentation on http://localhost:8000/ and\n it will rebuild the documentation and refresh the page automatically\n whenever a file is edited.\n \"\"\"\n\n # Create a temporary build directory, and set some options to serve it\n # PY2 returns a byte string by default. The Unicode prefix ensures a Unicode\n # string is returned. And it makes MkDocs temp dirs easier to identify.\n site_dir = tempfile.mkdtemp(prefix='mkdocs_')\n\n def builder():\n log.info(\"Building documentation...\")\n config = load_config(\n config_file=config_file,\n dev_addr=dev_addr,\n strict=strict,\n theme=theme,\n theme_dir=theme_dir,\n site_dir=site_dir\n )\n # Override a few config settings after validation\n config['site_url'] = 'http://{0}/'.format(config['dev_addr'])\n\n live_server = livereload in ['dirty', 'livereload']\n dirty = livereload == 'dirty'\n build(config, live_server=live_server, dirty=dirty)\n return config\n\n try:\n # Perform the initial build\n config = builder()\n\n host, port = config['dev_addr']\n\n if livereload in ['livereload', 'dirty']:\n _livereload(host, port, config, builder, site_dir)\n else:\n _static_server(host, port, site_dir)\n finally:\n shutil.rmtree(site_dir)\n", "path": "mkdocs/commands/serve.py"}]}
| 1,885 | 380 |
gh_patches_debug_4427
|
rasdani/github-patches
|
git_diff
|
python__mypy-15218
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Daemon `dmypy` crashes with `disable_error_code` configuration option
## Description
Evertything was working until i tried to disable some error codes using the `disable_error_code = 'no-untyped-def,empty-body'` option in the `pyproject.toml` file.
After restarting the daemon, it crashed with the error `Timed out waiting for daemon to start`
**Log**
```
Mypy extension activated, version 0.2.3
Registering listener for interpreter changed event
Listener registered
[1] Check folder: c:\Users\lucas\Desktop\myFolder
Activation complete
[1] Received python path from Python extension: C:\Python39\python.exe
[1] Running dmypy in folder c:\Users\lucas\Desktop\myFolder
'C:\Python39\Scripts\dmypy.EXE' --status-file 'c:\Users\lucas\AppData\Roaming\Code\User\workspaceStorage\41737679a5dd5649bc304b3214d8b429\matangover.mypy\dmypy-6e071d9aa88ca0124b79d66d19a862665ea10e28-14032.json' run --log-file 'c:\Users\lucas\AppData\Roaming\Code\User\workspaceStorage\41737679a5dd5649bc304b3214d8b429\matangover.mypy\dmypy-6e071d9aa88ca0124b79d66d19a862665ea10e28.log' -- . --show-column-numbers --no-error-summary --no-pretty --no-color-output --python-executable 'C:\Python39\python.exe'
[1] stderr:
Timed out waiting for daemon to start
[1] Error running mypy in c:\Users\lucas\Desktop\myFolder: mypy failed with error: "Timed out waiting for daemon to start
". See Output panel for details.
```
**To Reproduce**
Use the `disable_error_code` configuration option either in the `pyproject.toml` or in the `mypy.ini` files.
**Your Environment**
<!-- Include as many relevant details about the environment you experienced the bug in -->
- Mypy version used: `mypy 1.0.0 (compiled: yes)`
- Mypy command-line flags: I used the _vscode extension_ [Mypy](https://marketplace.visualstudio.com/items?itemName=matangover.mypy)
- Mypy configuration options from `mypy.ini` (and other config files):
```toml
# Inside `pyproject.toml`...
[tool.mypy]
strict = true
warn_no_return = false
warn_return_any = false
disallow_untyped_defs = false
warn_incomplete_stub = false
disable_error_code = 'no-untyped-def,empty-body'
```
- Python version used: `Python 3.9.6`
- Operating system and version: `Windows 10 (version 10.0.19044 Build 19044)`
<!--
You can freely edit this text, please remove all the lines
you believe are unnecessary.
-->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mypy/errorcodes.py`
Content:
```
1 """Classification of possible errors mypy can detect.
2
3 These can be used for filtering specific errors.
4 """
5
6 from __future__ import annotations
7
8 from collections import defaultdict
9 from typing_extensions import Final
10
11 error_codes: dict[str, ErrorCode] = {}
12 sub_code_map: dict[str, set[str]] = defaultdict(set)
13
14
15 class ErrorCode:
16 def __init__(
17 self,
18 code: str,
19 description: str,
20 category: str,
21 default_enabled: bool = True,
22 sub_code_of: ErrorCode | None = None,
23 ) -> None:
24 self.code = code
25 self.description = description
26 self.category = category
27 self.default_enabled = default_enabled
28 self.sub_code_of = sub_code_of
29 if sub_code_of is not None:
30 assert sub_code_of.sub_code_of is None, "Nested subcategories are not supported"
31 sub_code_map[sub_code_of.code].add(code)
32 error_codes[code] = self
33
34 def __str__(self) -> str:
35 return f"<ErrorCode {self.code}>"
36
37
38 ATTR_DEFINED: Final = ErrorCode("attr-defined", "Check that attribute exists", "General")
39 NAME_DEFINED: Final = ErrorCode("name-defined", "Check that name is defined", "General")
40 CALL_ARG: Final[ErrorCode] = ErrorCode(
41 "call-arg", "Check number, names and kinds of arguments in calls", "General"
42 )
43 ARG_TYPE: Final = ErrorCode("arg-type", "Check argument types in calls", "General")
44 CALL_OVERLOAD: Final = ErrorCode(
45 "call-overload", "Check that an overload variant matches arguments", "General"
46 )
47 VALID_TYPE: Final[ErrorCode] = ErrorCode(
48 "valid-type", "Check that type (annotation) is valid", "General"
49 )
50 VAR_ANNOTATED: Final = ErrorCode(
51 "var-annotated", "Require variable annotation if type can't be inferred", "General"
52 )
53 OVERRIDE: Final = ErrorCode(
54 "override", "Check that method override is compatible with base class", "General"
55 )
56 RETURN: Final[ErrorCode] = ErrorCode(
57 "return", "Check that function always returns a value", "General"
58 )
59 RETURN_VALUE: Final[ErrorCode] = ErrorCode(
60 "return-value", "Check that return value is compatible with signature", "General"
61 )
62 ASSIGNMENT: Final[ErrorCode] = ErrorCode(
63 "assignment", "Check that assigned value is compatible with target", "General"
64 )
65 METHOD_ASSIGN: Final[ErrorCode] = ErrorCode(
66 "method-assign",
67 "Check that assignment target is not a method",
68 "General",
69 sub_code_of=ASSIGNMENT,
70 )
71 TYPE_ARG: Final = ErrorCode("type-arg", "Check that generic type arguments are present", "General")
72 TYPE_VAR: Final = ErrorCode("type-var", "Check that type variable values are valid", "General")
73 UNION_ATTR: Final = ErrorCode(
74 "union-attr", "Check that attribute exists in each item of a union", "General"
75 )
76 INDEX: Final = ErrorCode("index", "Check indexing operations", "General")
77 OPERATOR: Final = ErrorCode("operator", "Check that operator is valid for operands", "General")
78 LIST_ITEM: Final = ErrorCode(
79 "list-item", "Check list items in a list expression [item, ...]", "General"
80 )
81 DICT_ITEM: Final = ErrorCode(
82 "dict-item", "Check dict items in a dict expression {key: value, ...}", "General"
83 )
84 TYPEDDICT_ITEM: Final = ErrorCode(
85 "typeddict-item", "Check items when constructing TypedDict", "General"
86 )
87 TYPEDDICT_UNKNOWN_KEY: Final = ErrorCode(
88 "typeddict-unknown-key",
89 "Check unknown keys when constructing TypedDict",
90 "General",
91 sub_code_of=TYPEDDICT_ITEM,
92 )
93 HAS_TYPE: Final = ErrorCode(
94 "has-type", "Check that type of reference can be determined", "General"
95 )
96 IMPORT: Final = ErrorCode(
97 "import", "Require that imported module can be found or has stubs", "General"
98 )
99 NO_REDEF: Final = ErrorCode("no-redef", "Check that each name is defined once", "General")
100 FUNC_RETURNS_VALUE: Final = ErrorCode(
101 "func-returns-value", "Check that called function returns a value in value context", "General"
102 )
103 ABSTRACT: Final = ErrorCode(
104 "abstract", "Prevent instantiation of classes with abstract attributes", "General"
105 )
106 TYPE_ABSTRACT: Final = ErrorCode(
107 "type-abstract", "Require only concrete classes where Type[...] is expected", "General"
108 )
109 VALID_NEWTYPE: Final = ErrorCode(
110 "valid-newtype", "Check that argument 2 to NewType is valid", "General"
111 )
112 STRING_FORMATTING: Final = ErrorCode(
113 "str-format", "Check that string formatting/interpolation is type-safe", "General"
114 )
115 STR_BYTES_PY3: Final = ErrorCode(
116 "str-bytes-safe", "Warn about implicit coercions related to bytes and string types", "General"
117 )
118 EXIT_RETURN: Final = ErrorCode(
119 "exit-return", "Warn about too general return type for '__exit__'", "General"
120 )
121 LITERAL_REQ: Final = ErrorCode("literal-required", "Check that value is a literal", "General")
122 UNUSED_COROUTINE: Final = ErrorCode(
123 "unused-coroutine", "Ensure that all coroutines are used", "General"
124 )
125 # TODO: why do we need the explicit type here? Without it mypyc CI builds fail with
126 # mypy/message_registry.py:37: error: Cannot determine type of "EMPTY_BODY" [has-type]
127 EMPTY_BODY: Final[ErrorCode] = ErrorCode(
128 "empty-body",
129 "A dedicated error code to opt out return errors for empty/trivial bodies",
130 "General",
131 )
132 SAFE_SUPER: Final = ErrorCode(
133 "safe-super", "Warn about calls to abstract methods with empty/trivial bodies", "General"
134 )
135 TOP_LEVEL_AWAIT: Final = ErrorCode(
136 "top-level-await", "Warn about top level await experessions", "General"
137 )
138
139 # These error codes aren't enabled by default.
140 NO_UNTYPED_DEF: Final[ErrorCode] = ErrorCode(
141 "no-untyped-def", "Check that every function has an annotation", "General"
142 )
143 NO_UNTYPED_CALL: Final = ErrorCode(
144 "no-untyped-call",
145 "Disallow calling functions without type annotations from annotated functions",
146 "General",
147 )
148 REDUNDANT_CAST: Final = ErrorCode(
149 "redundant-cast", "Check that cast changes type of expression", "General"
150 )
151 ASSERT_TYPE: Final = ErrorCode("assert-type", "Check that assert_type() call succeeds", "General")
152 COMPARISON_OVERLAP: Final = ErrorCode(
153 "comparison-overlap", "Check that types in comparisons and 'in' expressions overlap", "General"
154 )
155 NO_ANY_UNIMPORTED: Final = ErrorCode(
156 "no-any-unimported", 'Reject "Any" types from unfollowed imports', "General"
157 )
158 NO_ANY_RETURN: Final = ErrorCode(
159 "no-any-return",
160 'Reject returning value with "Any" type if return type is not "Any"',
161 "General",
162 )
163 UNREACHABLE: Final = ErrorCode(
164 "unreachable", "Warn about unreachable statements or expressions", "General"
165 )
166 ANNOTATION_UNCHECKED = ErrorCode(
167 "annotation-unchecked", "Notify about type annotations in unchecked functions", "General"
168 )
169 POSSIBLY_UNDEFINED: Final[ErrorCode] = ErrorCode(
170 "possibly-undefined",
171 "Warn about variables that are defined only in some execution paths",
172 "General",
173 default_enabled=False,
174 )
175 REDUNDANT_EXPR: Final = ErrorCode(
176 "redundant-expr", "Warn about redundant expressions", "General", default_enabled=False
177 )
178 TRUTHY_BOOL: Final[ErrorCode] = ErrorCode(
179 "truthy-bool",
180 "Warn about expressions that could always evaluate to true in boolean contexts",
181 "General",
182 default_enabled=False,
183 )
184 TRUTHY_FUNCTION: Final[ErrorCode] = ErrorCode(
185 "truthy-function",
186 "Warn about function that always evaluate to true in boolean contexts",
187 "General",
188 )
189 TRUTHY_ITERABLE: Final[ErrorCode] = ErrorCode(
190 "truthy-iterable",
191 "Warn about Iterable expressions that could always evaluate to true in boolean contexts",
192 "General",
193 default_enabled=False,
194 )
195 NAME_MATCH: Final = ErrorCode(
196 "name-match", "Check that type definition has consistent naming", "General"
197 )
198 NO_OVERLOAD_IMPL: Final = ErrorCode(
199 "no-overload-impl",
200 "Check that overloaded functions outside stub files have an implementation",
201 "General",
202 )
203 IGNORE_WITHOUT_CODE: Final = ErrorCode(
204 "ignore-without-code",
205 "Warn about '# type: ignore' comments which do not have error codes",
206 "General",
207 default_enabled=False,
208 )
209 UNUSED_AWAITABLE: Final = ErrorCode(
210 "unused-awaitable",
211 "Ensure that all awaitable values are used",
212 "General",
213 default_enabled=False,
214 )
215 REDUNDANT_SELF_TYPE = ErrorCode(
216 "redundant-self",
217 "Warn about redundant Self type annotations on method first argument",
218 "General",
219 default_enabled=False,
220 )
221 USED_BEFORE_DEF: Final[ErrorCode] = ErrorCode(
222 "used-before-def", "Warn about variables that are used before they are defined", "General"
223 )
224 UNUSED_IGNORE: Final = ErrorCode(
225 "unused-ignore", "Ensure that all type ignores are used", "General", default_enabled=False
226 )
227
228
229 # Syntax errors are often blocking.
230 SYNTAX: Final[ErrorCode] = ErrorCode("syntax", "Report syntax errors", "General")
231
232 # This is an internal marker code for a whole-file ignore. It is not intended to
233 # be user-visible.
234 FILE: Final = ErrorCode("file", "Internal marker for a whole file being ignored", "General")
235 del error_codes[FILE.code]
236
237 # This is a catch-all for remaining uncategorized errors.
238 MISC: Final = ErrorCode("misc", "Miscellaneous other checks", "General")
239
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mypy/errorcodes.py b/mypy/errorcodes.py
--- a/mypy/errorcodes.py
+++ b/mypy/errorcodes.py
@@ -8,10 +8,13 @@
from collections import defaultdict
from typing_extensions import Final
+from mypy_extensions import mypyc_attr
+
error_codes: dict[str, ErrorCode] = {}
sub_code_map: dict[str, set[str]] = defaultdict(set)
+@mypyc_attr(serializable=True)
class ErrorCode:
def __init__(
self,
|
{"golden_diff": "diff --git a/mypy/errorcodes.py b/mypy/errorcodes.py\n--- a/mypy/errorcodes.py\n+++ b/mypy/errorcodes.py\n@@ -8,10 +8,13 @@\n from collections import defaultdict\n from typing_extensions import Final\n \n+from mypy_extensions import mypyc_attr\n+\n error_codes: dict[str, ErrorCode] = {}\n sub_code_map: dict[str, set[str]] = defaultdict(set)\n \n \n+@mypyc_attr(serializable=True)\n class ErrorCode:\n def __init__(\n self,\n", "issue": "Daemon `dmypy` crashes with `disable_error_code` configuration option\n## Description \r\nEvertything was working until i tried to disable some error codes using the `disable_error_code = 'no-untyped-def,empty-body'` option in the `pyproject.toml` file. \r\n\r\nAfter restarting the daemon, it crashed with the error `Timed out waiting for daemon to start`\r\n\r\n**Log**\r\n```\r\nMypy extension activated, version 0.2.3\r\nRegistering listener for interpreter changed event\r\nListener registered\r\n[1] Check folder: c:\\Users\\lucas\\Desktop\\myFolder\r\nActivation complete\r\n[1] Received python path from Python extension: C:\\Python39\\python.exe\r\n[1] Running dmypy in folder c:\\Users\\lucas\\Desktop\\myFolder\r\n'C:\\Python39\\Scripts\\dmypy.EXE' --status-file 'c:\\Users\\lucas\\AppData\\Roaming\\Code\\User\\workspaceStorage\\41737679a5dd5649bc304b3214d8b429\\matangover.mypy\\dmypy-6e071d9aa88ca0124b79d66d19a862665ea10e28-14032.json' run --log-file 'c:\\Users\\lucas\\AppData\\Roaming\\Code\\User\\workspaceStorage\\41737679a5dd5649bc304b3214d8b429\\matangover.mypy\\dmypy-6e071d9aa88ca0124b79d66d19a862665ea10e28.log' -- . --show-column-numbers --no-error-summary --no-pretty --no-color-output --python-executable 'C:\\Python39\\python.exe'\r\n[1] stderr:\r\nTimed out waiting for daemon to start\r\n\r\n[1] Error running mypy in c:\\Users\\lucas\\Desktop\\myFolder: mypy failed with error: \"Timed out waiting for daemon to start\r\n\". See Output panel for details.\r\n```\r\n\r\n**To Reproduce**\r\n\r\nUse the `disable_error_code` configuration option either in the `pyproject.toml` or in the `mypy.ini` files.\r\n\r\n**Your Environment**\r\n\r\n<!-- Include as many relevant details about the environment you experienced the bug in -->\r\n\r\n- Mypy version used: `mypy 1.0.0 (compiled: yes)`\r\n- Mypy command-line flags: I used the _vscode extension_ [Mypy](https://marketplace.visualstudio.com/items?itemName=matangover.mypy) \r\n- Mypy configuration options from `mypy.ini` (and other config files):\r\n ```toml\r\n # Inside `pyproject.toml`...\r\n [tool.mypy]\r\n strict = true\r\n warn_no_return = false\r\n warn_return_any = false\r\n disallow_untyped_defs = false\r\n warn_incomplete_stub = false\r\n \r\n disable_error_code = 'no-untyped-def,empty-body'\r\n ```\r\n- Python version used: `Python 3.9.6`\r\n- Operating system and version: `Windows 10 (version 10.0.19044 Build 19044)`\r\n\r\n<!--\r\nYou can freely edit this text, please remove all the lines\r\nyou believe are unnecessary.\r\n-->\r\n\n", "before_files": [{"content": "\"\"\"Classification of possible errors mypy can detect.\n\nThese can be used for filtering specific errors.\n\"\"\"\n\nfrom __future__ import annotations\n\nfrom collections import defaultdict\nfrom typing_extensions import Final\n\nerror_codes: dict[str, ErrorCode] = {}\nsub_code_map: dict[str, set[str]] = defaultdict(set)\n\n\nclass ErrorCode:\n def __init__(\n self,\n code: str,\n description: str,\n category: str,\n default_enabled: bool = True,\n sub_code_of: ErrorCode | None = None,\n ) -> None:\n self.code = code\n self.description = description\n self.category = category\n self.default_enabled = default_enabled\n self.sub_code_of = sub_code_of\n if sub_code_of is not None:\n assert sub_code_of.sub_code_of is None, \"Nested subcategories are not supported\"\n sub_code_map[sub_code_of.code].add(code)\n error_codes[code] = self\n\n def __str__(self) -> str:\n return f\"<ErrorCode {self.code}>\"\n\n\nATTR_DEFINED: Final = ErrorCode(\"attr-defined\", \"Check that attribute exists\", \"General\")\nNAME_DEFINED: Final = ErrorCode(\"name-defined\", \"Check that name is defined\", \"General\")\nCALL_ARG: Final[ErrorCode] = ErrorCode(\n \"call-arg\", \"Check number, names and kinds of arguments in calls\", \"General\"\n)\nARG_TYPE: Final = ErrorCode(\"arg-type\", \"Check argument types in calls\", \"General\")\nCALL_OVERLOAD: Final = ErrorCode(\n \"call-overload\", \"Check that an overload variant matches arguments\", \"General\"\n)\nVALID_TYPE: Final[ErrorCode] = ErrorCode(\n \"valid-type\", \"Check that type (annotation) is valid\", \"General\"\n)\nVAR_ANNOTATED: Final = ErrorCode(\n \"var-annotated\", \"Require variable annotation if type can't be inferred\", \"General\"\n)\nOVERRIDE: Final = ErrorCode(\n \"override\", \"Check that method override is compatible with base class\", \"General\"\n)\nRETURN: Final[ErrorCode] = ErrorCode(\n \"return\", \"Check that function always returns a value\", \"General\"\n)\nRETURN_VALUE: Final[ErrorCode] = ErrorCode(\n \"return-value\", \"Check that return value is compatible with signature\", \"General\"\n)\nASSIGNMENT: Final[ErrorCode] = ErrorCode(\n \"assignment\", \"Check that assigned value is compatible with target\", \"General\"\n)\nMETHOD_ASSIGN: Final[ErrorCode] = ErrorCode(\n \"method-assign\",\n \"Check that assignment target is not a method\",\n \"General\",\n sub_code_of=ASSIGNMENT,\n)\nTYPE_ARG: Final = ErrorCode(\"type-arg\", \"Check that generic type arguments are present\", \"General\")\nTYPE_VAR: Final = ErrorCode(\"type-var\", \"Check that type variable values are valid\", \"General\")\nUNION_ATTR: Final = ErrorCode(\n \"union-attr\", \"Check that attribute exists in each item of a union\", \"General\"\n)\nINDEX: Final = ErrorCode(\"index\", \"Check indexing operations\", \"General\")\nOPERATOR: Final = ErrorCode(\"operator\", \"Check that operator is valid for operands\", \"General\")\nLIST_ITEM: Final = ErrorCode(\n \"list-item\", \"Check list items in a list expression [item, ...]\", \"General\"\n)\nDICT_ITEM: Final = ErrorCode(\n \"dict-item\", \"Check dict items in a dict expression {key: value, ...}\", \"General\"\n)\nTYPEDDICT_ITEM: Final = ErrorCode(\n \"typeddict-item\", \"Check items when constructing TypedDict\", \"General\"\n)\nTYPEDDICT_UNKNOWN_KEY: Final = ErrorCode(\n \"typeddict-unknown-key\",\n \"Check unknown keys when constructing TypedDict\",\n \"General\",\n sub_code_of=TYPEDDICT_ITEM,\n)\nHAS_TYPE: Final = ErrorCode(\n \"has-type\", \"Check that type of reference can be determined\", \"General\"\n)\nIMPORT: Final = ErrorCode(\n \"import\", \"Require that imported module can be found or has stubs\", \"General\"\n)\nNO_REDEF: Final = ErrorCode(\"no-redef\", \"Check that each name is defined once\", \"General\")\nFUNC_RETURNS_VALUE: Final = ErrorCode(\n \"func-returns-value\", \"Check that called function returns a value in value context\", \"General\"\n)\nABSTRACT: Final = ErrorCode(\n \"abstract\", \"Prevent instantiation of classes with abstract attributes\", \"General\"\n)\nTYPE_ABSTRACT: Final = ErrorCode(\n \"type-abstract\", \"Require only concrete classes where Type[...] is expected\", \"General\"\n)\nVALID_NEWTYPE: Final = ErrorCode(\n \"valid-newtype\", \"Check that argument 2 to NewType is valid\", \"General\"\n)\nSTRING_FORMATTING: Final = ErrorCode(\n \"str-format\", \"Check that string formatting/interpolation is type-safe\", \"General\"\n)\nSTR_BYTES_PY3: Final = ErrorCode(\n \"str-bytes-safe\", \"Warn about implicit coercions related to bytes and string types\", \"General\"\n)\nEXIT_RETURN: Final = ErrorCode(\n \"exit-return\", \"Warn about too general return type for '__exit__'\", \"General\"\n)\nLITERAL_REQ: Final = ErrorCode(\"literal-required\", \"Check that value is a literal\", \"General\")\nUNUSED_COROUTINE: Final = ErrorCode(\n \"unused-coroutine\", \"Ensure that all coroutines are used\", \"General\"\n)\n# TODO: why do we need the explicit type here? Without it mypyc CI builds fail with\n# mypy/message_registry.py:37: error: Cannot determine type of \"EMPTY_BODY\" [has-type]\nEMPTY_BODY: Final[ErrorCode] = ErrorCode(\n \"empty-body\",\n \"A dedicated error code to opt out return errors for empty/trivial bodies\",\n \"General\",\n)\nSAFE_SUPER: Final = ErrorCode(\n \"safe-super\", \"Warn about calls to abstract methods with empty/trivial bodies\", \"General\"\n)\nTOP_LEVEL_AWAIT: Final = ErrorCode(\n \"top-level-await\", \"Warn about top level await experessions\", \"General\"\n)\n\n# These error codes aren't enabled by default.\nNO_UNTYPED_DEF: Final[ErrorCode] = ErrorCode(\n \"no-untyped-def\", \"Check that every function has an annotation\", \"General\"\n)\nNO_UNTYPED_CALL: Final = ErrorCode(\n \"no-untyped-call\",\n \"Disallow calling functions without type annotations from annotated functions\",\n \"General\",\n)\nREDUNDANT_CAST: Final = ErrorCode(\n \"redundant-cast\", \"Check that cast changes type of expression\", \"General\"\n)\nASSERT_TYPE: Final = ErrorCode(\"assert-type\", \"Check that assert_type() call succeeds\", \"General\")\nCOMPARISON_OVERLAP: Final = ErrorCode(\n \"comparison-overlap\", \"Check that types in comparisons and 'in' expressions overlap\", \"General\"\n)\nNO_ANY_UNIMPORTED: Final = ErrorCode(\n \"no-any-unimported\", 'Reject \"Any\" types from unfollowed imports', \"General\"\n)\nNO_ANY_RETURN: Final = ErrorCode(\n \"no-any-return\",\n 'Reject returning value with \"Any\" type if return type is not \"Any\"',\n \"General\",\n)\nUNREACHABLE: Final = ErrorCode(\n \"unreachable\", \"Warn about unreachable statements or expressions\", \"General\"\n)\nANNOTATION_UNCHECKED = ErrorCode(\n \"annotation-unchecked\", \"Notify about type annotations in unchecked functions\", \"General\"\n)\nPOSSIBLY_UNDEFINED: Final[ErrorCode] = ErrorCode(\n \"possibly-undefined\",\n \"Warn about variables that are defined only in some execution paths\",\n \"General\",\n default_enabled=False,\n)\nREDUNDANT_EXPR: Final = ErrorCode(\n \"redundant-expr\", \"Warn about redundant expressions\", \"General\", default_enabled=False\n)\nTRUTHY_BOOL: Final[ErrorCode] = ErrorCode(\n \"truthy-bool\",\n \"Warn about expressions that could always evaluate to true in boolean contexts\",\n \"General\",\n default_enabled=False,\n)\nTRUTHY_FUNCTION: Final[ErrorCode] = ErrorCode(\n \"truthy-function\",\n \"Warn about function that always evaluate to true in boolean contexts\",\n \"General\",\n)\nTRUTHY_ITERABLE: Final[ErrorCode] = ErrorCode(\n \"truthy-iterable\",\n \"Warn about Iterable expressions that could always evaluate to true in boolean contexts\",\n \"General\",\n default_enabled=False,\n)\nNAME_MATCH: Final = ErrorCode(\n \"name-match\", \"Check that type definition has consistent naming\", \"General\"\n)\nNO_OVERLOAD_IMPL: Final = ErrorCode(\n \"no-overload-impl\",\n \"Check that overloaded functions outside stub files have an implementation\",\n \"General\",\n)\nIGNORE_WITHOUT_CODE: Final = ErrorCode(\n \"ignore-without-code\",\n \"Warn about '# type: ignore' comments which do not have error codes\",\n \"General\",\n default_enabled=False,\n)\nUNUSED_AWAITABLE: Final = ErrorCode(\n \"unused-awaitable\",\n \"Ensure that all awaitable values are used\",\n \"General\",\n default_enabled=False,\n)\nREDUNDANT_SELF_TYPE = ErrorCode(\n \"redundant-self\",\n \"Warn about redundant Self type annotations on method first argument\",\n \"General\",\n default_enabled=False,\n)\nUSED_BEFORE_DEF: Final[ErrorCode] = ErrorCode(\n \"used-before-def\", \"Warn about variables that are used before they are defined\", \"General\"\n)\nUNUSED_IGNORE: Final = ErrorCode(\n \"unused-ignore\", \"Ensure that all type ignores are used\", \"General\", default_enabled=False\n)\n\n\n# Syntax errors are often blocking.\nSYNTAX: Final[ErrorCode] = ErrorCode(\"syntax\", \"Report syntax errors\", \"General\")\n\n# This is an internal marker code for a whole-file ignore. It is not intended to\n# be user-visible.\nFILE: Final = ErrorCode(\"file\", \"Internal marker for a whole file being ignored\", \"General\")\ndel error_codes[FILE.code]\n\n# This is a catch-all for remaining uncategorized errors.\nMISC: Final = ErrorCode(\"misc\", \"Miscellaneous other checks\", \"General\")\n", "path": "mypy/errorcodes.py"}], "after_files": [{"content": "\"\"\"Classification of possible errors mypy can detect.\n\nThese can be used for filtering specific errors.\n\"\"\"\n\nfrom __future__ import annotations\n\nfrom collections import defaultdict\nfrom typing_extensions import Final\n\nfrom mypy_extensions import mypyc_attr\n\nerror_codes: dict[str, ErrorCode] = {}\nsub_code_map: dict[str, set[str]] = defaultdict(set)\n\n\n@mypyc_attr(serializable=True)\nclass ErrorCode:\n def __init__(\n self,\n code: str,\n description: str,\n category: str,\n default_enabled: bool = True,\n sub_code_of: ErrorCode | None = None,\n ) -> None:\n self.code = code\n self.description = description\n self.category = category\n self.default_enabled = default_enabled\n self.sub_code_of = sub_code_of\n if sub_code_of is not None:\n assert sub_code_of.sub_code_of is None, \"Nested subcategories are not supported\"\n sub_code_map[sub_code_of.code].add(code)\n error_codes[code] = self\n\n def __str__(self) -> str:\n return f\"<ErrorCode {self.code}>\"\n\n\nATTR_DEFINED: Final = ErrorCode(\"attr-defined\", \"Check that attribute exists\", \"General\")\nNAME_DEFINED: Final = ErrorCode(\"name-defined\", \"Check that name is defined\", \"General\")\nCALL_ARG: Final[ErrorCode] = ErrorCode(\n \"call-arg\", \"Check number, names and kinds of arguments in calls\", \"General\"\n)\nARG_TYPE: Final = ErrorCode(\"arg-type\", \"Check argument types in calls\", \"General\")\nCALL_OVERLOAD: Final = ErrorCode(\n \"call-overload\", \"Check that an overload variant matches arguments\", \"General\"\n)\nVALID_TYPE: Final[ErrorCode] = ErrorCode(\n \"valid-type\", \"Check that type (annotation) is valid\", \"General\"\n)\nVAR_ANNOTATED: Final = ErrorCode(\n \"var-annotated\", \"Require variable annotation if type can't be inferred\", \"General\"\n)\nOVERRIDE: Final = ErrorCode(\n \"override\", \"Check that method override is compatible with base class\", \"General\"\n)\nRETURN: Final[ErrorCode] = ErrorCode(\n \"return\", \"Check that function always returns a value\", \"General\"\n)\nRETURN_VALUE: Final[ErrorCode] = ErrorCode(\n \"return-value\", \"Check that return value is compatible with signature\", \"General\"\n)\nASSIGNMENT: Final[ErrorCode] = ErrorCode(\n \"assignment\", \"Check that assigned value is compatible with target\", \"General\"\n)\nMETHOD_ASSIGN: Final[ErrorCode] = ErrorCode(\n \"method-assign\",\n \"Check that assignment target is not a method\",\n \"General\",\n sub_code_of=ASSIGNMENT,\n)\nTYPE_ARG: Final = ErrorCode(\"type-arg\", \"Check that generic type arguments are present\", \"General\")\nTYPE_VAR: Final = ErrorCode(\"type-var\", \"Check that type variable values are valid\", \"General\")\nUNION_ATTR: Final = ErrorCode(\n \"union-attr\", \"Check that attribute exists in each item of a union\", \"General\"\n)\nINDEX: Final = ErrorCode(\"index\", \"Check indexing operations\", \"General\")\nOPERATOR: Final = ErrorCode(\"operator\", \"Check that operator is valid for operands\", \"General\")\nLIST_ITEM: Final = ErrorCode(\n \"list-item\", \"Check list items in a list expression [item, ...]\", \"General\"\n)\nDICT_ITEM: Final = ErrorCode(\n \"dict-item\", \"Check dict items in a dict expression {key: value, ...}\", \"General\"\n)\nTYPEDDICT_ITEM: Final = ErrorCode(\n \"typeddict-item\", \"Check items when constructing TypedDict\", \"General\"\n)\nTYPEDDICT_UNKNOWN_KEY: Final = ErrorCode(\n \"typeddict-unknown-key\",\n \"Check unknown keys when constructing TypedDict\",\n \"General\",\n sub_code_of=TYPEDDICT_ITEM,\n)\nHAS_TYPE: Final = ErrorCode(\n \"has-type\", \"Check that type of reference can be determined\", \"General\"\n)\nIMPORT: Final = ErrorCode(\n \"import\", \"Require that imported module can be found or has stubs\", \"General\"\n)\nNO_REDEF: Final = ErrorCode(\"no-redef\", \"Check that each name is defined once\", \"General\")\nFUNC_RETURNS_VALUE: Final = ErrorCode(\n \"func-returns-value\", \"Check that called function returns a value in value context\", \"General\"\n)\nABSTRACT: Final = ErrorCode(\n \"abstract\", \"Prevent instantiation of classes with abstract attributes\", \"General\"\n)\nTYPE_ABSTRACT: Final = ErrorCode(\n \"type-abstract\", \"Require only concrete classes where Type[...] is expected\", \"General\"\n)\nVALID_NEWTYPE: Final = ErrorCode(\n \"valid-newtype\", \"Check that argument 2 to NewType is valid\", \"General\"\n)\nSTRING_FORMATTING: Final = ErrorCode(\n \"str-format\", \"Check that string formatting/interpolation is type-safe\", \"General\"\n)\nSTR_BYTES_PY3: Final = ErrorCode(\n \"str-bytes-safe\", \"Warn about implicit coercions related to bytes and string types\", \"General\"\n)\nEXIT_RETURN: Final = ErrorCode(\n \"exit-return\", \"Warn about too general return type for '__exit__'\", \"General\"\n)\nLITERAL_REQ: Final = ErrorCode(\"literal-required\", \"Check that value is a literal\", \"General\")\nUNUSED_COROUTINE: Final = ErrorCode(\n \"unused-coroutine\", \"Ensure that all coroutines are used\", \"General\"\n)\n# TODO: why do we need the explicit type here? Without it mypyc CI builds fail with\n# mypy/message_registry.py:37: error: Cannot determine type of \"EMPTY_BODY\" [has-type]\nEMPTY_BODY: Final[ErrorCode] = ErrorCode(\n \"empty-body\",\n \"A dedicated error code to opt out return errors for empty/trivial bodies\",\n \"General\",\n)\nSAFE_SUPER: Final = ErrorCode(\n \"safe-super\", \"Warn about calls to abstract methods with empty/trivial bodies\", \"General\"\n)\nTOP_LEVEL_AWAIT: Final = ErrorCode(\n \"top-level-await\", \"Warn about top level await experessions\", \"General\"\n)\n\n# These error codes aren't enabled by default.\nNO_UNTYPED_DEF: Final[ErrorCode] = ErrorCode(\n \"no-untyped-def\", \"Check that every function has an annotation\", \"General\"\n)\nNO_UNTYPED_CALL: Final = ErrorCode(\n \"no-untyped-call\",\n \"Disallow calling functions without type annotations from annotated functions\",\n \"General\",\n)\nREDUNDANT_CAST: Final = ErrorCode(\n \"redundant-cast\", \"Check that cast changes type of expression\", \"General\"\n)\nASSERT_TYPE: Final = ErrorCode(\"assert-type\", \"Check that assert_type() call succeeds\", \"General\")\nCOMPARISON_OVERLAP: Final = ErrorCode(\n \"comparison-overlap\", \"Check that types in comparisons and 'in' expressions overlap\", \"General\"\n)\nNO_ANY_UNIMPORTED: Final = ErrorCode(\n \"no-any-unimported\", 'Reject \"Any\" types from unfollowed imports', \"General\"\n)\nNO_ANY_RETURN: Final = ErrorCode(\n \"no-any-return\",\n 'Reject returning value with \"Any\" type if return type is not \"Any\"',\n \"General\",\n)\nUNREACHABLE: Final = ErrorCode(\n \"unreachable\", \"Warn about unreachable statements or expressions\", \"General\"\n)\nANNOTATION_UNCHECKED = ErrorCode(\n \"annotation-unchecked\", \"Notify about type annotations in unchecked functions\", \"General\"\n)\nPOSSIBLY_UNDEFINED: Final[ErrorCode] = ErrorCode(\n \"possibly-undefined\",\n \"Warn about variables that are defined only in some execution paths\",\n \"General\",\n default_enabled=False,\n)\nREDUNDANT_EXPR: Final = ErrorCode(\n \"redundant-expr\", \"Warn about redundant expressions\", \"General\", default_enabled=False\n)\nTRUTHY_BOOL: Final[ErrorCode] = ErrorCode(\n \"truthy-bool\",\n \"Warn about expressions that could always evaluate to true in boolean contexts\",\n \"General\",\n default_enabled=False,\n)\nTRUTHY_FUNCTION: Final[ErrorCode] = ErrorCode(\n \"truthy-function\",\n \"Warn about function that always evaluate to true in boolean contexts\",\n \"General\",\n)\nTRUTHY_ITERABLE: Final[ErrorCode] = ErrorCode(\n \"truthy-iterable\",\n \"Warn about Iterable expressions that could always evaluate to true in boolean contexts\",\n \"General\",\n default_enabled=False,\n)\nNAME_MATCH: Final = ErrorCode(\n \"name-match\", \"Check that type definition has consistent naming\", \"General\"\n)\nNO_OVERLOAD_IMPL: Final = ErrorCode(\n \"no-overload-impl\",\n \"Check that overloaded functions outside stub files have an implementation\",\n \"General\",\n)\nIGNORE_WITHOUT_CODE: Final = ErrorCode(\n \"ignore-without-code\",\n \"Warn about '# type: ignore' comments which do not have error codes\",\n \"General\",\n default_enabled=False,\n)\nUNUSED_AWAITABLE: Final = ErrorCode(\n \"unused-awaitable\",\n \"Ensure that all awaitable values are used\",\n \"General\",\n default_enabled=False,\n)\nREDUNDANT_SELF_TYPE = ErrorCode(\n \"redundant-self\",\n \"Warn about redundant Self type annotations on method first argument\",\n \"General\",\n default_enabled=False,\n)\nUSED_BEFORE_DEF: Final[ErrorCode] = ErrorCode(\n \"used-before-def\", \"Warn about variables that are used before they are defined\", \"General\"\n)\nUNUSED_IGNORE: Final = ErrorCode(\n \"unused-ignore\", \"Ensure that all type ignores are used\", \"General\", default_enabled=False\n)\n\n\n# Syntax errors are often blocking.\nSYNTAX: Final[ErrorCode] = ErrorCode(\"syntax\", \"Report syntax errors\", \"General\")\n\n# This is an internal marker code for a whole-file ignore. It is not intended to\n# be user-visible.\nFILE: Final = ErrorCode(\"file\", \"Internal marker for a whole file being ignored\", \"General\")\ndel error_codes[FILE.code]\n\n# This is a catch-all for remaining uncategorized errors.\nMISC: Final = ErrorCode(\"misc\", \"Miscellaneous other checks\", \"General\")\n", "path": "mypy/errorcodes.py"}]}
| 3,743 | 112 |
gh_patches_debug_34083
|
rasdani/github-patches
|
git_diff
|
Nitrate__Nitrate-532
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Replace deprecated inspect.getargspec call in log_call
`inspect.getargspec` has been deprecated. Replace it with equivalent function call.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/tcms/xmlrpc/decorators.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 import inspect
4 import logging
5
6 from functools import wraps
7
8 from django.conf import settings
9 from kobo.django.xmlrpc.models import XmlRpcLog
10
11
12 __all__ = ('log_call',)
13
14 logger = logging.getLogger('nitrate.xmlrpc')
15
16 if settings.DEBUG:
17 # To avoid pollute XMLRPC logs with those generated during development
18 def create_log(user, method, args):
19 log_msg = 'user: {}, method: {}, args: {}'.format(
20 user.username if hasattr(user, 'username') else user,
21 method,
22 args)
23 logger.debug(log_msg)
24 else:
25 create_log = XmlRpcLog.objects.create
26
27
28 def log_call(*args, **kwargs):
29 """Log XMLRPC-specific invocations
30
31 This is copied from kobo.django.xmlrpc.decorators to add custom abitlities,
32 so that we don't have to wait upstream to make the changes.
33
34 Usage::
35
36 from tcms.core.decorators import log_call
37 @log_call(namespace='TestNamespace')
38 def func(request):
39 return None
40 """
41 namespace = kwargs.get('namespace', '')
42 if namespace:
43 namespace = namespace + '.'
44
45 def decorator(function):
46 argspec = inspect.getargspec(function)
47 # Each XMLRPC method has an HttpRequest argument as the first one,
48 # it'll be ignored in the log.
49 arg_names = argspec.args[1:]
50
51 @wraps(function)
52 def _new_function(request, *args, **kwargs):
53 try:
54 known_args = zip(arg_names, args)
55 unknown_args = list(enumerate(args[len(arg_names):]))
56 keyword_args = [(key, value) for key, value in
57 kwargs.items()
58 if (key, value) not in known_args]
59
60 create_log(user=request.user,
61 method=f'{namespace}{function.__name__}',
62 args=str(known_args + unknown_args + keyword_args))
63 except Exception:
64 pass
65 return function(request, *args, **kwargs)
66
67 return _new_function
68
69 return decorator
70
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/tcms/xmlrpc/decorators.py b/src/tcms/xmlrpc/decorators.py
--- a/src/tcms/xmlrpc/decorators.py
+++ b/src/tcms/xmlrpc/decorators.py
@@ -28,7 +28,7 @@
def log_call(*args, **kwargs):
"""Log XMLRPC-specific invocations
- This is copied from kobo.django.xmlrpc.decorators to add custom abitlities,
+ This is copied from kobo.django.xmlrpc.decorators to add custom abilities,
so that we don't have to wait upstream to make the changes.
Usage::
@@ -43,7 +43,7 @@
namespace = namespace + '.'
def decorator(function):
- argspec = inspect.getargspec(function)
+ argspec = inspect.getfullargspec(function)
# Each XMLRPC method has an HttpRequest argument as the first one,
# it'll be ignored in the log.
arg_names = argspec.args[1:]
@@ -51,17 +51,19 @@
@wraps(function)
def _new_function(request, *args, **kwargs):
try:
- known_args = zip(arg_names, args)
+ known_args = list(zip(arg_names, args))
unknown_args = list(enumerate(args[len(arg_names):]))
- keyword_args = [(key, value) for key, value in
- kwargs.items()
- if (key, value) not in known_args]
+ keyword_args = [
+ (key, value) for key, value in kwargs.items()
+ if (key, value) not in known_args
+ ]
create_log(user=request.user,
method=f'{namespace}{function.__name__}',
args=str(known_args + unknown_args + keyword_args))
except Exception:
- pass
+ logger.exception(
+ f'Fail to log XMLRPC call on {function.__name__}')
return function(request, *args, **kwargs)
return _new_function
|
{"golden_diff": "diff --git a/src/tcms/xmlrpc/decorators.py b/src/tcms/xmlrpc/decorators.py\n--- a/src/tcms/xmlrpc/decorators.py\n+++ b/src/tcms/xmlrpc/decorators.py\n@@ -28,7 +28,7 @@\n def log_call(*args, **kwargs):\n \"\"\"Log XMLRPC-specific invocations\n \n- This is copied from kobo.django.xmlrpc.decorators to add custom abitlities,\n+ This is copied from kobo.django.xmlrpc.decorators to add custom abilities,\n so that we don't have to wait upstream to make the changes.\n \n Usage::\n@@ -43,7 +43,7 @@\n namespace = namespace + '.'\n \n def decorator(function):\n- argspec = inspect.getargspec(function)\n+ argspec = inspect.getfullargspec(function)\n # Each XMLRPC method has an HttpRequest argument as the first one,\n # it'll be ignored in the log.\n arg_names = argspec.args[1:]\n@@ -51,17 +51,19 @@\n @wraps(function)\n def _new_function(request, *args, **kwargs):\n try:\n- known_args = zip(arg_names, args)\n+ known_args = list(zip(arg_names, args))\n unknown_args = list(enumerate(args[len(arg_names):]))\n- keyword_args = [(key, value) for key, value in\n- kwargs.items()\n- if (key, value) not in known_args]\n+ keyword_args = [\n+ (key, value) for key, value in kwargs.items()\n+ if (key, value) not in known_args\n+ ]\n \n create_log(user=request.user,\n method=f'{namespace}{function.__name__}',\n args=str(known_args + unknown_args + keyword_args))\n except Exception:\n- pass\n+ logger.exception(\n+ f'Fail to log XMLRPC call on {function.__name__}')\n return function(request, *args, **kwargs)\n \n return _new_function\n", "issue": "Replace deprecated inspect.getargspec call in log_call\n`inspect.getargspec` has been deprecated. Replace it with equivalent function call.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport inspect\nimport logging\n\nfrom functools import wraps\n\nfrom django.conf import settings\nfrom kobo.django.xmlrpc.models import XmlRpcLog\n\n\n__all__ = ('log_call',)\n\nlogger = logging.getLogger('nitrate.xmlrpc')\n\nif settings.DEBUG:\n # To avoid pollute XMLRPC logs with those generated during development\n def create_log(user, method, args):\n log_msg = 'user: {}, method: {}, args: {}'.format(\n user.username if hasattr(user, 'username') else user,\n method,\n args)\n logger.debug(log_msg)\nelse:\n create_log = XmlRpcLog.objects.create\n\n\ndef log_call(*args, **kwargs):\n \"\"\"Log XMLRPC-specific invocations\n\n This is copied from kobo.django.xmlrpc.decorators to add custom abitlities,\n so that we don't have to wait upstream to make the changes.\n\n Usage::\n\n from tcms.core.decorators import log_call\n @log_call(namespace='TestNamespace')\n def func(request):\n return None\n \"\"\"\n namespace = kwargs.get('namespace', '')\n if namespace:\n namespace = namespace + '.'\n\n def decorator(function):\n argspec = inspect.getargspec(function)\n # Each XMLRPC method has an HttpRequest argument as the first one,\n # it'll be ignored in the log.\n arg_names = argspec.args[1:]\n\n @wraps(function)\n def _new_function(request, *args, **kwargs):\n try:\n known_args = zip(arg_names, args)\n unknown_args = list(enumerate(args[len(arg_names):]))\n keyword_args = [(key, value) for key, value in\n kwargs.items()\n if (key, value) not in known_args]\n\n create_log(user=request.user,\n method=f'{namespace}{function.__name__}',\n args=str(known_args + unknown_args + keyword_args))\n except Exception:\n pass\n return function(request, *args, **kwargs)\n\n return _new_function\n\n return decorator\n", "path": "src/tcms/xmlrpc/decorators.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport inspect\nimport logging\n\nfrom functools import wraps\n\nfrom django.conf import settings\nfrom kobo.django.xmlrpc.models import XmlRpcLog\n\n\n__all__ = ('log_call',)\n\nlogger = logging.getLogger('nitrate.xmlrpc')\n\nif settings.DEBUG:\n # To avoid pollute XMLRPC logs with those generated during development\n def create_log(user, method, args):\n log_msg = 'user: {}, method: {}, args: {}'.format(\n user.username if hasattr(user, 'username') else user,\n method,\n args)\n logger.debug(log_msg)\nelse:\n create_log = XmlRpcLog.objects.create\n\n\ndef log_call(*args, **kwargs):\n \"\"\"Log XMLRPC-specific invocations\n\n This is copied from kobo.django.xmlrpc.decorators to add custom abilities,\n so that we don't have to wait upstream to make the changes.\n\n Usage::\n\n from tcms.core.decorators import log_call\n @log_call(namespace='TestNamespace')\n def func(request):\n return None\n \"\"\"\n namespace = kwargs.get('namespace', '')\n if namespace:\n namespace = namespace + '.'\n\n def decorator(function):\n argspec = inspect.getfullargspec(function)\n # Each XMLRPC method has an HttpRequest argument as the first one,\n # it'll be ignored in the log.\n arg_names = argspec.args[1:]\n\n @wraps(function)\n def _new_function(request, *args, **kwargs):\n try:\n known_args = list(zip(arg_names, args))\n unknown_args = list(enumerate(args[len(arg_names):]))\n keyword_args = [\n (key, value) for key, value in kwargs.items()\n if (key, value) not in known_args\n ]\n\n create_log(user=request.user,\n method=f'{namespace}{function.__name__}',\n args=str(known_args + unknown_args + keyword_args))\n except Exception:\n logger.exception(\n f'Fail to log XMLRPC call on {function.__name__}')\n return function(request, *args, **kwargs)\n\n return _new_function\n\n return decorator\n", "path": "src/tcms/xmlrpc/decorators.py"}]}
| 868 | 442 |
gh_patches_debug_5812
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-713
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Typo in wagtailforms.forms.FormBuilder.formfields
Line 86:
``` python
raise Exception("Unrecognised field type: " + form.field_type)
```
This raises `NameError: global name 'form' is not defined`
Ordinarily the flow of things wouldn't run into this line, but I was caught out when badly naming a form field in the json fixtures.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `wagtail/wagtailforms/forms.py`
Content:
```
1 import django.forms
2 from django.utils.datastructures import SortedDict
3
4
5 class BaseForm(django.forms.Form):
6 def __init__(self, *args, **kwargs):
7 kwargs.setdefault('label_suffix', '')
8 return super(BaseForm, self).__init__(*args, **kwargs)
9
10
11 class FormBuilder(object):
12 def __init__(self, fields):
13 self.fields = fields
14
15 def create_singleline_field(self, field, options):
16 # TODO: This is a default value - it may need to be changed
17 options['max_length'] = 255
18 return django.forms.CharField(**options)
19
20 def create_multiline_field(self, field, options):
21 return django.forms.CharField(widget=django.forms.Textarea, **options)
22
23 def create_date_field(self, field, options):
24 return django.forms.DateField(**options)
25
26 def create_datetime_field(self, field, options):
27 return django.forms.DateTimeField(**options)
28
29 def create_email_field(self, field, options):
30 return django.forms.EmailField(**options)
31
32 def create_url_field(self, field, options):
33 return django.forms.URLField(**options)
34
35 def create_number_field(self, field, options):
36 return django.forms.DecimalField(**options)
37
38 def create_dropdown_field(self, field, options):
39 options['choices'] = map(
40 lambda x: (x.strip(), x.strip()),
41 field.choices.split(',')
42 )
43 return django.forms.ChoiceField(**options)
44
45 def create_radio_field(self, field, options):
46 options['choices'] = map(
47 lambda x: (x.strip(), x.strip()),
48 field.choices.split(',')
49 )
50 return django.forms.ChoiceField(widget=django.forms.RadioSelect, **options)
51
52 def create_checkboxes_field(self, field, options):
53 options['choices'] = [(x.strip(), x.strip()) for x in field.choices.split(',')]
54 options['initial'] = [x.strip() for x in field.default_value.split(',')]
55 return django.forms.MultipleChoiceField(
56 widget=django.forms.CheckboxSelectMultiple, **options
57 )
58
59 def create_checkbox_field(self, field, options):
60 return django.forms.BooleanField(**options)
61
62 FIELD_TYPES = {
63 'singleline': create_singleline_field,
64 'multiline': create_multiline_field,
65 'date': create_date_field,
66 'datetime': create_datetime_field,
67 'email': create_email_field,
68 'url': create_url_field,
69 'number': create_number_field,
70 'dropdown': create_dropdown_field,
71 'radio': create_radio_field,
72 'checkboxes': create_checkboxes_field,
73 'checkbox': create_checkbox_field,
74 }
75
76 @property
77 def formfields(self):
78 formfields = SortedDict()
79
80 for field in self.fields:
81 options = self.get_field_options(field)
82
83 if field.field_type in self.FIELD_TYPES:
84 formfields[field.clean_name] = self.FIELD_TYPES[field.field_type](self, field, options)
85 else:
86 raise Exception("Unrecognised field type: " + form.field_type)
87
88 return formfields
89
90 def get_field_options(self, field):
91 options = {}
92 options['label'] = field.label
93 options['help_text'] = field.help_text
94 options['required'] = field.required
95 options['initial'] = field.default_value
96 return options
97
98 def get_form_class(self):
99 return type('WagtailForm', (BaseForm,), self.formfields)
100
101
102 class SelectDateForm(django.forms.Form):
103 date_from = django.forms.DateTimeField(
104 required=False,
105 widget=django.forms.DateInput(attrs={'placeholder': 'Date from'})
106 )
107 date_to = django.forms.DateTimeField(
108 required=False,
109 widget=django.forms.DateInput(attrs={'placeholder': 'Date to'})
110 )
111
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/wagtail/wagtailforms/forms.py b/wagtail/wagtailforms/forms.py
--- a/wagtail/wagtailforms/forms.py
+++ b/wagtail/wagtailforms/forms.py
@@ -83,7 +83,7 @@
if field.field_type in self.FIELD_TYPES:
formfields[field.clean_name] = self.FIELD_TYPES[field.field_type](self, field, options)
else:
- raise Exception("Unrecognised field type: " + form.field_type)
+ raise Exception("Unrecognised field type: " + field.field_type)
return formfields
|
{"golden_diff": "diff --git a/wagtail/wagtailforms/forms.py b/wagtail/wagtailforms/forms.py\n--- a/wagtail/wagtailforms/forms.py\n+++ b/wagtail/wagtailforms/forms.py\n@@ -83,7 +83,7 @@\n if field.field_type in self.FIELD_TYPES:\n formfields[field.clean_name] = self.FIELD_TYPES[field.field_type](self, field, options)\n else:\n- raise Exception(\"Unrecognised field type: \" + form.field_type)\n+ raise Exception(\"Unrecognised field type: \" + field.field_type)\n \n return formfields\n", "issue": "Typo in wagtailforms.forms.FormBuilder.formfields\nLine 86:\n\n``` python\nraise Exception(\"Unrecognised field type: \" + form.field_type)\n```\n\nThis raises `NameError: global name 'form' is not defined`\n\nOrdinarily the flow of things wouldn't run into this line, but I was caught out when badly naming a form field in the json fixtures.\n\n", "before_files": [{"content": "import django.forms\nfrom django.utils.datastructures import SortedDict\n\n\nclass BaseForm(django.forms.Form):\n def __init__(self, *args, **kwargs):\n kwargs.setdefault('label_suffix', '')\n return super(BaseForm, self).__init__(*args, **kwargs)\n\n\nclass FormBuilder(object):\n def __init__(self, fields):\n self.fields = fields\n\n def create_singleline_field(self, field, options):\n # TODO: This is a default value - it may need to be changed\n options['max_length'] = 255\n return django.forms.CharField(**options)\n\n def create_multiline_field(self, field, options):\n return django.forms.CharField(widget=django.forms.Textarea, **options)\n\n def create_date_field(self, field, options):\n return django.forms.DateField(**options)\n\n def create_datetime_field(self, field, options):\n return django.forms.DateTimeField(**options)\n\n def create_email_field(self, field, options):\n return django.forms.EmailField(**options)\n\n def create_url_field(self, field, options):\n return django.forms.URLField(**options)\n\n def create_number_field(self, field, options):\n return django.forms.DecimalField(**options)\n\n def create_dropdown_field(self, field, options):\n options['choices'] = map(\n lambda x: (x.strip(), x.strip()),\n field.choices.split(',')\n )\n return django.forms.ChoiceField(**options)\n\n def create_radio_field(self, field, options):\n options['choices'] = map(\n lambda x: (x.strip(), x.strip()),\n field.choices.split(',')\n )\n return django.forms.ChoiceField(widget=django.forms.RadioSelect, **options)\n\n def create_checkboxes_field(self, field, options):\n options['choices'] = [(x.strip(), x.strip()) for x in field.choices.split(',')]\n options['initial'] = [x.strip() for x in field.default_value.split(',')]\n return django.forms.MultipleChoiceField(\n widget=django.forms.CheckboxSelectMultiple, **options\n )\n\n def create_checkbox_field(self, field, options):\n return django.forms.BooleanField(**options)\n\n FIELD_TYPES = {\n 'singleline': create_singleline_field,\n 'multiline': create_multiline_field,\n 'date': create_date_field,\n 'datetime': create_datetime_field,\n 'email': create_email_field,\n 'url': create_url_field,\n 'number': create_number_field,\n 'dropdown': create_dropdown_field,\n 'radio': create_radio_field,\n 'checkboxes': create_checkboxes_field,\n 'checkbox': create_checkbox_field,\n }\n\n @property\n def formfields(self):\n formfields = SortedDict()\n\n for field in self.fields:\n options = self.get_field_options(field)\n\n if field.field_type in self.FIELD_TYPES:\n formfields[field.clean_name] = self.FIELD_TYPES[field.field_type](self, field, options)\n else:\n raise Exception(\"Unrecognised field type: \" + form.field_type)\n\n return formfields\n\n def get_field_options(self, field):\n options = {}\n options['label'] = field.label\n options['help_text'] = field.help_text\n options['required'] = field.required\n options['initial'] = field.default_value\n return options\n\n def get_form_class(self):\n return type('WagtailForm', (BaseForm,), self.formfields)\n\n\nclass SelectDateForm(django.forms.Form):\n date_from = django.forms.DateTimeField(\n required=False,\n widget=django.forms.DateInput(attrs={'placeholder': 'Date from'})\n )\n date_to = django.forms.DateTimeField(\n required=False,\n widget=django.forms.DateInput(attrs={'placeholder': 'Date to'})\n )\n", "path": "wagtail/wagtailforms/forms.py"}], "after_files": [{"content": "import django.forms\nfrom django.utils.datastructures import SortedDict\n\n\nclass BaseForm(django.forms.Form):\n def __init__(self, *args, **kwargs):\n kwargs.setdefault('label_suffix', '')\n return super(BaseForm, self).__init__(*args, **kwargs)\n\n\nclass FormBuilder(object):\n def __init__(self, fields):\n self.fields = fields\n\n def create_singleline_field(self, field, options):\n # TODO: This is a default value - it may need to be changed\n options['max_length'] = 255\n return django.forms.CharField(**options)\n\n def create_multiline_field(self, field, options):\n return django.forms.CharField(widget=django.forms.Textarea, **options)\n\n def create_date_field(self, field, options):\n return django.forms.DateField(**options)\n\n def create_datetime_field(self, field, options):\n return django.forms.DateTimeField(**options)\n\n def create_email_field(self, field, options):\n return django.forms.EmailField(**options)\n\n def create_url_field(self, field, options):\n return django.forms.URLField(**options)\n\n def create_number_field(self, field, options):\n return django.forms.DecimalField(**options)\n\n def create_dropdown_field(self, field, options):\n options['choices'] = map(\n lambda x: (x.strip(), x.strip()),\n field.choices.split(',')\n )\n return django.forms.ChoiceField(**options)\n\n def create_radio_field(self, field, options):\n options['choices'] = map(\n lambda x: (x.strip(), x.strip()),\n field.choices.split(',')\n )\n return django.forms.ChoiceField(widget=django.forms.RadioSelect, **options)\n\n def create_checkboxes_field(self, field, options):\n options['choices'] = [(x.strip(), x.strip()) for x in field.choices.split(',')]\n options['initial'] = [x.strip() for x in field.default_value.split(',')]\n return django.forms.MultipleChoiceField(\n widget=django.forms.CheckboxSelectMultiple, **options\n )\n\n def create_checkbox_field(self, field, options):\n return django.forms.BooleanField(**options)\n\n FIELD_TYPES = {\n 'singleline': create_singleline_field,\n 'multiline': create_multiline_field,\n 'date': create_date_field,\n 'datetime': create_datetime_field,\n 'email': create_email_field,\n 'url': create_url_field,\n 'number': create_number_field,\n 'dropdown': create_dropdown_field,\n 'radio': create_radio_field,\n 'checkboxes': create_checkboxes_field,\n 'checkbox': create_checkbox_field,\n }\n\n @property\n def formfields(self):\n formfields = SortedDict()\n\n for field in self.fields:\n options = self.get_field_options(field)\n\n if field.field_type in self.FIELD_TYPES:\n formfields[field.clean_name] = self.FIELD_TYPES[field.field_type](self, field, options)\n else:\n raise Exception(\"Unrecognised field type: \" + field.field_type)\n\n return formfields\n\n def get_field_options(self, field):\n options = {}\n options['label'] = field.label\n options['help_text'] = field.help_text\n options['required'] = field.required\n options['initial'] = field.default_value\n return options\n\n def get_form_class(self):\n return type('WagtailForm', (BaseForm,), self.formfields)\n\n\nclass SelectDateForm(django.forms.Form):\n date_from = django.forms.DateTimeField(\n required=False,\n widget=django.forms.DateInput(attrs={'placeholder': 'Date from'})\n )\n date_to = django.forms.DateTimeField(\n required=False,\n widget=django.forms.DateInput(attrs={'placeholder': 'Date to'})\n )\n", "path": "wagtail/wagtailforms/forms.py"}]}
| 1,375 | 134 |
gh_patches_debug_43427
|
rasdani/github-patches
|
git_diff
|
shuup__shuup-1716
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Admin: product visibility mass action doesn't bump caches
After products are cached in xtheme plugins (like highlight) and products are hided through mass action in product admin, the storefront just doesn't change. Looks like we are missing to bump caches.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `shuup/admin/modules/orders/mass_actions.py`
Content:
```
1 # This file is part of Shuup.
2 #
3 # Copyright (c) 2012-2019, Shoop Commerce Ltd. All rights reserved.
4 #
5 # This source code is licensed under the OSL-3.0 license found in the
6 # LICENSE file in the root directory of this source tree.
7 import zipfile
8
9 import six
10 from django.db.models import Q
11 from django.http import HttpResponse, JsonResponse
12 from django.utils.encoding import force_text
13 from django.utils.translation import ugettext_lazy as _
14 from django.utils.translation import ugettext
15 from six import BytesIO
16
17 from shuup.admin.utils.picotable import (
18 PicotableFileMassAction, PicotableMassAction
19 )
20 from shuup.core.models import Order, Shipment
21 from shuup.order_printouts.admin_module.views import (
22 get_confirmation_pdf, get_delivery_pdf
23 )
24
25
26 class CancelOrderAction(PicotableMassAction):
27 label = _("Cancel")
28 identifier = "mass_action_order_cancel"
29
30 def process(self, request, ids):
31 query = Q(id__in=ids)
32 if isinstance(ids, six.string_types) and ids == "all":
33 query = Q()
34 for order in Order.objects.filter(query):
35 if not order.can_set_canceled():
36 continue
37 order.set_canceled()
38
39
40 class OrderConfirmationPdfAction(PicotableFileMassAction):
41 label = _("Print Confirmation PDF(s)")
42 identifier = "mass_action_order_confirmation_pdf"
43
44 def process(self, request, ids):
45 if isinstance(ids, six.string_types) and ids == "all":
46 return JsonResponse({"error": ugettext("Selecting all is not supported.")}, status=400)
47 if len(ids) == 1:
48 try:
49 response = get_confirmation_pdf(request, ids[0])
50 response['Content-Disposition'] = 'attachment; filename=order_%s_confirmation.pdf' % ids[0]
51 return response
52 except Exception as e:
53 msg = e.message if hasattr(e, "message") else e
54 return JsonResponse({"error": force_text(msg)}, status=400)
55
56 buff = BytesIO()
57 archive = zipfile.ZipFile(buff, 'w', zipfile.ZIP_DEFLATED)
58 added = 0
59 errors = []
60 for id in ids:
61 try:
62 pdf_file = get_confirmation_pdf(request, id)
63 filename = "order_%d_confirmation.pdf" % id
64 archive.writestr(filename, pdf_file.content)
65 added += 1
66 except Exception as e:
67 msg = e.message if hasattr(e, "message") else e
68 errors.append(force_text(msg))
69 continue
70 if added:
71 archive.close()
72 buff.flush()
73 ret_zip = buff.getvalue()
74 buff.close()
75 response = HttpResponse(content_type='application/zip')
76 response['Content-Disposition'] = 'attachment; filename=order_confirmation_pdf.zip'
77 response.write(ret_zip)
78 return response
79 return JsonResponse({"errors": errors}, status=400)
80
81
82 class OrderDeliveryPdfAction(PicotableFileMassAction):
83 label = _("Print Delivery PDF(s)")
84 identifier = "mass_action_order_delivery_pdf"
85
86 def process(self, request, ids):
87 if isinstance(ids, six.string_types) and ids == "all":
88 return JsonResponse({"error": ugettext("Selecting all is not supported.")})
89 shipment_ids = set(Shipment.objects.filter(order_id__in=ids).values_list("id", flat=True))
90 if len(shipment_ids) == 1:
91 try:
92 response = get_delivery_pdf(request, ids[0])
93 response['Content-Disposition'] = 'attachment; filename=shipment_%s_delivery.pdf' % ids[0]
94 return response
95 except Exception as e:
96 msg = e.message if hasattr(e, "message") else e
97 return JsonResponse({"error": force_text(msg)})
98 buff = BytesIO()
99 archive = zipfile.ZipFile(buff, 'w', zipfile.ZIP_DEFLATED)
100
101 added = 0
102 errors = []
103 for id in shipment_ids:
104 try:
105 pdf_file = get_delivery_pdf(request, id)
106 filename = "shipment_%d_delivery.pdf" % id
107 archive.writestr(filename, pdf_file.content)
108 added += 1
109 except Exception as e:
110 msg = e.message if hasattr(e, "message") else e
111 errors.append(force_text(msg))
112 continue
113 if added:
114 archive.close()
115 buff.flush()
116 ret_zip = buff.getvalue()
117 buff.close()
118 response = HttpResponse(content_type='application/zip')
119 response['Content-Disposition'] = 'attachment; filename=order_delivery_pdf.zip'
120 response.write(ret_zip)
121 return response
122 return JsonResponse({"errors": errors})
123
```
Path: `shuup/admin/modules/products/mass_actions.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # This file is part of Shuup.
3 #
4 # Copyright (c) 2012-2019, Shoop Commerce Ltd. All rights reserved.
5 #
6 # This source code is licensed under the OSL-3.0 license found in the
7 # LICENSE file in the root directory of this source tree.
8 import unicodecsv as csv
9 from django.core.urlresolvers import reverse
10 from django.db.models import Q
11 from django.http import HttpResponse
12 from django.utils.translation import ugettext_lazy as _
13 from six import string_types
14
15 from shuup.admin.modules.products.views.list import ProductListView
16 from shuup.admin.modules.settings.view_settings import ViewSettings
17 from shuup.admin.utils.picotable import (
18 PicotableFileMassAction, PicotableMassAction, PicotableRedirectMassAction
19 )
20 from shuup.core.models import ShopProduct, ShopProductVisibility
21
22
23 class VisibleMassAction(PicotableMassAction):
24 label = _("Set visible")
25 identifier = "mass_action_product_visible"
26
27 def process(self, request, ids):
28 query = Q(product__pk__in=ids)
29 if isinstance(ids, string_types) and ids == "all":
30 query = Q()
31 ShopProduct.objects.filter(query).update(visibility=ShopProductVisibility.ALWAYS_VISIBLE)
32
33
34 class InvisibleMassAction(PicotableMassAction):
35 label = _("Set invisible")
36 identifier = "mass_action_product_invisible"
37
38 def process(self, request, ids):
39 query = Q(product__pk__in=ids)
40 if isinstance(ids, string_types) and ids == "all":
41 query = Q()
42 ShopProduct.objects.filter(query).update(visibility=ShopProductVisibility.NOT_VISIBLE)
43
44
45 class FileResponseAction(PicotableFileMassAction):
46 label = _("Export CSV")
47 identifier = "mass_action_product_simple_csv"
48
49 def process(self, request, ids):
50 query = Q(id__in=ids)
51 if isinstance(ids, string_types) and ids == "all":
52 query = Q()
53 view_settings = ViewSettings(ShopProduct, ProductListView.default_columns, ProductListView)
54 response = HttpResponse(content_type='text/csv')
55 response['Content-Disposition'] = 'attachment; filename="products.csv"'
56 writer = csv.writer(response, delimiter=";", encoding='utf-8')
57 writer.writerow([col.title for col in view_settings.columns])
58 for shop_product in ShopProduct.objects.filter(query):
59 row = []
60 for dr in [col.id for col in view_settings.columns]:
61 if dr.startswith("shopproduct_"):
62 row.append(getattr(shop_product, dr.replace("shopproduct_", "")))
63 elif dr.startswith("product_"):
64 row.append(getattr(shop_product.product, dr.replace("product_", "")))
65 else:
66 row.append(getattr(shop_product.product, dr))
67 writer.writerow(row)
68 return response
69
70
71 class EditProductAttributesAction(PicotableRedirectMassAction):
72 label = _("Edit products")
73 identifier = "mass_action_edit_product"
74 redirect_url = reverse("shuup_admin:shop_product.mass_edit")
75
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/shuup/admin/modules/orders/mass_actions.py b/shuup/admin/modules/orders/mass_actions.py
--- a/shuup/admin/modules/orders/mass_actions.py
+++ b/shuup/admin/modules/orders/mass_actions.py
@@ -14,6 +14,7 @@
from django.utils.translation import ugettext
from six import BytesIO
+from shuup.admin.shop_provider import get_shop
from shuup.admin.utils.picotable import (
PicotableFileMassAction, PicotableMassAction
)
@@ -28,9 +29,11 @@
identifier = "mass_action_order_cancel"
def process(self, request, ids):
- query = Q(id__in=ids)
+ shop = get_shop(request)
if isinstance(ids, six.string_types) and ids == "all":
- query = Q()
+ query = Q(shop=shop)
+ else:
+ query = Q(id__in=ids, shop=shop)
for order in Order.objects.filter(query):
if not order.can_set_canceled():
continue
diff --git a/shuup/admin/modules/products/mass_actions.py b/shuup/admin/modules/products/mass_actions.py
--- a/shuup/admin/modules/products/mass_actions.py
+++ b/shuup/admin/modules/products/mass_actions.py
@@ -14,10 +14,12 @@
from shuup.admin.modules.products.views.list import ProductListView
from shuup.admin.modules.settings.view_settings import ViewSettings
+from shuup.admin.shop_provider import get_shop
from shuup.admin.utils.picotable import (
PicotableFileMassAction, PicotableMassAction, PicotableRedirectMassAction
)
from shuup.core.models import ShopProduct, ShopProductVisibility
+from shuup.core.utils import context_cache
class VisibleMassAction(PicotableMassAction):
@@ -25,10 +27,16 @@
identifier = "mass_action_product_visible"
def process(self, request, ids):
- query = Q(product__pk__in=ids)
+ shop = get_shop(request)
+
if isinstance(ids, string_types) and ids == "all":
- query = Q()
+ query = Q(shop=shop)
+ else:
+ query = Q(product__pk__in=ids, shop=shop)
+
ShopProduct.objects.filter(query).update(visibility=ShopProductVisibility.ALWAYS_VISIBLE)
+ for shop_product in ShopProduct.objects.filter(query).iterator():
+ context_cache.bump_cache_for_shop_product(shop_product)
class InvisibleMassAction(PicotableMassAction):
@@ -36,10 +44,15 @@
identifier = "mass_action_product_invisible"
def process(self, request, ids):
- query = Q(product__pk__in=ids)
+ shop = get_shop(request)
if isinstance(ids, string_types) and ids == "all":
- query = Q()
+ query = Q(shop=shop)
+ else:
+ query = Q(product__pk__in=ids, shop=shop)
+
ShopProduct.objects.filter(query).update(visibility=ShopProductVisibility.NOT_VISIBLE)
+ for shop_product in ShopProduct.objects.filter(query).iterator():
+ context_cache.bump_cache_for_shop_product(shop_product)
class FileResponseAction(PicotableFileMassAction):
@@ -47,9 +60,11 @@
identifier = "mass_action_product_simple_csv"
def process(self, request, ids):
- query = Q(id__in=ids)
+ shop = get_shop(request)
if isinstance(ids, string_types) and ids == "all":
- query = Q()
+ query = Q(shop=shop)
+ else:
+ query = Q(product__pk__in=ids, shop=shop)
view_settings = ViewSettings(ShopProduct, ProductListView.default_columns, ProductListView)
response = HttpResponse(content_type='text/csv')
response['Content-Disposition'] = 'attachment; filename="products.csv"'
|
{"golden_diff": "diff --git a/shuup/admin/modules/orders/mass_actions.py b/shuup/admin/modules/orders/mass_actions.py\n--- a/shuup/admin/modules/orders/mass_actions.py\n+++ b/shuup/admin/modules/orders/mass_actions.py\n@@ -14,6 +14,7 @@\n from django.utils.translation import ugettext\n from six import BytesIO\n \n+from shuup.admin.shop_provider import get_shop\n from shuup.admin.utils.picotable import (\n PicotableFileMassAction, PicotableMassAction\n )\n@@ -28,9 +29,11 @@\n identifier = \"mass_action_order_cancel\"\n \n def process(self, request, ids):\n- query = Q(id__in=ids)\n+ shop = get_shop(request)\n if isinstance(ids, six.string_types) and ids == \"all\":\n- query = Q()\n+ query = Q(shop=shop)\n+ else:\n+ query = Q(id__in=ids, shop=shop)\n for order in Order.objects.filter(query):\n if not order.can_set_canceled():\n continue\ndiff --git a/shuup/admin/modules/products/mass_actions.py b/shuup/admin/modules/products/mass_actions.py\n--- a/shuup/admin/modules/products/mass_actions.py\n+++ b/shuup/admin/modules/products/mass_actions.py\n@@ -14,10 +14,12 @@\n \n from shuup.admin.modules.products.views.list import ProductListView\n from shuup.admin.modules.settings.view_settings import ViewSettings\n+from shuup.admin.shop_provider import get_shop\n from shuup.admin.utils.picotable import (\n PicotableFileMassAction, PicotableMassAction, PicotableRedirectMassAction\n )\n from shuup.core.models import ShopProduct, ShopProductVisibility\n+from shuup.core.utils import context_cache\n \n \n class VisibleMassAction(PicotableMassAction):\n@@ -25,10 +27,16 @@\n identifier = \"mass_action_product_visible\"\n \n def process(self, request, ids):\n- query = Q(product__pk__in=ids)\n+ shop = get_shop(request)\n+\n if isinstance(ids, string_types) and ids == \"all\":\n- query = Q()\n+ query = Q(shop=shop)\n+ else:\n+ query = Q(product__pk__in=ids, shop=shop)\n+\n ShopProduct.objects.filter(query).update(visibility=ShopProductVisibility.ALWAYS_VISIBLE)\n+ for shop_product in ShopProduct.objects.filter(query).iterator():\n+ context_cache.bump_cache_for_shop_product(shop_product)\n \n \n class InvisibleMassAction(PicotableMassAction):\n@@ -36,10 +44,15 @@\n identifier = \"mass_action_product_invisible\"\n \n def process(self, request, ids):\n- query = Q(product__pk__in=ids)\n+ shop = get_shop(request)\n if isinstance(ids, string_types) and ids == \"all\":\n- query = Q()\n+ query = Q(shop=shop)\n+ else:\n+ query = Q(product__pk__in=ids, shop=shop)\n+\n ShopProduct.objects.filter(query).update(visibility=ShopProductVisibility.NOT_VISIBLE)\n+ for shop_product in ShopProduct.objects.filter(query).iterator():\n+ context_cache.bump_cache_for_shop_product(shop_product)\n \n \n class FileResponseAction(PicotableFileMassAction):\n@@ -47,9 +60,11 @@\n identifier = \"mass_action_product_simple_csv\"\n \n def process(self, request, ids):\n- query = Q(id__in=ids)\n+ shop = get_shop(request)\n if isinstance(ids, string_types) and ids == \"all\":\n- query = Q()\n+ query = Q(shop=shop)\n+ else:\n+ query = Q(product__pk__in=ids, shop=shop)\n view_settings = ViewSettings(ShopProduct, ProductListView.default_columns, ProductListView)\n response = HttpResponse(content_type='text/csv')\n response['Content-Disposition'] = 'attachment; filename=\"products.csv\"'\n", "issue": "Admin: product visibility mass action doesn't bump caches\nAfter products are cached in xtheme plugins (like highlight) and products are hided through mass action in product admin, the storefront just doesn't change. Looks like we are missing to bump caches.\n", "before_files": [{"content": "# This file is part of Shuup.\n#\n# Copyright (c) 2012-2019, Shoop Commerce Ltd. All rights reserved.\n#\n# This source code is licensed under the OSL-3.0 license found in the\n# LICENSE file in the root directory of this source tree.\nimport zipfile\n\nimport six\nfrom django.db.models import Q\nfrom django.http import HttpResponse, JsonResponse\nfrom django.utils.encoding import force_text\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.utils.translation import ugettext\nfrom six import BytesIO\n\nfrom shuup.admin.utils.picotable import (\n PicotableFileMassAction, PicotableMassAction\n)\nfrom shuup.core.models import Order, Shipment\nfrom shuup.order_printouts.admin_module.views import (\n get_confirmation_pdf, get_delivery_pdf\n)\n\n\nclass CancelOrderAction(PicotableMassAction):\n label = _(\"Cancel\")\n identifier = \"mass_action_order_cancel\"\n\n def process(self, request, ids):\n query = Q(id__in=ids)\n if isinstance(ids, six.string_types) and ids == \"all\":\n query = Q()\n for order in Order.objects.filter(query):\n if not order.can_set_canceled():\n continue\n order.set_canceled()\n\n\nclass OrderConfirmationPdfAction(PicotableFileMassAction):\n label = _(\"Print Confirmation PDF(s)\")\n identifier = \"mass_action_order_confirmation_pdf\"\n\n def process(self, request, ids):\n if isinstance(ids, six.string_types) and ids == \"all\":\n return JsonResponse({\"error\": ugettext(\"Selecting all is not supported.\")}, status=400)\n if len(ids) == 1:\n try:\n response = get_confirmation_pdf(request, ids[0])\n response['Content-Disposition'] = 'attachment; filename=order_%s_confirmation.pdf' % ids[0]\n return response\n except Exception as e:\n msg = e.message if hasattr(e, \"message\") else e\n return JsonResponse({\"error\": force_text(msg)}, status=400)\n\n buff = BytesIO()\n archive = zipfile.ZipFile(buff, 'w', zipfile.ZIP_DEFLATED)\n added = 0\n errors = []\n for id in ids:\n try:\n pdf_file = get_confirmation_pdf(request, id)\n filename = \"order_%d_confirmation.pdf\" % id\n archive.writestr(filename, pdf_file.content)\n added += 1\n except Exception as e:\n msg = e.message if hasattr(e, \"message\") else e\n errors.append(force_text(msg))\n continue\n if added:\n archive.close()\n buff.flush()\n ret_zip = buff.getvalue()\n buff.close()\n response = HttpResponse(content_type='application/zip')\n response['Content-Disposition'] = 'attachment; filename=order_confirmation_pdf.zip'\n response.write(ret_zip)\n return response\n return JsonResponse({\"errors\": errors}, status=400)\n\n\nclass OrderDeliveryPdfAction(PicotableFileMassAction):\n label = _(\"Print Delivery PDF(s)\")\n identifier = \"mass_action_order_delivery_pdf\"\n\n def process(self, request, ids):\n if isinstance(ids, six.string_types) and ids == \"all\":\n return JsonResponse({\"error\": ugettext(\"Selecting all is not supported.\")})\n shipment_ids = set(Shipment.objects.filter(order_id__in=ids).values_list(\"id\", flat=True))\n if len(shipment_ids) == 1:\n try:\n response = get_delivery_pdf(request, ids[0])\n response['Content-Disposition'] = 'attachment; filename=shipment_%s_delivery.pdf' % ids[0]\n return response\n except Exception as e:\n msg = e.message if hasattr(e, \"message\") else e\n return JsonResponse({\"error\": force_text(msg)})\n buff = BytesIO()\n archive = zipfile.ZipFile(buff, 'w', zipfile.ZIP_DEFLATED)\n\n added = 0\n errors = []\n for id in shipment_ids:\n try:\n pdf_file = get_delivery_pdf(request, id)\n filename = \"shipment_%d_delivery.pdf\" % id\n archive.writestr(filename, pdf_file.content)\n added += 1\n except Exception as e:\n msg = e.message if hasattr(e, \"message\") else e\n errors.append(force_text(msg))\n continue\n if added:\n archive.close()\n buff.flush()\n ret_zip = buff.getvalue()\n buff.close()\n response = HttpResponse(content_type='application/zip')\n response['Content-Disposition'] = 'attachment; filename=order_delivery_pdf.zip'\n response.write(ret_zip)\n return response\n return JsonResponse({\"errors\": errors})\n", "path": "shuup/admin/modules/orders/mass_actions.py"}, {"content": "# -*- coding: utf-8 -*-\n# This file is part of Shuup.\n#\n# Copyright (c) 2012-2019, Shoop Commerce Ltd. All rights reserved.\n#\n# This source code is licensed under the OSL-3.0 license found in the\n# LICENSE file in the root directory of this source tree.\nimport unicodecsv as csv\nfrom django.core.urlresolvers import reverse\nfrom django.db.models import Q\nfrom django.http import HttpResponse\nfrom django.utils.translation import ugettext_lazy as _\nfrom six import string_types\n\nfrom shuup.admin.modules.products.views.list import ProductListView\nfrom shuup.admin.modules.settings.view_settings import ViewSettings\nfrom shuup.admin.utils.picotable import (\n PicotableFileMassAction, PicotableMassAction, PicotableRedirectMassAction\n)\nfrom shuup.core.models import ShopProduct, ShopProductVisibility\n\n\nclass VisibleMassAction(PicotableMassAction):\n label = _(\"Set visible\")\n identifier = \"mass_action_product_visible\"\n\n def process(self, request, ids):\n query = Q(product__pk__in=ids)\n if isinstance(ids, string_types) and ids == \"all\":\n query = Q()\n ShopProduct.objects.filter(query).update(visibility=ShopProductVisibility.ALWAYS_VISIBLE)\n\n\nclass InvisibleMassAction(PicotableMassAction):\n label = _(\"Set invisible\")\n identifier = \"mass_action_product_invisible\"\n\n def process(self, request, ids):\n query = Q(product__pk__in=ids)\n if isinstance(ids, string_types) and ids == \"all\":\n query = Q()\n ShopProduct.objects.filter(query).update(visibility=ShopProductVisibility.NOT_VISIBLE)\n\n\nclass FileResponseAction(PicotableFileMassAction):\n label = _(\"Export CSV\")\n identifier = \"mass_action_product_simple_csv\"\n\n def process(self, request, ids):\n query = Q(id__in=ids)\n if isinstance(ids, string_types) and ids == \"all\":\n query = Q()\n view_settings = ViewSettings(ShopProduct, ProductListView.default_columns, ProductListView)\n response = HttpResponse(content_type='text/csv')\n response['Content-Disposition'] = 'attachment; filename=\"products.csv\"'\n writer = csv.writer(response, delimiter=\";\", encoding='utf-8')\n writer.writerow([col.title for col in view_settings.columns])\n for shop_product in ShopProduct.objects.filter(query):\n row = []\n for dr in [col.id for col in view_settings.columns]:\n if dr.startswith(\"shopproduct_\"):\n row.append(getattr(shop_product, dr.replace(\"shopproduct_\", \"\")))\n elif dr.startswith(\"product_\"):\n row.append(getattr(shop_product.product, dr.replace(\"product_\", \"\")))\n else:\n row.append(getattr(shop_product.product, dr))\n writer.writerow(row)\n return response\n\n\nclass EditProductAttributesAction(PicotableRedirectMassAction):\n label = _(\"Edit products\")\n identifier = \"mass_action_edit_product\"\n redirect_url = reverse(\"shuup_admin:shop_product.mass_edit\")\n", "path": "shuup/admin/modules/products/mass_actions.py"}], "after_files": [{"content": "# This file is part of Shuup.\n#\n# Copyright (c) 2012-2019, Shoop Commerce Ltd. All rights reserved.\n#\n# This source code is licensed under the OSL-3.0 license found in the\n# LICENSE file in the root directory of this source tree.\nimport zipfile\n\nimport six\nfrom django.db.models import Q\nfrom django.http import HttpResponse, JsonResponse\nfrom django.utils.encoding import force_text\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.utils.translation import ugettext\nfrom six import BytesIO\n\nfrom shuup.admin.shop_provider import get_shop\nfrom shuup.admin.utils.picotable import (\n PicotableFileMassAction, PicotableMassAction\n)\nfrom shuup.core.models import Order, Shipment\nfrom shuup.order_printouts.admin_module.views import (\n get_confirmation_pdf, get_delivery_pdf\n)\n\n\nclass CancelOrderAction(PicotableMassAction):\n label = _(\"Cancel\")\n identifier = \"mass_action_order_cancel\"\n\n def process(self, request, ids):\n shop = get_shop(request)\n if isinstance(ids, six.string_types) and ids == \"all\":\n query = Q(shop=shop)\n else:\n query = Q(id__in=ids, shop=shop)\n for order in Order.objects.filter(query):\n if not order.can_set_canceled():\n continue\n order.set_canceled()\n\n\nclass OrderConfirmationPdfAction(PicotableFileMassAction):\n label = _(\"Print Confirmation PDF(s)\")\n identifier = \"mass_action_order_confirmation_pdf\"\n\n def process(self, request, ids):\n if isinstance(ids, six.string_types) and ids == \"all\":\n return JsonResponse({\"error\": ugettext(\"Selecting all is not supported.\")}, status=400)\n if len(ids) == 1:\n try:\n response = get_confirmation_pdf(request, ids[0])\n response['Content-Disposition'] = 'attachment; filename=order_%s_confirmation.pdf' % ids[0]\n return response\n except Exception as e:\n msg = e.message if hasattr(e, \"message\") else e\n return JsonResponse({\"error\": force_text(msg)}, status=400)\n\n buff = BytesIO()\n archive = zipfile.ZipFile(buff, 'w', zipfile.ZIP_DEFLATED)\n added = 0\n errors = []\n for id in ids:\n try:\n pdf_file = get_confirmation_pdf(request, id)\n filename = \"order_%d_confirmation.pdf\" % id\n archive.writestr(filename, pdf_file.content)\n added += 1\n except Exception as e:\n msg = e.message if hasattr(e, \"message\") else e\n errors.append(force_text(msg))\n continue\n if added:\n archive.close()\n buff.flush()\n ret_zip = buff.getvalue()\n buff.close()\n response = HttpResponse(content_type='application/zip')\n response['Content-Disposition'] = 'attachment; filename=order_confirmation_pdf.zip'\n response.write(ret_zip)\n return response\n return JsonResponse({\"errors\": errors}, status=400)\n\n\nclass OrderDeliveryPdfAction(PicotableFileMassAction):\n label = _(\"Print Delivery PDF(s)\")\n identifier = \"mass_action_order_delivery_pdf\"\n\n def process(self, request, ids):\n if isinstance(ids, six.string_types) and ids == \"all\":\n return JsonResponse({\"error\": ugettext(\"Selecting all is not supported.\")})\n shipment_ids = set(Shipment.objects.filter(order_id__in=ids).values_list(\"id\", flat=True))\n if len(shipment_ids) == 1:\n try:\n response = get_delivery_pdf(request, ids[0])\n response['Content-Disposition'] = 'attachment; filename=shipment_%s_delivery.pdf' % ids[0]\n return response\n except Exception as e:\n msg = e.message if hasattr(e, \"message\") else e\n return JsonResponse({\"error\": force_text(msg)})\n buff = BytesIO()\n archive = zipfile.ZipFile(buff, 'w', zipfile.ZIP_DEFLATED)\n\n added = 0\n errors = []\n for id in shipment_ids:\n try:\n pdf_file = get_delivery_pdf(request, id)\n filename = \"shipment_%d_delivery.pdf\" % id\n archive.writestr(filename, pdf_file.content)\n added += 1\n except Exception as e:\n msg = e.message if hasattr(e, \"message\") else e\n errors.append(force_text(msg))\n continue\n if added:\n archive.close()\n buff.flush()\n ret_zip = buff.getvalue()\n buff.close()\n response = HttpResponse(content_type='application/zip')\n response['Content-Disposition'] = 'attachment; filename=order_delivery_pdf.zip'\n response.write(ret_zip)\n return response\n return JsonResponse({\"errors\": errors})\n", "path": "shuup/admin/modules/orders/mass_actions.py"}, {"content": "# -*- coding: utf-8 -*-\n# This file is part of Shuup.\n#\n# Copyright (c) 2012-2019, Shoop Commerce Ltd. All rights reserved.\n#\n# This source code is licensed under the OSL-3.0 license found in the\n# LICENSE file in the root directory of this source tree.\nimport unicodecsv as csv\nfrom django.core.urlresolvers import reverse\nfrom django.db.models import Q\nfrom django.http import HttpResponse\nfrom django.utils.translation import ugettext_lazy as _\nfrom six import string_types\n\nfrom shuup.admin.modules.products.views.list import ProductListView\nfrom shuup.admin.modules.settings.view_settings import ViewSettings\nfrom shuup.admin.shop_provider import get_shop\nfrom shuup.admin.utils.picotable import (\n PicotableFileMassAction, PicotableMassAction, PicotableRedirectMassAction\n)\nfrom shuup.core.models import ShopProduct, ShopProductVisibility\nfrom shuup.core.utils import context_cache\n\n\nclass VisibleMassAction(PicotableMassAction):\n label = _(\"Set visible\")\n identifier = \"mass_action_product_visible\"\n\n def process(self, request, ids):\n shop = get_shop(request)\n\n if isinstance(ids, string_types) and ids == \"all\":\n query = Q(shop=shop)\n else:\n query = Q(product__pk__in=ids, shop=shop)\n\n ShopProduct.objects.filter(query).update(visibility=ShopProductVisibility.ALWAYS_VISIBLE)\n for shop_product in ShopProduct.objects.filter(query).iterator():\n context_cache.bump_cache_for_shop_product(shop_product)\n\n\nclass InvisibleMassAction(PicotableMassAction):\n label = _(\"Set invisible\")\n identifier = \"mass_action_product_invisible\"\n\n def process(self, request, ids):\n shop = get_shop(request)\n if isinstance(ids, string_types) and ids == \"all\":\n query = Q(shop=shop)\n else:\n query = Q(product__pk__in=ids, shop=shop)\n\n ShopProduct.objects.filter(query).update(visibility=ShopProductVisibility.NOT_VISIBLE)\n for shop_product in ShopProduct.objects.filter(query).iterator():\n context_cache.bump_cache_for_shop_product(shop_product)\n\n\nclass FileResponseAction(PicotableFileMassAction):\n label = _(\"Export CSV\")\n identifier = \"mass_action_product_simple_csv\"\n\n def process(self, request, ids):\n shop = get_shop(request)\n if isinstance(ids, string_types) and ids == \"all\":\n query = Q(shop=shop)\n else:\n query = Q(product__pk__in=ids, shop=shop)\n view_settings = ViewSettings(ShopProduct, ProductListView.default_columns, ProductListView)\n response = HttpResponse(content_type='text/csv')\n response['Content-Disposition'] = 'attachment; filename=\"products.csv\"'\n writer = csv.writer(response, delimiter=\";\", encoding='utf-8')\n writer.writerow([col.title for col in view_settings.columns])\n for shop_product in ShopProduct.objects.filter(query):\n row = []\n for dr in [col.id for col in view_settings.columns]:\n if dr.startswith(\"shopproduct_\"):\n row.append(getattr(shop_product, dr.replace(\"shopproduct_\", \"\")))\n elif dr.startswith(\"product_\"):\n row.append(getattr(shop_product.product, dr.replace(\"product_\", \"\")))\n else:\n row.append(getattr(shop_product.product, dr))\n writer.writerow(row)\n return response\n\n\nclass EditProductAttributesAction(PicotableRedirectMassAction):\n label = _(\"Edit products\")\n identifier = \"mass_action_edit_product\"\n redirect_url = reverse(\"shuup_admin:shop_product.mass_edit\")\n", "path": "shuup/admin/modules/products/mass_actions.py"}]}
| 2,402 | 886 |
gh_patches_debug_23126
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-2635
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Spider riteaid is broken
During the global build at 2021-08-11-14-42-19, spider **riteaid** failed with **1234 features** and **1 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-08-11-14-42-19/logs/riteaid.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-08-11-14-42-19/output/riteaid.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-08-11-14-42-19/output/riteaid.geojson))
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `locations/spiders/riteaid.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 import scrapy
3 import json
4 import re
5 from locations.items import GeojsonPointItem
6
7 class RiteAidSpider(scrapy.Spider):
8 name = "riteaid"
9 allowed_domains = ["riteaid.com"]
10 start_urls = (
11 'https://locations.riteaid.com/',
12 )
13
14 def store_hours(self, store_hours):
15 day_groups = []
16 this_day_group = None
17 for day_info in store_hours:
18 day = day_info['day'][:2].title()
19
20 hour_intervals = []
21 for interval in day_info['intervals']:
22 f_time = str(interval['start']).zfill(4)
23 t_time = str(interval['end']).zfill(4)
24 hour_intervals.append('{}:{}-{}:{}'.format(
25 f_time[0:2],
26 f_time[2:4],
27 t_time[0:2],
28 t_time[2:4],
29 ))
30 hours = ','.join(hour_intervals)
31
32 if not this_day_group:
33 this_day_group = {
34 'from_day': day,
35 'to_day': day,
36 'hours': hours
37 }
38 elif this_day_group['hours'] != hours:
39 day_groups.append(this_day_group)
40 this_day_group = {
41 'from_day': day,
42 'to_day': day,
43 'hours': hours
44 }
45 elif this_day_group['hours'] == hours:
46 this_day_group['to_day'] = day
47
48 day_groups.append(this_day_group)
49
50 opening_hours = ""
51 if len(day_groups) == 1 and day_groups[0]['hours'] in ('00:00-23:59', '00:00-00:00'):
52 opening_hours = '24/7'
53 else:
54 for day_group in day_groups:
55 if day_group['from_day'] == day_group['to_day']:
56 opening_hours += '{from_day} {hours}; '.format(**day_group)
57 elif day_group['from_day'] == 'Su' and day_group['to_day'] == 'Sa':
58 opening_hours += '{hours}; '.format(**day_group)
59 else:
60 opening_hours += '{from_day}-{to_day} {hours}; '.format(**day_group)
61 opening_hours = opening_hours[:-2]
62
63 return opening_hours
64
65 def parse(self, response):
66 urls = response.xpath('//a[@class="c-directory-list-content-item-link"]/@href').extract()
67
68 for url in urls:
69 if len(url.split('/')) == 3:
70 yield scrapy.Request(response.urljoin(url), callback=self.parse_city)
71 elif len(url.split('/')) == 4:
72 yield scrapy.Request(response.urljoin(url), callback=self.parse_location)
73 else:
74 yield scrapy.Request(response.urljoin(url), callback=self.parse_state)
75
76 def parse_state(self, response):
77 state_urls = response.xpath('//a[@class="c-directory-list-content-item-link"]/@href').extract()
78
79 for url in state_urls:
80 if len(url.split('/')) == 5:
81 yield scrapy.Request(response.urljoin(url), callback=self.parse_location)
82 else:
83 yield scrapy.Request(response.urljoin(url), callback=self.parse_city)
84
85 def parse_city(self, response):
86 city_urls = response.xpath('//a[@itemprop="url"]/@href').extract()
87
88 for url in city_urls:
89 yield scrapy.Request(response.urljoin(url), callback=self.parse_location)
90
91 def parse_location(self, response):
92 ref = response.xpath('normalize-space(//h1[contains(@itemprop,"name")]/text())').extract_first()
93 brand_elem = response.xpath('//div[@class="alert alert-danger"]/text()').extract_first()
94
95 if brand_elem: #Changed ownership as part of the sale of select Rite Aid stores to Walgreens
96 brand = 'Walgreens'
97 else:
98 brand = re.search(r'([^#//s*]+)', ref).group(1)
99
100 hours_elem = response.xpath('//div[@class="Hours-store"]//div[contains(@class,"c-location-hours-details-wrapper")]/@data-days')
101 if hours_elem: # not shop, only clinic
102 hours = json.loads(hours_elem.extract_first())
103 else:
104 hours = json.loads(response.xpath('//div[contains(@class,"c-location-hours-details-wrapper")]/@data-days').extract_first())
105
106 properties = {
107 'ref': ref,
108 'addr_full': response.xpath('normalize-space(//span[contains(@itemprop,"streetAddress")]/span/text())').extract_first(),
109 'state': response.xpath('normalize-space(//abbr[contains(@itemprop,"addressRegion")]/text())').extract_first(),
110 'city': response.xpath('normalize-space(//span[contains(@itemprop,"addressLocality")]/text())').extract_first(),
111 'postcode': response.xpath('normalize-space(//span[contains(@itemprop,"postalCode")]/text())').extract_first(),
112 'country': response.xpath('normalize-space(//abbr[contains(@itemprop,"addressCountry")]/text())').extract_first(),
113 'phone': response.xpath('//span[contains(@itemprop,"telephone")]/text()').extract_first(),
114 'lat': float(response.xpath('//meta[contains(@itemprop,"latitude")]/@content').extract_first()),
115 'lon' : float(response.xpath('//meta[contains(@itemprop,"longitude")]/@content').extract_first()),
116 'website': response.url,
117 'opening_hours': self.store_hours(hours),
118 'brand': brand.strip(),
119 }
120
121 yield GeojsonPointItem(**properties)
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/locations/spiders/riteaid.py b/locations/spiders/riteaid.py
--- a/locations/spiders/riteaid.py
+++ b/locations/spiders/riteaid.py
@@ -8,7 +8,7 @@
name = "riteaid"
allowed_domains = ["riteaid.com"]
start_urls = (
- 'https://locations.riteaid.com/',
+ 'https://www.riteaid.com/locations/',
)
def store_hours(self, store_hours):
@@ -77,6 +77,9 @@
state_urls = response.xpath('//a[@class="c-directory-list-content-item-link"]/@href').extract()
for url in state_urls:
+ if url == 'https://www.riteaid.com/locations/pa/philadelphia.html':
+ # As of 2021-08-21, This URL 500's reliably, so skipping it.
+ continue
if len(url.split('/')) == 5:
yield scrapy.Request(response.urljoin(url), callback=self.parse_location)
else:
@@ -118,4 +121,4 @@
'brand': brand.strip(),
}
- yield GeojsonPointItem(**properties)
\ No newline at end of file
+ yield GeojsonPointItem(**properties)
|
{"golden_diff": "diff --git a/locations/spiders/riteaid.py b/locations/spiders/riteaid.py\n--- a/locations/spiders/riteaid.py\n+++ b/locations/spiders/riteaid.py\n@@ -8,7 +8,7 @@\n name = \"riteaid\"\n allowed_domains = [\"riteaid.com\"]\n start_urls = (\n- 'https://locations.riteaid.com/',\n+ 'https://www.riteaid.com/locations/',\n )\n \n def store_hours(self, store_hours):\n@@ -77,6 +77,9 @@\n state_urls = response.xpath('//a[@class=\"c-directory-list-content-item-link\"]/@href').extract()\n \n for url in state_urls:\n+ if url == 'https://www.riteaid.com/locations/pa/philadelphia.html':\n+ # As of 2021-08-21, This URL 500's reliably, so skipping it.\n+ continue\n if len(url.split('/')) == 5:\n yield scrapy.Request(response.urljoin(url), callback=self.parse_location)\n else:\n@@ -118,4 +121,4 @@\n 'brand': brand.strip(),\n }\n \n- yield GeojsonPointItem(**properties)\n\\ No newline at end of file\n+ yield GeojsonPointItem(**properties)\n", "issue": "Spider riteaid is broken\nDuring the global build at 2021-08-11-14-42-19, spider **riteaid** failed with **1234 features** and **1 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-08-11-14-42-19/logs/riteaid.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-08-11-14-42-19/output/riteaid.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-08-11-14-42-19/output/riteaid.geojson))\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport scrapy\nimport json\nimport re\nfrom locations.items import GeojsonPointItem\n\nclass RiteAidSpider(scrapy.Spider):\n name = \"riteaid\"\n allowed_domains = [\"riteaid.com\"]\n start_urls = (\n 'https://locations.riteaid.com/',\n )\n\n def store_hours(self, store_hours):\n day_groups = []\n this_day_group = None\n for day_info in store_hours:\n day = day_info['day'][:2].title()\n\n hour_intervals = []\n for interval in day_info['intervals']:\n f_time = str(interval['start']).zfill(4)\n t_time = str(interval['end']).zfill(4)\n hour_intervals.append('{}:{}-{}:{}'.format(\n f_time[0:2],\n f_time[2:4],\n t_time[0:2],\n t_time[2:4],\n ))\n hours = ','.join(hour_intervals)\n\n if not this_day_group:\n this_day_group = {\n 'from_day': day,\n 'to_day': day,\n 'hours': hours\n }\n elif this_day_group['hours'] != hours:\n day_groups.append(this_day_group)\n this_day_group = {\n 'from_day': day,\n 'to_day': day,\n 'hours': hours\n }\n elif this_day_group['hours'] == hours:\n this_day_group['to_day'] = day\n\n day_groups.append(this_day_group)\n\n opening_hours = \"\"\n if len(day_groups) == 1 and day_groups[0]['hours'] in ('00:00-23:59', '00:00-00:00'):\n opening_hours = '24/7'\n else:\n for day_group in day_groups:\n if day_group['from_day'] == day_group['to_day']:\n opening_hours += '{from_day} {hours}; '.format(**day_group)\n elif day_group['from_day'] == 'Su' and day_group['to_day'] == 'Sa':\n opening_hours += '{hours}; '.format(**day_group)\n else:\n opening_hours += '{from_day}-{to_day} {hours}; '.format(**day_group)\n opening_hours = opening_hours[:-2]\n\n return opening_hours\n\n def parse(self, response):\n urls = response.xpath('//a[@class=\"c-directory-list-content-item-link\"]/@href').extract()\n\n for url in urls:\n if len(url.split('/')) == 3:\n yield scrapy.Request(response.urljoin(url), callback=self.parse_city)\n elif len(url.split('/')) == 4:\n yield scrapy.Request(response.urljoin(url), callback=self.parse_location)\n else:\n yield scrapy.Request(response.urljoin(url), callback=self.parse_state)\n\n def parse_state(self, response):\n state_urls = response.xpath('//a[@class=\"c-directory-list-content-item-link\"]/@href').extract()\n\n for url in state_urls:\n if len(url.split('/')) == 5:\n yield scrapy.Request(response.urljoin(url), callback=self.parse_location)\n else:\n yield scrapy.Request(response.urljoin(url), callback=self.parse_city)\n\n def parse_city(self, response):\n city_urls = response.xpath('//a[@itemprop=\"url\"]/@href').extract()\n\n for url in city_urls:\n yield scrapy.Request(response.urljoin(url), callback=self.parse_location)\n\n def parse_location(self, response):\n ref = response.xpath('normalize-space(//h1[contains(@itemprop,\"name\")]/text())').extract_first()\n brand_elem = response.xpath('//div[@class=\"alert alert-danger\"]/text()').extract_first()\n\n if brand_elem: #Changed ownership as part of the sale of select Rite Aid stores to Walgreens\n brand = 'Walgreens'\n else:\n brand = re.search(r'([^#//s*]+)', ref).group(1)\n\n hours_elem = response.xpath('//div[@class=\"Hours-store\"]//div[contains(@class,\"c-location-hours-details-wrapper\")]/@data-days')\n if hours_elem: # not shop, only clinic\n hours = json.loads(hours_elem.extract_first())\n else:\n hours = json.loads(response.xpath('//div[contains(@class,\"c-location-hours-details-wrapper\")]/@data-days').extract_first())\n\n properties = {\n 'ref': ref,\n 'addr_full': response.xpath('normalize-space(//span[contains(@itemprop,\"streetAddress\")]/span/text())').extract_first(),\n 'state': response.xpath('normalize-space(//abbr[contains(@itemprop,\"addressRegion\")]/text())').extract_first(),\n 'city': response.xpath('normalize-space(//span[contains(@itemprop,\"addressLocality\")]/text())').extract_first(),\n 'postcode': response.xpath('normalize-space(//span[contains(@itemprop,\"postalCode\")]/text())').extract_first(),\n 'country': response.xpath('normalize-space(//abbr[contains(@itemprop,\"addressCountry\")]/text())').extract_first(),\n 'phone': response.xpath('//span[contains(@itemprop,\"telephone\")]/text()').extract_first(),\n 'lat': float(response.xpath('//meta[contains(@itemprop,\"latitude\")]/@content').extract_first()),\n 'lon' : float(response.xpath('//meta[contains(@itemprop,\"longitude\")]/@content').extract_first()),\n 'website': response.url,\n 'opening_hours': self.store_hours(hours),\n 'brand': brand.strip(),\n }\n\n yield GeojsonPointItem(**properties)", "path": "locations/spiders/riteaid.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nimport scrapy\nimport json\nimport re\nfrom locations.items import GeojsonPointItem\n\nclass RiteAidSpider(scrapy.Spider):\n name = \"riteaid\"\n allowed_domains = [\"riteaid.com\"]\n start_urls = (\n 'https://www.riteaid.com/locations/',\n )\n\n def store_hours(self, store_hours):\n day_groups = []\n this_day_group = None\n for day_info in store_hours:\n day = day_info['day'][:2].title()\n\n hour_intervals = []\n for interval in day_info['intervals']:\n f_time = str(interval['start']).zfill(4)\n t_time = str(interval['end']).zfill(4)\n hour_intervals.append('{}:{}-{}:{}'.format(\n f_time[0:2],\n f_time[2:4],\n t_time[0:2],\n t_time[2:4],\n ))\n hours = ','.join(hour_intervals)\n\n if not this_day_group:\n this_day_group = {\n 'from_day': day,\n 'to_day': day,\n 'hours': hours\n }\n elif this_day_group['hours'] != hours:\n day_groups.append(this_day_group)\n this_day_group = {\n 'from_day': day,\n 'to_day': day,\n 'hours': hours\n }\n elif this_day_group['hours'] == hours:\n this_day_group['to_day'] = day\n\n day_groups.append(this_day_group)\n\n opening_hours = \"\"\n if len(day_groups) == 1 and day_groups[0]['hours'] in ('00:00-23:59', '00:00-00:00'):\n opening_hours = '24/7'\n else:\n for day_group in day_groups:\n if day_group['from_day'] == day_group['to_day']:\n opening_hours += '{from_day} {hours}; '.format(**day_group)\n elif day_group['from_day'] == 'Su' and day_group['to_day'] == 'Sa':\n opening_hours += '{hours}; '.format(**day_group)\n else:\n opening_hours += '{from_day}-{to_day} {hours}; '.format(**day_group)\n opening_hours = opening_hours[:-2]\n\n return opening_hours\n\n def parse(self, response):\n urls = response.xpath('//a[@class=\"c-directory-list-content-item-link\"]/@href').extract()\n\n for url in urls:\n if len(url.split('/')) == 3:\n yield scrapy.Request(response.urljoin(url), callback=self.parse_city)\n elif len(url.split('/')) == 4:\n yield scrapy.Request(response.urljoin(url), callback=self.parse_location)\n else:\n yield scrapy.Request(response.urljoin(url), callback=self.parse_state)\n\n def parse_state(self, response):\n state_urls = response.xpath('//a[@class=\"c-directory-list-content-item-link\"]/@href').extract()\n\n for url in state_urls:\n if url == 'https://www.riteaid.com/locations/pa/philadelphia.html':\n # As of 2021-08-21, This URL 500's reliably, so skipping it.\n continue\n if len(url.split('/')) == 5:\n yield scrapy.Request(response.urljoin(url), callback=self.parse_location)\n else:\n yield scrapy.Request(response.urljoin(url), callback=self.parse_city)\n\n def parse_city(self, response):\n city_urls = response.xpath('//a[@itemprop=\"url\"]/@href').extract()\n\n for url in city_urls:\n yield scrapy.Request(response.urljoin(url), callback=self.parse_location)\n\n def parse_location(self, response):\n ref = response.xpath('normalize-space(//h1[contains(@itemprop,\"name\")]/text())').extract_first()\n brand_elem = response.xpath('//div[@class=\"alert alert-danger\"]/text()').extract_first()\n\n if brand_elem: #Changed ownership as part of the sale of select Rite Aid stores to Walgreens\n brand = 'Walgreens'\n else:\n brand = re.search(r'([^#//s*]+)', ref).group(1)\n\n hours_elem = response.xpath('//div[@class=\"Hours-store\"]//div[contains(@class,\"c-location-hours-details-wrapper\")]/@data-days')\n if hours_elem: # not shop, only clinic\n hours = json.loads(hours_elem.extract_first())\n else:\n hours = json.loads(response.xpath('//div[contains(@class,\"c-location-hours-details-wrapper\")]/@data-days').extract_first())\n\n properties = {\n 'ref': ref,\n 'addr_full': response.xpath('normalize-space(//span[contains(@itemprop,\"streetAddress\")]/span/text())').extract_first(),\n 'state': response.xpath('normalize-space(//abbr[contains(@itemprop,\"addressRegion\")]/text())').extract_first(),\n 'city': response.xpath('normalize-space(//span[contains(@itemprop,\"addressLocality\")]/text())').extract_first(),\n 'postcode': response.xpath('normalize-space(//span[contains(@itemprop,\"postalCode\")]/text())').extract_first(),\n 'country': response.xpath('normalize-space(//abbr[contains(@itemprop,\"addressCountry\")]/text())').extract_first(),\n 'phone': response.xpath('//span[contains(@itemprop,\"telephone\")]/text()').extract_first(),\n 'lat': float(response.xpath('//meta[contains(@itemprop,\"latitude\")]/@content').extract_first()),\n 'lon' : float(response.xpath('//meta[contains(@itemprop,\"longitude\")]/@content').extract_first()),\n 'website': response.url,\n 'opening_hours': self.store_hours(hours),\n 'brand': brand.strip(),\n }\n\n yield GeojsonPointItem(**properties)\n", "path": "locations/spiders/riteaid.py"}]}
| 1,890 | 290 |
gh_patches_debug_17793
|
rasdani/github-patches
|
git_diff
|
ytdl-org__youtube-dl-21536
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Mixer VODs won't download at all
The tool (latest version being 2019.06.21 at the time of posting this) thinks that the vod link is for downloading a currently online stream.
I think Mixer may have changed its stuff recently. Here is the example below:
Before (when it worked perfectly):
https://mixer.com/streamer?vod=000000000
After (where the problems most likely started at, used on the bottom for references):
https://mixer.com/streamer?vod=IxFno1rqC0S_XJ1a2yGgNw
https://mixer.com/streamer?vod=uODrzy4OOk24ZFYcBGOhdA
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `youtube_dl/extractor/beampro.py`
Content:
```
1 # coding: utf-8
2 from __future__ import unicode_literals
3
4 from .common import InfoExtractor
5 from ..utils import (
6 ExtractorError,
7 clean_html,
8 compat_str,
9 float_or_none,
10 int_or_none,
11 parse_iso8601,
12 try_get,
13 urljoin,
14 )
15
16
17 class BeamProBaseIE(InfoExtractor):
18 _API_BASE = 'https://mixer.com/api/v1'
19 _RATINGS = {'family': 0, 'teen': 13, '18+': 18}
20
21 def _extract_channel_info(self, chan):
22 user_id = chan.get('userId') or try_get(chan, lambda x: x['user']['id'])
23 return {
24 'uploader': chan.get('token') or try_get(
25 chan, lambda x: x['user']['username'], compat_str),
26 'uploader_id': compat_str(user_id) if user_id else None,
27 'age_limit': self._RATINGS.get(chan.get('audience')),
28 }
29
30
31 class BeamProLiveIE(BeamProBaseIE):
32 IE_NAME = 'Mixer:live'
33 _VALID_URL = r'https?://(?:\w+\.)?(?:beam\.pro|mixer\.com)/(?P<id>[^/?#&]+)'
34 _TEST = {
35 'url': 'http://mixer.com/niterhayven',
36 'info_dict': {
37 'id': '261562',
38 'ext': 'mp4',
39 'title': 'Introducing The Witcher 3 // The Grind Starts Now!',
40 'description': 'md5:0b161ac080f15fe05d18a07adb44a74d',
41 'thumbnail': r're:https://.*\.jpg$',
42 'timestamp': 1483477281,
43 'upload_date': '20170103',
44 'uploader': 'niterhayven',
45 'uploader_id': '373396',
46 'age_limit': 18,
47 'is_live': True,
48 'view_count': int,
49 },
50 'skip': 'niterhayven is offline',
51 'params': {
52 'skip_download': True,
53 },
54 }
55
56 _MANIFEST_URL_TEMPLATE = '%s/channels/%%s/manifest.%%s' % BeamProBaseIE._API_BASE
57
58 @classmethod
59 def suitable(cls, url):
60 return False if BeamProVodIE.suitable(url) else super(BeamProLiveIE, cls).suitable(url)
61
62 def _real_extract(self, url):
63 channel_name = self._match_id(url)
64
65 chan = self._download_json(
66 '%s/channels/%s' % (self._API_BASE, channel_name), channel_name)
67
68 if chan.get('online') is False:
69 raise ExtractorError(
70 '{0} is offline'.format(channel_name), expected=True)
71
72 channel_id = chan['id']
73
74 def manifest_url(kind):
75 return self._MANIFEST_URL_TEMPLATE % (channel_id, kind)
76
77 formats = self._extract_m3u8_formats(
78 manifest_url('m3u8'), channel_name, ext='mp4', m3u8_id='hls',
79 fatal=False)
80 formats.extend(self._extract_smil_formats(
81 manifest_url('smil'), channel_name, fatal=False))
82 self._sort_formats(formats)
83
84 info = {
85 'id': compat_str(chan.get('id') or channel_name),
86 'title': self._live_title(chan.get('name') or channel_name),
87 'description': clean_html(chan.get('description')),
88 'thumbnail': try_get(
89 chan, lambda x: x['thumbnail']['url'], compat_str),
90 'timestamp': parse_iso8601(chan.get('updatedAt')),
91 'is_live': True,
92 'view_count': int_or_none(chan.get('viewersTotal')),
93 'formats': formats,
94 }
95 info.update(self._extract_channel_info(chan))
96
97 return info
98
99
100 class BeamProVodIE(BeamProBaseIE):
101 IE_NAME = 'Mixer:vod'
102 _VALID_URL = r'https?://(?:\w+\.)?(?:beam\.pro|mixer\.com)/[^/?#&]+\?.*?\bvod=(?P<id>\d+)'
103 _TEST = {
104 'url': 'https://mixer.com/willow8714?vod=2259830',
105 'md5': 'b2431e6e8347dc92ebafb565d368b76b',
106 'info_dict': {
107 'id': '2259830',
108 'ext': 'mp4',
109 'title': 'willow8714\'s Channel',
110 'duration': 6828.15,
111 'thumbnail': r're:https://.*source\.png$',
112 'timestamp': 1494046474,
113 'upload_date': '20170506',
114 'uploader': 'willow8714',
115 'uploader_id': '6085379',
116 'age_limit': 13,
117 'view_count': int,
118 },
119 'params': {
120 'skip_download': True,
121 },
122 }
123
124 @staticmethod
125 def _extract_format(vod, vod_type):
126 if not vod.get('baseUrl'):
127 return []
128
129 if vod_type == 'hls':
130 filename, protocol = 'manifest.m3u8', 'm3u8_native'
131 elif vod_type == 'raw':
132 filename, protocol = 'source.mp4', 'https'
133 else:
134 assert False
135
136 data = vod.get('data') if isinstance(vod.get('data'), dict) else {}
137
138 format_id = [vod_type]
139 if isinstance(data.get('Height'), compat_str):
140 format_id.append('%sp' % data['Height'])
141
142 return [{
143 'url': urljoin(vod['baseUrl'], filename),
144 'format_id': '-'.join(format_id),
145 'ext': 'mp4',
146 'protocol': protocol,
147 'width': int_or_none(data.get('Width')),
148 'height': int_or_none(data.get('Height')),
149 'fps': int_or_none(data.get('Fps')),
150 'tbr': int_or_none(data.get('Bitrate'), 1000),
151 }]
152
153 def _real_extract(self, url):
154 vod_id = self._match_id(url)
155
156 vod_info = self._download_json(
157 '%s/recordings/%s' % (self._API_BASE, vod_id), vod_id)
158
159 state = vod_info.get('state')
160 if state != 'AVAILABLE':
161 raise ExtractorError(
162 'VOD %s is not available (state: %s)' % (vod_id, state),
163 expected=True)
164
165 formats = []
166 thumbnail_url = None
167
168 for vod in vod_info['vods']:
169 vod_type = vod.get('format')
170 if vod_type in ('hls', 'raw'):
171 formats.extend(self._extract_format(vod, vod_type))
172 elif vod_type == 'thumbnail':
173 thumbnail_url = urljoin(vod.get('baseUrl'), 'source.png')
174
175 self._sort_formats(formats)
176
177 info = {
178 'id': vod_id,
179 'title': vod_info.get('name') or vod_id,
180 'duration': float_or_none(vod_info.get('duration')),
181 'thumbnail': thumbnail_url,
182 'timestamp': parse_iso8601(vod_info.get('createdAt')),
183 'view_count': int_or_none(vod_info.get('viewsTotal')),
184 'formats': formats,
185 }
186 info.update(self._extract_channel_info(vod_info.get('channel') or {}))
187
188 return info
189
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/youtube_dl/extractor/beampro.py b/youtube_dl/extractor/beampro.py
--- a/youtube_dl/extractor/beampro.py
+++ b/youtube_dl/extractor/beampro.py
@@ -99,8 +99,8 @@
class BeamProVodIE(BeamProBaseIE):
IE_NAME = 'Mixer:vod'
- _VALID_URL = r'https?://(?:\w+\.)?(?:beam\.pro|mixer\.com)/[^/?#&]+\?.*?\bvod=(?P<id>\d+)'
- _TEST = {
+ _VALID_URL = r'https?://(?:\w+\.)?(?:beam\.pro|mixer\.com)/[^/?#&]+\?.*?\bvod=(?P<id>\w+)'
+ _TESTS = [{
'url': 'https://mixer.com/willow8714?vod=2259830',
'md5': 'b2431e6e8347dc92ebafb565d368b76b',
'info_dict': {
@@ -119,7 +119,10 @@
'params': {
'skip_download': True,
},
- }
+ }, {
+ 'url': 'https://mixer.com/streamer?vod=IxFno1rqC0S_XJ1a2yGgNw',
+ 'only_matching': True,
+ }]
@staticmethod
def _extract_format(vod, vod_type):
|
{"golden_diff": "diff --git a/youtube_dl/extractor/beampro.py b/youtube_dl/extractor/beampro.py\n--- a/youtube_dl/extractor/beampro.py\n+++ b/youtube_dl/extractor/beampro.py\n@@ -99,8 +99,8 @@\n \n class BeamProVodIE(BeamProBaseIE):\n IE_NAME = 'Mixer:vod'\n- _VALID_URL = r'https?://(?:\\w+\\.)?(?:beam\\.pro|mixer\\.com)/[^/?#&]+\\?.*?\\bvod=(?P<id>\\d+)'\n- _TEST = {\n+ _VALID_URL = r'https?://(?:\\w+\\.)?(?:beam\\.pro|mixer\\.com)/[^/?#&]+\\?.*?\\bvod=(?P<id>\\w+)'\n+ _TESTS = [{\n 'url': 'https://mixer.com/willow8714?vod=2259830',\n 'md5': 'b2431e6e8347dc92ebafb565d368b76b',\n 'info_dict': {\n@@ -119,7 +119,10 @@\n 'params': {\n 'skip_download': True,\n },\n- }\n+ }, {\n+ 'url': 'https://mixer.com/streamer?vod=IxFno1rqC0S_XJ1a2yGgNw',\n+ 'only_matching': True,\n+ }]\n \n @staticmethod\n def _extract_format(vod, vod_type):\n", "issue": "Mixer VODs won't download at all\nThe tool (latest version being 2019.06.21 at the time of posting this) thinks that the vod link is for downloading a currently online stream.\r\nI think Mixer may have changed its stuff recently. Here is the example below:\r\n\r\nBefore (when it worked perfectly):\r\nhttps://mixer.com/streamer?vod=000000000\r\n\r\nAfter (where the problems most likely started at, used on the bottom for references):\r\nhttps://mixer.com/streamer?vod=IxFno1rqC0S_XJ1a2yGgNw\r\nhttps://mixer.com/streamer?vod=uODrzy4OOk24ZFYcBGOhdA\n", "before_files": [{"content": "# coding: utf-8\nfrom __future__ import unicode_literals\n\nfrom .common import InfoExtractor\nfrom ..utils import (\n ExtractorError,\n clean_html,\n compat_str,\n float_or_none,\n int_or_none,\n parse_iso8601,\n try_get,\n urljoin,\n)\n\n\nclass BeamProBaseIE(InfoExtractor):\n _API_BASE = 'https://mixer.com/api/v1'\n _RATINGS = {'family': 0, 'teen': 13, '18+': 18}\n\n def _extract_channel_info(self, chan):\n user_id = chan.get('userId') or try_get(chan, lambda x: x['user']['id'])\n return {\n 'uploader': chan.get('token') or try_get(\n chan, lambda x: x['user']['username'], compat_str),\n 'uploader_id': compat_str(user_id) if user_id else None,\n 'age_limit': self._RATINGS.get(chan.get('audience')),\n }\n\n\nclass BeamProLiveIE(BeamProBaseIE):\n IE_NAME = 'Mixer:live'\n _VALID_URL = r'https?://(?:\\w+\\.)?(?:beam\\.pro|mixer\\.com)/(?P<id>[^/?#&]+)'\n _TEST = {\n 'url': 'http://mixer.com/niterhayven',\n 'info_dict': {\n 'id': '261562',\n 'ext': 'mp4',\n 'title': 'Introducing The Witcher 3 // The Grind Starts Now!',\n 'description': 'md5:0b161ac080f15fe05d18a07adb44a74d',\n 'thumbnail': r're:https://.*\\.jpg$',\n 'timestamp': 1483477281,\n 'upload_date': '20170103',\n 'uploader': 'niterhayven',\n 'uploader_id': '373396',\n 'age_limit': 18,\n 'is_live': True,\n 'view_count': int,\n },\n 'skip': 'niterhayven is offline',\n 'params': {\n 'skip_download': True,\n },\n }\n\n _MANIFEST_URL_TEMPLATE = '%s/channels/%%s/manifest.%%s' % BeamProBaseIE._API_BASE\n\n @classmethod\n def suitable(cls, url):\n return False if BeamProVodIE.suitable(url) else super(BeamProLiveIE, cls).suitable(url)\n\n def _real_extract(self, url):\n channel_name = self._match_id(url)\n\n chan = self._download_json(\n '%s/channels/%s' % (self._API_BASE, channel_name), channel_name)\n\n if chan.get('online') is False:\n raise ExtractorError(\n '{0} is offline'.format(channel_name), expected=True)\n\n channel_id = chan['id']\n\n def manifest_url(kind):\n return self._MANIFEST_URL_TEMPLATE % (channel_id, kind)\n\n formats = self._extract_m3u8_formats(\n manifest_url('m3u8'), channel_name, ext='mp4', m3u8_id='hls',\n fatal=False)\n formats.extend(self._extract_smil_formats(\n manifest_url('smil'), channel_name, fatal=False))\n self._sort_formats(formats)\n\n info = {\n 'id': compat_str(chan.get('id') or channel_name),\n 'title': self._live_title(chan.get('name') or channel_name),\n 'description': clean_html(chan.get('description')),\n 'thumbnail': try_get(\n chan, lambda x: x['thumbnail']['url'], compat_str),\n 'timestamp': parse_iso8601(chan.get('updatedAt')),\n 'is_live': True,\n 'view_count': int_or_none(chan.get('viewersTotal')),\n 'formats': formats,\n }\n info.update(self._extract_channel_info(chan))\n\n return info\n\n\nclass BeamProVodIE(BeamProBaseIE):\n IE_NAME = 'Mixer:vod'\n _VALID_URL = r'https?://(?:\\w+\\.)?(?:beam\\.pro|mixer\\.com)/[^/?#&]+\\?.*?\\bvod=(?P<id>\\d+)'\n _TEST = {\n 'url': 'https://mixer.com/willow8714?vod=2259830',\n 'md5': 'b2431e6e8347dc92ebafb565d368b76b',\n 'info_dict': {\n 'id': '2259830',\n 'ext': 'mp4',\n 'title': 'willow8714\\'s Channel',\n 'duration': 6828.15,\n 'thumbnail': r're:https://.*source\\.png$',\n 'timestamp': 1494046474,\n 'upload_date': '20170506',\n 'uploader': 'willow8714',\n 'uploader_id': '6085379',\n 'age_limit': 13,\n 'view_count': int,\n },\n 'params': {\n 'skip_download': True,\n },\n }\n\n @staticmethod\n def _extract_format(vod, vod_type):\n if not vod.get('baseUrl'):\n return []\n\n if vod_type == 'hls':\n filename, protocol = 'manifest.m3u8', 'm3u8_native'\n elif vod_type == 'raw':\n filename, protocol = 'source.mp4', 'https'\n else:\n assert False\n\n data = vod.get('data') if isinstance(vod.get('data'), dict) else {}\n\n format_id = [vod_type]\n if isinstance(data.get('Height'), compat_str):\n format_id.append('%sp' % data['Height'])\n\n return [{\n 'url': urljoin(vod['baseUrl'], filename),\n 'format_id': '-'.join(format_id),\n 'ext': 'mp4',\n 'protocol': protocol,\n 'width': int_or_none(data.get('Width')),\n 'height': int_or_none(data.get('Height')),\n 'fps': int_or_none(data.get('Fps')),\n 'tbr': int_or_none(data.get('Bitrate'), 1000),\n }]\n\n def _real_extract(self, url):\n vod_id = self._match_id(url)\n\n vod_info = self._download_json(\n '%s/recordings/%s' % (self._API_BASE, vod_id), vod_id)\n\n state = vod_info.get('state')\n if state != 'AVAILABLE':\n raise ExtractorError(\n 'VOD %s is not available (state: %s)' % (vod_id, state),\n expected=True)\n\n formats = []\n thumbnail_url = None\n\n for vod in vod_info['vods']:\n vod_type = vod.get('format')\n if vod_type in ('hls', 'raw'):\n formats.extend(self._extract_format(vod, vod_type))\n elif vod_type == 'thumbnail':\n thumbnail_url = urljoin(vod.get('baseUrl'), 'source.png')\n\n self._sort_formats(formats)\n\n info = {\n 'id': vod_id,\n 'title': vod_info.get('name') or vod_id,\n 'duration': float_or_none(vod_info.get('duration')),\n 'thumbnail': thumbnail_url,\n 'timestamp': parse_iso8601(vod_info.get('createdAt')),\n 'view_count': int_or_none(vod_info.get('viewsTotal')),\n 'formats': formats,\n }\n info.update(self._extract_channel_info(vod_info.get('channel') or {}))\n\n return info\n", "path": "youtube_dl/extractor/beampro.py"}], "after_files": [{"content": "# coding: utf-8\nfrom __future__ import unicode_literals\n\nfrom .common import InfoExtractor\nfrom ..utils import (\n ExtractorError,\n clean_html,\n compat_str,\n float_or_none,\n int_or_none,\n parse_iso8601,\n try_get,\n urljoin,\n)\n\n\nclass BeamProBaseIE(InfoExtractor):\n _API_BASE = 'https://mixer.com/api/v1'\n _RATINGS = {'family': 0, 'teen': 13, '18+': 18}\n\n def _extract_channel_info(self, chan):\n user_id = chan.get('userId') or try_get(chan, lambda x: x['user']['id'])\n return {\n 'uploader': chan.get('token') or try_get(\n chan, lambda x: x['user']['username'], compat_str),\n 'uploader_id': compat_str(user_id) if user_id else None,\n 'age_limit': self._RATINGS.get(chan.get('audience')),\n }\n\n\nclass BeamProLiveIE(BeamProBaseIE):\n IE_NAME = 'Mixer:live'\n _VALID_URL = r'https?://(?:\\w+\\.)?(?:beam\\.pro|mixer\\.com)/(?P<id>[^/?#&]+)'\n _TEST = {\n 'url': 'http://mixer.com/niterhayven',\n 'info_dict': {\n 'id': '261562',\n 'ext': 'mp4',\n 'title': 'Introducing The Witcher 3 // The Grind Starts Now!',\n 'description': 'md5:0b161ac080f15fe05d18a07adb44a74d',\n 'thumbnail': r're:https://.*\\.jpg$',\n 'timestamp': 1483477281,\n 'upload_date': '20170103',\n 'uploader': 'niterhayven',\n 'uploader_id': '373396',\n 'age_limit': 18,\n 'is_live': True,\n 'view_count': int,\n },\n 'skip': 'niterhayven is offline',\n 'params': {\n 'skip_download': True,\n },\n }\n\n _MANIFEST_URL_TEMPLATE = '%s/channels/%%s/manifest.%%s' % BeamProBaseIE._API_BASE\n\n @classmethod\n def suitable(cls, url):\n return False if BeamProVodIE.suitable(url) else super(BeamProLiveIE, cls).suitable(url)\n\n def _real_extract(self, url):\n channel_name = self._match_id(url)\n\n chan = self._download_json(\n '%s/channels/%s' % (self._API_BASE, channel_name), channel_name)\n\n if chan.get('online') is False:\n raise ExtractorError(\n '{0} is offline'.format(channel_name), expected=True)\n\n channel_id = chan['id']\n\n def manifest_url(kind):\n return self._MANIFEST_URL_TEMPLATE % (channel_id, kind)\n\n formats = self._extract_m3u8_formats(\n manifest_url('m3u8'), channel_name, ext='mp4', m3u8_id='hls',\n fatal=False)\n formats.extend(self._extract_smil_formats(\n manifest_url('smil'), channel_name, fatal=False))\n self._sort_formats(formats)\n\n info = {\n 'id': compat_str(chan.get('id') or channel_name),\n 'title': self._live_title(chan.get('name') or channel_name),\n 'description': clean_html(chan.get('description')),\n 'thumbnail': try_get(\n chan, lambda x: x['thumbnail']['url'], compat_str),\n 'timestamp': parse_iso8601(chan.get('updatedAt')),\n 'is_live': True,\n 'view_count': int_or_none(chan.get('viewersTotal')),\n 'formats': formats,\n }\n info.update(self._extract_channel_info(chan))\n\n return info\n\n\nclass BeamProVodIE(BeamProBaseIE):\n IE_NAME = 'Mixer:vod'\n _VALID_URL = r'https?://(?:\\w+\\.)?(?:beam\\.pro|mixer\\.com)/[^/?#&]+\\?.*?\\bvod=(?P<id>\\w+)'\n _TESTS = [{\n 'url': 'https://mixer.com/willow8714?vod=2259830',\n 'md5': 'b2431e6e8347dc92ebafb565d368b76b',\n 'info_dict': {\n 'id': '2259830',\n 'ext': 'mp4',\n 'title': 'willow8714\\'s Channel',\n 'duration': 6828.15,\n 'thumbnail': r're:https://.*source\\.png$',\n 'timestamp': 1494046474,\n 'upload_date': '20170506',\n 'uploader': 'willow8714',\n 'uploader_id': '6085379',\n 'age_limit': 13,\n 'view_count': int,\n },\n 'params': {\n 'skip_download': True,\n },\n }, {\n 'url': 'https://mixer.com/streamer?vod=IxFno1rqC0S_XJ1a2yGgNw',\n 'only_matching': True,\n }]\n\n @staticmethod\n def _extract_format(vod, vod_type):\n if not vod.get('baseUrl'):\n return []\n\n if vod_type == 'hls':\n filename, protocol = 'manifest.m3u8', 'm3u8_native'\n elif vod_type == 'raw':\n filename, protocol = 'source.mp4', 'https'\n else:\n assert False\n\n data = vod.get('data') if isinstance(vod.get('data'), dict) else {}\n\n format_id = [vod_type]\n if isinstance(data.get('Height'), compat_str):\n format_id.append('%sp' % data['Height'])\n\n return [{\n 'url': urljoin(vod['baseUrl'], filename),\n 'format_id': '-'.join(format_id),\n 'ext': 'mp4',\n 'protocol': protocol,\n 'width': int_or_none(data.get('Width')),\n 'height': int_or_none(data.get('Height')),\n 'fps': int_or_none(data.get('Fps')),\n 'tbr': int_or_none(data.get('Bitrate'), 1000),\n }]\n\n def _real_extract(self, url):\n vod_id = self._match_id(url)\n\n vod_info = self._download_json(\n '%s/recordings/%s' % (self._API_BASE, vod_id), vod_id)\n\n state = vod_info.get('state')\n if state != 'AVAILABLE':\n raise ExtractorError(\n 'VOD %s is not available (state: %s)' % (vod_id, state),\n expected=True)\n\n formats = []\n thumbnail_url = None\n\n for vod in vod_info['vods']:\n vod_type = vod.get('format')\n if vod_type in ('hls', 'raw'):\n formats.extend(self._extract_format(vod, vod_type))\n elif vod_type == 'thumbnail':\n thumbnail_url = urljoin(vod.get('baseUrl'), 'source.png')\n\n self._sort_formats(formats)\n\n info = {\n 'id': vod_id,\n 'title': vod_info.get('name') or vod_id,\n 'duration': float_or_none(vod_info.get('duration')),\n 'thumbnail': thumbnail_url,\n 'timestamp': parse_iso8601(vod_info.get('createdAt')),\n 'view_count': int_or_none(vod_info.get('viewsTotal')),\n 'formats': formats,\n }\n info.update(self._extract_channel_info(vod_info.get('channel') or {}))\n\n return info\n", "path": "youtube_dl/extractor/beampro.py"}]}
| 2,630 | 357 |
gh_patches_debug_20289
|
rasdani/github-patches
|
git_diff
|
ansible__awx-14386
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Conjur credential retrieval differs between Conjur OSS and Conjur Enterprise
### Please confirm the following
- [X] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).
- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.
- [X] I understand that AWX is open source software provided for free and that I might not receive a timely response.
- [X] I am **NOT** reporting a (potential) security vulnerability. (These should be emailed to `[email protected]` instead.)
### Bug Summary
When attempting to retrieve credentials using Ansible AWX 22.7.x from Conjur Enterprise 13, I consistently encounter a 401 error. After thorough investigation, I've identified that the root of the issue lies within the `conjur_backend` function, which executes two requests to Conjur in order to fetch the necessary credential information:
1. Initial authentication is performed through the endpoint `api/authn/<account>/<username>/authenticate/`. The response from this request includes a signature.
2. The actual credential retrieval takes place using the endpoint `api/secrets/<account>/variable/<path_to_secret>/`, where users provide the relevant variable or secret.
Upon closer inspection, it becomes clear that the authentication response (as described in point 1) differs between Conjur OSS and Conjur Enterprise. To illustrate these differences, I wrote a test script, and the subsequent output from the console is documented in the provided images (Image 1: Test Code, Image 2: Console Output).
Image 1:
<img width="848" alt="Screenshot 2023-08-24 at 10 48 32" src="https://github.com/ansible/awx/assets/10104752/57a82fb0-c2fa-4a69-96b0-3fe755e8dc59">
Image 2:
<img width="784" alt="Screenshot 2023-08-24 at 10 46 50" src="https://github.com/ansible/awx/assets/10104752/d0eeea49-d21a-4bd5-bd44-4df9fef7ab1b">
The Conjur Enterprise API returns a response containing the keys `signature`, `payload`, and `protected`. In contrast, the Conjur OSS response presents the same keys, encoded in base64, though. The result is that the plain message from Conjur Enterprise should be encoded to base64 first, before added as a header to the second request (point 2).
~~An alternative approach involves including the header `{"Accept-Encoding": "base64"}` within the headers for the second request. This adjustment is performed within the `awx/main/credential_plugins/conjur.py` file, wherein the modification is as follows:~~
Original Code:
```python
lookup_kwargs = {
'headers': {'Authorization': 'Token token="{}"'.format(token)},
'allow_redirects': False,
}
```
Modified Code:
```python
lookup_kwargs = {
'headers': {'Authorization': 'Token token="{}"'.format(token), 'Accept-Encoding': 'base64'},
'allow_redirects': False,
}
```
~~By incorporating this change, we ensure compatibility with both Conjur OSS and Conjur Enterprise instances, enhancing the credential retrieval process from AWX.~~
---
**EDIT:** Following further investigation into this issue, it appears that my initial solution of adding headers may not be effective. I attempted to rectify this within my local AWX environment, but unfortunately, the issue persisted.
A more viable approach could involve checking whether the authentication response is already in base64 format. This can be accomplished using the following steps:
1. Begin by importing the necessary modules:
```python
import base64
import binascii
```
2. Integrate the following function into your codebase:
```python
def _is_base64(s: str) -> bool:
try:
return base64.b64encode(base64.b64decode(s.encode("utf-8"))) == s.encode("utf-8")
except binascii.Error:
return False
```
3. Adjust the declaration of the `lookup_kwargs` as shown below. This modification ensures that the authentication token is properly encoded if it's not already in base64 format:
```python
lookup_kwargs = {
'headers': {'Authorization': 'Token token="{}"'.format(
token if _is_base64(token) else base64.b64encode(token.encode('utf-8')).decode('utf-8')
)},
'allow_redirects': False,
}
```
@infamousjoeg can you help with this? And do you agree with this change?
### AWX version
22.7.1
### Select the relevant components
- [ ] UI
- [ ] UI (tech preview)
- [ ] API
- [ ] Docs
- [ ] Collection
- [ ] CLI
- [X] Other
### Installation method
docker development environment
### Modifications
yes
### Ansible version
_No response_
### Operating system
MacOS
### Web browser
Chrome
### Steps to reproduce
- Setup a Conjur Enterprise and a Conjur OSS environment
- Create 2 credentials (both for Conjur Enterprice and OSS)
- Create identical users and variables in both environments
- Test the credential retrieval in both environments
### Expected results
The retrieval of a secret from OSS will work, but the retrieval of a secret from Enterprise will result in a 401 error.
### Actual results
The retrieval of a secret from OSS works, and the retrieval of a secret from Enterprise results in a 401 error.
### Additional information
I tested the suggested code change. That was the only change I did in AWX.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `awx/main/credential_plugins/conjur.py`
Content:
```
1 from .plugin import CredentialPlugin, CertFiles, raise_for_status
2
3 from urllib.parse import urljoin, quote
4
5 from django.utils.translation import gettext_lazy as _
6 import requests
7
8
9 conjur_inputs = {
10 'fields': [
11 {
12 'id': 'url',
13 'label': _('Conjur URL'),
14 'type': 'string',
15 'format': 'url',
16 },
17 {
18 'id': 'api_key',
19 'label': _('API Key'),
20 'type': 'string',
21 'secret': True,
22 },
23 {
24 'id': 'account',
25 'label': _('Account'),
26 'type': 'string',
27 },
28 {
29 'id': 'username',
30 'label': _('Username'),
31 'type': 'string',
32 },
33 {'id': 'cacert', 'label': _('Public Key Certificate'), 'type': 'string', 'multiline': True},
34 ],
35 'metadata': [
36 {
37 'id': 'secret_path',
38 'label': _('Secret Identifier'),
39 'type': 'string',
40 'help_text': _('The identifier for the secret e.g., /some/identifier'),
41 },
42 {
43 'id': 'secret_version',
44 'label': _('Secret Version'),
45 'type': 'string',
46 'help_text': _('Used to specify a specific secret version (if left empty, the latest version will be used).'),
47 },
48 ],
49 'required': ['url', 'api_key', 'account', 'username'],
50 }
51
52
53 def conjur_backend(**kwargs):
54 url = kwargs['url']
55 api_key = kwargs['api_key']
56 account = quote(kwargs['account'], safe='')
57 username = quote(kwargs['username'], safe='')
58 secret_path = quote(kwargs['secret_path'], safe='')
59 version = kwargs.get('secret_version')
60 cacert = kwargs.get('cacert', None)
61
62 auth_kwargs = {
63 'headers': {'Content-Type': 'text/plain', 'Accept-Encoding': 'base64'},
64 'data': api_key,
65 'allow_redirects': False,
66 }
67
68 with CertFiles(cacert) as cert:
69 # https://www.conjur.org/api.html#authentication-authenticate-post
70 auth_kwargs['verify'] = cert
71 try:
72 resp = requests.post(urljoin(url, '/'.join(['authn', account, username, 'authenticate'])), **auth_kwargs)
73 resp.raise_for_status()
74 except requests.exceptions.HTTPError:
75 resp = requests.post(urljoin(url, '/'.join(['api', 'authn', account, username, 'authenticate'])), **auth_kwargs)
76 raise_for_status(resp)
77 token = resp.content.decode('utf-8')
78
79 lookup_kwargs = {
80 'headers': {'Authorization': 'Token token="{}"'.format(token)},
81 'allow_redirects': False,
82 }
83
84 # https://www.conjur.org/api.html#secrets-retrieve-a-secret-get
85 path = urljoin(url, '/'.join(['secrets', account, 'variable', secret_path]))
86 path_conjurcloud = urljoin(url, '/'.join(['api', 'secrets', account, 'variable', secret_path]))
87 if version:
88 ver = "version={}".format(version)
89 path = '?'.join([path, ver])
90 path_conjurcloud = '?'.join([path_conjurcloud, ver])
91
92 with CertFiles(cacert) as cert:
93 lookup_kwargs['verify'] = cert
94 try:
95 resp = requests.get(path, timeout=30, **lookup_kwargs)
96 resp.raise_for_status()
97 except requests.exceptions.HTTPError:
98 resp = requests.get(path_conjurcloud, timeout=30, **lookup_kwargs)
99 raise_for_status(resp)
100 return resp.text
101
102
103 conjur_plugin = CredentialPlugin('CyberArk Conjur Secrets Manager Lookup', inputs=conjur_inputs, backend=conjur_backend)
104
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/awx/main/credential_plugins/conjur.py b/awx/main/credential_plugins/conjur.py
--- a/awx/main/credential_plugins/conjur.py
+++ b/awx/main/credential_plugins/conjur.py
@@ -4,6 +4,8 @@
from django.utils.translation import gettext_lazy as _
import requests
+import base64
+import binascii
conjur_inputs = {
@@ -50,6 +52,13 @@
}
+def _is_base64(s: str) -> bool:
+ try:
+ return base64.b64encode(base64.b64decode(s.encode("utf-8"))) == s.encode("utf-8")
+ except binascii.Error:
+ return False
+
+
def conjur_backend(**kwargs):
url = kwargs['url']
api_key = kwargs['api_key']
@@ -77,7 +86,7 @@
token = resp.content.decode('utf-8')
lookup_kwargs = {
- 'headers': {'Authorization': 'Token token="{}"'.format(token)},
+ 'headers': {'Authorization': 'Token token="{}"'.format(token if _is_base64(token) else base64.b64encode(token.encode('utf-8')).decode('utf-8'))},
'allow_redirects': False,
}
|
{"golden_diff": "diff --git a/awx/main/credential_plugins/conjur.py b/awx/main/credential_plugins/conjur.py\n--- a/awx/main/credential_plugins/conjur.py\n+++ b/awx/main/credential_plugins/conjur.py\n@@ -4,6 +4,8 @@\n \n from django.utils.translation import gettext_lazy as _\n import requests\n+import base64\n+import binascii\n \n \n conjur_inputs = {\n@@ -50,6 +52,13 @@\n }\n \n \n+def _is_base64(s: str) -> bool:\n+ try:\n+ return base64.b64encode(base64.b64decode(s.encode(\"utf-8\"))) == s.encode(\"utf-8\")\n+ except binascii.Error:\n+ return False\n+\n+\n def conjur_backend(**kwargs):\n url = kwargs['url']\n api_key = kwargs['api_key']\n@@ -77,7 +86,7 @@\n token = resp.content.decode('utf-8')\n \n lookup_kwargs = {\n- 'headers': {'Authorization': 'Token token=\"{}\"'.format(token)},\n+ 'headers': {'Authorization': 'Token token=\"{}\"'.format(token if _is_base64(token) else base64.b64encode(token.encode('utf-8')).decode('utf-8'))},\n 'allow_redirects': False,\n }\n", "issue": "Conjur credential retrieval differs between Conjur OSS and Conjur Enterprise\n### Please confirm the following\r\n\r\n- [X] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).\r\n- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.\r\n- [X] I understand that AWX is open source software provided for free and that I might not receive a timely response.\r\n- [X] I am **NOT** reporting a (potential) security vulnerability. (These should be emailed to `[email protected]` instead.)\r\n\r\n### Bug Summary\r\n\r\nWhen attempting to retrieve credentials using Ansible AWX 22.7.x from Conjur Enterprise 13, I consistently encounter a 401 error. After thorough investigation, I've identified that the root of the issue lies within the `conjur_backend` function, which executes two requests to Conjur in order to fetch the necessary credential information:\r\n\r\n1. Initial authentication is performed through the endpoint `api/authn/<account>/<username>/authenticate/`. The response from this request includes a signature.\r\n2. The actual credential retrieval takes place using the endpoint `api/secrets/<account>/variable/<path_to_secret>/`, where users provide the relevant variable or secret.\r\n\r\nUpon closer inspection, it becomes clear that the authentication response (as described in point 1) differs between Conjur OSS and Conjur Enterprise. To illustrate these differences, I wrote a test script, and the subsequent output from the console is documented in the provided images (Image 1: Test Code, Image 2: Console Output).\r\n\r\nImage 1:\r\n<img width=\"848\" alt=\"Screenshot 2023-08-24 at 10 48 32\" src=\"https://github.com/ansible/awx/assets/10104752/57a82fb0-c2fa-4a69-96b0-3fe755e8dc59\">\r\n\r\nImage 2:\r\n<img width=\"784\" alt=\"Screenshot 2023-08-24 at 10 46 50\" src=\"https://github.com/ansible/awx/assets/10104752/d0eeea49-d21a-4bd5-bd44-4df9fef7ab1b\">\r\n\r\n\r\nThe Conjur Enterprise API returns a response containing the keys `signature`, `payload`, and `protected`. In contrast, the Conjur OSS response presents the same keys, encoded in base64, though. The result is that the plain message from Conjur Enterprise should be encoded to base64 first, before added as a header to the second request (point 2).\r\n\r\n~~An alternative approach involves including the header `{\"Accept-Encoding\": \"base64\"}` within the headers for the second request. This adjustment is performed within the `awx/main/credential_plugins/conjur.py` file, wherein the modification is as follows:~~\r\n\r\nOriginal Code:\r\n```python\r\n lookup_kwargs = {\r\n 'headers': {'Authorization': 'Token token=\"{}\"'.format(token)},\r\n 'allow_redirects': False,\r\n }\r\n```\r\n\r\nModified Code:\r\n```python\r\n lookup_kwargs = {\r\n 'headers': {'Authorization': 'Token token=\"{}\"'.format(token), 'Accept-Encoding': 'base64'},\r\n 'allow_redirects': False,\r\n }\r\n```\r\n\r\n~~By incorporating this change, we ensure compatibility with both Conjur OSS and Conjur Enterprise instances, enhancing the credential retrieval process from AWX.~~\r\n\r\n---\r\n\r\n**EDIT:** Following further investigation into this issue, it appears that my initial solution of adding headers may not be effective. I attempted to rectify this within my local AWX environment, but unfortunately, the issue persisted.\r\n\r\nA more viable approach could involve checking whether the authentication response is already in base64 format. This can be accomplished using the following steps:\r\n\r\n1. Begin by importing the necessary modules:\r\n```python\r\nimport base64\r\nimport binascii\r\n```\r\n\r\n2. Integrate the following function into your codebase:\r\n```python\r\ndef _is_base64(s: str) -> bool:\r\n try:\r\n return base64.b64encode(base64.b64decode(s.encode(\"utf-8\"))) == s.encode(\"utf-8\")\r\n except binascii.Error:\r\n return False\r\n```\r\n\r\n3. Adjust the declaration of the `lookup_kwargs` as shown below. This modification ensures that the authentication token is properly encoded if it's not already in base64 format:\r\n```python\r\nlookup_kwargs = {\r\n 'headers': {'Authorization': 'Token token=\"{}\"'.format(\r\n token if _is_base64(token) else base64.b64encode(token.encode('utf-8')).decode('utf-8')\r\n )},\r\n 'allow_redirects': False,\r\n}\r\n```\r\n\r\n@infamousjoeg can you help with this? And do you agree with this change?\r\n\r\n### AWX version\r\n\r\n22.7.1\r\n\r\n### Select the relevant components\r\n\r\n- [ ] UI\r\n- [ ] UI (tech preview)\r\n- [ ] API\r\n- [ ] Docs\r\n- [ ] Collection\r\n- [ ] CLI\r\n- [X] Other\r\n\r\n### Installation method\r\n\r\ndocker development environment\r\n\r\n### Modifications\r\n\r\nyes\r\n\r\n### Ansible version\r\n\r\n_No response_\r\n\r\n### Operating system\r\n\r\nMacOS\r\n\r\n### Web browser\r\n\r\nChrome\r\n\r\n### Steps to reproduce\r\n\r\n- Setup a Conjur Enterprise and a Conjur OSS environment\r\n- Create 2 credentials (both for Conjur Enterprice and OSS)\r\n- Create identical users and variables in both environments\r\n- Test the credential retrieval in both environments\r\n\r\n### Expected results\r\n\r\nThe retrieval of a secret from OSS will work, but the retrieval of a secret from Enterprise will result in a 401 error.\r\n\r\n### Actual results\r\n\r\nThe retrieval of a secret from OSS works, and the retrieval of a secret from Enterprise results in a 401 error.\r\n\r\n### Additional information\r\n\r\nI tested the suggested code change. That was the only change I did in AWX.\n", "before_files": [{"content": "from .plugin import CredentialPlugin, CertFiles, raise_for_status\n\nfrom urllib.parse import urljoin, quote\n\nfrom django.utils.translation import gettext_lazy as _\nimport requests\n\n\nconjur_inputs = {\n 'fields': [\n {\n 'id': 'url',\n 'label': _('Conjur URL'),\n 'type': 'string',\n 'format': 'url',\n },\n {\n 'id': 'api_key',\n 'label': _('API Key'),\n 'type': 'string',\n 'secret': True,\n },\n {\n 'id': 'account',\n 'label': _('Account'),\n 'type': 'string',\n },\n {\n 'id': 'username',\n 'label': _('Username'),\n 'type': 'string',\n },\n {'id': 'cacert', 'label': _('Public Key Certificate'), 'type': 'string', 'multiline': True},\n ],\n 'metadata': [\n {\n 'id': 'secret_path',\n 'label': _('Secret Identifier'),\n 'type': 'string',\n 'help_text': _('The identifier for the secret e.g., /some/identifier'),\n },\n {\n 'id': 'secret_version',\n 'label': _('Secret Version'),\n 'type': 'string',\n 'help_text': _('Used to specify a specific secret version (if left empty, the latest version will be used).'),\n },\n ],\n 'required': ['url', 'api_key', 'account', 'username'],\n}\n\n\ndef conjur_backend(**kwargs):\n url = kwargs['url']\n api_key = kwargs['api_key']\n account = quote(kwargs['account'], safe='')\n username = quote(kwargs['username'], safe='')\n secret_path = quote(kwargs['secret_path'], safe='')\n version = kwargs.get('secret_version')\n cacert = kwargs.get('cacert', None)\n\n auth_kwargs = {\n 'headers': {'Content-Type': 'text/plain', 'Accept-Encoding': 'base64'},\n 'data': api_key,\n 'allow_redirects': False,\n }\n\n with CertFiles(cacert) as cert:\n # https://www.conjur.org/api.html#authentication-authenticate-post\n auth_kwargs['verify'] = cert\n try:\n resp = requests.post(urljoin(url, '/'.join(['authn', account, username, 'authenticate'])), **auth_kwargs)\n resp.raise_for_status()\n except requests.exceptions.HTTPError:\n resp = requests.post(urljoin(url, '/'.join(['api', 'authn', account, username, 'authenticate'])), **auth_kwargs)\n raise_for_status(resp)\n token = resp.content.decode('utf-8')\n\n lookup_kwargs = {\n 'headers': {'Authorization': 'Token token=\"{}\"'.format(token)},\n 'allow_redirects': False,\n }\n\n # https://www.conjur.org/api.html#secrets-retrieve-a-secret-get\n path = urljoin(url, '/'.join(['secrets', account, 'variable', secret_path]))\n path_conjurcloud = urljoin(url, '/'.join(['api', 'secrets', account, 'variable', secret_path]))\n if version:\n ver = \"version={}\".format(version)\n path = '?'.join([path, ver])\n path_conjurcloud = '?'.join([path_conjurcloud, ver])\n\n with CertFiles(cacert) as cert:\n lookup_kwargs['verify'] = cert\n try:\n resp = requests.get(path, timeout=30, **lookup_kwargs)\n resp.raise_for_status()\n except requests.exceptions.HTTPError:\n resp = requests.get(path_conjurcloud, timeout=30, **lookup_kwargs)\n raise_for_status(resp)\n return resp.text\n\n\nconjur_plugin = CredentialPlugin('CyberArk Conjur Secrets Manager Lookup', inputs=conjur_inputs, backend=conjur_backend)\n", "path": "awx/main/credential_plugins/conjur.py"}], "after_files": [{"content": "from .plugin import CredentialPlugin, CertFiles, raise_for_status\n\nfrom urllib.parse import urljoin, quote\n\nfrom django.utils.translation import gettext_lazy as _\nimport requests\nimport base64\nimport binascii\n\n\nconjur_inputs = {\n 'fields': [\n {\n 'id': 'url',\n 'label': _('Conjur URL'),\n 'type': 'string',\n 'format': 'url',\n },\n {\n 'id': 'api_key',\n 'label': _('API Key'),\n 'type': 'string',\n 'secret': True,\n },\n {\n 'id': 'account',\n 'label': _('Account'),\n 'type': 'string',\n },\n {\n 'id': 'username',\n 'label': _('Username'),\n 'type': 'string',\n },\n {'id': 'cacert', 'label': _('Public Key Certificate'), 'type': 'string', 'multiline': True},\n ],\n 'metadata': [\n {\n 'id': 'secret_path',\n 'label': _('Secret Identifier'),\n 'type': 'string',\n 'help_text': _('The identifier for the secret e.g., /some/identifier'),\n },\n {\n 'id': 'secret_version',\n 'label': _('Secret Version'),\n 'type': 'string',\n 'help_text': _('Used to specify a specific secret version (if left empty, the latest version will be used).'),\n },\n ],\n 'required': ['url', 'api_key', 'account', 'username'],\n}\n\n\ndef _is_base64(s: str) -> bool:\n try:\n return base64.b64encode(base64.b64decode(s.encode(\"utf-8\"))) == s.encode(\"utf-8\")\n except binascii.Error:\n return False\n\n\ndef conjur_backend(**kwargs):\n url = kwargs['url']\n api_key = kwargs['api_key']\n account = quote(kwargs['account'], safe='')\n username = quote(kwargs['username'], safe='')\n secret_path = quote(kwargs['secret_path'], safe='')\n version = kwargs.get('secret_version')\n cacert = kwargs.get('cacert', None)\n\n auth_kwargs = {\n 'headers': {'Content-Type': 'text/plain', 'Accept-Encoding': 'base64'},\n 'data': api_key,\n 'allow_redirects': False,\n }\n\n with CertFiles(cacert) as cert:\n # https://www.conjur.org/api.html#authentication-authenticate-post\n auth_kwargs['verify'] = cert\n try:\n resp = requests.post(urljoin(url, '/'.join(['authn', account, username, 'authenticate'])), **auth_kwargs)\n resp.raise_for_status()\n except requests.exceptions.HTTPError:\n resp = requests.post(urljoin(url, '/'.join(['api', 'authn', account, username, 'authenticate'])), **auth_kwargs)\n raise_for_status(resp)\n token = resp.content.decode('utf-8')\n\n lookup_kwargs = {\n 'headers': {'Authorization': 'Token token=\"{}\"'.format(token if _is_base64(token) else base64.b64encode(token.encode('utf-8')).decode('utf-8'))},\n 'allow_redirects': False,\n }\n\n # https://www.conjur.org/api.html#secrets-retrieve-a-secret-get\n path = urljoin(url, '/'.join(['secrets', account, 'variable', secret_path]))\n path_conjurcloud = urljoin(url, '/'.join(['api', 'secrets', account, 'variable', secret_path]))\n if version:\n ver = \"version={}\".format(version)\n path = '?'.join([path, ver])\n path_conjurcloud = '?'.join([path_conjurcloud, ver])\n\n with CertFiles(cacert) as cert:\n lookup_kwargs['verify'] = cert\n try:\n resp = requests.get(path, timeout=30, **lookup_kwargs)\n resp.raise_for_status()\n except requests.exceptions.HTTPError:\n resp = requests.get(path_conjurcloud, timeout=30, **lookup_kwargs)\n raise_for_status(resp)\n return resp.text\n\n\nconjur_plugin = CredentialPlugin('CyberArk Conjur Secrets Manager Lookup', inputs=conjur_inputs, backend=conjur_backend)\n", "path": "awx/main/credential_plugins/conjur.py"}]}
| 2,592 | 298 |
gh_patches_debug_15764
|
rasdani/github-patches
|
git_diff
|
matrix-org__synapse-14007
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`parse_and_validate_server_name(":80")` raises `IndexError` instead of `ValueError`
Currently `parse_server_name("")` raises a ValueError by accident, while `parse_server_name(":80")` returns `("", 80)`.
The latter causes `parse_and_validate_server_name` to raise an IndexError when it tries to inspect the first character of the hostname.
As part of the fix, we should make `parse_server_name` behave consistently. Either `parse_server_name("")` should return `("", None)`, or `parse_server_name(":80")` should raise a ValueError.
I'm mildly in favor of the former, since in all other cases `parse_server_name` behaves like a hostname-port splitter without regard for the validity of the hostname.
https://sentry.matrix.org/sentry/synapse-matrixorg/issues/231342/
https://sentry.matrix.org/sentry/synapse-matrixorg/issues/242910/
https://sentry.matrix.org/sentry/synapse-matrixorg/issues/197400/
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `synapse/util/stringutils.py`
Content:
```
1 # Copyright 2014-2016 OpenMarket Ltd
2 # Copyright 2020 The Matrix.org Foundation C.I.C.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 import itertools
16 import re
17 import secrets
18 import string
19 from typing import Any, Iterable, Optional, Tuple
20
21 from netaddr import valid_ipv6
22
23 from synapse.api.errors import Codes, SynapseError
24
25 _string_with_symbols = string.digits + string.ascii_letters + ".,;:^&*-_+=#~@"
26
27 # https://matrix.org/docs/spec/client_server/r0.6.0#post-matrix-client-r0-register-email-requesttoken
28 CLIENT_SECRET_REGEX = re.compile(r"^[0-9a-zA-Z\.=_\-]+$")
29
30 # https://matrix.org/docs/spec/client_server/r0.6.1#matrix-content-mxc-uris,
31 # together with https://github.com/matrix-org/matrix-doc/issues/2177 which basically
32 # says "there is no grammar for media ids"
33 #
34 # The server_name part of this is purposely lax: use parse_and_validate_mxc for
35 # additional validation.
36 #
37 MXC_REGEX = re.compile("^mxc://([^/]+)/([^/#?]+)$")
38
39
40 def random_string(length: int) -> str:
41 """Generate a cryptographically secure string of random letters.
42
43 Drawn from the characters: `a-z` and `A-Z`
44 """
45 return "".join(secrets.choice(string.ascii_letters) for _ in range(length))
46
47
48 def random_string_with_symbols(length: int) -> str:
49 """Generate a cryptographically secure string of random letters/numbers/symbols.
50
51 Drawn from the characters: `a-z`, `A-Z`, `0-9`, and `.,;:^&*-_+=#~@`
52 """
53 return "".join(secrets.choice(_string_with_symbols) for _ in range(length))
54
55
56 def is_ascii(s: bytes) -> bool:
57 try:
58 s.decode("ascii").encode("ascii")
59 except UnicodeError:
60 return False
61 return True
62
63
64 def assert_valid_client_secret(client_secret: str) -> None:
65 """Validate that a given string matches the client_secret defined by the spec"""
66 if (
67 len(client_secret) <= 0
68 or len(client_secret) > 255
69 or CLIENT_SECRET_REGEX.match(client_secret) is None
70 ):
71 raise SynapseError(
72 400, "Invalid client_secret parameter", errcode=Codes.INVALID_PARAM
73 )
74
75
76 def parse_server_name(server_name: str) -> Tuple[str, Optional[int]]:
77 """Split a server name into host/port parts.
78
79 Args:
80 server_name: server name to parse
81
82 Returns:
83 host/port parts.
84
85 Raises:
86 ValueError if the server name could not be parsed.
87 """
88 try:
89 if server_name[-1] == "]":
90 # ipv6 literal, hopefully
91 return server_name, None
92
93 domain_port = server_name.rsplit(":", 1)
94 domain = domain_port[0]
95 port = int(domain_port[1]) if domain_port[1:] else None
96 return domain, port
97 except Exception:
98 raise ValueError("Invalid server name '%s'" % server_name)
99
100
101 # An approximation of the domain name syntax in RFC 1035, section 2.3.1.
102 # NB: "\Z" is not equivalent to "$".
103 # The latter will match the position before a "\n" at the end of a string.
104 VALID_HOST_REGEX = re.compile("\\A[0-9a-zA-Z-]+(?:\\.[0-9a-zA-Z-]+)*\\Z")
105
106
107 def parse_and_validate_server_name(server_name: str) -> Tuple[str, Optional[int]]:
108 """Split a server name into host/port parts and do some basic validation.
109
110 Args:
111 server_name: server name to parse
112
113 Returns:
114 host/port parts.
115
116 Raises:
117 ValueError if the server name could not be parsed.
118 """
119 host, port = parse_server_name(server_name)
120
121 # these tests don't need to be bulletproof as we'll find out soon enough
122 # if somebody is giving us invalid data. What we *do* need is to be sure
123 # that nobody is sneaking IP literals in that look like hostnames, etc.
124
125 # look for ipv6 literals
126 if host[0] == "[":
127 if host[-1] != "]":
128 raise ValueError("Mismatched [...] in server name '%s'" % (server_name,))
129
130 # valid_ipv6 raises when given an empty string
131 ipv6_address = host[1:-1]
132 if not ipv6_address or not valid_ipv6(ipv6_address):
133 raise ValueError(
134 "Server name '%s' is not a valid IPv6 address" % (server_name,)
135 )
136 elif not VALID_HOST_REGEX.match(host):
137 raise ValueError("Server name '%s' has an invalid format" % (server_name,))
138
139 return host, port
140
141
142 def valid_id_server_location(id_server: str) -> bool:
143 """Check whether an identity server location, such as the one passed as the
144 `id_server` parameter to `/_matrix/client/r0/account/3pid/bind`, is valid.
145
146 A valid identity server location consists of a valid hostname and optional
147 port number, optionally followed by any number of `/` delimited path
148 components, without any fragment or query string parts.
149
150 Args:
151 id_server: identity server location string to validate
152
153 Returns:
154 True if valid, False otherwise.
155 """
156
157 components = id_server.split("/", 1)
158
159 host = components[0]
160
161 try:
162 parse_and_validate_server_name(host)
163 except ValueError:
164 return False
165
166 if len(components) < 2:
167 # no path
168 return True
169
170 path = components[1]
171 return "#" not in path and "?" not in path
172
173
174 def parse_and_validate_mxc_uri(mxc: str) -> Tuple[str, Optional[int], str]:
175 """Parse the given string as an MXC URI
176
177 Checks that the "server name" part is a valid server name
178
179 Args:
180 mxc: the (alleged) MXC URI to be checked
181 Returns:
182 hostname, port, media id
183 Raises:
184 ValueError if the URI cannot be parsed
185 """
186 m = MXC_REGEX.match(mxc)
187 if not m:
188 raise ValueError("mxc URI %r did not match expected format" % (mxc,))
189 server_name = m.group(1)
190 media_id = m.group(2)
191 host, port = parse_and_validate_server_name(server_name)
192 return host, port, media_id
193
194
195 def shortstr(iterable: Iterable, maxitems: int = 5) -> str:
196 """If iterable has maxitems or fewer, return the stringification of a list
197 containing those items.
198
199 Otherwise, return the stringification of a list with the first maxitems items,
200 followed by "...".
201
202 Args:
203 iterable: iterable to truncate
204 maxitems: number of items to return before truncating
205 """
206
207 items = list(itertools.islice(iterable, maxitems + 1))
208 if len(items) <= maxitems:
209 return str(items)
210 return "[" + ", ".join(repr(r) for r in items[:maxitems]) + ", ...]"
211
212
213 def strtobool(val: str) -> bool:
214 """Convert a string representation of truth to True or False
215
216 True values are 'y', 'yes', 't', 'true', 'on', and '1'; false values
217 are 'n', 'no', 'f', 'false', 'off', and '0'. Raises ValueError if
218 'val' is anything else.
219
220 This is lifted from distutils.util.strtobool, with the exception that it actually
221 returns a bool, rather than an int.
222 """
223 val = val.lower()
224 if val in ("y", "yes", "t", "true", "on", "1"):
225 return True
226 elif val in ("n", "no", "f", "false", "off", "0"):
227 return False
228 else:
229 raise ValueError("invalid truth value %r" % (val,))
230
231
232 _BASE62 = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
233
234
235 def base62_encode(num: int, minwidth: int = 1) -> str:
236 """Encode a number using base62
237
238 Args:
239 num: number to be encoded
240 minwidth: width to pad to, if the number is small
241 """
242 res = ""
243 while num:
244 num, rem = divmod(num, 62)
245 res = _BASE62[rem] + res
246
247 # pad to minimum width
248 pad = "0" * (minwidth - len(res))
249 return pad + res
250
251
252 def non_null_str_or_none(val: Any) -> Optional[str]:
253 """Check that the arg is a string containing no null (U+0000) codepoints.
254
255 If so, returns the given string unmodified; otherwise, returns None.
256 """
257 return val if isinstance(val, str) and "\u0000" not in val else None
258
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/synapse/util/stringutils.py b/synapse/util/stringutils.py
--- a/synapse/util/stringutils.py
+++ b/synapse/util/stringutils.py
@@ -86,7 +86,7 @@
ValueError if the server name could not be parsed.
"""
try:
- if server_name[-1] == "]":
+ if server_name and server_name[-1] == "]":
# ipv6 literal, hopefully
return server_name, None
@@ -123,7 +123,7 @@
# that nobody is sneaking IP literals in that look like hostnames, etc.
# look for ipv6 literals
- if host[0] == "[":
+ if host and host[0] == "[":
if host[-1] != "]":
raise ValueError("Mismatched [...] in server name '%s'" % (server_name,))
|
{"golden_diff": "diff --git a/synapse/util/stringutils.py b/synapse/util/stringutils.py\n--- a/synapse/util/stringutils.py\n+++ b/synapse/util/stringutils.py\n@@ -86,7 +86,7 @@\n ValueError if the server name could not be parsed.\n \"\"\"\n try:\n- if server_name[-1] == \"]\":\n+ if server_name and server_name[-1] == \"]\":\n # ipv6 literal, hopefully\n return server_name, None\n \n@@ -123,7 +123,7 @@\n # that nobody is sneaking IP literals in that look like hostnames, etc.\n \n # look for ipv6 literals\n- if host[0] == \"[\":\n+ if host and host[0] == \"[\":\n if host[-1] != \"]\":\n raise ValueError(\"Mismatched [...] in server name '%s'\" % (server_name,))\n", "issue": "`parse_and_validate_server_name(\":80\")` raises `IndexError` instead of `ValueError`\nCurrently `parse_server_name(\"\")` raises a ValueError by accident, while `parse_server_name(\":80\")` returns `(\"\", 80)`.\r\nThe latter causes `parse_and_validate_server_name` to raise an IndexError when it tries to inspect the first character of the hostname.\r\n\r\nAs part of the fix, we should make `parse_server_name` behave consistently. Either `parse_server_name(\"\")` should return `(\"\", None)`, or `parse_server_name(\":80\")` should raise a ValueError.\r\n\r\nI'm mildly in favor of the former, since in all other cases `parse_server_name` behaves like a hostname-port splitter without regard for the validity of the hostname.\r\n\r\nhttps://sentry.matrix.org/sentry/synapse-matrixorg/issues/231342/\r\nhttps://sentry.matrix.org/sentry/synapse-matrixorg/issues/242910/\r\nhttps://sentry.matrix.org/sentry/synapse-matrixorg/issues/197400/\r\n\n", "before_files": [{"content": "# Copyright 2014-2016 OpenMarket Ltd\n# Copyright 2020 The Matrix.org Foundation C.I.C.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport itertools\nimport re\nimport secrets\nimport string\nfrom typing import Any, Iterable, Optional, Tuple\n\nfrom netaddr import valid_ipv6\n\nfrom synapse.api.errors import Codes, SynapseError\n\n_string_with_symbols = string.digits + string.ascii_letters + \".,;:^&*-_+=#~@\"\n\n# https://matrix.org/docs/spec/client_server/r0.6.0#post-matrix-client-r0-register-email-requesttoken\nCLIENT_SECRET_REGEX = re.compile(r\"^[0-9a-zA-Z\\.=_\\-]+$\")\n\n# https://matrix.org/docs/spec/client_server/r0.6.1#matrix-content-mxc-uris,\n# together with https://github.com/matrix-org/matrix-doc/issues/2177 which basically\n# says \"there is no grammar for media ids\"\n#\n# The server_name part of this is purposely lax: use parse_and_validate_mxc for\n# additional validation.\n#\nMXC_REGEX = re.compile(\"^mxc://([^/]+)/([^/#?]+)$\")\n\n\ndef random_string(length: int) -> str:\n \"\"\"Generate a cryptographically secure string of random letters.\n\n Drawn from the characters: `a-z` and `A-Z`\n \"\"\"\n return \"\".join(secrets.choice(string.ascii_letters) for _ in range(length))\n\n\ndef random_string_with_symbols(length: int) -> str:\n \"\"\"Generate a cryptographically secure string of random letters/numbers/symbols.\n\n Drawn from the characters: `a-z`, `A-Z`, `0-9`, and `.,;:^&*-_+=#~@`\n \"\"\"\n return \"\".join(secrets.choice(_string_with_symbols) for _ in range(length))\n\n\ndef is_ascii(s: bytes) -> bool:\n try:\n s.decode(\"ascii\").encode(\"ascii\")\n except UnicodeError:\n return False\n return True\n\n\ndef assert_valid_client_secret(client_secret: str) -> None:\n \"\"\"Validate that a given string matches the client_secret defined by the spec\"\"\"\n if (\n len(client_secret) <= 0\n or len(client_secret) > 255\n or CLIENT_SECRET_REGEX.match(client_secret) is None\n ):\n raise SynapseError(\n 400, \"Invalid client_secret parameter\", errcode=Codes.INVALID_PARAM\n )\n\n\ndef parse_server_name(server_name: str) -> Tuple[str, Optional[int]]:\n \"\"\"Split a server name into host/port parts.\n\n Args:\n server_name: server name to parse\n\n Returns:\n host/port parts.\n\n Raises:\n ValueError if the server name could not be parsed.\n \"\"\"\n try:\n if server_name[-1] == \"]\":\n # ipv6 literal, hopefully\n return server_name, None\n\n domain_port = server_name.rsplit(\":\", 1)\n domain = domain_port[0]\n port = int(domain_port[1]) if domain_port[1:] else None\n return domain, port\n except Exception:\n raise ValueError(\"Invalid server name '%s'\" % server_name)\n\n\n# An approximation of the domain name syntax in RFC 1035, section 2.3.1.\n# NB: \"\\Z\" is not equivalent to \"$\".\n# The latter will match the position before a \"\\n\" at the end of a string.\nVALID_HOST_REGEX = re.compile(\"\\\\A[0-9a-zA-Z-]+(?:\\\\.[0-9a-zA-Z-]+)*\\\\Z\")\n\n\ndef parse_and_validate_server_name(server_name: str) -> Tuple[str, Optional[int]]:\n \"\"\"Split a server name into host/port parts and do some basic validation.\n\n Args:\n server_name: server name to parse\n\n Returns:\n host/port parts.\n\n Raises:\n ValueError if the server name could not be parsed.\n \"\"\"\n host, port = parse_server_name(server_name)\n\n # these tests don't need to be bulletproof as we'll find out soon enough\n # if somebody is giving us invalid data. What we *do* need is to be sure\n # that nobody is sneaking IP literals in that look like hostnames, etc.\n\n # look for ipv6 literals\n if host[0] == \"[\":\n if host[-1] != \"]\":\n raise ValueError(\"Mismatched [...] in server name '%s'\" % (server_name,))\n\n # valid_ipv6 raises when given an empty string\n ipv6_address = host[1:-1]\n if not ipv6_address or not valid_ipv6(ipv6_address):\n raise ValueError(\n \"Server name '%s' is not a valid IPv6 address\" % (server_name,)\n )\n elif not VALID_HOST_REGEX.match(host):\n raise ValueError(\"Server name '%s' has an invalid format\" % (server_name,))\n\n return host, port\n\n\ndef valid_id_server_location(id_server: str) -> bool:\n \"\"\"Check whether an identity server location, such as the one passed as the\n `id_server` parameter to `/_matrix/client/r0/account/3pid/bind`, is valid.\n\n A valid identity server location consists of a valid hostname and optional\n port number, optionally followed by any number of `/` delimited path\n components, without any fragment or query string parts.\n\n Args:\n id_server: identity server location string to validate\n\n Returns:\n True if valid, False otherwise.\n \"\"\"\n\n components = id_server.split(\"/\", 1)\n\n host = components[0]\n\n try:\n parse_and_validate_server_name(host)\n except ValueError:\n return False\n\n if len(components) < 2:\n # no path\n return True\n\n path = components[1]\n return \"#\" not in path and \"?\" not in path\n\n\ndef parse_and_validate_mxc_uri(mxc: str) -> Tuple[str, Optional[int], str]:\n \"\"\"Parse the given string as an MXC URI\n\n Checks that the \"server name\" part is a valid server name\n\n Args:\n mxc: the (alleged) MXC URI to be checked\n Returns:\n hostname, port, media id\n Raises:\n ValueError if the URI cannot be parsed\n \"\"\"\n m = MXC_REGEX.match(mxc)\n if not m:\n raise ValueError(\"mxc URI %r did not match expected format\" % (mxc,))\n server_name = m.group(1)\n media_id = m.group(2)\n host, port = parse_and_validate_server_name(server_name)\n return host, port, media_id\n\n\ndef shortstr(iterable: Iterable, maxitems: int = 5) -> str:\n \"\"\"If iterable has maxitems or fewer, return the stringification of a list\n containing those items.\n\n Otherwise, return the stringification of a list with the first maxitems items,\n followed by \"...\".\n\n Args:\n iterable: iterable to truncate\n maxitems: number of items to return before truncating\n \"\"\"\n\n items = list(itertools.islice(iterable, maxitems + 1))\n if len(items) <= maxitems:\n return str(items)\n return \"[\" + \", \".join(repr(r) for r in items[:maxitems]) + \", ...]\"\n\n\ndef strtobool(val: str) -> bool:\n \"\"\"Convert a string representation of truth to True or False\n\n True values are 'y', 'yes', 't', 'true', 'on', and '1'; false values\n are 'n', 'no', 'f', 'false', 'off', and '0'. Raises ValueError if\n 'val' is anything else.\n\n This is lifted from distutils.util.strtobool, with the exception that it actually\n returns a bool, rather than an int.\n \"\"\"\n val = val.lower()\n if val in (\"y\", \"yes\", \"t\", \"true\", \"on\", \"1\"):\n return True\n elif val in (\"n\", \"no\", \"f\", \"false\", \"off\", \"0\"):\n return False\n else:\n raise ValueError(\"invalid truth value %r\" % (val,))\n\n\n_BASE62 = \"0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz\"\n\n\ndef base62_encode(num: int, minwidth: int = 1) -> str:\n \"\"\"Encode a number using base62\n\n Args:\n num: number to be encoded\n minwidth: width to pad to, if the number is small\n \"\"\"\n res = \"\"\n while num:\n num, rem = divmod(num, 62)\n res = _BASE62[rem] + res\n\n # pad to minimum width\n pad = \"0\" * (minwidth - len(res))\n return pad + res\n\n\ndef non_null_str_or_none(val: Any) -> Optional[str]:\n \"\"\"Check that the arg is a string containing no null (U+0000) codepoints.\n\n If so, returns the given string unmodified; otherwise, returns None.\n \"\"\"\n return val if isinstance(val, str) and \"\\u0000\" not in val else None\n", "path": "synapse/util/stringutils.py"}], "after_files": [{"content": "# Copyright 2014-2016 OpenMarket Ltd\n# Copyright 2020 The Matrix.org Foundation C.I.C.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport itertools\nimport re\nimport secrets\nimport string\nfrom typing import Any, Iterable, Optional, Tuple\n\nfrom netaddr import valid_ipv6\n\nfrom synapse.api.errors import Codes, SynapseError\n\n_string_with_symbols = string.digits + string.ascii_letters + \".,;:^&*-_+=#~@\"\n\n# https://matrix.org/docs/spec/client_server/r0.6.0#post-matrix-client-r0-register-email-requesttoken\nCLIENT_SECRET_REGEX = re.compile(r\"^[0-9a-zA-Z\\.=_\\-]+$\")\n\n# https://matrix.org/docs/spec/client_server/r0.6.1#matrix-content-mxc-uris,\n# together with https://github.com/matrix-org/matrix-doc/issues/2177 which basically\n# says \"there is no grammar for media ids\"\n#\n# The server_name part of this is purposely lax: use parse_and_validate_mxc for\n# additional validation.\n#\nMXC_REGEX = re.compile(\"^mxc://([^/]+)/([^/#?]+)$\")\n\n\ndef random_string(length: int) -> str:\n \"\"\"Generate a cryptographically secure string of random letters.\n\n Drawn from the characters: `a-z` and `A-Z`\n \"\"\"\n return \"\".join(secrets.choice(string.ascii_letters) for _ in range(length))\n\n\ndef random_string_with_symbols(length: int) -> str:\n \"\"\"Generate a cryptographically secure string of random letters/numbers/symbols.\n\n Drawn from the characters: `a-z`, `A-Z`, `0-9`, and `.,;:^&*-_+=#~@`\n \"\"\"\n return \"\".join(secrets.choice(_string_with_symbols) for _ in range(length))\n\n\ndef is_ascii(s: bytes) -> bool:\n try:\n s.decode(\"ascii\").encode(\"ascii\")\n except UnicodeError:\n return False\n return True\n\n\ndef assert_valid_client_secret(client_secret: str) -> None:\n \"\"\"Validate that a given string matches the client_secret defined by the spec\"\"\"\n if (\n len(client_secret) <= 0\n or len(client_secret) > 255\n or CLIENT_SECRET_REGEX.match(client_secret) is None\n ):\n raise SynapseError(\n 400, \"Invalid client_secret parameter\", errcode=Codes.INVALID_PARAM\n )\n\n\ndef parse_server_name(server_name: str) -> Tuple[str, Optional[int]]:\n \"\"\"Split a server name into host/port parts.\n\n Args:\n server_name: server name to parse\n\n Returns:\n host/port parts.\n\n Raises:\n ValueError if the server name could not be parsed.\n \"\"\"\n try:\n if server_name and server_name[-1] == \"]\":\n # ipv6 literal, hopefully\n return server_name, None\n\n domain_port = server_name.rsplit(\":\", 1)\n domain = domain_port[0]\n port = int(domain_port[1]) if domain_port[1:] else None\n return domain, port\n except Exception:\n raise ValueError(\"Invalid server name '%s'\" % server_name)\n\n\n# An approximation of the domain name syntax in RFC 1035, section 2.3.1.\n# NB: \"\\Z\" is not equivalent to \"$\".\n# The latter will match the position before a \"\\n\" at the end of a string.\nVALID_HOST_REGEX = re.compile(\"\\\\A[0-9a-zA-Z-]+(?:\\\\.[0-9a-zA-Z-]+)*\\\\Z\")\n\n\ndef parse_and_validate_server_name(server_name: str) -> Tuple[str, Optional[int]]:\n \"\"\"Split a server name into host/port parts and do some basic validation.\n\n Args:\n server_name: server name to parse\n\n Returns:\n host/port parts.\n\n Raises:\n ValueError if the server name could not be parsed.\n \"\"\"\n host, port = parse_server_name(server_name)\n\n # these tests don't need to be bulletproof as we'll find out soon enough\n # if somebody is giving us invalid data. What we *do* need is to be sure\n # that nobody is sneaking IP literals in that look like hostnames, etc.\n\n # look for ipv6 literals\n if host and host[0] == \"[\":\n if host[-1] != \"]\":\n raise ValueError(\"Mismatched [...] in server name '%s'\" % (server_name,))\n\n # valid_ipv6 raises when given an empty string\n ipv6_address = host[1:-1]\n if not ipv6_address or not valid_ipv6(ipv6_address):\n raise ValueError(\n \"Server name '%s' is not a valid IPv6 address\" % (server_name,)\n )\n elif not VALID_HOST_REGEX.match(host):\n raise ValueError(\"Server name '%s' has an invalid format\" % (server_name,))\n\n return host, port\n\n\ndef valid_id_server_location(id_server: str) -> bool:\n \"\"\"Check whether an identity server location, such as the one passed as the\n `id_server` parameter to `/_matrix/client/r0/account/3pid/bind`, is valid.\n\n A valid identity server location consists of a valid hostname and optional\n port number, optionally followed by any number of `/` delimited path\n components, without any fragment or query string parts.\n\n Args:\n id_server: identity server location string to validate\n\n Returns:\n True if valid, False otherwise.\n \"\"\"\n\n components = id_server.split(\"/\", 1)\n\n host = components[0]\n\n try:\n parse_and_validate_server_name(host)\n except ValueError:\n return False\n\n if len(components) < 2:\n # no path\n return True\n\n path = components[1]\n return \"#\" not in path and \"?\" not in path\n\n\ndef parse_and_validate_mxc_uri(mxc: str) -> Tuple[str, Optional[int], str]:\n \"\"\"Parse the given string as an MXC URI\n\n Checks that the \"server name\" part is a valid server name\n\n Args:\n mxc: the (alleged) MXC URI to be checked\n Returns:\n hostname, port, media id\n Raises:\n ValueError if the URI cannot be parsed\n \"\"\"\n m = MXC_REGEX.match(mxc)\n if not m:\n raise ValueError(\"mxc URI %r did not match expected format\" % (mxc,))\n server_name = m.group(1)\n media_id = m.group(2)\n host, port = parse_and_validate_server_name(server_name)\n return host, port, media_id\n\n\ndef shortstr(iterable: Iterable, maxitems: int = 5) -> str:\n \"\"\"If iterable has maxitems or fewer, return the stringification of a list\n containing those items.\n\n Otherwise, return the stringification of a list with the first maxitems items,\n followed by \"...\".\n\n Args:\n iterable: iterable to truncate\n maxitems: number of items to return before truncating\n \"\"\"\n\n items = list(itertools.islice(iterable, maxitems + 1))\n if len(items) <= maxitems:\n return str(items)\n return \"[\" + \", \".join(repr(r) for r in items[:maxitems]) + \", ...]\"\n\n\ndef strtobool(val: str) -> bool:\n \"\"\"Convert a string representation of truth to True or False\n\n True values are 'y', 'yes', 't', 'true', 'on', and '1'; false values\n are 'n', 'no', 'f', 'false', 'off', and '0'. Raises ValueError if\n 'val' is anything else.\n\n This is lifted from distutils.util.strtobool, with the exception that it actually\n returns a bool, rather than an int.\n \"\"\"\n val = val.lower()\n if val in (\"y\", \"yes\", \"t\", \"true\", \"on\", \"1\"):\n return True\n elif val in (\"n\", \"no\", \"f\", \"false\", \"off\", \"0\"):\n return False\n else:\n raise ValueError(\"invalid truth value %r\" % (val,))\n\n\n_BASE62 = \"0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz\"\n\n\ndef base62_encode(num: int, minwidth: int = 1) -> str:\n \"\"\"Encode a number using base62\n\n Args:\n num: number to be encoded\n minwidth: width to pad to, if the number is small\n \"\"\"\n res = \"\"\n while num:\n num, rem = divmod(num, 62)\n res = _BASE62[rem] + res\n\n # pad to minimum width\n pad = \"0\" * (minwidth - len(res))\n return pad + res\n\n\ndef non_null_str_or_none(val: Any) -> Optional[str]:\n \"\"\"Check that the arg is a string containing no null (U+0000) codepoints.\n\n If so, returns the given string unmodified; otherwise, returns None.\n \"\"\"\n return val if isinstance(val, str) and \"\\u0000\" not in val else None\n", "path": "synapse/util/stringutils.py"}]}
| 3,289 | 198 |
gh_patches_debug_29536
|
rasdani/github-patches
|
git_diff
|
fossasia__open-event-server-2067
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Internal server error in promotion link
https://open-event-dev.herokuapp.com/events/110/tickets/promotion/
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `app/views/admin/models_views/ticket_sales.py`
Content:
```
1 import flask_login
2 import pycountry
3 from flask import redirect
4 from flask import request
5 from flask import url_for
6 from flask_admin import BaseView, expose
7
8 from app import get_settings
9 from app.helpers.cache import cache
10 from app.helpers.data_getter import DataGetter
11 from app.helpers.ticketing import TicketingManager
12 from app.models.ticket import Ticket
13
14 class TicketSalesView(BaseView):
15 @cache.memoize(50)
16 def get_ticket(self, ticket_id):
17 return Ticket.query.get(ticket_id)
18
19 @expose('/')
20 @flask_login.login_required
21 def display_ticket_stats(self, event_id):
22 event = DataGetter.get_event(event_id)
23 orders = TicketingManager.get_orders(event_id)
24
25 completed_count = 0
26 completed_amount = 0
27 tickets_count = 0
28
29 orders_summary = {
30 'completed': {
31 'class': 'success',
32 'tickets_count': 0,
33 'orders_count': 0,
34 'total_sales': 0
35 },
36 'pending': {
37 'class': 'warning',
38 'tickets_count': 0,
39 'orders_count': 0,
40 'total_sales': 0
41 },
42 'expired': {
43 'class': 'danger',
44 'tickets_count': 0,
45 'orders_count': 0,
46 'total_sales': 0
47 }
48 }
49
50 tickets_summary = {}
51
52 for ticket in event.tickets:
53 tickets_summary[str(ticket.id)] = {
54 'name': ticket.name,
55 'quantity': ticket.quantity,
56 'completed': {
57 'tickets_count': 0,
58 'sales': 0
59 },
60 'pending': {
61 'tickets_count': 0,
62 'sales': 0
63 },
64 'expired': {
65 'class': 'danger',
66 'tickets_count': 0,
67 'sales': 0
68 }
69 }
70
71 for order in orders:
72 if order.status == 'initialized':
73 order.status = 'pending'
74 orders_summary[str(order.status)]['orders_count'] += 1
75 orders_summary[str(order.status)]['total_sales'] += order.amount
76 for order_ticket in order.tickets:
77 orders_summary[str(order.status)]['tickets_count'] += order_ticket.quantity
78 ticket = self.get_ticket(order_ticket.ticket_id)
79 tickets_summary[str(ticket.id)][str(order.status)]['tickets_count'] += order_ticket.quantity
80 tickets_summary[str(ticket.id)][str(order.status)]['sales'] += order_ticket.quantity * ticket.price
81
82 return self.render('/gentelella/admin/event/tickets/tickets.html', event=event, event_id=event_id,
83 orders_summary=orders_summary, tickets_summary=tickets_summary)
84
85 @expose('/orders/')
86 @flask_login.login_required
87 def display_orders(self, event_id):
88 event = DataGetter.get_event(event_id)
89 orders = TicketingManager.get_orders(event_id)
90 return self.render('/gentelella/admin/event/tickets/orders.html', event=event, event_id=event_id, orders=orders)
91
92 @expose('/attendees/')
93 @flask_login.login_required
94 def display_attendees(self, event_id):
95 event = DataGetter.get_event(event_id)
96 orders = TicketingManager.get_orders(event_id)
97 return self.render('/gentelella/admin/event/tickets/attendees.html', event=event,
98 event_id=event_id, orders=orders)
99
100 @expose('/add-order/', methods=('GET', 'POST'))
101 @flask_login.login_required
102 def add_order(self, event_id):
103
104 if request.method == 'POST':
105 order = TicketingManager.create_order(request.form, True)
106 return redirect(url_for('.proceed_order', event_id=event_id, order_identifier=order.identifier))
107
108 event = DataGetter.get_event(event_id)
109 return self.render('/gentelella/admin/event/tickets/add_order.html', event=event, event_id=event_id)
110
111 @expose('/<order_identifier>/', methods=('GET',))
112 def proceed_order(self, event_id, order_identifier):
113 order = TicketingManager.get_order_by_identifier(order_identifier)
114 if order.status == 'completed':
115 return redirect(url_for('ticketing.view_order_after_payment', order_identifier=order_identifier))
116 return self.render('/gentelella/guest/ticketing/order_pre_payment.html', order=order, event=order.event,
117 countries=list(pycountry.countries),
118 from_organizer=True,
119 pay_via=order.paid_via,
120 stripe_publishable_key=get_settings()['stripe_publishable_key'])
121
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/app/views/admin/models_views/ticket_sales.py b/app/views/admin/models_views/ticket_sales.py
--- a/app/views/admin/models_views/ticket_sales.py
+++ b/app/views/admin/models_views/ticket_sales.py
@@ -1,6 +1,6 @@
import flask_login
import pycountry
-from flask import redirect
+from flask import redirect, flash
from flask import request
from flask import url_for
from flask_admin import BaseView, expose
@@ -111,10 +111,17 @@
@expose('/<order_identifier>/', methods=('GET',))
def proceed_order(self, event_id, order_identifier):
order = TicketingManager.get_order_by_identifier(order_identifier)
- if order.status == 'completed':
- return redirect(url_for('ticketing.view_order_after_payment', order_identifier=order_identifier))
- return self.render('/gentelella/guest/ticketing/order_pre_payment.html', order=order, event=order.event,
- countries=list(pycountry.countries),
- from_organizer=True,
- pay_via=order.paid_via,
- stripe_publishable_key=get_settings()['stripe_publishable_key'])
+ if order:
+ if self.is_order_completed(order):
+ return redirect(url_for('ticketing.view_order_after_payment', order_identifier=order_identifier))
+ return self.render('/gentelella/guest/ticketing/order_pre_payment.html', order=order, event=order.event,
+ countries=list(pycountry.countries),
+ from_organizer=True,
+ pay_via=order.paid_via,
+ stripe_publishable_key=get_settings()['stripe_publishable_key'])
+ flash("Can't find order", 'warning')
+ return redirect(url_for('.display_ticket_stats', event_id=event_id))
+
+ @staticmethod
+ def is_order_completed(order):
+ return order.status == 'completed'
|
{"golden_diff": "diff --git a/app/views/admin/models_views/ticket_sales.py b/app/views/admin/models_views/ticket_sales.py\n--- a/app/views/admin/models_views/ticket_sales.py\n+++ b/app/views/admin/models_views/ticket_sales.py\n@@ -1,6 +1,6 @@\n import flask_login\n import pycountry\n-from flask import redirect\n+from flask import redirect, flash\n from flask import request\n from flask import url_for\n from flask_admin import BaseView, expose\n@@ -111,10 +111,17 @@\n @expose('/<order_identifier>/', methods=('GET',))\n def proceed_order(self, event_id, order_identifier):\n order = TicketingManager.get_order_by_identifier(order_identifier)\n- if order.status == 'completed':\n- return redirect(url_for('ticketing.view_order_after_payment', order_identifier=order_identifier))\n- return self.render('/gentelella/guest/ticketing/order_pre_payment.html', order=order, event=order.event,\n- countries=list(pycountry.countries),\n- from_organizer=True,\n- pay_via=order.paid_via,\n- stripe_publishable_key=get_settings()['stripe_publishable_key'])\n+ if order:\n+ if self.is_order_completed(order):\n+ return redirect(url_for('ticketing.view_order_after_payment', order_identifier=order_identifier))\n+ return self.render('/gentelella/guest/ticketing/order_pre_payment.html', order=order, event=order.event,\n+ countries=list(pycountry.countries),\n+ from_organizer=True,\n+ pay_via=order.paid_via,\n+ stripe_publishable_key=get_settings()['stripe_publishable_key'])\n+ flash(\"Can't find order\", 'warning')\n+ return redirect(url_for('.display_ticket_stats', event_id=event_id))\n+\n+ @staticmethod\n+ def is_order_completed(order):\n+ return order.status == 'completed'\n", "issue": "Internal server error in promotion link\nhttps://open-event-dev.herokuapp.com/events/110/tickets/promotion/\n\n", "before_files": [{"content": "import flask_login\nimport pycountry\nfrom flask import redirect\nfrom flask import request\nfrom flask import url_for\nfrom flask_admin import BaseView, expose\n\nfrom app import get_settings\nfrom app.helpers.cache import cache\nfrom app.helpers.data_getter import DataGetter\nfrom app.helpers.ticketing import TicketingManager\nfrom app.models.ticket import Ticket\n\nclass TicketSalesView(BaseView):\n @cache.memoize(50)\n def get_ticket(self, ticket_id):\n return Ticket.query.get(ticket_id)\n\n @expose('/')\n @flask_login.login_required\n def display_ticket_stats(self, event_id):\n event = DataGetter.get_event(event_id)\n orders = TicketingManager.get_orders(event_id)\n\n completed_count = 0\n completed_amount = 0\n tickets_count = 0\n\n orders_summary = {\n 'completed': {\n 'class': 'success',\n 'tickets_count': 0,\n 'orders_count': 0,\n 'total_sales': 0\n },\n 'pending': {\n 'class': 'warning',\n 'tickets_count': 0,\n 'orders_count': 0,\n 'total_sales': 0\n },\n 'expired': {\n 'class': 'danger',\n 'tickets_count': 0,\n 'orders_count': 0,\n 'total_sales': 0\n }\n }\n\n tickets_summary = {}\n\n for ticket in event.tickets:\n tickets_summary[str(ticket.id)] = {\n 'name': ticket.name,\n 'quantity': ticket.quantity,\n 'completed': {\n 'tickets_count': 0,\n 'sales': 0\n },\n 'pending': {\n 'tickets_count': 0,\n 'sales': 0\n },\n 'expired': {\n 'class': 'danger',\n 'tickets_count': 0,\n 'sales': 0\n }\n }\n\n for order in orders:\n if order.status == 'initialized':\n order.status = 'pending'\n orders_summary[str(order.status)]['orders_count'] += 1\n orders_summary[str(order.status)]['total_sales'] += order.amount\n for order_ticket in order.tickets:\n orders_summary[str(order.status)]['tickets_count'] += order_ticket.quantity\n ticket = self.get_ticket(order_ticket.ticket_id)\n tickets_summary[str(ticket.id)][str(order.status)]['tickets_count'] += order_ticket.quantity\n tickets_summary[str(ticket.id)][str(order.status)]['sales'] += order_ticket.quantity * ticket.price\n\n return self.render('/gentelella/admin/event/tickets/tickets.html', event=event, event_id=event_id,\n orders_summary=orders_summary, tickets_summary=tickets_summary)\n\n @expose('/orders/')\n @flask_login.login_required\n def display_orders(self, event_id):\n event = DataGetter.get_event(event_id)\n orders = TicketingManager.get_orders(event_id)\n return self.render('/gentelella/admin/event/tickets/orders.html', event=event, event_id=event_id, orders=orders)\n\n @expose('/attendees/')\n @flask_login.login_required\n def display_attendees(self, event_id):\n event = DataGetter.get_event(event_id)\n orders = TicketingManager.get_orders(event_id)\n return self.render('/gentelella/admin/event/tickets/attendees.html', event=event,\n event_id=event_id, orders=orders)\n\n @expose('/add-order/', methods=('GET', 'POST'))\n @flask_login.login_required\n def add_order(self, event_id):\n\n if request.method == 'POST':\n order = TicketingManager.create_order(request.form, True)\n return redirect(url_for('.proceed_order', event_id=event_id, order_identifier=order.identifier))\n\n event = DataGetter.get_event(event_id)\n return self.render('/gentelella/admin/event/tickets/add_order.html', event=event, event_id=event_id)\n\n @expose('/<order_identifier>/', methods=('GET',))\n def proceed_order(self, event_id, order_identifier):\n order = TicketingManager.get_order_by_identifier(order_identifier)\n if order.status == 'completed':\n return redirect(url_for('ticketing.view_order_after_payment', order_identifier=order_identifier))\n return self.render('/gentelella/guest/ticketing/order_pre_payment.html', order=order, event=order.event,\n countries=list(pycountry.countries),\n from_organizer=True,\n pay_via=order.paid_via,\n stripe_publishable_key=get_settings()['stripe_publishable_key'])\n", "path": "app/views/admin/models_views/ticket_sales.py"}], "after_files": [{"content": "import flask_login\nimport pycountry\nfrom flask import redirect, flash\nfrom flask import request\nfrom flask import url_for\nfrom flask_admin import BaseView, expose\n\nfrom app import get_settings\nfrom app.helpers.cache import cache\nfrom app.helpers.data_getter import DataGetter\nfrom app.helpers.ticketing import TicketingManager\nfrom app.models.ticket import Ticket\n\nclass TicketSalesView(BaseView):\n @cache.memoize(50)\n def get_ticket(self, ticket_id):\n return Ticket.query.get(ticket_id)\n\n @expose('/')\n @flask_login.login_required\n def display_ticket_stats(self, event_id):\n event = DataGetter.get_event(event_id)\n orders = TicketingManager.get_orders(event_id)\n\n completed_count = 0\n completed_amount = 0\n tickets_count = 0\n\n orders_summary = {\n 'completed': {\n 'class': 'success',\n 'tickets_count': 0,\n 'orders_count': 0,\n 'total_sales': 0\n },\n 'pending': {\n 'class': 'warning',\n 'tickets_count': 0,\n 'orders_count': 0,\n 'total_sales': 0\n },\n 'expired': {\n 'class': 'danger',\n 'tickets_count': 0,\n 'orders_count': 0,\n 'total_sales': 0\n }\n }\n\n tickets_summary = {}\n\n for ticket in event.tickets:\n tickets_summary[str(ticket.id)] = {\n 'name': ticket.name,\n 'quantity': ticket.quantity,\n 'completed': {\n 'tickets_count': 0,\n 'sales': 0\n },\n 'pending': {\n 'tickets_count': 0,\n 'sales': 0\n },\n 'expired': {\n 'class': 'danger',\n 'tickets_count': 0,\n 'sales': 0\n }\n }\n\n for order in orders:\n if order.status == 'initialized':\n order.status = 'pending'\n orders_summary[str(order.status)]['orders_count'] += 1\n orders_summary[str(order.status)]['total_sales'] += order.amount\n for order_ticket in order.tickets:\n orders_summary[str(order.status)]['tickets_count'] += order_ticket.quantity\n ticket = self.get_ticket(order_ticket.ticket_id)\n tickets_summary[str(ticket.id)][str(order.status)]['tickets_count'] += order_ticket.quantity\n tickets_summary[str(ticket.id)][str(order.status)]['sales'] += order_ticket.quantity * ticket.price\n\n return self.render('/gentelella/admin/event/tickets/tickets.html', event=event, event_id=event_id,\n orders_summary=orders_summary, tickets_summary=tickets_summary)\n\n @expose('/orders/')\n @flask_login.login_required\n def display_orders(self, event_id):\n event = DataGetter.get_event(event_id)\n orders = TicketingManager.get_orders(event_id)\n return self.render('/gentelella/admin/event/tickets/orders.html', event=event, event_id=event_id, orders=orders)\n\n @expose('/attendees/')\n @flask_login.login_required\n def display_attendees(self, event_id):\n event = DataGetter.get_event(event_id)\n orders = TicketingManager.get_orders(event_id)\n return self.render('/gentelella/admin/event/tickets/attendees.html', event=event,\n event_id=event_id, orders=orders)\n\n @expose('/add-order/', methods=('GET', 'POST'))\n @flask_login.login_required\n def add_order(self, event_id):\n\n if request.method == 'POST':\n order = TicketingManager.create_order(request.form, True)\n return redirect(url_for('.proceed_order', event_id=event_id, order_identifier=order.identifier))\n\n event = DataGetter.get_event(event_id)\n return self.render('/gentelella/admin/event/tickets/add_order.html', event=event, event_id=event_id)\n\n @expose('/<order_identifier>/', methods=('GET',))\n def proceed_order(self, event_id, order_identifier):\n order = TicketingManager.get_order_by_identifier(order_identifier)\n if order:\n if self.is_order_completed(order):\n return redirect(url_for('ticketing.view_order_after_payment', order_identifier=order_identifier))\n return self.render('/gentelella/guest/ticketing/order_pre_payment.html', order=order, event=order.event,\n countries=list(pycountry.countries),\n from_organizer=True,\n pay_via=order.paid_via,\n stripe_publishable_key=get_settings()['stripe_publishable_key'])\n flash(\"Can't find order\", 'warning')\n return redirect(url_for('.display_ticket_stats', event_id=event_id))\n\n @staticmethod\n def is_order_completed(order):\n return order.status == 'completed'\n", "path": "app/views/admin/models_views/ticket_sales.py"}]}
| 1,521 | 411 |
gh_patches_debug_7709
|
rasdani/github-patches
|
git_diff
|
urllib3__urllib3-792
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Need to update error handling for pyOpenSSL
If an `SSLError` comes from `pyOpenSSL`, we attempt to determine if it's an error due to request timeouts on python 2.6 being raised as `BaseSSLErrors` [here](https://github.com/shazow/urllib3/blob/29aa09bde9c42cc9a8d79aac47ee3d362b438cca/urllib3/connectionpool.py#L314). If the handshake ends unexpectedly under pyOpenSSL, then we get an `SSLError` that has a captured `SysCallError` which when you call `str(SSLError(msg, SysCallError(code, msg)))` you get
``` py
TypeError: __str__ returned non-string (type SysCallError)
```
So we might want to update how we handle SSLErrors to accomodate pyOpenSSL. To be clear, I observed this on: python 2.7.9 with openssl 1.0.1l (from brew) and I was using requests to debug an issue with `https://apissl.cloudfactory.com`, e.g., `requests.get('https://apissl.cloudfactory.com')`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `urllib3/contrib/pyopenssl.py`
Content:
```
1 '''SSL with SNI_-support for Python 2. Follow these instructions if you would
2 like to verify SSL certificates in Python 2. Note, the default libraries do
3 *not* do certificate checking; you need to do additional work to validate
4 certificates yourself.
5
6 This needs the following packages installed:
7
8 * pyOpenSSL (tested with 0.13)
9 * ndg-httpsclient (tested with 0.3.2)
10 * pyasn1 (tested with 0.1.6)
11
12 You can install them with the following command:
13
14 pip install pyopenssl ndg-httpsclient pyasn1
15
16 To activate certificate checking, call
17 :func:`~urllib3.contrib.pyopenssl.inject_into_urllib3` from your Python code
18 before you begin making HTTP requests. This can be done in a ``sitecustomize``
19 module, or at any other time before your application begins using ``urllib3``,
20 like this::
21
22 try:
23 import urllib3.contrib.pyopenssl
24 urllib3.contrib.pyopenssl.inject_into_urllib3()
25 except ImportError:
26 pass
27
28 Now you can use :mod:`urllib3` as you normally would, and it will support SNI
29 when the required modules are installed.
30
31 Activating this module also has the positive side effect of disabling SSL/TLS
32 compression in Python 2 (see `CRIME attack`_).
33
34 If you want to configure the default list of supported cipher suites, you can
35 set the ``urllib3.contrib.pyopenssl.DEFAULT_SSL_CIPHER_LIST`` variable.
36
37 Module Variables
38 ----------------
39
40 :var DEFAULT_SSL_CIPHER_LIST: The list of supported SSL/TLS cipher suites.
41
42 .. _sni: https://en.wikipedia.org/wiki/Server_Name_Indication
43 .. _crime attack: https://en.wikipedia.org/wiki/CRIME_(security_exploit)
44
45 '''
46 from __future__ import absolute_import
47
48 try:
49 from ndg.httpsclient.ssl_peer_verification import SUBJ_ALT_NAME_SUPPORT
50 from ndg.httpsclient.subj_alt_name import SubjectAltName as BaseSubjectAltName
51 except SyntaxError as e:
52 raise ImportError(e)
53
54 import OpenSSL.SSL
55 from pyasn1.codec.der import decoder as der_decoder
56 from pyasn1.type import univ, constraint
57 from socket import _fileobject, timeout, error as SocketError
58 import ssl
59 import select
60
61 from .. import connection
62 from .. import util
63
64 __all__ = ['inject_into_urllib3', 'extract_from_urllib3']
65
66 # SNI only *really* works if we can read the subjectAltName of certificates.
67 HAS_SNI = SUBJ_ALT_NAME_SUPPORT
68
69 # Map from urllib3 to PyOpenSSL compatible parameter-values.
70 _openssl_versions = {
71 ssl.PROTOCOL_SSLv23: OpenSSL.SSL.SSLv23_METHOD,
72 ssl.PROTOCOL_TLSv1: OpenSSL.SSL.TLSv1_METHOD,
73 }
74
75 if hasattr(ssl, 'PROTOCOL_TLSv1_1') and hasattr(OpenSSL.SSL, 'TLSv1_1_METHOD'):
76 _openssl_versions[ssl.PROTOCOL_TLSv1_1] = OpenSSL.SSL.TLSv1_1_METHOD
77
78 if hasattr(ssl, 'PROTOCOL_TLSv1_2') and hasattr(OpenSSL.SSL, 'TLSv1_2_METHOD'):
79 _openssl_versions[ssl.PROTOCOL_TLSv1_2] = OpenSSL.SSL.TLSv1_2_METHOD
80
81 try:
82 _openssl_versions.update({ssl.PROTOCOL_SSLv3: OpenSSL.SSL.SSLv3_METHOD})
83 except AttributeError:
84 pass
85
86 _openssl_verify = {
87 ssl.CERT_NONE: OpenSSL.SSL.VERIFY_NONE,
88 ssl.CERT_OPTIONAL: OpenSSL.SSL.VERIFY_PEER,
89 ssl.CERT_REQUIRED:
90 OpenSSL.SSL.VERIFY_PEER + OpenSSL.SSL.VERIFY_FAIL_IF_NO_PEER_CERT,
91 }
92
93 DEFAULT_SSL_CIPHER_LIST = util.ssl_.DEFAULT_CIPHERS
94
95 # OpenSSL will only write 16K at a time
96 SSL_WRITE_BLOCKSIZE = 16384
97
98 orig_util_HAS_SNI = util.HAS_SNI
99 orig_connection_ssl_wrap_socket = connection.ssl_wrap_socket
100
101
102 def inject_into_urllib3():
103 'Monkey-patch urllib3 with PyOpenSSL-backed SSL-support.'
104
105 connection.ssl_wrap_socket = ssl_wrap_socket
106 util.HAS_SNI = HAS_SNI
107
108
109 def extract_from_urllib3():
110 'Undo monkey-patching by :func:`inject_into_urllib3`.'
111
112 connection.ssl_wrap_socket = orig_connection_ssl_wrap_socket
113 util.HAS_SNI = orig_util_HAS_SNI
114
115
116 # Note: This is a slightly bug-fixed version of same from ndg-httpsclient.
117 class SubjectAltName(BaseSubjectAltName):
118 '''ASN.1 implementation for subjectAltNames support'''
119
120 # There is no limit to how many SAN certificates a certificate may have,
121 # however this needs to have some limit so we'll set an arbitrarily high
122 # limit.
123 sizeSpec = univ.SequenceOf.sizeSpec + \
124 constraint.ValueSizeConstraint(1, 1024)
125
126
127 # Note: This is a slightly bug-fixed version of same from ndg-httpsclient.
128 def get_subj_alt_name(peer_cert):
129 # Search through extensions
130 dns_name = []
131 if not SUBJ_ALT_NAME_SUPPORT:
132 return dns_name
133
134 general_names = SubjectAltName()
135 for i in range(peer_cert.get_extension_count()):
136 ext = peer_cert.get_extension(i)
137 ext_name = ext.get_short_name()
138 if ext_name != 'subjectAltName':
139 continue
140
141 # PyOpenSSL returns extension data in ASN.1 encoded form
142 ext_dat = ext.get_data()
143 decoded_dat = der_decoder.decode(ext_dat,
144 asn1Spec=general_names)
145
146 for name in decoded_dat:
147 if not isinstance(name, SubjectAltName):
148 continue
149 for entry in range(len(name)):
150 component = name.getComponentByPosition(entry)
151 if component.getName() != 'dNSName':
152 continue
153 dns_name.append(str(component.getComponent()))
154
155 return dns_name
156
157
158 class WrappedSocket(object):
159 '''API-compatibility wrapper for Python OpenSSL's Connection-class.
160
161 Note: _makefile_refs, _drop() and _reuse() are needed for the garbage
162 collector of pypy.
163 '''
164
165 def __init__(self, connection, socket, suppress_ragged_eofs=True):
166 self.connection = connection
167 self.socket = socket
168 self.suppress_ragged_eofs = suppress_ragged_eofs
169 self._makefile_refs = 0
170
171 def fileno(self):
172 return self.socket.fileno()
173
174 def makefile(self, mode, bufsize=-1):
175 self._makefile_refs += 1
176 return _fileobject(self, mode, bufsize, close=True)
177
178 def recv(self, *args, **kwargs):
179 try:
180 data = self.connection.recv(*args, **kwargs)
181 except OpenSSL.SSL.SysCallError as e:
182 if self.suppress_ragged_eofs and e.args == (-1, 'Unexpected EOF'):
183 return b''
184 else:
185 raise SocketError(e)
186 except OpenSSL.SSL.ZeroReturnError as e:
187 if self.connection.get_shutdown() == OpenSSL.SSL.RECEIVED_SHUTDOWN:
188 return b''
189 else:
190 raise
191 except OpenSSL.SSL.WantReadError:
192 rd, wd, ed = select.select(
193 [self.socket], [], [], self.socket.gettimeout())
194 if not rd:
195 raise timeout('The read operation timed out')
196 else:
197 return self.recv(*args, **kwargs)
198 else:
199 return data
200
201 def settimeout(self, timeout):
202 return self.socket.settimeout(timeout)
203
204 def _send_until_done(self, data):
205 while True:
206 try:
207 return self.connection.send(data)
208 except OpenSSL.SSL.WantWriteError:
209 _, wlist, _ = select.select([], [self.socket], [],
210 self.socket.gettimeout())
211 if not wlist:
212 raise timeout()
213 continue
214
215 def sendall(self, data):
216 total_sent = 0
217 while total_sent < len(data):
218 sent = self._send_until_done(data[total_sent:total_sent + SSL_WRITE_BLOCKSIZE])
219 total_sent += sent
220
221 def shutdown(self):
222 # FIXME rethrow compatible exceptions should we ever use this
223 self.connection.shutdown()
224
225 def close(self):
226 if self._makefile_refs < 1:
227 try:
228 return self.connection.close()
229 except OpenSSL.SSL.Error:
230 return
231 else:
232 self._makefile_refs -= 1
233
234 def getpeercert(self, binary_form=False):
235 x509 = self.connection.get_peer_certificate()
236
237 if not x509:
238 return x509
239
240 if binary_form:
241 return OpenSSL.crypto.dump_certificate(
242 OpenSSL.crypto.FILETYPE_ASN1,
243 x509)
244
245 return {
246 'subject': (
247 (('commonName', x509.get_subject().CN),),
248 ),
249 'subjectAltName': [
250 ('DNS', value)
251 for value in get_subj_alt_name(x509)
252 ]
253 }
254
255 def _reuse(self):
256 self._makefile_refs += 1
257
258 def _drop(self):
259 if self._makefile_refs < 1:
260 self.close()
261 else:
262 self._makefile_refs -= 1
263
264
265 def _verify_callback(cnx, x509, err_no, err_depth, return_code):
266 return err_no == 0
267
268
269 def ssl_wrap_socket(sock, keyfile=None, certfile=None, cert_reqs=None,
270 ca_certs=None, server_hostname=None,
271 ssl_version=None, ca_cert_dir=None):
272 ctx = OpenSSL.SSL.Context(_openssl_versions[ssl_version])
273 if certfile:
274 keyfile = keyfile or certfile # Match behaviour of the normal python ssl library
275 ctx.use_certificate_file(certfile)
276 if keyfile:
277 ctx.use_privatekey_file(keyfile)
278 if cert_reqs != ssl.CERT_NONE:
279 ctx.set_verify(_openssl_verify[cert_reqs], _verify_callback)
280 if ca_certs or ca_cert_dir:
281 try:
282 ctx.load_verify_locations(ca_certs, ca_cert_dir)
283 except OpenSSL.SSL.Error as e:
284 raise ssl.SSLError('bad ca_certs: %r' % ca_certs, e)
285 else:
286 ctx.set_default_verify_paths()
287
288 # Disable TLS compression to mitigate CRIME attack (issue #309)
289 OP_NO_COMPRESSION = 0x20000
290 ctx.set_options(OP_NO_COMPRESSION)
291
292 # Set list of supported ciphersuites.
293 ctx.set_cipher_list(DEFAULT_SSL_CIPHER_LIST)
294
295 cnx = OpenSSL.SSL.Connection(ctx, sock)
296 cnx.set_tlsext_host_name(server_hostname)
297 cnx.set_connect_state()
298 while True:
299 try:
300 cnx.do_handshake()
301 except OpenSSL.SSL.WantReadError:
302 rd, _, _ = select.select([sock], [], [], sock.gettimeout())
303 if not rd:
304 raise timeout('select timed out')
305 continue
306 except OpenSSL.SSL.Error as e:
307 raise ssl.SSLError('bad handshake: %r' % e)
308 break
309
310 return WrappedSocket(cnx, sock)
311
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/urllib3/contrib/pyopenssl.py b/urllib3/contrib/pyopenssl.py
--- a/urllib3/contrib/pyopenssl.py
+++ b/urllib3/contrib/pyopenssl.py
@@ -182,7 +182,7 @@
if self.suppress_ragged_eofs and e.args == (-1, 'Unexpected EOF'):
return b''
else:
- raise SocketError(e)
+ raise SocketError(str(e))
except OpenSSL.SSL.ZeroReturnError as e:
if self.connection.get_shutdown() == OpenSSL.SSL.RECEIVED_SHUTDOWN:
return b''
|
{"golden_diff": "diff --git a/urllib3/contrib/pyopenssl.py b/urllib3/contrib/pyopenssl.py\n--- a/urllib3/contrib/pyopenssl.py\n+++ b/urllib3/contrib/pyopenssl.py\n@@ -182,7 +182,7 @@\n if self.suppress_ragged_eofs and e.args == (-1, 'Unexpected EOF'):\n return b''\n else:\n- raise SocketError(e)\n+ raise SocketError(str(e))\n except OpenSSL.SSL.ZeroReturnError as e:\n if self.connection.get_shutdown() == OpenSSL.SSL.RECEIVED_SHUTDOWN:\n return b''\n", "issue": "Need to update error handling for pyOpenSSL\nIf an `SSLError` comes from `pyOpenSSL`, we attempt to determine if it's an error due to request timeouts on python 2.6 being raised as `BaseSSLErrors` [here](https://github.com/shazow/urllib3/blob/29aa09bde9c42cc9a8d79aac47ee3d362b438cca/urllib3/connectionpool.py#L314). If the handshake ends unexpectedly under pyOpenSSL, then we get an `SSLError` that has a captured `SysCallError` which when you call `str(SSLError(msg, SysCallError(code, msg)))` you get\n\n``` py\nTypeError: __str__ returned non-string (type SysCallError)\n```\n\nSo we might want to update how we handle SSLErrors to accomodate pyOpenSSL. To be clear, I observed this on: python 2.7.9 with openssl 1.0.1l (from brew) and I was using requests to debug an issue with `https://apissl.cloudfactory.com`, e.g., `requests.get('https://apissl.cloudfactory.com')`\n\n", "before_files": [{"content": "'''SSL with SNI_-support for Python 2. Follow these instructions if you would\nlike to verify SSL certificates in Python 2. Note, the default libraries do\n*not* do certificate checking; you need to do additional work to validate\ncertificates yourself.\n\nThis needs the following packages installed:\n\n* pyOpenSSL (tested with 0.13)\n* ndg-httpsclient (tested with 0.3.2)\n* pyasn1 (tested with 0.1.6)\n\nYou can install them with the following command:\n\n pip install pyopenssl ndg-httpsclient pyasn1\n\nTo activate certificate checking, call\n:func:`~urllib3.contrib.pyopenssl.inject_into_urllib3` from your Python code\nbefore you begin making HTTP requests. This can be done in a ``sitecustomize``\nmodule, or at any other time before your application begins using ``urllib3``,\nlike this::\n\n try:\n import urllib3.contrib.pyopenssl\n urllib3.contrib.pyopenssl.inject_into_urllib3()\n except ImportError:\n pass\n\nNow you can use :mod:`urllib3` as you normally would, and it will support SNI\nwhen the required modules are installed.\n\nActivating this module also has the positive side effect of disabling SSL/TLS\ncompression in Python 2 (see `CRIME attack`_).\n\nIf you want to configure the default list of supported cipher suites, you can\nset the ``urllib3.contrib.pyopenssl.DEFAULT_SSL_CIPHER_LIST`` variable.\n\nModule Variables\n----------------\n\n:var DEFAULT_SSL_CIPHER_LIST: The list of supported SSL/TLS cipher suites.\n\n.. _sni: https://en.wikipedia.org/wiki/Server_Name_Indication\n.. _crime attack: https://en.wikipedia.org/wiki/CRIME_(security_exploit)\n\n'''\nfrom __future__ import absolute_import\n\ntry:\n from ndg.httpsclient.ssl_peer_verification import SUBJ_ALT_NAME_SUPPORT\n from ndg.httpsclient.subj_alt_name import SubjectAltName as BaseSubjectAltName\nexcept SyntaxError as e:\n raise ImportError(e)\n\nimport OpenSSL.SSL\nfrom pyasn1.codec.der import decoder as der_decoder\nfrom pyasn1.type import univ, constraint\nfrom socket import _fileobject, timeout, error as SocketError\nimport ssl\nimport select\n\nfrom .. import connection\nfrom .. import util\n\n__all__ = ['inject_into_urllib3', 'extract_from_urllib3']\n\n# SNI only *really* works if we can read the subjectAltName of certificates.\nHAS_SNI = SUBJ_ALT_NAME_SUPPORT\n\n# Map from urllib3 to PyOpenSSL compatible parameter-values.\n_openssl_versions = {\n ssl.PROTOCOL_SSLv23: OpenSSL.SSL.SSLv23_METHOD,\n ssl.PROTOCOL_TLSv1: OpenSSL.SSL.TLSv1_METHOD,\n}\n\nif hasattr(ssl, 'PROTOCOL_TLSv1_1') and hasattr(OpenSSL.SSL, 'TLSv1_1_METHOD'):\n _openssl_versions[ssl.PROTOCOL_TLSv1_1] = OpenSSL.SSL.TLSv1_1_METHOD\n\nif hasattr(ssl, 'PROTOCOL_TLSv1_2') and hasattr(OpenSSL.SSL, 'TLSv1_2_METHOD'):\n _openssl_versions[ssl.PROTOCOL_TLSv1_2] = OpenSSL.SSL.TLSv1_2_METHOD\n\ntry:\n _openssl_versions.update({ssl.PROTOCOL_SSLv3: OpenSSL.SSL.SSLv3_METHOD})\nexcept AttributeError:\n pass\n\n_openssl_verify = {\n ssl.CERT_NONE: OpenSSL.SSL.VERIFY_NONE,\n ssl.CERT_OPTIONAL: OpenSSL.SSL.VERIFY_PEER,\n ssl.CERT_REQUIRED:\n OpenSSL.SSL.VERIFY_PEER + OpenSSL.SSL.VERIFY_FAIL_IF_NO_PEER_CERT,\n}\n\nDEFAULT_SSL_CIPHER_LIST = util.ssl_.DEFAULT_CIPHERS\n\n# OpenSSL will only write 16K at a time\nSSL_WRITE_BLOCKSIZE = 16384\n\norig_util_HAS_SNI = util.HAS_SNI\norig_connection_ssl_wrap_socket = connection.ssl_wrap_socket\n\n\ndef inject_into_urllib3():\n 'Monkey-patch urllib3 with PyOpenSSL-backed SSL-support.'\n\n connection.ssl_wrap_socket = ssl_wrap_socket\n util.HAS_SNI = HAS_SNI\n\n\ndef extract_from_urllib3():\n 'Undo monkey-patching by :func:`inject_into_urllib3`.'\n\n connection.ssl_wrap_socket = orig_connection_ssl_wrap_socket\n util.HAS_SNI = orig_util_HAS_SNI\n\n\n# Note: This is a slightly bug-fixed version of same from ndg-httpsclient.\nclass SubjectAltName(BaseSubjectAltName):\n '''ASN.1 implementation for subjectAltNames support'''\n\n # There is no limit to how many SAN certificates a certificate may have,\n # however this needs to have some limit so we'll set an arbitrarily high\n # limit.\n sizeSpec = univ.SequenceOf.sizeSpec + \\\n constraint.ValueSizeConstraint(1, 1024)\n\n\n# Note: This is a slightly bug-fixed version of same from ndg-httpsclient.\ndef get_subj_alt_name(peer_cert):\n # Search through extensions\n dns_name = []\n if not SUBJ_ALT_NAME_SUPPORT:\n return dns_name\n\n general_names = SubjectAltName()\n for i in range(peer_cert.get_extension_count()):\n ext = peer_cert.get_extension(i)\n ext_name = ext.get_short_name()\n if ext_name != 'subjectAltName':\n continue\n\n # PyOpenSSL returns extension data in ASN.1 encoded form\n ext_dat = ext.get_data()\n decoded_dat = der_decoder.decode(ext_dat,\n asn1Spec=general_names)\n\n for name in decoded_dat:\n if not isinstance(name, SubjectAltName):\n continue\n for entry in range(len(name)):\n component = name.getComponentByPosition(entry)\n if component.getName() != 'dNSName':\n continue\n dns_name.append(str(component.getComponent()))\n\n return dns_name\n\n\nclass WrappedSocket(object):\n '''API-compatibility wrapper for Python OpenSSL's Connection-class.\n\n Note: _makefile_refs, _drop() and _reuse() are needed for the garbage\n collector of pypy.\n '''\n\n def __init__(self, connection, socket, suppress_ragged_eofs=True):\n self.connection = connection\n self.socket = socket\n self.suppress_ragged_eofs = suppress_ragged_eofs\n self._makefile_refs = 0\n\n def fileno(self):\n return self.socket.fileno()\n\n def makefile(self, mode, bufsize=-1):\n self._makefile_refs += 1\n return _fileobject(self, mode, bufsize, close=True)\n\n def recv(self, *args, **kwargs):\n try:\n data = self.connection.recv(*args, **kwargs)\n except OpenSSL.SSL.SysCallError as e:\n if self.suppress_ragged_eofs and e.args == (-1, 'Unexpected EOF'):\n return b''\n else:\n raise SocketError(e)\n except OpenSSL.SSL.ZeroReturnError as e:\n if self.connection.get_shutdown() == OpenSSL.SSL.RECEIVED_SHUTDOWN:\n return b''\n else:\n raise\n except OpenSSL.SSL.WantReadError:\n rd, wd, ed = select.select(\n [self.socket], [], [], self.socket.gettimeout())\n if not rd:\n raise timeout('The read operation timed out')\n else:\n return self.recv(*args, **kwargs)\n else:\n return data\n\n def settimeout(self, timeout):\n return self.socket.settimeout(timeout)\n\n def _send_until_done(self, data):\n while True:\n try:\n return self.connection.send(data)\n except OpenSSL.SSL.WantWriteError:\n _, wlist, _ = select.select([], [self.socket], [],\n self.socket.gettimeout())\n if not wlist:\n raise timeout()\n continue\n\n def sendall(self, data):\n total_sent = 0\n while total_sent < len(data):\n sent = self._send_until_done(data[total_sent:total_sent + SSL_WRITE_BLOCKSIZE])\n total_sent += sent\n\n def shutdown(self):\n # FIXME rethrow compatible exceptions should we ever use this\n self.connection.shutdown()\n\n def close(self):\n if self._makefile_refs < 1:\n try:\n return self.connection.close()\n except OpenSSL.SSL.Error:\n return\n else:\n self._makefile_refs -= 1\n\n def getpeercert(self, binary_form=False):\n x509 = self.connection.get_peer_certificate()\n\n if not x509:\n return x509\n\n if binary_form:\n return OpenSSL.crypto.dump_certificate(\n OpenSSL.crypto.FILETYPE_ASN1,\n x509)\n\n return {\n 'subject': (\n (('commonName', x509.get_subject().CN),),\n ),\n 'subjectAltName': [\n ('DNS', value)\n for value in get_subj_alt_name(x509)\n ]\n }\n\n def _reuse(self):\n self._makefile_refs += 1\n\n def _drop(self):\n if self._makefile_refs < 1:\n self.close()\n else:\n self._makefile_refs -= 1\n\n\ndef _verify_callback(cnx, x509, err_no, err_depth, return_code):\n return err_no == 0\n\n\ndef ssl_wrap_socket(sock, keyfile=None, certfile=None, cert_reqs=None,\n ca_certs=None, server_hostname=None,\n ssl_version=None, ca_cert_dir=None):\n ctx = OpenSSL.SSL.Context(_openssl_versions[ssl_version])\n if certfile:\n keyfile = keyfile or certfile # Match behaviour of the normal python ssl library\n ctx.use_certificate_file(certfile)\n if keyfile:\n ctx.use_privatekey_file(keyfile)\n if cert_reqs != ssl.CERT_NONE:\n ctx.set_verify(_openssl_verify[cert_reqs], _verify_callback)\n if ca_certs or ca_cert_dir:\n try:\n ctx.load_verify_locations(ca_certs, ca_cert_dir)\n except OpenSSL.SSL.Error as e:\n raise ssl.SSLError('bad ca_certs: %r' % ca_certs, e)\n else:\n ctx.set_default_verify_paths()\n\n # Disable TLS compression to mitigate CRIME attack (issue #309)\n OP_NO_COMPRESSION = 0x20000\n ctx.set_options(OP_NO_COMPRESSION)\n\n # Set list of supported ciphersuites.\n ctx.set_cipher_list(DEFAULT_SSL_CIPHER_LIST)\n\n cnx = OpenSSL.SSL.Connection(ctx, sock)\n cnx.set_tlsext_host_name(server_hostname)\n cnx.set_connect_state()\n while True:\n try:\n cnx.do_handshake()\n except OpenSSL.SSL.WantReadError:\n rd, _, _ = select.select([sock], [], [], sock.gettimeout())\n if not rd:\n raise timeout('select timed out')\n continue\n except OpenSSL.SSL.Error as e:\n raise ssl.SSLError('bad handshake: %r' % e)\n break\n\n return WrappedSocket(cnx, sock)\n", "path": "urllib3/contrib/pyopenssl.py"}], "after_files": [{"content": "'''SSL with SNI_-support for Python 2. Follow these instructions if you would\nlike to verify SSL certificates in Python 2. Note, the default libraries do\n*not* do certificate checking; you need to do additional work to validate\ncertificates yourself.\n\nThis needs the following packages installed:\n\n* pyOpenSSL (tested with 0.13)\n* ndg-httpsclient (tested with 0.3.2)\n* pyasn1 (tested with 0.1.6)\n\nYou can install them with the following command:\n\n pip install pyopenssl ndg-httpsclient pyasn1\n\nTo activate certificate checking, call\n:func:`~urllib3.contrib.pyopenssl.inject_into_urllib3` from your Python code\nbefore you begin making HTTP requests. This can be done in a ``sitecustomize``\nmodule, or at any other time before your application begins using ``urllib3``,\nlike this::\n\n try:\n import urllib3.contrib.pyopenssl\n urllib3.contrib.pyopenssl.inject_into_urllib3()\n except ImportError:\n pass\n\nNow you can use :mod:`urllib3` as you normally would, and it will support SNI\nwhen the required modules are installed.\n\nActivating this module also has the positive side effect of disabling SSL/TLS\ncompression in Python 2 (see `CRIME attack`_).\n\nIf you want to configure the default list of supported cipher suites, you can\nset the ``urllib3.contrib.pyopenssl.DEFAULT_SSL_CIPHER_LIST`` variable.\n\nModule Variables\n----------------\n\n:var DEFAULT_SSL_CIPHER_LIST: The list of supported SSL/TLS cipher suites.\n\n.. _sni: https://en.wikipedia.org/wiki/Server_Name_Indication\n.. _crime attack: https://en.wikipedia.org/wiki/CRIME_(security_exploit)\n\n'''\nfrom __future__ import absolute_import\n\ntry:\n from ndg.httpsclient.ssl_peer_verification import SUBJ_ALT_NAME_SUPPORT\n from ndg.httpsclient.subj_alt_name import SubjectAltName as BaseSubjectAltName\nexcept SyntaxError as e:\n raise ImportError(e)\n\nimport OpenSSL.SSL\nfrom pyasn1.codec.der import decoder as der_decoder\nfrom pyasn1.type import univ, constraint\nfrom socket import _fileobject, timeout, error as SocketError\nimport ssl\nimport select\n\nfrom .. import connection\nfrom .. import util\n\n__all__ = ['inject_into_urllib3', 'extract_from_urllib3']\n\n# SNI only *really* works if we can read the subjectAltName of certificates.\nHAS_SNI = SUBJ_ALT_NAME_SUPPORT\n\n# Map from urllib3 to PyOpenSSL compatible parameter-values.\n_openssl_versions = {\n ssl.PROTOCOL_SSLv23: OpenSSL.SSL.SSLv23_METHOD,\n ssl.PROTOCOL_TLSv1: OpenSSL.SSL.TLSv1_METHOD,\n}\n\nif hasattr(ssl, 'PROTOCOL_TLSv1_1') and hasattr(OpenSSL.SSL, 'TLSv1_1_METHOD'):\n _openssl_versions[ssl.PROTOCOL_TLSv1_1] = OpenSSL.SSL.TLSv1_1_METHOD\n\nif hasattr(ssl, 'PROTOCOL_TLSv1_2') and hasattr(OpenSSL.SSL, 'TLSv1_2_METHOD'):\n _openssl_versions[ssl.PROTOCOL_TLSv1_2] = OpenSSL.SSL.TLSv1_2_METHOD\n\ntry:\n _openssl_versions.update({ssl.PROTOCOL_SSLv3: OpenSSL.SSL.SSLv3_METHOD})\nexcept AttributeError:\n pass\n\n_openssl_verify = {\n ssl.CERT_NONE: OpenSSL.SSL.VERIFY_NONE,\n ssl.CERT_OPTIONAL: OpenSSL.SSL.VERIFY_PEER,\n ssl.CERT_REQUIRED:\n OpenSSL.SSL.VERIFY_PEER + OpenSSL.SSL.VERIFY_FAIL_IF_NO_PEER_CERT,\n}\n\nDEFAULT_SSL_CIPHER_LIST = util.ssl_.DEFAULT_CIPHERS\n\n# OpenSSL will only write 16K at a time\nSSL_WRITE_BLOCKSIZE = 16384\n\norig_util_HAS_SNI = util.HAS_SNI\norig_connection_ssl_wrap_socket = connection.ssl_wrap_socket\n\n\ndef inject_into_urllib3():\n 'Monkey-patch urllib3 with PyOpenSSL-backed SSL-support.'\n\n connection.ssl_wrap_socket = ssl_wrap_socket\n util.HAS_SNI = HAS_SNI\n\n\ndef extract_from_urllib3():\n 'Undo monkey-patching by :func:`inject_into_urllib3`.'\n\n connection.ssl_wrap_socket = orig_connection_ssl_wrap_socket\n util.HAS_SNI = orig_util_HAS_SNI\n\n\n# Note: This is a slightly bug-fixed version of same from ndg-httpsclient.\nclass SubjectAltName(BaseSubjectAltName):\n '''ASN.1 implementation for subjectAltNames support'''\n\n # There is no limit to how many SAN certificates a certificate may have,\n # however this needs to have some limit so we'll set an arbitrarily high\n # limit.\n sizeSpec = univ.SequenceOf.sizeSpec + \\\n constraint.ValueSizeConstraint(1, 1024)\n\n\n# Note: This is a slightly bug-fixed version of same from ndg-httpsclient.\ndef get_subj_alt_name(peer_cert):\n # Search through extensions\n dns_name = []\n if not SUBJ_ALT_NAME_SUPPORT:\n return dns_name\n\n general_names = SubjectAltName()\n for i in range(peer_cert.get_extension_count()):\n ext = peer_cert.get_extension(i)\n ext_name = ext.get_short_name()\n if ext_name != 'subjectAltName':\n continue\n\n # PyOpenSSL returns extension data in ASN.1 encoded form\n ext_dat = ext.get_data()\n decoded_dat = der_decoder.decode(ext_dat,\n asn1Spec=general_names)\n\n for name in decoded_dat:\n if not isinstance(name, SubjectAltName):\n continue\n for entry in range(len(name)):\n component = name.getComponentByPosition(entry)\n if component.getName() != 'dNSName':\n continue\n dns_name.append(str(component.getComponent()))\n\n return dns_name\n\n\nclass WrappedSocket(object):\n '''API-compatibility wrapper for Python OpenSSL's Connection-class.\n\n Note: _makefile_refs, _drop() and _reuse() are needed for the garbage\n collector of pypy.\n '''\n\n def __init__(self, connection, socket, suppress_ragged_eofs=True):\n self.connection = connection\n self.socket = socket\n self.suppress_ragged_eofs = suppress_ragged_eofs\n self._makefile_refs = 0\n\n def fileno(self):\n return self.socket.fileno()\n\n def makefile(self, mode, bufsize=-1):\n self._makefile_refs += 1\n return _fileobject(self, mode, bufsize, close=True)\n\n def recv(self, *args, **kwargs):\n try:\n data = self.connection.recv(*args, **kwargs)\n except OpenSSL.SSL.SysCallError as e:\n if self.suppress_ragged_eofs and e.args == (-1, 'Unexpected EOF'):\n return b''\n else:\n raise SocketError(str(e))\n except OpenSSL.SSL.ZeroReturnError as e:\n if self.connection.get_shutdown() == OpenSSL.SSL.RECEIVED_SHUTDOWN:\n return b''\n else:\n raise\n except OpenSSL.SSL.WantReadError:\n rd, wd, ed = select.select(\n [self.socket], [], [], self.socket.gettimeout())\n if not rd:\n raise timeout('The read operation timed out')\n else:\n return self.recv(*args, **kwargs)\n else:\n return data\n\n def settimeout(self, timeout):\n return self.socket.settimeout(timeout)\n\n def _send_until_done(self, data):\n while True:\n try:\n return self.connection.send(data)\n except OpenSSL.SSL.WantWriteError:\n _, wlist, _ = select.select([], [self.socket], [],\n self.socket.gettimeout())\n if not wlist:\n raise timeout()\n continue\n\n def sendall(self, data):\n total_sent = 0\n while total_sent < len(data):\n sent = self._send_until_done(data[total_sent:total_sent + SSL_WRITE_BLOCKSIZE])\n total_sent += sent\n\n def shutdown(self):\n # FIXME rethrow compatible exceptions should we ever use this\n self.connection.shutdown()\n\n def close(self):\n if self._makefile_refs < 1:\n try:\n return self.connection.close()\n except OpenSSL.SSL.Error:\n return\n else:\n self._makefile_refs -= 1\n\n def getpeercert(self, binary_form=False):\n x509 = self.connection.get_peer_certificate()\n\n if not x509:\n return x509\n\n if binary_form:\n return OpenSSL.crypto.dump_certificate(\n OpenSSL.crypto.FILETYPE_ASN1,\n x509)\n\n return {\n 'subject': (\n (('commonName', x509.get_subject().CN),),\n ),\n 'subjectAltName': [\n ('DNS', value)\n for value in get_subj_alt_name(x509)\n ]\n }\n\n def _reuse(self):\n self._makefile_refs += 1\n\n def _drop(self):\n if self._makefile_refs < 1:\n self.close()\n else:\n self._makefile_refs -= 1\n\n\ndef _verify_callback(cnx, x509, err_no, err_depth, return_code):\n return err_no == 0\n\n\ndef ssl_wrap_socket(sock, keyfile=None, certfile=None, cert_reqs=None,\n ca_certs=None, server_hostname=None,\n ssl_version=None, ca_cert_dir=None):\n ctx = OpenSSL.SSL.Context(_openssl_versions[ssl_version])\n if certfile:\n keyfile = keyfile or certfile # Match behaviour of the normal python ssl library\n ctx.use_certificate_file(certfile)\n if keyfile:\n ctx.use_privatekey_file(keyfile)\n if cert_reqs != ssl.CERT_NONE:\n ctx.set_verify(_openssl_verify[cert_reqs], _verify_callback)\n if ca_certs or ca_cert_dir:\n try:\n ctx.load_verify_locations(ca_certs, ca_cert_dir)\n except OpenSSL.SSL.Error as e:\n raise ssl.SSLError('bad ca_certs: %r' % ca_certs, e)\n else:\n ctx.set_default_verify_paths()\n\n # Disable TLS compression to mitigate CRIME attack (issue #309)\n OP_NO_COMPRESSION = 0x20000\n ctx.set_options(OP_NO_COMPRESSION)\n\n # Set list of supported ciphersuites.\n ctx.set_cipher_list(DEFAULT_SSL_CIPHER_LIST)\n\n cnx = OpenSSL.SSL.Connection(ctx, sock)\n cnx.set_tlsext_host_name(server_hostname)\n cnx.set_connect_state()\n while True:\n try:\n cnx.do_handshake()\n except OpenSSL.SSL.WantReadError:\n rd, _, _ = select.select([sock], [], [], sock.gettimeout())\n if not rd:\n raise timeout('select timed out')\n continue\n except OpenSSL.SSL.Error as e:\n raise ssl.SSLError('bad handshake: %r' % e)\n break\n\n return WrappedSocket(cnx, sock)\n", "path": "urllib3/contrib/pyopenssl.py"}]}
| 3,797 | 136 |
gh_patches_debug_29406
|
rasdani/github-patches
|
git_diff
|
facebookresearch__fairscale-709
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
FSDP(checkpoint()) causing issues in the optimizer when returning to training after evaluating
## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
When wrapping a `module` with `FSDP(checkpoint_wrapper(module))`, the first training epoch and validation pass go fine, but the second training pass will fail due to a size mismatch of gradients.
## Command
## To Reproduce
I modified a test in https://github.com/facebookresearch/fairscale/pull/709/files to show the failure. This PR also includes a work-around. But I'm still not entirely sure what causes the bug.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `fairscale/nn/checkpoint/checkpoint_activations.py`
Content:
```
1 # Copyright (c) Facebook, Inc. and its affiliates.
2 #
3 # This source code is licensed under the BSD license found in the
4 # LICENSE file in the root directory of this source tree.
5
6 from contextlib import contextmanager
7 import functools
8 import threading
9 from typing import Any, Dict, Generator, Optional, Tuple
10 import weakref
11
12 import torch
13 from torch import Tensor
14 import torch.nn as nn
15 import torch.utils.checkpoint as torch_checkpoint
16
17 from fairscale.utils.containers import pack_kwargs, split_non_tensors, unpack_kwargs, unpack_non_tensors
18
19 from .checkpoint_utils import dec_counter, inc_counter, init_counter, patch_batchnorm
20
21
22 # https://docs.python.org/3/library/threading.html#thread-local-data
23 # Manage the checkpoint context with thread-local data.
24 class ThreadLocal(threading.local):
25 def __init__(self) -> None:
26 self.is_checkpointing = False
27 self.is_recomputing = False
28
29
30 thread_local = ThreadLocal()
31
32
33 @contextmanager
34 def enable_checkpointing() -> Generator[None, None, None]:
35 """Makes :func:`is_checkpointing` return :data:`True` within a context."""
36 orig = thread_local.is_checkpointing
37 thread_local.is_checkpointing = True
38 try:
39 yield
40 finally:
41 thread_local.is_checkpointing = orig
42
43
44 @contextmanager
45 def enable_recomputing() -> Generator[None, None, None]:
46 """Makes :func:`is_recomputing` return :data:`True` within a context."""
47 orig = thread_local.is_recomputing
48 thread_local.is_recomputing = True
49 try:
50 yield
51 finally:
52 thread_local.is_recomputing = orig
53
54
55 def is_checkpointing() -> bool:
56 """Whether the current forward propagation is under checkpointing.
57
58 Returns:
59 bool: :data:`True` if it's under checkpointing.
60
61 """
62 return thread_local.is_checkpointing
63
64
65 def is_recomputing() -> bool:
66 """Whether the current forward propagation is under checkpoint
67 recomputation. Use this to prevent duplicated side-effects at forward
68 propagation::
69
70 class Counter(nn.Module):
71 def __init__(self):
72 super().__init__()
73 self.counter = 0
74
75 def forward(self, input):
76 if not is_recomputing():
77 self.counter += 1
78 return input
79
80 Returns:
81 bool: :data:`True` if it's under checkpoint recomputation.
82 """
83 return thread_local.is_recomputing
84
85
86 def checkpoint_wrapper(
87 module: nn.Module, offload_to_cpu: bool = False, maintain_forward_counter: bool = False
88 ) -> nn.Module:
89 """
90 A friendlier wrapper for performing activation checkpointing.
91
92 Compared to the PyTorch version, this version:
93
94 - wraps an nn.Module, so that all subsequent calls will use checkpointing
95 - handles keyword arguments in the forward
96 - handles non-Tensor outputs from the forward
97 - supports offloading activations to CPU
98
99 Usage::
100
101 checkpointed_module = checkpoint_wrapper(my_module, offload_to_cpu=True)
102 a, b = checkpointed_module(x, y=3, z=torch.Tensor([1]))
103
104 To understand the benefits of checkpointing and the `offload_to_cpu` flag,
105 let's divide activations into 2 types: inner activations and outer
106 activations w.r.t. the checkpointed modules. The inner ones are saved
107 by activation checkpointing, the outer ones are saved by offload_to_cpu.
108
109 In terms of GPU memory savings:
110
111 - When inner ones are large in size and outer ones are small,
112 checkpointing helps a lot, offload_to_cpu may help a little.
113 - When inner ones are small and outer ones are large,
114 checkpointing helps little, offload_to_cpu helps a lot.
115 - When both inner and outer are large, both help and the
116 benefit is additive.
117
118 ..Note::
119
120 The first and last layers are not likely to benefit from the `offload_to_cpu` flag
121 because (1) there are typically other references to the first layer's input, so
122 the GPU memory won't be freed; (2) the input to the last layer is immediately
123 used by the backward pass and won't result in memory savings.
124
125 Args:
126 module (nn.Module):
127 The module to be wrapped
128 offload_to_cpu (bool):
129 Whether to offload activations to CPU.
130 maintain_forward_counter (bool):
131 If True, maintain a forward counter per inner module. The counter will first
132 increases in forward calls of outer forward pass and then decreases in the
133 forward calls of outer backward pass. It is used by FullyShardedDataParallel.
134
135 Returns:
136 (nn.Module):
137 Wrapped module
138 """
139 # Patch the batchnorm layers in case there are any in this module.
140 patch_batchnorm(module)
141
142 if maintain_forward_counter:
143 init_counter(module)
144
145 # The use of weakref here is to prevent creating a ref cycle: m -> m.forward -> m.
146 # When such cycle exists, gc won't collect the module when the module is freed.
147 # That causes GPU memory to be leaked. See the unit test for how we catch that.
148 #
149 # We prefer this over a class wrapper since the class wrapper would have to
150 # proxy a lot of fields and methods.
151 module.forward = functools.partial( # type: ignore
152 _checkpointed_forward, type(module).forward, weakref.ref(module), offload_to_cpu
153 )
154 return module
155
156
157 def _checkpointed_forward(
158 original_forward: Any, weak_self: Any, offload_to_cpu: bool, *args: Any, **kwargs: Any
159 ) -> Any:
160 # Autograd Functions in PyTorch work best with positional args, since
161 # the backward must return gradients (or None) for every input argument.
162 # We can flatten keyword arguments to make this easier.
163 args = (weak_self(),) + args
164 kwarg_keys, flat_args = pack_kwargs(*args, **kwargs)
165 parent_ctx_dict: Dict[str, Any] = {
166 "offload": offload_to_cpu,
167 }
168 # Dummy tensor with grad is used to ensure the backward pass is called. This is needed
169 # when original_forward's input are non-tensor (i.e. a tuple). Using this dummy tensor
170 # avoids requiring users to set their input tensors's requires_grad flag. In the case
171 # of tuple type inputs, setting the flag won't even trigger the backward pass.
172 output = CheckpointFunction.apply(
173 torch.tensor([], requires_grad=True), original_forward, parent_ctx_dict, kwarg_keys, *flat_args
174 )
175 if not isinstance(output, torch.Tensor):
176 packed_non_tensor_outputs = parent_ctx_dict["packed_non_tensor_outputs"]
177 if packed_non_tensor_outputs:
178 output = unpack_non_tensors(output, packed_non_tensor_outputs)
179 return output
180
181
182 def get_rng_state() -> Dict[str, Any]:
183 state = {"torch_rng_state": torch.get_rng_state()}
184 if torch.cuda.is_available():
185 state["cuda_rng_state"] = torch.cuda.get_rng_state()
186 return state
187
188
189 def set_rng_state(state: Dict[str, Any]) -> None:
190 torch.set_rng_state(state["torch_rng_state"])
191 if torch.cuda.is_available():
192 torch.cuda.set_rng_state(state["cuda_rng_state"])
193
194
195 def is_autocast_enabled() -> bool:
196 """Similar to torch.is_autocast_enabled, but compatible with torch 1.5.1"""
197 if hasattr(torch, "is_autocast_enabled"):
198 return torch.is_autocast_enabled()
199 return False
200
201
202 @contextmanager
203 def autocast(enabled: bool) -> Generator:
204 """Similar to torch.cuda.amp.autocast, but compatible with torch 1.5.1"""
205 if enabled:
206 with torch.cuda.amp.autocast(enabled):
207 yield
208 else:
209 yield
210
211
212 class CheckpointFunction(torch.autograd.Function):
213 """Similar to the torch version, but support non-Tensor outputs.
214
215 The caller is expected to provide a dict (*parent_ctx_dict*) that will hold
216 the non-Tensor outputs. These should be combined with the Tensor *outputs*
217 by calling :func:`unpack_non_tensors`.
218 """
219
220 @staticmethod
221 def forward( # type: ignore
222 ctx: Any,
223 dummy_tensor_requires_grad: torch.Tensor,
224 run_function: Any,
225 parent_ctx_dict: Dict[str, Any],
226 kwarg_keys: Tuple[str, ...],
227 *args: Any,
228 **kwargs: Any
229 ) -> Any:
230 if torch.is_grad_enabled(): # grad may be disabled, e.g., during validation
231 torch_checkpoint.check_backward_validity(args)
232
233 ctx.run_function = run_function
234 ctx.kwarg_keys = kwarg_keys
235 ctx.fwd_rng_state = get_rng_state()
236 ctx.had_autocast_in_fwd = is_autocast_enabled()
237
238 tensor_inputs, packed_non_tensor_inputs = split_non_tensors(args)
239 if parent_ctx_dict["offload"]:
240 ctx.fwd_device = tuple(x.device for x in tensor_inputs)
241 ctx.grad_requirements = tuple(x.requires_grad for x in tensor_inputs)
242 tensor_inputs = tuple(x.cpu() for x in tensor_inputs)
243 else:
244 ctx.fwd_device, ctx.grad_requirements = None, None
245
246 ctx.save_for_backward(*tensor_inputs)
247 ctx.packed_non_tensor_inputs = packed_non_tensor_inputs
248
249 with torch.no_grad(), enable_checkpointing():
250 unpacked_args, unpacked_kwargs = unpack_kwargs(kwarg_keys, args)
251 outputs = run_function(*unpacked_args, **unpacked_kwargs)
252 the_module = unpacked_args[0]
253 inc_counter(the_module)
254
255 if not isinstance(outputs, torch.Tensor):
256 # Autograd Functions don't like non-Tensor outputs. We can split the
257 # non-Tensor and Tensor outputs, returning the former by reference
258 # through *parent_ctx_dict* and returning the latter directly.
259 outputs, packed_non_tensor_outputs = split_non_tensors(outputs)
260 parent_ctx_dict["packed_non_tensor_outputs"] = packed_non_tensor_outputs
261 return outputs
262
263 @staticmethod
264 def backward(ctx: Any, *args: Any) -> Tuple[Optional[Tensor], ...]:
265 if not torch.autograd._is_checkpoint_valid():
266 raise RuntimeError("Checkpointing is not compatible with .grad(), please use .backward() if possible")
267
268 tensor_inputs: Tuple = ctx.saved_tensors
269 tensor_inputs = torch_checkpoint.detach_variable(tensor_inputs)
270 if ctx.fwd_device is not None:
271 tensor_inputs = tuple(t.to(ctx.fwd_device[i]) for i, t in enumerate(tensor_inputs))
272 for i, need_grad in enumerate(ctx.grad_requirements):
273 tensor_inputs[i].requires_grad = need_grad
274 inputs = unpack_non_tensors(tensor_inputs, ctx.packed_non_tensor_inputs)
275
276 # Store the current states.
277 bwd_rng_state = get_rng_state()
278
279 # Set the states to what it used to be before the forward pass.
280 set_rng_state(ctx.fwd_rng_state)
281
282 with torch.enable_grad(), enable_recomputing(), autocast(ctx.had_autocast_in_fwd):
283 unpacked_args, unpacked_kwargs = unpack_kwargs(ctx.kwarg_keys, inputs)
284 outputs = ctx.run_function(*unpacked_args, **unpacked_kwargs)
285 tensor_outputs, _ = split_non_tensors(outputs)
286 the_module = unpacked_args[0]
287 dec_counter(the_module)
288
289 # Set the states back to what it was at the start of this function.
290 set_rng_state(bwd_rng_state)
291
292 # Run backward() with only Tensors that require grad
293 outputs_with_grad = []
294 args_with_grad = []
295 for i in range(len(tensor_outputs)):
296 if tensor_outputs[i].requires_grad:
297 outputs_with_grad.append(tensor_outputs[i])
298 args_with_grad.append(args[i])
299 if len(outputs_with_grad) == 0:
300 raise RuntimeError("None of the outputs have requires_grad=True, " "this checkpoint() is not necessary")
301
302 torch.autograd.backward(outputs_with_grad, args_with_grad)
303
304 grads = tuple(inp.grad if isinstance(inp, torch.Tensor) else None for inp in inputs)
305 return (None, None, None, None) + grads
306
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/fairscale/nn/checkpoint/checkpoint_activations.py b/fairscale/nn/checkpoint/checkpoint_activations.py
--- a/fairscale/nn/checkpoint/checkpoint_activations.py
+++ b/fairscale/nn/checkpoint/checkpoint_activations.py
@@ -157,10 +157,20 @@
def _checkpointed_forward(
original_forward: Any, weak_self: Any, offload_to_cpu: bool, *args: Any, **kwargs: Any
) -> Any:
+ module = weak_self()
+
+ # If gradients are disabled, just use original `.forward()` method directly.
+ # Doing so also ensures the internal fwd counter is not incremented in the forward pass,
+ # which would be an issue during eval since there wouldn't be a corresponding backward pass
+ # to decrement the fwd counter.
+ # See https://github.com/facebookresearch/fairscale/pull/709.
+ if not torch.is_grad_enabled():
+ return original_forward(module, *args, **kwargs)
+
# Autograd Functions in PyTorch work best with positional args, since
# the backward must return gradients (or None) for every input argument.
# We can flatten keyword arguments to make this easier.
- args = (weak_self(),) + args
+ args = (module,) + args
kwarg_keys, flat_args = pack_kwargs(*args, **kwargs)
parent_ctx_dict: Dict[str, Any] = {
"offload": offload_to_cpu,
@@ -227,8 +237,7 @@
*args: Any,
**kwargs: Any
) -> Any:
- if torch.is_grad_enabled(): # grad may be disabled, e.g., during validation
- torch_checkpoint.check_backward_validity(args)
+ torch_checkpoint.check_backward_validity(args)
ctx.run_function = run_function
ctx.kwarg_keys = kwarg_keys
|
{"golden_diff": "diff --git a/fairscale/nn/checkpoint/checkpoint_activations.py b/fairscale/nn/checkpoint/checkpoint_activations.py\n--- a/fairscale/nn/checkpoint/checkpoint_activations.py\n+++ b/fairscale/nn/checkpoint/checkpoint_activations.py\n@@ -157,10 +157,20 @@\n def _checkpointed_forward(\n original_forward: Any, weak_self: Any, offload_to_cpu: bool, *args: Any, **kwargs: Any\n ) -> Any:\n+ module = weak_self()\n+\n+ # If gradients are disabled, just use original `.forward()` method directly.\n+ # Doing so also ensures the internal fwd counter is not incremented in the forward pass,\n+ # which would be an issue during eval since there wouldn't be a corresponding backward pass\n+ # to decrement the fwd counter.\n+ # See https://github.com/facebookresearch/fairscale/pull/709.\n+ if not torch.is_grad_enabled():\n+ return original_forward(module, *args, **kwargs)\n+\n # Autograd Functions in PyTorch work best with positional args, since\n # the backward must return gradients (or None) for every input argument.\n # We can flatten keyword arguments to make this easier.\n- args = (weak_self(),) + args\n+ args = (module,) + args\n kwarg_keys, flat_args = pack_kwargs(*args, **kwargs)\n parent_ctx_dict: Dict[str, Any] = {\n \"offload\": offload_to_cpu,\n@@ -227,8 +237,7 @@\n *args: Any,\n **kwargs: Any\n ) -> Any:\n- if torch.is_grad_enabled(): # grad may be disabled, e.g., during validation\n- torch_checkpoint.check_backward_validity(args)\n+ torch_checkpoint.check_backward_validity(args)\n \n ctx.run_function = run_function\n ctx.kwarg_keys = kwarg_keys\n", "issue": "FSDP(checkpoint()) causing issues in the optimizer when returning to training after evaluating\n## \ud83d\udc1b Bug\r\n\r\n<!-- A clear and concise description of what the bug is. -->\r\n\r\nWhen wrapping a `module` with `FSDP(checkpoint_wrapper(module))`, the first training epoch and validation pass go fine, but the second training pass will fail due to a size mismatch of gradients.\r\n\r\n## Command\r\n\r\n## To Reproduce\r\n\r\nI modified a test in https://github.com/facebookresearch/fairscale/pull/709/files to show the failure. This PR also includes a work-around. But I'm still not entirely sure what causes the bug.\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the BSD license found in the\n# LICENSE file in the root directory of this source tree.\n\nfrom contextlib import contextmanager\nimport functools\nimport threading\nfrom typing import Any, Dict, Generator, Optional, Tuple\nimport weakref\n\nimport torch\nfrom torch import Tensor\nimport torch.nn as nn\nimport torch.utils.checkpoint as torch_checkpoint\n\nfrom fairscale.utils.containers import pack_kwargs, split_non_tensors, unpack_kwargs, unpack_non_tensors\n\nfrom .checkpoint_utils import dec_counter, inc_counter, init_counter, patch_batchnorm\n\n\n# https://docs.python.org/3/library/threading.html#thread-local-data\n# Manage the checkpoint context with thread-local data.\nclass ThreadLocal(threading.local):\n def __init__(self) -> None:\n self.is_checkpointing = False\n self.is_recomputing = False\n\n\nthread_local = ThreadLocal()\n\n\n@contextmanager\ndef enable_checkpointing() -> Generator[None, None, None]:\n \"\"\"Makes :func:`is_checkpointing` return :data:`True` within a context.\"\"\"\n orig = thread_local.is_checkpointing\n thread_local.is_checkpointing = True\n try:\n yield\n finally:\n thread_local.is_checkpointing = orig\n\n\n@contextmanager\ndef enable_recomputing() -> Generator[None, None, None]:\n \"\"\"Makes :func:`is_recomputing` return :data:`True` within a context.\"\"\"\n orig = thread_local.is_recomputing\n thread_local.is_recomputing = True\n try:\n yield\n finally:\n thread_local.is_recomputing = orig\n\n\ndef is_checkpointing() -> bool:\n \"\"\"Whether the current forward propagation is under checkpointing.\n\n Returns:\n bool: :data:`True` if it's under checkpointing.\n\n \"\"\"\n return thread_local.is_checkpointing\n\n\ndef is_recomputing() -> bool:\n \"\"\"Whether the current forward propagation is under checkpoint\n recomputation. Use this to prevent duplicated side-effects at forward\n propagation::\n\n class Counter(nn.Module):\n def __init__(self):\n super().__init__()\n self.counter = 0\n\n def forward(self, input):\n if not is_recomputing():\n self.counter += 1\n return input\n\n Returns:\n bool: :data:`True` if it's under checkpoint recomputation.\n \"\"\"\n return thread_local.is_recomputing\n\n\ndef checkpoint_wrapper(\n module: nn.Module, offload_to_cpu: bool = False, maintain_forward_counter: bool = False\n) -> nn.Module:\n \"\"\"\n A friendlier wrapper for performing activation checkpointing.\n\n Compared to the PyTorch version, this version:\n\n - wraps an nn.Module, so that all subsequent calls will use checkpointing\n - handles keyword arguments in the forward\n - handles non-Tensor outputs from the forward\n - supports offloading activations to CPU\n\n Usage::\n\n checkpointed_module = checkpoint_wrapper(my_module, offload_to_cpu=True)\n a, b = checkpointed_module(x, y=3, z=torch.Tensor([1]))\n\n To understand the benefits of checkpointing and the `offload_to_cpu` flag,\n let's divide activations into 2 types: inner activations and outer\n activations w.r.t. the checkpointed modules. The inner ones are saved\n by activation checkpointing, the outer ones are saved by offload_to_cpu.\n\n In terms of GPU memory savings:\n\n - When inner ones are large in size and outer ones are small,\n checkpointing helps a lot, offload_to_cpu may help a little.\n - When inner ones are small and outer ones are large,\n checkpointing helps little, offload_to_cpu helps a lot.\n - When both inner and outer are large, both help and the\n benefit is additive.\n\n ..Note::\n\n The first and last layers are not likely to benefit from the `offload_to_cpu` flag\n because (1) there are typically other references to the first layer's input, so\n the GPU memory won't be freed; (2) the input to the last layer is immediately\n used by the backward pass and won't result in memory savings.\n\n Args:\n module (nn.Module):\n The module to be wrapped\n offload_to_cpu (bool):\n Whether to offload activations to CPU.\n maintain_forward_counter (bool):\n If True, maintain a forward counter per inner module. The counter will first\n increases in forward calls of outer forward pass and then decreases in the\n forward calls of outer backward pass. It is used by FullyShardedDataParallel.\n\n Returns:\n (nn.Module):\n Wrapped module\n \"\"\"\n # Patch the batchnorm layers in case there are any in this module.\n patch_batchnorm(module)\n\n if maintain_forward_counter:\n init_counter(module)\n\n # The use of weakref here is to prevent creating a ref cycle: m -> m.forward -> m.\n # When such cycle exists, gc won't collect the module when the module is freed.\n # That causes GPU memory to be leaked. See the unit test for how we catch that.\n #\n # We prefer this over a class wrapper since the class wrapper would have to\n # proxy a lot of fields and methods.\n module.forward = functools.partial( # type: ignore\n _checkpointed_forward, type(module).forward, weakref.ref(module), offload_to_cpu\n )\n return module\n\n\ndef _checkpointed_forward(\n original_forward: Any, weak_self: Any, offload_to_cpu: bool, *args: Any, **kwargs: Any\n) -> Any:\n # Autograd Functions in PyTorch work best with positional args, since\n # the backward must return gradients (or None) for every input argument.\n # We can flatten keyword arguments to make this easier.\n args = (weak_self(),) + args\n kwarg_keys, flat_args = pack_kwargs(*args, **kwargs)\n parent_ctx_dict: Dict[str, Any] = {\n \"offload\": offload_to_cpu,\n }\n # Dummy tensor with grad is used to ensure the backward pass is called. This is needed\n # when original_forward's input are non-tensor (i.e. a tuple). Using this dummy tensor\n # avoids requiring users to set their input tensors's requires_grad flag. In the case\n # of tuple type inputs, setting the flag won't even trigger the backward pass.\n output = CheckpointFunction.apply(\n torch.tensor([], requires_grad=True), original_forward, parent_ctx_dict, kwarg_keys, *flat_args\n )\n if not isinstance(output, torch.Tensor):\n packed_non_tensor_outputs = parent_ctx_dict[\"packed_non_tensor_outputs\"]\n if packed_non_tensor_outputs:\n output = unpack_non_tensors(output, packed_non_tensor_outputs)\n return output\n\n\ndef get_rng_state() -> Dict[str, Any]:\n state = {\"torch_rng_state\": torch.get_rng_state()}\n if torch.cuda.is_available():\n state[\"cuda_rng_state\"] = torch.cuda.get_rng_state()\n return state\n\n\ndef set_rng_state(state: Dict[str, Any]) -> None:\n torch.set_rng_state(state[\"torch_rng_state\"])\n if torch.cuda.is_available():\n torch.cuda.set_rng_state(state[\"cuda_rng_state\"])\n\n\ndef is_autocast_enabled() -> bool:\n \"\"\"Similar to torch.is_autocast_enabled, but compatible with torch 1.5.1\"\"\"\n if hasattr(torch, \"is_autocast_enabled\"):\n return torch.is_autocast_enabled()\n return False\n\n\n@contextmanager\ndef autocast(enabled: bool) -> Generator:\n \"\"\"Similar to torch.cuda.amp.autocast, but compatible with torch 1.5.1\"\"\"\n if enabled:\n with torch.cuda.amp.autocast(enabled):\n yield\n else:\n yield\n\n\nclass CheckpointFunction(torch.autograd.Function):\n \"\"\"Similar to the torch version, but support non-Tensor outputs.\n\n The caller is expected to provide a dict (*parent_ctx_dict*) that will hold\n the non-Tensor outputs. These should be combined with the Tensor *outputs*\n by calling :func:`unpack_non_tensors`.\n \"\"\"\n\n @staticmethod\n def forward( # type: ignore\n ctx: Any,\n dummy_tensor_requires_grad: torch.Tensor,\n run_function: Any,\n parent_ctx_dict: Dict[str, Any],\n kwarg_keys: Tuple[str, ...],\n *args: Any,\n **kwargs: Any\n ) -> Any:\n if torch.is_grad_enabled(): # grad may be disabled, e.g., during validation\n torch_checkpoint.check_backward_validity(args)\n\n ctx.run_function = run_function\n ctx.kwarg_keys = kwarg_keys\n ctx.fwd_rng_state = get_rng_state()\n ctx.had_autocast_in_fwd = is_autocast_enabled()\n\n tensor_inputs, packed_non_tensor_inputs = split_non_tensors(args)\n if parent_ctx_dict[\"offload\"]:\n ctx.fwd_device = tuple(x.device for x in tensor_inputs)\n ctx.grad_requirements = tuple(x.requires_grad for x in tensor_inputs)\n tensor_inputs = tuple(x.cpu() for x in tensor_inputs)\n else:\n ctx.fwd_device, ctx.grad_requirements = None, None\n\n ctx.save_for_backward(*tensor_inputs)\n ctx.packed_non_tensor_inputs = packed_non_tensor_inputs\n\n with torch.no_grad(), enable_checkpointing():\n unpacked_args, unpacked_kwargs = unpack_kwargs(kwarg_keys, args)\n outputs = run_function(*unpacked_args, **unpacked_kwargs)\n the_module = unpacked_args[0]\n inc_counter(the_module)\n\n if not isinstance(outputs, torch.Tensor):\n # Autograd Functions don't like non-Tensor outputs. We can split the\n # non-Tensor and Tensor outputs, returning the former by reference\n # through *parent_ctx_dict* and returning the latter directly.\n outputs, packed_non_tensor_outputs = split_non_tensors(outputs)\n parent_ctx_dict[\"packed_non_tensor_outputs\"] = packed_non_tensor_outputs\n return outputs\n\n @staticmethod\n def backward(ctx: Any, *args: Any) -> Tuple[Optional[Tensor], ...]:\n if not torch.autograd._is_checkpoint_valid():\n raise RuntimeError(\"Checkpointing is not compatible with .grad(), please use .backward() if possible\")\n\n tensor_inputs: Tuple = ctx.saved_tensors\n tensor_inputs = torch_checkpoint.detach_variable(tensor_inputs)\n if ctx.fwd_device is not None:\n tensor_inputs = tuple(t.to(ctx.fwd_device[i]) for i, t in enumerate(tensor_inputs))\n for i, need_grad in enumerate(ctx.grad_requirements):\n tensor_inputs[i].requires_grad = need_grad\n inputs = unpack_non_tensors(tensor_inputs, ctx.packed_non_tensor_inputs)\n\n # Store the current states.\n bwd_rng_state = get_rng_state()\n\n # Set the states to what it used to be before the forward pass.\n set_rng_state(ctx.fwd_rng_state)\n\n with torch.enable_grad(), enable_recomputing(), autocast(ctx.had_autocast_in_fwd):\n unpacked_args, unpacked_kwargs = unpack_kwargs(ctx.kwarg_keys, inputs)\n outputs = ctx.run_function(*unpacked_args, **unpacked_kwargs)\n tensor_outputs, _ = split_non_tensors(outputs)\n the_module = unpacked_args[0]\n dec_counter(the_module)\n\n # Set the states back to what it was at the start of this function.\n set_rng_state(bwd_rng_state)\n\n # Run backward() with only Tensors that require grad\n outputs_with_grad = []\n args_with_grad = []\n for i in range(len(tensor_outputs)):\n if tensor_outputs[i].requires_grad:\n outputs_with_grad.append(tensor_outputs[i])\n args_with_grad.append(args[i])\n if len(outputs_with_grad) == 0:\n raise RuntimeError(\"None of the outputs have requires_grad=True, \" \"this checkpoint() is not necessary\")\n\n torch.autograd.backward(outputs_with_grad, args_with_grad)\n\n grads = tuple(inp.grad if isinstance(inp, torch.Tensor) else None for inp in inputs)\n return (None, None, None, None) + grads\n", "path": "fairscale/nn/checkpoint/checkpoint_activations.py"}], "after_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the BSD license found in the\n# LICENSE file in the root directory of this source tree.\n\nfrom contextlib import contextmanager\nimport functools\nimport threading\nfrom typing import Any, Dict, Generator, Optional, Tuple\nimport weakref\n\nimport torch\nfrom torch import Tensor\nimport torch.nn as nn\nimport torch.utils.checkpoint as torch_checkpoint\n\nfrom fairscale.utils.containers import pack_kwargs, split_non_tensors, unpack_kwargs, unpack_non_tensors\n\nfrom .checkpoint_utils import dec_counter, inc_counter, init_counter, patch_batchnorm\n\n\n# https://docs.python.org/3/library/threading.html#thread-local-data\n# Manage the checkpoint context with thread-local data.\nclass ThreadLocal(threading.local):\n def __init__(self) -> None:\n self.is_checkpointing = False\n self.is_recomputing = False\n\n\nthread_local = ThreadLocal()\n\n\n@contextmanager\ndef enable_checkpointing() -> Generator[None, None, None]:\n \"\"\"Makes :func:`is_checkpointing` return :data:`True` within a context.\"\"\"\n orig = thread_local.is_checkpointing\n thread_local.is_checkpointing = True\n try:\n yield\n finally:\n thread_local.is_checkpointing = orig\n\n\n@contextmanager\ndef enable_recomputing() -> Generator[None, None, None]:\n \"\"\"Makes :func:`is_recomputing` return :data:`True` within a context.\"\"\"\n orig = thread_local.is_recomputing\n thread_local.is_recomputing = True\n try:\n yield\n finally:\n thread_local.is_recomputing = orig\n\n\ndef is_checkpointing() -> bool:\n \"\"\"Whether the current forward propagation is under checkpointing.\n\n Returns:\n bool: :data:`True` if it's under checkpointing.\n\n \"\"\"\n return thread_local.is_checkpointing\n\n\ndef is_recomputing() -> bool:\n \"\"\"Whether the current forward propagation is under checkpoint\n recomputation. Use this to prevent duplicated side-effects at forward\n propagation::\n\n class Counter(nn.Module):\n def __init__(self):\n super().__init__()\n self.counter = 0\n\n def forward(self, input):\n if not is_recomputing():\n self.counter += 1\n return input\n\n Returns:\n bool: :data:`True` if it's under checkpoint recomputation.\n \"\"\"\n return thread_local.is_recomputing\n\n\ndef checkpoint_wrapper(\n module: nn.Module, offload_to_cpu: bool = False, maintain_forward_counter: bool = False\n) -> nn.Module:\n \"\"\"\n A friendlier wrapper for performing activation checkpointing.\n\n Compared to the PyTorch version, this version:\n\n - wraps an nn.Module, so that all subsequent calls will use checkpointing\n - handles keyword arguments in the forward\n - handles non-Tensor outputs from the forward\n - supports offloading activations to CPU\n\n Usage::\n\n checkpointed_module = checkpoint_wrapper(my_module, offload_to_cpu=True)\n a, b = checkpointed_module(x, y=3, z=torch.Tensor([1]))\n\n To understand the benefits of checkpointing and the `offload_to_cpu` flag,\n let's divide activations into 2 types: inner activations and outer\n activations w.r.t. the checkpointed modules. The inner ones are saved\n by activation checkpointing, the outer ones are saved by offload_to_cpu.\n\n In terms of GPU memory savings:\n\n - When inner ones are large in size and outer ones are small,\n checkpointing helps a lot, offload_to_cpu may help a little.\n - When inner ones are small and outer ones are large,\n checkpointing helps little, offload_to_cpu helps a lot.\n - When both inner and outer are large, both help and the\n benefit is additive.\n\n ..Note::\n\n The first and last layers are not likely to benefit from the `offload_to_cpu` flag\n because (1) there are typically other references to the first layer's input, so\n the GPU memory won't be freed; (2) the input to the last layer is immediately\n used by the backward pass and won't result in memory savings.\n\n Args:\n module (nn.Module):\n The module to be wrapped\n offload_to_cpu (bool):\n Whether to offload activations to CPU.\n maintain_forward_counter (bool):\n If True, maintain a forward counter per inner module. The counter will first\n increases in forward calls of outer forward pass and then decreases in the\n forward calls of outer backward pass. It is used by FullyShardedDataParallel.\n\n Returns:\n (nn.Module):\n Wrapped module\n \"\"\"\n # Patch the batchnorm layers in case there are any in this module.\n patch_batchnorm(module)\n\n if maintain_forward_counter:\n init_counter(module)\n\n # The use of weakref here is to prevent creating a ref cycle: m -> m.forward -> m.\n # When such cycle exists, gc won't collect the module when the module is freed.\n # That causes GPU memory to be leaked. See the unit test for how we catch that.\n #\n # We prefer this over a class wrapper since the class wrapper would have to\n # proxy a lot of fields and methods.\n module.forward = functools.partial( # type: ignore\n _checkpointed_forward, type(module).forward, weakref.ref(module), offload_to_cpu\n )\n return module\n\n\ndef _checkpointed_forward(\n original_forward: Any, weak_self: Any, offload_to_cpu: bool, *args: Any, **kwargs: Any\n) -> Any:\n module = weak_self()\n\n # If gradients are disabled, just use original `.forward()` method directly.\n # Doing so also ensures the internal fwd counter is not incremented in the forward pass,\n # which would be an issue during eval since there wouldn't be a corresponding backward pass\n # to decrement the fwd counter.\n # See https://github.com/facebookresearch/fairscale/pull/709.\n if not torch.is_grad_enabled():\n return original_forward(module, *args, **kwargs)\n\n # Autograd Functions in PyTorch work best with positional args, since\n # the backward must return gradients (or None) for every input argument.\n # We can flatten keyword arguments to make this easier.\n args = (module,) + args\n kwarg_keys, flat_args = pack_kwargs(*args, **kwargs)\n parent_ctx_dict: Dict[str, Any] = {\n \"offload\": offload_to_cpu,\n }\n # Dummy tensor with grad is used to ensure the backward pass is called. This is needed\n # when original_forward's input are non-tensor (i.e. a tuple). Using this dummy tensor\n # avoids requiring users to set their input tensors's requires_grad flag. In the case\n # of tuple type inputs, setting the flag won't even trigger the backward pass.\n output = CheckpointFunction.apply(\n torch.tensor([], requires_grad=True), original_forward, parent_ctx_dict, kwarg_keys, *flat_args\n )\n if not isinstance(output, torch.Tensor):\n packed_non_tensor_outputs = parent_ctx_dict[\"packed_non_tensor_outputs\"]\n if packed_non_tensor_outputs:\n output = unpack_non_tensors(output, packed_non_tensor_outputs)\n return output\n\n\ndef get_rng_state() -> Dict[str, Any]:\n state = {\"torch_rng_state\": torch.get_rng_state()}\n if torch.cuda.is_available():\n state[\"cuda_rng_state\"] = torch.cuda.get_rng_state()\n return state\n\n\ndef set_rng_state(state: Dict[str, Any]) -> None:\n torch.set_rng_state(state[\"torch_rng_state\"])\n if torch.cuda.is_available():\n torch.cuda.set_rng_state(state[\"cuda_rng_state\"])\n\n\ndef is_autocast_enabled() -> bool:\n \"\"\"Similar to torch.is_autocast_enabled, but compatible with torch 1.5.1\"\"\"\n if hasattr(torch, \"is_autocast_enabled\"):\n return torch.is_autocast_enabled()\n return False\n\n\n@contextmanager\ndef autocast(enabled: bool) -> Generator:\n \"\"\"Similar to torch.cuda.amp.autocast, but compatible with torch 1.5.1\"\"\"\n if enabled:\n with torch.cuda.amp.autocast(enabled):\n yield\n else:\n yield\n\n\nclass CheckpointFunction(torch.autograd.Function):\n \"\"\"Similar to the torch version, but support non-Tensor outputs.\n\n The caller is expected to provide a dict (*parent_ctx_dict*) that will hold\n the non-Tensor outputs. These should be combined with the Tensor *outputs*\n by calling :func:`unpack_non_tensors`.\n \"\"\"\n\n @staticmethod\n def forward( # type: ignore\n ctx: Any,\n dummy_tensor_requires_grad: torch.Tensor,\n run_function: Any,\n parent_ctx_dict: Dict[str, Any],\n kwarg_keys: Tuple[str, ...],\n *args: Any,\n **kwargs: Any\n ) -> Any:\n torch_checkpoint.check_backward_validity(args)\n\n ctx.run_function = run_function\n ctx.kwarg_keys = kwarg_keys\n ctx.fwd_rng_state = get_rng_state()\n ctx.had_autocast_in_fwd = is_autocast_enabled()\n\n tensor_inputs, packed_non_tensor_inputs = split_non_tensors(args)\n if parent_ctx_dict[\"offload\"]:\n ctx.fwd_device = tuple(x.device for x in tensor_inputs)\n ctx.grad_requirements = tuple(x.requires_grad for x in tensor_inputs)\n tensor_inputs = tuple(x.cpu() for x in tensor_inputs)\n else:\n ctx.fwd_device, ctx.grad_requirements = None, None\n\n ctx.save_for_backward(*tensor_inputs)\n ctx.packed_non_tensor_inputs = packed_non_tensor_inputs\n\n with torch.no_grad(), enable_checkpointing():\n unpacked_args, unpacked_kwargs = unpack_kwargs(kwarg_keys, args)\n outputs = run_function(*unpacked_args, **unpacked_kwargs)\n the_module = unpacked_args[0]\n inc_counter(the_module)\n\n if not isinstance(outputs, torch.Tensor):\n # Autograd Functions don't like non-Tensor outputs. We can split the\n # non-Tensor and Tensor outputs, returning the former by reference\n # through *parent_ctx_dict* and returning the latter directly.\n outputs, packed_non_tensor_outputs = split_non_tensors(outputs)\n parent_ctx_dict[\"packed_non_tensor_outputs\"] = packed_non_tensor_outputs\n return outputs\n\n @staticmethod\n def backward(ctx: Any, *args: Any) -> Tuple[Optional[Tensor], ...]:\n if not torch.autograd._is_checkpoint_valid():\n raise RuntimeError(\"Checkpointing is not compatible with .grad(), please use .backward() if possible\")\n\n tensor_inputs: Tuple = ctx.saved_tensors\n tensor_inputs = torch_checkpoint.detach_variable(tensor_inputs)\n if ctx.fwd_device is not None:\n tensor_inputs = tuple(t.to(ctx.fwd_device[i]) for i, t in enumerate(tensor_inputs))\n for i, need_grad in enumerate(ctx.grad_requirements):\n tensor_inputs[i].requires_grad = need_grad\n inputs = unpack_non_tensors(tensor_inputs, ctx.packed_non_tensor_inputs)\n\n # Store the current states.\n bwd_rng_state = get_rng_state()\n\n # Set the states to what it used to be before the forward pass.\n set_rng_state(ctx.fwd_rng_state)\n\n with torch.enable_grad(), enable_recomputing(), autocast(ctx.had_autocast_in_fwd):\n unpacked_args, unpacked_kwargs = unpack_kwargs(ctx.kwarg_keys, inputs)\n outputs = ctx.run_function(*unpacked_args, **unpacked_kwargs)\n tensor_outputs, _ = split_non_tensors(outputs)\n the_module = unpacked_args[0]\n dec_counter(the_module)\n\n # Set the states back to what it was at the start of this function.\n set_rng_state(bwd_rng_state)\n\n # Run backward() with only Tensors that require grad\n outputs_with_grad = []\n args_with_grad = []\n for i in range(len(tensor_outputs)):\n if tensor_outputs[i].requires_grad:\n outputs_with_grad.append(tensor_outputs[i])\n args_with_grad.append(args[i])\n if len(outputs_with_grad) == 0:\n raise RuntimeError(\"None of the outputs have requires_grad=True, \" \"this checkpoint() is not necessary\")\n\n torch.autograd.backward(outputs_with_grad, args_with_grad)\n\n grads = tuple(inp.grad if isinstance(inp, torch.Tensor) else None for inp in inputs)\n return (None, None, None, None) + grads\n", "path": "fairscale/nn/checkpoint/checkpoint_activations.py"}]}
| 3,853 | 427 |
gh_patches_debug_31238
|
rasdani/github-patches
|
git_diff
|
marshmallow-code__webargs-832
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Dealing with empty values in `DelimitedFieldMixin`
`DelimitedList(String())` deserializes "a,,c" as `["a", "", "c"]`.
I guess this meets user expectations.
My expectation with integers would be that
`DelimitedList(Integer(allow_none=True))` deserializes `"1,,3"` as `[1,None,3]`
but it errors.
The reason for this is that when the string is split, it is turned into `["1", "", "3"]`. This is why it works in the string case.
I'm not sure this was really intended. It may be a side effect of the `split` function that happens to do well with strings.
We could change that to replace empty values with `None`. But it would break the string use case, unless the user overloads `String` field to deserialize `None` as `""`.
Likewise, users may already overload `Integer` to deserialize `""` as `None` and no modification is required to `DelimitedFieldMixin`.
Just been caught by this and wondering out loud. Advice welcome.
In any case, there is an intrinsic limitation in the delimited string format: one can't distinguish empty string from missing value (as opposed to a JSON payload). It is not clear to me how OpenAPI (for instance) deals with the case of an empty element in an array (in a query argument).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/webargs/fields.py`
Content:
```
1 """Field classes.
2
3 Includes all fields from `marshmallow.fields` in addition to a custom
4 `Nested` field and `DelimitedList`.
5
6 All fields can optionally take a special `location` keyword argument, which
7 tells webargs where to parse the request argument from.
8
9 .. code-block:: python
10
11 args = {
12 "active": fields.Bool(location="query"),
13 "content_type": fields.Str(data_key="Content-Type", location="headers"),
14 }
15 """
16 from __future__ import annotations
17
18 import marshmallow as ma
19
20 # Expose all fields from marshmallow.fields.
21 from marshmallow.fields import * # noqa: F40
22
23 __all__ = ["DelimitedList", "DelimitedTuple"] + ma.fields.__all__
24
25
26 # TODO: remove custom `Nested` in the next major release
27 #
28 # the `Nested` class is only needed on versions of marshmallow prior to v3.15.0
29 # in that version, `ma.fields.Nested` gained the ability to consume dict inputs
30 # prior to that, this subclass adds this capability
31 #
32 # if we drop support for ma.__version_info__ < (3, 15) we can do this
33 class Nested(ma.fields.Nested): # type: ignore[no-redef]
34 """Same as `marshmallow.fields.Nested`, except can be passed a dictionary as
35 the first argument, which will be converted to a `marshmallow.Schema`.
36
37 .. note::
38
39 The schema class here will always be `marshmallow.Schema`, regardless
40 of whether a custom schema class is set on the parser. Pass an explicit schema
41 class if necessary.
42 """
43
44 def __init__(self, nested, *args, **kwargs):
45 if isinstance(nested, dict):
46 nested = ma.Schema.from_dict(nested)
47 super().__init__(nested, *args, **kwargs)
48
49
50 class DelimitedFieldMixin:
51 """
52 This is a mixin class for subclasses of ma.fields.List and ma.fields.Tuple
53 which split on a pre-specified delimiter. By default, the delimiter will be ","
54
55 Because we want the MRO to reach this class before the List or Tuple class,
56 it must be listed first in the superclasses
57
58 For example, a DelimitedList-like type can be defined like so:
59
60 >>> class MyDelimitedList(DelimitedFieldMixin, ma.fields.List):
61 >>> pass
62 """
63
64 delimiter: str = ","
65 # delimited fields set is_multiple=False for webargs.core.is_multiple
66 is_multiple: bool = False
67
68 def _serialize(self, value, attr, obj, **kwargs):
69 # serializing will start with parent-class serialization, so that we correctly
70 # output lists of non-primitive types, e.g. DelimitedList(DateTime)
71 return self.delimiter.join(
72 format(each) for each in super()._serialize(value, attr, obj, **kwargs)
73 )
74
75 def _deserialize(self, value, attr, data, **kwargs):
76 # attempting to deserialize from a non-string source is an error
77 if not isinstance(value, (str, bytes)):
78 raise self.make_error("invalid")
79 values = value.split(self.delimiter) if value else []
80 return super()._deserialize(values, attr, data, **kwargs)
81
82
83 class DelimitedList(DelimitedFieldMixin, ma.fields.List):
84 """A field which is similar to a List, but takes its input as a delimited
85 string (e.g. "foo,bar,baz").
86
87 Like List, it can be given a nested field type which it will use to
88 de/serialize each element of the list.
89
90 :param Field cls_or_instance: A field class or instance.
91 :param str delimiter: Delimiter between values.
92 """
93
94 default_error_messages = {"invalid": "Not a valid delimited list."}
95
96 def __init__(
97 self,
98 cls_or_instance: ma.fields.Field | type,
99 *,
100 delimiter: str | None = None,
101 **kwargs,
102 ):
103 self.delimiter = delimiter or self.delimiter
104 super().__init__(cls_or_instance, **kwargs)
105
106
107 class DelimitedTuple(DelimitedFieldMixin, ma.fields.Tuple):
108 """A field which is similar to a Tuple, but takes its input as a delimited
109 string (e.g. "foo,bar,baz").
110
111 Like Tuple, it can be given a tuple of nested field types which it will use to
112 de/serialize each element of the tuple.
113
114 :param Iterable[Field] tuple_fields: An iterable of field classes or instances.
115 :param str delimiter: Delimiter between values.
116 """
117
118 default_error_messages = {"invalid": "Not a valid delimited tuple."}
119
120 def __init__(self, tuple_fields, *, delimiter: str | None = None, **kwargs):
121 self.delimiter = delimiter or self.delimiter
122 super().__init__(tuple_fields, **kwargs)
123
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/webargs/fields.py b/src/webargs/fields.py
--- a/src/webargs/fields.py
+++ b/src/webargs/fields.py
@@ -15,6 +15,8 @@
"""
from __future__ import annotations
+import typing
+
import marshmallow as ma
# Expose all fields from marshmallow.fields.
@@ -64,6 +66,8 @@
delimiter: str = ","
# delimited fields set is_multiple=False for webargs.core.is_multiple
is_multiple: bool = False
+ # NOTE: in 8.x this defaults to "" but in 9.x it will be 'missing'
+ empty_value: typing.Any = ""
def _serialize(self, value, attr, obj, **kwargs):
# serializing will start with parent-class serialization, so that we correctly
@@ -77,6 +81,8 @@
if not isinstance(value, (str, bytes)):
raise self.make_error("invalid")
values = value.split(self.delimiter) if value else []
+ # convert empty strings to the empty value; typically "" and therefore a no-op
+ values = [v or self.empty_value for v in values]
return super()._deserialize(values, attr, data, **kwargs)
@@ -117,6 +123,12 @@
default_error_messages = {"invalid": "Not a valid delimited tuple."}
- def __init__(self, tuple_fields, *, delimiter: str | None = None, **kwargs):
+ def __init__(
+ self,
+ tuple_fields,
+ *,
+ delimiter: str | None = None,
+ **kwargs,
+ ):
self.delimiter = delimiter or self.delimiter
super().__init__(tuple_fields, **kwargs)
|
{"golden_diff": "diff --git a/src/webargs/fields.py b/src/webargs/fields.py\n--- a/src/webargs/fields.py\n+++ b/src/webargs/fields.py\n@@ -15,6 +15,8 @@\n \"\"\"\n from __future__ import annotations\n \n+import typing\n+\n import marshmallow as ma\n \n # Expose all fields from marshmallow.fields.\n@@ -64,6 +66,8 @@\n delimiter: str = \",\"\n # delimited fields set is_multiple=False for webargs.core.is_multiple\n is_multiple: bool = False\n+ # NOTE: in 8.x this defaults to \"\" but in 9.x it will be 'missing'\n+ empty_value: typing.Any = \"\"\n \n def _serialize(self, value, attr, obj, **kwargs):\n # serializing will start with parent-class serialization, so that we correctly\n@@ -77,6 +81,8 @@\n if not isinstance(value, (str, bytes)):\n raise self.make_error(\"invalid\")\n values = value.split(self.delimiter) if value else []\n+ # convert empty strings to the empty value; typically \"\" and therefore a no-op\n+ values = [v or self.empty_value for v in values]\n return super()._deserialize(values, attr, data, **kwargs)\n \n \n@@ -117,6 +123,12 @@\n \n default_error_messages = {\"invalid\": \"Not a valid delimited tuple.\"}\n \n- def __init__(self, tuple_fields, *, delimiter: str | None = None, **kwargs):\n+ def __init__(\n+ self,\n+ tuple_fields,\n+ *,\n+ delimiter: str | None = None,\n+ **kwargs,\n+ ):\n self.delimiter = delimiter or self.delimiter\n super().__init__(tuple_fields, **kwargs)\n", "issue": "Dealing with empty values in `DelimitedFieldMixin`\n`DelimitedList(String())` deserializes \"a,,c\" as `[\"a\", \"\", \"c\"]`.\r\n\r\nI guess this meets user expectations.\r\n\r\nMy expectation with integers would be that\r\n\r\n`DelimitedList(Integer(allow_none=True))` deserializes `\"1,,3\"` as `[1,None,3]`\r\n\r\nbut it errors.\r\n\r\nThe reason for this is that when the string is split, it is turned into `[\"1\", \"\", \"3\"]`. This is why it works in the string case.\r\n\r\nI'm not sure this was really intended. It may be a side effect of the `split` function that happens to do well with strings.\r\n\r\nWe could change that to replace empty values with `None`. But it would break the string use case, unless the user overloads `String` field to deserialize `None` as `\"\"`.\r\n\r\nLikewise, users may already overload `Integer` to deserialize `\"\"` as `None` and no modification is required to `DelimitedFieldMixin`.\r\n\r\nJust been caught by this and wondering out loud. Advice welcome.\r\n\r\nIn any case, there is an intrinsic limitation in the delimited string format: one can't distinguish empty string from missing value (as opposed to a JSON payload). It is not clear to me how OpenAPI (for instance) deals with the case of an empty element in an array (in a query argument).\n", "before_files": [{"content": "\"\"\"Field classes.\n\nIncludes all fields from `marshmallow.fields` in addition to a custom\n`Nested` field and `DelimitedList`.\n\nAll fields can optionally take a special `location` keyword argument, which\ntells webargs where to parse the request argument from.\n\n.. code-block:: python\n\n args = {\n \"active\": fields.Bool(location=\"query\"),\n \"content_type\": fields.Str(data_key=\"Content-Type\", location=\"headers\"),\n }\n\"\"\"\nfrom __future__ import annotations\n\nimport marshmallow as ma\n\n# Expose all fields from marshmallow.fields.\nfrom marshmallow.fields import * # noqa: F40\n\n__all__ = [\"DelimitedList\", \"DelimitedTuple\"] + ma.fields.__all__\n\n\n# TODO: remove custom `Nested` in the next major release\n#\n# the `Nested` class is only needed on versions of marshmallow prior to v3.15.0\n# in that version, `ma.fields.Nested` gained the ability to consume dict inputs\n# prior to that, this subclass adds this capability\n#\n# if we drop support for ma.__version_info__ < (3, 15) we can do this\nclass Nested(ma.fields.Nested): # type: ignore[no-redef]\n \"\"\"Same as `marshmallow.fields.Nested`, except can be passed a dictionary as\n the first argument, which will be converted to a `marshmallow.Schema`.\n\n .. note::\n\n The schema class here will always be `marshmallow.Schema`, regardless\n of whether a custom schema class is set on the parser. Pass an explicit schema\n class if necessary.\n \"\"\"\n\n def __init__(self, nested, *args, **kwargs):\n if isinstance(nested, dict):\n nested = ma.Schema.from_dict(nested)\n super().__init__(nested, *args, **kwargs)\n\n\nclass DelimitedFieldMixin:\n \"\"\"\n This is a mixin class for subclasses of ma.fields.List and ma.fields.Tuple\n which split on a pre-specified delimiter. By default, the delimiter will be \",\"\n\n Because we want the MRO to reach this class before the List or Tuple class,\n it must be listed first in the superclasses\n\n For example, a DelimitedList-like type can be defined like so:\n\n >>> class MyDelimitedList(DelimitedFieldMixin, ma.fields.List):\n >>> pass\n \"\"\"\n\n delimiter: str = \",\"\n # delimited fields set is_multiple=False for webargs.core.is_multiple\n is_multiple: bool = False\n\n def _serialize(self, value, attr, obj, **kwargs):\n # serializing will start with parent-class serialization, so that we correctly\n # output lists of non-primitive types, e.g. DelimitedList(DateTime)\n return self.delimiter.join(\n format(each) for each in super()._serialize(value, attr, obj, **kwargs)\n )\n\n def _deserialize(self, value, attr, data, **kwargs):\n # attempting to deserialize from a non-string source is an error\n if not isinstance(value, (str, bytes)):\n raise self.make_error(\"invalid\")\n values = value.split(self.delimiter) if value else []\n return super()._deserialize(values, attr, data, **kwargs)\n\n\nclass DelimitedList(DelimitedFieldMixin, ma.fields.List):\n \"\"\"A field which is similar to a List, but takes its input as a delimited\n string (e.g. \"foo,bar,baz\").\n\n Like List, it can be given a nested field type which it will use to\n de/serialize each element of the list.\n\n :param Field cls_or_instance: A field class or instance.\n :param str delimiter: Delimiter between values.\n \"\"\"\n\n default_error_messages = {\"invalid\": \"Not a valid delimited list.\"}\n\n def __init__(\n self,\n cls_or_instance: ma.fields.Field | type,\n *,\n delimiter: str | None = None,\n **kwargs,\n ):\n self.delimiter = delimiter or self.delimiter\n super().__init__(cls_or_instance, **kwargs)\n\n\nclass DelimitedTuple(DelimitedFieldMixin, ma.fields.Tuple):\n \"\"\"A field which is similar to a Tuple, but takes its input as a delimited\n string (e.g. \"foo,bar,baz\").\n\n Like Tuple, it can be given a tuple of nested field types which it will use to\n de/serialize each element of the tuple.\n\n :param Iterable[Field] tuple_fields: An iterable of field classes or instances.\n :param str delimiter: Delimiter between values.\n \"\"\"\n\n default_error_messages = {\"invalid\": \"Not a valid delimited tuple.\"}\n\n def __init__(self, tuple_fields, *, delimiter: str | None = None, **kwargs):\n self.delimiter = delimiter or self.delimiter\n super().__init__(tuple_fields, **kwargs)\n", "path": "src/webargs/fields.py"}], "after_files": [{"content": "\"\"\"Field classes.\n\nIncludes all fields from `marshmallow.fields` in addition to a custom\n`Nested` field and `DelimitedList`.\n\nAll fields can optionally take a special `location` keyword argument, which\ntells webargs where to parse the request argument from.\n\n.. code-block:: python\n\n args = {\n \"active\": fields.Bool(location=\"query\"),\n \"content_type\": fields.Str(data_key=\"Content-Type\", location=\"headers\"),\n }\n\"\"\"\nfrom __future__ import annotations\n\nimport typing\n\nimport marshmallow as ma\n\n# Expose all fields from marshmallow.fields.\nfrom marshmallow.fields import * # noqa: F40\n\n__all__ = [\"DelimitedList\", \"DelimitedTuple\"] + ma.fields.__all__\n\n\n# TODO: remove custom `Nested` in the next major release\n#\n# the `Nested` class is only needed on versions of marshmallow prior to v3.15.0\n# in that version, `ma.fields.Nested` gained the ability to consume dict inputs\n# prior to that, this subclass adds this capability\n#\n# if we drop support for ma.__version_info__ < (3, 15) we can do this\nclass Nested(ma.fields.Nested): # type: ignore[no-redef]\n \"\"\"Same as `marshmallow.fields.Nested`, except can be passed a dictionary as\n the first argument, which will be converted to a `marshmallow.Schema`.\n\n .. note::\n\n The schema class here will always be `marshmallow.Schema`, regardless\n of whether a custom schema class is set on the parser. Pass an explicit schema\n class if necessary.\n \"\"\"\n\n def __init__(self, nested, *args, **kwargs):\n if isinstance(nested, dict):\n nested = ma.Schema.from_dict(nested)\n super().__init__(nested, *args, **kwargs)\n\n\nclass DelimitedFieldMixin:\n \"\"\"\n This is a mixin class for subclasses of ma.fields.List and ma.fields.Tuple\n which split on a pre-specified delimiter. By default, the delimiter will be \",\"\n\n Because we want the MRO to reach this class before the List or Tuple class,\n it must be listed first in the superclasses\n\n For example, a DelimitedList-like type can be defined like so:\n\n >>> class MyDelimitedList(DelimitedFieldMixin, ma.fields.List):\n >>> pass\n \"\"\"\n\n delimiter: str = \",\"\n # delimited fields set is_multiple=False for webargs.core.is_multiple\n is_multiple: bool = False\n # NOTE: in 8.x this defaults to \"\" but in 9.x it will be 'missing'\n empty_value: typing.Any = \"\"\n\n def _serialize(self, value, attr, obj, **kwargs):\n # serializing will start with parent-class serialization, so that we correctly\n # output lists of non-primitive types, e.g. DelimitedList(DateTime)\n return self.delimiter.join(\n format(each) for each in super()._serialize(value, attr, obj, **kwargs)\n )\n\n def _deserialize(self, value, attr, data, **kwargs):\n # attempting to deserialize from a non-string source is an error\n if not isinstance(value, (str, bytes)):\n raise self.make_error(\"invalid\")\n values = value.split(self.delimiter) if value else []\n # convert empty strings to the empty value; typically \"\" and therefore a no-op\n values = [v or self.empty_value for v in values]\n return super()._deserialize(values, attr, data, **kwargs)\n\n\nclass DelimitedList(DelimitedFieldMixin, ma.fields.List):\n \"\"\"A field which is similar to a List, but takes its input as a delimited\n string (e.g. \"foo,bar,baz\").\n\n Like List, it can be given a nested field type which it will use to\n de/serialize each element of the list.\n\n :param Field cls_or_instance: A field class or instance.\n :param str delimiter: Delimiter between values.\n \"\"\"\n\n default_error_messages = {\"invalid\": \"Not a valid delimited list.\"}\n\n def __init__(\n self,\n cls_or_instance: ma.fields.Field | type,\n *,\n delimiter: str | None = None,\n **kwargs,\n ):\n self.delimiter = delimiter or self.delimiter\n super().__init__(cls_or_instance, **kwargs)\n\n\nclass DelimitedTuple(DelimitedFieldMixin, ma.fields.Tuple):\n \"\"\"A field which is similar to a Tuple, but takes its input as a delimited\n string (e.g. \"foo,bar,baz\").\n\n Like Tuple, it can be given a tuple of nested field types which it will use to\n de/serialize each element of the tuple.\n\n :param Iterable[Field] tuple_fields: An iterable of field classes or instances.\n :param str delimiter: Delimiter between values.\n \"\"\"\n\n default_error_messages = {\"invalid\": \"Not a valid delimited tuple.\"}\n\n def __init__(\n self,\n tuple_fields,\n *,\n delimiter: str | None = None,\n **kwargs,\n ):\n self.delimiter = delimiter or self.delimiter\n super().__init__(tuple_fields, **kwargs)\n", "path": "src/webargs/fields.py"}]}
| 1,876 | 390 |
gh_patches_debug_22574
|
rasdani/github-patches
|
git_diff
|
python-discord__bot-1157
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
!reddit command doesn’t filter nsfw subreddits.
So yeah, as the title says `!reddit` command doesn’t filter nsfw subreddits ._.
doing: `!reddit top nsfw` displays the direct URL link to the nsfw subreddit.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bot/exts/info/reddit.py`
Content:
```
1 import asyncio
2 import logging
3 import random
4 import textwrap
5 from collections import namedtuple
6 from datetime import datetime, timedelta
7 from typing import List
8
9 from aiohttp import BasicAuth, ClientError
10 from discord import Colour, Embed, TextChannel
11 from discord.ext.commands import Cog, Context, group, has_any_role
12 from discord.ext.tasks import loop
13 from discord.utils import escape_markdown, sleep_until
14
15 from bot.bot import Bot
16 from bot.constants import Channels, ERROR_REPLIES, Emojis, Reddit as RedditConfig, STAFF_ROLES, Webhooks
17 from bot.converters import Subreddit
18 from bot.pagination import LinePaginator
19 from bot.utils.messages import sub_clyde
20
21 log = logging.getLogger(__name__)
22
23 AccessToken = namedtuple("AccessToken", ["token", "expires_at"])
24
25
26 class Reddit(Cog):
27 """Track subreddit posts and show detailed statistics about them."""
28
29 HEADERS = {"User-Agent": "python3:python-discord/bot:1.0.0 (by /u/PythonDiscord)"}
30 URL = "https://www.reddit.com"
31 OAUTH_URL = "https://oauth.reddit.com"
32 MAX_RETRIES = 3
33
34 def __init__(self, bot: Bot):
35 self.bot = bot
36
37 self.webhook = None
38 self.access_token = None
39 self.client_auth = BasicAuth(RedditConfig.client_id, RedditConfig.secret)
40
41 bot.loop.create_task(self.init_reddit_ready())
42 self.auto_poster_loop.start()
43
44 def cog_unload(self) -> None:
45 """Stop the loop task and revoke the access token when the cog is unloaded."""
46 self.auto_poster_loop.cancel()
47 if self.access_token and self.access_token.expires_at > datetime.utcnow():
48 asyncio.create_task(self.revoke_access_token())
49
50 async def init_reddit_ready(self) -> None:
51 """Sets the reddit webhook when the cog is loaded."""
52 await self.bot.wait_until_guild_available()
53 if not self.webhook:
54 self.webhook = await self.bot.fetch_webhook(Webhooks.reddit)
55
56 @property
57 def channel(self) -> TextChannel:
58 """Get the #reddit channel object from the bot's cache."""
59 return self.bot.get_channel(Channels.reddit)
60
61 async def get_access_token(self) -> None:
62 """
63 Get a Reddit API OAuth2 access token and assign it to self.access_token.
64
65 A token is valid for 1 hour. There will be MAX_RETRIES to get a token, after which the cog
66 will be unloaded and a ClientError raised if retrieval was still unsuccessful.
67 """
68 for i in range(1, self.MAX_RETRIES + 1):
69 response = await self.bot.http_session.post(
70 url=f"{self.URL}/api/v1/access_token",
71 headers=self.HEADERS,
72 auth=self.client_auth,
73 data={
74 "grant_type": "client_credentials",
75 "duration": "temporary"
76 }
77 )
78
79 if response.status == 200 and response.content_type == "application/json":
80 content = await response.json()
81 expiration = int(content["expires_in"]) - 60 # Subtract 1 minute for leeway.
82 self.access_token = AccessToken(
83 token=content["access_token"],
84 expires_at=datetime.utcnow() + timedelta(seconds=expiration)
85 )
86
87 log.debug(f"New token acquired; expires on UTC {self.access_token.expires_at}")
88 return
89 else:
90 log.debug(
91 f"Failed to get an access token: "
92 f"status {response.status} & content type {response.content_type}; "
93 f"retrying ({i}/{self.MAX_RETRIES})"
94 )
95
96 await asyncio.sleep(3)
97
98 self.bot.remove_cog(self.qualified_name)
99 raise ClientError("Authentication with the Reddit API failed. Unloading the cog.")
100
101 async def revoke_access_token(self) -> None:
102 """
103 Revoke the OAuth2 access token for the Reddit API.
104
105 For security reasons, it's good practice to revoke the token when it's no longer being used.
106 """
107 response = await self.bot.http_session.post(
108 url=f"{self.URL}/api/v1/revoke_token",
109 headers=self.HEADERS,
110 auth=self.client_auth,
111 data={
112 "token": self.access_token.token,
113 "token_type_hint": "access_token"
114 }
115 )
116
117 if response.status == 204 and response.content_type == "application/json":
118 self.access_token = None
119 else:
120 log.warning(f"Unable to revoke access token: status {response.status}.")
121
122 async def fetch_posts(self, route: str, *, amount: int = 25, params: dict = None) -> List[dict]:
123 """A helper method to fetch a certain amount of Reddit posts at a given route."""
124 # Reddit's JSON responses only provide 25 posts at most.
125 if not 25 >= amount > 0:
126 raise ValueError("Invalid amount of subreddit posts requested.")
127
128 # Renew the token if necessary.
129 if not self.access_token or self.access_token.expires_at < datetime.utcnow():
130 await self.get_access_token()
131
132 url = f"{self.OAUTH_URL}/{route}"
133 for _ in range(self.MAX_RETRIES):
134 response = await self.bot.http_session.get(
135 url=url,
136 headers={**self.HEADERS, "Authorization": f"bearer {self.access_token.token}"},
137 params=params
138 )
139 if response.status == 200 and response.content_type == 'application/json':
140 # Got appropriate response - process and return.
141 content = await response.json()
142 posts = content["data"]["children"]
143 return posts[:amount]
144
145 await asyncio.sleep(3)
146
147 log.debug(f"Invalid response from: {url} - status code {response.status}, mimetype {response.content_type}")
148 return list() # Failed to get appropriate response within allowed number of retries.
149
150 async def get_top_posts(self, subreddit: Subreddit, time: str = "all", amount: int = 5) -> Embed:
151 """
152 Get the top amount of posts for a given subreddit within a specified timeframe.
153
154 A time of "all" will get posts from all time, "day" will get top daily posts and "week" will get the top
155 weekly posts.
156
157 The amount should be between 0 and 25 as Reddit's JSON requests only provide 25 posts at most.
158 """
159 embed = Embed(description="")
160
161 posts = await self.fetch_posts(
162 route=f"{subreddit}/top",
163 amount=amount,
164 params={"t": time}
165 )
166
167 if not posts:
168 embed.title = random.choice(ERROR_REPLIES)
169 embed.colour = Colour.red()
170 embed.description = (
171 "Sorry! We couldn't find any posts from that subreddit. "
172 "If this problem persists, please let us know."
173 )
174
175 return embed
176
177 for post in posts:
178 data = post["data"]
179
180 text = data["selftext"]
181 if text:
182 text = textwrap.shorten(text, width=128, placeholder="...")
183 text += "\n" # Add newline to separate embed info
184
185 ups = data["ups"]
186 comments = data["num_comments"]
187 author = data["author"]
188
189 title = textwrap.shorten(data["title"], width=64, placeholder="...")
190 # Normal brackets interfere with Markdown.
191 title = escape_markdown(title).replace("[", "⦋").replace("]", "⦌")
192 link = self.URL + data["permalink"]
193
194 embed.description += (
195 f"**[{title}]({link})**\n"
196 f"{text}"
197 f"{Emojis.upvotes} {ups} {Emojis.comments} {comments} {Emojis.user} {author}\n\n"
198 )
199
200 embed.colour = Colour.blurple()
201 return embed
202
203 @loop()
204 async def auto_poster_loop(self) -> None:
205 """Post the top 5 posts daily, and the top 5 posts weekly."""
206 # once d.py get support for `time` parameter in loop decorator,
207 # this can be removed and the loop can use the `time=datetime.time.min` parameter
208 now = datetime.utcnow()
209 tomorrow = now + timedelta(days=1)
210 midnight_tomorrow = tomorrow.replace(hour=0, minute=0, second=0)
211
212 await sleep_until(midnight_tomorrow)
213
214 await self.bot.wait_until_guild_available()
215 if not self.webhook:
216 await self.bot.fetch_webhook(Webhooks.reddit)
217
218 if datetime.utcnow().weekday() == 0:
219 await self.top_weekly_posts()
220 # if it's a monday send the top weekly posts
221
222 for subreddit in RedditConfig.subreddits:
223 top_posts = await self.get_top_posts(subreddit=subreddit, time="day")
224 username = sub_clyde(f"{subreddit} Top Daily Posts")
225 message = await self.webhook.send(username=username, embed=top_posts, wait=True)
226
227 if message.channel.is_news():
228 await message.publish()
229
230 async def top_weekly_posts(self) -> None:
231 """Post a summary of the top posts."""
232 for subreddit in RedditConfig.subreddits:
233 # Send and pin the new weekly posts.
234 top_posts = await self.get_top_posts(subreddit=subreddit, time="week")
235 username = sub_clyde(f"{subreddit} Top Weekly Posts")
236 message = await self.webhook.send(wait=True, username=username, embed=top_posts)
237
238 if subreddit.lower() == "r/python":
239 if not self.channel:
240 log.warning("Failed to get #reddit channel to remove pins in the weekly loop.")
241 return
242
243 # Remove the oldest pins so that only 12 remain at most.
244 pins = await self.channel.pins()
245
246 while len(pins) >= 12:
247 await pins[-1].unpin()
248 del pins[-1]
249
250 await message.pin()
251
252 if message.channel.is_news():
253 await message.publish()
254
255 @group(name="reddit", invoke_without_command=True)
256 async def reddit_group(self, ctx: Context) -> None:
257 """View the top posts from various subreddits."""
258 await ctx.send_help(ctx.command)
259
260 @reddit_group.command(name="top")
261 async def top_command(self, ctx: Context, subreddit: Subreddit = "r/Python") -> None:
262 """Send the top posts of all time from a given subreddit."""
263 async with ctx.typing():
264 embed = await self.get_top_posts(subreddit=subreddit, time="all")
265
266 await ctx.send(content=f"Here are the top {subreddit} posts of all time!", embed=embed)
267
268 @reddit_group.command(name="daily")
269 async def daily_command(self, ctx: Context, subreddit: Subreddit = "r/Python") -> None:
270 """Send the top posts of today from a given subreddit."""
271 async with ctx.typing():
272 embed = await self.get_top_posts(subreddit=subreddit, time="day")
273
274 await ctx.send(content=f"Here are today's top {subreddit} posts!", embed=embed)
275
276 @reddit_group.command(name="weekly")
277 async def weekly_command(self, ctx: Context, subreddit: Subreddit = "r/Python") -> None:
278 """Send the top posts of this week from a given subreddit."""
279 async with ctx.typing():
280 embed = await self.get_top_posts(subreddit=subreddit, time="week")
281
282 await ctx.send(content=f"Here are this week's top {subreddit} posts!", embed=embed)
283
284 @has_any_role(*STAFF_ROLES)
285 @reddit_group.command(name="subreddits", aliases=("subs",))
286 async def subreddits_command(self, ctx: Context) -> None:
287 """Send a paginated embed of all the subreddits we're relaying."""
288 embed = Embed()
289 embed.title = "Relayed subreddits."
290 embed.colour = Colour.blurple()
291
292 await LinePaginator.paginate(
293 RedditConfig.subreddits,
294 ctx, embed,
295 footer_text="Use the reddit commands along with these to view their posts.",
296 empty=False,
297 max_lines=15
298 )
299
300
301 def setup(bot: Bot) -> None:
302 """Load the Reddit cog."""
303 if not RedditConfig.secret or not RedditConfig.client_id:
304 log.error("Credentials not provided, cog not loaded.")
305 return
306 bot.add_cog(Reddit(bot))
307
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bot/exts/info/reddit.py b/bot/exts/info/reddit.py
--- a/bot/exts/info/reddit.py
+++ b/bot/exts/info/reddit.py
@@ -140,7 +140,10 @@
# Got appropriate response - process and return.
content = await response.json()
posts = content["data"]["children"]
- return posts[:amount]
+
+ filtered_posts = [post for post in posts if not post["data"]["over_18"]]
+
+ return filtered_posts[:amount]
await asyncio.sleep(3)
@@ -163,12 +166,11 @@
amount=amount,
params={"t": time}
)
-
if not posts:
embed.title = random.choice(ERROR_REPLIES)
embed.colour = Colour.red()
embed.description = (
- "Sorry! We couldn't find any posts from that subreddit. "
+ "Sorry! We couldn't find any SFW posts from that subreddit. "
"If this problem persists, please let us know."
)
|
{"golden_diff": "diff --git a/bot/exts/info/reddit.py b/bot/exts/info/reddit.py\n--- a/bot/exts/info/reddit.py\n+++ b/bot/exts/info/reddit.py\n@@ -140,7 +140,10 @@\n # Got appropriate response - process and return.\n content = await response.json()\n posts = content[\"data\"][\"children\"]\n- return posts[:amount]\n+\n+ filtered_posts = [post for post in posts if not post[\"data\"][\"over_18\"]]\n+\n+ return filtered_posts[:amount]\n \n await asyncio.sleep(3)\n \n@@ -163,12 +166,11 @@\n amount=amount,\n params={\"t\": time}\n )\n-\n if not posts:\n embed.title = random.choice(ERROR_REPLIES)\n embed.colour = Colour.red()\n embed.description = (\n- \"Sorry! We couldn't find any posts from that subreddit. \"\n+ \"Sorry! We couldn't find any SFW posts from that subreddit. \"\n \"If this problem persists, please let us know.\"\n )\n", "issue": "!reddit command doesn\u2019t filter nsfw subreddits.\nSo yeah, as the title says `!reddit` command doesn\u2019t filter nsfw subreddits ._.\r\n\r\ndoing: `!reddit top nsfw` displays the direct URL link to the nsfw subreddit.\n", "before_files": [{"content": "import asyncio\nimport logging\nimport random\nimport textwrap\nfrom collections import namedtuple\nfrom datetime import datetime, timedelta\nfrom typing import List\n\nfrom aiohttp import BasicAuth, ClientError\nfrom discord import Colour, Embed, TextChannel\nfrom discord.ext.commands import Cog, Context, group, has_any_role\nfrom discord.ext.tasks import loop\nfrom discord.utils import escape_markdown, sleep_until\n\nfrom bot.bot import Bot\nfrom bot.constants import Channels, ERROR_REPLIES, Emojis, Reddit as RedditConfig, STAFF_ROLES, Webhooks\nfrom bot.converters import Subreddit\nfrom bot.pagination import LinePaginator\nfrom bot.utils.messages import sub_clyde\n\nlog = logging.getLogger(__name__)\n\nAccessToken = namedtuple(\"AccessToken\", [\"token\", \"expires_at\"])\n\n\nclass Reddit(Cog):\n \"\"\"Track subreddit posts and show detailed statistics about them.\"\"\"\n\n HEADERS = {\"User-Agent\": \"python3:python-discord/bot:1.0.0 (by /u/PythonDiscord)\"}\n URL = \"https://www.reddit.com\"\n OAUTH_URL = \"https://oauth.reddit.com\"\n MAX_RETRIES = 3\n\n def __init__(self, bot: Bot):\n self.bot = bot\n\n self.webhook = None\n self.access_token = None\n self.client_auth = BasicAuth(RedditConfig.client_id, RedditConfig.secret)\n\n bot.loop.create_task(self.init_reddit_ready())\n self.auto_poster_loop.start()\n\n def cog_unload(self) -> None:\n \"\"\"Stop the loop task and revoke the access token when the cog is unloaded.\"\"\"\n self.auto_poster_loop.cancel()\n if self.access_token and self.access_token.expires_at > datetime.utcnow():\n asyncio.create_task(self.revoke_access_token())\n\n async def init_reddit_ready(self) -> None:\n \"\"\"Sets the reddit webhook when the cog is loaded.\"\"\"\n await self.bot.wait_until_guild_available()\n if not self.webhook:\n self.webhook = await self.bot.fetch_webhook(Webhooks.reddit)\n\n @property\n def channel(self) -> TextChannel:\n \"\"\"Get the #reddit channel object from the bot's cache.\"\"\"\n return self.bot.get_channel(Channels.reddit)\n\n async def get_access_token(self) -> None:\n \"\"\"\n Get a Reddit API OAuth2 access token and assign it to self.access_token.\n\n A token is valid for 1 hour. There will be MAX_RETRIES to get a token, after which the cog\n will be unloaded and a ClientError raised if retrieval was still unsuccessful.\n \"\"\"\n for i in range(1, self.MAX_RETRIES + 1):\n response = await self.bot.http_session.post(\n url=f\"{self.URL}/api/v1/access_token\",\n headers=self.HEADERS,\n auth=self.client_auth,\n data={\n \"grant_type\": \"client_credentials\",\n \"duration\": \"temporary\"\n }\n )\n\n if response.status == 200 and response.content_type == \"application/json\":\n content = await response.json()\n expiration = int(content[\"expires_in\"]) - 60 # Subtract 1 minute for leeway.\n self.access_token = AccessToken(\n token=content[\"access_token\"],\n expires_at=datetime.utcnow() + timedelta(seconds=expiration)\n )\n\n log.debug(f\"New token acquired; expires on UTC {self.access_token.expires_at}\")\n return\n else:\n log.debug(\n f\"Failed to get an access token: \"\n f\"status {response.status} & content type {response.content_type}; \"\n f\"retrying ({i}/{self.MAX_RETRIES})\"\n )\n\n await asyncio.sleep(3)\n\n self.bot.remove_cog(self.qualified_name)\n raise ClientError(\"Authentication with the Reddit API failed. Unloading the cog.\")\n\n async def revoke_access_token(self) -> None:\n \"\"\"\n Revoke the OAuth2 access token for the Reddit API.\n\n For security reasons, it's good practice to revoke the token when it's no longer being used.\n \"\"\"\n response = await self.bot.http_session.post(\n url=f\"{self.URL}/api/v1/revoke_token\",\n headers=self.HEADERS,\n auth=self.client_auth,\n data={\n \"token\": self.access_token.token,\n \"token_type_hint\": \"access_token\"\n }\n )\n\n if response.status == 204 and response.content_type == \"application/json\":\n self.access_token = None\n else:\n log.warning(f\"Unable to revoke access token: status {response.status}.\")\n\n async def fetch_posts(self, route: str, *, amount: int = 25, params: dict = None) -> List[dict]:\n \"\"\"A helper method to fetch a certain amount of Reddit posts at a given route.\"\"\"\n # Reddit's JSON responses only provide 25 posts at most.\n if not 25 >= amount > 0:\n raise ValueError(\"Invalid amount of subreddit posts requested.\")\n\n # Renew the token if necessary.\n if not self.access_token or self.access_token.expires_at < datetime.utcnow():\n await self.get_access_token()\n\n url = f\"{self.OAUTH_URL}/{route}\"\n for _ in range(self.MAX_RETRIES):\n response = await self.bot.http_session.get(\n url=url,\n headers={**self.HEADERS, \"Authorization\": f\"bearer {self.access_token.token}\"},\n params=params\n )\n if response.status == 200 and response.content_type == 'application/json':\n # Got appropriate response - process and return.\n content = await response.json()\n posts = content[\"data\"][\"children\"]\n return posts[:amount]\n\n await asyncio.sleep(3)\n\n log.debug(f\"Invalid response from: {url} - status code {response.status}, mimetype {response.content_type}\")\n return list() # Failed to get appropriate response within allowed number of retries.\n\n async def get_top_posts(self, subreddit: Subreddit, time: str = \"all\", amount: int = 5) -> Embed:\n \"\"\"\n Get the top amount of posts for a given subreddit within a specified timeframe.\n\n A time of \"all\" will get posts from all time, \"day\" will get top daily posts and \"week\" will get the top\n weekly posts.\n\n The amount should be between 0 and 25 as Reddit's JSON requests only provide 25 posts at most.\n \"\"\"\n embed = Embed(description=\"\")\n\n posts = await self.fetch_posts(\n route=f\"{subreddit}/top\",\n amount=amount,\n params={\"t\": time}\n )\n\n if not posts:\n embed.title = random.choice(ERROR_REPLIES)\n embed.colour = Colour.red()\n embed.description = (\n \"Sorry! We couldn't find any posts from that subreddit. \"\n \"If this problem persists, please let us know.\"\n )\n\n return embed\n\n for post in posts:\n data = post[\"data\"]\n\n text = data[\"selftext\"]\n if text:\n text = textwrap.shorten(text, width=128, placeholder=\"...\")\n text += \"\\n\" # Add newline to separate embed info\n\n ups = data[\"ups\"]\n comments = data[\"num_comments\"]\n author = data[\"author\"]\n\n title = textwrap.shorten(data[\"title\"], width=64, placeholder=\"...\")\n # Normal brackets interfere with Markdown.\n title = escape_markdown(title).replace(\"[\", \"\u298b\").replace(\"]\", \"\u298c\")\n link = self.URL + data[\"permalink\"]\n\n embed.description += (\n f\"**[{title}]({link})**\\n\"\n f\"{text}\"\n f\"{Emojis.upvotes} {ups} {Emojis.comments} {comments} {Emojis.user} {author}\\n\\n\"\n )\n\n embed.colour = Colour.blurple()\n return embed\n\n @loop()\n async def auto_poster_loop(self) -> None:\n \"\"\"Post the top 5 posts daily, and the top 5 posts weekly.\"\"\"\n # once d.py get support for `time` parameter in loop decorator,\n # this can be removed and the loop can use the `time=datetime.time.min` parameter\n now = datetime.utcnow()\n tomorrow = now + timedelta(days=1)\n midnight_tomorrow = tomorrow.replace(hour=0, minute=0, second=0)\n\n await sleep_until(midnight_tomorrow)\n\n await self.bot.wait_until_guild_available()\n if not self.webhook:\n await self.bot.fetch_webhook(Webhooks.reddit)\n\n if datetime.utcnow().weekday() == 0:\n await self.top_weekly_posts()\n # if it's a monday send the top weekly posts\n\n for subreddit in RedditConfig.subreddits:\n top_posts = await self.get_top_posts(subreddit=subreddit, time=\"day\")\n username = sub_clyde(f\"{subreddit} Top Daily Posts\")\n message = await self.webhook.send(username=username, embed=top_posts, wait=True)\n\n if message.channel.is_news():\n await message.publish()\n\n async def top_weekly_posts(self) -> None:\n \"\"\"Post a summary of the top posts.\"\"\"\n for subreddit in RedditConfig.subreddits:\n # Send and pin the new weekly posts.\n top_posts = await self.get_top_posts(subreddit=subreddit, time=\"week\")\n username = sub_clyde(f\"{subreddit} Top Weekly Posts\")\n message = await self.webhook.send(wait=True, username=username, embed=top_posts)\n\n if subreddit.lower() == \"r/python\":\n if not self.channel:\n log.warning(\"Failed to get #reddit channel to remove pins in the weekly loop.\")\n return\n\n # Remove the oldest pins so that only 12 remain at most.\n pins = await self.channel.pins()\n\n while len(pins) >= 12:\n await pins[-1].unpin()\n del pins[-1]\n\n await message.pin()\n\n if message.channel.is_news():\n await message.publish()\n\n @group(name=\"reddit\", invoke_without_command=True)\n async def reddit_group(self, ctx: Context) -> None:\n \"\"\"View the top posts from various subreddits.\"\"\"\n await ctx.send_help(ctx.command)\n\n @reddit_group.command(name=\"top\")\n async def top_command(self, ctx: Context, subreddit: Subreddit = \"r/Python\") -> None:\n \"\"\"Send the top posts of all time from a given subreddit.\"\"\"\n async with ctx.typing():\n embed = await self.get_top_posts(subreddit=subreddit, time=\"all\")\n\n await ctx.send(content=f\"Here are the top {subreddit} posts of all time!\", embed=embed)\n\n @reddit_group.command(name=\"daily\")\n async def daily_command(self, ctx: Context, subreddit: Subreddit = \"r/Python\") -> None:\n \"\"\"Send the top posts of today from a given subreddit.\"\"\"\n async with ctx.typing():\n embed = await self.get_top_posts(subreddit=subreddit, time=\"day\")\n\n await ctx.send(content=f\"Here are today's top {subreddit} posts!\", embed=embed)\n\n @reddit_group.command(name=\"weekly\")\n async def weekly_command(self, ctx: Context, subreddit: Subreddit = \"r/Python\") -> None:\n \"\"\"Send the top posts of this week from a given subreddit.\"\"\"\n async with ctx.typing():\n embed = await self.get_top_posts(subreddit=subreddit, time=\"week\")\n\n await ctx.send(content=f\"Here are this week's top {subreddit} posts!\", embed=embed)\n\n @has_any_role(*STAFF_ROLES)\n @reddit_group.command(name=\"subreddits\", aliases=(\"subs\",))\n async def subreddits_command(self, ctx: Context) -> None:\n \"\"\"Send a paginated embed of all the subreddits we're relaying.\"\"\"\n embed = Embed()\n embed.title = \"Relayed subreddits.\"\n embed.colour = Colour.blurple()\n\n await LinePaginator.paginate(\n RedditConfig.subreddits,\n ctx, embed,\n footer_text=\"Use the reddit commands along with these to view their posts.\",\n empty=False,\n max_lines=15\n )\n\n\ndef setup(bot: Bot) -> None:\n \"\"\"Load the Reddit cog.\"\"\"\n if not RedditConfig.secret or not RedditConfig.client_id:\n log.error(\"Credentials not provided, cog not loaded.\")\n return\n bot.add_cog(Reddit(bot))\n", "path": "bot/exts/info/reddit.py"}], "after_files": [{"content": "import asyncio\nimport logging\nimport random\nimport textwrap\nfrom collections import namedtuple\nfrom datetime import datetime, timedelta\nfrom typing import List\n\nfrom aiohttp import BasicAuth, ClientError\nfrom discord import Colour, Embed, TextChannel\nfrom discord.ext.commands import Cog, Context, group, has_any_role\nfrom discord.ext.tasks import loop\nfrom discord.utils import escape_markdown, sleep_until\n\nfrom bot.bot import Bot\nfrom bot.constants import Channels, ERROR_REPLIES, Emojis, Reddit as RedditConfig, STAFF_ROLES, Webhooks\nfrom bot.converters import Subreddit\nfrom bot.pagination import LinePaginator\nfrom bot.utils.messages import sub_clyde\n\nlog = logging.getLogger(__name__)\n\nAccessToken = namedtuple(\"AccessToken\", [\"token\", \"expires_at\"])\n\n\nclass Reddit(Cog):\n \"\"\"Track subreddit posts and show detailed statistics about them.\"\"\"\n\n HEADERS = {\"User-Agent\": \"python3:python-discord/bot:1.0.0 (by /u/PythonDiscord)\"}\n URL = \"https://www.reddit.com\"\n OAUTH_URL = \"https://oauth.reddit.com\"\n MAX_RETRIES = 3\n\n def __init__(self, bot: Bot):\n self.bot = bot\n\n self.webhook = None\n self.access_token = None\n self.client_auth = BasicAuth(RedditConfig.client_id, RedditConfig.secret)\n\n bot.loop.create_task(self.init_reddit_ready())\n self.auto_poster_loop.start()\n\n def cog_unload(self) -> None:\n \"\"\"Stop the loop task and revoke the access token when the cog is unloaded.\"\"\"\n self.auto_poster_loop.cancel()\n if self.access_token and self.access_token.expires_at > datetime.utcnow():\n asyncio.create_task(self.revoke_access_token())\n\n async def init_reddit_ready(self) -> None:\n \"\"\"Sets the reddit webhook when the cog is loaded.\"\"\"\n await self.bot.wait_until_guild_available()\n if not self.webhook:\n self.webhook = await self.bot.fetch_webhook(Webhooks.reddit)\n\n @property\n def channel(self) -> TextChannel:\n \"\"\"Get the #reddit channel object from the bot's cache.\"\"\"\n return self.bot.get_channel(Channels.reddit)\n\n async def get_access_token(self) -> None:\n \"\"\"\n Get a Reddit API OAuth2 access token and assign it to self.access_token.\n\n A token is valid for 1 hour. There will be MAX_RETRIES to get a token, after which the cog\n will be unloaded and a ClientError raised if retrieval was still unsuccessful.\n \"\"\"\n for i in range(1, self.MAX_RETRIES + 1):\n response = await self.bot.http_session.post(\n url=f\"{self.URL}/api/v1/access_token\",\n headers=self.HEADERS,\n auth=self.client_auth,\n data={\n \"grant_type\": \"client_credentials\",\n \"duration\": \"temporary\"\n }\n )\n\n if response.status == 200 and response.content_type == \"application/json\":\n content = await response.json()\n expiration = int(content[\"expires_in\"]) - 60 # Subtract 1 minute for leeway.\n self.access_token = AccessToken(\n token=content[\"access_token\"],\n expires_at=datetime.utcnow() + timedelta(seconds=expiration)\n )\n\n log.debug(f\"New token acquired; expires on UTC {self.access_token.expires_at}\")\n return\n else:\n log.debug(\n f\"Failed to get an access token: \"\n f\"status {response.status} & content type {response.content_type}; \"\n f\"retrying ({i}/{self.MAX_RETRIES})\"\n )\n\n await asyncio.sleep(3)\n\n self.bot.remove_cog(self.qualified_name)\n raise ClientError(\"Authentication with the Reddit API failed. Unloading the cog.\")\n\n async def revoke_access_token(self) -> None:\n \"\"\"\n Revoke the OAuth2 access token for the Reddit API.\n\n For security reasons, it's good practice to revoke the token when it's no longer being used.\n \"\"\"\n response = await self.bot.http_session.post(\n url=f\"{self.URL}/api/v1/revoke_token\",\n headers=self.HEADERS,\n auth=self.client_auth,\n data={\n \"token\": self.access_token.token,\n \"token_type_hint\": \"access_token\"\n }\n )\n\n if response.status == 204 and response.content_type == \"application/json\":\n self.access_token = None\n else:\n log.warning(f\"Unable to revoke access token: status {response.status}.\")\n\n async def fetch_posts(self, route: str, *, amount: int = 25, params: dict = None) -> List[dict]:\n \"\"\"A helper method to fetch a certain amount of Reddit posts at a given route.\"\"\"\n # Reddit's JSON responses only provide 25 posts at most.\n if not 25 >= amount > 0:\n raise ValueError(\"Invalid amount of subreddit posts requested.\")\n\n # Renew the token if necessary.\n if not self.access_token or self.access_token.expires_at < datetime.utcnow():\n await self.get_access_token()\n\n url = f\"{self.OAUTH_URL}/{route}\"\n for _ in range(self.MAX_RETRIES):\n response = await self.bot.http_session.get(\n url=url,\n headers={**self.HEADERS, \"Authorization\": f\"bearer {self.access_token.token}\"},\n params=params\n )\n if response.status == 200 and response.content_type == 'application/json':\n # Got appropriate response - process and return.\n content = await response.json()\n posts = content[\"data\"][\"children\"]\n\n filtered_posts = [post for post in posts if not post[\"data\"][\"over_18\"]]\n\n return filtered_posts[:amount]\n\n await asyncio.sleep(3)\n\n log.debug(f\"Invalid response from: {url} - status code {response.status}, mimetype {response.content_type}\")\n return list() # Failed to get appropriate response within allowed number of retries.\n\n async def get_top_posts(self, subreddit: Subreddit, time: str = \"all\", amount: int = 5) -> Embed:\n \"\"\"\n Get the top amount of posts for a given subreddit within a specified timeframe.\n\n A time of \"all\" will get posts from all time, \"day\" will get top daily posts and \"week\" will get the top\n weekly posts.\n\n The amount should be between 0 and 25 as Reddit's JSON requests only provide 25 posts at most.\n \"\"\"\n embed = Embed(description=\"\")\n\n posts = await self.fetch_posts(\n route=f\"{subreddit}/top\",\n amount=amount,\n params={\"t\": time}\n )\n if not posts:\n embed.title = random.choice(ERROR_REPLIES)\n embed.colour = Colour.red()\n embed.description = (\n \"Sorry! We couldn't find any SFW posts from that subreddit. \"\n \"If this problem persists, please let us know.\"\n )\n\n return embed\n\n for post in posts:\n data = post[\"data\"]\n\n text = data[\"selftext\"]\n if text:\n text = textwrap.shorten(text, width=128, placeholder=\"...\")\n text += \"\\n\" # Add newline to separate embed info\n\n ups = data[\"ups\"]\n comments = data[\"num_comments\"]\n author = data[\"author\"]\n\n title = textwrap.shorten(data[\"title\"], width=64, placeholder=\"...\")\n # Normal brackets interfere with Markdown.\n title = escape_markdown(title).replace(\"[\", \"\u298b\").replace(\"]\", \"\u298c\")\n link = self.URL + data[\"permalink\"]\n\n embed.description += (\n f\"**[{title}]({link})**\\n\"\n f\"{text}\"\n f\"{Emojis.upvotes} {ups} {Emojis.comments} {comments} {Emojis.user} {author}\\n\\n\"\n )\n\n embed.colour = Colour.blurple()\n return embed\n\n @loop()\n async def auto_poster_loop(self) -> None:\n \"\"\"Post the top 5 posts daily, and the top 5 posts weekly.\"\"\"\n # once d.py get support for `time` parameter in loop decorator,\n # this can be removed and the loop can use the `time=datetime.time.min` parameter\n now = datetime.utcnow()\n tomorrow = now + timedelta(days=1)\n midnight_tomorrow = tomorrow.replace(hour=0, minute=0, second=0)\n\n await sleep_until(midnight_tomorrow)\n\n await self.bot.wait_until_guild_available()\n if not self.webhook:\n await self.bot.fetch_webhook(Webhooks.reddit)\n\n if datetime.utcnow().weekday() == 0:\n await self.top_weekly_posts()\n # if it's a monday send the top weekly posts\n\n for subreddit in RedditConfig.subreddits:\n top_posts = await self.get_top_posts(subreddit=subreddit, time=\"day\")\n username = sub_clyde(f\"{subreddit} Top Daily Posts\")\n message = await self.webhook.send(username=username, embed=top_posts, wait=True)\n\n if message.channel.is_news():\n await message.publish()\n\n async def top_weekly_posts(self) -> None:\n \"\"\"Post a summary of the top posts.\"\"\"\n for subreddit in RedditConfig.subreddits:\n # Send and pin the new weekly posts.\n top_posts = await self.get_top_posts(subreddit=subreddit, time=\"week\")\n username = sub_clyde(f\"{subreddit} Top Weekly Posts\")\n message = await self.webhook.send(wait=True, username=username, embed=top_posts)\n\n if subreddit.lower() == \"r/python\":\n if not self.channel:\n log.warning(\"Failed to get #reddit channel to remove pins in the weekly loop.\")\n return\n\n # Remove the oldest pins so that only 12 remain at most.\n pins = await self.channel.pins()\n\n while len(pins) >= 12:\n await pins[-1].unpin()\n del pins[-1]\n\n await message.pin()\n\n if message.channel.is_news():\n await message.publish()\n\n @group(name=\"reddit\", invoke_without_command=True)\n async def reddit_group(self, ctx: Context) -> None:\n \"\"\"View the top posts from various subreddits.\"\"\"\n await ctx.send_help(ctx.command)\n\n @reddit_group.command(name=\"top\")\n async def top_command(self, ctx: Context, subreddit: Subreddit = \"r/Python\") -> None:\n \"\"\"Send the top posts of all time from a given subreddit.\"\"\"\n async with ctx.typing():\n embed = await self.get_top_posts(subreddit=subreddit, time=\"all\")\n\n await ctx.send(content=f\"Here are the top {subreddit} posts of all time!\", embed=embed)\n\n @reddit_group.command(name=\"daily\")\n async def daily_command(self, ctx: Context, subreddit: Subreddit = \"r/Python\") -> None:\n \"\"\"Send the top posts of today from a given subreddit.\"\"\"\n async with ctx.typing():\n embed = await self.get_top_posts(subreddit=subreddit, time=\"day\")\n\n await ctx.send(content=f\"Here are today's top {subreddit} posts!\", embed=embed)\n\n @reddit_group.command(name=\"weekly\")\n async def weekly_command(self, ctx: Context, subreddit: Subreddit = \"r/Python\") -> None:\n \"\"\"Send the top posts of this week from a given subreddit.\"\"\"\n async with ctx.typing():\n embed = await self.get_top_posts(subreddit=subreddit, time=\"week\")\n\n await ctx.send(content=f\"Here are this week's top {subreddit} posts!\", embed=embed)\n\n @has_any_role(*STAFF_ROLES)\n @reddit_group.command(name=\"subreddits\", aliases=(\"subs\",))\n async def subreddits_command(self, ctx: Context) -> None:\n \"\"\"Send a paginated embed of all the subreddits we're relaying.\"\"\"\n embed = Embed()\n embed.title = \"Relayed subreddits.\"\n embed.colour = Colour.blurple()\n\n await LinePaginator.paginate(\n RedditConfig.subreddits,\n ctx, embed,\n footer_text=\"Use the reddit commands along with these to view their posts.\",\n empty=False,\n max_lines=15\n )\n\n\ndef setup(bot: Bot) -> None:\n \"\"\"Load the Reddit cog.\"\"\"\n if not RedditConfig.secret or not RedditConfig.client_id:\n log.error(\"Credentials not provided, cog not loaded.\")\n return\n bot.add_cog(Reddit(bot))\n", "path": "bot/exts/info/reddit.py"}]}
| 3,806 | 241 |
gh_patches_debug_15073
|
rasdani/github-patches
|
git_diff
|
allegro__ralph-3365
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
min_ip, max_ip fields erroring despite being specified via JSON REST API
As of commit 4794c4c04fced29b397b58a7689ff725c20ff6bd I'm having a problem where the JSON rest API won't let me create networks - https://22.0.0.2/api/networks/ (docker container instance of Ralph)
a request sent to
```json
{
"name":"test3",
"address":"2.0.0.0/8",
"remarks":"",
"vlan":1,
"dhcp_broadcast":false,
"reserved_from_beginning":0,
"reserved_from_end":0,
"gateway":null,
"network_environment":null,
"kind":null,
"service_env":null,
"terminators":[
],
"racks":[
],
"dns_servers":[
],
"min_ip":16777216,
"max_ip":33554431
}
```
produces the following result:
```json
{
"min_ip": [
"This field is required."
],
"max_ip": [
"This field is required."
]
}
```
This seems to be a known issue with Django REST API, and is possibly a result of min_ip and max_ip being set as non-editable in the model?
The same request works via the form request mechanism.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/ralph/networks/api.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 from django.conf import settings
3 from rest_framework.exceptions import ValidationError
4
5 from ralph.api import RalphAPISerializer, RalphAPIViewSet, router
6 from ralph.api.serializers import RalphAPISaveSerializer
7 from ralph.assets.api.serializers import EthernetSerializer
8 from ralph.networks.models import (
9 IPAddress,
10 Network,
11 NetworkEnvironment,
12 NetworkKind
13 )
14
15
16 class NetworkEnvironmentSerializer(RalphAPISerializer):
17 class Meta:
18 model = NetworkEnvironment
19 depth = 1
20
21
22 class NetworkKindSerializer(RalphAPISerializer):
23 class Meta:
24 model = NetworkKind
25 depth = 1
26
27
28 class NetworkSimpleSerializer(RalphAPISerializer):
29 class Meta:
30 model = Network
31 fields = (
32 'id', 'url', 'name', 'remarks', 'vlan', 'dhcp_broadcast', 'parent',
33 'network_environment'
34 )
35
36
37 class NetworkSerializer(RalphAPISerializer):
38 class Meta:
39 model = Network
40 depth = 1
41
42
43 class IPAddressSerializer(RalphAPISerializer):
44 network = NetworkSimpleSerializer()
45 ethernet = EthernetSerializer()
46
47 class Meta:
48 model = IPAddress
49 depth = 1
50 exclude = ('number',)
51
52
53 class IPAddressSaveSerializer(RalphAPISaveSerializer):
54 class Meta:
55 model = IPAddress
56
57 def validate_dhcp_expose(self, value):
58 """
59 Check if dhcp_expose value has changed from True to False.
60 """
61 if (
62 settings.DHCP_ENTRY_FORBID_CHANGE and
63 self.instance and
64 self.instance.dhcp_expose and
65 not value
66 ):
67 raise ValidationError(
68 'Cannot remove entry from DHCP. Use transition to do this.'
69 )
70 return value
71
72
73 class IPAddressViewSet(RalphAPIViewSet):
74 queryset = IPAddress.objects.all()
75 serializer_class = IPAddressSerializer
76 save_serializer_class = IPAddressSaveSerializer
77 prefetch_related = [
78 'ethernet', 'ethernet__base_object', 'ethernet__base_object__tags',
79 'network',
80 ]
81 filter_fields = [
82 'hostname', 'ethernet__base_object', 'network', 'network__address',
83 'status', 'is_public', 'is_management', 'dhcp_expose', 'ethernet__mac',
84 ]
85
86 def destroy(self, request, *args, **kwargs):
87 instance = self.get_object()
88 if instance and instance.dhcp_expose:
89 raise ValidationError(
90 'Could not delete IPAddress when it is exposed in DHCP'
91 )
92 return super().destroy(request, *args, **kwargs)
93
94
95 class NetworkViewSet(RalphAPIViewSet):
96 queryset = Network.objects.all()
97 serializer_class = NetworkSerializer
98 select_related = ['network_environment', 'kind']
99 prefetch_related = ['racks']
100 extended_filter_fields = {
101 # workaround for custom field for address field defined in admin
102 'address': ['address'],
103 }
104
105
106 class NetworkEnvironmentViewSet(RalphAPIViewSet):
107 queryset = NetworkEnvironment.objects.all()
108 serializer_class = NetworkEnvironmentSerializer
109
110
111 class NetworkKindViewSet(RalphAPIViewSet):
112 queryset = NetworkKind.objects.all()
113 serializer_class = NetworkKindSerializer
114
115 router.register(r'ipaddresses', IPAddressViewSet)
116 router.register(r'networks', NetworkViewSet)
117 router.register(r'network-environments', NetworkEnvironmentViewSet)
118 router.register(r'network-kinds', NetworkKindViewSet)
119 urlpatterns = []
120
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/ralph/networks/api.py b/src/ralph/networks/api.py
--- a/src/ralph/networks/api.py
+++ b/src/ralph/networks/api.py
@@ -34,6 +34,13 @@
)
+class NetworkSaveSerializer(RalphAPISerializer):
+ class Meta:
+ model = Network
+ depth = 1
+ exclude = ('min_ip', 'max_ip')
+
+
class NetworkSerializer(RalphAPISerializer):
class Meta:
model = Network
@@ -95,6 +102,7 @@
class NetworkViewSet(RalphAPIViewSet):
queryset = Network.objects.all()
serializer_class = NetworkSerializer
+ save_serializer_class = NetworkSaveSerializer
select_related = ['network_environment', 'kind']
prefetch_related = ['racks']
extended_filter_fields = {
|
{"golden_diff": "diff --git a/src/ralph/networks/api.py b/src/ralph/networks/api.py\n--- a/src/ralph/networks/api.py\n+++ b/src/ralph/networks/api.py\n@@ -34,6 +34,13 @@\n )\n \n \n+class NetworkSaveSerializer(RalphAPISerializer):\n+ class Meta:\n+ model = Network\n+ depth = 1\n+ exclude = ('min_ip', 'max_ip')\n+\n+\n class NetworkSerializer(RalphAPISerializer):\n class Meta:\n model = Network\n@@ -95,6 +102,7 @@\n class NetworkViewSet(RalphAPIViewSet):\n queryset = Network.objects.all()\n serializer_class = NetworkSerializer\n+ save_serializer_class = NetworkSaveSerializer\n select_related = ['network_environment', 'kind']\n prefetch_related = ['racks']\n extended_filter_fields = {\n", "issue": "min_ip, max_ip fields erroring despite being specified via JSON REST API\nAs of commit 4794c4c04fced29b397b58a7689ff725c20ff6bd I'm having a problem where the JSON rest API won't let me create networks - https://22.0.0.2/api/networks/ (docker container instance of Ralph)\r\na request sent to \r\n```json\r\n{\r\n \"name\":\"test3\",\r\n \"address\":\"2.0.0.0/8\",\r\n \"remarks\":\"\",\r\n \"vlan\":1,\r\n \"dhcp_broadcast\":false,\r\n \"reserved_from_beginning\":0,\r\n \"reserved_from_end\":0,\r\n \"gateway\":null,\r\n \"network_environment\":null,\r\n \"kind\":null,\r\n \"service_env\":null,\r\n \"terminators\":[\r\n\r\n ],\r\n \"racks\":[\r\n\r\n ],\r\n \"dns_servers\":[\r\n\r\n ],\r\n \"min_ip\":16777216,\r\n \"max_ip\":33554431\r\n}\r\n```\r\nproduces the following result:\r\n```json\r\n{\r\n \"min_ip\": [\r\n \"This field is required.\"\r\n ],\r\n \"max_ip\": [\r\n \"This field is required.\"\r\n ]\r\n}\r\n```\r\n\r\nThis seems to be a known issue with Django REST API, and is possibly a result of min_ip and max_ip being set as non-editable in the model? \r\n\r\nThe same request works via the form request mechanism.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom django.conf import settings\nfrom rest_framework.exceptions import ValidationError\n\nfrom ralph.api import RalphAPISerializer, RalphAPIViewSet, router\nfrom ralph.api.serializers import RalphAPISaveSerializer\nfrom ralph.assets.api.serializers import EthernetSerializer\nfrom ralph.networks.models import (\n IPAddress,\n Network,\n NetworkEnvironment,\n NetworkKind\n)\n\n\nclass NetworkEnvironmentSerializer(RalphAPISerializer):\n class Meta:\n model = NetworkEnvironment\n depth = 1\n\n\nclass NetworkKindSerializer(RalphAPISerializer):\n class Meta:\n model = NetworkKind\n depth = 1\n\n\nclass NetworkSimpleSerializer(RalphAPISerializer):\n class Meta:\n model = Network\n fields = (\n 'id', 'url', 'name', 'remarks', 'vlan', 'dhcp_broadcast', 'parent',\n 'network_environment'\n )\n\n\nclass NetworkSerializer(RalphAPISerializer):\n class Meta:\n model = Network\n depth = 1\n\n\nclass IPAddressSerializer(RalphAPISerializer):\n network = NetworkSimpleSerializer()\n ethernet = EthernetSerializer()\n\n class Meta:\n model = IPAddress\n depth = 1\n exclude = ('number',)\n\n\nclass IPAddressSaveSerializer(RalphAPISaveSerializer):\n class Meta:\n model = IPAddress\n\n def validate_dhcp_expose(self, value):\n \"\"\"\n Check if dhcp_expose value has changed from True to False.\n \"\"\"\n if (\n settings.DHCP_ENTRY_FORBID_CHANGE and\n self.instance and\n self.instance.dhcp_expose and\n not value\n ):\n raise ValidationError(\n 'Cannot remove entry from DHCP. Use transition to do this.'\n )\n return value\n\n\nclass IPAddressViewSet(RalphAPIViewSet):\n queryset = IPAddress.objects.all()\n serializer_class = IPAddressSerializer\n save_serializer_class = IPAddressSaveSerializer\n prefetch_related = [\n 'ethernet', 'ethernet__base_object', 'ethernet__base_object__tags',\n 'network',\n ]\n filter_fields = [\n 'hostname', 'ethernet__base_object', 'network', 'network__address',\n 'status', 'is_public', 'is_management', 'dhcp_expose', 'ethernet__mac',\n ]\n\n def destroy(self, request, *args, **kwargs):\n instance = self.get_object()\n if instance and instance.dhcp_expose:\n raise ValidationError(\n 'Could not delete IPAddress when it is exposed in DHCP'\n )\n return super().destroy(request, *args, **kwargs)\n\n\nclass NetworkViewSet(RalphAPIViewSet):\n queryset = Network.objects.all()\n serializer_class = NetworkSerializer\n select_related = ['network_environment', 'kind']\n prefetch_related = ['racks']\n extended_filter_fields = {\n # workaround for custom field for address field defined in admin\n 'address': ['address'],\n }\n\n\nclass NetworkEnvironmentViewSet(RalphAPIViewSet):\n queryset = NetworkEnvironment.objects.all()\n serializer_class = NetworkEnvironmentSerializer\n\n\nclass NetworkKindViewSet(RalphAPIViewSet):\n queryset = NetworkKind.objects.all()\n serializer_class = NetworkKindSerializer\n\nrouter.register(r'ipaddresses', IPAddressViewSet)\nrouter.register(r'networks', NetworkViewSet)\nrouter.register(r'network-environments', NetworkEnvironmentViewSet)\nrouter.register(r'network-kinds', NetworkKindViewSet)\nurlpatterns = []\n", "path": "src/ralph/networks/api.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nfrom django.conf import settings\nfrom rest_framework.exceptions import ValidationError\n\nfrom ralph.api import RalphAPISerializer, RalphAPIViewSet, router\nfrom ralph.api.serializers import RalphAPISaveSerializer\nfrom ralph.assets.api.serializers import EthernetSerializer\nfrom ralph.networks.models import (\n IPAddress,\n Network,\n NetworkEnvironment,\n NetworkKind\n)\n\n\nclass NetworkEnvironmentSerializer(RalphAPISerializer):\n class Meta:\n model = NetworkEnvironment\n depth = 1\n\n\nclass NetworkKindSerializer(RalphAPISerializer):\n class Meta:\n model = NetworkKind\n depth = 1\n\n\nclass NetworkSimpleSerializer(RalphAPISerializer):\n class Meta:\n model = Network\n fields = (\n 'id', 'url', 'name', 'remarks', 'vlan', 'dhcp_broadcast', 'parent',\n 'network_environment'\n )\n\n\nclass NetworkSaveSerializer(RalphAPISerializer):\n class Meta:\n model = Network\n depth = 1\n exclude = ('min_ip', 'max_ip')\n\n\nclass NetworkSerializer(RalphAPISerializer):\n class Meta:\n model = Network\n depth = 1\n\n\nclass IPAddressSerializer(RalphAPISerializer):\n network = NetworkSimpleSerializer()\n ethernet = EthernetSerializer()\n\n class Meta:\n model = IPAddress\n depth = 1\n exclude = ('number',)\n\n\nclass IPAddressSaveSerializer(RalphAPISaveSerializer):\n class Meta:\n model = IPAddress\n\n def validate_dhcp_expose(self, value):\n \"\"\"\n Check if dhcp_expose value has changed from True to False.\n \"\"\"\n if (\n settings.DHCP_ENTRY_FORBID_CHANGE and\n self.instance and\n self.instance.dhcp_expose and\n not value\n ):\n raise ValidationError(\n 'Cannot remove entry from DHCP. Use transition to do this.'\n )\n return value\n\n\nclass IPAddressViewSet(RalphAPIViewSet):\n queryset = IPAddress.objects.all()\n serializer_class = IPAddressSerializer\n save_serializer_class = IPAddressSaveSerializer\n prefetch_related = [\n 'ethernet', 'ethernet__base_object', 'ethernet__base_object__tags',\n 'network',\n ]\n filter_fields = [\n 'hostname', 'ethernet__base_object', 'network', 'network__address',\n 'status', 'is_public', 'is_management', 'dhcp_expose', 'ethernet__mac',\n ]\n\n def destroy(self, request, *args, **kwargs):\n instance = self.get_object()\n if instance and instance.dhcp_expose:\n raise ValidationError(\n 'Could not delete IPAddress when it is exposed in DHCP'\n )\n return super().destroy(request, *args, **kwargs)\n\n\nclass NetworkViewSet(RalphAPIViewSet):\n queryset = Network.objects.all()\n serializer_class = NetworkSerializer\n save_serializer_class = NetworkSaveSerializer\n select_related = ['network_environment', 'kind']\n prefetch_related = ['racks']\n extended_filter_fields = {\n # workaround for custom field for address field defined in admin\n 'address': ['address'],\n }\n\n\nclass NetworkEnvironmentViewSet(RalphAPIViewSet):\n queryset = NetworkEnvironment.objects.all()\n serializer_class = NetworkEnvironmentSerializer\n\n\nclass NetworkKindViewSet(RalphAPIViewSet):\n queryset = NetworkKind.objects.all()\n serializer_class = NetworkKindSerializer\n\nrouter.register(r'ipaddresses', IPAddressViewSet)\nrouter.register(r'networks', NetworkViewSet)\nrouter.register(r'network-environments', NetworkEnvironmentViewSet)\nrouter.register(r'network-kinds', NetworkKindViewSet)\nurlpatterns = []\n", "path": "src/ralph/networks/api.py"}]}
| 1,569 | 191 |
gh_patches_debug_2894
|
rasdani/github-patches
|
git_diff
|
pymodbus-dev__pymodbus-1604
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pymodbus.server does not listen on modbus port
<!--
Before opening a new issue, make sure you do the following:
- Check that your issue isn't already filed: https://github.com/pymodbus-dev/pymodbus/issues
- Check the discussions forum https://github.com/pymodbus-dev/pymodbus/discussions
- Prepare a short, runnable example that reproduce the issue with the latest development version of Pymodbus
-->
### Versions
- Python: 3.11.3
- OS: Fedora 37
- Pymodbus: 3.3.1
### Pymodbus Specific
- Server: tcp
### Description
- start pymodbus server:
```
pymodbus.server --verbose run -u 1
__________ .______. _________
\______ \___.__. _____ ____ __| _/\_ |__ __ __ ______ / _____/ ______________ __ ___________
| ___< | |/ \ / _ \ / __ | | __ \| | \/ ___/ \_____ \_/ __ \_ __ \ \/ // __ \_ __ \\
| | \___ | Y Y ( <_> ) /_/ | | \_\ \ | /\___ \ / \ ___/| | \/\ /\ ___/| | \/
|____| / ____|__|_| /\____/\____ | |___ /____//____ > /_______ /\___ >__| \_/ \___ >__|
\/ \/ \/ \/ \/ \/ \/ \/
SERVER >
```
- try to connect to port 5020 or check which process is listening on port 5020
- current result
- server does not listen on port 5020
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pymodbus/repl/server/main.py`
Content:
```
1 """Repl server main."""
2 import asyncio
3 import json
4 import logging
5 import sys
6 from enum import Enum
7 from pathlib import Path
8 from typing import List
9
10 import typer
11
12 from pymodbus import pymodbus_apply_logging_config
13 from pymodbus.framer.socket_framer import ModbusSocketFramer
14 from pymodbus.logging import Log
15 from pymodbus.repl.server.cli import run_repl
16 from pymodbus.server.reactive.default_config import DEFAULT_CONFIG
17 from pymodbus.server.reactive.main import (
18 DEFAULT_FRAMER,
19 DEFUALT_HANDLERS,
20 ReactiveServer,
21 )
22
23
24 CANCELLED_ERROR = asyncio.exceptions.CancelledError
25 CONTEXT_SETTING = {"allow_extra_args": True, "ignore_unknown_options": True}
26
27
28 # TBD class ModbusServerConfig:
29
30
31 class ModbusServerTypes(str, Enum):
32 """Server types."""
33
34 # ["tcp", "serial", "tls", "udp"]
35 tcp = "tcp" # pylint: disable=invalid-name
36 serial = "serial" # pylint: disable=invalid-name
37 tls = "tls" # pylint: disable=invalid-name
38 udp = "udp" # pylint: disable=invalid-name
39
40
41 class ModbusFramerTypes(str, Enum):
42 """Framer types."""
43
44 # ["socket", "rtu", "tls", "ascii", "binary"]
45 socket = "socket" # pylint: disable=invalid-name
46 rtu = "rtu" # pylint: disable=invalid-name
47 tls = "tls" # pylint: disable=invalid-name
48 ascii = "ascii" # pylint: disable=invalid-name
49 binary = "binary" # pylint: disable=invalid-name
50
51
52 def _completer(incomplete: str, valid_values: List[str]) -> List[str]:
53 """Complete value."""
54 completion = []
55 for name in valid_values:
56 if name.startswith(incomplete):
57 completion.append(name)
58 return completion
59
60
61 def framers(incomplete: str) -> List[str]:
62 """Return an autocompleted list of supported clouds."""
63 _framers = ["socket", "rtu", "tls", "ascii", "binary"]
64 return _completer(incomplete, _framers)
65
66
67 def servers(incomplete: str) -> List[str]:
68 """Return an autocompleted list of supported clouds."""
69 _servers = ["tcp", "serial", "tls", "udp"]
70 return _completer(incomplete, _servers)
71
72
73 def process_extra_args(extra_args: List[str], modbus_config: dict) -> dict:
74 """Process extra args passed to server."""
75 options_stripped = [x.strip().replace("--", "") for x in extra_args[::2]]
76 extra_args_dict = dict(list(zip(options_stripped, extra_args[1::2])))
77 for option, value in extra_args_dict.items():
78 if option in modbus_config:
79 try:
80 modbus_config[option] = type(modbus_config[option])(value)
81 except ValueError as err:
82 Log.error(
83 "Error parsing extra arg {} with value '{}'. {}", option, value, err
84 )
85 sys.exit(1)
86 return modbus_config
87
88
89 app = typer.Typer(
90 no_args_is_help=True,
91 context_settings=CONTEXT_SETTING,
92 help="Reactive Modbus server",
93 )
94
95
96 @app.callback()
97 def server(
98 ctx: typer.Context,
99 host: str = typer.Option("localhost", "--host", help="Host address"),
100 web_port: int = typer.Option(8080, "--web-port", help="Web app port"),
101 broadcast_support: bool = typer.Option(
102 False, "-b", help="Support broadcast messages"
103 ),
104 repl: bool = typer.Option(True, help="Enable/Disable repl for server"),
105 verbose: bool = typer.Option(
106 False, help="Run with debug logs enabled for pymodbus"
107 ),
108 ):
109 """Run server code."""
110 log_level = logging.DEBUG if verbose else logging.ERROR
111 pymodbus_apply_logging_config(log_level)
112
113 ctx.obj = {
114 "repl": repl,
115 "host": host,
116 "web_port": web_port,
117 "broadcast": broadcast_support,
118 }
119
120
121 @app.command("run", context_settings=CONTEXT_SETTING)
122 def run(
123 ctx: typer.Context,
124 modbus_server: str = typer.Option(
125 ModbusServerTypes.tcp.value,
126 "--modbus-server",
127 "-s",
128 case_sensitive=False,
129 autocompletion=servers,
130 help="Modbus Server",
131 ),
132 modbus_framer: str = typer.Option(
133 ModbusFramerTypes.socket.value,
134 "--framer",
135 "-f",
136 case_sensitive=False,
137 autocompletion=framers,
138 help="Modbus framer to use",
139 ),
140 modbus_port: int = typer.Option(5020, "--modbus-port", "-p", help="Modbus port"),
141 modbus_slave_id: List[int] = typer.Option(
142 [1], "--slave-id", "-u", help="Supported Modbus slave id's"
143 ),
144 modbus_config_path: Path = typer.Option(
145 None, help="Path to additional modbus server config"
146 ),
147 randomize: int = typer.Option(
148 0,
149 "--random",
150 "-r",
151 help="Randomize every `r` reads. 0=never, 1=always,2=every-second-read"
152 ", and so on. Applicable IR and DI.",
153 ),
154 change_rate: int = typer.Option(
155 0,
156 "--change-rate",
157 "-c",
158 help="Rate in % registers to change. 0=none, 100=all, 12=12% of registers"
159 ", and so on. Applicable IR and DI.",
160 ),
161 ):
162 """Run Reactive Modbus server.
163
164 Exposing REST endpoint for response manipulation.
165 """
166 repl = ctx.obj.pop("repl")
167 # TBD extra_args = ctx.args
168 web_app_config = ctx.obj
169 loop = asyncio.get_event_loop()
170 framer = DEFAULT_FRAMER.get(modbus_framer, ModbusSocketFramer)
171 if modbus_config_path:
172 with open(modbus_config_path, encoding="utf-8") as my_file:
173 modbus_config = json.load(my_file)
174 else:
175 modbus_config = DEFAULT_CONFIG
176
177 extra_args = ctx.args
178 data_block_settings = modbus_config.pop("data_block_settings", {})
179 modbus_config = modbus_config.get(modbus_server, {})
180 modbus_config = process_extra_args(extra_args, modbus_config)
181 if modbus_server != "serial":
182 handler = modbus_config.pop("handler", "ModbusConnectedRequestHandler")
183 else:
184 handler = modbus_config.pop("handler", "ModbusSingleRequestHandler")
185 handler = DEFUALT_HANDLERS.get(handler.strip())
186
187 modbus_config["handler"] = handler
188 modbus_config["randomize"] = randomize
189 modbus_config["change_rate"] = change_rate
190 app = ReactiveServer.factory(
191 modbus_server,
192 framer,
193 modbus_port=modbus_port,
194 slave=modbus_slave_id,
195 loop=loop,
196 single=False,
197 data_block_settings=data_block_settings,
198 **web_app_config,
199 **modbus_config,
200 )
201 if repl:
202 loop.run_until_complete(run_repl(app))
203 else:
204 loop.run_until_complete(app.run_async(repl))
205 loop.run_forever()
206
207
208 if __name__ == "__main__":
209 app()
210
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pymodbus/repl/server/main.py b/pymodbus/repl/server/main.py
--- a/pymodbus/repl/server/main.py
+++ b/pymodbus/repl/server/main.py
@@ -198,10 +198,10 @@
**web_app_config,
**modbus_config,
)
+ loop.run_until_complete(app.run_async(repl))
if repl:
loop.run_until_complete(run_repl(app))
else:
- loop.run_until_complete(app.run_async(repl))
loop.run_forever()
|
{"golden_diff": "diff --git a/pymodbus/repl/server/main.py b/pymodbus/repl/server/main.py\n--- a/pymodbus/repl/server/main.py\n+++ b/pymodbus/repl/server/main.py\n@@ -198,10 +198,10 @@\n **web_app_config,\n **modbus_config,\n )\n+ loop.run_until_complete(app.run_async(repl))\n if repl:\n loop.run_until_complete(run_repl(app))\n else:\n- loop.run_until_complete(app.run_async(repl))\n loop.run_forever()\n", "issue": "pymodbus.server does not listen on modbus port\n<!--\r\nBefore opening a new issue, make sure you do the following:\r\n\r\n- Check that your issue isn't already filed: https://github.com/pymodbus-dev/pymodbus/issues\r\n- Check the discussions forum https://github.com/pymodbus-dev/pymodbus/discussions\r\n- Prepare a short, runnable example that reproduce the issue with the latest development version of Pymodbus\r\n-->\r\n\r\n### Versions\r\n\r\n- Python: 3.11.3\r\n- OS: Fedora 37\r\n- Pymodbus: 3.3.1\r\n\r\n### Pymodbus Specific\r\n\r\n- Server: tcp\r\n\r\n### Description\r\n\r\n- start pymodbus server:\r\n```\r\npymodbus.server --verbose run -u 1\r\n\r\n\r\n__________ .______. _________\r\n\\______ \\___.__. _____ ____ __| _/\\_ |__ __ __ ______ / _____/ ______________ __ ___________\r\n | ___< | |/ \\ / _ \\ / __ | | __ \\| | \\/ ___/ \\_____ \\_/ __ \\_ __ \\ \\/ // __ \\_ __ \\\\\r\n | | \\___ | Y Y ( <_> ) /_/ | | \\_\\ \\ | /\\___ \\ / \\ ___/| | \\/\\ /\\ ___/| | \\/\r\n |____| / ____|__|_| /\\____/\\____ | |___ /____//____ > /_______ /\\___ >__| \\_/ \\___ >__|\r\n \\/ \\/ \\/ \\/ \\/ \\/ \\/ \\/\r\n\r\n\r\nSERVER >\r\n\r\n\r\n```\r\n- try to connect to port 5020 or check which process is listening on port 5020\r\n- current result\r\n - server does not listen on port 5020\r\n\n", "before_files": [{"content": "\"\"\"Repl server main.\"\"\"\nimport asyncio\nimport json\nimport logging\nimport sys\nfrom enum import Enum\nfrom pathlib import Path\nfrom typing import List\n\nimport typer\n\nfrom pymodbus import pymodbus_apply_logging_config\nfrom pymodbus.framer.socket_framer import ModbusSocketFramer\nfrom pymodbus.logging import Log\nfrom pymodbus.repl.server.cli import run_repl\nfrom pymodbus.server.reactive.default_config import DEFAULT_CONFIG\nfrom pymodbus.server.reactive.main import (\n DEFAULT_FRAMER,\n DEFUALT_HANDLERS,\n ReactiveServer,\n)\n\n\nCANCELLED_ERROR = asyncio.exceptions.CancelledError\nCONTEXT_SETTING = {\"allow_extra_args\": True, \"ignore_unknown_options\": True}\n\n\n# TBD class ModbusServerConfig:\n\n\nclass ModbusServerTypes(str, Enum):\n \"\"\"Server types.\"\"\"\n\n # [\"tcp\", \"serial\", \"tls\", \"udp\"]\n tcp = \"tcp\" # pylint: disable=invalid-name\n serial = \"serial\" # pylint: disable=invalid-name\n tls = \"tls\" # pylint: disable=invalid-name\n udp = \"udp\" # pylint: disable=invalid-name\n\n\nclass ModbusFramerTypes(str, Enum):\n \"\"\"Framer types.\"\"\"\n\n # [\"socket\", \"rtu\", \"tls\", \"ascii\", \"binary\"]\n socket = \"socket\" # pylint: disable=invalid-name\n rtu = \"rtu\" # pylint: disable=invalid-name\n tls = \"tls\" # pylint: disable=invalid-name\n ascii = \"ascii\" # pylint: disable=invalid-name\n binary = \"binary\" # pylint: disable=invalid-name\n\n\ndef _completer(incomplete: str, valid_values: List[str]) -> List[str]:\n \"\"\"Complete value.\"\"\"\n completion = []\n for name in valid_values:\n if name.startswith(incomplete):\n completion.append(name)\n return completion\n\n\ndef framers(incomplete: str) -> List[str]:\n \"\"\"Return an autocompleted list of supported clouds.\"\"\"\n _framers = [\"socket\", \"rtu\", \"tls\", \"ascii\", \"binary\"]\n return _completer(incomplete, _framers)\n\n\ndef servers(incomplete: str) -> List[str]:\n \"\"\"Return an autocompleted list of supported clouds.\"\"\"\n _servers = [\"tcp\", \"serial\", \"tls\", \"udp\"]\n return _completer(incomplete, _servers)\n\n\ndef process_extra_args(extra_args: List[str], modbus_config: dict) -> dict:\n \"\"\"Process extra args passed to server.\"\"\"\n options_stripped = [x.strip().replace(\"--\", \"\") for x in extra_args[::2]]\n extra_args_dict = dict(list(zip(options_stripped, extra_args[1::2])))\n for option, value in extra_args_dict.items():\n if option in modbus_config:\n try:\n modbus_config[option] = type(modbus_config[option])(value)\n except ValueError as err:\n Log.error(\n \"Error parsing extra arg {} with value '{}'. {}\", option, value, err\n )\n sys.exit(1)\n return modbus_config\n\n\napp = typer.Typer(\n no_args_is_help=True,\n context_settings=CONTEXT_SETTING,\n help=\"Reactive Modbus server\",\n)\n\n\[email protected]()\ndef server(\n ctx: typer.Context,\n host: str = typer.Option(\"localhost\", \"--host\", help=\"Host address\"),\n web_port: int = typer.Option(8080, \"--web-port\", help=\"Web app port\"),\n broadcast_support: bool = typer.Option(\n False, \"-b\", help=\"Support broadcast messages\"\n ),\n repl: bool = typer.Option(True, help=\"Enable/Disable repl for server\"),\n verbose: bool = typer.Option(\n False, help=\"Run with debug logs enabled for pymodbus\"\n ),\n):\n \"\"\"Run server code.\"\"\"\n log_level = logging.DEBUG if verbose else logging.ERROR\n pymodbus_apply_logging_config(log_level)\n\n ctx.obj = {\n \"repl\": repl,\n \"host\": host,\n \"web_port\": web_port,\n \"broadcast\": broadcast_support,\n }\n\n\[email protected](\"run\", context_settings=CONTEXT_SETTING)\ndef run(\n ctx: typer.Context,\n modbus_server: str = typer.Option(\n ModbusServerTypes.tcp.value,\n \"--modbus-server\",\n \"-s\",\n case_sensitive=False,\n autocompletion=servers,\n help=\"Modbus Server\",\n ),\n modbus_framer: str = typer.Option(\n ModbusFramerTypes.socket.value,\n \"--framer\",\n \"-f\",\n case_sensitive=False,\n autocompletion=framers,\n help=\"Modbus framer to use\",\n ),\n modbus_port: int = typer.Option(5020, \"--modbus-port\", \"-p\", help=\"Modbus port\"),\n modbus_slave_id: List[int] = typer.Option(\n [1], \"--slave-id\", \"-u\", help=\"Supported Modbus slave id's\"\n ),\n modbus_config_path: Path = typer.Option(\n None, help=\"Path to additional modbus server config\"\n ),\n randomize: int = typer.Option(\n 0,\n \"--random\",\n \"-r\",\n help=\"Randomize every `r` reads. 0=never, 1=always,2=every-second-read\"\n \", and so on. Applicable IR and DI.\",\n ),\n change_rate: int = typer.Option(\n 0,\n \"--change-rate\",\n \"-c\",\n help=\"Rate in % registers to change. 0=none, 100=all, 12=12% of registers\"\n \", and so on. Applicable IR and DI.\",\n ),\n):\n \"\"\"Run Reactive Modbus server.\n\n Exposing REST endpoint for response manipulation.\n \"\"\"\n repl = ctx.obj.pop(\"repl\")\n # TBD extra_args = ctx.args\n web_app_config = ctx.obj\n loop = asyncio.get_event_loop()\n framer = DEFAULT_FRAMER.get(modbus_framer, ModbusSocketFramer)\n if modbus_config_path:\n with open(modbus_config_path, encoding=\"utf-8\") as my_file:\n modbus_config = json.load(my_file)\n else:\n modbus_config = DEFAULT_CONFIG\n\n extra_args = ctx.args\n data_block_settings = modbus_config.pop(\"data_block_settings\", {})\n modbus_config = modbus_config.get(modbus_server, {})\n modbus_config = process_extra_args(extra_args, modbus_config)\n if modbus_server != \"serial\":\n handler = modbus_config.pop(\"handler\", \"ModbusConnectedRequestHandler\")\n else:\n handler = modbus_config.pop(\"handler\", \"ModbusSingleRequestHandler\")\n handler = DEFUALT_HANDLERS.get(handler.strip())\n\n modbus_config[\"handler\"] = handler\n modbus_config[\"randomize\"] = randomize\n modbus_config[\"change_rate\"] = change_rate\n app = ReactiveServer.factory(\n modbus_server,\n framer,\n modbus_port=modbus_port,\n slave=modbus_slave_id,\n loop=loop,\n single=False,\n data_block_settings=data_block_settings,\n **web_app_config,\n **modbus_config,\n )\n if repl:\n loop.run_until_complete(run_repl(app))\n else:\n loop.run_until_complete(app.run_async(repl))\n loop.run_forever()\n\n\nif __name__ == \"__main__\":\n app()\n", "path": "pymodbus/repl/server/main.py"}], "after_files": [{"content": "\"\"\"Repl server main.\"\"\"\nimport asyncio\nimport json\nimport logging\nimport sys\nfrom enum import Enum\nfrom pathlib import Path\nfrom typing import List\n\nimport typer\n\nfrom pymodbus import pymodbus_apply_logging_config\nfrom pymodbus.framer.socket_framer import ModbusSocketFramer\nfrom pymodbus.logging import Log\nfrom pymodbus.repl.server.cli import run_repl\nfrom pymodbus.server.reactive.default_config import DEFAULT_CONFIG\nfrom pymodbus.server.reactive.main import (\n DEFAULT_FRAMER,\n DEFUALT_HANDLERS,\n ReactiveServer,\n)\n\n\nCANCELLED_ERROR = asyncio.exceptions.CancelledError\nCONTEXT_SETTING = {\"allow_extra_args\": True, \"ignore_unknown_options\": True}\n\n\n# TBD class ModbusServerConfig:\n\n\nclass ModbusServerTypes(str, Enum):\n \"\"\"Server types.\"\"\"\n\n # [\"tcp\", \"serial\", \"tls\", \"udp\"]\n tcp = \"tcp\" # pylint: disable=invalid-name\n serial = \"serial\" # pylint: disable=invalid-name\n tls = \"tls\" # pylint: disable=invalid-name\n udp = \"udp\" # pylint: disable=invalid-name\n\n\nclass ModbusFramerTypes(str, Enum):\n \"\"\"Framer types.\"\"\"\n\n # [\"socket\", \"rtu\", \"tls\", \"ascii\", \"binary\"]\n socket = \"socket\" # pylint: disable=invalid-name\n rtu = \"rtu\" # pylint: disable=invalid-name\n tls = \"tls\" # pylint: disable=invalid-name\n ascii = \"ascii\" # pylint: disable=invalid-name\n binary = \"binary\" # pylint: disable=invalid-name\n\n\ndef _completer(incomplete: str, valid_values: List[str]) -> List[str]:\n \"\"\"Complete value.\"\"\"\n completion = []\n for name in valid_values:\n if name.startswith(incomplete):\n completion.append(name)\n return completion\n\n\ndef framers(incomplete: str) -> List[str]:\n \"\"\"Return an autocompleted list of supported clouds.\"\"\"\n _framers = [\"socket\", \"rtu\", \"tls\", \"ascii\", \"binary\"]\n return _completer(incomplete, _framers)\n\n\ndef servers(incomplete: str) -> List[str]:\n \"\"\"Return an autocompleted list of supported clouds.\"\"\"\n _servers = [\"tcp\", \"serial\", \"tls\", \"udp\"]\n return _completer(incomplete, _servers)\n\n\ndef process_extra_args(extra_args: List[str], modbus_config: dict) -> dict:\n \"\"\"Process extra args passed to server.\"\"\"\n options_stripped = [x.strip().replace(\"--\", \"\") for x in extra_args[::2]]\n extra_args_dict = dict(list(zip(options_stripped, extra_args[1::2])))\n for option, value in extra_args_dict.items():\n if option in modbus_config:\n try:\n modbus_config[option] = type(modbus_config[option])(value)\n except ValueError as err:\n Log.error(\n \"Error parsing extra arg {} with value '{}'. {}\", option, value, err\n )\n sys.exit(1)\n return modbus_config\n\n\napp = typer.Typer(\n no_args_is_help=True,\n context_settings=CONTEXT_SETTING,\n help=\"Reactive Modbus server\",\n)\n\n\[email protected]()\ndef server(\n ctx: typer.Context,\n host: str = typer.Option(\"localhost\", \"--host\", help=\"Host address\"),\n web_port: int = typer.Option(8080, \"--web-port\", help=\"Web app port\"),\n broadcast_support: bool = typer.Option(\n False, \"-b\", help=\"Support broadcast messages\"\n ),\n repl: bool = typer.Option(True, help=\"Enable/Disable repl for server\"),\n verbose: bool = typer.Option(\n False, help=\"Run with debug logs enabled for pymodbus\"\n ),\n):\n \"\"\"Run server code.\"\"\"\n log_level = logging.DEBUG if verbose else logging.ERROR\n pymodbus_apply_logging_config(log_level)\n\n ctx.obj = {\n \"repl\": repl,\n \"host\": host,\n \"web_port\": web_port,\n \"broadcast\": broadcast_support,\n }\n\n\[email protected](\"run\", context_settings=CONTEXT_SETTING)\ndef run(\n ctx: typer.Context,\n modbus_server: str = typer.Option(\n ModbusServerTypes.tcp.value,\n \"--modbus-server\",\n \"-s\",\n case_sensitive=False,\n autocompletion=servers,\n help=\"Modbus Server\",\n ),\n modbus_framer: str = typer.Option(\n ModbusFramerTypes.socket.value,\n \"--framer\",\n \"-f\",\n case_sensitive=False,\n autocompletion=framers,\n help=\"Modbus framer to use\",\n ),\n modbus_port: int = typer.Option(5020, \"--modbus-port\", \"-p\", help=\"Modbus port\"),\n modbus_slave_id: List[int] = typer.Option(\n [1], \"--slave-id\", \"-u\", help=\"Supported Modbus slave id's\"\n ),\n modbus_config_path: Path = typer.Option(\n None, help=\"Path to additional modbus server config\"\n ),\n randomize: int = typer.Option(\n 0,\n \"--random\",\n \"-r\",\n help=\"Randomize every `r` reads. 0=never, 1=always,2=every-second-read\"\n \", and so on. Applicable IR and DI.\",\n ),\n change_rate: int = typer.Option(\n 0,\n \"--change-rate\",\n \"-c\",\n help=\"Rate in % registers to change. 0=none, 100=all, 12=12% of registers\"\n \", and so on. Applicable IR and DI.\",\n ),\n):\n \"\"\"Run Reactive Modbus server.\n\n Exposing REST endpoint for response manipulation.\n \"\"\"\n repl = ctx.obj.pop(\"repl\")\n # TBD extra_args = ctx.args\n web_app_config = ctx.obj\n loop = asyncio.get_event_loop()\n framer = DEFAULT_FRAMER.get(modbus_framer, ModbusSocketFramer)\n if modbus_config_path:\n with open(modbus_config_path, encoding=\"utf-8\") as my_file:\n modbus_config = json.load(my_file)\n else:\n modbus_config = DEFAULT_CONFIG\n\n extra_args = ctx.args\n data_block_settings = modbus_config.pop(\"data_block_settings\", {})\n modbus_config = modbus_config.get(modbus_server, {})\n modbus_config = process_extra_args(extra_args, modbus_config)\n if modbus_server != \"serial\":\n handler = modbus_config.pop(\"handler\", \"ModbusConnectedRequestHandler\")\n else:\n handler = modbus_config.pop(\"handler\", \"ModbusSingleRequestHandler\")\n handler = DEFUALT_HANDLERS.get(handler.strip())\n\n modbus_config[\"handler\"] = handler\n modbus_config[\"randomize\"] = randomize\n modbus_config[\"change_rate\"] = change_rate\n app = ReactiveServer.factory(\n modbus_server,\n framer,\n modbus_port=modbus_port,\n slave=modbus_slave_id,\n loop=loop,\n single=False,\n data_block_settings=data_block_settings,\n **web_app_config,\n **modbus_config,\n )\n loop.run_until_complete(app.run_async(repl))\n if repl:\n loop.run_until_complete(run_repl(app))\n else:\n loop.run_forever()\n\n\nif __name__ == \"__main__\":\n app()\n", "path": "pymodbus/repl/server/main.py"}]}
| 2,871 | 125 |
gh_patches_debug_24344
|
rasdani/github-patches
|
git_diff
|
getnikola__nikola-1068
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
nikola auto not working
I'm a newb so suspect user error, but I installed nikola v6.3.0 (pip install nikola) and have not been able to get **nikola auto** to work.
Initially I was getting errors due to a more recent version of livereload (which, isn't this marked as fixed?) and resolved by forcing livereload=2.0.0.
The next problem is that the site appears not to rebuild when I save edits to a post. I have not RTFM yet (as instructed :) but when I do:
nikola auto -b
I should be able to edit a post file (e.g. 1.rst) and on save, see the changes immediately, correct? What I see in the server log output and in Chrome dev tools shows that the browser is re-requesting a bunch of files, but I have to manually do **nikola build** to get the site to rebuild.
I'm using OS X 10.9.1, Python 2.7. Let me know if I can provide any other info; if I get it worked out I'll update the issue.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nikola/plugins/command/auto.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Copyright © 2012-2014 Roberto Alsina and others.
4
5 # Permission is hereby granted, free of charge, to any
6 # person obtaining a copy of this software and associated
7 # documentation files (the "Software"), to deal in the
8 # Software without restriction, including without limitation
9 # the rights to use, copy, modify, merge, publish,
10 # distribute, sublicense, and/or sell copies of the
11 # Software, and to permit persons to whom the Software is
12 # furnished to do so, subject to the following conditions:
13 #
14 # The above copyright notice and this permission notice
15 # shall be included in all copies or substantial portions of
16 # the Software.
17 #
18 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY
19 # KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
20 # WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
21 # PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS
22 # OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR
23 # OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
24 # OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
25 # SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
26
27 from __future__ import print_function, unicode_literals
28
29 import os
30 import subprocess
31 import webbrowser
32
33 from nikola.plugin_categories import Command
34 from nikola.utils import req_missing
35
36
37 class CommandAuto(Command):
38 """Start debugging console."""
39 name = "auto"
40 doc_purpose = "automatically detect site changes, rebuild and optionally refresh a browser"
41 cmd_options = [
42 {
43 'name': 'browser',
44 'short': 'b',
45 'type': bool,
46 'help': 'Start a web browser.',
47 'default': False,
48 },
49 {
50 'name': 'port',
51 'short': 'p',
52 'long': 'port',
53 'default': 8000,
54 'type': int,
55 'help': 'Port nummber (default: 8000)',
56 },
57 ]
58
59 def _execute(self, options, args):
60 """Start the watcher."""
61 try:
62 from livereload import Server
63 except ImportError:
64 req_missing(['livereload>=2.0.0'], 'use the "auto" command')
65 return
66
67 # Run an initial build so we are uptodate
68 subprocess.call(("nikola", "build"))
69
70 port = options and options.get('port')
71
72 server = Server()
73 server.watch('conf.py')
74 server.watch('themes/')
75 server.watch('templates/')
76 server.watch(self.site.config['GALLERY_PATH'])
77 for item in self.site.config['post_pages']:
78 server.watch(os.path.dirname(item[0]))
79 for item in self.site.config['FILES_FOLDERS']:
80 server.watch(os.path.dirname(item))
81
82 out_folder = self.site.config['OUTPUT_FOLDER']
83 if options and options.get('browser'):
84 webbrowser.open('http://localhost:{0}'.format(port))
85
86 server.serve(port, None, out_folder)
87
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nikola/plugins/command/auto.py b/nikola/plugins/command/auto.py
--- a/nikola/plugins/command/auto.py
+++ b/nikola/plugins/command/auto.py
@@ -64,20 +64,20 @@
req_missing(['livereload>=2.0.0'], 'use the "auto" command')
return
- # Run an initial build so we are uptodate
+ # Run an initial build so we are up-to-date
subprocess.call(("nikola", "build"))
port = options and options.get('port')
server = Server()
- server.watch('conf.py')
- server.watch('themes/')
- server.watch('templates/')
+ server.watch('conf.py', 'nikola build')
+ server.watch('themes/', 'nikola build')
+ server.watch('templates/', 'nikola build')
server.watch(self.site.config['GALLERY_PATH'])
for item in self.site.config['post_pages']:
- server.watch(os.path.dirname(item[0]))
+ server.watch(os.path.dirname(item[0]), 'nikola build')
for item in self.site.config['FILES_FOLDERS']:
- server.watch(os.path.dirname(item))
+ server.watch(os.path.dirname(item), 'nikola build')
out_folder = self.site.config['OUTPUT_FOLDER']
if options and options.get('browser'):
|
{"golden_diff": "diff --git a/nikola/plugins/command/auto.py b/nikola/plugins/command/auto.py\n--- a/nikola/plugins/command/auto.py\n+++ b/nikola/plugins/command/auto.py\n@@ -64,20 +64,20 @@\n req_missing(['livereload>=2.0.0'], 'use the \"auto\" command')\n return\n \n- # Run an initial build so we are uptodate\n+ # Run an initial build so we are up-to-date\n subprocess.call((\"nikola\", \"build\"))\n \n port = options and options.get('port')\n \n server = Server()\n- server.watch('conf.py')\n- server.watch('themes/')\n- server.watch('templates/')\n+ server.watch('conf.py', 'nikola build')\n+ server.watch('themes/', 'nikola build')\n+ server.watch('templates/', 'nikola build')\n server.watch(self.site.config['GALLERY_PATH'])\n for item in self.site.config['post_pages']:\n- server.watch(os.path.dirname(item[0]))\n+ server.watch(os.path.dirname(item[0]), 'nikola build')\n for item in self.site.config['FILES_FOLDERS']:\n- server.watch(os.path.dirname(item))\n+ server.watch(os.path.dirname(item), 'nikola build')\n \n out_folder = self.site.config['OUTPUT_FOLDER']\n if options and options.get('browser'):\n", "issue": "nikola auto not working \nI'm a newb so suspect user error, but I installed nikola v6.3.0 (pip install nikola) and have not been able to get **nikola auto** to work.\n\nInitially I was getting errors due to a more recent version of livereload (which, isn't this marked as fixed?) and resolved by forcing livereload=2.0.0. \n\nThe next problem is that the site appears not to rebuild when I save edits to a post. I have not RTFM yet (as instructed :) but when I do:\n nikola auto -b \n\nI should be able to edit a post file (e.g. 1.rst) and on save, see the changes immediately, correct? What I see in the server log output and in Chrome dev tools shows that the browser is re-requesting a bunch of files, but I have to manually do **nikola build** to get the site to rebuild. \n\nI'm using OS X 10.9.1, Python 2.7. Let me know if I can provide any other info; if I get it worked out I'll update the issue. \n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2014 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\nfrom __future__ import print_function, unicode_literals\n\nimport os\nimport subprocess\nimport webbrowser\n\nfrom nikola.plugin_categories import Command\nfrom nikola.utils import req_missing\n\n\nclass CommandAuto(Command):\n \"\"\"Start debugging console.\"\"\"\n name = \"auto\"\n doc_purpose = \"automatically detect site changes, rebuild and optionally refresh a browser\"\n cmd_options = [\n {\n 'name': 'browser',\n 'short': 'b',\n 'type': bool,\n 'help': 'Start a web browser.',\n 'default': False,\n },\n {\n 'name': 'port',\n 'short': 'p',\n 'long': 'port',\n 'default': 8000,\n 'type': int,\n 'help': 'Port nummber (default: 8000)',\n },\n ]\n\n def _execute(self, options, args):\n \"\"\"Start the watcher.\"\"\"\n try:\n from livereload import Server\n except ImportError:\n req_missing(['livereload>=2.0.0'], 'use the \"auto\" command')\n return\n\n # Run an initial build so we are uptodate\n subprocess.call((\"nikola\", \"build\"))\n\n port = options and options.get('port')\n\n server = Server()\n server.watch('conf.py')\n server.watch('themes/')\n server.watch('templates/')\n server.watch(self.site.config['GALLERY_PATH'])\n for item in self.site.config['post_pages']:\n server.watch(os.path.dirname(item[0]))\n for item in self.site.config['FILES_FOLDERS']:\n server.watch(os.path.dirname(item))\n\n out_folder = self.site.config['OUTPUT_FOLDER']\n if options and options.get('browser'):\n webbrowser.open('http://localhost:{0}'.format(port))\n\n server.serve(port, None, out_folder)\n", "path": "nikola/plugins/command/auto.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2014 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\nfrom __future__ import print_function, unicode_literals\n\nimport os\nimport subprocess\nimport webbrowser\n\nfrom nikola.plugin_categories import Command\nfrom nikola.utils import req_missing\n\n\nclass CommandAuto(Command):\n \"\"\"Start debugging console.\"\"\"\n name = \"auto\"\n doc_purpose = \"automatically detect site changes, rebuild and optionally refresh a browser\"\n cmd_options = [\n {\n 'name': 'browser',\n 'short': 'b',\n 'type': bool,\n 'help': 'Start a web browser.',\n 'default': False,\n },\n {\n 'name': 'port',\n 'short': 'p',\n 'long': 'port',\n 'default': 8000,\n 'type': int,\n 'help': 'Port nummber (default: 8000)',\n },\n ]\n\n def _execute(self, options, args):\n \"\"\"Start the watcher.\"\"\"\n try:\n from livereload import Server\n except ImportError:\n req_missing(['livereload>=2.0.0'], 'use the \"auto\" command')\n return\n\n # Run an initial build so we are up-to-date\n subprocess.call((\"nikola\", \"build\"))\n\n port = options and options.get('port')\n\n server = Server()\n server.watch('conf.py', 'nikola build')\n server.watch('themes/', 'nikola build')\n server.watch('templates/', 'nikola build')\n server.watch(self.site.config['GALLERY_PATH'])\n for item in self.site.config['post_pages']:\n server.watch(os.path.dirname(item[0]), 'nikola build')\n for item in self.site.config['FILES_FOLDERS']:\n server.watch(os.path.dirname(item), 'nikola build')\n\n out_folder = self.site.config['OUTPUT_FOLDER']\n if options and options.get('browser'):\n webbrowser.open('http://localhost:{0}'.format(port))\n\n server.serve(port, None, out_folder)\n", "path": "nikola/plugins/command/auto.py"}]}
| 1,325 | 298 |
gh_patches_debug_5496
|
rasdani/github-patches
|
git_diff
|
mne-tools__mne-bids-pipeline-427
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
CTF source localization bug
During Step-10 I get an error. Bids pipeline is trying to find a fif file in the original bids meg directory, but the original dataset is a CTF .ds. The BIDSPath is also trying to find the -ave.fif file, so the designation of 'extension' during the BIDSPath initiation is ambiguous.
ERROR:
21:36:00 [Step-10][sub-ON26309, ses-01] Estimating head ↔ MRI transform
21:36:01 A critical error occurred.
....
FileNotFoundError: fname does not exist: /fast/BIDS_HV_V1mod/sub-ON26309/ses-01/meg/sub-ON26309_ses-01_task-airpuff_run-01_meg.fif
______________
The file it is looking for is : /fast/BIDS_HV_V1mod/sub-ON26309/ses-01/meg/sub-ON26309_ses-01_task-airpuff_run-01_meg.**ds**
_______________
The issue appears to arise in - Line 107 of 02-make-forward.py. The bids_path is expecting a .fif file. I tested changing this to .ds in the bids_path designation, but it does not resolve the issue - since the source projection is being done on the average file, which has been saved out as a .fif file in the derivatives folder.
```
def run_forward(cfg, subject, session=None):
bids_path = BIDSPath(subject=subject,
session=session,
task=cfg.task,
acquisition=cfg.acq,
run=None,
recording=cfg.rec,
space=cfg.space,
extension='.fif', #<<<<<<<<<<<
datatype=cfg.datatype,
root=cfg.deriv_root,
check=False)
```
I am assuming that the way to solve this would be to call/instantiate BIDSPath twice, once for the acquisition dataset and once for the derivatives dataset.
extra info:
mne-bids v 0.8 (commit - 3a4543076912cebbc89a5f0b9433 )
mne-bids-pipeline: (commit - 861aa05c332ea9e215fd1250df4)
OS: ubuntu linux
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scripts/source/02-make_forward.py`
Content:
```
1 """
2 ====================
3 10. Forward solution
4 ====================
5
6 Calculate forward solution for MEG channels.
7 """
8
9 import itertools
10 import logging
11 from typing import Optional
12
13 import mne
14 from mne.utils import BunchConst
15 from mne.parallel import parallel_func
16 from mne.datasets import fetch_fsaverage
17 from mne_bids import BIDSPath, get_head_mri_trans
18
19 import config
20 from config import gen_log_message, on_error, failsafe_run
21
22 logger = logging.getLogger('mne-bids-pipeline')
23
24
25 def _prepare_forward_fsaverage(cfg):
26 assert cfg.fs_subject == 'fsaverage'
27 trans = 'fsaverage' # MNE has a built-in fsaverage transformation
28 bem_sol = cfg.fs_subjects_dir / 'fsaverage' / \
29 'bem' / 'fsaverage-5120-5120-5120-bem-sol.fif'
30 if not bem_sol.exists():
31 fetch_fsaverage(cfg.fs_subjects_dir)
32 src = mne.setup_source_space(subject='fsaverage',
33 subjects_dir=cfg.fs_subjects_dir,
34 spacing=cfg.spacing,
35 add_dist=False,
36 n_jobs=cfg.n_jobs)
37 return src, trans, str(bem_sol)
38
39
40 def _prepare_forward(cfg, bids_path, fname_trans):
41 # Generate a head ↔ MRI transformation matrix from the
42 # electrophysiological and MRI sidecar files, and save it to an MNE
43 # "trans" file in the derivatives folder.
44 subject, session = bids_path.subject, bids_path.session
45
46 if cfg.mri_t1_path_generator is None:
47 t1_bids_path = None
48 else:
49 t1_bids_path = BIDSPath(subject=subject,
50 session=session,
51 root=cfg.bids_root)
52 t1_bids_path = cfg.mri_t1_path_generator(t1_bids_path.copy())
53 if t1_bids_path.suffix is None:
54 t1_bids_path.update(suffix='T1w')
55 if t1_bids_path.datatype is None:
56 t1_bids_path.update(datatype='anat')
57
58 msg = 'Estimating head ↔ MRI transform'
59 logger.info(gen_log_message(message=msg, step=10, subject=subject,
60 session=session))
61
62 trans = get_head_mri_trans(
63 bids_path.copy().update(run=cfg.runs[0],
64 root=cfg.bids_root),
65 t1_bids_path=t1_bids_path,
66 fs_subject=cfg.fs_subject,
67 fs_subjects_dir=cfg.fs_subjects_dir)
68
69 # Create the source space.
70 msg = 'Creating source space'
71 logger.info(gen_log_message(message=msg, step=10, subject=subject,
72 session=session))
73 src = mne.setup_source_space(subject=cfg.fs_subject,
74 subjects_dir=cfg.fs_subjects_dir,
75 spacing=cfg.spacing,
76 add_dist=False,
77 n_jobs=cfg.n_jobs)
78
79 # Calculate the BEM solution.
80 # Here we only use a 3-layers BEM only if EEG is available.
81 msg = 'Calculating BEM solution'
82 logger.info(gen_log_message(message=msg, step=10, subject=subject,
83 session=session))
84
85 if 'eeg' in cfg.ch_types:
86 conductivity = (0.3, 0.006, 0.3)
87 else:
88 conductivity = (0.3,)
89
90 try:
91 bem_model = mne.make_bem_model(subject=cfg.fs_subject,
92 subjects_dir=cfg.fs_subjects_dir,
93 ico=4, conductivity=conductivity)
94 except FileNotFoundError:
95 message = ("Could not make BEM model due to a missing file. \n"
96 "Can be solved by setting recreate_bem=True in the config "
97 "to force recreation of the BEM model, or by deleting the\n"
98 f" {cfg.bids_root}/derivatives/freesurfer/"
99 f"subjects/sub-{subject}/bem/ folder")
100 raise FileNotFoundError(message)
101
102 bem_sol = mne.make_bem_solution(bem_model)
103 return src, trans, bem_sol
104
105
106 @failsafe_run(on_error=on_error)
107 def run_forward(cfg, subject, session=None):
108 bids_path = BIDSPath(subject=subject,
109 session=session,
110 task=cfg.task,
111 acquisition=cfg.acq,
112 run=None,
113 recording=cfg.rec,
114 space=cfg.space,
115 extension='.fif',
116 datatype=cfg.datatype,
117 root=cfg.deriv_root,
118 check=False)
119
120 fname_evoked = bids_path.copy().update(suffix='ave')
121 fname_trans = bids_path.copy().update(suffix='trans')
122 fname_fwd = bids_path.copy().update(suffix='fwd')
123
124 if cfg.use_template_mri:
125 src, trans, bem_sol = _prepare_forward_fsaverage(cfg)
126 else:
127 src, trans, bem_sol = _prepare_forward(cfg, bids_path, fname_trans)
128
129 # Finally, calculate and save the forward solution.
130 msg = 'Calculating forward solution'
131 logger.info(gen_log_message(message=msg, step=10, subject=subject,
132 session=session))
133 info = mne.io.read_info(fname_evoked)
134 fwd = mne.make_forward_solution(info, trans=trans, src=src,
135 bem=bem_sol, mindist=cfg.mindist)
136
137 mne.write_trans(fname_trans, fwd['mri_head_t'])
138 mne.write_forward_solution(fname_fwd, fwd, overwrite=True)
139
140
141 def get_config(
142 subject: Optional[str] = None,
143 session: Optional[str] = None
144 ) -> BunchConst:
145 cfg = BunchConst(
146 task=config.get_task(),
147 runs=config.get_runs(subject=subject),
148 datatype=config.get_datatype(),
149 acq=config.acq,
150 rec=config.rec,
151 space=config.space,
152 mri_t1_path_generator=config.mri_t1_path_generator,
153 mindist=config.mindist,
154 spacing=config.spacing,
155 use_template_mri=config.use_template_mri,
156 ch_types=config.ch_types,
157 fs_subject=config.get_fs_subject(subject=subject),
158 fs_subjects_dir=config.get_fs_subjects_dir(),
159 deriv_root=config.get_deriv_root(),
160 bids_root=config.get_bids_root(),
161 n_jobs=config.get_n_jobs()
162 )
163 return cfg
164
165
166 def main():
167 """Run forward."""
168 msg = 'Running Step 10: Create forward solution'
169 logger.info(gen_log_message(step=10, message=msg))
170
171 if not config.run_source_estimation:
172 msg = ' … skipping: run_source_estimation is set to False.'
173 logger.info(gen_log_message(step=10, message=msg))
174 return
175
176 parallel, run_func, _ = parallel_func(run_forward,
177 n_jobs=config.get_n_jobs())
178 parallel(run_func(get_config(subject=subject), subject, session)
179 for subject, session in
180 itertools.product(config.get_subjects(),
181 config.get_sessions()))
182
183 msg = 'Completed Step 10: Create forward solution'
184 logger.info(gen_log_message(step=10, message=msg))
185
186
187 if __name__ == '__main__':
188 main()
189
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scripts/source/02-make_forward.py b/scripts/source/02-make_forward.py
--- a/scripts/source/02-make_forward.py
+++ b/scripts/source/02-make_forward.py
@@ -61,7 +61,8 @@
trans = get_head_mri_trans(
bids_path.copy().update(run=cfg.runs[0],
- root=cfg.bids_root),
+ root=cfg.bids_root,
+ extension=None),
t1_bids_path=t1_bids_path,
fs_subject=cfg.fs_subject,
fs_subjects_dir=cfg.fs_subjects_dir)
|
{"golden_diff": "diff --git a/scripts/source/02-make_forward.py b/scripts/source/02-make_forward.py\n--- a/scripts/source/02-make_forward.py\n+++ b/scripts/source/02-make_forward.py\n@@ -61,7 +61,8 @@\n \n trans = get_head_mri_trans(\n bids_path.copy().update(run=cfg.runs[0],\n- root=cfg.bids_root),\n+ root=cfg.bids_root,\n+ extension=None),\n t1_bids_path=t1_bids_path,\n fs_subject=cfg.fs_subject,\n fs_subjects_dir=cfg.fs_subjects_dir)\n", "issue": "CTF source localization bug\nDuring Step-10 I get an error. Bids pipeline is trying to find a fif file in the original bids meg directory, but the original dataset is a CTF .ds. The BIDSPath is also trying to find the -ave.fif file, so the designation of 'extension' during the BIDSPath initiation is ambiguous.\r\n\r\nERROR:\r\n21:36:00 [Step-10][sub-ON26309, ses-01] Estimating head \u2194 MRI transform\r\n21:36:01 A critical error occurred.\r\n....\r\nFileNotFoundError: fname does not exist: /fast/BIDS_HV_V1mod/sub-ON26309/ses-01/meg/sub-ON26309_ses-01_task-airpuff_run-01_meg.fif\r\n\r\n______________\r\nThe file it is looking for is : /fast/BIDS_HV_V1mod/sub-ON26309/ses-01/meg/sub-ON26309_ses-01_task-airpuff_run-01_meg.**ds**\r\n\r\n\r\n_______________\r\n\r\nThe issue appears to arise in - Line 107 of 02-make-forward.py. The bids_path is expecting a .fif file. I tested changing this to .ds in the bids_path designation, but it does not resolve the issue - since the source projection is being done on the average file, which has been saved out as a .fif file in the derivatives folder.\r\n\r\n```\r\ndef run_forward(cfg, subject, session=None):\r\n bids_path = BIDSPath(subject=subject,\r\n session=session,\r\n task=cfg.task,\r\n acquisition=cfg.acq,\r\n run=None,\r\n recording=cfg.rec,\r\n space=cfg.space,\r\n extension='.fif', #<<<<<<<<<<<\r\n datatype=cfg.datatype,\r\n root=cfg.deriv_root,\r\n check=False)\r\n```\r\nI am assuming that the way to solve this would be to call/instantiate BIDSPath twice, once for the acquisition dataset and once for the derivatives dataset. \r\n\r\n\r\nextra info:\r\nmne-bids v 0.8 (commit - 3a4543076912cebbc89a5f0b9433 )\r\nmne-bids-pipeline: (commit - 861aa05c332ea9e215fd1250df4)\r\nOS: ubuntu linux\r\n\r\n\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "\"\"\"\n====================\n10. Forward solution\n====================\n\nCalculate forward solution for MEG channels.\n\"\"\"\n\nimport itertools\nimport logging\nfrom typing import Optional\n\nimport mne\nfrom mne.utils import BunchConst\nfrom mne.parallel import parallel_func\nfrom mne.datasets import fetch_fsaverage\nfrom mne_bids import BIDSPath, get_head_mri_trans\n\nimport config\nfrom config import gen_log_message, on_error, failsafe_run\n\nlogger = logging.getLogger('mne-bids-pipeline')\n\n\ndef _prepare_forward_fsaverage(cfg):\n assert cfg.fs_subject == 'fsaverage'\n trans = 'fsaverage' # MNE has a built-in fsaverage transformation\n bem_sol = cfg.fs_subjects_dir / 'fsaverage' / \\\n 'bem' / 'fsaverage-5120-5120-5120-bem-sol.fif'\n if not bem_sol.exists():\n fetch_fsaverage(cfg.fs_subjects_dir)\n src = mne.setup_source_space(subject='fsaverage',\n subjects_dir=cfg.fs_subjects_dir,\n spacing=cfg.spacing,\n add_dist=False,\n n_jobs=cfg.n_jobs)\n return src, trans, str(bem_sol)\n\n\ndef _prepare_forward(cfg, bids_path, fname_trans):\n # Generate a head \u2194 MRI transformation matrix from the\n # electrophysiological and MRI sidecar files, and save it to an MNE\n # \"trans\" file in the derivatives folder.\n subject, session = bids_path.subject, bids_path.session\n\n if cfg.mri_t1_path_generator is None:\n t1_bids_path = None\n else:\n t1_bids_path = BIDSPath(subject=subject,\n session=session,\n root=cfg.bids_root)\n t1_bids_path = cfg.mri_t1_path_generator(t1_bids_path.copy())\n if t1_bids_path.suffix is None:\n t1_bids_path.update(suffix='T1w')\n if t1_bids_path.datatype is None:\n t1_bids_path.update(datatype='anat')\n\n msg = 'Estimating head \u2194 MRI transform'\n logger.info(gen_log_message(message=msg, step=10, subject=subject,\n session=session))\n\n trans = get_head_mri_trans(\n bids_path.copy().update(run=cfg.runs[0],\n root=cfg.bids_root),\n t1_bids_path=t1_bids_path,\n fs_subject=cfg.fs_subject,\n fs_subjects_dir=cfg.fs_subjects_dir)\n\n # Create the source space.\n msg = 'Creating source space'\n logger.info(gen_log_message(message=msg, step=10, subject=subject,\n session=session))\n src = mne.setup_source_space(subject=cfg.fs_subject,\n subjects_dir=cfg.fs_subjects_dir,\n spacing=cfg.spacing,\n add_dist=False,\n n_jobs=cfg.n_jobs)\n\n # Calculate the BEM solution.\n # Here we only use a 3-layers BEM only if EEG is available.\n msg = 'Calculating BEM solution'\n logger.info(gen_log_message(message=msg, step=10, subject=subject,\n session=session))\n\n if 'eeg' in cfg.ch_types:\n conductivity = (0.3, 0.006, 0.3)\n else:\n conductivity = (0.3,)\n\n try:\n bem_model = mne.make_bem_model(subject=cfg.fs_subject,\n subjects_dir=cfg.fs_subjects_dir,\n ico=4, conductivity=conductivity)\n except FileNotFoundError:\n message = (\"Could not make BEM model due to a missing file. \\n\"\n \"Can be solved by setting recreate_bem=True in the config \"\n \"to force recreation of the BEM model, or by deleting the\\n\"\n f\" {cfg.bids_root}/derivatives/freesurfer/\"\n f\"subjects/sub-{subject}/bem/ folder\")\n raise FileNotFoundError(message)\n\n bem_sol = mne.make_bem_solution(bem_model)\n return src, trans, bem_sol\n\n\n@failsafe_run(on_error=on_error)\ndef run_forward(cfg, subject, session=None):\n bids_path = BIDSPath(subject=subject,\n session=session,\n task=cfg.task,\n acquisition=cfg.acq,\n run=None,\n recording=cfg.rec,\n space=cfg.space,\n extension='.fif',\n datatype=cfg.datatype,\n root=cfg.deriv_root,\n check=False)\n\n fname_evoked = bids_path.copy().update(suffix='ave')\n fname_trans = bids_path.copy().update(suffix='trans')\n fname_fwd = bids_path.copy().update(suffix='fwd')\n\n if cfg.use_template_mri:\n src, trans, bem_sol = _prepare_forward_fsaverage(cfg)\n else:\n src, trans, bem_sol = _prepare_forward(cfg, bids_path, fname_trans)\n\n # Finally, calculate and save the forward solution.\n msg = 'Calculating forward solution'\n logger.info(gen_log_message(message=msg, step=10, subject=subject,\n session=session))\n info = mne.io.read_info(fname_evoked)\n fwd = mne.make_forward_solution(info, trans=trans, src=src,\n bem=bem_sol, mindist=cfg.mindist)\n\n mne.write_trans(fname_trans, fwd['mri_head_t'])\n mne.write_forward_solution(fname_fwd, fwd, overwrite=True)\n\n\ndef get_config(\n subject: Optional[str] = None,\n session: Optional[str] = None\n) -> BunchConst:\n cfg = BunchConst(\n task=config.get_task(),\n runs=config.get_runs(subject=subject),\n datatype=config.get_datatype(),\n acq=config.acq,\n rec=config.rec,\n space=config.space,\n mri_t1_path_generator=config.mri_t1_path_generator,\n mindist=config.mindist,\n spacing=config.spacing,\n use_template_mri=config.use_template_mri,\n ch_types=config.ch_types,\n fs_subject=config.get_fs_subject(subject=subject),\n fs_subjects_dir=config.get_fs_subjects_dir(),\n deriv_root=config.get_deriv_root(),\n bids_root=config.get_bids_root(),\n n_jobs=config.get_n_jobs()\n )\n return cfg\n\n\ndef main():\n \"\"\"Run forward.\"\"\"\n msg = 'Running Step 10: Create forward solution'\n logger.info(gen_log_message(step=10, message=msg))\n\n if not config.run_source_estimation:\n msg = ' \u2026 skipping: run_source_estimation is set to False.'\n logger.info(gen_log_message(step=10, message=msg))\n return\n\n parallel, run_func, _ = parallel_func(run_forward,\n n_jobs=config.get_n_jobs())\n parallel(run_func(get_config(subject=subject), subject, session)\n for subject, session in\n itertools.product(config.get_subjects(),\n config.get_sessions()))\n\n msg = 'Completed Step 10: Create forward solution'\n logger.info(gen_log_message(step=10, message=msg))\n\n\nif __name__ == '__main__':\n main()\n", "path": "scripts/source/02-make_forward.py"}], "after_files": [{"content": "\"\"\"\n====================\n10. Forward solution\n====================\n\nCalculate forward solution for MEG channels.\n\"\"\"\n\nimport itertools\nimport logging\nfrom typing import Optional\n\nimport mne\nfrom mne.utils import BunchConst\nfrom mne.parallel import parallel_func\nfrom mne.datasets import fetch_fsaverage\nfrom mne_bids import BIDSPath, get_head_mri_trans\n\nimport config\nfrom config import gen_log_message, on_error, failsafe_run\n\nlogger = logging.getLogger('mne-bids-pipeline')\n\n\ndef _prepare_forward_fsaverage(cfg):\n assert cfg.fs_subject == 'fsaverage'\n trans = 'fsaverage' # MNE has a built-in fsaverage transformation\n bem_sol = cfg.fs_subjects_dir / 'fsaverage' / \\\n 'bem' / 'fsaverage-5120-5120-5120-bem-sol.fif'\n if not bem_sol.exists():\n fetch_fsaverage(cfg.fs_subjects_dir)\n src = mne.setup_source_space(subject='fsaverage',\n subjects_dir=cfg.fs_subjects_dir,\n spacing=cfg.spacing,\n add_dist=False,\n n_jobs=cfg.n_jobs)\n return src, trans, str(bem_sol)\n\n\ndef _prepare_forward(cfg, bids_path, fname_trans):\n # Generate a head \u2194 MRI transformation matrix from the\n # electrophysiological and MRI sidecar files, and save it to an MNE\n # \"trans\" file in the derivatives folder.\n subject, session = bids_path.subject, bids_path.session\n\n if cfg.mri_t1_path_generator is None:\n t1_bids_path = None\n else:\n t1_bids_path = BIDSPath(subject=subject,\n session=session,\n root=cfg.bids_root)\n t1_bids_path = cfg.mri_t1_path_generator(t1_bids_path.copy())\n if t1_bids_path.suffix is None:\n t1_bids_path.update(suffix='T1w')\n if t1_bids_path.datatype is None:\n t1_bids_path.update(datatype='anat')\n\n msg = 'Estimating head \u2194 MRI transform'\n logger.info(gen_log_message(message=msg, step=10, subject=subject,\n session=session))\n\n trans = get_head_mri_trans(\n bids_path.copy().update(run=cfg.runs[0],\n root=cfg.bids_root,\n extension=None),\n t1_bids_path=t1_bids_path,\n fs_subject=cfg.fs_subject,\n fs_subjects_dir=cfg.fs_subjects_dir)\n\n # Create the source space.\n msg = 'Creating source space'\n logger.info(gen_log_message(message=msg, step=10, subject=subject,\n session=session))\n src = mne.setup_source_space(subject=cfg.fs_subject,\n subjects_dir=cfg.fs_subjects_dir,\n spacing=cfg.spacing,\n add_dist=False,\n n_jobs=cfg.n_jobs)\n\n # Calculate the BEM solution.\n # Here we only use a 3-layers BEM only if EEG is available.\n msg = 'Calculating BEM solution'\n logger.info(gen_log_message(message=msg, step=10, subject=subject,\n session=session))\n\n if 'eeg' in cfg.ch_types:\n conductivity = (0.3, 0.006, 0.3)\n else:\n conductivity = (0.3,)\n\n try:\n bem_model = mne.make_bem_model(subject=cfg.fs_subject,\n subjects_dir=cfg.fs_subjects_dir,\n ico=4, conductivity=conductivity)\n except FileNotFoundError:\n message = (\"Could not make BEM model due to a missing file. \\n\"\n \"Can be solved by setting recreate_bem=True in the config \"\n \"to force recreation of the BEM model, or by deleting the\\n\"\n f\" {cfg.bids_root}/derivatives/freesurfer/\"\n f\"subjects/sub-{subject}/bem/ folder\")\n raise FileNotFoundError(message)\n\n bem_sol = mne.make_bem_solution(bem_model)\n return src, trans, bem_sol\n\n\n@failsafe_run(on_error=on_error)\ndef run_forward(cfg, subject, session=None):\n bids_path = BIDSPath(subject=subject,\n session=session,\n task=cfg.task,\n acquisition=cfg.acq,\n run=None,\n recording=cfg.rec,\n space=cfg.space,\n extension='.fif',\n datatype=cfg.datatype,\n root=cfg.deriv_root,\n check=False)\n\n fname_evoked = bids_path.copy().update(suffix='ave')\n fname_trans = bids_path.copy().update(suffix='trans')\n fname_fwd = bids_path.copy().update(suffix='fwd')\n\n if cfg.use_template_mri:\n src, trans, bem_sol = _prepare_forward_fsaverage(cfg)\n else:\n src, trans, bem_sol = _prepare_forward(cfg, bids_path, fname_trans)\n\n # Finally, calculate and save the forward solution.\n msg = 'Calculating forward solution'\n logger.info(gen_log_message(message=msg, step=10, subject=subject,\n session=session))\n info = mne.io.read_info(fname_evoked)\n fwd = mne.make_forward_solution(info, trans=trans, src=src,\n bem=bem_sol, mindist=cfg.mindist)\n\n mne.write_trans(fname_trans, fwd['mri_head_t'])\n mne.write_forward_solution(fname_fwd, fwd, overwrite=True)\n\n\ndef get_config(\n subject: Optional[str] = None,\n session: Optional[str] = None\n) -> BunchConst:\n cfg = BunchConst(\n task=config.get_task(),\n runs=config.get_runs(subject=subject),\n datatype=config.get_datatype(),\n acq=config.acq,\n rec=config.rec,\n space=config.space,\n mri_t1_path_generator=config.mri_t1_path_generator,\n mindist=config.mindist,\n spacing=config.spacing,\n use_template_mri=config.use_template_mri,\n ch_types=config.ch_types,\n fs_subject=config.get_fs_subject(subject=subject),\n fs_subjects_dir=config.get_fs_subjects_dir(),\n deriv_root=config.get_deriv_root(),\n bids_root=config.get_bids_root(),\n n_jobs=config.get_n_jobs()\n )\n return cfg\n\n\ndef main():\n \"\"\"Run forward.\"\"\"\n msg = 'Running Step 10: Create forward solution'\n logger.info(gen_log_message(step=10, message=msg))\n\n if not config.run_source_estimation:\n msg = ' \u2026 skipping: run_source_estimation is set to False.'\n logger.info(gen_log_message(step=10, message=msg))\n return\n\n parallel, run_func, _ = parallel_func(run_forward,\n n_jobs=config.get_n_jobs())\n parallel(run_func(get_config(subject=subject), subject, session)\n for subject, session in\n itertools.product(config.get_subjects(),\n config.get_sessions()))\n\n msg = 'Completed Step 10: Create forward solution'\n logger.info(gen_log_message(step=10, message=msg))\n\n\nif __name__ == '__main__':\n main()\n", "path": "scripts/source/02-make_forward.py"}]}
| 2,814 | 135 |
gh_patches_debug_2908
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-13216
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
iscomplexobj
Was mentioned here #11223, but it's open for almost a month now 😅
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ivy/functional/frontends/jax/numpy/logic.py`
Content:
```
1 # local
2 import ivy
3 from ivy.functional.frontends.jax.func_wrapper import (
4 to_ivy_arrays_and_back,
5 )
6 from ivy.functional.frontends.jax.numpy import (
7 promote_types_of_jax_inputs as promote_jax_arrays,
8 )
9
10
11 @to_ivy_arrays_and_back
12 def allclose(a, b, rtol=1e-05, atol=1e-08, equal_nan=False):
13 a, b = promote_jax_arrays(a, b)
14 return ivy.allclose(a, b, rtol=rtol, atol=atol, equal_nan=equal_nan)
15
16
17 @to_ivy_arrays_and_back
18 def array_equal(a1, a2, equal_nan: bool) -> bool:
19 a1, a2 = promote_jax_arrays(a1, a2)
20 if ivy.shape(a1) != ivy.shape(a2):
21 return False
22 eq = ivy.asarray(a1 == a2)
23 if equal_nan:
24 eq = ivy.logical_or(eq, ivy.logical_and(ivy.isnan(a1), ivy.isnan(a2)))
25 return ivy.all(eq)
26
27
28 @to_ivy_arrays_and_back
29 def array_equiv(a1, a2) -> bool:
30 a1, a2 = promote_jax_arrays(a1, a2)
31 try:
32 eq = ivy.equal(a1, a2)
33 except ValueError:
34 # shapes are not broadcastable
35 return False
36 return ivy.all(eq)
37
38
39 @to_ivy_arrays_and_back
40 def isneginf(x, out=None):
41 return ivy.isneginf(x, out=out)
42
43
44 @to_ivy_arrays_and_back
45 def isposinf(x, out=None):
46 return ivy.isposinf(x, out=out)
47
48
49 @to_ivy_arrays_and_back
50 def not_equal(x1, x2):
51 x1, x2 = promote_jax_arrays(x1, x2)
52 return ivy.not_equal(x1, x2)
53
54
55 @to_ivy_arrays_and_back
56 def less(x1, x2):
57 x1, x2 = promote_jax_arrays(x1, x2)
58 return ivy.less(x1, x2)
59
60
61 @to_ivy_arrays_and_back
62 def less_equal(x1, x2):
63 x1, x2 = promote_jax_arrays(x1, x2)
64 return ivy.less_equal(x1, x2)
65
66
67 @to_ivy_arrays_and_back
68 def greater(x1, x2):
69 x1, x2 = promote_jax_arrays(x1, x2)
70 return ivy.greater(x1, x2)
71
72
73 @to_ivy_arrays_and_back
74 def greater_equal(x1, x2):
75 x1, x2 = promote_jax_arrays(x1, x2)
76 return ivy.greater_equal(x1, x2)
77
78
79 @to_ivy_arrays_and_back
80 def isnan(x, out=None):
81 return ivy.isnan(x, out=out)
82
83
84 @to_ivy_arrays_and_back
85 def equal(x1, x2):
86 x1, x2 = promote_jax_arrays(x1, x2)
87 return ivy.equal(x1, x2)
88
89
90 @to_ivy_arrays_and_back
91 def all(a, axis=None, out=None, keepdims=False, *, where=False):
92 return ivy.all(a, axis=axis, keepdims=keepdims, out=out)
93
94
95 @to_ivy_arrays_and_back
96 def bitwise_and(x1, x2):
97 x1, x2 = promote_jax_arrays(x1, x2)
98 return ivy.bitwise_and(x1, x2)
99
100
101 @to_ivy_arrays_and_back
102 def bitwise_not(x):
103 return ivy.bitwise_invert(x)
104
105
106 @to_ivy_arrays_and_back
107 def bitwise_or(x1, x2):
108 x1, x2 = promote_jax_arrays(x1, x2)
109 return ivy.bitwise_or(x1, x2)
110
111
112 @to_ivy_arrays_and_back
113 def bitwise_xor(x1, x2):
114 x1, x2 = promote_jax_arrays(x1, x2)
115 return ivy.bitwise_xor(x1, x2)
116
117
118 @to_ivy_arrays_and_back
119 def any(a, axis=None, out=None, keepdims=False, *, where=None):
120 # TODO: Out not supported
121 ret = ivy.any(a, axis=axis, keepdims=keepdims)
122 if ivy.is_array(where):
123 where = ivy.array(where, dtype=ivy.bool)
124 ret = ivy.where(where, ret, ivy.default(None, ivy.zeros_like(ret)))
125 return ret
126
127
128 alltrue = all
129
130
131 sometrue = any
132
133
134 @to_ivy_arrays_and_back
135 # known issue in jnp's documentation of arguments
136 # https://github.com/google/jax/issues/9119
137 def logical_and(x1, x2, /):
138 if x1.dtype == "complex128" or x2.dtype == "complex128":
139 x1 = ivy.astype(x1, ivy.complex128)
140 x2 = ivy.astype(x2, ivy.complex128)
141 else:
142 x1, x2 = promote_jax_arrays(x1, x2)
143 return ivy.logical_and(x1, x2)
144
145
146 @to_ivy_arrays_and_back
147 def invert(x, /):
148 return ivy.bitwise_invert(x)
149
150
151 @to_ivy_arrays_and_back
152 def isfinite(x, /):
153 return ivy.isfinite(x)
154
155
156 @to_ivy_arrays_and_back
157 def isinf(x, /):
158 return ivy.isinf(x)
159
160
161 @to_ivy_arrays_and_back
162 def isclose(a, b, rtol=1e-05, atol=1e-08, equal_nan=False):
163 a, b = promote_jax_arrays(a, b)
164 return ivy.isclose(a, b, rtol=rtol, atol=atol, equal_nan=equal_nan)
165
166
167 @to_ivy_arrays_and_back
168 def logical_not(x, /):
169 return ivy.logical_not(x)
170
171
172 @to_ivy_arrays_and_back
173 def logical_or(x1, x2, /):
174 x1, x2 = promote_jax_arrays(x1, x2)
175 return ivy.logical_or(x1, x2)
176
177
178 @to_ivy_arrays_and_back
179 def isscalar(x, /):
180 return ivy.isscalar(x)
181
182
183 @to_ivy_arrays_and_back
184 def left_shift(x1, x2):
185 return ivy.isscalar(x1, x2)
186
187
188 @to_ivy_arrays_and_back
189 def isreal(x, out=None):
190 return ivy.isreal(x, out=out)
191
192
193 @to_ivy_arrays_and_back
194 def logical_xor(x1, x2, /):
195 x1, x2 = promote_jax_arrays(x1, x2)
196 return ivy.logical_xor(x1, x2)
197
198
199 @to_ivy_arrays_and_back
200 def right_shift(x1, x2, /):
201 return ivy.bitwise_right_shift(x1, x2)
202
203
204 @to_ivy_arrays_and_back
205 def isrealobj(x: any):
206 return not ivy.is_complex_dtype(ivy.dtype(x))
207
208
209 @to_ivy_arrays_and_back
210 def iscomplex(x: any):
211 return ivy.bitwise_invert(ivy.isreal(x))
212
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ivy/functional/frontends/jax/numpy/logic.py b/ivy/functional/frontends/jax/numpy/logic.py
--- a/ivy/functional/frontends/jax/numpy/logic.py
+++ b/ivy/functional/frontends/jax/numpy/logic.py
@@ -209,3 +209,14 @@
@to_ivy_arrays_and_back
def iscomplex(x: any):
return ivy.bitwise_invert(ivy.isreal(x))
+
+
+@to_ivy_arrays_and_back
+def iscomplexobj(x):
+ if x.ndim == 0:
+ return ivy.is_complex_dtype(ivy.dtype(x))
+ for ele in x:
+ if ivy.is_complex_dtype(ivy.dtype(ele)):
+ return True
+ else:
+ return False
\ No newline at end of file
|
{"golden_diff": "diff --git a/ivy/functional/frontends/jax/numpy/logic.py b/ivy/functional/frontends/jax/numpy/logic.py\n--- a/ivy/functional/frontends/jax/numpy/logic.py\n+++ b/ivy/functional/frontends/jax/numpy/logic.py\n@@ -209,3 +209,14 @@\n @to_ivy_arrays_and_back\n def iscomplex(x: any):\n return ivy.bitwise_invert(ivy.isreal(x))\n+\n+\n+@to_ivy_arrays_and_back\n+def iscomplexobj(x):\n+ if x.ndim == 0:\n+ return ivy.is_complex_dtype(ivy.dtype(x))\n+ for ele in x:\n+ if ivy.is_complex_dtype(ivy.dtype(ele)):\n+ return True\n+ else:\n+ return False\n\\ No newline at end of file\n", "issue": "iscomplexobj\nWas mentioned here #11223, but it's open for almost a month now \ud83d\ude05\n", "before_files": [{"content": "# local\nimport ivy\nfrom ivy.functional.frontends.jax.func_wrapper import (\n to_ivy_arrays_and_back,\n)\nfrom ivy.functional.frontends.jax.numpy import (\n promote_types_of_jax_inputs as promote_jax_arrays,\n)\n\n\n@to_ivy_arrays_and_back\ndef allclose(a, b, rtol=1e-05, atol=1e-08, equal_nan=False):\n a, b = promote_jax_arrays(a, b)\n return ivy.allclose(a, b, rtol=rtol, atol=atol, equal_nan=equal_nan)\n\n\n@to_ivy_arrays_and_back\ndef array_equal(a1, a2, equal_nan: bool) -> bool:\n a1, a2 = promote_jax_arrays(a1, a2)\n if ivy.shape(a1) != ivy.shape(a2):\n return False\n eq = ivy.asarray(a1 == a2)\n if equal_nan:\n eq = ivy.logical_or(eq, ivy.logical_and(ivy.isnan(a1), ivy.isnan(a2)))\n return ivy.all(eq)\n\n\n@to_ivy_arrays_and_back\ndef array_equiv(a1, a2) -> bool:\n a1, a2 = promote_jax_arrays(a1, a2)\n try:\n eq = ivy.equal(a1, a2)\n except ValueError:\n # shapes are not broadcastable\n return False\n return ivy.all(eq)\n\n\n@to_ivy_arrays_and_back\ndef isneginf(x, out=None):\n return ivy.isneginf(x, out=out)\n\n\n@to_ivy_arrays_and_back\ndef isposinf(x, out=None):\n return ivy.isposinf(x, out=out)\n\n\n@to_ivy_arrays_and_back\ndef not_equal(x1, x2):\n x1, x2 = promote_jax_arrays(x1, x2)\n return ivy.not_equal(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef less(x1, x2):\n x1, x2 = promote_jax_arrays(x1, x2)\n return ivy.less(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef less_equal(x1, x2):\n x1, x2 = promote_jax_arrays(x1, x2)\n return ivy.less_equal(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef greater(x1, x2):\n x1, x2 = promote_jax_arrays(x1, x2)\n return ivy.greater(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef greater_equal(x1, x2):\n x1, x2 = promote_jax_arrays(x1, x2)\n return ivy.greater_equal(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef isnan(x, out=None):\n return ivy.isnan(x, out=out)\n\n\n@to_ivy_arrays_and_back\ndef equal(x1, x2):\n x1, x2 = promote_jax_arrays(x1, x2)\n return ivy.equal(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef all(a, axis=None, out=None, keepdims=False, *, where=False):\n return ivy.all(a, axis=axis, keepdims=keepdims, out=out)\n\n\n@to_ivy_arrays_and_back\ndef bitwise_and(x1, x2):\n x1, x2 = promote_jax_arrays(x1, x2)\n return ivy.bitwise_and(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef bitwise_not(x):\n return ivy.bitwise_invert(x)\n\n\n@to_ivy_arrays_and_back\ndef bitwise_or(x1, x2):\n x1, x2 = promote_jax_arrays(x1, x2)\n return ivy.bitwise_or(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef bitwise_xor(x1, x2):\n x1, x2 = promote_jax_arrays(x1, x2)\n return ivy.bitwise_xor(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef any(a, axis=None, out=None, keepdims=False, *, where=None):\n # TODO: Out not supported\n ret = ivy.any(a, axis=axis, keepdims=keepdims)\n if ivy.is_array(where):\n where = ivy.array(where, dtype=ivy.bool)\n ret = ivy.where(where, ret, ivy.default(None, ivy.zeros_like(ret)))\n return ret\n\n\nalltrue = all\n\n\nsometrue = any\n\n\n@to_ivy_arrays_and_back\n# known issue in jnp's documentation of arguments\n# https://github.com/google/jax/issues/9119\ndef logical_and(x1, x2, /):\n if x1.dtype == \"complex128\" or x2.dtype == \"complex128\":\n x1 = ivy.astype(x1, ivy.complex128)\n x2 = ivy.astype(x2, ivy.complex128)\n else:\n x1, x2 = promote_jax_arrays(x1, x2)\n return ivy.logical_and(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef invert(x, /):\n return ivy.bitwise_invert(x)\n\n\n@to_ivy_arrays_and_back\ndef isfinite(x, /):\n return ivy.isfinite(x)\n\n\n@to_ivy_arrays_and_back\ndef isinf(x, /):\n return ivy.isinf(x)\n\n\n@to_ivy_arrays_and_back\ndef isclose(a, b, rtol=1e-05, atol=1e-08, equal_nan=False):\n a, b = promote_jax_arrays(a, b)\n return ivy.isclose(a, b, rtol=rtol, atol=atol, equal_nan=equal_nan)\n\n\n@to_ivy_arrays_and_back\ndef logical_not(x, /):\n return ivy.logical_not(x)\n\n\n@to_ivy_arrays_and_back\ndef logical_or(x1, x2, /):\n x1, x2 = promote_jax_arrays(x1, x2)\n return ivy.logical_or(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef isscalar(x, /):\n return ivy.isscalar(x)\n\n\n@to_ivy_arrays_and_back\ndef left_shift(x1, x2):\n return ivy.isscalar(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef isreal(x, out=None):\n return ivy.isreal(x, out=out)\n\n\n@to_ivy_arrays_and_back\ndef logical_xor(x1, x2, /):\n x1, x2 = promote_jax_arrays(x1, x2)\n return ivy.logical_xor(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef right_shift(x1, x2, /):\n return ivy.bitwise_right_shift(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef isrealobj(x: any):\n return not ivy.is_complex_dtype(ivy.dtype(x))\n\n\n@to_ivy_arrays_and_back\ndef iscomplex(x: any):\n return ivy.bitwise_invert(ivy.isreal(x))\n", "path": "ivy/functional/frontends/jax/numpy/logic.py"}], "after_files": [{"content": "# local\nimport ivy\nfrom ivy.functional.frontends.jax.func_wrapper import (\n to_ivy_arrays_and_back,\n)\nfrom ivy.functional.frontends.jax.numpy import (\n promote_types_of_jax_inputs as promote_jax_arrays,\n)\n\n\n@to_ivy_arrays_and_back\ndef allclose(a, b, rtol=1e-05, atol=1e-08, equal_nan=False):\n a, b = promote_jax_arrays(a, b)\n return ivy.allclose(a, b, rtol=rtol, atol=atol, equal_nan=equal_nan)\n\n\n@to_ivy_arrays_and_back\ndef array_equal(a1, a2, equal_nan: bool) -> bool:\n a1, a2 = promote_jax_arrays(a1, a2)\n if ivy.shape(a1) != ivy.shape(a2):\n return False\n eq = ivy.asarray(a1 == a2)\n if equal_nan:\n eq = ivy.logical_or(eq, ivy.logical_and(ivy.isnan(a1), ivy.isnan(a2)))\n return ivy.all(eq)\n\n\n@to_ivy_arrays_and_back\ndef array_equiv(a1, a2) -> bool:\n a1, a2 = promote_jax_arrays(a1, a2)\n try:\n eq = ivy.equal(a1, a2)\n except ValueError:\n # shapes are not broadcastable\n return False\n return ivy.all(eq)\n\n\n@to_ivy_arrays_and_back\ndef isneginf(x, out=None):\n return ivy.isneginf(x, out=out)\n\n\n@to_ivy_arrays_and_back\ndef isposinf(x, out=None):\n return ivy.isposinf(x, out=out)\n\n\n@to_ivy_arrays_and_back\ndef not_equal(x1, x2):\n x1, x2 = promote_jax_arrays(x1, x2)\n return ivy.not_equal(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef less(x1, x2):\n x1, x2 = promote_jax_arrays(x1, x2)\n return ivy.less(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef less_equal(x1, x2):\n x1, x2 = promote_jax_arrays(x1, x2)\n return ivy.less_equal(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef greater(x1, x2):\n x1, x2 = promote_jax_arrays(x1, x2)\n return ivy.greater(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef greater_equal(x1, x2):\n x1, x2 = promote_jax_arrays(x1, x2)\n return ivy.greater_equal(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef isnan(x, out=None):\n return ivy.isnan(x, out=out)\n\n\n@to_ivy_arrays_and_back\ndef equal(x1, x2):\n x1, x2 = promote_jax_arrays(x1, x2)\n return ivy.equal(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef all(a, axis=None, out=None, keepdims=False, *, where=False):\n return ivy.all(a, axis=axis, keepdims=keepdims, out=out)\n\n\n@to_ivy_arrays_and_back\ndef bitwise_and(x1, x2):\n x1, x2 = promote_jax_arrays(x1, x2)\n return ivy.bitwise_and(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef bitwise_not(x):\n return ivy.bitwise_invert(x)\n\n\n@to_ivy_arrays_and_back\ndef bitwise_or(x1, x2):\n x1, x2 = promote_jax_arrays(x1, x2)\n return ivy.bitwise_or(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef bitwise_xor(x1, x2):\n x1, x2 = promote_jax_arrays(x1, x2)\n return ivy.bitwise_xor(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef any(a, axis=None, out=None, keepdims=False, *, where=None):\n # TODO: Out not supported\n ret = ivy.any(a, axis=axis, keepdims=keepdims)\n if ivy.is_array(where):\n where = ivy.array(where, dtype=ivy.bool)\n ret = ivy.where(where, ret, ivy.default(None, ivy.zeros_like(ret)))\n return ret\n\n\nalltrue = all\n\n\nsometrue = any\n\n\n@to_ivy_arrays_and_back\n# known issue in jnp's documentation of arguments\n# https://github.com/google/jax/issues/9119\ndef logical_and(x1, x2, /):\n if x1.dtype == \"complex128\" or x2.dtype == \"complex128\":\n x1 = ivy.astype(x1, ivy.complex128)\n x2 = ivy.astype(x2, ivy.complex128)\n else:\n x1, x2 = promote_jax_arrays(x1, x2)\n return ivy.logical_and(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef invert(x, /):\n return ivy.bitwise_invert(x)\n\n\n@to_ivy_arrays_and_back\ndef isfinite(x, /):\n return ivy.isfinite(x)\n\n\n@to_ivy_arrays_and_back\ndef isinf(x, /):\n return ivy.isinf(x)\n\n\n@to_ivy_arrays_and_back\ndef isclose(a, b, rtol=1e-05, atol=1e-08, equal_nan=False):\n a, b = promote_jax_arrays(a, b)\n return ivy.isclose(a, b, rtol=rtol, atol=atol, equal_nan=equal_nan)\n\n\n@to_ivy_arrays_and_back\ndef logical_not(x, /):\n return ivy.logical_not(x)\n\n\n@to_ivy_arrays_and_back\ndef logical_or(x1, x2, /):\n x1, x2 = promote_jax_arrays(x1, x2)\n return ivy.logical_or(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef isscalar(x, /):\n return ivy.isscalar(x)\n\n\n@to_ivy_arrays_and_back\ndef left_shift(x1, x2):\n return ivy.isscalar(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef isreal(x, out=None):\n return ivy.isreal(x, out=out)\n\n\n@to_ivy_arrays_and_back\ndef logical_xor(x1, x2, /):\n x1, x2 = promote_jax_arrays(x1, x2)\n return ivy.logical_xor(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef right_shift(x1, x2, /):\n return ivy.bitwise_right_shift(x1, x2)\n\n\n@to_ivy_arrays_and_back\ndef isrealobj(x: any):\n return not ivy.is_complex_dtype(ivy.dtype(x))\n\n\n@to_ivy_arrays_and_back\ndef iscomplex(x: any):\n return ivy.bitwise_invert(ivy.isreal(x))\n\n\n@to_ivy_arrays_and_back\ndef iscomplexobj(x):\n if x.ndim == 0:\n return ivy.is_complex_dtype(ivy.dtype(x))\n for ele in x:\n if ivy.is_complex_dtype(ivy.dtype(ele)):\n return True\n else:\n return False", "path": "ivy/functional/frontends/jax/numpy/logic.py"}]}
| 2,451 | 190 |
gh_patches_debug_11789
|
rasdani/github-patches
|
git_diff
|
nipy__nipype-3509
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
MATLAB:mpath:PathAlterationNotSupported / Modifying the search path is not supported by MATLAB Compiler using MAtlab 2019b
[It seems modifying the matlab path using addpath() is not likely to be supported at any point after MATLAB MCR_R2018b](https://github.com/populse/populse_mia/issues/238).
However, [nipype use addpath()](https://github.com/nipy/nipype/blob/master/nipype/interfaces/matlab.py#L194) command in the matlab script generated .
So [the easy fix is to stick with R2018b.](https://fr.mathworks.com/matlabcentral/answers/554821-compiling-failing-using-matlab-2019b)
But it's a real problem not to be able to use newer MCRs in the future.
Can you remove the addpath() command when generating the script ? Or is there another way to use MCR after R2018b?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nipype/interfaces/matlab.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # emacs: -*- mode: python; py-indent-offset: 4; indent-tabs-mode: nil -*-
3 # vi: set ft=python sts=4 ts=4 sw=4 et:
4 """Interfaces to run MATLAB scripts."""
5 import os
6
7 from .. import config
8 from .base import (
9 CommandLineInputSpec,
10 InputMultiPath,
11 isdefined,
12 CommandLine,
13 traits,
14 File,
15 Directory,
16 )
17
18
19 def get_matlab_command():
20 """Determine whether Matlab is installed and can be executed."""
21 if "NIPYPE_NO_MATLAB" not in os.environ:
22 from nipype.utils.filemanip import which
23
24 return which(os.getenv("MATLABCMD", "matlab"))
25
26
27 no_matlab = get_matlab_command() is None
28
29
30 class MatlabInputSpec(CommandLineInputSpec):
31 """Basic expected inputs to Matlab interface"""
32
33 script = traits.Str(
34 argstr='-r "%s;exit"', desc="m-code to run", mandatory=True, position=-1
35 )
36 uses_mcr = traits.Bool(
37 desc="use MCR interface",
38 xor=["nodesktop", "nosplash", "single_comp_thread"],
39 nohash=True,
40 )
41 nodesktop = traits.Bool(
42 True,
43 argstr="-nodesktop",
44 usedefault=True,
45 desc="Switch off desktop mode on unix platforms",
46 nohash=True,
47 )
48 nosplash = traits.Bool(
49 True,
50 argstr="-nosplash",
51 usedefault=True,
52 desc="Switch of splash screen",
53 nohash=True,
54 )
55 logfile = File(argstr="-logfile %s", desc="Save matlab output to log")
56 single_comp_thread = traits.Bool(
57 argstr="-singleCompThread", desc="force single threaded operation", nohash=True
58 )
59 # non-commandline options
60 mfile = traits.Bool(True, desc="Run m-code using m-file", usedefault=True)
61 script_file = File(
62 "pyscript.m", usedefault=True, desc="Name of file to write m-code to"
63 )
64 paths = InputMultiPath(Directory(), desc="Paths to add to matlabpath")
65 prescript = traits.List(
66 ["ver,", "try,"], usedefault=True, desc="prescript to be added before code"
67 )
68 postscript = traits.List(
69 [
70 "\n,catch ME,",
71 "fprintf(2,'MATLAB code threw an exception:\\n');",
72 "fprintf(2,'%s\\n',ME.message);",
73 "if length(ME.stack) ~= 0, fprintf(2,'File:%s\\nName:%s\\nLine:%d\\n',ME.stack.file,ME.stack.name,ME.stack.line);, end;",
74 "end;",
75 ],
76 desc="script added after code",
77 usedefault=True,
78 )
79
80
81 class MatlabCommand(CommandLine):
82 """Interface that runs matlab code
83
84 >>> import nipype.interfaces.matlab as matlab
85 >>> mlab = matlab.MatlabCommand(mfile=False) # don't write script file
86 >>> mlab.inputs.script = "which('who')"
87 >>> out = mlab.run() # doctest: +SKIP
88 """
89
90 _cmd = "matlab"
91 _default_matlab_cmd = None
92 _default_mfile = None
93 _default_paths = None
94 input_spec = MatlabInputSpec
95
96 def __init__(self, matlab_cmd=None, **inputs):
97 """initializes interface to matlab
98 (default 'matlab -nodesktop -nosplash')
99 """
100 super(MatlabCommand, self).__init__(**inputs)
101 if matlab_cmd and isdefined(matlab_cmd):
102 self._cmd = matlab_cmd
103 elif self._default_matlab_cmd:
104 self._cmd = self._default_matlab_cmd
105
106 if self._default_mfile and not isdefined(self.inputs.mfile):
107 self.inputs.mfile = self._default_mfile
108
109 if self._default_paths and not isdefined(self.inputs.paths):
110 self.inputs.paths = self._default_paths
111
112 if not isdefined(self.inputs.single_comp_thread) and not isdefined(
113 self.inputs.uses_mcr
114 ):
115 if config.getboolean("execution", "single_thread_matlab"):
116 self.inputs.single_comp_thread = True
117 # For matlab commands force all output to be returned since matlab
118 # does not have a clean way of notifying an error
119 self.terminal_output = "allatonce"
120
121 @classmethod
122 def set_default_matlab_cmd(cls, matlab_cmd):
123 """Set the default MATLAB command line for MATLAB classes.
124
125 This method is used to set values for all MATLAB
126 subclasses. However, setting this will not update the output
127 type for any existing instances. For these, assign the
128 <instance>.inputs.matlab_cmd.
129 """
130 cls._default_matlab_cmd = matlab_cmd
131
132 @classmethod
133 def set_default_mfile(cls, mfile):
134 """Set the default MATLAB script file format for MATLAB classes.
135
136 This method is used to set values for all MATLAB
137 subclasses. However, setting this will not update the output
138 type for any existing instances. For these, assign the
139 <instance>.inputs.mfile.
140 """
141 cls._default_mfile = mfile
142
143 @classmethod
144 def set_default_paths(cls, paths):
145 """Set the default MATLAB paths for MATLAB classes.
146
147 This method is used to set values for all MATLAB
148 subclasses. However, setting this will not update the output
149 type for any existing instances. For these, assign the
150 <instance>.inputs.paths.
151 """
152 cls._default_paths = paths
153
154 def _run_interface(self, runtime):
155 self.terminal_output = "allatonce"
156 runtime = super(MatlabCommand, self)._run_interface(runtime)
157 try:
158 # Matlab can leave the terminal in a barbbled state
159 os.system("stty sane")
160 except:
161 # We might be on a system where stty doesn't exist
162 pass
163 if "MATLAB code threw an exception" in runtime.stderr:
164 self.raise_exception(runtime)
165 return runtime
166
167 def _format_arg(self, name, trait_spec, value):
168 if name in ["script"]:
169 argstr = trait_spec.argstr
170 if self.inputs.uses_mcr:
171 argstr = "%s"
172 return self._gen_matlab_command(argstr, value)
173 return super(MatlabCommand, self)._format_arg(name, trait_spec, value)
174
175 def _gen_matlab_command(self, argstr, script_lines):
176 """Generates commands and, if mfile specified, writes it to disk."""
177 cwd = os.getcwd()
178 mfile = self.inputs.mfile or self.inputs.uses_mcr
179 paths = []
180 if isdefined(self.inputs.paths):
181 paths = self.inputs.paths
182 # prescript
183 prescript = self.inputs.prescript
184 postscript = self.inputs.postscript
185
186 # prescript takes different default value depending on the mfile argument
187 if mfile:
188 prescript.insert(
189 0, "fprintf(1,'Executing %s at %s:\\n',mfilename(),datestr(now));"
190 )
191 else:
192 prescript.insert(0, "fprintf(1,'Executing code at %s:\\n',datestr(now));")
193 for path in paths:
194 prescript.append("addpath('%s');\n" % path)
195
196 if not mfile:
197 # clean up the code of comments and replace newlines with commas
198 script_lines = ",".join(
199 [
200 line
201 for line in script_lines.split("\n")
202 if not line.strip().startswith("%")
203 ]
204 )
205
206 script_lines = "\n".join(prescript) + script_lines + "\n".join(postscript)
207 if mfile:
208 with open(os.path.join(cwd, self.inputs.script_file), "wt") as mfile:
209 mfile.write(script_lines)
210 if self.inputs.uses_mcr:
211 script = "%s" % (os.path.join(cwd, self.inputs.script_file))
212 else:
213 script = "addpath('%s');%s" % (
214 cwd,
215 self.inputs.script_file.split(".")[0],
216 )
217 else:
218 script = "".join(script_lines.split("\n"))
219 return argstr % script
220
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nipype/interfaces/matlab.py b/nipype/interfaces/matlab.py
--- a/nipype/interfaces/matlab.py
+++ b/nipype/interfaces/matlab.py
@@ -191,7 +191,10 @@
else:
prescript.insert(0, "fprintf(1,'Executing code at %s:\\n',datestr(now));")
for path in paths:
- prescript.append("addpath('%s');\n" % path)
+ # addpath() is not available after compliation
+ # https://www.mathworks.com/help/compiler/ismcc.html
+ # https://www.mathworks.com/help/compiler/isdeployed.html
+ prescript.append("if ~(ismcc || isdeployed), addpath('%s'); end;\n" % path)
if not mfile:
# clean up the code of comments and replace newlines with commas
|
{"golden_diff": "diff --git a/nipype/interfaces/matlab.py b/nipype/interfaces/matlab.py\n--- a/nipype/interfaces/matlab.py\n+++ b/nipype/interfaces/matlab.py\n@@ -191,7 +191,10 @@\n else:\n prescript.insert(0, \"fprintf(1,'Executing code at %s:\\\\n',datestr(now));\")\n for path in paths:\n- prescript.append(\"addpath('%s');\\n\" % path)\n+ # addpath() is not available after compliation\n+ # https://www.mathworks.com/help/compiler/ismcc.html\n+ # https://www.mathworks.com/help/compiler/isdeployed.html\n+ prescript.append(\"if ~(ismcc || isdeployed), addpath('%s'); end;\\n\" % path)\n \n if not mfile:\n # clean up the code of comments and replace newlines with commas\n", "issue": "MATLAB:mpath:PathAlterationNotSupported / Modifying the search path is not supported by MATLAB Compiler using MAtlab 2019b\n[It seems modifying the matlab path using addpath() is not likely to be supported at any point after MATLAB MCR_R2018b](https://github.com/populse/populse_mia/issues/238).\r\nHowever, [nipype use addpath()](https://github.com/nipy/nipype/blob/master/nipype/interfaces/matlab.py#L194) command in the matlab script generated .\r\nSo [the easy fix is to stick with R2018b.](https://fr.mathworks.com/matlabcentral/answers/554821-compiling-failing-using-matlab-2019b)\r\nBut it's a real problem not to be able to use newer MCRs in the future.\r\nCan you remove the addpath() command when generating the script ? Or is there another way to use MCR after R2018b?\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# emacs: -*- mode: python; py-indent-offset: 4; indent-tabs-mode: nil -*-\n# vi: set ft=python sts=4 ts=4 sw=4 et:\n\"\"\"Interfaces to run MATLAB scripts.\"\"\"\nimport os\n\nfrom .. import config\nfrom .base import (\n CommandLineInputSpec,\n InputMultiPath,\n isdefined,\n CommandLine,\n traits,\n File,\n Directory,\n)\n\n\ndef get_matlab_command():\n \"\"\"Determine whether Matlab is installed and can be executed.\"\"\"\n if \"NIPYPE_NO_MATLAB\" not in os.environ:\n from nipype.utils.filemanip import which\n\n return which(os.getenv(\"MATLABCMD\", \"matlab\"))\n\n\nno_matlab = get_matlab_command() is None\n\n\nclass MatlabInputSpec(CommandLineInputSpec):\n \"\"\"Basic expected inputs to Matlab interface\"\"\"\n\n script = traits.Str(\n argstr='-r \"%s;exit\"', desc=\"m-code to run\", mandatory=True, position=-1\n )\n uses_mcr = traits.Bool(\n desc=\"use MCR interface\",\n xor=[\"nodesktop\", \"nosplash\", \"single_comp_thread\"],\n nohash=True,\n )\n nodesktop = traits.Bool(\n True,\n argstr=\"-nodesktop\",\n usedefault=True,\n desc=\"Switch off desktop mode on unix platforms\",\n nohash=True,\n )\n nosplash = traits.Bool(\n True,\n argstr=\"-nosplash\",\n usedefault=True,\n desc=\"Switch of splash screen\",\n nohash=True,\n )\n logfile = File(argstr=\"-logfile %s\", desc=\"Save matlab output to log\")\n single_comp_thread = traits.Bool(\n argstr=\"-singleCompThread\", desc=\"force single threaded operation\", nohash=True\n )\n # non-commandline options\n mfile = traits.Bool(True, desc=\"Run m-code using m-file\", usedefault=True)\n script_file = File(\n \"pyscript.m\", usedefault=True, desc=\"Name of file to write m-code to\"\n )\n paths = InputMultiPath(Directory(), desc=\"Paths to add to matlabpath\")\n prescript = traits.List(\n [\"ver,\", \"try,\"], usedefault=True, desc=\"prescript to be added before code\"\n )\n postscript = traits.List(\n [\n \"\\n,catch ME,\",\n \"fprintf(2,'MATLAB code threw an exception:\\\\n');\",\n \"fprintf(2,'%s\\\\n',ME.message);\",\n \"if length(ME.stack) ~= 0, fprintf(2,'File:%s\\\\nName:%s\\\\nLine:%d\\\\n',ME.stack.file,ME.stack.name,ME.stack.line);, end;\",\n \"end;\",\n ],\n desc=\"script added after code\",\n usedefault=True,\n )\n\n\nclass MatlabCommand(CommandLine):\n \"\"\"Interface that runs matlab code\n\n >>> import nipype.interfaces.matlab as matlab\n >>> mlab = matlab.MatlabCommand(mfile=False) # don't write script file\n >>> mlab.inputs.script = \"which('who')\"\n >>> out = mlab.run() # doctest: +SKIP\n \"\"\"\n\n _cmd = \"matlab\"\n _default_matlab_cmd = None\n _default_mfile = None\n _default_paths = None\n input_spec = MatlabInputSpec\n\n def __init__(self, matlab_cmd=None, **inputs):\n \"\"\"initializes interface to matlab\n (default 'matlab -nodesktop -nosplash')\n \"\"\"\n super(MatlabCommand, self).__init__(**inputs)\n if matlab_cmd and isdefined(matlab_cmd):\n self._cmd = matlab_cmd\n elif self._default_matlab_cmd:\n self._cmd = self._default_matlab_cmd\n\n if self._default_mfile and not isdefined(self.inputs.mfile):\n self.inputs.mfile = self._default_mfile\n\n if self._default_paths and not isdefined(self.inputs.paths):\n self.inputs.paths = self._default_paths\n\n if not isdefined(self.inputs.single_comp_thread) and not isdefined(\n self.inputs.uses_mcr\n ):\n if config.getboolean(\"execution\", \"single_thread_matlab\"):\n self.inputs.single_comp_thread = True\n # For matlab commands force all output to be returned since matlab\n # does not have a clean way of notifying an error\n self.terminal_output = \"allatonce\"\n\n @classmethod\n def set_default_matlab_cmd(cls, matlab_cmd):\n \"\"\"Set the default MATLAB command line for MATLAB classes.\n\n This method is used to set values for all MATLAB\n subclasses. However, setting this will not update the output\n type for any existing instances. For these, assign the\n <instance>.inputs.matlab_cmd.\n \"\"\"\n cls._default_matlab_cmd = matlab_cmd\n\n @classmethod\n def set_default_mfile(cls, mfile):\n \"\"\"Set the default MATLAB script file format for MATLAB classes.\n\n This method is used to set values for all MATLAB\n subclasses. However, setting this will not update the output\n type for any existing instances. For these, assign the\n <instance>.inputs.mfile.\n \"\"\"\n cls._default_mfile = mfile\n\n @classmethod\n def set_default_paths(cls, paths):\n \"\"\"Set the default MATLAB paths for MATLAB classes.\n\n This method is used to set values for all MATLAB\n subclasses. However, setting this will not update the output\n type for any existing instances. For these, assign the\n <instance>.inputs.paths.\n \"\"\"\n cls._default_paths = paths\n\n def _run_interface(self, runtime):\n self.terminal_output = \"allatonce\"\n runtime = super(MatlabCommand, self)._run_interface(runtime)\n try:\n # Matlab can leave the terminal in a barbbled state\n os.system(\"stty sane\")\n except:\n # We might be on a system where stty doesn't exist\n pass\n if \"MATLAB code threw an exception\" in runtime.stderr:\n self.raise_exception(runtime)\n return runtime\n\n def _format_arg(self, name, trait_spec, value):\n if name in [\"script\"]:\n argstr = trait_spec.argstr\n if self.inputs.uses_mcr:\n argstr = \"%s\"\n return self._gen_matlab_command(argstr, value)\n return super(MatlabCommand, self)._format_arg(name, trait_spec, value)\n\n def _gen_matlab_command(self, argstr, script_lines):\n \"\"\"Generates commands and, if mfile specified, writes it to disk.\"\"\"\n cwd = os.getcwd()\n mfile = self.inputs.mfile or self.inputs.uses_mcr\n paths = []\n if isdefined(self.inputs.paths):\n paths = self.inputs.paths\n # prescript\n prescript = self.inputs.prescript\n postscript = self.inputs.postscript\n\n # prescript takes different default value depending on the mfile argument\n if mfile:\n prescript.insert(\n 0, \"fprintf(1,'Executing %s at %s:\\\\n',mfilename(),datestr(now));\"\n )\n else:\n prescript.insert(0, \"fprintf(1,'Executing code at %s:\\\\n',datestr(now));\")\n for path in paths:\n prescript.append(\"addpath('%s');\\n\" % path)\n\n if not mfile:\n # clean up the code of comments and replace newlines with commas\n script_lines = \",\".join(\n [\n line\n for line in script_lines.split(\"\\n\")\n if not line.strip().startswith(\"%\")\n ]\n )\n\n script_lines = \"\\n\".join(prescript) + script_lines + \"\\n\".join(postscript)\n if mfile:\n with open(os.path.join(cwd, self.inputs.script_file), \"wt\") as mfile:\n mfile.write(script_lines)\n if self.inputs.uses_mcr:\n script = \"%s\" % (os.path.join(cwd, self.inputs.script_file))\n else:\n script = \"addpath('%s');%s\" % (\n cwd,\n self.inputs.script_file.split(\".\")[0],\n )\n else:\n script = \"\".join(script_lines.split(\"\\n\"))\n return argstr % script\n", "path": "nipype/interfaces/matlab.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# emacs: -*- mode: python; py-indent-offset: 4; indent-tabs-mode: nil -*-\n# vi: set ft=python sts=4 ts=4 sw=4 et:\n\"\"\"Interfaces to run MATLAB scripts.\"\"\"\nimport os\n\nfrom .. import config\nfrom .base import (\n CommandLineInputSpec,\n InputMultiPath,\n isdefined,\n CommandLine,\n traits,\n File,\n Directory,\n)\n\n\ndef get_matlab_command():\n \"\"\"Determine whether Matlab is installed and can be executed.\"\"\"\n if \"NIPYPE_NO_MATLAB\" not in os.environ:\n from nipype.utils.filemanip import which\n\n return which(os.getenv(\"MATLABCMD\", \"matlab\"))\n\n\nno_matlab = get_matlab_command() is None\n\n\nclass MatlabInputSpec(CommandLineInputSpec):\n \"\"\"Basic expected inputs to Matlab interface\"\"\"\n\n script = traits.Str(\n argstr='-r \"%s;exit\"', desc=\"m-code to run\", mandatory=True, position=-1\n )\n uses_mcr = traits.Bool(\n desc=\"use MCR interface\",\n xor=[\"nodesktop\", \"nosplash\", \"single_comp_thread\"],\n nohash=True,\n )\n nodesktop = traits.Bool(\n True,\n argstr=\"-nodesktop\",\n usedefault=True,\n desc=\"Switch off desktop mode on unix platforms\",\n nohash=True,\n )\n nosplash = traits.Bool(\n True,\n argstr=\"-nosplash\",\n usedefault=True,\n desc=\"Switch of splash screen\",\n nohash=True,\n )\n logfile = File(argstr=\"-logfile %s\", desc=\"Save matlab output to log\")\n single_comp_thread = traits.Bool(\n argstr=\"-singleCompThread\", desc=\"force single threaded operation\", nohash=True\n )\n # non-commandline options\n mfile = traits.Bool(True, desc=\"Run m-code using m-file\", usedefault=True)\n script_file = File(\n \"pyscript.m\", usedefault=True, desc=\"Name of file to write m-code to\"\n )\n paths = InputMultiPath(Directory(), desc=\"Paths to add to matlabpath\")\n prescript = traits.List(\n [\"ver,\", \"try,\"], usedefault=True, desc=\"prescript to be added before code\"\n )\n postscript = traits.List(\n [\n \"\\n,catch ME,\",\n \"fprintf(2,'MATLAB code threw an exception:\\\\n');\",\n \"fprintf(2,'%s\\\\n',ME.message);\",\n \"if length(ME.stack) ~= 0, fprintf(2,'File:%s\\\\nName:%s\\\\nLine:%d\\\\n',ME.stack.file,ME.stack.name,ME.stack.line);, end;\",\n \"end;\",\n ],\n desc=\"script added after code\",\n usedefault=True,\n )\n\n\nclass MatlabCommand(CommandLine):\n \"\"\"Interface that runs matlab code\n\n >>> import nipype.interfaces.matlab as matlab\n >>> mlab = matlab.MatlabCommand(mfile=False) # don't write script file\n >>> mlab.inputs.script = \"which('who')\"\n >>> out = mlab.run() # doctest: +SKIP\n \"\"\"\n\n _cmd = \"matlab\"\n _default_matlab_cmd = None\n _default_mfile = None\n _default_paths = None\n input_spec = MatlabInputSpec\n\n def __init__(self, matlab_cmd=None, **inputs):\n \"\"\"initializes interface to matlab\n (default 'matlab -nodesktop -nosplash')\n \"\"\"\n super(MatlabCommand, self).__init__(**inputs)\n if matlab_cmd and isdefined(matlab_cmd):\n self._cmd = matlab_cmd\n elif self._default_matlab_cmd:\n self._cmd = self._default_matlab_cmd\n\n if self._default_mfile and not isdefined(self.inputs.mfile):\n self.inputs.mfile = self._default_mfile\n\n if self._default_paths and not isdefined(self.inputs.paths):\n self.inputs.paths = self._default_paths\n\n if not isdefined(self.inputs.single_comp_thread) and not isdefined(\n self.inputs.uses_mcr\n ):\n if config.getboolean(\"execution\", \"single_thread_matlab\"):\n self.inputs.single_comp_thread = True\n # For matlab commands force all output to be returned since matlab\n # does not have a clean way of notifying an error\n self.terminal_output = \"allatonce\"\n\n @classmethod\n def set_default_matlab_cmd(cls, matlab_cmd):\n \"\"\"Set the default MATLAB command line for MATLAB classes.\n\n This method is used to set values for all MATLAB\n subclasses. However, setting this will not update the output\n type for any existing instances. For these, assign the\n <instance>.inputs.matlab_cmd.\n \"\"\"\n cls._default_matlab_cmd = matlab_cmd\n\n @classmethod\n def set_default_mfile(cls, mfile):\n \"\"\"Set the default MATLAB script file format for MATLAB classes.\n\n This method is used to set values for all MATLAB\n subclasses. However, setting this will not update the output\n type for any existing instances. For these, assign the\n <instance>.inputs.mfile.\n \"\"\"\n cls._default_mfile = mfile\n\n @classmethod\n def set_default_paths(cls, paths):\n \"\"\"Set the default MATLAB paths for MATLAB classes.\n\n This method is used to set values for all MATLAB\n subclasses. However, setting this will not update the output\n type for any existing instances. For these, assign the\n <instance>.inputs.paths.\n \"\"\"\n cls._default_paths = paths\n\n def _run_interface(self, runtime):\n self.terminal_output = \"allatonce\"\n runtime = super(MatlabCommand, self)._run_interface(runtime)\n try:\n # Matlab can leave the terminal in a barbbled state\n os.system(\"stty sane\")\n except:\n # We might be on a system where stty doesn't exist\n pass\n if \"MATLAB code threw an exception\" in runtime.stderr:\n self.raise_exception(runtime)\n return runtime\n\n def _format_arg(self, name, trait_spec, value):\n if name in [\"script\"]:\n argstr = trait_spec.argstr\n if self.inputs.uses_mcr:\n argstr = \"%s\"\n return self._gen_matlab_command(argstr, value)\n return super(MatlabCommand, self)._format_arg(name, trait_spec, value)\n\n def _gen_matlab_command(self, argstr, script_lines):\n \"\"\"Generates commands and, if mfile specified, writes it to disk.\"\"\"\n cwd = os.getcwd()\n mfile = self.inputs.mfile or self.inputs.uses_mcr\n paths = []\n if isdefined(self.inputs.paths):\n paths = self.inputs.paths\n # prescript\n prescript = self.inputs.prescript\n postscript = self.inputs.postscript\n\n # prescript takes different default value depending on the mfile argument\n if mfile:\n prescript.insert(\n 0, \"fprintf(1,'Executing %s at %s:\\\\n',mfilename(),datestr(now));\"\n )\n else:\n prescript.insert(0, \"fprintf(1,'Executing code at %s:\\\\n',datestr(now));\")\n for path in paths:\n # addpath() is not available after compliation\n # https://www.mathworks.com/help/compiler/ismcc.html\n # https://www.mathworks.com/help/compiler/isdeployed.html\n prescript.append(\"if ~(ismcc || isdeployed), addpath('%s'); end;\\n\" % path)\n\n if not mfile:\n # clean up the code of comments and replace newlines with commas\n script_lines = \",\".join(\n [\n line\n for line in script_lines.split(\"\\n\")\n if not line.strip().startswith(\"%\")\n ]\n )\n\n script_lines = \"\\n\".join(prescript) + script_lines + \"\\n\".join(postscript)\n if mfile:\n with open(os.path.join(cwd, self.inputs.script_file), \"wt\") as mfile:\n mfile.write(script_lines)\n if self.inputs.uses_mcr:\n script = \"%s\" % (os.path.join(cwd, self.inputs.script_file))\n else:\n script = \"addpath('%s');%s\" % (\n cwd,\n self.inputs.script_file.split(\".\")[0],\n )\n else:\n script = \"\".join(script_lines.split(\"\\n\"))\n return argstr % script\n", "path": "nipype/interfaces/matlab.py"}]}
| 2,844 | 200 |
gh_patches_debug_24665
|
rasdani/github-patches
|
git_diff
|
TabbycatDebate__tabbycat-1173
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
NonExistentTimeError and AmbiguousTimeError on daylight time changes with checkin filter window
I believe this error occurs when:
- There is a change into or out of daylight saving time
- A user loads a view that displays check-in statuses
- The current time is such that the beginning of the check-in window would be during the daylight saving time transition.
For example, if the check-in window is 12 hours, then loading any page that seeks check-in information (check-ins, results entry, private URL landing) at 2:15 p.m. would cause this error, because 2:15 a.m. is either ambiguous (if daylight saving just finished) or non-existent (if it just started).
https://sentry.io/organizations/tabbycat-ig/issues/975799227/?project=185382&referrer=github_plugin
```
NonExistentTimeError: 2019-04-07 02:51:30.519504
(24 additional frame(s) were not displayed)
...
File "utils/views.py", line 127, in get_tables
return [self.get_table()]
File "availability/views.py", line 167, in get_table
self.annotate_checkins(queryset, self.tournament)
File "availability/views.py", line 232, in annotate_checkins
return get_checkins(queryset, t, 'checkin_window_people')
File "checkins/utils.py", line 124, in get_checkins
events = get_unexpired_checkins(t, window_preference_type).values(
File "checkins/utils.py", line 61, in get_unexpired_checkins
time__gte=time_window).select_related('identifier').order_by('time')
NonExistentTimeError: 2019-04-07 02:51:30.519504
```
Relates to feature originally implemented from #513.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tabbycat/checkins/utils.py`
Content:
```
1 import datetime
2 import logging
3 import random
4 import string
5
6 from django.db import IntegrityError
7 from django.core.exceptions import ObjectDoesNotExist
8 from django.utils.translation import gettext as _
9
10 from .models import DebateIdentifier, Event, PersonIdentifier, VenueIdentifier
11
12 logger = logging.getLogger(__name__)
13
14
15 def generate_identifier(length=6):
16 """Generates a random identifier and saves it to the database."""
17 chars = string.ascii_uppercase + string.digits
18 return ''.join(random.SystemRandom().choice(chars) for _ in range(length))
19
20
21 IDENTIFIER_CLASSES = {
22 'participants.Person': PersonIdentifier,
23 'draw.Debate': DebateIdentifier,
24 'venues.Venue': VenueIdentifier,
25 }
26
27
28 def generate_identifiers(queryset, length=6, num_attempts=10):
29 """Generates identifiers for every instance in the given QuerySet."""
30 klass = IDENTIFIER_CLASSES[queryset.model._meta.label]
31 attr = klass.instance_attr
32
33 for instance in queryset:
34 identifier = generate_identifier(length=length)
35 for i in range(num_attempts):
36 try:
37 klass.objects.create(identifier=identifier, **{attr: instance})
38 except IntegrityError:
39 logger.warning("Identifier was not unique, trying again (%d of %d)", i, num_attempts)
40 continue
41 else:
42 break
43 else:
44 logger.error("Could not generate unique identifier for %r after %d tries", instance, num_attempts)
45
46
47 def delete_identifiers(queryset):
48 klass = IDENTIFIER_CLASSES[queryset.model._meta.label]
49 attr = klass.instance_attr
50 klass.objects.filter(**{attr + '__in': queryset}).delete()
51
52
53 def get_unexpired_checkins(tournament, window_preference_type):
54 if not window_preference_type:
55 time_window = datetime.datetime.fromtimestamp(0) # Unix start
56 else:
57 start = datetime.timedelta(hours=tournament.pref(window_preference_type))
58 time_window = datetime.datetime.now() - start
59
60 events = Event.objects.filter(tournament=tournament,
61 time__gte=time_window).select_related('identifier').order_by('time')
62 return events
63
64
65 def create_identifiers(model_to_make, items_to_check):
66 kind = model_to_make.instance_attr
67 identifiers_to_make = items_to_check.filter(checkin_identifier__isnull=True)
68
69 for item in identifiers_to_make:
70 model_to_make.objects.create(**{kind: item})
71
72 return
73
74
75 def single_checkin(instance, events):
76 instance.checked_icon = ''
77 instance.checked_in = False
78 try:
79 identifier = instance.checkin_identifier
80 instance.barcode = identifier.barcode
81 instance.checked_tooltip = _("Not checked in (barcode %(barcode)s)") % {'barcode': identifier.barcode}
82 except ObjectDoesNotExist:
83 identifier = None
84 instance.barcode = None
85 instance.checked_tooltip = _("Not checked in; no barcode assigned")
86
87 if identifier:
88 instance.time = next((e['time'] for e in events if e['identifier__barcode'] == identifier.barcode), None)
89 if instance.time:
90 instance.checked_in = True
91 instance.checked_icon = 'check'
92 instance.checked_tooltip = _("checked in at %(time)s") % {'time': instance.time.strftime('%H:%M')}
93 return instance
94
95
96 def multi_checkin(team, events, t):
97 team.checked_icon = ''
98 team.checked_in = False
99 tooltips = []
100
101 for speaker in team.speaker_set.all():
102 speaker = single_checkin(speaker, events)
103 if speaker.checked_in:
104 tooltip = _("%(speaker)s checked in at %(time)s.") % {'speaker': speaker.name, 'time': speaker.time.strftime('%H:%M')}
105 else:
106 tooltip = _("%(speaker)s is missing.") % {'speaker': speaker.name}
107 tooltips.append(tooltip)
108
109 team.checked_tooltip = " ".join(tooltips)
110
111 check_ins = sum(s.checked_in for s in team.speaker_set.all())
112 nsubstantives = t.pref('substantive_speakers')
113 if check_ins >= nsubstantives:
114 team.checked_in = True
115 team.checked_icon = 'check'
116 elif check_ins == nsubstantives - 1:
117 team.checked_in = True
118 team.checked_icon = 'shuffle'
119
120 return team
121
122
123 def get_checkins(queryset, t, window_preference_type):
124 events = get_unexpired_checkins(t, window_preference_type).values(
125 'time', 'identifier__barcode')
126 for instance in queryset:
127 if hasattr(instance, 'use_institution_prefix'):
128 instance = multi_checkin(instance, events, t)
129 else:
130 instance = single_checkin(instance, events)
131
132 return queryset
133
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tabbycat/checkins/utils.py b/tabbycat/checkins/utils.py
--- a/tabbycat/checkins/utils.py
+++ b/tabbycat/checkins/utils.py
@@ -4,7 +4,9 @@
import string
from django.db import IntegrityError
+from django.db.models import Q
from django.core.exceptions import ObjectDoesNotExist
+from django.utils import timezone
from django.utils.translation import gettext as _
from .models import DebateIdentifier, Event, PersonIdentifier, VenueIdentifier
@@ -51,15 +53,13 @@
def get_unexpired_checkins(tournament, window_preference_type):
- if not window_preference_type:
- time_window = datetime.datetime.fromtimestamp(0) # Unix start
- else:
+ filters = Q(tournament=tournament)
+ if window_preference_type:
start = datetime.timedelta(hours=tournament.pref(window_preference_type))
- time_window = datetime.datetime.now() - start
+ time_window = timezone.now() - start
+ filters &= Q(time_gte=time_window)
- events = Event.objects.filter(tournament=tournament,
- time__gte=time_window).select_related('identifier').order_by('time')
- return events
+ return Event.objects.filter(filters).select_related('identifier').order_by('time')
def create_identifiers(model_to_make, items_to_check):
|
{"golden_diff": "diff --git a/tabbycat/checkins/utils.py b/tabbycat/checkins/utils.py\n--- a/tabbycat/checkins/utils.py\n+++ b/tabbycat/checkins/utils.py\n@@ -4,7 +4,9 @@\n import string\n \n from django.db import IntegrityError\n+from django.db.models import Q\n from django.core.exceptions import ObjectDoesNotExist\n+from django.utils import timezone\n from django.utils.translation import gettext as _\n \n from .models import DebateIdentifier, Event, PersonIdentifier, VenueIdentifier\n@@ -51,15 +53,13 @@\n \n \n def get_unexpired_checkins(tournament, window_preference_type):\n- if not window_preference_type:\n- time_window = datetime.datetime.fromtimestamp(0) # Unix start\n- else:\n+ filters = Q(tournament=tournament)\n+ if window_preference_type:\n start = datetime.timedelta(hours=tournament.pref(window_preference_type))\n- time_window = datetime.datetime.now() - start\n+ time_window = timezone.now() - start\n+ filters &= Q(time_gte=time_window)\n \n- events = Event.objects.filter(tournament=tournament,\n- time__gte=time_window).select_related('identifier').order_by('time')\n- return events\n+ return Event.objects.filter(filters).select_related('identifier').order_by('time')\n \n \n def create_identifiers(model_to_make, items_to_check):\n", "issue": "NonExistentTimeError and AmbiguousTimeError on daylight time changes with checkin filter window\nI believe this error occurs when:\n- There is a change into or out of daylight saving time\n- A user loads a view that displays check-in statuses\n- The current time is such that the beginning of the check-in window would be during the daylight saving time transition.\n\nFor example, if the check-in window is 12 hours, then loading any page that seeks check-in information (check-ins, results entry, private URL landing) at 2:15 p.m. would cause this error, because 2:15 a.m. is either ambiguous (if daylight saving just finished) or non-existent (if it just started).\n\nhttps://sentry.io/organizations/tabbycat-ig/issues/975799227/?project=185382&referrer=github_plugin\n\n```\nNonExistentTimeError: 2019-04-07 02:51:30.519504\n(24 additional frame(s) were not displayed)\n...\n File \"utils/views.py\", line 127, in get_tables\n return [self.get_table()]\n File \"availability/views.py\", line 167, in get_table\n self.annotate_checkins(queryset, self.tournament)\n File \"availability/views.py\", line 232, in annotate_checkins\n return get_checkins(queryset, t, 'checkin_window_people')\n File \"checkins/utils.py\", line 124, in get_checkins\n events = get_unexpired_checkins(t, window_preference_type).values(\n File \"checkins/utils.py\", line 61, in get_unexpired_checkins\n time__gte=time_window).select_related('identifier').order_by('time')\n\nNonExistentTimeError: 2019-04-07 02:51:30.519504\n```\n\nRelates to feature originally implemented from #513.\n", "before_files": [{"content": "import datetime\nimport logging\nimport random\nimport string\n\nfrom django.db import IntegrityError\nfrom django.core.exceptions import ObjectDoesNotExist\nfrom django.utils.translation import gettext as _\n\nfrom .models import DebateIdentifier, Event, PersonIdentifier, VenueIdentifier\n\nlogger = logging.getLogger(__name__)\n\n\ndef generate_identifier(length=6):\n \"\"\"Generates a random identifier and saves it to the database.\"\"\"\n chars = string.ascii_uppercase + string.digits\n return ''.join(random.SystemRandom().choice(chars) for _ in range(length))\n\n\nIDENTIFIER_CLASSES = {\n 'participants.Person': PersonIdentifier,\n 'draw.Debate': DebateIdentifier,\n 'venues.Venue': VenueIdentifier,\n}\n\n\ndef generate_identifiers(queryset, length=6, num_attempts=10):\n \"\"\"Generates identifiers for every instance in the given QuerySet.\"\"\"\n klass = IDENTIFIER_CLASSES[queryset.model._meta.label]\n attr = klass.instance_attr\n\n for instance in queryset:\n identifier = generate_identifier(length=length)\n for i in range(num_attempts):\n try:\n klass.objects.create(identifier=identifier, **{attr: instance})\n except IntegrityError:\n logger.warning(\"Identifier was not unique, trying again (%d of %d)\", i, num_attempts)\n continue\n else:\n break\n else:\n logger.error(\"Could not generate unique identifier for %r after %d tries\", instance, num_attempts)\n\n\ndef delete_identifiers(queryset):\n klass = IDENTIFIER_CLASSES[queryset.model._meta.label]\n attr = klass.instance_attr\n klass.objects.filter(**{attr + '__in': queryset}).delete()\n\n\ndef get_unexpired_checkins(tournament, window_preference_type):\n if not window_preference_type:\n time_window = datetime.datetime.fromtimestamp(0) # Unix start\n else:\n start = datetime.timedelta(hours=tournament.pref(window_preference_type))\n time_window = datetime.datetime.now() - start\n\n events = Event.objects.filter(tournament=tournament,\n time__gte=time_window).select_related('identifier').order_by('time')\n return events\n\n\ndef create_identifiers(model_to_make, items_to_check):\n kind = model_to_make.instance_attr\n identifiers_to_make = items_to_check.filter(checkin_identifier__isnull=True)\n\n for item in identifiers_to_make:\n model_to_make.objects.create(**{kind: item})\n\n return\n\n\ndef single_checkin(instance, events):\n instance.checked_icon = ''\n instance.checked_in = False\n try:\n identifier = instance.checkin_identifier\n instance.barcode = identifier.barcode\n instance.checked_tooltip = _(\"Not checked in (barcode %(barcode)s)\") % {'barcode': identifier.barcode}\n except ObjectDoesNotExist:\n identifier = None\n instance.barcode = None\n instance.checked_tooltip = _(\"Not checked in; no barcode assigned\")\n\n if identifier:\n instance.time = next((e['time'] for e in events if e['identifier__barcode'] == identifier.barcode), None)\n if instance.time:\n instance.checked_in = True\n instance.checked_icon = 'check'\n instance.checked_tooltip = _(\"checked in at %(time)s\") % {'time': instance.time.strftime('%H:%M')}\n return instance\n\n\ndef multi_checkin(team, events, t):\n team.checked_icon = ''\n team.checked_in = False\n tooltips = []\n\n for speaker in team.speaker_set.all():\n speaker = single_checkin(speaker, events)\n if speaker.checked_in:\n tooltip = _(\"%(speaker)s checked in at %(time)s.\") % {'speaker': speaker.name, 'time': speaker.time.strftime('%H:%M')}\n else:\n tooltip = _(\"%(speaker)s is missing.\") % {'speaker': speaker.name}\n tooltips.append(tooltip)\n\n team.checked_tooltip = \" \".join(tooltips)\n\n check_ins = sum(s.checked_in for s in team.speaker_set.all())\n nsubstantives = t.pref('substantive_speakers')\n if check_ins >= nsubstantives:\n team.checked_in = True\n team.checked_icon = 'check'\n elif check_ins == nsubstantives - 1:\n team.checked_in = True\n team.checked_icon = 'shuffle'\n\n return team\n\n\ndef get_checkins(queryset, t, window_preference_type):\n events = get_unexpired_checkins(t, window_preference_type).values(\n 'time', 'identifier__barcode')\n for instance in queryset:\n if hasattr(instance, 'use_institution_prefix'):\n instance = multi_checkin(instance, events, t)\n else:\n instance = single_checkin(instance, events)\n\n return queryset\n", "path": "tabbycat/checkins/utils.py"}], "after_files": [{"content": "import datetime\nimport logging\nimport random\nimport string\n\nfrom django.db import IntegrityError\nfrom django.db.models import Q\nfrom django.core.exceptions import ObjectDoesNotExist\nfrom django.utils import timezone\nfrom django.utils.translation import gettext as _\n\nfrom .models import DebateIdentifier, Event, PersonIdentifier, VenueIdentifier\n\nlogger = logging.getLogger(__name__)\n\n\ndef generate_identifier(length=6):\n \"\"\"Generates a random identifier and saves it to the database.\"\"\"\n chars = string.ascii_uppercase + string.digits\n return ''.join(random.SystemRandom().choice(chars) for _ in range(length))\n\n\nIDENTIFIER_CLASSES = {\n 'participants.Person': PersonIdentifier,\n 'draw.Debate': DebateIdentifier,\n 'venues.Venue': VenueIdentifier,\n}\n\n\ndef generate_identifiers(queryset, length=6, num_attempts=10):\n \"\"\"Generates identifiers for every instance in the given QuerySet.\"\"\"\n klass = IDENTIFIER_CLASSES[queryset.model._meta.label]\n attr = klass.instance_attr\n\n for instance in queryset:\n identifier = generate_identifier(length=length)\n for i in range(num_attempts):\n try:\n klass.objects.create(identifier=identifier, **{attr: instance})\n except IntegrityError:\n logger.warning(\"Identifier was not unique, trying again (%d of %d)\", i, num_attempts)\n continue\n else:\n break\n else:\n logger.error(\"Could not generate unique identifier for %r after %d tries\", instance, num_attempts)\n\n\ndef delete_identifiers(queryset):\n klass = IDENTIFIER_CLASSES[queryset.model._meta.label]\n attr = klass.instance_attr\n klass.objects.filter(**{attr + '__in': queryset}).delete()\n\n\ndef get_unexpired_checkins(tournament, window_preference_type):\n filters = Q(tournament=tournament)\n if window_preference_type:\n start = datetime.timedelta(hours=tournament.pref(window_preference_type))\n time_window = timezone.now() - start\n filters &= Q(time_gte=time_window)\n\n return Event.objects.filter(filters).select_related('identifier').order_by('time')\n\n\ndef create_identifiers(model_to_make, items_to_check):\n kind = model_to_make.instance_attr\n identifiers_to_make = items_to_check.filter(checkin_identifier__isnull=True)\n\n for item in identifiers_to_make:\n model_to_make.objects.create(**{kind: item})\n\n return\n\n\ndef single_checkin(instance, events):\n instance.checked_icon = ''\n instance.checked_in = False\n try:\n identifier = instance.checkin_identifier\n instance.barcode = identifier.barcode\n instance.checked_tooltip = _(\"Not checked in (barcode %(barcode)s)\") % {'barcode': identifier.barcode}\n except ObjectDoesNotExist:\n identifier = None\n instance.barcode = None\n instance.checked_tooltip = _(\"Not checked in; no barcode assigned\")\n\n if identifier:\n instance.time = next((e['time'] for e in events if e['identifier__barcode'] == identifier.barcode), None)\n if instance.time:\n instance.checked_in = True\n instance.checked_icon = 'check'\n instance.checked_tooltip = _(\"checked in at %(time)s\") % {'time': instance.time.strftime('%H:%M')}\n return instance\n\n\ndef multi_checkin(team, events, t):\n team.checked_icon = ''\n team.checked_in = False\n tooltips = []\n\n for speaker in team.speaker_set.all():\n speaker = single_checkin(speaker, events)\n if speaker.checked_in:\n tooltip = _(\"%(speaker)s checked in at %(time)s.\") % {'speaker': speaker.name, 'time': speaker.time.strftime('%H:%M')}\n else:\n tooltip = _(\"%(speaker)s is missing.\") % {'speaker': speaker.name}\n tooltips.append(tooltip)\n\n team.checked_tooltip = \" \".join(tooltips)\n\n check_ins = sum(s.checked_in for s in team.speaker_set.all())\n nsubstantives = t.pref('substantive_speakers')\n if check_ins >= nsubstantives:\n team.checked_in = True\n team.checked_icon = 'check'\n elif check_ins == nsubstantives - 1:\n team.checked_in = True\n team.checked_icon = 'shuffle'\n\n return team\n\n\ndef get_checkins(queryset, t, window_preference_type):\n events = get_unexpired_checkins(t, window_preference_type).values(\n 'time', 'identifier__barcode')\n for instance in queryset:\n if hasattr(instance, 'use_institution_prefix'):\n instance = multi_checkin(instance, events, t)\n else:\n instance = single_checkin(instance, events)\n\n return queryset\n", "path": "tabbycat/checkins/utils.py"}]}
| 1,997 | 296 |
gh_patches_debug_39039
|
rasdani/github-patches
|
git_diff
|
Mailu__Mailu-1392
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
certwatcher.py is not using TLS_CERT_FILENAME nor TLS_KEYPAIR_FILENAME
certwatcher.py is assuming that the certificate and the key are in /certs and named respectively cert.pem and key.pem
However, Mailu offer two environment variables to allow specific path & filename for the certificate and the key which are used in config.py:
TLS_CERT_FILENAME
TLS_KEYPAIR_FILENAME
I would add that in my use case (https-portal as a reverse proxy), those files are not directly in /certs. My environment variables look like:
TLS_CERT_FILENAME=mail.example.net/production/signed.crt
TLS_KEYPAIR_FILENAME=mail.example.net/production/domain.key
Currently, certwatcher.py is monitoring `/certs`, whereas I would need to monitor
`/certs/mail.example.net/production`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/nginx/certwatcher.py`
Content:
```
1 #!/usr/bin/python3
2 """
3 Certificate watcher which reloads nginx or reconfigures it, depending on what
4 happens to externally supplied certificates. Only executed by start.py in case
5 of TLS_FLAVOR=[mail, cert]
6 """
7
8 from os.path import exists, split as path_split
9 from os import system
10 import time
11 from watchdog.observers.polling import PollingObserver
12 from watchdog.events import FileSystemEventHandler, FileDeletedEvent, \
13 FileCreatedEvent, FileModifiedEvent, FileMovedEvent
14
15 class ChangeHandler(FileSystemEventHandler):
16 "watchdog-handler listening on any event, executing the correct configuration/reload steps"
17 @staticmethod
18 def reload_nginx():
19 "merely reload nginx without re-configuring everything"
20 if exists("/var/run/nginx.pid"):
21 print("Reloading a running nginx")
22 system("nginx -s reload")
23
24 @staticmethod
25 def reexec_config():
26 "execute a reconfiguration of the system, which also reloads"
27 print("Reconfiguring system")
28 system("/config.py")
29
30 def on_any_event(self, event):
31 "event-listener checking if the affected files are the cert-files we're interested in"
32 if event.is_directory:
33 return
34
35 filename = path_split(event.src_path)[-1]
36 if isinstance(event, FileMovedEvent):
37 filename = path_split(event.dest_path)[-1]
38
39 if filename in ['cert.pem', 'key.pem']:
40 # all cases except for FileModified need re-configure
41 if isinstance(event, (FileCreatedEvent, FileMovedEvent, FileDeletedEvent)):
42 ChangeHandler.reexec_config()
43 # file modification needs only a nginx reload without config.py
44 elif isinstance(event, FileModifiedEvent):
45 ChangeHandler.reload_nginx()
46 # cert files have been moved away, re-configure
47 elif isinstance(event, FileMovedEvent) and path_split(event.src_path)[-1] in ['cert.pem', 'key.pem']:
48 ChangeHandler.reexec_config()
49
50
51 if __name__ == '__main__':
52 observer = PollingObserver()
53 handler = ChangeHandler()
54 observer.schedule(handler, "/certs", recursive=False)
55 observer.start()
56
57 try:
58 while True:
59 time.sleep(1)
60 except KeyboardInterrupt:
61 observer.stop()
62
63 observer.join()
64
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/core/nginx/certwatcher.py b/core/nginx/certwatcher.py
--- a/core/nginx/certwatcher.py
+++ b/core/nginx/certwatcher.py
@@ -5,8 +5,8 @@
of TLS_FLAVOR=[mail, cert]
"""
-from os.path import exists, split as path_split
-from os import system
+from os.path import exists, split as path_split, join as path_join
+from os import system, getenv
import time
from watchdog.observers.polling import PollingObserver
from watchdog.events import FileSystemEventHandler, FileDeletedEvent, \
@@ -14,6 +14,13 @@
class ChangeHandler(FileSystemEventHandler):
"watchdog-handler listening on any event, executing the correct configuration/reload steps"
+
+ def __init__(self, cert_path, keypair_path):
+ "Initialize a new changehandler"""
+ super().__init__()
+ self.cert_path = cert_path
+ self.keypair_path = keypair_path
+
@staticmethod
def reload_nginx():
"merely reload nginx without re-configuring everything"
@@ -32,11 +39,11 @@
if event.is_directory:
return
- filename = path_split(event.src_path)[-1]
+ filename = event.src_path
if isinstance(event, FileMovedEvent):
- filename = path_split(event.dest_path)[-1]
+ filename = event.dest_path
- if filename in ['cert.pem', 'key.pem']:
+ if filename in [self.cert_path, self.keypair_path]:
# all cases except for FileModified need re-configure
if isinstance(event, (FileCreatedEvent, FileMovedEvent, FileDeletedEvent)):
ChangeHandler.reexec_config()
@@ -44,14 +51,21 @@
elif isinstance(event, FileModifiedEvent):
ChangeHandler.reload_nginx()
# cert files have been moved away, re-configure
- elif isinstance(event, FileMovedEvent) and path_split(event.src_path)[-1] in ['cert.pem', 'key.pem']:
+ elif isinstance(event, FileMovedEvent) and event.src_path in [self.cert_path, self.keypair_path]:
ChangeHandler.reexec_config()
if __name__ == '__main__':
+ cert_path = path_join("/certs/", getenv("TLS_CERT_FILENAME", default="cert.pem"))
+ cert_dir = path_split(cert_path)[0]
+ keypair_path = path_join("/certs/", getenv("TLS_KEYPAIR_FILENAME", default="key.pem"))
+ keypair_dir = path_split(keypair_path)[0]
+
observer = PollingObserver()
- handler = ChangeHandler()
- observer.schedule(handler, "/certs", recursive=False)
+ handler = ChangeHandler(cert_path, keypair_path)
+ observer.schedule(handler, cert_dir, recursive=False)
+ if keypair_dir != cert_dir:
+ observer.schedule(handler, keypair_dir, recursive=False)
observer.start()
try:
|
{"golden_diff": "diff --git a/core/nginx/certwatcher.py b/core/nginx/certwatcher.py\n--- a/core/nginx/certwatcher.py\n+++ b/core/nginx/certwatcher.py\n@@ -5,8 +5,8 @@\n of TLS_FLAVOR=[mail, cert]\n \"\"\"\n \n-from os.path import exists, split as path_split\n-from os import system\n+from os.path import exists, split as path_split, join as path_join\n+from os import system, getenv\n import time\n from watchdog.observers.polling import PollingObserver\n from watchdog.events import FileSystemEventHandler, FileDeletedEvent, \\\n@@ -14,6 +14,13 @@\n \n class ChangeHandler(FileSystemEventHandler):\n \"watchdog-handler listening on any event, executing the correct configuration/reload steps\"\n+\n+ def __init__(self, cert_path, keypair_path):\n+ \"Initialize a new changehandler\"\"\"\n+ super().__init__()\n+ self.cert_path = cert_path\n+ self.keypair_path = keypair_path\n+\n @staticmethod\n def reload_nginx():\n \"merely reload nginx without re-configuring everything\"\n@@ -32,11 +39,11 @@\n if event.is_directory:\n return\n \n- filename = path_split(event.src_path)[-1]\n+ filename = event.src_path\n if isinstance(event, FileMovedEvent):\n- filename = path_split(event.dest_path)[-1]\n+ filename = event.dest_path\n \n- if filename in ['cert.pem', 'key.pem']:\n+ if filename in [self.cert_path, self.keypair_path]:\n # all cases except for FileModified need re-configure\n if isinstance(event, (FileCreatedEvent, FileMovedEvent, FileDeletedEvent)):\n ChangeHandler.reexec_config()\n@@ -44,14 +51,21 @@\n elif isinstance(event, FileModifiedEvent):\n ChangeHandler.reload_nginx()\n # cert files have been moved away, re-configure\n- elif isinstance(event, FileMovedEvent) and path_split(event.src_path)[-1] in ['cert.pem', 'key.pem']:\n+ elif isinstance(event, FileMovedEvent) and event.src_path in [self.cert_path, self.keypair_path]:\n ChangeHandler.reexec_config()\n \n \n if __name__ == '__main__':\n+ cert_path = path_join(\"/certs/\", getenv(\"TLS_CERT_FILENAME\", default=\"cert.pem\"))\n+ cert_dir = path_split(cert_path)[0]\n+ keypair_path = path_join(\"/certs/\", getenv(\"TLS_KEYPAIR_FILENAME\", default=\"key.pem\"))\n+ keypair_dir = path_split(keypair_path)[0]\n+\n observer = PollingObserver()\n- handler = ChangeHandler()\n- observer.schedule(handler, \"/certs\", recursive=False)\n+ handler = ChangeHandler(cert_path, keypair_path)\n+ observer.schedule(handler, cert_dir, recursive=False)\n+ if keypair_dir != cert_dir:\n+ observer.schedule(handler, keypair_dir, recursive=False)\n observer.start()\n \n try:\n", "issue": "certwatcher.py is not using TLS_CERT_FILENAME nor TLS_KEYPAIR_FILENAME\ncertwatcher.py is assuming that the certificate and the key are in /certs and named respectively cert.pem and key.pem\r\n\r\nHowever, Mailu offer two environment variables to allow specific path & filename for the certificate and the key which are used in config.py:\r\nTLS_CERT_FILENAME\r\nTLS_KEYPAIR_FILENAME\r\n\r\nI would add that in my use case (https-portal as a reverse proxy), those files are not directly in /certs. My environment variables look like:\r\nTLS_CERT_FILENAME=mail.example.net/production/signed.crt\r\nTLS_KEYPAIR_FILENAME=mail.example.net/production/domain.key\r\nCurrently, certwatcher.py is monitoring `/certs`, whereas I would need to monitor \r\n`/certs/mail.example.net/production`\n", "before_files": [{"content": "#!/usr/bin/python3\n\"\"\"\nCertificate watcher which reloads nginx or reconfigures it, depending on what\nhappens to externally supplied certificates. Only executed by start.py in case\nof TLS_FLAVOR=[mail, cert]\n\"\"\"\n\nfrom os.path import exists, split as path_split\nfrom os import system\nimport time\nfrom watchdog.observers.polling import PollingObserver\nfrom watchdog.events import FileSystemEventHandler, FileDeletedEvent, \\\n FileCreatedEvent, FileModifiedEvent, FileMovedEvent\n\nclass ChangeHandler(FileSystemEventHandler):\n \"watchdog-handler listening on any event, executing the correct configuration/reload steps\"\n @staticmethod\n def reload_nginx():\n \"merely reload nginx without re-configuring everything\"\n if exists(\"/var/run/nginx.pid\"):\n print(\"Reloading a running nginx\")\n system(\"nginx -s reload\")\n\n @staticmethod\n def reexec_config():\n \"execute a reconfiguration of the system, which also reloads\"\n print(\"Reconfiguring system\")\n system(\"/config.py\")\n\n def on_any_event(self, event):\n \"event-listener checking if the affected files are the cert-files we're interested in\"\n if event.is_directory:\n return\n\n filename = path_split(event.src_path)[-1]\n if isinstance(event, FileMovedEvent):\n filename = path_split(event.dest_path)[-1]\n\n if filename in ['cert.pem', 'key.pem']:\n # all cases except for FileModified need re-configure\n if isinstance(event, (FileCreatedEvent, FileMovedEvent, FileDeletedEvent)):\n ChangeHandler.reexec_config()\n # file modification needs only a nginx reload without config.py\n elif isinstance(event, FileModifiedEvent):\n ChangeHandler.reload_nginx()\n # cert files have been moved away, re-configure\n elif isinstance(event, FileMovedEvent) and path_split(event.src_path)[-1] in ['cert.pem', 'key.pem']:\n ChangeHandler.reexec_config()\n\n\nif __name__ == '__main__':\n observer = PollingObserver()\n handler = ChangeHandler()\n observer.schedule(handler, \"/certs\", recursive=False)\n observer.start()\n\n try:\n while True:\n time.sleep(1)\n except KeyboardInterrupt:\n observer.stop()\n\n observer.join()\n", "path": "core/nginx/certwatcher.py"}], "after_files": [{"content": "#!/usr/bin/python3\n\"\"\"\nCertificate watcher which reloads nginx or reconfigures it, depending on what\nhappens to externally supplied certificates. Only executed by start.py in case\nof TLS_FLAVOR=[mail, cert]\n\"\"\"\n\nfrom os.path import exists, split as path_split, join as path_join\nfrom os import system, getenv\nimport time\nfrom watchdog.observers.polling import PollingObserver\nfrom watchdog.events import FileSystemEventHandler, FileDeletedEvent, \\\n FileCreatedEvent, FileModifiedEvent, FileMovedEvent\n\nclass ChangeHandler(FileSystemEventHandler):\n \"watchdog-handler listening on any event, executing the correct configuration/reload steps\"\n\n def __init__(self, cert_path, keypair_path):\n \"Initialize a new changehandler\"\"\"\n super().__init__()\n self.cert_path = cert_path\n self.keypair_path = keypair_path\n\n @staticmethod\n def reload_nginx():\n \"merely reload nginx without re-configuring everything\"\n if exists(\"/var/run/nginx.pid\"):\n print(\"Reloading a running nginx\")\n system(\"nginx -s reload\")\n\n @staticmethod\n def reexec_config():\n \"execute a reconfiguration of the system, which also reloads\"\n print(\"Reconfiguring system\")\n system(\"/config.py\")\n\n def on_any_event(self, event):\n \"event-listener checking if the affected files are the cert-files we're interested in\"\n if event.is_directory:\n return\n\n filename = event.src_path\n if isinstance(event, FileMovedEvent):\n filename = event.dest_path\n\n if filename in [self.cert_path, self.keypair_path]:\n # all cases except for FileModified need re-configure\n if isinstance(event, (FileCreatedEvent, FileMovedEvent, FileDeletedEvent)):\n ChangeHandler.reexec_config()\n # file modification needs only a nginx reload without config.py\n elif isinstance(event, FileModifiedEvent):\n ChangeHandler.reload_nginx()\n # cert files have been moved away, re-configure\n elif isinstance(event, FileMovedEvent) and event.src_path in [self.cert_path, self.keypair_path]:\n ChangeHandler.reexec_config()\n\n\nif __name__ == '__main__':\n cert_path = path_join(\"/certs/\", getenv(\"TLS_CERT_FILENAME\", default=\"cert.pem\"))\n cert_dir = path_split(cert_path)[0]\n keypair_path = path_join(\"/certs/\", getenv(\"TLS_KEYPAIR_FILENAME\", default=\"key.pem\"))\n keypair_dir = path_split(keypair_path)[0]\n\n observer = PollingObserver()\n handler = ChangeHandler(cert_path, keypair_path)\n observer.schedule(handler, cert_dir, recursive=False)\n if keypair_dir != cert_dir:\n observer.schedule(handler, keypair_dir, recursive=False)\n observer.start()\n\n try:\n while True:\n time.sleep(1)\n except KeyboardInterrupt:\n observer.stop()\n\n observer.join()\n", "path": "core/nginx/certwatcher.py"}]}
| 1,028 | 647 |
gh_patches_debug_4390
|
rasdani/github-patches
|
git_diff
|
PrefectHQ__prefect-1991
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ifelse checks for True/False rather than truthy/falsy values
## Description
`prefect.tasks.control_flow.conditional.ifelse` should check for truthy/falsy values, but (relying on `switch`) checks for exact equality to `True` or `False`.
## Expected Behavior
[From the docs](https://docs.prefect.io/core/task_library/control_flow.html#if-else):
> If the condition evaluates True(ish), the true_task will run. If it evaluates False(ish), the false_task will run.
`ifelse` should run the `true_branch` for any value that evaluates to `True`: non-empty strings, dicts and lists, ints not equal to 0...
## Reproduction
```python
from prefect import Flow, task
from prefect.tasks.control_flow.conditional import ifelse, merge
@task
def run_if_truthy():
return 'a'
@task
def run_if_falsy():
return 'b'
@task
def return_truthy_value():
# non-empty strings are truthy
assert('c')
return 'c'
with Flow('test-flow') as flow:
branch_truthy = run_if_truthy()
branch_falsy = run_if_falsy()
ifelse(return_truthy_value(), branch_truthy, branch_falsy)
merged_result = merge(branch_truthy, branch_falsy)
result = flow.run()
assert(not result.result.get(merged_result).is_skipped())
assert(result.result.get(merged_result)._result.value == 'a')
```
Output:
```
[2020-02-03 16:38:57,428] INFO - prefect.FlowRunner | Beginning Flow run for 'test-flow'
[2020-02-03 16:38:57,431] INFO - prefect.FlowRunner | Starting flow run.
[2020-02-03 16:38:57,441] INFO - prefect.TaskRunner | Task 'return_truthy_value': Starting task run...
[2020-02-03 16:38:57,445] INFO - prefect.TaskRunner | Task 'return_truthy_value': finished task run for task with final state: 'Success'
[2020-02-03 16:38:57,455] INFO - prefect.TaskRunner | Task 'CompareValue: "True"': Starting task run...
[2020-02-03 16:38:57,460] INFO - prefect.TaskRunner | Task 'CompareValue: "True"': finished task run for task with final state: 'Skipped'
[2020-02-03 16:38:57,470] INFO - prefect.TaskRunner | Task 'run_if_truthy': Starting task run...
[2020-02-03 16:38:57,474] INFO - prefect.TaskRunner | Task 'run_if_truthy': finished task run for task with final state: 'Skipped'
[2020-02-03 16:38:57,483] INFO - prefect.TaskRunner | Task 'CompareValue: "False"': Starting task run...
[2020-02-03 16:38:57,488] INFO - prefect.TaskRunner | Task 'CompareValue: "False"': finished task run for task with final state: 'Skipped'
[2020-02-03 16:38:57,497] INFO - prefect.TaskRunner | Task 'run_if_falsy': Starting task run...
[2020-02-03 16:38:57,501] INFO - prefect.TaskRunner | Task 'run_if_falsy': finished task run for task with final state: 'Skipped'
[2020-02-03 16:38:57,510] INFO - prefect.TaskRunner | Task 'Merge': Starting task run...
[2020-02-03 16:38:57,514] INFO - prefect.TaskRunner | Task 'Merge': finished task run for task with final state: 'Skipped'
[2020-02-03 16:38:57,516] INFO - prefect.FlowRunner | Flow run SUCCESS: all reference tasks succeeded
Traceback (most recent call last):
File "/tmp/test-flow.py", line 25, in <module>
assert(not result.result.get(merged_result).is_skipped())
AssertionError
```
## Environment
Prefect 0.9.2, Python 3.6, on Linux x64.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/prefect/tasks/control_flow/conditional.py`
Content:
```
1 from typing import Any, Dict
2
3 import prefect
4 from prefect import Task
5 from prefect.engine import signals
6
7 __all__ = ["switch", "ifelse"]
8
9
10 class Merge(Task):
11 def __init__(self, **kwargs) -> None:
12 if kwargs.setdefault("skip_on_upstream_skip", False):
13 raise ValueError("Merge tasks must have `skip_on_upstream_skip=False`.")
14 kwargs.setdefault("trigger", prefect.triggers.not_all_skipped)
15 super().__init__(**kwargs)
16
17 def run(self, **task_results: Any) -> Any:
18 return next(
19 (v for k, v in sorted(task_results.items()) if v is not None), None,
20 )
21
22
23 class CompareValue(Task):
24 """
25 This task stores a `value` at initialization and compares it to a `value` received at runtime.
26 If the values don't match, it raises a SKIP exception.
27
28 Args:
29 - value (Any): the value this task will attempt to match when it runs
30 - **kwargs: keyword arguments for the Task
31 """
32
33 def __init__(self, value: Any, **kwargs: Any):
34 self.value = value
35 kwargs.setdefault("name", 'CompareValue: "{}"'.format(value))
36 super().__init__(**kwargs)
37
38 def run(self, value: Any) -> None:
39 """
40 Raises a SKIP signal if the passed value does not match the task's match value;
41 succeeds silently otherwise.
42
43 Args:
44 - value (Any): the value that will be matched against the task's value.
45 """
46 if value != self.value:
47 raise signals.SKIP(
48 'Provided value "{}" did not match "{}"'.format(value, self.value)
49 )
50
51
52 def switch(condition: Task, cases: Dict[Any, Task]) -> None:
53 """
54 Adds a SWITCH to a workflow.
55
56 The condition task is evaluated and the result is compared to the keys of the cases
57 dictionary. The task corresponding to the matching key is run; all other tasks are
58 skipped. Any tasks downstream of the skipped tasks are also skipped unless they set
59 `skip_on_upstream_skip=False`.
60
61 Example:
62 ```python
63 @task
64 def condition():
65 return "b" # returning 'b' will take the b_branch
66
67 @task
68 def a_branch():
69 return "A Branch"
70
71 @task
72 def b_branch():
73 return "B Branch"
74
75 with Flow("switch-flow") as flow:
76 switch(condition, dict(a=a_branch, b=b_branch))
77 ```
78
79 Args:
80 - condition (Task): a task whose result forms the condition for the switch
81 - cases (Dict[Any, Task]): a dict representing the "case" statements of the switch.
82 The value of the `condition` task will be compared to the keys of this dict, and
83 the matching task will be executed.
84
85 Raises:
86 - PrefectWarning: if any of the tasks in "cases" have upstream dependencies,
87 then this task will warn that those upstream tasks may run whether or not the switch condition matches their branch. The most common cause of this
88 is passing a list of tasks as one of the cases, which adds the `List` task
89 to the switch condition but leaves the tasks themselves upstream.
90 """
91
92 with prefect.tags("switch"):
93 for value, task in cases.items():
94 task = prefect.utilities.tasks.as_task(task)
95 match_condition = CompareValue(value=value).bind(value=condition)
96 task.set_dependencies(upstream_tasks=[match_condition])
97
98
99 def ifelse(condition: Task, true_task: Task, false_task: Task) -> None:
100 """
101 Builds a conditional branch into a workflow.
102
103 If the condition evaluates True(ish), the true_task will run. If it
104 evaluates False(ish), the false_task will run. The task doesn't run is Skipped, as are
105 all downstream tasks that don't set `skip_on_upstream_skip=False`.
106
107 Args:
108 - condition (Task): a task whose boolean result forms the condition for the ifelse
109 - true_task (Task): a task that will be executed if the condition is True
110 - false_task (Task): a task that will be executed if the condition is False
111 """
112
113 switch(condition=condition, cases={True: true_task, False: false_task})
114
115
116 def merge(*tasks: Task) -> Task:
117 """
118 Merges conditional branches back together.
119
120 A conditional branch in a flow results in one or more tasks proceeding and one or
121 more tasks skipping. It is often convenient to merge those branches back into a
122 single result. This function is a simple way to achieve that goal. By default this
123 task will skip if all its upstream dependencies are also skipped.
124
125 The merge will return the first real result it encounters, or `None`. If multiple
126 tasks might return a result, group them with a list.
127
128 Example:
129 ```python
130 with Flow("My Flow"):
131 true_branch = ActionIfTrue()
132 false_branch = ActionIfFalse()
133 ifelse(CheckCondition(), true_branch, false_branch)
134
135 merged_result = merge(true_branch, false_branch)
136 ```
137
138 Args:
139 - *tasks (Task): tasks whose results should be merged into a single result. The tasks are
140 assumed to all sit downstream of different `switch` branches, such that only
141 one of them will contain a result and the others will all be skipped.
142
143 Returns:
144 - Task: a Task representing the merged result.
145
146 """
147 return Merge().bind(**{"task_{}".format(i + 1): t for i, t in enumerate(tasks)})
148
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/prefect/tasks/control_flow/conditional.py b/src/prefect/tasks/control_flow/conditional.py
--- a/src/prefect/tasks/control_flow/conditional.py
+++ b/src/prefect/tasks/control_flow/conditional.py
@@ -110,7 +110,11 @@
- false_task (Task): a task that will be executed if the condition is False
"""
- switch(condition=condition, cases={True: true_task, False: false_task})
+ @prefect.task
+ def as_bool(x):
+ return bool(x)
+
+ switch(condition=as_bool(condition), cases={True: true_task, False: false_task})
def merge(*tasks: Task) -> Task:
|
{"golden_diff": "diff --git a/src/prefect/tasks/control_flow/conditional.py b/src/prefect/tasks/control_flow/conditional.py\n--- a/src/prefect/tasks/control_flow/conditional.py\n+++ b/src/prefect/tasks/control_flow/conditional.py\n@@ -110,7 +110,11 @@\n - false_task (Task): a task that will be executed if the condition is False\n \"\"\"\n \n- switch(condition=condition, cases={True: true_task, False: false_task})\n+ @prefect.task\n+ def as_bool(x):\n+ return bool(x)\n+\n+ switch(condition=as_bool(condition), cases={True: true_task, False: false_task})\n \n \n def merge(*tasks: Task) -> Task:\n", "issue": "ifelse checks for True/False rather than truthy/falsy values\n## Description\r\n`prefect.tasks.control_flow.conditional.ifelse` should check for truthy/falsy values, but (relying on `switch`) checks for exact equality to `True` or `False`.\r\n\r\n## Expected Behavior\r\n[From the docs](https://docs.prefect.io/core/task_library/control_flow.html#if-else):\r\n\r\n> If the condition evaluates True(ish), the true_task will run. If it evaluates False(ish), the false_task will run.\r\n\r\n`ifelse` should run the `true_branch` for any value that evaluates to `True`: non-empty strings, dicts and lists, ints not equal to 0...\r\n\r\n## Reproduction\r\n```python\r\nfrom prefect import Flow, task\r\nfrom prefect.tasks.control_flow.conditional import ifelse, merge\r\n\r\n@task\r\ndef run_if_truthy():\r\n\treturn 'a'\r\n\r\n@task\r\ndef run_if_falsy():\r\n\treturn 'b'\r\n\r\n@task\r\ndef return_truthy_value():\r\n\t# non-empty strings are truthy\r\n\tassert('c')\r\n\treturn 'c'\r\n\r\nwith Flow('test-flow') as flow:\r\n\tbranch_truthy = run_if_truthy()\r\n\tbranch_falsy = run_if_falsy()\r\n\tifelse(return_truthy_value(), branch_truthy, branch_falsy)\r\n\tmerged_result = merge(branch_truthy, branch_falsy)\r\n\r\nresult = flow.run()\r\nassert(not result.result.get(merged_result).is_skipped())\r\nassert(result.result.get(merged_result)._result.value == 'a')\r\n```\r\nOutput:\r\n```\r\n[2020-02-03 16:38:57,428] INFO - prefect.FlowRunner | Beginning Flow run for 'test-flow'\r\n[2020-02-03 16:38:57,431] INFO - prefect.FlowRunner | Starting flow run.\r\n[2020-02-03 16:38:57,441] INFO - prefect.TaskRunner | Task 'return_truthy_value': Starting task run...\r\n[2020-02-03 16:38:57,445] INFO - prefect.TaskRunner | Task 'return_truthy_value': finished task run for task with final state: 'Success'\r\n[2020-02-03 16:38:57,455] INFO - prefect.TaskRunner | Task 'CompareValue: \"True\"': Starting task run...\r\n[2020-02-03 16:38:57,460] INFO - prefect.TaskRunner | Task 'CompareValue: \"True\"': finished task run for task with final state: 'Skipped'\r\n[2020-02-03 16:38:57,470] INFO - prefect.TaskRunner | Task 'run_if_truthy': Starting task run...\r\n[2020-02-03 16:38:57,474] INFO - prefect.TaskRunner | Task 'run_if_truthy': finished task run for task with final state: 'Skipped'\r\n[2020-02-03 16:38:57,483] INFO - prefect.TaskRunner | Task 'CompareValue: \"False\"': Starting task run...\r\n[2020-02-03 16:38:57,488] INFO - prefect.TaskRunner | Task 'CompareValue: \"False\"': finished task run for task with final state: 'Skipped'\r\n[2020-02-03 16:38:57,497] INFO - prefect.TaskRunner | Task 'run_if_falsy': Starting task run...\r\n[2020-02-03 16:38:57,501] INFO - prefect.TaskRunner | Task 'run_if_falsy': finished task run for task with final state: 'Skipped'\r\n[2020-02-03 16:38:57,510] INFO - prefect.TaskRunner | Task 'Merge': Starting task run...\r\n[2020-02-03 16:38:57,514] INFO - prefect.TaskRunner | Task 'Merge': finished task run for task with final state: 'Skipped'\r\n[2020-02-03 16:38:57,516] INFO - prefect.FlowRunner | Flow run SUCCESS: all reference tasks succeeded\r\nTraceback (most recent call last):\r\n File \"/tmp/test-flow.py\", line 25, in <module>\r\n assert(not result.result.get(merged_result).is_skipped())\r\nAssertionError\r\n```\r\n\r\n## Environment\r\nPrefect 0.9.2, Python 3.6, on Linux x64.\r\n\n", "before_files": [{"content": "from typing import Any, Dict\n\nimport prefect\nfrom prefect import Task\nfrom prefect.engine import signals\n\n__all__ = [\"switch\", \"ifelse\"]\n\n\nclass Merge(Task):\n def __init__(self, **kwargs) -> None:\n if kwargs.setdefault(\"skip_on_upstream_skip\", False):\n raise ValueError(\"Merge tasks must have `skip_on_upstream_skip=False`.\")\n kwargs.setdefault(\"trigger\", prefect.triggers.not_all_skipped)\n super().__init__(**kwargs)\n\n def run(self, **task_results: Any) -> Any:\n return next(\n (v for k, v in sorted(task_results.items()) if v is not None), None,\n )\n\n\nclass CompareValue(Task):\n \"\"\"\n This task stores a `value` at initialization and compares it to a `value` received at runtime.\n If the values don't match, it raises a SKIP exception.\n\n Args:\n - value (Any): the value this task will attempt to match when it runs\n - **kwargs: keyword arguments for the Task\n \"\"\"\n\n def __init__(self, value: Any, **kwargs: Any):\n self.value = value\n kwargs.setdefault(\"name\", 'CompareValue: \"{}\"'.format(value))\n super().__init__(**kwargs)\n\n def run(self, value: Any) -> None:\n \"\"\"\n Raises a SKIP signal if the passed value does not match the task's match value;\n succeeds silently otherwise.\n\n Args:\n - value (Any): the value that will be matched against the task's value.\n \"\"\"\n if value != self.value:\n raise signals.SKIP(\n 'Provided value \"{}\" did not match \"{}\"'.format(value, self.value)\n )\n\n\ndef switch(condition: Task, cases: Dict[Any, Task]) -> None:\n \"\"\"\n Adds a SWITCH to a workflow.\n\n The condition task is evaluated and the result is compared to the keys of the cases\n dictionary. The task corresponding to the matching key is run; all other tasks are\n skipped. Any tasks downstream of the skipped tasks are also skipped unless they set\n `skip_on_upstream_skip=False`.\n\n Example:\n ```python\n @task\n def condition():\n return \"b\" # returning 'b' will take the b_branch\n\n @task\n def a_branch():\n return \"A Branch\"\n\n @task\n def b_branch():\n return \"B Branch\"\n\n with Flow(\"switch-flow\") as flow:\n switch(condition, dict(a=a_branch, b=b_branch))\n ```\n\n Args:\n - condition (Task): a task whose result forms the condition for the switch\n - cases (Dict[Any, Task]): a dict representing the \"case\" statements of the switch.\n The value of the `condition` task will be compared to the keys of this dict, and\n the matching task will be executed.\n\n Raises:\n - PrefectWarning: if any of the tasks in \"cases\" have upstream dependencies,\n then this task will warn that those upstream tasks may run whether or not the switch condition matches their branch. The most common cause of this\n is passing a list of tasks as one of the cases, which adds the `List` task\n to the switch condition but leaves the tasks themselves upstream.\n \"\"\"\n\n with prefect.tags(\"switch\"):\n for value, task in cases.items():\n task = prefect.utilities.tasks.as_task(task)\n match_condition = CompareValue(value=value).bind(value=condition)\n task.set_dependencies(upstream_tasks=[match_condition])\n\n\ndef ifelse(condition: Task, true_task: Task, false_task: Task) -> None:\n \"\"\"\n Builds a conditional branch into a workflow.\n\n If the condition evaluates True(ish), the true_task will run. If it\n evaluates False(ish), the false_task will run. The task doesn't run is Skipped, as are\n all downstream tasks that don't set `skip_on_upstream_skip=False`.\n\n Args:\n - condition (Task): a task whose boolean result forms the condition for the ifelse\n - true_task (Task): a task that will be executed if the condition is True\n - false_task (Task): a task that will be executed if the condition is False\n \"\"\"\n\n switch(condition=condition, cases={True: true_task, False: false_task})\n\n\ndef merge(*tasks: Task) -> Task:\n \"\"\"\n Merges conditional branches back together.\n\n A conditional branch in a flow results in one or more tasks proceeding and one or\n more tasks skipping. It is often convenient to merge those branches back into a\n single result. This function is a simple way to achieve that goal. By default this\n task will skip if all its upstream dependencies are also skipped.\n\n The merge will return the first real result it encounters, or `None`. If multiple\n tasks might return a result, group them with a list.\n\n Example:\n ```python\n with Flow(\"My Flow\"):\n true_branch = ActionIfTrue()\n false_branch = ActionIfFalse()\n ifelse(CheckCondition(), true_branch, false_branch)\n\n merged_result = merge(true_branch, false_branch)\n ```\n\n Args:\n - *tasks (Task): tasks whose results should be merged into a single result. The tasks are\n assumed to all sit downstream of different `switch` branches, such that only\n one of them will contain a result and the others will all be skipped.\n\n Returns:\n - Task: a Task representing the merged result.\n\n \"\"\"\n return Merge().bind(**{\"task_{}\".format(i + 1): t for i, t in enumerate(tasks)})\n", "path": "src/prefect/tasks/control_flow/conditional.py"}], "after_files": [{"content": "from typing import Any, Dict\n\nimport prefect\nfrom prefect import Task\nfrom prefect.engine import signals\n\n__all__ = [\"switch\", \"ifelse\"]\n\n\nclass Merge(Task):\n def __init__(self, **kwargs) -> None:\n if kwargs.setdefault(\"skip_on_upstream_skip\", False):\n raise ValueError(\"Merge tasks must have `skip_on_upstream_skip=False`.\")\n kwargs.setdefault(\"trigger\", prefect.triggers.not_all_skipped)\n super().__init__(**kwargs)\n\n def run(self, **task_results: Any) -> Any:\n return next(\n (v for k, v in sorted(task_results.items()) if v is not None), None,\n )\n\n\nclass CompareValue(Task):\n \"\"\"\n This task stores a `value` at initialization and compares it to a `value` received at runtime.\n If the values don't match, it raises a SKIP exception.\n\n Args:\n - value (Any): the value this task will attempt to match when it runs\n - **kwargs: keyword arguments for the Task\n \"\"\"\n\n def __init__(self, value: Any, **kwargs: Any):\n self.value = value\n kwargs.setdefault(\"name\", 'CompareValue: \"{}\"'.format(value))\n super().__init__(**kwargs)\n\n def run(self, value: Any) -> None:\n \"\"\"\n Raises a SKIP signal if the passed value does not match the task's match value;\n succeeds silently otherwise.\n\n Args:\n - value (Any): the value that will be matched against the task's value.\n \"\"\"\n if value != self.value:\n raise signals.SKIP(\n 'Provided value \"{}\" did not match \"{}\"'.format(value, self.value)\n )\n\n\ndef switch(condition: Task, cases: Dict[Any, Task]) -> None:\n \"\"\"\n Adds a SWITCH to a workflow.\n\n The condition task is evaluated and the result is compared to the keys of the cases\n dictionary. The task corresponding to the matching key is run; all other tasks are\n skipped. Any tasks downstream of the skipped tasks are also skipped unless they set\n `skip_on_upstream_skip=False`.\n\n Example:\n ```python\n @task\n def condition():\n return \"b\" # returning 'b' will take the b_branch\n\n @task\n def a_branch():\n return \"A Branch\"\n\n @task\n def b_branch():\n return \"B Branch\"\n\n with Flow(\"switch-flow\") as flow:\n switch(condition, dict(a=a_branch, b=b_branch))\n ```\n\n Args:\n - condition (Task): a task whose result forms the condition for the switch\n - cases (Dict[Any, Task]): a dict representing the \"case\" statements of the switch.\n The value of the `condition` task will be compared to the keys of this dict, and\n the matching task will be executed.\n\n Raises:\n - PrefectWarning: if any of the tasks in \"cases\" have upstream dependencies,\n then this task will warn that those upstream tasks may run whether or not the switch condition matches their branch. The most common cause of this\n is passing a list of tasks as one of the cases, which adds the `List` task\n to the switch condition but leaves the tasks themselves upstream.\n \"\"\"\n\n with prefect.tags(\"switch\"):\n for value, task in cases.items():\n task = prefect.utilities.tasks.as_task(task)\n match_condition = CompareValue(value=value).bind(value=condition)\n task.set_dependencies(upstream_tasks=[match_condition])\n\n\ndef ifelse(condition: Task, true_task: Task, false_task: Task) -> None:\n \"\"\"\n Builds a conditional branch into a workflow.\n\n If the condition evaluates True(ish), the true_task will run. If it\n evaluates False(ish), the false_task will run. The task doesn't run is Skipped, as are\n all downstream tasks that don't set `skip_on_upstream_skip=False`.\n\n Args:\n - condition (Task): a task whose boolean result forms the condition for the ifelse\n - true_task (Task): a task that will be executed if the condition is True\n - false_task (Task): a task that will be executed if the condition is False\n \"\"\"\n\n @prefect.task\n def as_bool(x):\n return bool(x)\n\n switch(condition=as_bool(condition), cases={True: true_task, False: false_task})\n\n\ndef merge(*tasks: Task) -> Task:\n \"\"\"\n Merges conditional branches back together.\n\n A conditional branch in a flow results in one or more tasks proceeding and one or\n more tasks skipping. It is often convenient to merge those branches back into a\n single result. This function is a simple way to achieve that goal. By default this\n task will skip if all its upstream dependencies are also skipped.\n\n The merge will return the first real result it encounters, or `None`. If multiple\n tasks might return a result, group them with a list.\n\n Example:\n ```python\n with Flow(\"My Flow\"):\n true_branch = ActionIfTrue()\n false_branch = ActionIfFalse()\n ifelse(CheckCondition(), true_branch, false_branch)\n\n merged_result = merge(true_branch, false_branch)\n ```\n\n Args:\n - *tasks (Task): tasks whose results should be merged into a single result. The tasks are\n assumed to all sit downstream of different `switch` branches, such that only\n one of them will contain a result and the others will all be skipped.\n\n Returns:\n - Task: a Task representing the merged result.\n\n \"\"\"\n return Merge().bind(**{\"task_{}\".format(i + 1): t for i, t in enumerate(tasks)})\n", "path": "src/prefect/tasks/control_flow/conditional.py"}]}
| 2,885 | 161 |
gh_patches_debug_5433
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmocr-221
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Make default ingnored class to -100 in SDMGRLoss
In most cases, class 0 should not be ignored.
ref https://github.com/open-mmlab/mmocr/blob/main/mmocr/models/kie/losses/sdmgr_loss.py#L17
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mmocr/models/kie/losses/sdmgr_loss.py`
Content:
```
1 import torch
2 from torch import nn
3
4 from mmdet.models.builder import LOSSES
5 from mmdet.models.losses import accuracy
6
7
8 @LOSSES.register_module()
9 class SDMGRLoss(nn.Module):
10 """The implementation the loss of key information extraction proposed in
11 the paper: Spatial Dual-Modality Graph Reasoning for Key Information
12 Extraction.
13
14 https://arxiv.org/abs/2103.14470.
15 """
16
17 def __init__(self, node_weight=1.0, edge_weight=1.0, ignore=0):
18 super().__init__()
19 self.loss_node = nn.CrossEntropyLoss(ignore_index=ignore)
20 self.loss_edge = nn.CrossEntropyLoss(ignore_index=-1)
21 self.node_weight = node_weight
22 self.edge_weight = edge_weight
23 self.ignore = ignore
24
25 def forward(self, node_preds, edge_preds, gts):
26 node_gts, edge_gts = [], []
27 for gt in gts:
28 node_gts.append(gt[:, 0])
29 edge_gts.append(gt[:, 1:].contiguous().view(-1))
30 node_gts = torch.cat(node_gts).long()
31 edge_gts = torch.cat(edge_gts).long()
32
33 node_valids = torch.nonzero(node_gts != self.ignore).view(-1)
34 edge_valids = torch.nonzero(edge_gts != -1).view(-1)
35 return dict(
36 loss_node=self.node_weight * self.loss_node(node_preds, node_gts),
37 loss_edge=self.edge_weight * self.loss_edge(edge_preds, edge_gts),
38 acc_node=accuracy(node_preds[node_valids], node_gts[node_valids]),
39 acc_edge=accuracy(edge_preds[edge_valids], edge_gts[edge_valids]))
40
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mmocr/models/kie/losses/sdmgr_loss.py b/mmocr/models/kie/losses/sdmgr_loss.py
--- a/mmocr/models/kie/losses/sdmgr_loss.py
+++ b/mmocr/models/kie/losses/sdmgr_loss.py
@@ -14,7 +14,7 @@
https://arxiv.org/abs/2103.14470.
"""
- def __init__(self, node_weight=1.0, edge_weight=1.0, ignore=0):
+ def __init__(self, node_weight=1.0, edge_weight=1.0, ignore=-100):
super().__init__()
self.loss_node = nn.CrossEntropyLoss(ignore_index=ignore)
self.loss_edge = nn.CrossEntropyLoss(ignore_index=-1)
|
{"golden_diff": "diff --git a/mmocr/models/kie/losses/sdmgr_loss.py b/mmocr/models/kie/losses/sdmgr_loss.py\n--- a/mmocr/models/kie/losses/sdmgr_loss.py\n+++ b/mmocr/models/kie/losses/sdmgr_loss.py\n@@ -14,7 +14,7 @@\n https://arxiv.org/abs/2103.14470.\n \"\"\"\n \n- def __init__(self, node_weight=1.0, edge_weight=1.0, ignore=0):\n+ def __init__(self, node_weight=1.0, edge_weight=1.0, ignore=-100):\n super().__init__()\n self.loss_node = nn.CrossEntropyLoss(ignore_index=ignore)\n self.loss_edge = nn.CrossEntropyLoss(ignore_index=-1)\n", "issue": "Make default ingnored class to -100 in SDMGRLoss\nIn most cases, class 0 should not be ignored.\r\n\r\nref https://github.com/open-mmlab/mmocr/blob/main/mmocr/models/kie/losses/sdmgr_loss.py#L17\n", "before_files": [{"content": "import torch\nfrom torch import nn\n\nfrom mmdet.models.builder import LOSSES\nfrom mmdet.models.losses import accuracy\n\n\[email protected]_module()\nclass SDMGRLoss(nn.Module):\n \"\"\"The implementation the loss of key information extraction proposed in\n the paper: Spatial Dual-Modality Graph Reasoning for Key Information\n Extraction.\n\n https://arxiv.org/abs/2103.14470.\n \"\"\"\n\n def __init__(self, node_weight=1.0, edge_weight=1.0, ignore=0):\n super().__init__()\n self.loss_node = nn.CrossEntropyLoss(ignore_index=ignore)\n self.loss_edge = nn.CrossEntropyLoss(ignore_index=-1)\n self.node_weight = node_weight\n self.edge_weight = edge_weight\n self.ignore = ignore\n\n def forward(self, node_preds, edge_preds, gts):\n node_gts, edge_gts = [], []\n for gt in gts:\n node_gts.append(gt[:, 0])\n edge_gts.append(gt[:, 1:].contiguous().view(-1))\n node_gts = torch.cat(node_gts).long()\n edge_gts = torch.cat(edge_gts).long()\n\n node_valids = torch.nonzero(node_gts != self.ignore).view(-1)\n edge_valids = torch.nonzero(edge_gts != -1).view(-1)\n return dict(\n loss_node=self.node_weight * self.loss_node(node_preds, node_gts),\n loss_edge=self.edge_weight * self.loss_edge(edge_preds, edge_gts),\n acc_node=accuracy(node_preds[node_valids], node_gts[node_valids]),\n acc_edge=accuracy(edge_preds[edge_valids], edge_gts[edge_valids]))\n", "path": "mmocr/models/kie/losses/sdmgr_loss.py"}], "after_files": [{"content": "import torch\nfrom torch import nn\n\nfrom mmdet.models.builder import LOSSES\nfrom mmdet.models.losses import accuracy\n\n\[email protected]_module()\nclass SDMGRLoss(nn.Module):\n \"\"\"The implementation the loss of key information extraction proposed in\n the paper: Spatial Dual-Modality Graph Reasoning for Key Information\n Extraction.\n\n https://arxiv.org/abs/2103.14470.\n \"\"\"\n\n def __init__(self, node_weight=1.0, edge_weight=1.0, ignore=-100):\n super().__init__()\n self.loss_node = nn.CrossEntropyLoss(ignore_index=ignore)\n self.loss_edge = nn.CrossEntropyLoss(ignore_index=-1)\n self.node_weight = node_weight\n self.edge_weight = edge_weight\n self.ignore = ignore\n\n def forward(self, node_preds, edge_preds, gts):\n node_gts, edge_gts = [], []\n for gt in gts:\n node_gts.append(gt[:, 0])\n edge_gts.append(gt[:, 1:].contiguous().view(-1))\n node_gts = torch.cat(node_gts).long()\n edge_gts = torch.cat(edge_gts).long()\n\n node_valids = torch.nonzero(node_gts != self.ignore).view(-1)\n edge_valids = torch.nonzero(edge_gts != -1).view(-1)\n return dict(\n loss_node=self.node_weight * self.loss_node(node_preds, node_gts),\n loss_edge=self.edge_weight * self.loss_edge(edge_preds, edge_gts),\n acc_node=accuracy(node_preds[node_valids], node_gts[node_valids]),\n acc_edge=accuracy(edge_preds[edge_valids], edge_gts[edge_valids]))\n", "path": "mmocr/models/kie/losses/sdmgr_loss.py"}]}
| 778 | 186 |
gh_patches_debug_525
|
rasdani/github-patches
|
git_diff
|
fidals__shopelectro-592
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fix env substitution in docker-compose.yml for docker-rm
https://ci.fidals.com/fidals/shopelectro/938/12
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `shopelectro/management/commands/excel.py`
Content:
```
1 """
2 Generate Excel price-list.
3
4 Use this excel editor lib: https://openpyxl.readthedocs.io/en/default/
5 """
6 import datetime
7 import os
8 from collections import namedtuple
9
10 import openpyxl
11 from django.conf import settings
12 from django.core.management.base import BaseCommand
13 from openpyxl.styles import borders, colors, Font
14
15 from shopelectro.models import Product, Category
16
17
18 class Command(BaseCommand):
19 TEMPLATE = 'templates/ecommerce/template.xlsx'
20 NAME = 'pricelist.xlsx'
21 SHEET_TITLE = 'Прайс Shopelectro'
22 CATEGORY_FILL = openpyxl.styles.PatternFill(
23 start_color='F4FEFD',
24 end_color='F4FEFD',
25 fill_type='solid'
26 )
27 BUY_FILL = openpyxl.styles.PatternFill(
28 start_color='FEFEF0',
29 end_color='FEFEF0',
30 fill_type='solid'
31 )
32 THIN_BORDER = borders.Border(
33 top=borders.Side(style='thin'),
34 right=borders.Side(style='thin'),
35 bottom=borders.Side(style='thin'),
36 left=borders.Side(style='thin')
37 )
38 CURRENT_ROW = '9' # Start of catalog section in file.
39 cell = namedtuple('cell', ['row', 'col'])
40 BAD_STYLED_CELLS = ['D5', 'E5', 'D6', 'G8']
41
42 def __init__(self, *args, **kwargs):
43 super(Command, self).__init__(*args, **kwargs)
44 self.file, self.sheet = self.load_file_and_sheet()
45
46 def handle(self, *args, **options):
47 """Open template's file and start proceeding it."""
48 self.set_collapse_controls()
49 self.fill_header()
50 self.write_catalog()
51 self.hide_formulas()
52 self.set_styles()
53 base_dir = settings.ASSETS_DIR
54 self.file.save(os.path.join(base_dir, self.NAME))
55
56 def set_styles(self):
57 for cell in self.BAD_STYLED_CELLS:
58 self.sheet[cell].border = self.THIN_BORDER
59
60 def set_collapse_controls(self):
61 """
62 Place collapse buttons above rows.
63
64 Collapse controls looks like this: http://prntscr.com/clf9xh. # Ignore InvalidLinkBear
65 Doc link: https://goo.gl/nR5pLO
66 """
67 self.sheet.sheet_properties.outlinePr.summaryBelow = False
68
69 def increase_row(self):
70 self.CURRENT_ROW = str(int(self.CURRENT_ROW) + 1)
71 return self.CURRENT_ROW
72
73 def get_row(self, row_number):
74 return self.sheet.row_dimensions[int(row_number)]
75
76 def load_file_and_sheet(self):
77 """
78 Load template file into openpyxl.
79
80 Return tuple with opened openpyxl file's object and active price sheet.
81 """
82 file = openpyxl.load_workbook(os.path.join(
83 settings.BASE_DIR, self.TEMPLATE))
84 return file, file.get_sheet_by_name('Прайслист')
85
86 def fill_header(self):
87 """Fill header of a sheet with date and title."""
88 date_cell = 'C5'
89 self.sheet.title = self.SHEET_TITLE
90 self.sheet[date_cell] = datetime.date.strftime(
91 datetime.date.today(), '%d.%m.%Y')
92
93 def hide_formulas(self):
94 """Hide formulas for calculating totals."""
95 self.sheet.column_dimensions.group('H', 'K', hidden=True, outline_level=0)
96
97 def write_catalog(self):
98 """Write categories and products to sheet."""
99 categories = Category.objects.all().order_by('name').filter(children=None)
100 for category in categories.iterator():
101 self.write_category_with_products(category)
102
103 def write_category_with_products(self, category):
104 """Write category line and beside that - all of products in this category."""
105 def hide_row(row):
106 row.hidden = True
107 row.outlineLevel = 1
108
109 def collapse_row(row):
110 row.collapsed = True
111
112 def write_product_rows():
113 """Write products lines."""
114 sheet = self.sheet
115 products = Product.objects.filter(category=category, page__is_active=True)
116 for product in products.iterator():
117 product_start = 'A' + self.CURRENT_ROW
118 sheet[product_start] = product.name
119 sheet[product_start].font = Font(color=colors.BLUE)
120 sheet[product_start].hyperlink = settings.BASE_URL + product.url
121 sheet[product_start].border = self.THIN_BORDER
122 prices = [
123 product.price,
124 product.wholesale_small,
125 product.wholesale_medium,
126 product.wholesale_large,
127 ]
128 for price, total in zip('CDEF', 'HIJK'):
129 sheet[price + self.CURRENT_ROW] = prices.pop(0)
130 sheet[total + self.CURRENT_ROW] = (
131 '={0}{1}*G{1}'.format(price, self.CURRENT_ROW)
132 )
133
134 sheet[price + self.CURRENT_ROW].border = self.THIN_BORDER
135
136 sheet['G' + self.CURRENT_ROW].fill = self.BUY_FILL
137 sheet['G' + self.CURRENT_ROW].border = self.THIN_BORDER
138
139 hide_row(self.get_row(self.CURRENT_ROW))
140 self.increase_row()
141
142 def write_category_row():
143 """Merge category line into one cell and write to it."""
144 sheet = self.sheet
145 collapse_row(self.get_row(self.CURRENT_ROW))
146
147 category_start = 'A' + self.CURRENT_ROW
148 category_line = '{}:{}'.format(
149 category_start, 'G' + self.CURRENT_ROW)
150 sheet.merge_cells(category_line)
151 sheet[category_start] = category.name
152 sheet[category_start].fill = self.CATEGORY_FILL
153
154 self.increase_row()
155
156 write_category_row()
157 write_product_rows()
158
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/shopelectro/management/commands/excel.py b/shopelectro/management/commands/excel.py
--- a/shopelectro/management/commands/excel.py
+++ b/shopelectro/management/commands/excel.py
@@ -1,7 +1,7 @@
"""
Generate Excel price-list.
-Use this excel editor lib: https://openpyxl.readthedocs.io/en/default/
+Use this excel editor lib: https://openpyxl.readthedocs.io/en/stable/
"""
import datetime
import os
|
{"golden_diff": "diff --git a/shopelectro/management/commands/excel.py b/shopelectro/management/commands/excel.py\n--- a/shopelectro/management/commands/excel.py\n+++ b/shopelectro/management/commands/excel.py\n@@ -1,7 +1,7 @@\n \"\"\"\n Generate Excel price-list.\n \n-Use this excel editor lib: https://openpyxl.readthedocs.io/en/default/\n+Use this excel editor lib: https://openpyxl.readthedocs.io/en/stable/\n \"\"\"\n import datetime\n import os\n", "issue": "Fix env substitution in docker-compose.yml for docker-rm\nhttps://ci.fidals.com/fidals/shopelectro/938/12\n", "before_files": [{"content": "\"\"\"\nGenerate Excel price-list.\n\nUse this excel editor lib: https://openpyxl.readthedocs.io/en/default/\n\"\"\"\nimport datetime\nimport os\nfrom collections import namedtuple\n\nimport openpyxl\nfrom django.conf import settings\nfrom django.core.management.base import BaseCommand\nfrom openpyxl.styles import borders, colors, Font\n\nfrom shopelectro.models import Product, Category\n\n\nclass Command(BaseCommand):\n TEMPLATE = 'templates/ecommerce/template.xlsx'\n NAME = 'pricelist.xlsx'\n SHEET_TITLE = '\u041f\u0440\u0430\u0439\u0441 Shopelectro'\n CATEGORY_FILL = openpyxl.styles.PatternFill(\n start_color='F4FEFD',\n end_color='F4FEFD',\n fill_type='solid'\n )\n BUY_FILL = openpyxl.styles.PatternFill(\n start_color='FEFEF0',\n end_color='FEFEF0',\n fill_type='solid'\n )\n THIN_BORDER = borders.Border(\n top=borders.Side(style='thin'),\n right=borders.Side(style='thin'),\n bottom=borders.Side(style='thin'),\n left=borders.Side(style='thin')\n )\n CURRENT_ROW = '9' # Start of catalog section in file.\n cell = namedtuple('cell', ['row', 'col'])\n BAD_STYLED_CELLS = ['D5', 'E5', 'D6', 'G8']\n\n def __init__(self, *args, **kwargs):\n super(Command, self).__init__(*args, **kwargs)\n self.file, self.sheet = self.load_file_and_sheet()\n\n def handle(self, *args, **options):\n \"\"\"Open template's file and start proceeding it.\"\"\"\n self.set_collapse_controls()\n self.fill_header()\n self.write_catalog()\n self.hide_formulas()\n self.set_styles()\n base_dir = settings.ASSETS_DIR\n self.file.save(os.path.join(base_dir, self.NAME))\n\n def set_styles(self):\n for cell in self.BAD_STYLED_CELLS:\n self.sheet[cell].border = self.THIN_BORDER\n\n def set_collapse_controls(self):\n \"\"\"\n Place collapse buttons above rows.\n\n Collapse controls looks like this: http://prntscr.com/clf9xh. # Ignore InvalidLinkBear\n Doc link: https://goo.gl/nR5pLO\n \"\"\"\n self.sheet.sheet_properties.outlinePr.summaryBelow = False\n\n def increase_row(self):\n self.CURRENT_ROW = str(int(self.CURRENT_ROW) + 1)\n return self.CURRENT_ROW\n\n def get_row(self, row_number):\n return self.sheet.row_dimensions[int(row_number)]\n\n def load_file_and_sheet(self):\n \"\"\"\n Load template file into openpyxl.\n\n Return tuple with opened openpyxl file's object and active price sheet.\n \"\"\"\n file = openpyxl.load_workbook(os.path.join(\n settings.BASE_DIR, self.TEMPLATE))\n return file, file.get_sheet_by_name('\u041f\u0440\u0430\u0439\u0441\u043b\u0438\u0441\u0442')\n\n def fill_header(self):\n \"\"\"Fill header of a sheet with date and title.\"\"\"\n date_cell = 'C5'\n self.sheet.title = self.SHEET_TITLE\n self.sheet[date_cell] = datetime.date.strftime(\n datetime.date.today(), '%d.%m.%Y')\n\n def hide_formulas(self):\n \"\"\"Hide formulas for calculating totals.\"\"\"\n self.sheet.column_dimensions.group('H', 'K', hidden=True, outline_level=0)\n\n def write_catalog(self):\n \"\"\"Write categories and products to sheet.\"\"\"\n categories = Category.objects.all().order_by('name').filter(children=None)\n for category in categories.iterator():\n self.write_category_with_products(category)\n\n def write_category_with_products(self, category):\n \"\"\"Write category line and beside that - all of products in this category.\"\"\"\n def hide_row(row):\n row.hidden = True\n row.outlineLevel = 1\n\n def collapse_row(row):\n row.collapsed = True\n\n def write_product_rows():\n \"\"\"Write products lines.\"\"\"\n sheet = self.sheet\n products = Product.objects.filter(category=category, page__is_active=True)\n for product in products.iterator():\n product_start = 'A' + self.CURRENT_ROW\n sheet[product_start] = product.name\n sheet[product_start].font = Font(color=colors.BLUE)\n sheet[product_start].hyperlink = settings.BASE_URL + product.url\n sheet[product_start].border = self.THIN_BORDER\n prices = [\n product.price,\n product.wholesale_small,\n product.wholesale_medium,\n product.wholesale_large,\n ]\n for price, total in zip('CDEF', 'HIJK'):\n sheet[price + self.CURRENT_ROW] = prices.pop(0)\n sheet[total + self.CURRENT_ROW] = (\n '={0}{1}*G{1}'.format(price, self.CURRENT_ROW)\n )\n\n sheet[price + self.CURRENT_ROW].border = self.THIN_BORDER\n\n sheet['G' + self.CURRENT_ROW].fill = self.BUY_FILL\n sheet['G' + self.CURRENT_ROW].border = self.THIN_BORDER\n\n hide_row(self.get_row(self.CURRENT_ROW))\n self.increase_row()\n\n def write_category_row():\n \"\"\"Merge category line into one cell and write to it.\"\"\"\n sheet = self.sheet\n collapse_row(self.get_row(self.CURRENT_ROW))\n\n category_start = 'A' + self.CURRENT_ROW\n category_line = '{}:{}'.format(\n category_start, 'G' + self.CURRENT_ROW)\n sheet.merge_cells(category_line)\n sheet[category_start] = category.name\n sheet[category_start].fill = self.CATEGORY_FILL\n\n self.increase_row()\n\n write_category_row()\n write_product_rows()\n", "path": "shopelectro/management/commands/excel.py"}], "after_files": [{"content": "\"\"\"\nGenerate Excel price-list.\n\nUse this excel editor lib: https://openpyxl.readthedocs.io/en/stable/\n\"\"\"\nimport datetime\nimport os\nfrom collections import namedtuple\n\nimport openpyxl\nfrom django.conf import settings\nfrom django.core.management.base import BaseCommand\nfrom openpyxl.styles import borders, colors, Font\n\nfrom shopelectro.models import Product, Category\n\n\nclass Command(BaseCommand):\n TEMPLATE = 'templates/ecommerce/template.xlsx'\n NAME = 'pricelist.xlsx'\n SHEET_TITLE = '\u041f\u0440\u0430\u0439\u0441 Shopelectro'\n CATEGORY_FILL = openpyxl.styles.PatternFill(\n start_color='F4FEFD',\n end_color='F4FEFD',\n fill_type='solid'\n )\n BUY_FILL = openpyxl.styles.PatternFill(\n start_color='FEFEF0',\n end_color='FEFEF0',\n fill_type='solid'\n )\n THIN_BORDER = borders.Border(\n top=borders.Side(style='thin'),\n right=borders.Side(style='thin'),\n bottom=borders.Side(style='thin'),\n left=borders.Side(style='thin')\n )\n CURRENT_ROW = '9' # Start of catalog section in file.\n cell = namedtuple('cell', ['row', 'col'])\n BAD_STYLED_CELLS = ['D5', 'E5', 'D6', 'G8']\n\n def __init__(self, *args, **kwargs):\n super(Command, self).__init__(*args, **kwargs)\n self.file, self.sheet = self.load_file_and_sheet()\n\n def handle(self, *args, **options):\n \"\"\"Open template's file and start proceeding it.\"\"\"\n self.set_collapse_controls()\n self.fill_header()\n self.write_catalog()\n self.hide_formulas()\n self.set_styles()\n base_dir = settings.ASSETS_DIR\n self.file.save(os.path.join(base_dir, self.NAME))\n\n def set_styles(self):\n for cell in self.BAD_STYLED_CELLS:\n self.sheet[cell].border = self.THIN_BORDER\n\n def set_collapse_controls(self):\n \"\"\"\n Place collapse buttons above rows.\n\n Collapse controls looks like this: http://prntscr.com/clf9xh. # Ignore InvalidLinkBear\n Doc link: https://goo.gl/nR5pLO\n \"\"\"\n self.sheet.sheet_properties.outlinePr.summaryBelow = False\n\n def increase_row(self):\n self.CURRENT_ROW = str(int(self.CURRENT_ROW) + 1)\n return self.CURRENT_ROW\n\n def get_row(self, row_number):\n return self.sheet.row_dimensions[int(row_number)]\n\n def load_file_and_sheet(self):\n \"\"\"\n Load template file into openpyxl.\n\n Return tuple with opened openpyxl file's object and active price sheet.\n \"\"\"\n file = openpyxl.load_workbook(os.path.join(\n settings.BASE_DIR, self.TEMPLATE))\n return file, file.get_sheet_by_name('\u041f\u0440\u0430\u0439\u0441\u043b\u0438\u0441\u0442')\n\n def fill_header(self):\n \"\"\"Fill header of a sheet with date and title.\"\"\"\n date_cell = 'C5'\n self.sheet.title = self.SHEET_TITLE\n self.sheet[date_cell] = datetime.date.strftime(\n datetime.date.today(), '%d.%m.%Y')\n\n def hide_formulas(self):\n \"\"\"Hide formulas for calculating totals.\"\"\"\n self.sheet.column_dimensions.group('H', 'K', hidden=True, outline_level=0)\n\n def write_catalog(self):\n \"\"\"Write categories and products to sheet.\"\"\"\n categories = Category.objects.all().order_by('name').filter(children=None)\n for category in categories.iterator():\n self.write_category_with_products(category)\n\n def write_category_with_products(self, category):\n \"\"\"Write category line and beside that - all of products in this category.\"\"\"\n def hide_row(row):\n row.hidden = True\n row.outlineLevel = 1\n\n def collapse_row(row):\n row.collapsed = True\n\n def write_product_rows():\n \"\"\"Write products lines.\"\"\"\n sheet = self.sheet\n products = Product.objects.filter(category=category, page__is_active=True)\n for product in products.iterator():\n product_start = 'A' + self.CURRENT_ROW\n sheet[product_start] = product.name\n sheet[product_start].font = Font(color=colors.BLUE)\n sheet[product_start].hyperlink = settings.BASE_URL + product.url\n sheet[product_start].border = self.THIN_BORDER\n prices = [\n product.price,\n product.wholesale_small,\n product.wholesale_medium,\n product.wholesale_large,\n ]\n for price, total in zip('CDEF', 'HIJK'):\n sheet[price + self.CURRENT_ROW] = prices.pop(0)\n sheet[total + self.CURRENT_ROW] = (\n '={0}{1}*G{1}'.format(price, self.CURRENT_ROW)\n )\n\n sheet[price + self.CURRENT_ROW].border = self.THIN_BORDER\n\n sheet['G' + self.CURRENT_ROW].fill = self.BUY_FILL\n sheet['G' + self.CURRENT_ROW].border = self.THIN_BORDER\n\n hide_row(self.get_row(self.CURRENT_ROW))\n self.increase_row()\n\n def write_category_row():\n \"\"\"Merge category line into one cell and write to it.\"\"\"\n sheet = self.sheet\n collapse_row(self.get_row(self.CURRENT_ROW))\n\n category_start = 'A' + self.CURRENT_ROW\n category_line = '{}:{}'.format(\n category_start, 'G' + self.CURRENT_ROW)\n sheet.merge_cells(category_line)\n sheet[category_start] = category.name\n sheet[category_start].fill = self.CATEGORY_FILL\n\n self.increase_row()\n\n write_category_row()\n write_product_rows()\n", "path": "shopelectro/management/commands/excel.py"}]}
| 1,907 | 119 |
gh_patches_debug_23961
|
rasdani/github-patches
|
git_diff
|
mindsdb__mindsdb-1858
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Feat] convert query to string using new mindsdb_sql feature
Since [that works](https://github.com/mindsdb/mindsdb_sql/issues/130) is finished, we can add this changes to mindsdb. So ve can delete dirtyfix for escape symbols and that should prevent from other hidden errors.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mindsdb/api/mysql/mysql_proxy/utilities/sql.py`
Content:
```
1 import duckdb
2 import pandas as pd
3 from mindsdb_sql import parse_sql
4 from mindsdb_sql.parser.ast import Select, Identifier, BinaryOperation, OrderBy
5
6
7 def _remove_table_name(root):
8 if isinstance(root, BinaryOperation):
9 _remove_table_name(root.args[0])
10 _remove_table_name(root.args[1])
11 elif isinstance(root, Identifier):
12 root.parts = [root.parts[-1]]
13
14
15 def query_df(df, query):
16 """ Perform simple query ('select' from one table, without subqueries and joins) on DataFrame.
17
18 Args:
19 df (pandas.DataFrame): data
20 query (mindsdb_sql.parser.ast.Select | str): select query
21
22 Returns:
23 pandas.DataFrame
24 """
25
26 query = parse_sql(str(query), dialect='mysql')
27 if isinstance(query, Select) is False or isinstance(query.from_table, Identifier) is False:
28 raise Exception("Only 'SELECT from TABLE' statements supported for internal query")
29
30 query.from_table.parts = ['df_table']
31 for identifier in query.targets:
32 if isinstance(identifier, Identifier):
33 identifier.parts = [identifier.parts[-1]]
34 if isinstance(query.order_by, list):
35 for orderby in query.order_by:
36 if isinstance(orderby, OrderBy) and isinstance(orderby.field, Identifier):
37 orderby.field.parts = [orderby.field.parts[-1]]
38 _remove_table_name(query.where)
39
40 # FIXME https://github.com/mindsdb/mindsdb_sql/issues/130
41 # we need way to dump suery in postgres dialect
42 sql_query = str(query).replace('`', '')
43 res = duckdb.query_df(df, 'df_table', sql_query)
44 result_df = res.df()
45 result_df = result_df.where(pd.notnull(result_df), None)
46 return result_df
47
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mindsdb/api/mysql/mysql_proxy/utilities/sql.py b/mindsdb/api/mysql/mysql_proxy/utilities/sql.py
--- a/mindsdb/api/mysql/mysql_proxy/utilities/sql.py
+++ b/mindsdb/api/mysql/mysql_proxy/utilities/sql.py
@@ -2,6 +2,9 @@
import pandas as pd
from mindsdb_sql import parse_sql
from mindsdb_sql.parser.ast import Select, Identifier, BinaryOperation, OrderBy
+from mindsdb_sql.render.sqlalchemy_render import SqlalchemyRender
+
+from mindsdb.utilities.log import log
def _remove_table_name(root):
@@ -37,10 +40,14 @@
orderby.field.parts = [orderby.field.parts[-1]]
_remove_table_name(query.where)
- # FIXME https://github.com/mindsdb/mindsdb_sql/issues/130
- # we need way to dump suery in postgres dialect
- sql_query = str(query).replace('`', '')
- res = duckdb.query_df(df, 'df_table', sql_query)
+ render = SqlalchemyRender('postgres')
+ try:
+ query_str = render.get_string(query, with_failback=False)
+ except Exception as e:
+ log.error(f"Exception during query casting to 'postgres' dialect. Query: {query}. Error: {e}")
+ query_str = render.get_string(query, with_failback=True)
+
+ res = duckdb.query_df(df, 'df_table', query_str)
result_df = res.df()
result_df = result_df.where(pd.notnull(result_df), None)
return result_df
|
{"golden_diff": "diff --git a/mindsdb/api/mysql/mysql_proxy/utilities/sql.py b/mindsdb/api/mysql/mysql_proxy/utilities/sql.py\n--- a/mindsdb/api/mysql/mysql_proxy/utilities/sql.py\n+++ b/mindsdb/api/mysql/mysql_proxy/utilities/sql.py\n@@ -2,6 +2,9 @@\n import pandas as pd\n from mindsdb_sql import parse_sql\n from mindsdb_sql.parser.ast import Select, Identifier, BinaryOperation, OrderBy\n+from mindsdb_sql.render.sqlalchemy_render import SqlalchemyRender\n+\n+from mindsdb.utilities.log import log\n \n \n def _remove_table_name(root):\n@@ -37,10 +40,14 @@\n orderby.field.parts = [orderby.field.parts[-1]]\n _remove_table_name(query.where)\n \n- # FIXME https://github.com/mindsdb/mindsdb_sql/issues/130\n- # we need way to dump suery in postgres dialect\n- sql_query = str(query).replace('`', '')\n- res = duckdb.query_df(df, 'df_table', sql_query)\n+ render = SqlalchemyRender('postgres')\n+ try:\n+ query_str = render.get_string(query, with_failback=False)\n+ except Exception as e:\n+ log.error(f\"Exception during query casting to 'postgres' dialect. Query: {query}. Error: {e}\")\n+ query_str = render.get_string(query, with_failback=True)\n+\n+ res = duckdb.query_df(df, 'df_table', query_str)\n result_df = res.df()\n result_df = result_df.where(pd.notnull(result_df), None)\n return result_df\n", "issue": "[Feat] convert query to string using new mindsdb_sql feature\nSince [that works](https://github.com/mindsdb/mindsdb_sql/issues/130) is finished, we can add this changes to mindsdb. So ve can delete dirtyfix for escape symbols and that should prevent from other hidden errors.\r\n\n", "before_files": [{"content": "import duckdb\nimport pandas as pd\nfrom mindsdb_sql import parse_sql\nfrom mindsdb_sql.parser.ast import Select, Identifier, BinaryOperation, OrderBy\n\n\ndef _remove_table_name(root):\n if isinstance(root, BinaryOperation):\n _remove_table_name(root.args[0])\n _remove_table_name(root.args[1])\n elif isinstance(root, Identifier):\n root.parts = [root.parts[-1]]\n\n\ndef query_df(df, query):\n \"\"\" Perform simple query ('select' from one table, without subqueries and joins) on DataFrame.\n\n Args:\n df (pandas.DataFrame): data\n query (mindsdb_sql.parser.ast.Select | str): select query\n\n Returns:\n pandas.DataFrame\n \"\"\"\n\n query = parse_sql(str(query), dialect='mysql')\n if isinstance(query, Select) is False or isinstance(query.from_table, Identifier) is False:\n raise Exception(\"Only 'SELECT from TABLE' statements supported for internal query\")\n\n query.from_table.parts = ['df_table']\n for identifier in query.targets:\n if isinstance(identifier, Identifier):\n identifier.parts = [identifier.parts[-1]]\n if isinstance(query.order_by, list):\n for orderby in query.order_by:\n if isinstance(orderby, OrderBy) and isinstance(orderby.field, Identifier):\n orderby.field.parts = [orderby.field.parts[-1]]\n _remove_table_name(query.where)\n\n # FIXME https://github.com/mindsdb/mindsdb_sql/issues/130\n # we need way to dump suery in postgres dialect\n sql_query = str(query).replace('`', '')\n res = duckdb.query_df(df, 'df_table', sql_query)\n result_df = res.df()\n result_df = result_df.where(pd.notnull(result_df), None)\n return result_df\n", "path": "mindsdb/api/mysql/mysql_proxy/utilities/sql.py"}], "after_files": [{"content": "import duckdb\nimport pandas as pd\nfrom mindsdb_sql import parse_sql\nfrom mindsdb_sql.parser.ast import Select, Identifier, BinaryOperation, OrderBy\nfrom mindsdb_sql.render.sqlalchemy_render import SqlalchemyRender\n\nfrom mindsdb.utilities.log import log\n\n\ndef _remove_table_name(root):\n if isinstance(root, BinaryOperation):\n _remove_table_name(root.args[0])\n _remove_table_name(root.args[1])\n elif isinstance(root, Identifier):\n root.parts = [root.parts[-1]]\n\n\ndef query_df(df, query):\n \"\"\" Perform simple query ('select' from one table, without subqueries and joins) on DataFrame.\n\n Args:\n df (pandas.DataFrame): data\n query (mindsdb_sql.parser.ast.Select | str): select query\n\n Returns:\n pandas.DataFrame\n \"\"\"\n\n query = parse_sql(str(query), dialect='mysql')\n if isinstance(query, Select) is False or isinstance(query.from_table, Identifier) is False:\n raise Exception(\"Only 'SELECT from TABLE' statements supported for internal query\")\n\n query.from_table.parts = ['df_table']\n for identifier in query.targets:\n if isinstance(identifier, Identifier):\n identifier.parts = [identifier.parts[-1]]\n if isinstance(query.order_by, list):\n for orderby in query.order_by:\n if isinstance(orderby, OrderBy) and isinstance(orderby.field, Identifier):\n orderby.field.parts = [orderby.field.parts[-1]]\n _remove_table_name(query.where)\n\n render = SqlalchemyRender('postgres')\n try:\n query_str = render.get_string(query, with_failback=False)\n except Exception as e:\n log.error(f\"Exception during query casting to 'postgres' dialect. Query: {query}. Error: {e}\")\n query_str = render.get_string(query, with_failback=True)\n\n res = duckdb.query_df(df, 'df_table', query_str)\n result_df = res.df()\n result_df = result_df.where(pd.notnull(result_df), None)\n return result_df\n", "path": "mindsdb/api/mysql/mysql_proxy/utilities/sql.py"}]}
| 802 | 350 |
gh_patches_debug_49603
|
rasdani/github-patches
|
git_diff
|
buildbot__buildbot-7258
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Rebuilt buildsets lack parent_buildid on the new messages in the Data API
Pretty much what the title says.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `master/buildbot/data/buildsets.py`
Content:
```
1 # This file is part of Buildbot. Buildbot is free software: you can
2 # redistribute it and/or modify it under the terms of the GNU General Public
3 # License as published by the Free Software Foundation, version 2.
4 #
5 # This program is distributed in the hope that it will be useful, but WITHOUT
6 # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
7 # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
8 # details.
9 #
10 # You should have received a copy of the GNU General Public License along with
11 # this program; if not, write to the Free Software Foundation, Inc., 51
12 # Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
13 #
14 # Copyright Buildbot Team Members
15
16 import copy
17
18 from twisted.internet import defer
19 from twisted.python import log
20
21 from buildbot.data import base
22 from buildbot.data import sourcestamps as sourcestampsapi
23 from buildbot.data import types
24 from buildbot.db.buildsets import AlreadyCompleteError
25 from buildbot.process.buildrequest import BuildRequestCollapser
26 from buildbot.process.results import SUCCESS
27 from buildbot.process.results import worst_status
28 from buildbot.util import datetime2epoch
29 from buildbot.util import epoch2datetime
30
31
32 class Db2DataMixin:
33
34 @defer.inlineCallbacks
35 def db2data(self, bsdict):
36 if not bsdict:
37 return None
38
39 buildset = bsdict.copy()
40
41 # gather the actual sourcestamps, in parallel
42 sourcestamps = []
43
44 @defer.inlineCallbacks
45 def getSs(ssid):
46 ss = yield self.master.data.get(('sourcestamps', str(ssid)))
47 sourcestamps.append(ss)
48 yield defer.DeferredList([getSs(id)
49 for id in buildset['sourcestamps']],
50 fireOnOneErrback=True, consumeErrors=True)
51 buildset['sourcestamps'] = sourcestamps
52
53 # minor modifications
54 buildset['submitted_at'] = datetime2epoch(buildset['submitted_at'])
55 buildset['complete_at'] = datetime2epoch(buildset['complete_at'])
56
57 return buildset
58
59 fieldMapping = {
60 'bsid': 'buildsets.id',
61 'external_idstring': 'buildsets.external_idstring',
62 'reason': 'buildsets.reason',
63 'submitted_at': 'buildsets.submitted_at',
64 'complete': 'buildsets.complete',
65 'complete_at': 'buildsets.complete_at',
66 'results': 'buildsets.results',
67 'parent_buildid': 'buildsets.parent_buildid',
68 'parent_relationship': 'buildsets.parent_relationship'
69 }
70
71
72 class BuildsetEndpoint(Db2DataMixin, base.Endpoint):
73
74 kind = base.EndpointKind.SINGLE
75 pathPatterns = """
76 /buildsets/n:bsid
77 """
78
79 @defer.inlineCallbacks
80 def get(self, resultSpec, kwargs):
81 res = yield self.master.db.buildsets.getBuildset(kwargs['bsid'])
82 res = yield self.db2data(res)
83 return res
84
85
86 class BuildsetsEndpoint(Db2DataMixin, base.Endpoint):
87
88 kind = base.EndpointKind.COLLECTION
89 pathPatterns = """
90 /buildsets
91 """
92 rootLinkName = 'buildsets'
93
94 def get(self, resultSpec, kwargs):
95 complete = resultSpec.popBooleanFilter('complete')
96 resultSpec.fieldMapping = self.fieldMapping
97 d = self.master.db.buildsets.getBuildsets(
98 complete=complete, resultSpec=resultSpec)
99
100 @d.addCallback
101 def db2data(buildsets):
102 d = defer.DeferredList([self.db2data(bs) for bs in buildsets],
103 fireOnOneErrback=True, consumeErrors=True)
104
105 @d.addCallback
106 def getResults(res):
107 return [r[1] for r in res]
108 return d
109 return d
110
111
112 class Buildset(base.ResourceType):
113
114 name = "buildset"
115 plural = "buildsets"
116 endpoints = [BuildsetEndpoint, BuildsetsEndpoint]
117 keyField = 'bsid'
118 eventPathPatterns = """
119 /buildsets/:bsid
120 """
121
122 class EntityType(types.Entity):
123 bsid = types.Integer()
124 external_idstring = types.NoneOk(types.String())
125 reason = types.String()
126 submitted_at = types.Integer()
127 complete = types.Boolean()
128 complete_at = types.NoneOk(types.Integer())
129 results = types.NoneOk(types.Integer())
130 sourcestamps = types.List(
131 of=sourcestampsapi.SourceStamp.entityType)
132 parent_buildid = types.NoneOk(types.Integer())
133 parent_relationship = types.NoneOk(types.String())
134 entityType = EntityType(name, 'Buildset')
135 subresources = ["Property"]
136
137 @base.updateMethod
138 @defer.inlineCallbacks
139 def addBuildset(self, waited_for, scheduler=None, sourcestamps=None, reason='',
140 properties=None, builderids=None, external_idstring=None,
141 parent_buildid=None, parent_relationship=None, priority=0):
142 if sourcestamps is None:
143 sourcestamps = []
144 if properties is None:
145 properties = {}
146 if builderids is None:
147 builderids = []
148 submitted_at = int(self.master.reactor.seconds())
149 bsid, brids = yield self.master.db.buildsets.addBuildset(
150 sourcestamps=sourcestamps, reason=reason,
151 properties=properties, builderids=builderids,
152 waited_for=waited_for, external_idstring=external_idstring,
153 submitted_at=epoch2datetime(submitted_at),
154 parent_buildid=parent_buildid, parent_relationship=parent_relationship,
155 priority=priority)
156
157 yield BuildRequestCollapser(self.master, list(brids.values())).collapse()
158
159 # get each of the sourcestamps for this buildset (sequentially)
160 bsdict = yield self.master.db.buildsets.getBuildset(bsid)
161 sourcestamps = []
162 for ssid in bsdict['sourcestamps']:
163 sourcestamps.append(
164 (yield self.master.data.get(('sourcestamps', str(ssid)))).copy()
165 )
166
167 # notify about the component build requests
168 brResource = self.master.data.getResourceType("buildrequest")
169 brResource.generateEvent(list(brids.values()), 'new')
170
171 # and the buildset itself
172 msg = {
173 "bsid": bsid,
174 "external_idstring": external_idstring,
175 "reason": reason,
176 "submitted_at": submitted_at,
177 "complete": False,
178 "complete_at": None,
179 "results": None,
180 "scheduler": scheduler,
181 "sourcestamps": sourcestamps
182 }
183 # TODO: properties=properties)
184 self.produceEvent(msg, "new")
185
186 log.msg(f"added buildset {bsid} to database")
187
188 # if there are no builders, then this is done already, so send the
189 # appropriate messages for that
190 if not builderids:
191 yield self.maybeBuildsetComplete(bsid)
192
193 return (bsid, brids)
194
195 @base.updateMethod
196 @defer.inlineCallbacks
197 def maybeBuildsetComplete(self, bsid):
198 brdicts = yield self.master.db.buildrequests.getBuildRequests(
199 bsid=bsid, complete=False)
200
201 # if there are incomplete buildrequests, bail out
202 if brdicts:
203 return
204
205 brdicts = yield self.master.db.buildrequests.getBuildRequests(bsid=bsid)
206
207 # figure out the overall results of the buildset:
208 cumulative_results = SUCCESS
209 for brdict in brdicts:
210 cumulative_results = worst_status(
211 cumulative_results, brdict['results'])
212
213 # get a copy of the buildset
214 bsdict = yield self.master.db.buildsets.getBuildset(bsid)
215
216 # if it's already completed, we're late to the game, and there's
217 # nothing to do.
218 #
219 # NOTE: there's still a strong possibility of a race condition here,
220 # which would cause buildset being completed twice.
221 # in this case, the db layer will detect that and raise AlreadyCompleteError
222 if bsdict['complete']:
223 return
224
225 # mark it as completed in the database
226 complete_at = epoch2datetime(int(self.master.reactor.seconds()))
227 try:
228 yield self.master.db.buildsets.completeBuildset(bsid, cumulative_results,
229 complete_at=complete_at)
230 except AlreadyCompleteError:
231 return
232 # get the sourcestamps for the message
233 # get each of the sourcestamps for this buildset (sequentially)
234 bsdict = yield self.master.db.buildsets.getBuildset(bsid)
235 sourcestamps = []
236 for ssid in bsdict['sourcestamps']:
237 sourcestamps.append(
238 copy.deepcopy(
239 (yield self.master.data.get(('sourcestamps', str(ssid))))
240 )
241 )
242
243 msg = {
244 "bsid": bsid,
245 "external_idstring": bsdict['external_idstring'],
246 "reason": bsdict['reason'],
247 "sourcestamps": sourcestamps,
248 "submitted_at": bsdict['submitted_at'],
249 "complete": True,
250 "complete_at": complete_at,
251 "results": cumulative_results,
252 "parent_buildid": bsdict["parent_buildid"],
253 "parent_relationship": bsdict["parent_relationship"],
254 }
255 # TODO: properties=properties)
256 self.produceEvent(msg, "complete")
257
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/master/buildbot/data/buildsets.py b/master/buildbot/data/buildsets.py
--- a/master/buildbot/data/buildsets.py
+++ b/master/buildbot/data/buildsets.py
@@ -173,6 +173,7 @@
"bsid": bsid,
"external_idstring": external_idstring,
"reason": reason,
+ "parent_buildid": parent_buildid,
"submitted_at": submitted_at,
"complete": False,
"complete_at": None,
|
{"golden_diff": "diff --git a/master/buildbot/data/buildsets.py b/master/buildbot/data/buildsets.py\n--- a/master/buildbot/data/buildsets.py\n+++ b/master/buildbot/data/buildsets.py\n@@ -173,6 +173,7 @@\n \"bsid\": bsid,\n \"external_idstring\": external_idstring,\n \"reason\": reason,\n+ \"parent_buildid\": parent_buildid,\n \"submitted_at\": submitted_at,\n \"complete\": False,\n \"complete_at\": None,\n", "issue": "Rebuilt buildsets lack parent_buildid on the new messages in the Data API\nPretty much what the title says.\n", "before_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nimport copy\n\nfrom twisted.internet import defer\nfrom twisted.python import log\n\nfrom buildbot.data import base\nfrom buildbot.data import sourcestamps as sourcestampsapi\nfrom buildbot.data import types\nfrom buildbot.db.buildsets import AlreadyCompleteError\nfrom buildbot.process.buildrequest import BuildRequestCollapser\nfrom buildbot.process.results import SUCCESS\nfrom buildbot.process.results import worst_status\nfrom buildbot.util import datetime2epoch\nfrom buildbot.util import epoch2datetime\n\n\nclass Db2DataMixin:\n\n @defer.inlineCallbacks\n def db2data(self, bsdict):\n if not bsdict:\n return None\n\n buildset = bsdict.copy()\n\n # gather the actual sourcestamps, in parallel\n sourcestamps = []\n\n @defer.inlineCallbacks\n def getSs(ssid):\n ss = yield self.master.data.get(('sourcestamps', str(ssid)))\n sourcestamps.append(ss)\n yield defer.DeferredList([getSs(id)\n for id in buildset['sourcestamps']],\n fireOnOneErrback=True, consumeErrors=True)\n buildset['sourcestamps'] = sourcestamps\n\n # minor modifications\n buildset['submitted_at'] = datetime2epoch(buildset['submitted_at'])\n buildset['complete_at'] = datetime2epoch(buildset['complete_at'])\n\n return buildset\n\n fieldMapping = {\n 'bsid': 'buildsets.id',\n 'external_idstring': 'buildsets.external_idstring',\n 'reason': 'buildsets.reason',\n 'submitted_at': 'buildsets.submitted_at',\n 'complete': 'buildsets.complete',\n 'complete_at': 'buildsets.complete_at',\n 'results': 'buildsets.results',\n 'parent_buildid': 'buildsets.parent_buildid',\n 'parent_relationship': 'buildsets.parent_relationship'\n }\n\n\nclass BuildsetEndpoint(Db2DataMixin, base.Endpoint):\n\n kind = base.EndpointKind.SINGLE\n pathPatterns = \"\"\"\n /buildsets/n:bsid\n \"\"\"\n\n @defer.inlineCallbacks\n def get(self, resultSpec, kwargs):\n res = yield self.master.db.buildsets.getBuildset(kwargs['bsid'])\n res = yield self.db2data(res)\n return res\n\n\nclass BuildsetsEndpoint(Db2DataMixin, base.Endpoint):\n\n kind = base.EndpointKind.COLLECTION\n pathPatterns = \"\"\"\n /buildsets\n \"\"\"\n rootLinkName = 'buildsets'\n\n def get(self, resultSpec, kwargs):\n complete = resultSpec.popBooleanFilter('complete')\n resultSpec.fieldMapping = self.fieldMapping\n d = self.master.db.buildsets.getBuildsets(\n complete=complete, resultSpec=resultSpec)\n\n @d.addCallback\n def db2data(buildsets):\n d = defer.DeferredList([self.db2data(bs) for bs in buildsets],\n fireOnOneErrback=True, consumeErrors=True)\n\n @d.addCallback\n def getResults(res):\n return [r[1] for r in res]\n return d\n return d\n\n\nclass Buildset(base.ResourceType):\n\n name = \"buildset\"\n plural = \"buildsets\"\n endpoints = [BuildsetEndpoint, BuildsetsEndpoint]\n keyField = 'bsid'\n eventPathPatterns = \"\"\"\n /buildsets/:bsid\n \"\"\"\n\n class EntityType(types.Entity):\n bsid = types.Integer()\n external_idstring = types.NoneOk(types.String())\n reason = types.String()\n submitted_at = types.Integer()\n complete = types.Boolean()\n complete_at = types.NoneOk(types.Integer())\n results = types.NoneOk(types.Integer())\n sourcestamps = types.List(\n of=sourcestampsapi.SourceStamp.entityType)\n parent_buildid = types.NoneOk(types.Integer())\n parent_relationship = types.NoneOk(types.String())\n entityType = EntityType(name, 'Buildset')\n subresources = [\"Property\"]\n\n @base.updateMethod\n @defer.inlineCallbacks\n def addBuildset(self, waited_for, scheduler=None, sourcestamps=None, reason='',\n properties=None, builderids=None, external_idstring=None,\n parent_buildid=None, parent_relationship=None, priority=0):\n if sourcestamps is None:\n sourcestamps = []\n if properties is None:\n properties = {}\n if builderids is None:\n builderids = []\n submitted_at = int(self.master.reactor.seconds())\n bsid, brids = yield self.master.db.buildsets.addBuildset(\n sourcestamps=sourcestamps, reason=reason,\n properties=properties, builderids=builderids,\n waited_for=waited_for, external_idstring=external_idstring,\n submitted_at=epoch2datetime(submitted_at),\n parent_buildid=parent_buildid, parent_relationship=parent_relationship,\n priority=priority)\n\n yield BuildRequestCollapser(self.master, list(brids.values())).collapse()\n\n # get each of the sourcestamps for this buildset (sequentially)\n bsdict = yield self.master.db.buildsets.getBuildset(bsid)\n sourcestamps = []\n for ssid in bsdict['sourcestamps']:\n sourcestamps.append(\n (yield self.master.data.get(('sourcestamps', str(ssid)))).copy()\n )\n\n # notify about the component build requests\n brResource = self.master.data.getResourceType(\"buildrequest\")\n brResource.generateEvent(list(brids.values()), 'new')\n\n # and the buildset itself\n msg = {\n \"bsid\": bsid,\n \"external_idstring\": external_idstring,\n \"reason\": reason,\n \"submitted_at\": submitted_at,\n \"complete\": False,\n \"complete_at\": None,\n \"results\": None,\n \"scheduler\": scheduler,\n \"sourcestamps\": sourcestamps\n }\n # TODO: properties=properties)\n self.produceEvent(msg, \"new\")\n\n log.msg(f\"added buildset {bsid} to database\")\n\n # if there are no builders, then this is done already, so send the\n # appropriate messages for that\n if not builderids:\n yield self.maybeBuildsetComplete(bsid)\n\n return (bsid, brids)\n\n @base.updateMethod\n @defer.inlineCallbacks\n def maybeBuildsetComplete(self, bsid):\n brdicts = yield self.master.db.buildrequests.getBuildRequests(\n bsid=bsid, complete=False)\n\n # if there are incomplete buildrequests, bail out\n if brdicts:\n return\n\n brdicts = yield self.master.db.buildrequests.getBuildRequests(bsid=bsid)\n\n # figure out the overall results of the buildset:\n cumulative_results = SUCCESS\n for brdict in brdicts:\n cumulative_results = worst_status(\n cumulative_results, brdict['results'])\n\n # get a copy of the buildset\n bsdict = yield self.master.db.buildsets.getBuildset(bsid)\n\n # if it's already completed, we're late to the game, and there's\n # nothing to do.\n #\n # NOTE: there's still a strong possibility of a race condition here,\n # which would cause buildset being completed twice.\n # in this case, the db layer will detect that and raise AlreadyCompleteError\n if bsdict['complete']:\n return\n\n # mark it as completed in the database\n complete_at = epoch2datetime(int(self.master.reactor.seconds()))\n try:\n yield self.master.db.buildsets.completeBuildset(bsid, cumulative_results,\n complete_at=complete_at)\n except AlreadyCompleteError:\n return\n # get the sourcestamps for the message\n # get each of the sourcestamps for this buildset (sequentially)\n bsdict = yield self.master.db.buildsets.getBuildset(bsid)\n sourcestamps = []\n for ssid in bsdict['sourcestamps']:\n sourcestamps.append(\n copy.deepcopy(\n (yield self.master.data.get(('sourcestamps', str(ssid))))\n )\n )\n\n msg = {\n \"bsid\": bsid,\n \"external_idstring\": bsdict['external_idstring'],\n \"reason\": bsdict['reason'],\n \"sourcestamps\": sourcestamps,\n \"submitted_at\": bsdict['submitted_at'],\n \"complete\": True,\n \"complete_at\": complete_at,\n \"results\": cumulative_results,\n \"parent_buildid\": bsdict[\"parent_buildid\"],\n \"parent_relationship\": bsdict[\"parent_relationship\"],\n }\n # TODO: properties=properties)\n self.produceEvent(msg, \"complete\")\n", "path": "master/buildbot/data/buildsets.py"}], "after_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nimport copy\n\nfrom twisted.internet import defer\nfrom twisted.python import log\n\nfrom buildbot.data import base\nfrom buildbot.data import sourcestamps as sourcestampsapi\nfrom buildbot.data import types\nfrom buildbot.db.buildsets import AlreadyCompleteError\nfrom buildbot.process.buildrequest import BuildRequestCollapser\nfrom buildbot.process.results import SUCCESS\nfrom buildbot.process.results import worst_status\nfrom buildbot.util import datetime2epoch\nfrom buildbot.util import epoch2datetime\n\n\nclass Db2DataMixin:\n\n @defer.inlineCallbacks\n def db2data(self, bsdict):\n if not bsdict:\n return None\n\n buildset = bsdict.copy()\n\n # gather the actual sourcestamps, in parallel\n sourcestamps = []\n\n @defer.inlineCallbacks\n def getSs(ssid):\n ss = yield self.master.data.get(('sourcestamps', str(ssid)))\n sourcestamps.append(ss)\n yield defer.DeferredList([getSs(id)\n for id in buildset['sourcestamps']],\n fireOnOneErrback=True, consumeErrors=True)\n buildset['sourcestamps'] = sourcestamps\n\n # minor modifications\n buildset['submitted_at'] = datetime2epoch(buildset['submitted_at'])\n buildset['complete_at'] = datetime2epoch(buildset['complete_at'])\n\n return buildset\n\n fieldMapping = {\n 'bsid': 'buildsets.id',\n 'external_idstring': 'buildsets.external_idstring',\n 'reason': 'buildsets.reason',\n 'submitted_at': 'buildsets.submitted_at',\n 'complete': 'buildsets.complete',\n 'complete_at': 'buildsets.complete_at',\n 'results': 'buildsets.results',\n 'parent_buildid': 'buildsets.parent_buildid',\n 'parent_relationship': 'buildsets.parent_relationship'\n }\n\n\nclass BuildsetEndpoint(Db2DataMixin, base.Endpoint):\n\n kind = base.EndpointKind.SINGLE\n pathPatterns = \"\"\"\n /buildsets/n:bsid\n \"\"\"\n\n @defer.inlineCallbacks\n def get(self, resultSpec, kwargs):\n res = yield self.master.db.buildsets.getBuildset(kwargs['bsid'])\n res = yield self.db2data(res)\n return res\n\n\nclass BuildsetsEndpoint(Db2DataMixin, base.Endpoint):\n\n kind = base.EndpointKind.COLLECTION\n pathPatterns = \"\"\"\n /buildsets\n \"\"\"\n rootLinkName = 'buildsets'\n\n def get(self, resultSpec, kwargs):\n complete = resultSpec.popBooleanFilter('complete')\n resultSpec.fieldMapping = self.fieldMapping\n d = self.master.db.buildsets.getBuildsets(\n complete=complete, resultSpec=resultSpec)\n\n @d.addCallback\n def db2data(buildsets):\n d = defer.DeferredList([self.db2data(bs) for bs in buildsets],\n fireOnOneErrback=True, consumeErrors=True)\n\n @d.addCallback\n def getResults(res):\n return [r[1] for r in res]\n return d\n return d\n\n\nclass Buildset(base.ResourceType):\n\n name = \"buildset\"\n plural = \"buildsets\"\n endpoints = [BuildsetEndpoint, BuildsetsEndpoint]\n keyField = 'bsid'\n eventPathPatterns = \"\"\"\n /buildsets/:bsid\n \"\"\"\n\n class EntityType(types.Entity):\n bsid = types.Integer()\n external_idstring = types.NoneOk(types.String())\n reason = types.String()\n submitted_at = types.Integer()\n complete = types.Boolean()\n complete_at = types.NoneOk(types.Integer())\n results = types.NoneOk(types.Integer())\n sourcestamps = types.List(\n of=sourcestampsapi.SourceStamp.entityType)\n parent_buildid = types.NoneOk(types.Integer())\n parent_relationship = types.NoneOk(types.String())\n entityType = EntityType(name, 'Buildset')\n subresources = [\"Property\"]\n\n @base.updateMethod\n @defer.inlineCallbacks\n def addBuildset(self, waited_for, scheduler=None, sourcestamps=None, reason='',\n properties=None, builderids=None, external_idstring=None,\n parent_buildid=None, parent_relationship=None, priority=0):\n if sourcestamps is None:\n sourcestamps = []\n if properties is None:\n properties = {}\n if builderids is None:\n builderids = []\n submitted_at = int(self.master.reactor.seconds())\n bsid, brids = yield self.master.db.buildsets.addBuildset(\n sourcestamps=sourcestamps, reason=reason,\n properties=properties, builderids=builderids,\n waited_for=waited_for, external_idstring=external_idstring,\n submitted_at=epoch2datetime(submitted_at),\n parent_buildid=parent_buildid, parent_relationship=parent_relationship,\n priority=priority)\n\n yield BuildRequestCollapser(self.master, list(brids.values())).collapse()\n\n # get each of the sourcestamps for this buildset (sequentially)\n bsdict = yield self.master.db.buildsets.getBuildset(bsid)\n sourcestamps = []\n for ssid in bsdict['sourcestamps']:\n sourcestamps.append(\n (yield self.master.data.get(('sourcestamps', str(ssid)))).copy()\n )\n\n # notify about the component build requests\n brResource = self.master.data.getResourceType(\"buildrequest\")\n brResource.generateEvent(list(brids.values()), 'new')\n\n # and the buildset itself\n msg = {\n \"bsid\": bsid,\n \"external_idstring\": external_idstring,\n \"reason\": reason,\n \"parent_buildid\": parent_buildid,\n \"submitted_at\": submitted_at,\n \"complete\": False,\n \"complete_at\": None,\n \"results\": None,\n \"scheduler\": scheduler,\n \"sourcestamps\": sourcestamps\n }\n # TODO: properties=properties)\n self.produceEvent(msg, \"new\")\n\n log.msg(f\"added buildset {bsid} to database\")\n\n # if there are no builders, then this is done already, so send the\n # appropriate messages for that\n if not builderids:\n yield self.maybeBuildsetComplete(bsid)\n\n return (bsid, brids)\n\n @base.updateMethod\n @defer.inlineCallbacks\n def maybeBuildsetComplete(self, bsid):\n brdicts = yield self.master.db.buildrequests.getBuildRequests(\n bsid=bsid, complete=False)\n\n # if there are incomplete buildrequests, bail out\n if brdicts:\n return\n\n brdicts = yield self.master.db.buildrequests.getBuildRequests(bsid=bsid)\n\n # figure out the overall results of the buildset:\n cumulative_results = SUCCESS\n for brdict in brdicts:\n cumulative_results = worst_status(\n cumulative_results, brdict['results'])\n\n # get a copy of the buildset\n bsdict = yield self.master.db.buildsets.getBuildset(bsid)\n\n # if it's already completed, we're late to the game, and there's\n # nothing to do.\n #\n # NOTE: there's still a strong possibility of a race condition here,\n # which would cause buildset being completed twice.\n # in this case, the db layer will detect that and raise AlreadyCompleteError\n if bsdict['complete']:\n return\n\n # mark it as completed in the database\n complete_at = epoch2datetime(int(self.master.reactor.seconds()))\n try:\n yield self.master.db.buildsets.completeBuildset(bsid, cumulative_results,\n complete_at=complete_at)\n except AlreadyCompleteError:\n return\n # get the sourcestamps for the message\n # get each of the sourcestamps for this buildset (sequentially)\n bsdict = yield self.master.db.buildsets.getBuildset(bsid)\n sourcestamps = []\n for ssid in bsdict['sourcestamps']:\n sourcestamps.append(\n copy.deepcopy(\n (yield self.master.data.get(('sourcestamps', str(ssid))))\n )\n )\n\n msg = {\n \"bsid\": bsid,\n \"external_idstring\": bsdict['external_idstring'],\n \"reason\": bsdict['reason'],\n \"sourcestamps\": sourcestamps,\n \"submitted_at\": bsdict['submitted_at'],\n \"complete\": True,\n \"complete_at\": complete_at,\n \"results\": cumulative_results,\n \"parent_buildid\": bsdict[\"parent_buildid\"],\n \"parent_relationship\": bsdict[\"parent_relationship\"],\n }\n # TODO: properties=properties)\n self.produceEvent(msg, \"complete\")\n", "path": "master/buildbot/data/buildsets.py"}]}
| 2,983 | 110 |
gh_patches_debug_30403
|
rasdani/github-patches
|
git_diff
|
pytorch__pytorch-2645
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug in legacy padding layer
I've found a bug in [Padding.py](https://github.com/pytorch/pytorch/blob/master/torch/legacy/nn/Padding.py).
It doesn't handle nInputDim original Torch Padding layer's parameter . As far as I've unterstood, you've rewritten lua code from [here](https://github.com/torch/nn/blob/master/Padding.lua), but not fully. 19th line in this file contains code for dealing with nInputDim parameter.
To reproduce issue, you need to download ENet model from [here](https://www.dropbox.com/sh/dywzk3gyb12hpe5/AAD5YkUa8XgMpHs2gCRgmCVCa)(original model from ENet authors) and make inference:
`import numpy as np`
`import torch`
`from torch.utils.serialization import load_lua`
`image = np.ones((1,3,1024,2048))`
`tensor = torch.FloatTensor(image)`
`net_torch = load_lua(torch_model)`
`out_torch = net_torch.forward(tensor)`
Now I've got en exception:
Traceback (most recent call last):
```
File "/hdd/PycharmProjects/untitled/test.py", line 110, in <module>
out_torch = net_torch.forward(tensor).numpy()
File "/usr/local/lib/python2.7/dist-packages/torch/legacy/nn/Module.py", line 33, in forward
return self.updateOutput(input)
File "/usr/local/lib/python2.7/dist-packages/torch/legacy/nn/Sequential.py", line 36, in updateOutput
currentOutput = module.updateOutput(currentOutput)
File "/usr/local/lib/python2.7/dist-packages/torch/legacy/nn/Sequential.py", line 36, in updateOutput
currentOutput = module.updateOutput(currentOutput)
File "/usr/local/lib/python2.7/dist-packages/torch/legacy/nn/CAddTable.py", line 20, in updateOutput
self.output.add_(input[i])
RuntimeError: inconsistent tensor size at /b/wheel/pytorch-src/torch/lib/TH/generic/THTensorMath.c:827
```
Padding is added to wrong axis, what's why CAddTable can't sum blobs with different shapes and throws exception.
If I edit the code of Padding.py by adding one to self.dim variables (lines 21 and 23 in Padding.py), all works correctly.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torch/legacy/nn/Padding.py`
Content:
```
1 import torch
2 from .Module import Module
3
4
5 class Padding(Module):
6 # pad puts in [pad] amount of [value] over dimension [dim], starting at
7 # index [index] in that dimension. If pad<0, index counts from the left.
8 # If pad>0 index counts from the right index = 1 pads before index 1.
9 # index = 2 pads starting before index 2 and after index 1 in dimension [dim]
10
11 def __init__(self, dim, pad, value=0, index=0):
12 self.value = value
13 self.index = index
14 self.dim = dim
15 self.pad = pad
16 self.outputSize = torch.Size()
17 super(Padding, self).__init__()
18
19 def updateOutput(self, input):
20 outputSize = list(input.size())
21 outputSize[self.dim] += abs(self.pad)
22 self.outputSize = torch.Size(outputSize)
23 dim = self.dim
24
25 self.output.resize_(self.outputSize)
26 self.output.fill_(self.value)
27 index = self.index
28 pad = self.pad
29 if pad > 0:
30 index = input.size(dim) - index
31 else:
32 pad = -pad
33
34 if index == 0:
35 self.output.narrow(dim, pad, input.size(dim)).copy_(input)
36 elif index == input.size(dim):
37 self.output.narrow(dim, 0, input.size(dim)).copy_(input)
38 else:
39 self.output.narrow(dim, 0, index).copy_(input.narrow(dim, 0, index))
40 self.output.narrow(dim, index + pad, input.size(dim) -
41 index).copy_(input.narrow(dim, index, input.size(dim) - index))
42
43 return self.output
44
45 def updateGradInput(self, input, gradOutput):
46 self.gradInput.resize_as_(input)
47 dim = self.dim
48
49 index = self.index
50 pad = self.pad
51 if pad > 0:
52 index = input.size(dim) - index
53 else:
54 pad = -pad
55
56 if index == 0:
57 self.gradInput.copy_(gradOutput.narrow(dim, pad, input.size(dim)))
58 elif index == input.size(dim):
59 self.gradInput.copy_(gradOutput.narrow(dim, 0, input.size(dim)))
60 else:
61 self.gradInput.narrow(dim, 0, index).copy_(gradOutput.narrow(dim, 0, index))
62 self.gradInput.narrow(dim, index, input.size(
63 dim) - index).copy_(gradOutput.narrow(dim, index + pad, input.size(dim) - index))
64
65 return self.gradInput
66
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torch/legacy/nn/Padding.py b/torch/legacy/nn/Padding.py
--- a/torch/legacy/nn/Padding.py
+++ b/torch/legacy/nn/Padding.py
@@ -7,12 +7,15 @@
# index [index] in that dimension. If pad<0, index counts from the left.
# If pad>0 index counts from the right index = 1 pads before index 1.
# index = 2 pads starting before index 2 and after index 1 in dimension [dim]
+ # When nInputDim is provided, inputs larger than that value will be considered batches
+ # where the actual dim to be padded will be dimension dim + 1.
- def __init__(self, dim, pad, value=0, index=0):
+ def __init__(self, dim, pad, value=0, index=0, nInputDim=0):
self.value = value
self.index = index
self.dim = dim
self.pad = pad
+ self.nInputDim = nInputDim
self.outputSize = torch.Size()
super(Padding, self).__init__()
@@ -22,6 +25,9 @@
self.outputSize = torch.Size(outputSize)
dim = self.dim
+ if hasattr(self, "nInputDim") and self.nInputDim > 0 and input.dim() != self.nInputDim:
+ dim = dim + 1
+
self.output.resize_(self.outputSize)
self.output.fill_(self.value)
index = self.index
@@ -46,6 +52,9 @@
self.gradInput.resize_as_(input)
dim = self.dim
+ if hasattr(self, "nInputDim") and self.nInputDim > 0 and input.dim() != self.nInputDim:
+ dim = dim + 1
+
index = self.index
pad = self.pad
if pad > 0:
|
{"golden_diff": "diff --git a/torch/legacy/nn/Padding.py b/torch/legacy/nn/Padding.py\n--- a/torch/legacy/nn/Padding.py\n+++ b/torch/legacy/nn/Padding.py\n@@ -7,12 +7,15 @@\n # index [index] in that dimension. If pad<0, index counts from the left.\n # If pad>0 index counts from the right index = 1 pads before index 1.\n # index = 2 pads starting before index 2 and after index 1 in dimension [dim]\n+ # When nInputDim is provided, inputs larger than that value will be considered batches\n+ # where the actual dim to be padded will be dimension dim + 1.\n \n- def __init__(self, dim, pad, value=0, index=0):\n+ def __init__(self, dim, pad, value=0, index=0, nInputDim=0):\n self.value = value\n self.index = index\n self.dim = dim\n self.pad = pad\n+ self.nInputDim = nInputDim\n self.outputSize = torch.Size()\n super(Padding, self).__init__()\n \n@@ -22,6 +25,9 @@\n self.outputSize = torch.Size(outputSize)\n dim = self.dim\n \n+ if hasattr(self, \"nInputDim\") and self.nInputDim > 0 and input.dim() != self.nInputDim:\n+ dim = dim + 1\n+\n self.output.resize_(self.outputSize)\n self.output.fill_(self.value)\n index = self.index\n@@ -46,6 +52,9 @@\n self.gradInput.resize_as_(input)\n dim = self.dim\n \n+ if hasattr(self, \"nInputDim\") and self.nInputDim > 0 and input.dim() != self.nInputDim:\n+ dim = dim + 1\n+\n index = self.index\n pad = self.pad\n if pad > 0:\n", "issue": "Bug in legacy padding layer\nI've found a bug in [Padding.py](https://github.com/pytorch/pytorch/blob/master/torch/legacy/nn/Padding.py).\r\nIt doesn't handle nInputDim original Torch Padding layer's parameter . As far as I've unterstood, you've rewritten lua code from [here](https://github.com/torch/nn/blob/master/Padding.lua), but not fully. 19th line in this file contains code for dealing with nInputDim parameter.\r\nTo reproduce issue, you need to download ENet model from [here](https://www.dropbox.com/sh/dywzk3gyb12hpe5/AAD5YkUa8XgMpHs2gCRgmCVCa)(original model from ENet authors) and make inference:\r\n`import numpy as np`\r\n`import torch`\r\n`from torch.utils.serialization import load_lua`\r\n`image = np.ones((1,3,1024,2048))`\r\n`tensor = torch.FloatTensor(image)`\r\n`net_torch = load_lua(torch_model)`\r\n`out_torch = net_torch.forward(tensor)`\r\n\r\nNow I've got en exception: \r\nTraceback (most recent call last):\r\n```\r\n File \"/hdd/PycharmProjects/untitled/test.py\", line 110, in <module>\r\n out_torch = net_torch.forward(tensor).numpy()\r\n File \"/usr/local/lib/python2.7/dist-packages/torch/legacy/nn/Module.py\", line 33, in forward\r\n return self.updateOutput(input)\r\n File \"/usr/local/lib/python2.7/dist-packages/torch/legacy/nn/Sequential.py\", line 36, in updateOutput\r\n currentOutput = module.updateOutput(currentOutput)\r\n File \"/usr/local/lib/python2.7/dist-packages/torch/legacy/nn/Sequential.py\", line 36, in updateOutput\r\n currentOutput = module.updateOutput(currentOutput)\r\n File \"/usr/local/lib/python2.7/dist-packages/torch/legacy/nn/CAddTable.py\", line 20, in updateOutput\r\n self.output.add_(input[i])\r\nRuntimeError: inconsistent tensor size at /b/wheel/pytorch-src/torch/lib/TH/generic/THTensorMath.c:827\r\n```\r\n\r\nPadding is added to wrong axis, what's why CAddTable can't sum blobs with different shapes and throws exception.\r\nIf I edit the code of Padding.py by adding one to self.dim variables (lines 21 and 23 in Padding.py), all works correctly.\n", "before_files": [{"content": "import torch\nfrom .Module import Module\n\n\nclass Padding(Module):\n # pad puts in [pad] amount of [value] over dimension [dim], starting at\n # index [index] in that dimension. If pad<0, index counts from the left.\n # If pad>0 index counts from the right index = 1 pads before index 1.\n # index = 2 pads starting before index 2 and after index 1 in dimension [dim]\n\n def __init__(self, dim, pad, value=0, index=0):\n self.value = value\n self.index = index\n self.dim = dim\n self.pad = pad\n self.outputSize = torch.Size()\n super(Padding, self).__init__()\n\n def updateOutput(self, input):\n outputSize = list(input.size())\n outputSize[self.dim] += abs(self.pad)\n self.outputSize = torch.Size(outputSize)\n dim = self.dim\n\n self.output.resize_(self.outputSize)\n self.output.fill_(self.value)\n index = self.index\n pad = self.pad\n if pad > 0:\n index = input.size(dim) - index\n else:\n pad = -pad\n\n if index == 0:\n self.output.narrow(dim, pad, input.size(dim)).copy_(input)\n elif index == input.size(dim):\n self.output.narrow(dim, 0, input.size(dim)).copy_(input)\n else:\n self.output.narrow(dim, 0, index).copy_(input.narrow(dim, 0, index))\n self.output.narrow(dim, index + pad, input.size(dim) -\n index).copy_(input.narrow(dim, index, input.size(dim) - index))\n\n return self.output\n\n def updateGradInput(self, input, gradOutput):\n self.gradInput.resize_as_(input)\n dim = self.dim\n\n index = self.index\n pad = self.pad\n if pad > 0:\n index = input.size(dim) - index\n else:\n pad = -pad\n\n if index == 0:\n self.gradInput.copy_(gradOutput.narrow(dim, pad, input.size(dim)))\n elif index == input.size(dim):\n self.gradInput.copy_(gradOutput.narrow(dim, 0, input.size(dim)))\n else:\n self.gradInput.narrow(dim, 0, index).copy_(gradOutput.narrow(dim, 0, index))\n self.gradInput.narrow(dim, index, input.size(\n dim) - index).copy_(gradOutput.narrow(dim, index + pad, input.size(dim) - index))\n\n return self.gradInput\n", "path": "torch/legacy/nn/Padding.py"}], "after_files": [{"content": "import torch\nfrom .Module import Module\n\n\nclass Padding(Module):\n # pad puts in [pad] amount of [value] over dimension [dim], starting at\n # index [index] in that dimension. If pad<0, index counts from the left.\n # If pad>0 index counts from the right index = 1 pads before index 1.\n # index = 2 pads starting before index 2 and after index 1 in dimension [dim]\n # When nInputDim is provided, inputs larger than that value will be considered batches\n # where the actual dim to be padded will be dimension dim + 1.\n\n def __init__(self, dim, pad, value=0, index=0, nInputDim=0):\n self.value = value\n self.index = index\n self.dim = dim\n self.pad = pad\n self.nInputDim = nInputDim\n self.outputSize = torch.Size()\n super(Padding, self).__init__()\n\n def updateOutput(self, input):\n outputSize = list(input.size())\n outputSize[self.dim] += abs(self.pad)\n self.outputSize = torch.Size(outputSize)\n dim = self.dim\n\n if hasattr(self, \"nInputDim\") and self.nInputDim > 0 and input.dim() != self.nInputDim:\n dim = dim + 1\n\n self.output.resize_(self.outputSize)\n self.output.fill_(self.value)\n index = self.index\n pad = self.pad\n if pad > 0:\n index = input.size(dim) - index\n else:\n pad = -pad\n\n if index == 0:\n self.output.narrow(dim, pad, input.size(dim)).copy_(input)\n elif index == input.size(dim):\n self.output.narrow(dim, 0, input.size(dim)).copy_(input)\n else:\n self.output.narrow(dim, 0, index).copy_(input.narrow(dim, 0, index))\n self.output.narrow(dim, index + pad, input.size(dim) -\n index).copy_(input.narrow(dim, index, input.size(dim) - index))\n\n return self.output\n\n def updateGradInput(self, input, gradOutput):\n self.gradInput.resize_as_(input)\n dim = self.dim\n\n if hasattr(self, \"nInputDim\") and self.nInputDim > 0 and input.dim() != self.nInputDim:\n dim = dim + 1\n\n index = self.index\n pad = self.pad\n if pad > 0:\n index = input.size(dim) - index\n else:\n pad = -pad\n\n if index == 0:\n self.gradInput.copy_(gradOutput.narrow(dim, pad, input.size(dim)))\n elif index == input.size(dim):\n self.gradInput.copy_(gradOutput.narrow(dim, 0, input.size(dim)))\n else:\n self.gradInput.narrow(dim, 0, index).copy_(gradOutput.narrow(dim, 0, index))\n self.gradInput.narrow(dim, index, input.size(\n dim) - index).copy_(gradOutput.narrow(dim, index + pad, input.size(dim) - index))\n\n return self.gradInput\n", "path": "torch/legacy/nn/Padding.py"}]}
| 1,502 | 437 |
gh_patches_debug_33344
|
rasdani/github-patches
|
git_diff
|
learningequality__kolibri-6089
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
zeroconf: Crashes when starting devserver
### Observed behavior
Tried to run devserver.
```
Traceback (most recent call last):
File "/home/richard/.virtualenvs/kolibri/bin/kolibri", line 11, in <module>
load_entry_point('kolibri', 'console_scripts', 'kolibri')()
File "/home/richard/.virtualenvs/kolibri/local/lib/python2.7/site-packages/click/core.py", line 764, in __call__
return self.main(*args, **kwargs)
File "/home/richard/.virtualenvs/kolibri/local/lib/python2.7/site-packages/click/core.py", line 717, in main
rv = self.invoke(ctx)
File "/home/richard/.virtualenvs/kolibri/local/lib/python2.7/site-packages/click/core.py", line 1137, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/home/richard/github/kolibri/kolibri/utils/cli.py", line 237, in invoke
return super(KolibriDjangoCommand, self).invoke(ctx)
File "/home/richard/.virtualenvs/kolibri/local/lib/python2.7/site-packages/click/core.py", line 956, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/home/richard/.virtualenvs/kolibri/local/lib/python2.7/site-packages/click/core.py", line 555, in invoke
return callback(*args, **kwargs)
File "/home/richard/github/kolibri/kolibri/utils/cli.py", line 610, in services
server.services()
File "/home/richard/github/kolibri/kolibri/utils/server.py", line 167, in services
run_services(port=port)
File "/home/richard/github/kolibri/kolibri/utils/server.py", line 121, in run_services
register_zeroconf_service(port=port, id=instance.id[:4])
File "/home/richard/github/kolibri/kolibri/core/discovery/utils/network/search.py", line 160, in register_zeroconf_service
ZEROCONF_STATE["service"].register()
File "/home/richard/github/kolibri/kolibri/core/discovery/utils/network/search.py", line 68, in register
properties=self.data,
File "/home/richard/.virtualenvs/kolibri/local/lib/python2.7/site-packages/zeroconf.py", line 1485, in __init__
self._set_properties(properties)
File "/home/richard/.virtualenvs/kolibri/local/lib/python2.7/site-packages/zeroconf.py", line 1516, in _set_properties
result = b"".join((result, int2byte(len(item)), item))
ValueError: chr() arg not in range(256)
```
### Expected behavior
Devserver should run :)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kolibri/core/discovery/utils/network/search.py`
Content:
```
1 import atexit
2 import json
3 import logging
4 import socket
5 import time
6 from contextlib import closing
7
8 from zeroconf import get_all_addresses
9 from zeroconf import NonUniqueNameException
10 from zeroconf import ServiceInfo
11 from zeroconf import USE_IP_OF_OUTGOING_INTERFACE
12 from zeroconf import Zeroconf
13
14 from kolibri.core.auth.models import Facility
15 from kolibri.core.content.models import ChannelMetadata
16
17 logger = logging.getLogger(__name__)
18
19 SERVICE_TYPE = "Kolibri._sub._http._tcp.local."
20 LOCAL_DOMAIN = "kolibri.local"
21
22 ZEROCONF_STATE = {"zeroconf": None, "listener": None, "service": None}
23
24
25 def _id_from_name(name):
26 assert name.endswith(SERVICE_TYPE), (
27 "Invalid service name; must end with '%s'" % SERVICE_TYPE
28 )
29 return name.replace(SERVICE_TYPE, "").strip(".")
30
31
32 def _is_port_open(host, port, timeout=1):
33 with closing(socket.socket(socket.AF_INET, socket.SOCK_STREAM)) as sock:
34 sock.settimeout(timeout)
35 return sock.connect_ex((host, port)) == 0
36
37
38 class KolibriZeroconfService(object):
39
40 info = None
41
42 def __init__(self, id, port=8080, data={}):
43 self.id = id
44 self.port = port
45 self.data = {key: json.dumps(val) for (key, val) in data.items()}
46 atexit.register(self.cleanup)
47
48 def register(self):
49
50 if not ZEROCONF_STATE["zeroconf"]:
51 initialize_zeroconf_listener()
52
53 assert self.info is None, "Service is already registered!"
54
55 i = 1
56 id = self.id
57
58 while not self.info:
59
60 # attempt to create an mDNS service and register it on the network
61 try:
62 info = ServiceInfo(
63 SERVICE_TYPE,
64 name=".".join([id, SERVICE_TYPE]),
65 server=".".join([id, LOCAL_DOMAIN, ""]),
66 address=USE_IP_OF_OUTGOING_INTERFACE,
67 port=self.port,
68 properties=self.data,
69 )
70
71 ZEROCONF_STATE["zeroconf"].register_service(info, ttl=60)
72
73 self.info = info
74
75 except NonUniqueNameException:
76 # if there's a name conflict, append incrementing integer until no conflict
77 i += 1
78 id = "%s-%d" % (self.id, i)
79
80 if i > 100:
81 raise NonUniqueNameException()
82
83 self.id = id
84
85 return self
86
87 def unregister(self):
88
89 assert self.info is not None, "Service is not registered!"
90
91 ZEROCONF_STATE["zeroconf"].unregister_service(self.info)
92
93 self.info = None
94
95 def cleanup(self, *args, **kwargs):
96
97 if self.info and ZEROCONF_STATE["zeroconf"]:
98 self.unregister()
99
100
101 class KolibriZeroconfListener(object):
102
103 instances = {}
104
105 def add_service(self, zeroconf, type, name):
106 info = zeroconf.get_service_info(type, name)
107 id = _id_from_name(name)
108 ip = socket.inet_ntoa(info.address)
109 self.instances[id] = {
110 "id": id,
111 "ip": ip,
112 "local": ip in get_all_addresses(),
113 "port": info.port,
114 "host": info.server.strip("."),
115 "data": {key: json.loads(val) for (key, val) in info.properties.items()},
116 "base_url": "http://{ip}:{port}/".format(ip=ip, port=info.port),
117 }
118 logger.info(
119 "Kolibri instance '%s' joined zeroconf network; service info: %s\n"
120 % (id, self.instances[id])
121 )
122
123 def remove_service(self, zeroconf, type, name):
124 id = _id_from_name(name)
125 logger.info("\nKolibri instance '%s' has left the zeroconf network.\n" % (id,))
126 if id in self.instances:
127 del self.instances[id]
128
129
130 def get_available_instances(timeout=2, include_local=True):
131 """Retrieve a list of dicts with information about the discovered Kolibri instances on the local network,
132 filtering out those that can't be accessed at the specified port (via attempting to open a socket)."""
133 if not ZEROCONF_STATE["listener"]:
134 initialize_zeroconf_listener()
135 time.sleep(3)
136 instances = []
137 for instance in ZEROCONF_STATE["listener"].instances.values():
138 if instance["local"] and not include_local:
139 continue
140 if not _is_port_open(instance["ip"], instance["port"], timeout=timeout):
141 continue
142 instance["self"] = (
143 ZEROCONF_STATE["service"] and ZEROCONF_STATE["service"].id == instance["id"]
144 )
145 instances.append(instance)
146 return instances
147
148
149 def register_zeroconf_service(port, id):
150 if ZEROCONF_STATE["service"] is not None:
151 unregister_zeroconf_service()
152 logger.info("Registering ourselves to zeroconf network with id '%s'..." % id)
153 data = {
154 "facilities": list(Facility.objects.values("id", "dataset_id", "name")),
155 "channels": list(
156 ChannelMetadata.objects.filter(root__available=True).values("id", "name")
157 ),
158 }
159 ZEROCONF_STATE["service"] = KolibriZeroconfService(id=id, port=port, data=data)
160 ZEROCONF_STATE["service"].register()
161
162
163 def unregister_zeroconf_service():
164 logger.info("Unregistering ourselves from zeroconf network...")
165 if ZEROCONF_STATE["service"] is not None:
166 ZEROCONF_STATE["service"].cleanup()
167 ZEROCONF_STATE["service"] = None
168
169
170 def initialize_zeroconf_listener():
171 ZEROCONF_STATE["zeroconf"] = Zeroconf()
172 ZEROCONF_STATE["listener"] = KolibriZeroconfListener()
173 ZEROCONF_STATE["zeroconf"].add_service_listener(
174 SERVICE_TYPE, ZEROCONF_STATE["listener"]
175 )
176
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kolibri/core/discovery/utils/network/search.py b/kolibri/core/discovery/utils/network/search.py
--- a/kolibri/core/discovery/utils/network/search.py
+++ b/kolibri/core/discovery/utils/network/search.py
@@ -11,8 +11,7 @@
from zeroconf import USE_IP_OF_OUTGOING_INTERFACE
from zeroconf import Zeroconf
-from kolibri.core.auth.models import Facility
-from kolibri.core.content.models import ChannelMetadata
+import kolibri
logger = logging.getLogger(__name__)
@@ -106,13 +105,17 @@
info = zeroconf.get_service_info(type, name)
id = _id_from_name(name)
ip = socket.inet_ntoa(info.address)
+
self.instances[id] = {
"id": id,
"ip": ip,
"local": ip in get_all_addresses(),
"port": info.port,
"host": info.server.strip("."),
- "data": {key: json.loads(val) for (key, val) in info.properties.items()},
+ "data": {
+ bytes.decode(key): json.loads(val)
+ for (key, val) in info.properties.items()
+ },
"base_url": "http://{ip}:{port}/".format(ip=ip, port=info.port),
}
logger.info(
@@ -150,12 +153,7 @@
if ZEROCONF_STATE["service"] is not None:
unregister_zeroconf_service()
logger.info("Registering ourselves to zeroconf network with id '%s'..." % id)
- data = {
- "facilities": list(Facility.objects.values("id", "dataset_id", "name")),
- "channels": list(
- ChannelMetadata.objects.filter(root__available=True).values("id", "name")
- ),
- }
+ data = {"version": kolibri.VERSION}
ZEROCONF_STATE["service"] = KolibriZeroconfService(id=id, port=port, data=data)
ZEROCONF_STATE["service"].register()
|
{"golden_diff": "diff --git a/kolibri/core/discovery/utils/network/search.py b/kolibri/core/discovery/utils/network/search.py\n--- a/kolibri/core/discovery/utils/network/search.py\n+++ b/kolibri/core/discovery/utils/network/search.py\n@@ -11,8 +11,7 @@\n from zeroconf import USE_IP_OF_OUTGOING_INTERFACE\n from zeroconf import Zeroconf\n \n-from kolibri.core.auth.models import Facility\n-from kolibri.core.content.models import ChannelMetadata\n+import kolibri\n \n logger = logging.getLogger(__name__)\n \n@@ -106,13 +105,17 @@\n info = zeroconf.get_service_info(type, name)\n id = _id_from_name(name)\n ip = socket.inet_ntoa(info.address)\n+\n self.instances[id] = {\n \"id\": id,\n \"ip\": ip,\n \"local\": ip in get_all_addresses(),\n \"port\": info.port,\n \"host\": info.server.strip(\".\"),\n- \"data\": {key: json.loads(val) for (key, val) in info.properties.items()},\n+ \"data\": {\n+ bytes.decode(key): json.loads(val)\n+ for (key, val) in info.properties.items()\n+ },\n \"base_url\": \"http://{ip}:{port}/\".format(ip=ip, port=info.port),\n }\n logger.info(\n@@ -150,12 +153,7 @@\n if ZEROCONF_STATE[\"service\"] is not None:\n unregister_zeroconf_service()\n logger.info(\"Registering ourselves to zeroconf network with id '%s'...\" % id)\n- data = {\n- \"facilities\": list(Facility.objects.values(\"id\", \"dataset_id\", \"name\")),\n- \"channels\": list(\n- ChannelMetadata.objects.filter(root__available=True).values(\"id\", \"name\")\n- ),\n- }\n+ data = {\"version\": kolibri.VERSION}\n ZEROCONF_STATE[\"service\"] = KolibriZeroconfService(id=id, port=port, data=data)\n ZEROCONF_STATE[\"service\"].register()\n", "issue": "zeroconf: Crashes when starting devserver\n### Observed behavior\r\nTried to run devserver.\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/richard/.virtualenvs/kolibri/bin/kolibri\", line 11, in <module>\r\n load_entry_point('kolibri', 'console_scripts', 'kolibri')()\r\n File \"/home/richard/.virtualenvs/kolibri/local/lib/python2.7/site-packages/click/core.py\", line 764, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/home/richard/.virtualenvs/kolibri/local/lib/python2.7/site-packages/click/core.py\", line 717, in main\r\n rv = self.invoke(ctx)\r\n File \"/home/richard/.virtualenvs/kolibri/local/lib/python2.7/site-packages/click/core.py\", line 1137, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"/home/richard/github/kolibri/kolibri/utils/cli.py\", line 237, in invoke\r\n return super(KolibriDjangoCommand, self).invoke(ctx)\r\n File \"/home/richard/.virtualenvs/kolibri/local/lib/python2.7/site-packages/click/core.py\", line 956, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/home/richard/.virtualenvs/kolibri/local/lib/python2.7/site-packages/click/core.py\", line 555, in invoke\r\n return callback(*args, **kwargs)\r\n File \"/home/richard/github/kolibri/kolibri/utils/cli.py\", line 610, in services\r\n server.services()\r\n File \"/home/richard/github/kolibri/kolibri/utils/server.py\", line 167, in services\r\n run_services(port=port)\r\n File \"/home/richard/github/kolibri/kolibri/utils/server.py\", line 121, in run_services\r\n register_zeroconf_service(port=port, id=instance.id[:4])\r\n File \"/home/richard/github/kolibri/kolibri/core/discovery/utils/network/search.py\", line 160, in register_zeroconf_service\r\n ZEROCONF_STATE[\"service\"].register()\r\n File \"/home/richard/github/kolibri/kolibri/core/discovery/utils/network/search.py\", line 68, in register\r\n properties=self.data,\r\n File \"/home/richard/.virtualenvs/kolibri/local/lib/python2.7/site-packages/zeroconf.py\", line 1485, in __init__\r\n self._set_properties(properties)\r\n File \"/home/richard/.virtualenvs/kolibri/local/lib/python2.7/site-packages/zeroconf.py\", line 1516, in _set_properties\r\n result = b\"\".join((result, int2byte(len(item)), item))\r\nValueError: chr() arg not in range(256)\r\n```\r\n\r\n### Expected behavior\r\nDevserver should run :)\n", "before_files": [{"content": "import atexit\nimport json\nimport logging\nimport socket\nimport time\nfrom contextlib import closing\n\nfrom zeroconf import get_all_addresses\nfrom zeroconf import NonUniqueNameException\nfrom zeroconf import ServiceInfo\nfrom zeroconf import USE_IP_OF_OUTGOING_INTERFACE\nfrom zeroconf import Zeroconf\n\nfrom kolibri.core.auth.models import Facility\nfrom kolibri.core.content.models import ChannelMetadata\n\nlogger = logging.getLogger(__name__)\n\nSERVICE_TYPE = \"Kolibri._sub._http._tcp.local.\"\nLOCAL_DOMAIN = \"kolibri.local\"\n\nZEROCONF_STATE = {\"zeroconf\": None, \"listener\": None, \"service\": None}\n\n\ndef _id_from_name(name):\n assert name.endswith(SERVICE_TYPE), (\n \"Invalid service name; must end with '%s'\" % SERVICE_TYPE\n )\n return name.replace(SERVICE_TYPE, \"\").strip(\".\")\n\n\ndef _is_port_open(host, port, timeout=1):\n with closing(socket.socket(socket.AF_INET, socket.SOCK_STREAM)) as sock:\n sock.settimeout(timeout)\n return sock.connect_ex((host, port)) == 0\n\n\nclass KolibriZeroconfService(object):\n\n info = None\n\n def __init__(self, id, port=8080, data={}):\n self.id = id\n self.port = port\n self.data = {key: json.dumps(val) for (key, val) in data.items()}\n atexit.register(self.cleanup)\n\n def register(self):\n\n if not ZEROCONF_STATE[\"zeroconf\"]:\n initialize_zeroconf_listener()\n\n assert self.info is None, \"Service is already registered!\"\n\n i = 1\n id = self.id\n\n while not self.info:\n\n # attempt to create an mDNS service and register it on the network\n try:\n info = ServiceInfo(\n SERVICE_TYPE,\n name=\".\".join([id, SERVICE_TYPE]),\n server=\".\".join([id, LOCAL_DOMAIN, \"\"]),\n address=USE_IP_OF_OUTGOING_INTERFACE,\n port=self.port,\n properties=self.data,\n )\n\n ZEROCONF_STATE[\"zeroconf\"].register_service(info, ttl=60)\n\n self.info = info\n\n except NonUniqueNameException:\n # if there's a name conflict, append incrementing integer until no conflict\n i += 1\n id = \"%s-%d\" % (self.id, i)\n\n if i > 100:\n raise NonUniqueNameException()\n\n self.id = id\n\n return self\n\n def unregister(self):\n\n assert self.info is not None, \"Service is not registered!\"\n\n ZEROCONF_STATE[\"zeroconf\"].unregister_service(self.info)\n\n self.info = None\n\n def cleanup(self, *args, **kwargs):\n\n if self.info and ZEROCONF_STATE[\"zeroconf\"]:\n self.unregister()\n\n\nclass KolibriZeroconfListener(object):\n\n instances = {}\n\n def add_service(self, zeroconf, type, name):\n info = zeroconf.get_service_info(type, name)\n id = _id_from_name(name)\n ip = socket.inet_ntoa(info.address)\n self.instances[id] = {\n \"id\": id,\n \"ip\": ip,\n \"local\": ip in get_all_addresses(),\n \"port\": info.port,\n \"host\": info.server.strip(\".\"),\n \"data\": {key: json.loads(val) for (key, val) in info.properties.items()},\n \"base_url\": \"http://{ip}:{port}/\".format(ip=ip, port=info.port),\n }\n logger.info(\n \"Kolibri instance '%s' joined zeroconf network; service info: %s\\n\"\n % (id, self.instances[id])\n )\n\n def remove_service(self, zeroconf, type, name):\n id = _id_from_name(name)\n logger.info(\"\\nKolibri instance '%s' has left the zeroconf network.\\n\" % (id,))\n if id in self.instances:\n del self.instances[id]\n\n\ndef get_available_instances(timeout=2, include_local=True):\n \"\"\"Retrieve a list of dicts with information about the discovered Kolibri instances on the local network,\n filtering out those that can't be accessed at the specified port (via attempting to open a socket).\"\"\"\n if not ZEROCONF_STATE[\"listener\"]:\n initialize_zeroconf_listener()\n time.sleep(3)\n instances = []\n for instance in ZEROCONF_STATE[\"listener\"].instances.values():\n if instance[\"local\"] and not include_local:\n continue\n if not _is_port_open(instance[\"ip\"], instance[\"port\"], timeout=timeout):\n continue\n instance[\"self\"] = (\n ZEROCONF_STATE[\"service\"] and ZEROCONF_STATE[\"service\"].id == instance[\"id\"]\n )\n instances.append(instance)\n return instances\n\n\ndef register_zeroconf_service(port, id):\n if ZEROCONF_STATE[\"service\"] is not None:\n unregister_zeroconf_service()\n logger.info(\"Registering ourselves to zeroconf network with id '%s'...\" % id)\n data = {\n \"facilities\": list(Facility.objects.values(\"id\", \"dataset_id\", \"name\")),\n \"channels\": list(\n ChannelMetadata.objects.filter(root__available=True).values(\"id\", \"name\")\n ),\n }\n ZEROCONF_STATE[\"service\"] = KolibriZeroconfService(id=id, port=port, data=data)\n ZEROCONF_STATE[\"service\"].register()\n\n\ndef unregister_zeroconf_service():\n logger.info(\"Unregistering ourselves from zeroconf network...\")\n if ZEROCONF_STATE[\"service\"] is not None:\n ZEROCONF_STATE[\"service\"].cleanup()\n ZEROCONF_STATE[\"service\"] = None\n\n\ndef initialize_zeroconf_listener():\n ZEROCONF_STATE[\"zeroconf\"] = Zeroconf()\n ZEROCONF_STATE[\"listener\"] = KolibriZeroconfListener()\n ZEROCONF_STATE[\"zeroconf\"].add_service_listener(\n SERVICE_TYPE, ZEROCONF_STATE[\"listener\"]\n )\n", "path": "kolibri/core/discovery/utils/network/search.py"}], "after_files": [{"content": "import atexit\nimport json\nimport logging\nimport socket\nimport time\nfrom contextlib import closing\n\nfrom zeroconf import get_all_addresses\nfrom zeroconf import NonUniqueNameException\nfrom zeroconf import ServiceInfo\nfrom zeroconf import USE_IP_OF_OUTGOING_INTERFACE\nfrom zeroconf import Zeroconf\n\nimport kolibri\n\nlogger = logging.getLogger(__name__)\n\nSERVICE_TYPE = \"Kolibri._sub._http._tcp.local.\"\nLOCAL_DOMAIN = \"kolibri.local\"\n\nZEROCONF_STATE = {\"zeroconf\": None, \"listener\": None, \"service\": None}\n\n\ndef _id_from_name(name):\n assert name.endswith(SERVICE_TYPE), (\n \"Invalid service name; must end with '%s'\" % SERVICE_TYPE\n )\n return name.replace(SERVICE_TYPE, \"\").strip(\".\")\n\n\ndef _is_port_open(host, port, timeout=1):\n with closing(socket.socket(socket.AF_INET, socket.SOCK_STREAM)) as sock:\n sock.settimeout(timeout)\n return sock.connect_ex((host, port)) == 0\n\n\nclass KolibriZeroconfService(object):\n\n info = None\n\n def __init__(self, id, port=8080, data={}):\n self.id = id\n self.port = port\n self.data = {key: json.dumps(val) for (key, val) in data.items()}\n atexit.register(self.cleanup)\n\n def register(self):\n\n if not ZEROCONF_STATE[\"zeroconf\"]:\n initialize_zeroconf_listener()\n\n assert self.info is None, \"Service is already registered!\"\n\n i = 1\n id = self.id\n\n while not self.info:\n\n # attempt to create an mDNS service and register it on the network\n try:\n info = ServiceInfo(\n SERVICE_TYPE,\n name=\".\".join([id, SERVICE_TYPE]),\n server=\".\".join([id, LOCAL_DOMAIN, \"\"]),\n address=USE_IP_OF_OUTGOING_INTERFACE,\n port=self.port,\n properties=self.data,\n )\n\n ZEROCONF_STATE[\"zeroconf\"].register_service(info, ttl=60)\n\n self.info = info\n\n except NonUniqueNameException:\n # if there's a name conflict, append incrementing integer until no conflict\n i += 1\n id = \"%s-%d\" % (self.id, i)\n\n if i > 100:\n raise NonUniqueNameException()\n\n self.id = id\n\n return self\n\n def unregister(self):\n\n assert self.info is not None, \"Service is not registered!\"\n\n ZEROCONF_STATE[\"zeroconf\"].unregister_service(self.info)\n\n self.info = None\n\n def cleanup(self, *args, **kwargs):\n\n if self.info and ZEROCONF_STATE[\"zeroconf\"]:\n self.unregister()\n\n\nclass KolibriZeroconfListener(object):\n\n instances = {}\n\n def add_service(self, zeroconf, type, name):\n info = zeroconf.get_service_info(type, name)\n id = _id_from_name(name)\n ip = socket.inet_ntoa(info.address)\n\n self.instances[id] = {\n \"id\": id,\n \"ip\": ip,\n \"local\": ip in get_all_addresses(),\n \"port\": info.port,\n \"host\": info.server.strip(\".\"),\n \"data\": {\n bytes.decode(key): json.loads(val)\n for (key, val) in info.properties.items()\n },\n \"base_url\": \"http://{ip}:{port}/\".format(ip=ip, port=info.port),\n }\n logger.info(\n \"Kolibri instance '%s' joined zeroconf network; service info: %s\\n\"\n % (id, self.instances[id])\n )\n\n def remove_service(self, zeroconf, type, name):\n id = _id_from_name(name)\n logger.info(\"\\nKolibri instance '%s' has left the zeroconf network.\\n\" % (id,))\n if id in self.instances:\n del self.instances[id]\n\n\ndef get_available_instances(timeout=2, include_local=True):\n \"\"\"Retrieve a list of dicts with information about the discovered Kolibri instances on the local network,\n filtering out those that can't be accessed at the specified port (via attempting to open a socket).\"\"\"\n if not ZEROCONF_STATE[\"listener\"]:\n initialize_zeroconf_listener()\n time.sleep(3)\n instances = []\n for instance in ZEROCONF_STATE[\"listener\"].instances.values():\n if instance[\"local\"] and not include_local:\n continue\n if not _is_port_open(instance[\"ip\"], instance[\"port\"], timeout=timeout):\n continue\n instance[\"self\"] = (\n ZEROCONF_STATE[\"service\"] and ZEROCONF_STATE[\"service\"].id == instance[\"id\"]\n )\n instances.append(instance)\n return instances\n\n\ndef register_zeroconf_service(port, id):\n if ZEROCONF_STATE[\"service\"] is not None:\n unregister_zeroconf_service()\n logger.info(\"Registering ourselves to zeroconf network with id '%s'...\" % id)\n data = {\"version\": kolibri.VERSION}\n ZEROCONF_STATE[\"service\"] = KolibriZeroconfService(id=id, port=port, data=data)\n ZEROCONF_STATE[\"service\"].register()\n\n\ndef unregister_zeroconf_service():\n logger.info(\"Unregistering ourselves from zeroconf network...\")\n if ZEROCONF_STATE[\"service\"] is not None:\n ZEROCONF_STATE[\"service\"].cleanup()\n ZEROCONF_STATE[\"service\"] = None\n\n\ndef initialize_zeroconf_listener():\n ZEROCONF_STATE[\"zeroconf\"] = Zeroconf()\n ZEROCONF_STATE[\"listener\"] = KolibriZeroconfListener()\n ZEROCONF_STATE[\"zeroconf\"].add_service_listener(\n SERVICE_TYPE, ZEROCONF_STATE[\"listener\"]\n )\n", "path": "kolibri/core/discovery/utils/network/search.py"}]}
| 2,627 | 447 |
gh_patches_debug_22994
|
rasdani/github-patches
|
git_diff
|
numba__numba-2610
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Lowering error when removing element from the middle of linked list
Hi
I am having a hard time trying to figure out an error when I reassign "element_0.next = element_1.next" of a linked list. I posted my error at stackoverflow: https://stackoverflow.com/questions/47232035/numba-lowering-error-when-reassigning-next-link-of-a-linked-list-element
I am creating this issue to make it closer to you.
I have visited most of your examples and documentation pages, no ideas whatsoever.
What am I missing?
I am using numba **0.35.0** (from Anaconda, python 3.6.2).
Thanks
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `numba/targets/optional.py`
Content:
```
1 from __future__ import print_function, absolute_import, division
2
3 from numba import types, cgutils
4
5 from .imputils import (lower_cast, lower_builtin, lower_getattr_generic,
6 impl_ret_untracked)
7
8
9 def always_return_true_impl(context, builder, sig, args):
10 return cgutils.true_bit
11
12
13 def always_return_false_impl(context, builder, sig, args):
14 return cgutils.false_bit
15
16
17 def optional_is_none(context, builder, sig, args):
18 """
19 Check if an Optional value is invalid
20 """
21 [lty, rty] = sig.args
22 [lval, rval] = args
23
24 # Make sure None is on the right
25 if lty == types.none:
26 lty, rty = rty, lty
27 lval, rval = rval, lval
28
29 opt_type = lty
30 opt_val = lval
31
32 opt = context.make_helper(builder, opt_type, opt_val)
33 res = builder.not_(cgutils.as_bool_bit(builder, opt.valid))
34 return impl_ret_untracked(context, builder, sig.return_type, res)
35
36
37 # None is/not None
38 lower_builtin('is', types.none, types.none)(always_return_true_impl)
39
40 # Optional is None
41 lower_builtin('is', types.Optional, types.none)(optional_is_none)
42 lower_builtin('is', types.none, types.Optional)(optional_is_none)
43
44
45 @lower_getattr_generic(types.Optional)
46 def optional_getattr(context, builder, typ, value, attr):
47 """
48 Optional.__getattr__ => redirect to the wrapped type.
49 """
50 inner_type = typ.type
51 val = context.cast(builder, value, typ, inner_type)
52 imp = context.get_getattr(inner_type, attr)
53 return imp(context, builder, inner_type, val, attr)
54
55
56 @lower_cast(types.Optional, types.Optional)
57 def optional_to_optional(context, builder, fromty, toty, val):
58 """
59 The handling of optional->optional cast must be special cased for
60 correct propagation of None value. Given type T and U. casting of
61 T? to U? (? denotes optional) should always succeed. If the from-value
62 is None, the None value the casted value (U?) should be None; otherwise,
63 the from-value is casted to U. This is different from casting T? to U,
64 which requires the from-value must not be None.
65 """
66 optval = context.make_helper(builder, fromty, value=val)
67 validbit = cgutils.as_bool_bit(builder, optval.valid)
68 # Create uninitialized optional value
69 outoptval = context.make_helper(builder, toty)
70
71 with builder.if_else(validbit) as (is_valid, is_not_valid):
72 with is_valid:
73 # Cast internal value
74 outoptval.valid = cgutils.true_bit
75 outoptval.data = context.cast(builder, optval.data,
76 fromty.type, toty.type)
77
78 with is_not_valid:
79 # Store None to result
80 outoptval.valid = cgutils.false_bit
81 outoptval.data = cgutils.get_null_value(
82 outoptval.data.type)
83
84 return outoptval._getvalue()
85
86
87 @lower_cast(types.Any, types.Optional)
88 def any_to_optional(context, builder, fromty, toty, val):
89 if fromty == types.none:
90 return context.make_optional_none(builder, toty.type)
91 else:
92 val = context.cast(builder, val, fromty, toty.type)
93 return context.make_optional_value(builder, toty.type, val)
94
95
96 @lower_cast(types.Optional, types.Any)
97 @lower_cast(types.Optional, types.Boolean)
98 def optional_to_any(context, builder, fromty, toty, val):
99 optval = context.make_helper(builder, fromty, value=val)
100 validbit = cgutils.as_bool_bit(builder, optval.valid)
101 with builder.if_then(builder.not_(validbit), likely=False):
102 msg = "expected %s, got None" % (fromty.type,)
103 context.call_conv.return_user_exc(builder, TypeError, (msg,))
104
105 return context.cast(builder, optval.data, fromty.type, toty)
106
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/numba/targets/optional.py b/numba/targets/optional.py
--- a/numba/targets/optional.py
+++ b/numba/targets/optional.py
@@ -1,9 +1,9 @@
from __future__ import print_function, absolute_import, division
-from numba import types, cgutils
+from numba import types, cgutils, typing
from .imputils import (lower_cast, lower_builtin, lower_getattr_generic,
- impl_ret_untracked)
+ impl_ret_untracked, lower_setattr_generic)
def always_return_true_impl(context, builder, sig, args):
@@ -53,6 +53,21 @@
return imp(context, builder, inner_type, val, attr)
+@lower_setattr_generic(types.Optional)
+def optional_setattr(context, builder, sig, args, attr):
+ """
+ Optional.__setattr__ => redirect to the wrapped type.
+ """
+ basety, valty = sig.args
+ target, val = args
+ target_type = basety.type
+ target = context.cast(builder, target, basety, target_type)
+
+ newsig = typing.signature(sig.return_type, target_type, valty)
+ imp = context.get_setattr(attr, newsig)
+ return imp(builder, (target, val))
+
+
@lower_cast(types.Optional, types.Optional)
def optional_to_optional(context, builder, fromty, toty, val):
"""
|
{"golden_diff": "diff --git a/numba/targets/optional.py b/numba/targets/optional.py\n--- a/numba/targets/optional.py\n+++ b/numba/targets/optional.py\n@@ -1,9 +1,9 @@\n from __future__ import print_function, absolute_import, division\n \n-from numba import types, cgutils\n+from numba import types, cgutils, typing\n \n from .imputils import (lower_cast, lower_builtin, lower_getattr_generic,\n- impl_ret_untracked)\n+ impl_ret_untracked, lower_setattr_generic)\n \n \n def always_return_true_impl(context, builder, sig, args):\n@@ -53,6 +53,21 @@\n return imp(context, builder, inner_type, val, attr)\n \n \n+@lower_setattr_generic(types.Optional)\n+def optional_setattr(context, builder, sig, args, attr):\n+ \"\"\"\n+ Optional.__setattr__ => redirect to the wrapped type.\n+ \"\"\"\n+ basety, valty = sig.args\n+ target, val = args\n+ target_type = basety.type\n+ target = context.cast(builder, target, basety, target_type)\n+\n+ newsig = typing.signature(sig.return_type, target_type, valty)\n+ imp = context.get_setattr(attr, newsig)\n+ return imp(builder, (target, val))\n+\n+\n @lower_cast(types.Optional, types.Optional)\n def optional_to_optional(context, builder, fromty, toty, val):\n \"\"\"\n", "issue": "Lowering error when removing element from the middle of linked list\nHi\r\n\r\nI am having a hard time trying to figure out an error when I reassign \"element_0.next = element_1.next\" of a linked list. I posted my error at stackoverflow: https://stackoverflow.com/questions/47232035/numba-lowering-error-when-reassigning-next-link-of-a-linked-list-element\r\n\r\nI am creating this issue to make it closer to you.\r\n\r\nI have visited most of your examples and documentation pages, no ideas whatsoever.\r\n\r\nWhat am I missing?\r\n\r\nI am using numba **0.35.0** (from Anaconda, python 3.6.2).\r\n\r\nThanks\n", "before_files": [{"content": "from __future__ import print_function, absolute_import, division\n\nfrom numba import types, cgutils\n\nfrom .imputils import (lower_cast, lower_builtin, lower_getattr_generic,\n impl_ret_untracked)\n\n\ndef always_return_true_impl(context, builder, sig, args):\n return cgutils.true_bit\n\n\ndef always_return_false_impl(context, builder, sig, args):\n return cgutils.false_bit\n\n\ndef optional_is_none(context, builder, sig, args):\n \"\"\"\n Check if an Optional value is invalid\n \"\"\"\n [lty, rty] = sig.args\n [lval, rval] = args\n\n # Make sure None is on the right\n if lty == types.none:\n lty, rty = rty, lty\n lval, rval = rval, lval\n\n opt_type = lty\n opt_val = lval\n\n opt = context.make_helper(builder, opt_type, opt_val)\n res = builder.not_(cgutils.as_bool_bit(builder, opt.valid))\n return impl_ret_untracked(context, builder, sig.return_type, res)\n\n\n# None is/not None\nlower_builtin('is', types.none, types.none)(always_return_true_impl)\n\n# Optional is None\nlower_builtin('is', types.Optional, types.none)(optional_is_none)\nlower_builtin('is', types.none, types.Optional)(optional_is_none)\n\n\n@lower_getattr_generic(types.Optional)\ndef optional_getattr(context, builder, typ, value, attr):\n \"\"\"\n Optional.__getattr__ => redirect to the wrapped type.\n \"\"\"\n inner_type = typ.type\n val = context.cast(builder, value, typ, inner_type)\n imp = context.get_getattr(inner_type, attr)\n return imp(context, builder, inner_type, val, attr)\n\n\n@lower_cast(types.Optional, types.Optional)\ndef optional_to_optional(context, builder, fromty, toty, val):\n \"\"\"\n The handling of optional->optional cast must be special cased for\n correct propagation of None value. Given type T and U. casting of\n T? to U? (? denotes optional) should always succeed. If the from-value\n is None, the None value the casted value (U?) should be None; otherwise,\n the from-value is casted to U. This is different from casting T? to U,\n which requires the from-value must not be None.\n \"\"\"\n optval = context.make_helper(builder, fromty, value=val)\n validbit = cgutils.as_bool_bit(builder, optval.valid)\n # Create uninitialized optional value\n outoptval = context.make_helper(builder, toty)\n\n with builder.if_else(validbit) as (is_valid, is_not_valid):\n with is_valid:\n # Cast internal value\n outoptval.valid = cgutils.true_bit\n outoptval.data = context.cast(builder, optval.data,\n fromty.type, toty.type)\n\n with is_not_valid:\n # Store None to result\n outoptval.valid = cgutils.false_bit\n outoptval.data = cgutils.get_null_value(\n outoptval.data.type)\n\n return outoptval._getvalue()\n\n\n@lower_cast(types.Any, types.Optional)\ndef any_to_optional(context, builder, fromty, toty, val):\n if fromty == types.none:\n return context.make_optional_none(builder, toty.type)\n else:\n val = context.cast(builder, val, fromty, toty.type)\n return context.make_optional_value(builder, toty.type, val)\n\n\n@lower_cast(types.Optional, types.Any)\n@lower_cast(types.Optional, types.Boolean)\ndef optional_to_any(context, builder, fromty, toty, val):\n optval = context.make_helper(builder, fromty, value=val)\n validbit = cgutils.as_bool_bit(builder, optval.valid)\n with builder.if_then(builder.not_(validbit), likely=False):\n msg = \"expected %s, got None\" % (fromty.type,)\n context.call_conv.return_user_exc(builder, TypeError, (msg,))\n\n return context.cast(builder, optval.data, fromty.type, toty)\n", "path": "numba/targets/optional.py"}], "after_files": [{"content": "from __future__ import print_function, absolute_import, division\n\nfrom numba import types, cgutils, typing\n\nfrom .imputils import (lower_cast, lower_builtin, lower_getattr_generic,\n impl_ret_untracked, lower_setattr_generic)\n\n\ndef always_return_true_impl(context, builder, sig, args):\n return cgutils.true_bit\n\n\ndef always_return_false_impl(context, builder, sig, args):\n return cgutils.false_bit\n\n\ndef optional_is_none(context, builder, sig, args):\n \"\"\"\n Check if an Optional value is invalid\n \"\"\"\n [lty, rty] = sig.args\n [lval, rval] = args\n\n # Make sure None is on the right\n if lty == types.none:\n lty, rty = rty, lty\n lval, rval = rval, lval\n\n opt_type = lty\n opt_val = lval\n\n opt = context.make_helper(builder, opt_type, opt_val)\n res = builder.not_(cgutils.as_bool_bit(builder, opt.valid))\n return impl_ret_untracked(context, builder, sig.return_type, res)\n\n\n# None is/not None\nlower_builtin('is', types.none, types.none)(always_return_true_impl)\n\n# Optional is None\nlower_builtin('is', types.Optional, types.none)(optional_is_none)\nlower_builtin('is', types.none, types.Optional)(optional_is_none)\n\n\n@lower_getattr_generic(types.Optional)\ndef optional_getattr(context, builder, typ, value, attr):\n \"\"\"\n Optional.__getattr__ => redirect to the wrapped type.\n \"\"\"\n inner_type = typ.type\n val = context.cast(builder, value, typ, inner_type)\n imp = context.get_getattr(inner_type, attr)\n return imp(context, builder, inner_type, val, attr)\n\n\n@lower_setattr_generic(types.Optional)\ndef optional_setattr(context, builder, sig, args, attr):\n \"\"\"\n Optional.__setattr__ => redirect to the wrapped type.\n \"\"\"\n basety, valty = sig.args\n target, val = args\n target_type = basety.type\n target = context.cast(builder, target, basety, target_type)\n\n newsig = typing.signature(sig.return_type, target_type, valty)\n imp = context.get_setattr(attr, newsig)\n return imp(builder, (target, val))\n\n\n@lower_cast(types.Optional, types.Optional)\ndef optional_to_optional(context, builder, fromty, toty, val):\n \"\"\"\n The handling of optional->optional cast must be special cased for\n correct propagation of None value. Given type T and U. casting of\n T? to U? (? denotes optional) should always succeed. If the from-value\n is None, the None value the casted value (U?) should be None; otherwise,\n the from-value is casted to U. This is different from casting T? to U,\n which requires the from-value must not be None.\n \"\"\"\n optval = context.make_helper(builder, fromty, value=val)\n validbit = cgutils.as_bool_bit(builder, optval.valid)\n # Create uninitialized optional value\n outoptval = context.make_helper(builder, toty)\n\n with builder.if_else(validbit) as (is_valid, is_not_valid):\n with is_valid:\n # Cast internal value\n outoptval.valid = cgutils.true_bit\n outoptval.data = context.cast(builder, optval.data,\n fromty.type, toty.type)\n\n with is_not_valid:\n # Store None to result\n outoptval.valid = cgutils.false_bit\n outoptval.data = cgutils.get_null_value(\n outoptval.data.type)\n\n return outoptval._getvalue()\n\n\n@lower_cast(types.Any, types.Optional)\ndef any_to_optional(context, builder, fromty, toty, val):\n if fromty == types.none:\n return context.make_optional_none(builder, toty.type)\n else:\n val = context.cast(builder, val, fromty, toty.type)\n return context.make_optional_value(builder, toty.type, val)\n\n\n@lower_cast(types.Optional, types.Any)\n@lower_cast(types.Optional, types.Boolean)\ndef optional_to_any(context, builder, fromty, toty, val):\n optval = context.make_helper(builder, fromty, value=val)\n validbit = cgutils.as_bool_bit(builder, optval.valid)\n with builder.if_then(builder.not_(validbit), likely=False):\n msg = \"expected %s, got None\" % (fromty.type,)\n context.call_conv.return_user_exc(builder, TypeError, (msg,))\n\n return context.cast(builder, optval.data, fromty.type, toty)\n", "path": "numba/targets/optional.py"}]}
| 1,524 | 325 |
gh_patches_debug_29721
|
rasdani/github-patches
|
git_diff
|
pyodide__pyodide-1186
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Use proper duck typing for JsProxy
I think the idea of duck typing is to be able to implement functions like:
```python
def isaduck(obj):
return hasattr(obj, "quack") and iscallable(obj.quack)
```
If we implement quack on every `JsProxy` and just throw an error if we can't figure out how to quack:
```python
class JsProxy:
def quack(self):
if not hasattr(self.jsobject, "quack"):
raise TypeError("Underlying Js object is not a duck")
return self.jsobject.quack()
```
Now `isaduck(jsproxy)` _always_ returns `True`, but the `jsproxy` may be planning to raise a type error every time you call `jsproxy.quack()`. If we know that `quack()` has no side effects, then you can try:
```python
def isaduck(obj):
try:
obj.quack()
return True
except TypeError, NotImplementedError:
return False
```
but this is a dangerous assumption. Thus I view writing a wrapper class like this as a problematic antipattern. The point of this PR is to gradually move away from this antipattern towards conditionally implementing exactly the set of capabilities that the underlying javascript object can support.
Instead, I am trying to switch to:
```python
class JsProxyDuck(JsProxy):
def quack(self):
return self.jsobject.quack()
```
and then in the factory function `jsproxy_create` we decide whether to inherit from `JsProxyDuck`.
The already merged PRs #1124 and #1153 are both work in this direction.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `packages/micropip/micropip/micropip.py`
Content:
```
1 try:
2 from js import Promise, XMLHttpRequest
3 except ImportError:
4 XMLHttpRequest = None
5
6 try:
7 from js import pyodide as js_pyodide
8 except ImportError:
9
10 class js_pyodide: # type: ignore
11 """A mock object to allow import of this package outside pyodide"""
12
13 class _module:
14 class packages:
15 dependencies = [] # type: ignore
16
17
18 import hashlib
19 import importlib
20 import io
21 import json
22 from pathlib import Path
23 import zipfile
24 from typing import Dict, Any, Union, List, Tuple
25
26 from distlib import markers, util, version
27
28
29 def _nullop(*args):
30 return
31
32
33 # Provide implementations of HTTP fetching for in-browser and out-of-browser to
34 # make testing easier
35 if XMLHttpRequest is not None:
36 import pyodide # noqa
37
38 def _get_url(url):
39 req = XMLHttpRequest.new()
40 req.open("GET", url, False)
41 req.send(None)
42 return io.StringIO(req.response)
43
44 def _get_url_async(url, cb):
45 req = XMLHttpRequest.new()
46 req.open("GET", url, True)
47 req.responseType = "arraybuffer"
48
49 def callback(e):
50 if req.readyState == 4:
51 cb(io.BytesIO(req.response))
52
53 req.onreadystatechange = callback
54 req.send(None)
55
56 # In practice, this is the `site-packages` directory.
57 WHEEL_BASE = Path(__file__).parent
58 else:
59 # Outside the browser
60 from urllib.request import urlopen
61
62 def _get_url(url):
63 with urlopen(url) as fd:
64 content = fd.read()
65 return io.BytesIO(content)
66
67 def _get_url_async(url, cb):
68 cb(_get_url(url))
69
70 WHEEL_BASE = Path(".") / "wheels"
71
72
73 def _get_pypi_json(pkgname):
74 url = f"https://pypi.org/pypi/{pkgname}/json"
75 fd = _get_url(url)
76 return json.load(fd)
77
78
79 def _parse_wheel_url(url: str) -> Tuple[str, Dict[str, Any], str]:
80 """Parse wheels url and extract available metadata
81
82 See https://www.python.org/dev/peps/pep-0427/#file-name-convention
83 """
84 file_name = Path(url).name
85 # also strip '.whl' extension.
86 wheel_name = Path(url).stem
87 tokens = wheel_name.split("-")
88 # TODO: support optional build tags in the filename (cf PEP 427)
89 if len(tokens) < 5:
90 raise ValueError(f"{file_name} is not a valid wheel file name.")
91 version, python_tag, abi_tag, platform = tokens[-4:]
92 name = "-".join(tokens[:-4])
93 wheel = {
94 "digests": None, # checksums not available
95 "filename": file_name,
96 "packagetype": "bdist_wheel",
97 "python_version": python_tag,
98 "abi_tag": abi_tag,
99 "platform": platform,
100 "url": url,
101 }
102
103 return name, wheel, version
104
105
106 def _extract_wheel(fd):
107 with zipfile.ZipFile(fd) as zf:
108 zf.extractall(WHEEL_BASE)
109
110
111 def _validate_wheel(data, fileinfo):
112 if fileinfo.get("digests") is None:
113 # No checksums available, e.g. because installing
114 # from a different location than PyPi.
115 return
116 sha256 = fileinfo["digests"]["sha256"]
117 m = hashlib.sha256()
118 m.update(data.getvalue())
119 if m.hexdigest() != sha256:
120 raise ValueError("Contents don't match hash")
121
122
123 def _install_wheel(name, fileinfo, resolve, reject):
124 url = fileinfo["url"]
125
126 def callback(wheel):
127 try:
128 _validate_wheel(wheel, fileinfo)
129 _extract_wheel(wheel)
130 except Exception as e:
131 reject(str(e))
132 else:
133 resolve()
134
135 _get_url_async(url, callback)
136
137
138 class _PackageManager:
139 version_scheme = version.get_scheme("normalized")
140
141 def __init__(self):
142 self.builtin_packages = {}
143 self.builtin_packages.update(js_pyodide._module.packages.dependencies)
144 self.installed_packages = {}
145
146 def install(
147 self,
148 requirements: Union[str, List[str]],
149 ctx=None,
150 resolve=_nullop,
151 reject=_nullop,
152 ):
153 try:
154 if ctx is None:
155 ctx = {"extra": None}
156
157 complete_ctx = dict(markers.DEFAULT_CONTEXT)
158 complete_ctx.update(ctx)
159
160 if isinstance(requirements, str):
161 requirements = [requirements]
162
163 transaction: Dict[str, Any] = {
164 "wheels": [],
165 "pyodide_packages": set(),
166 "locked": dict(self.installed_packages),
167 }
168 for requirement in requirements:
169 self.add_requirement(requirement, complete_ctx, transaction)
170 except Exception as e:
171 reject(str(e))
172
173 resolve_count = [len(transaction["wheels"])]
174
175 def do_resolve(*args):
176 resolve_count[0] -= 1
177 if resolve_count[0] == 0:
178 resolve(f'Installed {", ".join(self.installed_packages.keys())}')
179
180 # Install built-in packages
181 pyodide_packages = transaction["pyodide_packages"]
182 if len(pyodide_packages):
183 resolve_count[0] += 1
184 self.installed_packages.update(dict((k, None) for k in pyodide_packages))
185 js_pyodide.loadPackage(list(pyodide_packages)).then(do_resolve)
186
187 # Now install PyPI packages
188 for name, wheel, ver in transaction["wheels"]:
189 _install_wheel(name, wheel, do_resolve, reject)
190 self.installed_packages[name] = ver
191
192 def add_requirement(self, requirement: str, ctx, transaction):
193 if requirement.endswith(".whl"):
194 # custom download location
195 name, wheel, version = _parse_wheel_url(requirement)
196 transaction["wheels"].append((name, wheel, version))
197 return
198
199 req = util.parse_requirement(requirement)
200
201 # If it's a Pyodide package, use that instead of the one on PyPI
202 if req.name in self.builtin_packages:
203 transaction["pyodide_packages"].add(req.name)
204 return
205
206 if req.marker:
207 if not markers.evaluator.evaluate(req.marker, ctx):
208 return
209
210 matcher = self.version_scheme.matcher(req.requirement)
211
212 # If we already have something that will work, don't
213 # fetch again
214 for name, ver in transaction["locked"].items():
215 if name == req.name:
216 if matcher.match(ver):
217 break
218 else:
219 raise ValueError(
220 f"Requested '{requirement}', "
221 f"but {name}=={ver} is already installed"
222 )
223 else:
224 metadata = _get_pypi_json(req.name)
225 wheel, ver = self.find_wheel(metadata, req)
226 transaction["locked"][req.name] = ver
227
228 recurs_reqs = metadata.get("info", {}).get("requires_dist") or []
229 for recurs_req in recurs_reqs:
230 self.add_requirement(recurs_req, ctx, transaction)
231
232 transaction["wheels"].append((req.name, wheel, ver))
233
234 def find_wheel(self, metadata, req):
235 releases = []
236 for ver, files in metadata.get("releases", {}).items():
237 ver = self.version_scheme.suggest(ver)
238 if ver is not None:
239 releases.append((ver, files))
240
241 def version_number(release):
242 return version.NormalizedVersion(release[0])
243
244 releases = sorted(releases, key=version_number, reverse=True)
245 matcher = self.version_scheme.matcher(req.requirement)
246 for ver, meta in releases:
247 if matcher.match(ver):
248 for fileinfo in meta:
249 if fileinfo["filename"].endswith("py3-none-any.whl"):
250 return fileinfo, ver
251
252 raise ValueError(f"Couldn't find a pure Python 3 wheel for '{req.requirement}'")
253
254
255 # Make PACKAGE_MANAGER singleton
256 PACKAGE_MANAGER = _PackageManager()
257 del _PackageManager
258
259
260 def install(requirements: Union[str, List[str]]):
261 """Install the given package and all of its dependencies.
262
263 See :ref:`loading packages <loading_packages>` for more information.
264
265 This only works for packages that are either pure Python or for packages with
266 C extensions that are built in pyodide. If a pure Python package is not found
267 in the pyodide repository it will be loaded from PyPi.
268
269 Parameters
270 ----------
271 requirements
272 A requirement or list of requirements to install.
273 Each requirement is a string.
274
275 - If the requirement ends in ".whl", the file will be interpreted as a url.
276 The file must be a wheel named in compliance with the
277 [PEP 427 naming convention](https://www.python.org/dev/peps/pep-0427/#file-format)
278
279 - A package name. A package by this name must either be present in the pyodide
280 repository at `languagePluginUrl` or on PyPi.
281
282 Returns
283 -------
284 A Promise that resolves when all packages have been downloaded and installed.
285 """
286
287 def do_install(resolve, reject):
288 PACKAGE_MANAGER.install(requirements, resolve=resolve, reject=reject)
289 importlib.invalidate_caches()
290
291 return Promise.new(do_install)
292
293
294 __all__ = ["install"]
295
296
297 if __name__ == "__main__":
298 install("snowballstemmer")
299
```
Path: `src/pyodide-py/pyodide/_core.py`
Content:
```
1 # type: ignore
2 import platform
3
4 if platform.system() == "Emscripten":
5 from _pyodide_core import JsProxy, JsMethod, JsException, JsBuffer
6 else:
7 # Can add shims here if we are so inclined.
8 class JsException(Exception):
9 """
10 A wrapper around a Javascript Error to allow the Error to be thrown in Python.
11 """
12
13 # Defined in jsproxy.c
14
15 class JsProxy:
16 """A proxy to make a Javascript object behave like a Python object"""
17
18 # Defined in jsproxy.c
19
20 class JsMethod:
21 """A proxy to make it possible to call Javascript bound methods from Python."""
22
23 # Defined in jsproxy.c
24
25 class JsBuffer:
26 """A proxy to make it possible to call Javascript typed arrays from Python."""
27
28 # Defined in jsproxy.c
29
30
31 __all__ = [JsProxy, JsMethod, JsException]
32
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/packages/micropip/micropip/micropip.py b/packages/micropip/micropip/micropip.py
--- a/packages/micropip/micropip/micropip.py
+++ b/packages/micropip/micropip/micropip.py
@@ -12,7 +12,10 @@
class _module:
class packages:
- dependencies = [] # type: ignore
+ class dependencies:
+ @staticmethod
+ def object_entries():
+ return []
import hashlib
@@ -140,7 +143,9 @@
def __init__(self):
self.builtin_packages = {}
- self.builtin_packages.update(js_pyodide._module.packages.dependencies)
+ self.builtin_packages.update(
+ js_pyodide._module.packages.dependencies.object_entries()
+ )
self.installed_packages = {}
def install(
diff --git a/src/pyodide-py/pyodide/_core.py b/src/pyodide-py/pyodide/_core.py
--- a/src/pyodide-py/pyodide/_core.py
+++ b/src/pyodide-py/pyodide/_core.py
@@ -2,7 +2,7 @@
import platform
if platform.system() == "Emscripten":
- from _pyodide_core import JsProxy, JsMethod, JsException, JsBuffer
+ from _pyodide_core import JsProxy, JsException, JsBuffer
else:
# Can add shims here if we are so inclined.
class JsException(Exception):
@@ -17,15 +17,10 @@
# Defined in jsproxy.c
- class JsMethod:
- """A proxy to make it possible to call Javascript bound methods from Python."""
-
- # Defined in jsproxy.c
-
class JsBuffer:
"""A proxy to make it possible to call Javascript typed arrays from Python."""
# Defined in jsproxy.c
-__all__ = [JsProxy, JsMethod, JsException]
+__all__ = [JsProxy, JsException]
|
{"golden_diff": "diff --git a/packages/micropip/micropip/micropip.py b/packages/micropip/micropip/micropip.py\n--- a/packages/micropip/micropip/micropip.py\n+++ b/packages/micropip/micropip/micropip.py\n@@ -12,7 +12,10 @@\n \n class _module:\n class packages:\n- dependencies = [] # type: ignore\n+ class dependencies:\n+ @staticmethod\n+ def object_entries():\n+ return []\n \n \n import hashlib\n@@ -140,7 +143,9 @@\n \n def __init__(self):\n self.builtin_packages = {}\n- self.builtin_packages.update(js_pyodide._module.packages.dependencies)\n+ self.builtin_packages.update(\n+ js_pyodide._module.packages.dependencies.object_entries()\n+ )\n self.installed_packages = {}\n \n def install(\ndiff --git a/src/pyodide-py/pyodide/_core.py b/src/pyodide-py/pyodide/_core.py\n--- a/src/pyodide-py/pyodide/_core.py\n+++ b/src/pyodide-py/pyodide/_core.py\n@@ -2,7 +2,7 @@\n import platform\n \n if platform.system() == \"Emscripten\":\n- from _pyodide_core import JsProxy, JsMethod, JsException, JsBuffer\n+ from _pyodide_core import JsProxy, JsException, JsBuffer\n else:\n # Can add shims here if we are so inclined.\n class JsException(Exception):\n@@ -17,15 +17,10 @@\n \n # Defined in jsproxy.c\n \n- class JsMethod:\n- \"\"\"A proxy to make it possible to call Javascript bound methods from Python.\"\"\"\n-\n- # Defined in jsproxy.c\n-\n class JsBuffer:\n \"\"\"A proxy to make it possible to call Javascript typed arrays from Python.\"\"\"\n \n # Defined in jsproxy.c\n \n \n-__all__ = [JsProxy, JsMethod, JsException]\n+__all__ = [JsProxy, JsException]\n", "issue": "Use proper duck typing for JsProxy\nI think the idea of duck typing is to be able to implement functions like:\r\n```python\r\ndef isaduck(obj):\r\n return hasattr(obj, \"quack\") and iscallable(obj.quack)\r\n```\r\nIf we implement quack on every `JsProxy` and just throw an error if we can't figure out how to quack:\r\n```python\r\nclass JsProxy:\r\n def quack(self):\r\n if not hasattr(self.jsobject, \"quack\"):\r\n raise TypeError(\"Underlying Js object is not a duck\")\r\n return self.jsobject.quack()\r\n```\r\nNow `isaduck(jsproxy)` _always_ returns `True`, but the `jsproxy` may be planning to raise a type error every time you call `jsproxy.quack()`. If we know that `quack()` has no side effects, then you can try:\r\n```python\r\ndef isaduck(obj):\r\n try:\r\n obj.quack()\r\n return True\r\n except TypeError, NotImplementedError:\r\n return False\r\n```\r\nbut this is a dangerous assumption. Thus I view writing a wrapper class like this as a problematic antipattern. The point of this PR is to gradually move away from this antipattern towards conditionally implementing exactly the set of capabilities that the underlying javascript object can support.\r\n\r\nInstead, I am trying to switch to:\r\n```python\r\nclass JsProxyDuck(JsProxy):\r\n def quack(self):\r\n return self.jsobject.quack()\r\n```\r\nand then in the factory function `jsproxy_create` we decide whether to inherit from `JsProxyDuck`.\r\n\r\nThe already merged PRs #1124 and #1153 are both work in this direction.\n", "before_files": [{"content": "try:\n from js import Promise, XMLHttpRequest\nexcept ImportError:\n XMLHttpRequest = None\n\ntry:\n from js import pyodide as js_pyodide\nexcept ImportError:\n\n class js_pyodide: # type: ignore\n \"\"\"A mock object to allow import of this package outside pyodide\"\"\"\n\n class _module:\n class packages:\n dependencies = [] # type: ignore\n\n\nimport hashlib\nimport importlib\nimport io\nimport json\nfrom pathlib import Path\nimport zipfile\nfrom typing import Dict, Any, Union, List, Tuple\n\nfrom distlib import markers, util, version\n\n\ndef _nullop(*args):\n return\n\n\n# Provide implementations of HTTP fetching for in-browser and out-of-browser to\n# make testing easier\nif XMLHttpRequest is not None:\n import pyodide # noqa\n\n def _get_url(url):\n req = XMLHttpRequest.new()\n req.open(\"GET\", url, False)\n req.send(None)\n return io.StringIO(req.response)\n\n def _get_url_async(url, cb):\n req = XMLHttpRequest.new()\n req.open(\"GET\", url, True)\n req.responseType = \"arraybuffer\"\n\n def callback(e):\n if req.readyState == 4:\n cb(io.BytesIO(req.response))\n\n req.onreadystatechange = callback\n req.send(None)\n\n # In practice, this is the `site-packages` directory.\n WHEEL_BASE = Path(__file__).parent\nelse:\n # Outside the browser\n from urllib.request import urlopen\n\n def _get_url(url):\n with urlopen(url) as fd:\n content = fd.read()\n return io.BytesIO(content)\n\n def _get_url_async(url, cb):\n cb(_get_url(url))\n\n WHEEL_BASE = Path(\".\") / \"wheels\"\n\n\ndef _get_pypi_json(pkgname):\n url = f\"https://pypi.org/pypi/{pkgname}/json\"\n fd = _get_url(url)\n return json.load(fd)\n\n\ndef _parse_wheel_url(url: str) -> Tuple[str, Dict[str, Any], str]:\n \"\"\"Parse wheels url and extract available metadata\n\n See https://www.python.org/dev/peps/pep-0427/#file-name-convention\n \"\"\"\n file_name = Path(url).name\n # also strip '.whl' extension.\n wheel_name = Path(url).stem\n tokens = wheel_name.split(\"-\")\n # TODO: support optional build tags in the filename (cf PEP 427)\n if len(tokens) < 5:\n raise ValueError(f\"{file_name} is not a valid wheel file name.\")\n version, python_tag, abi_tag, platform = tokens[-4:]\n name = \"-\".join(tokens[:-4])\n wheel = {\n \"digests\": None, # checksums not available\n \"filename\": file_name,\n \"packagetype\": \"bdist_wheel\",\n \"python_version\": python_tag,\n \"abi_tag\": abi_tag,\n \"platform\": platform,\n \"url\": url,\n }\n\n return name, wheel, version\n\n\ndef _extract_wheel(fd):\n with zipfile.ZipFile(fd) as zf:\n zf.extractall(WHEEL_BASE)\n\n\ndef _validate_wheel(data, fileinfo):\n if fileinfo.get(\"digests\") is None:\n # No checksums available, e.g. because installing\n # from a different location than PyPi.\n return\n sha256 = fileinfo[\"digests\"][\"sha256\"]\n m = hashlib.sha256()\n m.update(data.getvalue())\n if m.hexdigest() != sha256:\n raise ValueError(\"Contents don't match hash\")\n\n\ndef _install_wheel(name, fileinfo, resolve, reject):\n url = fileinfo[\"url\"]\n\n def callback(wheel):\n try:\n _validate_wheel(wheel, fileinfo)\n _extract_wheel(wheel)\n except Exception as e:\n reject(str(e))\n else:\n resolve()\n\n _get_url_async(url, callback)\n\n\nclass _PackageManager:\n version_scheme = version.get_scheme(\"normalized\")\n\n def __init__(self):\n self.builtin_packages = {}\n self.builtin_packages.update(js_pyodide._module.packages.dependencies)\n self.installed_packages = {}\n\n def install(\n self,\n requirements: Union[str, List[str]],\n ctx=None,\n resolve=_nullop,\n reject=_nullop,\n ):\n try:\n if ctx is None:\n ctx = {\"extra\": None}\n\n complete_ctx = dict(markers.DEFAULT_CONTEXT)\n complete_ctx.update(ctx)\n\n if isinstance(requirements, str):\n requirements = [requirements]\n\n transaction: Dict[str, Any] = {\n \"wheels\": [],\n \"pyodide_packages\": set(),\n \"locked\": dict(self.installed_packages),\n }\n for requirement in requirements:\n self.add_requirement(requirement, complete_ctx, transaction)\n except Exception as e:\n reject(str(e))\n\n resolve_count = [len(transaction[\"wheels\"])]\n\n def do_resolve(*args):\n resolve_count[0] -= 1\n if resolve_count[0] == 0:\n resolve(f'Installed {\", \".join(self.installed_packages.keys())}')\n\n # Install built-in packages\n pyodide_packages = transaction[\"pyodide_packages\"]\n if len(pyodide_packages):\n resolve_count[0] += 1\n self.installed_packages.update(dict((k, None) for k in pyodide_packages))\n js_pyodide.loadPackage(list(pyodide_packages)).then(do_resolve)\n\n # Now install PyPI packages\n for name, wheel, ver in transaction[\"wheels\"]:\n _install_wheel(name, wheel, do_resolve, reject)\n self.installed_packages[name] = ver\n\n def add_requirement(self, requirement: str, ctx, transaction):\n if requirement.endswith(\".whl\"):\n # custom download location\n name, wheel, version = _parse_wheel_url(requirement)\n transaction[\"wheels\"].append((name, wheel, version))\n return\n\n req = util.parse_requirement(requirement)\n\n # If it's a Pyodide package, use that instead of the one on PyPI\n if req.name in self.builtin_packages:\n transaction[\"pyodide_packages\"].add(req.name)\n return\n\n if req.marker:\n if not markers.evaluator.evaluate(req.marker, ctx):\n return\n\n matcher = self.version_scheme.matcher(req.requirement)\n\n # If we already have something that will work, don't\n # fetch again\n for name, ver in transaction[\"locked\"].items():\n if name == req.name:\n if matcher.match(ver):\n break\n else:\n raise ValueError(\n f\"Requested '{requirement}', \"\n f\"but {name}=={ver} is already installed\"\n )\n else:\n metadata = _get_pypi_json(req.name)\n wheel, ver = self.find_wheel(metadata, req)\n transaction[\"locked\"][req.name] = ver\n\n recurs_reqs = metadata.get(\"info\", {}).get(\"requires_dist\") or []\n for recurs_req in recurs_reqs:\n self.add_requirement(recurs_req, ctx, transaction)\n\n transaction[\"wheels\"].append((req.name, wheel, ver))\n\n def find_wheel(self, metadata, req):\n releases = []\n for ver, files in metadata.get(\"releases\", {}).items():\n ver = self.version_scheme.suggest(ver)\n if ver is not None:\n releases.append((ver, files))\n\n def version_number(release):\n return version.NormalizedVersion(release[0])\n\n releases = sorted(releases, key=version_number, reverse=True)\n matcher = self.version_scheme.matcher(req.requirement)\n for ver, meta in releases:\n if matcher.match(ver):\n for fileinfo in meta:\n if fileinfo[\"filename\"].endswith(\"py3-none-any.whl\"):\n return fileinfo, ver\n\n raise ValueError(f\"Couldn't find a pure Python 3 wheel for '{req.requirement}'\")\n\n\n# Make PACKAGE_MANAGER singleton\nPACKAGE_MANAGER = _PackageManager()\ndel _PackageManager\n\n\ndef install(requirements: Union[str, List[str]]):\n \"\"\"Install the given package and all of its dependencies.\n\n See :ref:`loading packages <loading_packages>` for more information.\n\n This only works for packages that are either pure Python or for packages with\n C extensions that are built in pyodide. If a pure Python package is not found\n in the pyodide repository it will be loaded from PyPi.\n\n Parameters\n ----------\n requirements\n A requirement or list of requirements to install.\n Each requirement is a string.\n\n - If the requirement ends in \".whl\", the file will be interpreted as a url.\n The file must be a wheel named in compliance with the\n [PEP 427 naming convention](https://www.python.org/dev/peps/pep-0427/#file-format)\n\n - A package name. A package by this name must either be present in the pyodide\n repository at `languagePluginUrl` or on PyPi.\n\n Returns\n -------\n A Promise that resolves when all packages have been downloaded and installed.\n \"\"\"\n\n def do_install(resolve, reject):\n PACKAGE_MANAGER.install(requirements, resolve=resolve, reject=reject)\n importlib.invalidate_caches()\n\n return Promise.new(do_install)\n\n\n__all__ = [\"install\"]\n\n\nif __name__ == \"__main__\":\n install(\"snowballstemmer\")\n", "path": "packages/micropip/micropip/micropip.py"}, {"content": "# type: ignore\nimport platform\n\nif platform.system() == \"Emscripten\":\n from _pyodide_core import JsProxy, JsMethod, JsException, JsBuffer\nelse:\n # Can add shims here if we are so inclined.\n class JsException(Exception):\n \"\"\"\n A wrapper around a Javascript Error to allow the Error to be thrown in Python.\n \"\"\"\n\n # Defined in jsproxy.c\n\n class JsProxy:\n \"\"\"A proxy to make a Javascript object behave like a Python object\"\"\"\n\n # Defined in jsproxy.c\n\n class JsMethod:\n \"\"\"A proxy to make it possible to call Javascript bound methods from Python.\"\"\"\n\n # Defined in jsproxy.c\n\n class JsBuffer:\n \"\"\"A proxy to make it possible to call Javascript typed arrays from Python.\"\"\"\n\n # Defined in jsproxy.c\n\n\n__all__ = [JsProxy, JsMethod, JsException]\n", "path": "src/pyodide-py/pyodide/_core.py"}], "after_files": [{"content": "try:\n from js import Promise, XMLHttpRequest\nexcept ImportError:\n XMLHttpRequest = None\n\ntry:\n from js import pyodide as js_pyodide\nexcept ImportError:\n\n class js_pyodide: # type: ignore\n \"\"\"A mock object to allow import of this package outside pyodide\"\"\"\n\n class _module:\n class packages:\n class dependencies:\n @staticmethod\n def object_entries():\n return []\n\n\nimport hashlib\nimport importlib\nimport io\nimport json\nfrom pathlib import Path\nimport zipfile\nfrom typing import Dict, Any, Union, List, Tuple\n\nfrom distlib import markers, util, version\n\n\ndef _nullop(*args):\n return\n\n\n# Provide implementations of HTTP fetching for in-browser and out-of-browser to\n# make testing easier\nif XMLHttpRequest is not None:\n import pyodide # noqa\n\n def _get_url(url):\n req = XMLHttpRequest.new()\n req.open(\"GET\", url, False)\n req.send(None)\n return io.StringIO(req.response)\n\n def _get_url_async(url, cb):\n req = XMLHttpRequest.new()\n req.open(\"GET\", url, True)\n req.responseType = \"arraybuffer\"\n\n def callback(e):\n if req.readyState == 4:\n cb(io.BytesIO(req.response))\n\n req.onreadystatechange = callback\n req.send(None)\n\n # In practice, this is the `site-packages` directory.\n WHEEL_BASE = Path(__file__).parent\nelse:\n # Outside the browser\n from urllib.request import urlopen\n\n def _get_url(url):\n with urlopen(url) as fd:\n content = fd.read()\n return io.BytesIO(content)\n\n def _get_url_async(url, cb):\n cb(_get_url(url))\n\n WHEEL_BASE = Path(\".\") / \"wheels\"\n\n\ndef _get_pypi_json(pkgname):\n url = f\"https://pypi.org/pypi/{pkgname}/json\"\n fd = _get_url(url)\n return json.load(fd)\n\n\ndef _parse_wheel_url(url: str) -> Tuple[str, Dict[str, Any], str]:\n \"\"\"Parse wheels url and extract available metadata\n\n See https://www.python.org/dev/peps/pep-0427/#file-name-convention\n \"\"\"\n file_name = Path(url).name\n # also strip '.whl' extension.\n wheel_name = Path(url).stem\n tokens = wheel_name.split(\"-\")\n # TODO: support optional build tags in the filename (cf PEP 427)\n if len(tokens) < 5:\n raise ValueError(f\"{file_name} is not a valid wheel file name.\")\n version, python_tag, abi_tag, platform = tokens[-4:]\n name = \"-\".join(tokens[:-4])\n wheel = {\n \"digests\": None, # checksums not available\n \"filename\": file_name,\n \"packagetype\": \"bdist_wheel\",\n \"python_version\": python_tag,\n \"abi_tag\": abi_tag,\n \"platform\": platform,\n \"url\": url,\n }\n\n return name, wheel, version\n\n\ndef _extract_wheel(fd):\n with zipfile.ZipFile(fd) as zf:\n zf.extractall(WHEEL_BASE)\n\n\ndef _validate_wheel(data, fileinfo):\n if fileinfo.get(\"digests\") is None:\n # No checksums available, e.g. because installing\n # from a different location than PyPi.\n return\n sha256 = fileinfo[\"digests\"][\"sha256\"]\n m = hashlib.sha256()\n m.update(data.getvalue())\n if m.hexdigest() != sha256:\n raise ValueError(\"Contents don't match hash\")\n\n\ndef _install_wheel(name, fileinfo, resolve, reject):\n url = fileinfo[\"url\"]\n\n def callback(wheel):\n try:\n _validate_wheel(wheel, fileinfo)\n _extract_wheel(wheel)\n except Exception as e:\n reject(str(e))\n else:\n resolve()\n\n _get_url_async(url, callback)\n\n\nclass _PackageManager:\n version_scheme = version.get_scheme(\"normalized\")\n\n def __init__(self):\n self.builtin_packages = {}\n self.builtin_packages.update(\n js_pyodide._module.packages.dependencies.object_entries()\n )\n self.installed_packages = {}\n\n def install(\n self,\n requirements: Union[str, List[str]],\n ctx=None,\n resolve=_nullop,\n reject=_nullop,\n ):\n try:\n if ctx is None:\n ctx = {\"extra\": None}\n\n complete_ctx = dict(markers.DEFAULT_CONTEXT)\n complete_ctx.update(ctx)\n\n if isinstance(requirements, str):\n requirements = [requirements]\n\n transaction: Dict[str, Any] = {\n \"wheels\": [],\n \"pyodide_packages\": set(),\n \"locked\": dict(self.installed_packages),\n }\n for requirement in requirements:\n self.add_requirement(requirement, complete_ctx, transaction)\n except Exception as e:\n reject(str(e))\n\n resolve_count = [len(transaction[\"wheels\"])]\n\n def do_resolve(*args):\n resolve_count[0] -= 1\n if resolve_count[0] == 0:\n resolve(f'Installed {\", \".join(self.installed_packages.keys())}')\n\n # Install built-in packages\n pyodide_packages = transaction[\"pyodide_packages\"]\n if len(pyodide_packages):\n resolve_count[0] += 1\n self.installed_packages.update(dict((k, None) for k in pyodide_packages))\n js_pyodide.loadPackage(list(pyodide_packages)).then(do_resolve)\n\n # Now install PyPI packages\n for name, wheel, ver in transaction[\"wheels\"]:\n _install_wheel(name, wheel, do_resolve, reject)\n self.installed_packages[name] = ver\n\n def add_requirement(self, requirement: str, ctx, transaction):\n if requirement.endswith(\".whl\"):\n # custom download location\n name, wheel, version = _parse_wheel_url(requirement)\n transaction[\"wheels\"].append((name, wheel, version))\n return\n\n req = util.parse_requirement(requirement)\n\n # If it's a Pyodide package, use that instead of the one on PyPI\n if req.name in self.builtin_packages:\n transaction[\"pyodide_packages\"].add(req.name)\n return\n\n if req.marker:\n if not markers.evaluator.evaluate(req.marker, ctx):\n return\n\n matcher = self.version_scheme.matcher(req.requirement)\n\n # If we already have something that will work, don't\n # fetch again\n for name, ver in transaction[\"locked\"].items():\n if name == req.name:\n if matcher.match(ver):\n break\n else:\n raise ValueError(\n f\"Requested '{requirement}', \"\n f\"but {name}=={ver} is already installed\"\n )\n else:\n metadata = _get_pypi_json(req.name)\n wheel, ver = self.find_wheel(metadata, req)\n transaction[\"locked\"][req.name] = ver\n\n recurs_reqs = metadata.get(\"info\", {}).get(\"requires_dist\") or []\n for recurs_req in recurs_reqs:\n self.add_requirement(recurs_req, ctx, transaction)\n\n transaction[\"wheels\"].append((req.name, wheel, ver))\n\n def find_wheel(self, metadata, req):\n releases = []\n for ver, files in metadata.get(\"releases\", {}).items():\n ver = self.version_scheme.suggest(ver)\n if ver is not None:\n releases.append((ver, files))\n\n def version_number(release):\n return version.NormalizedVersion(release[0])\n\n releases = sorted(releases, key=version_number, reverse=True)\n matcher = self.version_scheme.matcher(req.requirement)\n for ver, meta in releases:\n if matcher.match(ver):\n for fileinfo in meta:\n if fileinfo[\"filename\"].endswith(\"py3-none-any.whl\"):\n return fileinfo, ver\n\n raise ValueError(f\"Couldn't find a pure Python 3 wheel for '{req.requirement}'\")\n\n\n# Make PACKAGE_MANAGER singleton\nPACKAGE_MANAGER = _PackageManager()\ndel _PackageManager\n\n\ndef install(requirements: Union[str, List[str]]):\n \"\"\"Install the given package and all of its dependencies.\n\n See :ref:`loading packages <loading_packages>` for more information.\n\n This only works for packages that are either pure Python or for packages with\n C extensions that are built in pyodide. If a pure Python package is not found\n in the pyodide repository it will be loaded from PyPi.\n\n Parameters\n ----------\n requirements\n A requirement or list of requirements to install.\n Each requirement is a string.\n\n - If the requirement ends in \".whl\", the file will be interpreted as a url.\n The file must be a wheel named in compliance with the\n [PEP 427 naming convention](https://www.python.org/dev/peps/pep-0427/#file-format)\n\n - A package name. A package by this name must either be present in the pyodide\n repository at `languagePluginUrl` or on PyPi.\n\n Returns\n -------\n A Promise that resolves when all packages have been downloaded and installed.\n \"\"\"\n\n def do_install(resolve, reject):\n PACKAGE_MANAGER.install(requirements, resolve=resolve, reject=reject)\n importlib.invalidate_caches()\n\n return Promise.new(do_install)\n\n\n__all__ = [\"install\"]\n\n\nif __name__ == \"__main__\":\n install(\"snowballstemmer\")\n", "path": "packages/micropip/micropip/micropip.py"}, {"content": "# type: ignore\nimport platform\n\nif platform.system() == \"Emscripten\":\n from _pyodide_core import JsProxy, JsException, JsBuffer\nelse:\n # Can add shims here if we are so inclined.\n class JsException(Exception):\n \"\"\"\n A wrapper around a Javascript Error to allow the Error to be thrown in Python.\n \"\"\"\n\n # Defined in jsproxy.c\n\n class JsProxy:\n \"\"\"A proxy to make a Javascript object behave like a Python object\"\"\"\n\n # Defined in jsproxy.c\n\n class JsBuffer:\n \"\"\"A proxy to make it possible to call Javascript typed arrays from Python.\"\"\"\n\n # Defined in jsproxy.c\n\n\n__all__ = [JsProxy, JsException]\n", "path": "src/pyodide-py/pyodide/_core.py"}]}
| 3,782 | 468 |
gh_patches_debug_8179
|
rasdani/github-patches
|
git_diff
|
Gallopsled__pwntools-1659
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fatal error when $TERM is not set
I am trying to use `pwntools` in a SageMath script. This works great interactively, but when I run my script with `sage foo.sage`, it fails somewhere in terminal code. I have traced this back to sage unsetting $TERM in non-interactive calls due to https://trac.sagemath.org/ticket/12263. Thus, issue can be easily reproduced without SageMath:
```sh
~$ docker run -it pwntools/pwntools:stable
pwntools@bce19e99e965:~$ TERM= python -c 'import pwn'
Warning: error: setupterm: could not find terminfo database
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/usr/local/lib/python2.7/dist-packages/pwn/__init__.py", line 4, in <module>
from pwn.toplevel import *
File "/usr/local/lib/python2.7/dist-packages/pwn/toplevel.py", line 20, in <module>
import pwnlib
File "/usr/local/lib/python2.7/dist-packages/pwnlib/__init__.py", line 43, in <module>
importlib.import_module('.%s' % module, 'pwnlib')
File "/usr/lib/python2.7/importlib/__init__.py", line 37, in import_module
__import__(name)
File "/usr/local/lib/python2.7/dist-packages/pwnlib/args.py", line 62, in <module>
from pwnlib import term
File "/usr/local/lib/python2.7/dist-packages/pwnlib/term/__init__.py", line 6, in <module>
from pwnlib.term import completer
File "/usr/local/lib/python2.7/dist-packages/pwnlib/term/completer.py", line 7, in <module>
from pwnlib.term import readline
File "/usr/local/lib/python2.7/dist-packages/pwnlib/term/readline.py", line 13, in <module>
from pwnlib.term import text
File "/usr/local/lib/python2.7/dist-packages/pwnlib/term/text.py", line 126, in <module>
sys.modules[__name__] = Module()
File "/usr/local/lib/python2.7/dist-packages/pwnlib/term/text.py", line 49, in __init__
s = termcap.get(y)
File "/usr/local/lib/python2.7/dist-packages/pwnlib/term/unix_termcap.py", line 28, in get
s = curses.tigetstr(cap)
_curses.error: must call (at least) setupterm() first
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pwnlib/term/unix_termcap.py`
Content:
```
1 from __future__ import division
2 from __future__ import print_function
3
4 __all__ = ['get']
5 import curses
6 import os
7 import sys
8
9 cache = None
10
11 def get(cap, *args, **kwargs):
12 default = kwargs.pop('default', '')
13
14 if 'PWNLIB_NOTERM' in os.environ:
15 return ''
16
17 # Hack for readthedocs.org
18 if 'READTHEDOCS' in os.environ:
19 return ''
20
21 if kwargs != {}:
22 raise TypeError("get(): No such argument %r" % kwargs.popitem()[0])
23
24 if cache is None:
25 init()
26 s = cache.get(cap)
27 if not s:
28 s = curses.tigetstr(cap)
29 if s is None:
30 s = curses.tigetnum(cap)
31 if s == -2:
32 s = curses.tigetflag(cap)
33 if s == -1:
34 # default to empty string so tparm doesn't fail
35 s = ''
36 else:
37 s = bool(s)
38 cache[cap] = s
39 # if `s' is not set `curses.tparm' will throw an error if given arguments
40 if args and s:
41 return curses.tparm(s, *args)
42 else:
43 return s
44
45 def init():
46 global cache
47
48 # Detect running under Jupyter
49 try:
50 if get_ipython().__class__.__name__ == 'ZMQInteractiveShell':
51 os.environ['PWNLIB_NOTERM'] = '1'
52 os.environ['JUPYTER_DETECTED'] ='yes'
53 except NameError:
54 pass
55
56 if 'PWNLIB_NOTERM' not in os.environ:
57 # Fix for BPython
58 try:
59 curses.setupterm()
60 except curses.error as e:
61 import traceback
62 print('Warning:', ''.join(traceback.format_exception_only(e.__class__, e)), file=sys.stderr)
63
64 cache = {}
65 # Manually add reset sequence into the cache.
66 # Can't look it up using tigetstr.
67 cache['reset'] = '\x1b[m'
68
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pwnlib/term/unix_termcap.py b/pwnlib/term/unix_termcap.py
--- a/pwnlib/term/unix_termcap.py
+++ b/pwnlib/term/unix_termcap.py
@@ -60,6 +60,8 @@
except curses.error as e:
import traceback
print('Warning:', ''.join(traceback.format_exception_only(e.__class__, e)), file=sys.stderr)
+ print('Terminal features will not be available. Consider setting TERM variable to your current terminal name (or xterm).', file=sys.stderr)
+ os.environ['PWNLIB_NOTERM'] = '1'
cache = {}
# Manually add reset sequence into the cache.
|
{"golden_diff": "diff --git a/pwnlib/term/unix_termcap.py b/pwnlib/term/unix_termcap.py\n--- a/pwnlib/term/unix_termcap.py\n+++ b/pwnlib/term/unix_termcap.py\n@@ -60,6 +60,8 @@\n except curses.error as e:\n import traceback\n print('Warning:', ''.join(traceback.format_exception_only(e.__class__, e)), file=sys.stderr)\n+ print('Terminal features will not be available. Consider setting TERM variable to your current terminal name (or xterm).', file=sys.stderr)\n+ os.environ['PWNLIB_NOTERM'] = '1'\n \n cache = {}\n # Manually add reset sequence into the cache.\n", "issue": "Fatal error when $TERM is not set\nI am trying to use `pwntools` in a SageMath script. This works great interactively, but when I run my script with `sage foo.sage`, it fails somewhere in terminal code. I have traced this back to sage unsetting $TERM in non-interactive calls due to https://trac.sagemath.org/ticket/12263. Thus, issue can be easily reproduced without SageMath:\r\n\r\n```sh\r\n~$ docker run -it pwntools/pwntools:stable\r\npwntools@bce19e99e965:~$ TERM= python -c 'import pwn'\r\nWarning: error: setupterm: could not find terminfo database\r\n\r\nTraceback (most recent call last):\r\n File \"<string>\", line 1, in <module>\r\n File \"/usr/local/lib/python2.7/dist-packages/pwn/__init__.py\", line 4, in <module>\r\n from pwn.toplevel import *\r\n File \"/usr/local/lib/python2.7/dist-packages/pwn/toplevel.py\", line 20, in <module>\r\n import pwnlib\r\n File \"/usr/local/lib/python2.7/dist-packages/pwnlib/__init__.py\", line 43, in <module>\r\n importlib.import_module('.%s' % module, 'pwnlib')\r\n File \"/usr/lib/python2.7/importlib/__init__.py\", line 37, in import_module\r\n __import__(name)\r\n File \"/usr/local/lib/python2.7/dist-packages/pwnlib/args.py\", line 62, in <module>\r\n from pwnlib import term\r\n File \"/usr/local/lib/python2.7/dist-packages/pwnlib/term/__init__.py\", line 6, in <module>\r\n from pwnlib.term import completer\r\n File \"/usr/local/lib/python2.7/dist-packages/pwnlib/term/completer.py\", line 7, in <module>\r\n from pwnlib.term import readline\r\n File \"/usr/local/lib/python2.7/dist-packages/pwnlib/term/readline.py\", line 13, in <module>\r\n from pwnlib.term import text\r\n File \"/usr/local/lib/python2.7/dist-packages/pwnlib/term/text.py\", line 126, in <module>\r\n sys.modules[__name__] = Module()\r\n File \"/usr/local/lib/python2.7/dist-packages/pwnlib/term/text.py\", line 49, in __init__\r\n s = termcap.get(y)\r\n File \"/usr/local/lib/python2.7/dist-packages/pwnlib/term/unix_termcap.py\", line 28, in get\r\n s = curses.tigetstr(cap)\r\n_curses.error: must call (at least) setupterm() first\r\n```\n", "before_files": [{"content": "from __future__ import division\nfrom __future__ import print_function\n\n__all__ = ['get']\nimport curses\nimport os\nimport sys\n\ncache = None\n\ndef get(cap, *args, **kwargs):\n default = kwargs.pop('default', '')\n\n if 'PWNLIB_NOTERM' in os.environ:\n return ''\n\n # Hack for readthedocs.org\n if 'READTHEDOCS' in os.environ:\n return ''\n\n if kwargs != {}:\n raise TypeError(\"get(): No such argument %r\" % kwargs.popitem()[0])\n\n if cache is None:\n init()\n s = cache.get(cap)\n if not s:\n s = curses.tigetstr(cap)\n if s is None:\n s = curses.tigetnum(cap)\n if s == -2:\n s = curses.tigetflag(cap)\n if s == -1:\n # default to empty string so tparm doesn't fail\n s = ''\n else:\n s = bool(s)\n cache[cap] = s\n # if `s' is not set `curses.tparm' will throw an error if given arguments\n if args and s:\n return curses.tparm(s, *args)\n else:\n return s\n\ndef init():\n global cache\n\n # Detect running under Jupyter\n try:\n if get_ipython().__class__.__name__ == 'ZMQInteractiveShell':\n os.environ['PWNLIB_NOTERM'] = '1'\n os.environ['JUPYTER_DETECTED'] ='yes'\n except NameError:\n pass\n\n if 'PWNLIB_NOTERM' not in os.environ:\n # Fix for BPython\n try:\n curses.setupterm()\n except curses.error as e:\n import traceback\n print('Warning:', ''.join(traceback.format_exception_only(e.__class__, e)), file=sys.stderr)\n\n cache = {}\n # Manually add reset sequence into the cache.\n # Can't look it up using tigetstr.\n cache['reset'] = '\\x1b[m'\n", "path": "pwnlib/term/unix_termcap.py"}], "after_files": [{"content": "from __future__ import division\nfrom __future__ import print_function\n\n__all__ = ['get']\nimport curses\nimport os\nimport sys\n\ncache = None\n\ndef get(cap, *args, **kwargs):\n default = kwargs.pop('default', '')\n\n if 'PWNLIB_NOTERM' in os.environ:\n return ''\n\n # Hack for readthedocs.org\n if 'READTHEDOCS' in os.environ:\n return ''\n\n if kwargs != {}:\n raise TypeError(\"get(): No such argument %r\" % kwargs.popitem()[0])\n\n if cache is None:\n init()\n s = cache.get(cap)\n if not s:\n s = curses.tigetstr(cap)\n if s is None:\n s = curses.tigetnum(cap)\n if s == -2:\n s = curses.tigetflag(cap)\n if s == -1:\n # default to empty string so tparm doesn't fail\n s = ''\n else:\n s = bool(s)\n cache[cap] = s\n # if `s' is not set `curses.tparm' will throw an error if given arguments\n if args and s:\n return curses.tparm(s, *args)\n else:\n return s\n\ndef init():\n global cache\n\n # Detect running under Jupyter\n try:\n if get_ipython().__class__.__name__ == 'ZMQInteractiveShell':\n os.environ['PWNLIB_NOTERM'] = '1'\n os.environ['JUPYTER_DETECTED'] ='yes'\n except NameError:\n pass\n\n if 'PWNLIB_NOTERM' not in os.environ:\n # Fix for BPython\n try:\n curses.setupterm()\n except curses.error as e:\n import traceback\n print('Warning:', ''.join(traceback.format_exception_only(e.__class__, e)), file=sys.stderr)\n print('Terminal features will not be available. Consider setting TERM variable to your current terminal name (or xterm).', file=sys.stderr)\n os.environ['PWNLIB_NOTERM'] = '1'\n\n cache = {}\n # Manually add reset sequence into the cache.\n # Can't look it up using tigetstr.\n cache['reset'] = '\\x1b[m'\n", "path": "pwnlib/term/unix_termcap.py"}]}
| 1,463 | 159 |
gh_patches_debug_41425
|
rasdani/github-patches
|
git_diff
|
ansible-collections__community.general-7487
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
community.general.gitlab_runner SSLError cert verify failed
### Summary
I am trying to register some gitlab runners. On new openstack instances.
I get a SSL certificate verify failed error as the return.
If I curl the gitlab url from the command line of the box that I am trying to register I get a response back no TLS issues.
The gitlab servers certificate is signed by an internal CA, which is installed into the system ca-trust /etc/pki/ca-trust/source/anchors and update-ca-trust has been run.
I am unable to copy and paste the actual out from the servers. Due to interal work policy
### Issue Type
Bug Report
### Component Name
gitlab_runner
### Ansible Version
```console (paste below)
$ ansible --version
```
ansible 2.9.33
python version 3.9.5
### Configuration
```
```
### OS / Environment
CentOS 8 on Openstack train
Gitlab 14.0.1 runner same version
### Steps to Reproduce
<!--- Paste example playbooks or commands between quotes below -->
```yaml (paste below)
- name: register gitlab runner
community.general.gitlab_runner
api_url: https://gitlab.internal.addressing
api_token: abc
registration_token: def
description: "{{ anisble_hostname }}"
state: present
active: false
tag_list: shell
run_untagged: false
locked: false
```
### Expected Results
The ansible task to connect to the gitlab server and register the runner
### Actual Results
```console (paste below)
SSLError "Certificate_verify_failed"
```
### Code of Conduct
- [X] I agree to follow the Ansible Code of Conduct
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `plugins/module_utils/gitlab.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Copyright (c) 2019, Guillaume Martinez ([email protected])
4 # Copyright (c) 2018, Marcus Watkins <[email protected]>
5 # GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)
6 # SPDX-License-Identifier: GPL-3.0-or-later
7
8 from __future__ import (absolute_import, division, print_function)
9 __metaclass__ = type
10
11 from ansible.module_utils.basic import missing_required_lib
12 from ansible.module_utils.common.text.converters import to_native
13 from ansible.module_utils.six import integer_types, string_types
14
15 from ansible_collections.community.general.plugins.module_utils.version import LooseVersion
16
17 try:
18 from urlparse import urljoin
19 except ImportError:
20 from urllib.parse import urljoin # Python 3+
21
22 import traceback
23
24 GITLAB_IMP_ERR = None
25 try:
26 import gitlab
27 import requests
28 HAS_GITLAB_PACKAGE = True
29 except Exception:
30 gitlab = None
31 GITLAB_IMP_ERR = traceback.format_exc()
32 HAS_GITLAB_PACKAGE = False
33
34
35 def auth_argument_spec(spec=None):
36 arg_spec = (dict(
37 api_token=dict(type='str', no_log=True),
38 api_oauth_token=dict(type='str', no_log=True),
39 api_job_token=dict(type='str', no_log=True),
40 ))
41 if spec:
42 arg_spec.update(spec)
43 return arg_spec
44
45
46 def find_project(gitlab_instance, identifier):
47 try:
48 project = gitlab_instance.projects.get(identifier)
49 except Exception as e:
50 current_user = gitlab_instance.user
51 try:
52 project = gitlab_instance.projects.get(current_user.username + '/' + identifier)
53 except Exception as e:
54 return None
55
56 return project
57
58
59 def find_group(gitlab_instance, identifier):
60 try:
61 project = gitlab_instance.groups.get(identifier)
62 except Exception as e:
63 return None
64
65 return project
66
67
68 def ensure_gitlab_package(module):
69 if not HAS_GITLAB_PACKAGE:
70 module.fail_json(
71 msg=missing_required_lib("python-gitlab", url='https://python-gitlab.readthedocs.io/en/stable/'),
72 exception=GITLAB_IMP_ERR
73 )
74
75
76 def gitlab_authentication(module):
77 gitlab_url = module.params['api_url']
78 validate_certs = module.params['validate_certs']
79 gitlab_user = module.params['api_username']
80 gitlab_password = module.params['api_password']
81 gitlab_token = module.params['api_token']
82 gitlab_oauth_token = module.params['api_oauth_token']
83 gitlab_job_token = module.params['api_job_token']
84
85 ensure_gitlab_package(module)
86
87 try:
88 # python-gitlab library remove support for username/password authentication since 1.13.0
89 # Changelog : https://github.com/python-gitlab/python-gitlab/releases/tag/v1.13.0
90 # This condition allow to still support older version of the python-gitlab library
91 if LooseVersion(gitlab.__version__) < LooseVersion("1.13.0"):
92 gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=validate_certs, email=gitlab_user, password=gitlab_password,
93 private_token=gitlab_token, api_version=4)
94 else:
95 # We can create an oauth_token using a username and password
96 # https://docs.gitlab.com/ee/api/oauth2.html#authorization-code-flow
97 if gitlab_user:
98 data = {'grant_type': 'password', 'username': gitlab_user, 'password': gitlab_password}
99 resp = requests.post(urljoin(gitlab_url, "oauth/token"), data=data, verify=validate_certs)
100 resp_data = resp.json()
101 gitlab_oauth_token = resp_data["access_token"]
102
103 gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=validate_certs, private_token=gitlab_token,
104 oauth_token=gitlab_oauth_token, job_token=gitlab_job_token, api_version=4)
105
106 gitlab_instance.auth()
107 except (gitlab.exceptions.GitlabAuthenticationError, gitlab.exceptions.GitlabGetError) as e:
108 module.fail_json(msg="Failed to connect to GitLab server: %s" % to_native(e))
109 except (gitlab.exceptions.GitlabHttpError) as e:
110 module.fail_json(msg="Failed to connect to GitLab server: %s. \
111 GitLab remove Session API now that private tokens are removed from user API endpoints since version 10.2." % to_native(e))
112
113 return gitlab_instance
114
115
116 def filter_returned_variables(gitlab_variables):
117 # pop properties we don't know
118 existing_variables = [dict(x.attributes) for x in gitlab_variables]
119 KNOWN = ['key', 'value', 'masked', 'protected', 'variable_type', 'environment_scope', 'raw']
120 for item in existing_variables:
121 for key in list(item.keys()):
122 if key not in KNOWN:
123 item.pop(key)
124 return existing_variables
125
126
127 def vars_to_variables(vars, module):
128 # transform old vars to new variables structure
129 variables = list()
130 for item, value in vars.items():
131 if isinstance(value, (string_types, integer_types, float)):
132 variables.append(
133 {
134 "name": item,
135 "value": str(value),
136 "masked": False,
137 "protected": False,
138 "raw": False,
139 "variable_type": "env_var",
140 }
141 )
142
143 elif isinstance(value, dict):
144 new_item = {
145 "name": item,
146 "value": value.get('value'),
147 "masked": value.get('masked'),
148 "protected": value.get('protected'),
149 "raw": value.get('raw'),
150 "variable_type": value.get('variable_type'),
151 }
152
153 if value.get('environment_scope'):
154 new_item['environment_scope'] = value.get('environment_scope')
155
156 variables.append(new_item)
157
158 else:
159 module.fail_json(msg="value must be of type string, integer, float or dict")
160
161 return variables
162
```
Path: `plugins/doc_fragments/gitlab.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # Copyright (c) Ansible project
3 # GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)
4 # SPDX-License-Identifier: GPL-3.0-or-later
5
6 from __future__ import (absolute_import, division, print_function)
7 __metaclass__ = type
8
9
10 class ModuleDocFragment(object):
11
12 # Standard files documentation fragment
13 DOCUMENTATION = r'''
14 requirements:
15 - requests (Python library U(https://pypi.org/project/requests/))
16
17 options:
18 api_token:
19 description:
20 - GitLab access token with API permissions.
21 type: str
22 api_oauth_token:
23 description:
24 - GitLab OAuth token for logging in.
25 type: str
26 version_added: 4.2.0
27 api_job_token:
28 description:
29 - GitLab CI job token for logging in.
30 type: str
31 version_added: 4.2.0
32 '''
33
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/plugins/doc_fragments/gitlab.py b/plugins/doc_fragments/gitlab.py
--- a/plugins/doc_fragments/gitlab.py
+++ b/plugins/doc_fragments/gitlab.py
@@ -29,4 +29,9 @@
- GitLab CI job token for logging in.
type: str
version_added: 4.2.0
+ ca_path:
+ description:
+ - The CA certificates bundle to use to verify GitLab server certificate.
+ type: str
+ version_added: 8.1.0
'''
diff --git a/plugins/module_utils/gitlab.py b/plugins/module_utils/gitlab.py
--- a/plugins/module_utils/gitlab.py
+++ b/plugins/module_utils/gitlab.py
@@ -34,6 +34,7 @@
def auth_argument_spec(spec=None):
arg_spec = (dict(
+ ca_path=dict(type='str'),
api_token=dict(type='str', no_log=True),
api_oauth_token=dict(type='str', no_log=True),
api_job_token=dict(type='str', no_log=True),
@@ -76,6 +77,7 @@
def gitlab_authentication(module):
gitlab_url = module.params['api_url']
validate_certs = module.params['validate_certs']
+ ca_path = module.params['ca_path']
gitlab_user = module.params['api_username']
gitlab_password = module.params['api_password']
gitlab_token = module.params['api_token']
@@ -84,23 +86,25 @@
ensure_gitlab_package(module)
+ verify = ca_path if validate_certs and ca_path else validate_certs
+
try:
# python-gitlab library remove support for username/password authentication since 1.13.0
# Changelog : https://github.com/python-gitlab/python-gitlab/releases/tag/v1.13.0
# This condition allow to still support older version of the python-gitlab library
if LooseVersion(gitlab.__version__) < LooseVersion("1.13.0"):
- gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=validate_certs, email=gitlab_user, password=gitlab_password,
+ gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=verify, email=gitlab_user, password=gitlab_password,
private_token=gitlab_token, api_version=4)
else:
# We can create an oauth_token using a username and password
# https://docs.gitlab.com/ee/api/oauth2.html#authorization-code-flow
if gitlab_user:
data = {'grant_type': 'password', 'username': gitlab_user, 'password': gitlab_password}
- resp = requests.post(urljoin(gitlab_url, "oauth/token"), data=data, verify=validate_certs)
+ resp = requests.post(urljoin(gitlab_url, "oauth/token"), data=data, verify=verify)
resp_data = resp.json()
gitlab_oauth_token = resp_data["access_token"]
- gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=validate_certs, private_token=gitlab_token,
+ gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=verify, private_token=gitlab_token,
oauth_token=gitlab_oauth_token, job_token=gitlab_job_token, api_version=4)
gitlab_instance.auth()
|
{"golden_diff": "diff --git a/plugins/doc_fragments/gitlab.py b/plugins/doc_fragments/gitlab.py\n--- a/plugins/doc_fragments/gitlab.py\n+++ b/plugins/doc_fragments/gitlab.py\n@@ -29,4 +29,9 @@\n - GitLab CI job token for logging in.\n type: str\n version_added: 4.2.0\n+ ca_path:\n+ description:\n+ - The CA certificates bundle to use to verify GitLab server certificate.\n+ type: str\n+ version_added: 8.1.0\n '''\ndiff --git a/plugins/module_utils/gitlab.py b/plugins/module_utils/gitlab.py\n--- a/plugins/module_utils/gitlab.py\n+++ b/plugins/module_utils/gitlab.py\n@@ -34,6 +34,7 @@\n \n def auth_argument_spec(spec=None):\n arg_spec = (dict(\n+ ca_path=dict(type='str'),\n api_token=dict(type='str', no_log=True),\n api_oauth_token=dict(type='str', no_log=True),\n api_job_token=dict(type='str', no_log=True),\n@@ -76,6 +77,7 @@\n def gitlab_authentication(module):\n gitlab_url = module.params['api_url']\n validate_certs = module.params['validate_certs']\n+ ca_path = module.params['ca_path']\n gitlab_user = module.params['api_username']\n gitlab_password = module.params['api_password']\n gitlab_token = module.params['api_token']\n@@ -84,23 +86,25 @@\n \n ensure_gitlab_package(module)\n \n+ verify = ca_path if validate_certs and ca_path else validate_certs\n+\n try:\n # python-gitlab library remove support for username/password authentication since 1.13.0\n # Changelog : https://github.com/python-gitlab/python-gitlab/releases/tag/v1.13.0\n # This condition allow to still support older version of the python-gitlab library\n if LooseVersion(gitlab.__version__) < LooseVersion(\"1.13.0\"):\n- gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=validate_certs, email=gitlab_user, password=gitlab_password,\n+ gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=verify, email=gitlab_user, password=gitlab_password,\n private_token=gitlab_token, api_version=4)\n else:\n # We can create an oauth_token using a username and password\n # https://docs.gitlab.com/ee/api/oauth2.html#authorization-code-flow\n if gitlab_user:\n data = {'grant_type': 'password', 'username': gitlab_user, 'password': gitlab_password}\n- resp = requests.post(urljoin(gitlab_url, \"oauth/token\"), data=data, verify=validate_certs)\n+ resp = requests.post(urljoin(gitlab_url, \"oauth/token\"), data=data, verify=verify)\n resp_data = resp.json()\n gitlab_oauth_token = resp_data[\"access_token\"]\n \n- gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=validate_certs, private_token=gitlab_token,\n+ gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=verify, private_token=gitlab_token,\n oauth_token=gitlab_oauth_token, job_token=gitlab_job_token, api_version=4)\n \n gitlab_instance.auth()\n", "issue": "community.general.gitlab_runner SSLError cert verify failed\n### Summary\n\nI am trying to register some gitlab runners. On new openstack instances.\r\nI get a SSL certificate verify failed error as the return.\r\n\r\nIf I curl the gitlab url from the command line of the box that I am trying to register I get a response back no TLS issues. \r\nThe gitlab servers certificate is signed by an internal CA, which is installed into the system ca-trust /etc/pki/ca-trust/source/anchors and update-ca-trust has been run.\r\n\r\nI am unable to copy and paste the actual out from the servers. Due to interal work policy\n\n### Issue Type\n\nBug Report\n\n### Component Name\n\ngitlab_runner\n\n### Ansible Version\n\n```console (paste below)\r\n$ ansible --version\r\n\r\n```\r\nansible 2.9.33\r\npython version 3.9.5\n\n### Configuration\n\n```\r\n\r\n```\r\n\n\n### OS / Environment\n\nCentOS 8 on Openstack train\r\nGitlab 14.0.1 runner same version\r\n\n\n### Steps to Reproduce\n\n<!--- Paste example playbooks or commands between quotes below -->\r\n```yaml (paste below)\r\n- name: register gitlab runner\r\n community.general.gitlab_runner\r\n api_url: https://gitlab.internal.addressing\r\n api_token: abc\r\n registration_token: def\r\n description: \"{{ anisble_hostname }}\"\r\n state: present\r\n active: false\r\n tag_list: shell\r\n run_untagged: false\r\n locked: false\r\n```\r\n\n\n### Expected Results\n\nThe ansible task to connect to the gitlab server and register the runner\n\n### Actual Results\n\n```console (paste below)\r\nSSLError \"Certificate_verify_failed\"\r\n```\r\n\n\n### Code of Conduct\n\n- [X] I agree to follow the Ansible Code of Conduct\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright (c) 2019, Guillaume Martinez ([email protected])\n# Copyright (c) 2018, Marcus Watkins <[email protected]>\n# GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)\n# SPDX-License-Identifier: GPL-3.0-or-later\n\nfrom __future__ import (absolute_import, division, print_function)\n__metaclass__ = type\n\nfrom ansible.module_utils.basic import missing_required_lib\nfrom ansible.module_utils.common.text.converters import to_native\nfrom ansible.module_utils.six import integer_types, string_types\n\nfrom ansible_collections.community.general.plugins.module_utils.version import LooseVersion\n\ntry:\n from urlparse import urljoin\nexcept ImportError:\n from urllib.parse import urljoin # Python 3+\n\nimport traceback\n\nGITLAB_IMP_ERR = None\ntry:\n import gitlab\n import requests\n HAS_GITLAB_PACKAGE = True\nexcept Exception:\n gitlab = None\n GITLAB_IMP_ERR = traceback.format_exc()\n HAS_GITLAB_PACKAGE = False\n\n\ndef auth_argument_spec(spec=None):\n arg_spec = (dict(\n api_token=dict(type='str', no_log=True),\n api_oauth_token=dict(type='str', no_log=True),\n api_job_token=dict(type='str', no_log=True),\n ))\n if spec:\n arg_spec.update(spec)\n return arg_spec\n\n\ndef find_project(gitlab_instance, identifier):\n try:\n project = gitlab_instance.projects.get(identifier)\n except Exception as e:\n current_user = gitlab_instance.user\n try:\n project = gitlab_instance.projects.get(current_user.username + '/' + identifier)\n except Exception as e:\n return None\n\n return project\n\n\ndef find_group(gitlab_instance, identifier):\n try:\n project = gitlab_instance.groups.get(identifier)\n except Exception as e:\n return None\n\n return project\n\n\ndef ensure_gitlab_package(module):\n if not HAS_GITLAB_PACKAGE:\n module.fail_json(\n msg=missing_required_lib(\"python-gitlab\", url='https://python-gitlab.readthedocs.io/en/stable/'),\n exception=GITLAB_IMP_ERR\n )\n\n\ndef gitlab_authentication(module):\n gitlab_url = module.params['api_url']\n validate_certs = module.params['validate_certs']\n gitlab_user = module.params['api_username']\n gitlab_password = module.params['api_password']\n gitlab_token = module.params['api_token']\n gitlab_oauth_token = module.params['api_oauth_token']\n gitlab_job_token = module.params['api_job_token']\n\n ensure_gitlab_package(module)\n\n try:\n # python-gitlab library remove support for username/password authentication since 1.13.0\n # Changelog : https://github.com/python-gitlab/python-gitlab/releases/tag/v1.13.0\n # This condition allow to still support older version of the python-gitlab library\n if LooseVersion(gitlab.__version__) < LooseVersion(\"1.13.0\"):\n gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=validate_certs, email=gitlab_user, password=gitlab_password,\n private_token=gitlab_token, api_version=4)\n else:\n # We can create an oauth_token using a username and password\n # https://docs.gitlab.com/ee/api/oauth2.html#authorization-code-flow\n if gitlab_user:\n data = {'grant_type': 'password', 'username': gitlab_user, 'password': gitlab_password}\n resp = requests.post(urljoin(gitlab_url, \"oauth/token\"), data=data, verify=validate_certs)\n resp_data = resp.json()\n gitlab_oauth_token = resp_data[\"access_token\"]\n\n gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=validate_certs, private_token=gitlab_token,\n oauth_token=gitlab_oauth_token, job_token=gitlab_job_token, api_version=4)\n\n gitlab_instance.auth()\n except (gitlab.exceptions.GitlabAuthenticationError, gitlab.exceptions.GitlabGetError) as e:\n module.fail_json(msg=\"Failed to connect to GitLab server: %s\" % to_native(e))\n except (gitlab.exceptions.GitlabHttpError) as e:\n module.fail_json(msg=\"Failed to connect to GitLab server: %s. \\\n GitLab remove Session API now that private tokens are removed from user API endpoints since version 10.2.\" % to_native(e))\n\n return gitlab_instance\n\n\ndef filter_returned_variables(gitlab_variables):\n # pop properties we don't know\n existing_variables = [dict(x.attributes) for x in gitlab_variables]\n KNOWN = ['key', 'value', 'masked', 'protected', 'variable_type', 'environment_scope', 'raw']\n for item in existing_variables:\n for key in list(item.keys()):\n if key not in KNOWN:\n item.pop(key)\n return existing_variables\n\n\ndef vars_to_variables(vars, module):\n # transform old vars to new variables structure\n variables = list()\n for item, value in vars.items():\n if isinstance(value, (string_types, integer_types, float)):\n variables.append(\n {\n \"name\": item,\n \"value\": str(value),\n \"masked\": False,\n \"protected\": False,\n \"raw\": False,\n \"variable_type\": \"env_var\",\n }\n )\n\n elif isinstance(value, dict):\n new_item = {\n \"name\": item,\n \"value\": value.get('value'),\n \"masked\": value.get('masked'),\n \"protected\": value.get('protected'),\n \"raw\": value.get('raw'),\n \"variable_type\": value.get('variable_type'),\n }\n\n if value.get('environment_scope'):\n new_item['environment_scope'] = value.get('environment_scope')\n\n variables.append(new_item)\n\n else:\n module.fail_json(msg=\"value must be of type string, integer, float or dict\")\n\n return variables\n", "path": "plugins/module_utils/gitlab.py"}, {"content": "# -*- coding: utf-8 -*-\n# Copyright (c) Ansible project\n# GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)\n# SPDX-License-Identifier: GPL-3.0-or-later\n\nfrom __future__ import (absolute_import, division, print_function)\n__metaclass__ = type\n\n\nclass ModuleDocFragment(object):\n\n # Standard files documentation fragment\n DOCUMENTATION = r'''\nrequirements:\n - requests (Python library U(https://pypi.org/project/requests/))\n\noptions:\n api_token:\n description:\n - GitLab access token with API permissions.\n type: str\n api_oauth_token:\n description:\n - GitLab OAuth token for logging in.\n type: str\n version_added: 4.2.0\n api_job_token:\n description:\n - GitLab CI job token for logging in.\n type: str\n version_added: 4.2.0\n'''\n", "path": "plugins/doc_fragments/gitlab.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright (c) 2019, Guillaume Martinez ([email protected])\n# Copyright (c) 2018, Marcus Watkins <[email protected]>\n# GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)\n# SPDX-License-Identifier: GPL-3.0-or-later\n\nfrom __future__ import (absolute_import, division, print_function)\n__metaclass__ = type\n\nfrom ansible.module_utils.basic import missing_required_lib\nfrom ansible.module_utils.common.text.converters import to_native\nfrom ansible.module_utils.six import integer_types, string_types\n\nfrom ansible_collections.community.general.plugins.module_utils.version import LooseVersion\n\ntry:\n from urlparse import urljoin\nexcept ImportError:\n from urllib.parse import urljoin # Python 3+\n\nimport traceback\n\nGITLAB_IMP_ERR = None\ntry:\n import gitlab\n import requests\n HAS_GITLAB_PACKAGE = True\nexcept Exception:\n gitlab = None\n GITLAB_IMP_ERR = traceback.format_exc()\n HAS_GITLAB_PACKAGE = False\n\n\ndef auth_argument_spec(spec=None):\n arg_spec = (dict(\n ca_path=dict(type='str'),\n api_token=dict(type='str', no_log=True),\n api_oauth_token=dict(type='str', no_log=True),\n api_job_token=dict(type='str', no_log=True),\n ))\n if spec:\n arg_spec.update(spec)\n return arg_spec\n\n\ndef find_project(gitlab_instance, identifier):\n try:\n project = gitlab_instance.projects.get(identifier)\n except Exception as e:\n current_user = gitlab_instance.user\n try:\n project = gitlab_instance.projects.get(current_user.username + '/' + identifier)\n except Exception as e:\n return None\n\n return project\n\n\ndef find_group(gitlab_instance, identifier):\n try:\n project = gitlab_instance.groups.get(identifier)\n except Exception as e:\n return None\n\n return project\n\n\ndef ensure_gitlab_package(module):\n if not HAS_GITLAB_PACKAGE:\n module.fail_json(\n msg=missing_required_lib(\"python-gitlab\", url='https://python-gitlab.readthedocs.io/en/stable/'),\n exception=GITLAB_IMP_ERR\n )\n\n\ndef gitlab_authentication(module):\n gitlab_url = module.params['api_url']\n validate_certs = module.params['validate_certs']\n ca_path = module.params['ca_path']\n gitlab_user = module.params['api_username']\n gitlab_password = module.params['api_password']\n gitlab_token = module.params['api_token']\n gitlab_oauth_token = module.params['api_oauth_token']\n gitlab_job_token = module.params['api_job_token']\n\n ensure_gitlab_package(module)\n\n verify = ca_path if validate_certs and ca_path else validate_certs\n\n try:\n # python-gitlab library remove support for username/password authentication since 1.13.0\n # Changelog : https://github.com/python-gitlab/python-gitlab/releases/tag/v1.13.0\n # This condition allow to still support older version of the python-gitlab library\n if LooseVersion(gitlab.__version__) < LooseVersion(\"1.13.0\"):\n gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=verify, email=gitlab_user, password=gitlab_password,\n private_token=gitlab_token, api_version=4)\n else:\n # We can create an oauth_token using a username and password\n # https://docs.gitlab.com/ee/api/oauth2.html#authorization-code-flow\n if gitlab_user:\n data = {'grant_type': 'password', 'username': gitlab_user, 'password': gitlab_password}\n resp = requests.post(urljoin(gitlab_url, \"oauth/token\"), data=data, verify=verify)\n resp_data = resp.json()\n gitlab_oauth_token = resp_data[\"access_token\"]\n\n gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=verify, private_token=gitlab_token,\n oauth_token=gitlab_oauth_token, job_token=gitlab_job_token, api_version=4)\n\n gitlab_instance.auth()\n except (gitlab.exceptions.GitlabAuthenticationError, gitlab.exceptions.GitlabGetError) as e:\n module.fail_json(msg=\"Failed to connect to GitLab server: %s\" % to_native(e))\n except (gitlab.exceptions.GitlabHttpError) as e:\n module.fail_json(msg=\"Failed to connect to GitLab server: %s. \\\n GitLab remove Session API now that private tokens are removed from user API endpoints since version 10.2.\" % to_native(e))\n\n return gitlab_instance\n\n\ndef filter_returned_variables(gitlab_variables):\n # pop properties we don't know\n existing_variables = [dict(x.attributes) for x in gitlab_variables]\n KNOWN = ['key', 'value', 'masked', 'protected', 'variable_type', 'environment_scope', 'raw']\n for item in existing_variables:\n for key in list(item.keys()):\n if key not in KNOWN:\n item.pop(key)\n return existing_variables\n\n\ndef vars_to_variables(vars, module):\n # transform old vars to new variables structure\n variables = list()\n for item, value in vars.items():\n if isinstance(value, (string_types, integer_types, float)):\n variables.append(\n {\n \"name\": item,\n \"value\": str(value),\n \"masked\": False,\n \"protected\": False,\n \"raw\": False,\n \"variable_type\": \"env_var\",\n }\n )\n\n elif isinstance(value, dict):\n new_item = {\n \"name\": item,\n \"value\": value.get('value'),\n \"masked\": value.get('masked'),\n \"protected\": value.get('protected'),\n \"raw\": value.get('raw'),\n \"variable_type\": value.get('variable_type'),\n }\n\n if value.get('environment_scope'):\n new_item['environment_scope'] = value.get('environment_scope')\n\n variables.append(new_item)\n\n else:\n module.fail_json(msg=\"value must be of type string, integer, float or dict\")\n\n return variables\n", "path": "plugins/module_utils/gitlab.py"}, {"content": "# -*- coding: utf-8 -*-\n# Copyright (c) Ansible project\n# GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)\n# SPDX-License-Identifier: GPL-3.0-or-later\n\nfrom __future__ import (absolute_import, division, print_function)\n__metaclass__ = type\n\n\nclass ModuleDocFragment(object):\n\n # Standard files documentation fragment\n DOCUMENTATION = r'''\nrequirements:\n - requests (Python library U(https://pypi.org/project/requests/))\n\noptions:\n api_token:\n description:\n - GitLab access token with API permissions.\n type: str\n api_oauth_token:\n description:\n - GitLab OAuth token for logging in.\n type: str\n version_added: 4.2.0\n api_job_token:\n description:\n - GitLab CI job token for logging in.\n type: str\n version_added: 4.2.0\n ca_path:\n description:\n - The CA certificates bundle to use to verify GitLab server certificate.\n type: str\n version_added: 8.1.0\n'''\n", "path": "plugins/doc_fragments/gitlab.py"}]}
| 2,674 | 755 |
gh_patches_debug_5519
|
rasdani/github-patches
|
git_diff
|
freqtrade__freqtrade-2697
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
db-url defaults during dryrun
In the [docker doc](https://www.freqtrade.io/en/latest/docker/#create-your-database-file) the doc recommend to create the database in live with ` touch tradesv3.sqlite`, and in dryrun with`touch tradesv3.dryrun.sqlite`.
But then in the note below it says :
> db-url defaults to sqlite:///tradesv3.sqlite but it defaults to sqlite:// if dry_run=True is being used. To override this behaviour use a custom db-url value: i.e.: --db-url sqlite:///tradesv3.dryrun.sqlite
1/ not sure end user know what _sqlite://_ means : create in memory or create a default file, but we don't know his name ?
2/ When we say the end-user to create the files `touch tradesv3.dryrun.sqlite` for dry-run then the default should be _sqlite:///tradesv3.dryrun.sqlite_ and not _sqlite://_ .If we give recommandations for naming the databases in the doc, then we should take this in account for default. And It can be seen like a convention over configuration approach.
Have a nice day.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `freqtrade/constants.py`
Content:
```
1 # pragma pylint: disable=too-few-public-methods
2
3 """
4 bot constants
5 """
6 DEFAULT_CONFIG = 'config.json'
7 DEFAULT_EXCHANGE = 'bittrex'
8 PROCESS_THROTTLE_SECS = 5 # sec
9 HYPEROPT_EPOCH = 100 # epochs
10 RETRY_TIMEOUT = 30 # sec
11 DEFAULT_HYPEROPT_LOSS = 'DefaultHyperOptLoss'
12 DEFAULT_DB_PROD_URL = 'sqlite:///tradesv3.sqlite'
13 DEFAULT_DB_DRYRUN_URL = 'sqlite://'
14 UNLIMITED_STAKE_AMOUNT = 'unlimited'
15 DEFAULT_AMOUNT_RESERVE_PERCENT = 0.05
16 REQUIRED_ORDERTIF = ['buy', 'sell']
17 REQUIRED_ORDERTYPES = ['buy', 'sell', 'stoploss', 'stoploss_on_exchange']
18 ORDERTYPE_POSSIBILITIES = ['limit', 'market']
19 ORDERTIF_POSSIBILITIES = ['gtc', 'fok', 'ioc']
20 AVAILABLE_PAIRLISTS = ['StaticPairList', 'VolumePairList', 'PrecisionFilter', 'PriceFilter']
21 DRY_RUN_WALLET = 1000
22 MATH_CLOSE_PREC = 1e-14 # Precision used for float comparisons
23
24 USERPATH_HYPEROPTS = 'hyperopts'
25 USERPATH_STRATEGY = 'strategies'
26
27 # Soure files with destination directories within user-directory
28 USER_DATA_FILES = {
29 'sample_strategy.py': USERPATH_STRATEGY,
30 'sample_hyperopt_advanced.py': USERPATH_HYPEROPTS,
31 'sample_hyperopt_loss.py': USERPATH_HYPEROPTS,
32 'sample_hyperopt.py': USERPATH_HYPEROPTS,
33 'strategy_analysis_example.ipynb': 'notebooks',
34 }
35
36 TIMEFRAMES = [
37 '1m', '3m', '5m', '15m', '30m',
38 '1h', '2h', '4h', '6h', '8h', '12h',
39 '1d', '3d', '1w',
40 ]
41
42 SUPPORTED_FIAT = [
43 "AUD", "BRL", "CAD", "CHF", "CLP", "CNY", "CZK", "DKK",
44 "EUR", "GBP", "HKD", "HUF", "IDR", "ILS", "INR", "JPY",
45 "KRW", "MXN", "MYR", "NOK", "NZD", "PHP", "PKR", "PLN",
46 "RUB", "SEK", "SGD", "THB", "TRY", "TWD", "ZAR", "USD",
47 "BTC", "XBT", "ETH", "XRP", "LTC", "BCH", "USDT"
48 ]
49
50 MINIMAL_CONFIG = {
51 'stake_currency': '',
52 'dry_run': True,
53 'exchange': {
54 'name': '',
55 'key': '',
56 'secret': '',
57 'pair_whitelist': [],
58 'ccxt_async_config': {
59 'enableRateLimit': True,
60 }
61 }
62 }
63
64 # Required json-schema for user specified config
65 CONF_SCHEMA = {
66 'type': 'object',
67 'properties': {
68 'max_open_trades': {'type': ['integer', 'number'], 'minimum': -1},
69 'ticker_interval': {'type': 'string', 'enum': TIMEFRAMES},
70 'stake_currency': {'type': 'string', 'enum': ['BTC', 'XBT', 'ETH', 'USDT', 'EUR', 'USD']},
71 'stake_amount': {
72 'type': ['number', 'string'],
73 'minimum': 0.0001,
74 'pattern': UNLIMITED_STAKE_AMOUNT
75 },
76 'fiat_display_currency': {'type': 'string', 'enum': SUPPORTED_FIAT},
77 'dry_run': {'type': 'boolean'},
78 'dry_run_wallet': {'type': 'number', 'default': DRY_RUN_WALLET},
79 'process_only_new_candles': {'type': 'boolean'},
80 'minimal_roi': {
81 'type': 'object',
82 'patternProperties': {
83 '^[0-9.]+$': {'type': 'number'}
84 },
85 'minProperties': 1
86 },
87 'amount_reserve_percent': {'type': 'number', 'minimum': 0.0, 'maximum': 0.5},
88 'stoploss': {'type': 'number', 'maximum': 0, 'exclusiveMaximum': True},
89 'trailing_stop': {'type': 'boolean'},
90 'trailing_stop_positive': {'type': 'number', 'minimum': 0, 'maximum': 1},
91 'trailing_stop_positive_offset': {'type': 'number', 'minimum': 0, 'maximum': 1},
92 'trailing_only_offset_is_reached': {'type': 'boolean'},
93 'unfilledtimeout': {
94 'type': 'object',
95 'properties': {
96 'buy': {'type': 'number', 'minimum': 1},
97 'sell': {'type': 'number', 'minimum': 1}
98 }
99 },
100 'bid_strategy': {
101 'type': 'object',
102 'properties': {
103 'ask_last_balance': {
104 'type': 'number',
105 'minimum': 0,
106 'maximum': 1,
107 'exclusiveMaximum': False,
108 'use_order_book': {'type': 'boolean'},
109 'order_book_top': {'type': 'integer', 'maximum': 20, 'minimum': 1},
110 'check_depth_of_market': {
111 'type': 'object',
112 'properties': {
113 'enabled': {'type': 'boolean'},
114 'bids_to_ask_delta': {'type': 'number', 'minimum': 0},
115 }
116 },
117 },
118 },
119 'required': ['ask_last_balance']
120 },
121 'ask_strategy': {
122 'type': 'object',
123 'properties': {
124 'use_order_book': {'type': 'boolean'},
125 'order_book_min': {'type': 'integer', 'minimum': 1},
126 'order_book_max': {'type': 'integer', 'minimum': 1, 'maximum': 50},
127 'use_sell_signal': {'type': 'boolean'},
128 'sell_profit_only': {'type': 'boolean'},
129 'ignore_roi_if_buy_signal': {'type': 'boolean'}
130 }
131 },
132 'order_types': {
133 'type': 'object',
134 'properties': {
135 'buy': {'type': 'string', 'enum': ORDERTYPE_POSSIBILITIES},
136 'sell': {'type': 'string', 'enum': ORDERTYPE_POSSIBILITIES},
137 'emergencysell': {'type': 'string', 'enum': ORDERTYPE_POSSIBILITIES},
138 'stoploss': {'type': 'string', 'enum': ORDERTYPE_POSSIBILITIES},
139 'stoploss_on_exchange': {'type': 'boolean'},
140 'stoploss_on_exchange_interval': {'type': 'number'}
141 },
142 'required': ['buy', 'sell', 'stoploss', 'stoploss_on_exchange']
143 },
144 'order_time_in_force': {
145 'type': 'object',
146 'properties': {
147 'buy': {'type': 'string', 'enum': ORDERTIF_POSSIBILITIES},
148 'sell': {'type': 'string', 'enum': ORDERTIF_POSSIBILITIES}
149 },
150 'required': ['buy', 'sell']
151 },
152 'exchange': {'$ref': '#/definitions/exchange'},
153 'edge': {'$ref': '#/definitions/edge'},
154 'experimental': {
155 'type': 'object',
156 'properties': {
157 'use_sell_signal': {'type': 'boolean'},
158 'sell_profit_only': {'type': 'boolean'},
159 'ignore_roi_if_buy_signal': {'type': 'boolean'},
160 'block_bad_exchanges': {'type': 'boolean'}
161 }
162 },
163 'pairlists': {
164 'type': 'array',
165 'items': {
166 'type': 'object',
167 'properties': {
168 'method': {'type': 'string', 'enum': AVAILABLE_PAIRLISTS},
169 'config': {'type': 'object'}
170 },
171 'required': ['method'],
172 }
173 },
174 'telegram': {
175 'type': 'object',
176 'properties': {
177 'enabled': {'type': 'boolean'},
178 'token': {'type': 'string'},
179 'chat_id': {'type': 'string'},
180 },
181 'required': ['enabled', 'token', 'chat_id']
182 },
183 'webhook': {
184 'type': 'object',
185 'properties': {
186 'enabled': {'type': 'boolean'},
187 'webhookbuy': {'type': 'object'},
188 'webhooksell': {'type': 'object'},
189 'webhookstatus': {'type': 'object'},
190 },
191 },
192 'api_server': {
193 'type': 'object',
194 'properties': {
195 'enabled': {'type': 'boolean'},
196 'listen_ip_address': {'format': 'ipv4'},
197 'listen_port': {
198 'type': 'integer',
199 'minimum': 1024,
200 'maximum': 65535
201 },
202 'username': {'type': 'string'},
203 'password': {'type': 'string'},
204 },
205 'required': ['enabled', 'listen_ip_address', 'listen_port', 'username', 'password']
206 },
207 'db_url': {'type': 'string'},
208 'initial_state': {'type': 'string', 'enum': ['running', 'stopped']},
209 'forcebuy_enable': {'type': 'boolean'},
210 'internals': {
211 'type': 'object',
212 'properties': {
213 'process_throttle_secs': {'type': 'integer'},
214 'interval': {'type': 'integer'},
215 'sd_notify': {'type': 'boolean'},
216 }
217 }
218 },
219 'definitions': {
220 'exchange': {
221 'type': 'object',
222 'properties': {
223 'name': {'type': 'string'},
224 'sandbox': {'type': 'boolean', 'default': False},
225 'key': {'type': 'string', 'default': ''},
226 'secret': {'type': 'string', 'default': ''},
227 'password': {'type': 'string', 'default': ''},
228 'uid': {'type': 'string'},
229 'pair_whitelist': {
230 'type': 'array',
231 'items': {
232 'type': 'string',
233 'pattern': '^[0-9A-Z]+/[0-9A-Z]+$'
234 },
235 'uniqueItems': True
236 },
237 'pair_blacklist': {
238 'type': 'array',
239 'items': {
240 'type': 'string',
241 'pattern': '^[0-9A-Z]+/[0-9A-Z]+$'
242 },
243 'uniqueItems': True
244 },
245 'outdated_offset': {'type': 'integer', 'minimum': 1},
246 'markets_refresh_interval': {'type': 'integer'},
247 'ccxt_config': {'type': 'object'},
248 'ccxt_async_config': {'type': 'object'}
249 },
250 'required': ['name']
251 },
252 'edge': {
253 'type': 'object',
254 'properties': {
255 'enabled': {'type': 'boolean'},
256 'process_throttle_secs': {'type': 'integer', 'minimum': 600},
257 'calculate_since_number_of_days': {'type': 'integer'},
258 'allowed_risk': {'type': 'number'},
259 'capital_available_percentage': {'type': 'number'},
260 'stoploss_range_min': {'type': 'number'},
261 'stoploss_range_max': {'type': 'number'},
262 'stoploss_range_step': {'type': 'number'},
263 'minimum_winrate': {'type': 'number'},
264 'minimum_expectancy': {'type': 'number'},
265 'min_trade_number': {'type': 'number'},
266 'max_trade_duration_minute': {'type': 'integer'},
267 'remove_pumps': {'type': 'boolean'}
268 },
269 'required': ['process_throttle_secs', 'allowed_risk', 'capital_available_percentage']
270 }
271 },
272 'required': [
273 'exchange',
274 'max_open_trades',
275 'stake_currency',
276 'stake_amount',
277 'dry_run',
278 'dry_run_wallet',
279 'bid_strategy',
280 'unfilledtimeout',
281 'stoploss',
282 'minimal_roi',
283 ]
284 }
285
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/freqtrade/constants.py b/freqtrade/constants.py
--- a/freqtrade/constants.py
+++ b/freqtrade/constants.py
@@ -10,7 +10,7 @@
RETRY_TIMEOUT = 30 # sec
DEFAULT_HYPEROPT_LOSS = 'DefaultHyperOptLoss'
DEFAULT_DB_PROD_URL = 'sqlite:///tradesv3.sqlite'
-DEFAULT_DB_DRYRUN_URL = 'sqlite://'
+DEFAULT_DB_DRYRUN_URL = 'sqlite:///tradesv3.dryrun.sqlite'
UNLIMITED_STAKE_AMOUNT = 'unlimited'
DEFAULT_AMOUNT_RESERVE_PERCENT = 0.05
REQUIRED_ORDERTIF = ['buy', 'sell']
|
{"golden_diff": "diff --git a/freqtrade/constants.py b/freqtrade/constants.py\n--- a/freqtrade/constants.py\n+++ b/freqtrade/constants.py\n@@ -10,7 +10,7 @@\n RETRY_TIMEOUT = 30 # sec\n DEFAULT_HYPEROPT_LOSS = 'DefaultHyperOptLoss'\n DEFAULT_DB_PROD_URL = 'sqlite:///tradesv3.sqlite'\n-DEFAULT_DB_DRYRUN_URL = 'sqlite://'\n+DEFAULT_DB_DRYRUN_URL = 'sqlite:///tradesv3.dryrun.sqlite'\n UNLIMITED_STAKE_AMOUNT = 'unlimited'\n DEFAULT_AMOUNT_RESERVE_PERCENT = 0.05\n REQUIRED_ORDERTIF = ['buy', 'sell']\n", "issue": "db-url defaults during dryrun\nIn the [docker doc](https://www.freqtrade.io/en/latest/docker/#create-your-database-file) the doc recommend to create the database in live with ` touch tradesv3.sqlite`, and in dryrun with`touch tradesv3.dryrun.sqlite`.\r\n\r\nBut then in the note below it says :\r\n\r\n> db-url defaults to sqlite:///tradesv3.sqlite but it defaults to sqlite:// if dry_run=True is being used. To override this behaviour use a custom db-url value: i.e.: --db-url sqlite:///tradesv3.dryrun.sqlite\r\n\r\n1/ not sure end user know what _sqlite://_ means : create in memory or create a default file, but we don't know his name ?\r\n2/ When we say the end-user to create the files `touch tradesv3.dryrun.sqlite` for dry-run then the default should be _sqlite:///tradesv3.dryrun.sqlite_ and not _sqlite://_ .If we give recommandations for naming the databases in the doc, then we should take this in account for default. And It can be seen like a convention over configuration approach.\r\n\r\nHave a nice day.\r\n\n", "before_files": [{"content": "# pragma pylint: disable=too-few-public-methods\n\n\"\"\"\nbot constants\n\"\"\"\nDEFAULT_CONFIG = 'config.json'\nDEFAULT_EXCHANGE = 'bittrex'\nPROCESS_THROTTLE_SECS = 5 # sec\nHYPEROPT_EPOCH = 100 # epochs\nRETRY_TIMEOUT = 30 # sec\nDEFAULT_HYPEROPT_LOSS = 'DefaultHyperOptLoss'\nDEFAULT_DB_PROD_URL = 'sqlite:///tradesv3.sqlite'\nDEFAULT_DB_DRYRUN_URL = 'sqlite://'\nUNLIMITED_STAKE_AMOUNT = 'unlimited'\nDEFAULT_AMOUNT_RESERVE_PERCENT = 0.05\nREQUIRED_ORDERTIF = ['buy', 'sell']\nREQUIRED_ORDERTYPES = ['buy', 'sell', 'stoploss', 'stoploss_on_exchange']\nORDERTYPE_POSSIBILITIES = ['limit', 'market']\nORDERTIF_POSSIBILITIES = ['gtc', 'fok', 'ioc']\nAVAILABLE_PAIRLISTS = ['StaticPairList', 'VolumePairList', 'PrecisionFilter', 'PriceFilter']\nDRY_RUN_WALLET = 1000\nMATH_CLOSE_PREC = 1e-14 # Precision used for float comparisons\n\nUSERPATH_HYPEROPTS = 'hyperopts'\nUSERPATH_STRATEGY = 'strategies'\n\n# Soure files with destination directories within user-directory\nUSER_DATA_FILES = {\n 'sample_strategy.py': USERPATH_STRATEGY,\n 'sample_hyperopt_advanced.py': USERPATH_HYPEROPTS,\n 'sample_hyperopt_loss.py': USERPATH_HYPEROPTS,\n 'sample_hyperopt.py': USERPATH_HYPEROPTS,\n 'strategy_analysis_example.ipynb': 'notebooks',\n}\n\nTIMEFRAMES = [\n '1m', '3m', '5m', '15m', '30m',\n '1h', '2h', '4h', '6h', '8h', '12h',\n '1d', '3d', '1w',\n]\n\nSUPPORTED_FIAT = [\n \"AUD\", \"BRL\", \"CAD\", \"CHF\", \"CLP\", \"CNY\", \"CZK\", \"DKK\",\n \"EUR\", \"GBP\", \"HKD\", \"HUF\", \"IDR\", \"ILS\", \"INR\", \"JPY\",\n \"KRW\", \"MXN\", \"MYR\", \"NOK\", \"NZD\", \"PHP\", \"PKR\", \"PLN\",\n \"RUB\", \"SEK\", \"SGD\", \"THB\", \"TRY\", \"TWD\", \"ZAR\", \"USD\",\n \"BTC\", \"XBT\", \"ETH\", \"XRP\", \"LTC\", \"BCH\", \"USDT\"\n]\n\nMINIMAL_CONFIG = {\n 'stake_currency': '',\n 'dry_run': True,\n 'exchange': {\n 'name': '',\n 'key': '',\n 'secret': '',\n 'pair_whitelist': [],\n 'ccxt_async_config': {\n 'enableRateLimit': True,\n }\n }\n}\n\n# Required json-schema for user specified config\nCONF_SCHEMA = {\n 'type': 'object',\n 'properties': {\n 'max_open_trades': {'type': ['integer', 'number'], 'minimum': -1},\n 'ticker_interval': {'type': 'string', 'enum': TIMEFRAMES},\n 'stake_currency': {'type': 'string', 'enum': ['BTC', 'XBT', 'ETH', 'USDT', 'EUR', 'USD']},\n 'stake_amount': {\n 'type': ['number', 'string'],\n 'minimum': 0.0001,\n 'pattern': UNLIMITED_STAKE_AMOUNT\n },\n 'fiat_display_currency': {'type': 'string', 'enum': SUPPORTED_FIAT},\n 'dry_run': {'type': 'boolean'},\n 'dry_run_wallet': {'type': 'number', 'default': DRY_RUN_WALLET},\n 'process_only_new_candles': {'type': 'boolean'},\n 'minimal_roi': {\n 'type': 'object',\n 'patternProperties': {\n '^[0-9.]+$': {'type': 'number'}\n },\n 'minProperties': 1\n },\n 'amount_reserve_percent': {'type': 'number', 'minimum': 0.0, 'maximum': 0.5},\n 'stoploss': {'type': 'number', 'maximum': 0, 'exclusiveMaximum': True},\n 'trailing_stop': {'type': 'boolean'},\n 'trailing_stop_positive': {'type': 'number', 'minimum': 0, 'maximum': 1},\n 'trailing_stop_positive_offset': {'type': 'number', 'minimum': 0, 'maximum': 1},\n 'trailing_only_offset_is_reached': {'type': 'boolean'},\n 'unfilledtimeout': {\n 'type': 'object',\n 'properties': {\n 'buy': {'type': 'number', 'minimum': 1},\n 'sell': {'type': 'number', 'minimum': 1}\n }\n },\n 'bid_strategy': {\n 'type': 'object',\n 'properties': {\n 'ask_last_balance': {\n 'type': 'number',\n 'minimum': 0,\n 'maximum': 1,\n 'exclusiveMaximum': False,\n 'use_order_book': {'type': 'boolean'},\n 'order_book_top': {'type': 'integer', 'maximum': 20, 'minimum': 1},\n 'check_depth_of_market': {\n 'type': 'object',\n 'properties': {\n 'enabled': {'type': 'boolean'},\n 'bids_to_ask_delta': {'type': 'number', 'minimum': 0},\n }\n },\n },\n },\n 'required': ['ask_last_balance']\n },\n 'ask_strategy': {\n 'type': 'object',\n 'properties': {\n 'use_order_book': {'type': 'boolean'},\n 'order_book_min': {'type': 'integer', 'minimum': 1},\n 'order_book_max': {'type': 'integer', 'minimum': 1, 'maximum': 50},\n 'use_sell_signal': {'type': 'boolean'},\n 'sell_profit_only': {'type': 'boolean'},\n 'ignore_roi_if_buy_signal': {'type': 'boolean'}\n }\n },\n 'order_types': {\n 'type': 'object',\n 'properties': {\n 'buy': {'type': 'string', 'enum': ORDERTYPE_POSSIBILITIES},\n 'sell': {'type': 'string', 'enum': ORDERTYPE_POSSIBILITIES},\n 'emergencysell': {'type': 'string', 'enum': ORDERTYPE_POSSIBILITIES},\n 'stoploss': {'type': 'string', 'enum': ORDERTYPE_POSSIBILITIES},\n 'stoploss_on_exchange': {'type': 'boolean'},\n 'stoploss_on_exchange_interval': {'type': 'number'}\n },\n 'required': ['buy', 'sell', 'stoploss', 'stoploss_on_exchange']\n },\n 'order_time_in_force': {\n 'type': 'object',\n 'properties': {\n 'buy': {'type': 'string', 'enum': ORDERTIF_POSSIBILITIES},\n 'sell': {'type': 'string', 'enum': ORDERTIF_POSSIBILITIES}\n },\n 'required': ['buy', 'sell']\n },\n 'exchange': {'$ref': '#/definitions/exchange'},\n 'edge': {'$ref': '#/definitions/edge'},\n 'experimental': {\n 'type': 'object',\n 'properties': {\n 'use_sell_signal': {'type': 'boolean'},\n 'sell_profit_only': {'type': 'boolean'},\n 'ignore_roi_if_buy_signal': {'type': 'boolean'},\n 'block_bad_exchanges': {'type': 'boolean'}\n }\n },\n 'pairlists': {\n 'type': 'array',\n 'items': {\n 'type': 'object',\n 'properties': {\n 'method': {'type': 'string', 'enum': AVAILABLE_PAIRLISTS},\n 'config': {'type': 'object'}\n },\n 'required': ['method'],\n }\n },\n 'telegram': {\n 'type': 'object',\n 'properties': {\n 'enabled': {'type': 'boolean'},\n 'token': {'type': 'string'},\n 'chat_id': {'type': 'string'},\n },\n 'required': ['enabled', 'token', 'chat_id']\n },\n 'webhook': {\n 'type': 'object',\n 'properties': {\n 'enabled': {'type': 'boolean'},\n 'webhookbuy': {'type': 'object'},\n 'webhooksell': {'type': 'object'},\n 'webhookstatus': {'type': 'object'},\n },\n },\n 'api_server': {\n 'type': 'object',\n 'properties': {\n 'enabled': {'type': 'boolean'},\n 'listen_ip_address': {'format': 'ipv4'},\n 'listen_port': {\n 'type': 'integer',\n 'minimum': 1024,\n 'maximum': 65535\n },\n 'username': {'type': 'string'},\n 'password': {'type': 'string'},\n },\n 'required': ['enabled', 'listen_ip_address', 'listen_port', 'username', 'password']\n },\n 'db_url': {'type': 'string'},\n 'initial_state': {'type': 'string', 'enum': ['running', 'stopped']},\n 'forcebuy_enable': {'type': 'boolean'},\n 'internals': {\n 'type': 'object',\n 'properties': {\n 'process_throttle_secs': {'type': 'integer'},\n 'interval': {'type': 'integer'},\n 'sd_notify': {'type': 'boolean'},\n }\n }\n },\n 'definitions': {\n 'exchange': {\n 'type': 'object',\n 'properties': {\n 'name': {'type': 'string'},\n 'sandbox': {'type': 'boolean', 'default': False},\n 'key': {'type': 'string', 'default': ''},\n 'secret': {'type': 'string', 'default': ''},\n 'password': {'type': 'string', 'default': ''},\n 'uid': {'type': 'string'},\n 'pair_whitelist': {\n 'type': 'array',\n 'items': {\n 'type': 'string',\n 'pattern': '^[0-9A-Z]+/[0-9A-Z]+$'\n },\n 'uniqueItems': True\n },\n 'pair_blacklist': {\n 'type': 'array',\n 'items': {\n 'type': 'string',\n 'pattern': '^[0-9A-Z]+/[0-9A-Z]+$'\n },\n 'uniqueItems': True\n },\n 'outdated_offset': {'type': 'integer', 'minimum': 1},\n 'markets_refresh_interval': {'type': 'integer'},\n 'ccxt_config': {'type': 'object'},\n 'ccxt_async_config': {'type': 'object'}\n },\n 'required': ['name']\n },\n 'edge': {\n 'type': 'object',\n 'properties': {\n 'enabled': {'type': 'boolean'},\n 'process_throttle_secs': {'type': 'integer', 'minimum': 600},\n 'calculate_since_number_of_days': {'type': 'integer'},\n 'allowed_risk': {'type': 'number'},\n 'capital_available_percentage': {'type': 'number'},\n 'stoploss_range_min': {'type': 'number'},\n 'stoploss_range_max': {'type': 'number'},\n 'stoploss_range_step': {'type': 'number'},\n 'minimum_winrate': {'type': 'number'},\n 'minimum_expectancy': {'type': 'number'},\n 'min_trade_number': {'type': 'number'},\n 'max_trade_duration_minute': {'type': 'integer'},\n 'remove_pumps': {'type': 'boolean'}\n },\n 'required': ['process_throttle_secs', 'allowed_risk', 'capital_available_percentage']\n }\n },\n 'required': [\n 'exchange',\n 'max_open_trades',\n 'stake_currency',\n 'stake_amount',\n 'dry_run',\n 'dry_run_wallet',\n 'bid_strategy',\n 'unfilledtimeout',\n 'stoploss',\n 'minimal_roi',\n ]\n}\n", "path": "freqtrade/constants.py"}], "after_files": [{"content": "# pragma pylint: disable=too-few-public-methods\n\n\"\"\"\nbot constants\n\"\"\"\nDEFAULT_CONFIG = 'config.json'\nDEFAULT_EXCHANGE = 'bittrex'\nPROCESS_THROTTLE_SECS = 5 # sec\nHYPEROPT_EPOCH = 100 # epochs\nRETRY_TIMEOUT = 30 # sec\nDEFAULT_HYPEROPT_LOSS = 'DefaultHyperOptLoss'\nDEFAULT_DB_PROD_URL = 'sqlite:///tradesv3.sqlite'\nDEFAULT_DB_DRYRUN_URL = 'sqlite:///tradesv3.dryrun.sqlite'\nUNLIMITED_STAKE_AMOUNT = 'unlimited'\nDEFAULT_AMOUNT_RESERVE_PERCENT = 0.05\nREQUIRED_ORDERTIF = ['buy', 'sell']\nREQUIRED_ORDERTYPES = ['buy', 'sell', 'stoploss', 'stoploss_on_exchange']\nORDERTYPE_POSSIBILITIES = ['limit', 'market']\nORDERTIF_POSSIBILITIES = ['gtc', 'fok', 'ioc']\nAVAILABLE_PAIRLISTS = ['StaticPairList', 'VolumePairList', 'PrecisionFilter', 'PriceFilter']\nDRY_RUN_WALLET = 1000\nMATH_CLOSE_PREC = 1e-14 # Precision used for float comparisons\n\nUSERPATH_HYPEROPTS = 'hyperopts'\nUSERPATH_STRATEGY = 'strategies'\n\n# Soure files with destination directories within user-directory\nUSER_DATA_FILES = {\n 'sample_strategy.py': USERPATH_STRATEGY,\n 'sample_hyperopt_advanced.py': USERPATH_HYPEROPTS,\n 'sample_hyperopt_loss.py': USERPATH_HYPEROPTS,\n 'sample_hyperopt.py': USERPATH_HYPEROPTS,\n 'strategy_analysis_example.ipynb': 'notebooks',\n}\n\nTIMEFRAMES = [\n '1m', '3m', '5m', '15m', '30m',\n '1h', '2h', '4h', '6h', '8h', '12h',\n '1d', '3d', '1w',\n]\n\nSUPPORTED_FIAT = [\n \"AUD\", \"BRL\", \"CAD\", \"CHF\", \"CLP\", \"CNY\", \"CZK\", \"DKK\",\n \"EUR\", \"GBP\", \"HKD\", \"HUF\", \"IDR\", \"ILS\", \"INR\", \"JPY\",\n \"KRW\", \"MXN\", \"MYR\", \"NOK\", \"NZD\", \"PHP\", \"PKR\", \"PLN\",\n \"RUB\", \"SEK\", \"SGD\", \"THB\", \"TRY\", \"TWD\", \"ZAR\", \"USD\",\n \"BTC\", \"XBT\", \"ETH\", \"XRP\", \"LTC\", \"BCH\", \"USDT\"\n]\n\nMINIMAL_CONFIG = {\n 'stake_currency': '',\n 'dry_run': True,\n 'exchange': {\n 'name': '',\n 'key': '',\n 'secret': '',\n 'pair_whitelist': [],\n 'ccxt_async_config': {\n 'enableRateLimit': True,\n }\n }\n}\n\n# Required json-schema for user specified config\nCONF_SCHEMA = {\n 'type': 'object',\n 'properties': {\n 'max_open_trades': {'type': ['integer', 'number'], 'minimum': -1},\n 'ticker_interval': {'type': 'string', 'enum': TIMEFRAMES},\n 'stake_currency': {'type': 'string', 'enum': ['BTC', 'XBT', 'ETH', 'USDT', 'EUR', 'USD']},\n 'stake_amount': {\n 'type': ['number', 'string'],\n 'minimum': 0.0001,\n 'pattern': UNLIMITED_STAKE_AMOUNT\n },\n 'fiat_display_currency': {'type': 'string', 'enum': SUPPORTED_FIAT},\n 'dry_run': {'type': 'boolean'},\n 'dry_run_wallet': {'type': 'number', 'default': DRY_RUN_WALLET},\n 'process_only_new_candles': {'type': 'boolean'},\n 'minimal_roi': {\n 'type': 'object',\n 'patternProperties': {\n '^[0-9.]+$': {'type': 'number'}\n },\n 'minProperties': 1\n },\n 'amount_reserve_percent': {'type': 'number', 'minimum': 0.0, 'maximum': 0.5},\n 'stoploss': {'type': 'number', 'maximum': 0, 'exclusiveMaximum': True},\n 'trailing_stop': {'type': 'boolean'},\n 'trailing_stop_positive': {'type': 'number', 'minimum': 0, 'maximum': 1},\n 'trailing_stop_positive_offset': {'type': 'number', 'minimum': 0, 'maximum': 1},\n 'trailing_only_offset_is_reached': {'type': 'boolean'},\n 'unfilledtimeout': {\n 'type': 'object',\n 'properties': {\n 'buy': {'type': 'number', 'minimum': 1},\n 'sell': {'type': 'number', 'minimum': 1}\n }\n },\n 'bid_strategy': {\n 'type': 'object',\n 'properties': {\n 'ask_last_balance': {\n 'type': 'number',\n 'minimum': 0,\n 'maximum': 1,\n 'exclusiveMaximum': False,\n 'use_order_book': {'type': 'boolean'},\n 'order_book_top': {'type': 'integer', 'maximum': 20, 'minimum': 1},\n 'check_depth_of_market': {\n 'type': 'object',\n 'properties': {\n 'enabled': {'type': 'boolean'},\n 'bids_to_ask_delta': {'type': 'number', 'minimum': 0},\n }\n },\n },\n },\n 'required': ['ask_last_balance']\n },\n 'ask_strategy': {\n 'type': 'object',\n 'properties': {\n 'use_order_book': {'type': 'boolean'},\n 'order_book_min': {'type': 'integer', 'minimum': 1},\n 'order_book_max': {'type': 'integer', 'minimum': 1, 'maximum': 50},\n 'use_sell_signal': {'type': 'boolean'},\n 'sell_profit_only': {'type': 'boolean'},\n 'ignore_roi_if_buy_signal': {'type': 'boolean'}\n }\n },\n 'order_types': {\n 'type': 'object',\n 'properties': {\n 'buy': {'type': 'string', 'enum': ORDERTYPE_POSSIBILITIES},\n 'sell': {'type': 'string', 'enum': ORDERTYPE_POSSIBILITIES},\n 'emergencysell': {'type': 'string', 'enum': ORDERTYPE_POSSIBILITIES},\n 'stoploss': {'type': 'string', 'enum': ORDERTYPE_POSSIBILITIES},\n 'stoploss_on_exchange': {'type': 'boolean'},\n 'stoploss_on_exchange_interval': {'type': 'number'}\n },\n 'required': ['buy', 'sell', 'stoploss', 'stoploss_on_exchange']\n },\n 'order_time_in_force': {\n 'type': 'object',\n 'properties': {\n 'buy': {'type': 'string', 'enum': ORDERTIF_POSSIBILITIES},\n 'sell': {'type': 'string', 'enum': ORDERTIF_POSSIBILITIES}\n },\n 'required': ['buy', 'sell']\n },\n 'exchange': {'$ref': '#/definitions/exchange'},\n 'edge': {'$ref': '#/definitions/edge'},\n 'experimental': {\n 'type': 'object',\n 'properties': {\n 'use_sell_signal': {'type': 'boolean'},\n 'sell_profit_only': {'type': 'boolean'},\n 'ignore_roi_if_buy_signal': {'type': 'boolean'},\n 'block_bad_exchanges': {'type': 'boolean'}\n }\n },\n 'pairlists': {\n 'type': 'array',\n 'items': {\n 'type': 'object',\n 'properties': {\n 'method': {'type': 'string', 'enum': AVAILABLE_PAIRLISTS},\n 'config': {'type': 'object'}\n },\n 'required': ['method'],\n }\n },\n 'telegram': {\n 'type': 'object',\n 'properties': {\n 'enabled': {'type': 'boolean'},\n 'token': {'type': 'string'},\n 'chat_id': {'type': 'string'},\n },\n 'required': ['enabled', 'token', 'chat_id']\n },\n 'webhook': {\n 'type': 'object',\n 'properties': {\n 'enabled': {'type': 'boolean'},\n 'webhookbuy': {'type': 'object'},\n 'webhooksell': {'type': 'object'},\n 'webhookstatus': {'type': 'object'},\n },\n },\n 'api_server': {\n 'type': 'object',\n 'properties': {\n 'enabled': {'type': 'boolean'},\n 'listen_ip_address': {'format': 'ipv4'},\n 'listen_port': {\n 'type': 'integer',\n 'minimum': 1024,\n 'maximum': 65535\n },\n 'username': {'type': 'string'},\n 'password': {'type': 'string'},\n },\n 'required': ['enabled', 'listen_ip_address', 'listen_port', 'username', 'password']\n },\n 'db_url': {'type': 'string'},\n 'initial_state': {'type': 'string', 'enum': ['running', 'stopped']},\n 'forcebuy_enable': {'type': 'boolean'},\n 'internals': {\n 'type': 'object',\n 'properties': {\n 'process_throttle_secs': {'type': 'integer'},\n 'interval': {'type': 'integer'},\n 'sd_notify': {'type': 'boolean'},\n }\n }\n },\n 'definitions': {\n 'exchange': {\n 'type': 'object',\n 'properties': {\n 'name': {'type': 'string'},\n 'sandbox': {'type': 'boolean', 'default': False},\n 'key': {'type': 'string', 'default': ''},\n 'secret': {'type': 'string', 'default': ''},\n 'password': {'type': 'string', 'default': ''},\n 'uid': {'type': 'string'},\n 'pair_whitelist': {\n 'type': 'array',\n 'items': {\n 'type': 'string',\n 'pattern': '^[0-9A-Z]+/[0-9A-Z]+$'\n },\n 'uniqueItems': True\n },\n 'pair_blacklist': {\n 'type': 'array',\n 'items': {\n 'type': 'string',\n 'pattern': '^[0-9A-Z]+/[0-9A-Z]+$'\n },\n 'uniqueItems': True\n },\n 'outdated_offset': {'type': 'integer', 'minimum': 1},\n 'markets_refresh_interval': {'type': 'integer'},\n 'ccxt_config': {'type': 'object'},\n 'ccxt_async_config': {'type': 'object'}\n },\n 'required': ['name']\n },\n 'edge': {\n 'type': 'object',\n 'properties': {\n 'enabled': {'type': 'boolean'},\n 'process_throttle_secs': {'type': 'integer', 'minimum': 600},\n 'calculate_since_number_of_days': {'type': 'integer'},\n 'allowed_risk': {'type': 'number'},\n 'capital_available_percentage': {'type': 'number'},\n 'stoploss_range_min': {'type': 'number'},\n 'stoploss_range_max': {'type': 'number'},\n 'stoploss_range_step': {'type': 'number'},\n 'minimum_winrate': {'type': 'number'},\n 'minimum_expectancy': {'type': 'number'},\n 'min_trade_number': {'type': 'number'},\n 'max_trade_duration_minute': {'type': 'integer'},\n 'remove_pumps': {'type': 'boolean'}\n },\n 'required': ['process_throttle_secs', 'allowed_risk', 'capital_available_percentage']\n }\n },\n 'required': [\n 'exchange',\n 'max_open_trades',\n 'stake_currency',\n 'stake_amount',\n 'dry_run',\n 'dry_run_wallet',\n 'bid_strategy',\n 'unfilledtimeout',\n 'stoploss',\n 'minimal_roi',\n ]\n}\n", "path": "freqtrade/constants.py"}]}
| 3,959 | 149 |
gh_patches_debug_18516
|
rasdani/github-patches
|
git_diff
|
AUTOMATIC1111__stable-diffusion-webui-9219
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Feature Request]: img2img batch should ignore non-image files
### Is there an existing issue for this?
- [X] I have searched the existing issues and checked the recent builds/commits
### What would your feature do ?
I may place some parameter files along the image files in the same folder.
Currently an exception is throw for non-image files when do "Image.open()".
### Proposed workflow
1. Place a txt file along with the png file in folder A
2. Set batch input folder to A
3. Press generate
### Additional information
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `modules/img2img.py`
Content:
```
1 import math
2 import os
3 import sys
4 import traceback
5
6 import numpy as np
7 from PIL import Image, ImageOps, ImageFilter, ImageEnhance, ImageChops
8
9 from modules import devices, sd_samplers
10 from modules.generation_parameters_copypaste import create_override_settings_dict
11 from modules.processing import Processed, StableDiffusionProcessingImg2Img, process_images
12 from modules.shared import opts, state
13 import modules.shared as shared
14 import modules.processing as processing
15 from modules.ui import plaintext_to_html
16 import modules.images as images
17 import modules.scripts
18
19
20 def process_batch(p, input_dir, output_dir, inpaint_mask_dir, args):
21 processing.fix_seed(p)
22
23 images = shared.listfiles(input_dir)
24
25 is_inpaint_batch = False
26 if inpaint_mask_dir:
27 inpaint_masks = shared.listfiles(inpaint_mask_dir)
28 is_inpaint_batch = len(inpaint_masks) > 0
29 if is_inpaint_batch:
30 print(f"\nInpaint batch is enabled. {len(inpaint_masks)} masks found.")
31
32 print(f"Will process {len(images)} images, creating {p.n_iter * p.batch_size} new images for each.")
33
34 save_normally = output_dir == ''
35
36 p.do_not_save_grid = True
37 p.do_not_save_samples = not save_normally
38
39 state.job_count = len(images) * p.n_iter
40
41 for i, image in enumerate(images):
42 state.job = f"{i+1} out of {len(images)}"
43 if state.skipped:
44 state.skipped = False
45
46 if state.interrupted:
47 break
48
49 img = Image.open(image)
50 # Use the EXIF orientation of photos taken by smartphones.
51 img = ImageOps.exif_transpose(img)
52 p.init_images = [img] * p.batch_size
53
54 if is_inpaint_batch:
55 # try to find corresponding mask for an image using simple filename matching
56 mask_image_path = os.path.join(inpaint_mask_dir, os.path.basename(image))
57 # if not found use first one ("same mask for all images" use-case)
58 if not mask_image_path in inpaint_masks:
59 mask_image_path = inpaint_masks[0]
60 mask_image = Image.open(mask_image_path)
61 p.image_mask = mask_image
62
63 proc = modules.scripts.scripts_img2img.run(p, *args)
64 if proc is None:
65 proc = process_images(p)
66
67 for n, processed_image in enumerate(proc.images):
68 filename = os.path.basename(image)
69
70 if n > 0:
71 left, right = os.path.splitext(filename)
72 filename = f"{left}-{n}{right}"
73
74 if not save_normally:
75 os.makedirs(output_dir, exist_ok=True)
76 if processed_image.mode == 'RGBA':
77 processed_image = processed_image.convert("RGB")
78 processed_image.save(os.path.join(output_dir, filename))
79
80
81 def img2img(id_task: str, mode: int, prompt: str, negative_prompt: str, prompt_styles, init_img, sketch, init_img_with_mask, inpaint_color_sketch, inpaint_color_sketch_orig, init_img_inpaint, init_mask_inpaint, steps: int, sampler_index: int, mask_blur: int, mask_alpha: float, inpainting_fill: int, restore_faces: bool, tiling: bool, n_iter: int, batch_size: int, cfg_scale: float, image_cfg_scale: float, denoising_strength: float, seed: int, subseed: int, subseed_strength: float, seed_resize_from_h: int, seed_resize_from_w: int, seed_enable_extras: bool, height: int, width: int, resize_mode: int, inpaint_full_res: bool, inpaint_full_res_padding: int, inpainting_mask_invert: int, img2img_batch_input_dir: str, img2img_batch_output_dir: str, img2img_batch_inpaint_mask_dir: str, override_settings_texts, *args):
82 override_settings = create_override_settings_dict(override_settings_texts)
83
84 is_batch = mode == 5
85
86 if mode == 0: # img2img
87 image = init_img.convert("RGB")
88 mask = None
89 elif mode == 1: # img2img sketch
90 image = sketch.convert("RGB")
91 mask = None
92 elif mode == 2: # inpaint
93 image, mask = init_img_with_mask["image"], init_img_with_mask["mask"]
94 alpha_mask = ImageOps.invert(image.split()[-1]).convert('L').point(lambda x: 255 if x > 0 else 0, mode='1')
95 mask = ImageChops.lighter(alpha_mask, mask.convert('L')).convert('L')
96 image = image.convert("RGB")
97 elif mode == 3: # inpaint sketch
98 image = inpaint_color_sketch
99 orig = inpaint_color_sketch_orig or inpaint_color_sketch
100 pred = np.any(np.array(image) != np.array(orig), axis=-1)
101 mask = Image.fromarray(pred.astype(np.uint8) * 255, "L")
102 mask = ImageEnhance.Brightness(mask).enhance(1 - mask_alpha / 100)
103 blur = ImageFilter.GaussianBlur(mask_blur)
104 image = Image.composite(image.filter(blur), orig, mask.filter(blur))
105 image = image.convert("RGB")
106 elif mode == 4: # inpaint upload mask
107 image = init_img_inpaint
108 mask = init_mask_inpaint
109 else:
110 image = None
111 mask = None
112
113 # Use the EXIF orientation of photos taken by smartphones.
114 if image is not None:
115 image = ImageOps.exif_transpose(image)
116
117 assert 0. <= denoising_strength <= 1., 'can only work with strength in [0.0, 1.0]'
118
119 p = StableDiffusionProcessingImg2Img(
120 sd_model=shared.sd_model,
121 outpath_samples=opts.outdir_samples or opts.outdir_img2img_samples,
122 outpath_grids=opts.outdir_grids or opts.outdir_img2img_grids,
123 prompt=prompt,
124 negative_prompt=negative_prompt,
125 styles=prompt_styles,
126 seed=seed,
127 subseed=subseed,
128 subseed_strength=subseed_strength,
129 seed_resize_from_h=seed_resize_from_h,
130 seed_resize_from_w=seed_resize_from_w,
131 seed_enable_extras=seed_enable_extras,
132 sampler_name=sd_samplers.samplers_for_img2img[sampler_index].name,
133 batch_size=batch_size,
134 n_iter=n_iter,
135 steps=steps,
136 cfg_scale=cfg_scale,
137 width=width,
138 height=height,
139 restore_faces=restore_faces,
140 tiling=tiling,
141 init_images=[image],
142 mask=mask,
143 mask_blur=mask_blur,
144 inpainting_fill=inpainting_fill,
145 resize_mode=resize_mode,
146 denoising_strength=denoising_strength,
147 image_cfg_scale=image_cfg_scale,
148 inpaint_full_res=inpaint_full_res,
149 inpaint_full_res_padding=inpaint_full_res_padding,
150 inpainting_mask_invert=inpainting_mask_invert,
151 override_settings=override_settings,
152 )
153
154 p.scripts = modules.scripts.scripts_img2img
155 p.script_args = args
156
157 if shared.cmd_opts.enable_console_prompts:
158 print(f"\nimg2img: {prompt}", file=shared.progress_print_out)
159
160 if mask:
161 p.extra_generation_params["Mask blur"] = mask_blur
162
163 if is_batch:
164 assert not shared.cmd_opts.hide_ui_dir_config, "Launched with --hide-ui-dir-config, batch img2img disabled"
165
166 process_batch(p, img2img_batch_input_dir, img2img_batch_output_dir, img2img_batch_inpaint_mask_dir, args)
167
168 processed = Processed(p, [], p.seed, "")
169 else:
170 processed = modules.scripts.scripts_img2img.run(p, *args)
171 if processed is None:
172 processed = process_images(p)
173
174 p.close()
175
176 shared.total_tqdm.clear()
177
178 generation_info_js = processed.js()
179 if opts.samples_log_stdout:
180 print(generation_info_js)
181
182 if opts.do_not_show_images:
183 processed.images = []
184
185 return processed.images, generation_info_js, plaintext_to_html(processed.info), plaintext_to_html(processed.comments)
186
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/modules/img2img.py b/modules/img2img.py
--- a/modules/img2img.py
+++ b/modules/img2img.py
@@ -4,7 +4,7 @@
import traceback
import numpy as np
-from PIL import Image, ImageOps, ImageFilter, ImageEnhance, ImageChops
+from PIL import Image, ImageOps, ImageFilter, ImageEnhance, ImageChops, UnidentifiedImageError
from modules import devices, sd_samplers
from modules.generation_parameters_copypaste import create_override_settings_dict
@@ -46,7 +46,10 @@
if state.interrupted:
break
- img = Image.open(image)
+ try:
+ img = Image.open(image)
+ except UnidentifiedImageError:
+ continue
# Use the EXIF orientation of photos taken by smartphones.
img = ImageOps.exif_transpose(img)
p.init_images = [img] * p.batch_size
|
{"golden_diff": "diff --git a/modules/img2img.py b/modules/img2img.py\n--- a/modules/img2img.py\n+++ b/modules/img2img.py\n@@ -4,7 +4,7 @@\n import traceback\r\n \r\n import numpy as np\r\n-from PIL import Image, ImageOps, ImageFilter, ImageEnhance, ImageChops\r\n+from PIL import Image, ImageOps, ImageFilter, ImageEnhance, ImageChops, UnidentifiedImageError\r\n \r\n from modules import devices, sd_samplers\r\n from modules.generation_parameters_copypaste import create_override_settings_dict\r\n@@ -46,7 +46,10 @@\n if state.interrupted:\r\n break\r\n \r\n- img = Image.open(image)\r\n+ try:\r\n+ img = Image.open(image)\r\n+ except UnidentifiedImageError:\r\n+ continue\r\n # Use the EXIF orientation of photos taken by smartphones.\r\n img = ImageOps.exif_transpose(img)\r\n p.init_images = [img] * p.batch_size\n", "issue": "[Feature Request]: img2img batch should ignore non-image files\n### Is there an existing issue for this?\n\n- [X] I have searched the existing issues and checked the recent builds/commits\n\n### What would your feature do ?\n\nI may place some parameter files along the image files in the same folder.\r\nCurrently an exception is throw for non-image files when do \"Image.open()\".\n\n### Proposed workflow\n\n1. Place a txt file along with the png file in folder A\r\n2. Set batch input folder to A\r\n3. Press generate\r\n\n\n### Additional information\n\n_No response_\n", "before_files": [{"content": "import math\r\nimport os\r\nimport sys\r\nimport traceback\r\n\r\nimport numpy as np\r\nfrom PIL import Image, ImageOps, ImageFilter, ImageEnhance, ImageChops\r\n\r\nfrom modules import devices, sd_samplers\r\nfrom modules.generation_parameters_copypaste import create_override_settings_dict\r\nfrom modules.processing import Processed, StableDiffusionProcessingImg2Img, process_images\r\nfrom modules.shared import opts, state\r\nimport modules.shared as shared\r\nimport modules.processing as processing\r\nfrom modules.ui import plaintext_to_html\r\nimport modules.images as images\r\nimport modules.scripts\r\n\r\n\r\ndef process_batch(p, input_dir, output_dir, inpaint_mask_dir, args):\r\n processing.fix_seed(p)\r\n\r\n images = shared.listfiles(input_dir)\r\n\r\n is_inpaint_batch = False\r\n if inpaint_mask_dir:\r\n inpaint_masks = shared.listfiles(inpaint_mask_dir)\r\n is_inpaint_batch = len(inpaint_masks) > 0\r\n if is_inpaint_batch:\r\n print(f\"\\nInpaint batch is enabled. {len(inpaint_masks)} masks found.\")\r\n\r\n print(f\"Will process {len(images)} images, creating {p.n_iter * p.batch_size} new images for each.\")\r\n\r\n save_normally = output_dir == ''\r\n\r\n p.do_not_save_grid = True\r\n p.do_not_save_samples = not save_normally\r\n\r\n state.job_count = len(images) * p.n_iter\r\n\r\n for i, image in enumerate(images):\r\n state.job = f\"{i+1} out of {len(images)}\"\r\n if state.skipped:\r\n state.skipped = False\r\n\r\n if state.interrupted:\r\n break\r\n\r\n img = Image.open(image)\r\n # Use the EXIF orientation of photos taken by smartphones.\r\n img = ImageOps.exif_transpose(img)\r\n p.init_images = [img] * p.batch_size\r\n\r\n if is_inpaint_batch:\r\n # try to find corresponding mask for an image using simple filename matching\r\n mask_image_path = os.path.join(inpaint_mask_dir, os.path.basename(image))\r\n # if not found use first one (\"same mask for all images\" use-case)\r\n if not mask_image_path in inpaint_masks:\r\n mask_image_path = inpaint_masks[0]\r\n mask_image = Image.open(mask_image_path)\r\n p.image_mask = mask_image\r\n\r\n proc = modules.scripts.scripts_img2img.run(p, *args)\r\n if proc is None:\r\n proc = process_images(p)\r\n\r\n for n, processed_image in enumerate(proc.images):\r\n filename = os.path.basename(image)\r\n\r\n if n > 0:\r\n left, right = os.path.splitext(filename)\r\n filename = f\"{left}-{n}{right}\"\r\n\r\n if not save_normally:\r\n os.makedirs(output_dir, exist_ok=True)\r\n if processed_image.mode == 'RGBA':\r\n processed_image = processed_image.convert(\"RGB\")\r\n processed_image.save(os.path.join(output_dir, filename))\r\n\r\n\r\ndef img2img(id_task: str, mode: int, prompt: str, negative_prompt: str, prompt_styles, init_img, sketch, init_img_with_mask, inpaint_color_sketch, inpaint_color_sketch_orig, init_img_inpaint, init_mask_inpaint, steps: int, sampler_index: int, mask_blur: int, mask_alpha: float, inpainting_fill: int, restore_faces: bool, tiling: bool, n_iter: int, batch_size: int, cfg_scale: float, image_cfg_scale: float, denoising_strength: float, seed: int, subseed: int, subseed_strength: float, seed_resize_from_h: int, seed_resize_from_w: int, seed_enable_extras: bool, height: int, width: int, resize_mode: int, inpaint_full_res: bool, inpaint_full_res_padding: int, inpainting_mask_invert: int, img2img_batch_input_dir: str, img2img_batch_output_dir: str, img2img_batch_inpaint_mask_dir: str, override_settings_texts, *args):\r\n override_settings = create_override_settings_dict(override_settings_texts)\r\n\r\n is_batch = mode == 5\r\n\r\n if mode == 0: # img2img\r\n image = init_img.convert(\"RGB\")\r\n mask = None\r\n elif mode == 1: # img2img sketch\r\n image = sketch.convert(\"RGB\")\r\n mask = None\r\n elif mode == 2: # inpaint\r\n image, mask = init_img_with_mask[\"image\"], init_img_with_mask[\"mask\"]\r\n alpha_mask = ImageOps.invert(image.split()[-1]).convert('L').point(lambda x: 255 if x > 0 else 0, mode='1')\r\n mask = ImageChops.lighter(alpha_mask, mask.convert('L')).convert('L')\r\n image = image.convert(\"RGB\")\r\n elif mode == 3: # inpaint sketch\r\n image = inpaint_color_sketch\r\n orig = inpaint_color_sketch_orig or inpaint_color_sketch\r\n pred = np.any(np.array(image) != np.array(orig), axis=-1)\r\n mask = Image.fromarray(pred.astype(np.uint8) * 255, \"L\")\r\n mask = ImageEnhance.Brightness(mask).enhance(1 - mask_alpha / 100)\r\n blur = ImageFilter.GaussianBlur(mask_blur)\r\n image = Image.composite(image.filter(blur), orig, mask.filter(blur))\r\n image = image.convert(\"RGB\")\r\n elif mode == 4: # inpaint upload mask\r\n image = init_img_inpaint\r\n mask = init_mask_inpaint\r\n else:\r\n image = None\r\n mask = None\r\n\r\n # Use the EXIF orientation of photos taken by smartphones.\r\n if image is not None:\r\n image = ImageOps.exif_transpose(image)\r\n\r\n assert 0. <= denoising_strength <= 1., 'can only work with strength in [0.0, 1.0]'\r\n\r\n p = StableDiffusionProcessingImg2Img(\r\n sd_model=shared.sd_model,\r\n outpath_samples=opts.outdir_samples or opts.outdir_img2img_samples,\r\n outpath_grids=opts.outdir_grids or opts.outdir_img2img_grids,\r\n prompt=prompt,\r\n negative_prompt=negative_prompt,\r\n styles=prompt_styles,\r\n seed=seed,\r\n subseed=subseed,\r\n subseed_strength=subseed_strength,\r\n seed_resize_from_h=seed_resize_from_h,\r\n seed_resize_from_w=seed_resize_from_w,\r\n seed_enable_extras=seed_enable_extras,\r\n sampler_name=sd_samplers.samplers_for_img2img[sampler_index].name,\r\n batch_size=batch_size,\r\n n_iter=n_iter,\r\n steps=steps,\r\n cfg_scale=cfg_scale,\r\n width=width,\r\n height=height,\r\n restore_faces=restore_faces,\r\n tiling=tiling,\r\n init_images=[image],\r\n mask=mask,\r\n mask_blur=mask_blur,\r\n inpainting_fill=inpainting_fill,\r\n resize_mode=resize_mode,\r\n denoising_strength=denoising_strength,\r\n image_cfg_scale=image_cfg_scale,\r\n inpaint_full_res=inpaint_full_res,\r\n inpaint_full_res_padding=inpaint_full_res_padding,\r\n inpainting_mask_invert=inpainting_mask_invert,\r\n override_settings=override_settings,\r\n )\r\n\r\n p.scripts = modules.scripts.scripts_img2img\r\n p.script_args = args\r\n\r\n if shared.cmd_opts.enable_console_prompts:\r\n print(f\"\\nimg2img: {prompt}\", file=shared.progress_print_out)\r\n\r\n if mask:\r\n p.extra_generation_params[\"Mask blur\"] = mask_blur\r\n\r\n if is_batch:\r\n assert not shared.cmd_opts.hide_ui_dir_config, \"Launched with --hide-ui-dir-config, batch img2img disabled\"\r\n\r\n process_batch(p, img2img_batch_input_dir, img2img_batch_output_dir, img2img_batch_inpaint_mask_dir, args)\r\n\r\n processed = Processed(p, [], p.seed, \"\")\r\n else:\r\n processed = modules.scripts.scripts_img2img.run(p, *args)\r\n if processed is None:\r\n processed = process_images(p)\r\n\r\n p.close()\r\n\r\n shared.total_tqdm.clear()\r\n\r\n generation_info_js = processed.js()\r\n if opts.samples_log_stdout:\r\n print(generation_info_js)\r\n\r\n if opts.do_not_show_images:\r\n processed.images = []\r\n\r\n return processed.images, generation_info_js, plaintext_to_html(processed.info), plaintext_to_html(processed.comments)\r\n", "path": "modules/img2img.py"}], "after_files": [{"content": "import math\r\nimport os\r\nimport sys\r\nimport traceback\r\n\r\nimport numpy as np\r\nfrom PIL import Image, ImageOps, ImageFilter, ImageEnhance, ImageChops, UnidentifiedImageError\r\n\r\nfrom modules import devices, sd_samplers\r\nfrom modules.generation_parameters_copypaste import create_override_settings_dict\r\nfrom modules.processing import Processed, StableDiffusionProcessingImg2Img, process_images\r\nfrom modules.shared import opts, state\r\nimport modules.shared as shared\r\nimport modules.processing as processing\r\nfrom modules.ui import plaintext_to_html\r\nimport modules.images as images\r\nimport modules.scripts\r\n\r\n\r\ndef process_batch(p, input_dir, output_dir, inpaint_mask_dir, args):\r\n processing.fix_seed(p)\r\n\r\n images = shared.listfiles(input_dir)\r\n\r\n is_inpaint_batch = False\r\n if inpaint_mask_dir:\r\n inpaint_masks = shared.listfiles(inpaint_mask_dir)\r\n is_inpaint_batch = len(inpaint_masks) > 0\r\n if is_inpaint_batch:\r\n print(f\"\\nInpaint batch is enabled. {len(inpaint_masks)} masks found.\")\r\n\r\n print(f\"Will process {len(images)} images, creating {p.n_iter * p.batch_size} new images for each.\")\r\n\r\n save_normally = output_dir == ''\r\n\r\n p.do_not_save_grid = True\r\n p.do_not_save_samples = not save_normally\r\n\r\n state.job_count = len(images) * p.n_iter\r\n\r\n for i, image in enumerate(images):\r\n state.job = f\"{i+1} out of {len(images)}\"\r\n if state.skipped:\r\n state.skipped = False\r\n\r\n if state.interrupted:\r\n break\r\n\r\n try:\r\n img = Image.open(image)\r\n except UnidentifiedImageError:\r\n continue\r\n # Use the EXIF orientation of photos taken by smartphones.\r\n img = ImageOps.exif_transpose(img)\r\n p.init_images = [img] * p.batch_size\r\n\r\n if is_inpaint_batch:\r\n # try to find corresponding mask for an image using simple filename matching\r\n mask_image_path = os.path.join(inpaint_mask_dir, os.path.basename(image))\r\n # if not found use first one (\"same mask for all images\" use-case)\r\n if not mask_image_path in inpaint_masks:\r\n mask_image_path = inpaint_masks[0]\r\n mask_image = Image.open(mask_image_path)\r\n p.image_mask = mask_image\r\n\r\n proc = modules.scripts.scripts_img2img.run(p, *args)\r\n if proc is None:\r\n proc = process_images(p)\r\n\r\n for n, processed_image in enumerate(proc.images):\r\n filename = os.path.basename(image)\r\n\r\n if n > 0:\r\n left, right = os.path.splitext(filename)\r\n filename = f\"{left}-{n}{right}\"\r\n\r\n if not save_normally:\r\n os.makedirs(output_dir, exist_ok=True)\r\n if processed_image.mode == 'RGBA':\r\n processed_image = processed_image.convert(\"RGB\")\r\n processed_image.save(os.path.join(output_dir, filename))\r\n\r\n\r\ndef img2img(id_task: str, mode: int, prompt: str, negative_prompt: str, prompt_styles, init_img, sketch, init_img_with_mask, inpaint_color_sketch, inpaint_color_sketch_orig, init_img_inpaint, init_mask_inpaint, steps: int, sampler_index: int, mask_blur: int, mask_alpha: float, inpainting_fill: int, restore_faces: bool, tiling: bool, n_iter: int, batch_size: int, cfg_scale: float, image_cfg_scale: float, denoising_strength: float, seed: int, subseed: int, subseed_strength: float, seed_resize_from_h: int, seed_resize_from_w: int, seed_enable_extras: bool, height: int, width: int, resize_mode: int, inpaint_full_res: bool, inpaint_full_res_padding: int, inpainting_mask_invert: int, img2img_batch_input_dir: str, img2img_batch_output_dir: str, img2img_batch_inpaint_mask_dir: str, override_settings_texts, *args):\r\n override_settings = create_override_settings_dict(override_settings_texts)\r\n\r\n is_batch = mode == 5\r\n\r\n if mode == 0: # img2img\r\n image = init_img.convert(\"RGB\")\r\n mask = None\r\n elif mode == 1: # img2img sketch\r\n image = sketch.convert(\"RGB\")\r\n mask = None\r\n elif mode == 2: # inpaint\r\n image, mask = init_img_with_mask[\"image\"], init_img_with_mask[\"mask\"]\r\n alpha_mask = ImageOps.invert(image.split()[-1]).convert('L').point(lambda x: 255 if x > 0 else 0, mode='1')\r\n mask = ImageChops.lighter(alpha_mask, mask.convert('L')).convert('L')\r\n image = image.convert(\"RGB\")\r\n elif mode == 3: # inpaint sketch\r\n image = inpaint_color_sketch\r\n orig = inpaint_color_sketch_orig or inpaint_color_sketch\r\n pred = np.any(np.array(image) != np.array(orig), axis=-1)\r\n mask = Image.fromarray(pred.astype(np.uint8) * 255, \"L\")\r\n mask = ImageEnhance.Brightness(mask).enhance(1 - mask_alpha / 100)\r\n blur = ImageFilter.GaussianBlur(mask_blur)\r\n image = Image.composite(image.filter(blur), orig, mask.filter(blur))\r\n image = image.convert(\"RGB\")\r\n elif mode == 4: # inpaint upload mask\r\n image = init_img_inpaint\r\n mask = init_mask_inpaint\r\n else:\r\n image = None\r\n mask = None\r\n\r\n # Use the EXIF orientation of photos taken by smartphones.\r\n if image is not None:\r\n image = ImageOps.exif_transpose(image)\r\n\r\n assert 0. <= denoising_strength <= 1., 'can only work with strength in [0.0, 1.0]'\r\n\r\n p = StableDiffusionProcessingImg2Img(\r\n sd_model=shared.sd_model,\r\n outpath_samples=opts.outdir_samples or opts.outdir_img2img_samples,\r\n outpath_grids=opts.outdir_grids or opts.outdir_img2img_grids,\r\n prompt=prompt,\r\n negative_prompt=negative_prompt,\r\n styles=prompt_styles,\r\n seed=seed,\r\n subseed=subseed,\r\n subseed_strength=subseed_strength,\r\n seed_resize_from_h=seed_resize_from_h,\r\n seed_resize_from_w=seed_resize_from_w,\r\n seed_enable_extras=seed_enable_extras,\r\n sampler_name=sd_samplers.samplers_for_img2img[sampler_index].name,\r\n batch_size=batch_size,\r\n n_iter=n_iter,\r\n steps=steps,\r\n cfg_scale=cfg_scale,\r\n width=width,\r\n height=height,\r\n restore_faces=restore_faces,\r\n tiling=tiling,\r\n init_images=[image],\r\n mask=mask,\r\n mask_blur=mask_blur,\r\n inpainting_fill=inpainting_fill,\r\n resize_mode=resize_mode,\r\n denoising_strength=denoising_strength,\r\n image_cfg_scale=image_cfg_scale,\r\n inpaint_full_res=inpaint_full_res,\r\n inpaint_full_res_padding=inpaint_full_res_padding,\r\n inpainting_mask_invert=inpainting_mask_invert,\r\n override_settings=override_settings,\r\n )\r\n\r\n p.scripts = modules.scripts.scripts_txt2img\r\n p.script_args = args\r\n\r\n if shared.cmd_opts.enable_console_prompts:\r\n print(f\"\\nimg2img: {prompt}\", file=shared.progress_print_out)\r\n\r\n if mask:\r\n p.extra_generation_params[\"Mask blur\"] = mask_blur\r\n\r\n if is_batch:\r\n assert not shared.cmd_opts.hide_ui_dir_config, \"Launched with --hide-ui-dir-config, batch img2img disabled\"\r\n\r\n process_batch(p, img2img_batch_input_dir, img2img_batch_output_dir, img2img_batch_inpaint_mask_dir, args)\r\n\r\n processed = Processed(p, [], p.seed, \"\")\r\n else:\r\n processed = modules.scripts.scripts_img2img.run(p, *args)\r\n if processed is None:\r\n processed = process_images(p)\r\n\r\n p.close()\r\n\r\n shared.total_tqdm.clear()\r\n\r\n generation_info_js = processed.js()\r\n if opts.samples_log_stdout:\r\n print(generation_info_js)\r\n\r\n if opts.do_not_show_images:\r\n processed.images = []\r\n\r\n return processed.images, generation_info_js, plaintext_to_html(processed.info), plaintext_to_html(processed.comments)\r\n", "path": "modules/img2img.py"}]}
| 2,663 | 213 |
gh_patches_debug_30175
|
rasdani/github-patches
|
git_diff
|
microsoft__ptvsd-480
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
PyPI package missing information
Looking at https://pypi.org/project/ptvsd/4.0.0a1/ we are currently missing:
* link to GitHub
* long description
* specific classifiers
* any mention of VS Code
* link to doc pages
Would be nice to get these added.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2
3 # Copyright (c) Microsoft Corporation. All rights reserved.
4 # Licensed under the MIT License. See LICENSE in the project root
5 # for license information.
6
7 import os
8 import os.path
9 import subprocess
10 import sys
11
12 from setuptools import setup
13
14 import versioneer
15 import ptvsd
16 import ptvsd._vendored
17
18
19 PYDEVD_ROOT = ptvsd._vendored.project_root('pydevd')
20 PTVSD_ROOT = os.path.dirname(os.path.abspath(ptvsd.__file__))
21
22
23 def cython_build():
24 print('Compiling extension modules (set SKIP_CYTHON_BUILD=1 to omit)')
25 subprocess.call([
26 sys.executable,
27 os.path.join(PYDEVD_ROOT, 'setup_cython.py'),
28 'build_ext',
29 '-i',
30 ])
31
32
33 def iter_vendored_files():
34 # Add pydevd files as data files for this package. They are not
35 # treated as a package of their own, because we don't actually
36 # want to provide pydevd - just use our own copy internally.
37 for project in ptvsd._vendored.list_all():
38 for filename in ptvsd._vendored.iter_packaging_files(project):
39 yield filename
40
41
42 if __name__ == '__main__':
43 if not os.getenv('SKIP_CYTHON_BUILD'):
44 cython_build()
45
46 setup(
47 name='ptvsd',
48 version=versioneer.get_version(),
49 description='Remote debugging server for Python support in Visual Studio and Visual Studio Code', # noqa
50 #long_description=open('DESCRIPTION.md').read(),
51 #long_description_content_type='text/markdown',
52 license='MIT',
53 author='Microsoft Corporation',
54 author_email='[email protected]',
55 url='https://aka.ms/ptvs',
56 classifiers=[
57 'Development Status :: 3 - Alpha',
58 'Programming Language :: Python',
59 'Programming Language :: Python :: 2',
60 'Programming Language :: Python :: 3',
61 'License :: OSI Approved :: MIT License',
62 ],
63 packages=[
64 'ptvsd',
65 'ptvsd._vendored',
66 ],
67 package_data={
68 'ptvsd': ['ThirdPartyNotices.txt'],
69 'ptvsd._vendored': list(iter_vendored_files()),
70 },
71 cmdclass=versioneer.get_cmdclass(),
72 )
73
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -39,6 +39,10 @@
yield filename
+with open('DESCRIPTION.md', 'r') as fh:
+ long_description = fh.read()
+
+
if __name__ == '__main__':
if not os.getenv('SKIP_CYTHON_BUILD'):
cython_build()
@@ -47,17 +51,22 @@
name='ptvsd',
version=versioneer.get_version(),
description='Remote debugging server for Python support in Visual Studio and Visual Studio Code', # noqa
- #long_description=open('DESCRIPTION.md').read(),
- #long_description_content_type='text/markdown',
+ long_description=long_description,
+ long_description_content_type='text/markdown',
license='MIT',
author='Microsoft Corporation',
author_email='[email protected]',
url='https://aka.ms/ptvs',
+ python_requires=">=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*,!=3.4.*",
classifiers=[
'Development Status :: 3 - Alpha',
- 'Programming Language :: Python',
- 'Programming Language :: Python :: 2',
- 'Programming Language :: Python :: 3',
+ 'Programming Language :: Python :: 2.7',
+ 'Programming Language :: Python :: 3.5',
+ 'Programming Language :: Python :: 3.6',
+ 'Programming Language :: Python :: 3.7',
+ 'Topic :: Software Development :: Debuggers',
+ 'Operating System :: OS Independent',
+ 'License :: OSI Approved :: Eclipse Public License 2.0 (EPL-2.0)',
'License :: OSI Approved :: MIT License',
],
packages=[
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -39,6 +39,10 @@\n yield filename\n \n \n+with open('DESCRIPTION.md', 'r') as fh:\n+ long_description = fh.read()\n+\n+\n if __name__ == '__main__':\n if not os.getenv('SKIP_CYTHON_BUILD'):\n cython_build()\n@@ -47,17 +51,22 @@\n name='ptvsd',\n version=versioneer.get_version(),\n description='Remote debugging server for Python support in Visual Studio and Visual Studio Code', # noqa\n- #long_description=open('DESCRIPTION.md').read(),\n- #long_description_content_type='text/markdown',\n+ long_description=long_description,\n+ long_description_content_type='text/markdown',\n license='MIT',\n author='Microsoft Corporation',\n author_email='[email protected]',\n url='https://aka.ms/ptvs',\n+ python_requires=\">=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*,!=3.4.*\",\n classifiers=[\n 'Development Status :: 3 - Alpha',\n- 'Programming Language :: Python',\n- 'Programming Language :: Python :: 2',\n- 'Programming Language :: Python :: 3',\n+ 'Programming Language :: Python :: 2.7',\n+ 'Programming Language :: Python :: 3.5',\n+ 'Programming Language :: Python :: 3.6',\n+ 'Programming Language :: Python :: 3.7',\n+ 'Topic :: Software Development :: Debuggers',\n+ 'Operating System :: OS Independent',\n+ 'License :: OSI Approved :: Eclipse Public License 2.0 (EPL-2.0)',\n 'License :: OSI Approved :: MIT License',\n ],\n packages=[\n", "issue": "PyPI package missing information\nLooking at https://pypi.org/project/ptvsd/4.0.0a1/ we are currently missing:\r\n* link to GitHub\r\n* long description\r\n* specific classifiers\r\n* any mention of VS Code\r\n* link to doc pages\r\n\r\nWould be nice to get these added.\n", "before_files": [{"content": "#!/usr/bin/env python\n\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See LICENSE in the project root\n# for license information.\n\nimport os\nimport os.path\nimport subprocess\nimport sys\n\nfrom setuptools import setup\n\nimport versioneer\nimport ptvsd\nimport ptvsd._vendored\n\n\nPYDEVD_ROOT = ptvsd._vendored.project_root('pydevd')\nPTVSD_ROOT = os.path.dirname(os.path.abspath(ptvsd.__file__))\n\n\ndef cython_build():\n print('Compiling extension modules (set SKIP_CYTHON_BUILD=1 to omit)')\n subprocess.call([\n sys.executable,\n os.path.join(PYDEVD_ROOT, 'setup_cython.py'),\n 'build_ext',\n '-i',\n ])\n\n\ndef iter_vendored_files():\n # Add pydevd files as data files for this package. They are not\n # treated as a package of their own, because we don't actually\n # want to provide pydevd - just use our own copy internally.\n for project in ptvsd._vendored.list_all():\n for filename in ptvsd._vendored.iter_packaging_files(project):\n yield filename\n\n\nif __name__ == '__main__':\n if not os.getenv('SKIP_CYTHON_BUILD'):\n cython_build()\n\n setup(\n name='ptvsd',\n version=versioneer.get_version(),\n description='Remote debugging server for Python support in Visual Studio and Visual Studio Code', # noqa\n #long_description=open('DESCRIPTION.md').read(),\n #long_description_content_type='text/markdown',\n license='MIT',\n author='Microsoft Corporation',\n author_email='[email protected]',\n url='https://aka.ms/ptvs',\n classifiers=[\n 'Development Status :: 3 - Alpha',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 3',\n 'License :: OSI Approved :: MIT License',\n ],\n packages=[\n 'ptvsd',\n 'ptvsd._vendored',\n ],\n package_data={\n 'ptvsd': ['ThirdPartyNotices.txt'],\n 'ptvsd._vendored': list(iter_vendored_files()),\n },\n cmdclass=versioneer.get_cmdclass(),\n )\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See LICENSE in the project root\n# for license information.\n\nimport os\nimport os.path\nimport subprocess\nimport sys\n\nfrom setuptools import setup\n\nimport versioneer\nimport ptvsd\nimport ptvsd._vendored\n\n\nPYDEVD_ROOT = ptvsd._vendored.project_root('pydevd')\nPTVSD_ROOT = os.path.dirname(os.path.abspath(ptvsd.__file__))\n\n\ndef cython_build():\n print('Compiling extension modules (set SKIP_CYTHON_BUILD=1 to omit)')\n subprocess.call([\n sys.executable,\n os.path.join(PYDEVD_ROOT, 'setup_cython.py'),\n 'build_ext',\n '-i',\n ])\n\n\ndef iter_vendored_files():\n # Add pydevd files as data files for this package. They are not\n # treated as a package of their own, because we don't actually\n # want to provide pydevd - just use our own copy internally.\n for project in ptvsd._vendored.list_all():\n for filename in ptvsd._vendored.iter_packaging_files(project):\n yield filename\n\n\nwith open('DESCRIPTION.md', 'r') as fh:\n long_description = fh.read()\n\n\nif __name__ == '__main__':\n if not os.getenv('SKIP_CYTHON_BUILD'):\n cython_build()\n\n setup(\n name='ptvsd',\n version=versioneer.get_version(),\n description='Remote debugging server for Python support in Visual Studio and Visual Studio Code', # noqa\n long_description=long_description,\n long_description_content_type='text/markdown',\n license='MIT',\n author='Microsoft Corporation',\n author_email='[email protected]',\n url='https://aka.ms/ptvs',\n python_requires=\">=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*,!=3.4.*\",\n classifiers=[\n 'Development Status :: 3 - Alpha',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Topic :: Software Development :: Debuggers',\n 'Operating System :: OS Independent',\n 'License :: OSI Approved :: Eclipse Public License 2.0 (EPL-2.0)',\n 'License :: OSI Approved :: MIT License',\n ],\n packages=[\n 'ptvsd',\n 'ptvsd._vendored',\n ],\n package_data={\n 'ptvsd': ['ThirdPartyNotices.txt'],\n 'ptvsd._vendored': list(iter_vendored_files()),\n },\n cmdclass=versioneer.get_cmdclass(),\n )\n", "path": "setup.py"}]}
| 972 | 400 |
gh_patches_debug_18596
|
rasdani/github-patches
|
git_diff
|
mkdocs__mkdocs-647
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Mailto links not correctly interpreted
Hi,
I've noticed "mailto" links are not correctly interpreted.
- This code:
```
Contact us at <foo@bar>
```
- Renders the following link:
http://localhost//mailto:foo@bar
---
- This code:
```
You can [contact us](foo@bar)
```
- Renders the following link:
http://localhost/page/permalink/foo@bar
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mkdocs/relative_path_ext.py`
Content:
```
1 """
2 # Relative Path Markdown Extension
3
4 During the MkDocs build we rewrite URLs that link to local
5 Markdown or media files. Using the following pages configuration
6 we can look at how the output is changed.
7
8 pages:
9 - ['index.md']
10 - ['tutorial/install.md']
11 - ['tutorial/intro.md']
12
13 ## Markdown URLs
14
15 When linking from `install.md` to `intro.md` the link would
16 simply be `[intro](intro.md)`. However, when we build
17 `install.md` we place it in a directory to create nicer URLs.
18 This means that the path to `intro.md` becomes `../intro/`
19
20 ## Media URLs
21
22 To make it easier to work with media files and store them all
23 under one directory we re-write those to all be based on the
24 root. So, with the following markdown to add an image.
25
26 
27
28 The output would depend on the location of the Markdown file it
29 was added too.
30
31 Source file | Generated Path | Image Path |
32 ------------------- | ----------------- | ---------------------------- |
33 index.md | / | ./img/initial-layout.png |
34 tutorial/install.md | tutorial/install/ | ../img/initial-layout.png |
35 tutorial/intro.md | tutorial/intro/ | ../../img/initial-layout.png |
36
37 """
38
39 from __future__ import unicode_literals
40
41 import logging
42 import os
43
44 from markdown.extensions import Extension
45 from markdown.treeprocessors import Treeprocessor
46
47 from mkdocs import utils
48 from mkdocs.exceptions import MarkdownNotFound
49
50 log = logging.getLogger(__name__)
51
52
53 def _iter(node):
54 # TODO: Remove when dropping Python 2.6. Replace this
55 # function call with note.iter()
56 return [node] + node.findall('.//*')
57
58
59 def path_to_url(url, nav, strict):
60
61 scheme, netloc, path, params, query, fragment = (
62 utils.urlparse(url))
63
64 if scheme or netloc or not path:
65 # Ignore URLs unless they are a relative link to a markdown file.
66 return url
67
68 if nav and not utils.is_markdown_file(path):
69 path = utils.create_relative_media_url(nav, path)
70 elif nav:
71 # If the site navigation has been provided, then validate
72 # the internal hyperlink, making sure the target actually exists.
73 target_file = nav.file_context.make_absolute(path)
74
75 if target_file.startswith(os.path.sep):
76 target_file = target_file[1:]
77
78 if target_file not in nav.source_files:
79 source_file = nav.file_context.current_file
80 msg = (
81 'The page "%s" contained a hyperlink to "%s" which '
82 'is not listed in the "pages" configuration.'
83 ) % (source_file, target_file)
84
85 # In strict mode raise an error at this point.
86 if strict:
87 raise MarkdownNotFound(msg)
88 # Otherwise, when strict mode isn't enabled, log a warning
89 # to the user and leave the URL as it is.
90 log.warning(msg)
91 return url
92 path = utils.get_url_path(target_file, nav.use_directory_urls)
93 path = nav.url_context.make_relative(path)
94 else:
95 path = utils.get_url_path(path).lstrip('/')
96
97 # Convert the .md hyperlink to a relative hyperlink to the HTML page.
98 fragments = (scheme, netloc, path, params, query, fragment)
99 url = utils.urlunparse(fragments)
100 return url
101
102
103 class RelativePathTreeprocessor(Treeprocessor):
104
105 def __init__(self, site_navigation, strict):
106 self.site_navigation = site_navigation
107 self.strict = strict
108
109 def run(self, root):
110 """Update urls on anchors and images to make them relative
111
112 Iterates through the full document tree looking for specific
113 tags and then makes them relative based on the site navigation
114 """
115
116 for element in _iter(root):
117
118 if element.tag == 'a':
119 key = 'href'
120 elif element.tag == 'img':
121 key = 'src'
122 else:
123 continue
124
125 url = element.get(key)
126 new_url = path_to_url(url, self.site_navigation, self.strict)
127 element.set(key, new_url)
128
129 return root
130
131
132 class RelativePathExtension(Extension):
133 """
134 The Extension class is what we pass to markdown, it then
135 registers the Treeprocessor.
136 """
137
138 def __init__(self, site_navigation, strict):
139 self.site_navigation = site_navigation
140 self.strict = strict
141
142 def extendMarkdown(self, md, md_globals):
143 relpath = RelativePathTreeprocessor(self.site_navigation, self.strict)
144 md.treeprocessors.add("relpath", relpath, "_end")
145
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mkdocs/relative_path_ext.py b/mkdocs/relative_path_ext.py
--- a/mkdocs/relative_path_ext.py
+++ b/mkdocs/relative_path_ext.py
@@ -43,6 +43,7 @@
from markdown.extensions import Extension
from markdown.treeprocessors import Treeprocessor
+from markdown.util import AMP_SUBSTITUTE
from mkdocs import utils
from mkdocs.exceptions import MarkdownNotFound
@@ -61,8 +62,10 @@
scheme, netloc, path, params, query, fragment = (
utils.urlparse(url))
- if scheme or netloc or not path:
+ if scheme or netloc or not path or AMP_SUBSTITUTE in url:
# Ignore URLs unless they are a relative link to a markdown file.
+ # AMP_SUBSTITUTE is used internally by Markdown only for email,which is
+ # not a relative link. As urlparse errors on them, skip explicitly
return url
if nav and not utils.is_markdown_file(path):
|
{"golden_diff": "diff --git a/mkdocs/relative_path_ext.py b/mkdocs/relative_path_ext.py\n--- a/mkdocs/relative_path_ext.py\n+++ b/mkdocs/relative_path_ext.py\n@@ -43,6 +43,7 @@\n \n from markdown.extensions import Extension\n from markdown.treeprocessors import Treeprocessor\n+from markdown.util import AMP_SUBSTITUTE\n \n from mkdocs import utils\n from mkdocs.exceptions import MarkdownNotFound\n@@ -61,8 +62,10 @@\n scheme, netloc, path, params, query, fragment = (\n utils.urlparse(url))\n \n- if scheme or netloc or not path:\n+ if scheme or netloc or not path or AMP_SUBSTITUTE in url:\n # Ignore URLs unless they are a relative link to a markdown file.\n+ # AMP_SUBSTITUTE is used internally by Markdown only for email,which is\n+ # not a relative link. As urlparse errors on them, skip explicitly\n return url\n \n if nav and not utils.is_markdown_file(path):\n", "issue": "Mailto links not correctly interpreted\nHi, \nI've noticed \"mailto\" links are not correctly interpreted.\n- This code:\n\n```\nContact us at <foo@bar>\n```\n- Renders the following link: \n http://localhost//mailto:foo@bar \n\n---\n- This code:\n\n```\nYou can [contact us](foo@bar)\n```\n- Renders the following link: \n http://localhost/page/permalink/foo@bar\n\n", "before_files": [{"content": "\"\"\"\n# Relative Path Markdown Extension\n\nDuring the MkDocs build we rewrite URLs that link to local\nMarkdown or media files. Using the following pages configuration\nwe can look at how the output is changed.\n\n pages:\n - ['index.md']\n - ['tutorial/install.md']\n - ['tutorial/intro.md']\n\n## Markdown URLs\n\nWhen linking from `install.md` to `intro.md` the link would\nsimply be `[intro](intro.md)`. However, when we build\n`install.md` we place it in a directory to create nicer URLs.\nThis means that the path to `intro.md` becomes `../intro/`\n\n## Media URLs\n\nTo make it easier to work with media files and store them all\nunder one directory we re-write those to all be based on the\nroot. So, with the following markdown to add an image.\n\n \n\nThe output would depend on the location of the Markdown file it\nwas added too.\n\nSource file | Generated Path | Image Path |\n------------------- | ----------------- | ---------------------------- |\nindex.md | / | ./img/initial-layout.png |\ntutorial/install.md | tutorial/install/ | ../img/initial-layout.png |\ntutorial/intro.md | tutorial/intro/ | ../../img/initial-layout.png |\n\n\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport logging\nimport os\n\nfrom markdown.extensions import Extension\nfrom markdown.treeprocessors import Treeprocessor\n\nfrom mkdocs import utils\nfrom mkdocs.exceptions import MarkdownNotFound\n\nlog = logging.getLogger(__name__)\n\n\ndef _iter(node):\n # TODO: Remove when dropping Python 2.6. Replace this\n # function call with note.iter()\n return [node] + node.findall('.//*')\n\n\ndef path_to_url(url, nav, strict):\n\n scheme, netloc, path, params, query, fragment = (\n utils.urlparse(url))\n\n if scheme or netloc or not path:\n # Ignore URLs unless they are a relative link to a markdown file.\n return url\n\n if nav and not utils.is_markdown_file(path):\n path = utils.create_relative_media_url(nav, path)\n elif nav:\n # If the site navigation has been provided, then validate\n # the internal hyperlink, making sure the target actually exists.\n target_file = nav.file_context.make_absolute(path)\n\n if target_file.startswith(os.path.sep):\n target_file = target_file[1:]\n\n if target_file not in nav.source_files:\n source_file = nav.file_context.current_file\n msg = (\n 'The page \"%s\" contained a hyperlink to \"%s\" which '\n 'is not listed in the \"pages\" configuration.'\n ) % (source_file, target_file)\n\n # In strict mode raise an error at this point.\n if strict:\n raise MarkdownNotFound(msg)\n # Otherwise, when strict mode isn't enabled, log a warning\n # to the user and leave the URL as it is.\n log.warning(msg)\n return url\n path = utils.get_url_path(target_file, nav.use_directory_urls)\n path = nav.url_context.make_relative(path)\n else:\n path = utils.get_url_path(path).lstrip('/')\n\n # Convert the .md hyperlink to a relative hyperlink to the HTML page.\n fragments = (scheme, netloc, path, params, query, fragment)\n url = utils.urlunparse(fragments)\n return url\n\n\nclass RelativePathTreeprocessor(Treeprocessor):\n\n def __init__(self, site_navigation, strict):\n self.site_navigation = site_navigation\n self.strict = strict\n\n def run(self, root):\n \"\"\"Update urls on anchors and images to make them relative\n\n Iterates through the full document tree looking for specific\n tags and then makes them relative based on the site navigation\n \"\"\"\n\n for element in _iter(root):\n\n if element.tag == 'a':\n key = 'href'\n elif element.tag == 'img':\n key = 'src'\n else:\n continue\n\n url = element.get(key)\n new_url = path_to_url(url, self.site_navigation, self.strict)\n element.set(key, new_url)\n\n return root\n\n\nclass RelativePathExtension(Extension):\n \"\"\"\n The Extension class is what we pass to markdown, it then\n registers the Treeprocessor.\n \"\"\"\n\n def __init__(self, site_navigation, strict):\n self.site_navigation = site_navigation\n self.strict = strict\n\n def extendMarkdown(self, md, md_globals):\n relpath = RelativePathTreeprocessor(self.site_navigation, self.strict)\n md.treeprocessors.add(\"relpath\", relpath, \"_end\")\n", "path": "mkdocs/relative_path_ext.py"}], "after_files": [{"content": "\"\"\"\n# Relative Path Markdown Extension\n\nDuring the MkDocs build we rewrite URLs that link to local\nMarkdown or media files. Using the following pages configuration\nwe can look at how the output is changed.\n\n pages:\n - ['index.md']\n - ['tutorial/install.md']\n - ['tutorial/intro.md']\n\n## Markdown URLs\n\nWhen linking from `install.md` to `intro.md` the link would\nsimply be `[intro](intro.md)`. However, when we build\n`install.md` we place it in a directory to create nicer URLs.\nThis means that the path to `intro.md` becomes `../intro/`\n\n## Media URLs\n\nTo make it easier to work with media files and store them all\nunder one directory we re-write those to all be based on the\nroot. So, with the following markdown to add an image.\n\n \n\nThe output would depend on the location of the Markdown file it\nwas added too.\n\nSource file | Generated Path | Image Path |\n------------------- | ----------------- | ---------------------------- |\nindex.md | / | ./img/initial-layout.png |\ntutorial/install.md | tutorial/install/ | ../img/initial-layout.png |\ntutorial/intro.md | tutorial/intro/ | ../../img/initial-layout.png |\n\n\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport logging\nimport os\n\nfrom markdown.extensions import Extension\nfrom markdown.treeprocessors import Treeprocessor\nfrom markdown.util import AMP_SUBSTITUTE\n\nfrom mkdocs import utils\nfrom mkdocs.exceptions import MarkdownNotFound\n\nlog = logging.getLogger(__name__)\n\n\ndef _iter(node):\n # TODO: Remove when dropping Python 2.6. Replace this\n # function call with note.iter()\n return [node] + node.findall('.//*')\n\n\ndef path_to_url(url, nav, strict):\n\n scheme, netloc, path, params, query, fragment = (\n utils.urlparse(url))\n\n if scheme or netloc or not path or AMP_SUBSTITUTE in url:\n # Ignore URLs unless they are a relative link to a markdown file.\n # AMP_SUBSTITUTE is used internally by Markdown only for email,which is\n # not a relative link. As urlparse errors on them, skip explicitly\n return url\n\n if nav and not utils.is_markdown_file(path):\n path = utils.create_relative_media_url(nav, path)\n elif nav:\n # If the site navigation has been provided, then validate\n # the internal hyperlink, making sure the target actually exists.\n target_file = nav.file_context.make_absolute(path)\n\n if target_file.startswith(os.path.sep):\n target_file = target_file[1:]\n\n if target_file not in nav.source_files:\n source_file = nav.file_context.current_file\n msg = (\n 'The page \"%s\" contained a hyperlink to \"%s\" which '\n 'is not listed in the \"pages\" configuration.'\n ) % (source_file, target_file)\n\n # In strict mode raise an error at this point.\n if strict:\n raise MarkdownNotFound(msg)\n # Otherwise, when strict mode isn't enabled, log a warning\n # to the user and leave the URL as it is.\n log.warning(msg)\n return url\n path = utils.get_url_path(target_file, nav.use_directory_urls)\n path = nav.url_context.make_relative(path)\n else:\n path = utils.get_url_path(path).lstrip('/')\n\n # Convert the .md hyperlink to a relative hyperlink to the HTML page.\n fragments = (scheme, netloc, path, params, query, fragment)\n url = utils.urlunparse(fragments)\n return url\n\n\nclass RelativePathTreeprocessor(Treeprocessor):\n\n def __init__(self, site_navigation, strict):\n self.site_navigation = site_navigation\n self.strict = strict\n\n def run(self, root):\n \"\"\"Update urls on anchors and images to make them relative\n\n Iterates through the full document tree looking for specific\n tags and then makes them relative based on the site navigation\n \"\"\"\n\n for element in _iter(root):\n\n if element.tag == 'a':\n key = 'href'\n elif element.tag == 'img':\n key = 'src'\n else:\n continue\n\n url = element.get(key)\n new_url = path_to_url(url, self.site_navigation, self.strict)\n element.set(key, new_url)\n\n return root\n\n\nclass RelativePathExtension(Extension):\n \"\"\"\n The Extension class is what we pass to markdown, it then\n registers the Treeprocessor.\n \"\"\"\n\n def __init__(self, site_navigation, strict):\n self.site_navigation = site_navigation\n self.strict = strict\n\n def extendMarkdown(self, md, md_globals):\n relpath = RelativePathTreeprocessor(self.site_navigation, self.strict)\n md.treeprocessors.add(\"relpath\", relpath, \"_end\")\n", "path": "mkdocs/relative_path_ext.py"}]}
| 1,712 | 228 |
gh_patches_debug_30640
|
rasdani/github-patches
|
git_diff
|
sanic-org__sanic-326
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
During handling of the above exception, another exception occurred
In the examples/exception_monitoring.py, when i try to run the app and hit the default route, it prints out the exception and then it calls "return super.default(self, request, exception)", it returns with the following exception:
AttributeError: type object 'super' has no attribute 'default'
looks like in the exceptions.py, this line is the culprit (i could be wrong):
`handler = self.handlers.get(type(exception), self.default)
`
since __init__ does not have that attribute defined. I am running python 3.6
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/exception_monitoring.py`
Content:
```
1 """
2 Example intercepting uncaught exceptions using Sanic's error handler framework.
3
4 This may be useful for developers wishing to use Sentry, Airbrake, etc.
5 or a custom system to log and monitor unexpected errors in production.
6
7 First we create our own class inheriting from Handler in sanic.exceptions,
8 and pass in an instance of it when we create our Sanic instance. Inside this
9 class' default handler, we can do anything including sending exceptions to
10 an external service.
11 """
12
13
14
15 """
16 Imports and code relevant for our CustomHandler class
17 (Ordinarily this would be in a separate file)
18 """
19 from sanic.response import text
20 from sanic.exceptions import Handler, SanicException
21
22 class CustomHandler(Handler):
23 def default(self, request, exception):
24 # Here, we have access to the exception object
25 # and can do anything with it (log, send to external service, etc)
26
27 # Some exceptions are trivial and built into Sanic (404s, etc)
28 if not issubclass(type(exception), SanicException):
29 print(exception)
30
31 # Then, we must finish handling the exception by returning
32 # our response to the client
33 # For this we can just call the super class' default handler
34 return super.default(self, request, exception)
35
36
37
38
39 """
40 This is an ordinary Sanic server, with the exception that we set the
41 server's error_handler to an instance of our CustomHandler
42 """
43
44 from sanic import Sanic
45 from sanic.response import json
46
47 app = Sanic(__name__)
48
49 handler = CustomHandler(sanic=app)
50 app.error_handler = handler
51
52 @app.route("/")
53 async def test(request):
54 # Here, something occurs which causes an unexpected exception
55 # This exception will flow to our custom handler.
56 x = 1 / 0
57 return json({"test": True})
58
59
60 app.run(host="0.0.0.0", port=8000, debug=True)
61
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/exception_monitoring.py b/examples/exception_monitoring.py
--- a/examples/exception_monitoring.py
+++ b/examples/exception_monitoring.py
@@ -9,17 +9,15 @@
class' default handler, we can do anything including sending exceptions to
an external service.
"""
-
-
-
+from sanic.exceptions import Handler, SanicException
"""
Imports and code relevant for our CustomHandler class
(Ordinarily this would be in a separate file)
"""
-from sanic.response import text
-from sanic.exceptions import Handler, SanicException
+
class CustomHandler(Handler):
+
def default(self, request, exception):
# Here, we have access to the exception object
# and can do anything with it (log, send to external service, etc)
@@ -31,9 +29,7 @@
# Then, we must finish handling the exception by returning
# our response to the client
# For this we can just call the super class' default handler
- return super.default(self, request, exception)
-
-
+ return super().default(request, exception)
"""
@@ -49,11 +45,12 @@
handler = CustomHandler(sanic=app)
app.error_handler = handler
+
@app.route("/")
async def test(request):
# Here, something occurs which causes an unexpected exception
# This exception will flow to our custom handler.
- x = 1 / 0
+ 1 / 0
return json({"test": True})
|
{"golden_diff": "diff --git a/examples/exception_monitoring.py b/examples/exception_monitoring.py\n--- a/examples/exception_monitoring.py\n+++ b/examples/exception_monitoring.py\n@@ -9,17 +9,15 @@\n class' default handler, we can do anything including sending exceptions to\n an external service.\n \"\"\"\n-\n-\n-\n+from sanic.exceptions import Handler, SanicException\n \"\"\"\n Imports and code relevant for our CustomHandler class\n (Ordinarily this would be in a separate file)\n \"\"\"\n-from sanic.response import text\n-from sanic.exceptions import Handler, SanicException\n+\n \n class CustomHandler(Handler):\n+\n def default(self, request, exception):\n # Here, we have access to the exception object\n # and can do anything with it (log, send to external service, etc)\n@@ -31,9 +29,7 @@\n # Then, we must finish handling the exception by returning\n # our response to the client\n # For this we can just call the super class' default handler\n- return super.default(self, request, exception)\n-\n-\n+ return super().default(request, exception)\n \n \n \"\"\"\n@@ -49,11 +45,12 @@\n handler = CustomHandler(sanic=app)\n app.error_handler = handler\n \n+\n @app.route(\"/\")\n async def test(request):\n # Here, something occurs which causes an unexpected exception\n # This exception will flow to our custom handler.\n- x = 1 / 0\n+ 1 / 0\n return json({\"test\": True})\n", "issue": "During handling of the above exception, another exception occurred\nIn the examples/exception_monitoring.py, when i try to run the app and hit the default route, it prints out the exception and then it calls \"return super.default(self, request, exception)\", it returns with the following exception:\r\n\r\nAttributeError: type object 'super' has no attribute 'default'\r\n\r\nlooks like in the exceptions.py, this line is the culprit (i could be wrong):\r\n\r\n`handler = self.handlers.get(type(exception), self.default)\r\n`\r\n since __init__ does not have that attribute defined. I am running python 3.6\n", "before_files": [{"content": "\"\"\"\nExample intercepting uncaught exceptions using Sanic's error handler framework.\n\nThis may be useful for developers wishing to use Sentry, Airbrake, etc.\nor a custom system to log and monitor unexpected errors in production.\n\nFirst we create our own class inheriting from Handler in sanic.exceptions,\nand pass in an instance of it when we create our Sanic instance. Inside this\nclass' default handler, we can do anything including sending exceptions to\nan external service.\n\"\"\"\n\n\n\n\"\"\"\nImports and code relevant for our CustomHandler class\n(Ordinarily this would be in a separate file)\n\"\"\"\nfrom sanic.response import text\nfrom sanic.exceptions import Handler, SanicException\n\nclass CustomHandler(Handler):\n def default(self, request, exception):\n # Here, we have access to the exception object\n # and can do anything with it (log, send to external service, etc)\n\n # Some exceptions are trivial and built into Sanic (404s, etc)\n if not issubclass(type(exception), SanicException):\n print(exception)\n\n # Then, we must finish handling the exception by returning\n # our response to the client\n # For this we can just call the super class' default handler\n return super.default(self, request, exception)\n\n\n\n\n\"\"\"\nThis is an ordinary Sanic server, with the exception that we set the\nserver's error_handler to an instance of our CustomHandler\n\"\"\"\n\nfrom sanic import Sanic\nfrom sanic.response import json\n\napp = Sanic(__name__)\n\nhandler = CustomHandler(sanic=app)\napp.error_handler = handler\n\[email protected](\"/\")\nasync def test(request):\n # Here, something occurs which causes an unexpected exception\n # This exception will flow to our custom handler.\n x = 1 / 0\n return json({\"test\": True})\n\n\napp.run(host=\"0.0.0.0\", port=8000, debug=True)\n", "path": "examples/exception_monitoring.py"}], "after_files": [{"content": "\"\"\"\nExample intercepting uncaught exceptions using Sanic's error handler framework.\n\nThis may be useful for developers wishing to use Sentry, Airbrake, etc.\nor a custom system to log and monitor unexpected errors in production.\n\nFirst we create our own class inheriting from Handler in sanic.exceptions,\nand pass in an instance of it when we create our Sanic instance. Inside this\nclass' default handler, we can do anything including sending exceptions to\nan external service.\n\"\"\"\nfrom sanic.exceptions import Handler, SanicException\n\"\"\"\nImports and code relevant for our CustomHandler class\n(Ordinarily this would be in a separate file)\n\"\"\"\n\n\nclass CustomHandler(Handler):\n\n def default(self, request, exception):\n # Here, we have access to the exception object\n # and can do anything with it (log, send to external service, etc)\n\n # Some exceptions are trivial and built into Sanic (404s, etc)\n if not issubclass(type(exception), SanicException):\n print(exception)\n\n # Then, we must finish handling the exception by returning\n # our response to the client\n # For this we can just call the super class' default handler\n return super().default(request, exception)\n\n\n\"\"\"\nThis is an ordinary Sanic server, with the exception that we set the\nserver's error_handler to an instance of our CustomHandler\n\"\"\"\n\nfrom sanic import Sanic\nfrom sanic.response import json\n\napp = Sanic(__name__)\n\nhandler = CustomHandler(sanic=app)\napp.error_handler = handler\n\n\[email protected](\"/\")\nasync def test(request):\n # Here, something occurs which causes an unexpected exception\n # This exception will flow to our custom handler.\n 1 / 0\n return json({\"test\": True})\n\n\napp.run(host=\"0.0.0.0\", port=8000, debug=True)\n", "path": "examples/exception_monitoring.py"}]}
| 918 | 333 |
gh_patches_debug_13210
|
rasdani/github-patches
|
git_diff
|
fossasia__open-event-server-7862
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Calendar link in calendar not working properly
In the description, "Join using link: https://eventyay.com/e/fa96ae2c/video/Main Hall/187"
The space is treated as a break, clipping the link at Main"
"Main Hall" should be HTTP encoded to Main%20Hall
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `app/api/helpers/calendar/ical.py`
Content:
```
1 import pytz
2 from flask import jsonify
3 from flask_jwt_extended import current_user
4 from icalendar import Calendar, Event
5 from sqlalchemy import or_
6 from sqlalchemy.orm import joinedload
7
8 from app.models.session import Session
9
10
11 def to_ical(event, include_sessions=False, my_schedule=False, user_id=None):
12 cal = Calendar()
13 cal.add('version', '2.0')
14 cal.add('METHOD', 'PUBLISH')
15 cal.add('X-WR-CALNAME', event.name)
16 cal.add('X-WR-CALDESC', 'Event Calendar')
17
18 event_component = Event()
19 event_component.add('uid', event.identifier)
20 event_component.add('summary', event.name)
21 event_component.add('url', event.site_link)
22 event_component.add('dtstart', event.starts_at_tz)
23 event_component.add('dtend', event.ends_at_tz)
24 event_component.add('location', event.normalized_location)
25 event_component.add('description', event.description)
26 if event.has_coordinates:
27 event_component.add('geo', (event.latitude, event.longitude))
28 if event.owner_description:
29 event_component.add('organizer', event.owner_description)
30
31 cal.add_component(event_component)
32
33 if include_sessions:
34 sessions_query = (
35 Session.query.filter_by(event_id=event.id)
36 .options(joinedload(Session.microlocation))
37 .filter_by(deleted_at=None)
38 .filter(or_(Session.state == 'accepted', Session.state == 'confirmed'))
39 .order_by(Session.starts_at.asc())
40 )
41 if my_schedule:
42 if not (current_user or user_id):
43 return jsonify(error='Login or User ID required'), 401
44
45 user_id = user_id or current_user.id
46 sessions_query = sessions_query.join(Session.favourites).filter_by(
47 user_id=user_id
48 )
49 sessions = sessions_query.all()
50
51 for session in sessions:
52
53 if not (session and session.starts_at and session.ends_at):
54 continue
55
56 session_video_url = (
57 " "
58 + event.site_link
59 + '/video/'
60 + session.microlocation.video_stream.name
61 + "/"
62 + str(session.microlocation.video_stream.id)
63 if session.microlocation.video_stream
64 else ""
65 )
66 session_link_heading = (
67 "Join using link: " + session_video_url + "<br/>"
68 if session_video_url
69 else ""
70 )
71 session_description = (
72 " "
73 + "Room: "
74 + session.microlocation.name
75 + "<br/>"
76 + session_link_heading
77 + "<br/>"
78 + session.short_abstract
79 )
80 session_component = Event()
81 session_component.add('summary', session.title)
82 session_component.add('uid', str(session.id) + "-" + event.identifier)
83 session_component.add('geo', (event.latitude, event.longitude))
84 session_component.add(
85 'location',
86 session_video_url
87 or (session.microlocation and session.microlocation.name)
88 or '' + " " + event.location_name,
89 )
90 session_component.add(
91 'dtstart', session.starts_at.astimezone(pytz.timezone(event.timezone))
92 )
93 session_component.add(
94 'dtend', session.ends_at.astimezone(pytz.timezone(event.timezone))
95 )
96 session_component.add('description', session_description)
97 session_component.add('url', event.site_link + '/session/' + str(session.id))
98
99 cal.add_component(session_component)
100
101 return cal.to_ical()
102
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/app/api/helpers/calendar/ical.py b/app/api/helpers/calendar/ical.py
--- a/app/api/helpers/calendar/ical.py
+++ b/app/api/helpers/calendar/ical.py
@@ -1,3 +1,5 @@
+from urllib.parse import quote
+
import pytz
from flask import jsonify
from flask_jwt_extended import current_user
@@ -57,7 +59,7 @@
" "
+ event.site_link
+ '/video/'
- + session.microlocation.video_stream.name
+ + quote(session.microlocation.video_stream.name)
+ "/"
+ str(session.microlocation.video_stream.id)
if session.microlocation.video_stream
|
{"golden_diff": "diff --git a/app/api/helpers/calendar/ical.py b/app/api/helpers/calendar/ical.py\n--- a/app/api/helpers/calendar/ical.py\n+++ b/app/api/helpers/calendar/ical.py\n@@ -1,3 +1,5 @@\n+from urllib.parse import quote\n+\n import pytz\n from flask import jsonify\n from flask_jwt_extended import current_user\n@@ -57,7 +59,7 @@\n \" \"\n + event.site_link\n + '/video/'\n- + session.microlocation.video_stream.name\n+ + quote(session.microlocation.video_stream.name)\n + \"/\"\n + str(session.microlocation.video_stream.id)\n if session.microlocation.video_stream\n", "issue": "Calendar link in calendar not working properly\nIn the description, \"Join using link: https://eventyay.com/e/fa96ae2c/video/Main Hall/187\"\r\n\r\nThe space is treated as a break, clipping the link at Main\"\r\n\r\n\"Main Hall\" should be HTTP encoded to Main%20Hall\n", "before_files": [{"content": "import pytz\nfrom flask import jsonify\nfrom flask_jwt_extended import current_user\nfrom icalendar import Calendar, Event\nfrom sqlalchemy import or_\nfrom sqlalchemy.orm import joinedload\n\nfrom app.models.session import Session\n\n\ndef to_ical(event, include_sessions=False, my_schedule=False, user_id=None):\n cal = Calendar()\n cal.add('version', '2.0')\n cal.add('METHOD', 'PUBLISH')\n cal.add('X-WR-CALNAME', event.name)\n cal.add('X-WR-CALDESC', 'Event Calendar')\n\n event_component = Event()\n event_component.add('uid', event.identifier)\n event_component.add('summary', event.name)\n event_component.add('url', event.site_link)\n event_component.add('dtstart', event.starts_at_tz)\n event_component.add('dtend', event.ends_at_tz)\n event_component.add('location', event.normalized_location)\n event_component.add('description', event.description)\n if event.has_coordinates:\n event_component.add('geo', (event.latitude, event.longitude))\n if event.owner_description:\n event_component.add('organizer', event.owner_description)\n\n cal.add_component(event_component)\n\n if include_sessions:\n sessions_query = (\n Session.query.filter_by(event_id=event.id)\n .options(joinedload(Session.microlocation))\n .filter_by(deleted_at=None)\n .filter(or_(Session.state == 'accepted', Session.state == 'confirmed'))\n .order_by(Session.starts_at.asc())\n )\n if my_schedule:\n if not (current_user or user_id):\n return jsonify(error='Login or User ID required'), 401\n\n user_id = user_id or current_user.id\n sessions_query = sessions_query.join(Session.favourites).filter_by(\n user_id=user_id\n )\n sessions = sessions_query.all()\n\n for session in sessions:\n\n if not (session and session.starts_at and session.ends_at):\n continue\n\n session_video_url = (\n \" \"\n + event.site_link\n + '/video/'\n + session.microlocation.video_stream.name\n + \"/\"\n + str(session.microlocation.video_stream.id)\n if session.microlocation.video_stream\n else \"\"\n )\n session_link_heading = (\n \"Join using link: \" + session_video_url + \"<br/>\"\n if session_video_url\n else \"\"\n )\n session_description = (\n \" \"\n + \"Room: \"\n + session.microlocation.name\n + \"<br/>\"\n + session_link_heading\n + \"<br/>\"\n + session.short_abstract\n )\n session_component = Event()\n session_component.add('summary', session.title)\n session_component.add('uid', str(session.id) + \"-\" + event.identifier)\n session_component.add('geo', (event.latitude, event.longitude))\n session_component.add(\n 'location',\n session_video_url\n or (session.microlocation and session.microlocation.name)\n or '' + \" \" + event.location_name,\n )\n session_component.add(\n 'dtstart', session.starts_at.astimezone(pytz.timezone(event.timezone))\n )\n session_component.add(\n 'dtend', session.ends_at.astimezone(pytz.timezone(event.timezone))\n )\n session_component.add('description', session_description)\n session_component.add('url', event.site_link + '/session/' + str(session.id))\n\n cal.add_component(session_component)\n\n return cal.to_ical()\n", "path": "app/api/helpers/calendar/ical.py"}], "after_files": [{"content": "from urllib.parse import quote\n\nimport pytz\nfrom flask import jsonify\nfrom flask_jwt_extended import current_user\nfrom icalendar import Calendar, Event\nfrom sqlalchemy import or_\nfrom sqlalchemy.orm import joinedload\n\nfrom app.models.session import Session\n\n\ndef to_ical(event, include_sessions=False, my_schedule=False, user_id=None):\n cal = Calendar()\n cal.add('version', '2.0')\n cal.add('METHOD', 'PUBLISH')\n cal.add('X-WR-CALNAME', event.name)\n cal.add('X-WR-CALDESC', 'Event Calendar')\n\n event_component = Event()\n event_component.add('uid', event.identifier)\n event_component.add('summary', event.name)\n event_component.add('url', event.site_link)\n event_component.add('dtstart', event.starts_at_tz)\n event_component.add('dtend', event.ends_at_tz)\n event_component.add('location', event.normalized_location)\n event_component.add('description', event.description)\n if event.has_coordinates:\n event_component.add('geo', (event.latitude, event.longitude))\n if event.owner_description:\n event_component.add('organizer', event.owner_description)\n\n cal.add_component(event_component)\n\n if include_sessions:\n sessions_query = (\n Session.query.filter_by(event_id=event.id)\n .options(joinedload(Session.microlocation))\n .filter_by(deleted_at=None)\n .filter(or_(Session.state == 'accepted', Session.state == 'confirmed'))\n .order_by(Session.starts_at.asc())\n )\n if my_schedule:\n if not (current_user or user_id):\n return jsonify(error='Login or User ID required'), 401\n\n user_id = user_id or current_user.id\n sessions_query = sessions_query.join(Session.favourites).filter_by(\n user_id=user_id\n )\n sessions = sessions_query.all()\n\n for session in sessions:\n\n if not (session and session.starts_at and session.ends_at):\n continue\n\n session_video_url = (\n \" \"\n + event.site_link\n + '/video/'\n + quote(session.microlocation.video_stream.name)\n + \"/\"\n + str(session.microlocation.video_stream.id)\n if session.microlocation.video_stream\n else \"\"\n )\n session_link_heading = (\n \"Join using link: \" + session_video_url + \"<br/>\"\n if session_video_url\n else \"\"\n )\n session_description = (\n \" \"\n + \"Room: \"\n + session.microlocation.name\n + \"<br/>\"\n + session_link_heading\n + \"<br/>\"\n + session.short_abstract\n )\n session_component = Event()\n session_component.add('summary', session.title)\n session_component.add('uid', str(session.id) + \"-\" + event.identifier)\n session_component.add('geo', (event.latitude, event.longitude))\n session_component.add(\n 'location',\n session_video_url\n or (session.microlocation and session.microlocation.name)\n or '' + \" \" + event.location_name,\n )\n session_component.add(\n 'dtstart', session.starts_at.astimezone(pytz.timezone(event.timezone))\n )\n session_component.add(\n 'dtend', session.ends_at.astimezone(pytz.timezone(event.timezone))\n )\n session_component.add('description', session_description)\n session_component.add('url', event.site_link + '/session/' + str(session.id))\n\n cal.add_component(session_component)\n\n return cal.to_ical()\n", "path": "app/api/helpers/calendar/ical.py"}]}
| 1,267 | 143 |
gh_patches_debug_5686
|
rasdani/github-patches
|
git_diff
|
mitmproxy__mitmproxy-2155
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
cryptography dependency update?
The template here wasn't relevant so I cut it, apologies.
`mitmproxy` currently mandates `cryptography <1.8` which when built from source on macOS/OS X El Capitan (10.11) using Xcode 8 results in `Symbol not found: _getentropy` errors. Reported and explained in more detail [here](https://github.com/pyca/cryptography/issues/3332), hence my short summary. These issues were fixed in https://github.com/pyca/cryptography/pull/3354, which was released in the 1.8 branch.
This is also currently causing some "fun" for downstream package managers having to carry their own somewhat hacky patches like [this](https://github.com/Homebrew/homebrew-core/blob/37abcfc55099f635d0e187657a55a1eed36b5ccf/Formula/mitmproxy.rb#L193-L202). The gist of my request is whether `mitmproxy` has plans to/would consider update/updating [cryptography](https://github.com/mitmproxy/mitmproxy/blob/e723a58af5dc4fc7a46958aa9ce8c386a7387450/setup.py#L67) to use the latest release without these issues.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import os
2 import runpy
3 from codecs import open
4
5 from setuptools import setup, find_packages
6
7 # Based on https://github.com/pypa/sampleproject/blob/master/setup.py
8 # and https://python-packaging-user-guide.readthedocs.org/
9
10 here = os.path.abspath(os.path.dirname(__file__))
11
12 with open(os.path.join(here, 'README.rst'), encoding='utf-8') as f:
13 long_description = f.read()
14
15 VERSION = runpy.run_path(os.path.join(here, "mitmproxy", "version.py"))["VERSION"]
16
17 setup(
18 name="mitmproxy",
19 version=VERSION,
20 description="An interactive, SSL-capable, man-in-the-middle HTTP proxy for penetration testers and software developers.",
21 long_description=long_description,
22 url="http://mitmproxy.org",
23 author="Aldo Cortesi",
24 author_email="[email protected]",
25 license="MIT",
26 classifiers=[
27 "License :: OSI Approved :: MIT License",
28 "Development Status :: 5 - Production/Stable",
29 "Environment :: Console",
30 "Environment :: Console :: Curses",
31 "Operating System :: MacOS :: MacOS X",
32 "Operating System :: POSIX",
33 "Operating System :: Microsoft :: Windows",
34 "Programming Language :: Python",
35 "Programming Language :: Python :: 3",
36 "Programming Language :: Python :: 3 :: Only",
37 "Programming Language :: Python :: 3.5",
38 "Programming Language :: Python :: 3.6",
39 "Programming Language :: Python :: Implementation :: CPython",
40 "Topic :: Security",
41 "Topic :: Internet",
42 "Topic :: Internet :: WWW/HTTP",
43 "Topic :: Internet :: Proxy Servers",
44 "Topic :: Software Development :: Testing"
45 ],
46 packages=find_packages(include=[
47 "mitmproxy", "mitmproxy.*",
48 "pathod", "pathod.*",
49 ]),
50 include_package_data=True,
51 entry_points={
52 'console_scripts': [
53 "mitmproxy = mitmproxy.tools.main:mitmproxy",
54 "mitmdump = mitmproxy.tools.main:mitmdump",
55 "mitmweb = mitmproxy.tools.main:mitmweb",
56 "pathod = pathod.pathod_cmdline:go_pathod",
57 "pathoc = pathod.pathoc_cmdline:go_pathoc"
58 ]
59 },
60 # https://packaging.python.org/en/latest/requirements/#install-requires
61 # It is not considered best practice to use install_requires to pin dependencies to specific versions.
62 install_requires=[
63 "blinker>=1.4, <1.5",
64 "click>=6.2, <7",
65 "certifi>=2015.11.20.1", # no semver here - this should always be on the last release!
66 "construct>=2.8, <2.9",
67 "cryptography>=1.3, <1.8",
68 "cssutils>=1.0.1, <1.1",
69 "h2>=2.5.1, <3",
70 "html2text>=2016.1.8, <=2016.9.19",
71 "hyperframe>=4.0.1, <5",
72 "jsbeautifier>=1.6.3, <1.7",
73 "kaitaistruct>=0.6, <0.7",
74 "passlib>=1.6.5, <1.8",
75 "pyasn1>=0.1.9, <0.3",
76 "pyOpenSSL>=16.0, <17.0",
77 "pyparsing>=2.1.3, <2.2",
78 "pyperclip>=1.5.22, <1.6",
79 "requests>=2.9.1, <3",
80 "ruamel.yaml>=0.13.2, <0.14",
81 "tornado>=4.3, <4.5",
82 "urwid>=1.3.1, <1.4",
83 "watchdog>=0.8.3, <0.9",
84 "brotlipy>=0.5.1, <0.7",
85 "sortedcontainers>=1.5.4, <1.6",
86 # transitive from cryptography, we just blacklist here.
87 # https://github.com/pypa/setuptools/issues/861
88 "setuptools>=11.3, !=29.0.0",
89 ],
90 extras_require={
91 ':sys_platform == "win32"': [
92 "pydivert>=2.0.3, <2.1",
93 ],
94 ':sys_platform != "win32"': [
95 ],
96 'dev': [
97 "Flask>=0.10.1, <0.13",
98 "flake8>=3.2.1, <3.4",
99 "mypy>=0.471, <0.480",
100 "rstcheck>=2.2, <4.0",
101 "tox>=2.3, <3",
102 "pytest>=3, <3.1",
103 "pytest-cov>=2.2.1, <3",
104 "pytest-timeout>=1.0.0, <2",
105 "pytest-xdist>=1.14, <2",
106 "pytest-faulthandler>=1.3.0, <2",
107 "sphinx>=1.3.5, <1.6",
108 "sphinx-autobuild>=0.5.2, <0.7",
109 "sphinxcontrib-documentedlist>=0.5.0, <0.6",
110 "sphinx_rtd_theme>=0.1.9, <0.2",
111 ],
112 'contentviews': [
113 ],
114 'examples': [
115 "beautifulsoup4>=4.4.1, <4.6",
116 "Pillow>=3.2, <4.1",
117 ]
118 }
119 )
120
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -64,7 +64,7 @@
"click>=6.2, <7",
"certifi>=2015.11.20.1", # no semver here - this should always be on the last release!
"construct>=2.8, <2.9",
- "cryptography>=1.3, <1.8",
+ "cryptography>=1.3, <1.9",
"cssutils>=1.0.1, <1.1",
"h2>=2.5.1, <3",
"html2text>=2016.1.8, <=2016.9.19",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -64,7 +64,7 @@\n \"click>=6.2, <7\",\n \"certifi>=2015.11.20.1\", # no semver here - this should always be on the last release!\n \"construct>=2.8, <2.9\",\n- \"cryptography>=1.3, <1.8\",\n+ \"cryptography>=1.3, <1.9\",\n \"cssutils>=1.0.1, <1.1\",\n \"h2>=2.5.1, <3\",\n \"html2text>=2016.1.8, <=2016.9.19\",\n", "issue": "cryptography dependency update?\nThe template here wasn't relevant so I cut it, apologies.\r\n\r\n`mitmproxy` currently mandates `cryptography <1.8` which when built from source on macOS/OS X El Capitan (10.11) using Xcode 8 results in `Symbol not found: _getentropy` errors. Reported and explained in more detail [here](https://github.com/pyca/cryptography/issues/3332), hence my short summary. These issues were fixed in https://github.com/pyca/cryptography/pull/3354, which was released in the 1.8 branch.\r\n\r\nThis is also currently causing some \"fun\" for downstream package managers having to carry their own somewhat hacky patches like [this](https://github.com/Homebrew/homebrew-core/blob/37abcfc55099f635d0e187657a55a1eed36b5ccf/Formula/mitmproxy.rb#L193-L202). The gist of my request is whether `mitmproxy` has plans to/would consider update/updating [cryptography](https://github.com/mitmproxy/mitmproxy/blob/e723a58af5dc4fc7a46958aa9ce8c386a7387450/setup.py#L67) to use the latest release without these issues.\n", "before_files": [{"content": "import os\nimport runpy\nfrom codecs import open\n\nfrom setuptools import setup, find_packages\n\n# Based on https://github.com/pypa/sampleproject/blob/master/setup.py\n# and https://python-packaging-user-guide.readthedocs.org/\n\nhere = os.path.abspath(os.path.dirname(__file__))\n\nwith open(os.path.join(here, 'README.rst'), encoding='utf-8') as f:\n long_description = f.read()\n\nVERSION = runpy.run_path(os.path.join(here, \"mitmproxy\", \"version.py\"))[\"VERSION\"]\n\nsetup(\n name=\"mitmproxy\",\n version=VERSION,\n description=\"An interactive, SSL-capable, man-in-the-middle HTTP proxy for penetration testers and software developers.\",\n long_description=long_description,\n url=\"http://mitmproxy.org\",\n author=\"Aldo Cortesi\",\n author_email=\"[email protected]\",\n license=\"MIT\",\n classifiers=[\n \"License :: OSI Approved :: MIT License\",\n \"Development Status :: 5 - Production/Stable\",\n \"Environment :: Console\",\n \"Environment :: Console :: Curses\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: POSIX\",\n \"Operating System :: Microsoft :: Windows\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3 :: Only\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Topic :: Security\",\n \"Topic :: Internet\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Internet :: Proxy Servers\",\n \"Topic :: Software Development :: Testing\"\n ],\n packages=find_packages(include=[\n \"mitmproxy\", \"mitmproxy.*\",\n \"pathod\", \"pathod.*\",\n ]),\n include_package_data=True,\n entry_points={\n 'console_scripts': [\n \"mitmproxy = mitmproxy.tools.main:mitmproxy\",\n \"mitmdump = mitmproxy.tools.main:mitmdump\",\n \"mitmweb = mitmproxy.tools.main:mitmweb\",\n \"pathod = pathod.pathod_cmdline:go_pathod\",\n \"pathoc = pathod.pathoc_cmdline:go_pathoc\"\n ]\n },\n # https://packaging.python.org/en/latest/requirements/#install-requires\n # It is not considered best practice to use install_requires to pin dependencies to specific versions.\n install_requires=[\n \"blinker>=1.4, <1.5\",\n \"click>=6.2, <7\",\n \"certifi>=2015.11.20.1\", # no semver here - this should always be on the last release!\n \"construct>=2.8, <2.9\",\n \"cryptography>=1.3, <1.8\",\n \"cssutils>=1.0.1, <1.1\",\n \"h2>=2.5.1, <3\",\n \"html2text>=2016.1.8, <=2016.9.19\",\n \"hyperframe>=4.0.1, <5\",\n \"jsbeautifier>=1.6.3, <1.7\",\n \"kaitaistruct>=0.6, <0.7\",\n \"passlib>=1.6.5, <1.8\",\n \"pyasn1>=0.1.9, <0.3\",\n \"pyOpenSSL>=16.0, <17.0\",\n \"pyparsing>=2.1.3, <2.2\",\n \"pyperclip>=1.5.22, <1.6\",\n \"requests>=2.9.1, <3\",\n \"ruamel.yaml>=0.13.2, <0.14\",\n \"tornado>=4.3, <4.5\",\n \"urwid>=1.3.1, <1.4\",\n \"watchdog>=0.8.3, <0.9\",\n \"brotlipy>=0.5.1, <0.7\",\n \"sortedcontainers>=1.5.4, <1.6\",\n # transitive from cryptography, we just blacklist here.\n # https://github.com/pypa/setuptools/issues/861\n \"setuptools>=11.3, !=29.0.0\",\n ],\n extras_require={\n ':sys_platform == \"win32\"': [\n \"pydivert>=2.0.3, <2.1\",\n ],\n ':sys_platform != \"win32\"': [\n ],\n 'dev': [\n \"Flask>=0.10.1, <0.13\",\n \"flake8>=3.2.1, <3.4\",\n \"mypy>=0.471, <0.480\",\n \"rstcheck>=2.2, <4.0\",\n \"tox>=2.3, <3\",\n \"pytest>=3, <3.1\",\n \"pytest-cov>=2.2.1, <3\",\n \"pytest-timeout>=1.0.0, <2\",\n \"pytest-xdist>=1.14, <2\",\n \"pytest-faulthandler>=1.3.0, <2\",\n \"sphinx>=1.3.5, <1.6\",\n \"sphinx-autobuild>=0.5.2, <0.7\",\n \"sphinxcontrib-documentedlist>=0.5.0, <0.6\",\n \"sphinx_rtd_theme>=0.1.9, <0.2\",\n ],\n 'contentviews': [\n ],\n 'examples': [\n \"beautifulsoup4>=4.4.1, <4.6\",\n \"Pillow>=3.2, <4.1\",\n ]\n }\n)\n", "path": "setup.py"}], "after_files": [{"content": "import os\nimport runpy\nfrom codecs import open\n\nfrom setuptools import setup, find_packages\n\n# Based on https://github.com/pypa/sampleproject/blob/master/setup.py\n# and https://python-packaging-user-guide.readthedocs.org/\n\nhere = os.path.abspath(os.path.dirname(__file__))\n\nwith open(os.path.join(here, 'README.rst'), encoding='utf-8') as f:\n long_description = f.read()\n\nVERSION = runpy.run_path(os.path.join(here, \"mitmproxy\", \"version.py\"))[\"VERSION\"]\n\nsetup(\n name=\"mitmproxy\",\n version=VERSION,\n description=\"An interactive, SSL-capable, man-in-the-middle HTTP proxy for penetration testers and software developers.\",\n long_description=long_description,\n url=\"http://mitmproxy.org\",\n author=\"Aldo Cortesi\",\n author_email=\"[email protected]\",\n license=\"MIT\",\n classifiers=[\n \"License :: OSI Approved :: MIT License\",\n \"Development Status :: 5 - Production/Stable\",\n \"Environment :: Console\",\n \"Environment :: Console :: Curses\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: POSIX\",\n \"Operating System :: Microsoft :: Windows\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3 :: Only\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Topic :: Security\",\n \"Topic :: Internet\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Internet :: Proxy Servers\",\n \"Topic :: Software Development :: Testing\"\n ],\n packages=find_packages(include=[\n \"mitmproxy\", \"mitmproxy.*\",\n \"pathod\", \"pathod.*\",\n ]),\n include_package_data=True,\n entry_points={\n 'console_scripts': [\n \"mitmproxy = mitmproxy.tools.main:mitmproxy\",\n \"mitmdump = mitmproxy.tools.main:mitmdump\",\n \"mitmweb = mitmproxy.tools.main:mitmweb\",\n \"pathod = pathod.pathod_cmdline:go_pathod\",\n \"pathoc = pathod.pathoc_cmdline:go_pathoc\"\n ]\n },\n # https://packaging.python.org/en/latest/requirements/#install-requires\n # It is not considered best practice to use install_requires to pin dependencies to specific versions.\n install_requires=[\n \"blinker>=1.4, <1.5\",\n \"click>=6.2, <7\",\n \"certifi>=2015.11.20.1\", # no semver here - this should always be on the last release!\n \"construct>=2.8, <2.9\",\n \"cryptography>=1.3, <1.9\",\n \"cssutils>=1.0.1, <1.1\",\n \"h2>=2.5.1, <3\",\n \"html2text>=2016.1.8, <=2016.9.19\",\n \"hyperframe>=4.0.1, <5\",\n \"jsbeautifier>=1.6.3, <1.7\",\n \"kaitaistruct>=0.6, <0.7\",\n \"passlib>=1.6.5, <1.8\",\n \"pyasn1>=0.1.9, <0.3\",\n \"pyOpenSSL>=16.0, <17.0\",\n \"pyparsing>=2.1.3, <2.2\",\n \"pyperclip>=1.5.22, <1.6\",\n \"requests>=2.9.1, <3\",\n \"ruamel.yaml>=0.13.2, <0.14\",\n \"tornado>=4.3, <4.5\",\n \"urwid>=1.3.1, <1.4\",\n \"watchdog>=0.8.3, <0.9\",\n \"brotlipy>=0.5.1, <0.7\",\n \"sortedcontainers>=1.5.4, <1.6\",\n # transitive from cryptography, we just blacklist here.\n # https://github.com/pypa/setuptools/issues/861\n \"setuptools>=11.3, !=29.0.0\",\n ],\n extras_require={\n ':sys_platform == \"win32\"': [\n \"pydivert>=2.0.3, <2.1\",\n ],\n ':sys_platform != \"win32\"': [\n ],\n 'dev': [\n \"Flask>=0.10.1, <0.13\",\n \"flake8>=3.2.1, <3.4\",\n \"mypy>=0.471, <0.480\",\n \"rstcheck>=2.2, <4.0\",\n \"tox>=2.3, <3\",\n \"pytest>=3, <3.1\",\n \"pytest-cov>=2.2.1, <3\",\n \"pytest-timeout>=1.0.0, <2\",\n \"pytest-xdist>=1.14, <2\",\n \"pytest-faulthandler>=1.3.0, <2\",\n \"sphinx>=1.3.5, <1.6\",\n \"sphinx-autobuild>=0.5.2, <0.7\",\n \"sphinxcontrib-documentedlist>=0.5.0, <0.6\",\n \"sphinx_rtd_theme>=0.1.9, <0.2\",\n ],\n 'contentviews': [\n ],\n 'examples': [\n \"beautifulsoup4>=4.4.1, <4.6\",\n \"Pillow>=3.2, <4.1\",\n ]\n }\n)\n", "path": "setup.py"}]}
| 2,121 | 176 |
gh_patches_debug_38935
|
rasdani/github-patches
|
git_diff
|
Zeroto521__my-data-toolkit-833
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ENH: New geoaccessor `geocentroid` to get the center point of points
<!--
Thanks for contributing a pull request!
Please follow these standard acronyms to start the commit message:
- ENH: enhancement
- BUG: bug fix
- DOC: documentation
- TYP: type annotations
- TST: addition or modification of tests
- MAINT: maintenance commit (refactoring, typos, etc.)
- BLD: change related to building
- REL: related to releasing
- API: an (incompatible) API change
- DEP: deprecate something, or remove a deprecated object
- DEV: development tool or utility
- REV: revert an earlier commit
- PERF: performance improvement
- BOT: always commit via a bot
- CI: related to CI or CD
- CLN: Code cleanup
-->
- [ ] closes #xxxx
- [x] whatsnew entry
```python
>>> import dtoolkit.geoaccessor
>>> import geopandas as gpd
>>> from shapely import Point
>>> df = gpd.GeoDataFrame(
... geometry=[
... Point(100, 32),
... Point(120, 50),
... Point(122, 55)
... ],
... crs=4326,
... )
>>> df
geometry
0 POINT (100.00000 32.00000)
1 POINT (120.00000 50.00000)
2 POINT (122.00000 55.00000)
>>> df.geocentroid()
<POINT (112.213 44.119)>
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dtoolkit/geoaccessor/geoseries/geocentroid.py`
Content:
```
1 import geopandas as gpd
2 import numpy as np
3 import pandas as pd
4 from shapely import Point
5
6 from dtoolkit.geoaccessor.geoseries.geodistance import geodistance
7 from dtoolkit.geoaccessor.geoseries.xy import xy
8 from dtoolkit.geoaccessor.register import register_geoseries_method
9
10
11 @register_geoseries_method
12 def geocentroid(
13 s: gpd.GeoSeries,
14 /,
15 weights: pd.Series = None,
16 max_iter: int = 300,
17 tol: float = 1e-4,
18 ) -> Point:
19 """
20 Return the centroid of all points via the center of gravity method.
21
22 Parameters
23 ----------
24 weights : Hashable or 1d array-like, optional
25 - None : All weights will be set to 1.
26 - Hashable : Only for DataFrame, the column name.
27 - 1d array-like : The weights of each point.
28
29 max_iter : int, default 300
30 Maximum number of iterations to perform.
31
32 tol : float, default 1e-4
33 Tolerance for convergence.
34
35 Returns
36 -------
37 Point
38
39 Raises
40 ------
41 ValueError
42 If the CRS is not ``ESGP:4326``.
43
44 See Also
45 --------
46 geopandas.GeoSeries.centroid
47 dtoolkit.geoaccessor.geoseries.geocentroid
48 dtoolkit.geoaccessor.geodataframe.geocentroid
49
50 Examples
51 --------
52 >>> import dtoolkit.geoaccessor
53 >>> import geopandas as gpd
54 >>> from shapely import Point
55 >>> df = gpd.GeoDataFrame(
56 ... {
57 ... "weights": [1, 2, 3],
58 ... "geometry": [Point(100, 32), Point(120, 50), Point(122, 55)],
59 ... },
60 ... crs=4326,
61 ... )
62 >>> df
63 weights geometry
64 0 1 POINT (100.00000 32.00000)
65 1 2 POINT (120.00000 50.00000)
66 2 3 POINT (122.00000 55.00000)
67 >>> df.geocentroid()
68 <POINT (112.375 44.276)>
69
70 Set weights for each point.
71
72 >>> df.geocentroid("weights")
73 <POINT (114.516 46.675)>
74 >>> df.geocentroid([1, 2, 3])
75 <POINT (114.516 46.675)>
76 """
77
78 if s.crs != 4326:
79 raise ValueError(f"Only support 'EPSG:4326' CRS, but got {s.crs!r}.")
80
81 weights = np.asarray(weights) if weights is not None else 1
82 coord = xy(s)
83 X = coord.mean()
84 for _ in range(max_iter):
85 dis = geodistance(s, Point(*X.tolist())).mul(weights, axis=0)
86 Xt = coord.mul(dis, axis=0).sum() / dis.sum()
87
88 if ((X - Xt).abs() <= tol).all():
89 X = Xt
90 break
91
92 X = Xt
93
94 return Point(*X.tolist())
95
```
Path: `dtoolkit/geoaccessor/geodataframe/geocentroid.py`
Content:
```
1 from __future__ import annotations
2
3 from typing import Hashable
4
5 import geopandas as gpd
6 import pandas as pd
7 from pandas.util._decorators import doc
8 from shapely import Point
9
10 from dtoolkit.geoaccessor.geoseries import geocentroid as s_geocentroid
11 from dtoolkit.geoaccessor.register import register_geodataframe_method
12
13
14 @register_geodataframe_method
15 @doc(s_geocentroid)
16 def geocentroid(
17 df: gpd.GeoDataFrame,
18 /,
19 weights: Hashable | pd.Series = None,
20 max_iter: int = 300,
21 tol: float = 1e-4,
22 ) -> Point:
23 if weights is not None and isinstance(weights, Hashable):
24 weights = df[weights]
25
26 return s_geocentroid(df.geometry, weights=weights, max_iter=max_iter, tol=tol)
27
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/dtoolkit/geoaccessor/geodataframe/geocentroid.py b/dtoolkit/geoaccessor/geodataframe/geocentroid.py
--- a/dtoolkit/geoaccessor/geodataframe/geocentroid.py
+++ b/dtoolkit/geoaccessor/geodataframe/geocentroid.py
@@ -18,7 +18,7 @@
/,
weights: Hashable | pd.Series = None,
max_iter: int = 300,
- tol: float = 1e-4,
+ tol: float = 1e-5,
) -> Point:
if weights is not None and isinstance(weights, Hashable):
weights = df[weights]
diff --git a/dtoolkit/geoaccessor/geoseries/geocentroid.py b/dtoolkit/geoaccessor/geoseries/geocentroid.py
--- a/dtoolkit/geoaccessor/geoseries/geocentroid.py
+++ b/dtoolkit/geoaccessor/geoseries/geocentroid.py
@@ -14,11 +14,21 @@
/,
weights: pd.Series = None,
max_iter: int = 300,
- tol: float = 1e-4,
+ tol: float = 1e-5,
) -> Point:
- """
+ r"""
Return the centroid of all points via the center of gravity method.
+ .. math::
+
+ \left\{\begin{matrix}
+ d_i &=& D(P(\bar{x}_n, \bar{y}_n), P(x_i, y_i)) \\
+ \bar{x}_0 &=& \frac{\sum w_i x_i}{\sum w_i} \\
+ \bar{y}_0 &=& \frac{\sum w_i y_i}{\sum w_i} \\
+ \bar{x}_{n+1} &=& \frac{\sum w_i x_i / d_i}{\sum w_i / d_i} \\
+ \bar{y}_{n+1} &=& \frac{\sum w_i y_i / d_i}{\sum w_i / d_i} \\
+ \end{matrix}\right.
+
Parameters
----------
weights : Hashable or 1d array-like, optional
@@ -29,18 +39,13 @@
max_iter : int, default 300
Maximum number of iterations to perform.
- tol : float, default 1e-4
+ tol : float, default 1e-5
Tolerance for convergence.
Returns
-------
Point
- Raises
- ------
- ValueError
- If the CRS is not ``ESGP:4326``.
-
See Also
--------
geopandas.GeoSeries.centroid
@@ -65,24 +70,21 @@
1 2 POINT (120.00000 50.00000)
2 3 POINT (122.00000 55.00000)
>>> df.geocentroid()
- <POINT (112.375 44.276)>
+ <POINT (120 50)>
Set weights for each point.
>>> df.geocentroid("weights")
- <POINT (114.516 46.675)>
+ <POINT (121.999 54.998)>
>>> df.geocentroid([1, 2, 3])
- <POINT (114.516 46.675)>
+ <POINT (121.999 54.998)>
"""
- if s.crs != 4326:
- raise ValueError(f"Only support 'EPSG:4326' CRS, but got {s.crs!r}.")
-
weights = np.asarray(weights) if weights is not None else 1
coord = xy(s)
X = coord.mean()
for _ in range(max_iter):
- dis = geodistance(s, Point(*X.tolist())).mul(weights, axis=0)
+ dis = geodistance(s, Point(*X.tolist())).rdiv(1).mul(weights, axis=0)
Xt = coord.mul(dis, axis=0).sum() / dis.sum()
if ((X - Xt).abs() <= tol).all():
|
{"golden_diff": "diff --git a/dtoolkit/geoaccessor/geodataframe/geocentroid.py b/dtoolkit/geoaccessor/geodataframe/geocentroid.py\n--- a/dtoolkit/geoaccessor/geodataframe/geocentroid.py\n+++ b/dtoolkit/geoaccessor/geodataframe/geocentroid.py\n@@ -18,7 +18,7 @@\n /,\n weights: Hashable | pd.Series = None,\n max_iter: int = 300,\n- tol: float = 1e-4,\n+ tol: float = 1e-5,\n ) -> Point:\n if weights is not None and isinstance(weights, Hashable):\n weights = df[weights]\ndiff --git a/dtoolkit/geoaccessor/geoseries/geocentroid.py b/dtoolkit/geoaccessor/geoseries/geocentroid.py\n--- a/dtoolkit/geoaccessor/geoseries/geocentroid.py\n+++ b/dtoolkit/geoaccessor/geoseries/geocentroid.py\n@@ -14,11 +14,21 @@\n /,\n weights: pd.Series = None,\n max_iter: int = 300,\n- tol: float = 1e-4,\n+ tol: float = 1e-5,\n ) -> Point:\n- \"\"\"\n+ r\"\"\"\n Return the centroid of all points via the center of gravity method.\n \n+ .. math::\n+\n+ \\left\\{\\begin{matrix}\n+ d_i &=& D(P(\\bar{x}_n, \\bar{y}_n), P(x_i, y_i)) \\\\\n+ \\bar{x}_0 &=& \\frac{\\sum w_i x_i}{\\sum w_i} \\\\\n+ \\bar{y}_0 &=& \\frac{\\sum w_i y_i}{\\sum w_i} \\\\\n+ \\bar{x}_{n+1} &=& \\frac{\\sum w_i x_i / d_i}{\\sum w_i / d_i} \\\\\n+ \\bar{y}_{n+1} &=& \\frac{\\sum w_i y_i / d_i}{\\sum w_i / d_i} \\\\\n+ \\end{matrix}\\right.\n+\n Parameters\n ----------\n weights : Hashable or 1d array-like, optional\n@@ -29,18 +39,13 @@\n max_iter : int, default 300\n Maximum number of iterations to perform.\n \n- tol : float, default 1e-4\n+ tol : float, default 1e-5\n Tolerance for convergence.\n \n Returns\n -------\n Point\n \n- Raises\n- ------\n- ValueError\n- If the CRS is not ``ESGP:4326``.\n-\n See Also\n --------\n geopandas.GeoSeries.centroid\n@@ -65,24 +70,21 @@\n 1 2 POINT (120.00000 50.00000)\n 2 3 POINT (122.00000 55.00000)\n >>> df.geocentroid()\n- <POINT (112.375 44.276)>\n+ <POINT (120 50)>\n \n Set weights for each point.\n \n >>> df.geocentroid(\"weights\")\n- <POINT (114.516 46.675)>\n+ <POINT (121.999 54.998)>\n >>> df.geocentroid([1, 2, 3])\n- <POINT (114.516 46.675)>\n+ <POINT (121.999 54.998)>\n \"\"\"\n \n- if s.crs != 4326:\n- raise ValueError(f\"Only support 'EPSG:4326' CRS, but got {s.crs!r}.\")\n-\n weights = np.asarray(weights) if weights is not None else 1\n coord = xy(s)\n X = coord.mean()\n for _ in range(max_iter):\n- dis = geodistance(s, Point(*X.tolist())).mul(weights, axis=0)\n+ dis = geodistance(s, Point(*X.tolist())).rdiv(1).mul(weights, axis=0)\n Xt = coord.mul(dis, axis=0).sum() / dis.sum()\n \n if ((X - Xt).abs() <= tol).all():\n", "issue": "ENH: New geoaccessor `geocentroid` to get the center point of points\n<!--\r\nThanks for contributing a pull request!\r\n\r\nPlease follow these standard acronyms to start the commit message:\r\n\r\n- ENH: enhancement\r\n- BUG: bug fix\r\n- DOC: documentation\r\n- TYP: type annotations\r\n- TST: addition or modification of tests\r\n- MAINT: maintenance commit (refactoring, typos, etc.)\r\n- BLD: change related to building\r\n- REL: related to releasing\r\n- API: an (incompatible) API change\r\n- DEP: deprecate something, or remove a deprecated object\r\n- DEV: development tool or utility\r\n- REV: revert an earlier commit\r\n- PERF: performance improvement\r\n- BOT: always commit via a bot\r\n- CI: related to CI or CD\r\n- CLN: Code cleanup\r\n-->\r\n\r\n- [ ] closes #xxxx\r\n- [x] whatsnew entry\r\n\r\n```python\r\n >>> import dtoolkit.geoaccessor\r\n >>> import geopandas as gpd\r\n >>> from shapely import Point\r\n >>> df = gpd.GeoDataFrame(\r\n ... geometry=[\r\n ... Point(100, 32),\r\n ... Point(120, 50),\r\n ... Point(122, 55)\r\n ... ],\r\n ... crs=4326,\r\n ... )\r\n >>> df\r\n geometry\r\n 0 POINT (100.00000 32.00000)\r\n 1 POINT (120.00000 50.00000)\r\n 2 POINT (122.00000 55.00000)\r\n >>> df.geocentroid()\r\n <POINT (112.213 44.119)>\r\n```\n", "before_files": [{"content": "import geopandas as gpd\nimport numpy as np\nimport pandas as pd\nfrom shapely import Point\n\nfrom dtoolkit.geoaccessor.geoseries.geodistance import geodistance\nfrom dtoolkit.geoaccessor.geoseries.xy import xy\nfrom dtoolkit.geoaccessor.register import register_geoseries_method\n\n\n@register_geoseries_method\ndef geocentroid(\n s: gpd.GeoSeries,\n /,\n weights: pd.Series = None,\n max_iter: int = 300,\n tol: float = 1e-4,\n) -> Point:\n \"\"\"\n Return the centroid of all points via the center of gravity method.\n\n Parameters\n ----------\n weights : Hashable or 1d array-like, optional\n - None : All weights will be set to 1.\n - Hashable : Only for DataFrame, the column name.\n - 1d array-like : The weights of each point.\n\n max_iter : int, default 300\n Maximum number of iterations to perform.\n\n tol : float, default 1e-4\n Tolerance for convergence.\n\n Returns\n -------\n Point\n\n Raises\n ------\n ValueError\n If the CRS is not ``ESGP:4326``.\n\n See Also\n --------\n geopandas.GeoSeries.centroid\n dtoolkit.geoaccessor.geoseries.geocentroid\n dtoolkit.geoaccessor.geodataframe.geocentroid\n\n Examples\n --------\n >>> import dtoolkit.geoaccessor\n >>> import geopandas as gpd\n >>> from shapely import Point\n >>> df = gpd.GeoDataFrame(\n ... {\n ... \"weights\": [1, 2, 3],\n ... \"geometry\": [Point(100, 32), Point(120, 50), Point(122, 55)],\n ... },\n ... crs=4326,\n ... )\n >>> df\n weights geometry\n 0 1 POINT (100.00000 32.00000)\n 1 2 POINT (120.00000 50.00000)\n 2 3 POINT (122.00000 55.00000)\n >>> df.geocentroid()\n <POINT (112.375 44.276)>\n\n Set weights for each point.\n\n >>> df.geocentroid(\"weights\")\n <POINT (114.516 46.675)>\n >>> df.geocentroid([1, 2, 3])\n <POINT (114.516 46.675)>\n \"\"\"\n\n if s.crs != 4326:\n raise ValueError(f\"Only support 'EPSG:4326' CRS, but got {s.crs!r}.\")\n\n weights = np.asarray(weights) if weights is not None else 1\n coord = xy(s)\n X = coord.mean()\n for _ in range(max_iter):\n dis = geodistance(s, Point(*X.tolist())).mul(weights, axis=0)\n Xt = coord.mul(dis, axis=0).sum() / dis.sum()\n\n if ((X - Xt).abs() <= tol).all():\n X = Xt\n break\n\n X = Xt\n\n return Point(*X.tolist())\n", "path": "dtoolkit/geoaccessor/geoseries/geocentroid.py"}, {"content": "from __future__ import annotations\n\nfrom typing import Hashable\n\nimport geopandas as gpd\nimport pandas as pd\nfrom pandas.util._decorators import doc\nfrom shapely import Point\n\nfrom dtoolkit.geoaccessor.geoseries import geocentroid as s_geocentroid\nfrom dtoolkit.geoaccessor.register import register_geodataframe_method\n\n\n@register_geodataframe_method\n@doc(s_geocentroid)\ndef geocentroid(\n df: gpd.GeoDataFrame,\n /,\n weights: Hashable | pd.Series = None,\n max_iter: int = 300,\n tol: float = 1e-4,\n) -> Point:\n if weights is not None and isinstance(weights, Hashable):\n weights = df[weights]\n\n return s_geocentroid(df.geometry, weights=weights, max_iter=max_iter, tol=tol)\n", "path": "dtoolkit/geoaccessor/geodataframe/geocentroid.py"}], "after_files": [{"content": "import geopandas as gpd\nimport numpy as np\nimport pandas as pd\nfrom shapely import Point\n\nfrom dtoolkit.geoaccessor.geoseries.geodistance import geodistance\nfrom dtoolkit.geoaccessor.geoseries.xy import xy\nfrom dtoolkit.geoaccessor.register import register_geoseries_method\n\n\n@register_geoseries_method\ndef geocentroid(\n s: gpd.GeoSeries,\n /,\n weights: pd.Series = None,\n max_iter: int = 300,\n tol: float = 1e-5,\n) -> Point:\n r\"\"\"\n Return the centroid of all points via the center of gravity method.\n\n .. math::\n\n \\left\\{\\begin{matrix}\n d_i &=& D(P(\\bar{x}_n, \\bar{y}_n), P(x_i, y_i)) \\\\\n \\bar{x}_0 &=& \\frac{\\sum w_i x_i}{\\sum w_i} \\\\\n \\bar{y}_0 &=& \\frac{\\sum w_i y_i}{\\sum w_i} \\\\\n \\bar{x}_{n+1} &=& \\frac{\\sum w_i x_i / d_i}{\\sum w_i / d_i} \\\\\n \\bar{y}_{n+1} &=& \\frac{\\sum w_i y_i / d_i}{\\sum w_i / d_i} \\\\\n \\end{matrix}\\right.\n\n Parameters\n ----------\n weights : Hashable or 1d array-like, optional\n - None : All weights will be set to 1.\n - Hashable : Only for DataFrame, the column name.\n - 1d array-like : The weights of each point.\n\n max_iter : int, default 300\n Maximum number of iterations to perform.\n\n tol : float, default 1e-5\n Tolerance for convergence.\n\n Returns\n -------\n Point\n\n See Also\n --------\n geopandas.GeoSeries.centroid\n dtoolkit.geoaccessor.geoseries.geocentroid\n dtoolkit.geoaccessor.geodataframe.geocentroid\n\n Examples\n --------\n >>> import dtoolkit.geoaccessor\n >>> import geopandas as gpd\n >>> from shapely import Point\n >>> df = gpd.GeoDataFrame(\n ... {\n ... \"weights\": [1, 2, 3],\n ... \"geometry\": [Point(100, 32), Point(120, 50), Point(122, 55)],\n ... },\n ... crs=4326,\n ... )\n >>> df\n weights geometry\n 0 1 POINT (100.00000 32.00000)\n 1 2 POINT (120.00000 50.00000)\n 2 3 POINT (122.00000 55.00000)\n >>> df.geocentroid()\n <POINT (120 50)>\n\n Set weights for each point.\n\n >>> df.geocentroid(\"weights\")\n <POINT (121.999 54.998)>\n >>> df.geocentroid([1, 2, 3])\n <POINT (121.999 54.998)>\n \"\"\"\n\n weights = np.asarray(weights) if weights is not None else 1\n coord = xy(s)\n X = coord.mean()\n for _ in range(max_iter):\n dis = geodistance(s, Point(*X.tolist())).rdiv(1).mul(weights, axis=0)\n Xt = coord.mul(dis, axis=0).sum() / dis.sum()\n\n if ((X - Xt).abs() <= tol).all():\n X = Xt\n break\n\n X = Xt\n\n return Point(*X.tolist())\n", "path": "dtoolkit/geoaccessor/geoseries/geocentroid.py"}, {"content": "from __future__ import annotations\n\nfrom typing import Hashable\n\nimport geopandas as gpd\nimport pandas as pd\nfrom pandas.util._decorators import doc\nfrom shapely import Point\n\nfrom dtoolkit.geoaccessor.geoseries import geocentroid as s_geocentroid\nfrom dtoolkit.geoaccessor.register import register_geodataframe_method\n\n\n@register_geodataframe_method\n@doc(s_geocentroid)\ndef geocentroid(\n df: gpd.GeoDataFrame,\n /,\n weights: Hashable | pd.Series = None,\n max_iter: int = 300,\n tol: float = 1e-5,\n) -> Point:\n if weights is not None and isinstance(weights, Hashable):\n weights = df[weights]\n\n return s_geocentroid(df.geometry, weights=weights, max_iter=max_iter, tol=tol)\n", "path": "dtoolkit/geoaccessor/geodataframe/geocentroid.py"}]}
| 1,933 | 1,014 |
gh_patches_debug_33369
|
rasdani/github-patches
|
git_diff
|
OCA__stock-logistics-warehouse-1192
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[12.0] stock_secondary_unit "secondary qty" value in picking not affecting "initial demand"
AFFECTED VERSIONS
12.0 (it works ok on 13.0)
STEPS TO REPRODUCE
Activate Units of Measure in general settings > inventory
Inventory > Master Data > Products > Set a secondary unit in a product

Create a new transfer > add product > select secondary UoM > input secondary qty

CURRENT BEHAVIOR
Value "Initial demand" is not affected by secondary qty input
In the same way, if "Initial demand" is set, "secondary qty" does not change - basically there is no relation between the two fields

REQUIRED BEHAVIOR
When "secondary qty" is updated, also "initial demand" should update - and viceversa, as it happens in SO with secondary unit modules
VIDEO
https://recordit.co/zcuDUx6xco
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `stock_secondary_unit/models/stock_move.py`
Content:
```
1 # Copyright 2018 Tecnativa - Sergio Teruel
2 # License AGPL-3.0 or later (https://www.gnu.org/licenses/agpl).
3 from odoo import api, fields, models
4 from odoo.addons import decimal_precision as dp
5 from odoo.tools.float_utils import float_round
6
7
8 class StockSecondaryUnitMixin(models.AbstractModel):
9 _name = 'stock.secondary.unit.mixin'
10 _description = 'Stock Secondary Unit Mixin'
11
12 secondary_uom_id = fields.Many2one(
13 comodel_name='product.secondary.unit',
14 string='Second unit',
15 )
16 secondary_uom_qty = fields.Float(
17 string='Secondary Qty',
18 digits=dp.get_precision('Product Unit of Measure'),
19 )
20
21
22 class StockMove(models.Model):
23 _inherit = ['stock.move', 'stock.secondary.unit.mixin']
24 _name = 'stock.move'
25
26 def _merge_moves_fields(self):
27 res = super(StockMove, self)._merge_moves_fields()
28 res['secondary_uom_qty'] = self[-1:].secondary_uom_qty
29 return res
30
31
32 class StockMoveLine(models.Model):
33 _inherit = ['stock.move.line', 'stock.secondary.unit.mixin']
34 _name = 'stock.move.line'
35
36 @api.model
37 def create(self, vals):
38 move = self.env['stock.move'].browse(vals.get('move_id', False))
39 if move.secondary_uom_id:
40 uom = self.env['uom.uom'].browse(vals['product_uom_id'])
41 factor = move.secondary_uom_id.factor * uom.factor
42 move_line_qty = vals.get(
43 'product_uom_qty', vals.get('qty_done', 0.0))
44 qty = float_round(
45 move_line_qty / (factor or 1.0),
46 precision_rounding=move.secondary_uom_id.uom_id.rounding
47 )
48 vals.update({
49 'secondary_uom_qty': qty,
50 'secondary_uom_id': move.secondary_uom_id.id,
51 })
52 return super().create(vals)
53
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/stock_secondary_unit/models/stock_move.py b/stock_secondary_unit/models/stock_move.py
--- a/stock_secondary_unit/models/stock_move.py
+++ b/stock_secondary_unit/models/stock_move.py
@@ -2,7 +2,7 @@
# License AGPL-3.0 or later (https://www.gnu.org/licenses/agpl).
from odoo import api, fields, models
from odoo.addons import decimal_precision as dp
-from odoo.tools.float_utils import float_round
+from odoo.tools.float_utils import float_compare, float_round
class StockSecondaryUnitMixin(models.AbstractModel):
@@ -28,6 +28,52 @@
res['secondary_uom_qty'] = self[-1:].secondary_uom_qty
return res
+ @api.onchange('secondary_uom_id', 'secondary_uom_qty')
+ def onchange_secondary_uom(self):
+ if not self.secondary_uom_id:
+ return
+ factor = self.secondary_uom_id.factor * self.product_uom.factor
+
+ qty = float_round(
+ self.secondary_uom_qty * factor,
+ precision_rounding=self.product_uom.rounding
+ )
+ if float_compare(
+ self.product_uom_qty, qty, precision_rounding=self.product_uom.rounding
+ ) != 0:
+ self.product_uom_qty = qty
+
+ @api.onchange('product_uom_qty')
+ def onchange_secondary_unit_product_uom_qty(self):
+ if not self.secondary_uom_id:
+ return
+ factor = self.secondary_uom_id.factor * self.product_uom.factor
+
+ qty = float_round(
+ self.product_uom_qty / (factor or 1.0),
+ precision_rounding=self.secondary_uom_id.uom_id.rounding
+ )
+ if float_compare(
+ self.secondary_uom_qty,
+ qty,
+ precision_rounding=self.secondary_uom_id.uom_id.rounding
+ ) != 0:
+ self.secondary_uom_qty = qty
+
+ @api.onchange('product_uom')
+ def onchange_product_uom_for_secondary(self):
+ if not self.secondary_uom_id:
+ return
+ factor = self.product_uom.factor * self.secondary_uom_id.factor
+ qty = float_round(
+ self.product_uom_qty / (factor or 1.0),
+ precision_rounding=self.product_uom.rounding
+ )
+ if float_compare(
+ self.secondary_uom_qty, qty, precision_rounding=self.product_uom.rounding
+ ) != 0:
+ self.secondary_uom_qty = qty
+
class StockMoveLine(models.Model):
_inherit = ['stock.move.line', 'stock.secondary.unit.mixin']
|
{"golden_diff": "diff --git a/stock_secondary_unit/models/stock_move.py b/stock_secondary_unit/models/stock_move.py\n--- a/stock_secondary_unit/models/stock_move.py\n+++ b/stock_secondary_unit/models/stock_move.py\n@@ -2,7 +2,7 @@\n # License AGPL-3.0 or later (https://www.gnu.org/licenses/agpl).\n from odoo import api, fields, models\n from odoo.addons import decimal_precision as dp\n-from odoo.tools.float_utils import float_round\n+from odoo.tools.float_utils import float_compare, float_round\n \n \n class StockSecondaryUnitMixin(models.AbstractModel):\n@@ -28,6 +28,52 @@\n res['secondary_uom_qty'] = self[-1:].secondary_uom_qty\n return res\n \n+ @api.onchange('secondary_uom_id', 'secondary_uom_qty')\n+ def onchange_secondary_uom(self):\n+ if not self.secondary_uom_id:\n+ return\n+ factor = self.secondary_uom_id.factor * self.product_uom.factor\n+\n+ qty = float_round(\n+ self.secondary_uom_qty * factor,\n+ precision_rounding=self.product_uom.rounding\n+ )\n+ if float_compare(\n+ self.product_uom_qty, qty, precision_rounding=self.product_uom.rounding\n+ ) != 0:\n+ self.product_uom_qty = qty\n+\n+ @api.onchange('product_uom_qty')\n+ def onchange_secondary_unit_product_uom_qty(self):\n+ if not self.secondary_uom_id:\n+ return\n+ factor = self.secondary_uom_id.factor * self.product_uom.factor\n+\n+ qty = float_round(\n+ self.product_uom_qty / (factor or 1.0),\n+ precision_rounding=self.secondary_uom_id.uom_id.rounding\n+ )\n+ if float_compare(\n+ self.secondary_uom_qty,\n+ qty,\n+ precision_rounding=self.secondary_uom_id.uom_id.rounding\n+ ) != 0:\n+ self.secondary_uom_qty = qty\n+\n+ @api.onchange('product_uom')\n+ def onchange_product_uom_for_secondary(self):\n+ if not self.secondary_uom_id:\n+ return\n+ factor = self.product_uom.factor * self.secondary_uom_id.factor\n+ qty = float_round(\n+ self.product_uom_qty / (factor or 1.0),\n+ precision_rounding=self.product_uom.rounding\n+ )\n+ if float_compare(\n+ self.secondary_uom_qty, qty, precision_rounding=self.product_uom.rounding\n+ ) != 0:\n+ self.secondary_uom_qty = qty\n+\n \n class StockMoveLine(models.Model):\n _inherit = ['stock.move.line', 'stock.secondary.unit.mixin']\n", "issue": "[12.0] stock_secondary_unit \"secondary qty\" value in picking not affecting \"initial demand\"\nAFFECTED VERSIONS\r\n\r\n12.0 (it works ok on 13.0)\r\n\r\nSTEPS TO REPRODUCE\r\n\r\nActivate Units of Measure in general settings > inventory\r\n\r\nInventory > Master Data > Products > Set a secondary unit in a product\r\n\r\n\r\n\r\nCreate a new transfer > add product > select secondary UoM > input secondary qty\r\n\r\n\r\n\r\nCURRENT BEHAVIOR\r\n\r\nValue \"Initial demand\" is not affected by secondary qty input\r\nIn the same way, if \"Initial demand\" is set, \"secondary qty\" does not change - basically there is no relation between the two fields\r\n\r\n\r\n\r\nREQUIRED BEHAVIOR \r\n\r\nWhen \"secondary qty\" is updated, also \"initial demand\" should update - and viceversa, as it happens in SO with secondary unit modules\r\n\r\nVIDEO\r\n\r\nhttps://recordit.co/zcuDUx6xco\r\n\r\n\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "# Copyright 2018 Tecnativa - Sergio Teruel\n# License AGPL-3.0 or later (https://www.gnu.org/licenses/agpl).\nfrom odoo import api, fields, models\nfrom odoo.addons import decimal_precision as dp\nfrom odoo.tools.float_utils import float_round\n\n\nclass StockSecondaryUnitMixin(models.AbstractModel):\n _name = 'stock.secondary.unit.mixin'\n _description = 'Stock Secondary Unit Mixin'\n\n secondary_uom_id = fields.Many2one(\n comodel_name='product.secondary.unit',\n string='Second unit',\n )\n secondary_uom_qty = fields.Float(\n string='Secondary Qty',\n digits=dp.get_precision('Product Unit of Measure'),\n )\n\n\nclass StockMove(models.Model):\n _inherit = ['stock.move', 'stock.secondary.unit.mixin']\n _name = 'stock.move'\n\n def _merge_moves_fields(self):\n res = super(StockMove, self)._merge_moves_fields()\n res['secondary_uom_qty'] = self[-1:].secondary_uom_qty\n return res\n\n\nclass StockMoveLine(models.Model):\n _inherit = ['stock.move.line', 'stock.secondary.unit.mixin']\n _name = 'stock.move.line'\n\n @api.model\n def create(self, vals):\n move = self.env['stock.move'].browse(vals.get('move_id', False))\n if move.secondary_uom_id:\n uom = self.env['uom.uom'].browse(vals['product_uom_id'])\n factor = move.secondary_uom_id.factor * uom.factor\n move_line_qty = vals.get(\n 'product_uom_qty', vals.get('qty_done', 0.0))\n qty = float_round(\n move_line_qty / (factor or 1.0),\n precision_rounding=move.secondary_uom_id.uom_id.rounding\n )\n vals.update({\n 'secondary_uom_qty': qty,\n 'secondary_uom_id': move.secondary_uom_id.id,\n })\n return super().create(vals)\n", "path": "stock_secondary_unit/models/stock_move.py"}], "after_files": [{"content": "# Copyright 2018 Tecnativa - Sergio Teruel\n# License AGPL-3.0 or later (https://www.gnu.org/licenses/agpl).\nfrom odoo import api, fields, models\nfrom odoo.addons import decimal_precision as dp\nfrom odoo.tools.float_utils import float_compare, float_round\n\n\nclass StockSecondaryUnitMixin(models.AbstractModel):\n _name = 'stock.secondary.unit.mixin'\n _description = 'Stock Secondary Unit Mixin'\n\n secondary_uom_id = fields.Many2one(\n comodel_name='product.secondary.unit',\n string='Second unit',\n )\n secondary_uom_qty = fields.Float(\n string='Secondary Qty',\n digits=dp.get_precision('Product Unit of Measure'),\n )\n\n\nclass StockMove(models.Model):\n _inherit = ['stock.move', 'stock.secondary.unit.mixin']\n _name = 'stock.move'\n\n def _merge_moves_fields(self):\n res = super(StockMove, self)._merge_moves_fields()\n res['secondary_uom_qty'] = self[-1:].secondary_uom_qty\n return res\n\n @api.onchange('secondary_uom_id', 'secondary_uom_qty')\n def onchange_secondary_uom(self):\n if not self.secondary_uom_id:\n return\n factor = self.secondary_uom_id.factor * self.product_uom.factor\n\n qty = float_round(\n self.secondary_uom_qty * factor,\n precision_rounding=self.product_uom.rounding\n )\n if float_compare(\n self.product_uom_qty, qty, precision_rounding=self.product_uom.rounding\n ) != 0:\n self.product_uom_qty = qty\n\n @api.onchange('product_uom_qty')\n def onchange_secondary_unit_product_uom_qty(self):\n if not self.secondary_uom_id:\n return\n factor = self.secondary_uom_id.factor * self.product_uom.factor\n\n qty = float_round(\n self.product_uom_qty / (factor or 1.0),\n precision_rounding=self.secondary_uom_id.uom_id.rounding\n )\n if float_compare(\n self.secondary_uom_qty,\n qty,\n precision_rounding=self.secondary_uom_id.uom_id.rounding\n ) != 0:\n self.secondary_uom_qty = qty\n\n @api.onchange('product_uom')\n def onchange_product_uom_for_secondary(self):\n if not self.secondary_uom_id:\n return\n factor = self.product_uom.factor * self.secondary_uom_id.factor\n qty = float_round(\n self.product_uom_qty / (factor or 1.0),\n precision_rounding=self.product_uom.rounding\n )\n if float_compare(\n self.secondary_uom_qty, qty, precision_rounding=self.product_uom.rounding\n ) != 0:\n self.secondary_uom_qty = qty\n\n\nclass StockMoveLine(models.Model):\n _inherit = ['stock.move.line', 'stock.secondary.unit.mixin']\n _name = 'stock.move.line'\n\n @api.model\n def create(self, vals):\n move = self.env['stock.move'].browse(vals.get('move_id', False))\n if move.secondary_uom_id:\n uom = self.env['uom.uom'].browse(vals['product_uom_id'])\n factor = move.secondary_uom_id.factor * uom.factor\n move_line_qty = vals.get(\n 'product_uom_qty', vals.get('qty_done', 0.0))\n qty = float_round(\n move_line_qty / (factor or 1.0),\n precision_rounding=move.secondary_uom_id.uom_id.rounding\n )\n vals.update({\n 'secondary_uom_qty': qty,\n 'secondary_uom_id': move.secondary_uom_id.id,\n })\n return super().create(vals)\n", "path": "stock_secondary_unit/models/stock_move.py"}]}
| 1,177 | 611 |
gh_patches_debug_14880
|
rasdani/github-patches
|
git_diff
|
google__pytype-520
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pytype can't parse hex literals
The following code causes the error `ParseError: syntax error, unexpected NAME, expecting ']'`:
```py
from typing import Literal
a: Literal[0x00ff]
```
Add lexing for base 2, 8, and 16 literals
Alters lexer.lex and adds a test for the new numeric types, Closes #494
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pytype/tools/traces/source.py`
Content:
```
1 # Lint as: python2, python3
2 """Source and trace information."""
3
4 from __future__ import print_function
5 import collections
6
7 Location = collections.namedtuple("Location", ("line", "column"))
8
9
10 class AbstractTrace(
11 collections.namedtuple("AbstractTrace", ("op", "symbol", "types"))):
12
13 def __new__(cls, op, symbol, types):
14 if cls is AbstractTrace:
15 raise TypeError("cannot instantiate AbstractTrace")
16 return super(AbstractTrace, cls).__new__(cls, op, symbol, types)
17
18 def __repr__(self):
19 return "%s : %s <- %s" % self
20
21
22 class Code(object):
23 """Line-based source code access.
24
25 Attributes:
26 text: The source text.
27 traces: A dictionary from line number to traces.
28 filename: The filename - when using traces.trace(), this value is meaningful
29 only if an options object containing the filename was provided.
30 """
31
32 def __init__(self, src, raw_traces, trace_factory, filename):
33 """Initializer.
34
35 Args:
36 src: The source text.
37 raw_traces: Raw (opcode, symbol, types) values.
38 trace_factory: A subclass of source.AbstractTrace that will be used to
39 instantiate traces from raw values.
40 filename: The filename.
41 """
42 self.text = src
43 self.traces = _collect_traces(raw_traces, trace_factory)
44 self.filename = filename
45 self._lines = src.split("\n")
46 self._offsets = []
47 self._init_byte_offsets()
48
49 def _init_byte_offsets(self):
50 offset = 0
51 for line in self._lines:
52 self._offsets.append(offset)
53 offset += len(line) + 1 # account for the \n
54
55 def get_offset(self, location):
56 """Gets the utf-8 byte offset of a source.Location from start of source."""
57 return self._offsets[location.line - 1] + location.column
58
59 def line(self, n):
60 """Gets the text at a line number."""
61 return self._lines[n - 1]
62
63 def get_closest_line_range(self, start, end):
64 """Gets all valid line numbers in the [start, end) line range."""
65 return range(start, min(end, len(self._lines) + 1))
66
67 def find_first_text(self, start, end, text):
68 """Gets first location, if any, the string appears at in the line range."""
69
70 for l in self.get_closest_line_range(start, end):
71 col = self.line(l).find(text)
72 if col > -1:
73 # TODO(mdemello): Temporary hack, replace with a token stream!
74 # This will break if we have a # in a string before our desired text.
75 comment_marker = self.line(l).find("#")
76 if -1 < comment_marker < col:
77 continue
78 return Location(l, col)
79 return None
80
81 def next_non_comment_line(self, line):
82 """Gets the next non-comment line, if any, after the given line."""
83 for l in range(line + 1, len(self._lines) + 1):
84 if self.line(l).lstrip().startswith("#"):
85 continue
86 return l
87 return None
88
89 def display_traces(self):
90 """Prints the source file with traces for debugging."""
91 for line in sorted(self.traces):
92 print("%d %s" % (line, self.line(line)))
93 for trace in self.traces[line]:
94 print(" %s" % (trace,))
95 print("-------------------")
96
97 def get_attr_location(self, name, location):
98 """Returns the location and span of the attribute in an attribute access.
99
100 Args:
101 name: The attribute name.
102 location: The location of the value the attribute is accessed on.
103 """
104 # TODO(mdemello): This is pretty crude, and does not for example take into
105 # account multiple calls of the same attribute in a line. It is just to get
106 # our tests passing until we incorporate asttokens.
107 line, _ = location
108 src_line = self.line(line)
109 attr = name.split(".")[-1]
110 dot_attr = "." + attr
111 if dot_attr in src_line:
112 col = src_line.index(dot_attr)
113 return (Location(line, col + 1), len(attr))
114 else:
115 # We have something like
116 # (foo
117 # .bar)
118 # or
119 # (foo.
120 # bar)
121 # Lookahead up to 5 lines to find '.attr' (the ast node always starts from
122 # the beginning of the chain, so foo.\nbar.\nbaz etc could span several
123 # lines).
124 attr_loc = self._get_multiline_location(location, 5, dot_attr)
125 if attr_loc:
126 return (Location(attr_loc.line, attr_loc.column + 1), len(attr))
127 else:
128 # Find consecutive lines ending with '.' and starting with 'attr'.
129 for l in self.get_closest_line_range(line, line + 5):
130 if self.line(l).endswith("."):
131 next_line = self.next_non_comment_line(l)
132 text = self.line(next_line)
133 if text.lstrip().startswith(attr):
134 c = text.index(attr)
135 return (Location(next_line, c), len(attr))
136 # if all else fails, fall back to just spanning the name
137 return (location, len(name))
138
139 def _get_multiline_location(self, location, n_lines, text):
140 """Gets the start location of text anywhere within n_lines of location."""
141 line, _ = location
142 text_loc = self.find_first_text(line, line + n_lines, text)
143 if text_loc:
144 return text_loc
145 else:
146 return None
147
148
149 def _collect_traces(raw_traces, trace_factory):
150 """Postprocesses pytype's opcode traces."""
151 out = collections.defaultdict(list)
152 for op, symbol, data in raw_traces:
153 out[op.line].append(trace_factory(op.name, symbol, data))
154 return out
155
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pytype/tools/traces/source.py b/pytype/tools/traces/source.py
--- a/pytype/tools/traces/source.py
+++ b/pytype/tools/traces/source.py
@@ -4,6 +4,9 @@
from __future__ import print_function
import collections
+from pytype import compat
+
+
Location = collections.namedtuple("Location", ("line", "column"))
@@ -50,7 +53,9 @@
offset = 0
for line in self._lines:
self._offsets.append(offset)
- offset += len(line) + 1 # account for the \n
+ # convert line to bytes
+ bytes_ = compat.bytestring(line)
+ offset += len(bytes_) + 1 # account for the \n
def get_offset(self, location):
"""Gets the utf-8 byte offset of a source.Location from start of source."""
|
{"golden_diff": "diff --git a/pytype/tools/traces/source.py b/pytype/tools/traces/source.py\n--- a/pytype/tools/traces/source.py\n+++ b/pytype/tools/traces/source.py\n@@ -4,6 +4,9 @@\n from __future__ import print_function\n import collections\n \n+from pytype import compat\n+\n+\n Location = collections.namedtuple(\"Location\", (\"line\", \"column\"))\n \n \n@@ -50,7 +53,9 @@\n offset = 0\n for line in self._lines:\n self._offsets.append(offset)\n- offset += len(line) + 1 # account for the \\n\n+ # convert line to bytes\n+ bytes_ = compat.bytestring(line)\n+ offset += len(bytes_) + 1 # account for the \\n\n \n def get_offset(self, location):\n \"\"\"Gets the utf-8 byte offset of a source.Location from start of source.\"\"\"\n", "issue": "pytype can't parse hex literals\nThe following code causes the error `ParseError: syntax error, unexpected NAME, expecting ']'`:\r\n\r\n```py\r\nfrom typing import Literal\r\n\r\na: Literal[0x00ff]\r\n```\nAdd lexing for base 2, 8, and 16 literals\nAlters lexer.lex and adds a test for the new numeric types, Closes #494 \n", "before_files": [{"content": "# Lint as: python2, python3\n\"\"\"Source and trace information.\"\"\"\n\nfrom __future__ import print_function\nimport collections\n\nLocation = collections.namedtuple(\"Location\", (\"line\", \"column\"))\n\n\nclass AbstractTrace(\n collections.namedtuple(\"AbstractTrace\", (\"op\", \"symbol\", \"types\"))):\n\n def __new__(cls, op, symbol, types):\n if cls is AbstractTrace:\n raise TypeError(\"cannot instantiate AbstractTrace\")\n return super(AbstractTrace, cls).__new__(cls, op, symbol, types)\n\n def __repr__(self):\n return \"%s : %s <- %s\" % self\n\n\nclass Code(object):\n \"\"\"Line-based source code access.\n\n Attributes:\n text: The source text.\n traces: A dictionary from line number to traces.\n filename: The filename - when using traces.trace(), this value is meaningful\n only if an options object containing the filename was provided.\n \"\"\"\n\n def __init__(self, src, raw_traces, trace_factory, filename):\n \"\"\"Initializer.\n\n Args:\n src: The source text.\n raw_traces: Raw (opcode, symbol, types) values.\n trace_factory: A subclass of source.AbstractTrace that will be used to\n instantiate traces from raw values.\n filename: The filename.\n \"\"\"\n self.text = src\n self.traces = _collect_traces(raw_traces, trace_factory)\n self.filename = filename\n self._lines = src.split(\"\\n\")\n self._offsets = []\n self._init_byte_offsets()\n\n def _init_byte_offsets(self):\n offset = 0\n for line in self._lines:\n self._offsets.append(offset)\n offset += len(line) + 1 # account for the \\n\n\n def get_offset(self, location):\n \"\"\"Gets the utf-8 byte offset of a source.Location from start of source.\"\"\"\n return self._offsets[location.line - 1] + location.column\n\n def line(self, n):\n \"\"\"Gets the text at a line number.\"\"\"\n return self._lines[n - 1]\n\n def get_closest_line_range(self, start, end):\n \"\"\"Gets all valid line numbers in the [start, end) line range.\"\"\"\n return range(start, min(end, len(self._lines) + 1))\n\n def find_first_text(self, start, end, text):\n \"\"\"Gets first location, if any, the string appears at in the line range.\"\"\"\n\n for l in self.get_closest_line_range(start, end):\n col = self.line(l).find(text)\n if col > -1:\n # TODO(mdemello): Temporary hack, replace with a token stream!\n # This will break if we have a # in a string before our desired text.\n comment_marker = self.line(l).find(\"#\")\n if -1 < comment_marker < col:\n continue\n return Location(l, col)\n return None\n\n def next_non_comment_line(self, line):\n \"\"\"Gets the next non-comment line, if any, after the given line.\"\"\"\n for l in range(line + 1, len(self._lines) + 1):\n if self.line(l).lstrip().startswith(\"#\"):\n continue\n return l\n return None\n\n def display_traces(self):\n \"\"\"Prints the source file with traces for debugging.\"\"\"\n for line in sorted(self.traces):\n print(\"%d %s\" % (line, self.line(line)))\n for trace in self.traces[line]:\n print(\" %s\" % (trace,))\n print(\"-------------------\")\n\n def get_attr_location(self, name, location):\n \"\"\"Returns the location and span of the attribute in an attribute access.\n\n Args:\n name: The attribute name.\n location: The location of the value the attribute is accessed on.\n \"\"\"\n # TODO(mdemello): This is pretty crude, and does not for example take into\n # account multiple calls of the same attribute in a line. It is just to get\n # our tests passing until we incorporate asttokens.\n line, _ = location\n src_line = self.line(line)\n attr = name.split(\".\")[-1]\n dot_attr = \".\" + attr\n if dot_attr in src_line:\n col = src_line.index(dot_attr)\n return (Location(line, col + 1), len(attr))\n else:\n # We have something like\n # (foo\n # .bar)\n # or\n # (foo.\n # bar)\n # Lookahead up to 5 lines to find '.attr' (the ast node always starts from\n # the beginning of the chain, so foo.\\nbar.\\nbaz etc could span several\n # lines).\n attr_loc = self._get_multiline_location(location, 5, dot_attr)\n if attr_loc:\n return (Location(attr_loc.line, attr_loc.column + 1), len(attr))\n else:\n # Find consecutive lines ending with '.' and starting with 'attr'.\n for l in self.get_closest_line_range(line, line + 5):\n if self.line(l).endswith(\".\"):\n next_line = self.next_non_comment_line(l)\n text = self.line(next_line)\n if text.lstrip().startswith(attr):\n c = text.index(attr)\n return (Location(next_line, c), len(attr))\n # if all else fails, fall back to just spanning the name\n return (location, len(name))\n\n def _get_multiline_location(self, location, n_lines, text):\n \"\"\"Gets the start location of text anywhere within n_lines of location.\"\"\"\n line, _ = location\n text_loc = self.find_first_text(line, line + n_lines, text)\n if text_loc:\n return text_loc\n else:\n return None\n\n\ndef _collect_traces(raw_traces, trace_factory):\n \"\"\"Postprocesses pytype's opcode traces.\"\"\"\n out = collections.defaultdict(list)\n for op, symbol, data in raw_traces:\n out[op.line].append(trace_factory(op.name, symbol, data))\n return out\n", "path": "pytype/tools/traces/source.py"}], "after_files": [{"content": "# Lint as: python2, python3\n\"\"\"Source and trace information.\"\"\"\n\nfrom __future__ import print_function\nimport collections\n\nfrom pytype import compat\n\n\nLocation = collections.namedtuple(\"Location\", (\"line\", \"column\"))\n\n\nclass AbstractTrace(\n collections.namedtuple(\"AbstractTrace\", (\"op\", \"symbol\", \"types\"))):\n\n def __new__(cls, op, symbol, types):\n if cls is AbstractTrace:\n raise TypeError(\"cannot instantiate AbstractTrace\")\n return super(AbstractTrace, cls).__new__(cls, op, symbol, types)\n\n def __repr__(self):\n return \"%s : %s <- %s\" % self\n\n\nclass Code(object):\n \"\"\"Line-based source code access.\n\n Attributes:\n text: The source text.\n traces: A dictionary from line number to traces.\n filename: The filename - when using traces.trace(), this value is meaningful\n only if an options object containing the filename was provided.\n \"\"\"\n\n def __init__(self, src, raw_traces, trace_factory, filename):\n \"\"\"Initializer.\n\n Args:\n src: The source text.\n raw_traces: Raw (opcode, symbol, types) values.\n trace_factory: A subclass of source.AbstractTrace that will be used to\n instantiate traces from raw values.\n filename: The filename.\n \"\"\"\n self.text = src\n self.traces = _collect_traces(raw_traces, trace_factory)\n self.filename = filename\n self._lines = src.split(\"\\n\")\n self._offsets = []\n self._init_byte_offsets()\n\n def _init_byte_offsets(self):\n offset = 0\n for line in self._lines:\n self._offsets.append(offset)\n # convert line to bytes\n bytes_ = compat.bytestring(line)\n offset += len(bytes_) + 1 # account for the \\n\n\n def get_offset(self, location):\n \"\"\"Gets the utf-8 byte offset of a source.Location from start of source.\"\"\"\n return self._offsets[location.line - 1] + location.column\n\n def line(self, n):\n \"\"\"Gets the text at a line number.\"\"\"\n return self._lines[n - 1]\n\n def get_closest_line_range(self, start, end):\n \"\"\"Gets all valid line numbers in the [start, end) line range.\"\"\"\n return range(start, min(end, len(self._lines) + 1))\n\n def find_first_text(self, start, end, text):\n \"\"\"Gets first location, if any, the string appears at in the line range.\"\"\"\n\n for l in self.get_closest_line_range(start, end):\n col = self.line(l).find(text)\n if col > -1:\n # TODO(mdemello): Temporary hack, replace with a token stream!\n # This will break if we have a # in a string before our desired text.\n comment_marker = self.line(l).find(\"#\")\n if -1 < comment_marker < col:\n continue\n return Location(l, col)\n return None\n\n def next_non_comment_line(self, line):\n \"\"\"Gets the next non-comment line, if any, after the given line.\"\"\"\n for l in range(line + 1, len(self._lines) + 1):\n if self.line(l).lstrip().startswith(\"#\"):\n continue\n return l\n return None\n\n def display_traces(self):\n \"\"\"Prints the source file with traces for debugging.\"\"\"\n for line in sorted(self.traces):\n print(\"%d %s\" % (line, self.line(line)))\n for trace in self.traces[line]:\n print(\" %s\" % (trace,))\n print(\"-------------------\")\n\n def get_attr_location(self, name, location):\n \"\"\"Returns the location and span of the attribute in an attribute access.\n\n Args:\n name: The attribute name.\n location: The location of the value the attribute is accessed on.\n \"\"\"\n # TODO(mdemello): This is pretty crude, and does not for example take into\n # account multiple calls of the same attribute in a line. It is just to get\n # our tests passing until we incorporate asttokens.\n line, _ = location\n src_line = self.line(line)\n attr = name.split(\".\")[-1]\n dot_attr = \".\" + attr\n if dot_attr in src_line:\n col = src_line.index(dot_attr)\n return (Location(line, col + 1), len(attr))\n else:\n # We have something like\n # (foo\n # .bar)\n # or\n # (foo.\n # bar)\n # Lookahead up to 5 lines to find '.attr' (the ast node always starts from\n # the beginning of the chain, so foo.\\nbar.\\nbaz etc could span several\n # lines).\n attr_loc = self._get_multiline_location(location, 5, dot_attr)\n if attr_loc:\n return (Location(attr_loc.line, attr_loc.column + 1), len(attr))\n else:\n # Find consecutive lines ending with '.' and starting with 'attr'.\n for l in self.get_closest_line_range(line, line + 5):\n if self.line(l).endswith(\".\"):\n next_line = self.next_non_comment_line(l)\n text = self.line(next_line)\n if text.lstrip().startswith(attr):\n c = text.index(attr)\n return (Location(next_line, c), len(attr))\n # if all else fails, fall back to just spanning the name\n return (location, len(name))\n\n def _get_multiline_location(self, location, n_lines, text):\n \"\"\"Gets the start location of text anywhere within n_lines of location.\"\"\"\n line, _ = location\n text_loc = self.find_first_text(line, line + n_lines, text)\n if text_loc:\n return text_loc\n else:\n return None\n\n\ndef _collect_traces(raw_traces, trace_factory):\n \"\"\"Postprocesses pytype's opcode traces.\"\"\"\n out = collections.defaultdict(list)\n for op, symbol, data in raw_traces:\n out[op.line].append(trace_factory(op.name, symbol, data))\n return out\n", "path": "pytype/tools/traces/source.py"}]}
| 2,024 | 200 |
gh_patches_debug_1511
|
rasdani/github-patches
|
git_diff
|
bentoml__BentoML-4665
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
feature: Allow removal of server header
### Feature request
Currently the server header is being exposed with the value 'uvicorn'. This does not pose an immediate security threat. However it exposes implementation details that could potentially aid bad actors in targeting specific software. Minimizing such disclosures is advisable to reduce the risk of targeted attacks.
Uvicorn has an option to disable sending server headers. Ref: https://www.uvicorn.org/settings/#http
### Motivation
We are trying to get some models deployed to production and this is is one of the security blockers.
### Other
I am working on a possible fix that would be unbreaking and backwards compatible.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/_bentoml_impl/worker/service.py`
Content:
```
1 from __future__ import annotations
2
3 import json
4 import os
5 import typing as t
6
7 import click
8
9
10 @click.command()
11 @click.argument("bento_identifier", type=click.STRING, required=False, default=".")
12 @click.option("--service-name", type=click.STRING, required=False, default="")
13 @click.option(
14 "--fd",
15 type=click.INT,
16 required=True,
17 help="File descriptor of the socket to listen on",
18 )
19 @click.option(
20 "--runner-map",
21 type=click.STRING,
22 envvar="BENTOML_RUNNER_MAP",
23 help="JSON string of runners map, default sets to envars `BENTOML_RUNNER_MAP`",
24 )
25 @click.option(
26 "--backlog", type=click.INT, default=2048, help="Backlog size for the socket"
27 )
28 @click.option(
29 "--prometheus-dir",
30 type=click.Path(exists=True),
31 help="Required by prometheus to pass the metrics in multi-process mode",
32 )
33 @click.option(
34 "--worker-env", type=click.STRING, default=None, help="Environment variables"
35 )
36 @click.option(
37 "--worker-id",
38 required=False,
39 type=click.INT,
40 default=None,
41 help="If set, start the server as a bare worker with the given worker ID. Otherwise start a standalone server with a supervisor process.",
42 )
43 @click.option(
44 "--ssl-certfile",
45 type=str,
46 default=None,
47 help="SSL certificate file",
48 )
49 @click.option(
50 "--ssl-keyfile",
51 type=str,
52 default=None,
53 help="SSL key file",
54 )
55 @click.option(
56 "--ssl-keyfile-password",
57 type=str,
58 default=None,
59 help="SSL keyfile password",
60 )
61 @click.option(
62 "--ssl-version",
63 type=int,
64 default=None,
65 help="SSL version to use (see stdlib 'ssl' module)",
66 )
67 @click.option(
68 "--ssl-cert-reqs",
69 type=int,
70 default=None,
71 help="Whether client certificate is required (see stdlib 'ssl' module)",
72 )
73 @click.option(
74 "--ssl-ca-certs",
75 type=str,
76 default=None,
77 help="CA certificates file",
78 )
79 @click.option(
80 "--ssl-ciphers",
81 type=str,
82 default=None,
83 help="Ciphers to use (see stdlib 'ssl' module)",
84 )
85 @click.option(
86 "--development-mode",
87 type=click.BOOL,
88 help="Run the API server in development mode",
89 is_flag=True,
90 default=False,
91 show_default=True,
92 )
93 @click.option(
94 "--timeout",
95 type=click.INT,
96 help="Specify the timeout for API server",
97 )
98 def main(
99 bento_identifier: str,
100 service_name: str,
101 fd: int,
102 runner_map: str | None,
103 backlog: int,
104 worker_env: str | None,
105 worker_id: int | None,
106 prometheus_dir: str | None,
107 ssl_certfile: str | None,
108 ssl_keyfile: str | None,
109 ssl_keyfile_password: str | None,
110 ssl_version: int | None,
111 ssl_cert_reqs: int | None,
112 ssl_ca_certs: str | None,
113 ssl_ciphers: str | None,
114 development_mode: bool,
115 timeout: int,
116 ):
117 """
118 Start a HTTP server worker for given service.
119 """
120 import psutil
121 import uvicorn
122
123 if worker_env:
124 env_list: list[dict[str, t.Any]] = json.loads(worker_env)
125 if worker_id is not None:
126 # worker id from circus starts from 1
127 worker_key = worker_id - 1
128 if worker_key >= len(env_list):
129 raise IndexError(
130 f"Worker ID {worker_id} is out of range, "
131 f"the maximum worker ID is {len(env_list)}"
132 )
133 os.environ.update(env_list[worker_key])
134
135 from _bentoml_impl.loader import import_service
136 from bentoml._internal.container import BentoMLContainer
137 from bentoml._internal.context import server_context
138 from bentoml._internal.log import configure_server_logging
139
140 if runner_map:
141 BentoMLContainer.remote_runner_mapping.set(
142 t.cast(t.Dict[str, str], json.loads(runner_map))
143 )
144
145 service = import_service(bento_identifier)
146
147 if service_name and service_name != service.name:
148 service = service.find_dependent(service_name)
149 server_context.service_type = "service"
150 else:
151 server_context.service_type = "entry_service"
152
153 if worker_id is not None:
154 server_context.worker_index = worker_id
155
156 configure_server_logging()
157 BentoMLContainer.development_mode.set(development_mode)
158
159 if prometheus_dir is not None:
160 BentoMLContainer.prometheus_multiproc_dir.set(prometheus_dir)
161 server_context.service_name = service.name
162
163 asgi_app = service.to_asgi(
164 is_main=server_context.service_type == "entry_service", init=False
165 )
166
167 uvicorn_extra_options: dict[str, t.Any] = {}
168 if ssl_version is not None:
169 uvicorn_extra_options["ssl_version"] = ssl_version
170 if ssl_cert_reqs is not None:
171 uvicorn_extra_options["ssl_cert_reqs"] = ssl_cert_reqs
172 if ssl_ciphers is not None:
173 uvicorn_extra_options["ssl_ciphers"] = ssl_ciphers
174
175 if psutil.WINDOWS:
176 # 1. uvloop is not supported on Windows
177 # 2. the default policy for Python > 3.8 on Windows is ProactorEventLoop, which doesn't
178 # support listen on a existing socket file descriptors
179 # See https://docs.python.org/3.8/library/asyncio-platforms.html#windows
180 uvicorn_extra_options["loop"] = "asyncio"
181 import asyncio
182
183 asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy()) # type: ignore
184
185 uvicorn.run(
186 app=asgi_app,
187 fd=fd,
188 backlog=backlog,
189 log_config=None,
190 workers=1,
191 ssl_certfile=ssl_certfile,
192 ssl_keyfile=ssl_keyfile,
193 ssl_keyfile_password=ssl_keyfile_password,
194 ssl_ca_certs=ssl_ca_certs,
195 **uvicorn_extra_options,
196 )
197
198
199 if __name__ == "__main__":
200 main() # pylint: disable=no-value-for-parameter
201
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/_bentoml_impl/worker/service.py b/src/_bentoml_impl/worker/service.py
--- a/src/_bentoml_impl/worker/service.py
+++ b/src/_bentoml_impl/worker/service.py
@@ -192,6 +192,7 @@
ssl_keyfile=ssl_keyfile,
ssl_keyfile_password=ssl_keyfile_password,
ssl_ca_certs=ssl_ca_certs,
+ server_header=False,
**uvicorn_extra_options,
)
|
{"golden_diff": "diff --git a/src/_bentoml_impl/worker/service.py b/src/_bentoml_impl/worker/service.py\n--- a/src/_bentoml_impl/worker/service.py\n+++ b/src/_bentoml_impl/worker/service.py\n@@ -192,6 +192,7 @@\n ssl_keyfile=ssl_keyfile,\n ssl_keyfile_password=ssl_keyfile_password,\n ssl_ca_certs=ssl_ca_certs,\n+ server_header=False,\n **uvicorn_extra_options,\n )\n", "issue": "feature: Allow removal of server header\n### Feature request\n\nCurrently the server header is being exposed with the value 'uvicorn'. This does not pose an immediate security threat. However it exposes implementation details that could potentially aid bad actors in targeting specific software. Minimizing such disclosures is advisable to reduce the risk of targeted attacks.\r\n\r\nUvicorn has an option to disable sending server headers. Ref: https://www.uvicorn.org/settings/#http\n\n### Motivation\n\nWe are trying to get some models deployed to production and this is is one of the security blockers.\n\n### Other\n\nI am working on a possible fix that would be unbreaking and backwards compatible.\n", "before_files": [{"content": "from __future__ import annotations\n\nimport json\nimport os\nimport typing as t\n\nimport click\n\n\[email protected]()\[email protected](\"bento_identifier\", type=click.STRING, required=False, default=\".\")\[email protected](\"--service-name\", type=click.STRING, required=False, default=\"\")\[email protected](\n \"--fd\",\n type=click.INT,\n required=True,\n help=\"File descriptor of the socket to listen on\",\n)\[email protected](\n \"--runner-map\",\n type=click.STRING,\n envvar=\"BENTOML_RUNNER_MAP\",\n help=\"JSON string of runners map, default sets to envars `BENTOML_RUNNER_MAP`\",\n)\[email protected](\n \"--backlog\", type=click.INT, default=2048, help=\"Backlog size for the socket\"\n)\[email protected](\n \"--prometheus-dir\",\n type=click.Path(exists=True),\n help=\"Required by prometheus to pass the metrics in multi-process mode\",\n)\[email protected](\n \"--worker-env\", type=click.STRING, default=None, help=\"Environment variables\"\n)\[email protected](\n \"--worker-id\",\n required=False,\n type=click.INT,\n default=None,\n help=\"If set, start the server as a bare worker with the given worker ID. Otherwise start a standalone server with a supervisor process.\",\n)\[email protected](\n \"--ssl-certfile\",\n type=str,\n default=None,\n help=\"SSL certificate file\",\n)\[email protected](\n \"--ssl-keyfile\",\n type=str,\n default=None,\n help=\"SSL key file\",\n)\[email protected](\n \"--ssl-keyfile-password\",\n type=str,\n default=None,\n help=\"SSL keyfile password\",\n)\[email protected](\n \"--ssl-version\",\n type=int,\n default=None,\n help=\"SSL version to use (see stdlib 'ssl' module)\",\n)\[email protected](\n \"--ssl-cert-reqs\",\n type=int,\n default=None,\n help=\"Whether client certificate is required (see stdlib 'ssl' module)\",\n)\[email protected](\n \"--ssl-ca-certs\",\n type=str,\n default=None,\n help=\"CA certificates file\",\n)\[email protected](\n \"--ssl-ciphers\",\n type=str,\n default=None,\n help=\"Ciphers to use (see stdlib 'ssl' module)\",\n)\[email protected](\n \"--development-mode\",\n type=click.BOOL,\n help=\"Run the API server in development mode\",\n is_flag=True,\n default=False,\n show_default=True,\n)\[email protected](\n \"--timeout\",\n type=click.INT,\n help=\"Specify the timeout for API server\",\n)\ndef main(\n bento_identifier: str,\n service_name: str,\n fd: int,\n runner_map: str | None,\n backlog: int,\n worker_env: str | None,\n worker_id: int | None,\n prometheus_dir: str | None,\n ssl_certfile: str | None,\n ssl_keyfile: str | None,\n ssl_keyfile_password: str | None,\n ssl_version: int | None,\n ssl_cert_reqs: int | None,\n ssl_ca_certs: str | None,\n ssl_ciphers: str | None,\n development_mode: bool,\n timeout: int,\n):\n \"\"\"\n Start a HTTP server worker for given service.\n \"\"\"\n import psutil\n import uvicorn\n\n if worker_env:\n env_list: list[dict[str, t.Any]] = json.loads(worker_env)\n if worker_id is not None:\n # worker id from circus starts from 1\n worker_key = worker_id - 1\n if worker_key >= len(env_list):\n raise IndexError(\n f\"Worker ID {worker_id} is out of range, \"\n f\"the maximum worker ID is {len(env_list)}\"\n )\n os.environ.update(env_list[worker_key])\n\n from _bentoml_impl.loader import import_service\n from bentoml._internal.container import BentoMLContainer\n from bentoml._internal.context import server_context\n from bentoml._internal.log import configure_server_logging\n\n if runner_map:\n BentoMLContainer.remote_runner_mapping.set(\n t.cast(t.Dict[str, str], json.loads(runner_map))\n )\n\n service = import_service(bento_identifier)\n\n if service_name and service_name != service.name:\n service = service.find_dependent(service_name)\n server_context.service_type = \"service\"\n else:\n server_context.service_type = \"entry_service\"\n\n if worker_id is not None:\n server_context.worker_index = worker_id\n\n configure_server_logging()\n BentoMLContainer.development_mode.set(development_mode)\n\n if prometheus_dir is not None:\n BentoMLContainer.prometheus_multiproc_dir.set(prometheus_dir)\n server_context.service_name = service.name\n\n asgi_app = service.to_asgi(\n is_main=server_context.service_type == \"entry_service\", init=False\n )\n\n uvicorn_extra_options: dict[str, t.Any] = {}\n if ssl_version is not None:\n uvicorn_extra_options[\"ssl_version\"] = ssl_version\n if ssl_cert_reqs is not None:\n uvicorn_extra_options[\"ssl_cert_reqs\"] = ssl_cert_reqs\n if ssl_ciphers is not None:\n uvicorn_extra_options[\"ssl_ciphers\"] = ssl_ciphers\n\n if psutil.WINDOWS:\n # 1. uvloop is not supported on Windows\n # 2. the default policy for Python > 3.8 on Windows is ProactorEventLoop, which doesn't\n # support listen on a existing socket file descriptors\n # See https://docs.python.org/3.8/library/asyncio-platforms.html#windows\n uvicorn_extra_options[\"loop\"] = \"asyncio\"\n import asyncio\n\n asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy()) # type: ignore\n\n uvicorn.run(\n app=asgi_app,\n fd=fd,\n backlog=backlog,\n log_config=None,\n workers=1,\n ssl_certfile=ssl_certfile,\n ssl_keyfile=ssl_keyfile,\n ssl_keyfile_password=ssl_keyfile_password,\n ssl_ca_certs=ssl_ca_certs,\n **uvicorn_extra_options,\n )\n\n\nif __name__ == \"__main__\":\n main() # pylint: disable=no-value-for-parameter\n", "path": "src/_bentoml_impl/worker/service.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport json\nimport os\nimport typing as t\n\nimport click\n\n\[email protected]()\[email protected](\"bento_identifier\", type=click.STRING, required=False, default=\".\")\[email protected](\"--service-name\", type=click.STRING, required=False, default=\"\")\[email protected](\n \"--fd\",\n type=click.INT,\n required=True,\n help=\"File descriptor of the socket to listen on\",\n)\[email protected](\n \"--runner-map\",\n type=click.STRING,\n envvar=\"BENTOML_RUNNER_MAP\",\n help=\"JSON string of runners map, default sets to envars `BENTOML_RUNNER_MAP`\",\n)\[email protected](\n \"--backlog\", type=click.INT, default=2048, help=\"Backlog size for the socket\"\n)\[email protected](\n \"--prometheus-dir\",\n type=click.Path(exists=True),\n help=\"Required by prometheus to pass the metrics in multi-process mode\",\n)\[email protected](\n \"--worker-env\", type=click.STRING, default=None, help=\"Environment variables\"\n)\[email protected](\n \"--worker-id\",\n required=False,\n type=click.INT,\n default=None,\n help=\"If set, start the server as a bare worker with the given worker ID. Otherwise start a standalone server with a supervisor process.\",\n)\[email protected](\n \"--ssl-certfile\",\n type=str,\n default=None,\n help=\"SSL certificate file\",\n)\[email protected](\n \"--ssl-keyfile\",\n type=str,\n default=None,\n help=\"SSL key file\",\n)\[email protected](\n \"--ssl-keyfile-password\",\n type=str,\n default=None,\n help=\"SSL keyfile password\",\n)\[email protected](\n \"--ssl-version\",\n type=int,\n default=None,\n help=\"SSL version to use (see stdlib 'ssl' module)\",\n)\[email protected](\n \"--ssl-cert-reqs\",\n type=int,\n default=None,\n help=\"Whether client certificate is required (see stdlib 'ssl' module)\",\n)\[email protected](\n \"--ssl-ca-certs\",\n type=str,\n default=None,\n help=\"CA certificates file\",\n)\[email protected](\n \"--ssl-ciphers\",\n type=str,\n default=None,\n help=\"Ciphers to use (see stdlib 'ssl' module)\",\n)\[email protected](\n \"--development-mode\",\n type=click.BOOL,\n help=\"Run the API server in development mode\",\n is_flag=True,\n default=False,\n show_default=True,\n)\[email protected](\n \"--timeout\",\n type=click.INT,\n help=\"Specify the timeout for API server\",\n)\ndef main(\n bento_identifier: str,\n service_name: str,\n fd: int,\n runner_map: str | None,\n backlog: int,\n worker_env: str | None,\n worker_id: int | None,\n prometheus_dir: str | None,\n ssl_certfile: str | None,\n ssl_keyfile: str | None,\n ssl_keyfile_password: str | None,\n ssl_version: int | None,\n ssl_cert_reqs: int | None,\n ssl_ca_certs: str | None,\n ssl_ciphers: str | None,\n development_mode: bool,\n timeout: int,\n):\n \"\"\"\n Start a HTTP server worker for given service.\n \"\"\"\n import psutil\n import uvicorn\n\n if worker_env:\n env_list: list[dict[str, t.Any]] = json.loads(worker_env)\n if worker_id is not None:\n # worker id from circus starts from 1\n worker_key = worker_id - 1\n if worker_key >= len(env_list):\n raise IndexError(\n f\"Worker ID {worker_id} is out of range, \"\n f\"the maximum worker ID is {len(env_list)}\"\n )\n os.environ.update(env_list[worker_key])\n\n from _bentoml_impl.loader import import_service\n from bentoml._internal.container import BentoMLContainer\n from bentoml._internal.context import server_context\n from bentoml._internal.log import configure_server_logging\n\n if runner_map:\n BentoMLContainer.remote_runner_mapping.set(\n t.cast(t.Dict[str, str], json.loads(runner_map))\n )\n\n service = import_service(bento_identifier)\n\n if service_name and service_name != service.name:\n service = service.find_dependent(service_name)\n server_context.service_type = \"service\"\n else:\n server_context.service_type = \"entry_service\"\n\n if worker_id is not None:\n server_context.worker_index = worker_id\n\n configure_server_logging()\n BentoMLContainer.development_mode.set(development_mode)\n\n if prometheus_dir is not None:\n BentoMLContainer.prometheus_multiproc_dir.set(prometheus_dir)\n server_context.service_name = service.name\n\n asgi_app = service.to_asgi(\n is_main=server_context.service_type == \"entry_service\", init=False\n )\n\n uvicorn_extra_options: dict[str, t.Any] = {}\n if ssl_version is not None:\n uvicorn_extra_options[\"ssl_version\"] = ssl_version\n if ssl_cert_reqs is not None:\n uvicorn_extra_options[\"ssl_cert_reqs\"] = ssl_cert_reqs\n if ssl_ciphers is not None:\n uvicorn_extra_options[\"ssl_ciphers\"] = ssl_ciphers\n\n if psutil.WINDOWS:\n # 1. uvloop is not supported on Windows\n # 2. the default policy for Python > 3.8 on Windows is ProactorEventLoop, which doesn't\n # support listen on a existing socket file descriptors\n # See https://docs.python.org/3.8/library/asyncio-platforms.html#windows\n uvicorn_extra_options[\"loop\"] = \"asyncio\"\n import asyncio\n\n asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy()) # type: ignore\n\n uvicorn.run(\n app=asgi_app,\n fd=fd,\n backlog=backlog,\n log_config=None,\n workers=1,\n ssl_certfile=ssl_certfile,\n ssl_keyfile=ssl_keyfile,\n ssl_keyfile_password=ssl_keyfile_password,\n ssl_ca_certs=ssl_ca_certs,\n server_header=False,\n **uvicorn_extra_options,\n )\n\n\nif __name__ == \"__main__\":\n main() # pylint: disable=no-value-for-parameter\n", "path": "src/_bentoml_impl/worker/service.py"}]}
| 2,285 | 116 |
gh_patches_debug_57768
|
rasdani/github-patches
|
git_diff
|
openstates__openstates-scrapers-3135
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
KY-scrape failing since at least 2020-01-30
KY-scrape has failed 5 times since 2020-01-30
Logs:
```
subcommands[args.subcommand].handle(args, other)
File "/root/.cache/pypoetry/virtualenvs/**BACKUPS/PGUSER**-vRcYrsYN-py3.7/lib/python3.7/site-packages/pupa/cli/commands/update.py", line 270, in handle
juris, module = self.get_jurisdiction(args.module)
File "/root/.cache/pypoetry/virtualenvs/**BACKUPS/PGUSER**-vRcYrsYN-py3.7/lib/python3.7/site-packages/pupa/cli/commands/update.py", line 142, in get_jurisdiction
module = importlib.import_module(module_name)
File "/usr/local/lib/python3.7/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1006, in _gcd_import
File "<frozen importlib._bootstrap>", line 983, in _find_and_load
File "<frozen importlib._bootstrap>", line 967, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 677, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 728, in exec_module
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "/opt/**BACKUPS/PGUSER**/**BACKUPS/PGUSER**/**BACKUPS/PGUSER**/ky/__init__.py", line 10, in <module>
from .bills import KYBillScraper
File "/opt/**BACKUPS/PGUSER**/**BACKUPS/PGUSER**/**BACKUPS/PGUSER**/ky/bills.py", line 22, in <module>
class KYBillScraper(Scraper, LXMLMixin):
File "/opt/**BACKUPS/PGUSER**/**BACKUPS/PGUSER**/**BACKUPS/PGUSER**/ky/bills.py", line 36, in KYBillScraper
("1st reading", "reading-1"),
TypeError: 'tuple' object is not callable
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `openstates/ky/bills.py`
Content:
```
1 import re
2 import datetime
3 import scrapelib
4 from collections import defaultdict
5 from pytz import timezone
6
7 from pupa.scrape import Scraper, Bill
8 from openstates.utils import LXMLMixin
9
10
11 def chamber_abbr(chamber):
12 if chamber == "upper":
13 return "S"
14 else:
15 return "H"
16
17
18 def session_url(session):
19 return "https://apps.legislature.ky.gov/record/%s/" % session[2:]
20
21
22 class KYBillScraper(Scraper, LXMLMixin):
23 _TZ = timezone("America/Kentucky/Louisville")
24 _subjects = defaultdict(list)
25 _is_post_2016 = False
26
27 _action_classifiers = [
28 ("introduced in", "introduction"),
29 ("signed by Governor", ["executive-signature"]),
30 ("vetoed", "executive-veto"),
31 (r"^to [A-Z]", "referral-committee"),
32 (" to [A-Z]", "referral-committee"),
33 ("reported favorably", "committee-passage"),
34 ("adopted by voice vote", "passage"),
35 ("3rd reading, passed", ["reading-3", "passage"])
36 ("1st reading", "reading-1"),
37 ("2nd reading", "reading-2"),
38 ("3rd reading", "reading-3"),
39 ("passed", "passage"),
40 ("delivered to secretary of state", "became-law"),
41 ("veto overridden", "veto-override-passage"),
42 ("adopted by voice vote", "passage"),
43 (
44 r"floor amendments?( \([a-z\d\-]+\))*" r"( and \([a-z\d\-]+\))? filed",
45 "amendment-introduction",
46 ),
47 ]
48
49 def classify_action(self, action):
50 for regex, classification in self._action_classifiers:
51 if re.match(regex, action):
52 return classification
53 return None
54
55 def scrape(self, session=None, chamber=None):
56 if not session:
57 session = self.latest_session()
58 self.info("no session specified, using %s", session)
59 # Bill page markup changed starting with the 2016 regular session.
60 # kinda gross
61 if int(session[0:4]) >= 2016:
62 self._is_post_2016 = True
63
64 # self.scrape_subjects(session)
65 chambers = [chamber] if chamber else ["upper", "lower"]
66 for chamber in chambers:
67 yield from self.scrape_session(chamber, session)
68
69 def scrape_session(self, chamber, session):
70 chamber_map = {"upper": "senate", "lower": "house"}
71 bill_url = session_url(session) + "%s_bills.html" % chamber_map[chamber]
72 yield from self.scrape_bill_list(chamber, session, bill_url)
73
74 resolution_url = (
75 session_url(session) + "%s_resolutions.html" % chamber_map[chamber]
76 )
77 yield from self.scrape_bill_list(chamber, session, resolution_url)
78
79 def scrape_bill_list(self, chamber, session, url):
80 bill_abbr = None
81 page = self.lxmlize(url)
82
83 for link in page.xpath("//div[contains(@class,'container')]/p/a"):
84 if re.search(r"\d{1,4}\.htm", link.attrib.get("href", "")):
85 bill_id = link.text
86 match = re.match(
87 r".*\/([a-z]+)([\d+])\.html", link.attrib.get("href", "")
88 )
89 if match:
90 bill_abbr = match.group(1)
91 bill_id = bill_abbr.upper() + bill_id.replace(" ", "")
92 else:
93 bill_id = bill_abbr + bill_id
94
95 yield from self.parse_bill(
96 chamber, session, bill_id, link.attrib["href"]
97 )
98
99 def parse_actions(self, page, bill, chamber):
100 # //div[preceding-sibling::a[@id="actions"]]
101 action_rows = page.xpath(
102 '//div[preceding-sibling::a[@id="actions"]][1]/table[1]/tbody/tr'
103 )
104 for row in action_rows:
105 action_date = row.xpath("th[1]/text()")[0].strip()
106
107 action_date = datetime.datetime.strptime(action_date, "%m/%d/%y")
108 action_date = self._TZ.localize(action_date)
109
110 action_texts = row.xpath("td[1]/ul/li/text() | td[1]/ul/li/strong/text()")
111
112 for action_text in action_texts:
113 action_text = action_text.strip()
114 if action_text.endswith("House") or action_text.endswith("(H)"):
115 actor = "lower"
116 elif action_text.endswith("Senate") or action_text.endswith("(S)"):
117 actor = "upper"
118 else:
119 actor = chamber
120
121 classifications = self.classify_action(action_text)
122 bill.add_action(
123 action_text,
124 action_date,
125 chamber=actor,
126 classification=classifications,
127 )
128
129 # Get the field to the right for a given table header
130 def parse_bill_field(self, page, header):
131 xpath_expr = '//tr[th[text()="{}"]]/td[1]'.format(header)
132 return page.xpath(xpath_expr)[0]
133
134 def parse_bill(self, chamber, session, bill_id, url):
135 try:
136 page = self.lxmlize(url)
137 except scrapelib.HTTPError as e:
138 self.logger.warning(e)
139 return
140
141 last_action = self.parse_bill_field(page, "Last Action").xpath("text()")[0]
142 if "WITHDRAWN" in last_action.upper():
143 self.info("{} Withdrawn, skipping".format(bill_id))
144 return
145
146 version = self.parse_bill_field(page, "Bill Documents")
147 source_url = version.xpath("a[1]/@href")[0]
148 version_title = version.xpath("a[1]/text()")[0].strip()
149
150 if version is None:
151 # Bill withdrawn
152 self.logger.warning("Bill withdrawn.")
153 return
154 else:
155 if source_url.endswith(".doc"):
156 mimetype = "application/msword"
157 elif source_url.endswith(".pdf"):
158 mimetype = "application/pdf"
159
160 title = self.parse_bill_field(page, "Title").text_content()
161
162 # actions = self.get_nodes(
163 # page,
164 # '//div[@class="StandardText leftDivMargin"]/'
165 # 'div[@class="StandardText"][last()]//text()[normalize-space()]')
166
167 if "CR" in bill_id:
168 bill_type = "concurrent resolution"
169 elif "JR" in bill_id:
170 bill_type = "joint resolution"
171 elif "R" in bill_id:
172 bill_type = "resolution"
173 else:
174 bill_type = "bill"
175
176 bill = Bill(
177 bill_id,
178 legislative_session=session,
179 chamber=chamber,
180 title=title,
181 classification=bill_type,
182 )
183 bill.subject = self._subjects[bill_id]
184 bill.add_source(url)
185
186 bill.add_version_link(version_title, source_url, media_type=mimetype)
187
188 self.parse_actions(page, bill, chamber)
189 self.parse_subjects(page, bill)
190
191 # LM is "Locally Mandated fiscal impact"
192 fiscal_notes = page.xpath('//a[contains(@href, "/LM.pdf")]')
193 for fiscal_note in fiscal_notes:
194 source_url = fiscal_note.attrib["href"]
195 if source_url.endswith(".doc"):
196 mimetype = "application/msword"
197 elif source_url.endswith(".pdf"):
198 mimetype = "application/pdf"
199
200 bill.add_document_link("Fiscal Note", source_url, media_type=mimetype)
201
202 for link in page.xpath("//td/span/a[contains(@href, 'Legislator-Profile')]"):
203 bill.add_sponsorship(
204 link.text.strip(),
205 classification="primary",
206 entity_type="person",
207 primary=True,
208 )
209
210 bdr_no = self.parse_bill_field(page, "Bill Request Number")
211 if bdr_no.xpath("text()"):
212 bdr = bdr_no.xpath("text()")[0].strip()
213 bill.extras["BDR"] = bdr
214
215 yield bill
216
217 def parse_subjects(self, page, bill):
218 subject_div = self.parse_bill_field(page, "Index Headings of Original Version")
219 subjects = subject_div.xpath("a/text()")
220 seen_subjects = []
221 for subject in subjects:
222 if subject not in seen_subjects:
223 bill.add_subject(subject.strip())
224 seen_subjects.append(subject)
225
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/openstates/ky/bills.py b/openstates/ky/bills.py
--- a/openstates/ky/bills.py
+++ b/openstates/ky/bills.py
@@ -32,7 +32,7 @@
(" to [A-Z]", "referral-committee"),
("reported favorably", "committee-passage"),
("adopted by voice vote", "passage"),
- ("3rd reading, passed", ["reading-3", "passage"])
+ ("3rd reading, passed", ["reading-3", "passage"]),
("1st reading", "reading-1"),
("2nd reading", "reading-2"),
("3rd reading", "reading-3"),
|
{"golden_diff": "diff --git a/openstates/ky/bills.py b/openstates/ky/bills.py\n--- a/openstates/ky/bills.py\n+++ b/openstates/ky/bills.py\n@@ -32,7 +32,7 @@\n (\" to [A-Z]\", \"referral-committee\"),\n (\"reported favorably\", \"committee-passage\"),\n (\"adopted by voice vote\", \"passage\"),\n- (\"3rd reading, passed\", [\"reading-3\", \"passage\"])\n+ (\"3rd reading, passed\", [\"reading-3\", \"passage\"]),\n (\"1st reading\", \"reading-1\"),\n (\"2nd reading\", \"reading-2\"),\n (\"3rd reading\", \"reading-3\"),\n", "issue": "KY-scrape failing since at least 2020-01-30\nKY-scrape has failed 5 times since 2020-01-30\n\nLogs:\n```\n subcommands[args.subcommand].handle(args, other)\n File \"/root/.cache/pypoetry/virtualenvs/**BACKUPS/PGUSER**-vRcYrsYN-py3.7/lib/python3.7/site-packages/pupa/cli/commands/update.py\", line 270, in handle\n juris, module = self.get_jurisdiction(args.module)\n File \"/root/.cache/pypoetry/virtualenvs/**BACKUPS/PGUSER**-vRcYrsYN-py3.7/lib/python3.7/site-packages/pupa/cli/commands/update.py\", line 142, in get_jurisdiction\n module = importlib.import_module(module_name)\n File \"/usr/local/lib/python3.7/importlib/__init__.py\", line 127, in import_module\n return _bootstrap._gcd_import(name[level:], package, level)\n File \"<frozen importlib._bootstrap>\", line 1006, in _gcd_import\n File \"<frozen importlib._bootstrap>\", line 983, in _find_and_load\n File \"<frozen importlib._bootstrap>\", line 967, in _find_and_load_unlocked\n File \"<frozen importlib._bootstrap>\", line 677, in _load_unlocked\n File \"<frozen importlib._bootstrap_external>\", line 728, in exec_module\n File \"<frozen importlib._bootstrap>\", line 219, in _call_with_frames_removed\n File \"/opt/**BACKUPS/PGUSER**/**BACKUPS/PGUSER**/**BACKUPS/PGUSER**/ky/__init__.py\", line 10, in <module>\n from .bills import KYBillScraper\n File \"/opt/**BACKUPS/PGUSER**/**BACKUPS/PGUSER**/**BACKUPS/PGUSER**/ky/bills.py\", line 22, in <module>\n class KYBillScraper(Scraper, LXMLMixin):\n File \"/opt/**BACKUPS/PGUSER**/**BACKUPS/PGUSER**/**BACKUPS/PGUSER**/ky/bills.py\", line 36, in KYBillScraper\n (\"1st reading\", \"reading-1\"),\nTypeError: 'tuple' object is not callable\n```\n \n", "before_files": [{"content": "import re\nimport datetime\nimport scrapelib\nfrom collections import defaultdict\nfrom pytz import timezone\n\nfrom pupa.scrape import Scraper, Bill\nfrom openstates.utils import LXMLMixin\n\n\ndef chamber_abbr(chamber):\n if chamber == \"upper\":\n return \"S\"\n else:\n return \"H\"\n\n\ndef session_url(session):\n return \"https://apps.legislature.ky.gov/record/%s/\" % session[2:]\n\n\nclass KYBillScraper(Scraper, LXMLMixin):\n _TZ = timezone(\"America/Kentucky/Louisville\")\n _subjects = defaultdict(list)\n _is_post_2016 = False\n\n _action_classifiers = [\n (\"introduced in\", \"introduction\"),\n (\"signed by Governor\", [\"executive-signature\"]),\n (\"vetoed\", \"executive-veto\"),\n (r\"^to [A-Z]\", \"referral-committee\"),\n (\" to [A-Z]\", \"referral-committee\"),\n (\"reported favorably\", \"committee-passage\"),\n (\"adopted by voice vote\", \"passage\"),\n (\"3rd reading, passed\", [\"reading-3\", \"passage\"])\n (\"1st reading\", \"reading-1\"),\n (\"2nd reading\", \"reading-2\"),\n (\"3rd reading\", \"reading-3\"),\n (\"passed\", \"passage\"),\n (\"delivered to secretary of state\", \"became-law\"),\n (\"veto overridden\", \"veto-override-passage\"),\n (\"adopted by voice vote\", \"passage\"),\n (\n r\"floor amendments?( \\([a-z\\d\\-]+\\))*\" r\"( and \\([a-z\\d\\-]+\\))? filed\",\n \"amendment-introduction\",\n ),\n ]\n\n def classify_action(self, action):\n for regex, classification in self._action_classifiers:\n if re.match(regex, action):\n return classification\n return None\n\n def scrape(self, session=None, chamber=None):\n if not session:\n session = self.latest_session()\n self.info(\"no session specified, using %s\", session)\n # Bill page markup changed starting with the 2016 regular session.\n # kinda gross\n if int(session[0:4]) >= 2016:\n self._is_post_2016 = True\n\n # self.scrape_subjects(session)\n chambers = [chamber] if chamber else [\"upper\", \"lower\"]\n for chamber in chambers:\n yield from self.scrape_session(chamber, session)\n\n def scrape_session(self, chamber, session):\n chamber_map = {\"upper\": \"senate\", \"lower\": \"house\"}\n bill_url = session_url(session) + \"%s_bills.html\" % chamber_map[chamber]\n yield from self.scrape_bill_list(chamber, session, bill_url)\n\n resolution_url = (\n session_url(session) + \"%s_resolutions.html\" % chamber_map[chamber]\n )\n yield from self.scrape_bill_list(chamber, session, resolution_url)\n\n def scrape_bill_list(self, chamber, session, url):\n bill_abbr = None\n page = self.lxmlize(url)\n\n for link in page.xpath(\"//div[contains(@class,'container')]/p/a\"):\n if re.search(r\"\\d{1,4}\\.htm\", link.attrib.get(\"href\", \"\")):\n bill_id = link.text\n match = re.match(\n r\".*\\/([a-z]+)([\\d+])\\.html\", link.attrib.get(\"href\", \"\")\n )\n if match:\n bill_abbr = match.group(1)\n bill_id = bill_abbr.upper() + bill_id.replace(\" \", \"\")\n else:\n bill_id = bill_abbr + bill_id\n\n yield from self.parse_bill(\n chamber, session, bill_id, link.attrib[\"href\"]\n )\n\n def parse_actions(self, page, bill, chamber):\n # //div[preceding-sibling::a[@id=\"actions\"]]\n action_rows = page.xpath(\n '//div[preceding-sibling::a[@id=\"actions\"]][1]/table[1]/tbody/tr'\n )\n for row in action_rows:\n action_date = row.xpath(\"th[1]/text()\")[0].strip()\n\n action_date = datetime.datetime.strptime(action_date, \"%m/%d/%y\")\n action_date = self._TZ.localize(action_date)\n\n action_texts = row.xpath(\"td[1]/ul/li/text() | td[1]/ul/li/strong/text()\")\n\n for action_text in action_texts:\n action_text = action_text.strip()\n if action_text.endswith(\"House\") or action_text.endswith(\"(H)\"):\n actor = \"lower\"\n elif action_text.endswith(\"Senate\") or action_text.endswith(\"(S)\"):\n actor = \"upper\"\n else:\n actor = chamber\n\n classifications = self.classify_action(action_text)\n bill.add_action(\n action_text,\n action_date,\n chamber=actor,\n classification=classifications,\n )\n\n # Get the field to the right for a given table header\n def parse_bill_field(self, page, header):\n xpath_expr = '//tr[th[text()=\"{}\"]]/td[1]'.format(header)\n return page.xpath(xpath_expr)[0]\n\n def parse_bill(self, chamber, session, bill_id, url):\n try:\n page = self.lxmlize(url)\n except scrapelib.HTTPError as e:\n self.logger.warning(e)\n return\n\n last_action = self.parse_bill_field(page, \"Last Action\").xpath(\"text()\")[0]\n if \"WITHDRAWN\" in last_action.upper():\n self.info(\"{} Withdrawn, skipping\".format(bill_id))\n return\n\n version = self.parse_bill_field(page, \"Bill Documents\")\n source_url = version.xpath(\"a[1]/@href\")[0]\n version_title = version.xpath(\"a[1]/text()\")[0].strip()\n\n if version is None:\n # Bill withdrawn\n self.logger.warning(\"Bill withdrawn.\")\n return\n else:\n if source_url.endswith(\".doc\"):\n mimetype = \"application/msword\"\n elif source_url.endswith(\".pdf\"):\n mimetype = \"application/pdf\"\n\n title = self.parse_bill_field(page, \"Title\").text_content()\n\n # actions = self.get_nodes(\n # page,\n # '//div[@class=\"StandardText leftDivMargin\"]/'\n # 'div[@class=\"StandardText\"][last()]//text()[normalize-space()]')\n\n if \"CR\" in bill_id:\n bill_type = \"concurrent resolution\"\n elif \"JR\" in bill_id:\n bill_type = \"joint resolution\"\n elif \"R\" in bill_id:\n bill_type = \"resolution\"\n else:\n bill_type = \"bill\"\n\n bill = Bill(\n bill_id,\n legislative_session=session,\n chamber=chamber,\n title=title,\n classification=bill_type,\n )\n bill.subject = self._subjects[bill_id]\n bill.add_source(url)\n\n bill.add_version_link(version_title, source_url, media_type=mimetype)\n\n self.parse_actions(page, bill, chamber)\n self.parse_subjects(page, bill)\n\n # LM is \"Locally Mandated fiscal impact\"\n fiscal_notes = page.xpath('//a[contains(@href, \"/LM.pdf\")]')\n for fiscal_note in fiscal_notes:\n source_url = fiscal_note.attrib[\"href\"]\n if source_url.endswith(\".doc\"):\n mimetype = \"application/msword\"\n elif source_url.endswith(\".pdf\"):\n mimetype = \"application/pdf\"\n\n bill.add_document_link(\"Fiscal Note\", source_url, media_type=mimetype)\n\n for link in page.xpath(\"//td/span/a[contains(@href, 'Legislator-Profile')]\"):\n bill.add_sponsorship(\n link.text.strip(),\n classification=\"primary\",\n entity_type=\"person\",\n primary=True,\n )\n\n bdr_no = self.parse_bill_field(page, \"Bill Request Number\")\n if bdr_no.xpath(\"text()\"):\n bdr = bdr_no.xpath(\"text()\")[0].strip()\n bill.extras[\"BDR\"] = bdr\n\n yield bill\n\n def parse_subjects(self, page, bill):\n subject_div = self.parse_bill_field(page, \"Index Headings of Original Version\")\n subjects = subject_div.xpath(\"a/text()\")\n seen_subjects = []\n for subject in subjects:\n if subject not in seen_subjects:\n bill.add_subject(subject.strip())\n seen_subjects.append(subject)\n", "path": "openstates/ky/bills.py"}], "after_files": [{"content": "import re\nimport datetime\nimport scrapelib\nfrom collections import defaultdict\nfrom pytz import timezone\n\nfrom pupa.scrape import Scraper, Bill\nfrom openstates.utils import LXMLMixin\n\n\ndef chamber_abbr(chamber):\n if chamber == \"upper\":\n return \"S\"\n else:\n return \"H\"\n\n\ndef session_url(session):\n return \"https://apps.legislature.ky.gov/record/%s/\" % session[2:]\n\n\nclass KYBillScraper(Scraper, LXMLMixin):\n _TZ = timezone(\"America/Kentucky/Louisville\")\n _subjects = defaultdict(list)\n _is_post_2016 = False\n\n _action_classifiers = [\n (\"introduced in\", \"introduction\"),\n (\"signed by Governor\", [\"executive-signature\"]),\n (\"vetoed\", \"executive-veto\"),\n (r\"^to [A-Z]\", \"referral-committee\"),\n (\" to [A-Z]\", \"referral-committee\"),\n (\"reported favorably\", \"committee-passage\"),\n (\"adopted by voice vote\", \"passage\"),\n (\"3rd reading, passed\", [\"reading-3\", \"passage\"]),\n (\"1st reading\", \"reading-1\"),\n (\"2nd reading\", \"reading-2\"),\n (\"3rd reading\", \"reading-3\"),\n (\"passed\", \"passage\"),\n (\"delivered to secretary of state\", \"became-law\"),\n (\"veto overridden\", \"veto-override-passage\"),\n (\"adopted by voice vote\", \"passage\"),\n (\n r\"floor amendments?( \\([a-z\\d\\-]+\\))*\" r\"( and \\([a-z\\d\\-]+\\))? filed\",\n \"amendment-introduction\",\n ),\n ]\n\n def classify_action(self, action):\n for regex, classification in self._action_classifiers:\n if re.match(regex, action):\n return classification\n return None\n\n def scrape(self, session=None, chamber=None):\n if not session:\n session = self.latest_session()\n self.info(\"no session specified, using %s\", session)\n # Bill page markup changed starting with the 2016 regular session.\n # kinda gross\n if int(session[0:4]) >= 2016:\n self._is_post_2016 = True\n\n # self.scrape_subjects(session)\n chambers = [chamber] if chamber else [\"upper\", \"lower\"]\n for chamber in chambers:\n yield from self.scrape_session(chamber, session)\n\n def scrape_session(self, chamber, session):\n chamber_map = {\"upper\": \"senate\", \"lower\": \"house\"}\n bill_url = session_url(session) + \"%s_bills.html\" % chamber_map[chamber]\n yield from self.scrape_bill_list(chamber, session, bill_url)\n\n resolution_url = (\n session_url(session) + \"%s_resolutions.html\" % chamber_map[chamber]\n )\n yield from self.scrape_bill_list(chamber, session, resolution_url)\n\n def scrape_bill_list(self, chamber, session, url):\n bill_abbr = None\n page = self.lxmlize(url)\n\n for link in page.xpath(\"//div[contains(@class,'container')]/p/a\"):\n if re.search(r\"\\d{1,4}\\.htm\", link.attrib.get(\"href\", \"\")):\n bill_id = link.text\n match = re.match(\n r\".*\\/([a-z]+)([\\d+])\\.html\", link.attrib.get(\"href\", \"\")\n )\n if match:\n bill_abbr = match.group(1)\n bill_id = bill_abbr.upper() + bill_id.replace(\" \", \"\")\n else:\n bill_id = bill_abbr + bill_id\n\n yield from self.parse_bill(\n chamber, session, bill_id, link.attrib[\"href\"]\n )\n\n def parse_actions(self, page, bill, chamber):\n # //div[preceding-sibling::a[@id=\"actions\"]]\n action_rows = page.xpath(\n '//div[preceding-sibling::a[@id=\"actions\"]][1]/table[1]/tbody/tr'\n )\n for row in action_rows:\n action_date = row.xpath(\"th[1]/text()\")[0].strip()\n\n action_date = datetime.datetime.strptime(action_date, \"%m/%d/%y\")\n action_date = self._TZ.localize(action_date)\n\n action_texts = row.xpath(\"td[1]/ul/li/text() | td[1]/ul/li/strong/text()\")\n\n for action_text in action_texts:\n action_text = action_text.strip()\n if action_text.endswith(\"House\") or action_text.endswith(\"(H)\"):\n actor = \"lower\"\n elif action_text.endswith(\"Senate\") or action_text.endswith(\"(S)\"):\n actor = \"upper\"\n else:\n actor = chamber\n\n classifications = self.classify_action(action_text)\n bill.add_action(\n action_text,\n action_date,\n chamber=actor,\n classification=classifications,\n )\n\n # Get the field to the right for a given table header\n def parse_bill_field(self, page, header):\n xpath_expr = '//tr[th[text()=\"{}\"]]/td[1]'.format(header)\n return page.xpath(xpath_expr)[0]\n\n def parse_bill(self, chamber, session, bill_id, url):\n try:\n page = self.lxmlize(url)\n except scrapelib.HTTPError as e:\n self.logger.warning(e)\n return\n\n last_action = self.parse_bill_field(page, \"Last Action\").xpath(\"text()\")[0]\n if \"WITHDRAWN\" in last_action.upper():\n self.info(\"{} Withdrawn, skipping\".format(bill_id))\n return\n\n version = self.parse_bill_field(page, \"Bill Documents\")\n source_url = version.xpath(\"a[1]/@href\")[0]\n version_title = version.xpath(\"a[1]/text()\")[0].strip()\n\n if version is None:\n # Bill withdrawn\n self.logger.warning(\"Bill withdrawn.\")\n return\n else:\n if source_url.endswith(\".doc\"):\n mimetype = \"application/msword\"\n elif source_url.endswith(\".pdf\"):\n mimetype = \"application/pdf\"\n\n title = self.parse_bill_field(page, \"Title\").text_content()\n\n # actions = self.get_nodes(\n # page,\n # '//div[@class=\"StandardText leftDivMargin\"]/'\n # 'div[@class=\"StandardText\"][last()]//text()[normalize-space()]')\n\n if \"CR\" in bill_id:\n bill_type = \"concurrent resolution\"\n elif \"JR\" in bill_id:\n bill_type = \"joint resolution\"\n elif \"R\" in bill_id:\n bill_type = \"resolution\"\n else:\n bill_type = \"bill\"\n\n bill = Bill(\n bill_id,\n legislative_session=session,\n chamber=chamber,\n title=title,\n classification=bill_type,\n )\n bill.subject = self._subjects[bill_id]\n bill.add_source(url)\n\n bill.add_version_link(version_title, source_url, media_type=mimetype)\n\n self.parse_actions(page, bill, chamber)\n self.parse_subjects(page, bill)\n\n # LM is \"Locally Mandated fiscal impact\"\n fiscal_notes = page.xpath('//a[contains(@href, \"/LM.pdf\")]')\n for fiscal_note in fiscal_notes:\n source_url = fiscal_note.attrib[\"href\"]\n if source_url.endswith(\".doc\"):\n mimetype = \"application/msword\"\n elif source_url.endswith(\".pdf\"):\n mimetype = \"application/pdf\"\n\n bill.add_document_link(\"Fiscal Note\", source_url, media_type=mimetype)\n\n for link in page.xpath(\"//td/span/a[contains(@href, 'Legislator-Profile')]\"):\n bill.add_sponsorship(\n link.text.strip(),\n classification=\"primary\",\n entity_type=\"person\",\n primary=True,\n )\n\n bdr_no = self.parse_bill_field(page, \"Bill Request Number\")\n if bdr_no.xpath(\"text()\"):\n bdr = bdr_no.xpath(\"text()\")[0].strip()\n bill.extras[\"BDR\"] = bdr\n\n yield bill\n\n def parse_subjects(self, page, bill):\n subject_div = self.parse_bill_field(page, \"Index Headings of Original Version\")\n subjects = subject_div.xpath(\"a/text()\")\n seen_subjects = []\n for subject in subjects:\n if subject not in seen_subjects:\n bill.add_subject(subject.strip())\n seen_subjects.append(subject)\n", "path": "openstates/ky/bills.py"}]}
| 3,214 | 157 |
gh_patches_debug_11603
|
rasdani/github-patches
|
git_diff
|
opsdroid__opsdroid-1648
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Migrate tests from unittest to pytest
Our existing test suite has been written with the Python [`unittest`](https://docs.python.org/3/library/unittest.html) framework. However, as the test suite has grown and opsdroid has become more complex we are running into issues with the tests. Mainly around setting up and tearing down tests.
The @opsdroid/maintainers team have decided that we want to migrate all tests to be written with the [`pytest`](https://docs.pytest.org/en/latest/contents.html) framework instead so that we can make better use of fixtures. Fixtures are more reusable and portable and should help reduce complexity all over.
There's a lot to be done but it can be done piece by piece as `pytest` can run tests in either format. So if you wish to help in the effort you can start by searching the codebase for unittest suites. These are classes which are subclassed from `unittest.TestCase` or `asynctest.TestCase`, so searching all files for `unittest.TestCase` and `asynctest.TestCase` should be a good place to start.
For detailed information on running the test suite and contributing to opsdroid [see the docs](https://docs.opsdroid.dev/en/latest/contributing/index.html). But the quickest way to get started us with [`tox`](https://tox.readthedocs.io/en/latest/).
```bash
pip install -U tox # You only need to install tox once
tox -e py36,lint # Run the Python 3.6 tests (the lowest version we support) and the linter
```
Once you have found a test suite you wish to convert there are a few steps you need to follow to convert from unittest to pytest:
- Move tests from top level `tests` directory to a nested `tests` directory in opsdroid. Create one in an appropriate place if there isn't already one.
- Remove test from class, pytest tests are just regular functions.
- Change assertions to use regular `assert` or [pytest assertions](https://docs.pytest.org/en/latest/assert.html).
- Mark async tests. In unittest we write async tests by using the `asynctest.TestCase`, but in pytest we decorate our tests with `@pytest.mark.asyncio` instead.
- Move setup operations to fixtures. If a test class contains a `setUp` method anything created here should become a fixture. Check the existing fixtures in `conftest.py` before creating new ones.
- Add docstrings to tests and fixtures to explain what they do. We have been pretty rubbish with this up until now and there are many tests which are not obvious in what they are testing.
Here's an example:
```python
# Before (unittest)
import asynctest
import asynctest.mock as mock
from opsdroid.cli.start import configure_lang
from opsdroid.core import OpsDroid
from opsdroid.events import Message
from opsdroid.matchers import match_regex
from opsdroid import constraints
class TestConstraints(asynctest.TestCase):
"""Test the opsdroid constraint decorators."""
async def setUp(self):
configure_lang({})
async def getMockSkill(self):
async def mockedskill(opsdroid, config, message):
pass
mockedskill.config = {}
return mockedskill
async def test_constrain_rooms_constrains(self):
with OpsDroid() as opsdroid:
skill = await self.getMockSkill()
skill = match_regex(r".*")(skill)
skill = constraints.constrain_rooms(["#general"])(skill)
opsdroid.skills.append(skill)
tasks = await opsdroid.parse(
Message(text="Hello", user="user", target="#random", connector=None)
)
self.assertEqual(len(tasks), 2) # Just match_always and match_event
```
```python
# After (pytest)
import pytest
from opsdroid.cli.start import configure_lang
from opsdroid.core import OpsDroid
from opsdroid.events import Message
from opsdroid.matchers import match_regex
from opsdroid import constraints
configure_lang({}) # Required for our internationalization of error messages
@pytest.fixture
def opsdroid():
"""An instance of the OpsDroid class."""
with OpsDroid() as opsdroid:
yield opsdroid
@pytest.fixture
def mock_skill():
"""A skill which does nothing but follows the skill API."""
async def mockedskill(opsdroid, config, message):
pass
mockedskill.config = {}
return mockedskill
@pytest.mark.asyncio
async def test_constrain_rooms_constrains(opsdroid, mock_skill):
"""Test that with the room constraint a skill is not called."""
skill = match_regex(r".*")(mock_skill)
skill = constraints.constrain_rooms(["#general"])(skill)
opsdroid.skills.append(skill)
tasks = await opsdroid.parse(
Message(text="Hello", user="user", target="#random", connector=None)
)
assert len(tasks) == 2 # Just match_always and match_event
```
Fixtures such as the `opsdroid` fixture will be extremely useful in many tests, so we will be creating some standard ones like this which will be available in all tests. If you write a fixture that you think could be useful in other places please don't hesitate to contribute it to the `conftest.py` file.
If you have any questions you can chat to us on [Matrix](https://riot.im/app/#/room/#opsdroid-general:matrix.org). We encourage you to get started and if you have issues or get stuck then open a [draft PR](https://github.blog/2019-02-14-introducing-draft-pull-requests/) with your changes and we can take a look.
---
When this issue is complete the documentation about the migration should be removed from the testing docs.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `opsdroid/conftest.py`
Content:
```
1 """Pytest config for all opsdroid tests."""
2 from opsdroid.testing import opsdroid
3
4 from opsdroid.cli.start import configure_lang
5
6 __all__ = ["opsdroid"]
7
8 configure_lang({})
9
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/opsdroid/conftest.py b/opsdroid/conftest.py
--- a/opsdroid/conftest.py
+++ b/opsdroid/conftest.py
@@ -1,8 +1,29 @@
"""Pytest config for all opsdroid tests."""
+import pytest
+
+import asyncio
+
from opsdroid.testing import opsdroid
+from opsdroid.connector import Connector
from opsdroid.cli.start import configure_lang
__all__ = ["opsdroid"]
configure_lang({})
+
+
[email protected](scope="session")
+def get_connector():
+ def _get_connector(config={}):
+ return Connector(config, opsdroid=opsdroid)
+
+ return _get_connector
+
+
[email protected]_fixture
+def event_loop():
+ """Create an instance of the default event loop for each test case."""
+ loop = asyncio.get_event_loop_policy().new_event_loop()
+ yield loop
+ loop.close()
|
{"golden_diff": "diff --git a/opsdroid/conftest.py b/opsdroid/conftest.py\n--- a/opsdroid/conftest.py\n+++ b/opsdroid/conftest.py\n@@ -1,8 +1,29 @@\n \"\"\"Pytest config for all opsdroid tests.\"\"\"\n+import pytest\n+\n+import asyncio\n+\n from opsdroid.testing import opsdroid\n+from opsdroid.connector import Connector\n \n from opsdroid.cli.start import configure_lang\n \n __all__ = [\"opsdroid\"]\n \n configure_lang({})\n+\n+\[email protected](scope=\"session\")\n+def get_connector():\n+ def _get_connector(config={}):\n+ return Connector(config, opsdroid=opsdroid)\n+\n+ return _get_connector\n+\n+\[email protected]_fixture\n+def event_loop():\n+ \"\"\"Create an instance of the default event loop for each test case.\"\"\"\n+ loop = asyncio.get_event_loop_policy().new_event_loop()\n+ yield loop\n+ loop.close()\n", "issue": "Migrate tests from unittest to pytest\nOur existing test suite has been written with the Python [`unittest`](https://docs.python.org/3/library/unittest.html) framework. However, as the test suite has grown and opsdroid has become more complex we are running into issues with the tests. Mainly around setting up and tearing down tests.\r\n\r\nThe @opsdroid/maintainers team have decided that we want to migrate all tests to be written with the [`pytest`](https://docs.pytest.org/en/latest/contents.html) framework instead so that we can make better use of fixtures. Fixtures are more reusable and portable and should help reduce complexity all over.\r\n\r\nThere's a lot to be done but it can be done piece by piece as `pytest` can run tests in either format. So if you wish to help in the effort you can start by searching the codebase for unittest suites. These are classes which are subclassed from `unittest.TestCase` or `asynctest.TestCase`, so searching all files for `unittest.TestCase` and `asynctest.TestCase` should be a good place to start.\r\n\r\nFor detailed information on running the test suite and contributing to opsdroid [see the docs](https://docs.opsdroid.dev/en/latest/contributing/index.html). But the quickest way to get started us with [`tox`](https://tox.readthedocs.io/en/latest/).\r\n\r\n```bash\r\npip install -U tox # You only need to install tox once\r\n\r\ntox -e py36,lint # Run the Python 3.6 tests (the lowest version we support) and the linter\r\n```\r\n\r\nOnce you have found a test suite you wish to convert there are a few steps you need to follow to convert from unittest to pytest:\r\n- Move tests from top level `tests` directory to a nested `tests` directory in opsdroid. Create one in an appropriate place if there isn't already one.\r\n- Remove test from class, pytest tests are just regular functions.\r\n- Change assertions to use regular `assert` or [pytest assertions](https://docs.pytest.org/en/latest/assert.html).\r\n- Mark async tests. In unittest we write async tests by using the `asynctest.TestCase`, but in pytest we decorate our tests with `@pytest.mark.asyncio` instead.\r\n- Move setup operations to fixtures. If a test class contains a `setUp` method anything created here should become a fixture. Check the existing fixtures in `conftest.py` before creating new ones.\r\n- Add docstrings to tests and fixtures to explain what they do. We have been pretty rubbish with this up until now and there are many tests which are not obvious in what they are testing.\r\n\r\nHere's an example:\r\n\r\n```python\r\n# Before (unittest)\r\nimport asynctest\r\nimport asynctest.mock as mock\r\n\r\nfrom opsdroid.cli.start import configure_lang\r\nfrom opsdroid.core import OpsDroid\r\nfrom opsdroid.events import Message\r\nfrom opsdroid.matchers import match_regex\r\nfrom opsdroid import constraints\r\n\r\n\r\nclass TestConstraints(asynctest.TestCase):\r\n \"\"\"Test the opsdroid constraint decorators.\"\"\"\r\n\r\n async def setUp(self):\r\n configure_lang({})\r\n\r\n async def getMockSkill(self):\r\n async def mockedskill(opsdroid, config, message):\r\n pass\r\n\r\n mockedskill.config = {}\r\n return mockedskill\r\n\r\n async def test_constrain_rooms_constrains(self):\r\n with OpsDroid() as opsdroid:\r\n skill = await self.getMockSkill()\r\n skill = match_regex(r\".*\")(skill)\r\n skill = constraints.constrain_rooms([\"#general\"])(skill)\r\n opsdroid.skills.append(skill)\r\n\r\n tasks = await opsdroid.parse(\r\n Message(text=\"Hello\", user=\"user\", target=\"#random\", connector=None)\r\n )\r\n self.assertEqual(len(tasks), 2) # Just match_always and match_event\r\n```\r\n\r\n```python\r\n# After (pytest)\r\nimport pytest\r\n\r\nfrom opsdroid.cli.start import configure_lang\r\nfrom opsdroid.core import OpsDroid\r\nfrom opsdroid.events import Message\r\nfrom opsdroid.matchers import match_regex\r\nfrom opsdroid import constraints\r\n\r\n\r\nconfigure_lang({}) # Required for our internationalization of error messages\r\n\r\n\r\[email protected]\r\ndef opsdroid():\r\n \"\"\"An instance of the OpsDroid class.\"\"\"\r\n with OpsDroid() as opsdroid:\r\n yield opsdroid\r\n\r\n\r\[email protected]\r\ndef mock_skill():\r\n \"\"\"A skill which does nothing but follows the skill API.\"\"\"\r\n\r\n async def mockedskill(opsdroid, config, message):\r\n pass\r\n\r\n mockedskill.config = {}\r\n return mockedskill\r\n\r\n\r\[email protected]\r\nasync def test_constrain_rooms_constrains(opsdroid, mock_skill):\r\n \"\"\"Test that with the room constraint a skill is not called.\"\"\"\r\n skill = match_regex(r\".*\")(mock_skill)\r\n skill = constraints.constrain_rooms([\"#general\"])(skill)\r\n opsdroid.skills.append(skill)\r\n\r\n tasks = await opsdroid.parse(\r\n Message(text=\"Hello\", user=\"user\", target=\"#random\", connector=None)\r\n )\r\n assert len(tasks) == 2 # Just match_always and match_event\r\n```\r\n\r\nFixtures such as the `opsdroid` fixture will be extremely useful in many tests, so we will be creating some standard ones like this which will be available in all tests. If you write a fixture that you think could be useful in other places please don't hesitate to contribute it to the `conftest.py` file.\r\n\r\nIf you have any questions you can chat to us on [Matrix](https://riot.im/app/#/room/#opsdroid-general:matrix.org). We encourage you to get started and if you have issues or get stuck then open a [draft PR](https://github.blog/2019-02-14-introducing-draft-pull-requests/) with your changes and we can take a look.\r\n\r\n---\r\n\r\nWhen this issue is complete the documentation about the migration should be removed from the testing docs.\n", "before_files": [{"content": "\"\"\"Pytest config for all opsdroid tests.\"\"\"\nfrom opsdroid.testing import opsdroid\n\nfrom opsdroid.cli.start import configure_lang\n\n__all__ = [\"opsdroid\"]\n\nconfigure_lang({})\n", "path": "opsdroid/conftest.py"}], "after_files": [{"content": "\"\"\"Pytest config for all opsdroid tests.\"\"\"\nimport pytest\n\nimport asyncio\n\nfrom opsdroid.testing import opsdroid\nfrom opsdroid.connector import Connector\n\nfrom opsdroid.cli.start import configure_lang\n\n__all__ = [\"opsdroid\"]\n\nconfigure_lang({})\n\n\[email protected](scope=\"session\")\ndef get_connector():\n def _get_connector(config={}):\n return Connector(config, opsdroid=opsdroid)\n\n return _get_connector\n\n\[email protected]_fixture\ndef event_loop():\n \"\"\"Create an instance of the default event loop for each test case.\"\"\"\n loop = asyncio.get_event_loop_policy().new_event_loop()\n yield loop\n loop.close()\n", "path": "opsdroid/conftest.py"}]}
| 1,570 | 218 |
gh_patches_debug_7378
|
rasdani/github-patches
|
git_diff
|
NVIDIA__NVFlare-329
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fix docstring in FLComponent
https://github.com/NVIDIA/NVFlare/blob/main/nvflare/apis/fl_component.py#L32
aggregrators should be aggregators
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nvflare/apis/fl_component.py`
Content:
```
1 # Copyright (c) 2021-2022, NVIDIA CORPORATION. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import logging
16 import traceback
17
18 from nvflare.apis.utils.fl_context_utils import generate_log_message
19
20 from .analytix import AnalyticsData, AnalyticsDataType
21 from .event_type import EventType
22 from .fl_constant import EventScope, FedEventHeader, FLContextKey, LogMessageTag
23 from .fl_context import FLContext
24 from .persistable import StatePersistable
25 from .shareable import Shareable
26
27
28 class FLComponent(StatePersistable):
29 def __init__(self):
30 """Init FLComponent.
31
32 The FLComponent is the base class of all FL Components.
33 (executors, controllers, responders, filters, aggregrators, and widgets are all FLComponents)
34
35 FLComponents have the capability to handle and fire events and contain various methods for logging.
36 """
37 self._name = self.__class__.__name__
38 self.logger = logging.getLogger(self._name)
39
40 def _fire(self, event_type: str, fl_ctx: FLContext):
41 fl_ctx.set_prop(FLContextKey.EVENT_ORIGIN, self._name, private=True, sticky=False)
42 engine = fl_ctx.get_engine()
43 if engine is None:
44 self.log_error(fl_ctx=fl_ctx, msg="Logic Error: no engine in fl_ctx: {}".format(fl_ctx), fire_event=False)
45 else:
46 engine.fire_event(event_type, fl_ctx)
47
48 def fire_event(self, event_type: str, fl_ctx: FLContext):
49 """Fires an event.
50
51 Args:
52 event_type (str): The type of event.
53 fl_ctx (FLContext): FLContext information.
54 """
55 if not isinstance(event_type, str):
56 raise TypeError("expect event_type to be str, but got {}".format(type(event_type)))
57
58 if not event_type:
59 raise ValueError("event_type must be specified")
60
61 if not isinstance(fl_ctx, FLContext):
62 raise TypeError("expect fl_ctx to be FLContext, but got {}".format(type(fl_ctx)))
63
64 fl_ctx.set_prop(FLContextKey.EVENT_SCOPE, value=EventScope.LOCAL, private=True, sticky=False)
65 self._fire(event_type, fl_ctx)
66
67 def fire_fed_event(self, event_type: str, event_data: Shareable, fl_ctx: FLContext, targets=None):
68 """Fires a federation event.
69
70 A federation event means that the event will be sent to different sites.
71 For example, if fire a federation event on the server side, one can decide what clients to send via the
72 parameter `targets`.
73 If fire a federation event on the client side, the event will be sent to the server.
74
75 Args:
76 event_type (str): The type of event.
77 event_data (Shareable): The data of this fed event.
78 fl_ctx (FLContext): FLContext information.
79 targets: The targets to send to. It is only used when fire federation event from server side.
80 """
81 if not isinstance(fl_ctx, FLContext):
82 raise TypeError("expect fl_ctx to be FLContext, but got {}".format(type(fl_ctx)))
83
84 if not isinstance(event_data, Shareable):
85 raise TypeError("expect event_data to be Shareable, but got {}".format(type(event_data)))
86
87 event_data.set_header(key=FedEventHeader.TARGETS, value=targets)
88 fl_ctx.set_prop(FLContextKey.EVENT_DATA, event_data, private=True, sticky=False)
89 fl_ctx.set_prop(FLContextKey.EVENT_SCOPE, value=EventScope.FEDERATION, private=True, sticky=False)
90 self._fire(event_type, fl_ctx)
91
92 def system_panic(self, reason: str, fl_ctx: FLContext):
93 """Signals a fatal condition that could cause the RUN to end.
94
95 Args:
96 reason (str): The reason for panic.
97 fl_ctx (FLContext): FLContext information.
98 """
99 fl_ctx.set_prop(FLContextKey.EVENT_DATA, reason, private=True, sticky=False)
100 self.fire_event(EventType.FATAL_SYSTEM_ERROR, fl_ctx)
101
102 def task_panic(self, reason: str, fl_ctx: FLContext):
103 """Signals a fatal condition that could cause the current task (on Client) to end.
104
105 Args:
106 reason (str): The reason for panic.
107 fl_ctx (FLContext): FLContext information.
108 """
109 fl_ctx.set_prop(FLContextKey.EVENT_DATA, reason, private=True, sticky=False)
110 self.fire_event(EventType.FATAL_TASK_ERROR, fl_ctx)
111
112 def handle_event(self, event_type: str, fl_ctx: FLContext):
113 """Handles events.
114
115 Args:
116 event_type (str): event type fired by workflow.
117 fl_ctx (FLContext): FLContext information.
118 """
119 pass
120
121 def log_info(self, fl_ctx: FLContext, msg: str, fire_event=False):
122 """Logs a message with logger.info.
123
124 These log_XXX methods are implemented because we want to have a unified way of logging messages.
125 For example, in this method, we are using generate_log_message to add the FLContext information
126 into the message. And we can decide whether to fire a log event afterwards.
127
128 Args:
129 fl_ctx (FLContext): FLContext information.
130 msg (str): The message to log.
131 fire_event (bool): Whether to fire a log event.
132 """
133 log_msg = generate_log_message(fl_ctx, msg)
134 self.logger.info(log_msg)
135
136 if fire_event:
137 self._fire_log_event(
138 event_type=EventType.INFO_LOG_AVAILABLE, log_tag=LogMessageTag.INFO, log_msg=log_msg, fl_ctx=fl_ctx
139 )
140
141 def log_warning(self, fl_ctx: FLContext, msg: str, fire_event=True):
142 """Logs a message with logger.warning.
143
144 Args:
145 fl_ctx (FLContext): FLContext information.
146 msg (str): The message to log.
147 fire_event (bool): Whether to fire a log event.
148 """
149 log_msg = generate_log_message(fl_ctx, msg)
150 self.logger.warning(log_msg)
151 if fire_event:
152 self._fire_log_event(
153 event_type=EventType.WARNING_LOG_AVAILABLE,
154 log_tag=LogMessageTag.WARNING,
155 log_msg=log_msg,
156 fl_ctx=fl_ctx,
157 )
158
159 def log_error(self, fl_ctx: FLContext, msg: str, fire_event=True):
160 """Logs a message with logger.error.
161
162 Args:
163 fl_ctx (FLContext): FLContext information.
164 msg (str): The message to log.
165 fire_event (bool): Whether to fire a log event.
166 """
167 log_msg = generate_log_message(fl_ctx, msg)
168 self.logger.error(log_msg)
169 if fire_event:
170 self._fire_log_event(
171 event_type=EventType.ERROR_LOG_AVAILABLE, log_tag=LogMessageTag.ERROR, log_msg=log_msg, fl_ctx=fl_ctx
172 )
173
174 def log_debug(self, fl_ctx: FLContext, msg: str, fire_event=False):
175 """Logs a message with logger.debug.
176
177 Args:
178 fl_ctx (FLContext): FLContext information.
179 msg (str): The message to log.
180 fire_event (bool): Whether to fire a log event.
181 """
182 log_msg = generate_log_message(fl_ctx, msg)
183 self.logger.debug(log_msg)
184 if fire_event:
185 self._fire_log_event(
186 event_type=EventType.DEBUG_LOG_AVAILABLE, log_tag=LogMessageTag.DEBUG, log_msg=log_msg, fl_ctx=fl_ctx
187 )
188
189 def log_critical(self, fl_ctx: FLContext, msg: str, fire_event=True):
190 """Logs a message with logger.critical.
191
192 Args:
193 fl_ctx (FLContext): FLContext information.
194 msg (str): The message to log.
195 fire_event (bool): Whether to fire a log event.
196 """
197 log_msg = generate_log_message(fl_ctx, msg)
198 self.logger.critical(log_msg)
199 if fire_event:
200 self._fire_log_event(
201 event_type=EventType.CRITICAL_LOG_AVAILABLE,
202 log_tag=LogMessageTag.CRITICAL,
203 log_msg=log_msg,
204 fl_ctx=fl_ctx,
205 )
206
207 def log_exception(self, fl_ctx: FLContext, msg: str, fire_event=False):
208 """Logs exception message with logger.error.
209
210 Args:
211 fl_ctx (FLContext): FLContext information.
212 msg (str): The message to log.
213 fire_event (bool): Whether to fire a log event. Unused.
214 """
215 log_msg = generate_log_message(fl_ctx, msg)
216 self.logger.error(log_msg)
217 traceback.print_exc()
218
219 if fire_event:
220 ex_text = traceback.format_exc()
221 ex_msg = "{}\n{}".format(log_msg, ex_text)
222 self._fire_log_event(
223 event_type=EventType.EXCEPTION_LOG_AVAILABLE,
224 log_tag=LogMessageTag.EXCEPTION,
225 log_msg=ex_msg,
226 fl_ctx=fl_ctx,
227 )
228
229 def _fire_log_event(self, event_type: str, log_tag: str, log_msg: str, fl_ctx: FLContext):
230 event_data = AnalyticsData(tag=log_tag, value=log_msg, data_type=AnalyticsDataType.TEXT, kwargs=None)
231 dxo = event_data.to_dxo()
232 fl_ctx.set_prop(key=FLContextKey.EVENT_DATA, value=dxo.to_shareable(), private=True, sticky=False)
233 self.fire_event(event_type=event_type, fl_ctx=fl_ctx)
234
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nvflare/apis/fl_component.py b/nvflare/apis/fl_component.py
--- a/nvflare/apis/fl_component.py
+++ b/nvflare/apis/fl_component.py
@@ -30,7 +30,7 @@
"""Init FLComponent.
The FLComponent is the base class of all FL Components.
- (executors, controllers, responders, filters, aggregrators, and widgets are all FLComponents)
+ (executors, controllers, responders, filters, aggregators, and widgets are all FLComponents)
FLComponents have the capability to handle and fire events and contain various methods for logging.
"""
|
{"golden_diff": "diff --git a/nvflare/apis/fl_component.py b/nvflare/apis/fl_component.py\n--- a/nvflare/apis/fl_component.py\n+++ b/nvflare/apis/fl_component.py\n@@ -30,7 +30,7 @@\n \"\"\"Init FLComponent.\n \n The FLComponent is the base class of all FL Components.\n- (executors, controllers, responders, filters, aggregrators, and widgets are all FLComponents)\n+ (executors, controllers, responders, filters, aggregators, and widgets are all FLComponents)\n \n FLComponents have the capability to handle and fire events and contain various methods for logging.\n \"\"\"\n", "issue": "Fix docstring in FLComponent\nhttps://github.com/NVIDIA/NVFlare/blob/main/nvflare/apis/fl_component.py#L32\r\n\r\naggregrators should be aggregators\n", "before_files": [{"content": "# Copyright (c) 2021-2022, NVIDIA CORPORATION. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nimport traceback\n\nfrom nvflare.apis.utils.fl_context_utils import generate_log_message\n\nfrom .analytix import AnalyticsData, AnalyticsDataType\nfrom .event_type import EventType\nfrom .fl_constant import EventScope, FedEventHeader, FLContextKey, LogMessageTag\nfrom .fl_context import FLContext\nfrom .persistable import StatePersistable\nfrom .shareable import Shareable\n\n\nclass FLComponent(StatePersistable):\n def __init__(self):\n \"\"\"Init FLComponent.\n\n The FLComponent is the base class of all FL Components.\n (executors, controllers, responders, filters, aggregrators, and widgets are all FLComponents)\n\n FLComponents have the capability to handle and fire events and contain various methods for logging.\n \"\"\"\n self._name = self.__class__.__name__\n self.logger = logging.getLogger(self._name)\n\n def _fire(self, event_type: str, fl_ctx: FLContext):\n fl_ctx.set_prop(FLContextKey.EVENT_ORIGIN, self._name, private=True, sticky=False)\n engine = fl_ctx.get_engine()\n if engine is None:\n self.log_error(fl_ctx=fl_ctx, msg=\"Logic Error: no engine in fl_ctx: {}\".format(fl_ctx), fire_event=False)\n else:\n engine.fire_event(event_type, fl_ctx)\n\n def fire_event(self, event_type: str, fl_ctx: FLContext):\n \"\"\"Fires an event.\n\n Args:\n event_type (str): The type of event.\n fl_ctx (FLContext): FLContext information.\n \"\"\"\n if not isinstance(event_type, str):\n raise TypeError(\"expect event_type to be str, but got {}\".format(type(event_type)))\n\n if not event_type:\n raise ValueError(\"event_type must be specified\")\n\n if not isinstance(fl_ctx, FLContext):\n raise TypeError(\"expect fl_ctx to be FLContext, but got {}\".format(type(fl_ctx)))\n\n fl_ctx.set_prop(FLContextKey.EVENT_SCOPE, value=EventScope.LOCAL, private=True, sticky=False)\n self._fire(event_type, fl_ctx)\n\n def fire_fed_event(self, event_type: str, event_data: Shareable, fl_ctx: FLContext, targets=None):\n \"\"\"Fires a federation event.\n\n A federation event means that the event will be sent to different sites.\n For example, if fire a federation event on the server side, one can decide what clients to send via the\n parameter `targets`.\n If fire a federation event on the client side, the event will be sent to the server.\n\n Args:\n event_type (str): The type of event.\n event_data (Shareable): The data of this fed event.\n fl_ctx (FLContext): FLContext information.\n targets: The targets to send to. It is only used when fire federation event from server side.\n \"\"\"\n if not isinstance(fl_ctx, FLContext):\n raise TypeError(\"expect fl_ctx to be FLContext, but got {}\".format(type(fl_ctx)))\n\n if not isinstance(event_data, Shareable):\n raise TypeError(\"expect event_data to be Shareable, but got {}\".format(type(event_data)))\n\n event_data.set_header(key=FedEventHeader.TARGETS, value=targets)\n fl_ctx.set_prop(FLContextKey.EVENT_DATA, event_data, private=True, sticky=False)\n fl_ctx.set_prop(FLContextKey.EVENT_SCOPE, value=EventScope.FEDERATION, private=True, sticky=False)\n self._fire(event_type, fl_ctx)\n\n def system_panic(self, reason: str, fl_ctx: FLContext):\n \"\"\"Signals a fatal condition that could cause the RUN to end.\n\n Args:\n reason (str): The reason for panic.\n fl_ctx (FLContext): FLContext information.\n \"\"\"\n fl_ctx.set_prop(FLContextKey.EVENT_DATA, reason, private=True, sticky=False)\n self.fire_event(EventType.FATAL_SYSTEM_ERROR, fl_ctx)\n\n def task_panic(self, reason: str, fl_ctx: FLContext):\n \"\"\"Signals a fatal condition that could cause the current task (on Client) to end.\n\n Args:\n reason (str): The reason for panic.\n fl_ctx (FLContext): FLContext information.\n \"\"\"\n fl_ctx.set_prop(FLContextKey.EVENT_DATA, reason, private=True, sticky=False)\n self.fire_event(EventType.FATAL_TASK_ERROR, fl_ctx)\n\n def handle_event(self, event_type: str, fl_ctx: FLContext):\n \"\"\"Handles events.\n\n Args:\n event_type (str): event type fired by workflow.\n fl_ctx (FLContext): FLContext information.\n \"\"\"\n pass\n\n def log_info(self, fl_ctx: FLContext, msg: str, fire_event=False):\n \"\"\"Logs a message with logger.info.\n\n These log_XXX methods are implemented because we want to have a unified way of logging messages.\n For example, in this method, we are using generate_log_message to add the FLContext information\n into the message. And we can decide whether to fire a log event afterwards.\n\n Args:\n fl_ctx (FLContext): FLContext information.\n msg (str): The message to log.\n fire_event (bool): Whether to fire a log event.\n \"\"\"\n log_msg = generate_log_message(fl_ctx, msg)\n self.logger.info(log_msg)\n\n if fire_event:\n self._fire_log_event(\n event_type=EventType.INFO_LOG_AVAILABLE, log_tag=LogMessageTag.INFO, log_msg=log_msg, fl_ctx=fl_ctx\n )\n\n def log_warning(self, fl_ctx: FLContext, msg: str, fire_event=True):\n \"\"\"Logs a message with logger.warning.\n\n Args:\n fl_ctx (FLContext): FLContext information.\n msg (str): The message to log.\n fire_event (bool): Whether to fire a log event.\n \"\"\"\n log_msg = generate_log_message(fl_ctx, msg)\n self.logger.warning(log_msg)\n if fire_event:\n self._fire_log_event(\n event_type=EventType.WARNING_LOG_AVAILABLE,\n log_tag=LogMessageTag.WARNING,\n log_msg=log_msg,\n fl_ctx=fl_ctx,\n )\n\n def log_error(self, fl_ctx: FLContext, msg: str, fire_event=True):\n \"\"\"Logs a message with logger.error.\n\n Args:\n fl_ctx (FLContext): FLContext information.\n msg (str): The message to log.\n fire_event (bool): Whether to fire a log event.\n \"\"\"\n log_msg = generate_log_message(fl_ctx, msg)\n self.logger.error(log_msg)\n if fire_event:\n self._fire_log_event(\n event_type=EventType.ERROR_LOG_AVAILABLE, log_tag=LogMessageTag.ERROR, log_msg=log_msg, fl_ctx=fl_ctx\n )\n\n def log_debug(self, fl_ctx: FLContext, msg: str, fire_event=False):\n \"\"\"Logs a message with logger.debug.\n\n Args:\n fl_ctx (FLContext): FLContext information.\n msg (str): The message to log.\n fire_event (bool): Whether to fire a log event.\n \"\"\"\n log_msg = generate_log_message(fl_ctx, msg)\n self.logger.debug(log_msg)\n if fire_event:\n self._fire_log_event(\n event_type=EventType.DEBUG_LOG_AVAILABLE, log_tag=LogMessageTag.DEBUG, log_msg=log_msg, fl_ctx=fl_ctx\n )\n\n def log_critical(self, fl_ctx: FLContext, msg: str, fire_event=True):\n \"\"\"Logs a message with logger.critical.\n\n Args:\n fl_ctx (FLContext): FLContext information.\n msg (str): The message to log.\n fire_event (bool): Whether to fire a log event.\n \"\"\"\n log_msg = generate_log_message(fl_ctx, msg)\n self.logger.critical(log_msg)\n if fire_event:\n self._fire_log_event(\n event_type=EventType.CRITICAL_LOG_AVAILABLE,\n log_tag=LogMessageTag.CRITICAL,\n log_msg=log_msg,\n fl_ctx=fl_ctx,\n )\n\n def log_exception(self, fl_ctx: FLContext, msg: str, fire_event=False):\n \"\"\"Logs exception message with logger.error.\n\n Args:\n fl_ctx (FLContext): FLContext information.\n msg (str): The message to log.\n fire_event (bool): Whether to fire a log event. Unused.\n \"\"\"\n log_msg = generate_log_message(fl_ctx, msg)\n self.logger.error(log_msg)\n traceback.print_exc()\n\n if fire_event:\n ex_text = traceback.format_exc()\n ex_msg = \"{}\\n{}\".format(log_msg, ex_text)\n self._fire_log_event(\n event_type=EventType.EXCEPTION_LOG_AVAILABLE,\n log_tag=LogMessageTag.EXCEPTION,\n log_msg=ex_msg,\n fl_ctx=fl_ctx,\n )\n\n def _fire_log_event(self, event_type: str, log_tag: str, log_msg: str, fl_ctx: FLContext):\n event_data = AnalyticsData(tag=log_tag, value=log_msg, data_type=AnalyticsDataType.TEXT, kwargs=None)\n dxo = event_data.to_dxo()\n fl_ctx.set_prop(key=FLContextKey.EVENT_DATA, value=dxo.to_shareable(), private=True, sticky=False)\n self.fire_event(event_type=event_type, fl_ctx=fl_ctx)\n", "path": "nvflare/apis/fl_component.py"}], "after_files": [{"content": "# Copyright (c) 2021-2022, NVIDIA CORPORATION. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nimport traceback\n\nfrom nvflare.apis.utils.fl_context_utils import generate_log_message\n\nfrom .analytix import AnalyticsData, AnalyticsDataType\nfrom .event_type import EventType\nfrom .fl_constant import EventScope, FedEventHeader, FLContextKey, LogMessageTag\nfrom .fl_context import FLContext\nfrom .persistable import StatePersistable\nfrom .shareable import Shareable\n\n\nclass FLComponent(StatePersistable):\n def __init__(self):\n \"\"\"Init FLComponent.\n\n The FLComponent is the base class of all FL Components.\n (executors, controllers, responders, filters, aggregators, and widgets are all FLComponents)\n\n FLComponents have the capability to handle and fire events and contain various methods for logging.\n \"\"\"\n self._name = self.__class__.__name__\n self.logger = logging.getLogger(self._name)\n\n def _fire(self, event_type: str, fl_ctx: FLContext):\n fl_ctx.set_prop(FLContextKey.EVENT_ORIGIN, self._name, private=True, sticky=False)\n engine = fl_ctx.get_engine()\n if engine is None:\n self.log_error(fl_ctx=fl_ctx, msg=\"Logic Error: no engine in fl_ctx: {}\".format(fl_ctx), fire_event=False)\n else:\n engine.fire_event(event_type, fl_ctx)\n\n def fire_event(self, event_type: str, fl_ctx: FLContext):\n \"\"\"Fires an event.\n\n Args:\n event_type (str): The type of event.\n fl_ctx (FLContext): FLContext information.\n \"\"\"\n if not isinstance(event_type, str):\n raise TypeError(\"expect event_type to be str, but got {}\".format(type(event_type)))\n\n if not event_type:\n raise ValueError(\"event_type must be specified\")\n\n if not isinstance(fl_ctx, FLContext):\n raise TypeError(\"expect fl_ctx to be FLContext, but got {}\".format(type(fl_ctx)))\n\n fl_ctx.set_prop(FLContextKey.EVENT_SCOPE, value=EventScope.LOCAL, private=True, sticky=False)\n self._fire(event_type, fl_ctx)\n\n def fire_fed_event(self, event_type: str, event_data: Shareable, fl_ctx: FLContext, targets=None):\n \"\"\"Fires a federation event.\n\n A federation event means that the event will be sent to different sites.\n For example, if fire a federation event on the server side, one can decide what clients to send via the\n parameter `targets`.\n If fire a federation event on the client side, the event will be sent to the server.\n\n Args:\n event_type (str): The type of event.\n event_data (Shareable): The data of this fed event.\n fl_ctx (FLContext): FLContext information.\n targets: The targets to send to. It is only used when fire federation event from server side.\n \"\"\"\n if not isinstance(fl_ctx, FLContext):\n raise TypeError(\"expect fl_ctx to be FLContext, but got {}\".format(type(fl_ctx)))\n\n if not isinstance(event_data, Shareable):\n raise TypeError(\"expect event_data to be Shareable, but got {}\".format(type(event_data)))\n\n event_data.set_header(key=FedEventHeader.TARGETS, value=targets)\n fl_ctx.set_prop(FLContextKey.EVENT_DATA, event_data, private=True, sticky=False)\n fl_ctx.set_prop(FLContextKey.EVENT_SCOPE, value=EventScope.FEDERATION, private=True, sticky=False)\n self._fire(event_type, fl_ctx)\n\n def system_panic(self, reason: str, fl_ctx: FLContext):\n \"\"\"Signals a fatal condition that could cause the RUN to end.\n\n Args:\n reason (str): The reason for panic.\n fl_ctx (FLContext): FLContext information.\n \"\"\"\n fl_ctx.set_prop(FLContextKey.EVENT_DATA, reason, private=True, sticky=False)\n self.fire_event(EventType.FATAL_SYSTEM_ERROR, fl_ctx)\n\n def task_panic(self, reason: str, fl_ctx: FLContext):\n \"\"\"Signals a fatal condition that could cause the current task (on Client) to end.\n\n Args:\n reason (str): The reason for panic.\n fl_ctx (FLContext): FLContext information.\n \"\"\"\n fl_ctx.set_prop(FLContextKey.EVENT_DATA, reason, private=True, sticky=False)\n self.fire_event(EventType.FATAL_TASK_ERROR, fl_ctx)\n\n def handle_event(self, event_type: str, fl_ctx: FLContext):\n \"\"\"Handles events.\n\n Args:\n event_type (str): event type fired by workflow.\n fl_ctx (FLContext): FLContext information.\n \"\"\"\n pass\n\n def log_info(self, fl_ctx: FLContext, msg: str, fire_event=False):\n \"\"\"Logs a message with logger.info.\n\n These log_XXX methods are implemented because we want to have a unified way of logging messages.\n For example, in this method, we are using generate_log_message to add the FLContext information\n into the message. And we can decide whether to fire a log event afterwards.\n\n Args:\n fl_ctx (FLContext): FLContext information.\n msg (str): The message to log.\n fire_event (bool): Whether to fire a log event.\n \"\"\"\n log_msg = generate_log_message(fl_ctx, msg)\n self.logger.info(log_msg)\n\n if fire_event:\n self._fire_log_event(\n event_type=EventType.INFO_LOG_AVAILABLE, log_tag=LogMessageTag.INFO, log_msg=log_msg, fl_ctx=fl_ctx\n )\n\n def log_warning(self, fl_ctx: FLContext, msg: str, fire_event=True):\n \"\"\"Logs a message with logger.warning.\n\n Args:\n fl_ctx (FLContext): FLContext information.\n msg (str): The message to log.\n fire_event (bool): Whether to fire a log event.\n \"\"\"\n log_msg = generate_log_message(fl_ctx, msg)\n self.logger.warning(log_msg)\n if fire_event:\n self._fire_log_event(\n event_type=EventType.WARNING_LOG_AVAILABLE,\n log_tag=LogMessageTag.WARNING,\n log_msg=log_msg,\n fl_ctx=fl_ctx,\n )\n\n def log_error(self, fl_ctx: FLContext, msg: str, fire_event=True):\n \"\"\"Logs a message with logger.error.\n\n Args:\n fl_ctx (FLContext): FLContext information.\n msg (str): The message to log.\n fire_event (bool): Whether to fire a log event.\n \"\"\"\n log_msg = generate_log_message(fl_ctx, msg)\n self.logger.error(log_msg)\n if fire_event:\n self._fire_log_event(\n event_type=EventType.ERROR_LOG_AVAILABLE, log_tag=LogMessageTag.ERROR, log_msg=log_msg, fl_ctx=fl_ctx\n )\n\n def log_debug(self, fl_ctx: FLContext, msg: str, fire_event=False):\n \"\"\"Logs a message with logger.debug.\n\n Args:\n fl_ctx (FLContext): FLContext information.\n msg (str): The message to log.\n fire_event (bool): Whether to fire a log event.\n \"\"\"\n log_msg = generate_log_message(fl_ctx, msg)\n self.logger.debug(log_msg)\n if fire_event:\n self._fire_log_event(\n event_type=EventType.DEBUG_LOG_AVAILABLE, log_tag=LogMessageTag.DEBUG, log_msg=log_msg, fl_ctx=fl_ctx\n )\n\n def log_critical(self, fl_ctx: FLContext, msg: str, fire_event=True):\n \"\"\"Logs a message with logger.critical.\n\n Args:\n fl_ctx (FLContext): FLContext information.\n msg (str): The message to log.\n fire_event (bool): Whether to fire a log event.\n \"\"\"\n log_msg = generate_log_message(fl_ctx, msg)\n self.logger.critical(log_msg)\n if fire_event:\n self._fire_log_event(\n event_type=EventType.CRITICAL_LOG_AVAILABLE,\n log_tag=LogMessageTag.CRITICAL,\n log_msg=log_msg,\n fl_ctx=fl_ctx,\n )\n\n def log_exception(self, fl_ctx: FLContext, msg: str, fire_event=False):\n \"\"\"Logs exception message with logger.error.\n\n Args:\n fl_ctx (FLContext): FLContext information.\n msg (str): The message to log.\n fire_event (bool): Whether to fire a log event. Unused.\n \"\"\"\n log_msg = generate_log_message(fl_ctx, msg)\n self.logger.error(log_msg)\n traceback.print_exc()\n\n if fire_event:\n ex_text = traceback.format_exc()\n ex_msg = \"{}\\n{}\".format(log_msg, ex_text)\n self._fire_log_event(\n event_type=EventType.EXCEPTION_LOG_AVAILABLE,\n log_tag=LogMessageTag.EXCEPTION,\n log_msg=ex_msg,\n fl_ctx=fl_ctx,\n )\n\n def _fire_log_event(self, event_type: str, log_tag: str, log_msg: str, fl_ctx: FLContext):\n event_data = AnalyticsData(tag=log_tag, value=log_msg, data_type=AnalyticsDataType.TEXT, kwargs=None)\n dxo = event_data.to_dxo()\n fl_ctx.set_prop(key=FLContextKey.EVENT_DATA, value=dxo.to_shareable(), private=True, sticky=False)\n self.fire_event(event_type=event_type, fl_ctx=fl_ctx)\n", "path": "nvflare/apis/fl_component.py"}]}
| 3,036 | 139 |
gh_patches_debug_759
|
rasdani/github-patches
|
git_diff
|
meltano__meltano-7022
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
bug: Integration tests failing on main
### Meltano Version
N/A
### Python Version
NA
### Bug scope
Other
### Operating System
N/A
### Description
Example failures on `main`:
- https://github.com/meltano/meltano/actions/runs/3534445738
- https://github.com/meltano/meltano/actions/runs/3534480620
Example success on `release/2.10.0`:
- https://github.com/meltano/meltano/actions/runs/3534468951
Affects all integration tests, and may be responsible for failures in the Pytest workflow:
- https://github.com/meltano/meltano/actions/runs/3534001638/jobs/5930358463
- https://github.com/meltano/meltano/actions/runs/3534001638/jobs/5930359021
- https://github.com/meltano/meltano/actions/runs/3534001638/jobs/5930359587
### Code
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/meltano/core/venv_service.py`
Content:
```
1 """Manage Python virtual environments."""
2
3 from __future__ import annotations
4
5 import asyncio
6 import hashlib
7 import logging
8 import os
9 import platform
10 import shutil
11 import subprocess
12 import sys
13 from asyncio.subprocess import Process
14 from collections import namedtuple
15 from collections.abc import Iterable
16 from pathlib import Path
17
18 from meltano.core.error import AsyncSubprocessError
19 from meltano.core.project import Project
20
21 logger = logging.getLogger(__name__)
22
23 VenvSpecs = namedtuple("VenvSpecs", ("lib_dir", "bin_dir", "site_packages_dir"))
24
25 POSIX = VenvSpecs(
26 lib_dir="lib",
27 bin_dir="bin",
28 site_packages_dir=os.path.join(
29 "lib",
30 f"python{'.'.join(str(part) for part in sys.version_info[:2])}",
31 "site-packages",
32 ),
33 )
34
35 NT = VenvSpecs(
36 lib_dir="Lib",
37 bin_dir="Scripts",
38 site_packages_dir=os.path.join("Lib", "site-packages"),
39 )
40
41 PLATFORM_SPECS = {"Linux": POSIX, "Darwin": POSIX, "Windows": NT}
42
43
44 def venv_platform_specs():
45 """Get virtual environment sub-path info for the current platform.
46
47 Raises:
48 Exception: This platform is not supported.
49
50 Returns:
51 Virtual environment sub-path info for the current platform.
52 """
53 system = platform.system()
54 try:
55 return PLATFORM_SPECS[system]
56 except KeyError as ex:
57 raise Exception(f"Platform {system!r} not supported.") from ex
58
59
60 PIP_PACKAGES = ("pip", "setuptools", "wheel")
61
62
63 class VirtualEnv:
64 """Info about a single virtual environment."""
65
66 def __init__(self, root: Path):
67 """Initialize the `VirtualEnv` instance.
68
69 Args:
70 root: The root directory of the virtual environment.
71 """
72 self.root = root.resolve()
73 self.specs = venv_platform_specs()
74
75 def __getattr__(self, key: str):
76 """Get a specific attribute from this instance.
77
78 Used to provide `VenvSpecs` attributes for this specific virtual environment.
79
80 Args:
81 key: The attribute name. Must be one of the `VenvSpecs` attributes.
82
83 Returns:
84 The root directory of this virtual environment joined to the requested
85 platform-specific path using this platform's `VenvSpecs` instance.
86 """
87 return self.root / getattr(self.specs, key)
88
89 def __str__(self):
90 """_summary_.
91
92 Returns:
93 _description_.
94 """
95 return str(self.root)
96
97
98 async def exec_async(*args, **kwargs) -> Process:
99 """Run an executable asyncronously in a subprocess.
100
101 Args:
102 args: Positional arguments for `asyncio.create_subprocess_exec`.
103 kwargs: Keyword arguments for `asyncio.create_subprocess_exec`.
104
105 Raises:
106 AsyncSubprocessError: The command failed.
107
108 Returns:
109 The subprocess.
110 """
111 run = await asyncio.create_subprocess_exec(
112 *args,
113 stdout=subprocess.PIPE,
114 stderr=subprocess.PIPE,
115 **kwargs,
116 )
117 await run.wait()
118
119 if run.returncode != 0:
120 raise AsyncSubprocessError("Command failed", run)
121
122 return run
123
124
125 def fingerprint(pip_install_args: Iterable[str]) -> str:
126 """Generate a hash identifying pip install args.
127
128 Arguments are sorted and deduplicated before the hash is generated.
129
130 Args:
131 pip_install_args: Arguments for `pip install`.
132
133 Returns:
134 The SHA256 hash hex digest of the sorted set of pip install args.
135 """
136 return hashlib.sha256(" ".join(sorted(set(pip_install_args))).encode()).hexdigest()
137
138
139 class VenvService: # noqa: WPS214
140 """Manages virtual environments.
141
142 The methods in this class are not threadsafe.
143 """
144
145 def __init__(self, project: Project, namespace: str = "", name: str = ""):
146 """Initialize the `VenvService`.
147
148 Args:
149 project: The Meltano project.
150 namespace: The namespace for the venv, e.g. a Plugin type.
151 name: The name of the venv, e.g. a Plugin name.
152 """
153 self.project = project
154 self.namespace = namespace
155 self.name = name
156 self.venv = VirtualEnv(self.project.venvs_dir(namespace, name))
157 self.plugin_fingerprint_path = self.venv.root / ".meltano_plugin_fingerprint"
158
159 async def install(self, pip_install_args: list[str], clean: bool = False) -> None:
160 """Configure a virtual environment, then run pip install with the given args.
161
162 Args:
163 pip_install_args: Arguments passed to `pip install`.
164 clean: Whether to not attempt to use an existing virtual environment.
165 """
166 if not clean and self.requires_clean_install(pip_install_args):
167 logger.debug(
168 f"Packages for '{self.namespace}/{self.name}' have changed so performing a clean install."
169 )
170 clean = True
171
172 self.clean_run_files()
173 await self._pip_install(pip_install_args=pip_install_args, clean=clean)
174 self.write_fingerprint(pip_install_args)
175
176 def requires_clean_install(self, pip_install_args: list[str]) -> bool:
177 """Determine whether a clean install is needed.
178
179 Args:
180 pip_install_args: The arguments being passed to `pip install`, used
181 for fingerprinting the installation.
182
183 Returns:
184 Whether virtual environment doesn't exist or can't be reused.
185 """
186 # A generator function is used to perform the checks lazily
187 def checks():
188 # The Python installation used to create this venv no longer exists
189 yield not self.exec_path("python").exists()
190 # The deprecated `meltano_venv.pth` feature is used by this venv
191 yield self.venv.site_packages_dir.joinpath("meltano_venv.pth").exists()
192 # The fingerprint of the venv does not match the pip install args
193 existing_fingerprint = self.read_fingerprint()
194 yield existing_fingerprint is None
195 yield existing_fingerprint != fingerprint(pip_install_args)
196
197 return any(checks())
198
199 def clean_run_files(self) -> None:
200 """Destroy cached configuration files, if they exist."""
201 try:
202 shutil.rmtree(self.project.run_dir(self.name, make_dirs=False))
203 except FileNotFoundError:
204 logger.debug("No cached configuration files to remove")
205
206 def clean(self) -> None:
207 """Destroy the virtual environment, if it exists."""
208 try:
209 shutil.rmtree(self.venv.root)
210 logger.debug(
211 "Removed old virtual environment for '%s/%s'", # noqa: WPS323
212 self.namespace,
213 self.name,
214 )
215 except FileNotFoundError:
216 # If the VirtualEnv has never been created before do nothing
217 logger.debug("No old virtual environment to remove")
218
219 async def create(self) -> Process:
220 """Create a new virtual environment.
221
222 Raises:
223 AsyncSubprocessError: The virtual environment could not be created.
224
225 Returns:
226 The Python process creating the virtual environment.
227 """
228 logger.debug(f"Creating virtual environment for '{self.namespace}/{self.name}'")
229 try:
230 return await exec_async(sys.executable, "-m", "venv", str(self.venv))
231 except AsyncSubprocessError as err:
232 raise AsyncSubprocessError(
233 f"Could not create the virtualenv for '{self.namespace}/{self.name}'",
234 err.process,
235 ) from err
236
237 async def upgrade_pip(self) -> Process:
238 """Upgrade the `pip` package to the latest version in the virtual environment.
239
240 Raises:
241 AsyncSubprocessError: Failed to upgrade pip to the latest version.
242
243 Returns:
244 The process running `pip install --upgrade ...`.
245 """
246 logger.debug(f"Upgrading pip for '{self.namespace}/{self.name}'")
247 try:
248 return await self._pip_install(["--upgrade", *PIP_PACKAGES])
249 except AsyncSubprocessError as err:
250 raise AsyncSubprocessError(
251 "Failed to upgrade pip to the latest version.", err.process
252 ) from err
253
254 def read_fingerprint(self) -> str | None:
255 """Get the fingerprint of the existing virtual environment.
256
257 Returns:
258 The fingerprint of the existing virtual environment if it exists.
259 `None` otherwise.
260 """
261 if not self.plugin_fingerprint_path.exists():
262 return None
263 with open(self.plugin_fingerprint_path) as fingerprint_file:
264 return fingerprint_file.read()
265
266 def write_fingerprint(self, pip_install_args: list[str]) -> None:
267 """Save the fingerprint for this installation.
268
269 Args:
270 pip_install_args: The arguments being passed to `pip install`.
271 """
272 with open(self.plugin_fingerprint_path, "wt") as fingerprint_file:
273 fingerprint_file.write(fingerprint(pip_install_args))
274
275 def exec_path(self, executable: str) -> Path:
276 """Return the absolute path for the given executable in the virtual environment.
277
278 Args:
279 executable: The path to the executable relative to the venv bin directory.
280
281 Returns:
282 The venv bin directory joined to the provided executable.
283 """
284 absolute_executable = self.venv.bin_dir / executable
285 if platform.system() != "Windows":
286 return absolute_executable
287
288 # On Windows, try using the '.exe' suffixed version if it exists. Use the
289 # regular executable path as a fallback (and for backwards compatibility).
290 absolute_executable_windows = absolute_executable.with_suffix(".exe")
291 return (
292 absolute_executable_windows
293 if absolute_executable_windows.exists()
294 else absolute_executable
295 )
296
297 async def _pip_install(
298 self, pip_install_args: list[str], clean: bool = False
299 ) -> Process:
300 """Install a package using `pip` in the proper virtual environment.
301
302 Args:
303 pip_install_args: The arguments to pass to `pip install`.
304 clean: Whether the installation should be done in a clean venv.
305
306 Raises:
307 AsyncSubprocessError: The command failed.
308
309 Returns:
310 The process running `pip install` with the provided args.
311 """
312 if clean:
313 self.clean()
314 await self.create()
315 await self.upgrade_pip()
316
317 pip_install_args_str = " ".join(pip_install_args)
318 log_msg_prefix = (
319 f"Upgrading with args {pip_install_args_str!r} in existing"
320 if "--upgrade" in pip_install_args
321 else f"Installing with args {pip_install_args_str!r} into"
322 )
323 logger.debug(
324 f"{log_msg_prefix} virtual environment for '{self.namespace}/{self.name}'"
325 )
326
327 try:
328 return await exec_async(
329 str(self.exec_path("python")), "-m", "pip", "install", *pip_install_args
330 )
331 except AsyncSubprocessError as err:
332 raise AsyncSubprocessError(
333 f"Failed to install plugin '{self.name}'.", err.process
334 ) from err
335
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/meltano/core/venv_service.py b/src/meltano/core/venv_service.py
--- a/src/meltano/core/venv_service.py
+++ b/src/meltano/core/venv_service.py
@@ -57,7 +57,7 @@
raise Exception(f"Platform {system!r} not supported.") from ex
-PIP_PACKAGES = ("pip", "setuptools", "wheel")
+PIP_PACKAGES = ("pip", "setuptools==57.5.0", "wheel")
class VirtualEnv:
|
{"golden_diff": "diff --git a/src/meltano/core/venv_service.py b/src/meltano/core/venv_service.py\n--- a/src/meltano/core/venv_service.py\n+++ b/src/meltano/core/venv_service.py\n@@ -57,7 +57,7 @@\n raise Exception(f\"Platform {system!r} not supported.\") from ex\n \n \n-PIP_PACKAGES = (\"pip\", \"setuptools\", \"wheel\")\n+PIP_PACKAGES = (\"pip\", \"setuptools==57.5.0\", \"wheel\")\n \n \n class VirtualEnv:\n", "issue": "bug: Integration tests failing on main\n### Meltano Version\n\nN/A\n\n### Python Version\n\nNA\n\n### Bug scope\n\nOther\n\n### Operating System\n\nN/A\n\n### Description\n\nExample failures on `main`:\r\n- https://github.com/meltano/meltano/actions/runs/3534445738\r\n- https://github.com/meltano/meltano/actions/runs/3534480620\r\n\r\nExample success on `release/2.10.0`:\r\n- https://github.com/meltano/meltano/actions/runs/3534468951\r\n\r\nAffects all integration tests, and may be responsible for failures in the Pytest workflow:\r\n- https://github.com/meltano/meltano/actions/runs/3534001638/jobs/5930358463\r\n- https://github.com/meltano/meltano/actions/runs/3534001638/jobs/5930359021\r\n- https://github.com/meltano/meltano/actions/runs/3534001638/jobs/5930359587 \n\n### Code\n\n_No response_\n", "before_files": [{"content": "\"\"\"Manage Python virtual environments.\"\"\"\n\nfrom __future__ import annotations\n\nimport asyncio\nimport hashlib\nimport logging\nimport os\nimport platform\nimport shutil\nimport subprocess\nimport sys\nfrom asyncio.subprocess import Process\nfrom collections import namedtuple\nfrom collections.abc import Iterable\nfrom pathlib import Path\n\nfrom meltano.core.error import AsyncSubprocessError\nfrom meltano.core.project import Project\n\nlogger = logging.getLogger(__name__)\n\nVenvSpecs = namedtuple(\"VenvSpecs\", (\"lib_dir\", \"bin_dir\", \"site_packages_dir\"))\n\nPOSIX = VenvSpecs(\n lib_dir=\"lib\",\n bin_dir=\"bin\",\n site_packages_dir=os.path.join(\n \"lib\",\n f\"python{'.'.join(str(part) for part in sys.version_info[:2])}\",\n \"site-packages\",\n ),\n)\n\nNT = VenvSpecs(\n lib_dir=\"Lib\",\n bin_dir=\"Scripts\",\n site_packages_dir=os.path.join(\"Lib\", \"site-packages\"),\n)\n\nPLATFORM_SPECS = {\"Linux\": POSIX, \"Darwin\": POSIX, \"Windows\": NT}\n\n\ndef venv_platform_specs():\n \"\"\"Get virtual environment sub-path info for the current platform.\n\n Raises:\n Exception: This platform is not supported.\n\n Returns:\n Virtual environment sub-path info for the current platform.\n \"\"\"\n system = platform.system()\n try:\n return PLATFORM_SPECS[system]\n except KeyError as ex:\n raise Exception(f\"Platform {system!r} not supported.\") from ex\n\n\nPIP_PACKAGES = (\"pip\", \"setuptools\", \"wheel\")\n\n\nclass VirtualEnv:\n \"\"\"Info about a single virtual environment.\"\"\"\n\n def __init__(self, root: Path):\n \"\"\"Initialize the `VirtualEnv` instance.\n\n Args:\n root: The root directory of the virtual environment.\n \"\"\"\n self.root = root.resolve()\n self.specs = venv_platform_specs()\n\n def __getattr__(self, key: str):\n \"\"\"Get a specific attribute from this instance.\n\n Used to provide `VenvSpecs` attributes for this specific virtual environment.\n\n Args:\n key: The attribute name. Must be one of the `VenvSpecs` attributes.\n\n Returns:\n The root directory of this virtual environment joined to the requested\n platform-specific path using this platform's `VenvSpecs` instance.\n \"\"\"\n return self.root / getattr(self.specs, key)\n\n def __str__(self):\n \"\"\"_summary_.\n\n Returns:\n _description_.\n \"\"\"\n return str(self.root)\n\n\nasync def exec_async(*args, **kwargs) -> Process:\n \"\"\"Run an executable asyncronously in a subprocess.\n\n Args:\n args: Positional arguments for `asyncio.create_subprocess_exec`.\n kwargs: Keyword arguments for `asyncio.create_subprocess_exec`.\n\n Raises:\n AsyncSubprocessError: The command failed.\n\n Returns:\n The subprocess.\n \"\"\"\n run = await asyncio.create_subprocess_exec(\n *args,\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE,\n **kwargs,\n )\n await run.wait()\n\n if run.returncode != 0:\n raise AsyncSubprocessError(\"Command failed\", run)\n\n return run\n\n\ndef fingerprint(pip_install_args: Iterable[str]) -> str:\n \"\"\"Generate a hash identifying pip install args.\n\n Arguments are sorted and deduplicated before the hash is generated.\n\n Args:\n pip_install_args: Arguments for `pip install`.\n\n Returns:\n The SHA256 hash hex digest of the sorted set of pip install args.\n \"\"\"\n return hashlib.sha256(\" \".join(sorted(set(pip_install_args))).encode()).hexdigest()\n\n\nclass VenvService: # noqa: WPS214\n \"\"\"Manages virtual environments.\n\n The methods in this class are not threadsafe.\n \"\"\"\n\n def __init__(self, project: Project, namespace: str = \"\", name: str = \"\"):\n \"\"\"Initialize the `VenvService`.\n\n Args:\n project: The Meltano project.\n namespace: The namespace for the venv, e.g. a Plugin type.\n name: The name of the venv, e.g. a Plugin name.\n \"\"\"\n self.project = project\n self.namespace = namespace\n self.name = name\n self.venv = VirtualEnv(self.project.venvs_dir(namespace, name))\n self.plugin_fingerprint_path = self.venv.root / \".meltano_plugin_fingerprint\"\n\n async def install(self, pip_install_args: list[str], clean: bool = False) -> None:\n \"\"\"Configure a virtual environment, then run pip install with the given args.\n\n Args:\n pip_install_args: Arguments passed to `pip install`.\n clean: Whether to not attempt to use an existing virtual environment.\n \"\"\"\n if not clean and self.requires_clean_install(pip_install_args):\n logger.debug(\n f\"Packages for '{self.namespace}/{self.name}' have changed so performing a clean install.\"\n )\n clean = True\n\n self.clean_run_files()\n await self._pip_install(pip_install_args=pip_install_args, clean=clean)\n self.write_fingerprint(pip_install_args)\n\n def requires_clean_install(self, pip_install_args: list[str]) -> bool:\n \"\"\"Determine whether a clean install is needed.\n\n Args:\n pip_install_args: The arguments being passed to `pip install`, used\n for fingerprinting the installation.\n\n Returns:\n Whether virtual environment doesn't exist or can't be reused.\n \"\"\"\n # A generator function is used to perform the checks lazily\n def checks():\n # The Python installation used to create this venv no longer exists\n yield not self.exec_path(\"python\").exists()\n # The deprecated `meltano_venv.pth` feature is used by this venv\n yield self.venv.site_packages_dir.joinpath(\"meltano_venv.pth\").exists()\n # The fingerprint of the venv does not match the pip install args\n existing_fingerprint = self.read_fingerprint()\n yield existing_fingerprint is None\n yield existing_fingerprint != fingerprint(pip_install_args)\n\n return any(checks())\n\n def clean_run_files(self) -> None:\n \"\"\"Destroy cached configuration files, if they exist.\"\"\"\n try:\n shutil.rmtree(self.project.run_dir(self.name, make_dirs=False))\n except FileNotFoundError:\n logger.debug(\"No cached configuration files to remove\")\n\n def clean(self) -> None:\n \"\"\"Destroy the virtual environment, if it exists.\"\"\"\n try:\n shutil.rmtree(self.venv.root)\n logger.debug(\n \"Removed old virtual environment for '%s/%s'\", # noqa: WPS323\n self.namespace,\n self.name,\n )\n except FileNotFoundError:\n # If the VirtualEnv has never been created before do nothing\n logger.debug(\"No old virtual environment to remove\")\n\n async def create(self) -> Process:\n \"\"\"Create a new virtual environment.\n\n Raises:\n AsyncSubprocessError: The virtual environment could not be created.\n\n Returns:\n The Python process creating the virtual environment.\n \"\"\"\n logger.debug(f\"Creating virtual environment for '{self.namespace}/{self.name}'\")\n try:\n return await exec_async(sys.executable, \"-m\", \"venv\", str(self.venv))\n except AsyncSubprocessError as err:\n raise AsyncSubprocessError(\n f\"Could not create the virtualenv for '{self.namespace}/{self.name}'\",\n err.process,\n ) from err\n\n async def upgrade_pip(self) -> Process:\n \"\"\"Upgrade the `pip` package to the latest version in the virtual environment.\n\n Raises:\n AsyncSubprocessError: Failed to upgrade pip to the latest version.\n\n Returns:\n The process running `pip install --upgrade ...`.\n \"\"\"\n logger.debug(f\"Upgrading pip for '{self.namespace}/{self.name}'\")\n try:\n return await self._pip_install([\"--upgrade\", *PIP_PACKAGES])\n except AsyncSubprocessError as err:\n raise AsyncSubprocessError(\n \"Failed to upgrade pip to the latest version.\", err.process\n ) from err\n\n def read_fingerprint(self) -> str | None:\n \"\"\"Get the fingerprint of the existing virtual environment.\n\n Returns:\n The fingerprint of the existing virtual environment if it exists.\n `None` otherwise.\n \"\"\"\n if not self.plugin_fingerprint_path.exists():\n return None\n with open(self.plugin_fingerprint_path) as fingerprint_file:\n return fingerprint_file.read()\n\n def write_fingerprint(self, pip_install_args: list[str]) -> None:\n \"\"\"Save the fingerprint for this installation.\n\n Args:\n pip_install_args: The arguments being passed to `pip install`.\n \"\"\"\n with open(self.plugin_fingerprint_path, \"wt\") as fingerprint_file:\n fingerprint_file.write(fingerprint(pip_install_args))\n\n def exec_path(self, executable: str) -> Path:\n \"\"\"Return the absolute path for the given executable in the virtual environment.\n\n Args:\n executable: The path to the executable relative to the venv bin directory.\n\n Returns:\n The venv bin directory joined to the provided executable.\n \"\"\"\n absolute_executable = self.venv.bin_dir / executable\n if platform.system() != \"Windows\":\n return absolute_executable\n\n # On Windows, try using the '.exe' suffixed version if it exists. Use the\n # regular executable path as a fallback (and for backwards compatibility).\n absolute_executable_windows = absolute_executable.with_suffix(\".exe\")\n return (\n absolute_executable_windows\n if absolute_executable_windows.exists()\n else absolute_executable\n )\n\n async def _pip_install(\n self, pip_install_args: list[str], clean: bool = False\n ) -> Process:\n \"\"\"Install a package using `pip` in the proper virtual environment.\n\n Args:\n pip_install_args: The arguments to pass to `pip install`.\n clean: Whether the installation should be done in a clean venv.\n\n Raises:\n AsyncSubprocessError: The command failed.\n\n Returns:\n The process running `pip install` with the provided args.\n \"\"\"\n if clean:\n self.clean()\n await self.create()\n await self.upgrade_pip()\n\n pip_install_args_str = \" \".join(pip_install_args)\n log_msg_prefix = (\n f\"Upgrading with args {pip_install_args_str!r} in existing\"\n if \"--upgrade\" in pip_install_args\n else f\"Installing with args {pip_install_args_str!r} into\"\n )\n logger.debug(\n f\"{log_msg_prefix} virtual environment for '{self.namespace}/{self.name}'\"\n )\n\n try:\n return await exec_async(\n str(self.exec_path(\"python\")), \"-m\", \"pip\", \"install\", *pip_install_args\n )\n except AsyncSubprocessError as err:\n raise AsyncSubprocessError(\n f\"Failed to install plugin '{self.name}'.\", err.process\n ) from err\n", "path": "src/meltano/core/venv_service.py"}], "after_files": [{"content": "\"\"\"Manage Python virtual environments.\"\"\"\n\nfrom __future__ import annotations\n\nimport asyncio\nimport hashlib\nimport logging\nimport os\nimport platform\nimport shutil\nimport subprocess\nimport sys\nfrom asyncio.subprocess import Process\nfrom collections import namedtuple\nfrom collections.abc import Iterable\nfrom pathlib import Path\n\nfrom meltano.core.error import AsyncSubprocessError\nfrom meltano.core.project import Project\n\nlogger = logging.getLogger(__name__)\n\nVenvSpecs = namedtuple(\"VenvSpecs\", (\"lib_dir\", \"bin_dir\", \"site_packages_dir\"))\n\nPOSIX = VenvSpecs(\n lib_dir=\"lib\",\n bin_dir=\"bin\",\n site_packages_dir=os.path.join(\n \"lib\",\n f\"python{'.'.join(str(part) for part in sys.version_info[:2])}\",\n \"site-packages\",\n ),\n)\n\nNT = VenvSpecs(\n lib_dir=\"Lib\",\n bin_dir=\"Scripts\",\n site_packages_dir=os.path.join(\"Lib\", \"site-packages\"),\n)\n\nPLATFORM_SPECS = {\"Linux\": POSIX, \"Darwin\": POSIX, \"Windows\": NT}\n\n\ndef venv_platform_specs():\n \"\"\"Get virtual environment sub-path info for the current platform.\n\n Raises:\n Exception: This platform is not supported.\n\n Returns:\n Virtual environment sub-path info for the current platform.\n \"\"\"\n system = platform.system()\n try:\n return PLATFORM_SPECS[system]\n except KeyError as ex:\n raise Exception(f\"Platform {system!r} not supported.\") from ex\n\n\nPIP_PACKAGES = (\"pip\", \"setuptools==57.5.0\", \"wheel\")\n\n\nclass VirtualEnv:\n \"\"\"Info about a single virtual environment.\"\"\"\n\n def __init__(self, root: Path):\n \"\"\"Initialize the `VirtualEnv` instance.\n\n Args:\n root: The root directory of the virtual environment.\n \"\"\"\n self.root = root.resolve()\n self.specs = venv_platform_specs()\n\n def __getattr__(self, key: str):\n \"\"\"Get a specific attribute from this instance.\n\n Used to provide `VenvSpecs` attributes for this specific virtual environment.\n\n Args:\n key: The attribute name. Must be one of the `VenvSpecs` attributes.\n\n Returns:\n The root directory of this virtual environment joined to the requested\n platform-specific path using this platform's `VenvSpecs` instance.\n \"\"\"\n return self.root / getattr(self.specs, key)\n\n def __str__(self):\n \"\"\"_summary_.\n\n Returns:\n _description_.\n \"\"\"\n return str(self.root)\n\n\nasync def exec_async(*args, **kwargs) -> Process:\n \"\"\"Run an executable asyncronously in a subprocess.\n\n Args:\n args: Positional arguments for `asyncio.create_subprocess_exec`.\n kwargs: Keyword arguments for `asyncio.create_subprocess_exec`.\n\n Raises:\n AsyncSubprocessError: The command failed.\n\n Returns:\n The subprocess.\n \"\"\"\n run = await asyncio.create_subprocess_exec(\n *args,\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE,\n **kwargs,\n )\n await run.wait()\n\n if run.returncode != 0:\n raise AsyncSubprocessError(\"Command failed\", run)\n\n return run\n\n\ndef fingerprint(pip_install_args: Iterable[str]) -> str:\n \"\"\"Generate a hash identifying pip install args.\n\n Arguments are sorted and deduplicated before the hash is generated.\n\n Args:\n pip_install_args: Arguments for `pip install`.\n\n Returns:\n The SHA256 hash hex digest of the sorted set of pip install args.\n \"\"\"\n return hashlib.sha256(\" \".join(sorted(set(pip_install_args))).encode()).hexdigest()\n\n\nclass VenvService: # noqa: WPS214\n \"\"\"Manages virtual environments.\n\n The methods in this class are not threadsafe.\n \"\"\"\n\n def __init__(self, project: Project, namespace: str = \"\", name: str = \"\"):\n \"\"\"Initialize the `VenvService`.\n\n Args:\n project: The Meltano project.\n namespace: The namespace for the venv, e.g. a Plugin type.\n name: The name of the venv, e.g. a Plugin name.\n \"\"\"\n self.project = project\n self.namespace = namespace\n self.name = name\n self.venv = VirtualEnv(self.project.venvs_dir(namespace, name))\n self.plugin_fingerprint_path = self.venv.root / \".meltano_plugin_fingerprint\"\n\n async def install(self, pip_install_args: list[str], clean: bool = False) -> None:\n \"\"\"Configure a virtual environment, then run pip install with the given args.\n\n Args:\n pip_install_args: Arguments passed to `pip install`.\n clean: Whether to not attempt to use an existing virtual environment.\n \"\"\"\n if not clean and self.requires_clean_install(pip_install_args):\n logger.debug(\n f\"Packages for '{self.namespace}/{self.name}' have changed so performing a clean install.\"\n )\n clean = True\n\n self.clean_run_files()\n await self._pip_install(pip_install_args=pip_install_args, clean=clean)\n self.write_fingerprint(pip_install_args)\n\n def requires_clean_install(self, pip_install_args: list[str]) -> bool:\n \"\"\"Determine whether a clean install is needed.\n\n Args:\n pip_install_args: The arguments being passed to `pip install`, used\n for fingerprinting the installation.\n\n Returns:\n Whether virtual environment doesn't exist or can't be reused.\n \"\"\"\n # A generator function is used to perform the checks lazily\n def checks():\n # The Python installation used to create this venv no longer exists\n yield not self.exec_path(\"python\").exists()\n # The deprecated `meltano_venv.pth` feature is used by this venv\n yield self.venv.site_packages_dir.joinpath(\"meltano_venv.pth\").exists()\n # The fingerprint of the venv does not match the pip install args\n existing_fingerprint = self.read_fingerprint()\n yield existing_fingerprint is None\n yield existing_fingerprint != fingerprint(pip_install_args)\n\n return any(checks())\n\n def clean_run_files(self) -> None:\n \"\"\"Destroy cached configuration files, if they exist.\"\"\"\n try:\n shutil.rmtree(self.project.run_dir(self.name, make_dirs=False))\n except FileNotFoundError:\n logger.debug(\"No cached configuration files to remove\")\n\n def clean(self) -> None:\n \"\"\"Destroy the virtual environment, if it exists.\"\"\"\n try:\n shutil.rmtree(self.venv.root)\n logger.debug(\n \"Removed old virtual environment for '%s/%s'\", # noqa: WPS323\n self.namespace,\n self.name,\n )\n except FileNotFoundError:\n # If the VirtualEnv has never been created before do nothing\n logger.debug(\"No old virtual environment to remove\")\n\n async def create(self) -> Process:\n \"\"\"Create a new virtual environment.\n\n Raises:\n AsyncSubprocessError: The virtual environment could not be created.\n\n Returns:\n The Python process creating the virtual environment.\n \"\"\"\n logger.debug(f\"Creating virtual environment for '{self.namespace}/{self.name}'\")\n try:\n return await exec_async(sys.executable, \"-m\", \"venv\", str(self.venv))\n except AsyncSubprocessError as err:\n raise AsyncSubprocessError(\n f\"Could not create the virtualenv for '{self.namespace}/{self.name}'\",\n err.process,\n ) from err\n\n async def upgrade_pip(self) -> Process:\n \"\"\"Upgrade the `pip` package to the latest version in the virtual environment.\n\n Raises:\n AsyncSubprocessError: Failed to upgrade pip to the latest version.\n\n Returns:\n The process running `pip install --upgrade ...`.\n \"\"\"\n logger.debug(f\"Upgrading pip for '{self.namespace}/{self.name}'\")\n try:\n return await self._pip_install([\"--upgrade\", *PIP_PACKAGES])\n except AsyncSubprocessError as err:\n raise AsyncSubprocessError(\n \"Failed to upgrade pip to the latest version.\", err.process\n ) from err\n\n def read_fingerprint(self) -> str | None:\n \"\"\"Get the fingerprint of the existing virtual environment.\n\n Returns:\n The fingerprint of the existing virtual environment if it exists.\n `None` otherwise.\n \"\"\"\n if not self.plugin_fingerprint_path.exists():\n return None\n with open(self.plugin_fingerprint_path) as fingerprint_file:\n return fingerprint_file.read()\n\n def write_fingerprint(self, pip_install_args: list[str]) -> None:\n \"\"\"Save the fingerprint for this installation.\n\n Args:\n pip_install_args: The arguments being passed to `pip install`.\n \"\"\"\n with open(self.plugin_fingerprint_path, \"wt\") as fingerprint_file:\n fingerprint_file.write(fingerprint(pip_install_args))\n\n def exec_path(self, executable: str) -> Path:\n \"\"\"Return the absolute path for the given executable in the virtual environment.\n\n Args:\n executable: The path to the executable relative to the venv bin directory.\n\n Returns:\n The venv bin directory joined to the provided executable.\n \"\"\"\n absolute_executable = self.venv.bin_dir / executable\n if platform.system() != \"Windows\":\n return absolute_executable\n\n # On Windows, try using the '.exe' suffixed version if it exists. Use the\n # regular executable path as a fallback (and for backwards compatibility).\n absolute_executable_windows = absolute_executable.with_suffix(\".exe\")\n return (\n absolute_executable_windows\n if absolute_executable_windows.exists()\n else absolute_executable\n )\n\n async def _pip_install(\n self, pip_install_args: list[str], clean: bool = False\n ) -> Process:\n \"\"\"Install a package using `pip` in the proper virtual environment.\n\n Args:\n pip_install_args: The arguments to pass to `pip install`.\n clean: Whether the installation should be done in a clean venv.\n\n Raises:\n AsyncSubprocessError: The command failed.\n\n Returns:\n The process running `pip install` with the provided args.\n \"\"\"\n if clean:\n self.clean()\n await self.create()\n await self.upgrade_pip()\n\n pip_install_args_str = \" \".join(pip_install_args)\n log_msg_prefix = (\n f\"Upgrading with args {pip_install_args_str!r} in existing\"\n if \"--upgrade\" in pip_install_args\n else f\"Installing with args {pip_install_args_str!r} into\"\n )\n logger.debug(\n f\"{log_msg_prefix} virtual environment for '{self.namespace}/{self.name}'\"\n )\n\n try:\n return await exec_async(\n str(self.exec_path(\"python\")), \"-m\", \"pip\", \"install\", *pip_install_args\n )\n except AsyncSubprocessError as err:\n raise AsyncSubprocessError(\n f\"Failed to install plugin '{self.name}'.\", err.process\n ) from err\n", "path": "src/meltano/core/venv_service.py"}]}
| 3,824 | 124 |
gh_patches_debug_38667
|
rasdani/github-patches
|
git_diff
|
encode__uvicorn-22
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Signal handlers
In the worker class
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `uvicorn/worker.py`
Content:
```
1 import asyncio
2 import functools
3
4 import uvloop
5
6 from gunicorn.workers.base import Worker
7 from uvicorn.protocols import http
8
9
10 class UvicornWorker(Worker):
11 """
12 A worker class for Gunicorn that interfaces with an ASGI consumer callable,
13 rather than a WSGI callable.
14
15 We use a couple of packages from MagicStack in order to achieve an
16 extremely high-throughput and low-latency implementation:
17
18 * `uvloop` as the event loop policy.
19 * `httptools` as the HTTP request parser.
20 """
21
22 def init_process(self):
23 # Close any existing event loop before setting a
24 # new policy.
25 asyncio.get_event_loop().close()
26
27 # Setup uvloop policy, so that every
28 # asyncio.get_event_loop() will create an instance
29 # of uvloop event loop.
30 asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())
31
32 super().init_process()
33
34 def run(self):
35 loop = asyncio.get_event_loop()
36 loop.create_task(self.create_servers(loop))
37 loop.create_task(tick(loop, self.notify))
38 loop.run_forever()
39
40 async def create_servers(self, loop):
41 cfg = self.cfg
42 consumer = self.wsgi
43
44 for sock in self.sockets:
45 protocol = functools.partial(
46 http.HttpProtocol,
47 consumer=consumer, loop=loop, sock=sock, cfg=cfg
48 )
49 await loop.create_server(protocol, sock=sock)
50
51
52 async def tick(loop, notify):
53 cycle = 0
54 while True:
55 http.set_time_and_date()
56 cycle = (cycle + 1) % 10
57 if cycle == 0:
58 notify()
59 await asyncio.sleep(1)
60
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/uvicorn/worker.py b/uvicorn/worker.py
--- a/uvicorn/worker.py
+++ b/uvicorn/worker.py
@@ -1,5 +1,7 @@
import asyncio
import functools
+import signal
+import sys
import uvloop
@@ -19,6 +21,11 @@
* `httptools` as the HTTP request parser.
"""
+ def __init__(self, *args, **kwargs): # pragma: no cover
+ super().__init__(*args, **kwargs)
+ self.servers = []
+ self.exit_code = 0
+
def init_process(self):
# Close any existing event loop before setting a
# new policy.
@@ -34,8 +41,45 @@
def run(self):
loop = asyncio.get_event_loop()
loop.create_task(self.create_servers(loop))
- loop.create_task(tick(loop, self.notify))
+ loop.create_task(self.tick(loop))
loop.run_forever()
+ sys.exit(self.exit_code)
+
+ def init_signals(self):
+ # Set up signals through the event loop API.
+ loop = asyncio.get_event_loop()
+
+ loop.add_signal_handler(signal.SIGQUIT, self.handle_quit,
+ signal.SIGQUIT, None)
+
+ loop.add_signal_handler(signal.SIGTERM, self.handle_exit,
+ signal.SIGTERM, None)
+
+ loop.add_signal_handler(signal.SIGINT, self.handle_quit,
+ signal.SIGINT, None)
+
+ loop.add_signal_handler(signal.SIGWINCH, self.handle_winch,
+ signal.SIGWINCH, None)
+
+ loop.add_signal_handler(signal.SIGUSR1, self.handle_usr1,
+ signal.SIGUSR1, None)
+
+ loop.add_signal_handler(signal.SIGABRT, self.handle_abort,
+ signal.SIGABRT, None)
+
+ # Don't let SIGTERM and SIGUSR1 disturb active requests
+ # by interrupting system calls
+ signal.siginterrupt(signal.SIGTERM, False)
+ signal.siginterrupt(signal.SIGUSR1, False)
+
+ def handle_quit(self, sig, frame):
+ self.alive = False
+ self.cfg.worker_int(self)
+
+ def handle_abort(self, sig, frame):
+ self.alive = False
+ self.exit_code = 1
+ self.cfg.worker_abort(self)
async def create_servers(self, loop):
cfg = self.cfg
@@ -46,14 +90,19 @@
http.HttpProtocol,
consumer=consumer, loop=loop, sock=sock, cfg=cfg
)
- await loop.create_server(protocol, sock=sock)
+ server = await loop.create_server(protocol, sock=sock)
+ self.servers.append(server)
+ async def tick(self, loop):
+ cycle = 0
+ while self.alive:
+ http.set_time_and_date()
+ cycle = (cycle + 1) % 10
+ if cycle == 0:
+ self.notify()
+ await asyncio.sleep(1)
-async def tick(loop, notify):
- cycle = 0
- while True:
- http.set_time_and_date()
- cycle = (cycle + 1) % 10
- if cycle == 0:
- notify()
- await asyncio.sleep(1)
+ for server in self.servers:
+ server.close()
+ await server.wait_closed()
+ loop.stop()
|
{"golden_diff": "diff --git a/uvicorn/worker.py b/uvicorn/worker.py\n--- a/uvicorn/worker.py\n+++ b/uvicorn/worker.py\n@@ -1,5 +1,7 @@\n import asyncio\n import functools\n+import signal\n+import sys\n \n import uvloop\n \n@@ -19,6 +21,11 @@\n * `httptools` as the HTTP request parser.\n \"\"\"\n \n+ def __init__(self, *args, **kwargs): # pragma: no cover\n+ super().__init__(*args, **kwargs)\n+ self.servers = []\n+ self.exit_code = 0\n+\n def init_process(self):\n # Close any existing event loop before setting a\n # new policy.\n@@ -34,8 +41,45 @@\n def run(self):\n loop = asyncio.get_event_loop()\n loop.create_task(self.create_servers(loop))\n- loop.create_task(tick(loop, self.notify))\n+ loop.create_task(self.tick(loop))\n loop.run_forever()\n+ sys.exit(self.exit_code)\n+\n+ def init_signals(self):\n+ # Set up signals through the event loop API.\n+ loop = asyncio.get_event_loop()\n+\n+ loop.add_signal_handler(signal.SIGQUIT, self.handle_quit,\n+ signal.SIGQUIT, None)\n+\n+ loop.add_signal_handler(signal.SIGTERM, self.handle_exit,\n+ signal.SIGTERM, None)\n+\n+ loop.add_signal_handler(signal.SIGINT, self.handle_quit,\n+ signal.SIGINT, None)\n+\n+ loop.add_signal_handler(signal.SIGWINCH, self.handle_winch,\n+ signal.SIGWINCH, None)\n+\n+ loop.add_signal_handler(signal.SIGUSR1, self.handle_usr1,\n+ signal.SIGUSR1, None)\n+\n+ loop.add_signal_handler(signal.SIGABRT, self.handle_abort,\n+ signal.SIGABRT, None)\n+\n+ # Don't let SIGTERM and SIGUSR1 disturb active requests\n+ # by interrupting system calls\n+ signal.siginterrupt(signal.SIGTERM, False)\n+ signal.siginterrupt(signal.SIGUSR1, False)\n+\n+ def handle_quit(self, sig, frame):\n+ self.alive = False\n+ self.cfg.worker_int(self)\n+\n+ def handle_abort(self, sig, frame):\n+ self.alive = False\n+ self.exit_code = 1\n+ self.cfg.worker_abort(self)\n \n async def create_servers(self, loop):\n cfg = self.cfg\n@@ -46,14 +90,19 @@\n http.HttpProtocol,\n consumer=consumer, loop=loop, sock=sock, cfg=cfg\n )\n- await loop.create_server(protocol, sock=sock)\n+ server = await loop.create_server(protocol, sock=sock)\n+ self.servers.append(server)\n \n+ async def tick(self, loop):\n+ cycle = 0\n+ while self.alive:\n+ http.set_time_and_date()\n+ cycle = (cycle + 1) % 10\n+ if cycle == 0:\n+ self.notify()\n+ await asyncio.sleep(1)\n \n-async def tick(loop, notify):\n- cycle = 0\n- while True:\n- http.set_time_and_date()\n- cycle = (cycle + 1) % 10\n- if cycle == 0:\n- notify()\n- await asyncio.sleep(1)\n+ for server in self.servers:\n+ server.close()\n+ await server.wait_closed()\n+ loop.stop()\n", "issue": "Signal handlers\nIn the worker class\n", "before_files": [{"content": "import asyncio\nimport functools\n\nimport uvloop\n\nfrom gunicorn.workers.base import Worker\nfrom uvicorn.protocols import http\n\n\nclass UvicornWorker(Worker):\n \"\"\"\n A worker class for Gunicorn that interfaces with an ASGI consumer callable,\n rather than a WSGI callable.\n\n We use a couple of packages from MagicStack in order to achieve an\n extremely high-throughput and low-latency implementation:\n\n * `uvloop` as the event loop policy.\n * `httptools` as the HTTP request parser.\n \"\"\"\n\n def init_process(self):\n # Close any existing event loop before setting a\n # new policy.\n asyncio.get_event_loop().close()\n\n # Setup uvloop policy, so that every\n # asyncio.get_event_loop() will create an instance\n # of uvloop event loop.\n asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())\n\n super().init_process()\n\n def run(self):\n loop = asyncio.get_event_loop()\n loop.create_task(self.create_servers(loop))\n loop.create_task(tick(loop, self.notify))\n loop.run_forever()\n\n async def create_servers(self, loop):\n cfg = self.cfg\n consumer = self.wsgi\n\n for sock in self.sockets:\n protocol = functools.partial(\n http.HttpProtocol,\n consumer=consumer, loop=loop, sock=sock, cfg=cfg\n )\n await loop.create_server(protocol, sock=sock)\n\n\nasync def tick(loop, notify):\n cycle = 0\n while True:\n http.set_time_and_date()\n cycle = (cycle + 1) % 10\n if cycle == 0:\n notify()\n await asyncio.sleep(1)\n", "path": "uvicorn/worker.py"}], "after_files": [{"content": "import asyncio\nimport functools\nimport signal\nimport sys\n\nimport uvloop\n\nfrom gunicorn.workers.base import Worker\nfrom uvicorn.protocols import http\n\n\nclass UvicornWorker(Worker):\n \"\"\"\n A worker class for Gunicorn that interfaces with an ASGI consumer callable,\n rather than a WSGI callable.\n\n We use a couple of packages from MagicStack in order to achieve an\n extremely high-throughput and low-latency implementation:\n\n * `uvloop` as the event loop policy.\n * `httptools` as the HTTP request parser.\n \"\"\"\n\n def __init__(self, *args, **kwargs): # pragma: no cover\n super().__init__(*args, **kwargs)\n self.servers = []\n self.exit_code = 0\n\n def init_process(self):\n # Close any existing event loop before setting a\n # new policy.\n asyncio.get_event_loop().close()\n\n # Setup uvloop policy, so that every\n # asyncio.get_event_loop() will create an instance\n # of uvloop event loop.\n asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())\n\n super().init_process()\n\n def run(self):\n loop = asyncio.get_event_loop()\n loop.create_task(self.create_servers(loop))\n loop.create_task(self.tick(loop))\n loop.run_forever()\n sys.exit(self.exit_code)\n\n def init_signals(self):\n # Set up signals through the event loop API.\n loop = asyncio.get_event_loop()\n\n loop.add_signal_handler(signal.SIGQUIT, self.handle_quit,\n signal.SIGQUIT, None)\n\n loop.add_signal_handler(signal.SIGTERM, self.handle_exit,\n signal.SIGTERM, None)\n\n loop.add_signal_handler(signal.SIGINT, self.handle_quit,\n signal.SIGINT, None)\n\n loop.add_signal_handler(signal.SIGWINCH, self.handle_winch,\n signal.SIGWINCH, None)\n\n loop.add_signal_handler(signal.SIGUSR1, self.handle_usr1,\n signal.SIGUSR1, None)\n\n loop.add_signal_handler(signal.SIGABRT, self.handle_abort,\n signal.SIGABRT, None)\n\n # Don't let SIGTERM and SIGUSR1 disturb active requests\n # by interrupting system calls\n signal.siginterrupt(signal.SIGTERM, False)\n signal.siginterrupt(signal.SIGUSR1, False)\n\n def handle_quit(self, sig, frame):\n self.alive = False\n self.cfg.worker_int(self)\n\n def handle_abort(self, sig, frame):\n self.alive = False\n self.exit_code = 1\n self.cfg.worker_abort(self)\n\n async def create_servers(self, loop):\n cfg = self.cfg\n consumer = self.wsgi\n\n for sock in self.sockets:\n protocol = functools.partial(\n http.HttpProtocol,\n consumer=consumer, loop=loop, sock=sock, cfg=cfg\n )\n server = await loop.create_server(protocol, sock=sock)\n self.servers.append(server)\n\n async def tick(self, loop):\n cycle = 0\n while self.alive:\n http.set_time_and_date()\n cycle = (cycle + 1) % 10\n if cycle == 0:\n self.notify()\n await asyncio.sleep(1)\n\n for server in self.servers:\n server.close()\n await server.wait_closed()\n loop.stop()\n", "path": "uvicorn/worker.py"}]}
| 753 | 766 |
gh_patches_debug_12899
|
rasdani/github-patches
|
git_diff
|
OpenMined__PySyft-2612
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fix precision with large storage fails
**Describe the bug**
The following operation fails
`lpt = torch.Tensor([-2., 4]).fix_prec(storage="large")`
**To Reproduce**
Steps to reproduce the behavior:
Use the above expression in a test and see the result:
`TypeError`
**Expected behavior**
The expression should not crash
**Screenshots**
**Desktop (please complete the following information):**
**Additional context**
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `syft/frameworks/torch/tensors/interpreters/large_precision.py`
Content:
```
1 import numpy as np
2 import math
3 import torch
4
5 from syft.generic.frameworks.hook.hook_args import (
6 register_type_rule,
7 register_forward_func,
8 register_backward_func,
9 one,
10 )
11 from syft.generic.frameworks.overload import overloaded
12 from syft.generic.tensor import AbstractTensor
13
14
15 class LargePrecisionTensor(AbstractTensor):
16 """LargePrecisionTensor allows handling of numbers bigger than LongTensor
17
18 Some systems using Syft require larger types than those supported natively. This tensor type supports arbitrarily
19 large values by packing them in smaller ones.
20 Typically a user will require to enlarge a float number by fixing its precision
21 tensor.fix_prec()
22
23 The large value is defined by `precision_fractional`.
24
25 The smaller values are of type `internal_type`. The split of the large number into the smaller values
26 is in the range ±2**(size - 1).
27
28 By default operations are done with NumPy. This implies unpacking the representation and packing it again.
29
30 Sharing a LPT requires using a arithmetic field where the shares will live. This field cannot bigger than 2 ** 62
31 or the process would trigger a RuntimeError: Overflow when unpacking long. Note that this field will be applied to
32 the internal representation and not to the scaled tensor.
33
34 Check the tests to see how to play with the different parameters.
35 """
36
37 def __init__(
38 self,
39 owner=None,
40 id=None,
41 tags=None,
42 description=None,
43 field: int = 2 ** 512,
44 base: int = 10,
45 precision_fractional=0,
46 internal_type=torch.int32,
47 verbose=False,
48 ):
49 """Initializes a LargePrecisionTensor.
50
51 Args:
52 owner (BaseWorker): An optional BaseWorker object to specify the worker on which
53 the tensor is located.
54 id (str or int): An optional string or integer id of the LargePrecisionTensor.
55 tags (list): list of tags for searching.
56 description (str): a description of this tensor.
57 field (int): size of the arithmetic field used to truncate and scale the large numbers
58 base (int): The base that will be used to to calculate the precision.
59 precision_fractional (int): The precision required by the caller.
60 internal_type (dtype): The large tensor will be stored using tensor of this type.
61 """
62 super().__init__(id=id, owner=owner, tags=tags, description=description)
63 self.field = field
64 self.base = base
65 self.internal_type = internal_type
66 self.precision_fractional = precision_fractional
67 self.verbose = verbose
68 # This is the maximum size of the arithmetic field that is applied when sharing
69 self.internal_field = 2 ** 62
70
71 def _create_internal_representation(self):
72 """Decompose a tensor into an array of numbers that represent such tensor with the required precision"""
73 self_scaled = self.child.numpy() * self.base ** self.precision_fractional
74
75 # floor is applied otherwise, long float is not accurate
76 self_scaled = np.vectorize(math.floor)(self_scaled)
77 self_scaled %= self.field
78
79 # self_scaled can be an array of floats. As multiplying an array of int with an int
80 # still gives an array of int, I think it should be because self.child is a float tensor at this point.
81 # Right now, it does not cause any problem, LargePrecisionTensor._split_numbers() returns an array of int.
82 result = LargePrecisionTensor._split_numbers(
83 self_scaled, self.internal_precision, self.internal_type
84 )
85 return torch.tensor(result, dtype=self.internal_type)
86
87 @staticmethod
88 def _expand_item(a_number, max_length):
89 return [0] * (max_length - len(a_number)) + a_number
90
91 @property
92 def internal_precision(self):
93 """"The internal precision used to decompose the large numbers is the size of the type - 1.
94 The large number is decomposed into positive smaller numbers. This could provoke overflow if any of these
95 smaller parts are bigger than type_precision/2.
96 """
97 return type_precision[self.internal_type] - 1
98
99 def get_class_attributes(self):
100 """
101 Specify all the attributes need to build a wrapper correctly when returning a response.
102 """
103 return {
104 "field": self.field,
105 "base": self.base,
106 "internal_type": self.internal_type,
107 "precision_fractional": self.precision_fractional,
108 }
109
110 @overloaded.method
111 def add(self, self_, other):
112 return self_ + other
113
114 __add__ = add
115
116 def __iadd__(self, other):
117 """Add two fixed precision tensors together.
118 """
119 self.child = self.add(other).child
120
121 return self
122
123 add_ = __iadd__
124
125 @overloaded.method
126 def sub(self, self_, other):
127 return self_ - other
128
129 __sub__ = sub
130
131 def __isub__(self, other):
132 """Add two fixed precision tensors together.
133 """
134 self.child = self.sub(other).child
135
136 return self
137
138 sub_ = __isub__
139
140 @overloaded.method
141 def mul(self, self_, other):
142 if isinstance(other, int):
143 return self_ * other
144 elif isinstance(self_, np.ndarray) and isinstance(other, np.ndarray):
145 res = (self_ * other) % self.field
146
147 # We need to truncate the result
148 truncation = self.base ** self.precision_fractional
149 gate = 1 * (res > self.field / 2)
150 neg_nums = (res - self.field) // truncation + self.field
151 pos_nums = res // truncation
152 trunc_res = np.where(gate, neg_nums, pos_nums)
153
154 return trunc_res
155 else:
156 raise NotImplementedError
157
158 __mul__ = mul
159
160 def __imul__(self, other):
161 self.child = self.mul(other).child
162 return self
163
164 mul_ = __imul__
165
166 @overloaded.method
167 def mod(self, self_, other):
168 return self_ % other
169
170 __mod__ = mod
171
172 @overloaded.method
173 def gt(self, self_, other):
174 return 1 * (self_ > other)
175
176 __gt__ = gt
177
178 @overloaded.method
179 def lt(self, self_, other):
180 return 1 * (self_ < other)
181
182 __lt__ = lt
183
184 def fix_large_precision(self):
185 self.child = self._create_internal_representation()
186 return self
187
188 def float_precision(self):
189 """
190 Restore the tensor from the internal representation.
191
192 Returns:
193 tensor: the original tensor.
194 """
195 result = self._internal_representation_to_large_ints()
196
197 gate = 1 * (result > self.field / 2)
198 neg_nums = (result - self.field) * gate
199 pos_nums = result * (1 - gate)
200 result = (neg_nums + pos_nums) / self.base ** self.precision_fractional
201
202 # At this point the value is an object type. Force cast to float before creating torch.tensor
203 return torch.from_numpy(result.reshape(self.child.shape[:-1]).astype(np.float32))
204
205 @staticmethod
206 def create_tensor_from_numpy(ndarray, **kwargs):
207 """Decompose a NumPy array into an array of numbers that represent such tensor with the required precision.
208
209 Typically this method is called on the result of an operation.
210 """
211 # This method is called to rebuild an LTP after operations.
212 # The wrapping is done here and not in each operation.
213 ndarray %= kwargs.get("field", 2 ** 62)
214
215 internal_type = kwargs["internal_type"]
216 internal_precision = type_precision[internal_type] - 1
217
218 result = LargePrecisionTensor._split_numbers(ndarray, internal_precision, internal_type)
219 return torch.tensor(result, dtype=internal_type)
220
221 @staticmethod
222 def _split_numbers(numbers, bits, internal_type) -> np.array:
223 """Splits a tensor of numbers in numbers of a smaller power.
224
225 Args:
226 numbers (array): the tensor to split.
227 bits (int): the bits to use in the split.
228
229 Returns:
230 array: a tensor with one more dimension representing the original one.
231
232 """
233 if np.all(numbers == 0):
234 # numbers is an array of objects if the values are too large
235 # we need to cast it back to an array of integers
236 numbers = numbers.astype(np.int)
237 return np.expand_dims(numbers, -1)
238
239 sign_mask = np.where(numbers > 0, 1, -1)
240 if internal_type == torch.uint8:
241 assert np.all(
242 sign_mask == 1
243 ), "LargePrecisionTensors with negative values cannot be represented with uint8"
244 numbers = np.where(numbers > 0, numbers, -numbers)
245
246 base = 2 ** bits
247 number_parts = []
248 while np.any(numbers):
249 # number, part = np.divmod(number, base) # Not sure why this doesn't work
250 part = numbers % base
251 numbers = numbers // base
252 number_parts.append(part * sign_mask)
253
254 res = np.array(number_parts[::-1], dtype=np.int)
255 return res.transpose(*range(1, res.ndim), 0)
256
257 def _internal_representation_to_large_ints(self) -> np.array:
258 """Creates an numpy array containing the objective large numbers."""
259 ndarray = self.child.numpy()
260 ndarray = ndarray.reshape(-1, ndarray.shape[-1])
261 result = []
262 for elem in ndarray:
263 result.append(LargePrecisionTensor._restore_large_number(elem, self.internal_precision))
264 return np.array(result).reshape(self.child.shape[:-1])
265
266 @staticmethod
267 def _restore_large_number(number_parts, bits) -> int:
268 """Rebuilds a number from a numpy array.
269
270 Args:
271 number_parts (ndarray): the numpy array of numbers representing the original one.
272 bits (int): the bits used in the split.
273
274 Returns:
275 Number: the large number represented by this tensor
276 """
277
278 def _restore_recursive(parts, acc, base):
279 if len(parts) == 0:
280 return acc
281 return _restore_recursive(parts[1:], acc * base + parts[0].item(), base)
282
283 return _restore_recursive(number_parts, 0, 2 ** bits)
284
285 @staticmethod
286 def _forward_func(tensor):
287 if hasattr(tensor, "child") and isinstance(tensor.child, torch.Tensor):
288 return tensor._internal_representation_to_large_ints()
289 return tensor.child
290
291 @staticmethod
292 def _backward_func(tensor, **kwargs):
293 if isinstance(tensor, np.ndarray):
294 return LargePrecisionTensor(**kwargs).on(
295 LargePrecisionTensor.create_tensor_from_numpy(tensor, **kwargs), wrap=False
296 )
297 return LargePrecisionTensor(**kwargs).on(tensor, wrap=False)
298
299 def share(self, *owners, field=None, crypto_provider=None):
300 if field is None:
301 field = self.internal_field
302 else:
303 assert field <= self.internal_field, "internal_field max value is 2 ** 62"
304 assert (
305 field == self.internal_field
306 ), "When sharing a LargePrecisionTensor, the field of the resulting AdditiveSharingTensor \
307 must be the same as the one of the original tensor"
308
309 self.child = self.child.share(
310 *owners, field=field, crypto_provider=crypto_provider, no_wrap=True
311 )
312 return self
313
314
315 # The size of each type
316 type_precision = {
317 torch.uint8: 8,
318 torch.int8: 8,
319 torch.int16: 16,
320 torch.short: 16,
321 torch.int32: 32,
322 torch.int: 32,
323 torch.int64: 64,
324 torch.long: 64,
325 }
326
327 ### Register the tensor with hook_args.py ###
328 register_type_rule({LargePrecisionTensor: one})
329 register_forward_func({LargePrecisionTensor: lambda i: LargePrecisionTensor._forward_func(i)})
330 register_backward_func(
331 {LargePrecisionTensor: lambda i, **kwargs: LargePrecisionTensor._backward_func(i, **kwargs)}
332 )
333
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/syft/frameworks/torch/tensors/interpreters/large_precision.py b/syft/frameworks/torch/tensors/interpreters/large_precision.py
--- a/syft/frameworks/torch/tensors/interpreters/large_precision.py
+++ b/syft/frameworks/torch/tensors/interpreters/large_precision.py
@@ -74,7 +74,8 @@
# floor is applied otherwise, long float is not accurate
self_scaled = np.vectorize(math.floor)(self_scaled)
- self_scaled %= self.field
+ # https://github.com/numpy/numpy/issues/6464
+ self_scaled = np.remainder(self_scaled, np.array(self.field), casting="unsafe")
# self_scaled can be an array of floats. As multiplying an array of int with an int
# still gives an array of int, I think it should be because self.child is a float tensor at this point.
|
{"golden_diff": "diff --git a/syft/frameworks/torch/tensors/interpreters/large_precision.py b/syft/frameworks/torch/tensors/interpreters/large_precision.py\n--- a/syft/frameworks/torch/tensors/interpreters/large_precision.py\n+++ b/syft/frameworks/torch/tensors/interpreters/large_precision.py\n@@ -74,7 +74,8 @@\n \n # floor is applied otherwise, long float is not accurate\n self_scaled = np.vectorize(math.floor)(self_scaled)\n- self_scaled %= self.field\n+ # https://github.com/numpy/numpy/issues/6464\n+ self_scaled = np.remainder(self_scaled, np.array(self.field), casting=\"unsafe\")\n \n # self_scaled can be an array of floats. As multiplying an array of int with an int\n # still gives an array of int, I think it should be because self.child is a float tensor at this point.\n", "issue": "Fix precision with large storage fails\n**Describe the bug**\r\nThe following operation fails\r\n\r\n`lpt = torch.Tensor([-2., 4]).fix_prec(storage=\"large\")`\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\nUse the above expression in a test and see the result:\r\n`TypeError`\r\n**Expected behavior**\r\nThe expression should not crash\r\n**Screenshots**\r\n\r\n**Desktop (please complete the following information):**\r\n\r\n**Additional context**\r\n\n", "before_files": [{"content": "import numpy as np\nimport math\nimport torch\n\nfrom syft.generic.frameworks.hook.hook_args import (\n register_type_rule,\n register_forward_func,\n register_backward_func,\n one,\n)\nfrom syft.generic.frameworks.overload import overloaded\nfrom syft.generic.tensor import AbstractTensor\n\n\nclass LargePrecisionTensor(AbstractTensor):\n \"\"\"LargePrecisionTensor allows handling of numbers bigger than LongTensor\n\n Some systems using Syft require larger types than those supported natively. This tensor type supports arbitrarily\n large values by packing them in smaller ones.\n Typically a user will require to enlarge a float number by fixing its precision\n tensor.fix_prec()\n\n The large value is defined by `precision_fractional`.\n\n The smaller values are of type `internal_type`. The split of the large number into the smaller values\n is in the range \u00b12**(size - 1).\n\n By default operations are done with NumPy. This implies unpacking the representation and packing it again.\n\n Sharing a LPT requires using a arithmetic field where the shares will live. This field cannot bigger than 2 ** 62\n or the process would trigger a RuntimeError: Overflow when unpacking long. Note that this field will be applied to\n the internal representation and not to the scaled tensor.\n\n Check the tests to see how to play with the different parameters.\n \"\"\"\n\n def __init__(\n self,\n owner=None,\n id=None,\n tags=None,\n description=None,\n field: int = 2 ** 512,\n base: int = 10,\n precision_fractional=0,\n internal_type=torch.int32,\n verbose=False,\n ):\n \"\"\"Initializes a LargePrecisionTensor.\n\n Args:\n owner (BaseWorker): An optional BaseWorker object to specify the worker on which\n the tensor is located.\n id (str or int): An optional string or integer id of the LargePrecisionTensor.\n tags (list): list of tags for searching.\n description (str): a description of this tensor.\n field (int): size of the arithmetic field used to truncate and scale the large numbers\n base (int): The base that will be used to to calculate the precision.\n precision_fractional (int): The precision required by the caller.\n internal_type (dtype): The large tensor will be stored using tensor of this type.\n \"\"\"\n super().__init__(id=id, owner=owner, tags=tags, description=description)\n self.field = field\n self.base = base\n self.internal_type = internal_type\n self.precision_fractional = precision_fractional\n self.verbose = verbose\n # This is the maximum size of the arithmetic field that is applied when sharing\n self.internal_field = 2 ** 62\n\n def _create_internal_representation(self):\n \"\"\"Decompose a tensor into an array of numbers that represent such tensor with the required precision\"\"\"\n self_scaled = self.child.numpy() * self.base ** self.precision_fractional\n\n # floor is applied otherwise, long float is not accurate\n self_scaled = np.vectorize(math.floor)(self_scaled)\n self_scaled %= self.field\n\n # self_scaled can be an array of floats. As multiplying an array of int with an int\n # still gives an array of int, I think it should be because self.child is a float tensor at this point.\n # Right now, it does not cause any problem, LargePrecisionTensor._split_numbers() returns an array of int.\n result = LargePrecisionTensor._split_numbers(\n self_scaled, self.internal_precision, self.internal_type\n )\n return torch.tensor(result, dtype=self.internal_type)\n\n @staticmethod\n def _expand_item(a_number, max_length):\n return [0] * (max_length - len(a_number)) + a_number\n\n @property\n def internal_precision(self):\n \"\"\"\"The internal precision used to decompose the large numbers is the size of the type - 1.\n The large number is decomposed into positive smaller numbers. This could provoke overflow if any of these\n smaller parts are bigger than type_precision/2.\n \"\"\"\n return type_precision[self.internal_type] - 1\n\n def get_class_attributes(self):\n \"\"\"\n Specify all the attributes need to build a wrapper correctly when returning a response.\n \"\"\"\n return {\n \"field\": self.field,\n \"base\": self.base,\n \"internal_type\": self.internal_type,\n \"precision_fractional\": self.precision_fractional,\n }\n\n @overloaded.method\n def add(self, self_, other):\n return self_ + other\n\n __add__ = add\n\n def __iadd__(self, other):\n \"\"\"Add two fixed precision tensors together.\n \"\"\"\n self.child = self.add(other).child\n\n return self\n\n add_ = __iadd__\n\n @overloaded.method\n def sub(self, self_, other):\n return self_ - other\n\n __sub__ = sub\n\n def __isub__(self, other):\n \"\"\"Add two fixed precision tensors together.\n \"\"\"\n self.child = self.sub(other).child\n\n return self\n\n sub_ = __isub__\n\n @overloaded.method\n def mul(self, self_, other):\n if isinstance(other, int):\n return self_ * other\n elif isinstance(self_, np.ndarray) and isinstance(other, np.ndarray):\n res = (self_ * other) % self.field\n\n # We need to truncate the result\n truncation = self.base ** self.precision_fractional\n gate = 1 * (res > self.field / 2)\n neg_nums = (res - self.field) // truncation + self.field\n pos_nums = res // truncation\n trunc_res = np.where(gate, neg_nums, pos_nums)\n\n return trunc_res\n else:\n raise NotImplementedError\n\n __mul__ = mul\n\n def __imul__(self, other):\n self.child = self.mul(other).child\n return self\n\n mul_ = __imul__\n\n @overloaded.method\n def mod(self, self_, other):\n return self_ % other\n\n __mod__ = mod\n\n @overloaded.method\n def gt(self, self_, other):\n return 1 * (self_ > other)\n\n __gt__ = gt\n\n @overloaded.method\n def lt(self, self_, other):\n return 1 * (self_ < other)\n\n __lt__ = lt\n\n def fix_large_precision(self):\n self.child = self._create_internal_representation()\n return self\n\n def float_precision(self):\n \"\"\"\n Restore the tensor from the internal representation.\n\n Returns:\n tensor: the original tensor.\n \"\"\"\n result = self._internal_representation_to_large_ints()\n\n gate = 1 * (result > self.field / 2)\n neg_nums = (result - self.field) * gate\n pos_nums = result * (1 - gate)\n result = (neg_nums + pos_nums) / self.base ** self.precision_fractional\n\n # At this point the value is an object type. Force cast to float before creating torch.tensor\n return torch.from_numpy(result.reshape(self.child.shape[:-1]).astype(np.float32))\n\n @staticmethod\n def create_tensor_from_numpy(ndarray, **kwargs):\n \"\"\"Decompose a NumPy array into an array of numbers that represent such tensor with the required precision.\n\n Typically this method is called on the result of an operation.\n \"\"\"\n # This method is called to rebuild an LTP after operations.\n # The wrapping is done here and not in each operation.\n ndarray %= kwargs.get(\"field\", 2 ** 62)\n\n internal_type = kwargs[\"internal_type\"]\n internal_precision = type_precision[internal_type] - 1\n\n result = LargePrecisionTensor._split_numbers(ndarray, internal_precision, internal_type)\n return torch.tensor(result, dtype=internal_type)\n\n @staticmethod\n def _split_numbers(numbers, bits, internal_type) -> np.array:\n \"\"\"Splits a tensor of numbers in numbers of a smaller power.\n\n Args:\n numbers (array): the tensor to split.\n bits (int): the bits to use in the split.\n\n Returns:\n array: a tensor with one more dimension representing the original one.\n\n \"\"\"\n if np.all(numbers == 0):\n # numbers is an array of objects if the values are too large\n # we need to cast it back to an array of integers\n numbers = numbers.astype(np.int)\n return np.expand_dims(numbers, -1)\n\n sign_mask = np.where(numbers > 0, 1, -1)\n if internal_type == torch.uint8:\n assert np.all(\n sign_mask == 1\n ), \"LargePrecisionTensors with negative values cannot be represented with uint8\"\n numbers = np.where(numbers > 0, numbers, -numbers)\n\n base = 2 ** bits\n number_parts = []\n while np.any(numbers):\n # number, part = np.divmod(number, base) # Not sure why this doesn't work\n part = numbers % base\n numbers = numbers // base\n number_parts.append(part * sign_mask)\n\n res = np.array(number_parts[::-1], dtype=np.int)\n return res.transpose(*range(1, res.ndim), 0)\n\n def _internal_representation_to_large_ints(self) -> np.array:\n \"\"\"Creates an numpy array containing the objective large numbers.\"\"\"\n ndarray = self.child.numpy()\n ndarray = ndarray.reshape(-1, ndarray.shape[-1])\n result = []\n for elem in ndarray:\n result.append(LargePrecisionTensor._restore_large_number(elem, self.internal_precision))\n return np.array(result).reshape(self.child.shape[:-1])\n\n @staticmethod\n def _restore_large_number(number_parts, bits) -> int:\n \"\"\"Rebuilds a number from a numpy array.\n\n Args:\n number_parts (ndarray): the numpy array of numbers representing the original one.\n bits (int): the bits used in the split.\n\n Returns:\n Number: the large number represented by this tensor\n \"\"\"\n\n def _restore_recursive(parts, acc, base):\n if len(parts) == 0:\n return acc\n return _restore_recursive(parts[1:], acc * base + parts[0].item(), base)\n\n return _restore_recursive(number_parts, 0, 2 ** bits)\n\n @staticmethod\n def _forward_func(tensor):\n if hasattr(tensor, \"child\") and isinstance(tensor.child, torch.Tensor):\n return tensor._internal_representation_to_large_ints()\n return tensor.child\n\n @staticmethod\n def _backward_func(tensor, **kwargs):\n if isinstance(tensor, np.ndarray):\n return LargePrecisionTensor(**kwargs).on(\n LargePrecisionTensor.create_tensor_from_numpy(tensor, **kwargs), wrap=False\n )\n return LargePrecisionTensor(**kwargs).on(tensor, wrap=False)\n\n def share(self, *owners, field=None, crypto_provider=None):\n if field is None:\n field = self.internal_field\n else:\n assert field <= self.internal_field, \"internal_field max value is 2 ** 62\"\n assert (\n field == self.internal_field\n ), \"When sharing a LargePrecisionTensor, the field of the resulting AdditiveSharingTensor \\\n must be the same as the one of the original tensor\"\n\n self.child = self.child.share(\n *owners, field=field, crypto_provider=crypto_provider, no_wrap=True\n )\n return self\n\n\n# The size of each type\ntype_precision = {\n torch.uint8: 8,\n torch.int8: 8,\n torch.int16: 16,\n torch.short: 16,\n torch.int32: 32,\n torch.int: 32,\n torch.int64: 64,\n torch.long: 64,\n}\n\n### Register the tensor with hook_args.py ###\nregister_type_rule({LargePrecisionTensor: one})\nregister_forward_func({LargePrecisionTensor: lambda i: LargePrecisionTensor._forward_func(i)})\nregister_backward_func(\n {LargePrecisionTensor: lambda i, **kwargs: LargePrecisionTensor._backward_func(i, **kwargs)}\n)\n", "path": "syft/frameworks/torch/tensors/interpreters/large_precision.py"}], "after_files": [{"content": "import numpy as np\nimport math\nimport torch\n\nfrom syft.generic.frameworks.hook.hook_args import (\n register_type_rule,\n register_forward_func,\n register_backward_func,\n one,\n)\nfrom syft.generic.frameworks.overload import overloaded\nfrom syft.generic.tensor import AbstractTensor\n\n\nclass LargePrecisionTensor(AbstractTensor):\n \"\"\"LargePrecisionTensor allows handling of numbers bigger than LongTensor\n\n Some systems using Syft require larger types than those supported natively. This tensor type supports arbitrarily\n large values by packing them in smaller ones.\n Typically a user will require to enlarge a float number by fixing its precision\n tensor.fix_prec()\n\n The large value is defined by `precision_fractional`.\n\n The smaller values are of type `internal_type`. The split of the large number into the smaller values\n is in the range \u00b12**(size - 1).\n\n By default operations are done with NumPy. This implies unpacking the representation and packing it again.\n\n Sharing a LPT requires using a arithmetic field where the shares will live. This field cannot bigger than 2 ** 62\n or the process would trigger a RuntimeError: Overflow when unpacking long. Note that this field will be applied to\n the internal representation and not to the scaled tensor.\n\n Check the tests to see how to play with the different parameters.\n \"\"\"\n\n def __init__(\n self,\n owner=None,\n id=None,\n tags=None,\n description=None,\n field: int = 2 ** 512,\n base: int = 10,\n precision_fractional=0,\n internal_type=torch.int32,\n verbose=False,\n ):\n \"\"\"Initializes a LargePrecisionTensor.\n\n Args:\n owner (BaseWorker): An optional BaseWorker object to specify the worker on which\n the tensor is located.\n id (str or int): An optional string or integer id of the LargePrecisionTensor.\n tags (list): list of tags for searching.\n description (str): a description of this tensor.\n field (int): size of the arithmetic field used to truncate and scale the large numbers\n base (int): The base that will be used to to calculate the precision.\n precision_fractional (int): The precision required by the caller.\n internal_type (dtype): The large tensor will be stored using tensor of this type.\n \"\"\"\n super().__init__(id=id, owner=owner, tags=tags, description=description)\n self.field = field\n self.base = base\n self.internal_type = internal_type\n self.precision_fractional = precision_fractional\n self.verbose = verbose\n # This is the maximum size of the arithmetic field that is applied when sharing\n self.internal_field = 2 ** 62\n\n def _create_internal_representation(self):\n \"\"\"Decompose a tensor into an array of numbers that represent such tensor with the required precision\"\"\"\n self_scaled = self.child.numpy() * self.base ** self.precision_fractional\n\n # floor is applied otherwise, long float is not accurate\n self_scaled = np.vectorize(math.floor)(self_scaled)\n # https://github.com/numpy/numpy/issues/6464\n self_scaled = np.remainder(self_scaled, np.array(self.field), casting=\"unsafe\")\n\n # self_scaled can be an array of floats. As multiplying an array of int with an int\n # still gives an array of int, I think it should be because self.child is a float tensor at this point.\n # Right now, it does not cause any problem, LargePrecisionTensor._split_numbers() returns an array of int.\n result = LargePrecisionTensor._split_numbers(\n self_scaled, self.internal_precision, self.internal_type\n )\n return torch.tensor(result, dtype=self.internal_type)\n\n @staticmethod\n def _expand_item(a_number, max_length):\n return [0] * (max_length - len(a_number)) + a_number\n\n @property\n def internal_precision(self):\n \"\"\"\"The internal precision used to decompose the large numbers is the size of the type - 1.\n The large number is decomposed into positive smaller numbers. This could provoke overflow if any of these\n smaller parts are bigger than type_precision/2.\n \"\"\"\n return type_precision[self.internal_type] - 1\n\n def get_class_attributes(self):\n \"\"\"\n Specify all the attributes need to build a wrapper correctly when returning a response.\n \"\"\"\n return {\n \"field\": self.field,\n \"base\": self.base,\n \"internal_type\": self.internal_type,\n \"precision_fractional\": self.precision_fractional,\n }\n\n @overloaded.method\n def add(self, self_, other):\n return self_ + other\n\n __add__ = add\n\n def __iadd__(self, other):\n \"\"\"Add two fixed precision tensors together.\n \"\"\"\n self.child = self.add(other).child\n\n return self\n\n add_ = __iadd__\n\n @overloaded.method\n def sub(self, self_, other):\n return self_ - other\n\n __sub__ = sub\n\n def __isub__(self, other):\n \"\"\"Add two fixed precision tensors together.\n \"\"\"\n self.child = self.sub(other).child\n\n return self\n\n sub_ = __isub__\n\n @overloaded.method\n def mul(self, self_, other):\n if isinstance(other, int):\n return self_ * other\n elif isinstance(self_, np.ndarray) and isinstance(other, np.ndarray):\n res = (self_ * other) % self.field\n\n # We need to truncate the result\n truncation = self.base ** self.precision_fractional\n gate = 1 * (res > self.field / 2)\n neg_nums = (res - self.field) // truncation + self.field\n pos_nums = res // truncation\n trunc_res = np.where(gate, neg_nums, pos_nums)\n\n return trunc_res\n else:\n raise NotImplementedError\n\n __mul__ = mul\n\n def __imul__(self, other):\n self.child = self.mul(other).child\n return self\n\n mul_ = __imul__\n\n @overloaded.method\n def mod(self, self_, other):\n return self_ % other\n\n __mod__ = mod\n\n @overloaded.method\n def gt(self, self_, other):\n return 1 * (self_ > other)\n\n __gt__ = gt\n\n @overloaded.method\n def lt(self, self_, other):\n return 1 * (self_ < other)\n\n __lt__ = lt\n\n def fix_large_precision(self):\n self.child = self._create_internal_representation()\n return self\n\n def float_precision(self):\n \"\"\"\n Restore the tensor from the internal representation.\n\n Returns:\n tensor: the original tensor.\n \"\"\"\n result = self._internal_representation_to_large_ints()\n\n gate = 1 * (result > self.field / 2)\n neg_nums = (result - self.field) * gate\n pos_nums = result * (1 - gate)\n result = (neg_nums + pos_nums) / self.base ** self.precision_fractional\n\n # At this point the value is an object type. Force cast to float before creating torch.tensor\n return torch.from_numpy(result.reshape(self.child.shape[:-1]).astype(np.float32))\n\n @staticmethod\n def create_tensor_from_numpy(ndarray, **kwargs):\n \"\"\"Decompose a NumPy array into an array of numbers that represent such tensor with the required precision.\n\n Typically this method is called on the result of an operation.\n \"\"\"\n # This method is called to rebuild an LTP after operations.\n # The wrapping is done here and not in each operation.\n ndarray %= kwargs.get(\"field\", 2 ** 62)\n\n internal_type = kwargs[\"internal_type\"]\n internal_precision = type_precision[internal_type] - 1\n\n result = LargePrecisionTensor._split_numbers(ndarray, internal_precision, internal_type)\n return torch.tensor(result, dtype=internal_type)\n\n @staticmethod\n def _split_numbers(numbers, bits, internal_type) -> np.array:\n \"\"\"Splits a tensor of numbers in numbers of a smaller power.\n\n Args:\n numbers (array): the tensor to split.\n bits (int): the bits to use in the split.\n\n Returns:\n array: a tensor with one more dimension representing the original one.\n\n \"\"\"\n if np.all(numbers == 0):\n # numbers is an array of objects if the values are too large\n # we need to cast it back to an array of integers\n numbers = numbers.astype(np.int)\n return np.expand_dims(numbers, -1)\n\n sign_mask = np.where(numbers > 0, 1, -1)\n if internal_type == torch.uint8:\n assert np.all(\n sign_mask == 1\n ), \"LargePrecisionTensors with negative values cannot be represented with uint8\"\n numbers = np.where(numbers > 0, numbers, -numbers)\n\n base = 2 ** bits\n number_parts = []\n while np.any(numbers):\n # number, part = np.divmod(number, base) # Not sure why this doesn't work\n part = numbers % base\n numbers = numbers // base\n number_parts.append(part * sign_mask)\n\n res = np.array(number_parts[::-1], dtype=np.int)\n return res.transpose(*range(1, res.ndim), 0)\n\n def _internal_representation_to_large_ints(self) -> np.array:\n \"\"\"Creates an numpy array containing the objective large numbers.\"\"\"\n ndarray = self.child.numpy()\n ndarray = ndarray.reshape(-1, ndarray.shape[-1])\n result = []\n for elem in ndarray:\n result.append(LargePrecisionTensor._restore_large_number(elem, self.internal_precision))\n return np.array(result).reshape(self.child.shape[:-1])\n\n @staticmethod\n def _restore_large_number(number_parts, bits) -> int:\n \"\"\"Rebuilds a number from a numpy array.\n\n Args:\n number_parts (ndarray): the numpy array of numbers representing the original one.\n bits (int): the bits used in the split.\n\n Returns:\n Number: the large number represented by this tensor\n \"\"\"\n\n def _restore_recursive(parts, acc, base):\n if len(parts) == 0:\n return acc\n return _restore_recursive(parts[1:], acc * base + parts[0].item(), base)\n\n return _restore_recursive(number_parts, 0, 2 ** bits)\n\n @staticmethod\n def _forward_func(tensor):\n if hasattr(tensor, \"child\") and isinstance(tensor.child, torch.Tensor):\n return tensor._internal_representation_to_large_ints()\n return tensor.child\n\n @staticmethod\n def _backward_func(tensor, **kwargs):\n if isinstance(tensor, np.ndarray):\n return LargePrecisionTensor(**kwargs).on(\n LargePrecisionTensor.create_tensor_from_numpy(tensor, **kwargs), wrap=False\n )\n return LargePrecisionTensor(**kwargs).on(tensor, wrap=False)\n\n def share(self, *owners, field=None, crypto_provider=None):\n if field is None:\n field = self.internal_field\n else:\n assert field <= self.internal_field, \"internal_field max value is 2 ** 62\"\n assert (\n field == self.internal_field\n ), \"When sharing a LargePrecisionTensor, the field of the resulting AdditiveSharingTensor \\\n must be the same as the one of the original tensor\"\n\n self.child = self.child.share(\n *owners, field=field, crypto_provider=crypto_provider, no_wrap=True\n )\n return self\n\n\n# The size of each type\ntype_precision = {\n torch.uint8: 8,\n torch.int8: 8,\n torch.int16: 16,\n torch.short: 16,\n torch.int32: 32,\n torch.int: 32,\n torch.int64: 64,\n torch.long: 64,\n}\n\n### Register the tensor with hook_args.py ###\nregister_type_rule({LargePrecisionTensor: one})\nregister_forward_func({LargePrecisionTensor: lambda i: LargePrecisionTensor._forward_func(i)})\nregister_backward_func(\n {LargePrecisionTensor: lambda i, **kwargs: LargePrecisionTensor._backward_func(i, **kwargs)}\n)\n", "path": "syft/frameworks/torch/tensors/interpreters/large_precision.py"}]}
| 3,908 | 209 |
gh_patches_debug_2047
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-7286
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[package] aws-c-event-stream/0.2.7: conflicting openssl versions
```
ERROR: Conflict in s2n/1.0.11:
's2n/1.0.11' requires 'openssl/1.1.1k' while 'aws-c-cal/0.5.11' requires 'openssl/1.1.1l'.
To fix this conflict you need to override the package 'openssl' in your root package.
```
seems like it was introduced by #7260
### Package and Environment Details (include every applicable attribute)
* Package Name/Version: **aws-c-event-stream/0.2.7**
* Conan version: **conan 1.39.0**
### Conan profile (output of `conan profile show default` or `conan profile show <profile>` if custom profile is in use)
```
[settings]
arch=x86_64
arch_build=x86_64
build_type=Release
compiler=gcc
compiler.libcxx=libstdc++
compiler.version=7
os=Linux
os_build=Linux
[options]
[build_requires]
[env]
```
### Steps to reproduce (Include if Applicable)
conan install --build missing aws-c-event-stream/0.2.7@
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `recipes/s2n/all/conanfile.py`
Content:
```
1 from conans import ConanFile, CMake, tools
2 from conans.errors import ConanInvalidConfiguration
3 import os
4
5 required_conan_version = ">=1.33.0"
6
7 class S2n(ConanFile):
8 name = "s2n"
9 description = "An implementation of the TLS/SSL protocols"
10 topics = ("conan", "aws", "amazon", "cloud", )
11 url = "https://github.com/conan-io/conan-center-index"
12 homepage = "https://github.com/aws/s2n-tls"
13 license = "Apache-2.0",
14 exports_sources = "CMakeLists.txt"
15 generators = "cmake", "cmake_find_package"
16 settings = "os", "arch", "compiler", "build_type"
17 options = {
18 "shared": [True, False],
19 "fPIC": [True, False],
20 }
21 default_options = {
22 "shared": False,
23 "fPIC": True,
24 }
25
26 _cmake = None
27
28 @property
29 def _source_subfolder(self):
30 return "source_subfolder"
31
32 def configure(self):
33 if self.options.shared:
34 del self.options.fPIC
35 del self.settings.compiler.cppstd
36 del self.settings.compiler.libcxx
37
38 def requirements(self):
39 self.requires("openssl/1.1.1k")
40
41 def source(self):
42 tools.get(**self.conan_data["sources"][self.version],
43 destination=self._source_subfolder, strip_root=True)
44
45 def validate(self):
46 if self.settings.os == "Windows":
47 raise ConanInvalidConfiguration("Not supported (yet)")
48
49 def _configure_cmake(self):
50 if self._cmake:
51 return self._cmake
52 self._cmake = CMake(self)
53 self._cmake.definitions["BUILD_TESTING"] = False
54 self._cmake.definitions["UNSAFE_TREAT_WARNINGS_AS_ERRORS"] = False
55 self._cmake.configure()
56 return self._cmake
57
58 def build(self):
59 cmake = self._configure_cmake()
60 cmake.build()
61
62 def package(self):
63 self.copy(pattern="LICENSE", dst="licenses", src=self._source_subfolder)
64 cmake = self._configure_cmake()
65 cmake.install()
66 tools.rmdir(os.path.join(self.package_folder, "lib", "s2n"))
67
68 def package_info(self):
69 self.cpp_info.filenames["cmake_find_package"] = "s2n"
70 self.cpp_info.filenames["cmake_find_package_multi"] = "s2n"
71 self.cpp_info.names["cmake_find_package"] = "AWS"
72 self.cpp_info.names["cmake_find_package_multi"] = "AWS"
73 self.cpp_info.components["s2n-lib"].names["cmake_find_package"] = "s2n"
74 self.cpp_info.components["s2n-lib"].names["cmake_find_package_multi"] = "s2n"
75 self.cpp_info.components["s2n-lib"].libs = ["s2n"]
76 self.cpp_info.components["s2n-lib"].requires = ["openssl::crypto"]
77 if self.settings.os in ("FreeBSD", "Linux"):
78 self.cpp_info.components["s2n-lib"].system_libs = ["m", "pthread"]
79
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/recipes/s2n/all/conanfile.py b/recipes/s2n/all/conanfile.py
--- a/recipes/s2n/all/conanfile.py
+++ b/recipes/s2n/all/conanfile.py
@@ -36,7 +36,7 @@
del self.settings.compiler.libcxx
def requirements(self):
- self.requires("openssl/1.1.1k")
+ self.requires("openssl/1.1.1l")
def source(self):
tools.get(**self.conan_data["sources"][self.version],
|
{"golden_diff": "diff --git a/recipes/s2n/all/conanfile.py b/recipes/s2n/all/conanfile.py\n--- a/recipes/s2n/all/conanfile.py\n+++ b/recipes/s2n/all/conanfile.py\n@@ -36,7 +36,7 @@\n del self.settings.compiler.libcxx\n \n def requirements(self):\n- self.requires(\"openssl/1.1.1k\")\n+ self.requires(\"openssl/1.1.1l\")\n \n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version],\n", "issue": "[package] aws-c-event-stream/0.2.7: conflicting openssl versions\n```\r\nERROR: Conflict in s2n/1.0.11:\r\n 's2n/1.0.11' requires 'openssl/1.1.1k' while 'aws-c-cal/0.5.11' requires 'openssl/1.1.1l'.\r\n To fix this conflict you need to override the package 'openssl' in your root package.\r\n```\r\n\r\nseems like it was introduced by #7260 \r\n\r\n### Package and Environment Details (include every applicable attribute)\r\n * Package Name/Version: **aws-c-event-stream/0.2.7**\r\n * Conan version: **conan 1.39.0**\r\n\r\n\r\n### Conan profile (output of `conan profile show default` or `conan profile show <profile>` if custom profile is in use)\r\n```\r\n[settings]\r\narch=x86_64\r\narch_build=x86_64\r\nbuild_type=Release\r\ncompiler=gcc\r\ncompiler.libcxx=libstdc++\r\ncompiler.version=7\r\nos=Linux\r\nos_build=Linux\r\n[options]\r\n[build_requires]\r\n[env]\r\n```\r\n\r\n\r\n### Steps to reproduce (Include if Applicable)\r\nconan install --build missing aws-c-event-stream/0.2.7@\n", "before_files": [{"content": "from conans import ConanFile, CMake, tools\nfrom conans.errors import ConanInvalidConfiguration\nimport os\n\nrequired_conan_version = \">=1.33.0\"\n\nclass S2n(ConanFile):\n name = \"s2n\"\n description = \"An implementation of the TLS/SSL protocols\"\n topics = (\"conan\", \"aws\", \"amazon\", \"cloud\", )\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"https://github.com/aws/s2n-tls\"\n license = \"Apache-2.0\",\n exports_sources = \"CMakeLists.txt\"\n generators = \"cmake\", \"cmake_find_package\"\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n options = {\n \"shared\": [True, False],\n \"fPIC\": [True, False],\n }\n default_options = {\n \"shared\": False,\n \"fPIC\": True,\n }\n\n _cmake = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n def configure(self):\n if self.options.shared:\n del self.options.fPIC\n del self.settings.compiler.cppstd\n del self.settings.compiler.libcxx\n\n def requirements(self):\n self.requires(\"openssl/1.1.1k\")\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version],\n destination=self._source_subfolder, strip_root=True)\n\n def validate(self):\n if self.settings.os == \"Windows\":\n raise ConanInvalidConfiguration(\"Not supported (yet)\")\n\n def _configure_cmake(self):\n if self._cmake:\n return self._cmake\n self._cmake = CMake(self)\n self._cmake.definitions[\"BUILD_TESTING\"] = False\n self._cmake.definitions[\"UNSAFE_TREAT_WARNINGS_AS_ERRORS\"] = False\n self._cmake.configure()\n return self._cmake\n\n def build(self):\n cmake = self._configure_cmake()\n cmake.build()\n\n def package(self):\n self.copy(pattern=\"LICENSE\", dst=\"licenses\", src=self._source_subfolder)\n cmake = self._configure_cmake()\n cmake.install()\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"s2n\"))\n\n def package_info(self):\n self.cpp_info.filenames[\"cmake_find_package\"] = \"s2n\"\n self.cpp_info.filenames[\"cmake_find_package_multi\"] = \"s2n\"\n self.cpp_info.names[\"cmake_find_package\"] = \"AWS\"\n self.cpp_info.names[\"cmake_find_package_multi\"] = \"AWS\"\n self.cpp_info.components[\"s2n-lib\"].names[\"cmake_find_package\"] = \"s2n\"\n self.cpp_info.components[\"s2n-lib\"].names[\"cmake_find_package_multi\"] = \"s2n\"\n self.cpp_info.components[\"s2n-lib\"].libs = [\"s2n\"]\n self.cpp_info.components[\"s2n-lib\"].requires = [\"openssl::crypto\"]\n if self.settings.os in (\"FreeBSD\", \"Linux\"):\n self.cpp_info.components[\"s2n-lib\"].system_libs = [\"m\", \"pthread\"]\n", "path": "recipes/s2n/all/conanfile.py"}], "after_files": [{"content": "from conans import ConanFile, CMake, tools\nfrom conans.errors import ConanInvalidConfiguration\nimport os\n\nrequired_conan_version = \">=1.33.0\"\n\nclass S2n(ConanFile):\n name = \"s2n\"\n description = \"An implementation of the TLS/SSL protocols\"\n topics = (\"conan\", \"aws\", \"amazon\", \"cloud\", )\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"https://github.com/aws/s2n-tls\"\n license = \"Apache-2.0\",\n exports_sources = \"CMakeLists.txt\"\n generators = \"cmake\", \"cmake_find_package\"\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n options = {\n \"shared\": [True, False],\n \"fPIC\": [True, False],\n }\n default_options = {\n \"shared\": False,\n \"fPIC\": True,\n }\n\n _cmake = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n def configure(self):\n if self.options.shared:\n del self.options.fPIC\n del self.settings.compiler.cppstd\n del self.settings.compiler.libcxx\n\n def requirements(self):\n self.requires(\"openssl/1.1.1l\")\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version],\n destination=self._source_subfolder, strip_root=True)\n\n def validate(self):\n if self.settings.os == \"Windows\":\n raise ConanInvalidConfiguration(\"Not supported (yet)\")\n\n def _configure_cmake(self):\n if self._cmake:\n return self._cmake\n self._cmake = CMake(self)\n self._cmake.definitions[\"BUILD_TESTING\"] = False\n self._cmake.definitions[\"UNSAFE_TREAT_WARNINGS_AS_ERRORS\"] = False\n self._cmake.configure()\n return self._cmake\n\n def build(self):\n cmake = self._configure_cmake()\n cmake.build()\n\n def package(self):\n self.copy(pattern=\"LICENSE\", dst=\"licenses\", src=self._source_subfolder)\n cmake = self._configure_cmake()\n cmake.install()\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"s2n\"))\n\n def package_info(self):\n self.cpp_info.filenames[\"cmake_find_package\"] = \"s2n\"\n self.cpp_info.filenames[\"cmake_find_package_multi\"] = \"s2n\"\n self.cpp_info.names[\"cmake_find_package\"] = \"AWS\"\n self.cpp_info.names[\"cmake_find_package_multi\"] = \"AWS\"\n self.cpp_info.components[\"s2n-lib\"].names[\"cmake_find_package\"] = \"s2n\"\n self.cpp_info.components[\"s2n-lib\"].names[\"cmake_find_package_multi\"] = \"s2n\"\n self.cpp_info.components[\"s2n-lib\"].libs = [\"s2n\"]\n self.cpp_info.components[\"s2n-lib\"].requires = [\"openssl::crypto\"]\n if self.settings.os in (\"FreeBSD\", \"Linux\"):\n self.cpp_info.components[\"s2n-lib\"].system_libs = [\"m\", \"pthread\"]\n", "path": "recipes/s2n/all/conanfile.py"}]}
| 1,401 | 125 |
gh_patches_debug_3880
|
rasdani/github-patches
|
git_diff
|
ckan__ckan-4307
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Internal server error when viewing /dashboard when logged out
### CKAN Version if known (or site URL)
2.8.0
### Please describe the expected behaviour
When attempting to visit /dashboard as a non-logged in user, the user should be sent to the login page.
### Please describe the actual behaviour
An internal server error occurs.
```
File "/usr/lib/ckan/default/src/ckan/ckan/views/dashboard.py", line 99, in index
u'id': g.userobj.id,
AttributeError: 'NoneType' object has no attribute 'id'
```
### What steps can be taken to reproduce the issue?
Visit http://demo.ckan.org/dashboard when not logged in
Internal server error when viewing /dashboard when logged out
### CKAN Version if known (or site URL)
2.8.0
### Please describe the expected behaviour
When attempting to visit /dashboard as a non-logged in user, the user should be sent to the login page.
### Please describe the actual behaviour
An internal server error occurs.
```
File "/usr/lib/ckan/default/src/ckan/ckan/views/dashboard.py", line 99, in index
u'id': g.userobj.id,
AttributeError: 'NoneType' object has no attribute 'id'
```
### What steps can be taken to reproduce the issue?
Visit http://demo.ckan.org/dashboard when not logged in
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ckan/views/dashboard.py`
Content:
```
1 # encoding: utf-8
2 import logging
3
4 from flask import Blueprint
5
6 import ckan.lib.base as base
7 import ckan.lib.helpers as h
8 import ckan.logic as logic
9 import ckan.model as model
10 from ckan.common import _, g, request
11 from ckan.views.user import _extra_template_variables
12
13 log = logging.getLogger(__name__)
14
15 dashboard = Blueprint(u'dashboard', __name__, url_prefix=u'/dashboard')
16
17
18 @dashboard.before_request
19 def before_request():
20 try:
21 context = dict(model=model, user=g.user, auth_user_obj=g.userobj)
22 logic.check_access(u'site_read', context)
23 except logic.NotAuthorized:
24 base.abort(403, _(u'Not authorized to see this page'))
25
26
27 def _get_dashboard_context(self, filter_type=None, filter_id=None, q=None):
28 u'''Return a dict needed by the dashboard view to determine context.'''
29
30 def display_name(followee):
31 u'''Return a display name for a user, group or dataset dict.'''
32 display_name = followee.get(u'display_name')
33 fullname = followee.get(u'fullname')
34 title = followee.get(u'title')
35 name = followee.get(u'name')
36 return display_name or fullname or title or name
37
38 if (filter_type and filter_id):
39 context = {
40 u'model': model,
41 u'session': model.Session,
42 u'user': g.user,
43 u'auth_user_obj': g.userobj,
44 u'for_view': True
45 }
46 data_dict = {u'id': filter_id, u'include_num_followers': True}
47 followee = None
48
49 action_functions = {
50 u'dataset': u'package_show',
51 u'user': u'user_show',
52 u'group': u'group_show',
53 u'organization': u'organization_show',
54 }
55 action_function = logic.get_action(action_functions.get(filter_type))
56 # Is this a valid type?
57 if action_function is None:
58 base.abort(404, _(u'Follow item not found'))
59 try:
60 followee = action_function(context, data_dict)
61 except (logic.NotFound, logic.NotAuthorized):
62 base.abort(404, _(u'{0} not found').format(filter_type))
63
64 if followee is not None:
65 return {
66 u'filter_type': filter_type,
67 u'q': q,
68 u'context': display_name(followee),
69 u'selected_id': followee.get(u'id'),
70 u'dict': followee,
71 }
72
73 return {
74 u'filter_type': filter_type,
75 u'q': q,
76 u'context': _(u'Everything'),
77 u'selected_id': False,
78 u'dict': None,
79 }
80
81
82 def index(offset=0):
83 context = {
84 u'model': model,
85 u'session': model.Session,
86 u'user': g.user,
87 u'auth_user_obj': g.userobj,
88 u'for_view': True
89 }
90 data_dict = {u'user_obj': g.userobj, u'offset': offset}
91 extra_vars = _extra_template_variables(context, data_dict)
92
93 q = request.params.get(u'q', u'')
94 filter_type = request.params.get(u'type', u'')
95 filter_id = request.params.get(u'name', u'')
96
97 extra_vars[u'followee_list'] = logic.get_action(u'followee_list')(
98 context, {
99 u'id': g.userobj.id,
100 u'q': q
101 })
102 extra_vars[u'dashboard_activity_stream_context'] = _get_dashboard_context(
103 filter_type, filter_id, q)
104 extra_vars[u'dashboard_activity_stream'] = h.dashboard_activity_stream(
105 g.userobj.id, filter_type, filter_id, offset)
106
107 # Mark the useru's new activities as old whenever they view their
108 # dashboard page.
109 logic.get_action(u'dashboard_mark_activities_old')(context, {})
110
111 return base.render(u'user/dashboard.html', extra_vars)
112
113
114 def datasets():
115 context = {u'for_view': True, u'user': g.user, u'auth_user_obj': g.userobj}
116 data_dict = {u'user_obj': g.userobj, u'include_datasets': True}
117 extra_vars = _extra_template_variables(context, data_dict)
118 return base.render(u'user/dashboard_datasets.html', extra_vars)
119
120
121 def organizations():
122 context = {u'for_view': True, u'user': g.user, u'auth_user_obj': g.userobj}
123 data_dict = {u'user_obj': g.userobj}
124 extra_vars = _extra_template_variables(context, data_dict)
125 return base.render(u'user/dashboard_organizations.html', extra_vars)
126
127
128 def groups():
129 context = {u'for_view': True, u'user': g.user, u'auth_user_obj': g.userobj}
130 data_dict = {u'user_obj': g.userobj}
131 extra_vars = _extra_template_variables(context, data_dict)
132 return base.render(u'user/dashboard_groups.html', extra_vars)
133
134
135 dashboard.add_url_rule(
136 u'/', view_func=index, strict_slashes=False, defaults={
137 u'offset': 0
138 })
139 dashboard.add_url_rule(u'/<int:offset>', view_func=index)
140
141 dashboard.add_url_rule(u'/datasets', view_func=datasets)
142 dashboard.add_url_rule(u'/groups', view_func=groups)
143 dashboard.add_url_rule(u'/organizations', view_func=organizations)
144
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ckan/views/dashboard.py b/ckan/views/dashboard.py
--- a/ckan/views/dashboard.py
+++ b/ckan/views/dashboard.py
@@ -18,6 +18,9 @@
@dashboard.before_request
def before_request():
try:
+ if not g.userobj:
+ raise logic.NotAuthorized()
+
context = dict(model=model, user=g.user, auth_user_obj=g.userobj)
logic.check_access(u'site_read', context)
except logic.NotAuthorized:
|
{"golden_diff": "diff --git a/ckan/views/dashboard.py b/ckan/views/dashboard.py\n--- a/ckan/views/dashboard.py\n+++ b/ckan/views/dashboard.py\n@@ -18,6 +18,9 @@\n @dashboard.before_request\n def before_request():\n try:\n+ if not g.userobj:\n+ raise logic.NotAuthorized()\n+\n context = dict(model=model, user=g.user, auth_user_obj=g.userobj)\n logic.check_access(u'site_read', context)\n except logic.NotAuthorized:\n", "issue": "Internal server error when viewing /dashboard when logged out\n### CKAN Version if known (or site URL)\r\n\r\n2.8.0\r\n\r\n### Please describe the expected behaviour\r\n\r\nWhen attempting to visit /dashboard as a non-logged in user, the user should be sent to the login page.\r\n\r\n### Please describe the actual behaviour\r\n\r\nAn internal server error occurs.\r\n\r\n```\r\n File \"/usr/lib/ckan/default/src/ckan/ckan/views/dashboard.py\", line 99, in index\r\n u'id': g.userobj.id,\r\nAttributeError: 'NoneType' object has no attribute 'id'\r\n```\r\n\r\n### What steps can be taken to reproduce the issue? \r\n\r\nVisit http://demo.ckan.org/dashboard when not logged in\r\n\nInternal server error when viewing /dashboard when logged out\n### CKAN Version if known (or site URL)\r\n\r\n2.8.0\r\n\r\n### Please describe the expected behaviour\r\n\r\nWhen attempting to visit /dashboard as a non-logged in user, the user should be sent to the login page.\r\n\r\n### Please describe the actual behaviour\r\n\r\nAn internal server error occurs.\r\n\r\n```\r\n File \"/usr/lib/ckan/default/src/ckan/ckan/views/dashboard.py\", line 99, in index\r\n u'id': g.userobj.id,\r\nAttributeError: 'NoneType' object has no attribute 'id'\r\n```\r\n\r\n### What steps can be taken to reproduce the issue? \r\n\r\nVisit http://demo.ckan.org/dashboard when not logged in\r\n\n", "before_files": [{"content": "# encoding: utf-8\nimport logging\n\nfrom flask import Blueprint\n\nimport ckan.lib.base as base\nimport ckan.lib.helpers as h\nimport ckan.logic as logic\nimport ckan.model as model\nfrom ckan.common import _, g, request\nfrom ckan.views.user import _extra_template_variables\n\nlog = logging.getLogger(__name__)\n\ndashboard = Blueprint(u'dashboard', __name__, url_prefix=u'/dashboard')\n\n\[email protected]_request\ndef before_request():\n try:\n context = dict(model=model, user=g.user, auth_user_obj=g.userobj)\n logic.check_access(u'site_read', context)\n except logic.NotAuthorized:\n base.abort(403, _(u'Not authorized to see this page'))\n\n\ndef _get_dashboard_context(self, filter_type=None, filter_id=None, q=None):\n u'''Return a dict needed by the dashboard view to determine context.'''\n\n def display_name(followee):\n u'''Return a display name for a user, group or dataset dict.'''\n display_name = followee.get(u'display_name')\n fullname = followee.get(u'fullname')\n title = followee.get(u'title')\n name = followee.get(u'name')\n return display_name or fullname or title or name\n\n if (filter_type and filter_id):\n context = {\n u'model': model,\n u'session': model.Session,\n u'user': g.user,\n u'auth_user_obj': g.userobj,\n u'for_view': True\n }\n data_dict = {u'id': filter_id, u'include_num_followers': True}\n followee = None\n\n action_functions = {\n u'dataset': u'package_show',\n u'user': u'user_show',\n u'group': u'group_show',\n u'organization': u'organization_show',\n }\n action_function = logic.get_action(action_functions.get(filter_type))\n # Is this a valid type?\n if action_function is None:\n base.abort(404, _(u'Follow item not found'))\n try:\n followee = action_function(context, data_dict)\n except (logic.NotFound, logic.NotAuthorized):\n base.abort(404, _(u'{0} not found').format(filter_type))\n\n if followee is not None:\n return {\n u'filter_type': filter_type,\n u'q': q,\n u'context': display_name(followee),\n u'selected_id': followee.get(u'id'),\n u'dict': followee,\n }\n\n return {\n u'filter_type': filter_type,\n u'q': q,\n u'context': _(u'Everything'),\n u'selected_id': False,\n u'dict': None,\n }\n\n\ndef index(offset=0):\n context = {\n u'model': model,\n u'session': model.Session,\n u'user': g.user,\n u'auth_user_obj': g.userobj,\n u'for_view': True\n }\n data_dict = {u'user_obj': g.userobj, u'offset': offset}\n extra_vars = _extra_template_variables(context, data_dict)\n\n q = request.params.get(u'q', u'')\n filter_type = request.params.get(u'type', u'')\n filter_id = request.params.get(u'name', u'')\n\n extra_vars[u'followee_list'] = logic.get_action(u'followee_list')(\n context, {\n u'id': g.userobj.id,\n u'q': q\n })\n extra_vars[u'dashboard_activity_stream_context'] = _get_dashboard_context(\n filter_type, filter_id, q)\n extra_vars[u'dashboard_activity_stream'] = h.dashboard_activity_stream(\n g.userobj.id, filter_type, filter_id, offset)\n\n # Mark the useru's new activities as old whenever they view their\n # dashboard page.\n logic.get_action(u'dashboard_mark_activities_old')(context, {})\n\n return base.render(u'user/dashboard.html', extra_vars)\n\n\ndef datasets():\n context = {u'for_view': True, u'user': g.user, u'auth_user_obj': g.userobj}\n data_dict = {u'user_obj': g.userobj, u'include_datasets': True}\n extra_vars = _extra_template_variables(context, data_dict)\n return base.render(u'user/dashboard_datasets.html', extra_vars)\n\n\ndef organizations():\n context = {u'for_view': True, u'user': g.user, u'auth_user_obj': g.userobj}\n data_dict = {u'user_obj': g.userobj}\n extra_vars = _extra_template_variables(context, data_dict)\n return base.render(u'user/dashboard_organizations.html', extra_vars)\n\n\ndef groups():\n context = {u'for_view': True, u'user': g.user, u'auth_user_obj': g.userobj}\n data_dict = {u'user_obj': g.userobj}\n extra_vars = _extra_template_variables(context, data_dict)\n return base.render(u'user/dashboard_groups.html', extra_vars)\n\n\ndashboard.add_url_rule(\n u'/', view_func=index, strict_slashes=False, defaults={\n u'offset': 0\n })\ndashboard.add_url_rule(u'/<int:offset>', view_func=index)\n\ndashboard.add_url_rule(u'/datasets', view_func=datasets)\ndashboard.add_url_rule(u'/groups', view_func=groups)\ndashboard.add_url_rule(u'/organizations', view_func=organizations)\n", "path": "ckan/views/dashboard.py"}], "after_files": [{"content": "# encoding: utf-8\nimport logging\n\nfrom flask import Blueprint\n\nimport ckan.lib.base as base\nimport ckan.lib.helpers as h\nimport ckan.logic as logic\nimport ckan.model as model\nfrom ckan.common import _, g, request\nfrom ckan.views.user import _extra_template_variables\n\nlog = logging.getLogger(__name__)\n\ndashboard = Blueprint(u'dashboard', __name__, url_prefix=u'/dashboard')\n\n\[email protected]_request\ndef before_request():\n try:\n if not g.userobj:\n raise logic.NotAuthorized()\n\n context = dict(model=model, user=g.user, auth_user_obj=g.userobj)\n logic.check_access(u'site_read', context)\n except logic.NotAuthorized:\n base.abort(403, _(u'Not authorized to see this page'))\n\n\ndef _get_dashboard_context(self, filter_type=None, filter_id=None, q=None):\n u'''Return a dict needed by the dashboard view to determine context.'''\n\n def display_name(followee):\n u'''Return a display name for a user, group or dataset dict.'''\n display_name = followee.get(u'display_name')\n fullname = followee.get(u'fullname')\n title = followee.get(u'title')\n name = followee.get(u'name')\n return display_name or fullname or title or name\n\n if (filter_type and filter_id):\n context = {\n u'model': model,\n u'session': model.Session,\n u'user': g.user,\n u'auth_user_obj': g.userobj,\n u'for_view': True\n }\n data_dict = {u'id': filter_id, u'include_num_followers': True}\n followee = None\n\n action_functions = {\n u'dataset': u'package_show',\n u'user': u'user_show',\n u'group': u'group_show',\n u'organization': u'organization_show',\n }\n action_function = logic.get_action(action_functions.get(filter_type))\n # Is this a valid type?\n if action_function is None:\n base.abort(404, _(u'Follow item not found'))\n try:\n followee = action_function(context, data_dict)\n except (logic.NotFound, logic.NotAuthorized):\n base.abort(404, _(u'{0} not found').format(filter_type))\n\n if followee is not None:\n return {\n u'filter_type': filter_type,\n u'q': q,\n u'context': display_name(followee),\n u'selected_id': followee.get(u'id'),\n u'dict': followee,\n }\n\n return {\n u'filter_type': filter_type,\n u'q': q,\n u'context': _(u'Everything'),\n u'selected_id': False,\n u'dict': None,\n }\n\n\ndef index(offset=0):\n context = {\n u'model': model,\n u'session': model.Session,\n u'user': g.user,\n u'auth_user_obj': g.userobj,\n u'for_view': True\n }\n data_dict = {u'user_obj': g.userobj, u'offset': offset}\n extra_vars = _extra_template_variables(context, data_dict)\n\n q = request.params.get(u'q', u'')\n filter_type = request.params.get(u'type', u'')\n filter_id = request.params.get(u'name', u'')\n\n extra_vars[u'followee_list'] = logic.get_action(u'followee_list')(\n context, {\n u'id': g.userobj.id,\n u'q': q\n })\n extra_vars[u'dashboard_activity_stream_context'] = _get_dashboard_context(\n filter_type, filter_id, q)\n extra_vars[u'dashboard_activity_stream'] = h.dashboard_activity_stream(\n g.userobj.id, filter_type, filter_id, offset)\n\n # Mark the useru's new activities as old whenever they view their\n # dashboard page.\n logic.get_action(u'dashboard_mark_activities_old')(context, {})\n\n return base.render(u'user/dashboard.html', extra_vars)\n\n\ndef datasets():\n context = {u'for_view': True, u'user': g.user, u'auth_user_obj': g.userobj}\n data_dict = {u'user_obj': g.userobj, u'include_datasets': True}\n extra_vars = _extra_template_variables(context, data_dict)\n return base.render(u'user/dashboard_datasets.html', extra_vars)\n\n\ndef organizations():\n context = {u'for_view': True, u'user': g.user, u'auth_user_obj': g.userobj}\n data_dict = {u'user_obj': g.userobj}\n extra_vars = _extra_template_variables(context, data_dict)\n return base.render(u'user/dashboard_organizations.html', extra_vars)\n\n\ndef groups():\n context = {u'for_view': True, u'user': g.user, u'auth_user_obj': g.userobj}\n data_dict = {u'user_obj': g.userobj}\n extra_vars = _extra_template_variables(context, data_dict)\n return base.render(u'user/dashboard_groups.html', extra_vars)\n\n\ndashboard.add_url_rule(\n u'/', view_func=index, strict_slashes=False, defaults={\n u'offset': 0\n })\ndashboard.add_url_rule(u'/<int:offset>', view_func=index)\n\ndashboard.add_url_rule(u'/datasets', view_func=datasets)\ndashboard.add_url_rule(u'/groups', view_func=groups)\ndashboard.add_url_rule(u'/organizations', view_func=organizations)\n", "path": "ckan/views/dashboard.py"}]}
| 2,071 | 111 |
gh_patches_debug_1035
|
rasdani/github-patches
|
git_diff
|
plone__Products.CMFPlone-3404
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Expose the human_readable_size helper in the @@plone view
The [@@plone view](https://github.com/plone/Products.CMFPlone/blob/009f785e450430ee7b143624480aef9268491c0b/Products/CMFPlone/browser/ploneview.py#L19) has helper methods that can be used in templates.
It would be handy to add the [Products.CMFPlone.utils.human_readable_size](https://github.com/plone/Products.CMFPlone/blob/009f785e450430ee7b143624480aef9268491c0b/Products/CMFPlone/utils.py#L855-L876) function as a method of that view.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `Products/CMFPlone/browser/ploneview.py`
Content:
```
1 from Acquisition import aq_inner
2 from plone.memoize.view import memoize
3 from Products.CMFCore.utils import getToolByName
4 from Products.CMFPlone import utils
5 from Products.CMFPlone.browser.interfaces import IPlone
6 from Products.Five import BrowserView
7 from zope.component import getMultiAdapter
8 from zope.i18n import translate
9 from zope.interface import implementer
10 from zope.size import byteDisplay
11
12 _marker = []
13
14
15 @implementer(IPlone)
16 class Plone(BrowserView):
17
18 # Utility methods
19
20 @memoize
21 def uniqueItemIndex(self, pos=0):
22 """Return an index iterator."""
23 return utils.RealIndexIterator(pos=pos)
24
25 def toLocalizedTime(self, time, long_format=None, time_only=None):
26 """Convert time to localized time
27 """
28 context = aq_inner(self.context)
29 util = getToolByName(context, 'translation_service')
30 return util.ulocalized_time(time, long_format, time_only,
31 context=context, domain='plonelocales',
32 request=self.request)
33
34 def toLocalizedSize(self, size):
35 """Convert an integer to a localized size string
36 """
37 return translate(byteDisplay(size), context=self.request)
38
39 # This can't be request-memoized, because it won't necessarily remain
40 # valid across traversals. For example, you may get tabs on an error
41 # message.
42 def showToolbar(self):
43 """Determine if the editable border should be shown
44 """
45 request = self.request
46 if 'disable_border' in request or 'disable_toolbar' in request:
47 return False
48 if 'enable_border' in request or 'enable_toolbar' in request:
49 return True
50
51 context = aq_inner(self.context)
52
53 portal_membership = getToolByName(context, 'portal_membership')
54 checkPerm = portal_membership.checkPermission
55
56 if (checkPerm('Modify portal content', context) or
57 checkPerm('Add portal content', context) or
58 checkPerm('Review portal content', context)):
59 return True
60
61 if portal_membership.isAnonymousUser():
62 return False
63
64 context_state = getMultiAdapter(
65 (context, request),
66 name="plone_context_state"
67 )
68 actions = context_state.actions
69
70 if actions('workflow', max=1):
71 return True
72
73 if actions('batch', max=1):
74 return True
75
76 for action in actions('object'):
77 if action.get('id', '') != 'view':
78 return True
79
80 template_id = None
81 if 'PUBLISHED' in request:
82 if getattr(request['PUBLISHED'], 'getId', None):
83 template_id = request['PUBLISHED'].getId()
84
85 idActions = {}
86 for obj in actions('object') + actions('folder'):
87 idActions[obj.get('id', '')] = 1
88
89 if 'edit' in idActions:
90 if (template_id in idActions or
91 template_id in ['synPropertiesForm', 'folder_contents',
92 'folder_listing', 'listing_view']):
93 return True
94
95 # Check to see if the user is able to add content
96 allowedTypes = context.allowedContentTypes()
97 if allowedTypes:
98 return True
99
100 return False
101
102 def normalizeString(self, text):
103 """Normalizes a title to an id.
104 """
105 return utils.normalizeString(text, context=self)
106
107 def cropText(self, text, length, ellipsis='...'):
108 """Crop text on a word boundary
109 """
110 if not length:
111 return text
112 converted = False
113 if not isinstance(text, str):
114 text = utils.safe_unicode(text)
115 converted = True
116 if len(text) > length:
117 text = text[:length]
118 l = text.rfind(' ')
119 if l > length / 2:
120 text = text[:l + 1]
121 text += ellipsis
122 if converted:
123 # encode back from unicode
124 text = text.encode('utf-8')
125 return text
126
127 def site_encoding(self):
128 return 'utf-8'
129
130 # Deprecated in favour of @@plone_context_state and @@plone_portal_state
131
132 def getCurrentUrl(self):
133 context_state = getMultiAdapter(
134 (aq_inner(self.context), self.request),
135 name='plone_context_state')
136 return context_state.current_page_url()
137
138 def isDefaultPageInFolder(self):
139 context_state = getMultiAdapter(
140 (aq_inner(self.context), self.request),
141 name='plone_context_state')
142 return context_state.is_default_page()
143
144 def isStructuralFolder(self):
145 context_state = getMultiAdapter(
146 (aq_inner(self.context), self.request),
147 name='plone_context_state')
148 return context_state.is_structural_folder()
149
150 def navigationRootPath(self):
151 portal_state = getMultiAdapter(
152 (aq_inner(self.context), self.request),
153 name='plone_portal_state')
154 return portal_state.navigation_root_path()
155
156 def navigationRootUrl(self):
157 portal_state = getMultiAdapter(
158 (aq_inner(self.context), self.request),
159 name='plone_portal_state')
160 return portal_state.navigation_root_url()
161
162 def getParentObject(self):
163 context_state = getMultiAdapter(
164 (aq_inner(self.context), self.request),
165 name='plone_context_state')
166 return context_state.parent()
167
168 def getCurrentFolder(self):
169 context_state = getMultiAdapter(
170 (aq_inner(self.context), self.request),
171 name='plone_context_state')
172 return context_state.folder()
173
174 def getCurrentFolderUrl(self):
175 context_state = getMultiAdapter(
176 (aq_inner(self.context), self.request),
177 name='plone_context_state')
178 return context_state.folder().absolute_url()
179
180 @memoize
181 def getCurrentObjectUrl(self):
182 context_state = getMultiAdapter(
183 (aq_inner(self.context), self.request),
184 name='plone_context_state')
185 return context_state.canonical_object_url()
186
187 @memoize
188 def isFolderOrFolderDefaultPage(self):
189 state = getMultiAdapter(
190 (aq_inner(self.context), self.request),
191 name='plone_context_state')
192 return state.is_structural_folder() or state.is_default_page()
193
194 @memoize
195 def isPortalOrPortalDefaultPage(self):
196 context_state = getMultiAdapter(
197 (aq_inner(self.context), self.request),
198 name='plone_context_state')
199 return context_state.is_portal_root()
200
201 @memoize
202 def getViewTemplateId(self):
203 context_state = getMultiAdapter(
204 (aq_inner(self.context), self.request),
205 name='plone_context_state')
206 return context_state.view_template_id()
207
208 @memoize
209 def patterns_settings(self):
210 context = aq_inner(self.context)
211 return getMultiAdapter(
212 (context, self.request),
213 name='plone_patterns_settings')()
214
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/Products/CMFPlone/browser/ploneview.py b/Products/CMFPlone/browser/ploneview.py
--- a/Products/CMFPlone/browser/ploneview.py
+++ b/Products/CMFPlone/browser/ploneview.py
@@ -211,3 +211,7 @@
return getMultiAdapter(
(context, self.request),
name='plone_patterns_settings')()
+
+ @property
+ def human_readable_size(self):
+ return utils.human_readable_size
|
{"golden_diff": "diff --git a/Products/CMFPlone/browser/ploneview.py b/Products/CMFPlone/browser/ploneview.py\n--- a/Products/CMFPlone/browser/ploneview.py\n+++ b/Products/CMFPlone/browser/ploneview.py\n@@ -211,3 +211,7 @@\n return getMultiAdapter(\n (context, self.request),\n name='plone_patterns_settings')()\n+\n+ @property\n+ def human_readable_size(self):\n+ return utils.human_readable_size\n", "issue": "Expose the human_readable_size helper in the @@plone view\nThe [@@plone view](https://github.com/plone/Products.CMFPlone/blob/009f785e450430ee7b143624480aef9268491c0b/Products/CMFPlone/browser/ploneview.py#L19) has helper methods that can be used in templates.\r\nIt would be handy to add the [Products.CMFPlone.utils.human_readable_size](https://github.com/plone/Products.CMFPlone/blob/009f785e450430ee7b143624480aef9268491c0b/Products/CMFPlone/utils.py#L855-L876) function as a method of that view.\n", "before_files": [{"content": "from Acquisition import aq_inner\nfrom plone.memoize.view import memoize\nfrom Products.CMFCore.utils import getToolByName\nfrom Products.CMFPlone import utils\nfrom Products.CMFPlone.browser.interfaces import IPlone\nfrom Products.Five import BrowserView\nfrom zope.component import getMultiAdapter\nfrom zope.i18n import translate\nfrom zope.interface import implementer\nfrom zope.size import byteDisplay\n\n_marker = []\n\n\n@implementer(IPlone)\nclass Plone(BrowserView):\n\n # Utility methods\n\n @memoize\n def uniqueItemIndex(self, pos=0):\n \"\"\"Return an index iterator.\"\"\"\n return utils.RealIndexIterator(pos=pos)\n\n def toLocalizedTime(self, time, long_format=None, time_only=None):\n \"\"\"Convert time to localized time\n \"\"\"\n context = aq_inner(self.context)\n util = getToolByName(context, 'translation_service')\n return util.ulocalized_time(time, long_format, time_only,\n context=context, domain='plonelocales',\n request=self.request)\n\n def toLocalizedSize(self, size):\n \"\"\"Convert an integer to a localized size string\n \"\"\"\n return translate(byteDisplay(size), context=self.request)\n\n # This can't be request-memoized, because it won't necessarily remain\n # valid across traversals. For example, you may get tabs on an error\n # message.\n def showToolbar(self):\n \"\"\"Determine if the editable border should be shown\n \"\"\"\n request = self.request\n if 'disable_border' in request or 'disable_toolbar' in request:\n return False\n if 'enable_border' in request or 'enable_toolbar' in request:\n return True\n\n context = aq_inner(self.context)\n\n portal_membership = getToolByName(context, 'portal_membership')\n checkPerm = portal_membership.checkPermission\n\n if (checkPerm('Modify portal content', context) or\n checkPerm('Add portal content', context) or\n checkPerm('Review portal content', context)):\n return True\n\n if portal_membership.isAnonymousUser():\n return False\n\n context_state = getMultiAdapter(\n (context, request),\n name=\"plone_context_state\"\n )\n actions = context_state.actions\n\n if actions('workflow', max=1):\n return True\n\n if actions('batch', max=1):\n return True\n\n for action in actions('object'):\n if action.get('id', '') != 'view':\n return True\n\n template_id = None\n if 'PUBLISHED' in request:\n if getattr(request['PUBLISHED'], 'getId', None):\n template_id = request['PUBLISHED'].getId()\n\n idActions = {}\n for obj in actions('object') + actions('folder'):\n idActions[obj.get('id', '')] = 1\n\n if 'edit' in idActions:\n if (template_id in idActions or\n template_id in ['synPropertiesForm', 'folder_contents',\n 'folder_listing', 'listing_view']):\n return True\n\n # Check to see if the user is able to add content\n allowedTypes = context.allowedContentTypes()\n if allowedTypes:\n return True\n\n return False\n\n def normalizeString(self, text):\n \"\"\"Normalizes a title to an id.\n \"\"\"\n return utils.normalizeString(text, context=self)\n\n def cropText(self, text, length, ellipsis='...'):\n \"\"\"Crop text on a word boundary\n \"\"\"\n if not length:\n return text\n converted = False\n if not isinstance(text, str):\n text = utils.safe_unicode(text)\n converted = True\n if len(text) > length:\n text = text[:length]\n l = text.rfind(' ')\n if l > length / 2:\n text = text[:l + 1]\n text += ellipsis\n if converted:\n # encode back from unicode\n text = text.encode('utf-8')\n return text\n\n def site_encoding(self):\n return 'utf-8'\n\n # Deprecated in favour of @@plone_context_state and @@plone_portal_state\n\n def getCurrentUrl(self):\n context_state = getMultiAdapter(\n (aq_inner(self.context), self.request),\n name='plone_context_state')\n return context_state.current_page_url()\n\n def isDefaultPageInFolder(self):\n context_state = getMultiAdapter(\n (aq_inner(self.context), self.request),\n name='plone_context_state')\n return context_state.is_default_page()\n\n def isStructuralFolder(self):\n context_state = getMultiAdapter(\n (aq_inner(self.context), self.request),\n name='plone_context_state')\n return context_state.is_structural_folder()\n\n def navigationRootPath(self):\n portal_state = getMultiAdapter(\n (aq_inner(self.context), self.request),\n name='plone_portal_state')\n return portal_state.navigation_root_path()\n\n def navigationRootUrl(self):\n portal_state = getMultiAdapter(\n (aq_inner(self.context), self.request),\n name='plone_portal_state')\n return portal_state.navigation_root_url()\n\n def getParentObject(self):\n context_state = getMultiAdapter(\n (aq_inner(self.context), self.request),\n name='plone_context_state')\n return context_state.parent()\n\n def getCurrentFolder(self):\n context_state = getMultiAdapter(\n (aq_inner(self.context), self.request),\n name='plone_context_state')\n return context_state.folder()\n\n def getCurrentFolderUrl(self):\n context_state = getMultiAdapter(\n (aq_inner(self.context), self.request),\n name='plone_context_state')\n return context_state.folder().absolute_url()\n\n @memoize\n def getCurrentObjectUrl(self):\n context_state = getMultiAdapter(\n (aq_inner(self.context), self.request),\n name='plone_context_state')\n return context_state.canonical_object_url()\n\n @memoize\n def isFolderOrFolderDefaultPage(self):\n state = getMultiAdapter(\n (aq_inner(self.context), self.request),\n name='plone_context_state')\n return state.is_structural_folder() or state.is_default_page()\n\n @memoize\n def isPortalOrPortalDefaultPage(self):\n context_state = getMultiAdapter(\n (aq_inner(self.context), self.request),\n name='plone_context_state')\n return context_state.is_portal_root()\n\n @memoize\n def getViewTemplateId(self):\n context_state = getMultiAdapter(\n (aq_inner(self.context), self.request),\n name='plone_context_state')\n return context_state.view_template_id()\n\n @memoize\n def patterns_settings(self):\n context = aq_inner(self.context)\n return getMultiAdapter(\n (context, self.request),\n name='plone_patterns_settings')()\n", "path": "Products/CMFPlone/browser/ploneview.py"}], "after_files": [{"content": "from Acquisition import aq_inner\nfrom plone.memoize.view import memoize\nfrom Products.CMFCore.utils import getToolByName\nfrom Products.CMFPlone import utils\nfrom Products.CMFPlone.browser.interfaces import IPlone\nfrom Products.Five import BrowserView\nfrom zope.component import getMultiAdapter\nfrom zope.i18n import translate\nfrom zope.interface import implementer\nfrom zope.size import byteDisplay\n\n_marker = []\n\n\n@implementer(IPlone)\nclass Plone(BrowserView):\n\n # Utility methods\n\n @memoize\n def uniqueItemIndex(self, pos=0):\n \"\"\"Return an index iterator.\"\"\"\n return utils.RealIndexIterator(pos=pos)\n\n def toLocalizedTime(self, time, long_format=None, time_only=None):\n \"\"\"Convert time to localized time\n \"\"\"\n context = aq_inner(self.context)\n util = getToolByName(context, 'translation_service')\n return util.ulocalized_time(time, long_format, time_only,\n context=context, domain='plonelocales',\n request=self.request)\n\n def toLocalizedSize(self, size):\n \"\"\"Convert an integer to a localized size string\n \"\"\"\n return translate(byteDisplay(size), context=self.request)\n\n # This can't be request-memoized, because it won't necessarily remain\n # valid across traversals. For example, you may get tabs on an error\n # message.\n def showToolbar(self):\n \"\"\"Determine if the editable border should be shown\n \"\"\"\n request = self.request\n if 'disable_border' in request or 'disable_toolbar' in request:\n return False\n if 'enable_border' in request or 'enable_toolbar' in request:\n return True\n\n context = aq_inner(self.context)\n\n portal_membership = getToolByName(context, 'portal_membership')\n checkPerm = portal_membership.checkPermission\n\n if (checkPerm('Modify portal content', context) or\n checkPerm('Add portal content', context) or\n checkPerm('Review portal content', context)):\n return True\n\n if portal_membership.isAnonymousUser():\n return False\n\n context_state = getMultiAdapter(\n (context, request),\n name=\"plone_context_state\"\n )\n actions = context_state.actions\n\n if actions('workflow', max=1):\n return True\n\n if actions('batch', max=1):\n return True\n\n for action in actions('object'):\n if action.get('id', '') != 'view':\n return True\n\n template_id = None\n if 'PUBLISHED' in request:\n if getattr(request['PUBLISHED'], 'getId', None):\n template_id = request['PUBLISHED'].getId()\n\n idActions = {}\n for obj in actions('object') + actions('folder'):\n idActions[obj.get('id', '')] = 1\n\n if 'edit' in idActions:\n if (template_id in idActions or\n template_id in ['synPropertiesForm', 'folder_contents',\n 'folder_listing', 'listing_view']):\n return True\n\n # Check to see if the user is able to add content\n allowedTypes = context.allowedContentTypes()\n if allowedTypes:\n return True\n\n return False\n\n def normalizeString(self, text):\n \"\"\"Normalizes a title to an id.\n \"\"\"\n return utils.normalizeString(text, context=self)\n\n def cropText(self, text, length, ellipsis='...'):\n \"\"\"Crop text on a word boundary\n \"\"\"\n if not length:\n return text\n converted = False\n if not isinstance(text, str):\n text = utils.safe_unicode(text)\n converted = True\n if len(text) > length:\n text = text[:length]\n l = text.rfind(' ')\n if l > length / 2:\n text = text[:l + 1]\n text += ellipsis\n if converted:\n # encode back from unicode\n text = text.encode('utf-8')\n return text\n\n def site_encoding(self):\n return 'utf-8'\n\n # Deprecated in favour of @@plone_context_state and @@plone_portal_state\n\n def getCurrentUrl(self):\n context_state = getMultiAdapter(\n (aq_inner(self.context), self.request),\n name='plone_context_state')\n return context_state.current_page_url()\n\n def isDefaultPageInFolder(self):\n context_state = getMultiAdapter(\n (aq_inner(self.context), self.request),\n name='plone_context_state')\n return context_state.is_default_page()\n\n def isStructuralFolder(self):\n context_state = getMultiAdapter(\n (aq_inner(self.context), self.request),\n name='plone_context_state')\n return context_state.is_structural_folder()\n\n def navigationRootPath(self):\n portal_state = getMultiAdapter(\n (aq_inner(self.context), self.request),\n name='plone_portal_state')\n return portal_state.navigation_root_path()\n\n def navigationRootUrl(self):\n portal_state = getMultiAdapter(\n (aq_inner(self.context), self.request),\n name='plone_portal_state')\n return portal_state.navigation_root_url()\n\n def getParentObject(self):\n context_state = getMultiAdapter(\n (aq_inner(self.context), self.request),\n name='plone_context_state')\n return context_state.parent()\n\n def getCurrentFolder(self):\n context_state = getMultiAdapter(\n (aq_inner(self.context), self.request),\n name='plone_context_state')\n return context_state.folder()\n\n def getCurrentFolderUrl(self):\n context_state = getMultiAdapter(\n (aq_inner(self.context), self.request),\n name='plone_context_state')\n return context_state.folder().absolute_url()\n\n @memoize\n def getCurrentObjectUrl(self):\n context_state = getMultiAdapter(\n (aq_inner(self.context), self.request),\n name='plone_context_state')\n return context_state.canonical_object_url()\n\n @memoize\n def isFolderOrFolderDefaultPage(self):\n state = getMultiAdapter(\n (aq_inner(self.context), self.request),\n name='plone_context_state')\n return state.is_structural_folder() or state.is_default_page()\n\n @memoize\n def isPortalOrPortalDefaultPage(self):\n context_state = getMultiAdapter(\n (aq_inner(self.context), self.request),\n name='plone_context_state')\n return context_state.is_portal_root()\n\n @memoize\n def getViewTemplateId(self):\n context_state = getMultiAdapter(\n (aq_inner(self.context), self.request),\n name='plone_context_state')\n return context_state.view_template_id()\n\n @memoize\n def patterns_settings(self):\n context = aq_inner(self.context)\n return getMultiAdapter(\n (context, self.request),\n name='plone_patterns_settings')()\n\n @property\n def human_readable_size(self):\n return utils.human_readable_size\n", "path": "Products/CMFPlone/browser/ploneview.py"}]}
| 2,481 | 119 |
gh_patches_debug_9833
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-1187
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Wrong case in configuration example
[This](https://github.com/open-telemetry/opentelemetry-python/blob/master/opentelemetry-api/src/opentelemetry/configuration/__init__.py#L46) should be ``Configuration().METER_PROVIDER == "my_meter_provider"`` would be ``True``.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `opentelemetry-api/src/opentelemetry/configuration/__init__.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """
16 Simple configuration manager
17
18 This is a configuration manager for OpenTelemetry. It reads configuration
19 values from environment variables prefixed with ``OTEL_`` (for environment
20 variables that apply to any OpenTelemetry implementation) or with
21 ``OTEL_PYTHON_`` (for environment variables that are specific to the Python
22 implementation of OpenTelemetry) whose characters are only alphanumeric
23 characters and unserscores, except for the first character after ``OTEL_`` or
24 ``OTEL_PYTHON_`` which must not be a number.
25
26 For example, these environment variables will be read:
27
28 1. ``OTEL_SOMETHING``
29 2. ``OTEL_SOMETHING_ELSE_``
30 3. ``OTEL_SOMETHING_ELSE_AND__ELSE``
31 4. ``OTEL_SOMETHING_ELSE_AND_else``
32 5. ``OTEL_SOMETHING_ELSE_AND_else2``
33
34 These won't:
35
36 1. ``OPENTELEMETRY_PYTH_SOMETHING``
37 2. ``OTEL_2_SOMETHING_AND__ELSE``
38 3. ``OTEL_SOMETHING_%_ELSE``
39
40 The values stored in the environment variables can be found in an instance of
41 ``opentelemetry.configuration.Configuration``. This class can be instantiated
42 freely because instantiating it returns always the same object.
43
44 For example, if the environment variable
45 ``OTEL_PYTHON_METER_PROVIDER`` value is ``my_meter_provider``, then
46 ``Configuration().meter_provider == "my_meter_provider"`` would be ``True``.
47
48 Non defined attributes will always return ``None``. This is intended to make it
49 easier to use the ``Configuration`` object in actual code, because it won't be
50 necessary to check for the attribute to be defined first.
51
52 Environment variables used by OpenTelemetry
53 -------------------------------------------
54
55 1. OTEL_PYTHON_METER_PROVIDER
56 2. OTEL_PYTHON_TRACER_PROVIDER
57
58 The value of these environment variables should be the name of the entry point
59 that points to the class that implements either provider. This OpenTelemetry
60 API package provides one entry point for each, which can be found in the
61 setup.py file::
62
63 entry_points={
64 ...
65 "opentelemetry_meter_provider": [
66 "default_meter_provider = "
67 "opentelemetry.metrics:DefaultMeterProvider"
68 ],
69 "opentelemetry_tracer_provider": [
70 "default_tracer_provider = "
71 "opentelemetry.trace:DefaultTracerProvider"
72 ],
73 }
74
75 To use the meter provider above, then the
76 ``OTEL_PYTHON_METER_PROVIDER`` should be set to
77 ``"default_meter_provider"`` (this is not actually necessary since the
78 OpenTelemetry API provided providers are the default ones used if no
79 configuration is found in the environment variables).
80
81 Configuration values that are exactly ``"True"`` or ``"False"`` will be
82 converted to its boolean values of ``True`` and ``False`` respectively.
83
84 Configuration values that can be casted to integers or floats will be casted.
85
86 This object can be used by any OpenTelemetry component, native or external.
87 For that reason, the ``Configuration`` object is designed to be immutable.
88 If a component would change the value of one of the ``Configuration`` object
89 attributes then another component that relied on that value may break, leading
90 to bugs that are very hard to debug. To avoid this situation, the preferred
91 approach for components that need a different value than the one provided by
92 the ``Configuration`` object is to implement a mechanism that allows the user
93 to override this value instead of changing it.
94 """
95
96 from os import environ
97 from re import fullmatch
98 from typing import ClassVar, Dict, Optional, TypeVar, Union
99
100 ConfigValue = Union[str, bool, int, float]
101 _T = TypeVar("_T", ConfigValue, Optional[ConfigValue])
102
103
104 class Configuration:
105 _instance = None # type: ClassVar[Optional[Configuration]]
106 _config_map = {} # type: ClassVar[Dict[str, ConfigValue]]
107
108 def __new__(cls) -> "Configuration":
109 if cls._instance is not None:
110 instance = cls._instance
111 else:
112
113 instance = super().__new__(cls)
114 for key, value_str in environ.items():
115
116 match = fullmatch(r"OTEL_(PYTHON_)?([A-Za-z_][\w_]*)", key)
117
118 if match is not None:
119
120 key = match.group(2)
121 value = value_str # type: ConfigValue
122
123 if value_str == "True":
124 value = True
125 elif value_str == "False":
126 value = False
127 else:
128 try:
129 value = int(value_str)
130 except ValueError:
131 try:
132 value = float(value_str)
133 except ValueError:
134 pass
135
136 instance._config_map[key] = value
137
138 cls._instance = instance
139
140 return instance
141
142 def __getattr__(self, name: str) -> Optional[ConfigValue]:
143 return self._config_map.get(name)
144
145 def __setattr__(self, name: str, value: ConfigValue) -> None:
146 if name not in self._config_map.keys():
147 self._config_map[name] = value
148 else:
149 raise AttributeError(name)
150
151 def get(self, name: str, default: _T) -> _T:
152 """Use this typed method for dynamic access instead of `getattr`
153
154 :rtype: str or bool or int or float or None
155 """
156 return self._config_map.get(name, default)
157
158 @classmethod
159 def _reset(cls) -> None:
160 """
161 This method "resets" the global configuration attributes
162
163 It is not intended to be used by production code but by testing code
164 only.
165 """
166
167 if cls._instance:
168 cls._instance._config_map.clear() # pylint: disable=protected-access
169 cls._instance = None
170
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/opentelemetry-api/src/opentelemetry/configuration/__init__.py b/opentelemetry-api/src/opentelemetry/configuration/__init__.py
--- a/opentelemetry-api/src/opentelemetry/configuration/__init__.py
+++ b/opentelemetry-api/src/opentelemetry/configuration/__init__.py
@@ -43,7 +43,7 @@
For example, if the environment variable
``OTEL_PYTHON_METER_PROVIDER`` value is ``my_meter_provider``, then
-``Configuration().meter_provider == "my_meter_provider"`` would be ``True``.
+``Configuration().METER_PROVIDER == "my_meter_provider"`` would be ``True``.
Non defined attributes will always return ``None``. This is intended to make it
easier to use the ``Configuration`` object in actual code, because it won't be
|
{"golden_diff": "diff --git a/opentelemetry-api/src/opentelemetry/configuration/__init__.py b/opentelemetry-api/src/opentelemetry/configuration/__init__.py\n--- a/opentelemetry-api/src/opentelemetry/configuration/__init__.py\n+++ b/opentelemetry-api/src/opentelemetry/configuration/__init__.py\n@@ -43,7 +43,7 @@\n \n For example, if the environment variable\n ``OTEL_PYTHON_METER_PROVIDER`` value is ``my_meter_provider``, then\n-``Configuration().meter_provider == \"my_meter_provider\"`` would be ``True``.\n+``Configuration().METER_PROVIDER == \"my_meter_provider\"`` would be ``True``.\n \n Non defined attributes will always return ``None``. This is intended to make it\n easier to use the ``Configuration`` object in actual code, because it won't be\n", "issue": "Wrong case in configuration example\n[This](https://github.com/open-telemetry/opentelemetry-python/blob/master/opentelemetry-api/src/opentelemetry/configuration/__init__.py#L46) should be ``Configuration().METER_PROVIDER == \"my_meter_provider\"`` would be ``True``.\r\n\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nSimple configuration manager\n\nThis is a configuration manager for OpenTelemetry. It reads configuration\nvalues from environment variables prefixed with ``OTEL_`` (for environment\nvariables that apply to any OpenTelemetry implementation) or with\n``OTEL_PYTHON_`` (for environment variables that are specific to the Python\nimplementation of OpenTelemetry) whose characters are only alphanumeric\ncharacters and unserscores, except for the first character after ``OTEL_`` or\n``OTEL_PYTHON_`` which must not be a number.\n\nFor example, these environment variables will be read:\n\n1. ``OTEL_SOMETHING``\n2. ``OTEL_SOMETHING_ELSE_``\n3. ``OTEL_SOMETHING_ELSE_AND__ELSE``\n4. ``OTEL_SOMETHING_ELSE_AND_else``\n5. ``OTEL_SOMETHING_ELSE_AND_else2``\n\nThese won't:\n\n1. ``OPENTELEMETRY_PYTH_SOMETHING``\n2. ``OTEL_2_SOMETHING_AND__ELSE``\n3. ``OTEL_SOMETHING_%_ELSE``\n\nThe values stored in the environment variables can be found in an instance of\n``opentelemetry.configuration.Configuration``. This class can be instantiated\nfreely because instantiating it returns always the same object.\n\nFor example, if the environment variable\n``OTEL_PYTHON_METER_PROVIDER`` value is ``my_meter_provider``, then\n``Configuration().meter_provider == \"my_meter_provider\"`` would be ``True``.\n\nNon defined attributes will always return ``None``. This is intended to make it\neasier to use the ``Configuration`` object in actual code, because it won't be\nnecessary to check for the attribute to be defined first.\n\nEnvironment variables used by OpenTelemetry\n-------------------------------------------\n\n1. OTEL_PYTHON_METER_PROVIDER\n2. OTEL_PYTHON_TRACER_PROVIDER\n\nThe value of these environment variables should be the name of the entry point\nthat points to the class that implements either provider. This OpenTelemetry\nAPI package provides one entry point for each, which can be found in the\nsetup.py file::\n\n entry_points={\n ...\n \"opentelemetry_meter_provider\": [\n \"default_meter_provider = \"\n \"opentelemetry.metrics:DefaultMeterProvider\"\n ],\n \"opentelemetry_tracer_provider\": [\n \"default_tracer_provider = \"\n \"opentelemetry.trace:DefaultTracerProvider\"\n ],\n }\n\nTo use the meter provider above, then the\n``OTEL_PYTHON_METER_PROVIDER`` should be set to\n``\"default_meter_provider\"`` (this is not actually necessary since the\nOpenTelemetry API provided providers are the default ones used if no\nconfiguration is found in the environment variables).\n\nConfiguration values that are exactly ``\"True\"`` or ``\"False\"`` will be\nconverted to its boolean values of ``True`` and ``False`` respectively.\n\nConfiguration values that can be casted to integers or floats will be casted.\n\nThis object can be used by any OpenTelemetry component, native or external.\nFor that reason, the ``Configuration`` object is designed to be immutable.\nIf a component would change the value of one of the ``Configuration`` object\nattributes then another component that relied on that value may break, leading\nto bugs that are very hard to debug. To avoid this situation, the preferred\napproach for components that need a different value than the one provided by\nthe ``Configuration`` object is to implement a mechanism that allows the user\nto override this value instead of changing it.\n\"\"\"\n\nfrom os import environ\nfrom re import fullmatch\nfrom typing import ClassVar, Dict, Optional, TypeVar, Union\n\nConfigValue = Union[str, bool, int, float]\n_T = TypeVar(\"_T\", ConfigValue, Optional[ConfigValue])\n\n\nclass Configuration:\n _instance = None # type: ClassVar[Optional[Configuration]]\n _config_map = {} # type: ClassVar[Dict[str, ConfigValue]]\n\n def __new__(cls) -> \"Configuration\":\n if cls._instance is not None:\n instance = cls._instance\n else:\n\n instance = super().__new__(cls)\n for key, value_str in environ.items():\n\n match = fullmatch(r\"OTEL_(PYTHON_)?([A-Za-z_][\\w_]*)\", key)\n\n if match is not None:\n\n key = match.group(2)\n value = value_str # type: ConfigValue\n\n if value_str == \"True\":\n value = True\n elif value_str == \"False\":\n value = False\n else:\n try:\n value = int(value_str)\n except ValueError:\n try:\n value = float(value_str)\n except ValueError:\n pass\n\n instance._config_map[key] = value\n\n cls._instance = instance\n\n return instance\n\n def __getattr__(self, name: str) -> Optional[ConfigValue]:\n return self._config_map.get(name)\n\n def __setattr__(self, name: str, value: ConfigValue) -> None:\n if name not in self._config_map.keys():\n self._config_map[name] = value\n else:\n raise AttributeError(name)\n\n def get(self, name: str, default: _T) -> _T:\n \"\"\"Use this typed method for dynamic access instead of `getattr`\n\n :rtype: str or bool or int or float or None\n \"\"\"\n return self._config_map.get(name, default)\n\n @classmethod\n def _reset(cls) -> None:\n \"\"\"\n This method \"resets\" the global configuration attributes\n\n It is not intended to be used by production code but by testing code\n only.\n \"\"\"\n\n if cls._instance:\n cls._instance._config_map.clear() # pylint: disable=protected-access\n cls._instance = None\n", "path": "opentelemetry-api/src/opentelemetry/configuration/__init__.py"}], "after_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nSimple configuration manager\n\nThis is a configuration manager for OpenTelemetry. It reads configuration\nvalues from environment variables prefixed with ``OTEL_`` (for environment\nvariables that apply to any OpenTelemetry implementation) or with\n``OTEL_PYTHON_`` (for environment variables that are specific to the Python\nimplementation of OpenTelemetry) whose characters are only alphanumeric\ncharacters and unserscores, except for the first character after ``OTEL_`` or\n``OTEL_PYTHON_`` which must not be a number.\n\nFor example, these environment variables will be read:\n\n1. ``OTEL_SOMETHING``\n2. ``OTEL_SOMETHING_ELSE_``\n3. ``OTEL_SOMETHING_ELSE_AND__ELSE``\n4. ``OTEL_SOMETHING_ELSE_AND_else``\n5. ``OTEL_SOMETHING_ELSE_AND_else2``\n\nThese won't:\n\n1. ``OPENTELEMETRY_PYTH_SOMETHING``\n2. ``OTEL_2_SOMETHING_AND__ELSE``\n3. ``OTEL_SOMETHING_%_ELSE``\n\nThe values stored in the environment variables can be found in an instance of\n``opentelemetry.configuration.Configuration``. This class can be instantiated\nfreely because instantiating it returns always the same object.\n\nFor example, if the environment variable\n``OTEL_PYTHON_METER_PROVIDER`` value is ``my_meter_provider``, then\n``Configuration().METER_PROVIDER == \"my_meter_provider\"`` would be ``True``.\n\nNon defined attributes will always return ``None``. This is intended to make it\neasier to use the ``Configuration`` object in actual code, because it won't be\nnecessary to check for the attribute to be defined first.\n\nEnvironment variables used by OpenTelemetry\n-------------------------------------------\n\n1. OTEL_PYTHON_METER_PROVIDER\n2. OTEL_PYTHON_TRACER_PROVIDER\n\nThe value of these environment variables should be the name of the entry point\nthat points to the class that implements either provider. This OpenTelemetry\nAPI package provides one entry point for each, which can be found in the\nsetup.py file::\n\n entry_points={\n ...\n \"opentelemetry_meter_provider\": [\n \"default_meter_provider = \"\n \"opentelemetry.metrics:DefaultMeterProvider\"\n ],\n \"opentelemetry_tracer_provider\": [\n \"default_tracer_provider = \"\n \"opentelemetry.trace:DefaultTracerProvider\"\n ],\n }\n\nTo use the meter provider above, then the\n``OTEL_PYTHON_METER_PROVIDER`` should be set to\n``\"default_meter_provider\"`` (this is not actually necessary since the\nOpenTelemetry API provided providers are the default ones used if no\nconfiguration is found in the environment variables).\n\nConfiguration values that are exactly ``\"True\"`` or ``\"False\"`` will be\nconverted to its boolean values of ``True`` and ``False`` respectively.\n\nConfiguration values that can be casted to integers or floats will be casted.\n\nThis object can be used by any OpenTelemetry component, native or external.\nFor that reason, the ``Configuration`` object is designed to be immutable.\nIf a component would change the value of one of the ``Configuration`` object\nattributes then another component that relied on that value may break, leading\nto bugs that are very hard to debug. To avoid this situation, the preferred\napproach for components that need a different value than the one provided by\nthe ``Configuration`` object is to implement a mechanism that allows the user\nto override this value instead of changing it.\n\"\"\"\n\nfrom os import environ\nfrom re import fullmatch\nfrom typing import ClassVar, Dict, Optional, TypeVar, Union\n\nConfigValue = Union[str, bool, int, float]\n_T = TypeVar(\"_T\", ConfigValue, Optional[ConfigValue])\n\n\nclass Configuration:\n _instance = None # type: ClassVar[Optional[Configuration]]\n _config_map = {} # type: ClassVar[Dict[str, ConfigValue]]\n\n def __new__(cls) -> \"Configuration\":\n if cls._instance is not None:\n instance = cls._instance\n else:\n\n instance = super().__new__(cls)\n for key, value_str in environ.items():\n\n match = fullmatch(r\"OTEL_(PYTHON_)?([A-Za-z_][\\w_]*)\", key)\n\n if match is not None:\n\n key = match.group(2)\n value = value_str # type: ConfigValue\n\n if value_str == \"True\":\n value = True\n elif value_str == \"False\":\n value = False\n else:\n try:\n value = int(value_str)\n except ValueError:\n try:\n value = float(value_str)\n except ValueError:\n pass\n\n instance._config_map[key] = value\n\n cls._instance = instance\n\n return instance\n\n def __getattr__(self, name: str) -> Optional[ConfigValue]:\n return self._config_map.get(name)\n\n def __setattr__(self, name: str, value: ConfigValue) -> None:\n if name not in self._config_map.keys():\n self._config_map[name] = value\n else:\n raise AttributeError(name)\n\n def get(self, name: str, default: _T) -> _T:\n \"\"\"Use this typed method for dynamic access instead of `getattr`\n\n :rtype: str or bool or int or float or None\n \"\"\"\n return self._config_map.get(name, default)\n\n @classmethod\n def _reset(cls) -> None:\n \"\"\"\n This method \"resets\" the global configuration attributes\n\n It is not intended to be used by production code but by testing code\n only.\n \"\"\"\n\n if cls._instance:\n cls._instance._config_map.clear() # pylint: disable=protected-access\n cls._instance = None\n", "path": "opentelemetry-api/src/opentelemetry/configuration/__init__.py"}]}
| 2,137 | 178 |
gh_patches_debug_3768
|
rasdani/github-patches
|
git_diff
|
quantumlib__Cirq-1794
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
QubitOrder.explicit fails when given an iterator
Also affects `QubitOrder.as_qubit_order()`. I believe the issue is on line 77 of cirq/ops/qubit_order.py.
Example:
```
cirq.QubitOrder.as_qubit_order(reversed(cirq.LineQubit.range(5))).order_for(
(cirq.LineQubit(3),))
```
The example raises `ValueError: Unexpected extra qubits: {cirq.LineQubit(3)}.` because `reversed()` is an iterator and QubitOrder tried to iterate it twice.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cirq/ops/qubit_order.py`
Content:
```
1 # Copyright 2018 The Cirq Developers
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15
16 from typing import (
17 Any,
18 Callable,
19 Iterable,
20 Optional,
21 Tuple,
22 TypeVar,
23 TYPE_CHECKING,
24 )
25
26 import collections
27
28 from cirq.ops import raw_types
29
30 if TYPE_CHECKING:
31 # pylint: disable=unused-import
32 from cirq.ops import qubit_order_or_list
33
34
35 TInternalQubit = TypeVar('TInternalQubit')
36 TExternalQubit = TypeVar('TExternalQubit')
37
38
39 class QubitOrder:
40 """Defines the kronecker product order of qubits."""
41
42 def __init__(self, explicit_func: Callable[[Iterable[raw_types.Qid]],
43 Tuple[raw_types.Qid, ...]]
44 ) -> None:
45 self._explicit_func = explicit_func
46
47 DEFAULT = None # type: QubitOrder
48 """A basis that orders qubits in the same way that calling `sorted` does.
49
50 Specifically, qubits are ordered first by their type name and then by
51 whatever comparison value qubits of a given type provide (e.g. for LineQubit
52 it is the x coordinate of the qubit).
53 """
54
55 @staticmethod
56 def explicit(fixed_qubits: Iterable[raw_types.Qid],
57 fallback: Optional['QubitOrder']=None) -> 'QubitOrder':
58 """A basis that contains exactly the given qubits in the given order.
59
60 Args:
61 fixed_qubits: The qubits in basis order.
62 fallback: A fallback order to use for extra qubits not in the
63 fixed_qubits list. Extra qubits will always come after the
64 fixed_qubits, but will be ordered based on the fallback. If no
65 fallback is specified, a ValueError is raised when extra qubits
66 are specified.
67
68 Returns:
69 A Basis instance that forces the given qubits in the given order.
70 """
71 result = tuple(fixed_qubits)
72 if len(set(result)) < len(result):
73 raise ValueError(
74 'Qubits appear in fixed_order twice: {}.'.format(result))
75
76 def func(qubits):
77 remaining = set(qubits) - set(fixed_qubits)
78 if not remaining:
79 return result
80 if not fallback:
81 raise ValueError(
82 'Unexpected extra qubits: {}.'.format(remaining))
83 return result + fallback.order_for(remaining)
84
85 return QubitOrder(func)
86
87 @staticmethod
88 def sorted_by(key: Callable[[raw_types.Qid], Any]) -> 'QubitOrder':
89 """A basis that orders qubits ascending based on a key function.
90
91 Args:
92 key: A function that takes a qubit and returns a key value. The
93 basis will be ordered ascending according to these key values.
94
95
96 Returns:
97 A basis that orders qubits ascending based on a key function.
98 """
99 return QubitOrder(lambda qubits: tuple(sorted(qubits, key=key)))
100
101 def order_for(self, qubits: Iterable[raw_types.Qid]
102 ) -> Tuple[raw_types.Qid, ...]:
103 """Returns a qubit tuple ordered corresponding to the basis.
104
105 Args:
106 qubits: Qubits that should be included in the basis. (Additional
107 qubits may be added into the output by the basis.)
108
109 Returns:
110 A tuple of qubits in the same order that their single-qubit
111 matrices would be passed into `np.kron` when producing a matrix for
112 the entire system.
113 """
114 return self._explicit_func(qubits)
115
116 @staticmethod
117 def as_qubit_order(val: 'qubit_order_or_list.QubitOrderOrList'
118 ) -> 'QubitOrder':
119 """Converts a value into a basis.
120
121 Args:
122 val: An iterable or a basis.
123
124 Returns:
125 The basis implied by the value.
126 """
127 if isinstance(val, collections.Iterable):
128 return QubitOrder.explicit(val)
129 if isinstance(val, QubitOrder):
130 return val
131 raise ValueError(
132 "Don't know how to interpret <{}> as a Basis.".format(val))
133
134 def map(self,
135 internalize: Callable[[TExternalQubit], TInternalQubit],
136 externalize: Callable[[TInternalQubit], TExternalQubit]
137 ) -> 'QubitOrder':
138 """Transforms the Basis so that it applies to wrapped qubits.
139
140 Args:
141 externalize: Converts an internal qubit understood by the underlying
142 basis into an external qubit understood by the caller.
143 internalize: Converts an external qubit understood by the caller
144 into an internal qubit understood by the underlying basis.
145
146 Returns:
147 A basis that transforms qubits understood by the caller into qubits
148 understood by an underlying basis, uses that to order the qubits,
149 then wraps the ordered qubits back up for the caller.
150 """
151
152 def func(qubits):
153 unwrapped_qubits = [internalize(q) for q in qubits]
154 unwrapped_result = self.order_for(unwrapped_qubits)
155 return tuple(externalize(q) for q in unwrapped_result)
156
157 return QubitOrder(func)
158
159
160 QubitOrder.DEFAULT = QubitOrder.sorted_by(lambda v: v)
161
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/cirq/ops/qubit_order.py b/cirq/ops/qubit_order.py
--- a/cirq/ops/qubit_order.py
+++ b/cirq/ops/qubit_order.py
@@ -74,7 +74,7 @@
'Qubits appear in fixed_order twice: {}.'.format(result))
def func(qubits):
- remaining = set(qubits) - set(fixed_qubits)
+ remaining = set(qubits) - set(result)
if not remaining:
return result
if not fallback:
|
{"golden_diff": "diff --git a/cirq/ops/qubit_order.py b/cirq/ops/qubit_order.py\n--- a/cirq/ops/qubit_order.py\n+++ b/cirq/ops/qubit_order.py\n@@ -74,7 +74,7 @@\n 'Qubits appear in fixed_order twice: {}.'.format(result))\n \n def func(qubits):\n- remaining = set(qubits) - set(fixed_qubits)\n+ remaining = set(qubits) - set(result)\n if not remaining:\n return result\n if not fallback:\n", "issue": "QubitOrder.explicit fails when given an iterator\nAlso affects `QubitOrder.as_qubit_order()`. I believe the issue is on line 77 of cirq/ops/qubit_order.py.\r\n\r\nExample:\r\n```\r\ncirq.QubitOrder.as_qubit_order(reversed(cirq.LineQubit.range(5))).order_for(\r\n (cirq.LineQubit(3),))\r\n```\r\n\r\nThe example raises `ValueError: Unexpected extra qubits: {cirq.LineQubit(3)}.` because `reversed()` is an iterator and QubitOrder tried to iterate it twice.\n", "before_files": [{"content": "# Copyright 2018 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nfrom typing import (\n Any,\n Callable,\n Iterable,\n Optional,\n Tuple,\n TypeVar,\n TYPE_CHECKING,\n)\n\nimport collections\n\nfrom cirq.ops import raw_types\n\nif TYPE_CHECKING:\n # pylint: disable=unused-import\n from cirq.ops import qubit_order_or_list\n\n\nTInternalQubit = TypeVar('TInternalQubit')\nTExternalQubit = TypeVar('TExternalQubit')\n\n\nclass QubitOrder:\n \"\"\"Defines the kronecker product order of qubits.\"\"\"\n\n def __init__(self, explicit_func: Callable[[Iterable[raw_types.Qid]],\n Tuple[raw_types.Qid, ...]]\n ) -> None:\n self._explicit_func = explicit_func\n\n DEFAULT = None # type: QubitOrder\n \"\"\"A basis that orders qubits in the same way that calling `sorted` does.\n\n Specifically, qubits are ordered first by their type name and then by\n whatever comparison value qubits of a given type provide (e.g. for LineQubit\n it is the x coordinate of the qubit).\n \"\"\"\n\n @staticmethod\n def explicit(fixed_qubits: Iterable[raw_types.Qid],\n fallback: Optional['QubitOrder']=None) -> 'QubitOrder':\n \"\"\"A basis that contains exactly the given qubits in the given order.\n\n Args:\n fixed_qubits: The qubits in basis order.\n fallback: A fallback order to use for extra qubits not in the\n fixed_qubits list. Extra qubits will always come after the\n fixed_qubits, but will be ordered based on the fallback. If no\n fallback is specified, a ValueError is raised when extra qubits\n are specified.\n\n Returns:\n A Basis instance that forces the given qubits in the given order.\n \"\"\"\n result = tuple(fixed_qubits)\n if len(set(result)) < len(result):\n raise ValueError(\n 'Qubits appear in fixed_order twice: {}.'.format(result))\n\n def func(qubits):\n remaining = set(qubits) - set(fixed_qubits)\n if not remaining:\n return result\n if not fallback:\n raise ValueError(\n 'Unexpected extra qubits: {}.'.format(remaining))\n return result + fallback.order_for(remaining)\n\n return QubitOrder(func)\n\n @staticmethod\n def sorted_by(key: Callable[[raw_types.Qid], Any]) -> 'QubitOrder':\n \"\"\"A basis that orders qubits ascending based on a key function.\n\n Args:\n key: A function that takes a qubit and returns a key value. The\n basis will be ordered ascending according to these key values.\n\n\n Returns:\n A basis that orders qubits ascending based on a key function.\n \"\"\"\n return QubitOrder(lambda qubits: tuple(sorted(qubits, key=key)))\n\n def order_for(self, qubits: Iterable[raw_types.Qid]\n ) -> Tuple[raw_types.Qid, ...]:\n \"\"\"Returns a qubit tuple ordered corresponding to the basis.\n\n Args:\n qubits: Qubits that should be included in the basis. (Additional\n qubits may be added into the output by the basis.)\n\n Returns:\n A tuple of qubits in the same order that their single-qubit\n matrices would be passed into `np.kron` when producing a matrix for\n the entire system.\n \"\"\"\n return self._explicit_func(qubits)\n\n @staticmethod\n def as_qubit_order(val: 'qubit_order_or_list.QubitOrderOrList'\n ) -> 'QubitOrder':\n \"\"\"Converts a value into a basis.\n\n Args:\n val: An iterable or a basis.\n\n Returns:\n The basis implied by the value.\n \"\"\"\n if isinstance(val, collections.Iterable):\n return QubitOrder.explicit(val)\n if isinstance(val, QubitOrder):\n return val\n raise ValueError(\n \"Don't know how to interpret <{}> as a Basis.\".format(val))\n\n def map(self,\n internalize: Callable[[TExternalQubit], TInternalQubit],\n externalize: Callable[[TInternalQubit], TExternalQubit]\n ) -> 'QubitOrder':\n \"\"\"Transforms the Basis so that it applies to wrapped qubits.\n\n Args:\n externalize: Converts an internal qubit understood by the underlying\n basis into an external qubit understood by the caller.\n internalize: Converts an external qubit understood by the caller\n into an internal qubit understood by the underlying basis.\n\n Returns:\n A basis that transforms qubits understood by the caller into qubits\n understood by an underlying basis, uses that to order the qubits,\n then wraps the ordered qubits back up for the caller.\n \"\"\"\n\n def func(qubits):\n unwrapped_qubits = [internalize(q) for q in qubits]\n unwrapped_result = self.order_for(unwrapped_qubits)\n return tuple(externalize(q) for q in unwrapped_result)\n\n return QubitOrder(func)\n\n\nQubitOrder.DEFAULT = QubitOrder.sorted_by(lambda v: v)\n", "path": "cirq/ops/qubit_order.py"}], "after_files": [{"content": "# Copyright 2018 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nfrom typing import (\n Any,\n Callable,\n Iterable,\n Optional,\n Tuple,\n TypeVar,\n TYPE_CHECKING,\n)\n\nimport collections\n\nfrom cirq.ops import raw_types\n\nif TYPE_CHECKING:\n # pylint: disable=unused-import\n from cirq.ops import qubit_order_or_list\n\n\nTInternalQubit = TypeVar('TInternalQubit')\nTExternalQubit = TypeVar('TExternalQubit')\n\n\nclass QubitOrder:\n \"\"\"Defines the kronecker product order of qubits.\"\"\"\n\n def __init__(self, explicit_func: Callable[[Iterable[raw_types.Qid]],\n Tuple[raw_types.Qid, ...]]\n ) -> None:\n self._explicit_func = explicit_func\n\n DEFAULT = None # type: QubitOrder\n \"\"\"A basis that orders qubits in the same way that calling `sorted` does.\n\n Specifically, qubits are ordered first by their type name and then by\n whatever comparison value qubits of a given type provide (e.g. for LineQubit\n it is the x coordinate of the qubit).\n \"\"\"\n\n @staticmethod\n def explicit(fixed_qubits: Iterable[raw_types.Qid],\n fallback: Optional['QubitOrder']=None) -> 'QubitOrder':\n \"\"\"A basis that contains exactly the given qubits in the given order.\n\n Args:\n fixed_qubits: The qubits in basis order.\n fallback: A fallback order to use for extra qubits not in the\n fixed_qubits list. Extra qubits will always come after the\n fixed_qubits, but will be ordered based on the fallback. If no\n fallback is specified, a ValueError is raised when extra qubits\n are specified.\n\n Returns:\n A Basis instance that forces the given qubits in the given order.\n \"\"\"\n result = tuple(fixed_qubits)\n if len(set(result)) < len(result):\n raise ValueError(\n 'Qubits appear in fixed_order twice: {}.'.format(result))\n\n def func(qubits):\n remaining = set(qubits) - set(result)\n if not remaining:\n return result\n if not fallback:\n raise ValueError(\n 'Unexpected extra qubits: {}.'.format(remaining))\n return result + fallback.order_for(remaining)\n\n return QubitOrder(func)\n\n @staticmethod\n def sorted_by(key: Callable[[raw_types.Qid], Any]) -> 'QubitOrder':\n \"\"\"A basis that orders qubits ascending based on a key function.\n\n Args:\n key: A function that takes a qubit and returns a key value. The\n basis will be ordered ascending according to these key values.\n\n\n Returns:\n A basis that orders qubits ascending based on a key function.\n \"\"\"\n return QubitOrder(lambda qubits: tuple(sorted(qubits, key=key)))\n\n def order_for(self, qubits: Iterable[raw_types.Qid]\n ) -> Tuple[raw_types.Qid, ...]:\n \"\"\"Returns a qubit tuple ordered corresponding to the basis.\n\n Args:\n qubits: Qubits that should be included in the basis. (Additional\n qubits may be added into the output by the basis.)\n\n Returns:\n A tuple of qubits in the same order that their single-qubit\n matrices would be passed into `np.kron` when producing a matrix for\n the entire system.\n \"\"\"\n return self._explicit_func(qubits)\n\n @staticmethod\n def as_qubit_order(val: 'qubit_order_or_list.QubitOrderOrList'\n ) -> 'QubitOrder':\n \"\"\"Converts a value into a basis.\n\n Args:\n val: An iterable or a basis.\n\n Returns:\n The basis implied by the value.\n \"\"\"\n if isinstance(val, collections.Iterable):\n return QubitOrder.explicit(val)\n if isinstance(val, QubitOrder):\n return val\n raise ValueError(\n \"Don't know how to interpret <{}> as a Basis.\".format(val))\n\n def map(self,\n internalize: Callable[[TExternalQubit], TInternalQubit],\n externalize: Callable[[TInternalQubit], TExternalQubit]\n ) -> 'QubitOrder':\n \"\"\"Transforms the Basis so that it applies to wrapped qubits.\n\n Args:\n externalize: Converts an internal qubit understood by the underlying\n basis into an external qubit understood by the caller.\n internalize: Converts an external qubit understood by the caller\n into an internal qubit understood by the underlying basis.\n\n Returns:\n A basis that transforms qubits understood by the caller into qubits\n understood by an underlying basis, uses that to order the qubits,\n then wraps the ordered qubits back up for the caller.\n \"\"\"\n\n def func(qubits):\n unwrapped_qubits = [internalize(q) for q in qubits]\n unwrapped_result = self.order_for(unwrapped_qubits)\n return tuple(externalize(q) for q in unwrapped_result)\n\n return QubitOrder(func)\n\n\nQubitOrder.DEFAULT = QubitOrder.sorted_by(lambda v: v)\n", "path": "cirq/ops/qubit_order.py"}]}
| 2,010 | 119 |
gh_patches_debug_15731
|
rasdani/github-patches
|
git_diff
|
chaoss__augur-2099
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Release Task Periodic Error : branch: `main`
**Description:**
When release metadata is not fully populated on a repo (a rare occurrence), the following error is generated:
```
Traceback (most recent call last):
File "/home/sean/github/virtualenv/ag3/lib/python3.8/site-packages/celery/app/trace.py", line 451, in trace_task
R = retval = fun(*args, **kwargs)
File "/home/sean/github/virtualenv/ag3/lib/python3.8/site-packages/celery/app/trace.py", line 734, in __protected_call__
return self.run(*args, **kwargs)
File "/home/sean/github/ag3/augur/tasks/github/releases/tasks.py", line 15, in collect_releases
releases_model(session, repo.repo_git, repo.repo_id)
File "/home/sean/github/ag3/augur/tasks/github/releases/core.py", line 186, in releases_model
insert_release(session, repo_id, data['owner'], release)
File "/home/sean/github/ag3/augur/tasks/github/releases/core.py", line 79, in insert_release
release_inf = get_release_inf(session, repo_id, release, tag_only)
File "/home/sean/github/ag3/augur/tasks/github/releases/core.py", line 19, in get_release_inf
name = "" if release['author']['name'] is None else release['author']['name']
TypeError: 'NoneType' object is not subscriptable
```
**How to reproduce:**
The `ag3` instance on our test server has this error right now.
**Expected behavior:**
No error
**Software versions:**
- `augur-new-dev`
- OS: Ubuntu 20.5
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `augur/tasks/github/releases/core.py`
Content:
```
1 #SPDX-License-Identifier: MIT
2 import logging, os, sys, time, requests, json
3 from datetime import datetime
4 from multiprocessing import Process, Queue
5 from urllib.parse import urlparse
6 import pandas as pd
7 import sqlalchemy as s
8 from sqlalchemy import MetaData
9 from sqlalchemy.ext.automap import automap_base
10 from augur.tasks.github.util.github_task_session import *
11 from augur.application.db.models import *
12 from augur.tasks.github.util.util import get_owner_repo
13 from augur.tasks.github.util.gh_graphql_entities import hit_api_graphql, request_graphql_dict
14 from augur.application.db.util import execute_session_query
15
16
17 def get_release_inf(session, repo_id, release, tag_only):
18 if not tag_only:
19 name = "" if release['author']['name'] is None else release['author']['name']
20 company = "" if release['author']['company'] is None else release['author']['company']
21 author = name + '_' + company
22 release_inf = {
23 'release_id': release['id'],
24 'repo_id': repo_id,
25 'release_name': release['name'],
26 'release_description': release['description'],
27 'release_author': author,
28 'release_created_at': release['createdAt'],
29 'release_published_at': release['publishedAt'],
30 'release_updated_at': release['updatedAt'],
31 'release_is_draft': release['isDraft'],
32 'release_is_prerelease': release['isPrerelease'],
33 'release_tag_name': release['tagName'],
34 'release_url': release['url'],
35 'tag_only': tag_only
36 }
37 else:
38 if 'tagger' in release['target']:
39 if 'name' in release['target']['tagger']:
40 name = release['target']['tagger']['name']
41 else:
42 name = ""
43 if 'email' in release['target']['tagger']:
44 email = '_' + release['target']['tagger']['email']
45 else:
46 email = ""
47 author = name + email
48 if 'date' in release['target']['tagger']:
49 date = release['target']['tagger']['date']
50 else:
51 date = ""
52 else:
53 author = ""
54 date = ""
55 release_inf = {
56 'release_id': release['id'],
57 'repo_id': repo_id,
58 'release_name': release['name'],
59 'release_author': author,
60 'release_tag_name': release['name'],
61 'tag_only': tag_only
62 }
63 if date:
64 release_inf['release_created_at'] = date
65
66 return release_inf
67
68
69 def insert_release(session, repo_id, owner, release, tag_only = False):
70
71 # Get current table values
72 session.logger.info('Getting release table values\n')
73 query = session.query(Release.release_id).filter(Release.repo_id == repo_id)
74 release_id_data = execute_session_query(query, 'all')#pd.read_sql(release_id_data_sql, self.db, params={'repo_id': repo_id})
75 release_id_data = [str(r_id).strip() for r_id in release_id_data]#release_id_data.apply(lambda x: x.str.strip())
76
77 # Put all data together in format of the table
78 session.logger.info(f'Inserting release for repo with id:{repo_id}, owner:{owner}, release name:{release["name"]}\n')
79 release_inf = get_release_inf(session, repo_id, release, tag_only)
80
81 #Do an upsert
82 session.insert_data(release_inf,Release,['release_id'])
83
84 session.logger.info(f"Inserted info for {owner}/{repo_id}/{release['name']}\n")
85
86 return
87
88
89 def get_query(session, owner, repo, tag_only):
90 if not tag_only:
91 query = """
92 {
93 repository(owner:"%s", name:"%s"){
94 id
95 releases(orderBy: {field: CREATED_AT, direction: ASC}, last: %d) {
96 edges {
97 node {
98 name
99 publishedAt
100 createdAt
101 description
102 id
103 isDraft
104 isPrerelease
105 tagName
106 url
107 updatedAt
108 author {
109 name
110 company
111 }
112 }
113 }
114 }
115 }
116 }
117 """ % (owner, repo, 100)
118 else:
119 query = """
120 {
121 repository(owner:"%s", name:"%s"){
122 id
123 refs(refPrefix: "refs/tags/", last: %d){
124 edges {
125 node {
126 name
127 id
128 target {
129 ... on Tag {
130 tagger {
131 name
132 email
133 date
134 }
135 }
136 }
137 }
138 }
139 }
140 }
141 }
142 """ % (owner, repo, 100)
143
144 session.logger.debug(f"query is: {query}")
145
146 return query
147
148
149
150 def fetch_data(session, github_url, repo_id, tag_only = False):
151
152 session.logger.info("Beginning filling the releases model for repo: " + github_url + "\n")
153
154 owner, repo = get_owner_repo(github_url)
155
156 url = 'https://api.github.com/graphql'
157
158 query = get_query(session,owner, repo, tag_only)
159
160 # Hit the graphql endpoint
161 session.logger.info("Hitting endpoint: {} ...\n".format(url))
162 data = request_graphql_dict(session, url, query)
163
164 if 'data' in data:
165 data = data['data']['repository']
166
167 data['owner'] = owner
168
169 return data
170
171 def releases_model(session, repo_git, repo_id):
172
173 try:
174 data = fetch_data(session,repo_git, repo_id)
175 except Exception as e:
176 session.logger.info(f"Ran into problem when fetching data for repo {repo_git}: {e}")
177 return
178
179 session.logger.info("repository value is: {}\n".format(data))
180 if 'releases' in data:
181 if 'edges' in data['releases'] and data['releases']['edges']:
182 for n in data['releases']['edges']:
183 if 'node' in n:
184 release = n['node']
185 #self.insert_release(task, repo_id, data['owner'], release)
186 insert_release(session, repo_id, data['owner'], release)
187 else:
188 session.logger.info("There's no release to insert. Current node is not available in releases: {}\n".format(n))
189 elif 'edges' in data['releases'] and not data['releases']['edges']:
190 session.logger.info("Searching for tags instead of releases...")
191 data = fetch_data(session,repo_git, repo_id,True)
192 session.logger.info("refs value is: {}\n".format(data))
193 if 'refs' in data:
194 if 'edges' in data['refs']:
195 for n in data['refs']['edges']:
196 if 'node' in n:
197 release = n['node']
198 #self.insert_release(task, repo_id, data['owner'], release, True)
199 insert_release(session, repo_id, data['owner'], release, True)
200 else:
201 session.logger.info("There's no release to insert. Current node is not available in releases: {}\n".format(n))
202 else:
203 session.logger.info("There are no releases to insert for current repository: {}\n".format(data))
204 else:
205 session.logger.info("There are no refs in data: {}\n".format(data))
206 else:
207 session.logger.info("There are no releases to insert for current repository: {}\n".format(data))
208 else:
209 session.logger.info("Graphql response does not contain repository: {}\n".format(data))
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/augur/tasks/github/releases/core.py b/augur/tasks/github/releases/core.py
--- a/augur/tasks/github/releases/core.py
+++ b/augur/tasks/github/releases/core.py
@@ -16,9 +16,17 @@
def get_release_inf(session, repo_id, release, tag_only):
if not tag_only:
- name = "" if release['author']['name'] is None else release['author']['name']
- company = "" if release['author']['company'] is None else release['author']['company']
- author = name + '_' + company
+
+ if release['author'] is None:
+ author = 'No Author Available.'
+ name = "N/A"
+ company = "N/A"
+ else:
+ name = "" if release['author']['name'] is None else release['author']['name']
+ company = "" if release['author']['company'] is None else release['author']['company']
+ author = name + '_' + company
+
+
release_inf = {
'release_id': release['id'],
'repo_id': repo_id,
|
{"golden_diff": "diff --git a/augur/tasks/github/releases/core.py b/augur/tasks/github/releases/core.py\n--- a/augur/tasks/github/releases/core.py\n+++ b/augur/tasks/github/releases/core.py\n@@ -16,9 +16,17 @@\n \n def get_release_inf(session, repo_id, release, tag_only):\n if not tag_only:\n- name = \"\" if release['author']['name'] is None else release['author']['name']\n- company = \"\" if release['author']['company'] is None else release['author']['company']\n- author = name + '_' + company\n+\n+ if release['author'] is None:\n+ author = 'No Author Available.'\n+ name = \"N/A\"\n+ company = \"N/A\"\n+ else:\n+ name = \"\" if release['author']['name'] is None else release['author']['name']\n+ company = \"\" if release['author']['company'] is None else release['author']['company']\n+ author = name + '_' + company\n+\n+\n release_inf = {\n 'release_id': release['id'],\n 'repo_id': repo_id,\n", "issue": "Release Task Periodic Error : branch: `main`\n**Description:**\r\nWhen release metadata is not fully populated on a repo (a rare occurrence), the following error is generated: \r\n```\r\nTraceback (most recent call last):\r\n File \"/home/sean/github/virtualenv/ag3/lib/python3.8/site-packages/celery/app/trace.py\", line 451, in trace_task\r\n R = retval = fun(*args, **kwargs)\r\n File \"/home/sean/github/virtualenv/ag3/lib/python3.8/site-packages/celery/app/trace.py\", line 734, in __protected_call__\r\n return self.run(*args, **kwargs)\r\n File \"/home/sean/github/ag3/augur/tasks/github/releases/tasks.py\", line 15, in collect_releases\r\n releases_model(session, repo.repo_git, repo.repo_id)\r\n File \"/home/sean/github/ag3/augur/tasks/github/releases/core.py\", line 186, in releases_model\r\n insert_release(session, repo_id, data['owner'], release)\r\n File \"/home/sean/github/ag3/augur/tasks/github/releases/core.py\", line 79, in insert_release\r\n release_inf = get_release_inf(session, repo_id, release, tag_only)\r\n File \"/home/sean/github/ag3/augur/tasks/github/releases/core.py\", line 19, in get_release_inf\r\n name = \"\" if release['author']['name'] is None else release['author']['name']\r\nTypeError: 'NoneType' object is not subscriptable\r\n\r\n```\r\n\r\n**How to reproduce:**\r\nThe `ag3` instance on our test server has this error right now. \r\n\r\n**Expected behavior:**\r\nNo error\r\n\r\n**Software versions:**\r\n - `augur-new-dev`\r\n - OS: Ubuntu 20.5\r\n\n", "before_files": [{"content": "#SPDX-License-Identifier: MIT\nimport logging, os, sys, time, requests, json\nfrom datetime import datetime\nfrom multiprocessing import Process, Queue\nfrom urllib.parse import urlparse\nimport pandas as pd\nimport sqlalchemy as s\nfrom sqlalchemy import MetaData\nfrom sqlalchemy.ext.automap import automap_base\nfrom augur.tasks.github.util.github_task_session import *\nfrom augur.application.db.models import *\nfrom augur.tasks.github.util.util import get_owner_repo\nfrom augur.tasks.github.util.gh_graphql_entities import hit_api_graphql, request_graphql_dict\nfrom augur.application.db.util import execute_session_query\n\n\ndef get_release_inf(session, repo_id, release, tag_only):\n if not tag_only:\n name = \"\" if release['author']['name'] is None else release['author']['name']\n company = \"\" if release['author']['company'] is None else release['author']['company']\n author = name + '_' + company\n release_inf = {\n 'release_id': release['id'],\n 'repo_id': repo_id,\n 'release_name': release['name'],\n 'release_description': release['description'],\n 'release_author': author,\n 'release_created_at': release['createdAt'],\n 'release_published_at': release['publishedAt'],\n 'release_updated_at': release['updatedAt'],\n 'release_is_draft': release['isDraft'],\n 'release_is_prerelease': release['isPrerelease'],\n 'release_tag_name': release['tagName'],\n 'release_url': release['url'],\n 'tag_only': tag_only\n }\n else:\n if 'tagger' in release['target']:\n if 'name' in release['target']['tagger']:\n name = release['target']['tagger']['name']\n else:\n name = \"\"\n if 'email' in release['target']['tagger']:\n email = '_' + release['target']['tagger']['email']\n else:\n email = \"\"\n author = name + email\n if 'date' in release['target']['tagger']:\n date = release['target']['tagger']['date']\n else:\n date = \"\"\n else:\n author = \"\"\n date = \"\"\n release_inf = {\n 'release_id': release['id'],\n 'repo_id': repo_id,\n 'release_name': release['name'],\n 'release_author': author,\n 'release_tag_name': release['name'],\n 'tag_only': tag_only\n }\n if date:\n release_inf['release_created_at'] = date\n\n return release_inf\n\n\ndef insert_release(session, repo_id, owner, release, tag_only = False):\n\n # Get current table values\n session.logger.info('Getting release table values\\n')\n query = session.query(Release.release_id).filter(Release.repo_id == repo_id)\n release_id_data = execute_session_query(query, 'all')#pd.read_sql(release_id_data_sql, self.db, params={'repo_id': repo_id})\n release_id_data = [str(r_id).strip() for r_id in release_id_data]#release_id_data.apply(lambda x: x.str.strip())\n\n # Put all data together in format of the table\n session.logger.info(f'Inserting release for repo with id:{repo_id}, owner:{owner}, release name:{release[\"name\"]}\\n')\n release_inf = get_release_inf(session, repo_id, release, tag_only)\n\n #Do an upsert\n session.insert_data(release_inf,Release,['release_id'])\n\n session.logger.info(f\"Inserted info for {owner}/{repo_id}/{release['name']}\\n\")\n\n return\n\n\ndef get_query(session, owner, repo, tag_only):\n if not tag_only:\n query = \"\"\"\n {\n repository(owner:\"%s\", name:\"%s\"){\n id\n releases(orderBy: {field: CREATED_AT, direction: ASC}, last: %d) {\n edges {\n node {\n name\n publishedAt\n createdAt\n description\n id\n isDraft\n isPrerelease\n tagName\n url\n updatedAt\n author {\n name\n company\n }\n }\n }\n }\n }\n }\n \"\"\" % (owner, repo, 100)\n else:\n query = \"\"\"\n {\n repository(owner:\"%s\", name:\"%s\"){\n id\n refs(refPrefix: \"refs/tags/\", last: %d){\n edges {\n node {\n name\n id\n target {\n ... on Tag {\n tagger {\n name\n email\n date\n }\n }\n }\n }\n }\n }\n }\n }\n \"\"\" % (owner, repo, 100)\n\n session.logger.debug(f\"query is: {query}\")\n\n return query\n\n\n\ndef fetch_data(session, github_url, repo_id, tag_only = False):\n\n session.logger.info(\"Beginning filling the releases model for repo: \" + github_url + \"\\n\")\n\n owner, repo = get_owner_repo(github_url)\n\n url = 'https://api.github.com/graphql'\n\n query = get_query(session,owner, repo, tag_only)\n\n # Hit the graphql endpoint\n session.logger.info(\"Hitting endpoint: {} ...\\n\".format(url))\n data = request_graphql_dict(session, url, query)\n\n if 'data' in data:\n data = data['data']['repository']\n\n data['owner'] = owner\n\n return data\n\ndef releases_model(session, repo_git, repo_id):\n\n try:\n data = fetch_data(session,repo_git, repo_id)\n except Exception as e:\n session.logger.info(f\"Ran into problem when fetching data for repo {repo_git}: {e}\")\n return\n\n session.logger.info(\"repository value is: {}\\n\".format(data))\n if 'releases' in data:\n if 'edges' in data['releases'] and data['releases']['edges']:\n for n in data['releases']['edges']:\n if 'node' in n:\n release = n['node']\n #self.insert_release(task, repo_id, data['owner'], release)\n insert_release(session, repo_id, data['owner'], release)\n else:\n session.logger.info(\"There's no release to insert. Current node is not available in releases: {}\\n\".format(n))\n elif 'edges' in data['releases'] and not data['releases']['edges']:\n session.logger.info(\"Searching for tags instead of releases...\")\n data = fetch_data(session,repo_git, repo_id,True)\n session.logger.info(\"refs value is: {}\\n\".format(data))\n if 'refs' in data:\n if 'edges' in data['refs']:\n for n in data['refs']['edges']:\n if 'node' in n:\n release = n['node']\n #self.insert_release(task, repo_id, data['owner'], release, True)\n insert_release(session, repo_id, data['owner'], release, True)\n else:\n session.logger.info(\"There's no release to insert. Current node is not available in releases: {}\\n\".format(n))\n else:\n session.logger.info(\"There are no releases to insert for current repository: {}\\n\".format(data))\n else:\n session.logger.info(\"There are no refs in data: {}\\n\".format(data))\n else:\n session.logger.info(\"There are no releases to insert for current repository: {}\\n\".format(data))\n else:\n session.logger.info(\"Graphql response does not contain repository: {}\\n\".format(data))", "path": "augur/tasks/github/releases/core.py"}], "after_files": [{"content": "#SPDX-License-Identifier: MIT\nimport logging, os, sys, time, requests, json\nfrom datetime import datetime\nfrom multiprocessing import Process, Queue\nfrom urllib.parse import urlparse\nimport pandas as pd\nimport sqlalchemy as s\nfrom sqlalchemy import MetaData\nfrom sqlalchemy.ext.automap import automap_base\nfrom augur.tasks.github.util.github_task_session import *\nfrom augur.application.db.models import *\nfrom augur.tasks.github.util.util import get_owner_repo\nfrom augur.tasks.github.util.gh_graphql_entities import hit_api_graphql, request_graphql_dict\nfrom augur.application.db.util import execute_session_query\n\n\ndef get_release_inf(session, repo_id, release, tag_only):\n if not tag_only:\n\n if release['author'] is None:\n author = 'No Author Available.'\n name = \"N/A\"\n company = \"N/A\"\n else:\n name = \"\" if release['author']['name'] is None else release['author']['name']\n company = \"\" if release['author']['company'] is None else release['author']['company']\n author = name + '_' + company\n\n\n release_inf = {\n 'release_id': release['id'],\n 'repo_id': repo_id,\n 'release_name': release['name'],\n 'release_description': release['description'],\n 'release_author': author,\n 'release_created_at': release['createdAt'],\n 'release_published_at': release['publishedAt'],\n 'release_updated_at': release['updatedAt'],\n 'release_is_draft': release['isDraft'],\n 'release_is_prerelease': release['isPrerelease'],\n 'release_tag_name': release['tagName'],\n 'release_url': release['url'],\n 'tag_only': tag_only\n }\n else:\n if 'tagger' in release['target']:\n if 'name' in release['target']['tagger']:\n name = release['target']['tagger']['name']\n else:\n name = \"\"\n if 'email' in release['target']['tagger']:\n email = '_' + release['target']['tagger']['email']\n else:\n email = \"\"\n author = name + email\n if 'date' in release['target']['tagger']:\n date = release['target']['tagger']['date']\n else:\n date = \"\"\n else:\n author = \"\"\n date = \"\"\n release_inf = {\n 'release_id': release['id'],\n 'repo_id': repo_id,\n 'release_name': release['name'],\n 'release_author': author,\n 'release_tag_name': release['name'],\n 'tag_only': tag_only\n }\n if date:\n release_inf['release_created_at'] = date\n\n return release_inf\n\n\ndef insert_release(session, repo_id, owner, release, tag_only = False):\n\n # Get current table values\n session.logger.info('Getting release table values\\n')\n query = session.query(Release.release_id).filter(Release.repo_id == repo_id)\n release_id_data = execute_session_query(query, 'all')#pd.read_sql(release_id_data_sql, self.db, params={'repo_id': repo_id})\n release_id_data = [str(r_id).strip() for r_id in release_id_data]#release_id_data.apply(lambda x: x.str.strip())\n\n # Put all data together in format of the table\n session.logger.info(f'Inserting release for repo with id:{repo_id}, owner:{owner}, release name:{release[\"name\"]}\\n')\n release_inf = get_release_inf(session, repo_id, release, tag_only)\n\n #Do an upsert\n session.insert_data(release_inf,Release,['release_id'])\n\n session.logger.info(f\"Inserted info for {owner}/{repo_id}/{release['name']}\\n\")\n\n return\n\n\ndef get_query(session, owner, repo, tag_only):\n if not tag_only:\n query = \"\"\"\n {\n repository(owner:\"%s\", name:\"%s\"){\n id\n releases(orderBy: {field: CREATED_AT, direction: ASC}, last: %d) {\n edges {\n node {\n name\n publishedAt\n createdAt\n description\n id\n isDraft\n isPrerelease\n tagName\n url\n updatedAt\n author {\n name\n company\n }\n }\n }\n }\n }\n }\n \"\"\" % (owner, repo, 100)\n else:\n query = \"\"\"\n {\n repository(owner:\"%s\", name:\"%s\"){\n id\n refs(refPrefix: \"refs/tags/\", last: %d){\n edges {\n node {\n name\n id\n target {\n ... on Tag {\n tagger {\n name\n email\n date\n }\n }\n }\n }\n }\n }\n }\n }\n \"\"\" % (owner, repo, 100)\n\n session.logger.debug(f\"query is: {query}\")\n\n return query\n\n\n\ndef fetch_data(session, github_url, repo_id, tag_only = False):\n\n session.logger.info(\"Beginning filling the releases model for repo: \" + github_url + \"\\n\")\n\n owner, repo = get_owner_repo(github_url)\n\n url = 'https://api.github.com/graphql'\n\n query = get_query(session,owner, repo, tag_only)\n\n # Hit the graphql endpoint\n session.logger.info(\"Hitting endpoint: {} ...\\n\".format(url))\n data = request_graphql_dict(session, url, query)\n\n if 'data' in data:\n data = data['data']['repository']\n\n data['owner'] = owner\n\n return data\n\ndef releases_model(session, repo_git, repo_id):\n\n try:\n data = fetch_data(session,repo_git, repo_id)\n except Exception as e:\n session.logger.info(f\"Ran into problem when fetching data for repo {repo_git}: {e}\")\n return\n\n session.logger.info(\"repository value is: {}\\n\".format(data))\n if 'releases' in data:\n if 'edges' in data['releases'] and data['releases']['edges']:\n for n in data['releases']['edges']:\n if 'node' in n:\n release = n['node']\n #self.insert_release(task, repo_id, data['owner'], release)\n insert_release(session, repo_id, data['owner'], release)\n else:\n session.logger.info(\"There's no release to insert. Current node is not available in releases: {}\\n\".format(n))\n elif 'edges' in data['releases'] and not data['releases']['edges']:\n session.logger.info(\"Searching for tags instead of releases...\")\n data = fetch_data(session,repo_git, repo_id,True)\n session.logger.info(\"refs value is: {}\\n\".format(data))\n if 'refs' in data:\n if 'edges' in data['refs']:\n for n in data['refs']['edges']:\n if 'node' in n:\n release = n['node']\n #self.insert_release(task, repo_id, data['owner'], release, True)\n insert_release(session, repo_id, data['owner'], release, True)\n else:\n session.logger.info(\"There's no release to insert. Current node is not available in releases: {}\\n\".format(n))\n else:\n session.logger.info(\"There are no releases to insert for current repository: {}\\n\".format(data))\n else:\n session.logger.info(\"There are no refs in data: {}\\n\".format(data))\n else:\n session.logger.info(\"There are no releases to insert for current repository: {}\\n\".format(data))\n else:\n session.logger.info(\"Graphql response does not contain repository: {}\\n\".format(data))", "path": "augur/tasks/github/releases/core.py"}]}
| 2,793 | 246 |
gh_patches_debug_8659
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-trace-py-1745
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
RuntimeError: Set changed size during iteration
Python Version: 3.7.7
Error:
```
RuntimeError: Set changed size during iteration
File "django/core/handlers/wsgi.py", line 141, in __call__
response = self.get_response(request)
File "ddtrace/contrib/django/patch.py", line 82, in wrapper
return func(mod, pin, wrapped, instance, args, kwargs)
File "ddtrace/contrib/django/patch.py", line 406, in traced_get_response
span_type=SpanTypes.HTTP,
File "ddtrace/tracer.py", line 638, in trace
span_type=span_type,
File "ddtrace/tracer.py", line 389, in start_span
new_ctx = self._check_new_process()
File "ddtrace/tracer.py", line 570, in _check_new_process
self._update_dogstatsd_constant_tags()
File "ddtrace/tracer.py", line 525, in _update_dogstatsd_constant_tags
for k, v in RuntimeTags()
File "ddtrace/tracer.py", line 524, in <listcomp>
'{}:{}'.format(k, v)
File "ddtrace/internal/runtime/runtime_metrics.py", line 29, in <genexpr>
collected = (collector.collect(self._enabled) for collector in self._collectors)
File "ddtrace/internal/runtime/collector.py", line 67, in collect
self.value = self.collect_fn(keys)
File "ddtrace/internal/runtime/tag_collectors.py", line 25, in collect_fn
tags = [(SERVICE, service) for service in ddtrace.tracer._services]
File "ddtrace/internal/runtime/tag_collectors.py", line 25, in <listcomp>
tags = [(SERVICE, service) for service in ddtrace.tracer._services]
```
### Which version of dd-trace-py are you using?
```
0.42.0
```
### Which version of the libraries are you using?
```
django==2.2.14
ddtrace==0.42.0
gunicorn==20.0.4
```
### How can we reproduce your problem?
It's not clear if there's anything specific about the WSGI requests that triggers this condition.
### What is the result that you get?
-
### What is the result that you expected?
-
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ddtrace/internal/runtime/tag_collectors.py`
Content:
```
1 from .collector import ValueCollector
2 from .constants import (
3 SERVICE,
4 LANG_INTERPRETER,
5 LANG_VERSION,
6 LANG,
7 TRACER_VERSION,
8 )
9 from ...constants import ENV_KEY
10
11
12 class RuntimeTagCollector(ValueCollector):
13 periodic = False
14 value = []
15
16
17 class TracerTagCollector(RuntimeTagCollector):
18 """Tag collector for the ddtrace Tracer"""
19
20 required_modules = ["ddtrace"]
21
22 def collect_fn(self, keys):
23 ddtrace = self.modules.get("ddtrace")
24 tags = [(SERVICE, service) for service in ddtrace.tracer._services]
25 if ENV_KEY in ddtrace.tracer.tags:
26 tags.append((ENV_KEY, ddtrace.tracer.tags[ENV_KEY]))
27 return tags
28
29
30 class PlatformTagCollector(RuntimeTagCollector):
31 """Tag collector for the Python interpreter implementation.
32
33 Tags collected:
34 - ``lang_interpreter``:
35
36 * For CPython this is 'CPython'.
37 * For Pypy this is ``PyPy``
38 * For Jython this is ``Jython``
39
40 - `lang_version``, eg ``2.7.10``
41 - ``lang`` e.g. ``Python``
42 - ``tracer_version`` e.g. ``0.29.0``
43
44 """
45
46 required_modules = ("platform", "ddtrace")
47
48 def collect_fn(self, keys):
49 platform = self.modules.get("platform")
50 ddtrace = self.modules.get("ddtrace")
51 tags = [
52 (LANG, "python"),
53 (LANG_INTERPRETER, platform.python_implementation()),
54 (LANG_VERSION, platform.python_version()),
55 (TRACER_VERSION, ddtrace.__version__),
56 ]
57 return tags
58
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ddtrace/internal/runtime/tag_collectors.py b/ddtrace/internal/runtime/tag_collectors.py
--- a/ddtrace/internal/runtime/tag_collectors.py
+++ b/ddtrace/internal/runtime/tag_collectors.py
@@ -21,7 +21,8 @@
def collect_fn(self, keys):
ddtrace = self.modules.get("ddtrace")
- tags = [(SERVICE, service) for service in ddtrace.tracer._services]
+ # make sure to copy _services to avoid RuntimeError: Set changed size during iteration
+ tags = [(SERVICE, service) for service in list(ddtrace.tracer._services)]
if ENV_KEY in ddtrace.tracer.tags:
tags.append((ENV_KEY, ddtrace.tracer.tags[ENV_KEY]))
return tags
|
{"golden_diff": "diff --git a/ddtrace/internal/runtime/tag_collectors.py b/ddtrace/internal/runtime/tag_collectors.py\n--- a/ddtrace/internal/runtime/tag_collectors.py\n+++ b/ddtrace/internal/runtime/tag_collectors.py\n@@ -21,7 +21,8 @@\n \n def collect_fn(self, keys):\n ddtrace = self.modules.get(\"ddtrace\")\n- tags = [(SERVICE, service) for service in ddtrace.tracer._services]\n+ # make sure to copy _services to avoid RuntimeError: Set changed size during iteration\n+ tags = [(SERVICE, service) for service in list(ddtrace.tracer._services)]\n if ENV_KEY in ddtrace.tracer.tags:\n tags.append((ENV_KEY, ddtrace.tracer.tags[ENV_KEY]))\n return tags\n", "issue": "RuntimeError: Set changed size during iteration\nPython Version: 3.7.7\r\n\r\nError:\r\n```\r\nRuntimeError: Set changed size during iteration\r\n File \"django/core/handlers/wsgi.py\", line 141, in __call__\r\n response = self.get_response(request)\r\n File \"ddtrace/contrib/django/patch.py\", line 82, in wrapper\r\n return func(mod, pin, wrapped, instance, args, kwargs)\r\n File \"ddtrace/contrib/django/patch.py\", line 406, in traced_get_response\r\n span_type=SpanTypes.HTTP,\r\n File \"ddtrace/tracer.py\", line 638, in trace\r\n span_type=span_type,\r\n File \"ddtrace/tracer.py\", line 389, in start_span\r\n new_ctx = self._check_new_process()\r\n File \"ddtrace/tracer.py\", line 570, in _check_new_process\r\n self._update_dogstatsd_constant_tags()\r\n File \"ddtrace/tracer.py\", line 525, in _update_dogstatsd_constant_tags\r\n for k, v in RuntimeTags()\r\n File \"ddtrace/tracer.py\", line 524, in <listcomp>\r\n '{}:{}'.format(k, v)\r\n File \"ddtrace/internal/runtime/runtime_metrics.py\", line 29, in <genexpr>\r\n collected = (collector.collect(self._enabled) for collector in self._collectors)\r\n File \"ddtrace/internal/runtime/collector.py\", line 67, in collect\r\n self.value = self.collect_fn(keys)\r\n File \"ddtrace/internal/runtime/tag_collectors.py\", line 25, in collect_fn\r\n tags = [(SERVICE, service) for service in ddtrace.tracer._services]\r\n File \"ddtrace/internal/runtime/tag_collectors.py\", line 25, in <listcomp>\r\n tags = [(SERVICE, service) for service in ddtrace.tracer._services]\r\n```\r\n\r\n### Which version of dd-trace-py are you using?\r\n```\r\n0.42.0\r\n```\r\n\r\n### Which version of the libraries are you using?\r\n```\r\ndjango==2.2.14\r\nddtrace==0.42.0\r\ngunicorn==20.0.4\r\n```\r\n\r\n### How can we reproduce your problem?\r\nIt's not clear if there's anything specific about the WSGI requests that triggers this condition. \r\n\r\n### What is the result that you get?\r\n-\r\n\r\n### What is the result that you expected?\r\n-\n", "before_files": [{"content": "from .collector import ValueCollector\nfrom .constants import (\n SERVICE,\n LANG_INTERPRETER,\n LANG_VERSION,\n LANG,\n TRACER_VERSION,\n)\nfrom ...constants import ENV_KEY\n\n\nclass RuntimeTagCollector(ValueCollector):\n periodic = False\n value = []\n\n\nclass TracerTagCollector(RuntimeTagCollector):\n \"\"\"Tag collector for the ddtrace Tracer\"\"\"\n\n required_modules = [\"ddtrace\"]\n\n def collect_fn(self, keys):\n ddtrace = self.modules.get(\"ddtrace\")\n tags = [(SERVICE, service) for service in ddtrace.tracer._services]\n if ENV_KEY in ddtrace.tracer.tags:\n tags.append((ENV_KEY, ddtrace.tracer.tags[ENV_KEY]))\n return tags\n\n\nclass PlatformTagCollector(RuntimeTagCollector):\n \"\"\"Tag collector for the Python interpreter implementation.\n\n Tags collected:\n - ``lang_interpreter``:\n\n * For CPython this is 'CPython'.\n * For Pypy this is ``PyPy``\n * For Jython this is ``Jython``\n\n - `lang_version``, eg ``2.7.10``\n - ``lang`` e.g. ``Python``\n - ``tracer_version`` e.g. ``0.29.0``\n\n \"\"\"\n\n required_modules = (\"platform\", \"ddtrace\")\n\n def collect_fn(self, keys):\n platform = self.modules.get(\"platform\")\n ddtrace = self.modules.get(\"ddtrace\")\n tags = [\n (LANG, \"python\"),\n (LANG_INTERPRETER, platform.python_implementation()),\n (LANG_VERSION, platform.python_version()),\n (TRACER_VERSION, ddtrace.__version__),\n ]\n return tags\n", "path": "ddtrace/internal/runtime/tag_collectors.py"}], "after_files": [{"content": "from .collector import ValueCollector\nfrom .constants import (\n SERVICE,\n LANG_INTERPRETER,\n LANG_VERSION,\n LANG,\n TRACER_VERSION,\n)\nfrom ...constants import ENV_KEY\n\n\nclass RuntimeTagCollector(ValueCollector):\n periodic = False\n value = []\n\n\nclass TracerTagCollector(RuntimeTagCollector):\n \"\"\"Tag collector for the ddtrace Tracer\"\"\"\n\n required_modules = [\"ddtrace\"]\n\n def collect_fn(self, keys):\n ddtrace = self.modules.get(\"ddtrace\")\n # make sure to copy _services to avoid RuntimeError: Set changed size during iteration\n tags = [(SERVICE, service) for service in list(ddtrace.tracer._services)]\n if ENV_KEY in ddtrace.tracer.tags:\n tags.append((ENV_KEY, ddtrace.tracer.tags[ENV_KEY]))\n return tags\n\n\nclass PlatformTagCollector(RuntimeTagCollector):\n \"\"\"Tag collector for the Python interpreter implementation.\n\n Tags collected:\n - ``lang_interpreter``:\n\n * For CPython this is 'CPython'.\n * For Pypy this is ``PyPy``\n * For Jython this is ``Jython``\n\n - `lang_version``, eg ``2.7.10``\n - ``lang`` e.g. ``Python``\n - ``tracer_version`` e.g. ``0.29.0``\n\n \"\"\"\n\n required_modules = (\"platform\", \"ddtrace\")\n\n def collect_fn(self, keys):\n platform = self.modules.get(\"platform\")\n ddtrace = self.modules.get(\"ddtrace\")\n tags = [\n (LANG, \"python\"),\n (LANG_INTERPRETER, platform.python_implementation()),\n (LANG_VERSION, platform.python_version()),\n (TRACER_VERSION, ddtrace.__version__),\n ]\n return tags\n", "path": "ddtrace/internal/runtime/tag_collectors.py"}]}
| 1,280 | 165 |
gh_patches_debug_39127
|
rasdani/github-patches
|
git_diff
|
ietf-tools__datatracker-4309
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
session_purpose_demo management command no longer needed
### Description
When the session purpose project was in development, we added a management command `session_purpose_demo` to add a fake meeting that exercised the new features. Since the session purposes are now in active use, I think that management command can be pruned.
### Code of Conduct
- [X] I agree to follow the [IETF's Code of Conduct](https://github.com/ietf-tools/.github/blob/main/CODE_OF_CONDUCT.md)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ietf/meeting/management/commands/session_purpose_demo.py`
Content:
```
1 import datetime
2 import random
3
4 from django.core.management.base import BaseCommand, CommandError
5
6 from ietf.group.models import Group
7 from ietf.meeting.factories import RoomFactory, TimeSlotFactory, SessionFactory
8 from ietf.meeting.helpers import get_meeting
9 from ietf.meeting.models import Room, Session
10 from ietf.name.models import SessionPurposeName
11
12
13 class Command(BaseCommand):
14 help = 'Set up a demo of the session purpose updates'
15
16 DEMO_PREFIX='PDemo' # used to identify things added by this command
17
18 def add_arguments(self, parser):
19 parser.add_argument('--remove', action='store_true')
20
21 def handle(self, *args, **options):
22 if options['remove']:
23 self.remove_demo()
24 else:
25 self.install_demo()
26
27 def remove_demo(self):
28 self.stdout.write(f'Removing rooms with "{self.DEMO_PREFIX}" name prefix...\n')
29 Room.objects.filter(name__startswith=self.DEMO_PREFIX).delete()
30 self.stdout.write(f'Removing sessions with "{self.DEMO_PREFIX}" name prefix...\n')
31 Session.objects.filter(name__startswith=self.DEMO_PREFIX).delete()
32
33 def install_demo(self):
34 # get meeting
35 try:
36 meeting = get_meeting(days=14) # matches how secr app finds meetings
37 except:
38 raise CommandError('No upcoming meeting to modify')
39
40 # create rooms
41 self.stdout.write('Creating rooms...\n')
42 rooms = [
43 RoomFactory(meeting=meeting, name=f'{self.DEMO_PREFIX} 1'),
44 RoomFactory(meeting=meeting, name=f'{self.DEMO_PREFIX} 2'),
45 RoomFactory(meeting=meeting, name=f'{self.DEMO_PREFIX} 3'),
46 ]
47
48 # get all the timeslot types used by a session purpose
49 type_ids = set()
50 for purpose in SessionPurposeName.objects.filter(used=True):
51 type_ids.update(purpose.timeslot_types)
52
53 # set up timeslots
54 self.stdout.write('Creating timeslots...\n')
55 for room in rooms:
56 for day in range(meeting.days):
57 date = meeting.get_meeting_date(day)
58 for n, type_id in enumerate(type_ids):
59 TimeSlotFactory(
60 type_id=type_id,
61 meeting=meeting,
62 location=room,
63 time=datetime.datetime.combine(date, datetime.time(10, 0, 0)) + datetime.timedelta(hours=n),
64 duration=datetime.timedelta(hours=1),
65 )
66
67 # set up sessions
68 self.stdout.write('Creating sessions...')
69 groups_for_session_purpose = {
70 purpose.slug: list(
71 Group.objects.filter(
72 type__features__session_purposes__contains=f'"{purpose.slug}"',
73 state_id='active',
74 )
75 )
76 for purpose in SessionPurposeName.objects.filter(used=True)
77 }
78 for purpose in SessionPurposeName.objects.filter(used=True):
79 for type_id in purpose.timeslot_types:
80 group=random.choice(groups_for_session_purpose[purpose.slug])
81 SessionFactory(
82 meeting=meeting,
83 purpose=purpose,
84 type_id=type_id,
85 group=group,
86 name=f'{self.DEMO_PREFIX} for {group.acronym}',
87 status_id='schedw',
88 add_to_schedule=False,
89 )
90
91 self.stdout.write(f'\nRooms and sessions created with "{self.DEMO_PREFIX}" as name prefix\n')
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ietf/meeting/management/commands/session_purpose_demo.py b/ietf/meeting/management/commands/session_purpose_demo.py
deleted file mode 100644
--- a/ietf/meeting/management/commands/session_purpose_demo.py
+++ /dev/null
@@ -1,91 +0,0 @@
-import datetime
-import random
-
-from django.core.management.base import BaseCommand, CommandError
-
-from ietf.group.models import Group
-from ietf.meeting.factories import RoomFactory, TimeSlotFactory, SessionFactory
-from ietf.meeting.helpers import get_meeting
-from ietf.meeting.models import Room, Session
-from ietf.name.models import SessionPurposeName
-
-
-class Command(BaseCommand):
- help = 'Set up a demo of the session purpose updates'
-
- DEMO_PREFIX='PDemo' # used to identify things added by this command
-
- def add_arguments(self, parser):
- parser.add_argument('--remove', action='store_true')
-
- def handle(self, *args, **options):
- if options['remove']:
- self.remove_demo()
- else:
- self.install_demo()
-
- def remove_demo(self):
- self.stdout.write(f'Removing rooms with "{self.DEMO_PREFIX}" name prefix...\n')
- Room.objects.filter(name__startswith=self.DEMO_PREFIX).delete()
- self.stdout.write(f'Removing sessions with "{self.DEMO_PREFIX}" name prefix...\n')
- Session.objects.filter(name__startswith=self.DEMO_PREFIX).delete()
-
- def install_demo(self):
- # get meeting
- try:
- meeting = get_meeting(days=14) # matches how secr app finds meetings
- except:
- raise CommandError('No upcoming meeting to modify')
-
- # create rooms
- self.stdout.write('Creating rooms...\n')
- rooms = [
- RoomFactory(meeting=meeting, name=f'{self.DEMO_PREFIX} 1'),
- RoomFactory(meeting=meeting, name=f'{self.DEMO_PREFIX} 2'),
- RoomFactory(meeting=meeting, name=f'{self.DEMO_PREFIX} 3'),
- ]
-
- # get all the timeslot types used by a session purpose
- type_ids = set()
- for purpose in SessionPurposeName.objects.filter(used=True):
- type_ids.update(purpose.timeslot_types)
-
- # set up timeslots
- self.stdout.write('Creating timeslots...\n')
- for room in rooms:
- for day in range(meeting.days):
- date = meeting.get_meeting_date(day)
- for n, type_id in enumerate(type_ids):
- TimeSlotFactory(
- type_id=type_id,
- meeting=meeting,
- location=room,
- time=datetime.datetime.combine(date, datetime.time(10, 0, 0)) + datetime.timedelta(hours=n),
- duration=datetime.timedelta(hours=1),
- )
-
- # set up sessions
- self.stdout.write('Creating sessions...')
- groups_for_session_purpose = {
- purpose.slug: list(
- Group.objects.filter(
- type__features__session_purposes__contains=f'"{purpose.slug}"',
- state_id='active',
- )
- )
- for purpose in SessionPurposeName.objects.filter(used=True)
- }
- for purpose in SessionPurposeName.objects.filter(used=True):
- for type_id in purpose.timeslot_types:
- group=random.choice(groups_for_session_purpose[purpose.slug])
- SessionFactory(
- meeting=meeting,
- purpose=purpose,
- type_id=type_id,
- group=group,
- name=f'{self.DEMO_PREFIX} for {group.acronym}',
- status_id='schedw',
- add_to_schedule=False,
- )
-
- self.stdout.write(f'\nRooms and sessions created with "{self.DEMO_PREFIX}" as name prefix\n')
\ No newline at end of file
|
{"golden_diff": "diff --git a/ietf/meeting/management/commands/session_purpose_demo.py b/ietf/meeting/management/commands/session_purpose_demo.py\ndeleted file mode 100644\n--- a/ietf/meeting/management/commands/session_purpose_demo.py\n+++ /dev/null\n@@ -1,91 +0,0 @@\n-import datetime\n-import random\n-\n-from django.core.management.base import BaseCommand, CommandError\n-\n-from ietf.group.models import Group\n-from ietf.meeting.factories import RoomFactory, TimeSlotFactory, SessionFactory\n-from ietf.meeting.helpers import get_meeting\n-from ietf.meeting.models import Room, Session\n-from ietf.name.models import SessionPurposeName\n-\n-\n-class Command(BaseCommand):\n- help = 'Set up a demo of the session purpose updates'\n-\n- DEMO_PREFIX='PDemo' # used to identify things added by this command\n-\n- def add_arguments(self, parser):\n- parser.add_argument('--remove', action='store_true')\n-\n- def handle(self, *args, **options):\n- if options['remove']:\n- self.remove_demo()\n- else:\n- self.install_demo()\n-\n- def remove_demo(self):\n- self.stdout.write(f'Removing rooms with \"{self.DEMO_PREFIX}\" name prefix...\\n')\n- Room.objects.filter(name__startswith=self.DEMO_PREFIX).delete()\n- self.stdout.write(f'Removing sessions with \"{self.DEMO_PREFIX}\" name prefix...\\n')\n- Session.objects.filter(name__startswith=self.DEMO_PREFIX).delete()\n-\n- def install_demo(self):\n- # get meeting\n- try:\n- meeting = get_meeting(days=14) # matches how secr app finds meetings\n- except:\n- raise CommandError('No upcoming meeting to modify')\n-\n- # create rooms\n- self.stdout.write('Creating rooms...\\n')\n- rooms = [\n- RoomFactory(meeting=meeting, name=f'{self.DEMO_PREFIX} 1'),\n- RoomFactory(meeting=meeting, name=f'{self.DEMO_PREFIX} 2'),\n- RoomFactory(meeting=meeting, name=f'{self.DEMO_PREFIX} 3'),\n- ]\n-\n- # get all the timeslot types used by a session purpose\n- type_ids = set()\n- for purpose in SessionPurposeName.objects.filter(used=True):\n- type_ids.update(purpose.timeslot_types)\n-\n- # set up timeslots\n- self.stdout.write('Creating timeslots...\\n')\n- for room in rooms:\n- for day in range(meeting.days):\n- date = meeting.get_meeting_date(day)\n- for n, type_id in enumerate(type_ids):\n- TimeSlotFactory(\n- type_id=type_id,\n- meeting=meeting,\n- location=room,\n- time=datetime.datetime.combine(date, datetime.time(10, 0, 0)) + datetime.timedelta(hours=n),\n- duration=datetime.timedelta(hours=1),\n- )\n-\n- # set up sessions\n- self.stdout.write('Creating sessions...')\n- groups_for_session_purpose = {\n- purpose.slug: list(\n- Group.objects.filter(\n- type__features__session_purposes__contains=f'\"{purpose.slug}\"',\n- state_id='active',\n- )\n- )\n- for purpose in SessionPurposeName.objects.filter(used=True)\n- }\n- for purpose in SessionPurposeName.objects.filter(used=True):\n- for type_id in purpose.timeslot_types:\n- group=random.choice(groups_for_session_purpose[purpose.slug])\n- SessionFactory(\n- meeting=meeting,\n- purpose=purpose,\n- type_id=type_id,\n- group=group,\n- name=f'{self.DEMO_PREFIX} for {group.acronym}',\n- status_id='schedw',\n- add_to_schedule=False,\n- )\n-\n- self.stdout.write(f'\\nRooms and sessions created with \"{self.DEMO_PREFIX}\" as name prefix\\n')\n\\ No newline at end of file\n", "issue": "session_purpose_demo management command no longer needed\n### Description\n\nWhen the session purpose project was in development, we added a management command `session_purpose_demo` to add a fake meeting that exercised the new features. Since the session purposes are now in active use, I think that management command can be pruned.\n\n### Code of Conduct\n\n- [X] I agree to follow the [IETF's Code of Conduct](https://github.com/ietf-tools/.github/blob/main/CODE_OF_CONDUCT.md)\n", "before_files": [{"content": "import datetime\nimport random\n\nfrom django.core.management.base import BaseCommand, CommandError\n\nfrom ietf.group.models import Group\nfrom ietf.meeting.factories import RoomFactory, TimeSlotFactory, SessionFactory\nfrom ietf.meeting.helpers import get_meeting\nfrom ietf.meeting.models import Room, Session\nfrom ietf.name.models import SessionPurposeName\n\n\nclass Command(BaseCommand):\n help = 'Set up a demo of the session purpose updates'\n\n DEMO_PREFIX='PDemo' # used to identify things added by this command\n\n def add_arguments(self, parser):\n parser.add_argument('--remove', action='store_true')\n\n def handle(self, *args, **options):\n if options['remove']:\n self.remove_demo()\n else:\n self.install_demo()\n\n def remove_demo(self):\n self.stdout.write(f'Removing rooms with \"{self.DEMO_PREFIX}\" name prefix...\\n')\n Room.objects.filter(name__startswith=self.DEMO_PREFIX).delete()\n self.stdout.write(f'Removing sessions with \"{self.DEMO_PREFIX}\" name prefix...\\n')\n Session.objects.filter(name__startswith=self.DEMO_PREFIX).delete()\n\n def install_demo(self):\n # get meeting\n try:\n meeting = get_meeting(days=14) # matches how secr app finds meetings\n except:\n raise CommandError('No upcoming meeting to modify')\n\n # create rooms\n self.stdout.write('Creating rooms...\\n')\n rooms = [\n RoomFactory(meeting=meeting, name=f'{self.DEMO_PREFIX} 1'),\n RoomFactory(meeting=meeting, name=f'{self.DEMO_PREFIX} 2'),\n RoomFactory(meeting=meeting, name=f'{self.DEMO_PREFIX} 3'),\n ]\n\n # get all the timeslot types used by a session purpose\n type_ids = set()\n for purpose in SessionPurposeName.objects.filter(used=True):\n type_ids.update(purpose.timeslot_types)\n\n # set up timeslots\n self.stdout.write('Creating timeslots...\\n')\n for room in rooms:\n for day in range(meeting.days):\n date = meeting.get_meeting_date(day)\n for n, type_id in enumerate(type_ids):\n TimeSlotFactory(\n type_id=type_id,\n meeting=meeting,\n location=room,\n time=datetime.datetime.combine(date, datetime.time(10, 0, 0)) + datetime.timedelta(hours=n),\n duration=datetime.timedelta(hours=1),\n )\n\n # set up sessions\n self.stdout.write('Creating sessions...')\n groups_for_session_purpose = {\n purpose.slug: list(\n Group.objects.filter(\n type__features__session_purposes__contains=f'\"{purpose.slug}\"',\n state_id='active',\n )\n )\n for purpose in SessionPurposeName.objects.filter(used=True)\n }\n for purpose in SessionPurposeName.objects.filter(used=True):\n for type_id in purpose.timeslot_types:\n group=random.choice(groups_for_session_purpose[purpose.slug])\n SessionFactory(\n meeting=meeting,\n purpose=purpose,\n type_id=type_id,\n group=group,\n name=f'{self.DEMO_PREFIX} for {group.acronym}',\n status_id='schedw',\n add_to_schedule=False,\n )\n\n self.stdout.write(f'\\nRooms and sessions created with \"{self.DEMO_PREFIX}\" as name prefix\\n')", "path": "ietf/meeting/management/commands/session_purpose_demo.py"}], "after_files": [{"content": null, "path": "ietf/meeting/management/commands/session_purpose_demo.py"}]}
| 1,280 | 889 |
gh_patches_debug_17322
|
rasdani/github-patches
|
git_diff
|
tensorflow__addons-811
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
tf.keras.load_model throws error when trained using the tfa.losses.TripletSemiHardLoss
**System information**
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 16.04
- TensorFlow version and how it was installed (source or binary): 2.0 -source
- TensorFlow-Addons version and how it was installed (source or binary): 0.6.0;
- Python version: 3.6
- Is GPU used? (yes/no):yes
I get the following error when running the following command. I get this error when training the network with tfa.losses.TripletSemiHardLoss but do not get this error when training with tf.keras.losses.CategoricalCrossentropy().
Command:
loaded_model=tf.keras.models.load_model(filepath)
Error:
TypeError
Traceback (most recent call last)
<ipython-input-33-dd68e3d40410> in <module>()
----> 1 loaded_model=tf.keras.models.load_model(filepath)
6 frames
/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/losses.py in from_config(cls, config)
138 A `Loss` instance.
139 """
--> 140 return cls(**config)
141
142 def get_config(self):
TypeError: __init__() got an unexpected keyword argument 'reduction'
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tensorflow_addons/losses/triplet.py`
Content:
```
1 # Copyright 2019 The TensorFlow Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15 """Implements triplet loss."""
16 from __future__ import absolute_import
17 from __future__ import division
18 from __future__ import print_function
19
20 import tensorflow as tf
21 from tensorflow_addons.losses import metric_learning
22
23
24 def _masked_maximum(data, mask, dim=1):
25 """Computes the axis wise maximum over chosen elements.
26
27 Args:
28 data: 2-D float `Tensor` of size [n, m].
29 mask: 2-D Boolean `Tensor` of size [n, m].
30 dim: The dimension over which to compute the maximum.
31
32 Returns:
33 masked_maximums: N-D `Tensor`.
34 The maximized dimension is of size 1 after the operation.
35 """
36 axis_minimums = tf.math.reduce_min(data, dim, keepdims=True)
37 masked_maximums = tf.math.reduce_max(
38 tf.math.multiply(data - axis_minimums, mask), dim,
39 keepdims=True) + axis_minimums
40 return masked_maximums
41
42
43 def _masked_minimum(data, mask, dim=1):
44 """Computes the axis wise minimum over chosen elements.
45
46 Args:
47 data: 2-D float `Tensor` of size [n, m].
48 mask: 2-D Boolean `Tensor` of size [n, m].
49 dim: The dimension over which to compute the minimum.
50
51 Returns:
52 masked_minimums: N-D `Tensor`.
53 The minimized dimension is of size 1 after the operation.
54 """
55 axis_maximums = tf.math.reduce_max(data, dim, keepdims=True)
56 masked_minimums = tf.math.reduce_min(
57 tf.math.multiply(data - axis_maximums, mask), dim,
58 keepdims=True) + axis_maximums
59 return masked_minimums
60
61
62 @tf.keras.utils.register_keras_serializable(package='Addons')
63 @tf.function
64 def triplet_semihard_loss(y_true, y_pred, margin=1.0):
65 """Computes the triplet loss with semi-hard negative mining.
66
67 Args:
68 y_true: 1-D integer `Tensor` with shape [batch_size] of
69 multiclass integer labels.
70 y_pred: 2-D float `Tensor` of embedding vectors. Embeddings should
71 be l2 normalized.
72 margin: Float, margin term in the loss definition.
73 """
74 labels, embeddings = y_true, y_pred
75 # Reshape label tensor to [batch_size, 1].
76 lshape = tf.shape(labels)
77 labels = tf.reshape(labels, [lshape[0], 1])
78
79 # Build pairwise squared distance matrix.
80 pdist_matrix = metric_learning.pairwise_distance(embeddings, squared=True)
81 # Build pairwise binary adjacency matrix.
82 adjacency = tf.math.equal(labels, tf.transpose(labels))
83 # Invert so we can select negatives only.
84 adjacency_not = tf.math.logical_not(adjacency)
85
86 batch_size = tf.size(labels)
87
88 # Compute the mask.
89 pdist_matrix_tile = tf.tile(pdist_matrix, [batch_size, 1])
90 mask = tf.math.logical_and(
91 tf.tile(adjacency_not, [batch_size, 1]),
92 tf.math.greater(pdist_matrix_tile,
93 tf.reshape(tf.transpose(pdist_matrix), [-1, 1])))
94 mask_final = tf.reshape(
95 tf.math.greater(
96 tf.math.reduce_sum(
97 tf.cast(mask, dtype=tf.dtypes.float32), 1, keepdims=True),
98 0.0), [batch_size, batch_size])
99 mask_final = tf.transpose(mask_final)
100
101 adjacency_not = tf.cast(adjacency_not, dtype=tf.dtypes.float32)
102 mask = tf.cast(mask, dtype=tf.dtypes.float32)
103
104 # negatives_outside: smallest D_an where D_an > D_ap.
105 negatives_outside = tf.reshape(
106 _masked_minimum(pdist_matrix_tile, mask), [batch_size, batch_size])
107 negatives_outside = tf.transpose(negatives_outside)
108
109 # negatives_inside: largest D_an.
110 negatives_inside = tf.tile(
111 _masked_maximum(pdist_matrix, adjacency_not), [1, batch_size])
112 semi_hard_negatives = tf.where(mask_final, negatives_outside,
113 negatives_inside)
114
115 loss_mat = tf.math.add(margin, pdist_matrix - semi_hard_negatives)
116
117 mask_positives = tf.cast(
118 adjacency, dtype=tf.dtypes.float32) - tf.linalg.diag(
119 tf.ones([batch_size]))
120
121 # In lifted-struct, the authors multiply 0.5 for upper triangular
122 # in semihard, they take all positive pairs except the diagonal.
123 num_positives = tf.math.reduce_sum(mask_positives)
124
125 triplet_loss = tf.math.truediv(
126 tf.math.reduce_sum(
127 tf.math.maximum(tf.math.multiply(loss_mat, mask_positives), 0.0)),
128 num_positives)
129
130 return triplet_loss
131
132
133 @tf.keras.utils.register_keras_serializable(package='Addons')
134 class TripletSemiHardLoss(tf.keras.losses.Loss):
135 """Computes the triplet loss with semi-hard negative mining.
136
137 The loss encourages the positive distances (between a pair of embeddings
138 with the same labels) to be smaller than the minimum negative distance
139 among which are at least greater than the positive distance plus the
140 margin constant (called semi-hard negative) in the mini-batch.
141 If no such negative exists, uses the largest negative distance instead.
142 See: https://arxiv.org/abs/1503.03832.
143
144 We expect labels `y_true` to be provided as 1-D integer `Tensor` with shape
145 [batch_size] of multi-class integer labels. And embeddings `y_pred` must be
146 2-D float `Tensor` of l2 normalized embedding vectors.
147
148 Args:
149 margin: Float, margin term in the loss definition. Default value is 1.0.
150 name: Optional name for the op.
151 """
152
153 def __init__(self, margin=1.0, name=None):
154 super(TripletSemiHardLoss, self).__init__(
155 name=name, reduction=tf.keras.losses.Reduction.NONE)
156 self.margin = margin
157
158 def call(self, y_true, y_pred):
159 return triplet_semihard_loss(y_true, y_pred, self.margin)
160
161 def get_config(self):
162 config = {
163 "margin": self.margin,
164 }
165 base_config = super(TripletSemiHardLoss, self).get_config()
166 return dict(list(base_config.items()) + list(config.items()))
167
```
Path: `tensorflow_addons/losses/lifted.py`
Content:
```
1 # Copyright 2019 The TensorFlow Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15 """Implements lifted_struct_loss."""
16
17 from __future__ import absolute_import
18 from __future__ import division
19 from __future__ import print_function
20
21 import tensorflow as tf
22 from tensorflow_addons.losses import metric_learning
23
24
25 @tf.keras.utils.register_keras_serializable(package='Addons')
26 @tf.function
27 def lifted_struct_loss(labels, embeddings, margin=1.0):
28 """Computes the lifted structured loss.
29
30 Args:
31 labels: 1-D tf.int32 `Tensor` with shape [batch_size] of
32 multiclass integer labels.
33 embeddings: 2-D float `Tensor` of embedding vectors. Embeddings should
34 not be l2 normalized.
35 margin: Float, margin term in the loss definition.
36
37 Returns:
38 lifted_loss: tf.float32 scalar.
39 """
40 # Reshape [batch_size] label tensor to a [batch_size, 1] label tensor.
41 lshape = tf.shape(labels)
42 labels = tf.reshape(labels, [lshape[0], 1])
43
44 # Build pairwise squared distance matrix.
45 pairwise_distances = metric_learning.pairwise_distance(embeddings)
46
47 # Build pairwise binary adjacency matrix.
48 adjacency = tf.math.equal(labels, tf.transpose(labels))
49 # Invert so we can select negatives only.
50 adjacency_not = tf.math.logical_not(adjacency)
51
52 batch_size = tf.size(labels)
53
54 diff = margin - pairwise_distances
55 mask = tf.cast(adjacency_not, dtype=tf.dtypes.float32)
56 # Safe maximum: Temporarily shift negative distances
57 # above zero before taking max.
58 # this is to take the max only among negatives.
59 row_minimums = tf.math.reduce_min(diff, 1, keepdims=True)
60 row_negative_maximums = tf.math.reduce_max(
61 tf.math.multiply(diff - row_minimums, mask), 1,
62 keepdims=True) + row_minimums
63
64 # Compute the loss.
65 # Keep track of matrix of maximums where M_ij = max(m_i, m_j)
66 # where m_i is the max of alpha - negative D_i's.
67 # This matches the Caffe loss layer implementation at:
68 # https://github.com/rksltnl/Caffe-Deep-Metric-Learning-CVPR16/blob/0efd7544a9846f58df923c8b992198ba5c355454/src/caffe/layers/lifted_struct_similarity_softmax_layer.cpp # pylint: disable=line-too-long
69
70 max_elements = tf.math.maximum(row_negative_maximums,
71 tf.transpose(row_negative_maximums))
72 diff_tiled = tf.tile(diff, [batch_size, 1])
73 mask_tiled = tf.tile(mask, [batch_size, 1])
74 max_elements_vect = tf.reshape(tf.transpose(max_elements), [-1, 1])
75
76 loss_exp_left = tf.reshape(
77 tf.math.reduce_sum(
78 tf.math.multiply(
79 tf.math.exp(diff_tiled - max_elements_vect), mask_tiled),
80 1,
81 keepdims=True), [batch_size, batch_size])
82
83 loss_mat = max_elements + tf.math.log(loss_exp_left +
84 tf.transpose(loss_exp_left))
85 # Add the positive distance.
86 loss_mat += pairwise_distances
87
88 mask_positives = tf.cast(
89 adjacency, dtype=tf.dtypes.float32) - tf.linalg.diag(
90 tf.ones([batch_size]))
91
92 # *0.5 for upper triangular, and another *0.5 for 1/2 factor for loss^2.
93 num_positives = tf.math.reduce_sum(mask_positives) / 2.0
94
95 lifted_loss = tf.math.truediv(
96 0.25 * tf.math.reduce_sum(
97 tf.math.square(
98 tf.math.maximum(
99 tf.math.multiply(loss_mat, mask_positives), 0.0))),
100 num_positives)
101 return lifted_loss
102
103
104 @tf.keras.utils.register_keras_serializable(package='Addons')
105 class LiftedStructLoss(tf.keras.losses.Loss):
106 """Computes the lifted structured loss.
107
108 The loss encourages the positive distances (between a pair of embeddings
109 with the same labels) to be smaller than any negative distances (between
110 a pair of embeddings with different labels) in the mini-batch in a way
111 that is differentiable with respect to the embedding vectors.
112 See: https://arxiv.org/abs/1511.06452.
113
114 Args:
115 margin: Float, margin term in the loss definition.
116 name: Optional name for the op.
117 """
118
119 def __init__(self, margin=1.0, name=None):
120 super(LiftedStructLoss, self).__init__(
121 name=name, reduction=tf.keras.losses.Reduction.NONE)
122 self.margin = margin
123
124 def call(self, y_true, y_pred):
125 return lifted_struct_loss(y_true, y_pred, self.margin)
126
127 def get_config(self):
128 config = {
129 "margin": self.margin,
130 }
131 base_config = super(LiftedStructLoss, self).get_config()
132 return dict(list(base_config.items()) + list(config.items()))
133
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tensorflow_addons/losses/lifted.py b/tensorflow_addons/losses/lifted.py
--- a/tensorflow_addons/losses/lifted.py
+++ b/tensorflow_addons/losses/lifted.py
@@ -116,7 +116,7 @@
name: Optional name for the op.
"""
- def __init__(self, margin=1.0, name=None):
+ def __init__(self, margin=1.0, name=None, **kwargs):
super(LiftedStructLoss, self).__init__(
name=name, reduction=tf.keras.losses.Reduction.NONE)
self.margin = margin
diff --git a/tensorflow_addons/losses/triplet.py b/tensorflow_addons/losses/triplet.py
--- a/tensorflow_addons/losses/triplet.py
+++ b/tensorflow_addons/losses/triplet.py
@@ -150,7 +150,7 @@
name: Optional name for the op.
"""
- def __init__(self, margin=1.0, name=None):
+ def __init__(self, margin=1.0, name=None, **kwargs):
super(TripletSemiHardLoss, self).__init__(
name=name, reduction=tf.keras.losses.Reduction.NONE)
self.margin = margin
|
{"golden_diff": "diff --git a/tensorflow_addons/losses/lifted.py b/tensorflow_addons/losses/lifted.py\n--- a/tensorflow_addons/losses/lifted.py\n+++ b/tensorflow_addons/losses/lifted.py\n@@ -116,7 +116,7 @@\n name: Optional name for the op.\n \"\"\"\n \n- def __init__(self, margin=1.0, name=None):\n+ def __init__(self, margin=1.0, name=None, **kwargs):\n super(LiftedStructLoss, self).__init__(\n name=name, reduction=tf.keras.losses.Reduction.NONE)\n self.margin = margin\ndiff --git a/tensorflow_addons/losses/triplet.py b/tensorflow_addons/losses/triplet.py\n--- a/tensorflow_addons/losses/triplet.py\n+++ b/tensorflow_addons/losses/triplet.py\n@@ -150,7 +150,7 @@\n name: Optional name for the op.\n \"\"\"\n \n- def __init__(self, margin=1.0, name=None):\n+ def __init__(self, margin=1.0, name=None, **kwargs):\n super(TripletSemiHardLoss, self).__init__(\n name=name, reduction=tf.keras.losses.Reduction.NONE)\n self.margin = margin\n", "issue": "tf.keras.load_model throws error when trained using the tfa.losses.TripletSemiHardLoss\n**System information**\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 16.04\r\n- TensorFlow version and how it was installed (source or binary): 2.0 -source\r\n- TensorFlow-Addons version and how it was installed (source or binary): 0.6.0; \r\n- Python version: 3.6\r\n- Is GPU used? (yes/no):yes\r\n\r\nI get the following error when running the following command. I get this error when training the network with tfa.losses.TripletSemiHardLoss but do not get this error when training with tf.keras.losses.CategoricalCrossentropy().\r\n\r\nCommand:\r\nloaded_model=tf.keras.models.load_model(filepath)\r\n\r\nError:\r\nTypeError \r\nTraceback (most recent call last)\r\n<ipython-input-33-dd68e3d40410> in <module>()\r\n----> 1 loaded_model=tf.keras.models.load_model(filepath)\r\n\r\n6 frames\r\n/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/keras/losses.py in from_config(cls, config)\r\n 138 A `Loss` instance.\r\n 139 \"\"\"\r\n--> 140 return cls(**config)\r\n 141 \r\n 142 def get_config(self):\r\n\r\nTypeError: __init__() got an unexpected keyword argument 'reduction'\r\n\r\n\r\n\n", "before_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Implements triplet loss.\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport tensorflow as tf\nfrom tensorflow_addons.losses import metric_learning\n\n\ndef _masked_maximum(data, mask, dim=1):\n \"\"\"Computes the axis wise maximum over chosen elements.\n\n Args:\n data: 2-D float `Tensor` of size [n, m].\n mask: 2-D Boolean `Tensor` of size [n, m].\n dim: The dimension over which to compute the maximum.\n\n Returns:\n masked_maximums: N-D `Tensor`.\n The maximized dimension is of size 1 after the operation.\n \"\"\"\n axis_minimums = tf.math.reduce_min(data, dim, keepdims=True)\n masked_maximums = tf.math.reduce_max(\n tf.math.multiply(data - axis_minimums, mask), dim,\n keepdims=True) + axis_minimums\n return masked_maximums\n\n\ndef _masked_minimum(data, mask, dim=1):\n \"\"\"Computes the axis wise minimum over chosen elements.\n\n Args:\n data: 2-D float `Tensor` of size [n, m].\n mask: 2-D Boolean `Tensor` of size [n, m].\n dim: The dimension over which to compute the minimum.\n\n Returns:\n masked_minimums: N-D `Tensor`.\n The minimized dimension is of size 1 after the operation.\n \"\"\"\n axis_maximums = tf.math.reduce_max(data, dim, keepdims=True)\n masked_minimums = tf.math.reduce_min(\n tf.math.multiply(data - axis_maximums, mask), dim,\n keepdims=True) + axis_maximums\n return masked_minimums\n\n\[email protected]_keras_serializable(package='Addons')\[email protected]\ndef triplet_semihard_loss(y_true, y_pred, margin=1.0):\n \"\"\"Computes the triplet loss with semi-hard negative mining.\n\n Args:\n y_true: 1-D integer `Tensor` with shape [batch_size] of\n multiclass integer labels.\n y_pred: 2-D float `Tensor` of embedding vectors. Embeddings should\n be l2 normalized.\n margin: Float, margin term in the loss definition.\n \"\"\"\n labels, embeddings = y_true, y_pred\n # Reshape label tensor to [batch_size, 1].\n lshape = tf.shape(labels)\n labels = tf.reshape(labels, [lshape[0], 1])\n\n # Build pairwise squared distance matrix.\n pdist_matrix = metric_learning.pairwise_distance(embeddings, squared=True)\n # Build pairwise binary adjacency matrix.\n adjacency = tf.math.equal(labels, tf.transpose(labels))\n # Invert so we can select negatives only.\n adjacency_not = tf.math.logical_not(adjacency)\n\n batch_size = tf.size(labels)\n\n # Compute the mask.\n pdist_matrix_tile = tf.tile(pdist_matrix, [batch_size, 1])\n mask = tf.math.logical_and(\n tf.tile(adjacency_not, [batch_size, 1]),\n tf.math.greater(pdist_matrix_tile,\n tf.reshape(tf.transpose(pdist_matrix), [-1, 1])))\n mask_final = tf.reshape(\n tf.math.greater(\n tf.math.reduce_sum(\n tf.cast(mask, dtype=tf.dtypes.float32), 1, keepdims=True),\n 0.0), [batch_size, batch_size])\n mask_final = tf.transpose(mask_final)\n\n adjacency_not = tf.cast(adjacency_not, dtype=tf.dtypes.float32)\n mask = tf.cast(mask, dtype=tf.dtypes.float32)\n\n # negatives_outside: smallest D_an where D_an > D_ap.\n negatives_outside = tf.reshape(\n _masked_minimum(pdist_matrix_tile, mask), [batch_size, batch_size])\n negatives_outside = tf.transpose(negatives_outside)\n\n # negatives_inside: largest D_an.\n negatives_inside = tf.tile(\n _masked_maximum(pdist_matrix, adjacency_not), [1, batch_size])\n semi_hard_negatives = tf.where(mask_final, negatives_outside,\n negatives_inside)\n\n loss_mat = tf.math.add(margin, pdist_matrix - semi_hard_negatives)\n\n mask_positives = tf.cast(\n adjacency, dtype=tf.dtypes.float32) - tf.linalg.diag(\n tf.ones([batch_size]))\n\n # In lifted-struct, the authors multiply 0.5 for upper triangular\n # in semihard, they take all positive pairs except the diagonal.\n num_positives = tf.math.reduce_sum(mask_positives)\n\n triplet_loss = tf.math.truediv(\n tf.math.reduce_sum(\n tf.math.maximum(tf.math.multiply(loss_mat, mask_positives), 0.0)),\n num_positives)\n\n return triplet_loss\n\n\[email protected]_keras_serializable(package='Addons')\nclass TripletSemiHardLoss(tf.keras.losses.Loss):\n \"\"\"Computes the triplet loss with semi-hard negative mining.\n\n The loss encourages the positive distances (between a pair of embeddings\n with the same labels) to be smaller than the minimum negative distance\n among which are at least greater than the positive distance plus the\n margin constant (called semi-hard negative) in the mini-batch.\n If no such negative exists, uses the largest negative distance instead.\n See: https://arxiv.org/abs/1503.03832.\n\n We expect labels `y_true` to be provided as 1-D integer `Tensor` with shape\n [batch_size] of multi-class integer labels. And embeddings `y_pred` must be\n 2-D float `Tensor` of l2 normalized embedding vectors.\n\n Args:\n margin: Float, margin term in the loss definition. Default value is 1.0.\n name: Optional name for the op.\n \"\"\"\n\n def __init__(self, margin=1.0, name=None):\n super(TripletSemiHardLoss, self).__init__(\n name=name, reduction=tf.keras.losses.Reduction.NONE)\n self.margin = margin\n\n def call(self, y_true, y_pred):\n return triplet_semihard_loss(y_true, y_pred, self.margin)\n\n def get_config(self):\n config = {\n \"margin\": self.margin,\n }\n base_config = super(TripletSemiHardLoss, self).get_config()\n return dict(list(base_config.items()) + list(config.items()))\n", "path": "tensorflow_addons/losses/triplet.py"}, {"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Implements lifted_struct_loss.\"\"\"\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport tensorflow as tf\nfrom tensorflow_addons.losses import metric_learning\n\n\[email protected]_keras_serializable(package='Addons')\[email protected]\ndef lifted_struct_loss(labels, embeddings, margin=1.0):\n \"\"\"Computes the lifted structured loss.\n\n Args:\n labels: 1-D tf.int32 `Tensor` with shape [batch_size] of\n multiclass integer labels.\n embeddings: 2-D float `Tensor` of embedding vectors. Embeddings should\n not be l2 normalized.\n margin: Float, margin term in the loss definition.\n\n Returns:\n lifted_loss: tf.float32 scalar.\n \"\"\"\n # Reshape [batch_size] label tensor to a [batch_size, 1] label tensor.\n lshape = tf.shape(labels)\n labels = tf.reshape(labels, [lshape[0], 1])\n\n # Build pairwise squared distance matrix.\n pairwise_distances = metric_learning.pairwise_distance(embeddings)\n\n # Build pairwise binary adjacency matrix.\n adjacency = tf.math.equal(labels, tf.transpose(labels))\n # Invert so we can select negatives only.\n adjacency_not = tf.math.logical_not(adjacency)\n\n batch_size = tf.size(labels)\n\n diff = margin - pairwise_distances\n mask = tf.cast(adjacency_not, dtype=tf.dtypes.float32)\n # Safe maximum: Temporarily shift negative distances\n # above zero before taking max.\n # this is to take the max only among negatives.\n row_minimums = tf.math.reduce_min(diff, 1, keepdims=True)\n row_negative_maximums = tf.math.reduce_max(\n tf.math.multiply(diff - row_minimums, mask), 1,\n keepdims=True) + row_minimums\n\n # Compute the loss.\n # Keep track of matrix of maximums where M_ij = max(m_i, m_j)\n # where m_i is the max of alpha - negative D_i's.\n # This matches the Caffe loss layer implementation at:\n # https://github.com/rksltnl/Caffe-Deep-Metric-Learning-CVPR16/blob/0efd7544a9846f58df923c8b992198ba5c355454/src/caffe/layers/lifted_struct_similarity_softmax_layer.cpp # pylint: disable=line-too-long\n\n max_elements = tf.math.maximum(row_negative_maximums,\n tf.transpose(row_negative_maximums))\n diff_tiled = tf.tile(diff, [batch_size, 1])\n mask_tiled = tf.tile(mask, [batch_size, 1])\n max_elements_vect = tf.reshape(tf.transpose(max_elements), [-1, 1])\n\n loss_exp_left = tf.reshape(\n tf.math.reduce_sum(\n tf.math.multiply(\n tf.math.exp(diff_tiled - max_elements_vect), mask_tiled),\n 1,\n keepdims=True), [batch_size, batch_size])\n\n loss_mat = max_elements + tf.math.log(loss_exp_left +\n tf.transpose(loss_exp_left))\n # Add the positive distance.\n loss_mat += pairwise_distances\n\n mask_positives = tf.cast(\n adjacency, dtype=tf.dtypes.float32) - tf.linalg.diag(\n tf.ones([batch_size]))\n\n # *0.5 for upper triangular, and another *0.5 for 1/2 factor for loss^2.\n num_positives = tf.math.reduce_sum(mask_positives) / 2.0\n\n lifted_loss = tf.math.truediv(\n 0.25 * tf.math.reduce_sum(\n tf.math.square(\n tf.math.maximum(\n tf.math.multiply(loss_mat, mask_positives), 0.0))),\n num_positives)\n return lifted_loss\n\n\[email protected]_keras_serializable(package='Addons')\nclass LiftedStructLoss(tf.keras.losses.Loss):\n \"\"\"Computes the lifted structured loss.\n\n The loss encourages the positive distances (between a pair of embeddings\n with the same labels) to be smaller than any negative distances (between\n a pair of embeddings with different labels) in the mini-batch in a way\n that is differentiable with respect to the embedding vectors.\n See: https://arxiv.org/abs/1511.06452.\n\n Args:\n margin: Float, margin term in the loss definition.\n name: Optional name for the op.\n \"\"\"\n\n def __init__(self, margin=1.0, name=None):\n super(LiftedStructLoss, self).__init__(\n name=name, reduction=tf.keras.losses.Reduction.NONE)\n self.margin = margin\n\n def call(self, y_true, y_pred):\n return lifted_struct_loss(y_true, y_pred, self.margin)\n\n def get_config(self):\n config = {\n \"margin\": self.margin,\n }\n base_config = super(LiftedStructLoss, self).get_config()\n return dict(list(base_config.items()) + list(config.items()))\n", "path": "tensorflow_addons/losses/lifted.py"}], "after_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Implements triplet loss.\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport tensorflow as tf\nfrom tensorflow_addons.losses import metric_learning\n\n\ndef _masked_maximum(data, mask, dim=1):\n \"\"\"Computes the axis wise maximum over chosen elements.\n\n Args:\n data: 2-D float `Tensor` of size [n, m].\n mask: 2-D Boolean `Tensor` of size [n, m].\n dim: The dimension over which to compute the maximum.\n\n Returns:\n masked_maximums: N-D `Tensor`.\n The maximized dimension is of size 1 after the operation.\n \"\"\"\n axis_minimums = tf.math.reduce_min(data, dim, keepdims=True)\n masked_maximums = tf.math.reduce_max(\n tf.math.multiply(data - axis_minimums, mask), dim,\n keepdims=True) + axis_minimums\n return masked_maximums\n\n\ndef _masked_minimum(data, mask, dim=1):\n \"\"\"Computes the axis wise minimum over chosen elements.\n\n Args:\n data: 2-D float `Tensor` of size [n, m].\n mask: 2-D Boolean `Tensor` of size [n, m].\n dim: The dimension over which to compute the minimum.\n\n Returns:\n masked_minimums: N-D `Tensor`.\n The minimized dimension is of size 1 after the operation.\n \"\"\"\n axis_maximums = tf.math.reduce_max(data, dim, keepdims=True)\n masked_minimums = tf.math.reduce_min(\n tf.math.multiply(data - axis_maximums, mask), dim,\n keepdims=True) + axis_maximums\n return masked_minimums\n\n\[email protected]_keras_serializable(package='Addons')\[email protected]\ndef triplet_semihard_loss(y_true, y_pred, margin=1.0):\n \"\"\"Computes the triplet loss with semi-hard negative mining.\n\n Args:\n y_true: 1-D integer `Tensor` with shape [batch_size] of\n multiclass integer labels.\n y_pred: 2-D float `Tensor` of embedding vectors. Embeddings should\n be l2 normalized.\n margin: Float, margin term in the loss definition.\n \"\"\"\n labels, embeddings = y_true, y_pred\n # Reshape label tensor to [batch_size, 1].\n lshape = tf.shape(labels)\n labels = tf.reshape(labels, [lshape[0], 1])\n\n # Build pairwise squared distance matrix.\n pdist_matrix = metric_learning.pairwise_distance(embeddings, squared=True)\n # Build pairwise binary adjacency matrix.\n adjacency = tf.math.equal(labels, tf.transpose(labels))\n # Invert so we can select negatives only.\n adjacency_not = tf.math.logical_not(adjacency)\n\n batch_size = tf.size(labels)\n\n # Compute the mask.\n pdist_matrix_tile = tf.tile(pdist_matrix, [batch_size, 1])\n mask = tf.math.logical_and(\n tf.tile(adjacency_not, [batch_size, 1]),\n tf.math.greater(pdist_matrix_tile,\n tf.reshape(tf.transpose(pdist_matrix), [-1, 1])))\n mask_final = tf.reshape(\n tf.math.greater(\n tf.math.reduce_sum(\n tf.cast(mask, dtype=tf.dtypes.float32), 1, keepdims=True),\n 0.0), [batch_size, batch_size])\n mask_final = tf.transpose(mask_final)\n\n adjacency_not = tf.cast(adjacency_not, dtype=tf.dtypes.float32)\n mask = tf.cast(mask, dtype=tf.dtypes.float32)\n\n # negatives_outside: smallest D_an where D_an > D_ap.\n negatives_outside = tf.reshape(\n _masked_minimum(pdist_matrix_tile, mask), [batch_size, batch_size])\n negatives_outside = tf.transpose(negatives_outside)\n\n # negatives_inside: largest D_an.\n negatives_inside = tf.tile(\n _masked_maximum(pdist_matrix, adjacency_not), [1, batch_size])\n semi_hard_negatives = tf.where(mask_final, negatives_outside,\n negatives_inside)\n\n loss_mat = tf.math.add(margin, pdist_matrix - semi_hard_negatives)\n\n mask_positives = tf.cast(\n adjacency, dtype=tf.dtypes.float32) - tf.linalg.diag(\n tf.ones([batch_size]))\n\n # In lifted-struct, the authors multiply 0.5 for upper triangular\n # in semihard, they take all positive pairs except the diagonal.\n num_positives = tf.math.reduce_sum(mask_positives)\n\n triplet_loss = tf.math.truediv(\n tf.math.reduce_sum(\n tf.math.maximum(tf.math.multiply(loss_mat, mask_positives), 0.0)),\n num_positives)\n\n return triplet_loss\n\n\[email protected]_keras_serializable(package='Addons')\nclass TripletSemiHardLoss(tf.keras.losses.Loss):\n \"\"\"Computes the triplet loss with semi-hard negative mining.\n\n The loss encourages the positive distances (between a pair of embeddings\n with the same labels) to be smaller than the minimum negative distance\n among which are at least greater than the positive distance plus the\n margin constant (called semi-hard negative) in the mini-batch.\n If no such negative exists, uses the largest negative distance instead.\n See: https://arxiv.org/abs/1503.03832.\n\n We expect labels `y_true` to be provided as 1-D integer `Tensor` with shape\n [batch_size] of multi-class integer labels. And embeddings `y_pred` must be\n 2-D float `Tensor` of l2 normalized embedding vectors.\n\n Args:\n margin: Float, margin term in the loss definition. Default value is 1.0.\n name: Optional name for the op.\n \"\"\"\n\n def __init__(self, margin=1.0, name=None, **kwargs):\n super(TripletSemiHardLoss, self).__init__(\n name=name, reduction=tf.keras.losses.Reduction.NONE)\n self.margin = margin\n\n def call(self, y_true, y_pred):\n return triplet_semihard_loss(y_true, y_pred, self.margin)\n\n def get_config(self):\n config = {\n \"margin\": self.margin,\n }\n base_config = super(TripletSemiHardLoss, self).get_config()\n return dict(list(base_config.items()) + list(config.items()))\n", "path": "tensorflow_addons/losses/triplet.py"}, {"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Implements lifted_struct_loss.\"\"\"\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport tensorflow as tf\nfrom tensorflow_addons.losses import metric_learning\n\n\[email protected]_keras_serializable(package='Addons')\[email protected]\ndef lifted_struct_loss(labels, embeddings, margin=1.0):\n \"\"\"Computes the lifted structured loss.\n\n Args:\n labels: 1-D tf.int32 `Tensor` with shape [batch_size] of\n multiclass integer labels.\n embeddings: 2-D float `Tensor` of embedding vectors. Embeddings should\n not be l2 normalized.\n margin: Float, margin term in the loss definition.\n\n Returns:\n lifted_loss: tf.float32 scalar.\n \"\"\"\n # Reshape [batch_size] label tensor to a [batch_size, 1] label tensor.\n lshape = tf.shape(labels)\n labels = tf.reshape(labels, [lshape[0], 1])\n\n # Build pairwise squared distance matrix.\n pairwise_distances = metric_learning.pairwise_distance(embeddings)\n\n # Build pairwise binary adjacency matrix.\n adjacency = tf.math.equal(labels, tf.transpose(labels))\n # Invert so we can select negatives only.\n adjacency_not = tf.math.logical_not(adjacency)\n\n batch_size = tf.size(labels)\n\n diff = margin - pairwise_distances\n mask = tf.cast(adjacency_not, dtype=tf.dtypes.float32)\n # Safe maximum: Temporarily shift negative distances\n # above zero before taking max.\n # this is to take the max only among negatives.\n row_minimums = tf.math.reduce_min(diff, 1, keepdims=True)\n row_negative_maximums = tf.math.reduce_max(\n tf.math.multiply(diff - row_minimums, mask), 1,\n keepdims=True) + row_minimums\n\n # Compute the loss.\n # Keep track of matrix of maximums where M_ij = max(m_i, m_j)\n # where m_i is the max of alpha - negative D_i's.\n # This matches the Caffe loss layer implementation at:\n # https://github.com/rksltnl/Caffe-Deep-Metric-Learning-CVPR16/blob/0efd7544a9846f58df923c8b992198ba5c355454/src/caffe/layers/lifted_struct_similarity_softmax_layer.cpp # pylint: disable=line-too-long\n\n max_elements = tf.math.maximum(row_negative_maximums,\n tf.transpose(row_negative_maximums))\n diff_tiled = tf.tile(diff, [batch_size, 1])\n mask_tiled = tf.tile(mask, [batch_size, 1])\n max_elements_vect = tf.reshape(tf.transpose(max_elements), [-1, 1])\n\n loss_exp_left = tf.reshape(\n tf.math.reduce_sum(\n tf.math.multiply(\n tf.math.exp(diff_tiled - max_elements_vect), mask_tiled),\n 1,\n keepdims=True), [batch_size, batch_size])\n\n loss_mat = max_elements + tf.math.log(loss_exp_left +\n tf.transpose(loss_exp_left))\n # Add the positive distance.\n loss_mat += pairwise_distances\n\n mask_positives = tf.cast(\n adjacency, dtype=tf.dtypes.float32) - tf.linalg.diag(\n tf.ones([batch_size]))\n\n # *0.5 for upper triangular, and another *0.5 for 1/2 factor for loss^2.\n num_positives = tf.math.reduce_sum(mask_positives) / 2.0\n\n lifted_loss = tf.math.truediv(\n 0.25 * tf.math.reduce_sum(\n tf.math.square(\n tf.math.maximum(\n tf.math.multiply(loss_mat, mask_positives), 0.0))),\n num_positives)\n return lifted_loss\n\n\[email protected]_keras_serializable(package='Addons')\nclass LiftedStructLoss(tf.keras.losses.Loss):\n \"\"\"Computes the lifted structured loss.\n\n The loss encourages the positive distances (between a pair of embeddings\n with the same labels) to be smaller than any negative distances (between\n a pair of embeddings with different labels) in the mini-batch in a way\n that is differentiable with respect to the embedding vectors.\n See: https://arxiv.org/abs/1511.06452.\n\n Args:\n margin: Float, margin term in the loss definition.\n name: Optional name for the op.\n \"\"\"\n\n def __init__(self, margin=1.0, name=None, **kwargs):\n super(LiftedStructLoss, self).__init__(\n name=name, reduction=tf.keras.losses.Reduction.NONE)\n self.margin = margin\n\n def call(self, y_true, y_pred):\n return lifted_struct_loss(y_true, y_pred, self.margin)\n\n def get_config(self):\n config = {\n \"margin\": self.margin,\n }\n base_config = super(LiftedStructLoss, self).get_config()\n return dict(list(base_config.items()) + list(config.items()))\n", "path": "tensorflow_addons/losses/lifted.py"}]}
| 4,079 | 310 |
gh_patches_debug_29684
|
rasdani/github-patches
|
git_diff
|
secondmind-labs__trieste-194
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Pareto set: hypervolume
As a user, I want functionality available to calculate the hypervolume of a Pareto front given the cell bounds, so that I can easily find the hypervolume when defining multi-objective acquisition functionality
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `trieste/utils/pareto.py`
Content:
```
1 # Copyright 2020 The Trieste Contributors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """ This module contains functions and classes for Pareto based multi-objective optimization. """
15
16 from typing import Tuple
17
18 import tensorflow as tf
19 from typing_extensions import Final
20
21 from ..type import TensorType
22
23
24 def non_dominated(observations: TensorType) -> Tuple[TensorType, TensorType]:
25 """
26 Computes the non-dominated set for a set of data points.
27 if there are duplicate point(s) in the non-dominated set, this function will return
28 as it is without removing the duplicate.
29
30 :param observations: set of points with shape [N,D]
31 :return: tf.Tensor of the non-dominated set [P,D] and the degree of dominance [N],
32 P is the number of points in pareto front
33 dominances gives the number of dominating points for each data point
34
35
36 """
37 extended = tf.tile(observations[None], [len(observations), 1, 1])
38 swapped_ext = tf.transpose(extended, [1, 0, 2])
39 dominance = tf.math.count_nonzero(
40 tf.logical_and(
41 tf.reduce_all(extended <= swapped_ext, axis=2),
42 tf.reduce_any(extended < swapped_ext, axis=2),
43 ),
44 axis=1,
45 )
46
47 return tf.boolean_mask(observations, dominance == 0), dominance
48
49
50 class BoundedVolumes:
51 """
52 A :class:`BoundedVolumes` store the index of the Pareto front to form lower and upper
53 bounds of the pseudo cells decomposition.
54 """
55
56 def __init__(self, lower_idx: tf.Tensor, upper_idx: tf.Tensor):
57 """
58 Construct bounded volumes.
59
60 :param lower_idx: the lowerbounds index of the volumes
61 :param upper_idx: the upperbounds index of the volumes
62 """
63
64 tf.debugging.assert_shapes([(lower_idx, ["N", "D"]), (upper_idx, ["N", "D"])])
65 self.lower_idx: Final[TensorType] = lower_idx
66 self.upper_idx: Final[TensorType] = upper_idx
67
68
69 class Pareto:
70 """
71 A :class:`Pareto` Construct a Pareto set.
72 Stores a Pareto set and calculates the cell bounds covering the non-dominated region.
73 The latter is needed for certain multiobjective acquisition functions.
74 """
75
76 def __init__(self, observations: TensorType):
77 """
78 :param observations: The observations for all objectives, with shape [N, 2].
79 :raise ValueError (or InvalidArgumentError): If ``observations`` has an invalid shape.
80 """
81 tf.debugging.assert_shapes([(observations, [None, 2])])
82
83 pf, _ = non_dominated(observations)
84 self.front: Final[TensorType] = tf.gather_nd(pf, tf.argsort(pf[:, :1], axis=0))
85 self.bounds: Final[BoundedVolumes] = self._bounds_2d(self.front)
86
87 @staticmethod
88 def _bounds_2d(front: TensorType) -> BoundedVolumes:
89
90 # this assumes the Pareto set has been sorted in ascending order on the first
91 # objective, which implies the second objective is sorted in descending order
92 len_front, number_of_objectives = front.shape
93
94 pf_ext_idx = tf.concat(
95 [
96 tf.zeros([1, number_of_objectives], dtype=tf.int32),
97 tf.argsort(front, axis=0) + 1,
98 tf.ones([1, number_of_objectives], dtype=tf.int32) * len_front + 1,
99 ],
100 axis=0,
101 )
102
103 range_ = tf.range(len_front + 1)[:, None]
104 lower = tf.concat([range_, tf.zeros_like(range_)], axis=-1)
105 upper = tf.concat([range_ + 1, pf_ext_idx[::-1, 1:][: pf_ext_idx[-1, 0]]], axis=-1)
106
107 return BoundedVolumes(lower, upper)
108
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/trieste/utils/pareto.py b/trieste/utils/pareto.py
--- a/trieste/utils/pareto.py
+++ b/trieste/utils/pareto.py
@@ -105,3 +105,46 @@
upper = tf.concat([range_ + 1, pf_ext_idx[::-1, 1:][: pf_ext_idx[-1, 0]]], axis=-1)
return BoundedVolumes(lower, upper)
+
+ def hypervolume_indicator(self, reference: TensorType) -> TensorType:
+ """
+ Calculate the hypervolume indicator
+ The hypervolume indicator is the volume of the dominated region.
+
+ :param reference: a reference point to use, with shape [D].
+ Defines the upper bound of the hypervolume.
+ Should be equal or bigger than the anti-ideal point of the Pareto set.
+ For comparing results across runs, the same reference point must be used.
+ :return: hypervolume indicator
+ :raise ValueError (or `tf.errors.InvalidArgumentError`): If ``reference`` has an invalid
+ shape.
+ :raise `tf.errors.InvalidArgumentError`: If ``reference`` is less than the anti-ideal point
+ in any dimension.
+ """
+ tf.debugging.assert_greater_equal(reference, self.front)
+
+ tf.debugging.assert_shapes(
+ [
+ (self.bounds.lower_idx, ["N", "D"]),
+ (self.bounds.upper_idx, ["N", "D"]),
+ (self.front, ["M", "D"]),
+ (reference, ["D"]),
+ ]
+ )
+
+ min_pfront = tf.reduce_min(self.front, 0, keepdims=True)
+ pseudo_pfront = tf.concat((min_pfront, self.front, reference[None]), 0)
+ N, D = tf.shape(self.bounds.upper_idx)
+
+ idx = tf.tile(tf.expand_dims(tf.range(D), -1), [1, N])
+ upper_idx = tf.reshape(
+ tf.stack([tf.transpose(self.bounds.upper_idx), idx], axis=2), [N * D, 2]
+ )
+ lower_idx = tf.reshape(
+ tf.stack([tf.transpose(self.bounds.lower_idx), idx], axis=2), [N * D, 2]
+ )
+ upper = tf.reshape(tf.gather_nd(pseudo_pfront, upper_idx), [D, N])
+ lower = tf.reshape(tf.gather_nd(pseudo_pfront, lower_idx), [D, N])
+ hypervolume = tf.reduce_sum(tf.reduce_prod(upper - lower, 0))
+
+ return tf.reduce_prod(reference[None] - min_pfront) - hypervolume
|
{"golden_diff": "diff --git a/trieste/utils/pareto.py b/trieste/utils/pareto.py\n--- a/trieste/utils/pareto.py\n+++ b/trieste/utils/pareto.py\n@@ -105,3 +105,46 @@\n upper = tf.concat([range_ + 1, pf_ext_idx[::-1, 1:][: pf_ext_idx[-1, 0]]], axis=-1)\n \n return BoundedVolumes(lower, upper)\n+\n+ def hypervolume_indicator(self, reference: TensorType) -> TensorType:\n+ \"\"\"\n+ Calculate the hypervolume indicator\n+ The hypervolume indicator is the volume of the dominated region.\n+\n+ :param reference: a reference point to use, with shape [D].\n+ Defines the upper bound of the hypervolume.\n+ Should be equal or bigger than the anti-ideal point of the Pareto set.\n+ For comparing results across runs, the same reference point must be used.\n+ :return: hypervolume indicator\n+ :raise ValueError (or `tf.errors.InvalidArgumentError`): If ``reference`` has an invalid\n+ shape.\n+ :raise `tf.errors.InvalidArgumentError`: If ``reference`` is less than the anti-ideal point\n+ in any dimension.\n+ \"\"\"\n+ tf.debugging.assert_greater_equal(reference, self.front)\n+\n+ tf.debugging.assert_shapes(\n+ [\n+ (self.bounds.lower_idx, [\"N\", \"D\"]),\n+ (self.bounds.upper_idx, [\"N\", \"D\"]),\n+ (self.front, [\"M\", \"D\"]),\n+ (reference, [\"D\"]),\n+ ]\n+ )\n+\n+ min_pfront = tf.reduce_min(self.front, 0, keepdims=True)\n+ pseudo_pfront = tf.concat((min_pfront, self.front, reference[None]), 0)\n+ N, D = tf.shape(self.bounds.upper_idx)\n+\n+ idx = tf.tile(tf.expand_dims(tf.range(D), -1), [1, N])\n+ upper_idx = tf.reshape(\n+ tf.stack([tf.transpose(self.bounds.upper_idx), idx], axis=2), [N * D, 2]\n+ )\n+ lower_idx = tf.reshape(\n+ tf.stack([tf.transpose(self.bounds.lower_idx), idx], axis=2), [N * D, 2]\n+ )\n+ upper = tf.reshape(tf.gather_nd(pseudo_pfront, upper_idx), [D, N])\n+ lower = tf.reshape(tf.gather_nd(pseudo_pfront, lower_idx), [D, N])\n+ hypervolume = tf.reduce_sum(tf.reduce_prod(upper - lower, 0))\n+\n+ return tf.reduce_prod(reference[None] - min_pfront) - hypervolume\n", "issue": "Pareto set: hypervolume\nAs a user, I want functionality available to calculate the hypervolume of a Pareto front given the cell bounds, so that I can easily find the hypervolume when defining multi-objective acquisition functionality\n", "before_files": [{"content": "# Copyright 2020 The Trieste Contributors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\" This module contains functions and classes for Pareto based multi-objective optimization. \"\"\"\n\nfrom typing import Tuple\n\nimport tensorflow as tf\nfrom typing_extensions import Final\n\nfrom ..type import TensorType\n\n\ndef non_dominated(observations: TensorType) -> Tuple[TensorType, TensorType]:\n \"\"\"\n Computes the non-dominated set for a set of data points.\n if there are duplicate point(s) in the non-dominated set, this function will return\n as it is without removing the duplicate.\n\n :param observations: set of points with shape [N,D]\n :return: tf.Tensor of the non-dominated set [P,D] and the degree of dominance [N],\n P is the number of points in pareto front\n dominances gives the number of dominating points for each data point\n\n\n \"\"\"\n extended = tf.tile(observations[None], [len(observations), 1, 1])\n swapped_ext = tf.transpose(extended, [1, 0, 2])\n dominance = tf.math.count_nonzero(\n tf.logical_and(\n tf.reduce_all(extended <= swapped_ext, axis=2),\n tf.reduce_any(extended < swapped_ext, axis=2),\n ),\n axis=1,\n )\n\n return tf.boolean_mask(observations, dominance == 0), dominance\n\n\nclass BoundedVolumes:\n \"\"\"\n A :class:`BoundedVolumes` store the index of the Pareto front to form lower and upper\n bounds of the pseudo cells decomposition.\n \"\"\"\n\n def __init__(self, lower_idx: tf.Tensor, upper_idx: tf.Tensor):\n \"\"\"\n Construct bounded volumes.\n\n :param lower_idx: the lowerbounds index of the volumes\n :param upper_idx: the upperbounds index of the volumes\n \"\"\"\n\n tf.debugging.assert_shapes([(lower_idx, [\"N\", \"D\"]), (upper_idx, [\"N\", \"D\"])])\n self.lower_idx: Final[TensorType] = lower_idx\n self.upper_idx: Final[TensorType] = upper_idx\n\n\nclass Pareto:\n \"\"\"\n A :class:`Pareto` Construct a Pareto set.\n Stores a Pareto set and calculates the cell bounds covering the non-dominated region.\n The latter is needed for certain multiobjective acquisition functions.\n \"\"\"\n\n def __init__(self, observations: TensorType):\n \"\"\"\n :param observations: The observations for all objectives, with shape [N, 2].\n :raise ValueError (or InvalidArgumentError): If ``observations`` has an invalid shape.\n \"\"\"\n tf.debugging.assert_shapes([(observations, [None, 2])])\n\n pf, _ = non_dominated(observations)\n self.front: Final[TensorType] = tf.gather_nd(pf, tf.argsort(pf[:, :1], axis=0))\n self.bounds: Final[BoundedVolumes] = self._bounds_2d(self.front)\n\n @staticmethod\n def _bounds_2d(front: TensorType) -> BoundedVolumes:\n\n # this assumes the Pareto set has been sorted in ascending order on the first\n # objective, which implies the second objective is sorted in descending order\n len_front, number_of_objectives = front.shape\n\n pf_ext_idx = tf.concat(\n [\n tf.zeros([1, number_of_objectives], dtype=tf.int32),\n tf.argsort(front, axis=0) + 1,\n tf.ones([1, number_of_objectives], dtype=tf.int32) * len_front + 1,\n ],\n axis=0,\n )\n\n range_ = tf.range(len_front + 1)[:, None]\n lower = tf.concat([range_, tf.zeros_like(range_)], axis=-1)\n upper = tf.concat([range_ + 1, pf_ext_idx[::-1, 1:][: pf_ext_idx[-1, 0]]], axis=-1)\n\n return BoundedVolumes(lower, upper)\n", "path": "trieste/utils/pareto.py"}], "after_files": [{"content": "# Copyright 2020 The Trieste Contributors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\" This module contains functions and classes for Pareto based multi-objective optimization. \"\"\"\n\nfrom typing import Tuple\n\nimport tensorflow as tf\nfrom typing_extensions import Final\n\nfrom ..type import TensorType\n\n\ndef non_dominated(observations: TensorType) -> Tuple[TensorType, TensorType]:\n \"\"\"\n Computes the non-dominated set for a set of data points.\n if there are duplicate point(s) in the non-dominated set, this function will return\n as it is without removing the duplicate.\n\n :param observations: set of points with shape [N,D]\n :return: tf.Tensor of the non-dominated set [P,D] and the degree of dominance [N],\n P is the number of points in pareto front\n dominances gives the number of dominating points for each data point\n\n\n \"\"\"\n extended = tf.tile(observations[None], [len(observations), 1, 1])\n swapped_ext = tf.transpose(extended, [1, 0, 2])\n dominance = tf.math.count_nonzero(\n tf.logical_and(\n tf.reduce_all(extended <= swapped_ext, axis=2),\n tf.reduce_any(extended < swapped_ext, axis=2),\n ),\n axis=1,\n )\n\n return tf.boolean_mask(observations, dominance == 0), dominance\n\n\nclass BoundedVolumes:\n \"\"\"\n A :class:`BoundedVolumes` store the index of the Pareto front to form lower and upper\n bounds of the pseudo cells decomposition.\n \"\"\"\n\n def __init__(self, lower_idx: tf.Tensor, upper_idx: tf.Tensor):\n \"\"\"\n Construct bounded volumes.\n\n :param lower_idx: the lowerbounds index of the volumes\n :param upper_idx: the upperbounds index of the volumes\n \"\"\"\n\n tf.debugging.assert_shapes([(lower_idx, [\"N\", \"D\"]), (upper_idx, [\"N\", \"D\"])])\n self.lower_idx: Final[TensorType] = lower_idx\n self.upper_idx: Final[TensorType] = upper_idx\n\n\nclass Pareto:\n \"\"\"\n A :class:`Pareto` Construct a Pareto set.\n Stores a Pareto set and calculates the cell bounds covering the non-dominated region.\n The latter is needed for certain multiobjective acquisition functions.\n \"\"\"\n\n def __init__(self, observations: TensorType):\n \"\"\"\n :param observations: The observations for all objectives, with shape [N, 2].\n :raise ValueError (or InvalidArgumentError): If ``observations`` has an invalid shape.\n \"\"\"\n tf.debugging.assert_shapes([(observations, [None, 2])])\n\n pf, _ = non_dominated(observations)\n self.front: Final[TensorType] = tf.gather_nd(pf, tf.argsort(pf[:, :1], axis=0))\n self.bounds: Final[BoundedVolumes] = self._bounds_2d(self.front)\n\n @staticmethod\n def _bounds_2d(front: TensorType) -> BoundedVolumes:\n\n # this assumes the Pareto set has been sorted in ascending order on the first\n # objective, which implies the second objective is sorted in descending order\n len_front, number_of_objectives = front.shape\n\n pf_ext_idx = tf.concat(\n [\n tf.zeros([1, number_of_objectives], dtype=tf.int32),\n tf.argsort(front, axis=0) + 1,\n tf.ones([1, number_of_objectives], dtype=tf.int32) * len_front + 1,\n ],\n axis=0,\n )\n\n range_ = tf.range(len_front + 1)[:, None]\n lower = tf.concat([range_, tf.zeros_like(range_)], axis=-1)\n upper = tf.concat([range_ + 1, pf_ext_idx[::-1, 1:][: pf_ext_idx[-1, 0]]], axis=-1)\n\n return BoundedVolumes(lower, upper)\n\n def hypervolume_indicator(self, reference: TensorType) -> TensorType:\n \"\"\"\n Calculate the hypervolume indicator\n The hypervolume indicator is the volume of the dominated region.\n\n :param reference: a reference point to use, with shape [D].\n Defines the upper bound of the hypervolume.\n Should be equal or bigger than the anti-ideal point of the Pareto set.\n For comparing results across runs, the same reference point must be used.\n :return: hypervolume indicator\n :raise ValueError (or `tf.errors.InvalidArgumentError`): If ``reference`` has an invalid\n shape.\n :raise `tf.errors.InvalidArgumentError`: If ``reference`` is less than the anti-ideal point\n in any dimension.\n \"\"\"\n tf.debugging.assert_greater_equal(reference, self.front)\n\n tf.debugging.assert_shapes(\n [\n (self.bounds.lower_idx, [\"N\", \"D\"]),\n (self.bounds.upper_idx, [\"N\", \"D\"]),\n (self.front, [\"M\", \"D\"]),\n (reference, [\"D\"]),\n ]\n )\n\n min_pfront = tf.reduce_min(self.front, 0, keepdims=True)\n pseudo_pfront = tf.concat((min_pfront, self.front, reference[None]), 0)\n N, D = tf.shape(self.bounds.upper_idx)\n\n idx = tf.tile(tf.expand_dims(tf.range(D), -1), [1, N])\n upper_idx = tf.reshape(\n tf.stack([tf.transpose(self.bounds.upper_idx), idx], axis=2), [N * D, 2]\n )\n lower_idx = tf.reshape(\n tf.stack([tf.transpose(self.bounds.lower_idx), idx], axis=2), [N * D, 2]\n )\n upper = tf.reshape(tf.gather_nd(pseudo_pfront, upper_idx), [D, N])\n lower = tf.reshape(tf.gather_nd(pseudo_pfront, lower_idx), [D, N])\n hypervolume = tf.reduce_sum(tf.reduce_prod(upper - lower, 0))\n\n return tf.reduce_prod(reference[None] - min_pfront) - hypervolume\n", "path": "trieste/utils/pareto.py"}]}
| 1,503 | 604 |
gh_patches_debug_20014
|
rasdani/github-patches
|
git_diff
|
huggingface__optimum-1141
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Unpin onnx version to allow using v1.14
### Feature request
Remove the version constraint on onnx package to allow using onnx==1.14.
### Motivation
- The latest version of onnxruntime (v1.15 at the time of writing) supports onnx==1.14.
- onnx==1.14 introduces support for protobuf v4, which is also useful.
### Your contribution
Seems removing the pin from setup.py would be all that is needed as long as the existing tests provide enough validation.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import re
2
3 from setuptools import find_namespace_packages, setup
4
5
6 # Ensure we match the version set in src/optimum/version.py
7 try:
8 filepath = "optimum/version.py"
9 with open(filepath) as version_file:
10 (__version__,) = re.findall('__version__ = "(.*)"', version_file.read())
11 except Exception as error:
12 assert False, "Error: Could not open '%s' due %s\n" % (filepath, error)
13
14
15 REQUIRED_PKGS = [
16 "coloredlogs",
17 "sympy",
18 "transformers[sentencepiece]>=4.26.0",
19 "torch>=1.9",
20 "packaging",
21 "numpy",
22 "huggingface_hub>=0.8.0",
23 "datasets",
24 ]
25
26 TESTS_REQUIRE = [
27 "pytest",
28 "requests",
29 "parameterized",
30 "pytest-xdist",
31 "Pillow",
32 "sacremoses",
33 "torchvision",
34 "diffusers>=0.17.0",
35 "torchaudio",
36 ]
37
38 QUALITY_REQUIRE = ["black~=23.1", "ruff>=0.0.241,<=0.0.259"]
39
40 BENCHMARK_REQUIRE = ["optuna", "tqdm", "scikit-learn", "seqeval", "torchvision", "evaluate>=0.2.0"]
41
42 EXTRAS_REQUIRE = {
43 "onnxruntime": [
44 "onnx<1.14.0",
45 "onnxruntime>=1.9.0",
46 "datasets>=1.2.1",
47 "evaluate",
48 "protobuf>=3.20.1",
49 ],
50 "onnxruntime-gpu": [
51 "onnx<1.14.0",
52 "onnxruntime-gpu>=1.9.0",
53 "datasets>=1.2.1",
54 "evaluate",
55 "protobuf>=3.20.1",
56 ],
57 "exporters": ["onnx<1.14.0", "onnxruntime", "timm"],
58 "exporters-gpu": ["onnx<1.14.0", "onnxruntime-gpu", "timm"],
59 "exporters-tf": ["tensorflow>=2.4,<2.11", "tf2onnx", "onnx", "onnxruntime", "timm", "h5py", "numpy<1.24.0"],
60 "intel": "optimum-intel",
61 "openvino": "optimum-intel[openvino]",
62 "nncf": "optimum-intel[nncf]",
63 "neural-compressor": "optimum-intel[neural-compressor]",
64 "graphcore": "optimum-graphcore",
65 "habana": ["transformers<4.29.0", "optimum-habana"],
66 "neuron": "optimum-neuron[neuron]",
67 "neuronx": "optimum-neuron[neuronx]",
68 "dev": TESTS_REQUIRE + QUALITY_REQUIRE,
69 "tests": TESTS_REQUIRE,
70 "quality": QUALITY_REQUIRE,
71 "benchmark": BENCHMARK_REQUIRE,
72 }
73
74 setup(
75 name="optimum",
76 version=__version__,
77 description="Optimum Library is an extension of the Hugging Face Transformers library, providing a framework to "
78 "integrate third-party libraries from Hardware Partners and interface with their specific "
79 "functionality.",
80 long_description=open("README.md", "r", encoding="utf-8").read(),
81 long_description_content_type="text/markdown",
82 classifiers=[
83 "Development Status :: 5 - Production/Stable",
84 "License :: OSI Approved :: Apache Software License",
85 "Intended Audience :: Developers",
86 "Intended Audience :: Education",
87 "Intended Audience :: Science/Research",
88 "Operating System :: OS Independent",
89 "Programming Language :: Python :: 3.7",
90 "Programming Language :: Python :: 3.8",
91 "Programming Language :: Python :: 3.9",
92 "Topic :: Scientific/Engineering :: Artificial Intelligence",
93 ],
94 keywords="transformers, quantization, pruning, optimization, training, inference, onnx, onnx runtime, intel, "
95 "habana, graphcore, neural compressor, ipu, hpu",
96 url="https://github.com/huggingface/optimum",
97 author="HuggingFace Inc. Special Ops Team",
98 author_email="[email protected]",
99 license="Apache",
100 packages=find_namespace_packages(include=["optimum*"]),
101 install_requires=REQUIRED_PKGS,
102 extras_require=EXTRAS_REQUIRE,
103 python_requires=">=3.7.0",
104 include_package_data=True,
105 zip_safe=False,
106 entry_points={"console_scripts": ["optimum-cli=optimum.commands.optimum_cli:main"]},
107 )
108
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -41,21 +41,21 @@
EXTRAS_REQUIRE = {
"onnxruntime": [
- "onnx<1.14.0",
+ "onnx",
"onnxruntime>=1.9.0",
"datasets>=1.2.1",
"evaluate",
"protobuf>=3.20.1",
],
"onnxruntime-gpu": [
- "onnx<1.14.0",
+ "onnx",
"onnxruntime-gpu>=1.9.0",
"datasets>=1.2.1",
"evaluate",
"protobuf>=3.20.1",
],
- "exporters": ["onnx<1.14.0", "onnxruntime", "timm"],
- "exporters-gpu": ["onnx<1.14.0", "onnxruntime-gpu", "timm"],
+ "exporters": ["onnx", "onnxruntime", "timm"],
+ "exporters-gpu": ["onnx", "onnxruntime-gpu", "timm"],
"exporters-tf": ["tensorflow>=2.4,<2.11", "tf2onnx", "onnx", "onnxruntime", "timm", "h5py", "numpy<1.24.0"],
"intel": "optimum-intel",
"openvino": "optimum-intel[openvino]",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -41,21 +41,21 @@\n \n EXTRAS_REQUIRE = {\n \"onnxruntime\": [\n- \"onnx<1.14.0\",\n+ \"onnx\",\n \"onnxruntime>=1.9.0\",\n \"datasets>=1.2.1\",\n \"evaluate\",\n \"protobuf>=3.20.1\",\n ],\n \"onnxruntime-gpu\": [\n- \"onnx<1.14.0\",\n+ \"onnx\",\n \"onnxruntime-gpu>=1.9.0\",\n \"datasets>=1.2.1\",\n \"evaluate\",\n \"protobuf>=3.20.1\",\n ],\n- \"exporters\": [\"onnx<1.14.0\", \"onnxruntime\", \"timm\"],\n- \"exporters-gpu\": [\"onnx<1.14.0\", \"onnxruntime-gpu\", \"timm\"],\n+ \"exporters\": [\"onnx\", \"onnxruntime\", \"timm\"],\n+ \"exporters-gpu\": [\"onnx\", \"onnxruntime-gpu\", \"timm\"],\n \"exporters-tf\": [\"tensorflow>=2.4,<2.11\", \"tf2onnx\", \"onnx\", \"onnxruntime\", \"timm\", \"h5py\", \"numpy<1.24.0\"],\n \"intel\": \"optimum-intel\",\n \"openvino\": \"optimum-intel[openvino]\",\n", "issue": "Unpin onnx version to allow using v1.14\n### Feature request\r\n\r\nRemove the version constraint on onnx package to allow using onnx==1.14.\r\n\r\n### Motivation\r\n\r\n- The latest version of onnxruntime (v1.15 at the time of writing) supports onnx==1.14.\r\n- onnx==1.14 introduces support for protobuf v4, which is also useful.\r\n\r\n### Your contribution\r\n\r\nSeems removing the pin from setup.py would be all that is needed as long as the existing tests provide enough validation.\n", "before_files": [{"content": "import re\n\nfrom setuptools import find_namespace_packages, setup\n\n\n# Ensure we match the version set in src/optimum/version.py\ntry:\n filepath = \"optimum/version.py\"\n with open(filepath) as version_file:\n (__version__,) = re.findall('__version__ = \"(.*)\"', version_file.read())\nexcept Exception as error:\n assert False, \"Error: Could not open '%s' due %s\\n\" % (filepath, error)\n\n\nREQUIRED_PKGS = [\n \"coloredlogs\",\n \"sympy\",\n \"transformers[sentencepiece]>=4.26.0\",\n \"torch>=1.9\",\n \"packaging\",\n \"numpy\",\n \"huggingface_hub>=0.8.0\",\n \"datasets\",\n]\n\nTESTS_REQUIRE = [\n \"pytest\",\n \"requests\",\n \"parameterized\",\n \"pytest-xdist\",\n \"Pillow\",\n \"sacremoses\",\n \"torchvision\",\n \"diffusers>=0.17.0\",\n \"torchaudio\",\n]\n\nQUALITY_REQUIRE = [\"black~=23.1\", \"ruff>=0.0.241,<=0.0.259\"]\n\nBENCHMARK_REQUIRE = [\"optuna\", \"tqdm\", \"scikit-learn\", \"seqeval\", \"torchvision\", \"evaluate>=0.2.0\"]\n\nEXTRAS_REQUIRE = {\n \"onnxruntime\": [\n \"onnx<1.14.0\",\n \"onnxruntime>=1.9.0\",\n \"datasets>=1.2.1\",\n \"evaluate\",\n \"protobuf>=3.20.1\",\n ],\n \"onnxruntime-gpu\": [\n \"onnx<1.14.0\",\n \"onnxruntime-gpu>=1.9.0\",\n \"datasets>=1.2.1\",\n \"evaluate\",\n \"protobuf>=3.20.1\",\n ],\n \"exporters\": [\"onnx<1.14.0\", \"onnxruntime\", \"timm\"],\n \"exporters-gpu\": [\"onnx<1.14.0\", \"onnxruntime-gpu\", \"timm\"],\n \"exporters-tf\": [\"tensorflow>=2.4,<2.11\", \"tf2onnx\", \"onnx\", \"onnxruntime\", \"timm\", \"h5py\", \"numpy<1.24.0\"],\n \"intel\": \"optimum-intel\",\n \"openvino\": \"optimum-intel[openvino]\",\n \"nncf\": \"optimum-intel[nncf]\",\n \"neural-compressor\": \"optimum-intel[neural-compressor]\",\n \"graphcore\": \"optimum-graphcore\",\n \"habana\": [\"transformers<4.29.0\", \"optimum-habana\"],\n \"neuron\": \"optimum-neuron[neuron]\",\n \"neuronx\": \"optimum-neuron[neuronx]\",\n \"dev\": TESTS_REQUIRE + QUALITY_REQUIRE,\n \"tests\": TESTS_REQUIRE,\n \"quality\": QUALITY_REQUIRE,\n \"benchmark\": BENCHMARK_REQUIRE,\n}\n\nsetup(\n name=\"optimum\",\n version=__version__,\n description=\"Optimum Library is an extension of the Hugging Face Transformers library, providing a framework to \"\n \"integrate third-party libraries from Hardware Partners and interface with their specific \"\n \"functionality.\",\n long_description=open(\"README.md\", \"r\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n keywords=\"transformers, quantization, pruning, optimization, training, inference, onnx, onnx runtime, intel, \"\n \"habana, graphcore, neural compressor, ipu, hpu\",\n url=\"https://github.com/huggingface/optimum\",\n author=\"HuggingFace Inc. Special Ops Team\",\n author_email=\"[email protected]\",\n license=\"Apache\",\n packages=find_namespace_packages(include=[\"optimum*\"]),\n install_requires=REQUIRED_PKGS,\n extras_require=EXTRAS_REQUIRE,\n python_requires=\">=3.7.0\",\n include_package_data=True,\n zip_safe=False,\n entry_points={\"console_scripts\": [\"optimum-cli=optimum.commands.optimum_cli:main\"]},\n)\n", "path": "setup.py"}], "after_files": [{"content": "import re\n\nfrom setuptools import find_namespace_packages, setup\n\n\n# Ensure we match the version set in src/optimum/version.py\ntry:\n filepath = \"optimum/version.py\"\n with open(filepath) as version_file:\n (__version__,) = re.findall('__version__ = \"(.*)\"', version_file.read())\nexcept Exception as error:\n assert False, \"Error: Could not open '%s' due %s\\n\" % (filepath, error)\n\n\nREQUIRED_PKGS = [\n \"coloredlogs\",\n \"sympy\",\n \"transformers[sentencepiece]>=4.26.0\",\n \"torch>=1.9\",\n \"packaging\",\n \"numpy\",\n \"huggingface_hub>=0.8.0\",\n \"datasets\",\n]\n\nTESTS_REQUIRE = [\n \"pytest\",\n \"requests\",\n \"parameterized\",\n \"pytest-xdist\",\n \"Pillow\",\n \"sacremoses\",\n \"torchvision\",\n \"diffusers>=0.17.0\",\n \"torchaudio\",\n]\n\nQUALITY_REQUIRE = [\"black~=23.1\", \"ruff>=0.0.241,<=0.0.259\"]\n\nBENCHMARK_REQUIRE = [\"optuna\", \"tqdm\", \"scikit-learn\", \"seqeval\", \"torchvision\", \"evaluate>=0.2.0\"]\n\nEXTRAS_REQUIRE = {\n \"onnxruntime\": [\n \"onnx\",\n \"onnxruntime>=1.9.0\",\n \"datasets>=1.2.1\",\n \"evaluate\",\n \"protobuf>=3.20.1\",\n ],\n \"onnxruntime-gpu\": [\n \"onnx\",\n \"onnxruntime-gpu>=1.9.0\",\n \"datasets>=1.2.1\",\n \"evaluate\",\n \"protobuf>=3.20.1\",\n ],\n \"exporters\": [\"onnx\", \"onnxruntime\", \"timm\"],\n \"exporters-gpu\": [\"onnx\", \"onnxruntime-gpu\", \"timm\"],\n \"exporters-tf\": [\"tensorflow>=2.4,<2.11\", \"tf2onnx\", \"onnx\", \"onnxruntime\", \"timm\", \"h5py\", \"numpy<1.24.0\"],\n \"intel\": \"optimum-intel\",\n \"openvino\": \"optimum-intel[openvino]\",\n \"nncf\": \"optimum-intel[nncf]\",\n \"neural-compressor\": \"optimum-intel[neural-compressor]\",\n \"graphcore\": \"optimum-graphcore\",\n \"habana\": [\"transformers<4.29.0\", \"optimum-habana\"],\n \"neuron\": \"optimum-neuron[neuron]\",\n \"neuronx\": \"optimum-neuron[neuronx]\",\n \"dev\": TESTS_REQUIRE + QUALITY_REQUIRE,\n \"tests\": TESTS_REQUIRE,\n \"quality\": QUALITY_REQUIRE,\n \"benchmark\": BENCHMARK_REQUIRE,\n}\n\nsetup(\n name=\"optimum\",\n version=__version__,\n description=\"Optimum Library is an extension of the Hugging Face Transformers library, providing a framework to \"\n \"integrate third-party libraries from Hardware Partners and interface with their specific \"\n \"functionality.\",\n long_description=open(\"README.md\", \"r\", encoding=\"utf-8\").read(),\n long_description_content_type=\"text/markdown\",\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n keywords=\"transformers, quantization, pruning, optimization, training, inference, onnx, onnx runtime, intel, \"\n \"habana, graphcore, neural compressor, ipu, hpu\",\n url=\"https://github.com/huggingface/optimum\",\n author=\"HuggingFace Inc. Special Ops Team\",\n author_email=\"[email protected]\",\n license=\"Apache\",\n packages=find_namespace_packages(include=[\"optimum*\"]),\n install_requires=REQUIRED_PKGS,\n extras_require=EXTRAS_REQUIRE,\n python_requires=\">=3.7.0\",\n include_package_data=True,\n zip_safe=False,\n entry_points={\"console_scripts\": [\"optimum-cli=optimum.commands.optimum_cli:main\"]},\n)\n", "path": "setup.py"}]}
| 1,635 | 352 |
gh_patches_debug_1767
|
rasdani/github-patches
|
git_diff
|
ansible-collections__community.general-1383
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Apache2 module workaround for Shibboleth needs updating
##### SUMMARY
The workaround for Shibboleth previously added in [#20341](https://github.com/ansible/ansible/pull/20341) no longer works (on Debian 10) since the module *name* has meanwhile been changed from `shib2` (for which a workaround [currently exists](https://github.com/ansible-collections/community.general/blob/a1c03a3cfea17fdecf7b333a4f5665707283875d/plugins/modules/web_infrastructure/apache2_module.py#L161)) to `shib` (to account for the increasingly unfortunate naming `shib2` when the software currently has a major version of 3) which is not covered by the workaround.
Since [upstream is unable to change the module identifer](https://issues.shibboleth.net/jira/browse/SSPCPP-718) (easily, without causing breakage) the obvious and simple fix would be to amend the existing workaround to *also* match the current (and likely to remain that way in the future) module name, taking into account that different versions of the module may be in use:
```diff
# web_infrastructure/apache2_module.py
# a2enmod name replacement to apache2ctl -M names
text_workarounds = [
- ('shib2', 'mod_shib'),
+ ('shib', 'mod_shib'),
+ ('shib2', 'mod_shib'),
('evasive', 'evasive20_module'),
]
```
Once (if ever) the module identifier changes upstream to match the Apache httpd convension the workaround can be removed.
##### ISSUE TYPE
- Bug Report
##### COMPONENT NAME
apache2_module
##### ANSIBLE VERSION
Current `main` branch.
##### STEPS TO REPRODUCE
See [#20288](https://github.com/ansible/ansible/issues/20288), i.e., the behaviour matches the pre-workaround one exactly since the module name is no longer matched.
Ansible again fails with "Maybe the module identifier (shib) was guessed incorrectly":
```yaml
failed: [filesender.lab.aco.net] (item=shib) => changed=false
ansible_loop_var: item
item: shib
msg: |-
Failed to set module shib
to enabled:
Module shib already enabled
Maybe the module identifier (shib) was guessed incorrectly.Consider setting the "identifier" option.
rc: 0
stderr: ''
stderr_lines: <omitted>
stdout: |-
Module shib already enabled
stdout_lines: <omitted>
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `plugins/modules/web_infrastructure/apache2_module.py`
Content:
```
1 #!/usr/bin/python
2 # coding: utf-8 -*-
3
4 # (c) 2013-2014, Christian Berendt <[email protected]>
5 # GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)
6
7 from __future__ import absolute_import, division, print_function
8 __metaclass__ = type
9
10
11 DOCUMENTATION = '''
12 ---
13 module: apache2_module
14 author:
15 - Christian Berendt (@berendt)
16 - Ralf Hertel (@n0trax)
17 - Robin Roth (@robinro)
18 short_description: Enables/disables a module of the Apache2 webserver.
19 description:
20 - Enables or disables a specified module of the Apache2 webserver.
21 options:
22 name:
23 type: str
24 description:
25 - Name of the module to enable/disable as given to C(a2enmod/a2dismod).
26 required: true
27 identifier:
28 type: str
29 description:
30 - Identifier of the module as listed by C(apache2ctl -M).
31 This is optional and usually determined automatically by the common convention of
32 appending C(_module) to I(name) as well as custom exception for popular modules.
33 required: False
34 force:
35 description:
36 - Force disabling of default modules and override Debian warnings.
37 required: false
38 type: bool
39 default: False
40 state:
41 type: str
42 description:
43 - Desired state of the module.
44 choices: ['present', 'absent']
45 default: present
46 ignore_configcheck:
47 description:
48 - Ignore configuration checks about inconsistent module configuration. Especially for mpm_* modules.
49 type: bool
50 default: False
51 requirements: ["a2enmod","a2dismod"]
52 '''
53
54 EXAMPLES = '''
55 - name: Enable the Apache2 module wsgi
56 community.general.apache2_module:
57 state: present
58 name: wsgi
59
60 - name: Disables the Apache2 module wsgi
61 community.general.apache2_module:
62 state: absent
63 name: wsgi
64
65 - name: Disable default modules for Debian
66 community.general.apache2_module:
67 state: absent
68 name: autoindex
69 force: True
70
71 - name: Disable mpm_worker and ignore warnings about missing mpm module
72 community.general.apache2_module:
73 state: absent
74 name: mpm_worker
75 ignore_configcheck: True
76
77 - name: Enable dump_io module, which is identified as dumpio_module inside apache2
78 community.general.apache2_module:
79 state: present
80 name: dump_io
81 identifier: dumpio_module
82 '''
83
84 RETURN = '''
85 result:
86 description: message about action taken
87 returned: always
88 type: str
89 warnings:
90 description: list of warning messages
91 returned: when needed
92 type: list
93 rc:
94 description: return code of underlying command
95 returned: failed
96 type: int
97 stdout:
98 description: stdout of underlying command
99 returned: failed
100 type: str
101 stderr:
102 description: stderr of underlying command
103 returned: failed
104 type: str
105 '''
106
107 import re
108
109 # import module snippets
110 from ansible.module_utils.basic import AnsibleModule
111
112
113 def _run_threaded(module):
114 control_binary = _get_ctl_binary(module)
115
116 result, stdout, stderr = module.run_command("%s -V" % control_binary)
117
118 return bool(re.search(r'threaded:[ ]*yes', stdout))
119
120
121 def _get_ctl_binary(module):
122 for command in ['apache2ctl', 'apachectl']:
123 ctl_binary = module.get_bin_path(command)
124 if ctl_binary is not None:
125 return ctl_binary
126
127 module.fail_json(
128 msg="Neither of apache2ctl nor apachctl found."
129 " At least one apache control binary is necessary."
130 )
131
132
133 def _module_is_enabled(module):
134 control_binary = _get_ctl_binary(module)
135 result, stdout, stderr = module.run_command("%s -M" % control_binary)
136
137 if result != 0:
138 error_msg = "Error executing %s: %s" % (control_binary, stderr)
139 if module.params['ignore_configcheck']:
140 if 'AH00534' in stderr and 'mpm_' in module.params['name']:
141 module.warnings.append(
142 "No MPM module loaded! apache2 reload AND other module actions"
143 " will fail if no MPM module is loaded immediately."
144 )
145 else:
146 module.warnings.append(error_msg)
147 return False
148 else:
149 module.fail_json(msg=error_msg)
150
151 searchstring = ' ' + module.params['identifier']
152 return searchstring in stdout
153
154
155 def create_apache_identifier(name):
156 """
157 By convention if a module is loaded via name, it appears in apache2ctl -M as
158 name_module.
159
160 Some modules don't follow this convention and we use replacements for those."""
161
162 # a2enmod name replacement to apache2ctl -M names
163 text_workarounds = [
164 ('shib2', 'mod_shib'),
165 ('evasive', 'evasive20_module'),
166 ]
167
168 # re expressions to extract subparts of names
169 re_workarounds = [
170 ('php', r'^(php\d)\.'),
171 ]
172
173 for a2enmod_spelling, module_name in text_workarounds:
174 if a2enmod_spelling in name:
175 return module_name
176
177 for search, reexpr in re_workarounds:
178 if search in name:
179 try:
180 rematch = re.search(reexpr, name)
181 return rematch.group(1) + '_module'
182 except AttributeError:
183 pass
184
185 return name + '_module'
186
187
188 def _set_state(module, state):
189 name = module.params['name']
190 force = module.params['force']
191
192 want_enabled = state == 'present'
193 state_string = {'present': 'enabled', 'absent': 'disabled'}[state]
194 a2mod_binary = {'present': 'a2enmod', 'absent': 'a2dismod'}[state]
195 success_msg = "Module %s %s" % (name, state_string)
196
197 if _module_is_enabled(module) != want_enabled:
198 if module.check_mode:
199 module.exit_json(changed=True,
200 result=success_msg,
201 warnings=module.warnings)
202
203 a2mod_binary = module.get_bin_path(a2mod_binary)
204 if a2mod_binary is None:
205 module.fail_json(msg="%s not found. Perhaps this system does not use %s to manage apache" % (a2mod_binary, a2mod_binary))
206
207 if not want_enabled and force:
208 # force exists only for a2dismod on debian
209 a2mod_binary += ' -f'
210
211 result, stdout, stderr = module.run_command("%s %s" % (a2mod_binary, name))
212
213 if _module_is_enabled(module) == want_enabled:
214 module.exit_json(changed=True,
215 result=success_msg,
216 warnings=module.warnings)
217 else:
218 msg = (
219 'Failed to set module {name} to {state}:\n'
220 '{stdout}\n'
221 'Maybe the module identifier ({identifier}) was guessed incorrectly.'
222 'Consider setting the "identifier" option.'
223 ).format(
224 name=name,
225 state=state_string,
226 stdout=stdout,
227 identifier=module.params['identifier']
228 )
229 module.fail_json(msg=msg,
230 rc=result,
231 stdout=stdout,
232 stderr=stderr)
233 else:
234 module.exit_json(changed=False,
235 result=success_msg,
236 warnings=module.warnings)
237
238
239 def main():
240 module = AnsibleModule(
241 argument_spec=dict(
242 name=dict(required=True),
243 identifier=dict(required=False, type='str'),
244 force=dict(required=False, type='bool', default=False),
245 state=dict(default='present', choices=['absent', 'present']),
246 ignore_configcheck=dict(required=False, type='bool', default=False),
247 ),
248 supports_check_mode=True,
249 )
250
251 module.warnings = []
252
253 name = module.params['name']
254 if name == 'cgi' and _run_threaded(module):
255 module.fail_json(msg="Your MPM seems to be threaded. No automatic actions on module %s possible." % name)
256
257 if not module.params['identifier']:
258 module.params['identifier'] = create_apache_identifier(module.params['name'])
259
260 if module.params['state'] in ['present', 'absent']:
261 _set_state(module, module.params['state'])
262
263
264 if __name__ == '__main__':
265 main()
266
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/plugins/modules/web_infrastructure/apache2_module.py b/plugins/modules/web_infrastructure/apache2_module.py
--- a/plugins/modules/web_infrastructure/apache2_module.py
+++ b/plugins/modules/web_infrastructure/apache2_module.py
@@ -161,6 +161,7 @@
# a2enmod name replacement to apache2ctl -M names
text_workarounds = [
+ ('shib', 'mod_shib'),
('shib2', 'mod_shib'),
('evasive', 'evasive20_module'),
]
|
{"golden_diff": "diff --git a/plugins/modules/web_infrastructure/apache2_module.py b/plugins/modules/web_infrastructure/apache2_module.py\n--- a/plugins/modules/web_infrastructure/apache2_module.py\n+++ b/plugins/modules/web_infrastructure/apache2_module.py\n@@ -161,6 +161,7 @@\n \n # a2enmod name replacement to apache2ctl -M names\n text_workarounds = [\n+ ('shib', 'mod_shib'),\n ('shib2', 'mod_shib'),\n ('evasive', 'evasive20_module'),\n ]\n", "issue": "Apache2 module workaround for Shibboleth needs updating\n##### SUMMARY\r\n\r\nThe workaround for Shibboleth previously added in [#20341](https://github.com/ansible/ansible/pull/20341) no longer works (on Debian 10) since the module *name* has meanwhile been changed from `shib2` (for which a workaround [currently exists](https://github.com/ansible-collections/community.general/blob/a1c03a3cfea17fdecf7b333a4f5665707283875d/plugins/modules/web_infrastructure/apache2_module.py#L161)) to `shib` (to account for the increasingly unfortunate naming `shib2` when the software currently has a major version of 3) which is not covered by the workaround.\r\n\r\nSince [upstream is unable to change the module identifer](https://issues.shibboleth.net/jira/browse/SSPCPP-718) (easily, without causing breakage) the obvious and simple fix would be to amend the existing workaround to *also* match the current (and likely to remain that way in the future) module name, taking into account that different versions of the module may be in use:\r\n\r\n```diff\r\n# web_infrastructure/apache2_module.py\r\n # a2enmod name replacement to apache2ctl -M names\r\n text_workarounds = [\r\n- ('shib2', 'mod_shib'),\r\n+ ('shib', 'mod_shib'),\r\n+ ('shib2', 'mod_shib'),\r\n ('evasive', 'evasive20_module'),\r\n ]\r\n```\r\n\r\nOnce (if ever) the module identifier changes upstream to match the Apache httpd convension the workaround can be removed.\r\n\r\n##### ISSUE TYPE\r\n- Bug Report\r\n\r\n##### COMPONENT NAME\r\napache2_module\r\n\r\n##### ANSIBLE VERSION\r\n\r\nCurrent `main` branch.\r\n\r\n##### STEPS TO REPRODUCE\r\nSee [#20288](https://github.com/ansible/ansible/issues/20288), i.e., the behaviour matches the pre-workaround one exactly since the module name is no longer matched. \r\nAnsible again fails with \"Maybe the module identifier (shib) was guessed incorrectly\":\r\n\r\n```yaml\r\nfailed: [filesender.lab.aco.net] (item=shib) => changed=false \r\n ansible_loop_var: item\r\n item: shib\r\n msg: |-\r\n Failed to set module shib\r\n to enabled:\r\n Module shib already enabled\r\n \r\n Maybe the module identifier (shib) was guessed incorrectly.Consider setting the \"identifier\" option.\r\n rc: 0\r\n stderr: ''\r\n stderr_lines: <omitted>\r\n stdout: |-\r\n Module shib already enabled\r\n stdout_lines: <omitted>\r\n```\n", "before_files": [{"content": "#!/usr/bin/python\n# coding: utf-8 -*-\n\n# (c) 2013-2014, Christian Berendt <[email protected]>\n# GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)\n\nfrom __future__ import absolute_import, division, print_function\n__metaclass__ = type\n\n\nDOCUMENTATION = '''\n---\nmodule: apache2_module\nauthor:\n - Christian Berendt (@berendt)\n - Ralf Hertel (@n0trax)\n - Robin Roth (@robinro)\nshort_description: Enables/disables a module of the Apache2 webserver.\ndescription:\n - Enables or disables a specified module of the Apache2 webserver.\noptions:\n name:\n type: str\n description:\n - Name of the module to enable/disable as given to C(a2enmod/a2dismod).\n required: true\n identifier:\n type: str\n description:\n - Identifier of the module as listed by C(apache2ctl -M).\n This is optional and usually determined automatically by the common convention of\n appending C(_module) to I(name) as well as custom exception for popular modules.\n required: False\n force:\n description:\n - Force disabling of default modules and override Debian warnings.\n required: false\n type: bool\n default: False\n state:\n type: str\n description:\n - Desired state of the module.\n choices: ['present', 'absent']\n default: present\n ignore_configcheck:\n description:\n - Ignore configuration checks about inconsistent module configuration. Especially for mpm_* modules.\n type: bool\n default: False\nrequirements: [\"a2enmod\",\"a2dismod\"]\n'''\n\nEXAMPLES = '''\n- name: Enable the Apache2 module wsgi\n community.general.apache2_module:\n state: present\n name: wsgi\n\n- name: Disables the Apache2 module wsgi\n community.general.apache2_module:\n state: absent\n name: wsgi\n\n- name: Disable default modules for Debian\n community.general.apache2_module:\n state: absent\n name: autoindex\n force: True\n\n- name: Disable mpm_worker and ignore warnings about missing mpm module\n community.general.apache2_module:\n state: absent\n name: mpm_worker\n ignore_configcheck: True\n\n- name: Enable dump_io module, which is identified as dumpio_module inside apache2\n community.general.apache2_module:\n state: present\n name: dump_io\n identifier: dumpio_module\n'''\n\nRETURN = '''\nresult:\n description: message about action taken\n returned: always\n type: str\nwarnings:\n description: list of warning messages\n returned: when needed\n type: list\nrc:\n description: return code of underlying command\n returned: failed\n type: int\nstdout:\n description: stdout of underlying command\n returned: failed\n type: str\nstderr:\n description: stderr of underlying command\n returned: failed\n type: str\n'''\n\nimport re\n\n# import module snippets\nfrom ansible.module_utils.basic import AnsibleModule\n\n\ndef _run_threaded(module):\n control_binary = _get_ctl_binary(module)\n\n result, stdout, stderr = module.run_command(\"%s -V\" % control_binary)\n\n return bool(re.search(r'threaded:[ ]*yes', stdout))\n\n\ndef _get_ctl_binary(module):\n for command in ['apache2ctl', 'apachectl']:\n ctl_binary = module.get_bin_path(command)\n if ctl_binary is not None:\n return ctl_binary\n\n module.fail_json(\n msg=\"Neither of apache2ctl nor apachctl found.\"\n \" At least one apache control binary is necessary.\"\n )\n\n\ndef _module_is_enabled(module):\n control_binary = _get_ctl_binary(module)\n result, stdout, stderr = module.run_command(\"%s -M\" % control_binary)\n\n if result != 0:\n error_msg = \"Error executing %s: %s\" % (control_binary, stderr)\n if module.params['ignore_configcheck']:\n if 'AH00534' in stderr and 'mpm_' in module.params['name']:\n module.warnings.append(\n \"No MPM module loaded! apache2 reload AND other module actions\"\n \" will fail if no MPM module is loaded immediately.\"\n )\n else:\n module.warnings.append(error_msg)\n return False\n else:\n module.fail_json(msg=error_msg)\n\n searchstring = ' ' + module.params['identifier']\n return searchstring in stdout\n\n\ndef create_apache_identifier(name):\n \"\"\"\n By convention if a module is loaded via name, it appears in apache2ctl -M as\n name_module.\n\n Some modules don't follow this convention and we use replacements for those.\"\"\"\n\n # a2enmod name replacement to apache2ctl -M names\n text_workarounds = [\n ('shib2', 'mod_shib'),\n ('evasive', 'evasive20_module'),\n ]\n\n # re expressions to extract subparts of names\n re_workarounds = [\n ('php', r'^(php\\d)\\.'),\n ]\n\n for a2enmod_spelling, module_name in text_workarounds:\n if a2enmod_spelling in name:\n return module_name\n\n for search, reexpr in re_workarounds:\n if search in name:\n try:\n rematch = re.search(reexpr, name)\n return rematch.group(1) + '_module'\n except AttributeError:\n pass\n\n return name + '_module'\n\n\ndef _set_state(module, state):\n name = module.params['name']\n force = module.params['force']\n\n want_enabled = state == 'present'\n state_string = {'present': 'enabled', 'absent': 'disabled'}[state]\n a2mod_binary = {'present': 'a2enmod', 'absent': 'a2dismod'}[state]\n success_msg = \"Module %s %s\" % (name, state_string)\n\n if _module_is_enabled(module) != want_enabled:\n if module.check_mode:\n module.exit_json(changed=True,\n result=success_msg,\n warnings=module.warnings)\n\n a2mod_binary = module.get_bin_path(a2mod_binary)\n if a2mod_binary is None:\n module.fail_json(msg=\"%s not found. Perhaps this system does not use %s to manage apache\" % (a2mod_binary, a2mod_binary))\n\n if not want_enabled and force:\n # force exists only for a2dismod on debian\n a2mod_binary += ' -f'\n\n result, stdout, stderr = module.run_command(\"%s %s\" % (a2mod_binary, name))\n\n if _module_is_enabled(module) == want_enabled:\n module.exit_json(changed=True,\n result=success_msg,\n warnings=module.warnings)\n else:\n msg = (\n 'Failed to set module {name} to {state}:\\n'\n '{stdout}\\n'\n 'Maybe the module identifier ({identifier}) was guessed incorrectly.'\n 'Consider setting the \"identifier\" option.'\n ).format(\n name=name,\n state=state_string,\n stdout=stdout,\n identifier=module.params['identifier']\n )\n module.fail_json(msg=msg,\n rc=result,\n stdout=stdout,\n stderr=stderr)\n else:\n module.exit_json(changed=False,\n result=success_msg,\n warnings=module.warnings)\n\n\ndef main():\n module = AnsibleModule(\n argument_spec=dict(\n name=dict(required=True),\n identifier=dict(required=False, type='str'),\n force=dict(required=False, type='bool', default=False),\n state=dict(default='present', choices=['absent', 'present']),\n ignore_configcheck=dict(required=False, type='bool', default=False),\n ),\n supports_check_mode=True,\n )\n\n module.warnings = []\n\n name = module.params['name']\n if name == 'cgi' and _run_threaded(module):\n module.fail_json(msg=\"Your MPM seems to be threaded. No automatic actions on module %s possible.\" % name)\n\n if not module.params['identifier']:\n module.params['identifier'] = create_apache_identifier(module.params['name'])\n\n if module.params['state'] in ['present', 'absent']:\n _set_state(module, module.params['state'])\n\n\nif __name__ == '__main__':\n main()\n", "path": "plugins/modules/web_infrastructure/apache2_module.py"}], "after_files": [{"content": "#!/usr/bin/python\n# coding: utf-8 -*-\n\n# (c) 2013-2014, Christian Berendt <[email protected]>\n# GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)\n\nfrom __future__ import absolute_import, division, print_function\n__metaclass__ = type\n\n\nDOCUMENTATION = '''\n---\nmodule: apache2_module\nauthor:\n - Christian Berendt (@berendt)\n - Ralf Hertel (@n0trax)\n - Robin Roth (@robinro)\nshort_description: Enables/disables a module of the Apache2 webserver.\ndescription:\n - Enables or disables a specified module of the Apache2 webserver.\noptions:\n name:\n type: str\n description:\n - Name of the module to enable/disable as given to C(a2enmod/a2dismod).\n required: true\n identifier:\n type: str\n description:\n - Identifier of the module as listed by C(apache2ctl -M).\n This is optional and usually determined automatically by the common convention of\n appending C(_module) to I(name) as well as custom exception for popular modules.\n required: False\n force:\n description:\n - Force disabling of default modules and override Debian warnings.\n required: false\n type: bool\n default: False\n state:\n type: str\n description:\n - Desired state of the module.\n choices: ['present', 'absent']\n default: present\n ignore_configcheck:\n description:\n - Ignore configuration checks about inconsistent module configuration. Especially for mpm_* modules.\n type: bool\n default: False\nrequirements: [\"a2enmod\",\"a2dismod\"]\n'''\n\nEXAMPLES = '''\n- name: Enable the Apache2 module wsgi\n community.general.apache2_module:\n state: present\n name: wsgi\n\n- name: Disables the Apache2 module wsgi\n community.general.apache2_module:\n state: absent\n name: wsgi\n\n- name: Disable default modules for Debian\n community.general.apache2_module:\n state: absent\n name: autoindex\n force: True\n\n- name: Disable mpm_worker and ignore warnings about missing mpm module\n community.general.apache2_module:\n state: absent\n name: mpm_worker\n ignore_configcheck: True\n\n- name: Enable dump_io module, which is identified as dumpio_module inside apache2\n community.general.apache2_module:\n state: present\n name: dump_io\n identifier: dumpio_module\n'''\n\nRETURN = '''\nresult:\n description: message about action taken\n returned: always\n type: str\nwarnings:\n description: list of warning messages\n returned: when needed\n type: list\nrc:\n description: return code of underlying command\n returned: failed\n type: int\nstdout:\n description: stdout of underlying command\n returned: failed\n type: str\nstderr:\n description: stderr of underlying command\n returned: failed\n type: str\n'''\n\nimport re\n\n# import module snippets\nfrom ansible.module_utils.basic import AnsibleModule\n\n\ndef _run_threaded(module):\n control_binary = _get_ctl_binary(module)\n\n result, stdout, stderr = module.run_command(\"%s -V\" % control_binary)\n\n return bool(re.search(r'threaded:[ ]*yes', stdout))\n\n\ndef _get_ctl_binary(module):\n for command in ['apache2ctl', 'apachectl']:\n ctl_binary = module.get_bin_path(command)\n if ctl_binary is not None:\n return ctl_binary\n\n module.fail_json(\n msg=\"Neither of apache2ctl nor apachctl found.\"\n \" At least one apache control binary is necessary.\"\n )\n\n\ndef _module_is_enabled(module):\n control_binary = _get_ctl_binary(module)\n result, stdout, stderr = module.run_command(\"%s -M\" % control_binary)\n\n if result != 0:\n error_msg = \"Error executing %s: %s\" % (control_binary, stderr)\n if module.params['ignore_configcheck']:\n if 'AH00534' in stderr and 'mpm_' in module.params['name']:\n module.warnings.append(\n \"No MPM module loaded! apache2 reload AND other module actions\"\n \" will fail if no MPM module is loaded immediately.\"\n )\n else:\n module.warnings.append(error_msg)\n return False\n else:\n module.fail_json(msg=error_msg)\n\n searchstring = ' ' + module.params['identifier']\n return searchstring in stdout\n\n\ndef create_apache_identifier(name):\n \"\"\"\n By convention if a module is loaded via name, it appears in apache2ctl -M as\n name_module.\n\n Some modules don't follow this convention and we use replacements for those.\"\"\"\n\n # a2enmod name replacement to apache2ctl -M names\n text_workarounds = [\n ('shib', 'mod_shib'),\n ('shib2', 'mod_shib'),\n ('evasive', 'evasive20_module'),\n ]\n\n # re expressions to extract subparts of names\n re_workarounds = [\n ('php', r'^(php\\d)\\.'),\n ]\n\n for a2enmod_spelling, module_name in text_workarounds:\n if a2enmod_spelling in name:\n return module_name\n\n for search, reexpr in re_workarounds:\n if search in name:\n try:\n rematch = re.search(reexpr, name)\n return rematch.group(1) + '_module'\n except AttributeError:\n pass\n\n return name + '_module'\n\n\ndef _set_state(module, state):\n name = module.params['name']\n force = module.params['force']\n\n want_enabled = state == 'present'\n state_string = {'present': 'enabled', 'absent': 'disabled'}[state]\n a2mod_binary = {'present': 'a2enmod', 'absent': 'a2dismod'}[state]\n success_msg = \"Module %s %s\" % (name, state_string)\n\n if _module_is_enabled(module) != want_enabled:\n if module.check_mode:\n module.exit_json(changed=True,\n result=success_msg,\n warnings=module.warnings)\n\n a2mod_binary = module.get_bin_path(a2mod_binary)\n if a2mod_binary is None:\n module.fail_json(msg=\"%s not found. Perhaps this system does not use %s to manage apache\" % (a2mod_binary, a2mod_binary))\n\n if not want_enabled and force:\n # force exists only for a2dismod on debian\n a2mod_binary += ' -f'\n\n result, stdout, stderr = module.run_command(\"%s %s\" % (a2mod_binary, name))\n\n if _module_is_enabled(module) == want_enabled:\n module.exit_json(changed=True,\n result=success_msg,\n warnings=module.warnings)\n else:\n msg = (\n 'Failed to set module {name} to {state}:\\n'\n '{stdout}\\n'\n 'Maybe the module identifier ({identifier}) was guessed incorrectly.'\n 'Consider setting the \"identifier\" option.'\n ).format(\n name=name,\n state=state_string,\n stdout=stdout,\n identifier=module.params['identifier']\n )\n module.fail_json(msg=msg,\n rc=result,\n stdout=stdout,\n stderr=stderr)\n else:\n module.exit_json(changed=False,\n result=success_msg,\n warnings=module.warnings)\n\n\ndef main():\n module = AnsibleModule(\n argument_spec=dict(\n name=dict(required=True),\n identifier=dict(required=False, type='str'),\n force=dict(required=False, type='bool', default=False),\n state=dict(default='present', choices=['absent', 'present']),\n ignore_configcheck=dict(required=False, type='bool', default=False),\n ),\n supports_check_mode=True,\n )\n\n module.warnings = []\n\n name = module.params['name']\n if name == 'cgi' and _run_threaded(module):\n module.fail_json(msg=\"Your MPM seems to be threaded. No automatic actions on module %s possible.\" % name)\n\n if not module.params['identifier']:\n module.params['identifier'] = create_apache_identifier(module.params['name'])\n\n if module.params['state'] in ['present', 'absent']:\n _set_state(module, module.params['state'])\n\n\nif __name__ == '__main__':\n main()\n", "path": "plugins/modules/web_infrastructure/apache2_module.py"}]}
| 3,438 | 122 |
gh_patches_debug_28777
|
rasdani/github-patches
|
git_diff
|
lk-geimfari__mimesis-922
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add UUID objects support for uuid()
- [x] Add parameter `as_object`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mimesis/__init__.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 """Mimesis is a Python library, which helps generate fake data.
4
5 Copyright (c) 2016 - 2020 Isaak Uchakaev (Likid Geimfari)
6 Repository: https://github.com/lk-geimfari/mimesis
7 Email: <[email protected]>
8 """
9
10 from mimesis.providers import (
11 Address,
12 BaseDataProvider,
13 BaseProvider,
14 Business,
15 Choice,
16 Clothing,
17 Code,
18 Cryptographic,
19 Datetime,
20 Development,
21 File,
22 Food,
23 Generic,
24 Hardware,
25 Internet,
26 Numbers,
27 Path,
28 Payment,
29 Person,
30 Science,
31 Structure,
32 Text,
33 Transport,
34 UnitSystem,
35 )
36
37 __all__ = [
38 'Address',
39 'BaseDataProvider',
40 'BaseProvider',
41 'Business',
42 'Clothing',
43 'Code',
44 'Choice',
45 'Datetime',
46 'Development',
47 'File',
48 'Food',
49 'Hardware',
50 'Internet',
51 'Numbers',
52 'Path',
53 'Payment',
54 'Person',
55 'Science',
56 'Structure',
57 'Text',
58 'Transport',
59 'UnitSystem',
60 'Cryptographic',
61
62 # Has all:
63 'Generic',
64
65 # Meta:
66 '__version__',
67 '__title__',
68 '__description__',
69 '__url__',
70 '__author__',
71 '__author_email__',
72 '__license__',
73 ]
74
75 __version__ = '4.0.0'
76 __title__ = 'mimesis'
77 __description__ = 'Mimesis: fake data generator.'
78 __url__ = 'https://github.com/lk-geimfari/mimesis'
79 __author__ = 'Isaak Uchakaev (Likid Geimfari)'
80 __author_email__ = '[email protected]'
81 __license__ = 'MIT License'
82
```
Path: `mimesis/providers/cryptographic.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 """Cryptographic data provider."""
4
5 import hashlib
6 import secrets
7 import uuid
8 from typing import Optional
9
10 from mimesis.enums import Algorithm
11 from mimesis.providers.base import BaseProvider
12 from mimesis.providers.text import Text
13
14 __all__ = ['Cryptographic']
15
16
17 class Cryptographic(BaseProvider):
18 """Class that provides cryptographic data."""
19
20 def __init__(self, *args, **kwargs) -> None:
21 """Initialize attributes.
22
23 :param seed: Seed.
24 """
25 super().__init__(*args, **kwargs)
26 self.__words = Text('en')._data.get('words', {})
27
28 class Meta:
29 """Class for metadata."""
30
31 name = 'cryptographic'
32
33 def uuid(self, version: int = None) -> str:
34 """Generate random UUID.
35
36 :param version: UUID version.
37 :return: UUID
38 """
39 bits = self.random.getrandbits(128)
40 return str(uuid.UUID(int=bits, version=version))
41
42 def hash(self, algorithm: Algorithm = None) -> str: # noqa: A003
43 """Generate random hash.
44
45 To change hashing algorithm, pass parameter ``algorithm``
46 with needed value of the enum object :class:`~mimesis.enums.Algorithm`
47
48 :param algorithm: Enum object :class:`~mimesis.enums.Algorithm`.
49 :return: Hash.
50 :raises NonEnumerableError: When algorithm is unsupported.
51 """
52 key = self._validate_enum(algorithm, Algorithm)
53
54 if hasattr(hashlib, key):
55 fn = getattr(hashlib, key)
56 return fn(self.uuid().encode()).hexdigest()
57
58 @staticmethod
59 def token_bytes(entropy: int = 32) -> bytes:
60 """Generate byte string containing ``entropy`` bytes.
61
62 The string has ``entropy`` random bytes, each byte
63 converted to two hex digits.
64
65 .. warning:: Seed is not applicable to this method,
66 because of its cryptographic-safe nature.
67
68 :param entropy: Number of bytes (default: 32).
69 :return: Random bytes.
70 """
71 return secrets.token_bytes(entropy)
72
73 @staticmethod
74 def token_hex(entropy: int = 32) -> str:
75 """Return a random text string, in hexadecimal.
76
77 The string has *entropy* random bytes, each byte converted to two
78 hex digits. If *entropy* is ``None`` or not supplied, a reasonable
79 default is used.
80
81 .. warning:: Seed is not applicable to this method,
82 because of its cryptographic-safe nature.
83
84 :param entropy: Number of bytes (default: 32).
85 :return: Token.
86 """
87 return secrets.token_hex(entropy)
88
89 @staticmethod
90 def token_urlsafe(entropy: int = 32):
91 """Return a random URL-safe text string, in Base64 encoding.
92
93 The string has *entropy* random bytes. If *entropy* is ``None``
94 or not supplied, a reasonable default is used.
95
96 .. warning:: Seed is not applicable to this method,
97 because of its cryptographic-safe nature.
98
99 :param entropy: Number of bytes (default: 32).
100 :return: URL-safe token.
101 """
102 return secrets.token_urlsafe(entropy)
103
104 def mnemonic_phrase(self, length: int = 12,
105 separator: Optional[str] = None) -> str:
106 """Generate pseudo mnemonic phrase.
107
108 Please, keep in mind that this method generates
109 crypto-insecure values.
110
111 :param separator: Separator of phrases (Default is " ").
112 :param length: Number of words.
113 :return: Mnemonic phrase.
114 """
115 if not separator:
116 separator = ' '
117
118 words = self.__words['normal']
119 words_generator = (self.random.choice(words) for _ in range(length))
120 return '{}'.format(separator).join(words_generator)
121
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mimesis/__init__.py b/mimesis/__init__.py
--- a/mimesis/__init__.py
+++ b/mimesis/__init__.py
@@ -72,7 +72,7 @@
'__license__',
]
-__version__ = '4.0.0'
+__version__ = '4.1.0'
__title__ = 'mimesis'
__description__ = 'Mimesis: fake data generator.'
__url__ = 'https://github.com/lk-geimfari/mimesis'
diff --git a/mimesis/providers/cryptographic.py b/mimesis/providers/cryptographic.py
--- a/mimesis/providers/cryptographic.py
+++ b/mimesis/providers/cryptographic.py
@@ -4,8 +4,8 @@
import hashlib
import secrets
-import uuid
-from typing import Optional
+from typing import Optional, Union
+from uuid import UUID
from mimesis.enums import Algorithm
from mimesis.providers.base import BaseProvider
@@ -30,14 +30,25 @@
name = 'cryptographic'
- def uuid(self, version: int = None) -> str:
+ def uuid(self, version: int = None,
+ as_object: bool = False) -> Union[UUID, str]:
"""Generate random UUID.
+ This method returns string by default,
+ but yoy can make it return uuid.UUID object using
+ parameter **as_object**
+
+ :param as_object: Returns uuid.UUID object instead of string.
:param version: UUID version.
- :return: UUID
+ :return: UUID.
"""
bits = self.random.getrandbits(128)
- return str(uuid.UUID(int=bits, version=version))
+ uuid_obj = UUID(int=bits, version=version)
+
+ if not as_object:
+ return str(uuid_obj)
+
+ return uuid_obj
def hash(self, algorithm: Algorithm = None) -> str: # noqa: A003
"""Generate random hash.
|
{"golden_diff": "diff --git a/mimesis/__init__.py b/mimesis/__init__.py\n--- a/mimesis/__init__.py\n+++ b/mimesis/__init__.py\n@@ -72,7 +72,7 @@\n '__license__',\n ]\n \n-__version__ = '4.0.0'\n+__version__ = '4.1.0'\n __title__ = 'mimesis'\n __description__ = 'Mimesis: fake data generator.'\n __url__ = 'https://github.com/lk-geimfari/mimesis'\ndiff --git a/mimesis/providers/cryptographic.py b/mimesis/providers/cryptographic.py\n--- a/mimesis/providers/cryptographic.py\n+++ b/mimesis/providers/cryptographic.py\n@@ -4,8 +4,8 @@\n \n import hashlib\n import secrets\n-import uuid\n-from typing import Optional\n+from typing import Optional, Union\n+from uuid import UUID\n \n from mimesis.enums import Algorithm\n from mimesis.providers.base import BaseProvider\n@@ -30,14 +30,25 @@\n \n name = 'cryptographic'\n \n- def uuid(self, version: int = None) -> str:\n+ def uuid(self, version: int = None,\n+ as_object: bool = False) -> Union[UUID, str]:\n \"\"\"Generate random UUID.\n \n+ This method returns string by default,\n+ but yoy can make it return uuid.UUID object using\n+ parameter **as_object**\n+\n+ :param as_object: Returns uuid.UUID object instead of string.\n :param version: UUID version.\n- :return: UUID\n+ :return: UUID.\n \"\"\"\n bits = self.random.getrandbits(128)\n- return str(uuid.UUID(int=bits, version=version))\n+ uuid_obj = UUID(int=bits, version=version)\n+\n+ if not as_object:\n+ return str(uuid_obj)\n+\n+ return uuid_obj\n \n def hash(self, algorithm: Algorithm = None) -> str: # noqa: A003\n \"\"\"Generate random hash.\n", "issue": "Add UUID objects support for uuid()\n- [x] Add parameter `as_object` \n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Mimesis is a Python library, which helps generate fake data.\n\nCopyright (c) 2016 - 2020 Isaak Uchakaev (Likid Geimfari)\nRepository: https://github.com/lk-geimfari/mimesis\nEmail: <[email protected]>\n\"\"\"\n\nfrom mimesis.providers import (\n Address,\n BaseDataProvider,\n BaseProvider,\n Business,\n Choice,\n Clothing,\n Code,\n Cryptographic,\n Datetime,\n Development,\n File,\n Food,\n Generic,\n Hardware,\n Internet,\n Numbers,\n Path,\n Payment,\n Person,\n Science,\n Structure,\n Text,\n Transport,\n UnitSystem,\n)\n\n__all__ = [\n 'Address',\n 'BaseDataProvider',\n 'BaseProvider',\n 'Business',\n 'Clothing',\n 'Code',\n 'Choice',\n 'Datetime',\n 'Development',\n 'File',\n 'Food',\n 'Hardware',\n 'Internet',\n 'Numbers',\n 'Path',\n 'Payment',\n 'Person',\n 'Science',\n 'Structure',\n 'Text',\n 'Transport',\n 'UnitSystem',\n 'Cryptographic',\n\n # Has all:\n 'Generic',\n\n # Meta:\n '__version__',\n '__title__',\n '__description__',\n '__url__',\n '__author__',\n '__author_email__',\n '__license__',\n]\n\n__version__ = '4.0.0'\n__title__ = 'mimesis'\n__description__ = 'Mimesis: fake data generator.'\n__url__ = 'https://github.com/lk-geimfari/mimesis'\n__author__ = 'Isaak Uchakaev (Likid Geimfari)'\n__author_email__ = '[email protected]'\n__license__ = 'MIT License'\n", "path": "mimesis/__init__.py"}, {"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Cryptographic data provider.\"\"\"\n\nimport hashlib\nimport secrets\nimport uuid\nfrom typing import Optional\n\nfrom mimesis.enums import Algorithm\nfrom mimesis.providers.base import BaseProvider\nfrom mimesis.providers.text import Text\n\n__all__ = ['Cryptographic']\n\n\nclass Cryptographic(BaseProvider):\n \"\"\"Class that provides cryptographic data.\"\"\"\n\n def __init__(self, *args, **kwargs) -> None:\n \"\"\"Initialize attributes.\n\n :param seed: Seed.\n \"\"\"\n super().__init__(*args, **kwargs)\n self.__words = Text('en')._data.get('words', {})\n\n class Meta:\n \"\"\"Class for metadata.\"\"\"\n\n name = 'cryptographic'\n\n def uuid(self, version: int = None) -> str:\n \"\"\"Generate random UUID.\n\n :param version: UUID version.\n :return: UUID\n \"\"\"\n bits = self.random.getrandbits(128)\n return str(uuid.UUID(int=bits, version=version))\n\n def hash(self, algorithm: Algorithm = None) -> str: # noqa: A003\n \"\"\"Generate random hash.\n\n To change hashing algorithm, pass parameter ``algorithm``\n with needed value of the enum object :class:`~mimesis.enums.Algorithm`\n\n :param algorithm: Enum object :class:`~mimesis.enums.Algorithm`.\n :return: Hash.\n :raises NonEnumerableError: When algorithm is unsupported.\n \"\"\"\n key = self._validate_enum(algorithm, Algorithm)\n\n if hasattr(hashlib, key):\n fn = getattr(hashlib, key)\n return fn(self.uuid().encode()).hexdigest()\n\n @staticmethod\n def token_bytes(entropy: int = 32) -> bytes:\n \"\"\"Generate byte string containing ``entropy`` bytes.\n\n The string has ``entropy`` random bytes, each byte\n converted to two hex digits.\n\n .. warning:: Seed is not applicable to this method,\n because of its cryptographic-safe nature.\n\n :param entropy: Number of bytes (default: 32).\n :return: Random bytes.\n \"\"\"\n return secrets.token_bytes(entropy)\n\n @staticmethod\n def token_hex(entropy: int = 32) -> str:\n \"\"\"Return a random text string, in hexadecimal.\n\n The string has *entropy* random bytes, each byte converted to two\n hex digits. If *entropy* is ``None`` or not supplied, a reasonable\n default is used.\n\n .. warning:: Seed is not applicable to this method,\n because of its cryptographic-safe nature.\n\n :param entropy: Number of bytes (default: 32).\n :return: Token.\n \"\"\"\n return secrets.token_hex(entropy)\n\n @staticmethod\n def token_urlsafe(entropy: int = 32):\n \"\"\"Return a random URL-safe text string, in Base64 encoding.\n\n The string has *entropy* random bytes. If *entropy* is ``None``\n or not supplied, a reasonable default is used.\n\n .. warning:: Seed is not applicable to this method,\n because of its cryptographic-safe nature.\n\n :param entropy: Number of bytes (default: 32).\n :return: URL-safe token.\n \"\"\"\n return secrets.token_urlsafe(entropy)\n\n def mnemonic_phrase(self, length: int = 12,\n separator: Optional[str] = None) -> str:\n \"\"\"Generate pseudo mnemonic phrase.\n\n Please, keep in mind that this method generates\n crypto-insecure values.\n\n :param separator: Separator of phrases (Default is \" \").\n :param length: Number of words.\n :return: Mnemonic phrase.\n \"\"\"\n if not separator:\n separator = ' '\n\n words = self.__words['normal']\n words_generator = (self.random.choice(words) for _ in range(length))\n return '{}'.format(separator).join(words_generator)\n", "path": "mimesis/providers/cryptographic.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Mimesis is a Python library, which helps generate fake data.\n\nCopyright (c) 2016 - 2020 Isaak Uchakaev (Likid Geimfari)\nRepository: https://github.com/lk-geimfari/mimesis\nEmail: <[email protected]>\n\"\"\"\n\nfrom mimesis.providers import (\n Address,\n BaseDataProvider,\n BaseProvider,\n Business,\n Choice,\n Clothing,\n Code,\n Cryptographic,\n Datetime,\n Development,\n File,\n Food,\n Generic,\n Hardware,\n Internet,\n Numbers,\n Path,\n Payment,\n Person,\n Science,\n Structure,\n Text,\n Transport,\n UnitSystem,\n)\n\n__all__ = [\n 'Address',\n 'BaseDataProvider',\n 'BaseProvider',\n 'Business',\n 'Clothing',\n 'Code',\n 'Choice',\n 'Datetime',\n 'Development',\n 'File',\n 'Food',\n 'Hardware',\n 'Internet',\n 'Numbers',\n 'Path',\n 'Payment',\n 'Person',\n 'Science',\n 'Structure',\n 'Text',\n 'Transport',\n 'UnitSystem',\n 'Cryptographic',\n\n # Has all:\n 'Generic',\n\n # Meta:\n '__version__',\n '__title__',\n '__description__',\n '__url__',\n '__author__',\n '__author_email__',\n '__license__',\n]\n\n__version__ = '4.1.0'\n__title__ = 'mimesis'\n__description__ = 'Mimesis: fake data generator.'\n__url__ = 'https://github.com/lk-geimfari/mimesis'\n__author__ = 'Isaak Uchakaev (Likid Geimfari)'\n__author_email__ = '[email protected]'\n__license__ = 'MIT License'\n", "path": "mimesis/__init__.py"}, {"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Cryptographic data provider.\"\"\"\n\nimport hashlib\nimport secrets\nfrom typing import Optional, Union\nfrom uuid import UUID\n\nfrom mimesis.enums import Algorithm\nfrom mimesis.providers.base import BaseProvider\nfrom mimesis.providers.text import Text\n\n__all__ = ['Cryptographic']\n\n\nclass Cryptographic(BaseProvider):\n \"\"\"Class that provides cryptographic data.\"\"\"\n\n def __init__(self, *args, **kwargs) -> None:\n \"\"\"Initialize attributes.\n\n :param seed: Seed.\n \"\"\"\n super().__init__(*args, **kwargs)\n self.__words = Text('en')._data.get('words', {})\n\n class Meta:\n \"\"\"Class for metadata.\"\"\"\n\n name = 'cryptographic'\n\n def uuid(self, version: int = None,\n as_object: bool = False) -> Union[UUID, str]:\n \"\"\"Generate random UUID.\n\n This method returns string by default,\n but yoy can make it return uuid.UUID object using\n parameter **as_object**\n\n :param as_object: Returns uuid.UUID object instead of string.\n :param version: UUID version.\n :return: UUID.\n \"\"\"\n bits = self.random.getrandbits(128)\n uuid_obj = UUID(int=bits, version=version)\n\n if not as_object:\n return str(uuid_obj)\n\n return uuid_obj\n\n def hash(self, algorithm: Algorithm = None) -> str: # noqa: A003\n \"\"\"Generate random hash.\n\n To change hashing algorithm, pass parameter ``algorithm``\n with needed value of the enum object :class:`~mimesis.enums.Algorithm`\n\n :param algorithm: Enum object :class:`~mimesis.enums.Algorithm`.\n :return: Hash.\n :raises NonEnumerableError: When algorithm is unsupported.\n \"\"\"\n key = self._validate_enum(algorithm, Algorithm)\n\n if hasattr(hashlib, key):\n fn = getattr(hashlib, key)\n return fn(self.uuid().encode()).hexdigest()\n\n @staticmethod\n def token_bytes(entropy: int = 32) -> bytes:\n \"\"\"Generate byte string containing ``entropy`` bytes.\n\n The string has ``entropy`` random bytes, each byte\n converted to two hex digits.\n\n .. warning:: Seed is not applicable to this method,\n because of its cryptographic-safe nature.\n\n :param entropy: Number of bytes (default: 32).\n :return: Random bytes.\n \"\"\"\n return secrets.token_bytes(entropy)\n\n @staticmethod\n def token_hex(entropy: int = 32) -> str:\n \"\"\"Return a random text string, in hexadecimal.\n\n The string has *entropy* random bytes, each byte converted to two\n hex digits. If *entropy* is ``None`` or not supplied, a reasonable\n default is used.\n\n .. warning:: Seed is not applicable to this method,\n because of its cryptographic-safe nature.\n\n :param entropy: Number of bytes (default: 32).\n :return: Token.\n \"\"\"\n return secrets.token_hex(entropy)\n\n @staticmethod\n def token_urlsafe(entropy: int = 32):\n \"\"\"Return a random URL-safe text string, in Base64 encoding.\n\n The string has *entropy* random bytes. If *entropy* is ``None``\n or not supplied, a reasonable default is used.\n\n .. warning:: Seed is not applicable to this method,\n because of its cryptographic-safe nature.\n\n :param entropy: Number of bytes (default: 32).\n :return: URL-safe token.\n \"\"\"\n return secrets.token_urlsafe(entropy)\n\n def mnemonic_phrase(self, length: int = 12,\n separator: Optional[str] = None) -> str:\n \"\"\"Generate pseudo mnemonic phrase.\n\n Please, keep in mind that this method generates\n crypto-insecure values.\n\n :param separator: Separator of phrases (Default is \" \").\n :param length: Number of words.\n :return: Mnemonic phrase.\n \"\"\"\n if not separator:\n separator = ' '\n\n words = self.__words['normal']\n words_generator = (self.random.choice(words) for _ in range(length))\n return '{}'.format(separator).join(words_generator)\n", "path": "mimesis/providers/cryptographic.py"}]}
| 1,981 | 461 |
gh_patches_debug_31368
|
rasdani/github-patches
|
git_diff
|
pystiche__pystiche-12
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Pyramid fails with GuidedPixelRegularization operators
Right now the pyramid only extract the initial states from `Comparison` operators:
https://github.com/pmeier/pystiche/blob/d962951471d32124c9f164f1ba74dcdf50ecb938/pystiche/nst/image_optimizer/pyramid.py#L116-L117
If used with a `GuidedPixelRegularization` operator, this would fail to extract the input guide.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pystiche/nst/image_optimizer/pyramid.py`
Content:
```
1 import warnings
2 from typing import Union, Optional, Sequence, Tuple, Dict, Callable
3 import numpy as np
4 import torch
5 import pystiche
6 from pystiche.misc import zip_equal
7 from pystiche.image import (
8 is_image_size,
9 is_edge_size,
10 calculate_aspect_ratio,
11 image_to_edge_size,
12 extract_image_size,
13 )
14 from pystiche.image.transforms import (
15 Transform,
16 ResizeTransform,
17 Resize,
18 FixedAspectRatioResize,
19 GrayscaleToBinary,
20 )
21 from ..operators import Operator, Comparison, Guidance, ComparisonGuidance
22 from .image_optimizer import ImageOptimizer
23
24 __all__ = ["PyramidLevel", "ImageOptimizerPyramid", "ImageOptimizerOctavePyramid"]
25
26
27 class PyramidLevel(pystiche.object):
28 def __init__(
29 self,
30 num: int,
31 num_steps: int,
32 transform: Callable,
33 guide_transform: Optional[Callable] = None,
34 ) -> None:
35 super().__init__()
36 self.num: int = num
37 self.num_steps: int = num_steps
38
39 if isinstance(transform, ResizeTransform) and not transform.has_fixed_size:
40 msg = (
41 "The usage of a resize transformation that calculates the image size "
42 "at runtime is not recommended. If you experience size-mismatch "
43 "errors, consider using resize transformations with a fixed size."
44 )
45 warnings.warn(msg, RuntimeWarning)
46 self.transform: Callable = transform
47
48 if guide_transform is None and isinstance(transform, Transform):
49 guide_transform = transform + GrayscaleToBinary()
50 self.guide_transform: Callable = guide_transform
51
52 def extra_str(self) -> str:
53 extra = "num={num}", "num_steps={num_steps}", "size={size}"
54 return ", ".join(extra).format(size=self.transform.size, **self.__dict__)
55
56
57 class ImageOptimizerPyramid(pystiche.object):
58 InitialState = pystiche.namedtuple(
59 "init_state", ("target_image", "input_guide", "target_guide")
60 )
61
62 def __init__(self, image_optimizer: ImageOptimizer):
63 super().__init__()
64 self.image_optimizer: ImageOptimizer = image_optimizer
65 self._levels = None
66
67 def build_levels(
68 self, level_image_sizes, level_steps: Union[Sequence[int], int], **kwargs
69 ):
70 if isinstance(level_steps, int):
71 level_steps = tuple([level_steps] * len(level_image_sizes))
72
73 level_transforms = [
74 Resize(level_image_size)
75 if is_image_size(level_image_size)
76 else FixedAspectRatioResize(level_image_size, **kwargs)
77 for level_image_size in level_image_sizes
78 ]
79
80 levels = [
81 PyramidLevel(num, num_steps, transform)
82 for num, (num_steps, transform) in enumerate(
83 zip_equal(level_steps, level_transforms)
84 )
85 ]
86 self._levels = pystiche.tuple(levels)
87
88 @property
89 def has_levels(self) -> bool:
90 return self._levels is not None
91
92 def assert_has_levels(self):
93 if not self.has_levels:
94 # TODO: add error message
95 raise RuntimeError
96
97 @property
98 def max_level_transform(self) -> Callable:
99 self.assert_has_levels()
100 return self._levels[-1].transform
101
102 @property
103 def max_level_guide_transform(self) -> Callable:
104 self.assert_has_levels()
105 return self._levels[-1].guide_transform
106
107 def __call__(self, input_image: torch.Tensor, quiet: bool = False, **kwargs):
108 self.assert_has_levels()
109
110 init_states = self._extract_comparison_initial_states()
111
112 output_images = self._iterate(input_image, init_states, quiet, **kwargs)
113
114 return pystiche.tuple(output_images).detach()
115
116 def _extract_comparison_initial_states(self) -> Dict[Operator, InitialState]:
117 operators = tuple(self.image_optimizer.operators(Comparison))
118 init_states = []
119 for operator in operators:
120 target_image = operator.target_image
121
122 has_input_guide = (
123 isinstance(operator, Guidance) and operator.has_input_guide
124 )
125 input_guide = operator.input_guide if has_input_guide else None
126
127 has_target_guide = isinstance(operator, ComparisonGuidance)
128 target_guide = operator.target_guide if has_target_guide else None
129
130 init_states.append(
131 self.InitialState(target_image, input_guide, target_guide)
132 )
133 return dict(zip(operators, init_states))
134
135 def _iterate(
136 self,
137 input_image: torch.Tensor,
138 init_states: InitialState,
139 quiet: bool,
140 **kwargs
141 ):
142 output_images = [input_image]
143 for level in self._levels:
144 input_image = level.transform(output_images[-1])
145 self._transform_targets(level.transform, level.guide_transform, init_states)
146
147 if not quiet:
148 self._print_header(level.num, input_image)
149
150 output_image = self.image_optimizer(
151 input_image, level.num_steps, quiet=quiet, **kwargs
152 )
153 output_images.append(output_image)
154
155 return pystiche.tuple(output_images[1:])
156
157 def _transform_targets(
158 self,
159 transform: Callable,
160 guide_transform: Callable,
161 init_states: Dict[Operator, InitialState],
162 ):
163 for operator, init_state in init_states.items():
164 if isinstance(operator, Guidance) and init_state.input_guide is not None:
165 guide = guide_transform(init_state.input_guide)
166 operator.set_input_guide(guide)
167
168 if (
169 isinstance(operator, ComparisonGuidance)
170 and init_state.target_guide is not None
171 ):
172 guide = guide_transform(init_state.target_guide)
173 operator.set_target_guide(guide)
174
175 image = transform(init_state.target_image)
176 operator.set_target(image)
177
178 def _print_header(self, level: int, image: torch.Tensor):
179 image_size = extract_image_size(image)
180 line = " Pyramid level {0} ({2} x {1}) ".format(level, *reversed(image_size))
181 sep_line = "=" * max((len(line), 39))
182 print(sep_line)
183 print(line)
184 print(sep_line)
185
186
187 class ImageOptimizerOctavePyramid(ImageOptimizerPyramid):
188 def build_levels(
189 self,
190 size: Union[Tuple[int, int], int],
191 level_steps: Union[Sequence[int], int],
192 num_levels: Optional[int] = None,
193 min_edge_size: int = 64,
194 edge: str = "short",
195 ):
196 edge_size, aspect_ratio = self._extract_image_params(size, edge)
197
198 if num_levels is None:
199 num_levels = int(np.floor(np.log2(edge_size / min_edge_size))) + 1
200
201 level_image_sizes = [
202 round(edge_size / (2.0 ** ((num_levels - 1) - level)))
203 for level in range(num_levels)
204 ]
205 super().build_levels(
206 level_image_sizes, level_steps, aspect_ratio=aspect_ratio, edge=edge
207 )
208
209 @staticmethod
210 def _extract_image_params(size: Union[Tuple[int, int], int], edge: str):
211 if is_image_size(size):
212 return image_to_edge_size(size, edge), calculate_aspect_ratio(size)
213 elif is_edge_size(size):
214 return size, None
215 else:
216 # FIXME: error message
217 raise ValueError
218
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pystiche/nst/image_optimizer/pyramid.py b/pystiche/nst/image_optimizer/pyramid.py
--- a/pystiche/nst/image_optimizer/pyramid.py
+++ b/pystiche/nst/image_optimizer/pyramid.py
@@ -107,26 +107,31 @@
def __call__(self, input_image: torch.Tensor, quiet: bool = False, **kwargs):
self.assert_has_levels()
- init_states = self._extract_comparison_initial_states()
+ init_states = self._extract_operator_initial_states()
output_images = self._iterate(input_image, init_states, quiet, **kwargs)
return pystiche.tuple(output_images).detach()
- def _extract_comparison_initial_states(self) -> Dict[Operator, InitialState]:
- operators = tuple(self.image_optimizer.operators(Comparison))
+ def _extract_operator_initial_states(self) -> Dict[Operator, InitialState]:
+ operators = tuple(self.image_optimizer.operators())
init_states = []
for operator in operators:
- target_image = operator.target_image
-
has_input_guide = (
isinstance(operator, Guidance) and operator.has_input_guide
)
input_guide = operator.input_guide if has_input_guide else None
- has_target_guide = isinstance(operator, ComparisonGuidance)
+ has_target_guide = (
+ isinstance(operator, ComparisonGuidance) and operator.has_target_guide
+ )
target_guide = operator.target_guide if has_target_guide else None
+ has_target_image = (
+ isinstance(operator, Comparison) and operator.has_target_image
+ )
+ target_image = operator.target_image if has_target_image else None
+
init_states.append(
self.InitialState(target_image, input_guide, target_guide)
)
|
{"golden_diff": "diff --git a/pystiche/nst/image_optimizer/pyramid.py b/pystiche/nst/image_optimizer/pyramid.py\n--- a/pystiche/nst/image_optimizer/pyramid.py\n+++ b/pystiche/nst/image_optimizer/pyramid.py\n@@ -107,26 +107,31 @@\n def __call__(self, input_image: torch.Tensor, quiet: bool = False, **kwargs):\n self.assert_has_levels()\n \n- init_states = self._extract_comparison_initial_states()\n+ init_states = self._extract_operator_initial_states()\n \n output_images = self._iterate(input_image, init_states, quiet, **kwargs)\n \n return pystiche.tuple(output_images).detach()\n \n- def _extract_comparison_initial_states(self) -> Dict[Operator, InitialState]:\n- operators = tuple(self.image_optimizer.operators(Comparison))\n+ def _extract_operator_initial_states(self) -> Dict[Operator, InitialState]:\n+ operators = tuple(self.image_optimizer.operators())\n init_states = []\n for operator in operators:\n- target_image = operator.target_image\n-\n has_input_guide = (\n isinstance(operator, Guidance) and operator.has_input_guide\n )\n input_guide = operator.input_guide if has_input_guide else None\n \n- has_target_guide = isinstance(operator, ComparisonGuidance)\n+ has_target_guide = (\n+ isinstance(operator, ComparisonGuidance) and operator.has_target_guide\n+ )\n target_guide = operator.target_guide if has_target_guide else None\n \n+ has_target_image = (\n+ isinstance(operator, Comparison) and operator.has_target_image\n+ )\n+ target_image = operator.target_image if has_target_image else None\n+\n init_states.append(\n self.InitialState(target_image, input_guide, target_guide)\n )\n", "issue": "Pyramid fails with GuidedPixelRegularization operators\nRight now the pyramid only extract the initial states from `Comparison` operators:\r\n\r\nhttps://github.com/pmeier/pystiche/blob/d962951471d32124c9f164f1ba74dcdf50ecb938/pystiche/nst/image_optimizer/pyramid.py#L116-L117\r\n\r\nIf used with a `GuidedPixelRegularization` operator, this would fail to extract the input guide.\n", "before_files": [{"content": "import warnings\nfrom typing import Union, Optional, Sequence, Tuple, Dict, Callable\nimport numpy as np\nimport torch\nimport pystiche\nfrom pystiche.misc import zip_equal\nfrom pystiche.image import (\n is_image_size,\n is_edge_size,\n calculate_aspect_ratio,\n image_to_edge_size,\n extract_image_size,\n)\nfrom pystiche.image.transforms import (\n Transform,\n ResizeTransform,\n Resize,\n FixedAspectRatioResize,\n GrayscaleToBinary,\n)\nfrom ..operators import Operator, Comparison, Guidance, ComparisonGuidance\nfrom .image_optimizer import ImageOptimizer\n\n__all__ = [\"PyramidLevel\", \"ImageOptimizerPyramid\", \"ImageOptimizerOctavePyramid\"]\n\n\nclass PyramidLevel(pystiche.object):\n def __init__(\n self,\n num: int,\n num_steps: int,\n transform: Callable,\n guide_transform: Optional[Callable] = None,\n ) -> None:\n super().__init__()\n self.num: int = num\n self.num_steps: int = num_steps\n\n if isinstance(transform, ResizeTransform) and not transform.has_fixed_size:\n msg = (\n \"The usage of a resize transformation that calculates the image size \"\n \"at runtime is not recommended. If you experience size-mismatch \"\n \"errors, consider using resize transformations with a fixed size.\"\n )\n warnings.warn(msg, RuntimeWarning)\n self.transform: Callable = transform\n\n if guide_transform is None and isinstance(transform, Transform):\n guide_transform = transform + GrayscaleToBinary()\n self.guide_transform: Callable = guide_transform\n\n def extra_str(self) -> str:\n extra = \"num={num}\", \"num_steps={num_steps}\", \"size={size}\"\n return \", \".join(extra).format(size=self.transform.size, **self.__dict__)\n\n\nclass ImageOptimizerPyramid(pystiche.object):\n InitialState = pystiche.namedtuple(\n \"init_state\", (\"target_image\", \"input_guide\", \"target_guide\")\n )\n\n def __init__(self, image_optimizer: ImageOptimizer):\n super().__init__()\n self.image_optimizer: ImageOptimizer = image_optimizer\n self._levels = None\n\n def build_levels(\n self, level_image_sizes, level_steps: Union[Sequence[int], int], **kwargs\n ):\n if isinstance(level_steps, int):\n level_steps = tuple([level_steps] * len(level_image_sizes))\n\n level_transforms = [\n Resize(level_image_size)\n if is_image_size(level_image_size)\n else FixedAspectRatioResize(level_image_size, **kwargs)\n for level_image_size in level_image_sizes\n ]\n\n levels = [\n PyramidLevel(num, num_steps, transform)\n for num, (num_steps, transform) in enumerate(\n zip_equal(level_steps, level_transforms)\n )\n ]\n self._levels = pystiche.tuple(levels)\n\n @property\n def has_levels(self) -> bool:\n return self._levels is not None\n\n def assert_has_levels(self):\n if not self.has_levels:\n # TODO: add error message\n raise RuntimeError\n\n @property\n def max_level_transform(self) -> Callable:\n self.assert_has_levels()\n return self._levels[-1].transform\n\n @property\n def max_level_guide_transform(self) -> Callable:\n self.assert_has_levels()\n return self._levels[-1].guide_transform\n\n def __call__(self, input_image: torch.Tensor, quiet: bool = False, **kwargs):\n self.assert_has_levels()\n\n init_states = self._extract_comparison_initial_states()\n\n output_images = self._iterate(input_image, init_states, quiet, **kwargs)\n\n return pystiche.tuple(output_images).detach()\n\n def _extract_comparison_initial_states(self) -> Dict[Operator, InitialState]:\n operators = tuple(self.image_optimizer.operators(Comparison))\n init_states = []\n for operator in operators:\n target_image = operator.target_image\n\n has_input_guide = (\n isinstance(operator, Guidance) and operator.has_input_guide\n )\n input_guide = operator.input_guide if has_input_guide else None\n\n has_target_guide = isinstance(operator, ComparisonGuidance)\n target_guide = operator.target_guide if has_target_guide else None\n\n init_states.append(\n self.InitialState(target_image, input_guide, target_guide)\n )\n return dict(zip(operators, init_states))\n\n def _iterate(\n self,\n input_image: torch.Tensor,\n init_states: InitialState,\n quiet: bool,\n **kwargs\n ):\n output_images = [input_image]\n for level in self._levels:\n input_image = level.transform(output_images[-1])\n self._transform_targets(level.transform, level.guide_transform, init_states)\n\n if not quiet:\n self._print_header(level.num, input_image)\n\n output_image = self.image_optimizer(\n input_image, level.num_steps, quiet=quiet, **kwargs\n )\n output_images.append(output_image)\n\n return pystiche.tuple(output_images[1:])\n\n def _transform_targets(\n self,\n transform: Callable,\n guide_transform: Callable,\n init_states: Dict[Operator, InitialState],\n ):\n for operator, init_state in init_states.items():\n if isinstance(operator, Guidance) and init_state.input_guide is not None:\n guide = guide_transform(init_state.input_guide)\n operator.set_input_guide(guide)\n\n if (\n isinstance(operator, ComparisonGuidance)\n and init_state.target_guide is not None\n ):\n guide = guide_transform(init_state.target_guide)\n operator.set_target_guide(guide)\n\n image = transform(init_state.target_image)\n operator.set_target(image)\n\n def _print_header(self, level: int, image: torch.Tensor):\n image_size = extract_image_size(image)\n line = \" Pyramid level {0} ({2} x {1}) \".format(level, *reversed(image_size))\n sep_line = \"=\" * max((len(line), 39))\n print(sep_line)\n print(line)\n print(sep_line)\n\n\nclass ImageOptimizerOctavePyramid(ImageOptimizerPyramid):\n def build_levels(\n self,\n size: Union[Tuple[int, int], int],\n level_steps: Union[Sequence[int], int],\n num_levels: Optional[int] = None,\n min_edge_size: int = 64,\n edge: str = \"short\",\n ):\n edge_size, aspect_ratio = self._extract_image_params(size, edge)\n\n if num_levels is None:\n num_levels = int(np.floor(np.log2(edge_size / min_edge_size))) + 1\n\n level_image_sizes = [\n round(edge_size / (2.0 ** ((num_levels - 1) - level)))\n for level in range(num_levels)\n ]\n super().build_levels(\n level_image_sizes, level_steps, aspect_ratio=aspect_ratio, edge=edge\n )\n\n @staticmethod\n def _extract_image_params(size: Union[Tuple[int, int], int], edge: str):\n if is_image_size(size):\n return image_to_edge_size(size, edge), calculate_aspect_ratio(size)\n elif is_edge_size(size):\n return size, None\n else:\n # FIXME: error message\n raise ValueError\n", "path": "pystiche/nst/image_optimizer/pyramid.py"}], "after_files": [{"content": "import warnings\nfrom typing import Union, Optional, Sequence, Tuple, Dict, Callable\nimport numpy as np\nimport torch\nimport pystiche\nfrom pystiche.misc import zip_equal\nfrom pystiche.image import (\n is_image_size,\n is_edge_size,\n calculate_aspect_ratio,\n image_to_edge_size,\n extract_image_size,\n)\nfrom pystiche.image.transforms import (\n Transform,\n ResizeTransform,\n Resize,\n FixedAspectRatioResize,\n GrayscaleToBinary,\n)\nfrom ..operators import Operator, Comparison, Guidance, ComparisonGuidance\nfrom .image_optimizer import ImageOptimizer\n\n__all__ = [\"PyramidLevel\", \"ImageOptimizerPyramid\", \"ImageOptimizerOctavePyramid\"]\n\n\nclass PyramidLevel(pystiche.object):\n def __init__(\n self,\n num: int,\n num_steps: int,\n transform: Callable,\n guide_transform: Optional[Callable] = None,\n ) -> None:\n super().__init__()\n self.num: int = num\n self.num_steps: int = num_steps\n\n if isinstance(transform, ResizeTransform) and not transform.has_fixed_size:\n msg = (\n \"The usage of a resize transformation that calculates the image size \"\n \"at runtime is not recommended. If you experience size-mismatch \"\n \"errors, consider using resize transformations with a fixed size.\"\n )\n warnings.warn(msg, RuntimeWarning)\n self.transform: Callable = transform\n\n if guide_transform is None and isinstance(transform, Transform):\n guide_transform = transform + GrayscaleToBinary()\n self.guide_transform: Callable = guide_transform\n\n def extra_str(self) -> str:\n extra = \"num={num}\", \"num_steps={num_steps}\", \"size={size}\"\n return \", \".join(extra).format(size=self.transform.size, **self.__dict__)\n\n\nclass ImageOptimizerPyramid(pystiche.object):\n InitialState = pystiche.namedtuple(\n \"init_state\", (\"target_image\", \"input_guide\", \"target_guide\")\n )\n\n def __init__(self, image_optimizer: ImageOptimizer):\n super().__init__()\n self.image_optimizer: ImageOptimizer = image_optimizer\n self._levels = None\n\n def build_levels(\n self, level_image_sizes, level_steps: Union[Sequence[int], int], **kwargs\n ):\n if isinstance(level_steps, int):\n level_steps = tuple([level_steps] * len(level_image_sizes))\n\n level_transforms = [\n Resize(level_image_size)\n if is_image_size(level_image_size)\n else FixedAspectRatioResize(level_image_size, **kwargs)\n for level_image_size in level_image_sizes\n ]\n\n levels = [\n PyramidLevel(num, num_steps, transform)\n for num, (num_steps, transform) in enumerate(\n zip_equal(level_steps, level_transforms)\n )\n ]\n self._levels = pystiche.tuple(levels)\n\n @property\n def has_levels(self) -> bool:\n return self._levels is not None\n\n def assert_has_levels(self):\n if not self.has_levels:\n # TODO: add error message\n raise RuntimeError\n\n @property\n def max_level_transform(self) -> Callable:\n self.assert_has_levels()\n return self._levels[-1].transform\n\n @property\n def max_level_guide_transform(self) -> Callable:\n self.assert_has_levels()\n return self._levels[-1].guide_transform\n\n def __call__(self, input_image: torch.Tensor, quiet: bool = False, **kwargs):\n self.assert_has_levels()\n\n init_states = self._extract_operator_initial_states()\n\n output_images = self._iterate(input_image, init_states, quiet, **kwargs)\n\n return pystiche.tuple(output_images).detach()\n\n def _extract_operator_initial_states(self) -> Dict[Operator, InitialState]:\n operators = tuple(self.image_optimizer.operators())\n init_states = []\n for operator in operators:\n has_input_guide = (\n isinstance(operator, Guidance) and operator.has_input_guide\n )\n input_guide = operator.input_guide if has_input_guide else None\n\n has_target_guide = (\n isinstance(operator, ComparisonGuidance) and operator.has_target_guide\n )\n target_guide = operator.target_guide if has_target_guide else None\n\n has_target_image = (\n isinstance(operator, Comparison) and operator.has_target_image\n )\n target_image = operator.target_image if has_target_image else None\n\n init_states.append(\n self.InitialState(target_image, input_guide, target_guide)\n )\n return dict(zip(operators, init_states))\n\n def _iterate(\n self,\n input_image: torch.Tensor,\n init_states: InitialState,\n quiet: bool,\n **kwargs\n ):\n output_images = [input_image]\n for level in self._levels:\n input_image = level.transform(output_images[-1])\n self._transform_targets(level.transform, level.guide_transform, init_states)\n\n if not quiet:\n self._print_header(level.num, input_image)\n\n output_image = self.image_optimizer(\n input_image, level.num_steps, quiet=quiet, **kwargs\n )\n output_images.append(output_image)\n\n return pystiche.tuple(output_images[1:])\n\n def _transform_targets(\n self,\n transform: Callable,\n guide_transform: Callable,\n init_states: Dict[Operator, InitialState],\n ):\n for operator, init_state in init_states.items():\n if isinstance(operator, Guidance) and init_state.input_guide is not None:\n guide = guide_transform(init_state.input_guide)\n operator.set_input_guide(guide)\n\n if (\n isinstance(operator, ComparisonGuidance)\n and init_state.target_guide is not None\n ):\n guide = guide_transform(init_state.target_guide)\n operator.set_target_guide(guide)\n\n image = transform(init_state.target_image)\n operator.set_target(image)\n\n def _print_header(self, level: int, image: torch.Tensor):\n image_size = extract_image_size(image)\n line = \" Pyramid level {0} ({2} x {1}) \".format(level, *reversed(image_size))\n sep_line = \"=\" * max((len(line), 39))\n print(sep_line)\n print(line)\n print(sep_line)\n\n\nclass ImageOptimizerOctavePyramid(ImageOptimizerPyramid):\n def build_levels(\n self,\n size: Union[Tuple[int, int], int],\n level_steps: Union[Sequence[int], int],\n num_levels: Optional[int] = None,\n min_edge_size: int = 64,\n edge: str = \"short\",\n ):\n edge_size, aspect_ratio = self._extract_image_params(size, edge)\n\n if num_levels is None:\n num_levels = int(np.floor(np.log2(edge_size / min_edge_size))) + 1\n\n level_image_sizes = [\n round(edge_size / (2.0 ** ((num_levels - 1) - level)))\n for level in range(num_levels)\n ]\n super().build_levels(\n level_image_sizes, level_steps, aspect_ratio=aspect_ratio, edge=edge\n )\n\n @staticmethod\n def _extract_image_params(size: Union[Tuple[int, int], int], edge: str):\n if is_image_size(size):\n return image_to_edge_size(size, edge), calculate_aspect_ratio(size)\n elif is_edge_size(size):\n return size, None\n else:\n # FIXME: error message\n raise ValueError\n", "path": "pystiche/nst/image_optimizer/pyramid.py"}]}
| 2,487 | 380 |
gh_patches_debug_14282
|
rasdani/github-patches
|
git_diff
|
google__turbinia-384
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Local installation requires filled-out GCP section of config
I'm attempting to get Turbinia working locally on a laptop. The laptop has internet for at least the installation part of this process.
Running into an issue with the config. I set the TASK_MANAGER to use Celery, but the installation process is still requiring me to have values for:
- TURBINIA_PROJECT
- TURBINIA_ZONE
- TURBINIA_REGION
- BUCKET_NAME
According to the instructions in the config, these values should only matter if the TASK_MANAGER is set to PSQ.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `turbinia/config/turbinia_config.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # Copyright 2016 Google Inc.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 """Turbinia Config Template"""
16
17 from __future__ import unicode_literals
18
19 ################################################################################
20 # Base Turbinia configuration
21 #
22 # All options in this section are required to be set to non-empty values.
23 ################################################################################
24
25 # A unique ID per Turbinia instance. Used to keep multiple Turbinia instances
26 # separate when running with the same Cloud projects or backend servers.
27 INSTANCE_ID = 'turbinia-instance1'
28
29 # Which state manager to use. Valid options are 'Datastore' or 'Redis'.
30 STATE_MANAGER = 'Datastore'
31
32 # Which Task manager to use. Valid options are 'PSQ' and 'Celery'.
33 TASK_MANAGER = 'PSQ'
34
35 # Default base output directory for worker results and evidence.
36 OUTPUT_DIR = '/var/tmp'
37
38 # Directory for temporary files. Some temporary files can be quite large (e.g.
39 # Plaso files can easily be multiple gigabytes), so make sure there is enough
40 # space. Nothing from this directory will be saved. This directory should be
41 # different from the OUTPUT_DIR.
42 TMP_DIR = '/tmp'
43
44 # File to log debugging output to.
45 LOG_FILE = '%s/turbinia.log' % OUTPUT_DIR
46
47 # Path to a lock file used for the worker tasks.
48 LOCK_FILE = '%s/turbinia-worker.lock' % OUTPUT_DIR
49
50 # Time in seconds to sleep in task management loops
51 SLEEP_TIME = 10
52
53 # Whether to run as a single run, or to keep server running indefinitely
54 SINGLE_RUN = False
55
56 # Local directory in the worker to put other mount directories for locally
57 # mounting images/disks
58 MOUNT_DIR_PREFIX = '/mnt/turbinia-mounts'
59
60 # This indicates whether the workers are running in an environment with a shared
61 # filesystem. This should be False for environments with workers running in
62 # GCE, and True for environments that have workers on dedicated machines with
63 # NFS or a SAN for storing Evidence objects.
64 SHARED_FILESYSTEM = False
65
66 # This will set debugging flags for processes executed by Tasks (for
67 # Tasks/binaries that support it). This could cause performance issues with
68 # some tasks, so it is recommended to only set this to True when debugging
69 # problems.
70 DEBUG_TASKS = False
71
72 ################################################################################
73 # Google Cloud Platform (GCP)
74 #
75 # Options in this section are required if the TASK_MANAGER is set to 'PSQ'.
76 ################################################################################
77
78 # GCP project, region and zone where Turbinia will run. Note that Turbinia does
79 # not currently support multi-zone operation. Even if you are running Turbinia
80 # in Hybrid mode (with the Server and Workers running on local machines), you
81 # will still need to provide these three parameters.
82 TURBINIA_PROJECT = None
83 TURBINIA_ZONE = None
84 TURBINIA_REGION = None
85
86 # GCS bucket that has Turbinia specific scripts and can be used to store logs.
87 # This must be globally unique within GCP.
88 BUCKET_NAME = None
89
90 # This is the internal PubSub topic that PSQ will use. This should be different
91 # than the PUBSUB_TOPIC variable. The actual PubSub topic created will be this
92 # variable prefixed with 'psq-'.
93 PSQ_TOPIC = 'turbinia-psq'
94
95 # The PubSub topic Turbinia will listen on for new requests. This should be
96 # different than the PSQ_TOPIC variable.
97 PUBSUB_TOPIC = INSTANCE_ID
98
99 # GCS Path to copy worker results and Evidence output to.
100 # Otherwise, set this as 'None' if output will be stored in shared storage.
101 # GCS_OUTPUT_PATH = 'gs://%s/output' % BUCKET_NAME
102 GCS_OUTPUT_PATH = None
103
104 ################################################################################
105 # Celery / Redis / Kombu
106 #
107 # Options in this section are required if TASK_MANAGER is set to 'Celery'
108 ################################################################################
109
110 # Method for communication between nodes
111 CELERY_BROKER = 'redis://localhost'
112
113 # Storage for task results/status
114 CELERY_BACKEND = 'redis://localhost'
115
116 # Can be the same as CELERY_BROKER
117 KOMBU_BROKER = CELERY_BROKER
118
119 # Used to namespace communications.
120 KOMBU_CHANNEL = '%s-kombu' % INSTANCE_ID
121
122 # Will messages be persistent and require acknowledgment?
123 # http://docs.celeryproject.org/projects/kombu/en/4.0/reference/kombu.html#kombu.Connection.SimpleBuffer
124 KOMBU_DURABLE = True
125
126 # Use Redis for state management
127 REDIS_HOST = 'localhost'
128 REDIS_PORT = '6379'
129 REDIS_DB = '0'
130
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/turbinia/config/turbinia_config.py b/turbinia/config/turbinia_config.py
--- a/turbinia/config/turbinia_config.py
+++ b/turbinia/config/turbinia_config.py
@@ -26,10 +26,14 @@
# separate when running with the same Cloud projects or backend servers.
INSTANCE_ID = 'turbinia-instance1'
-# Which state manager to use. Valid options are 'Datastore' or 'Redis'.
+# Which state manager to use. Valid options are 'Datastore' or 'Redis'. Use
+# 'Datastore' for Cloud (GCP) or hybrid installations, and 'Redis' for local
+# installations.
STATE_MANAGER = 'Datastore'
-# Which Task manager to use. Valid options are 'PSQ' and 'Celery'.
+# Which Task manager to use. Valid options are 'PSQ' and 'Celery'. Use 'PSQ'
+# for Cloud (GCP) or hybrid installations, and 'Celery' for local
+# installations.
TASK_MANAGER = 'PSQ'
# Default base output directory for worker results and evidence.
|
{"golden_diff": "diff --git a/turbinia/config/turbinia_config.py b/turbinia/config/turbinia_config.py\n--- a/turbinia/config/turbinia_config.py\n+++ b/turbinia/config/turbinia_config.py\n@@ -26,10 +26,14 @@\n # separate when running with the same Cloud projects or backend servers.\n INSTANCE_ID = 'turbinia-instance1'\n \n-# Which state manager to use. Valid options are 'Datastore' or 'Redis'.\n+# Which state manager to use. Valid options are 'Datastore' or 'Redis'. Use\n+# 'Datastore' for Cloud (GCP) or hybrid installations, and 'Redis' for local\n+# installations.\n STATE_MANAGER = 'Datastore'\n \n-# Which Task manager to use. Valid options are 'PSQ' and 'Celery'.\n+# Which Task manager to use. Valid options are 'PSQ' and 'Celery'. Use 'PSQ'\n+# for Cloud (GCP) or hybrid installations, and 'Celery' for local\n+# installations.\n TASK_MANAGER = 'PSQ'\n \n # Default base output directory for worker results and evidence.\n", "issue": "Local installation requires filled-out GCP section of config\nI'm attempting to get Turbinia working locally on a laptop. The laptop has internet for at least the installation part of this process.\r\n\r\nRunning into an issue with the config. I set the TASK_MANAGER to use Celery, but the installation process is still requiring me to have values for:\r\n\r\n- TURBINIA_PROJECT\r\n- TURBINIA_ZONE\r\n- TURBINIA_REGION\r\n- BUCKET_NAME\r\n\r\nAccording to the instructions in the config, these values should only matter if the TASK_MANAGER is set to PSQ.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright 2016 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Turbinia Config Template\"\"\"\n\nfrom __future__ import unicode_literals\n\n################################################################################\n# Base Turbinia configuration\n#\n# All options in this section are required to be set to non-empty values.\n################################################################################\n\n# A unique ID per Turbinia instance. Used to keep multiple Turbinia instances\n# separate when running with the same Cloud projects or backend servers.\nINSTANCE_ID = 'turbinia-instance1'\n\n# Which state manager to use. Valid options are 'Datastore' or 'Redis'.\nSTATE_MANAGER = 'Datastore'\n\n# Which Task manager to use. Valid options are 'PSQ' and 'Celery'.\nTASK_MANAGER = 'PSQ'\n\n# Default base output directory for worker results and evidence.\nOUTPUT_DIR = '/var/tmp'\n\n# Directory for temporary files. Some temporary files can be quite large (e.g.\n# Plaso files can easily be multiple gigabytes), so make sure there is enough\n# space. Nothing from this directory will be saved. This directory should be\n# different from the OUTPUT_DIR.\nTMP_DIR = '/tmp'\n\n# File to log debugging output to.\nLOG_FILE = '%s/turbinia.log' % OUTPUT_DIR\n\n# Path to a lock file used for the worker tasks.\nLOCK_FILE = '%s/turbinia-worker.lock' % OUTPUT_DIR\n\n# Time in seconds to sleep in task management loops\nSLEEP_TIME = 10\n\n# Whether to run as a single run, or to keep server running indefinitely\nSINGLE_RUN = False\n\n# Local directory in the worker to put other mount directories for locally\n# mounting images/disks\nMOUNT_DIR_PREFIX = '/mnt/turbinia-mounts'\n\n# This indicates whether the workers are running in an environment with a shared\n# filesystem. This should be False for environments with workers running in\n# GCE, and True for environments that have workers on dedicated machines with\n# NFS or a SAN for storing Evidence objects.\nSHARED_FILESYSTEM = False\n\n# This will set debugging flags for processes executed by Tasks (for\n# Tasks/binaries that support it). This could cause performance issues with\n# some tasks, so it is recommended to only set this to True when debugging\n# problems.\nDEBUG_TASKS = False\n\n################################################################################\n# Google Cloud Platform (GCP)\n#\n# Options in this section are required if the TASK_MANAGER is set to 'PSQ'.\n################################################################################\n\n# GCP project, region and zone where Turbinia will run. Note that Turbinia does\n# not currently support multi-zone operation. Even if you are running Turbinia\n# in Hybrid mode (with the Server and Workers running on local machines), you\n# will still need to provide these three parameters.\nTURBINIA_PROJECT = None\nTURBINIA_ZONE = None\nTURBINIA_REGION = None\n\n# GCS bucket that has Turbinia specific scripts and can be used to store logs.\n# This must be globally unique within GCP.\nBUCKET_NAME = None\n\n# This is the internal PubSub topic that PSQ will use. This should be different\n# than the PUBSUB_TOPIC variable. The actual PubSub topic created will be this\n# variable prefixed with 'psq-'.\nPSQ_TOPIC = 'turbinia-psq'\n\n# The PubSub topic Turbinia will listen on for new requests. This should be\n# different than the PSQ_TOPIC variable.\nPUBSUB_TOPIC = INSTANCE_ID\n\n# GCS Path to copy worker results and Evidence output to.\n# Otherwise, set this as 'None' if output will be stored in shared storage.\n# GCS_OUTPUT_PATH = 'gs://%s/output' % BUCKET_NAME\nGCS_OUTPUT_PATH = None\n\n################################################################################\n# Celery / Redis / Kombu\n#\n# Options in this section are required if TASK_MANAGER is set to 'Celery'\n################################################################################\n\n# Method for communication between nodes\nCELERY_BROKER = 'redis://localhost'\n\n# Storage for task results/status\nCELERY_BACKEND = 'redis://localhost'\n\n# Can be the same as CELERY_BROKER\nKOMBU_BROKER = CELERY_BROKER\n\n# Used to namespace communications.\nKOMBU_CHANNEL = '%s-kombu' % INSTANCE_ID\n\n# Will messages be persistent and require acknowledgment?\n# http://docs.celeryproject.org/projects/kombu/en/4.0/reference/kombu.html#kombu.Connection.SimpleBuffer\nKOMBU_DURABLE = True\n\n# Use Redis for state management\nREDIS_HOST = 'localhost'\nREDIS_PORT = '6379'\nREDIS_DB = '0'\n", "path": "turbinia/config/turbinia_config.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright 2016 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Turbinia Config Template\"\"\"\n\nfrom __future__ import unicode_literals\n\n################################################################################\n# Base Turbinia configuration\n#\n# All options in this section are required to be set to non-empty values.\n################################################################################\n\n# A unique ID per Turbinia instance. Used to keep multiple Turbinia instances\n# separate when running with the same Cloud projects or backend servers.\nINSTANCE_ID = 'turbinia-instance1'\n\n# Which state manager to use. Valid options are 'Datastore' or 'Redis'. Use\n# 'Datastore' for Cloud (GCP) or hybrid installations, and 'Redis' for local\n# installations.\nSTATE_MANAGER = 'Datastore'\n\n# Which Task manager to use. Valid options are 'PSQ' and 'Celery'. Use 'PSQ'\n# for Cloud (GCP) or hybrid installations, and 'Celery' for local\n# installations.\nTASK_MANAGER = 'PSQ'\n\n# Default base output directory for worker results and evidence.\nOUTPUT_DIR = '/var/tmp'\n\n# Directory for temporary files. Some temporary files can be quite large (e.g.\n# Plaso files can easily be multiple gigabytes), so make sure there is enough\n# space. Nothing from this directory will be saved. This directory should be\n# different from the OUTPUT_DIR.\nTMP_DIR = '/tmp'\n\n# File to log debugging output to.\nLOG_FILE = '%s/turbinia.log' % OUTPUT_DIR\n\n# Path to a lock file used for the worker tasks.\nLOCK_FILE = '%s/turbinia-worker.lock' % OUTPUT_DIR\n\n# Time in seconds to sleep in task management loops\nSLEEP_TIME = 10\n\n# Whether to run as a single run, or to keep server running indefinitely\nSINGLE_RUN = False\n\n# Local directory in the worker to put other mount directories for locally\n# mounting images/disks\nMOUNT_DIR_PREFIX = '/mnt/turbinia-mounts'\n\n# This indicates whether the workers are running in an environment with a shared\n# filesystem. This should be False for environments with workers running in\n# GCE, and True for environments that have workers on dedicated machines with\n# NFS or a SAN for storing Evidence objects.\nSHARED_FILESYSTEM = False\n\n# This will set debugging flags for processes executed by Tasks (for\n# Tasks/binaries that support it). This could cause performance issues with\n# some tasks, so it is recommended to only set this to True when debugging\n# problems.\nDEBUG_TASKS = False\n\n################################################################################\n# Google Cloud Platform (GCP)\n#\n# Options in this section are required if the TASK_MANAGER is set to 'PSQ'.\n################################################################################\n\n# GCP project, region and zone where Turbinia will run. Note that Turbinia does\n# not currently support multi-zone operation. Even if you are running Turbinia\n# in Hybrid mode (with the Server and Workers running on local machines), you\n# will still need to provide these three parameters.\nTURBINIA_PROJECT = None\nTURBINIA_ZONE = None\nTURBINIA_REGION = None\n\n# GCS bucket that has Turbinia specific scripts and can be used to store logs.\n# This must be globally unique within GCP.\nBUCKET_NAME = None\n\n# This is the internal PubSub topic that PSQ will use. This should be different\n# than the PUBSUB_TOPIC variable. The actual PubSub topic created will be this\n# variable prefixed with 'psq-'.\nPSQ_TOPIC = 'turbinia-psq'\n\n# The PubSub topic Turbinia will listen on for new requests. This should be\n# different than the PSQ_TOPIC variable.\nPUBSUB_TOPIC = INSTANCE_ID\n\n# GCS Path to copy worker results and Evidence output to.\n# Otherwise, set this as 'None' if output will be stored in shared storage.\n# GCS_OUTPUT_PATH = 'gs://%s/output' % BUCKET_NAME\nGCS_OUTPUT_PATH = None\n\n################################################################################\n# Celery / Redis / Kombu\n#\n# Options in this section are required if TASK_MANAGER is set to 'Celery'\n################################################################################\n\n# Method for communication between nodes\nCELERY_BROKER = 'redis://localhost'\n\n# Storage for task results/status\nCELERY_BACKEND = 'redis://localhost'\n\n# Can be the same as CELERY_BROKER\nKOMBU_BROKER = CELERY_BROKER\n\n# Used to namespace communications.\nKOMBU_CHANNEL = '%s-kombu' % INSTANCE_ID\n\n# Will messages be persistent and require acknowledgment?\n# http://docs.celeryproject.org/projects/kombu/en/4.0/reference/kombu.html#kombu.Connection.SimpleBuffer\nKOMBU_DURABLE = True\n\n# Use Redis for state management\nREDIS_HOST = 'localhost'\nREDIS_PORT = '6379'\nREDIS_DB = '0'\n", "path": "turbinia/config/turbinia_config.py"}]}
| 1,798 | 253 |
gh_patches_debug_37430
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-4638
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
plugins.vk: fixes required
### Checklist
- [X] This is a plugin issue and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest build from the master branch
### Description
Needs support for the web application firewall cookie.
~Seems necessary to add all parameters to the API POST data in `_get_streams()` now.~
ref: https://github.com/streamlink/streamlink/pull/4613#issuecomment-1173040359
### Debug log
```text
$ streamlink -l debug https://vk.com/video-211154316_456239169
[cli][debug] OS: Linux-4.9.0-18-amd64-x86_64-with-debian-9.13
[cli][debug] Python: 3.7.3
[cli][debug] Streamlink: 4.1.0+45.gb277114d
[cli][debug] Dependencies:
[cli][debug] isodate: 0.6.1
[cli][debug] lxml: 4.9.1
[cli][debug] pycountry: 22.3.5
[cli][debug] pycryptodome: 3.15.0
[cli][debug] PySocks: 1.7.1
[cli][debug] requests: 2.28.1
[cli][debug] websocket-client: 1.3.3
[cli][debug] importlib-metadata: 4.12.0
[cli][debug] Arguments:
[cli][debug] url=https://vk.com/video-211154316_456239169
[cli][debug] --loglevel=debug
[cli][info] Found matching plugin vk for URL https://vk.com/video-211154316_456239169
[plugins.vk][debug] video ID: -211154316_456239169
[plugins.vk][error] Could not parse API response
error: No playable streams found on this URL: https://vk.com/video-211154316_456239169
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/streamlink/plugins/vk.py`
Content:
```
1 """
2 $description Russian live-streaming and video hosting social platform.
3 $url vk.com
4 $type live, vod
5 """
6
7 import logging
8 import re
9 from urllib.parse import parse_qsl, unquote, urlparse
10
11 from streamlink.exceptions import NoStreamsError
12 from streamlink.plugin import Plugin, PluginError, pluginmatcher
13 from streamlink.plugin.api import validate
14 from streamlink.stream.dash import DASHStream
15 from streamlink.stream.hls import HLSStream
16
17 log = logging.getLogger(__name__)
18
19
20 @pluginmatcher(re.compile(
21 r"https?://(?:\w+\.)?vk\.com/videos?(?:\?z=video)?(?P<video_id>-?\d+_\d+)"
22 ))
23 @pluginmatcher(re.compile(
24 r"https?://(\w+\.)?vk\.com/.+"
25 ))
26 class VK(Plugin):
27 API_URL = "https://vk.com/al_video.php"
28
29 def _has_video_id(self):
30 return any(m for m in self.matches[:-1])
31
32 def follow_vk_redirect(self):
33 if self._has_video_id():
34 return
35
36 try:
37 parsed_url = urlparse(self.url)
38 true_path = next(unquote(v).split("/")[0] for k, v in parse_qsl(parsed_url.query) if k == "z" and len(v) > 0)
39 self.url = f"{parsed_url.scheme}://{parsed_url.netloc}/{true_path}"
40 if self._has_video_id():
41 return
42 except StopIteration:
43 pass
44
45 try:
46 self.url = self.session.http.get(self.url, schema=validate.Schema(
47 validate.parse_html(),
48 validate.xml_xpath_string(".//head/meta[@property='og:url'][@content]/@content"),
49 str
50 ))
51 except PluginError:
52 pass
53 if self._has_video_id():
54 return
55
56 raise NoStreamsError(self.url)
57
58 def _get_streams(self):
59 self.follow_vk_redirect()
60
61 video_id = self.match.group("video_id")
62 if not video_id:
63 return
64
65 log.debug(f"video ID: {video_id}")
66 try:
67 data = self.session.http.post(
68 self.API_URL,
69 params={
70 "act": "show",
71 "al": "1",
72 "video": video_id,
73 },
74 headers={"Referer": self.url},
75 schema=validate.Schema(
76 validate.transform(lambda text: re.sub(r"^\s*<!--\s*", "", text)),
77 validate.parse_json(),
78 {"payload": list},
79 validate.get(("payload", -1)),
80 list,
81 validate.get(-1),
82 {"player": {"params": [dict]}},
83 validate.get(("player", "params", 0)),
84 {
85 validate.optional("hls"): validate.url(),
86 validate.optional("manifest"): validate.startswith("<?xml"),
87 validate.optional("md_author"): validate.any(str, None),
88 validate.optional("md_title"): validate.any(str, None),
89 }
90 )
91 )
92 except PluginError:
93 log.error("Could not parse API response")
94 return
95
96 self.id = video_id
97 self.author = data.get("md_author")
98 self.title = data.get("md_title")
99
100 hls = data.get("hls")
101 if hls:
102 return HLSStream.parse_variant_playlist(self.session, hls)
103
104 dash_manifest = data.get("manifest")
105 if dash_manifest:
106 return DASHStream.parse_manifest(self.session, dash_manifest)
107
108
109 __plugin__ = VK
110
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/streamlink/plugins/vk.py b/src/streamlink/plugins/vk.py
--- a/src/streamlink/plugins/vk.py
+++ b/src/streamlink/plugins/vk.py
@@ -6,6 +6,7 @@
import logging
import re
+from hashlib import md5
from urllib.parse import parse_qsl, unquote, urlparse
from streamlink.exceptions import NoStreamsError
@@ -13,6 +14,7 @@
from streamlink.plugin.api import validate
from streamlink.stream.dash import DASHStream
from streamlink.stream.hls import HLSStream
+from streamlink.utils.url import update_qsd
log = logging.getLogger(__name__)
@@ -25,6 +27,22 @@
))
class VK(Plugin):
API_URL = "https://vk.com/al_video.php"
+ HASH_COOKIE = "hash429"
+
+ def _get_cookies(self):
+ def on_response(res, **kwargs):
+ if res.headers.get("x-waf-redirect") == "1":
+ if not res.headers.get("X-WAF-Backend-Status"):
+ log.debug("Getting WAF cookie")
+ cookie = res.cookies.get(self.HASH_COOKIE)
+ key = md5(cookie.encode("utf-8")).hexdigest()
+ res.headers["Location"] = update_qsd(res.headers["Location"], qsd={"key": key})
+ return res
+ elif res.headers.get("X-WAF-Backend-Status") == "challenge_success":
+ self.session.http.cookies.update(res.cookies)
+ return res
+
+ self.session.http.get("https://vk.com/", hooks={"response": on_response})
def _has_video_id(self):
return any(m for m in self.matches[:-1])
@@ -56,21 +74,19 @@
raise NoStreamsError(self.url)
def _get_streams(self):
+ self._get_cookies()
self.follow_vk_redirect()
video_id = self.match.group("video_id")
if not video_id:
return
- log.debug(f"video ID: {video_id}")
+ log.debug(f"Video ID: {video_id}")
try:
data = self.session.http.post(
self.API_URL,
- params={
- "act": "show",
- "al": "1",
- "video": video_id,
- },
+ params={"act": "show"},
+ data={"act": "show", "al": "1", "video": video_id},
headers={"Referer": self.url},
schema=validate.Schema(
validate.transform(lambda text: re.sub(r"^\s*<!--\s*", "", text)),
|
{"golden_diff": "diff --git a/src/streamlink/plugins/vk.py b/src/streamlink/plugins/vk.py\n--- a/src/streamlink/plugins/vk.py\n+++ b/src/streamlink/plugins/vk.py\n@@ -6,6 +6,7 @@\n \n import logging\n import re\n+from hashlib import md5\n from urllib.parse import parse_qsl, unquote, urlparse\n \n from streamlink.exceptions import NoStreamsError\n@@ -13,6 +14,7 @@\n from streamlink.plugin.api import validate\n from streamlink.stream.dash import DASHStream\n from streamlink.stream.hls import HLSStream\n+from streamlink.utils.url import update_qsd\n \n log = logging.getLogger(__name__)\n \n@@ -25,6 +27,22 @@\n ))\n class VK(Plugin):\n API_URL = \"https://vk.com/al_video.php\"\n+ HASH_COOKIE = \"hash429\"\n+\n+ def _get_cookies(self):\n+ def on_response(res, **kwargs):\n+ if res.headers.get(\"x-waf-redirect\") == \"1\":\n+ if not res.headers.get(\"X-WAF-Backend-Status\"):\n+ log.debug(\"Getting WAF cookie\")\n+ cookie = res.cookies.get(self.HASH_COOKIE)\n+ key = md5(cookie.encode(\"utf-8\")).hexdigest()\n+ res.headers[\"Location\"] = update_qsd(res.headers[\"Location\"], qsd={\"key\": key})\n+ return res\n+ elif res.headers.get(\"X-WAF-Backend-Status\") == \"challenge_success\":\n+ self.session.http.cookies.update(res.cookies)\n+ return res\n+\n+ self.session.http.get(\"https://vk.com/\", hooks={\"response\": on_response})\n \n def _has_video_id(self):\n return any(m for m in self.matches[:-1])\n@@ -56,21 +74,19 @@\n raise NoStreamsError(self.url)\n \n def _get_streams(self):\n+ self._get_cookies()\n self.follow_vk_redirect()\n \n video_id = self.match.group(\"video_id\")\n if not video_id:\n return\n \n- log.debug(f\"video ID: {video_id}\")\n+ log.debug(f\"Video ID: {video_id}\")\n try:\n data = self.session.http.post(\n self.API_URL,\n- params={\n- \"act\": \"show\",\n- \"al\": \"1\",\n- \"video\": video_id,\n- },\n+ params={\"act\": \"show\"},\n+ data={\"act\": \"show\", \"al\": \"1\", \"video\": video_id},\n headers={\"Referer\": self.url},\n schema=validate.Schema(\n validate.transform(lambda text: re.sub(r\"^\\s*<!--\\s*\", \"\", text)),\n", "issue": "plugins.vk: fixes required\n### Checklist\r\n\r\n- [X] This is a plugin issue and not a different kind of issue\r\n- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)\r\n- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)\r\n- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)\r\n\r\n### Streamlink version\r\n\r\nLatest build from the master branch\r\n\r\n### Description\r\n\r\nNeeds support for the web application firewall cookie.\r\n\r\n~Seems necessary to add all parameters to the API POST data in `_get_streams()` now.~\r\n\r\nref: https://github.com/streamlink/streamlink/pull/4613#issuecomment-1173040359\r\n\r\n\r\n### Debug log\r\n\r\n```text\r\n$ streamlink -l debug https://vk.com/video-211154316_456239169\r\n[cli][debug] OS: Linux-4.9.0-18-amd64-x86_64-with-debian-9.13\r\n[cli][debug] Python: 3.7.3\r\n[cli][debug] Streamlink: 4.1.0+45.gb277114d\r\n[cli][debug] Dependencies:\r\n[cli][debug] isodate: 0.6.1\r\n[cli][debug] lxml: 4.9.1\r\n[cli][debug] pycountry: 22.3.5\r\n[cli][debug] pycryptodome: 3.15.0\r\n[cli][debug] PySocks: 1.7.1\r\n[cli][debug] requests: 2.28.1\r\n[cli][debug] websocket-client: 1.3.3\r\n[cli][debug] importlib-metadata: 4.12.0\r\n[cli][debug] Arguments:\r\n[cli][debug] url=https://vk.com/video-211154316_456239169\r\n[cli][debug] --loglevel=debug\r\n[cli][info] Found matching plugin vk for URL https://vk.com/video-211154316_456239169\r\n[plugins.vk][debug] video ID: -211154316_456239169\r\n[plugins.vk][error] Could not parse API response\r\nerror: No playable streams found on this URL: https://vk.com/video-211154316_456239169\r\n```\r\n\n", "before_files": [{"content": "\"\"\"\n$description Russian live-streaming and video hosting social platform.\n$url vk.com\n$type live, vod\n\"\"\"\n\nimport logging\nimport re\nfrom urllib.parse import parse_qsl, unquote, urlparse\n\nfrom streamlink.exceptions import NoStreamsError\nfrom streamlink.plugin import Plugin, PluginError, pluginmatcher\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream.dash import DASHStream\nfrom streamlink.stream.hls import HLSStream\n\nlog = logging.getLogger(__name__)\n\n\n@pluginmatcher(re.compile(\n r\"https?://(?:\\w+\\.)?vk\\.com/videos?(?:\\?z=video)?(?P<video_id>-?\\d+_\\d+)\"\n))\n@pluginmatcher(re.compile(\n r\"https?://(\\w+\\.)?vk\\.com/.+\"\n))\nclass VK(Plugin):\n API_URL = \"https://vk.com/al_video.php\"\n\n def _has_video_id(self):\n return any(m for m in self.matches[:-1])\n\n def follow_vk_redirect(self):\n if self._has_video_id():\n return\n\n try:\n parsed_url = urlparse(self.url)\n true_path = next(unquote(v).split(\"/\")[0] for k, v in parse_qsl(parsed_url.query) if k == \"z\" and len(v) > 0)\n self.url = f\"{parsed_url.scheme}://{parsed_url.netloc}/{true_path}\"\n if self._has_video_id():\n return\n except StopIteration:\n pass\n\n try:\n self.url = self.session.http.get(self.url, schema=validate.Schema(\n validate.parse_html(),\n validate.xml_xpath_string(\".//head/meta[@property='og:url'][@content]/@content\"),\n str\n ))\n except PluginError:\n pass\n if self._has_video_id():\n return\n\n raise NoStreamsError(self.url)\n\n def _get_streams(self):\n self.follow_vk_redirect()\n\n video_id = self.match.group(\"video_id\")\n if not video_id:\n return\n\n log.debug(f\"video ID: {video_id}\")\n try:\n data = self.session.http.post(\n self.API_URL,\n params={\n \"act\": \"show\",\n \"al\": \"1\",\n \"video\": video_id,\n },\n headers={\"Referer\": self.url},\n schema=validate.Schema(\n validate.transform(lambda text: re.sub(r\"^\\s*<!--\\s*\", \"\", text)),\n validate.parse_json(),\n {\"payload\": list},\n validate.get((\"payload\", -1)),\n list,\n validate.get(-1),\n {\"player\": {\"params\": [dict]}},\n validate.get((\"player\", \"params\", 0)),\n {\n validate.optional(\"hls\"): validate.url(),\n validate.optional(\"manifest\"): validate.startswith(\"<?xml\"),\n validate.optional(\"md_author\"): validate.any(str, None),\n validate.optional(\"md_title\"): validate.any(str, None),\n }\n )\n )\n except PluginError:\n log.error(\"Could not parse API response\")\n return\n\n self.id = video_id\n self.author = data.get(\"md_author\")\n self.title = data.get(\"md_title\")\n\n hls = data.get(\"hls\")\n if hls:\n return HLSStream.parse_variant_playlist(self.session, hls)\n\n dash_manifest = data.get(\"manifest\")\n if dash_manifest:\n return DASHStream.parse_manifest(self.session, dash_manifest)\n\n\n__plugin__ = VK\n", "path": "src/streamlink/plugins/vk.py"}], "after_files": [{"content": "\"\"\"\n$description Russian live-streaming and video hosting social platform.\n$url vk.com\n$type live, vod\n\"\"\"\n\nimport logging\nimport re\nfrom hashlib import md5\nfrom urllib.parse import parse_qsl, unquote, urlparse\n\nfrom streamlink.exceptions import NoStreamsError\nfrom streamlink.plugin import Plugin, PluginError, pluginmatcher\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream.dash import DASHStream\nfrom streamlink.stream.hls import HLSStream\nfrom streamlink.utils.url import update_qsd\n\nlog = logging.getLogger(__name__)\n\n\n@pluginmatcher(re.compile(\n r\"https?://(?:\\w+\\.)?vk\\.com/videos?(?:\\?z=video)?(?P<video_id>-?\\d+_\\d+)\"\n))\n@pluginmatcher(re.compile(\n r\"https?://(\\w+\\.)?vk\\.com/.+\"\n))\nclass VK(Plugin):\n API_URL = \"https://vk.com/al_video.php\"\n HASH_COOKIE = \"hash429\"\n\n def _get_cookies(self):\n def on_response(res, **kwargs):\n if res.headers.get(\"x-waf-redirect\") == \"1\":\n if not res.headers.get(\"X-WAF-Backend-Status\"):\n log.debug(\"Getting WAF cookie\")\n cookie = res.cookies.get(self.HASH_COOKIE)\n key = md5(cookie.encode(\"utf-8\")).hexdigest()\n res.headers[\"Location\"] = update_qsd(res.headers[\"Location\"], qsd={\"key\": key})\n return res\n elif res.headers.get(\"X-WAF-Backend-Status\") == \"challenge_success\":\n self.session.http.cookies.update(res.cookies)\n return res\n\n self.session.http.get(\"https://vk.com/\", hooks={\"response\": on_response})\n\n def _has_video_id(self):\n return any(m for m in self.matches[:-1])\n\n def follow_vk_redirect(self):\n if self._has_video_id():\n return\n\n try:\n parsed_url = urlparse(self.url)\n true_path = next(unquote(v).split(\"/\")[0] for k, v in parse_qsl(parsed_url.query) if k == \"z\" and len(v) > 0)\n self.url = f\"{parsed_url.scheme}://{parsed_url.netloc}/{true_path}\"\n if self._has_video_id():\n return\n except StopIteration:\n pass\n\n try:\n self.url = self.session.http.get(self.url, schema=validate.Schema(\n validate.parse_html(),\n validate.xml_xpath_string(\".//head/meta[@property='og:url'][@content]/@content\"),\n str\n ))\n except PluginError:\n pass\n if self._has_video_id():\n return\n\n raise NoStreamsError(self.url)\n\n def _get_streams(self):\n self._get_cookies()\n self.follow_vk_redirect()\n\n video_id = self.match.group(\"video_id\")\n if not video_id:\n return\n\n log.debug(f\"Video ID: {video_id}\")\n try:\n data = self.session.http.post(\n self.API_URL,\n params={\"act\": \"show\"},\n data={\"act\": \"show\", \"al\": \"1\", \"video\": video_id},\n headers={\"Referer\": self.url},\n schema=validate.Schema(\n validate.transform(lambda text: re.sub(r\"^\\s*<!--\\s*\", \"\", text)),\n validate.parse_json(),\n {\"payload\": list},\n validate.get((\"payload\", -1)),\n list,\n validate.get(-1),\n {\"player\": {\"params\": [dict]}},\n validate.get((\"player\", \"params\", 0)),\n {\n validate.optional(\"hls\"): validate.url(),\n validate.optional(\"manifest\"): validate.startswith(\"<?xml\"),\n validate.optional(\"md_author\"): validate.any(str, None),\n validate.optional(\"md_title\"): validate.any(str, None),\n }\n )\n )\n except PluginError:\n log.error(\"Could not parse API response\")\n return\n\n self.id = video_id\n self.author = data.get(\"md_author\")\n self.title = data.get(\"md_title\")\n\n hls = data.get(\"hls\")\n if hls:\n return HLSStream.parse_variant_playlist(self.session, hls)\n\n dash_manifest = data.get(\"manifest\")\n if dash_manifest:\n return DASHStream.parse_manifest(self.session, dash_manifest)\n\n\n__plugin__ = VK\n", "path": "src/streamlink/plugins/vk.py"}]}
| 1,876 | 584 |
gh_patches_debug_28570
|
rasdani/github-patches
|
git_diff
|
fedora-infra__bodhi-2952
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bodhi should not allow retired releases to be composed
Today composes for F26 (currently EOL) were accidentally run, which failed and required manual clean up. Bodhi should not allow composing retired releases.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bodhi/server/push.py`
Content:
```
1 # Copyright © 2007-2019 Red Hat, Inc.
2 #
3 # This file is part of Bodhi.
4 #
5 # This program is free software; you can redistribute it and/or
6 # modify it under the terms of the GNU General Public License
7 # as published by the Free Software Foundation; either version 2
8 # of the License, or (at your option) any later version.
9 #
10 # This program is distributed in the hope that it will be useful,
11 # but WITHOUT ANY WARRANTY; without even the implied warranty of
12 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
13 # GNU General Public License for more details.
14 #
15 # You should have received a copy of the GNU General Public License
16 # along with this program; if not, write to the Free Software
17 # Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
18 """The CLI tool for triggering update pushes."""
19 from sqlalchemy.sql import or_
20 import click
21
22 from bodhi.server import (buildsys, initialize_db, get_koji)
23 from bodhi.server.config import config
24 from bodhi.server.models import (Compose, ComposeState, Release, ReleaseState, Build, Update,
25 UpdateRequest)
26 from bodhi.server.util import transactional_session_maker
27 import bodhi.server.notifications
28
29
30 _koji = None
31
32
33 def update_sig_status(update):
34 """Update build signature status for builds in update."""
35 global _koji
36 if _koji is None:
37 # We don't want to authenticate to the buildsystem, because this script is often mistakenly
38 # run as root and this can cause the ticket cache to become root owned with 0600 perms,
39 # which will cause the compose to fail when it tries to use it to authenticate to Koji.
40 buildsys.setup_buildsystem(config, authenticate=False)
41 _koji = get_koji(None)
42 for build in update.builds:
43 if not build.signed:
44 build_tags = build.get_tags(_koji)
45 if update.release.pending_signing_tag not in build_tags:
46 click.echo('Build %s was refreshed as signed' % build.nvr)
47 build.signed = True
48 else:
49 click.echo('Build %s still unsigned' % build.nvr)
50
51
52 @click.command()
53 @click.option('--builds', help='Push updates for a comma-separated list of builds')
54 @click.option('--cert-prefix', default="shell",
55 help="The prefix of a fedmsg cert used to sign the message")
56 @click.option('--releases', help=('Push updates for a comma-separated list of releases (default: '
57 'current and pending releases)'))
58 @click.option('--request', default='testing,stable',
59 help='Push updates with a specific request (default: testing,stable)')
60 @click.option('--resume', help='Resume one or more previously failed pushes',
61 is_flag=True, default=False)
62 @click.option('--username', prompt=True)
63 @click.option('--yes', '-y', is_flag=True, default=False,
64 help='Answers yes to the various questions')
65 @click.version_option(message='%(version)s')
66 def push(username, cert_prefix, yes, **kwargs):
67 """Push builds out to the repositories."""
68 resume = kwargs.pop('resume')
69 resume_all = False
70
71 initialize_db(config)
72 db_factory = transactional_session_maker()
73 composes = []
74 with db_factory() as session:
75 if not resume and session.query(Compose).count():
76 if yes:
77 click.echo('Existing composes detected: {}. Resuming all.'.format(
78 ', '.join([str(c) for c in session.query(Compose).all()])))
79 else:
80 click.confirm(
81 'Existing composes detected: {}. Do you wish to resume them all?'.format(
82 ', '.join([str(c) for c in session.query(Compose).all()])),
83 abort=True)
84 resume = True
85 resume_all = True
86
87 # If we're resuming a push
88 if resume:
89 for compose in session.query(Compose).all():
90 if len(compose.updates) == 0:
91 # Compose objects can end up with 0 updates in them if the composer ejects all
92 # the updates in a compose for some reason. Composes with no updates cannot be
93 # serialized because their content_type property uses the content_type of the
94 # first update in the Compose. Additionally, it doesn't really make sense to go
95 # forward with running an empty Compose. It makes the most sense to delete them.
96 click.echo("{} has no updates. It is being removed.".format(compose))
97 session.delete(compose)
98 continue
99
100 if not resume_all:
101 if yes:
102 click.echo('Resuming {}.'.format(compose))
103 elif not click.confirm('Resume {}?'.format(compose)):
104 continue
105
106 # Reset the Compose's state and error message.
107 compose.state = ComposeState.requested
108 compose.error_message = u''
109
110 composes.append(compose)
111 else:
112 updates = []
113 # Accept both comma and space separated request list
114 requests = kwargs['request'].replace(',', ' ').split(' ')
115 requests = [UpdateRequest.from_string(val) for val in requests]
116
117 query = session.query(Update).filter(Update.request.in_(requests))
118
119 if kwargs.get('builds'):
120 query = query.join(Update.builds)
121 query = query.filter(
122 or_(*[Build.nvr == build for build in kwargs['builds'].split(',')]))
123
124 query = _filter_releases(session, query, kwargs.get('releases'))
125
126 for update in query.all():
127 # Skip unsigned updates (this checks that all builds in the update are signed)
128 update_sig_status(update)
129
130 if not update.signed:
131 click.echo('Warning: %s has unsigned builds and has been skipped' %
132 update.title)
133 continue
134
135 updates.append(update)
136
137 composes = Compose.from_updates(updates)
138 for c in composes:
139 session.add(c)
140
141 # We need to flush so the database knows about the new Compose objects, so the
142 # Compose.updates relationship will work properly. This is due to us overriding the
143 # primaryjoin on the relationship between Composes and Updates.
144 session.flush()
145
146 # Now we need to refresh the composes so their updates property will not be empty.
147 for compose in composes:
148 session.refresh(compose)
149
150 # Now we need to sort the composes so their security property can be used to prioritize
151 # security updates. The security property relies on the updates property being
152 # non-empty, so this must happen after the refresh above.
153 composes = sorted(composes)
154
155 for compose in composes:
156 click.echo('\n\n===== {} =====\n'.format(compose))
157 for update in compose.updates:
158 click.echo(update.title)
159
160 if composes:
161 if yes:
162 click.echo('\n\nPushing {:d} updates.'.format(
163 sum([len(c.updates) for c in composes])))
164 else:
165 click.confirm('\n\nPush these {:d} updates?'.format(
166 sum([len(c.updates) for c in composes])), abort=True)
167 click.echo('\nLocking updates...')
168 else:
169 click.echo('\nThere are no updates to push.')
170
171 composes = [c.__json__(composer=True) for c in composes]
172
173 if composes:
174 click.echo('\nSending composer.start fedmsg')
175 # Because we're a script, we want to send to the fedmsg-relay,
176 # that's why we say active=True
177 bodhi.server.notifications.init(active=True, cert_prefix=cert_prefix)
178 bodhi.server.notifications.publish(
179 topic='composer.start',
180 msg=dict(
181 api_version=2,
182 composes=composes,
183 resume=resume,
184 agent=username,
185 ),
186 force=True,
187 )
188
189
190 def _filter_releases(session, query, releases=None):
191 """
192 Filter the given query by releases.
193
194 Apply a filter() transformation to the given query on Updates to filter updates that match the
195 given releases argument. If releases evaluates "Falsey", this function will filter for Updates
196 that are part of a current Release.
197
198 :param session: The database session
199 :param query: An Update query that we want to modify by filtering based on Releases
200 :param releases: A comma-separated string of release names
201
202 :returns: A filtered version of query with an additional filter based on releases.
203 """
204 # We will store models.Release object here that we want to filter by
205 _releases = []
206
207 # Filter only releases composed by Bodhi.
208 releases_query = session.query(Release).filter(Release.composed_by_bodhi == True)
209
210 if releases:
211 for r in releases.split(','):
212 release = releases_query.filter(
213 or_(Release.name == r,
214 Release.name == r.upper(),
215 Release.version == r)).first()
216 if not release:
217 raise click.BadParameter('Unknown release: %s' % r)
218 else:
219 _releases.append(release)
220 else:
221 # Since the user didn't ask for specific Releases, let's just filter for releases that are
222 # current or pending.
223 _releases = releases_query.filter(or_(Release.state == ReleaseState.current,
224 Release.state == ReleaseState.pending))
225
226 return query.filter(or_(*[Update.release == r for r in _releases]))
227
228
229 if __name__ == '__main__':
230 push()
231
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bodhi/server/push.py b/bodhi/server/push.py
--- a/bodhi/server/push.py
+++ b/bodhi/server/push.py
@@ -207,6 +207,10 @@
# Filter only releases composed by Bodhi.
releases_query = session.query(Release).filter(Release.composed_by_bodhi == True)
+ # Filter only releases that are current or pending.
+ releases_query = releases_query.filter(or_(Release.state == ReleaseState.current,
+ Release.state == ReleaseState.pending))
+
if releases:
for r in releases.split(','):
release = releases_query.filter(
@@ -214,14 +218,15 @@
Release.name == r.upper(),
Release.version == r)).first()
if not release:
- raise click.BadParameter('Unknown release: %s' % r)
+ raise click.BadParameter(
+ 'Unknown release, or release not allowed to be composed: %s' % r
+ )
else:
_releases.append(release)
else:
# Since the user didn't ask for specific Releases, let's just filter for releases that are
# current or pending.
- _releases = releases_query.filter(or_(Release.state == ReleaseState.current,
- Release.state == ReleaseState.pending))
+ _releases = releases_query
return query.filter(or_(*[Update.release == r for r in _releases]))
|
{"golden_diff": "diff --git a/bodhi/server/push.py b/bodhi/server/push.py\n--- a/bodhi/server/push.py\n+++ b/bodhi/server/push.py\n@@ -207,6 +207,10 @@\n # Filter only releases composed by Bodhi.\n releases_query = session.query(Release).filter(Release.composed_by_bodhi == True)\n \n+ # Filter only releases that are current or pending.\n+ releases_query = releases_query.filter(or_(Release.state == ReleaseState.current,\n+ Release.state == ReleaseState.pending))\n+\n if releases:\n for r in releases.split(','):\n release = releases_query.filter(\n@@ -214,14 +218,15 @@\n Release.name == r.upper(),\n Release.version == r)).first()\n if not release:\n- raise click.BadParameter('Unknown release: %s' % r)\n+ raise click.BadParameter(\n+ 'Unknown release, or release not allowed to be composed: %s' % r\n+ )\n else:\n _releases.append(release)\n else:\n # Since the user didn't ask for specific Releases, let's just filter for releases that are\n # current or pending.\n- _releases = releases_query.filter(or_(Release.state == ReleaseState.current,\n- Release.state == ReleaseState.pending))\n+ _releases = releases_query\n \n return query.filter(or_(*[Update.release == r for r in _releases]))\n", "issue": "Bodhi should not allow retired releases to be composed\nToday composes for F26 (currently EOL) were accidentally run, which failed and required manual clean up. Bodhi should not allow composing retired releases.\n", "before_files": [{"content": "# Copyright \u00a9 2007-2019 Red Hat, Inc.\n#\n# This file is part of Bodhi.\n#\n# This program is free software; you can redistribute it and/or\n# modify it under the terms of the GNU General Public License\n# as published by the Free Software Foundation; either version 2\n# of the License, or (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program; if not, write to the Free Software\n# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.\n\"\"\"The CLI tool for triggering update pushes.\"\"\"\nfrom sqlalchemy.sql import or_\nimport click\n\nfrom bodhi.server import (buildsys, initialize_db, get_koji)\nfrom bodhi.server.config import config\nfrom bodhi.server.models import (Compose, ComposeState, Release, ReleaseState, Build, Update,\n UpdateRequest)\nfrom bodhi.server.util import transactional_session_maker\nimport bodhi.server.notifications\n\n\n_koji = None\n\n\ndef update_sig_status(update):\n \"\"\"Update build signature status for builds in update.\"\"\"\n global _koji\n if _koji is None:\n # We don't want to authenticate to the buildsystem, because this script is often mistakenly\n # run as root and this can cause the ticket cache to become root owned with 0600 perms,\n # which will cause the compose to fail when it tries to use it to authenticate to Koji.\n buildsys.setup_buildsystem(config, authenticate=False)\n _koji = get_koji(None)\n for build in update.builds:\n if not build.signed:\n build_tags = build.get_tags(_koji)\n if update.release.pending_signing_tag not in build_tags:\n click.echo('Build %s was refreshed as signed' % build.nvr)\n build.signed = True\n else:\n click.echo('Build %s still unsigned' % build.nvr)\n\n\[email protected]()\[email protected]('--builds', help='Push updates for a comma-separated list of builds')\[email protected]('--cert-prefix', default=\"shell\",\n help=\"The prefix of a fedmsg cert used to sign the message\")\[email protected]('--releases', help=('Push updates for a comma-separated list of releases (default: '\n 'current and pending releases)'))\[email protected]('--request', default='testing,stable',\n help='Push updates with a specific request (default: testing,stable)')\[email protected]('--resume', help='Resume one or more previously failed pushes',\n is_flag=True, default=False)\[email protected]('--username', prompt=True)\[email protected]('--yes', '-y', is_flag=True, default=False,\n help='Answers yes to the various questions')\[email protected]_option(message='%(version)s')\ndef push(username, cert_prefix, yes, **kwargs):\n \"\"\"Push builds out to the repositories.\"\"\"\n resume = kwargs.pop('resume')\n resume_all = False\n\n initialize_db(config)\n db_factory = transactional_session_maker()\n composes = []\n with db_factory() as session:\n if not resume and session.query(Compose).count():\n if yes:\n click.echo('Existing composes detected: {}. Resuming all.'.format(\n ', '.join([str(c) for c in session.query(Compose).all()])))\n else:\n click.confirm(\n 'Existing composes detected: {}. Do you wish to resume them all?'.format(\n ', '.join([str(c) for c in session.query(Compose).all()])),\n abort=True)\n resume = True\n resume_all = True\n\n # If we're resuming a push\n if resume:\n for compose in session.query(Compose).all():\n if len(compose.updates) == 0:\n # Compose objects can end up with 0 updates in them if the composer ejects all\n # the updates in a compose for some reason. Composes with no updates cannot be\n # serialized because their content_type property uses the content_type of the\n # first update in the Compose. Additionally, it doesn't really make sense to go\n # forward with running an empty Compose. It makes the most sense to delete them.\n click.echo(\"{} has no updates. It is being removed.\".format(compose))\n session.delete(compose)\n continue\n\n if not resume_all:\n if yes:\n click.echo('Resuming {}.'.format(compose))\n elif not click.confirm('Resume {}?'.format(compose)):\n continue\n\n # Reset the Compose's state and error message.\n compose.state = ComposeState.requested\n compose.error_message = u''\n\n composes.append(compose)\n else:\n updates = []\n # Accept both comma and space separated request list\n requests = kwargs['request'].replace(',', ' ').split(' ')\n requests = [UpdateRequest.from_string(val) for val in requests]\n\n query = session.query(Update).filter(Update.request.in_(requests))\n\n if kwargs.get('builds'):\n query = query.join(Update.builds)\n query = query.filter(\n or_(*[Build.nvr == build for build in kwargs['builds'].split(',')]))\n\n query = _filter_releases(session, query, kwargs.get('releases'))\n\n for update in query.all():\n # Skip unsigned updates (this checks that all builds in the update are signed)\n update_sig_status(update)\n\n if not update.signed:\n click.echo('Warning: %s has unsigned builds and has been skipped' %\n update.title)\n continue\n\n updates.append(update)\n\n composes = Compose.from_updates(updates)\n for c in composes:\n session.add(c)\n\n # We need to flush so the database knows about the new Compose objects, so the\n # Compose.updates relationship will work properly. This is due to us overriding the\n # primaryjoin on the relationship between Composes and Updates.\n session.flush()\n\n # Now we need to refresh the composes so their updates property will not be empty.\n for compose in composes:\n session.refresh(compose)\n\n # Now we need to sort the composes so their security property can be used to prioritize\n # security updates. The security property relies on the updates property being\n # non-empty, so this must happen after the refresh above.\n composes = sorted(composes)\n\n for compose in composes:\n click.echo('\\n\\n===== {} =====\\n'.format(compose))\n for update in compose.updates:\n click.echo(update.title)\n\n if composes:\n if yes:\n click.echo('\\n\\nPushing {:d} updates.'.format(\n sum([len(c.updates) for c in composes])))\n else:\n click.confirm('\\n\\nPush these {:d} updates?'.format(\n sum([len(c.updates) for c in composes])), abort=True)\n click.echo('\\nLocking updates...')\n else:\n click.echo('\\nThere are no updates to push.')\n\n composes = [c.__json__(composer=True) for c in composes]\n\n if composes:\n click.echo('\\nSending composer.start fedmsg')\n # Because we're a script, we want to send to the fedmsg-relay,\n # that's why we say active=True\n bodhi.server.notifications.init(active=True, cert_prefix=cert_prefix)\n bodhi.server.notifications.publish(\n topic='composer.start',\n msg=dict(\n api_version=2,\n composes=composes,\n resume=resume,\n agent=username,\n ),\n force=True,\n )\n\n\ndef _filter_releases(session, query, releases=None):\n \"\"\"\n Filter the given query by releases.\n\n Apply a filter() transformation to the given query on Updates to filter updates that match the\n given releases argument. If releases evaluates \"Falsey\", this function will filter for Updates\n that are part of a current Release.\n\n :param session: The database session\n :param query: An Update query that we want to modify by filtering based on Releases\n :param releases: A comma-separated string of release names\n\n :returns: A filtered version of query with an additional filter based on releases.\n \"\"\"\n # We will store models.Release object here that we want to filter by\n _releases = []\n\n # Filter only releases composed by Bodhi.\n releases_query = session.query(Release).filter(Release.composed_by_bodhi == True)\n\n if releases:\n for r in releases.split(','):\n release = releases_query.filter(\n or_(Release.name == r,\n Release.name == r.upper(),\n Release.version == r)).first()\n if not release:\n raise click.BadParameter('Unknown release: %s' % r)\n else:\n _releases.append(release)\n else:\n # Since the user didn't ask for specific Releases, let's just filter for releases that are\n # current or pending.\n _releases = releases_query.filter(or_(Release.state == ReleaseState.current,\n Release.state == ReleaseState.pending))\n\n return query.filter(or_(*[Update.release == r for r in _releases]))\n\n\nif __name__ == '__main__':\n push()\n", "path": "bodhi/server/push.py"}], "after_files": [{"content": "# Copyright \u00a9 2007-2019 Red Hat, Inc.\n#\n# This file is part of Bodhi.\n#\n# This program is free software; you can redistribute it and/or\n# modify it under the terms of the GNU General Public License\n# as published by the Free Software Foundation; either version 2\n# of the License, or (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program; if not, write to the Free Software\n# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.\n\"\"\"The CLI tool for triggering update pushes.\"\"\"\nfrom sqlalchemy.sql import or_\nimport click\n\nfrom bodhi.server import (buildsys, initialize_db, get_koji)\nfrom bodhi.server.config import config\nfrom bodhi.server.models import (Compose, ComposeState, Release, ReleaseState, Build, Update,\n UpdateRequest)\nfrom bodhi.server.util import transactional_session_maker\nimport bodhi.server.notifications\n\n\n_koji = None\n\n\ndef update_sig_status(update):\n \"\"\"Update build signature status for builds in update.\"\"\"\n global _koji\n if _koji is None:\n # We don't want to authenticate to the buildsystem, because this script is often mistakenly\n # run as root and this can cause the ticket cache to become root owned with 0600 perms,\n # which will cause the compose to fail when it tries to use it to authenticate to Koji.\n buildsys.setup_buildsystem(config, authenticate=False)\n _koji = get_koji(None)\n for build in update.builds:\n if not build.signed:\n build_tags = build.get_tags(_koji)\n if update.release.pending_signing_tag not in build_tags:\n click.echo('Build %s was refreshed as signed' % build.nvr)\n build.signed = True\n else:\n click.echo('Build %s still unsigned' % build.nvr)\n\n\[email protected]()\[email protected]('--builds', help='Push updates for a comma-separated list of builds')\[email protected]('--cert-prefix', default=\"shell\",\n help=\"The prefix of a fedmsg cert used to sign the message\")\[email protected]('--releases', help=('Push updates for a comma-separated list of releases (default: '\n 'current and pending releases)'))\[email protected]('--request', default='testing,stable',\n help='Push updates with a specific request (default: testing,stable)')\[email protected]('--resume', help='Resume one or more previously failed pushes',\n is_flag=True, default=False)\[email protected]('--username', prompt=True)\[email protected]('--yes', '-y', is_flag=True, default=False,\n help='Answers yes to the various questions')\[email protected]_option(message='%(version)s')\ndef push(username, cert_prefix, yes, **kwargs):\n \"\"\"Push builds out to the repositories.\"\"\"\n resume = kwargs.pop('resume')\n resume_all = False\n\n initialize_db(config)\n db_factory = transactional_session_maker()\n composes = []\n with db_factory() as session:\n if not resume and session.query(Compose).count():\n if yes:\n click.echo('Existing composes detected: {}. Resuming all.'.format(\n ', '.join([str(c) for c in session.query(Compose).all()])))\n else:\n click.confirm(\n 'Existing composes detected: {}. Do you wish to resume them all?'.format(\n ', '.join([str(c) for c in session.query(Compose).all()])),\n abort=True)\n resume = True\n resume_all = True\n\n # If we're resuming a push\n if resume:\n for compose in session.query(Compose).all():\n if len(compose.updates) == 0:\n # Compose objects can end up with 0 updates in them if the composer ejects all\n # the updates in a compose for some reason. Composes with no updates cannot be\n # serialized because their content_type property uses the content_type of the\n # first update in the Compose. Additionally, it doesn't really make sense to go\n # forward with running an empty Compose. It makes the most sense to delete them.\n click.echo(\"{} has no updates. It is being removed.\".format(compose))\n session.delete(compose)\n continue\n\n if not resume_all:\n if yes:\n click.echo('Resuming {}.'.format(compose))\n elif not click.confirm('Resume {}?'.format(compose)):\n continue\n\n # Reset the Compose's state and error message.\n compose.state = ComposeState.requested\n compose.error_message = u''\n\n composes.append(compose)\n else:\n updates = []\n # Accept both comma and space separated request list\n requests = kwargs['request'].replace(',', ' ').split(' ')\n requests = [UpdateRequest.from_string(val) for val in requests]\n\n query = session.query(Update).filter(Update.request.in_(requests))\n\n if kwargs.get('builds'):\n query = query.join(Update.builds)\n query = query.filter(\n or_(*[Build.nvr == build for build in kwargs['builds'].split(',')]))\n\n query = _filter_releases(session, query, kwargs.get('releases'))\n\n for update in query.all():\n # Skip unsigned updates (this checks that all builds in the update are signed)\n update_sig_status(update)\n\n if not update.signed:\n click.echo('Warning: %s has unsigned builds and has been skipped' %\n update.title)\n continue\n\n updates.append(update)\n\n composes = Compose.from_updates(updates)\n for c in composes:\n session.add(c)\n\n # We need to flush so the database knows about the new Compose objects, so the\n # Compose.updates relationship will work properly. This is due to us overriding the\n # primaryjoin on the relationship between Composes and Updates.\n session.flush()\n\n # Now we need to refresh the composes so their updates property will not be empty.\n for compose in composes:\n session.refresh(compose)\n\n # Now we need to sort the composes so their security property can be used to prioritize\n # security updates. The security property relies on the updates property being\n # non-empty, so this must happen after the refresh above.\n composes = sorted(composes)\n\n for compose in composes:\n click.echo('\\n\\n===== {} =====\\n'.format(compose))\n for update in compose.updates:\n click.echo(update.title)\n\n if composes:\n if yes:\n click.echo('\\n\\nPushing {:d} updates.'.format(\n sum([len(c.updates) for c in composes])))\n else:\n click.confirm('\\n\\nPush these {:d} updates?'.format(\n sum([len(c.updates) for c in composes])), abort=True)\n click.echo('\\nLocking updates...')\n else:\n click.echo('\\nThere are no updates to push.')\n\n composes = [c.__json__(composer=True) for c in composes]\n\n if composes:\n click.echo('\\nSending composer.start fedmsg')\n # Because we're a script, we want to send to the fedmsg-relay,\n # that's why we say active=True\n bodhi.server.notifications.init(active=True, cert_prefix=cert_prefix)\n bodhi.server.notifications.publish(\n topic='composer.start',\n msg=dict(\n api_version=2,\n composes=composes,\n resume=resume,\n agent=username,\n ),\n force=True,\n )\n\n\ndef _filter_releases(session, query, releases=None):\n \"\"\"\n Filter the given query by releases.\n\n Apply a filter() transformation to the given query on Updates to filter updates that match the\n given releases argument. If releases evaluates \"Falsey\", this function will filter for Updates\n that are part of a current Release.\n\n :param session: The database session\n :param query: An Update query that we want to modify by filtering based on Releases\n :param releases: A comma-separated string of release names\n\n :returns: A filtered version of query with an additional filter based on releases.\n \"\"\"\n # We will store models.Release object here that we want to filter by\n _releases = []\n\n # Filter only releases composed by Bodhi.\n releases_query = session.query(Release).filter(Release.composed_by_bodhi == True)\n\n # Filter only releases that are current or pending.\n releases_query = releases_query.filter(or_(Release.state == ReleaseState.current,\n Release.state == ReleaseState.pending))\n\n if releases:\n for r in releases.split(','):\n release = releases_query.filter(\n or_(Release.name == r,\n Release.name == r.upper(),\n Release.version == r)).first()\n if not release:\n raise click.BadParameter(\n 'Unknown release, or release not allowed to be composed: %s' % r\n )\n else:\n _releases.append(release)\n else:\n # Since the user didn't ask for specific Releases, let's just filter for releases that are\n # current or pending.\n _releases = releases_query\n\n return query.filter(or_(*[Update.release == r for r in _releases]))\n\n\nif __name__ == '__main__':\n push()\n", "path": "bodhi/server/push.py"}]}
| 2,956 | 323 |
gh_patches_debug_30160
|
rasdani/github-patches
|
git_diff
|
tensorflow__addons-2114
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
List TensorFlow as an "extra" requirement to install the correct TFA for a given TF version
When installing `tensorflow_addons` without specifying an exact version, users may install a version that is incompatible with their existing TensorFlow version.
As such, users are advised to check the [Python Op Compatibility Matrix](https://github.com/tensorflow/addons#python-op-compatibility-matrix) and manually install the correct version of TFA to be safe.
For most Python projects, this can be taken care of automatically by listing a specific `tensorflow` version(s) as a requirement in the `setup.py` file:
```
install_requires=['tensorflow>=2.2,<2.4']
```
I suspect that this project does not do this because of the various different pip package names TensorFlow uses (e.g., `tf-nightly`, `tensorflow-gpu`, `tensorflow-cpu`). By having such a requirement, user could accidentally install two different versions of TensorFlow at the same time.
To get around this, we could introduce an extra requirement:
```
extras_require = {'tensorflow': ['tensorflow>=2.2,<2.4']}
```
This way, users will only get automatic dependency resolution when running `pip install tensorflow_addons[tensorflow]`.
The benefit of doing this is that if a new version of TFA is released that no longer supports TensorFlow 2.2 (for example), pip will fall back to installing the previous version of TFA if the user has TF 2.2 installed.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # Copyright 2019 The TensorFlow Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15 """TensorFlow Addons.
16
17 TensorFlow Addons is a repository of contributions that conform to well-
18 established API patterns, but implement new functionality not available
19 in core TensorFlow. TensorFlow natively supports a large number of
20 operators, layers, metrics, losses, and optimizers. However, in a fast
21 moving field like ML, there are many interesting new developments that
22 cannot be integrated into core TensorFlow (because their broad
23 applicability is not yet clear, or it is mostly used by a smaller subset
24 of the community).
25 """
26
27 import os
28 from pathlib import Path
29 import sys
30
31 from datetime import datetime
32 from setuptools import find_packages
33 from setuptools import setup
34 from setuptools.dist import Distribution
35 from setuptools import Extension
36
37 DOCLINES = __doc__.split("\n")
38
39
40 def get_last_commit_time() -> str:
41 string_time = os.getenv("NIGHTLY_TIME").replace('"', "")
42 return datetime.strptime(string_time, "%Y-%m-%dT%H:%M:%SZ").strftime("%Y%m%d%H%M%S")
43
44
45 def get_project_name_version():
46 # Version
47 version = {}
48 base_dir = os.path.dirname(os.path.abspath(__file__))
49 with open(os.path.join(base_dir, "tensorflow_addons", "version.py")) as fp:
50 exec(fp.read(), version)
51
52 project_name = "tensorflow-addons"
53 if "--nightly" in sys.argv:
54 project_name = "tfa-nightly"
55 version["__version__"] += get_last_commit_time()
56 sys.argv.remove("--nightly")
57
58 return project_name, version
59
60
61 def get_ext_modules():
62 ext_modules = []
63 if "--platlib-patch" in sys.argv:
64 if sys.platform.startswith("linux"):
65 # Manylinux2010 requires a patch for platlib
66 ext_modules = [Extension("_foo", ["stub.cc"])]
67 sys.argv.remove("--platlib-patch")
68 return ext_modules
69
70
71 class BinaryDistribution(Distribution):
72 """This class is needed in order to create OS specific wheels."""
73
74 def has_ext_modules(self):
75 return True
76
77
78 project_name, version = get_project_name_version()
79 setup(
80 name=project_name,
81 version=version["__version__"],
82 description=DOCLINES[0],
83 long_description="\n".join(DOCLINES[2:]),
84 author="Google Inc.",
85 author_email="[email protected]",
86 packages=find_packages(),
87 ext_modules=get_ext_modules(),
88 install_requires=Path("requirements.txt").read_text().splitlines(),
89 include_package_data=True,
90 zip_safe=False,
91 distclass=BinaryDistribution,
92 classifiers=[
93 "Development Status :: 4 - Beta",
94 "Intended Audience :: Developers",
95 "Intended Audience :: Education",
96 "Intended Audience :: Science/Research",
97 "License :: OSI Approved :: Apache Software License",
98 "Programming Language :: Python :: 3",
99 "Programming Language :: Python :: 3.5",
100 "Programming Language :: Python :: 3.6",
101 "Programming Language :: Python :: 3.7",
102 "Programming Language :: Python :: 3.8",
103 "Topic :: Scientific/Engineering :: Mathematics",
104 "Topic :: Software Development :: Libraries :: Python Modules",
105 "Topic :: Software Development :: Libraries",
106 ],
107 license="Apache 2.0",
108 keywords="tensorflow addons machine learning",
109 )
110
```
Path: `tensorflow_addons/version.py`
Content:
```
1 # Copyright 2019 The TensorFlow Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ============================================================================
15 """Define TensorFlow Addons version information."""
16
17 # We follow Semantic Versioning (https://semver.org/)
18 _MAJOR_VERSION = "0"
19 _MINOR_VERSION = "12"
20 _PATCH_VERSION = "0"
21
22 # When building releases, we can update this value on the release branch to
23 # reflect the current release candidate ('rc0', 'rc1') or, finally, the official
24 # stable release (indicated by `_VERSION_SUFFIX = ''`). Outside the context of a
25 # release branch, the current version is by default assumed to be a
26 # 'development' version, labeled 'dev'.
27 _VERSION_SUFFIX = "dev"
28
29 # Example, '0.1.0-dev'
30 __version__ = ".".join([_MAJOR_VERSION, _MINOR_VERSION, _PATCH_VERSION])
31 if _VERSION_SUFFIX:
32 __version__ = "{}-{}".format(__version__, _VERSION_SUFFIX)
33
```
Path: `tensorflow_addons/utils/ensure_tf_install.py`
Content:
```
1 # Copyright 2019 The TensorFlow Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15
16
17 # Ensure the TensorFlow version is in the right range. This
18 # needs to happen before anything else, since the imports below will try to
19 # import TensorFlow, too.
20
21 from distutils.version import LooseVersion
22 import warnings
23
24 import tensorflow as tf
25
26 MIN_TF_VERSION = "2.2.0"
27 MAX_TF_VERSION = "2.4.0"
28
29
30 def _check_tf_version():
31 """Warn the user if the version of TensorFlow used is not supported.
32
33 This is not a check for custom ops compatibility. This check only ensure that
34 we support this TensorFlow version if the user uses only Addons' Python code.
35 """
36
37 if "dev" in tf.__version__:
38 warnings.warn(
39 "You are currently using a nightly version of TensorFlow ({}). \n"
40 "TensorFlow Addons offers no support for the nightly versions of "
41 "TensorFlow. Some things might work, some other might not. \n"
42 "If you encounter a bug, do not file an issue on GitHub."
43 "".format(tf.__version__),
44 UserWarning,
45 )
46 return
47
48 min_version = LooseVersion(MIN_TF_VERSION)
49 max_version = LooseVersion(MAX_TF_VERSION)
50
51 if min_version <= LooseVersion(tf.__version__) < max_version:
52 return
53
54 warnings.warn(
55 "Tensorflow Addons supports using Python ops for all Tensorflow versions "
56 "above or equal to {} and strictly below {} (nightly versions are not "
57 "supported). \n "
58 "The versions of TensorFlow you are currently using is {} and is not "
59 "supported. \n"
60 "Some things might work, some things might not.\n"
61 "If you were to encounter a bug, do not file an issue.\n"
62 "If you want to make sure you're using a tested and supported configuration, "
63 "either change the TensorFlow version or the TensorFlow Addons's version. \n"
64 "You can find the compatibility matrix in TensorFlow Addon's readme:\n"
65 "https://github.com/tensorflow/addons".format(
66 MIN_TF_VERSION, MAX_TF_VERSION, tf.__version__
67 ),
68 UserWarning,
69 )
70
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -76,6 +76,8 @@
project_name, version = get_project_name_version()
+min_tf_version = version["MIN_TF_VERSION"]
+max_tf_version = version["MAX_TF_VERSION"]
setup(
name=project_name,
version=version["__version__"],
@@ -86,6 +88,15 @@
packages=find_packages(),
ext_modules=get_ext_modules(),
install_requires=Path("requirements.txt").read_text().splitlines(),
+ extras_require={
+ "tensorflow": ["tensorflow>={},<{}".format(min_tf_version, max_tf_version)],
+ "tensorflow-gpu": [
+ "tensorflow-gpu>={},<{}".format(min_tf_version, max_tf_version)
+ ],
+ "tensorflow-cpu": [
+ "tensorflow-cpu>={},<{}".format(min_tf_version, max_tf_version)
+ ],
+ },
include_package_data=True,
zip_safe=False,
distclass=BinaryDistribution,
diff --git a/tensorflow_addons/utils/ensure_tf_install.py b/tensorflow_addons/utils/ensure_tf_install.py
--- a/tensorflow_addons/utils/ensure_tf_install.py
+++ b/tensorflow_addons/utils/ensure_tf_install.py
@@ -23,8 +23,7 @@
import tensorflow as tf
-MIN_TF_VERSION = "2.2.0"
-MAX_TF_VERSION = "2.4.0"
+from tensorflow_addons.version import MIN_TF_VERSION, MAX_TF_VERSION
def _check_tf_version():
diff --git a/tensorflow_addons/version.py b/tensorflow_addons/version.py
--- a/tensorflow_addons/version.py
+++ b/tensorflow_addons/version.py
@@ -14,6 +14,10 @@
# ============================================================================
"""Define TensorFlow Addons version information."""
+# Required TensorFlow version [min, max)
+MIN_TF_VERSION = "2.2.0"
+MAX_TF_VERSION = "2.4.0"
+
# We follow Semantic Versioning (https://semver.org/)
_MAJOR_VERSION = "0"
_MINOR_VERSION = "12"
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -76,6 +76,8 @@\n \n \n project_name, version = get_project_name_version()\n+min_tf_version = version[\"MIN_TF_VERSION\"]\n+max_tf_version = version[\"MAX_TF_VERSION\"]\n setup(\n name=project_name,\n version=version[\"__version__\"],\n@@ -86,6 +88,15 @@\n packages=find_packages(),\n ext_modules=get_ext_modules(),\n install_requires=Path(\"requirements.txt\").read_text().splitlines(),\n+ extras_require={\n+ \"tensorflow\": [\"tensorflow>={},<{}\".format(min_tf_version, max_tf_version)],\n+ \"tensorflow-gpu\": [\n+ \"tensorflow-gpu>={},<{}\".format(min_tf_version, max_tf_version)\n+ ],\n+ \"tensorflow-cpu\": [\n+ \"tensorflow-cpu>={},<{}\".format(min_tf_version, max_tf_version)\n+ ],\n+ },\n include_package_data=True,\n zip_safe=False,\n distclass=BinaryDistribution,\ndiff --git a/tensorflow_addons/utils/ensure_tf_install.py b/tensorflow_addons/utils/ensure_tf_install.py\n--- a/tensorflow_addons/utils/ensure_tf_install.py\n+++ b/tensorflow_addons/utils/ensure_tf_install.py\n@@ -23,8 +23,7 @@\n \n import tensorflow as tf\n \n-MIN_TF_VERSION = \"2.2.0\"\n-MAX_TF_VERSION = \"2.4.0\"\n+from tensorflow_addons.version import MIN_TF_VERSION, MAX_TF_VERSION\n \n \n def _check_tf_version():\ndiff --git a/tensorflow_addons/version.py b/tensorflow_addons/version.py\n--- a/tensorflow_addons/version.py\n+++ b/tensorflow_addons/version.py\n@@ -14,6 +14,10 @@\n # ============================================================================\n \"\"\"Define TensorFlow Addons version information.\"\"\"\n \n+# Required TensorFlow version [min, max)\n+MIN_TF_VERSION = \"2.2.0\"\n+MAX_TF_VERSION = \"2.4.0\"\n+\n # We follow Semantic Versioning (https://semver.org/)\n _MAJOR_VERSION = \"0\"\n _MINOR_VERSION = \"12\"\n", "issue": "List TensorFlow as an \"extra\" requirement to install the correct TFA for a given TF version\nWhen installing `tensorflow_addons` without specifying an exact version, users may install a version that is incompatible with their existing TensorFlow version. \r\n\r\nAs such, users are advised to check the [Python Op Compatibility Matrix](https://github.com/tensorflow/addons#python-op-compatibility-matrix) and manually install the correct version of TFA to be safe.\r\n\r\nFor most Python projects, this can be taken care of automatically by listing a specific `tensorflow` version(s) as a requirement in the `setup.py` file:\r\n\r\n```\r\ninstall_requires=['tensorflow>=2.2,<2.4']\r\n```\r\n\r\nI suspect that this project does not do this because of the various different pip package names TensorFlow uses (e.g., `tf-nightly`, `tensorflow-gpu`, `tensorflow-cpu`). By having such a requirement, user could accidentally install two different versions of TensorFlow at the same time.\r\n\r\nTo get around this, we could introduce an extra requirement:\r\n\r\n```\r\nextras_require = {'tensorflow': ['tensorflow>=2.2,<2.4']}\r\n```\r\n\r\nThis way, users will only get automatic dependency resolution when running `pip install tensorflow_addons[tensorflow]`.\r\n\r\nThe benefit of doing this is that if a new version of TFA is released that no longer supports TensorFlow 2.2 (for example), pip will fall back to installing the previous version of TFA if the user has TF 2.2 installed.\n", "before_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"TensorFlow Addons.\n\nTensorFlow Addons is a repository of contributions that conform to well-\nestablished API patterns, but implement new functionality not available\nin core TensorFlow. TensorFlow natively supports a large number of\noperators, layers, metrics, losses, and optimizers. However, in a fast\nmoving field like ML, there are many interesting new developments that\ncannot be integrated into core TensorFlow (because their broad\napplicability is not yet clear, or it is mostly used by a smaller subset\nof the community).\n\"\"\"\n\nimport os\nfrom pathlib import Path\nimport sys\n\nfrom datetime import datetime\nfrom setuptools import find_packages\nfrom setuptools import setup\nfrom setuptools.dist import Distribution\nfrom setuptools import Extension\n\nDOCLINES = __doc__.split(\"\\n\")\n\n\ndef get_last_commit_time() -> str:\n string_time = os.getenv(\"NIGHTLY_TIME\").replace('\"', \"\")\n return datetime.strptime(string_time, \"%Y-%m-%dT%H:%M:%SZ\").strftime(\"%Y%m%d%H%M%S\")\n\n\ndef get_project_name_version():\n # Version\n version = {}\n base_dir = os.path.dirname(os.path.abspath(__file__))\n with open(os.path.join(base_dir, \"tensorflow_addons\", \"version.py\")) as fp:\n exec(fp.read(), version)\n\n project_name = \"tensorflow-addons\"\n if \"--nightly\" in sys.argv:\n project_name = \"tfa-nightly\"\n version[\"__version__\"] += get_last_commit_time()\n sys.argv.remove(\"--nightly\")\n\n return project_name, version\n\n\ndef get_ext_modules():\n ext_modules = []\n if \"--platlib-patch\" in sys.argv:\n if sys.platform.startswith(\"linux\"):\n # Manylinux2010 requires a patch for platlib\n ext_modules = [Extension(\"_foo\", [\"stub.cc\"])]\n sys.argv.remove(\"--platlib-patch\")\n return ext_modules\n\n\nclass BinaryDistribution(Distribution):\n \"\"\"This class is needed in order to create OS specific wheels.\"\"\"\n\n def has_ext_modules(self):\n return True\n\n\nproject_name, version = get_project_name_version()\nsetup(\n name=project_name,\n version=version[\"__version__\"],\n description=DOCLINES[0],\n long_description=\"\\n\".join(DOCLINES[2:]),\n author=\"Google Inc.\",\n author_email=\"[email protected]\",\n packages=find_packages(),\n ext_modules=get_ext_modules(),\n install_requires=Path(\"requirements.txt\").read_text().splitlines(),\n include_package_data=True,\n zip_safe=False,\n distclass=BinaryDistribution,\n classifiers=[\n \"Development Status :: 4 - Beta\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Topic :: Scientific/Engineering :: Mathematics\",\n \"Topic :: Software Development :: Libraries :: Python Modules\",\n \"Topic :: Software Development :: Libraries\",\n ],\n license=\"Apache 2.0\",\n keywords=\"tensorflow addons machine learning\",\n)\n", "path": "setup.py"}, {"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ============================================================================\n\"\"\"Define TensorFlow Addons version information.\"\"\"\n\n# We follow Semantic Versioning (https://semver.org/)\n_MAJOR_VERSION = \"0\"\n_MINOR_VERSION = \"12\"\n_PATCH_VERSION = \"0\"\n\n# When building releases, we can update this value on the release branch to\n# reflect the current release candidate ('rc0', 'rc1') or, finally, the official\n# stable release (indicated by `_VERSION_SUFFIX = ''`). Outside the context of a\n# release branch, the current version is by default assumed to be a\n# 'development' version, labeled 'dev'.\n_VERSION_SUFFIX = \"dev\"\n\n# Example, '0.1.0-dev'\n__version__ = \".\".join([_MAJOR_VERSION, _MINOR_VERSION, _PATCH_VERSION])\nif _VERSION_SUFFIX:\n __version__ = \"{}-{}\".format(__version__, _VERSION_SUFFIX)\n", "path": "tensorflow_addons/version.py"}, {"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\n\n# Ensure the TensorFlow version is in the right range. This\n# needs to happen before anything else, since the imports below will try to\n# import TensorFlow, too.\n\nfrom distutils.version import LooseVersion\nimport warnings\n\nimport tensorflow as tf\n\nMIN_TF_VERSION = \"2.2.0\"\nMAX_TF_VERSION = \"2.4.0\"\n\n\ndef _check_tf_version():\n \"\"\"Warn the user if the version of TensorFlow used is not supported.\n\n This is not a check for custom ops compatibility. This check only ensure that\n we support this TensorFlow version if the user uses only Addons' Python code.\n \"\"\"\n\n if \"dev\" in tf.__version__:\n warnings.warn(\n \"You are currently using a nightly version of TensorFlow ({}). \\n\"\n \"TensorFlow Addons offers no support for the nightly versions of \"\n \"TensorFlow. Some things might work, some other might not. \\n\"\n \"If you encounter a bug, do not file an issue on GitHub.\"\n \"\".format(tf.__version__),\n UserWarning,\n )\n return\n\n min_version = LooseVersion(MIN_TF_VERSION)\n max_version = LooseVersion(MAX_TF_VERSION)\n\n if min_version <= LooseVersion(tf.__version__) < max_version:\n return\n\n warnings.warn(\n \"Tensorflow Addons supports using Python ops for all Tensorflow versions \"\n \"above or equal to {} and strictly below {} (nightly versions are not \"\n \"supported). \\n \"\n \"The versions of TensorFlow you are currently using is {} and is not \"\n \"supported. \\n\"\n \"Some things might work, some things might not.\\n\"\n \"If you were to encounter a bug, do not file an issue.\\n\"\n \"If you want to make sure you're using a tested and supported configuration, \"\n \"either change the TensorFlow version or the TensorFlow Addons's version. \\n\"\n \"You can find the compatibility matrix in TensorFlow Addon's readme:\\n\"\n \"https://github.com/tensorflow/addons\".format(\n MIN_TF_VERSION, MAX_TF_VERSION, tf.__version__\n ),\n UserWarning,\n )\n", "path": "tensorflow_addons/utils/ensure_tf_install.py"}], "after_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"TensorFlow Addons.\n\nTensorFlow Addons is a repository of contributions that conform to well-\nestablished API patterns, but implement new functionality not available\nin core TensorFlow. TensorFlow natively supports a large number of\noperators, layers, metrics, losses, and optimizers. However, in a fast\nmoving field like ML, there are many interesting new developments that\ncannot be integrated into core TensorFlow (because their broad\napplicability is not yet clear, or it is mostly used by a smaller subset\nof the community).\n\"\"\"\n\nimport os\nfrom pathlib import Path\nimport sys\n\nfrom datetime import datetime\nfrom setuptools import find_packages\nfrom setuptools import setup\nfrom setuptools.dist import Distribution\nfrom setuptools import Extension\n\nDOCLINES = __doc__.split(\"\\n\")\n\n\ndef get_last_commit_time() -> str:\n string_time = os.getenv(\"NIGHTLY_TIME\").replace('\"', \"\")\n return datetime.strptime(string_time, \"%Y-%m-%dT%H:%M:%SZ\").strftime(\"%Y%m%d%H%M%S\")\n\n\ndef get_project_name_version():\n # Version\n version = {}\n base_dir = os.path.dirname(os.path.abspath(__file__))\n with open(os.path.join(base_dir, \"tensorflow_addons\", \"version.py\")) as fp:\n exec(fp.read(), version)\n\n project_name = \"tensorflow-addons\"\n if \"--nightly\" in sys.argv:\n project_name = \"tfa-nightly\"\n version[\"__version__\"] += get_last_commit_time()\n sys.argv.remove(\"--nightly\")\n\n return project_name, version\n\n\ndef get_ext_modules():\n ext_modules = []\n if \"--platlib-patch\" in sys.argv:\n if sys.platform.startswith(\"linux\"):\n # Manylinux2010 requires a patch for platlib\n ext_modules = [Extension(\"_foo\", [\"stub.cc\"])]\n sys.argv.remove(\"--platlib-patch\")\n return ext_modules\n\n\nclass BinaryDistribution(Distribution):\n \"\"\"This class is needed in order to create OS specific wheels.\"\"\"\n\n def has_ext_modules(self):\n return True\n\n\nproject_name, version = get_project_name_version()\nmin_tf_version = version[\"MIN_TF_VERSION\"]\nmax_tf_version = version[\"MAX_TF_VERSION\"]\nsetup(\n name=project_name,\n version=version[\"__version__\"],\n description=DOCLINES[0],\n long_description=\"\\n\".join(DOCLINES[2:]),\n author=\"Google Inc.\",\n author_email=\"[email protected]\",\n packages=find_packages(),\n ext_modules=get_ext_modules(),\n install_requires=Path(\"requirements.txt\").read_text().splitlines(),\n extras_require={\n \"tensorflow\": [\"tensorflow>={},<{}\".format(min_tf_version, max_tf_version)],\n \"tensorflow-gpu\": [\n \"tensorflow-gpu>={},<{}\".format(min_tf_version, max_tf_version)\n ],\n \"tensorflow-cpu\": [\n \"tensorflow-cpu>={},<{}\".format(min_tf_version, max_tf_version)\n ],\n },\n include_package_data=True,\n zip_safe=False,\n distclass=BinaryDistribution,\n classifiers=[\n \"Development Status :: 4 - Beta\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Education\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Topic :: Scientific/Engineering :: Mathematics\",\n \"Topic :: Software Development :: Libraries :: Python Modules\",\n \"Topic :: Software Development :: Libraries\",\n ],\n license=\"Apache 2.0\",\n keywords=\"tensorflow addons machine learning\",\n)\n", "path": "setup.py"}, {"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ============================================================================\n\"\"\"Define TensorFlow Addons version information.\"\"\"\n\n# Required TensorFlow version [min, max)\nMIN_TF_VERSION = \"2.2.0\"\nMAX_TF_VERSION = \"2.4.0\"\n\n# We follow Semantic Versioning (https://semver.org/)\n_MAJOR_VERSION = \"0\"\n_MINOR_VERSION = \"12\"\n_PATCH_VERSION = \"0\"\n\n# When building releases, we can update this value on the release branch to\n# reflect the current release candidate ('rc0', 'rc1') or, finally, the official\n# stable release (indicated by `_VERSION_SUFFIX = ''`). Outside the context of a\n# release branch, the current version is by default assumed to be a\n# 'development' version, labeled 'dev'.\n_VERSION_SUFFIX = \"dev\"\n\n# Example, '0.1.0-dev'\n__version__ = \".\".join([_MAJOR_VERSION, _MINOR_VERSION, _PATCH_VERSION])\nif _VERSION_SUFFIX:\n __version__ = \"{}-{}\".format(__version__, _VERSION_SUFFIX)\n", "path": "tensorflow_addons/version.py"}, {"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\n\n# Ensure the TensorFlow version is in the right range. This\n# needs to happen before anything else, since the imports below will try to\n# import TensorFlow, too.\n\nfrom distutils.version import LooseVersion\nimport warnings\n\nimport tensorflow as tf\n\nfrom tensorflow_addons.version import MIN_TF_VERSION, MAX_TF_VERSION\n\n\ndef _check_tf_version():\n \"\"\"Warn the user if the version of TensorFlow used is not supported.\n\n This is not a check for custom ops compatibility. This check only ensure that\n we support this TensorFlow version if the user uses only Addons' Python code.\n \"\"\"\n\n if \"dev\" in tf.__version__:\n warnings.warn(\n \"You are currently using a nightly version of TensorFlow ({}). \\n\"\n \"TensorFlow Addons offers no support for the nightly versions of \"\n \"TensorFlow. Some things might work, some other might not. \\n\"\n \"If you encounter a bug, do not file an issue on GitHub.\"\n \"\".format(tf.__version__),\n UserWarning,\n )\n return\n\n min_version = LooseVersion(MIN_TF_VERSION)\n max_version = LooseVersion(MAX_TF_VERSION)\n\n if min_version <= LooseVersion(tf.__version__) < max_version:\n return\n\n warnings.warn(\n \"Tensorflow Addons supports using Python ops for all Tensorflow versions \"\n \"above or equal to {} and strictly below {} (nightly versions are not \"\n \"supported). \\n \"\n \"The versions of TensorFlow you are currently using is {} and is not \"\n \"supported. \\n\"\n \"Some things might work, some things might not.\\n\"\n \"If you were to encounter a bug, do not file an issue.\\n\"\n \"If you want to make sure you're using a tested and supported configuration, \"\n \"either change the TensorFlow version or the TensorFlow Addons's version. \\n\"\n \"You can find the compatibility matrix in TensorFlow Addon's readme:\\n\"\n \"https://github.com/tensorflow/addons\".format(\n MIN_TF_VERSION, MAX_TF_VERSION, tf.__version__\n ),\n UserWarning,\n )\n", "path": "tensorflow_addons/utils/ensure_tf_install.py"}]}
| 2,802 | 484 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.