
question_slug
stringlengths 3
77
| title
stringlengths 1
183
| slug
stringlengths 12
45
| summary
stringlengths 1
160
⌀ | author
stringlengths 2
30
| certification
stringclasses 2
values | created_at
stringdate 2013-10-25 17:32:12
2025-04-12 09:38:24
| updated_at
stringdate 2013-10-25 17:32:12
2025-04-12 09:38:24
| hit_count
int64 0
10.6M
| has_video
bool 2
classes | content
stringlengths 4
576k
| upvotes
int64 0
11.5k
| downvotes
int64 0
358
| tags
stringlengths 2
193
| comments
int64 0
2.56k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
maximum-path-quality-of-a-graph | Simple and clean || C++ solution || Beats 96% of run-time | simple-and-clean-c-solution-beats-96-of-fo1p9 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \nit\'s pretty much strai | Shwet_Patel | NORMAL | 2024-08-17T14:07:28.756519+00:00 | 2024-08-17T14:07:28.756536+00:00 | 3 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nit\'s pretty much straightforward. i am keeping track of frequency of node in my path in the visited array. keeping track of time while doing DFS. calling recursive call if only the time + time of that edge is less than or equal to the limit.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\npublic:\n int time = 0;\n int ans = INT_MIN;\n\n void solve( int i , int quality , vector<int>& val \n , vector<vector<pair<int,int>>>& adj , vector<int>& visited , int maxi )\n {\n visited[i]++;\n if( visited[i] == 1 )\n {\n quality = quality + val[i];\n }\n\n if( i == 0 )\n {\n ans = max( ans , quality );\n }\n\n for( auto it : adj[i] )\n {\n if( time + it.second <= maxi )\n {\n time = time + it.second;\n solve( it.first , quality , val , adj , visited , maxi );\n time = time - it.second;\n }\n }\n\n visited[i]--;\n }\n\n int maximalPathQuality(vector<int>& values, vector<vector<int>>& edges, int maxTime) \n {\n int n = values.size();\n vector<int> visited(n,0);\n\n vector<vector<pair<int,int>>> adj(n);\n for(auto e : edges)\n {\n adj[e[0]].push_back({e[1],e[2]});\n adj[e[1]].push_back({e[0],e[2]});\n }\n\n solve(0,0,values,adj,visited,maxTime);\n return ans;\n }\n};\n``` | 0 | 0 | ['C++'] | 0 |
maximum-path-quality-of-a-graph | C++ backtracking | c-backtracking-by-user5976fh-k18l | The key is to notice that the minimum time for an edge is 10, and the maximum time total is 100, which leads to a max amount of paths of 4 ^ 10\n\n\nclass Solut | user5976fh | NORMAL | 2024-08-14T18:54:35.340382+00:00 | 2024-08-14T18:54:35.340412+00:00 | 2 | false | The key is to notice that the minimum time for an edge is 10, and the maximum time total is 100, which leads to a max amount of paths of 4 ^ 10\n\n```\nclass Solution {\npublic:\n vector<int> b, v;\n vector<vector<pair<int,int>>> g;\n int maximalPathQuality(vector<int>& values, vector<vector<int>>& edges, int maxTime) {\n b.resize(values.size());\n g.resize(values.size());\n v = values;\n for (auto& e : edges)\n g[e[0]].push_back({e[1], e[2]}),\n g[e[1]].push_back({e[0], e[2]});\n return dfs(0, maxTime);\n }\n \n int dfs(int node, int t){\n if (t < 0) return -1;\n int ans = !node ? (!b[node] ? v[node] : 0) : -1;\n ++b[node];\n for (auto& [edgeNode, edgeCost] : g[node]){\n int next = dfs(edgeNode, t - edgeCost);\n if (next != -1)\n ans = max(ans, (b[node] == 1) * v[node] + next);\n }\n --b[node];\n return ans;\n }\n};\n``` | 0 | 0 | [] | 0 |
maximum-path-quality-of-a-graph | Python (Simple Backtracking) | python-simple-backtracking-by-rnotappl-wut5 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | rnotappl | NORMAL | 2024-08-14T15:06:34.538099+00:00 | 2024-08-14T15:06:34.538123+00:00 | 3 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def maximalPathQuality(self, values, edges, maxTime):\n n, graph = len(values), defaultdict(list)\n\n for u,v,t in edges:\n graph[u].append((v,t))\n graph[v].append((u,t))\n\n self.max_sum = 0\n\n def backtrack(node,values,total,time):\n if node == 0 and time <= maxTime:\n self.max_sum = max(self.max_sum,total)\n\n for neighbor,t in graph[node]:\n if time + t <= maxTime:\n val = values[neighbor]\n values[neighbor] = 0\n backtrack(neighbor,values,total+val,time+t)\n values[neighbor] = val\n\n val = values[0]\n values[0] = 0\n backtrack(0,values,val,0)\n return self.max_sum\n``` | 0 | 0 | ['Python3'] | 0 |
maximum-path-quality-of-a-graph | Simple solution | simple-solution-by-dmitrik-ue4d | Code\n\nclass Solution:\n def maximalPathQuality(self, values: List[int], edges: List[List[int]], maxTime: int) -> int:\n graph = defaultdict(list)\n | dmitrik | NORMAL | 2024-07-26T13:15:29.704506+00:00 | 2024-07-26T13:15:29.704542+00:00 | 23 | false | # Code\n```\nclass Solution:\n def maximalPathQuality(self, values: List[int], edges: List[List[int]], maxTime: int) -> int:\n graph = defaultdict(list)\n for node1, node2, time in edges:\n graph[node1].append([node2, time])\n graph[node2].append([node1, time])\n result = 0\n queue = deque()\n queue.append([0, 0, 0, set()])\n while queue:\n node, currentTime, points, visited = queue.popleft()\n if node not in visited:\n points += values[node]\n visited.add(node)\n if node == 0:\n result = max(result, points)\n for neighbor, time in graph[node]:\n if currentTime + time <= maxTime:\n queue.append([neighbor, currentTime + time, points, visited.copy()])\n return result\n``` | 0 | 0 | ['Breadth-First Search', 'Python3'] | 0 |
maximum-path-quality-of-a-graph | C++ | DFS | c-dfs-by-jeetendrakumar123-7tst | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | jeetendrakumar123 | NORMAL | 2024-07-07T16:44:06.558697+00:00 | 2024-07-07T16:44:06.558720+00:00 | 11 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\npublic:\n // Graph represented as an adjacency list, where each node points to a list of pairs (neighbor, travel time)\n vector<pair<int, int>> graph[1001];\n\n // Depth-First Search (DFS) function to explore all paths\n void dfs(int node, int currTime, int sum, int maxTime, int& ans, vector<int>& values) {\n // Base case: if the current time exceeds the maximum allowed time, return\n if (currTime > maxTime) {\n return;\n }\n\n // If we are at the starting node and within the allowed time, update the answer\n if (node == 0 && currTime <= maxTime) {\n ans = max(ans, sum);\n }\n\n // Store the value of the current node and set it to 0 to avoid double-counting\n int val = values[node];\n values[node] = 0;\n\n // Explore all neighboring nodes\n for (auto& [nextNode, time] : graph[node]) {\n if (currTime + time <= maxTime) {\n // Recursive call to DFS for the next node\n dfs(nextNode, currTime + time, sum + val, maxTime, ans, values);\n }\n }\n\n // Restore the value of the current node before backtracking\n values[node] = val;\n }\n\n // Function to calculate the maximal path quality\n int maximalPathQuality(vector<int>& values, vector<vector<int>>& edges, int maxTime) {\n // Build the graph from the given edges\n for (auto& edge : edges) {\n graph[edge[0]].emplace_back(edge[1], edge[2]);\n graph[edge[1]].emplace_back(edge[0], edge[2]);\n }\n\n // Initialize the answer and start DFS from node 0\n int ans = 0;\n dfs(0, 0, 0, maxTime, ans, values);\n\n // Return the maximal path quality, considering the starting node\'s value\n return max(ans, values[0]);\n }\n};\n\n``` | 0 | 0 | ['C++'] | 0 |
maximum-path-quality-of-a-graph | c++ dfs | c-dfs-by-wufengxuan1230-imxv | \nclass Solution {\npublic:\n int maximalPathQuality(vector<int>& values, vector<vector<int>>& edges, int maxTime) {\n vector<vector<array<int, 2>>> g | wufengxuan1230 | NORMAL | 2024-07-01T02:25:33.214464+00:00 | 2024-07-01T02:25:33.214489+00:00 | 1 | false | ```\nclass Solution {\npublic:\n int maximalPathQuality(vector<int>& values, vector<vector<int>>& edges, int maxTime) {\n vector<vector<array<int, 2>>> graph(values.size());\n for (auto &e : edges) {\n graph[e[0]].push_back({e[1], e[2]});\n graph[e[1]].push_back({e[0], e[2]});\n }\n\n int res = values[0];\n vector<int> seen(values.size());\n function<void(int, int, int)> dfs = [&](int n, int v, int t) {\n for (auto& [nxt, time] : graph[n]) {\n if (t < time) {\n continue;\n }\n\n if (nxt == 0) {\n res = max(res, v);\n }\n\n int val = seen[nxt] ? 0 : values[nxt];\n ++seen[nxt];\n dfs(nxt, val + v, t - time);\n --seen[nxt];\n }\n };\n \n seen[0] = 1;\n dfs(0, values[0], maxTime);\n seen[0] = 0;\n return res;\n }\n};\n``` | 0 | 0 | [] | 0 |
maximum-path-quality-of-a-graph | ap | ap-by-ap5123-3t53 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | ap5123 | NORMAL | 2024-06-21T06:43:26.743569+00:00 | 2024-06-21T06:43:26.743603+00:00 | 0 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\npublic:\n\nvoid dfs(int i,vector<pair<int,int>> adj[],unordered_map<int,int>&vis,int mt,vector<int>&values,int val,int &maxi)\n{\n if(mt<0)return;\n if(vis[i]==0)\n {\n val+=values[i];\n }\n vis[i]++;\n if(i==0)\n {\n maxi=max(maxi,val);\n }\n for(auto j:adj[i])\n {\n dfs(j.first,adj,vis,mt-j.second,values,val,maxi);\n }\n vis[i]--;\n}\n int maximalPathQuality(vector<int>& values, vector<vector<int>>& edges, int mt) {\n int n=values.size();\n unordered_map<int,int> vis;\n vector<pair<int,int>> adj[n];\n for(auto i:edges)\n {\n adj[i[0]].push_back({i[1],i[2]});\n adj[i[1]].push_back({i[0],i[2]});\n }\n int maxi=-1;\n int val=0;\n dfs(0,adj,vis,mt,values,val,maxi);\n return maxi;\n }\n};\n``` | 0 | 0 | ['C++'] | 0 |
maximum-path-quality-of-a-graph | A More Intuitive dfs implementation using returned value instead of pararmeter. | a-more-intuitive-dfs-implementation-usin-vuu1 | Intuition\n Describe your first thoughts on how to solve this problem. \nYou can read the other\'s intuition as it is pretty straightforward.\n\n# Approach\n De | zenmaaan003 | NORMAL | 2024-06-01T19:08:56.606287+00:00 | 2024-06-01T19:08:56.606318+00:00 | 6 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nYou can read the other\'s intuition as it is pretty straightforward.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nAll the solutions I saw were actually storing the answer as some parameter and if was zero we will store the max answer.\n\n# Code\n```\nclass Solution {\npublic:\n vector<int> vis;\n int res;\n\n int dfs(int i, vector<vector<pair<int,int>>> &graph, int maxi, vector<int> &values, int cost) {\n int ans = INT_MIN;// if we can\'t go anywhere from this node as ends here but it\n // cost is higher than allowed means the path can only end on zero so we return -inf. if it does return 0;\n\n if (i == 0) ans = 0;\n int val = vis[i] == 0 ? values[i] : 0;\n vis[i]++;\n \n for (auto &it : graph[i]) {\n if (cost + it.second <= maxi) {\n int temp = dfs(it.first, graph, maxi, values, cost + it.second);// if from this node we can form a valid path it will return some value not infity\n ans = max(ans, val + temp); //this represent the answer at 0 all the paths will be computed and the maximum out of them will be returned\n }\n }\n \n vis[i]--;\n return ans;\n }\n\n int maximalPathQuality(vector<int>& values, vector<vector<int>>& edges, int maxi) {\n int n = values.size();\n res = values[0];\n vis.resize(n, 0);\n vector<vector<pair<int, int>>> graph(n);\n \n for (auto &edge : edges) {\n graph[edge[0]].emplace_back(edge[1], edge[2]);\n graph[edge[1]].emplace_back(edge[0], edge[2]);\n }\n \n vis[0] = 1;\n int result = dfs(0, graph, maxi, values, 0);\n vis[0] = 0;\n return result+values[0];\n }\n};\n\n``` | 0 | 0 | ['C++'] | 0 |
maximum-path-quality-of-a-graph | Reason of int visited and not boolean | DFS | with explanation. | reason-of-int-visited-and-not-boolean-df-a9d5 | Intuition\n- We need to travel all the possible path\u2019s and if we come back to 0 then check the max score.\n- We wont fall into infinite loop because we are | vaibhav1701 | NORMAL | 2024-05-28T22:15:44.393694+00:00 | 2024-05-28T22:15:44.393713+00:00 | 14 | false | # Intuition\n- We need to travel all the possible path\u2019s and if we come back to 0 then check the max score.\n- We wont fall into infinite loop because we are reducing the time in every dfs call, if we dont have enough time it wont call other nodes and simply return.\n- We cannot have boolean visited because\n - suppose 0 - 1 - 2 && 0 - 3 are the edges connected\n - In the above scenario 0 1 and 2 will be marked visited after 0 \u2192 2 dfs.\n - Now 2 goes back to 1 \u2192 0 \u2192 3 (considering we have enough time to cover all nodes in graph)\n - Now when we track back from 3 \u2192 0 that time 0 will be marked unvisited which is actually not true\n - It is the 2nd visit of 0\u2019th node.\n - so we must keep track of visited count.\n\n\n\n# Code\n```\nclass Solution {\n int ans;\n int[] values;\n ArrayList<ArrayList<int[]>> graph;\n int[] visisted;\n\n public int maximalPathQuality(int[] vals, int[][] edges, int maxTime) {\n values = vals;\n ans = 0;\n visisted = new int[vals.length];\n\n graph = new ArrayList<>();\n for (int i : values) {\n graph.add(new ArrayList());\n }\n for (int[] edge : edges) {\n int u = edge[0];\n int v = edge[1];\n int t = edge[2];\n graph.get(u).add(new int[] { v, t });\n graph.get(v).add(new int[] { u, t });\n }\n dfs(0, maxTime, 0);\n return ans;\n }\n\n public void dfs(int src, int maxTime, int score) {\n\n if (visisted[src] == 0) {\n score += values[src];\n }\n if (src == 0) {\n ans = Math.max(ans, score);\n }\n visisted[src]++;\n for (int[] nbr_time : graph.get(src)) {\n int nbr = nbr_time[0];\n int currTime = nbr_time[1];\n if (maxTime - currTime >= 0) { // this wont let infinite loop as time is reducing\n dfs(nbr, maxTime - currTime, score);\n }\n }\n visisted[src]--;\n }\n}\n``` | 0 | 0 | ['Depth-First Search', 'Java'] | 0 |
maximum-path-quality-of-a-graph | Simple but slow(7%) | simple-but-slow7-by-yoongyeom-a2wq | Code\n\nclass Solution:\n def maximalPathQuality(self, values: List[int], edges: List[List[int]], maxTime: int) -> int:\n d = defaultdict(list)\n | YoonGyeom | NORMAL | 2024-05-20T02:52:24.367911+00:00 | 2024-05-20T02:52:24.367972+00:00 | 10 | false | # Code\n```\nclass Solution:\n def maximalPathQuality(self, values: List[int], edges: List[List[int]], maxTime: int) -> int:\n d = defaultdict(list)\n for u, v, w in edges:\n d[u].append((v, w))\n d[v].append((u, w))\n res = values[0]\n q = deque([[0, 0, values[0], set([0])]])\n while q:\n node, time, score, visited = q.popleft()\n if node == 0: res = max(res, score)\n for ch, w in d[node]:\n if time + w <=maxTime:\n vis = visited.copy()\n vis.add(ch)\n k = 0 if ch in visited else values[ch]\n q.append([ch, time+w, score+k, vis])\n return res\n``` | 0 | 0 | ['Python3'] | 0 |
maximum-path-quality-of-a-graph | Python solution with comments | python-solution-with-comments-by-yashjaj-vh0t | \nclass Solution:\n def maximalPathQuality(self, values: List[int], edges: List[List[int]], maxTime: int) -> int:\n from collections import defaultdic | yashjajoo | NORMAL | 2024-04-29T19:19:48.655298+00:00 | 2024-04-29T19:19:48.655321+00:00 | 20 | false | ```\nclass Solution:\n def maximalPathQuality(self, values: List[int], edges: List[List[int]], maxTime: int) -> int:\n from collections import defaultdict\n\n # Create a graph from the edges\n graph = defaultdict(list)\n for u, v, time in edges:\n graph[u].append((v, time))\n graph[v].append((u, time))\n\n # Store maximum quality of path found\n max_quality = 0\n\n # DFS function to explore all paths starting from node 0\n def dfs(node, time_spent, visited, current_quality):\n nonlocal max_quality\n \n # If back at node 0 and not the first call, consider updating the maximum quality\n if node == 0 and visited:\n max_quality = max(max_quality, current_quality)\n \n # Try all possible next steps from current node\n for neighbor, travel_time in graph[node]:\n next_time = time_spent + travel_time\n \n # Only continue if the next_time is within allowable maximum time\n if next_time <= maxTime:\n if neighbor not in visited:\n # Visit the node if it hasn\'t been visited yet\n visited.add(neighbor)\n dfs(neighbor, next_time, visited, current_quality + values[neighbor])\n visited.remove(neighbor)\n else:\n # If already visited, continue without adding the quality\n dfs(neighbor, next_time, visited, current_quality)\n\n # Start DFS from node 0\n visited = set([0])\n dfs(0, 0, visited, values[0])\n\n return max_quality\n``` | 0 | 0 | ['Depth-First Search', 'Python3'] | 0 |
maximum-path-quality-of-a-graph | C++ || simple and easy DFS solution || 🚀🚀beats 80% 🚀🚀 | c-simple-and-easy-dfs-solution-beats-80-nk001 | \n# Code\n\nclass Solution {\npublic:\n void dfs(int node, vector<int>& values, vector<vector<pair<int,int>>>& edges, int& ans, int maxTime, int time, int co | Adnan_Alkam | NORMAL | 2024-04-17T23:01:37.245083+00:00 | 2024-04-17T23:01:37.245117+00:00 | 12 | false | \n# Code\n```\nclass Solution {\npublic:\n void dfs(int node, vector<int>& values, vector<vector<pair<int,int>>>& edges, int& ans, int maxTime, int time, int cost) {\n if (time > maxTime) return;\n\n cost += values[node];\n if (node == 0) ans = max(ans, cost);\n \n //use the value of the node once\n int tmp = 0;\n swap(values[node], tmp);\n\n //go to the adjacent nodes\n for (auto edge : edges[node]) \n dfs(edge.first, values, edges, ans, maxTime, time+edge.second, cost);\n //we can use the values of nodes again\n swap(values[node], tmp);\n }\n int maximalPathQuality(vector<int>& values, vector<vector<int>>& edges, int maxTime) {\n ios_base::sync_with_stdio(false);\n\t\tcin.tie(NULL);\n\t\tcout.tie(NULL);\n\n int n = values.size();\n vector<vector<pair<int, int>>> e(n);\n int ans = 0;\n\n for (auto edge : edges) {\n e[edge[0]].push_back({edge[1], edge[2]});\n e[edge[1]].push_back({edge[0], edge[2]});\n }\n\n dfs(0, values, e, ans, maxTime, 0, 0);\n return ans;\n }\n};\n``` | 0 | 0 | ['Backtracking', 'Depth-First Search', 'C++'] | 0 |
maximum-path-quality-of-a-graph | Python backtracking | python-backtracking-by-yuxue010625-qk4r | \nfrom typing import List\nfrom collections import defaultdict\n\nclass Solution:\n def solve(self, values: List[int], graph, m, max_time, curr_score, curr_n | yuxue010625 | NORMAL | 2024-04-07T16:43:10.256451+00:00 | 2024-04-07T16:43:10.256477+00:00 | 2 | false | ```\nfrom typing import List\nfrom collections import defaultdict\n\nclass Solution:\n def solve(self, values: List[int], graph, m, max_time, curr_score, curr_node, curr_time):\n if curr_time > max_time:\n return\n \n # If node we visit is 0, then valid path\n if curr_node == 0:\n self.max_score = max(self.max_score, curr_score)\n \n # Try each neighbor\n for edge in graph[curr_node]:\n if edge[1] + curr_time > max_time:\n continue\n\n # First node in the path\n if edge[0] not in m or m[edge[0]] == 0:\n m[edge[0]] = 1\n curr_score += values[edge[0]]\n else:\n m[edge[0]] += 1\n\n self.solve(values, graph, m, max_time, curr_score, edge[0], curr_time + edge[1])\n \n # Backtracking, remove from the path\n m[edge[0]] -= 1\n if m[edge[0]] == 0:\n # Last node in the path\n curr_score -= values[edge[0]]\n \n def maximalPathQuality(self, values: List[int], edges: List[List[int]], maxTime: int) -> int:\n self.max_score = 0\n m = {0 : 1}\n\n # Build the graph\n graph = defaultdict(list)\n for edge in edges:\n graph[edge[0]].append((edge[1], edge[2]))\n graph[edge[1]].append((edge[0], edge[2]))\n\n self.solve(values, graph, m, maxTime, values[0], 0, 0)\n return self.max_score\n \n\n\n``` | 0 | 0 | ['Backtracking', 'Python'] | 0 |
maximum-path-quality-of-a-graph | dfs+memorize | dfsmemorize-by-hidanie-b3nm | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | hidanie | NORMAL | 2024-04-03T17:49:11.019070+00:00 | 2024-04-03T17:49:11.019102+00:00 | 14 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\n int result=0;\n public int maximalPathQuality(int[] values, int[][] edges, int maxTime) {\n List<Node>[]connections=new ArrayList[values.length];\n for(int i=0;i<values.length;i++)\n connections[i]=new ArrayList<>();\n for(int []edge:edges)\n {\n connections[edge[0]].add(new Node(edge[1],edge[2]));\n connections[edge[1]].add(new Node(edge[0],edge[2]));\n }\n dfs(new Edg(0,0,0),connections,maxTime, new boolean[values.length][values.length],values);\n return result;\n }\n\n void dfs(Edg edg, List<Node>[]connections,int maxTime,boolean [][]visited,int []values)\n {\n if(edg.sumTime>maxTime)\n return;\n edg.sum+=values[edg.num];\n if(edg.num==0)\n result=Math.max(result,edg.sum);\n int temp=values[edg.num];\n values[edg.num]=0;\n for(Node nod:connections[edg.num])\n {\n if(visited[edg.num][nod.num])\n continue;\n visited[edg.num][nod.num]=true;\n dfs(new Edg(nod.num,edg.sumTime+nod.time,edg.sum),connections,maxTime,visited,values);\n visited[edg.num][nod.num]=false; \n }\n values[edg.num]=temp; \n }\n\n}\n\nclass Node{\n int num;\n int time;\n public Node(int n, int t){num=n;time=t;}\n}\nclass Edg{\n int num;\n int sumTime;\n int sum;\n public Edg(int n, int t, int s){num=n; sumTime=t; sum=s;}\n \n}\n``` | 0 | 0 | ['Java'] | 0 |
maximum-path-quality-of-a-graph | DFS | Python3 | Approach Explained | dfs-python3-approach-explained-by-realbl-bv1q | Approach\nBrute force all paths possible using a depth first search and backtracking method.\n\nWhen we traverse any path, we check if the node we are visiting | realblingy | NORMAL | 2024-04-01T08:56:44.354344+00:00 | 2024-04-01T08:56:44.354364+00:00 | 34 | false | # Approach\nBrute force all paths possible using a depth first search and backtracking method.\n\nWhen we traverse any path, we check if the node we are visiting is 0. If it is, check if the current path we are on is the max quality. \n\nWhen calculating the sum of qualities, it is important to only add them if we haven\'t visited it yet. To do this, we use a hashmap and backtracking to determine how many times we have visited a node during a traversal.\n\n# Complexity\n\n### Time complexity:\nThe constraints of the problem tell us\n1. $$10 <= timej, maxTime <= 100$$ which means we can have up to traverse up to 91 nodes\n2. There are at most four edges connected to each node.\n\nThis means at all 91 nodes, we can traverse at MOST 4 edges each. This means at most $$4^{91}$$ visits to nodes can occur.\n\nSo, the time complexity should be $$O(1)$$\n\n### Space complexity:\nWe create two objects in this algorithm: adjacency list and visited hashmap. The visited hashmap has complexity $$O(V)$$ because it tracks how many times we have visited a node. The adjacency list however is $$O(V+E)$$ since it contains edges between nodes.\n\nHence, the overall space complexity is $$O(V+E)$$ where $$V$$ represents values and $$E$$ represents edges \n\n# Code\n```\nclass Solution:\n def maximalPathQuality(self, values: List[int], edges: List[List[int]], maxTime: int) -> int:\n adj = defaultdict(set)\n for e in edges:\n u, v, t = e[0], e[1], e[2]\n adj[u].add((v, t))\n adj[v].add((u, t))\n\n result = 0\n visited = defaultdict(int)\n\n def dfs(u, maxTime, quality):\n if u == 0:\n nonlocal result\n result = max(result, quality)\n\n visited[u] += 1\n for v, t in adj[u]:\n if maxTime - t >= 0:\n dfs(v, maxTime - t, quality + values[v] if v not in visited else quality)\n visited[u] -= 1\n if visited[u] == 0:\n del visited[u]\n\n dfs(0, maxTime, values[0])\n\n return result\n``` | 0 | 0 | ['Depth-First Search', 'Python3'] | 0 |
maximum-path-quality-of-a-graph | Swift DFS | swift-dfs-by-mudejar-3tua | Code\n\nclass Solution {\n var res = 0\n var map = [Int: [Int: Int]]()\n var values = [Int]()\n\n func maximalPathQuality(_ values: [Int], _ edges: | mudejar | NORMAL | 2024-03-16T02:11:37.081922+00:00 | 2024-03-16T02:11:37.081959+00:00 | 3 | false | # Code\n```\nclass Solution {\n var res = 0\n var map = [Int: [Int: Int]]()\n var values = [Int]()\n\n func maximalPathQuality(_ values: [Int], _ edges: [[Int]], _ maxTime: Int) -> Int {\n for e in edges {\n let (a, b, c) = (e[0], e[1], e[2])\n map[a] = map[a] ?? [:]\n map[a]![b] = c\n map[b] = map[b] ?? [:]\n map[b]![a] = c\n }\n self.values = values\n dfs(0, Set([0]), values[0], maxTime)\n return res\n }\n\n func dfs(_ node: Int, _ visited: Set<Int>, _ gain: Int, _ cost: Int) {\n if cost < 0 { return }\n if node == 0 { res = max(res, gain) }\n for (nextNode, nextCost) in map[node] ?? [:] {\n let nextGain = gain + (visited.contains(nextNode) ? 0 : values[nextNode])\n dfs(nextNode, visited.union([nextNode]), nextGain, cost - nextCost)\n }\n }\n}\n\n``` | 0 | 0 | ['Swift'] | 0 |
maximum-path-quality-of-a-graph | python | python-by-k_kireeti_07-jaxq | Code\n\nclass Solution:\n def maximalPathQuality(self, values: List[int], edges: List[List[int]], maxTime: int) -> int:\n graph = defaultdict(list)\n\ | k_kireeti_07 | NORMAL | 2024-02-25T07:09:01.402966+00:00 | 2024-02-25T07:09:01.403021+00:00 | 10 | false | # Code\n```\nclass Solution:\n def maximalPathQuality(self, values: List[int], edges: List[List[int]], maxTime: int) -> int:\n graph = defaultdict(list)\n\n for i, j, k in edges:\n graph[i].append((j, k))\n graph[j].append((i, k))\n\n def dfs(root, values, s, t):\n\n ans = -float(\'inf\')\n if root == 0:\n ans = max(ans, s)\n \n for nei, time in graph[root]:\n t_ = values[nei]\n values[nei] = 0\n\n if t+time>maxTime:\n if root == 0:\n ans = max(ans, s)\n else:\n ans = max(ans, dfs(nei, values, s+t_, t+time))\n\n values[nei] = t_\n \n return ans\n \n t = values[0]\n values[0] = 0\n\n return dfs(0, values, t, 0)\n \n\n``` | 0 | 0 | ['Python3'] | 0 |
maximum-path-quality-of-a-graph | Backtracking Solution || Clean Java Code | backtracking-solution-clean-java-code-by-33yy | Code\n\nclass Edge {\n int to;\n int time;\n\n public Edge(int to, int time) {\n this.to = to;\n this.time = time;\n }\n}\n\nclass Sol | youssef1998 | NORMAL | 2024-02-21T14:07:43.260680+00:00 | 2024-02-21T14:07:43.260710+00:00 | 34 | false | # Code\n```\nclass Edge {\n int to;\n int time;\n\n public Edge(int to, int time) {\n this.to = to;\n this.time = time;\n }\n}\n\nclass Solution {\n private int maxCost = 0;\n private final Map<Integer, Set<Edge>> children = new HashMap<>();\n\n public int maximalPathQuality(int[] values, int[][] edges, int maxTime) {\n for (int[] edge: edges) {\n int from = edge[0], to = edge[1], time = edge[2];\n children.computeIfAbsent(from, e-> new HashSet<>()).add(new Edge(to, time));\n children.computeIfAbsent(to, e -> new HashSet<>()).add(new Edge(from, time));\n }\n slv(0, 0, maxTime, values, new ArrayList<>(List.of(0)));\n return maxCost;\n }\n\n private void slv(int node, int time, int maxTime, int[] values, List<Integer> path) {\n if (time > maxTime) return;\n if (node == 0) {\n Set<Integer> visited = new HashSet<>();\n int cost = 0;\n for (int n: path) {\n if (!visited.contains(n)) {\n cost += values[n];\n visited.add(n);\n }\n }\n maxCost = Math.max(cost, maxCost);\n }\n for (Edge edge: children.getOrDefault(node, new HashSet<>())) {\n path.add(edge.to);\n slv(edge.to, time + edge.time, maxTime, values, path);\n path.remove(path.size() -1);\n }\n }\n}\n``` | 0 | 0 | ['Java'] | 0 |
maximum-path-quality-of-a-graph | Easy Java Solution | easy-java-solution-by-harshkumar_23-uphv | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | harshkumar_23 | NORMAL | 2024-02-19T16:48:55.505079+00:00 | 2024-02-19T16:48:55.505117+00:00 | 24 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n\nclass Solution {\n Map<Integer, Map<Integer, Integer> > g = new HashMap();\n int res = 0;\n int[] values;\n public int maximalPathQuality(int[] values, int[][] edges, int maxTime) {\n this.values = values;\n for(int[] e : edges) {\n int u = e[0], v = e[1], t = e[2];\n g.computeIfAbsent(u, x -> new HashMap()).put(v, t);\n g.computeIfAbsent(v, x -> new HashMap()).put(u, t);\n }\n dfs(new ArrayList(), 0, maxTime, 0);\n return res;\n }\n void dfs(List<Integer> path, int cur, int maxTime, int time) {\n path.add(cur);\n if(cur == 0) {\n int tmp = 0;\n Set<Integer> hs = new HashSet();\n for(int i : path) {\n if(hs.add(i)) tmp += values[i];\n }\n res = Math.max(res, tmp);\n }\n for(var en : g.getOrDefault(cur, new HashMap<>()).entrySet()) {\n int nei = en.getKey(), t = en.getValue();\n if(t + time > maxTime) continue;\n dfs(path, nei, maxTime, t + time);\n }\n path.remove(path.size() - 1);\n }\n}\n``` | 0 | 0 | ['Java'] | 0 |
maximum-path-quality-of-a-graph | Deep First Search with convient acces to nodes data | deep-first-search-with-convient-acces-to-kq2y | Code\n\nclass Solution {\n\n /**\n * @param Integer[] $values\n * @param Integer[][] $edges\n * @param Integer $maxTime\n * @return Integer\n | DemetriSam | NORMAL | 2024-01-31T13:48:36.832102+00:00 | 2024-01-31T13:48:36.832128+00:00 | 2 | false | # Code\n```\nclass Solution {\n\n /**\n * @param Integer[] $values\n * @param Integer[][] $edges\n * @param Integer $maxTime\n * @return Integer\n */\n function maximalPathQuality($values, $edges, $maxTime) {\n $hash = [];\n\n foreach($edges as $edge) {\n [$a, $b, $cost] = $edge;\n if(!isset($hash[$a])) $hash[$a] = [];\n if(!isset($hash[$b])) $hash[$b] = [];\n\n $hash[$a][$b] = $cost;\n $hash[$b][$a] = $cost;\n }\n\n $checked = array_map(fn($val) => false, $values);\n\n $dfs = function($node, $maxTime, $max, $checked) use ($hash, $values, &$dfs) {\n if($maxTime < 0) return 0;\n\n if(!$checked[$node]) {\n $checked[$node] = true;\n $max += $values[$node];\n }\n \n $maxes = $node === 0 ? [$max] : [];\n foreach($hash[$node] as $nbr => $cost) {\n $maxes[] = $dfs($nbr, $maxTime - $cost, $max, $checked);\n }\n return max($maxes);\n };\n\n return $dfs(0, $maxTime, 0, $checked);\n }\n}\n``` | 0 | 0 | ['Hash Table', 'Depth-First Search', 'PHP'] | 0 |
maximum-path-quality-of-a-graph | python3 backtracking | python3-backtracking-by-0icy-9218 | \n\n# Code\n\nclass Solution:\n def maximalPathQuality(self,values, edges, maxTime):\n s = set([0])\n d = defaultdict(list)\n cost = def | 0icy | NORMAL | 2024-01-30T07:48:19.254959+00:00 | 2024-01-30T07:48:19.254988+00:00 | 19 | false | \n\n# Code\n```\nclass Solution:\n def maximalPathQuality(self,values, edges, maxTime):\n s = set([0])\n d = defaultdict(list)\n cost = defaultdict(int)\n ans = 0\n for a,b,c in edges:\n d[a].append(b)\n d[b].append(a)\n cost[(a,b)] = c\n cost[(b,a)] = c\n\n def bt(node,total,remTime):\n nonlocal ans\n if node == 0:\n ans = max(ans,total) \n for e in d[node]:\n if remTime-cost[(node,e)] >=0:\n if e not in s:\n s.add(e)\n bt(e,total+values[e],remTime-cost[(node,e)])\n s.remove(e)\n else:\n bt(e,total,remTime-cost[(node,e)])\n\n bt(0,values[0],maxTime)\n return ans \n``` | 0 | 0 | ['Python3'] | 0 |
maximum-path-quality-of-a-graph | Time Efficient JS Solution - Backtracking (Beat 100% time) | time-efficient-js-solution-backtracking-o6dxs | \n\nPro tip: Love Justina Xi\xE8 \uD83D\uDC9C \u7231\u5C0F\u8C22 \uD83D\uDC9C\nThe hardest part of the problem is to figure out what are the constraints really | CuteTN | NORMAL | 2024-01-20T03:07:34.101140+00:00 | 2024-01-20T03:07:34.101184+00:00 | 15 | false | \n\nPro tip: Love Justina Xi\xE8 \uD83D\uDC9C \u7231\u5C0F\u8C22 \uD83D\uDC9C\nThe hardest part of the problem is to figure out what are the constraints really trying to tell you. Good luck!\n\n# Complexity\n- Let `n = values.length`; `m = edges.length`; `d = max degree of a node = 4`, `l = max number of nodes (not necessarily distinct) on a valid path = maxTime / max(time[i]) <= 10`\n- Time complexity: $$O(d^l + n + m)$$\n- Space complexity: $$O(dn)$$\n\n# Code\n```js\n/**\n * @typedef {{ aNodes: number[], aTimes: number[] }} TGraphNode\n * @param {number} n\n * @param {[number,number,number?][]} edges\n * @return {TGraphNode[]}\n */\nfunction buildGraph(n, edges) {\n /** @type {TGraphNode[]} */\n let nodes = [];\n for (let i = 0; i < n; i++) nodes.push({ aNodes: [], aTimes: [] });\n\n let m = edges.length;\n for (let i = 0; i < m; i++) {\n let [u, v, t] = edges[i];\n nodes[u].aNodes.push(v);\n nodes[u].aTimes.push(t);\n nodes[v].aNodes.push(u);\n nodes[v].aTimes.push(t);\n }\n\n return nodes;\n}\n\nlet curUseds = new Uint8Array(1000);\n\n/**\n * @param {number[]} values\n * @param {number[][]} edges\n * @param {number} maxTime\n * @return {number}\n */\nvar maximalPathQuality = function (values, edges, maxTime) {\n let n = values.length;\n let g = buildGraph(n, edges);\n\n let curTime = 0;\n let curQual = 0;\n let res = 0;\n curUseds.fill(0, 0, n);\n\n function bt(u) {\n if (!curUseds[u]) curQual += values[u];\n ++curUseds[u];\n\n if (!u) res = Math.max(res, curQual)\n\n let { aNodes, aTimes } = g[u];\n\n for (let i = 0; i < aNodes.length; ++i) {\n if (aTimes[i] + curTime <= maxTime) {\n curTime += aTimes[i];\n bt(aNodes[i]);\n curTime -= aTimes[i];\n }\n }\n\n --curUseds[u];\n if (!curUseds[u]) curQual -= values[u];\n }\n\n bt(0);\n return res;\n};\n``` | 0 | 0 | ['Backtracking', 'JavaScript'] | 0 |
vowels-of-all-substrings | [Java/C++/Python] Easy and Concise O(n) | javacpython-easy-and-concise-on-by-lee21-q8wz | Explanation\nFor each vowels s[i],\nit could be in the substring starting at s[x] and ending at s[y],\nwhere 0 <= x <= i and i <= y < n,\nthat is (i + 1) choice | lee215 | NORMAL | 2021-11-07T04:05:53.585612+00:00 | 2021-11-07T12:34:53.422760+00:00 | 11,443 | false | # **Explanation**\nFor each vowels `s[i]`,\nit could be in the substring starting at `s[x]` and ending at `s[y]`,\nwhere `0 <= x <= i` and `i <= y < n`,\nthat is `(i + 1)` choices for `x` and `(n - i)` choices for `y`.\n\nSo there are `(i + 1) * (n - i)` substrings containing `s[i]`.\n<br>\n\n\n# **Complexity**\nTime `O(n)`\nSpace `O(1)`\nCand use a const `"aeiou"` to save the space cost.\n<br>\n\n**Java**\n```java\n public long countVowels(String s) {\n long res = 0, n = s.length();\n for (int i = 0; i < n; ++i)\n if ("aeiou".indexOf(s.charAt(i)) >= 0)\n res += (i + 1) * (n - i);\n return res;\n }\n```\n\n**C++**\n```cpp\n long long countVowels(string s) {\n long res = 0, n = s.size();\n for (int i = 0; i < n; ++i)\n if (string("aeiou").find(s[i]) != string::npos)\n res += (i + 1) * (n - i);\n return res;\n }\n```\n\n**Python**\n```py\n def countVowels(self, s):\n return sum((i + 1) * (len(s) - i) for i, c in enumerate(s) if c in \'aeiou\')\n```\n | 293 | 2 | [] | 28 |
vowels-of-all-substrings | Detailed explanation of why (len - pos) * (pos + 1) works | detailed-explanation-of-why-len-pos-pos-dqnjo | \nLet us understand this problem with an example\nlet word = "abei"\n\nAll possible substrings:\n\na b e i\nab be ei\nabe bei\ | bitmasker | NORMAL | 2021-11-07T06:22:32.407353+00:00 | 2021-11-08T19:48:16.522772+00:00 | 6,056 | false | <br>\nLet us understand this problem with an example\n<br>let word = "abei"\n\n**All possible substrings:**\n```\na b e i\nab be ei\nabe bei\nabei\n```\n\nSo for counting occurences of vowels in each substring, we can count the occurence of each vowel in each substring\nIn this example, count of vowels in substrings are\n```\na - 4 times\ne - 6 times\ni - 4 times\n```\nAnd you can observe that occurence of each vowel depends on it\'s position like below:\n* a is at position 0 so it can be present only in the substrings starting at 0\n* e is in the middle so it can be present in the substrings starting at it\'s position, substrings ending at it\'s position, and substrings containing it in middle\n* i is at last so it can be present only in the substrings ending at that position\n<br>\n\n**Did you see any pattern ?** Yes !\n<br>A character at position pos can be present in substrings starting at i and substrings ending at j, <br>where **0 <= i <= pos** (pos + 1 choices) and **pos <= j <= len** (len - pos choices) <br>so there are total **(len - pos) * (pos + 1)** substrings that contain the character word[pos]\n\n(You can see from above example that e is at position 2 and it\'s present in substrings "abei", "bei", "ei", "abe", "be", "e"<br> (0 <= start <= pos and pos <= end <= len) and same will be true for each vowel.\n<br>\n**From this observation we can generalise the occurence of each vowel in the string as**\n```\nhere len(abei) = 4\na, pos = 0, count = (4 - 0) * (0 + 1) = 4\ne, pos = 2, count = (4 - 2) * (2 + 1) = 6\ni, pos = 3, count = (4 - 3) * (3 + 1) = 4\n```\n**So the generalised formula will be**\n```\ncount = (len - pos) * (pos + 1)\n```\nand we can keep summing the count of each vowel (don\'t forget to convert to long)\n<br>\n\n\n**C++ code:**\n\n```\nclass Solution {\npublic:\n bool isVowel(char ch) {\n return ch == \'a\' or ch == \'e\' or ch == \'i\' or ch == \'o\' or ch == \'u\';\n }\n \n long long countVowels(string word) {\n long long count = 0;\n int len = word.size();\n \n for(int pos = 0; pos < len; pos++) {\n if(isVowel(word[pos])) {\n count += (long)(len - pos) * (long)(pos + 1);\n }\n }\n \n return count;\n }\n};\n```\n\n<br>\n\n**Python Code:**\n```\nclass Solution:\n def countVowels(self, word: str) -> int:\n count = 0\n sz = len(word)\n \n for pos in range(sz):\n if word[pos] in \'aeiou\':\n count += (sz - pos) * (pos + 1)\n \n return count\n```\n\n<br>\n\n**Java Code:**\n\n```\nclass Solution {\n \n boolean isVowel(char ch) {\n return ch == \'a\' || ch == \'e\' || ch == \'i\' || ch == \'o\' || ch == \'u\';\n }\n \n public long countVowels(String word) {\n long count = 0;\n int len = word.length();\n \n for(int pos = 0; pos < len; pos++) {\n if(isVowel(word.charAt(pos))) {\n count += (long)(len - pos) * (long)(pos + 1);\n }\n }\n \n return count;\n }\n}\n```\n\n<br>\nDo upvote if you liked the explanation :)\n\n<br> | 122 | 1 | ['C', 'Python', 'C++', 'Java', 'Python3'] | 8 |
vowels-of-all-substrings | (i + 1) * (sz - i) | i-1-sz-i-by-votrubac-fnxg | A vowel at position i appears in (i + 1) * (sz - i) substrings. \n\nSo, we just sum and return the appearances for all vowels.\n\nPython 3\npython\nclass Soluti | votrubac | NORMAL | 2021-11-07T04:00:42.160489+00:00 | 2021-11-07T23:07:13.279825+00:00 | 4,869 | false | A vowel at position `i` appears in `(i + 1) * (sz - i)` substrings. \n\nSo, we just sum and return the appearances for all vowels.\n\n**Python 3**\n```python\nclass Solution:\n def countVowels(self, word: str) -> int:\n return sum((i + 1) * (len(word) - i) for i, ch in enumerate(word) if ch in \'aeiou\')\n```\n\n**C++**\n```cpp\nbool v[26] = {1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0};\nlong long countVowels(string w) {\n long long res = 0, sz = w.size();\n for (int i = 0; i < w.size(); ++i)\n res += v[w[i] - \'a\'] * (i + 1) * (sz - i);\n return res;\n}\n```\n**Java**\n```java\npublic long countVowels(String word) {\n long res = 0, sz = word.length();\n for (int i = 0; i < sz; ++i)\n if ("aeiou".indexOf(word.charAt(i)) != -1)\n res += (i + 1) * (sz - i);\n return res; \n}\n``` | 41 | 1 | ['C', 'Java', 'Python3'] | 8 |
vowels-of-all-substrings | Simple Java O(n) | simple-java-on-by-aayushbhala-zygw | \nclass Solution {\n public long countVowels(String word) {\n long res = 0, prev = 0;\n for(int i=0; i<word.length(); i++) {\n char | aayushbhala | NORMAL | 2021-11-07T04:26:13.523615+00:00 | 2021-11-07T10:58:10.238205+00:00 | 2,162 | false | ```\nclass Solution {\n public long countVowels(String word) {\n long res = 0, prev = 0;\n for(int i=0; i<word.length(); i++) {\n char c = word.charAt(i);\n if(c == \'a\' || c == \'e\' || c == \'i\' || c == \'o\' || c == \'u\')\n prev += i + 1;\n res += prev;\n }\n \n return res;\n }\n}\n``` | 30 | 0 | ['Dynamic Programming', 'Java'] | 1 |
vowels-of-all-substrings | C++ | O(n) | Brute to Optimal | Best Explanation | c-on-brute-to-optimal-best-explanation-b-8epw | The Brute force approach to this problem is very simple. Just go through all the substring of the string and find the number of vowels in all those substrings a | deepakdpk77 | NORMAL | 2021-11-07T04:02:33.322242+00:00 | 2021-11-07T04:20:56.933692+00:00 | 2,545 | false | The **Brute force** approach to this problem is very simple. Just go through all the substring of the string and find the number of vowels in all those substrings and add them.\n\nBut, it would take O(n^2) to find all the subtrings which will result in **TLE.**\n\nThe **better solution** would be to check - the number of times every character would occur in any substring.And, if we observe carefully, this is what we want - i.e, the sum of vowels in every substring. So, why not find the occurance of evry character in each substring. This will eventually give us the same result. **Right?**\n\nFor example -> the 0th index character would occur in substring starting from 0 and ending at i. Where, i =(0 to n).\n\n\n Ex- s= "aba"\n Let us say, first a as a1 and second a as a2 to avoid confusion.\n\n a1 -> occurs in substring "a", "ab", "aba" . Count 3\n b -> occurs in substring "ab","b", "ba","aba". Count 4\n a2-> occurs in substring "aba", "ba", "a". Count 3\n \n **Now, the question is How to get that count?**\n And ths answer for that is - \n For each character, we will store no. of substrings starting with that character + the number of substrings formed by the previous characters containing this character \u2013 the number of substrings formed by the previous characters only.\nAnd this will be **dp[i-1] + (n-i) -i**\n\n Now, when we got this value, that is number of times each character will occur in any subtring. Then , we will just check if the character is a vowel or not. If vowel, then add the count of number of times that character will occur in any substring.We will be using an array/vector to store the count.\n\n\n\n**Time Complexity :- O(n)**\n\nBelow is a C++ solution for the same.\n\n\n```\nclass Solution {\npublic:\n bool isVowel(char ch){\n if(ch==\'a\' or ch==\'e\' or ch==\'i\' or ch==\'o\' or ch==\'u\')\n return true;\n return false;\n }\n long long countVowels(string word) {\n int n=word.size();\n long long int ans=0;\n vector<long long int> dp;\n \n for (int i = 0; i < n; i++) {\n if (i == 0)\n dp.push_back(n);\n else\n dp.push_back((n - i) + dp[i - 1] - i);\n }\n for (int i = 0; i < n; i++)\n if(isVowel(word[i]))\n ans += dp[i];\n return ans;\n }\n \n};\n\n```\nHope it helps!\nPlease upvote if you like.\n\nThank you! | 25 | 3 | ['C'] | 6 |
vowels-of-all-substrings | C++ O(N) Time | c-on-time-by-lzl124631x-2chl | See my latest update in repo LeetCode\n## Solution 1.\n\nIf s[i] is vowel, there are (i + 1) * (N - i) substrings that contain s[i] where i + 1 and N - i are th | lzl124631x | NORMAL | 2021-11-07T04:03:04.605943+00:00 | 2021-11-07T04:03:04.605984+00:00 | 1,188 | false | See my latest update in repo [LeetCode](https://github.com/lzl124631x/LeetCode)\n## Solution 1.\n\nIf `s[i]` is vowel, there are `(i + 1) * (N - i)` substrings that contain `s[i]` where `i + 1` and `N - i` are the number of possible left and right end points of the substrings, respectively.\n\n```cpp\n// OJ: https://leetcode.com/contest/weekly-contest-266/problems/vowels-of-all-substrings/\n// Author: github.com/lzl124631x\n// Time: O(N)\n// Space: O(1)\nclass Solution {\n bool isVowel(char c) {\n return c == \'a\' || c == \'e\' || c == \'i\' || c == \'o\' || c == \'u\';\n };\npublic:\n long long countVowels(string s) {\n long long N = s.size(), ans = 0;\n for (long long i = 0; i < N; ++i) {\n if (!isVowel(s[i])) continue;\n ans += (i + 1) * (N - i);\n }\n return ans;\n }\n};\n``` | 15 | 2 | [] | 0 |
vowels-of-all-substrings | C++, Easily explained | c-easily-explained-by-subhankar_99-s3kq | Intuition\n Describe your first thoughts on how to solve this problem. \nWe can solve this problem by finding all substrings of the given string and count total | Subhankar_99 | NORMAL | 2023-01-18T07:00:25.031847+00:00 | 2023-01-18T07:00:25.031878+00:00 | 842 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nWe can solve this problem by finding all substrings of the given string and count total no of vowels. But it will take O(2^n) complexity so it will not work.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nInstead of finding all substrings and counting vowels we can traverse each character and if it is vowel then we can find the no of substrings in which this character will be present. And this is easy. As an example, let the string is \'fbacd\' and we have to find the no of substrings in which \'a\' will be present. \n See carefully the substrings are\n ss = {\'a\', \'ac\', \'acd\', \n\'ba\', \'bac\', \'bacd\',\n\'fba\', \'fbac\', \'fbacd\' }\nAt first we will find how many character present at right side from the current character including that character. here it is 3 {a, c, d}\nand how many are in the left side including that character is 3 {f, b, a}\nSo the total substrings are 3 * 3 = 9 which are present in ss.\nSimilarly in "rabbit", \'a\' present in 2 * 5=10 substrings.\nSo for a given string we will traverse each character and if it is vowel then we will calculate the total no of substrings by above process and add it with result.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nTo traverse each character it will take O(n) time and to find the no of substrings it will take O(1) time. So total time complexity is O(n)\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nHere We are not using any extra space. So Space complesity is O(1)\n\n# Code\n```\nclass Solution {\npublic:\n long long countVowels(string word) {\n int n = word.size();\n long long res = 0;\n for(int i=0; i<n; i++){\n if(word[i]==\'a\' || word[i]==\'e\' || word[i]==\'i\' || word[i]==\'o\' || word[i]==\'u\')\n {\n res += (long long)(n-i)*(long long)(i+1);\n }\n }\n return res;\n }\n};\n``` | 12 | 0 | ['C++'] | 0 |
vowels-of-all-substrings | C++ || Logic Explained || DP | c-logic-explained-dp-by-kevinujunior-d2n0 | Intution:\n\nThe main idea is how the current substring will behave when a new character will be added.\nSuppose we have S = {a,b,c} and u is added so total vo | kevinujunior | NORMAL | 2022-01-31T08:53:00.903258+00:00 | 2022-01-31T08:53:00.903303+00:00 | 719 | false | ***Intution:***\n\nThe main idea is how the current substring will behave when a new character will be added.\nSuppose we have **S = {a,b,c}** and **u** is added so total vowels in S becomes 2, if a consonant is added No change is reflected.\n\n***Building the solution:***\n\n\n\n***Code***\n\n```\n long long countVowels(string s) {\n int n = s.size();\n long long sum=0, dp[n];\n\n if(s[0]==\'a\'||s[0]==\'e\'||s[0]==\'i\'||s[0]==\'o\'||s[0]==\'u\') \n\t\t\tdp[0] = 1;\n \n else\n\t\t\tdp[0] = 0;\n \n sum += dp[0];\n \n for(int i=1;i<n;i++){\n \n if(s[i]==\'a\'||s[i]==\'e\'||s[i]==\'i\'||s[i]==\'o\'||s[i]==\'u\') \n dp[i] = dp[i-1]+i+1;\n \n else \n dp[i] = dp[i-1];\n \n sum += dp[i];\n }\n \n return sum; \n }\n```\n**Questions are welcome**\n\nPS: Please forgive me for the handwriting. | 9 | 0 | ['Dynamic Programming'] | 3 |
vowels-of-all-substrings | Intuition Explained || Calculate Contribution || C++ Clean Code | intuition-explained-calculate-contributi-pe4o | Intuition : \n\n Idea is to find the contribution of each vowel in substrings which it is part of.\n Thus, either it can part of substrings on its left, or on i | i_quasar | NORMAL | 2021-11-21T08:49:34.539827+00:00 | 2021-11-21T09:18:24.799892+00:00 | 577 | false | **Intuition :** \n\n* Idea is to find the contribution of each vowel in substrings which it is part of.\n* Thus, either it can part of substrings on its left, or on its right.\n\t* i.e substring ending at current character , or starting at current character.\n\n\t* We can calculate number of substrings between [i..j] = `(j - i + 1)`\n\n* Thus, contibution = (no. of substrings on its left) * (no. of substrings on its right)\n\t* Formula : **`contribution = (i+1) * (n-i)`** , here `i` is index of current vowel character\n* Finally, sum of contibution of each vowel will give us the answer. \n* Lets do a dry run on a TC : \n\t\t\n\t\tEx: word = "a b a"\n\n\t\t0. word[0] = a, which is a vowel \n\t\t\t=> So, substrings in which word[0] is part of = {\'a\', \'a\'b, \'a\'ba}\n\t\t\t=> contibution(word[0]) = (0+1) * (3 - 0) = 3 \n\n\t\t1. word[1] = b, which is not a vowel\n\t\t\n\t\t2. word[2] = a, which is a vowel\n\t\t\t=> So, substrings in which word[2] is part of : {ab\'a\', b\'a\', \'a\'}\n\t\t\t=> contibution(word[2]) = (2 + 1) * (3 - 2) = 3\n\n\t\tTherefore, answer = contibution(word[0]) + contibution(word[1]) + contibution(word[2]) = 3 + 0 + 3 = 6\n\n# Code: \n\n```\nclass Solution {\npublic:\n \n bool isVowel(char c) {\n return (c == \'a\' || c == \'e\' || c == \'i\' || c == \'o\' || c == \'u\');\n }\n \n long long countVowels(string word) {\n \n int n = word.size();\n long long count = 0;\n \n for(int i=0; i<n; i++) {\n if(isVowel(word[i]))\n count += (long long)(i+1) * (long long)(n-i);\n }\n \n return count;\n }\n};\n```\n\n**Complexity :** \n\n* Time : `O(N)` , N : size of word\n* Space : `O(1)`\n\n***If you find this helpful, do give it a like :)*** | 7 | 0 | [] | 0 |
vowels-of-all-substrings | Fastest Python Solution | 108ms | fastest-python-solution-108ms-by-the_sky-be9j | Fastest Python Solution | 108ms\nRuntime: 108 ms, faster than 100.00% of Python3 online submissions for Vowels of All Substrings.\nMemory Usage: 14.8 MB, less t | the_sky_high | NORMAL | 2021-11-07T05:55:26.599881+00:00 | 2021-11-07T11:38:17.416136+00:00 | 772 | false | # Fastest Python Solution | 108ms\n**Runtime: 108 ms, faster than 100.00% of Python3 online submissions for Vowels of All Substrings.\nMemory Usage: 14.8 MB, less than 100.00% of Python3 online submissions for Vowels of All Substrings.**\n```\nclass Solution:\n def countVowels(self, word: str) -> int:\n c, l = 0, len(word)\n d = {\'a\':1, \'e\':1,\'i\':1,\'o\':1,\'u\':1}\n \n for i in range(l):\n if word[i] in d:\n c += (l-i)*(i+1)\n return c\n```\n\n\n | 7 | 1 | ['Python', 'Python3'] | 1 |
vowels-of-all-substrings | Easy-to-understand python dp | easy-to-understand-python-dp-by-williame-0co0 | \nclass Solution:\n def countVowels(self, word: str) -> int:\n dp = []\n for i, el in enumerate(word):\n if el in \'aeiou\':\n | williame3120 | NORMAL | 2021-11-07T04:07:00.624507+00:00 | 2021-11-07T04:07:14.658758+00:00 | 897 | false | ```\nclass Solution:\n def countVowels(self, word: str) -> int:\n dp = []\n for i, el in enumerate(word):\n if el in \'aeiou\':\n running_sum = i + 1 + (dp[-1] if dp else 0)\n dp.append(running_sum)\n else:\n dp.append(dp[-1] if dp else 0)\n return sum(dp)\n``` | 7 | 1 | ['Dynamic Programming', 'Python'] | 1 |
vowels-of-all-substrings | Best Code So far ?? One Pass Solution | best-code-so-far-one-pass-solution-by-ia-w459 | class Solution {\n\n public long countVowels(String word) {\n\n int len=word.length();\n long count=0;\n for(int i=0;i<len;i++){\n | IAmCoderrr | NORMAL | 2021-11-07T04:03:23.849523+00:00 | 2021-11-07T04:39:26.408657+00:00 | 834 | false | `class Solution {\n\n public long countVowels(String word) {\n\n int len=word.length();\n long count=0;\n for(int i=0;i<len;i++){\n if(check(word.charAt(i))){\n \n count+=((long)(len-i))*((long)(i+1));\n }\n }\n return count;\n }\n boolean check(char ch){\n return ch==\'a\' || ch==\'e\' || ch==\'i\' || ch==\'o\' || ch==\'u\';\n }\n}`\nHit Like if this solution helps you | 7 | 3 | ['Java'] | 3 |
vowels-of-all-substrings | Simple Math, C++ Beats 95% | simple-math-c-beats-95-by-deepak_5910-0lgh | if it Helps You, Please Upvote Me..!\n# Approach\n Describe your approach to solving the problem. \nApproach very is simple,Just Count the number of the substri | Deepak_5910 | NORMAL | 2023-06-17T07:06:39.125974+00:00 | 2023-06-17T07:06:39.125998+00:00 | 485 | false | # if it Helps You, Please Upvote Me..!\n# Approach\n<!-- Describe your approach to solving the problem. -->\nApproach very is simple,Just Count the number of the substring in which a particular Vowel Appear. \n\n**Formula: if Vowel Appera at ith position(0 based)**\n\n**number of substrings = i+(n-i-1)+(i(n-i-1))+1**\n\n\n\n# Complexity\n- Time complexity:O(N)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:o(1)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\npublic:\n long long countVowels(string word) {\n \n long long n = word.size(),ans = 0;\n vector<int> pos;\n \n for(int i = 0;i<word.size();i++)\n {\n if(word[i] ==\'a\' ||word[i]==\'i\' || word[i]==\'o\' || word[i]==\'e\'|| word[i]==\'u\')\n {\n long long left = i,right = n-i-1;\n ans+=(left+right+left*right+1);\n } \n }\n return ans;\n }\n};\n```\n\n | 6 | 0 | ['Math', 'C++'] | 0 |
vowels-of-all-substrings | Explanation | C++ Solution | explanation-c-solution-by-s1nghprashant-2psy | Lets suppose we have a string abaace. Lets see sum of number of vowels in each substring.\n\n\na(1) b(0) a(1) a(1) c(0) | s1nghPrashant | NORMAL | 2021-11-07T04:52:40.547433+00:00 | 2022-02-02T08:09:44.974650+00:00 | 397 | false | Lets suppose we have a string `abaace`. Lets see sum of number of vowels in each substring.\n\n```\na(1) b(0) a(1) a(1) c(0) e(1)\nab(1) ba(1) aa(2) ac(1) ce(1)\naba(2) baa(2) aac(2) ace(2) \nabaa(3) baac(2) aace(3)\nabaac(3) baace(3)\nabaace(4)\n```\n\nNow, we can see whenever a new character appears suppose `b` it is contributing to 2 string `ab` and `b` (similarly e is contributing to 5 strings ). So total sum when` b` appears becomes 0+1=1 (similarly for e it becomes 4+3+3+2+1+1 = 14. It is basically your diagonal sum from left to right for each row element of 1st col). Thus we can find for each character their contribution array . It will look like \n```\na b a a c e\n1 1 4 8 8 14\n```\nand now we can see this pattern and maintain a dp array if its non-vowel character its contribution is equal to dp[ i-1] else it `dp[i-1] +i+1`\n\n```\nlong long countVowels(string word) {\n int n = word.length();\n if(n==0)\n return 0;\n vector<long long> dp(n,0);\n long long sum = 0;\n for(int i = 0;i<n;i++)\n {\n if(word[i]==\'a\' || word[i]==\'e\' ||word[i]==\'i\' ||word[i]==\'o\' || word[i]==\'u\' )\n dp[i] = i==0 ? 1 : dp[i-1]+i+1;\n else\n dp[i] = i==0? 0 : dp[i-1] ;\n }\n \n for(int i = 0;i<n;i++)\n sum += dp[i];\n \n return sum ;\n \n }\n```\nand then we can take the sum of whole array . | 6 | 1 | [] | 1 |
vowels-of-all-substrings | [JavaScript] Dynamic Programming | javascript-dynamic-programming-by-steven-8nwl | javascript\nvar countVowels = function(word) {\n const vowels = new Set([\'a\', \'e\', \'i\', \'o\', \'u\']);\n let total = 0;\n let count = 0;\n fo | stevenkinouye | NORMAL | 2021-11-07T04:04:30.186651+00:00 | 2021-11-07T04:04:30.186682+00:00 | 462 | false | ```javascript\nvar countVowels = function(word) {\n const vowels = new Set([\'a\', \'e\', \'i\', \'o\', \'u\']);\n let total = 0;\n let count = 0;\n for (let i = 0; i < word.length; i++) {\n if (vowels.has(word[i])) {\n count += i + 1;\n }\n total += count;\n }\n return total;\n};\n``` | 6 | 0 | ['Dynamic Programming', 'JavaScript'] | 2 |
vowels-of-all-substrings | byte[] explained || 2 ways || fastest and simplest || best for beginners | byte-explained-2-ways-fastest-and-simple-abkx | \n# jsut read and you will understand the approach : \nlet word = "abei"\nAll possible substrings:\n\n\na b e i\nab be ei\nabe | devvarunbhardwaj | NORMAL | 2023-10-02T08:40:08.380579+00:00 | 2023-10-02T08:40:08.380603+00:00 | 132 | false | \n# jsut read and you will understand the approach : \nlet word = "abei"\nAll possible substrings:\n```\n\na b e i\nab be ei\nabe bei\nabei\n```\nSo for counting occurences of vowels in each substring, we can count the occurence of each vowel in each substring\nIn this example, count of vowels in substrings are\n```\na - 4 times\ne - 6 times\ni - 4 times\n```\nAnd you can observe that occurence of each vowel depends on it\'s position like below:\n\na is at position 0 so it can be present only in the substrings starting at 0\ne is in the middle so it can be present in the substrings starting at it\'s position, substrings ending at it\'s position, and substrings containing it in middle\ni is at last so it can be present only in the substrings ending at that position\nDid you see any pattern ? Yes !\n\nA character at position pos can be present in substrings starting at i and substrings ending at j,\nwhere 0 <= i <= pos (pos + 1 choices) and pos <= j <= len (len - pos choices)\nso there are total (len - pos) * (pos + 1) substrings that contain the character word[pos]\n\n(You can see from above example that e is at position 2 and it\'s present in substrings "abei", "bei", "ei", "abe", "be", "e"\n(0 <= start <= pos and pos <= end <= len) and same will be true for each vowel.\n\n\nFrom this observation we can generalise the occurence of each vowel in the string as\n\nhere len(abei) = 4\n```\na, pos = 0, count = (4 - 0) * (0 + 1) = 4\ne, pos = 2, count = (4 - 2) * (2 + 1) = 6\ni, pos = 3, count = (4 - 3) * (3 + 1) = 4\n```\nSo the generalised formula will be\n\ncount = (len - pos) * (pos + 1)\nand we can keep summing the count of each vowel (don\'t forget to convert to long)\n## faster code is just below \n# Code\n```\nclass Solution {\n public boolean isVowel(char ch){\n return ch==\'a\'||ch==\'e\'||ch==\'i\'||ch==\'o\'||ch==\'u\';\n }\n public long countVowels(String word) {\n long count = 0 ; \n int len = word.length() ; \n for(int i=0;i<len;i++){\n if(isVowel(word.charAt(i))){\n count+=(long)(len-i)*(long)(i+1);\n }\n }\n return count ; \n }\n}\n```\n \n\nexplanation is just below \n\n```\nclass Solution {\n public long countVowels(String word) {\n long n = word.length();\n long res = 0; int i = 0;\n byte[] w = word.getBytes();\n for (byte c : w) {\n c = w[i];\n if (c == \'a\' || c == \'e\' || c == \'i\' || c == \'o\' || c == \'u\') {\n res += (n - i) * (i + 1);\n }\n i++;\n }\n return res;\n }\n}\n```\n\n\n\n## Explanation:\n\n- The function countVowels takes a string word as input and calculates the count of vowels in the word using a specific formula.\n\n- An array of byte called vowels is created with a size of 128. Each element of this array corresponds to a character\'s ASCII value, and if the character is a vowel (\'a\', \'e\', \'i\', \'o\', \'u\'), the corresponding element in the vowels array is set to 1.\n\n- res is initialized to 0, and prev is unused in this code.\n\n- byte[] arr is created by encoding the input word into bytes using the default character encoding. This allows the code to work with any string.\n\n- The code then iterates over each character in the arr array. If the character is a vowel (as determined by looking up the vowels array), it calculates a value and adds it to res.\n\n- The value added to res is (i + 1) * (len - i), which appears to be a way of counting the position of the vowel within the word and how many characters are to the right of it.\n\n- The final result, stored in res, represents the count of vowels according to the formula used.\n\n\n\n# some more info \nThe `getBytes()` function does convert a string into an array of bytes, but the resulting `byte[]` does not directly contain the ASCII values of the characters. Instead, it contains the bytes representing the characters based on the character encoding used.\n\nIf you have the string "abc" and you call `getBytes()` without specifying a character encoding, it will use the platform\'s default encoding (usually UTF-8 on modern systems). In this case, the resulting `byte[]` will contain the UTF-8 encoded bytes for the characters \'a\', \'b\', and \'c\'.\n\nSo, the `byte[]` array might look something like this (assuming UTF-8 encoding):\n\n```\n[97, 98, 99]\n\n```\n\nIn this example, `97` corresponds to the UTF-8 representation of \'a\', `98` corresponds to \'b\', and `99` corresponds to \'c\'. These values are not the ASCII values but rather the UTF-8 encoded bytes for these characters. If you want to obtain the ASCII values, you can simply cast them to `int`:\n\n```\nint asciiValueOfA = (int) w[0]; // This will be 97\nint asciiValueOfB = (int) w[1]; // This will be 98\nint asciiValueOfC = (int) w[2]; // This will be 99\n\n```\n\nKeep in mind that if you specify a different character encoding when calling `getBytes()`, the resulting `byte[]` will contain bytes according to that encoding, which may not be the same as the ASCII values. | 5 | 0 | ['Java'] | 0 |
vowels-of-all-substrings | Maths || Observational || 12MS || Simple Formula Observation Unique Solution & Explaination | maths-observational-12ms-simple-formula-1flq0 | I simply Observe the Pattern by taking different size strings using pen and paper and Observe that the number of occurance of every character in a string follow | int_float_double | NORMAL | 2021-11-08T18:15:23.253654+00:00 | 2022-02-25T09:48:17.000445+00:00 | 356 | false | I simply Observe the Pattern by taking different size strings using pen and paper and Observe that the number of occurance of every character in a string follows a Simple pattern using Arithmetic Progression with (n-2) as its first element with d=-2 upto middle element then start decreasing using same progression (or you can say start from end with same initial element and d upto middle element) \n\n\n\n\n```\nlong long countVowels(string word) {\n\t\tios::sync_with_stdio(false);\n cin.tie(nullptr);\n int n=word.length();\n long long ans=0;\n for(int i=0;i<n;i++){\n if(word[i]==\'a\' || word[i]==\'e\' || word[i]==\'i\' || word[i]==\'o\' || word[i]==\'u\'){\n long long j=(i)<(n-i-1)?i:(n-i-1);\n long long k=(j*(2*(n-2)+(j-1)*(-2))/2); //sum of AP\n ans+=(n+k); \n }\n }\n return ans;\n }\n\n``` | 5 | 0 | [] | 0 |
vowels-of-all-substrings | Beats 100% runtime and memory time | beats-100-runtime-and-memory-time-by-sub-edpi | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | SUBASH_AL | NORMAL | 2023-07-29T09:29:22.474300+00:00 | 2023-07-29T09:29:22.474324+00:00 | 351 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\n public long countVowels(String word) {\n long count=0;\n int len=word.length();\n for(int i=len-1;i>=0;i--){\n if(vowelschck(word.charAt(i))){\n count+=(long)(i+1)*(len-i);\n }\n }\n \n \n return count;\n\n }\n\n boolean vowelschck(char c){\n \n if(c==\'a\' || c==\'e\' || c==\'i\' ||\n c==\'o\' || c==\'u\'){\n return true;\n }\n \n return false;\n }\n\n\n}\n``` | 4 | 0 | ['Java'] | 0 |
vowels-of-all-substrings | Easy C++ solution using Only 2 variables | Linear Time | Constant Space | easy-c-solution-using-only-2-variables-l-rm53 | Use two variables a and b.\n For each index i , variable a represents the no of vowels in all the substrings ending at (i-2)th index and variable b represents t | persistentBeast | NORMAL | 2022-04-12T14:29:49.344651+00:00 | 2022-04-12T14:29:49.344682+00:00 | 405 | false | * Use two variables a and b.\n* For each index `i` , variable `a` represents the no of vowels in all the substrings ending at `(i-2)th` index and variable `b` represents the no. of vowels in all the substrings ending at `(i-1)th` index.\n* Using `a` and `b` compute the no of vowels in all the substrings ending at `(i-1)th`**(new a)** index and `ith` index **(new b)**. \n```\nclass Solution {\npublic:\n long long countVowels(string word) {\n \n long long int a = 0,b = 0;\n int n = word.length();\n for(int i = 0; i < n; i++){\n \n auto x = word[i];\n \n a = a + b;\n \n b = b + ((x==\'a\' || x==\'e\' || x==\'i\' || x==\'o\' || x==\'u\') ? (i+1) : 0);\n \n }\n \n return a + b;\n \n }\n};\n``` | 4 | 0 | ['C'] | 0 |
vowels-of-all-substrings | C++ || Diagram Explanation || O(N) | c-diagram-explanation-on-by-divyatez-003i | Consider example : \n"decab"\n \n\nHere vowels are e and a, so we rehrase the answer are total substrings in which each vowel occur.\n\nSo for "e",\n\n\nl | Divyatez | NORMAL | 2022-01-28T16:03:59.948816+00:00 | 2022-01-28T16:03:59.948861+00:00 | 318 | false | Consider example : \n"decab"\n \n\nHere vowels are e and a, so we rehrase the answer are total substrings in which each vowel occur.\n\nSo for "e",\n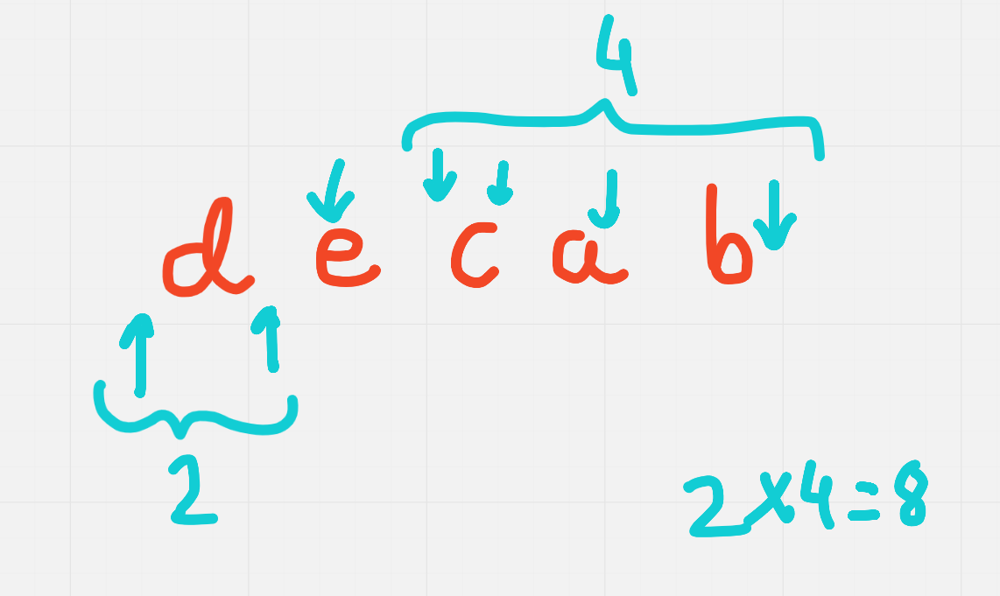\n\nleft end of substring having e has 2 options \nRight end of substring having e has 4 options.\nSo total substring having e can be 2*4 = 8 \n\nSimilarly for "a"\n\n\nThis also has total of 8\n\nSo final answer is 8+8 = 16\n\n```\nclass Solution {\npublic:\n long long countVowels(string word) {\n long long int cnt=0;\n long long int n = word.size();\n for(int i=0;i<word.size();i++)\n {\n if(word[i]==\'a\'||word[i]==\'e\'||word[i]==\'i\'||word[i]==\'o\'||word[i]==\'u\')\n cnt+=((i+1)*(n-i));\n }\n return cnt;\n }\n};\n``` | 4 | 0 | ['C'] | 0 |
vowels-of-all-substrings | C++ || SUPER EASY SOLUTION | c-super-easy-solution-by-vineet_raosahab-r0yg | \nclass Solution {\npublic:\n long long countVowels(string word) {\n long long answer=0;\n for(int i=0;i<word.size();i++)\n {\n | VineetKumar2023 | NORMAL | 2021-11-07T04:01:10.351914+00:00 | 2021-11-07T04:01:10.351943+00:00 | 228 | false | ```\nclass Solution {\npublic:\n long long countVowels(string word) {\n long long answer=0;\n for(int i=0;i<word.size();i++)\n {\n if(word[i]==\'a\' || word[i]==\'e\' || word[i]==\'i\' || word[i]==\'o\' || word[i]==\'u\')\n answer+=(word.size()-i)*(i+1);\n }\n return answer;\n }\n};\n``` | 4 | 0 | [] | 1 |
vowels-of-all-substrings | O(n) simple DP approach (based on substring ending at ith pos) | on-simple-dp-approach-based-on-substring-bo9x | IntuitionUsing DP, We can find current answer using pre computed ansApproachWe can observe from above, if the current char is vowel, then current count will be | pritam1512 | NORMAL | 2025-03-26T18:52:34.140058+00:00 | 2025-04-08T15:45:26.978531+00:00 | 40 | false | # Intuition
<!-- Describe your first thoughts on how to solve this problem. -->
Using DP, We can find current answer using pre computed ans
# Approach
<!-- Describe your approach to solving the problem. -->
We can observe from above, if the current char is vowel, then current count will be count of vowel from previous answer + number of substring that ends at ith position (as the vowel can be added to all the substring and it will be a valid substring )+ 1.
// if vowel --> dp[i] = 1 + (dp[i-1]+i)
// if not vowel --> dp[i] = dp[i-1]
# Complexity
- Time complexity:
<!-- Add your time complexity here, e.g. $$O(n)$$ -->
O(N)
- Space complexity:
<!-- Add your space complexity here, e.g. $$O(n)$$ -->
O(N)
# Code
```cpp []
class Solution {
public:
bool isVowel(char c){
if(c == 'a' || c == 'e' || c == 'i' || c == 'o' || c == 'u'){
return true;
}else{
return false;
}
return false;
}
long long countVowels(string word) {
int n = word.length();
vector<long long> dp(n,0);
if(isVowel(word[0])){
dp[0] = 1;
}else{
dp[0] = 0;
}
for(int i=1;i<n;i++){
if(isVowel(word[i])){
dp[i] = 1 + dp[i-1]+i;
}else{
dp[i] = dp[i-1];
}
}
long long ans = 0;
for(int i=0;i<n;i++){
ans += dp[i];
}
return ans;
}
};
if(helpful){
do(upvote)
}
``` | 3 | 0 | ['Dynamic Programming', 'C++'] | 0 |
vowels-of-all-substrings | An alternative simple and clear solution. O(n) | an-alternative-simple-and-clear-solution-flj6 | \nclass Solution:\n def countVowels(self, word: str) -> int:\n total, cnt_substrig = 0, 0\n for i, ch in enumerate(word, 1):\n if ch | xxxxkav | NORMAL | 2024-08-24T18:29:15.082644+00:00 | 2024-08-24T18:29:30.628805+00:00 | 183 | false | ```\nclass Solution:\n def countVowels(self, word: str) -> int:\n total, cnt_substrig = 0, 0\n for i, ch in enumerate(word, 1):\n if ch in {\'a\', \'e\', \'i\', \'o\', \'u\'}:\n cnt_substrig += i\n total += cnt_substrig\n return total \n``` | 3 | 0 | ['Python3'] | 0 |
vowels-of-all-substrings | Simple Approach O(N) -- calculating No of vowels in all substrings using prefix sum in O(N) | simple-approach-on-calculating-no-of-vow-cedj | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\nfirst we store no of vowels in string till index i in v[i].\nthen calcul | harsh_0412 | NORMAL | 2023-02-01T07:29:32.153268+00:00 | 2023-02-01T07:29:32.153312+00:00 | 113 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\nfirst we store no of vowels in string till index i in v[i].\nthen calculating current ans =prev ans + no of vowels in new substrings generated by adding w[i] char using i*v[i]-pre_sum\nif this char is also vowel then add into ans and reduce pre_sum by 1 \n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\npublic:\n long long countVowels(string w) {\n long long ans=0;\n int n=w.size();\n vector<int>v(n);\n unordered_set<int>s;\n s.insert(\'a\');\n s.insert(\'e\');\n s.insert(\'i\');\n s.insert(\'o\');\n s.insert(\'u\');\n if(s.find(w[0])!=s.end())v[0]=1;\n else v[0]=0;\nfor(int i=1;i<n;i++)\n{ v[i]=v[i-1];\nif(s.find(w[i])!=s.end())v[i]++;\n}\n\n long long prf_sum=0;\n\nfor(int i=0;i<n;i++){\n ans+=i*(1LL)*v[i]-prf_sum;\n prf_sum+=v[i];\n if(s.find(w[i])!=s.end()){\n prf_sum--;\n ans++;\n }\n}\n return ans;\n }\n};\n``` | 3 | 0 | ['C++'] | 0 |
vowels-of-all-substrings | O(n) DP | Detailed explanation | on-dp-detailed-explanation-by-nadaralp-bp2u | There are great solutions using combinatorics. I also want to share a Dynamic Programming solution.\n\n# DP solution\nIf we go over a string/array from left to | nadaralp | NORMAL | 2022-06-10T15:47:50.709128+00:00 | 2022-06-10T15:51:03.349998+00:00 | 381 | false | There are great solutions using combinatorics. I also want to share a Dynamic Programming solution.\n\n# DP solution\nIf we go over a string/array from left to right, we know that at each `i` index we have `i+1 **new**` contiguous substrings.\nExample: "a" has 1 substring, and at "ab" we have 2 *new substrings* ("ab", "b") so "ab" has total of 3 substrings.\n\nThis can hint to us that we can reuse the previously solved step to calculate the new step we take, but how?\n\nAt each index `i` we know that it contains at least the same amount of vowels as the previous index `i-1` since it contains all the substrings of the previous string, including the `i\'th` character.\nBut if the `i\'th` character is a vowel itself, then it also adds a vowel to each of the newly added substrings - `i+1` substrings as we\'ve seen previously, since all the substrings contain that character.\n\nExample the string `"abaef"`\n\n\nAt the end, we **sum** all the vowels of the substrings and we will get the total result.\nThe base case of the DP, i.e. dp[0] is 1 if the first character is vowel and 0 otherwise.\n\n# Code\n```\nclass Solution:\n # DP -> O(n) time and space\n def countVowels(self, word: str) -> int:\n n = len(word)\n dp = [-1] * n\n if self.is_vowel(word[0]):\n dp[0] = 1\n else:\n dp[0] = 0\n \n for i in range(1, n):\n dp[i] = dp[i-1]\n if self.is_vowel(word[i]):\n dp[i] += i+1\n \n return sum(dp)\n \n def is_vowel(self, char: str) -> bool:\n return char in "aeiou"\n```\n | 3 | 0 | ['Dynamic Programming'] | 1 |
vowels-of-all-substrings | Faster than 97% || C++ || | faster-than-97-c-by-bhaskarv2000-o6i6 | \nclass Solution\n{\npublic:\n long long countVowels(string word)\n {\n long long int cnt = 0, cur = 0;\n for (int i = 0; i < word.size(); i | BhaskarV2000 | NORMAL | 2022-05-03T07:12:34.835158+00:00 | 2022-05-03T07:12:34.835202+00:00 | 220 | false | ```\nclass Solution\n{\npublic:\n long long countVowels(string word)\n {\n long long int cnt = 0, cur = 0;\n for (int i = 0; i < word.size(); i++)\n {\n if (word[i] == \'a\' || word[i] == \'e\' || word[i] == \'i\' || word[i] == \'o\' || word[i] == \'u\')\n cur += (i+1);\n cnt += cur;\n }\n return cnt;\n }\n};\n// add the position(=index+1) art which vowel occurs\n// aeio\n// a 1\n// ae 1+2\n// aei 1+2+3\n// aeio 1+2+3+4\n// ADD ALL\n``` | 3 | 0 | [] | 0 |
vowels-of-all-substrings | [C++] Counting the contribution of each index O(n) time | c-counting-the-contribution-of-each-inde-gzl0 | Number of substrings that contain the i\'th index is (i+1)\(n-i)\nWe count the contribution of each vowel, for this we count the number of subarrays it can be a | kediaharshit9 | NORMAL | 2021-11-10T07:53:38.623221+00:00 | 2021-11-11T11:00:55.492567+00:00 | 223 | false | Number of substrings that contain the i\'th index is (i+1)\\*(n-i)\nWe count the contribution of each vowel, for this we count the number of subarrays it can be a part of.\nThe subarrays which start at index [0, i] (inclusive) and the subarrays which end at index [i, n-1] (inclusive) will all contain the i\'th index.\nHence total such sub arrays will be (i+1)*(n-i)\n\n```\nclass Solution {\npublic:\n long long countVowels(string word) {\n long long n = word.size();\n long long ans = 0;\n for(int i=0; i<n; i++){\n if(word[i]==\'a\' || word[i]==\'e\' || word[i]==\'i\' || word[i]==\'o\' || word[i]==\'u\'){\n ans += (n-i)*(i+1);\n }\n }\n return ans;\n }\n};\n``` | 3 | 0 | ['C'] | 2 |
vowels-of-all-substrings | C++ O(N) Time | Easy Solution | c-on-time-easy-solution-by-nishantjain15-1kvi | This problem can be viewed as sum of total number of substrings having index i where word[i] is vowel. Basically we have to find the count of substrings that in | nishantjain1501 | NORMAL | 2021-11-07T09:07:04.664168+00:00 | 2021-11-07T09:22:31.087001+00:00 | 228 | false | This problem can be viewed as sum of total number of substrings having index i where word[i] is vowel. Basically we have to find the count of substrings that include index i (for word[i] is vowel) .\n\nE.g:- For String "abc" -> total substrings with index 0 is 3 i.e - a, ab, abc so Ans is 3\nFor String "aba" -> total substrings with index 0 is 3 and total substrings with index 2 is 3 so Ans is 6\n\nSolution Appproach:-\n\nFor each index i total substring will be -> (i+1) * (n-i)\nLets say for eg -> "abcdefgh". Here for index 4 (i.e for e) e, ef, efg, efgh, de, def ... these will be the substring so indexes before e combined with indexes after e will result in all the substring.\n\nThere will be two type of substrings that will include e. One with the letter that will start with letters coming before e and one with those start from e itself.\n\n```\nclass Solution {\npublic:\n long long countVowels(string word) {\n int len = word.size();\n \n long long ans = 0;\n \n for(int i=0; i<len; i++)\n {\n if(word[i] == \'a\' || word[i] == \'e\' || word[i] == \'i\' || word[i] == \'o\' || word[i] == \'u\')\n {\n ans += (long long) (i+1) * (long long) (len-i);\n }\n }\n \n return ans;\n \n }\n};\n``` | 3 | 1 | ['String', 'C', 'Combinatorics', 'C++'] | 0 |
vowels-of-all-substrings | Fastest javascript solution | 92ms | fastest-javascript-solution-92ms-by-saur-agre | Explanation\nThe approach is to go through each character of the string and check whether\xA0the character\xA0is a vowel or not.\nIf it\'s vowel then the number | saurabhsiddhu | NORMAL | 2021-11-07T05:41:42.947422+00:00 | 2021-11-09T08:32:22.377202+00:00 | 340 | false | **Explanation**\nThe approach is to go through each character of the string and check whether\xA0the character\xA0is a vowel or not.\nIf it\'s vowel then the number of new vowels added is equal to the number of new substrings added plus number vowels added in previous iterations;Else\xA0 number of new vowels added is number of vowels added in previous iterations;\xA0\n\nFor example for string "aba"\n1) "a"\xA0 \xA0 **New vowels** 1 **Result** 1 **Last Vowels** 0\n2) "ab" "b" \xA0 **New vowels** 0 **Result** 2 **Last Vowels** 1\n3) "aba" "ba" "a" \xA0 **New vowels** 3 **Result** 6 **Last Vowels** 1\n\n```\n var countVowels = function (word) {\n let lastVowels = 0;\n let result = 0;\n for (let i = 0; i < word.length; i++) {\n\t let newVowels = 0;\n if (isVowel(word[i])) {\n newVowels= (i + 1);\n }\n result += lastVowels + newVowels;\n\t\tlastVowels = newVowels + lastVowels;\n }\n return result;\n};\nlet isVowel = function (char) {\n return "aeiou".indexOf(char) !== -1 ? true : false;\n}; | 3 | 0 | ['Dynamic Programming', 'JavaScript'] | 0 |
vowels-of-all-substrings | Java solution | java-solution-by-iambond26-30ol | Note: I wasted lot of time on this via brute force but couldn\'t come up with right solution (mine was timing out). \nBelow is from one of submission (not mine) | iambond26 | NORMAL | 2021-11-07T04:24:14.450740+00:00 | 2021-11-07T04:24:14.450785+00:00 | 313 | false | Note: I wasted lot of time on this via brute force but couldn\'t come up with right solution (mine was timing out). \nBelow is from one of submission (not mine), sharing with others here.\n\n```\n public long countVowels(String word) {\n \n long ans = 0; //focus on long (return type)\n long size = word.length();\n \n for(long i=0; i<size; i++) {\n char ch = word.charAt((int) i);\n \n if(ch == \'a\' || ch == \'e\' || ch == \'i\' || ch == \'o\' || ch == \'u\') {\n \n ans += (i+1)*(size-i); //magical line\n }\n }\n \n return ans;\n\t\t} | 3 | 0 | ['Java'] | 0 |
vowels-of-all-substrings | JAVA Easy O(n) | java-easy-on-by-dheeraj_dev-3li2 | ```\nclass Solution {\n public long countVowels(String word) {\n long ans = 0;\n \n HashSet vowel = new HashSet<>();\n vowel.add(\'a\ | dheeraj_dev | NORMAL | 2021-11-07T04:07:16.817784+00:00 | 2021-11-07T04:07:16.817819+00:00 | 252 | false | ```\nclass Solution {\n public long countVowels(String word) {\n long ans = 0;\n \n HashSet<Character> vowel = new HashSet<>();\n vowel.add(\'a\'); vowel.add(\'e\'); vowel.add(\'i\'); vowel.add(\'o\'); vowel.add(\'u\');\n \n for(int i = 0; i < word.length(); i++){\n if(vowel.contains(word.charAt(i))){\n ans += ((long)(word.length() - i) * (i + 1));\n }\n }\n \n return ans;\n }\n} | 3 | 0 | [] | 1 |
vowels-of-all-substrings | One Liner Python | one-liner-python-by-betterleetcoder-czp8 | \n def countVowels(self, word: str) -> int:\n return sum((i+1)*(len(word)-i) for i,c in enumerate(word) if c in \'aeiou\')\n | BetterLeetCoder | NORMAL | 2021-11-07T04:01:44.307571+00:00 | 2021-11-07T04:01:44.307621+00:00 | 245 | false | ```\n def countVowels(self, word: str) -> int:\n return sum((i+1)*(len(word)-i) for i,c in enumerate(word) if c in \'aeiou\')\n``` | 3 | 1 | [] | 2 |
vowels-of-all-substrings | Greedy approch | greedy-approch-by-madhavendrasinh44-8bp8 | Intuitionfind the code as the approchApproachIts simple maths.Complexity
Time complexity: O(n)
Space complexity: O(n)
Code | Madhavendrasinh44 | NORMAL | 2025-03-03T16:19:15.250999+00:00 | 2025-03-03T16:19:15.250999+00:00 | 220 | false | # Intuition
find the code as the approch
# Approach
Its simple maths.
# Complexity
- Time complexity: $$O(n)$$
- Space complexity: $$O(n)$$
# Code
```cpp []
class Solution {
public:
long long countVowels(string words) {
long long ans=0;
for(int i=0;i<words.size();i++){
if(words[i]=='a' || words[i]=='e' || words[i]=='i' || words[i]=='o' || words[i]=='u'){
ans+=(i+1)*(words.size()-i);
}
}
return ans;
}
};
``` | 2 | 0 | ['Math', 'String', 'C++'] | 0 |
vowels-of-all-substrings | Beautifully Explained || Add contribution of each vowel | beautifully-explained-add-contribution-o-r3rg | Explanation\n\nif words[i] is a vowel,\nthere are (i+1) choices for start of substring\nand (n-i) choices for end of substring.\nSo, total (i+1)*(n-i) substring | coder_rastogi_21 | NORMAL | 2024-05-06T16:30:28.445471+00:00 | 2024-05-06T16:30:28.445500+00:00 | 116 | false | # Explanation\n```\nif words[i] is a vowel,\nthere are (i+1) choices for start of substring\nand (n-i) choices for end of substring.\nSo, total (i+1)*(n-i) substrings contain the vowel word[i].\n\nEx, \nConsider the string "bcaklm" (n = 6)\n\n0 1 2 3 4 5 \nb c a k l m\n\nwe have word[2] = \'a\' which is a vowel\nThere are 3(i+1) choices to start a substring i.e. \'b\', \'c\', \'a\'\nThere are 4(n-i) choices for ending a substring i.e. \'a\', \'k\', \'l\', \'m\'\n\nSo, total 3 * 4 = 12 substrings are possible which are as follows -\n1. bc\'a\'\n2. c\'a\'\n3. \'a\'\n\n4. bc\'a\'k\n5. c\'a\'k\n6. \'a\'k\n\n7. bc\'a\'kl\n8. c\'a\'kl\n9. \'a\'kl\n\n10. bc\'a\'klm\n11. c\'a\'klm\n12. \'a\'klm\n```\n# Complexity\n- Time complexity: $$O(n)$$ \n\n- Space complexity: $$O(1)$$ \n# Code\n```\nclass Solution {\n bool isVowel(char ch) {\n return ch == \'a\' || ch == \'e\' || ch == \'i\' || ch == \'o\' || ch == \'u\';\n }\npublic:\n long long countVowels(string word) {\n long long ans = 0, n = word.length();\n\n for(int i=0; i<n; i++) {\n if(isVowel(word[i])) {\n ans += 1LL*(i+1)*(n-i);\n }\n }\n return ans;\n }\n};\n``` | 2 | 0 | ['C++'] | 0 |
vowels-of-all-substrings | SImple CPP solution with clear explanation and comments | simple-cpp-solution-with-clear-explanati-xqbs | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \nWe need to find out in | piraj | NORMAL | 2024-01-31T21:48:00.822949+00:00 | 2024-01-31T21:48:00.822968+00:00 | 166 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nWe need to find out in how many substrings a vowel occurs. The approach is simple.\nConsider a given string "bcedru"\nSuppose I want to know in how many strings e is occuring.\nOne way to find out the number of occurences with e as the starting character and e is not the start character.\n1)e as start character: to the right of e, there are 3 character and including e, there will be 4. The length of string is 6 and the current index of e is 2. So,with e as start character, in 6-2 or n - i sub strings, where n is the length of string and i is the current index of string,e will be the starting character.\n2)e is not the starting character: From the starting index, i.e 0, to the current index of e, i.e. 2, there will 2-0 +1 substrings, or i - 0 + 1 = i +1 substrings, where e will be present but not as a starting character. \nSo, you get the frequencies where e is not the starting character and e is the starting character. Multiply them and add it to your answer.\nSimilarly, calculate for all vowels\n\n\n\n# Complexity\n- Time complexity: O(n)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(1)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\npublic:\n bool isVowel(char c){\n return c==\'a\' || c==\'e\' || c==\'i\' || c==\'o\' || c==\'u\';\n }\n \n long long countVowels(string word) {\n \n long long ans = 0;\n int n = word.length();\n for(int i=0; i< n;i++){\n if(isVowel(word[i])){\n //calculating left substring frequency\n long long leftSubStr = i+1;\n //calculating right substring frequency\n long long rightSubStr = n-i;\n ans+=(leftSubStr * rightSubStr); \n }\n \n }\n return ans;\n }\n};\n``` | 2 | 0 | ['C++'] | 0 |
vowels-of-all-substrings | Intuitive, easy to understand Solution. time ~ O(n), space ~ O(1) | intuitive-easy-to-understand-solution-ti-mtzr | Intuition\n Describe your first thoughts on how to solve this problem. \nOur first intuition must be a O(n^2) solution which makes the every possible subset, th | AjayVarshney2117 | NORMAL | 2023-06-03T12:35:57.210365+00:00 | 2023-06-03T12:36:49.275347+00:00 | 54 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nOur first intuition must be a O(n^2) solution which makes the every possible subset, then count the total number of vowel in it and then add to the counter.\n\nBut think some reverse look-up here. Instead of thinking as founding the every subset then counting vowel in it.\nThink like for every character how much it contribute to the answer.\n\nfor example, input = "aba",\n- (first a) a comes in substrings "a", "ab", "aba" -> contributes 1 each = 3\n- b comes in substrings "ab", "aba", "b", "ba" -> contribute 0 each = 0\n- (second a) a comes in substrings "aba", "ba", "a" -> contribute 1 each = 3\n\nAdding all give the answer 3 + 0 + 3 = 6.\n\nImportant points :\n- Consonents won\'t add. If consonent appear skip it.\n- If vowel appear, we need to find to find in how many substring it can appear, this can be done in O(1).\n- Two same characters are totally independent of other same characters, so we don\'t have to care about \'does other same character would contribute with current character ?\'\n- Answer can be big here, use "long long int" or any respective bigger data type to not get any overflow.\n\n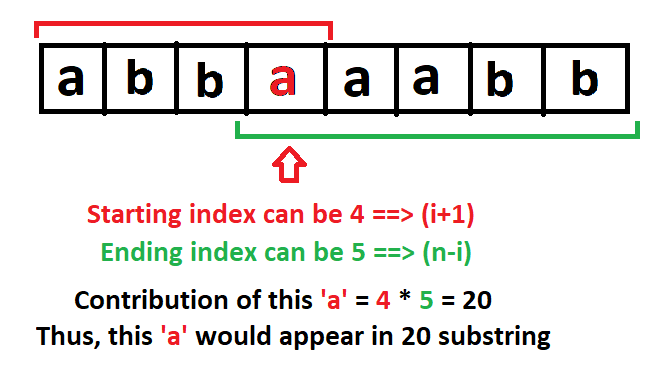\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n1. Initialize counter cnt = 0.\n2. Iterate i from 0 to n-1\n 2.1. if word[i] is vowel, then add (i+1) * (n-i) to the cnt.\n3. Return cnt\n\n\n# Complexity\n- Time complexity: $$O(n)$$, as we only iterate for each character\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: $$O(1)$$, as we only use cnt and i variables, also we are using one function stack space as we are calling one isVowel() function. \n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\n bool isVowel(char c) {\n if(c == \'a\' || c == \'e\' || c == \'i\' || c == \'o\' || c == \'u\') return true;\n return false;\n }\npublic:\n long long countVowels(string word) {\n long long cnt = 0;\n for(int i=0 ; i<word.size() ; ++i)\n if(isVowel(word[i])) \n cnt += (i + 1)*(word.size() - i);\n return cnt;\n }\n};\n``` | 2 | 0 | ['Math', 'String', 'Combinatorics', 'Counting', 'C++'] | 1 |
vowels-of-all-substrings | 80% FASTER || C++ || VOWEL COUNT || SIMPLE & EASY TO UNDERSTAND | 80-faster-c-vowel-count-simple-easy-to-u-8rm7 | \nclass Solution {\npublic:\n long long countVowels(string word) {\n long long int ans = 0,k=0;\n for(int i = 0; i < word.length(); i++){\n | yash___sharma_ | NORMAL | 2023-02-08T10:21:47.657007+00:00 | 2023-02-08T10:21:47.657078+00:00 | 656 | false | ```\nclass Solution {\npublic:\n long long countVowels(string word) {\n long long int ans = 0,k=0;\n for(int i = 0; i < word.length(); i++){\n if(word[i]==\'a\'||word[i]==\'e\'||word[i]==\'i\'||word[i]==\'o\'||word[i]==\'u\'){\n k += (i+1);\n ans = ans+k;\n }else{\n ans = ans+k;\n }\n // cout<<ans<<" ";\n }\n return ans;\n }\n};\n``` | 2 | 0 | ['Math', 'C', 'C++'] | 0 |
vowels-of-all-substrings | Python3 | Explained | Top Down DP | O(n) | python3-explained-top-down-dp-on-by-chet-kp6c | We have to iterate over the list and just have to count the number of times a vovel is used in a substring, so if we are at index i and it is a vovel then it wi | Chetan_007 | NORMAL | 2022-08-23T09:38:07.962624+00:00 | 2023-01-08T11:30:50.573860+00:00 | 497 | false | We have to iterate over the list and just have to count the number of times a vovel is used in a substring, so if we are at index i and it is a vovel then it will be used in i+1 (from 0 to i) and x-i (form i to x) where x is the length of the string.\nAnd if we multiply these two to get the sum for that vovel i.e (i+1)*(x-i) \nAnd at the end we will add the vovel sum to get the ans.\n\nfor example:\naba\nall the possible substring for 0th index is a, ab aba\nso the count for a (0+1)*(3-0)=3\n\nwe will skip b, as it is not counted in any substring\n\nnow for i=2\nthe last a will be used in aba, ba and a\nso the count will be 3.\n\nand the total count for a is 6.\n\nand there are no other vovel in the string.\nso their count will be 0.\n\nso ans=6+0+0+0+0=6\n\nNote: we are only counting the number of times a vovel is used in total number of substring.\n\ndef countVowels(self, words: str) -> int:\n\n vov={\'a\':0,\'e\':0,\'i\':0,\'o\':0,\'u\':0}\n x=len(words)\n for i in range(x):\n if words[i] in vov:\n vov[words[i]]+=(i+1)*(x-i) \n summ=0 \n for i,j in vov.items():\n summ+=j \n return summ | 2 | 0 | ['Dynamic Programming', 'Python3'] | 0 |
vowels-of-all-substrings | C++| Easy Code with Explanation | 90% Fast | c-easy-code-with-explanation-90-fast-by-id9zy | Please Upvote :)\n\n\nclass Solution {\npublic:\n long long countVowels(string word) {\n long long res=0;\n for(int i=0;i<word.length();i++)\n | ankit4601 | NORMAL | 2022-07-27T09:27:16.099331+00:00 | 2022-07-27T09:27:16.099372+00:00 | 255 | false | Please Upvote :)\n\n```\nclass Solution {\npublic:\n long long countVowels(string word) {\n long long res=0;\n for(int i=0;i<word.length();i++)\n {\n if(vowel(word[i]))\n {\n long long t=word.length()-i;\n// there are i char till here soo each of them can create t substrings using this char\n res+=i*t; \n res+=t; // contribution to subtstrings starting from here\n }\n }\n return res;\n }\n bool vowel(char c)\n {\n if(c==\'a\' || c==\'e\' || c==\'i\' || c==\'o\' || c==\'u\')\n return true;\n return false;\n }\n};\n``` | 2 | 1 | ['C', 'C++'] | 0 |
vowels-of-all-substrings | O(n) || C++ || Simple Maths Solution | on-c-simple-maths-solution-by-ranjan_him-2sb2 | \nclass Solution {\npublic:\n long long countVowels(string word) {\n long long ans = 0 , n = word.size();\n for(long long i = 0 ; i < n ; i++)\ | ranjan_him212 | NORMAL | 2022-07-05T17:56:29.415862+00:00 | 2022-07-05T17:56:29.415910+00:00 | 276 | false | ```\nclass Solution {\npublic:\n long long countVowels(string word) {\n long long ans = 0 , n = word.size();\n for(long long i = 0 ; i < n ; i++)\n if(word[i] == \'a\' || word[i] == \'e\' || word[i] == \'o\' || word[i] == \'i\' || word[i] == \'u\')\n ans += ((i+1)*(n-i));//Number of substrings if the ith index is a vowel\n return ans;\n }\n};\n``` | 2 | 0 | [] | 0 |
vowels-of-all-substrings | [JAVA] BEATS 100.00% MEMORY/SPEED 0ms // APRIL 2022 | java-beats-10000-memoryspeed-0ms-april-2-g0rc | \nclass Solution {\n public long countVowels(String word) {\n long res = 0, prev = 0;\n for(int i=0; i<word.length(); i++) {\n char | darian-catalin-cucer | NORMAL | 2022-04-23T20:41:08.146623+00:00 | 2022-04-23T20:41:08.146649+00:00 | 366 | false | ```\nclass Solution {\n public long countVowels(String word) {\n long res = 0, prev = 0;\n for(int i=0; i<word.length(); i++) {\n char c = word.charAt(i);\n if(c == \'a\' || c == \'e\' || c == \'i\' || c == \'o\' || c == \'u\')\n prev += i + 1;\n res += prev;\n }\n \n return res;\n }\n}\n```\n\n***Consider upvote if usefull!*** | 2 | 0 | ['Java'] | 1 |
vowels-of-all-substrings | C++ Easy and Concise O(N) | c-easy-and-concise-on-by-nazir1-cm7r | when ever i see a vowel i find its contribution in ans . the contribution of a vowel at index i can be calculated as\n(i+1)*(n-i)\n\nclass Solution {\npublic:\n | nazir1 | NORMAL | 2022-03-14T10:26:41.436674+00:00 | 2022-03-14T10:26:41.436703+00:00 | 101 | false | when ever i see a vowel i find its contribution in ans . the contribution of a vowel at index i can be calculated as\n```(i+1)*(n-i)```\n```\nclass Solution {\npublic:\n long long countVowels(string word) {\n \n int n=word.size();\n \n long long ans=0;\n for(int i=0;i<n;i++)\n {\n if(word[i]==\'a\'||word[i]==\'u\'||word[i]==\'o\'||word[i]==\'i\'||word[i]==\'e\')\n {\n long long a=(i+1),b=(n-i);\n ans+=a*b;\n }\n }\n return ans;\n \n }\n};\n``` | 2 | 0 | [] | 0 |
vowels-of-all-substrings | Python || Simple Math and Combinatorics | python-simple-math-and-combinatorics-by-j9ggp | \n\n\nclass Solution:\n def countVowels(self, word: str) -> int:\n vows = set("aeiou")\n l = len(word)\n s = 0\n for i in range(l | cherrysri1997 | NORMAL | 2022-02-23T16:21:19.102151+00:00 | 2022-02-23T16:21:19.102189+00:00 | 143 | false | \n\n```\nclass Solution:\n def countVowels(self, word: str) -> int:\n vows = set("aeiou")\n l = len(word)\n s = 0\n for i in range(l):\n if word[i] in vows:\n s += (i + 1) * (l - i)\n return s\n```\n**Please upvote if you find it interesting and helpful!!!\nThank you.** | 2 | 0 | ['String', 'Combinatorics', 'Ordered Set', 'Python3'] | 0 |
vowels-of-all-substrings | Python O(n) by DP//math [w/ Comment] | python-on-by-dpmath-w-comment-by-brianch-1pvv | Hint:\n\nDefine dp[i] = count of vowels of substring ending at index i, i is from 0 to len(word)-1\n\nState Transfer function\n\n\nIf word[i] is vowel:\n\t\t# c | brianchiang_tw | NORMAL | 2021-12-21T03:50:42.116865+00:00 | 2021-12-23T09:47:27.888238+00:00 | 220 | false | **Hint**:\n\nDefine dp[i] = **count of vowels** of **substring ending at index i**, i is from 0 to len(word)-1\n\n**State Transfer function**\n\n```\nIf word[i] is vowel:\n\t\t# current index i contributes extra (i+1) substring with current vowel character, which is ending at index i\n\t\tdp[i] = dp[i-1] + (i+1)\n```\n\n```\nIf word[i] is not vowel:\n\t\t# current index i has no contribution\n\t\tdp[i] = dp[i-1] + 0 = dp[i-1]\n```\n\n---\n\nFinal answer = **count of vowels of all substrings**\n= dp[0] + dp[1] + ... + dp[ len(word)-1 ]\n= **summation of all dp table values**\n= sum( dp(i) for i in range( len(word) ) ) \n\n---\n\n**Implementation** by top-down DP in Python\n\n```\nclass Solution:\n def countVowels(self, word: str) -> int:\n \n vowels = set("aeiou")\n \n @cache\n def dp( i ):\n \n ## Base case:\n if i == 0:\n \n return 1 if word[i] in vowels else 0\n \n \n ## General cases:\n prev = dp(i-1)\n \n if word[i] in vowels:\n # current index i contributes (i+1) substring with current vowel character, which is ending at index i\n return prev + (i+1)\n else:\n # current index i has not contribution\n return prev\n \n # -----------------------------------------\n return sum( [dp(i) for i in range(len(word))] )\n```\n\n---\n\n**Implementation** by bottom-up DP in Python\n\n```\nclass Solution:\n def countVowels(self, word: str) -> int:\n \n vowels = set("aeiou")\n \n\n \n # {-1: 0} is for vowel count = 0 on empty string\n dp = {-1: 0}\n \n for i, char in enumerate(word):\n \n prev_vowel_count = dp[i-1]\n \n if char in vowels:\n \n # current index i contributes (i+1) substring with current vowel character, which is ending at index i\n cur_vowel_count = prev_vowel_count + (i + 1)\n \n else:\n # current index i has not contribution\n cur_vowel_count = prev_vowel_count\n\n\n dp[i] = cur_vowel_count\n \n\n return sum( dp.values() )\n```\n\n---\n\n**Implementation** by math in Python\n\n```\nclass Solution:\n def countVowels(self, word: str) -> int:\n \n n = len(word)\n vowel = set("aeiou")\n \n count = 0\n \n for i, char in enumerate(word):\n \n if char in vowel:\n \n # curent vowel char can be covered by s[start:end]\n \n # start is from index 0 to i inclusively, total i+1 choices\n # end is from index i to n-1 inclusively, total n-i choices\n \n start_combination, end_combination = (i+1), (n-i)\n count += start_combination * end_combination\n \n return count\n``` | 2 | 0 | ['Math', 'String', 'Dynamic Programming', 'Python'] | 1 |
vowels-of-all-substrings | Dynamic programming easy solution | dynamic-programming-easy-solution-by-jen-gkss | class Solution {\npublic:\n long long countVowels(string word) {\n \n long long ans=0;\n \n set s;\n \n s.insert(\' | jenacpp | NORMAL | 2021-11-11T18:30:09.496368+00:00 | 2021-11-11T18:30:09.496399+00:00 | 363 | false | class Solution {\npublic:\n long long countVowels(string word) {\n \n long long ans=0;\n \n set<char> s;\n \n s.insert(\'a\');\n s.insert(\'e\');\n s.insert(\'i\');\n s.insert(\'o\');\n s.insert(\'u\');\n \n \n int n=word.size();\n \n vector<long long > dp(n+1);\n int i;\n dp[n]=0;\n \n for(i=n-1;i>=0;i--){\n \n if(s.find(word[i])!=s.end()){\n dp[i]=(n-i)+dp[i+1];\n }\n \n else dp[i]=dp[i+1];\n \n ans+=dp[i];\n \n \n }\n \n \n \n \n \n return ans;\n \n \n }\n}; | 2 | 0 | ['Dynamic Programming'] | 2 |
vowels-of-all-substrings | C++ Fully explained With proof | c-fully-explained-with-proof-by-kshitijv-1cwc | Explanation\nFor each vowels s[i],\nit could be in the substring starting at s[x] and ending at s[y],\nwhere 0 <= x <= i and i <= y < n,\nthat is (i + 1) choice | kshitijvarshne1 | NORMAL | 2021-11-08T12:24:09.559384+00:00 | 2021-11-08T12:24:09.559415+00:00 | 66 | false | Explanation\nFor each vowels s[i],\nit could be in the substring starting at s[x] and ending at s[y],\nwhere 0 <= x <= i and i <= y < n,\nthat is (i + 1) choices for x and (n - i) choices for y.\n\nSo there are (i + 1) * (n - i) substrings containing s[i].\nTime O(n)\nSpace O(1)\n\n\n\n\tclass Solution {\n\n\tpublic:\n\n\t\tbool isVowel(char c){\n\t\t\treturn c==\'a\' or c==\'e\' or c==\'i\' or c==\'o\' or c==\'u\';\n\t\t}\n\n\t\tlong long countVowels(string s) {\n\t\t\tlong long n = s.size();\n\t\t\tlong long sum=0;\n\t\t\tfor (long long i = 0; i < n; i++) {\n\t\t\t if(isVowel(s[i])){\n\t\t\t\t sum+=(i+1)*(n-i);\n\t\t\t }\n\t\t\t}\n\t\t\treturn sum;\n\t\t}\n\t}; | 2 | 0 | [] | 0 |
vowels-of-all-substrings | c++ Solution | c-solution-by-bholanathbarik9748-hjhv | \ntypedef long long int ll;\nclass Solution\n{\n bool vowel(char &a)\n {\n return a == \'a\' or a == \'e\' or a == \'i\' or a == \'o\' or a == \'u\ | bholanathbarik9748 | NORMAL | 2021-11-07T08:23:47.599214+00:00 | 2021-11-07T08:23:47.599250+00:00 | 47 | false | ```\ntypedef long long int ll;\nclass Solution\n{\n bool vowel(char &a)\n {\n return a == \'a\' or a == \'e\' or a == \'i\' or a == \'o\' or a == \'u\';\n }\n \npublic:\n long long countVowels(string word)\n {\n ll res = 0;\n for (ll i = 0; i < word.size(); i++)\n {\n if (vowel(word[i]))\n res += (i + 1) * (word.size() - i);\n }\n return res;\n }\n};\n``` | 2 | 0 | [] | 0 |
vowels-of-all-substrings | python: dynamic programming | python-dynamic-programming-by-r4444-yse4 | start from the last position. that will be our base case. then count and store number of vowels.\n\n\nclass Solution:\n def countVowels(self, word: str) -> i | R4444 | NORMAL | 2021-11-07T04:07:21.830187+00:00 | 2021-11-07T04:23:37.544897+00:00 | 122 | false | start from the last position. that will be our base case. then count and store number of vowels.\n\n```\nclass Solution:\n def countVowels(self, word: str) -> int:\n # count and store number of vowels\n dp = [0] * (len(word)+1)\n for i in range(len(word)-1, -1, -1):\n if word[i] in "aeiou":\n dp[i] = dp[i+1] + len(word)-i\n else:\n dp[i] = dp[i+1]\n return sum(dp)\n``` | 2 | 1 | [] | 1 |
vowels-of-all-substrings | c++ O(N) solution 5 lines | c-on-solution-5-lines-by-sonkarkunal812-q65c | Intuitiontry to cnt all substring including the charcterApproachcounting the substringComplexity
Time complexity: O(N)
Space complexity:O(1)
Code | sonkarkunal812 | NORMAL | 2025-03-26T13:37:14.912786+00:00 | 2025-03-26T13:37:14.912786+00:00 | 23 | false | # Intuition
<!-- Describe your first thoughts on how to solve this problem. -->
try to cnt all substring including the charcter
# Approach
<!-- Describe your approach to solving the problem. -->
counting the substring
# Complexity
- Time complexity: O(N)
<!-- Add your time complexity here, e.g. $$O(n)$$ -->
- Space complexity:O(1)
<!-- Add your space complexity here, e.g. $$O(n)$$ -->
# Code
```cpp []
class Solution {
public:
long long countVowels(string word) {
int n = word.length() ;
long long cnt = 0 ;
for ( int i = 0 ; i < word.length() ; i++ ){
if ( word[i] == 'a' || word[i] == 'u' || word[i] == 'i' || word[i] == 'e' || word[i] == 'o' ){
cnt += ((long long) i + 1 ) * ( n - i ) ;
}
}
return cnt ;
}
};
``` | 1 | 0 | ['C++'] | 0 |
vowels-of-all-substrings | Easiest c++ solution 0ms beats 100% solve by counting | easiest-c-solution-0ms-beats-100-solve-b-zm65 | IntuitionApproachComplexity
Time complexity: O(n)
Space complexity: O(1)
Code | albert0909 | NORMAL | 2025-03-11T02:33:48.232770+00:00 | 2025-03-11T02:33:48.232770+00:00 | 357 | false | # Intuition
<!-- Describe your first thoughts on how to solve this problem. -->
# Approach
<!-- Describe your approach to solving the problem. -->
# Complexity
- Time complexity: $$O(n)$$
<!-- Add your time complexity here, e.g. $$O(n)$$ -->
- Space complexity: $$O(1)$$
<!-- Add your space complexity here, e.g. $$O(n)$$ -->
# Code
```cpp []
class Solution {
public:
long long countVowels(string word) {
long long ans = 0;
unordered_set<char> vowel = {'a', 'e', 'i', 'o', 'u'};
for(int i = 0;i < word.length();i++){
if(vowel.count(word[i])) ans += (i + 1) * (word.length() - i);
}
return ans;
}
};
auto init = []()
{
ios::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
return 'c';
}();
``` | 1 | 0 | ['Math', 'String', 'Combinatorics', 'Counting', 'C++'] | 0 |
vowels-of-all-substrings | 15MS 🏆 ||🌟JAVA ☕ | 15ms-java-by-galani_jenis-2fj0 | Code | Galani_jenis | NORMAL | 2025-02-20T09:59:13.369205+00:00 | 2025-02-20T09:59:13.369205+00:00 | 94 | false |
# Code
```java []
class Solution {
public long countVowels(String word) {
long res = 0,sz = word.length(); // Focus on return type
for (int i = 0; i < sz; i++)
if ("aeiou".indexOf(word.charAt(i)) != -1)
res += (i + 1) * (sz - i); // Magical line
return res;
}
}
```

| 1 | 0 | ['Java'] | 0 |
vowels-of-all-substrings | Very Easy Simple Problem Formula || C++ | very-easy-simple-problem-formula-c-by-pu-qwb5 | IntuitionTotal Substrings Including Character at
𝑖
i:Each starting point can pair with any valid ending point to form a substring. Therefore, the total number o | puneet_3225 | NORMAL | 2024-12-29T10:23:35.082194+00:00 | 2024-12-29T10:23:35.082194+00:00 | 115 | false | # Intuition
<!-- Describe your first thoughts on how to solve this problem. -->
Total Substrings Including Character at
𝑖
i:
Each starting point can pair with any valid ending point to form a substring. Therefore, the total number of substrings that include the character at
𝑖
i is:
Count
=
(
𝑖
+
1
)
×
(
𝑛
−
𝑖
)
Count=(i+1)×(n−i)
# Approach
<!-- Describe your approach to solving the problem. -->
# Complexity
- Time complexity:
<!-- Add your time complexity here, e.g. $$O(n)$$ -->
- Space complexity:
<!-- Add your space complexity here, e.g. $$O(n)$$ -->
# Code
```cpp []
class Solution {
public:
long long countVowels(string s) {
long long ans = 0, n = s.length();
for(int i = 0; i < s.length(); i++){
if(s[i] == 'a' || s[i] == 'e' || s[i] == 'i' || s[i] == 'o' || s[i] == 'u'){
ans += (n-i)*(i+1);
}
}
return ans;
}
};
``` | 1 | 0 | ['C++'] | 0 |
vowels-of-all-substrings | Python DP | python-dp-by-nanzhuangdalao-bb8o | Intuition\n Describe your first thoughts on how to solve this problem. \n$dp[i]$: the sum of the number of vowels in every substrings ending at index $i$.\n\n# | nanzhuangdalao | NORMAL | 2024-04-09T12:26:01.377854+00:00 | 2024-04-09T12:36:24.615361+00:00 | 28 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n$dp[i]$: the sum of the number of vowels in every substrings ending at index $i$.\n\n# Code\n```\nclass Solution:\n def countVowels(self, word: str) -> int:\n n = len(word)\n dp = [0] * n\n dp[0] = word[0] in \'aeiou\'\n for i in range(1, n):\n if word[i] in \'aeiou\':\n # 1: the single element substring \'word[i]\' has one vowel\n # dp[i - 1] + 1\uFF1Aevery substrings ending at index i - 1 can be extended to index i, and get 1 more number of vowels. Totally there are i substrings ending at index i - 1.\n dp[i] = 1 + dp[i - 1] + i\n else:\n dp[i] = dp[i - 1]\n return sum(dp)\n``` | 1 | 0 | ['Dynamic Programming', 'Python3'] | 0 |
vowels-of-all-substrings | [Python] One liner O(N) | python-one-liner-on-by-codingmonkey101-y2sh | \n\nclass Solution:\n def countVowels(self, word: str) -> int:\n return sum((i+1)*(len(word)-i) for i in range(len(word)) if word[i] in "aeiou")\n\n\n | CodingMonkey101 | NORMAL | 2023-11-26T16:48:35.783255+00:00 | 2023-11-26T16:48:35.783283+00:00 | 12 | false | \n```\nclass Solution:\n def countVowels(self, word: str) -> int:\n return sum((i+1)*(len(word)-i) for i in range(len(word)) if word[i] in "aeiou")\n\n\n\n \n\n\n \n``` | 1 | 1 | ['Python3'] | 0 |
vowels-of-all-substrings | simple maths | simple-maths-by-detective07-26lk | \n# Approach\njust check, in how many substrings that vowel is appears.\n\n# Complexity\n- Time complexity:\nO(n)\n\n- Space complexity:\nO(1)\n\n\n# Code\n\nc | detective07 | NORMAL | 2023-09-02T21:38:31.853162+00:00 | 2023-09-02T21:38:31.853179+00:00 | 5 | false | \n# Approach\njust check, in how many substrings that vowel is appears.\n\n# Complexity\n- Time complexity:\nO(n)\n\n- Space complexity:\nO(1)\n\n\n# Code\n```\nclass Solution {\npublic:\n long long countVowels(string s) {\n //(i+1)*(n-i)\n long long ans = 0, n = s.length();\n for(long long i = 0; i < s.length(); i++){\n if(s[i]==\'a\'||s[i]==\'e\'||s[i]==\'i\'||s[i]==\'o\'||s[i]==\'u\'){\n ans = ans + (i+1)*(n-i);\n }\n }\n return ans;\n }\n};\n``` | 1 | 0 | ['C++'] | 0 |
vowels-of-all-substrings | :: Kotlin :: Sliding Window | kotlin-sliding-window-by-znxkznxk1030-5xs5 | \n# Code\n\nclass Solution {\n fun countVowels(word: String): Long {\n val vowels = arrayOf(\'a\',\'e\',\'i\',\'o\',\'u\').toSet()\n var result | znxkznxk1030 | NORMAL | 2023-05-10T11:25:39.902728+00:00 | 2023-05-10T11:29:57.984997+00:00 | 12 | false | \n# Code\n```\nclass Solution {\n fun countVowels(word: String): Long {\n val vowels = arrayOf(\'a\',\'e\',\'i\',\'o\',\'u\').toSet()\n var result = 0L\n var accs = 0L\n\n for (i in 0 until word.length) {\n if (vowels.contains(word[i])) {\n accs = accs + i + 1\n }\n result += accs\n }\n\n return result\n }\n}\n``` | 1 | 0 | ['Kotlin'] | 1 |
vowels-of-all-substrings | [Accepted] Swift | accepted-swift-by-vasilisiniak-4cf7 | \nclass Solution {\n func countVowels(_ word: String) -> Int {\n\n let chs = Array(word)\n var res = 0\n\n for i in chs.indices\n | vasilisiniak | NORMAL | 2023-04-18T10:22:02.512303+00:00 | 2023-04-18T10:22:02.512388+00:00 | 219 | false | ```\nclass Solution {\n func countVowels(_ word: String) -> Int {\n\n let chs = Array(word)\n var res = 0\n\n for i in chs.indices\n where "aeiou".contains(chs[i]) {\n res += (chs.count - i) * (i + 1)\n }\n\n return res\n }\n}\n``` | 1 | 0 | ['Swift'] | 0 |
vowels-of-all-substrings | RB's Very Simple two Pointers Approach in Python | rbs-very-simple-two-pointers-approach-in-3v9s | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | Rb_anjali99 | NORMAL | 2023-02-20T05:03:37.693831+00:00 | 2023-02-20T05:03:37.693879+00:00 | 74 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def countVowels(self, word: str) -> int:\n cnt = 0\n vowel = \'aeiou\'\n ln = len(word)\n for i in range(len(word)-1,-1,-1):\n if word[i] in vowel:\n # for left and right and merged calulation \n left = i - 0\n right = ln - 1 - i\n left_to_right = left*right\n cnt += left + right + left_to_right + 1 # +1 for itself count as substring\n else:\n continue # for consonant char\n return cnt\n``` | 1 | 0 | ['Math', 'Two Pointers', 'String', 'Python3'] | 0 |
vowels-of-all-substrings | [Python] DP, no extra memory | python-dp-no-extra-memory-by-wtain-elib | Intuition\nWe can approach this problem with DP. Let\'s count total number of vowels in the substrings of word prefix word[0..i] and call it DP(i). \nThus given | wtain | NORMAL | 2023-02-13T23:02:20.328259+00:00 | 2023-02-13T23:02:20.328300+00:00 | 101 | false | # Intuition\nWe can approach this problem with DP. Let\'s count total number of vowels in the substrings of ``word`` prefix ``word[0..i]`` and call it ``DP(i)``. \nThus given we have ``DP(i-1)`` we can calculate ``DP(i)`` in the following way:\n1. If ``word[i]`` is a consonant, then total number of vowels in all substrings of the prefix ``word[0:i]`` will be the same as the number of vowels of all substrings of the prefix ``word[0:i-1]``, thus ``DP(i) = DP(i-1)``, assuming ``DP(-1) = 0`` - number of vowels in substrings of an empty string.\n2. If ``word[i]`` is a vowel, we add exactly ``len(word[0:i])`` vowels since we will have substrings ``word[0:i-1] + word[i]``, ``word[1:i-1] + word[i]``,... ``word[i-1:i-1] + word[i]``.\nFor the total value we need to sum up values for the substrings - all ``DP(i)``\n\n# Approach\nWe don\'t need extra memory apart from two variables to calculate the result. We actually need only to store the result and previous ``DP`` value. All we need is to iterate over the string, check if consequtive character is a vowel and add current prefix length to the previous ``DP`` value, and accumulate it into the ``result``.\n\n# Complexity\n- Time complexity:\n$$O(n)$$\n\n- Space complexity:\n$$O(1)$$\n\n# Code\n```\nclass Solution:\n def countVowels(self, word: str) -> int:\n result = 0\n current = 0\n for i, c in enumerate(word):\n if c in "aeiou":\n current += (i+1)\n result += current\n return result\n```\n\n\nShall you have any questions - please feel free to ask, and upvote if you like it! | 1 | 0 | ['Python3'] | 1 |
vowels-of-all-substrings | Java | Derived Formula | Easy & Concise | java-derived-formula-easy-concise-by-iam-6qkm | \nclass Solution {\n public long countVowels(String word) {\n long n = word.length() ;\n long result = 0 ;\n \n for (int i = 0; i | iamvarun111 | NORMAL | 2022-09-13T16:42:19.077700+00:00 | 2022-09-13T16:42:19.077747+00:00 | 576 | false | ```\nclass Solution {\n public long countVowels(String word) {\n long n = word.length() ;\n long result = 0 ;\n \n for (int i = 0; i < n; i++) {\n char ch = word.charAt(i) ;\n if (ch == \'a\' || ch == \'e\' || ch == \'i\' || ch == \'o\' || ch == \'u\')\n result += (i+1)*(n-i) ;\n }\n \n return result ;\n }\n}\n``` | 1 | 0 | ['Java'] | 0 |
vowels-of-all-substrings | 100% space | Bitmask | Easy | C++ | 100-space-bitmask-easy-c-by-prafull1kuma-soup | \nclass Solution {\npublic:\n int num=1065233;\n // this is how num created\n // int num=0;\n // for(int i=0;i<=26;i++){\n // char ch=\'a\'+i | prafull1kumar | NORMAL | 2022-09-03T08:53:32.143191+00:00 | 2022-09-03T08:53:32.143239+00:00 | 253 | false | ```\nclass Solution {\npublic:\n int num=1065233;\n // this is how num created\n // int num=0;\n // for(int i=0;i<=26;i++){\n // char ch=\'a\'+i;\n // if(ch==\'a\' || ch==\'e\' || ch==\'i\' || ch==\'o\' || ch==\'u\'){\n // num+=(1<<i);\n // }\n // }\n // cout<<num<<"\\n";\n long long countVowels(string &W) {\n long long ans=0;\n int n=W.size();\n \n for(int i=0;i<n;i++){\n int dig=W[i]-\'a\';\n if(num&(1<<dig)){\n ans+=1LL*(i+1)*(n-i);\n }\n }\n return ans;\n }\n};\n``` | 1 | 0 | ['String', 'C', 'Bitmask'] | 0 |
vowels-of-all-substrings | java | java-by-anilkumawat3104-516i | \nclass Solution {\n public long countVowels(String word) {\n long ans = 0;\n HashSet<Character> set = new HashSet<>();\n set.add(\'a\') | anilkumawat3104 | NORMAL | 2022-08-20T10:03:20.583388+00:00 | 2022-08-20T10:03:20.583426+00:00 | 41 | false | ```\nclass Solution {\n public long countVowels(String word) {\n long ans = 0;\n HashSet<Character> set = new HashSet<>();\n set.add(\'a\');\n set.add(\'e\');\n set.add(\'i\');\n set.add(\'o\');\n set.add(\'u\');\n for(int i=0;i<word.length();i++){\n if(set.contains(word.charAt(i))){\n ans += (long)(i+1)*(long)(word.length()-i);\n }\n }\n return ans;\n }\n}\n``` | 1 | 0 | [] | 0 |
vowels-of-all-substrings | O(N) C++ | 10 lines | on-c-10-lines-by-zerojude-i7wv | \n long long countVowels(string A ) {\n int N = A.size();\n int a = 1 ;\n int b = N ;\n long long res = 0 ;\n \n un | zerojude | NORMAL | 2022-07-31T10:11:45.818073+00:00 | 2022-07-31T10:11:45.818114+00:00 | 228 | false | ```\n long long countVowels(string A ) {\n int N = A.size();\n int a = 1 ;\n int b = N ;\n long long res = 0 ;\n \n unordered_set< char >st = { \'a\' , \'e\' , \'i\' , \'o\' , \'u\' };\n \n for( auto x : A )\n {\n if( st.find(x) != st.end() )\n res += 1LL*a*b ;\n \n a++;\n b--;\n }\n return res; \n }\n``` | 1 | 0 | ['C'] | 1 |
vowels-of-all-substrings | [C++] Simple Observation : O(N) - Pictorially explained | c-simple-observation-on-pictorially-expl-ahn7 | Hello, please upvote the answer if you found it helpful.\n\nThe main idea is to store the number of vowels we count at each index and then use the same count to | JaskaranS19 | NORMAL | 2022-07-27T19:05:01.743406+00:00 | 2022-07-27T19:05:01.743447+00:00 | 135 | false | Hello, please upvote the answer if you found it helpful.\n\nThe main idea is to store the number of vowels we count at each index and then use the same count to further count the number of vowels for next index. Any character will only contribute to the "prev" variable IF it is a vowel otherwise the number of vowels will remain the same.\nPlease watch the example to get a clear picture of the code.\n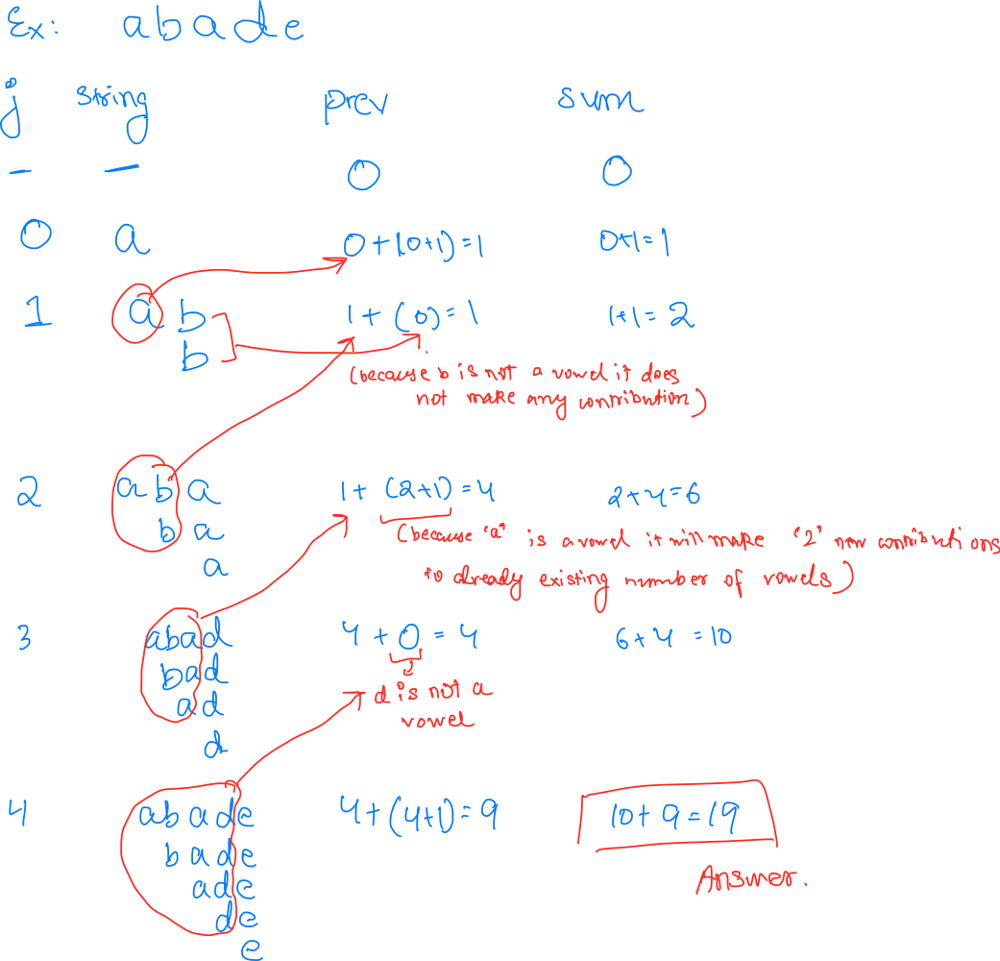\n\n```\nclass Solution {\npublic:\n long long countVowels(string word) {\n long long prev=0,sum=0;\n int n = word.size();\n for(int j=0;j<n;j++){\n if(word[j] == \'a\'|| word[j] == \'e\' || word[j] == \'i\' || word[j] == \'o\' || word[j] == \'u\' ) \n prev += j+1;\n sum+=prev;\n }\n return sum;\n }\n \n};\n``` | 1 | 0 | ['C'] | 0 |
vowels-of-all-substrings | c++||o(n) solution | con-solution-by-gauravkumart-h9nx | ```\n int n= w.length();\n bool v[26] = {1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0};\n long long ans=0;\n f | gauravkumart | NORMAL | 2022-07-12T06:20:15.787082+00:00 | 2022-07-12T06:20:15.787133+00:00 | 72 | false | ```\n int n= w.length();\n bool v[26] = {1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0};\n long long ans=0;\n for(int i=0;i<n;i++){\n //char ch=word[i];\n long long res1=(i+1);\n long long res2=(n-i);\n ans+=v[w[i]-\'a\']*res1*res2;\n }\n return ans; | 1 | 0 | [] | 0 |
vowels-of-all-substrings | Easy Understanding C++ Solution || O(n) Time Complexity | easy-understanding-c-solution-on-time-co-i3d1 | Thought Process:\nLet\'s take a word "barcode"\nWe need to find total number of occurance of vowels i.e. [a,o,e]\n1. Let\'s Try to make substrings that gonna in | anonymous_st | NORMAL | 2022-07-06T07:51:48.989837+00:00 | 2022-07-06T07:51:48.989887+00:00 | 177 | false | **Thought Process:**\nLet\'s take a word "barcode"\nWe need to find total number of occurance of vowels i.e. [a,o,e]\n1. Let\'s Try to make substrings that gonna include \'a\'.\n\t* \tsubstrings starting from \'b\' are: "ba", "bar", "barc", "barco", "barcod", "barcode" \n\t\t* \tit means we need to make substrings where the last letter is [a, ...]\n\t* \tsubstrings starting from \'a\' are: "a", "ar", "arc", "arco", "arcod", "arcode"\n\t\t* \tit also says we need to make substrings where the last letter is [a, ...]\n\t* \tSo, to include \'a\', we need substring that starts with letter which is on or before \'a\' and ends with letter which is on or after \'a\'.\n\t* \tCount of \'a\' = 2*6 = 12.\n2. Let\'s Try to make substrings that gonna include \'o\'.\n\t* \tsubstrings starting from \'b\' are: "barco", "barcod", "barcode" \n\t\t* \tit means we need to make substrings where the last letter is [o, ...]\n\t* \tsubstrings starting from \'a\' are: "arco", "arcod", "arcode"\n\t\t* \tit also says we need to make substrings where the last letter is [o, ...]\n\t* \tsubstrings starting from \'r\' are: "rco", "rcod", "rcode" \n\t\t* \tit also says we need to make substrings where the last letter is [o, ...]\n\t* \tsubstrings starting from \'c\' are: "co", "cod", "code"\n\t\t* \tit also says we need to make substrings where the last letter is [o, ...]\n\t* \tsubstrings starting from \'o\' are: "o", "od", "ode"\n\t\t* \tit also says we need to make substrings where the last letter is [o, ...]\n\t* \tSo, to include \'o\', we need substring that starts with letter which is on or before \'o\' and ends with letter which is on or after \'o\'.\n\t* \tCount of \'a\' = 3*5 = 15.\n* So, from the above observation, we can say that to include any vowel, we need **(pos[vowel]+1)**, **(len-pos[vowel])** number of different substrings i.e. that much number of occurrence of the vowel.\n* Here, **len** is **length of word** and **pos** is **position of vowel**.\n\n**Code:**\n```\nlong long countVowels(string word){\n int len=word.length();\n long long count=0;\n for(int pos=0; pos<len; pos++){\n char c = word[pos];\n if(c==\'a\' || c==\'e\' || c==\'i\' || c==\'o\' || c==\'u\'){\n count += 1ll*(n-pos)*(pos+1);\n }\n }\n return count;\n}\n```\n**Time Complexity: O(n)\nSpace Complexity: O(1)\nUpvote if you find it helpful, Comment For any explanation...** | 1 | 0 | ['C', 'C++'] | 0 |
vowels-of-all-substrings | c++ |simple approch without dp simple observation | c-simple-approch-without-dp-simple-obser-dpwh | \nclass Solution {\npublic:\n long long countVowels(string word) {\n long long ans=0;\n map<char,int>m;\n m[\'a\']++;\n m[\'e\'] | deepak_pal8790 | NORMAL | 2022-06-11T09:34:56.940453+00:00 | 2022-06-11T09:38:47.961311+00:00 | 157 | false | ```\nclass Solution {\npublic:\n long long countVowels(string word) {\n long long ans=0;\n map<char,int>m;\n m[\'a\']++;\n m[\'e\']++;\n m[\'i\']++;\n m[\'o\']++;\n m[\'u\']++;\n int n=word.length();\n\t\t//we need to check the contribution of every vowels in final ans\n\t\t//__________a[i]____________\n\t\t//suppose a[i] is vowel the we find number of substring such that a[i] is part of ths substring\n\t\t//op1= we find number of substring ending at i so this are i+1;\n\t\t//op2=we find number of substring that start at i so this is n-i-1\n\t\t//op3 we find number of substring such that a[i] is between in string \n\t\t//for this ----------a[i]______________ number of character to left of i and number of\n\t\tcharacter to right of i is total is left*right total answer for this i is sum of abover three options\n for(int i=0;i<word.length();i++){\n if(m.count(word[i])){\n long long a=i+1;\n long long b=n-i-1;\n long long c=i*b;\n ans+=a;\n ans+=b;\n ans+=c;\n \n }\n }\n return ans;\n \n }\n};\n\n``` | 1 | 0 | ['Math'] | 0 |
vowels-of-all-substrings | Clean Code || c++ || easy to understand! | clean-code-c-easy-to-understand-by-binay-lcua | \nclass Solution {\npublic:\n long long countVowels(string word) {\n vector<char> f = {\'a\',\'e\',\'i\',\'o\',\'u\'};\n set<char> s;\n | binayKr | NORMAL | 2022-05-20T19:58:57.349795+00:00 | 2022-05-20T19:58:57.349845+00:00 | 151 | false | ```\nclass Solution {\npublic:\n long long countVowels(string word) {\n vector<char> f = {\'a\',\'e\',\'i\',\'o\',\'u\'};\n set<char> s;\n s.insert(f.begin(),f.end());\n long long n = word.length();\n long long sum =0;\n for(long long i=0; i<n; i++)\n {\n if(s.find(word[i])!=s.end())\n {\n sum += (i+1)*(n-i);\n }\n }\n return long(sum);\n }\n};\n``` | 1 | 0 | ['Math', 'C'] | 0 |
vowels-of-all-substrings | Easy Java Solution O(n) with Expalanation | easy-java-solution-on-with-expalanation-vhyjb | Number of susbstrings in which the vowel at word.charAt(i) will occur will be its own substrings i.e. len-i and in the substrings of previous elements .Number o | kenkapo | NORMAL | 2022-05-13T12:53:01.367680+00:00 | 2022-05-13T12:53:01.367706+00:00 | 289 | false | Number of susbstrings in which the vowel at **word.charAt(i)** will occur will be its own substrings i.e. **len-i** and in the substrings of **previous** elements .Number of elements before it will be **i** and **(len-i)** will be the susbtrings in which it will occur.\n```\nclass Solution {\n public long countVowels(String word) {\n long ans=0;\n String vowels="aeiou";\n int len=word.length();\n for (int i=0;i<word.length();i++)\n {\n char ch=word.charAt(i);\n if (ch==\'a\'|| ch==\'e\'||ch==\'i\'||ch==\'o\'||ch==\'u\')\n {\n ans+=len-i+(long)(i)*(len-i);\n }\n }\n return ans;\n }\n}\n``` | 1 | 0 | ['Math', 'String', 'Java'] | 0 |
vowels-of-all-substrings | Python | Combinatrics | Math | python-combinatrics-math-by-kamikasai-vvh2 | Consider string "xxax"\n1. vowel can be part of substrings a, xa, xxa in left hand side of vowel\n2. vowel can be part of substrings a, ax in right hand side | KamiKasai | NORMAL | 2022-05-02T14:35:23.002029+00:00 | 2022-05-02T14:35:23.002068+00:00 | 147 | false | Consider string "xxax"\n1. vowel can be part of substrings a, xa, xxa in left hand side of vowel\n2. vowel can be part of substrings a, ax in right hand side of vowel\n3. Then simply we need to multiple l*r (a, xa, xxa) * (a, ax) => (aa, aax, xaa, xaax, xxaa, xxaax) **duplicates "aa" => "a" **\n```\nclass Solution(object):\n def countVowels(self, word):\n """\n :type word: str\n :rtype: int\n """\n vm = {\'a\': 1, \'e\': 1, \'i\': 1, \'o\': 1, \'u\': 1}\n c = 0\n for k, w in enumerate(word):\n if w in vm:\n r = len(word) - k # Calculate no of substrings formed in right side with vowel as pivot\n l = (k+1) # In left hand side\n c+=r*l # This for finding total no of strings crossing pivots\n return c\n``` | 1 | 0 | ['Combinatorics', 'Python'] | 0 |
vowels-of-all-substrings | Python (Simple Maths) | python-simple-maths-by-rnotappl-fg8c | \n def countVowels(self, word):\n total = 0\n \n for i in range(len(word)):\n if word[i] in "aeiou":\n total + | rnotappl | NORMAL | 2022-04-18T08:07:33.461452+00:00 | 2022-09-04T15:37:50.191109+00:00 | 107 | false | \n def countVowels(self, word):\n total = 0\n \n for i in range(len(word)):\n if word[i] in "aeiou":\n total += (i+1)*(len(word)-i)\n \n return total | 1 | 0 | [] | 0 |
vowels-of-all-substrings | C++ Solution - O(N) [SIMPLE & CONCISE] | c-solution-on-simple-concise-by-homeboy4-mz9g | \nclass Solution {\npublic:\n long long countVowels(string word) {\n auto isVow = [](char const &c) -> bool {\n return c == \'a\' || c == \ | homeboy445 | NORMAL | 2022-04-04T08:58:32.834326+00:00 | 2022-04-04T09:01:14.855350+00:00 | 91 | false | ```\nclass Solution {\npublic:\n long long countVowels(string word) {\n auto isVow = [](char const &c) -> bool {\n return c == \'a\' || c == \'e\' || c == \'i\' || c == \'o\' || c == \'u\';\n };\n long long sum = 0, n = word.size();\n for (long long i = 0; i < n; i++) {\n if (isVow(word[i])) { //Just count the number of sub-strings, the vowel - word[i] would be associated with;\n sum = (sum + n + i * (n - i - 1)); // adding \'n\' as word[i] would exist in the sub-string [0...i] & [i + 1...n],\n\t\t\t\t//and multiplying i * (n - i - 1) because, word[i] would also exist in the sub-strings [0...i] * [i + 1...n](i.e [0...i+1],[1...i+1]...[0...n] etc.);\n }\n }\n return sum;\n }\n};\n\n``` | 1 | 0 | ['C'] | 0 |
vowels-of-all-substrings | C++ || Easy to understand | c-easy-to-understand-by-ssangwan138-jyp0 | \nclass Solution {\npublic:\n long long countVowels(string word) {\n long long ans = 0;\n for(int i=0; i<word.size(); i++){\n long l | ssangwan138 | NORMAL | 2022-03-21T17:09:04.090615+00:00 | 2022-03-21T17:09:04.090660+00:00 | 69 | false | ```\nclass Solution {\npublic:\n long long countVowels(string word) {\n long long ans = 0;\n for(int i=0; i<word.size(); i++){\n long long c = 0;\n if(word[i] == \'a\' or word[i] == \'e\' or word[i] == \'i\' or word[i] == \'o\' or word[i] == \'u\'){\n \n if(i == 0 or i == word.size()-1){\n c = word.size();\n }\n else{\n c = word.size();\n long long a = i*(word.size()-i-1);\n c += a;\n }\n }\n ans += c;\n }\n return ans;\n }\n};\n``` | 1 | 0 | [] | 0 |
vowels-of-all-substrings | C++ || Easy || O(N) | c-easy-on-by-akshatprogrammer-j9cq | \nbool isvowel(char c){\n return (c==\'a\' or c ==\'e\' or c==\'i\' or c==\'o\' or c==\'u\');\n }\n long long countVowels(string word) {\n l | akshatprogrammer | NORMAL | 2022-03-09T17:41:45.819446+00:00 | 2022-03-09T17:41:45.819494+00:00 | 91 | false | ```\nbool isvowel(char c){\n return (c==\'a\' or c ==\'e\' or c==\'i\' or c==\'o\' or c==\'u\');\n }\n long long countVowels(string word) {\n long long int ans=0;\n for(int i=0;i<word.size();i++){\n if(isvowel(word[i]))\n ans += (i+1)*(word.size()-i);\n else continue;\n }\n return ans;\n }\n``` | 1 | 0 | ['C'] | 0 |
vowels-of-all-substrings | Simple logic | C++ | simple-logic-c-by-sauram228-clkd | \nclass Solution {\npublic:\n long long countVowels(string word) {\n long long n = word.size();\n long long result = 0;\n for(long long | sauram228 | NORMAL | 2022-01-25T10:19:46.192228+00:00 | 2022-01-25T10:19:46.192254+00:00 | 81 | false | ```\nclass Solution {\npublic:\n long long countVowels(string word) {\n long long n = word.size();\n long long result = 0;\n for(long long i=0;i<n;i++){\n if(word[i]==\'a\'||word[i]==\'e\'||word[i]==\'i\'||word[i]==\'o\'||word[i]==\'u\'){\n result += (1 + i + (n-i-1) + ( i * (n-i-1)));\n }\n }\n return result;\n }\n};\n``` | 1 | 1 | [] | 0 |
vowels-of-all-substrings | C++ O(N) | O(1) | c-on-o1-by-themaniac-7ujb | generating all substrings will take O(N^2) .\nBut length constraints are too high. So we need to find a better approach..\nwhat if we can find count of substrin | themaniac | NORMAL | 2022-01-17T04:09:06.548317+00:00 | 2022-01-17T04:09:06.548402+00:00 | 105 | false | generating all substrings will take O(N^2) .\nBut length constraints are too high. So we need to find a better approach..\nwhat if we can find count of substrings the charecter is in.\ntake for example \ns= abca\ncharecter b can be present in \nb\nbc \nbca\nbut also rememeber it can also be present in substring with charecters before it.\nso ab\n\t\tabc\n\t\tabca\nif we look at this pattern, we can see that we can multiply the number of charecters before it with the susbtring generated from \nb i.e ("b","bc","bca") so it will be 2 * 3 =6;\n\nsimilarly for charecter c \nwe can start with c , can start with bc and also abc . For all three of these substrings(before and including c) we can calculate # of string after c;\nafter c-\nc\nca\n\nbefore c -\nbc\nbca\nabc\nabca\n\n\nthus \nposition of c * string after c = total number of strings the charecter c is in.\n\nNow we just check if the charecter is vowel or not and just only add that result to end result.\n\n\n```\nclass Solution {\npublic:\n long long countVowels(string word) {\n long long ans=0;\n for(int i=0;i<word.size();i++)\n {\n if(word[i]==\'a\'||word[i]==\'e\'||word[i]==\'o\'||word[i]==\'u\'||word[i]==\'i\')\n ans+=(word.size()-i)*(i+1);\n }\n return ans;\n }\n};\n``` | 1 | 0 | ['Greedy', 'Combinatorics'] | 0 |
vowels-of-all-substrings | 2063. Vowels of All Substrings | C++ | Contribution Problem | 2063-vowels-of-all-substrings-c-contribu-r2x4 | Every element s[i] appears in two types of subarrays:\n1. In subarrays beginning with s[i]. There are \n (n - i) such subsets.\n2. In (n - i) * i subarrays w | renu_apk | NORMAL | 2022-01-11T11:15:45.480923+00:00 | 2022-01-12T04:46:42.329504+00:00 | 69 | false | Every element s[i] appears in two types of subarrays:\n1. In subarrays beginning with s[i]. There are \n `(n - i)` such subsets.\n2. In `(n - i) * i` subarrays where this element is not\n first element.\n\nThus, total appearance of each vowel at index `i`= `(n - i) * (i + 1)`\n\n```\nclass Solution {\npublic:\n long long countVowels(string s) {\n unordered_set<char> vowels{\'a\', \'e\', \'i\', \'o\', \'u\'};\n long long ans = 0, n = s.size();\n for(int i = 0; i < n; i++){\n if(vowels.count(s[i])) ans += (n - i) * (i + 1);\n }\n return ans;\n }\n};\n``` | 1 | 0 | ['Greedy'] | 0 |
vowels-of-all-substrings | c++, easy solution with complete explaination | c-easy-solution-with-complete-explainati-7d4s | \nclass Solution {\npublic:\n long long countVowels(string s) {\n long long cur=0; // for counting all the vowels in substring \n int n=s.lengt | lone___Wolf | NORMAL | 2021-12-31T16:58:33.880824+00:00 | 2021-12-31T16:58:33.880849+00:00 | 118 | false | ```\nclass Solution {\npublic:\n long long countVowels(string s) {\n long long cur=0; // for counting all the vowels in substring \n int n=s.length();\n long long prev=0; // store number of vowels in substring before current index initial value is 0\n for(int i=0;i<n;i++)\n {\n if(s[i]==\'a\' || s[i]==\'e\' || s[i]==\'i\' || s[i]==\'o\' || s[i]==\'u\')\n {\n\t\t\t // if a we have 2 element in a array [1,2] then if we add 3rd element let it be 3 then total number of new substring formed which //include this new eelement is the size of array after adding new element i,e 3 = [1,2,3] , [2,3] , [3]\n\t\t\t // we add prev sum, [a,b,e] current total vowel sum in all substring is prev=6 now if we add one more vowel [a,b,e,f] now cur=4+prev=6\n cur+=i+1+prev;\n prev=i+prev+1;\n }\n else\n cur+=prev;\n }\n return cur;\n }\n};\n\n``````\n\n\n``` | 1 | 0 | ['C', 'Counting'] | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.