
question_slug
stringlengths 3
77
| title
stringlengths 1
183
| slug
stringlengths 12
45
| summary
stringlengths 1
160
⌀ | author
stringlengths 2
30
| certification
stringclasses 2
values | created_at
stringdate 2013-10-25 17:32:12
2025-04-12 09:38:24
| updated_at
stringdate 2013-10-25 17:32:12
2025-04-12 09:38:24
| hit_count
int64 0
10.6M
| has_video
bool 2
classes | content
stringlengths 4
576k
| upvotes
int64 0
11.5k
| downvotes
int64 0
358
| tags
stringlengths 2
193
| comments
int64 0
2.56k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
count-anagrams | count Anagrams || Unordered_map || Easy to understand💯 | count-anagrams-unordered_map-easy-to-und-oi87 | \n\n# Code\n\n#define ll long long \nclass Solution {\npublic:\n int m = 1000000007;\n vector<long long > fact;\n void solve(){\n f | mikky_123 | NORMAL | 2022-12-29T09:17:46.860561+00:00 | 2022-12-29T09:17:46.860602+00:00 | 182 | false | \n\n# Code\n```\n#define ll long long \nclass Solution {\npublic:\n int m = 1000000007;\n vector<long long > fact;\n void solve(){\n fact[0] = fact[1] =1 ;\n for(int i=2;i<100001;i++){\n fact[i] = (fact[i-1]%m * i%m )%m;\n }\n }\n ll powmod(ll a, ll b){\n ll res = 1;\n while(b>0){\n if(b%2 == 1)res= res*a % m;\n a= a*a % m;\n b = b/2;\n }\n return res;\n }\n ll inverse(ll n){\n return powmod(n,m-2);\n }\n int countAnagrams(string s) {\n fact.resize(100001);\n solve();\n ll ans =1 , cnt=0;\n unordered_map<char,int>freq;\n s+=\' \';\n for(int i=0;i<s.size();i++){\n if(s[i]==\' \'){\n ll val = fact[cnt];\n for(auto c : freq){\n val = val * inverse(fact[c.second])%m;\n }\n ans= ans*val % m;\n cnt=0;\n freq.clear();\n }\n else{\n cnt++;\n freq[s[i]]++;\n }\n }\n return ans;\n }\n};\n``` | 1 | 0 | ['Ordered Map', 'C++'] | 0 |
count-anagrams | C++ | Easy Approach after learning Binary Exponentiation and Modular Multiplicative Inverse | c-easy-approach-after-learning-binary-ex-uukj | Intuition\n Total number of permutations of a word without duplicate letters Formula: N!\n\n Total number of permutations of a word with duplicate letters | janakrish_30 | NORMAL | 2022-12-28T15:27:24.284375+00:00 | 2022-12-28T15:30:07.731291+00:00 | 99 | false | # Intuition\n Total number of permutations of a word without duplicate letters Formula: N!\n\n Total number of permutations of a word with duplicate letters Formula: N! / ma! * mb! * .... * mz! where N is the total number of letters and ma, mb are the occurrences of repetitive letters in the word\n\n# Approach\n Next (a / b) % mod will not be equal to (a % mod) / (b % mod) as it is large number we tend to take mod for every multiplication we do and we cannot calculate the final a / b to arrive at total permutations. So we make use of Modular Multiplicative Inverse\n \n (a / b) % mod != (a % mod) / (b % mod)\n By applying Fermat\'s Little Theorem\n By Conclusion we have\n (a / b) % mod = a * (b ^ -1) % mod\n (b ^ -1) % mod = b ^ (mod - 2) --> O(N)\n\n But now the Time Complexity if O(N * N) which is quadratic\n So to reduce we can use Binary Exponentiation which is O(logN)\n\n# Complexity\n- Time complexity:\n # O(NlogN)\n\n- Space complexity:\n # O(N)\n\n# Code\n```\nclass Solution {\nprivate:\n const int mod = 1e9 + 7;\n long long fact[100005];\n\n void factorial(int n) {\n fact[0] = 1;\n for(int i = 1;i <= n;i++) {\n fact[i] = (fact[i - 1] * i) % mod;\n }\n }\n \n long long getFactorial(long long n) {\n return fact[n];\n }\n\n long long binExp(long long a, long long b) {\n long long res = 1;\n while(b) {\n if(b & 1) { // set bit \n res = (res * a) % mod;\n }\n a = (a * a) % mod;\n b >>= 1;\n }\n return res;\n }\n\n long long modMul(long long a, long long b) {\n return ((a % mod) * (b % mod)) % mod;\n }\n\n long long getPermuation(string &word) {\n int mp[26] = {0};\n long long pro = 1;\n long long n = word.size();\n\n for(auto &ch : word) {\n mp[ch - \'a\']++;\n }\n \n long long totalFact = getFactorial(n);\n long long fact;\n\n for(int i = 0;i < 26;i++) {\n if(mp[i] > 0) {\n fact = getFactorial(mp[i]);\n pro = (pro * fact) % mod;\n }\n }\n\n long long a = totalFact;\n long long b = binExp(pro, mod - 2);\n\n return modMul(a, b);\n }\npublic:\n int countAnagrams(string s) {\n long long total = 1;\n int n = s.size();\n factorial(n);\n\n stringstream ss(s);\n string word;\n\n while(getline(ss, word, \' \')) {\n total = (total * getPermuation(word)) % mod;\n }\n\n return total % mod;\n }\n};\n``` | 1 | 0 | ['C++'] | 0 |
count-anagrams | JavaScript solution, need math knowledge and BigInt class | javascript-solution-need-math-knowledge-3nrid | Intuition\nThe final result is from multipling each word result.\nFor a word (splitted by space), we count the frequence of characters and calculate result for | Gang-Li | NORMAL | 2022-12-27T18:50:07.327434+00:00 | 2022-12-27T18:50:07.327468+00:00 | 284 | false | # Intuition\nThe final result is from multipling each word result.\nFor a word (splitted by space), we count the frequence of characters and calculate result for that word.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\nO(n)\n\n- Space complexity:\nO(n)\n\n# Code\n```\n/**\n * @param {string} s\n * @return {number}\n */\nvar countAnagrams = function (s) {\n const BIGINT_MODULO = BigInt(Math.pow(10, 9) + 7);\n function countWord(word) {\n let map = new Map();\n for (let c of word) {\n let cnt = map.get(c) || 0;\n cnt++;\n map.set(c, cnt);\n }\n\n if (map.size === 1) return 1n;\n else {\n let finalResult = 1n;\n let cnts = Array.from(map.values())\n .sort((a, b) => a - b)\n .map((val) => BigInt(val));\n let sum = BigInt(word.length);\n let choice = sum;\n\n for (let i = 0; i < cnts.length - 1; i++) {\n let cnt = cnts[i];\n let combinations = 1n;\n let devisor = 1n;\n while (cnt > 0n) {\n combinations *= choice--;\n devisor *= cnt;\n cnt--;\n }\n finalResult *= combinations / devisor;\n }\n\n return finalResult;\n }\n }\n\n let ans = 1n;\n for (let word of s.split(" ")) {\n ans *= countWord(word);\n ans %= BIGINT_MODULO;\n }\n\n return Number(ans);\n};\n\n``` | 1 | 0 | ['JavaScript'] | 1 |
count-anagrams | Easy C++ || Fermat's Theorem || O(n*log(10^9)) | easy-c-fermats-theorem-onlog109-by-ahmed-ztxv | Intuition\n Describe your first thoughts on how to solve this problem. \nFermat\'s Theorem + factorial\n\n# Approach\n Describe your approach to solving the pro | ahmed786ajaz | NORMAL | 2022-12-25T10:38:15.222985+00:00 | 2022-12-25T10:38:52.599577+00:00 | 135 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nFermat\'s Theorem + factorial\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nFor every word, count no of distinct chars and equal chars freq(using HashMap), now use concept of permutations for every word and keep on multiplying res into "ans"\ne.g for word = "abbscs", res = 6!/(2!*2!) => 6! * $$(2!)^i$$*$$(2!)^i$$\nwhere i = -1 and inv(n) = modular inverse of n w.r.t p can be calculated using Fermat\'s Theorem:\ninv(n, p) = pow(n, p-2)%p\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n$$O(n*log(10^9))$$\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n$$O(n)$$ where n = size of fact array $$(10^5)$$\n\n# Code\n```\n#define ll long long\n#define mod 1000000007\n\nclass Solution {\npublic:\n \n ll bin_pow(ll a, ll n){\n ll res = 1;\n while(n > 0){\n if(n&1)\n res = (res*a)%mod;\n \n a = (a*a)%mod;\n n = n>>1;\n }\n \n return res;\n }\n \n// ll fun(ll n, ll r){\n \n// }\n \n int countAnagrams(string s) {\n int i, j;\n int n = s.length();\n int sz = 100000;\n ll fact[sz+1];\n fact[0] = 1;\n \n for(ll ind=1; ind <= sz; ind++){\n fact[ind] = (fact[ind-1]*ind)%mod;\n }\n \n ll ans = 1;\n \n i = 0;\n while(i < n){\n unordered_map<char, int> m;\n \n ll count = 0;\n \n while(i < n && s[i] != \' \'){\n count++;\n m[s[i]]++;\n i++;\n }\n \n ll N = fact[count];\n \n ll r = 1;\n for(auto it:m){\n r = (r*fact[it.second])%mod;\n }\n \n ll val = (N*bin_pow(r, mod-2))%mod;\n ans = (ans*val)%mod;\n \n i++;\n }\n \n return ans;\n \n \n }\n};\n``` | 1 | 0 | ['Math', 'Prefix Sum', 'C++'] | 0 |
count-anagrams | Kotlin simple solution | kotlin-simple-solution-by-neo204-v77t | \nclass Solution {\n val mod: Long = (1e9+7).toLong()\n\n fun power(x: Long, y: Long): Long {\n var x: Long = x\n var y: Long = y\n v | neo204 | NORMAL | 2022-12-25T06:28:29.763435+00:00 | 2022-12-25T06:28:29.763473+00:00 | 53 | false | ```\nclass Solution {\n val mod: Long = (1e9+7).toLong()\n\n fun power(x: Long, y: Long): Long {\n var x: Long = x\n var y: Long = y\n var ans: Long = 1\n x %= mod\n while (y > 0) {\n if (y and 1 == 1L) \n ans = (ans * x) % mod\n x = (x * x) % mod\n y = y shr 1\n }\n return ans\n }\n \n fun factorial(x: Long): Long{\n var fac: Long = 1L\n for(i in 1 until x+1)\n fac = (fac * i) % mod\n return fac\n }\n\n fun countAnagrams(s: String): Int {\n var ans = 1L\n s.split(\' \').forEach {\n val counts = LongArray(26){0}\n for(c in it) {\n counts[c-\'a\']++\n }\n var fac: Long = factorial(it.length.toLong())\n for(cnt in counts) {\n if(cnt != 0L) {\n fac = (fac * power(factorial(cnt),mod-2))%mod\n }\n }\n ans = (ans * fac) % mod\n }\n return ((ans + mod) % mod).toInt()\n }\n}\n``` | 1 | 0 | ['Kotlin'] | 0 |
count-anagrams | C++ | Modular Inverse | c-modular-inverse-by-aviprit-1wcw | Here the problem is quite straightforward, go through the observation points for intuition.\nObservations:\n1) Notice our permutation depends on every word of t | Aviprit | NORMAL | 2022-12-24T18:51:06.650375+00:00 | 2022-12-24T18:51:06.650413+00:00 | 174 | false | Here the problem is quite straightforward, go through the observation points for intuition.\nObservations:\n1) Notice our permutation depends on every word of the string i.e. string between two spaces.\n2) Spaces doesn\'t contribute to our final answer.\n3) Permutation of each word is the factorial of the number of charcters in that word divided by factorial of frequency of each character.\n\nEample - \n1) string - "too hot"\nanswer - (3! / (1! * 2!)) * (3! / (1! * 1! * 1!)) = 18\nExplanation - \na) "too" - its length is 3 and here frequency of o is 2 and t is 1 so its contribution in final is (3! / (1! * 2!))\nb) "hot" - its length is 3 and here frequency of o is 1, h is 1 and t is 1 so its contribution in final is (3! / (1! * 1! * 1!))\n\n2) string - "aa"\nanswer - (2! / 2!) = 1\nExplanation - \n"aa" - its length is 2 and frequency of letter 2 is 2 so its contribution in final answer is (2! / 2!).\n\n3) string - "topppo hot"\nanswer - (6! / (1! * 2! * 3!)) * (3! / (1! * 1! * 1!)) = 360\nExplanation - \na) "topppo" - its length is 6 and here frequency of o is 2, p is 3 and t is 1 so its contribution in final is (6! / (1! * 2! * 3!)).\nb) "hot" - its length is 3 and here frequency of o is 1, h is 1 and t is 1 so its contribution in final is (3! / (1! * 1! * 1!))\n\nNow you can observe the pattern here.\nIn this the most challenging part is to calculate mod of dividing the factorial as in the case of mod of dividing, doesn\'t yield the correct answer. So to come across this, modular inverse is used which is calculated using fermats little theorem. There are many good blogs present in internet for this theorem and modulo inverse, i recommend going through them for better understanding of the solution. I have linked them down below.\n\nModulo-Inverse - https://cp-algorithms.com/algebra/module-inverse.html\nCodeforces blog - https://codeforces.com/blog/entry/78873\n\nCode -\n```\nclass Solution {\n long long mod = 1e9 + 7;\n vector<long long> fact = vector<long long>(1e5 + 1);\n long long binpow(long long a, long long b) {\n long long res = 1; \n a = a % mod;\n while (b > 0) {\n if (b & 1) res = res * a % mod; \n a = a * a % mod; \n b >>= 1;\n } \n return res;\n }\n long long inv(long long a) {\n return binpow(a, mod - 2);\n }\npublic:\n // Constructor \n Solution() {\n int maxn = 1e5;\n fact[0] = 1;\n for(long long i = 1; i <= maxn; ++i) {\n fact[i] = fact[i - 1] * i % mod;\n }\n }\n int countAnagrams(string s) {\n long long ans = 1;\n int n = s.size();\n for(int i = 0; i < n; ++i) {\n vector<int> freq(26);\n int ind = i;\n while(ind < n && s[ind] != \' \') freq[s[ind++] - \'a\']++;\n int len = ind - i;\n long long perm = 1;\n for(int i = 0; i < 26; ++i) {\n perm = perm * inv(fact[freq[i]]) % mod;\n }\n ans = (ans * (fact[len] * perm % mod) % mod);\n i = ind;\n }\n return ans;\n }\n};\n```\n\nTC - O(100000) ```for calculating factorial``` + O(n * 26 * log(mod)) ```for calculating inverse of each frequency```\nSC - O(100000) ```for storing factorial``` + O(26) ```for storing frequency```\n\nNote - TC can be further reduced to ->O(100000 log(mod) + O(n * 26) if we also precompute the inverse array.\n\n**Please upvote if it helps** | 1 | 0 | ['C'] | 0 |
count-anagrams | Rust Module Division Using Fermat's Little Theorem | rust-module-division-using-fermats-littl-7et5 | Intuition\n Describe your first thoughts on how to solve this problem. \n1) The number of ways of counstructing the solution is the multiplication of the number | xiaoping3418 | NORMAL | 2022-12-24T17:51:07.699346+00:00 | 2022-12-24T17:51:07.699391+00:00 | 432 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n1) The number of ways of counstructing the solution is the multiplication of the number of ways of constructing each unique word.\n2) Assume f_1, f_2, ,, f_k are frequencies of distinct characters in a word, where f_1 + f_2 + ... + f_k = n. The number of ways to construct different anagram words is n! / (f_1! * f_2! * .. * f_k!).\n3) Fermat\'s Little Theorem states: for any a < p (1000000007, which is a prime), a ^ ( p - 1) == 1 (mod p).\n4) For any b (1 <= b <= p - 1) & a with b % a == 0, (b / a) % mod p == (b * a ^ (p - 2)) % mod p. We can use this equation to perform the division in helping getting the result from 2. \n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nuse std::collections::HashMap;\n\nimpl Solution {\n pub fn count_anagrams(s: String) -> i32 {\n let mut mp = HashMap::<char, i32>::new();\n let n = s.len();\n let s = s.chars().collect::<Vec<char>>();\n let mut ret = 1;\n \n for i in 0 ..= n {\n if i == n || s[i] == \' \' {\n let data = mp.values().map(|a| *a).collect::<Vec<i32>>();\n ret = (ret * Self::calculate(&data) as i64) % 1_000_000_007;\n mp.clear();\n } else { *mp.entry(s[i]).or_insert(0) += 1; }\n } \n \n ret as _\n }\n \n fn calculate(data: &Vec<i32>) -> i32 {\n let n = data.iter().sum::<i32>();\n let mut ret = 1;\n for k in 2 ..= n {\n ret = (ret * k as i64) % 1_000_000_007;\n }\n \n for d in data {\n for k in 2 ..= *d {\n ret = (ret * Self::divide(k) as i64) % 1_000_000_007;\n }\n }\n \n ret as _\n }\n \n fn divide(a: i32) -> i32 {\n let (mut base, mut ret) = (a as i64, 1);\n let mut m = 1_000_000_005;\n while m > 0 {\n if m % 2 == 1 { ret = (ret * base) % 1_000_000_007; }\n m >>= 1;\n base = (base * base) % 1_000_000_007;\n }\n \n ret as _\n }\n}\n``` | 1 | 0 | ['Rust'] | 0 |
count-anagrams | Brute Force Accepted || Formula | brute-force-accepted-formula-by-rushi_ja-xy2d | From basic math one can observe that answer is the product of the number of unique anagrams for each word in a sentence. So, we find number of anagrams of each | rushi_javiya | NORMAL | 2022-12-24T17:46:34.617353+00:00 | 2022-12-24T17:50:43.353832+00:00 | 99 | false | From basic math one can observe that answer is the product of the number of unique anagrams for each word in a sentence. So, we find number of anagrams of each word in sentence and multiple it.\n**Formula of finding number of anagrams of word:**\n```\nFactorial(length of word)/(multiple Factorial(count of each character in word))\n```\n**Example:**\n```\ns="too hot"\nunique number of anagrams of "too" = Factorial(3)/(Factorial(1)*Factorial(2)) = 3\nunique number of anagrams of "hot" = Factorial(3)/(Factorial(1)*Factorial(1)*Factorial(1)) = 6\nanswer = 6*3 =18\n```\n\n**Code:**\n```\nclass Solution:\n def countAnagrams(self, s: str) -> int:\n s=list(s.split())\n ans=1\n for word in s:\n length=len(word)\n c=Counter(word)\n temp=1\n for i in c:\n temp*=factorial(c[i])\n ans*=(factorial(length)//temp)\n return ans%(10**9+7)\n```\n\nYou can understand more about formula from [here](https://www.youtube.com/watch?v=ZL_vjZtnLSA) | 1 | 0 | ['Python3'] | 0 |
count-anagrams | [Python] Linear-time Modular Inverse 3-liner in with Explanation, The Best | python-linear-time-modular-inverse-3-lin-b0y5 | Intuition\nThe number of permutations of word w with possible letter repetitions is given by C_w = \dfrac{n_w!}{\prod_{c\in w} n_c!}, where n_c are counts of ea | Triquetra | NORMAL | 2022-12-24T17:20:28.155476+00:00 | 2022-12-24T21:51:27.050461+00:00 | 682 | false | # Intuition\nThe number of permutations of word $$w$$ with possible letter repetitions is given by $$C_w = \\dfrac{n_w!}{\\prod_{c\\in w} n_c!}$$, where $$n_c$$ are counts of each letter $$c \\in w$$. We need to compute $$\\prod_{w\\in s} C_w$$ for words $$w\\in s$$.\n\nThus, the final result is $$\\prod_{w\\in s} \\dfrac{n_w!}{\\prod_{c\\in w} n_c!} \\bmod M$$, where $$M = 10^9+7$$, a prime number.\n\n# Approach\nThe result must be computed in $$\\mathbb{Z}_M$$. Also note that computing the full $$n! \\in \\mathbb{Z}$$ may take too long. We can therefore compute numerator and denominator parts of the result separately in $$\\mathbb{Z}_M$$ and then divide them in $$\\mathbb{Z}_M$$ by computing the modular inverse of the denominator, which is possible since $$M$$ is prime.\n\nThe Best!\n\n# Complexity\n- Time complexity: $$O(\\lvert s\\rvert)$$\n- Space complexity: $$O(\\lvert s\\rvert)$$ due to word splitting, can be reduced to $$O(1)$$ by manually parsing $$s$$\n\n# Code\n```python\ndef countAnagrams(self, s: str) -> int:\n words, M, mul, fact = s.split(), 1000000007, lambda a, b: a*b % M, lambda n: functools.reduce(mul, range(2, n+1), 1)\n denom = functools.reduce(mul, (fact(count) for w in words for count in collections.Counter(w).values()), 1)\n return mul(functools.reduce(lambda t, w: mul(t, fact(len(w))), words, 1), pow(denom, -1, M))\n```\n\nFor comparison, here is a solution in imperative style:\n```python\ndef countAnagrams(self, s: str) -> int:\n def fact(n):\n product = 1\n for num in range(2, n + 1):\n product = (product * num) % M\n return product\n\n M = 1000000007\n numerator, denominator = 1, 1\n\n for word in s.split():\n numerator = (numerator * fact(len(word))) % M\n for count in collections.Counter(word).values():\n denominator = (denominator * fact(count)) % M\n\n return (numerator * pow(denominator, -1, M)) % M\n``` | 1 | 0 | ['Python3'] | 0 |
count-anagrams | [clean code] modulo multiplicative inverse using binary exponentiation - easy to understand - c++ | clean-code-modulo-multiplicative-inverse-cvfa | concept\nhttps://cp-algorithms.com/algebra/module-inverse.html#finding-the-modular-inverse-for-array-of-numbers-modulo-m\n# Code\n\n#define ll long long\n#defin | ravishankarnitr | NORMAL | 2022-12-24T17:02:41.899315+00:00 | 2022-12-24T17:10:03.049099+00:00 | 527 | false | # concept\nhttps://cp-algorithms.com/algebra/module-inverse.html#finding-the-modular-inverse-for-array-of-numbers-modulo-m\n# Code\n```\n#define ll long long\n#define mod 1000000007\nconst int N=1e5+1;\nclass Solution {\npublic:\n ll fact[N];\n\n void pre(){\n fact[0]=1;\n for(int i=1;i<N;i++){\n fact[i]=(1ll*fact[i-1]*i)%mod;\n }\n }\n \n ll binexp(int a,int b,int m){\n int result=1;\n while(b>0){\n if(b&1){\n result=(1ll*result*a)%m;\n }\n a=(1ll*a*a)%m;\n b>>=1;\n }\n\n return result;\n }\n \n int countAnagrams(string s) {\n pre();\n int i=0;\n int n=s.length();\n \n ll ans=1;\n while(i<n){\n vector<int> cnt(26,0);\n int count=0;\n ll curr;\n while(i<n && s[i]!=\' \'){\n count++;\n cnt[s[i]-\'a\']++;\n i++;\n }\n curr=fact[count];\n ll den=1;\n for(int i=0;i<26;i++) if(cnt[i]>1) den=(den*fact[cnt[i]])%mod;\n\n curr=(curr*binexp(den,mod-2,mod))%mod;\n ans=(ans*curr)%mod;\n i++;\n }\n \n return int(ans%mod);\n }\n};\n``` | 1 | 0 | ['C++'] | 1 |
count-anagrams | JAVA | Modulo Multiplicative Inverse | Neat and Clean Solution | java-modulo-multiplicative-inverse-neat-82y93 | Intuition\nFor each string (space seprated) find the count of unique permutation and multiply with the result.\n Describe your first thoughts on how to solve th | sahil58555 | NORMAL | 2022-12-24T16:58:07.468522+00:00 | 2022-12-24T17:52:20.625276+00:00 | 741 | false | # Intuition\nFor each string (space seprated) find the count of unique permutation and multiply with the result.\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\nHow to get unique permutation - \neg - string = "ababcb"\nunique permuation - 6! / (2! * 3! * 1!).\n\nAs max length of string is 1e5. So we can precomute the factorial from 1 to 1e5.\n\nNote :- when dealing with modulus in division. Use modulo multiplicative inverse technique.\ni.e. **a / b mod n = (a * pow(b, n - 2)) mod n** \n \n\n# Complexity\n- Time complexity: O(1e5 + n * log (1e9))\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(1e5)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n# Code\n```\nclass Solution {\n public int countAnagrams(String str) {\n \n Map<Integer,Long> map = new HashMap<>();\n int mod = 1000000000 + 7;\n \n long pro = 1;\n long ans = 1;\n \n for(int i = 1 ; i <= 100000 ; i++) {\n \n pro = (pro * i) % mod;\n \n map.put(i, pro);\n }\n \n for(String s : str.split(" ")) {\n \n long num = map.get(s.length());\n long den = 1;\n\n int[] freq = new int[26];\n \n for(char ch : s.toCharArray()) freq[ch - \'a\']++;\n \n for(int ele : freq) {\n \n if(ele != 0)\n \n den = (den * map.get(ele)) % mod;\n } \n \n long curr = (num * pow(den, mod - 2)) % mod;\n ans = (ans * curr) % mod;\n }\n \n return (int)ans;\n }\n \n long pow(long a,long n) {\n \n int mod = 1000000000 + 7;\n \n long res = 1;\n \n while(n > 0) {\n \n if(n % 2 == 1) {\n \n res = (res * a) % mod;\n n--;\n }\n else {\n \n a = (a * a) % mod;\n n = n / 2;\n }\n }\n \n return res;\n }\n}\n``` | 1 | 0 | ['Java'] | 2 |
count-anagrams | Self contained fast python code no import of math library | self-contained-fast-python-code-no-impor-3z9c | IntuitionBig_prime = 10**9 + 7
The problem with not using module Big_prime, is that the numbers become so large, multiplication and division are O(M(number of d | ___Arash___ | NORMAL | 2025-03-27T08:40:43.152378+00:00 | 2025-03-27T08:43:01.461744+00:00 | 2 | false | # Intuition
Big_prime = 10**9 + 7
The problem with not using module Big_prime, is that the numbers become so large, multiplication and division are O(M(number of digits)) and it is not O(1) anymore.
What to do? use mod Big_prime. But how divide mod Big_prime?
use a** p mod p =a (Fermat little theorem)
therefore a**(p-2) mod p is implementing 1/a
# Code
```python []
class Solution(object):
def countAnagrams(self, s):
Big = 10**9 + 7
memo = {}
def f(a):
# Define factorial modulo Big, with base case for 0 and 1.
if a <= 1:
return 1
if a in memo:
return memo[a]
memo[a] = (a * f(a-1)) % Big
return memo[a]
def fact(A):
summ = 0
out = 1
for a in A:
if a:
out = (out * f(a)) % Big
summ += a
# Instead of (f(summ)//out)%Big, we use modular division:
return (f(summ) * pow(out, Big-2, Big)) % Big
out = 1
cur = [0] * 26
for char in s:
if char == ' ':
out = (out * fact(cur)) % Big
cur = [0] * 26
else:
cur[ord(char)-ord('a')] += 1
return (out * fact(cur)) % Big
``` | 0 | 0 | ['Python'] | 0 |
count-anagrams | Easy Permutation Approach - Beats 91% ✅ | easy-permutation-approach-beats-91-by-da-a6fy | Intuition 🤔Calculate anagram counts using the permutation formula. Compute the factorial of total letters, divide by the product of factorials of repeating lett | dark_dementor | NORMAL | 2025-03-22T10:10:46.197296+00:00 | 2025-03-22T10:10:46.197296+00:00 | 4 | false | # Intuition 🤔
Calculate anagram counts using the permutation formula. Compute the factorial of total letters, divide by the product of factorials of repeating letters, and multiply results for each word in the string.
# Approach 🚀
1. Compute the factorial of the total number of letters.
2. Compute the factorial of each letter’s frequency and take the modular inverse to handle divisions.
3. Calculate permutations for each word separately and multiply the results.
4. Use modular arithmetic to prevent overflow.
# Complexity ⏳
- **Worst-case Time Complexity:** \(O(n + m \log m)\)
- **Average-case Time Complexity:** \(O(n)\)
- **Space Complexity:** \(O(1)\)
# Code 💻
```cpp
class Solution {
public:
const int mod = 1e9 + 7;
int fact(int n){
int ans = 1;
for(int i = 2; i <= n; i++){
ans = (1LL * ans * i) % mod;
}
return ans;
}
int modularInverse(int b){
int ans = 1, m = mod - 2;
while(m){
if(m & 1)ans = (1LL * ans * b) % mod;
b = (1LL * b * b) % mod;
m >>= 1;
}
return ans;
}
int permutations(int& size, vector<int>& count){
int sizeFact = fact(size);
int denomFact = 1;
for(auto i : count){
if(i > 1){
int temp = fact(i);
denomFact = (1LL * denomFact * temp) % mod;
}
}
return (1LL * sizeFact * modularInverse(denomFact)) % mod;
}
int countAnagrams(string s) {
vector<int> count(26);
int ans = 1;
int size = 0;
for(auto ch : s){
if(ch == ' '){
int temp = permutations(size, count);
ans = (1LL * ans * temp) % mod;
count = vector<int>(26);
size = 0;
}
else{
count[ch - 'a']++;
size++;
}
}
int temp = permutations(size, count);
ans = (1LL * ans * temp) % mod;
return ans;
}
};
``` | 0 | 0 | ['C++'] | 0 |
count-anagrams | Finest way of solving Count ANAGRAMS problem | finest-way-of-solving-count-anagrams-pro-xzdz | IntuitionApproachComplexity
Time complexity:
Space complexity:
Code | Shalman143 | NORMAL | 2025-03-15T09:40:32.746355+00:00 | 2025-03-15T09:40:32.746355+00:00 | 3 | false | # Intuition
<!-- Describe your first thoughts on how to solve this problem. -->
# Approach
<!-- Describe your approach to solving the problem. -->
# Complexity
- Time complexity:
<!-- Add your time complexity here, e.g. $$O(n)$$ -->
- Space complexity:
<!-- Add your space complexity here, e.g. $$O(n)$$ -->
# Code
```python3 []
class Solution:
def countAnagrams(self, s: str) -> int:
MOD = 10**9 + 7
max_n = 10**5
fact = [1] *( max_n + 1)
inv_fact = [1] *( max_n + 1)
for i in range (2,max_n+1):
fact[i] = (fact[i-1] *i) % MOD
inv_fact[max_n] = pow (fact[max_n],MOD-2,MOD)
for i in range(max_n-1 , 0 , -1):
inv_fact[i] = (inv_fact[i+1] * (i+1)) % MOD
words = s.split()
t = 1
for w in words :
frq = Counter(w)
so = sum(frq.values())
total = fact[so]
for i in frq.values():
total = (total * inv_fact[i]) % MOD
t = (t * total )% MOD
return t
``` | 0 | 0 | ['Python3'] | 0 |
count-anagrams | its very tricky solution | its-very-tricky-solution-by-rho_ruler-bnmm | IntuitionApproachComplexity
Time complexity:
Space complexity:
Code | Rho_Ruler | NORMAL | 2025-01-29T06:52:11.007368+00:00 | 2025-01-29T06:52:11.007368+00:00 | 9 | false | # Intuition
<!-- Describe your first thoughts on how to solve this problem. -->
# Approach
<!-- Describe your approach to solving the problem. -->
# Complexity
- Time complexity:
<!-- Add your time complexity here, e.g. $$O(n)$$ -->
O(N)
- Space complexity:
<!-- Add your space complexity here, e.g. $$O(n)$$ -->
O(N)
# Code
```python3 []
MOD = 10**9 + 7
def modinv(x, mod):
return pow(x, mod - 2, mod)
class Solution:
def countAnagrams(self, s: str) -> int:
max_len = len(s)
fact = [1] * (max_len + 1)
inv_fact = [1] * (max_len + 1)
for i in range(2, max_len + 1):
fact[i] = fact[i - 1] * i % MOD
inv_fact[max_len] = modinv(fact[max_len], MOD)
for i in range(max_len - 1, 0, -1):
inv_fact[i] = inv_fact[i + 1] * (i + 1) % MOD
words = s.split()
result = 1
for word in words:
n = len(word)
freq = [0] * 26
for char in word:
freq[ord(char) - ord('a')] += 1
word_anagrams = fact[n]
for count in freq:
if count > 0:
word_anagrams = word_anagrams * inv_fact[count] % MOD
result = result * word_anagrams % MOD
return result
``` | 0 | 0 | ['Python3'] | 0 |
count-anagrams | Comprehensive Solution by Reducing Problems Into Familiar Subproblems | comprehensive-solution-by-reducing-probl-0pau | IntuitionThis problem is about combinatorics, hence we make use of the math.comb library. We also need to keep a character frequency of each word so that we can | musk_eteer | NORMAL | 2025-01-13T15:10:33.248202+00:00 | 2025-01-13T15:10:33.248202+00:00 | 8 | false | # Intuition
This problem is about combinatorics, hence we make use of the math.comb library. We also need to keep a character frequency of each word so that we can calculate combinations where there are character repetitions
# Problem Decomposition
We can reduce this problem to the following subproblems:
- Converting space-delimited string into an array
- Traversing an array
- Creating and accessing values in a hashmap
- Calculating combinatorics
# Approach
To begin with, lets define a helper function `calculateFactorial` that takes a single `word` and the number of all possible combinations/ arrangements that `word` can take.
Within the scope of `calculateFactorial`:
- we create a hashmap `table` to store the frequency counts of all letters in `word`.
- save the length of word as `n`
- establish a `total` variable to save the answer for this function
- traverse the hashmap `table` and for each iteration:
- - multiply the current `total` by `n`! / (`n`! - `table[`w`]`!). This here is handled by making use of math.comb
- - decrement `n` by `table`[`w`]`.
- outside the traversal, return `total`
Now. let's implement the main function:
First, we establish a variable `res` that we shall use to incrementally build our final solution.
Split `s` into an array of words called `words`
Traverse the new array `words` and for each iteration:
- we multiply `res` by the combinatorial result of calling `calculateWordFactorial` on the current word. We ensure to bound the result using the provided modulus.
Outside of the for loop, we simply return `res`
# Complexity
- Time complexity:
`countAnagrams` - O(n)
`calculateWordFactorial` - O(k) where `k` == len('word')
total = O(nk)
- Space complexity:
`countAnagrams` - O(n)
`calculateWordFactorial` - O(k) where `k` == len('word')
total = O(nk)
# Code
```python3 []
import math
from collections import Counter
class Solution:
def countAnagrams(self, s: str) -> int:
'''
This is a mathematical problem. We can find the distinct number of permutation of each word in the string and multiply using the combinatorial formular
'''
res = 1
words = s.split(" ")
for word in words:
res = (res * self.calculateWordFactorial(word)) % (10**9 + 7)
return res
def calculateWordFactorial(self, word):
table = Counter(word)
n = len(word)
total = 1
for w in table:
total *= math.comb(n, table[w])
n -= table[w]
return int(total)
``` | 0 | 0 | ['Hash Table', 'String', 'Combinatorics', 'Python3'] | 0 |
count-anagrams | Permutation logic | permutation-logic-by-vats_lc-xogg | Code | vats_lc | NORMAL | 2025-01-09T13:05:59.071370+00:00 | 2025-01-09T13:05:59.071370+00:00 | 12 | false | # Code
```cpp []
#define li long long
const li MOD = 1e9 + 7;
class Solution {
public:
li mod_exp(li x, li y, li mod) {
li res = 1;
while (y > 0) {
if (y % 2 == 1)
res = (res * x) % mod;
x = (x * x) % mod;
y /= 2;
}
return res;
}
li mod_inv(li x, li mod) { return mod_exp(x, mod - 2, mod); }
int countAnagrams(string s) {
li n = s.size();
vector<int> dp(n + 1, 1);
for (li i = 1; i <= n; i++)
dp[i] = (i * dp[i - 1]) % MOD;
string str = "";
li i = 0, ans = 1;
while (i < n) {
vector<li> count(26, 0);
li p = 0;
while (i < n && s[i] != ' ') {
count[s[i] - 'a']++;
p++;
i++;
}
li r = dp[p];
for (li j = 0; j < 26; j++) {
if (count[j] > 0)
r = (r * mod_inv(dp[count[j]], MOD)) % MOD;
}
ans = (ans * r) % MOD;
i++;
}
return ans;
}
};
``` | 0 | 0 | ['C++'] | 0 |
count-anagrams | C++ SIMPLE MODULAR ARITHMATIC AND COMBINATORICS | O(N+M) SOLUTION | c-simple-modular-arithmatic-and-combinat-jqqo | \n\n# Code\ncpp []\nconst long long mxN = 1e5, MOD = 1e9 + 7;\nvector<long long> fact(mxN + 1), ifact(mxN + 1);\n\nlong long binaryExpo(long long a, long long b | ayushchavan | NORMAL | 2024-11-29T06:12:08.254935+00:00 | 2024-11-29T06:12:08.254977+00:00 | 13 | false | \n\n# Code\n```cpp []\nconst long long mxN = 1e5, MOD = 1e9 + 7;\nvector<long long> fact(mxN + 1), ifact(mxN + 1);\n\nlong long binaryExpo(long long a, long long b) {\n long long res = 1;\n while (b > 0) {\n if (b & 1)\n res = (res * a) % MOD;\n a = (a * a) % MOD;\n b >>= 1;\n }\n return res;\n}\n\nvoid calculate_factorials() {\n fact[0] = 1;\n for (long long i = 1; i <= mxN; ++i) {\n fact[i] = (fact[i - 1] * i) % MOD;\n }\n ifact[mxN] = binaryExpo(fact[mxN], MOD - 2);\n for (long long i = mxN - 1; i >= 0; --i) {\n ifact[i] = (ifact[i + 1] * (i + 1)) % MOD;\n }\n}\n\nclass Solution {\npublic:\n long long countAnagrams(string s) {\n calculate_factorials();\n vector<vector<long long>> freq;\n long long ptr = 0, n = s.length();\n while (ptr < n) {\n vector<long long> hash(26, 0);\n while (ptr < n && s[ptr] != \' \')\n hash[s[ptr++] - \'a\']++;\n freq.push_back(hash);\n ptr++;\n }\n\n long long ans = 1, cnt = 0, no = 0;\n for (auto& x : s) {\n if (x != \' \')\n cnt++;\n else {\n // cout << cnt << " " << no << endl;\n ans = (ans % MOD * fact[cnt] % MOD) % MOD;\n for (auto& x : freq[no])\n ans = (ans % MOD * ifact[x] % MOD) % MOD;\n ++no, cnt = 0;\n }\n }\n // cout << cnt << " " << no << endl;\n ans = (ans % MOD * fact[cnt] % MOD) % MOD;\n for (auto& x : freq[no])\n ans = (ans % MOD * ifact[x] % MOD) % MOD;\n return ans;\n }\n};\n\n``` | 0 | 0 | ['Hash Table', 'Math', 'String', 'Combinatorics', 'Counting', 'C++'] | 0 |
count-anagrams | Count Anagrams | count-anagrams-by-naeem_abd-bzb1 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | Naeem_ABD | NORMAL | 2024-11-20T10:29:00.408016+00:00 | 2024-11-20T10:29:00.408049+00:00 | 9 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```python3 []\nclass Solution:\n def countAnagrams(self, s: str) -> int:\n MOD = 10 ** 9 + 7\n ans = 1\n for word in s.split():\n ans = (ans * self.count(word)) % MOD\n return ans\n \n def count(self, word):\n n = len(word)\n ans = 1\n for f in Counter(word).values():\n ans *= math.comb(n, f)\n n -= f\n return ans\n \n``` | 0 | 0 | ['Python3'] | 0 |
count-anagrams | Python one-line solution | python-one-line-solution-by-arnoldioi-pc9v | This is just for fun.\nGo to https://leetcode.com/problems/count-anagrams/solutions/2947480/multiply-permutations for detailed math explanation.\n\n# Code\npyth | ArnoldIOI | NORMAL | 2024-10-28T18:52:52.105508+00:00 | 2024-10-28T18:52:52.105541+00:00 | 7 | false | This is just for fun.\nGo to https://leetcode.com/problems/count-anagrams/solutions/2947480/multiply-permutations for detailed math explanation.\n\n# Code\n```python3 []\nclass Solution:\n def countAnagrams(self, s: str) -> int:\n return reduce(operator.mul, [factorial(len(w)) // (reduce(operator.mul, [factorial(n) for n in Counter(w).values()])) for w in s.split(" ")])%(10**9 + 7)\n```\n\n# Credits\nhttps://leetcode.com/problems/count-anagrams/solutions/2947480/multiply-permutations | 0 | 0 | ['Python3'] | 0 |
count-anagrams | Easy Factorial Solution | easy-factorial-solution-by-kvivekcodes-nouc | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | kvivekcodes | NORMAL | 2024-10-08T11:21:07.658235+00:00 | 2024-10-08T11:21:07.658271+00:00 | 6 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```cpp []\nclass Solution {\npublic:\n const int M = 1e9+7;\n\n long long pow(long long a, long long b){\n if(b == 0) return 1;\n\n long long ret = pow(a, b/2);\n ret = ret * ret;\n ret %= M;\n if(b % 2) ret = ret * a;\n ret %= M;\n\n return ret;\n }\n int div(long long p, long long q){\n long long ret = p * pow(q, M-2);\n\n return ret % M;\n }\n int countAnagrams(string s) {\n int n = s.size();\n // number of distince anagrams of s. \n vector<string> v;\n\n string str = "";\n for(auto &c: s){\n if(c == \' \'){\n v.push_back(str);\n str = "";\n }\n else str += c;\n }\n v.push_back(str);\n\n int N = 1e5+10;\n vector<long long> fac(N);\n fac[0] = 1;\n fac[1] = 1;\n for(int i = 2; i < N; i++){\n fac[i] = (fac[i-1] * i) % M;\n }\n\n long long ans = 1;\n for(auto &word: v){\n int siz = word.size();\n map<char, int> mp;\n for(auto &c: word) mp[c]++;\n long long cnt = fac[siz];\n\n for(auto it: mp){\n cnt = div(cnt, fac[it.second]);\n }\n\n ans = (ans * cnt) % M;\n }\n\n return ans;\n }\n};\n``` | 0 | 0 | ['Hash Table', 'Math', 'String', 'Combinatorics', 'Counting', 'C++'] | 0 |
count-anagrams | Simple Python, Math Formula | simple-python-math-formula-by-lenibi1507-7w60 | Formula for anagram combinations is n! / (k1! * k2! * ... km!), where n is number of letters in word, k is count of letter in word (for all letters)\n\nSplit s | lenibi1507 | NORMAL | 2024-09-24T06:16:55.352826+00:00 | 2024-09-24T06:18:34.260554+00:00 | 4 | false | Formula for anagram combinations is n! / (k1! * k2! * ... km!), where n is number of letters in word, k is count of letter in word (for all letters)\n\nSplit s and multiply the number of combinations for each word together.\n\nModulo by pow(10,9) + 7\n\n# Code\n```python3 []\nclass Solution:\n def countAnagrams(self, s: str) -> int:\n out = 1\n words = s.split()\n for w in words:\n numerator = math.factorial(len(w))\n denominator = 1\n count = Counter(w)\n for c in count:\n denominator *= math.factorial(count[c])\n out *= (numerator // denominator)\n return out % (pow(10,9) + 7)\n``` | 0 | 0 | ['Python3'] | 0 |
count-anagrams | ASCII key and Fermat's Little Theorem | ascii-key-and-fermats-little-theorem-by-cbasm | Intuition\n Describe your first thoughts on how to solve this problem. \nASCII key and Fermat\'s Little Theorem\n# Approach\n Describe your approach to solving | kenjpais | NORMAL | 2024-08-22T18:22:41.459599+00:00 | 2024-08-22T18:25:26.192803+00:00 | 3 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nASCII key and Fermat\'s Little Theorem\n# Approach\n<!-- Describe your approach to solving the problem. -->\nASCII key and Fermat\'s Little Theorem\n\n# Complexity\n- Time complexity:\nO(nlogn)\n\n- Space complexity:\nO(1)\n\n# Code\n```golang []\nconst MOD = 1000000007\n\n// Function to compute factorial % MOD\nfunc factorial(n int) int {\n\tresult := 1\n\tfor i := 2; i <= n; i++ {\n\t\tresult = (result * i) % MOD\n\t}\n\treturn result\n}\n\n// Function to compute (base^exp) % mod\nfunc powerMod(base, exp, mod int) int {\n\tresult := 1\n\tbase = base % mod\n\tfor exp > 0 {\n\t\tif exp%2 == 1 {\n\t\t\tresult = (result * base) % mod\n\t\t}\n\t\texp = exp >> 1\n\t\tbase = (base * base) % mod\n\t}\n\treturn result\n}\n\n// Function to compute modular inverse using Fermat\'s Little Theorem\nfunc modInverse(a, mod int) int {\n\treturn powerMod(a, mod-2, mod)\n}\n\nfunc countAnagrams(s string) int {\n\tcount := 1\n\tfor _, w := range strings.Split(s, " ") {\n\t\tfreq := [26]int{}\n\t\twordFact := factorial(len(w))\n\t\tfor _, c := range w {\n\t\t\tfreq[c-\'a\']++\n\t\t}\n\t\tfor _, f := range freq {\n\t\t\tif f > 1 {\n\t\t\t\twordFact = (wordFact * modInverse(factorial(f), MOD)) % MOD\n\t\t\t}\n\t\t}\n\t\tcount = (count * wordFact) % MOD\n\t}\n\treturn count\n}\n``` | 0 | 0 | ['Go'] | 0 |
count-anagrams | Count Anagrams | count-anagrams-by-shaludroid-30a6 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | Shaludroid | NORMAL | 2024-08-17T12:27:14.367819+00:00 | 2024-08-17T12:27:14.367851+00:00 | 31 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\npublic class Solution {\n private static final int MOD = 1000000007;\n\n // Function to calculate factorial modulo MOD\n private long factorial(int n) {\n long result = 1;\n for (int i = 2; i <= n; i++) {\n result = (result * i) % MOD;\n }\n return result;\n }\n\n // Function to calculate the modular inverse using Fermat\'s little theorem\n private long modInverse(long a, int mod) {\n return pow(a, mod - 2, mod);\n }\n\n // Function to calculate (x^y) % mod\n private long pow(long x, long y, int mod) {\n long result = 1;\n x = x % mod;\n while (y > 0) {\n if ((y & 1) == 1) {\n result = (result * x) % mod;\n }\n y = y >> 1;\n x = (x * x) % mod;\n }\n return result;\n }\n\n public int countAnagrams(String s) {\n String[] words = s.split(" ");\n long result = 1;\n\n for (String word : words) {\n Map<Character, Integer> freq = new HashMap<>();\n for (char c : word.toCharArray()) {\n freq.put(c, freq.getOrDefault(c, 0) + 1);\n }\n\n // Calculate the number of anagrams for this word\n long wordAnagrams = factorial(word.length());\n for (int count : freq.values()) {\n wordAnagrams = (wordAnagrams * modInverse(factorial(count), MOD)) % MOD;\n }\n\n result = (result * wordAnagrams) % MOD;\n }\n\n return (int) result;\n }\n}\n``` | 0 | 0 | ['Java'] | 0 |
count-anagrams | Python : count anagram | python-count-anagram-by-shristysharma-4rws | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | shristysharma | NORMAL | 2024-08-12T16:57:14.155773+00:00 | 2024-08-12T16:57:14.155794+00:00 | 27 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def countAnagrams(self, s: str) -> int:\n def display(word):\n fact=math.factorial(len(word))\n hashmap={}\n for w in word:\n hashmap[w]=hashmap.get(w,0)+1\n \n for val in hashmap.values():\n fact//=math.factorial(val)\n \n return fact\n ways=1\n for word in s.split():\n ways*=display(word)\n return ways%((10**9)+ 7)\n \n``` | 0 | 0 | ['Hash Table', 'Python', 'Python3'] | 0 |
count-anagrams | Most Basic approach for beginners-C++(Beats -80%) | most-basic-approach-for-beginners-cbeats-nyl3 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | sanyam46 | NORMAL | 2024-08-09T09:51:40.354831+00:00 | 2024-08-09T09:51:40.354860+00:00 | 6 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\n int mod = 1e9+7;\n long long int helper(long long a, long long b)\n {\n long long res=1;\n while(b>0)\n {\n if(b%2==1)\n {\n res = (res*a)%mod;\n }\n a = (a*a)%mod;\n b=b/2;\n }\n return res;\n }\npublic:\n int countAnagrams(string s) {\n int mod = 1e9+7;\n int n=s.length();\n vector<long long int> fac(n+1,1);\n vector<long long int> inv(n+1,1);\n for(int i=1; i<=n; i++)\n {\n fac[i] = (fac[i-1]*(i))%mod;\n }\n inv[n] = helper(fac[n], mod-2);\n inv[n] %= mod;\n for(int i=n-1; i>=0; i--)\n {\n inv[i] = inv[i+1]*(i+1)%mod;\n }\n long long int ans=1;\n int idx=0;\n while(idx<n)\n {\n string res="";\n vector<int> count(26, 0);\n while(s[idx]!=\' \' and idx<n)\n {\n res+= s[idx];\n count[s[idx]-\'a\']++;\n idx++;\n }\n int len = res.length();\n ans = (ans*fac[len])%mod;\n for(int i=0; i<26; i++)\n {\n if(count[i]>0)\n {\n ans = (ans*inv[count[i]])%mod;\n }\n }\n idx++;\n }\n return ans%mod;\n }\n};\n``` | 0 | 0 | ['C++'] | 0 |
count-anagrams | Python (Simple Maths) | python-simple-maths-by-rnotappl-1bea | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | rnotappl | NORMAL | 2024-07-21T15:44:35.255479+00:00 | 2024-07-21T15:44:35.255509+00:00 | 4 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def countAnagrams(self, s):\n mod = 10**9+7 \n\n def function(t):\n n, dict1, v = len(t), Counter(t), 1\n\n for key,val in dict1.items():\n v = v*math.factorial(val)\n\n return math.factorial(n)//v \n\n ans, count = s.split(), 1 \n\n for i in ans:\n count *= function(i)\n\n return count%mod \n``` | 0 | 0 | ['Python3'] | 0 |
count-anagrams | yo! wanna see a one Liner ✅✅✅ | yo-wanna-see-a-one-liner-by-saisreenivas-u13d | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | saisreenivas21 | NORMAL | 2024-07-14T15:01:49.017984+00:00 | 2024-07-14T15:01:49.018011+00:00 | 8 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def countAnagrams(self, s: str) -> int: \n \n return reduce(mul,[factorial(len(i))//reduce(mul,[factorial(j) for j in dict(Counter(i)).values()]) for i in s.split(" ")]) % 1000000007\n``` | 0 | 0 | ['Math', 'Combinatorics', 'Counting', 'Python3'] | 0 |
count-anagrams | MATHS | C++ | O(N) | maths-c-on-by-pro-electro-h8ks | Time Complexity: O(N)\n## Theory:\n\nGiven string: "aabbc"\n\n- Total Length: The length of the string is 5 characters.\n \n- Character Counts:\n - \'a\' appe | pro-electro | NORMAL | 2024-06-17T15:25:56.363705+00:00 | 2024-06-17T15:25:56.363734+00:00 | 7 | false | ## Time Complexity: O(N)\n## Theory:\n\nGiven string: "aabbc"\n\n- **Total Length**: The length of the string is 5 characters.\n \n- **Character Counts**:\n - \'a\' appears twice.\n - \'b\' appears twice.\n - \'c\' appears once.\n\nTo find the total number of distinct permutations (anagrams) of the string "aabbc", we use the formula:\n\\[ \\frac{5!}{2! \\times 2! \\times 1!} \\]\n\nHere\'s how this formula works:\n- \\( 5! \\) (5 factorial) represents the total number of permutations if all characters were unique.\n- \\( 2! \\) represents the factorial of the count of \'a\', dividing by this accounts for the fact that \'a\' characters are indistinguishable.\n- \\( 2! \\) represents the factorial of the count of \'b\', dividing by this accounts for the fact that \'b\' characters are indistinguishable.\n- \\( 1! \\) represents the factorial of the count of \'c\', although in this case it is not technically necessary since 1!\n\n# Code\n```\nclass Solution {\npublic:\n int countAnagrams(string s) {\n const int MOD = 1000000007;\n int i = 0;\n long long NUM = 1;\n long long DEN = 1;\n \n unordered_map<char, int> hash;\n int offset = 0;\n \n while (i < s.length()) {\n if (s[i] == \' \') {\n hash.clear();\n offset = i + 1;\n i++;\n continue;\n }\n \n hash[s[i]]++;\n NUM = NUM * (i + 1 - offset) % MOD;\n DEN = DEN * hash[s[i]] % MOD;\n \n i++;\n }\n\n long long inverse_DEN = modInverse(DEN, MOD);\n\n int result = (NUM * inverse_DEN) % MOD;\n\n return result;\n }\n\nprivate:\n long long modInverse(long long a, long long m) {\n long long m0 = m;\n long long y = 0, x = 1;\n\n if (m == 1) return 0;\n\n while (a > 1) {\n long long q = a / m;\n long long t = m;\n\n m = a % m, a = t;\n t = y;\n\n y = x - q * y;\n x = t;\n }\n\n if (x < 0) x += m0;\n return x;\n }\n};\n\n``` | 0 | 0 | ['C++'] | 0 |
count-anagrams | Easy CPP Solution | easy-cpp-solution-by-pratima-bakshi-l9o8 | Complexity\n- Time complexity:\n O(N)\n\n- Space complexity:\n O(N)\n\n# Code\n\nclass Solution {\npublic:\n int mod = 1e9+7;\n vector<long long>fac | Pratima-Bakshi | NORMAL | 2024-06-11T19:41:19.941256+00:00 | 2024-06-11T19:41:19.941279+00:00 | 6 | false | # Complexity\n- Time complexity:\n O(N)\n\n- Space complexity:\n O(N)\n\n# Code\n```\nclass Solution {\npublic:\n int mod = 1e9+7;\n vector<long long>fact;\n long long power(long long x, long long y) {\n long long res = 1;\n x = x % mod;\n while (y > 0) {\n if (y & 1)\n res = (res * x) % mod;\n y = y >> 1;\n x = (x * x) % mod;\n }\n return res;\n }\n long long solve(string word)\n {\n unordered_map<char,int>m;\n for(auto s: word)\n {\n m[s]++;\n }\n long long res = 1;\n for(auto it= m.begin();it!=m.end();it++)\n {\n if(it->second>1)\n {\n res = ((res%mod)*(fact[it->second]%mod))%mod;\n }\n }\n return res%mod;\n }\n int countAnagrams(string s) \n {\n fact.resize(1e5+1,1);\n fact[0] = 1;\n for(int i=1;i<=1e5;i++)\n {\n fact[i] = ((fact[i-1]%mod)*(i%mod))%mod;\n }\n \n long long tot = 1;\n string word = "";\n for(int i=0;i<s.length();i++)\n {\n if(s[i]==\' \')\n {\n long long res = solve(word)%mod;\n long long ans = fact[word.length()]%mod;\n ans = (res==1)? ans%mod: (ans * power(res,mod-2))%mod;\n tot = ((tot%mod)*(ans%mod)%mod); \n word = "";\n }\n else\n {\n word+=s[i];\n }\n }\n long long res = solve(word)%mod;\n long long ans = fact[word.length()]%mod;\n ans = (res==1)? ans%mod: (ans * power(res,mod-2))%mod;\n tot = ((tot%mod)*(ans%mod)%mod);\n\n return tot%mod;\n }\n};\n``` | 0 | 0 | ['C++'] | 0 |
count-anagrams | [C++]Beats 100% Detailed Explanation Modulo Inverse and Fermat Theorem | cbeats-100-detailed-explanation-modulo-i-fyl2 | Approach/Explanation \n Describe your first thoughts on how to solve this problem. \nYou need knowledge of modulo inverse and fermat theorem to solve this prob | berserk5703 | NORMAL | 2024-06-05T13:57:04.579825+00:00 | 2024-06-05T13:57:04.579865+00:00 | 8 | false | # Approach/Explanation \n<!-- Describe your first thoughts on how to solve this problem. -->\nYou need knowledge of **modulo inverse** and **fermat theorem** to solve this problem\n\nMODULO INVERSE SAYS\n1. (a+b)%m = (a%m + b%m)%m \n2. (a-b)%m = (a%m - b%m + **m**)%m \n> in case "a%m - b%m" is negative the highlighted \'\'m\'\' is added\n3. (a*b)%m = (a%m * b%m)%m\n\nwe can\'t apply the same formula for divison though\nso we use FERMAT THEOREM for that\nit says\n(a/b)= (a*b^-1)\n(a*b^-1)%m = (a%m * b*-1%m)%m\nthis further can be reduced to\n(a/b)%m = (a%m * b^(m-2)%m)%m (not proving this)\n\n\n***This is all you need to know for solving this problem\nGive it a try first\nthen see my code***\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nDepends on how long the string is.\nAvg case time complexity = O(n)\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(1) (excluding the hash array of size 128)\n\n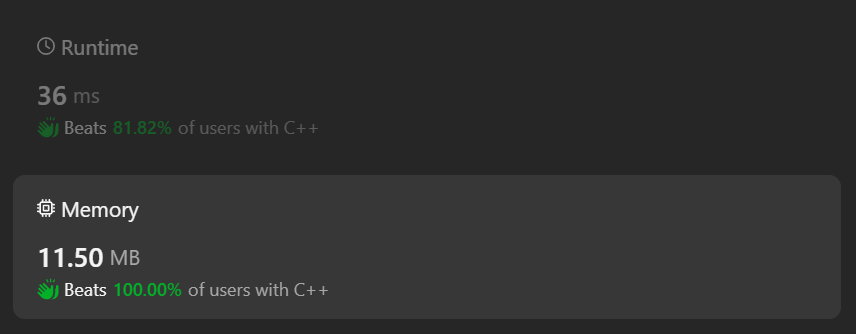\n\n\n\n# Code\n```\nclass Solution {\npublic:\n int modinverse(int b){\n int k = 1e9+5, mod = 1e9+7,ans = 1;\n while(k){\n if(k&1){ //if k is odd\n ans = (ans*1LL*b)%mod;\n }\n b = (b*1LL*b)%mod;\n k >>= 1; //equivalent to k / 2\n }\n return ans;\n }\n int countAnagrams(string s) {\n\n unsigned long long int ans = 1;\n unsigned long long int f1 = 1;\n unsigned long long int d = 1, f = 1, p = 0;\n vector<int> h(128, 0);\n int i = 0;\n for (int i = 0; i <= s.size(); i++) {\n if (s[i] == \' \' || i == s.size()) {\n f1 = f/d;\n if (f1 >= (1000000007)) {\n f1 = f1 % 1000000007;\n } \n ans *= f1;\n if (ans >= (1000000007)) {\n ans = ans % 1000000007;\n } \n fill(h.begin(), h.end(), 0);\n d = 1;\n f = 1;\n p = 0;\n } else {\n p++;\n f *= p; \n if (h[s[i]] != 0) {\n h[s[i]]++;\n d *= h[s[i]];\n } else\n h[s[i]]++;\n if(f==d){f=1;d=1;} \n if(f > 1e9+7)\n {\n f=((f%1000000007)*modinverse(d))%1000000007;\n d=1;\n } \n }\n }\n return ans;\n }\n};\n``` | 0 | 0 | ['C++'] | 0 |
count-anagrams | Beats 100% in time and memory | beats-100-in-time-and-memory-by-dipanshu-tsl4 | Intuition\n Describe your first thoughts on how to solve this problem. \nthis problem can be solved by using the basic concepts of permutation and combination \ | dipanshu-tiwari | NORMAL | 2024-06-04T14:20:18.233590+00:00 | 2024-06-04T14:20:18.233619+00:00 | 16 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nthis problem can be solved by using the basic concepts of permutation and combination \n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nwe will brreak the string in a list of word and return the product of all permutations of each words\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution(object):\n def countAnagrams(self, s):\n words = list(s.split(" "))\n #return len(words)\n ans = 1\n for i in words:\n ans = ans*self.perm(i)\n return ans%(10**9 + 7)\n def perm(self,word):\n ct=[]\n for i in set(word):\n ct.append(word.count(i))\n if max(ct)==sum(ct):\n return 1\n ans = self.fac(sum(ct))\n for i in ct:\n ans = ans/self.fac(i)\n return ans \n \n def fac(self,n):\n ans = 1\n for i in range(1,n+1):\n ans=ans*i \n return ans \n``` | 0 | 0 | ['Python'] | 0 |
count-anagrams | for only beginners🔥🔥🔥python | for-only-beginnerspython-by-sathish_loal-i3pg | \nclass Solution:\n def countAnagrams(self, s: str) -> int:\n def permute(st):\n dic = Counter(st)\n perm = 0\n perm | sathish_loal | NORMAL | 2024-06-03T17:07:53.050313+00:00 | 2024-06-03T17:07:53.050342+00:00 | 0 | false | ```\nclass Solution:\n def countAnagrams(self, s: str) -> int:\n def permute(st):\n dic = Counter(st)\n perm = 0\n perm = factorial(len(st))\n for k,v in dic.items():\n if v > 1:\n perm = perm//factorial(v)\n return perm\n \n \n li = list(s.split())\n ans = 1\n for word in li :\n ans *= permute(word)\n return ans%(10**9+7)\n \n``` | 0 | 0 | ['Math'] | 0 |
count-anagrams | # Easy and Simple Approach using Factorial And modular inverse | easy-and-simple-approach-using-factorial-pzvm | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | Gyanu_sahu | NORMAL | 2024-06-02T06:43:16.813163+00:00 | 2024-06-02T06:43:16.813193+00:00 | 2 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\npublic:\n const int MOD = 1e9 + 7; // Choose your modulo according to constraints\n long long fact(long long n){\n if(n==0 || n==1){\n return 1;\n }\n long long an=1;\n for(long long i=1;i<=n;i++){\n an=(an*i) % MOD; // Perform modulo operation here\n }\n return an;\n }\n long long countAnagrams(string s) {\n long long n=s.size();\n vector<pair<int,map<char,long long>>> v;\n map<char,long long> m;\n int j=0;\n for(long long i=0;i<n;i++){\n if(s[i]!=\' \'){\n m[s[i]]++;\n }else{\n v.push_back({i-j,m});\n j=i+1;\n m.clear();\n }\n }\n if(m.size()>0){\n v.push_back({n-j,m});\n }\n long long ans=1;\n for(long long i=0;i<v.size();i++){\n long long sz=v[i].first;\n long long res=fact(sz);\n for(auto it:v[i].second){\n res=(res * modularInverse(fact(it.second))) % MOD; // Modular inverse used here\n }\n ans=(ans*res) % MOD; // Perform modulo operation here\n }\n return ans;\n }\n \n // Function to calculate modular inverse using Extended Euclidean Algorithm\n long long modularInverse(long long a) {\n long long b = MOD, u = 1, v = 0;\n while (b) {\n long long t = a / b;\n a -= t * b; swap(a, b);\n u -= t * v; swap(u, v);\n }\n u %= MOD;\n if (u < 0) u += MOD;\n return u;\n }\n};\n``` | 0 | 0 | ['Ordered Map', 'C++'] | 0 |
count-anagrams | Fermat's Little Theorem || P&C | fermats-little-theorem-pc-by-ishaankulka-uubo | Intuition\nThis problem can be simply treated as basic P&C type of qs.We have to just calculate all the possible premutations of each word and multiply them.Onl | ishaankulkarni11 | NORMAL | 2024-05-29T09:18:39.918222+00:00 | 2024-05-29T09:18:39.918253+00:00 | 7 | false | # Intuition\nThis problem can be simply treated as basic P&C type of qs.We have to just calculate all the possible premutations of each word and multiply them.Only thing we have to consider is that the calculation of permutations of words with duplicate letters.\nFor eg - aabb -> fact(4)/fact(2)*fact(2)\n\n# Approach\nHere the constraints while taking factorial and multiplying stuff can lead to overflow case so we have to use/apply modular arithmetic.Another thing which makes this qs interesting is (a/b)%M.In order to calculate this we should be aware of Fermat\'s little theorem in order to calculate modular multiplicative inverse(MMI).We have to calculate MMI of denominator stuff and then perform modulo as mod_mul(num,MMI(den)).For clear understanding of MMI you can refer youtube videos and GFG articles.\n\n# Complexity\n- Time complexity:\nIt can be said to be O(N)\nMMI calculation needs binary exponentiation which takes log(n) time(base 2).\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nconst int M = 1e9+7;\n#define ll long long\nclass Solution {\npublic:\nll mod_add(ll a,ll b,ll mod=M){\n\treturn (a%mod + b%mod)%mod;\n}\nll mod_sub(ll a,ll b,ll mod=M){\n\treturn (a%mod - b%mod + mod)%mod;\n}\nll mod_mul(ll a,ll b,ll mod=M){\n\treturn ((a%mod) * (b%mod))%mod;\n}\nll binaryExpo(ll a,ll b){\n\tll ans = 1;\n\twhile(b){\n\t\tif(b&1){\n\t\t\tans = mod_mul(ans,a,M);\n\t\t}\n\t\ta = mod_mul(a,a,M);\n\t\tb >>= 1;\n\t}\n\treturn ans;\n}\nll MMI(ll n){\n\treturn binaryExpo(n,M-2); //Using Fermats Little Thm\n}\n int countAnagrams(string s) {\n vector<string>words;\n string temp;\n int ans = 1;\n int i = 0;\n int n = s.length();\n int maxi = INT_MIN;\n while(1){\n if(i==n) break;\n if(s[i] == \' \'){\n words.push_back(temp);\n int n = temp.size();\n maxi = max(maxi,n);\n temp = "";\n i++;\n continue;\n }\n temp.push_back(s[i]);\n i++;\n }\n if(temp != ""){\n int n = temp.size();\n maxi = max(maxi,n);\n words.push_back(temp);\n }\n vector<ll>fact(maxi+1,0);\n\t fact[0] = fact[1] = 1;\n for(ll i = 2;i<=maxi;++i){\n fact[i] = mod_mul(fact[i-1],i,M);\n }\n for(auto it:words){\n unordered_map<char,int>mpp;\n for(auto it1:it){\n mpp[it1]++;\n }\n ll num = fact[it.size()];\n ll den = 1;\n for(auto x:mpp){\n den = mod_mul(den,fact[x.second]);\n }\n ll mmi = MMI(den);\n ans = mod_mul(ans,mod_mul(num,mmi));\n }\n // for(auto it:s){\n // if(it == \' \'){\n // words.push_back(temp);\n // temp = "";\n // continue;\n // }\n // temp.push_back(it);\n // }\n // for(auto it:words) cout<<it<<" ";\n return ans;\n }\n};\n``` | 0 | 0 | ['C++'] | 0 |
count-anagrams | hard? | hard-by-qulinxao-oe5m | \nclass Solution:\n def countAnagrams(self, s: str) -> int:\n o,b=1,10**9+7\n for v in s.split(\' \'):\n r,n=1,sum(v:=Counter(v).val | qulinxao | NORMAL | 2024-05-26T16:14:11.749373+00:00 | 2024-05-26T16:14:11.749395+00:00 | 9 | false | ```\nclass Solution:\n def countAnagrams(self, s: str) -> int:\n o,b=1,10**9+7\n for v in s.split(\' \'):\n r,n=1,sum(v:=Counter(v).values())\n for k in v:r=r*comb(n,k)%b;n-=k\n o=o*r%b\n return o\n``` | 0 | 0 | ['Python3'] | 0 |
count-anagrams | [C++] Combinatorics, Permutations | c-combinatorics-permutations-by-amanmeha-tidw | \nclass Solution {\npublic:\n int countAnagrams(string s) {\n int mod = 1e9 + 7;\n int n = s.size();\n long anagrams = 1;\n vecto | amanmehara | NORMAL | 2024-05-12T14:12:03.987949+00:00 | 2024-05-12T14:15:46.517440+00:00 | 6 | false | ```\nclass Solution {\npublic:\n int countAnagrams(string s) {\n int mod = 1e9 + 7;\n int n = s.size();\n long anagrams = 1;\n vector<long> facts(n + 1);\n facts[0] = 1;\n for (int i = 1; i <= n; i++) {\n facts[i] = facts[i - 1] * i % mod;\n }\n unordered_map<int, long> invs;\n int count = 0;\n array<int, 26> counts = {0};\n for (int i = 0; i <= n; i++) {\n if (i < n && s[i] != \' \') {\n counts[s[i] - \'a\']++;\n count++;\n } else {\n long perms = facts[count];\n for (const auto& v : counts) {\n perms = perms * mod_inv(facts[v], mod, invs) % mod;\n }\n anagrams = anagrams * perms % mod;\n counts.fill(0);\n count = 0;\n }\n }\n return anagrams;\n }\n\nprivate:\n long mod_inv(long a, long m, unordered_map<int, long>& cache) {\n auto it = cache.find(a);\n if (it != cache.end()) {\n return it->second;\n } else {\n long inv = mod_exp(a, m - 2, m) % m;\n cache[a] = inv;\n return inv;\n }\n }\n\n long mod_exp(long a, long b, long m) {\n long power = 1;\n while (b > 0) {\n if (b & 1) {\n power = power * a % m;\n }\n a = a * a % m;\n b >>= 1;\n }\n return power;\n }\n};\n``` | 0 | 0 | ['Hash Table', 'Math', 'String', 'Combinatorics', 'C++'] | 0 |
count-anagrams | Rust - Basic combinatorics + some number theory | rust-basic-combinatorics-some-number-the-soqb | Basic permutation with repetition to find possible anagrams of each word. The answer is the product of that modulo 10^9 + 7\n\nThe challenge lies in the actual | ajmarin89 | NORMAL | 2024-04-25T03:54:49.617795+00:00 | 2024-04-25T03:54:49.617822+00:00 | 2 | false | Basic permutation with repetition to find possible anagrams of each word. The answer is the product of that modulo 10^9 + 7\n\nThe challenge lies in the actual computation of the factorials modulo a large number, specifically in dealing with the divisors. Using Fermat\'s little theorem it\'s possible to compute the modular inverses (invmod in the code) so we can just multiply everything:\n# Code\n```\nconst P: usize = 1_000_000_007;\n\nimpl Solution {\n pub fn count_anagrams(s: String) -> i32 {\n // computes x such that ax = 1 (mod p)\n // leverages Fermat\'s little theorem: a^(p-1) = 1 (mod p)\n // IOW x = a^(p-2) % p\n fn invmod(mut a: usize, p: usize) -> usize {\n let mut res = 1;\n let mut curr = a;\n let mut power = p - 2;\n while power > 0 {\n if power & 1 == 1 { \n res = (res * curr) % p;\n }\n power >>= 1;\n curr = (curr * curr) % p;\n }\n res\n }\n fn anagrams(word: &str) -> usize {\n let (mut anagrams, mut counts) = (1_usize, vec![0; 128]);\n for b in word.bytes() {\n counts[b as usize] += 1;\n }\n (2..=word.len()).for_each(|i| { anagrams = (anagrams * i) % P; });\n for c in counts {\n (2..=c).for_each(|i| { anagrams = (anagrams * invmod(i, P)) % P; })\n }\n anagrams\n }\n s.split_ascii_whitespace()\n .fold(1_usize, |a, word| (a * anagrams(word) % P)) as i32\n }\n}\n\n``` | 0 | 0 | ['Rust'] | 0 |
count-anagrams | Java Solution | java-solution-by-divyanshagrawal96-b9i4 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | divyanshagrawal96 | NORMAL | 2024-04-14T16:13:33.417569+00:00 | 2024-04-14T16:13:33.417596+00:00 | 44 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\n long mod = 1000000000 + 7;\n public long factorial(int a){\n long num = 1;\n while(a>0){\n num = mul(num, a);\n --a;\n }\n return num;\n }\n public long[] extendedEuclid(long a, long b){\n if(b == 0)\n return new long[]{1,0};\n long[] arr = extendedEuclid(b, a%b);\n long x = arr[1];\n long y = arr[0] -(a/b)*arr[1];\n return new long[]{x,y};\n }\n public long mul(long a, long b){\n if(b == 0)\n return 0;\n\n long halfAns = mul(a, b/2);\n\n if(b%2 == 0)\n return (halfAns + halfAns)%mod;\n \n return (halfAns + halfAns + a)%mod;\n }\n public int countPermutation(String newString){\n int[] freq = new int[26];\n for(int i=0;i<newString.length();i++){\n freq[newString.charAt(i) - \'a\']++;\n }\n long ans = factorial(newString.length())%mod;\n for(int i=0;i<freq.length;i++){\n long inv = extendedEuclid(factorial(freq[i]),mod)[0]%mod + mod;\n ans = mul(ans,inv);\n }\n return (int)(ans%mod);\n }\n public int countAnagrams(String s) {\n String arr[] = s.split(" ");\n long ans = 1;\n for(int i=0;i<arr.length;i++){\n ans = mul(ans, countPermutation(arr[i]));\n }\n return (int)ans;\n }\n}\n``` | 0 | 0 | ['Java'] | 0 |
count-anagrams | Simple C++ Solution | simple-c-solution-by-chikucool2012-k4jf | Intuition\n\nThe problem is asking for the number of distinct anagrams of a given string where each word in the string is permuted independently. So by using th | chikucool2012 | NORMAL | 2024-04-09T09:47:29.400585+00:00 | 2024-04-09T09:47:29.400603+00:00 | 4 | false | # Intuition\n\nThe problem is asking for the number of distinct anagrams of a given string where each word in the string is permuted independently. So by using the simple formula we use in Aptitude Questions i.e No of different permutations of a word with some repeating characters is:\n(No. of characters)! / (repating character frequency)!.\n\n# Approach\nThe approach is to split the string into words and then calculate the number of permutations for each word. For each word, we calculate the factorial of the length of the word and divide it by the factorial of the frequency of each character in the word. This gives us the number of distinct permutations of the word. We then multiply the number of permutations for each word together to get the total number of anagrams of the string.\nTo handle large numbers and prevent overflow, we perform all calculations modulo 10^9+7\nWhen dividing, we calculate the modulo inverse of the denominator using Fermat\u2019s Little Theorem.\n\n# Complexity\n- Time complexity: $$O(n)$$ \n\n- Space complexity: $$O(n)$$ \n\n# Code\n```\n#define MOD 1000000007\nclass Solution {\npublic:\n long long power(long long x, long long y) {\n long long res = 1;\n x = x % MOD;\n while (y > 0) {\n if (y & 1)\n res = (res * x) % MOD;\n y = y >> 1;\n x = (x * x) % MOD;\n }\n return res;\n }\n long long factorial(int N) {\n long long f = 1;\n for (int i = 2; i <= N; i++)\n f = (f * i) % MOD;\n\n return f;\n }\n long long wordVariety(string& str) {\n int n = str.size();\n long long ans = factorial(n);\n unordered_map<char, int> m;\n for (int i = 0; i < n; i++) {\n m[str[i]]++;\n }\n long long res = 1;\n for (auto i : m) {\n if (i.second > 1) {\n res = (res * factorial(i.second)) % MOD;\n }\n }\n ans = (ans * power(res, MOD - 2)) % MOD;\n return ans%MOD;\n }\n long long permutations(vector<string>& s) {\n int n = s.size();\n long long ans = 1;\n for (int i = 0; i < n; i++) {\n ans = (ans * wordVariety(s[i])) % MOD;\n }\n return ans%MOD;\n }\n int countAnagrams(string s) {\n vector<string> parts;\n string word = "";\n for (auto i : s) {\n if (i == \' \') {\n parts.push_back(word);\n word = "";\n } else {\n word += i;\n }\n }\n parts.push_back(word);\n return permutations(parts);\n }\n};\n``` | 0 | 0 | ['C++'] | 0 |
count-anagrams | Simple python3 solution with explanation | 199 ms - faster than 90.13% solutions | simple-python3-solution-with-explanation-2mzo | Approach\n Describe your approach to solving the problem. \n\nCalculate for "too hot":\n1. split into words: "too", "hot"\n2. answer is \prod_{i = 0}^n calc(wor | tigprog | NORMAL | 2024-03-25T17:28:45.031095+00:00 | 2024-03-25T17:28:45.031118+00:00 | 8 | false | # Approach\n<!-- Describe your approach to solving the problem. -->\n\nCalculate for `"too hot"`:\n1. split into words: `"too"`, `"hot"`\n2. answer is $$\\prod_{i = 0}^n calc(word_i) = \\prod_{i = 0}^n \\frac{m_i!}{\\prod{k_{ij}!}}$$\nwhere $$m_i$$ is length of i-word and $$k_{ij}$$ is number of repetitions of unique chars in i-word\nfor example: $$\\frac{3!}{1! \\cdot 2!} \\cdot \\frac{3!}{1! \\cdot1! \\cdot1!} = \\frac{6 \\cdot 6}{2} = 18$$\n\n3. count all $m_i$ (with positive counter) and $k_{ij}$ (with negative counter)\nfor example: `{3: 2, 2: -1, 1: -4}`\n4. for all $m_i$ and $k_{ij}$ count number of prime numbers in factorials it total\nfor example: `{3: 2, 2: 1}`\n5. multiply all $$(prime^{power}) \\space \\% \\space modulo$$\n\n# Complexity\n- Time complexity: $$O(m \\cdot \\log(\\log(m)) + n \\cdot m)$$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: $$O(n \\cdot m)$$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\nwhere `n = words.length`, `m = max(word[i].length)`\n\n# Code\n``` python3 []\nclass Solution:\n def countAnagrams(self, s: str) -> int:\n def get_primes(max_number):\n primes = [2]\n sieve = [True] * (max_number + 1)\n for i in range(3, max_number + 1, 2):\n if sieve[i]:\n primes.append(i)\n for k in range(i ** 2, max_number + 1, 2 * i):\n sieve[k] = False\n return primes\n\n words = s.split()\n max_number = max(len(word) for word in words)\n PRIMES = get_primes(max_number)\n \n def get_primes_number(value):\n result = Counter()\n for prime in PRIMES:\n if prime > value:\n break\n prime_in_pow = prime\n while prime_in_pow <= value:\n result[prime] += value // prime_in_pow\n prime_in_pow *= prime\n return result\n\n factorials = Counter()\n for word in words:\n factorials[len(word)] += 1\n for value, value_cnt in Counter(Counter(word).values()).items():\n factorials[value] -= value_cnt\n \n all_primes = Counter()\n for value, value_cnt in factorials.items():\n if value_cnt == 0:\n continue\n for prime, prime_cnt in get_primes_number(value).items():\n all_primes[prime] += value_cnt * prime_cnt\n\n modulo = 1_000_000_007\n result = 1\n for prime, pow_ in all_primes.items():\n current = pow(prime, pow_, modulo)\n result = (result * current) % modulo\n return result\n``` | 0 | 0 | ['Hash Table', 'Math', 'Combinatorics', 'Counting', 'Python3'] | 0 |
count-anagrams | C++ || Combinatorics under modular arithmetic | c-combinatorics-under-modular-arithmetic-n1or | Intuition\nWe can find the number of permutations for each word in the string. \nLet\'s consider the first example:\n\n\ns = "too hot"\n\n\nLet\'s find the numb | Gismet | NORMAL | 2024-03-12T12:08:52.216986+00:00 | 2024-03-12T12:10:39.276562+00:00 | 1 | false | # Intuition\nWe can find the number of permutations for each word in the string. \nLet\'s consider the first example:\n\n```\ns = "too hot"\n```\n\n**Let\'s find the number of permutations of the first word**\n\nIf we were given 3 distinct characters and asked to find the number of permutations, we can use the factorial to achieve that. So we would have 3! = 6 permutations. \n\nNow what if 2 of them are the same characters. As in our first word <code>too</code>. Let\'s just think about the permutations that are made of the same two characters <code>\'o\'</code>. Well, we have 2! = 2 permutations. Namely, \'oo\' and \'oo\'. As you can see these permutations are not distinguishable, meaning that they are all the same. So in reality, we can make only one permutation out of these two characters. For our word <code>too</code>, we have 3! = 6 permutations in which we have the indistinguishable permutations of the letter <code>\'o\'</code>. So we have to get rid of them. \n\nIn general, if we have a sequence of objects of size n and we have a1 of object 1 and a2 of object 2 and ... a_n of object n where a1 + a2 + ... + a_n = n, then the permutations are calculated as follows.\n\n```\nP = (n!) / (a1! * a2! * ... * a_n!)\n```\n\nSince the answer might get very large, we have to do our calculations under modulo operation. We need to use **modular inverse** for division. You can read about it [here](https://cp-algorithms.com/algebra/module-inverse.html), [here](https://codeforces.com/blog/entry/78873). \n\n\n# Code\n```\n#define vv std::vector\n#define ll long long\n\nconst int N = 1e5;\nconst int MOD = 1e9 + 7;\nll fact[N + 1];\n\nvoid precalcFact()\n{\n fact[0] = 1;\n fact[1] = 1;\n for (int i = 2; i <= N; i++)\n {\n fact[i] = (fact[i - 1] * i) % MOD;\n }\n}\n\nll powmod(ll a, ll b, ll p)\n{\n a %= p;\n if (a == 0)\n return 0;\n ll prod = 1;\n while (b > 0)\n {\n if (b & 1)\n {\n prod = (prod * a) % p;\n --b;\n }\n a = (a * a) % p;\n b >>=1;\n }\n return prod;\n}\n\nll inv(ll a, ll p)\n{\n return powmod(a, p - 2, p);\n}\n\nll denominator(vv<int> &vals)\n{\n ll res = 1;\n for (ll i : vals)\n {\n res = (res * inv(fact[i], MOD)) % MOD;\n }\n\n return res;\n}\n\n\nclass Solution {\npublic:\n int countAnagrams(string s) {\n\n precalcFact();\n ll ans = 1;\n int i = 0;\n int len = s.length();\n while (i < len)\n {\n vv<int> cnts(26);\n int cnt = 0;\n while (i < len && s[i] != \' \')\n {\n cnts[s[i] - \'a\']++;\n cnt++;\n i++;\n }\n ll x = (fact[cnt] * denominator(cnts)) % MOD;\n ans = (ans * x) % MOD;\n i++;\n }\n\n return ans;\n }\n};\n``` | 0 | 0 | ['C++'] | 0 |
count-anagrams | Python 3 | Solution | python-3-solution-by-mati44-66yo | Code\n\nclass Solution:\n def countAnagrams(self, s: str) -> int:\n \n res = 1\n mod = 10**9 + 7\n\n def count_anagram(word):\n\n | mati44 | NORMAL | 2024-03-11T22:03:38.317676+00:00 | 2024-03-11T22:03:38.317704+00:00 | 4 | false | # Code\n```\nclass Solution:\n def countAnagrams(self, s: str) -> int:\n \n res = 1\n mod = 10**9 + 7\n\n def count_anagram(word):\n\n D = Counter(word)\n res = math.factorial(len(word))\n\n for x in D.values():\n res //= math.factorial(x)\n \n return res%mod\n\n\n \n for x in s.split(" "):\n res *= count_anagram(x)\n res %= mod\n\n return res\n``` | 0 | 0 | ['Hash Table', 'Math', 'String', 'Combinatorics', 'Counting', 'Python3'] | 0 |
count-anagrams | Not a Hard Problem || Easy C++ Solution using (inverse modulo and binary exponentiation) | not-a-hard-problem-easy-c-solution-using-vfe5 | \n\n# Approach\n\nConsider each space seperated string as chunk of that string, find number of permutaion of each chunk and multiply them. \n\nfor finding numbe | viraj7403 | NORMAL | 2024-03-04T13:40:15.962025+00:00 | 2024-03-04T13:41:36.160106+00:00 | 3 | false | \n\n# Approach\n\nConsider each space seperated string as chunk of that string, find number of permutaion of each chunk and multiply them. \n\nfor finding number of ways you should we aware of basic formula like : \nto arrange k different things number of ways \n= (k1 + k2 + k3) ! / (k1! * k2! * k3!) , where ki\'s are number of things in ith portion. \n\nhere to find modulo inverse for range see code snippet and if you don\'t get it --> just dry run it. :)) \n\n\n\n# Code\n```\nclass Solution {\npublic:\n\n long long pow1(long long a , long long n , int md){\n\n if(n == 0) return 1; \n\n long long x = pow1(a , n/2 , md) % md; \n\n if(n % 2 == 0){\n return (x % md * x % md ) % md; \n }\n return (x % md * x % md * a) % md; \n }\n\n int countAnagrams(string s) {\n\n \n int n = s.size(); \n vector < long long > fact(n+1);\n\n fact[0] = 1; \n fact[1] = 1; \n\n int md = 1e9 + 7; \n for(int i = 2 ; i <= n ; i++){\n fact[i] = (fact[i-1] % md * i % md) % md; \n }\n\n long long forward = pow1(fact[n] , md - 2 , md) % md; \n\n vector < long long > invfact(n+1); \n invfact[n] = forward; \n\n for(int i = n-1 ; i > 0 ; i--){\n\n invfact[i] = (invfact[i+1] % md * (i+1) % md) % md; \n }\n\n long long ans = 1; \n\n map < char , int > mp; \n\n int curr = 0; \n\n for(int i = 0 ; i <=n ; i++){\n \n if(i == n || s[i] == \' \'){\n\n ans = (ans % md * fact[curr] % md) % md; \n\n for(auto & p : mp){\n ans = (ans % md * invfact[p.second] % md) % md; \n }\n\n mp.clear();\n\n curr = 0; \n }\n else{\n mp[s[i]]++; \n curr++; \n } \n }\n\n return ans % md; \n }\n};\n```\n\n\n | 0 | 0 | ['C++'] | 0 |
count-anagrams | Simple Python "in 2 lines" solution using map and distinct calculations | simple-python-in-2-lines-solution-using-175x1 | Description\n1e9 + 7 and 10**9 + 7 in Python are different (StackOverflow: 67438654)\n\n# Code\nPython\nclass Solution:\n def distinctAnagram(self, s: str) - | AriosJentu | NORMAL | 2024-02-23T19:35:12.860114+00:00 | 2024-02-23T19:35:30.889267+00:00 | 5 | false | # Description\n`1e9 + 7` and `10**9 + 7` in Python are different (StackOverflow: 67438654)\n\n# Code\n```Python\nclass Solution:\n def distinctAnagram(self, s: str) -> int:\n return math.factorial(len(s))//math.prod(map(lambda x: math.factorial(x), [s.count(i) for i in set(s)]))\n\n def countAnagrams(self, s: str) -> int:\n return int(math.prod(map(lambda x: self.distinctAnagram(x), s.split()))%(10**9 + 7))\n``` | 0 | 0 | ['Python3'] | 0 |
count-anagrams | Using Brute Force and Factorial - | using-brute-force-and-factorial-by-soban-g366 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n Using Brute-For | sobanss2001 | NORMAL | 2024-02-14T15:38:30.740577+00:00 | 2024-02-14T15:38:30.740606+00:00 | 4 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n Using Brute-Force and Math.Factorial \n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n O(n*k^2)\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n O(k)\n# Code\n```\nclass Solution:\n def countAnagrams(self, s: str) -> int:\n res=1\n s=s.split()\n for i in s:\n dic={}\n c=1\n for j in i:\n if j not in dic:\n dic[j]=1\n else:\n dic[j]+=1\n for j in dic:\n if dic[j]>1:\n c=(c*(math.factorial(dic[j])))\n t=math.factorial(len(i))\n n=t//c\n res=(res*n)\n return res%((10**9)+7)\n\n``` | 0 | 0 | ['Hash Table', 'Math', 'String', 'Combinatorics', 'Counting', 'Python3'] | 0 |
count-anagrams | C++ ,Simple with explanation , Easy ... | c-simple-with-explanation-easy-by-udaysi-rpfg | Intuition\nSimple Permuataion formaul\n\nfor duplicate = !N / !D1*!D2\n\nwhere d1 and d2 duplicate for character in aab , d1=2,d2=1\n\n# Code\n\n\ntypedef long | udaysinghp95 | NORMAL | 2024-02-09T18:53:19.686960+00:00 | 2024-02-09T18:53:19.686985+00:00 | 4 | false | # Intuition\nSimple Permuataion formaul\n\nfor duplicate = !N / !D1*!D2\n\nwhere d1 and d2 duplicate for character in aab , d1=2,d2=1\n\n# Code\n```\n\ntypedef long long int lli;\nint MOD=1e9+7;\n\nclass Solution {\n\n\npublic:\n\n int power(lli x, lli y) {\n lli res = 1;\n x = x % MOD; // Take modulo to avoid overflow\n while (y > 0) {\n if (y & 1) res = (res * x) % MOD;\n y = y >> 1;\n x = (x * x) % MOD;\n }\n return res;\n }\n\n int countAnagrams(string s) \n {\n \n vector<lli> fact(s.length()+1,1);\n for(int i=1;i<fact.size();i++)\n {\n fact[i]=fact[i-1]*i;\n fact[i]%=MOD;\n }\n\n s+=" ";\n lli res=1;\n vector<int> hash(26,0);\n\n for(int i=0;i<s.length();i++)\n {\n if(s[i]==\' \'){\n \n lli d=0;\n lli r=1;\n\n for(int i=0;i<26;i++)\n if(hash[i])\n {\n r*=fact[hash[i]];\n d+=hash[i];\n r%=MOD;\n }\n \n d=fact[d]; \n lli inverse_r = power(r, MOD - 2);\n res *= d * inverse_r % MOD;\n res%=MOD;\n\n hash.assign(26,0);\n }\n else {\n hash[s[i]-\'a\']++;\n }\n } \n\n return res%MOD;\n }\n};\n``` | 0 | 0 | ['C++'] | 0 |
count-anagrams | Easy Python Solution | easy-python-solution-by-sb012-6fnq | Code\n\nfrom collections import Counter\n\nclass Solution:\n def countAnagrams(self, s: str) -> int:\n s = s.split(" ")\n\n answer = 1\n | sb012 | NORMAL | 2024-02-07T19:54:54.484808+00:00 | 2024-02-07T19:54:54.484833+00:00 | 6 | false | # Code\n```\nfrom collections import Counter\n\nclass Solution:\n def countAnagrams(self, s: str) -> int:\n s = s.split(" ")\n\n answer = 1\n for i in s:\n answer = answer * self.permutations(i)\n \n return answer % ((10 ** 9) + 7)\n \n def permutations(self, s):\n count = Counter(s)\n\n permutations = factorial(len(s))\n repititions = 1\n\n for i in count:\n repititions *= factorial(count[i])\n\n return permutations // repititions\n``` | 0 | 0 | ['Python3'] | 0 |
count-anagrams | Using modulo inverse | using-modulo-inverse-by-shoukthik-bd1f | Intuition\n Describe your first thoughts on how to solve this problem. \nuse permutations concept : \n- The no of ways you can arrange n letters (unique) is n!\ | shoukthik | NORMAL | 2024-02-07T13:02:20.077825+00:00 | 2024-02-07T13:02:20.077856+00:00 | 5 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nuse permutations concept : \n- The no of ways you can arrange n letters (unique) is n!\n- If n letters includes ( x1 letters of same alphabet , x2 letters of another same alphabet and so on ..) , the formula is n! / (x1! * x2! * ...)\n- Since modulo division is not distributive, instead of dividing, we need to multiply by the modulo inverse.\n\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nFor each word , find the permutations possible ( as explained in intuition ) and multiply them. Modulo the result to get the answer\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def fast_pow(self,base, n, M):\n if n == 0:\n return 1\n if n == 1:\n return base\n half_n = self.fast_pow(base, n // 2, M)\n if n % 2 == 0:\n return (half_n * half_n) % M\n else:\n return (((half_n * half_n) % M) * base) % M\n\n def findMMI_fermat(self,n, M):\n return self.fast_pow(n, M - 2, M)\n\n def factorial(self,x,mod):\n res = 1\n while x:\n res = (res*x)%mod\n x-=1\n return res\n def solve(self,Upper,Lower,mod):\n res = self.factorial(Upper,mod)\n List = [self.factorial(x,mod) for x in Lower]\n denominator = reduce(( lambda x, y: (x * y)%mod ), List) if List else 1\n # print(Upper , res , denominator)\n y = self.findMMI_fermat(denominator,mod);\n return (res*y)%mod\n def countAnagrams(self, s: str) -> int:\n res = 1\n for w in s.split():\n n = len(w)\n u = [count for count in Counter(w).values() if count>1]\n res = (res*self.solve(n,u,1000000007))%1000000007\n # print(res,n,u,"----------")\n return int(res)\n``` | 0 | 0 | ['Python3'] | 0 |
count-anagrams | Not a good one but it's a beginner friendly brute force approach.....:) | not-a-good-one-but-its-a-beginner-friend-7c66 | Intuition\n1. The code leverages the concept of factorials to compute the number of distinct permutations of each word.\n\n2. It utilizes the Counter class to e | Rohini0802 | NORMAL | 2024-02-06T17:07:11.424400+00:00 | 2024-02-06T17:07:11.424430+00:00 | 133 | false | # Intuition\n1. The code leverages the concept of factorials to compute the number of distinct permutations of each word.\n\n2. It utilizes the Counter class to efficiently count the occurrences of each character in a word.\n3. By considering the multiplicities of characters and applying factorial calculations, it accurately counts the number of distinct anagrams for each word.\n4. The overall result is the product of the counts of distinct anagrams for all words in the input string s, modulo a large prime number to handle overflow.\n\n# Approach\n**Initialization:**\n>The code initializes a variable MOD to store the modulo value, which is set to 10^9 + 7.\nIt then splits the input string s into words and stores the unique words in a set called words.\n\n**Loop through Words:**\n>It iterates over each unique word in the set of words extracted from the input string.\nFor each word, it constructs a Counter object to count the occurrences of each character in the word.\n\n**Calculate Product of Factorials:**\n\n>For each word, it calculates the factorial of the length of the word using math.factorial(len(word)) and multiplies it with the product variable.\nAdditionally, for each character count in the Counter object, it divides the product by the factorial of that count.\nThis process effectively counts the number of distinct permutations of each word, considering the multiplicities of each character.\n\n**Return Result:**\n>Finally, it returns the product modulo MOD, which represents the count of distinct anagrams of the input string s.\n\n# Complexity\n- Time complexity:\n O(n * m)\nn is the number of words in the input string\nm is the maximum length of any word.\n\n- Space complexity:\n O(n + m)\nn is the number of words in the input string\nm is the maximum number of unique characters in any word.\n\n# Code\n```\nfrom collections import Counter\nclass Solution:\n def countAnagrams(self, s: str) -> int:\n MOD = 10**9 + 7\n words = set(s.split())\n product = 1\n for word in words:\n count = Counter(word)\n product = product * math.factorial(len(word))\n for i in count.values():\n if i == 1 or i == 2:\n product = product // i\n else:\n product = product // math.factorial(i)\n return product % MOD\n``` | 0 | 0 | ['Hash Table', 'Math', 'String', 'C', 'Combinatorics', 'Counting', 'Python', 'C++', 'Java', 'Python3'] | 0 |
count-anagrams | Two HashMaps | two-hashmaps-by-sav20011962-kezy | Intuition\nTwo HashMaps - for the frequencies of letters in words and a common one for inverted MODs for the frequencies of letters in words (memo).\nAll multip | sav20011962 | NORMAL | 2024-02-06T13:11:45.658762+00:00 | 2024-02-06T13:11:45.658795+00:00 | 4 | false | # Intuition\nTwo HashMaps - for the frequencies of letters in words and a common one for inverted MODs for the frequencies of letters in words (memo).\nAll multiplications and "divisions" in LONG, finally .toInt()\n# Approach\nTwo HashMaps - for the frequencies of letters in words and a common one for inverted MODs for the frequencies of letters in words (memo).\nAll multiplications and "divisions" in LONG, finally .toInt()\n# Complexity\n- Time complexity:\nO(n*log(n))\n\n- Space complexity:\nO(n)\n\n# Code\n```\nclass Solution {\n fun countAnagrams(s: String): Int {\n var prev = \'*\'\n var map = HashMap<Char, Int>()\n val INV_fact = HashMap<Int, Int>()\n INV_fact[1] = 1\n var rez = 1L\n var count = 0\n val mod = 1_000_000_007\n\n fun binPow (a: Long, b: Int): Long {\n var res = 1L\n var base = a\n var pow = b\n while (pow > 0) {\n if ((pow and 1) == 1) res = (res * base) % mod\n pow = pow shr 1\n base = (base * base) % mod\n }\n return res\n }\n fun inverseElement(x: Long): Long {\n return binPow(x, mod - 2)\n }\n for (i in 0 until s.length) {\n val ch = s[i]\n if (!(ch==\' \' || i==s.length-1)) {\n map[ch] = map.getOrDefault(ch, 0) + 1\n count++\n } \n else {\n if (i==s.length-1) {\n map[ch] = map.getOrDefault(ch, 0) + 1\n count++\n }\n while (count>1) {\n rez = (rez * count)%mod\n count--\n }\n count = 0\n// divide to value! \n for((key, value) in map){\n if (INV_fact.containsKey(value)) {\n rez = (rez * INV_fact.getValue(value))%mod\n }\n else {\n var fact = 1L\n for (j in 2..value) {\n fact = (fact * j) % mod\n }\n val INV = inverseElement(fact).toInt()\n INV_fact.put(value,INV) \n rez = (rez * INV)%mod\n }\n }\n map = HashMap<Char, Int>()\n }\n }\n return rez.toInt()\n }\n}\n``` | 0 | 0 | ['Kotlin'] | 0 |
count-anagrams | Count Anagrams, C++ Explained Solution With Complete Maths and Intuition | count-anagrams-c-explained-solution-with-f62g | Upvote If Found Helpful !!!\n\n# Approach\n Describe your approach to solving the problem. \nThe problem here is actually quite simple in terms of logic formul | ShuklaAmit1311 | NORMAL | 2024-02-06T08:47:48.282305+00:00 | 2024-02-06T08:47:48.282335+00:00 | 11 | false | ***Upvote If Found Helpful !!!***\n\n# Approach\n<!-- Describe your approach to solving the problem. --> \nThe problem here is actually quite simple in terms of logic formulation. We can directly see that we just have to multiply the number of permutations of each word to get the total distinct number of anagrams. The problem comes up in finding the number of permutations. The number of permutations of a string is given by **P = (M!) / (K1! * K2! * K3! * ...)** where **M** is the length of the word and **K1, K2, K3 and so on** is the count of each type of character present in the word. In our case, we can have atmost 26 types of characters (**Alphabets**). The problem is easy if **K1, K2** etc. are relatively small like **1, 2** but factorial goes on increasing exponentially so its possible to get fractional values which in turn would create problem in storing in terms of double data type. So what do we do ???\n\nHere comes in **Modular Arithmatic**. Lets recall the concept of finding **nCr mod p**, where **n and r** are some values and **p is a large prime number**. The main concept is to find **(1 / r!) mod p**. We can see that this looks somewhat similar to our problem too **((1 / K1!) mod p)**. Lets say **r! = J, then we need to find inverse(J) mod p**. How do we get this inverse ? \n\nHere we bring in ***Euler\'s Theorum*** which states that for some **a, m, a^(phi(m)) is congruent to 1 mod m** if **a and m are relatively prime i.e gcd(a,m) = 1**. Here **phi(m)** is basically Euler\'s totient function which gives the count of numbers from 1 to m that are coprime to m. Now if **m** is a prime number like **10^9+7**, then **phi(m) = m-1**. Thus it reduces down to ***Fermat\'s Little Theorum = a^(m-1) : 1 mod m***. If we multiply **a^(-1)** on both sides, we get **a^(m-2) : a^(-1) mod m**, where **a^(-1) is actually inverse of a**. Thus we see that inverse of a is basically **a^(m-2)** which we can easily find using binary exponentiation in logarithmic time. With this we have solved our main problem. Rest goes just multiplying values and regularly taking mod with **10^9+7**. Implementation goes below :\n\n# Complexity\n- Time complexity: **O(N*log(mod))**, where **N** is the size of the string and **mod** is 1000000007. You can also see that in order to save our time, we have pre-calculated the factorials of all values.\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: **O(N)**\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\npublic:\n #define ll long long\n ll mod = 1e9+7LL;\n ll fact[100005] = {1LL}; \n void initialize(){\n for(ll i = 1LL; i <= 100000; i++){\n fact[i] = (fact[i-1] * i) % mod;\n }\n }\n ll binexp(ll x){\n ll y = mod - 2LL, ans = 1LL;\n while(y){\n if(y & 1LL){\n ans = (ans * x) % mod;\n }\n x = (x * x) % mod;\n y >>= 1LL;\n }\n return ans;\n }\n int countAnagrams(string s) {\n ios_base::sync_with_stdio(0);\n initialize();\n int n = s.size();\n ll ans = 1LL,l = 0; vector<ll>c(26,0);\n for(int i = 0; i < n; i++){\n if(s[i] == \' \'){\n ll val = fact[l];\n for(ll j = 0; j < 26; j++){\n if(c[j]){\n val = (val * binexp(fact[c[j]])) % mod;\n }\n c[j] = 0LL;\n }\n ans = (ans * val) % mod;\n l = 0;\n }\n else{\n l++;\n c[s[i]-\'a\']++;\n }\n }\n ll val = fact[l];\n for(ll j = 0; j < 26; j++){\n if(c[j]){\n val = (val * binexp(fact[c[j]])) % mod;\n }\n c[j] = 0LL;\n }\n ans = (ans * val) % mod;\n return ans;\n }\n};\n``` | 0 | 0 | ['Math', 'C++'] | 0 |
count-anagrams | Simple approach using the basics of maths | simple-approach-using-the-basics-of-math-1arg | Intuition\n Describe your first thoughts on how to solve this problem. \nJust start thinking about the anagram so we get an idea that the total number of anagra | aamirsiddiqui1804 | NORMAL | 2024-02-06T07:36:13.919643+00:00 | 2024-02-06T07:36:13.919676+00:00 | 9 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nJust start thinking about the anagram so we get an idea that the total number of anagram for a word is the total number of permutation of this word.\nAnd second thing is that the total number of anagram is equal to the product of the permutations of the each word.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nMake a map use to keeep the count of the each character of one word.\nSo that we can calculate the permutation of the word.\nThen iterate over the loop-\nif get s[i]==\' \' that means a word end so calculate the number of permutation for this word and \nans*=f(m) f use to calculate the permutation using m map\nand m.clear() to clear the map\nelse m[s[i]]++ as to count the number of char\n\nat the end of loop there must be one last word remains that why \nans+=f(m);\n\nat last \nreturn ans;\n\n\n\n# Complexity\n- Important concept: To calulate the permutation we use formula:\n- P=(total cnt of char in word)! /((cnt of each char c1)! * (c2)! * ...)\n- To calculate the a/b%mod m:\n- a/b%mod m=(a mod m) *(b power -1 mod m)=(a mod m) *(b power(m-2) mod m)\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(nlogn)\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(26)\n\n# Code\n```\nclass Solution {\npublic:\n int mod=1e9+7;\n int myPow(int x, int n) {\n long long x1=x;\n long long ans=1;\n while(n>0){\n if(n%2!=0){\n ans=(ans*x1)%mod;\n }\n x1=(x1*x1)%mod;\n n=n/2;\n \n }\n return ans%mod;\n }\n long long fact(int n){\n if(n==0 || n==1){\n return 1;\n }\n long long ans=1;\n for(int i=2;i<=n;i++){\n ans=(ans*i)%mod;\n }\n return ans%mod;\n }\n long long f(unordered_map<char,int>&m){\n int cnt=0;\n long long b=1;\n for(auto i:m){\n cnt+=i.second;\n b=(b%mod*fact(i.second)%mod)%mod;\n }\n long long a=fact(cnt);\n long long c=myPow(b,mod-2)%mod;\n return (a*c)%mod;\n\n }\n int countAnagrams(string s) {\n int n=s.size();\n unordered_map<char,int>m;\n long long ans=1;\n for(int i=0;i<n;i++){\n if(s[i]==\' \'){\n ans=((ans%mod)*(f(m)%mod))%mod;\n m.clear();\n }\n else{\n m[s[i]]++;\n }\n }\n ans=((ans%mod)*(f(m)%mod))%mod;\n return ans%mod;\n }\n};\n``` | 0 | 0 | ['C++'] | 0 |
count-anagrams | Easy and concise solution! - Python | easy-and-concise-solution-python-by-abid-ni5s | Approach\n Describe your approach to solving the problem. \nThis is a simple permutation problem. If you know, how to calculate the permutation of a word, rest | Abid95 | NORMAL | 2024-02-06T02:13:05.383900+00:00 | 2024-02-06T02:13:05.383932+00:00 | 13 | false | # Approach\n<!-- Describe your approach to solving the problem. -->\nThis is a simple permutation problem. If you know, how to calculate the permutation of a word, rest is just multipying one\'s permutation with the previous one\'s. As simple as that.**Please upvote, if it helps you**.\n\n# Complexity\n- Time complexity: O(n^2)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(1)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def countAnagrams(self, s: str) -> int:\n res = 1\n for wrd in s.split():\n c, x = Counter(wrd), 1\n for k,v in c.items(): x *= math.factorial(v)\n res *= math.factorial(len(wrd))//x\n \n return res%(10**9+7)\n \n``` | 0 | 0 | ['Python3'] | 0 |
count-anagrams | Ruby math combinatorics RT 100% | ruby-math-combinatorics-rt-100-by-alobzo-hdqy | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | alobzov | NORMAL | 2024-01-28T17:58:17.970830+00:00 | 2024-01-28T17:58:17.970870+00:00 | 2 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n# @param {String} s\n# @return {Integer}\ndef count_anagrams(s)\n mod = 10 ** 9 + 7\n \n fact = -> (i, max_i = nil) { max_i ? ((max_i + 1)..i).inject(:*) : (1..i).inject(:*) } \n\n s.split.inject(1) do |acc, word|\n if word.chars.uniq.size == 1\n cnt = 1\n else\n chars = word.chars.inject(Hash.new(0)) { |h, e| h[e] += 1 ; h }.values.reject {|k| k <=1}\n cnt = fact.call(word.size, chars.max)\n chars.delete_at(chars.index(chars.max)) if chars.max\n chars.each { |k| cnt /= fact.call(k)} \n end\n acc * cnt % mod\n end \nend\n``` | 0 | 0 | ['Math', 'Ruby'] | 0 |
count-anagrams | Python3 solution w/ dp + modinv | python3-solution-w-dp-modinv-by-mhabtezg-sp9t | Code\n\nimport math\n\nclass Solution:\n def countAnagrams(self, s: str) -> int:\n dp = [0 for _ in range(100001)]\n dp[0] = 1\n MOD = 1 | mhabtezgi56 | NORMAL | 2024-01-26T15:49:10.313841+00:00 | 2024-01-26T15:49:10.313871+00:00 | 5 | false | # Code\n```\nimport math\n\nclass Solution:\n def countAnagrams(self, s: str) -> int:\n dp = [0 for _ in range(100001)]\n dp[0] = 1\n MOD = 1000000007\n for i in range(1, len(s) + 1):\n dp[i] = (dp[i - 1] * i) % MOD\n\n t = s.split(" ")\n\n res = 1\n for word in t:\n frq = {}\n for c in word:\n frq[c] = frq.get(c, 0) + 1\n\n ans = dp[len(word)]\n for i in range(26):\n ans = (ans * pow(dp[frq.get(chr(i + 97), 0)], MOD - 2, MOD)) % MOD\n\n res = (res * ans) % MOD\n return res\n``` | 0 | 0 | ['Python3'] | 0 |
count-anagrams | Using Permutation | using-permutation-by-sayan_kd-dlpd | \n# Code\n\nclass Solution:\n def countAnagrams(self, s: str) -> int:\n words, total = s.split(), 1\n for word in words:\n anagrams | sayan_kd | NORMAL | 2024-01-19T12:13:07.128911+00:00 | 2024-01-19T12:13:07.128943+00:00 | 7 | false | \n# Code\n```\nclass Solution:\n def countAnagrams(self, s: str) -> int:\n words, total = s.split(), 1\n for word in words:\n anagrams = math.factorial(len(word))\n letters = Counter(word)\n for occ in letters.values():\n anagrams //= math.factorial(occ)\n total *= anagrams\n return total % 1000000007\n``` | 0 | 0 | ['Hash Table', 'Math', 'Python3'] | 0 |
count-anagrams | || C++ | c-by-1abc-awgk | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | 1ABC | NORMAL | 2024-01-16T16:32:15.939338+00:00 | 2024-01-16T16:32:15.939376+00:00 | 14 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\npublic: \n const int mod = 1e9+7;\n \n long long mod_pow(long long b,long long e){\n long long result =1;\n while(e>0){\n if(e&1){\n result = (result*b)%mod;\n }\n b = (b*b)%mod;\n e/=2;\n }\n return result;\n }\n\n long long fac(long long n){\n if(n==0 || n==1) return 1;\n long long result = 1; \n for(int i=2;i<=n;i++){\n result = (result*i)%mod;\n }\n return result;\n }\n long long count(string s){\n long long n = s.size();\n long long fact = fac(n);\n map<char,int> mp;\n for(int i=0;i<s.size();i++) mp[s[i]]++;\n\n for(auto mp:mp){\n fact = (fact*mod_pow(fac(mp.second),mod-2))%mod;\n }\n \n return fact; \n }\n int countAnagrams(string s) {\n long long ans = (long long)1;\n vector<string> st;\n for(int i=0;i<s.size();i++){\n string str = "";\n while(i<s.size() && s[i]!=\' \'){\n str+=s[i];\n i++;\n }\n st.push_back(str);\n }\n for(auto st:st){\n ans =(ans*count(st))%mod;\n }\n return ans;\n }\n};\n\n``` | 0 | 0 | ['C++'] | 0 |
count-anagrams | inverse... | inverse-by-user3043sb-x4s6 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | user3043SB | NORMAL | 2023-12-20T18:23:59.786082+00:00 | 2023-12-20T18:23:59.786115+00:00 | 16 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nimport java.util.*;\n\n\nclass Solution {\n\n int M = (int) 1e9 + 7;\n\n\n // for each word: find perms and multiply for all words\n // Permutations of size N = N! = N! / 1! * 1! .. 1!\n // BUT with DUPLICATES INSIDE need to divide by the factorial! of each duplicate count:\n // aaabb\n // N!/(d1! * d2!) = 5!/3!*2! = 4*5/2 = 10\n\n // 3!/2! = 3\n // 3! = 6\n // 18\n public int countAnagrams(String s) {\n inverse[1] = 1; // map x -> 1 / x == x^(-1)\n for (int i = 2; i <= 100000; i++) {\n inverse[i] = (M - M / i) * inverse[M % i] % M;\n }\n\n long total = 1;\n String[] words = s.split(" ");\n for (String w : words) {\n int[] cnts = new int[26];\n int n = w.length();\n\n long perms = fact(n);\n for (int i = 0; i < n; i++) cnts[w.charAt(i) - \'a\']++;\n for (int cnt : cnts) {\n if (cnt == 0) continue;\n perms = (perms * inverseFact(cnt)) % M;\n }\n total = (total * perms) % M;\n }\n return (int) (total % M);\n }\n\n\n long[] inverse = new long[100005];\n long[] inverseFact = new long[100005];\n long[] fact = new long[100001];\n\n long fact(int n) {\n if (n < 3) return n;\n if (fact[n] != 0) return fact[n];\n return fact[n] = (n * fact(n - 1)) % M;\n }\n\n long inverseFact(int n) { // perform factorial! going down on numbers using their INVERSES!!!\n if (n == 1) return 1;\n if (inverseFact[n] != 0) return inverseFact[n];\n return inverseFact[n] = (inverse[n] * inverseFact(n - 1)) % M;\n }\n\n}\n\n``` | 0 | 0 | ['Java'] | 0 |
count-anagrams | Use extended Euclidian Algorithm to evaluate the faction mod p | use-extended-euclidian-algorithm-to-eval-ne7a | Code\n\nuse std::collections::HashMap;\n\nconst BIG:i64 = 1_000_000_007;\n\n// modular inverse\nfn inv(k: i64) -> i64 {\n egcd(k, BIG).1.rem_euclid(BIG)\n}\n | user5285Zn | NORMAL | 2023-12-20T12:38:45.039494+00:00 | 2023-12-20T12:38:45.039537+00:00 | 1 | false | # Code\n```\nuse std::collections::HashMap;\n\nconst BIG:i64 = 1_000_000_007;\n\n// modular inverse\nfn inv(k: i64) -> i64 {\n egcd(k, BIG).1.rem_euclid(BIG)\n}\n\nfn egcd(x: i64, y: i64) -> (i64, i64, i64) {\n match y {\n 0 => (x, 1, 0),\n _ => {let k = x/y; \n let r = x.rem_euclid(y);\n let (d, a, b) = egcd(y, r);\n (d, b, a-k*b)\n }\n }\n}\n\n\nfn cc(w:&str) -> i64 {\n let mut h : HashMap<char, i64> = HashMap::new();\n let mut a = 1;\n let mut b = 1;\n for (i,c) in w.chars().enumerate() {\n *h.entry(c).or_default() += 1;\n a = a * (i as i64+1) % BIG;\n b = b * h[&c] % BIG\n }\n a * inv(b) % BIG \n}\n\nimpl Solution {\n pub fn count_anagrams(s: String) -> i32 {\n s.split_ascii_whitespace().map(cc).fold(1,|acc,x|(acc*x)%BIG) as _\n }\n}\n``` | 0 | 0 | ['Rust'] | 0 |
count-anagrams | HERE is THE RECURSION APPROACH you all are searching for👾 | here-is-the-recursion-approach-you-all-a-imja | NOTE: MY FIRST SOlUTION I EVER POSTED!!\n# Intuition\n=> The code leverages factorials to compute the count of anagrams for each word efficiently.\n=> The calc | maneeshnandreddy | NORMAL | 2023-12-19T13:42:46.115741+00:00 | 2023-12-19T13:42:46.115777+00:00 | 1 | false | NOTE: MY FIRST SOlUTION I EVER POSTED!!\n# Intuition\n=> The code leverages factorials to compute the count of anagrams for each word efficiently.\n=> The calc function recursively computes the product of factorials for character counts.\n=> The outer loop handles each word, and the inner loops calculate factorials and update the result.\n=> Modular arithmetic is used to prevent integer overflow.\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n=>The code splits the input string into words and processes each word independently.\n=>For each word, it calculates the count of each character and computes the product of factorials for the character counts.\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: O(n * m * k), where n is the total characters, m is the average word length, and k is the total unique characters in all words.\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(n + k), where n is the total characters and k is the total unique characters in all words.\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nfrom math import factorial\n\n\nclass Solution:\n def countAnagrams(self, s: str) -> int:\n s=s.split(\' \')\n prod=1\n for word in s:\n seen={}\n for ch in word:\n seen[ch]= seen.get(ch,0)+1\n prod*=(factorial(len(word)))\n for key,val in seen.items():\n prod//= (factorial(val))\n return int(prod)% (10**9 +7)\n\'\'\'\n\nclass Solution:\n def countAnagrams(self, s: str) -> int:\n \'\'\'\n``` | 0 | 0 | ['Python3'] | 0 |
count-anagrams | Python: T/M - 92%/90% (Mathematical/Combinatorial) | python-tm-9290-mathematicalcombinatorial-unie | Intuition\n Describe your first thoughts on how to solve this problem. \nThe nature of this problem really defines it as more of a combinatorics problem wrapped | gmontes01 | NORMAL | 2023-12-16T21:32:24.351356+00:00 | 2023-12-16T21:32:24.351373+00:00 | 0 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThe nature of this problem really defines it as more of a combinatorics problem wrapped in a simple coding problem. \n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nFrom the [product rule](https://en.wikipedia.org/wiki/Rule_of_product) and the problem description we can first deduce that \n$$|\\{\\textbf{# of anagrams of w}\\}| = \\prod_{i=1}^{m}|\\{\\textbf{# of anagrams of } w_i\\}|\\\\$$ where $$w_i$$ is the i-th word in the string w with m total words.\n\nThis product can be taken with a simple for-loop which loops over all the words which is what I did. \n\nNext we just need to count the number of anagrams for any given word $$w_i$$. Next we take the formula [here](https://en.wikipedia.org/wiki/Combination#Number_of_ways_to_put_objects_into_bins) and think of each of the n positions in the word $$w_i$$ as individual items and each of the distinct letter types as having their own bin with a size of however many copies of that letter there are in the word. So if we take any word v with n letters in it and $l$ different types of letter each with $k_j$ copies of every j-th letter then\n$$|\\{\\textbf{# of anagrams of } v\\}|={n \\choose k_1,k_2,\\cdots k_l}$$\n\nNote that each of the values, $k_j$, can be found by simply counting the number of each letter in the word by creating a dictionary with the \'Counter\' function. Since the order of these values does not matter we can take the values of the dictionary in no particular order.\n\nFurther inspecting the defintion of the multinomial formula you can see that\n\n$${n \\choose k_1,k_2,\\cdots k_l}={n \\choose k_1}{n-k_1 \\choose k_2}{n-k_1-k_2\\choose k_3}\\cdots{n-k_1-\\cdots k_{l-1}\\choose k_l}$$ \n\nwhich can be computed using the \'comb\' function and an inner for-loop. \n\nAssuming that the words are english, the size of each word is bounded so we can take \'comb\' as running in $$O(1)$$ time.\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n$$O(n)$$\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n$$O(n)$$\n\n# Code\n```\nfrom math import comb\nclass Solution:\n def countAnagrams(self, s: str) -> int:\n anagrams = 1\n s = s.split()\n for word in s:\n counts = list(Counter(word).values())\n n = sum(counts)\n for count in counts:\n anagrams *= comb(n,count)\n n -= count\n return anagrams % 1000000007\n``` | 0 | 0 | ['Math', 'Combinatorics', 'Counting', 'Python3'] | 0 |
sender-with-largest-word-count | Count Spaces | count-spaces-by-votrubac-w8oz | The number of words in a message is the number of spaces, plus one.\n\nWe count words for each sender using a hash map, and track max count with the sender\'s n | votrubac | NORMAL | 2022-05-28T16:01:24.020359+00:00 | 2022-05-28T16:07:59.140138+00:00 | 3,795 | false | The number of words in a message is the number of spaces, plus one.\n\nWe count words for each sender using a hash map, and track max count with the sender\'s name.\n\n**C++**\n```cpp\nstring largestWordCount(vector<string>& messages, vector<string>& senders) {\n unordered_map<string, int> cnt;\n string res;\n int max_cnt = 0;\n for (int i = 0; i < messages.size(); ++i) {\n int words = count(begin(messages[i]), end(messages[i]), \' \') + 1;\n int total = cnt[senders[i]] += words;\n if (total > max_cnt || (total == max_cnt && senders[i] > res)) {\n max_cnt = total;\n res = senders[i];\n }\n }\n return res;\n}\n``` | 65 | 0 | ['C'] | 14 |
sender-with-largest-word-count | Two Solution (StringStream and Count Space) | two-solution-stringstream-and-count-spac-klbd | Store the count of words sent by each sender and find the sender with the largest word count in the hashmap.\n\n\nclass Solution {\npublic:\n string largestW | kamisamaaaa | NORMAL | 2022-05-28T16:02:56.285422+00:00 | 2022-06-03T05:54:05.521580+00:00 | 1,344 | false | ***Store the count of words sent by each sender and find the sender with the largest word count in the hashmap.***\n\n```\nclass Solution {\npublic:\n string largestWordCount(vector<string>& messages, vector<string>& senders) {\n \n int n(size(messages));\n map<string, int> m;\n for (auto i=0; i<n; i++) {\n \n stringstream ss(messages[i]);\n string word;\n int count(0);\n while (ss >> word) count++;\n m[senders[i]] += count;\n }\n \n int count(0);\n string res;\n for (auto& p : m) {\n if (p.second >= count) {\n count = p.second;\n if (!res.empty() or res < p.first) res = p.first;\n }\n }\n return res;\n }\n};\n```\n\n**Count space to find number of words**\n```\nclass Solution {\npublic:\n string largestWordCount(vector<string>& messages, vector<string>& senders) {\n \n auto doit = [&](string& message) {\n int word(1);\n for (auto& ch : message) if (ch == \' \') word++;\n return word;\n };\n \n int n(size(messages));\n map<string, int> m;\n for (auto i=0; i<n; i++)\n m[senders[i]] += doit(messages[i]);\n \n string res;\n int count(0);\n for (auto& p : m) {\n if (p.second >= count) {\n count = p.second;\n if (!res.empty() or res < p.first) res = p.first;\n }\n }\n return res;\n }\n};\n``` | 18 | 0 | ['C'] | 7 |
sender-with-largest-word-count | [Java/Python 3] Two codes w/ analysis. | javapython-3-two-codes-w-analysis-by-roc-xkv9 | Method 1: Sort the senders with the largest word count\njava\n public String largestWordCount(String[] messages, String[] senders) {\n Map<String, Int | rock | NORMAL | 2022-05-28T16:05:13.909008+00:00 | 2022-05-29T14:05:51.317963+00:00 | 1,361 | false | **Method 1: Sort the senders with the largest word count**\n```java\n public String largestWordCount(String[] messages, String[] senders) {\n Map<String, Integer> cnt = new HashMap<>();\n int largest = 0;\n for (int i = 0; i < senders.length; ++i) {\n largest = Math.max(largest, cnt.merge(senders[i], messages[i].split(" ").length, Integer::sum));\n }\n TreeSet<String> senderSet = new TreeSet<>();\n for (var entry : cnt.entrySet()) {\n if (entry.getValue() == largest) {\n senderSet.add(entry.getKey());\n }\n }\n return senderSet.pollLast();\n }\n```\n```python\n def largestWordCount(self, messages: List[str], senders: List[str]) -> str:\n c = Counter()\n mx = 0\n for s, m in zip(senders, messages):\n c[s] += len(m.split())\n mx = max(mx, c[s])\n for s in reversed(sorted(c)):\n if c[s] == mx:\n return s\n```\n**Analysis:**\nTime: `O(nlogn)`, space: `O(n)`, where `n = senders.length`.\n\n----\n\n**Method 2: No sort** - inspired by **@giulian**\n\n```java\n public String largestWordCount(String[] messages, String[] senders) {\n Map<String, Integer> cnt = new HashMap<>();\n int largest = 0;\n for (int i = 0; i < senders.length; ++i) {\n largest = Math.max(largest, cnt.merge(senders[i], messages[i].split(" ").length, Integer::sum));\n }\n String sender = "";\n for (var entry : cnt.entrySet()) {\n if (entry.getValue() == largest && sender.compareTo(entry.getKey()) < 0) {\n sender = entry.getKey();\n }\n }\n return sender;\n }\n```\n```python\n def largestWordCount(self, messages: List[str], senders: List[str]) -> str:\n c = Counter()\n mx = 0\n for s, m in zip(senders, messages):\n c[s] += len(m.split())\n mx = max(mx, c[s])\n sender = \'\' \n for k, v in c.items():\n if v == mx and sender < k:\n sender = k\n return sender\n```\n**Analysis:**\nTime & space: `O(n)`, where `n = senders.length`. | 13 | 0 | [] | 2 |
sender-with-largest-word-count | C++ || MAP || Easy | c-map-easy-by-aakash_mehta_2023-3u5j | \nclass Solution {\npublic:\n string largestWordCount(vector<string>& messages, vector<string>& senders){\n map<string, int> mp;\n for(int i = | aakash_mehta_2023 | NORMAL | 2022-05-28T16:28:56.461919+00:00 | 2022-05-30T18:37:57.890319+00:00 | 1,166 | false | ```\nclass Solution {\npublic:\n string largestWordCount(vector<string>& messages, vector<string>& senders){\n map<string, int> mp;\n for(int i = 0; i<messages.size(); ++i){\n int words = count(begin(messages[i]), end(messages[i]), \' \')+1;\n mp[senders[i]]+=words;\n }\n string ans = "";\n int count = 0;\n for(auto it = mp.begin(); it!=mp.end(); ++it){\n if(it->second >= count){\n count = it->second;\n ans = it->first;\n }\n }\n return ans;\n }\n};\n``` | 10 | 0 | ['C'] | 5 |
sender-with-largest-word-count | [Java] Code with comments || HashMap + PriorityQueue | java-code-with-comments-hashmap-priority-utbu | \nclass Solution {\n \n class Pair {\n String name;\n int cnt;\n \n public Pair(String n, int c) {\n this.name = n; | vj98 | NORMAL | 2022-05-28T16:04:46.998146+00:00 | 2022-05-30T06:52:07.398886+00:00 | 911 | false | ```\nclass Solution {\n \n class Pair {\n String name;\n int cnt;\n \n public Pair(String n, int c) {\n this.name = n;\n this.cnt = c;\n }\n }\n \n class Compare implements Comparator<Pair> {\n public int compare(Pair a, Pair b) {\n if (a.cnt == b.cnt) {\n return b.name.compareTo(a.name);\n }\n \n return b.cnt - a.cnt;\n }\n }\n \n public String largestWordCount(String[] messages, String[] senders) {\n PriorityQueue <Pair> pq = new PriorityQueue<>(new Compare());\n /* Pair ==> key -> name\n ==> Value -> cnt\n \n new Compare() ==> it sort the queue on the cnt in descending order.\n ==> if cnt are same than sort on the name\n */\n \n HashMap <String, Integer> hash = new HashMap<>();\n \n for (int i = 0; i < messages.length; i++) {\n String []str = messages[i].split(" "); // total words in a message\n int len = str.length + hash.getOrDefault(senders[i], 0);\n hash.put(senders[i], len);\n }\n \n for (Map.Entry <String, Integer> map: hash.entrySet()) {\n pq.add(new Pair(map.getKey(), map.getValue()));\n }\n \n return pq.poll().name;\n }\n \n}\n``` | 8 | 0 | ['Heap (Priority Queue)', 'Java'] | 1 |
sender-with-largest-word-count | Easy Python Solution With Dictionary | easy-python-solution-with-dictionary-by-sb9oe | \nclass Solution:\n def largestWordCount(self, messages: List[str], senders: List[str]) -> str:\n d={}\n l=[]\n for i in range(len(messa | aadi_2 | NORMAL | 2022-05-28T16:36:26.412523+00:00 | 2022-05-28T16:36:26.412552+00:00 | 1,142 | false | ```\nclass Solution:\n def largestWordCount(self, messages: List[str], senders: List[str]) -> str:\n d={}\n l=[]\n for i in range(len(messages)):\n if senders[i] not in d:\n d[senders[i]]=len(messages[i].split())\n else:\n d[senders[i]]+=len(messages[i].split())\n x=max(d.values())\n for k,v in d.items():\n if v==x :\n l.append(k)\n if len(l)==1:\n return l[0]\n else:\n l=sorted(l)[::-1] #Lexigograhical sorting of list\n return l[0]\n```\n\n***Please Upvote if you like it.*** | 7 | 0 | ['Python', 'Python3'] | 3 |
sender-with-largest-word-count | Easy Approach in Java | using HashMap Only | easy-approach-in-java-using-hashmap-only-1awr | \n\nclass Solution {\n public String largestWordCount(String[] messages, String[] senders) {\n HashMap<String,Integer> hm=new HashMap<>();\n\t\t\n | himanshusharma2024 | NORMAL | 2022-05-28T16:05:17.174979+00:00 | 2022-06-01T10:16:56.026049+00:00 | 940 | false | ```\n\nclass Solution {\n public String largestWordCount(String[] messages, String[] senders) {\n HashMap<String,Integer> hm=new HashMap<>();\n\t\t\n int max=0;\n String name="";\n for(int i=0;i<messages.length;i++){\n String[] words=messages[i].split(" ");\n \n int freq=hm.getOrDefault(senders[i],0)+words.length;\n hm.put(senders[i],freq);\n \n if(hm.get(senders[i])>max){\n max=hm.get(senders[i]);\n name=senders[i];\n }\n else if(hm.get(senders[i])==max && name.compareTo(senders[i])<0){\n name=senders[i];\n } \n }\n \n return name;\n }\n}\n```\n\n\n\n**Time Complexity - O(messages.length*messages[i].length)**\n**Space Compexity - O(senders.length);**\n\n**Connect with me ->** https://www.linkedin.com/in/himanshusharma2024/\n\n\n\n\n | 7 | 1 | ['Java'] | 0 |
sender-with-largest-word-count | Simple Space count solution || No String-Stream | simple-space-count-solution-no-string-st-y86a | \nclass Solution {\npublic:\n string largestWordCount(vector<string>& messages, vector<string>& senders) {\n map<string,int> m;\n int n=senders | ashu143 | NORMAL | 2022-05-28T16:29:11.207183+00:00 | 2022-05-28T16:29:11.207211+00:00 | 294 | false | ```\nclass Solution {\npublic:\n string largestWordCount(vector<string>& messages, vector<string>& senders) {\n map<string,int> m;\n int n=senders.size();\n for(int i=0;i<n;i++)\n {\n int cnt=0;\n for(int j=0;j<messages[i].size();j++)\n {\n if(messages[i][j]==\' \')cnt++; //counting spaces\n }\n m[senders[i]]+=(cnt+1);//words count = space count+1 bcz of no trailing and leading spaces\n }\n vector<pair<int,string>> v;\n for(auto& it:m)\n {\n v.push_back({it.second,it.first}); //sorting according to words sent\n }\n sort(v.begin(),v.end());\n return v[v.size()-1].second; //even if there is a tie lexicographically larger will be at last\n }\n};\n``` | 6 | 0 | ['C'] | 3 |
sender-with-largest-word-count | C++ || Map || count space || Easy-to-understand | c-map-count-space-easy-to-understand-by-cf211 | \nclass Solution {\npublic:\n int solve(string &s){\n int n=s.length();\n int cnt=1;\n for(int i=0;i<n;i++){\n if(s[i]==\' \' | Pitbull_45 | NORMAL | 2022-05-28T19:15:41.127933+00:00 | 2022-05-28T19:15:58.403980+00:00 | 115 | false | ```\nclass Solution {\npublic:\n int solve(string &s){\n int n=s.length();\n int cnt=1;\n for(int i=0;i<n;i++){\n if(s[i]==\' \'){\n cnt++;\n }\n }\n return cnt;\n }\n string largestWordCount(vector<string>& messages, vector<string>& senders) {\n int n=messages.size();\n int m=senders.size();\n map<string,int> mp;\n string res="";\n for(int i=0;i<n;i++){\n mp[senders[i]]=mp[senders[i]]+solve(messages[i]);\n }\n int maxx=INT_MIN;\n for(auto it=mp.begin();it!=mp.end();it++){\n if(it->second>=maxx){\n maxx=it->second;\n res=max(res,it->first);\n }\n }\n return res;\n }\n};\n``` | 5 | 0 | [] | 0 |
sender-with-largest-word-count | Map || C++ Solution | map-c-solution-by-shishir_sharma-xnrm | \nclass Solution {\npublic:\n\n int find(string str)\n{\n int count = 0;\n int temp = 0;\n int i=0;\n \n while (i!=str.length( | Shishir_Sharma | NORMAL | 2022-05-28T16:04:51.900623+00:00 | 2022-05-28T16:04:51.900654+00:00 | 701 | false | ```\nclass Solution {\npublic:\n\n int find(string str)\n{\n int count = 0;\n int temp = 0;\n int i=0;\n \n while (i!=str.length()){\n if (str[i] == \' \' || str[i] == \'\\n\' || str[i] == \'\\t\'){\n temp = 0;\n }\n else if(temp == 0){\n temp = 1;\n count++;\n }\n i++;\n }\n return count;\n}\n string largestWordCount(vector<string>& messages, vector<string>& senders) {\n \n //Map will sort senders lexicographically \n map<string,string> umap;\n string ans="";\n int count=0;\n for(int i=0;i<messages.size();i++)\n {\n if(umap[senders[i]]!="")\n umap[senders[i]]+=" ";\n umap[senders[i]]+=messages[i];\n }\n for(auto i=umap.begin();i!=umap.end();i++)\n {\n //Count Number of words for each Senders\n int c=find(i->second);\n //If count of words is greater than the last word count\n //Note: Map has already sorted Senders lexicographically\n if(c>=count)\n {\n count=c;\n ans=i->first;\n }\n }\n return ans;\n }\n};\n```\n**Like it? Please Upvote ;-)** | 5 | 0 | ['C', 'C++'] | 1 |
sender-with-largest-word-count | [Python 3] 2 solutions, one pass and dictionary search | python-3-2-solutions-one-pass-and-dictio-caxz | Find the max sender name durion one iteration:\npython3 []\nclass Solution:\n def largestWordCount(self, messages: List[str], senders: List[str]) -> str:\n | yourick | NORMAL | 2023-07-13T22:39:24.472550+00:00 | 2024-03-08T22:12:29.548134+00:00 | 426 | false | ##### Find the max sender name durion one iteration:\n```python3 []\nclass Solution:\n def largestWordCount(self, messages: List[str], senders: List[str]) -> str:\n d, maxSenderName= defaultdict(int), \'\'\n for mes, name in zip(messages, senders):\n d[name] += len(mes.split())\n if d[name] > d[maxSenderName]:\n maxSenderName = name\n elif d[name] == d[maxSenderName] and name > maxSenderName:\n maxSenderName = name\n \n return maxSenderName\n```\n##### Do search by dictionary:\n```python3 []\nclass Solution:\n def largestWordCount(self, messages: List[str], senders: List[str]) -> str:\n d = defaultdict(int)\n for m, n in zip(messages, senders):\n d[n] += len(m.split())\n return max(d, key = lambda k: (d[k], k))\n``` | 4 | 0 | ['Hash Table', 'Python', 'Python3'] | 0 |
sender-with-largest-word-count | Python fast solution with explanation | python-fast-solution-with-explanation-by-q158 | \nclass Solution:\n def largestWordCount(self, messages: List[str], senders: List[str]) -> str:\n \n # total will contain total sum of sender\' | a-miin | NORMAL | 2022-06-04T06:05:49.710413+00:00 | 2022-06-04T06:05:49.710457+00:00 | 301 | false | ```\nclass Solution:\n def largestWordCount(self, messages: List[str], senders: List[str]) -> str:\n \n # total will contain total sum of sender\'s words \n total = {}\n max_name = \'\'\n max_value = 0\n \n for i in range(len(senders)):\n # get num of words in message \n words_num = len(messages[i].split(\' \'))\n \n # if total contain sender\'s name\n # we add words_num to its value \n # else add new key \n if total.get(senders[i], None):\n total[senders[i]] += words_num\n else:\n total[senders[i]] = words_num\n \n # if max_num of words is equal to sender\'s total words num\n # and max_name is less then sender\'s name we change max_name \n if total[senders[i]]==max_value and max_name<senders[i]:\n max_name = senders[i]\n \n # if sender\'s total words num is greater then current max\n # we save its name and num of words \n elif total[senders[i]]>max_value:\n max_value = total[senders[i]]\n max_name = senders[i]\n return max_name\n \n``` | 4 | 0 | ['Python'] | 0 |
sender-with-largest-word-count | c++ || Count space || HashMap || 2284. Sender With Largest Word Count | c-count-space-hashmap-2284-sender-with-l-j0qo | \n\tclass Solution {\n\tpublic:\n\t\tstring largestWordCount(vector& messages, vector& senders) {\n\t\t\tmapm;\n\t\t\tfor(int i=0;imaxi)\n\t\t\t\t{\n\t\t\t\t\ta | anubhavsingh11 | NORMAL | 2022-05-28T17:12:17.949205+00:00 | 2022-05-28T17:12:17.949246+00:00 | 101 | false | \n\tclass Solution {\n\tpublic:\n\t\tstring largestWordCount(vector<string>& messages, vector<string>& senders) {\n\t\t\tmap<string,int>m;\n\t\t\tfor(int i=0;i<senders.size();i++)\n\t\t\t{\n\t\t\t\tint cnt=1;\n\t\t\t\tfor(int j=0;j<messages[i].size();j++)\n\t\t\t\t{\n\t\t\t\t\tif(messages[i][j]==\' \') cnt++;\n\t\t\t\t}\n\t\t\t\tm[senders[i]]+=cnt;\n\t\t\t}\n\t\t\tint maxi=INT_MIN;\n\t\t\tstring ans;\n\t\t\tfor(auto &i:m)\n\t\t\t{\n\t\t\t\tif(i.second>maxi)\n\t\t\t\t{\n\t\t\t\t\tans=i.first;\n\t\t\t\t}\n\t\t\t\telse if(i.second==maxi)\n\t\t\t\t{ \n\t\t\t\t\tif(i.first>ans) ans=i.first;\n\t\t\t\t}\n\t\t\t\tmaxi=max(maxi,i.second);\n\t\t\t}\n\t\t\treturn ans;\n\t\t}\n\t}; | 4 | 0 | ['C'] | 0 |
sender-with-largest-word-count | Count Spaces | Maps | C++ | Easy to understand | count-spaces-maps-c-easy-to-understand-b-sly9 | We simply count the words for each sender and store the sender and their count of words in a map.\n\nFinally we iterate over the map and find sender with max wo | rgarg2580 | NORMAL | 2022-05-28T16:04:20.837164+00:00 | 2022-05-28T16:34:32.643425+00:00 | 243 | false | We simply count the words for each sender and store the sender and their count of words in a map.\n\nFinally we iterate over the map and find sender with max word count.\n\n```\nclass Solution {\n\t// Count number of words in a message by counting spaces\n int f(string s) {\n int words = 0;\n for(auto &el: s) {\n if(el == \' \') words++;\n }\n return words + 1;\n }\npublic:\n string largestWordCount(vector<string>& m, vector<string>& s) {\n int n = m.size();\n map<string, int> mp;\n for(int i=0; i<n; i++) {\n int words = f(m[i]);\n mp[s[i]] += words;\n }\n \n int maxLen = INT_MIN;\n string ans;\n for(auto &el: mp) {\n if(el.second > maxLen) {\n maxLen = el.second;\n ans = el.first;\n }\n if(el.second == maxLen && el.first > ans) {\n ans = el.first;\n } \n }\n return ans;\n }\n};\n``` | 4 | 0 | ['C'] | 2 |
sender-with-largest-word-count | Map | map-by-yadavharsha50-y7mx | \nclass Solution {\n public String largestWordCount(String[] messages, String[] senders) {\n Map<String,Integer> map=new HashMap<>();\n int max | yadavharsha50 | NORMAL | 2022-05-28T16:02:22.650584+00:00 | 2022-05-28T16:02:22.650625+00:00 | 207 | false | ```\nclass Solution {\n public String largestWordCount(String[] messages, String[] senders) {\n Map<String,Integer> map=new HashMap<>();\n int max=0;\n for(int i=0;i<messages.length;i++){\n String s=messages[i];\n String str[]=s.split(" ");\n map.put(senders[i],map.getOrDefault(senders[i],0)+str.length);\n max=Math.max(max,map.get(senders[i]));\n }\n \n String res="";\n for(String e: map.keySet()){\n if(map.get(e)==max){\n if(res.compareTo(e)<0){\n res=e;\n }\n }\n }\n return res;\n }\n}\n``` | 4 | 0 | ['Java'] | 0 |
sender-with-largest-word-count | StringStream || Implementation Based Question || Sorting | stringstream-implementation-based-questi-83n6 | ```\nstatic bool cmp(pair &a,pair &b){\n \n if(a.first != b.first) return a.first > b.first;\n \n return a.second > b.second;\n | njcoder | NORMAL | 2022-05-28T16:00:55.981881+00:00 | 2022-05-28T16:00:55.981925+00:00 | 255 | false | ```\nstatic bool cmp(pair<int,string> &a,pair<int,string> &b){\n \n if(a.first != b.first) return a.first > b.first;\n \n return a.second > b.second;\n \n }\n \n string largestWordCount(vector<string>& M, vector<string>& S) {\n unordered_map<string,int> um;\n \n int n = M.size();\n \n for(int i=0;i<n;i++){\n stringstream ss(M[i]);\n string word;\n int cnt = 0;\n while(ss >> word){\n cnt++;\n }\n um[S[i]]+=cnt;\n }\n \n vector<pair<int,string>> vec;\n \n for(auto x : um){\n vec.push_back({x.second,x.first});\n }\n \n sort(vec.begin(),vec.end(),cmp);\n \n return vec[0].second;\n \n } | 4 | 0 | ['String', 'Sorting'] | 0 |
sender-with-largest-word-count | JAVA | Clean solution using HashMap | Explained ✅ | java-clean-solution-using-hashmap-explai-krcd | Solution explained using comments \uD83D\uDE07\n---\n### Code:\n\nclass Solution {\n public String largestWordCount(String[] messages, String[] senders) {\n | sourin_bruh | NORMAL | 2023-03-16T21:37:22.419373+00:00 | 2023-03-16T21:37:36.548092+00:00 | 258 | false | # Solution explained using comments \uD83D\uDE07\n---\n### Code:\n```\nclass Solution {\n public String largestWordCount(String[] messages, String[] senders) {\n // In a hashmap, record whhich person has sent how many words\n Map<String, Integer> map = new HashMap<>();\n for (int i = 0; i < messages.length; i++) {\n // doing this would get us the number of words in that particular message\n int words = messages[i].split(" ").length;\n String name = senders[i];\n // update in the map\n map.put(name, words + map.getOrDefault(name, 0));\n }\n\n // a string \'ans\' to record our final sender\'s name\n String ans = "";\n // variable to keep track of the maximum number of words spoken by a sender\n int max = 0; \n // go through the senders\n for (String name : map.keySet()) {\n // number of words current sender has sent\n int words = map.get(name); \n // if number of words > max spoken words\n if (words > max) {\n max = words; // update max\n ans = name; // make this sender our candidate\n } \n // if we have a tie in the max number of words spoken\n else if (words == max) {\n // keep the name which is lexicographically greater\n int x = ans.compareTo(name);\n ans = (x > 0)? ans : name;\n }\n }\n\n // return the final sender\'s name\n return ans;\n }\n}\n```\n---\n#### Clean solution:\n```\nclass Solution {\n public String largestWordCount(String[] messages, String[] senders) {\n Map<String, Integer> map = new HashMap<>();\n for (int i = 0; i < messages.length; i++) {\n int words = messages[i].split(" ").length;\n String name = senders[i];\n map.put(name, words + map.getOrDefault(name, 0));\n }\n\n String ans = "";\n int max = 0; \n for (String name : map.keySet()) {\n int words = map.get(name); \n if (words > max) {\n max = words; \n ans = name; \n } else if (words == max) {\n int x = ans.compareTo(name);\n ans = (x > 0)? ans : name;\n }\n }\n\n return ans;\n }\n}\n```\n---\n### Complexity analysis:\n##### Time complexity: $$O(n) + O(n) => O(n)$$\n> A $$O(n)$$ to populate our map. Another $$O(n)$$ to go thorugh the map to go through the map.\n\n##### Space complexity: $$O(n)$$\n> We use a hashmap to store the data of our senders.\n---\n Do comment if you have any doubt \uD83D\uDC4D\uD83C\uDFFB\n Upvote if you like \uD83D\uDC96 | 3 | 0 | ['Array', 'Hash Table', 'String', 'Java'] | 0 |
sender-with-largest-word-count | Simple Solution using Dictionary in Python | simple-solution-using-dictionary-in-pyth-fnrz | Intuition\n Describe your first thoughts on how to solve this problem. \nFirst of all , for this problem we are going to use a map which in python can be implem | niketh_1234 | NORMAL | 2022-11-18T12:23:25.601169+00:00 | 2022-11-18T12:23:25.601205+00:00 | 82 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nFirst of all , for this problem we are going to use a map which in python can be implemented by using dictionary.\nWe are going to find the words count of every sender\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nIn python we create an empty dictionary and traversing the senders list , if a particular element of senders in not in dictionary then we create key value pair with key as senders name and value as the respective message(count of words).If the element of senders is already present then we just add the respective count of words to the existing one and keep track of the maximum value\n\nBy the above steps we get maximum and for every element in map we are going to check if the value is maximum and keep track of maximum and return it.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nFor traversing into the senders list and adding values into the dictionary and keeping track of the maximum value takes O(n) and if we have multiple keys with same maximum traversing the map with the maximum and keeping track of answer takes O(n). Hence the time complexity is basically O(n+n) which equals O(n).\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nWe are using hashmap , which can be of size \'n\' in the worst case so..\nthe space complexity is O(n).\n\n# Code\n```\nclass Solution:\n def largestWordCount(self, messages: List[str], senders: List[str]) -> str:\n map = {}\n m=0\n ans=""\n for i in range(len(senders)):\n if senders[i] not in map:\n map[senders[i]] = messages[i].count(\' \')+1\n else:\n map[senders[i]]+= messages[i].count(\' \')+1\n m=max(m,map[senders[i]])\n for i,k in map.items():\n if k==m:\n ans=max(ans,i)\n return ans\n \n``` | 3 | 0 | ['Ordered Map', 'Python3'] | 0 |
sender-with-largest-word-count | C++ Solution || Easy Explained || using maps. | c-solution-easy-explained-using-maps-by-8duw8 | we create a new function to count total number of words in a string;\n2. we create a a map PerUserWordCount and a vector maxCounter;\n3. we put all the count | prasoonrajpoot | NORMAL | 2022-07-28T05:12:26.795115+00:00 | 2022-07-28T05:12:26.795149+00:00 | 134 | false | 1. we create a new function to count total number of words in a string;\n2. we create a a map PerUserWordCount and a vector maxCounter;\n3. we put all the count of words per user in the map, while doing so , we also save the maximum frequency.\n4. we also check that if a multiple senders have maximum words, if so then we sort them and return the last of them as required.\n\n``` \nint numberOfWords(string s){\n string word = "";\n int count = 0;\n for(int i = 0; i < s.size();i++){\n if(s[i] == \' \' && word != ""){\n word = "";\n count++;\n }\n word = word + s[i];\n }\n count++;\n return count;\n}\n\n\nclass Solution {\npublic:\n string largestWordCount(vector<string>& messages, vector<string>& senders) {\n map<string, int> PerUserWordCount;\n vector<string>maxCounter;\n int maxCount = 0;\n for(int i = 0; i < messages.size(); i++){\n string message = messages[i];\n PerUserWordCount[senders[i]] = PerUserWordCount[senders[i]] + numberOfWords(message);\n if(PerUserWordCount[senders[i]] > maxCount){\n maxCount = PerUserWordCount[senders[i]];\n }\n }\n\n for(auto i : PerUserWordCount){\n if(i.second == maxCount){\n maxCounter.push_back(i.first);\n }\n }\n\n if(maxCounter.size() == 1){\n return maxCounter[0];\n }else{\n sort(maxCounter.begin(), maxCounter.end());\n return maxCounter[maxCounter.size()-1];\n }\n\n return "";\n }\n}; ``` | 3 | 0 | ['String', 'C', 'Iterator'] | 0 |
sender-with-largest-word-count | Javascript || Count space || HashMap | javascript-count-space-hashmap-by-seymur-dcll | \n/**\n * @param {string[]} messages\n * @param {string[]} senders\n * @return {string}\n */\nvar largestWordCount = function(messages, senders) {\n let word | seymuromarov | NORMAL | 2022-06-02T15:15:39.655417+00:00 | 2022-06-02T15:24:55.917195+00:00 | 238 | false | ```\n/**\n * @param {string[]} messages\n * @param {string[]} senders\n * @return {string}\n */\nvar largestWordCount = function(messages, senders) {\n let wordCount = {}\n let result = \'\'\n let maxCount = -Infinity\n for (let i = 0; i < messages.length;i++) {\n let count=messages[i].split(\' \').length\n wordCount[senders[i]] = wordCount[senders[i]] == undefined ? count : wordCount[senders[i]] + count;\n if (wordCount[senders[i]] > maxCount || (wordCount[senders[i]] == maxCount && senders[i] > result)) {\n maxCount = wordCount[senders[i]];\n result = senders[i];\n }\n }\n return result;\n\n};\n``` | 3 | 0 | ['JavaScript'] | 0 |
sender-with-largest-word-count | Easy to Understand | Beginner Friendly | My Notes | easy-to-understand-beginner-friendly-my-1lesw | Keep a hashmap that stores keys as elements from sender and the value as a list with the indexes.\n\nIf Senders are [Alice,Zhund,Zhund,Alice]\n\nYour dictionary | thezhund | NORMAL | 2022-05-28T16:11:22.606904+00:00 | 2022-05-28T17:03:44.011027+00:00 | 292 | false | Keep a hashmap that stores keys as elements from sender and the value as a list with the indexes.\n\nIf Senders are [Alice,Zhund,Zhund,Alice]\n\nYour dictionary becomes: {\'Alice\': [0,3], \'Zhund\':[1,2]}\n\nNow you need to iterate within this dictionary.\nAnd use those indexes.\n\nSo, for every element, we can iterate in the list of indexes it has.\n\n*len(messages[each].split(\' \'))* will give you the word count for the index stored in the messages.\nand then you can compare the total count with the maximum count everytime.\n\n\n```\nans = \'\'\nd = {}\nfor i in range(0,len(senders)):\n\td.setdefault(senders[i], []).append(i)\n\nfor element in d.keys():\n\tcount = 0\n\tfor each in d[element]:\n\t\tcount+=len(messages[each].split(\' \'))\n\t\t#equal case\n\t\tif count == mc and element>ans:\n\t\t\tans = element\n\t\t#greater case\n\t\tif count>mc:\n\t\t\tmc = count\n\t\t\tans = element\n\nreturn ans\n```\n\n\nNote:\n\n[If these notes are helpful, do upvote! I also post the explanation on my channel. The link\ncan be found in my profile as website. If you feel my explanation needs to be improved either while writing here/explaning, feel free to comment.\n] | 3 | 0 | ['Python'] | 0 |
sender-with-largest-word-count | Sender with largest Word Count | Java Solution | sender-with-largest-word-count-java-solu-j1xy | \nclass Solution {\n public String largestWordCount(String[] messages, String[] senders) {\n HashMap<String, Integer> hm=new HashMap<>();//sender->wor | shaguftashahroz09 | NORMAL | 2022-05-28T16:04:51.584498+00:00 | 2022-05-28T16:05:29.207348+00:00 | 195 | false | ```\nclass Solution {\n public String largestWordCount(String[] messages, String[] senders) {\n HashMap<String, Integer> hm=new HashMap<>();//sender->word count\n int n=messages.length;\n for(int i=0;i<n;i++)\n {\n String sender=senders[i];\n int wordCount=messages[i].split("\\\\s").length;\n hm.put(sender,hm.getOrDefault(sender,0)+wordCount);\n }\n int largest=Integer.MIN_VALUE;\n String ans="";\n for(String sender:hm.keySet())\n {\n int value=hm.get(sender);\n if(value > largest)\n {\n largest=value;\n ans=sender;\n }\n else if(value == largest)\n {\n if(ans.compareTo(sender) < 0)\n {\n ans=sender;\n }\n }\n }\n return ans;\n }\n}\n``` | 3 | 0 | ['Java'] | 0 |
sender-with-largest-word-count | simple cpp solution | simple-cpp-solution-by-prithviraj26-8lbp | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | prithviraj26 | NORMAL | 2023-02-20T05:52:19.954146+00:00 | 2023-02-20T05:52:19.954198+00:00 | 124 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\no(n^2)\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\no(n)\n\n# Code\n```\nclass Solution {\npublic:\n int solve(string a)\n {\n int c=0;\n for(int i=0;i<a.length();i++)\n {\n if(a[i]==\' \')c++;\n }\n return c+1;\n }\n string largestWordCount(vector<string>& messages, vector<string>& senders) {\n vector<pair<string,int>>v;\n for(int i=0;i<messages.size();i++)\n {\n v.push_back({senders[i],solve(messages[i])});\n }\n unordered_map<string,int>m;\n for(int i=0;i<v.size();i++)\n {\n m[v[i].first]+=v[i].second;\n }\n string ans="";\n int temp=0;\n for(auto it:m)\n {\n if(temp<it.second)\n {\n ans=it.first;\n temp=it.second;\n }\n else if(temp==it.second)\n {\n if(ans<it.first)\n {\n ans=it.first;\n }\n\n }\n }\n return ans;\n }\n};\n```\n\n | 2 | 0 | ['Array', 'Hash Table', 'String', 'Counting', 'C++'] | 0 |
sender-with-largest-word-count | Java | HashMap | O(n) | Simple | java-hashmap-on-simple-by-judgementdey-r2iz | Intuition\n Describe your first thoughts on how to solve this problem. \nCalculate the word count for every message. Maintain a hash map of senders -> word coun | judgementdey | NORMAL | 2023-01-26T23:01:49.999534+00:00 | 2023-01-26T23:01:49.999565+00:00 | 190 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nCalculate the word count for every message. Maintain a hash map of senders -> word count. Iterate over the hash map and figure out the sender with the largest word count.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: $$O(n)$$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: $$O(n)$$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\n public String largestWordCount(String[] messages, String[] senders) {\n HashMap<String, Integer> map = new HashMap<>();\n\n for (int i=0; i < messages.length; i++) {\n int cnt = 0;\n for (int j=0; j < messages[i].length(); j++)\n if (messages[i].charAt(j) == \' \')\n cnt++;\n\n map.put(senders[i], map.getOrDefault(senders[i], 0) + cnt + 1);\n }\n String ans = "";\n int maxWordCount = Integer.MIN_VALUE;\n \n for (Map.Entry<String, Integer> entry : map.entrySet()) {\n String sender = map.getKey();\n int wordCount = map.getValue();\n\n if (wordCount >= maxWordCount) {\n ans = \n wordCount == maxWordCount\n ? ans.compareTo(sender) > 0 ? ans : sender\n : sender;\n maxWordCount = wordCount;\n }\n }\n return ans;\n }\n}\n``` | 2 | 0 | ['Hash Table', 'Java'] | 0 |
sender-with-largest-word-count | c++| Faster than 100% | Hashmap | c-faster-than-100-hashmap-by-zdansari-syjq | \n\n\n\n// This function takes in two vectors of strings, "messages" and "senders", and returns the sender \n// with the largest number of words in their messag | zdansari | NORMAL | 2023-01-13T06:11:16.023320+00:00 | 2023-01-13T06:15:52.367202+00:00 | 453 | false | \n\n\n```\n// This function takes in two vectors of strings, "messages" and "senders", and returns the sender \n// with the largest number of words in their messages. \nstring largestWordCount(vector<string>& messages, vector<string>& senders) {\n // Create an unordered map to store the number of words in each sender\'s messages\n unordered_map<string,int> mp;\n // Iterate through the "messages" vector\n for(int i=0;i<size(messages);i++)\n {\n int c=0;\n // Count the number of spaces in the current message\n for(int j=0;j<size(messages[i]);j++)\n {\n if(messages[i][j]==\' \')\n c++;\n }\n // Add the number of words (count of spaces + 1) to the corresponding sender\'s count in the map\n mp[senders[i]]+=c+1;\n }\n // Create a priority queue of pairs where the first element is the number of words and \n // the second element is the sender\'s name\n priority_queue<pair<int,string>> p;\n // Push all the pairs from the map into the priority queue\n for(auto it:mp)\n {\n p.push({it.second,it.first});\n }\n // Return the sender with the highest number of words (the top element of the priority queue)\n return p.top().second;\n}\n``` | 2 | 0 | ['C'] | 1 |
sender-with-largest-word-count | Simple Java Solution Beats 99% | simple-java-solution-beats-99-by-nomaana-ydp2 | \nclass Solution {\n public String largestWordCount(String[] messages, String[] senders) \n {\n HashMap<String,Integer> map = new HashMap<>();\n | nomaanansarii100 | NORMAL | 2022-10-19T05:35:43.896265+00:00 | 2022-10-19T05:35:43.896308+00:00 | 528 | false | ```\nclass Solution {\n public String largestWordCount(String[] messages, String[] senders) \n {\n HashMap<String,Integer> map = new HashMap<>();\n String res = "";int max =0;\n \n for(int i=0; i<messages.length;i++)\n {\n int words = get_count(messages[i]);\n \n if(!map.containsKey(senders[i]))\n map.put(senders[i] , words);\n \n else\n map.put(senders[i],map.get(senders[i]) + words);\n }\n \n for(String s: map.keySet())\n {\n if(map.get(s) > max)\n {\n res = s;\n max = map.get(s);\n }\n \n if(map.get(s) == max && res.compareTo(s) < 0)\n res = s;\n }\n return res;\n }\n \n private int get_count(String s)\n {\n int spaces = 0;\n \n for(int i=0; i<s.length();i++)\n {\n char ch = s.charAt(i);\n if(ch == \' \')\n spaces++;\n }\n return spaces+1;\n }\n}\n``` | 2 | 0 | ['Counting', 'Java'] | 0 |
sender-with-largest-word-count | Python Faster | python-faster-by-onosetaleoseghale-fvb2 | ```\n def largestWordCount(self, messages: List[str], senders: List[str]) -> str:\n \n hashMap = {}\n for message, sender in zip(messages, senders | onosetaleoseghale | NORMAL | 2022-10-07T08:52:20.199719+00:00 | 2022-10-07T08:52:20.199757+00:00 | 169 | false | ```\n def largestWordCount(self, messages: List[str], senders: List[str]) -> str:\n \n hashMap = {}\n for message, sender in zip(messages, senders):\n if sender in hashMap:\n hashMap[sender] += len(message.split())\n else:\n hashMap[sender] = len(message.split())\n \n \n return sorted(hashMap.items(), key=lambda item: (item[1], item[0]), reverse=True)[0][0]\n | 2 | 0 | ['Python'] | 0 |
sender-with-largest-word-count | Python3 | Hash word count associated with a sender's name then return max | python3-hash-word-count-associated-with-oywyd | \nclass Solution:\n def largestWordCount(self, messages: List[str], senders: List[str]) -> str:\n words_count = defaultdict(int)\n for m, perso | ploypaphat | NORMAL | 2022-09-30T18:24:34.888046+00:00 | 2022-09-30T18:24:34.888078+00:00 | 466 | false | ```\nclass Solution:\n def largestWordCount(self, messages: List[str], senders: List[str]) -> str:\n words_count = defaultdict(int)\n for m, person in zip(messages, senders):\n words_count[person] += len(m.split())\n \n max_len = max(words_count.values())\n \n names = sorted([name for name, words in words_count.items() if words == max_len], reverse=True)\n return names[0]\n``` | 2 | 0 | ['Python', 'Python3'] | 0 |
sender-with-largest-word-count | C++ Solution Using Hashmap | Simple & Easy | c-solution-using-hashmap-simple-easy-by-o3na4 | Just create a map of (string, int) pair and store the count of no of words for each word in the map. \nAfter this iterate and find the strings for maximum count | shrudex | NORMAL | 2022-09-06T19:16:20.234661+00:00 | 2022-09-06T19:16:20.234696+00:00 | 198 | false | Just create a map of (string, int) pair and store the count of no of words for each word in the map. \nAfter this iterate and find the strings for maximum count, if 2 such string exists, check which one is lexicographically greater and print the required output.\n\n```\nclass Solution {\npublic:\n string largestWordCount(vector<string>& messages, vector<string>& senders) {\n map<string, int> mp;\n for(int i = 0;i < messages.size(); i++)\n {\n int count = 0;\n string tmp = messages[i];\n for(char ch : tmp) \n if(ch == \' \') \n count++;\n mp[senders[i]] += count + 1;\n }\n string ans = "";\n int mx = INT_MIN;\n for(auto i : mp)\n {\n if(i.second >= mx)\n {\n mx = i.second;\n if(i.first > ans) \n ans = i.first;\n }\n }\n return ans;\n }\n};\n``` | 2 | 0 | ['Hash Table', 'C++'] | 0 |
sender-with-largest-word-count | Python: Easy Sorting & Map | python-easy-sorting-map-by-jijnasu-oqr4 | \nclass Solution:\n def largestWordCount(self, messages: List[str], senders: List[str]) -> str:\n d = defaultdict(int)\n mx = 0\n for i, | jijnasu | NORMAL | 2022-09-03T12:33:25.716944+00:00 | 2022-09-03T12:33:25.716982+00:00 | 145 | false | ```\nclass Solution:\n def largestWordCount(self, messages: List[str], senders: List[str]) -> str:\n d = defaultdict(int)\n mx = 0\n for i,snd in enumerate(senders):\n d[snd] += len(messages[i].split())\n mx = max(mx, d[snd])\n \n for snd in sorted(d.keys())[::-1]:\n if d[snd] == mx:\n return snd\n``` | 2 | 0 | [] | 1 |
sender-with-largest-word-count | Python 99.90 memory efficient - Simple | Fast | Detailed Explanation | python-9990-memory-efficient-simple-fast-qpo8 | Take a defaultdict of integers to store the count of words.\n Iterate over the senders array and count number of words during each iteration. If key already exi | hitttttt | NORMAL | 2022-08-10T08:54:24.820217+00:00 | 2022-08-10T08:54:46.736247+00:00 | 71 | false | * Take a `defaultdict` of integers to store the count of words.\n* Iterate over the `senders` array and count number of words during each iteration. If key already exisits in the hash table, add the current value in already exisiting value. For example, if `Alice` has send a message `Hi`. Add it to the dictionary with value as 1. If again, `Alice` sends out a message, for instance `Hello` then update the value this time. Now Alice will have `value = 2`.\n* Now after iterating through the array, you will have a hashtable ready with the senders and their number of words. \n* At this point, we only need to calculate the sender with max words. \n* Initialize a `max_` variable with value **0**, and `winner` with value equal to first index `senders[0]`\n* We need to take care of the case when their is a tie between two senders. \n* Python `max` function gives you the value in lexicographical order in case of strings. \n* return the `winner` in the end. \n\n```\nclass Solution:\n def largestWordCount(self, messages: List[str], senders: List[str]) -> str:\n d = defaultdict(int)\n for i in range(len(senders)):\n d[senders[i]] = d.get(senders[i], 0) + len(messages[i].split())\n\n max_ = 0\n winner = senders[0]\n for key, value in d.items():\n if value == max_:\n winner = max(winner, key)\n if value > max_:\n winner = key\n max_ = value\n\n return winner\n```\n\nDo comment if you have any doubt, feel free to reach out. \nIf you like the solution, please do upvote. Thanks. | 2 | 0 | ['String'] | 0 |
sender-with-largest-word-count | JAVA || HASHMAP || ONE PASS || COUNT SPACE +1 | java-hashmap-one-pass-count-space-1-by-2-tp1e | \nclass Solution {\n public String largestWordCount(String[] messages, String[] senders) \n {\n int n=messages.length;\n \n String an | 29nidhishah | NORMAL | 2022-06-28T06:37:06.334478+00:00 | 2022-06-28T06:37:06.334519+00:00 | 187 | false | ```\nclass Solution {\n public String largestWordCount(String[] messages, String[] senders) \n {\n int n=messages.length;\n \n String ans="";\n int max=0;\n Map<String,Integer> map=new HashMap<>();\n \n for(int i=0;i<n;i++)\n {\n int c=0;\n for(int j=0;j<messages[i].length();j++)\n {\n if(messages[i].charAt(j)==\' \')\n c++;\n }\n \n c++;\n map.put(senders[i],map.getOrDefault(senders[i],0)+c);\n \n int x=map.get(senders[i]);\n \n if(x<max)\n continue;\n \n if(x==max)\n ans=senders[i].compareTo(ans)>0?senders[i]:ans;\n \n else\n {\n max=x;\n ans=senders[i];\n }\n }\n \n return ans;\n }\n}\n``` | 2 | 0 | ['String', 'Java'] | 0 |
sender-with-largest-word-count | Python3 - Clear solution using dictionaries for word count per sender | python3-clear-solution-using-dictionarie-uvzu | At first glance, I thought that I can get the solution by making one loop over zip(messages, senders) and finding the sender with the maximum word count, But I | ahmadheshamzaki | NORMAL | 2022-06-14T16:50:40.853490+00:00 | 2022-06-14T16:50:40.853536+00:00 | 254 | false | At first glance, I thought that I can get the solution by making one loop over `zip(messages, senders)` and finding the sender with the maximum word count, But I realized that this won\'t work because a sender can send multple messages. Therefore, I had to create a dictionary to track the word count of each sender, then find the sender with the biggest word count.\n\nAnother thing to note is that I don\'t need to split the message into a list of words then get the length of that list. I can simply get the number of words by counting the number of spaces between each word then adding one to it. Therefore I won\'t need extra memory to store the words list in order to get its length. I thought about using generators instead of lists, but I think this approach in much simpler. \n\n```python\nclass Solution:\n def largestWordCount(self, messages: List[str], senders: List[str]) -> str:\n word_count = {}\n \n for message, sender in zip(messages, senders):\n message_word_count = message.count(" ") + 1\n word_count[sender] = word_count.get(sender, 0) + message_word_count\n \n top_sender = ""\n max_count = 0\n \n for sender, wc in word_count.items():\n if wc > max_count or (wc == max_count and sender > top_sender ):\n top_sender = sender\n max_count = wc\n \n return top_sender\n```\n\n**Time complexity:** `O(nm)` where `n` is the length of `messages` or `senders`, `m` is the maximum message length.\nwe loop over both lists at once, counting the spaces in each message, which takes `O(m)`. so the first `for` loop takes `O(nm)`. The second loop looks for the sender with the maximum word count. the worst case is that all the names in `senders` are unique, Therefore this loop would take `O(n)`.\n\n**Space complexity:** `O(n)`\nThe created dictionary would have `n` senders at the worst case, which requires a space complexity of `O(n)` | 2 | 0 | ['Counting', 'Python', 'Python3'] | 0 |
sender-with-largest-word-count | c# and Linq | c-and-linq-by-bytchenko-zkdl | We can just query the both arrays with a help of Linq. Instead of counting words (which can be time consuming for Split) we can count spaces:\n\n\n wordCount | bytchenko | NORMAL | 2022-05-29T09:58:05.895551+00:00 | 2022-05-29T09:58:21.064624+00:00 | 109 | false | We can just *query* the both arrays with a help of *Linq*. Instead of counting words (which can be time consuming for `Split`) we can count *spaces*:\n\n```\n wordCount = spaceCount + 1\n```\n\n**Code:**\n\n```\npublic class Solution {\n public string LargestWordCount(string[] messages, string[] senders) {\n return senders\n .Zip(messages, (s, m) => (sender : s, words : m.Count(c => c == \' \') + 1))\n .GroupBy(p => p.sender, p => p.words)\n .Select(g => (sender : g.Key, wc : g.Sum()))\n .OrderByDescending(p => p.wc)\n .ThenByDescending(p => p.sender, StringComparer.Ordinal)\n .First()\n .sender;\n }\n}\n``` | 2 | 0 | [] | 0 |
sender-with-largest-word-count | C# || Dictionary | c-dictionary-by-cdev-8k1d | \n public string LargestWordCount(string[] messages, string[] senders)\n {\n Dictionary<string, int> messageCount = new();\n for (int i = 0; | CDev | NORMAL | 2022-05-28T19:23:56.076178+00:00 | 2022-05-28T19:24:12.756150+00:00 | 120 | false | ```\n public string LargestWordCount(string[] messages, string[] senders)\n {\n Dictionary<string, int> messageCount = new();\n for (int i = 0; i < messages.Length; i++)\n {\n messageCount.TryAdd(senders[i], 0);\n messageCount[senders[i]] += messages[i].Split(\' \').Count();\n }\n\n List<string> names = new();\n int maxCount = 0;\n foreach (var kv in messageCount)\n {\n if (kv.Value == maxCount)\n {\n names.Add(kv.Key);\n }\n else if (kv.Value > maxCount)\n {\n maxCount = kv.Value;\n names = new List<string> { kv.Key };\n }\n }\n return names.OrderBy(n => n, StringComparer.Ordinal).Last();\n }\n``` | 2 | 0 | [] | 2 |
sender-with-largest-word-count | easiest explanation python | easiest-explanation-python-by-vansh_ika-6nal | class Solution:\n def largestWordCount(self, messages: List[str], senders: List[str]) -> str:\n \n f={}\n for i in range(len(senders)):\ | Vansh_ika | NORMAL | 2022-05-28T18:07:16.735335+00:00 | 2022-05-28T18:07:16.735372+00:00 | 68 | false | class Solution:\n def largestWordCount(self, messages: List[str], senders: List[str]) -> str:\n \n f={}\n for i in range(len(senders)):\n if senders[i] in f:\n f[senders[i]]=f[senders[i]]+" "+messages[i]\n else:\n f[senders[i]]=messages[i]\n \n for values in f:\n f[values]=(len((f[values]).split()))\n m=max(f.values())\n \n keys = [k for k, v in f.items() if v == m]\n keys.sort()\n \n return keys[-1]\n\n | 2 | 0 | ['Python'] | 0 |
sender-with-largest-word-count | c++ || priority queue + hashmap | c-priority-queue-hashmap-by-ayushanand24-0331 | \nclass Solution {\nprivate:\n struct my_comparator {\n bool operator() (const pair<int,string>&a, const pair<int,string>& b) {\n if(a.firs | ayushanand245 | NORMAL | 2022-05-28T17:16:38.674985+00:00 | 2022-05-28T17:16:38.675027+00:00 | 124 | false | ```\nclass Solution {\nprivate:\n struct my_comparator {\n bool operator() (const pair<int,string>&a, const pair<int,string>& b) {\n if(a.first != b.first) {\n return a.first > b.first;\n }\n else {\n return a.second > b.second;\n }\n }\n };\n \n int count_words(string str){\n int count=0;\n for(int i=0;i<str.size();i++){\n if(str[i]==\' \'){ count++; }\n }\n return count+1;\n }\npublic:\n string largestWordCount(vector<string>& messages, vector<string>& senders) {\n unordered_map<string, int> mp;\n for(int i=0;i<messages.size();i++){\n int temp = count_words(messages[i]);\n mp[senders[i]] += temp;\n }\n \n priority_queue<pair<int,string>, vector<pair<int,string>>,my_comparator> pq;\n for(auto itrator: mp){\n pq.push({itrator.second, itrator.first});\n if(pq.size()>1){ \n pq.pop(); \n }\n }\n return pq.top().second;\n }\n};\n``` | 2 | 0 | ['Heap (Priority Queue)'] | 0 |
sender-with-largest-word-count | ✅ C++ | Count space & map | Easy to understand | c-count-space-map-easy-to-understand-by-mm3gv | \nclass Solution {\npublic:\n\t// this function will return the number of words in the given string\n int countWord(string s){\n int cnt=1;\n f | rupam66 | NORMAL | 2022-05-28T16:26:55.745960+00:00 | 2022-05-28T16:26:55.745995+00:00 | 179 | false | ```\nclass Solution {\npublic:\n\t// this function will return the number of words in the given string\n int countWord(string s){\n int cnt=1;\n for(int i=0;i<s.size();i++) \n if(s[i]==\' \') cnt++;\n return cnt;\n }\n string largestWordCount(vector<string>& messages, vector<string>& senders) {\n map<string,int> mp;\n for(int i=0;i<messages.size();i++){\n int cnt=countWord(messages[i]); // count the number of word in i-th string\n mp[senders[i]]+=cnt; // store it into the map\n }\n string ans="";\n int count=0;\n\t\t// now just check the highest number of words\n for(auto x:mp){\n if(x.second>count or (x.second==count and x.first>ans)){\n ans=x.first;\n count=x.second;\n }\n }\n return ans;\n }\n};\n```\n\n**If you like this, Do Upvote!** | 2 | 0 | ['C'] | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.